Embed Size (px)
Citation preview

AltiscaleBig Data-as-a-ServicePaul Tibaldi RSD & Ajay Jha SA
2
• Market Background• Who is Altiscale?• Why are we different/better?• Hadoop Admin• Apache Hadoop Stack • Platform/Access/Demo• Q/A
Big Data As A Service

Market Background

4
Interest in Big Data is growing fast
5
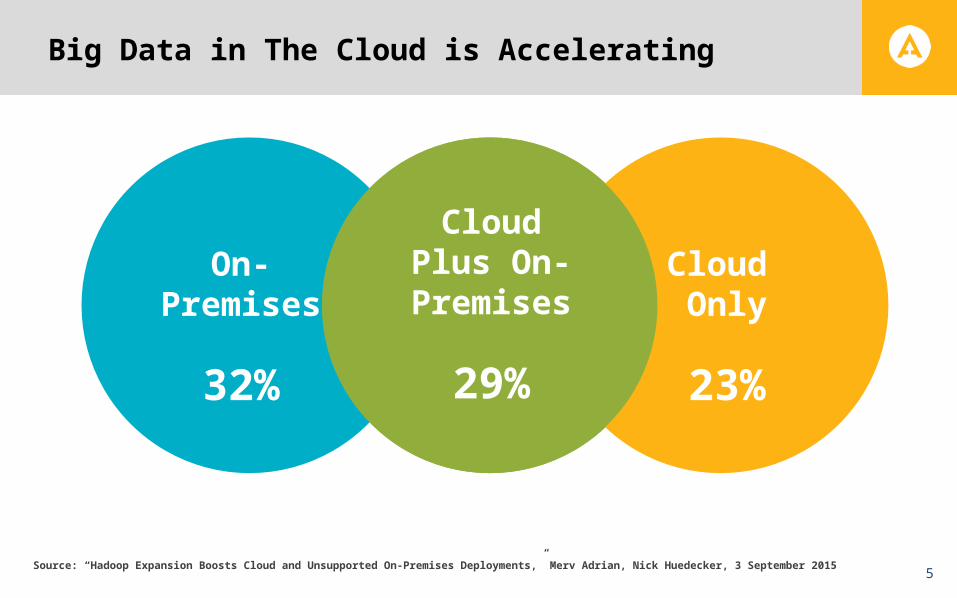
Big Data in The Cloud is Accelerating
On-Premises
32%
Cloud Only
23%
Cloud Plus On-Premises
29%
Source: “Hadoop Expansion Boosts Cloud and Unsupported On-Premises Deployments,” Merv Adrian, Nick Huedecker, 3 September 2015

But the journey has dangers
Gartner: 70% of independent Big Data implementations will fail to meet revenue and cost objectives, through 2018.

Who is Altiscale?

Altiscale Data Cloud GA in 2014
Financed by top-tier technology investors
Recognized innovator in Hadoop-as-a-Service
About Altiscale

About Altiscale
Led by experienced, renowned Hadoop team from Yahoo!• Raymie Stata, CEO. Former Yahoo! CTO,
well-known advocate of Apache Software Foundation
• David Chaiken, CTO. Former Yahoo! Chief Architect
Built and managed by veterans of Big Data, SaaS, and enterprise software• From Google, Netflix, LinkedIn, VMware, Oracle, and Yahoo!
40,000 nodes500 PB1,000 users$ billions at stake
Raymie Stata, CEO David Chaiken, CTO Ricardo JenezVP of Engineering
Charles Wimmer Head of Operations

Big data built for speed
Fast time to value—days not months
Easier, faster scalability—with elastic scaling
Operations support—so your jobs get done
Lower TCO—for fast investment payback

11
Unmatched Security
Altiscale is the only provider that delivers integrated security
encompassing its Big Data platform offering
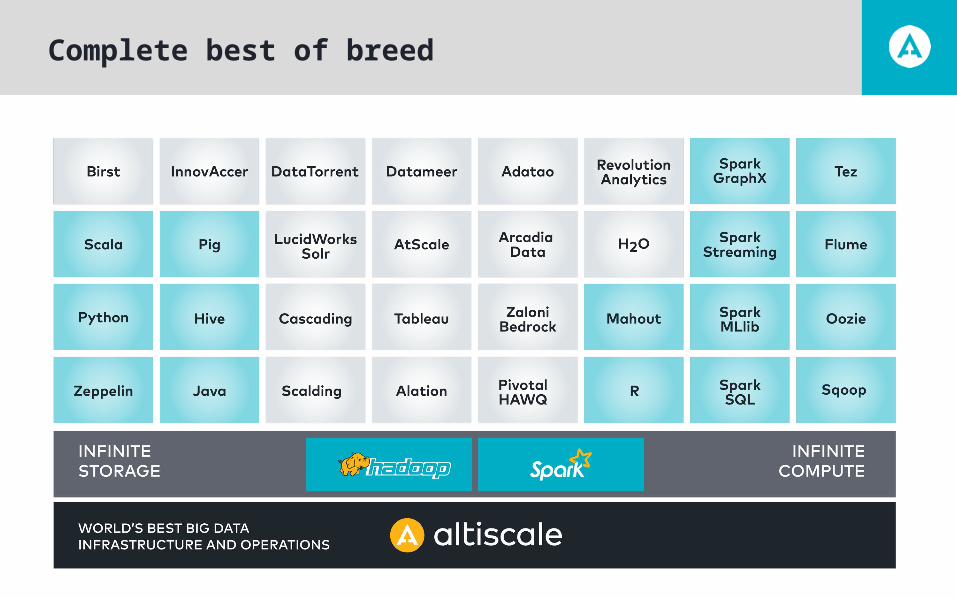
Complete best of breed
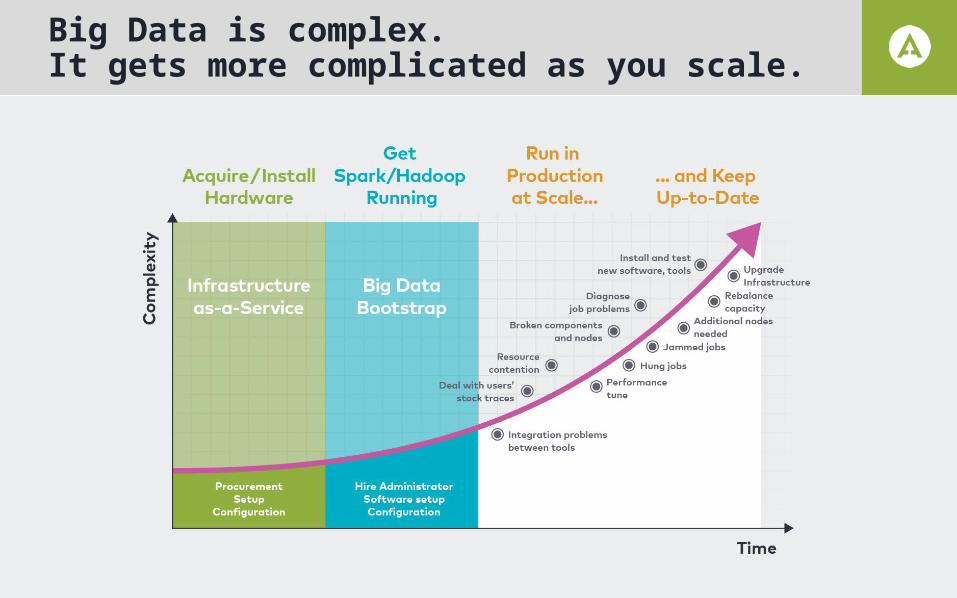
Big Data is complex.It gets more complicated as you scale.
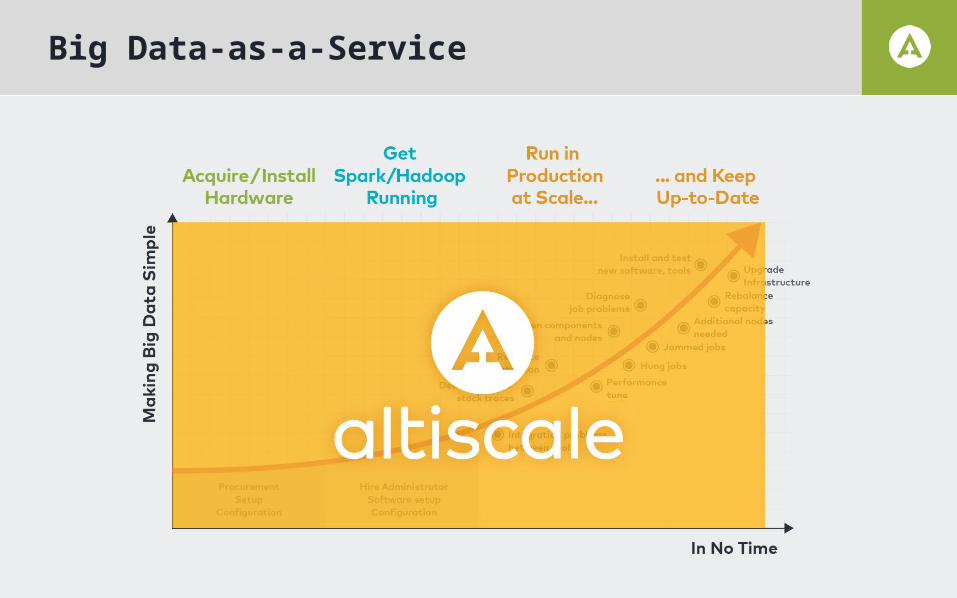
Big Data-as-a-Service
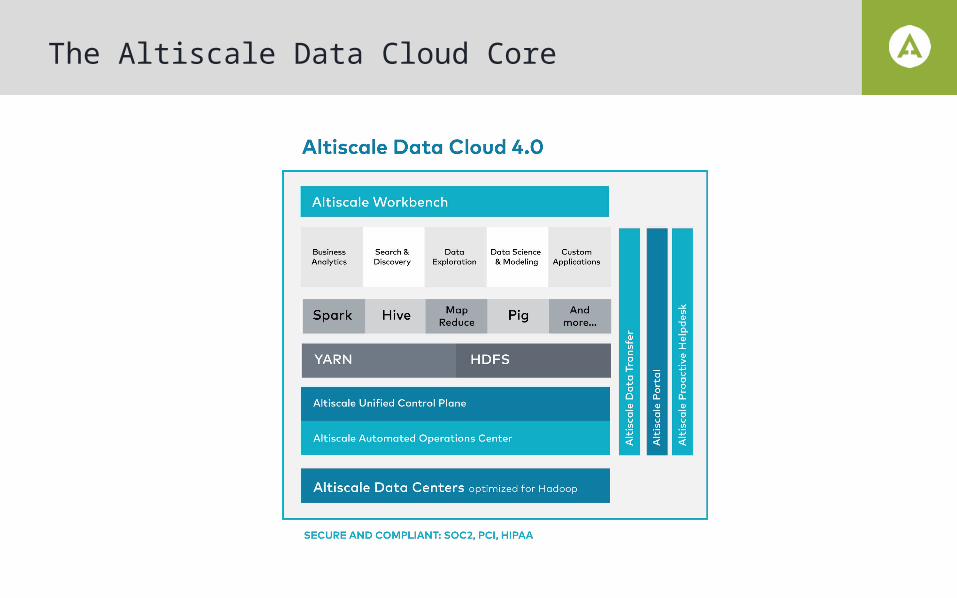
The Altiscale Data Cloud Core
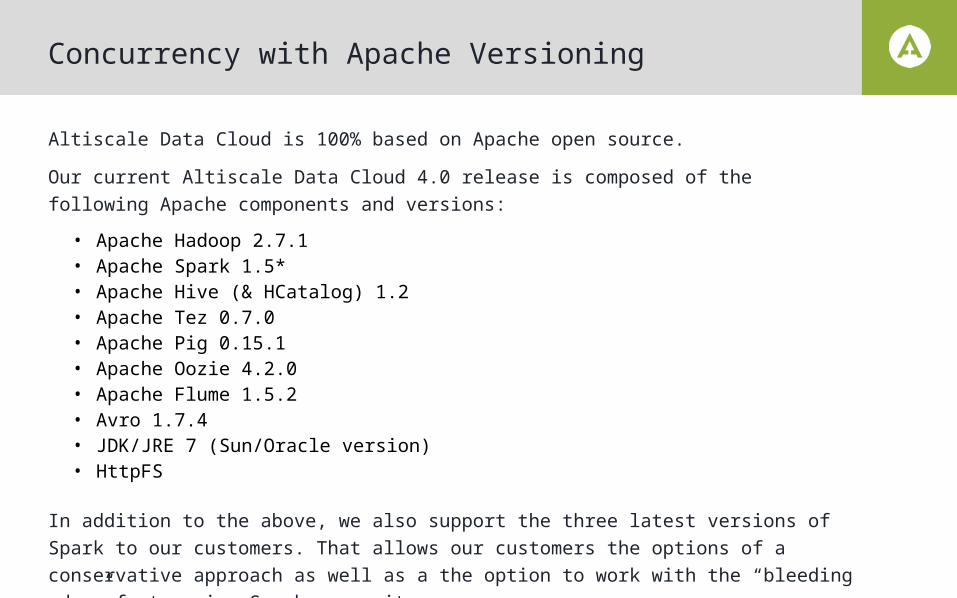
Altiscale Data Cloud is 100% based on Apache open source.
Our current Altiscale Data Cloud 4.0 release is composed of the following Apache components and versions:
• Apache Hadoop 2.7.1 • Apache Spark 1.5* • Apache Hive (& HCatalog) 1.2 • Apache Tez 0.7.0 • Apache Pig 0.15.1• Apache Oozie 4.2.0 • Apache Flume 1.5.2 • Avro 1.7.4 • JDK/JRE 7 (Sun/Oracle version) • HttpFS
In addition to the above, we also support the three latest versions of Spark to our customers. That allows our customers the options of a conservative approach as well as a the option to work with the “bleeding edge” fast moving Spark community.
Concurrency with Apache Versioning

Hire an expert to take care of the cluster
• Hardware setup and Cluster installation
• Address hardware failure
• Upgrade Hadoop stack
• Tuning config parameters
• yarn-site.xml ex : yarn.nodemanager.resource.memory-mb
• mapred-site.xml ex : mapreduce.task.io.sort.mb
• hdfs-site.xml ex : dfs.blocksize
Hadoop Administration
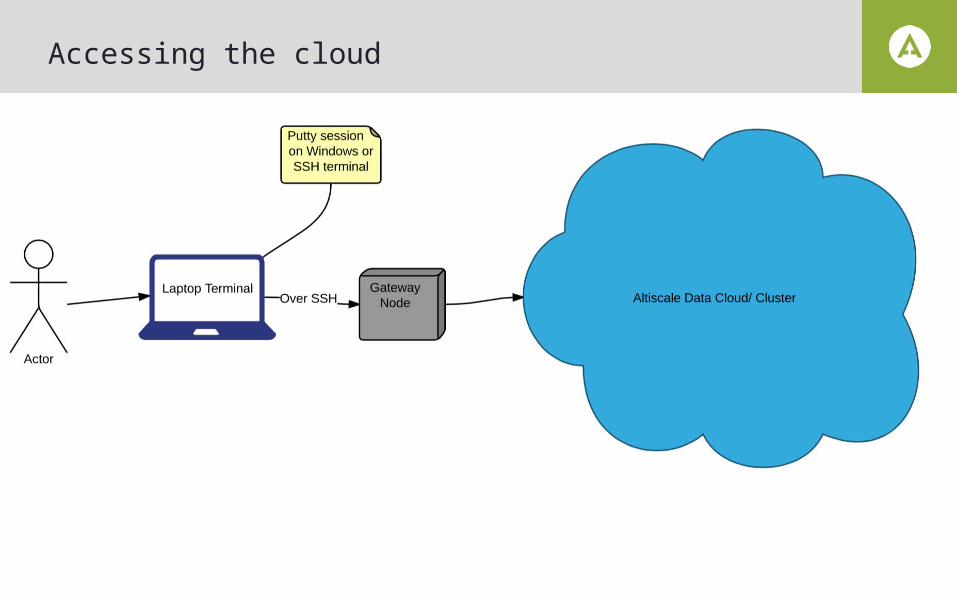
Accessing the cloud
Spark example
• Build Spark code laptop using maven
• Build the jar and copy over Altiscale’s workbench (Gateway) node.
• Launch Spark job on YARN.
• Monitor using Resource Manager
Quick Spark Demo

20
Thank You!





























