Embed Size (px)
Citation preview

BridgingRelational Learning
Algorithms
山口祐人
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 1

2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 2
関係データ”関係データとは、複数のデータの間に観測、定義される「関係」に関するデータのことです。”
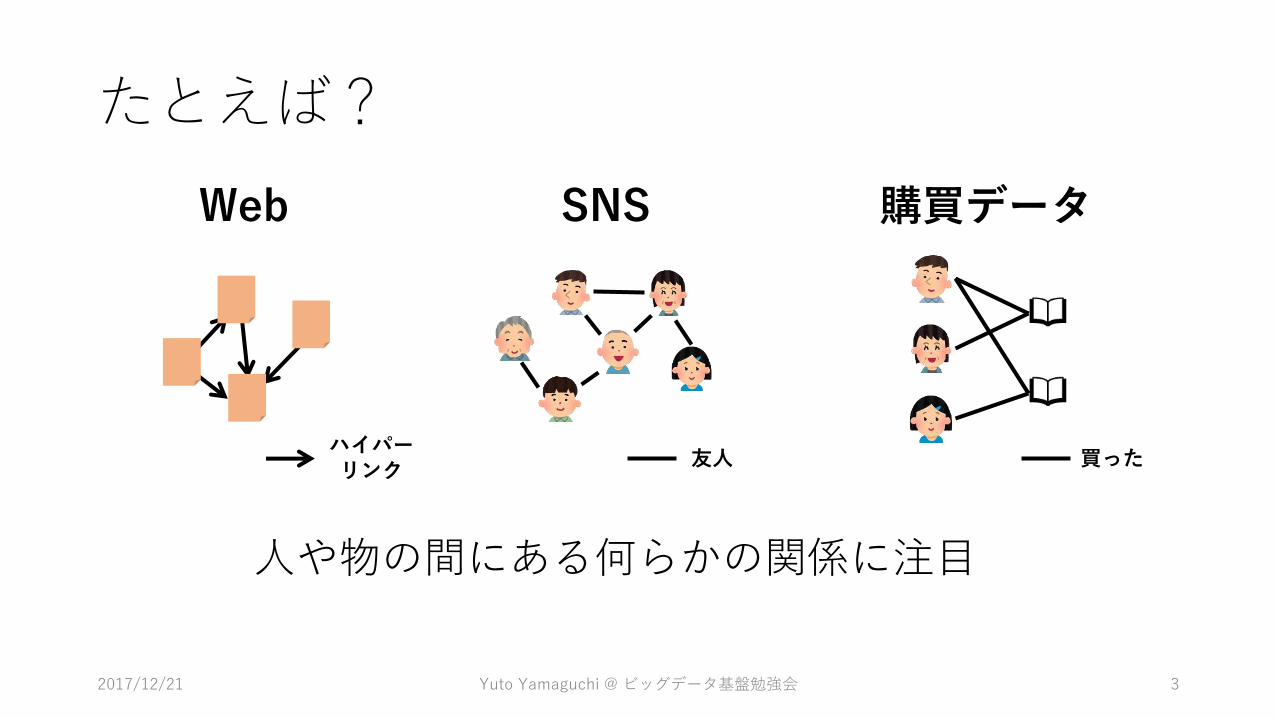
たとえば?
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 3
Web 購買データSNS
ハイパーリンク
友人 買った
人や物の間にある何らかの関係に注目

関係データ「学習」
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 4
1位
2位
3位
4位
関係データに対する機械学習
さまざまなタスクを解くことができる
ランキング 分類 クラスタリング リンク予測
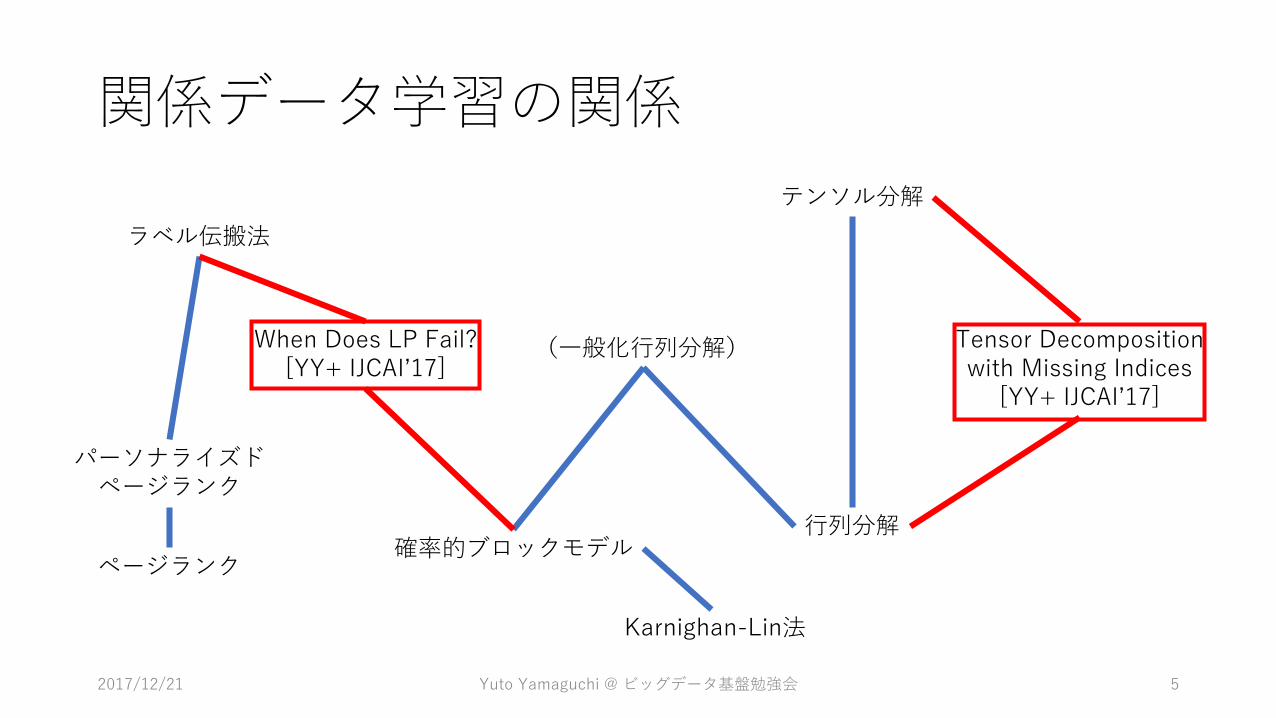
関係データ学習の関係
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 5
ページランク
パーソナライズドページランク
ラベル伝搬法
確率的ブロックモデル行列分解
テンソル分解
(一般化行列分解) Tensor Decompositionwith Missing Indices
[YY+ IJCAI’17]
When Does LP Fail?[YY+ IJCAI’17]
Karnighan-Lin法

関係データ学習の関係
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 6
ラベル伝搬法
確率的ブロックモデル
When Does LP Fail?[YY+ IJCAI’17]
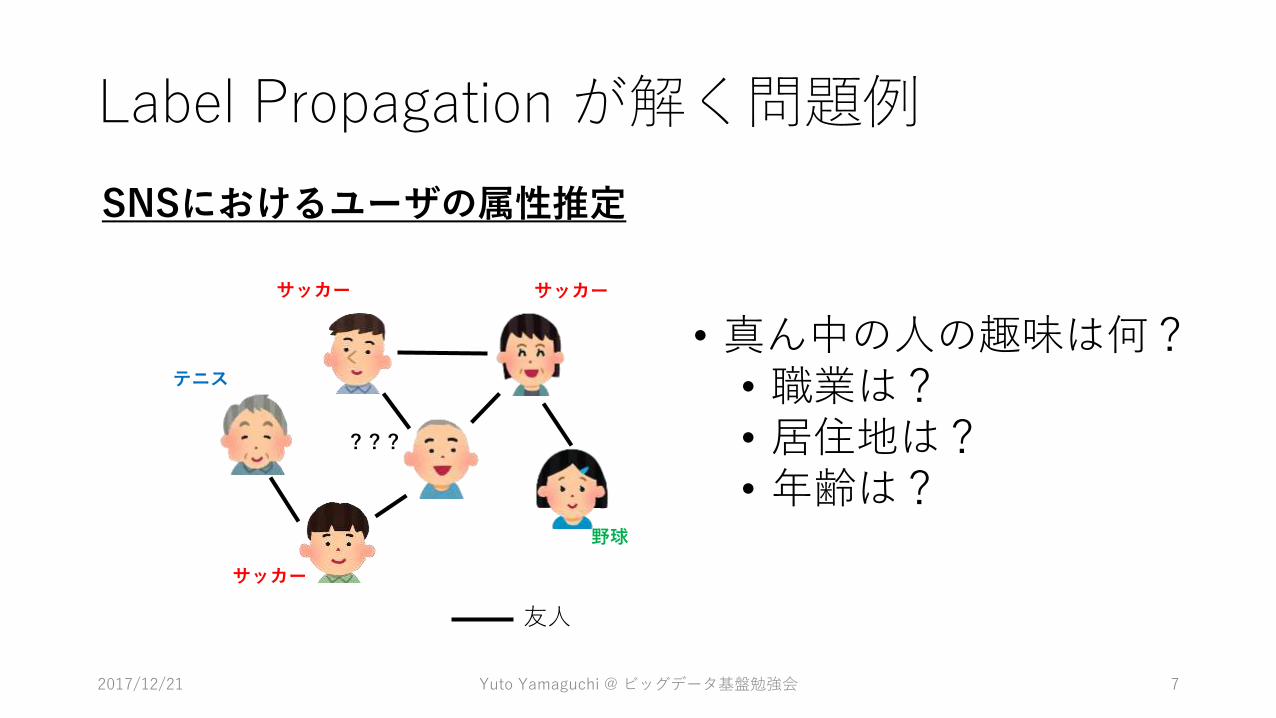
Label Propagation が解く問題例
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 7
友人
サッカー サッカー
サッカー
テニス
野球
???
• 真ん中の人の趣味は何?• 職業は?• 居住地は?• 年齢は?
SNSにおけるユーザの属性推定
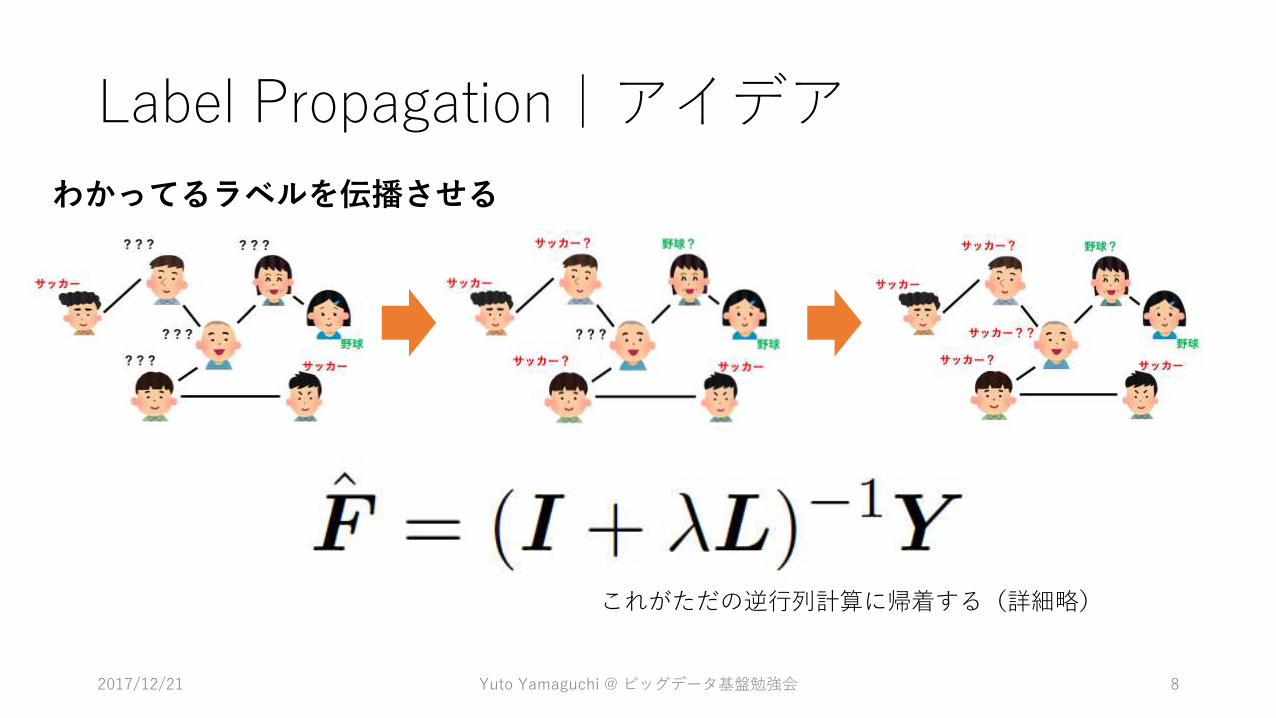
Label Propagation|アイデア
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 8
わかってるラベルを伝播させる
これがただの逆行列計算に帰着する(詳細略)
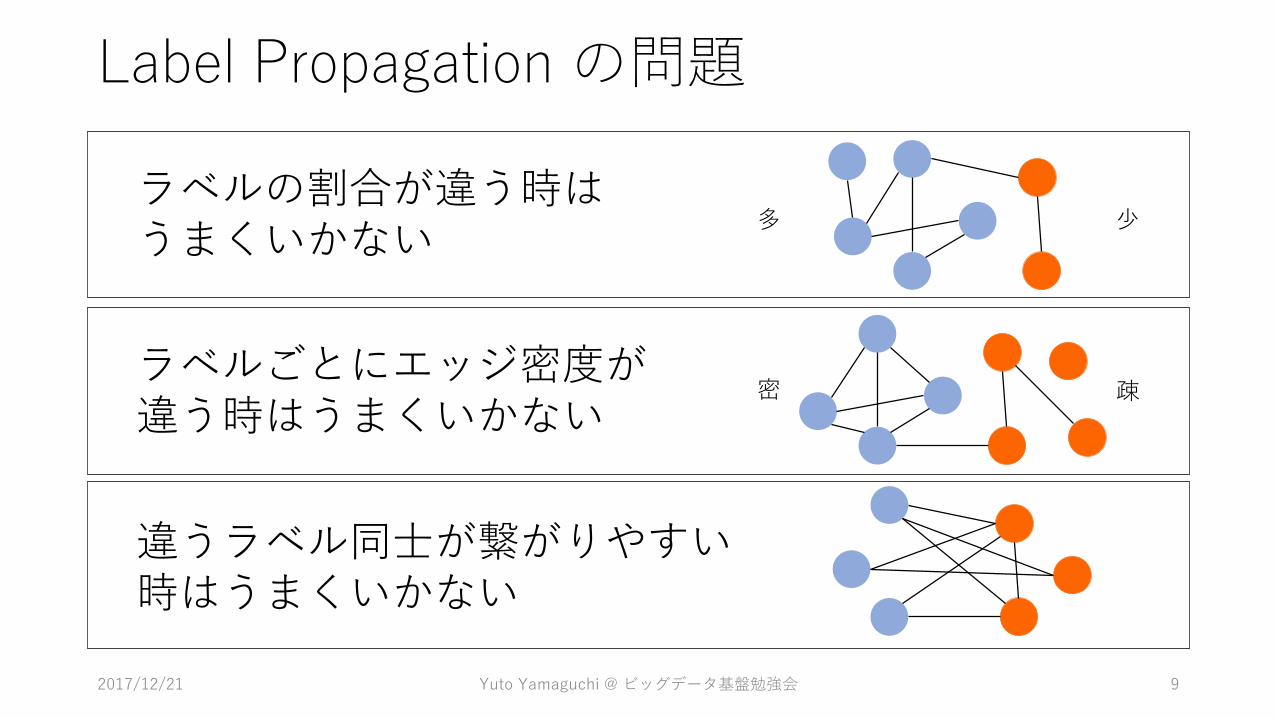
Label Propagation の問題
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 9
ラベルの割合が違う時はうまくいかない
ラベルごとにエッジ密度が違う時はうまくいかない
違うラベル同士が繋がりやすい時はうまくいかない
多 少
密 疎

2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 10
なぜ?

When Does Label Propagation Fail? A View from a Network Generative ModelYuto Yamaguchi, Kohei Hayashi
IJCAI 2017
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 11

概要
① LPの性質を説明するためにネットワーク生成モデルの一つである確率的ブロックモデル(SBM)に着目
② LPとSBMの理論的なつながりを示す• これを示すために “Partially-Labeled SBM” を提案
③ ネットワーク生成モデルの見地から、LPがうまくいかないケースを解析
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 12
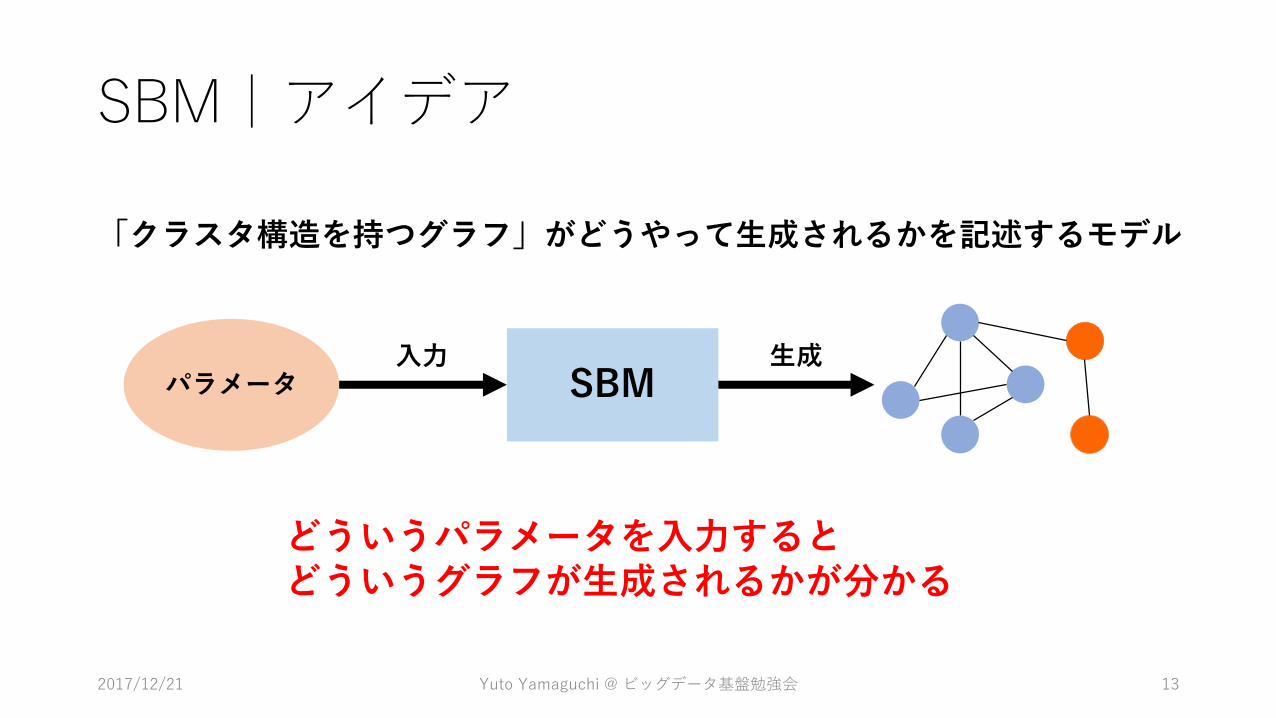
SBM|アイデア
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 13
「クラスタ構造を持つグラフ」がどうやって生成されるかを記述するモデル
SBMパラメータ入力 生成
どういうパラメータを入力するとどういうグラフが生成されるかが分かる

パラメータは3つ
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 14
g
P
スカラー。クラスタ数を表す。K
K 次元ベクトル。γk は k 番目のクラスタに属すノードの割合を表す。
K x K 行列。Πij は i 番目のクラスタに属すノードとj 番目に属すノード間にエッジが生成される確率を表す。
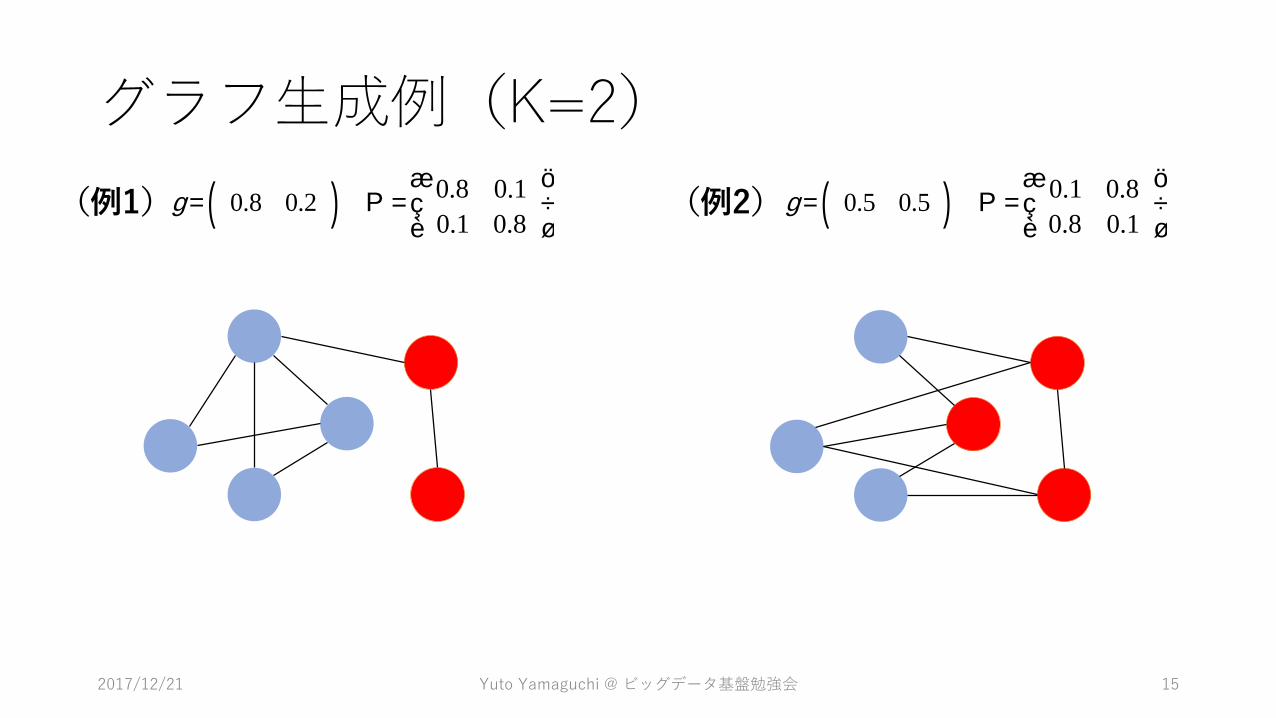
グラフ生成例(K=2)
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 15
(例1)g = 0.8 0.2( ) P =0.8 0.1
0.1 0.8
æ
èç
ö
ø÷ (例2)g = 0.5 0.5( ) P =
0.1 0.8
0.8 0.1
æ
èç
ö
ø÷

LPとSBMの関係を示したいが、難しい
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 16
ラベルとクラスタ割り当て両方の概念を持つモデルを作って、それを使ってLPとSBMの関係を示す
LP SBM PLSBM(提案)
ラベル ✓ ✓
クラスタ割り当て ✓ ✓
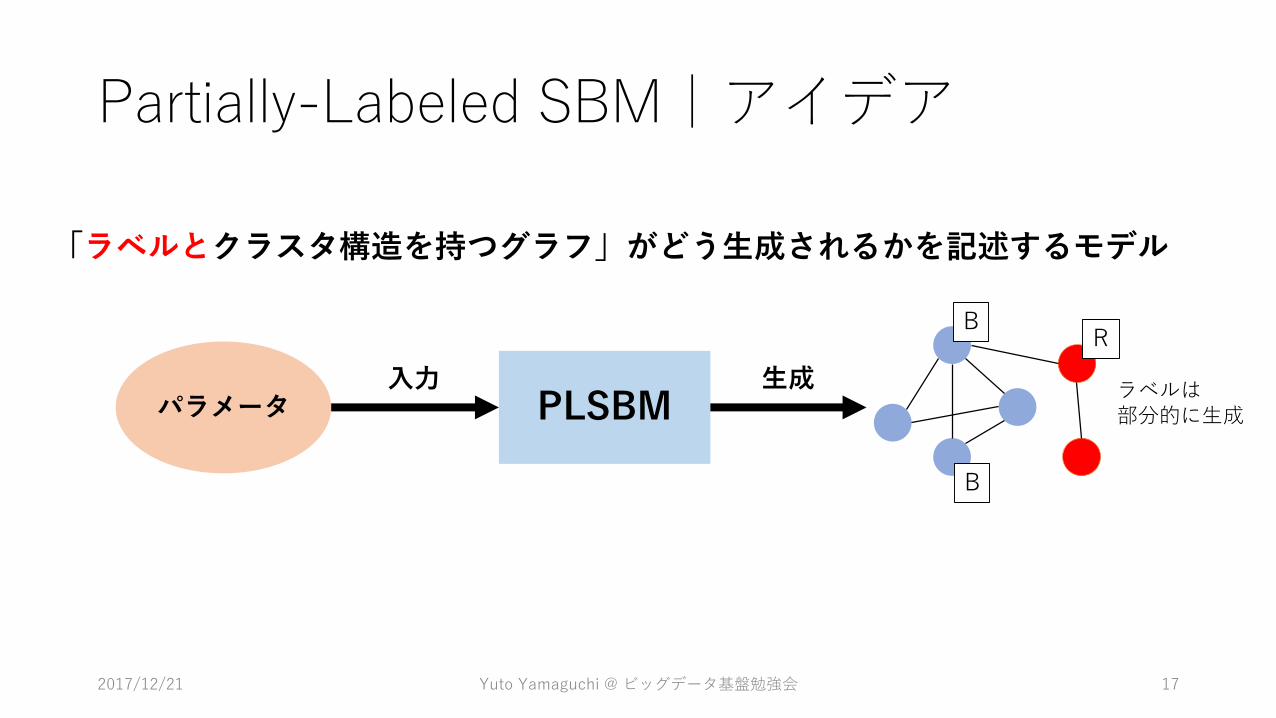
Partially-Labeled SBM|アイデア
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 17
「ラベルとクラスタ構造を持つグラフ」がどう生成されるかを記述するモデル
PLSBMパラメータ入力 生成
B
B
R
ラベルは部分的に生成

Partially-Labeled SBM|グラフ生成例
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 18
(例1)g = 0.8 0.2( ) P =
0.8 0.1
0.1 0.8
æ
èç
ö
ø÷
(例1)g = 0.8 0.2( ) P =
0.8 0.1
0.1 0.8
æ
èç
ö
ø÷
a =1.0 a = 0.7
BR
B
RR
B
(新パラメータ)0に近いほど
クラスタとラベルが異なる

定理1:SBMはPLSBMの特殊ケース(自明)
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 19
ラベル付けするノード数を0とすると、PLSBMとSBMは等価

定理2:(離散型)LPは(ある条件下において)PLSBMの特殊ケース
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 20
1.
2.
3.
( 4. )
PLSBMのパラメータをこうセットするとPLSBMと(離散型)LPは等価
0 £ m £1
0 £ n £1
ただし、

系1:(離散型)LPは「ラベルの割合が一定」だと仮定している
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 21
定理2の条件1から言える
(全てのラベル k について、ラベル割合 γk が同じ)
多 少
仮定に反している
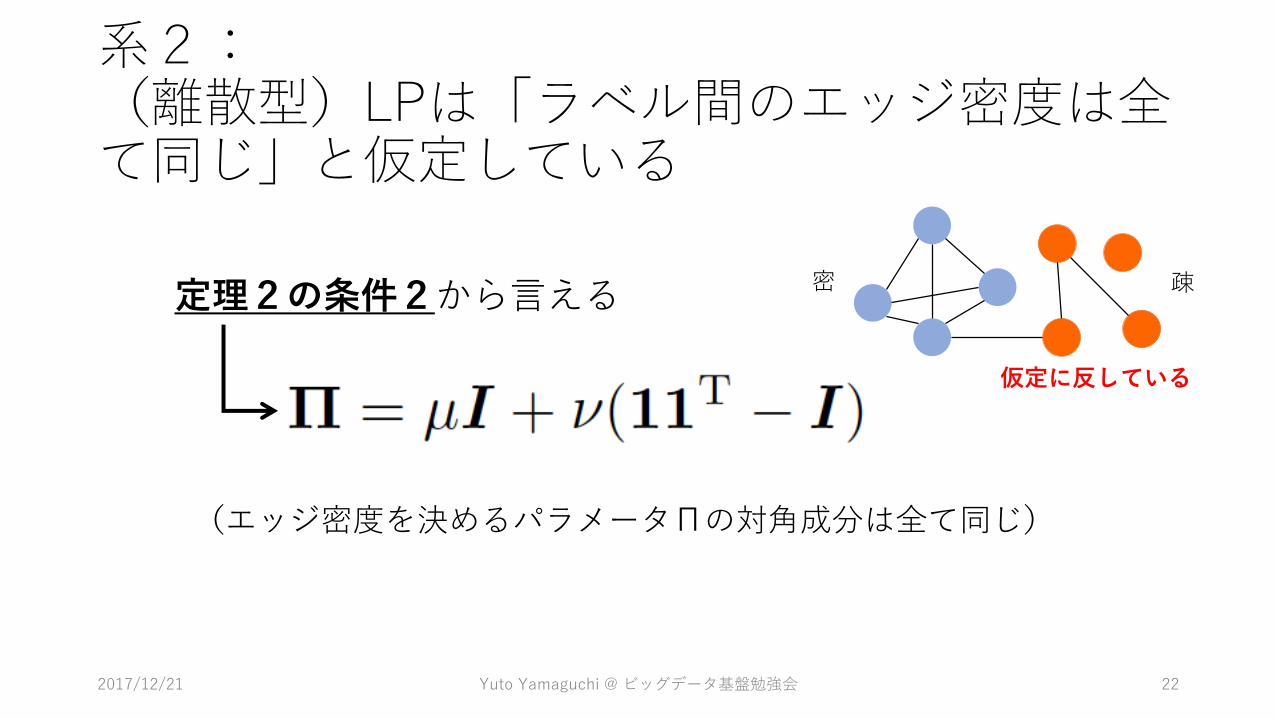
系2:(離散型)LPは「ラベル間のエッジ密度は全て同じ」と仮定している
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 22
定理2の条件2から言える
(エッジ密度を決めるパラメータΠの対角成分は全て同じ)
密 疎
仮定に反している

系3:(離散型)LPは「同じラベル同士が繋がりやすい」と仮定している
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 23
定理2の条件3から言える
(エッジ密度を決めるパラメータΠの対角成分は、非対角成分より大きい)
仮定に反している

まとめ
• LPがうまくいかないケースについて、何故そうなるのかをネットワーク生成モデルの見地から説明した
• それを説明するためにPLSBMを導入し、SBMとLPが特殊ケースであることを示した• → つまりLPとSBMの理論的つながりを示した
• 理論的結果をサポートするために実験をした• 理論通りの結果が出た
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 24
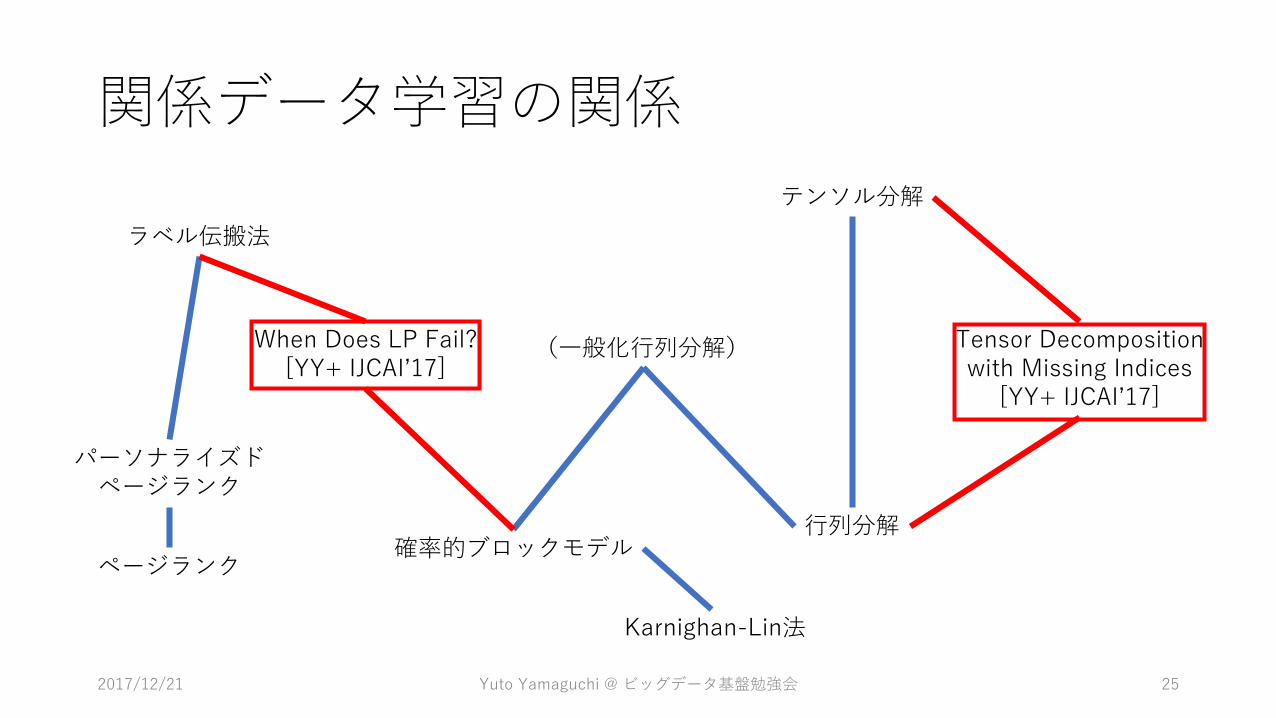
関係データ学習の関係
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 25
ページランク
パーソナライズドページランク
ラベル伝搬法
確率的ブロックモデル行列分解
テンソル分解
(一般化行列分解) Tensor Decompositionwith Missing Indices
[YY+ IJCAI’17]
When Does LP Fail?[YY+ IJCAI’17]
Karnighan-Lin法

関係データ学習の関係
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 26
行列分解
テンソル分解
Tensor Decompositionwith Missing Indices
[YY+ IJCAI’17]
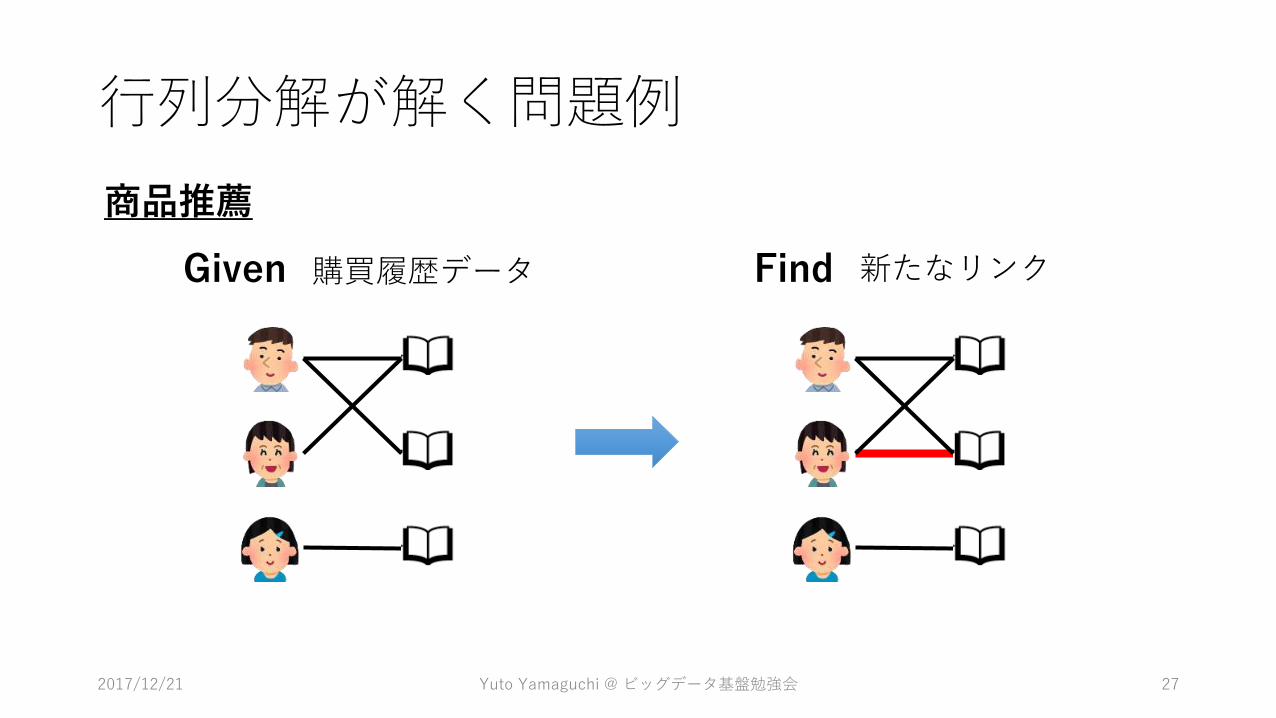
行列分解が解く問題例
Given Find
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 27
購買履歴データ 新たなリンク
商品推薦
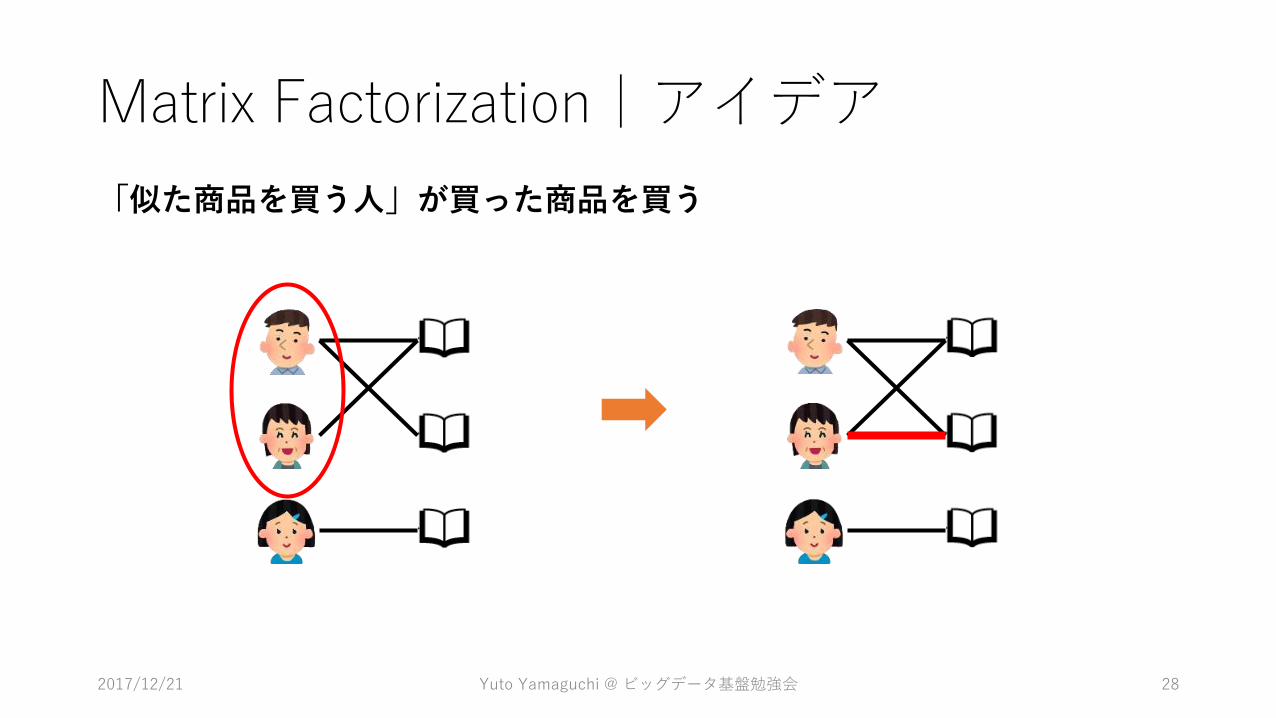
Matrix Factorization|アイデア
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 28
「似た商品を買う人」が買った商品を買う
Matrix Factorization|アイデア
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 29
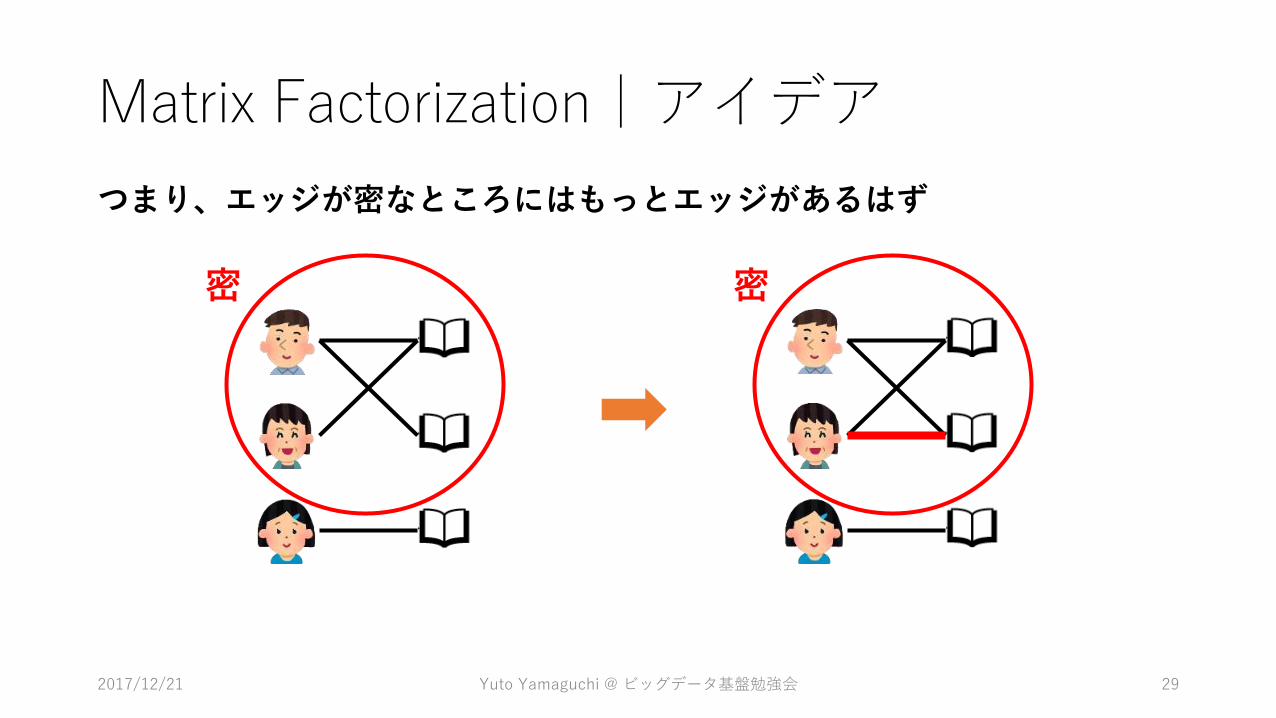
つまり、エッジが密なところにはもっとエッジがあるはず
密 密
Matrix Factorization |アイデア
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 30
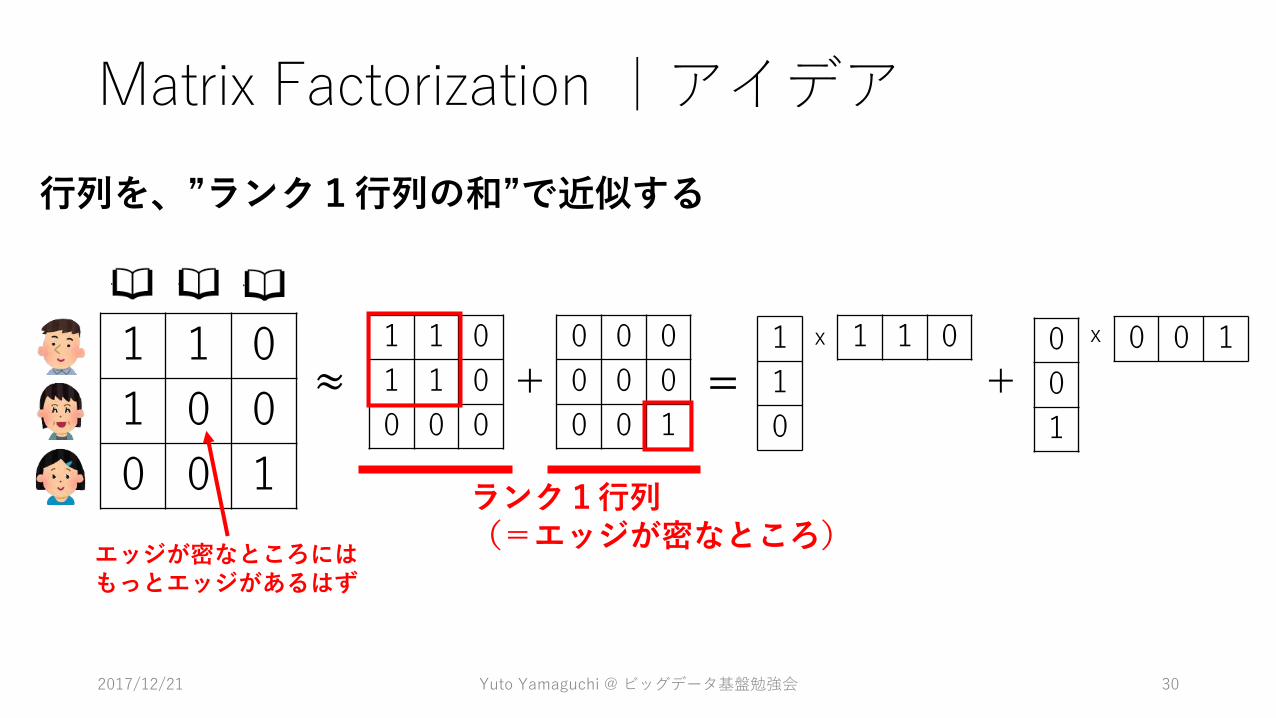
1 1 0
1 0 0
0 0 1
1 1 0
1 1 0
0 0 0
0 0 0
0 0 0
0 0 1
≈ + =1 1 01
1
0
0 0 10
0
1
x x
+
ランク1行列(=エッジが密なところ)
エッジが密なところにはもっとエッジがあるはず
行列を、”ランク1行列の和”で近似する
行列からテンソルへ
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 31
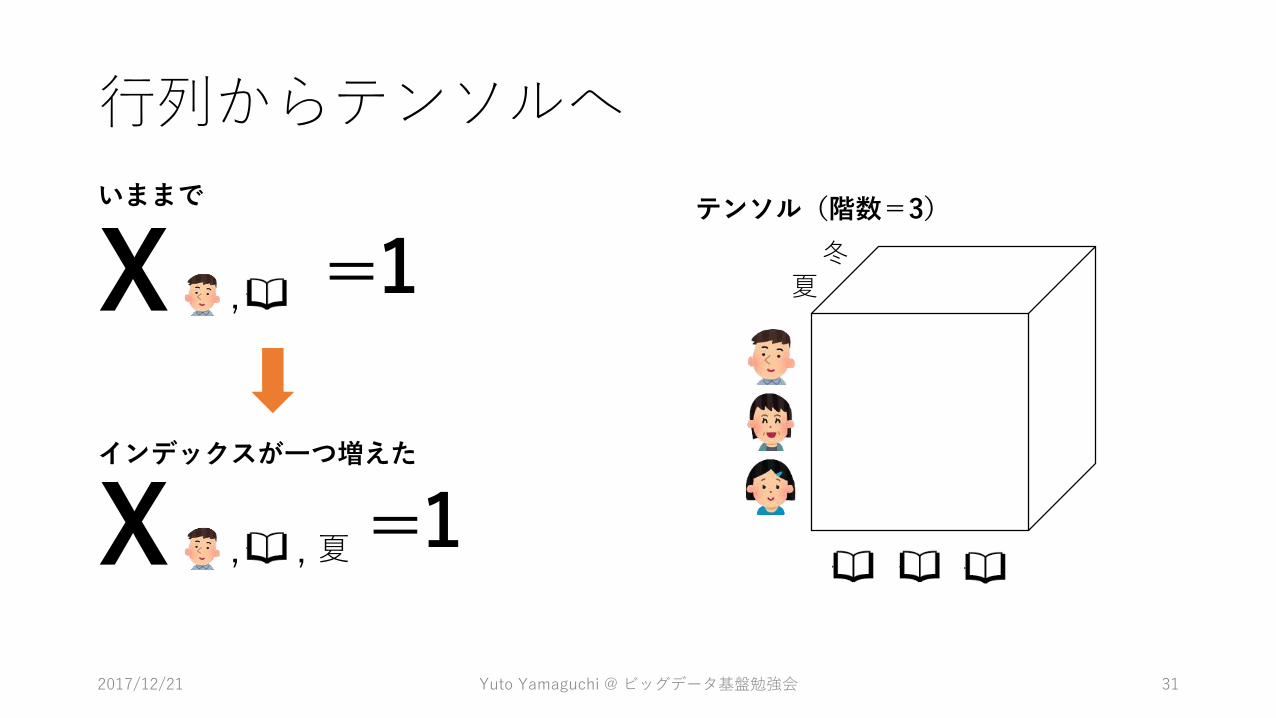
X , =1
X , =1, 夏
いままで
インデックスが一つ増えた
夏冬
テンソル(階数=3)

テンソル分解(CP分解)
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 32
テンソルを、”ランク1テンソルの和“ で近似する
X≈ + +
a1 a2
b1 b2
c2c1
…
ランク1テンソル

定理3:CP分解とMFの関係(自明)
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 33
階数が2のとき、CP分解はMFになる

じゃあこういうケースは?
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 34
(Aさん、本1、夏)(Aさん、本2、冬)(Bさん、本1、冬)(Cさん、本1、夏)(Cさん、本2、夏)
(Aさん、本1)(Aさん、本2)(Bさん、本1)(Cさん、本1)(Cさん、本2)
(Aさん、本1、?)(Aさん、本2、冬)(Bさん、本1、冬)(Cさん、本1、?)(Cさん、本2、夏)
本を買った時に観測されるデータ
行列分解で扱える テンソル分解で扱える ・・・?

Tensor Decomposition with Missing IndicesYuto Yamaguchi, Kohei Hayashi
IJCAI 2017
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 35

概要
• インデックスが欠損した場合でもテンソル分解できる手法を提案
• これによりテンソルの階数が k と k-1 の間みたいなデータも扱えるようになる• 行列分解とテンソル分解が
• 実データで実験• それなりに良い精度が出た
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 36
提案手法|アイデア
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 37
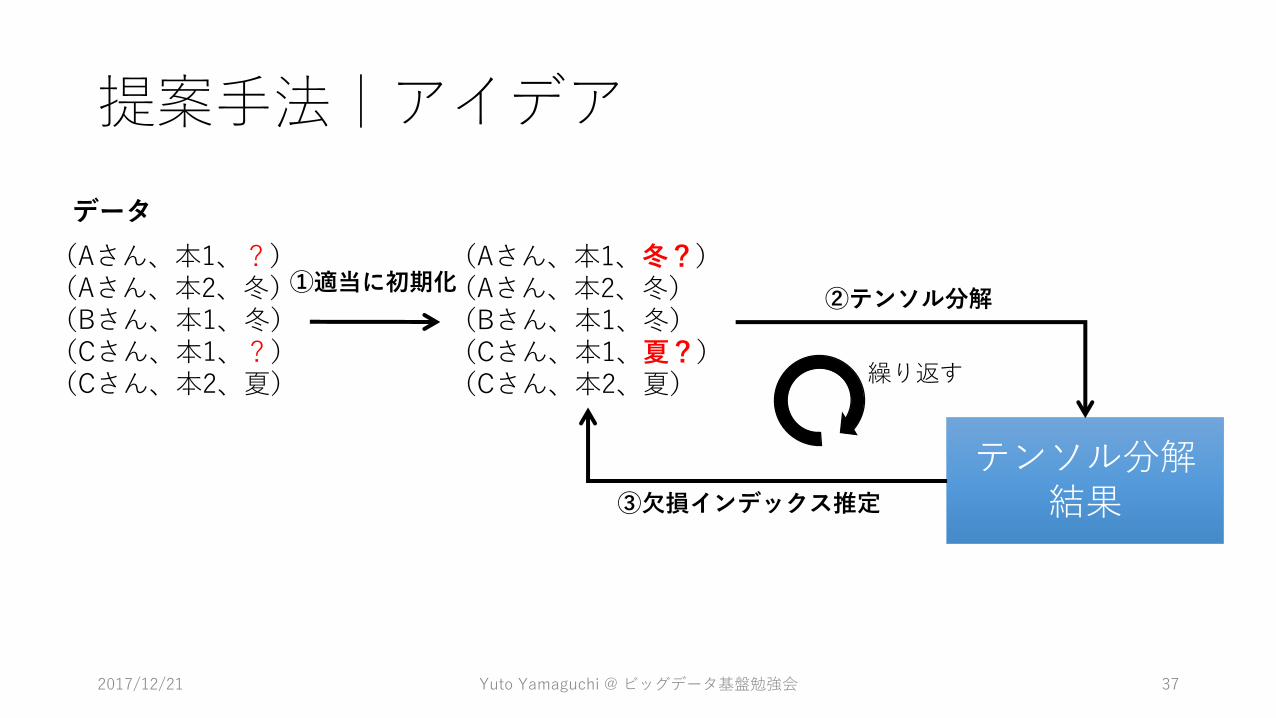
(Aさん、本1、冬?)(Aさん、本2、冬)(Bさん、本1、冬)(Cさん、本1、夏?)(Cさん、本2、夏)
テンソル分解結果
②テンソル分解
③欠損インデックス推定
(Aさん、本1、?)(Aさん、本2、冬)(Bさん、本1、冬)(Cさん、本1、?)(Cさん、本2、夏)
データ
①適当に初期化
繰り返す
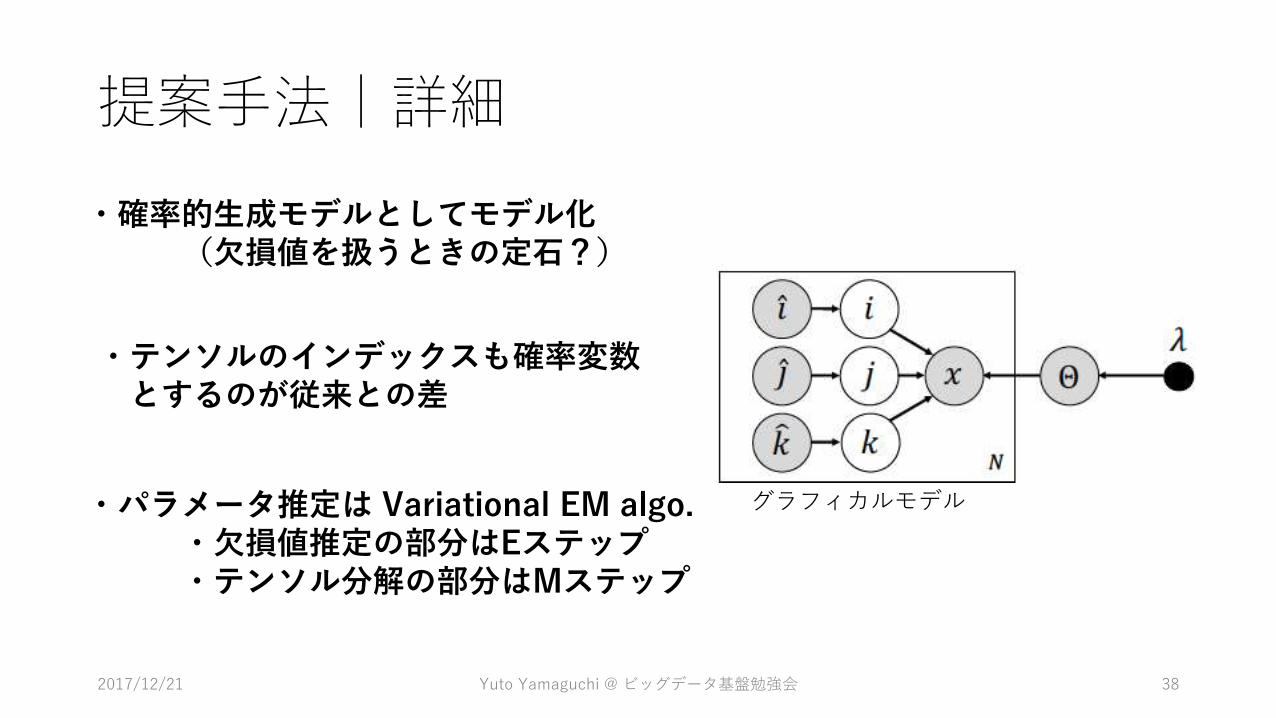
提案手法|詳細
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 38
・確率的生成モデルとしてモデル化(欠損値を扱うときの定石?)
グラフィカルモデル・パラメータ推定は Variational EM algo.・欠損値推定の部分はEステップ・テンソル分解の部分はMステップ
・テンソルのインデックスも確率変数とするのが従来との差
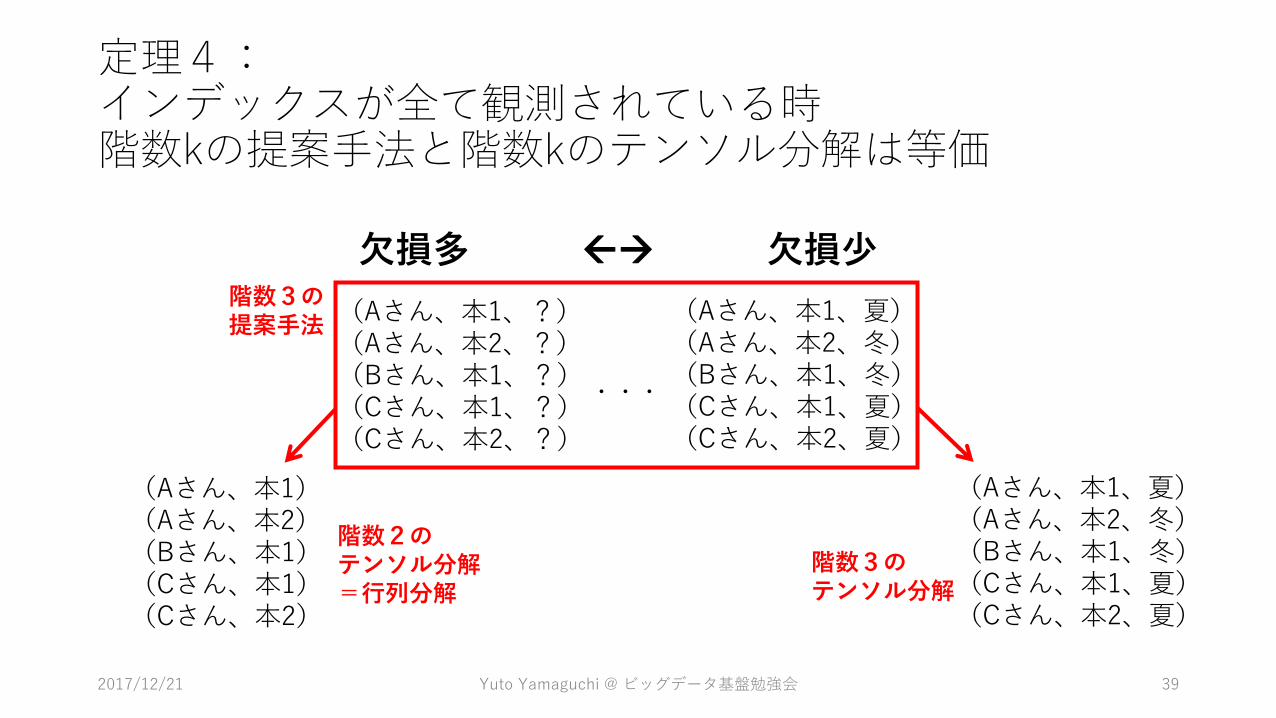
定理4:インデックスが全て観測されている時階数kの提案手法と階数kのテンソル分解は等価
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 39
(Aさん、本1、夏)(Aさん、本2、冬)(Bさん、本1、冬)(Cさん、本1、夏)(Cさん、本2、夏)
(Aさん、本1、?)(Aさん、本2、?)(Bさん、本1、?)(Cさん、本1、?)(Cさん、本2、?)
(Aさん、本1)(Aさん、本2)(Bさん、本1)(Cさん、本1)(Cさん、本2)
(Aさん、本1、夏)(Aさん、本2、冬)(Bさん、本1、冬)(Cさん、本1、夏)(Cさん、本2、夏)
階数3の提案手法
階数3のテンソル分解
階数2のテンソル分解=行列分解
・・・
欠損多 欠損少
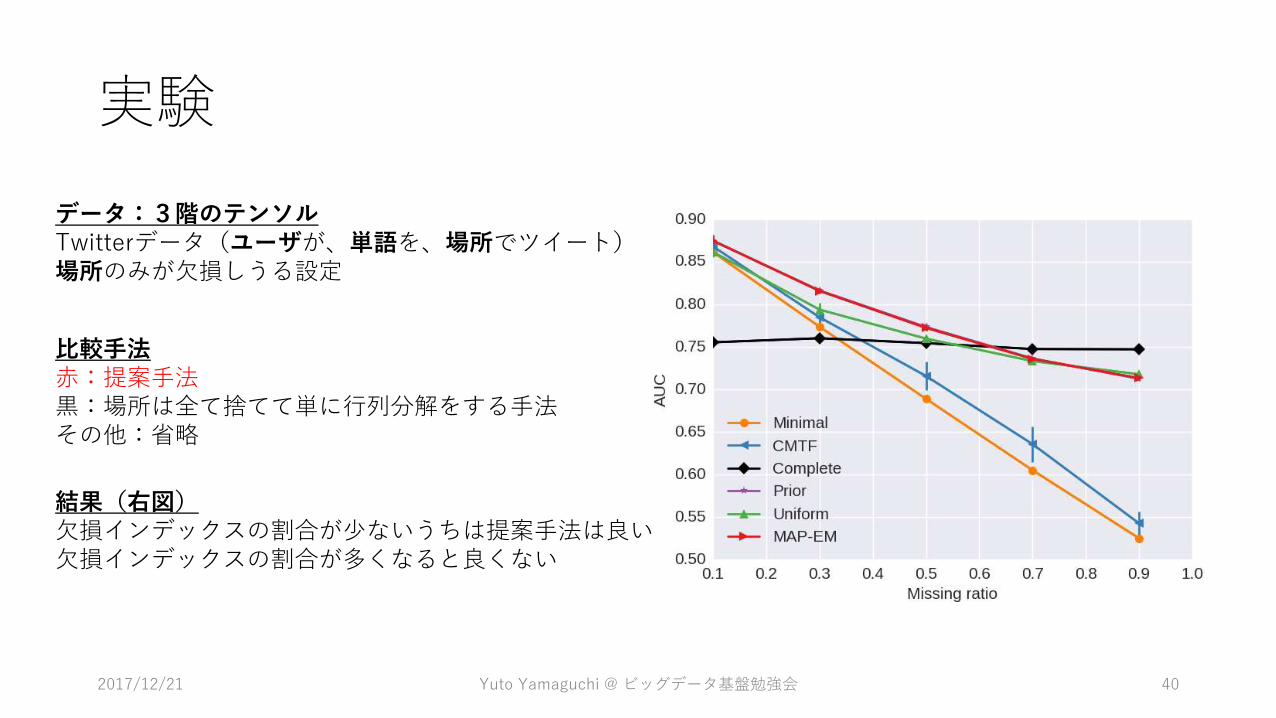
実験
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 40
データ:3階のテンソルTwitterデータ(ユーザが、単語を、場所でツイート)場所のみが欠損しうる設定
比較手法赤:提案手法黒:場所は全て捨てて単に行列分解をする手法その他:省略
結果(右図)欠損インデックスの割合が少ないうちは提案手法は良い欠損インデックスの割合が多くなると良くない

まとめ
• インデックスが欠損したデータに対してもテンソル分解できる手法を提案
• 提案手法は階数 k-1 のテンソル分解と階数 k のテンソル分解をスムースにつなぐことを示した
• 実験で(それなりに)いい結果が出ることを示した
2017/12/21 Yuto Yamaguchi @ ビッグデータ基盤勉強会 41





























