Embed Size (px)
Citation preview

천둥 사용자 매뉴얼
서울대학교 매니코어 프로그래밍 연구단
매니코어소프트(주)
버전 1.5
2017년 8월 10일

차 례
제 1 장 개요 2
제 2 장 시스템 구성 4
제 3 장 사용자 환경 6
1 로그인 노드 접속 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 파일 시스템 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
제 4장 프로그래밍 환경 8
1 컴파일러 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2 병렬 프로그래밍 모델 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1 SnuCL 사용 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3 라이브러리 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
4 개발 도구 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
제 5장 thor를 사용한 프로그램 실행 13
1 개요 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2 작업 추가 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3 작업 확인 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4 작업 삭제 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5 쿼터 확인 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
6 참고 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
제 6장 thor 웹 인터페이스 20
1

제 7 장 천둥 소프트웨어 설치 안내 25
1 개요 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2 Caffe 설치 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3 TensorFlow 설치 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2

제1장
개요
천둥은 계산 노드 52대, 스토리지 노드 3대, 로그인 노드 2대로 이루어진 이종 클러스터
(heterogeneous cluster)입니다. 천둥의 각 계산 노드에는 8코어 CPU 2개와 GPU 4대가
함께장착되어있습니다. OpenCL (Open Computing Language)이나 CUDA로GPU에서
범용계산을수행하는프로그램을작성하고천둥에서실행할수있습니다.나아가 MPI
(Message Passing Interface)나 SnuCL을 사용하여 여러 노드에서 병렬로 실행되는 프로
그램을 작성할 수 있습니다. (물론 CPU만을 사용하는 프로그램도 실행 가능합니다.)
천둥의 계산 노드 52대의 자원을 모두 활용하면 최대 CPU 832코어와 GPU 208대, 메
인 메모리 6656 GB를 동시에 사용할 수 있습니다. 이들의 이론 최대성능치(theoretical
peak)는 배정도(double precision) 부동소수점 연산 기준 148 TFLOPS, 단정도(single
precision) 기준 1269 TFLOPS에 이릅니다.
사용자는 로그인 노드에 접속한 다음 천둥에 설치된 클러스터 관리 소프트웨어인
thor1를 사용해 계산 노드에서 프로그램을 실행할 수 있습니다. 로그인 노드와 계산 노
드는 모두 스토리지 노드가 제공하는 144 TB 규모의 Lustre 파일 시스템을 공유하고
있습니다. 따라서 로그인 노드에서 프로그램을 작성하고 데이터를 저장하면, 계산 노
드에서 바로 그 프로그램을 실행하고 데이터를 불러올 수 있습니다. thor를 사용하지
않고 계산 노드에 직접 접근하는 것은 불가능합니다. 로그인 노드와 계산 노드는 각각
다음의 용도로 사용할 수 있습니다.
• 로그인 노드
– 프로그램 작성 및 컴파일
1) 토르(thor)는 북유럽 신화에 나오는 천둥의 신 이름입니다.
3

– 계산량이 적은 간단한 프로그램 실행: 로그인 노드에서는 CPU 시간이 10
분이 넘어가는 프로그램은 자동으로 종료됩니다.
– 인터넷 연결이 필요한 파일 업로드·다운로드 등의 작업: 계산 노드는 인터넷
에 연결되어 있지 않습니다.
• 계산 노드
– 계산량이 많은 프로그램 실행
– GPU를 범용 계산에 사용하는 프로그램 실행: 로그인 노드에서는 GPU를
사용할 수 없습니다.
– 여러 노드를 동시에 사용하는 프로그램 실행
본매뉴얼은다음과같이구성됩니다. 2장에서는천둥의구성과사양을설명합니다.
3장에서는 사용자 계정으로 천둥의 로그인 노드에 접속하고 파일 시스템을 사용하는
방법 등 기본적인 사용자 환경을 안내합니다. 4장은 작성한 프로그램을 컴파일하고
라이브러리와 링크하는 방법을 설명합니다. 5장에서는 thor를 사용해 계산 노드에서
프로그램을 실행하는 방법을, 6장에서는 thor의 웹 인터페이스를 사용해 사용자 정보
를 확인하는 방법을 설명합니다. 마지막으로 7장은 천둥 소프트웨어 관련 규정과 주요
소프트웨어 설치법을 안내합니다.
본 매뉴얼에 나와 있지 않은 사항은 천둥 홈페이지의 사용 안내를 참고하시거나
메일로 문의해 주시기 바랍니다.
4
제2장
시스템 구성
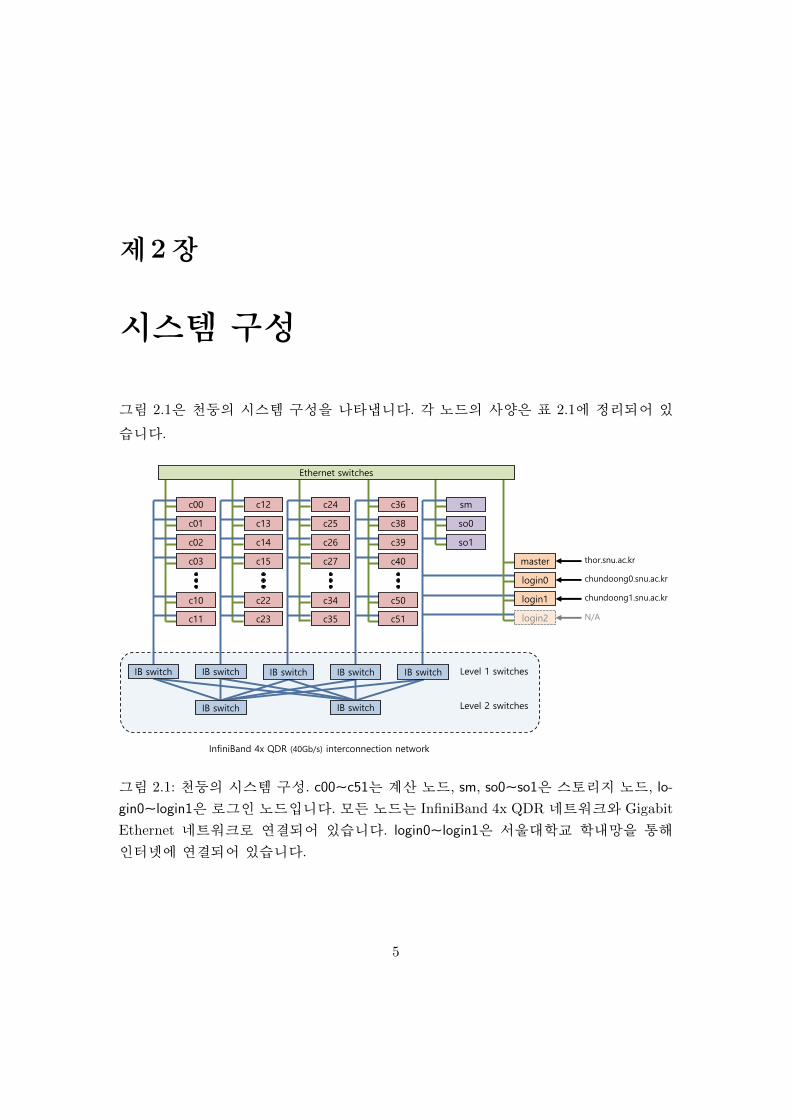
그림 2.1은 천둥의 시스템 구성을 나타냅니다. 각 노드의 사양은 표 2.1에 정리되어 있
습니다.
Ethernet switches
c00
c01
c02
c03
c10
c11
c12
c13
c14
c15
c22
c23
c24
c25
c26
c27
c34
c35
c36
c38
c39
c40
c50
c51
sm
so0
so1
master
login0
login1
login2
IB switch IB switch IB switch IB switch IB switch
IB switch IB switch
Level 1 switches
Level 2 switches
InfiniBand 4x QDR (40Gb/s) interconnection network
thor.snu.ac.kr
chundoong0.snu.ac.kr
chundoong1.snu.ac.kr
N/A
그림 2.1: 천둥의 시스템 구성. c00∼c51는 계산 노드, sm, so0∼so1은 스토리지 노드, lo-
gin0∼login1은로그인노드입니다.모든노드는 InfiniBand 4x QDR네트워크와 Gigabit
Ethernet 네트워크로 연결되어 있습니다. login0∼login1은 서울대학교 학내망을 통해
인터넷에 연결되어 있습니다.
5

표 2.1: 천둥 노드 사양
항목 내용
계산 노드 (c00∼c51)
CPU 2 × Intel Xeon E5-2650 (Sandy Bridge-EP, 8-core 2.00GHz)
GPU 4 × AMD Radeon R9 Nano (c00∼c07, 8 노드)
4 × AMD Radeon HD 7970 (c08∼c31, 24 노드)
4 × AMD Radeon R9 290X (c32∼c35, 4 노드)
4 × NVIDIA GeForce GTX 1080 (c36∼c51, 16 노드)
메인 메모리 128GB (DDR3 1,600MHz)
InfiniBand Single-port Mellanox InfiniBand QDR HCA
운영체제 CentOS Linux release 7.2
스토리지 노드 (sm, so0∼so1)
sm: MDS (metadata server); so0∼so1: OSS (object storage server)
CPU 2 × Intel Xeon E5-2620 v3 (Haswell, 6-core 2.40GHz)
메인 메모리 sm: 128GB (DDR4 2,133MHz)
so0∼so1: 256GB (DDR4 2,133MHz)
하드 디스크 sm: 16 × 300GB (ST SAS3, 15,000RPM)
so0∼so1: 16 × 6TB (ST SATA3, 7,200RPM)
RAID sm: RAID 10
so0∼so1: RAID 6
InfiniBand 2 × Dual-port Mellanox InfiniBand QDR HCA
운영체제 CentOS Linux release 7.2
파일 시스템 Lustre 2.8
로그인 노드 (login0∼login1)
CPU 2 × Intel Xeon E5-2650 (Sandy Bridge-EP, 8-core 2.00GHz)
메인 메모리 128GB (DDR3 1,333MHz)
InfiniBand Single-port Mellanox InfiniBand QDR HCA
운영체제 CentOS Linux release 7.2
6

제3장
사용자 환경
로그인 노드에는 CentOS Linux release 7.2이 설치되어 있으므로 기본적인 사용 방법은
일반적인 리눅스 서버와 동일합니다. 여기서는 천둥 사용을 위해 사용자가 특별히 알
아야 할 내용을 위주로 설명합니다. 리눅스 쉘의 일반적인 사용법에 대해서는 별도로
다루지 않으니 관련 서적 혹은 웹 사이트를 참고하십시오.
1 로그인 노드 접속
홈페이지에서 계정 신청 후 발급받은 아이디와 패스워드를 사용해 SSH로 로그인할 수
있습니다. 로그인 노드 정보는 표 3.1을 참고하십시오. 윈도 사용자는 PuTTY나 Xshell
등의 무료 SSH 클라이언트(단 Xshell은 개인 및 학교 사용자 한정)를 사용해 접속하실
수 있습니다. 리눅스 사용자는 터미널에서 ssh 명령을 사용합니다. 포트는 22번 혹은
2222번을 중 하나를 사용하실 수 있습니다.
표 3.1: 로그인 노드 목록
이름 도메인 IP 주소 SSH 포트
login0 chundoong0.snu.ac.kr 147.46.219.141 22, 2222
login1 chundoong1.snu.ac.kr 147.46.219.242 22, 2222
계정 발급 후 처음 로그인을 하셨다면 passwd 명령을 사용해 패스워드를 바꿔 주시
기 바랍니다. 보안을 위해 패스워드는 가급적 알파벳 대문자, 소문자, 숫자, 특수문자가
조합된 의미 없는 문자열로 설정해 주시기 바랍니다.
모든 사용자 계정은 기본값으로 bash 쉘을 사용하도록 설정되어 있습니다. 본 매뉴
얼도 bash 쉘을 기준으로 하여 천둥 사용법을 설명합니다.
7

2 파일 시스템
로그인노드와계산노드는 Lustre파일시스템을통해 /home과 /scratch를공유하고있
습니다.사용자는자신의홈디렉터리 /home/user id와스크래치디렉터리 /scratch/user id
를사용할수있습니다.홈디렉터리는 1인당최대 64 GB까지사용할수있습니다.스크
래치 디렉터리는 1인당 최대 2 TB까지 사용 가능하되, 7일 이상 사용하지 않은 파일은
임의로 삭제될 수 있습니다. 통상 홈 디렉터리는 사용자 프로그램이나 설정 파일 등 오
래보존해야할파일을저장하는용도로,스크래치디렉터리는프로그램실행에필요한
대용량 데이터를 임시로 저장하는 용도로 사용합니다. 이상의 내용을 요약하면 표 3.2
와 같습니다.
표 3.2: 파일 시스템
분류 파티션 사용자 디렉터리 용량 제한 비고
홈 디렉터리 /home /home/user id 64 GB
(66 TB)
스크래치 /scratch /scratch/user id 2 TB 7일 이상 사용하지 않은
디렉터리 (66 TB) 파일은 임의로 삭제 가능
현재 자신이 사용 중인 용량은 다음과 같이 확인할 수 있습니다.
[user_id@login0 ~]$ lfs quota -u user_id /home
[user_id@login0 ~]$ lfs quota -u user_id /scratch
로그인 노드에 SFTP로 접속해 홈 디렉터리나 스크래치 디렉터리에 파일을 업로드·다운로드할 수 있습니다. 윈도 사용자는 WinSCP나 FileZilla 등의 무료 SFTP 클라이
언트를 사용해 접속하실 수 있습니다. 리눅스 사용자는 터미널에서 scp 명령을 사용합
니다.
8

제4장
프로그래밍 환경
1 컴파일러
천둥에 설치된 컴파일러는 표 4.1과 같습니다.
표 4.1: 천둥의 컴파일러 목록
컴파일러 버전컴파일 명령
C C++ Fortran CUDA
GCC 4.8.5 gcc g++ gfortran
nvcc 8.0.61 nvcc
2 병렬 프로그래밍 모델
병렬 프로그래밍 모델은 병렬 프로그램이 어떻게 작성되어야 하는지 규정하고 이를
뒷받침하는 실행 시스템(runtime system)과 라이브러리를 제공합니다. CPU 코어 하나
에서실행되는프로그램을작성할때는별도의프로그래밍모델이필요치않습니다.하
지만프로그램을 (1)여러 CPU코어에서병렬로실행하거나, (2) GPU에서실행하거나,
(3) 여러 노드에서 병렬로 실행할 때는 이에 맞는 병렬 프로그래밍 모델이 필요합니다.
표 4.2는현재천둥에서사용할수있는병렬프로그래밍모델을정리한것입니다.표 4.3
과 표 4.4는 각 병렬 프로그래밍 모델을 사용한 프로그램을 컴파일하는 방법을 요약한
것입니다.
9
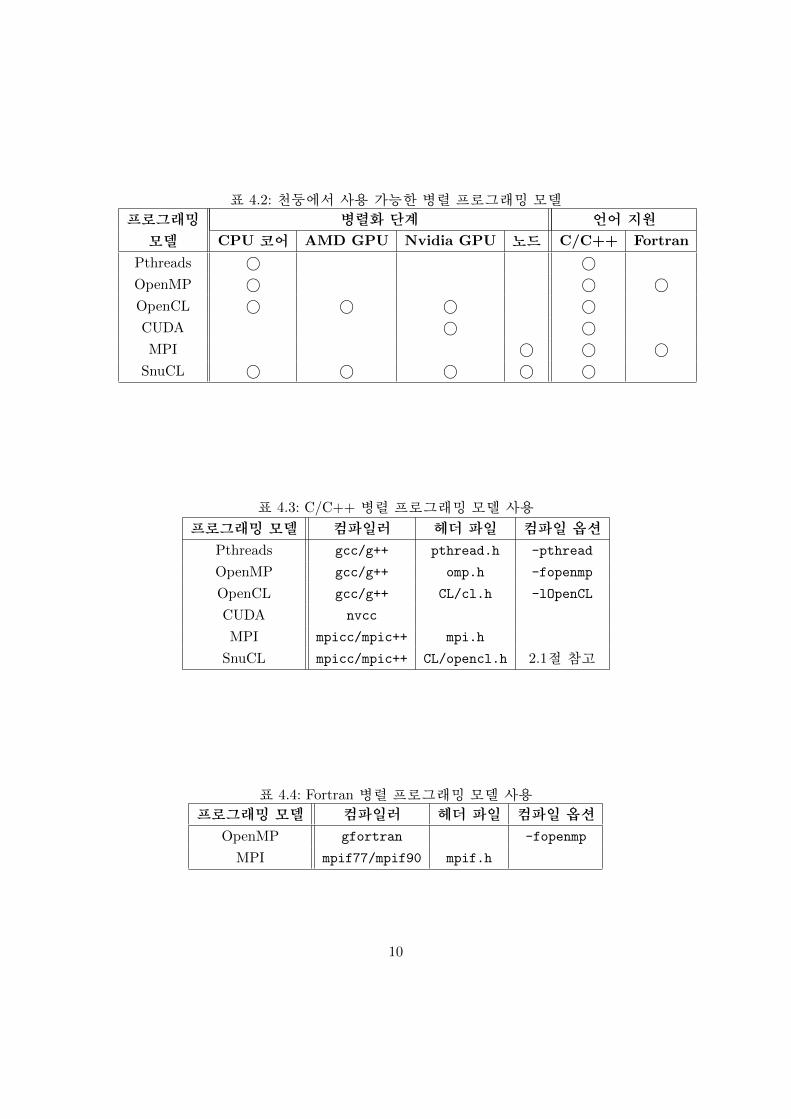
표 4.2: 천둥에서 사용 가능한 병렬 프로그래밍 모델
프로그래밍 병렬화 단계 언어 지원
모델 CPU 코어 AMD GPU Nvidia GPU 노드 C/C++ Fortran
Pthreads ⃝ ⃝OpenMP ⃝ ⃝ ⃝OpenCL ⃝ ⃝ ⃝ ⃝CUDA ⃝ ⃝MPI ⃝ ⃝ ⃝
SnuCL ⃝ ⃝ ⃝ ⃝ ⃝
표 4.3: C/C++ 병렬 프로그래밍 모델 사용
프로그래밍 모델 컴파일러 헤더 파일 컴파일 옵션
Pthreads gcc/g++ pthread.h -pthread
OpenMP gcc/g++ omp.h -fopenmp
OpenCL gcc/g++ CL/cl.h -lOpenCL
CUDA nvcc
MPI mpicc/mpic++ mpi.h
SnuCL mpicc/mpic++ CL/opencl.h 2.1절 참고
표 4.4: Fortran 병렬 프로그래밍 모델 사용
프로그래밍 모델 컴파일러 헤더 파일 컴파일 옵션
OpenMP gfortran -fopenmp
MPI mpif77/mpif90 mpif.h
10

2.1 SnuCL 사용
SnuCL은서울대학교매니코어프로그래밍연구단에서개발한프로그래밍모델로,여러
노드에 속한 CPU와 GPU가 모두 단일 시스템에 장착된 것처럼 가정하고 OpenCL 프
로그램을 작성할 수 있게 해 줍니다. 자세한 설명은 http://aces.snu.ac.kr/Center_
for_Manycore_Programming/SnuCL.html을 참고하십시오.
SnuCL을 사용하기 위해서는 우선 ~/.bashrc 파일에 다음의 두 줄을 추가한 다음,
쉘을 새로 시작하거나 source ~/.bashrc 명령을 실행해 추가한 내용을 반영합니다.
$PATH를 설정할 때 $SNUCLROOT/bin이 $PATH보다 먼저 나와야 함을 유의하십시오.
export PATH=$SNUCLROOT/bin:$PATH
export LD_LIBRARY_PATH=$SNUCLROOT/lib:$LD_LIBRARY_PATH
다음과같은형식으로 Makefile을작성한다음 make명령을실행하면프로그램이컴
파일됩니다. 여기서 <program name>과 <source files>에는 컴파일 결과 생성될 실행
파일의 이름과 소스 코드 파일 리스트가 들어갑니다.
EXECUTABLE := <program name >
CCFILES := <source files >
cluster := 1
include $(SNUCLROOT)/common.mk
3 라이브러리
천둥에는 이종 클러스터용 프로그램 개발에 필요한 여러 가지 라이브러리가 준비되어
있습니다.
천둥에 설치된 라이브러리 목록은 표 4.5와 같습니다. 각 라이브러리의 자세한 사용
법은 해당 라이브러리의 매뉴얼을 참고하시기 바랍니다.
라이브러리 사용을 위해서는 다음 설정이 필요합니다.
• $LD LIBRARY PATH 환경 변수에 라이브러리 파일 경로를 추가합니다. 예를 들어
cuBLAS를 사용하고자 하는 경 ~/.bashrc 파일에 다음의 내용을 추가한 다음
쉘을 새로 시작하거나 source ~/.bashrc 명령을 실행해 줍니다.
export LD_LIBRARY_PATH=\
$LD_LIBRARY_PATH:/usr/local/cuda/lib64
11
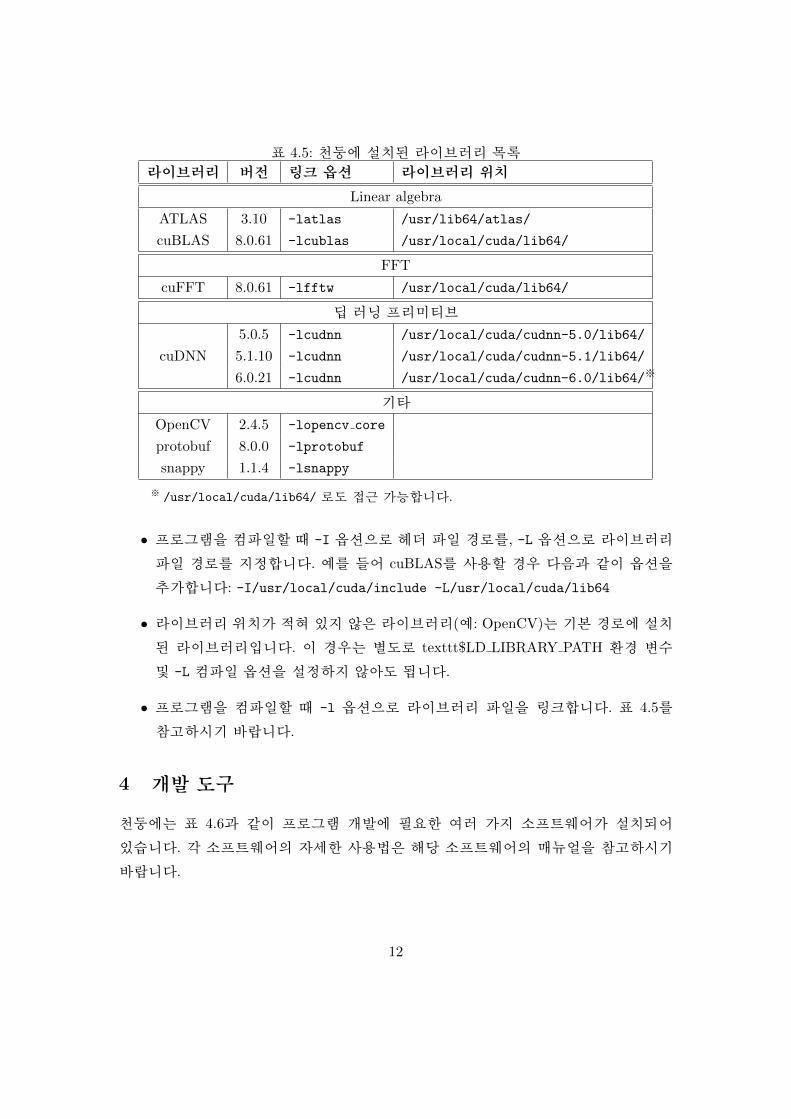
표 4.5: 천둥에 설치된 라이브러리 목록
라이브러리 버전 링크 옵션 라이브러리 위치
Linear algebra
ATLAS 3.10 -latlas /usr/lib64/atlas/
cuBLAS 8.0.61 -lcublas /usr/local/cuda/lib64/
FFT
cuFFT 8.0.61 -lfftw /usr/local/cuda/lib64/
딥 러닝 프리미티브
5.0.5 -lcudnn /usr/local/cuda/cudnn-5.0/lib64/
cuDNN 5.1.10 -lcudnn /usr/local/cuda/cudnn-5.1/lib64/
6.0.21 -lcudnn /usr/local/cuda/cudnn-6.0/lib64/※
기타
OpenCV 2.4.5 -lopencv core
protobuf 8.0.0 -lprotobuf
snappy 1.1.4 -lsnappy
※ /usr/local/cuda/lib64/ 로도 접근 가능합니다.
• 프로그램을 컴파일할 때 -I 옵션으로 헤더 파일 경로를, -L 옵션으로 라이브러리
파일 경로를 지정합니다. 예를 들어 cuBLAS를 사용할 경우 다음과 같이 옵션을
추가합니다: -I/usr/local/cuda/include -L/usr/local/cuda/lib64
• 라이브러리 위치가 적혀 있지 않은 라이브러리(예: OpenCV)는 기본 경로에 설치
된 라이브러리입니다. 이 경우는 별도로 texttt$LD LIBRARY PATH 환경 변수
및 -L 컴파일 옵션을 설정하지 않아도 됩니다.
• 프로그램을 컴파일할 때 -l 옵션으로 라이브러리 파일을 링크합니다. 표 4.5를
참고하시기 바랍니다.
4 개발 도구
천둥에는 표 4.6과 같이 프로그램 개발에 필요한 여러 가지 소프트웨어가 설치되어
있습니다. 각 소프트웨어의 자세한 사용법은 해당 소프트웨어의 매뉴얼을 참고하시기
바랍니다.
12

표 4.6: 천둥에 설치된 개발 도구 목록
개발 도구 버전 실행 명령
컴파일러 및 인터프리터
Java 1.8.0 65 javac
Perl 5.16.3 perl
Python 2.7.5 python
프로파일러
AMD CodeXL 2.2 CodeXLGpuProfiler ※
NVIDIA CUDA command line profiler 8.0.61 nvprof
버전 관리
git 1.8.3.1 git
Subversion 1.6.23 svn
텍스트 처리
Bison 2.7 bison
Flex 2.5.37 flex
Lex 2.5.37 lex
Yacc 1.9 yacc
※ /opt/CodeXL/를 $PATH 환경 변수에 추가한 다음 사용할 수 있습니다.
13

제5장
thor를 사용한 프로그램 실행
1 개요
프로그램이 노드에 장착된 계산 자원을 최대한 활용하고 다른 사용자의 프로그램으로
인한 성능 저하가 발생하지 않도록, thor는 천둥의 각 노드에서 한 번에 하나의 프로
그램만을 실행시킵니다. 사용자가 프로그램 실행을 요청하면 thor는 이를 작업 큐에
추가하고, 빈 노드(즉, 프로그램이 실행되지 않고 있는 노드)가 생길 때마다 먼저 추가
된 작업부터 순차적으로 할당해 실행시킵니다. 그림 5.1은 thor를 사용한 작업 추가와
할당 과정을 나타냅니다.
c00
c01
c02
c03
c04
c05
c50
c51
작업 큐
작업 추가작업 할당
그림 5.1: thor를 사용해 계산 노드에서 프로그램을 실행시키는 과정.
14

2 작업 추가
thorq --add명령을사용해작업큐에새로운작업을추가할수있습니다.다음과같은
형태로 실행합니다.
[user_id@login0 ~]$ thorq --add --mode [mode] [options]
executable_file [arg1 arg2 ...]
[mode]에는 실행시킬 프로그램의 종류에 따라 다음의 세 가지 중 하나가 들어갑
니다.
• single: 단일 노드를 위해 작성된 프로그램을 실행합니다.
• mpi: MPI를사용해작성된프로그램을여러노드혹은프로세스에서실행합니다.
• snucl: SnuCL을 사용해 작성된 프로그램을 여러 노드에서 실행합니다.
[options]에는 다음과 같은 옵션이 들어갈 수 있습니다. 옵션 사이는 공백으로 구
분됩니다.
• --nodes [num nodes]: mode로 mpi나 snucl을 사용하는 경우, 프로그램을 몇 개
의 노드에서 실행할지를 지정합니다. snucl의 경우 compute node 개수를 의미
합니다. 이 경우 노드 중 한 대가 host node와 compute node의 역할을 동시에
수행합니다.
• --slots [num slots]: mode로 mpi를 사용하는 경우, 각 노드에서 몇 개의 MPI
프로세스를 실행할지를 결정합니다. 지정하지 않을 경우 기본값은 1입니다.
• --device [cpu|gpu/nano|gpu/290x|gpu/1080]:프로그램이 CPU만사용할지(cpu)
CPU와 GPU를 모두 사용할지(gpu/nano, gpu/7970, gpu/290x, gpu/1080) 결정
합니다. 이 옵션을 cpu로 주면 OpenCL 프로그램에서 GPU를 사용할 수 없게
됩니다. 이 옵션에 따라 쿼터가 다른 비율로 차감됩니다. NVIDIA GPU를 사용
한 프로그램(예: CUDA 프로그램, Caffe 등)을 사용하고자 하는 경우, gpu/1080
옵션을 사용하여야 합니다. 지정하지 않을 경우 기본값은 cpu입니다.
• --base-dir [here|home]: 프로그램 내에서 상대 경로로 파일에 접근할 때 어느
디렉터리를기준으로할지결정합니다. here로주면현재 thorq를실행하는디렉
터리를, home으로 주면 /home/user id 디렉터리를 기준으로 합니다.
15

예를들어 thorq를 /home/user id/test디렉터리에서실행하였고프로그램내에
서 foo.txt파일에접근하는경우,이옵션을 here로주면 /home/user id/test/foo.txt
파일을, home으로 주면 /home/user id/foo.txt 파일을 읽어 오게 됩니다.
지정하지 않을 경우 기본값은 here입니다.
• --timeout [second|unlimited]:프로그램이지정된시간내에끝나지않을경우
강제 종료하게 만듭니다. 값은 초 단위로 지정합니다. unlimited 옵션을 사용할
경우 프로그램이 종료될 때 까지 쿼터가 소진됩니다. 옵션을 지정하지 않을 경우
기본 제한시간은 3일(259200 초)입니다.
CPU, 혹은 AMD GPU를 사용하고자 하는 경우 제한 시간을 원하는 만큼 늘릴
수 있습니다. 그러나 NVIDIA GPU를 사용하시는 경우 제한 시간을 늘릴 수 없습
니다. NVIDIA GPU를 사용하여 3일 이상 걸리는 작업을 수행하고자 하는 경우
천둥 관리자 메일([email protected])로 별도로 문의해주시기 바랍니다.
• --name [job name]: 현재 추가하는 작업을 식별할 수 있는 이름을 지정합니다.
지정하지 않으면 작업에 부여된 일련번호가 이름으로 사용됩니다.
executable file은 실행 파일의 이름이며, 그 뒤에는 실행 시 주어질 인자가 들어
갑니다. MPI나 SnuCL를사용하는경우, executable file에는 mpirun, snuclrun등의
스크립트가 아닌 실행 파일 이름을 바로 지정합니다. thor가 내부적으로 mpirun 혹은
snuclrun 스크립트를 사용해 프로그램을 실행시킬 것입니다. 다음은
• bin/a.out이라는 파일에 10 20 30을 인자로 줘서 실행시키며
• MPI를 사용해 실행하고
• 노드 10대에서 CPU와 GPU를 모두 사용하고
• 실행 후 100초가 지난 다음 프로그램을 강제 종료하며
• 작업의 이름을 thorq test라고 지정하는
경우의 예시를 나타냅니다. 성공적으로 작업이 추가된 경우 해당 작업에 부여된
일련번호(예시의 경우 229번)가 출력됩니다.
[user_id@login0 ~]$ thorq --add --mode mpi --nodes 10 --device
gpu /7970 --timeout 100 --name thorq_test bin/a.out 10 20 30
Enqueue a new job:
Name: thorq_test
16

Mode: mpi
Number of nodes: 10
Device: cpu
Base directory: here
Timeout: 100
Task: /home/user_id/bin/a.out 10 20 30
Path: /home/user_id
Command string: thorq --add --mode mpi --nodes 10 --device
gpu /7970
--timeout 100 --name thorq_test bin/a.out 10 20 30
=========================================
Task 229 is enqueued.
thor에 의해 프로그램 실행이 완료되면, thorq --add 명령을 실행했던 디렉터리에
(name).stdout, (name).stderr파일이생성됩니다.이파일은프로그램이 stdout(표준
출력)과 stderr(표준 에러)로 출력한 내용을 저장하고 있습니다. (name)은 --name 옵션
을 사용해 지정한 이름이며, 이름을 지정하지 않은 경우 작업의 일련번호가 task 229
와 같은 형식으로 들어갑니다.
3 작업 확인
thorq --stat명령을사용하면특정작업이현재작업큐에서대기중인지(Enqueued),
계산 노드에 할당되어 실행 중인지(Running), 혹은 실행이 완료되었는지(Finished)
확인할 수 있습니다. 다음은 작업 큐에서 대기 중인 229번 작업의 상태를 확인하는 예
입니다.
[user_id@login0 ~]$ thorq --stat 229
==================================================================
ID : 229
Name : thorq_test
Status : Enqueued
Enqueued : 2013 -03 -22 17:25:25
Executed :
Finished :
Assigned nodes:
Device : CPU & GPU (AMD Radeon HD 7970)
# of nodes : 10
Command string: thorq --add --mode mpi --nodes 10 --device
gpu /7970
--timeout 100 --name thorq_test bin/a.out 10 20 30
==================================================================
17

다음은 229번 작업의 실행이 완료된 후에 thorq --stat 명령을 사용한 예입니다.
이 경우 Finished 뒤에 작업이 어떻게 완료되었는지를 나타내는 메시지가 출력됩니다.
[user_id@login0 ~]$ thorq --stat 229
==================================================================
ID : 229
Name : thorq_test
Status : Finished (success)
Enqueued : 2013 -03 -22 17:25:25
Executed : 2013 -03 -22 17:25:35
Finished : 2013 -03 -22 17:25:50
Executed time : 15.090000 s
Assigned nodes: c16 , c17 , c18 , c19 , c20 , c21 , c22 , c23 , c24 , c25
Device : CPU & GPU (AMD Radeon HD 7970)
# of nodes : 10
Command string: thorq --add --mode mpi --nodes 10 --device
gpu /7970
--timeout 100 --name thorq_test bin/a.out 10 20 30
==================================================================
Finished 뒤에 나오는 메시지는 다음 중 하나입니다.
• success: 프로그램 실행이 끝나 작업이 완료되었음을 나타냅니다. 이것이 프로그
램이 ‘에러없이’끝났음을의미하는것은아닙니다.예를들어프로그램이잘못된
결과값을출력하고끝나거나, segmentation fault등의에러가발생하여끝난것일
수도 있습니다.
• killed by user: 사용자가 뒤에서 설명할 thorq --kill 명령을 사용해 작업을
강제 종료하였음을 의미합니다.
• timeout: 프로그램 실행 중에 thorq --add 명령에서 설정한 timeout만큼의 시간
이 지나 작업을 강제 종료하였음을 의미합니다.
• not enough quota:사용자의쿼터가모자라작업을실행시키지못했음을의미합
니다.
• not enough nodes: thorq --add 명령에서 지정한 노드 수가 현재 서비스 중인
노드 수보다 많아 작업을 실행시키지 못했음을 의미합니다.
18

• killed by system: 기타 천둥 시스템 혹은 thor 프로그램에 문제가 있어 작업이
종료되었음을나타냅니다.이경우기존에작업이실행중이었더라도따로쿼터를
차감하지 않습니다. 작업을 다시 실행해 보시거나 메일로 자세한 원인을 문의해
주시기 바랍니다.
thorq --stat-all명령을사용하면현재작업큐에서대기중이거나(Enqueued)계
산 노드에 할당되어 실행 중인(Running) 모든 작업 목록을 표시합니다. 이전에 thorq
--add명령으로추가한작업이이리스트에나타나지않는다면해당작업은이미완료된
것입니다. 다음은 thorq --stat-all 명령을 사용한 예입니다.
[user_id@login0 ~]$ thorq --stat -all
Job 229 (thorq_test): Running
Job 230 (second_test): Running
Job 234 (task_234): Enqueued
Job 240 (task_240): Enqueued
(end of the list)
4 작업 삭제
thorq --kill 명령을 사용하면 작업 큐에서 대기 중인 작업을 삭제하거나, 혹은 계산
노드에서 실행 중이던 작업을 강제 종료할 수 있습니다. 다음은 229번 작업을 삭제하는
예입니다. 작업 삭제에는 최대 10초 정도의 시간이 소요될 수 있으니 금방 완료되지
않더라도 잠시만 기다려 주십시오.
[user_id@login0 ~]$ thorq --kill 229
Job 229 is killed.
thorq --kill-all 명령을 사용하면 작업 큐에서 대기 중이거나 계산 노드에서 실
행 중인 모든 작업을 강제 종료할 수 있습니다. 작업 삭제에는 오랜 시간이 소요될 수
있으니 금방 완료되지 않더라도 잠시만 기다려 주십시오.
[user_id@login0 ~]$ thorq --kill -all
Job 230 is killed.
Job 234 is killed.
Job 240 is killed.
(end of the list)
19

5 쿼터 확인
thorq --quota 명령을 사용하면 현재 사용자의 쿼터가 얼마나 남아 있는지 확인할 수
있습니다. 단, 쿼터는 작업 실행이 완료된 후 차감되므로 현재 계산 노드에서 실행 중인
작업의 쿼터 사용량은 반영이 되어 있지 않습니다.
[user_id@login0 ~]$ thorq --quota
Quota: 300000
6 참고
• 계산 노드에서 실행되는 프로그램은 stdin(표준 입력)을 사용할 수 없습니다. 파
일혹은프로그램인자를사용해데이터를입력받으시기바랍니다.로그인노드와
계산 노드는 /home과 /scratch를 공유하고 있으므로 여기에 저장된 파일은 프로
그램이 읽고 쓸 수 있습니다.
• 여러작업에동일한이름을부여한경우,나중에실행된작업의 .stdout, .stderr
파일이 이전에 실행된 작업의 결과를 덮어쓸 수 있으니 유의하십시오.
• 계산 노드에서 프로그램 실행 전에 환경변수를 설정해야 한다면 ~/.bashrc 파
일에 export문을 추가하십시오. 예를 들어 프로그램이 표 4.5의 라이브러리를 사
용하는 경우, ~/.bashrc 파일에 $LD LIBRARY PATH 환경 변수를 설정하는 코드를
추가해 두어야 합니다.
• ~/.bashrc 파일에서 아래의 세 줄은 삭제하지 마십시오. 이를 삭제할 시 thorq
로 작업을 추가하면 ‘mpirun: command not found’ 에러가 발생하고 프로그램이
실행되지 않습니다.
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
20
제6장
thor 웹 인터페이스
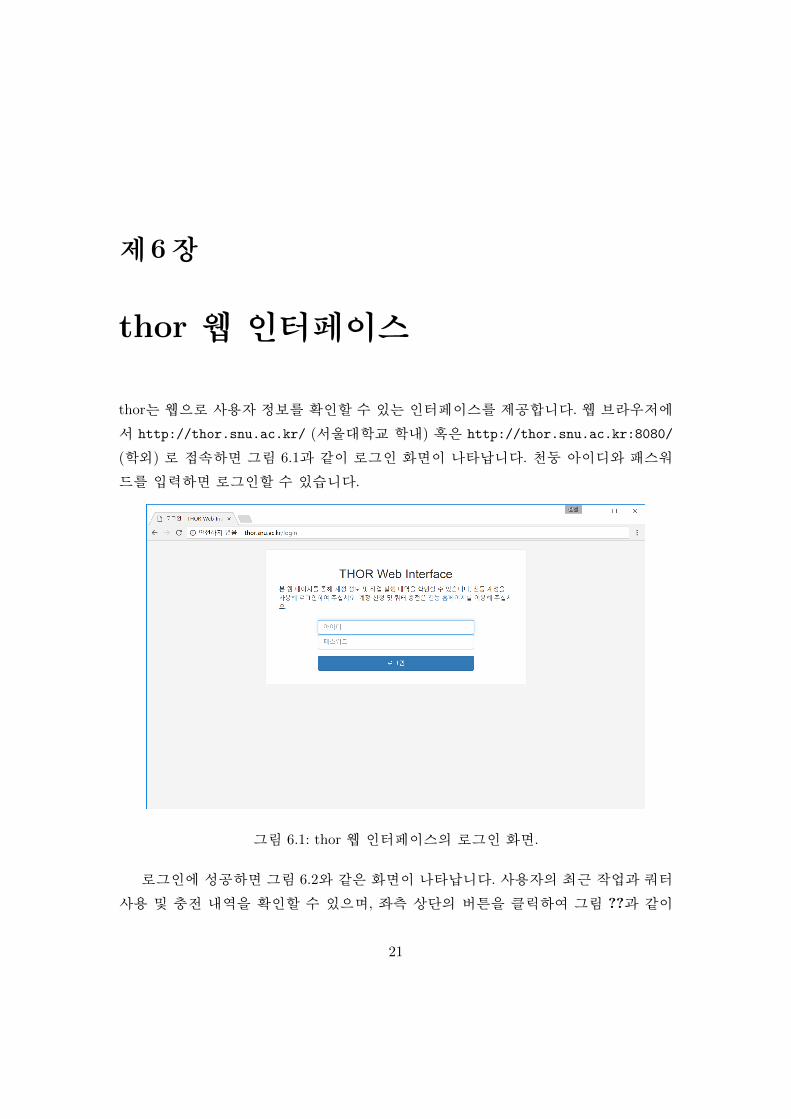
thor는 웹으로 사용자 정보를 확인할 수 있는 인터페이스를 제공합니다. 웹 브라우저에
서 http://thor.snu.ac.kr/ (서울대학교 학내) 혹은 http://thor.snu.ac.kr:8080/
(학외) 로 접속하면 그림 6.1과 같이 로그인 화면이 나타납니다. 천둥 아이디와 패스워
드를 입력하면 로그인할 수 있습니다.
그림 6.1: thor 웹 인터페이스의 로그인 화면.
로그인에 성공하면 그림 6.2와 같은 화면이 나타납니다. 사용자의 최근 작업과 쿼터
사용 및 충전 내역을 확인할 수 있으며, 좌측 상단의 버튼을 클릭하여 그림 ??과 같이
21

전체 작업 내역을 확인하거나 그림 6.4와 같이 쿼터 변경 내역을 확인할 수 있습니다..
끝으로, 우측 상단의 ‘로그아웃’ 버튼을 클릭하여 웹 인터페이스에서 로그아웃할 수
있습니다.
22
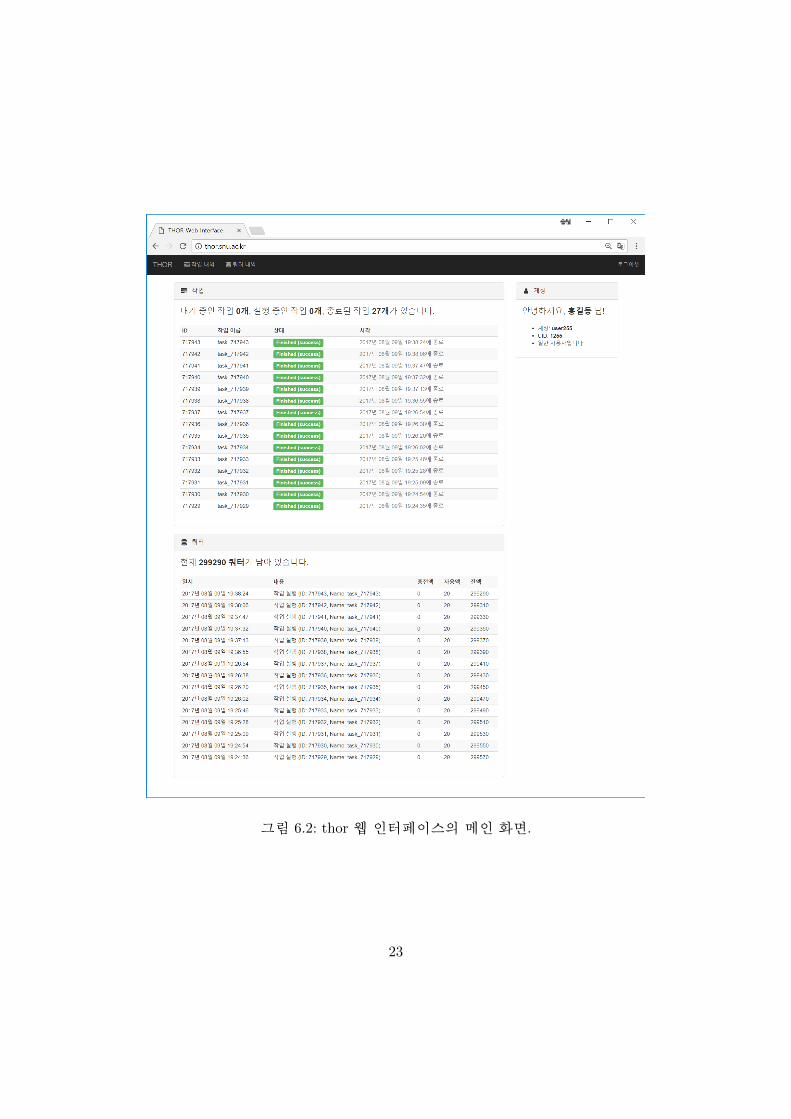
그림 6.2: thor 웹 인터페이스의 메인 화면.
23
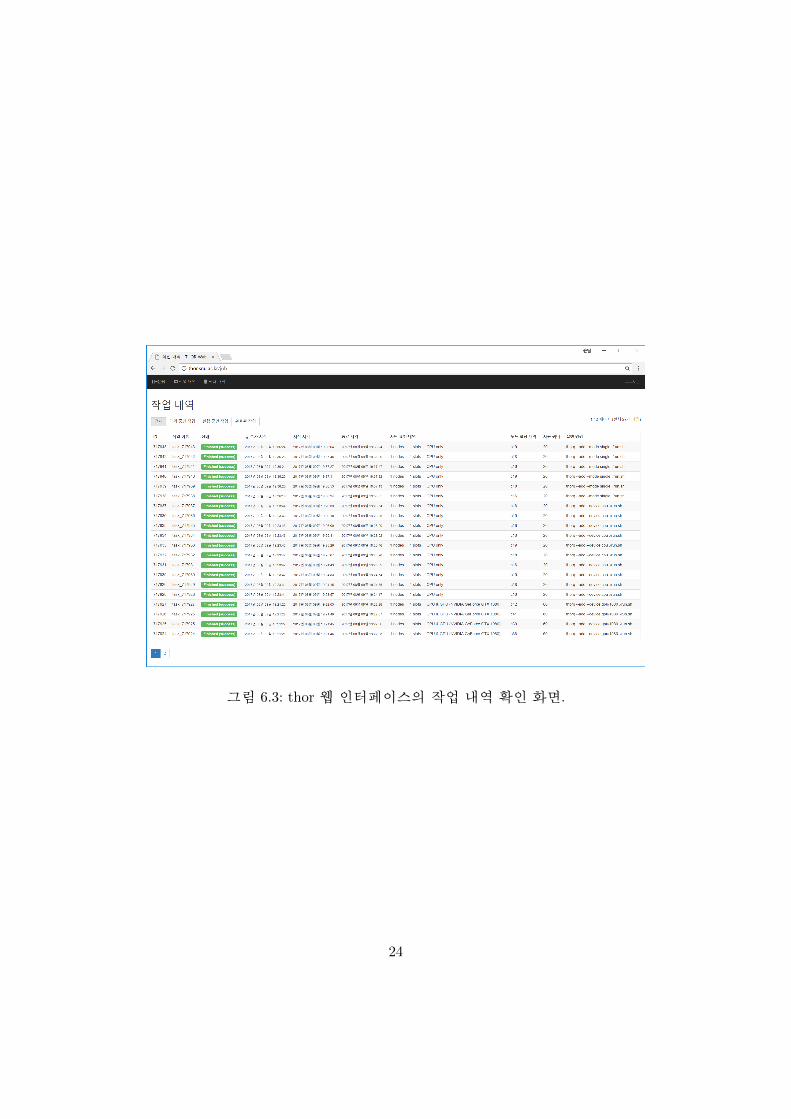
그림 6.3: thor 웹 인터페이스의 작업 내역 확인 화면.
24
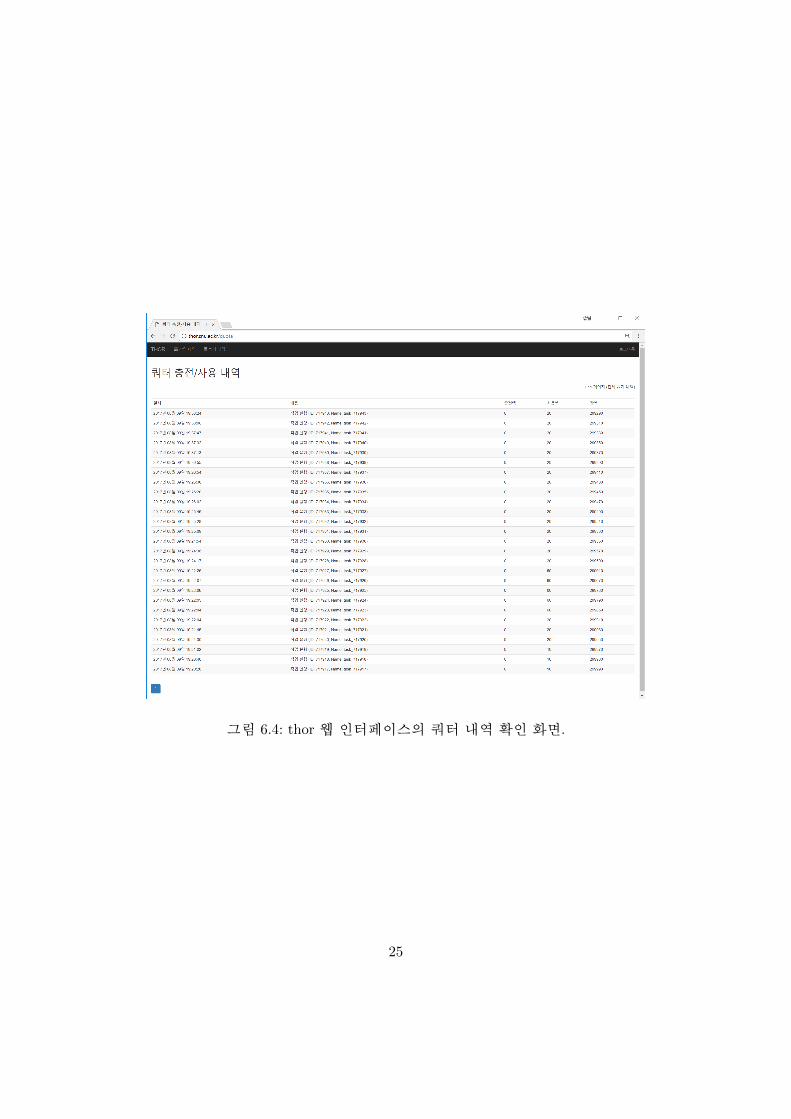
그림 6.4: thor 웹 인터페이스의 쿼터 내역 확인 화면.
25

제7장
천둥 소프트웨어 설치 안내
1 개요
천둥에서 기본적으로 제공하지 않는 응용 소프트웨어 및 라이브러리는 사용자의 홈
디렉토리에 설치하여 사용합니다. 설치 시 어려움을 겪으실 경우, 다음의 내용을 천둥
관리자 메일([email protected])로 보내 주시기 바랍니다.
• 소프트웨어의 이름 및 버전
• 소프트웨어를 소개하는 웹 사이트의 URL
• 소스 코드 혹은 설치 파일을 다운로드하는 방법 (다운로드가 불가능한 경우 파일
첨부)
• 소프트웨어의 이름 및 버전
다음과같은경우에는소프트웨어설치가불가능할수있으니양해해주시기바랍니다.
상용소프트웨어의경우구입한곳에서미리라이센스규정을확인해주시기바랍니다.
• 천둥 1.5 시스템에 설치할 수 없거나, 설치하더라도 정상적인 사용이 불가능한
경우 (예: Windows 시스템에서만 정상적으로 구동되는 프로그램의 경우)
• 상용 소프트웨어로 사용자가 라이센스를 보유하고 있지 않은 경우
• 상용 소프트웨어로 사용자가 라이센스를 보유하고 있으나, 라이센스 규정상 천둥
1.5에 설치가 불가능한 경우 (예: non-commercial 라이센스여서 천둥 1.5와 같이
사용료를 받는 서버에는 설치가 불가능한 경우)
26

• 기타 내부 방침에 따라 설치가 불가능할 경우
천둥에서는 딥 러닝을 위한 프리미티브 라이브러리(CUDA, cuBLAS, cuDNN)가 설치되
어있으며,이를사용하는딥러닝라이브러리(Caffe, TensorFlow)를설치할수있도록
지원하고 있습니다.
2 Caffe 설치
천둥에는 Caffe 설치를 위해 필요한 라이브러리들이 미리 설치되어 있으며, 사용자
홈 디렉토리에서 Caffe를 빌드하기 위한 스크립트를 제공합니다. 우선 아래 명령으로
설치를 위한 필요 파일을 준비합니다.
source /opt/caffe_prerequisites/prepare_caffe_prerequisites.sh
이후 Caffe git repository에서 소스 코드를 복사합니다.
git clone https:// github.com/BVLC/caffe.git
미리 준비된 Configuration 파일을 Caffe 소스 디렉토리에 복사합니다.
cd caffe
cp /opt/caffe_prerequisites/Makefile.config .
이 때 cuDNN을 사용하고자 하는 경우 Makefile.config를 vim 등의 에디터로 연 후, 5
번째 줄의 USE CUDNN := 1 앞의 # 을 지워 주석을 해제합니다. 이후 아래 명령으로
소스 코드를 빌드합니다.
make -j8
3 TensorFlow 설치
우선 사용자의 홈 디렉토리에 사용자 계정을 위한 pip(Python Package Index)를 설치
합니다.
wget https:// bootstrap.pypa.io/get -pip.py
python get -pip.py --user
27
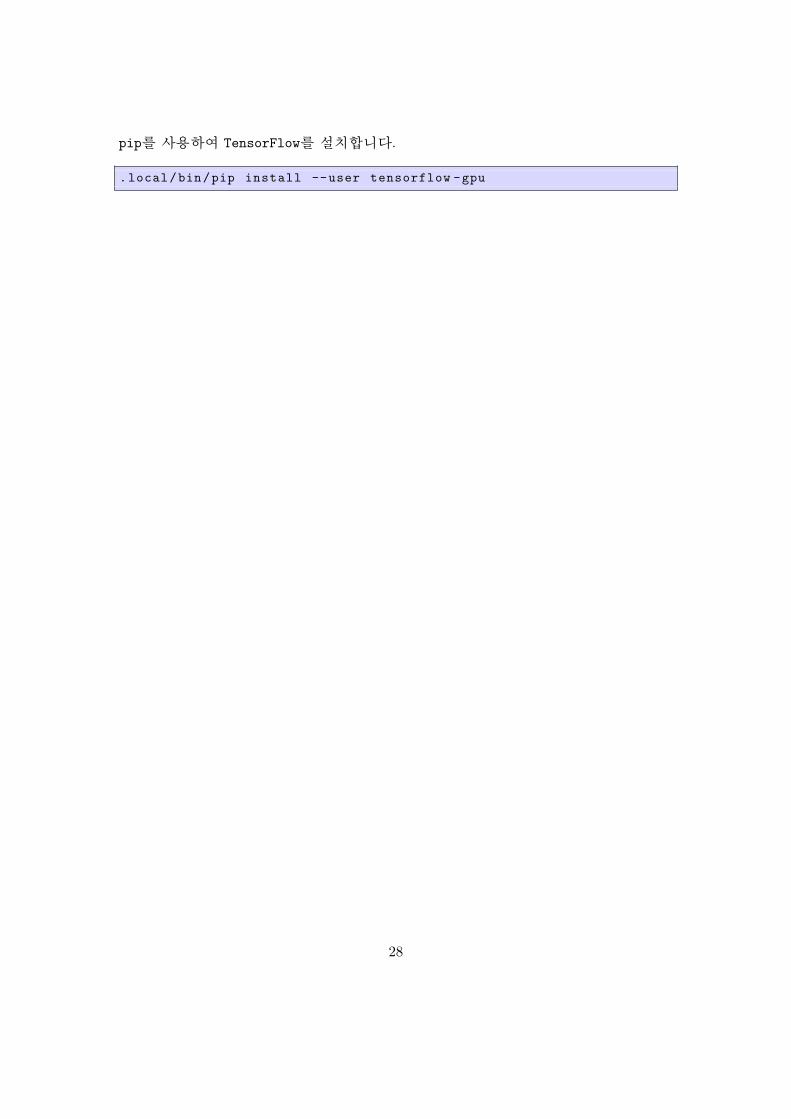
pip를 사용하여 TensorFlow를 설치합니다.
.local/bin/pip install --user tensorflow -gpu
28









![[BLT] 소개자료 (브로슈어) - 2016년 6월 버전](https://img.pdfslide.tips/doc/110x75/5884c1481a28ab34778b6e1d/blt-2016-6-.jpg)










![컴퓨터유지관리Q&A 필수가이드북 [온라인 저용량 버전]](https://img.pdfslide.tips/doc/110x75/559091df1a28abbc538b456a/qa-559091df1a28abbc538b456a.jpg)








