Embed Size (px)
Citation preview
A study of the theory of regular languages is often justified by the fact that they model the lexical analysis stage of a com-piler.
Type 3 Grammar(N. Chomsky)RLG : A → tB, A → t
LLG : A → Bt, A → t where, A,B V∈ N and t V∈ T*.
It is important to note that grammars in which left-linear produc-tions are intermixed with right-linear productions are not regular.
For example,
G : S → aR S → c R → Sb
L(G) = {ancbn | n 0} is a cfl.
3.1 정규 문법과 정규 언어

Definition
(1) A grammar is regular if each rule isi) A ® aB, A ® a, where a Î VT, A, B Î VN.
ii) if S ® ε Î P, then S doesn't appear in RHS.
우선형 문법 A ® tB, A ® t 의 형태에서 t 가 하나의 terminal 로 이루어진 경우로 정규 문법에 관한 속성을 체계적으로 전개하기 위하여 바람직한 형태이다 .
(2) A language is said to be a regular language(rl) if it can be generated by a regular grammar.
ex) L = { anbm| n, m ≥1 } is rl.
S ® aS | aA
A ® bA | b

[Theorem] The production forms of regular grammar can be derived from those of RLG.(RLG => RG) (Text p.73)
(proof)
A ® tB, where t Î VT*.Let t = a1a2... an, ai Î VT.
A ® a1A1
A1 ® a2A2 . . .An-1 ® anB.
If t = e, then A ® B (single production) or A ® e (epsilon production).
⇒ These forms of productions can be easily removed.
(Text pp.187-191)
ex) S ® abcA ⇒ S ® aS1, S1 ® bS2 S2 ® cA
A ® bcA ⇒ A ® bA1, A1 ® cA
A ® cd ⇒ A ® cA1', A1' ® d
Right-linear grammar : A → tB or A → t,
where A, B ∈ VN and t ∈ VT*.

1. 언어 L 은 우선형 문법에 의해 생성된다 .
2. 언어 L 은 좌선형 문법에 의해 생성된다 .
3. 언어 L 은 정규 문법에 의해 생성된다 .
정규 언어
[ 예 ] L = {anbm | n,m ≥ 1} : rl
S ® aS | aA
A ® bA | b
Equivalence
Text p. 74
토큰의 구조를 정의하는데 정규 언어를 사용하는 이유(1) 토큰의 구조는 간단하기 때문에 정규 문법으로 표현할 수 있다 .
(2) context-free 문법보다는 정규 문법으로부터 효율적인 인식기를 구현할 수 있다 .
(3) 컴파일러의 전반부를 모듈러하게 나누어 구성할 수 있다 .
(Scanner + Parser)
문법의 형태가 정규 문법이면 그 문법이 나타내는 언어의 형태를 체계적으로 구하여 정규 표현으로 나타낼 수 있다 .
if G = rg, L: re.
G Lderivation

A notation that allows us to describe the structures of sentences in regular language.
The methods for specifying the regular languages(1) regular grammar(rg)(2) regular expression(re)(3) finite automata(fa)
3.2 정규 표현
fa
rg
re

Text p. 76 Definition :
A regular expression over the alphabet T and the lan-guage denoted by that expression are defined recursively as follows :
I. Basis : f , e , a Î T.(1) f is a regular expression denoting the empty set.(2) e is a regular expression denoting {e}.(3) a where a Î T is a regular expression denoting {a}.
II. Recurse : + , • , *
If P and Q are regular expressions denoting Lp and Lq respectively, then
(1) (P + Q) is a regular expression denoting Lp U Lq. (union)(2) (P • Q) is a regular expression denoting Lp Lq. (concatena-
tion)(3) (P*) is a regular expression denoting (closure)
{e} U Lp U Lp2 U ... U Lp
n ...
Note : precedence : + < • < *
II. Nothing else is a regular expression.

ex) (0+1)* denotes {0,1}*. (0+1)*011 denotes the set of all strings of 0s and 1s
ending in 011.
Definition : if α is α regular expression, L(α) denotes the language associated with α. (Text p.72) Let a and b be regular expressions. Then, (1) L(α+ β) = L(α) L(β)
(2) L(α β) = L(α) L(β) (3) L(α*) = L(α)*
examples :
(1) L(a*) = {e, a, aa, aaa, … } = {an | n 0}
(2) L((aa)*(bb)*b) = {a2nb2m+1| n,m 0}

Definition : Two regular expressions are equal if and only if they denote the same language. α= β if L(α) = L(β).
Axioms : Some algebraic properties of regular ex-pressions. Let a, b and g be regular expressions. Then, (Text p.78)
A1. α+β = β+α A2. (α+β) +γ = α+ (β+γ)
A3. (αβ) γ = α (βγ) A4. α(β+γ) = αβ +αγ
A5. (β + γ) α = βα + γα A6. α+α=α
A7. α + f = α A8. αf = f = fα A9. e α = α = α e A10. α* = e +α•α*
A11. α* = (e + α)* A12. (α* )* = α*
A13. α* + α = α * A14. α* + α+ = α*
A15. (α + β)* = (α* β *) *

All of these identities(=Axioms) are easily proved by the definition of regular expression.
A8. αf = f = f α (proof) αf = { xy | x Î Lα and yÎ Lf }
Since y Î Lf is false, (x Î Lα and y Î Lf) is false.
Thus αf = f .
Definitions : regular expression equations.::= the set of equations whose coefficient
are regular expressions.
ex) α,β 가 정규 표현이면 , X = αX+β 가 정규 표현식이다 . 이때 , X 의 의미는 nonterminal 심볼이며 우측의 식이 그 non-terminal 이 생성하는 언어의 형태이다 .

▶ The solution of the regular expression equation
X = αX + β
When we substitute X = α*β in both side of the equation, each side of the equation represents the same language.
X = αX + β = α(α*β) + β = αα*β + β = (αα* + ε)β = α*β.
fixed point iteration
X = αX + β = α(αX + β) + β
= α2X + αβ + β = α2X + (ε + α)β...
= αk+1X + (ε + α + α2 + ... αk )β= (ε + α + α2 + ... + αk + ...)β = α*β.

Not all regular expression equations have unique solution. X = αX + β
(a) If ε is not in α, then X = α*β is the unique solution.
(b) If ε is in α, then X = α*(β + L) for some language L.
So it has an infinity of solutions.
⇒ Smallest solution : X = α*β.
ex) X = X + a : not unique solution
⇒ X = a + b or X = b*a or X = (a + b)* etc.
X = X + a X = X + a
= a + b + a = b*a + a
= a + a + b = (b* + ε) a
= a + b. = b*a

Finding a regular expression denoting L(G) for a given rg G.
L(A) where A VN denotes the language generated by A.
By definition, if S is a start symbol, then L(G)= L(S).
Two steps :1. Construct a set of simultaneous equations from G.
A ® aB, A ® a
L(A) = {a}·L(B) U {a} A = aB + a
In general, X ® α |β| γ ⇒ X = α + β + γ.
2. Solve these equations.X = αX + β Û X = α*β.
if G = rg, L: re.
G Lderivation
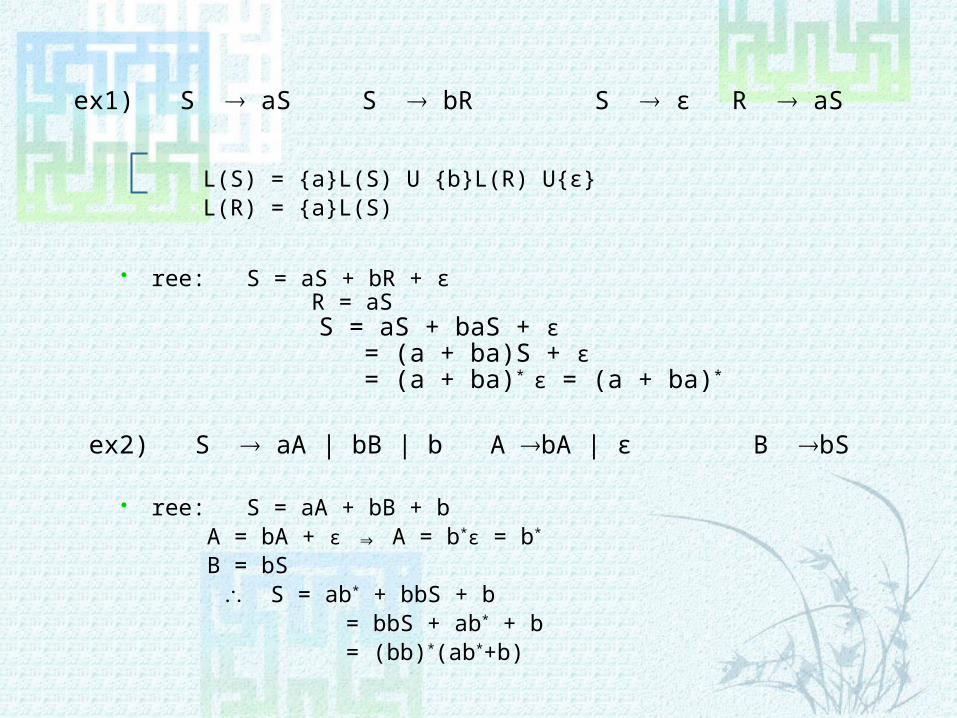
ex1) S ® aS S ® bR S ® ε R ® aS
L(S) = {a}L(S) U {b}L(R) U{ε} L(R) = {a}L(S)
ree: S = aS + bR + ε R = aS S = aS + baS + ε = (a + ba)S + ε = (a + ba)* ε = (a + ba)*
ex2) S ® aA | bB | b A ®bA | ε B ®bS
ree: S = aA + bB + b A = bA + ε ⇒ A = b*ε = b*
B = bS S = ab* + bbS + b = bbS + ab* + b = (bb)*(ab*+b)
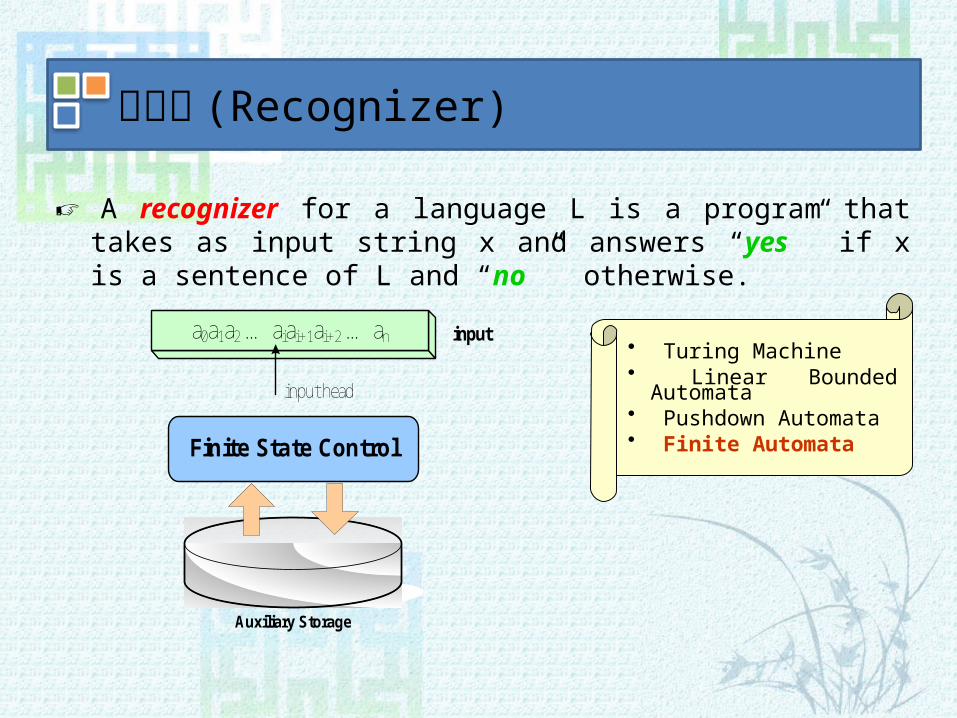
☞ A recognizer for a language L is a program that takes as input string x and answers “yes ” if x is a sentence of L and “no ” otherwise.
인식기 (Recognizer)
• Turing Machine• Linear Bounded Au-
tomata• Pushdown Automata• Finite Automata
a0a1a2 … aiai+1ai+2 … an
Finite State Control
input head
Auxiliary Storage
input
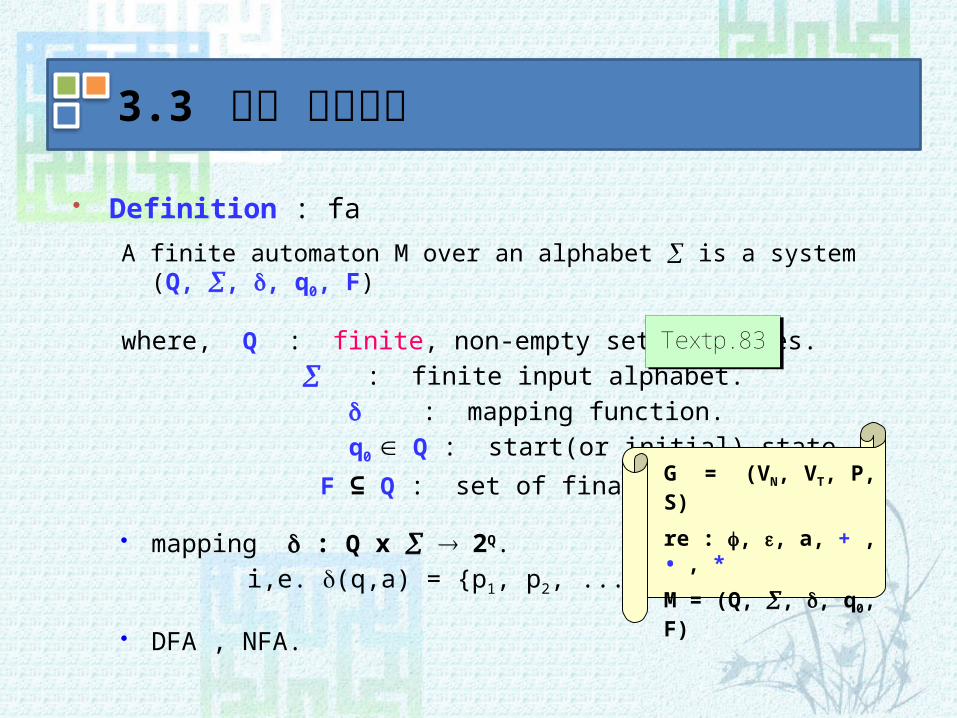
Definition : fa
A finite automaton M over an alphabet is a system (Q, , , q0, F)
where, Q : finite, non-empty set of states.
: finite input alphabet.
: mapping function.
q0 Q : start(or initial) state.
F ⊆ Q : set of final states.
mapping : Q x ® 2Q.
i,e. (q,a) = {p1, p2, ... , pn}
DFA , NFA.
Text p. 83
3.3 유한 오토마타
G = (VN, VT, P, S)
re : f, e, a, + , • , *
M = (Q, , , q0, F)

deterministic if (q,a) consists of one state.
We shall write "(q,a) = p " instead of (q,a) = {p} if deterministic.
If δ(q,a) always has exactly one number,
We say that M is completely specified.
extension of : Q x Q x ⇒ *
(q, ) = q
(q,xa) = ((q,x),a), where x * and a . A sentence x is said to be accepted by M
if (q0, x) = p , for some p F.
The language accepted by M :
L(M) = { x | (q0,x) F }
Deterministic Finite Automata(DFA)

ex) M = ( {p, q, r}, {0, 1}, , p, {r} )
: (p,0) = q (p,1) = p
(q,0) = r (q,1) = p
(r,0) = r δ(r,1) = r
1001 Î L(M) ?
(p,1001) = (p,001) = (q,01) = (r,1) = r F . ∴ 1001 L(M).
1010 Î L(M) ?
(p,1010) = (p,010) = (q,10) = (p,0) = q F.
∴ 1010 L(M).
: matrix 형태로 transition table. ex)
pqp
rrrprq
10Input symbols
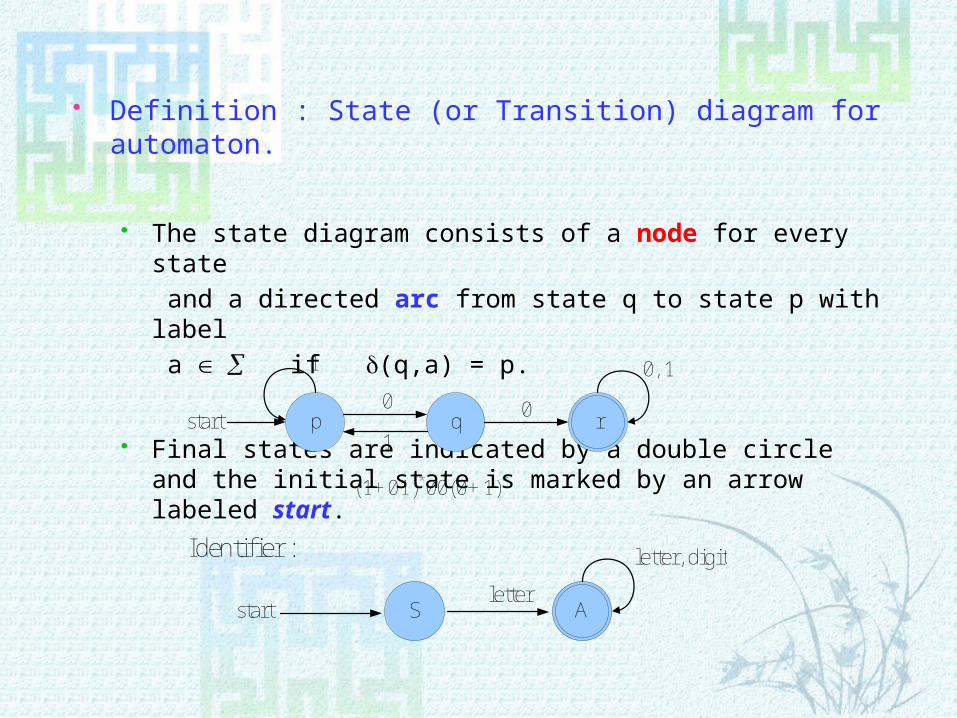
Definition : State (or Transition) diagram for automa-ton.
The state diagram consists of a node for every state and a directed arc from state q to state p with label a if (q,a) = p.
Final states are indicated by a double circle and the initial state is marked by an arrow labeled start.
p rstart
0, 11
q0
1
0
(1+01)*00(0+1)*
Astart
letter, digit
Sletter
Identifier :

Text p. 88Algorithm : w L(M).assume M = (Q, , , q0, F);
begin
currentstate := q0; (* start state *)
get(nextsymbol);
while not eof do
begin currentstate := (currentstate, nextsymbol);
get(nextsymbol)
end;
if currentstate in F then write(‘Valid String’)
else write(‘Invalid String’);
end.
?

δ 0 1 q0 {q1, q2} {q1, q3} q1 {q1, q2} {q1, q3} q2 {qf} q3 {qf} qf {qf} {qf}
Nondeterministic Finite Automata(NFA)
nondeterministic if (q,a) = {p1, p2, ..., pn}
In state q, scanning input data a, moves input head one symbol right and chooses any one of p1, p2, ..., pn as the next state.
ex) NFA (Nondeterministic Finite Automata) M = ( {q0,q1,q2,q3,qf}, {0,1}, , q0, {qf} )
if (q,a) = f, then (q,a) is undefined.

To define the language recognized by NFA, we must ex-tend .(i) : Q x * → 2Q
( q, ε ) = { q }
( q, xa ) = U (p,a), where a VT and x VT*.
p ( q, x )
(ii) : 2Q x * → 2Q
({p1, p2, ..., pk}, x) =
Definition : A sentence x is accepted by M if there is a state p in both F and (q0, x).
ex) 1011 L(M) ?
(q0, 1011) = ({q1,q3}, 011) = ({q1,q2},11)
= ({q1,q3},1) = {q1,q3,qf}
1011 L(M) ( {q∵ 1,q3,qf} ∩ {qf} Φ)
ex) 0100 L(M) ?
k
i=1 (pi,x)
É
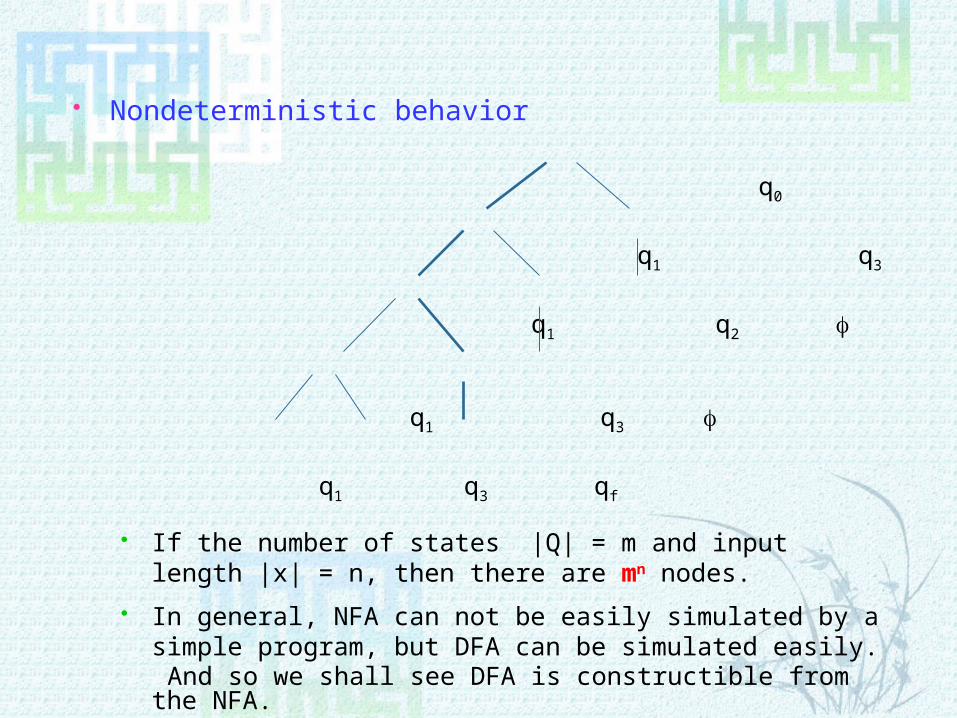
Nondeterministic behavior
q0
q1 q3
q1 q2
q1 q3
q1 q3 qf
If the number of states |Q| = m and input length |x| = n, then there are mn nodes.
In general, NFA can not be easily simulated by a simple program, but DFA can be simulated easily.
And so we shall see DFA is constructible from the NFA.

Text p. 92
Converting NFA into DFA
NFA : easily describe the real world.DFA : easily simulated by a simple program. ===> Fortunately, for each NFA we can find a DFA accept-
ing the same language.
Accepting Sequence(NFA)(q0, a1a2 ... an) = ({q1,q2, … ,qi}, a2a3 ... an)
... ...
= ({p1,p2, … ,pj}, ai ... an) ... ...
= {r1,r2, ... ,rk} Since the states of the DFA represent subsets of the
set of all states of the NFA, this algorithm is often called the subset construction.

[Theorem] Let L be a language accepted by NFA. Then there exists DFA which accepts L. Text p.86
(proof) Let M = (Q, , , q0, F) be a NFA accepting L.
Define DFA M' = (Q', , ', q0', F') such that
(1) Q' = 2Q, {q1, q2, ..., qi} ∈ Q', where qi ∈ Q.
denote a set of Q' as [q1, q2, ..., qi].
(2) q0' = {q0} = [q0]
(3) F' = {[r1, r2, ..., rk] | ri ∈ F}
(4) ' : ' ([q1, q2, ...,qi], a) = [p1, p2, ..., pj]
if ({q1, q2, ..., qj}, a) = {p1, p2, ..., pj}.
Now we must prove that L(M) = L(M’) i.e,
' (q0',x) F' Û (q0, x) ∩ F f. we can easily show that by inductive hypothesis on the
length of the input string x.

ex1) M = ({q0,q1}, {0,1}, , q0, {q1}),
Þ dfa M' = (Q', , ', q0', F'),
where Q' = 2Q = {[q0], [q1], [q0,q1]}
q0' = [q0]
F' = {[q1], [q0,q1]}
δ' :δ'([q0],0) = δ({q0},0) = {q0,q1} = [q0,q1]
δ'([q0],1) = {q0} = [q0]
δ' ([q1],0) = δ(q1,0) = f
δ' ([q1],1) = δ(q1,1) = {q0,q1} = [q0,q1]
δ' ([q0,q1],0) = δ({q0,q1},0) = {q0,q1} = [q0,q1]
δ' ([q0,q1],1) = δ({q0,q1},1) = {q0,q1} = [q0,q1]
d 0 1
q0 {q0 , q1} {q0}
q1 f {q0 , q1}
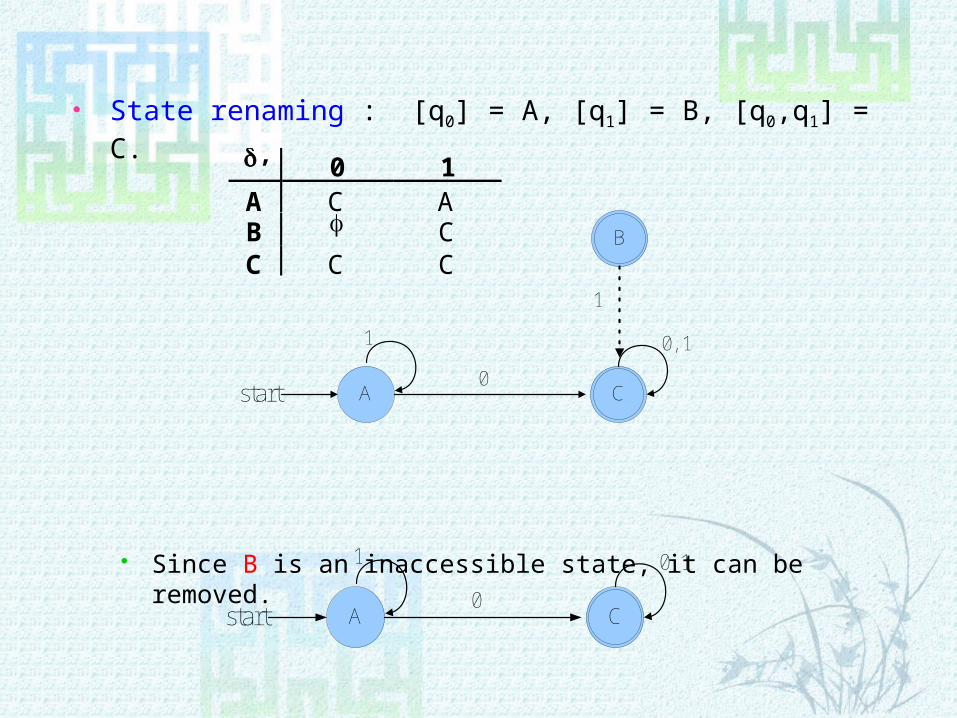
State renaming : [q0] = A, [q1] = B, [q0,q1] = C.
Since B is an inaccessible state, it can be removed.
’ 0 1A C AB CC C C
A Cstart
0, 11
0
B
1
A Cstart
0, 11
0

Definition : we call a state p accessible if there is w such that (q0, w) Þ (p, ε) , where q0 is the initial state.
ex2) NFA Þ DFA NFA : 0 1
q0 {q1,q2} {q1,q3}
q1 {q1,q2} {q1,q3}
q2 {qf}
q3 {qf}
qf {qf} {qf}
DFA : ’ 0 1q0 q1q2 q1q3
q1q2 q1q2qf q1q3
q1q3 q1q2 q1q3qf
q1q2qf q1q2qf q1q3qf
q1q3qf q1q2qf q1q3qf
*
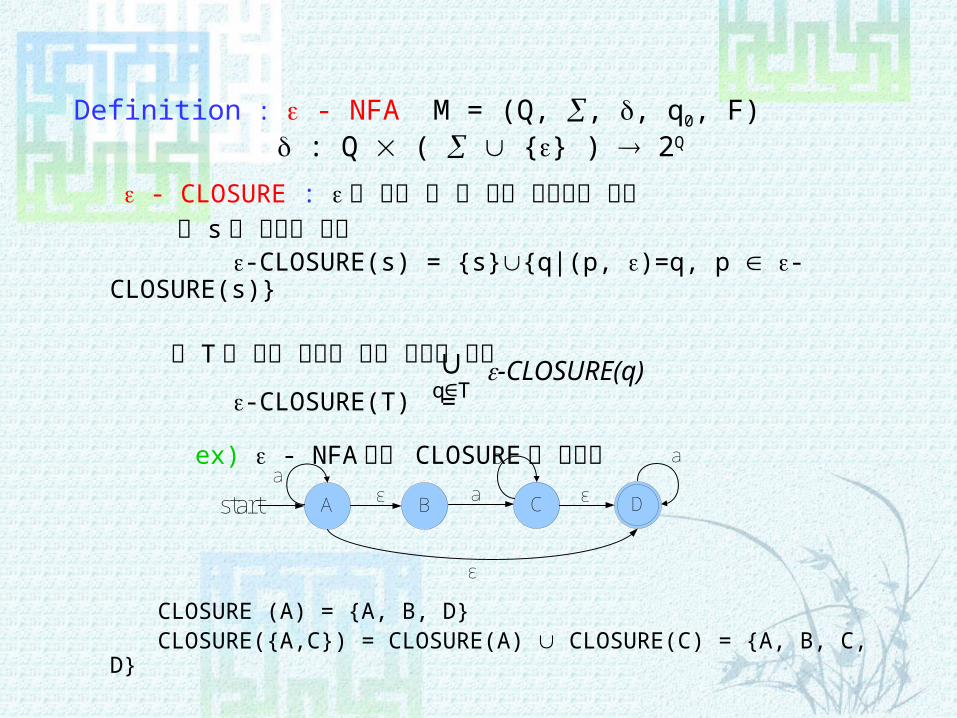
Definition : - NFA M = (Q, , , q0, F) : Q ( {} ) 2Q
- CLOSURE : 을 보고 갈 수 있는 상태들의 집합 s 가 하나의 상태
-CLOSURE(s) = {s}{q|(p, )=q, p -CLOSURE(s)}
T 가 하나 이상의 상태 집합인 경우
-CLOSURE(T) =
ex) - NFA 에서 CLOSURE 를 구하기
CLOSURE (A) = {A, B, D}CLOSURE({A,C}) = CLOSURE(A) CLOSURE(C) = {A, B, C, D}
A Dstarta
CaB
b
ε
εε
a
-CLOSURE(q) ∪q∈T
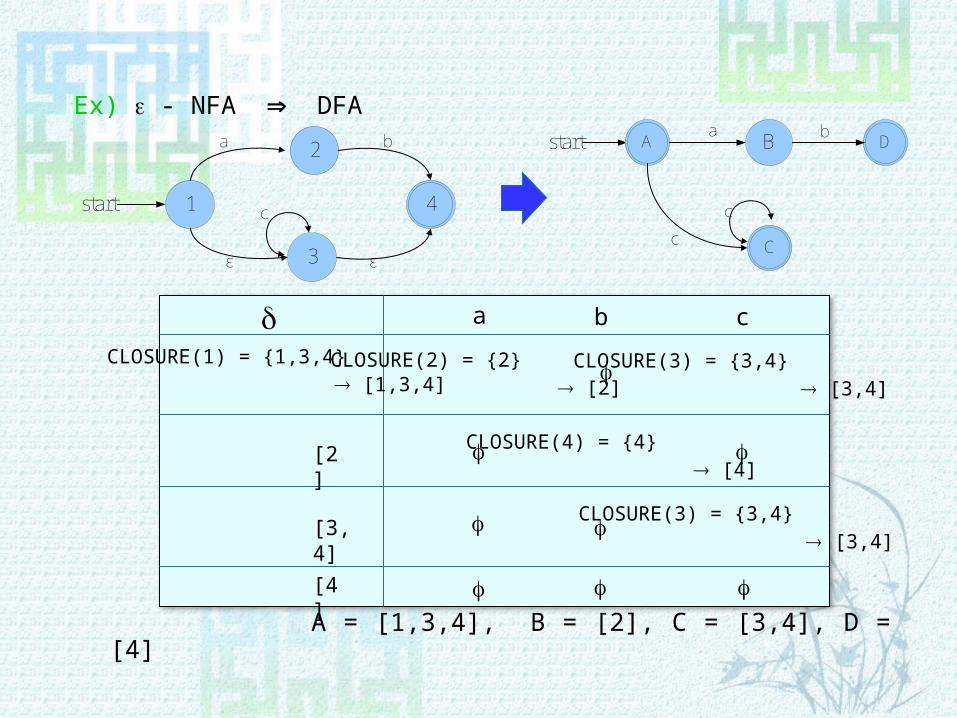
Ex) - NFA Þ DFA
A = [1,3,4], B = [2], C = [3,4], D = [4]
1start
a
c
2 b
ε ε3
4
Dstarta b
A B
C
c
c
CLOSURE(1) = {1,3,4} [1,3,4]
a
CLOSURE(2) = {2} [2]
b
CLOSURE(3) = {3,4} [3,4]
c
[2]
CLOSURE(4) = {4} [4]
[3,4]
[4]
CLOSURE(3) = {3,4} [3,4]

Text p. 101
Minimization of FA
State minimization => state merge
Definition : ω Î * distinguishes q1 from q2 if (q1,ω) = q3, (q2,ω) = q4 and exactly one of q3, q4 is in F.
Algorithm : equivalence relation(º) ⇒ partition.
(1) º : final state 인가 아닌 가로 partition.(2) º : input symbol 에 따라 다른 equivalence class 로 가는가 ? 그 symbol 로 distinguish 된다고 함 . :(3) º : 더 이상 partition 이 일어나지 않을 때까지 .
Þ The states that can not be distinguished are merged into a single state.

How to minimize the number of states in a fa.
<step 1> Delete all inaccessible states;<step 2> Construct the equivalence relations;<step 3> Construct fa M’ = (Q’, , ’, q0’, F’),
(a) Q’ : set of equivalence classes under º Let [p] be the equivalence class of state p under º.
(b) ’([p],a) = [q] if (p,a) = q. (c) q0’ is [q0].
(d) F' = {[q] | q Î F}.
Definition : M is said to be reduced. if (1) no state in Q is inaccessible and
(2) no two distinct states of Q are indistinguishable

[Theorem] If L1 and L2 are finite automaton languages (FAL),
then so are (i) L1 U L2 (ii) L1 • L2 (iii) L1*.
(proof) M1 = (Q1, , 1, q1, F1) M2 = (Q2, , 2, q2, F2), Q1 Ç Q2 = f (∵ renaming)
(i) M = (Q1 U Q2 U {q0}, , , q0, F)
where, (1) q0 is a new state.
(2) F = F1 U F2 if e L1 U L2.
F1 U F2 U {q0} if e Î L1 U L2.
(3) (a) (q0,a) = (q1,a) U (q2,a) for all a Î .
(b) (q,a) = 1(q,a) for all q Î Q1, a Î .
(c) (q,a) = 2(q,a) for all q Î Q2, a Î .
새로운 시작 상태를 만들어 각각의 fa 에 마치 각 fa 의 시작 상태에서 온 것처럼 연결한다 . 그리고 e 를 인식하면 새로 만든 시작 상태도 종결 상태로 만든다 .
ex) p.105 [ 예제 3.28]
Closure properties of FA
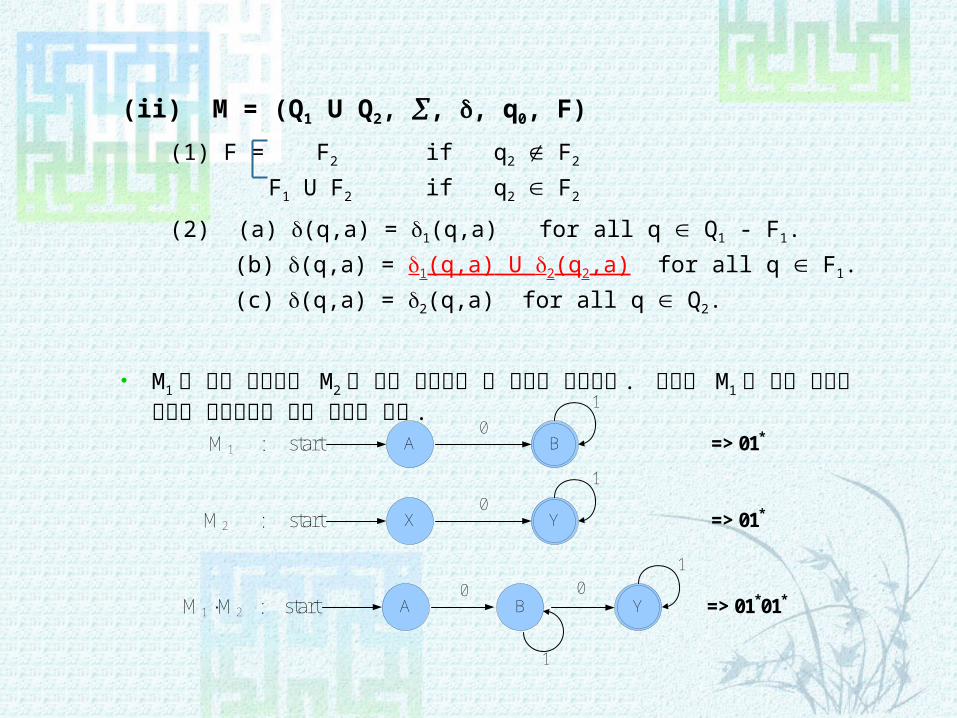
(ii) M = (Q1 U Q2, , , q0, F)
(1) F = F2 if q2 Ï F2
F1 U F2 if q2 Î F2
(2) (a) (q,a) = 1(q,a) for all q Î Q1 - F1.
(b) (q,a) = 1(q,a) U 2(q2,a) for all q Î F1.
(c) (q,a) = 2(q,a) for all q Î Q2.
M1 의 종결 상태에서 M2 의 시작 상태에서 온 것처럼 연결한다 . 그리고 M1 의 시작 상태가 접속한 오토마타의 시작 상태가 된다 .
A Bstart
1
0 M1 : => 01*
X Ystart
1
0 M2 : => 01*
A Ystart
1
0 M1 •M2 : => 01*01*B
0
1
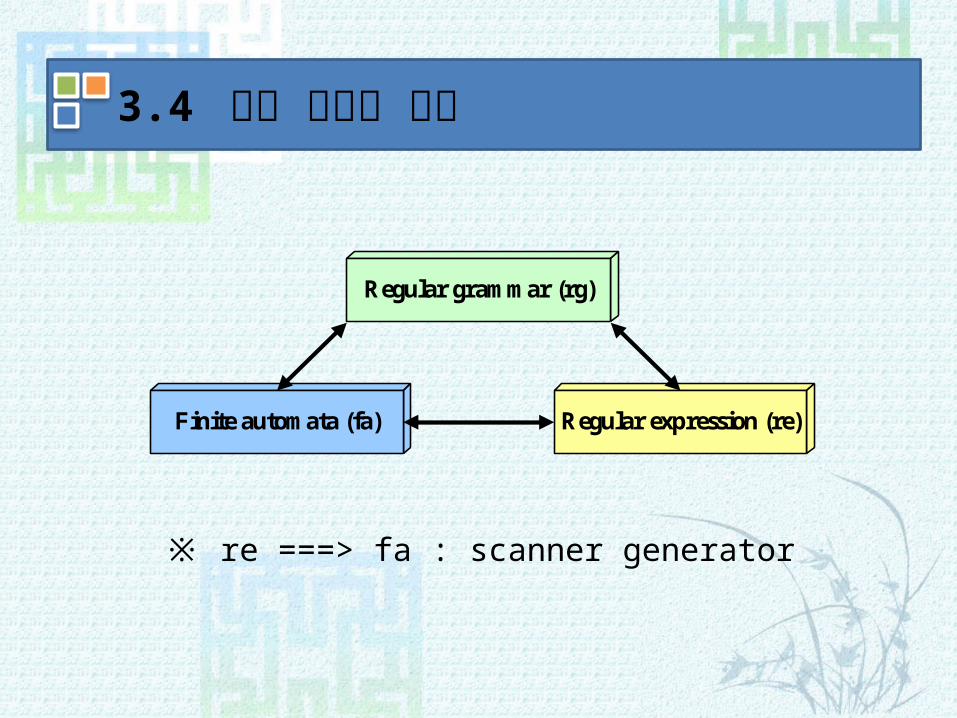
Regular grammar (rg)
Finite automata (fa) Regular expression (re)
3.4 정규 언어의 속성
※ re ===> fa : scanner generator
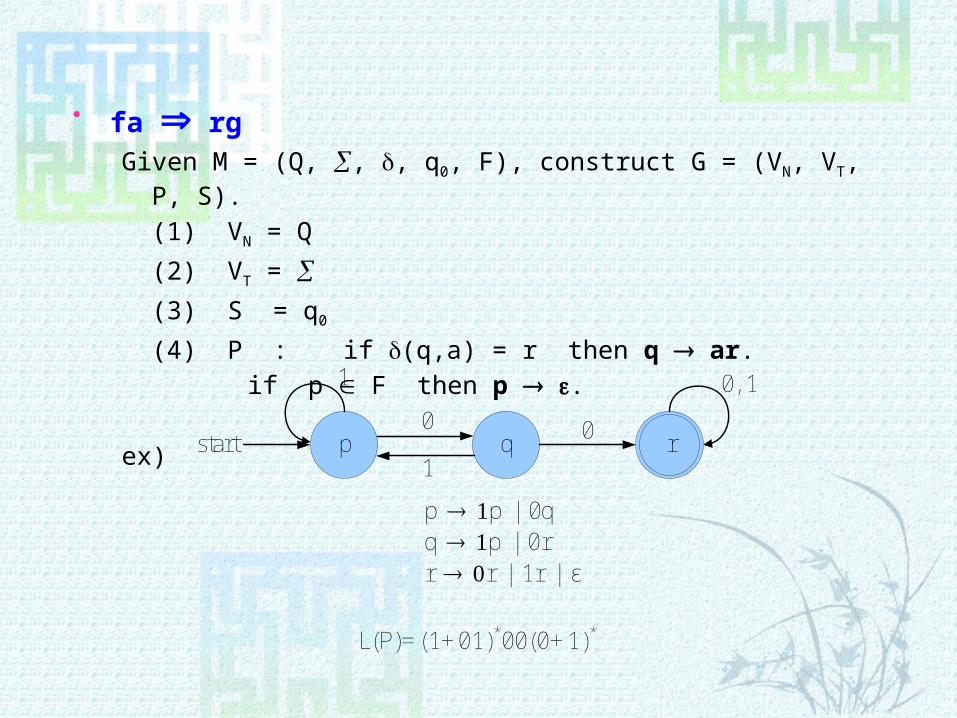
fa Þ rgGiven M = (Q, , , q0, F), construct G = (VN, VT, P, S).
(1) VN = Q
(2) VT =
(3) S = q0
(4) P : if (q,a) = r then q ® ar.
if p Î F then p ® e.
ex)p rstart
0, 11
q0
1
0
L(P)=(1+01)*00(0+1)*
p 1p | 0q q 1p | 0r r 0r | 1r | ε
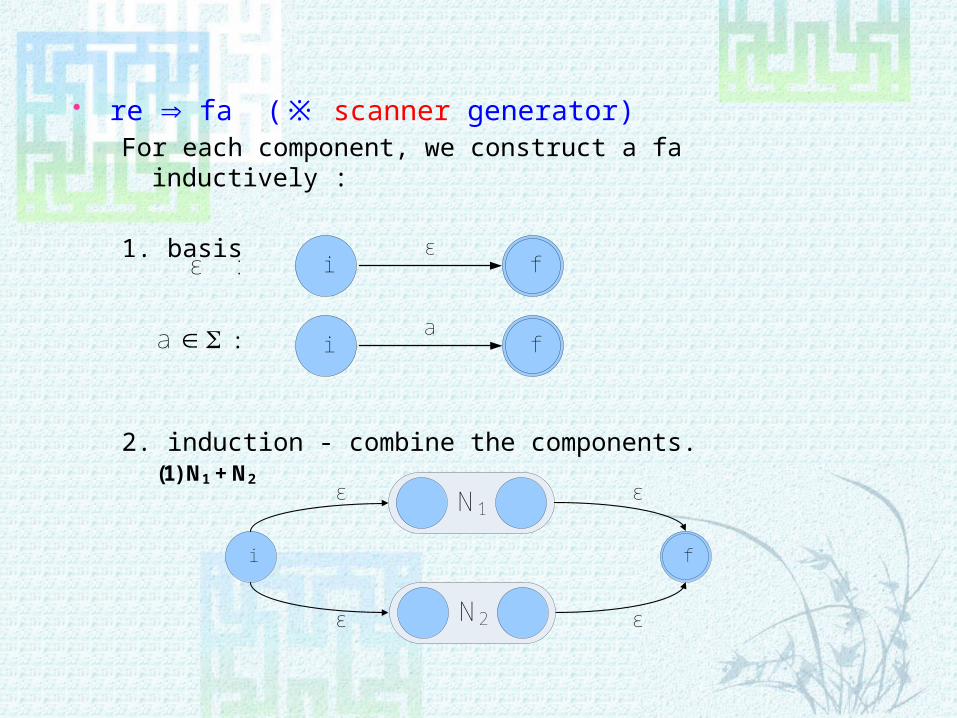
re Þ fa (※ scanner generator)For each component, we construct a fa inductively :
1. basis
2. induction - combine the components.
i f ε :ε
i fa : a
(1) N1 + N2
N1
i
ε
ε
ε
ε
N2
f
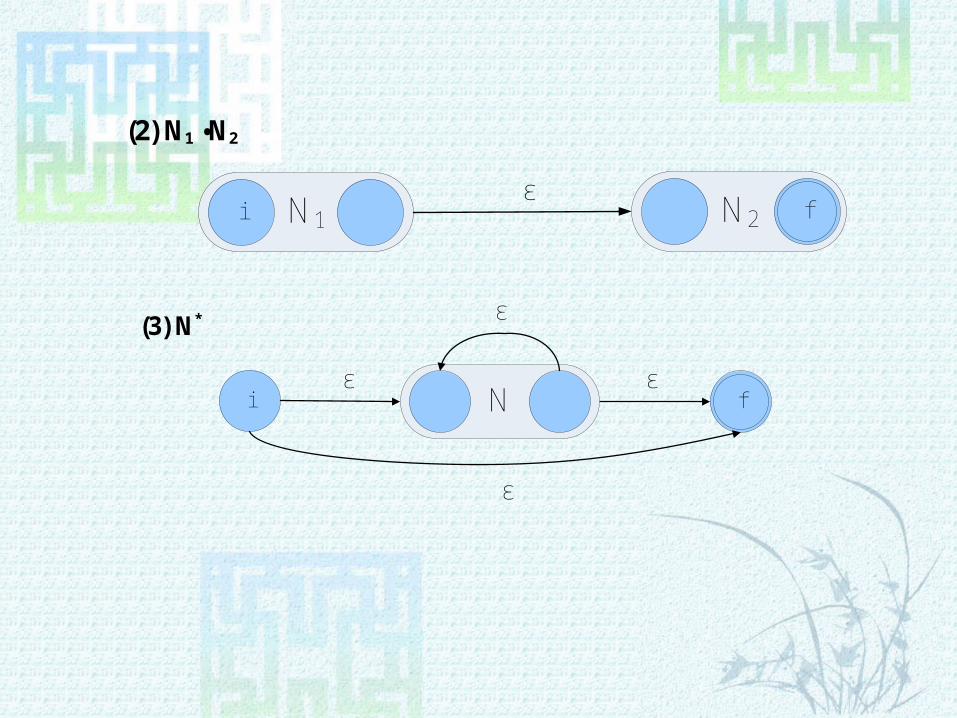
ε
(2) N1 •N2
N1i N2 f
(3) N*
i f ε ε
ε
ε
N

Definition : The size of a regular expression is the number of operations and operands in the expression.
ex) size(ab + c*) = 6
decomposition:
The number of state is at most twice the size of the expres-sion.
(∵ each operand introduces two states and each operator introduces at
most two states.) The number of arcs is at most four times the size of the ex-
pression.
*
R6
R3 +
R1 R2
R5
R4
a b c
.

Simplifications : p.113
※ -arc 로 연결된 두 상태는 소스 상태에서 나가는 다른 arc 가
없으면 같은 상태로 취급될 수 있다 .
ex) p.105 [ 예 31]
re Þ -NFA ( 간단화 ) Þ DFA ex) p.115 [ 예제 3.33]
The following statements are equivalent :
1. L is generated by some regular grammar.2. L is recognized by some finite automata.3. L is described by some regular expression.
A B ε
aA
a





























