Embed Size (px)
Citation preview

Занятие 5
Трансформация данных
Повторение из предыдущих занятий
Требования к выборке для проведения
параметрических тестов:
I. Случайность измерений (randomness)
II. Независимость измерений (independence)
III. Гомогенность дисперсии (homogeneity =
homoscedasticity)
IV. Соответствие нормальному распределению
V. Для факторной ANOVA – аддитивность
Параметрические тесты: нулевая гипотеза формулируется о конкретных ПАРАМЕТРАХ РАСПРЕДЕЛЕНИЯ
и/или эти параметры входят в формулу статистики критерия.
Параметры: среднее значение, стандартное отклонение, дисперсия…
Почему при проведении параметрических тестов важно соблюдать условия?
Нарушим условие соответствия выборки нормальному распределению и проведём
одновыборочный t-тест (односторонний)!
Пусть наше распределение скошено. Z-распределение тоже будет
скошено!
Вероятность, что среднее в выборке попадёт в критическую область
(рассчитанную для нормального распределения), будет выше, чем
0.05 – увеличится ошибка 1-го рода
Основной вывод:
пренебрежения условиями использования параметрических тестов
может увеличивать ошибку 1-го рода. (Неизвестно, насколько)
Примечание: слабые отклонения от нормального распределения не очень страшны (в
силу Центральной предельной теоремы), а для больших выборок ими можно
пренебречь (кроме регрессионного анализа).
ANOVA устойчива к отклонениям от нормального распределения, особенно если
выборки одинаковы по размеру.
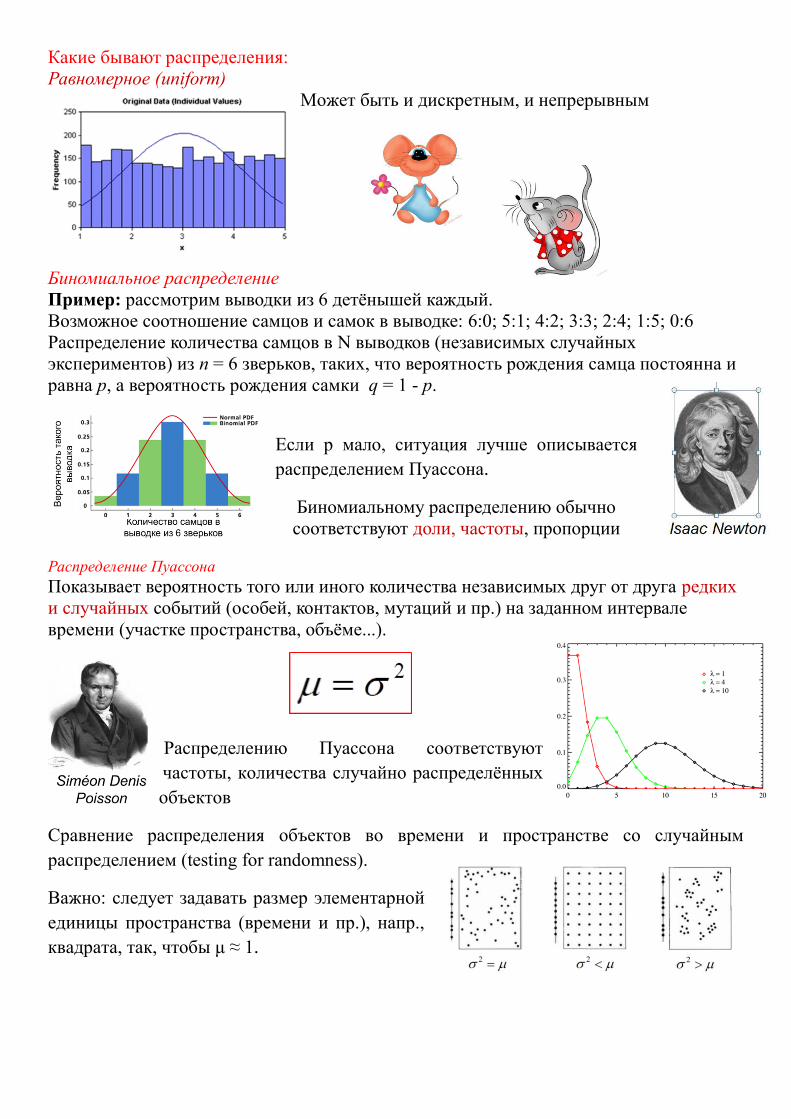
Какие бывают распределения:
Равномерное (uniform)
Может быть и дискретным, и непрерывным
Биномиальное распределение
Пример: рассмотрим выводки из 6 детёнышей каждый.
Возможное соотношение самцов и самок в выводке: 6:0; 5:1; 4:2; 3:3; 2:4; 1:5; 0:6
Распределение количества самцов в N выводков (независимых случайных
экспериментов) из n = 6 зверьков, таких, что вероятность рождения самца постоянна и
равна p, а вероятность рождения самки q = 1 - p.
Если р мало, ситуация лучше описывается
распределением Пуассона.
Биномиальному распределению обычно
соответствуют доли, частоты, пропорции
Распределение Пуассона
Показывает вероятность того или иного количества независимых друг от друга редких
и случайных событий (особей, контактов, мутаций и пр.) на заданном интервале
времени (участке пространства, объёме...).
Распределению Пуассона соответствуют
частоты, количества случайно распределённых
объектов
Сравнение распределения объектов во времени и пространстве со случайным
распределением (testing for randomness).
Важно: следует задавать размер элементарной
единицы пространства (времени и пр.), напр.,
квадрата, так, чтобы μ ≈ 1.
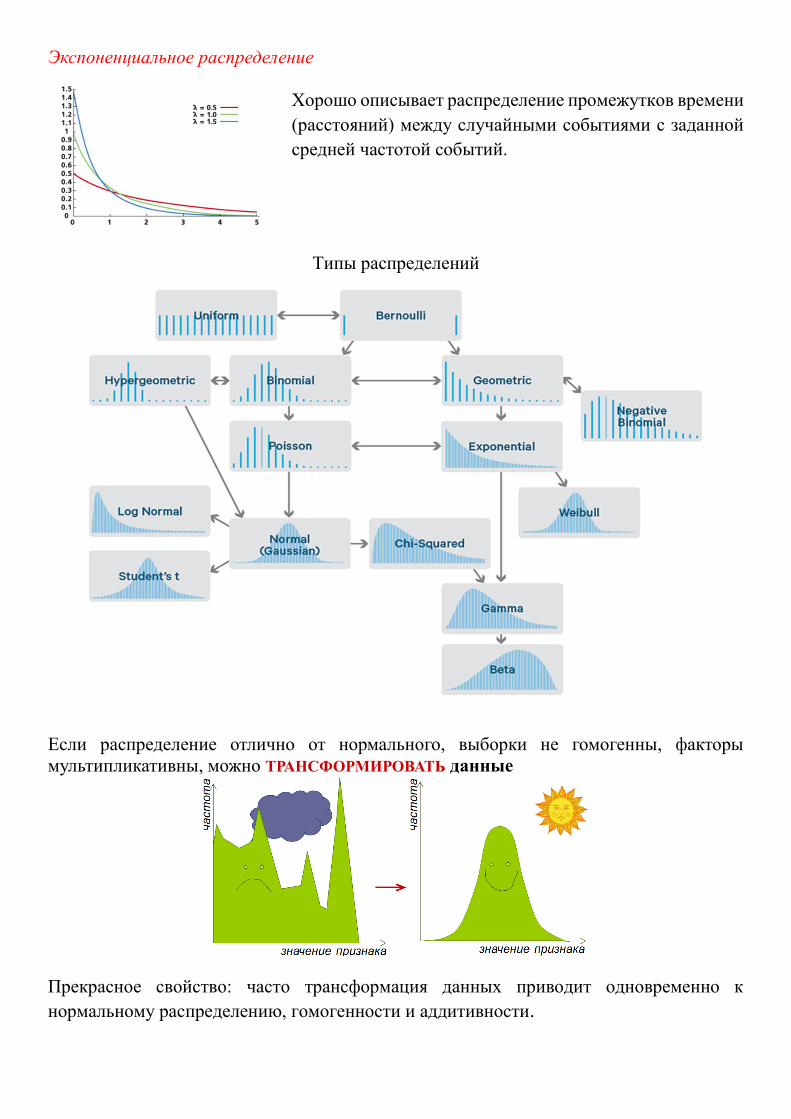
Экспоненциальное распределение
Хорошо описывает распределение промежутков времени
(расстояний) между случайными событиями с заданной
средней частотой событий.
Типы распределений
Если распределение отлично от нормального, выборки не гомогенны, факторы
мультипликативны, можно ТРАНСФОРМИРОВАТЬ данные
Прекрасное свойство: часто трансформация данных приводит одновременно к
нормальному распределению, гомогенности и аддитивности.

Трансформация данных
1. Логарифмическая трансформация (logarithmic transformation)
Делает симметричным скошенное вправо (positively skewed) распределение.
Используется в случае, когда среднее значение в группе прямо пропорционально
стандартному отклонению.
Если в результате логарифмирования получилось нормальное
распределение, исходное распределение было логнормальным.
2. Извлечение квадратного корня (square root transformation)
• Используется, когда среднее значение в группе прямо пропорционально
дисперсии.
• Обычно такое явление свойственно выборкам из распределения Пуассона
(т.е., данные представляют собой количества случайных событий,
объектов…).
3. Арксинусная трансформация (arcsine transformation)
применяется для процентов и долей (Xi ≤ 1), которые обычно формируют биномиальное
распределение.
Например, мы исследуем долю
самцов или долю переживших зиму
детёнышей в выводках сурков.
4. Box-Cox transformation Универсальная трансформация
данных, в которой программа методом
проб подбирает наилучшие параметры
и способ трансформации для
конкретных данных (ищется особый
параметр λ).

Непараметрические методы (nonparametric methods)
Если наше распределение не удовлетворяет условиям параметрических тестов и
трансформация не помогает или невозможна, наш выбор - Непараметрические методы
(nonparametric methods) = “distribution-free” tests.
Свойства распределения неизвестны, и параметры распределения (среднее,
дисперсию и т. п.) мы использовать не можем
Основной подход – ранжирование (ranking) наблюдений (выстраиваем их по
порядку от самого маленького значения к наибольшему).
подразумевается, что сравниваемые распределения имеют одинаковую форму и
дисперсию.
Сравнение 2-х независимых групп
Мы исследуем два редких вида сумчатых.
Хотим сравнить размеры выводков у этих зверей.
Фактор – вид. Группы: 1. длинноухие; 2.
пятнистые
Зависимая переменная – размер выводка
Сравнение 2-х независимых групп:
Манн-Уитни тест (Mann-Whitney U-test)
Н0: размер выводка у длинноухих сумчатых такой же, как и у пятнистых.
Н1: размер выводка не одинаков у этих видов.
Мы ничего не говорим про параметры распределений!
Тест Манна-Уитни можно использовать и для ранговых, и для
непрерывных переменных.
Это непараметрический аналог двухвыборочного t-теста.
Ранжируем данные от меньшего к большему (игнорируя
деление на группы).
Число 3 встретилось трижды (это называется связанные ранги,
ранги у них будут одинаковы = (1+2+3)/3=2
Статистика критерия:
n1 и n2 – размер выборок, R1 и R2 – суммы рангов в выборках.

Статистикой критерия Uobs
будет меньшее из этих двух значений. Причём Н0 мы
отвергнем в случае, если оно будет МЕНЬШЕ критического значения Ucv
. (т.е., это
исключение среди прочих критериев).
Сравнение 2-х независимых групп:
Тест Колмогорова-Смирнова (Kolmogorov-Smirnov two-sample test): отличается от
М-У теста тем, что М-У более чувствителен к различиям средних значений,
медианы и т.п., а К-С тест более чувствителен к различиям распределений по
форме.
Тест Вальда-Вольфовица (Wald-Wolfowitz Runs Test) – данные сортируются по
зависимой переменной и оцениваются последовательности элементов из разных
групп. Как и К-С тест, чувствителен к различиям распределений по форме.
Манн-Уитни тест более мощный, чем эти тесты.
Mann-Whitney U-test; Kolmogorov-Smirnov two-sample test; Wald-Wolfowitz Runs Test
В программе Statistica получены результаты сравнения размера выводка у длинноухих
и пятнистых сумчатых.
Отвергаем Н0: М-У тест показал, что размеры выводков у разных видов неодинаковые
(U=9,500; Z=-2,36297; p=0,018).
В отличие М-У теста в тестах К-С и В-В статистически значимые различия не
наблюдалось. К-С (р>0,10); В-В (р=0.604).
Сравнение 2-х связанных групп
Критерий Вилкоксона (Wilcoxon matched pair test)
Изучаем утконосов, и хотим знать – различается ли отношение самки к самцу и самца к
самке в парах. Мы считаем частоту дружелюбных контактов со стороны самки к самцу
и наоборот. У каждого самца есть по жене, а у каждой самки – по мужу.
Н0: количество контактов в популяции, из которой мы получили выборку самцов, такое
же, как и в популяции, из которой выборка самок.
Н1: количество контактов не одинаково.
Фактор – пол. (1. самцы; 2. самки)
Зависимая переменная – частота инициирования дружелюбных контактов.
1. Считают разности между значениями в парах;
исключают нулевые разности;
3. присуждают абсолютным значениям (по модулю)
разностей ранги;
суммируют отдельно ранги положительных и отрицательных
разностей;
5. Наименьшая из этих сумм - статистика Т.
6. Отвергаем Н0, если Т меньше T
cv.

Аналог t-теста для двух связанных выборок, мощность – около 95% мощности t-теста
. При числе пар >100 Т апроксимируется нормальным распределением.
Число дружелюбных контактов у самцов и самок в парах было неодинаковым (Т=0,00;
Z=2,80; p=0,005)
Сравнение 2-х связанных групп: Знаковый тест (Sign test)
Считают разности в парах, но не ранжируют их, а просто определяют число
положительных и отрицательных разностей (нули исключают). Сравнивают их
соотношение с 1:1. (биномиальным тестом)
Подходит для случаев, когда точные значения переменной не известны.
Имеет низкую мощность, поэтому применяется только в больших выборках
Сравнение ≥3-х независимых групп
Тест Крускала-Уоллиса (Kruskal-Wallis test)
Мы получили возможность включить в работу третий, особенно редкий вид
сумчатого. Теперь нас интересует, различается ли количество пищи, которую съедают
за день особи этих видов.
Фактор – вид. Группы: 1. длинноухие; 2. пятнистые; 3. хвостатые
Непараметрический аналог One-way ANOVA
на 95% настолько же мощный, как и ANOVA;
для 2-х групп идентичен Манн-Уитни тесту;
подразумевает сходство форм распределений и равенство дисперсий в группах
(хотя бы на глаз).
все значения ранжируются от меньшего к большему (игнорируя деление
на группы);
Считается сумма рангов в каждой группе;
считается статистика H (df, N).
Н0: распределение в популяциях, из которых мы получили выборки, одинаковое.
Н1: распределения не одинаковые.
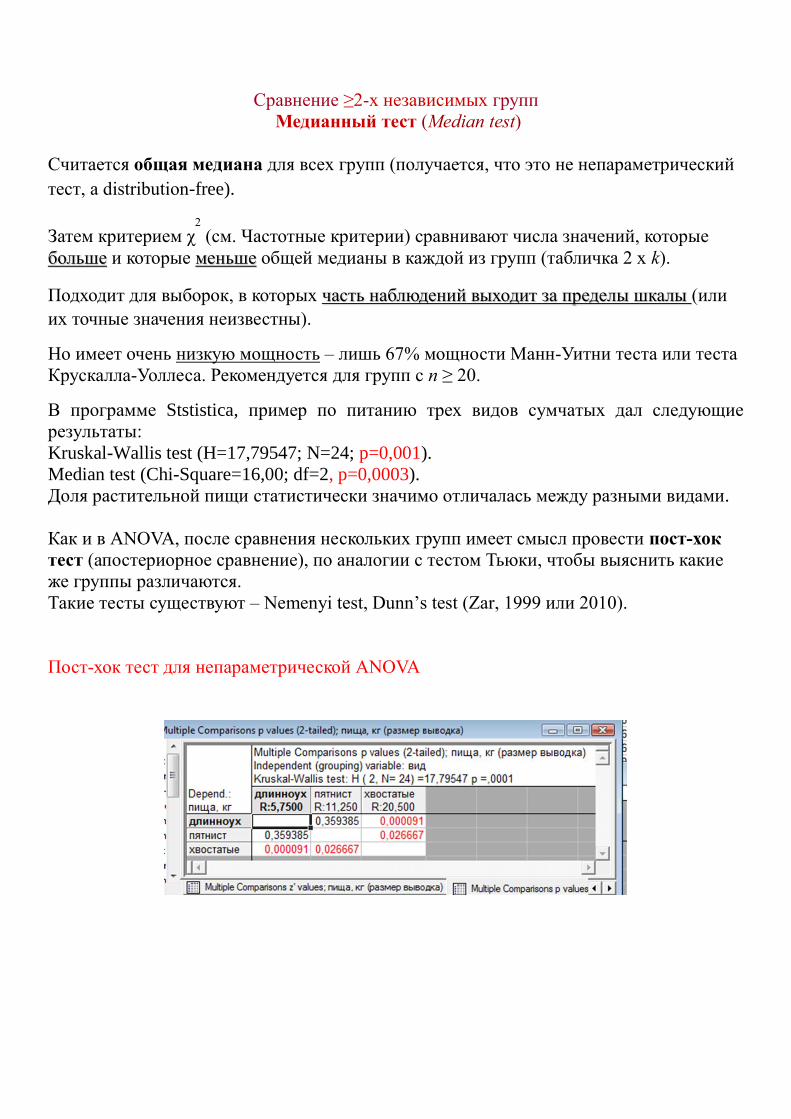
Сравнение ≥2-х независимых групп
Медианный тест (Median test)
Считается общая медиана для всех групп (получается, что это не непараметрический
тест, а distribution-free).
Затем критерием χ2
(см. Частотные критерии) сравнивают числа значений, которые
больше и которые меньше общей медианы в каждой из групп (табличка 2 х k).
Подходит для выборок, в которых часть наблюдений выходит за пределы шкалы (или
их точные значения неизвестны).
Но имеет очень низкую мощность – лишь 67% мощности Манн-Уитни теста или теста
Крускалла-Уоллеса. Рекомендуется для групп с n ≥ 20.
В программе Ststistica, пример по питанию трех видов сумчатых дал следующие
результаты:
Kruskal-Wallis test (H=17,79547; N=24; p=0,001).
Median test (Chi-Square=16,00; df=2, p=0,0003).
Доля растительной пищи статистически значимо отличалась между разными видами.
Как и в ANOVA, после сравнения нескольких групп имеет смысл провести пост-хок
тест (апостериорное сравнение), по аналогии с тестом Тьюки, чтобы выяснить какие
же группы различаются.
Такие тесты существуют – Nemenyi test, Dunn’s test (Zar, 1999 или 2010).
Пост-хок тест для непараметрической ANOVA

Сравнение ≥3 связанных групп
Критерий Фридмана (Friedman ANOVA)
У утконосов родились детёныши, и мы хотим знать, изменилась ли упитанность самок
после беременности и после выкармливания потомства (мы оценивали её в баллах).
1. состояние до беременности;
2. после рождения детей;
3. после выкармливания детёнышей.
для двух групп эквивалентен Знаковому тесту
по сравнению с аналогичными параметрическими тестами, для 2-х групп имеет
всего 64% мощности, для 3-х – 72%, для 100 стремится к 95%.
Основан на том, что значения ранжируются меньшего к большему внутри каждой
строки. Потом суммируют ранги для каждого столбца и считают статистику χ2
r,
которая имеет распределение χ2
.
Нулевая и альтернативная гипотезы - по аналогии с предыдущими тестами, о
сходстве выборок.
Пример с утконосами в программе Ststistica.
Отвергаем Н0 – состояние самок изменялось.
Ранговые корреляции
Требование к выборке для тестирования гипотезы о коэффициенте корреляции Пирсона:
Для каждого X значения Y должны быть распределены нормально, и для каждого Y все
X должны иметь нормальное распределение - двумерное нормальное распределение
Трансформация данных в регрессионном анализе и корреляциях
Применяется таким же образом, как и для других критериев, НО основанием для
применения должны служить несоответствие нормальному распределению и
гетерогенность дисперсий, а не нелинейность связи!
Если распределения нормальны и дисперсии гомогенны, нельзя использовать
трансформацию данных для получения линейной регрессии из нелинейной.
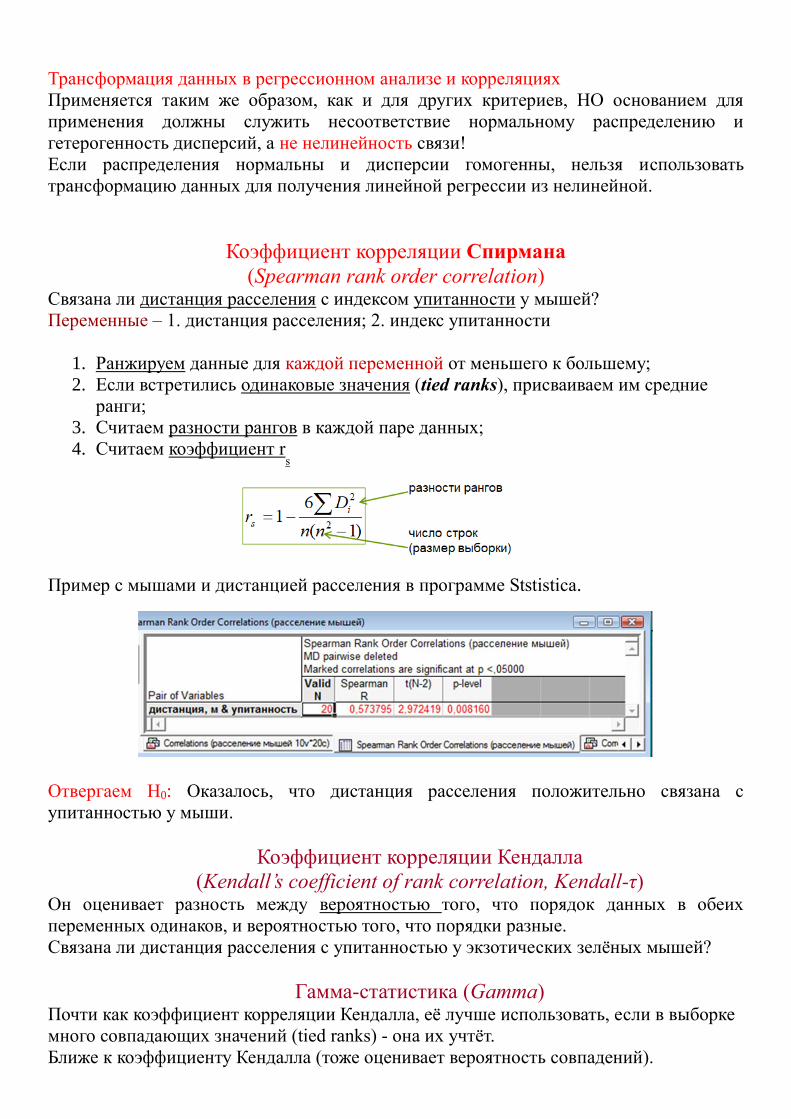
Коэффициент корреляции Спирмана
(Spearman rank order correlation) Связана ли дистанция расселения с индексом упитанности у мышей?
Переменные – 1. дистанция расселения; 2. индекс упитанности
1. Ранжируем данные для каждой переменной от меньшего к большему;
2. Если встретились одинаковые значения (tied ranks), присваиваем им средние
ранги;
3. Считаем разности рангов в каждой паре данных;
4. Считаем коэффициент rs
Пример с мышами и дистанцией расселения в программе Ststistica.
Отвергаем Н0: Оказалось, что дистанция расселения положительно связана с
упитанностью у мыши.
Коэффициент корреляции Кендалла
(Kendall’s coefficient of rank correlation, Kendall-τ) Он оценивает разность между вероятностью того, что порядок данных в обеих
переменных одинаков, и вероятностью того, что порядки разные.
Связана ли дистанция расселения с упитанностью у экзотических зелёных мышей?
Гамма-статистика (Gamma) Почти как коэффициент корреляции Кендалла, её лучше использовать, если в выборке
много совпадающих значений (tied ranks) - она их учтёт.
Ближе к коэффициенту Кендалла (тоже оценивает вероятность совпадений).

Пример с упитанностью зеленых мышей и дистанцией расселения в программе
Ststistica.
Kendall’s coefficient of rank correlation, Kendall-τ
Отвергаем Н0: дистанция расселения у зелёных мышей отрицательно связана с
упитанностью.
Коэффициент конкордантности Кендалла (Kendall’s coefficient of
concordance): ≥2 переменных
Переменных может быть 3 и более. Значения ранжируются внутри каждой
переменной, и считается общая статистика W, она примерно соответствует
среднему коэффициенту корреляции Спирмана для всех пар переменных.
Пример. Одна из задач – оценка согласия экспертов, например, детей, оценивающих
вкус 6 типов пирожных.
Коэффициент конкордантности Кендалла
Результаты в программе Ststistica:
0 ≤ W ≤ 1
Чем ближе коэффициент к 1, тем выше корреляция.
Чем ближе к нулю, тем меньше связь переменных (например, согласие экспертов).
Итак, при выборе теста важно, что:
1. Параметрические тесты более мощные, чем непараметрические;

2. Непараметрические безопаснее в плане ошибки 1-го рода;
3. Чем больше размер выборки, тем менее критичны требования к распределению
(по Центральной предельной теореме); для выборок N ≥ 100 используют
параметрические тесты даже при больших отклонениях от нормального
распределения (кроме регрессий).
4. АНОВА не очень чувствительна к отклонениям от нормального распределения
(для одинаковых по размеру групп).
Спасибо за внимание!





























