Embed Size (px)
Citation preview

Copyright © 2015 NTT DATA Corporation
2015年1月31日 株式会社NTT DATA
NTT DATA と PostgreSQL が挑んだ総力戦 裏話
~ セミナでは話せなかったこと ~

2 Copyright © 2015 NTT DATA Corporation
はじめに
本日のお話は、2014/12/5 の PostgreSQL カンファレンスの基調講演で
話せなかった技術的(特にトラブルにまつわる)な話のトピックを裏話と称して
お伝えするものです。
前半は先日の基調講演のダイジェスト、後半は特に手ごわかった(でも技術的には
興味深い)2つのトラブルについて、解決に至る過程と併せて紹介します。
PostgreSQLや周辺ツールのコアに関わる未知のバグに遭遇したケース、
そしてその解析などに関して、Hackers ML を除き、あまり世の中には
情報がないと思います。
有益な情報ではないかもしれませんが、何かのヒントになれば幸いです。

3 Copyright © 2015 NTT DATA Corporation
PostgreSQLカンファレンス 2014 の内容を振り返り。
以下の資料と同内容です
www.slideshare.net/hadoopxnttdata/ntt-data-postgresql

4 Copyright © 2015 NTT DATA Corporation
今日の本題
様々なトラブルがありました。
特に手を焼いた 2つ のトラブルを紹介。
・ SEGVでPostgreSQLが落ちた
・ SELECT結果が間違っている。
共通しているのは、いずれもPostgreSQL、周辺ツールの
バグであったこと。いずれも解決済みです。

5 Copyright © 2015 NTT DATA Corporation
SEGVでPostgreSQLが落ちた
1. ある日、本番環境での試験中にPostgreSQLがダウンした
2. とあるSQLが実行された際に、Segmentation Fault が発生していた PostgreSQLは、あるバックエンドプロセスがSEGVを出すと、インスタンス全体が落ち
ますね
3. 復旧後、同じSQLを発行したら、再度 PostgreSQL がダウン
4. とりあえず、そのSQLの発行を停止して様子見(その後はダウンせず)
SQLは特に変哲もないもの。今までは特に問題なかった。
では、直前に何かしたか?
・・・・ そういえばパーティションのローテートをした。
あと残されたのは core ファイル。
まずはここから解析が始まった。

6 Copyright © 2015 NTT DATA Corporation
coreの解析
実行計画作成中に統計情報を見ている箇所でクラッシュしている
(gdb) bt #0 pg_detoast_datum (datum=0x1d7f0f2c28ee3) at fmgr.c:2240
#1 0x000000000069c7b4 in numeric_lt (fcinfo=0x7fffaee58560) at numeric.c:1408
#2 0x000000000071a8c0 in FunctionCall2Coll (flinfo=<value optimized out>, collation=<value optimized out>, arg1=<value optimized out>, arg2=<value optimized out>) at fmgr.c:1326
#3 0x00000000006c320f in ineq_histogram_selectivity (root=0x107ab28, vardata=0x7fffaee58a80,
opproc=0x7fffaee589f0, isgt=0 '¥000', constval=17280952, consttype=1700) at selfuncs.c:834 #4 0x00000000006c3a8c in scalarineqsel (root=0x107ab28, operator=<value optimized out>, isgt=0 '¥000', vardata=0x7fffaee58a80, constval=17280952, consttype=<value optimized out>) at selfuncs.c:558
#5 0x00000000006c470c in scalarltsel (fcinfo=<value optimized out>) at selfuncs.c:1021
#6 0x000000000071cdb7 in OidFunctionCall4Coll (functionId=<value optimized out>, collation=0, arg1=17279784, arg2=1754, arg3=17280664, arg4=0) at fmgr.c:1682 #7 0x00000000005fc0e5 in restriction_selectivity (root=0x107ab28, operatorid=1754, args=0x107ae98, inputcollid=0, varRelid=0) at plancat.c:1021 #8 0x00000000005d079e in clause_selectivity (root=0x107ab28, clause=0x107b040, varRelid=0, jointype=JOIN_INNER, sjinfo=0x0) at clausesel.c:668 #9 0x00000000005d0274 in clauselist_selectivity (root=0x107ab28, clauses=<value optimized out>, varRelid=0, jointype=JOIN_INNER, sjinfo=0x0) at clausesel.c:108 #10 0x00000000005d1dad in set_baserel_size_estimates (root=0x107ab28, rel=0x107b120) at costsize.c:3411
#11 0x00000000005cec4a in set_plain_rel_size (root=0x107ab28, rel=0x107b120, rti=1, rte=0x1044090) at
allpaths.c:361

7 Copyright © 2015 NTT DATA Corporation
coreの解析
ちょっと追うと、何故か異なるテーブルの統計情報を見ていた・・・
(gdb) frame 3 #3 0x00000000006c320f in ineq_histogram_selectivity (root=0x107ab28, vardata=0x7fffaee58a80, opproc=0x7fffaee589f0, isgt=0 '¥000', constval=17280952, consttype=1700) at selfuncs.c:834 (gdb) p *vardata $15 = {var = 0x107ae28, rel = 0x107b120, statsTuple = 0x7f2bd2ee1da0, freefunc = 0x7f2bd5921830
<FreeHeapTuple>, vartype = 1700, atttype = 1700, atttypmod = -1,
isunique = 0 '¥000'} (gdb) p *(Form_pg_statistic) ((char *) vardata->statsTuple->t_data + vardata->statsTuple->t_data->t_hoff)
$14 = {starelid = 299892885, staattnum = 1, stainherit = 0 '¥000', stanullfrac = 0, stawidth = 8, stadistinct
= -1, stakind1 = 2, stakind2 = 3, stakind3 = 0,
stakind4 = 0, stakind5 = 0, staop1 = 2062, staop2 = 2062, staop3 = 0, staop4 = 0, staop5 = 0}
問題のSQLで参照しているテーブルのOID は 299106453。numeric型(oid=1700)の列に対し、WHERE句で col < xxxx の条件を使っていた。
しかし、上記のcoreからは OID = 299892885 のテーブルのtimestamp型(oid = 2062)の列の統計情報を
参照し、可変長データのアクセスロジックに行ってしまい、クラッシュしていた。

8 Copyright © 2015 NTT DATA Corporation
pg_dbms_statsで問題がある?
1. 統計情報固定化ツール(pg_dbms_stats)を使っている
まずはこいつを怪しむ
2. 固定化した統計情報の中身がまずいのか?
中身を確認するも、問題なし
3. 別の試験環境に当該の統計情報を持ってきてSQLを 発行しても大丈夫
当該環境でしか発生しない様子・・
ここまでの情報とコード解析を行った結果、特定の条件において、pg_dbms_statsが誤った統計情報を返していることが分かった。
9 Copyright © 2015 NTT DATA Corporation
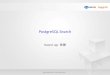
その前に、pg_dbms_statsの内部について
relid attnum stats
固定化した統計情報 本来の統計情報
pg_dbms_stats
Hash
relid attnum stats
Planning Phase Execute Phase
バックエンドプロセスのローカルメモリ
10 Copyright © 2015 NTT DATA Corporation
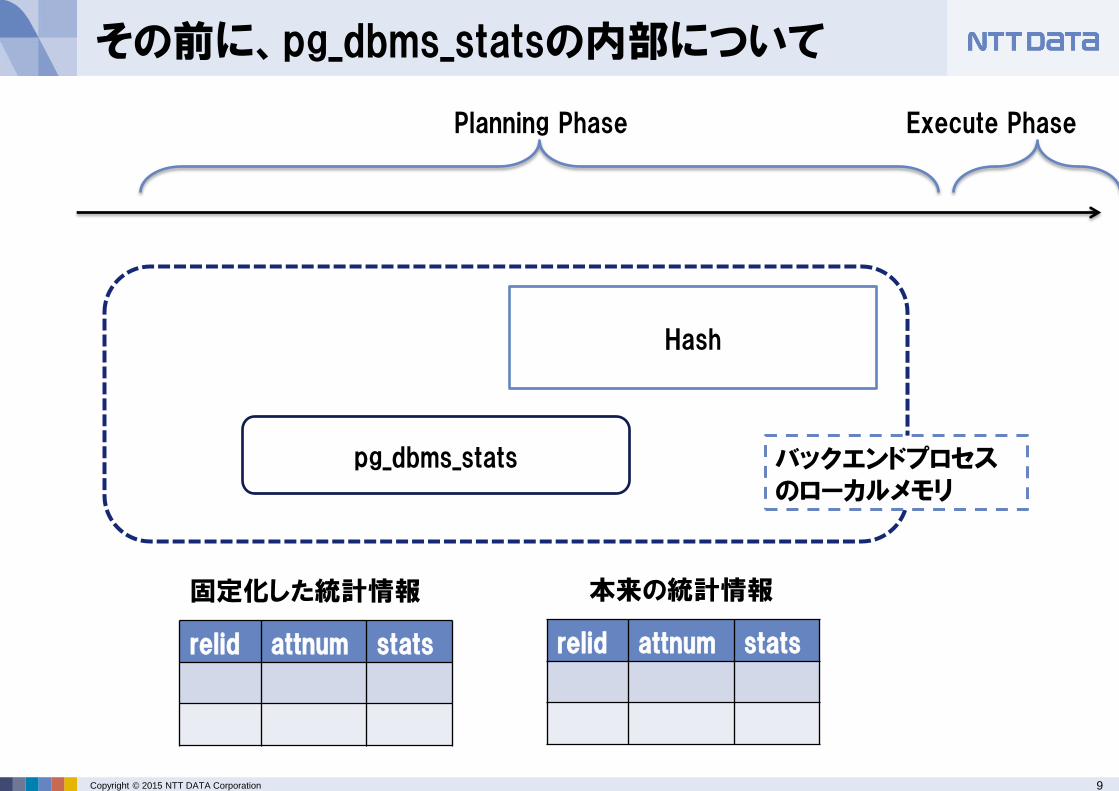
その前に、pg_dbms_statsの内部について
relid attnum stats
固定化した統計情報 本来の統計情報
pg_dbms_stats
Hash
Hook
relid attnum stats
Planning Phase
統計情報取得
Execute Phase
① 統計情報の取得時、pg_dbms_statsが有効になっていると、Hook経由でpg_dbms_statsのロジックに入る
バックエンドプロセスのローカルメモリ
11 Copyright © 2015 NTT DATA Corporation
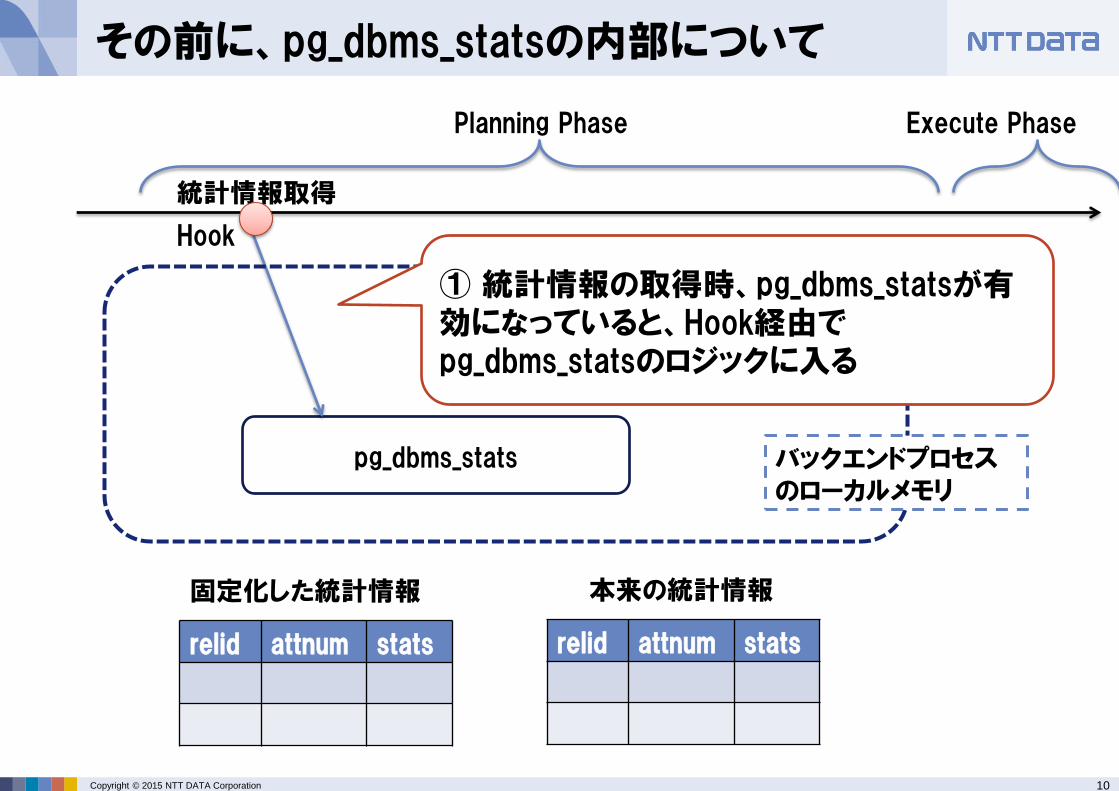
その前に、pg_dbms_statsの内部について
relid attnum stats
固定化した統計情報 本来の統計情報
pg_dbms_stats
Hash
Hook
relid attnum stats
Planning Phase
統計情報取得
Execute Phase
②固定化された統計情報と本来の統計情報(pg_statistics)をマージし、固定化されたものがあれば、それを使い、なければ本来の統計情報を使う
バックエンドプロセスのローカルメモリ
12 Copyright © 2015 NTT DATA Corporation
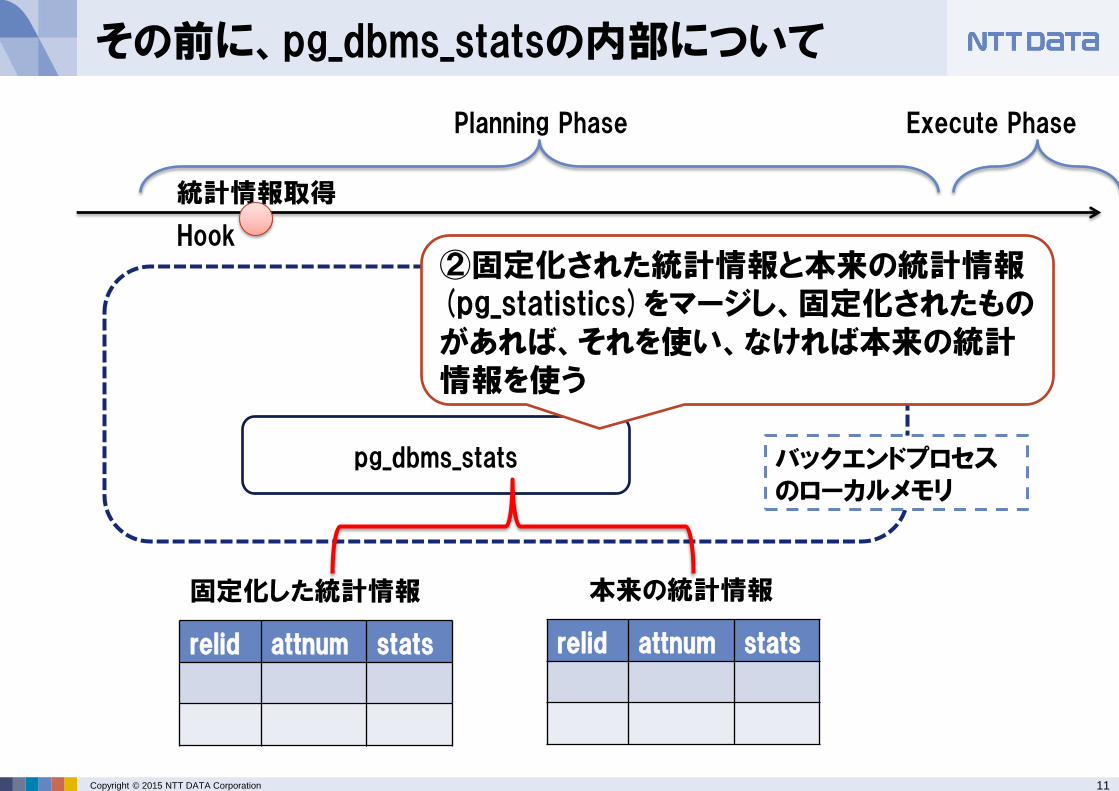
その前に、pg_dbms_statsの内部について
relid attnum stats
固定化した統計情報 本来の統計情報
pg_dbms_stats
Hash
Hook
relid attnum stats
Planning Phase
統計情報取得
Execute Phase
バックエンドプロセスのローカルメモリ
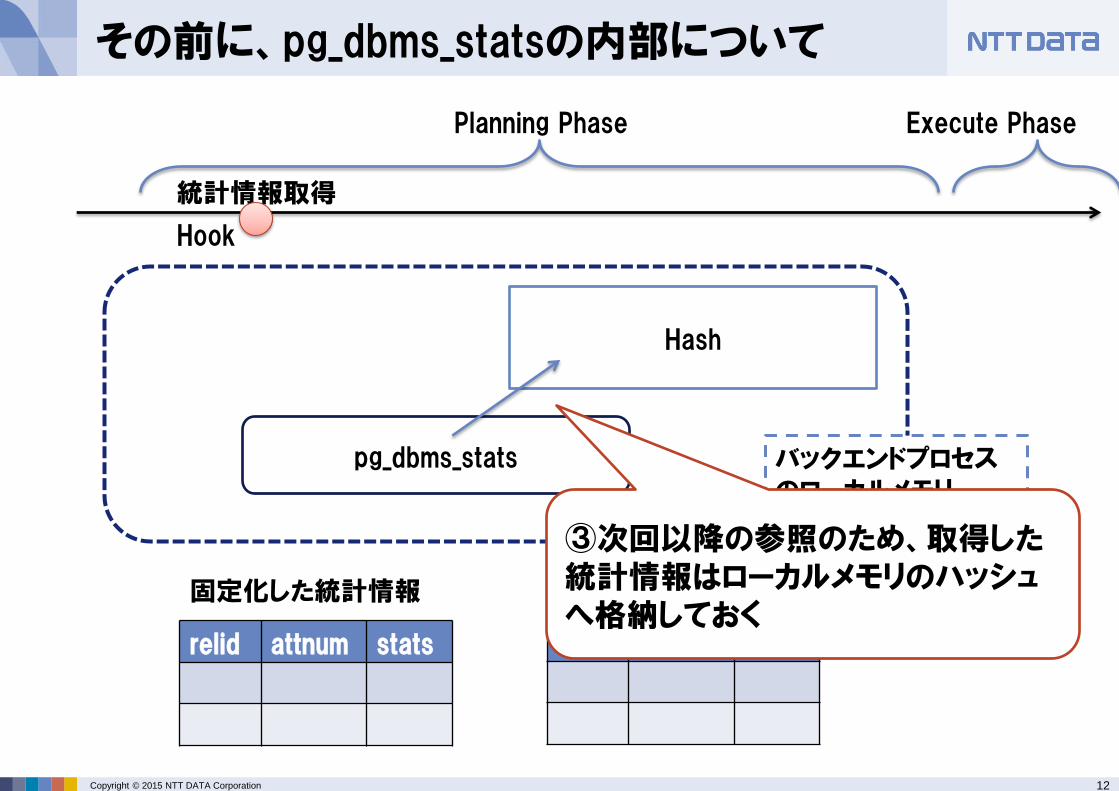
③次回以降の参照のため、取得した統計情報はローカルメモリのハッシュへ格納しておく
13 Copyright © 2015 NTT DATA Corporation
その前に、pg_dbms_statsの内部について
relid attnum stats
固定化した統計情報 本来の統計情報
pg_dbms_stats
Hash
Hook
relid attnum stats
Planning Phase
統計情報取得
Execute Phase
バックエンドプロセスのローカルメモリ
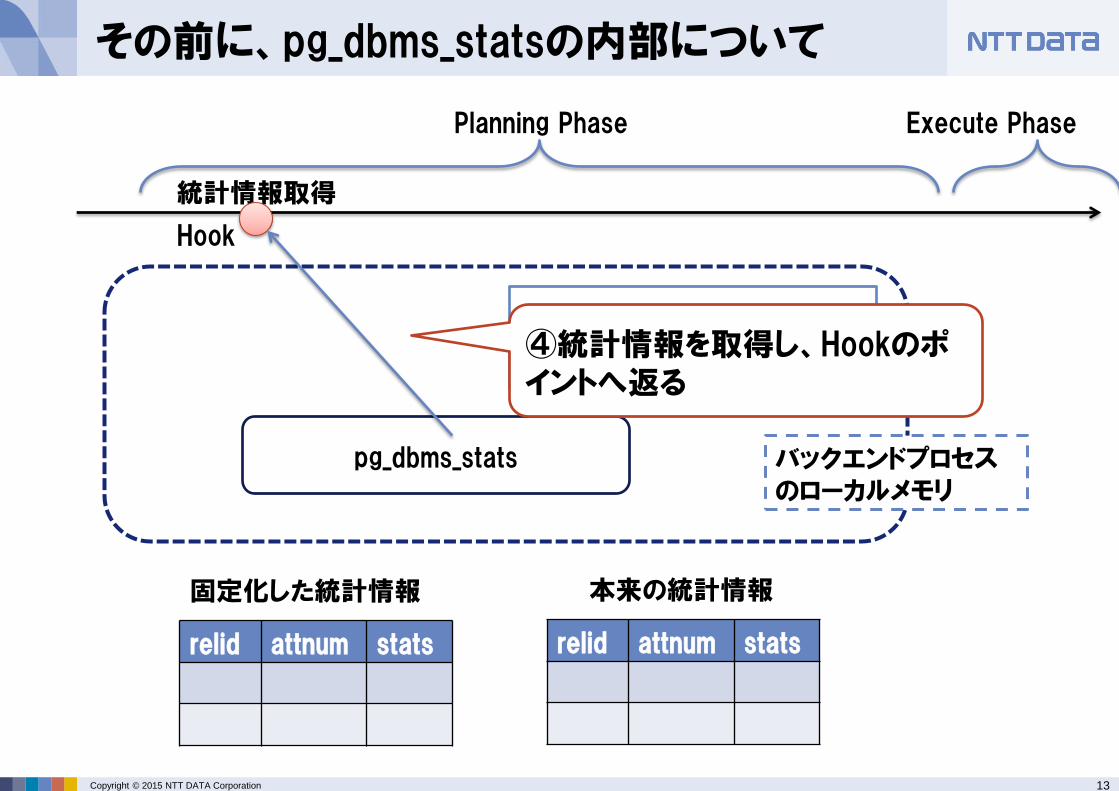
④統計情報を取得し、Hookのポイントへ返る
14 Copyright © 2015 NTT DATA Corporation
その前に、pg_dbms_statsの内部について
relid attnum stats
固定化した統計情報 本来の統計情報
pg_dbms_stats
Hash
Hook
relid attnum stats
Planning Phase
統計情報取得
Execute Phase
バックエンドプロセスのローカルメモリ
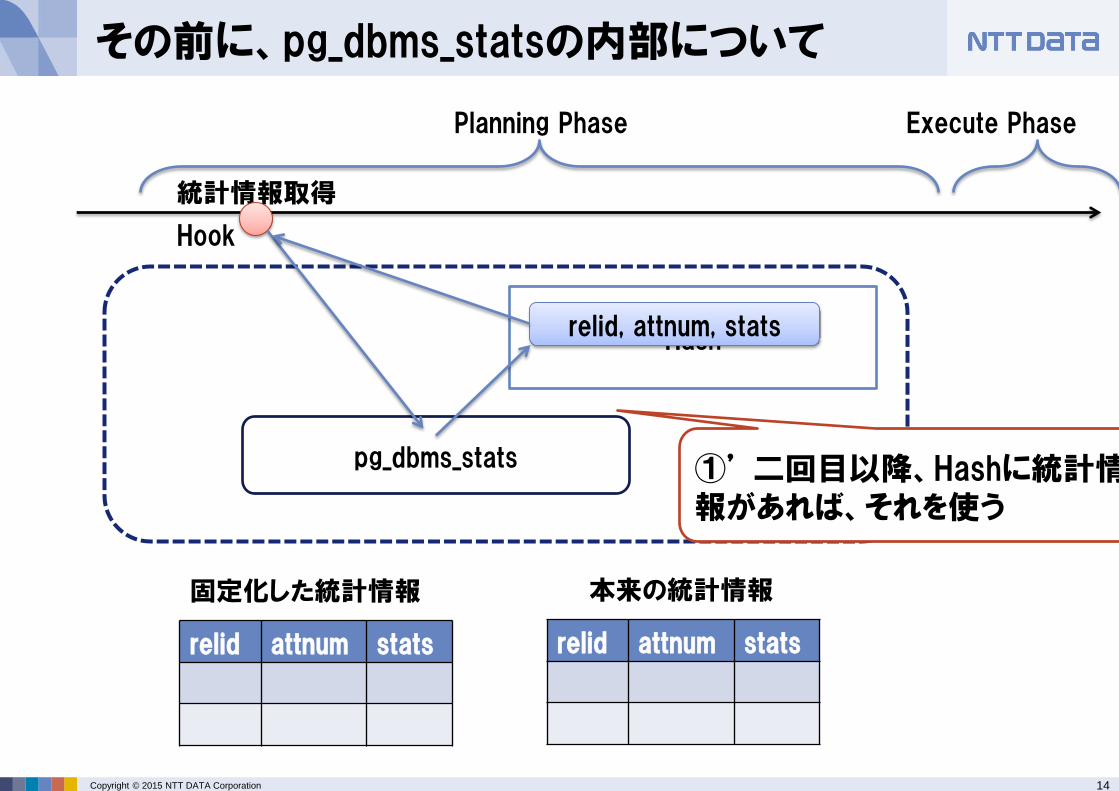
①’ 二回目以降、Hashに統計情報があれば、それを使う
relid, attnum, stats
15 Copyright © 2015 NTT DATA Corporation
Hashの仕組み
Hash
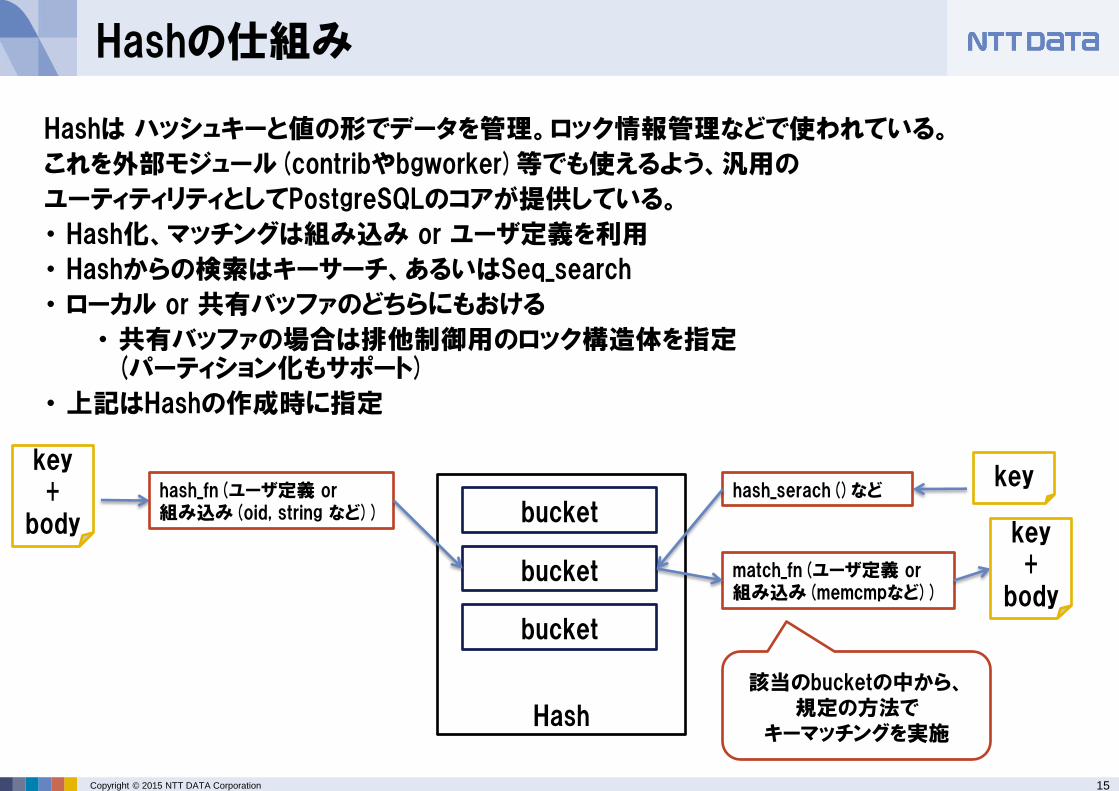
Hashは ハッシュキーと値の形でデータを管理。ロック情報管理などで使われている。
これを外部モジュール(contribやbgworker)等でも使えるよう、汎用の
ユーティティリティとしてPostgreSQLのコアが提供している。
・ Hash化、マッチングは組み込み or ユーザ定義を利用
・ Hashからの検索はキーサーチ、あるいはSeq_search
・ ローカル or 共有バッファのどちらにもおける
・ 共有バッファの場合は排他制御用のロック構造体を指定 (パーティション化もサポート)
・ 上記はHashの作成時に指定
hash_fn(ユーザ定義 or 組み込み(oid, string など)) bucket
bucket
bucket
hash_serach()など
match_fn(ユーザ定義 or 組み込み(memcmpなど))
key +
body key +
body
key
該当のbucketの中から、規定の方法で
キーマッチングを実施

16 Copyright © 2015 NTT DATA Corporation
今回のバグは・・
仕組みとしてはrelationのOID(relid)をキーとしていたが・・Hash_createの
引数フラグにHASH_FUNCTIONを指定していなかった・・
MemSet(&ctl, 0, sizeof(ctl)); ctl.keysize = sizeof(Oid); ctl.entrysize = sizeof(StatsRelationEntry); ctl.hash = oid_hash; ctl.hcxt = CacheMemoryContext; hash = hash_create("dbms_stats relation statistics cache", MAX_REL_CACHE, &ctl, HASH_ELEM | HASH_CONTEXT | HASH_FUNCTION ); rel_stats = hash;
この部分が無かった
pg_dbms_stats.c より

17 Copyright © 2015 NTT DATA Corporation
今回のバグは・・
そのため、ハッシュ化の関数として想定していたoid_hash は使われず、OIDを 文字列としてハッシュ化する string_hashが設定されていた。
/* Initialize the hash header, plus a copy of the table name */ hashp = (HTAB *) DynaHashAlloc(sizeof(HTAB) + strlen(tabname) +1); MemSet(hashp, 0, sizeof(HTAB)); hashp->tabname = (char *) (hashp + 1); strcpy(hashp->tabname, tabname); if (flags & HASH_FUNCTION) hashp->hash = info->hash; else hashp->hash = string_hash; /* default hash function */
hash化の関数にstring用の 関数が選択される
src/backend/utils/hash/dynahash.c より

18 Copyright © 2015 NTT DATA Corporation
今回のバグは・・
そしてHashサーチ時のマッチング手段も文字列として設定されていた
/* * If you don't specify a match function, it defaults to string_compare if * you used string_hash (either explicitly or by default) and to memcmp * otherwise. (Prior to PostgreSQL 7.4, memcmp was always used.) */ if (flags & HASH_COMPARE) hashp->match = info->match; else if (hashp->hash == string_hash) hashp->match = (HashCompareFunc) string_compare; else hashp->match = memcmp;
src/backend/utils/hash/dynahash.c より
19 Copyright © 2015 NTT DATA Corporation
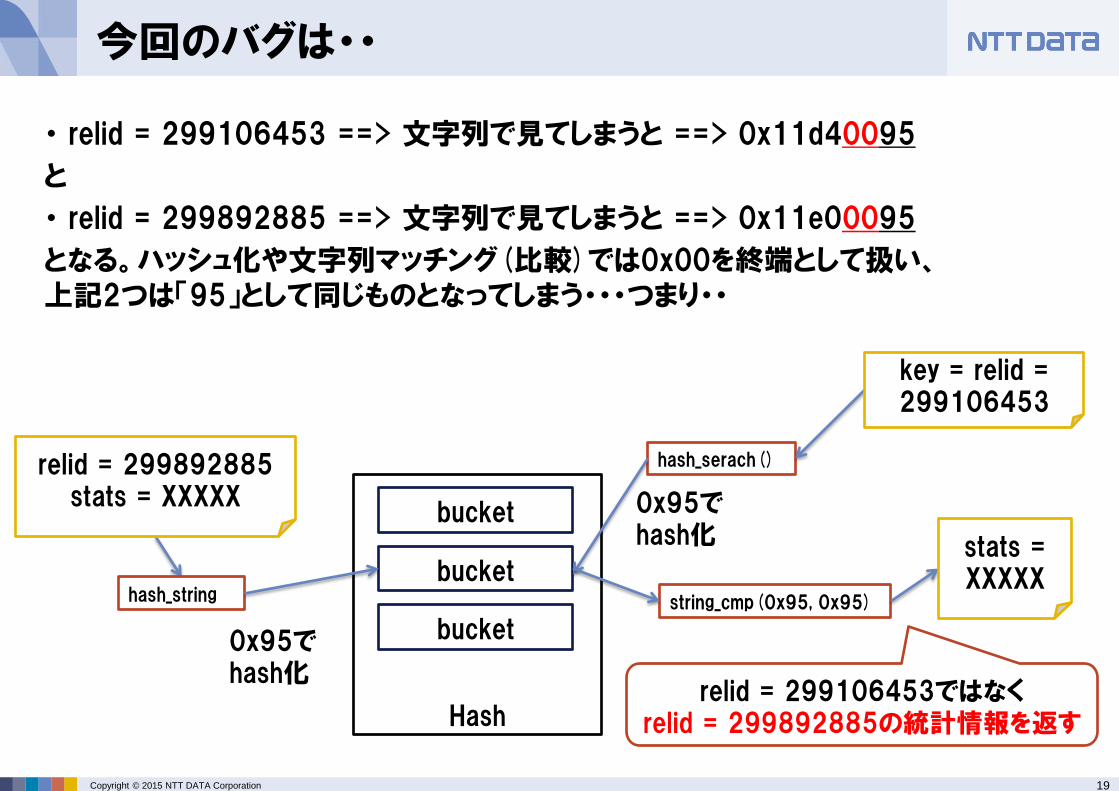
今回のバグは・・
・ relid = 299106453 ==> 文字列で見てしまうと ==> 0x11d40095
と
・ relid = 299892885 ==> 文字列で見てしまうと ==> 0x11e00095
となる。ハッシュ化や文字列マッチング(比較)では0x00を終端として扱い、 上記2つは「95」として同じものとなってしまう・・・つまり・・
Hash
hash_string
bucket
bucket
bucket
hash_serach()
string_cmp(0x95, 0x95)
relid = 299892885 stats = XXXXX
stats = XXXXX
key = relid = 299106453
0x95でhash化
0x95でhash化
relid = 299106453ではなく relid = 299892885の統計情報を返す

20 Copyright © 2015 NTT DATA Corporation
解決
というわけで、突然SEGVが発生した理由がわかった。
・ OIDに0x00を含み、かつその下位バイトが同じになるテーブルを 同じクライアントが読む時にだけ発生
・ ハッシュは各クライアントのローカルメモリにあるから
・ 突然発生したのは、パーティションローテで偶然にも上記に 該当するテーブルを読む状況が揃ってしまったため
・ 別環境で再現しなかったのは、pg_dbms_statsの統計情報のexport/importは、OIDは引き連れていかないから
修正は、hash_create()のフラグに正しく HASH_FUNCTIONを立てるのみ。
coreが無かったら解析は難航していた。最悪、迷宮入りになった可能性もある・・

21 Copyright © 2015 NTT DATA Corporation
SELECT結果が間違っている !?
1. 試験環境にて、AP側でSELECT結果がおかしい事象が出た。
2. AP側のログ解析から 「SELECT FOR UPDATEで未処理ステータスの行を取得し、ロックした行のステータスを処理済みにUPDATEしている。この処理において、なぜか処理済みのステータスの行をSELECT FOR UPDATEで取得してしまう」 という事象に見えた。
3. たまに出ていた。1日1回出るか出ないかの頻度。
SQLは特に変哲もないもの。
PostgreSQLに原因があるというが、前例がない・・
APのバグでは?いや、JDBC?JVM?・・
容疑者も当時の状況では絞り切れていない
22 Copyright © 2015 NTT DATA Corporation
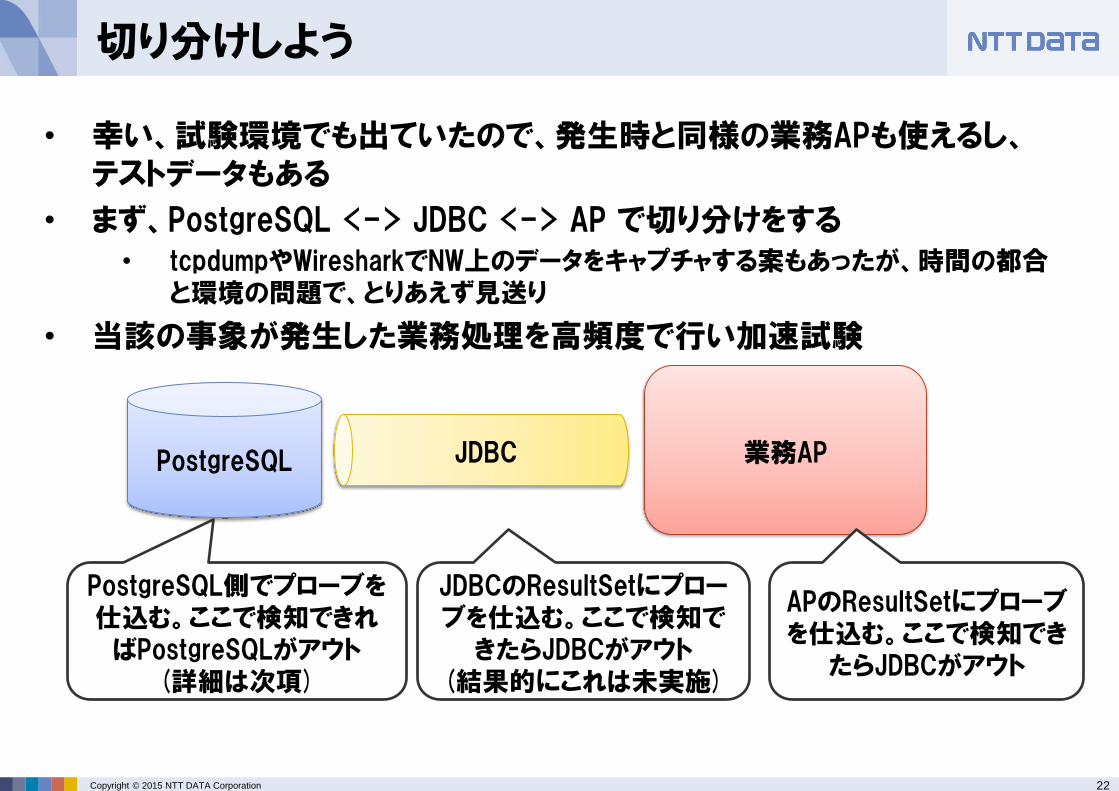
切り分けしよう
• 幸い、試験環境でも出ていたので、発生時と同様の業務APも使えるし、テストデータもある
• まず、PostgreSQL <-> JDBC <-> AP で切り分けをする • tcpdumpやWiresharkでNW上のデータをキャプチャする案もあったが、時間の都合
と環境の問題で、とりあえず見送り
• 当該の事象が発生した業務処理を高頻度で行い加速試験
PostgreSQL JDBC 業務AP
PostgreSQL側でプローブを仕込む。ここで検知できればPostgreSQLがアウト
(詳細は次項)
JDBCのResultSetにプローブを仕込む。ここで検知で
きたらJDBCがアウト (結果的にこれは未実施)
APのResultSetにプローブを仕込む。ここで検知でき
たらJDBCがアウト
23 Copyright © 2015 NTT DATA Corporation
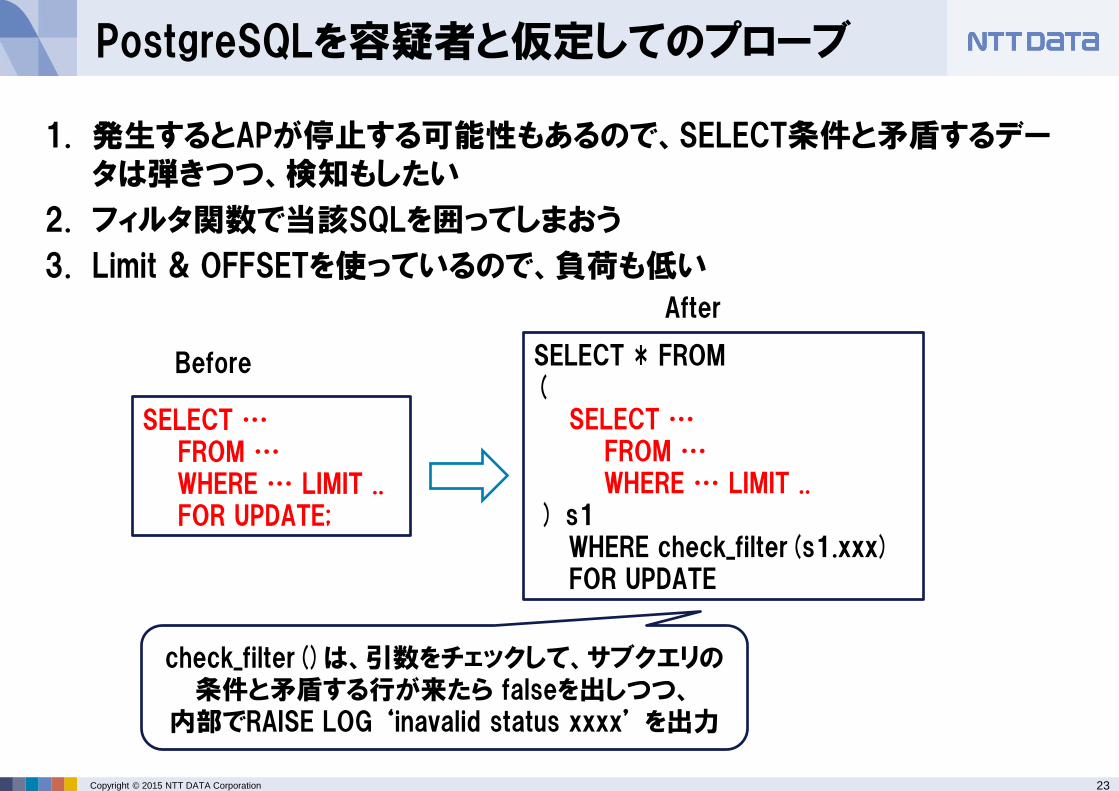
PostgreSQLを容疑者と仮定してのプローブ
1. 発生するとAPが停止する可能性もあるので、SELECT条件と矛盾するデータは弾きつつ、検知もしたい
2. フィルタ関数で当該SQLを囲ってしまおう
3. Limit & OFFSETを使っているので、負荷も低い
SELECT … FROM … WHERE … LIMIT .. FOR UPDATE;
SELECT * FROM ( SELECT … FROM … WHERE … LIMIT .. ) s1 WHERE check_filter(s1.xxx) FOR UPDATE
check_filter()は、引数をチェックして、サブクエリの条件と矛盾する行が来たら falseを出しつつ、
内部でRAISE LOG ‘inavalid status xxxx’ を出力
Before
After

24 Copyright © 2015 NTT DATA Corporation
出た
異常検知メッセージがPostgreSQLのフィルタ関数で出てしまった。
つまりPostgreSQLが黒だった。
急いで手元環境で再現できるよう、再現パターンを絞り込みつつ、
APの該当処理をJavaで作成。結果的に、手元でも再現した。
さらにミニマムなテストセットにより、psql 上でも確認できた・・・・
絞り込めた条件は、
1. パーティショニングされており、
2. 部分インデックスを使ったインデックススキャンを経由した
3. UPDATEとFOR UPDATE が競合する
こと。
ここからはコード解析も併せて問題の特定へ。

25 Copyright © 2015 NTT DATA Corporation
ヒントだったもの
実行計画を見ると、IndexScanの条件(IndexCond/Filter)がおかしい(事項から)
ソースコードとREADME(src/backend/executor/README など)から、部分インデックスの際の特別な最適化のコードがあることが分かる。
これらをヒントに、仮説と試験をして、原因が解明できた。

26 Copyright © 2015 NTT DATA Corporation
今回のバグは・・・
PostgreSQLのオプティマイザの問題だった
部分インデックス経由のインデックスアクセスをする際、部分インデックスの定義と同様のWHERE条件は、実行時に省略する最適化がされる
-> 部分インデックスのエントリには、その条件に合致するものしかないため
postgres=# EXPLAIN SELECT * FROM tbl WHERE c1 < 100; QUERY PLAN ----------------------------------------------------------- Index Scan using tbl_idx2 on tbl (cost=0.00..208.79 rows=100 width=10) Index Cond: (c1 < 100) (2 rows) postgres=# EXPLAIN SELECT * FROM tbl WHERE (c3 = '0' OR c3 = '1' OR c3 = '2'); QUERY PLAN ----------------------------------------------------------- Index Scan using tbl_idx on tbl (cost=0.00..114.34 rows=305 width=10) (1 row)
Indexのスキャン条件が無い!

27 Copyright © 2015 NTT DATA Corporation
今回のバグは・・・
PostgreSQLのオプティマイザの問題だった
PostgreSQLでは、FOR UPDATE やUPDATEなどの行ロックを必要とする場合、SELECT結果についてロック取得時に改めて再確認(EvalPlanQual)する -> ロック取得までにSELECT対象外のデータへ更新されている可能性があるので
postgres=# EXPLAIN SELECT * FROM tbl WHERE (c3 = '0' OR c3 = '1' OR c3 = '2') FOR UPDATE; QUERY PLAN --------------------------------------------------------------------- LockRows (cost=0.00..117.39 rows=305 width=16) -> Index Scan using tbl_idx on tbl (cost=0.00..114.34 rows=305 width=16) Filter: ((c3 = '0'::bpchar) OR (c3 = '1'::bpchar) OR (c3 = '2'::bpchar)) (3 rows)
そのため、部分インデックスを使っていたとしても、SELECT FOR UPDATE時にはWHERE句条件の省略最適化はしないようにしている・・・はずだった。
Indexのスキャン条件がある!

28 Copyright © 2015 NTT DATA Corporation
今回のバグは・・・
ところが・・
postgres=# EXPLAIN SELECT * FROM tbl WHERE (c3 = '0' OR c3 = '1' OR c3 = '2') FOR UPDATE;
QUERY PLAN
----------------------------------------------------------------------
LockRows (cost=0.00..198.78 rows=337 width=23)
-> Result (cost=0.00..195.41 rows=337 width=23)
-> Append (cost=0.00..195.41 rows=337 width=23)
-> Index Scan using tbl_idx on tbl (cost=0.00..114.34 rows=305 width=20)
-> Index Scan using tbl_c1_c3_c2_idx on tbl_c1 tbl (cost=0.00..40.54 rows=16 width=54)
-> Index Scan using tbl_c2_c3_c2_idx on tbl_c2 tbl (cost=0.00..40.54 rows=16 width=54)
Indexのスキャン条件が無い!
29 Copyright © 2015 NTT DATA Corporation
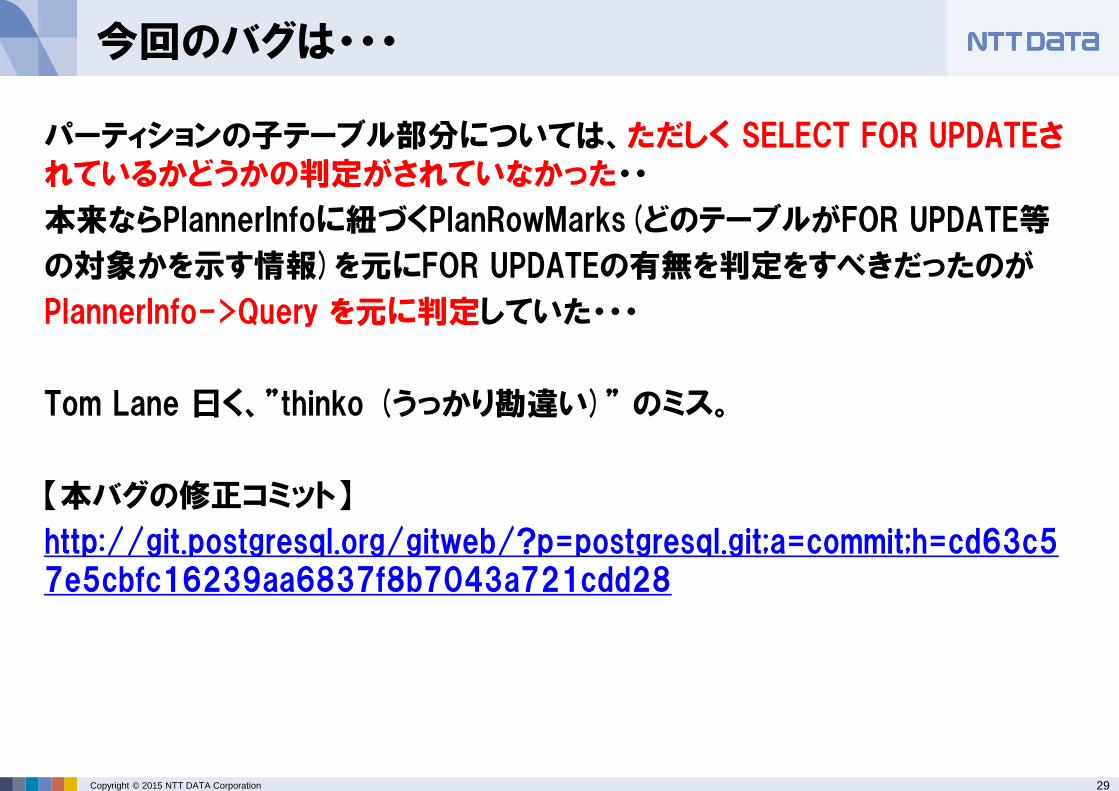
今回のバグは・・・
パーティションの子テーブル部分については、ただしく SELECT FOR UPDATEされているかどうかの判定がされていなかった・・
本来ならPlannerInfoに紐づくPlanRowMarks(どのテーブルがFOR UPDATE等
の対象かを示す情報)を元にFOR UPDATEの有無を判定をすべきだったのが
PlannerInfo->Query を元に判定していた・・・
Tom Lane 曰く、”thinko (うっかり勘違い)” のミス。
【本バグの修正コミット】
http://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=cd63c57e5cbfc16239aa6837f8b7043a721cdd28
30 Copyright © 2015 NTT DATA Corporation
今回のバグは・・・
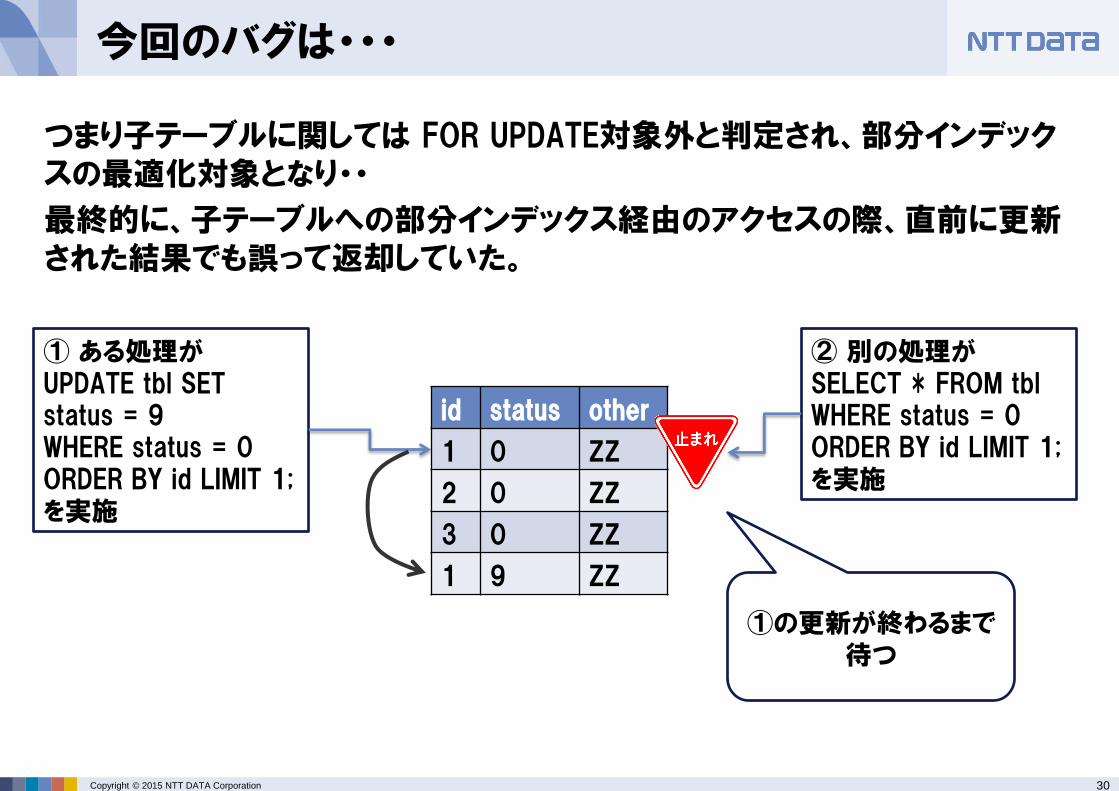
つまり子テーブルに関しては FOR UPDATE対象外と判定され、部分インデックスの最適化対象となり・・
最終的に、子テーブルへの部分インデックス経由のアクセスの際、直前に更新された結果でも誤って返却していた。
id status other
1 0 ZZ
2 0 ZZ
3 0 ZZ
1 9 ZZ
① ある処理が UPDATE tbl SET status = 9 WHERE status = 0 ORDER BY id LIMIT 1; を実施
② 別の処理が SELECT * FROM tbl WHERE status = 0 ORDER BY id LIMIT 1; を実施
①の更新が終わるまで待つ

31 Copyright © 2015 NTT DATA Corporation
今回のバグは・・・
つまり子テーブルに関しては FOR UPDATE対象外と判定され、部分インデックスの最適化対象となり・・
最終的に、子テーブルへの部分インデックス経由のアクセスの際、直前に更新された結果でも誤って返却していた。
id status other
1 0 ZZ
2 0 ZZ
3 0 ZZ
1 9 ZZ
③ COMMITする。 ④ SELECT * FROM tbl WHERE status = 0 ORDER BY id LIMIT 1; が走る
更新結果を参照する。

32 Copyright © 2015 NTT DATA Corporation
今回のバグは・・・
つまり子テーブルに関しては FOR UPDATE対象外と判定され、部分インデックスの最適化対象となり・・
最終的に、子テーブルへの部分インデックス経由のアクセスの際、直前に更新された結果でも誤って返却していた。
id status other
1 0 ZZ
2 0 ZZ
3 0 ZZ
1 9 ZZ
⑤ SELECT * FROM tbl WHERE status = 0 ORDER BY id LIMIT 1; の結果 status = 9 のものが返ってくる
本来であれば WHERE句 条件の status = 0 の再確認をすべきだが それをしないために、status = 9
であっても返してしまう

33 Copyright © 2015 NTT DATA Corporation
解決
というわけで、SELECT結果が間違っていた理由がわかった。
・ 再現頻度の低さは、当該のSQLは FOR UPDATE NOWAIT をしており、
よりシビアな条件だったから
一応、歯止めのフィルタ関数もあり、かつ発生条件に該当するSQLはそこだけだった。
(パーティションかつ部分インデックスを使っているSQLなので、絞り込みやすいことが幸いだった・・)

34 Copyright © 2015 NTT DATA Corporation
振り返って
エンタープライズ、に限りませんが、
深刻な問題は根本原因を特定すること
= ホワイトボックスとして明確にすることが大切です。
今回の事象も、根本原因が分かったため、
・なぜ今まで発生頻度が低かったか?
・不具合の発生影響が他にないのか?
・検討した対処が本当に正しいのか?
を見極めることができました。
PostgreSQLのコードには、親切なREADMEやコメントが多数あります。
これらの情報やcoreの情報、問題発生状況を元に、地道に検査していけば
多くの場合は何とかなります・・多分。
bugs ML などを通じてコミュニティに報告するのもアリです。ただし、必ず
再現資材(self-contained test case)を添えましょう。

35 Copyright © 2015 NTT DATA Corporation
ご清聴ありがとうございました!

Copyright © 2011 NTT DATA Corporation
Copyright © 2015 NTT DATA Corporation 本資料には、当社の秘密情報が含まれております。当社の許可なく第三者へ開示することはご遠慮ください。