Embed Size (px)
Citation preview

Feature Extraction for Effective Microblog Search and Adaptive Clustering Algorithms for TTG
PKUICST at TREC 2014 Microblog TrackChao Lv Feifan Fan Runwei Qiang Yue Fei Jianwu Yang
[email protected] University
北京大学计算机科学技术研究所Institute of Computer Science & Technology Peking University

2
Ad hoc Search Task• Challenges• System Overview• Feature Extraction• Experimental Results
(Q1 , t1)(Q2 , t2)
…(Qn , tn)

3
Challenges
• Tweet is under the length limitation of 140 characters• Severe vocabulary-mismatch problem• It is necessary to apply query expansion techniques
• Abundance of shortened URLs• We should offer ways to expand document
• Large quantities of pointless babble• Tweet quality should be defined to filter non-informative message.

4
Motivations
• Learning to rank can make full use of different models or factors in microblog search• different factors => different features
5
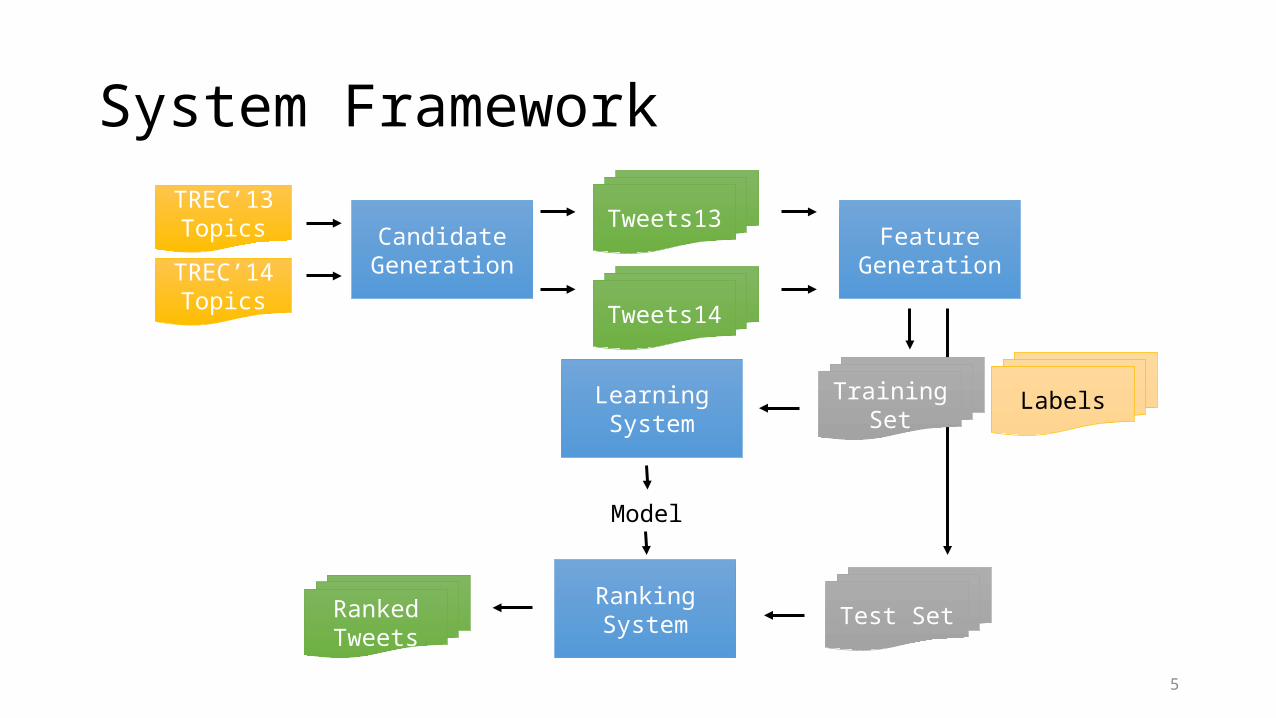
System FrameworkTREC’13Topics
TREC’14Topics
Candidate Generation
Tweets13
Tweets14
Feature Generation
Learning System
Test Set
Labels
Ranking System
Model
Ranked Tweets
Training Set

6
Feature ExtractionRelated Work in Microblog Search
• Many features have been proved useful• Semantic features between query and document• Tweet quality features, i.e. link, retweet, and mention count/binary
• An empirical study on learning to rank of tweets [1] (20)• Content relevance features (3)• Twitter’s specific features (6)• Account Authority Features (12)
• TREC 2012 microblog track experiments at Kobe University [2] (8)• Feature Analysis in Microblog Retrieval Based on Learning to Rank [3] (15)• Exploiting Ranking Factorization Machines for Microblog Retrieval [4] (29)

7
Feature ExtractionFeatures for Traditional Web Search
• Hundreds/Thousands of Features in the Full Ranker for Web Search• LETOR Dataset• A pack of benchmark data sets for research on Learning To Rank. • Each query-url pair is represented by a 136-dimensional vectors.• Features such as:
• covered query number of body, anchor, title, url and whole document• Page rank• url click count• url dwell time • …

8
Feature ExtractionRetrieval Model
Retrieval Model
Document
Query
• OKAPI BM25 Score (BM25)• Language Model Score (LM)• LM.DIR• LM.JM• LM.ABS
• TFIDF Model Score (TFIDF)

9
Feature ExtractionQuery
Query
Retrieval Model
Document
• Use different queries to better understand the user’s search intent• Original Query• Top Tweet Based Query• Web Based Query• Freebase Based Query
• Whether to use PRF based query expansion?
10
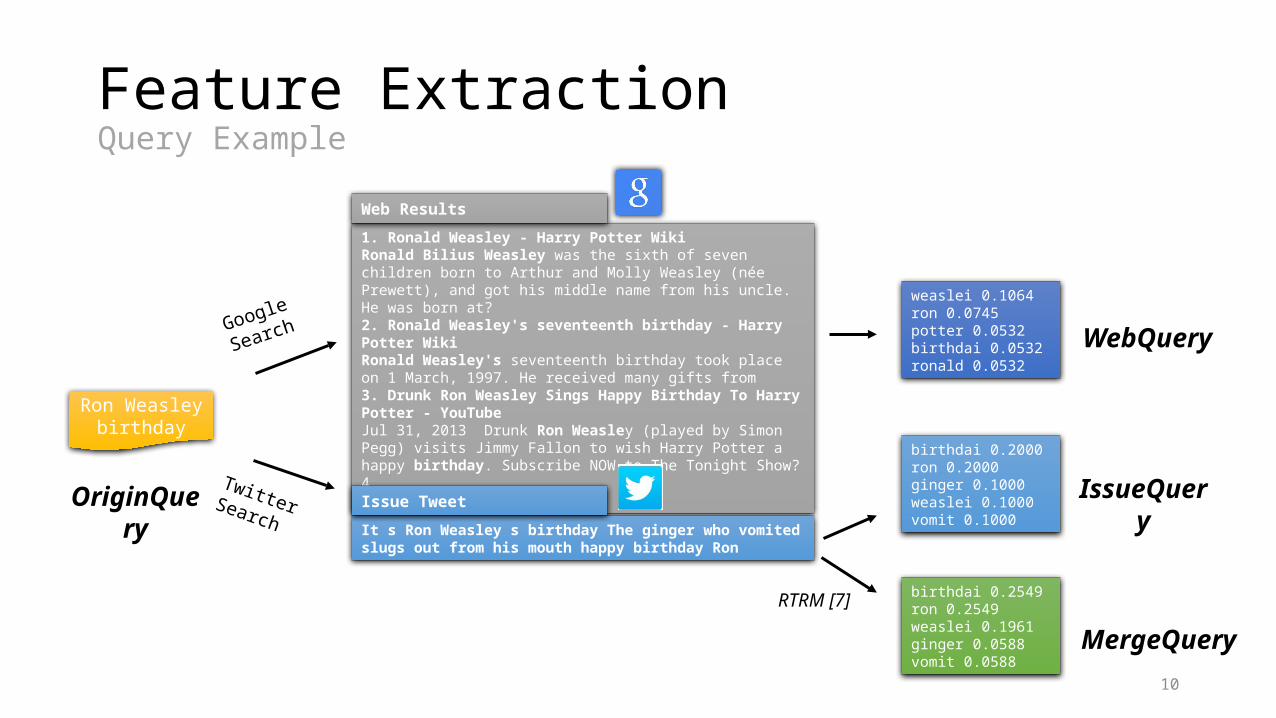
Feature ExtractionQuery Example
Ron Weasley birthday
Google Search
1. Ronald Weasley - Harry Potter WikiRonald Bilius Weasley was the sixth of seven children born to Arthur and Molly Weasley (née Prewett), and got his middle name from his uncle. He was born at?2. Ronald Weasley's seventeenth birthday - Harry Potter WikiRonald Weasley's seventeenth birthday took place on 1 March, 1997. He received many gifts from3. Drunk Ron Weasley Sings Happy Birthday To Harry Potter - YouTubeJul 31, 2013 Drunk Ron Weasley (played by Simon Pegg) visits Jimmy Fallon to wish Harry Potter a happy birthday. Subscribe NOW to The Tonight Show?4. …5. …
It s Ron Weasley s birthday The ginger who vomited slugs out from his mouth happy birthday Ron
Twitter Search
Web Results
Issue Tweet
weaslei 0.1064ron 0.0745potter 0.0532birthdai 0.0532ronald 0.0532
birthdai 0.2000ron 0.2000ginger 0.1000weaslei 0.1000vomit 0.1000
birthdai 0.2549ron 0.2549weaslei 0.1961ginger 0.0588vomit 0.0588
WebQuery
IssueQuery
MergeQuery
RTRM [7]
OriginQuery

11
Feature ExtractionDocument
Document
Query
Retrieval Model
• Plain Tweet Text (Origin)Say HappyBirthdayRonWeasley and share your creativity by submitting a drawing of Ron to celebrate
• Topic Information from URL (Title)Pottermore Insider Happy birthday Ron Weasley
• Merged Text (DocEx)Say HappyBirthdayRonWeasley and share your creativity by submitting a drawing of Ron to celebrate Pottermore Insider Happy birthday Ron Weasley

12
Feature ExtractionDocument
API• Get tweets with common API• Save time for crawling• Use general term statistics• Statistical Index with Lucence
Local• Local copy of the API corpus• Preprocessing before indexing• Non-English tweets removal with
ldig• RT tweets removal
• Dynamic Index with Lemur

13
Feature ExtractionQuality Features
• Quality Features1. Time Difference between Query Issue Time and Tweet Post Time2. Mention Count3. Hashtag Count4. Shortened URL Count5. Term Count of Text6. Length of Text
14
Experimental Results
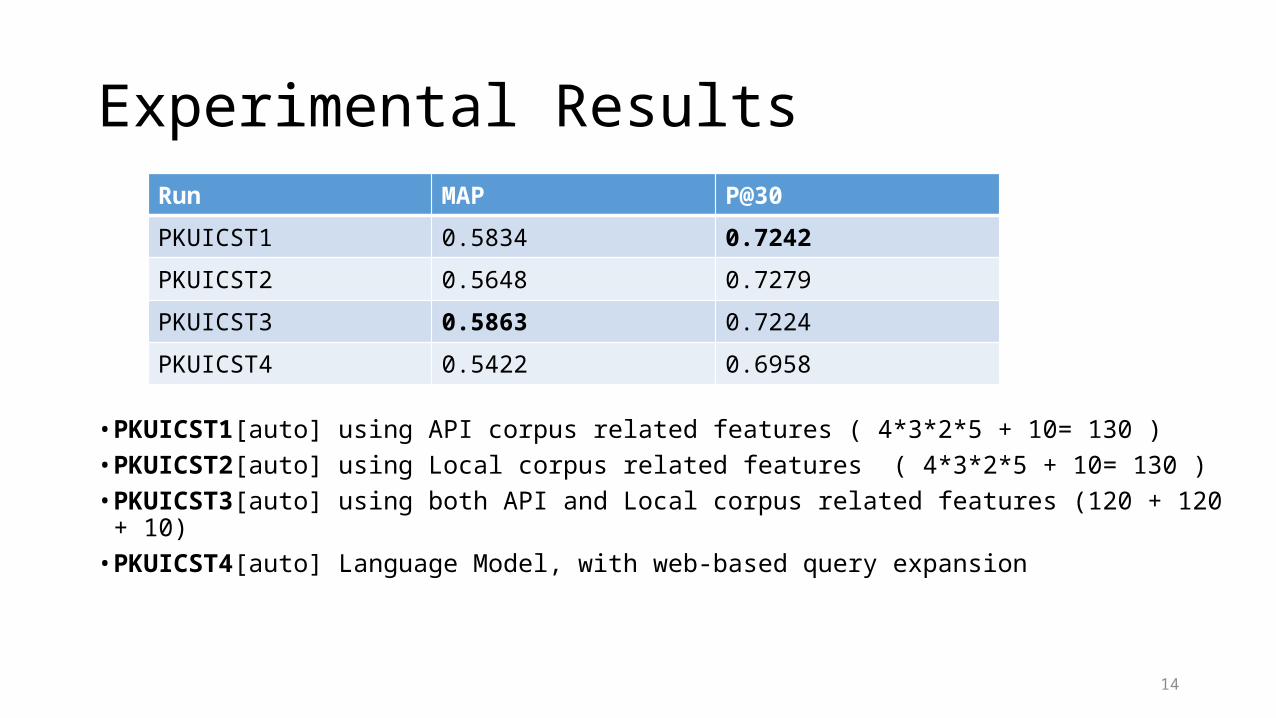
• PKUICST1[auto] using API corpus related features ( 4*3*2*5 + 10= 130 )• PKUICST2[auto] using Local corpus related features ( 4*3*2*5 + 10= 130 )• PKUICST3[auto] using both API and Local corpus related features (120 + 120 + 10)• PKUICST4[auto] Language Model, with web-based query expansion
Run MAP P@30
PKUICST1 0.5834 0.7242
PKUICST2 0.5648 0.7279
PKUICST3 0.5863 0.7224
PKUICST4 0.5422 0.6958

15
TTG Task• Challenges• System Overview• Candidate Selection• Clustering Algorithm• Experimental Results
"I have an information need expressed by a query Q at time t and I would like a summary that captures relevant information."

16
Challenges
• Systems will need to address two challenges:• Determine how many results to return.• Detect (and eliminate) redundant tweets.
17
System Overview
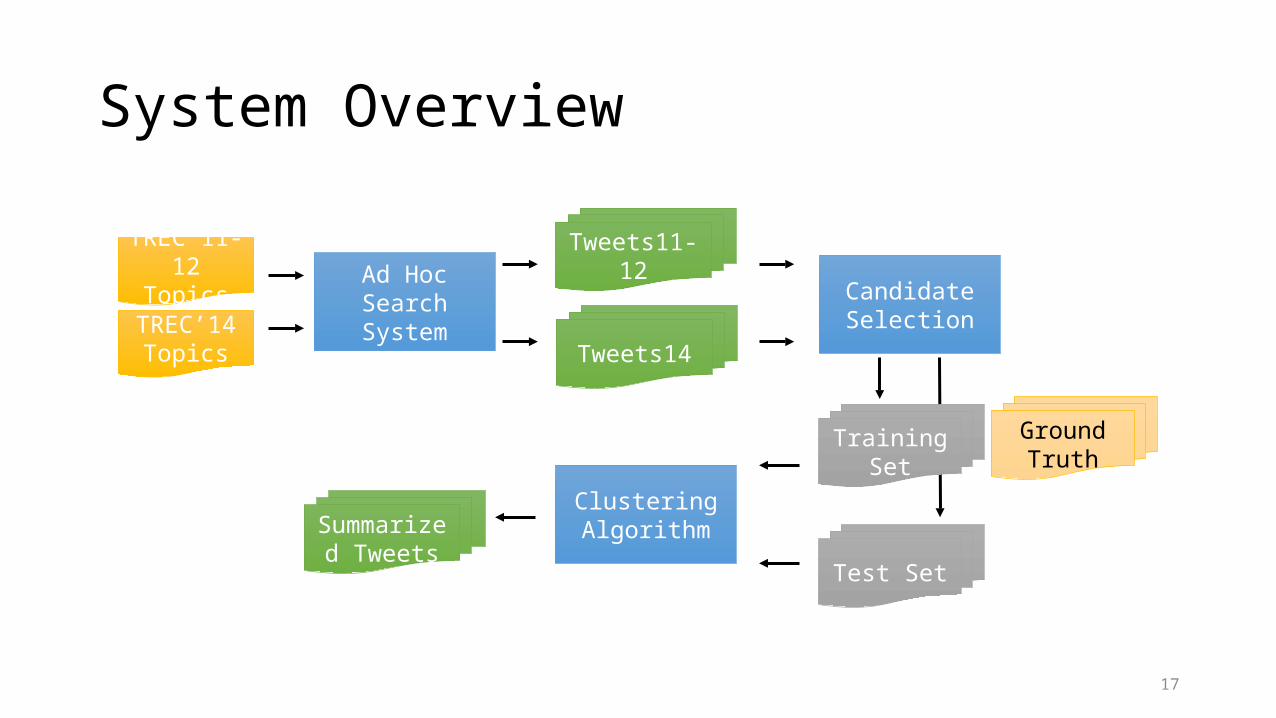
TREC’11-12Topics
TREC’14Topics
Ad HocSearch System
Tweets11-12
Summarized Tweets
Candidate Selection
Test Set
Ground Truth
Clustering Algorithm
Tweets14
Training Set
18
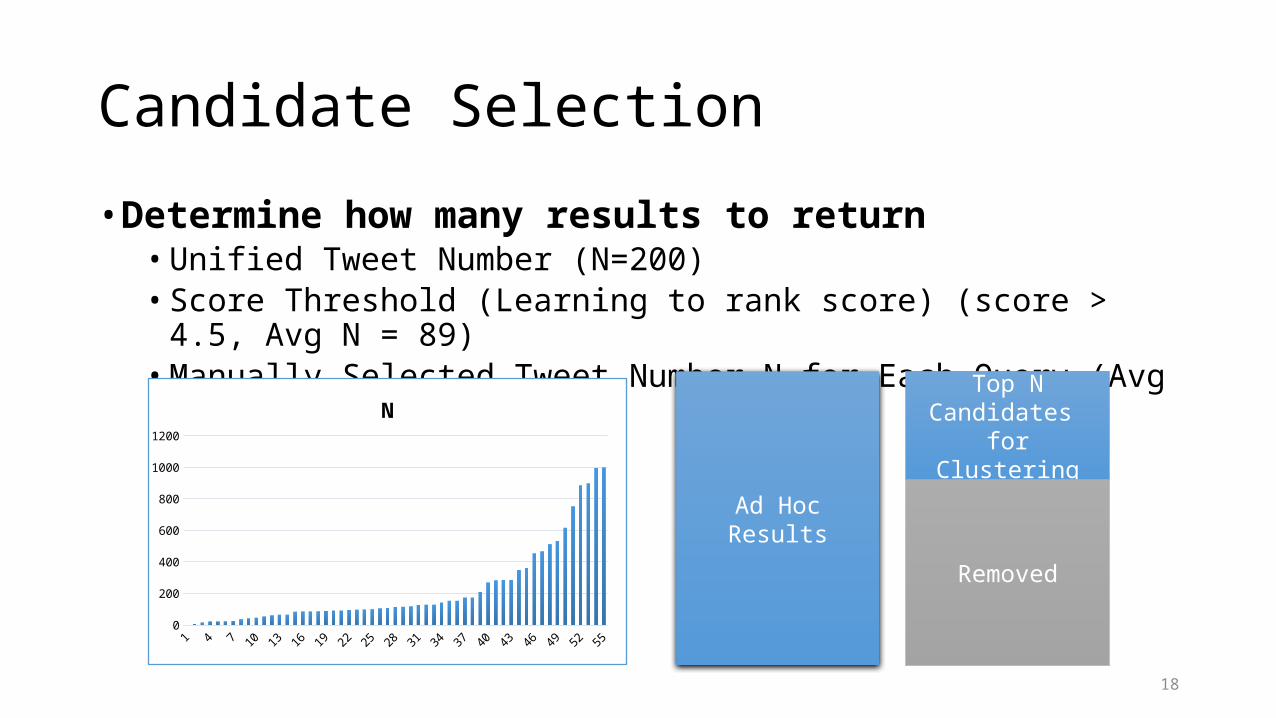
Candidate Selection
• Determine how many results to return• Unified Tweet Number (N=200)• Score Threshold (Learning to rank score) (score > 4.5, Avg N = 89)• Manually Selected Tweet Number N for Each Query (Avg N=225)
1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49 52 550
200
400
600
800
1000
1200
N
Ad Hoc Results
Top NCandidates
for Clustering
Removed
19
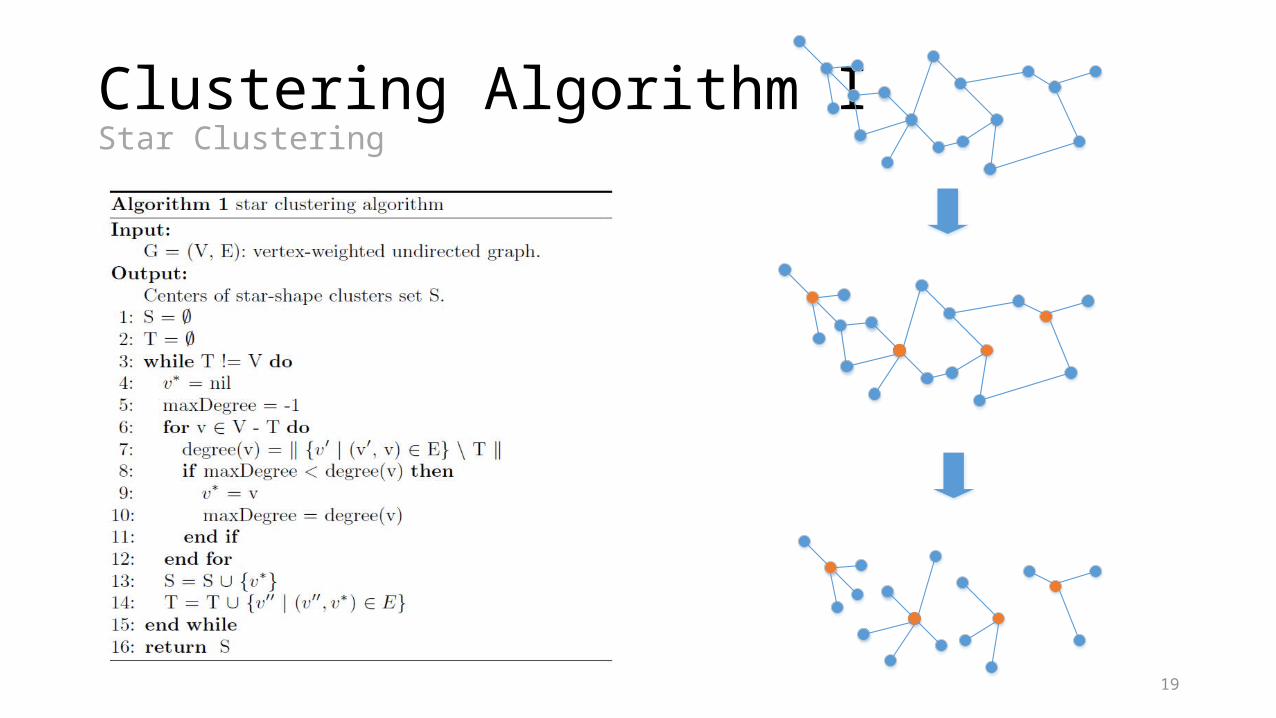
Clustering Algorithm IStar Clustering
20
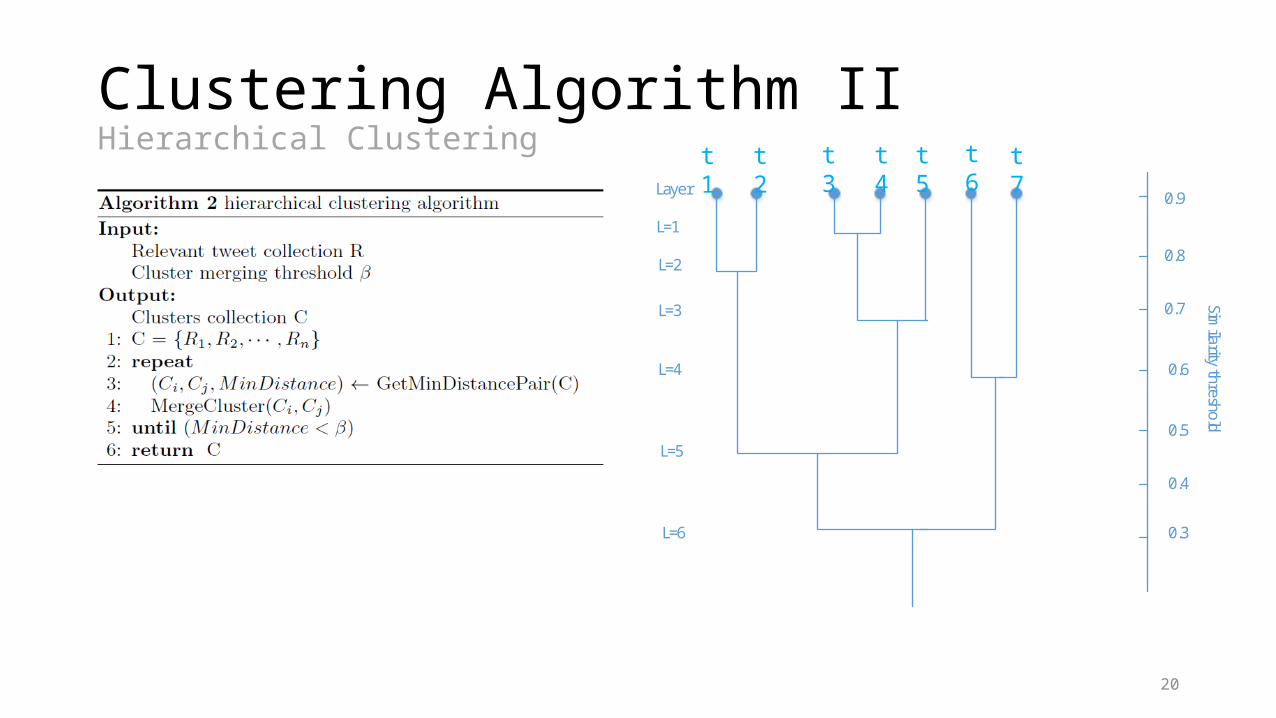
Clustering Algorithm IIHierarchical Clustering
Layer
L=1
L=2
L=3
L=4
L=5
L=6
Similarity threshold
0.9
0.8
0.7
0.6
0.5
0.4
0.3
t1 t2 t3 t4 t5 t6 t7
21
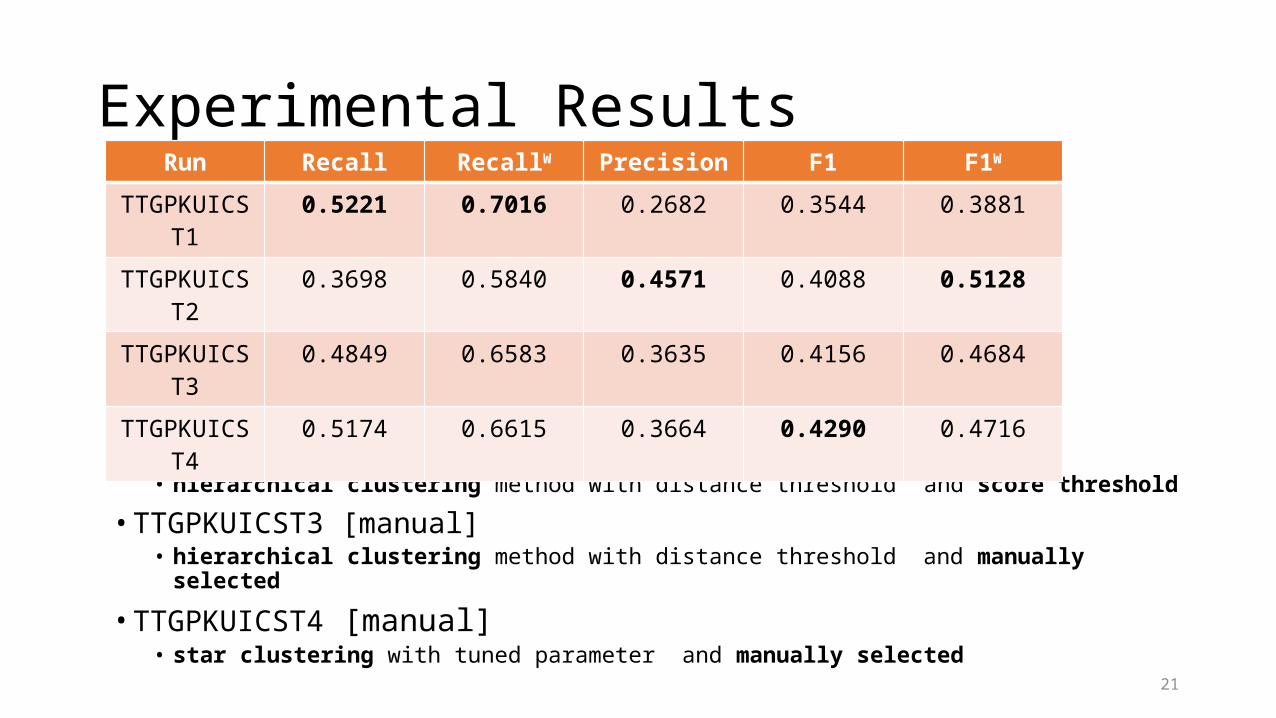
Experimental Results
• TTGPKUICST1 [auto]• star clustering with tuned parameter and uniform tweet number
• TTGPKUICST2 [auto]• hierarchical clustering method with distance threshold and score threshold
• TTGPKUICST3 [manual]• hierarchical clustering method with distance threshold and manually selected
• TTGPKUICST4 [manual]• star clustering with tuned parameter and manually selected
Run Recall RecallW Precision F1 F1W
TTGPKUICST1 0.5221 0.7016 0.2682 0.3544 0.3881
TTGPKUICST2 0.3698 0.5840 0.4571 0.4088 0.5128
TTGPKUICST3 0.4849 0.6583 0.3635 0.4156 0.4684
TTGPKUICST4 0.5174 0.6615 0.3664 0.4290 0.4716

22
Reference
1. Y. Duan, L. Jiang, T. Qin, M. Zhou and H.-Y. Shum. An empirical study on learning to rank of tweets. In Proceedings of the 23rd International Conference on Computational Linguistics, COLING ’10, pages 295–303. Association for Computational Linguistics, 2010.
2. Miyanishi, T., Okamura, N., Liu, X., Seki, K. and Uehara, K. Trec 2011 Microblog Track Experiments at Kobe University. In: Proceeding of the Twentieth Text REtrieval Conference, 2011
3. Z Han, X Li, M Yang and H Qi, S Li. Feature Analysis in Microblog Retrieval Based on Learning to Rank. atural Language Processing and Chinese Computing, 2013.
4. R Qiang, F Liang and J Yang. Exploiting Ranking Factorization Machines for Microblog Retrieval.
5. X Wang and C Zhai. Learn from web search logs to organize search results. In Proceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval, 2007.
6. Han J and Kamber M. Data Mining, Southeast Asia Edition: Concepts and Techniques[M]. Morgan kaufmann, 2006.
7. F Liang, R Qiang and J Yang. Exploiting real-time information retrieval in the microblogosphere. JCDL 2012.

Feature Extraction for Effective Microblog Search and Adaptive Clustering Algorithms for TTG
PKUICST at TREC 2014 Microblog TrackChao Lv Feifan Fan Runwei Qiang Yue Fei Jianwu Yang
[email protected] University
北京大学计算机科学技术研究所Institute of Computer Science & Technology Peking University
Q&A





























