Embed Size (px)
Citation preview

最近のDQN
藤田康博
Preferred Networks
2015/07/23

Outline
はじめにDQN
DQNの分析DQNの改善DQNの応用まとめ

Outline
はじめにDQN
DQNの分析DQNの改善DQNの応用まとめ

話す人
▶ 藤田康博▶ Twitter: @mooopan
▶ GitHub: muupan
▶ 2015年 4月 Preferred Networks入社

話すこと
DQN(Deep Q-Networks) [Mnih et al. 2013; Mnih et al.2015]のこと
▶ アルゴリズムの説明▶ 分析・改善・応用の紹介(本題)
▶ 2015年 7月 23日時点での DQN関連情報のまとめとして機能することを目指して

話さないこと
DQNと毛色の異なる深層強化学習(主に Policy Search系)▶ Deterministic Policy Gradient [Silver et al. 2014]
▶ Guided Policy Search [Levine and Koltun 2013]
▶ Trust Region Policy Optimization [Schulman et al. 2015b]
▶ Generalized Advantage Estimation [Schulman et al.2015a]
▶ 話したいが,説明する時間がない▶ 別の機会にでも…

Outline
はじめにDQN
DQNの分析DQNの改善DQNの応用まとめ

強化学習問題
▶ エージェントは各タイムステップ t = 0, 1, . . . で1. 現在の状態 st ∈ S を観測2. st に応じて行動 at ∈ Aを選択3. 報酬 rt ∈ R(と次状態 st+1 ∈ S)を観測
▶ 目標:累積報酬∑
t rt の最大化▶ どの行動を選ぶべきかという教師データは存在しない
▶ 試行錯誤を通じて学習する必要がある

強化学習の概念(1)
▶ 方策(policy)▶ 「どうやって行動を選ぶか」▶ π : S 7→ A
▶ 行動価値関数(action value function)▶ 状態 s で行動 aを選び,その後方策 πに従った場合の,期待累積報酬
▶ Qπ(s, a) = E[rt +γrt+1+γ2rt+2+ · · · | st = s, at = a, π]
▶ γは割引率

強化学習の概念(2)
▶ 最適方策▶ 期待累積報酬を最大化する方策 π∗
▶ 最適行動価値関数▶ Q∗(s, a) = Qπ∗
(s, a) = maxπ Qπ(s, a)
▶ これが求まると,π(s) = argmaxa Q∗(s, a)として最適
方策も求まる
▶ Bellman最適方程式▶ Q∗(s, a) = Es′ [r + γmaxa′ Q
∗(s ′, a′) | s, a]▶ 行動価値関数が最適である必要十分条件
▶ これを解けばQ∗が求まる

Q-learning [Watkins and Dayan 1992]
▶ DQNの元となるアルゴリズム▶ 一定の条件下でQ∗に収束
Input: γ, α1: Initialize Q(s, a) arbitrarily2: loop3: Initialize s4: while s is not terminal do5: Choose a from s using policy derived from Q6: Execute a, observe reward r and next state s ′
7: Q(s, a)← Q(s, a) + α[r + γmaxa′ Q(s ′, a′)− Q(s, a)]8: s ← s ′
9: end while10: end loop

Deep Q-learning
▶ 価値関数をDNNで近似
Q(s, a; θ) ≈ Q(s, a)
▶ 損失の定義
L(θ) = E[(r + γmaxa′
Q(s ′, a′; θ)− Q(s, a; θ))2]
∂L(θ)
∂θ= E[(r + γmax
a′Q(s ′, a′; θ)−Q(s, a; θ))
∂Q(s, a; θ)
∂θ]
▶ Stochastic Gradient Descentで最小化可能

何が新しいか
▶ 価値関数のNNによる近似?▶ 昔からある(有名な例:TD-Gammon [Tesauro 1994])
▶ 価値関数のDNNによる近似?▶ 何を deepと呼ぶかにもよるが,Deep Belief Networksを使うやつ [Abtahi and Fasel 2011]とかある
▶ LSTMを使うやつも古くからある [Bakker 2001]
▶ 学習を成功させるための工夫▶ 重要▶ これがあって初めて DQNと呼ぶらしい [Silver 2015]

学習の不安定化要因の除去
▶ 入力が時系列データであり,i.i.d.でない▶ → Experience Replay
▶ 価値関数の小さな更新でも方策が大きく変わってしまい,振動する
▶ → Target Q-Network
▶ 報酬のスケールがゲームによって異なる▶ → 報酬の clipping

Experience Replay
▶ エージェントが経験した遷移 (st , at , rt , st+1)を replaymemory Dに蓄える
▶ 損失の計算とQの更新はDからランダムサンプリングしたバッチ上で行うL(θ) = Es,a,r ,s′∼D[(r + γmax
a′Q(s ′, a′; θ)− Q(s, a; θ))2]

Target Q-Network
▶ 学習の目標値の計算に使う価値関数を固定(targetQ-network)
L(θ) = Es,a,r ,s′∼D[(r + γmaxa′
Q(s ′, a′; θ−)− Q(s, a; θ))2]
▶ 一定周期で学習中のQ-networkと同期
θ− ← θ

報酬の clipping
▶ 報酬を [−1, 1]の範囲に clip▶ 負なら−1,正なら 1,0なら 0
▶ 報酬の大小を区別できなくなるデメリットもある

Arcade Learning Environment(ALE) [Bellemare
et al. 2013]
図は [Mnih et al. 2013] から引用
▶ 家庭用ゲーム機 Atari 2600のエミュレータ+学習用インタフェース
▶ 50以上のゲームに対応▶ スコアの変動を読み取れる
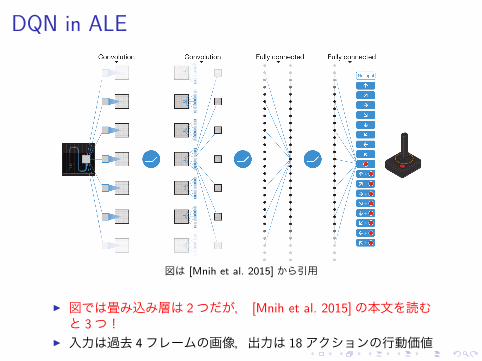
DQN in ALE
図は [Mnih et al. 2015] から引用
▶ 図では畳み込み層は 2つだが, [Mnih et al. 2015]の本文を読むと 3つ!
▶ 入力は過去 4フレームの画像,出力は 18アクションの行動価値

DQN vs. 人間
図は [Mnih et al. 2015] から引用
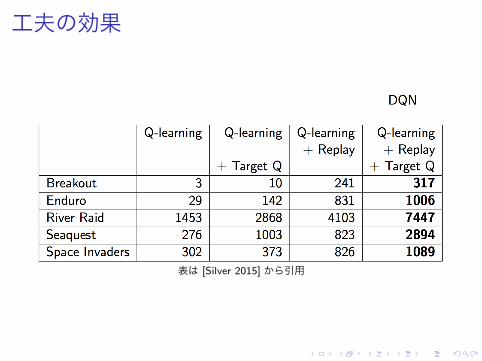
工夫の効果
表は [Silver 2015] から引用

Outline
はじめにDQN
DQNの分析DQNの改善DQNの応用まとめ

DQNの超パラメータ
▶ [Mnih et al. 2013]には学習率等の詳細が書いてなかった▶ 早くから TheanoによるDQNの再現 1を試みていた
Nathan Sprague氏がグリッドサーチして調べた▶ (一方自分は AdaDeltaでお茶を濁した)
1https://github.com/spragunr/deep_q_rl

DQNの超パラメータの分析 [Sprague 2015]
図は [Sprague 2015] から引用
DQN( [Mnih et al. 2013]の再現)の性能は超パラメータの設定に敏感▶ α:学習率,γ:割引率,ρ:RMSpropの移動平均の減衰率▶ target Q-network未使用

Outline
はじめにDQN
DQNの分析DQNの改善報酬のスケーリング並列化先読みExplorationの改善
DQNの応用まとめ

Outline
はじめにDQN
DQNの分析DQNの改善報酬のスケーリング並列化先読みExplorationの改善
DQNの応用まとめ

Normalized DQN [Silver 2015]
報酬を clippingする代わりに,報酬のスケーリングを学習▶ 報酬はそのままの値を使う▶ ネットワークはまずQ(s, a; θ)の代わりに
U(s, a; θ) ∈ [−1,+1]
を出力▶ これを学習可能なパラメータ π, σでQ値に変換
Q(s, a; θ, σ, π) = σU(s, a; θ) + π

Outline
はじめにDQN
DQNの分析DQNの改善報酬のスケーリング並列化先読みExplorationの改善
DQNの応用まとめ

Gorila(GOogle ReInforcement Learning Architecture)[Nair et al. 2015]
図は [Nair et al. 2015] から引用
DQNを並列に実行し高速化▶ Actor:行動を選び経験 (s, a, r , s ′)を積む▶ Memory:Actorが集めた経験を蓄える▶ Learner:Memoryから経験をサンプリングし更新量を計算▶ Bundle:(Actor ,Memory , Learner)の組

Gorilaの安定化
ノードの消滅,ネットワークの遅延や処理の遅延があっても安定して学習するための工夫
▶ 古いパラメータ θを使って計算された更新量はParameter Serverが無視する
▶ Learnerは誤差の絶対値の移動平均・標準偏差を保持しておき,そこから大きく外れるデータは捨てる
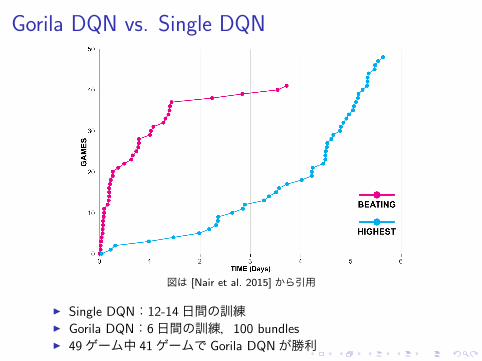
Gorila DQN vs. Single DQN
図は [Nair et al. 2015] から引用
▶ Single DQN:12-14日間の訓練▶ Gorila DQN:6日間の訓練,100 bundles▶ 49ゲーム中 41ゲームで Gorila DQNが勝利

Outline
はじめにDQN
DQNの分析DQNの改善報酬のスケーリング並列化先読みExplorationの改善
DQNの応用まとめ

ALEにおける先読み
チェス・将棋・囲碁のようなボードゲームでは先読み(ゲーム木探索)が使われるが,ALEでは?
▶ 実はDQNより強い! [Bellemare et al. 2013; Guo et al.2014]
▶ エミュレータの機能で状態を巻き戻す必要がある▶ TASさんのようなもの
▶ すごく遅い(行動を選ぶたびに数秒)
B. Rider Breakout Enduro Pong Q*bert Seaquest S. InvadersDQN [Mnih et al. 2013] 4092 168 470 20 1952 1705 581UCT [Guo et al. 2014] 7233 406 788 21 18850 3257 2354
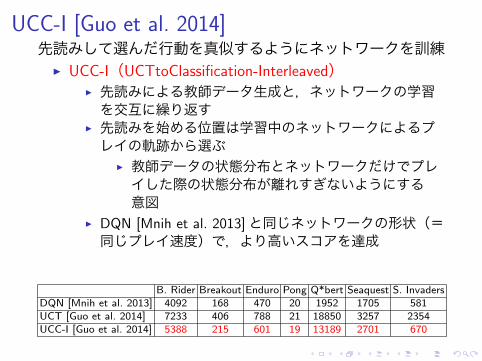
UCC-I [Guo et al. 2014]先読みして選んだ行動を真似するようにネットワークを訓練
▶ UCC-I(UCTtoClassification-Interleaved)▶ 先読みによる教師データ生成と,ネットワークの学習を交互に繰り返す
▶ 先読みを始める位置は学習中のネットワークによるプレイの軌跡から選ぶ
▶ 教師データの状態分布とネットワークだけでプレイした際の状態分布が離れすぎないようにする意図
▶ DQN [Mnih et al. 2013]と同じネットワークの形状(=同じプレイ速度)で,より高いスコアを達成
B. Rider Breakout Enduro Pong Q*bert Seaquest S. InvadersDQN [Mnih et al. 2013] 4092 168 470 20 1952 1705 581UCT [Guo et al. 2014] 7233 406 788 21 18850 3257 2354UCC-I [Guo et al. 2014] 5388 215 601 19 13189 2701 670

Outline
はじめにDQN
DQNの分析DQNの改善報酬のスケーリング並列化先読みExplorationの改善
DQNの応用まとめ

Exploration vs. Exploitation
▶ 強化学習では下の 2つのバランスをとる必要がある▶ Exploration:まだあまり知識がない状態・行動を試す▶ Exploitation:すでに良さそうだとわかっている状態・行動をもっと試す
▶ DQNではどうしてる?▶ ϵ-greedy:確率 ϵでランダムな行動,確率 1− ϵで
Q(s, a)が最大の行動を選ぶ▶ 最初の 1000000フレームで ϵを 1から 0.1になまし,それ以降は 0.1で固定

Exploration Bonus [Stadie et al. 2015]
あまり選んでない状態・行動対の報酬R(s, a)にボーナスN (s, a)を加えて学習する
▶ 次の状態の予測モデルMを学習し,予測誤差が大きいほど大きいボーナスを与える
e(s, a) = ∥σ(s ′)−M(σ(s), a)∥22
e(s, a) = et(s, a)/maxe
N (s, a) =e(s, a)
t ∗ C
▶ σ : S 7→ RN は状態の特徴表現,maxe はこれまでの eの値の最大値,t はイテレーション数,C は定数
▶ σ,Mはともにニューラルネットで学習する
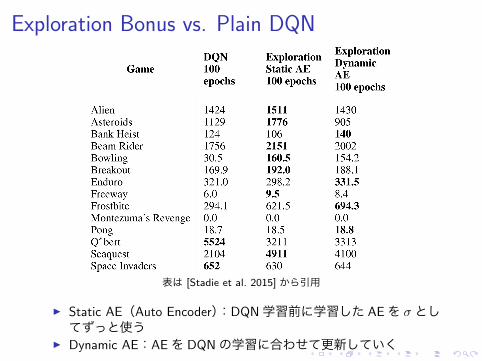
Exploration Bonus vs. Plain DQN
表は [Stadie et al. 2015] から引用
▶ Static AE(Auto Encoder):DQN学習前に学習した AEを σとしてずっと使う
▶ Dynamic AE:AEを DQNの学習に合わせて更新していく

Outline
はじめにDQN
DQNの分析DQNの改善DQNの応用テキストゲームロボット
まとめ

Outline
はじめにDQN
DQNの分析DQNの改善DQNの応用テキストゲームロボット
まとめ

テキストゲーム
図は [Narasimhan et al. 2015] から引用
▶ 状態:画像ではなく文章▶ 行動:動詞と目的語のペア

LSTM-DQN [Narasimhan et al. 2015]
図は [Narasimhan et al. 2015] から引用
▶ LSTM(Long Short-Term Memory)で文章を状態表現に落とす▶ 単語の word embeddingを前から順に入力し,最後に出力の平均をとる
▶ word embeddingも一緒に学習する▶ Q(s, a)(動詞)と Q(s, o)(目的語)の 2つの出力それぞれを学習

LSTM-DQN vs. BOW-DQN
図は [Narasimhan et al. 2015] から引用
▶ Fantasy Worldという Evennia2 のチュートリアルゲーム▶ 語彙数:1340▶ コマンドの組み合わせ数:222
▶ 1 epoch = 20 episodes × 250 steps▶ BOG(Bag-of-Words)より良い性能2http://www.evennia.com/

LSTM-DQNのWord Embeddings
図は [Narasimhan et al. 2015] から引用

Outline
はじめにDQN
DQNの分析DQNの改善DQNの応用テキストゲームロボット
まとめ
ロボット制御
まだ見てない人は今すぐ「分散深層強化学習でロボット制御 — Preferred Research」3
にアクセス!!!3http://research.preferred.jp/2015/06/
distributed-deep-reinforcement-learning/

ロボット制御
まだ見てない人は今すぐ「分散深層強化学習でロボット制御 — Preferred Research」3
にアクセス!!!3http://research.preferred.jp/2015/06/
distributed-deep-reinforcement-learning/

Outline
はじめにDQN
DQNの分析DQNの改善DQNの応用まとめ

まとめ
▶ DQNはまだまだこれから▶ ビデオゲーム以外への応用はまだ少ない▶ アルゴリズムもまだまだ改善されていくはず
▶ 今後も目が離せない!

参考文献 I
[1] Farnaz Abtahi and Ian Fasel. “Deep belief nets as function approximators forreinforcement learning”. In: AAAI 2011 Lifelong Learning Workshop (2011),pp. 183–219.
[2] Bram Bakker. “Reinforcement Learning with Long Short-Term Memory”. In:NIPS 2001. 2001.
[3] Marc C. Bellemare et al. “The arcade learning environment: An evaluationplatform for general agents”. In: Journal of Artificial Intelligence Research 47(2013), pp. 253–279.
[4] Xiaoxiao Guo et al. “Deep learning for real-time Atari game play using offlineMonte-Carlo tree search planning”. In: Advances in Neural InformationProcessing Systems (NIPS) 2600 (2014), pp. 1–9.
[5] Sergey Levine and Vladlen Koltun. “Guided Policy Search”. In: ICML 2013.Vol. 28. 2013, pp. 1–9.
[6] Volodymyr Mnih et al. “Human-level control through deep reinforcementlearning”. In: Nature 518.7540 (2015), pp. 529–533.
[7] Volodymyr Mnih et al. “Playing Atari with Deep Reinforcement Learning”.In: NIPS 2014 Deep Learning Workshop. 2013, pp. 1–9. arXiv:arXiv:1312.5602v1.

参考文献 II[8] Arun Nair et al. “Massively Parallel Methods for Deep Reinforcement
Learning”. In: ICML Deep Learning Workshop 2015. 2015.
[9] Karthik Narasimhan, Tejas Kulkarni, and Regina Barzilay. LanguageUnderstanding for Text-based Games Using Deep Reinforcement Learning.2015. arXiv: arXiv:1506.08941v1.
[10] John Schulman et al. High-Dimensional Continuous Control UsingGeneralized Advantage Estimation. 2015. arXiv: arXiv:1506.02438v1.
[11] John Schulman et al. “Trust Region Policy Optimization”. In: ICML 2015.2015. arXiv: arXiv:1502.05477v1.
[12] David Silver. Deep Reinforcement Learning. ICLR 2015 Keynote.http://www.iclr.cc/lib/exe/fetch.php?media=iclr2015:silver-
iclr2015.pdf. 2015.
[13] David Silver et al. “Deterministic Policy Gradient Algorithms”. In: ICML2014. 2014, pp. 387–395.
[14] Nathan Sprague. “Parameter Selection for the Deep Q-Learning Algorithm”.In: RLDM 2015. 2015.
[15] Bradly C. Stadie, Sergey Levine, and Pieter Abbeel. Incentivizing ExplorationIn Reinforcement Learning With Deep Predictive Models. 2015. arXiv:1507.00814v2.

参考文献 III[16] Gerald Tesauro. “TD-Gammon, A Self-Teaching Backgammon Program,
Achieves Master-Level Play”. In: Neural Computation 6(2) (1994),pp. 215–219.
[17] Christopher JCH Watkins and Peter Dayan. “Q-learning”. In: Machinelearning 8.3-4 (1992), pp. 279–292.




























