Embed Size (px)
Citation preview

集合知プログラミング
参考:『集合知プログラミング』,Toby Segaran著/當山 仁健,鴨澤 眞夫 訳,O'LEILLY
スライド作成:真嘉比 愛

集合知とは?
● 集合知(Collective Intelligence)とは,多くの人による大量の情報の寄せ集めの集計のこと.
→ 今までにない知見を生み出すために,集団の振る舞い,嗜好,アイディアを結びつける事
・ Wikipedia・ Google …PageRank etc
はてなキーワード:http://d.hatena.ne.jp/keyword/%BD%B8%B9%E7%C3%CE

Wikipedia と Google
● Wikipedia● 情報を提供してくれる利用者の存在に依る所が大きい.
● Google(PageRank)● 利用者のデータを利用して計算を行い,利用者の経験
を拡大する事のできるような新たな情報を作り上げる.
単に情報を集めて表示するのではなく,情報を知的な方法で処理して新たな情報を生み出す
オープンなAPI,機械学習,統計,...

ある人々の集団の選択を利用して,他の人への推薦を行う方法
(ex. Amazonの類似ユーザの購入物紹介)

協調フィルタリング
● 大規模な人々の集団を検索してその人と好みが似た人々の小集団を発見する.
● その集団が好きな他のものも見て,それらを組み合わせ,順位付けをした推薦のリストを作成する.
“人間の嗜好の情報を表現する”にはどうすればいいのか?
類似性スコアを算出すればよい. ・ ユークリッド距離 ・ ピアソン相関

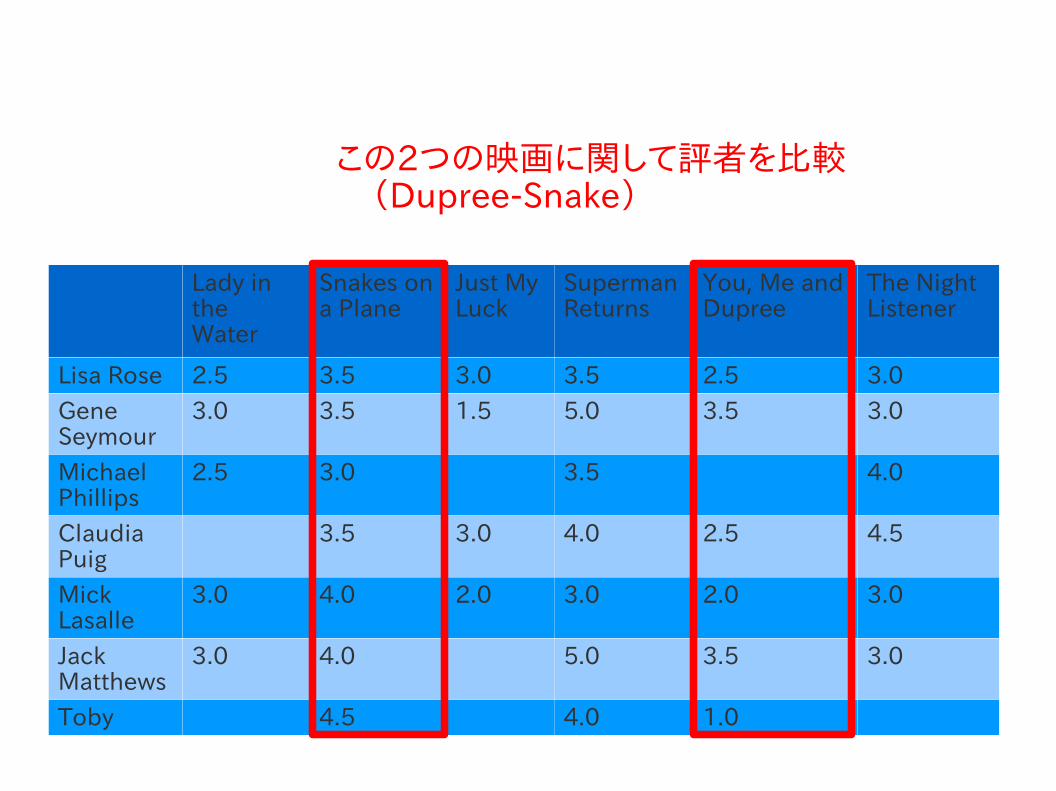
嗜好の収集
Lady in the Water
Snakes on a Plane
Just My Luck
Superman Returns
You, Me and Dupree
The Night Listener
Lisa Rose 2.5 3.5 3.0 3.5 2.5 3.0
Gene Seymour
3.0 3.5 1.5 5.0 3.5 3.0
Michael Phillips
2.5 3.0 3.5 4.0
Claudia Puig
3.5 3.0 4.0 2.5 4.5
Mick Lasalle
3.0 4.0 2.0 3.0 2.0 3.0
Jack Matthews
3.0 4.0 5.0 3.5 3.0
Toby 4.5 4.0 1.0
ex. 映画の評者といくつかの映画に対する彼らの評点

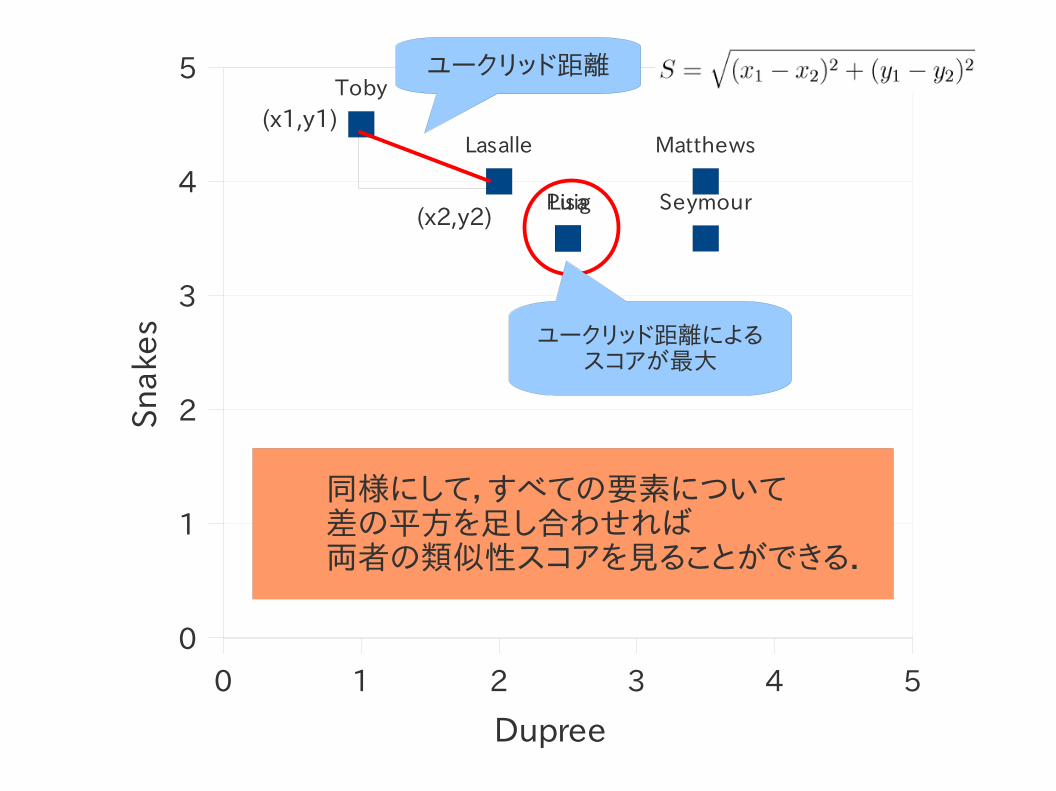
ユークリッド距離によるスコア
● ユークリッド距離とは?● の式により,2点間の距離を求める.● 距離が小さいほど似ているという事になる.
● 上記の式に1を加えて逆数をとる.● 似ていれば似ているほど高い数値を返す.● 常に0~1の間の値を返す.
– 値が1という事は,両者が寸分違わず同じという事
0で除算してエラーになるのを防ぐ
Lady in the Water
Snakes on a Plane
Just My Luck
Superman Returns
You, Me and Dupree
The Night Listener
Lisa Rose 2.5 3.5 3.0 3.5 2.5 3.0
Gene Seymour
3.0 3.5 1.5 5.0 3.5 3.0
Michael Phillips
2.5 3.0 3.5 4.0
Claudia Puig
3.5 3.0 4.0 2.5 4.5
Mick Lasalle
3.0 4.0 2.0 3.0 2.0 3.0
Jack Matthews
3.0 4.0 5.0 3.5 3.0
Toby 4.5 4.0 1.0
この2つの映画に関して評者を比較 (Dupree-Snake)
0 1 2 3 4 5
0
1
2
3
4
5
Lisa SeymourPuig
Lasalle Matthews
Toby
Dupree
Sn
ake
s(x1,y1)
(x2,y2)
ユークリッド距離
ユークリッド距離によるスコアが最大
同様にして,すべての要素について 差の平方を足し合わせれば 両者の類似性スコアを見ることができる.

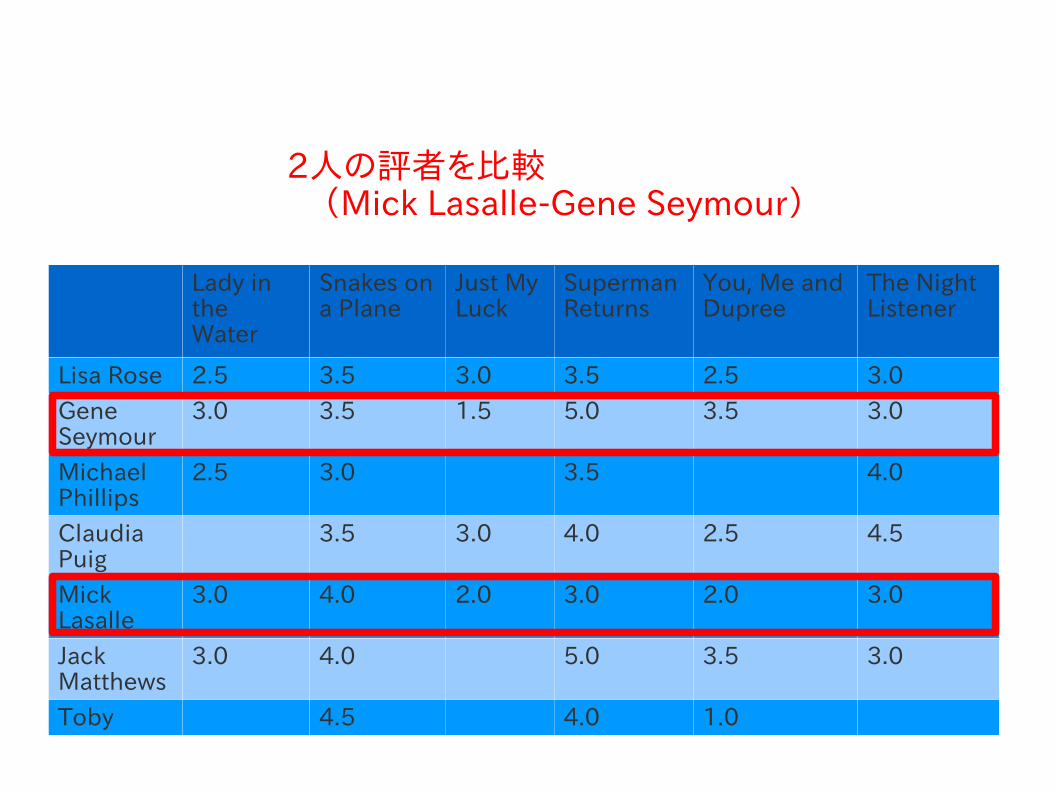
ピアソン相関によるスコア
● ピアソン相関係数● 2つのデータセットがある直線にどの程度沿っているか
を示す.● データが正規化されていないような状況では,ユーク
リッド距離を用いるより効果的.– ex. 映画の評価が平均より厳しい場合など
Lady in the Water
Snakes on a Plane
Just My Luck
Superman Returns
You, Me and Dupree
The Night Listener
Lisa Rose 2.5 3.5 3.0 3.5 2.5 3.0
Gene Seymour
3.0 3.5 1.5 5.0 3.5 3.0
Michael Phillips
2.5 3.0 3.5 4.0
Claudia Puig
3.5 3.0 4.0 2.5 4.5
Mick Lasalle
3.0 4.0 2.0 3.0 2.0 3.0
Jack Matthews
3.0 4.0 5.0 3.5 3.0
Toby 4.5 4.0 1.0
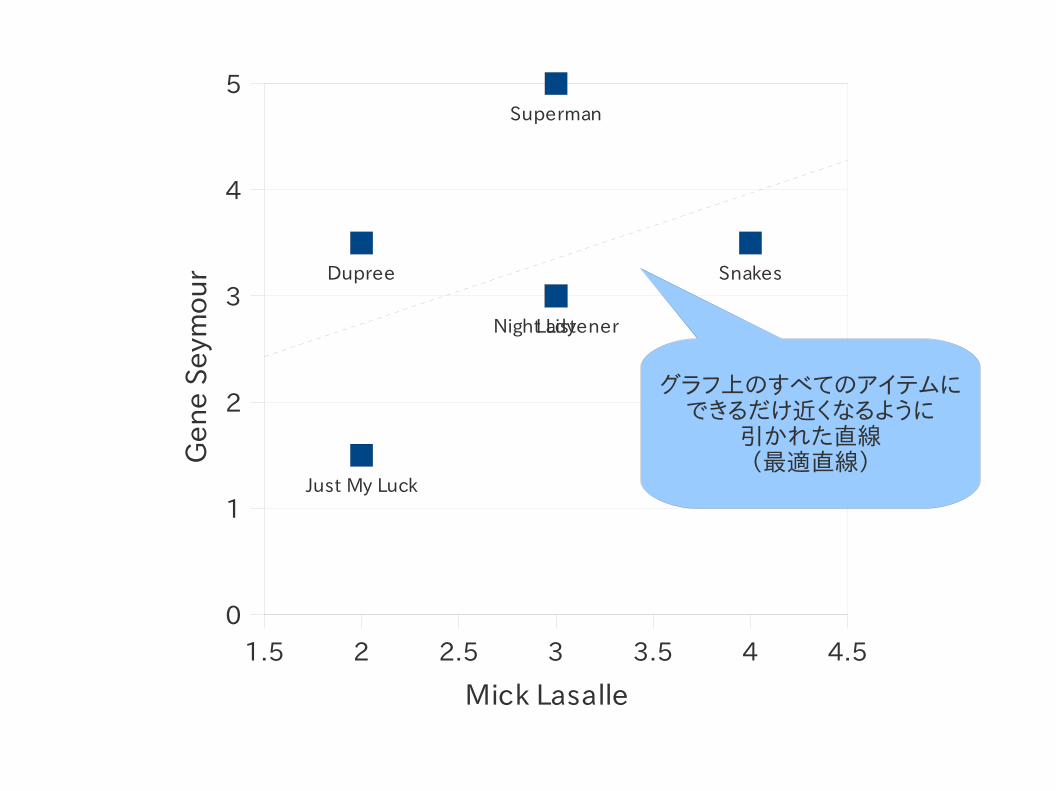
2人の評者を比較 (Mick Lasalle-Gene Seymour)
1.5 2 2.5 3 3.5 4 4.5
0
1
2
3
4
5
Lady
Snakes
Just My Luck
Superman
Dupree
Night Listener
Mick Lasalle
Ge
ne
Se
ymo
ur
グラフ上のすべてのアイテムにできるだけ近くなるように
引かれた直線(最適直線)
Lady in the Water
Snakes on a Plane
Just My Luck
Superman Returns
You, Me and Dupree
The Night Listener
Lisa Rose 2.5 3.5 3.0 3.5 2.5 3.0
Gene Seymour
3.0 3.5 1.5 5.0 3.5 3.0
Michael Phillips
2.5 3.0 3.5 4.0
Claudia Puig
3.5 3.0 4.0 2.5 4.5
Mick Lasalle
3.0 4.0 2.0 3.0 2.0 3.0
Jack Matthews
3.0 4.0 5.0 3.5 3.0
Toby 4.5 4.0 1.0
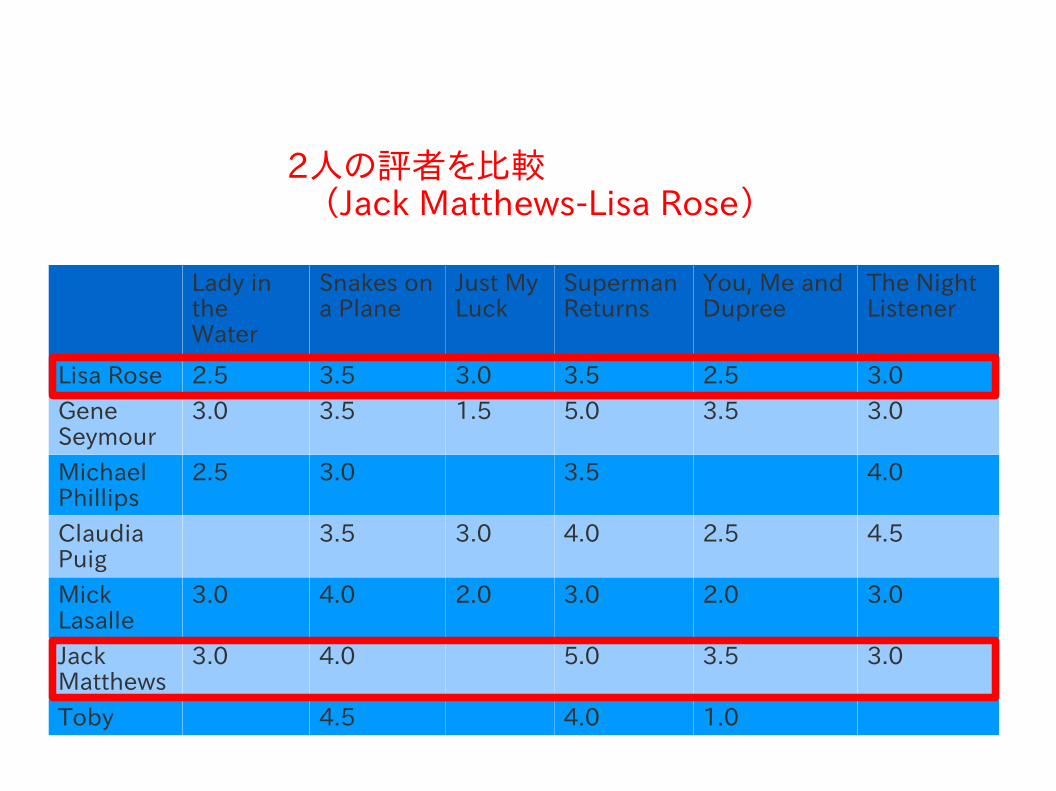
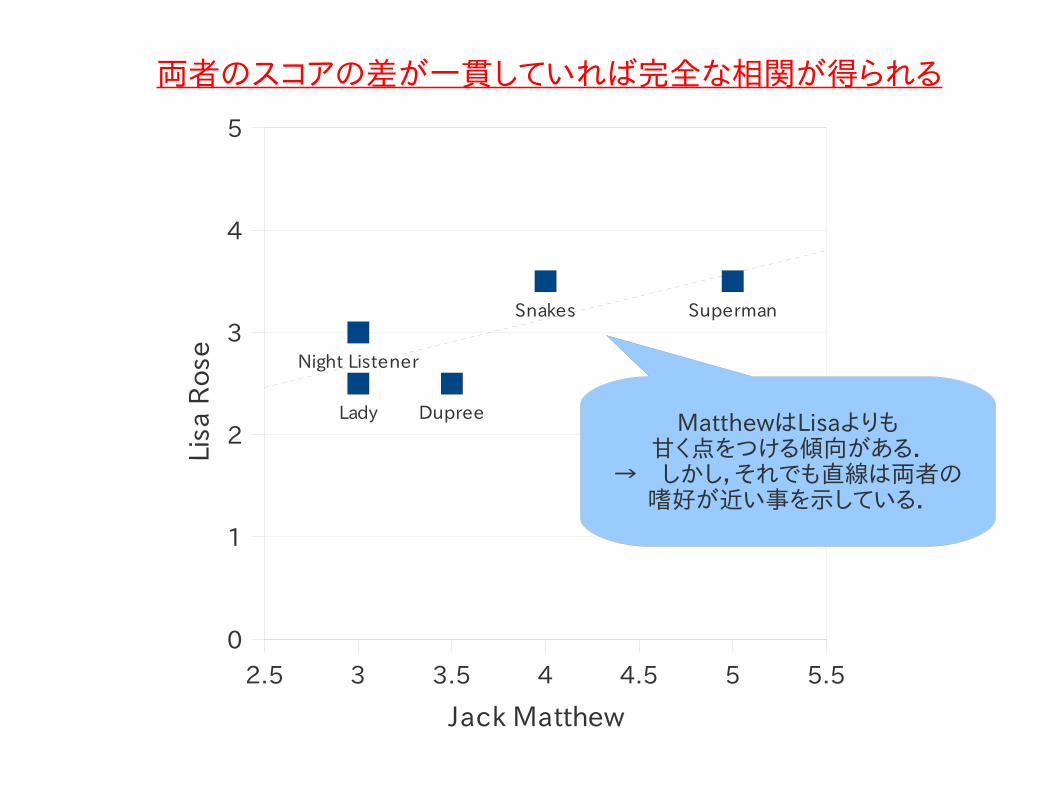
2人の評者を比較 (Jack Matthews-Lisa Rose)
2.5 3 3.5 4 4.5 5 5.5
0
1
2
3
4
5
Lady
Snakes Superman
Dupree
Night Listener
Jack Matthew
Lisa
Ro
se
MatthewはLisaよりも甘く点をつける傾向がある.
→ しかし,それでも直線は両者の嗜好が近い事を示している.
両者のスコアの差が一貫していれば完全な相関が得られる

ピアソン相関によるスコア
● スコアが完全に相関している場合(値:1)
→グラフ上の全てのアイテムが直線上にのる.
● -1~1の範囲で値をとる.
● num=pSum-(sum1*sum2/n)
● den=sqrt((sum1Sq-pow(sum1,2)/n)*(sum2Sq-pow(sum2,2)/n))
● sum1, sum2: それぞれの評者の評点の合計
● sum1Sq, sum2Sq: 評点の平方の合計
● n: 要素の数
● pSum: 評価をかけあわせた値の合計

類似性尺度は他にも色々ある・Jaccard係数
・マンハッタン距離
→ どの方法がよりベストなのかは,作るアプリケーションによって異なる

アイテムの推薦
● 評者をランキング● 最も類似性スコアが高いものを推薦リストの一番上に持ってくる.
→ よい評者を探し出せた!
しかし,本当にやりたいのは映画を今すぐ推薦してもらう事 → 推薦された評者が好きな映画で自分が見ていないものを探す? → 回りくどい!!&良い映画を逃してしまうかもしれない
評者に順位付けをした重み付きスコアを算出することで,アイテムにスコアをつける必要がある!!
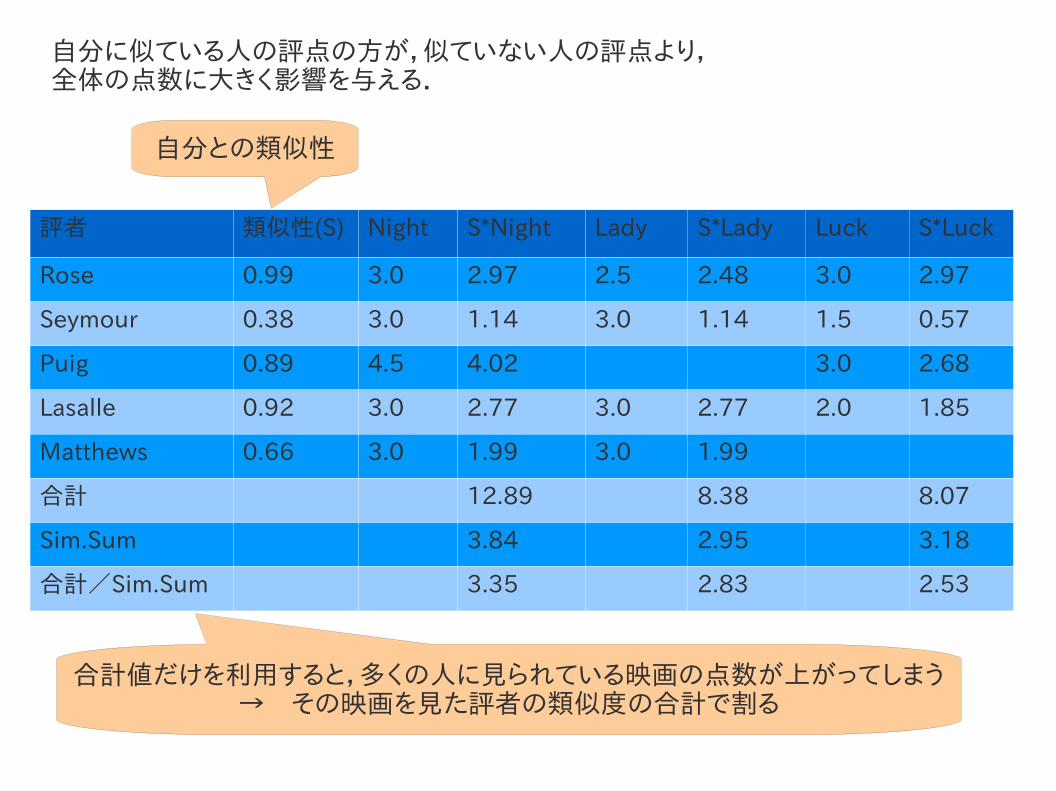
評者 類似性(S) Night S*Night Lady S*Lady Luck S*Luck
Rose 0.99 3.0 2.97 2.5 2.48 3.0 2.97
Seymour 0.38 3.0 1.14 3.0 1.14 1.5 0.57
Puig 0.89 4.5 4.02 3.0 2.68
Lasalle 0.92 3.0 2.77 3.0 2.77 2.0 1.85
Matthews 0.66 3.0 1.99 3.0 1.99
合計 12.89 8.38 8.07
Sim.Sum 3.84 2.95 3.18
合計/Sim.Sum 3.35 2.83 2.53
自分との類似性
自分に似ている人の評点の方が,似ていない人の評点より,全体の点数に大きく影響を与える.
合計値だけを利用すると,多くの人に見られている映画の点数が上がってしまう→ その映画を見た評者の類似度の合計で割る
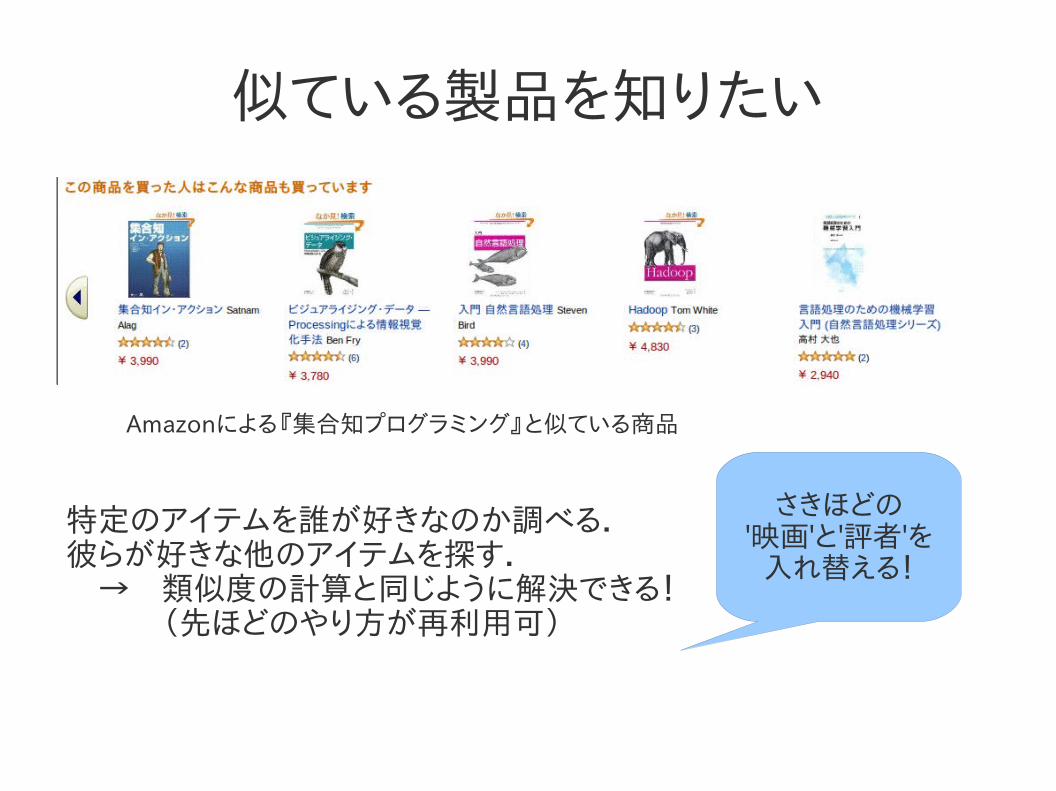
似ている製品を知りたい
Amazonによる『集合知プログラミング』と似ている商品
特定のアイテムを誰が好きなのか調べる.彼らが好きな他のアイテムを探す. → 類似度の計算と同じように解決できる! (先ほどのやり方が再利用可)
さきほどの'映画'と'評者'を
入れ替える!

これまで紹介してきた推薦エンジンは,データセットを作成するためには,
全てのユーザからのランキングが必要!
→ 人やアイテムの数が多くなった場合どう対処すればいいか

ユーザベースの協調フィルタリングの問題
● 大規模サイトでは,● あるユーザを他のすべてのユーザと比べたり,● ユーザが評価したそれぞれの製品を比較する.
→ 物凄く時間がかかる.● 数百万点の製品を売るような差しとでは,人々の重
なりあう部分が少ない.
→ 誰と誰が似ているのかを決めるのが難しい.
ユーザベースからアイテムベースへ

アイテムベースの協調フィルタリング
● それぞれのアイテムに似ているアイテムたちを前もって計算しておく.
● あるユーザに推薦をしたくなった時には,● そのユーザが高く評価しているアイテムたちを参照● それらに対して似ている順に重み付けされたアイテムたちのリ
ストを作る.
→ 大規模データセットを対象とする場合,アイテム ベース協調フィルタリングの方がよい結果を出す.
→ 計算の大部分は事前に行われる為,処理が速い.

アイテム間の類似度のデータセットを作る
● 似ているアイテムたちの完全なデータセットを作る.● 作るのは1度だけで,必要な時には再利用する.
1. それぞれのユーザがアイテムをどのように 評価しているのかというリストを作る. 2. すべてのアイテムをループして,似ているアイテムたちを その類似性スコアと共に取得. 3. 最後にアイテムをキーとして,それぞれのアイテムにもっとも似ている アイテムたちのリストを持ったディクショナリを返す. ex. {'Lady in the Water' : [(0.400000, 'You, Me and Dupree'), (0.285714, 'The Night listener'), ... 'Snakes on Plane' : [(0.222222, 'Lady in the water'), (0.181818, 'The Night Listenner'), … etc.

推薦を行う
● 特定のユーザが評価したすべてのアイテムを取得.● 似ているアイテムを探し,類似度を利用して重みを
つける.● ディクショナリを利用.

ユーザベース VS アイテムベース
● 大きなデータセットから,たくさんの推薦が得たい!● アイテムベースのフィルタリングは高速.
– アイテム類似度データベースをメンテナンスする必要がある.
● データセットがどの程度「疎」であるかによって正確性が異なる(データセットが密であれば性能はほぼ同等).
– 映画の例:評者たちはほとんどすべての映画に対して評価を持っていた → 密
– 大規模サイトの例:同じデータセットを持った人は少ない(多くのブックマークは少人数のグループによって記録されている) → 疎
● メモリに収まるサイズで,変更が頻繁に行われるようなデータせっとに関しては,ユーザーベースが良い.● ユーザベースはシンプルで,余計なステップを必要としない.
● ユーザの嗜好が独自の値を持っている音楽サイトなどに向いている.





























