Embed Size (px)
Citation preview

1
Amazon Redshift Update最近追加された新機能とRedshift Spectrum
2017年6月7日
(2017年9月18日更新)
アマゾン ウェブ サービス ジャパン
ソリューションアーキテクト
下佐粉 昭 (@simosako)

2
内容についての注意
• 本資料では2017年6月7日時点のサービス内容および価格についてご説明しています。最新の情報はAWS公式ウェブサイト(http://aws.amazon.com)にてご確認ください。
• 資料作成には十分注意しておりますが、資料内の価格とAWS公式ウェブサイト記載の価格に相違があった場合、AWS公式ウェブサイトの価格を優先とさせていただきます。
• 価格は税抜表記となっています。日本居住者のお客様が東京リージョンを使用する場合、別途消費税をご請求させていただきます。
• AWS does not offer binding price quotes. AWS pricing is publicly available and is subject to change in accordance with the AWS Customer Agreement available at http://aws.amazon.com/agreement/. Any pricing information included in this document is provided only as an estimate of usage charges for AWS services based on certain information that you have provided. Monthly charges will be based on your actual use of AWS services, and may vary from the estimates provided.
3
自己紹介
下佐粉 昭(しもさこ あきら)Twitter - @simosako
所属:アマゾン ウェブ サービス ジャパン技術統括本部 エンタープライズソリューション部ソリューションアーキテクト
好きなAWSサービス:Redshift, RDS, S3人間が運用等から解放されて楽になるサービスが好きです

4
アジェンダ
• Amazon Redshiftとは
• Amazon Redshift Spectrum
• 最近のアップデート
• まとめ

5
Amazon Redshift とは

6
DWH特化の高速RDB
ペタバイト級までスケールアウト
フルマネージド
多数の周辺ソフト; PgSQL互換性
$1,000/TB/年; 最小$0.314/時から
Amazon
Redshift
より速くよりシンプルにより安価に
※費用は2017年6月時点での東京リージョンのものです

7
どのようにして大容量かつ高速を実現しているか
• スケールアウトを実現する設計– 1つのSQLを複数ノードでパラレルに処理する設計
– ノードを増やすことでパフォーマンスと容量が増加
• ディスクIOを削減する機能– ディスクIOがデータベースの一番のボトルネック
– 圧縮、ゾーンマップ、ソートキー
8
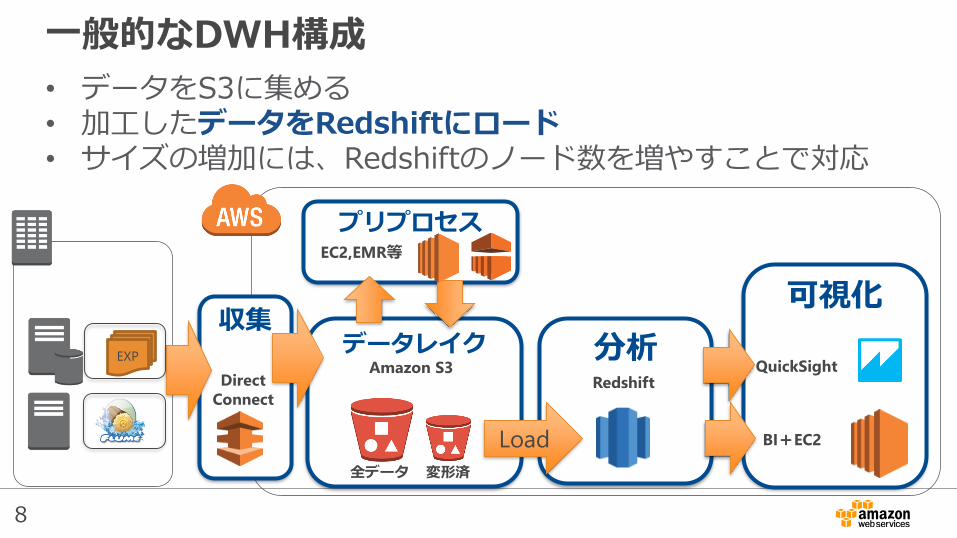
一般的なDWH構成
• データをS3に集める• 加工したデータをRedshiftにロード• サイズの増加には、Redshiftのノード数を増やすことで対応
分析データレイク収集
可視化
RedshiftQuickSight
EXPAmazon S3
BI+EC2
Direct
Connect
プリプロセスEC2,EMR等
Load
全データ 変形済

9
Amazon Redshift Spectrum

10
これまでの課題
分析データの多様化・大規模化に伴い、以下のような課題が発生していました
• S3からのデータロード(COPY)に掛かる時間
• データサイズ増加に対応するために、Redshift側のディスク量を増やすためにノードを増やすと、セットでCPUやメモリも増加する
• CSV/TSV以外のファイルフォーマットの増加– 特にHadoop(EMR)環境とのデータ連携ニーズの増加

11
1 2
...
N
Amazon Redshift Spectrum
• RedshiftからS3上に置いたファイルを外部テーブルとして定義し、クエリ可能に
• ローカルディスク上のデータと組み合わせたSQLが実行可能
• 多様なファイルフォーマットに対応
• バージニア北部、オレゴン、オハイオリージョンで利用可能(本資料執筆時点)
S3各種データ(CSV,Parquet等)
Spectrum層

12
Amazon Redshift Spectrumの特徴
エクサバイト級まで
対応可能
高速 オンデマンド、クエリ毎の費用
オープンファイル
フォーマットデータを移動させずにクエリ フルマネージド
大規模スケールアウトの処理層を使い、S3上のデータに対してSQLを実行する

13
Amazon Redshift Spectrumの使い方
Data CatalogData Catalog (Athena)
or 独自Hive Metastore
2CREATE EXTERNAL SCHEMA でクラスターと、データカタログもしくはHive Metastoreを接続
3CREATE EXTERNAL TABLE で外部表としてS3データを定義
Amazon S3 エクサバイト級にスケールするオブジェクトストレージ
1S3にParquet / CSV 等の形式でファイルを作成 4
クエリを実行
SELECT COUNT(*)
FROM S3.EXT_TABLE
GROUP BY…
Redshift Cluster
Spectrum層負荷に応じて自動スケール
1 2 3 4 ... N
14
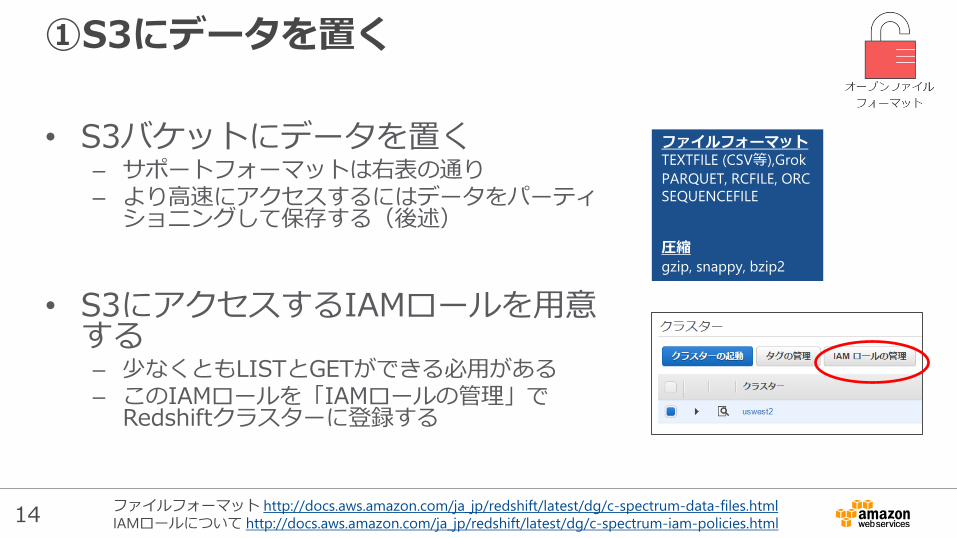
①S3にデータを置く
• S3バケットにデータを置く– サポートフォーマットは右表の通り– より高速にアクセスするにはデータをパーティ
ショニングして保存する(後述)
• S3にアクセスするIAMロールを用意する– 少なくともLISTとGETができる必用がある– このIAMロールを「IAMロールの管理」で
Redshiftクラスターに登録する
ファイルフォーマット http://docs.aws.amazon.com/ja_jp/redshift/latest/dg/c-spectrum-data-files.html
IAMロールについて http://docs.aws.amazon.com/ja_jp/redshift/latest/dg/c-spectrum-iam-policies.html
ファイルフォーマットTEXTFILE (CSV等),Grok
PARQUET, RCFILE, ORC
SEQUENCEFILE
圧縮
gzip, snappy, bzip2
15
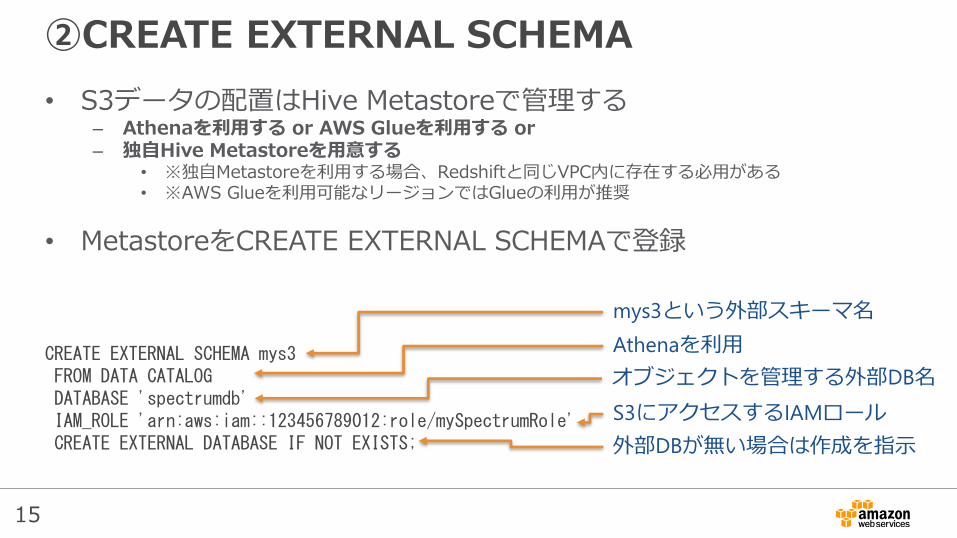
②CREATE EXTERNAL SCHEMA
• S3データの配置はHive Metastoreで管理する– Athenaを利用する or AWS Glueを利用する or– 独自Hive Metastoreを用意する
• ※独自Metastoreを利用する場合、Redshiftと同じVPC内に存在する必用がある• ※AWS Glueを利用可能なリージョンではGlueの利用が推奨
• MetastoreをCREATE EXTERNAL SCHEMAで登録
CREATE EXTERNAL SCHEMA mys3 FROM DATA CATALOG DATABASE 'spectrumdb' IAM_ROLE 'arn:aws:iam::123456789012:role/mySpectrumRole'CREATE EXTERNAL DATABASE IF NOT EXISTS;
mys3という外部スキーマ名
Athenaを利用
オブジェクトを管理する外部DB名
S3にアクセスするIAMロール
外部DBが無い場合は作成を指示
16
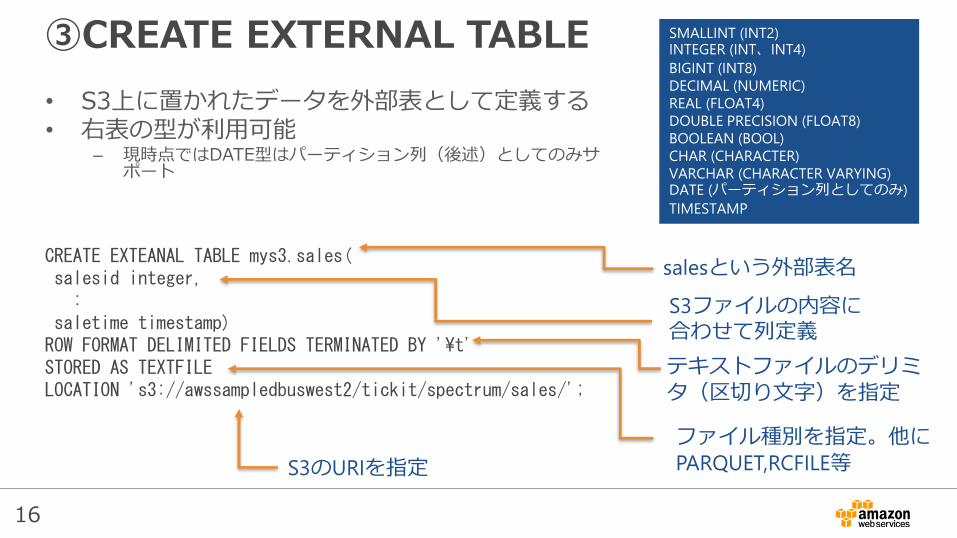
③CREATE EXTERNAL TABLE
• S3上に置かれたデータを外部表として定義する• 右表の型が利用可能
– 現時点ではDATE型はパーティション列(後述)としてのみサポート
SMALLINT (INT2)INTEGER (INT、INT4)
BIGINT (INT8)
DECIMAL (NUMERIC)
REAL (FLOAT4)
DOUBLE PRECISION (FLOAT8)
BOOLEAN (BOOL)
CHAR (CHARACTER)
VARCHAR (CHARACTER VARYING)DATE (パーティション列としてのみ)
TIMESTAMP
CREATE EXTEANAL TABLE mys3.sales(salesid integer,:
saletime timestamp)ROW FORMAT DELIMITED FIELDS TERMINATED BY '¥t'STORED AS TEXTFILELOCATION 's3://awssampledbuswest2/tickit/spectrum/sales/';
salesという外部表名
S3ファイルの内容に合わせて列定義
ファイル種別を指定。他にPARQUET,RCFILE等
テキストファイルのデリミタ(区切り文字)を指定
S3のURIを指定

17
④クエリを実行
• 外部スキーマ配下に外部表が配置される
• 通常のSQL(SELECT)が実行可能– RedshiftのSELECT構文、関数がそのまま利用可能– 外部表とローカル表のジョインも可能
SELECT ... FROM mys3.sales
外部スキーマ
外部表
18
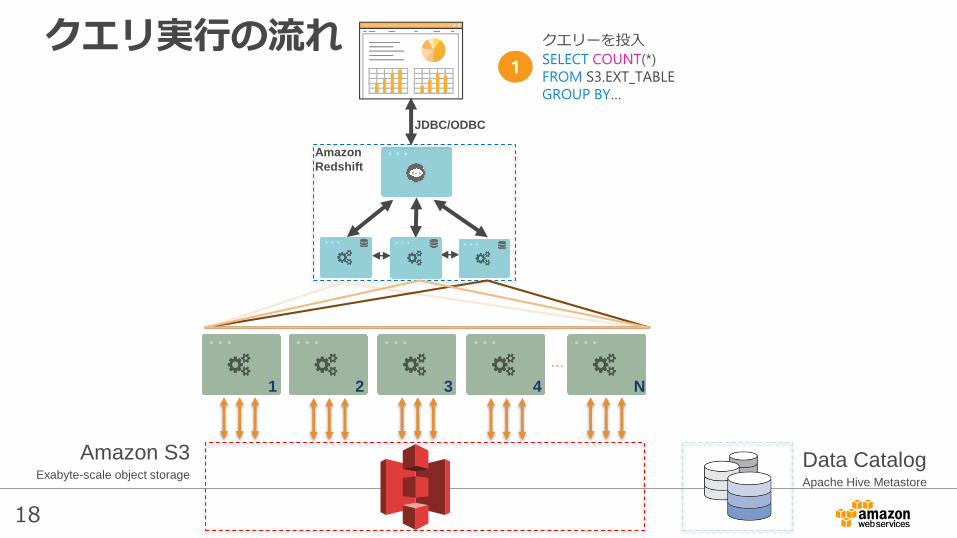
クエリーを投入
SELECT COUNT(*)
FROM S3.EXT_TABLE
GROUP BY…
クエリ実行の流れ
Amazon
Redshift
JDBC/ODBC
...
1 2 3 4 N
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore
1
19
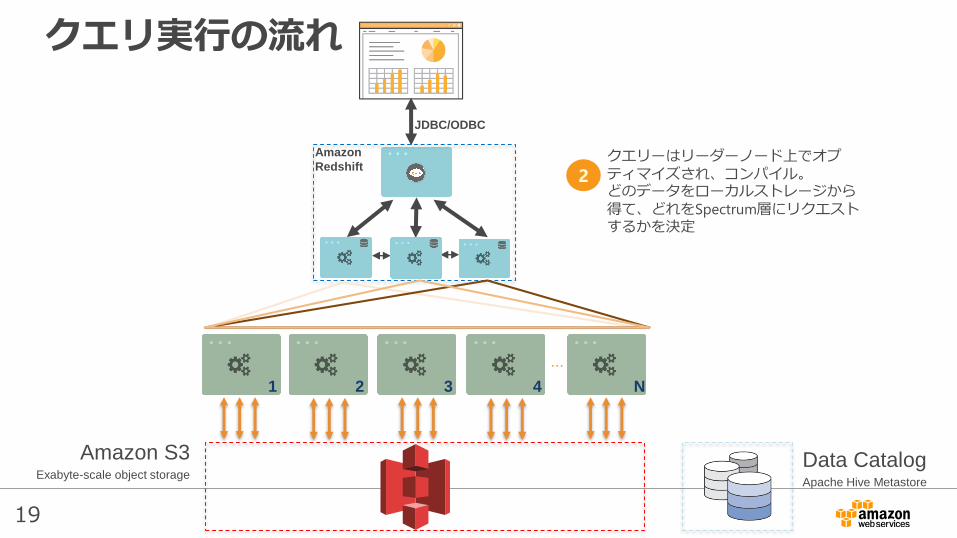
クエリーはリーダーノード上でオプティマイズされ、コンパイル。どのデータをローカルストレージから得て、どれをSpectrum層にリクエストするかを決定
クエリ実行の流れ
Amazon
Redshift
JDBC/ODBC
...
1 2 3 4 N
2
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore
20
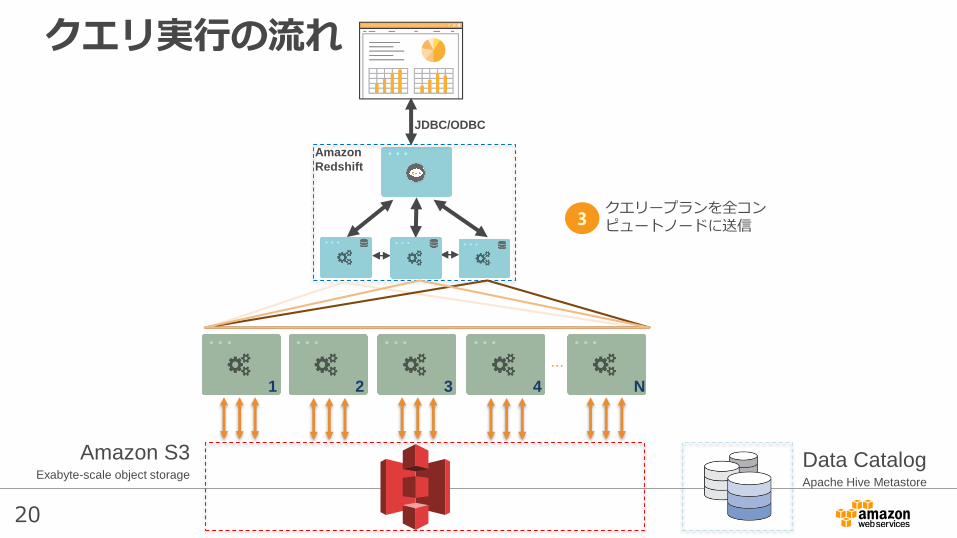
クエリープランを全コンピュートノードに送信
クエリ実行の流れ
Amazon
Redshift
JDBC/ODBC
...
1 2 3 4 N
3
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore

21
コンピュートノードはData Catalogからパーティション情報を取得 (Dynamically
prune partitions)
クエリ実行の流れ
Amazon
Redshift
JDBC/ODBC
...
1 2 3 4 N
4
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore

22
各コンピュートノードは、Amazon
Redshift Spectrum層に対して複数のリクエストを送信
クエリ実行の流れ
Amazon
Redshift
JDBC/ODBC
...
1 2 3 4 N
5
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore
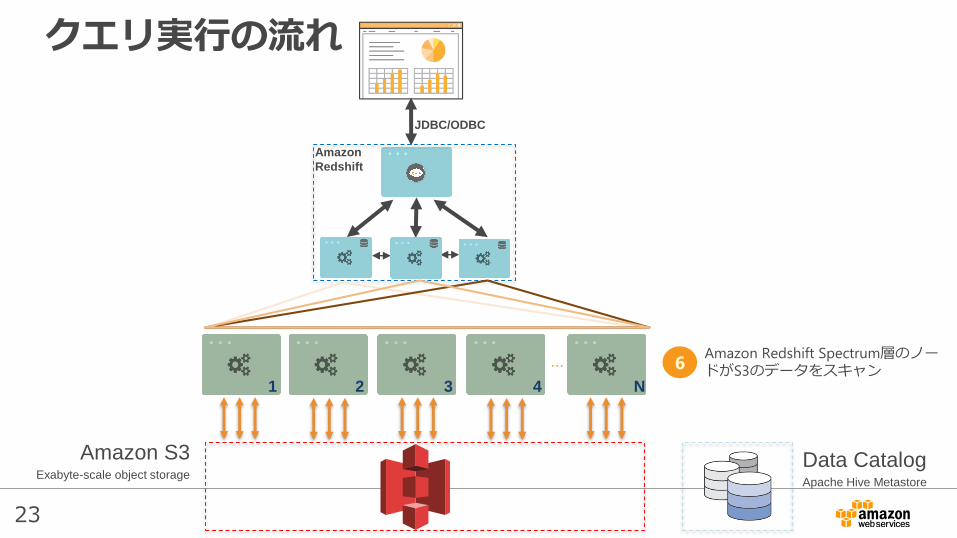
23
Amazon Redshift Spectrum層のノードがS3のデータをスキャン
クエリ実行の流れ
Amazon
Redshift
JDBC/ODBC
...
1 2 3 4 N
6
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore

24
7Amazon Redshift Spectrum層でデータの射影、フィルタ、ジョイン、アグリゲーションを実行
クエリ実行の流れ
Amazon
Redshift
JDBC/ODBC
...
1 2 3 4 N
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore
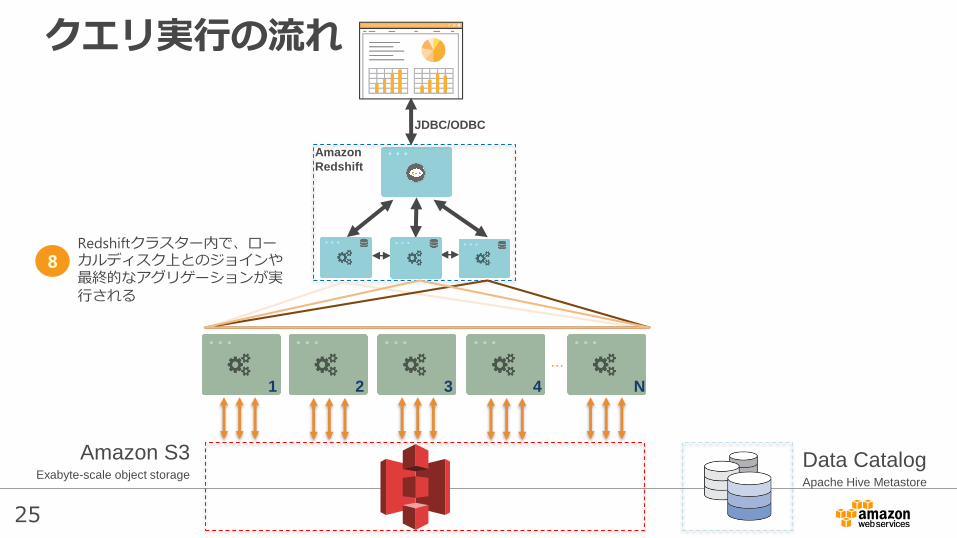
25
Redshiftクラスター内で、ローカルディスク上とのジョインや最終的なアグリゲーションが実行される
クエリ実行の流れ
Amazon
Redshift
JDBC/ODBC
...
1 2 3 4 N
8
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore

26
結果がクライアントに戻される
クエリ実行の流れ
Amazon
Redshift
JDBC/ODBC
...
1 2 3 4 N
9
Amazon S3Exabyte-scale object storage
Data CatalogApache Hive Metastore

27
大規模データを高速処理
• Spectrum層で大規模スケールアウトによるクエリ処理を実現– ~1000台までスケールアウト
– S3データへのクエリ実行を自動的にパラレル化
• Amazon Redshiftのオプティマイザを活用– 述部をプッシュダウンし、Spectrum層で処理を実行
– Dynamic partition elimination により処理対象データを削減
エクサバイト級まで対応可能
高速

28
フルマネージド
• Spectrum層に対し、準備も管理も不要
• 利用したい時にすぐに利用可能
• Spectrum層に機能拡張が入る場合もユーザの操作は不要
フルマネージド

29
高い費用対効果
• S3データの1TBスキャンあたり、$5
(スキャンしたデータサイズ)
• パーティションや、カラムナフォーマット、圧縮でコストを削減可能
• 1000台ものSpectrum層コンピュートノードのパワーを活用してクエリを実行
オンデマンド、
クエリ毎の費用

30
Amazon Redshift Spectrumを活用する上でのポイント

31
Amazon S3上のデータに直接クエリできるメリット
• Amazon Redshiftのクエリがそのまま活用できる
• ローディングにかかる手間や時間が不要。分析までの時間を最短に
• ファイルフォーマットを変更せずクエリーを実行可能
• Amazon Redshiftクラスター上のデータとS3上のデータをジョイン
• 1つのS3データに複数のAmazon Redshiftクラスターから共有アクセス可能(可用性の向上、ワークロードの分散)
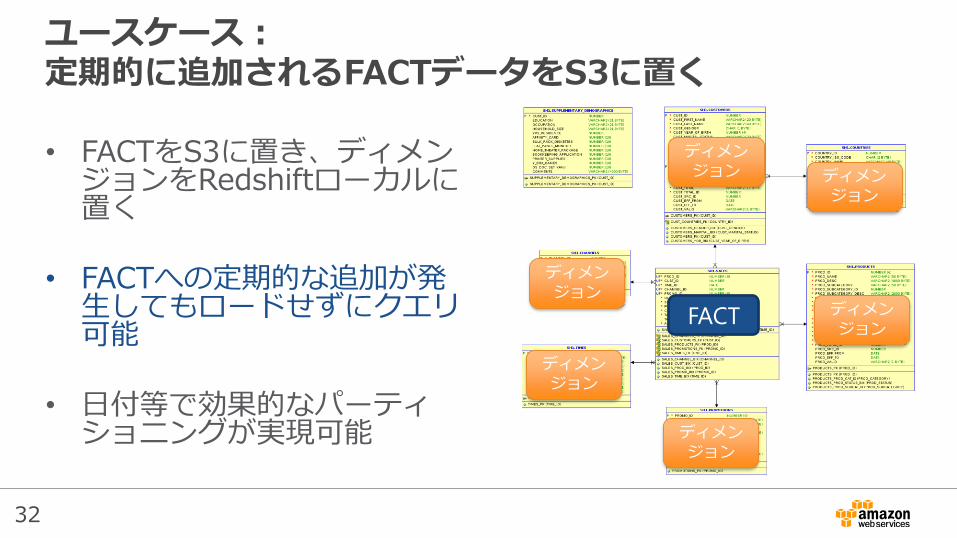
32
ユースケース:定期的に追加されるFACTデータをS3に置く
• FACTをS3に置き、ディメンジョンをRedshiftローカルに置く
• FACTへの定期的な追加が発生してもロードせずにクエリ可能
• 日付等で効果的なパーティショニングが実現可能
FACT ディメンジョン
ディメンジョン
ディメンジョン
ディメンジョン
ディメンジョン
ディメンジョン

33
ユースケース:アクセス頻度が低いデータをS3に
• 頻繁にアクセスされる直近のデータをローカルに置き、あまりアクセスされないデータはS3に置く
• 直近データの保存に必要なだけのノード数を維持しながら、多くのデータを分析対象にできる
• ※Spectrum層への指示はスライス数に依存するため、データサイズと比較して極端に少ないノード数の構成は推奨されません
Amazon
Redshift
...
1 2 3 4 N
2012年
直近データ2016年~2017年
2013年 2014年 2015年
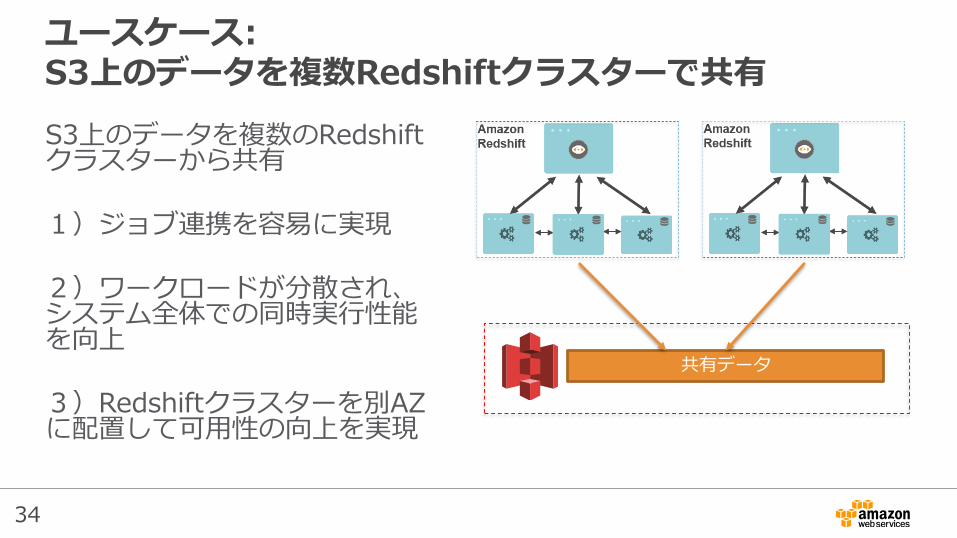
34
ユースケース:S3上のデータを複数Redshiftクラスターで共有
S3上のデータを複数のRedshiftクラスターから共有
1)ジョブ連携を容易に実現
2)ワークロードが分散され、システム全体での同時実行性能を向上
3)Redshiftクラスターを別AZに配置して可用性の向上を実現
共有データ

35
パフォーマンス・ベストプラクティス
読み取りデータ量の削減=パフォーマンス増加&コスト低下• 圧縮する : 圧縮効率と展開速度のバランスでアルゴリズムを選択• カラムナフォーマットでファイルを保存する:アクセス範囲を小さくする• サイズの不揃いは避け、 100MB~1GB程度に分割• パーティショニングする(後述)
表の配置• ファクト表(巨大で増加する)をS3に、ディメンジョン表をRedshiftロー
カルに置く
効果的なクエリの記述• 必用な列だけ取得する• アグリゲーション、フィルターで戻すデータを最小にする
36
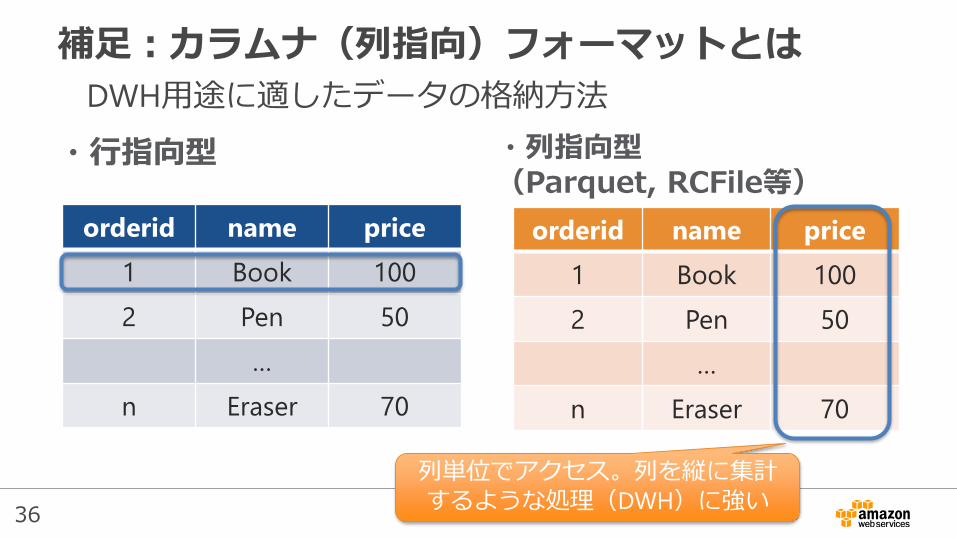
補足:カラムナ(列指向)フォーマットとは
・行指向型 ・列指向型(Parquet, RCFile等)
orderid name price
1 Book 100
2 Pen 50
…
n Eraser 70
orderid name price
1 Book 100
2 Pen 50
…
n Eraser 70
DWH用途に適したデータの格納方法
列単位でアクセス。列を縦に集計するような処理(DWH)に強い

37
パーティショニング
• 検索レンジに添ってフォルダ(プリフィクス)を作成し、ファイルを格納する
• Spectrum層が読み取る範囲を減らし、速度向上を実現 (Dynamically prune partitions)
• hive formatでのパーティショニングが推奨(year=2017/month=1/のようなフォルダ名)
• 年・月・日といった日付のレンジが良く利用される
例1 /ex1//l_date=2017-01-01/data-1/l_date=2017-01-02/data-2
:/l_date=2017-12-31/data-365
/ex2//year=2016/
/month=1/data-a, data-b/month=2/data-c, data-d
:/month=12/data-w, data-x
/year=2017//month=1/data-y, data-z
:
例2

38
パーティショニングされたデータの表定義
http://docs.aws.amazon.com/ja_jp/redshift/latest/dg/c-spectrum-external-tables.html
CREATE EXTERNAL TABLE mys3.tab1(:
)PARTITIONED BY (YEAR INTEGER, MONTH INTEGER)STORED AS PARQUET LOCATION 's3://MyData/ex2';
ALTER TABLE mys3.t1 ADD PARTITION(year='2016',month='1')LOCATION 's3://MyData/ex2/year=2016/month=1/';
ALTER TABLE mys3.t1 ADD PARTITION(year='2016',month='2')LOCATION 's3://MyData/ex2/year=2016/month=2/';
:
PARTITION BYでパーティション列を指定する
型の指定が必要。DATE型は現時点ではパーティション列にのみ指定可能
ALTER TABLEでパーティション情報を追加

39
補足:パーティショニングされたデータの表定義(Athena側で定義した表を参照する)
• Athena側で作成したEXTERNAL TABLEをSpectrumから利用することも可能– この場合、Redshift側ではCREATE EXTERNAL SCHEMAのみ実行する
• hive formatで格納されている場合、MSCK REPARE TABLEを実行することでパーティションを認識させることができる(ALTER TABLE ADD PARTITIONも利用可能)
CREATE EXTERNAL TABLE mys3.tab2(:
)PARTITIONED BY (YEAR INTEGER, MONTH INTEGER)STORED AS PARQUET LOCATION 's3://MyData/ex2';
MSCK REPAIR TABLE tab2
PARTITION BYはRedshift側で実行する場合と同じ書き方
hive formatでデータが格納されている場合はMSCK REPAIR TABLEでパーティション情報を認識させる
http://docs.aws.amazon.com/ja_jp/athena/latest/ug/partitions.html

40
未サポートの機能、制約
外部スキーマ・外部表で未サポートの機能(主要なもののみ)• 外部表の更新(SELECTのみ可能)• ネストデータ(配列)、JSON• Enhanced VPC RoutingによるSpectrumアクセスの設定• 外部スキーマへの権限設定
– 例)GRANT USAGE on SCHEMA s3 to dbuser; がエラーになる
補足:本セミナー実施時では外部表を含むVIEWは作成出来ませんでしたが、現在では作成可能になっています
制約• SpectrumでアクセスするS3バケットとRedshiftクラスターは同一リージョンである必要が
ある
これらは資料作成時のものであり、今後変わる可能性があります最新情報はRedshiftの公式ドキュメントで御確認ください

41
Amazon Redshift 最近の主要なアップデート内容

42
継続的なスループット向上への取り組み
• Redshiftではスループットを向上させるための改善が継続的に行われています
• 例)– v1.0.1012 : I/OとCommitのロジック改善により、読み書きす
るデータを減らし、一般的な利用で35%のスループット向上
– v1.0.1056:クエリ処理中のメモリアロケーションアルゴリズムの改善を改善。TPC-DS 3TBベンチマークにおいて最大60%のスループット向上
https://aws.amazon.com/jp/blogs/aws/amazon-redshift-up-to-2x-throughput-and-10x-vacuuming-performance-improvements/

43
オブジェクト名にUTF-8(日本語)が使用可能に
• 表名、列名といったオブジェクト名がUTF-8で格納可能に– 新しい接続ドライバーを利用し
てください(Redshift JDBCドライバー 1.2.1以降、Redshift ODBCドライバー 1.3.1以降)
• オブジェクト名は最大で127バイト– 日本語の漢字やひらがなは1文
字を表現するのに3バイト必要
https://aws.amazon.com/jp/blogs/news/multibyte-character-support-for-database-object-name/
bench=# CREATE TABLE "漢字の表" (ID INT, "漢字の列" varchar(100));
bench=# ¥dList of relations
schema | name | type | owner--------+----------+-------+--------public | 漢字の表 | table | master
bench=# ¥d "漢字の表"Table "public.漢字の表"
Column | Type | Modifiers----------+------------------------+-----------id | integer |漢字の列 | character varying(100) |

44
新しい圧縮エンコード – Zstandard (ZSTD)
• 圧縮&展開が高速で、かつ高い圧縮率を実現できるアルゴリズム– http://facebook.github.io/zstd/
• 全ての型に適用可能
• 長さがさまざまな文字列を保存する(VAR)CHAR 列に対して、特に効果を発揮
• ANALYZE COMPRESSIONもZSTDを含んだ推奨を返すように拡張された
http://docs.aws.amazon.com/ja_jp/redshift/latest/dg/zstd-encoding.html
https://aws.amazon.com/releasenotes/Amazon-Redshift/4458618984845879

45
Query Monitoring Rules (QMR)
• Amazon RedshiftのWorkload Management (WLM)が拡張され、より柔軟な制御が可能に
• クエリーを関するルールを8つまで作成し、そのルールに違反したクエリへのアクションが定義可能に
• ルール:CPU利用率、CPU時間、ブロック読み取り数、ジョイン対象行数等多数
• アクション:LOG(記録)、HOP(別キューに転送)、ABORT(停止)
• 例)ジョイン対象の行数が10億行を超える場合はABORT
• 例)CPUを80%以上消費した状態が10分(600秒)以上続いたクエリはABORTする
https://aws.amazon.com/jp/about-aws/whats-new/2017/04/amazon-redshift-announces-query-monitoring-rules-
qmr-a-new-feature-that-automates-workload-management-and-a-new-function-to-calculate-percentiles/

46
パーセンタイル関連の新しい関数の追加
• MEDIAN– 中央値を返す– ソートした結果を先頭から数えてちょうど中央にあたる値を計算(補完)
• PERCENTILE_CONT– パーセンタイルに該当する値を返す– PERCENTILE_CONT(0.5)は、中央値と同じ
• PERCENTILE_DISC ※これは以前から存在する関数– パーセンタイルに該当する値を返す– 線形補完せずに最も近い(存在する)値を返す
• APPROXIMATE PERCENTILE_DISC– 概算で実行することで、大規模データでも高速に実行可能なPERCENTILE_DISC– 相対誤差0.5%
https://aws.amazon.com/releasenotes/Amazon-Redshift/4458618984845879
https://aws.amazon.com/releasenotes/Amazon-Redshift/7611980060386824

47
CTASにおける自動圧縮のサポート
• CTAS : CREATE TABLE AS SELECT ...– SELECTの結果を元に新しい表を作成する– ELTや、分析処理の中間結果を別の表として作成する等、DWHでは頻出のクエリ
• CTASで作成された表の列は全て無圧縮(RAW)だった– このため特にCTASで大規模な結果セットを元に表を作成した場合、ディスク使用量や処理
パフォーマンスに問題が出るケースがあった
• 新機能によって、CTASで作成される表の列は全て自動的にLZOで圧縮される– 例外1)列が BOOLEAN, REAL, DOUBLE PRECISION の場合(LZOが適用できない)– 例外2)列がソートキーの場合(パフォーマンスのベストプラクティスに沿った動き)
https://aws.amazon.com/releasenotes/Amazon-Redshift/2171492400874984
https://aws.amazon.com/jp/blogs/news/redshift-compress-ctas/

48
ANALYZEを効率的に時間短縮するオプション
• 大規模環境ではANALYZEにかかる時間が課題になる場合がある– 列を明示的に指定することでANALYZE対象の列を絞る
ことが可能– クエリの最適化に必用な列を正しく指定する必用があ
る
• ANALYZEにPREDICATE COLUMNSが追加– 過去に述部(WHERE句等)に使用された列、もしくは
評価対象となった列のみ自動的に選択される
• 大規模表でのANALYZE時間を短縮しつつ、必用な統計情報を取得可能に
http://docs.aws.amazon.com/redshift/latest/dg/r_ANALYZE.html
https://forums.aws.amazon.com/ann.jspa?annID=4664
ID REGIST_DATE NAME AREA
001 2017-01-01 John US-EAST
002 2017-03-03 Kenny US-EAST
003 2016-12-30 Ken JAPAN
: : : :

49
UDF User Logging
• RedshiftはPython言語でUDF(ユーザ定義関数)を作成可能– UDFからは外部通信やファイルIOが一切
できないように制限されている
• UDF User Logging:– loggerに出力したエラーログが自動的に
Redshiftの中に蓄積される機能– デフォルトのログレベルはWARNING
• 必用に応じてsetLevelで変更可能
– SVL_UDF_LOG表にアクセスすることで参照可能
https://aws.amazon.com/releasenotes/Amazon-Redshift/3405966380796501
CREATE OR REPLACE FUNCTION f_pyerror() RETURNS INTEGERVOLATILE AS$$import logging
logger = logging.getLogger()logger.setLevel(logging.INFO)logger.info('Your info message here')
return 0$$ language plpythonu;

50
Timestamp with time zone
• TIMESTAMPTZ (time stamp with time zone)型が追加された– 例)1997-12-17 07:37:16-08– 例)12/17/1997 07:37:16.00 PST注)Redshiftの自体のTime zoneはUTC(GMT)固定である事には変わりない
• TIMESTAMP型の列にTIMESTAMPTZのデータを格納すると、自動的にUTC時刻に変換されて格納される
• タイムゾーンを含んだ時刻を比較するための新しい日付関数が追加– DATE_CMP_TIMESTAMPTZ– TIMESTAMP_CMP_TIMESTAMPTZ等
https://aws.amazon.com/releasenotes/Amazon-Redshift/2488705802295913
http://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_AT_TIME_ZONE.html
# create table t1(t timestamp);# insert into t1 values ('2017-06-07 18:00:00 JST'::timestamptz);# select * from t1;
t---------------------2017-06-07 09:00:00

51
Enhanced VPC Routing
• VPC-S3間のCOPY/UNLOADの通信ルートを調整するための機能– VPCエンドポイント経由– or NATゲートウェイ経由– or インターネットゲートウェイ経由
• メリット– S3への通信を特定のVPC EndpointもしくはGateway経由に強制できる(セキュリティ要
件への対応)– COPY/UNLOADの通信がVPC Flowlogでキャッチできる
• 注意点– 正しくルートを設定しないと、COPYやUNLOADが動かなくなる
https://aws.amazon.com/releasenotes/Amazon-Redshift/6021384302762607

52
まとめ
• Redshift SpectrumはS3に置いたデータをロードせずにクエリーする新機能– Spectrum層を活用することで高速なクエリを実現
• Spectrum以外にも、継続的なスループット向上、分析に必要な機能の追加、運用ユーティリティの機能向上等が行われています

53
オンラインセミナー資料の配置場所
• AWS クラウドサービス活用資料集– 「AWS 資料」で検索– http://aws.amazon.com/jp/aws-jp-introduction/
• AWS Solutions Architect ブログ– 最新の情報、セミナー中のQ&A等が掲載されています
– http://aws.typepad.com/sajp/

54
公式Twitter/FacebookAWSの最新情報をお届けします
@awscloud_jp
検索
最新技術情報、イベント情報、お役立ち情報、お得なキャンペーン情報などを日々更新しています!
もしくはhttp://on.fb.me/1vR8yWm
55
AWSの導入、お問い合わせのご相談
AWSクラウド導入に関するご質問、お見積り、資料請求をご希望のお客様は以下のリンクよりお気軽にご相談くださいhttps://aws.amazon.com/jp/contact-us/aws-sales/
※「AWS 問い合わせ」で検索してください
56
参考情報
• Amazon Redshift ホームページ– https://aws.amazon.com/jp/redshift/
• Amazon Redshift ドキュメント– https://aws.amazon.com/jp/documentation/redshift/
• Amazon Redshiftフォーラム(Q&Aや新機能の告知) ※要AWSアカウント– https://forums.aws.amazon.com/forum.jspa?forumID=155
• Amazon Redshift Release Notes(新機能、修正等)– https://aws.amazon.com/releasenotes/Amazon-Redshift
• Amazon Redshiftのパフォーマンスチューニングテクニック Top 10http://aws.typepad.com/sajp/2015/12/top-10-performance-tuning-techniques-for-amazon-redshift.html
• AWS Bigdata Blog– https://aws.amazon.com/jp/blogs/big-data/

57
ご参加ありがとうございました

58



![[AWS Black Belt Online Seminar] Next Generation Redshift...2020/02/18 · © 2020, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS Black Belt Online Seminar](https://img.pdfslide.tips/doc/110x75/5ff8300ce9c8d04d16518c3d/aws-black-belt-online-seminar-next-generation-redshift-20200218-2020.jpg)





















![[AWSマイスターシリーズ] Amazon Redshift](https://img.pdfslide.tips/doc/110x75/54831970b47959050d8b49ab/aws-amazon-redshift.jpg)



