Embed Size (px)
Citation preview

Glasgow広告ランキングTristan Irvine2016-11-10

概略
自己紹介
バンディットアルゴリズム
コンテキスチュアルバンディットアルゴリズム

自己紹介
名前:トリスタン (Tristan)
出身:イギリス人
年齢:29歳
入社:2015の10月
好きな飲み物:牛乳
寝る時間:22:00 - 06:00

自己紹介(2)
趣味は:サプリメントを飲む
なんでも病気をなおれるコンビ
ビタミン D 10,000 IUビタミン K2 MK7 360 ug(納豆)
肝油 10ml
怪我を早く回復するために
Cissus quadrangularis (シッサス属のツタ)

広告ランキング問題
一番売り上げが良い広告を配信したい
CPC (Cost per click) * CTR (Click through rate) * Impression数 = 売り上げ
では、CPC * CTRが高い広告を配信した方が良いです!
僕の仕事は、CPC * CTRによって広告をランキングすることです。
時間にCPCが固定ですので、CTRによってランキングするのを集中する。
なぜこれは難しい?!過去CTR順によってランキングすればいいじゃん?
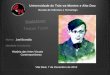
例1ー無知識
新しいサイトを作った!
四つの広告があるんだけど、どっちも配信したことない!
広告1 広告2 広告3 広告4
過去インプ 0 0 0 0
過去クリック 0 0 0 0
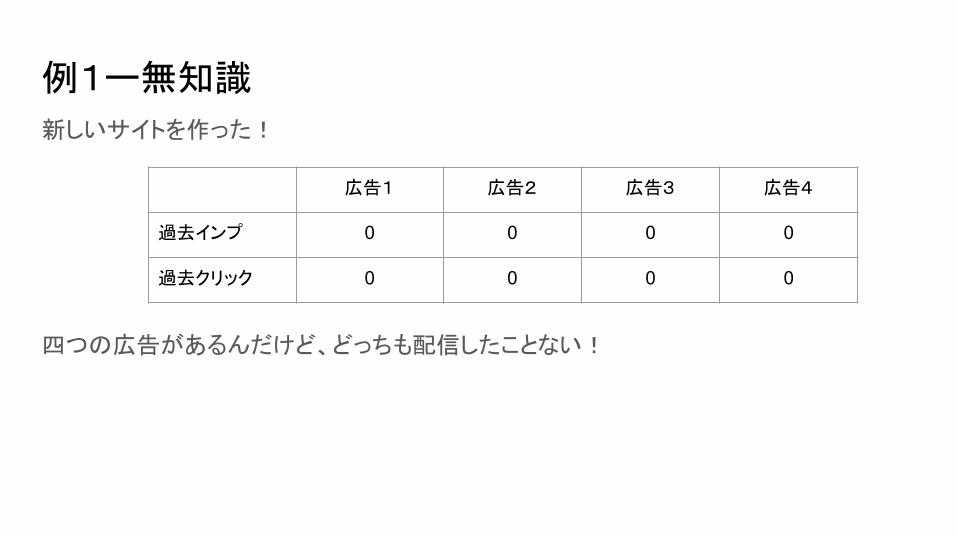
例1ー無知識
新しいサイトを作った!
四つの広告があるんだけど、どっちも配信したことない!
CTRによってのランキング作れないんです
ランダムで配信するしかないな〜
広告1 広告2 広告3 広告4
過去インプ 0 0 0 0
過去クリック 0 0 0 0
やっぱシンプルすぎるですね。。
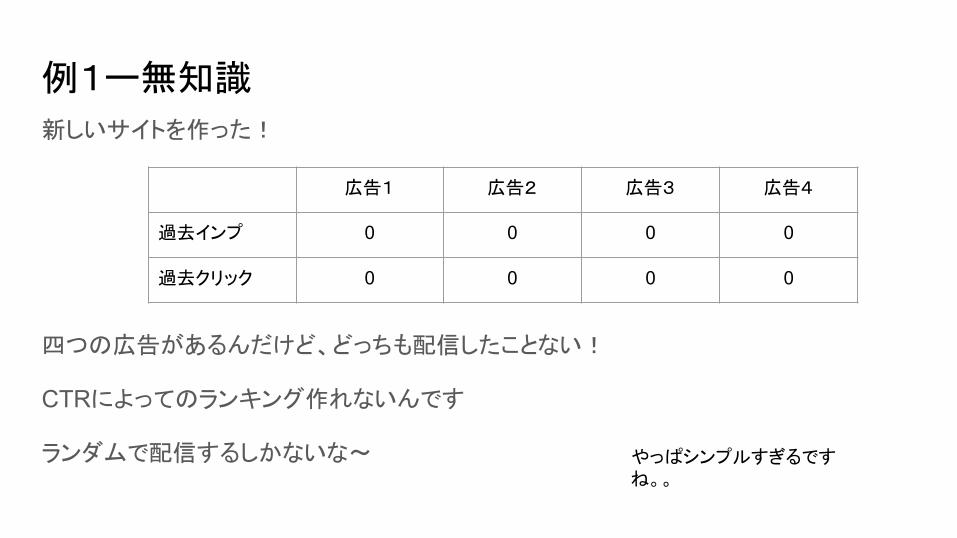
例2ー探求か、活用か
二つの広告を100回ずつ配信して見た
広告1 広告2 広告3 広告4
過去インプ 100 100 0 0
過去クリック 10 25 0 0
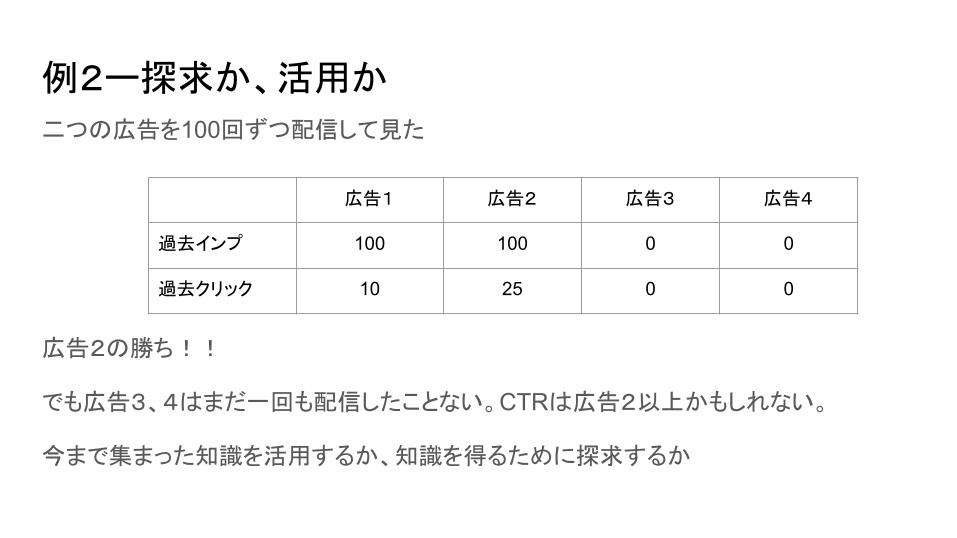
例2ー探求か、活用か
二つの広告を100回ずつ配信して見た
広告2の勝ち!!
でも広告3、4はまだ一回も配信したことない。CTRは広告2以上かもしれない。
今まで集まった知識を活用するか、知識を得るために探求するか
広告1 広告2 広告3 広告4
過去インプ 100 100 0 0
過去クリック 10 25 0 0
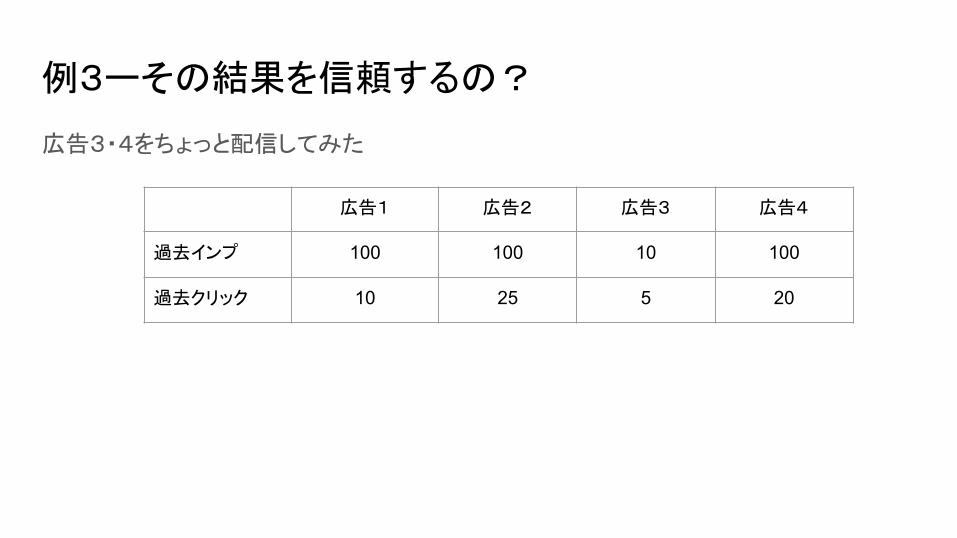
例3ーその結果を信頼するの?
広告3・4をちょっと配信してみた
広告1 広告2 広告3 広告4
過去インプ 100 100 10 100
過去クリック 10 25 5 20
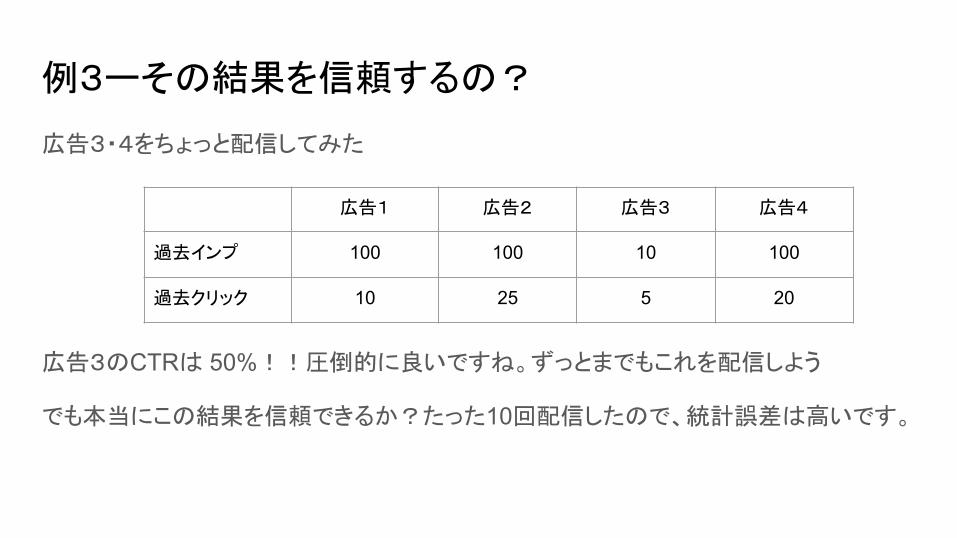
例3ーその結果を信頼するの?
広告3・4をちょっと配信してみた
広告3のCTRは 50%!!圧倒的に良いですね。ずっとまでもこれを配信しよう
でも本当にこの結果を信頼できるか?たった10回配信したので、統計誤差は高いです。
広告1 広告2 広告3 広告4
過去インプ 100 100 10 100
過去クリック 10 25 5 20

バンディットアルゴリズム
バンディットはこの問題を解決するためのアルゴリズムの種類です。
機械学習世界にはこれは「強化学習」の一種です。
幾つかのバンディットアルゴリズムがある。
● -first● -greedy● UCB● Thompson Sampling
ちょっと紹介しましょう
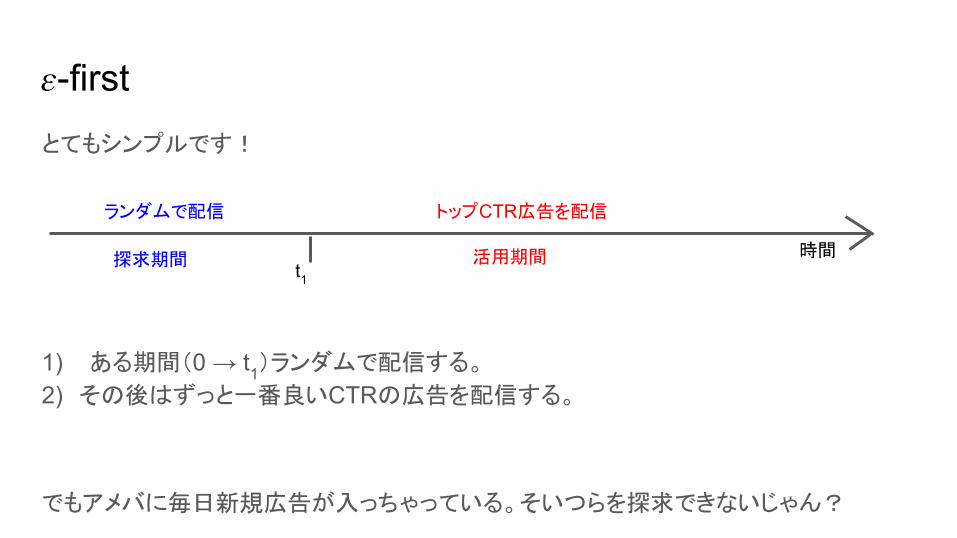
-firstとてもシンプルです!
1) ある期間(0 → t1)ランダムで配信する。
2) その後はずっと一番良いCTRの広告を配信する。
でもアメバに毎日新規広告が入っちゃっている。そいつらを探求できないじゃん?
t1時間
ランダムで配信 トップCTR広告を配信
探求期間 活用期間
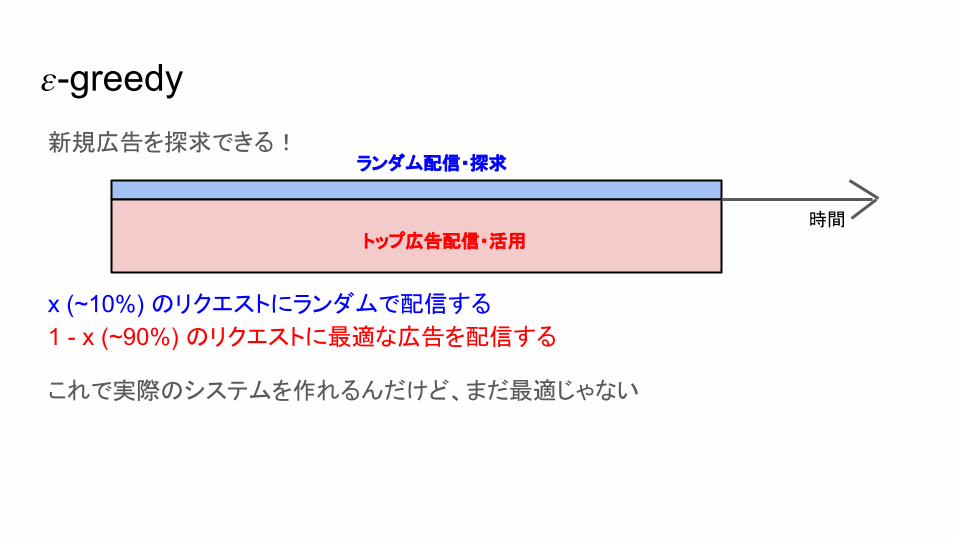
-greedy新規広告を探求できる!
x (~10%) のリクエストにランダムで配信する
1 - x (~90%) のリクエストに最適な広告を配信する
これで実際のシステムを作れるんだけど、まだ最適じゃない
時間
ランダム配信・探求
トップ広告配信・活用
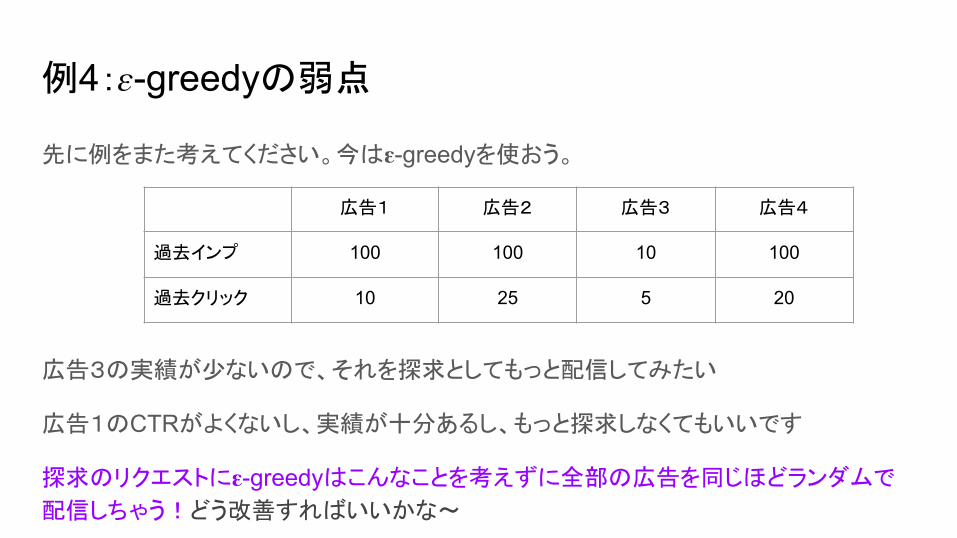
例4: -greedyの弱点
先に例をまた考えてください。今は -greedyを使おう。
広告3の実績が少ないので、それを探求としてもっと配信してみたい
広告1のCTRがよくないし、実績が十分あるし、もっと探求しなくてもいいです
探求のリクエストに -greedyはこんなことを考えずに全部の広告を同じほどランダムで
配信しちゃう!どう改善すればいいかな〜
広告1 広告2 広告3 広告4
過去インプ 100 100 10 100
過去クリック 10 25 5 20
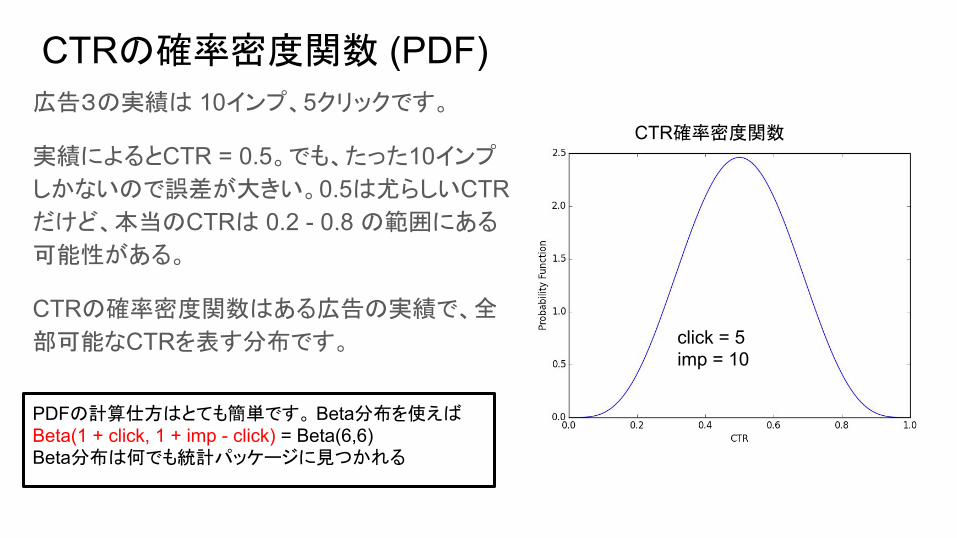
CTRの確率密度関数 (PDF)広告3の実績は 10インプ、5クリックです。
実績によるとCTR = 0.5。でも、たった10インプ
しかないので誤差が大きい。0.5は尤らしいCTRだけど、本当のCTRは 0.2 - 0.8 の範囲にある
可能性がある。
CTRの確率密度関数はある広告の実績で、全
部可能なCTRを表す分布です。
CTR確率密度関数
click = 5imp = 10
PDFの計算仕方はとても簡単です。 Beta分布を使えばBeta(1 + click, 1 + imp - click) = Beta(6,6)Beta分布は何でも統計パッケージに見つかれる
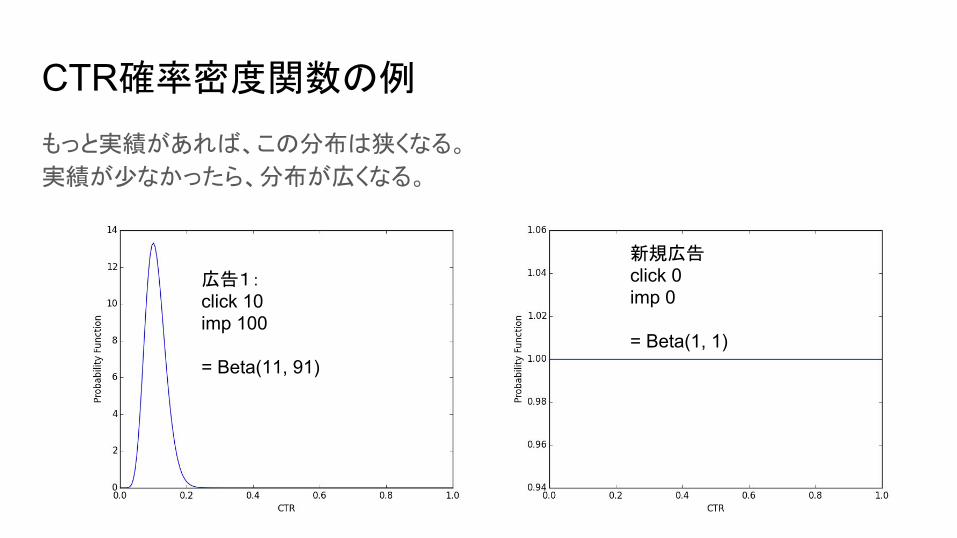
CTR確率密度関数の例
もっと実績があれば、この分布は狭くなる。
実績が少なかったら、分布が広くなる。
広告1:click 10imp 100
= Beta(11, 91)
新規広告click 0imp 0
= Beta(1, 1)
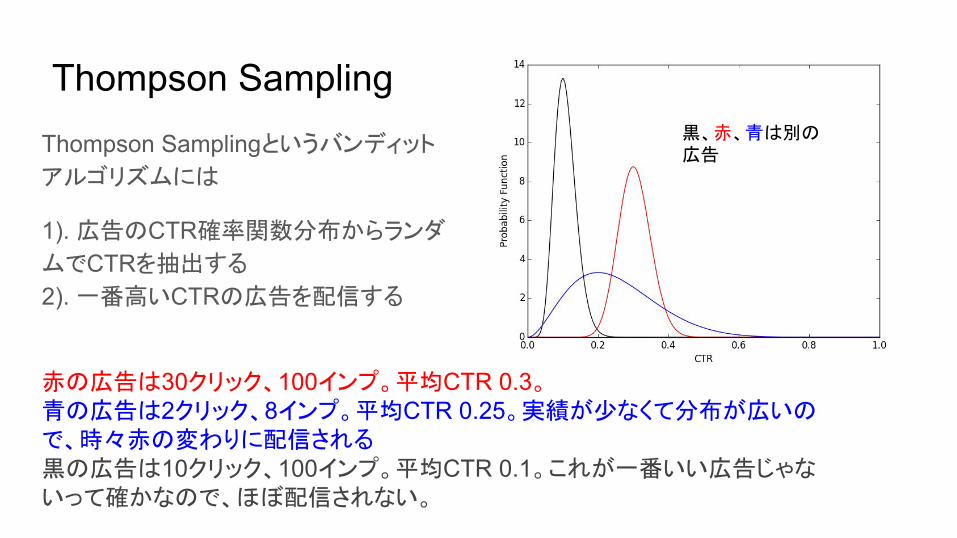
Thompson SamplingThompson Samplingというバンディット
アルゴリズムには
1). 広告のCTR確率関数分布からランダ
ムでCTRを抽出する
2). 一番高いCTRの広告を配信する
黒、赤、青は別の広告
赤の広告は30クリック、100インプ。平均CTR 0.3。青の広告は2クリック、8インプ。平均CTR 0.25。実績が少なくて分布が広いので、時々赤の変わりに配信される黒の広告は10クリック、100インプ。平均CTR 0.1。これが一番いい広告じゃないって確かなので、ほぼ配信されない。

Thompson Sampling 実装
Thompson Samplingは実際のglasgowレコメンドエンジンに回している。
これでスーパー簡単に誰でもレコメンドエンジンを作れる。コードは下記
クリック数 インプ数
alpha = 1beta = 1

コンテキスチュアルバンディット
今までの話はある広告の全部の実績を基づいて、ランキングする
でもユーザによって広告のCTRは変わるはずです!
女子はファションが好きだ
男子はゲームが好きだ
。。。みたいな傾向

メソッド1ー実績を分ける
実績を分けて、普通のバンディットアルゴリズムで計算する
性別の場合は別に問題ないんだけど、いつでも分けたら使える実績が減る。
性別 x 広告枠 x 年齢 x 時間帯別でやろうとしたら各バンディットで使えるインプは少な
すぎる。
性別分け
Thompson Samplingを使う
男性ユーザの場合Beta(1 + 男性click, 1 + 男性(imp-click))
女性ユーザの場合Beta(1 + 女性click, 1 + 女性(imp-click))
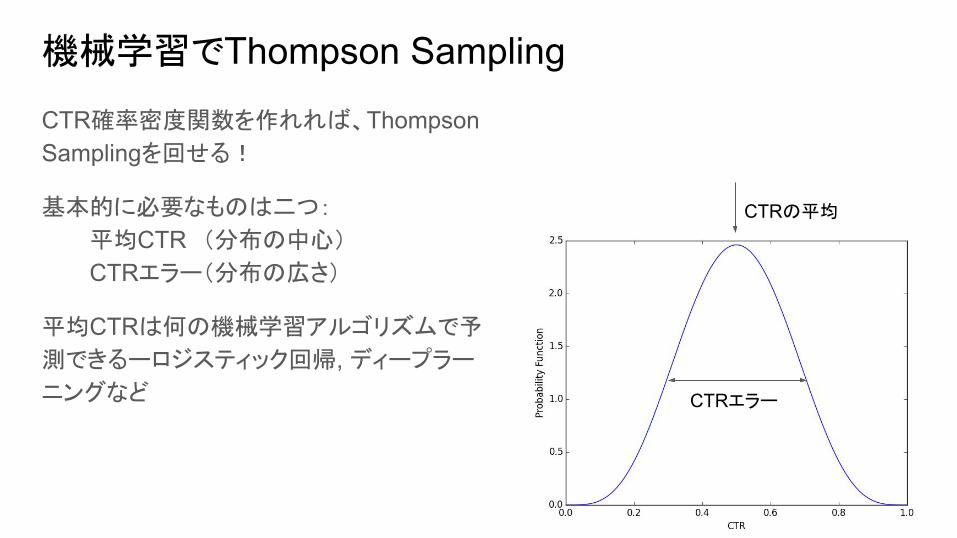
機械学習でThompson Sampling
CTR確率密度関数を作れれば、Thompson Samplingを回せる!
基本的に必要なものは二つ:
平均CTR (分布の中心)
CTRエラー(分布の広さ)
平均CTRは何の機械学習アルゴリズムで予
測できるーロジスティック回帰, ディープラー
ニングなど
CTRの平均
CTRエラー

機械学習紹介 - Stochastic Gradient Descent幾つかの広告CTRに関する素性を入力する:ad_id=5, ad_spot_id=23, user_id=655 など
各素性はあるウエートに対応する。それが高いほど予測CTRが高いです
wtotal ~ wad_id5 + wad_spot_id23 + wuser_id655
wtotalは制限されていないので、CTR (0-1)へ転換するためにシグモイド関数を使う。

Stochastic Gradient Descent (2) ウエート更新
予測してからウエートを調整する。予測誤差は大きーほど調整する。
y = 1 (実際クリックされた) 、0(実際クリックされてなかった)
変化率 = CTR予測 - y
wx = wx - 変化率 (各素性の対応ウエート)
以上!皆はSGDを使えるようになった。
でもSGDはエラーを予測しにくいし
予測精度あんまりよくないし
。。別のアルゴリズムを使いましょー

AdPredictor (Microsoft)Microsoft Bingが使っているCTR予測アルゴリズム
ベイズ系ですので、全部のウエートは固定ではなく正規分布の形です。平均( )+分散
( 2)で定義されている。
最初は
w. = 0w. 2 = 1 (好きに選べばいい)

AdPredictor(予測)
数学的になっちゃってすみません
は自分で設定するパラメター
xは入力素性のベクトル
は正規分布のCDF(累積分布関数)。前のシグモイド関数と同じ役目です。

AdPredictor(更新)
毎回平均と分散両方を調整しないといけないんです。
この方程式を作る数学はシンプルではない。詳しく知りたいと自分で論文を読んで!
i, j の二次元は フィールド (ad_id)、値 (5)の意味です。アルゴリズムに大事じゃない。
学習率は分散( 2)による。では、最初に見た素性は早く学習する、たくさん見たやつはほぼ変わらない。

AdPredictorでThompson SamplingThompson Samplingリマインド:広告のCTR確率関数分布からランダムでCTRを抽出
する。それで広告をランキングする。
では、予測エラーによってCTRを偏りたい。
合計予測エラーを知らないんだけど、各ウエートのエラーを知っている。
だから、予測する時は各ウエートをエラーによって偏ればランダムサーンプリングは行い
ます!
← N( , 2).ランダムサーンプル()
それで予測CTR順番に配信すれば良いです!
モデルを更新する時はこうしない〜

入力素性
広告系:business_id, ad_group_id, campaign_idなど
属性系:性別、年齢、URL、user_agent、広告枠など
目的はad_group_idをCTR順にランキングしたい
属性系素性は全部の候補広告に対して同じです。なのでそのまま使えば、ランキングに
何も影響ない。「女性ならCTRが上がる!」 ← 役に立てない
必要なのは属性系と広告系の素性の相互作用項です。「女性はad_group_id 5を見た
らCTRはどうなる」 ← 役に立てる!

多項式素性
では、属性素性から幾つかの多項式素性を作る
性別=女 → 女+ad_group_id1 女+ad_group_id2 女+ad_group_id3
これでたくさんの素性が作られちゃう!モデルサイズは数Gbになる可能です

話す暇がないこと
データサーンプリング
指標・アルゴリズム評価
強調フィルタリング
ストリーミング・バッチ更新
素性の前処理
他のアルゴリズム
実装の詳細
後で興味あればいつでも質問してもいいです!

まとめ
AdPredictorという機械学習アルゴリズムでThompson Sampling見たいなバンディットア
ルゴリズムを実装した
現在Glasgow(広告)とアメトピ(トピック)である程度回している。
コンテキストなしのバンディットよりの改善は
Glasgow CPM +7%アメトピ CTR +1%
まだ初期ですので、さらに改善するために頑張ります!