Embed Size (px)
DESCRIPTION
Слисенко Константин, Минск. Компания JazzTeam, Senior Software Engineer «Scrum для большого проекта. Как это работает на практике». Development секция. Agile отделение. «MapReduce и машинное обучение на Hadoop и Mahout». Development секция. Для разработчиков. Высокий уровень подготовки.
Citation preview

MapReduce и машинное обучение на Hadoop и
MahoutКонстантин Слисенко, JazzTeam

О чём это я?❏ Apache Hadoop
❏ Обзор, инфраструктура Hadoop
❏ MapReduce с примерами
❏ Как начать
❏ Apache Mahout
❏ Машинное обучение, обзор Mahout
❏ Что такое кластеризация данных
❏ Пример: кластеризация stackoverflow.com
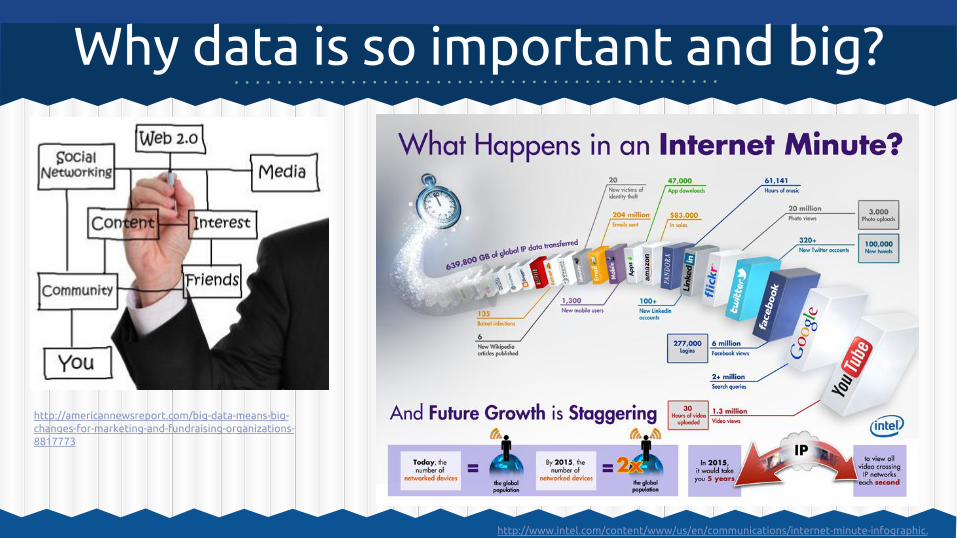
Why data is so important and big?
http://americannewsreport.com/big-data-means-big-changes-for-marketing-and-fundraising-organizations-8817773
http://www.intel.com/content/www/us/en/communications/internet-minute-infographic.html

Откуда столько данных?❏ Мы не знаем что захотим анализировать в
будущем❏ Сохраняем всё❏ Уже давно ничего не удаляется!
❏ 80% данных имеют неструктурированный характер❏ Web-краулинг, GPS, логи, медицинские
данные, статистика кликов, продажи, ...❏ Сам объём данных представляет проблему
Большие вычисления Большие данные
Использование CPU,GPU, CUDA Использование сети, дисков
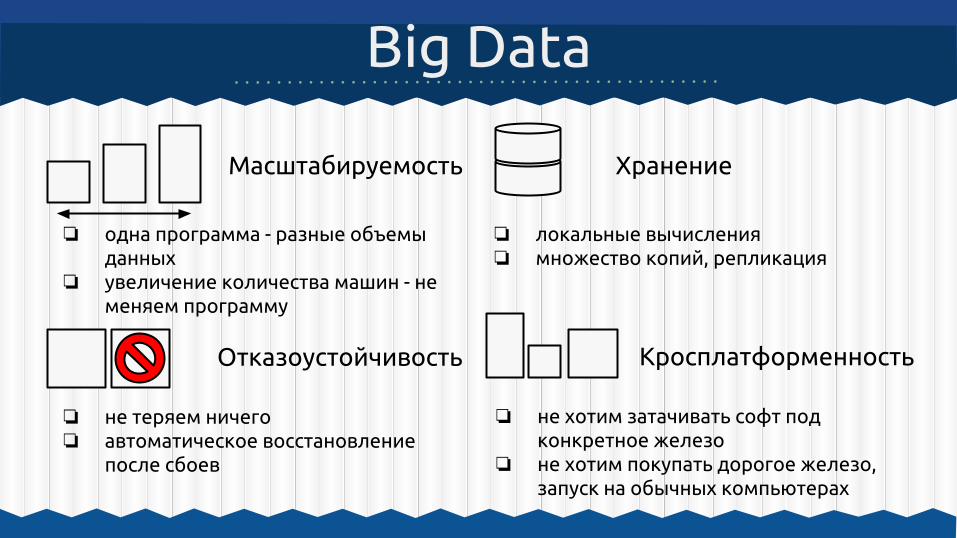
Масштабируемость
Big Data
Хранение
Отказоустойчивость Кросплатформенность
❏ одна программа - разные объемы данных
❏ увеличение количества машин - не меняем программу
❏ локальные вычисления❏ множество копий, репликация
❏ не теряем ничего❏ автоматическое восстановление
после сбоев
❏ не хотим затачивать софт под конкретное железо
❏ не хотим покупать дорогое железо, запуск на обычных компьютерах

Apache Hadoop
❏ Фреймворк для обработки данных❏ Масштабируется на множество машин❏ Написан на Java, открытый исходный код❏ Специальная файловая система❏ Не требует специального железа❏ Поддержка java, c#, c++, python, ruby,
javascript, ...
http://hadoop.apache.org
Дистрибутивы❏ Apache Hadoop❏ Cloudera❏ Hortonworks❏ MapR, IBM, Oracle, Intel...
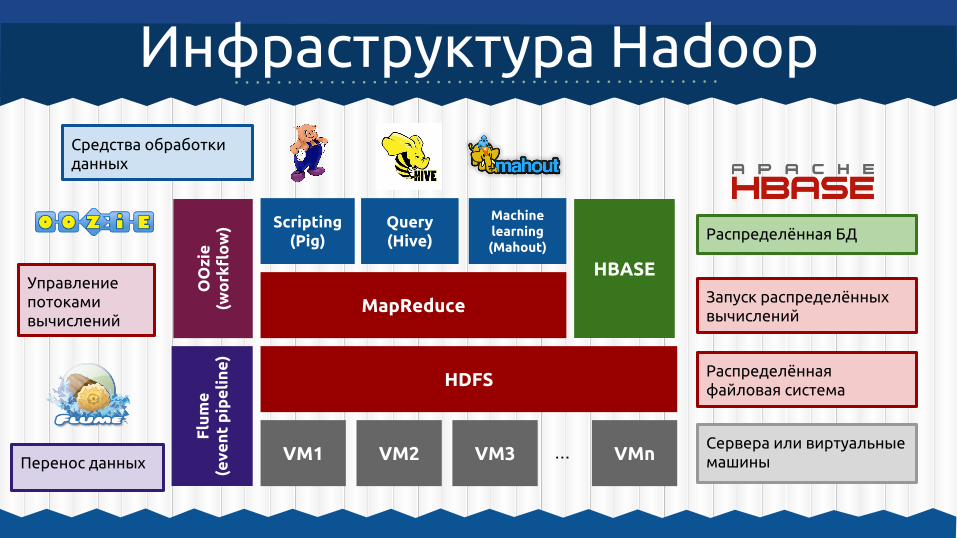
Инфраструктура Hadoop
MapReduce
HDFS
VM1 VM2 VM3 VMn...
Scripting (Pig)
Query (Hive)
Machine learning (Mahout)
Средства обработки данных
Запуск распределённых вычислений
Распределённая файловая система
Сервера или виртуальные машины
HBASE
OO
zie
(wo
rkfl
ow
)Fl
ume
(eve
nt p
ipel
ine)
Управление потоками вычислений
Перенос данных
Распределённая БД

Файловое хранилище HDFS
VM1
1 2
VM2
3 2
VM3
1 3
HDFS
❏ Распределённое хранение
❏ Локальность вычислений
❏ Репликация
1 2 3Файл
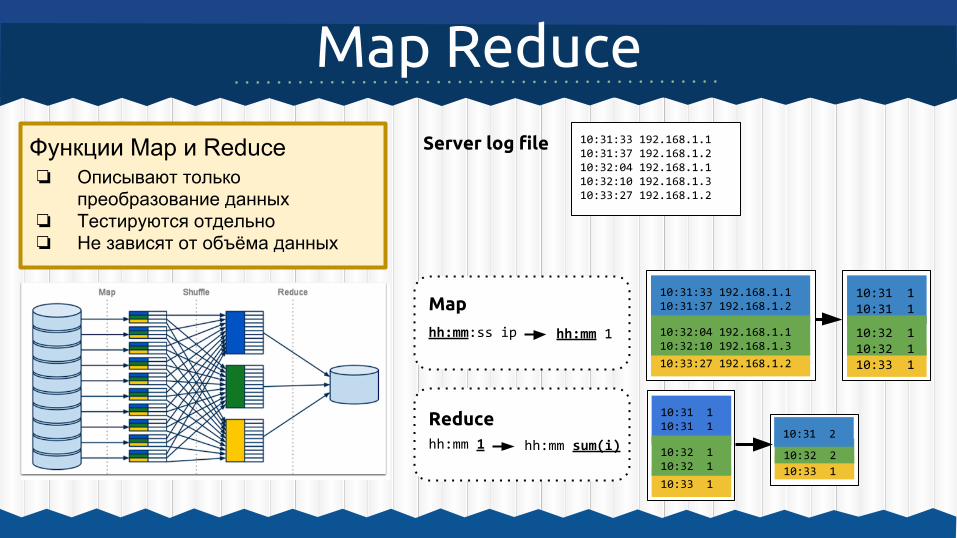
Map Reduce10:31:33 192.168.1.110:31:37 192.168.1.210:32:04 192.168.1.110:32:10 192.168.1.310:33:27 192.168.1.2
10:31:33 192.168.1.110:31:37 192.168.1.2Map
Server log file
Reduce
10:33 1
10:32 2
10:31 2
10:31 110:31 1
hh:mm:ss ip hh:mm 1
hh:mm 1
10:33:27 192.168.1.2
hh:mm sum(i)
10:33 1
10:32:04 192.168.1.110:32:10 192.168.1.3
10:32 110:32 1
10:33 1
10:31 110:31 1
10:32 110:32 1
Функции Map и Reduce❏ Описывают только
преобразование данных❏ Тестируются отдельно❏ Не зависят от объёма данных

Пример - статистика посещений сервера
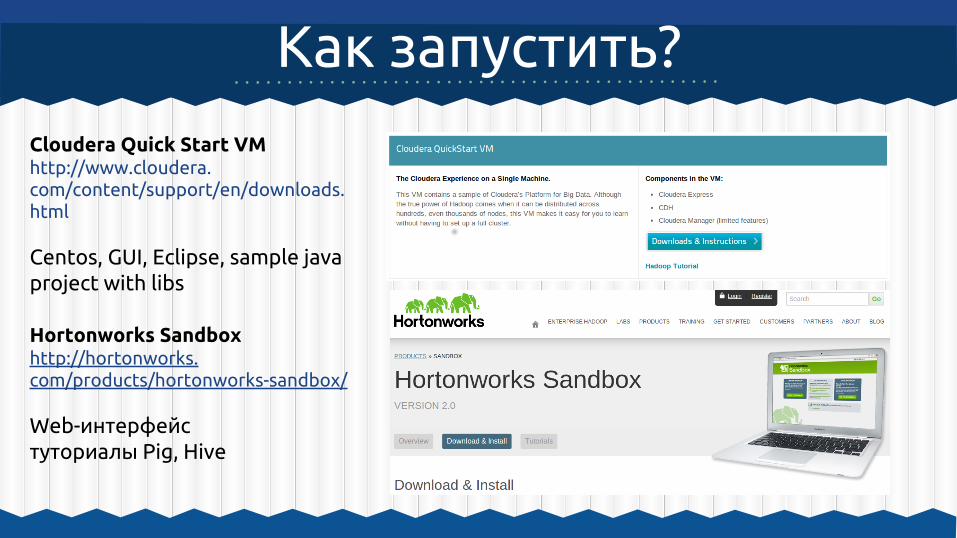
Как запустить?
Cloudera Quick Start VMhttp://www.cloudera.com/content/support/en/downloads.html
Centos, GUI, Eclipse, sample java project with libs
Hortonworks Sandboxhttp://hortonworks.com/products/hortonworks-sandbox/
Web-интерфейстуториалы Pig, Hive
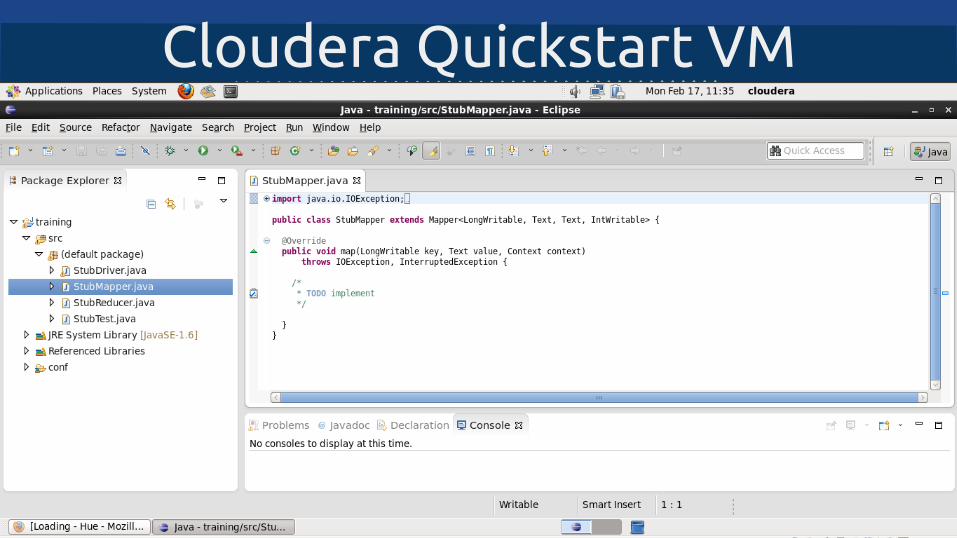
Cloudera Quickstart VM
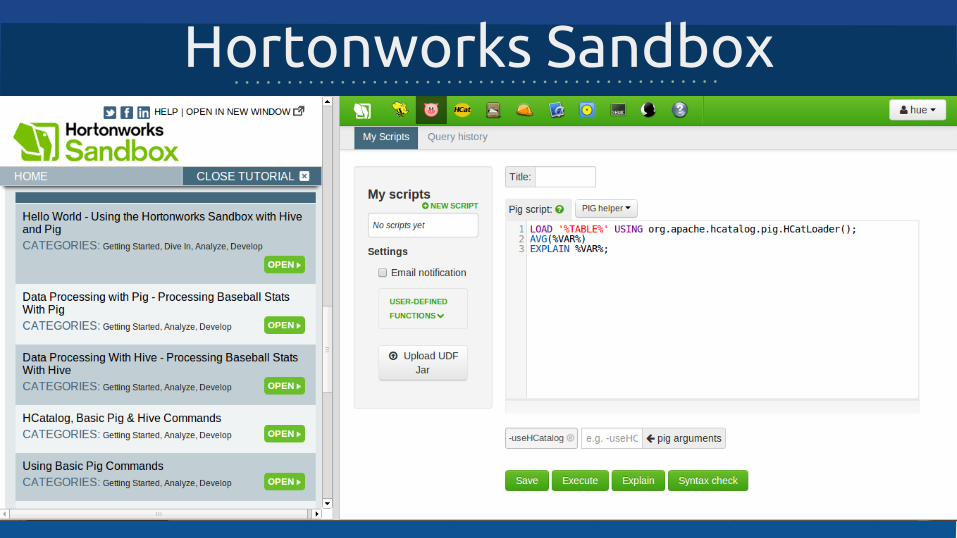
Hortonworks Sandbox

Почему бы не использовать Unit-тесты?
Подключаем библиотеку MRUnit и дебажим
+ не требует инсталляции Hadoop- нет гарантии работы на реальном кластере
Без инсталляции Hadoop

Approval tests MapReduce
http://approvaltests.sourceforge.net/
1. Создаём обёртки для Mapper и Reducer2. Передаём входные данные3. Генерируется текстовый файл c результатами
Всё визуально понятноСразу имеем покрытие кода Unit-тестами

Начинаем изучать Hadoop
Hadoop. The definitive guide
O’REILLY
Getting started with Apache Hadoop
DZone Refcardz
Немного обо всём наHortonworks Sandbox VM
Pig, Hive, HDFS, Hadoop.
http://hortonworks.com/tutorials/http://hortonworks.com/products/hortonworks-sandbox/
Примеры кода на Cloudera Quickstart VM

Hadoop в облаке - играемся серьёзно
Amazon Elastic MapReduce сервис hdinsight
http://aws.amazon.com/elasticmapreduce/ http://www.windowsazure.com/en-us/services/hdinsight/

Что такое машинное обучение?
Подраздел искусственного интеллекта
Machine learning is the science of getting computers to act without being explicitly programmed (Coursera)
❏ Системы рекомендаций❏ Классификация объекта на
принадлежность к группе❏ Нахождение похожих объектов❏ Нахождение шаблонов поведения❏ Ключевые темы в коллекции
документов❏ Определение аномалий❏ Определние спама❏ Ранжирование поисковой выдачии многое другое
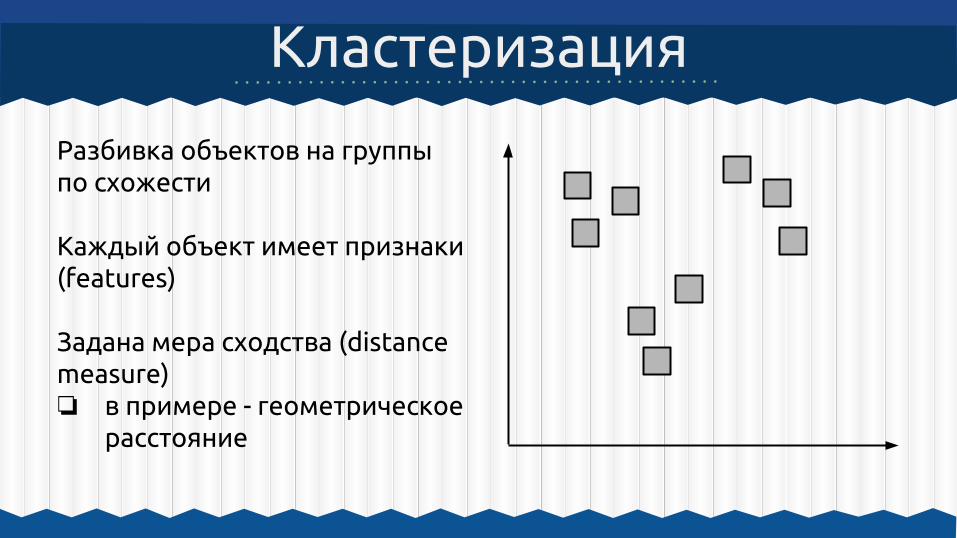
Разбивка объектов на группы по схожести
Каждый объект имеет признаки (features)
Задана мера сходства (distance measure)❏ в примере - геометрическое
расстояние
Кластеризация
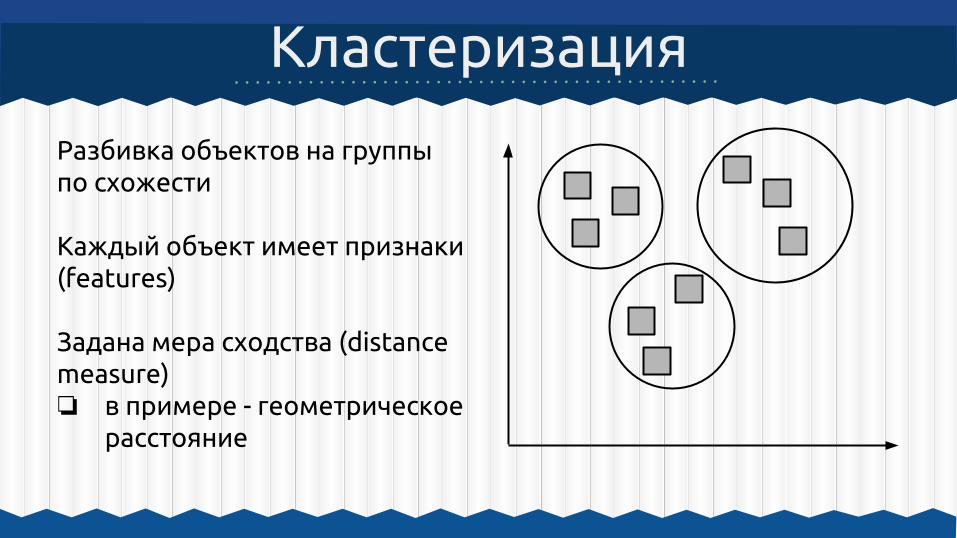
Разбивка объектов на группы по схожести
Каждый объект имеет признаки (features)
Задана мера сходства (distance measure)❏ в примере - геометрическое
расстояние
Кластеризация
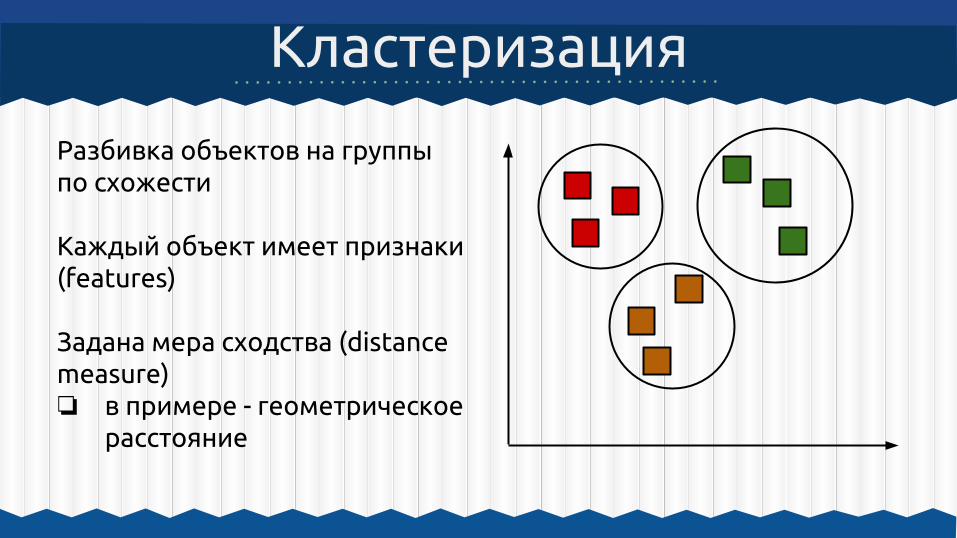
Разбивка объектов на группы по схожести
Каждый объект имеет признаки (features)
Задана мера сходства (distance measure)❏ в примере - геометрическое
расстояние
Кластеризация
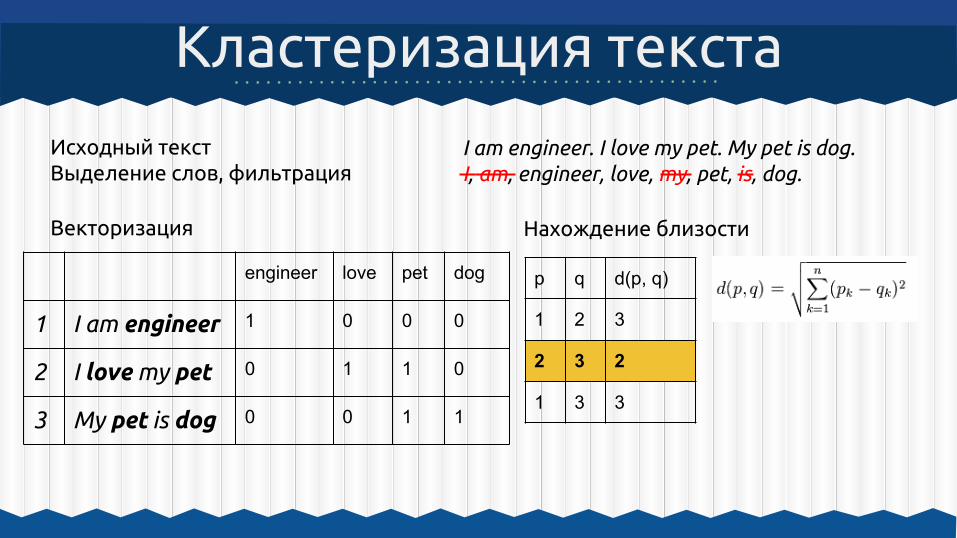
I am engineer. I love my pet. My pet is dog.I, am, engineer, love, my, pet, is, dog.
Кластеризация текста
Исходный текстВыделение слов, фильтрация
Векторизация
engineer love pet dog
1 I am engineer 1 0 0 0
2 I love my pet 0 1 1 0
3 My pet is dog 0 0 1 1
p q d(p, q)
1 2 3
2 3 2
1 3 3
Нахождение близости
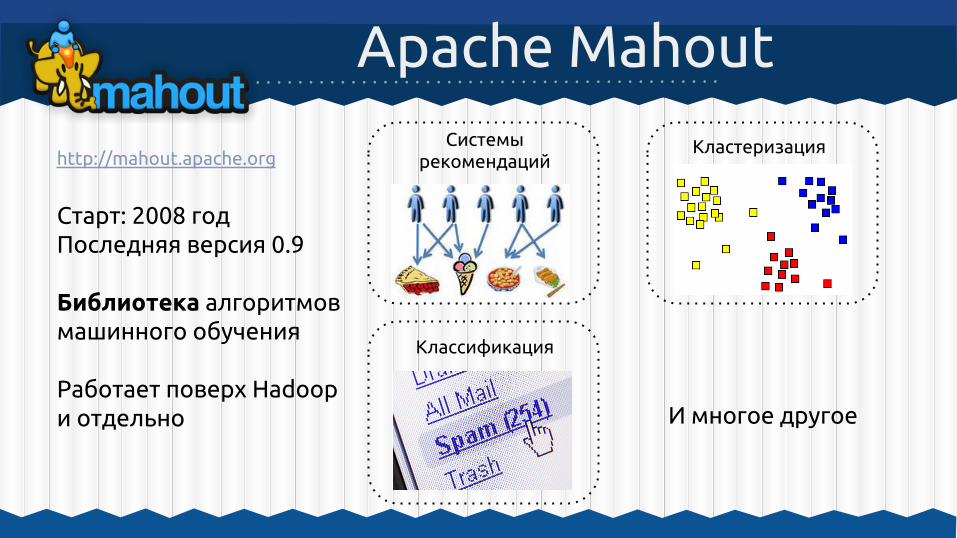
http://mahout.apache.org
Старт: 2008 годПоследняя версия 0.9
Библиотека алгоритмов машинного обучения
Работает поверх Hadoop и отдельно
Apache MahoutСистемы
рекомендацийКластеризация
Классификация
И многое другое
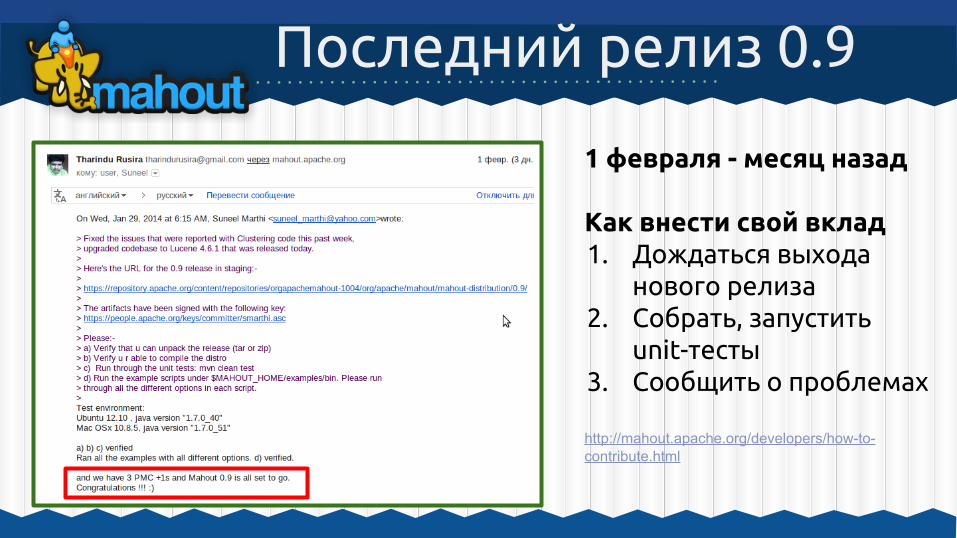
1 февраля - месяц назад
Как внести свой вклад1. Дождаться выхода
нового релиза2. Собрать, запустить
unit-тесты3. Сообщить о проблемах
http://mahout.apache.org/developers/how-to-contribute.html
Последний релиз 0.9

Пример: кластеризация посылок

Кластеризация посылок
ParcelClusteringMahoutExample.java Parcel.java
ParcelToVectorUtil.java
Output

stackoverflow.com

❏ 15.7 Гб (архив, Январь 2014)
❏ 6.7 миллионов вопросов
❏ 12 миллионов ответов
❏ 2.8 миллионов пользователей
https://archive.org/details/stackexchange
Открытые данные stackoverflow
<posts> <row Id="0" Title="Title1"
Body="Question 1 text" ... /> <row Id="1" Title="Title1"
Body="Question 2 text" ... /></posts>
Исходные данные в формате XML
PostTypeId, AcceptedAnswerId, CreationDate, Score, ViewCount, OwnerUserId, LastEditorUserId, LastEditorDisplayName, LastEditDate, LastActivityDate, Tags, AnswerCount, CommentCount, FavoriteCount
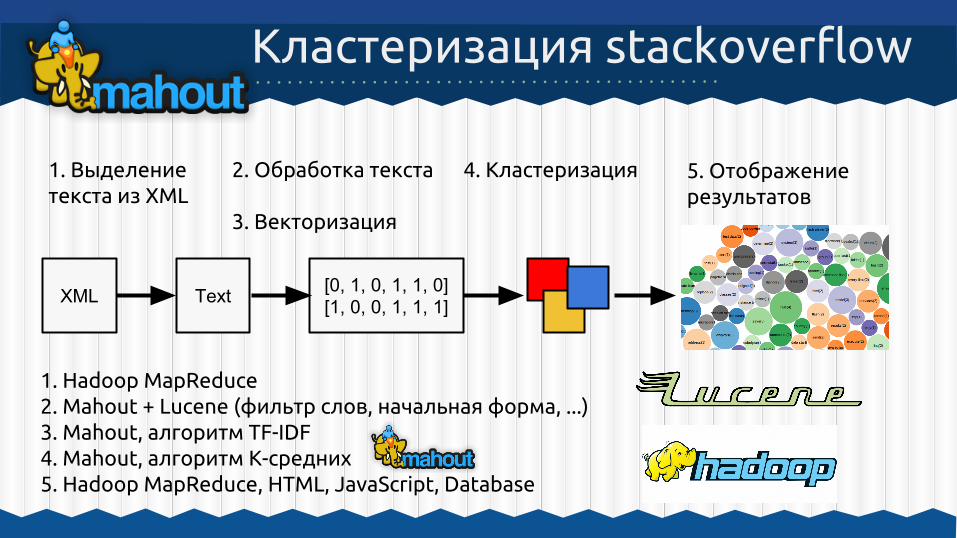
Кластеризация stackoverflow
XML Text [0, 1, 0, 1, 1, 0][1, 0, 0, 1, 1, 1]
1. Выделение текста из XML
2. Обработка текста
3. Векторизация
4. Кластеризация 5. Отображение результатов
1. Hadoop MapReduce2. Mahout + Lucene (фильтр слов, начальная форма, ...)3. Mahout, алгоритм TF-IDF4. Mahout, алгоритм К-средних5. Hadoop MapReduce, HTML, JavaScript, Database

Результат - облако тегов
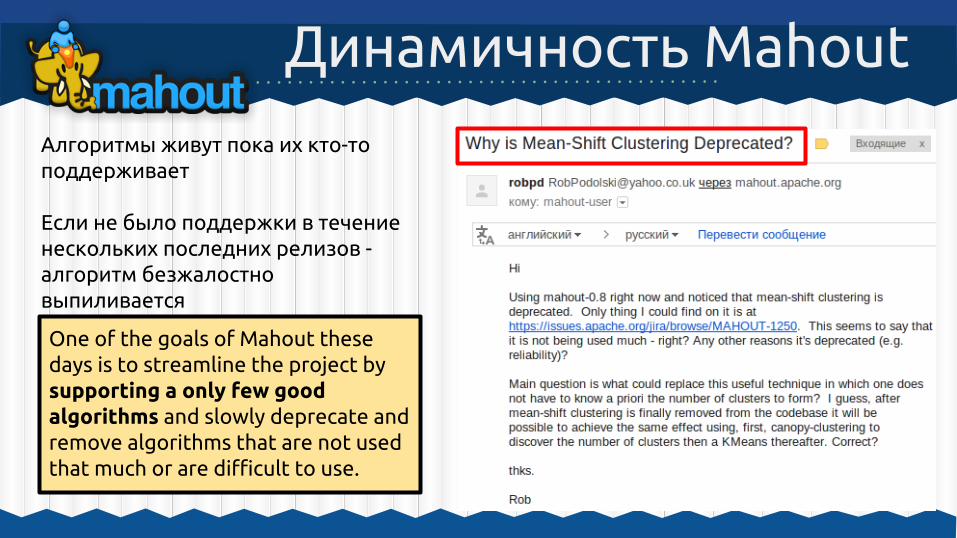
Динамичность Mahout
Алгоритмы живут пока их кто-то поддерживает
Если не было поддержки в течение нескольких последних релизов - алгоритм безжалостно выпиливается
One of the goals of Mahout these days is to streamline the project by supporting a only few good algorithms and slowly deprecate and remove algorithms that are not used that much or are difficult to use.

Изучаем Mahout
Mahout in action
Sean Oven, Robin Anil, Ted Dunning, Ellen Friedman
Manning
Кластеризация Stackoverflow от Frank Scholtenhttps://github.com/frankscholten/mahout-clustering-stackoverflow
Исходный код примеров Mahout in action:https://github.com/tdunning/MiA
Mailing [email protected]@mahout.apache.org
Hadoop & MapReduce & Mahout in action
H.Saygin Arkan
9/3/2009






























