Embed Size (px)
DESCRIPTION
言語プロセッサ 2006 -No.2( 平成 19 年 10 月 3 日 )-. 東京工科大学 コンピュータサイエンス学部 亀田弘之. 数式の例. A = B*3.14 + C/A Area = 2*3.14*R*R. 数式の解析. kingaku = teika + teika * shouhizei. =. kingaku. +. teika. *. teika. shouhizei. 数式の解析. 読み込み(文字列として) “ kingaku = teika + teika * shouhizei” - PowerPoint PPT Presentation
Citation preview

Copyright© 2007 School of Computer Science, Tokyo University of Technology
言語プロセッサ 2006-No.2( 平成 19 年 10 月 3 日 )-
東京工科大学コンピュータサイエンス学部
亀田弘之

Copyright© 2007 School of Computer Science, Tokyo University of Technology
数式の例• A = B*3.14 + C/A
• Area = 2*3.14*R*R

Copyright© 2007 School of Computer Science, Tokyo University of Technology
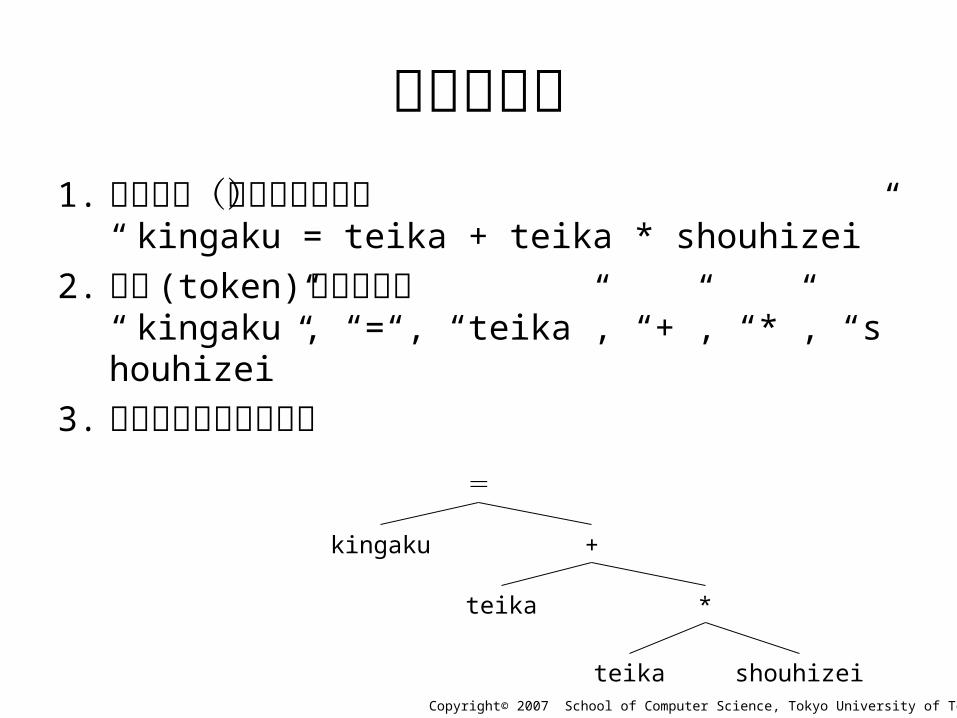
数式の解析• kingaku = teika + teika * shouhizei
Copyright© 2007 School of Computer Science, Tokyo University of Technology
数式の解析1. 読み込み(文字列として)
“ kingaku = teika + teika * shouhizei”
2. 要素 (token) の切り出し“ kingaku”, “=“, “teika”, “+”, “*”, “shouhizei”
3. 要素の相互関係の分析=
kingaku
teika
teika
+
shouhizei
*
Copyright© 2007 School of Computer Science, Tokyo University of Technology
ソース言語
読み込み
字句解析
構文解析
中間語生成
コード生成
目的言語
分析分析
合成合成
Copyright© 2007 School of Computer Science, Tokyo University of Technology
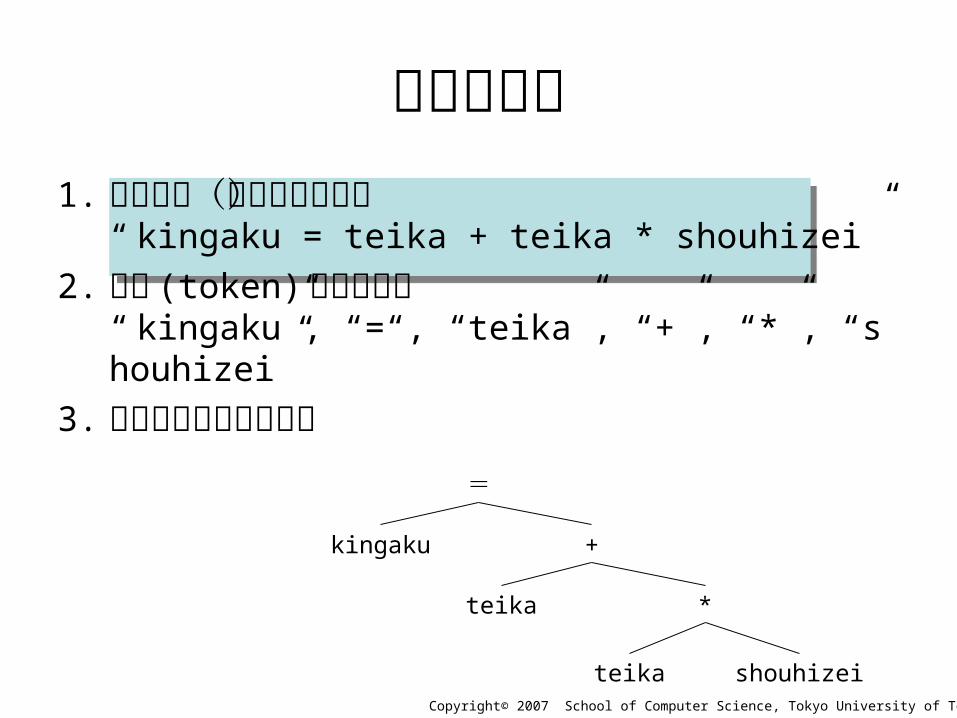
数式の解析1. 読み込み(文字列として)
“ kingaku = teika + teika * shouhizei”
2. 要素 (token) の切り出し“ kingaku”, “=“, “teika”, “+”, “*”, “shouhizei”
3. 要素の相互関係の分析=
kingaku
teika
teika
+
shouhizei
*
Copyright© 2007 School of Computer Science, Tokyo University of Technology
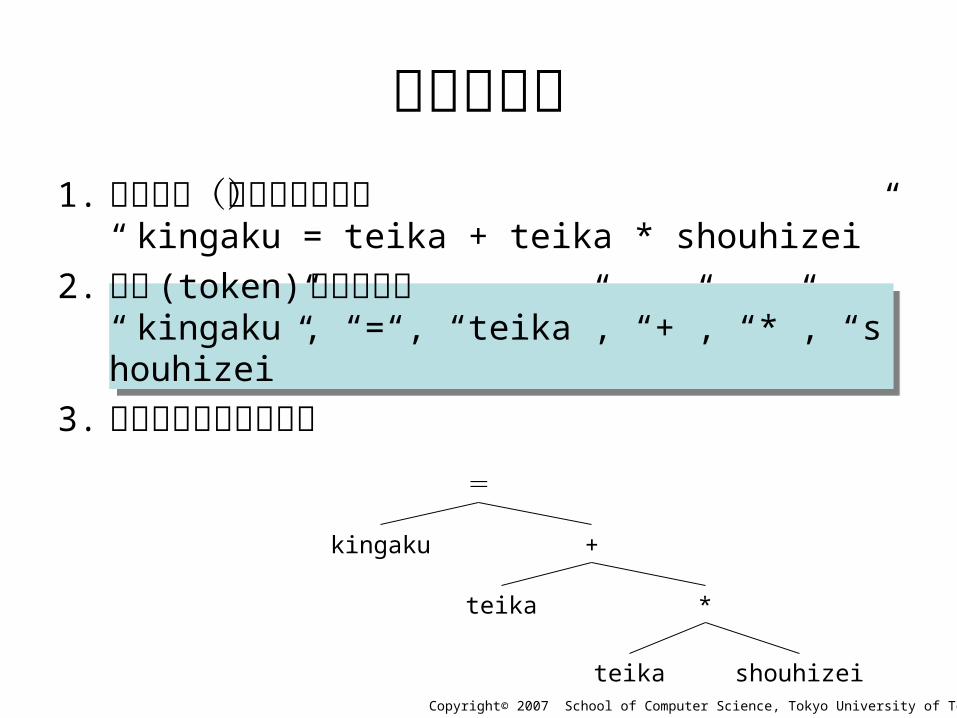
数式の解析1. 読み込み(文字列として)
“ kingaku = teika + teika * shouhizei”
2. 要素 (token) の切り出し“ kingaku”, “=“, “teika”, “+”, “*”, “shouhizei”
3. 要素の相互関係の分析=
kingaku
teika
teika
+
shouhizei
*
Copyright© 2007 School of Computer Science, Tokyo University of Technology
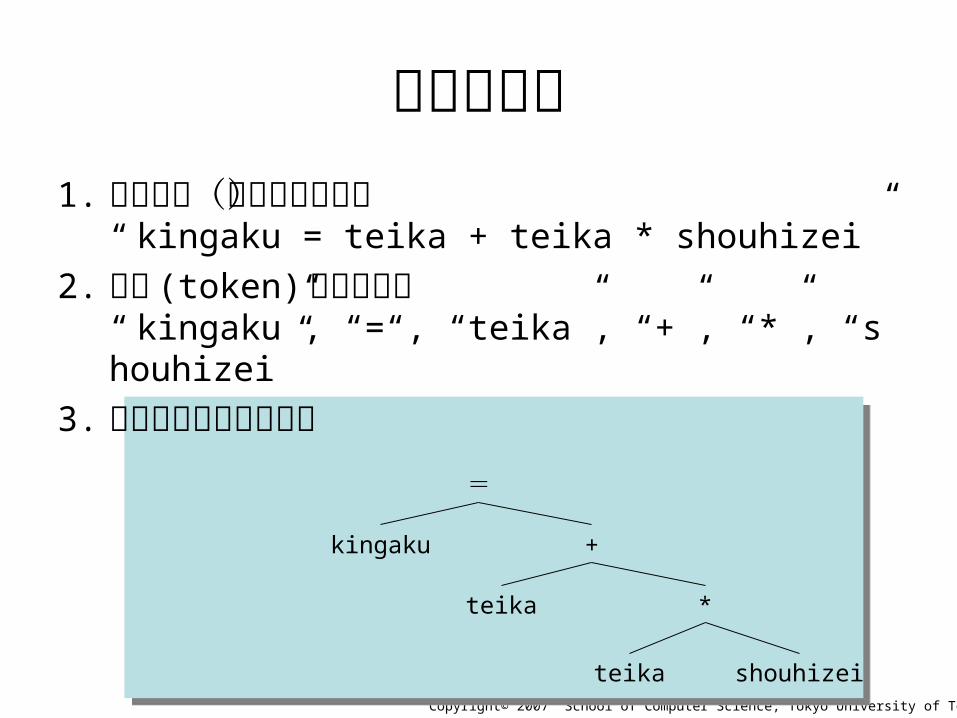
数式の解析1. 読み込み(文字列として)
“ kingaku = teika + teika * shouhizei”
2. 要素 (token) の切り出し“ kingaku”, “=“, “teika”, “+”, “*”, “shouhizei”
3. 要素の相互関係の分析=
kingaku
teika
teika
+
shouhizei
*
Copyright© 2007 School of Computer Science, Tokyo University of Technology
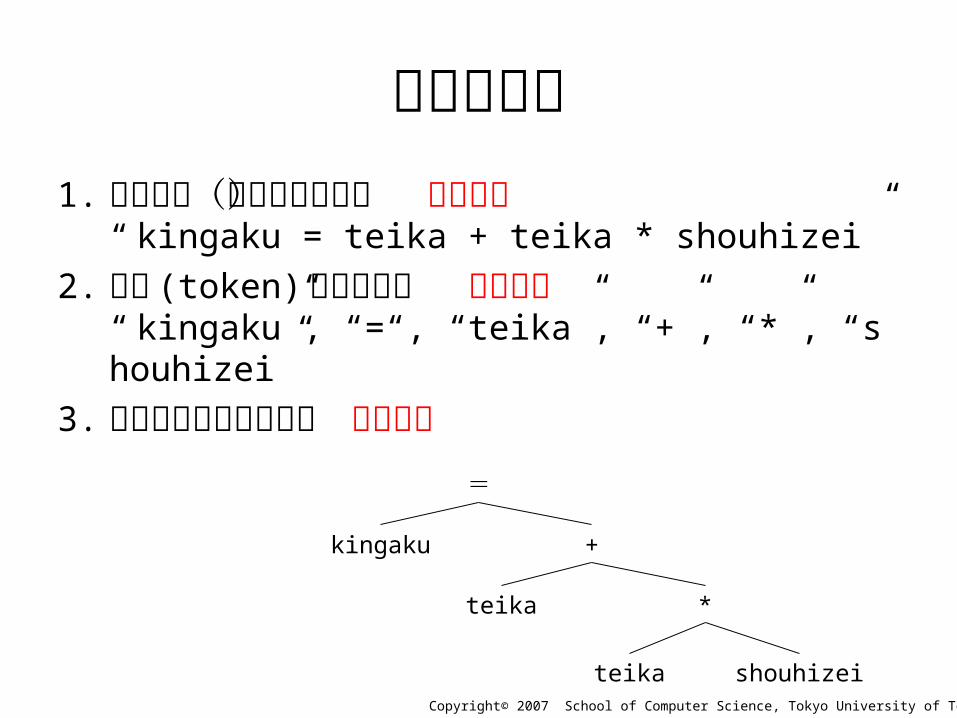
数式の解析1. 読み込み(文字列として) 読み込み
“ kingaku = teika + teika * shouhizei”
2. 要素 (token) の切り出し 語句解析“ kingaku”, “=“, “teika”, “+”, “*”, “shouhizei”
3. 要素の相互関係の分析 構文解析=
kingaku
teika
teika
+
shouhizei
*

Copyright© 2007 School of Computer Science, Tokyo University of Technology
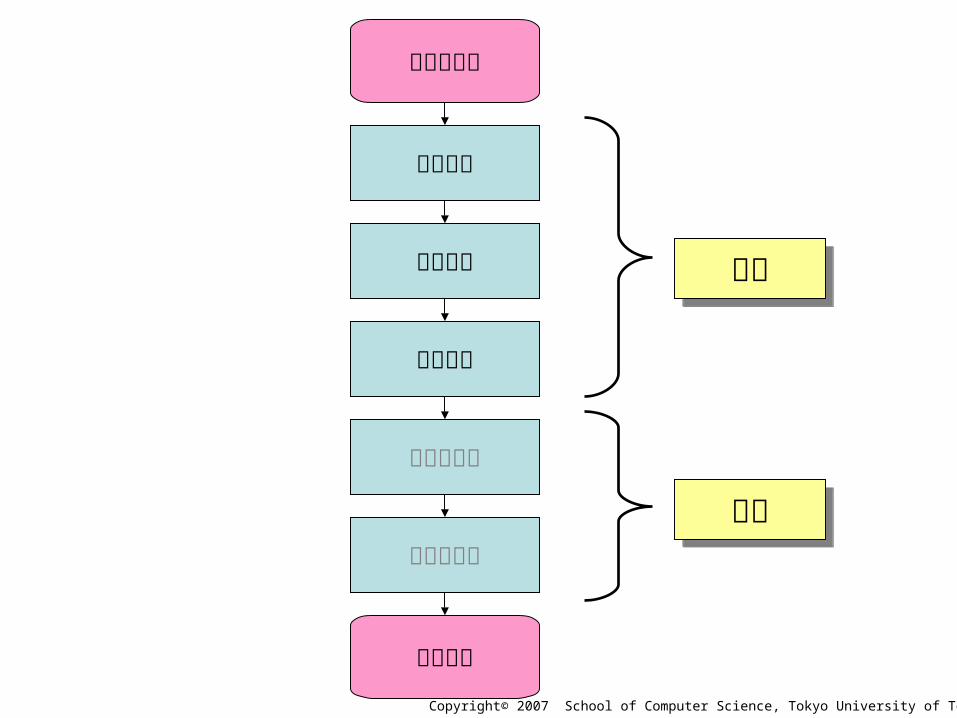
数式の解析1. 読み込み
– ファイルからの入力技法2. 語句解析
– 有限オートマトンの理論– 正規文法– 正規表現
3. 構文解析– 線形有界オートマトン理論– 文脈自由文法

Copyright© 2007 School of Computer Science, Tokyo University of Technology
前提知識• 言語理論とオートマトン
– 前期科目「言語理論とオートマトン」(横井教授)
– 抽象的・論理的な思考への慣れ
• プログラミング技法– 今までいろいろと習ってきましたよね!– 基本的な知識があれば一応 OK– ファイルの入出力が難しい人もいるかも…

Copyright© 2007 School of Computer Science, Tokyo University of Technology
学んで得られるもの• 言語理論とオートマトン
– 抽象的・論理的な思考への慣れ– ソフトウェア分野における基本的概念
• 正規表現 etc.• プログラミング言語へのより深い理解
• プログラミング技法– プログラミング力(知識)アップ– 洗練されたアルゴリズムの理解 などなど

Copyright© 2007 School of Computer Science, Tokyo University of Technology
• 言語プロセッサ関連は、コンピュータサイエンスの英知が集積されている!
• この授業を取った人は先見の明がある!

Copyright© 2007 School of Computer Science, Tokyo University of Technology
それでは基礎知識の話から( 今日の本題です。 )

Copyright© 2007 School of Computer Science, Tokyo University of Technology
そもそも言語とはなにか?
( CS では言語をどうとらえるのか?)
=>言語理論

Copyright© 2007 School of Computer Science, Tokyo University of Technology
言語理論とオートマトンの授業を覗いてみよう

オートマトンと言語オートマトンと言語Automaton & LanguagesAutomaton & Languages
平成16年度開講科目平成16年度開講科目
オートマトンとはオートマトンとは Automaton (pl. automata)Automaton (pl. automata) Αυτοματον(Αυτοματον( ギリシア語ギリシア語 ))
(( pl. Αυτοματαpl. Αυτοματα )) 自動機械自動機械

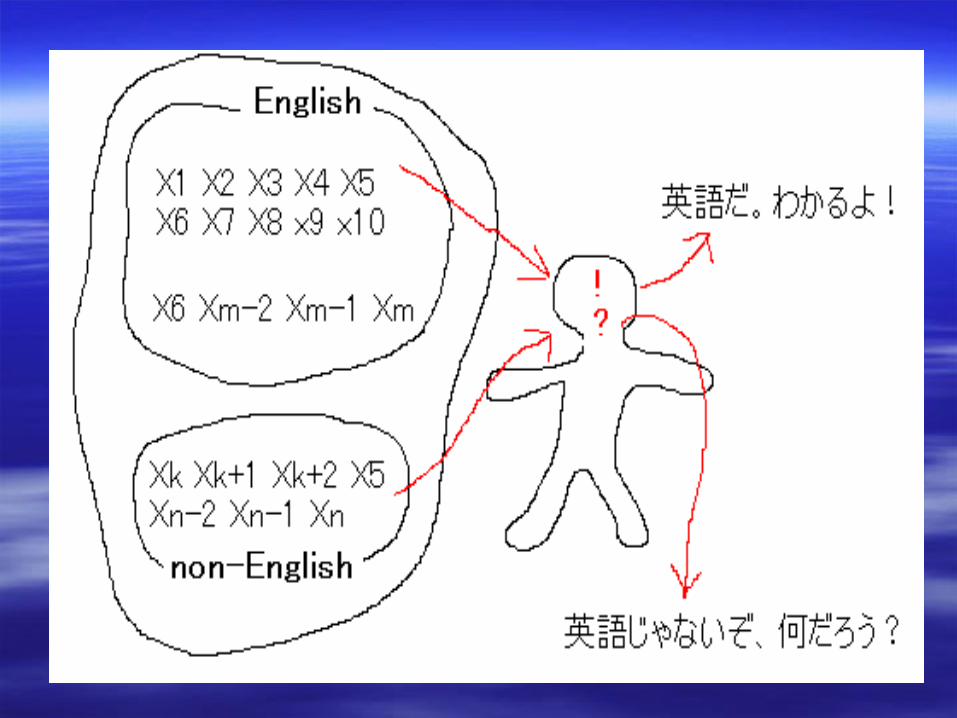
I have a book. 英語だ!

Tut mir Leid. ???!
記号列 Aha!Automaton


一般化一般化 単語の一般化単語の一般化
I ⇔xI ⇔x11, have ⇔x, have ⇔x22, a ⇔ x, a ⇔ x33, book ⇔ x, book ⇔ x44, ,
. ⇔ x. ⇔ x55, , ・・・・・・ , kanete ⇔ x, kanete ⇔ xn-1n-1, ;⇔ x, ;⇔ xnn

言語の形式的定義言語の形式的定義 単語w: 単語w: XX11, X, X22, X, X33, , ・・・・・・ , X, Xn n (はじめに単語あり(はじめに単語あり
き) き) 語彙語彙 V (Vocabulary) V (Vocabulary) : 単語の集合: 単語の集合
V = { XV = { X11, X, X22, X, X33, , ・・・・・・ , X, Xnn } ( } ( 有限集合有限集合 ))
文文 (sentence)(sentence) : 単語の並び(単語の列): 単語の並び(単語の列)
(注)(注)– VV の要素の要素 ( X( X11 や や XX22 などなど )) は単語は単語
– S1 = XS1 = Xaa X Xbb X Xcc X Xdd などなど– でも何でも良いわけではない。でも何でも良いわけではない。

例例 語彙語彙 V={ birds, fly }V={ birds, fly } 文文 :={ :={ birds, fly,birds, fly,
birds birds, birds fly, fly birds, fly fly,birds birds, birds fly, fly birds, fly fly,birds birds birds, birds birds fly,birds birds birds, birds birds fly,birds fly birds, fly birds birds,birds fly birds, fly birds birds,birds fly fly, fly birds fly, fly fly birds,birds fly fly, fly birds fly, fly fly birds,… … }}(無限個存在する!)(無限個存在する!)

考察考察 文は無限個存在する。文は無限個存在する。
(単語は有限個)(単語は有限個) 英語として意味のあるものとそうでないもの英語として意味のあるものとそうでないもの
とが混ざっている。とが混ざっている。⇒⇒ 英語として意味のある文をすべて集めた集合英語として意味のある文をすべて集めた集合
は、は、 1つの言語1つの言語 LL (今の場合は英語)を定める。(今の場合は英語)を定める。⇒⇒ 意味があるものとないものとを区別したい。意味があるものとないものとを区別したい。
つまり、つまり、任意の文に対して、それが言語任意の文に対して、それが言語 LL のの文か文か 否かを判定したい否かを判定したい。。

そんなことできるのだろうか?そんなことできるのだろうか?
でも、人間はやっているよ!でも、人間はやっているよ!
じゃあ、できるんだね!(信念)じゃあ、できるんだね!(信念)
自動機械(自動機械(オートマトンオートマトン)を作ってみよう!)を作ってみよう!
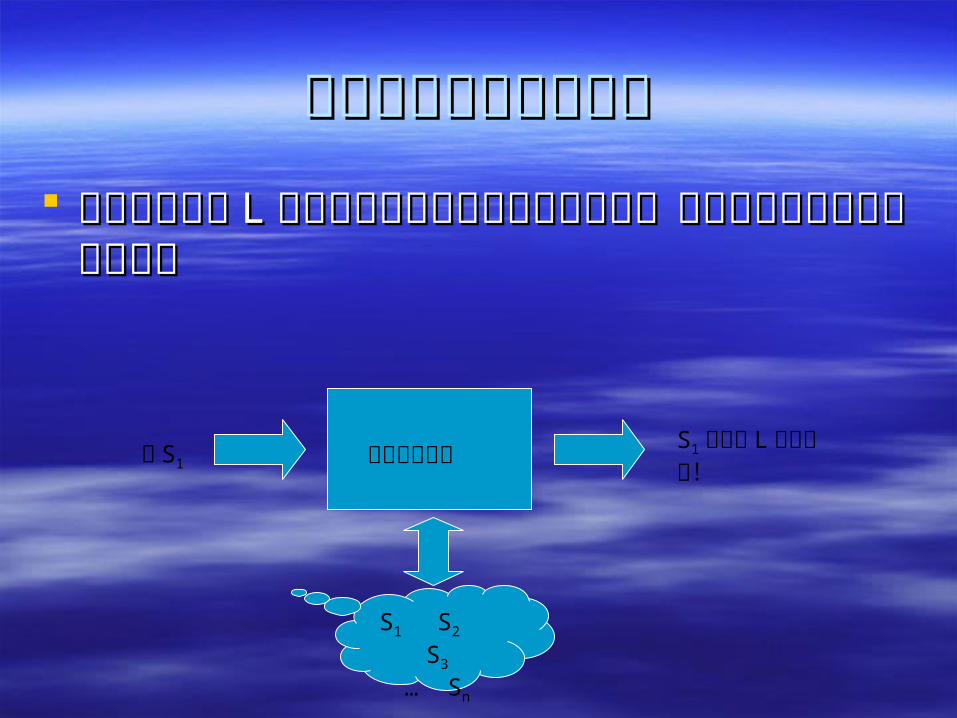
作成のためのアイデア作成のためのアイデア はじめに言語はじめに言語 LL の文すべてを知っているなの文すべてを知っているな
らば、下記のような機械ができる。らば、下記のような機械ができる。
文 S1
S1 S2 S3
… Sn
オートマトン
S1 は言語 L の文だよ!

問題点1問題点1 でも、でも、
「言語「言語 LL の文すべてを知っている」の文すべてを知っている」なんて、不可能だよ!なんて、不可能だよ!
例:「200例:「200 66 年年 1010 月4日は、言語プロセ月4日は、言語プロセッサの授業が、講ッサの授業が、講 AA 202教室で、パワー202教室で、パワーポイントを用いて行われた。」 ポイントを用いて行われた。」 という文という文ををあなたは事前に知っていましたか?あなたは事前に知っていましたか?
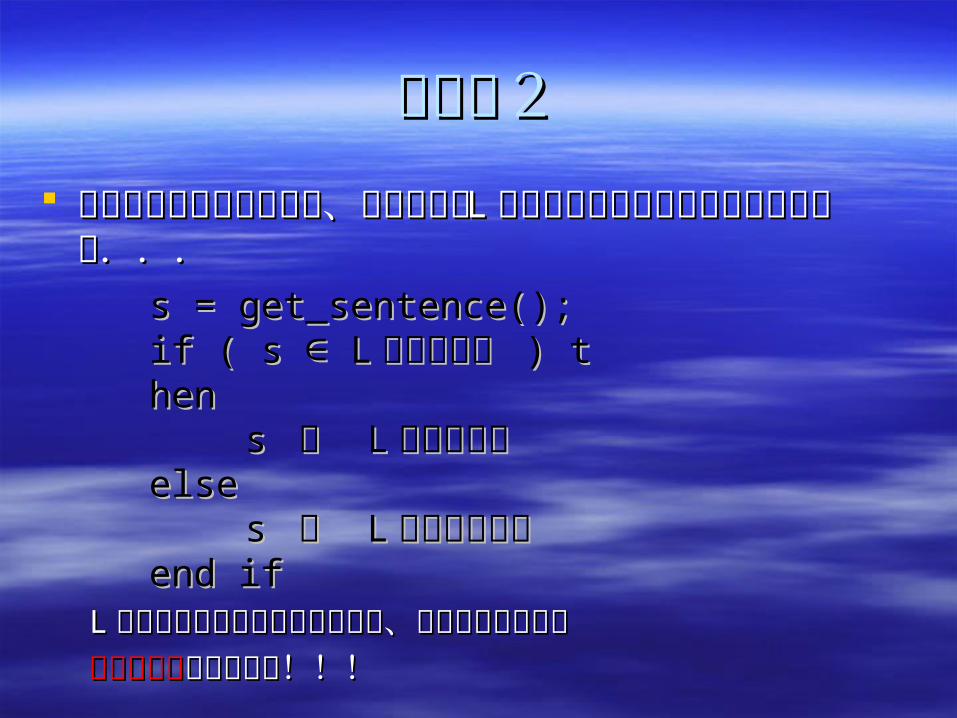
問題点2問題点2 もし何らかの方法により、事前に言語もし何らかの方法により、事前に言語 LL のすべてのすべて
の文を知っていたとしても...の文を知っていたとしても...
LL の文の集合が無限集合のときは、このプログラムはの文の集合が無限集合のときは、このプログラムは停止しない停止しないことがある!!!ことがある!!!
s = get_sentence();s = get_sentence();if ( s L∈if ( s L∈ の文の集合 の文の集合 ) then) then
s s は は LL の文であるの文であるelseelse
s s は は LL の文ではなの文ではないいend ifend if

それではどうしようか?!それではどうしようか?!

Copyright© 2007 School of Computer Science, Tokyo University of Technology
ここまでのまとめ• 言語
– 意味のある文の集合• 文法の必要性
– ある言語(例えば日本語)の文すべてをあらかじめ知っているなんてことは不可能!
• オートマトン– ある文が対象としている言語 L の文なのかを
自動判定する装置

Copyright© 2007 School of Computer Science, Tokyo University of Technology
どうも文法が大切らしい。
もう少し文法について学んでみよう!

Copyright© 2007 School of Computer Science, Tokyo University of Technology

オートマトンと言語Automaton & Languages
平成16年度開講科目2回目

文法とは? 一般的な定義:
規範としての文法 言語現象記述のための文法

規範としての文法(1) 「何々でなければならない」規則集 「ら抜きことば」は間違っている 若者語はけしからん!
この考え方の根底には、「言語とは社会的なものであり、みながその規約を守らなければ、言語は適切に機能しない。」という思想がある。
従って、「この事実と言語(文法)そのものを、規範として学校で教えるべきである。」という具合になる。

規範としての文法(2) 規範文法とは:
その言語を使用する人たちが皆で守り従わなければならない言語に関する規則の総体。

規範文法への批判(1) でも、ら抜き言葉は多くの人に使われてい
ますよ! これって、もう“日本語”ではないの? 今の日本語の中には、かつての日本語で
は使われていないものもありますよね。 言語は変化しますよね。

規範文法への批判(2) 言語変化の実例:
「進歩する」(100年ほど前は「進歩をする」)
「更なる進化」(20年ぐらい前は「更に進歩する」)
It’s bad! It’s cool.
など

規範文法も「言語政策」・「言語教育」のために重要だが、現在使われている日本語に関する言語規則はどうなっているのか?
このような観点からのものが、「言語現象記述のための文法」である。
このような文法は、機械翻訳・電話通訳などの実現のために重要である。

さらにもう一歩考えをすすめて...
「あらゆる言語に共通の言語規則はあるの?」と考えるのが、「一般普遍文法」である。
これについて、少し詳しく話すと...

一般普遍文法(1) 前回のオートマトンの説明を思い起こすと… すべての子供はやがて言葉を話しはじめる。 日本人のこどもも、エスキモーのこどもも、
エジプトのこどもも… 人種・民族にかかわらず話し始める。 でも、日本人は日本語、エスキモー人はエスキモー語をしゃべり始める。 Why?

Because…
その言語をしゃべる環境で育ったから?
環境が習得言語を決める?
でも、なぜ基本的に人は皆しゃべり始めるの? ミミズはしゃべらないのに?(ホント?)
それは、...
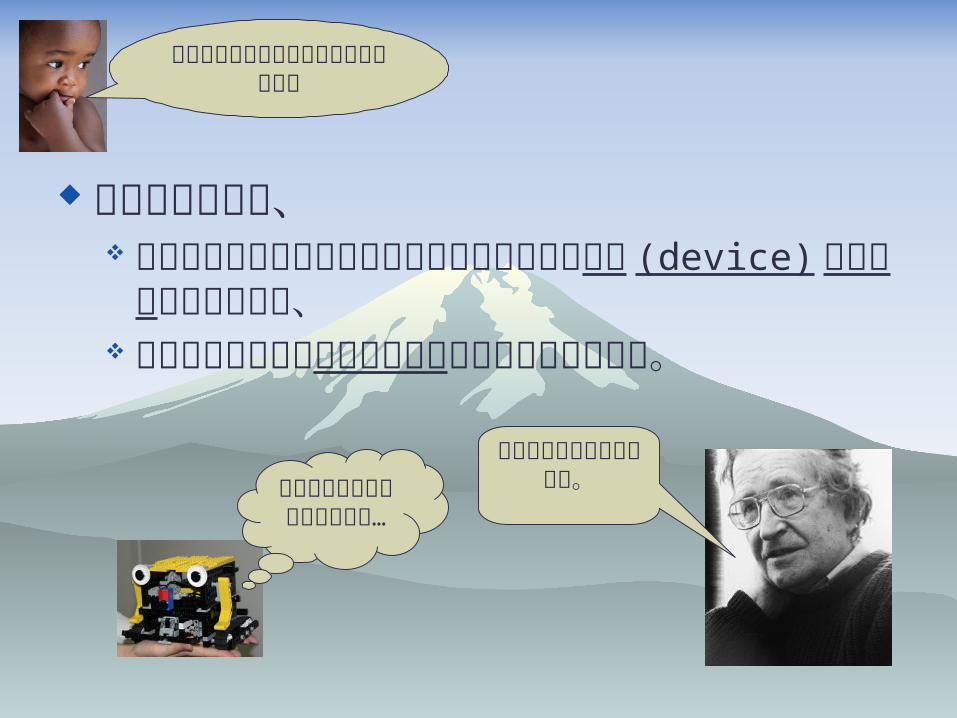
すべてのヒトは、 言語に依存しない普遍的な処理能力をもった
装置 (device) を生得的に持っており、 個別言語に関する知識は後天的に獲得される
からだ。これが私の基本的考えです。僕にもこ
んな装置がほしい
なぁ…
ホントにしゃべれるようになるのかなぁ

その知識は、「文法」という形で獲得される。
Chomsky はそのように考えた。
それでは彼の考えを見てみよう。

Copyright© 2007 School of Computer Science, Tokyo University of Technology
ここからが大切

文法の定義 文法 G= ( Vn, Vt, P, S ):
ただし、 Vn: 非終端記号の集合 Vt: 終端記号の集合 P: 書き換え規則の集合 S: 開始記号

文法 文法 G= ( Vn, Vt, P, S ):
ただし、 Vn: 非終端記号の集合 <= 構文木構成要
素の集合 Vt: 終端記号の集合 <= 単語の集合 P: 書き換え規則の集合 S: 開始記号

例1 -1
G=(Vn, Vt, P, S) Vn = { S, NPs, NPo, VP, PN, DET, N } Vt = { I, You, have, throw, a, the, book, ball } P = { ① : S → NPs VP, ② : NPs → PN,
③ : PN → I, ④ : PN → You,
⑤ : NPo → DET N, ⑥ : VP → V NPo,
⑦ : DET → a, ⑧ : DET → the,
⑨ : N → book, ⑩ : N → ball,
⑪ : V → have, ⑫ : V → throw }

例1 -2
S => NPs VP by ①=> PN VP by ②=> I VP by ③=> I V NPo by ⑥=> I throw NPo by ⑫=> I throw DET N by ⑤=> I throw a N by ⑦=> I throw a ball by ⑩
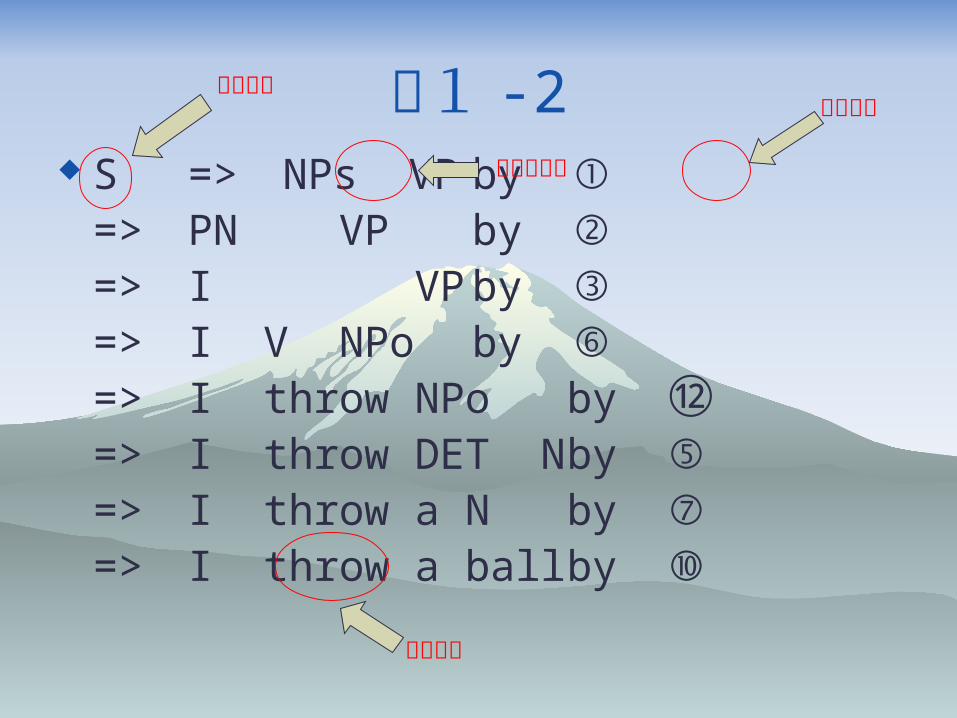
例1 -2 S => NPs VP by ①
=> PN VP by ②=> I VP by ③=> I V NPo by ⑥=> I throw NPo by ⑫=> I throw DET N by ⑤=> I throw a N by ⑦=> I throw a ball by ⑩
開始記号
非終端記号
適応規則
終端記号
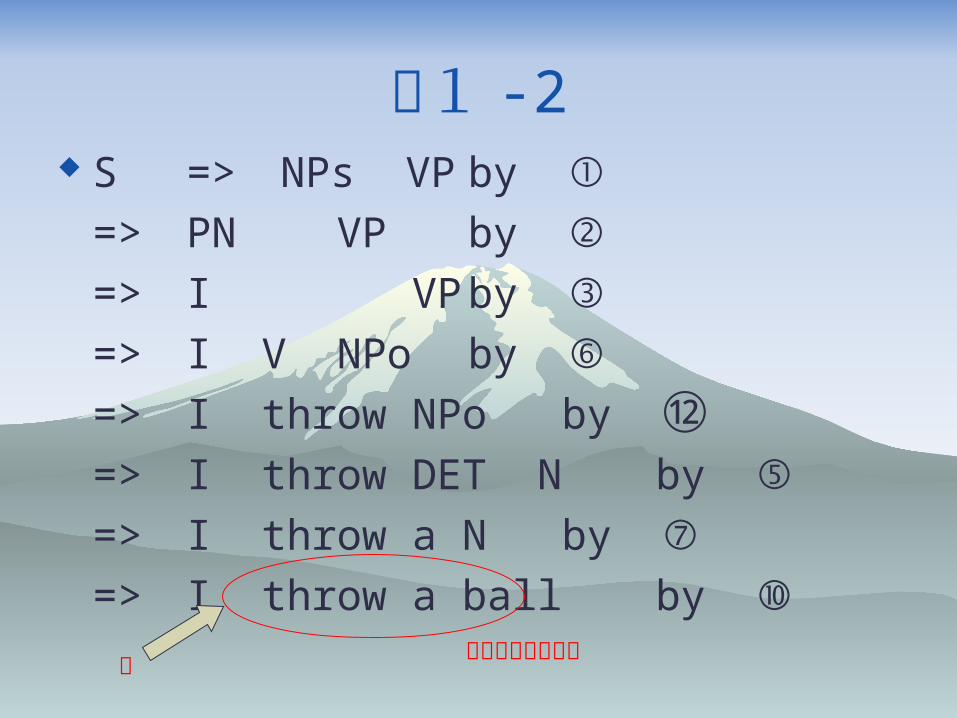
例1 -2 S => NPs VP by ①
=> PN VP by ②=> I VP by ③=> I V NPo by ⑥=> I throw NPo by ⑫=> I throw DET N by ⑤=> I throw a N by ⑦=> I throw a ball by ⑩
終端記号のみの列文

例1 -2 に対する問題 これを木 (tree) として記述せよ。 この文法 G により生成される文をすべて
列挙せよ。

言語の定義 言語 L とは、文法 G により生成されるあ
らゆる文の集合のこと。
つまり、 L = L(G) 。

問題( Palindrome ) Palindrome のみを生成する文法を示せ。
ただし、G=( Vn, Vt, P, S )
Vn = { S }, Vt = { a, b, c }
とする。

ヒント Palidrome の性質
1. ε, a, b, c は Palindrome 。2. wが Palindrome ならば、
xwx (x Vt)∈も Palindrome 。
3. 上記1と2のもののみが Palindrome 。

文法の分類 文法にはいくつかの種類がある。 それに応じて、処理装置・処理方法が異
なってくる。

Copyright© 2007 School of Computer Science, Tokyo University of Technology
ここまでのまとめ• 文法 : G= ( Vn, Vt, P, S ):
– ただし、• Vn: 非終端記号の集合 <= 構文木構成要
素の集合• Vt: 終端記号の集合 <= 単語の集合• P: 書き換え規則の集合• S: 開始記号
• 言語 : L=L(G)

Copyright© 2007 School of Computer Science, Tokyo University of Technology

Copyright© 2007 School of Computer Science, Tokyo University of Technology

Copyright© 2007 School of Computer Science, Tokyo University of Technology
オートマトンと言語Automaton & Languages
平成16年度開講科目3回目

Copyright© 2007 School of Computer Science, Tokyo University of Technology
前回までの復習• 人間の頭の中には、言語処理装置がある。• すべての文を記憶しているわけではない。• 文法として記憶している。• 文法とは何か?
– 規範文法 (Prescriptive Grammar) – 記述文法 (Descriptive Grammar)
• 形式文法と形式言語

Copyright© 2007 School of Computer Science, Tokyo University of Technology
形式文法と形式言語• 文法 G = ( Vn, Vt, P, S ):
– ただし、• Vn (非終端記号の集合) : 0 < #Vn < +∞• Vt: 終端記号の集合 : 0 < #Vt < +∞• P: 書き換え規則の集合
{α→β| α, β (Vn Vt)*}∈ ∪
• S: 開始記号 (S Vn)∈
• 言語 L = L(G) = { x | S =*> x }– ただし、 S => ・・・ => x ∈ Vt

Copyright© 2007 School of Computer Science, Tokyo University of Technology
形式文法と形式言語(例)• 文法 G = ( Vn, Vt, P, S ):
– Vn ={S}, Vt={}– P={ }
• 言語 L = L(G) = { x | S =*> x }
Copyright© 2007 School of Computer Science, Tokyo University of Technology
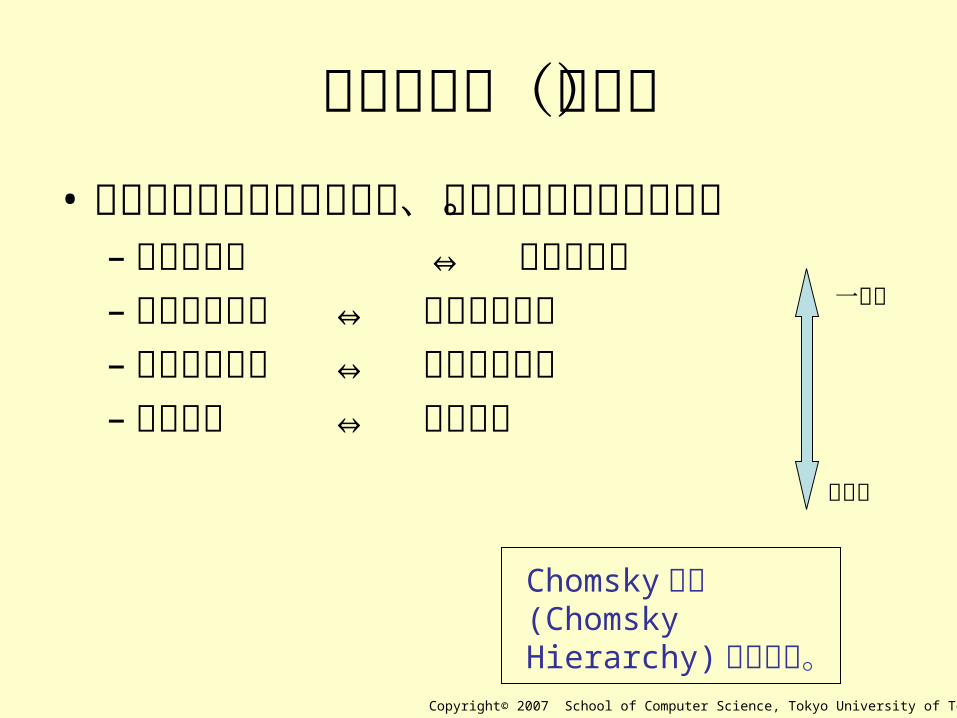
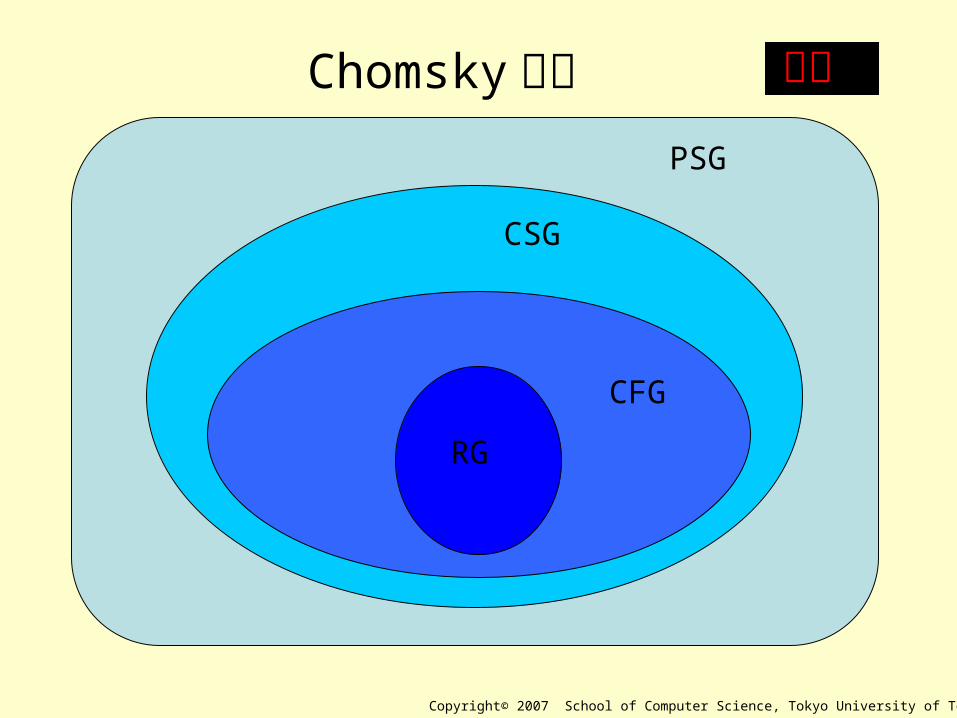
言語の階層(重要)• 言語は文法の種類に応じて、階層構造を
なしている。– 句構造言語 ⇔ 句構造文法– 文脈依存言語 ⇔ 文脈依存文法– 文脈自由言語 ⇔ 文脈自由文法– 正規言語 ⇔ 正規文法
一般的
特殊的
Chomsky階層(Chomsky Hierarchy)とも言う。

Copyright© 2007 School of Computer Science, Tokyo University of Technology
句構造文法(Phrase-Structure Grammar; PSG)
• 文法 G = ( Vn, Vt, P, S ):– Vn (非終端記号の集合) : 0 < #Vn < +∞– Vt: 終端記号の集合 : 0 < #Vt < +∞– P: 書き換え規則の集合
{α→β| α, β (Vn Vt)*}∈ ∪
– S: 開始記号 (S Vn)∈

Copyright© 2007 School of Computer Science, Tokyo University of Technology
• 文法 G = ( Vn, Vt, P, S ):– Vn (非終端記号の集合) : 0 < #Vn < +∞– Vt: 終端記号の集合 : 0 < #Vt < +∞– P: 書き換え規則の集合
{α→β| α, β (Vn Vt)*}∈ ∪
– S: 開始記号 (S Vn)∈
句構造文法 (Phrase-Structure Grammar; PSG)

Copyright© 2007 School of Computer Science, Tokyo University of Technology
• 文法 G = ( Vn, Vt, P, S ):– Vn (非終端記号の集合) : 0 < #Vn < +∞– Vt: 終端記号の集合 : 0 < #Vt < +∞– P: 書き換え規則の集合
{α→β| α, β (Vn Vt)*}∈ ∪
– S: 開始記号 (S Vn)∈
句構造文法 (Phrase-Structure Grammar; PSG)
ここに制限が付くと他の文法になる。

Copyright© 2007 School of Computer Science, Tokyo University of Technology
文脈依存文法(Context-Sensitive Grammar; CSG)• 文法 G = ( Vn, Vt, P, S ):
– Vn (非終端記号の集合) : 0 < #Vn < +∞– Vt: 終端記号の集合 : 0 < #Vt < +∞– P: 書き換え規則の集合
{αXβ→αγβ| α, β (Vn Vt)*, X Vn, ∈ ∪ ∈γ (Vn V∈ ∪
t)+ }
– S: 開始記号 (S Vn)∈

Copyright© 2007 School of Computer Science, Tokyo University of Technology
文脈自由文法(Context-Free Grammar; CFG)
• 文法 G = ( Vn, Vt, P, S ):– Vn (非終端記号の集合) : 0 < #Vn < +∞– Vt: 終端記号の集合 : 0 < #Vt < +∞– P: 書き換え規則の集合
{ X→α| α (Vn Vt)*}∈ ∪
– S: 開始記号 (S Vn)∈

Copyright© 2007 School of Computer Science, Tokyo University of Technology
正規文法(Regular Grammar; RG)
• 文法 G = ( Vn, Vt, P, S ):– Vn (非終端記号の集合) : 0 < #Vn < +∞– Vt: 終端記号の集合 : 0 < #Vt < +∞– P: 書き換え規則の集合
{X→aY, X→b| X,Y Vn, a,b Vt*}∈ ∈
– S: 開始記号 (S Vn)∈

Copyright© 2007 School of Computer Science, Tokyo University of Technology
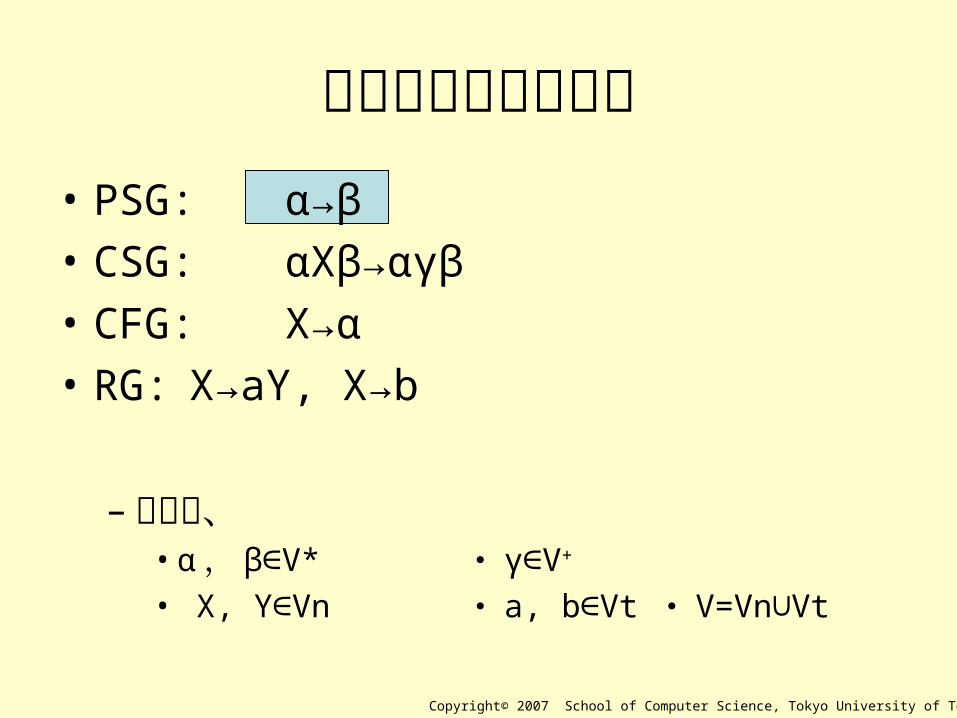
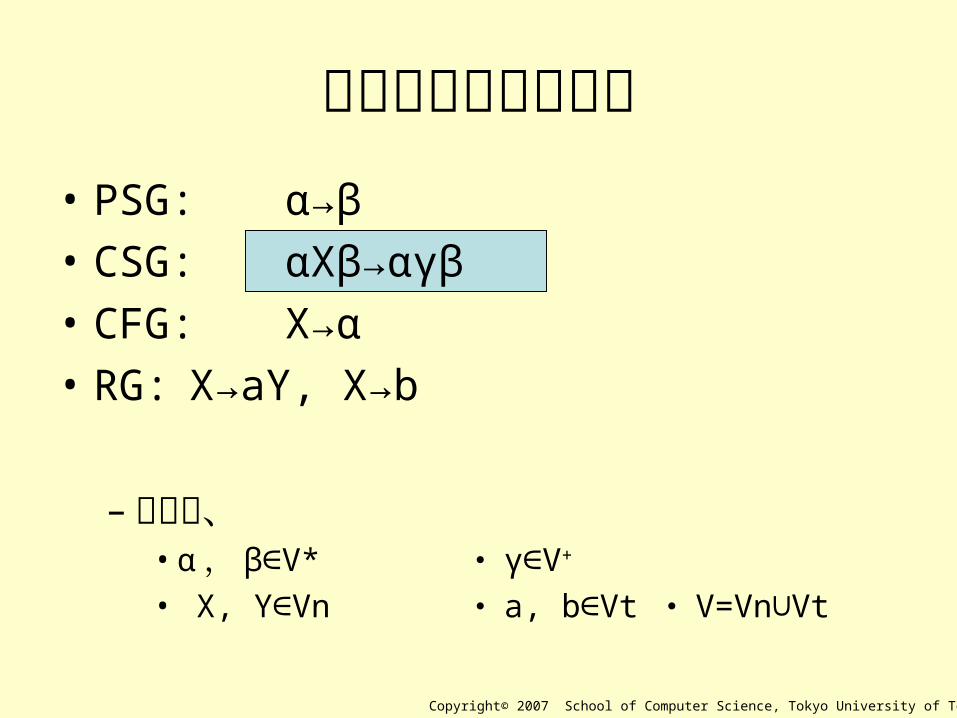
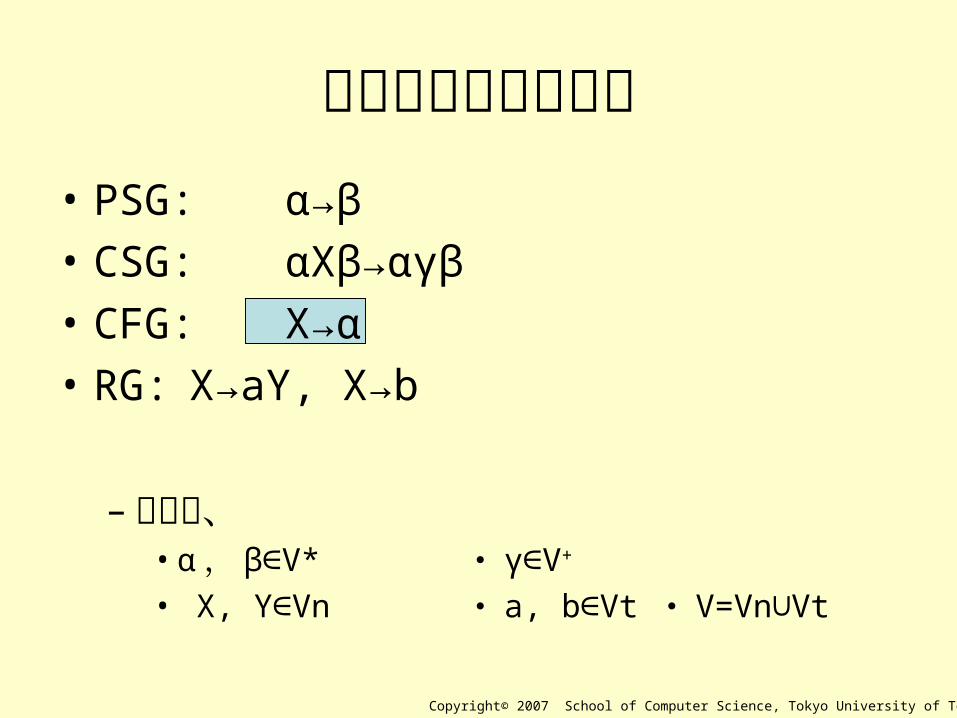
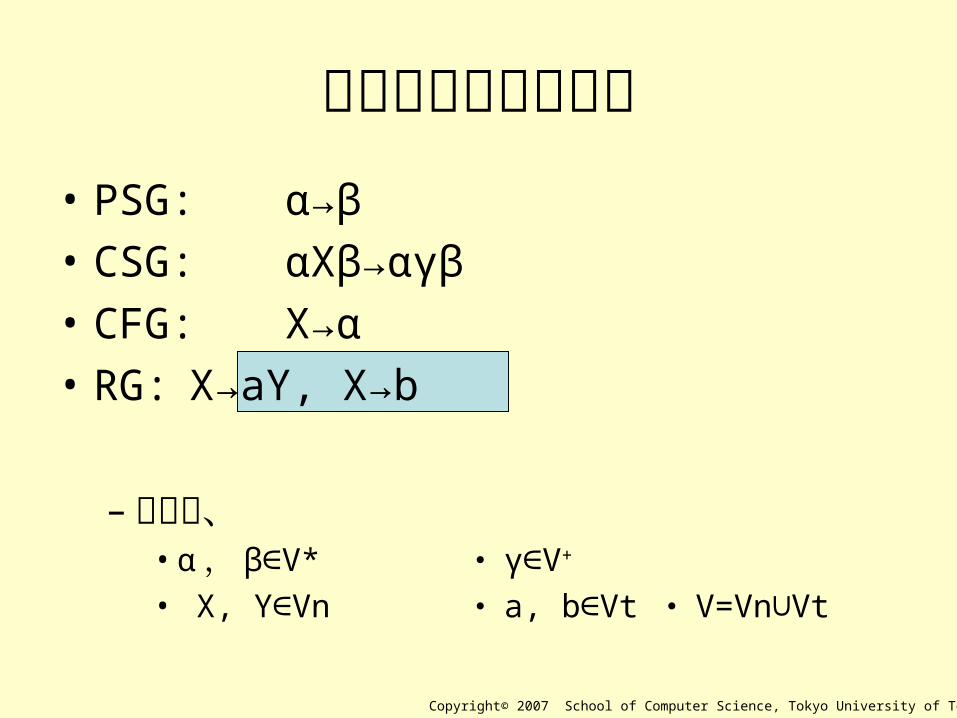
生成規則部分の比較• PSG: α→β
• CSG: αXβ→αγβ
• CFG: X→α
• RG: X→aY, X→b
– ただし、• α , β V*∈ ・ γ V∈ +
• X, Y Vn∈ ・ a, b Vt∈ ・ V=Vn Vt∪
Copyright© 2007 School of Computer Science, Tokyo University of Technology
生成規則部分の比較• PSG: α→β
• CSG: αXβ→αγβ
• CFG: X→α
• RG: X→aY, X→b
– ただし、• α , β V*∈ ・ γ V∈ +
• X, Y Vn∈ ・ a, b Vt∈ ・ V=Vn Vt∪
Copyright© 2007 School of Computer Science, Tokyo University of Technology
生成規則部分の比較• PSG: α→β
• CSG: αXβ→αγβ
• CFG: X→α
• RG: X→aY, X→b
– ただし、• α , β V*∈ ・ γ V∈ +
• X, Y Vn∈ ・ a, b Vt∈ ・ V=Vn Vt∪
Copyright© 2007 School of Computer Science, Tokyo University of Technology
生成規則部分の比較• PSG: α→β
• CSG: αXβ→αγβ
• CFG: X→α
• RG: X→aY, X→b
– ただし、• α , β V*∈ ・ γ V∈ +
• X, Y Vn∈ ・ a, b Vt∈ ・ V=Vn Vt∪
Copyright© 2007 School of Computer Science, Tokyo University of Technology
生成規則部分の比較• PSG: α→β
• CSG: αXβ→αγβ
• CFG: X→α
• RG: X→aY, X→b
– ただし、• α , β V*∈ ・ γ V∈ +
• X, Y Vn∈ ・ a, b Vt∈ ・ V=Vn Vt∪
Copyright© 2007 School of Computer Science, Tokyo University of Technology
PSG
CSG
CFG
RG
Chomsky階層 重要

Copyright© 2007 School of Computer Science, Tokyo University of Technology
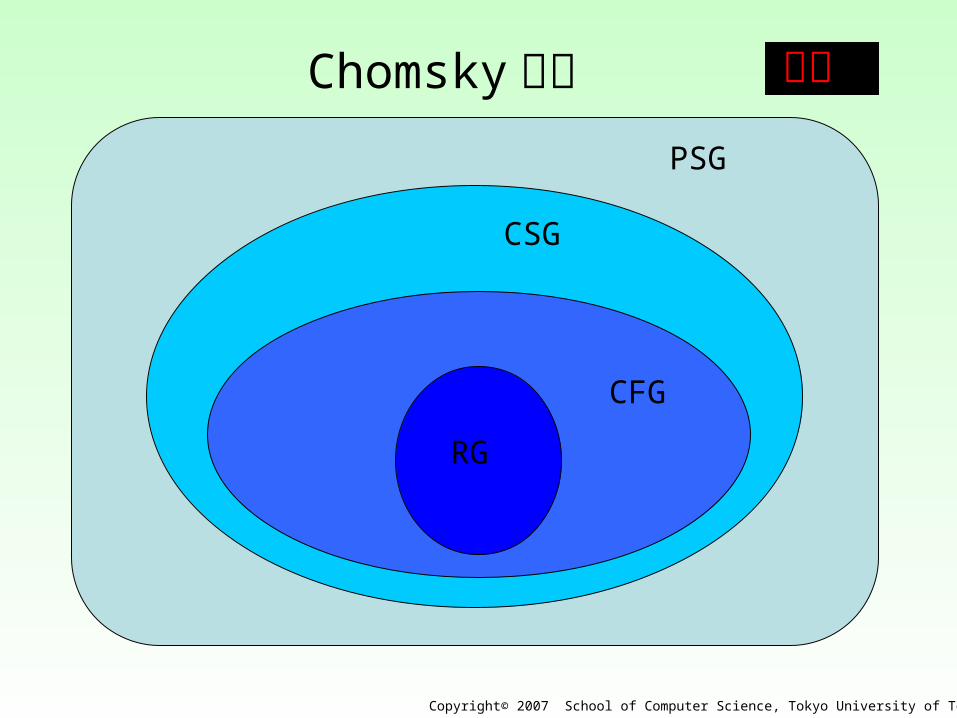
言語の包含関係L ( PSG) L(CSG) L(CFG) L(RG)⊃ ⊃ ⊃
このうち、大切なのは CFG と RG 。

Copyright© 2007 School of Computer Science, Tokyo University of Technology
CFG と RG
• CFG (文脈自由文法):– プログラミング言語設計– コンパイラの構文解析– 自然言語処理(機械翻訳・仮名漢字変換)
• RG (正規文法):– 正規表現(検索・コンパイラの語彙解析)

Copyright© 2007 School of Computer Science, Tokyo University of Technology
CFG の特徴1. CFG には標準形がある。2. 導出の過程を木で表現できる(導出木の存
在)。3. 解析手法が豊富に知られている。4. 自然言語処理に部分的に適用できる。5. プログラミング言語設計に利用されている。

Copyright© 2007 School of Computer Science, Tokyo University of Technology
1. CFG の標準形• Chomsky の標準形• Greibach の標準形
Copyright© 2007 School of Computer Science, Tokyo University of Technology
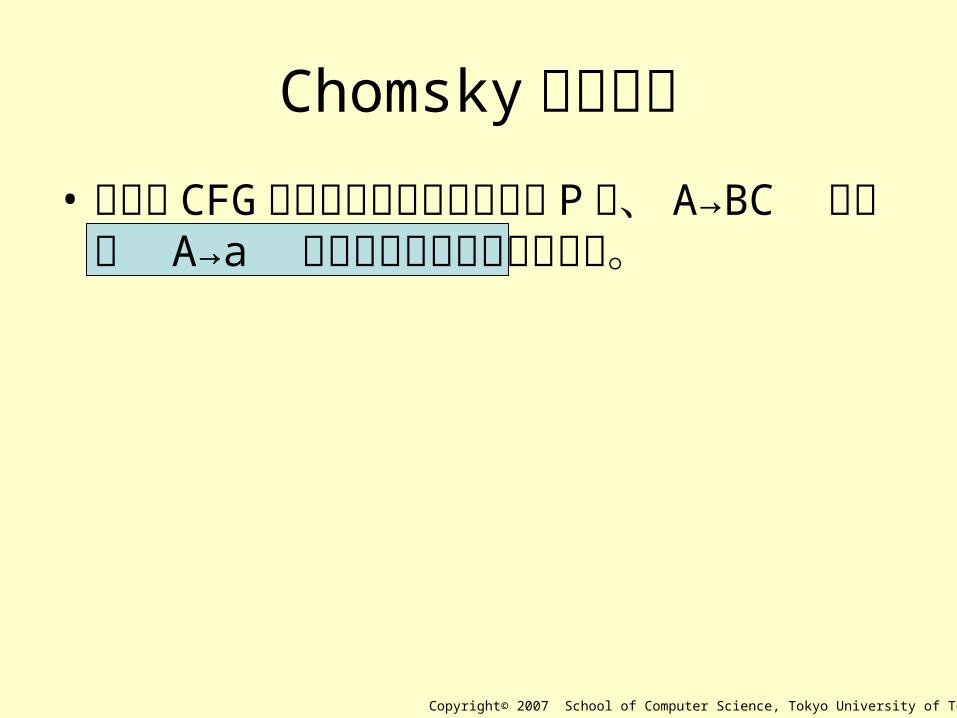
Chomsky の標準形• 任意の CFG における書き換え規則群 P は、
A→BC または A→a という形だけで表現できる。

Copyright© 2007 School of Computer Science, Tokyo University of Technology
Greibach の標準形
• 任意の CFG における書き換え規則群 P は、A→aα という形だけで表現できる。ただし、 X Vn, a Vt, α Vn*∈ ∈ ∈ 。

Copyright© 2007 School of Computer Science, Tokyo University of Technology
Chomsky の標準形への変換方法
(次回のお楽しみ。事前に予習すると理解しやすいですよ。)
Copyright© 2007 School of Computer Science, Tokyo University of Technology
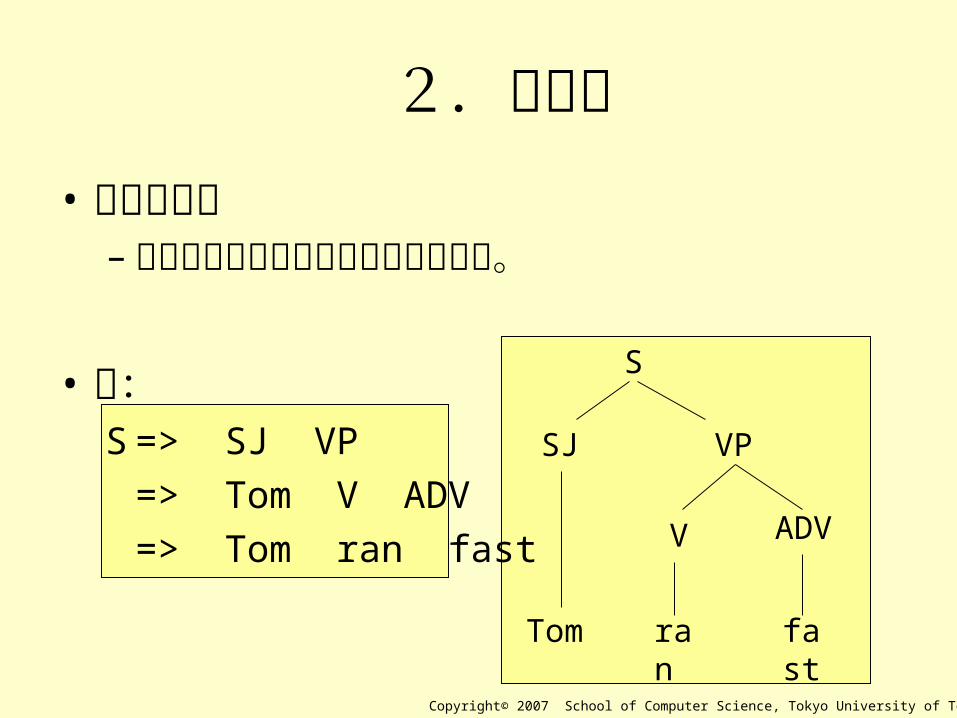
2.導出木• 導出木とは
–導出の過程を木構造で表現したもの。
• 例:S=> SJ VP
=> Tom V ADV
=> Tom ran fast
S
SJ VP
Tom
V ADV
ran fast

Copyright© 2007 School of Computer Science, Tokyo University of Technology
3.解析手法• CKY 法 (Cocke-Kasami-Younger method)• Early 法 (Early’s algorithm)• Chart 法 (Chart algorithm)• 優先順位文法法• LK ( R ) 法• LR( k ) 法• LALR( k ) 法• SLR( k ) 法• LL( k ) 法 などなど

Copyright© 2007 School of Computer Science, Tokyo University of Technology
解析手法は重要なので後日あらためて取り上げます。
• 機械翻訳・通訳電話などの自然言語処理• コンパイラ
などで応用されている。

Copyright© 2007 School of Computer Science, Tokyo University of Technology
参考文献• 文法:
– 英語学概論 -三大文法の流れと特徴-,松井千枝,朝日出版 (1980).

Copyright© 2007 School of Computer Science, Tokyo University of Technology
ここまでのまとめ• 言語には階層がある( Chomsky階層)• 正規言語(正規文法)は語句解析に深い
関係がある。• 文脈自由言語(文脈自由文法)は構文解
析に深い関係がある。

Copyright© 2007 School of Computer Science, Tokyo University of Technology
もう少し話を進めましょう!

Copyright© 2007 School of Computer Science, Tokyo University of Technology
文法と言語とオートマトン• 句構造文法 (PSG)
• 文脈依存文法 (CSG)
• 文脈自由文法 (CFG)
• 正規文法 (RG)
Copyright© 2007 School of Computer Science, Tokyo University of Technology
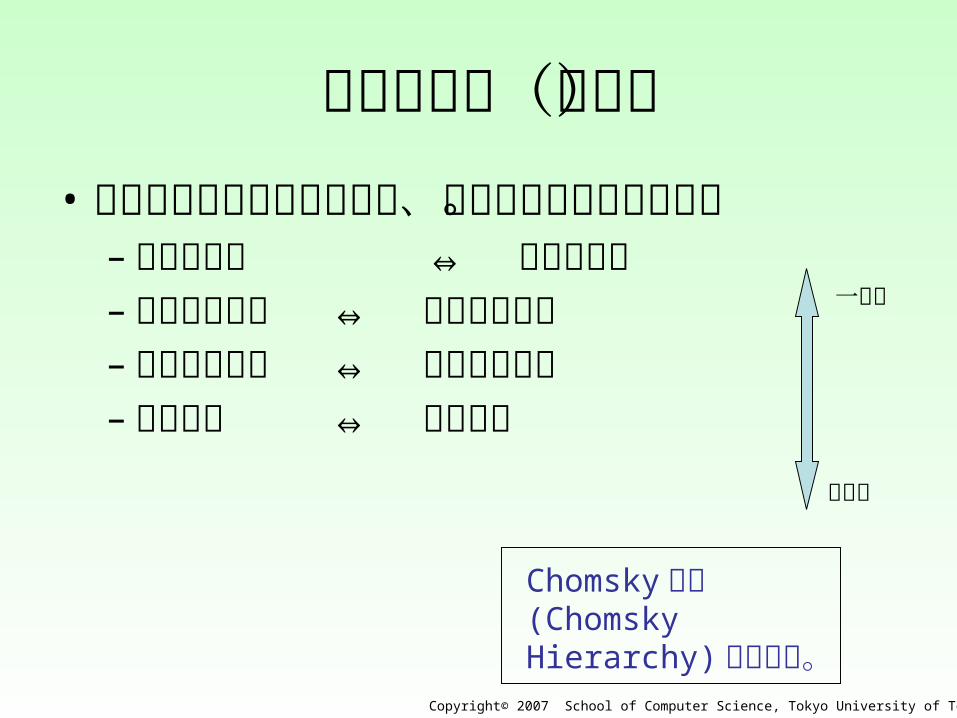
言語の階層(重要)• 言語は文法の種類に応じて、階層構造を
なしている。– 句構造言語 ⇔ 句構造文法– 文脈依存言語 ⇔ 文脈依存文法– 文脈自由言語 ⇔ 文脈自由文法– 正規言語 ⇔ 正規文法
一般的
特殊的
Chomsky階層(Chomsky Hierarchy)とも言う。
Copyright© 2007 School of Computer Science, Tokyo University of Technology
PSG
CSG
CFG
RG
Chomsky階層 重要
Copyright© 2007 School of Computer Science, Tokyo University of Technology
文法と言語とオートマトン-----------------------------------------------------
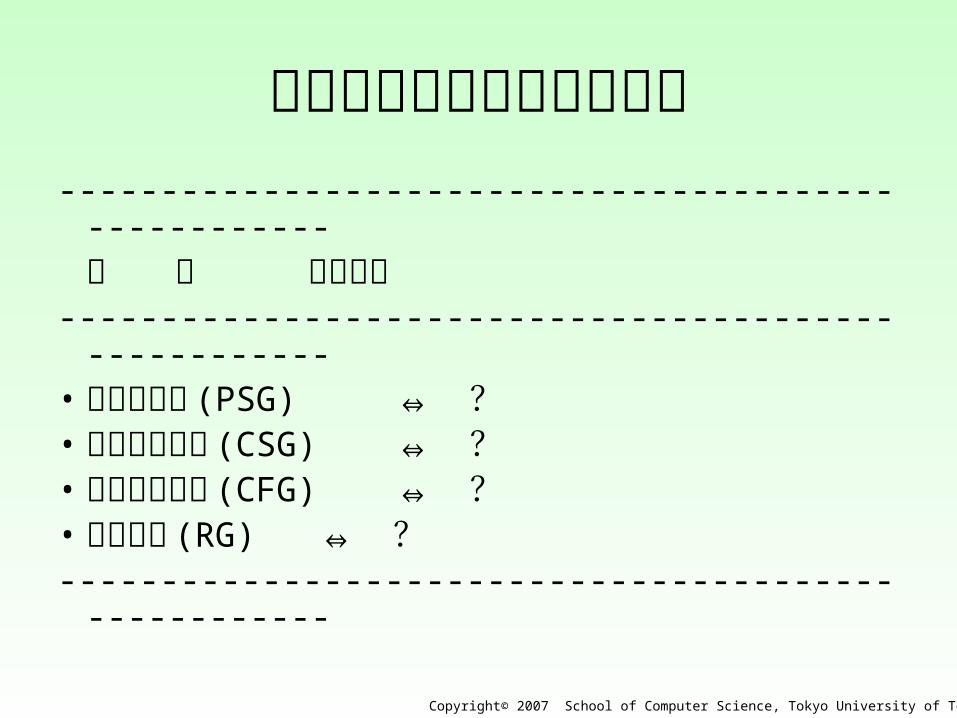
文 法 処理装置-----------------------------------------------------• 句構造文法 (PSG) ⇔ ?• 文脈依存文法 (CSG) ⇔ ?• 文脈自由文法 (CFG) ⇔ ?• 正規文法 (RG) ⇔ ?-----------------------------------------------------
Copyright© 2007 School of Computer Science, Tokyo University of Technology
文法と言語とオートマトン----------------------------------------------------------------
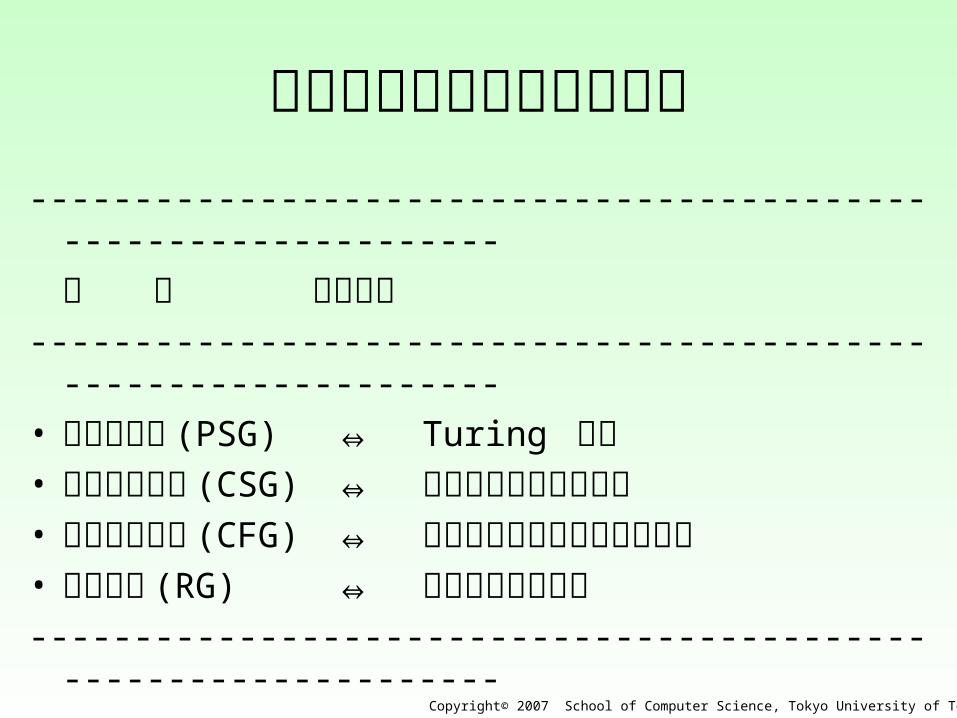
文 法 処理装置----------------------------------------------------------------• 句構造文法 (PSG) ⇔ Turing 機械• 文脈依存文法 (CSG) ⇔ 線形有界オートマトン• 文脈自由文法 (CFG) ⇔ プッシュダウンオート
マトン• 正規文法 (RG) ⇔ 有限オートマトン----------------------------------------------------------------

Copyright© 2007 School of Computer Science, Tokyo University of Technology
まずは有限オートマトンから
Copyright© 2007 School of Computer Science, Tokyo University of Technology
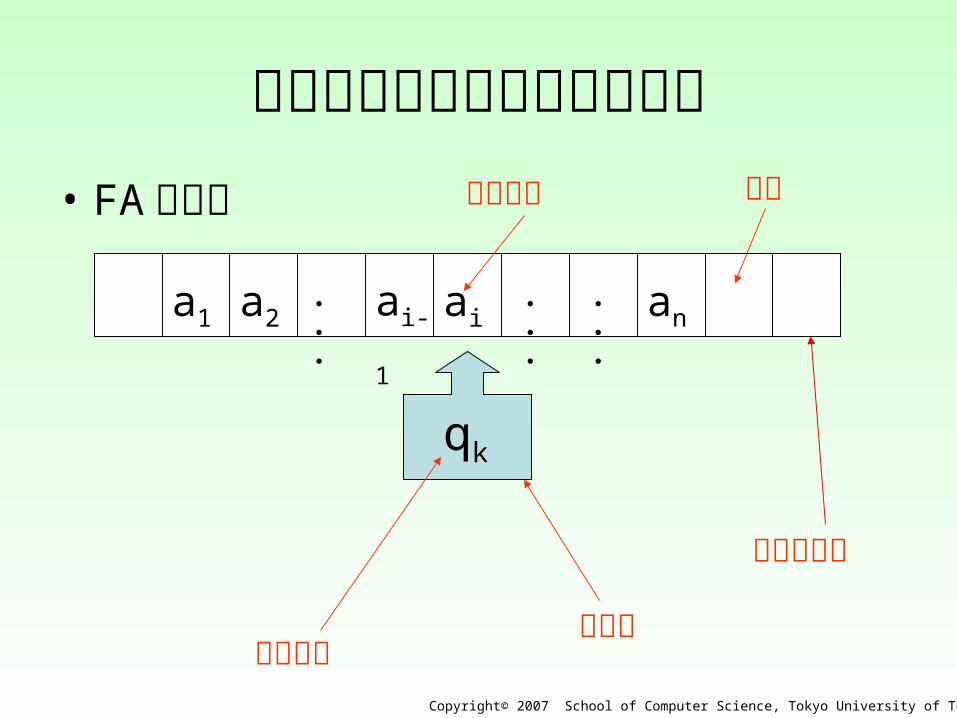
有限オートマトンのイメージ• FA の概観
anaia1 a2 ai-1・・・
・・・
・・・
qk
入力テープ
ヘッド内部状態
セル入力記号

Copyright© 2007 School of Computer Science, Tokyo University of Technology
有限オートマトンの定義FA = ( K, Σ, δ, q0, F )ただし、
K : 状態の集合 ( K は有限集合 )Σ : 入力アルファベット( Σ は有限集合)δ : 状態遷移関数
δ : K×Σ ( a, q∋ i ) → qj K ∈q0 : 初期状態F : 最終状態の集合 ( F K )⊆

Copyright© 2007 School of Computer Science, Tokyo University of Technology

Copyright© 2007 School of Computer Science, Tokyo University of Technology
次回、この続きを話します。• 有限オートマトン
–決定性有限オートマトン–非決定性有限オートマトン
• 正規表現• 正規表現から有限オートマトンの生成• 状態数最少有限オートマトン• 正規表現→非決定性有限オートマトン→決定性有限オートマトン→状態数最少有限オートマトン

Copyright© 2007 School of Computer Science, Tokyo University of Technology





























