Embed Size (px)
Citation preview

「ビジネス活用事例で学ぶ データサイエンス入門」輪読会
#6
第8章 どんな顧客群をターゲットとすべきか?
2016/4/15

自己紹介
しまじろう よう SIer で SE(金融・情報系) ⇒ 個人事業主 ソーシャルゲームベンチャーでデータ解析者・PM を担当 3月末まで不動産仲介プラットフォーム企業で解析基盤周りのお仕事をしていました C#/Ruby/R/Rails/DB 数学/統計・機械学習/経営/マーケティング ※中小企業診断士を取得したい
Twitter: you_s1025
2
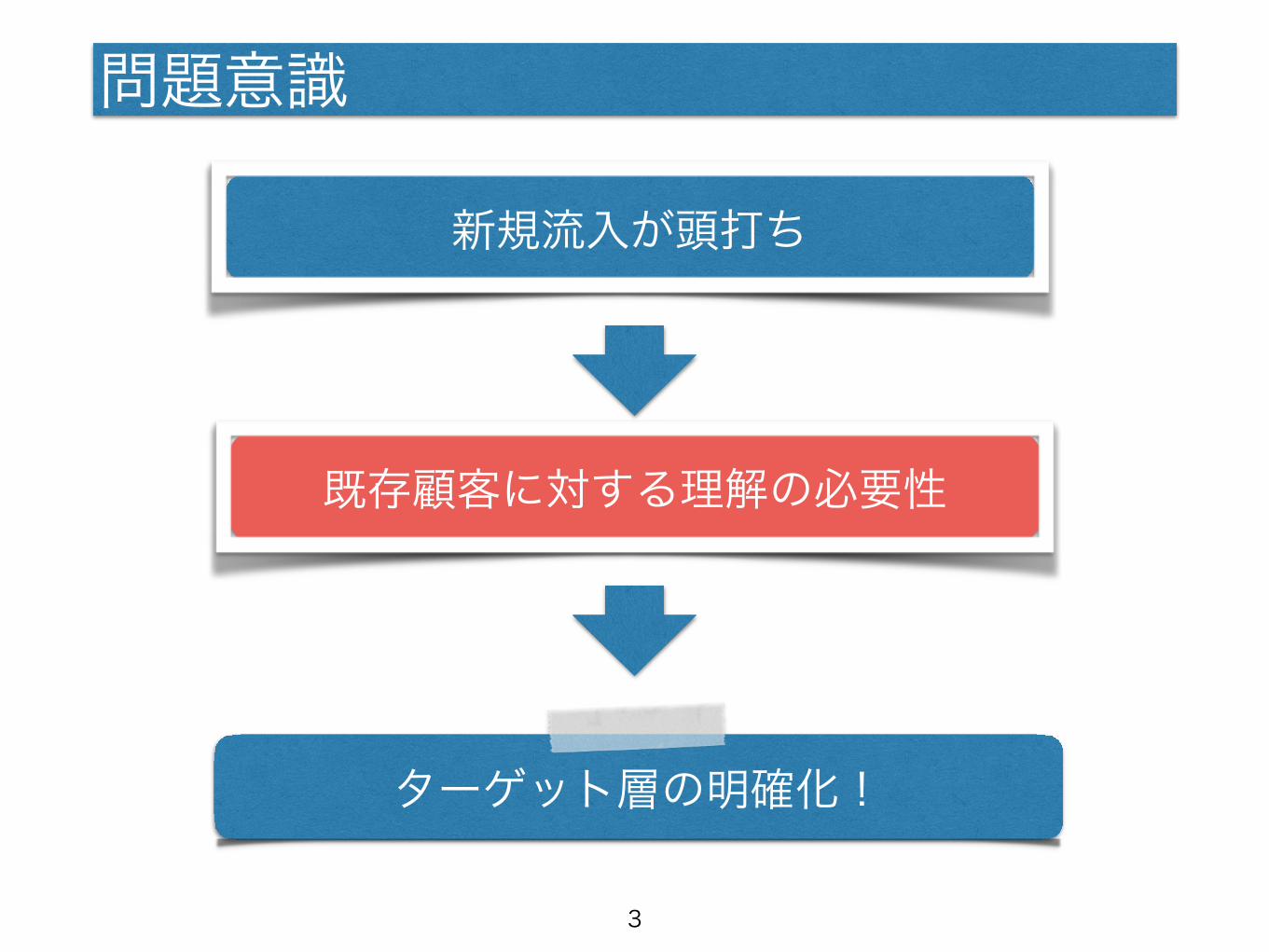
問題意識
新規流入が頭打ち
既存顧客に対する理解の必要性
ターゲット層の明確化!
3

全体の流れ1.既存顧客への注力の必要性 ☓: デモグラフィックによる分類 ◎: 行動履歴による分類
2.ランキング上位ユーザの抽出 1.ポイントによるユーザの3分割 ※上位2セグメントを対象
3.クラスタリングの実施 1.情報量がゼロに近い項目の除去 2.相関の高い変数の片方を除去 3.主成分分析を用いた新座標系の導入 4.k-means によるクラスタリング 5.レーダーチャートによる可視化
4
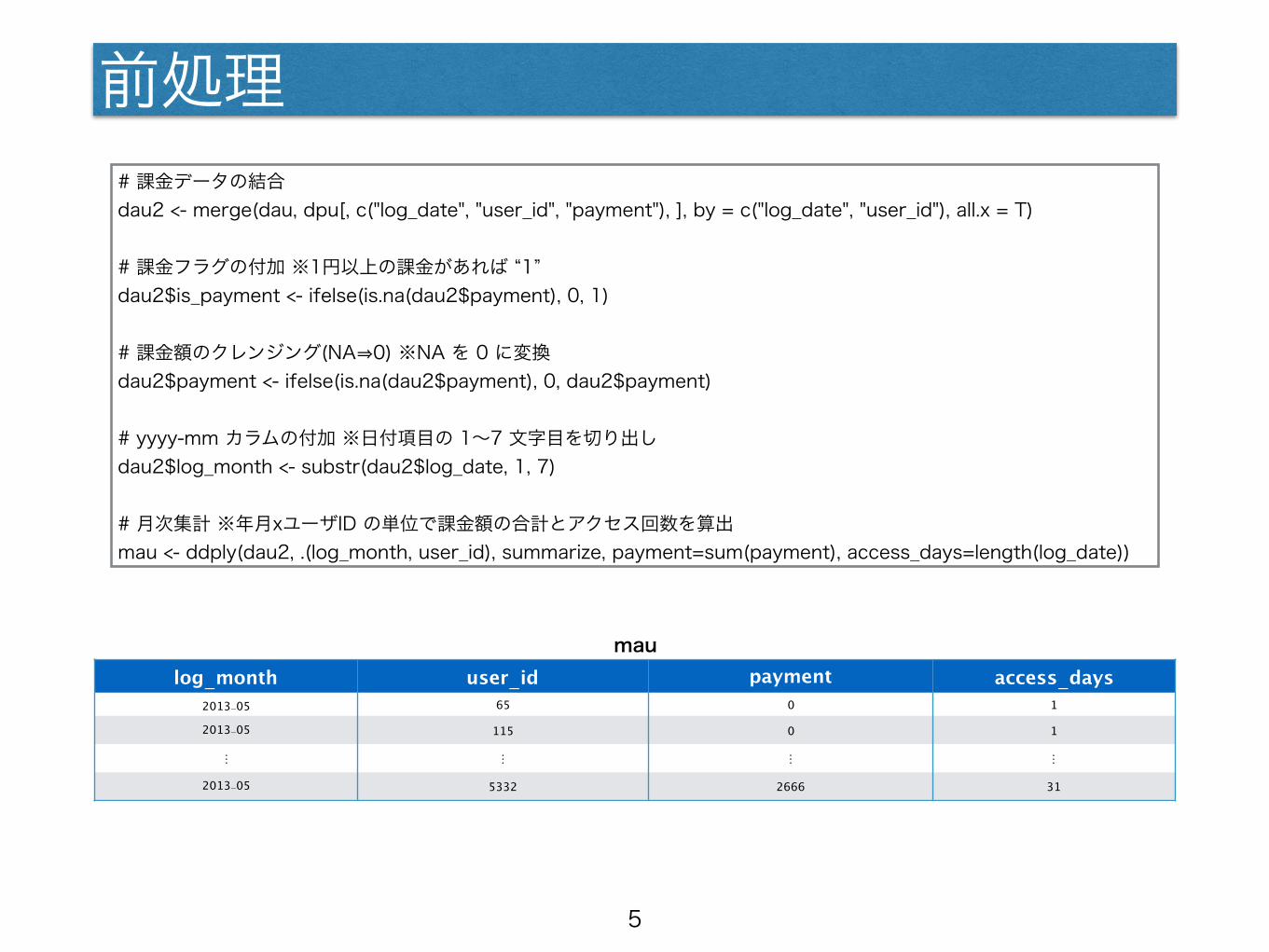
前処理# 課金データの結合 dau2 <- merge(dau, dpu[, c("log_date", "user_id", "payment"), ], by = c("log_date", "user_id"), all.x = T)
# 課金フラグの付加 ※1円以上の課金があれば “1” dau2$is_payment <- ifelse(is.na(dau2$payment), 0, 1)
# 課金額のクレンジング(NA⇒0) ※NA を 0 に変換 dau2$payment <- ifelse(is.na(dau2$payment), 0, dau2$payment)
# yyyy-mm カラムの付加 ※日付項目の 1~7 文字目を切り出し dau2$log_month <- substr(dau2$log_date, 1, 7)
# 月次集計 ※年月xユーザID の単位で課金額の合計とアクセス回数を算出 mau <- ddply(dau2, .(log_month, user_id), summarize, payment=sum(payment), access_days=length(log_date))
maulog_month user_id payment access_days
2013-05 65 0 1
2013-05 115 0 1
… … … …
2013-05 5332 2666 31
5

ランキング上位ユーザの抽出# kmeans を用いたランキングによるクラスタリングの実行 user.action2 <- ykmeans(user.action, "A47", "A47", 3)
# 描画 ggplot(arrange(user.action2, desc(A47)), aes(x = 1:length(user_id), y = A47, col = as.factor(cluster), shape = as.factor(cluster))) + geom_line() + xlab("user") + ylab("Ranking point") + scale_y_continuous(label = comma) + ggtitle("Ranking Point") + theme(legend.position = "none")
# ランキング上~中位者を抽出 user.action.h <- user.action2[user.action2$cluster >= 2, names(user.action)]
6
> table(user.action2$cluster)
1 2 3 2096 479 78
上位
中位下位
クラスタ毎のユーザ数を表示
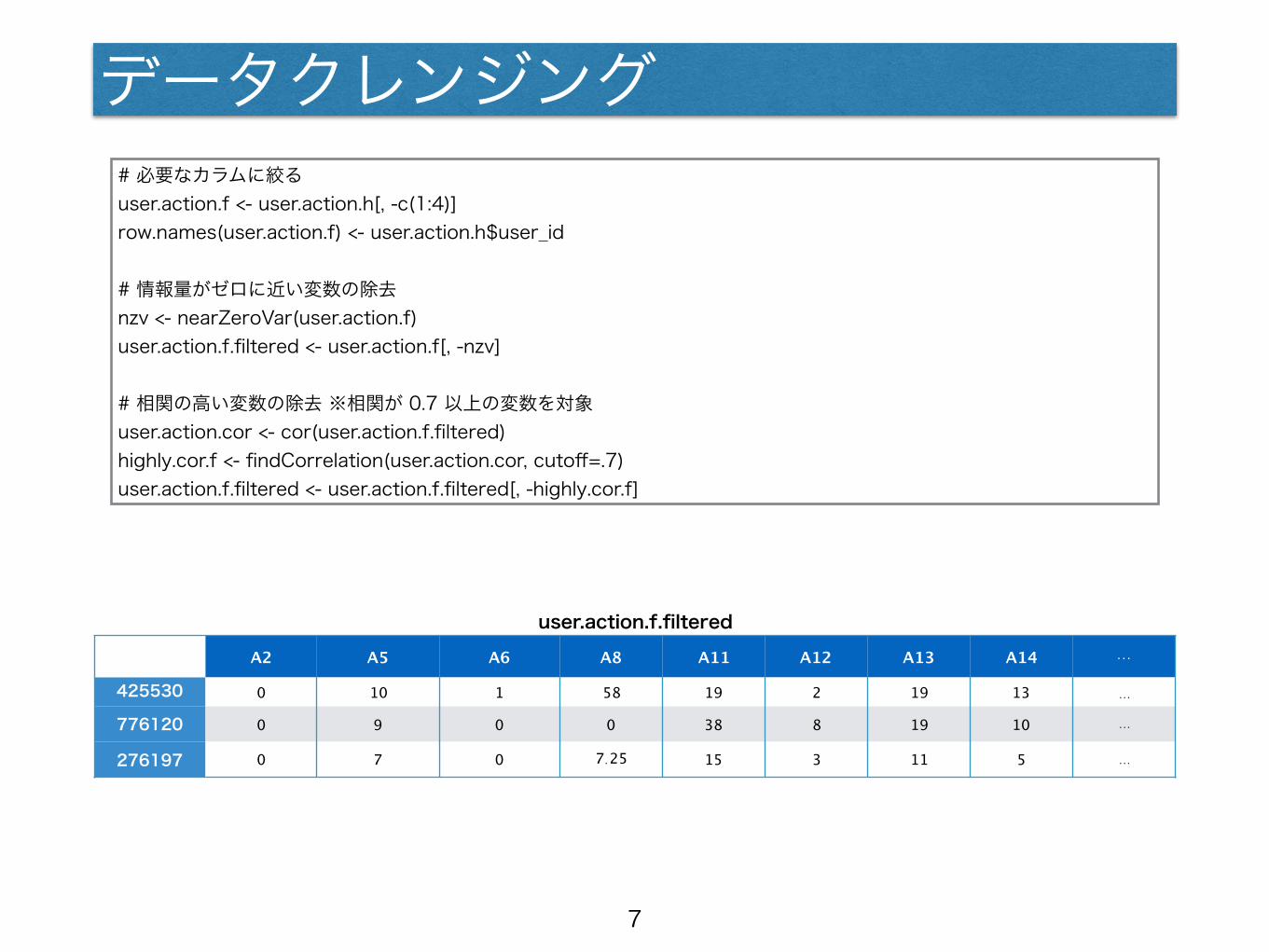
データクレンジング# 必要なカラムに絞る user.action.f <- user.action.h[, -c(1:4)] row.names(user.action.f) <- user.action.h$user_id
# 情報量がゼロに近い変数の除去 nzv <- nearZeroVar(user.action.f) user.action.f.filtered <- user.action.f[, -nzv]
# 相関の高い変数の除去 ※相関が 0.7 以上の変数を対象 user.action.cor <- cor(user.action.f.filtered) highly.cor.f <- findCorrelation(user.action.cor, cutoff=.7) user.action.f.filtered <- user.action.f.filtered[, -highly.cor.f]
7
user.action.f.filteredA2 A5 A6 A8 A11 A12 A13 A14 …
425530 77
0 10 1 58 19 2 19 13 …
776120 0 9 0 0 38 8 19 10 …
276197 0 7 0 7.25 15 3 11 5 …
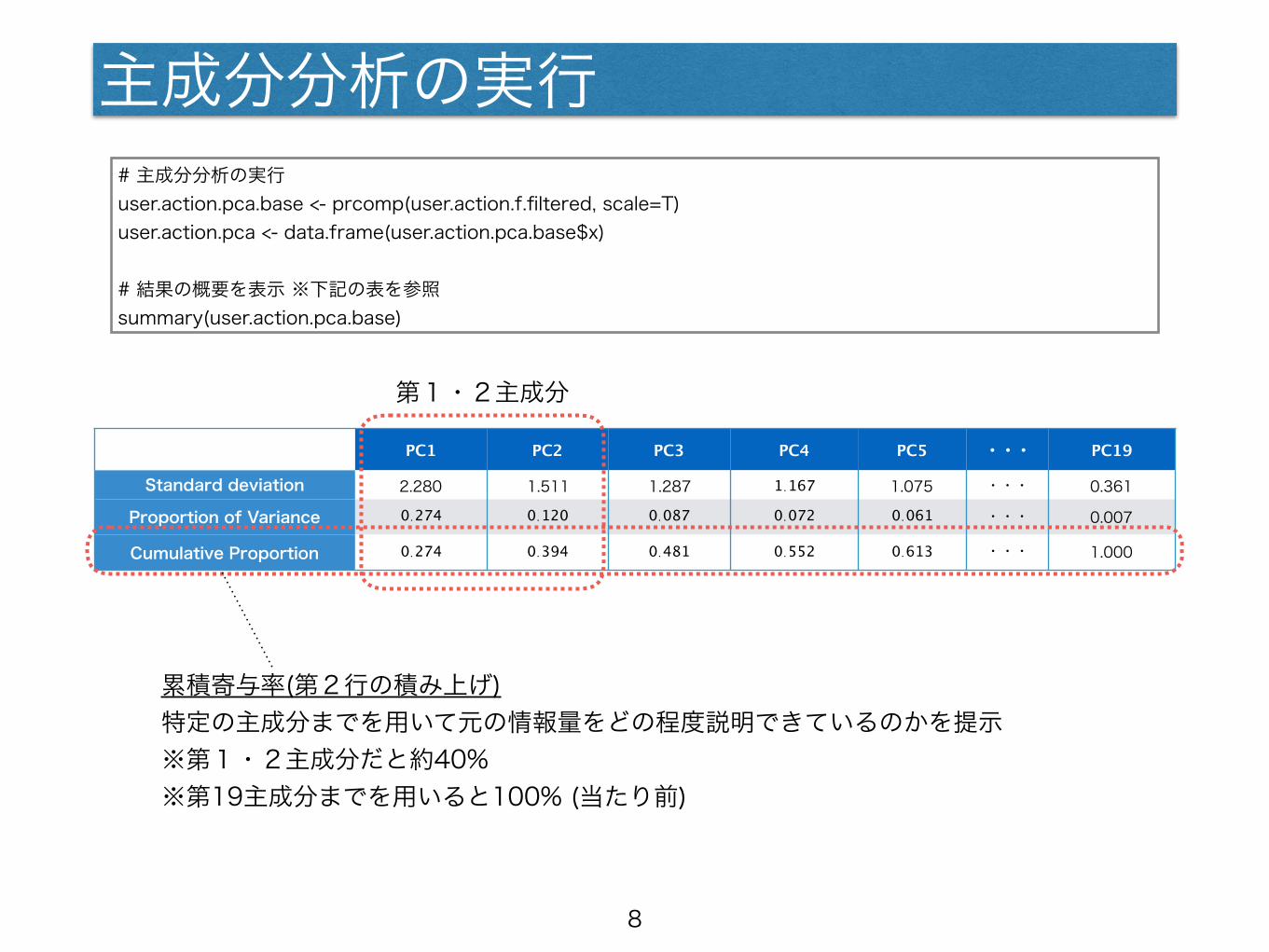
主成分分析の実行# 主成分分析の実行 user.action.pca.base <- prcomp(user.action.f.filtered, scale=T) user.action.pca <- data.frame(user.action.pca.base$x)
# 結果の概要を表示 ※下記の表を参照 summary(user.action.pca.base)
8
PC1 PC2 PC3 PC4 PC5 ・・・ PC19
Standard deviation 2.280 1.511 1.287 1.167 1.075 ・・・ 0.361
Proportion of Variance 0.274 0.120 0.087 0.072 0.061 ・・・ 0.007
Cumulative Proportion 0.274 0.394 0.481 0.552 0.613 ・・・ 1.000
第1・2主成分
累積寄与率(第2行の積み上げ) 特定の主成分までを用いて元の情報量をどの程度説明できているのかを提示 ※第1・2主成分だと約40% ※第19主成分までを用いると100% (当たり前)

クラスタリングの実施# k-means の実施 keys <- names(user.action.pca) user.action.km <- ykmeans(user.action.pca, keys, "PC1", 3:6)
# 描画 ggplot(user.action.km, aes(x=PC1,y=PC2,col=as.factor(cluster), shape=as.factor(cluster))) + geom_point()
9
第1・2主成分でデータ全体をプロット ※累積寄与率が40%程度だがそれなりに分類されている

レーダーチャートの描画(1)# クラスタ別に項目ごとの平均値を算出 user.action.f.filtered$cluster <- user.action.km$cluster clusters <- sort(unique(user.action.f.filtered$cluster)) user.action.f.center <- ldply(lapply(clusters, function(i) { x <- user.action.f.filtered[user.action.f.filtered$cluster == i, -ncol(user.action.f.filtered)] apply(x, 2, mean) }))
# 相関の高い変数を除外 ※理由は不明 df <- user.action.f.center[, -(ncol(user.action.f.center)-1)] df.cor <- cor(df) # テキストと異なる結果になったので手動で無理やり合わせる #df.highly.cor <- findCorrelation(df.cor, cutoff=0.91) #df.filtered <- df[, -df.highly.cor] df.highly.cor <- c("A2", "A11", "A13", "A43", "A44", "A51") df.filtered <- df[, df.highly.cor]
# チャート作成 df.filtered <- createRadarChartDataFrame(scale(df.filtered)) names(df.filtered) <- c("レベル", "救援回数", "被救援回数", "ボス討伐数", "バトル回数", "プレイ回数") par(family=“Ricty") # フォントの指定 radarchart(df.filtered, seg=5, plty=1:5, plwd=4, pcol=rainbow(5)) legend("topright", legend=1:5, col=rainbow(5), lty=1:5)
10
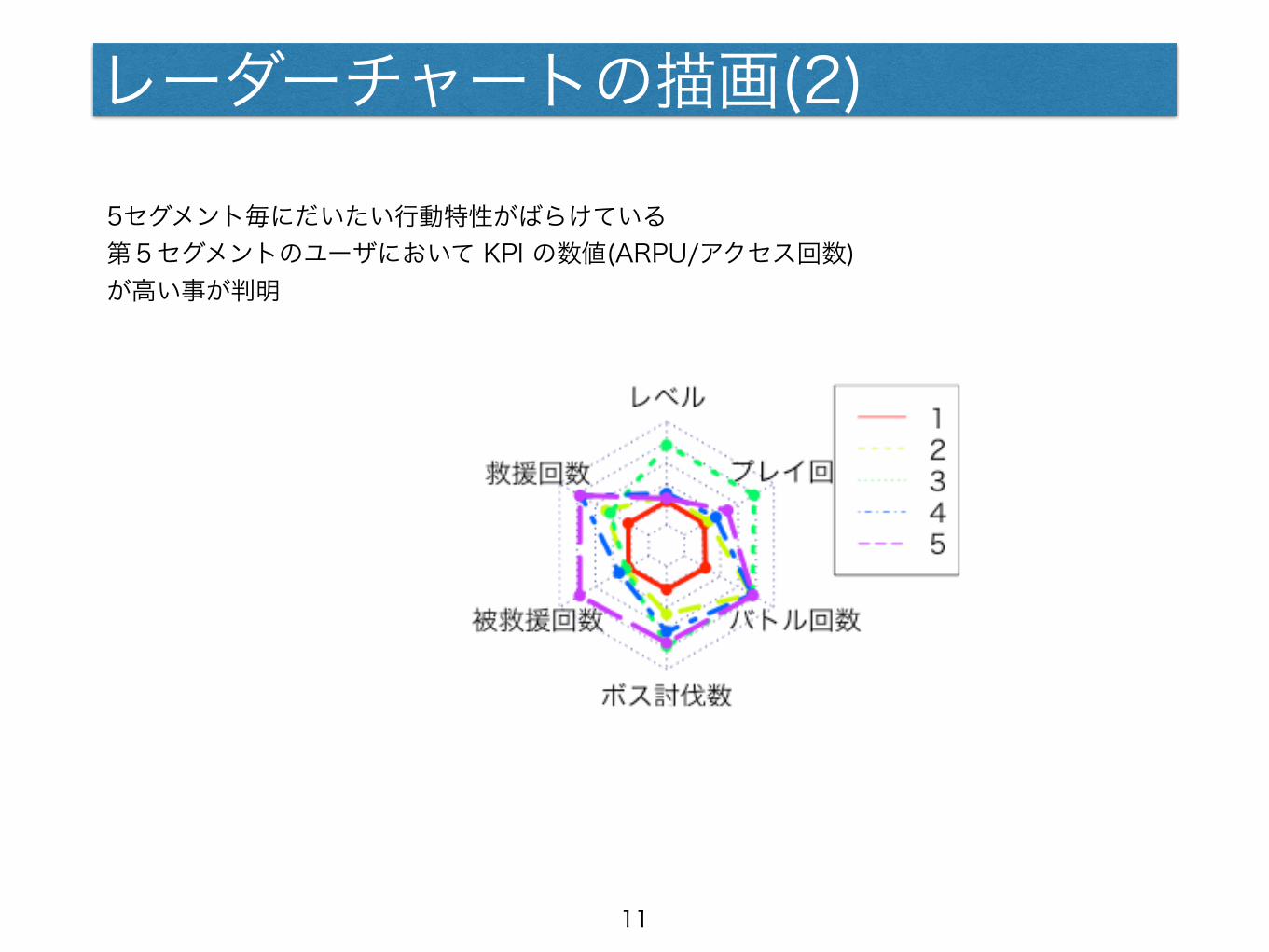
レーダーチャートの描画(2)
11
5セグメント毎にだいたい行動特性がばらけている 第5セグメントのユーザにおいて KPI の数値(ARPU/アクセス回数) が高い事が判明

まとめ
12
1.クラスタリングへの道筋 1.ランキング結果により上位ユーザを抽出 2.データクレンジングにより不要な項目を除去 3.ユーザクラスタリングの実施 4.クラスタリング結果の可視化(レーダーチャート) 5.クラスタ毎の KPI を確認
2.単純な属性ではなく行動履歴によるクラスタリング 1.アクセス頻度 2.課金額/回数 3.ゲーム内アクション
3.データクレンジングは大事