Embed Size (px)
Citation preview

Xapian vs Sphinx
潘俊勇
易度 everydo.com

我需要搜索服务器吗?

关系数据库的搜索已经很强了!

数据库
• 数据库搜索:对大部分应用足够
• 但当海量数据的情况下…
– 写得快,– 搜索得也快 ?
• 此事古难全– 更多索引表示数据库更慢!– MySQL starts to crawl at 100K+ rows– 全文搜索!
• 数据库真的有搜索吗? NoSQL ,对象数据库 (ZODB)

海量数据?
• Google / Baidu整个互联网建立索引
• ( 热 ) 互联网服务淘宝,豆瓣…
• 企业文档管理软件易度 edodocs.com

互联网服务系列技术
• 分布式计算
• 分布式存储
• 高可用
• NoSQL
• 搜索服务
• ….

让搜索更快?
没有免费的午餐

搜索服务器的开销
• 独立的索引数据库读优化:写慢读快存储空间, replication ,备份
• 搜索非实时异步操作,搜索可能滞后(实时索引技术?)
• 独立的搜索服务器?又一个进程!
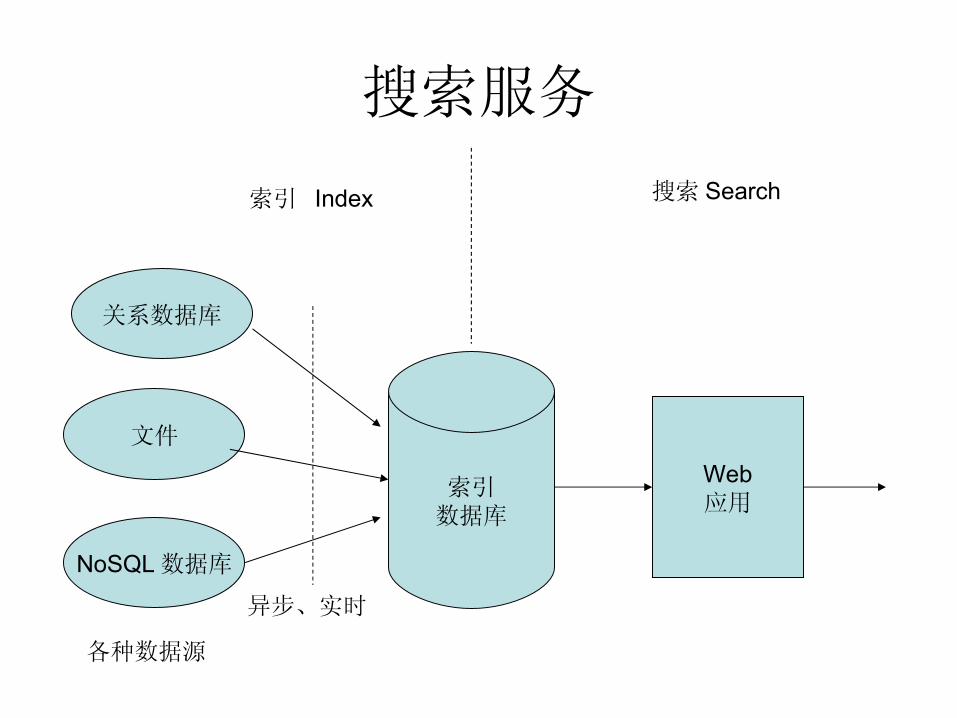
搜索服务
索引数据库
索引 Index 搜索 Search
关系数据库
文件
NoSQL 数据库
Web应用
各种数据源
异步、实时

关键功能
• 文本全文搜索
• 非文本搜索
• Facet 搜索

开源产品
• lucene solr
• Xapianxapian.org
• Sphinxsphinxsearch.com

Xapian
• del.icio.us (1 亿书签,但转到 yahoo 了 )
• Gmane (8 千万条消息 )
• Douban
类搜索引擎的简单服务

sphinx
• 最大: boardreader.com 论坛搜索引擎, 20 亿份文档 (50 亿 ?) , 2TB(6TB?)
• 最忙 : craigslist.org, 免费的分类广告站点 ( 美国的 top10), 每天 5 千万请求
各种复杂的应用

Lucene/Solr成熟
( 但俺不熟,这里暂不讨论 )
Lucene 这种 Java 系的东东, pythoner 是不大给爱的Sphix 说比 Lucence 快 2-4 倍

到底选谁?

豆瓣 sphinx xapian
原因: sphinx 可定制性不好
个人意见:搜索是豆瓣的短板

易度xapian sphinx
(计划中)
原因: xapian 功能不够,可靠性不够,维护团队不大

简单比较
• Xapian• 20 多年历史(老?)
• C++• 嵌入式
• 更少内存
• 写慢但读很快
• 功能不够
• 适合构建搜索引擎
• Sphinx• 起步 2003 年
• C++• 来自俄罗斯
• 和 mysql/nosql 等数据库整合非常好
• 提供 SQL API
• 适合更复杂应用

Xapian :
建立属于你自己的 Google

Xapian 特性
• Ranked probabilistic search 重要词汇
• Relevance feedback 相关的文档
• Phrase and proximity searching • Full range of structured boolean search
operators ("stock NOT market", etc) • stemming of search terms 近似词• Wildcard 任意匹配 (xap*)• Synonyms 同义词• Facet search 分面搜索

Xapian 术语
• Document , document id : 一个整数• 没有字段!
• terms 带位置信息的词或者短语,文本搜索
• values 短的字符串,用于二进制范围搜索和排序
• document data 用于返回显示的任何数据,不能搜索
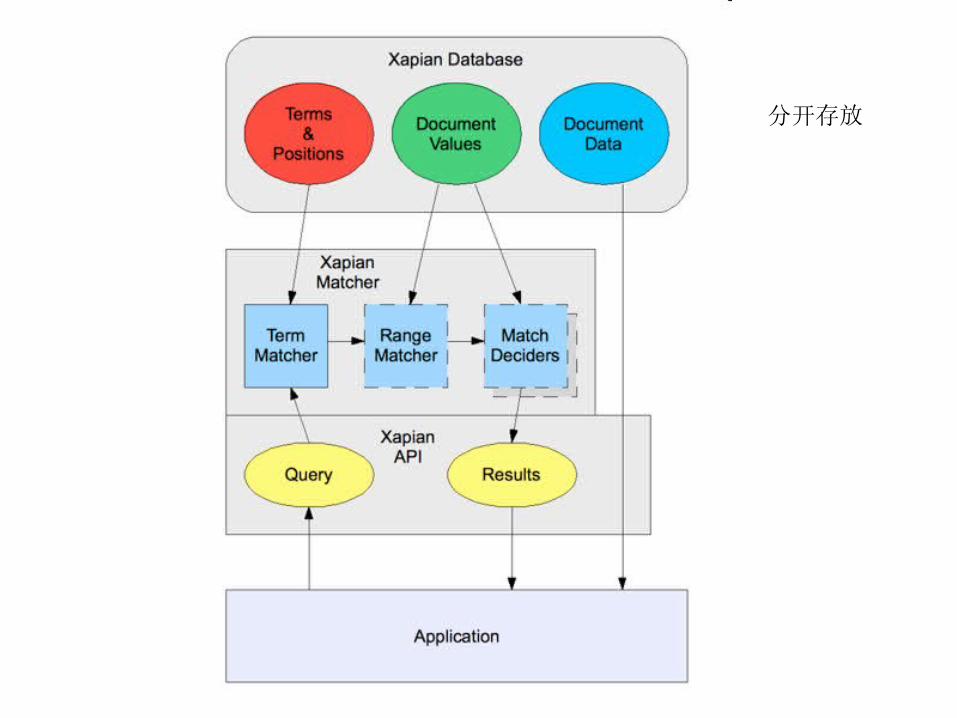
分开存放

Xapian-backend 存储格式
• flint : 1.0/1.2
• chert : 数据库更小,但搜索慢(失败 )
• Brass :更好的支持 replication( 开发中 )

新搜索插件
• 地图搜索
• 图片搜索

Xapian 的 python接口
• Xapian: swig 自动生成的接口底层,功能强,但使用不方便
• Xappy :高层的封装使用简单,封装很多怪异东西,功能不够
• Xappy2 : API改进(开发中)并提供类似 Lucene/Solr 的结构

定义数据库
• >>> import xappy • >>> conn = xappy.IndexerConnection('db1') • >>> conn.add_field_action('title', xappy.FieldActions.INDEX_FREETEXT,
weight=5, language='en') >>> conn.add_field_action('text', xappy.FieldActions.INDEX_FREETEXT, language='en', spell=True)
• >>> conn.add_field_action('category', xappy.FieldActions.INDEX_EXACT) • >>> conn.add_field_action('category', xappy.FieldActions.SORTABLE) >>>
conn.add_field_action('date', xappy.FieldActions.SORTABLE, type="date") >>> conn.add_field_action('price', xappy.FieldActions.SORTABLE, type="float")
• >>> conn.add_field_action('text', xappy.FieldActions.STORE_CONTENT) >>> conn.add_field_action('title', xappy.FieldActions.STORE_CONTENT) >>> conn.add_field_action('category', xappy.FieldActions.STORE_CONTENT)

建立索引
• >>> doc = xappy.UnprocessedDocument() >>> doc.fields.append(xappy.Field("title", "Our first document")) >>> doc.fields.append(xappy.Field("text", "This is a paragraph of text. It's quite short.")) >>> doc.fields.append(xappy.Field("text", "We can create another paragraph of text. " ... "We can have as many of these as we like.")) >>> doc.fields.append(xappy.Field("category", "Test documents")) >>> doc.fields.append(xappy.Field("tag", "Tag1")) >>> doc.fields.append(xappy.Field("tag", "Test document")) >>> doc.fields.append(xappy.Field("tag", "Test document")) >>> doc.fields.append(xappy.Field("price", "20.56"))
• >>> conn.add(doc) • >>> conn.flush() • >>> conn.close()

搜索
• >>> conn = xappy.SearchConnection('db1') • >>> conn.reopen() • >>> q = conn.query_field('text', 'create a
paragraph') • >>> q = conn.query_field('text', 'create a
paragraph', default_op=conn.OP_OR) • >>> rq = conn.query_range('date', '20000101',
'20010101') • >>> results = conn.search(q, 0, 10) • >>> for result in results: ... print result.rank,
result.id, result.data['category']

嵌入式:单写多读
• 写内存 flush 硬盘
• 读: MVCC?不完全的 MVCC ,如果写过于频繁,就出现读失效 (reopen)

Xapian 优点
• 搜索速度快
• 文字搜索功能支持很全
• 内存占用少
• 嵌入式,简单
• 提供 API ,“实时”索引

Xapian问题
• 数据库崩溃,无法修复 ( 我碰到 2次 )• 不真正支持字段
• Multi-Value 字段的支持
• 不能统计 : Sum/Group• 数据量大,索引非常慢
• Replicatoin支持不好
• 文档资料不够
• 开发维护人员少

Sphinx
不仅仅是全文搜索面向通用应用
NoSQL 的伙伴关系数据库的补充

Sphinx 特性
• 索引速度非常快(比其他的快 4-10 倍)
• 对非文本属性支持好
• 直接对关系数据库进行索引
• 很方便对 NoSQL 数据库索引
• 完整支持数据库查询特性ORDER/GROUP/MIN/MAX/AVG/SUM
• 轻松分布到多台服务器

索引三部曲
1. 定义数据源SQL query
2. 定义索引数据文件系统路径,一组文本处理设置
4. 执行索引!

config
• source test1• {• sql_query = SELECT id, title, descr, added, price \• FROM products• sql_attr_timestamp = added• sql_attr_float = price• }• index test1• {• source = test1• path = /my/index/store/test1• }

执行完全索引
• $ ./indexer lj• Sphinx 1.10.1-dev (4c7aaa426b6a)• Copyright (c) 2001-2010, Andrew Aksyonoff• Copyright (c) 2008-2010, Sphinx Technologies Inc (http://sph...• using config file './sphinx.conf'...• indexing index 'lj'...• collected 999944 docs, 1318.1 MB• sorted 224.2 Mhits, 100.0% done• total 999944 docs, 1318101119 bytes• total 158.080 sec, 8338160 bytes/sec, 6325.53 docs/sec• total 33 reads, 4.671 sec, 17032.9 kb/call avg, 141.5 msec/call• total 361 writes, 20.889 sec, 3566.1 kb/call avg, 57.8 msec/call
• 这个是完全索引,数据量大的时候,会很慢!

增量索引
• 独立的区域保留增量索引
• 定时合并
• 仍然不够快!

实时索引
• 支持 INSERT/DELETE/REPLACE
• 仅仅 SphinxQL 提供此接口
• Beta
• 不支持MVA

搜索
• 运行 searchd
• 连接到 searchd 执行搜索– SphinxAPI (native ports for PHP, Python,Perl,
Ruby, Java, C#, Haskell...)
– SphinxSE直接编译进你的 MySQL 服务器实例
– SphinxQL无需 MySQL ,使用现有 MySQL客户端

SphinxQL• $ mysql -P 9306• Welcome to the MySQL monitor. Commands end with ; or \g.• Your MySQL connection id is 1• Server version: 0.9.9-dev (r1734)• Type 'help;' or '\h' for help. Type '\c' to clear the buffer.• mysql> SELECT * FROM test1 WHERE MATCH('test')• -> ORDER BY group_id ASC OPTION ranker=bm25;• +------+--------+----------+------------+• | id | weight | group_id | date_added |• +------+--------+----------+------------+• | 4 | 1442 | 2 | 1231721236 |• | 2 | 2421 | 123 | 1231721236 |• | 1 | 2421 | 456 | 1231721236 |• +------+--------+----------+------------+• 3 rows in set (0.00 sec)

Searcher支持
• SphinxQL explains it pretty good now
• 支持 SELECT 的任意表达式
• 支持WHERE, ORDER BY, GROUP BY,COUNT, AVG/MIN/MAX/SUM
• 扩展– OPTION ranker=bm25– WITHIN GROUP ORDER BY ...

MVA: 多值属性
• 典型的:文章的标签

实时搜索
• 先在内存里面做索引
• 类似数据库索引
• alpha


Sphinx 和 MySQL
• 建立全文索引比 mysql 快 50-100 倍
• 全文搜索比 Mysql10-1000x (!!!)
• 非全文的扫描比 MySQL 快 2-3 倍
• Where/group/sort 可能比 mysql 快 100 倍!




MySQL vs Sphinx
结论:把尽可能多的东西
从MySQL 转移到 Sphinx!

Sphinx缺点
• 不能通过 API 来定义数据源
• 实时索引还不完善
• 没有嵌入式的访问方法
• (还不熟悉)

俺的结论:
Xapian rocks,
butSphinx is the future.

其他 参考
• woosh : 纯 python版本的 xapian
• Haystack : django上屏蔽各种搜索底层差异的一个东东
• Sphinx 中文站: http://www.coreseek.cn/
thanks