Embed Size (px)
Citation preview

Spring “BigData”
リクルートテクノロジーズ松﨑 遥(Haruka Matsuzaki)

(C) Recruit Technologies Co.,Ltd. All rights reserved.
Spring=Web?
“Spring Data”
知ってますか?
2

(C) Recruit Technologies Co.,Ltd. All rights reserved.
今日のお話
ビッグデータ界隈での
Spring活用法
3

(C) Recruit Technologies Co.,Ltd. All rights reserved.
話者紹介
4
職歴
専攻
~前職
所属
氏名
Recruit Technologies ITS統括部ビッグデータ部IDPoint領域 FrameworkTL (兼務:Holdings)
松﨑 遥(Haruka)
東京大学大学院広域科学研究科 複雑系科学
assembler→c++/qt→ObjC/tclTk→php/js→iOS→Java/js/css/Haskell→Lucene/Hadoop→Spark/Scala
Web → BigData
(C) Recruit Technologies Co.,Ltd. All rights reserved.
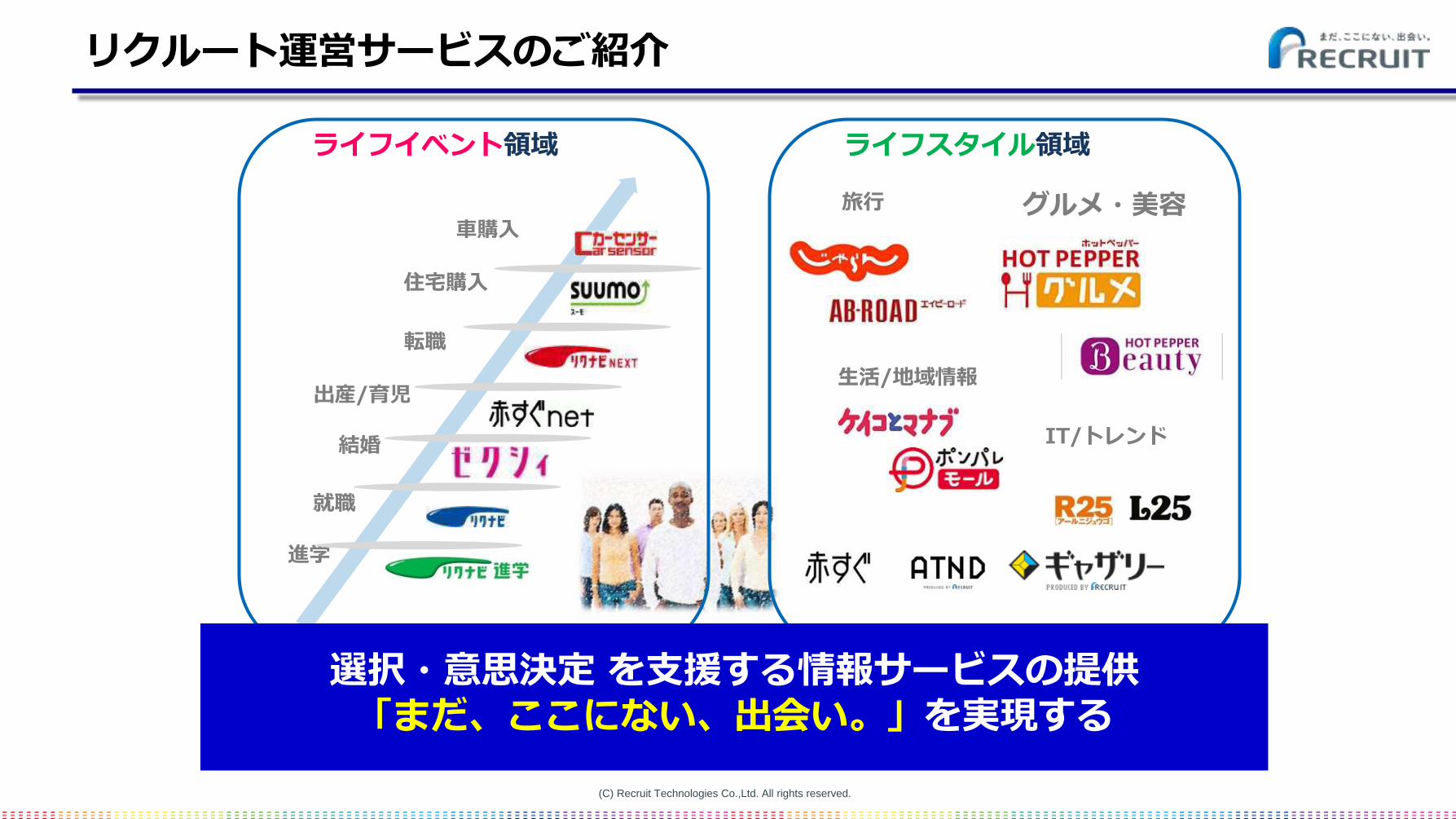
ライフイベント領域
進学
就職
結婚
転職
住宅購入
車購入
出産/育児
旅行
IT/トレンド
生活/地域情報
グルメ・美容
ライフスタイル領域
選択・意思決定 を支援する情報サービスの提供「まだ、ここにない、出会い。」を実現する
リクルート運営サービスのご紹介
(C) Recruit Technologies Co.,Ltd. All rights reserved.
ビッグデータ部の仕事内容とは?
6
数百億のログ
集計/予測/リコメンド etc
(C) Recruit Technologies Co.,Ltd. All rights reserved.
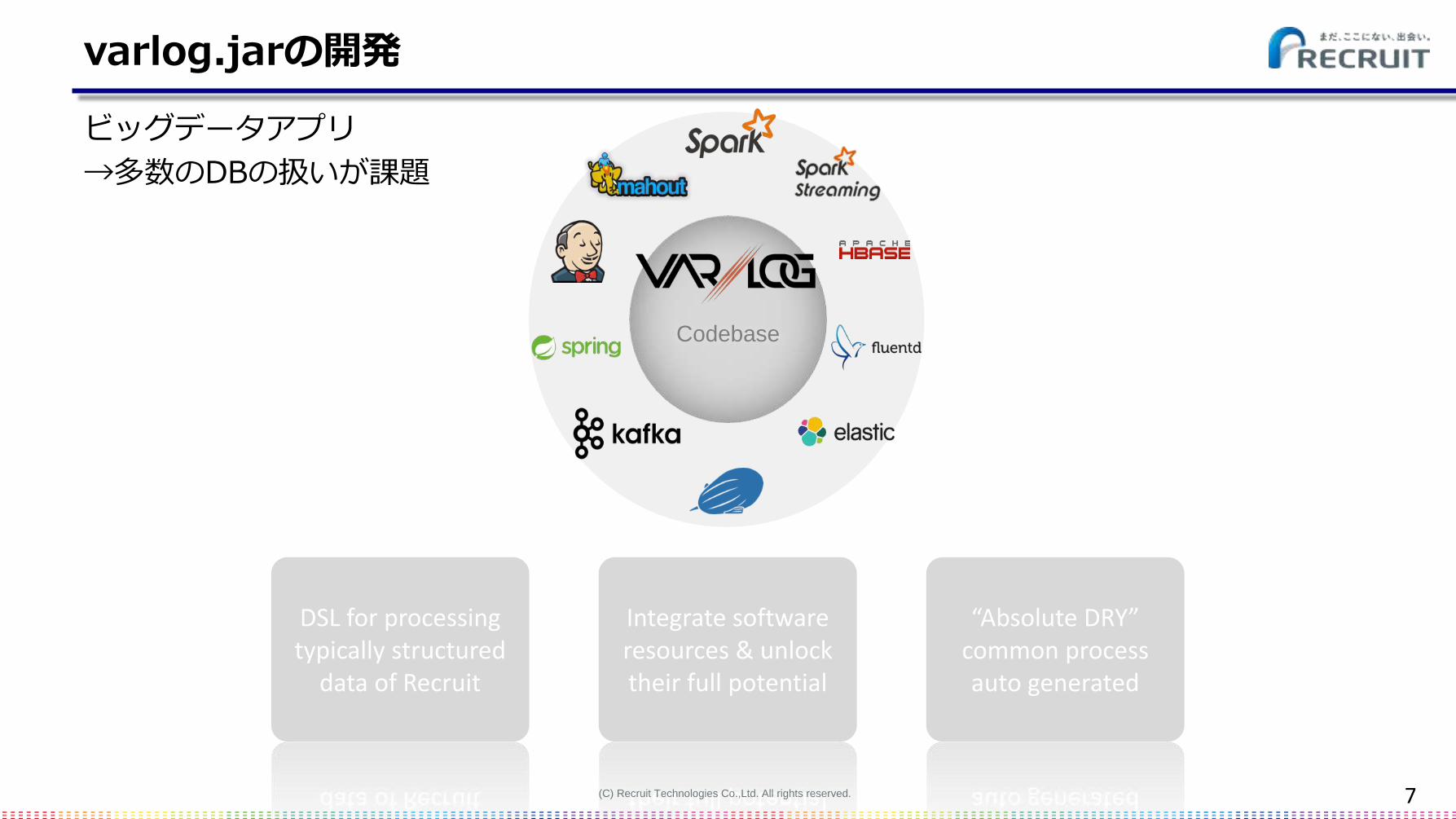
varlog.jarの開発
ビッグデータアプリ
→多数のDBの扱いが課題
7
Integrate software resources & unlocktheir full potential
“Absolute DRY”common process auto generated
DSL for processing typically structured
data of Recruit
Codebase
(C) Recruit Technologies Co.,Ltd. All rights reserved.
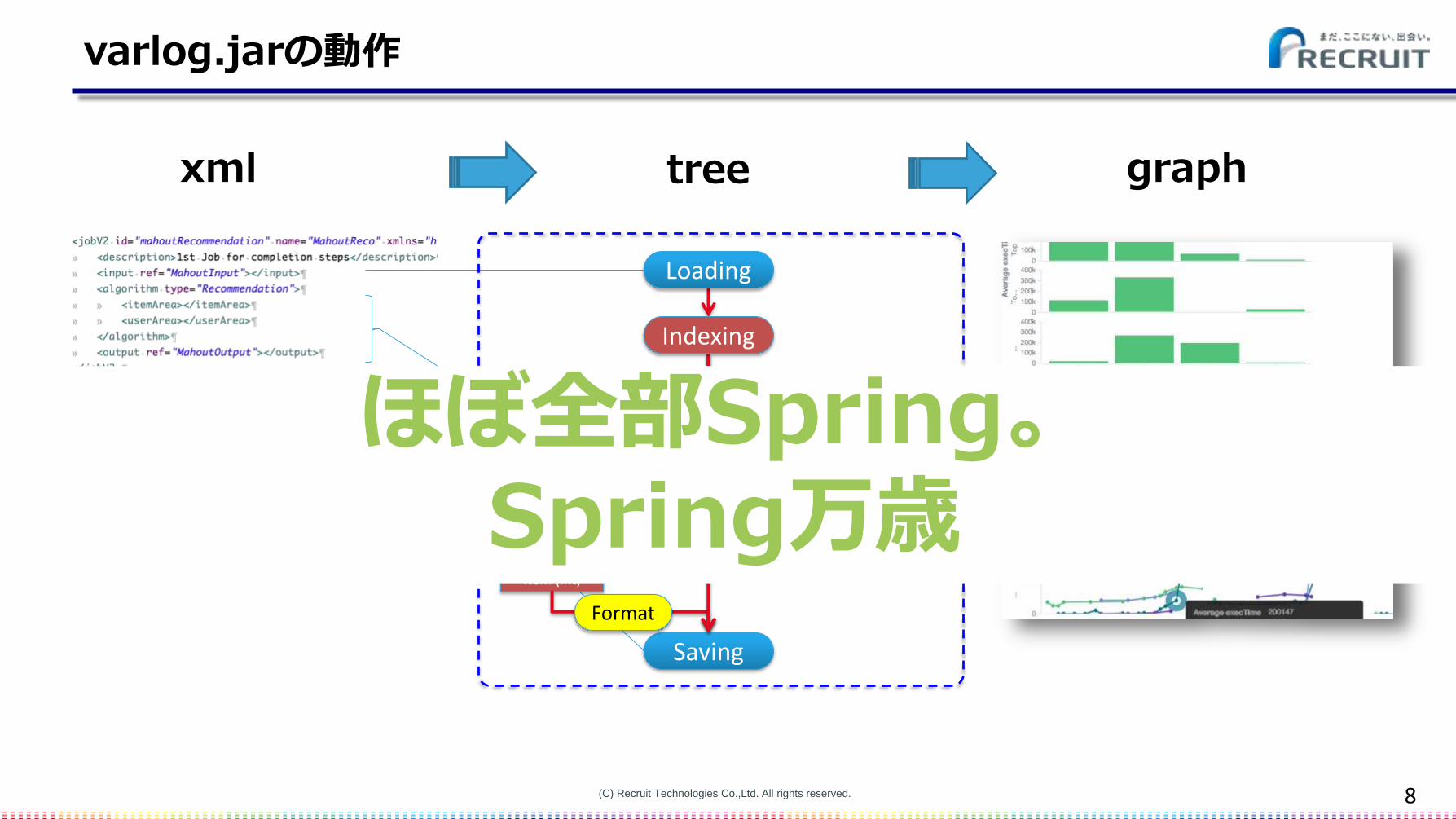
varlog.jarの動作
8
xml
RecommendUser (Int)Item (Int)
DictionaryUserId (Int)
User (String)
DictionaryItemId(Int)
Item(String)
InputUserId (Int)ItemId(Int)
Loading
ML
Saving
Indexing
Format
tree graph
.Jarほぼ全部Spring。Spring万歳

(C) Recruit Technologies Co.,Ltd. All rights reserved.
今日お伝えしたいこと
Spring Data
なんでもできるやん
9
(C) Recruit Technologies Co.,Ltd. All rights reserved.
Top5素晴らしいプラクティス
1.JDBC
2.DataStoreWriter
3.SparkYarnTasklet
4.CrudRepository
5.SpringBatch
6.?????(本題)
10
(C) Recruit Technologies Co.,Ltd. All rights reserved.
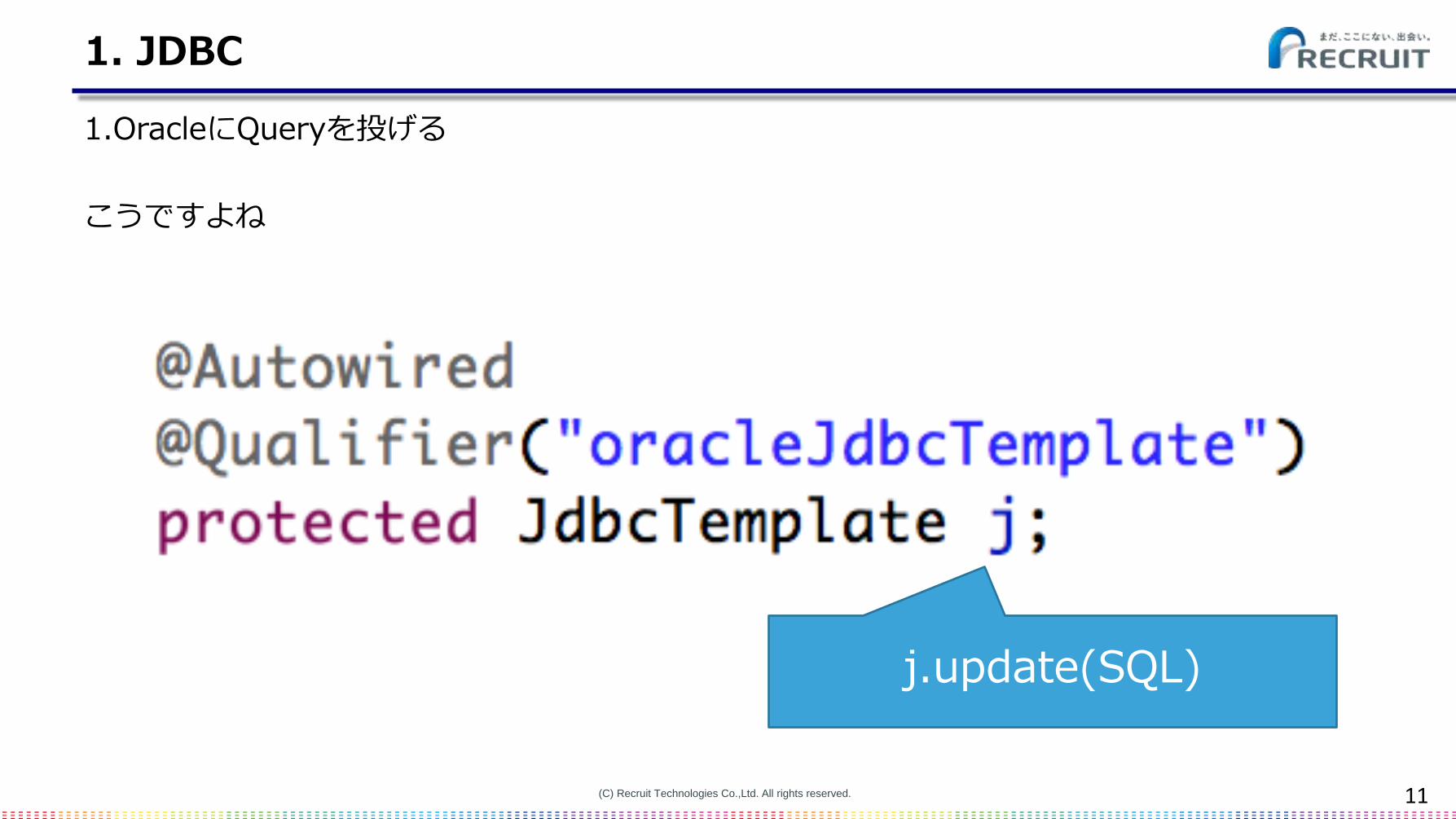
1. JDBC
1.OracleにQueryを投げる
こうですよね
11
j.update(SQL)
(C) Recruit Technologies Co.,Ltd. All rights reserved.
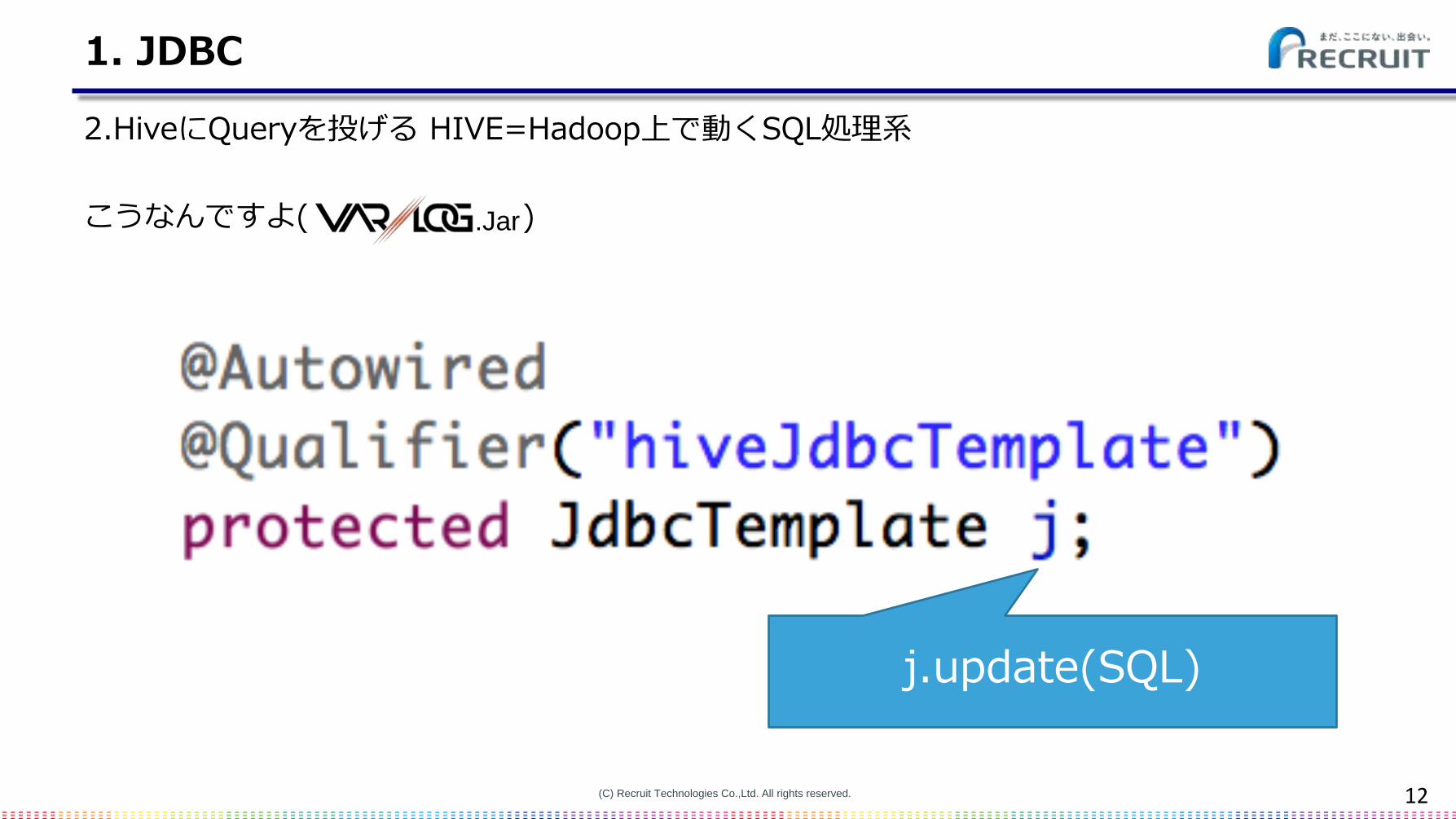
1. JDBC
2.HiveにQueryを投げる HIVE=Hadoop上で動くSQL処理系
こうなんですよ( )
12
.Jar
j.update(SQL)

(C) Recruit Technologies Co.,Ltd. All rights reserved.
1. JDBC
裏側=HiveServer2(Thrift Server)に対しJarCient(notCLI)を利用
13
Hive楽勝

(C) Recruit Technologies Co.,Ltd. All rights reserved.
1. JDBC
おまけ:Spring-Tx(Rollback, Timeout, etc…)
Hiveで動作しない機能も多い(Hadoop Distribution依存なので注意)
※そもそもREDOログなどをもたないHiveにRollbackという概念は無い
14
↑動かない
↑つくる
なんとかなる

(C) Recruit Technologies Co.,Ltd. All rights reserved.
2. DataStoreWriter
Oracle
Hive
はクリア。では、Hdfsは?(Hdfs = Hadoop分散ファイルシステム)
昔のコード↓
15
hadoop dfs –catからパイプで突っ込む
(awkは分散計算しない)
HadoopのNFS Gateway機能(Distribution依存)により
Hdfsに突っ込む
コレジャナイ感

(C) Recruit Technologies Co.,Ltd. All rights reserved.
2. DataStoreWriter
3.HdfsにJavaから直接書き込む
こうでしょ!( )
16
.Jar

(C) Recruit Technologies Co.,Ltd. All rights reserved.
2. DataStoreWriter
裏側=FactoryでPojoクラスからwriterを生成
17
Avro形式なのもポイント!
Default=Avro

(C) Recruit Technologies Co.,Ltd. All rights reserved.
2. DataStoreWriter
writer.write(obj)してみて、確認
18
前半:JSON部分=Avroスキーマ
後半:バイナリ部分=Avroシリアライズデータ
+ Snappy圧縮

(C) Recruit Technologies Co.,Ltd. All rights reserved.
2. DataStoreWriter with Kuromoji
Kuromojiとは、日本語を形態素解析するライブラリ
19
お手軽!
(C) Recruit Technologies Co.,Ltd. All rights reserved.
3. Spark
Oracle
Hive
Hdfs
はクリア。では、Sparkは? Spark = オンメモリ分散処理系
①
SparkYarnTasklet sparkTasklet = new SparkYarnTasklet();
②
@SpringBootApplication
@EnableBatchProcessing
public class SparkYarnApplication
20
面倒ぃ

(C) Recruit Technologies Co.,Ltd. All rights reserved.
3. Spark
こうしました
RDD = Resilient Distribute Dataset = 可塑分散データセット
21
(C) Recruit Technologies Co.,Ltd. All rights reserved.
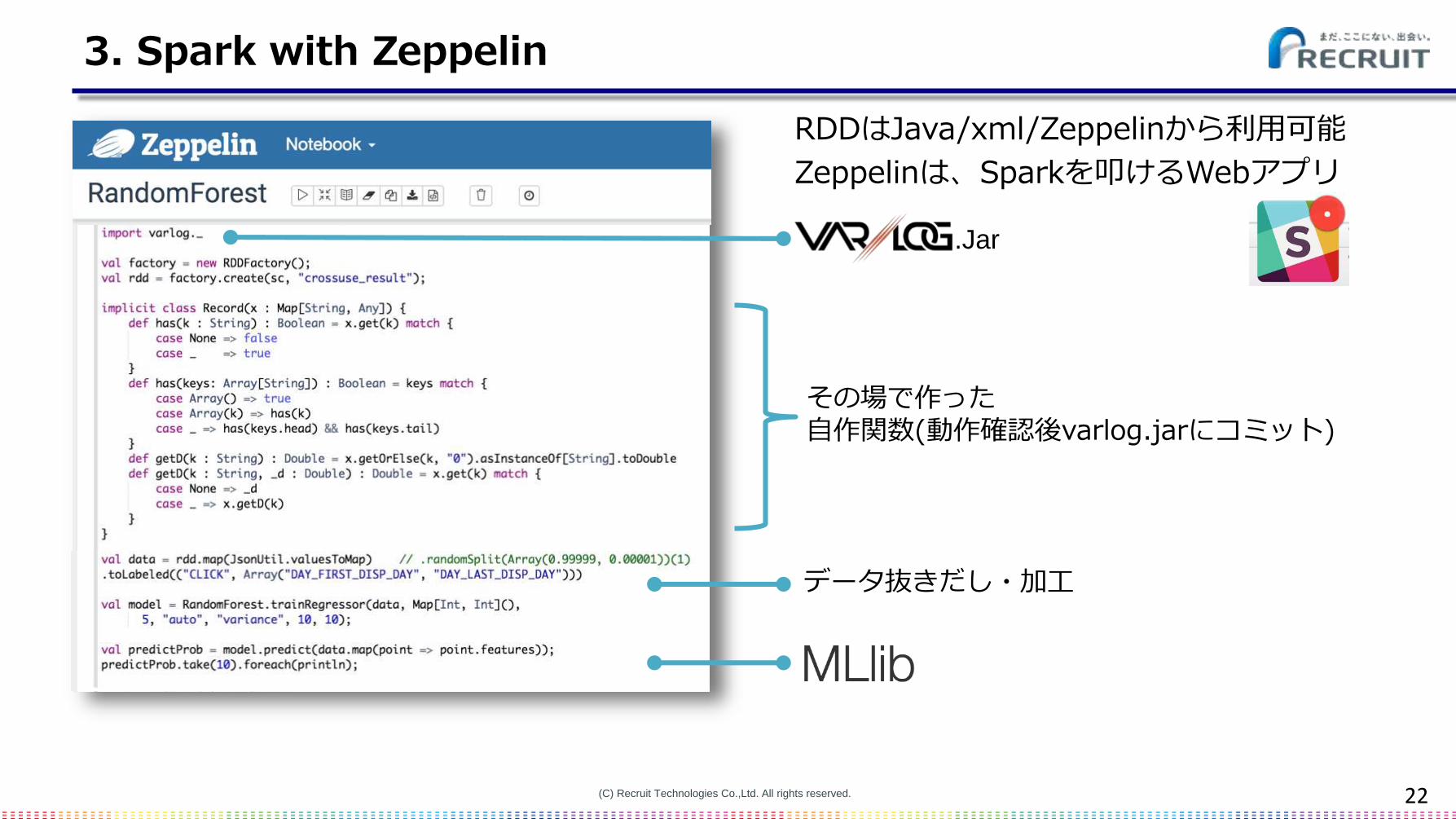
3. Spark with Zeppelin
22
.Jar
その場で作った自作関数(動作確認後varlog.jarにコミット)
データ抜きだし・加工
RDDはJava/xml/Zeppelinから利用可能
Zeppelinは、Sparkを叩けるWebアプリ
(C) Recruit Technologies Co.,Ltd. All rights reserved.
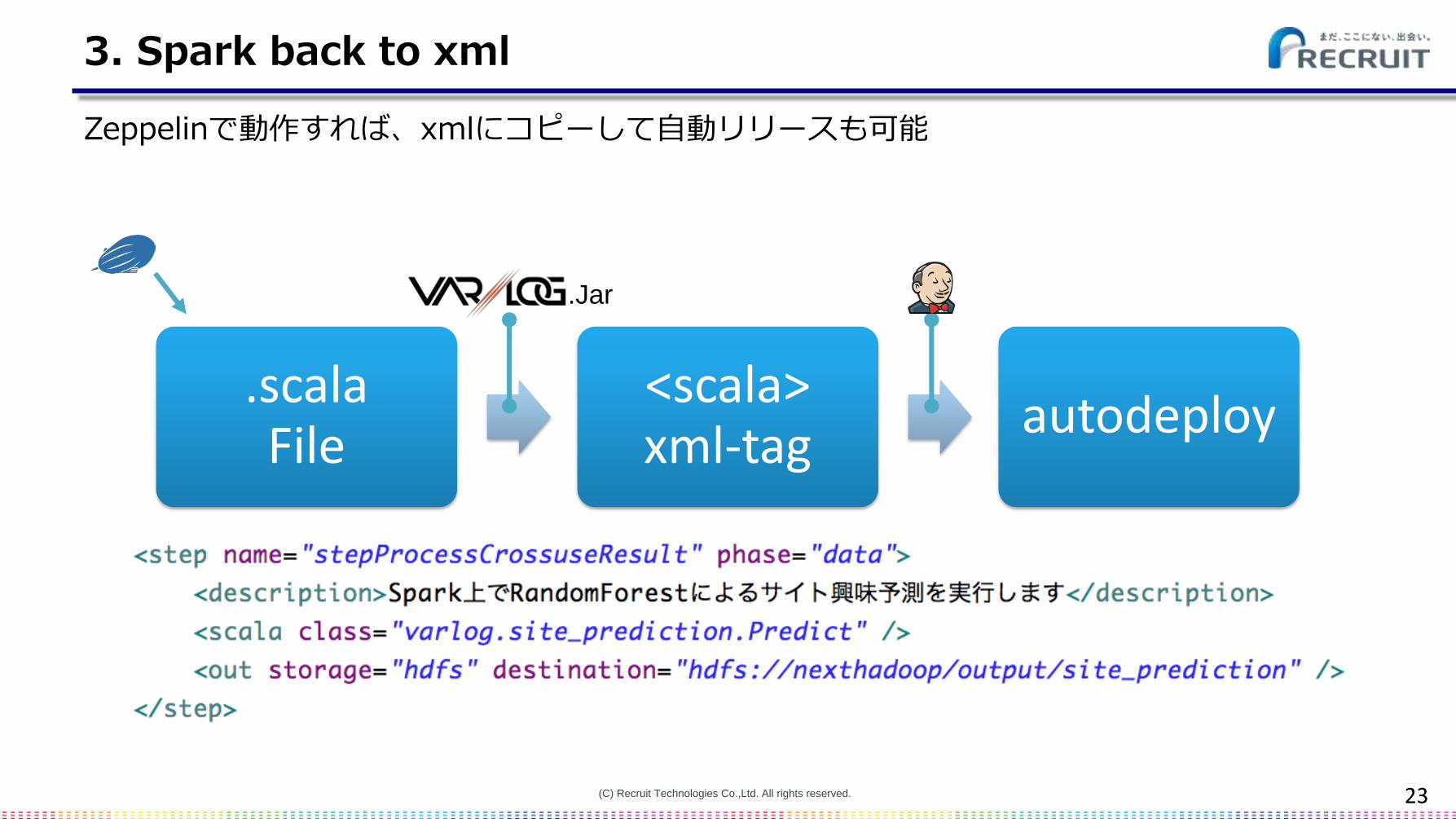
3. Spark back to xml
.scalaFile
<scala> xml-tag
autodeploy
23
Release Notes as a Job
.Jar
Zeppelinで動作すれば、xmlにコピーして自動リリースも可能

(C) Recruit Technologies Co.,Ltd. All rights reserved.
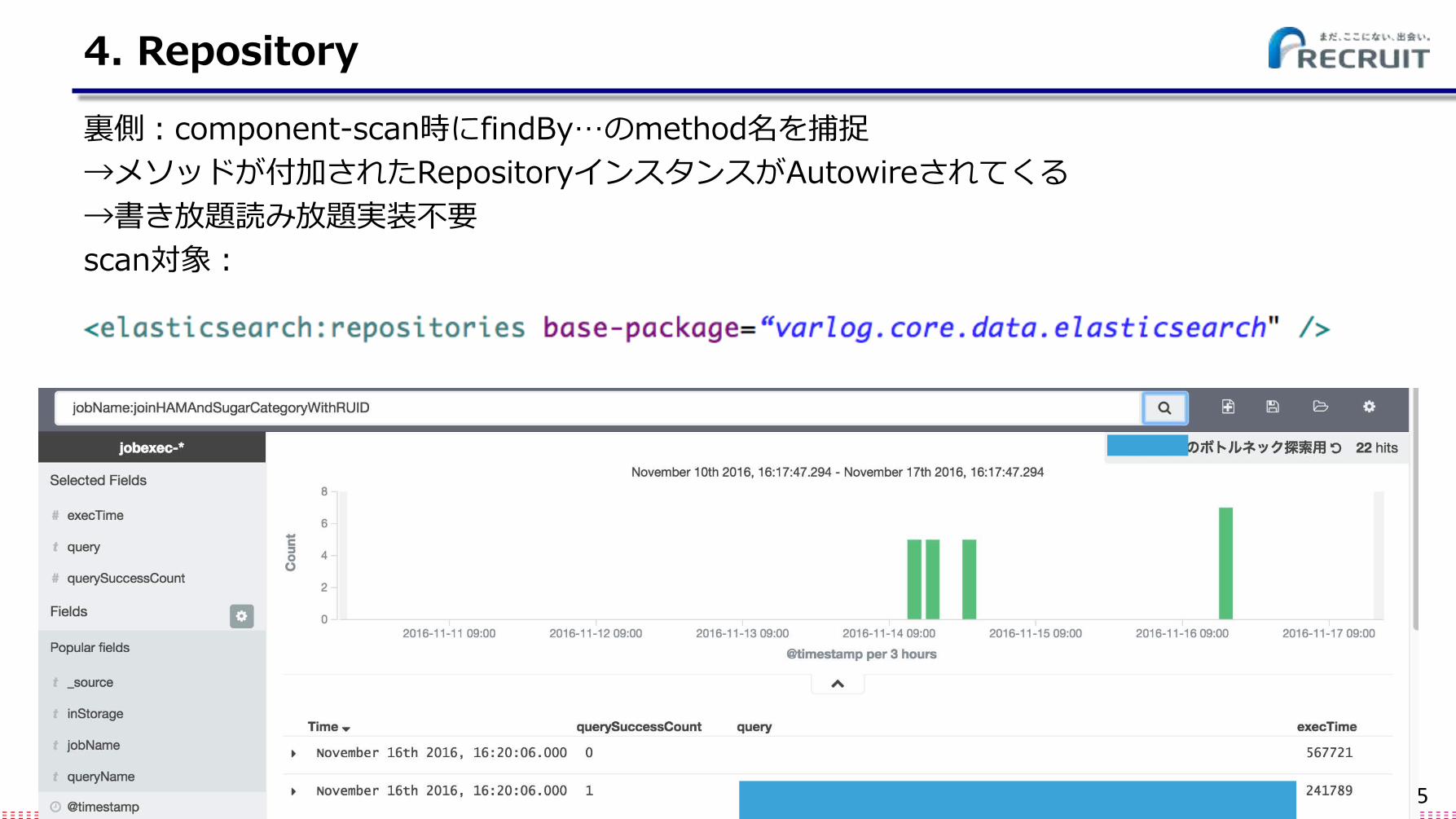
4. Repository
Oracle
Hive
Hdfs
Spark
はクリア。では、Elasticsearchは? ES = LuceneのWebサーバーラッパー(スケーラブル)
→ElasticSearch Repository
24
(C) Recruit Technologies Co.,Ltd. All rights reserved.
4. Repository
裏側:component-scan時にfindBy…のmethod名を捕捉
→メソッドが付加されたRepositoryインスタンスがAutowireされてくる
→書き放題読み放題実装不要
scan対象:
25

(C) Recruit Technologies Co.,Ltd. All rights reserved.
5. SpringBatch
Oracle
Hive
Hdfs
Spark
Elasticsearch
はクリア。並列実行も可能
26

(C) Recruit Technologies Co.,Ltd. All rights reserved.
6. Spring最強の機能について
Oracle/Hive/Hdfs/Spark/Elasticsearch/Kafka(略)/SpringBatch…
最強の機能とは????
27
(C) Recruit Technologies Co.,Ltd. All rights reserved.
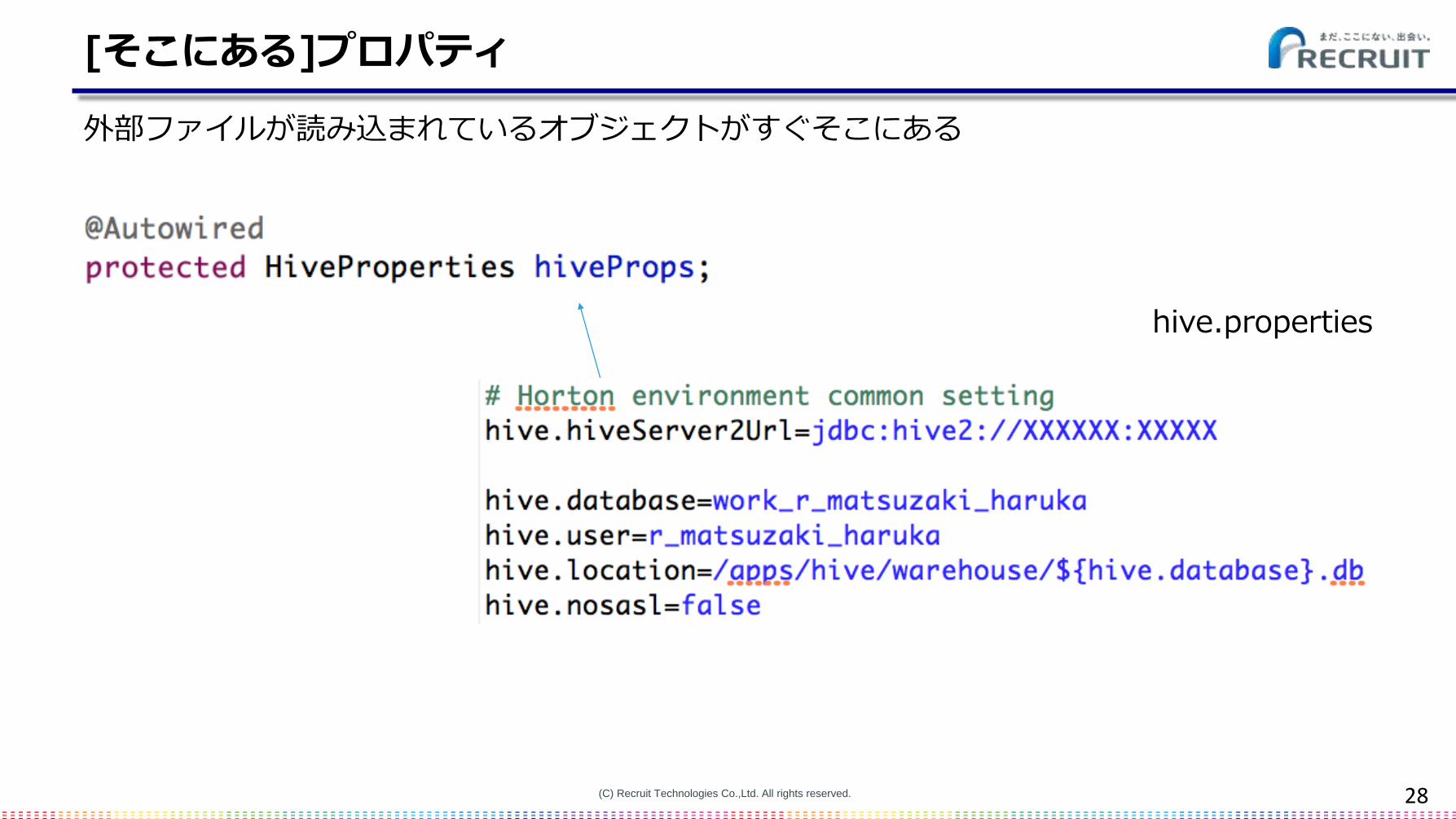
[そこにある]プロパティ
外部ファイルが読み込まれているオブジェクトがすぐそこにある
28
hive.properties
(C) Recruit Technologies Co.,Ltd. All rights reserved.
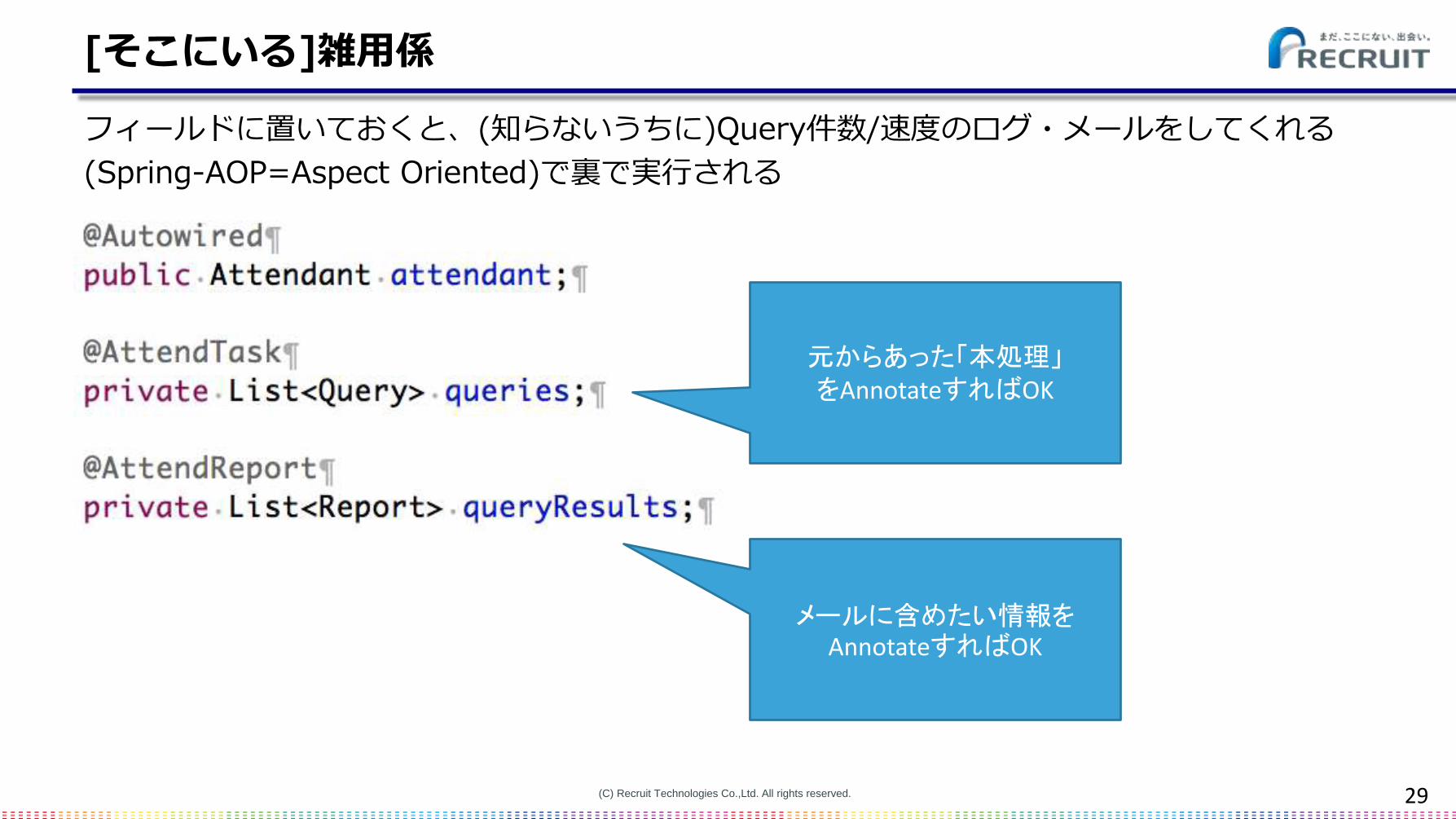
[そこにいる]雑用係
フィールドに置いておくと、(知らないうちに)Query件数/速度のログ・メールをしてくれる
(Spring-AOP=Aspect Oriented)で裏で実行される
29
元からあった「本処理」をAnnotateすればOK
メールに含めたい情報をAnnotateすればOK
(C) Recruit Technologies Co.,Ltd. All rights reserved.
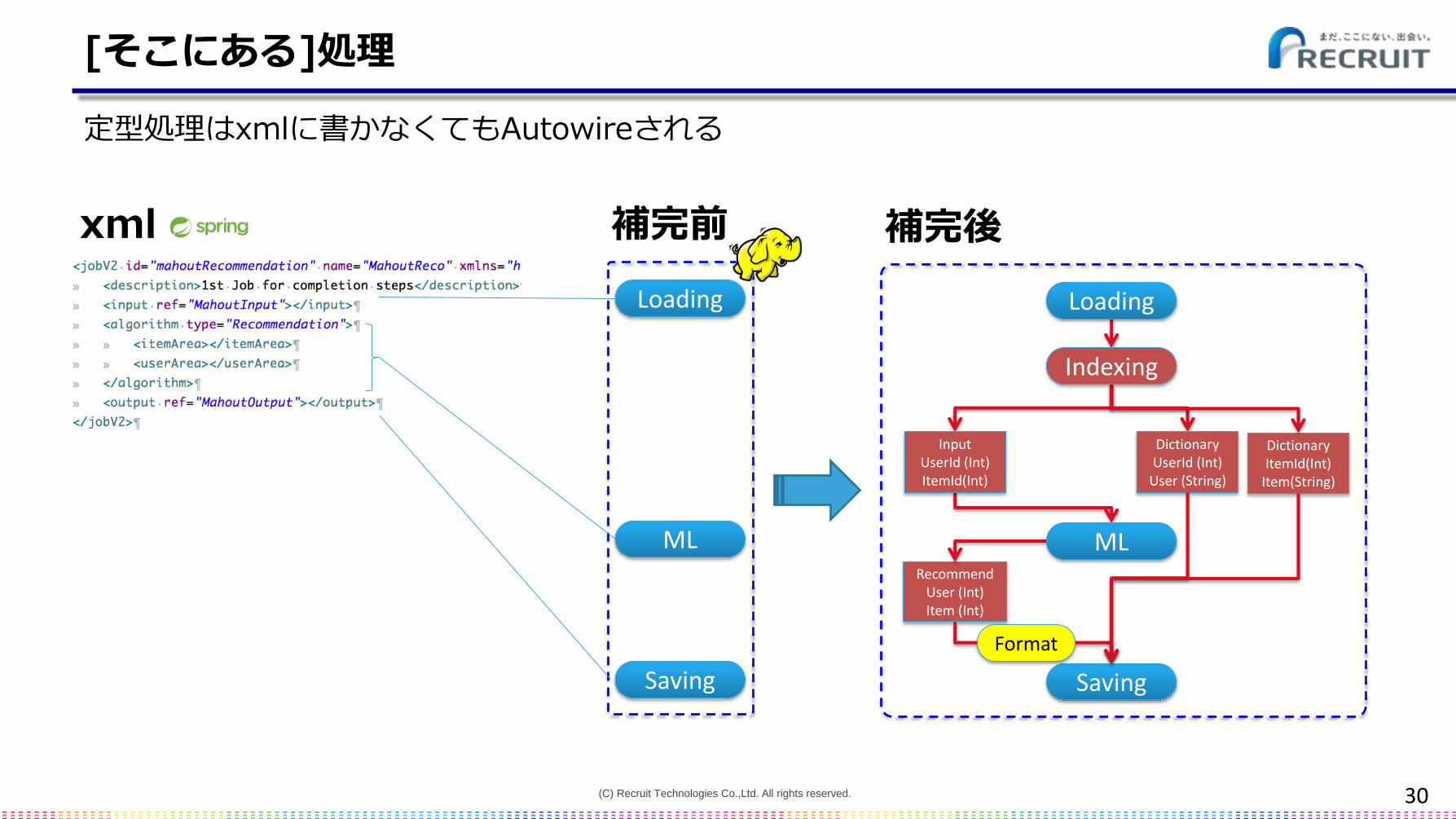
[そこにある]処理
定型処理はxmlに書かなくてもAutowireされる
30
補完前
Loading
ML
Saving
xml 補完後
RecommendUser (Int)Item (Int)
DictionaryUserId (Int)
User (String)
DictionaryItemId(Int)
Item(String)
InputUserId (Int)ItemId(Int)
Loading
ML
Saving
Indexing
Format
(C) Recruit Technologies Co.,Ltd. All rights reserved.
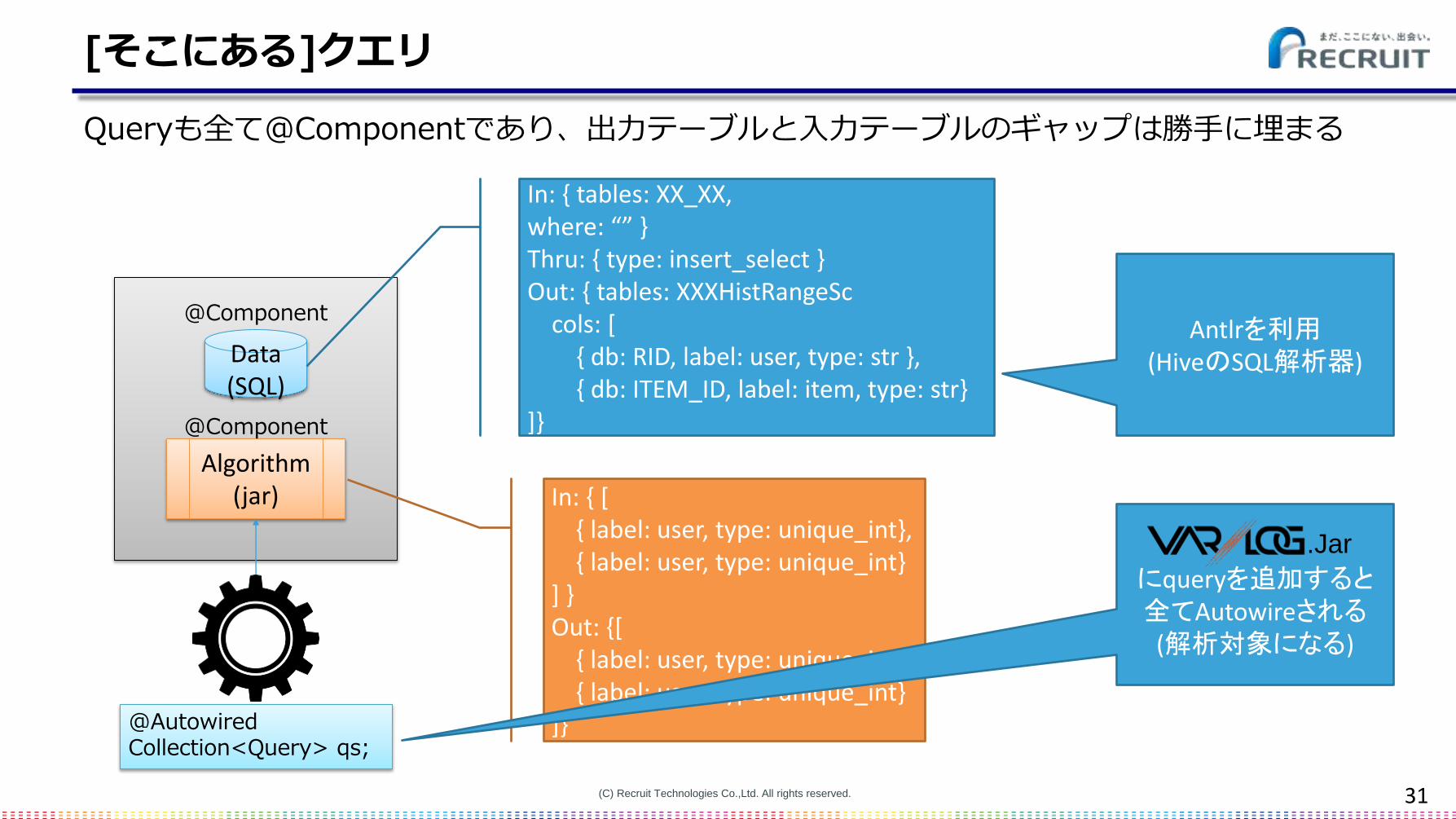
[そこにある]クエリ
Queryも全て@Componentであり、出力テーブルと入力テーブルのギャップは勝手に埋まる
31
Data(SQL)
Algorithm(jar)
In: { tables: XX_XX,where: “” }Thru: { type: insert_select }Out: { tables: XXXHistRangeSc
cols: [{ db: RID, label: user, type: str },{ db: ITEM_ID, label: item, type: str}
]}
In: { [{ label: user, type: unique_int}, { label: user, type: unique_int}
] }Out: {[
{ label: user, type: unique_int}, { label: user, type: unique_int}
]}@AutowiredCollection<Query> qs;
@Component
@Component
Antlrを利用(HiveのSQL解析器)
にqueryを追加すると全てAutowireされる
(解析対象になる)
.Jar

(C) Recruit Technologies Co.,Ltd. All rights reserved. 32
Join,
ご静聴ありがとうございました。





























