Embed Size (px)
Citation preview

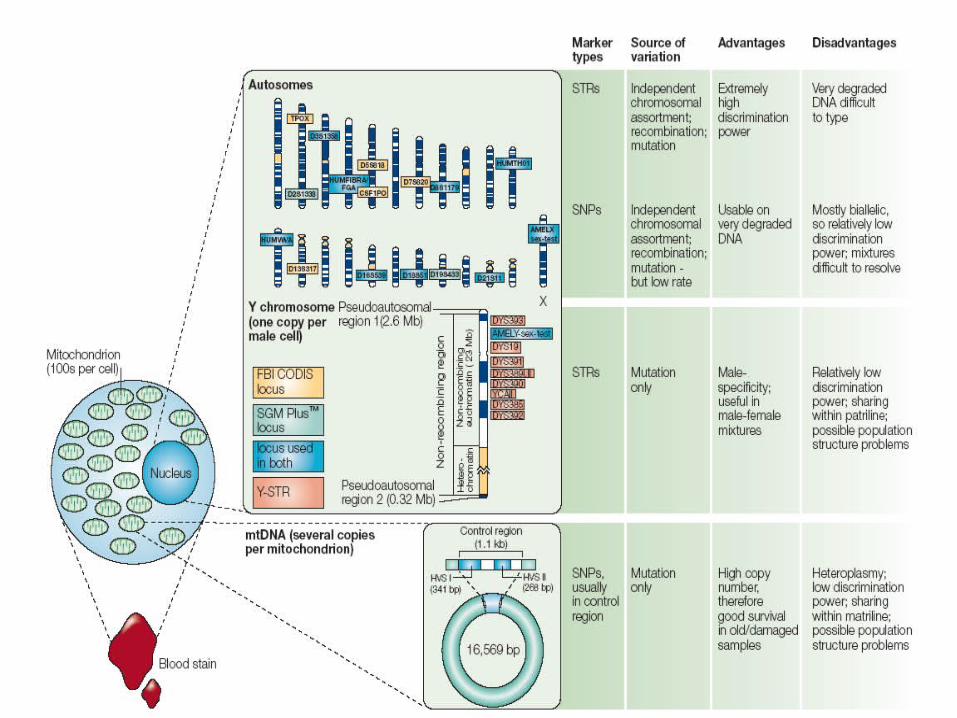
DNA mitocondriale e cromosoma Y
nella pratica forense
Dott.ssa Carla Bini
Genotipo vs aplotipo
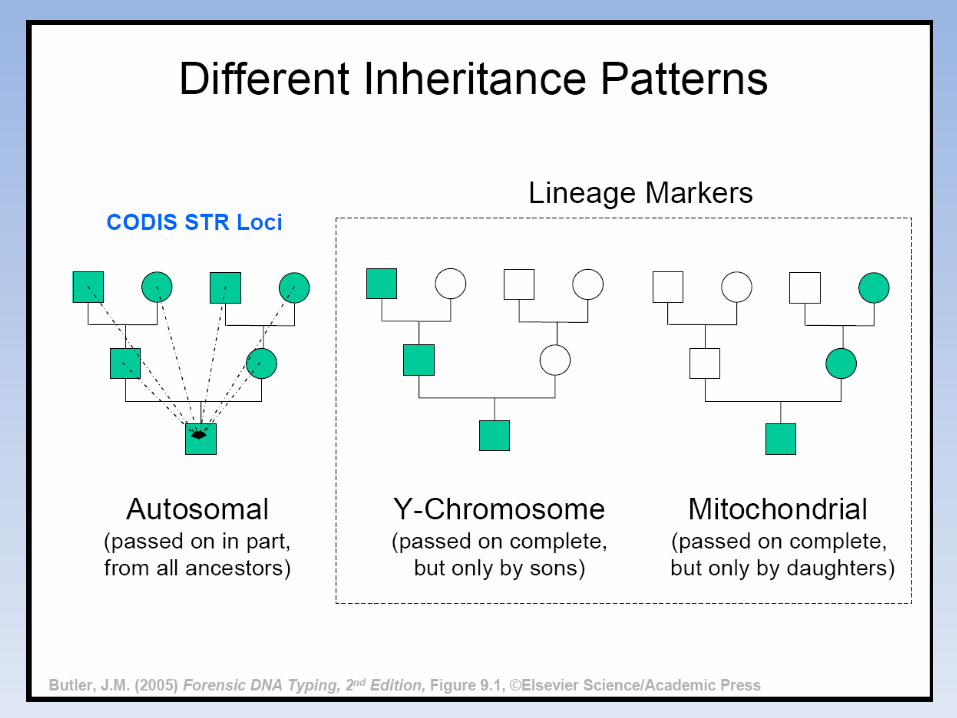
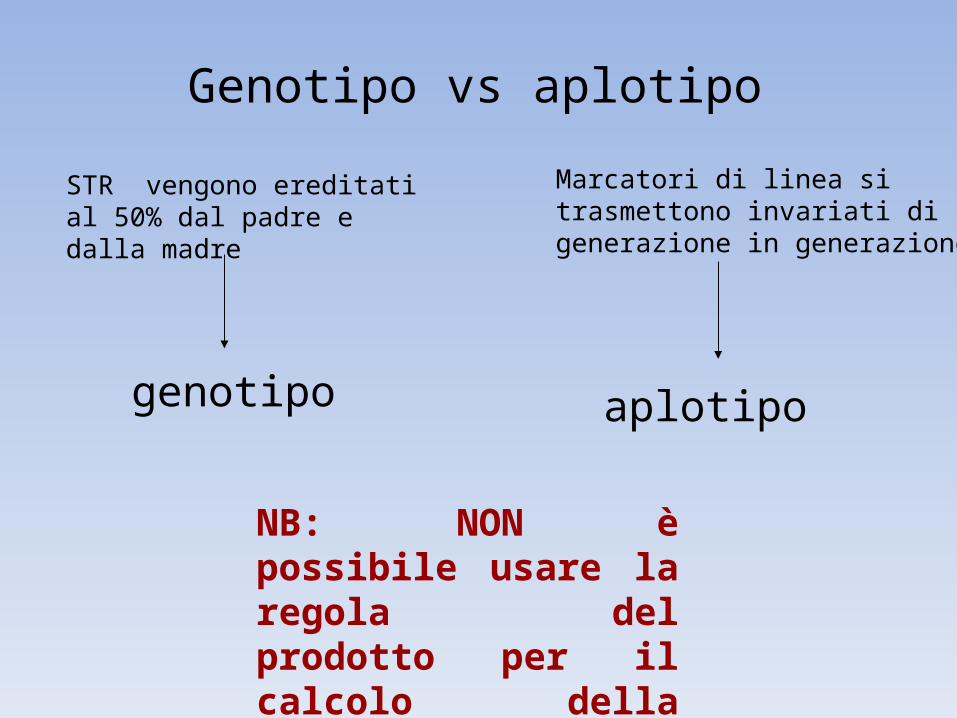
Marcatori di linea si trasmettono invariati di generazione in generazione
aplotipo
NB: NON è possibile usare la regola del prodotto per il calcolo della random match probability
STR vengono ereditati al 50% dal padre e dalla madre
genotipo
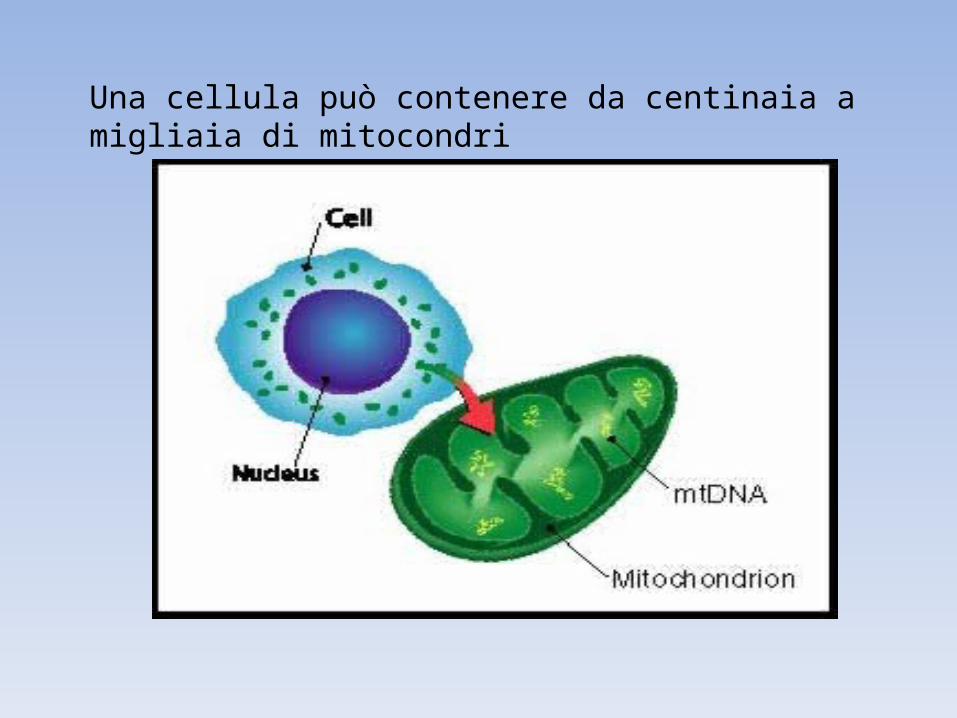
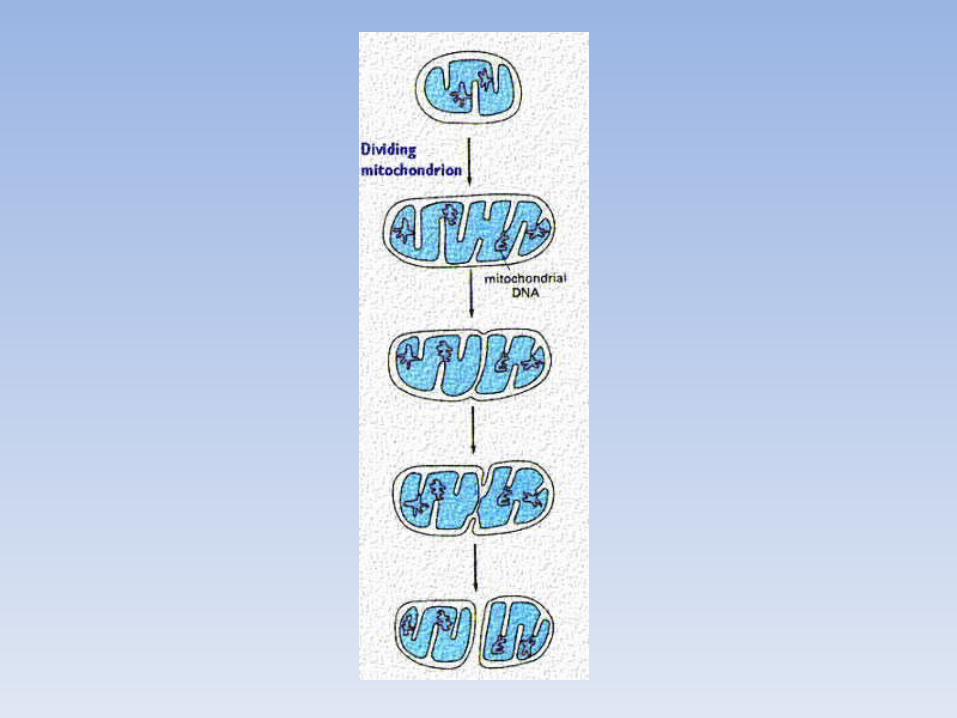
Una cellula può contenere da centinaia a migliaia di mitocondri
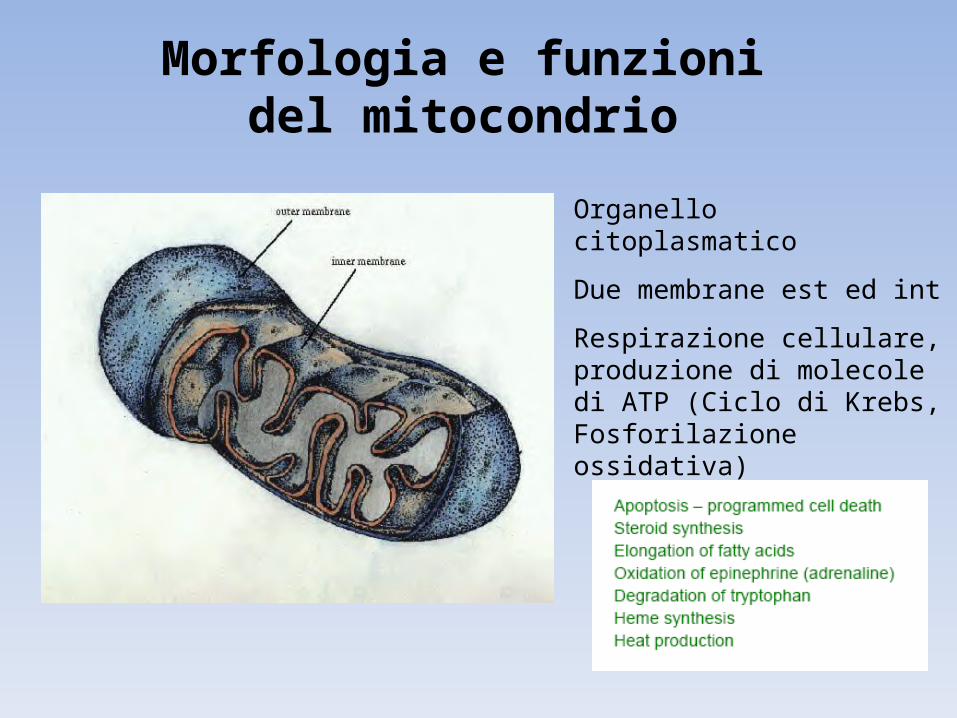
Morfologia e funzioni del mitocondrio
Organello citoplasmatico
Due membrane est ed int
Respirazione cellulare, produzione di molecole di ATP (Ciclo di Krebs, Fosforilazione ossidativa)
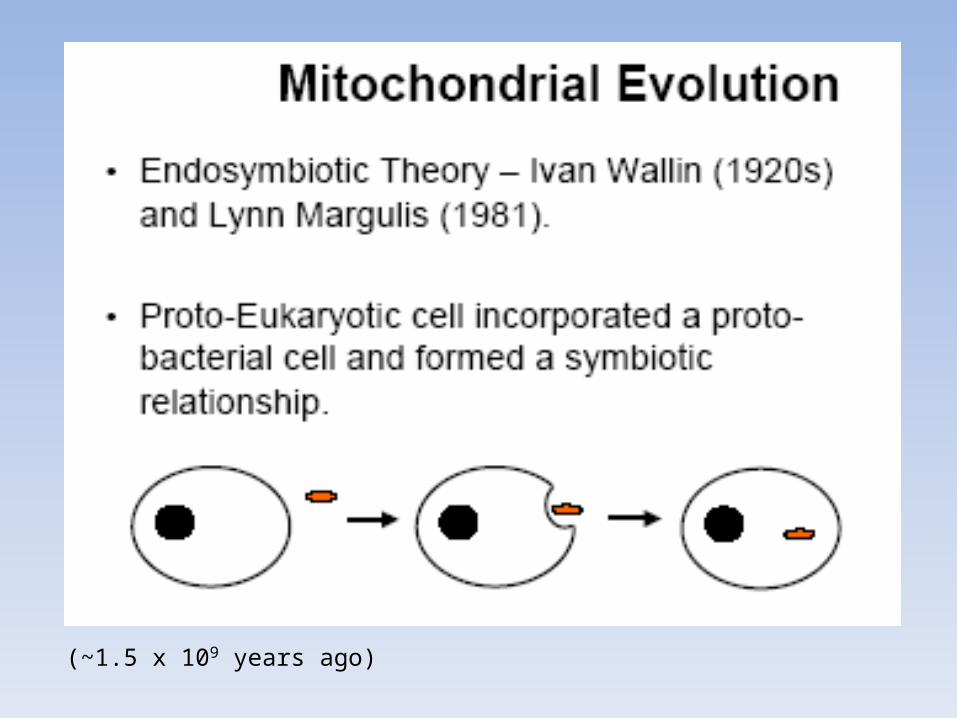
(~1.5 x 109 years ago)

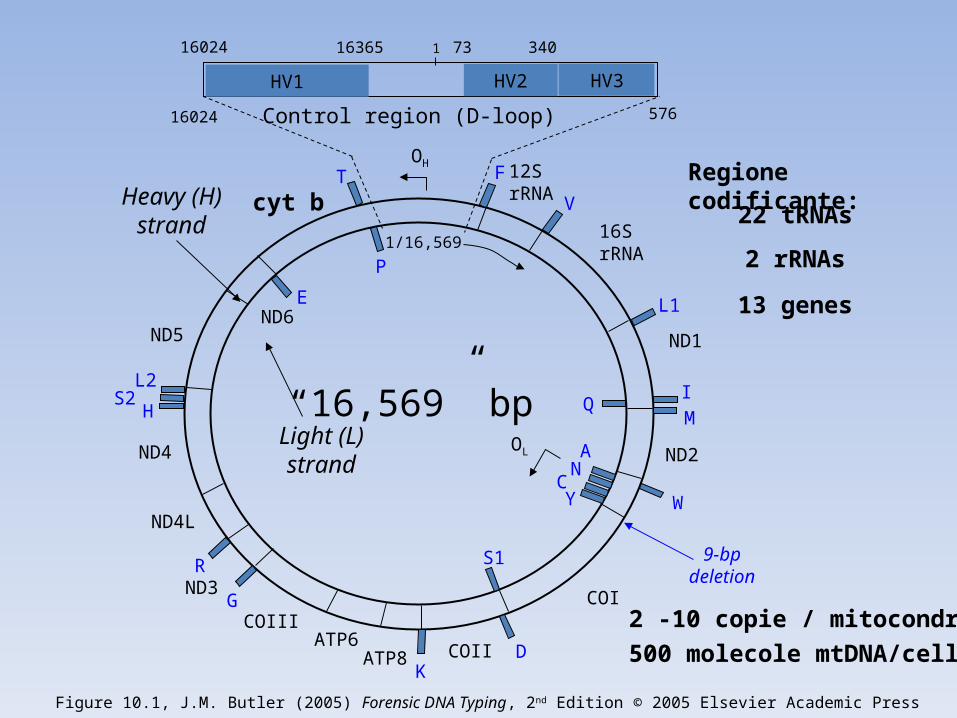
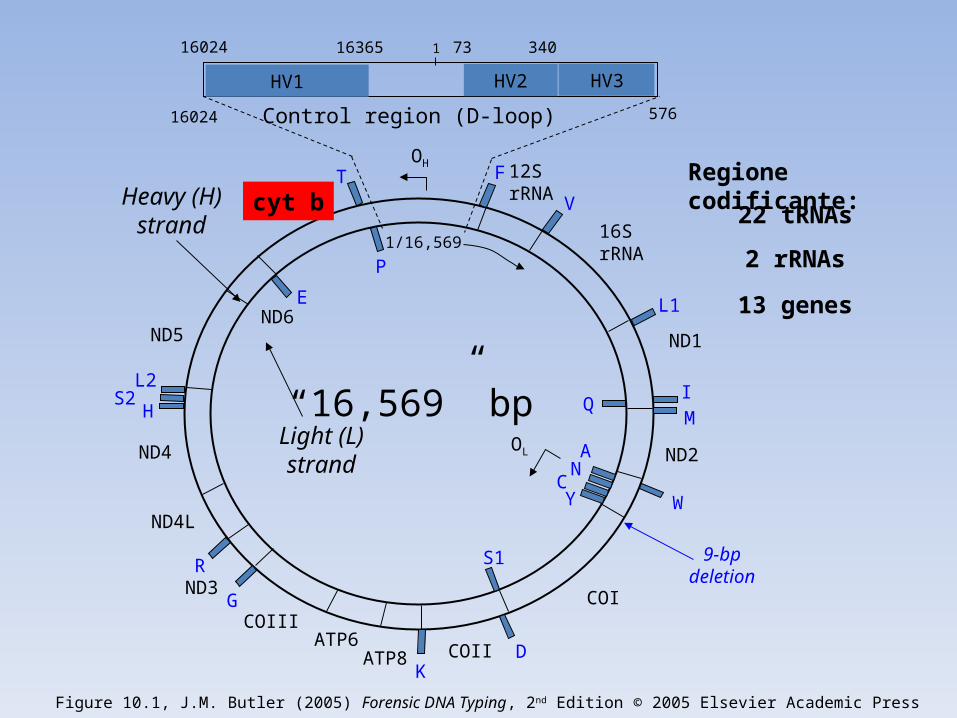
Control region (D-loop)
1/16,569
cyt b
ND5ND6
ND4
ND4L
ND3
COIIIATP6
ATP8 COII
12S rRNA
16S rRNA
ND1
ND2
COI
OH
9-bp deletion
OL
F
V
L1
IQ
M
W
AN
CY
S1
DK
G
R
HS2
L2
E
P
T
HV1 HV2
16024 16365 73 340
16024 576
“16,569” bp
1
22 tRNAs
2 rRNAs
13 genes
Heavy (H) strand
Light (L) strand
Figure 10.1, J.M. Butler (2005) Forensic DNA Typing, 2nd Edition © 2005 Elsevier Academic Press
HV3
2 -10 copie / mitocondrio
500 molecole mtDNA/cell
Regione codificante:
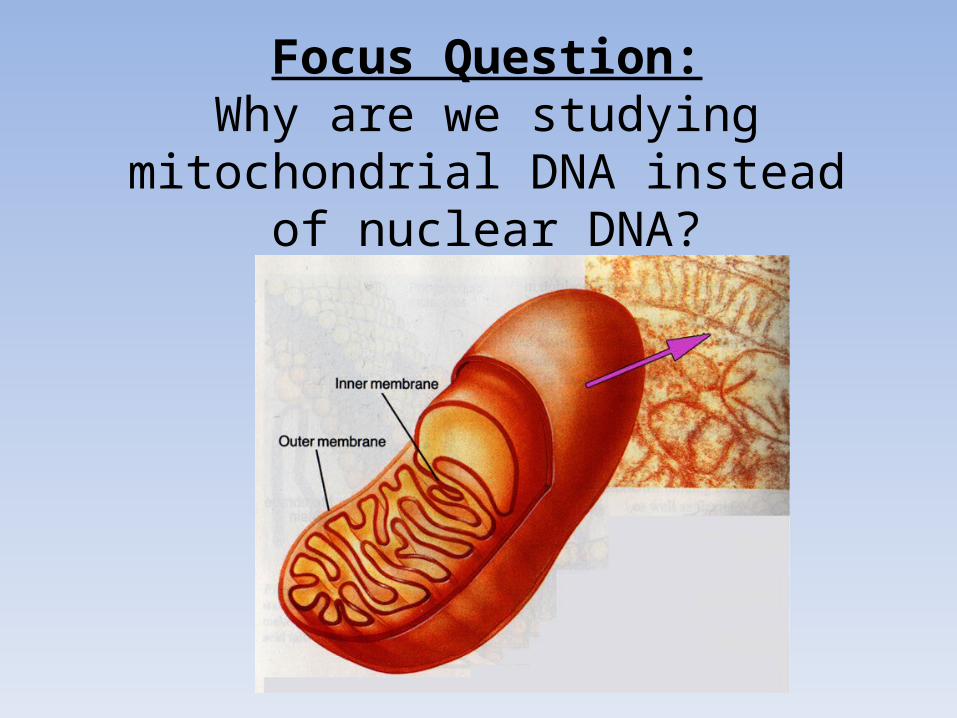
Focus Question:Why are we studying mitochondrial DNA
instead of nuclear DNA?
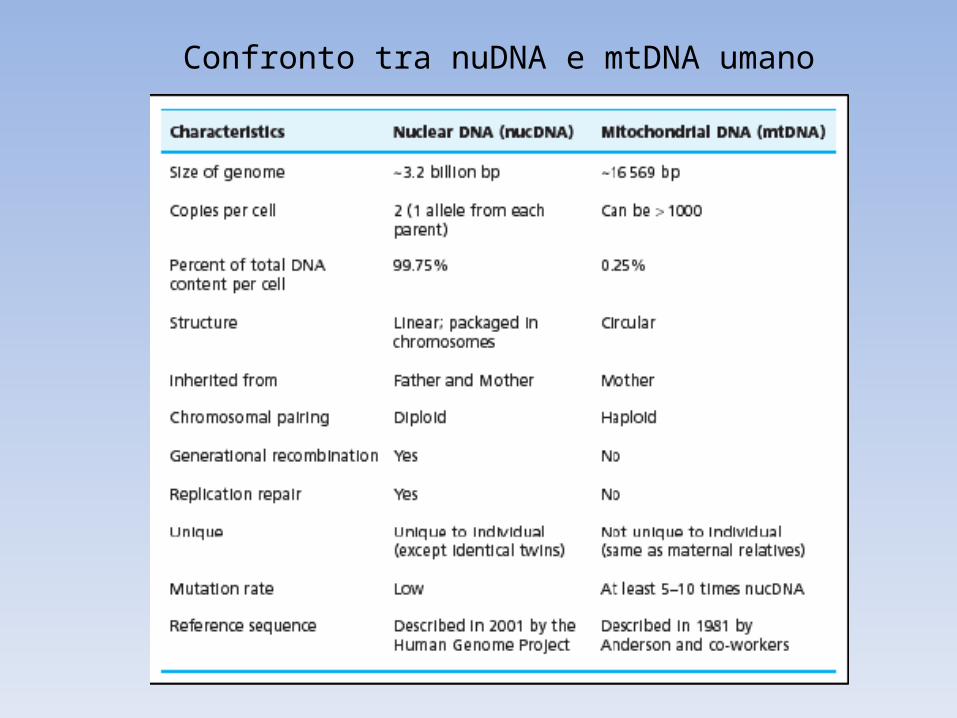
Confronto tra nuDNA e mtDNA umano

Caratteristiche
• Numero di copie: 1,000-100,000 copie/cell (2 copie/cell di nuDNA)
• No ricombinazione single locus• Elevato tasso di mutazione
(5-10 volte in HV > nuDNA)• Altamente polimorfico (8 pop. caucasica in HV, 15
pop. africana)
• Eredità materna

Vantaggi dell’analisi del mtDNA:Elevato numero di copie per cellula
Materiale degradato
Materiale quantitativamente scarso (fusto del capello)
Svantaggi dell’analisi del mtDNA:Basso potere discriminativo
Analisi costosa e laboriosa
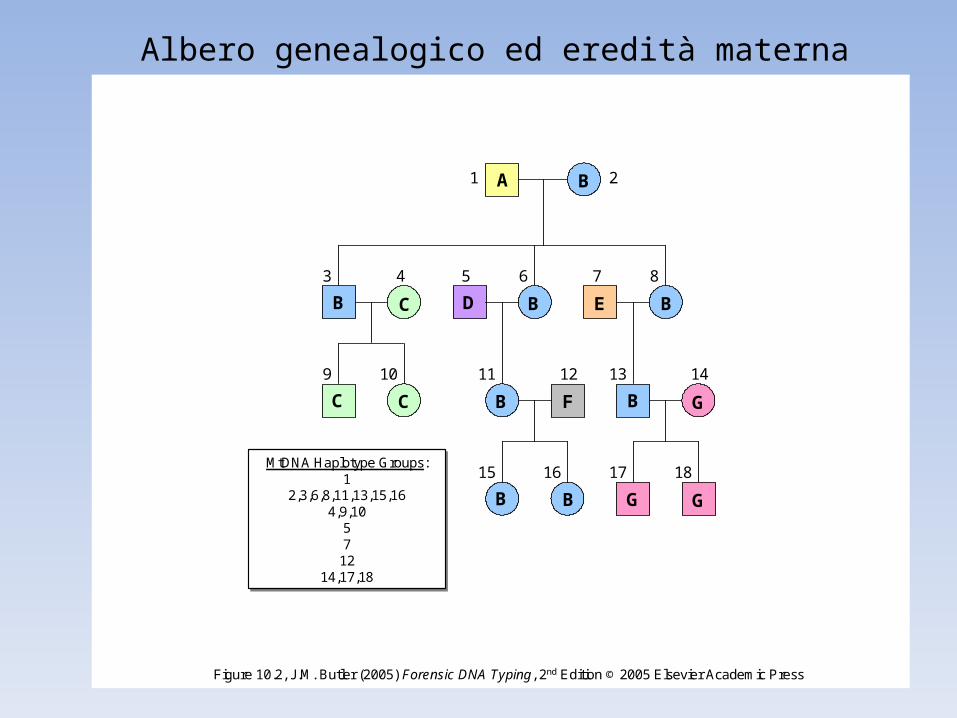
Albero genealogico ed eredità materna
1 2
3 54
1211109
6 7 8
181715 16
13 14
MtDNA Haplotype Groups:1
2,3,6,8,11,13,15,164,9,10
5712
14,17,18
MtDNA Haplotype Groups:1
2,3,6,8,11,13,15,164,9,10
5712
14,17,18
A B
B C
C C
D B
B
B
B
B B
E
F
G
G
G
Figure 10.2, J.M. Butler (2005) Forensic DNA Typing, 2nd Edition © 2005 Elsevier Academic Press
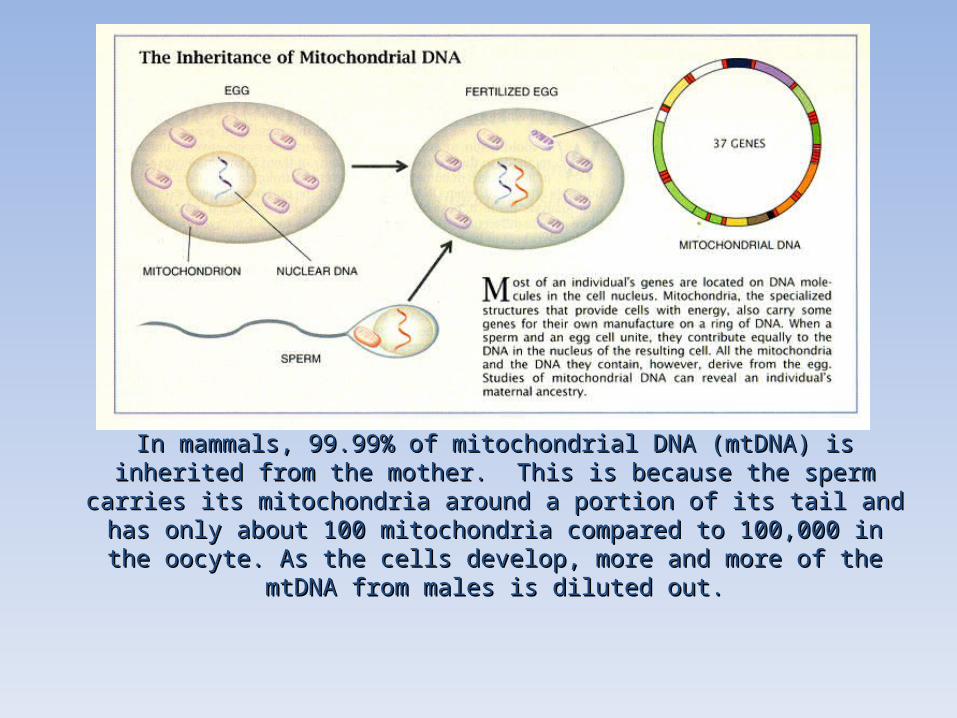
In mammals, 99.99% of mitochondrial DNA (mtDNA) is inherited from the In mammals, 99.99% of mitochondrial DNA (mtDNA) is inherited from the mother. This is because the sperm carries its mitochondria around a portion mother. This is because the sperm carries its mitochondria around a portion of its tail and has only about 100 mitochondria compared to 100,000 in the of its tail and has only about 100 mitochondria compared to 100,000 in the oocyte. As the cells develop, more and more of the mtDNA from males is oocyte. As the cells develop, more and more of the mtDNA from males is
diluted out.diluted out.

La sequenza di riferimento
Il mtDNA umano è stato sequenziato per la prima volta nel 1981 da F. Sanger (Nature 1981, 290: 457-465) da placenta di un soggetto di origine europea
Anderson è il primo autore indicato nel lavoro e quindi viene indicata come la “sequenza di Anderson” o CRS (Cambridge Reference Sequence)
Nel 1999 è stato rianalizzato lo stesso materiale placentare da Andrews et al trovando 11 differenze nucleotidiche revised Cambridge Reference Sequence (rCRS)

Applicazioni dell’analisi del mtDNA
• Scienze mediche: studi di associazione • Biologia dell’evoluzione umana ed animale• Antropologia molecolare: studio delle
migrazioni e della storia genetica umana• Scienze forensi: identificazione personale e
diagnosi di specie
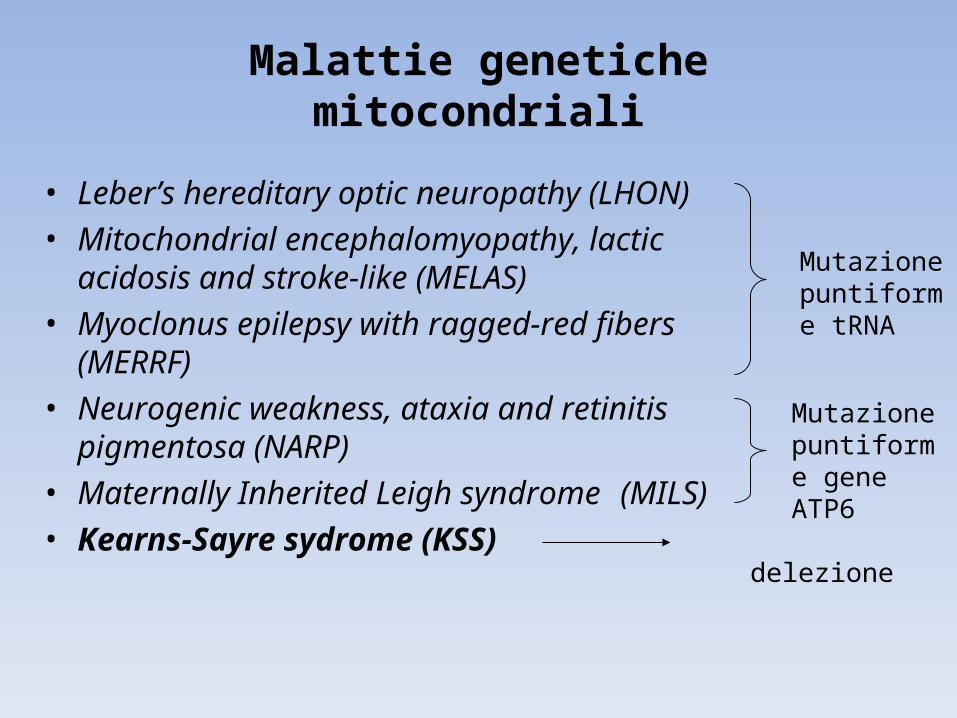
Malattie genetiche mitocondriali
• Leber’s hereditary optic neuropathy (LHON)• Mitochondrial encephalomyopathy, lactic acidosis
and stroke-like (MELAS) • Myoclonus epilepsy with ragged-red fibers (MERRF)• Neurogenic weakness, ataxia and retinitis
pigmentosa (NARP)• Maternally Inherited Leigh syndrome (MILS)• Kearns-Sayre sydrome (KSS)
Mutazione puntiforme tRNA
delezione
Mutazione puntiforme gene ATP6

Mutazioni somatiche del mtDNA nell’invecchiamento
Radicali liberi dell’ossigenoMutazioni somatiche nei tessuti post-mitotici Deficit bioenergetico Apoptosi (morte
cellulare)Lo stress ossidativo è implicato nella patogenesi di
malattie neurodegenerative (Alzheimer e Parkinson)

Tecniche di analisi delle varianti mitocondriali
RFLP bassa risoluzione (1980)
RFLP alta risoluzione (1990)
Sequenziamento delle regioni HVI e HVII della regione di controllo (1991- ad oggi)
Sequenziamento dell’intero genoma mitocondriale

L’analisi del mtDNA nella pratica forense
Quando si usa?DNA nucleare scarso o degradatoFormazioni pilifere, resti scheletrici, denti, materiale in fasedi decomposizione
Metodi di analisiSequenziamento Single Nucleotide Polymorphisms (SNPs)Restriction Fragment Length Polymorphism (RFLP)

Procedure d’analisi• Pulizia e decontaminazione dell’ambiente
• Analisi microscopica del reperto (formazione pilifera) ed eventuale confronto con il campione di riferimento (per ossa e denti esame antropologico ed odontoiatrico)
• decontaminazione del reperto per eliminare fonti di DNA esogeno
• estrazione ed amplificazione del DNA
• purificazione e quantificazione del DNA
• sequenziamento del DNA (metodo di Sanger, 1977)
• analisi ed interpretazione dei dati
• confronto con il database
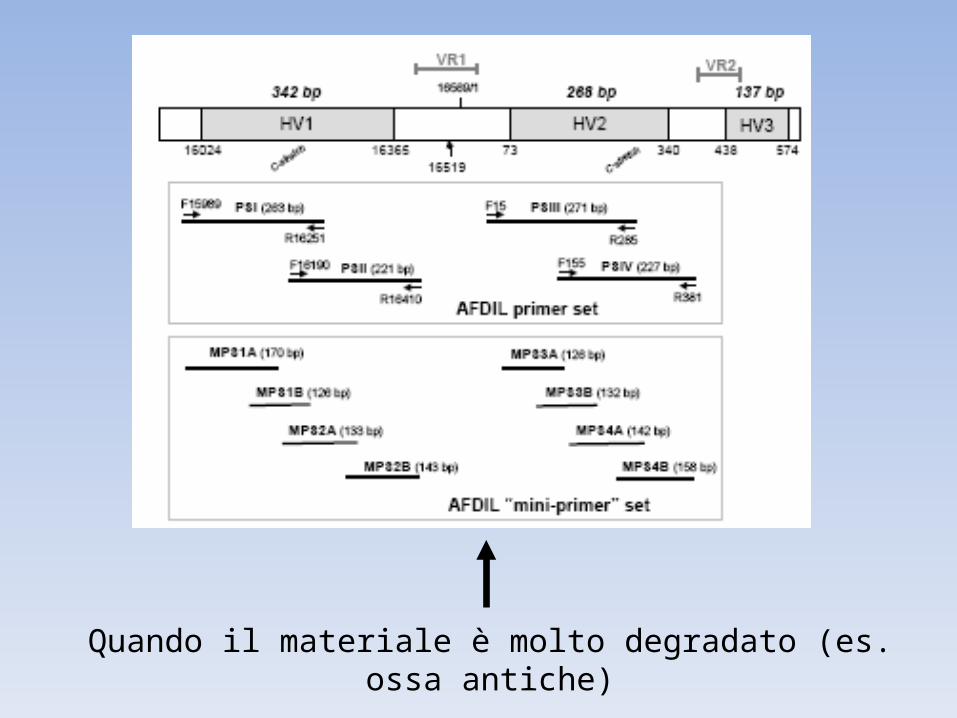
Quando il materiale è molto degradato (es. ossa antiche)

Sequenziamento del mtDNA
Tecnica introdotta intorno gli anni ’70
Riproduzione in vitro della composizione nucleotidica di frammenti di DNA sia di regioni codificanti (geni) sia di regioni non codificanti (introni)
Due metodiche principali: metodo chimico e metodo enzimatico

3’-TAAATGATTCC-5’
ATT
ATTTACTAA
ATTTACT ATTTAC
ATTTATTTA
AT
ATTTACTA
ATTTACTAAGATTTACTAAGG
A
DNA template5’ 3’
Primer anneals Extension produces a series of
ddNTP terminated products each one base different in length
Each ddNTP is labeled with a different color fluorescent dye
Sequence is read by noting peak color in electropherogram (possessing single base resolution)
Figure 10.5, J.M. Butler (2005) Forensic DNA Typing, 2nd Edition © 2005 Elsevier Academic Press
Metodo enzimatico
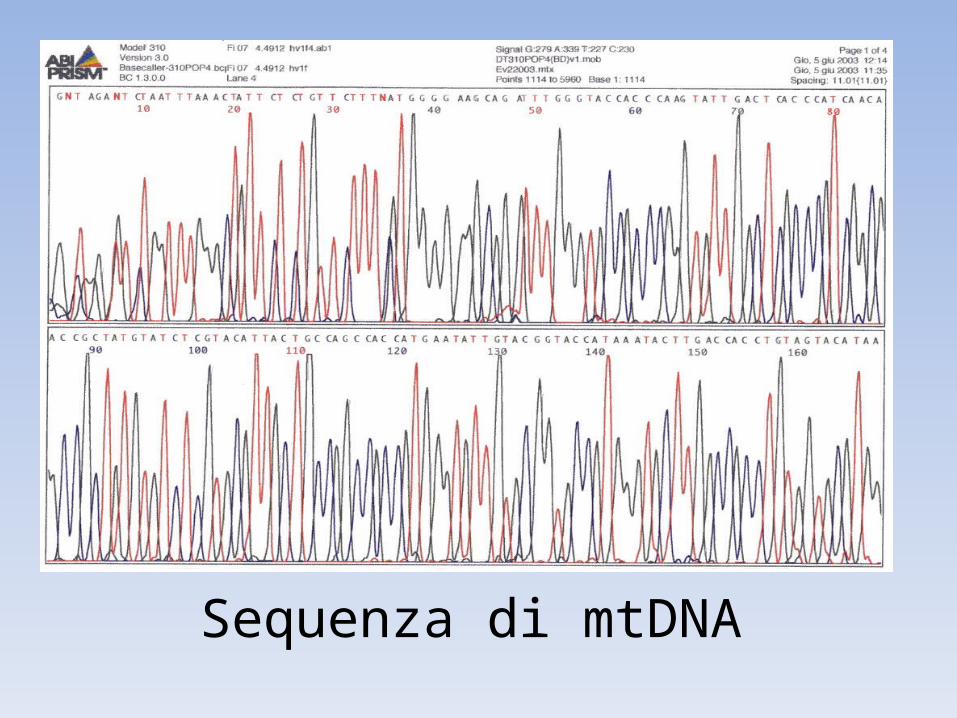
Sequenza di mtDNA
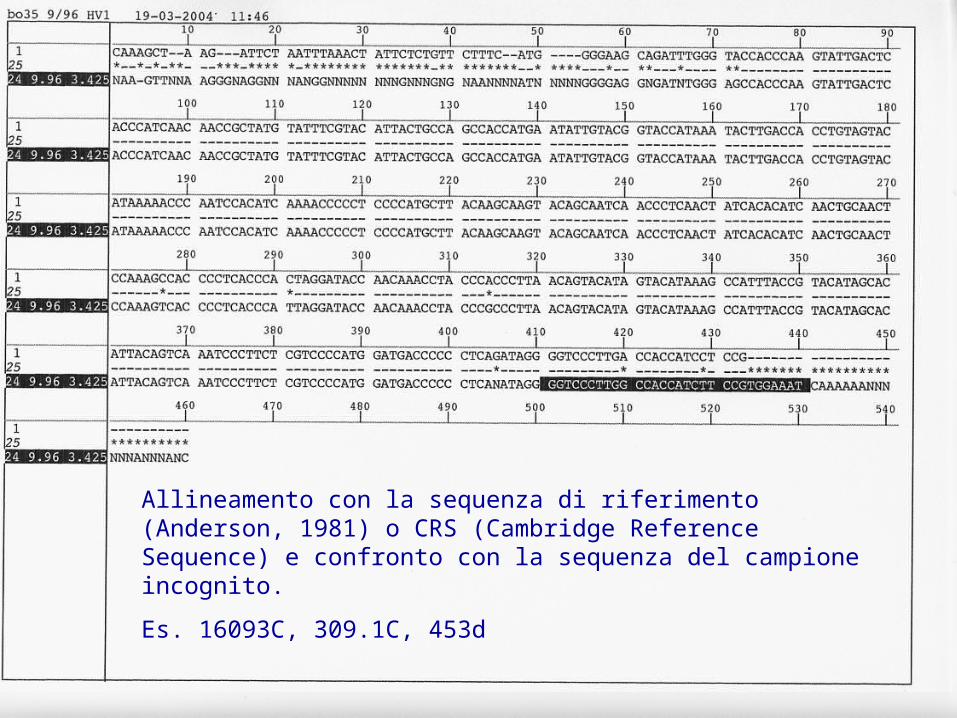
Allineamento con la sequenza di riferimento (Anderson, 1981) o CRS (Cambridge Reference Sequence) e confronto con la sequenza del campione incognito.
Es. 16093C, 309.1C, 453d

EteroplasmiaPresenza di due o più molecole differenti di mtDNA in un
individuoCondizione intermedia tra uno stato omoplasmico ed un altro
(processo di segregazione eteroplasmica)Eteroplasmia sembra essere presente in tutti gli individui a
qualche livello, in realtà è riscontrata solo nel 5% circa degli individui analizzati
Tecnologie odierne più sensibili (si evidenzia se la componente minore è > 10-20%)
Il livello di eteroplasmia può essere differente nei vari tessutiPuò aumentare il significato di match (es. Romanov)
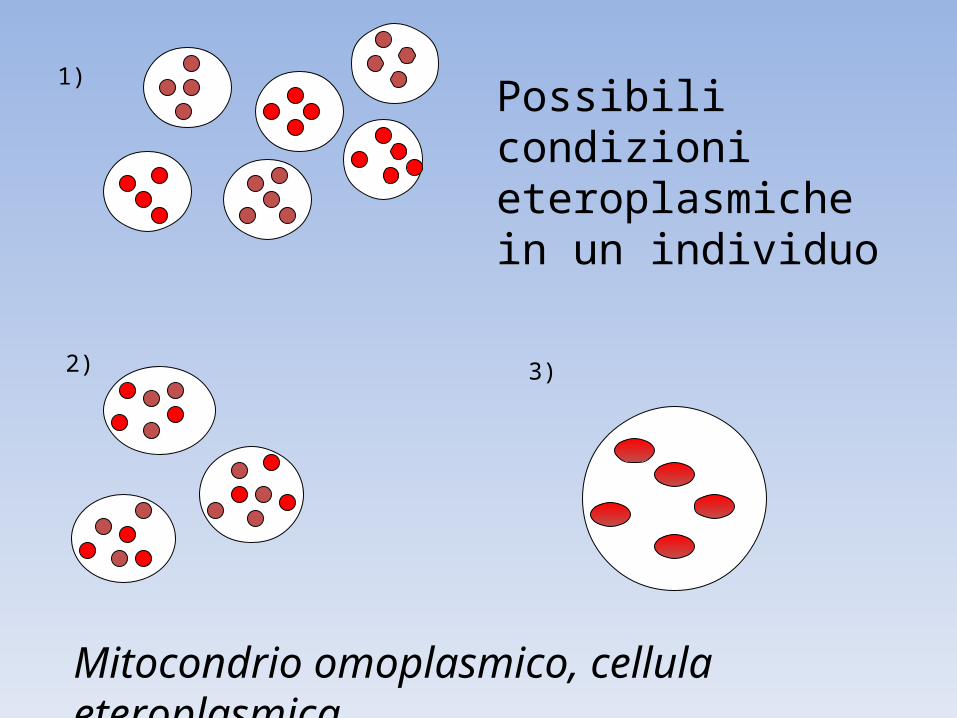
1)
2) 3)
Possibili condizioni eteroplasmiche in un individuo
Mitocondrio omoplasmico, cellula eteroplasmica

Ipotesi dell’eteroplasmia
• Pseudogeni (eventi rari di integrazione genetica nel genoma nucleare)
• Eredità biparentale (nessuna prova diretta)
• Mutazioni durante l’oogenesi e nelle linee germinali (posizioni nucleotidiche “hot spots”)

Teoria del “bottleneck”
Segregazione random delle molecole mitocondriali caratterizzata da una riduzione del n° di copie di mtDNA nelle cellule figlie
Mutazione nella linea germinale
eteroplasmia
Bottleneck: selezione e riduzione drastica del n° di molecole di mtDNA
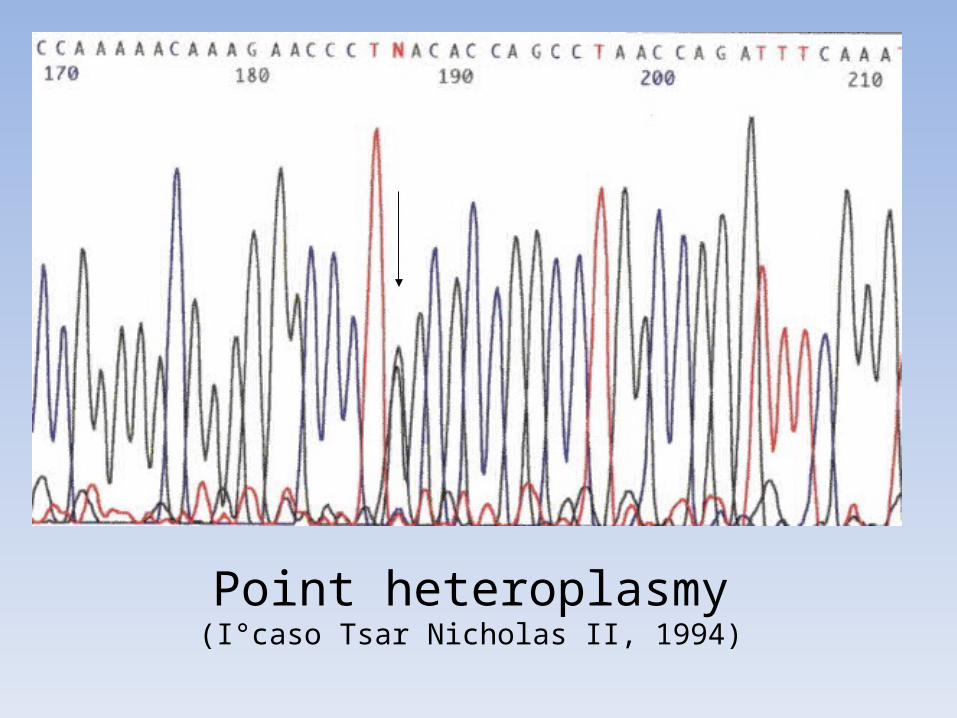
Point heteroplasmy(I°caso Tsar Nicholas II, 1994)
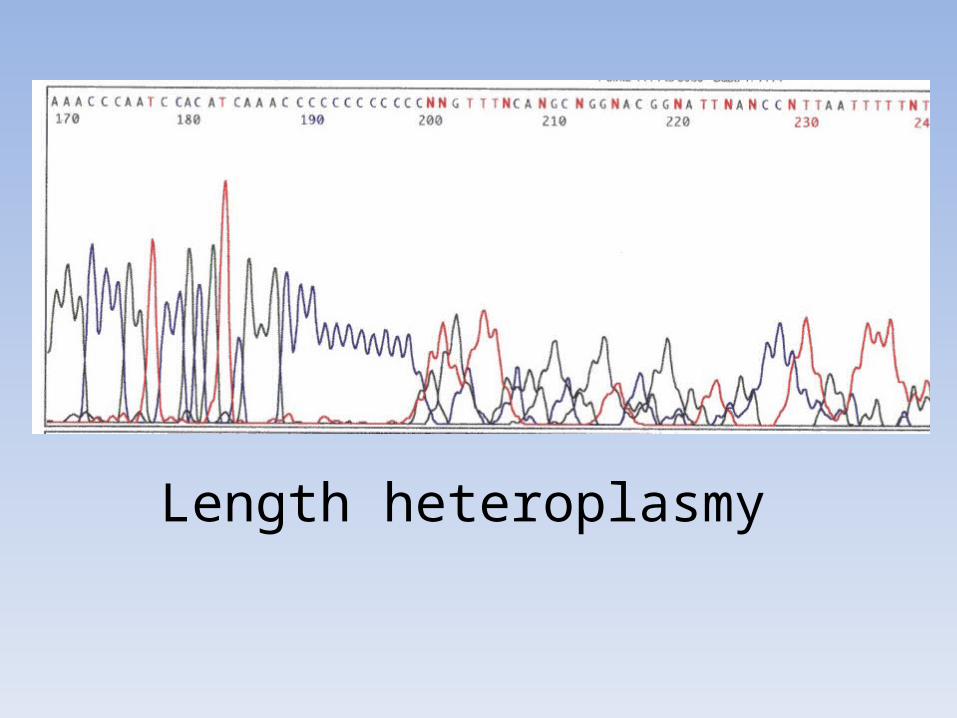
Length heteroplasmy
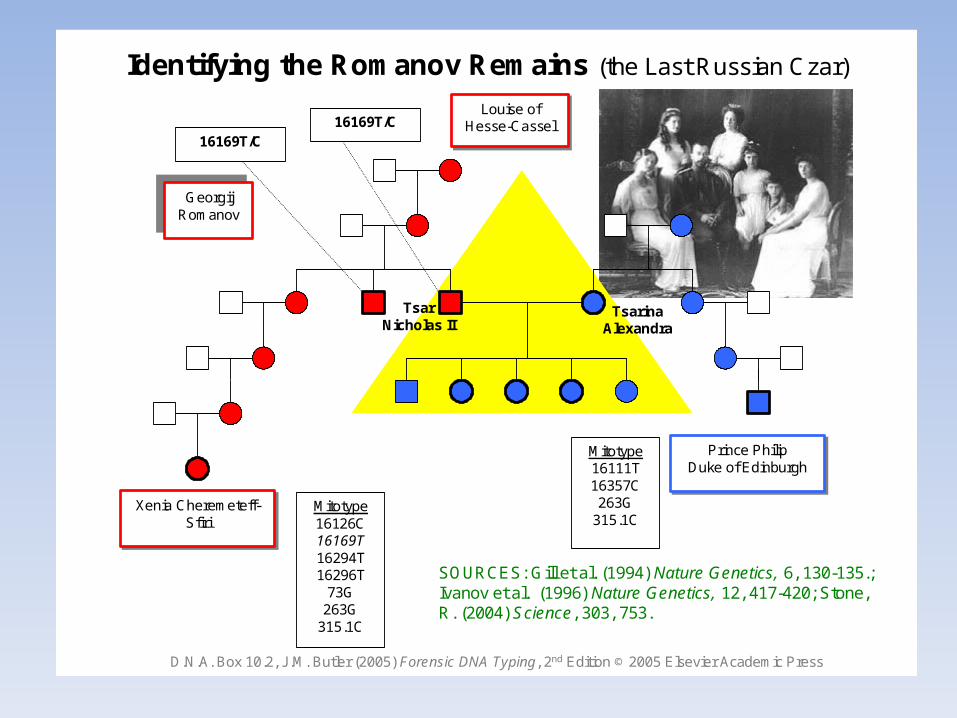
Identifying the Romanov Remains (the Last Russian Czar)
TsarinaAlexandra
Tsar Nicholas II
Xenia Cheremeteff-Sfiri
Xenia Cheremeteff-Sfiri
Prince PhilipDuke of Edinburgh
Prince PhilipDuke of Edinburgh
GeorgijRomanov
GeorgijRomanov
Mitotype16111T16357C263G
315.1CMitotype16126C16169T16294T16296T
73G263G
315.1C
16169T/C16169T/C
Louise of Hesse-Cassel
Louise of Hesse-Cassel
SOURCES: Gill et al. (1994) Nature Genetics, 6, 130-135.; Ivanov et al. (1996) Nature Genetics, 12, 417-420; Stone, R. (2004) Science, 303, 753.
D.N.A. Box 10.2, J.M. Butler (2005) Forensic DNA Typing, 2nd Edition © 2005 Elsevier Academic Press

Varianti della sequenza del mtDNA nella popolazione umana
Aplotipi = sequenze specifiche osservate Aplogruppo = insieme di aplotipi che mostrano
variabili ancestrali comuni (A,B,C,D,H,I,J,K,M,T,U,V,W)

Aplogruppi del DNA mitocondriale
76% mtDNA Africani aplogruppo Lnativi americani aplogruppi A-D99% pop.europee 10 aplogruppi
H,I,J,K,T, M,U,V,W,X
77% asiatici aplogruppo M
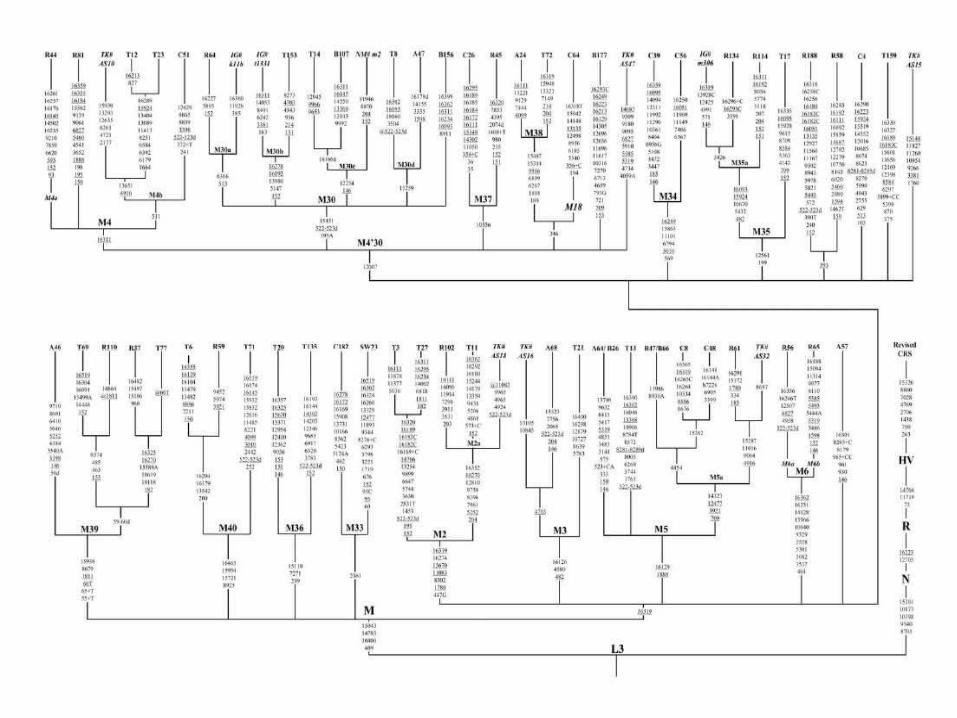

Le variazioni di sequenza del DNA mitocondriale possono essere utilizzate per costruire alberi filogenetici organizzati in network per mostrare i rapporti evoluzionari tra sequenze individuali
Storia filogenetica di un gene e stima degli eventi nella preistoria umana come i movimenti delle popolazioni da una regione ad un’altra e la loro distribuzione geografica
Molecola di mtDNA ancestrale dall’Africa ~ 200,000 anni fa

Raccomandazioni della Società Internazionale di Genetica Forense (ISFG) per assicurare una buona qualità del risultato:
• ambienti separati e materiali di consumo sterili (guanti, cappe, puntali con filtro…)
• identificazione delle sequenze di mtDNA degli addetti ai lavori
• analisi delle sequenze forward e rewerse
• allestimento di controlli negativi
• riproducibilità dei dati
• lettura e trascrizione dei dati svolte da due operatori
• tenere conto di eventuali errori clericali, “phantom mutations”, ricombinazioni artificiali
e contaminazioni
• conservare i dati grezzi (raw data)
• effettuare l’analisi filogenetica
• eteroplasmia
• tener conto del tessuto che si sta analizzando
• nomenclatura suggerita dalla ISFG

mtDNA come mezzo di identificazione personale
• World Trade Center (11 settembre 2001)
• Argentina (12,000 persone scomparse)
• Tsar Nicholas II Romanov (Gill P et al, 1994; Ivanov PL et al, 1996)
• Jessi James (Stone A et al,1996)
• Kaspar Hauser (Weichhold GM et al,1998)
• Milite ignoto (Holland MM,1999)
• Putative heart of Louis XVII (Jehanes E et al, 2001)

Applicazioni forensi
• Formazioni pilifere, denti, resti scheletrici, materiale degradato • Analisi del DNA mitocondriale del campione di riferimento e del
reperto• Confronto delle sequenze e descrizione dei polimorfismi• Interpretazione del dato• Informazione circa la frequenza dell’aplotipo nella popolazione
(database)• Aumento della richiesta dell’analisi del mtDNA: USA 7 laboratori di cui FBI dal 1996 ma solo nel 1999 alcuni stati
americani hanno ammesso il mtDNA come prova nei casi criminali (2.426 seq. nel database, 150 casi risolti)

Interpretazione dei dati
• ESCLUSIONE Se due campioni differiscono nella sequenza di mtDNA per più posizioni nucleotidiche si può escludere che derivino dalla stessa sorgente
• INCONCLUSIVO Se differiscono per una sola posizione nucleotidica il dato è inconclusivo, mutazione? (è necessario considerare il tessuto che si sta analizzando ed estendere l’analisi se possibile ad altri tessuti)
• NON ESCLUSIONE Se sono identici o se uno dei due presenta eteroplasmia in una posizione nucleotidica non si esclude che derivino dalla stessa sorgente
• Nel caso in cui i due campioni presentano eteroplasmia nella stessa posizione nucleotidica, ciò rafforza la prova che derivino dalla stessa sorgente.

In caso di match tra campione di riferimento e la traccia è necessario dare un significato statistico al dato.La pratica corrente è il metodo della conta:si riporta il numero di volte in cui l’aplotipo mitocondriale è presente in un data base di riferimento
Calcolo statistico

La banca dati del DNA mitocondriale
Importante per determinare la stima della frequenza attesa degli aplotipi mitocondriali osservati tra traccia e campione di riferimento
Elevato numero di campioni analizzati ed elevata qualità dei dati stima reale delle frequenze

EMPOP - mtDNA Population Database
Prof. Walther ParsonInstitute of Legal Medicine
Innsbruck Medical University
Austria
www.empop.org
Da ottobre 2006!> 8.000 sequenze di mtDNA altamente controllate
Control region (D-loop)
1/16,569
cyt b
ND5ND6
ND4
ND4L
ND3
COIIIATP6
ATP8 COII
12S rRNA
16S rRNA
ND1
ND2
COI
OH
9-bp deletion
OL
F
V
L1
IQ
M
W
AN
CY
S1
DK
G
R
HS2
L2
E
P
T
HV1 HV2
16024 16365 73 340
16024 576
“16,569” bp
1
22 tRNAs
2 rRNAs
13 genes
Heavy (H) strand
Light (L) strand
Figure 10.1, J.M. Butler (2005) Forensic DNA Typing, 2nd Edition © 2005 Elsevier Academic Press
HV3
Regione codificante:

DIAGNOSI DI SPECIECitocromo b
• La sequenza nucleotidica del gene del Cyt b contiene informazioni specie-specifiche utili nell’identificazione dell’origine biologica di un campione
• Utile sia negli studi filogenetici che in campo forense• Si amplifica una regione di circa 300 bp e la si confronta
con un data base• Sono disponibili più di 8000 sequenze di animali vertebrati
nel data base mondiale

Dog hair
Cat hair
Human hair

Hair with tissue Shed hair
Root band post-mortem Hair match

Caucasian hair Mongol hair
Negroid hair

Conclusioni
• DNA mitocondriale è un utile strumento di indagine non solo come mezzo di esclusione ma anche come tecnica complementare ad altre procedure di identificazione personale
• Ricostruzione di pedigree tra individui correlati lunga la linea materna (problemi sociali)
• Identificazione dell’origine biologica di una traccia
IL CROMOSOMA Y e SNPsNELLA PRATICA FORENSE
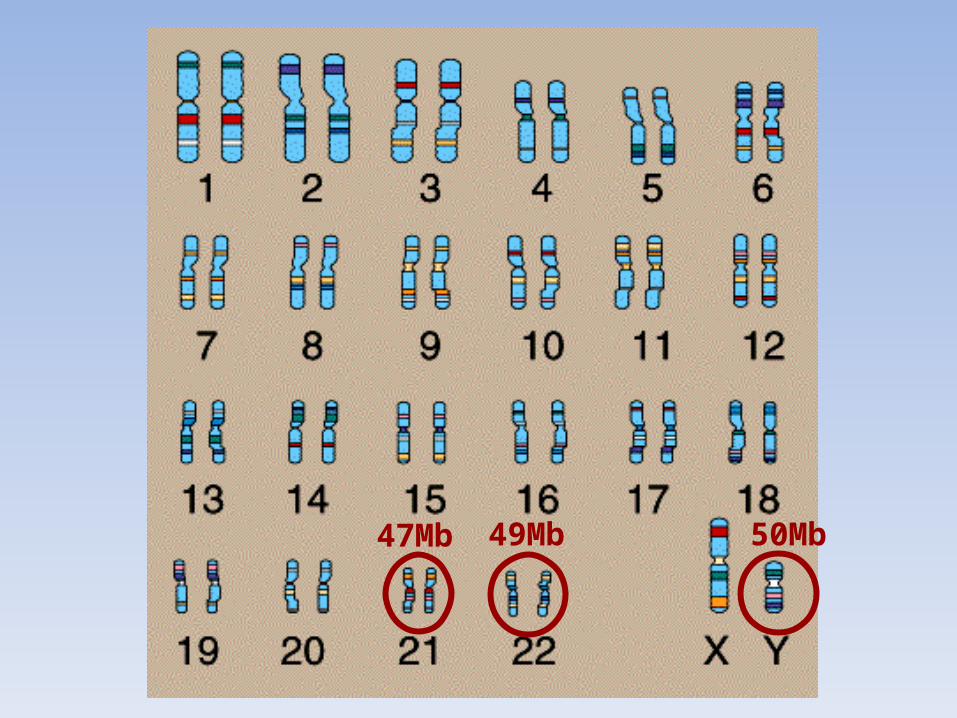
47Mb 49Mb 50Mb
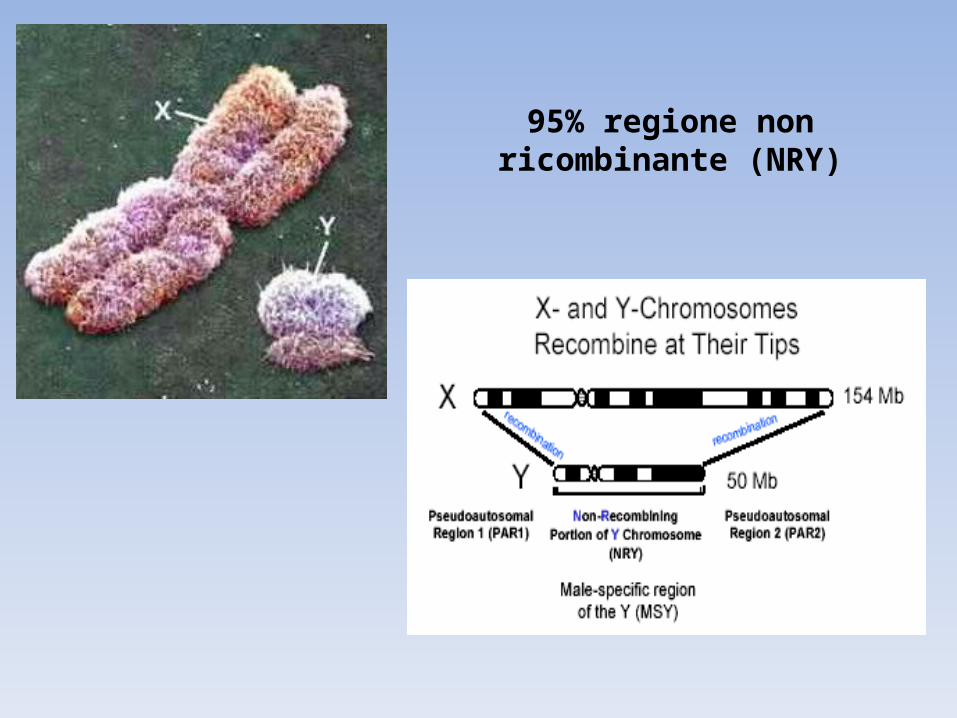
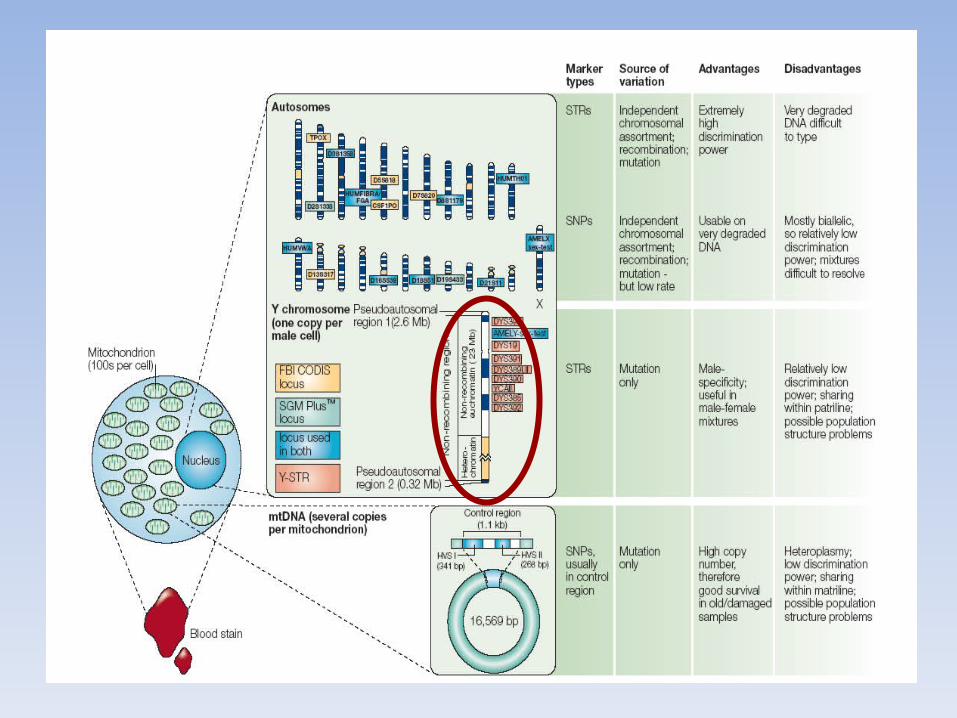
95% regione non ricombinante (NRY)
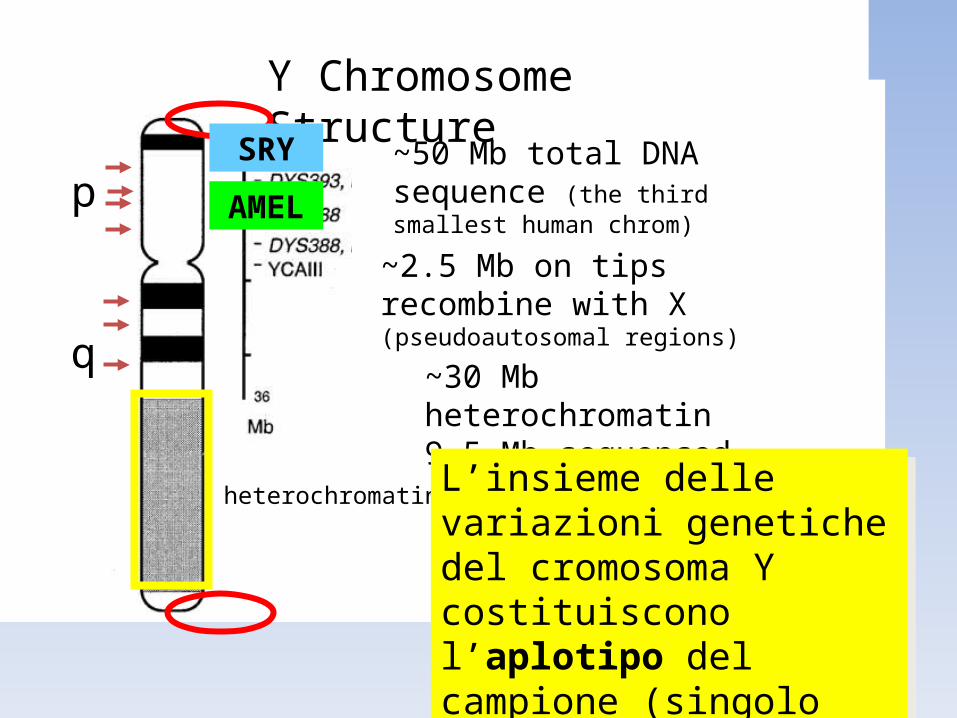
Y Chromosome Structure
~2.5 Mb on tips recombine with X (pseudoautosomal regions)
~50 Mb total DNA sequence (the third smallest human chrom)p
q
heterochromatin
~30 Mb heterochromatin 9.5 Mb sequenced (27%)
AMEL
SRY
L’insieme delle variazioni genetiche del cromosoma Y costituiscono l’aplotipo del campione (singolo allele/individuo)
L’insieme delle variazioni genetiche del cromosoma Y costituiscono l’aplotipo del campione (singolo allele/individuo)

Il cromosoma Y come marcatore genetico
Applicazioni VantaggiTest paternità casi deficitari
Casi di violenza sessuale amplificazione esclusiva (tracce miste) della componente maschile
Persone scomparse analisi dei discendenti / ascendentie disastri di massa lungo la linea paterna
Studi dell’evoluzione e la mancanza di ricombinazione delle migrazioni umane permette il confronto tra individui separati
nel tempo
Ricerche storiche cognomi generalmente sono portatie genealogiche dagli uomini, in mancanza del materiale
cartaceo

Vantaggi dell’analisi del Crom Y in campo forense
• Amplificazione specifica della componente maschile (es. misture di fluidi biologici, violenza sessuale perpetuata da un individuo azospermico, tracce miste maschili)
• Profilo genetico costituito da singoli alleli, quindi è possibile ottenere risultati anche da quantità di materiale maschile presente a livelli molto bassi; possibilità di determinare il numero di contributori della traccia
• Accettato come prova in sede giudiziaria e come dato statistico secondo il metodo della conta

Svantaggi
• Condiviso da tutti i soggetti imparentati lungo la linea paterna (padre, figlio, fratello, zio paterno, nipote..etc presentano lo stesso aplotipo)
• Meno informativo rispetto agli STRs autosomici• Mutazioni random determinano la variabilità
genetica• I loci non sono indipendenti uno dall’altro quindi non
si può applicare la regola del prodotto per il calcolo statistico (Random Match Probability)
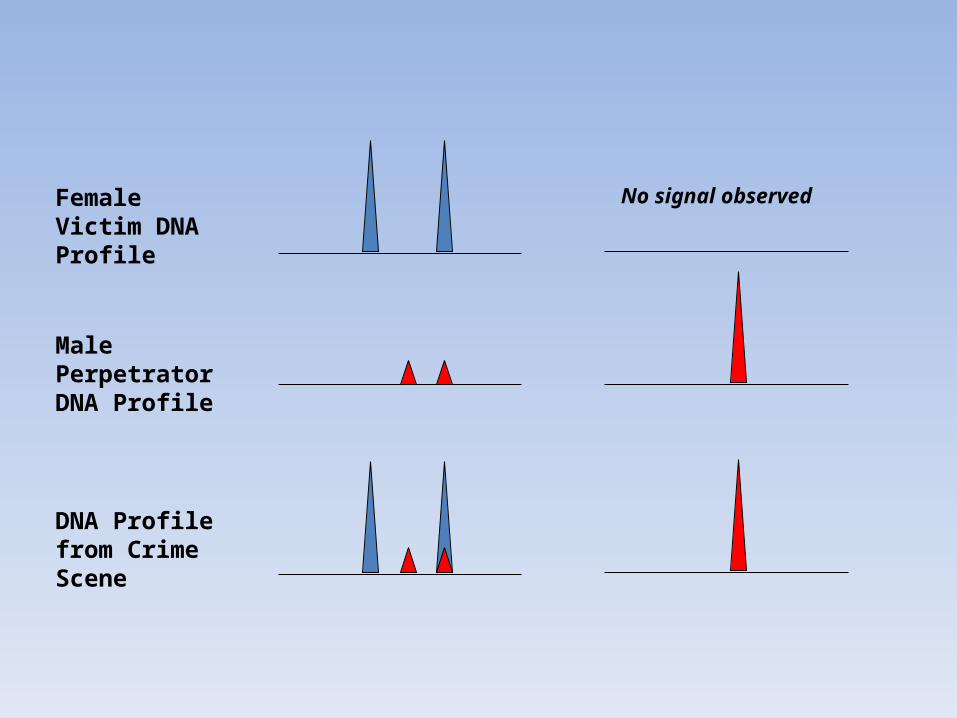
Female Victim DNA Profile
Male Perpetrator DNA Profile
DNA Profile from Crime Scene
No signal observed

Marcatori genetici DNA del cromosoma Y
Marcatori multi-alleliciY-STRs (microsatelliti) DYS19, DYS385, etc. (>200)- elevato tasso di mutazione, marcatori con seq tretranuc. ripetute
Marcatori bi-allelici (unique event polymorphisms-UEP, basso tasso di mutazione, ~250)-Y-SNPs (Single Nucleotide Polymorphisms)-Y Alu Polymorphism (YAP) o altre ins./del (indel)
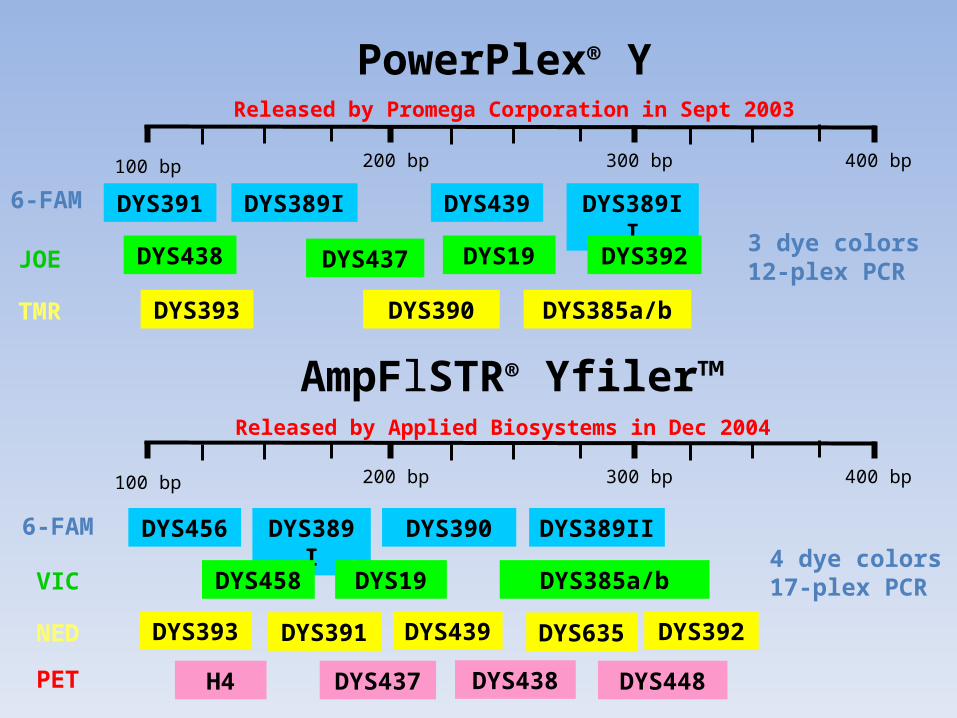
100 bp 400 bp300 bp200 bp
DYS391
PowerPlex® Y
DYS389I DYS439 DYS389II
DYS438 DYS437 DYS19 DYS392
DYS393 DYS390 DYS385a/b
Released by Promega Corporation in Sept 2003
AmpFlSTR® Yfiler™
DYS437 DYS448H4
100 bp 400 bp300 bp200 bp
DYS456 DYS389I DYS390 DYS389II
DYS458 DYS19 DYS385a/b
DYS393 DYS439 DYS392
DYS438
DYS391 DYS635
Released by Applied Biosystems in Dec 2004
3 dye colors12-plex PCR
4 dye colors17-plex PCR
JOE
TMR
6-FAM
VIC
NED
PET
6-FAM

Y-STR Haplotype Reference Database (YHRD)
Run only with minimal haplotype
DYS19DYS389I/II
DYS390DYS391DYS392DYS393
DYS385 a/b
US SWGDAM requires2 additional loci:
DYS438DYS439
Up to day: 84.771 haplotypes in a worldwide set of 464 populations.
http://www.yhrd.org(on-line dal 2000)

Interpretazione dei risultati
Se esiste match:
Metodo della conta (numero di volte in cui l’aplotipo è osservato nel database) come per il mtDNA
Aplotipo minimo più frequente 3% database europeo
Risultato di esclusione: aplotipi differenti
Risultato inconclusivo: dati insufficienti da interpretare o risultati ambigui
Risultato di inclusione: aplotipi uguali e quindi non si esclude che derivino dalla stessa fonte

Example Y-STR HaplotypeCore US Haplotype
• DYS19 – 14• DYS389I – 13• DYS389II – 29• DYS390 – 24• DYS391 – 11• DYS392 – 14• DYS393 – 13• DYS385 a/b – 11,15 • DYS438 – 12• DYS439 – 13
Matches by Databases
• YHRD (9 loci)– 7 matches in 27,773
• YHRD (11 loci)– 0 matches in 6,281
• ReliaGene (11 loci)– 0 matches in 3,403
• PowerPlex Y (12 loci)– 0 matches in 4,004
• Yfiler (17 loci)– 0 matches in 3,561
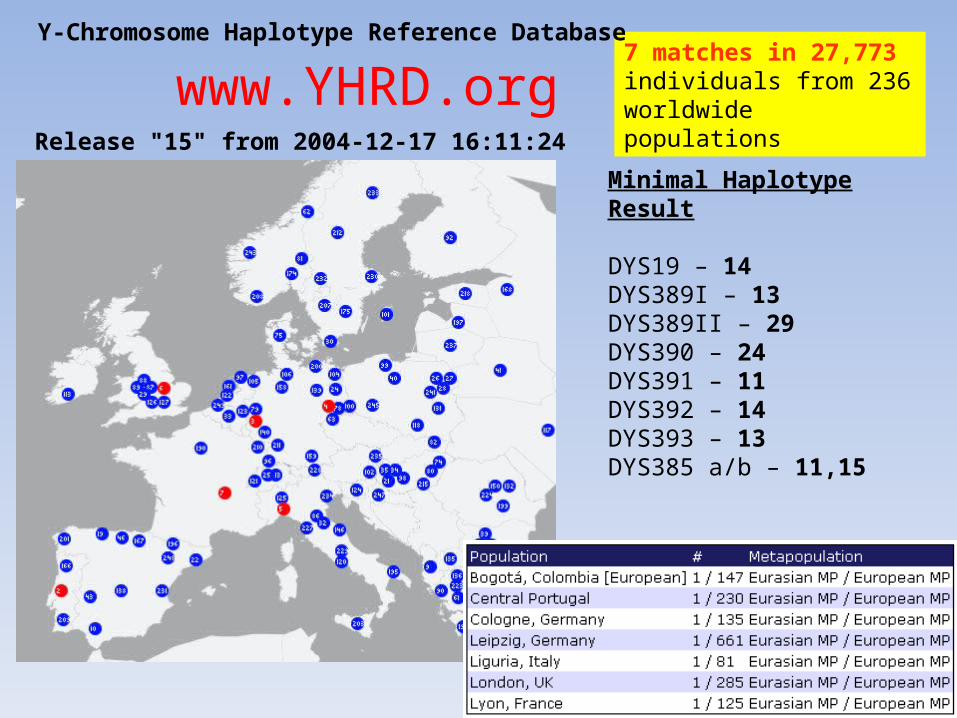
www.YHRD.orgRelease "15" from 2004-12-17 16:11:24
Minimal Haplotype Result
DYS19 – 14DYS389I – 13DYS389II – 29DYS390 – 24DYS391 – 11DYS392 – 14DYS393 – 13DYS385 a/b – 11,15
7 matches in 27,773 individuals from 236 worldwide populations
Y-Chromosome Haplotype Reference Database

Frequency Estimate CalculationsUsing the Counting Method
In cases where a Y-STR profile is observed a particular number of times (X) in a database containing N profiles, its frequency (p) can be calculated as follows:
p = X/N
An upper bound confidence interval can be placed on the profile’s frequency using:
N
ppp
)1)((96.1
7 matches in 27,773
p = 7/27,773 = 0.000252 = 0.025%
773,27
)000252.01)(000252.0(96.1000252.0
= 0.000252 + 0.000187 = 0.000439
= 0.044% (~1 in 2270)
Confidence interval: uncertainty of population database sampling

Considerazioni- Nessun database fornisce una stima reale delle frequenze
nella popolazione; - Se esiste match tra la traccia e il sospettato, non si esclude
quest’ultimo come possibile sorgente della traccia, ma nemmeno un fratello, il padre, lo zio etc..di questo o un numero di altri individui che presentano lo stesso aplotipo ma non sono imparentati con il sospettato
- La stima della frequenza calcolata non ha lo stesso potere informativo ottenuto con gli STRs ma può essere utilizzato come dato aggiuntivo
- Una risposta più accurata potrebbe essere fornita nel caso si conoscano la struttura etnica-geografica della popolazione di interesse e quindi le rispettive frequenze dei Y-STRs

Marcatori genetici DNA del cromosoma Y
Marcatori multi-alleliciSTRs (microsatelliti) DYS19, DYS385, etc. (> 200)-la maggior parte sono sequenze tetranucleotidiche ripetute
Marcatori bi-allelici (unique event polymorphisms-UEP)-SNPs (Single Nucleotide Polymorphisms)-Y Alu Polymorphism (YAP) o altre ins./del (indel)



SNPsAbbondanti nel genoma (milioni di SNP/individuo)Studi di linkage delle malattie genetiche e migrazioni umane
Vantaggi: Svantaggi
amplificati < 100 bp eterozigosità inferiorepoco informativi
PCR multiplex 50-100 SNPs x avere lo stesso PD di 10-16 STRs
Procedure d’analisi in automatico
No stutter bands miglioreinterpretazione del dato impossibilità di amplificare
molti SNP simultaneamente Basso tasso di mutazione da piccole quantità di DNA(1/108 generazioni)
Studio dei tratti fenotipici e dell’origine etnica

• Minisequencing/SNaPshot/Primer Extension assay • MALDI-TOF Mass Spectrometry with Primer Extension assay • TaqMan Real-time PCR assay • Luminex Bead Array with Allele-specific Hybridization assay • Pyrosequencing • Microarray technologies
TECNICHE PER L’ ANALISI SNPs
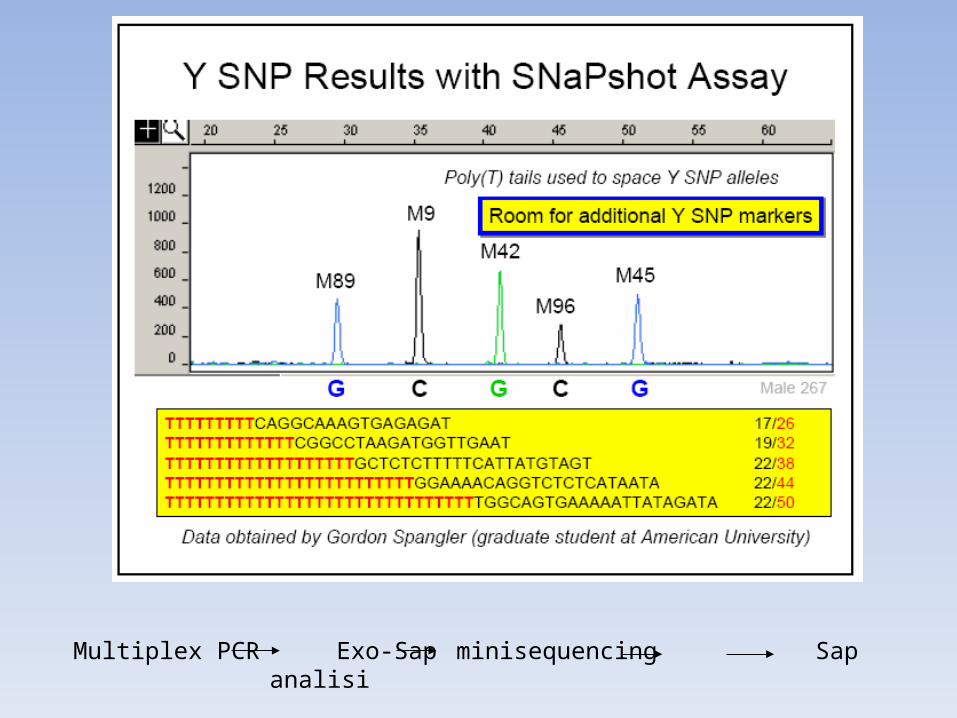
Multiplex PCR Exo-Sap minisequencing Sap analisi

Applicazioni degi SNPs nell’identificazione umana
- stima dell’origine etnica di un campione biologicoBasso tasso di mutazione si fissano nella pop popolazione-specifici
- predire i tratti fisici di un individuo
- maggiori informazioni di un campione degradato

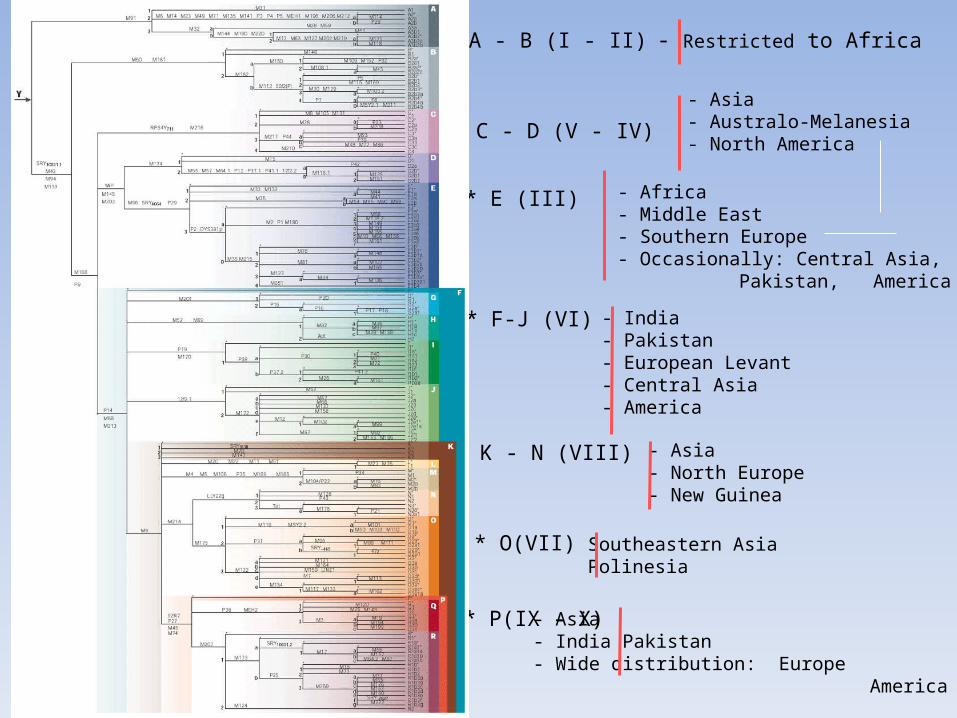
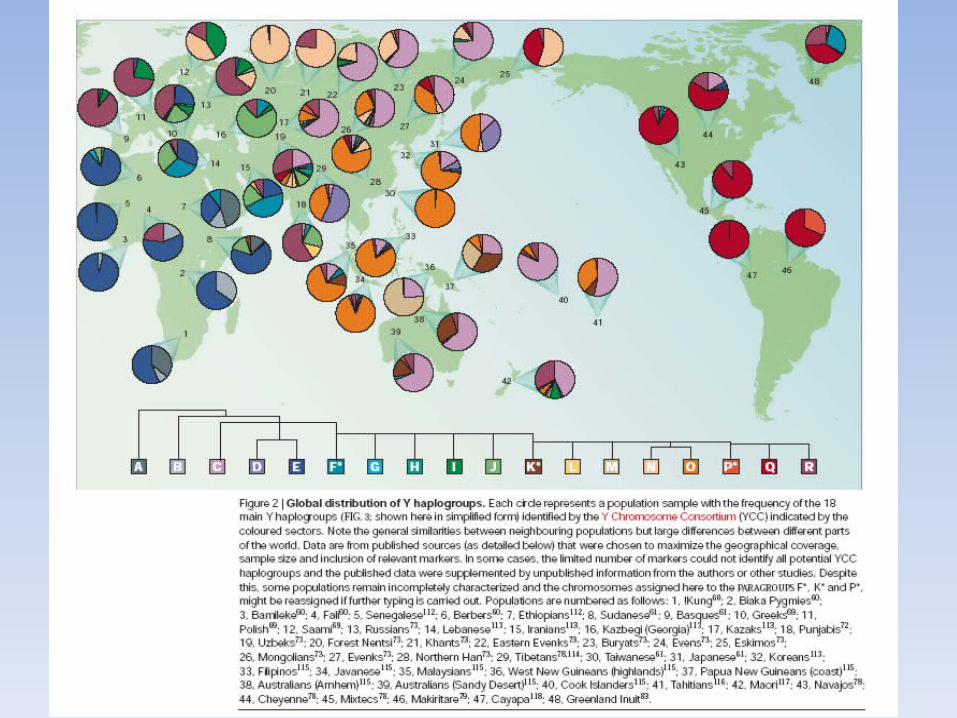
* A - B (I - II) - Restricted to Africa
* C - D (V - IV)
- Asia- Australo-Melanesia- North America
* E (III) - Africa- Middle East- Southern Europe- Occasionally: Central Asia, Pakistan,
America
* F-J (VI) - India- Pakistan- European Levant- Central Asia- America
* K - N (VIII) - Asia- North Europe- New Guinea
* O(VII) Southeastern AsiaPolinesia
* P(IX - X) - Asia- India Pakistan- Wide distribution: Europe America
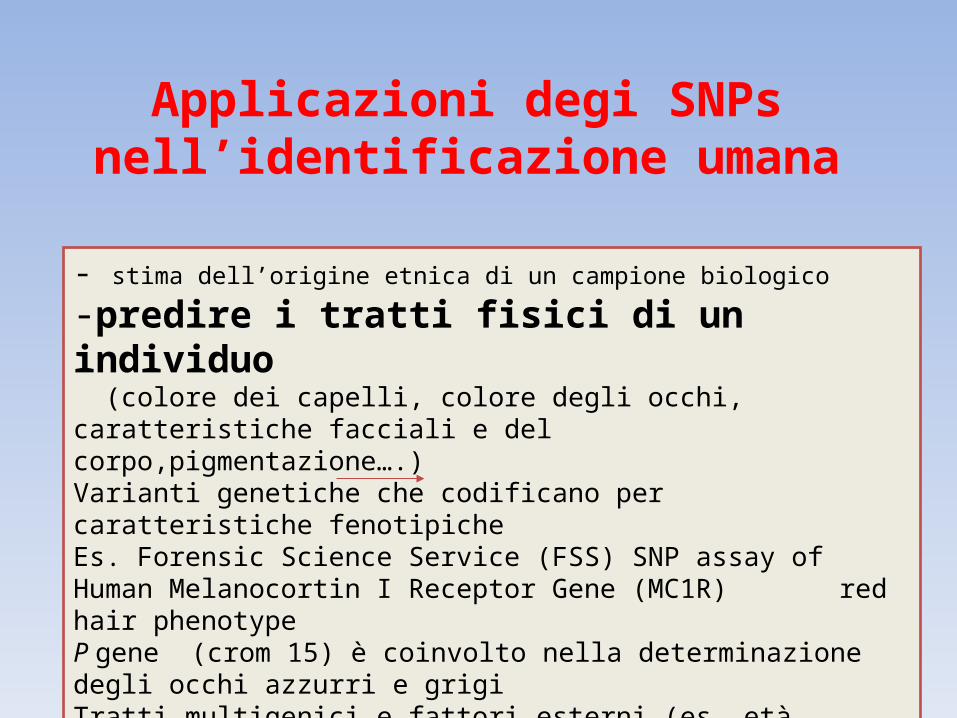
Applicazioni degi SNPs nell’identificazione umana
- stima dell’origine etnica di un campione biologico
-predire i tratti fisici di un individuo (colore dei capelli, colore degli occhi, caratteristiche facciali e del corpo,pigmentazione….)Varianti genetiche che codificano per caratteristiche fenotipicheEs. Forensic Science Service (FSS) SNP assay of Human Melanocortin I Receptor Gene (MC1R) red hair phenotypeP gene (crom 15) è coinvolto nella determinazione degli occhi azzurri e grigiTratti multigenici e fattori esterni (es. età, ambiente e differenze nutrizionali)- maggiori informazioni di un campione degradato

Applicazioni degi SNPs nell’identificazione umana
- stima dell’origine etnica di un campione biologico
- predire i tratti fisici di un individuo
- maggiori informazioni su un campione “difficile”Prodotti di PCR più piccoli maggior resa (~ 100bp)Utilizzati nell’analisi dei campioni del WTC insieme a quella dei miniSTRs

SVILUPPI NUOVI E FUTURI
-identificazione molecolare dei fluidi biologici (mRNA è più stabile)
- Patologia molecolare forense (Sindrome del QT lungo e CYP2D6)
-“Lab on a chip”

Principi di statistica applicata all’identificazione
forense


Interpretazione dei dati
1. Non–match - esclusione2. Inconclusivo – nessuna risposta3. Match – calcolo della frequenza
L’esclusione non richiede calcoliIl match necessita del calcolo statistico (stabilire con che probabilità un
individuo random e non correlato ha contribuito a lasciare la traccia significato del match)
Importante definire l’esatta espressione verbale dei numeri

Terminologia• ALLELE: variante genetica del marcatore
• GENOTIPO: profilo del DNA
• DATABASE: insieme delle frequenze alleliche nella popolazione
• POPOLAZIONE: insieme di individui raggruppati in base a determinati criteri di inclusione
• FREQUENZA ALLELICA: n. di copie di un allele/ n. di alleli totale
• FREQUENZA GENOTIPICA: n. di individui con un determinato genotipo/ n. di individui totale, quante volte quell’assetto genetico è presente nella popolazione (Random Match Probability)

STUDIO DELLE VARIAZIONI GENETICHE IN UNA POPOLAZIONE E TRA LE POPOLAZIONI E LORO MODIFICAZIONI NEL TEMPO E NELLO SPAZIO.
LEGGI DELLA PROBABILITA’ E DELL’EREDITA’ GENETICA
Probabilità rappresenta il n. di volte che un evento accade/ n. di possibilità che ciò possa accadere
1) 0 < p < 12) le prob di eventi mutualmente esclusivi si sommano (p+q=1)3) le prob di eventi indipendenti si moltiplicano
Random Match Probability = frequenza del genotipo nella popolazione
PRINCIPI DI GENETICA DI POPOLAZIONE

LEGGI DI MENDEL (segregazione ed assortimento indipendente)
GENITORI OMOZIGOTI DIVERSI POSSONO GENERARE SOLO FIGLI ETEROZIGOTI PER OGNUNO DEGLI ALLELI: MADRE AA PADRE BB FIGLI AB
GENITORI ETEROZIGOTI AB GENERANO FIGLI CON GENOTIPI AA AB BB CON DISTRIBUZIONE RISPETTIVAMENTE 1:2:1 (25% 50% 25%)
LEGGE DELL’ASSORTIMENTO INDIPENDENTE: OGNI LOCUS SEGREGA INDIPENDENTEMENTE DAGLI ALTRI
Per un marcatore genetico con alleli Aa, il genotipo può essere:
A a AA aa
con frequenze genotipiche
pq p2 q2 con p+q=1
Punnett square

HARDY-WEINBERG EQUILIBRIUM (HWE)
L’EQUILIBRIO DI HW INDICA LA RELAZIONE TRA LE FREQUENZE ALLELICHE E GENOTIPICHE PER I SINGOLI LOCI: SE UNA POPOLAZIONE E’ IN EQUILIBRIO ALLORA LE FREQUENZE DEGLI ALLELI SONO COSTANTI NEL TEMPO = (p + q )2 = 1Se le freq genotipiche obs si avvicinano a quelle attese, allora la pop è in equilibrio di HWEDEVIAZIONI DA QUESTO EQUILIBRIO SONO CAUSATE DA FATTORI COME ISOLAMENTO, RIDOTTE DIMENSIONI DELLA POPOLAZIONE, SELEZIONE ECC.QUESTO COMPORTA CHE SE PER UNA POPOLAZIONE ABBIAMO ALL’INIZIO IL 50% DEGLI ALLELI a ED IL 50% DEGLI ALLELI b ED INTERVENGONO I FATTORI PRECEDENTI, NEL TEMPO UNO DEI DUE ALLELI VERRA’ SELEZIONATO A FAVORE DELL’ALTRO (= 10% a E 90% b) = ECCESSO OMOZIGOTI E DI GENOTIPI PREFERENZIALI


La banca dati popolazionistica: tiene conto di quante volte ciascun allele è presente all’interno di una o più popolazioni
Regola del prodotto: la frequenza di un profilo STR multi-locus è il prodotto delle frequenze genotipiche per ciascun locusf locus1 x f locus2 x f locusn = f totale
Probabilità: numero di volte che un evento accade diviso il numero di volte
probabili che ciò possa accadere
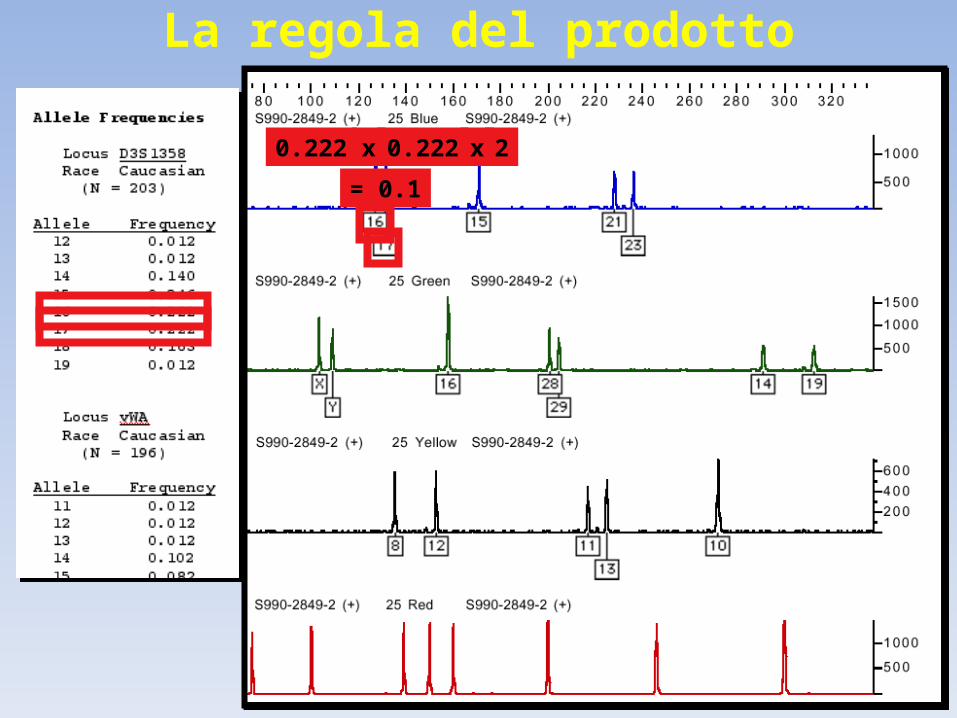
La regola del prodotto
0.222 x 0.222 x 2
= 0.1
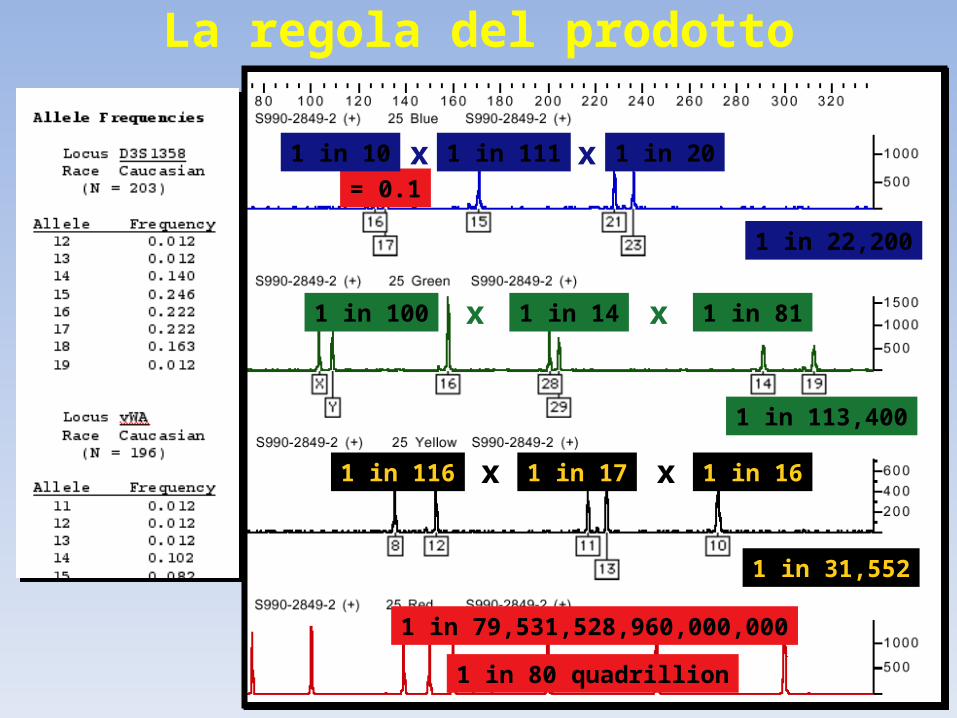
La regola del prodotto
= 0.1
1 in 79,531,528,960,000,000
1 in 80 quadrillion
1 in 10 1 in 111 1 in 20
1 in 22,200
x x
1 in 100 1 in 14 1 in 81
1 in 113,400
x x
1 in 116 1 in 17 1 in 16
1 in 31,552
x x

L’informazione statistica deve utilizzare i seguenti criteri:
RAPPORTO DI VEROSIMIGLIANZA confronto tra le probabilità della prova sotto due ipotesi alternative: ipotesi di identità contro quella di associazione casuale, secondo la formula LR= 1/ p (p= frequenza del carattere rinvenuto nei due termini del confronto secondo formule probabilistiche correnti). Più alto è il rapporto di verosimiglianza, maggiore è la forza con cui si asserisce l’identità. Tipicamente, un LR pari a 1000 indica che vi sono 1000 probabilità a favore dell’ipotesi che i due termini siano identici contro una che siano diversi.
PROBABILITA’ DI CONDIVISIONE CASUALE dei caratteri identici (corrispondente alla probabilità di rinvenire lo stesso genotipo in un individuo assunto a caso nella popolazione di riferimento).Questa corrisponde alla frequenza con cui il carattere che identifica è presente nella popolazione di riferimento.

LR=Hd
Hp==
Teorema di Bayes:

RAPPORTO DI VEROSIMIGLIANZA o LR = 1/ 0.00817 = 1 su 122.4
PROBABILITA’ DI CONDIVISIONE CASUALE = 0.00817

Allele 7 del D5S 818
a) nella popolazione italiana = < 1%b) negli amerindiani = 20%Calcolando il match x un campione omozigote con la regola del prodotto:a) 0.01 x 0.01 = 0.0001 % = 1 su 10000b) 0.2 x 0.2 = 0.04 = 1 su 25
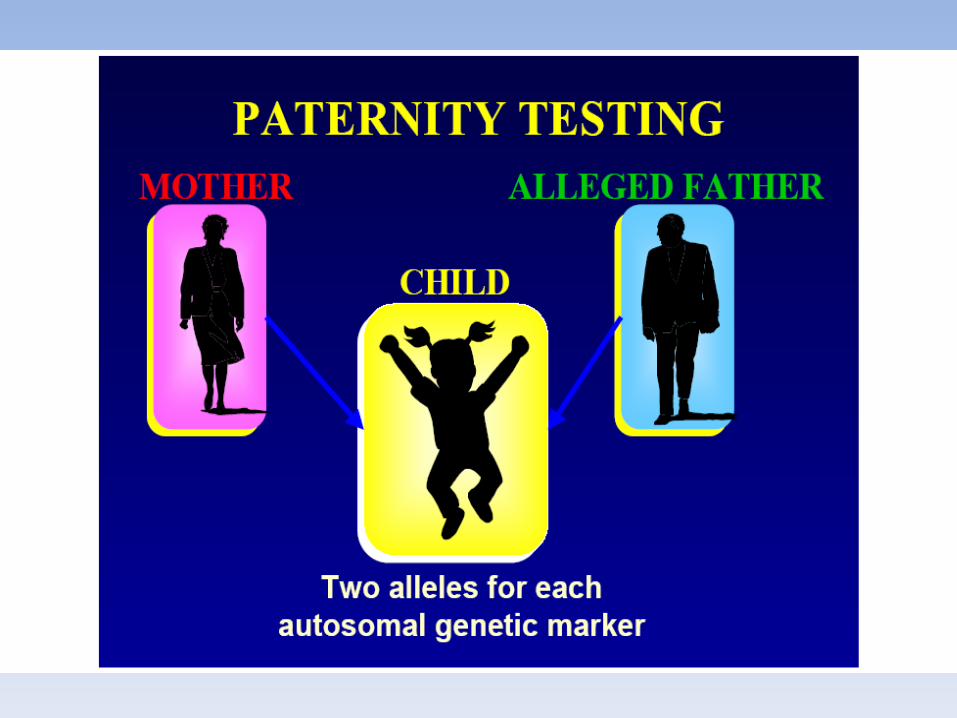

UN FIGLIO NON PUO’ AVERE UN MARCATORE ASSENTE NEI GENITORI
IL FIGLIO DEVE PORTARE UN ALLELE DI PROVENIENZA MATERNA ED UNO DI PROVENIENZA PATERNA

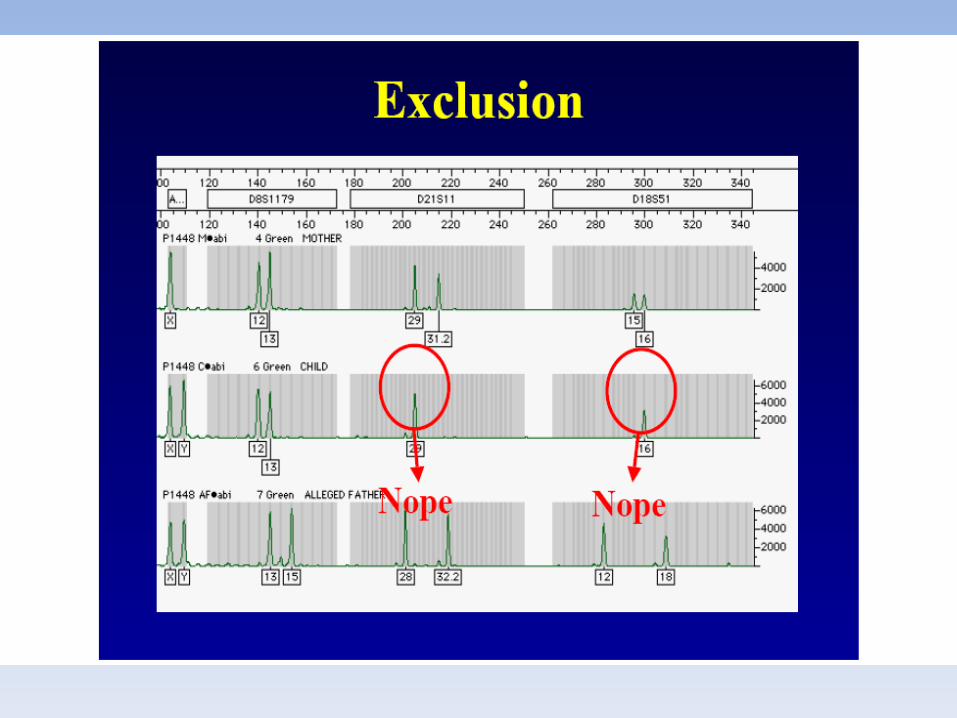
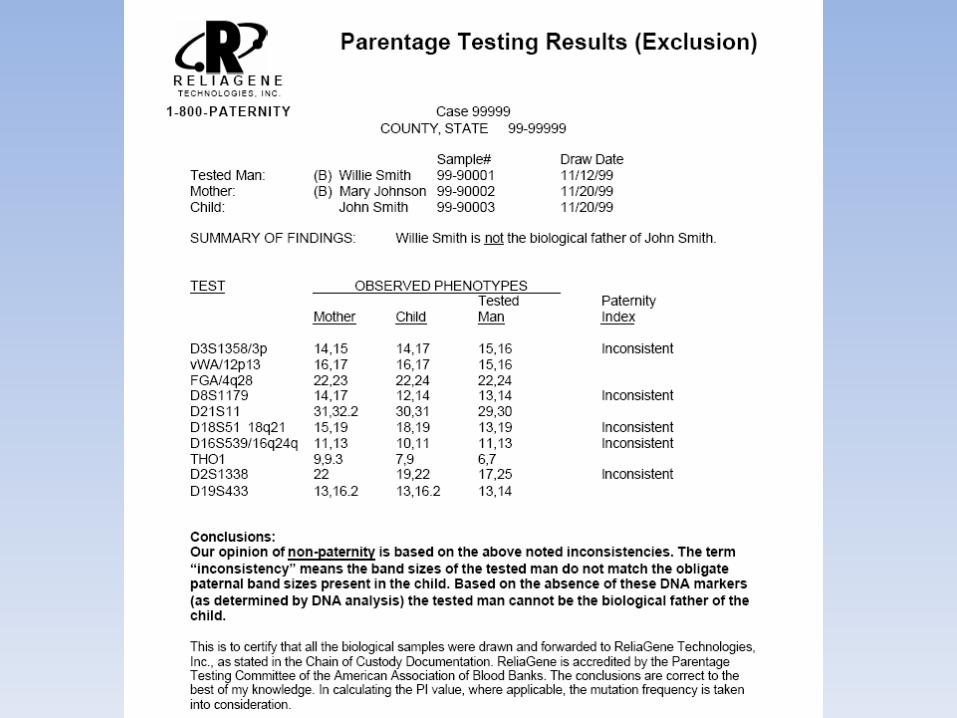

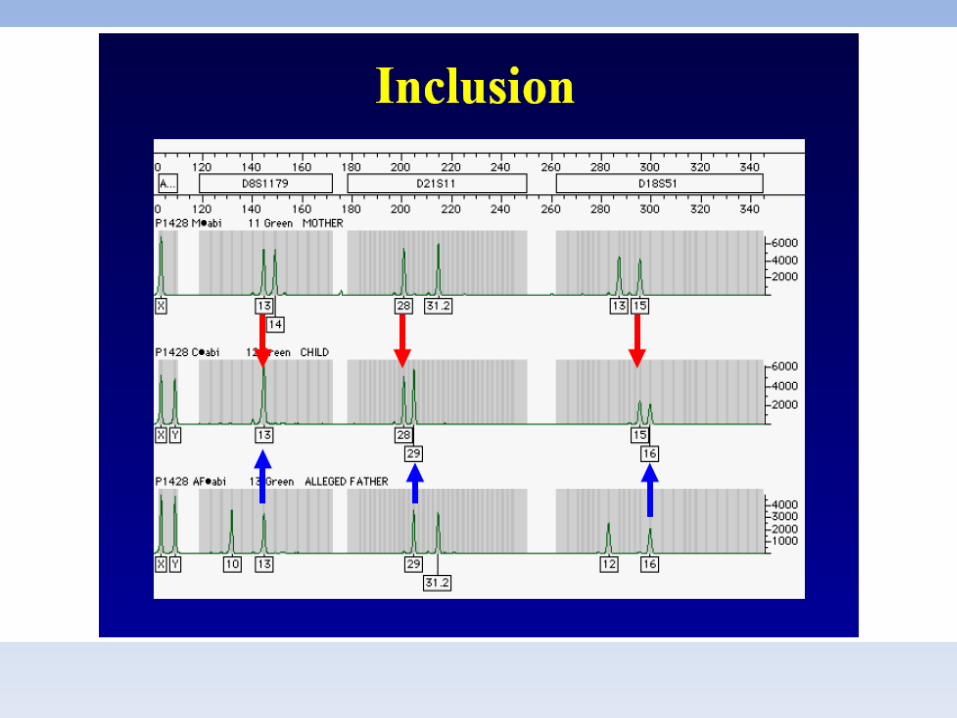
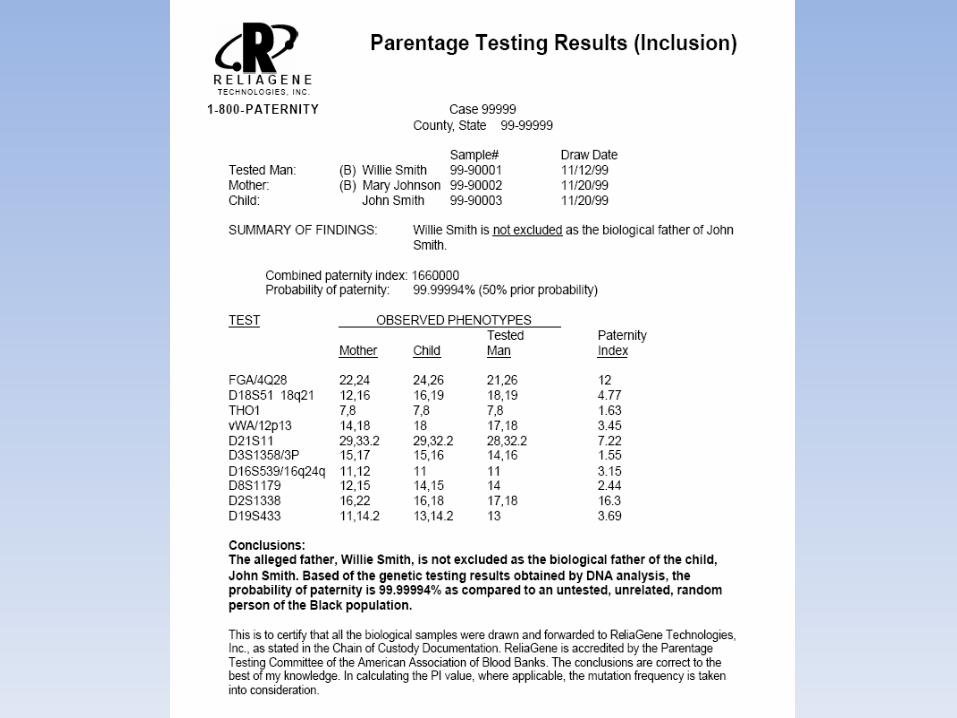


COMPATIBILITA’ GENETICA PER TUTTI I MARCATORI ESAMINATI
CALCOLO STATISTICO SECONDO FORMULEUTILIZZATE A LIVELLO INTERNAZIONALEVALORI PARI A 99,9999…. NON ESISTE IN STATISTICA IL CONCETTO DI100%
PREDICATO VERBALE DI PATERNITA’ PRATICAMENTE PROVATA


In linea di principio, tenendo conto di errori e mutazioni, anche l’ ipotesi di non paternità può essere descritta in termini probabilistici. La sua espressione in questi termini contribuirebbe anzi ad unificare sul piano formale l’espressione del giudizio in materia di discussa parentela. Non è tuttavia possibile ignorare che questo aspetto delle genetica forense è in fase di elaborazione e che l’opinione comune privilegia l’espressione del giudizio in termini di ‘certezza’.A prescindere da questo problema, l’espressione della probabilità di paternità in termini numerici deve assumere la forma dei seguenti indici probabilistici:
LR (likelihood ratio , o rapporto di verosimiglianza) o Indice di paternità= X/Y (X, fattore di segregazione; Y, frequenza del carattere trasmesso). LA LR è un numero intero, la cui grandezza esprime il favore con cui l’ipotesi di paternità gode rispetto a quella di non paternità, o in altre parole la probabilità di individuare soggetti per caso compatibili con l’assetto genetico di provenienza paterna del figlio. P (probabilità di paternità) = 1/(1+(Y/X). Questa formula è definita “probabilità di paternità”, e consiste praticamente in una trasformazione algebrica della LR. Meglio espressa in decimali dell’unita (ad es: 0.9995) oppure in percentuale (ad es: 99.95), essa esprime gli stessi concetti già enunciati per LR.

PATERNITY INDEX: riassume l’informazione fornita dal test geneticoLikelihood ratio o LR= la probabilità che un dato evento si verifichi secondo determinate condizioni o assunzioni
/ la probabilità che lo stesso evento si verifichi secondo altre condizioni o assunzioni che si escludono reciprocamente

“False trio”

Likelihood ratio(paternity trio)
• Two possible explanations of genetic Evidence• LR = PI = P(E if H0) / P (E if H1)
– (how much more likely H0 is, than H1)
M
C
AFAFM
C
Explanation H0 (AF=father) Explanation H1 (AF unrelated)

INCOMPATIBILITA’ ISOLATA


INCOMPATIBILITA’ ISOLATA
ALLARGAMENTO DELLA INDAGINE A PIU’MARCATORI
INSERIMENTO DELLA MUTAZIONE NEL CALCOLOSTATISTICO
EVENTO MUTAZIONALE
GIUDIZIO DI INCOMPATIBILITA’ ISOLATA
CHE NON ESCLUDE LA PATERNITA’

PATERNITA’ IN CASI DEFICITARI
MANCANZA DEL CAMPIONE MATERNO
MANCANZA DEL CAMPIONE PATERNO INDAGINE DI PATERNITA’ SUGLI ASCENDENTI
INDAGINE DI PATERNITA’ SUI CORRELATI
SISTEMI ESPERTI PER IL CALCOLO STATISTICO

Sommario• Esiste un grande numero di differenze tra le copie del DNA di
individui diversi• La probabilità di match è rappresentata dalla probabilità che
un profilo preso a caso nella popolazione sia identico a quello ritrovato sulla scena del crimine
• L’INDICE DI PATERNITA’ è la misura di quanto i risultati
ottenuti sono spiegati dalla vera relazione piuttosto che dalla casualita’
• Il cromosoma Y e il DNA mitocondriale sono condivisi dagli individui in linea rispettivamente patri e matrilineare. Hanno un uso specialistico nell’analisi forense

GRAZIE PER L’ATTENZIONE!




![Sistemi di arresto caduta[1] - Linea vita Linee vita e ... - Atti seminario - Ing... · Un sistema di arresto caduta ... • Freccia elastica campata linea ... dobbiamo calcolare](https://img.pdfslide.tips/doc/110x75/5c675de509d3f226188b862b/sistemi-di-arresto-caduta1-linea-vita-linee-vita-e-atti-seminario-ing.jpg)
























