Embed Size (px)
Citation preview

ディープラーニングの最新動向 強化学習とのコラボ編⑥ A3C
2017/1/11 株式会社ウェブファーマー
大政孝充

今回取り上げるのはこれ
[1] Volodymyr Mnih, Adria` Puigdome`nech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In Proceedings of the 33rd International Conference on Machine Learning (ICML), pp. 1928–1937, 2016. Asynchronousな手法によりreplay memoryを廃し、DQNより高速かつ高精度な学習を達成した!

DQNからA3Cまでのイメージ
DQN 2013NIPs
並列処理のしくみ
DQN 2015Nature
UNREAL
Q学習な手法
A3C
psedoな報酬
DistBrief Gorila
actore-criticな手法
Asynchronous なDQN

強化学習の基本①
Li θi( ) = E r +γmaxa 'Q s ',a ';θi−1( )−Q s,a;θi( )( )
2
1-step Q学習の損失関数
actor-criticにおける 目的関数の勾配
1-step Sarsaの損失関数 Li θi( ) = E r +γQ s ',a ';θi−1( )−Q s,a;θi( )( )2
n-step Q学習の損失関数 Li θi( ) = E γ krt+kk=0
n
∑ +maxγa '
n Q s ',a ';θi−1( )−Q s,a;θi( )⎛
⎝⎜
⎞
⎠⎟
2
∇θJ θ( ) = E ∇θ logπ at | st;θ( ) Rt −V π st( )( )⎡⎣
⎤⎦
r
γ Q s,a;θi( )V π st( )
:割引率
:報酬
:状態 s で行動 a を取る場合の行動価値関数
:状態 s の価値関数
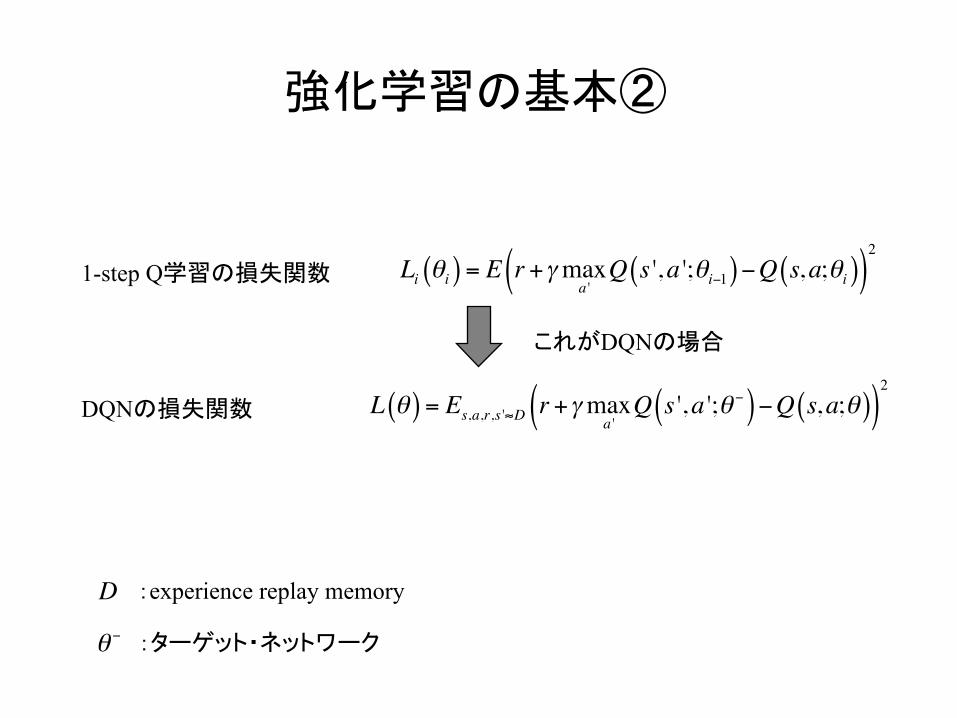
強化学習の基本②
Li θi( ) = E r +γmaxa 'Q s ',a ';θi−1( )−Q s,a;θi( )( )
2
1-step Q学習の損失関数
これがDQNの場合
L θ( ) = Es,a,r,s '≈D r +γmaxa 'Q s ',a ';θ −( )−Q s,a;θ( )( )
2
DQNの損失関数
:experience replay memory
:ターゲット・ネットワーク
D
θ −
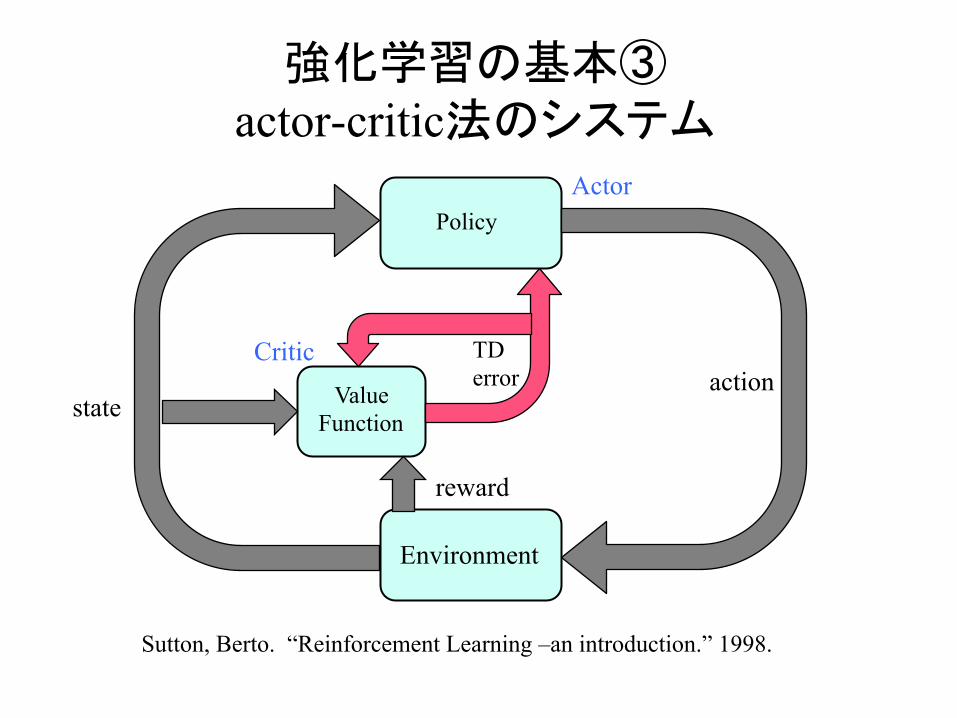
強化学習の基本③ actor-critic法のシステム
Value Function
Policy
Critic
Environment
Sutton, Berto. “Reinforcement Learning –an introduction.” 1998.
state
reward
Actor
TD error action
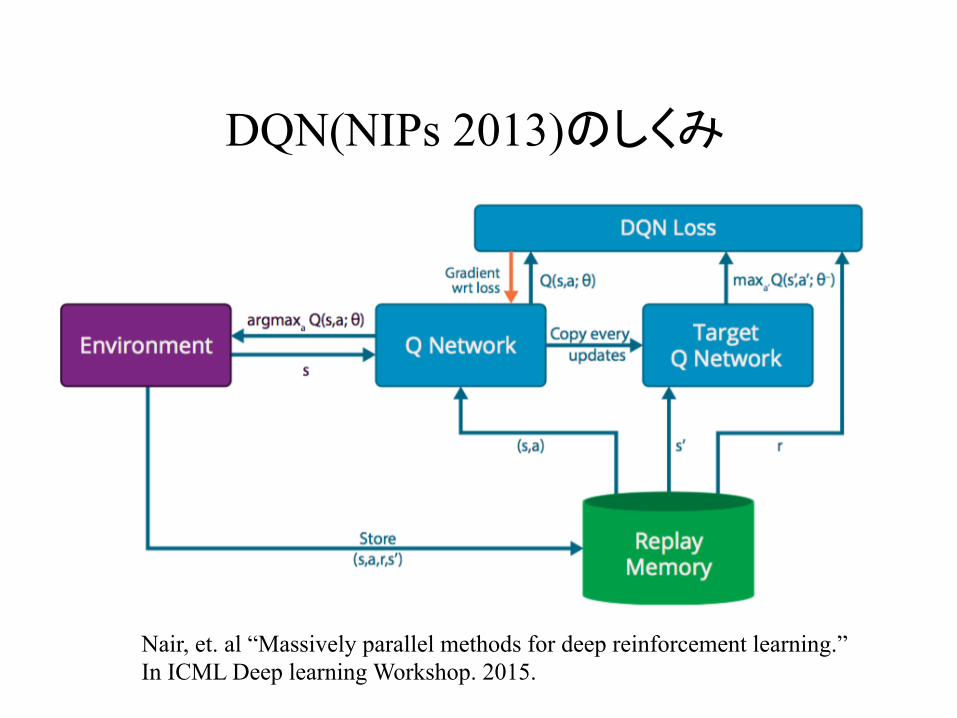
DQN(NIPs 2013)のしくみ
Nair, et. al “Massively parallel methods for deep reinforcement learning.” In ICML Deep learning Workshop. 2015.
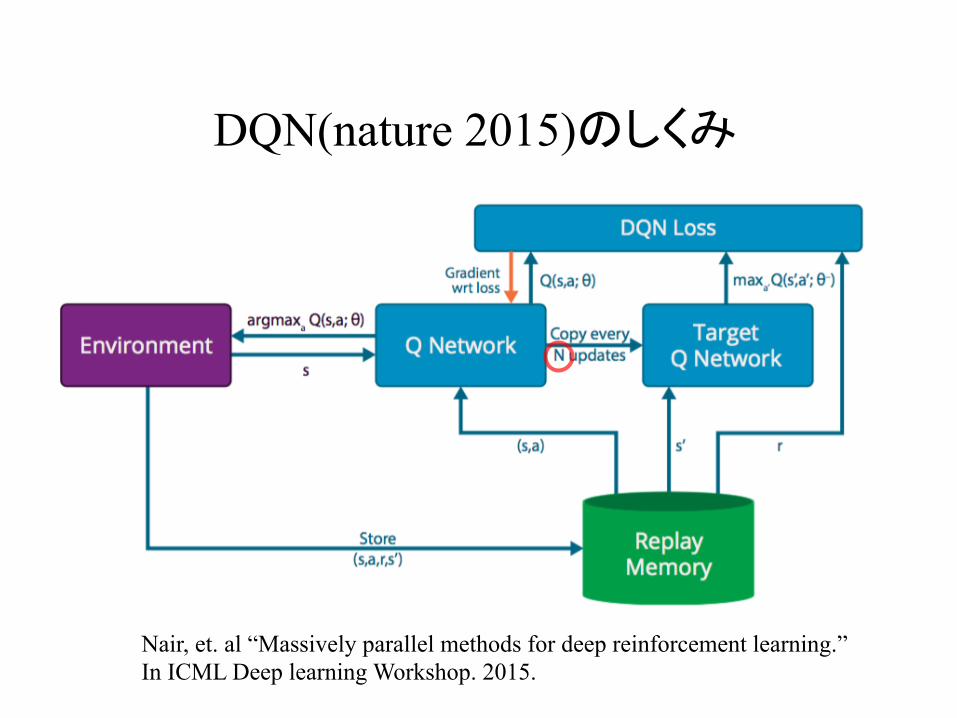
DQN(nature 2015)のしくみ
Nair, et. al “Massively parallel methods for deep reinforcement learning.” In ICML Deep learning Workshop. 2015.
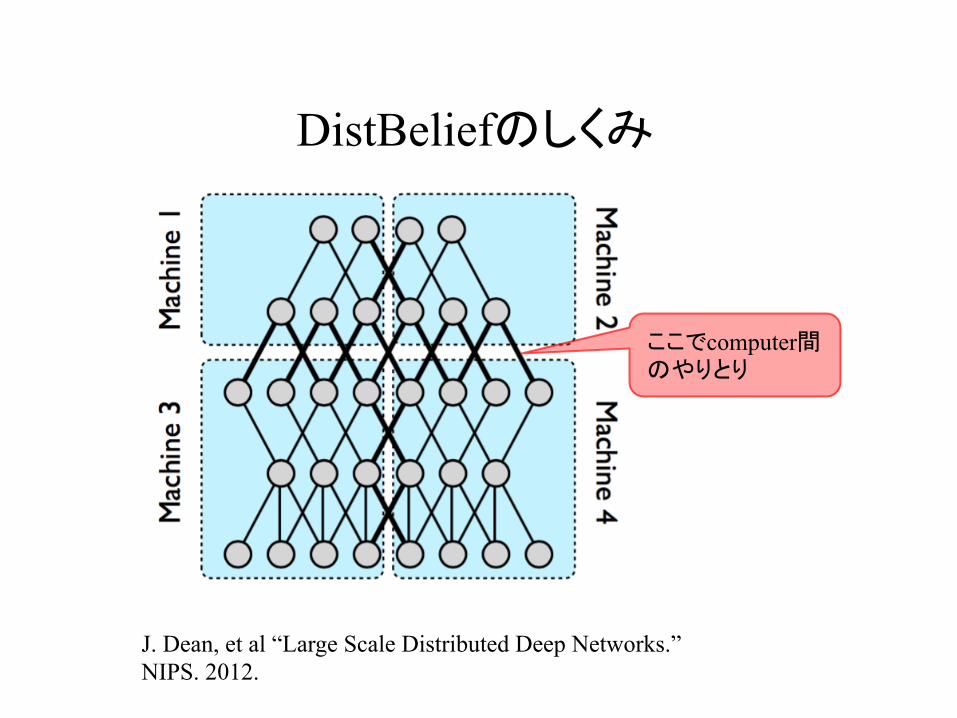
DistBeliefのしくみ
J. Dean, et al “Large Scale Distributed Deep Networks.” NIPS. 2012.
ここでcomputer間 のやりとり
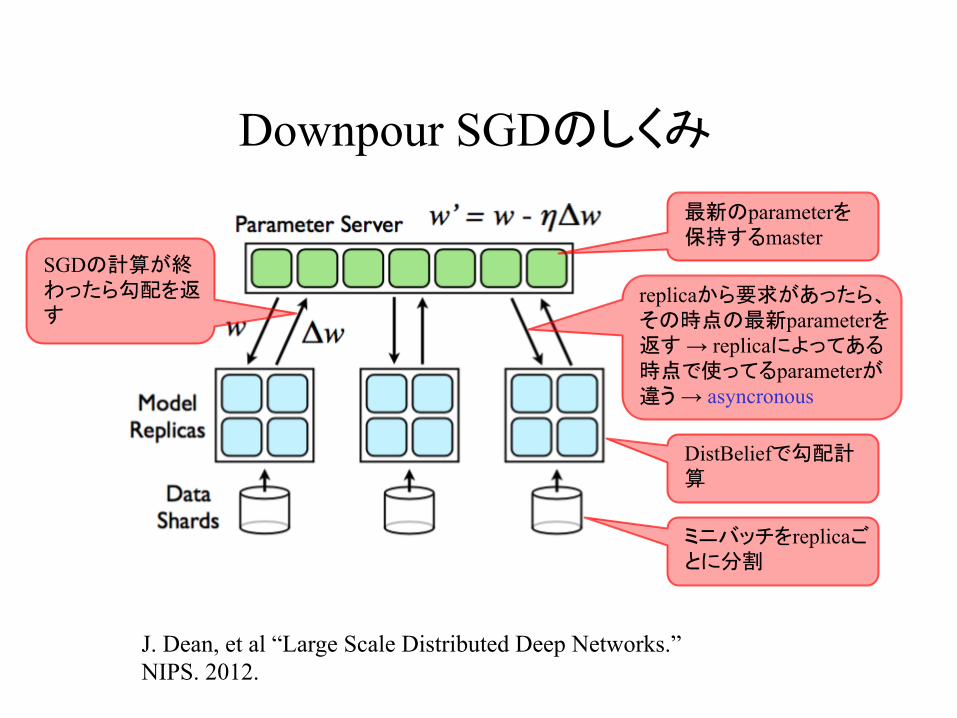
Downpour SGDのしくみ
J. Dean, et al “Large Scale Distributed Deep Networks.” NIPS. 2012.
最新のparameterを保持するmaster
replicaから要求があったら、その時点の最新parameterを返す → replicaによってある時点で使ってるparameterが違う → asyncronous
SGDの計算が終わったら勾配を返す
DistBeliefで勾配計算
ミニバッチをreplicaごとに分割
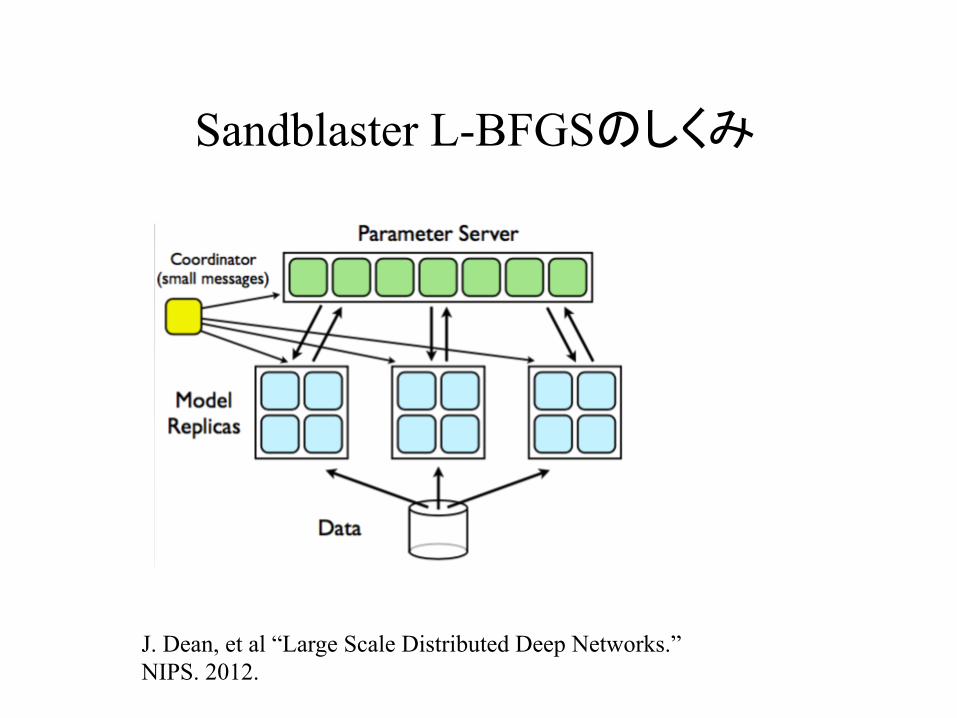
Sandblaster L-BFGSのしくみ
J. Dean, et al “Large Scale Distributed Deep Networks.” NIPS. 2012.
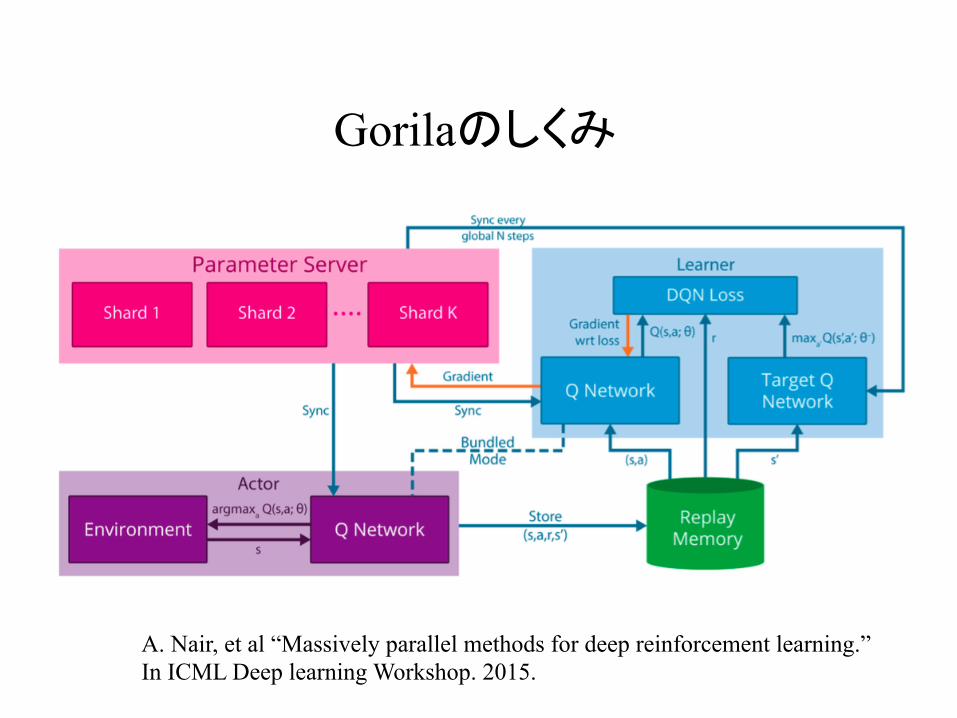
Gorilaのしくみ
A. Nair, et al “Massively parallel methods for deep reinforcement learning.” In ICML Deep learning Workshop. 2015.
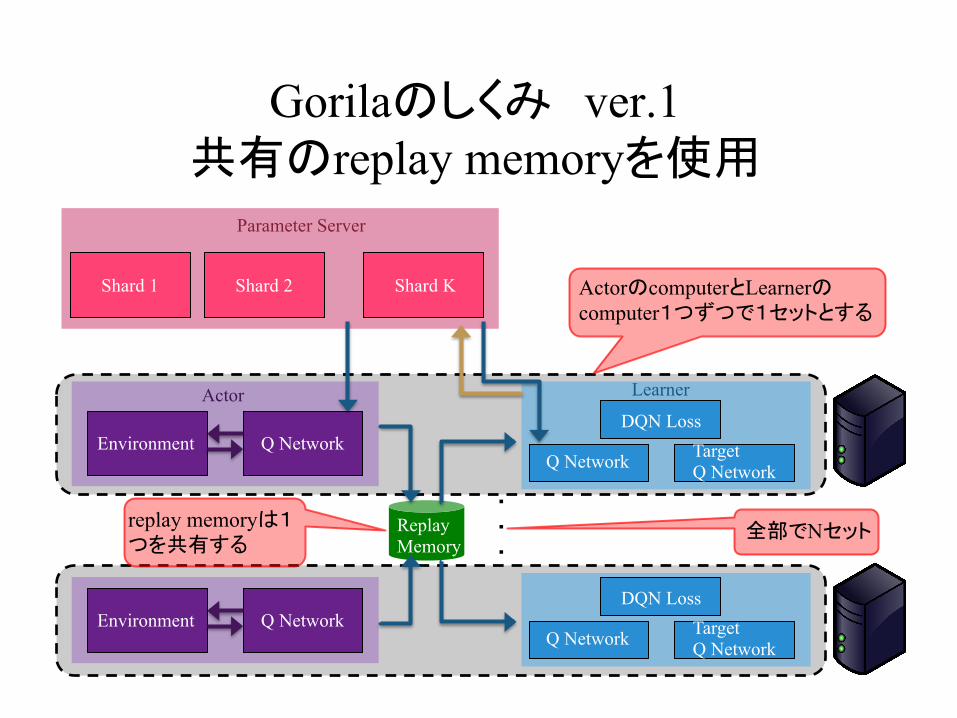
Gorilaのしくみ ver.1 共有のreplay memoryを使用
Environment Q Network
Shard 1 Shard 2 Shard K
Q NetworkTarget Q Network
DQN Loss
Parameter Server
Environment Q NetworkQ Network
Target Q Network
DQN Loss
・ ・ ・
ActorのcomputerとLearnerのcomputer1つずつで1セットとする
Actor Learner
全部でNセットreplay memoryは1つを共有する
Replay Memory
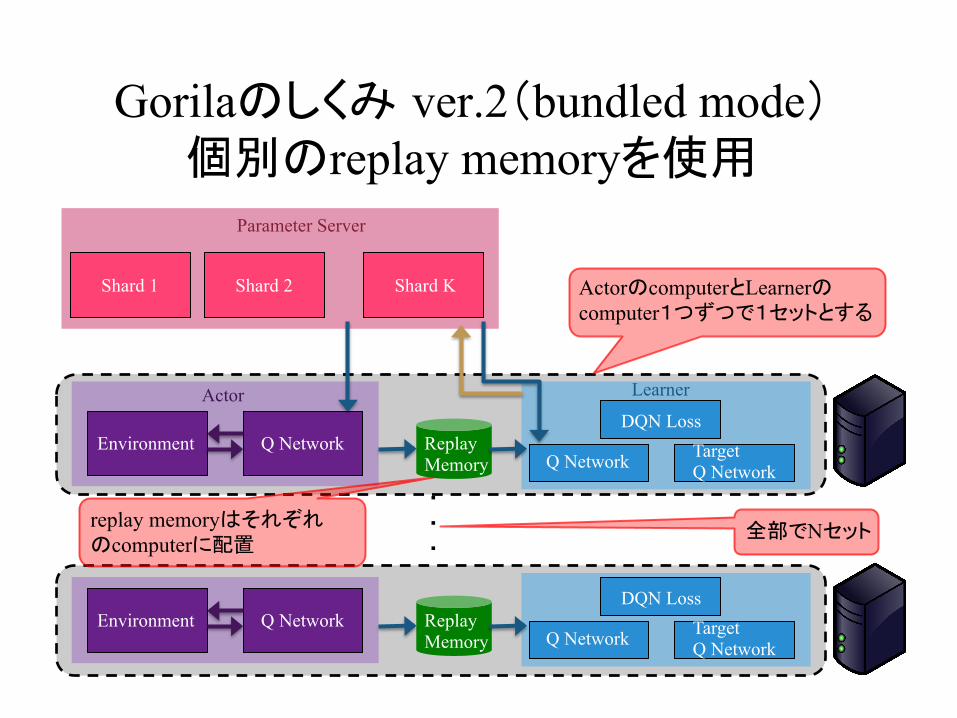
Gorilaのしくみ ver.2(bundled mode) 個別のreplay memoryを使用
Environment Q Network
Shard 1 Shard 2 Shard K
Q NetworkTarget Q Network
DQN LossReplay Memory
Parameter Server
Environment Q NetworkQ Network
Target Q Network
DQN LossReplay Memory
・ ・ ・
ActorのcomputerとLearnerのcomputer1つずつで1セットとする
Actor Learner
全部でNセットreplay memoryはそれぞれのcomputerに配置
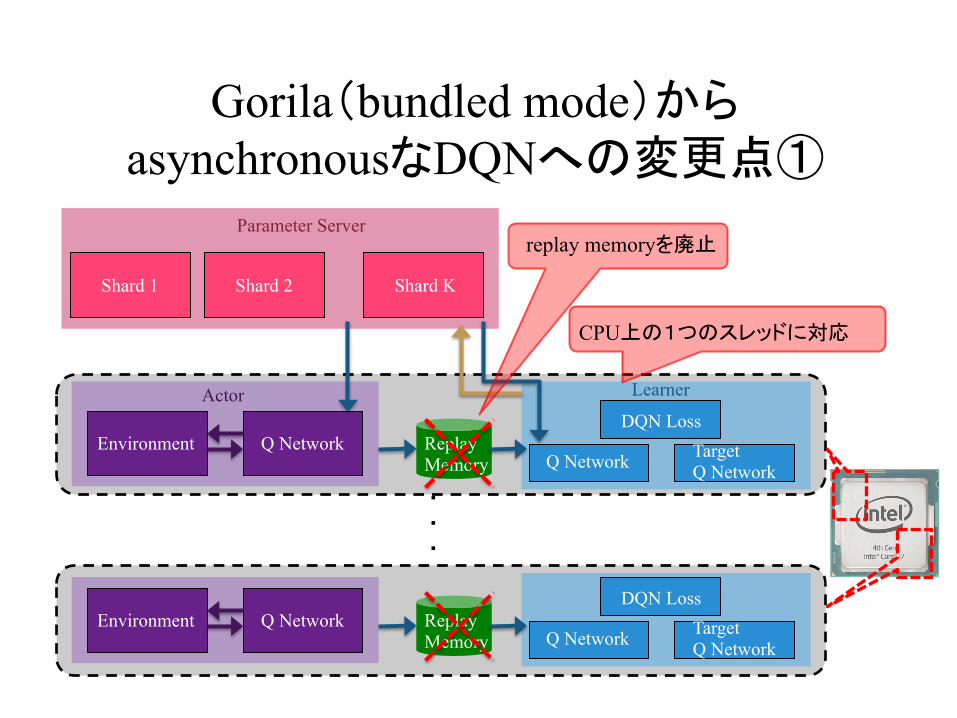
Gorila(bundled mode)からasynchronousなDQNへの変更点①
Environment Q Network
Shard 1 Shard 2 Shard K
Q NetworkTarget Q Network
DQN LossReplay Memory
Parameter Server
Environment Q NetworkQ Network
Target Q Network
DQN LossReplay Memory
・ ・ ・
CPU上の1つのスレッドに対応
Actor Learner
replay memoryを廃止
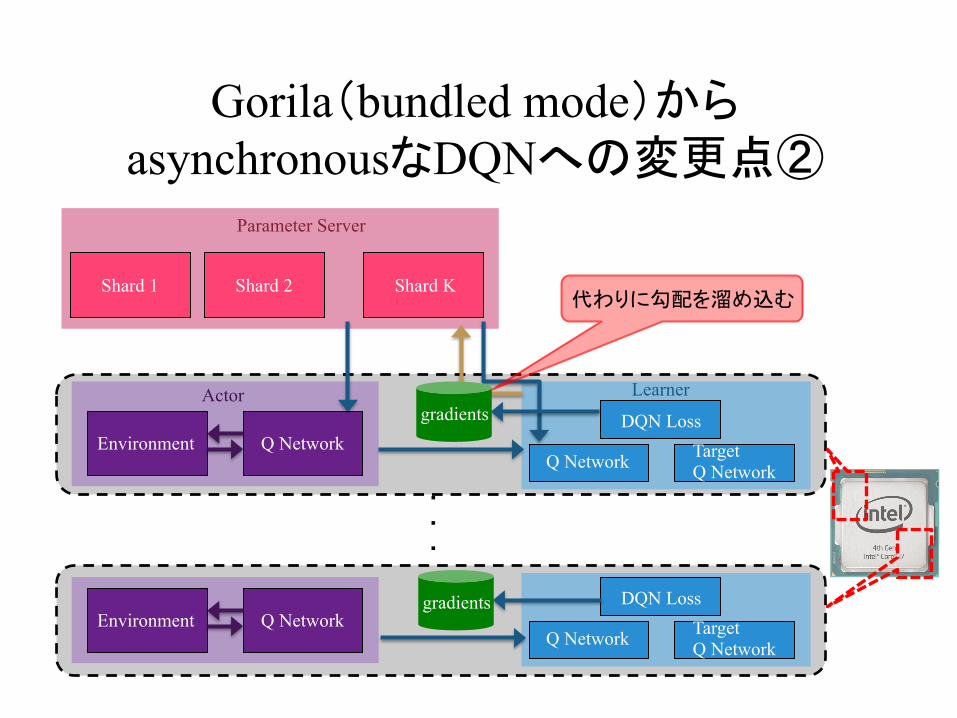
Gorila(bundled mode)からasynchronousなDQNへの変更点②
Environment Q Network
Shard 1 Shard 2 Shard K
Q NetworkTarget Q Network
DQN Loss
Parameter Server
Environment Q NetworkQ Network
Target Q Network
DQN Loss
・ ・ ・
Actor Learner
代わりに勾配を溜め込む
gradients
gradients
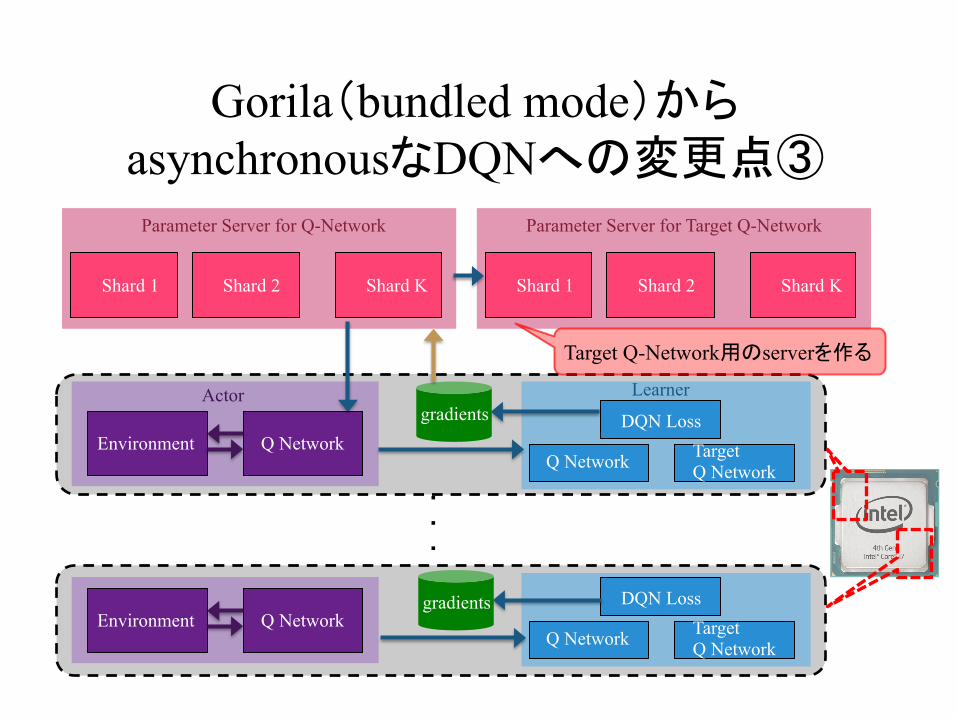
Gorila(bundled mode)からasynchronousなDQNへの変更点③
Environment Q Network
Shard 1 Shard 2 Shard K
Q NetworkTarget Q Network
DQN Loss
Parameter Server for Q-Network
Environment Q NetworkQ Network
Target Q Network
DQN Loss
・ ・ ・
Actor Learnergradients
gradients
Shard 1 Shard 2 Shard K
Parameter Server for Target Q-Network
Target Q-Network用のserverを作る
Shard 1 Shard 2 Shard K
Parameter Server for Q-Network
Shard 1 Shard 2 Shard K
Parameter Server for Target Q-Network
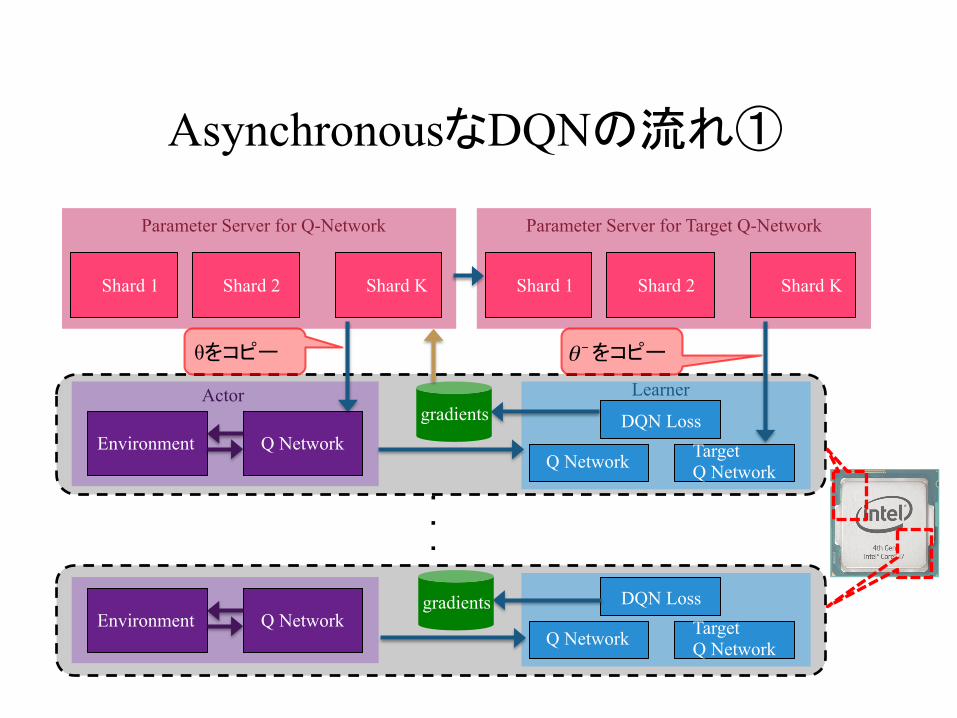
AsynchronousなDQNの流れ①
Environment Q NetworkQ Network
Target Q Network
DQN Loss
Environment Q NetworkQ Network
Target Q Network
DQN Loss
・ ・ ・
Actor Learner
θをコピー をコピー
gradients
gradients
θ −
Shard 1 Shard 2 Shard K
Parameter Server for Q-Network
Shard 1 Shard 2 Shard K
Parameter Server for Target Q-Network
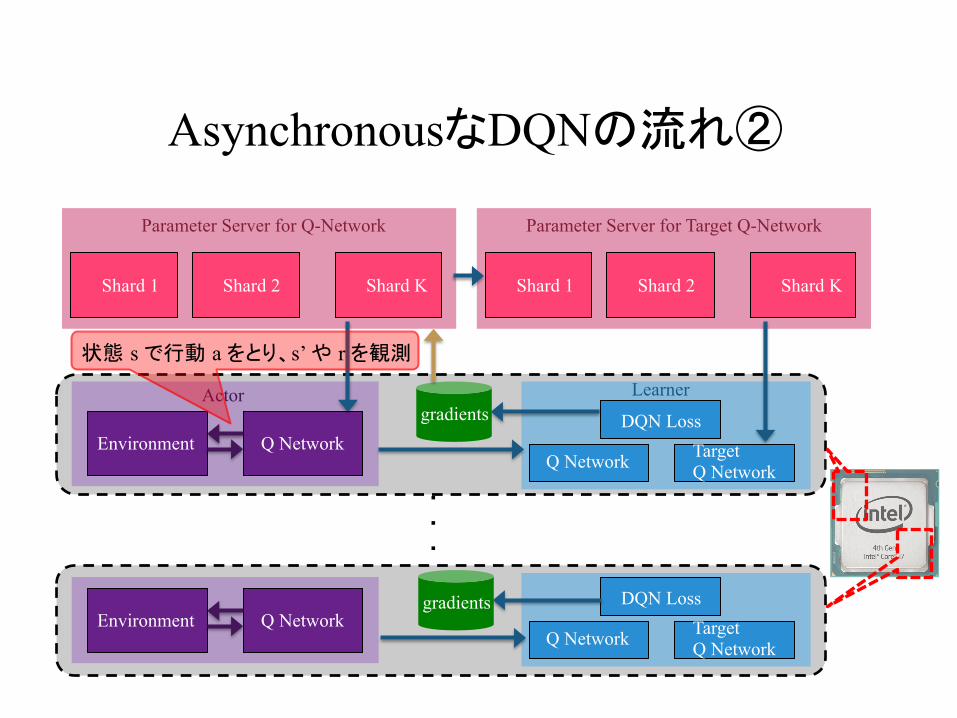
AsynchronousなDQNの流れ②
Environment Q NetworkQ Network
Target Q Network
DQN Lossgradients
Environment Q NetworkQ Network
Target Q Network
DQN Loss
・ ・ ・
Actor Learner
状態 s で行動 a をとり、s’ や r を観測
gradients
Shard 1 Shard 2 Shard K
Parameter Server for Q-Network
Shard 1 Shard 2 Shard K
Parameter Server for Target Q-Network
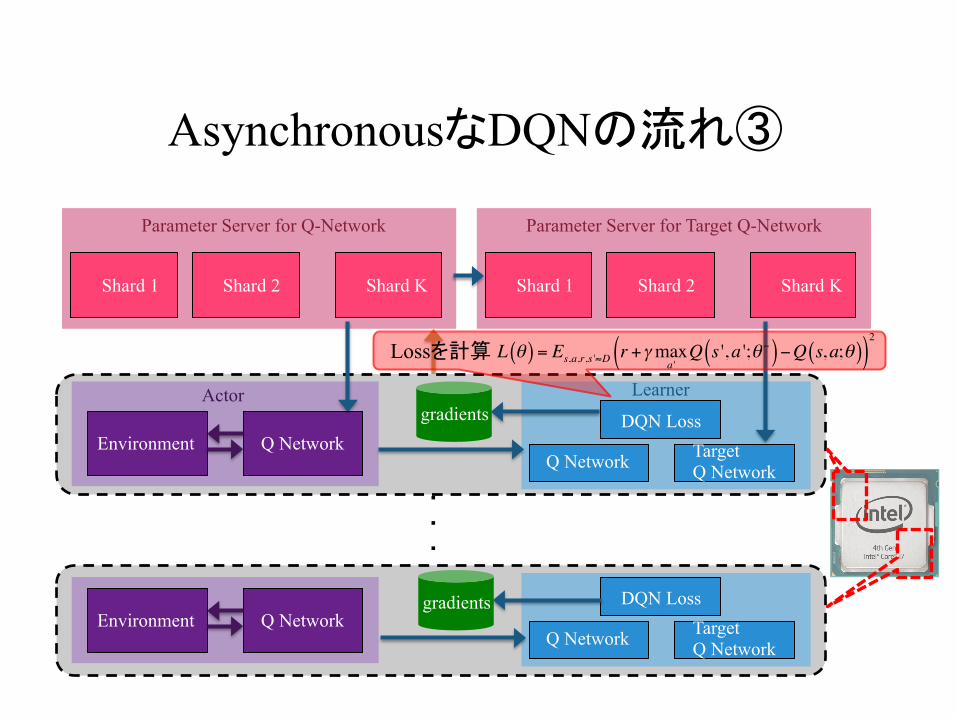
AsynchronousなDQNの流れ③
Environment Q NetworkQ Network
Target Q Network
DQN Lossgradients
Environment Q NetworkQ Network
Target Q Network
DQN Loss
・ ・ ・
Actor Learner
gradients
L θ( ) = Es,a,r,s '≈D r +γmaxa 'Q s ',a ';θ −( )−Q s,a;θ( )( )
2Lossを計算
Shard 1 Shard 2 Shard K
Parameter Server for Q-Network
Shard 1 Shard 2 Shard K
Parameter Server for Target Q-Network
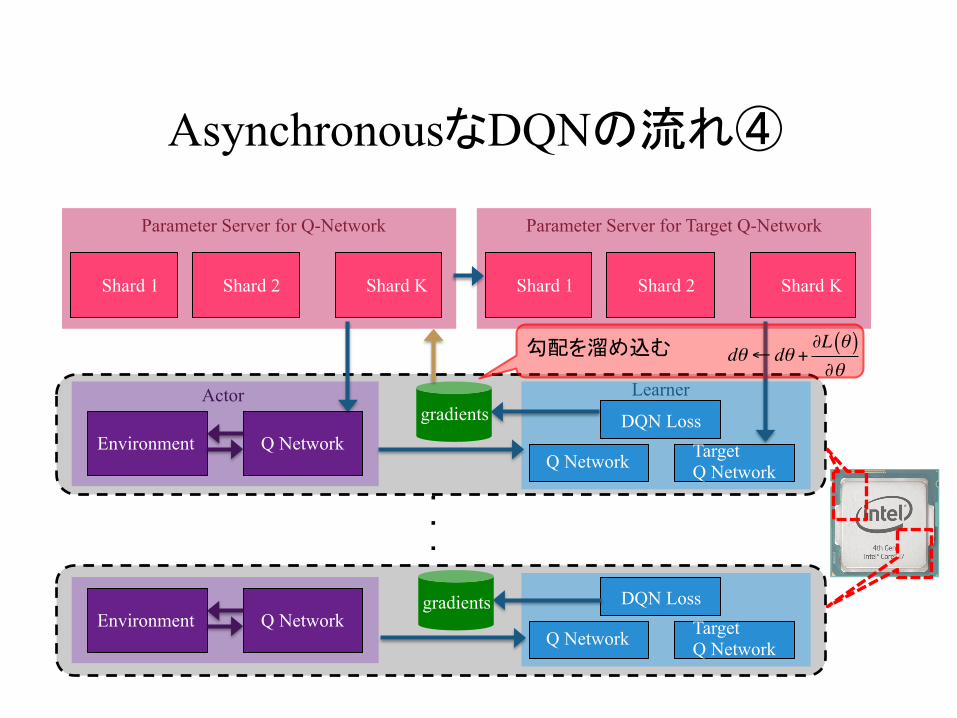
AsynchronousなDQNの流れ④
Environment Q NetworkQ Network
Target Q Network
DQN Lossgradients
Environment Q NetworkQ Network
Target Q Network
DQN Loss
・ ・ ・
Actor Learner
gradients
勾配を溜め込む dθ← dθ +∂L θ( )∂θ
Shard 1 Shard 2 Shard K
Parameter Server for Q-Network
Shard 1 Shard 2 Shard K
Parameter Server for Target Q-Network
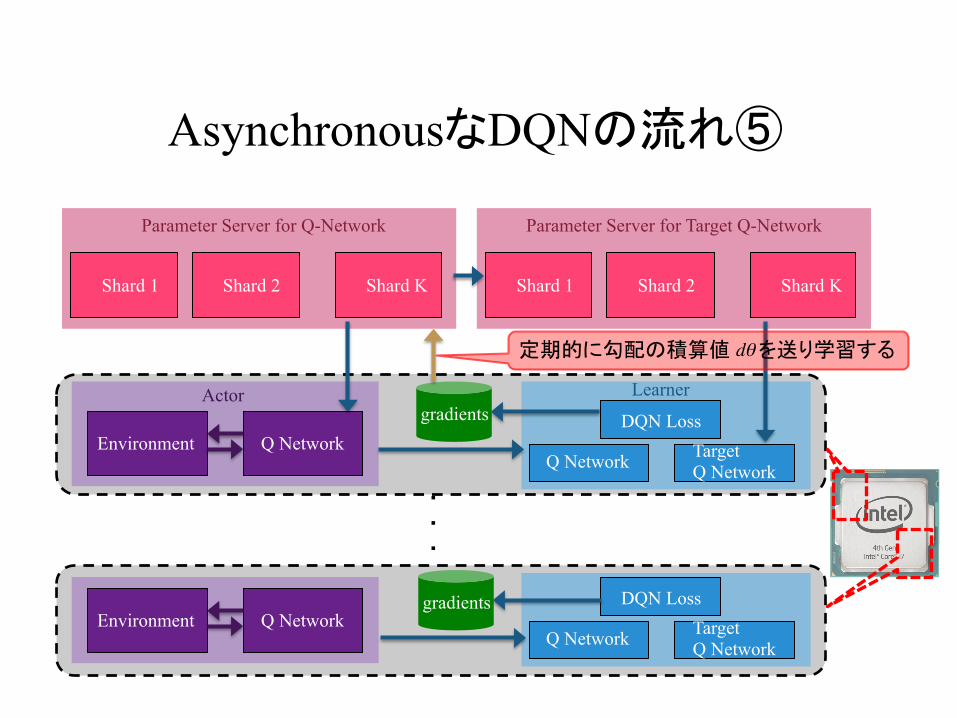
AsynchronousなDQNの流れ⑤
Environment Q NetworkQ Network
Target Q Network
DQN Lossgradients
Environment Q NetworkQ Network
Target Q Network
DQN Loss
・ ・ ・
Actor Learner
gradients
定期的に勾配の積算値 を送り学習するdθ
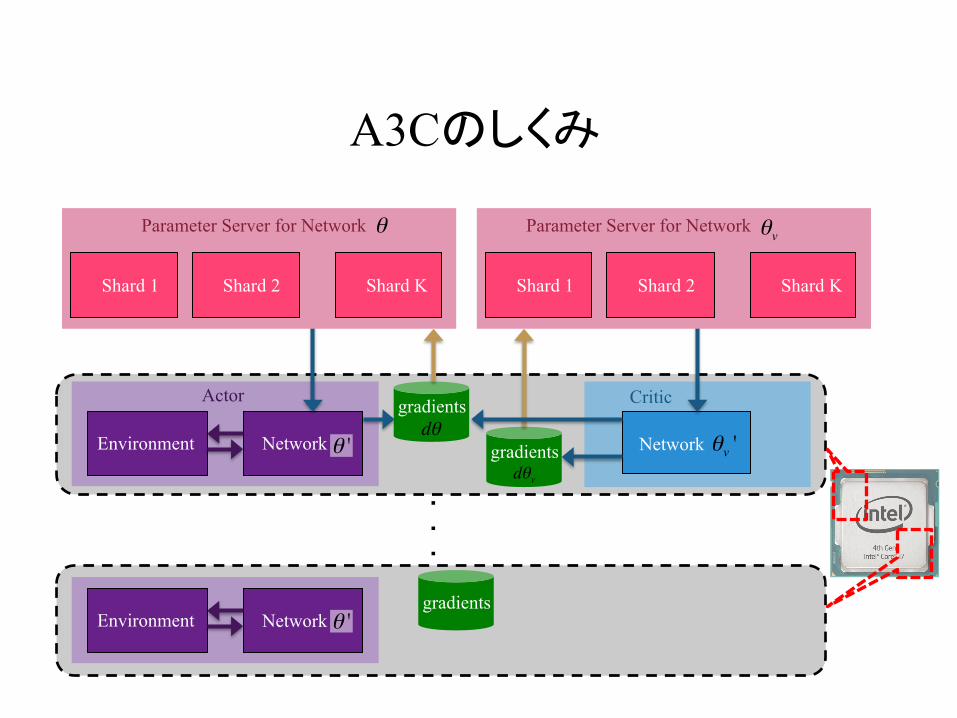
A3Cのしくみ
Environment Network Network
gradients
Environment
・ ・ ・
gradients
Actor Critic
Shard 1 Shard 2 Shard K
Parameter Server for Networkθ
θv '
Network
Shard 1 Shard 2 Shard K
Parameter Server for Networkθv
gradientsdθ
dθv
θ '
θ '
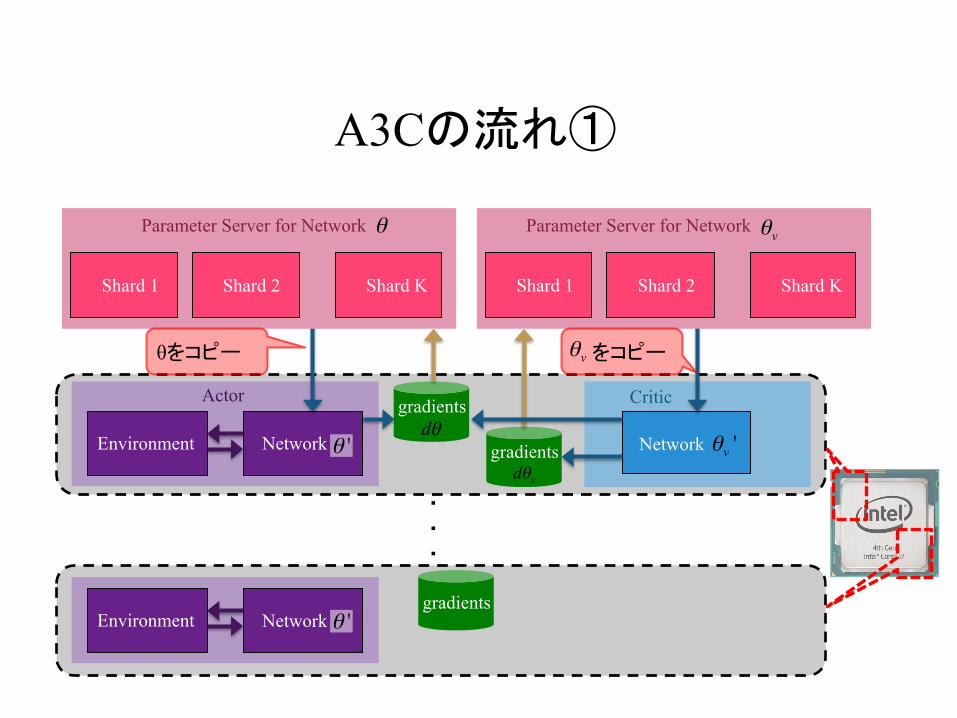
A3Cの流れ①
Environment Network Network
gradients
Environment
・ ・ ・
gradients
Actor Critic
Shard 1 Shard 2 Shard K
Parameter Server for Networkθ
θv '
Network
Shard 1 Shard 2 Shard K
Parameter Server for Networkθv
gradientsdθ
dθv
θをコピー をコピーθv
θ '
θ '
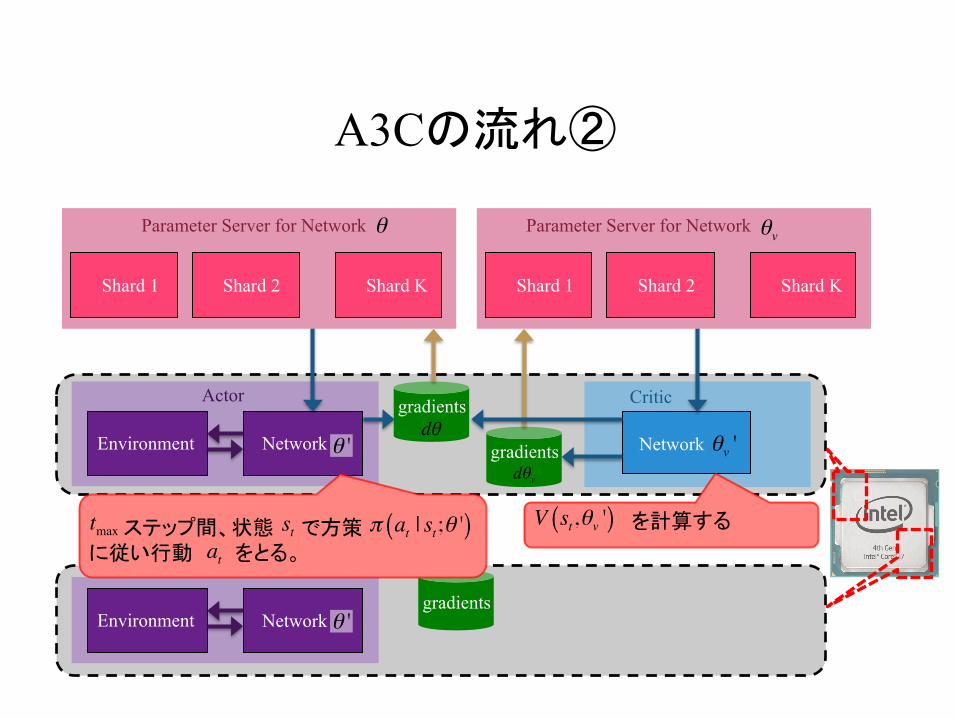
A3Cの流れ②
Environment Network Network
gradients
Environment
・ ・ ・
gradients
Actor Critic
Shard 1 Shard 2 Shard K
Parameter Server for Networkθ
θv '
Network
Shard 1 Shard 2 Shard K
Parameter Server for Networkθv
gradientsdθ
dθv
ステップ間、状態 で方策 に従い行動 をとる。 tmax π at | st;θ '( )
atst V st,θv '( ) を計算する
θ '
θ '
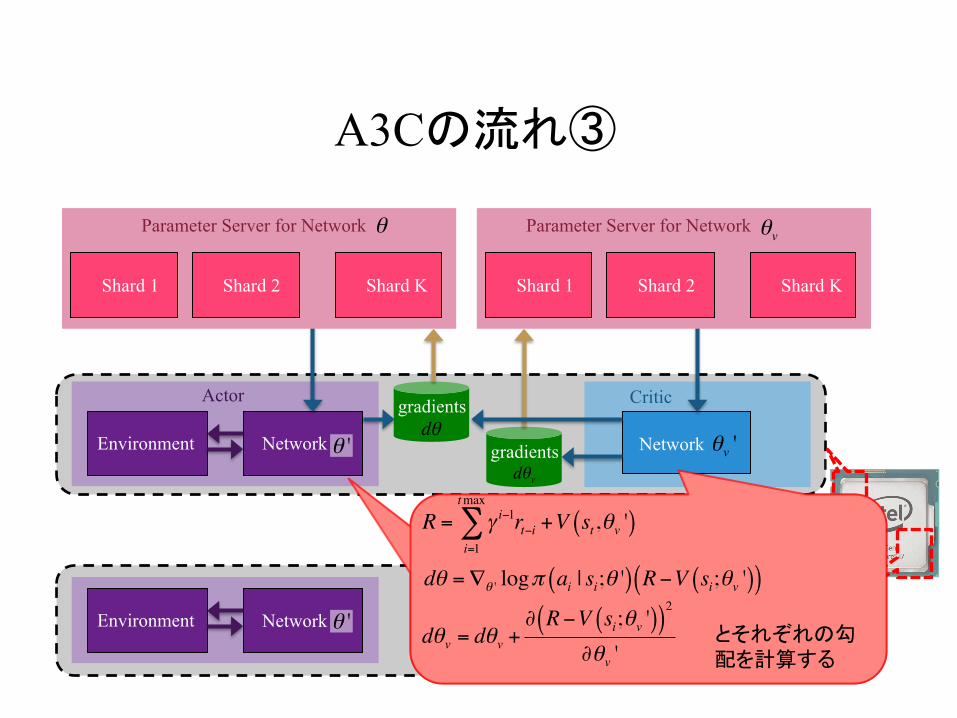
A3Cの流れ③
Environment Network Network
gradients
Environment
・ ・ ・
gradients
Actor Critic
Shard 1 Shard 2 Shard K
Parameter Server for Networkθ
θv '
Network
Shard 1 Shard 2 Shard K
Parameter Server for Networkθv
gradientsdθ
dθv
θ '
θ 'とそれぞれの勾配を計算する
R = γ i−1rt−ii=1
tmax
∑ +V st,θv '( )
dθ =∇θ ' logπ ai | si;θ '( ) R−V si;θv '( )( )
dθv = dθv +∂ R−V si;θv '( )( )
2
∂θv '
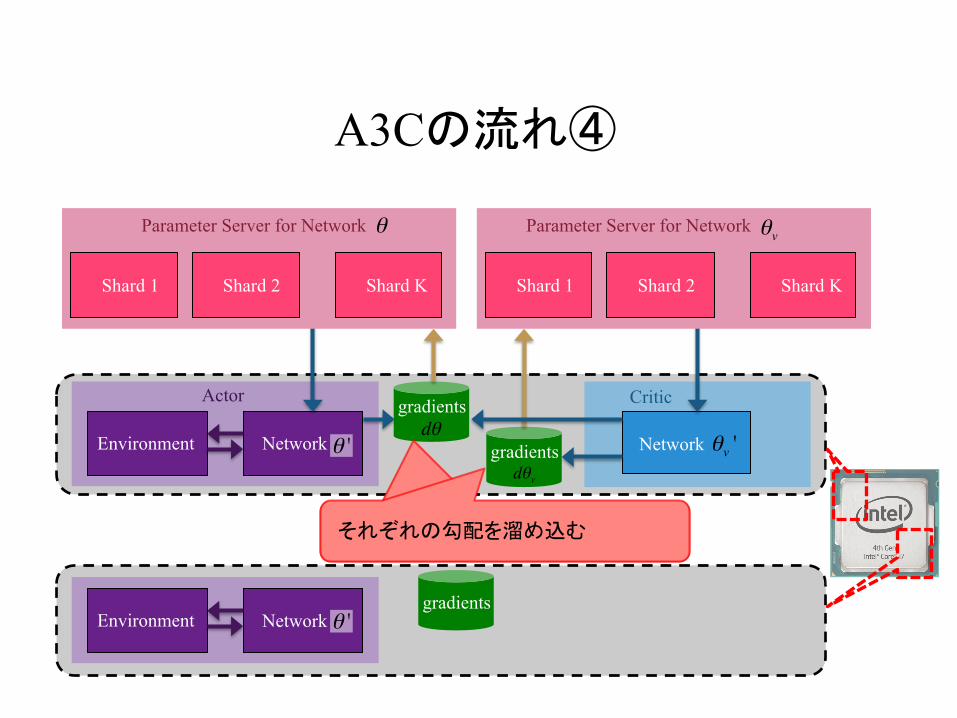
A3Cの流れ④
Environment Network Network
gradients
Environment
・ ・ ・
gradients
Actor Critic
Shard 1 Shard 2 Shard K
Parameter Server for Networkθ
θv '
Network
Shard 1 Shard 2 Shard K
Parameter Server for Networkθv
gradientsdθ
dθv
θ '
θ '
それぞれの勾配を溜め込む
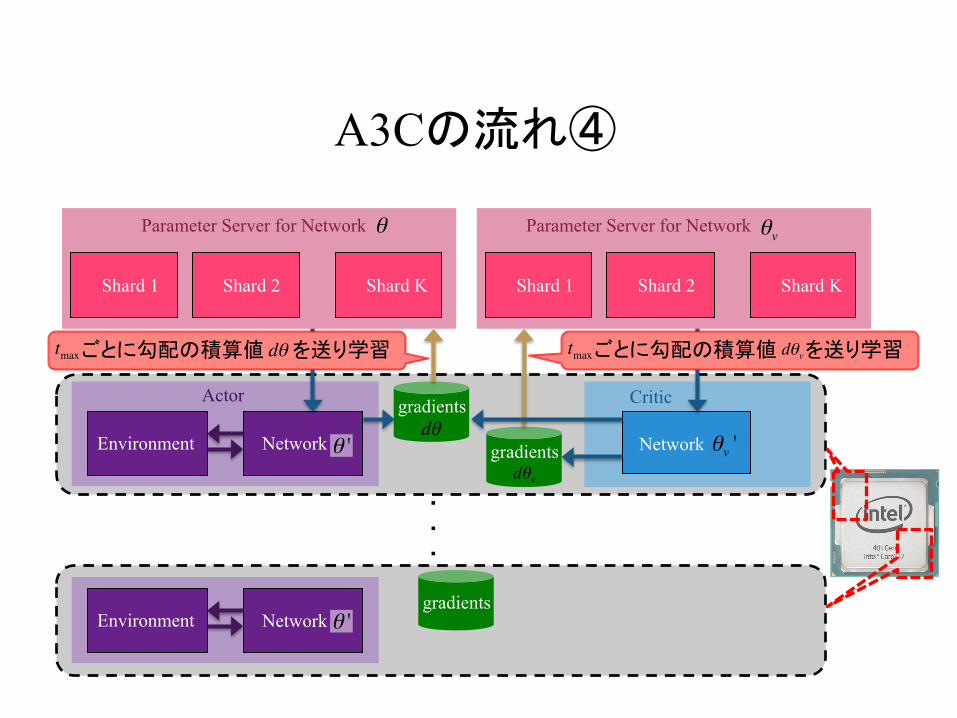
A3Cの流れ④
Environment Network Network
gradients
Environment
・ ・ ・
gradients
Actor Critic
Shard 1 Shard 2 Shard K
Parameter Server for Networkθ
θv '
Network
Shard 1 Shard 2 Shard K
Parameter Server for Networkθv
gradientsdθ
dθv
θ '
θ '
ごとに勾配の積算値 を送り学習dθtmax ごとに勾配の積算値 を送り学習tmax dθv
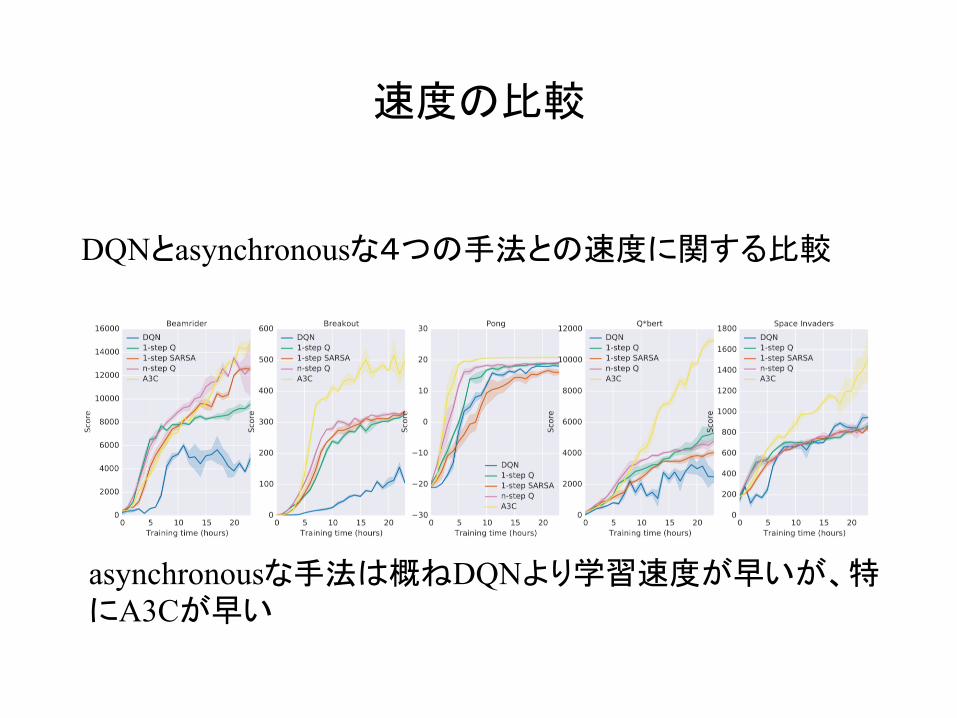
速度の比較
DQNとasynchronousな4つの手法との速度に関する比較
asynchronousな手法は概ねDQNより学習速度が早いが、特にA3Cが早い
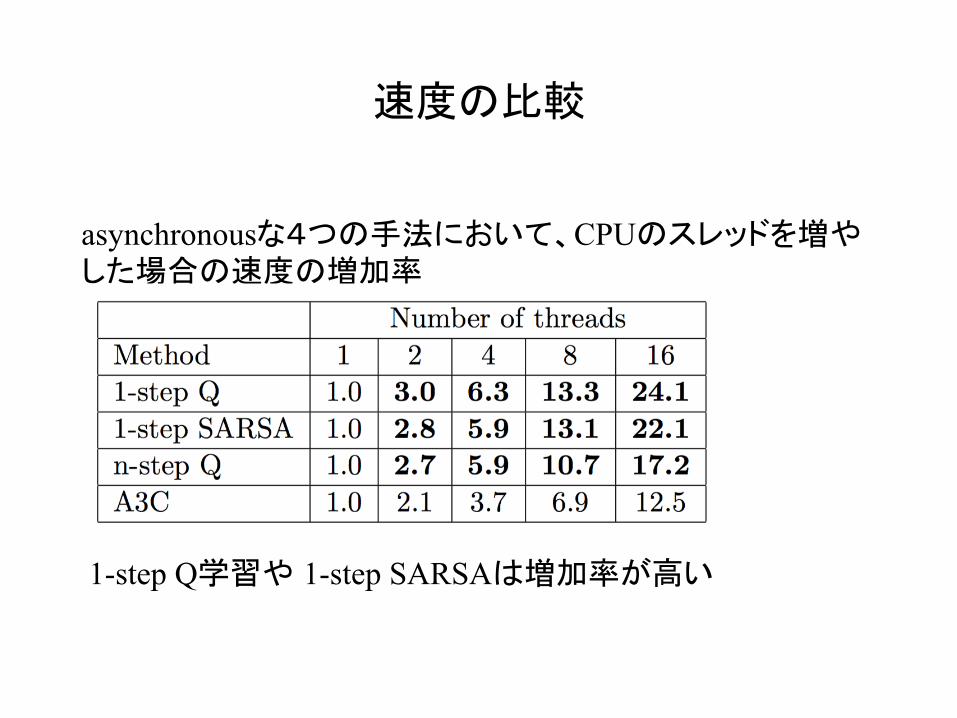
速度の比較
asynchronousな4つの手法において、CPUのスレッドを増やした場合の速度の増加率
1-step Q学習や 1-step SARSAは増加率が高い
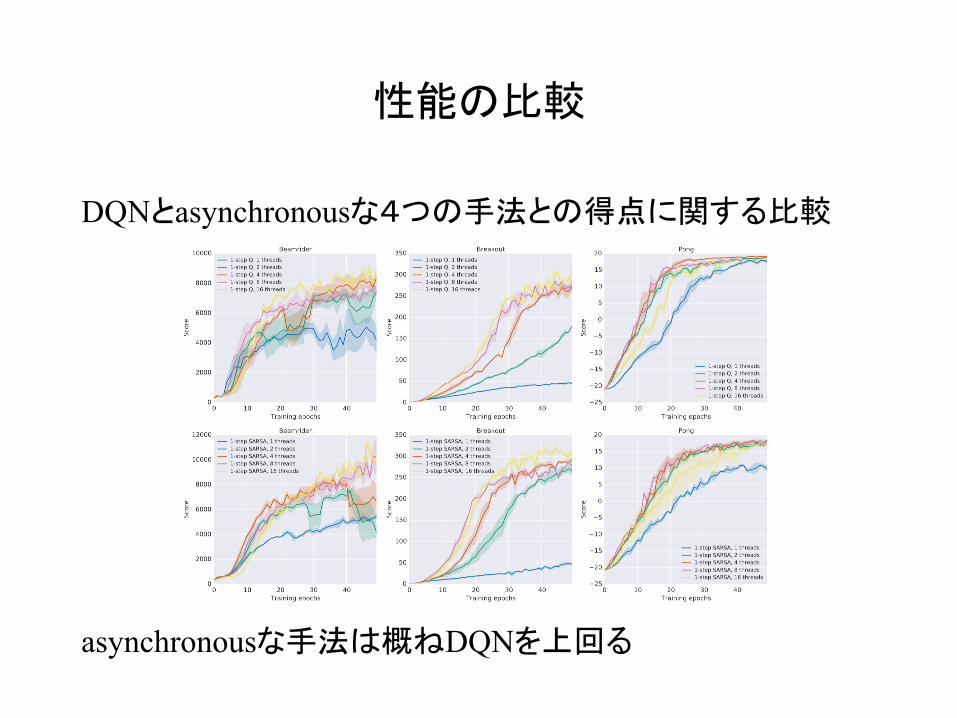
性能の比較
DQNとasynchronousな4つの手法との得点に関する比較
asynchronousな手法は概ねDQNを上回る

結論
l asynchronousな4つの手法はDQNよりも学習速度が早い。特にA3Cが早い。
l asynchronousな4つの手法はDQNよりも概ね得点が高い





























