Embed Size (px)
Citation preview

関西オープンフォーラム関西オープンフォーラム 20162016(2016-11-12)(2016-11-12)
PostgreSQL 9.6PostgreSQL 9.6 ががやってきた!やってきた!
ぬこ@横浜ぬこ@横浜 (@nuko_yokohama)(@nuko_yokohama)
http://wallpaper.free-photograph.net/jp/

2
自己紹介「 PostgreSQL ラーメン」
でググってください。

3
日本 PostgreSQL ユーザ会の自称ゆる枠担当やってる
PostgreSQL おじさんです。

4
今日は JPUG 枠として昨年に引き続き
関西オープンフォーラムへ参加することとなりました。

5
目次
はじめにPostgreSQL の概要と歴史PostgreSQL 9.6 の新機能
おわりに

6
はじめに

7
PostgreSQL を知ってる?
使っている?仕事で使ってる?

8
PostgreSQL の概要と歴史

9
PostgreSQL の概要
MySQL と並ぶ OSS DBMSライセンスは BSD ライクなもの高度なクエリにも対応性能面でも商用 DBMS とも遜色なし9.0 以降はレプリケーションも対応多種多様なデータ型サポート非常に高い拡張性活発な開発コミュニティ

10
要するに、無料で使えるスゲー ORDBMS

11
PostgreSQL の歴史(古代~近世)
POSTGRESプロジェクト
の時代
Postgres95の時代
※SQL サポート
PostgreSQLの時代
※6.0 から開始1986年
1995年1997年
2015年
POSTGRES プロジェクトからの年齢だと
何気にアラサー・・・

12
6.0 ~発展途上の時代
GEQOマルチバイト文字セット
MVCC
7.0 ~やっと実用的に
WALTOAST
VACUUM 改善
8.0 ~商用レベルへWindows 対応
PITR自動 VACUUM
HOT
9.0 ~エンタープライズ化
レプリケーション外部表
メニーコア性能向上マテリアライズドビュー
JSON 対応
1997年
2000年
2005年2010年
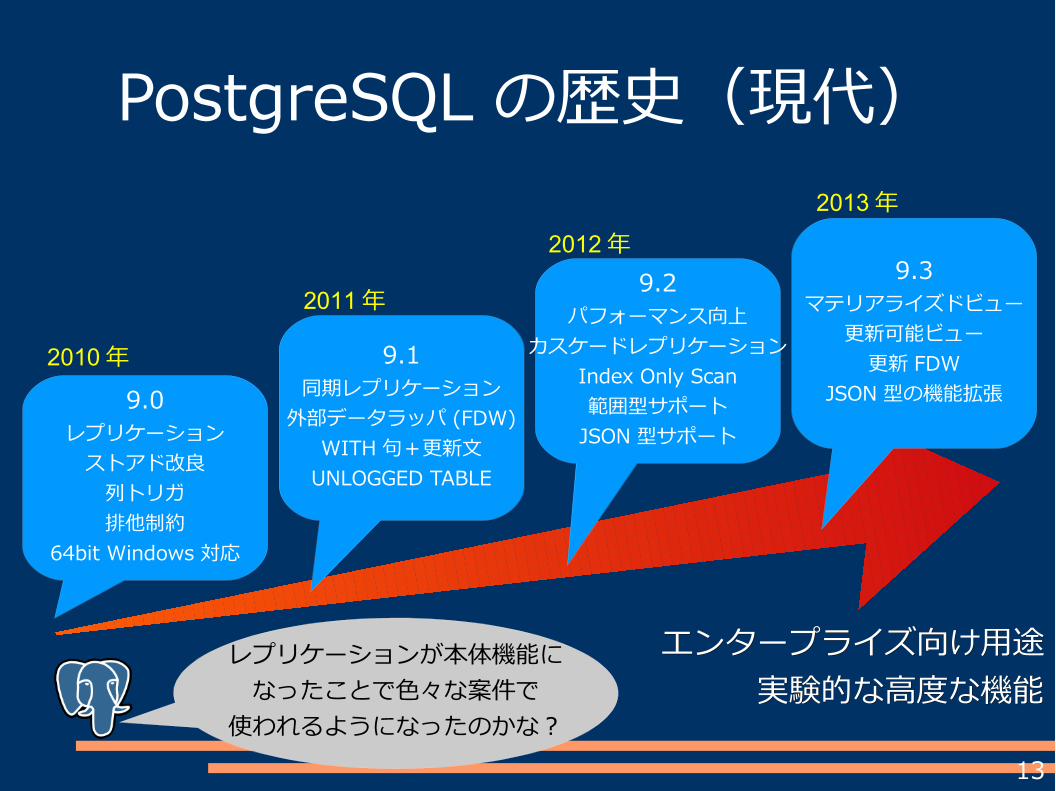
PostgreSQL の歴史(近代)
昔の (7.x 時代 ) の感覚でPostgreSQL 使えねーと
思ってる人もまだいるのかなあ。
13
9.0レプリケーション
ストアド改良列トリガ排他制約
64bit Windows 対応
9.1同期レプリケーション
外部データラッパ (FDW)WITH 句+更新文
UNLOGGED TABLE
9.2パフォーマンス向上
カスケードレプリケーションIndex Only Scan範囲型サポート
JSON 型サポート
9.3マテリアライズドビュー
更新可能ビュー更新 FDW
JSON 型の機能拡張
エンタープライズ向け用途エンタープライズ向け用途実験的な高度な機能実験的な高度な機能
2010年
2011年
2012年2013年
PostgreSQL の歴史(現代)
レプリケーションが本体機能になったことで色々な案件で
使われるようになったのかな?

14
9.4JSONB
ALTER SYSTEMマテビュー改善
ロジカル・デコーディングWAL バッファ並列挿入
9.5BRIN
UPSERTRow Level Security
Import foreign schemapg_rewind
9.6
さて、何が入るのか!
そして・・・そして・・・ 9.4, 9.59.4, 9.5そして開発中のそして開発中の 9.69.6 に至るに至る
2014年
2015年
2016年
PostgreSQL の歴史(現代)
9.4, 9.5 でも面白い機能がいろいろ入りました

15
PostgreSQL 9.6 への道
開発自体は昨年から開始数回の commitfest で取り込む機能を議論
2015/11, 2016/01, 2016/032016/05/12 beta1 リリース2016/06/23 beta2 リリース2016/09/01 RC1 リリース
2016/09/29 9.6.0 リリース!2016/10/27 9.6.1 リリース!

16
PostgreSQL 10!次期バージョンも開発中です。
なお、次期バージョンからは、X.X.X というバージョン番号ではなく、X.X という番号体系に変わります。

17
PostgreSQL 9.6 の新機能

18
PostgreSQL 9.6 新機能新機能カテゴリ 項目数 備考
サーバ 64 性能向上 18項目、監視 9項目
レプリケーションとリカバリ 5
クエリ 12
ユーティリティコマンド 19
権限管理 3
データ型 10
関数 18
サーバサイド言語 7
クライアント・インタフェース 3
クライアント・アプリケーション 25 psql は 13 項目
サーバ・アプリケーション 3
ソースコード 22
追加モジュール 20 postgres_fdwは 7項目
RC1 時点の情報合計 211項目

19
Parallel execution of sequential scans, joins and aggregatesAutovacuum no longer performs repetitive scanning of old dataSynchronous replication now allows multiple standby servers for increased reliabilityFull-text search can now search for phrases (multiple adjacent words)postgres_fdw now supports remote joins, sorts, UPDATEs, and DELETEsSubstantial performance improvements, especially in the area of scalability on multi-CPU-socket servers
PostgreSQL 9.6 主な新機能

20
PostgreSQL 9.6 主な新機能Parallel execution of sequential scans, joins and aggregatesAutovacuum no longer performs repetitive scanning of old dataSynchronous replication now allows multiple standby servers for increased reliabilityFull-text search can now search for phrases (multiple adjacent words)postgres_fdw now supports remote joins, sorts, UPDATEs, and DELETEsSubstantial performance improvements, especially in the area of scalability on multi-CPU-socket servers

21
パラレルクエリ
今、一番 HOT な機能。beta1 から RC1 の間で
いろいろ変更が入りました。

22
tmp=# EXPLAIN (ANALYZE, VERBOSE) SELECT AVG(data) FROM tmp; Aggregate (cost=16925.00..16925.01 rows=1 width=4) (actual time=187.215..187.215 rows=1 loops=1) Output: avg(data) -> Seq Scan on public.tmp (cost=0.00..14425.00 rows=1000000 width=4) (actual time=0.043..87.114 rows=1000000 loops=1) Output: id, data Planning time: 0.041 ms Execution time: 187.249 ms
PostgreSQL 9.5 まで
1つのクエリを 1 プロセスで順々に処理していた。
SeqScan Aggregate

23
tmp=# EXPLAIN (ANALYZE, VERBOSE) SELECT AVG(data) FROM tmp; Finalize Aggregate (cost=10633.55..10633.56 rows=1 width=32) (actual time=116.537..116.537 rows=1 loops=1) Output: avg(data) -> Gather (cost=10633.33..10633.54 rows=2 width=32) (actual time=114.831..116.524 rows=3 loops=1) Output: (PARTIAL avg(data)) Workers Planned: 2 Workers Launched: 2 -> Partial Aggregate (cost=9633.33..9633.34 rows=1 width=32) (actual time=110.293..110.294 rows=1 loops=3) Output: PARTIAL avg(data) Worker 0: actual time=104.469..104.470 rows=1 loops=1 Worker 1: actual time=111.816..111.816 rows=1 loops=1 -> Parallel Seq Scan on public.tmp (cost=0.00..8591.67 rows=416667 width=4) (actual time=3.734..66.547 rows=333333 loops=3) Output: id, data Worker 0: actual time=11.160..65.808 rows=295156 loops=1 Worker 1: actual time=0.014..57.334 rows=248600 loops=1 Planning time: 0.046 ms Execution time: 116.608 ms
PostgreSQL 9.6 から
1つのクエリでも複数プロセスを使って処理可能になった。
Paralell SeqScan
Partial Aggregate
Gather Final Aggregate
Worker
Worker
Worker
Worker

24
パラレルスキャンパラメータパラメータ名 意味 デフォルト値 備考
max_worker_processes ワーカープロセス数の最大値
8 変更のためには再起動が必要
max_parallel_workers_per_gather
並列度の最大値 0 beta2 で、名前が変わった。RC1 でデフォルト値 0 に。0 にすると並列化しなくなる。
force_parallel_mode 並列処理を強制させる。 of of/on/regress
parallel_setup_cost ワーカプロセス起動の推定コスト
1000
parallel_tuple_cost ワーカプロセスから別プロセスへ1タプルを転送する推定コスト
0.1
min_parallel_relation_size 並列化する最小のテーブルサイズ
1000 beta2 で追加単位はページ。
これと検索対象のテーブルサイズに依存

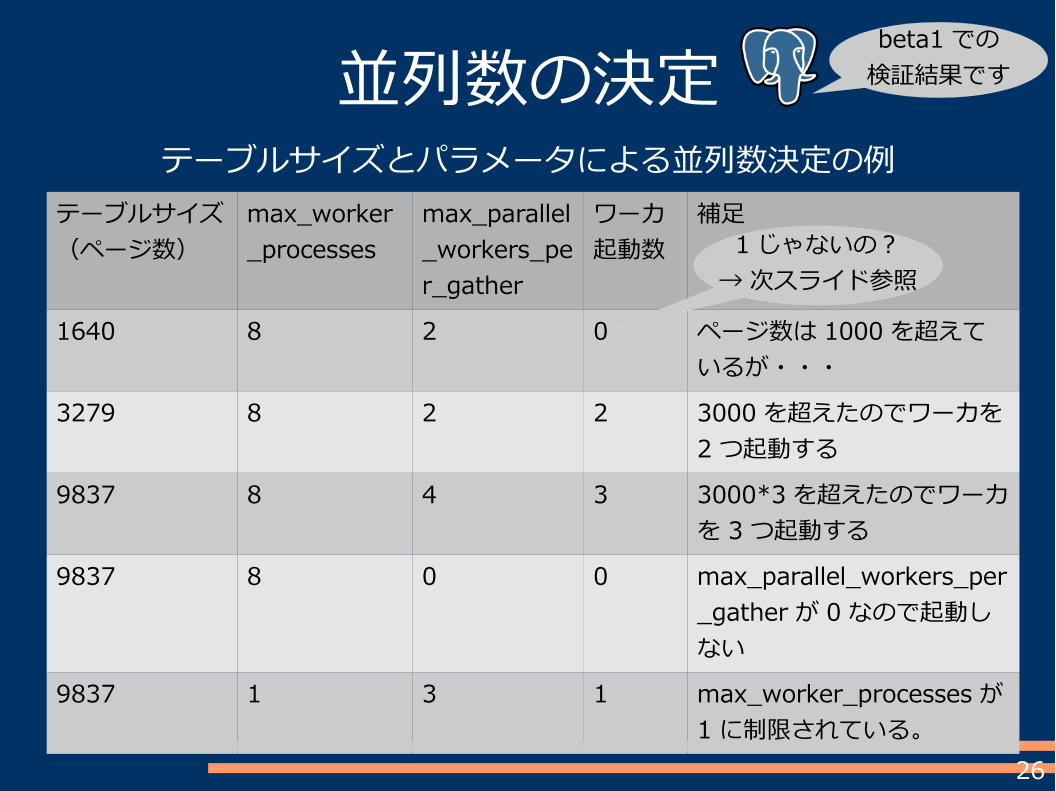
25
並列数の決定には、サーバの CPU 数は何も関係していない!(重要)
おおまかに言えば、テーブルサイズ(ページ数)がmin_parallel_relation_size( デフォルト: 1000) ページを
超えると並列スキャンを行う。以降、 3 倍毎に並列数が増加する。
並列数の決定
倍数も今後調整可能になるのかな・・・?
26
テーブルサイズとパラメータによる並列数決定の例
並列数の決定
テーブルサイズ(ページ数)
max_worker_processes
max_parallel_workers_per_gather
ワーカ起動数
補足
1640 8 2 0 ページ数は 1000 を超えているが・・・
3279 8 2 2 3000 を超えたのでワーカを2 つ起動する
9837 8 4 3 3000*3を超えたのでワーカを 3 つ起動する
9837 8 0 0 max_parallel_workers_per_gather が 0 なので起動しない
9837 1 3 1 max_worker_processes が1 に制限されている。
1 じゃないの?→次スライド参照
beta1 での検証結果です

27
bench=# SHOW parallel_setup_cost ; parallel_setup_cost --------------------- 1000(1 row)
bench=# EXPLAIN ANALYZE SELECT AVG(abalance) FROM pgbench_accounts ; QUERY PLAN Aggregate (cost=2890.00..2890.01 rows=1 width=32) (actual time=20.053..20.054 rows=1 loops=1) -> Seq Scan on pgbench_accounts (cost=0.00..2640.00 rows=100000 width=4) (actual time=0.006..6.521 rows=100000 loops=1) Planning time: 0.208 ms Execution time: 20.093 ms(4 rows)
パラレルクエリ用変数の調整
前スライドでページ数が 1600 のときにワーカが起動しないのは、 cost 上パラレルクエリで実施するよりも、フツーにSeqScan したほうが低いと判断されたから。

28
bench=# SET parallel_setup_cost TO 300;SETbench=# EXPLAIN ANALYZE SELECT AVG(abalance) FROM pgbench_accounts ; QUERY PLAN Finalize Aggregate (cost=2675.41..2675.42 rows=1 width=32) (actual time=12.707..12.708 rows=1 loops=1) -> Gather (cost=2675.29..2675.40 rows=1 width=32) (actual time=12.434..12.698 rows=2 loops=1) Workers Planned: 1 Workers Launched: 1 -> Partial Aggregate (cost=2375.29..2375.30 rows=1 width=32) (actual time=9.743..9.743 rows=1 loops=2) -> Parallel Seq Scan on pgbench_accounts (cost=0.00..2228.24 rows=58824 width=4) (actual time=0.007..6.190 rows=50000 loops=2) Planning time: 0.049 ms Execution time: 13.414 ms(8 rows)
パラレルクエリ用変数の調整
paralell_setup_cost/paralell_tuple_cost を調整することで、パラレルクエリに変更が可能。上の例は paralell_setup_cost を 1000→300 に調整。

29
パラレルスキャン対象でない実行計画パラレルスキャン対象外の SQL 関数を使っているときmax_worker_processes, max_parallel_workers_per_gather等のパラメータ設定他、細々とした制約があるっぽい
パラレルスキャンできない時

30
特定の SQL 関数を含む場合、パラレルスキャンの実行計画が選択されない。
一番身近な関数だと、シーケンス制御関数のnextval(), currval(), setval(), lastval() などが
パラレルスキャン対象外となる。
パラレルスキャンできない SQL 関数の一覧は、以下の SQL 文で取得可能。
パラレルスキャンできないSQL 関数
SELECT proname FROM pg_proc WHERE proparallel = 'u';

31
PostgreSQL 9.6 新機能Parallel execution of sequential scans, joins and aggregatesAutovacuum no longer performs repetitive scanning of old dataSynchronous replication now allows multiple standby servers for increased reliabilityFull-text search can now search for phrases (multiple adjacent words)postgres_fdw now supports remote joins, sorts, UPDATEs, and DELETEsSubstantial performance improvements, especially in the area of scalability on multi-CPU-socket servers

32
autovacuum 改善

33
9.5 までの autovacuum ではXID 周回を防ぐための vacuum 時に
全ページを処理していた。
9.6 からは frozen tuples しか含まないページを Visibility Map を参照して効率的に処理をスキップできる。
autovacuum 改善

34
この改善の恩恵
変更がほとんどないような巨大なテーブルの
autovacuum 時のコストを大きく削減する。
目立たないけど、とても重要な改善
autovacuum 改善

35
PostgreSQL 9.6 新機能Parallel execution of sequential scans, joins and aggregatesAutovacuum no longer performs repetitive scanning of old dataSynchronous replication now allows multiple standby servers for increased reliabilityFull-text search can now search for phrases (multiple adjacent words)postgres_fdw now supports remote joins, sorts, UPDATEs, and DELETEsSubstantial performance improvements, especially in the area of scalability on multi-CPU-socket servers

36
複数同期スタンバイサーバ

37
Master
async
async
PostgreSQL 9.5 まで
同期レプリケーション可能なスレーブサーバは 1台のみ。
Slave
Slave
Slave
sync

38
Master
sync
sync
PostgreSQL 9.6 から
同期レプリケーション可能なスレーブサーバが N台に!
Slave
Slave
Slave
sync
( N台構成のフェールオーバ機構、作るの大変そう・・・)

39
primary_conninfo = '2(standby1, standby2, standby3)'
synchronous_standby_names の書き方複数同期させる場合には recovery.confの primary_conninfo にN(name, name, ...) みたいに書く。
primary_conninfo = 'standby1, standby2, standby3'
従来の記法も対応している。この場合は、同期サーバ数は 1 になる。

40
9.6 からの注意点standby_name の扱いがSQL 識別子になった。(9.5 まではリテラル )

41
SQL 識別子の制約
"-" などはそのまま使えない。二重引用符で括る必要がある。

42
参考: SQL 識別子の定義
ident_start [A-Za-z\200-\377_]ident_cont [A-Za-z\200-\377_0-9\$]
identifier {ident_start}{ident_cont}*
backend/replicat_repl_scanner.l
standby_name に"-”は使えないけど、”_”は使えます。

43
PostgreSQL 9.6 新機能Parallel execution of sequential scans, joins and aggregatesAutovacuum no longer performs repetitive scanning of old dataSynchronous replication now allows multiple standby servers for increased reliabilityFull-text search can now search for phrases (multiple adjacent words)postgres_fdw now supports remote joins, sorts, UPDATEs, and DELETEsSubstantial performance improvements, especially in the area of scalability on multi-CPU-socket servers

44
PostgreSQL 自体に全文検索機能は昔からある。

45
9.6 から入った機能フレーズ検索ts_phrase()<-> 演算子

46
test=# SELECT test-# data test-# FROM animal test-# WHERE to_tsvector('english', data) @@ to_tsquery('english', 'dog'); data -------------------------------------------------- I like cats and dogs. In my bed, four dogs and five cats are sleeping. Miss Magee's dog is very strong.(3 rows)
test=# SELECT test-# data test-# FROM animal test-# WHERE to_tsvector('english', data) @@ to_tsquery('english', 'dog & cat'); data -------------------------------------------------- I like cats and dogs. In my bed, four dogs and five cats are sleeping.(2 rows)
これまでの全文検索
複数のワードの指定はできたが、語順を意識した検索は不可(dog, cat の順に出現する文書も cat, dog の順に出現する文書も両方ヒットしていた )

47
test=# SELECT data FROM animal WHERE to_tsvector('english', data) @@ tsquery_phrase( to_tsquery('english', 'dog'), to_tsquery('english', 'cat'), 3); data -------------------------------------------------- In my bed, four dogs and five cats are sleeping.(1 row)
test=# SELECT data FROM animal WHERE to_tsvector('english', data) @@ tsquery_phrase( to_tsquery('english', 'cat'), to_tsquery('english', 'dog'), 2); data ----------------------- I like cats and dogs.(1 row)
フレーズ検索
それぞれ、「 dog→cat 」「 cat→dog 」の順序で並んだテキストが検索されている。
フレーズ検索関数 tsquery_phrase() を使う。

48
test=# SELECT test-# datatest-# FROM animaltest-# WHERE test-# to_tsvector(data) @@ test-# (to_tsquery('like') <-> to_tsquery('cat')); data ----------------------- I like cats and dogs.(1 row)
<-> 演算子
X <-> Y はtsquery_phrase( X, Y, 1) と同義です。
全文検索用演算子として、 9.6では 新たに
<-> という演算子が追加された。
※ 演算子が簡単に追加できるのも PostgreSQLのいいところ。

49
閑話休題

50
なんかさっきから英文の例しかないんだけど
日本語全文検索は?

51
PostgreSQL本体機能だけでは日本語全文検索はできない (絶望 )

52
追加モジュールtextseach_ja を使えば日本語全文検索は可能
http://textsearch-ja.projects.pgfoundry.org/textsearch_ja.html
しかし、公式には 9.0 で開発が止まっている(泣)

53
が、少し修正すれば一応、 PostgreSQL 9.6 でも
textsearch_ja は動くようです(検証中)

54
9.6 + textsearch_ja
とりあえず、フレーズ検索を使っても動くようです (beta1) 。
tsearch=# SELECT ts_rank_cd( to_tsvector('japanese', data), tsquery_phrase( to_tsquery('japanese', ' セリヌンティウス '), to_tsquery('japanese', ' メロス '), 3) ), ts_headline('japanese', data, tsquery_phrase(to_tsquery( 'japanese', ' セリヌンティウス '), to_tsquery('japanese', ' メロス '), 10))FROM meros WHERE to_tsvector('japanese', data) @@ tsquery_phrase( to_tsquery('japanese', ' セリヌンティウス '), to_tsquery('japanese', ' メロス '), 3); ts_rank_cd | ts_headline 0.1 | <b> セリヌンティウス </b> 。」 <b> メロス </b>は眼に涙を浮べて言った。「私を殴れ。ちから一ぱいに頬を殴れ。私は、途中で一度、悪い(1 row)
\
tsquery_phrase() と textsearch_ja の組み合わせ例

55
PostgreSQL 9.6 新機能Parallel execution of sequential scans, joins and aggregatesAutovacuum no longer performs repetitive scanning of old dataSynchronous replication now allows multiple standby servers for increased reliabilityFull-text search can now search for phrases (multiple adjacent words)postgres_fdw now supports remote joins, sorts, UPDATEs, and DELETEsSubstantial performance improvements, especially in the area of scalability on multi-CPU-socket servers

56
postgres_fdw 改善リモート側での結合・ソート・更新

57
postgres_fdw とは別の PostgreSQL データベース内の表を
通常の表のように扱えるFDW(Foreign Data Wrapper) の一種
9.3から利用可能DBLINK みたいな機能。
透過的に SQL で書けるというのがメリットです

58
local
PostgreSQL 9.5 まで
remote サーバのテーブルから結果を受け取って、local 側で結合やソートを実施更新時はカーソルを使って 1行ずつ更新・・・
remote
外部テーブル 実テーブル結合やソートを含むクエリ
結合処理ソート処理
結果

59
local
PostgreSQL 9.6 から
remote サーバで結合やソートを実施。サーバ間転送量の削減になるかも!更新文もカーソルを使わず remote サーバでそのまま実行。
remote
外部テーブル 実テーブル結合やソートを含むクエリ
そのまま結果
結合処理ソート処理

60
bench=# EXPLAIN ANALYZE VERBOSE SELECT AVG(a.data1), AVG(a.data2) FROM table_a a JOIN table_b b ON (a.id = b.id) WHERE a.data1 = 10000 ; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------ Aggregate (cost=349.93..349.94 rows=1 width=8) (actual time=1741.557..1741.558 rows=1 loops=1) Output: avg(a.data1), avg(a.data2) -> Hash Join (cost=238.80..349.12 rows=161 width=8) (actual time=99.229..1741.404 rows=11 loops=1) Output: a.data1, a.data2 Hash Cond: (b.id = a.id) -> Foreign Scan on public.table_b b (cost=100.00..197.75 rows=2925 width=4) (actual time=1.066..1648.609 rows=1000000 loops=1) Output: b.id, b.data1, b.data2 Remote SQL: SELECT id FROM public.table_b -> Hash (cost=138.66..138.66 rows=11 width=12) (actual time=0.807..0.807 rows=11 loops=1) Output: a.data1, a.data2, a.id Buckets: 1024 Batches: 1 Memory Usage: 9kB -> Foreign Scan on public.table_a a (cost=100.00..138.66 rows=11 width=12) (actual time=0.794..0.796 rows=11 loops=1) Output: a.data1, a.data2, a.id Remote SQL: SELECT id, data1, data2 FROM public.table_a WHERE ((data1 = 10000)) Planning time: 1.559 ms Execution time: 1748.602 ms(16 rows)
9.5 での実行計画例(結合)
結合処理はローカル側で行っている。結合処理のソースはリモートからローカルに転送されている。

61
bench=# EXPLAIN ANALYZE VERBOSE SELECT AVG(a.data1), AVG(a.data2) FROM table_a a JOIN table_b b ON (a.id = b.id) WHERE a.data1 = 10000 ; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------------------------- Aggregate (cost=342.59..342.60 rows=1 width=64) (actual time=0.560..0.561 rows=1 loops=1) Output: avg(a.data1), avg(a.data2) -> Foreign Scan (cost=100.00..341.78 rows=161 width=8) (actual time=0.552..0.554 rows=10 loops=1) Output: a.data1, a.data2 Relations: (public.table_a a) INNER JOIN (public.table_b b) Remote SQL: SELECT r1.data1, r1.data2 FROM (public.table_a r1 INNER JOIN public.table_b r2 ON (((r1.id = r2.id)) AND ((r1.data1 = 10000)))) Planning time: 0.123 ms Execution time: 0.789 ms(8 rows)
9.6 での実行計画例(結合)
【ポイント】リモートサーバで結合 SQL を実行その結果、ローカルサーバに転送される行数は 10行!実行時間も 2000倍以上向上!

62
local
PostgreSQL 9.5 まで
remote サーバのテーブルから結果を受け取って、local 側で結合やソートを実施
remote
外部テーブル 実テーブル結合やソートを含むクエリ
結合処理ソート処理
結果1000000+10 件の
レコードが転送される

63
local
PostgreSQL 9.6 から
サーバ間転送量の削減→大幅な性能の向上!
remote
外部テーブル 実テーブル結合やソートを含むクエリ
そのまま結果
結合処理
結合結果の 10件のみレコードが転送される

64
PostgreSQL 9.6 新機能Parallel execution of sequential scans, joins and aggregatesAutovacuum no longer performs repetitive scanning of old dataSynchronous replication now allows multiple standby servers for increased reliabilityFull-text search can now search for phrases (multiple adjacent words)postgres_fdw now supports remote joins, sorts, UPDATEs, and DELETEsSubstantial performance improvements, especially in the area of scalability on multi-CPU-socket servers

65
様々な性能改善(特に CPU が多い環境での改善)

66
性能改善項目(一部)
frozen タプルのみのページの再 vacuum 抑止vacuum 時の無駄なヒープ切り詰め抑止btree vacuum 時のスタンバイへの影響低減特定の GROUP BY 改善ORDER BY 後まで SELECT 式評価を遅延カーネル・ディスク・バッファ管理改善Windows版限定: update_process_title のデフォルト値 of による性能向上。
他いろいろ・・・
性能改善については個人の環境では
なかなか試せない・・・

67
性能改善項目
性能改善項目に関しては、今後、 PostgreSQL に強い企業さんや (PostgreSQL Enterprise Consotium)
あたりが、検証結果を出してくれるんじゃないかな、と
期待しています。

68
その他
GUC の変更システムカタログの変更SQL コマンドの改善psql の改善contrib の改善

69
GUC の変更

70
パラメータ名 変更の種別 内容 ぬこメモ
autovacuum_max_workers 最大値の変更 8388607 から 262143 になった。 10 より大きくしたことない気がするのでわりとどうでもいい。
backend_flush_after 新規追加 ディスクフラッシュに関するパラメータ? 通常はデフォルト値 (16 ページ ) のままでいいのかなあ?
bgwriter_flush_after 新規追加 上のパラメータの bgwriter 版? これも通常はデフォルト (64 ページ ) のままでいいのかなあ?
checkpoint_flush_after 新規追加 上のパラメータの checkpointer 版? これも ( 略 )(32 ページ ) の ( 略 )
debug_assertions 既定値変更 既定値が on から ofに変更 開発者向けオプション。
force_parallel_mode 新規追加 パラレルスキャンを強制? enable_* パラメータみたいなものかな?
idle_in_transaction_session_timeout 新規追加 一定時間の idle in transaction session を切断 運用ミスによるロングトランザクション防止に使えそう?
max_connections 最大値の変更 8388607 から 262143 になった。 これもせいぜい 1000 くらいまでしか上げないからなあ・・・
max_parallel_workers_per_gather 新規追加 同期実行するワーカ数上限値 パラレルスキャンに関する重要なパラメータ。beta2 で名称変更。
max_prepared_transactions 最大値の変更 8388607 から 262143 になった。 このパラメータ自体チューニングで使ったこと、あったけなあ・・・
max_replication_slots 最大値の変更 8388607 から 262143 になった。 レプリケーションスロット数をそんな大きな値に設定したことがそもそもない。
max_wal_senders 最大値の変更 8388607 から 262143 になった。 wal sender プロセス数って、もうちょっと上限小さくてもいいんじゃないかなあという気も。
max_worker_processes 最大値の変更 8388607 から 262143 になった。 ワーカプロセス数って、もうちょっと上限 ( 略 )
min_parallel_relation_size 新規追加 パラレルスキャン対象とする最小ページ数 beta2 で追加。
old_snapshot_threshold 新規追加 非常に古いスナップショット読み込み挙動のフラグ? きちんと調べて、どういうときにデフォルト (-1) 以外之設定が必要か理解しないと・・・
9.5 と 9.6 のパラメータ差分

71
パラメータ名 変更の種別 内容 ぬこメモ
parallel_setup_cost 新規追加 パラレルスキャンのコスト推定パラメータ パラレルスキャンのチューニング時に重要なパラメータになるのか、だいたいの場合デフォルトでいいのかくらいは調べておかないと。
parallel_tuple_cost 新規追加 パラレルスキャンのコスト推定パラメータ パラレルスキャンのチューニング時に重要なパラメータになるのか ( 略 )
replacement_sort_tuples 新規追加 ソート方式 ( クイックソート / 外部ソート ) の切り替え閾値 ( タプル数 )
既存の work_men/maintenance_work_mem との関係も調べるのかな。
server_version 設定値変更 バージョン番号の変更 現状は 9.6 beta2
server_version_num 設定値変更 バージョン番号値の変更 90600
superuser_reserved_connections 最大値の変更 8388607 から 262143 になった。 max_connection と同じ話か。
synchronous_commit 値域の追加 値域に remote_apply の追加 WAL 反映完了まで待つモードの追加。各スレーブへの検索で同じ結果が保証されるはず。
synchronous_standby_names 説明の変更 複数同期スタンバイに対応した説明変更 これも早く自分で動かしてみないとなあ。
syslog_sequence_numbers 新規追加 syslog でメッセージ分割したときの通番付与フラグ? あんまり syslog 出力って使ってないんだよなー。
syslog_split_messages 新規追加 syslog でメッセージ分割するかどうかのフラグ? あんまり syslog(略 )
wal_level 値域の変更 archive,hot_standby が replica に統一された。 過去に PITR やレプリケーション設定方法を書いているドキュメントへの影響がw
wal_writer_delay 説明の変更 説明文の変更のみ。 フラッシュ関係のパラメータ追加とかが関係しているのかな。
wal_writer_flush_after 新規追加 wal_writer の制御パラメータ またフラッシュ関係のパラメータか!
今回はこのうち2つの GUC を紹介します。

72
idle_in_transaction_session_timeout
SET idle_in_transaction_session_timeout = 3000;SETBEGIN;BEGINSELECT 1; ?column? ---------- 1(1 row)
SELECT pg_sleep(3); pg_sleep ---------- (1 row)
SELECT 2; ?column? ---------- 2(1 row)
\! sleep 3SELECT 3;psql:timeout.sql:7: FATAL: terminating connection due to idle-in-transaction timeout
運用ミスで idel in transaction 状態が長時間継続するときに強制切断することができる。
Idle in transactionが3 秒以上になったら
セッションを切断するこの場合は、
query 実行中なので3 秒以上でもセッションは
切断されない。
この場合は、Idle in transaction状態で
3 秒経過する。
Idle in transaction状態で3 秒経過したので
セッションが切断される。

73
wal_level の変更9.6 では wal_level の値域が変更になった。
値域 9.5 まで 9.6 説明
minial ○ ○ デフォルト値。最も WAL サイズが小さくなるが、 PITR やレプリケーションはできない。
archive ○ - PITR 用。9.6 でも隠し設定値として使用可能。
hot_standby ○ - レプリケーション用9.6でも隠し設定値として使用可能。
replica - ○ 9.6 から追加されたレプリケーション /PITRの WAL 形式が 9.6 で統一された。
logcal ○ ○ ロジカルデコーディング用の WAL 形式。最もサイズが大きくなる。

74
PostgreSQL も毎年進化しているので数年前に本で書いたことが
すぐに時代遅れになる (´ ・ω ・ `)

75
システムカタログの変更

76
システムカタログ
テーブル / ビュー名 変更種別 変更内容 ぬこメモ
pg_aggregate 列の追加 aggcombinefn, aggserialfn, aggdeserialfn, aggserialtype の追加
パラレル集約の関係?要調査
pg_am 全面変更 個々のアクセスメソッド用フラグが消えて、ハンドラ関数ポインタに置き換わったみたい。
インデックスのサポート能力は SQL 関数で確認できるようになった模様。 (RC1)
pg_config カタログの追加 pg_config 相当の情報 リモートから config が参照可能になったってことだね。
pg_init_privs カタログの追加 システム内オブジェクトの初期権限管理用のカタログ?
普段使うものではない?要調査
pg_proc 列の追加 proparallel の追加 名前からすると、関数が並列処理に対応するかどうかのフラグ? CREATE FUNCTION に影響あるのかな。
pg_replication_slots 列の追加 confirmed_flush_lsn の追加。 ロジカルレプリケーション利用者が受信した場所を示す列かな。
pg_stat_activity 列の変更 waiting が wait_event_type とwait_event に分離した。
監視方式にも影響でるのかな?
pg_stat_progress_vacuum カタログの追加 VACUUM処理進捗表示のためのカタログ
PostgreSQL: Documentation: 9.6: Progress Reporting を見ればいいのだな。
pg_stat_wal_receiver カタログの追加 名前のとおり、 wal reciever の挙動に関する稼働統計情報かな。
これを使うと、どういう監視が出来るようになるのかなあ。

77
pg_stat_vacuum_progressbench=# SELECT p.relname, v.phase, v.heap_blks_total, v.heap_blks_scanned, v.heap_blks_vacuumed, v.index_vacuum_count FROM pg_stat_progress_vacuum as v JOIN pg_class as p ON (v.relid = p.oid);-[ RECORD 1 ]------+-----------------relname | pgbench_accountsphase | scanning heapheap_blks_total | 16394heap_blks_scanned | 8844heap_blks_vacuumed | 0index_vacuum_count | 0
phase, heap_blks_total, heap_blks_scanned の結果からVACUUM 処理の状況を判断する。VACUUM が完了すると、このビューからレコードは見えなくなる。

78
pg_stat_vacuum_progressSELECT p.relname, v.phase, v.heap_blks_total, v.heap_blks_scanned, v.heap_blks_vacuumed, v.index_vacuum_count FROM pg_stat_progress_vacuum as v JOIN pg_class as p ON (v.relid = p.oid);
pgbench_accounts | scanning heap | 18033 | 506 | 0 | 0 pgbench_accounts | scanning heap | 18033 | 1260 | 0 | 0 pgbench_accounts | scanning heap | 18033 | 17067 | 0 | 0 pgbench_accounts | scanning heap | 18033 | 17157 | 0 | 0 pgbench_accounts | scanning heap | 18033 | 17467 | 0 | 0 pgbench_accounts | vacuuming indexes | 18033 | 18033 | 0 | 0(中略 ) pgbench_accounts | vacuuming indexes | 18033 | 18033 | 0 | 0 pgbench_accounts | vacuuming indexes | 18033 | 18033 | 0 | 0 pgbench_accounts | vacuuming heap | 18033 | 18033 | 16767 | 1 pgbench_accounts | vacuuming heap | 18033 | 18033 | 17267 | 1 pgbench_accounts | vacuuming heap | 18033 | 18033 | 17997 | 1 pg_language | cleaning up indexes | 1 | 1 | 1 | 0 pg_tablespace | scanning heap | 1 | 0 | 0 | 0
ステータスが、 scanning heap → vacuuming indexes → vacuuming heap という具合に変更していくのが見える。

79
SQL コマンドの改善

80
SQL コマンドの改善COPY が RETURNING に対応EXTENSION 削除時の依存オブジェクトの削除CREATE EXTENSION の CASCADE オプション追加CREATE ACCESS METHOD の実装CREATEUSER/NOCREATEUSER オプションを CREATE ROLE 等から削除VACUUM に DISABLE_PAGE_SKIPPING オプションが追加etc...
今回はこのうち1 つだけ紹介します。

81
COPY が RETURNING に対応test=# TABLE book; id | title | price ----+------------------+------- 1 | 働けメロス | 600 2 | 我輩はぬこである | 550 3 | リア充 | 780(3 rows)
test=# COPY (DELETE FROM book RETURNING *) TO '/tmp/book.txt';COPY 3test=# TABLE book; id | title | price ----+-------+-------(0 rows)
test=# \q[nuko@localhost test]$ cat /tmp/book.txt 1 働けメロス 6002 我輩はぬこである 5503 リア充 780
RETURNING 句:更新結果を返却することが可能。9.6 からは RETURNING の結果を COPY TO でファイルに直接書き込むことが可能になった。
削除したレコードをCOPY を使ってファイルに
エクスポートする

82
psql の改善

83
PostgreSQL 標準の CUI 対話的ターミナル
多彩なメタコマンド、タブ補完・・・おそらく、商用含む RDBMS 標準の
対話的ターミナルとしては一番使いやすいんじゃないかと思う。
psql って何?
個人の感想です

84
直前クエリの実行結果をクエリとして再実行(\gexec)直前のエラー詳細出力クロスタブ表示(\crosstabview)タブ補完の改善SHOW_CONTEXT メッセージ出力制御etc...
psql の改善(一部)
今回は面白い追加機能を2つ紹介します。

85
psql の改善 (\gexec)test=# SELECT 'CREATE TABLE table_' || generate_series(1,4) || '(id int primary key, data jsonb)'; ?column? ------------------------------------------------------ CREATE TABLE table_1(id int primary key, data jsonb) CREATE TABLE table_2(id int primary key, data jsonb) CREATE TABLE table_3(id int primary key, data jsonb) CREATE TABLE table_4(id int primary key, data jsonb)(4 rows)
test=# \gexecCREATE TABLECREATE TABLECREATE TABLECREATE TABLEtest=# \d List of relations Schema | Name | Type | Owner --------+---------+-------+------- public | table_1 | table | nuko public | table_2 | table | nuko public | table_3 | table | nuko public | table_4 | table | nuko(4 rows)
名前の違うテーブルを多数生成する例

86
psql の改善 (\crosstabview)tmp=# TABLE sales ; date | item | sales ------------+-------+------- 2016-05-16 | Ramen | 1650 2016-05-16 | Curry | 2500 2016-05-16 | Udon | 500 2016-05-16 | Soba | 600 2016-05-17 | Ramen | 2400 2016-05-17 | Curry | 800 2016-05-18 | Ramen | 1400 2016-05-18 | Curry | 1600 2016-05-18 | Udon | 1000(9 rows)
tmp=# \crosstabview date item sales date | Ramen | Curry | Udon | Soba ------------+-------+-------+------+------ 2016-05-16 | 1650 | 2500 | 500 | 600 2016-05-17 | 2400 | 800 | | 2016-05-18 | 1400 | 1600 | 1000 | (3 rows)
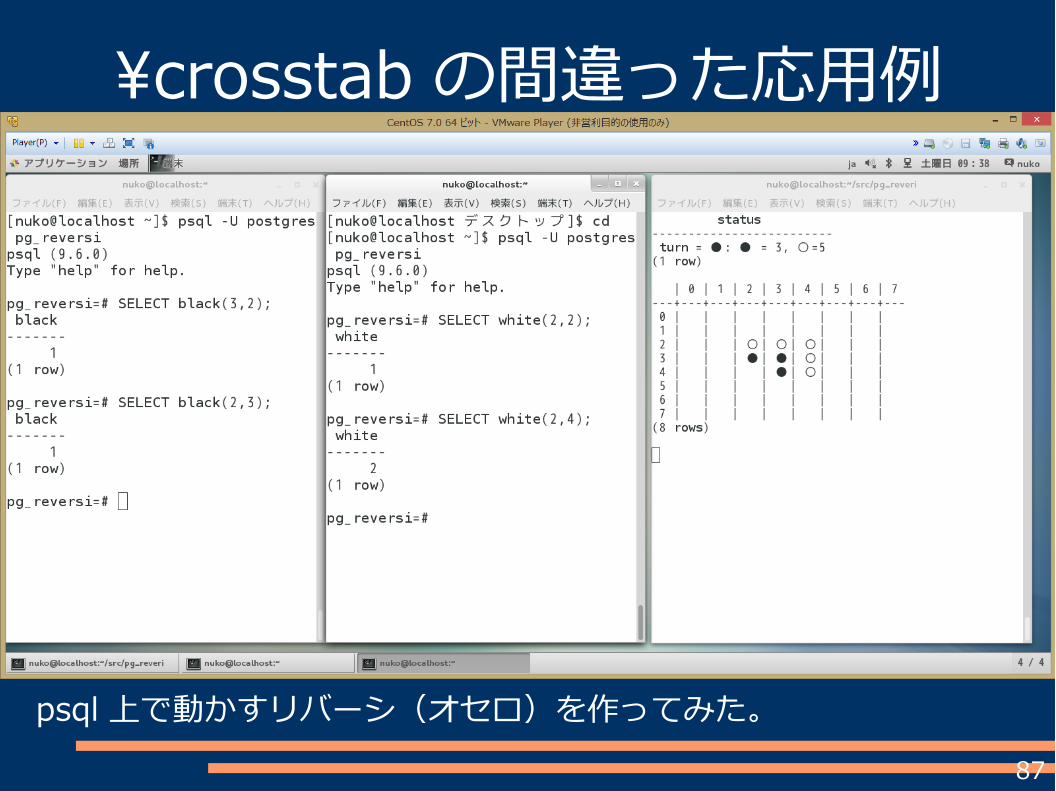
直前クエリの結果から、クロスタブっぽい表示にする謎機能
87
\crosstab の間違った応用例
psql 上で動かすリバーシ(オセロ)を作ってみた。

88
contrib 改善(追加モジュールの改善 )

89
auto_explain の ratio 指定bloom インデックスの追加cube での K近傍検索対応hstore と JSON 変換intarray のプラン改善用評価関数追加pageinspect に関数追加pgcrypto 関数の引数追加pg_trgm の機能追加etc...
contrib の改善(一部)
今回はこのうち1つだけ紹介します。

90
auto_explain というのは閾値を超えたスロークエリの実行計画を出力
閾値が低すぎるとログ量が多くなる→性能に影響が出てしまう・・・
9.6 での改善は、 ratio を指定して一定の割合のみログ出力するというもの
auto_explain の ratio 指定

91
これは 2月末のPostgreSQL
Newbie-hackerthonのときの測定結果
pgbench で測定。sample_ratio によるtps への影響軽減を確認できた。

92
おわりに

93
PostgreSQL 9.6 は地味だが今後、バージョン 10 で
化ける機能を含む重要なリリースになりそう!
メニー CPU 環境での更なる性能向上が見込めるはず

94
Let's Download & Using PostgreSQL 9.6!

96
PostgreSQL 9.6 RC1 Documentationhttps://www.postgresql.org/docs/9.6/static/release-9-6.htmlhttps://www.postgresql.org/docs/devel/static/release-9-6.htmlCommitfest 2016-03https://commitfest.postgresql.org/9/篠田の虎の巻 5 「 PostgreSQL 9.6 新機能検証結果」http://community.hpe.com/hpeb/attachments/hpeb/JapanEnterpriseTopics/195.6/1/PostgreSQL%209.6%20New%20Features%20ja%2020160530-1.pdfMichael Paquier - Open source developer based in Japanhttp://michael.otacoo.com/@snaga さんの PostgreSQL Deep DivePostgreSQL 9.6 のパラレルシーケンシャルスキャンを検証するhttp://pgsqldeepdive.blogspot.jp/2015/12/parallel-seq-scan.html@sawada_masahiko さんの Qiita ページPostgreSQL のマルチ同期レプリケーションhttp://qiita.com/sawada_masahiko/items/748dfe3dd1cbf92f601c
参考にしたもの

97
私も微力ながらPostgreSQL 9.6 新機能に関する調査・検証結果を
ブログや Qiita で公開予定ですhttp://d.hatena.ne.jp/nuko_yokohama/
http://qiita.com/nuko_yokohama































