Embed Size (px)
Citation preview

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Olivier Klein 奧樂凱Solutions Architect, Greater China
April 2016
Real-time Analytics with
Open-Source and AWS

“We see our customers as
invited guests to a party,
and we are the hosts. It’s
our job to make every
important aspect of the
customer experience
a little bit better.”Jeff Bezos
CEO, Amazon.com
Data analysis for a better customer experience
• Your business creates and stores
data and logs all the time
• Data points and logs allow you to
understand individual customer
experience and improve it
• Analysis of logs and trails help
gain insights

How does Open-Source fit into Data Analytics?
Most Notably: Apache Hadoop
• Open-Source Project for distributed
storage and distributed
processing of very large data sets
• Scales linearly on commodity
hardware compute nodes
• Has an entire ecosystem built
around it for various purposes
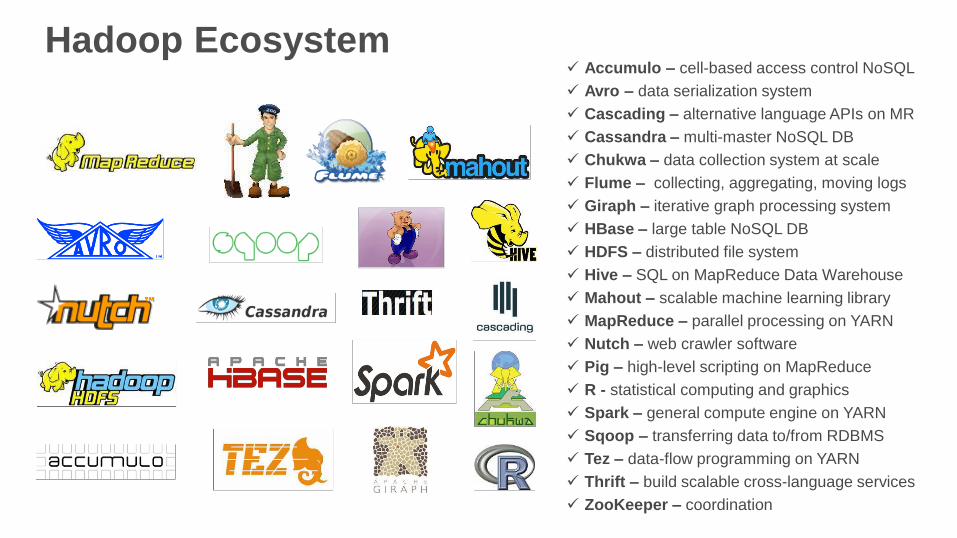
Accumulo – cell-based access control NoSQL
Avro – data serialization system
Cascading – alternative language APIs on MR
Cassandra – multi-master NoSQL DB
Chukwa – data collection system at scale
Flume – collecting, aggregating, moving logs
Giraph – iterative graph processing system
HBase – large table NoSQL DB
HDFS – distributed file system
Hive – SQL on MapReduce Data Warehouse
Mahout – scalable machine learning library
MapReduce – parallel processing on YARN
Nutch – web crawler software
Pig – high-level scripting on MapReduce
R - statistical computing and graphics
Spark – general compute engine on YARN
Sqoop – transferring data to/from RDBMS
Tez – data-flow programming on YARN
Thrift – build scalable cross-language services
ZooKeeper – coordination
Hadoop Ecosystem

Tell me more about Big Data!
Ever Increasing Amount of Data
Volume
Velocity
Variety
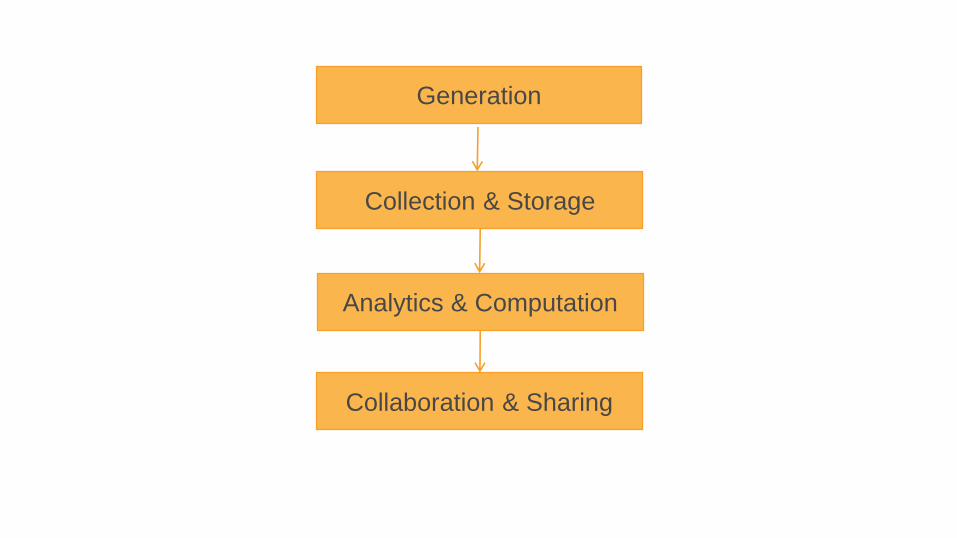
Generation
Collection & Storage
Analytics & Computation
Collaboration & Sharing
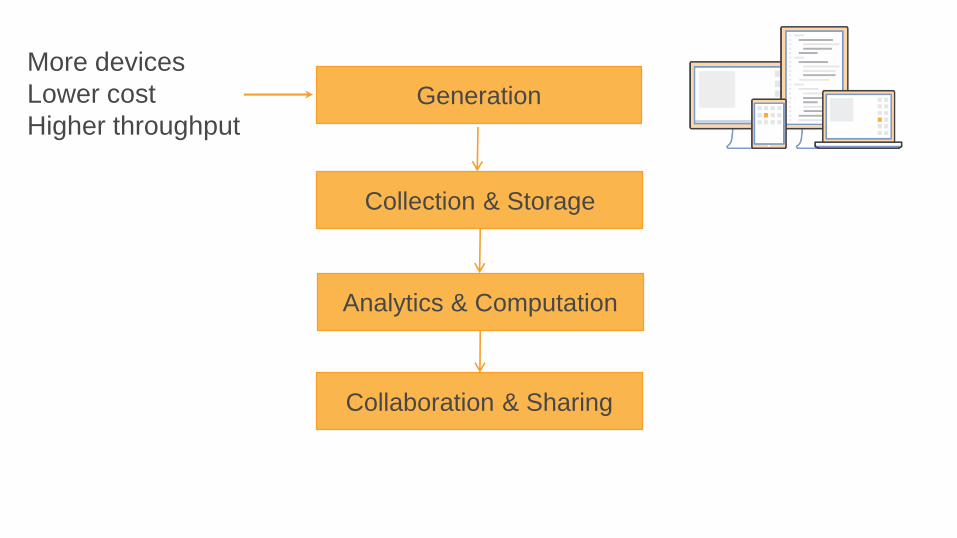
More devices
Lower cost
Higher throughputGeneration
Collection & Storage
Analytics & Computation
Collaboration & Sharing
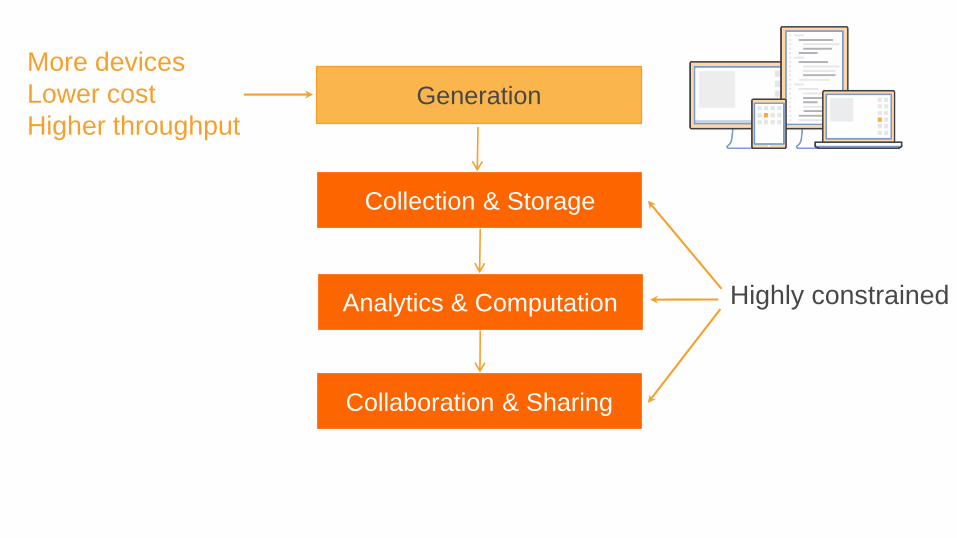
Highly constrained
More devices
Lower cost
Higher throughputGeneration
Collection & Storage
Analytics & Computation
Collaboration & Sharing
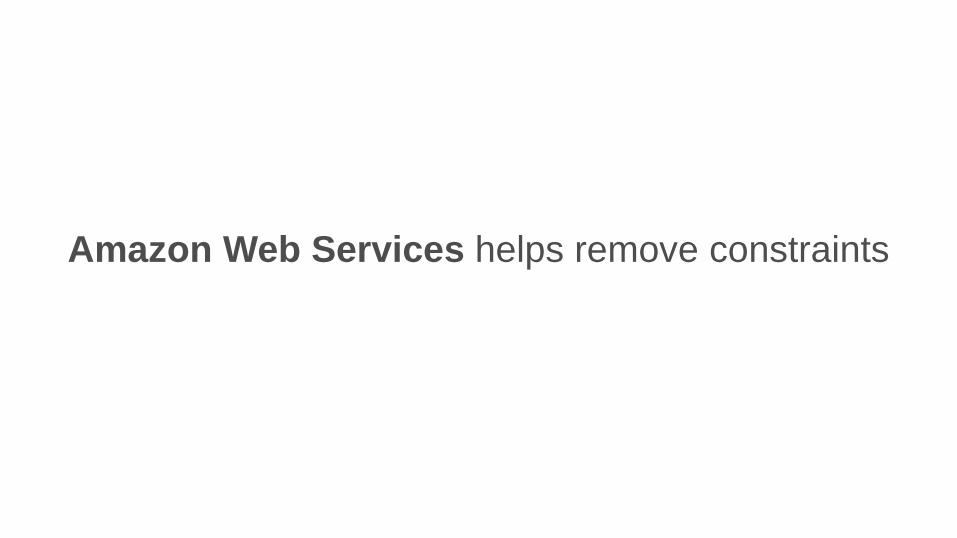
Amazon Web Services helps remove constraints

Big Data:
• Potentially massive datasets
• Iterative, experimental style of
data manipulation and analysis
• Frequently not a steady-state
workload; peaks and valleys
• Data is a combination of
structured and unstructured
data in many formats
AWS Cloud:
• Virtually unlimited capacity
• Iterative, experimental usage cost
through on-demand
infrastructure
• Fully scalable infrastructure for
highly variable workloads
• Tools & Services for managing
structured, unstructured and
stream data

Let’s simplify Big Data with AWS!
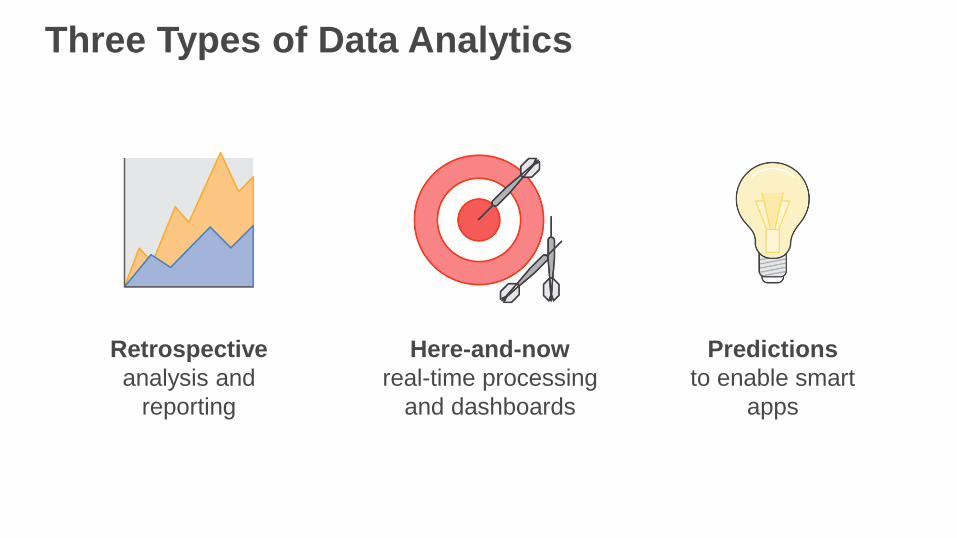
Three Types of Data Analytics
Retrospective
analysis and
reporting
Here-and-now
real-time processing
and dashboards
Predictions
to enable smart
apps
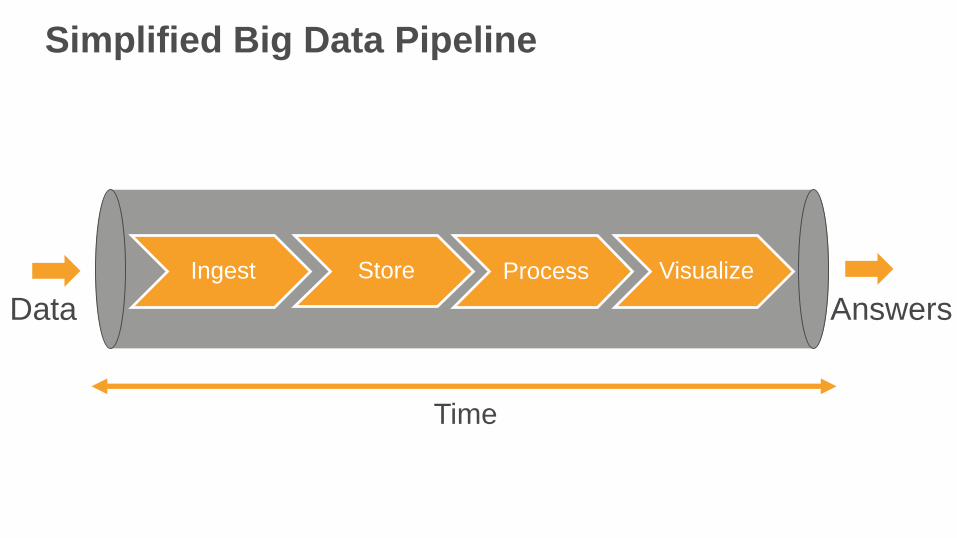
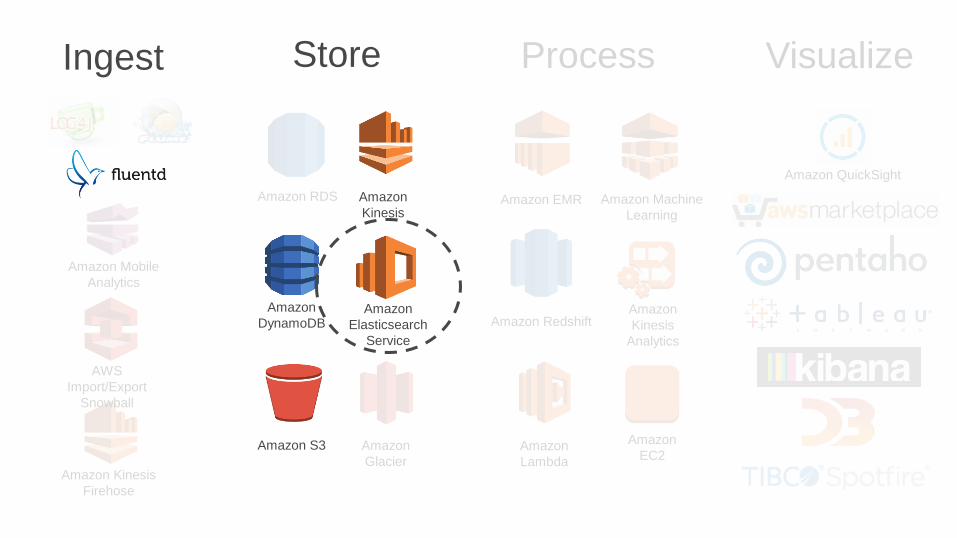
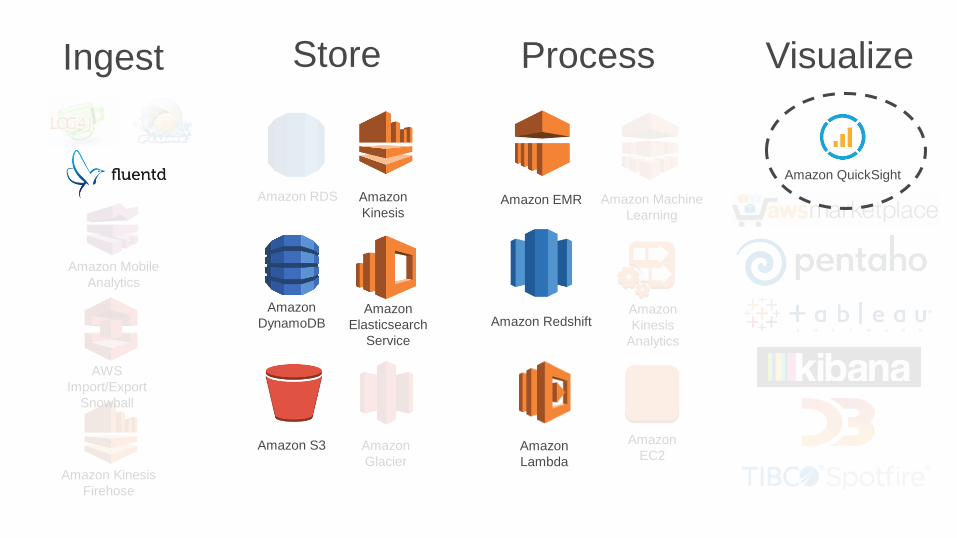
Ingest Store Process Visualize
Data Answers
Time
Simplified Big Data Pipeline
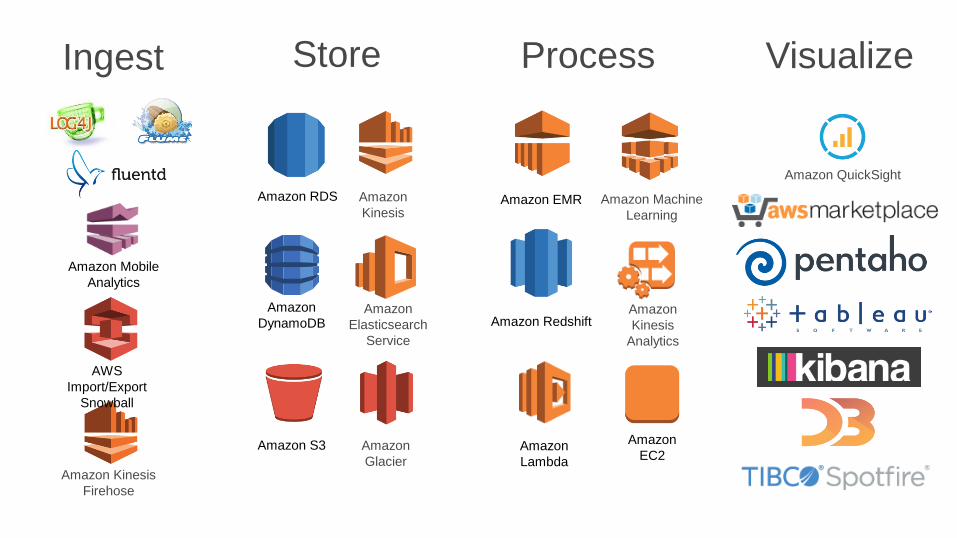
Amazon S3
Amazon
DynamoDB
Amazon RDS
Ingest Store Process Visualize
Amazon Mobile
Analytics
Amazon EMR
Amazon Redshift
Amazon
LambdaAmazon Kinesis
Firehose
Amazon Machine
Learning
Amazon
EC2Amazon
Glacier
Amazon
Elasticsearch
Service
Amazon
Kinesis
Analytics
Amazon QuickSight
AWS
Import/Export
Snowball
Amazon
Kinesis
Amazon S3
Amazon
DynamoDB
Amazon RDS
Ingest Store Process Visualize
Amazon Mobile
Analytics
Amazon EMR
Amazon Redshift
Amazon
LambdaAmazon Kinesis
Firehose
Amazon Machine
Learning
Amazon
EC2Amazon
Glacier
Amazon
Elasticsearch
Service
Amazon
Kinesis
Analytics
Amazon QuickSight
AWS
Import/Export
Snowball
Amazon
Kinesis

Fluentd: Open Source Log Collection
https://github.com/fluent/fluentd/
• Fluentd is an open source
data collector to unify data
collection and consumption
• Integration into many data
sources (App Logs, Syslogs,
Twitter etc.)
• Direct integration into AWS
such as S3 & Kinesis
<source>
type tail
format apache2
path /var/log/apache2/access_log
tag s3.apache.access
</source>
<match s3.*.*>
type s3
s3_bucket myweblogs
path logs/
</match>
Amazon S3
Amazon
DynamoDB
Amazon RDS
Ingest Store Process Visualize
Amazon Mobile
Analytics
Amazon EMR
Amazon Redshift
Amazon
LambdaAmazon Kinesis
Firehose
Amazon Machine
Learning
Amazon
EC2Amazon
Glacier
Amazon
Elasticsearch
Service
Amazon
Kinesis
Analytics
Amazon QuickSight
AWS
Import/Export
Snowball
Amazon
Kinesis

Amazon S3
• Highly available object storage
• Designed for 99.999999999% annual
data durability
• Replicated across 3 facilities
• Virtually unlimited scale
• Pay only for what you use, you don’t
need to pre-provision
• Allows event notifications to trigger
further action
Amazon S3
Amazon S3
Amazon
DynamoDB
Amazon RDS
Ingest Store Process Visualize
Amazon Mobile
Analytics
Amazon EMR
Amazon Redshift
Amazon
LambdaAmazon Kinesis
Firehose
Amazon Machine
Learning
Amazon
EC2Amazon
Glacier
Amazon
Elasticsearch
Service
Amazon
Kinesis
Analytics
Amazon QuickSight
AWS
Import/Export
Snowball
Amazon
Kinesis
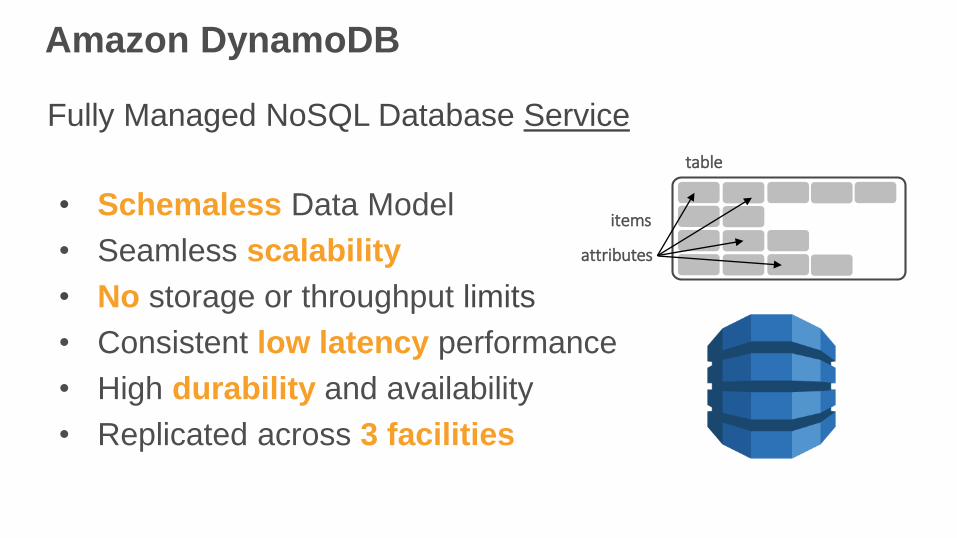
Amazon DynamoDB
• Schemaless Data Model
• Seamless scalability
• No storage or throughput limits
• Consistent low latency performance
• High durability and availability
• Replicated across 3 facilities
DynamoDB
table
items
attributes
Fully Managed NoSQL Database Service


500,000 writes / second to their Amazon
DynamoDB tables
200 additional servers during Superbowl
0 additional servers right after
Amazon S3
Amazon
DynamoDB
Amazon RDS
Ingest Store Process Visualize
Amazon Mobile
Analytics
Amazon EMR
Amazon Redshift
Amazon
LambdaAmazon Kinesis
Firehose
Amazon Machine
Learning
Amazon
EC2Amazon
Glacier
Amazon
Elasticsearch
Service
Amazon
Kinesis
Analytics
Amazon QuickSight
AWS
Import/Export
Snowball
Amazon
Kinesis
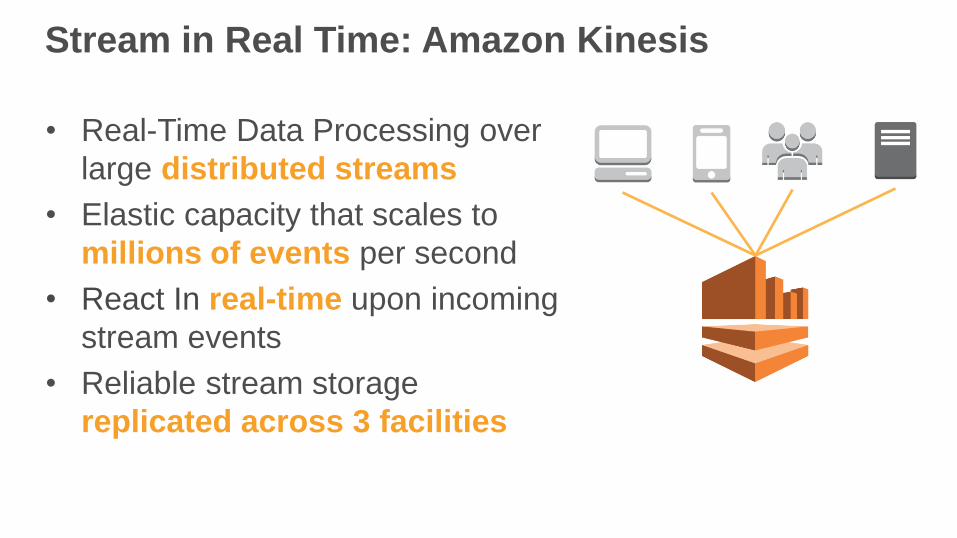
Stream in Real Time: Amazon Kinesis
• Real-Time Data Processing over
large distributed streams
• Elastic capacity that scales to
millions of events per second
• React In real-time upon incoming
stream events
• Reliable stream storage
replicated across 3 facilitiesAmazon Kinesis

Kinesis
for Real-
Time

AWS Labs – Open Source Code for AWS
• Code and Connectors used with
Amazon Kinesis and other AWS
services are Open-Source
• Available under Apache License 2.0
https://github.com/awslabs
Amazon S3
Amazon
DynamoDB
Amazon RDS
Ingest Store Process Visualize
Amazon Mobile
Analytics
Amazon EMR
Amazon Redshift
Amazon
LambdaAmazon Kinesis
Firehose
Amazon Machine
Learning
Amazon
EC2Amazon
Glacier
Amazon
Elasticsearch
Service
Amazon
Kinesis
Analytics
Amazon QuickSight
AWS
Import/Export
Snowball
Amazon
Kinesis
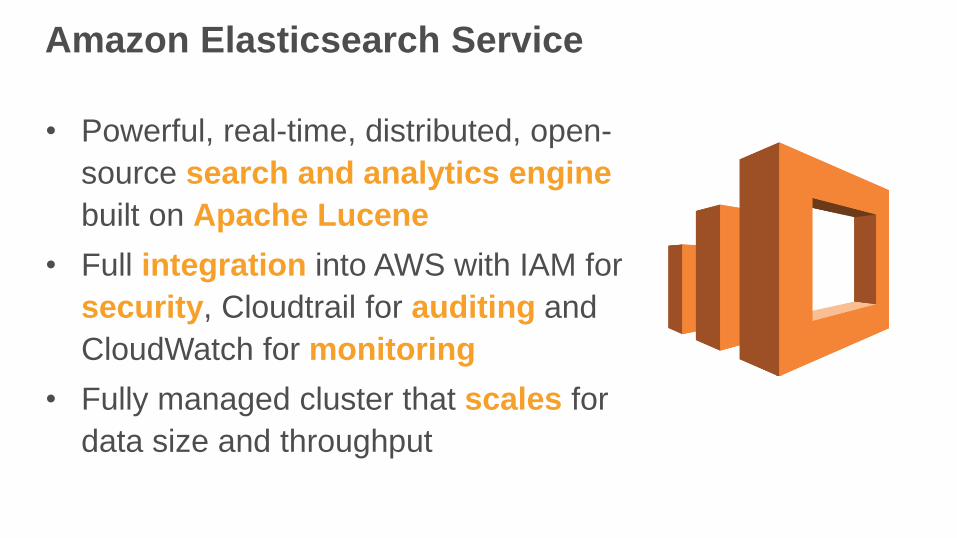
Amazon Elasticsearch Service
• Powerful, real-time, distributed, open-
source search and analytics engine
built on Apache Lucene
• Full integration into AWS with IAM for
security, Cloudtrail for auditing and
CloudWatch for monitoring
• Fully managed cluster that scales for
data size and throughput
Amazon S3
Amazon
DynamoDB
Amazon RDS
Ingest Store Process Visualize
Amazon Mobile
Analytics
Amazon EMR
Amazon Redshift
Amazon
LambdaAmazon Kinesis
Firehose
Amazon Machine
Learning
Amazon
EC2Amazon
Glacier
Amazon
Elasticsearch
Service
Amazon
Kinesis
Analytics
Amazon QuickSight
AWS
Import/Export
Snowball
Amazon
Kinesis
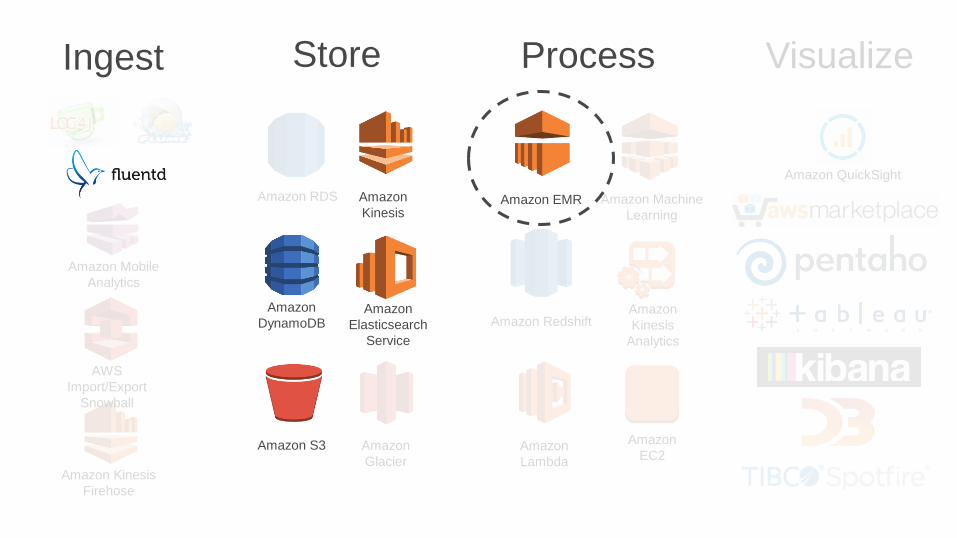
Amazon EMR
• Amazon EMR is a fully managed
Hadoop cluster
• Transient and long running clusters
• Direct integration into Amazon S3
and Amazon Kinesis
• Easy to scale and enable burstable
capacity
• Integration with AWS Spot Market

1 instance x 100 hours = 100 instances x 1 hour
(and with Spot Pricing not only faster but also cheaper)
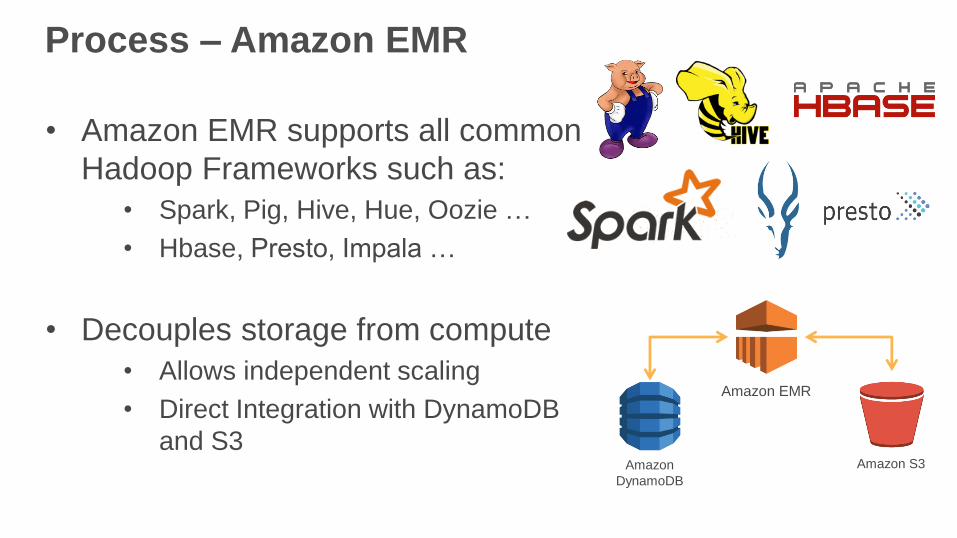
Process – Amazon EMR
• Amazon EMR supports all common
Hadoop Frameworks such as:
• Spark, Pig, Hive, Hue, Oozie …
• Hbase, Presto, Impala …
• Decouples storage from compute
• Allows independent scaling
• Direct Integration with DynamoDB
and S3Amazon S3Amazon
DynamoDB
Amazon EMR
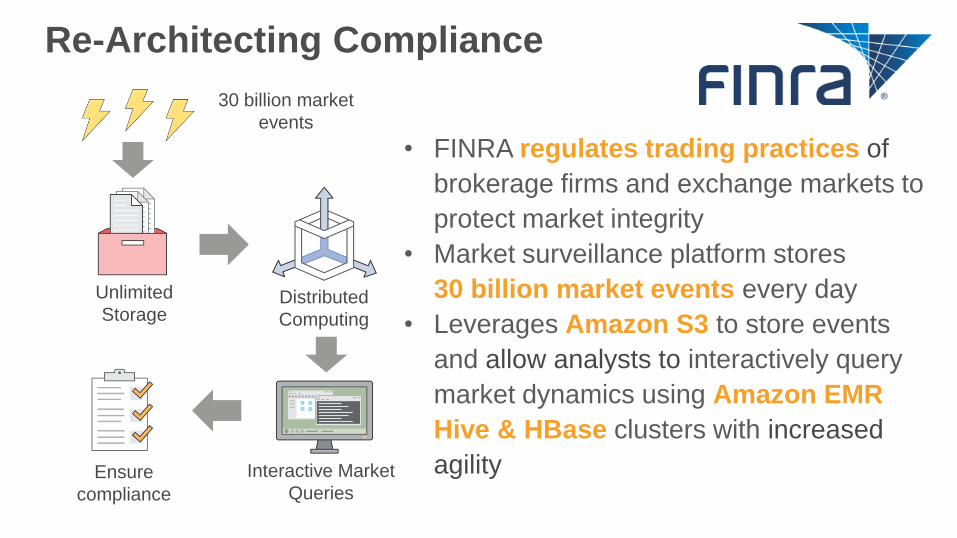
• FINRA regulates trading practices of
brokerage firms and exchange markets to
protect market integrity
• Market surveillance platform stores
30 billion market events every day
• Leverages Amazon S3 to store events
and allow analysts to interactively query
market dynamics using Amazon EMR
Hive & HBase clusters with increased
agility
Re-Architecting Compliance
Unlimited
StorageDistributed
Computing
Interactive Market
QueriesEnsure
compliance
30 billion market
events

CREATE TABLE call_data_records (
start_time bigint,
end_time bigint,
phone_number STRING,
carrier STRING,
recorded_duration bigint,
calculated_duration bigint,
lat double,
long double
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ","
STORED BY
'com.amazon.emr.kinesis.hive.KinesisStorageHandler'
TBLPROPERTIES("kinesis.stream.name"=”MyTestStream");
Amazon EMR integration: Hive

Apache Spark
• Apache Spark is an in-memory
analytics cluster using RDD (Resilient
Distributed Dataset) for fast processing
• Faster than Map-Reduce due to
removal of shuffling phases to HDFS
• Apache Spark Streaming can read
directly from DynamoDB, S3 and a
Kinesis stream
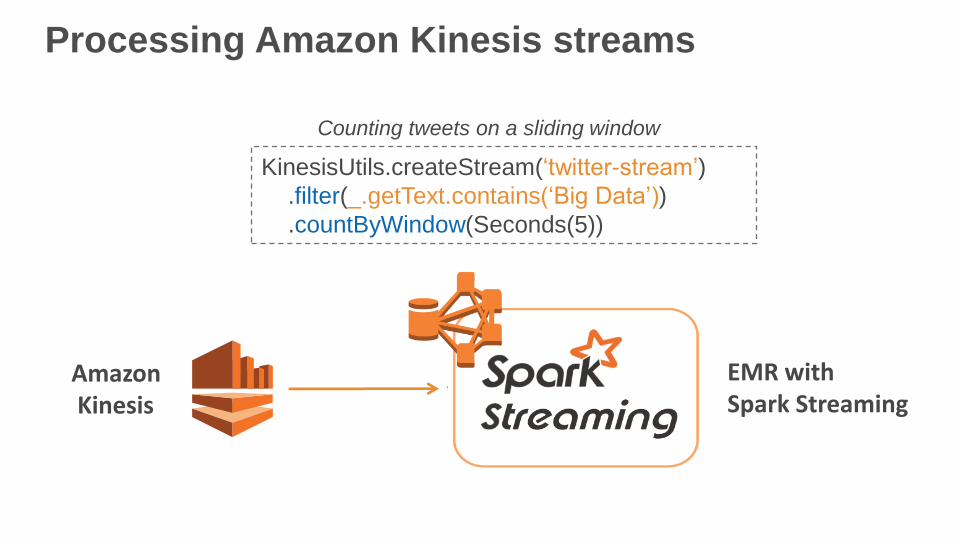
Processing Amazon Kinesis streams
AmazonKinesis
EMR with Spark Streaming
KinesisUtils.createStream(‘twitter-stream’)
.filter(_.getText.contains(‘Big Data’))
.countByWindow(Seconds(5))
Counting tweets on a sliding window
Amazon S3
Amazon
DynamoDB
Amazon RDS
Ingest Store Process Visualize
Amazon Mobile
Analytics
Amazon EMR
Amazon Redshift
Amazon
LambdaAmazon Kinesis
Firehose
Amazon Machine
Learning
Amazon
EC2Amazon
Glacier
Amazon
Elasticsearch
Service
Amazon
Kinesis
Analytics
Amazon QuickSight
AWS
Import/Export
Snowball
Amazon
Kinesis
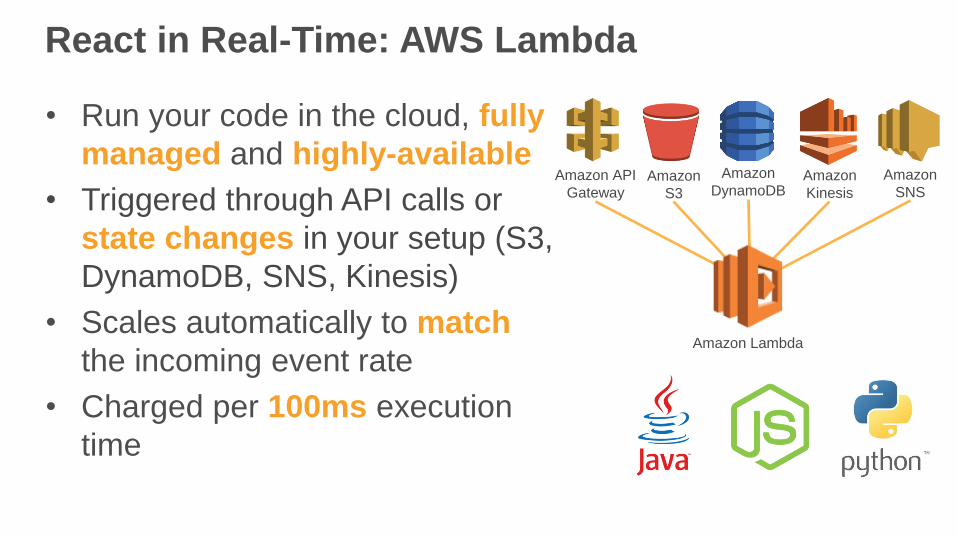
React in Real-Time: AWS Lambda
• Run your code in the cloud, fully
managed and highly-available
• Triggered through API calls or
state changes in your setup (S3,
DynamoDB, SNS, Kinesis)
• Scales automatically to match
the incoming event rate
• Charged per 100ms execution
time
Amazon
Kinesis
Amazon Lambda
Amazon
S3
Amazon
DynamoDBAmazon API
Gateway
Amazon
SNS

AWS Lambda
• Use AWS Lambda to clean and
massage incoming data
• Write code to load data sources
(S3, DynamoDB) automatically in your
data warehouse (e.g. Amazon Redshift)
• React in real-time to incoming events in
Amazon Kinesis
Amazon Lambda
Amazon Redshift
Amazon
Kinesis
Amazon S3
Amazon
DynamoDB
Amazon RDS
Ingest Store Process Visualize
Amazon Mobile
Analytics
Amazon EMR
Amazon Redshift
Amazon
LambdaAmazon Kinesis
Firehose
Amazon Machine
Learning
Amazon
EC2Amazon
Glacier
Amazon
Elasticsearch
Service
Amazon
Kinesis
Analytics
Amazon QuickSight
AWS
Import/Export
Snowball
Amazon
Kinesis
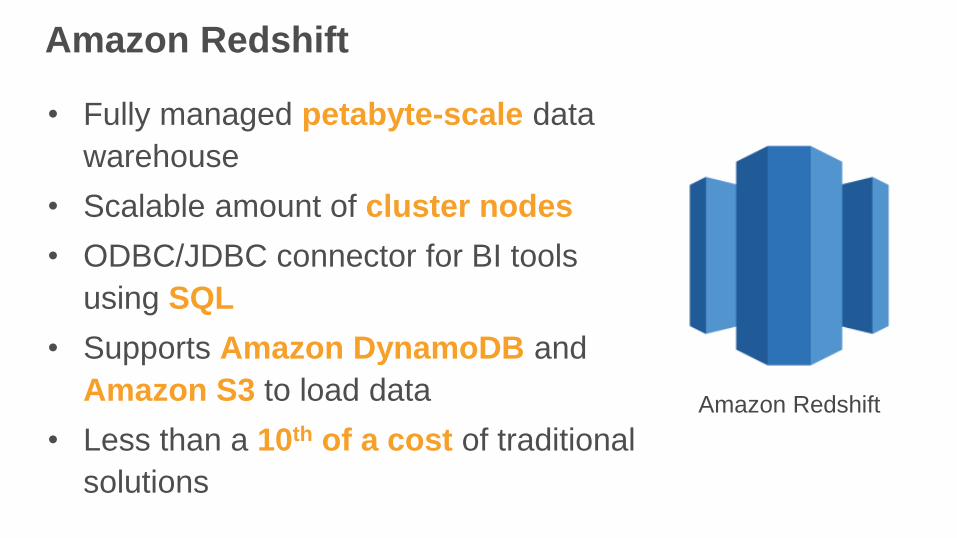
Amazon Redshift
• Fully managed petabyte-scale data
warehouse
• Scalable amount of cluster nodes
• ODBC/JDBC connector for BI tools
using SQL
• Supports Amazon DynamoDB and
Amazon S3 to load data
• Less than a 10th of a cost of traditional
solutions
Amazon Redshift

Amazon Redshift – Use Case
• Web Log Analaysis at amazon.com
(Online Retail Business)
• Understand customer behavior
• Who’s browsing but not buying?
• Which products are winners?
• What sequence led to higher
customer conversion?
• Metrics
• Every day 2TB new data
• Largest table: 400TB

Amazon Redshift – Use Case
• Performance
• Scan 2.25 trillion rows of data in
14 minutes
• Load 5 billion rows of data in
10 minutes
• Comparison
• Hadoop (Pig) to Redshift from
2 days to 1 hour
• Oracle DB to Redshift from
90 hours to 8 hours
Amazon S3
Amazon
DynamoDB
Amazon RDS
Ingest Store Process Visualize
Amazon Mobile
Analytics
Amazon EMR
Amazon Redshift
Amazon
LambdaAmazon Kinesis
Firehose
Amazon Machine
Learning
Amazon
EC2Amazon
Glacier
Amazon
Elasticsearch
Service
Amazon
Kinesis
Analytics
Amazon QuickSight
AWS
Import/Export
Snowball
Amazon
Kinesis

Amazon Quicksight
• Fast, cloud-powered, BI service for
1/10th the cost of old-guard BI software
• Connectors for files, third party platforms
and AWS services
• In-memory calculation engine (SPICE)
to accelerate analysis and visualization
• Supports other partner BI tools
• $9 per user per month
Amazon S3
Amazon
DynamoDB
Amazon RDS
Ingest Store Process Visualize
Amazon Mobile
Analytics
Amazon EMR
Amazon Redshift
Amazon
LambdaAmazon Kinesis
Firehose
Amazon
EC2Amazon
Glacier
Amazon
Elasticsearch
Service
Amazon
Kinesis
Analytics
Amazon QuickSight
AWS
Import/Export
Snowball
Amazon
KinesisAmazon Machine
Learning

Kibana: Open Source Visualization
https://github.com/elastic/kibana
• Kibana is an open-source
project of Elastic.IO to
visualize data in browser
• Uses Elasticsearch as
indexing engine (based on
Apache Lucene)

Let’s put it all together: Demo Time!

Amazon
KinesisTwitter Stream Amazon
Lambda
Demo: Live Twitter Feed Analysis
* https://blog.twitter.com/2013/new-tweets-per-second-record-and-how
Twitter Blog* - On a typical day (in 2013):
• More than 500 million Tweets sent
• Average 5,700 TPS
Amazon
Elasticsearch
Service

Thank you!
Olivier Klein 奧樂凱Solutions Architect, Greater China





























