Embed Size (px)
Citation preview

ビックデータ最適解とAWSにおける新しい武器
アマゾン ウェブ サービス ジャパン株式会社ソリューションアーキテクト 桑野 章弘

⾃⼰紹介
桑野 章弘(くわの あきひろ)ソリューションアーキテクト
主にメディア系のお客様を担当しております。
渋⾕のインフラエンジニア(仮)しておりました
好きなAWSのサービス:ElastiCache
好きなデータストア:MongoDB

Introduction
AWSにはビックデータでも様々なサービスがあります、それらサービスを使⽤して最適なビッグデータ処理基盤を構築する場合のベストプラクティスについてまとめていきます

ビッグデータ処理基盤 on クラウド:変わらないこと
• データを収集して、分析し、可視化• 分析では、標準的な技術・OSSや商⽤ソフトウェアを活⽤
• AWSのマネージドサービスを活⽤することでより便利に
収集 分析 可視化データを収集 ⼤規模データ
を⾼速に分析⼈間が参照しやすい形に
クラウド+ビッグデータ:ポイント
データは加⼯せず全期間を残すスケールアウトで解決する
CLOUD BIG DATA+
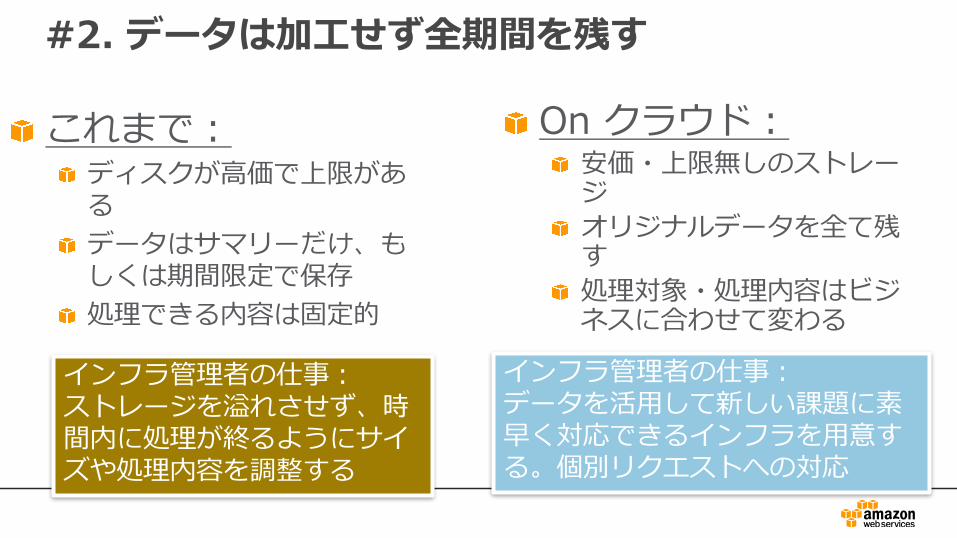
#2. データは加⼯せず全期間を残す
これまで:ディスクが⾼価で上限があるデータはサマリーだけ、もしくは期間限定で保存処理できる内容は固定的
On クラウド:安価・上限無しのストレージオリジナルデータを全て残す処理対象・処理内容はビジネスに合わせて変わる
インフラ管理者の仕事:データを活⽤して新しい課題に素早く対応できるインフラを⽤意する。個別リクエストへの対応
インフラ管理者の仕事:ストレージを溢れさせず、時間内に処理が終るようにサイズや処理内容を調整する
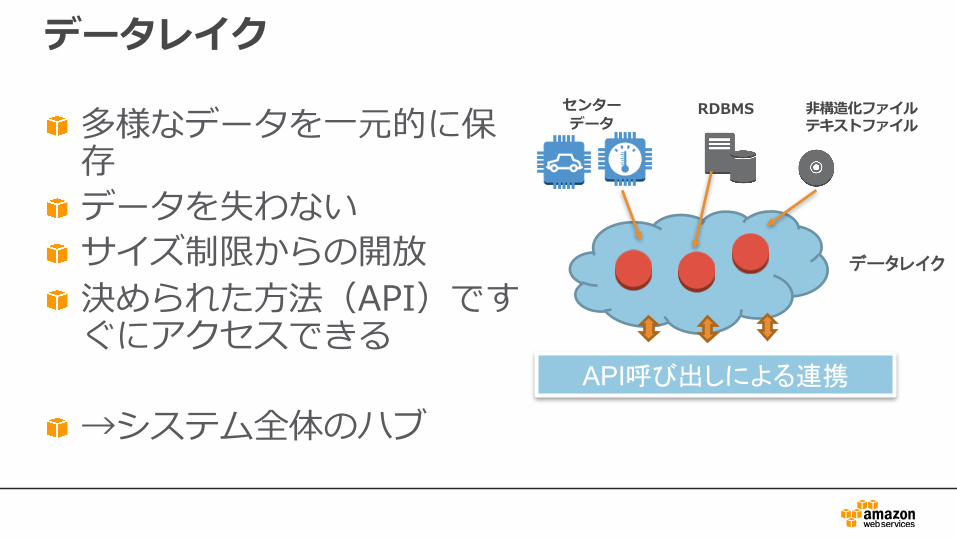
データレイク
多様なデータを⼀元的に保存データを失わないサイズ制限からの開放決められた⽅法(API)ですぐにアクセスできる
→システム全体のハブ
センターデータ
⾮構造化ファイルテキストファイル
RDBMS
データレイク
API呼び出しによる連携

⼤規模データ分析に必要な基盤
• データを消さずにデータレイクに集め、分析につなげる
収集 データレイク(保存)
分析 可視化
データを収集し、データレイクへ格納
全期間保存。共通APIでアクセス
ニーズ #1
分析 可視化ニーズ #2
API
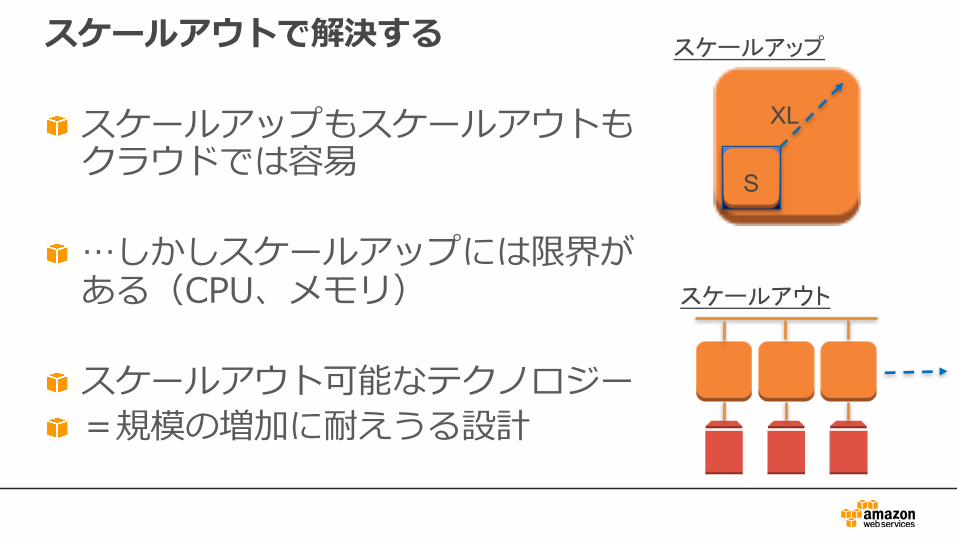
スケールアウトで解決する
スケールアップもスケールアウトもクラウドでは容易
…しかしスケールアップには限界がある(CPU、メモリ)
スケールアウト可能なテクノロジー=規模の増加に耐えうる設計
S
XL
スケールアップ
スケールアウト

スケールアウト ≠ ⾼価
クラウドではスケールアウトがコスト・時間の両⾯で効率的必要な時に必要なだけノードを追加できるノードを増やしても利⽤時間が短くなればコストは同じ
処理時間8時間 処理時間
2時間
JOB16ノードに
拡張
JOB
4ノード×8時間=32
16ノード×2時間=32
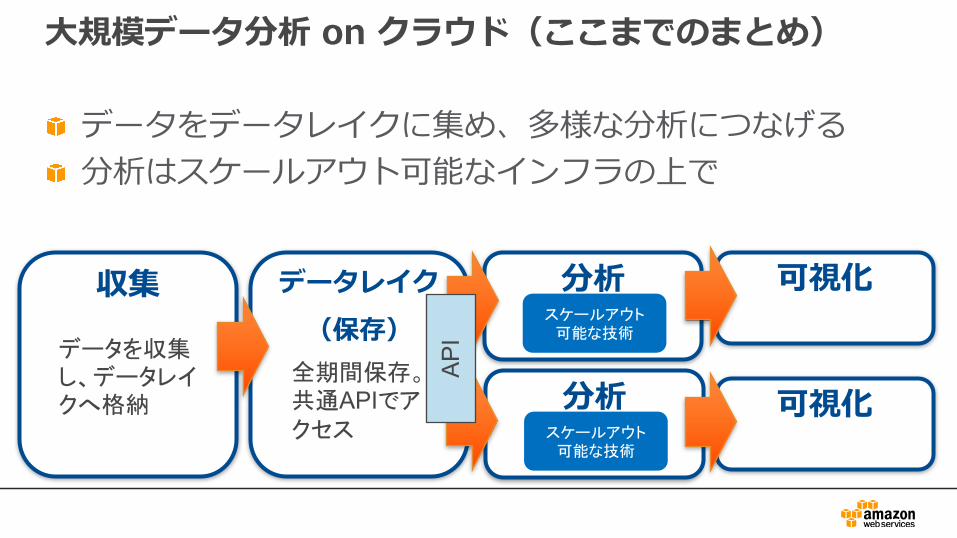
⼤規模データ分析 on クラウド(ここまでのまとめ)
データをデータレイクに集め、多様な分析につなげる分析はスケールアウト可能なインフラの上で
収集 データレイク(保存)
分析 可視化
データを収集し、データレイクへ格納
全期間保存。共通APIでアクセス
可視化
スケールアウト可能な技術
分析スケールアウト
可能な技術AP
I

AWS+ビッグデータ分析基盤

EC2があれば何でも出来るけど…マネージドサービスで管理負荷を低減可能
電源・ネットワークラッキング
HWメンテナンス
OSパッチ
ミドルウェアパッチ定形運⽤設計
スケールアウト設計
ミドルウェア導⼊
OS導⼊
アプリケーション作成
オンプレミス 独⾃構築 on EC2 AWSマネージドサービスお客様がご担当する作業 AWSが提供するマネージド機能
電源・ネットワークラッキング
HWメンテナンス
OSパッチ
ミドルウェアパッチ定形運⽤設計
スケールアウト設計
ミドルウェア導⼊
OS導⼊
アプリケーション作成
電源・ネットワークラッキング
HWメンテナンス
OSパッチ
ミドルウェアパッチ定形運⽤設計
スケールアウト設計
ミドルウェア導⼊
OS導⼊
アプリケーション作成
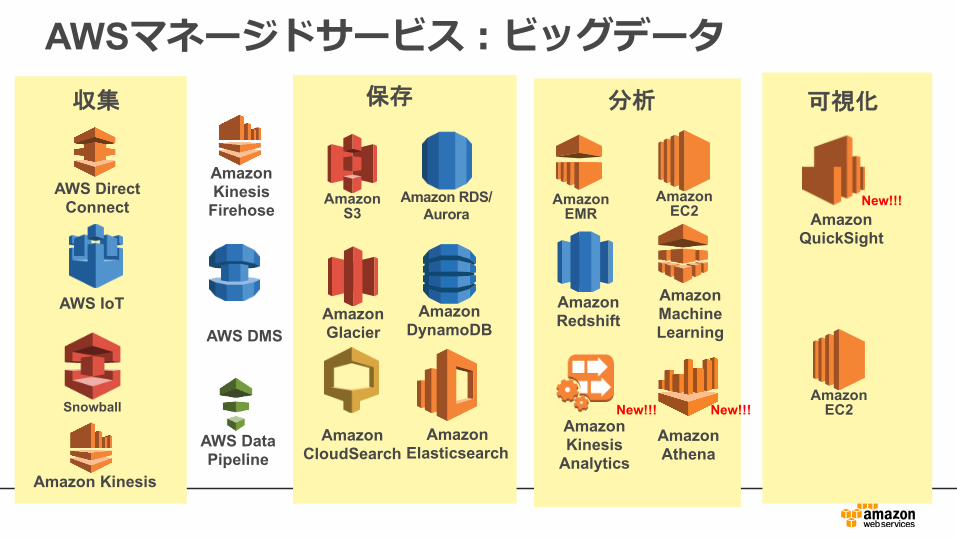
分析保存
Amazon Glacier
AmazonS3
Amazon DynamoDB
Amazon RDS/ Aurora
AWSマネージドサービス:ビッグデータ
AWS Data Pipeline
Amazon CloudSearch
Amazon EMR
Amazon EC2
Amazon Redshift
Amazon MachineLearning
AWS IoT
AWS Direct Connect
収集
Amazon Kinesis
Amazon Kinesis
Firehose
Amazon Elasticsearch
Amazon Kinesis
Analytics
Amazon QuickSight
AWS DMS
New!!!
New!!!
Snowball
可視化
Amazon EC2
Amazon Athena
New!!!
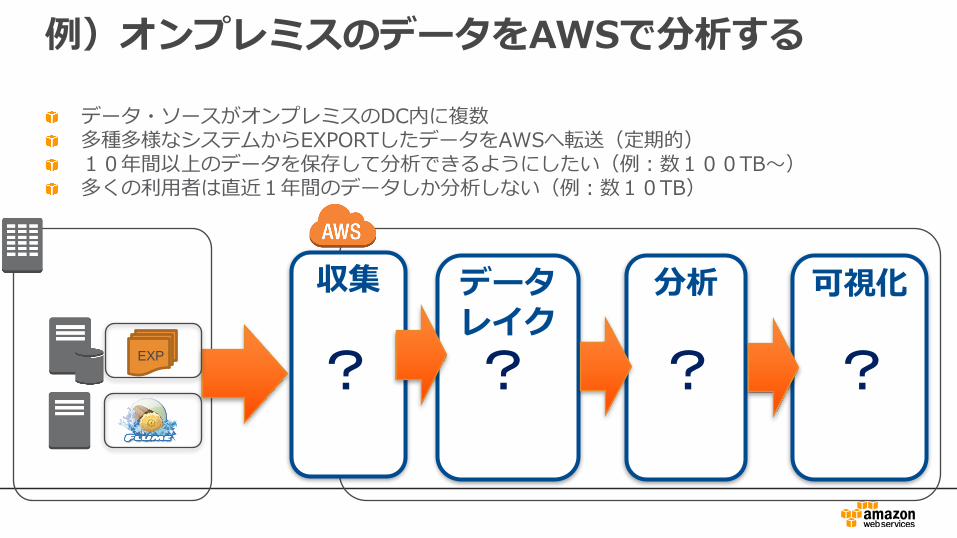
例)オンプレミスのデータをAWSで分析する
データ・ソースがオンプレミスのDC内に複数多種多様なシステムからEXPORTしたデータをAWSへ転送(定期的)10年間以上のデータを保存して分析できるようにしたい(例:数100TB〜)多くの利⽤者は直近1年間のデータしか分析しない(例:数10TB)
収集 データレイク
分析 可視化
EXP
? ? ? ?
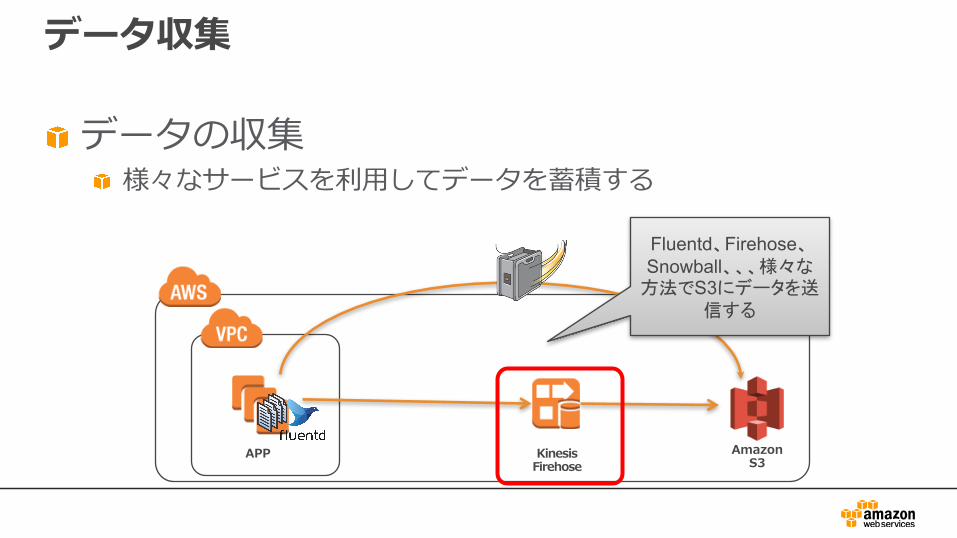
データ収集
データの収集様々なサービスを利⽤してデータを蓄積する
APP AmazonS3
Kinesis Firehose
Fluentd、Firehose、Snowball、、、様々な
方法でS3にデータを送信する
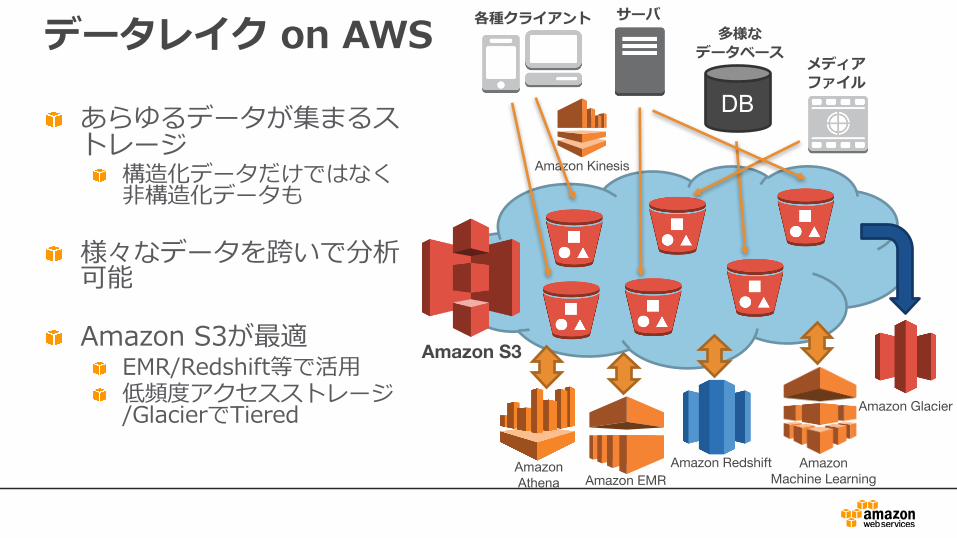
データレイク on AWS
あらゆるデータが集まるストレージ
構造化データだけではなく⾮構造化データも
様々なデータを跨いで分析可能
Amazon S3が最適EMR/Redshift等で活⽤低頻度アクセスストレージ/GlacierでTiered
DB
各種クライアント
メディアファイル
多様なデータベース
サーバ
Amazon Kinesis
Amazon S3
Amazon Glacier
Amazon EMRAmazon Redshift Amazon
Machine LearningAmazon Athena

全てのログはS3へ貯め続ける
S3はAWSのデータのハブ(=データレイク)として⾮常に重要な役割を担っているあとから⾃由に分析処理(ETL)を変更可能S3の耐久性で安全に保存可能消したログは⼆度と帰ってこない⾮常に安価にデータを保存できる(Glacierや、低頻度アクセスストレージも併⽤可能)
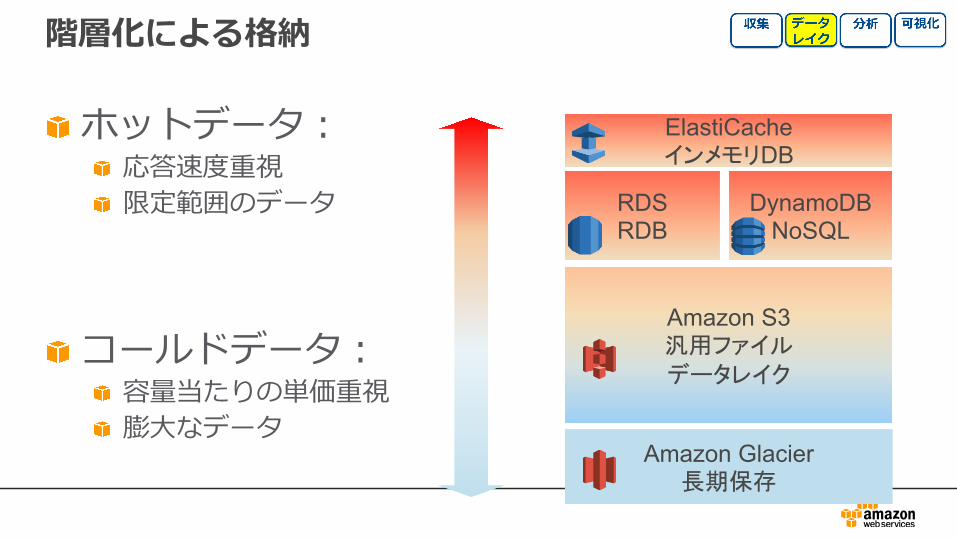
ElastiCacheインメモリDB
RDSRDB
DynamoDBNoSQL
Amazon S3汎用ファイルデータレイク
Amazon Glacier長期保存
階層化による格納
ホットデータ:応答速度重視限定範囲のデータ
コールドデータ:容量当たりの単価重視膨⼤なデータ

スケールアウト可能な分析サービス
Amazon RedshiftマネージドRDBMSSQL(標準)スケールアウト可能
Amazon Elastic MapReduce (EMR)
マネージドHadoopHadoop/Spark(標準)スケールアウト可能
OR
マネージド, 標準技術, スケールアウトが選択の鍵
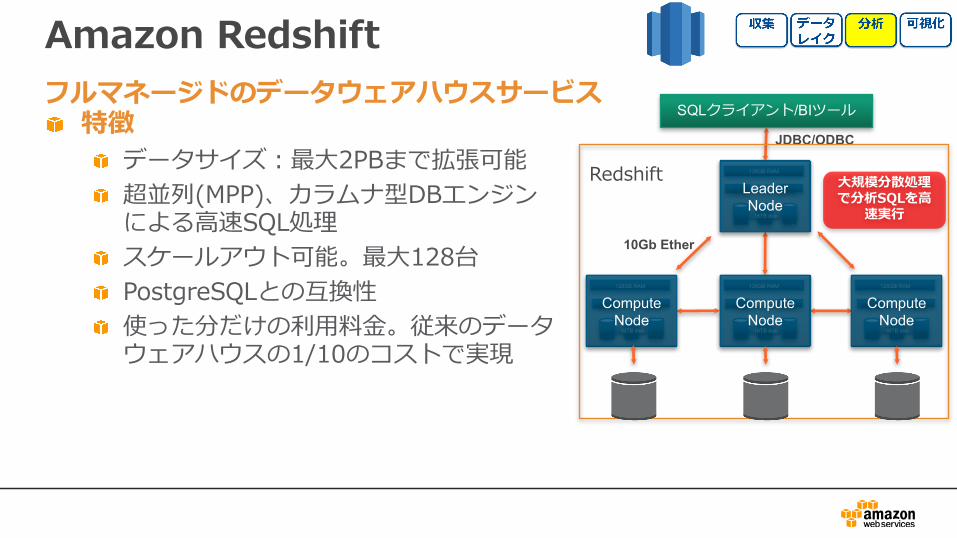
Amazon Redshift
特徴データサイズ:最⼤2PBまで拡張可能超並列(MPP)、カラムナ型DBエンジンによる⾼速SQL処理スケールアウト可能。最⼤128台PostgreSQLとの互換性使った分だけの利⽤料⾦。従来のデータウェアハウスの1/10のコストで実現
フルマネージドのデータウェアハウスサービス
10Gb Ether
JDBC/ODBC
Redshift ⼤規模分散処理で分析SQLを⾼
速実⾏

SQLを分散処理(スケールアウト)
SELECT * FROM …
SQLをコンピュートノードへ配信
CPU CPU CPU CPU CPU CPU
リーダーノード
コンピュートノード
ノードに直結した⾼速ストレージ

SQLを分散処理(スケールアウト)
SELECT * FROM …
CPU CPU CPU CPU CPU CPU
リーダーノード
コンピュートノード
ノードに直結した⾼速ストレージ

SQLを分散処理(スケールアウト)
SELECT * FROM …
SQLをコンピュートノードへ配信
CPU CPU CPU CPU CPU CPU
リーダーノード
コンピュートノード
分散してSQLを処理
ノードに直結した⾼速ストレージ

フルマネージド型のRDBMS
運⽤管理に必要な機能をビルトインS3からの⾼速ロード&アンロード⾃動バックアップ&リストアモニタリングデータの再編成クエリの解析
:

Amazon Elastic MapReduce(EMR)
⼤規模データ処理をHadoop/Sparkなどの分散処理フレームワークを使って効率的に処理
AWS上の分散処理サービス• 簡単かつ安全にBig Dataを処理• 多数のアプリケーションサポート
簡単スタート• 数クリックでセットアップ完了• 分散処理アプリも簡単セットアップ
低コスト• ハードウェアへの投資不要• 従量課⾦制• 処理の完了後、クラスタ削除• Spotインスタンスの活⽤
Hadoop
分散処理アプリ
分散処理基盤
Amazon EMRクラスタ
簡単に複製リサイズも1クリックSpotも利⽤可能

EMRFS: S3をHDFSの様に扱う
“s3://” と指定するだけでHDFSと同様にS3にアクセス計算資源とストレージを分離でき
コスト⾯でもメリット⼤クラスタのシャットダウンが可能
クラスタを消してもデータをロストしない複数クラスタ間でデータ共有が簡単データの⾼い耐久性(S3)
EMR
EMR
Amazon S3

EMRで稼動するSQLエンジンSQLエンジン操作アプリ ストレージ
YARN
MapReduce Tez Spark
Hive SparkSQL
Presto
JDBC
/ O
DBC
Hiv
e M
etas
tore
HDFS
EMRFS
Hue
Zeppelin
SELECT…

データ分析プラットフォーム⽐較Amazon Redshift Amazon EMR
分類 大規模データ処理に特化したマネージドRDBMS
Hadoop/Spark等分散処理フレームワークのマネージド環境
処理系 SQL(PostgreSQLと互換性) アプリケーションに依存:Hive、Pig …Presto等でSQLでの分析も可能
スケールアウト 可能 可能
ストレージの種類 高速なローカルストレージ HDFS、もしくはEMRFSでS3上のデータ
を取り込まずにアクセス
ノードとストレージの分離
ノードとストレージは同時に増加・削減
ストレージに影響を与えずにノード増減が
可能(EMRFSの場合)
最大処理サイズ 2PB(圧縮後) 上限無し(EMRFSの場合)
処理レイテンシー Low • Presto (Low)• Hive (Midium~High)
運用管理 運用管理に必要な機能がビルトイン 分散処理系+OSSアプリ環境を容易に
分析ツール、ETL等 JDBC/ODBC+プッシュバック対応等
ネイティブレベルでの対応JDBC/ODBC経由もしくはHive メタストア経由で多くの環境がサポート

分析サービスの選択例
Amazon RedshiftSQL処理に特化・⾼速ローカルディスク上で処理
Amazon Elastic MapReduce (EMR)
⾃由にアプリケーションを選択EMRFSでS3データにアクセス
S3に直接アクセスできるEMRFSを使い、データレイク上の全期間のデータ分析に活用
頻繁にアクセスされるホットデータを格納し、高速なSQLアクセス機能を活用して分析

分析に必要なプリプロセスをどこで実⾏するか?
AWSに転送前のオンプレミス環境で実施スケールアウトが困難データレイクをオンプレミス側に⽤意する必要がある
S3上のファイルをElastic MapReduceで変換スケールアウト可能なインフラで処理⾔語・アプリを柔軟に選択可能データレイクを含むAWSサービスへの接続性
Redshift内でSQLで変換スケールアウト可能Redshift内に取り込んだデータのみ操作可能
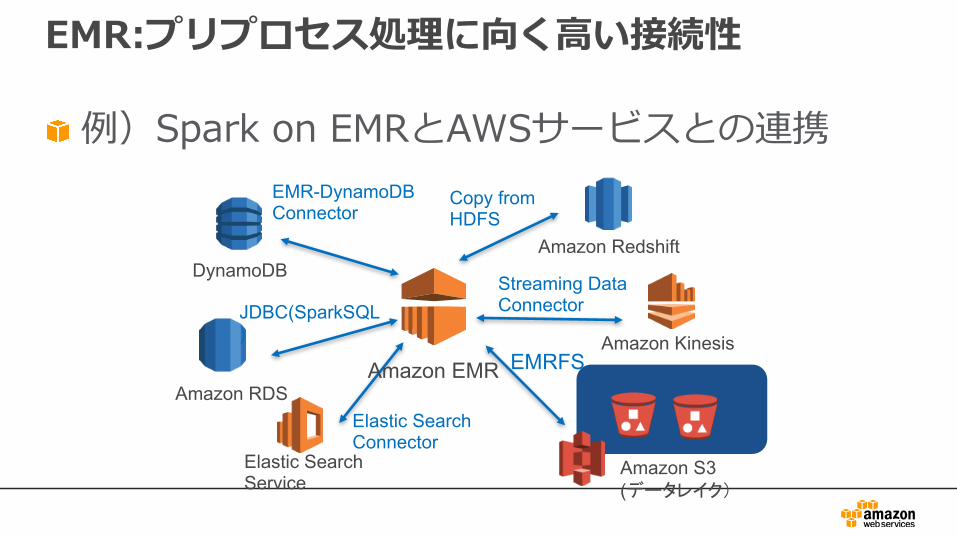
EMR:プリプロセス処理に向く⾼い接続性
例)Spark on EMRとAWSサービスとの連携
Amazon EMR
Amazon S3(データレイク)
DynamoDB
Amazon RDS
Amazon Kinesis
Amazon Redshift
Elastic SearchService
EMRFS
Streaming DataConnector
Copy fromHDFS
EMR-DynamoDBConnector
JDBC(SparkSQL)
Elastic SearchConnector

例)プリプロセスの構成例
Amazon RedshiftAmazon EMR• ⾮構造化データの構造化・整形• 構造化データのフィルタリング• S3へ変形済データを出⼒
サマリーテーブル
ファクトテーブル
マート・サマリー表の更新をSQLで実⾏
Amazon S3
全データ 変形済データ

Amazon Athenaリリース!
Amazon S3に置いたデータをインタラクティブにSQL実⾏可能AthenaはPrestoで提供するSQL Engineが利⽤でき、JSON, CSV, ログファイル, 区切り⽂字のあるテキストファイル, Apache Parquet, Apache ORCに対してクエリが可能ペタバイトクラスのデータに対するクエリをサポート、データをS3から取り込む⼿間はない、ANSI-SQLもサポートJDBCでのアクセスも可能バージニア、オレゴンで利⽤可能スキャンしたデータ1TBあたり$5の料⾦(⽶国)

Athenaを活⽤することでプリプロセスの部分が⼤幅に簡略化される
Hadoop関連の知識も必要無い
Amazon RedshiftAmazon Athena• ⾮構造化データの構造化・整形• 構造化データのフィルタリング• S3へ変形済データを出⼒
サマリーテーブル
ファクトテーブル
マート・サマリー表の更新をSQLで実⾏
Amazon S3
全データ 変形済データ
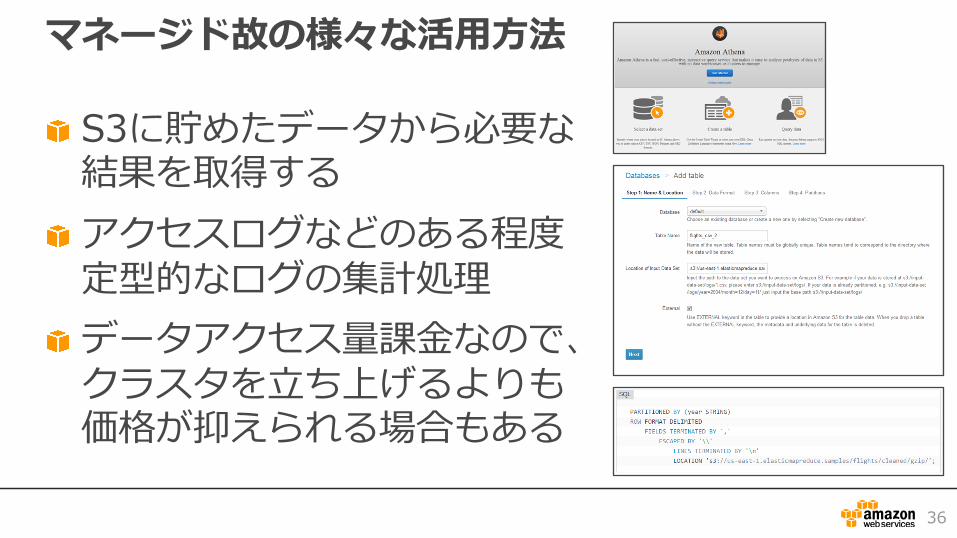
マネージド故の様々な活⽤⽅法
S3に貯めたデータから必要な結果を取得するアクセスログなどのある程度定型的なログの集計処理データアクセス量課⾦なので、クラスタを⽴ち上げるよりも価格が抑えられる場合もある
36
Athena Tips
Amazon AthenaはリージョンまたいだAmazon S3バケットにもクエリできるので、東京リージョンにあるS3にもアクセス可
転送量とレイテンシが許容できるなら今からでも使⽤可能
37

Athena Tips
Amazon S3の標準 - 低頻度アクセスの活⽤Amazon Athenaで何回もクエリしないようなデータには、Amazon S3の標準 - 低頻度アクセスにすることで耐久性等は標準そのままに、容量単価を節約
38
Athena Tips
Amazon Athenaの課⾦対象は処理したサイズではなくスキャンしたサイズ
データを単純に圧縮するだけで安価にパーティションで対象ファイルを絞ったり、列指向フォーマット(ORC、Parquet)にすることでもっと安くすることも可能
39

FeedBackお願いします!
40

可視化部分は⽤途に応じて選択可能
EC2+BIツール多彩なパートナーソリューション・OSSをEC2上で活⽤
Amazon QuickSight専⾨家不要のBIサービスAWS内外のデータソースにアクセス

分析
分析データレイク
選択の例:全体図データをAWSへ転送、S3で収集&保存、データレイクとするホットデータ(直近データ)分析環境としてRedshift全期間データ分析環境としてEMR
収集可視化
Presto/EMR
Redshift
QuickSightEXP
Amazon S3
BI+EC2
Direct Connect
プリプロセスEMR
全データ 変形済
Athena

事例で⾒るビッグデータ処理 on AWS
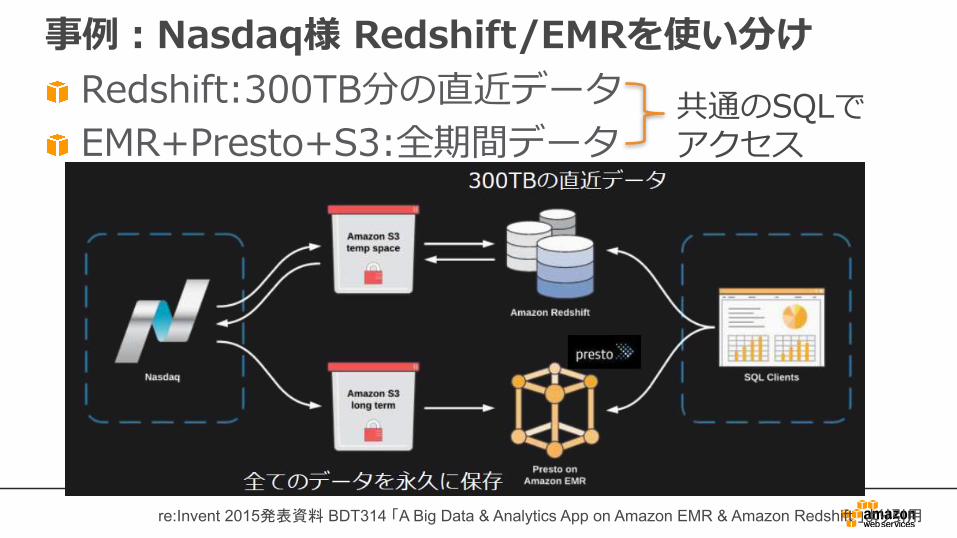
事例:Nasdaq様 Redshift/EMRを使い分けRedshift:300TB分の直近データEMR+Presto+S3:全期間データ
共通のSQLでアクセス
re:Invent 2015発表資料 BDT314 「A Big Data & Analytics App on Amazon EMR & Amazon Redshift 」より引用

事例:Finra様 750億イベント/⽇の処理基盤
• S3をデータ共有サービスとして定義し、EMRやRedshiftからアクセス
re:Invent 2015発表資料 BDT305 「Amazon EMR Deep Dive & Best Practices」より引用

Finra様:DWHアプライアンスとHive/Tez+S3⽐較S3に置いたままのデータをHive/Tez on EMRでアクセスDWHアプライアンスとの⽐較で⼗分な速度を実現
re:Invent 2015発表資料 BDT305 「Amazon EMR Deep Dive & Best Practices」より引用

事例:スマートニュース様マネージド・サービスを中⼼とした技術選択
http://www.slideshare.net/smartnews/20160127-building-a-sustainable-data-platform-on-aws より引用
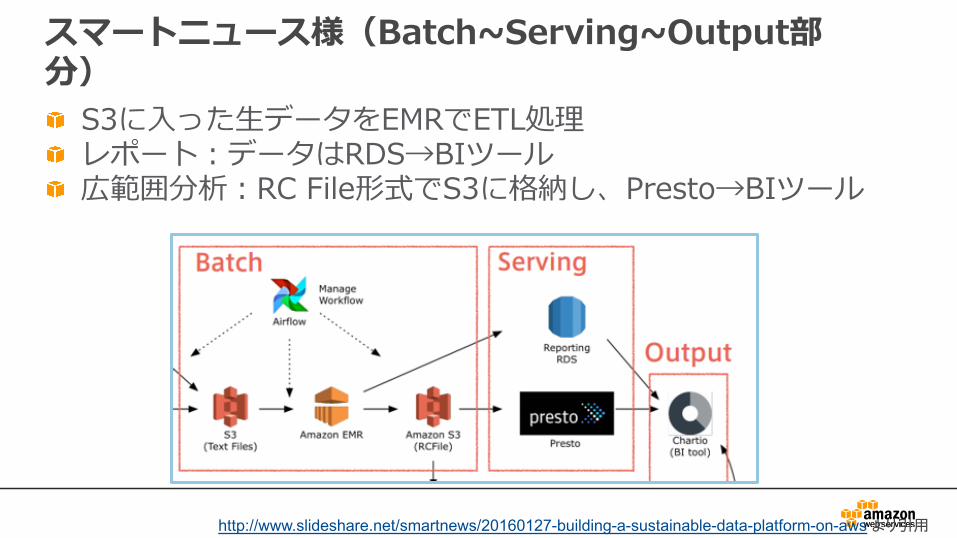
スマートニュース様(Batch~Serving~Output部分)
S3に⼊った⽣データをEMRでETL処理レポート:データはRDS→BIツール広範囲分析:RC File形式でS3に格納し、Presto→BIツール
http://www.slideshare.net/smartnews/20160127-building-a-sustainable-data-platform-on-aws より引用
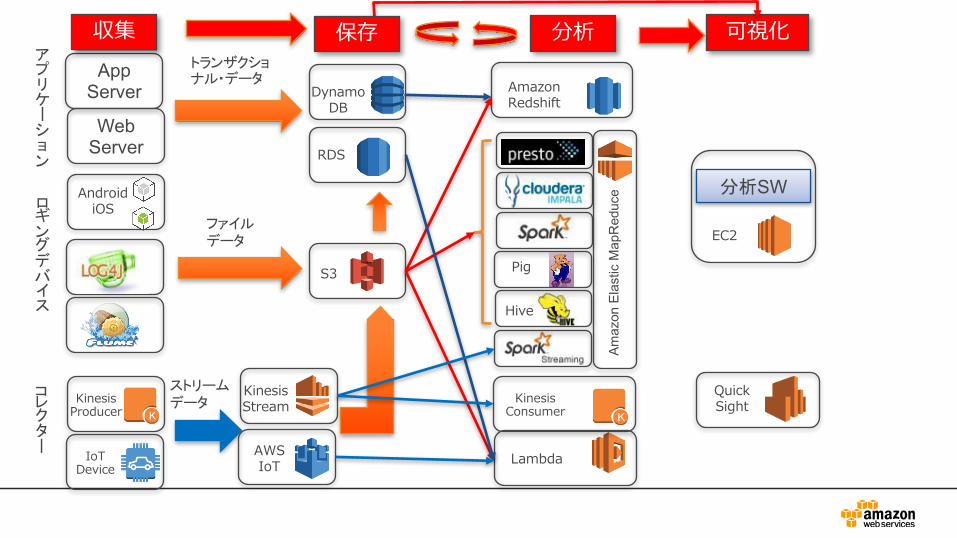
AppServer
アプリケ
ション
WebServer
トランザクショナル・データ
ロギングデバイス
コレクタ
AndroidiOS
KinesisProducer
ファイルデータ
ストリームデータ
S3
RDS
DynamoDB
AmazonRedshift
KinesisStream
Lambda
Pig
Hive
KinesisConsumer
Amaz
on E
last
ic M
apR
educ
e
AWSIoT
収集 分析 可視化
QuickSight
IoTDevice
保存
EC2
分析SW

まとめ:変化を織り込んだビッグデータ処理基盤
最適なツールを選択するデータは消さずにオリジナルを残すスケールアウトで解決する

ビックデータ最適解とAWSにおける新しい武器


















![[AWSマイスターシリーズ] AWS Elastic Beanstalk](https://img.pdfslide.tips/doc/110x75/54b774da4a795918738b45b7/aws-aws-elastic-beanstalk.jpg)







![[AWSマイスターシリーズ] AWS OpsWorks](https://img.pdfslide.tips/doc/110x75/54b75fe54a7959f71f8b4650/aws-aws-opsworks.jpg)
![[AWSマイスターシリーズ]AWS Storage Gateway](https://img.pdfslide.tips/doc/110x75/546ca885b4af9f702c8b5116/awsaws-storage-gateway.jpg)
![[C34] ビックデータ×マーケティング 進化するデジタルマーケティングを支えるビックデータ活用基盤 by Takatomo Kamatsu](https://img.pdfslide.tips/doc/110x75/55921ec51a28ab5f218b4734/c34-by-takatomo-kamatsu.jpg)

![[AWSマイスターシリーズ] AWS CLI / AWS Tools for Windows PowerShell](https://img.pdfslide.tips/doc/110x75/54c666a74a795928268b45ac/aws-aws-cli-aws-tools-for-windows-powershell.jpg)