Embed Size (px)
Citation preview

MapReduce: The Hadoop Connection
JAX 201006.05.2010 | 08:30 - 09:45
Tobias Jochinovex GmbH
Wir nutzen Technologien, um unsere Kunden glücklich zu machen. Und uns selbst.
MotivationMapReduceHadoopEinsatzmöglichkeitenUnited States Patent #7650331Zusammenfassung
2
Agenda

3
Motivation

lance@twitter
„In 140 characters tell me why map reduce is important please.“
4

Beispiel Antworten auf lance‘s Frage
infloop: @lance Some computing tasks can be split up into small chunks, processed simultaneously, and then reassembled at the end. Think SETI@HOMErjurney: @botchagalupe With map/reduce we’re going to start making productive use of all that data lying around, informing nothing.talltodd65: @Lance MapReduce is ideal for processing very large data sets on a cluster of computers
5

Motivation
Verarbeiten großer DatenmengenWeb ScaleHäufigkeiten zählen, Invertierten Index berechnen, ...
Verteiltes RechnenProgrammiermodellLast- und DatenverteilungHochverfügbarkeit auf billiger Standard HardwareBerechnung auf mehrere Rechner verteilenGeographisch verteilt
6
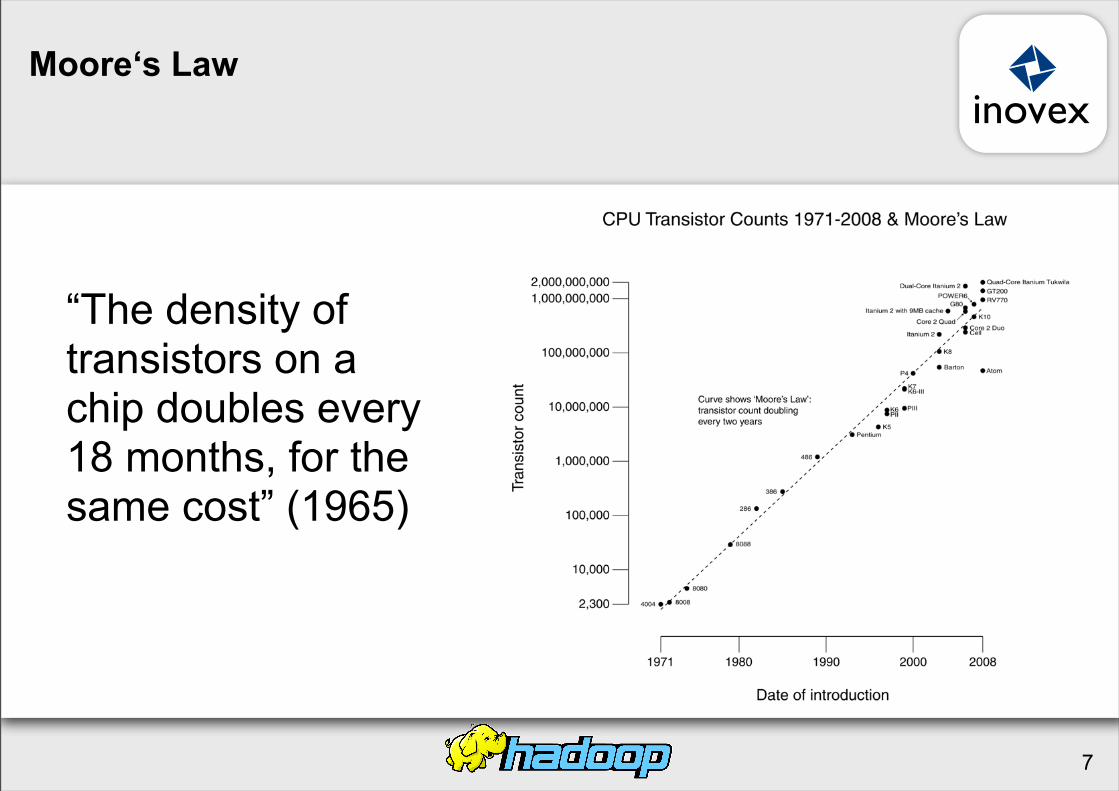
Moore‘s Law
“The density of transistors on a chip doubles every 18 months, for the same cost” (1965)
7

8

Commodity HardwareThe Google Way
9

Commodity Hardware ClusterLamont-Doherty Earth Observatory
Fats
10

Rechenzentrums Cluster
11

12
MapReduce
MapReduce
Paper von Google (2004)Software Framework zur parallelen Verarbeitung von großen DatenmengenEinsatz von „Commodity Hardware“ (Fehlertolerant)Inspiration durch die map/fold Funktionen aus der funktionsorientierte ProgrammierungKlare Abstraktion für ProgrammiererVersteckt Low-Level Details
Datenverteilung, Loadbalancing, Fehlertoleranz, Parallelisierung
13

MapReduceProgrammiermodel
Datenverarbeitungsmodell (Pipes, Queues, ...)Berechnung wird in Form von zwei Funktionen vom Benutzer beschrieben
map()Filterung und Transformation in ZwischenergebnisseAusführung findet parallel statt
reduce()Aggregation der ZwischenergebnisseTypischer Weise 0,1 Ergebnisse pro K‘Ausführung kann auch parallel statt finden
14

„Hello World“ für MapReduce: Word Count
map()
15
function map(String key, String value):// key: document name// value: document contentsforeach word w in value:
EmitIntermediate(w, "1");
reduce()function reduce(String key, Iterator values):
// key: a word// values: a list of countsint result = 0;foreach v in values:
result += ParseInt(v);Emit(AsString(result));

Endergebnis
Zwischenergebnisse (K‘, V)
„Hello World“ für MapReduce: Word Count
Eingabe (K, V)
16
„Satz 1“: „Die JAX ist die Konferenz fürganzheitliches ...“
„die“, 1 „JAX“, 1 „ist“, 1 ...„die“, 1
„die“, 2 „JAX“, 1 „ist“, 1 ...
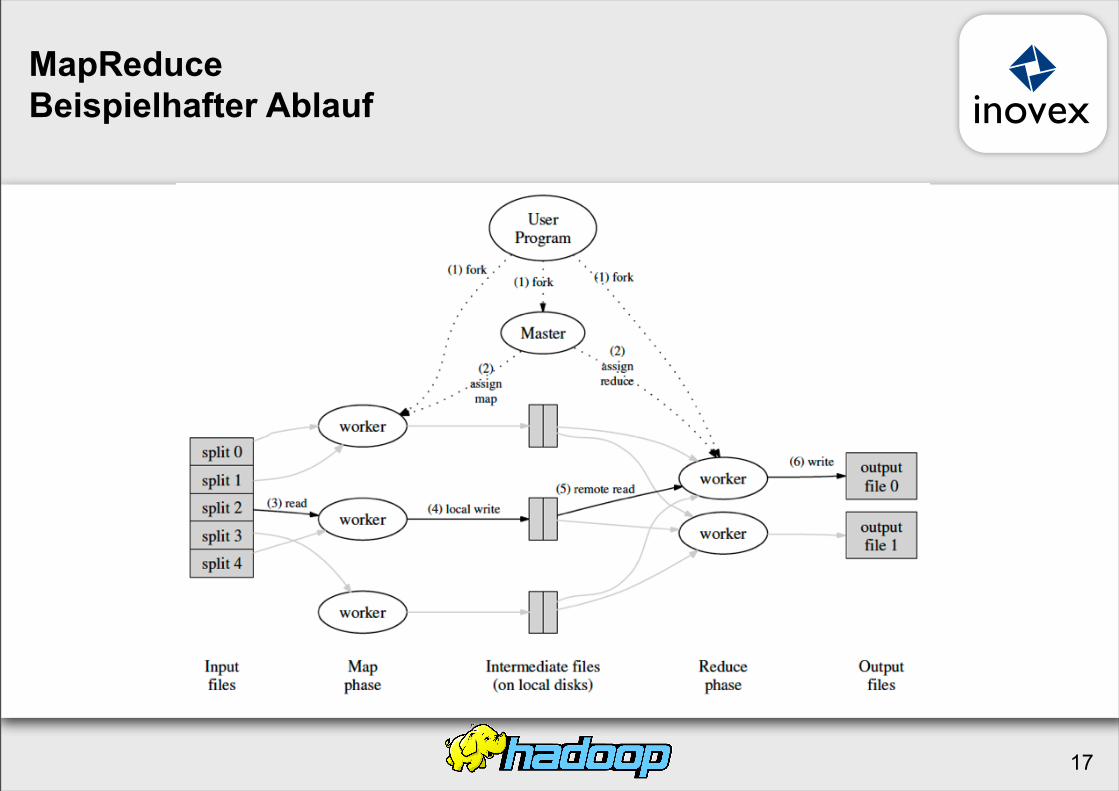
MapReduceBeispielhafter Ablauf
17

MapReduceScheduling
Ein Master, viele WorkerEingabedaten werden auf M map Tasks gesplitetZwischenergebnisse werden auf R reduce Tasks aufgeteiltTasks werden dynamisch auf W Worker zugeordnetBeispiel: M=200.000, R=4000, W=2000
Master weißt jeden map Task einem freien Worker zuDatenlokalität wird hierbei berücksichtig
Master weißt jeden reduce Task einem freien Worker zuWorker lesen K/V Paare (Zwischenergebnisse)sortieren und führen die reduce() auf den Daten aus
18

Fehlertoleranz
Worker Ausfall:Master überprüft Worker periodischAlle map Tasks werden neu verteilt
Ergebnisse werden lokal gespeichertNicht beendete reduce Tasks müssen neu verteilt werden
Ergebnisse werden global gespeichertAlle reduce Worker werden benachrichtigt, dass map Tasks erneut ausgeführt werden
Master Ausfall:Zustand wird zyklisch gesichertneuer Master stellt Zustand wieder her und übernimmt
19

Daten Lokalität
Ziel: Netzwerkbandbreite schonenHDFS teilt Dateien in Blöcke ein und speichert n Kopien auf unterschiedlichen Knoten im ClusterMaster verteilt map() Tasks unter Berücksichtigung des Speicherortes der EingabedatenZiel
map() Tasks physikalisch auf den selben Maschinen (selbes Rack, Rechenzentrum, ...) wie die Eingabedaten ausführen
20

21
Hadoop

HadoopHistory
2004Gegründet als Sub-Projekt von Nutch (Lucene)Java basierende OpenSource Implementierung von MapReduce
2006Doug Cutting wechselt zu Yahoo!Eigenes Hadoop-Team@Yahoo! Apache Projekt
2008Top Level Projekt10.000+ Linux Cluster
AktuellVersion 0.20.2Ökosystem mit vielen Subprojekten
22

HadoopGewinnt Terabyte Sort Benchmark (Juli 2008)
„One of Yahoo's Hadoop clusters sorted 1 terabyte of data in 209 seconds, which beat the previous record of 297 seconds in the annual general purpose (Daytona) terabyte sort benchmark. This is the first time that either a Java or an open source program has won.“
23

HadoopSteht für?
LuceneZweitname von Doug Cutting‘s Frau
Nutchsagte Doug Cutting‘s kleiner Sohn für jegliche Art von Mahlzeit
HadoopName eines kleinen gelben Stoffelefanten von seinem Doug Cutting‘s Sohn
24

HadoopSubprojekte
Hadoop Common: The common utilities that support the other Hadoop subprojects.Avro: A data serialization system that provides dynamic integration with scripting languages.Chukwa: A data collection system for managing large distributed systems.HBase: A scalable, distributed database that supports structured data storage for large tables.HDFS: A distributed file system that provides high throughput access to application data.Hive: A data warehouse infrastructure that provides data summarization and ad hoc querying.MapReduce: A software framework for distributed processing of large data sets on compute clusters.Pig: A high-level data-flow language and execution framework for parallel computation.ZooKeeper: A high-performance coordination service for distributed applications.
25

Wer setzt Hadoop ein?
Yahoo„Biggest cluster: 2000 nodes, used to support research for Ad Systems and Web Search.“
Amazon„Process millions of sessions daily for analytics, using both the Java and streaming APIs. Clusters vary from 1 to 100 nodes.“
Facebook„Use Hadoop to store copies of internal log and dimension data sources and use it as a source for reporting/analytics. 600 machine cluster.“
AOL, IBM, Rackspace, Hulu, the New York Times...
26

HadoopBasics
/usr/bin/hadoop --> Command-line wrapperZugriff auf mehrere Subsysteme von Hadoopfs --> HDFS
-ls, -put, -cat, -get, -copyToLocal-rm, -rmr, -mv, -cp, -mkdir, etc.
jar --> MapReduce Jobsjob --> Job-Steuerung
-list, -status, -kill
Java und Streaming Interface (Perl, PHP, Python, Ruby, Bash, etc.)
27

28
Einsatzmöglichkeiten

EinsatzmöglichkeitenVerteiltes Grep
Suche in großen Mengen von Log-Filesmap()
liefert eine Zeile als Zwischenergebnis, falls diese dem entsprechendem Pattern entspricht
reduce()kopiert Zwischenergebnisse als Endergebnis
29

EinsatzmöglichkeitenWeb-Server Statistik
Aus welchen Ländern und Städten erfolgen die meisten Zugriffe auf bestimmte Web-Seiten?map()
filtert Zugriffe auf bestimmte Web-Seten und liefert die entsprechenden IP-Adressen aus den Access-Logs als Zwischenergebnisse
reduce()Reduziert IP-Adresse auf Class C-Adresse
Ergebnisse können im Nachgang mit Geoinformationen aus IP-Adressdatenbanken angereichert werden
Hive (DWH), Sqoop (RDBMS)
30

EinsatzmöglichkeitenInvertierter Web-Link Graph
Bestimmung aller URLs, welche ein bestimmtest Ziel referenzierenmap()
liefert (Ziel, Quelle) Paare für jeden Link innerhalb einer Web-Seite
reduce()Fasst die Liste aller Quell-URLs zusammen, von welchen aus ein bestimmtest Ziel referenziert wird (Ziel, List(Quelle))
31

EinsatzmöglichkeitenRankingfaktor „Term Vector“
Welche Websites sind die Spezialisten für ein gesuchtes Thema?map()
liefert (Hostname, Term Vector) Paare für jedes EingabedokumentDer Hostname wird aus der URL bestimmt
reduce() Führt die häufigsten (z.B. Top 10) Zwischenergebnisse zu einem Endergebnis (Hostname, Term Vector) zusammen
32

EinsatzmöglichkeitenBeispiel Facebook
Backendsystem „Scribe“Logfiledaten Verarbeitung25 TByte Logfiles pro Tagchronologische KonsolidierungHadoop-Cluster mit rund 1.000 Nodes erlaubt Analysen des Nutzerverhaltens„wie neue Funktionen von Nutzern verwendet werden"
33

EinsatzmöglichkeitenWeitere spannenden Einsatzgebiete...
Business IntelligenceLog-File AnalyseWetterdaten Data MiningAuswertung von User VerhaltenProfil BerechnungenIndex ErstellungServer Monitoring --> Annomalien Reports...
34

EinsatzmöglichkeitenBeispiel Google
Web-Scale Search IndexGoogle‘s Suche umfasst n Milliarden Web-SeitenAugust 2004 29.000 Jobs September 2007 2.2 MillionenAktuell täglich ca. 100.000 Jobs
35

36
Google‘s Patent #7650331

Google‘s Patent #7650331 vom 19.01.2010
„A large-scale data processing system and method includes one or more application-independent map modules configured to read input data and to apply at least one application-specific map operation to the input data to produce intermediate data values...“
37
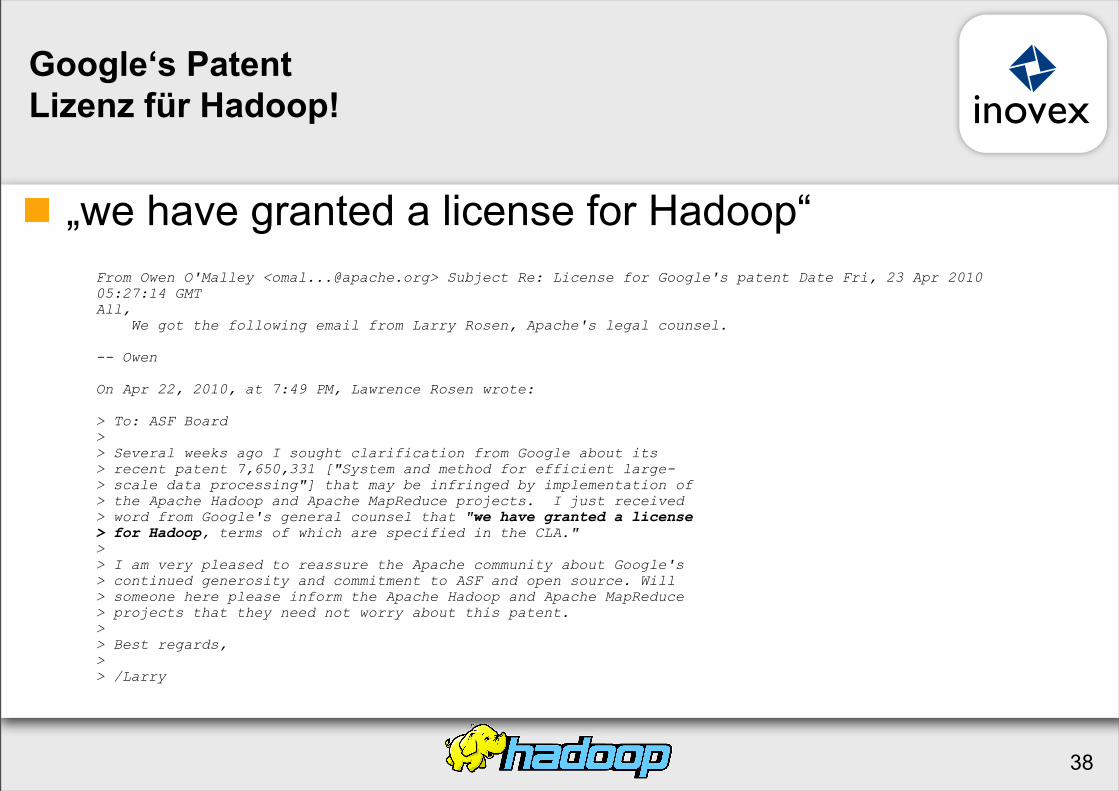
Google‘s PatentLizenz für Hadoop!
„we have granted a license for Hadoop“
38
From Owen O'Malley <[email protected]> Subject Re: License for Google's patent Date Fri, 23 Apr 2010 05:27:14 GMTAll, We got the following email from Larry Rosen, Apache's legal counsel.
-- Owen
On Apr 22, 2010, at 7:49 PM, Lawrence Rosen wrote:
> To: ASF Board>> Several weeks ago I sought clarification from Google about its > recent patent 7,650,331 ["System and method for efficient large- > scale data processing"] that may be infringed by implementation of > the Apache Hadoop and Apache MapReduce projects. I just received > word from Google's general counsel that "we have granted a license > for Hadoop, terms of which are specified in the CLA.">> I am very pleased to reassure the Apache community about Google's > continued generosity and commitment to ASF and open source. Will > someone here please inform the Apache Hadoop and Apache MapReduce > projects that they need not worry about this patent.>> Best regards,>> /Larry

39
Zusammenfassung
Zusammenfassung
Programmiermodell für verteiltes RechnenOSS Implementierung mit breiter Unterstützung verfügbarBewege Code anstelle von DatenLizenzfrage geklärtBreite Akzeptanz, wenig Kritik
„MapReduce: A major step backwards” (Michael Stonebraker)
Sehr guter kommerzieller Support VerfügbarPrädikat: Empfehlenswert! ;)
40
Tobias JochSystem ArchitectureProject Management
inovex GmbHKarlsruher Straße 7175179 Pforzheim
0173.3181 [email protected]
Fragen & Antworten
Wir nutzen Technologien, um unsere Kunden glücklich zu machen. Und uns selbst.

Tobias JochSystem ArchitectureProject Management
inovex GmbHKarlsruher Straße 7175179 Pforzheim
0173.3181 [email protected]
Vielen Dank! ;)
Wir nutzen Technologien, um unsere Kunden glücklich zu machen. Und uns selbst.


![BigData and MapReduce with Hadooppluton.ijs.si/CLASS/files/KC_CLASS_IJS_Tomasic_2012.pdf · Hadoop Distributed File System (HDFS), Hadoop YARN and Hadoop MapReduce [2]. At the beginning](https://img.pdfslide.tips/doc/110x75/5ec563644764cc6aa33a44d1/bigdata-and-mapreduce-with-hadoop-distributed-file-system-hdfs-hadoop-yarn-and.jpg)


























