Embed Size (px)
Citation preview

목차
• 클라우드 컴퓨팅 소개
• AWS 빅데이터 아키텍쳐
• S3 소개
• ElasticMapReduce 맛보기

클라우드 컴퓨팅이란?

클라우드 컴퓨팅 정의
• 컴퓨팅 자원(하드웨어, 소프트웨어 등등)을
네트웍을 통해 서비스 형태로 사용하는 것.
• 키워드: “No Provisioning”, “Pay As You Go”,
“Virtualization”
–클라우드상의 자원들을 필요한만큼 (거의) 실시간
으로 할당하여 사용한큼 지불한다.

클라우드 컴퓨팅의 장점
• No Up-Front Investment
–데이터센터의 공간을 사거나 하드웨어/소프트웨어등의 직접 살 필요가 없다.
• No Provisioning Delay
–용량증대등으로 인해 서버를 늘려야할 경우 주문,설치등으로 인한 지연이 없다.
• No Idling Computing Resource
–쓴만큼 지불하기 때문에 리소스 관리를 적절히 하면 비용을 최소화할 수 있다.

클라우드 컴퓨팅의 영향
• Easy to start an online service start-up
–클라우드 컴퓨팅으로 인해 초기 시작비용이 대폭
감소
–오픈소스로 인해 개발에 드는 비용도 대폭 감소
• Advance of Virtualization Technology
–데이터센터 자체를 Virtualization하려는 노력이 진
행중.
• Rackspace와 NASA 주도의 Open Stack.
• Facebook의 Open Compute (데이터센터 설계를 오픈소스
화)
클라우드 컴퓨팅의 단점
• Strong Tie-up with Provider–사용하는 클라우드 컴퓨팅 업체의 서비스에 최적화되어 다른
환경으로의 이전이 어려울 수 있다.
• Downtime–해당 업체 서비스에 문제가 있을 경우 같이 영향을 받는다
(2012년 6월 AWS 서비스 문제로 Netflix, Instagram, Pinterest 서비스 다운)
• Security Concern–데이터들이 외부에 더 노출됨 (데이터전송시 등등)
• More expensive–많은 업체들이 규모가 커지면 결국 자체 데이터센터를 설립
(Microsoft, Facebook, Google, Yahoo 등등)

AWS기반 빅데이터 아키덱쳐

AWS
• 가장 큰 클라우드 컴퓨팅 서비스 업체.
• 2002년 아마존의 상품데이터를 API로 제공하면서 시작하여현재 30여개의 서비스를 전세계 7개의 지역에서 제공.– 대부분의 서비스들이 오픈소스 프로젝트들을 기반으로 함.
ElasticMapReduce와 ElastiCache.
• 사용고객– Netflix, Zynga등의 상장업체들도 사용.
– 실리콘밸리 스타트업의 75% 이상이 AWS를 사용.
– 일부 국내 업체들도 사용시작.
• 다양한 종류의 소프트웨어/플랫폼 서비스를 제공.– AWS의 서비스만으로 쉽게 온라인서비스 생성.
– 뒤에서 일부 서비스를 따로 설명.

EC2 – Elastic Compute Cloud (1)
• AWS의 서버 호스팅 서비스.–리눅스 혹은 윈도우 서버를 론치하고 어카운트를 생성하
여 로그인 가능 (구글앱엔진과의 가장 큰 차이점).
–가상 서버들이라 전용서버에 비해 성능이 떨어짐.
• 다양한 종류의 서버 타입 제공–http://aws.amazon.com/ec2/
–예를 들어 미국 동부에서 스몰타입의 무료 리눅스 서버를하나 할당시 시간당 8.5센트의 비용지불.• 1.7GB 메모리, 1 가상코어, 160GB 하드디스크
– Incoming network bandwidth는 공짜이지만 outgoing은유료.

EC2 – Elastic Compute Cloud (2)
•세 가지 종류의 구매 옵션
구매 옵션 설명
On-Demand 시간당 비용을 지불되며 가장 흔히
사용하는 옵션
Reserved 1년이나 3년간 사용을 보장하고
1/3 정도 디스카운트를 받는 옵션
Spot
Instance
일종의 경매방식으로 놀고 있는 리
소스들을 보다 싼 비용으로 사용할
수 있는 옵션

AWS 빅데이터
아키덱쳐
S3Elastic
MapReduc
e
RDS
DynamoDB
/SimpleDB/
HBase
CloudSear
ch
Simple Workflow (SWF)
S3 API,
AWS
Direct
Connec
t,
AWS
Import

S3 구성• http://aws.amazon.com/s3/
• S3는 아마존이 제공하는 대용량 클라우드
스토리지 서비스
• S3는 데이터 저장관리를 위해 계층적 구조
를 제공
• 글로벌 내임스페이스를 제공하기 때문
에 톱레벨 디렉토리 이름 선정에 주의.
• S3에서는 디렉토리를 버킷(Bucket)이라
고 부름
• 버킷이나 파일별로 액세스 컨트롤 가능

S3 사용• 크게 세가지 방법이 흔히 쓰임
• AWS가 제공하는 웹기반 콘솔
• 3rd party가 제공해주는 프로그램
• Cloudberry S3 Explorer
• S3 Browser
• AWS 혹은 3rd party 제공 API (s3cmd)
• s3cmd가 가장 유명하고 유용
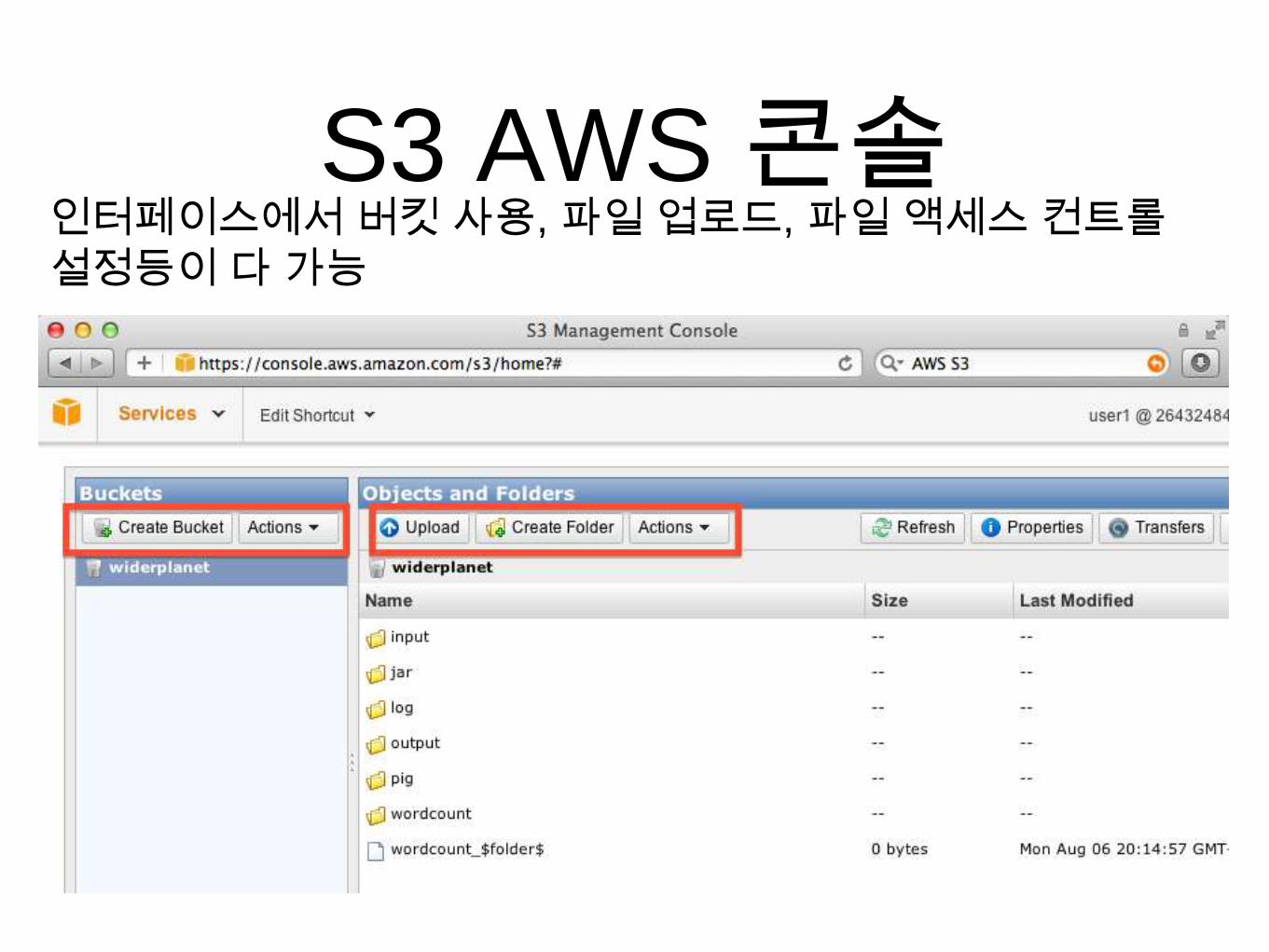
S3 AWS 콘솔인터페이스에서 버킷 사용, 파일 업로드, 파일 액세스 컨트롤
설정등이 다 가능

S3cmd • 크게 세가지 방법이 흔히 쓰임
• AWS가 제공하는 웹기반 콘솔
• 3rd party가 제공해주는 프로그램
• Cloudberry S3 Explorer
• S3 Browser
• AWS 혹은 3rd party 제공 API (s3cmd)
• s3cmd가 가장 유명하고 유용

S3cmd 설치
• python이 수행에 필요. 두 가지 방법
1. Ubuntu 머신에서는 “sudo apt-get install s3cmd”를 실행.
2. http://sourceforge.net/projects/s3tools/files/s3cmd/에서 패
키지를 선택후 다운로드.
• s3cmd-1.0.1.zip를 다운로드
• 압축 해제 후 패키지의 루트 디렉토리로 이동 후 아래 명령을
실행
• sudo python setup.py install
• 마지막으로 이 패키지에 사용할 AWS 어카운트 정보를 설정하는
데 AWS Access ID Key와 Secret Key가 필요.
• s3cmd --configure

s3cmd 사용예
• S3 서비스 싸인업이 필요
• 버킷 만들기예
• s3cmd mb s3://(버킷이름)
• 파일 복사 예
• s3cmd put map.java s3://(버킷이름)/map.java
• 특정 버킷 밑의 파일들 다 보기
• s3cmd ls --recursive s3://(버킷이름)
• 파일이나 디렉토리 삭제
• s3cmd del --force --recursive s3://(버킷이름)/input

ElasticMapReduce 맛보기

ElasticMapReduce
개요• AWS에서 제공해주는 Managed On-Demand 하둡서비
스.
• 필요한때 필요한 노드만큼 하둡 클러스터를 셋업하고 사용이 끝나면 클러스터를 셧다운. 결국 EC2 서버를 실행하는 것이기 때문에 실행된 만큼 EC2 서버 비용이 나감.
• 입력데이터와 최종출력데이터는 S3에 저장. S3가 결국 HDFS의 역할을 수행. 스크립트, JAR 파일등도S3에 저장되어 있어야함.
• 2012년 9월 현재 지원되는 하둡 버전은 1.0.3 (아마존버전)과 0.20.205(MapR버전)이고 Pig 버전은 0.9.1

ElasticMapReduce
사용방법• ElasticMapReduce 서비스에 싸인업해야하며 크게 두가지 방법이
존재.
• Wizard를 이용해서 사용할때는 AWS 콘솔에 로그인하며 됨.
• 커맨드라인 툴을 사용할 경우 대개 별도 라이브러리를 다운로드받아야하며 AWS시 어카운트셋업시 발급받는 AWS Access Key ID와 Secret Access Key를 알고 있어야 함.
• Amazon EMR Ruby 클라이언트를 사용할 예정.
• S3의 조작을 위해서는 s3cmd라는 툴이 설치하면 편리 (앞서 설명)
• sudo apt-get install s3cmd
• s3cmd –configure를 실행하면 위의 두 가지 키를 물어본다.

ElasticMapReduce
사용시 주의점• EMR에 사용되는 S3 버킷의 이름은 _나
대문자를 포함하면 에러 발생.
• 한 어카운트에서 EMR로 론치할 수 있는머신의 수에는 EC2와 마찬가지로 20개의 제약이 존재.
• EMR 사용시 지역(region)을 선택해야하는데 그 지역에서 할당된 key-pair를 사용해야함!!
• key-pair는 지역에 종속됨을 명심.

Interactive Job Flow (1)
• 앞서 언급한 위저드형식의
ElasticMapReduce Job Launcher이다.
• AWS 콘솔에서 실행하던지
http://console.aws.amazon.com/elasticm
apreduce/home를 방문.
• 위저드를 통해 코드의 위치, 입출력위치,
필요한 서버의 수와 타입등을 지정한다.

Interactive Job Flow (2)
• Create New Job Flow 버튼을 클릭
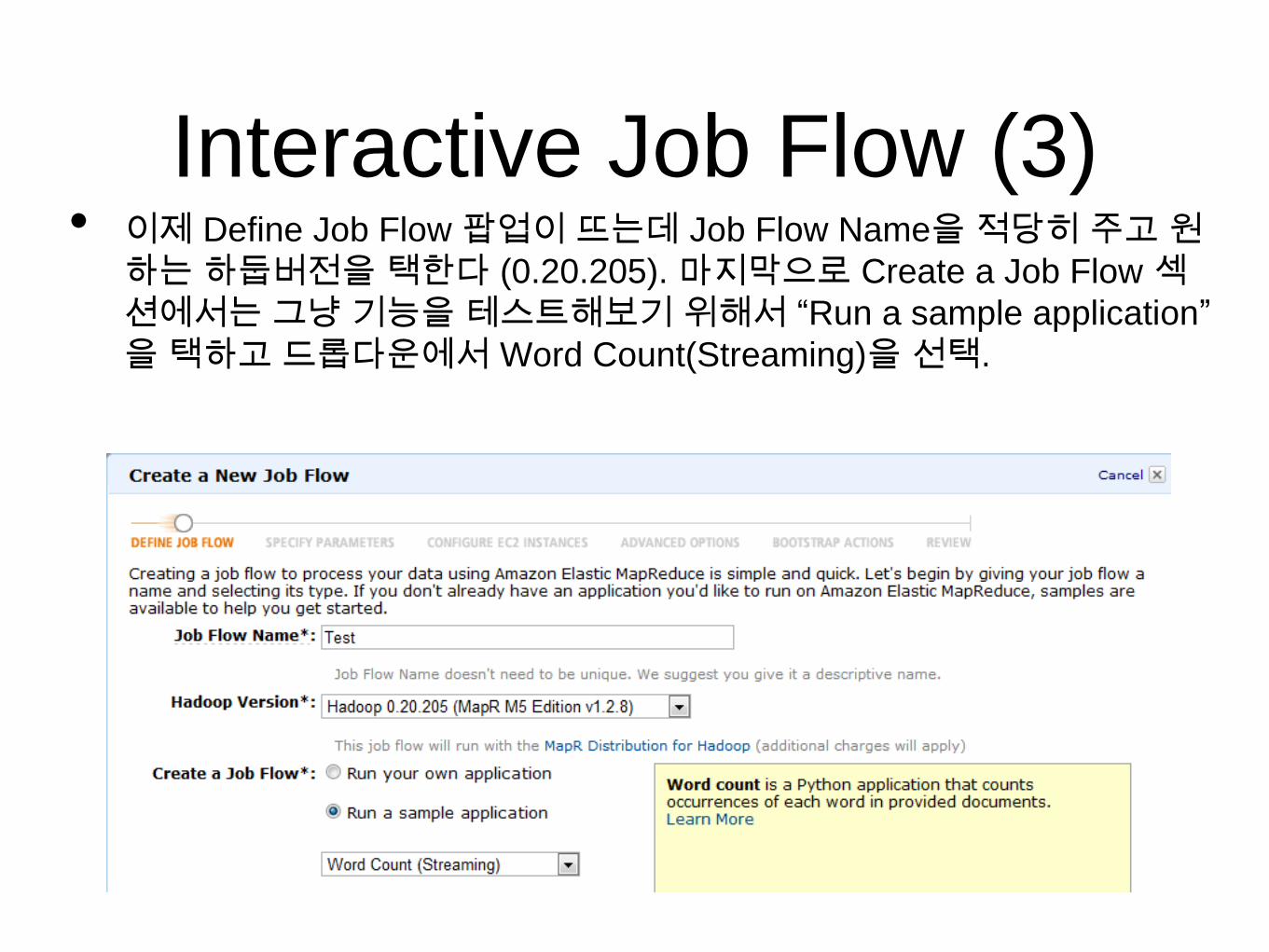
Interactive Job Flow (3)• 이제 Define Job Flow 팝업이 뜨는데 Job Flow Name을 적당히 주고 원
하는 하둡버전을 택한다 (0.20.205). 마지막으로 Create a Job Flow 섹
션에서는 그냥 기능을 테스트해보기 위해서 “Run a sample application”
을 택하고 드롭다운에서 Word Count(Streaming)을 선택.

Interactive Job Flow (4)• 다음 화면은 잡의 파라미터를 지정해주는 부분이다 (코드와 입출력파일
위치). 입력파일과 코드들(mapper, reducer)는 디폴트로 지정되는 것을
사용하면 되지만 출력은 자신만의 S3 버킷을 지정해야 한다.

Interactive Job Flow (5)• 다음은 Configure EC2 INSTANCES 화면이다. 여기서는 몇대의 서버를
어떤 타입으로 실행할지 결정한다. 마스터 인스턴스는 1대가 꼭 필요하
며 Core Instance Group에서 Large (m1.large)로 1대나 2대를 할당한다
(Task Instance는 0로 남겨둔다).

Interactive Job Flow (6)• Advanced Options와 Boostrap Actions은 디폴트를 그대로 택한다.
• 마지막 Review 페이지에서 “Create Job Flow” 버튼을 클릭한다.
• 그러면 아래와 같은 팝업이 뜨면서 실행이 시작되었음을 알린다.

Interactive Job Flow (7)• ElasticMapReduce 콘솔로 가보면 지금 실행한 잡의 상태를 볼 수 있다.
• 실행이 완료되었으면 반드시 Terminate한다.

Interactive Job Flow (8)
• 마지막으로 앞서 지정한 S3 출력 위치로 가서 아웃풋이 제대로 만들어
졌는지 확인한다.

EMR Ruby Client 설치
• 루비 1.8 이상이 필요.
• sudo apt-get install ruby
• http://elasticmapreduce.s3.amazonaws.com/elastic-mapreduce-ruby.zip 다운로드후 적당한 곳에 설치. 이 디렉토리를 PATH에 추가.
• 루트 디렉토리에 credentials.json이란 파일 생성 후 아래내용을 채워넣는다.• {
• "access-id": "",
• "private-key": "",
• "key-pair": "",
• "key-pair-file": "",
• "region": "ap-southeast-1"
• }
• 잘 설치되었는지 보려면 “elastic-mapreduce –list”를 실행

EMR Ruby CLI 명령예
(1)• 앞서 위저드의 예에서처럼 입력파일과 스크립트 파일을 S3에 업로드
• 다음으로 --create 명령을 이용해 Job flow를 생성
• $ elastic-mapreduce --create --name “EMR CLI test”--hadoop-version “0.20.205” --pig-script --argss3://[your_bucket_name]/[your_pig_script_path]
• Created job flow j-3LYO0YQE2PTJQ
• 리턴된 job flow ID를 이용해 실행상태를 볼 수도 있고 다른 액션을 더 택할 수 있음.
• $ elastic-mapreduce --describe --jobflow j-3LYO0YQE2PTJQ
• 상태는 결과 JSON 아웃풋에서 “JobFlows": "ExecutionStatusDetail": "State"의 값을 보면 된다. 이 값은“STARTING”, “RUNNING”, “COMPLETED”, “FAILED”중의 하나가된다.

EMR Ruby CLI 명령예
(2)• 하둡클러스터의 수와 타입 등의 컨트롤 파라미터
• --num-instances: 디폴트는 1
• --slave-instance-type: 디폴트는 m1.small
• --master-instance-type: 디폴트는 m1.small
• 기타 파라미터
• --alive : 이 파라미터로 생성된 경우 하둡클러스터는 바로terminate되지 않는다. 이 때는 아래 명령과 Job flow ID를 이용해명시적으로 클러스터를 셧다운해야한다
• $ elastic-mapreduce --terminate --jobflow j-3LYO0YQE2PTJQ






























