Embed Size (px)
Citation preview

Transfer learning在广告点击率预估的应用
黄晶微博:黄晶 PKU
2015.6
个人简介: jhuangpku.github.io
library(wordcloud)
wordcloud(blog$word, blog$freq, random.order=F, color=pal)

主要内容
业务问题
解决方案
学术界方案
Data-level transfer
Parameter-level transfer
应用效果 &Future Work
广告时间 ----WE ARE HIRING

什么是在线广告
广告 A 出价 5元
规则
广告主对关键词出价 bid
点击一次收费 bid (实际
GSP )
目标:收益最大化
有限位置怎么选择广告?
Bid* 广告点击率降序排列
核心问题:点击率怎么估计
点击率: 0 平均收益: 0 元
广告 B 出价 2元
广告 C 出价 1元
点击率: 0.1 平均收益: 0.2元
点击率: 0.1 平均收益: 0.1元

怎么预估点击率 数据 / 样本
一个广告的一次展现 特征
ID 类特征泛化特征统计特征….
模型LR->GBDT->DNN

怎么预估点击率 -LR
数据集
1 0 0 …
1 0 0 …
0 1 0 …
0 0 0 …
0 0 0 …
0 1 0 …
0 0 1 …
1
0
1
0
0
0
0
Target y
X1
X2
X3
X4
X5
X6
X7
0 0 0 …
1 0 0 …
1 0 0 …
0 1 0 …
0 0 0 …
0 1 0 …
0 0 1 …
。。
query 广告 ID
Y=1
Y=0
||||),,(min1
wCywXlm
iiii
距离分界面越远, loss 越小
))),(1log()1(),(log(),,( wXhywXhyywXl iiiiiii
)exp(1
1),(
iti Xw
wXh
)exp(1
1)|1(P
iti Xw
Xy
点击率学习目标:给定样本, y=1 的概率
0 0 1 … ?Xn 0 0 1 …

我们的问题 - 商业知心
广告
成
特点:同一套广告描述 VS 多种展现形式(不断有新展现形式)

学术界方法Instance-base
Feature-base Parameter-base借数据
借数据 借参数
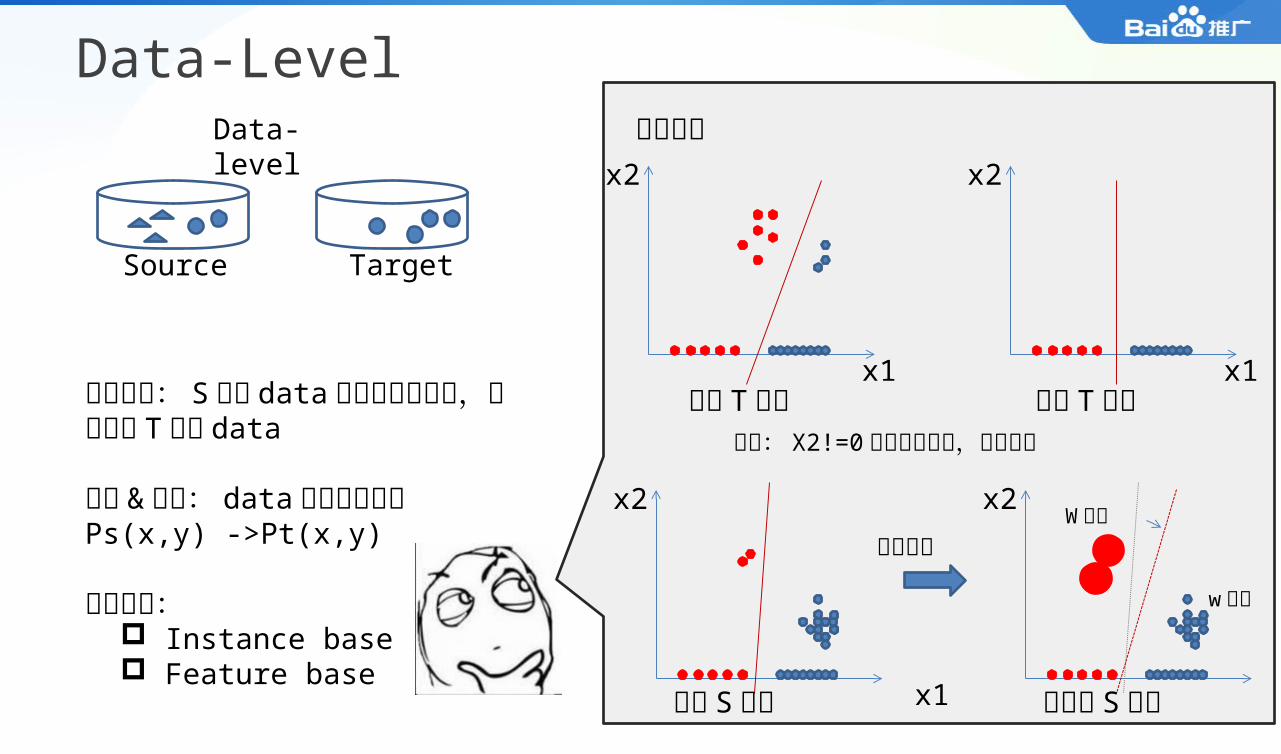
Data-Level
Source Target
Data-level
基本假设: S 上的 data 经过合理的变化,可以变成 T 上的 data
核心 & 问题: data 相似度的衡量Ps(x,y) ->Pt(x,y)
代表方法: Instance base Feature base x1
三维示例
x1
x2
问题: X2!=0 的由于数据少,未观测到
x1
x2
真实 T 分布x1
x2
相似变换
x2
w 降低
W 增加
观测 S 分布
观测 T 分布
调整后 S 分布

Data-Level
Source Target
Data-level
基本假设: S 上的 data 经过合理的变化,可以变成 T 上的 data
核心 & 问题: data 相似度的衡量Ps(x,y) ->Pt(x,y)
代表方法: Instance base Feature base
现实是噪音!噪音!!噪音!!!

Parameter-LevelParameter-level
基本假设: S 上的权重和 T 上的权值有”相似性”
核心 & 问题:权值相似度的衡量该度量方法表现为一个约束
代表方法: parameter base
W1W2
W3 W3’W4 W4’W5 W5’
Common
source target
||||)()(2
1)()( ''' wwCwwLwwLwwwLwf SSTSS
TSS
target 上的拟合 正则
新权值在 Source 的数据上的 loss 近似模拟
另一种观点: bayes LR 提供的是先验
:source 上的权重:target 上的权重
SwwwS Sw

Parameter revisitedParameter-level
W1W2
W3 W3’W4 W4’W5 W5’
Common
source target
近似实现 common-part 和 individual-part 的方法:Step1 :在 source 上的训练只训练“可迁移”的特征— common-partStep2 :在 target 上把所有特征带进去训练
效果: common-part 变动较少, individual-part 变动较多Common-part 的业务含义,不同 query 在不同卡片的 weight 近似一致
||||)()(2
1)()( ''' wwCwwLwwLwwwLwf SSTSS
TSS

应用效果 &Future Work
应用效果
Future Work数据: Source , target 的选择特征:可迁移特征的选择(单 slot 在 S 上训练 T 上校验)模型: multi-task / GBDT 增量
项目 线下 auc 线上 ctr
医疗知心中间页找医院 TL 模型 +0.8% 2.08%
教育知心无线找课程 TL 模型 +5%+ 7.52%































