Embed Size (px)
Citation preview

Distributed TensorFlow
on Kubernetes
資訊與通訊研究所 蔣是文 Mac Chiang

Copyright 2017 ITRI 工業技術研究院
Agenda
• Kubernetes Introduction
• Scheduling GPUs on Kubernetes
• Distributed TensorFlow Introduction
• Running Distributed TensorFlow on Kubernetes
• Experience Sharing
• Summary
2

Copyright 2017 ITRI 工業技術研究院
What’s Kubernetes
• “Kubernetes” is Greek for captain or pilot
• Experiences from Google and design by Goolge
• Kubernetes is a production-grade, open-source platform that orchestrates the placement (scheduling) and execution of application containers within and across computer clusters.
• Masters manage the cluster and the nodes are used to host the running applications.
3

Copyright 2017 ITRI 工業技術研究院
Why Kubernetes
4
• Automatic binpacking
• Horizontal scaling
• Automated rollouts and rollback
• Service monitor
• Self-healing
• Service discovery and load balancing
• 100% Open source, written in Go

Copyright 2017 ITRI 工業技術研究院
Scheduling GPUs on Kubernetes
• Nvidia drivers are installed
• Turned on alpha feature gate Accelerators across the system▪ --feature-gates="Accelerators=true“
• Nodes must be using docker engine as the container runtime
5

Copyright 2017 ITRI 工業技術研究院
Scheduling GPUs on Kubernetes (cont.)
6
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
-
name: gpu-container-1
image: gcr.io/google_containers/pause:2.0
resources:
limits:
alpha.kubernetes.io/nvidia-gpu: 2 # requesting 2 GPUs
-
name: gpu-container-2
image: gcr.io/google_containers/pause:2.0
resources:
limits:
alpha.kubernetes.io/nvidia-gpu: 3 # requesting 3 GPUs

Copyright 2017 ITRI 工業技術研究院
Scheduling on Different GPU Versions
7
• Labeling nodes with GPU HW type
• Specify the GPU types via Node Affinity rules
Tesla P100
Node1 Node2
2 * K80 1 * P100
Tesla K80
gpu:k80 gpu:p100
Copyright 2017 ITRI 工業技術研究院
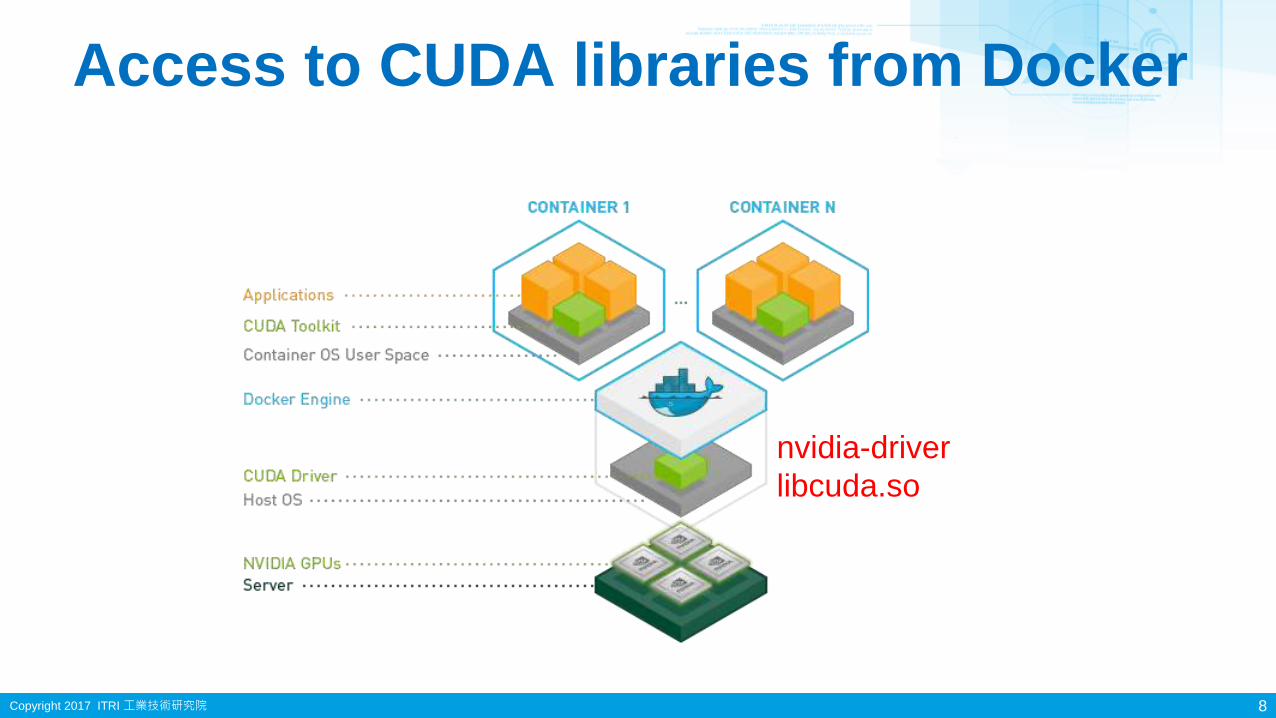
Access to CUDA libraries from Docker
nvidia-driver
libcuda.so
8

Copyright 2017 ITRI 工業技術研究院
TensorFlow
9
• Originally developed by the Google Brain Team within Google's Machine Intelligence research organization
• An open source software library for numerical computation using data flow graphs
• Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) communicated between them.
• Support one or more CPUs or GPUs in a desktop, server, or mobile device with a single API
Copyright 2017 ITRI 工業技術研究院
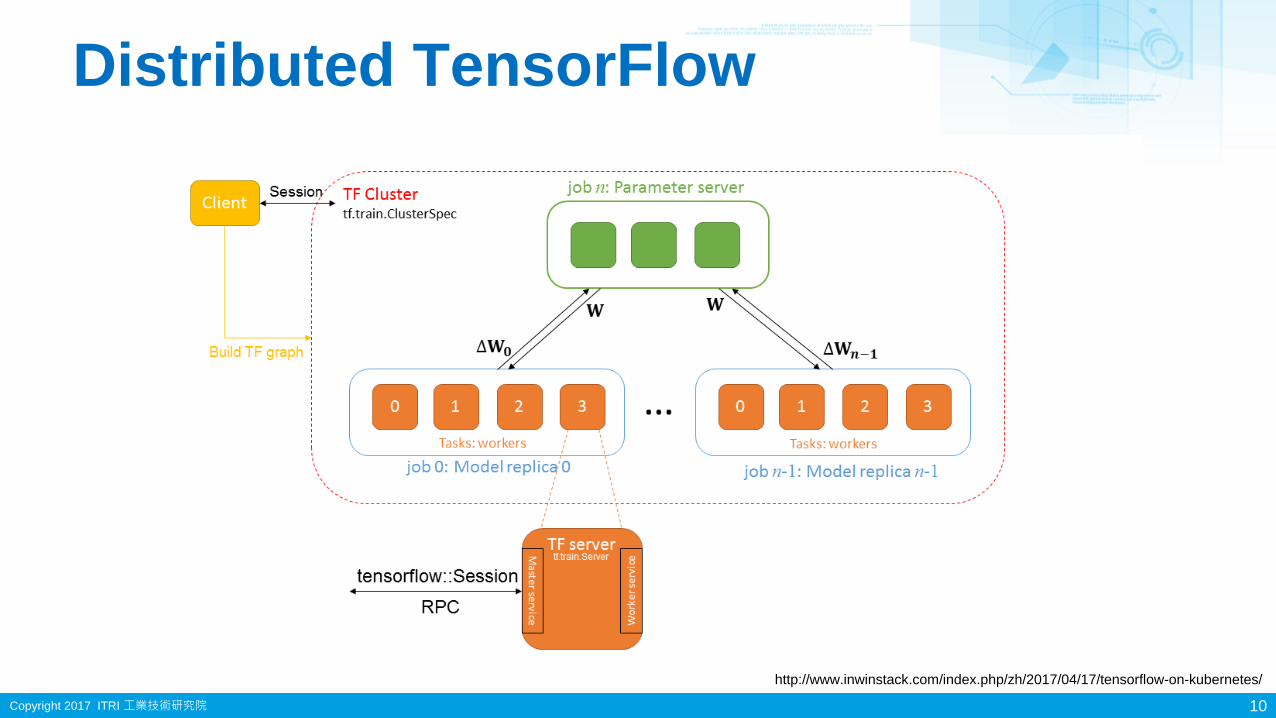
Distributed TensorFlow
10
http://www.inwinstack.com/index.php/zh/2017/04/17/tensorflow-on-kubernetes/
Copyright 2017 ITRI 工業技術研究院
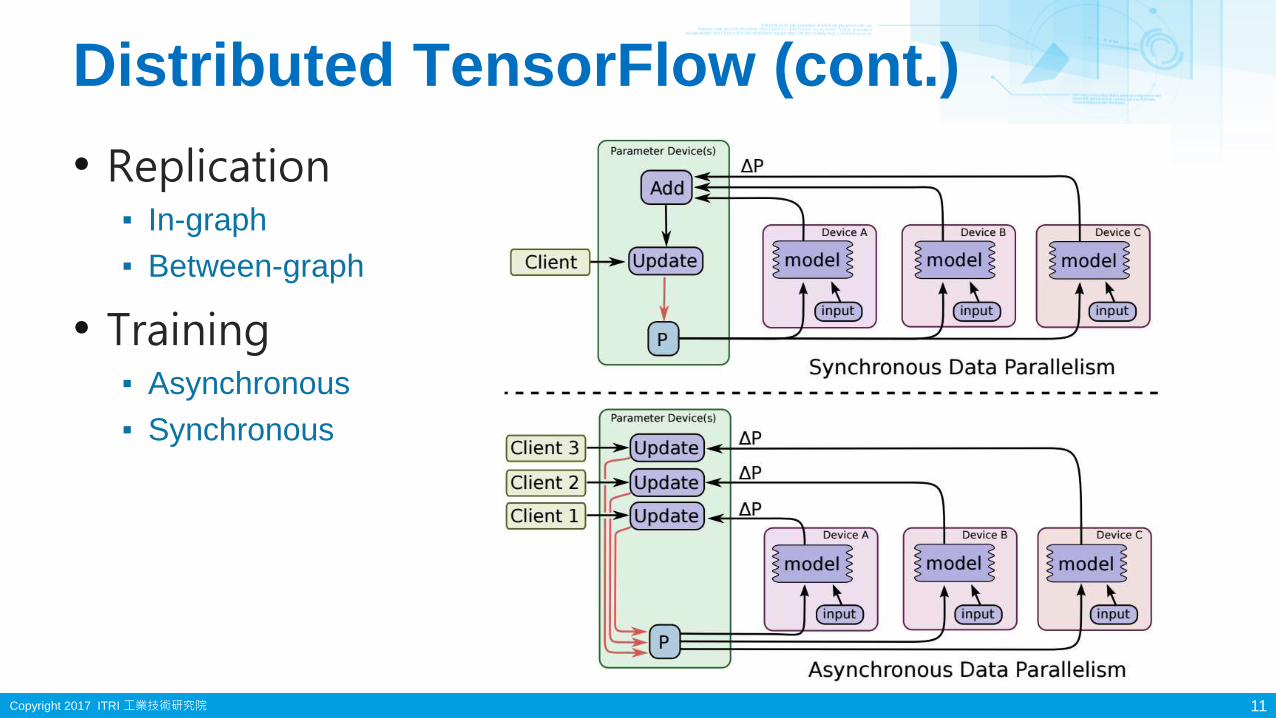
Distributed TensorFlow (cont.)
11
• Replication▪ In-graph
▪ Between-graph
• Training▪ Asynchronous
▪ Synchronous
Copyright 2017 ITRI 工業技術研究院
Distributed TensorFlow on K8S
12
• TensorFlow ecosystem▪ https://github.com/tensorflow/ecosystem

Copyright 2017 ITRI 工業技術研究院
Distributed TensorFlow on K8S (cont.)
13
• Prepare codes for distributed training▪ Flags for configuring the task
▪ Construct the cluster and start the server
▪ Set the device before graph construction
# Flags for configuring the task
flags.DEFINE_integer("task_index", None,
"Worker task index, should be >= 0. task_index=0 is "
"the master worker task the performs the variable "
"initialization.")
flags.DEFINE_string("ps_hosts", None,
"Comma-separated list of hostname:port pairs")
flags.DEFINE_string("worker_hosts", None,
"Comma-separated list of hostname:port pairs")
flags.DEFINE_string("job_name", None, "job name: worker or ps")
# Construct the cluster and start the server
ps_spec = FLAGS.ps_hosts.split(",")
worker_spec = FLAGS.worker_hosts.split(",")
cluster = tf.train.ClusterSpec({
"ps": ps_spec,
"worker": worker_spec})
server = tf.train.Server(
cluster, job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
if FLAGS.job_name == "ps":
server.join()
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index, Cluster=cluster)):
# Construct the TensorFlow graph.
# Run the TensorFlow graph.

Copyright 2017 ITRI 工業技術研究院
Distributed TensorFlow on K8S (cont.)
14
• Build docker image▪ Prepare Dockerfile
▪ Build docker image
docker build -t <image_name>:v1 -f Dockerfile .
docker build -t macchiang/mnist:v7 -f Dockerfile .
docker push <image_name>:v1 Push image to docker hub
docker push macchiang/mnist:v7
FROM tensorflow/tensorflow:latest-gpu
COPY mnist_replicatensorflow/tensorflow.py /
ENTRYPOINT ["python", "/mnist_replica.py"]
Copyright 2017 ITRI 工業技術研究院
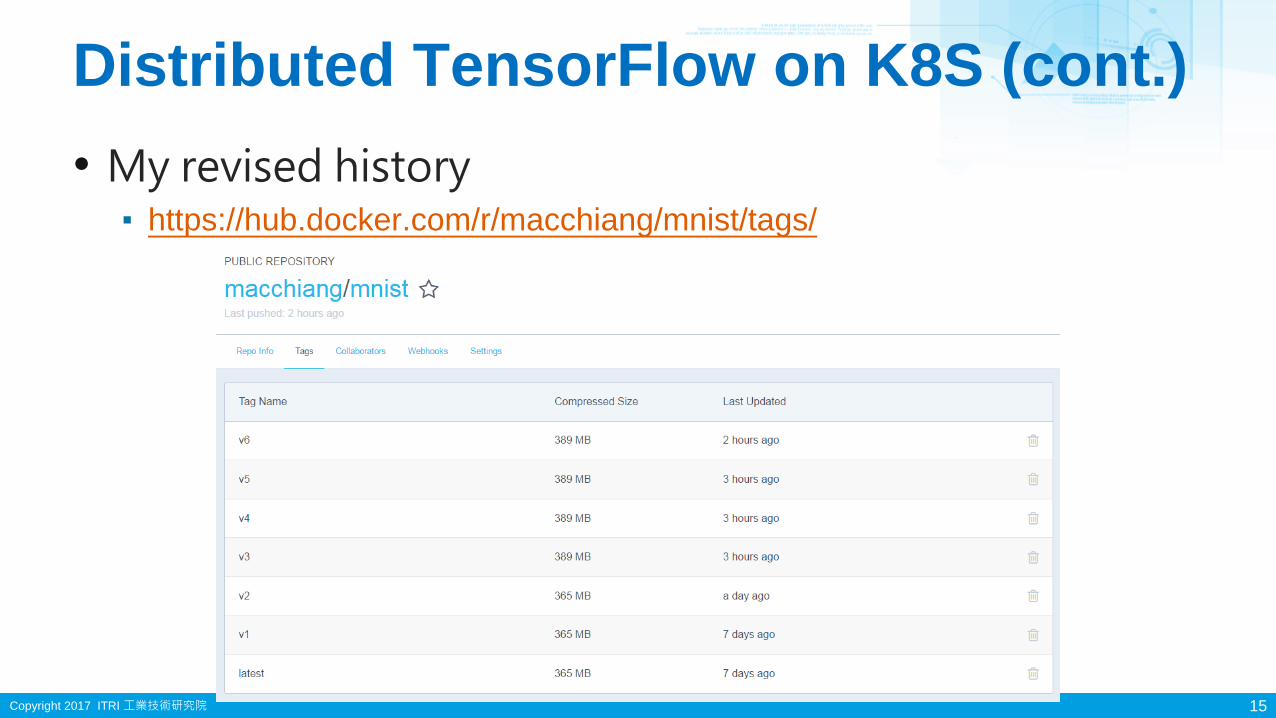
Distributed TensorFlow on K8S (cont.)
15
• My revised history▪ https://hub.docker.com/r/macchiang/mnist/tags/

Copyright 2017 ITRI 工業技術研究院
Distributed TensorFlow on K8S (cont.)
16
• Specify parameters in jinja template file▪ name, image, worker_replicas, ps_replicas, script, data_dir, and train_dir
▪ You may optionally specify credential_secret_name and
credential_secret_key if you need to read and write to Google Cloud
Storage
• Generate K8S YAML and create services and pods▪ python render_template.py mnist.yaml.jinja | kubectl create -f -
command:
- "/root/inception/bazel-bin/inception/imagenet_distributed_train"
args:
- "--data_dir=/data/raw-data"
- "--task_index=0"
- "--job_name=worker“
- "--worker_hosts=inception-worker-0:5000,inception-worker-1:5000“
- "--ps_hosts=inception-ps-0:5000"
Copyright 2017 ITRI 工業技術研究院
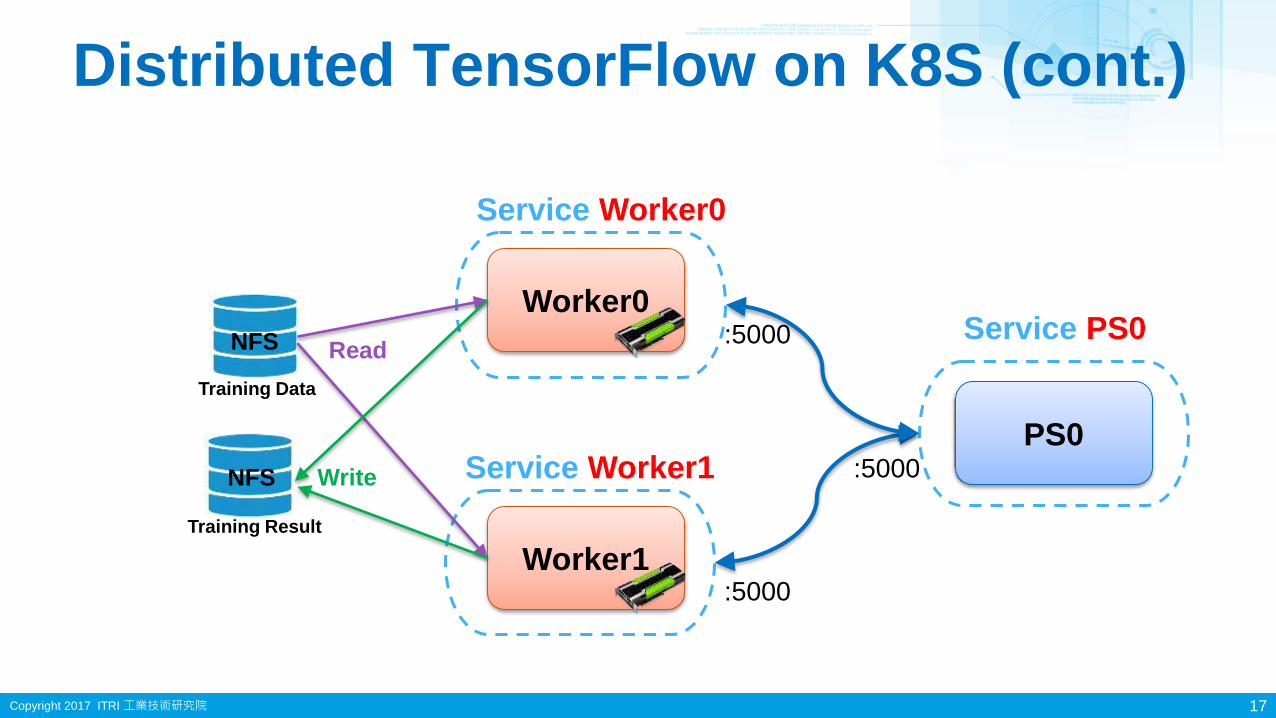
Distributed TensorFlow on K8S (cont.)
17
Worker0
Worker1
Service Worker0
Service Worker1
:5000
PS0
Service PS0
:5000
:5000
Training Data
NFS
Training Result
NFS
Read
Write
Copyright 2017 ITRI 工業技術研究院
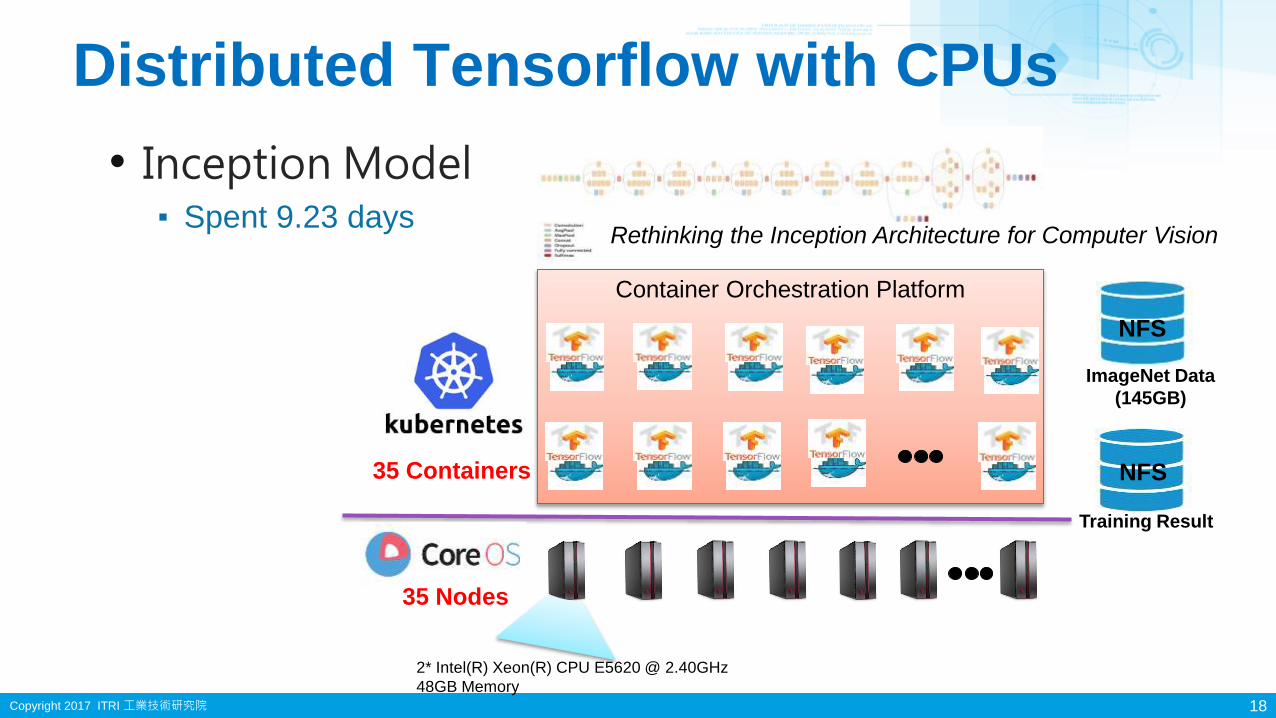
Distributed Tensorflow with CPUs
18
Container Orchestration Platform
35 Nodes
ImageNet Data
(145GB)
NFS
Training Result
NFS
2* Intel(R) Xeon(R) CPU E5620 @ 2.40GHz
48GB Memory
• Inception Model▪ Spent 9.23 days
35 Containers
Rethinking the Inception Architecture for Computer Vision

Copyright 2017 ITRI 工業技術研究院
Summary
• Kubernetes▪ Production-grade container orchestration platform
▪ GPU resources management
a. Nvidia GPU only now
b. In Kuberntest 1.8, you can use NVIDIA device plugin.
» https://github.com/NVIDIA/k8s-device-plugin
• Kubernetes + Distributed TensorFlow▪ Easy to build the distributed training cluster
▪ Leverage Kubernetes advantages
a. Restart failed container
b. Monitoring
c. Scheduling
19






























