Embed Size (px)
Citation preview

Distributed Stochastic GradientMCMC
Sungjin Ahn1 Babak Shahbaba2 Max Welling3
1Department of Computer Science, University of California, Irvine2Department of Statistics, University of California, Irvine
3Machine Learning Group, University of Amsterdam
June 20, 2016
1 / 28

1 おさらい
2 Stochastic Gradient Langevin Dynamics
3 Distributed Inference in LDA
4 Distributed Stochastic Gradient Langevin Dynamics
5 Experiments
2 / 28
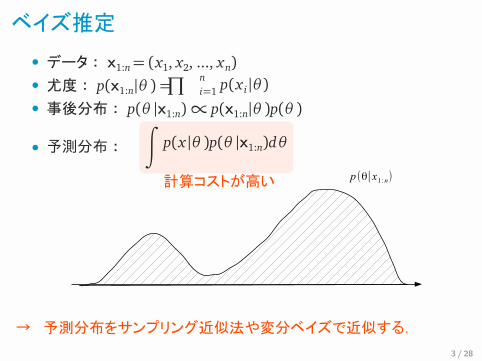
ベイズ推定
•• 尤度: p(x1:n|θ ) =
データ: x1:n = (x1,∏x2, ..., xn)ni=1 p(x i|θ )
• 事後分布: p(θ |x1:n) ∝ p(x1:n|θ )p(θ )
• 予測分布:∫
p(x |θ )p(θ |x1:n)dθ
計算コストが高い
→ 予測分布をサンプリング近似法や変分ベイズで近似する.
3 / 28

サンプリング近似法
点推定:一つの推定されたパラメータを用いて予測する.
サンプリング近似:
事後分布からサンプリングされた複数のパラメータの平均によって予
測をする.
θ (s) ∼ p(θ |x1:n),
∫p(x |θ )p(θ |x1:n)dθ ≈ 1
S
S∑s=1
p(x |θ (s))
n が大きいほど,モデルの学習に計算コストがかかる.
→ 近年,Subsampling を用いる手法が多く提案されている.
4 / 28

Abstract
• 確率的最適化に基づいた並列化 MCMC を提案した.
• stochastic gradient MCMC を並列化する際にの問題に対処法を示した.
• 提案手法を LDA に用いて Wikipedia と Pubmed の大規模コー
パスを学習させたところ,通常の並列化 MCMC での学習時間を
27 時間→ 30 分に軽減できた.(perplexity の収束時間)
5 / 28

Mini-batch-based MCMC
Stochastic Gradient Langevin Dynamics (SGLD)
[Welling & Teh, 2011]
• 単純な Stochastic gradient ascent を拡張する.
• MAP ではなく完全な事後分布からサンプリングするようなベイズ推定のアルゴリズムを考える.
• Langevin Dynamics [Neal, 2010] は MCMC の手法の一つ.解
が単なる MAP に陥らないよう,パラメータの更新時にGaussian noise を加える.
6 / 28

Mini-batch-based MCMC
準備
• データセット X = {x1, x2, ..., xN },パラメータ θ ∈ Rd
• モデルの同時分布 p(X , θ ) ∝ p(X |θ )p(θ )• 目的:事後分布 p(θ |X ) からのサンプルを得る.
7 / 28

Stochastic Gradient Ascent確率的最適化アルゴリズム [Robbins & Monro, 1951] At iterattion t = 1, 2, ... :
• データセットから subset {x t1, ..., x tn} (n << N) をとる.
• subset を用いて対数事後分布の勾配の近似値を計算する.
∇ log p(θt |X )≈∇ log p(θt) +nN
n∑i=1
∇ log p(x t i|θt)
• この値を用いてパラメータの値を更新する.
θt+1 = θt +εt
2
�∇ log p(θt) +
nN
n∑i=1
∇ log p(x t i|θt)
�
8 / 28

Stochastic Gradient Ascent
収束するためのステップサイズ εt の主な条件は次である.
∞∑t=1
εt =∞,∞∑t=1
ε2t <∞
• パラメータ空間を幅広く行ったり来たりさせるために,ス
テップサイズを小さくしすぎない.
• 局所最適解 (MAP) に収束させるために,ステップサイズを 0にまで減少させない.
9 / 28

Langevin Dynamics
事後分布 p(θ |X ) に収束するダイナミクスを描く確率微分方程式:
∆θ (t) =12∇ log p(θ (t)|X ) +∆b(t)
ここで,b(t) はブラウン運動である.
• 勾配項は確率が高い場所でより多くの時間を費やすようにダ
イナミクスを促進する.
• ダイナミクスがパラメータ空間全体を探索するようにブラウ
ン運動をノイズとして与える.
10 / 28

Langevin Dynamics
オイラーの有限差分法で離散化すると,
θt+1 = θt +ε
2∇ log p(θt |X ) +ηt ηt ∼ N(0,ε)
• ノイズの総計は勾配のステップサイズの平均
• 有限のステップサイズの場合は離散化誤差が発生する.
• 離散化はメトロポリス・ヘイスティング法(MH 法)のaccept/reject step により修正される.
• ε → 0 のとき,acceptance rate は 1 になる.
11 / 28

Stochastic Gradient Langevin Dynamicssubset X t = {x t1, ..., x tn} (n<< N)p(θt |X t)∝ p(θt)
∏ni=1 p(x t i|θt)
サンプル点は次の式から生成される.
θt+1 = θt +ε
2
�∇ log p(θt) +
Nn
n∑i=1
∇ log p(x t i|θt)
�Stochastic Gradient Acsent
+ ηt
noise
• Gaussian noise:ηt ∼ N(0,εt)• Annealed step-size:
∑∞t=1 εt =∞,∑∞
t=1 ε2t <∞
• MH 法の accept/reject step は計算コストが高いが,
acceptance probability が1になるので無視できる.
12 / 28

Distributed Inference in LDA
Approximate Distributed LDA (AD-LDA) [Newman et al, 2007]
• MCMC にかかる計算時間を減らすため,それぞれの localshard に周辺化ギブスサンプリングを行う手法.
• N1回のサンプリングごとの計算コストが O ( S ) まで減少.
• global states との同期により local copy の重みを修正できる.
13 / 28

Distributed Inference in LDA
AD-LDA の欠点:
• データセットのサイズが大きいと,worker を追加しても遅い.
• global states との同期のせいで block-by-the-slowest に苦し
む. block-by-the-slowest:最も遅い worker のタスク完了を他の
worker が待機している状態.
• 並列化した連鎖の実行に大きな overhead(並列化計算のための
処理) がかかる.
14 / 28

Distributed Inference in LDA
Yahoo-LDA (Y-LDA) [Ahmed et al, 2012]
• 非同期での更新により,block-by-the-slowest の解決をした.
• 非同期で無限に更新するとパフォーマンスが悪化する.
[Ho et al, 2013]
15 / 28

Distributed SGLD
Distributed Stochastic Gradient Langevin Dynamics (D-SGLD):
• SGLD を並列計算し,大規模データに対しても高速なサンプリングを可能にしたい.
• local shards からランダムにミニバッチをサンプリングするSGLD algorithm を提案する.
16 / 28

SGLD on Partitioned Datasets
準備
• sudataset X = {x1, ..., xN } を S 個の bset(shard) に分割:X1, ..., XS, X = ∪sX s, N =
∑s Ns
• データ x が与えられた時の対数尤度 (score function):g(θ ; x) = ∇θ log p(θ ; x)
• X からサンプリングされた n 個のデータ点のミニバッチ:X n
shard X s からサンプリングされたとき:X sn
イ テレーション t で X n s がサンプリングされたとき:X n s,t
• score function の合計:G(θ ; X ) =∑
x∈X g(θ ; x)score function の平均: g(θ ; X ) = |X
1|G(θ ; X )
17 / 28

SGLD on Partitioned Datasets
Propositionshard s = 1, ..., S:
• shard size: Ns(Ns > 0,∑
s Ns = N)• 正規化された shard の選択頻度: qs(qs ∈ (0, 1),
∑s qs = 1)
このとき以下の推定値は SGLD の推定値として妥当である.
gd(θ ; X ns )
de f=
Ns
Nqs
g(θ ; X ns )
ここで,shard s は,scheduler h(Q) からサンプリングされる.ただ
し,頻度 Q = {q1, ..., qS}.証明は省略(supplementary material があるらしい)
18 / 28

SGLD on Partitioned Datasets
流れ
(1) shard をサンプリングで選ぶ.
s ∼ h(Q) = Category(q1, ..., qS)
(2) 選んだ shard からミニバッチ X n s をサンプリングする.
(3) ミニバッチを使って score 平均 g(θ ; X sn )を計算する.
(4) score 平均に NN
q
s
sをかけて,重みを修正する.
19 / 28

SGLD on Partitioned Datasets
SGLD update rule
θt+1← θt +εt
2
�∇ log p(θt) +
Nst
qst
g(θt; X nst)
�+ νt
• g(θt; X nst) の項は step size の補正になっている.
• このアルゴリズムは相対的にサイズが大きい,または他より使用
されていない shard に対して,大きな step をとる.(全ての
data-case が連鎖の混合に等しく用いられている)
20 / 28

Traveling Worker Parallel Chains
問題点
• short-communication-cycle problem:連鎖はイテレーションごとに新しい worker に遷移する必要があるため,伝達サイクルが短い.
• block-by-the-slowest problem:
worker の偏りによる反応遅れのせいで,次にスケジューリングさ
れている worker が処理待ちになる.
21 / 28

Distributed Trajectory Sampling
short-communication-cycle problem への対処
→ trajectory sampling で軽減できる.
• 他の worker に移る代わりに,ひとつの worker を訪れるごとに連鎖 c で τ 回連続して更新する.
• τ 更新後.最後 (τ 番目) の状態から次の連鎖の worker に移る
• communication-cycle が O (n) → O (τn) に増加.
• communication overhead は減少.
22 / 28

Adaptive Load Balancing
block-by-the-slowest problem への対処
→ 遅い worker のタスクが終了するまで,速い worker を長めに働かせる.
• worker 全体の反応時間が可能な限り平均化される.
23 / 28

D-SGLD Psedo Code
24 / 28

Dataset
データセットは以下の2つを使用した.
• Wikipedia corpus:
4.6M articles of approximately 811M tokens in total.• PubMed Abstract corpus:
8.2M articles of approximately 730M tokens in total.
25 / 28

比較手法
• AD-LDA• Async-LDA (Y-LDA)
[Ahmed et al., 2012; Smola & Narayanamurthy, 2010]• SGRLD: Stochastic gradient Riemannian Langevin dynamics
[Patterson & Teh, 2013)]
26 / 28
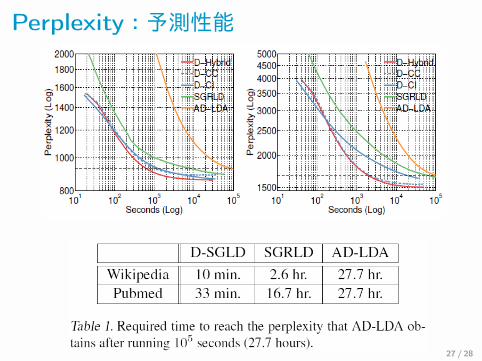
Perplexity:予測性能
27 / 28

Conclution
本論文では D-SGLD を紹介し,以下のことを示した.
• 適切な修正項を加えることで,提案アルゴリズムは local subset の偏りを防いだ.
• trajectory sampling により,communication overhead を減少させた.
• 分散低減法により,収束スピードを早めた.
28 / 28



![Learning the Privacy-Utility Trade-off with Bayesian ... › slides › simons-march-2019.pdf · Adam [21] is a first-order gradient-based optimization algorithm for stochastic objective](https://img.pdfslide.tips/doc/110x75/5f0b84b17e708231d430e9eb/learning-the-privacy-utility-trade-off-with-bayesian-a-slides-a-simons-march-2019pdf.jpg)

























