Embed Size (px)
Citation preview

Sparkを用いた ビッグデータ解析
~ 後編 ~株式会社サイバーエージェント アドテク本部アドテクスタジオ
谷口 和輝

Introduction
■ 所属: SAT(Scientific Advertising Team)
■ 職業: Data Scientist ■ 最近気になる技術:
■ Apache Spark
■ Presto.io
■ React.js
2

Apache Sparkが データサイエンティストの 次世代分析基盤となる
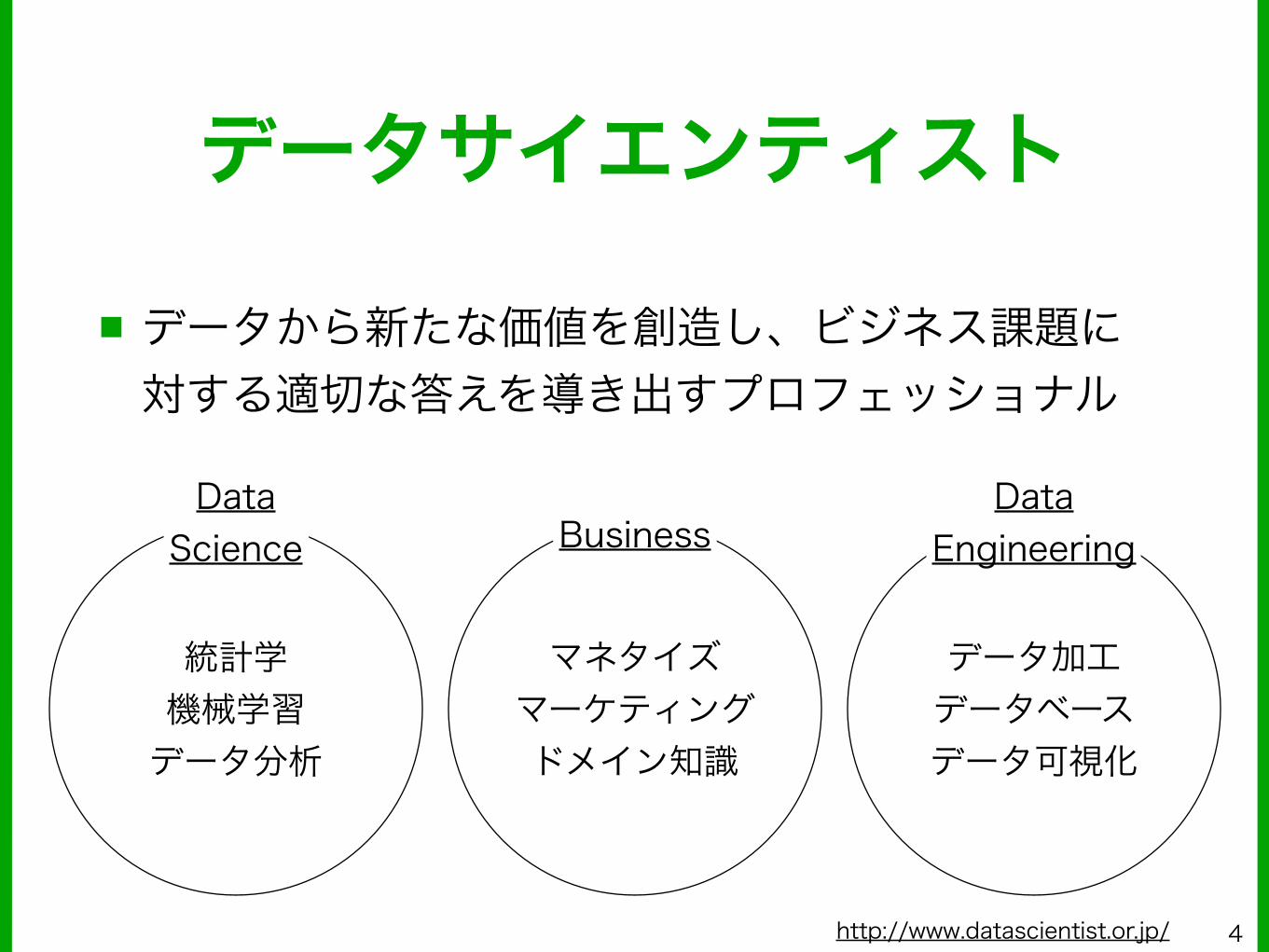
データサイエンティスト
4
Business
統計学 機械学習 データ分析
データ加工 データベース データ可視化
マネタイズ マーケティング ドメイン知識
Data Science
Data Engineering
■ データから新たな価値を創造し、ビジネス課題に対する適切な答えを導き出すプロフェッショナル
http://www.datascientist.or.jp/

アドテクにおける データサイエンティスト
■ ビッグデータとの格闘 ■ 数億レコード/日のデータ量 ■ 多種多様なデータ (impressions, users, conversions etc..)
!
■ ビジネスの意思決定スピード ■ 意思決定を支援することが非常に重要 ■ 正確かつ素早いデータ分析が求められる
5
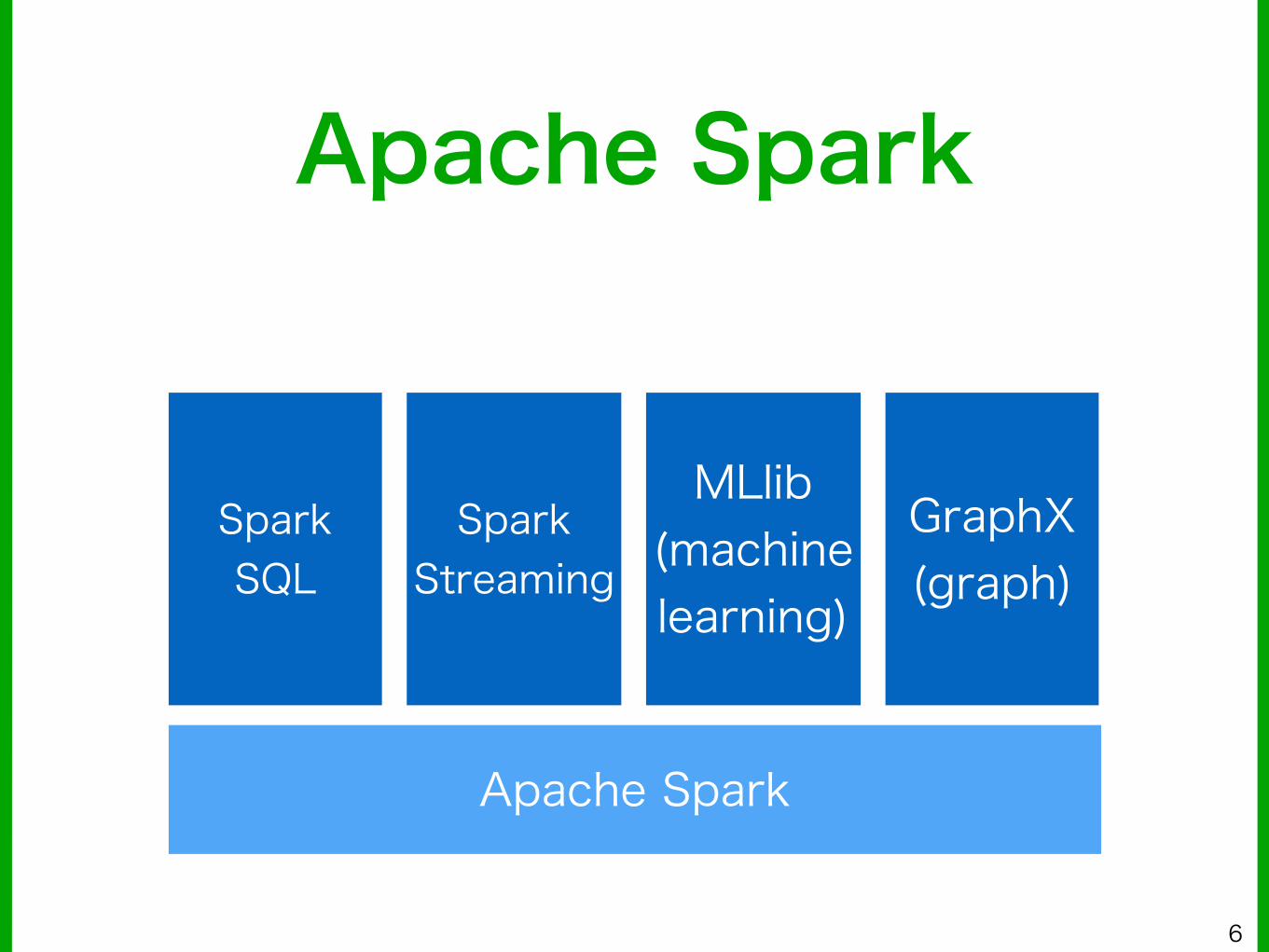
Apache Spark
6
Spark SQL
Spark Streaming
MLlib (machine learning)
GraphX (graph)
Apache Spark
Agenda
■ MLlib
■ Spark SQL
■ DataFrame
7
Spark SQL
Spark Streaming
MLlib (machine learning)
GraphX (graph)
Apache Spark

MLlib
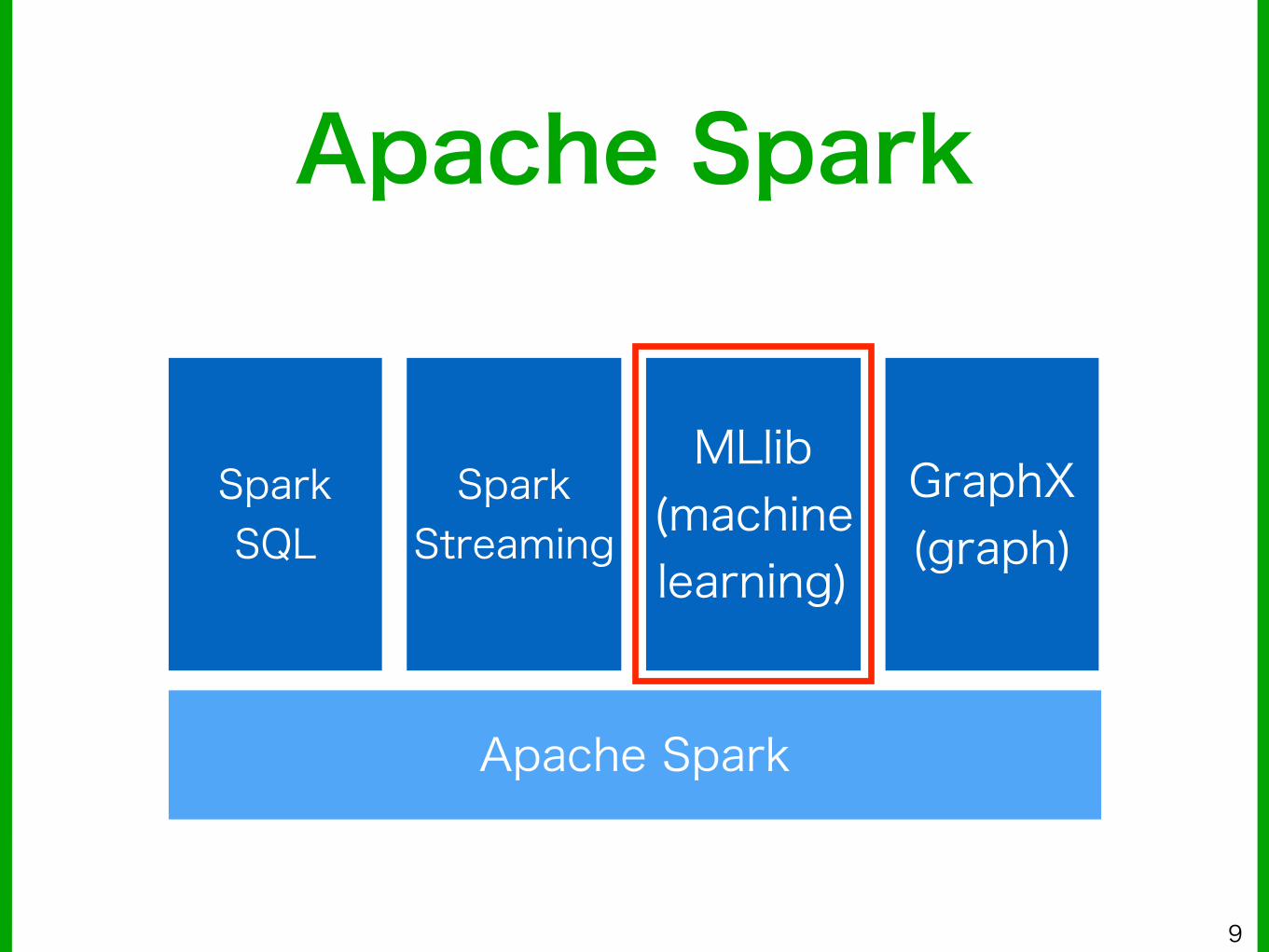
Apache Spark
9
Spark SQL
Spark Streaming
MLlib (machine learning)
GraphX (graph)
Apache Spark

MLlib■ Sparkのエコシステムの中の機械学習ライブラリ
■ Statistics
■ Classification
■ Regression
■ Tree
■ Clustering
■ Recommendation
■ Feature
■ Evaluation
■ etc...10
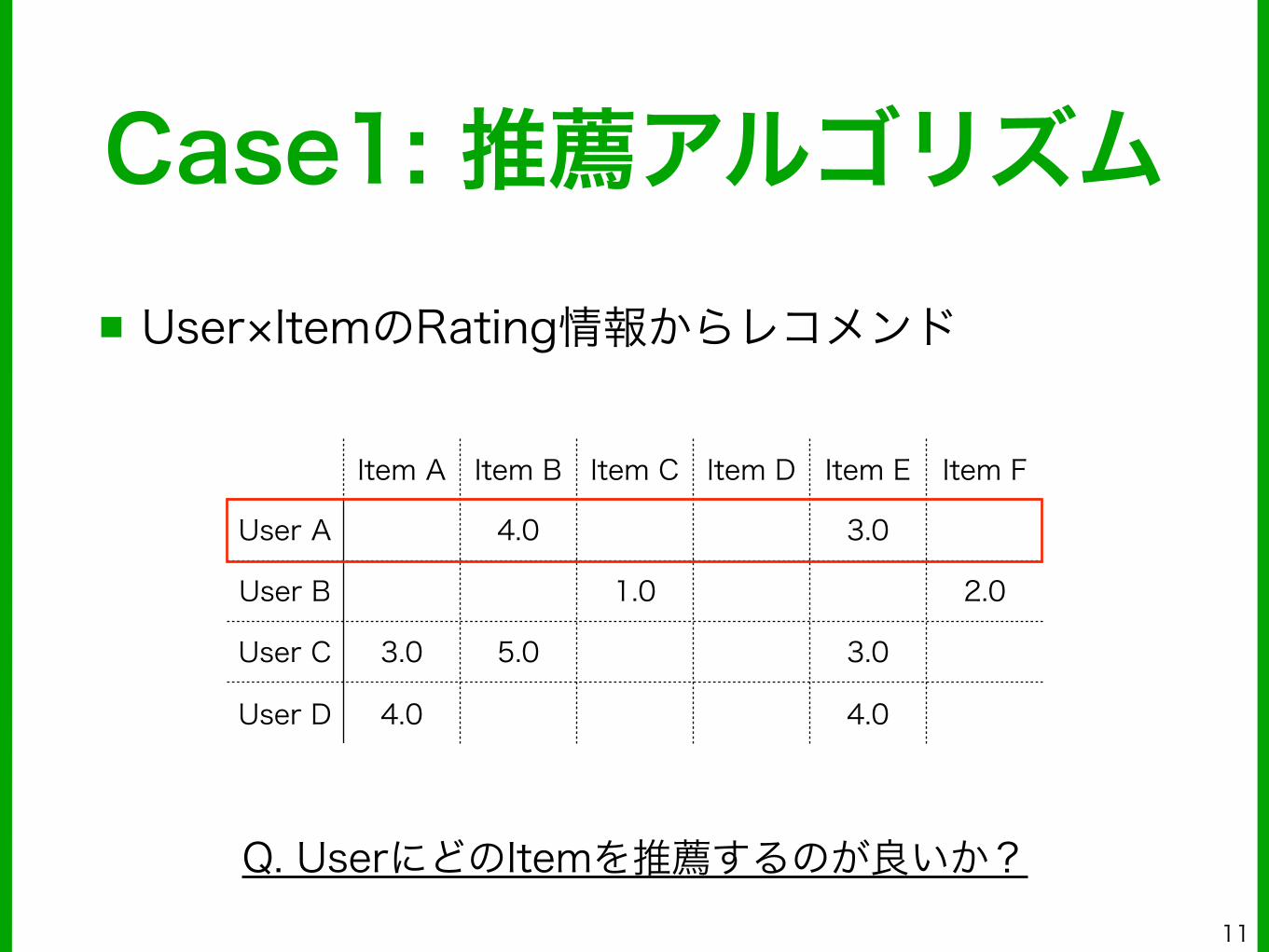
■ User×ItemのRating情報からレコメンド
Case1: 推薦アルゴリズム
11
Item A Item B Item C Item D Item E Item F
User A 4.0 3.0
User B 1.0 2.0
User C 3.0 5.0 3.0
User D 4.0 4.0
Q. UserにどのItemを推薦するのが良いか?
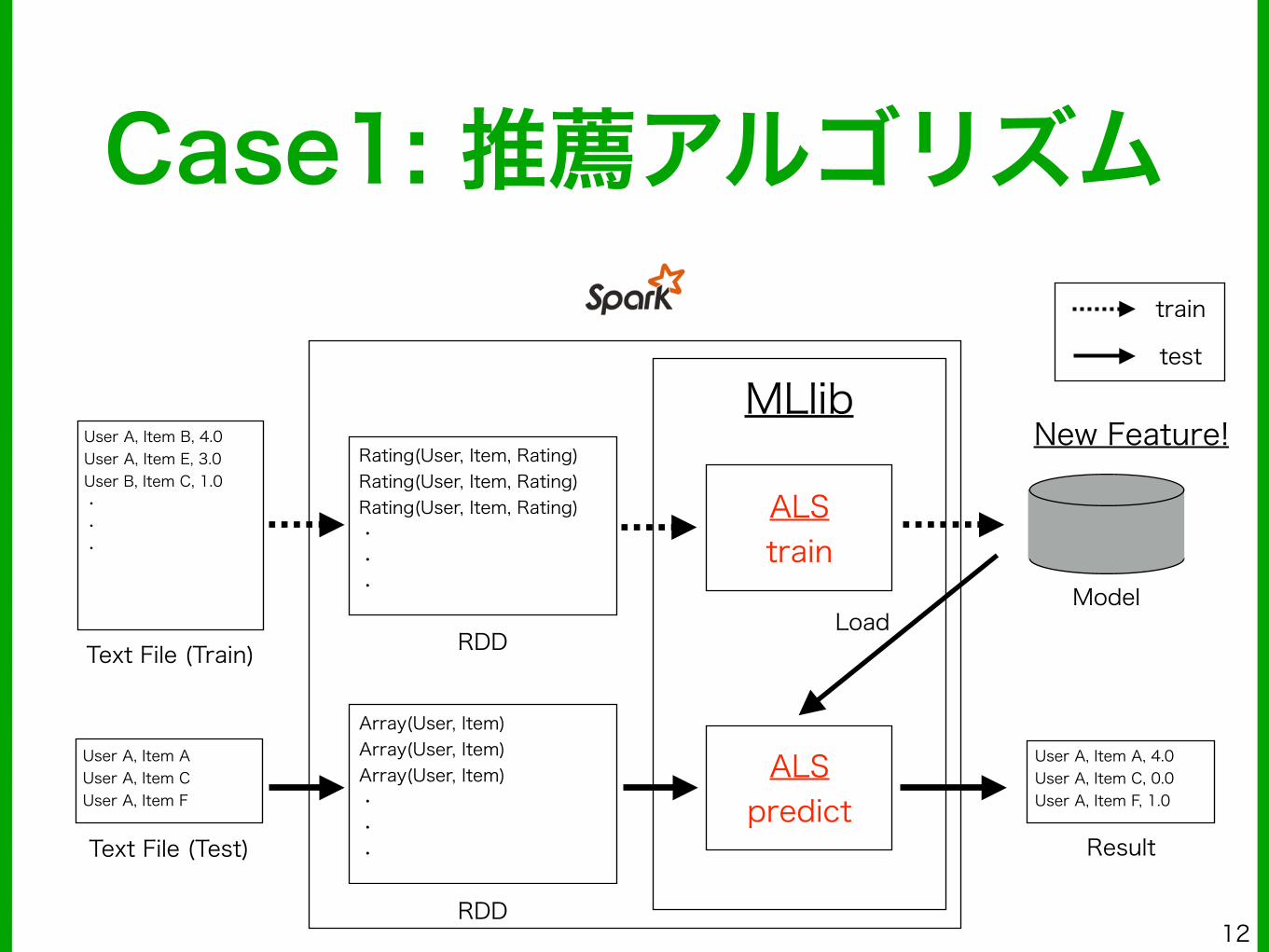
Case1: 推薦アルゴリズム
12
User A, Item B, 4.0 User A, Item E, 3.0 User B, Item C, 1.0 ・ ・ ・
Text File (Train)
Rating(User, Item, Rating) Rating(User, Item, Rating) Rating(User, Item, Rating) ・ ・ ・
RDD
Array(User, Item) Array(User, Item) Array(User, Item) ・ ・ ・
RDD
ALS train
MLlib
ALS predict
User A, Item A User A, Item C User A, Item F
Text File (Test)
ModelLoad
User A, Item A, 4.0 User A, Item C, 0.0 User A, Item F, 1.0
Result
train
test
New Feature!

Case2: トピックモデル
13
■ ある文章を各単語に与えられたトピックで表現
Topic A Topic B
学生 システム
授業 機能
大学 開発
学科 データ
0
2
3
5
6
学生 授業 大学 学科 システム 機能 開発 データ
トピックモデル※上の単語ほどトピックの
意味を強く表現
ある文章の単語の出現頻度
Topic Bに分類
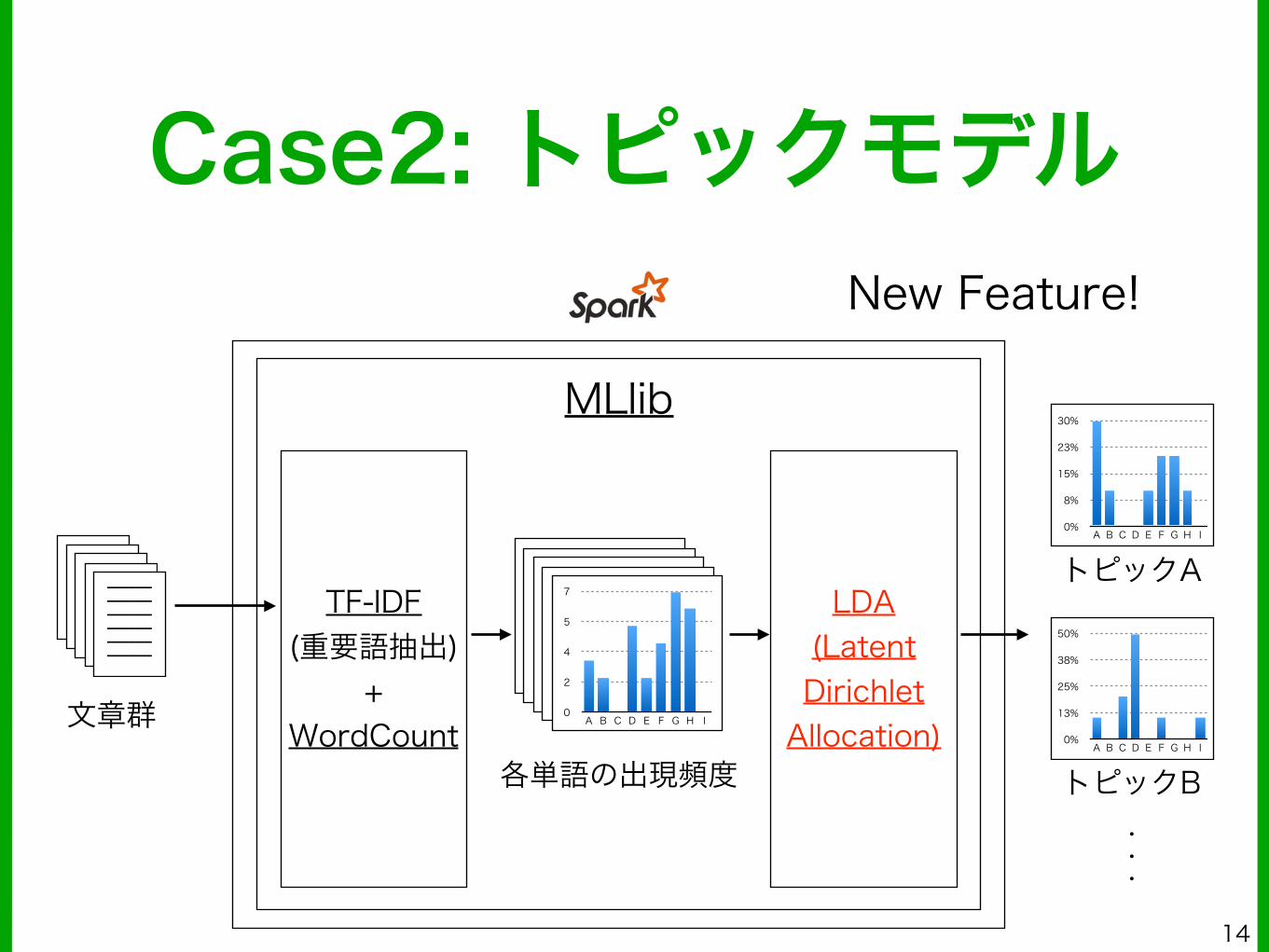
Case2: トピックモデル
14
MLlib
0
2
4
5
7
A B C D E F G H I0
2
4
5
7
A B C D E F G H I0
2
4
5
7
A B C D E F G H I0
2
4
5
7
A B C D E F G H I0
2
4
5
7
A B C D E F G H I
LDA (Latent Dirichlet Allocation)
TF-IDF (重要語抽出)
+ WordCount
各単語の出現頻度
0%
8%
15%
23%
30%
A B C D E F G H I
0%
13%
25%
38%
50%
A B C D E F G H I
トピックA
トピックB・ ・ ・
文章群
New Feature!

MLlibのこれから■ Deep Learning ■ Neural Network ■ Auto Encoder, RBM etc...
■ Streaming ML ■ LogisticRegression (Released in 1.3.1)
15

Spark SQL
Apache Spark
17
Spark SQL
Spark Streaming
MLlib (machine learning)
GraphX (graph)
Apache Spark

Spark SQL■ データサイエンティストのボトルネックはETL ■ ETL (Extract, Transform, Load) ■ 散らばった大規模データを収集, 利用する形に加工
!
■ Spark SQL ■ 複数のリソースに接続可能 ■ 取得したデータをそのままMLlibなどに使える
18

Data Sources■ RDD (TextFile, HDFS, AWS S3)
■ JSON Files
■ Parquet Files
■ Hive Tables
■ JDBC / ODBC (New Feature!)
19

SchemeRDD■ RDD[Row] ■ RDDの各要素がテーブルの行
■ Scheme名とDataTypeをプロパティとして所持
■ 通常のRDDの機能に加えてクエリの機能を追加
20

Query ~SchemeRDD~
■ registerTable()によりテーブルを登録
■ クエリは基本的なSQLに対応
21
val user = sqlContext.jsonFile(“user.json”) user.registerTable(“users”) val result: SchemeRDD = sqlContext.sql(“SELECT name FROM users WHERE age >= 20”)

DataFrame
Apache Spark
23
Spark SQL
Spark Streaming
MLlib (machine learning)
GraphX (graph)
Apache Spark

DataFrame■ データサイエンティスト待望の機能 ■ SchemeRDD (~ 1.2) => DataFrame (1.3 ~)
■ パフォーマンスもRDDでの処理より高速
■ Python => pandas, R => DataFrame
■ 従来の分析環境に慣れている人の移行コスト減
24

Query ~DataFrame~
■ 取得してきたデータをそのまま加工
■ メソッド(filter, groupby, agg, etc…)チェーンしていくことで柔軟に必要なデータを取得
■ UDF(User Defined Functions)も自ら実装可能25
val result = user.filter(“age >= 20”)

Pandasとの連携
■ 多くのデータサイエンティストに利用されているpandas.DataFrameに変換可能(逆も可)
ビッグデータ => spark.sql.DataFrame スモールデータ => pandas.DataFrame
26
pandas_df = df.toPandas()

Conclusion
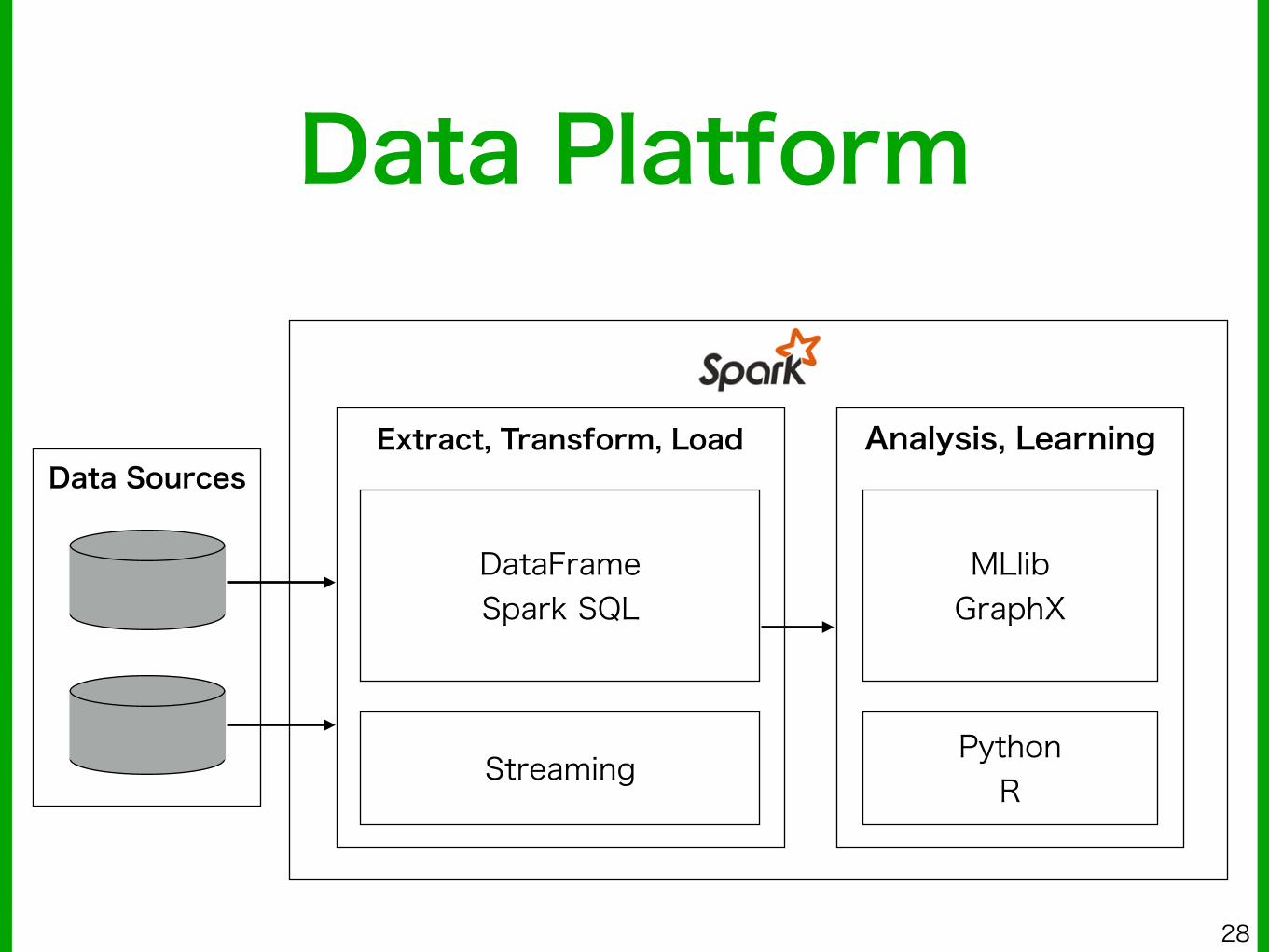
Data Platform
28
Extract, Transform, Load
DataFrame Spark SQL
Streaming
Analysis, Learning
MLlib GraphX
Python R
Data Sources

Summary!
■ Apache Sparkは大規模データを高速にETLから分析まで可能な次世代分析基盤
!
■ 1.3.0のリリースで既存のデータサイエンティストの移行コストが大幅に減少
29

Apache Sparkが データサイエンティストの 次世代分析基盤となる





























