Embed Size (px)
Citation preview

Артем Груздев
Прогнозное моделирование в IBM SPSS Statistics и R
Метод деревьев решений
Москва, 2017

УДК 519.7:004.9IBMSPSSStatisticsББК 21.18с
Г90
ГруздевА.В.Г90 Прогнозное моделирование в IBM SPSS Statistics и R: Метод деревьев реше-
ний. – М.: ДМК Пресс, 2017. – 278 с.: ил.
ISBN978-5-97060-456-4
Данная книга представляет собой практическое руководство по применению метода деревьев решений для задач сегментации, классификации и прогнозирования. Каждый раздел книги сопровождается практическим примером. Кроме того, книга содержит про-граммный код SPSS Syntax и R, позволяющий полностью автоматизировать процесс по-строения прогнозных моделей.
Издание будет интересно маркетологам, риск-аналитикам и другим специалистам, за-нимающимся разработкой и внедрением прогнозных моделей.
УДК 519.7:004.9IBM SPSS StatisticsББК 21.18с
Все права защищены. Любая часть этой книги не может быть воспроизведена в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав.
Материал, изложенный в данной книге, многократно проверен. Но поскольку вероятность технических ошибок все равно существует, издательство не может гарантировать абсолютную точ-ность и правильность приводимых сведений. В связи с этим издательство не несет ответственности за возможные ошибки, связанные с
использованием книги.
© Груздев А. В., 2016 ISBN 978-5-97060-456-4 © Оформление, издание, ДМК Пресс, 2017

Содержание
Предисловие ......................................................................7
Глава 1. Введение в метод деревьев решений ..........................91.1. Введение в методологию деревьев решений ....................................................................... 91.2. Преимущества и недостатки деревьев решений ..............................................................111.3. Задачи, выполняемые с помощью деревьев решений ...................................................12Вопросы к главе 1 ...............................................................................................................................14
Часть I. ПОСТРОЕНИЕ ДЕРЕВЬЕВ РЕШЕНИЙ В IBM SPSS STATISTICS ....................................................... 16
Глава 2. Основы прогнозного моделирования с помощью деревьев решений CHAID .................................................... 172.1. Запуск процедуры Деревья классификации.....................................................................172.2. Четыре метода деревьев решений .........................................................................................192.3. Шкалы переменных ...................................................................................................................212.4. Определение необходимого размера выборки .................................................................232.5. Знакомство с методом CHAID ..............................................................................................25
2.5.1. Описание алгоритма .........................................................................................................252.5.2. Немного о тесте хи-квадрат ............................................................................................282.5.3. Немного об F-тесте ............................................................................................................282.5.4. Способы объединения категорий предикторов .......................................................292.5.5. Поправка Бонферрони .....................................................................................................302.5.6. Иллюстрация работы CHAID на конкретном примере .......................................30
2.6. Построение дерева классификации CHAID .....................................................................352.6.1. Настройка процедуры Деревья классификации .....................................................352.6.2. Работа с отчетом о построении модели ......................................................................36
2.7. Работа с прогнозами модели ..................................................................................................432.7.1. Получение результатов классификации ...................................................................432.7.2. Сохранение прогнозов модели в файле данных ......................................................442.7.3. Самостоятельное построение таблицы классификации и изменение порогового значения вероятности ..........................................................................................48
2.8. Анализ ROC-кривой .................................................................................................................572.8.1. Терминология анализа ROC-кривой ..........................................................................572.8.2. Оценка дискриминирующей способности модели и выбор порогового значения с помощью ROC-кривой ..................................................................61
2.9. Проверка модели ........................................................................................................................672.9.1. Методы проверки модели в процедуре Деревья классификации .....................672.9.2. Работа с результатами проверки модели ...................................................................70
2.10. Дополнительные настройки вывода результатов .........................................................842.10.1. Настройки вывода дерева .............................................................................................842.10.2. Построение таблицы дерева .........................................................................................85

4 Содержание
2.10.3. Настройки вывода статистик ......................................................................................862.10.4. Построение таблиц выигрышей для узлов и процентилей ...............................882.10.5. Настройки вывода графиков .......................................................................................892.10.6. Построение графиков выигрышей, индексов и откликов .................................912.10.7. Настройки вывода правил классификации ............................................................932.10.8. Применение правил классификации к новому набору данных .............................................................................................................95
2.11. Построение дерева регрессии CHAID ........................................................................... 1042.12. Использование принудительной переменной расщепления ................................. 108Вопросы к главе 2 ............................................................................................................................ 109
Глава 3. Продвинутое моделирование с помощью деревьев решений CHAID .................................................. 1123.1. Построение деревьев CHAID с измененными критериями ..................................... 112
3.1.1. Настройка правил остановки ...................................................................................... 1123.1.2. Построение деревьев CHAID с измененными правилами остановки .......... 1133.1.3. Настройка статистических тестов для разбиения узлов и объединения категорий предикторов .............................................................................. 1193.1.4. Построение дерева CHAID с измененными статистическими тестами ...... 1203.1.5. Настройка обработки количественных предикторов ......................................... 1213.1.6. Построение дерева CHAID с измененным числом интервалов для количественных предикторов ....................................................................................... 122
3.2. Метод Исчерпывающий CHAID ....................................................................................... 1233.3. Обзор параметров деревьев решений ............................................................................... 1243.4. Работа с пропусками в методе CHAID ............................................................................ 126
3.4.1. Настройка обработки пропущенных значений .................................................... 1263.4.2. Построение дерева CHAID на основе данных, содержащих пропуски .............................................................................................................. 129
3.5. Работа со стоимостями ошибочной классификации в методе CHAID ................ 1303.5.1. Настройка стоимостей ошибочной классификации ........................................... 1303.5.2. Построение дерева CHAID с измененными стоимостями ошибочной классификации ........................................................................................................................... 133
3.6. Работа с прибылями в методе CHAID ............................................................................. 1363.6.1. Настройка прибылей ..................................................................................................... 1363.6.2. Построение дерева CHAID с заданными значениями прибыли .................... 137
3.7. Работа со значениями ............................................................................................................ 1413.8. Применение метода CHAID для биннинга переменных (на примере конкурсной задачи ОТП Банка) ................................................................................................ 144
3.8.1. Преимущества и недостатки биннинга ................................................................... 1443.8.2. Предварительная подготовка данных ...................................................................... 1463.8.3. Определение важности переменных с помощью случайного леса ................ 1623.8.4. Анализ мультиколлинеарности.................................................................................. 1653.8.5. Выполнение автоматического биннинга переменных ....................................... 1673.8.6. Построение моделей логистической регрессии на основе исходных предикторов и предикторов, категоризированных с помощью CHAID ................. 169

Содержание 5
3.8.7. Выполнение биннинга переменных с помощью процедуры Оптимальная категоризация .................................................................................................. 1723.8.8. Построение модели логистической регрессии на основе оптимально категоризированных предикторов .............................................................. 1753.8.9. Преобразование количественных переменных для максимизации нормальности .............................................................................................................................. 1763.8.10. Построение модели логистической регрессии с использованием CHAID и преобразования корня третьей степени ......................................................... 180
3.9. Построение ансамбля логистической регрессии и дерева CHAID ........................ 181Вопросы к главе 3 ............................................................................................................................ 186
Глава 4. Построение деревьев решений CRT и QUEST ............ 1884.1. Знакомство с методом CRT ................................................................................................. 188
4.1.1. Описание алгоритма ...................................................................................................... 1894.1.2. Неоднородность ............................................................................................................... 1904.1.3. Внутриузловая дисперсия ........................................................................................... 1914.1.4. Метод отсечения ветвей на основе меры стоимости-сложности ................... 1924.1.5. Обработка пропущенных значений .......................................................................... 1934.1.6. Иллюстрация работы CRT на конкретном примере .......................................... 193
4.2. Построение дерева классификации CRT ........................................................................ 1954.3. Построение дерева CRT с измененными критериями ............................................... 199
4.3.1. Настройка мер неоднородности для отбора предикторов и расщепления узлов ................................................................................................................ 1994.3.2. Настройка отсечения ветвей ....................................................................................... 2004.3.3. Построение дерева CRT с последующим отсечением ветвей .......................... 2014.3.4. Настройка суррогатов для обработки пропущенных значений ..................... 2034.3.5. Построение дерева CRT на основе данных, содержащих пропуски ............. 203
4.4. Вывод важности предикторов ............................................................................................. 2064.5. Работа с априорными вероятностями в методе CRT .................................................. 207
4.5.1. Настройка априорных вероятностей ....................................................................... 2074.5.2. Построение дерева CRT с измененными априорными вероятностями ....... 208
4.6. Знакомство с методом QUEST ........................................................................................... 2104.6.1. Описание алгоритма ...................................................................................................... 2114.6.2. Метод отсечения ветвей на основе меры стоимости-сложности ................... 213
4.7. Построение дерева классификации QUEST ................................................................. 2134.8. Сравнение метода QUEST с другими методами деревьев решений ..................... 2164.9. Построение дерева QUEST с измененными критериями ......................................... 216
4.9.1. Настройка статистических тестов для отбора предикторов ............................ 2174.9.2. Построение дерева QUEST с последующим отсечением ветвей ................... 217
Вопросы к главе 4 ............................................................................................................................ 219
Глава 5. Редактор дерева .................................................. 2205.1. Просмотр диаграммы дерева в Редакторе ...................................................................... 2205.2. Просмотр содержимого узла в Редакторе ....................................................................... 2215.3. Настройка внешнего вида диаграммы дерева в Редакторе ....................................... 222

6 Содержание
5.4. Изменение ориентации диаграммы дерева в Редакторе............................................ 2235.5. Настройка содержимого узла в Редакторе ..................................................................... 2235.6. Отбор наблюдений в Редакторе ......................................................................................... 2245.7. Иллюстрация работы в Редакторе дерева на конкретном примере ...................... 225
Часть II. ПОСТРОЕНИЕ ДЕРЕВЬЕВ РЕШЕНИЙ В R ................... 229
Глава 6. Построение деревьев решений CHAID с помощью пакета R CHAID ................................................................ 2306.1. Построение и интерпретация дерева классификации CHAID ............................... 2306.2. Работа с прогнозами модели ............................................................................................... 2346.3. Сохранение результатов прогноза ..................................................................................... 2396.4. Применение модели к новым данным ............................................................................. 2396.5. Проверка модели ..................................................................................................................... 2416.6. Биннинг переменных ............................................................................................................. 242
6.6.1. Биннинг в пакете rattle ................................................................................................ 2426.6.2. Биннинг в пакете smbinning .......................................................................................... 244
Вопросы к главе 6 ............................................................................................................................ 252
Глава 7. Построение деревьев решений CRT с помощью пакета R rpart .................................................................. 2537.1. Метод отсечения ветвей на основе стоимости-сложности с кросс-проверкой ........................................................................................................................... 2537.2. Построение и интерпретация дерева классификации CRT ..................................... 2547.3. Прунинг дерева CRT .............................................................................................................. 2627.4. Работа с прогнозами модели ............................................................................................... 2647.5. Сохранение результатов прогноза ..................................................................................... 2677.6. Применение модели к новым данным ............................................................................. 2687.7. Построение и интерпретация дерева регрессии CRT ................................................. 269Вопросы к главе 7 ............................................................................................................................ 273
Ключи к вопросам ............................................................ 275
Библиографический список .............................................. 276

Предисловие
Данная книга открывает серию пособий, посвященных практическому применению методов машинного обучения на базе популярных статистических пакетов IBM SPSS Statistics и R. В первом выпуске освещается метод деревьев решений. Деревья решений – это эффективный метод машинного обучения, использующийся в прог-нозном моделировании. Кроме того, при решении задач бинарной классифика-ции он нередко дополняет метод логистической регрессии. Аналитики кредитного бюро TransUnion для построения скоринговых моделей используют логистическую регрессию, а для отбора переменных в модель логистической регрессии (рассмат-риваются сотни переменных) – деревья решений CRT или случайный лес. Наша компания при построении прогнозных моделей на основе логистической регрессии использует метод деревьев решений, чтобы сформировать новые переменные для лучшего прогнозирования дефолта. Аналитики Citibank N.A. разбивают популяцию заемщиков на сегменты, применяя дерево решений, а затем в каждом сегменте стро-ят модели доходности с помощью линейной регрессии или модели риска с помощью логистической регрессии.
Кратко о самой книге. В ней я детально расскажу о том, как строить деревья реше-ний, интерпретировать их, оценивать дискриминирующую способность полученных моделей, улучшать их, сохранять результаты и применять правила классификации/прогноза, полученные с помощью дерева, к новым данным. Кроме того, я расскажу о том, как с помощью дерева решений улучшить модель логистической регрессии. Глава 1 кратко знакомит с терминологией метода деревьев решений, в ней расска-зывается о преимуществах и недостатках деревьев, задачах, которые можно выпол-нить с их помощью. Главы 2–4 посвящены построению деревьев решений в IBM SPSS Statistics 24.0. В главе 2 освещается CHAID – один из самых популярных ме-тодов деревьев решений. В главе 3 я покажу, как можно менять параметры дерева CHAID, влияя на результаты классификации. Здесь же я расскажу о том, как можно выполнить биннинг переменных для включения в модель логистической регрессии, использовав дерево решений CHAID и случайный лес. Для иллюстрации выбрана конкурсная задача предсказания отклика ОТП Банка. Кроме того, на данном примере я покажу, как выполняется предварительная подготовка данных и решаются вопро-сы, связанные с автоматизацией построения моделей (для этого будет использован командный синтаксис SPSS). Код, автоматизирующий процесс построения прогноз-ных моделей, вы можете в дальнейшем использовать в собственных проектах. В этой же главе будет рассмотрена разработка ансамбля модели логистической регрессии и дерева CHAID. Глава 4 посвящена методам деревьев CRT и QUEST. В главе 5 рас-сказывается о Редакторе дерева. В главах 6 и 7 я подробно рассмотрю процесс по-строения и интерпретации деревьев решений в пакетах R CHAID и rpart. Всю не-обходимую информацию об IBM SPSS Statistics вы найдете на официальном сайте компании IBM. Информацию о программном пакете R можно найти на официальной странице проекта R. Наборы данных и примеры программного кода, использующие в книге, находятся в папке Trees. Эту папку можно скачать в заархивированном виде

8 Предисловие
на сайте издательства ДМК Пресс и распаковать в корень диска. Все вопросы, воз-никшие в ходе чтения книги, можно направлять по адресу [email protected].
Освещаемые темы будут интересны маркетологам, риск-аналитикам и другим спе-циалистам, занимающимся разработкой и внедрением прогнозных моделей.
В заключение я хочу поблагодарить моих взыскательных клиентов и коллег из TransUnion, DBS Bank и Citibank N.A., в особенности Дмитрия Майорова (Citibank N. A., ArrowModel) и Барри Уилка (Google) за их ценные советы и замечания, выска-занные в ходе подготовки книги.
Артем Груздев,генеральный директор ИЦ «Гевисста»

Глава 1Введение в метод
деревьев решений
1.1. Введение в методологию деревьев решенийКак и регрессионный анализ, деревья решений являются методом изучения статис-тической взаимосвязи между одной зависимой переменной и несколькими незави-симыми (предикторными) переменными. Базовое отличие метода деревьев решений от регрессионного анализа заключается в том, что взаимосвязь между значением за-висимой переменной и значениями независимых переменных представлена не в виде общего прогнозного уравнения, а в виде древовидной структуры, которую получают с помощью иерархической сегментации данных.
Берется весь обучающий набор данных, называемый корневымузлом, и разбива-ется на два или более узлов(сегментов) так, чтобы наблюдения, попавшие в разные узлы, максимально отличались друг от друга по зависимой переменной (например, выделяем два узла с наибольшим и наименьшим процентами «плохих» заемщиков). В роли правилразбиения, максимизирующих эти различия, выступают значения не-зависимых переменных (пол, возраст, доход и др.). Качество разбиения оценивается с помощью статистических критериев. Правила и статистики отмечаются на ветвях – линиях, которые соединяют разбиваемый узел с узлами, полученными в результате разбиения. Для каждого узла вычисляются вероятностив видепроцентныхдолей категорий зависимой переменной (если зависимая переменная является категори-альной) или средние значения зависимой переменной (если зависимая переменная является количественной). В результате выносится решение – спрогнозированная категория зависимой переменной (если зависимая переменная является категори-альной) или спрогнозированное среднее значение зависимой переменной (если за-висимая переменная является количественной).
Аналогичным образом каждый узел, получившийся в результате разбиения кор-невого узла, разбивается дальше на узлы, т. е. узлы внутри узла, и т. д. Этот процесс продолжается до тех пор, пока есть возможность разбиения на узлы. Данный процесс сегментации называется рекурсивнымразделением. Получившаяся иерархическая структура, характеризующая взаимосвязь между значением зависимой переменной и значениями независимых переменных, называется деревом.
Иногда для обозначения разбиваемого узла применяется термин родительскийузел. Новые узлы, получившиеся в результате разбиения, называются дочерними

10 Введение в метод деревьев решений
узлами (или узлами-потомками). Когда впоследствии дочерний узел разбивается сам, он становится родительским узлом. Окончательные узлы, которые в дальней-шем не разбиваются, называются терминальнымиузлами дерева. Их еще называют листьями, потому что в них рост дерева останавливается. Лист представляет собой наилучшее окончательное решение, выдаваемое деревом. Здесь мы определяем груп-пы клиентов, обладающие желаемыми характеристиками (например, тех, кто погасит кредит или откликнется на наше маркетинговое предложение).
Обратите внимание, если вы прогнозируете вероятность значения категориальной зависимой переменной по соответствующим значениям предикторов, дерево реше-ний называют деревомклассификации(рис. 1.1). Например, дерево классификации строится для вычисления вероятности дефолта у заемщика (на основе спрогнозиро-ванной вероятности мы относим его к «плохому» или «хорошему» заемщику). Если дерево решений используется для того, чтобы спрогнозировать среднее значение ко-личественной зависимой переменной по соответствующим значениям предикторов, его называют деревом регрессии (рис. 1.2). Например, дерево регрессии строится, чтобы вычислить средний размер вклада у клиента.
Рис. 1.1 Пример дерева классификации

Преимущества и недостатки деревьев решений 11
Рис. 1.2 Пример дерева регрессии
1.2. Преимущества и недостатки деревьев решенийМетод деревьев решений обладает рядом преимуществ. Главное из них – это нагляд-ность представления результатов (в виде иерархической структуры дерева). Деревья решений позволяют работать с большим числом независимых переменных. На вход можно подавать все существующие переменные, алгоритм сам выберет наиболее зна-чимые среди них, и только они будут использованы для построения дерева (авто-матический отбор предикторов). Деревья решений способны выявлять нелинейные взаимосвязи, сложные взаимодействия, которые нелегко обнаружить в рамках стан-дартных статистических моделей. Они могут работать с любым типом переменной, таким образом, зависимые и незавиcимые переменные могут быть количественными, порядковыми и номинальными. Деревья решений устойчивы к выбросам, посколь-ку разбиения основаны на количестве наблюдений внутри диапазонов значений, выбранных для расщепления, а не на абсолютных значениях. Перед построением модели необязательно импутировать пропущенные значения, поскольку деревья ис-пользуют собственные процедуры обработки пропусков. Требования, выдвигаемые методом деревьев решений к распределению переменных, не являются строгими.
К недостаткам метода деревьев решений можно отнести отсутствие простого обще-го прогнозного уравнения, выражающего модель (в отличие от регрессионного ана-лиза). Другой недостаток заключается в том, что некоторым методам деревьев реше-ний (например, CRT) свойственно переобучение. Речь идет о ситуации, когда деревья получаются слишком детализированными, имеют много узлов и ветвей, сложны для интерпретации, что требует специальной процедуры отсечения ветвей (она называ-ется прунинг). Наконец, для методов одиночных деревьев характерна проблема мно-жественных сравнений. Перед расщеплением узла дерево сравнивает различные ва-рианты разбиения, число этих вариантов зависит от числа уровней предикторов, как правило, происходит смещение выбора в пользу переменных, у которых большее ко-

12 Введение в метод деревьев решений
личество уровней. Все это обусловливает определенную нестабильность результатов. Небольшие изменения в наборе данных могут приводить к построению совершенно другого дерева. В силу иерархичности дерева изменения в верхних узлах ведут к из-менениям во всех узлах, расположенных ниже. Отмечу, что в большей степени вы-шесказанное относится к методу CRT. Чтобы достигнуть удовлетворительной прог-ностической способности CRT, один из его разработчиков – Лео Брейман – пришел к идее случайного леса, когда из обучающего набора извлекаются случайные выборки (того же объема, что и исходный обучающий набор) с возвращением, по каждой стро-ится дерево с использованием случайно отобранных предикторов, и затем результа-ты, полученные по каждому дереву, усредняются. Однако при таком подходе теряется главное преимущество деревьев решений – простота интерпретации.
1.3. Задачи, выполняемые с помощью деревьев решенийПрежде всего деревья решений используются в маркетинге для сегментации клиент-ской базы. Например, деревья позволяют определить, какие демографические груп-пы имеют максимальный показатель отклика. Эту информацию можно использовать, чтобы максимизировать отклик при будущей прямой рассылке.
Кроме того, деревья применяются для задач прогнозирования и классифика-ции, когда моделируется взаимосвязь между зависимой переменной и предикто-ром. С этой точки зрения деревья решений сравнивают с логистической регрессией и линейной регрессией. Деревья решений более эффективны, по сравнению с ре-грессионным анализом, в тех случаях, когда взаимосвязи между предикторами и за-висимой переменной являются нелинейными, переменные имеют несимметричные распределения, наблюдаются большое количество коррелирующих между собой пе-ременных, взаимодействие высоких порядков, аномальные значения. Если же пред-посылки регрессионного анализа выполняются, то логистическая регрессия (когда зависимая переменная является категориальной) или линейная регрессия (когда за-висимая переменная является количественной) может дать лучший результат. Это обусловлено тем, что деревья пытаются описать линейную связь между перемен-ными путем многократных разбиений по предикторам. CHAID делает это за счет расщепления сразу на несколько категорий, CRT и QUEST пытаются уловить эту связь посредством серии бинарных делений, и это может быть менее эффективно, по сравнению с подбором параметров в регрессионном анализе. Однако проблема заключается в том, что данные обычно содержат как линейные, так и нелинейные зависимости, переменные с симметричными и асимметричными распределениями. Поэтому опытный моделер может построить ансамбль логистической регрессии и дерева решений (при условии, что оно использует строгие статистические крите-рии для отбора предикторов разбиения узлов), чтобы скомпенсировать недостатки обоих методов. Ансамбли дерева решений CHAID и логистической регрессии ис-пользуются в моделях оттока в телекоме, где данные часто характеризуются пере-менными с U-образным распределением.
В банковском скоринге деревья решений используются как вспомогательный ин-струмент при разработке модели логистической регрессии. Приведем конкретные примеры такого применения дерева.

Задачи, выполняемые с помощью деревьев решений 13
В кредитном скоринге использование нескольких скоринговых карт для одно-го портфеля обеспечивает лучшее дифференцирование риска, чем использование одной скоринговой карты. Это характерно, когда нам приходится работать с раз-нородной аудиторией, состоящей из различных групп, и одна и та же скоринговая карта не может работать достаточно эффективно для всех. Например, в скоринге кредитных карточек выделяют сегменты «активные клиенты» и «неактивные кли-енты», «клиенты в просрочке» и «клиенты, не имеющие просрочек». Переменные в таких сегментах будут сильно отличаться. Например, для активных кредитных карт утилизация будет сильной переменной, а для неактивных – слабой. И наобо-рот, может оказаться, что время неактивности для активных клиентов равно 0, а для неактивных клиентов время неактивности окажется сильной переменной. Для этих целей выполняют сегментацию клиентов. Первый способ сегментации – деление на группы на основе опыта и отраслевых знаний с последующей аналитической про-веркой. Второй способ – это сегментация с помощью статистических методов типа кластерного анализа или деревьев решений. При этом, по сравнению с кластерным анализом, деревья решений обладают преимуществом: они формулируют четкие правила выделения сегментов, а сами выделенные сегменты статистически значи-мо отличаются между собой по зависимой переменной. В дальнейшем для каждого из сегментов можно построить собственную модель логистической регрессии, раз-работать скоринговую карту и сформулировать кредитные правила. В Citibank N.A. является стандартной практикой делать дерево с двумя-тремя уровнями и в каж-дом узле подгонять свою модель логистической регрессии. В основе скорингового балла FICO также лежит сегментация на основе деревьев решений. Об эффектив-ности использования сегментации в кредитном скоринге пишет в своей книге «Ско-ринговые карты для оценки кредитных рисков» известный эксперт по управлению рисками Наим Сиддики1, а также один из разработчиков алгоритмов скоринга ком-пании FICO Брюс Ходли2.
С помощью деревьев решений из большого числа предикторов можно выбрать пе-ременные, полезные для построения модели логистической регрессии. Например, из 100 переменных дерево включило в модель 25 переменных, таким образом, у нас по-является информация о том, какие переменные наверняка можно включить в модель логистической регрессии. Метод деревьев решений CRT позволяет вычислить важ-ность переменных, использованных в модели дерева. Мы уже можем ранжировать переменные по степени полезности.
Деревья решений можно использовать для биннинга – перегруппировки кате-гориального предиктора или дискретизации количественного предиктора с целью лучшего описания взаимосвязи с зависимой переменной. Например, при построе-нии модели логистической регрессии часто обнаруживается, что взаимосвязи между количественным предиктором и интересующим событием являются нелинейными. Уравнение логистической регрессии, несмотря на нелинейное преобразование свое-го выходного значения (логит-преобразование), все равно моделирует линейные зависимости между предикторами и зависимой переменной. Возьмем пример нели-нейной зависимости между стажем работы в банке и внутренним мошенничеством.
1 Наим Сиддики. Скоринговые карты для оценки кредитных рисков. М.: Манн, Иванов и Фа-бер, 2014.
2 Breiman L. (2001). Statistical modeling: The two cultures.

14 Введение в метод деревьев решений
Допустим, рассчитанный регрессионный коэффициент в уравнении логистической регрессии получился отрицательным. Это значит, что вероятность совершения вну-треннего мошенничества с увеличением стажа работы уменьшается. Однако, вы-полнив разбивку переменной с помощью дерева CHAID на категории до 12 меся-цев, от 12 до 36 месяцев, от 36 до 60 месяцев и больше 60 месяцев, стало видно, что зависимость между стажем и внутренним мошенничеством нелинейная. Первая (до 12 месяцев) и последняя (больше 60 месяцев) категории склонны к внут реннему мошенничеству, а промежуточные сегменты, наоборот, не склонны к внутреннему мошенничеству. После правильной разбивки переменной, проведенной с помощью дерева, связь между предиктором и зависимой переменной становится больше по-хожа на реальную.
Строя модель логистической регрессии, нередко приходится работать с пре-дикторами, у которых большое количество категорий. Как правило, речь идет о географических переменных (регион, область регистрации, область фактиче-ского пребывания заемщика, область торговой точки, где клиент брал кредит) и переменных, фиксирующих профессию или сферу занятости заемщика. Если включить такие переменные в модель логистической регрессии, то переменная с k категориями будет преобразована в k – 1 дамми-переменных, которые станут в модели логистической регрессии статистически незначимыми. Только пред-ставьте, сколько будет дамми-переменных, если у вас 4 географические пере-менные с 89 категориями. Исключение таких переменных из анализа также не-рационально, поскольку они могут дать ценную информацию. Поэтому можно выполнить биннинг с целью укрупнения категорий, а можно построить по этим четырем переменным дерево решений. В результате дерево укрупнит категории переменных и скомбинирует переменные так, чтобы полученные комбинации ха-рактеристик максимизировали различия по зависимой переменной. Такую пере-менную, где категориями являются терминальные узлы дерева, можно включить в модель логистической регрессии.
Вопросы к главе 11. Терминальный узел – это:
a) самый верхний узел, представляющий всю выборку наблюдений;b) узел, в котором рост дерева останавливается;c) любой расщепляемый узел;d) новый узел, появившийся в результате расщепления узла.
2. Деревья классификации строятся:a) для количественной зависимой переменной;b) для категориальной зависимой переменной;c) для порядковой зависимой переменной;d) для номинальной зависимой переменной;e) для бинарной зависимой переменной;f) для любой зависимой переменной.
3. Деревья регрессии строятся:a) для количественной зависимой переменной;b) для категориальной зависимой переменной;

Вопросы к главе 1 15
c) для номинальной зависимой переменной;d) для бинарной зависимой переменной;e) для любой зависимой переменной.
4. В качестве правил разбиения используются:a) значения независимых переменных;b) значения зависимых переменных;c) значения категориальных переменных;d) значения количественных переменных.

ЧАСТЬ IПОСТРОЕНИЕ
ДЕРЕВЬЕВ РЕШЕНИЙ В IBM SPSS STATISTICS

Глава 2Основы прогнозного
моделирования с помощью деревьев решений CHAID
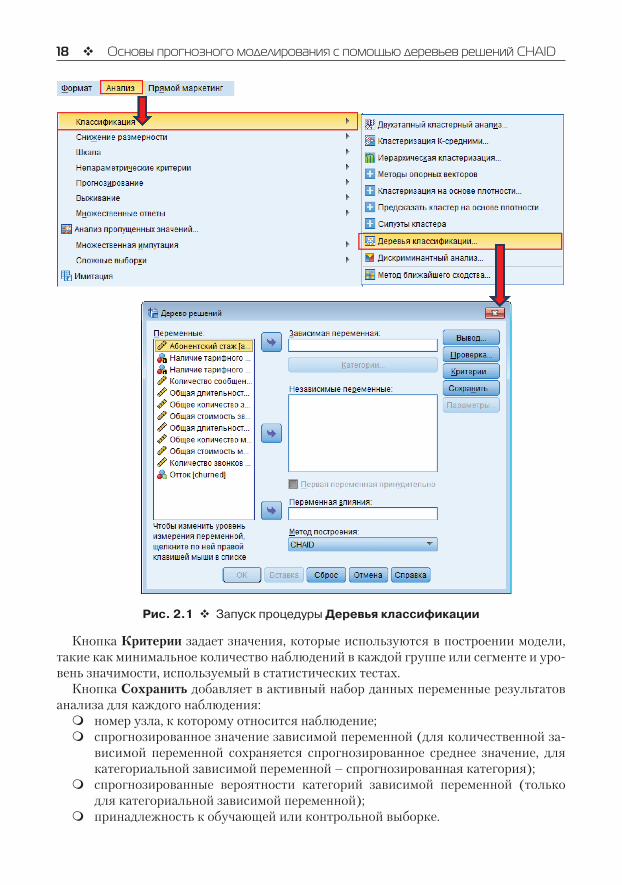
2.1. Запуск процедуры Деревья классификацииДерево решений в IBM SPSS Statistics можно построить с помощью процедуры Де-ревьяклассификации. Для вызова процедуры Деревьяклассификациинеобходимо в меню Анализ выбрать Классификация…Деревьяклассификации.
Вы оказываетесь в главном диалоговом окне Дереворешений(рис. 2.1).В поле Зависимаяпеременнаянеобходимо перенести одну зависимую переменную. Кнопка Категории позволяет включить/исключить из анализа категории зависимой пере-менной или задать их как целевые. Указание одной или нескольких категорий как целевых не влияет на модель дерева, оценки рисков и результаты классификации. В поле Независимыепеременныенеобходимоперенести одну или несколько неза-висимых переменных.
Параметр Перваяпеременнаяпринудительно позволяет задать первую перемен-ную из списка независимых переменных как первую переменную расщепления.
Поле Переменнаявлиянияпозволяет указать переменную, которая будет опреде-лять, насколько большое влияние данное наблюдение оказывает на процесс построе-ния дерева. Наблюдения с более низкими значениями переменной влияния будут иметь меньшее влияние, а наблюдения с более высокими значениями – большее влия-ние. При этом значения переменной влияния должны быть положительными.
Выпадающий список Методпостроения позволяет выбрать метод построения де-рева.
В правой части окна находятся пять кнопок, используемых для настройки проце-дуры Деревьяклассификации.
КнопкаВывод задает появление дерева решений и генерацию таблиц. Можно запро-сить дополнительную статистическую информацию о модели, графическую интерпре-тацию соответствующих статистик, также можно запросить генерацию правил клас-сификации для модели в SPSS синтаксисе, в SQL или в обычном текстовом формате.
КнопкаПроверкапозволяет построить модель, отобрав только часть данных, и за-тем посмотреть, как она работает на оставшейся части, которая была исключена при построении модели.
18 Основы прогнозного моделирования с помощью деревьев решений CHAID
Рис. 2.1 Запуск процедуры Деревья классификации
КнопкаКритериизадает значения, которые используются в построении модели, такие как минимальное количество наблюдений в каждой группе или сегменте и уро-вень значимости, используемый в статистических тестах.
КнопкаСохранитьдобавляет в активный набор данных переменные результатов анализа для каждого наблюдения:
� номер узла, к которому относится наблюдение;� спрогнозированное значение зависимой переменной (для количественной за-
висимой переменной сохраняется спрогнозированное среднее значение, длякатегориальной зависимой переменной – спрогнозированная категория);
� спрогнозированные вероятности категорий зависимой переменной (толькодля категориальной зависимой переменной);
� принадлежность к обучающей или контрольной выборке.

Четыре метода деревьев решений 19
КнопкаПараметры позволяет задать стоимости ошибочной классификации, апри-орные вероятности, прибыль и затраты по результатам классификации.
2.2. Четыре метода деревьев решенийВыпадающий список Методпостроения в диалоговом окне Дереворешений (рис. 2.2) позволяет вам выбрать четыре метода деревьев решений: CHAID(используется по умолчанию), Исчерпывающий CHAID, CRT, QUEST. CHAID (расшифровыва-ется как Chi-square Automatic Interaction Detector – Автоматический обнаружитель взаимодействий) используется процедурой Деревьяклассификации по умолчанию. Он был разработан Гордоном Каасом в 1980 году и представляет собой метод на основе дерева решений, который исследует взаимосвязь между предикторами и зависимой переменной с помощью статистических тестов.
Рис. 2.2 Выпадающий список Метод построения
Каждый раз для разбиения узла выбирается предиктор, сильнее всего взаимодей-ствующий с зависимой переменной. При этом категории каждого предиктора объединя-ются, если они не имеют между собой статистически значимых отличий по отношению к зависимой переменной, остальные категории рассматриваются как отдельные. Для количественной зависимой переменной используется F-тест, для категориальной зави-симой переменной – хи-квадрат Пирсона или хи-квадрат отношения правдоподобия.
Зависимая переменная и предикторы могут быть измерены в номинальной, поряд-ковой и количественной шкале, при этом количественные предикторы преобразо-вываются в порядковые переменные. CHAID позволяет осуществлять многомерные расщепления узлов. Каждый узел при разбиении может иметь более 2 потомков, по-этому CHAID имеет тенденцию выращивать более раскидистые деревья, чем бинар-ные методы. Вместе с тем из-за жестких статистических критериев расщепления не-редко дерево CHAID получается нереалистично коротким и тривиальным («грубое» дерево), поэтому требуется тонкая настройка уровней значимости для объединения категорий и разбиения узлов. По сравнению с другими методами, CHAID характери-зуется умеренным временем вычислений.
Помимо прочего, метод CHAID обладает собственным способом обработки пропу-щенных значений. Пропуски рассматриваются как отдельная фактическая категория. В ряде случаев это имеет смысл. Например, отказ отвечать на вопрос о доходе или за-нятости может оказаться предсказательной категорией для зависимой переменной.
ИсчерпывающийCHAID является модификацией метода CHAID, предложенной Биггсом, де Виллем и Суеном в 1991 году. Он был разработан для устранения недо-статка CHAID – ограниченного набора расщеплений для предиктора.
CHAID прекращает объединение категорий, когда обнаруживает, что все оставшиеся категории статистически различаются между собой. Исчерпывающий CHAID исправ-ляет это, продолжая объединять категории предиктора до тех пор, пока не останутся

20 Основы прогнозного моделирования с помощью деревьев решений CHAID
только две суперкатегории. Таким образом, он позволяет найти наилучшее расщепле-ние для каждого предиктора и затем выбрать, какой предиктор нужно расщепить.
Исчерпывающий CHAID идентичен CHAID с точки зрения используемых зависи-мой переменной и предикторов, статистических тестов значимости взаимодействия и способа обработки пропущенных значений. Вместе с тем, поскольку объединение категорий осуществляется более тщательно, чем в методе CHAID, исчерпывающий CHAID требует большего времени вычислений. Надежность результатов исчерпы-вающего CHAID выше, чем у CHAID.
CRT (расшифровывается как Classification and Regression Tree – Деревья класси-фикации и регрессии) был разработан в 1974–1984 годах профессорами статистики Лео Брейманом (Калифорнийский университет в Беркли), Джеромом Фридманом (Стэнфордский университет), Ричардом Олшеном (Калифорнийский университет в Беркли) и Чарльзом Стоуном (Стэнфордский университет).
Для построения дерева метод CRT использует принцип уменьшения неоднород-ности в узле. Расщепление узла происходит так, чтобы узел-потомок был более одно-родным, чем его узел-родитель. В абсолютно однородном узле все наблюдения име-ют одно и то же значение целевой переменной (все объекты принадлежат к одной и той же категории целевой переменной). Такой узел еще называют «чистым».
Зависимая переменная может быть измерена в номинальной, порядковой и коли-чественной шкале. Предикторы могут быть измерены в номинальной, порядковой и количественной шкале (подробнее о типах шкал читайте в разделе 2.3 «Шкалы переменных»). CRT позволяет только одномерные расщепления узлов. Каждый узел при разбиении может иметь лишь 2 потомков. Поэтому CRT имеет тенденцию вы-ращивать высокие деревья с большим количеством уровней. Часто деревья CRT по-лучаются слишком детализированными, имеют много узлов и ветвей, сложны для интерпретации, при этом усложнение дерева не приводит к повышению прогности-ческой способности дерева (эффект переобучения). Для упрощения структуры дере-ва и устранения переобучения в методе CRT предусмотрена возможность отсечения ветвей (прунинг). Прунинг позволяет получить дерево «подходящего размера», из-бежать построения ветвистых, усложненных деревьев и при этом достичь наиболее точной оценки классификации.
Для обработки наблюдений, у которых пропущено значение в предикторе, исполь-зуются суррогаты – другие предикторы, имеющие сильную корреляцию с исходной независимой переменной. Таким образом, разбиение, задаваемое суррогатом, будет наиболее близко к разбиению, задаваемому исходным предиктором, по которому имеются пропуски. Метод CRT требует большего времени вычислений, по сравне-нию с другими методами.
QUEST (расшифровывается как Quick, Unbiased, Efficient Statistical Tree – Быстрое, несмещенное, эффективное статистическое дерево) был предложен в 1997 году про-фессорами статистики Вэй Ин Ло (Университет Висконсина-Мэдисона) и Ю Шан Ши (Национальный университет Чун Чен, Тайвань).
Метод QUEST строит дерево следующим образом: для отбора предикторов ис-пользуются статистические тесты значимости взаимодействия между зависимой переменной и предиктором, а разбиение узлов задается путем выполнения квадра-тичного дискриминантного анализа с использованием отобранного предиктора. За-висимая переменная может быть измерена только в номинальной шкале. Предикто-ры могут быть измерены в номинальной, порядковой и количественной шкале.

Шкалы переменных 21
QUEST имеет схожие с CRT характеристики: � позволяет только одномерные расщепления узлов;� каждый узел при разбиении может иметь лишь 2 потомков;� есть возможность отсечения ветвей (прунинг);� для обработки наблюдений, у которых пропущено значение в предикторе, ис-
пользуются суррогаты – другие предикторы, имеющие сильную корреляцию с исходной независимой переменной.
Ниже на рис. 2.3 приводится таблица сходств и различий между четырьмя метода-ми деревьев решений, предлагаемых процедурой Деревьяклассификации.
Рис. 2.3 Четыре метода деревьев решений
2.3. Шкалы переменныхВ зависимости от шкалы (уровня измерения) зависимой переменной и независимых переменных деревья решений применяют различные критерии для отбора предикторов и разбиения узлов. Поэтому важно задать правильную шкалу переменной. В IBM SPSS Statistics существуют три типа шкалы: количественная, порядковая, номинальная.
Количественная шкала содержит информацию о расстояниях между уровнями переменной, порядке уровней и количестве объектов в уровнях. Пример предиктора с количественной шкалой – переменная Возраст. Например, я знаю, что расстояние между 25 и 30 в два раза меньше, чем расстояние между 30 и 40, 30-летний на 5 лет старше 25-летнего. Я могу упорядочить уровни по нарастанию или убыванию интен-сивности определенного признака (например, по увеличению возраста): после 25 сле-
22 Основы прогнозного моделирования с помощью деревьев решений CHAID
дует 30 и 30-летний старше 25-летнего. Наконец, я могу сказать, сколько в выборке человек с тем или иным уровнем (значением) возраста.
Порядковая шкала содержит информацию о порядке уровней и количестве объ-ектов в уровнях. Пример предиктора с порядковой шкалой – переменная Доход, раз-битая на уровни низкий, средний, высокий. Здесь я уже не могу сказать, что расстояние между уровнями низкий и средний больше или меньше в определенное количество раз расстояния между уровнями средний и высокий. Я не могу утверждать, что человек со средним доходом на n-ное количество единиц богаче, чем человек с низким дохо-дом. Однако я могу упорядочить уровни по нарастанию или убыванию интенсивно-сти определенного признака: сначала следует уровень низкий, затем уровень средний и потом уровень высокий. Респонденты, относящиеся к уровню средний, обладают меньшим доходом, по сравнению с респондентами, относящимися к уровню высо-кий, то есть демонстрируют меньшую интенсивность признака. Также я могу сказать, сколько в выборке человек с тем или иным уровнем дохода.
Номинальная шкала содержит только информацию о количестве объектов в уров-нях. Пример предиктора с номинальной шкалой – переменная Регион, который имеет уровни Алтайский край, Новосибирская область, Красноярский край, Кемеровская об-ласть. Я ничего не могу сказать о расстояниях между уровнями, о порядке уровней. Я могу лишь судить о количестве респондентов, проживающих в каждом регионе.
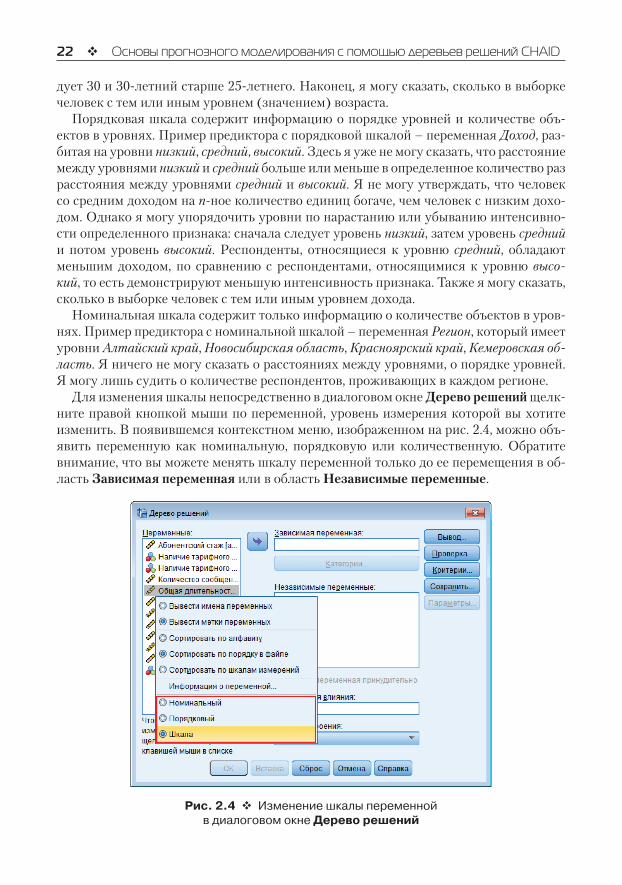
Для изменения шкалы непосредственно в диалоговом окне Дереворешений щелк-ните правой кнопкой мыши по переменной, уровень измерения которой вы хотите изменить. В появившемся контекстном меню, изображенном на рис. 2.4, можно объ-явить переменную как номинальную, порядковую или количественную. Обратите внимание, что вы можете менять шкалу переменной только до ее перемещения в об-ласть Зависимаяпеременная или в область Независимыепеременные.
Рис. 2.4 Изменение шкалы переменной в диалоговом окне Дерево решений
Определение необходимого размера выборки 23
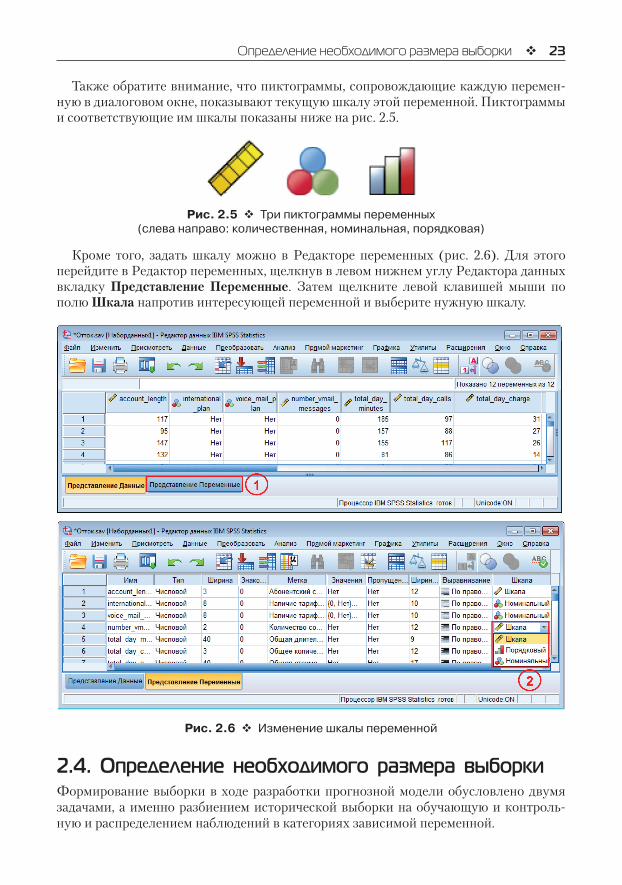
Также обратите внимание, что пиктограммы, сопровождающие каждую перемен-ную в диалоговом окне, показывают текущую шкалу этой переменной. Пиктограммы и соответствующие им шкалы показаны ниже на рис. 2.5.
Рис. 2.5 Три пиктограммы переменных (слева направо: количественная, номинальная, порядковая)
Кроме того, задать шкалу можно в Редакторе переменных (рис. 2.6). Для этого перейдите в Редактор переменных, щелкнув в левом нижнем углу Редактора данных вкладку Представление Переменные. Затем щелкните левой клавишей мыши по полю Шкала напротив интересующей переменной и выберите нужную шкалу.
Рис. 2.6 Изменение шкалы переменной
2.4. Определение необходимого размера выборкиФормирование выборки в ходе разработки прогнозной модели обусловлено двумя задачами, а именно разбиением исторической выборки на обучающую и контроль-ную и распределением наблюдений в категориях зависимой переменной.

24 Основы прогнозного моделирования с помощью деревьев решений CHAID
Предположим, мы хотим быть уверенным на 95%, что соотношение «плохих» и «хороших» заемщиков в выборке должно отражать генеральную популяцию заем-щиков. Зная долю интересующего признака (например, долю «плохих») в популя-ции, задав z-статистику, определяемую в зависимости от уровня значимости, и ши-рину доверительного интервала (точность оценки), вы можете найти минимальный объем выборки по нижеприведенной формуле:
n = (z2p(1 – p))/d 2,
где z – z-статистика для уровня значимости (например, 1,96 для уровня значимости 0,05); p – доля признака в популяции (например, доля «плохих»); d – половина шири-ны доверительного интервала для доли признака (точность оценки доли признака).
Например, предположив наихудший сценарий 50/50 (задающий максимально воз-можный размер выборки) и точность оценки 5%, или 0,05, вычислим минимальный объем выборки:
n = (1,962 × 0,5 × (1 – 0,5))/0,052 = 385.
Однако нужно помнить, что эти методы дают минимальные размеры выборки. Не-обходимо придерживаться такого метода формирования выборки, который считает-ся наиболее обоснованным до тех пор, пока размеры выборки позволяют убедиться в удовлетворительных статистических и практических результатах.
Я в своей практике использую правило 20 EPV (Event Per Variable), сформули-рованное американским стастистиком Фрэнком Харреллом1. Оно связывает мини-мальный объем выборки с количеством наблюдений в миноритарной (наименьшей по размеру) категории зависимой переменной и количеством предикторов, подан-ным на вход модели.
Согласно этому правилу, необходимо взять количество наблюдений в историче-ской выборке, относящихся к миноритарной категории зависимой переменной (в кре-дитном скоринге это «плохие» заемщики). Это число наблюдений нужно разделить на количество заданных предикторов. На один предиктор должно приходиться не ме-нее 20 наблюдений. Если это правило выполняется, то объем выборки достаточный.
Например, у меня есть выборка в 2000 наблюдений (1700 «хороших» и 300 «пло-хих») и 16 независимых переменных. Проверяя выполнение правила 20EPV, я полу-чаю 300/16 = 18,75. Наша выборка не обеспечивает достаточного количества наблю-дений в миноритарной категории зависимой переменной.
Если планируется проверка модели с разбиением набора данных на обучающую и контрольную выборки (например, 70%/30%), необходимо руководствоваться еще бо-лее жестким правилом: взять число наблюдений в миноритарной категории зависимой переменной по контрольной выборке и разделить на количество заданных предикторов.
Например, имеется историческая выборка объемом 5000 наблюдений (4000 «хо-роших» и 1000 «плохих») и 10 независимых переменных. Теперь разбиваем истори-ческую выборку случайным образом на обучающую и контрольную. В обучающую выборку попали 3500 наблюдений (2800 «хороших» и 700 «плохих»), а в контроль-ную выборку попали 1500 наблюдений (1200 «хороших» и «300 плохих»). Проверяя выполнение правила 20 EPV, я получаю 300/10 = 30. Историческую выборку данного объема можно использовать для моделирования.
1 http://biostat.mc.vanderbilt.edu/wiki/Main/ManuscriptChecklist.

Знакомство с методом CHAID 25
2.5. Знакомство с методом CHAID2.5.1. Описание алгоритмаПеред началом работы алгоритм CHAID преобразует все имеющиеся количественные предикторы в порядковые переменные, имеющие по умолчанию 10 приблизительно равных по объему категорий (число категорий можно устанавливать самостоятельно).
Затем алгоритм приступает к построению дерева, итеративно применяя к каждо-му узлу, начиная с корневого, процедуры объединения категорий, расщепления узла и проверки правил остановки.
Объединение категорий1. Для каждого предиктора с числом категорий больше двух1 алгоритм ищет пару
категорий, меньше всего статистически различающихся по зависимой переменной (т. е. с наибольшим p-значением). Для этого он вычисляет p-значения, выполняя ста-тистические тесты. Выбор теста определяется типом шкалы зависимой переменной. Для номинальной зависимой переменной используется тест хи-квадрат Пирсона или хи-квадрат отношения правдоподобия. Алгоритм строит двухвходовую таблицу со-пряженности с категориями предиктора в качестве строк и категориями зависимой переменной в качестве столбцов и проверяет гипотезу о независимости двух пере-менных. Для количественной зависимой переменной используется F-тест. Алгоритм осуществляет дисперсионный анализ и проверяет гипотезу о том, что средние зна-чения зависимой переменной для различных категорий предиктора не различаются между собой. Для порядковой зависимой переменной используется тест хи-квадрат отношения правдоподобия. Алгоритм подгоняет модель эффектов строк, где строки являются категориями предиктора, а столбцы – категориями зависимой переменной.
2. Найдя наибольшее p-значение для пары категорий, алгоритм сравнивает его с заданным уровнем значимости для объединения категорий.
Если p-значение:� меньше или равно заданному уровню значимости для объединения катего-
рий – алгоритм переходит к вычислению скорректированных p-значений для полученного набора категорий (шаг 3);
� больше уровня значимости для объединения категорий – эта пара объединяет-ся в отдельную составную категорию, в результате формируется новый набор категорий предиктора, и процесс начинается заново с поиска пары категорий с наибольшим p-значением.
ПРИМЕЧАНИЕЧтобы задать уровень значимости для объединения категорий, необходимо выпол-нить следующие действия: в главном диалоговом окне Дерево решений нажмите кнопку Критерии; в открывшемся диалоговом окне Деревья решений: Критерии откройте вкладку
CHAID; в панели Уровни значимости для выберите для параметра Объединения катего
рий необходимое значение (значение по умолчанию 0,05).
1 Если предиктор имеет одну категорию, он исключается из анализа. Если предиктор имеет две категории, происходит переход к шагу 3.

26 Основы прогнозного моделирования с помощью деревьев решений CHAID
Более подробно об этом читайте в разделе 3.1 «Построение деревьев CHAID с изме-ненными критериями».
(Опционно) Если новая составная категория состоит из трех и более исходных категорий, алгоритм находит внутри этой составной категории наилучшее бинарное расщепление, которое дает наименьшее p-значение. Алгоритм выполняет бинарное расщепление, если его p-значение не превышает уровня значимости для разбиения объединенных категорий.
ПРИМЕЧАНИЕЧтобы задать разбиение объединенных категорий, необходимо выполнить следую-щие действия: в главном диалоговом окне Дерево решений нажмите кнопку Критерии; в открывшемся диалоговом окне Деревья решений: Критерии откройте вкладку
CHAID; отметьте параметр Допускать разбиение объединенных категорий в узле (по
умолчанию не используется).Более подробно об этом читайте в разделе 3.1 «Построение деревьев CHAID с изме-ненными критериями».
3. Для сформированного набора категорий предиктора алгоритм вычисляет скор-ректированное p-значение как p-значение, умноженное на поправку Бонферонни. По-правка Бонферрони представляет собой число возможных способов, с помощью ко-торых исходные категории предиктора могут быть объединены в итоговые категории.
ПРИМЕЧАНИЕЧтобы отменить применение поправки Бонферрони, необходимо выполнить следую-щие действия: в главном диалоговом окне Дерево решений нажмите кнопку Критерии; в открывшемся диалоговом окне Деревья решений: Критерии откройте вкладку
CHAID; деактивируйте параметр Корректировать уровни значимости с использовани
ем поправки Бонферрони (по умолчанию активирован).
Расщепление узлаПосле вычисления скорректированных p-значений для итоговых наборов катего-
рий по всем предикторам алгоритм переходит к этапу расщепления узла. 1. На этапе расщепления алгоритм выбирает, какой предиктор обеспечит наилуч-
шее разбиение узла. Для этого предиктор должен иметь наименьшее скорректирован-ное p-значение (т. е. является наиболее статистически значимым).
2. Найдя предиктор с наименьшим скорректированным p-значением, алгоритм сравнивает его с заданным уровнем значимости для расщепления.
Если p-значение:� меньше или равно заданному уровню значимости для расщепления – алгоритм
разбивает узел с использованием данного предиктора (категории предиктора становятся дочерними узлами);

Знакомство с методом CHAID 27
� больше заданного уровня значимости для расщепления, то алгоритм не рас-щепляет узел и узел рассматривается как терминальный.
ПРИМЕЧАНИЕЧтобы задать уровень значимости для расщепления узла, необходимо выполнить сле-дующие действия: в главном диалоговом окне Дерево решений нажмите кнопку Критерии; в открывшемся диалоговом окне Деревья решений: Критерии откройте вкладку
CHAID; в панели Уровни значимости для выберите для параметра Разбиения узлов не-
обходимое значение (значение по умолчанию 0,05).Более подробно об этом читайте в разделе 3.1 «Построение деревьев CHAID с изме-ненными критериями».
ОстановкаАлгоритм проверяет, нужно ли прекратить построение дерева, в соответствии со
следующими правилами остановки.1. Если узел стал однородным, т. е. все наблюдения в узле имеют одинаковые зна-
чения зависимой переменной, узел не разбивается.2. Если все наблюдения в узле имеют одинаковые значения по каждому предикто-
ру, узел не разбивается.3. Если текущая глубина дерева достигает заданной пользователем максимальной
глубины дерева, процесс построения дерева останавливается.4. Если число наблюдений в родительском узле меньше заданного пользователем
минимума наблюдений в родительском узле, узел не разбивается.5. Если в результате расщепления узла число наблюдений в дочернем узле меньше
заданного минимального числа наблюдений в дочернем узле, то такие дочерние узлы объединяются с самым похожим дочерним узлом, дающим наибольшее из p-значений. Однако если число дочерних узлов, получающихся в результате разбиения, равно 1, узел не разбивается.
ПРИМЕЧАНИЕЧтобы изменить некоторые вышеперечисленные правила остановки, в главном диа-логовом окне Дерево решений нажмите кнопку Критерии.Во вкладке Ограничения на размер дерева открывшегося диалогового окна Деревья решений: Критерии настройте необходимые параметры:• параметр Пользовательские в панели Максимальное количество уровней за-
дает глубину дерева;• параметр Родительский узел в панели Минимум наблюдений в узле задает ми-
нимальное количество наблюдений в родительском узле;• параметр Дочерний узел в панели Минимум наблюдений в узле задает мини-
мальное количество наблюдений в дочернем узле.Более подробно об этом читайте в разделе 3.1 «Построение деревьев CHAID с изме-ненными критериями».

28 Основы прогнозного моделирования с помощью деревьев решений CHAID
2.5.2. Немного о тесте хиквадратПредположим, алгоритм проверяет, различаются ли значимо категории предиктора Семейное положение Холост и Женат по зависимой переменной Отклик. Нулевая ги-потеза звучит так: категории предиктора не отличаются друг от друга с точки зрения распределения категорий зависимой переменной. Строится двухвходовая таблица сопряженности, где строки являются категориями предиктора Семейное положение, а столбцы – категориями зависимой переменной Отклик. Наблюдения распредели-лись так, как показано в таблице ниже:
Нет отклика Есть отклик Всего
Холост 20 13 33
Женат 30 37 67
Всего 50 50 100
Согласно нулевой гипотезе, ожидаемые частоты имеют вид:
Нет отклика Есть отклик Всего
Холост 16,50 16,50 33
Женат 33,50 33,50 67
Всего 50 50 100
Хи-квадрат вычисляется по формуле:
где O – наблюдаемые частоты, а E – ожидаемые частоты.
Значение хи-квадрат 2,216 соответствует р-значению 0,1366.P-значение – это вероятность того, что случайная величина, имеющая распределение
хи-квадрат при условии верности нулевой гипотезы, примет значение, не меньшее, чем фактическое значение статистики. Применительно к нашему примеру p-значение – это вероятность того, что статистика хи-квадрат примет вычисленное значение 2,216 и выше, когда категории предиктора не отличаются друг от друга с точки зрения рас-пределения категорий зависимой переменной. В нашем случае оно равно 0,1366, что превышает уровень значимости 0,05. У нас нет оснований отвергнуть нулевую гипо-тезу. Можно сделать вывод, что категории действительно не отличаются друг от друга с точки зрения распределения неоткликнувшихся и откликнувшихся клиентов.
2.5.3. Немного об FтестеПредположим, алгоритм проверяет, различаются ли значимо категории предикто-ра Семейное положение Холост и Женат по количественной зависимой переменной Доход. Нулевая гипотеза звучит так: средние значения зависимой переменной в ка-тегориях предиктора или группах одинаковы. Чтобы проверить ее, нужно ответить на два вопроса: насколько сильно значения отклоняются от среднего значения зави-

Знакомство с методом CHAID 29
симой переменной в группах и насколько сильно средние значения зависимой пере-менной в группах отличаются от среднего значения зависимой переменной перед разбиением на группы. Соответственно, выполняется однофакторный дисперсион-ный анализ, в ходе которого подсчитывают внутригрупповую сумму квадратов от-клонений и межгрупповую сумму квадратов отклонений и вычисляют F-тест или критерий Фишера.
Сумма квадратов между группами (дочерними узлами) определяется по формуле:
где – среднее значение зависимой переменной в i-м дочернем узле и – среднее значение зависимой переменной в родительском узле.
Сумма квадратов внутри групп (дочерних узлов) определяется по формуле:
где yij – значение зависимой переменной для j-го наблюдения в i-м дочернем узле и – среднее значение зависимой переменной в i-м дочернем узле.Общая сумма квадратов отклонений имеет вид:
F-статистика – это отношение межгрупповой суммы квадратов отклонений к внут-ригрупповой:
Эта статистика подчиняется F-распределению с 1 и n – 2 степенями свободы, со-гласно нулевой гипотезе.
P-значение – это вероятность того, что случайная величина с распределением Фи-шера при условии верности нулевой гипотезы примет значение, не меньшее, чем фак-тическое значение статистики. Допустим, для нашего примера мы получили значение F-теста 15,943, соответствующее р-значению 0,000. Вероятность того, что F-статистика примет фактическое значение 15,943 и выше, когда средние значения зависимой пере-менной в категориях предиктора одинаковы, равна 0,000. Это меньше уровня значи-мости 0,05. Мы можем отклонить нулевую гипотезу и сделать вывод, что средние зна-чения зависимой переменной в категориях предиктора неодинаковы, а межгрупповые различия являются более существенными, чем внутригрупповые. Разбиение, дающее наименьшее p-значение, максимизирует межгрупповую сумму квадратов отклонений и минимизирует внутригруповую сумму квадратов отклонений.
2.5.4. Способы объединения категорий предикторовСпособ объединения категорий предиктора зависит от шкалы его измерения.
В номинальных предикторах можно объединять любые категории, если они не раз-личаются значимо по зависимой переменной. Таким образом, для номинальных пере-менных ограничения на объединение категорий не накладываются.

30 Основы прогнозного моделирования с помощью деревьев решений CHAID
В порядковых предикторах две категории могут быть объединены, только если к ним могут быть присоединены промежуточные категории. Например, переменная, представляющая группы по уровню доходов, может рассматриваться как порядковая. Людей с доходом менее 2000$ имеет смысл объединять с теми, кто зарабатывает бо-лее 3000$, только если к вновь образовавшейся группе можно также отнести людей с доходом от 2000$ до 3000$.
Если говорить о количественных предикторах, то по умолчанию CHAID преоб-разует количественный предиктор (например, возраст в годах или размер вклада в рублях) в порядковую переменную, имеющую 10 категорий с приблизительно рав-ным числом наблюдений. Эти категории формируются путем объединения соседних значений исходной переменной. На процесс формирования групп можно повлиять, используя вкладку Интервалы в диалоговом окне Критерии (ее можно открыть с по-мощью кнопки Критерии в главном диалоговом окне Деревьяклассификации).
2.5.5. Поправка БонферрониОсуществляя поиск незначимых категорий предиктора для объединения, CHAID выполняет большое количество статистических тестов для различных комбинаций категорий предиктора. Однако число таких комбинаций зависит от количества кате-горий, которое у каждой переменной разное. По одной переменной могут оцениваться 2 варианта объединения, рассматриваться 2 таблицы сопряженности и выполняться 2 статистических теста, а по другой переменной – 10 вариантов объединения, 10 таб-лиц сопряженности и 10 статистических тестов. Вероятность того, что из 10 тестов хи-квадрат для второй переменной, по крайней мере, один из тестов дает ложнопо-ложительное решение (ситуация, когда вы находите различия между категориями предиктора по зависимой переменной, тогда как этих различий на самом деле нет),
составляет . Групповая вероятность ошибки намного больше индиви-
дуальной вероятности ошибки ai. Например, если индивидуальная вероятность ошиб-ки (ai) по каждому тесту = 0,05, то групповая вероятность ошибки 1 – 0,9510 = 0,401. Это означает, что, когда вы проводите множественные проверки гипотез при помощи хи-квадрат (одна на каждое возможное объединение), р-значения недооценивают риск отклонения нулевой гипотезы, когда она верна. Например, вы можете сделать ошибочный вывод, что заемщики с разными профессиями отличаются по кредито-способности, тогда как они на самом не деле не отличаются.
Поэтому для контроля вероятности ошибки p-значения, вычисленные для объеди-ненных категорий, умножаются на поправку Бонферрони (получаем так называемые скорректированные p-значения).
2.5.6. Иллюстрация работы CHAID на конкретном примереПредположим, есть данные по клиентам микрофинансовой организации и извест-но, выплатили они займ или нет (категориальная зависимая переменная Просроч-ка). В качестве потенциальных предикторов фигурируют четыре переменные: Доход, Возраст, Сфера занятости, Пол. Переменные Пол, Сфера занятости являются но-минальными, переменная Доход является порядковой, переменная Возраст является количественной. Переменная Сфера занятости принимает значения Работает по найму, Свое дело, Учится или студент, Пенсионер. Переменная Доход принимает зна-