Embed Size (px)
Citation preview

Argenda
• Redis Management
• Data Structure in Redis
• Redis Roadmap
– From 2.8 to 3.2

Redis Management

REDIS
• Simple In-Memory Cache Server
• Support Collections, Replication, Persistent
– Collections(K/V, set, sorted set, hash)
– Replication(Master/Slave, support Chained replication)
– Persistent(RDB/AOF)

Single Threaded #1
• Redis is Single Threaded
– Can’t Process other commends during Processing a Command
– Command to need long-time
• O(N) Commands with Large items. – Keys, flushall, del
• Redis handles Lua Script as one command.
• MULTI/EXEC – Process all commands at a time when exec command is reached.

Single Threaded #2
• It is better to execute multiple instance if you have multi-cores
– Need more memory, but more reliable
• CPU 4 core, 32G Memory
Mem: 26G
Mem: 8G
Mem: 8G
Mem: 8G
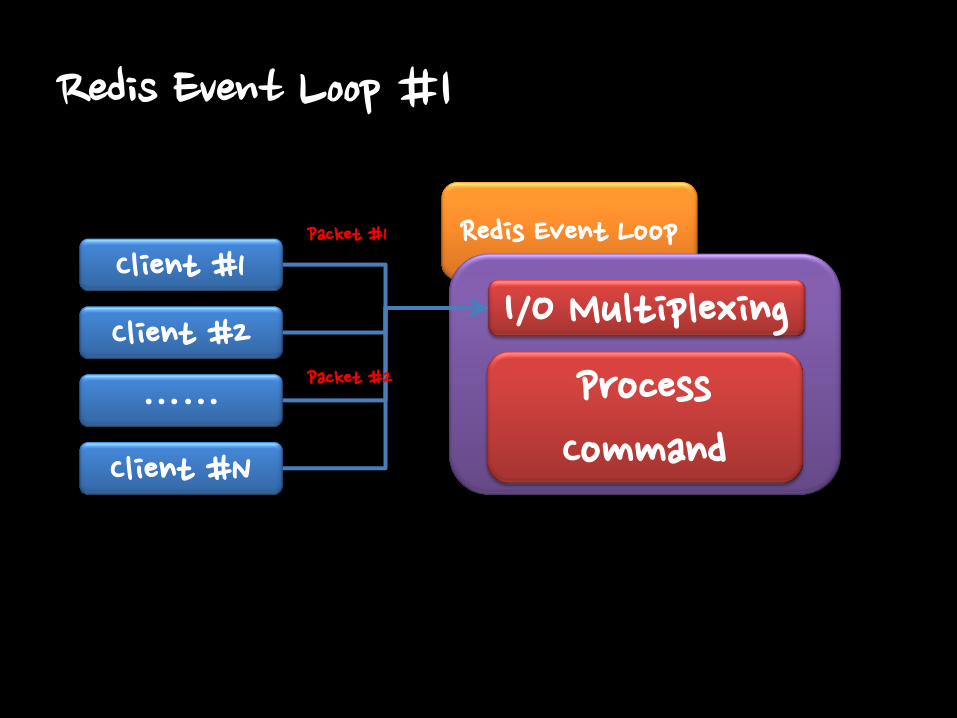
Redis Event Loop #1
Client #1
Client #2
……
Client #N
Redis Event Loop
I/O Multiplexing
Process Command
Packet #1
Packet #2

Redis Event Loop #2
• When command packet is complete, Redis process this command.
– Redis is single threaded, so other code can’t be processed.
• In a loop, multiple command can be processed sequentially.
– Like Reactor Pattern

How Slow?
Command Item Count Time
flashall 1,000,000 1000ms(1 second)

Quiz!!! If you send “Keys *”
command in Production?

Persistent
• RDB/AOF
– RDB and AOF are not related.
– Just They are methods to support persistent
– Can use them together.

RDB #1
• Dump memory to disk with special format. – Compressed(optional)
• When RDB is created? – When It satisfied “SAVE” condition – When slave send “SYNC” command(in replication) – When user order “SAVE” or “BGSAVE” commands
• Caution!!! – Don’t use default option.
• Most of Failure are related with Default Save Option • It is too small to use in production. • SAVE 900 1 • SAVE 60 10000 <- every 1 minute, redis can dump it’s memory
– If it is larger than “10G”

RDB #2
• Redis Uses fork system call to make RDB
– Redis can spend twice memory in creating RDB
– Command Service
• READ:WRITE = 8:2
– But Batch Job or Write-Back Service
• If you change all keys?
• Because of Copy on Write

Copy on Write
• When Parent Process fork
– At that time os doesn’t copy process memory in Read Page
• Copy memory page when write is occurred.

Copy on Write #1
Process - Parent
Physical Memory
Page A
Page B
Page C
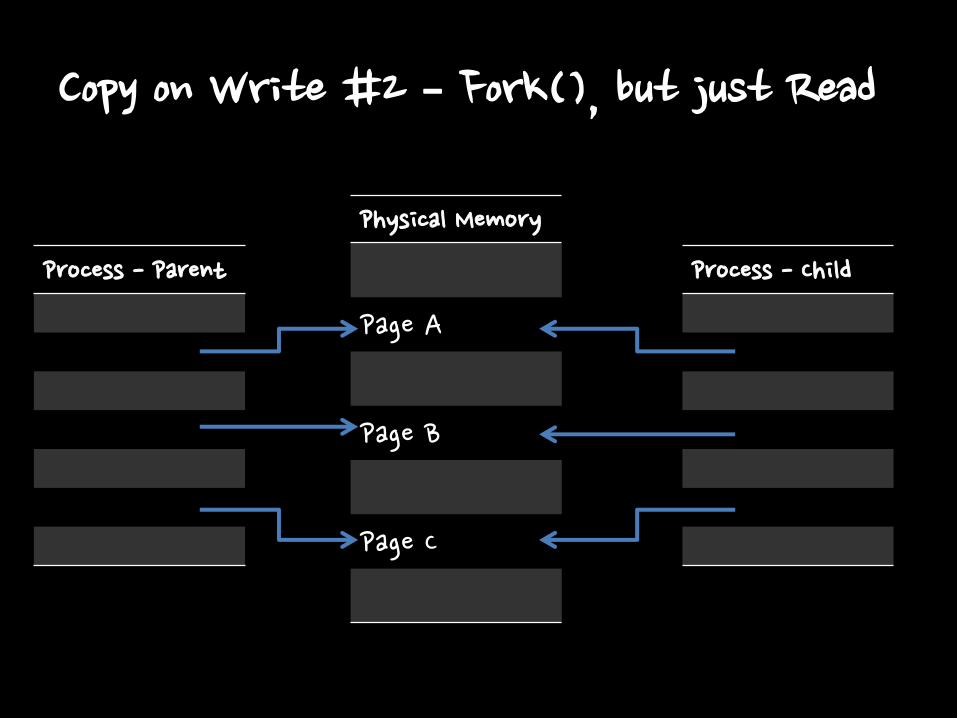
Copy on Write #2 – Fork(), but just Read
Process - Parent
Physical Memory
Page A
Page B
Page C
Process - Child
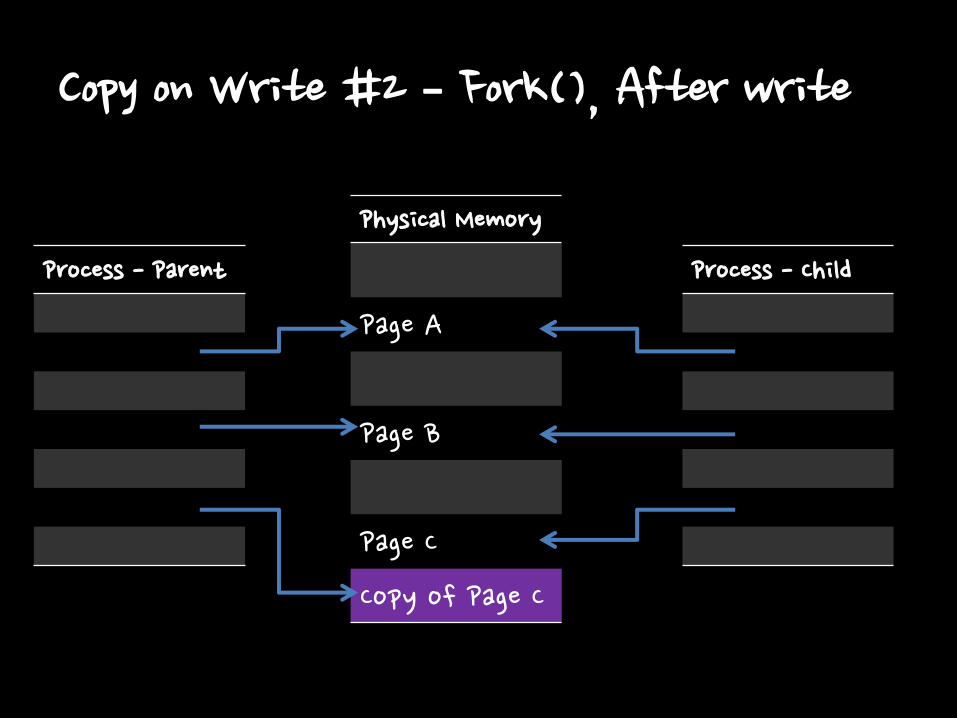
Copy on Write #2 – Fork(), After write
Process - Parent
Physical Memory
Page A
Page B
Page C
Copy of Page C
Process - Child

Copy on Write
• Redis can spend twice memory when all memory pages are changed.
• If you redis uses swap memory area.
– You can experience extreme performance degradation

AOF #1
• Append Only File
• Save data as redis protocol format
• After event loop, save all write command to aof file
– It is cheaper than RDB, just write small data at a time.
• AOF File can be larger than memory size.
– It can rewrite aof file with conf
– AOF rewrite also uses fork system call()

AOF #2
• Binary Logs and WAL save the data before modifying real data. But aof save data after data modifying

AOF Sample
*3\r\n
$3\r\n
Set\r\n
$3\r\n
Abc\r\n
$3\r\n
key\r\n

RDB/AOF Tips #1
• If you need RDB/AOF.
– Using Master/Slave and apply it to slave node
– Using Multiple instance
• Allocating small memory to each instance
• 16GB/4 Core Machine – 3 instances each instance use 3G or 4G
• Schedule RDB/AOF creation in maually
• Using Swap memory cause performance degradation

RDB/AOF Tips #2
• If you need using RDB in Master node. – config set stop-writes-on-bgsave-error no
– Default is yes. And If it is yes, all write commands are prohibited when creating RDB is failed. • Disk or memory, or someone kill the process. There are many reasons.
MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk. Commands that may modify the data set are disabled. Please check Redis logs for details about the error.”

Redis on AWS

AWS on PV. Using HVM
• If you use PV type Instance in Amazon AWS
– Amazon AWS uses XEN for virtualization
– PV type instance has performance degradation in XEN
• Depending on used memory size.
• It spend more then seconds.
• Just Use HVM type for REDIS
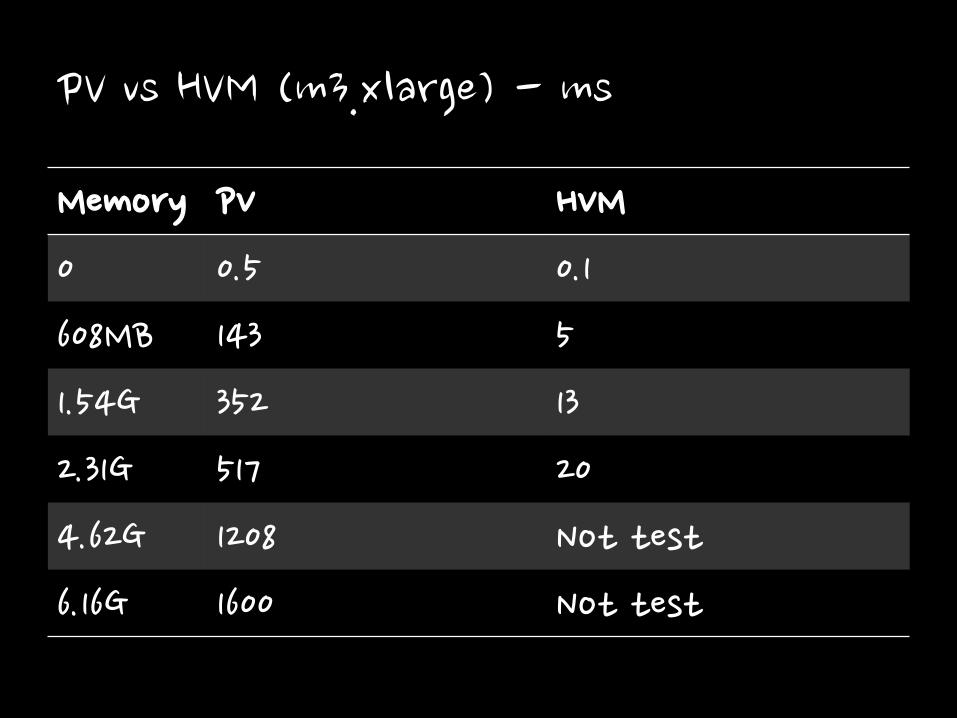
PV vs HVM (m3.xlarge) - ms
Memory PV HVM
0 0.5 0.1
608MB 143 5
1.54G 352 13
2.31G 517 20
4.62G 1208 Not test
6.16G 1600 Not test

PV vs HVM
• In PV, fork need to copy page tables
– But it is slow
• So It depends on Page tables Size

fork 20x~30x
Slow in PV

Disable THP option Also

Slow Disk IO
• EBS is slow Ephemeral Disk
• Frequent creating RDB is bad for performance.

Recommanded Redis Version
• After 2.8.13
– It uses Jemalloc 3.6.0
– Good at Memory fragmentation.
• Redis in AWS ElasticCache
– 2.8.19

Memory Fragmentation #1
• Redis depends on Memory Allocator(ex. Jemalloc)
– IN memcache, it uses slab allocator and using chunk internally
– Redis just calls malloc and free when it need memory allocation.
• It means you can’t avoid memory fragmentation.

Memory Fragmentation #2
• 2.6.16 and 2.8.6
– 2.4G Used memory, But rss is 12G

Redis Monitoring
name Host or Redis(info)
CPU Usage, Load Host
Network inbound, outbound
Host
Current clients max client config
Redis
keys count, commands count Redis
Used memory, RSS Redis
Disk size, io Host
Expired keys, Evicted keys Redis

Data Structure in Redis

Data Structure in Redis
• Support Redis Collections.
– K/V, list, set, sorted set, hash
• Sorted Set/Hash can use special Data Type for saving Memory : ziplist
Data Types Default Data Type Data Type for speed
Sorted Set ziplist Skiplist
Hash ziplist Dict

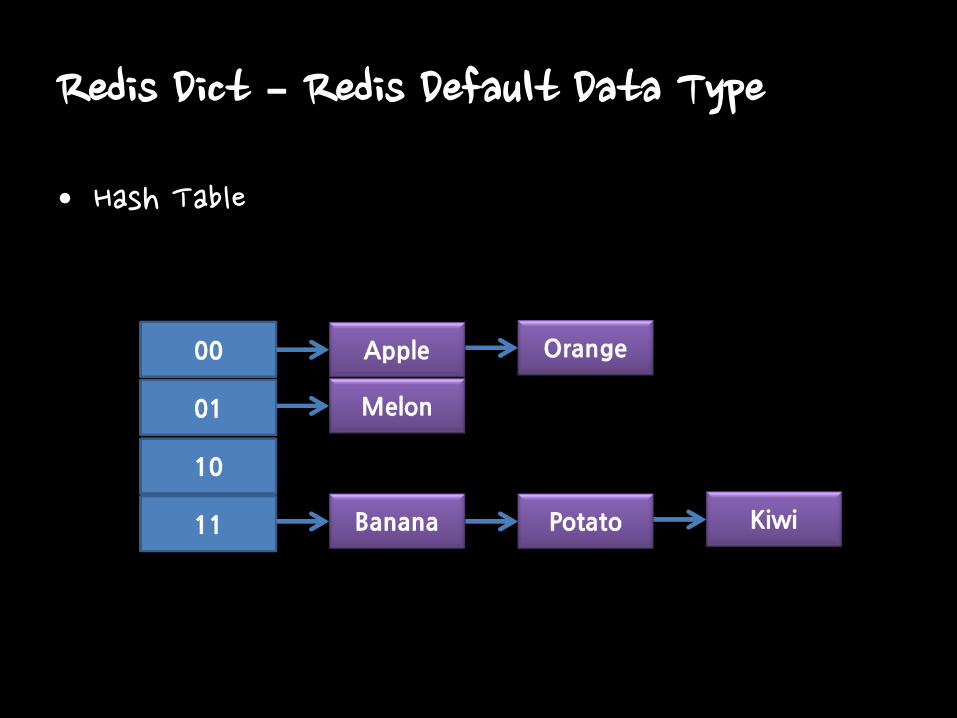
Redis Dict – Redis Default Data Type
• Hash Table
typedef struct dict { …… dictht ht[2]; …… }dict;
Redis Dict – Redis Default Data Type
• Hash Table

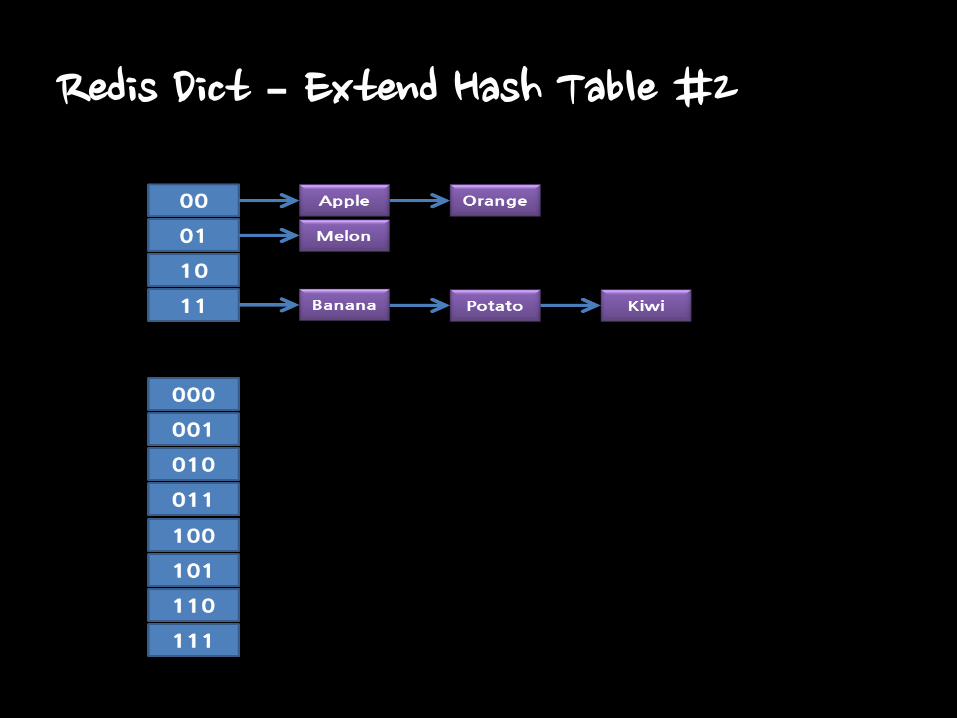
Redis Dict – Extend Hash Table #1
• Two Hash Table are in Dict.
• When need extending hash table
– Allocating new hash table in ht[1]
– After extending, change ht[0] and ht[1], and remove ht[1]
Redis Dict – Extend Hash Table #2
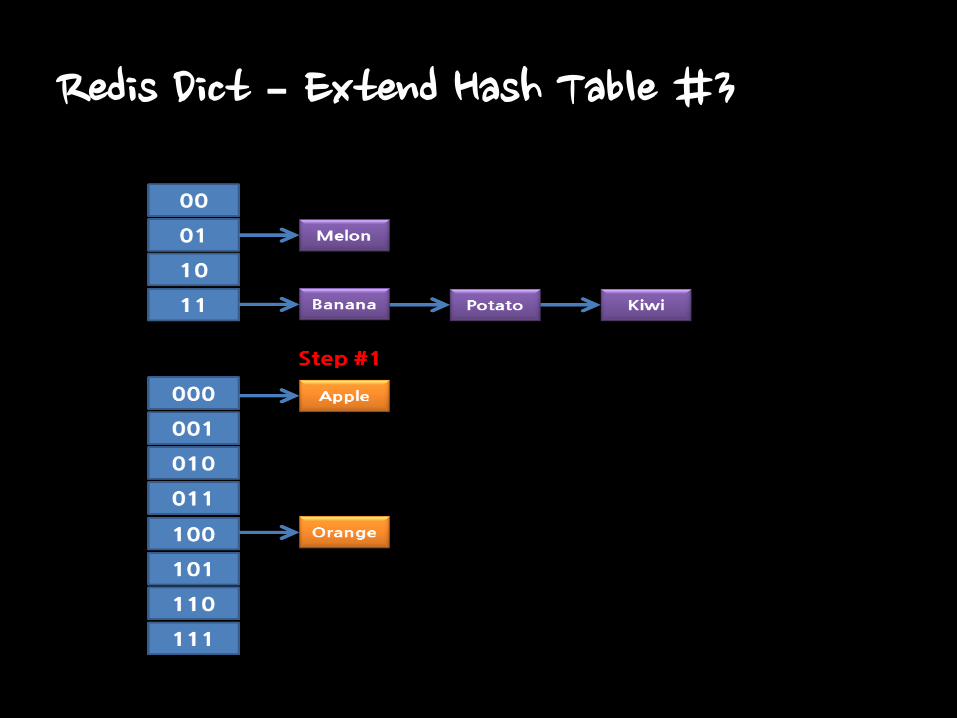
Redis Dict – Extend Hash Table #3
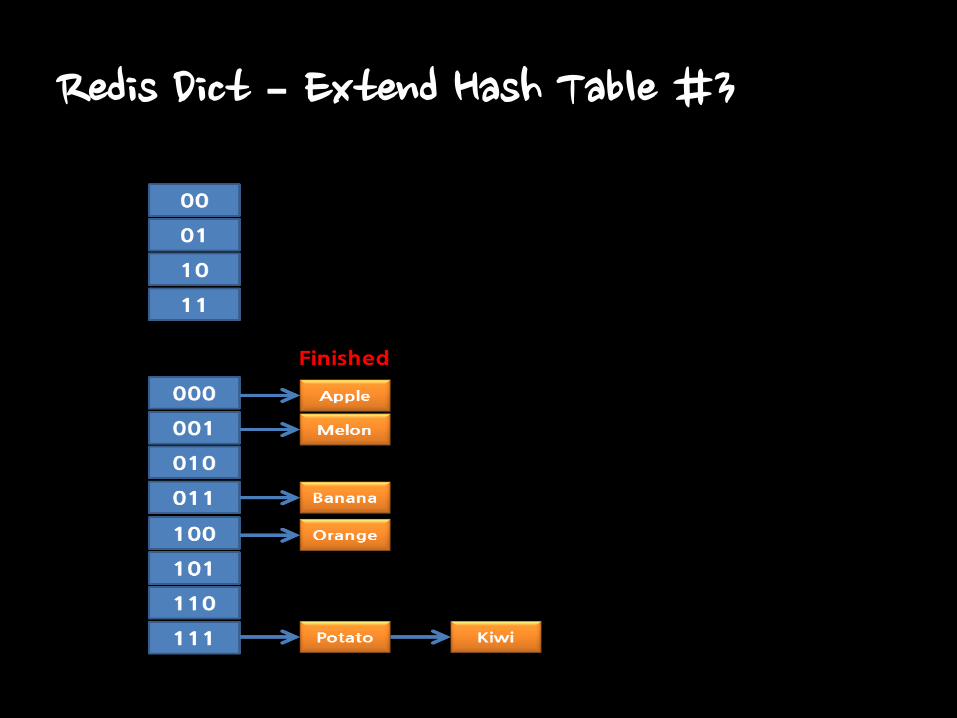
Redis Dict – Extend Hash Table #3

Question of Redis Dict?
• How to process commands during extending
– Redis is Single Threaded
– So If it takes long time. We can’t process others.
• How to search keys during extending?
– There are two hash tables

Don’t extend hash table at a time
• Extending Hash Table
– Making HT[1] as twice size of HT[0]
– Just move just one bucket in hash table
• New items only are added in HT[1]
• Searching Hash Table during Extending
– Search HT[0] and HT[1] also.
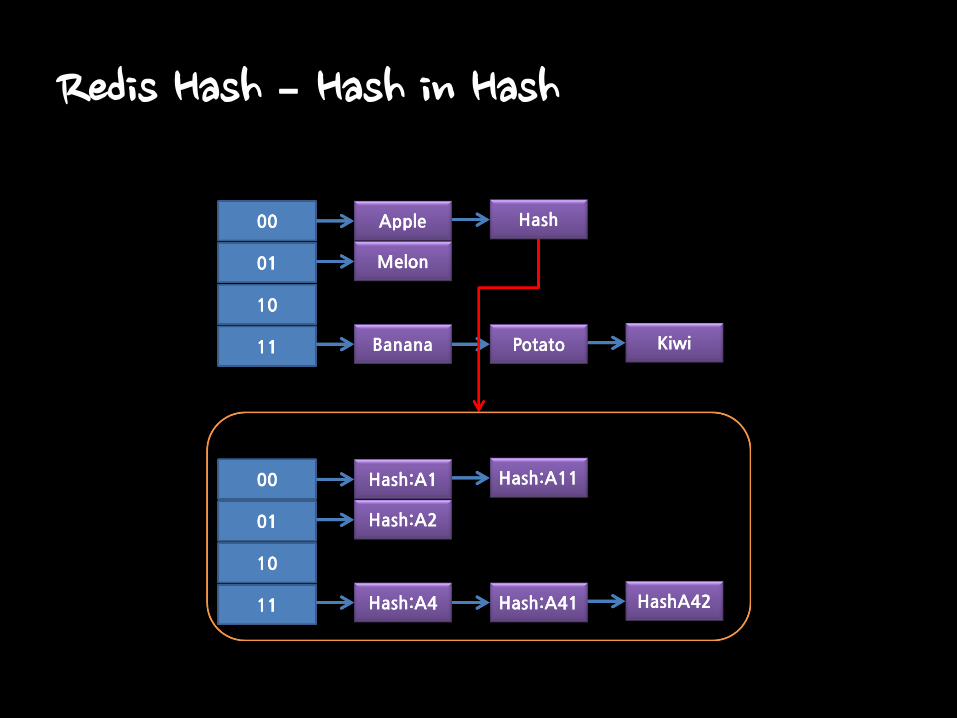
Redis Hash – Hash in Hash

Redis Sorted Set : Skiplist
• O(log(N))
• Using Level for searching speed.
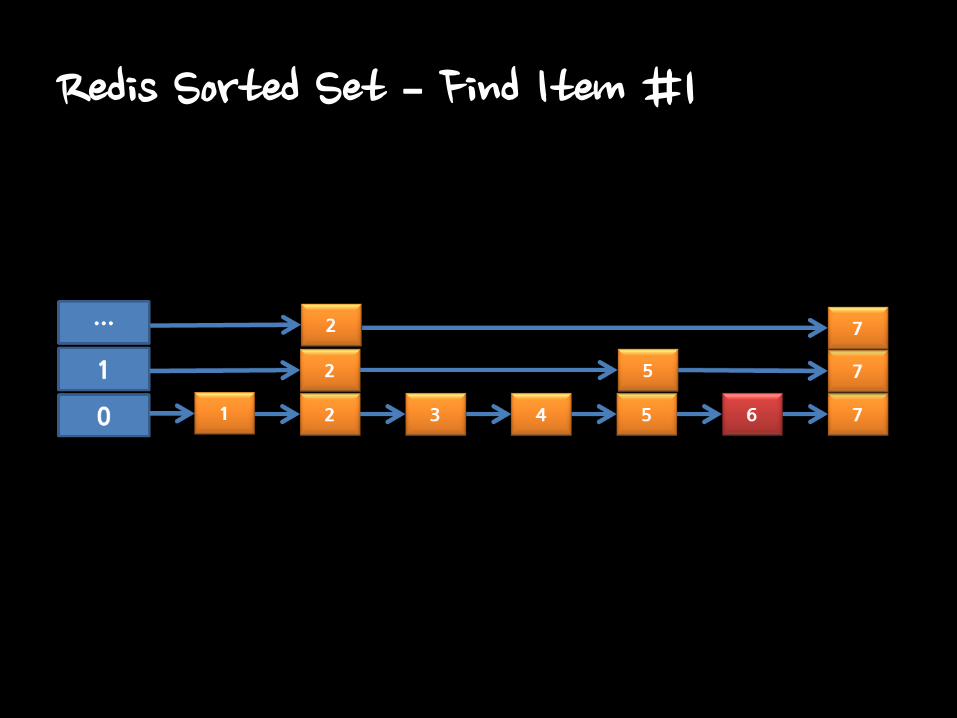
Redis Sorted Set – Find Item #1
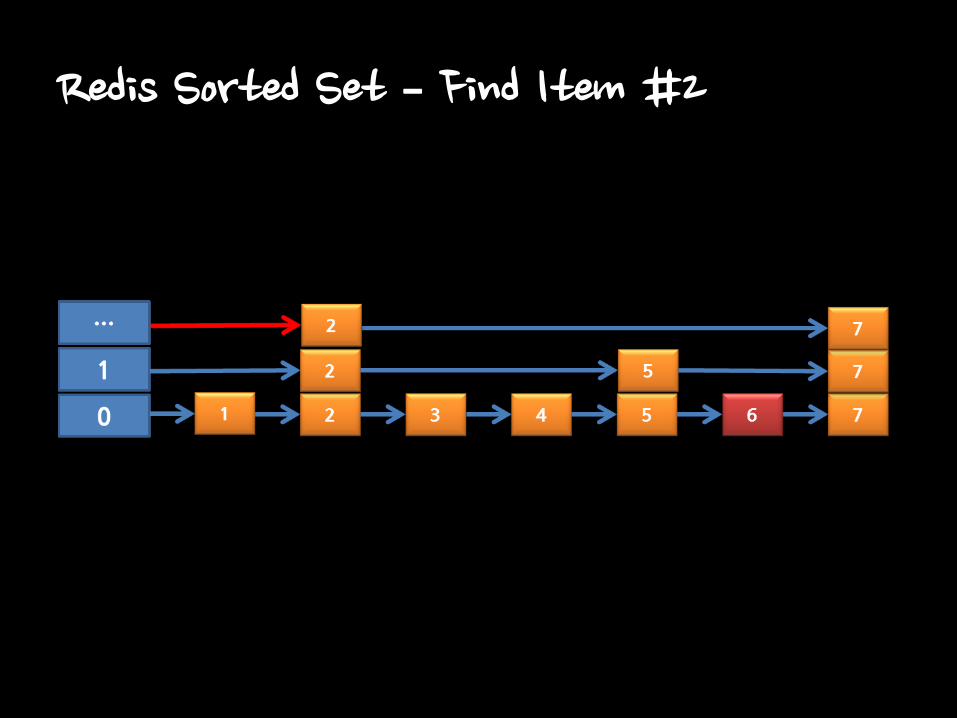
Redis Sorted Set – Find Item #2
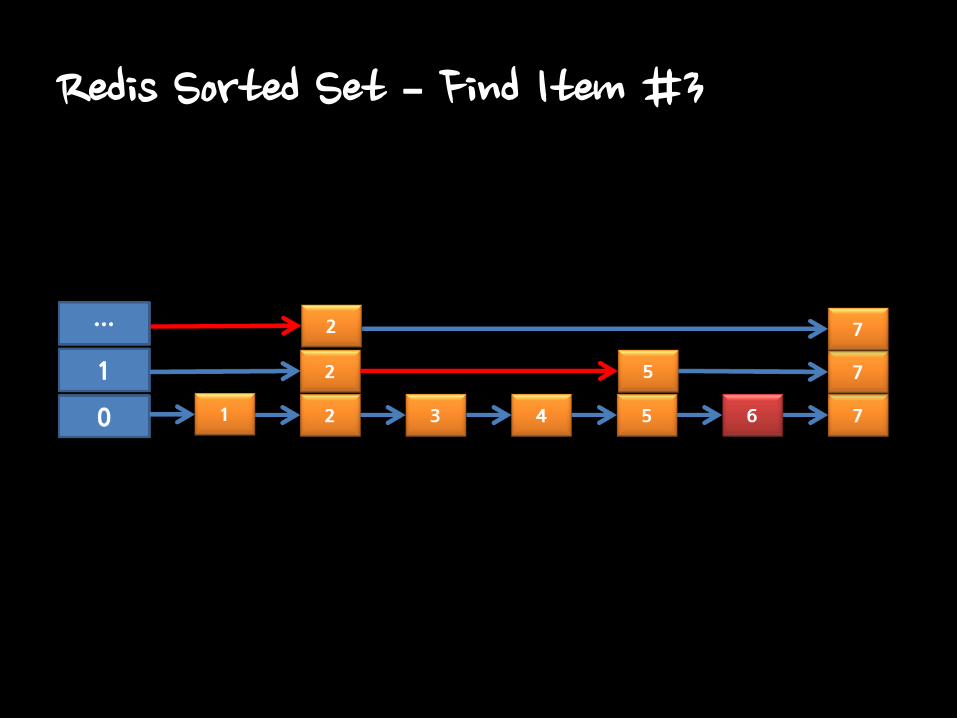
Redis Sorted Set – Find Item #3

Redis Sorted Set – Find Item #4

For Saving memory

ziplist
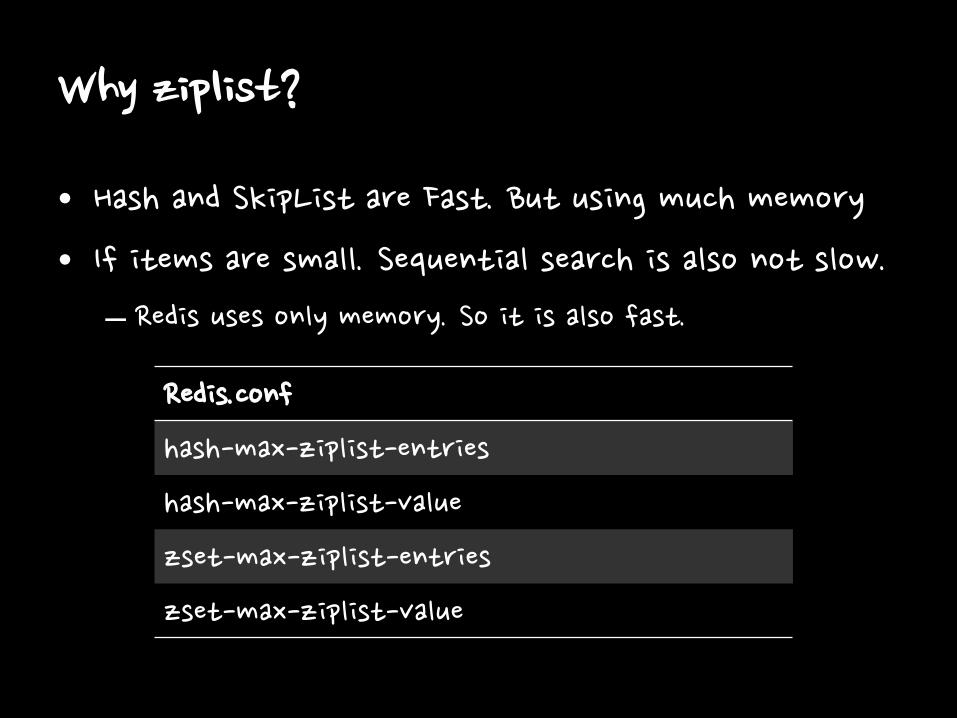
Why ziplist?
• Hash and SkipList are Fast. But using much memory
• If items are small. Sequential search is also not slow.
– Redis uses only memory. So it is also fast.
Redis.conf
hash-max-ziplist-entries
hash-max-ziplist-value
zset-max-ziplist-entries
zset-max-ziplist-value

Ziplist 구조
zlbytes zltail zllen entry entry zlend

Ziplist Drawback
• It is for few items (not many)
• Sequential Search
– It will be slower, Items count are increased.
• It need memory resizing when item is added.
– And moving items for adding

Redis ROadmap

Redis 2.8

Redis 2.8
• Scan
• Partial Sync

Scan

Scan
• From 2.8.x
– Replacement for “KEY *”
• Iterating Hash table bucket
• Cursor is Index of Hash Table Bucket
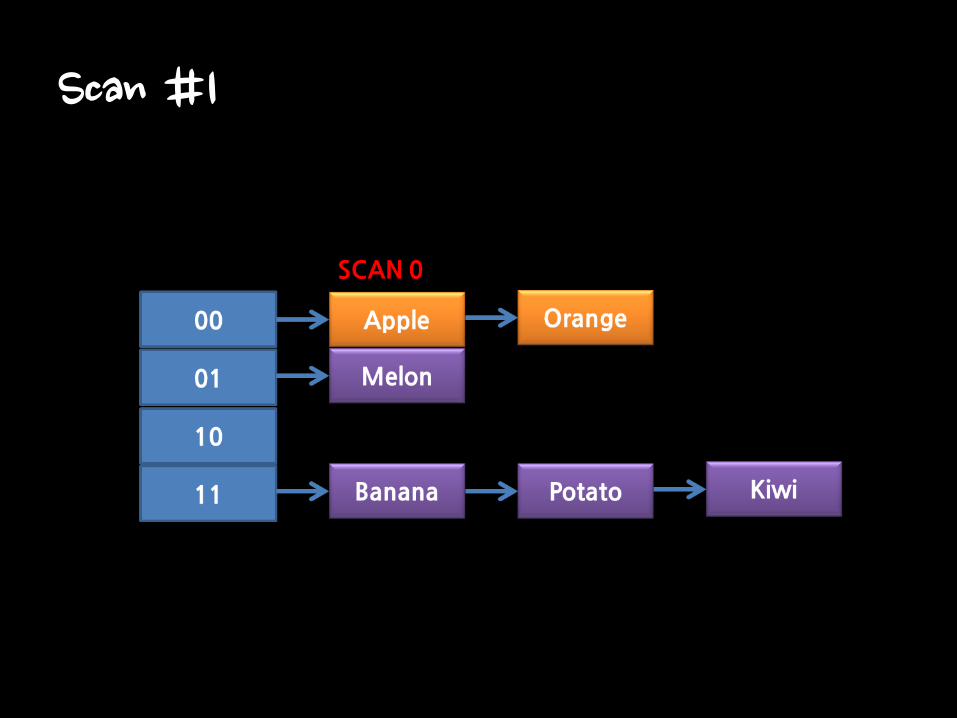
Scan #1
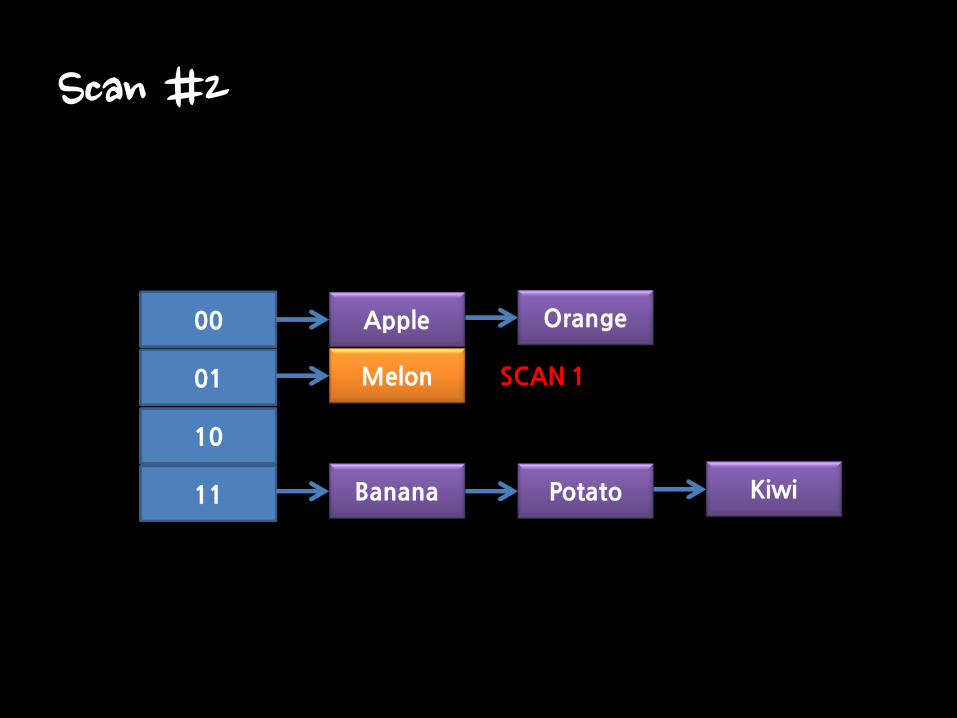
Scan #2
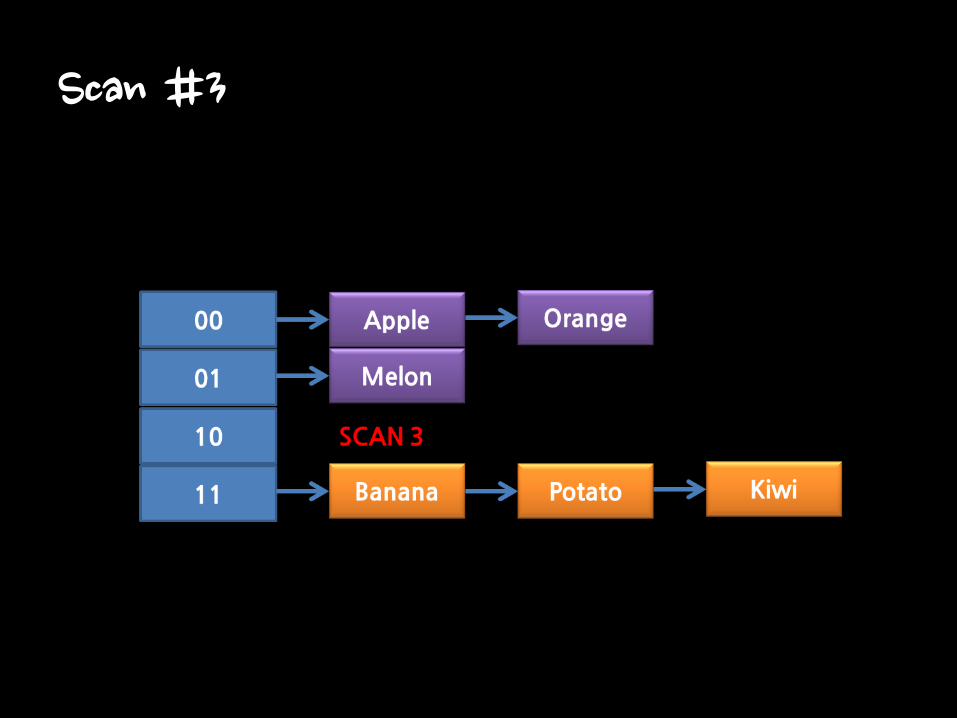
Scan #3

Scan Tips
• Redis also scans Sorted Set, Hash, and Set in the same way. – Sorted set also uses dict as dereference.
• But how to scan ziplist? – It dosen’t use hash tables.
– Just return all items, because it suppose that there are few items.
– So, If there are too many items. It works like O(n) command그

Partial Sync

Redis Replication
1. Slave send “Sync” command to Master
2. Master forks to make RDB File
3. After RDB creation, Master send RDB file to Slave
4. In 3 step, Redis master save commands that received from client for replication
5. After sending RDB, Slave loads RDB file
6. Master send saving commands to slave

Problem of Redis Repliaction
• If connection is closed
– Even it is very short.
– Slave needs full sync.
– Disk IO is expensive
• Slave checks master status using polling

Partial Sync
• If connection is closed.
– But it is short, so change are in replication buffer.
– Avoiding full sync, just send commands in replication buffer

Redis 3.0

Redis 3.0
• Redis Cluster
• Diskless Replication(Experimental)

Redis Cluster #1
• Minimum spec
– Master 3 nodes
– Slave 3 nodes
– It needs total 6 nodes for operation

Redis Cluster #2
• 16384 slots
• Don’t need sentinels.
• Using Redis-trib.rb to manage cluster.
– Only supporitng Manully slot migration
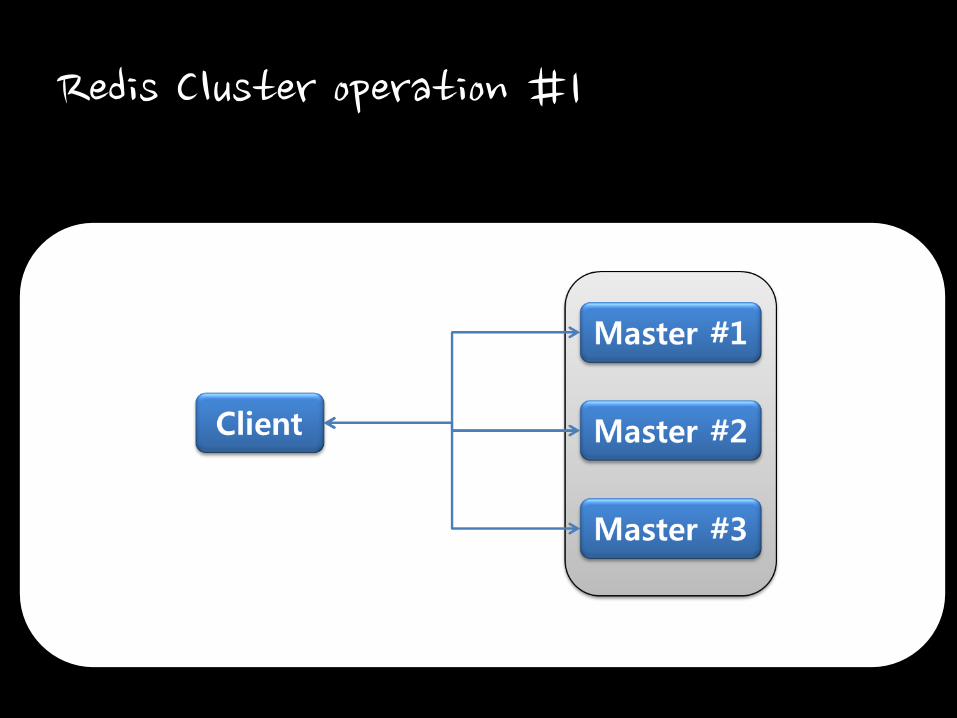
Redis Cluster operation #1
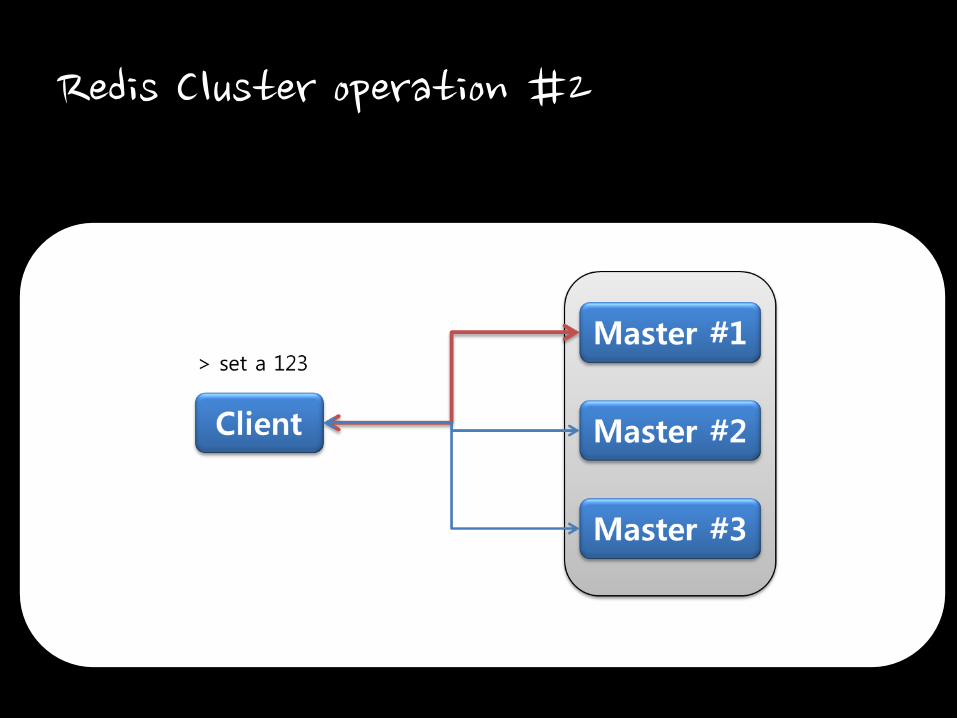
Redis Cluster operation #2
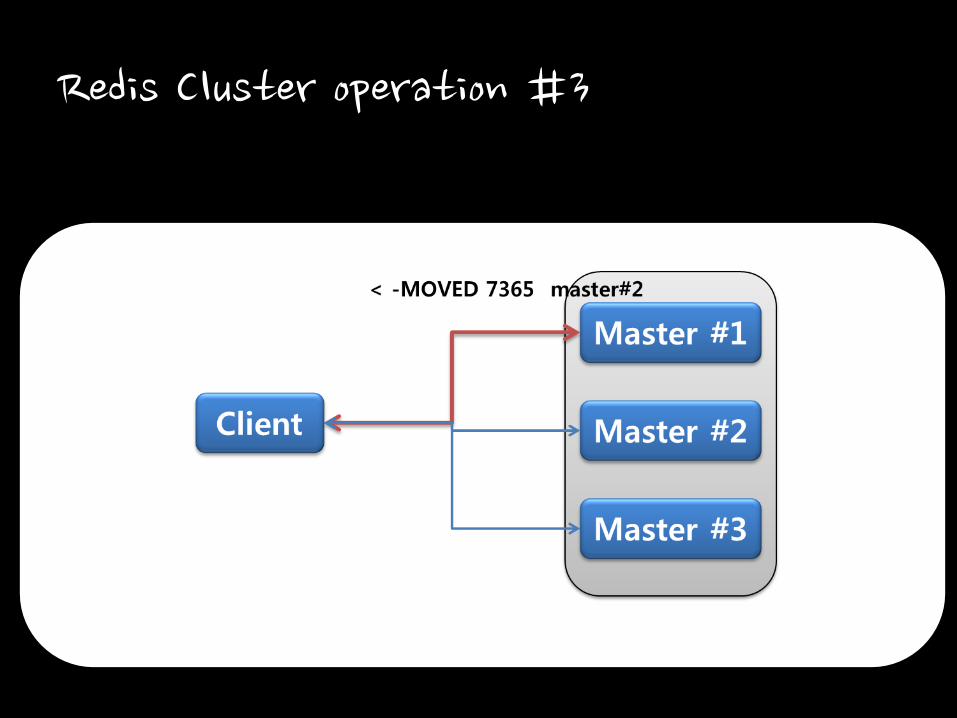
Redis Cluster operation #3
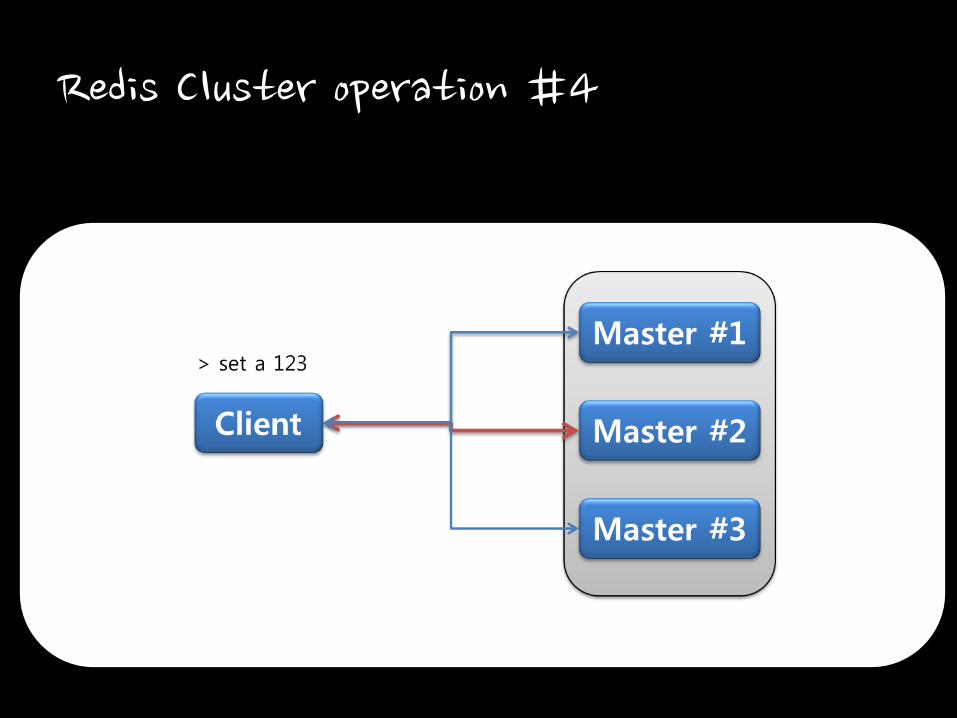
Redis Cluster operation #4
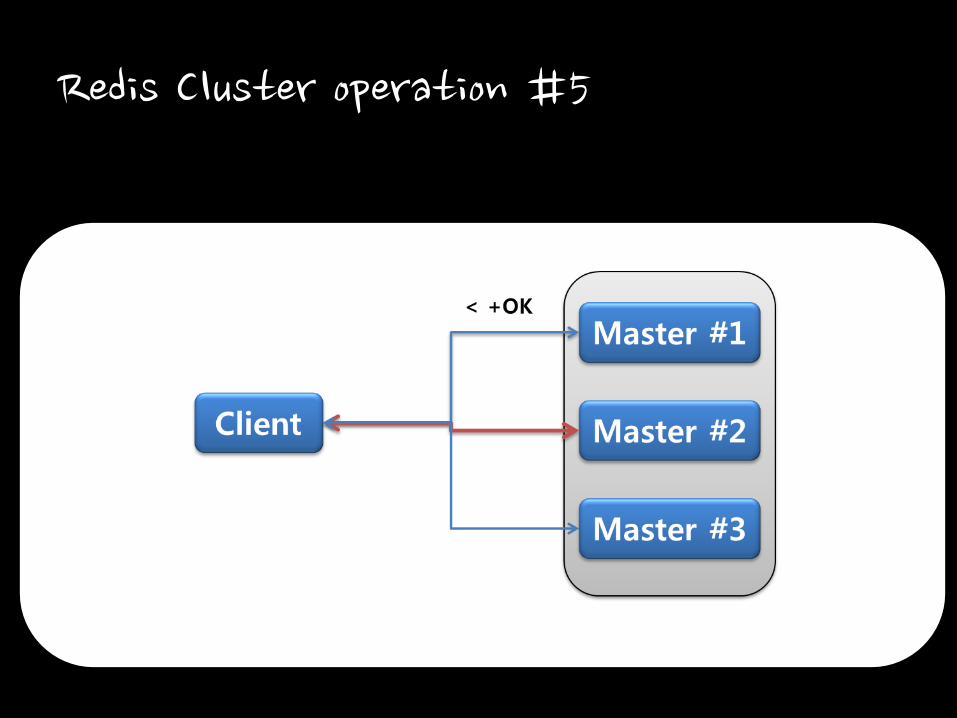
Redis Cluster operation #5

Redis Cluster Drawbacks
• Depending on Library
• Manual slot migration

Diskless Replication
• In replication, RDB file is created.
– But it spends disk IO
• Just send RDB data directly.
– Not creating RDB file in local.
– Removing time to save RDB

Redis 3.2

Redis 3.2
• Sds header Memory size Optimization
• GEO Command

Sds header Memory size Optimization #1
• Supporting variant sds header
• Adding classes for 24 bytes in Jemalloc
– Changed jemalloc code in Redis deps folder

Sds header Memory size Optimization #2
• Supporing variant sds header size.
String 길이 SDS 헤더 사이즈
8bit length 3 bytes
16bit length 5 bytes
32bit length 9 bytes
64 bit length 17 bytes

Sds header Memory size Optimization #3
There is no 24 bytes
Jemalloc increases memory 2^LG_QUANTUM Change #define LG_QUANTUM 4 to #define LG_QUANTUM 3

Sds header Memory size Optimization #4
• Changing memory size.
– Tested with 1M items
적용 메모리 사용량
original 115.57M
Just changing SDS size 92.69M
Jemalloc new classes 77.43M

GEO Command

GEO Command
• GEO 관련 커맨드 추가
– GEOADD
– GEOHASH
– GEOPOS
– GEODIST
– GEORADIUS
– GEORADIUSBYMEMBER

Thanks.