Embed Size (px)
Citation preview


2003−2010. (január): magyar nyelv és irodalom szakos bölcsész és tanár (Szegedi Tudományegyetem Bölcsészettudományi Kar)
2003−2010. (június) orosz nyelv és irodalom szakos bölcsész és tanár (Szegedi Tudományegyetem Bölcsészettudományi Kar)
2008−2012. (január): magyar mint idegen nyelv tanár / hungarológia (Szegedi Tudományegyetem Bölcsészettudományi Kar)
2010− Magyar Nyelvészet PhD-Program (Szegedi Tudományegyetem Bölcsészettudományi Kar, Nyelvtudományi Doktori Iskola)
2012. november 27. − 2013. szeptember 27.PhD-részképzés, Moszkva. (Национальный исследовательский университет«Высшая школа экономики» (НГУ-ВШЭ) (National Research University - Higher School of Economics))
2013. (június) PhD-abszolutórium megszerzése

2014 márciusa óta
Belső projektek: › Szentimentelemzés magyar nyelvre
› Emócióelemzés magyar nyelvre
(tervezés, szervezés, projektvezetés, kutatómunka, beszámolók készítése, konferenciázások, cikkek írása stb.)
Külső projektek: › Artklikk
› NER
› Sanoma (Jobmonitor)› Hulladékgazdálkodás
(kutatómunka, beszámolók készítése, adatszűrés)

A szentimentelemzés olyan számítógépes nyelvészeti feladat, amely
arra irányul, hogy Az értékelést, az értékelő tartalmakat megtalálja a a szövegekben,
meghatározza ezeknek az értékeknek a típusát,
valamint megállapítsa azok tárgyát, tehát azt, hogy az értékelés mire irányul.
Egy egyszerű példa:
A szentimentelemzés bonyolult feladat.
A magyar nyelvű irodalomban:
szentimentelemzés vagy véleménykivonatolás
Az angol nyelvű irodalomban:
sentiment analysis, opinion mining,
opinion extraction, sentiment mining,
review mining stb. (vö. Liu 2012: 7)
Kihívás a nyelvészeti kutatások és a nyelvtechnológia szempontjából:
vö. „A Szemantikus Web víziója” (Munk 2014)
A gazdasági oldal felől támasztott igény, pl.:
a tőzsdeindex mozgásának előrejelzése;
a fogyasztói csoport benyomásai, tapasztalatai bizonyos termékek és szolgáltatások vonatkozásában;
a fogyasztói csoport igényeinek detektálása;
politikusokkal, politikai eseményekkel kapcsolatos attitűdök felmérése;
választási előrejelzések
stb.
Számtalan szociális háló, blog, fórum és egyéb webes forrás → hatalmas
mennyiségű, elektronikus formájú szöveg

Az Opinhu rendszer (Miháltz 2010), illetve az OpinHuBank projekt (Miháltz 2012): internetes hírportálokon, blogokon és közösségi oldalakon publikált szövegek szentiment- annotálására törekszik automatikus és manuális megoldások segítségével;
Neticle ― Szekeres Péter
Berend és Farkas (2008): a kettős állampolgárság témájához kapcsolódó szövegek gépi tanuláson alapuló feldolgozását célozza;


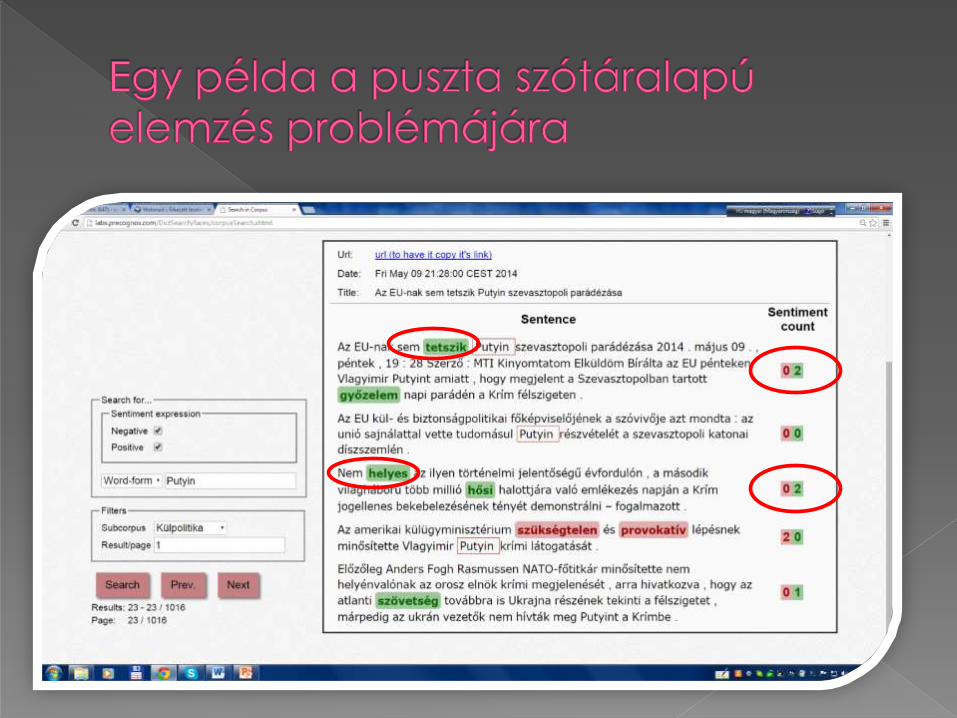
A teszteléshez és fejlesztéshez manuálisan annotált korpusz kell! Ez vagy nincs (Neticle), vagy egyszerűen nem megfelelő fejlesztési és tesztelési célokra (OpinHuBank).
Problémák az OpinHuBank korpusszal:
A szentimentkifejezéseket egyenként nem annotálták a korpusz építői: a szentimentértékeket a mondatok vagy a tagmondatok szintjén határozták meg.
Az annotátoroknak az aktuális mondat szentimentértékéről a mondatban szereplő tulajdonnévi entitás (PERSON) viszonylatában kellett döntést hozniuk: arra kérték őket, hogy ítéljék meg, vajon pozitív vagy negatív ítéletet fejez-e ki az elemzett mondat a bennfoglalt PERSON vonatkozásában. DE!! A szentiment targetjénekszerepét a mondatban a személynéven kívül számtalan elem (pl. egy hely, egy esemény, egy termék vagy akár a termék egy aspektusa is) betöltheti. → korlátozott használati lehetőségek
Bár a korpusz készítői hangsúlyozzák, hogy kiszűrték azokat az eseteket, ahol nem a PERSON volt a target, a korpusz számos ilyen esetet tartalmaz; pl.
Martonyi János leszögezte: noha a jelenlegi szlovák kormánykoalíció egyik pártjának vezetői gyakran elfogadhatatlan kijelentéseket tesznek, a magyar kormány nem ilyen stílusban fog reagálni (…) [http://www.belfoldihirek.com/belfold/martonyi-janos-szlovakiaba-latogat]

A szentimentelemzésnek vannak olyan részfeladatai, amelyekkel ezek a projektek nem, vagy alig foglalkoznak; pl.
A szentimentek targetjeit hogyan találjuk meg? Pl.A Fanta jobb a Pepsinél.
A formája nem győz meg, de a színe tetszik.
Bár a töltő nem bírja sokáig, ez a telefon messze a legjobb mindközül.
Mit csinálunk azzal a számtalan esettel, ahol a szentiment felismeréséhez és helyes kezeléséhez a szótár önmagában nem elegendő? Pl. a lexikai szintű értékjelentést (pl. jó, rossz, szép, csúnya) a szintaktikai szerkezetben
módosulhat; pl. tagadás vagy egyéb módosító elemek által; pl.
nem jó, elég jó, nem annyira jó, nem rossz, nem volt borzasztó
irreáló szerkezetben az érték nincs, vagy nem teljes; pl.
a forma talán jó; jó a hangminőség?; nem hinném, hogy ez a Nokia jó
implicit értékjelentés; pl. irónia vagy az indirekt beszédaktusok:
Ez az autó aztán egy igazi roncs!; Te el tudod képzelni, hogy ez a telefon jó?
Doménfüggés; pl.
beolt ige – orvoslás vagy kertészet vs. politika
Target- vagy kontextusfüggés; pl.
nagy melléknév – telefontöltő vs. számítógép-memória

Beható és minden részletre kiterjedő elméleti nyelvészeti és nyelvtechnológiai kutatást végzünk, és minden megoldást a vizsgálatok tapasztalataira alapozunk! (targetek, tagadás, a nyelvi értékelés mibenléte, a szótárkészítés alapelvei, irreálás, intenzifikálás, a skalaritáskérdése stb., a vonatkozó magyar és nemzetközi irodalom feldolgozásával és felhasználásával)
Van kézzel annotált korpuszunk! Van domén- és kontextusfüggetlen szótárunk! Benne
o a nemzetközi trenddel ellentétben nem csupán melléknevek, hanem határozószók, igék és főnevek is szerepelnek; pl.
szép, szépen, szépül, szépségo nem csupán egyszavas kifejezések, hanem frazeológiai egységek is
megtalálhatóak; pl. értéktelen; egy fabatkát sem ér
o vannak rétegnyelvi elemek is; pl.hómlessz; felakadt a lemez
o vannak „puszta” konnotatív sajátságokkal rendelkező elemek is (vö. Bruno 1980: 136; Feng et al. 2011; Liu 2012); pl.
jutalom, vérengzés
Van olyan programunk, amelynek segítségével a kiinduló szótárat 8 domén sajátságai szerint fejleszthetjük tovább!
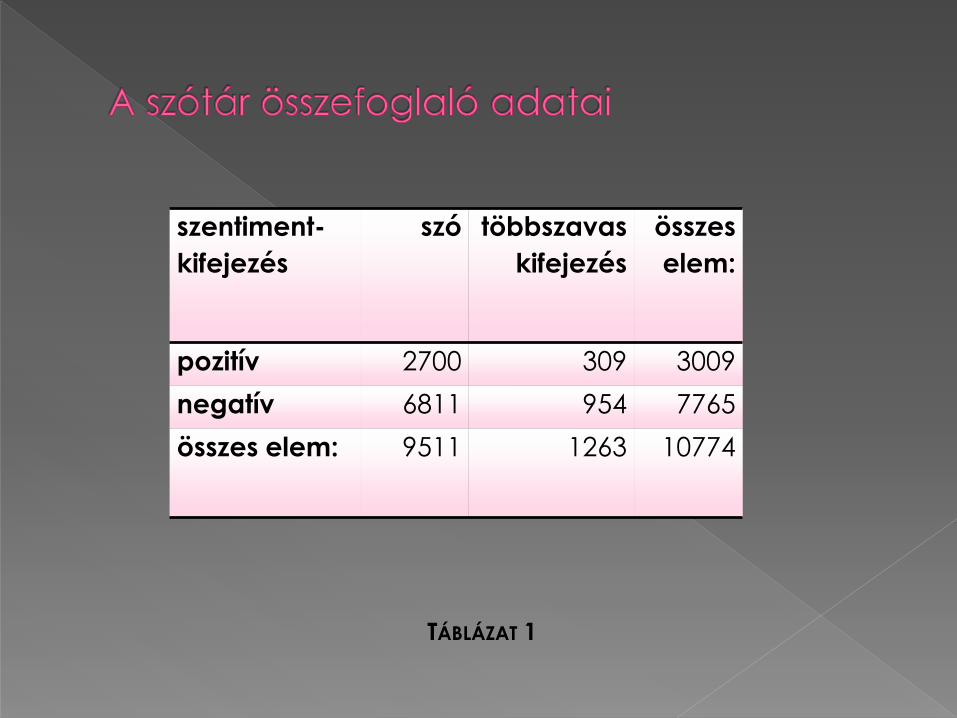
TÁBLÁZAT 1
szentiment-
kifejezés
szó többszavas
kifejezés
összes
elem:
pozitív 2700 309 3009
negatív 6811 954 7765
összes elem: 9511 1263 10774
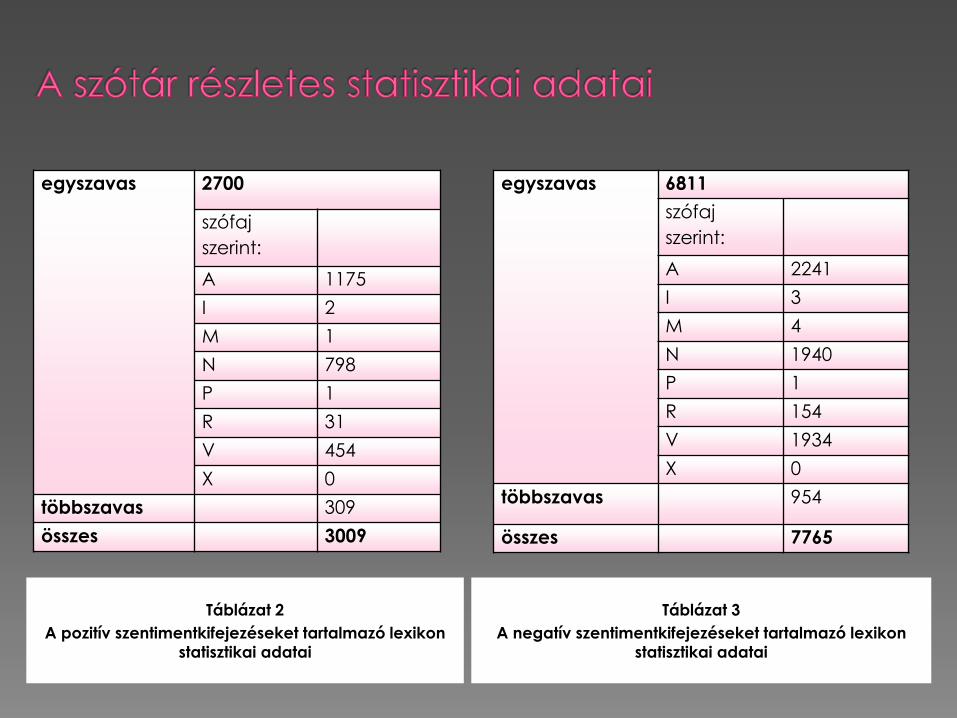
Táblázat 2
A pozitív szentimentkifejezéseket tartalmazó lexikon
statisztikai adatai
Táblázat 3
A negatív szentimentkifejezéseket tartalmazó lexikon
statisztikai adatai
egyszavas 2700
szófaj
szerint:
A 1175
I 2
M 1
N 798
P 1
R 31
V 454
X 0
többszavas 309
összes 3009
egyszavas 6811
szófaj
szerint:
A 2241
I 3
M 4
N 1940
P 1
R 154
V 1934
X 0
többszavas 954
összes 7765
Az alkalmazott
szentimentlexikon
Valamely szóalak vagy szótő
megadása esetén csak
azokat a mondatokat
elemzi, amelyek az adott
kifejezést tartalmazzák
Opciók:
Tudomány
Bulvár
Gazdaság
Technológia
Kultúra
Sport
Külpolitika
Belpolitika
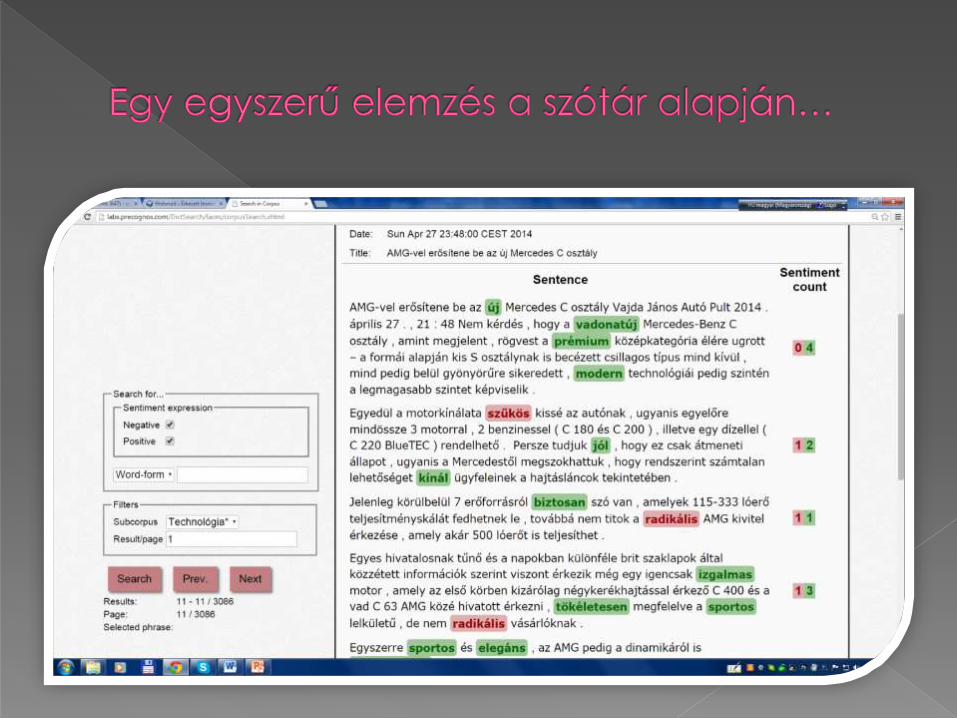
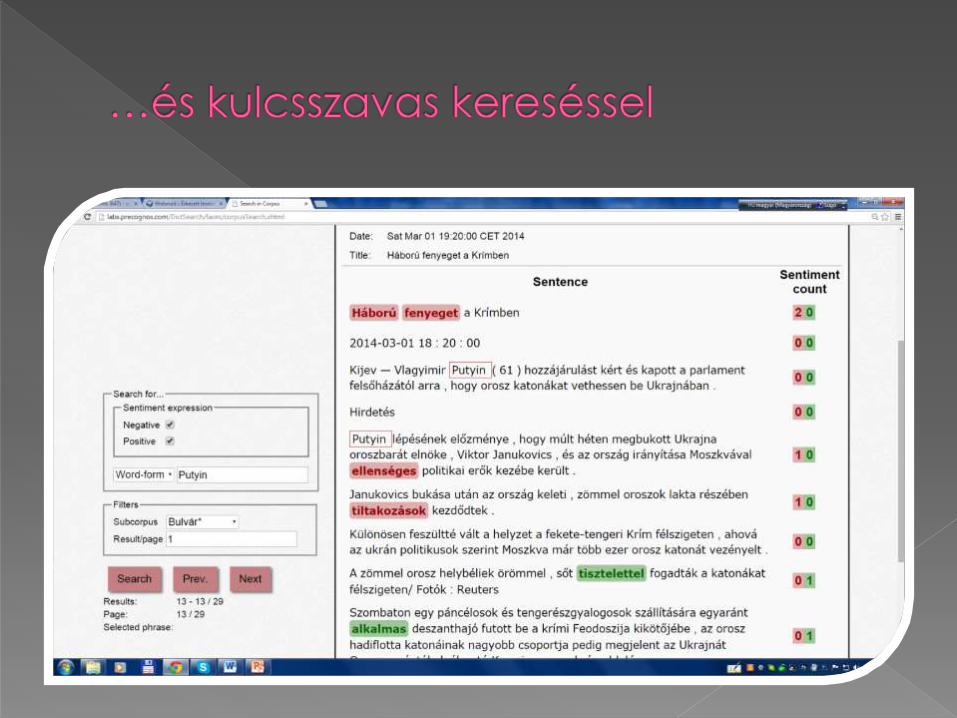

A korpusz szöveganyagát a [http://divany.hu/] honlap termékvéleményeiből állítottuk össze.
A korpusz jelenleg összesen 111 szövegből áll, ami mintegy 13 000 mondatot és 190 000 tokent tartalmaz.
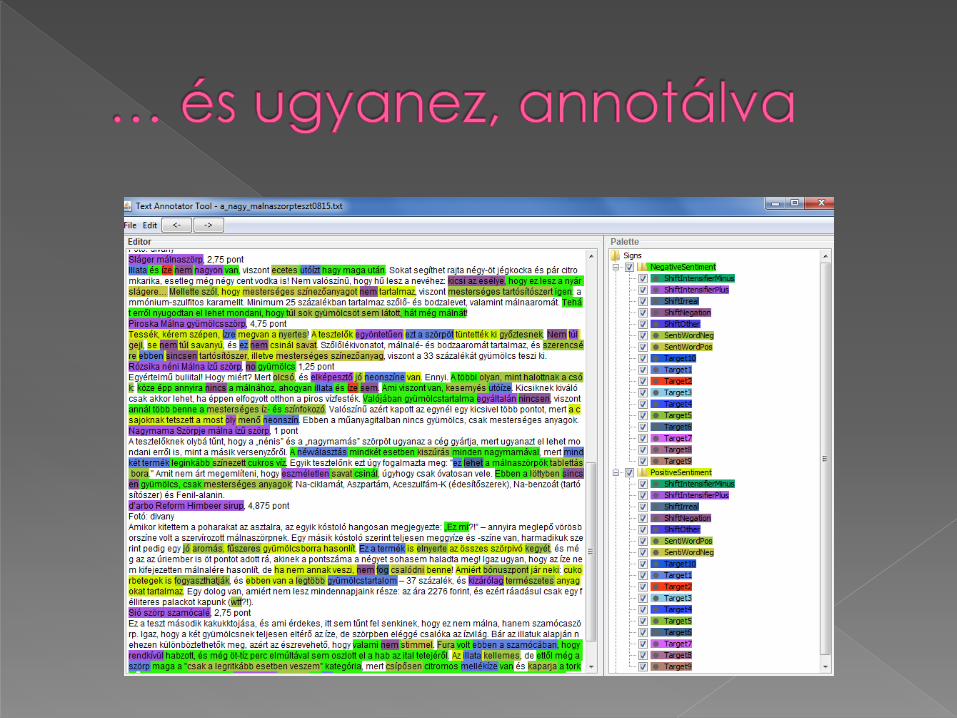
A manuális annotálás keretében a teljes értékelő kifejezést,
azon belül a pozitív és negatív polaritású szentimentkifejezéseket,
azok targetjeit,
a termékneveket topic-ként,
valamint a szentimentkifejezések esetleges siftereitjelöltük be a korpuszban.

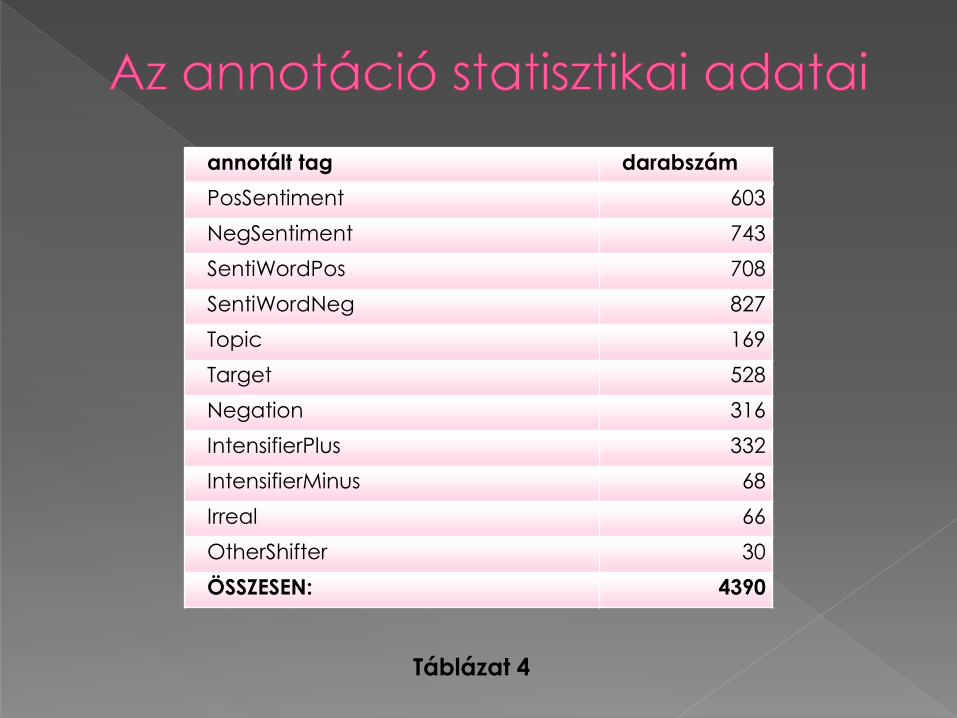
annotált tag darabszám
PosSentiment 603
NegSentiment 743
SentiWordPos 708
SentiWordNeg 827
Topic 169
Target 528
Negation 316
IntensifierPlus 332
IntensifierMinus 68
Irreal 66
OtherShifter 30
ÖSSZESEN: 4390
Táblázat 4

A negatív véleményt megfogalmazó kifejezések (NegSentiment) többségben vannak a pozitív véleményt megfogalmazó kifejezésekkel (PosSentiment) szemben. Hasonló megoszlást találunk a puszta szentimentkifejezések (SentiWordNeg; SentiWordPos) között is. → Meglepő a Pollyanna-hipotézistükrében (nyelvi univerzáléként tételezi a pozitív töltetű kifejezések magasabb arányát)
Az annotált korpuszrész 316 negáló kifejezést (Negation) tartalmaz (ebből 140 pozitív és 176 negatív polaritású véleményben szerepel) → jelentős előfordulási arány az összesen 1346 azonosított szentimenthez képest!
Az összesen 1535 szentimentkifejezésből összesen 167 a saját szótári polaritásával ellentétes polaritású kifejezésben szerepel! → A negáció kezelése jelentős javulást hozhat a szentimentelemzési hatékonyságban.

Az emócióelemzés (emotion analysis)
nem azonos a szentimentelemzéssel: a
két feladat vizsgálati köre, s ezzel
összefüggésben elméleti háttere teljesen
eltér egymástól: az emócióelemzés
során az érzelmeket kívánjuk detektálni a
nyelvi produktumokban

Újdonság! Az emócióelemzéssel nemzetközi viszonylatban is
kifejezetten csekély számú dolgozat foglalkozik. Bár az emóciók bizonyos tudományos diszciplínákban (pl. a pszichológiában és a viselkedéstudományban) kiemelt figyelmet kapnak, a természetesnyelv-feldolgozás területén nem → az emóciók automatikus kezelése kísérleti szakaszában jár (vö. Mulcrone 2012: 1).
Ami a magyar nyelvű szövegek emócióelemzését illeti: nincs tudomásunk olyan kutatásról, amely ennek anyelvtechnológiai feladatnak a megoldását célozná +
nem ismerünk egyetlen olyan dolgozatot sem, amely a problémakört az NLP szempontjából egyáltalán vizsgálná.
A magyarra tehát mi vagyunk az elsők, de nemzetközi szinten is ritkaságnak számítunk!

Gazdasági haszna lehet, hiszen › az érzelmek olyan tényezőkre adott reakciók,
amelyek fontosnak tűnnek számunkra
boldogulásunk, jólétünk szempontjából
› az érzelmek gyakran olyan gyorsan jelentkeznek,
hogy nem is vagyunk tudatában az érzelmi folyamatok pontos alakulásának (vö. Ekman2007) → az emóciótartalom feldolgozása eleddig rejtve maradt, értékes információkat hozhat a felszínre.
Az emóciók kezelése hatékony kiegészítője lehet a szentimentelemzésnek.

Létrehoztunk egy emóciószótárat, Ekman és Friesen (1969) érzelemkategorizálási rendszerét alapul véve:
BÁNAT, DÜH, FÉLELEM,
MEGLEPŐDÉS, ÖRÖM
és UNDOR
Létrehoztunk egy kézzel annotált emóciókorpuszt; tartalma: 2014-es év folyamán keletkezett tévés és mozis témájú blogoldalakról származó, különböző terjedelmű és szerzőségű kritikák, hírek és kommentek. A korpusz jelenleg 15987 mondatból és 197707 tokenből áll, ebból 3911 mondatot és 45955 tokent dolgoztunk fel eddig.
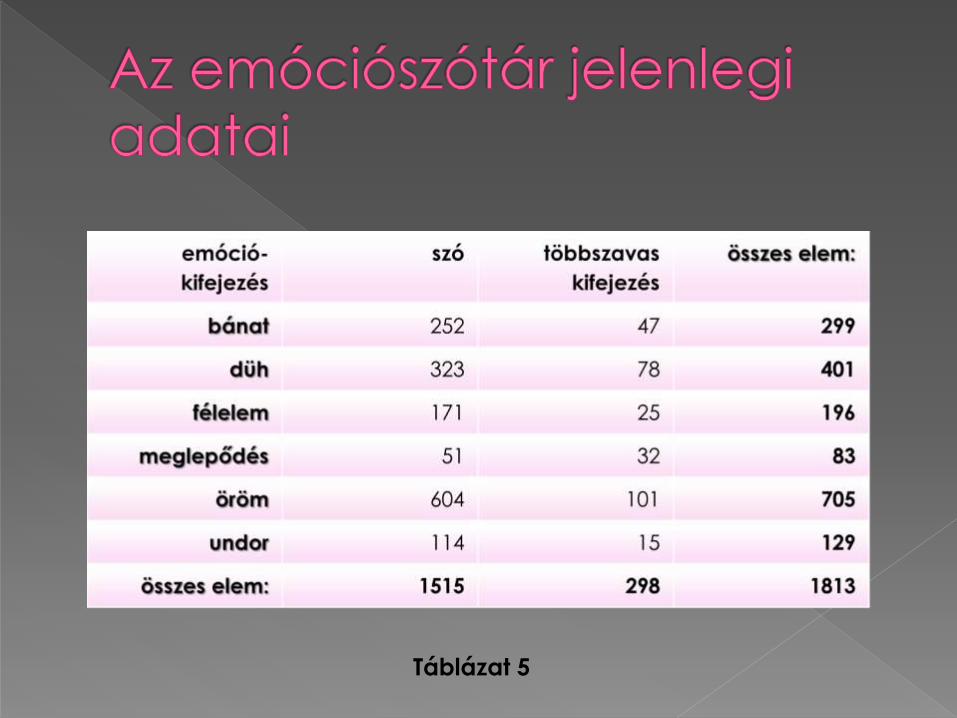
Táblázat 5

A következőket jelöljük:› az emóciót megfogalmazó teljes
szövegrészt,
› azon belül a konkrét emóciókifejezést típusok szerint,
› annak esetleges sifterét/siftereit típusok szerint,
› azokat a kifejezéseket, amelyek valamely érzelem meglétére utalnak (pl. wow!, azta!, bakker), de nem köthetőek egyértelműen egyik érzelemtípushoz sem.
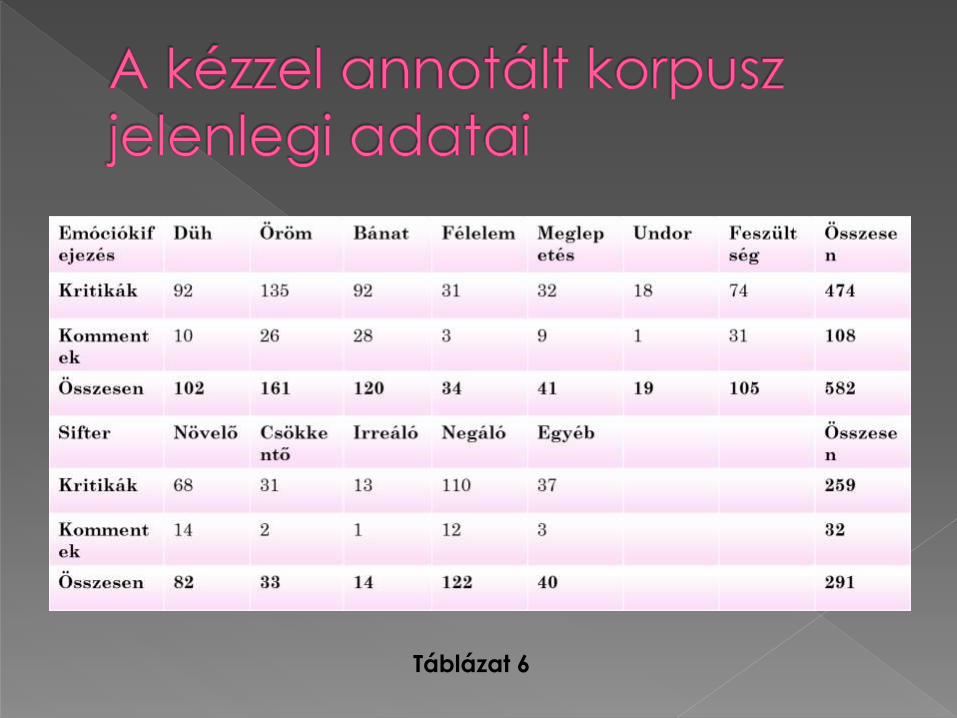
Táblázat 6

Szorosabb kapcsolatot az SZTE-vel
Publikációkat, konferencia-előadásokat,
posztokat:
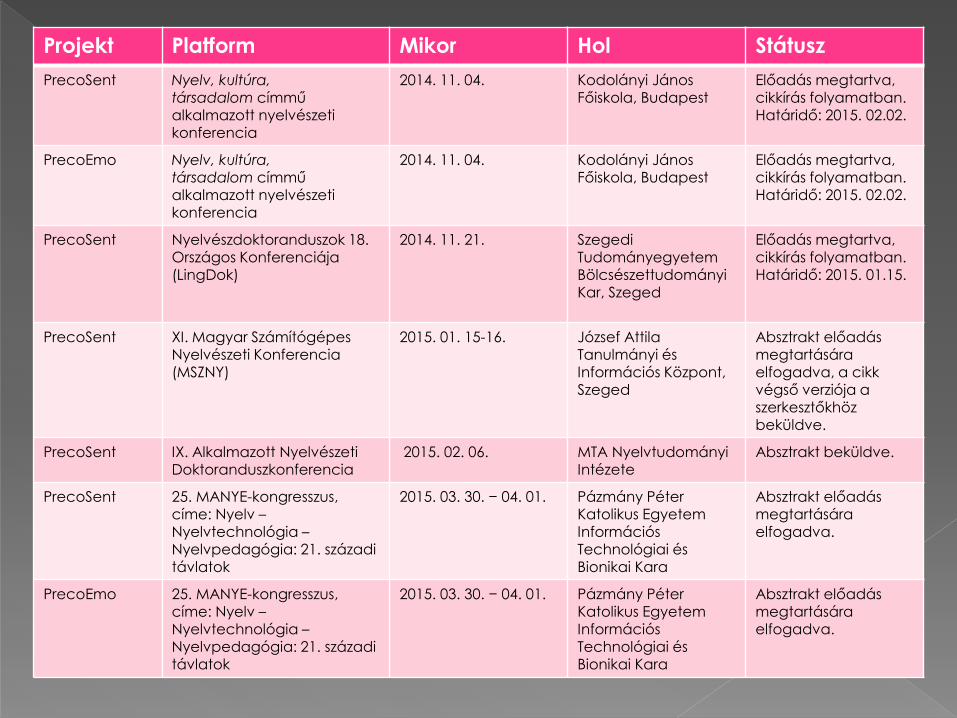
Projekt Platform Mikor Hol Státusz
PrecoSent Nyelv, kultúra, társadalom címműalkalmazott nyelvészeti konferencia
2014. 11. 04. Kodolányi János Főiskola, Budapest
Előadás megtartva, cikkírás folyamatban. Határidő: 2015. 02.02.
PrecoEmo Nyelv, kultúra, társadalom címműalkalmazott nyelvészeti konferencia
2014. 11. 04. Kodolányi János Főiskola, Budapest
Előadás megtartva, cikkírás folyamatban. Határidő: 2015. 02.02.
PrecoSent Nyelvészdoktoranduszok 18. Országos Konferenciája (LingDok)
2014. 11. 21. SzegediTudományegyetemBölcsészettudományi Kar, Szeged
Előadás megtartva, cikkírás folyamatban. Határidő: 2015. 01.15.
PrecoSent XI. Magyar Számítógépes Nyelvészeti Konferencia(MSZNY)
2015. 01. 15-16. József Attila Tanulmányi és Információs Központ, Szeged
Absztrakt előadás megtartására elfogadva, a cikk végső verziója a szerkesztőkhöz beküldve.
PrecoSent IX. Alkalmazott Nyelvészeti Doktoranduszkonferencia
2015. 02. 06. MTA NyelvtudományiIntézete
Absztrakt beküldve.
PrecoSent 25. MANYE-kongresszus,címe: Nyelv –Nyelvtechnológia –Nyelvpedagógia: 21. századi távlatok
2015. 03. 30. − 04. 01. Pázmány Péter Katolikus Egyetem Információs Technológiai és Bionikai Kara
Absztrakt előadás megtartására elfogadva.
PrecoEmo 25. MANYE-kongresszus,címe: Nyelv –Nyelvtechnológia –Nyelvpedagógia: 21. századi távlatok
2015. 03. 30. − 04. 01. Pázmány Péter Katolikus Egyetem Információs Technológiai és Bionikai Kara
Absztrakt előadás megtartására elfogadva.

Berend, G.–Farkas, R. 2008. Opinion Mining in Hungarian based on textual and
graphical clues, in Proceedings of the 4th Intern. Symposium on Data Mining and
Intelligent Information Processing. Santander.
Bruno, F.J. 1980. Behaviour and Life: An Introduction to Psychology. New York,
John Wiley and Sons.
Ekman P. 2007. Emotions revealed: recognizing faces and feelings to improve
communication and emotional life. Revised edition. New York, St. Martin's Griffin.
Ekman, P.–Friesen, W.V. 1969. The repertoire of nonverbal behavior: Categories,
origins, usage, and coding. Semiotica 1. 49–98.
Feng, S.–Bose, R.–Choi, Y. 2011. Learning general connotation of words using
graph-based algorithms, in Proceedings of Confernece on Empirical Methods in
Natural Language Processing (EMNLP-2011)
Liu, B. 2012. Sentiment Analysis and Opinion Mining. Draft
Munk Sándor 2014. Szemantika az informatikában. Hadmérnök IX. 2. szám. 311–
331.
Miháltz M. 2010. OpinHu: online szövegek többnyelvű véleményelemzése, in Ta-
nács A.–Vincze V. szerk. VII. Magyar Számítógépes Nyelvészeti Konferencia
(MSZNY 2010). SZTE, Szeged. 14–23.
Miháltz M. 2013. OpinHuBank: szabadon hozzáférhető annotált korpusz magyar
nyelvű véleményelemzéshez, in Tanács A.–Vincze V. szerk. IX. Magyar Számítógé-
pes Nyelvészeti Konferencia (MSZNY 2013), SZTE, Szeged. 343–345.
Munk Sándor 2014. Szemantika az informatikában. Hadmérnök IX. 2. szám. 311–
331.






























