Embed Size (px)
DESCRIPTION
Летняя Суперкомпьютерная Академия. Лекция для преподавателей информатики про "Большие Данные".
Citation preview

Большие данныем.н.с. С.В.Герасимов, к.ф.-м.н. доцент М.И. Петровский
Лаборатория Технологий ПрограммированияВМиК МГУ

Введение

Когда они стали большими?
2003Начало цивилизации
5 эксабайт
гига 109
тера 1012
пета 1015
экса 1018
зетта 1021
йотта 1023
2014:
22 эксабайта в сутки!
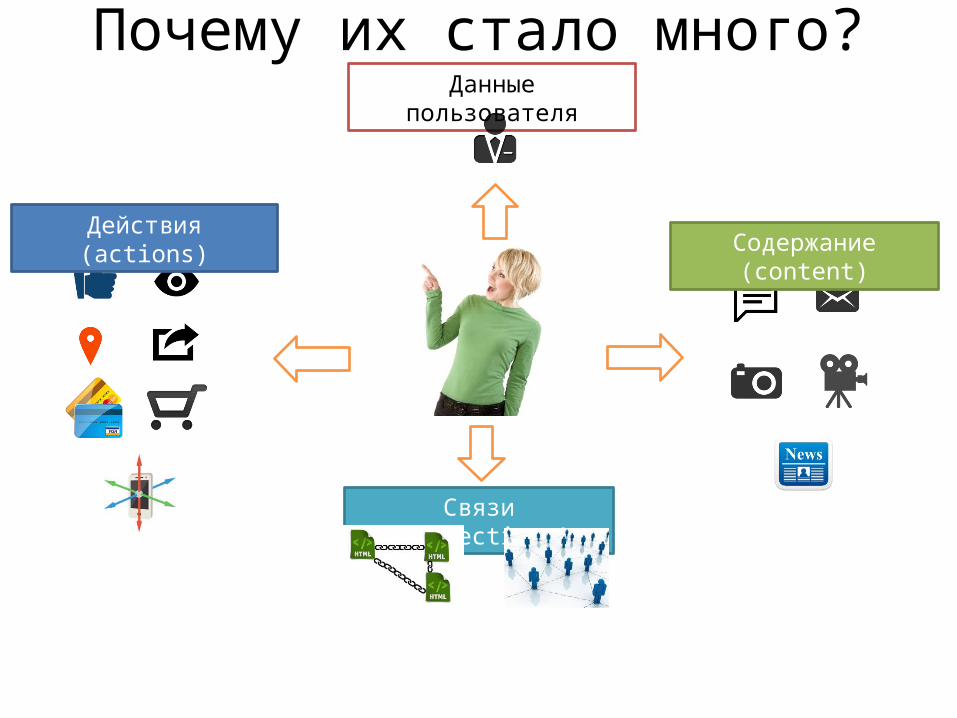
Почему их стало много?Данные пользователя
Действия (actions)Содержание (content)
Связи (connections)
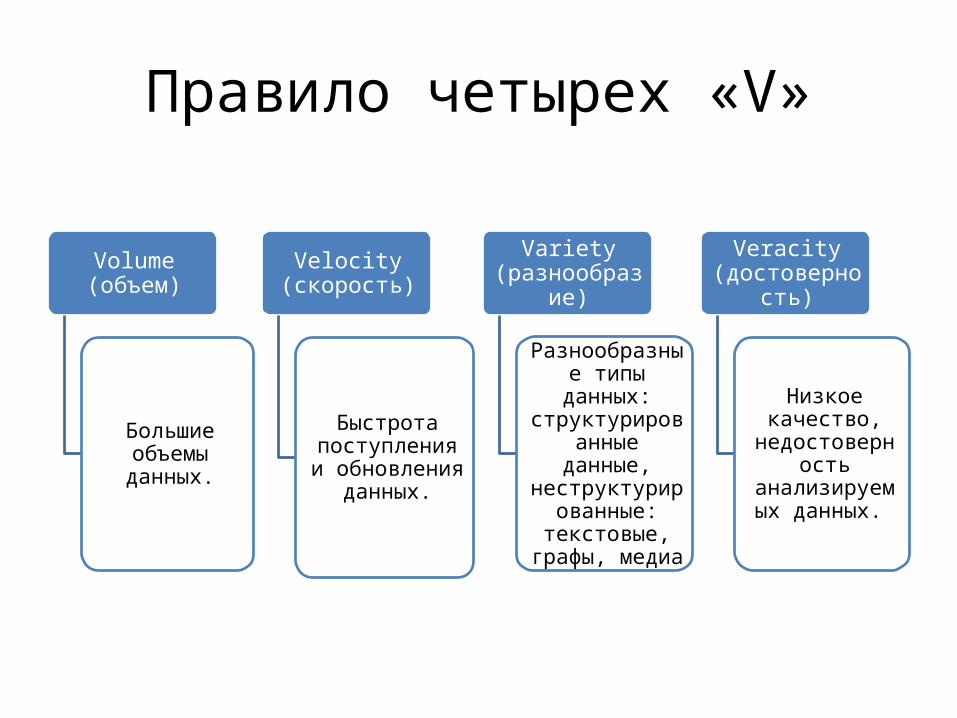
Правило четырех «V»
Volume (объем)
Большие объемы данных.
Velocity (скорость)
Быстрота поступления и
обновления данных.
Variety (разнообразие)
Разнообразные типы данных:
структурированные данные,
неструктурированные: текстовые,
графы, медиа
Veracity (достоверность)
Низкое качество, недостоверность анализируемых
данных.

DataficationData Science
Data Mining
Knowledge Discovery in Databases
Data Scientist
Big Data

Анализ данных: пример

Другие примерыПредоставить пользователю соцсети персонифицированный контент (статьи, статусы, музыка, видео), интересный ему.
Предложить пользователю товары и услуги (или рекламу), в которых он м.б. заинтересован.
Предотвратить снятие денег с кредитной карты в случае ее кражи путем анализа поведения держателя карты
Определить зависимость между образом жизни (питание, двигательная активность, сон) и показателями здоровья
Учесть поведение пользователя в соцсетях при принятии решения о выдаче кредита

Большие данные: резюме
• Рост объемов• Особенности• Востребованность задач анализа

Data Mining

Кто владеет информацией – тот владеет миромРотшильд
данные информация знания

Data Mining
• Data mining - методы обнаружения в данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности [Пятецкий-Шапиро, 1989]
Математическая
статистика
Линейная алгебра
Методы оптимизации
Теория вероятностей
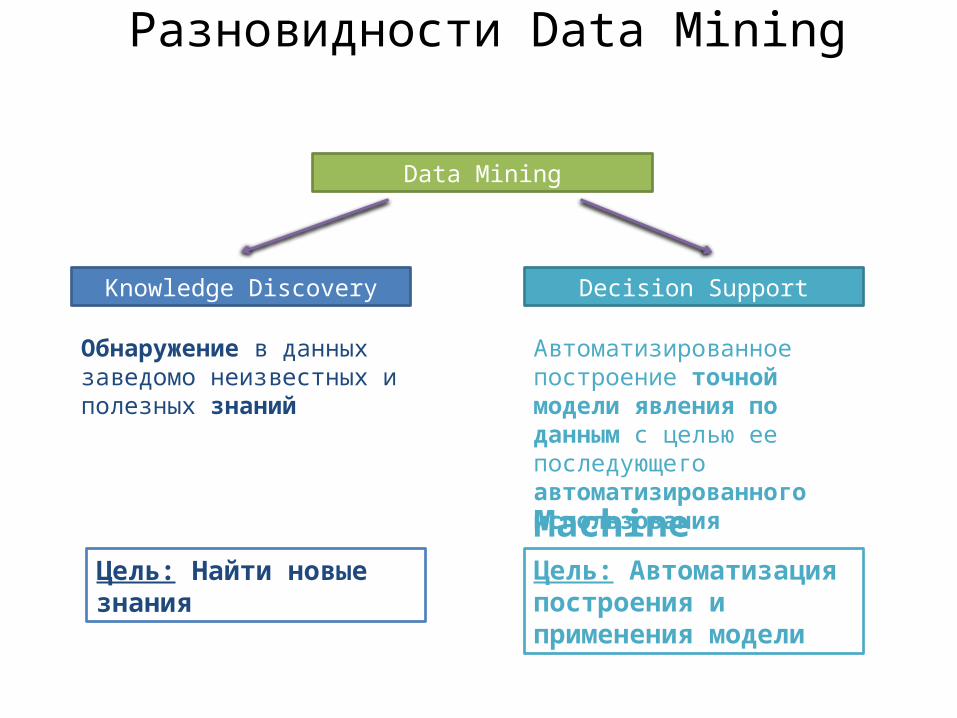
Разновидности Data Mining
Data Mining
Knowledge Discovery Decision Support
Обнаружение в данных заведомо неизвестных и полезных знаний
Автоматизированное построение точной модели явления по данным с целью ее последующего автоматизированного использованияMachine LearningЦель: Автоматизация построения и применения модели
Цель: Найти новые знания
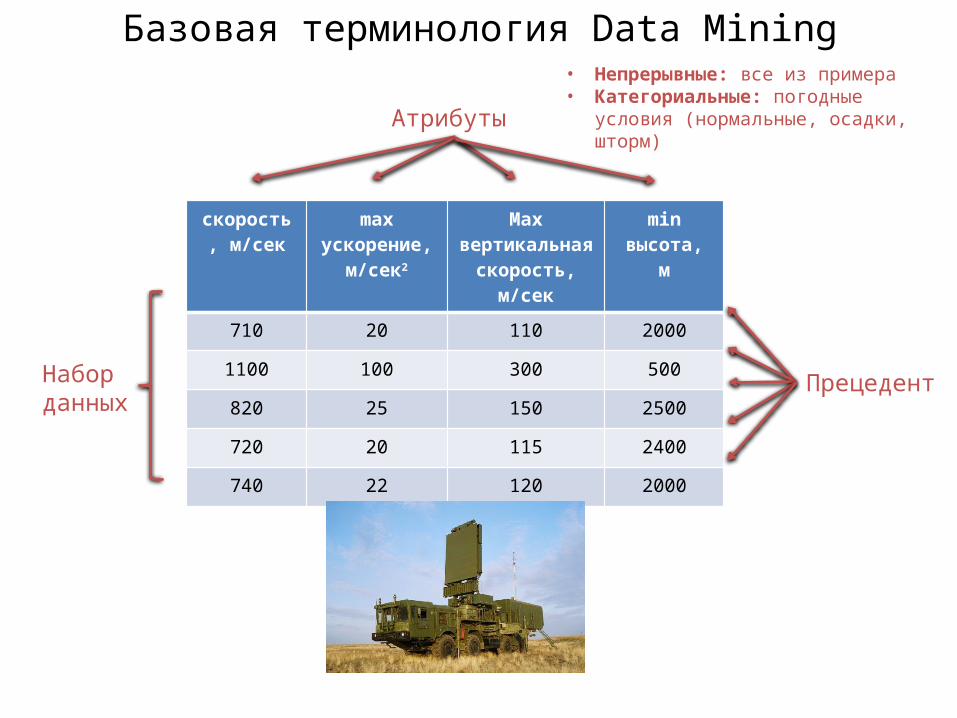
Базовая терминология Data Mining
скорость, м/сек
max ускорение,
м/сек2
Max вертикальная
скорость, м/сек
min высота,м
710 20 110 2000
1100 100 300 500
820 25 150 2500
720 20 115 2400
740 22 120 2000
Прецедент
Атрибуты
Наборданных
• Непрерывные: все из примера• Категориальные: погодные условия
(нормальные, осадки, шторм)

скорость, м/сек
max ускорение,
м/сек2
Max вертикальная
скорость, м/сек
min высота,м
Тип летательного средства
710 20 110 2000 С1
1100 100 300 1100 С2
820 25 180 2500 С2
Классификация
скорость, м/сек
max ускорение,
м/сек2
Max вертикальная
скорость, м/сек
min высота,м
Тип летательного средства
710 20 110 2000 С1
1100 100 300 1100 С2
820 25 180 2500 С2
720 20 115 1000
740 22 120 2000
С1 С2
обучающая выборка
обучение
Модельy=f(X)применение
С1
С1
Классификация
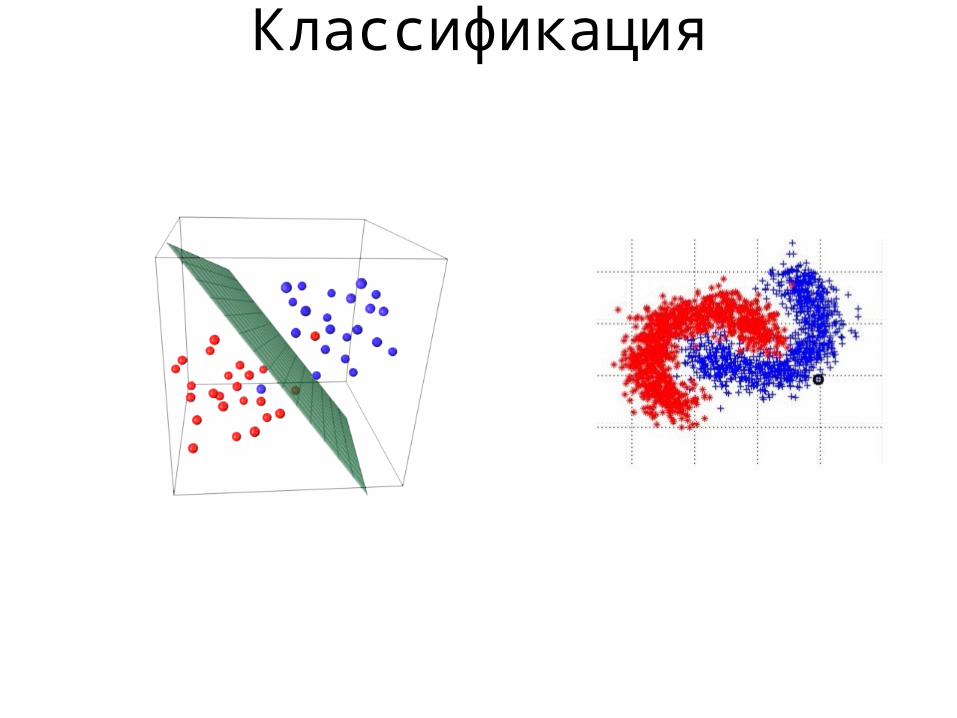
Классификация
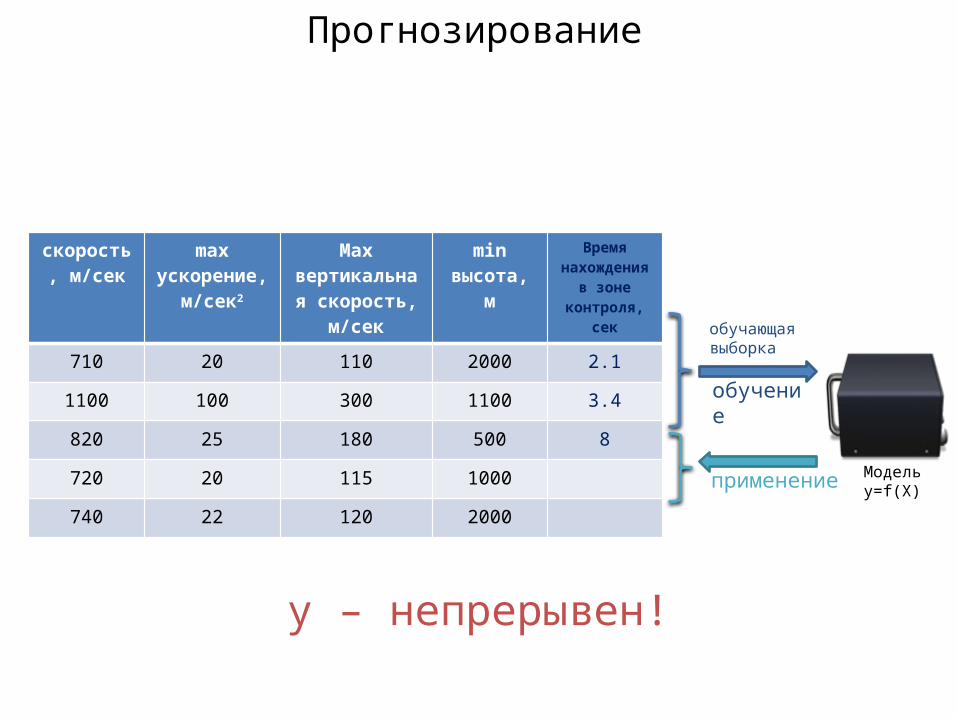
Прогнозирование
скорость, м/сек
max ускорение,
м/сек2
Max вертикальная
скорость, м/сек
min высота,м
Время нахождения в зоне контроля,
сек
710 20 110 2000 2.1
1100 100 300 1100 3.4
820 25 180 500 8
720 20 115 1000
740 22 120 2000
обучающая выборка
обучение
Модельy=f(X)применение
y – непрерывен!

Классификация и прогнозирование
y = f(X) Входные признаки: X=x1x2…xn
Целевая переменная: y
Обучающая выборка:X1,y1
X2,y2
…XM,yM

Классификация и прогнозирование
y = f(X)Задача X y
Персонификация контента пользователя соцсети
«Лайки» и контент Рекомендованный контент
Рекомендация товаров и услуг История покупок пользователя, «лайки»
Набор рекомендованных товаров и услуг
Карточный анти-фрод Последние транзакции Решение: фрод / норма
Кредитный скоринг с использованием данных соцсетей
Анкетные данные, поведение и контент, связанный с пользователем в соцсетях
Решение по кредиту
Поиск взаимосвязей между физической активностью, питанием и заболеваемостью
Общая информация о пациенте, данные диетологических дневников, показатели датчиков
Набор вероятных диагнозов
Кластерный анализ
скорость, м/сек
max ускорение,
м/сек2
Max вертикальная
скорость, м/сек
min высота,м
710 20 110 2000
1100 100 300 500
820 25 150 2500
720 20 115 2400
740 22 120 2000
Найти группы похожих летательных аппаратов, пролетающих над РЛС.
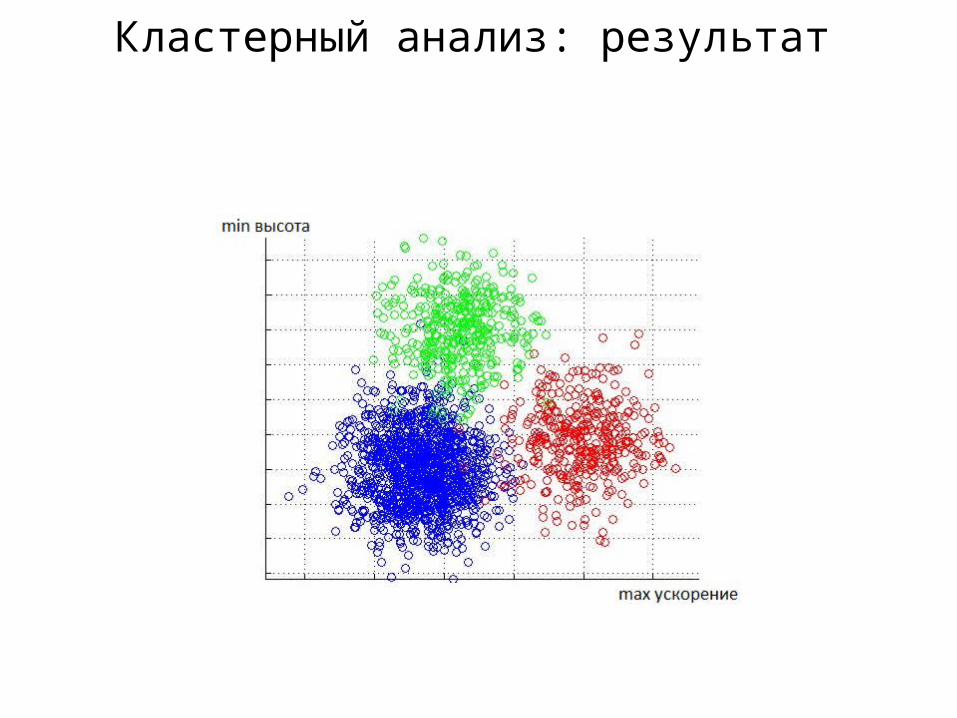
Кластерный анализ: результат
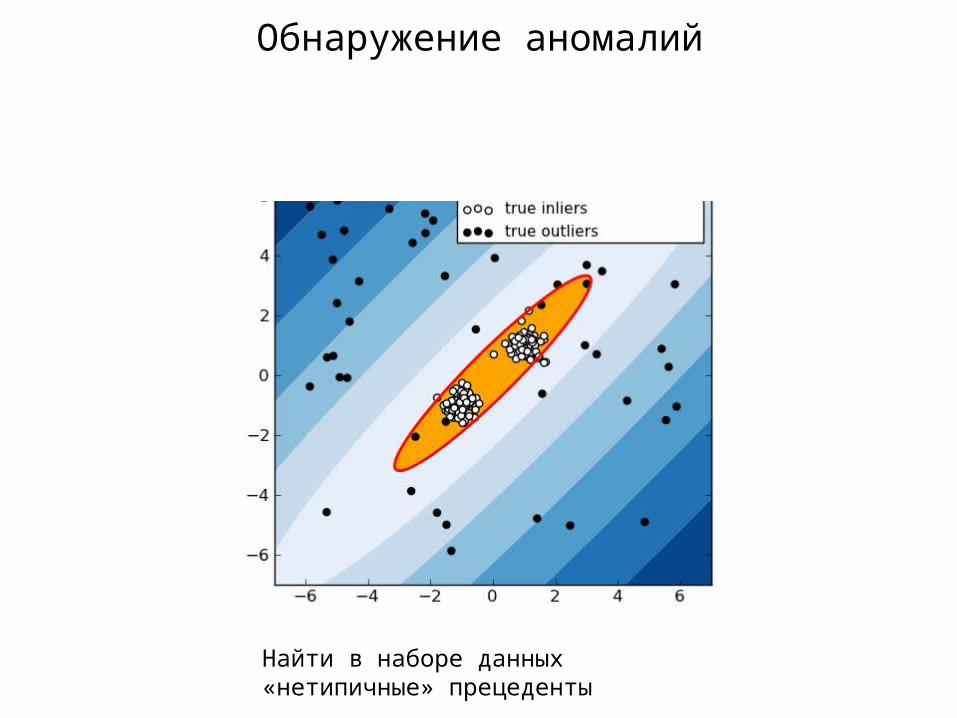
Обнаружение аномалий
Найти в наборе данных «нетипичные» прецеденты

Data Mining: резюме
• Математические методы для поиска скрытых закономерностей
• Бизнес-задачи → Математические задачи → Алгоритмы
• Математические задачи:– Классификация– Прогнозирование– Кластеризация– Обнаружение аномалий– …

Параллельное исполнение, распределенное хранение

Время чтения 25 TB данных
Sequential read speed : 70-120 MB/sec ~ 0,342 TB/hour
73 ЧАСА!!!

Сортировка
N logN speed=540 ∙ ∙часов !!!
Пусть 25 TB = 25 млн. документовпо ~ 1MB каждый
QuickSort O(N logN)∙N=25∙106
1MB читается за speed=2,92∙10-6 час.
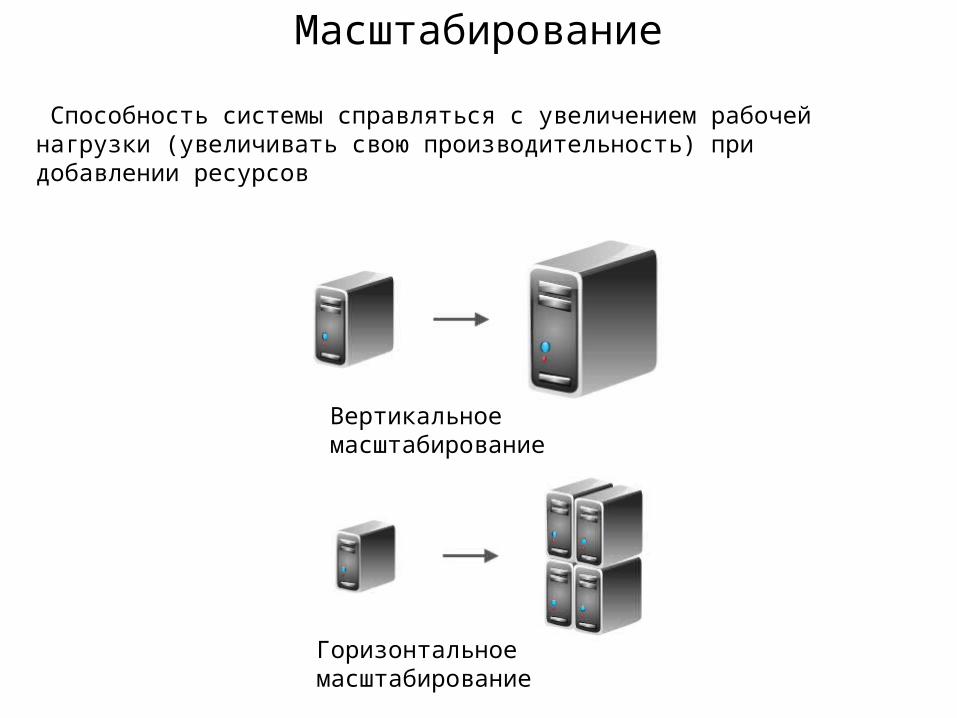
Масштабирование
Вертикальное масштабирование
Горизонтальное масштабирование
Способность системы справляться с увеличением рабочей нагрузки (увеличивать свою производительность) при добавлении ресурсов
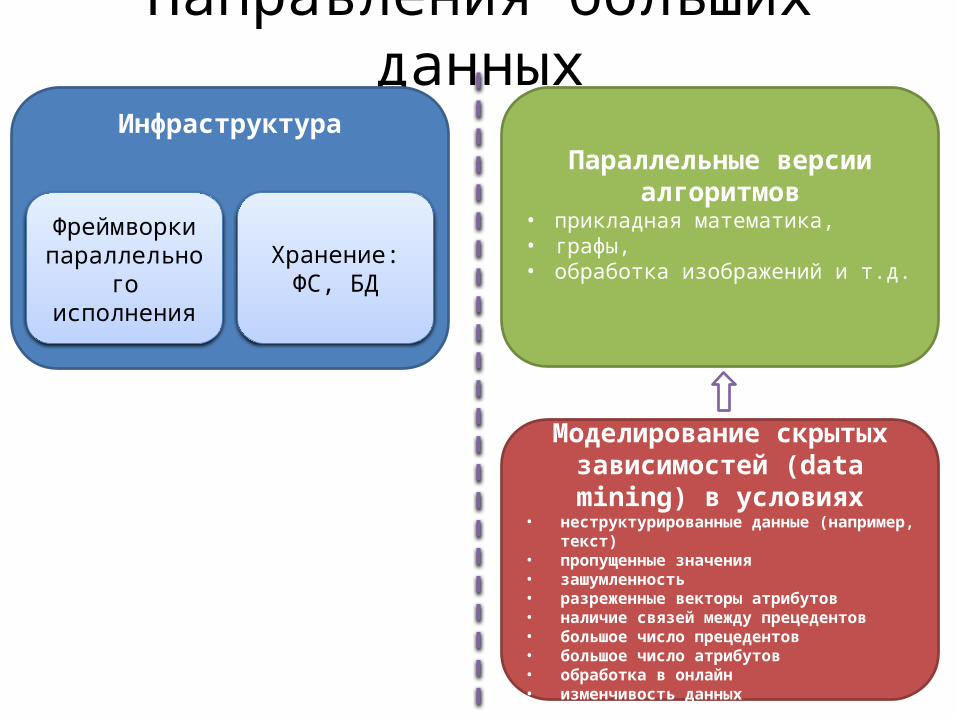
Направления больших данныхИнфраструктура
Параллельные версии алгоритмов
• прикладная математика,• графы,• обработка изображений и т.д.
Моделирование скрытых зависимостей (data mining) в
условиях• неструктурированные данные (например, текст)• пропущенные значения• зашумленность• разреженные векторы атрибутов • наличие связей между прецедентов• большое число прецедентов• большое число атрибутов• обработка в онлайн• изменчивость данных
Фреймворки параллельного
исполнения
Хранение: ФС, БД

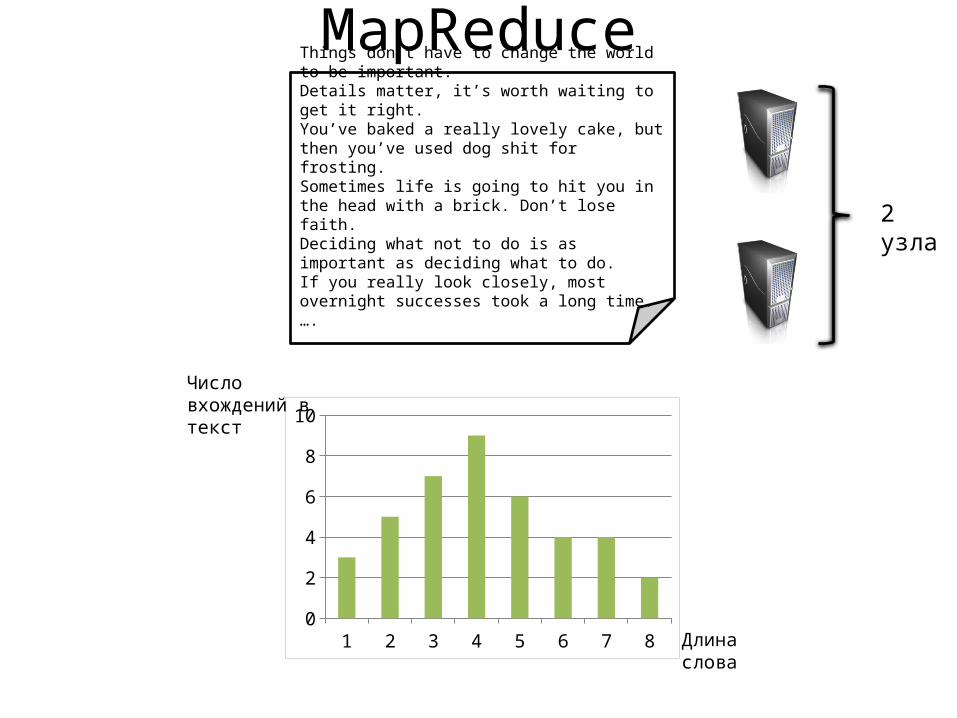
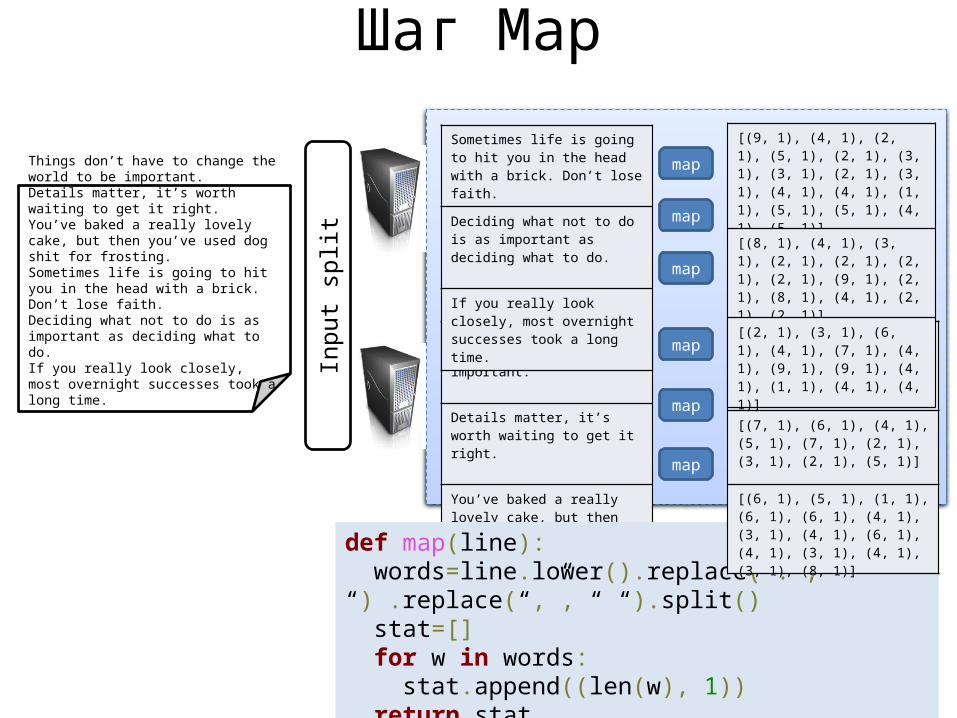
MapReduceThings don’t have to change the world to be important.Details matter, it’s worth waiting to get it right.You’ve baked a really lovely cake, but then you’ve used dog shit for frosting.Sometimes life is going to hit you in the head with a brick. Don’t lose faith.Deciding what not to do is as important as deciding what to do.If you really look closely, most overnight successes took a long time.….
1 2 3 4 5 6 7 80123456789
10Число вхождений в текст
Длина слова
2 узла
Шаг Map
Things don’t have to change the world to be important.Details matter, it’s worth waiting to get it right.You’ve baked a really lovely cake, but then you’ve used dog shit for frosting.Sometimes life is going to hit you in the head with a brick. Don’t lose faith.Deciding what not to do is as important as deciding what to do.If you really look closely, most overnight successes took a long time.
Things don’t have to change the world to be important.
Details matter, it’s worth waiting to get it right.
You’ve baked a really lovely cake, but then you’ve used dog shit for frosting.
Sometimes life is going to hit you in the head with a brick. Don’t lose faith.
Deciding what not to do is as important as deciding what to do.
If you really look closely, most overnight successes took a long time.
map
map
map
map
map
map
def map(line): words=line.lower().replace(“.”, “ “) .replace(“,”, “ “).split() stat=[] for w in words: stat.append((len(w), 1)) return stat
Inpu
t spl
it[(6, 1), (5, 1), (4, 1), (2, 1), (6, 1), (3, 1), (5, 1), (2, 1), (2, 1), (9, 1)]
[(7, 1), (6, 1), (4, 1), (5, 1), (7, 1), (2, 1), (3, 1), (2, 1), (5, 1)]
[(6, 1), (5, 1), (1, 1), (6, 1), (6, 1), (4, 1), (3, 1), (4, 1), (6, 1), (4, 1), (3, 1), (4, 1), (3, 1), (8, 1)]
[(9, 1), (4, 1), (2, 1), (5, 1), (2, 1), (3, 1), (3, 1), (2, 1), (3, 1), (4, 1), (4, 1), (1, 1), (5, 1), (5, 1), (4, 1), (5, 1)]
[(8, 1), (4, 1), (3, 1), (2, 1), (2, 1), (2, 1), (2, 1), (9, 1), (2, 1), (8, 1), (4, 1), (2, 1), (2, 1)]
[(2, 1), (3, 1), (6, 1), (4, 1), (7, 1), (4, 1), (9, 1), (9, 1), (4, 1), (1, 1), (4, 1), (4, 1)]
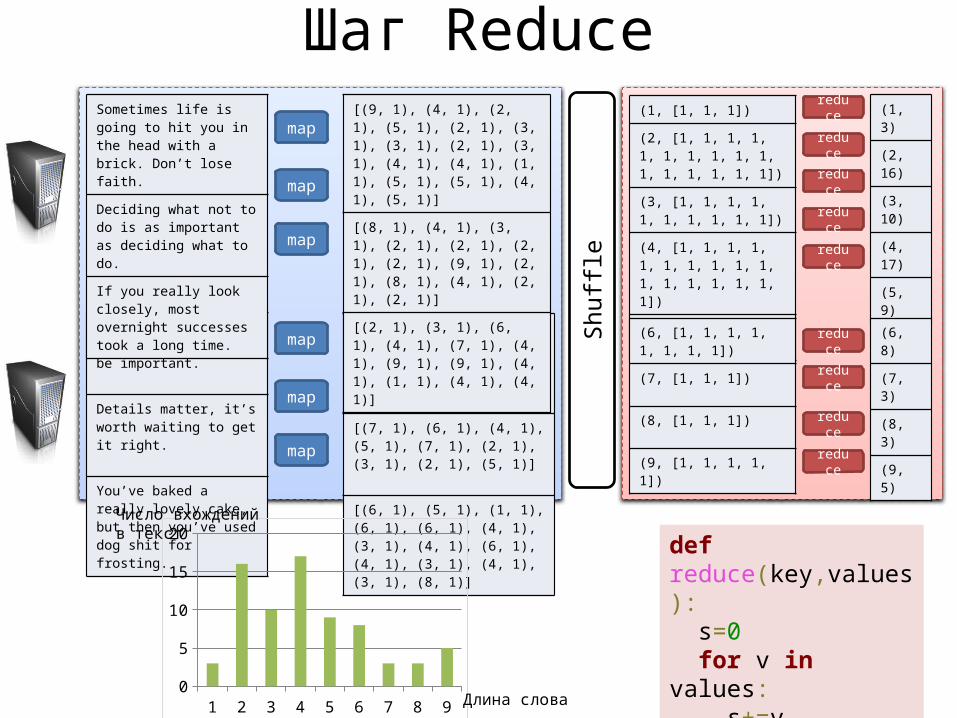
Шаг Reduce
Things don’t have to change the world to be important.
Details matter, it’s worth waiting to get it right.
You’ve baked a really lovely cake, but then you’ve used dog shit for frosting.
Sometimes life is going to hit you in the head with a brick. Don’t lose faith.
Deciding what not to do is as important as deciding what to do.
If you really look closely, most overnight successes took a long time.
map
map
map
[(6, 1), (5, 1), (4, 1), (2, 1), (6, 1), (3, 1), (5, 1), (2, 1), (2, 1), (9, 1)]
[(7, 1), (6, 1), (4, 1), (5, 1), (7, 1), (2, 1), (3, 1), (2, 1), (5, 1)]
[(6, 1), (5, 1), (1, 1), (6, 1), (6, 1), (4, 1), (3, 1), (4, 1), (6, 1), (4, 1), (3, 1), (4, 1), (3, 1), (8, 1)]
[(9, 1), (4, 1), (2, 1), (5, 1), (2, 1), (3, 1), (3, 1), (2, 1), (3, 1), (4, 1), (4, 1), (1, 1), (5, 1), (5, 1), (4, 1), (5, 1)]
[(8, 1), (4, 1), (3, 1), (2, 1), (2, 1), (2, 1), (2, 1), (9, 1), (2, 1), (8, 1), (4, 1), (2, 1), (2, 1)]
[(2, 1), (3, 1), (6, 1), (4, 1), (7, 1), (4, 1), (9, 1), (9, 1), (4, 1), (1, 1), (4, 1), (4, 1)]
(1, [1, 1, 1])
(2, [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
(3, [1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
(4, [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
(5, [1, 1, 1, 1, 1, 1, 1, 1, 1])
(6, [1, 1, 1, 1, 1, 1, 1, 1])
(7, [1, 1, 1])
(8, [1, 1, 1])
(9, [1, 1, 1, 1, 1])
map
map
map
reduce
reduce
reduce
reduce
reduce
reduce
reduce
reduce
reduce
Shuffl
e
(1, 3)
(2, 16)
(3, 10)
(4, 17)
(5, 9)
(6, 8)
(7, 3)
(8, 3)
(9, 5)
def reduce(key,values): s=0 for v in values: s+=v return (key,s)
1 2 3 4 5 6 7 8 902468
1012141618
Число вхождений в текст
Длина слова
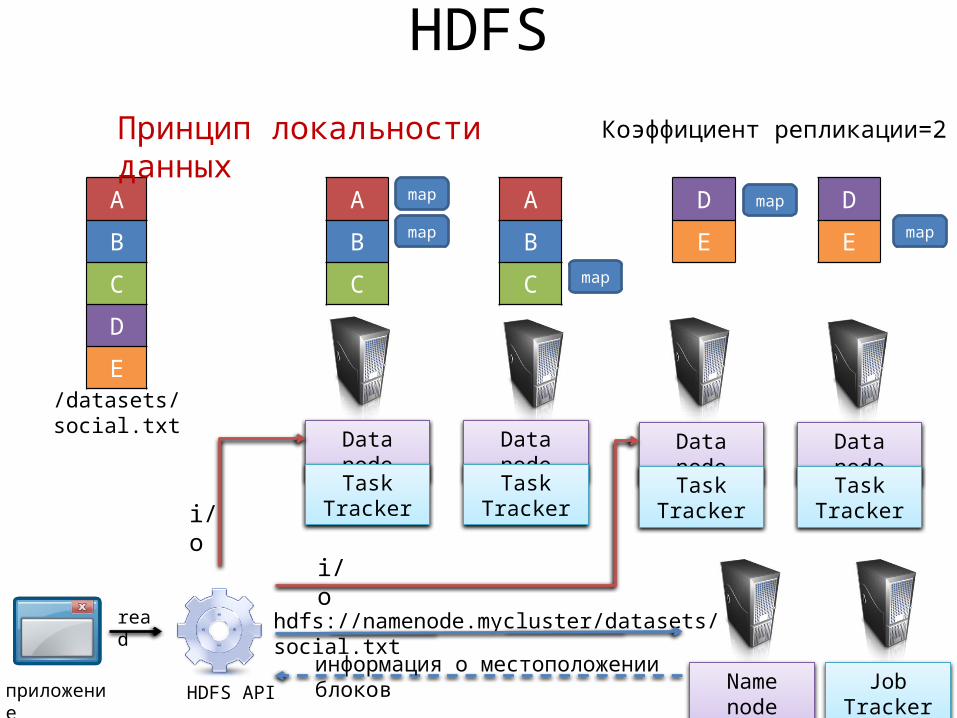
HDFS
A
B
C
D
E
A
B
C
A
B
C
D
E
D
E
Коэффициент репликации=2
/datasets/social.txt
Data node
Task Tracker
Data node
Task Tracker
Data node
Task Tracker
Data node
Task Tracker
map
map
map
map
map
Name node
hdfs://namenode.mycluster/datasets/social.txt
информация о местоположении блоков
i/o
i/o
приложение HDFS API
read
Принцип локальности данных
Job Tracker


Apache SparkHadoop• Hadoop MapReduce: обращение к данным = чтение из HDFS. При этом многие алгоритмы
итеративны (по многу раз обращаются к одним и тем же данным)• Разработка Hadoop MapReduce программ тяжеловесна (требуется писать Java-классы)• Hadoop не предполагает использование для обработки запросов в реальном времени
кеш
HDFS
Узел
кеш
HDFS
Узел
кеш
HDFS
Узел
Spark• Кеширование обрабатываемых коллекций (resilient distributed data set, RDD) данных в ОЗУ узлов
кластера• Интерактивное программирование логики обработки в функциональном стиле (Scala, Python)• Возможность обработка запросов, поступающих в реальном времени

Пример итеративного алгоритма
1. textFile=sc.textFile(“hdfs://data/numbers.txt”)2. data=textFile.map(lambda line: float(line))3. data.cache()4. sum=data.reduce(lambda x,y: x+y)5. mean=sum/data.count()6. devs=data.map(lambda x: (x-mean)**2)7. devs.cache()8. import math9. stddev=math.sqrt(devs.reduce(lambda x,y: x+y)/devs.count())

Параллельная обработка и распределенное хранение: резюме
• Hadoop=MapReduce+HDFS– Принцип локальности данных
• Spark– Кеширование наборов данных в ОЗУ– Наглядный код– Spark+HDFS

Хранение: СУБД
Хранение
Лог-файлВеб-сервер Data scientist
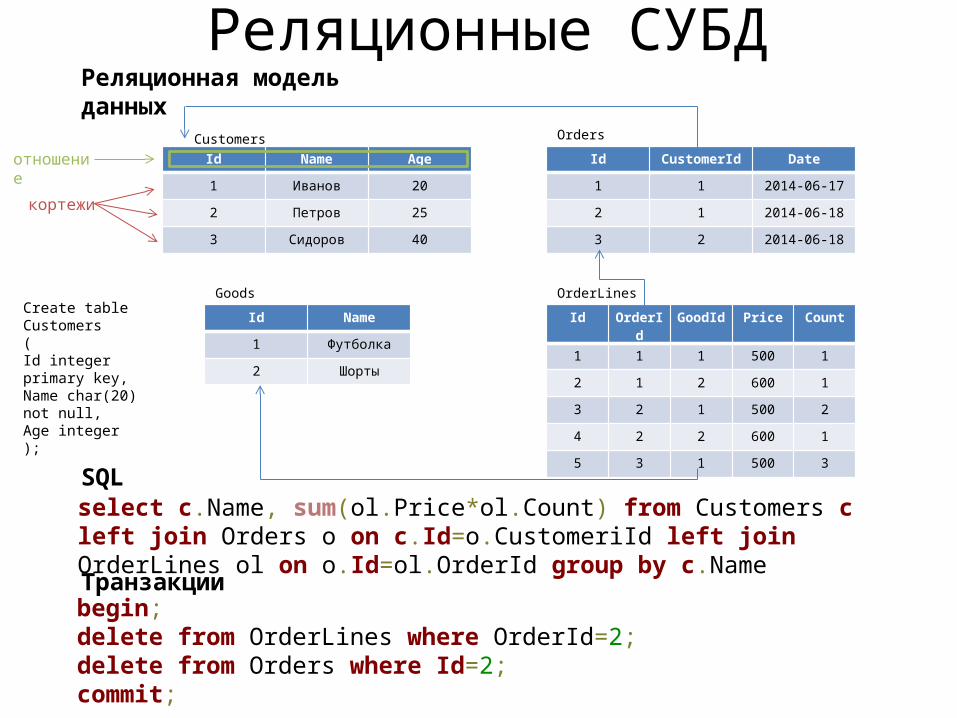
Реляционные СУБД
Id Name Age
1 Иванов 20
2 Петров 25
3 Сидоров 40
CustomersId CustomerId Date
1 1 2014-06-17
2 1 2014-06-18
3 2 2014-06-18
Orders
Id OrderId GoodId Price Count
1 1 1 500 1
2 1 2 600 1
3 2 1 500 2
4 2 2 600 1
5 3 1 500 3
OrderLinesId Name
1 Футболка
2 Шорты
Goods
select c.Name, sum(ol.Price*ol.Count) from Customers c left join Orders o on c.Id=o.CustomeriId left join OrderLines ol on o.Id=ol.OrderId group by c.Name
begin;delete from OrderLines where OrderId=2;delete from Orders where Id=2;commit;
SQL
Транзакции
кортежи
отношение
Реляционная модель данных
Create table Customers(Id integer primary key,Name char(20) not null,Age integer);

Реляционные СУБД• Реляционная модель данных
– Фиксированная схема– Нормализованность данных– Поддержка транзакций
• Использование SQL– Возможность произвольного соединения отношений в запросах– SQL – стандарт на «общение» приложений с БД. БД как способ
интеграции приложений• «Проблема несоответствия» реляционной и ОО моделей• Плохая горизонтальная масштабируемость• Коммерческое лицензирование

Тенденции развития информационных систем
• Рост объемов данных• Горизонтальное масштабирование,
использование кластеров• Уход от БД как средства интеграции систем
(SOA)• Бурное развитие Веб-приложений, частая
модификация их логики и структуры хранения данных

NoSQL
• No SQL• Not Only SQL = NOSQL
Разновидности NoSQL БД• Ключ-значение• Документные• Семейство столбцов• Графовые

Ключ-значениеКлюч Значение
1 “{Name:\”Иванов\”,Age:20}”
2 “{Name:\”Петров\”,Age:25}”
3 “{Name:\”Сидоров\”,Age:40}”
Customers
Ключ Значение
1“{CustomerId:1,Date:\”2014-06-16\”,OrderLines:
[{Name:\”футболка\”,Price:500,Count:1},{Name:\”шорты\”,Price:600,Count:1}]}”
2“{CustomerId:1,Date:\”2014-06-17\”,OrderLines:
[{Name:\”футболка\”,Price:500,Count:2},{Name:\”шорты\”,Price:600,Count:1}]}”
3 “{CustomerId:2,Date:\”2014-06-18\”,OrderLines:[{Name:\”футболка\”,Price:500,Count:3}]}”
Orders
• Агрегатно-ориентированность. Скорость важнее нормализованного хранения.
• «Значение» - поток байт. Запросы по значениям полей отсутствуют
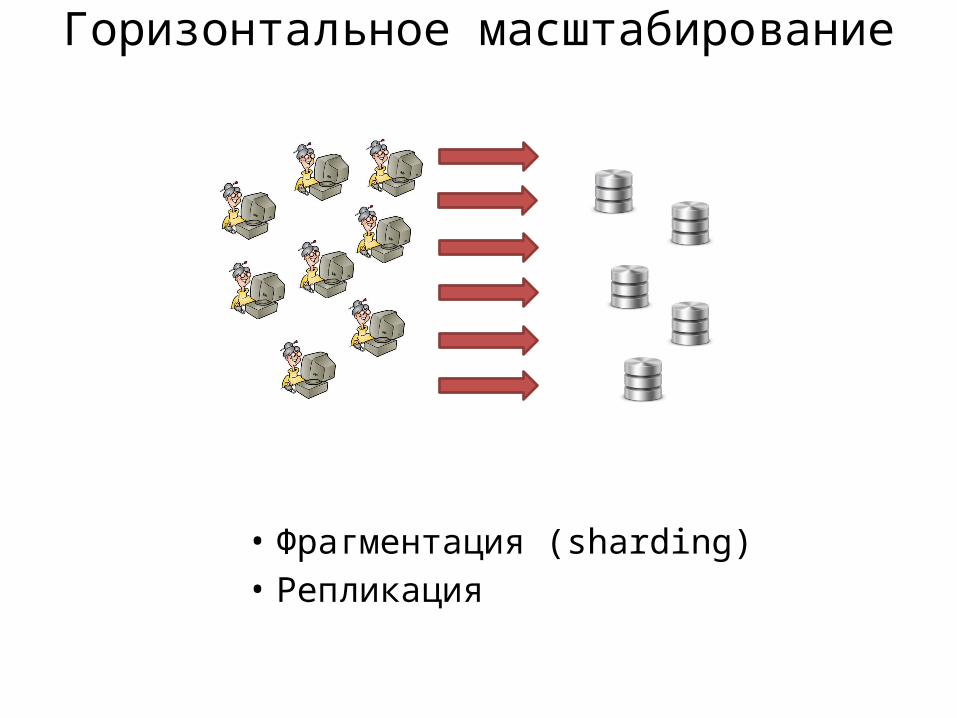
Горизонтальное масштабирование
• Фрагментация (sharding)• Репликация
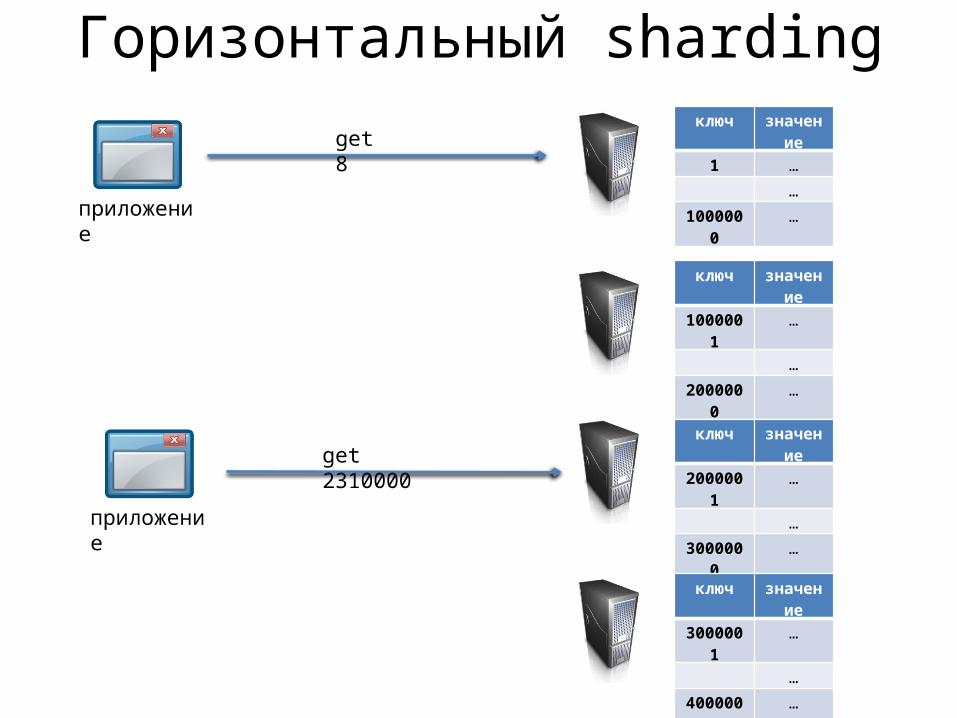
Горизонтальный sharding
приложение
ключ значение
1 …
…
1000000 …
ключ значение
1000001 …
…
2000000 …
ключ значение
2000001 …
…
3000000 …
ключ значение
3000001 …
…
4000000 …
get 8
get 2310000
приложение
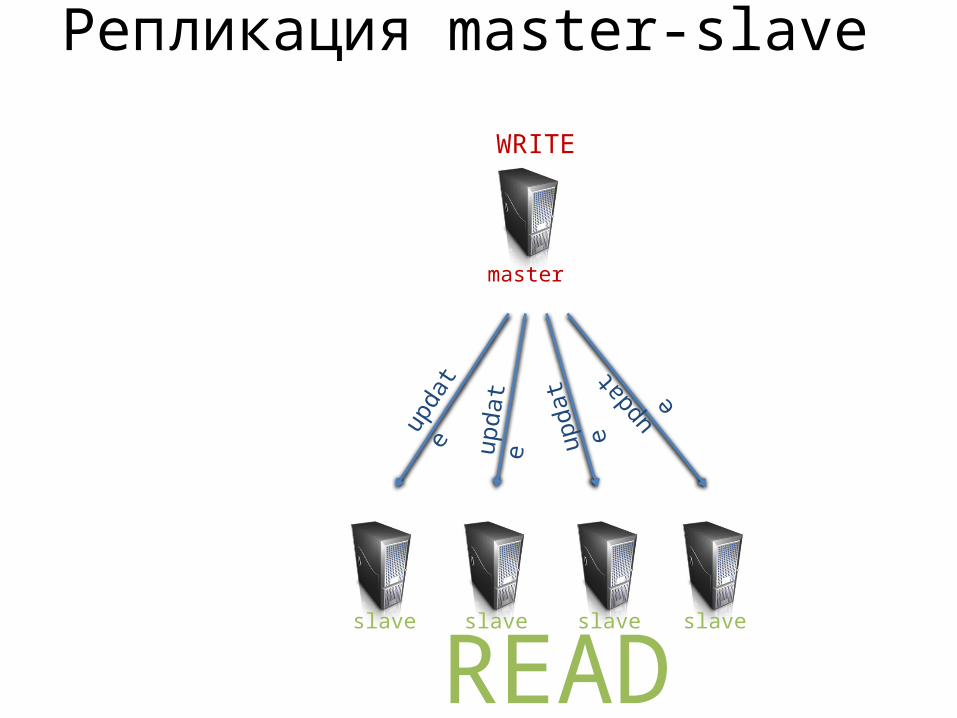
Репликация master-slave
master
slave slave slave slave
READ
WRITE
upda
te
upda
te
upda
te
update
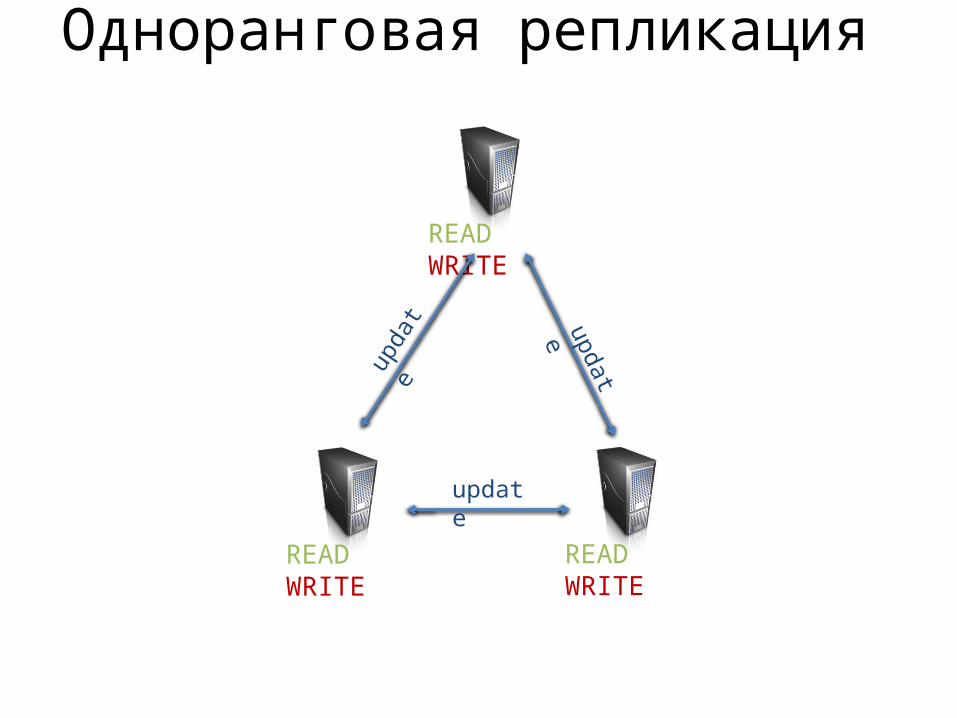
Одноранговая репликация
READ WRITE
upda
te
READ WRITE READ WRITE
update
update

Документная БДДокумент
{_Id:1, Name:”Иванов”,Age:20}
{_Id:2, Name:”Петров”,Age:25}
{_Id:3, Name:”Сидоров”,Age:40}
Customers
Документ
{_Id:1, CustomerId:1,Date:”2014-06-16”,OrderLines:[{Name:”футболка”,Price:500,Count:1},
{Name:”шорты”,Price:600,Count:1}]}
{_Id:2, CustomerId:1,Date:”2014-06-17”,OrderLines:[{Name:”футболка”,Price:500,Count:2},
{Name:”шорты”,Price:600,Count:1}]}
{_Id:3, CustomerId:2,Date:”2014-06-18”,OrderLines:[{Name:”футболка”,Price:500,Count:3}]}
Orders
• Запросы с условиями на поля документов, индексирование полей

MapReduce в NoSQL
Документ
{_Id:1, CustomerId:1,Date:”2014-06-16”,OrderLines:
[{Name:”футболка”,Price:500,Count:1},{Name:”шорты”,Price:600,Count:1}]}
{_Id:2, CustomerId:1,Date:”2014-06-17”,OrderLines:
[{Name:”футболка”,Price:500,Count:2},{Name:”шорты”,Price:600,Count:1}]}
{_Id:3, CustomerId:2,Date:”2014-06-18”,OrderLines:
[{Name:”футболка”,Price:500,Count:3}]}
…
Orders
Найти среднее число каждого товара в заказах
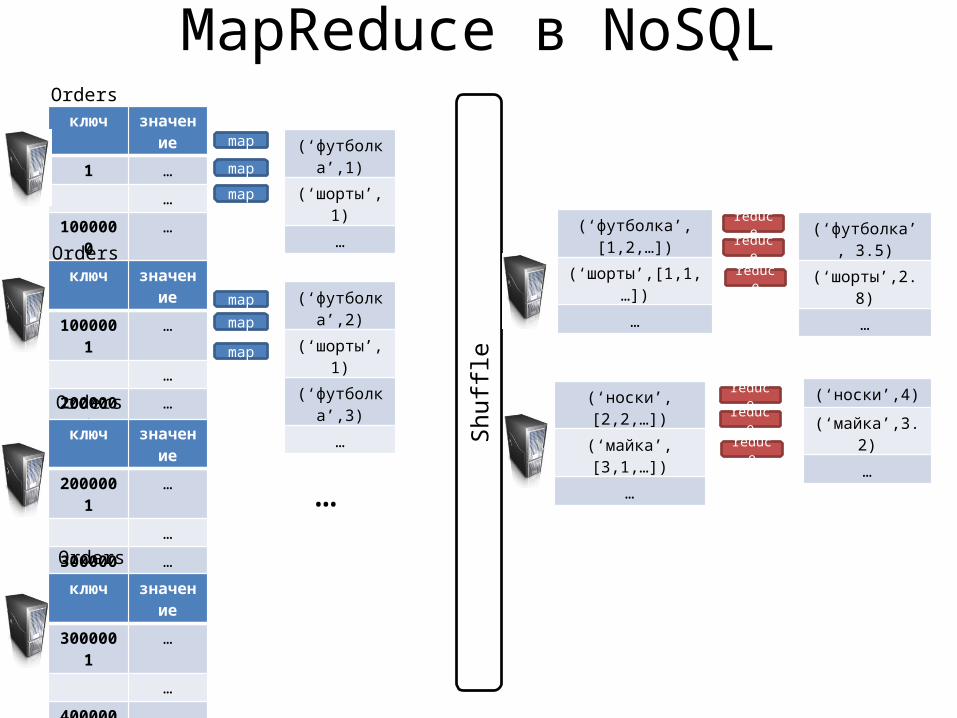
MapReduce в NoSQLключ значение
1 …
…
1000000 …
ключ значение
1000001 …
…
2000000 …
ключ значение
2000001 …
…
3000000 …
ключ значение
3000001 …
…
4000000 …
Orders
Orders
Orders
Orders
(‘футболка’,1)
(‘шорты’,1)
…
(‘футболка’,2)
(‘шорты’,1)
(‘футболка’,3)
…
…
map
map
map
map
map
map
(‘футболка’,[1,2,…])
(‘шорты’,[1,1,…])
…
(‘носки’,[2,2,…])
(‘майка’,[3,1,…])
…
Shuffl
e
reduce
reduce
reduce
reduce
reduce
reduce
(‘футболка’, 3.5)
(‘шорты’,2.8)
…
(‘носки’,4)
(‘майка’,3.2)
…

NoSQL
• Масштабируемость на кластере• Отсутствие схемы данных
(неструктурированность данных)• Концепция агрегатов• Open-source• Уход от SQL• Уход от транзакционности

Перспективы развития
• Hadoop HDFS + Spark • Развитие платформ и библиотек data mining
для big data

С чего начать?Готовые виртуальные машины, user-friendly инсталляция и управление кластером (например, для развертывания на школьном кластере):
Trial-лицензии, доступ для research и обучения big data:
Литература:
Data mining keywords: интеллектуальный анализ данных, ассоциативные правила, кластеризация K-means, метод Байеса, TF-IDF, text mining
www.basegroup.ru(статьи)






























