Embed Size (px)
Citation preview

VIỆN NGHIÊN CỨU Y XÃ HỘI HỌC
Ứng dụng phân tích hồi quy
Nguyễn Trương Nam
Copyright – Bản quyền thuộc về tác giả và thongke.info. Khi sử dụng một
phần hoặc toàn bộ bài giảng đề nghị mọi người trích dẫn: tên tác giả và
thongke.info. Ví dụ: Nguyễn Thị Linh – Thongke.info.

Nội dung
Tại sao cần phân tích hồi quy?
Các bước xây dựng mô hình hồi quy
Hồi quy tuyến tính đa biến
Hồi quy logic

Đây là ví dụ về hồi quy đa biến, chúng ta ước tính Y=Điểm tổng kết năm đầu tiên đại học X1=xếp hạng THPT, X2= Điểm thi vào đại học, X3=giới tính.

Tại sao cần phân tích hồi quy?
Trong nghiên cứu bán thử nghiệm (quasi-experiment), nghiên cứu viên
không thể có khả năng thay đổi (manipulate) các biến độc lập, do đó
thường có các biến nhiễu xuất hiện. Chúng ta cố gắng để khắc phục
tình huống này bằng phương pháp thống kê cụ thể là sử dụng hồi quy
đa biến.
Trong hồi quy đa biến mối liên hệ của biến phụ thuộc (kết quả) và biến
độc lập (tác động) được đánh giá trong khi kiểm soát các biến nhiễu
khác
Mục đích của hồi quy đa biến: 1) dự báo (prediction): tìm hiểu/phát
hiện các yếu tố có thể dự báo một hiện tượng (biến kết quả); 2) giải
thích (explaination): tìm hiểu/phát hiện các hệ thống/quy trình hoặc
nguyên nhân dẫn tới một hiện tượng.
James Cotter (2001) HUMD5122-Applied
Regression Analysis

Lý do cần phân tích đa biến- ví dụ
ISMS Nghiên cứu đánh giá tác động của một chương trình can thiệp
(kéo dài 2 năm) lên kiến thức và hành vi của trẻ em đường phố tại HP
và HCMC 2010
Hai nhóm: tham gia vào dự án (nhóm can thiệp) – nhóm không tham
gia dự án (nhóm chứng)
Sự thay đổi kiến thức, thái độ, hành vi của nhóm can thiệp sẽ không
chỉ chịu tác động của dự án nói riêng mà còn chịu tác động của các yếu
tố khác ví dụ các chương trình PC HIV khác trên địa bàn, môi trường
sống, tuổi tác, giới tính, có sử dụng ma túy, có bán dâm, nghề kiếm
sống….
Như vậy mối liên quan giữa tham gia dự án và thay đổi hành vi phải
được xem xét/phân tích khi kiểm soát các tác động của các yếu tố
nhiễu khác. Đây chính là nguyên lý của phân tích đa biến
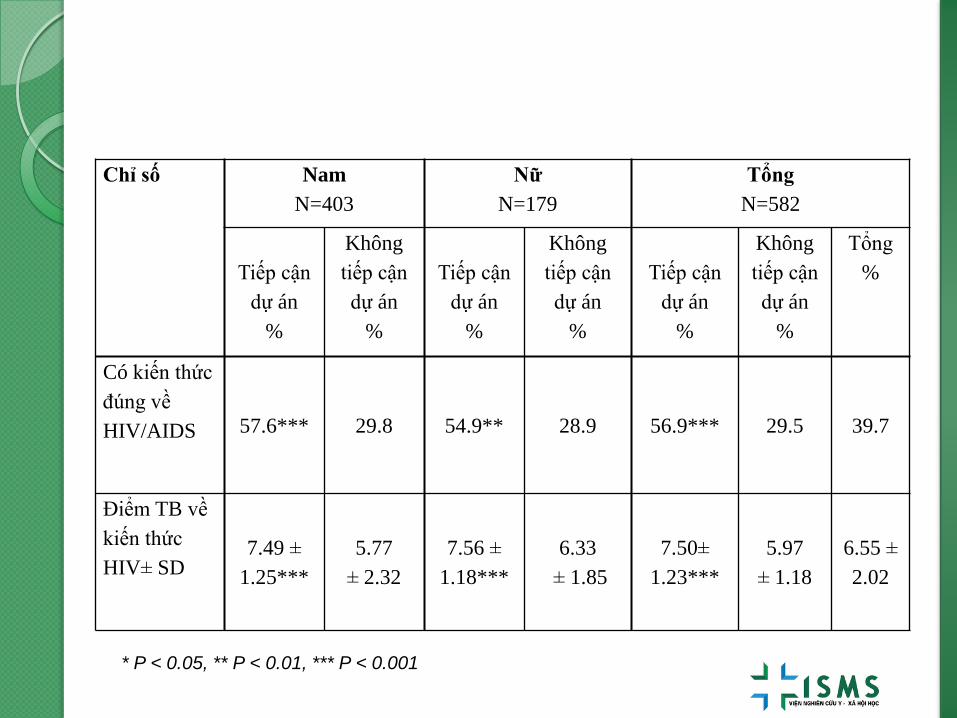
Chỉ số Nam
N=403
Nữ
N=179
Tổng
N=582
Tiếp cận
dự án
%
Không
tiếp cận
dự án
%
Tiếp cận
dự án
%
Không
tiếp cận
dự án
%
Tiếp cận
dự án
%
Không
tiếp cận
dự án
%
Tổng
%
Có kiến thức
đúng về
HIV/AIDS 57.6*** 29.8 54.9** 28.9 56.9*** 29.5 39.7
Điểm TB về
kiến thức
HIV± SD 7.49 ±
1.25***
5.77
± 2.32
7.56 ±
1.18***
6.33
± 1.85
7.50±
1.23***
5.97
± 1.18
6.55 ±
2.02
* P < 0.05, ** P < 0.01, *** P < 0.001
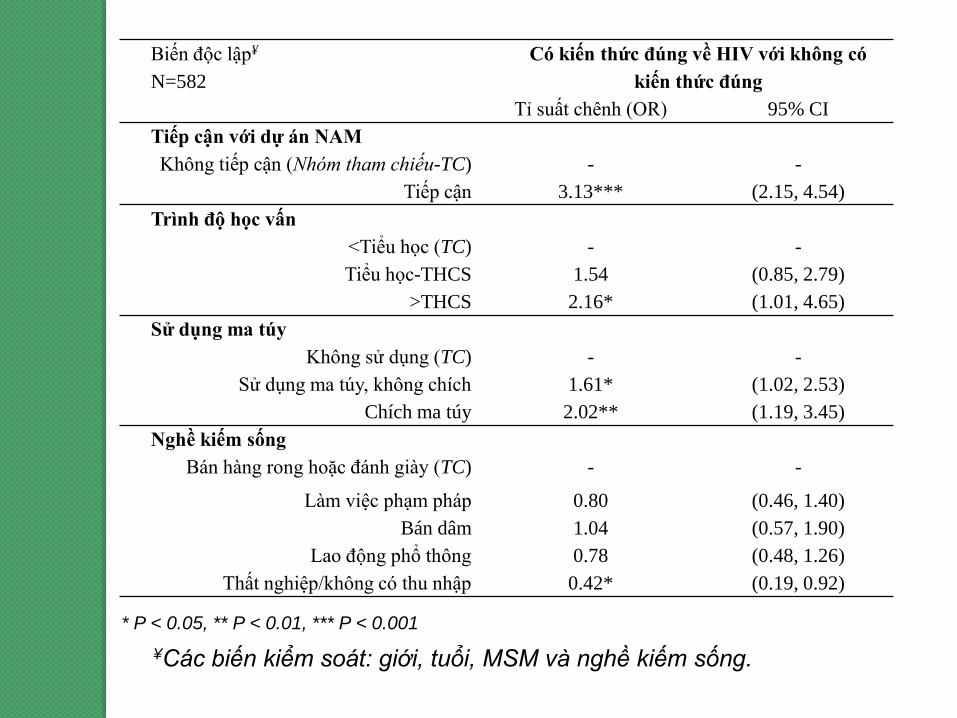
Biến độc lập¥
N=582
Có kiến thức đúng về HIV với không có
kiến thức đúng
Tỉ suất chênh (OR) 95% CI
Tiếp cận với dự án NAM
Không tiếp cận (Nhóm tham chiếu-TC) - -
Tiếp cận 3.13*** (2.15, 4.54)
Trình độ học vấn
<Tiểu học (TC) - -
Tiểu học-THCS 1.54 (0.85, 2.79)
>THCS 2.16* (1.01, 4.65)
Sử dụng ma túy
Không sử dụng (TC) - -
Sử dụng ma túy, không chích 1.61* (1.02, 2.53)
Chích ma túy 2.02** (1.19, 3.45)
Nghề kiếm sống
Bán hàng rong hoặc đánh giày (TC) - -
Làm việc phạm pháp 0.80 (0.46, 1.40)
Bán dâm 1.04 (0.57, 1.90)
Lao động phổ thông 0.78 (0.48, 1.26)
Thất nghiệp/không có thu nhập 0.42* (0.19, 0.92)
¥Các biến kiểm soát: giới, tuổi, MSM và nghề kiếm sống.
* P < 0.05, ** P < 0.01, *** P < 0.001

Bảng: So sánh mức độ sử dụng BCS với PNMD trong vòng 6 tháng qua giữa nhóm tiếp
cận và không tiếp cận dự án
Tiếp cận với dự
án
N=29
%
Không tiếp cận với
dự án
N=48
%
Tổng
N=77
%
Mức độ sử dụng BCS với
PNMD
Luôn luôn 58.6* 35.4 38.2
Thường xuyên 10.3 14.6 13.0
Thỉnh thoảng 31.0 22.9 26.0
Hiếm khi 0 27.9 16.0
Một số bằng chứng cho thấy dự án NAM đã có tác động tích cực vào hành vi sử
dụng BCS với PNMD của nam TNDP.Tỉ lệ luôn luôn sử dụng BCS trong vòng 6
tháng qua của trong nhóm có tiếp cận với dự án NAM là 59% trong khi đó tỉ lệ này
ở nhóm không tiếp cận với dự án chỉ là 35%.
* P < 0.05, ** P < 0.01, *** P < 0.001

Biến độc lâp
N=82
Sử dụng BCS với PNMD tất cả các lần
(So với không phải tất cả các lần)
OR (tỉ suất chênh) 95% CI
Tiếp cận với dự án NAM
Không tiếp cận (TC) - -
Tiếp cận 3.55 (0.89, 14.11)
Tỉnh/TP
Hai Phong (TC) - -
Ho Chi Minh 0.06*** (0.01, 0.28)
Phân loại TNDP
Các nhóm khác (TC) - -
Nhóm A 0.19* (0.04, 0.94)
Sử dụng ma túy
Không sử dụng (TC) -
Sử dụng ma túy nhưng
không chích
0.74 (0.16, 3.41)
Tiêm chích 0.13* (0.02, 0.91)
Mối quan hệ giữa tiếp cận dự án và sử dụng BCS trong phân tích đa biến không
còn ý nghĩa thống kê (P > 0.005). Kết quả này khác so với các phân tích đôi biến,
bởi vì mô hình đa biến kiểm soát các yếu tố nhiễu tiềm tàng
Hồi quy logic giữa sử dụng bao cao su với PNMD và tiếp cân với dự án NAM
*P < .05 **P<.01 ***P<.001

Xây dựng mô hình hồi quy: đa biến, logic

Hồi quy đa biến
Y = Biến phụ thuộc, liên tục
X1, X2,… Tất cả các biến độc lập là liên tục
hoặc
X1, X2, … Các biến độc lập bao gồm cả
biến liên tục và biến nhị phân (dummy).
X1, X2, … Tất cả các biến độc lập là biến
nhị phân (dummy).

Hồi quy Logic
Y: Biến phụ thuộc là biến nhị phân (biến
đầu ra).
X1, X2,… Tất cả các biến độc lập là biến
liên tục hoặc
X1, X2, … Các biến độc lập bao gồm cả
biến liên tục và biến nhị phân (dummy).
X1, X2, … Tất cả các biến độc lập là biến
nhị phân (dummy).

Ví dụ.
Hồi quy đa biến (Multiple Regression)
◦ Số lần khám thai = b0 + b1(tuổi) + b2(dân tộc)+
b3(học vấn) + b4(tình trạng hôn nhân).
Hồi quy Logic (Logistic Regression)
◦ Hành vi nạo phá thai = b0 + b1(tuổi) + b2(dân
tộc)+ b3(học vấn) + b4(tình trạng hôn nhân)+b5
(Nghề nghiệp) +b6 (tuổi quan hệ tình dục lần
đầu).

Các bước xây dựng mô hình hồi quy
1) Xác định mô hình
◦ Chuyển câu hỏi nghiên cứu thành phương trình
hồi quy.
◦ Xác định các biến độc lập (biến dự đoán).
2) Đánh giá các yếu tố nguy cơ ảnh hưởng tới hiệu
lực của kiểm định thống kê (valid inference)
◦ Cỡ mẫu: đủ mẫu để đảm bảo 20 mẫu/biến độc lập.
◦ Phân phối chuẩn của biến số.
◦ Đảm bảo các biến độc lập – không tương quan.
◦ Kiểm tra và loại trừ outliers.

Các bước xây dựng mô hình hồi quy
3) Xây dựng mô hình (fitting models)
Fitting full model (dựa trên học thuyết – theory).
Fitting từng model bằng cách thêm biến, đánh giá
model fit dựa trên các tiêu chí thống kê, lựa chọn
model tốt nhất – good fit (thăm dò – explotary).
Tự động, ví dụ Stepwise regression.
4) chạy mô hình hồi quy và trình bày kết quả

Xây dựng các mô hình- Chọn các biến trong
mô hình như thế nào?
Y: Biến phụ thuộc (biến kết quả).
X1, X2, X3: Biến độc lập (biến dự đoán).
Mô hình hồi quy đa biến lý tưởng là mô hình có các biến độc lập có mối liên quan lớn (tuyến tính) với Y (biến phụ thuộc) và biến độc lập tương đối độc lập với nhau.
Điều này đặt ra câu hỏi chung là làm thế nào để thiết kế mô hình hồi đa biến tốt?. Trong trường hợp chúng ta đang sư dụng hồi quy đa biến để kiểm định giả thuyết, tốt nhất là nên dựa vào chính giả thuyết đó để quyết định những biến độc lập nào sẽ được sử dụng trong mô hình.
Nhưng trong việc thiết kế mô hình tốt để kiểm định một giả thuyết, chúng ta cũng cần phải dùng một số các tiêu chí thống kê đã được đề cập để quyết định xây dựng mô hình.
James Cotter (2001) HUMD5122-Applied
Regression Analysis

Các nguyên tắc để thiết kế mô hình hồi quy đa
biến tốt.
Cố gắng đưa tất cả các biến có liên quan quan trọng vào mô hình hồi quy (nếu không thì tham số ước tính có thể bị sai số). Trong nghiên cứu bán thử nghiệm, chúng ta cố gắng đưa tất cả các biến nhiễu không kiểm soát được quan trọng vào mô hình.
Đảm bảo sự cân bằng giữa mô hình ít tham số“Parsimony” và “Good fit” (có thể làm tăng lên bằng cách thêm các tham số).
Không nên sử dụng quá nhiều biến độc lập cho một số hạn đinh đối tượng nghiên cứu. Một nguyên tắc là mỗi biến độc lập được đưa vào mô hình phải có ít nhất 20 đối tượng quan sát (Tốt nhất là 40-50 đối tượng cho 1 biến độc lập, nhất là khi xây dựng luận thuyết).

Các nguyên tắc để thiết kế mô hình hồi quy đa
biến tốt.
Sử dụng các biến độc lập không có mối tương quan lẫn
nhau (Tránh Multicolinearity). Biến độc lập phải tương đối
‘độc lập’.
Không đưa các biến độc lập giống nhau (thừa) vào cùng
một mô hình. Ví dụ: không sử dụng 2 biến (X1) cấp học
trong kỳ thi cuối cùng và (X2) xếp hạng trong kỳ thi cuối
cùng trong cùng một mô hình để dự đoán về một số các
thay đổi kết quả của học sinh- vì 2 biến này đều dựa trên
các khái niệm và thống kê gần như nhau (redundant).
James Cotter (2001) HUMD5122-Applied
Regression Analysis

Ví dụ.
Hồi quy đa biến (Multiple Regression)
◦ Số lần đi khám thai = b0 + b1(tuổi) + b2(dân
tộc)+ b3(học vấn) + b4(tình trạng hôn nhân) +
b5(nghề nghiệp).
Hồi quy Logic (Logistic Regression)
◦ Hành vi nạo phá thai = b0 + b1(tuổi) + b2(dân
tộc)+ b3(học vấn) + b4(tình trạng hôn nhân)+b5
(Nghề nghiệp) +b6 (tuổi quan hệ tình dục lần
đầu).

Các biến được sử dụng trong mô hình.
1/ Mô hình hồi quy đa biến.
Biến phụ thuộc: Số lần đi khám thai (Q83)
Biến độc lập.
1. Tuổi (Q2)
2. Dân tộc (q3)
3. Học vấn (q10)
4. Tình trạng hôn nhân (q5)
5. Nghề nghiệp (Q8)
2/ Mô hình hồi quy logistic.
Biến phụ thuộc: Đã từng nạo phá thai chưa? (Q40_recode).
Các biến độc lập.
1. Tuổi (Q2)
2. Dân tộc (q3)
3. Học vấn (q10)
4. Tình trạng hôn nhân (q5)
5. Nghề nghiệp (Q8)
6. Tuổi quan hệ tình dục lần đầu (Q27).

Chuẩn bị các biến cho mô hình hồi quy
(Variable transformation for regression).
1/ Kiểm tra sự phân bố chuẩn của biến phụ thuộc.
2/ Kiểm tra tính độc lập-không tương quan của các biến độc lập.
3/ tạo hoặc recode lại các biến độc lâp danh mục thành các biến dummy.
◦ Với các biến có 2 lựa chọn trả lời, recode lại thành 1 và 0.
◦ Với những biến có từ 3 lựa chọn trả lời trở lên, thì sẽ tạo các biến dummy (1-0) cho mỗi lựa chọn. Đưa (n-1) biến vào mô hình (biến còn lại mà không được đưa vào mô hình sẽ là biến tham khảo - reference cho các biến khác).

Ví dụ: Hồi quy đa biến.
Hồi quy đa biến (Multiple Regression)
◦ Số lần đi khám thai = b0 + b1(tuổi) + b2(dân
tộc)+ b3(học vấn) + b4(tình trạng hôn nhân) +
b5(nghề nghiệp).
◦ Có thể thêm: tình trạnh kinh tế

Kiếm tra sự phân bố chuẩn của biến phụ thuộc: Số lần đi khám thai?
Biến phụ thuộc:

Các biến độc lập trong mô hình phải độc lập và
không tương quan với nhau
1. Dựa vào kết quả từ các nghiên cứu khác
2. Dựa vào các phương pháp tính toán.
- Kiểm tra bằng lệnh correlate:
Analyze/correlate/bivariate.
- Kiểm tra trực tiếp trong linear thông qua
collinerity diagnostics: tolerance (<0.1 -
bad) and VIF (1/tolerance)

Cách 1: Kiểm tra bằng lệnh correlate:
Analyze/correlate/bivariate.
CORRELATIONS
/VARIABLES=Q2 Q3 Q10 Q5 Q8
/PRINT=TWOTAIL NOSIG
/MISSING=PAIRWISE.

Với những giá trị Pearson Corrleration >0.7, chứng tỏ các biến đó
tương quan lớn với nhau do đó phải loại 1 trong các biến đó ra khỏi
mô hình.

Cách 2: Kiểm tra trực tiếp khi chạy regression thông qua
colinearity diagnostics.
TOLERANCE (<0.1 – bad)
VIF (1/tolerance)

Chuyển các biến độc lập (rời rạc) về dạng
dummy.
*********independent vars*******
***ethnicity****
Recode Q3 (1=1) (2 thr 8 =0) into ethnicre.
var label ethnicre "Ethnicity-Kinh and other".
value label ethnicre 1"Kinh" 0"Other".
missing value ethnicre(9).

*******education********
RECODE q7 (SYSMIS=SYSMIS) (0 thru 5 = 1) (6 thru 9 = 2) (10 thru 12= 3) (13 thru 15=4) (99=SYSMIS) INTO educat.
VARIABLE LABEL educat 'educat - Education completed, categorized'.
VALUE LABEL educat
1 'Primary/Under primary School'
2 'Secondary School'
3 'High/vocational school'
4 'College/University and above'.
EXECUTE.
FREQUENCIES educat.
****Tạo các biến dummy
compute edu2=9.
if (educat=2) edu2=1.
if (educat=1 or educat=3 or educat=4) edu2=0.
VARIABLE LABELS edu2 "Edu2-Secondary school".
value labels edu2 1"Secondary school" 0 "Other".
missing values edu2 (9).
Compute edu3=9..
if (educat=3) edu3=1.
if (educat=1 or educat=2 or educat=4) edu3=0.
VARIABLE LABELS edu3 "Edu3-High school".
value labels edu3 1"High school" 0 "Other".
missing values edu3 (9).
Compute edu4=9.
if (educat=4) edu4=1.
if (educat=1 or educat=2 or educat=3) edu4=0.
VARIABLE LABELS edu4 "Edu4-College/higher".
value labels edu4 1"college/higher" 0 "Other".
missing values edu4 (9).

***************Marital status
RECODE q5 (1=1) (2=2) (3=1) (4=2) (5=3) INTO q5recode.
VARIABLE LABEL Q5RECODE 'Q5recode-Marital status recategorized'.
VALUE LABELs Q5recode
1 'Married or lives with partner'
2 'Divorced/widowed/separated/not living with spouse'
3 'Single (never married)'.
execute.
******Tạo các biến dummy.
compute mar1=9.
if (q5recode=1) mar1=1.
if (q5recode=2 or q5recode=3) mar1=0.
VARIABLE LABELS mar1 "Mar1-Married or lives with a partner".
value labels mar1 1"Married/live with a partner" 0"Other".
missing values mar1(9).
execute.
compute mar2=9.
if (q5recode=2) mar2=1.
if (q5recode=1 or q5recode=3) mar2=0.
VARIABLE LABELS mar2 "Mar2-divorced/widowed".
value labels mar2 1"widowed/divorced" 0"Other".
missing values mar2(9).
execute.

***********Occupation
Recode Q8 (1=0) (2 thr 8 =1) into occunew.
var label occunew "Occupation-Famer and other".
value label occunew 0"Famer" 1"Other".
missing value occunew(9).

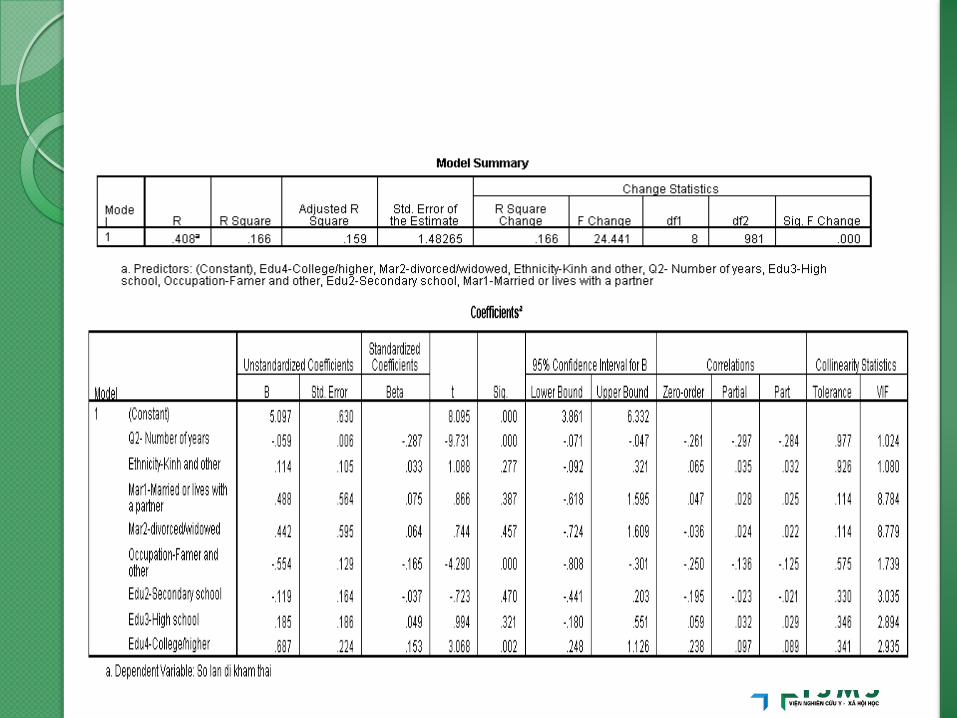
Fitting full model.
SỐ LẦN KHÁM THAI = a + b1(tuổi) + b2(dân tộc) + b3(học vấn cấp 2) + b4 (học vấn cấp 3) + b5(học vấn trên cấp 3) + b6 (tt hôn nhân)+ b7 (nghề nghiệp)
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT Q83_Re
/METHOD=ENTER Q2 ethnicre edu2 edu3 edu4 mar1 mar2 occunew.


Fitting từng model bằng cách thêm biến, đánh giá
model fit dựa trên các tiêu chí thống kê.
*****Model with 3 independent vars
SỐ LẦN KHÁM THAI = a + b1(tuổi) + b2(dân
tộc) + b3 (nghề nghiệp)
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT Q83_Re
/METHOD=ENTER Q2 ethnicre occunew.


*******5 independents vars
SỐ LẦN KHÁM THAI = a + b1(tuổi) + b2(dân tộc) + b3 (nghề
nghiệp) + b4(cấp 2) + b5(cấp 3) + b6(> cấp 3)+b7 (tt hôn nhân).
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT Q83_Re
/METHOD=ENTER Q2 ethnicre edu2 edu3 edu4 occunew mar1 mar2.


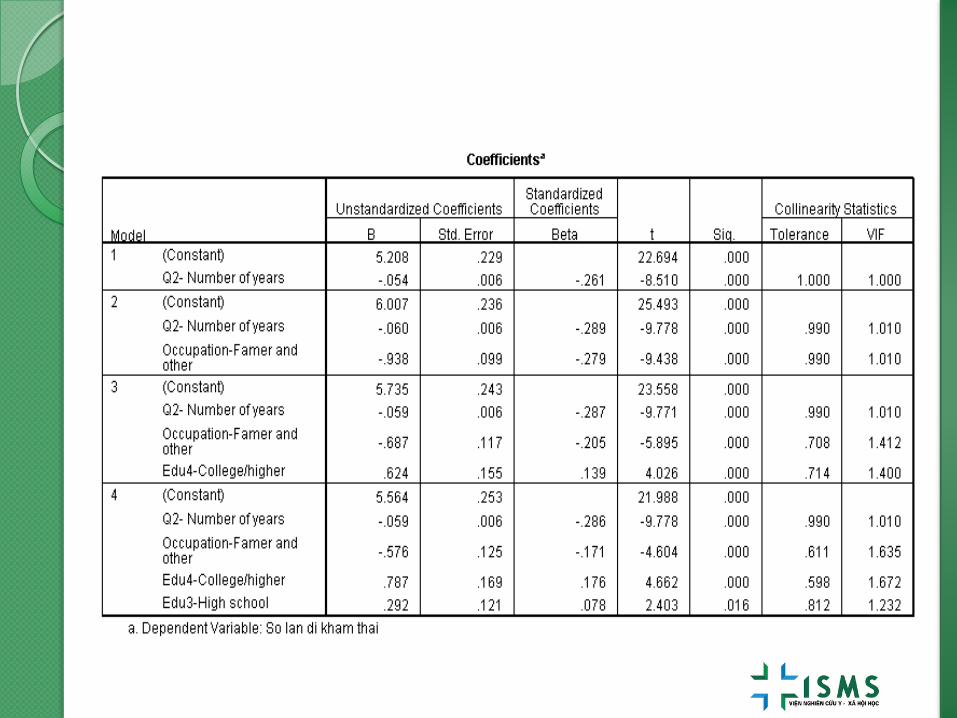
Sự thay đổi R2 sau khi thêm biến nghề nghiệp
và học vấn.

Stepwise.
*******Backward
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA COLLIN TOL CHANGE
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT Q83_Re
/METHOD=BACKWARD Q2 ethnicre mar1 mar2 occunew edu2 edu3 edu4.


******Forward
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA COLLIN TOL CHANGE
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT Q83_Re
/METHOD=FORWARD Q2 ethnicre mar1 mar2 ethnicre mar1 mar2
occunew edu2 edu3 edu4.

Ví dụ.
Hồi quy Logic (Logistic Regression)
◦ Hành vi nạo phá thai = b0 + b1(tuổi) + b2(dân
tộc)+ b3(học vấn) + b4(tình trạng hôn nhân)+b5
(Nghề nghiệp) +b7 (tuổi quan hệ tình dục lần
đầu).

Các biến độc lập trong mô hình phải uncorrelated or independent
với nhau
1. Dựa vào kết quả các nghiên cứu khác
2. Dựa vào các phương pháp tính toán. - Kiểm tra bằng lệnh correlate: Analyze/correlate/bivariate.
- Kiểm tra trực tiếp trong logistic regression thông qua
correlation.

Recode biến độc lập thành biến dummy
*********Age of first intercourse
Recode Q27 (14 thru 17=1) (18 thru 24=2) (25 thru highest=3) into agefirstsex_cat.
***Tạo biến dummy**
compute agefirstsex2=9.
if (agefirstsex_cat=2) agefirstsex2=1.
if (agefirstsex_cat=1) or (agefirstsex_cat=3) agefirstsex2=0.
VARIABLE LABELS agefirstsex2 "18-24 had first intercourse".
value labels agefirstsex2 1 "had first sex at 18-24" 0"Other".
missing values agefirstsex2(9).
compute agefirstsex3=9.
if (agefirstsex_cat= 3) agefirstsex3=1.
if (agefirstsex_cat=1) or (agefirstsex_cat=2) agefirstsex3=0.
VARIABLE LABELS agefirstsex3 ">24 had first intercourse".
value labels agefirstsex3 1 "had first sex at >24" 0"Other".
missing values agefirstsex3 (9).

Fitting full model.
Đã từng nạo thai = a + b1(tuổi) + b2(dân tộc) + b3(hôn
nhân) + b4(nghề nghiệp) + b5(học cấp 2) + b6(học cấp 3)
+ b7(trên cấp 3) + b8(tuổi lần đầu có sex)
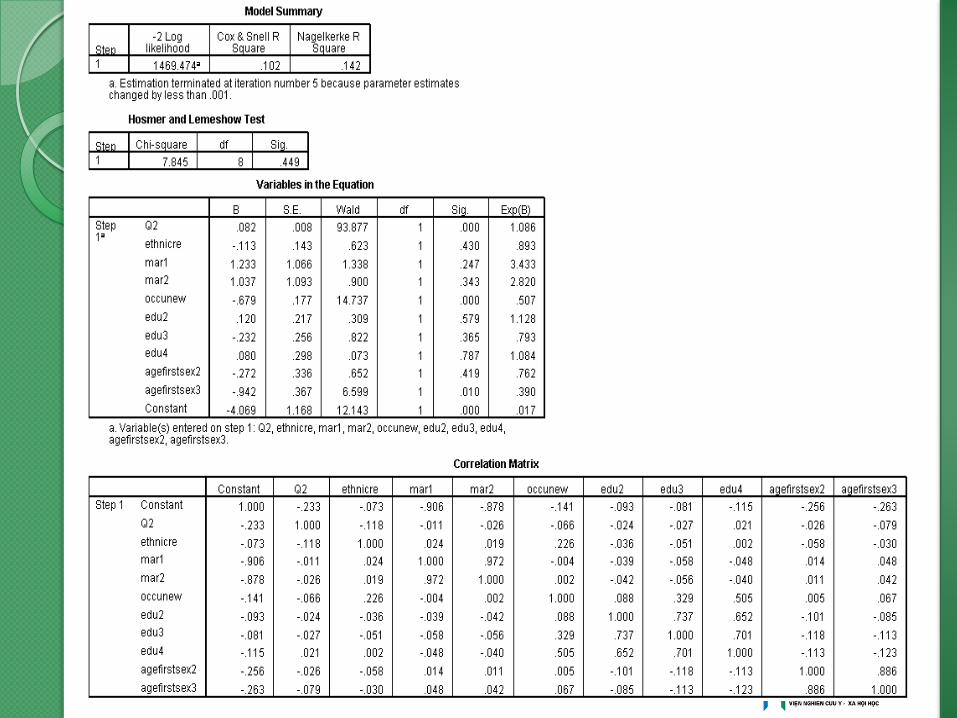
LOGISTIC REGRESSION VARIABLES everabor
/METHOD=ENTER Q2 ethnicre mar1 mar2 occunew edu2
edu3 edu4 agefirstsex2 agefirstsex3
/PRINT=GOODFIT CORR
/CRITERIA=PIN(0.05) POUT(0.10) ITERATE(20)
CUT(0.5).


Fitting từng model bằng cách thêm biến, đánh giá
model fit dựa trên các tiêu chí thống kê.
*****Model với 2 biến độc lập (independent vars)
Đã từng nạo thai = a + b1(tuổi) + b2(dân tộc)
LOGISTIC REGRESSION VARIABLES everabor
/METHOD=ENTER Q2 ethnicre
/PRINT=GOODFIT CORR
/CRITERIA=PIN(0.05) POUT(0.10) ITERATE(20) CUT(0.5).


*******mô hình với 4 biến độc lập - independents vars
Đã từng nạo thai = a + b1(tuổi) + b2(dân tộc) + b3(hôn
nhân) + b4(nghề nghiệp)
LOGISTIC REGRESSION VARIABLES everabor
/METHOD=ENTER Q2 ethnicre mar1 mar2 occunew’
/PRINT=GOODFIT CORR
/CRITERIA=PIN(0.05) POUT(0.10) ITERATE(20)
CUT(0.5).


Mô hình với 6 biến độc lập - independent vars
Đã từng nạo thai = a + b1(tuổi) + b2(dân tộc) +
b3a(đã lập gia đình) + b3b(ly dị/góa)+ b4(nghề
nghiệp) + b5a(học cấp 2) + b5b(học cấp 3) +
b5c(trên cấp 3) + b6a(tuổi lần đầu có sex 19-
24)+b6b(tuổi lần đầu có sex >24)
LOGISTIC REGRESSION VARIABLES everabor
/METHOD=ENTER Q2 ethnicre mar1 mar2 occunew
edu2 edu3 edu4 agefirstsex2 agefirstsex3
/PRINT=GOODFIT CORR
/CRITERIA=PIN(0.05) POUT(0.10) ITERATE(20)
CUT(0.5).


Sự thay đổi của -2log likelihooh
Mô hình 2 biến độc lập: 1509
Mô hình 4 biến: 1492
Mô hình 6 biến: 1469

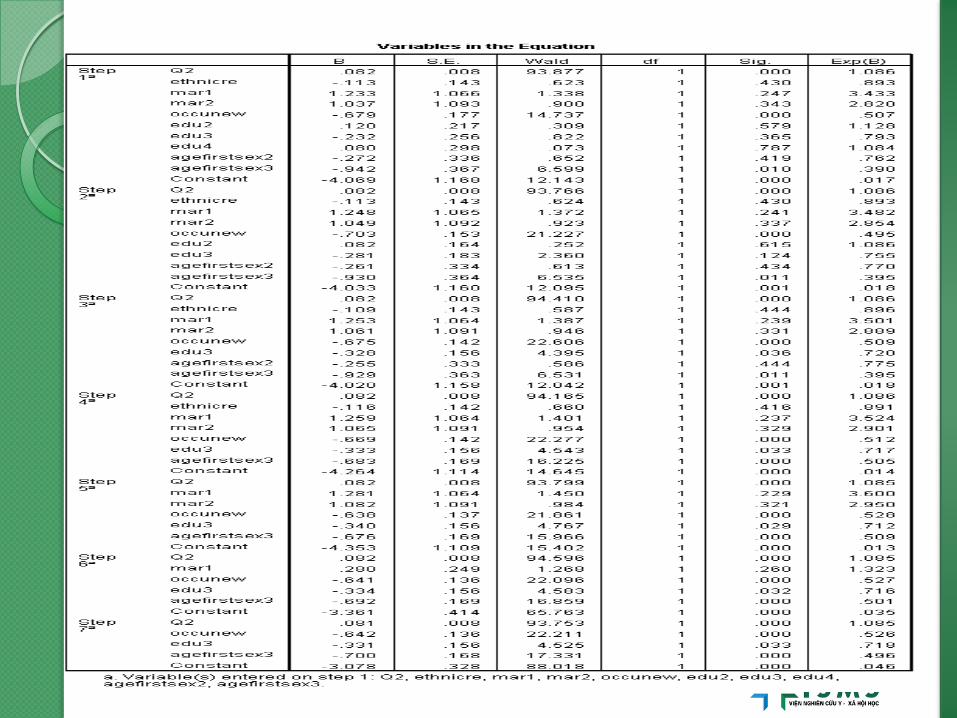
Stepwise.
*******Backward
LOGISTIC REGRESSION VARIABLES everabor
/METHOD=BSTEP(COND) Q2 ethnicre mar1 mar2 occunew edu2 edu3 edu4 agefirstsex2 agefirstsex3
/PRINT=GOODFIT CORR
/CRITERIA=PIN(0.05) POUT(0.10) ITERATE(20) CUT(0.5).


******Forward
LOGISTIC REGRESSION VARIABLES everabor
/METHOD=FSTEP(COND) Q2 edu2 edu3 edu4 ethnicre
mar1 mar2 occunew agefirstsex2 agefirstsex3
/PRINT=GOODFIT CORR
/CRITERIA=PIN(0.05) POUT(0.10) ITERATE(20)
CUT(0.5).






























