Embed Size (px)
Citation preview

Redisの
BitCountとHyperLogLogを使用した
超高速Unique User数集計
GMOインターネット 次世代システム研究室 松浦 岳登

2
●目次
▪なぜRedis?
▪ LinearCounting
▪ HyperLogLog
▪実運用での適用

3
はじめに

4
● 関連ページ
以降の内容についてはブログでも紹介中
http://recruit.gmo.jp/engineer/jisedai/blog/redis_fast
_counting/
GMO次世代システム研究室についての詳しい説明
http://recruit.gmo.jp/engineer/jisedai/

5
why redis?

6
● Redis
BitCountや、UU算出用アルゴリズムが実装済。
メモリ上でデータの読書きをするため超高速。
Bitの計算もCPU演算を直接使用して超高速。
どのくらい?
処理内容 時間
1億のUUカウント 10ms程度
1億UU同士の重複率計算 100ms程度

7
Linear Counting

8
● LinearCounting
RedisのBitCount機能を使用して、億単位の
UUを超高速に集計する。
とはいえ、超高精度 (99.9%程度)
( ただし、推定値 )
※ Linear CountingはRedisに実装されていないため、
アルゴリズムを理解しての実装が必要。

9
● ベースとなる論文
A Linear-Time Probabilistic Counting
Algorithm For Database Applications
KYU-YOUNG WHANG
BRAD T.VANDER-ZANDEN
HOWARD M.TAYLOR
http://dblab.kaist.ac.kr/Prof/pdf/Whang1990(linear).pdf
1990年…すごい

10
● 前提 (Hashの特徴)
• 元の値を特定の範囲内の数値に変える。
• 元の値が同ならば同じ値に変換される。
• 元の値が少しでも違えば算出される値が
大きく変わる
• 元の値が別でも衝突(collision)が発生
する可能性がある。

11
● 考え方
IDをHash化しBitMapに格納して
Bit数カウント
※ 8bitと少ないのは説明用

12
● グループ同士の重複数計算
単純にBitMapをANDでつなげれば算出可能

13
● Redisでの LinearCounting(Java)
2. Redisへの投入
4. BitMap内のBit数のカウント
3. AND (OR)の結合
1. Hash化
int hash = MurmurHash.hash(userId, SEED);
※ Jedis(Java-Redis-Client) のライブラリ追加は必要
int index = hash % mapSize;
jedis.setbit(data, Math.abs(index), true);
jedis.bitop(BitOP.AND, destKey, keys);
jedis.bitcount(key);

14
● bitサイズの削減
1つのBitMapに 255MB 使用していると、
複数のBitMap作成で、すぐメモリが枯渇し
てしまう。
衝突覚悟でメモリ領域を削減する。

15
● 衝突について
衝突については現在のビット数から推測可能。
(論文内で計算式が導出されている。)
𝑛 = −𝑚 ln𝑉𝑛 𝑛 : 推定UU数
𝑚 : Bitサイズ(箱の大きさ) 𝑉𝑛 : 𝑈𝑛/𝑚
𝑈𝑛 : フラグ無しのBit数 = −𝑚 ln
𝑈𝑛
𝑚
= −𝑚 ln𝑚 − 𝐵𝑛
𝑚
𝐵𝑛 : Bit数
n = - mapSize * Math.log((mapSize - bitCount) / mapSize);

16
● 複数グループ間の重複率の計算
Linear Countingでの重複率の計算は、
ORでもう一つのBitMapを作成し、
そのbit数を計算する。 A B
jedis.bitop(BitOP.OR, destKey, keyA, keyB);
int bitCount = jedis.bitcount(destKey);
double uu = - mapSize * Math.log((mapSize - bitCount) / mapSize);
𝐴 ∪ 𝐵
※ 概要説明のため変数の型変換については省略

17
● ANDは使わない?
精度の低い(衝突の発生ししている) グル
ープ同士のANDを取ると、AND領域の誤差
は非常に大きくなる。
[例]
𝐴 600万(精度97.4%)
B 500万(精度97.4%)
A ∩ 𝐵 30万(精度180.0%)
A B
𝐴 ∩ 𝐵

18
● ANDの誤差が大きくなる理由(イメージ)
衝突の起きているMapでは、下記の図の様に領域
が狭まるような事象が起きている。
特に 𝐴 と B に比べて A ∩ 𝐵 の領域が狭いと、同一
面積の差異でも誤差率が大きく出る。
A B A B
※ 本当はもっと複雑な理由があります。

19
● ANDの計算はどうする?
A. 中学生レベルの計算に頼る。
A B
A
B C
𝐴 ∩ 𝐵 = 𝐴 + 𝐵 − 𝐴 ∪ 𝐵
𝐴 ∩ 𝐵 ∩ 𝐶 = 𝐴 ∪ 𝐵 ∪ 𝐶 − 𝐴 − 𝐵 − 𝐶 +𝐴 ∩ 𝐵 + 𝐵 ∩ 𝐶 + 𝐶 ∩ 𝐴
= 𝐴 ∪ 𝐵 ∪ 𝐶 + 𝐴 + 𝐵 + 𝐶
−𝐴 ∪ 𝐵 − 𝐵 ∪ 𝐶 − 𝐶 ∪ 𝐴
⇒ すべてORになるように展開

20
HyperLogLog

21
● HyperLogLog
メモリ使用量を数キロバイトに抑えて、超
高速でUU数を計算する。
精度はUU数が増えるほど良くなり、メモリ
使用量の増加もない。
とはいえ、こちらも高精度 (99%程度)
( あ、もちろん、推定値 )
22
● RedisとHyperLogLog
HyperLogLog は LinearCounting と違い、
Redisの機能として実装されている。
2015年03月
ElasticCache(AWS) でも標準で利用できるようになった。
https://aws.amazon.com/jp/blogs/aws/amazon-
elasticache-update-redis-2-8-19-now-available/

23
● 早速使ってみる(Java)
2. 投入データのUU数のカウント
3. OR状態でのカウント取得 ※ ANDの計算は存在しない
1. 対象データの投入
jedis.pfadd(key, userId);
※ Jedis(Java-Redis-Client) のライブラリ追加は必要
jedis.pfcount(keys);
jedis.pfcount(key);
4. 複数のキーのマージ
jedis.pfmerge(destKey, sourceKeys);
jedis.pfcount(key);

24
● HyperLogLogアルゴリズムを理解する
ただ使うだけなら非常に簡単。
応用のため
・ 何ができて何ができないのか
・ どういった特徴があるのか
を理解するには、
少なくともアルゴリズムの概念/概要を押さえて
おく必要はある。

25
● HyperLogLogの論文
HyperLogLog: the analysis of a near-optimal
cardinality estimation algorithm
Philippe Flajolet
Éric Fusy
Olivier Gandouet
Frédéric Meunier
http://algo.inria.fr/flajolet/Publications/FlFuGaMe07.pdf
2007年

26
● HyperLogLogで使用するHash
HyperLogLogではBase-2 RanksというMin-Hash
の一つの手法を使用している。
UU計測対象の文字列を複数のHash関数にかけた
上で、その最小値または最大値だけ取り推定に利
用する手法は、よく用いられる。

27
● 推定にHashの最小値を用いる例 (1)
Hash関数-1
Hash関数-2
Hash関数-3
Hash関数-k 1 1 1
1 1 1
1 1 1
1 1 1
…
…
U001
U002
U003
1 2 3 4 5 6 7 8 ( Index + 1 )
3人のユーザをHash関数にかけてみる。

28
●推定にHashの最小値を用いる例(2)
最小値だけを取って置き、UU数3を推定する。
Hash関数-1
Hash関数-2
Hash関数-3
Hash関数-k 1 1
1 1
1 1
1 1
…
…
U001
U002
U003
1 2 3 4 5 6 7 8 ( Index + 1 )
2
4
1
3
…
※ 説明の簡略化のため、衝突は発生しないと仮定

29
左の数値1つを覚えるのに必要なサイズは、
MapのサイズがHash値になれば、
32bit(4byte)
必要なサイズは、Hash関数 k個とすると
4 x k byte
となる。
●推定にHashの最小値を用いる例(3)
最小値で計算した場合
2
4
1
3
…
平均2.25
※ 説明の簡略化のため、衝突は発生しないと仮定
2.25 9 (map + 1)
0
ここにbitがありそう…

30
● Base-2 Ranks の推定手法
00011001010010100101001010010111
文字列(IDなど)をHash化し、最初の0が連続する数
を記録する。
その0がp個連続する確率は「1/2𝑝」となる。
大量の文字列をHash化したときに、最も長く0が連続
した数p個だった場合、Hash値の種類(即ちUU数)は
「2𝑝」個あると推定できる。
[例] 32ビット(int)のHash値
𝒑 = 𝟑 ➡ 1/2𝑝 = 1/23 = 1/8
➡ 「8種類くらいのHash値で試したかな?」

31
● HyperLogLog
先述のHash最小値での推定例をBase-2 Rankに置き
換えた形式になる。
Hash関数-1
Hash関数-2
Hash関数-k
…
U001
U002
U003
2
0
1
…
1010…0111
0010…0111
0110…0111
1010…0111
1111…0111
1000…0111
1010…0111
0111…0111
0100…0111
指数なので
単純には平準化できない
論文内の計算式にかける
(詳細は論文参照)
∝𝑚 𝑚2 2−𝑀[𝑗]
𝑚
𝑗=1
−1
≅ 3
32
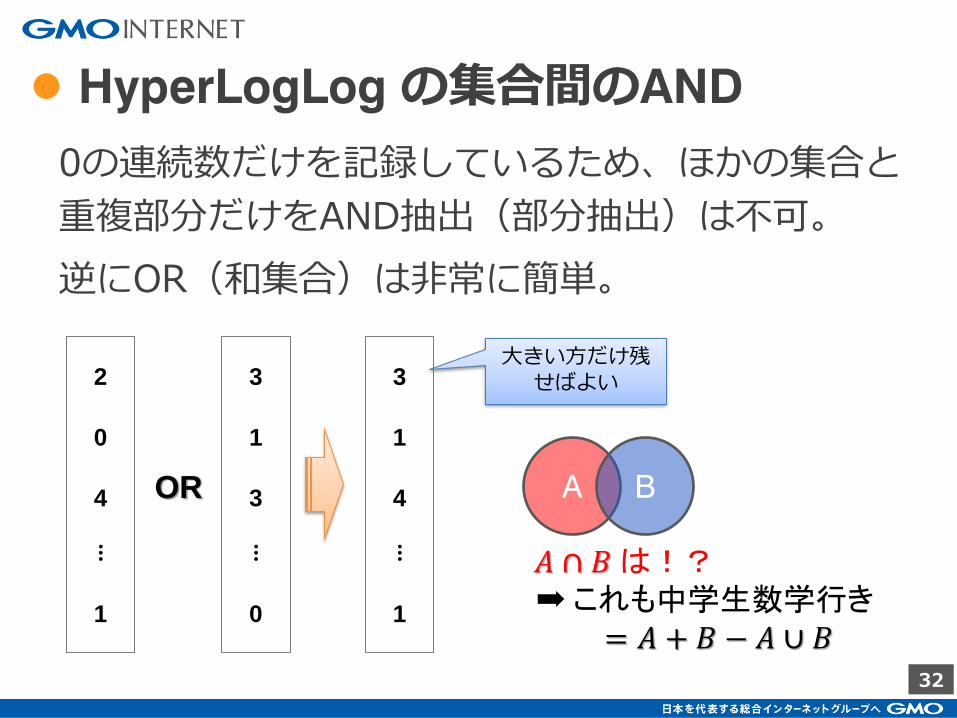
● HyperLogLog の集合間のAND
0の連続数だけを記録しているため、ほかの集合と
重複部分だけをAND抽出(部分抽出)は不可。
逆にOR(和集合)は非常に簡単。
0
1
…
2
4
1
0
…
3
3
1
1
…
3
4 OR
大きい方だけ残せばよい
A B
𝐴 ∩ 𝐵 は!? ➡ これも中学生数学行き = 𝐴 + 𝐵 − 𝐴 ∪ 𝐵

33
● HyperLogLogの使用メモリ
各Hash関数毎に保有する数値はhash関数のbitの桁数
が最大となる。
2
0
1
…
Hash桁数 bit数
32 5
64 6
Hash関数-1
Hash関数-2
Hash関数-k
…
左の数値1つを覚えるのに必要なサイズは、
Hashの桁数32bitであれば 5bit で済む。
全体で必要なサイズは、
Hash関数 k個とすると
5 x k bit
となる。

34
● HyperLogLogの精度
HyperLogLog in Practice [Figure2]
𝑛 のUUを数えるのに、確度 1 ± 𝜀 の近似に必要なメモ
リ領域は O 𝜀−2 log log𝑛 + log𝑛 となる。
nを極大化した際の理論のため小さいuu数では精度が悪い
HyperLogLogの由来

35
● HyperLogLogのGoogleによる改良
HyperLogLog in Practice: Algorithmic Engineering
of a State of The Art Cardinality Estimation
Algorithm
Stefan Heule
Marc Nunkesser
Alexander Hall
http://stefanheule.com/papers/edbt13-hyperloglog.pdf
この論文は2013年。 ただ、この実装は、
2012年に既にPowerDrillに組み込まれている。

36
● 改良の内容
UUと精度の関係 UU少 UU多
HyperLogLog × ○
LinearCounting ○ ×
閾値で切り替える
HyperLogLog in Practice [Figure3 | Figure4]

37
● HyperLogLogのさらなる改良
All-Distances Sketches, Revisited: HIP Estimators
for Massive Graphs Analysis
Edith Cohen
http://arxiv.org/pdf/1306.3284.pdf
HIP ( Historical Inverse Probability )
2014年
閾値って…という感じか。

38
● 改良の内容
ストリームで流しながら、数(UU数)を数えていってしまう。
確率𝑝の事象が発生するには、1 𝑝 回の試行が行われていると期待され
るので、BUCKETが更新される度に期待値を加算していく。
HIP Estimatior [Algorithm3]
データ投入過程の状態を考慮することで、少ないUUの状態
でも精度を向上させる。

39
● HyperLogLogだけでよいのでは?
A. NO
HyperLogLogは省メモリで大量のUUカウントに特化して
いるため他に応用が利きにくい。
[例]
LinearCountingであれば、BitMapを取り出して配信対象
のUser特定などの技術に応用できるが、HyperLogLogで
は全体のUU数が取れるのみ。
その他、並列化で分散させると、HyperLogLogは落ち、
LinearCountingは精度が向上する。

40
実運用への組込

41
● 実運用への組み込みの課題
今回の集計機構を活かすためには、実際にどのようなシス
テム構成で、どういった点を考慮すべきかを考える。
実運用を考えるにあたって、下記のような架空の広告配信
システムを仮定する。
・APサーバで広告配信+ログ出力
(ログの各行にユーザのカテゴリ分類複数記録されている)
・Hadoop環境へのログ集約
・Redis環境へのデータ投入
・管理画面からカテゴリの分析

42
● Redisへのデータ投入
本件で最もボトルネックとなる箇所はRedisへのデータ投入箇所になる
Redisのデータ投入性能(Local TO Local)
⇒ 秒間 3~5万 req/s
⇒ 1億件のデータ投入に1時間弱
ピーク時3~5万req/s であれば、おおよそ5-600億 req/月となる。
広告系の処理は1,000億 req/月を超えることもあり、且つ各レコード
に複数カテゴリが記録されていると厳しい。
並列化が必須
43
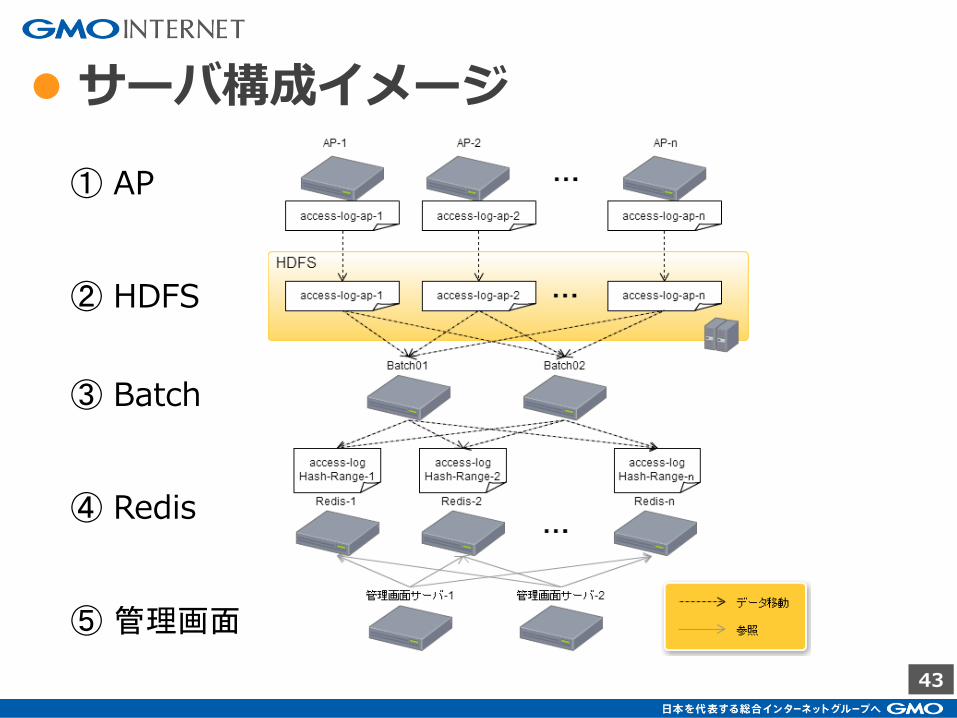
● サーバ構成イメージ
① AP
② HDFS
③ Batch
④ Redis
⑤ 管理画面

44
● ① AP
• 定期的(分単位)にログを転送する
• 転送機構は何でもよい。
• このタイミングではRedisサーバに転送しない。
• とにかくHDFSなどの安定した環境にデータを移行する。
• データの構造(仮定)
• 各レコードにはユーザIDと、
サービス内で分類したユーザのカテゴリ群が記載されているも
のとする。
TIME ユーザID カテゴリID
2015-12-21 01:23:45 USER01 CATE-1, CATE-2,CATE-4
2015-12-21 01:23:46 USER02 CATE-5, CATE-8
…

45
● ② HDFS
• APサーバから受け取ったデータを保存
• 分xサーバでファイルが集まると、ファイルアクセス数などで
問題が発生するため、サービス毎の適切な単位でサマリする。
サーバ x 10台+毎分ファイル転送だと
1時間 = 600ファイル
1日 = 14,400ファイル

46
● ③ Batch
• HDFSからデータを読み込みRedisに転送する
• 転送する際にIDをHash化し推定アルゴリズムに合わせてファイルを分
散する。
• 直接外部からRedisAPIを叩くと速度が出ないため、Redisサーバ内に
ファイルで一度保存する。
• LinearCountingの場合
• 可能な限り分散する。
(精度が上がり1台の必要なメモリ量も下がる。)
• 分散に使用したbit部分は分散後のサーバで使用しないようにする。
[例] 4で割った余りをサーバの分散に使用する場合、
bitを立てるIndexは4で割ってから使用する。
• HyperLogLogの場合
• あまり分散しすぎるとUU計測の精度が落ちるので、可能な限り分散数
を落とす。

47
● ④ Redis
• 外部から直接Redisへのデータ投入は受け付けない
• 外部から受け付けると投入速度が著しく低下する。
(Redisは基本シングルスレッドなので痛い)
• 内部で定期的にRedisに登録するプログラムを用意する。
• LinearCountingの場合
• Batch側で分散に使用したbitは切捨ててIndexに利用する。
[例] 4で割った余りをサーバの分散に使用する場合、
bitを立てるIndexは4で割ってから使用する。
• HyperLogLogの場合
• 特に注意点はなし

48
● ⑤ 管理画面
• ユーザの分散に対する考慮
• ユーザは各Redisサーバに分散しているため、UU数の計算はす
べてのRedisサーバからの取得値の合算値を使用する。

49
まとめ

50
● まとめ
▪ 精度の確認
• 実際にサンプルを作成し、その精度を確認できた。
▪ 理論の確認
• 内部のアルゴリズムを理解することでできること、で
きないことが明確になった。
▪ 実運用適用の検討
• 理論の内容を踏まえた上での、負荷分散の要点の提示
ができた。

51
● 今後の課題
▪ 精度の悪いグループ間のAND結合のより良い解法を導き
出したい。
▪ HIP Estimatorに関しては調査が不十分で、今後も注視し
ていく必要がある。





























