Embed Size (px)
Citation preview

Distance Metric Learning
2014-03-06
전상혁
2014-03-05 1

Introduction
• Distance Metric learning is to learn a distance metric for the input spaceof data
• Data is from a given collection of pair of similar/dissimilar points thatpreserves the distance relation among the training data
• Learned metric can significantly improve the performance of algorithmssuch as classification, clustering and many other tasks
2014-03-05 2

Distance Metric
• A distance metric or distance function is a function that defines adistance between elements of a set
• Example1: Euclidean metric
• Example2: Discrete metric
• 𝑖𝑓 𝑥 = 𝑦 𝑡ℎ𝑒𝑛 𝑑 𝑥, 𝑦 = 0, 𝑂𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒, 𝑑 𝑥, 𝑦 = 1
• A metric on a set X is a function 𝑑: 𝑋 × 𝑋 → 𝐑 (where R is real number)
• 𝑑 𝑥, 𝑦 ≥ 0
• 𝑑 𝑥, 𝑦 = 0 𝑖𝑓 𝑎𝑛𝑑 𝑜𝑛𝑙𝑦 𝑖𝑓 𝑥 = 𝑦
• 𝑑 𝑥, 𝑦 = 𝑑(𝑦, 𝑥)
• 𝑑 𝑥, 𝑧 ≤ d x, y + d(y, z)
2014-03-05 Aurelien Bellet, Tutorial on Metric Learning, 2013 3

Introduction
2014-03-05 Bellet, A., Habrard, A., and Sebban, M. A Survey on Metric Learning for Feature Vectors and Structured Data, 2013 4
Bellet, A., Habrard, A., and Sebban, M. A Survey on Metric Learning for Feature Vectors and Structured Data, 2013

Categories of distance metric learning
• Supervised distance metric learning
• Constraints or labels given to the algorithm
• Equivalence constraints where pairs of data points that belongto the same classes (semantically-similar)
• Inequivalence constraints where pairs of data points that belongto the different classes (semantically-dissimilar)
• local adaptive supervised distance metric learning, NCA, RCA
• Unsupervised distance metric learning
• Dimensionality reduction techniques
• Linear methods (PCA, MDS) and non-linear methods (ISOMAP, LLE, LE)
• Kernel methods towards learning distance metrics
• Kernel alignment, extension work of learning idealized kernel
2014-03-05 Liu Yang, An Overview of Distance Metric Learning, 2007 5
Liu Yang, Distance Metric Learning: A Comprehensive Survey, 2005Liu Yang, An Overview of Distance Metric Learning, 2007

Categories of distance metric learning
• Maximum margin based distance metric learning
• Formulate distance metric learning as a constrained convexprogramming problem, and attempt to learn complete distancemetric from training data
• Expensive computation, overfitting problem when limited trainingsamples and large feature dimension
• Large margin nearest neighbor classification (LMNN), SDP methods tosolve the kernelized margin maximization
2014-03-05 Liu Yang, An Overview of Distance Metric Learning, 2007 6
Liu Yang, Distance Metric Learning: A Comprehensive Survey, 2005Liu Yang, An Overview of Distance Metric Learning, 2007
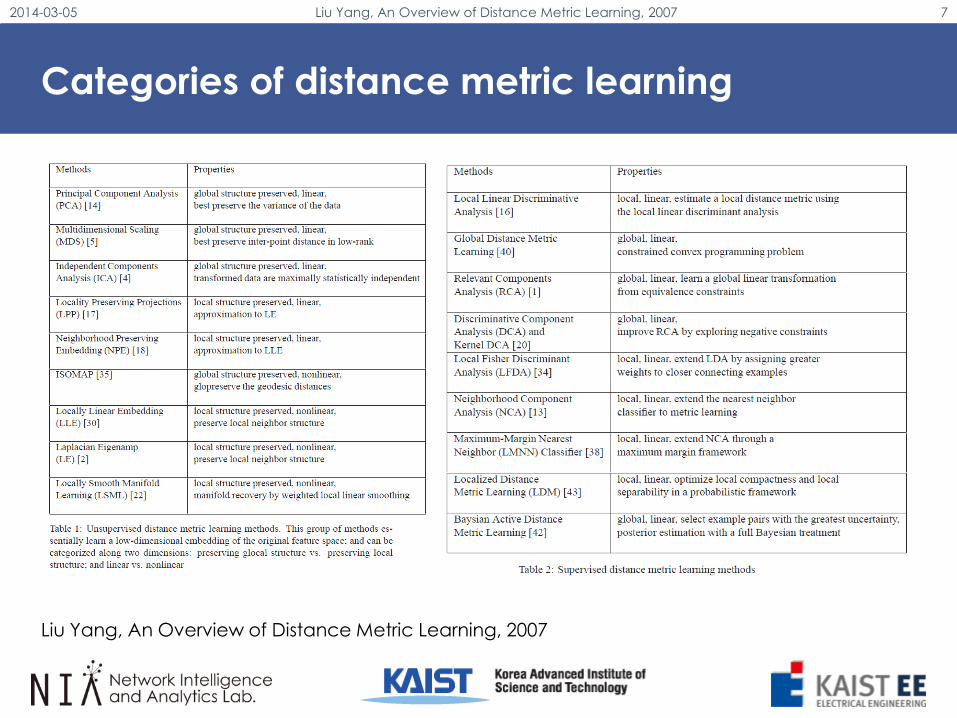
Categories of distance metric learning
2014-03-05 Liu Yang, An Overview of Distance Metric Learning, 2007 7
Liu Yang, An Overview of Distance Metric Learning, 2007

Large Margin Nearest Neighbor Classification (LMNN)Kilian Weinberger, et al. Distance metric learning for large margin nearestneighbor classification. NIPS, 2006.
2014-03-05 Kilian Weinberger, et al. Distance metric learning for large margin nearest neighbor classification. NIPS, 2006. 8

Motivation – better KNN
• KNN: simple non-parametric classification method (Also can be used forclustering, regression, anomaly detection, and etc.)
• 𝑘 is user-defined constant, and an unlabeled vector is classified byassigning the label which is most frequent among the 𝑘 training samplesnearest to that unlabeled vector
• Drawback: when the class distribution is skewed, basic “majority voting”classification may not works well.
2014-03-05 Kilian Weinberger, et al. Distance metric learning for large margin nearest neighbor classification. NIPS, 2006. 9

Introduction
• Large margin nearest neighbor (LMNN) method
• Neighbors are selected by using the learned Mahanalobis distancemetric
• Learn a Mahanalobis distance metric for kNN classification bysemidefinite programming
• Find 𝐿: 𝑅𝑑 → 𝑅𝑑, which will be used to compute squared distance as
𝐷 𝑥𝑖 , 𝑥𝑗 = 𝐿 𝑥𝑖 − 𝑥𝑗2
by minimizing some cost function 𝜖(𝐿)
2014-03-05 Kilian Weinberger, et al. Distance metric learning for large margin nearest neighbor classification. NIPS, 2006. 10

Mahanalobis Distance Metric
• Relative measure of a data point’s distance from a common point
• It differs from Euclidean distance in that it takes into account thecorrelations of the data set and is scale-invariant
• 𝑑 𝑥, 𝑦 = 𝑥 − 𝑦 ⊤𝛀( 𝑥 − 𝑦) where 𝛀 is positive semidefinte matrix
• Example: the distance between two random variable 𝑥, 𝑦 of the samedistribution with covariance matrix 𝑆 is defined as
• 𝑑 𝑥, 𝑦 = 𝑥 − 𝑦 ⊤𝑆−1( 𝑥 − 𝑦)
• Euclidean distance is special case when S is identity matrix
• Recall: distance 𝐷 𝑥𝑖 , 𝑥𝑗 = 𝐿 𝑥𝑖 − 𝑥𝑗2
• We can rewrite eq. as 𝐷 𝑥𝑖 , 𝑥𝑗 = 𝑥𝑖 − 𝑥𝑗 𝐌⊤ 𝑥𝑖 − 𝑥𝑗 where the matrix 𝐌 =𝐋⊤𝐋, parameterizes the Mahalanobis distance metric induced by thelinear transform 𝐋
2014-03-05 Kilian Weinberger, et al. Distance metric learning for large margin nearest neighbor classification. NIPS, 2006. 11

Semidefinite Programming
• A kind of convex optimization problem
• 𝑥 is a vector of n variables, 𝑐 is a constant n dimensional vector
• Linear programming (LP)
• 𝑚𝑖𝑛𝑖𝑚𝑖𝑧𝑒 𝑐 ∙ 𝑥𝑠. 𝑡. 𝑎𝑖 ∙ 𝑥 = 𝑏𝑖 , 𝑖 = 1,… ,𝑚𝑥 ∈ 𝑅+
𝑛
• X is positive semidefinite matrix if 𝑣⊤𝑋𝑣 ≥ 0 𝑓𝑜𝑟 𝑎𝑛𝑦 𝑣 ∈ 𝑅𝑛 (𝑋 ≽ 0)
• If 𝐶(𝑋) is a linear function of X, then 𝐶(𝑋) can be written as 𝐶 ∙ 𝑋
• Semidefinite program (SDP)
• 𝑚𝑖𝑛𝑖𝑚𝑖𝑧𝑒 𝐶 ∙ 𝑋𝑠. 𝑡. 𝐴𝑖 ∙ 𝑋 = 𝑏𝑖 , 𝑖 = 1, … ,𝑚𝑋 ≽ 0
2014-03-05 Kilian Weinberger, et al. Distance metric learning for large margin nearest neighbor classification. NIPS, 2006. 12

Cost Function
• 𝜖 𝐿 = 𝑖𝑗 𝜂𝑖𝑗 𝐋 𝑥𝑖 − 𝑥𝑗2+ 𝑐 𝑖𝑗𝑙 𝜂𝑖𝑗 1 − 𝑦𝑖𝑙 1 + 𝐋 𝑥𝑖 − 𝑥𝑗
2− 𝐋 𝑥𝑖 − 𝑥𝑙
2
+
• Let 𝑥𝑖 , yi i=1n denote a training set of n labeled examples with inputs 𝑥𝑖 ∈ 𝑅𝑑 and
discrete (but not necessarily binary) class labels 𝑦𝑖
• 𝑦𝑖𝑗 ∈ {0,1} is binary matrix to indicate whether or not the labels 𝑦𝑖 and 𝑦𝑗 match
• 𝜂𝑖𝑗 ∈ {0,1} to indicate whether input 𝑥𝑗 is a target neighbor of input 𝑥𝑖, this value isfixed and does not change during learning
• Target neighbor: each instance 𝑥𝑖 has exactly k different target neighborswithin data set, which all share the same class label 𝑦𝑖
• Target neighbors are the data points that should become nearest neighborsunder the learned metric
• C.f. Impostors: same as target neighbor except it has different class label
• Term 𝑧 + = max(𝑧, 0)
• 𝑐 > 0 some positive constant (typically set by cross validation)
2014-03-05 Kilian Weinberger, et al. Distance metric learning for large margin nearest neighbor classification. NIPS, 2006. 13

Cost Function
• 𝜖 𝐿 = 𝑖𝑗 𝜂𝑖𝑗 𝐋 𝑥𝑖 − 𝑥𝑗2+ 𝑐 𝑖𝑗𝑙 𝜂𝑖𝑗 1 − 𝑦𝑖𝑙 1 + 𝐋 𝑥𝑖 − 𝑥𝑗
2− 𝐋 𝑥𝑖 − 𝑥𝑙
2
+
• The first optimization goal is achieved by minimizing the average distancebetween instance and their target neighbors
•
• The second goal is achieved by constraining impostors 𝑥𝑙 to be one unit furtheraway than target neighbors 𝑥𝑗
•
• 𝑁𝑖 denote the set of target neighbors for a data point 𝑥𝑖
2014-03-05 Kilian Weinberger, et al. Distance metric learning for large margin nearest neighbor classification. NIPS, 2006. 14
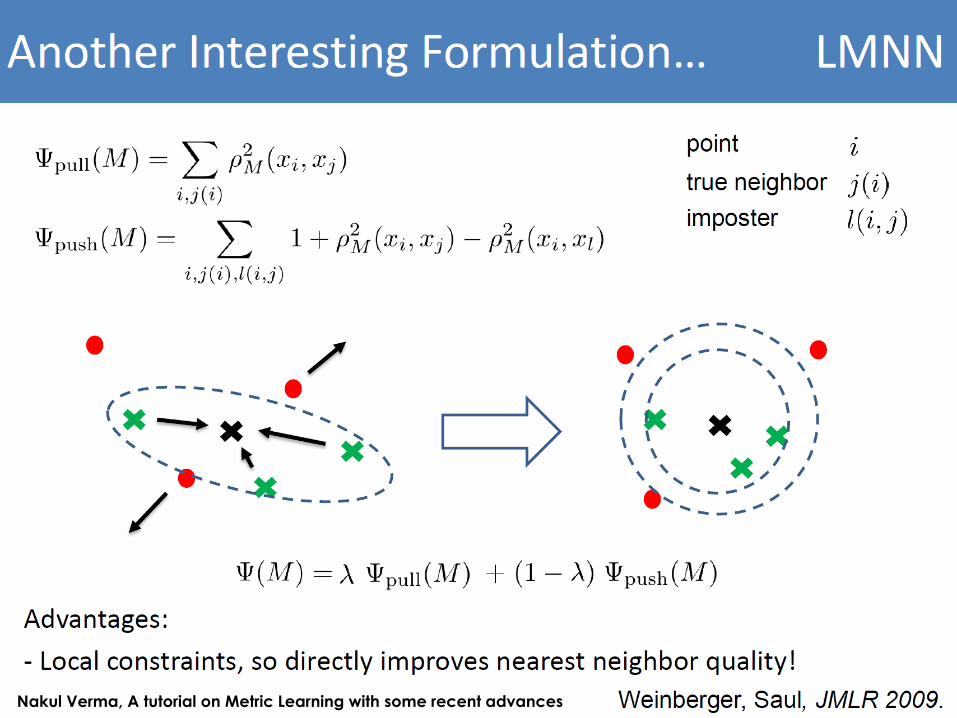
2014-03-05 15
Nakul Verma, A tutorial on Metric Learning with some recent advances

Convex Optimization
• Recall: distance 𝐷 𝑥𝑖 , 𝑥𝑗 = 𝐿 𝑥𝑖 − 𝑥𝑗2
• Recall: We can rewrite eq. as 𝐷 𝑥𝑖 , 𝑥𝑗 = 𝑥𝑖 − 𝑥𝑗 𝐌⊤ 𝑥𝑖 − 𝑥𝑗 where thematrix 𝐌 = 𝐋⊤𝐋, parameterizes the Mahalanobis distance metric inducedby the linear transform 𝐋
• The hinge loss can be “mimicked” by introducing slack variable 𝜁𝑖𝑗 for allpairs of differently labeled inputs (i.e., for all < 𝑖, 𝑗 > such that 𝑦𝑖𝑗 = 0)
2014-03-05 Kilian Weinberger, et al. Distance metric learning for large margin nearest neighbor classification. NIPS, 2006. 16

Results
• PCA was used to reduce the dimensionality of image, speech, and textdata, both to speed up training and avoid overfitting
• Both the number of target neighbors (k) and the weighting parameter (c)in optimization problem were set by cross validation
• KNN Euclidean distance
• KNN Mahalanobis distance
• Energy based classification
•
• Multiclass SVM
2014-03-05 Kilian Weinberger, et al. Distance metric learning for large margin nearest neighbor classification. NIPS, 2006. 17
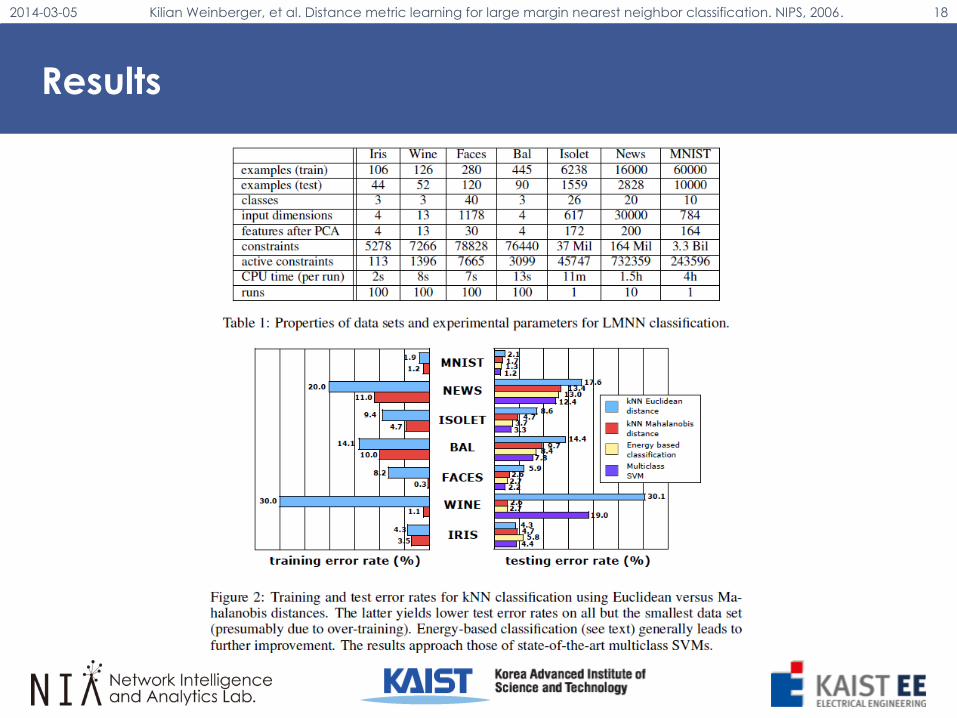
Results
2014-03-05 Kilian Weinberger, et al. Distance metric learning for large margin nearest neighbor classification. NIPS, 2006. 18

GBLMNN: Non-linear method for LMNN
• Building non-linear mapping for metric learning
• GBRT: Gradient Boosting Regression Tree
• Code: http://www.cse.wustl.edu/~kilian/code/code.html
2014-03-05 Kedem, D., Xu, Z., & Weinberger, K. (n.d.). Gradient Boosted Large Margin Nearest Neighbors, (1), 10–12. 19

Large Margin Component Analysis (LMCA)Torresani, L., & Lee, K. (2007). Large margin component analysis. Advances inNeural Information Processing
2014-03-05 Torresani, L., & Lee, K. (2007). Large margin component analysis. Advances in Neural Information Processing 20

Problem: large number of features
• In problems involving thousands of features, distance metric learningcannot be used
• High computation complexity
• Overffiting problem
• Previous works have relied on a two-step solution
• Apply dimension reduction algorithm (e.g. PCA)
• Learn a metric in the resulting low-dimensional subspace
• LMCA: provide better solution for high dimensional problem
2014-03-05 Torresani, L., & Lee, K. (2007). Large margin component analysis. Advances in Neural Information Processing 21

Linear Dimensionality Reduction for KNN (1/3)
• Recall: cost function of metric function
• In previous work, L was 𝐷 × 𝐷 matrix
• Idea: learn non square matrix size 𝑑 × 𝐷,𝑤𝑖𝑡ℎ 𝑑 ≪ 𝐷
• Problem: cost function 𝜖 𝐌 ,𝑤ℎ𝑒𝑟𝑒 𝐌 = 𝐋⊤𝐋 is no longer convex
• M has low rank d, not D
2014-03-05 Torresani, L., & Lee, K. (2007). Large margin component analysis. Advances in Neural Information Processing 22

Linear Dimensionality Reduction for KNN (2/3)
• Idea: optimize the objective function directly with respect to the nonsquare matrix L
• Although, equation is non-convex, it is better than minimizing theobjective function with respect to L rather than with respect to the rank-deficient D×D matrix M
• Since this optimization involves only 𝑑 ∙ 𝐷 rather than 𝐷2 unknowns, itcan reduce the risk of overffiting
• “the optimal rectangular matrix L computed with our methodautomatically satisfies the rank constraints on M without requiring thesolution of difficult constrained minimization problems”
2014-03-05 Torresani, L., & Lee, K. (2007). Large margin component analysis. Advances in Neural Information Processing 23

Linear Dimensionality Reduction for KNN (3/3)
• Minimize cost function using gradient-based optimizers
• “We handle the non-differentiability of h(s) at s = 0, by adopting asmooth hinge function as in [8]”
2014-03-05 Torresani, L., & Lee, K. (2007). Large margin component analysis. Advances in Neural Information Processing 24
[8] J. D. M. Rennie and N. Srebro. Fast maximum margin matrix factorization for collaborative prediction.In Proceedings of the 22nd International Conference on Machine Learning (ICML), 2005.

Nonlinear Feature Extraction (1/2)
• “Our approach learns a low-rank Mahalanobis distance metric in a highdimensional feature space F, related to the inputs by a nonlinear map𝜙: 𝑅𝐷 → 𝐹”
• k is kernel function computed by the feature input products
• L is now a transformation from the space F into a 𝑅𝑑 (𝑑 ≪ 𝐷)
•
2014-03-05 Torresani, L., & Lee, K. (2007). Large margin component analysis. Advances in Neural Information Processing 25

Nonlinear Feature Extraction (2/2)
•
•
•
• Update Ω ← (Ω − 𝜆Γ) until converge
• For classification, we project points onto the learned low-dim space byexploiting the kernel trick: 𝐿𝝓 = Ω𝐤
2014-03-05 Torresani, L., & Lee, K. (2007). Large margin component analysis. Advances in Neural Information Processing 26
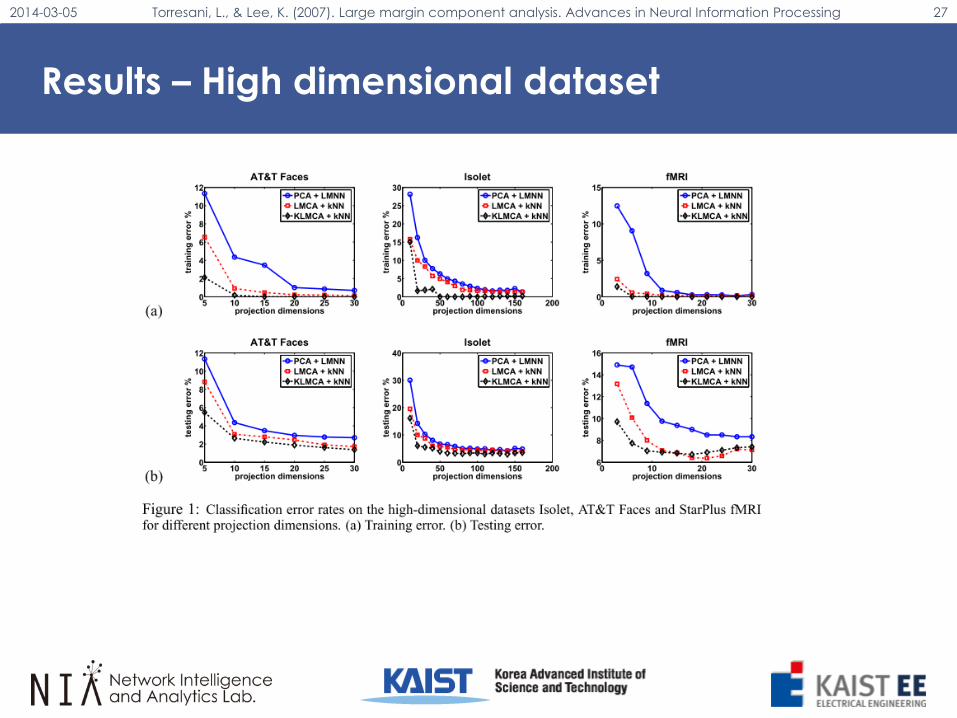
Results – High dimensional dataset
2014-03-05 Torresani, L., & Lee, K. (2007). Large margin component analysis. Advances in Neural Information Processing 27
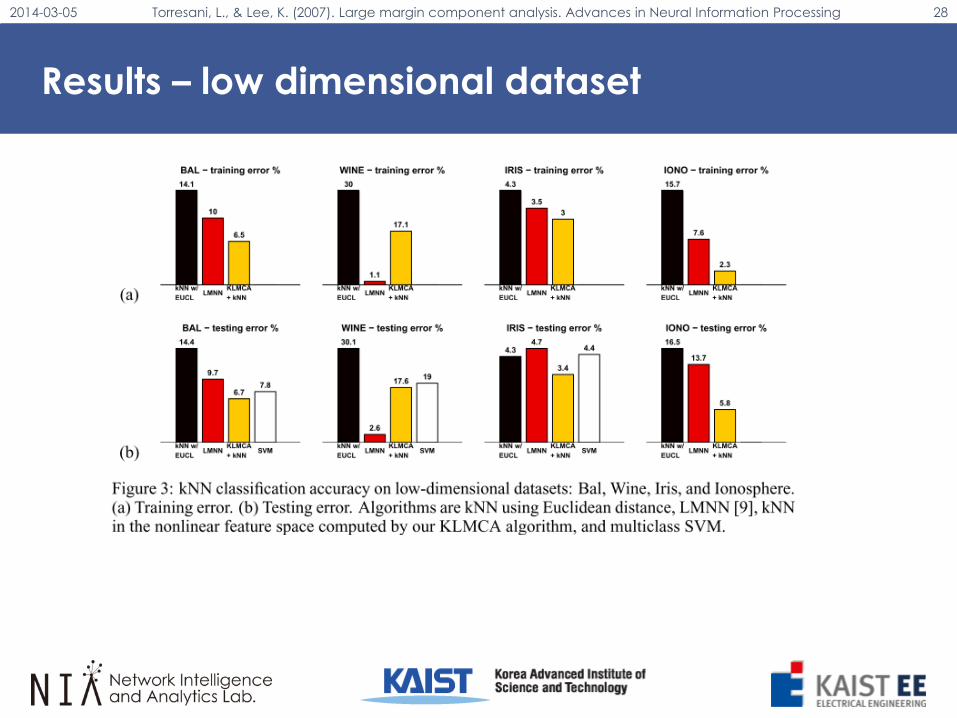
Results – low dimensional dataset
2014-03-05 Torresani, L., & Lee, K. (2007). Large margin component analysis. Advances in Neural Information Processing 28

Reference
• Bellet, A., Habrard, A., and Sebban, M. A Survey on Metric Learning forFeature Vectors and Structured Data, 2013
• Liu Yang, Distance Metric Learning: A Comprehensive Survey, 2005
• Liu Yang, An Overview of Distance Metric Learning, 2007
• Marco Cuturi. KAIST Machine Learning Tutorial Metrics and Kernels A fewrecent topics, 2013
• Nakul Verma, A tutorial on Metric Learning with some recent advances
• Aurelien Bellet, Tutorial on Metric Learning, 2013
• Brian Kulis. Tutorial on Metric Learning. International Conference onMachine Learning (ICML) 2010
2014-03-05 29

Reference
• K. Q. Weinberger, J. Blitzer, and L. K. Saul (2006). In Y. Weiss, B. Schoelkopf,and J. Platt (eds.), Distance Metric Learning for Large Margin NearestNeighbor Classification, Advances in Neural Information ProcessingSystems 18 (NIPS-18). MIT Press: Cambridge, MA.
• K. Q. Weinberger, L. K. Saul. Distance Metric Learning for Large MarginNearest Neighbor Classification. Journal of Machine Learning Research(JMLR) 2009, 10:207-244
• Torresani, L., & Lee, K. (2007). Large margin component analysis.Advances in Neural Information Processing
• Kedem, D., Xu, Z., & Weinberger, K. (n.d.). Gradient Boosted LargeMargin Nearest Neighbors, (1), 10–12.
2014-03-05 30





























