Embed Size (px)
Citation preview



はじめに
この度はDr.Sum EAをお買い上げいただき、誠にありがとうございます。
本マニュアルではDr.Sum EAが提供するSQLについて記述しています。Dr.Sum EA本体の機能、操作方法については、「Dr.Sum
EA ユーザーズ・マニュアル サーバ編」をお読みください。

ii
第1章 概要 1
Dr.Sum EA Ver3.0で新規追加された機能 1
追加されたSQL 1
追加された関数 2
サブクエリ(副問合せ) 2
テーブルの自己結合 3
列選択 3
表制約 3
デフォルト値の設定 3
ビューの操作 4
ビュー定義の変更 4 ビューコメントの変更 4
データディクショナリ 4
DWテーブル 4
Dr.Sum EA Ver2.xからの仕様変更点 5
第2章 SQL構文の基本事項 7
地域・言語 7
構文の表記法 7
文字 7
囲み文字 8
定数 8
文字列定数 8
数定数 9
識別子 9
トークン 9
字句規則 9
SQLコメント 10
予約語 11
OID(オブジェクトID) 12
ROWID 12
第3章 データ型 13
NULL値について 13
タイプ0でのNULL値の特性 14
NOT真理値表 14
AND真理値表 14
OR真理値表 14
BETWEEN演算子 14
IN,ANY,ALL演算子 15
NULLとソート 15 空文字列の評価ルール 15
文字列データ型 19
文字列リテラル 19

iii
数値データ型 20
真数データ型 20
概数データ型 20
数値リテラル 21
日付データ型 21
期間型 22
オブジェクトデータ型 (非推奨 ) 24
オブジェクト型に対するDML操作 24
オブジェクト型に対するその他の制限 24
データ型変換表 25
加算をおこなった場合 25
減算をおこなった場合 25
乗算をおこなった場合 26
除算をおこなった場合 26
演算後の精度 26
数値関数の精度 26
第4章 演算子 27
演算子の優先順位 27
算術演算子 27
連結演算子 27
比較演算子 28
特殊演算子 28
論理演算子 30
集合演算子 30
第5章 制約 31
制約 31
列制約 31
表制約 31
表制約が指定されているテーブルの結合 32
制約とJOINについて 33
第6章 式 34
スカラー式 (値式 ) 34
第7章 関数 35
集計関数 35
AVG 平均値 36
COUNT 行数のカウント 36
MAX 大値 37
MIN 小値 37
SUM 合計値 37
FIRST 初の値の検索 38
iv
文字列操作関数 38
CHR 文字変換 38
CONCAT 文字列の連結 38
INITCAP 頭文字を大文字にそれ以外を小文字に変換 39
LCASE 小文字への変換 39
LENGTH 文字数の取得 39
LENGTHB バイト数の取得 39
LOWER 小文字への変換 39
LPAD 左文字埋め 40
LTRIM 左指定文字削除 40
MID 文字列の抽出 41
REPLACE 文字列の置換 41
RPAD 右文字埋め 42
RTRIM 右指定文字削除 42
SUBSTR 文字列の抽出 43
SUBSTRING 文字列の抽出 43
TRIM 左右指定文字削除 43
UCASE 大文字への変換 43
UPPER 大文字への変換 43
数値操作関数 44
ABS 絶対値 44
ACOS 逆コサイン 44
ASIN 逆サイン 44
ATAN 逆タンジェント 45
ATAN2 逆タンジェント 45
CEIL 小数点以下の切り上げ 45
COS コサイン 45
COSH 双曲線コサイン 46
EXP 指数関数値 46
FLOOR 大整数 46
GREATEST 引数のうちの 大値 46
LEAST 引数のうちの 小値 47
LN 自然対数 47
LOG 対数 47
POWER べき乗 47
ROUND 四捨五入 48
SIGN 引数の符号 48
SIN サイン 48
SINH 双曲線サイン 48
SQRT 平方根 48
TAN タンジェント 49
TANH 双曲線タンジェント 49
TRUNC 小数点以下の切り捨て 49

v
日付書式指定子 50
フォーマット(TO_CHAR) 50
フォーマット(TO_TIMESTAMP) 51
フォーマット(TO_DATE) 51
フォーマット(TO_INTERVAL) 52
フォーマット(TO_TIME) 52
日付操作関数 53
ADD_MONTHS 月数の加算 53
LAST_DAY 月の 終日 53
MONTHS_BETWEEN 月単位の差 53
NEXT_DAY 翌日 54
ROUND 四捨五入 54
SYSDATE 現在の日付時刻 54
TRUNC 切り捨て 54
変換関数 55
COALESCE 初の引数 55
DECODE 値の変換 55
NULLIF 等しい場合にNULLを返す 55
NVL NULL値の変換 56
型変換関数 56
TO_CHAR 数値→文字列変換 56
TO_CHAR 日付→文字列変換 57
TO_CHAR 期間→文字列変換 57
TO_NUMERIC 文字列→数値変換 58
TO_TIMESTAMP 文字列→日付変換 58
TO_DATE 文字列→日付変換 59
TO_TIME 文字列→日付変換 59
TO_INTERVAL 期間変換 60
TO_COMPOUND COMPOUND KEYの検索 60
Dr.Sum EAセッション関数 60
GET_USER_INFO ユーザ情報の取得 60
GET_GROUP_INFO グループの取得 61
第8章 クエリとサブクエリ 62
基本構文 62
サブクエリの使用 62
選択列リストでのサブクエリ 62
FROM句でのサブクエリ 63
WHERE句でのサブクエリ 63
演算子とサブクエリ 63
HAVING句でのサブクエリ 64
集計関数の使用 64
サブクエリのネスト 64

vi
第9章 SQLコマンド 65
SQLの機能分類 65
データ操作言語 (DML) 66
テーブルからデータを検索する SELECT 66
データに対して行制約をかける CONSTRAINT ON TOP指定 67 指定した行数を戻す TOP指定 67 すべての行を戻す ALL指定 67 重複行を1行だけ戻す DISTINCT指定 67 すべての列を選択する アスタリスク「*」 67 取り出す列 /式を指定する select_list 68 列の別名を指定する AS 68 テーブルの別名を指定する AS 68 複数テーブルを指定する FROM句 68 テーブルを結合する 69
FROM句で複数テーブルを結合し、結合条件を指定する 69
3つ以上のテーブルを結合する 70
WHERE句での複数テーブルの結合 70 抽出条件を指定する WHERE句 70 データを並べ替える ORDER BY句 70 グループ別に集計する GROUP BY句 71 集計結果を条件として絞込む HAVING句 72 サブクエリ 72
データを追加する INSERT 73
データを変更する UPDATE 74
データを削除する DELETE 74
WHERE句 74
データ定義言語 (DDL) 75
テーブルを作成する CREATE TABLE 75
列の定義 76 列制約の設定 76 ■ NOT NULL制約 76 ■ UNIQUE制約 77 ■ デフォルト値の設定 77 テーブルをコピーする 77
リンクテーブルを作成する 78
検索インデックスを作成する CREATE INDEX 78
結合インデックスを作成する CREATE JOIN INDEX 79
ビューを作成する CREATE VIEW 80
ビューを参照作成する 81 ビューに対するクエリ 81 ビューの検索 81
マルチビューを作成する CREATE MULTIVIEW 82
CONNECT句 83
PARTITION BY句 83
ディストリビュータを作成する CREATE DISTRIBUTOR 90
CONNECT句 91
PARTITION BY句 91
グループを作成する CREATE GROUP 98
ユーザを作成する CREATE USER 99
テーブルの定義を変更する ALTER TABLE 100

vii
列の変更 100 列の追加 100 列の削除 101 列属性の変更 101 デフォルト値の変更・削除 102 列名の変更 103 列コメントの変更 103 列コメントの削除 103 テーブル名の変更 104 テーブルコメントの変更 104 テーブルコメントの削除 104 表制約の変更 105 表制約の削除 105
検索インデックスの有効・無効を切り替える ALTER INDEX 106
結合インデックスの有効・無効を切り替える ALTER JOIN INDEX 106
ビューの定義を変更する ALTER VIEW 107
ビュー名の変更 107 ビューコメントの変更 107 ビューコメントの削除 108 ビューのスキーマ情報の更新 108
マルチビューの定義を変更する ALTER MULTIVIEW 109
マルチビュー名の変更 110 マルチビューコメントの変更 110 マルチビューコメントの削除 111 マルチビューのスキーマ情報の更新 111 エラー発生時の処理の継続・停止 111
ディストリビュータの定義を変更する ALTER DISTRIBUTOR 112
ディストリビュータ名の変更 113 ディストリビュータコメントの変更 113 ディストリビュータコメントの削除 114 インポートポジションの変更 114 ディストリビュータのスキーマ情報の更新 114 循環設定の有無の変更 115
グループの定義を変更する ALTER GROUP 115
グループ名の変更 115 グループコメントの変更 116 グループコメントの削除 116
ユーザの定義を変更する ALTER USER 116
パスワードの変更 117 グループへの所属 117 グループからの削除 118 ユーザコメントの変更 118 ユーザコメントの削除 118
テーブル名を変更する RENAME 118
テーブルを削除する DROP TABLE 119
検索インデックスを削除する DROP INDEX 119
結合インデックスを削除する DROP JOIN INDEX 119
ビューを削除する DROP VIEW 119
マルチビューを削除する DROP MULTIVIEW 120
ディストリビュータを削除する DROP DISTRIBUTOR 120
グループを削除する DROP GROUP 120
ユーザを削除する DROP USER 120

viii
グループにアクセス権限を付与する GRANT 120
データベースへのアクセス権限の付与 122 テーブル・ビューへのアクセス権限の付与 122 列へのアクセス権限の付与 123
グループのアクセス権限を取り消す REVOKE 124
データベースへのアクセス権限の取り消し 125 テーブル・ビューへのアクセス権限の取り消し 125 列へのアクセス権限の取り消し 125
断片化したROWIDの再構成をおこなう COMPACTION TABLE 126
テーブルを再構築する REBUILD TABLE 126
検索インデックスを再構築する REBUILD INDEX 126
結合インデックスを再構築する REBUILD JOIN INDEX 127
システムテーブルを再構築する REBUILD SYSTEMTABLES 127
表の全データを切り捨てる TRUNCATE 127
データ制御言語 (DCL) 128
トランザクションを開始する BEGIN 128
トランザクションを確定する COMMIT 128
トランザクションを破棄する ROLLBACK 128
テーブルへのトランザクションを制御する LOCK TABLE 128
第10章 Appendix 基準表の決定方法 129
グラフの方向性 129
主キー(PK)、外部キー(FK)による方向性 (キーの方向性 ) 129
JOINの優先による方向性 (JOINの方向性 ) 130
基準表になるための条件 130
基準表決定の優先順位 130
VIEWを含むJOIN 131
索引 索引 -1

1
1 概要 Dr.Sum EA Ver3.0のSQLは、国際標準化機構(ISO)のSQL92(ISO/IEC 9075)を基にした機能を持っています。
Dr.Sum EA Ver3.0で新規追加された機能
Dr.Sum EA Ver3.0で追加されたSQL、関数や、その他の新機能について紹介します。
追加されたSQL
新しく追加されたSQLは、次の通りです。
ALTER GROUP ユーザグループに対して、名前の変更、コメントの追加・変更・削除をおこないます。
ALTER DISTRIBUTOR ディストリビュータに対して、名前の変更、コメントの追加・変更・削除、インポートポジションの変更、
循環設定の有無、ディストリビュータ定義の変更をおこないます。
ALTER MULTIVIEW マルチビューに対して、名前の変更、コメントの追加・変更・削除、スレーブへの接続エラー時の処理
継続の有無、マルチビュー定義の変更をおこないます。
ALTER TABLE テーブルに対して、名称の変更、コメントの変更・削除、列の追加・削除、列属性の変更、デフォルト
値の追加・削除、列コメントの変更・削除をおこないます。
ALTER USER ユーザに対して、パスワードの変更、任意グループへのユーザ追加・削除、コメントの変更・削除をお
こないます。
ALTER VIEW ビューに対して、名前の変更、コメントの変更・削除、ビュー定義の変更をおこないます。
COMPACTION TABLE 断片化したROWIDの再付与をおこないます。
CREATE DISTRIBUTOR ディストリビュータを作成します。
CREATE GROUP ユーザグループを作成します。
CREATE MULTIVIEW マルチビューを作成します。
CREATE USER ユーザを作成します。作成時にパスワードやコメントを設定することも可能です。
DROP DISTRIBUTOR ディストリビュータを削除します。
DROP GROUP ユーザグループを削除します。
DROP MULTIVIEW マルチビューを削除します。
DROP USER ユーザを削除します。
GRANT グループにテーブル権限、またはデータベース権限を付与します。
LOCK TABLE テーブルのトランザクションロックを取得します。
REBUILD SYSTEMTABLES システムテーブルの再構築をおこないます。

2
REBUILD TABLE テーブルの再構築をおこないます。
RENAME テーブル名を変更します。
REVOKE グループのテーブル権限、またはデータベース権限を取り消します。
ALTER INDEX 検索インデックスの有効、無効を切り替えます(Ver3.0SP1)。
ALTER JOIN INDEX 結合インデックスの有効、無効を切り替えます(Ver3.0SP1)。
CREATE INDEX 検索インデックスを作成します(Ver3.0SP1)。
CREATE JOIN INDEX 結合インデックスを作成します(Ver3.0SP1)。
DROP INDEX 検索インデックスを削除します(Ver3.0SP1)。
DROP JOIN INDEX 結合インデックスを削除します(Ver3.0SP1)。
REBUILD INDEX 検索インデックスの再構築をおこないます(Ver3.0SP1)。
REBUILD JOIN INDEX 結合インデックスの再構築をおこないます(Ver3.0SP1)。
追加された関数
Dr.Sum EA Ver2.xでは、集計関数のみをサポートしていましたが、Dr.Sum EA Ver3.0では、国際標準化機構(ISO)のSQL92(ISO/IEC
9075)でサポートされている関数をほぼ網羅しています。
集計関数は2レベルまでのネストが可能です。また、ログインユーザ・グループ情報を取得することのできるDr.Sum EAセッション関数を使
用することができます。Dr.Sum EAセッション関数については、p.60を参照してください。
サブクエリ(副問合せ)
SELECT文の中に、別のSELECT文をネスト(入れ子)させることができます。この場合は内側のSELECT文から実行されます。ただし、サブク
エリの結果を計算式または関数の引数に使用することはできません。
WHERE句やHAVING句で、サブクエリの結果が1つだけの場合は、関係演算子が使用可能です。複数の結果と比較したい場合は、IN /
ANY /ALL演算子を指定します。
FROM句においても、サブクエリが使用できます。
例 SELECT col1,SUM(b) FROM table1
GROUP BY col1
HAVING SUM(b) < (SELECT AVG (b) FROM table1)
WHERE句で、EXISTS・ANY・ALLの3演算子を使用することが可能です。
INSERT文の中でサブクエリを使用して、複数のデータを1度に別のテーブルにINSERTすることができます。
例1 INSERT INTO table2 SELECT * FROM table1
例2 INSERT INTO table2 ( col2 ) SELECT ( value1 ) FROM table1

3
テーブルの自己結合
同一テーブルの結合は、別名(エイリアス)をつけることで可能です。
例 SELECT X.col1, X.col2, Y.col2
FROM table1 X, table1 Y
WHERE X.col3 = Y.col1
列選択
ORDER BY句で、列名の代わりに列番号、または別の列名を指定することができます。列番号は1から始まる任意の整数値です。この番
号は、select_list(選択列リスト)に現れる順番に対応しています。
例 select_listの2番目にある列bでソートする
SELECT a, b FROM foo ORDER BY 2
選択列に式を指定することもできます。
例 SELECT a*c, b FROM foo ORDER BY 1
列を選択する際、テーブルに存在しない列番号を選択した場合はエラーが発生します。
表制約
テーブルにCompound Key表制約をつけることができます。Compound Keyは、複数の項目を組み合わせてレコードを指定する際に設定
します。
例 CREATE TABLE TABLES(CODE1 VARCHAR,
CODE2 VARCHAR,
VALUE NUMERIC(10,3),
CODE3 VARCHAR,
CODE4 VARCHAR,
COMPOUND KEY PK(CODE1,CODE2) NOT NULL UNIQUE,
COMPOUND KEY FK(CODE3,CODE4)
);
Compound Key値はすべてVARCHAR型となります。
デフォルト値の設定
列にデフォルト値を設定することができます。デフォルト値を指定した場合、INSERT時に値が指定されない列には、デフォルトに設定され
ている値がINSERTされます。
デフォルト値は、CREATE TABLE文でテーブルを作成する際に設定できます。いったん設定した後は、ALTER TABLE文を使用して設定・
値の変更・削除ができます。
例 列bにデフォルト値0とNOT NULL制約を設定します。
CREATE TABLE foo (a int, b int default 0 not null)

4
ビューの操作
ビューに対して、ビュー定義の変更、コメントの変更がおこなえます。
ビュー定義の変更
例 ALTER VIEW ビュー名
AS SELECT 列名,…… FROM テーブル名
WHERE列名 = 値
ビューコメントの変更
例 ALTER VIEW ビュー名 MODIFY COMMENT 'コメント'
定義したビューを通して、データを変更することはできません。
データディクショナリ
Dr.Sum EA Ver3.0は、次のデータディクショナリを持ちます。データディクショナリは読み取り専用のため、ユーザはデータディクショナリの
テーブルに対してクエリ(SELECT文)のみを発行することができます。
・__all_tables__
・__all_triggers __
・__all_users__
・__all_groups __
・__groupuser_relation__
・__all_views__
・__all_constraints__
・__prs__
・__all_indexes__
・__all_join_indexes__
DWテーブル
DWテーブルとは、データベース作成時に生成されるテーブルで、すべてのユーザが__dw__という名前でアクセスすることができます。DW
テーブルはデータ型VARCHARで定義されているダミー列を持ち、nullを持つ行を1行だけ持ちます。
任意のテーブルから定数、疑似列、または式を選択すると、テーブルの行数だけ値が返りますが、DWテーブルでは行を1行しか持たない
ため、値が返るのは一度だけとなります。そのため、定数式をSELECT文で計算する場合などに便利です。
例1 SELECT 1+1 FROM __dw__
取得値は2となります。
例2 SELECT NEXT_DAY(TO_TIMESTAMP(SYSDATE), 'Sunday') FROM __dw__
SYSDATEが04-06-16の場合、取得値は04-06-20となります。
5
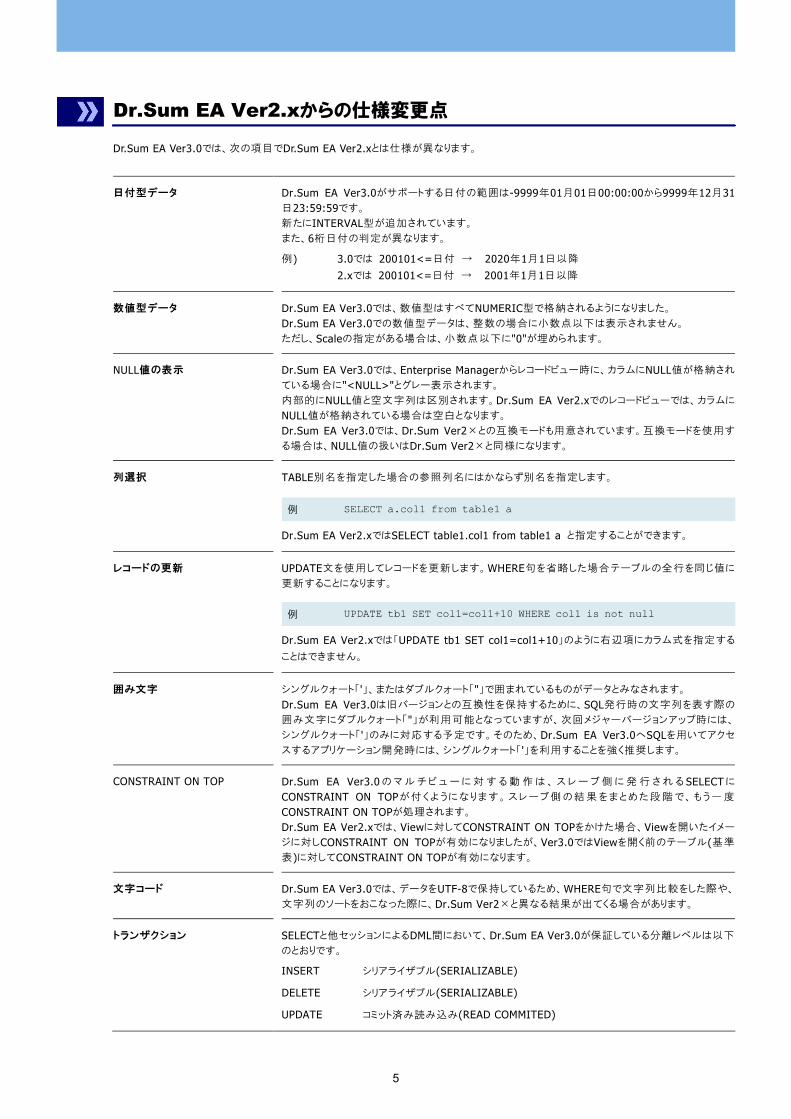
Dr.Sum EA Ver2.xからの仕様変更点
Dr.Sum EA Ver3.0では、次の項目でDr.Sum EA Ver2.xとは仕様が異なります。
日付型データ Dr.Sum EA Ver3.0がサポートする日付の範囲は-9999年01月01日00:00:00から9999年12月31日23:59:59です。 新たにINTERVAL型が追加されています。 また、6桁日付の判定が異なります。
例) 3.0では 200101<=日付 → 2020年1月1日以降
2.xでは 200101<=日付 → 2001年1月1日以降
数値型データ Dr.Sum EA Ver3.0では、数値型はすべてNUMERIC型で格納されるようになりました。 Dr.Sum EA Ver3.0での数値型データは、整数の場合に小数点以下は表示されません。 ただし、Scaleの指定がある場合は、小数点以下に"0"が埋められます。
NULL値の表示 Dr.Sum EA Ver3.0では、Enterprise Managerからレコードビュー時に、カラムにNULL値が格納され
ている場合に"<NULL>"とグレー表示されます。 内部的にNULL値と空文字列は区別されます。Dr.Sum EA Ver2.xでのレコードビューでは、カラムに
NULL値が格納されている場合は空白となります。 Dr.Sum EA Ver3.0では、Dr.Sum Ver2×との互換モードも用意されています。互換モードを使用す
る場合は、NULL値の扱いはDr.Sum Ver2×と同様になります。
列選択 TABLE別名を指定した場合の参照列名にはかならず別名を指定します。
例 SELECT a.col1 from table1 a
Dr.Sum EA Ver2.xではSELECT table1.col1 from table1 a と指定することができます。
レコードの更新 UPDATE文を使用してレコードを更新します。WHERE句を省略した場合テーブルの全行を同じ値に
更新することになります。
例 UPDATE tb1 SET col1=col1+10 WHERE col1 is not null
Dr.Sum EA Ver2.xでは「UPDATE tb1 SET col1=col1+10」のように右辺項にカラム式を指定する
ことはできません。
囲み文字 シングルクォート「'」、またはダブルクォート「"」で囲まれているものがデータとみなされます。 Dr.Sum EA Ver3.0は旧バージョンとの互換性を保持するために、SQL発行時の文字列を表す際の
囲み文字にダブルクォート「"」が利用可能となっていますが、次回メジャーバージョンアップ時には、
シングルクォート「'」のみに対応する予定です。そのため、Dr.Sum EA Ver3.0へSQLを用いてアクセ
スするアプリケーション開発時には、シングルクォート「'」を利用することを強く推奨します。
CONSTRAINT ON TOP Dr.Sum EA Ver3.0 の マ ル チ ビ ュ ー に 対 す る 動 作 は 、 ス レ ー ブ 側 に 発 行 さ れ る SELECT に
CONSTRAINT ON TOPが付 くようになります。スレーブ側 の結 果 をまとめた段 階で、もう一 度
CONSTRAINT ON TOPが処理されます。 Dr.Sum EA Ver2.xでは、Viewに対してCONSTRAINT ON TOPをかけた場合、Viewを開いたイメー
ジに対しCONSTRAINT ON TOPが有効になりましたが、Ver3.0ではViewを開く前のテーブル(基準
表)に対してCONSTRAINT ON TOPが有効になります。
文字コード Dr.Sum EA Ver3.0では、データをUTF-8で保持しているため、WHERE句で文字列比較をした際や、
文字列のソートをおこなった際に、Dr.Sum Ver2×と異なる結果が出てくる場合があります。
トランザクション SELECTと他セッションによるDML間において、Dr.Sum EA Ver3.0が保証している分離レベルは以下
のとおりです。
INSERT シリアライザブル(SERIALIZABLE)
DELETE シリアライザブル(SERIALIZABLE)
UPDATE コミット済み読み込み(READ COMMITED)

6
連結演算子 Dr.Sum EA Ver2.xでは、文字列の連結に「+」が使用できましたが、Dr.Sum EA Ver3.0では、「||」を用います。「+」は算術演算子として作動します。 また、Dr.Sum EA Ver2.xでは、NULLとの連結時はNULLを無視していましたが、Dr.Sum EA Ver3.0では、NULLとの連結はNULLを返します。
HAVING句 Dr.Sum EA Ver2.xでは、HAVING句を使用するとソートされた結果が返りますが、Dr.Sum EA Ver3.xでは自動的にソートはおこなわれません。 ソートをおこなう場合は、ORDER BY句を使用する必要があります。

7
2 SQL構文の基本事項 Dr.Sum EA Ver3.0で使用できるSQL構文上での基本事項は、次のとおりです。
地域・言語
日本語版ではShift-JIS(CP932)、英語版ではASCII、中国版ではGB2312であると仮定して動作します。
データベース内では、すべてのデータはUTF-8で格納されます。
構文の表記法
本マニュアル内で使用する構文は、次に規則に則って表記します。
縦棒「|」は、選択の対象を分離するのに使用します。
角括弧「[」と「]」は、これらの括弧で囲まれた要素がオプションであることを示しています。それらの要素は任意数選択することができま
す。
波括弧「{」と「}」は、これらの括弧内の縦棒で区切られた要素のうち、かならず1つ以上を選択する必要があります。
例 数定数::=
真数定数|概数定数
真数定数::=
[+|-]{整数[. |[整数]]|. 整数}
概数定数::=
真数定数e記号つき整数
符号付整数::=
[+|-] 整数
文字
Dr.Sum EA Ver3.0のSQL文では、以下の文字集合を利用することができます。
・半角英大文字
・半角英小文字
・半角数字
・半角空白 スペース(20h) タブ(09h) 改行(0dh, 0ah)
・半角記号 ( ) " ' + - * / % & | _ # $ = < > ? ¥ ; : [ ] { } @ , .
・すべての全角文字

8
囲み文字
シングルクォート「'」、またはダブルクォート「"」で囲まれているものはデータとみなされます。
例 '0123456789abcd'
Dr.Sum EA Ver3.0は旧バージョンとの互換性を保持するために、SQL発行時の文字列を表す際の囲み文字にダブル
クォート「"」が利用可能となっていますが、次回メジャーバージョンアップ時には、シングルクォート「 '」のみに対応する予定で
す。そのため、Dr.Sum EA Ver3.0へSQLを用いてアクセスするアプリケーション開発時には、シングルクォート「'」を利用する
ことを強く推奨します。
囲み文字を利用しなければならな
いデータ型
囲み文字を利用しなければならないデータ型は、次のものになります。
VARCHAR、DATE、TIME、TIMESTAMP、INTERVAL
INSERT、またはUPDATEの際にフォーマット指定が必要な次のデータ型に関しては囲み文字が必要です。
DATE、TIME、TIMESTAMP、INTERVAL
VARCHAR型に数値を入れる場合、暗黙的な変換がかかるので囲み文字を付けなくてもINSERT、またはUPDATEが可能で
す。ただし、文字をINSERT、またはUPDATEする場合は囲み文字は必須となります。
囲み文字を利用できるデータ型 囲み文字を利用できるデータ型は、次のものになります。
VARCHAR、DATE、TIME、TIMESTAMP、INTERVAL、NUMERIC
NUMERIC型に「1」をINSERT、またはUPDATEした場合、暗黙的な変換がかかり数値に変換されます。SELECTの中で囲み
文字で囲むと文字列型として処理されます。
定数
定数には文字列と数の2つの型があります。
文字列定数
文字列定数は、囲み文字で囲まれた文字列から成ります。定数内で、囲み文字自身を文字データとして扱う場合は、囲み文字を二つ続
けて記述します。
例 シングルクォートを使用する場合
'abc' 'SUM' '''EURO2004''' 'can''t' '20th anniversary'
次のように表示されます。
↓
abc SUM 'EURO2004' can't 20th anniversary
ダブルクォートを使用する場合
"abc" "SUM" """EURO2004""" "can't" "20th anniversary"
次のように表示されます。
↓
abc SUM "EURO2004" can't 20th anniversary

9
数定数
数定数は真数の型になります。符号付、または符号なしの小数点付、または小数点なしの10進数から成ります。
例 2 3.5 70.00 0.009 -3.85
概数定数は、省略可能な符号付の小数点付、または小数点なしの10進数と、それに続けて文字Eと符号付、または符号なし整数から成
ります。概数関数にて小数点の誤差がでることがあります。
例 9.2e49 -3.333333e51 -8.1e45 -4e-56
識別子
識別子はテーブル名、列名などのオブジェクトに名前を与えるのに使用されるトークンです。次のものはすべて識別子です。
・認証識別子(ユーザ名、パスワード、グループ名)
・テーブル名
・列名
・テーブル、列の別名
Dr.Sum EA Ver3.0は、識別子に使用される英大文字と英小文字を区別します。
通常の識別子に利用できる文字は、63文字までの半角英数字、半角カナ文字、全角文字、アンダースコア「_」、に限られ
ます。ただし、半角数字とアンダースコアを先頭の文字として利用することができません。
通常、識別子にSQL予約語を使用することはできませんが、SQL予約語をシングルクォート「 '」、またはダブルクォート「"」で
囲むことによって、ユーザ名とグループ名だけに使用することができます。
トークン
トークンは、言語における語彙単位を表し、区切り記号か区切り文字でないものに区別されます。
区切り文字 文字列定数、または特殊記号 , ( ) < > . : = + - * / <> != <= >= % || & = ¥ ¥r ¥n ¥t -- /* */ *= =* ; 0x20(スペース)
区切り記号でないもの 数定数、識別子、またはキーワード
字句規則
SQL文では、空白を記述できる部分には、任意の半角空白文字、改行、コメントを置くことができます。

10
SQLコメント
コメントを記載することで、SQL文の内容、実行には影響を与えずに、SQL文を読み易くすることや、SQL文の目的、背景等を記述すること
ができます。
コメントは、SQL文中のキーワード、リテラルの間に入れることが可能です。SQLコメントには次の2種類があります。
範囲コメント SQL文中の指定した範囲をコメントとします。 スラッシュ「/」とアスタリスク「*」を続けることでコメントの開始を示し、アスタリスク「*」とスラッシュ「/」を
続けることでコメントの終了を示します。 コメントの開始、終了の間に何も入らなくても問題ありません。
例 SELECT amount*rate FROM table1というSELECT文を、次のようにコメントを含め
て記述することができます。
SELECT /*コメント*/ amount* /*コメント*/ rate /*コメント*/FROM table1
/*コメント*/
行コメント SQL文中の指定した位置から改行までをコメントとします。
2つのハイフン「-」でコメントを開始します。改行、またはSQL文の文末でコメントは終了します。
例 SELECT amount*rate FROM table1というSELECT文を次のように記述することも
できます。
SELECT -- コメント
amount -- 金額
*
rate -- 率
FROM
Table1 -- コメント
11
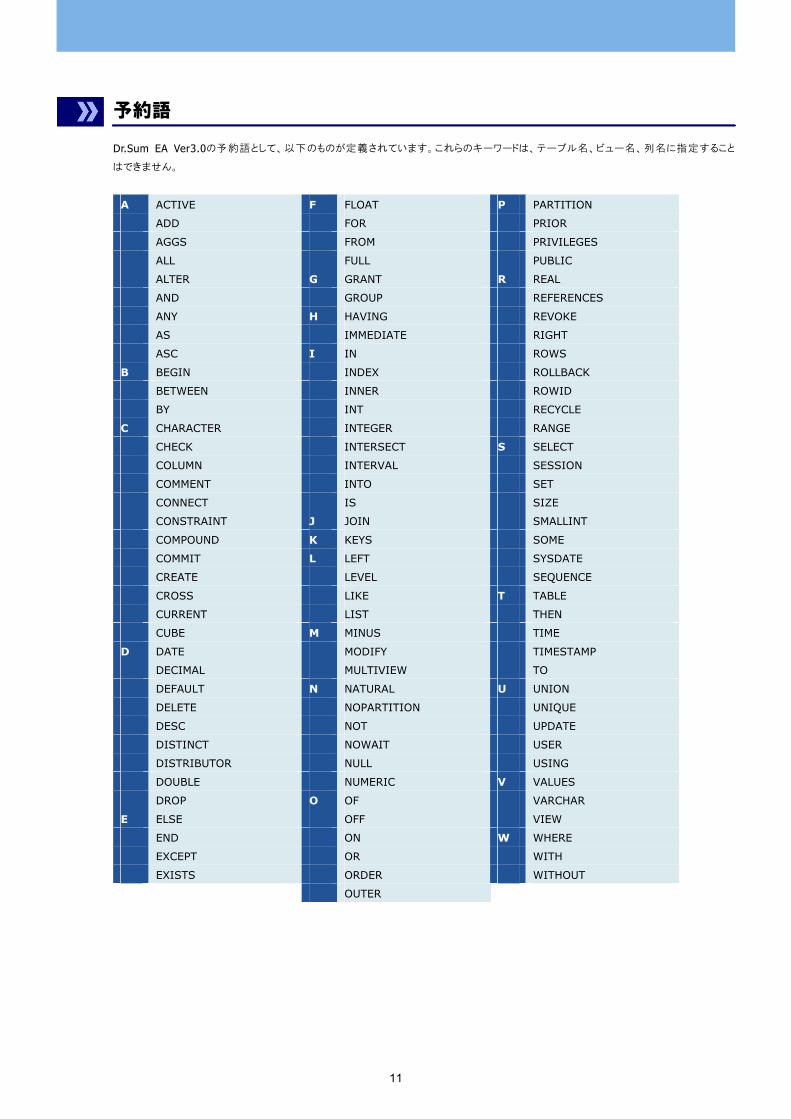
予約語
Dr.Sum EA Ver3.0の予約語として、以下のものが定義されています。これらのキーワードは、テーブル名、ビュー名、列名に指定すること
はできません。
A ACTIVE F FLOAT P PARTITION
ADD FOR PRIOR
AGGS FROM PRIVILEGES
ALL FULL PUBLIC
ALTER G GRANT R REAL
AND GROUP REFERENCES
ANY H HAVING REVOKE
AS IMMEDIATE RIGHT
ASC I IN ROWS
B BEGIN INDEX ROLLBACK
BETWEEN INNER ROWID
BY INT RECYCLE
C CHARACTER INTEGER RANGE
CHECK INTERSECT S SELECT
COLUMN INTERVAL SESSION
COMMENT INTO SET
CONNECT IS SIZE
CONSTRAINT J JOIN SMALLINT
COMPOUND K KEYS SOME
COMMIT L LEFT SYSDATE
CREATE LEVEL SEQUENCE
CROSS LIKE T TABLE
CURRENT LIST THEN
CUBE M MINUS TIME
D DATE MODIFY TIMESTAMP
DECIMAL MULTIVIEW TO
DEFAULT N NATURAL U UNION
DELETE NOPARTITION UNIQUE
DESC NOT UPDATE
DISTINCT NOWAIT USER
DISTRIBUTOR NULL USING
DOUBLE NUMERIC V VALUES
DROP O OF VARCHAR
E ELSE OFF VIEW
END ON W WHERE
EXCEPT OR WITH
EXISTS ORDER WITHOUT
OUTER

12
OID(オブジェクトID)
Dr.Sum EA Ver3.0は、テーブル内に保持するすべてのオブジェクト(列/管理情報/データなど)をOIDと呼ばれるIDで管理しています。OID
はテーブル単位で管理され、その上限値は40億となっています。
OIDが大量に使われるのは主にデータに対してであり、データの多様度(カーディナリティ)に比例します。カーディナリティが大きすぎる場合、
OIDが足りなくなりデータがそれ以上格納できなくなる場合があります。
例えば、列数が10個のテーブルにおいて、すべての列がユニークな2億件のデータ(列のカーディナリティ=2億)を持つとすると、
10列×2億件=20億となり、OIDは20億個使用されます。
実際にはテーブルの管理情報にもOIDが使用されているため、テーブル全体でのカーディナリティは30億程度が目安となります。
ROWID
ROWIDは、テーブル内において一意に行を特定できる擬似列です。テーブルを再構築しない限りROWIDは再利用されません。
例 SELECT ROWID, * FROM TBL_A;
UPDATE TBL_A SET COL1 = 1 WHERE ROWID = 1;
DELETE FROM TBL_A WHERE ROWID = 1;

13
3 データ型 Dr.Sum EA Ver3.0のSQLでは次のデータ型をサポートします。
<データ型>::=
{ { VARCHAR | CHAR | VARYING CHARACTER } [ (length) ]
| { INTEGER | INT | SMALLINT | TINYINT }
| { REAL| FLOAT |DOUBLE }
| NUMERIC | DECIMAL [ (precision [, scale]) ]
| TIMESTAMP | DATE | TIME | INTERVAL
| OBJECT
}
NUMERIC型以外の数値型はすべて内部的にNUMERIC型に自動変換されます。
NULL値について
SQLでは値が存在しない状態、値が不定な状態のことを「NULL」と言い、「NULL値が格納されている」と表現します。
数値型の列に「0」が格納されている場合や、文字列型の列に「空白文字(スペース)」が格納されている場合と「NULL」とは区別されます。
また、長さゼロの文字列とも異なります。すべてのデータ型でNULL値と非NULL値は区別されます。
関数の引数にNULLを指定した場合、NULLを返します(一部NULLを返さない関数があります「第7章 関数」参照)。リテラルのNULL値を
使用するときは、型変換関数を使用してください。
Dr.Sum EA Ver3.0より前のバージョンでは、NULL値は長さ0の文字列としていましたが、Ver3.0ではデータベースを作成する際に、NULL
値と空文字列の扱いについて次の2つの処理タイプから選択することができます。
タイプ0(区別する) 厳格NULL値処理タイプです。NULL値と空文字列を区別します。 空文字列は、長さゼロ、かつ 小値の文字列とします。空文字のINSERTはエラーとなります。 便宜上、UNKNOWNはFALSEと扱います。
タイプ1(2.x互換) Dr.Sum EA Ver2.x互換処理タイプです。検索条件時はNULL値を空文字列として扱います。それ
以外の場合には、空文字列をNULL値として扱います。
NUMERIC/DATE/TIMESTAMP/TIME/INTERVAL型において、NULLタイプ1の場合、空文字列(NULL)は 小値として評
価します。
14
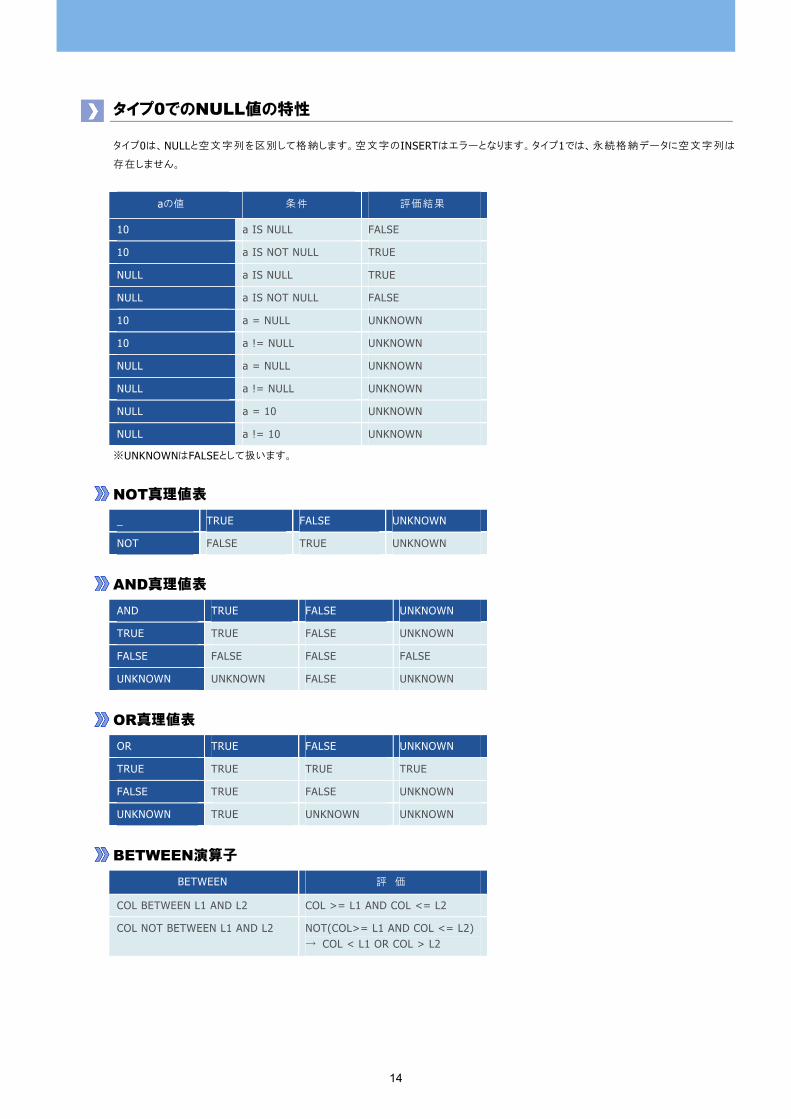
タイプ0でのNULL値の特性
タイプ0は、NULLと空文字列を区別して格納します。空文字のINSERTはエラーとなります。タイプ1では、永続格納データに空文字列は
存在しません。
aの値 条件 評価結果
10 a IS NULL FALSE
10 a IS NOT NULL TRUE
NULL a IS NULL TRUE
NULL a IS NOT NULL FALSE
10 a = NULL UNKNOWN
10 a != NULL UNKNOWN
NULL a = NULL UNKNOWN
NULL a != NULL UNKNOWN
NULL a = 10 UNKNOWN
NULL a != 10 UNKNOWN
※UNKNOWNはFALSEとして扱います。
NOT真理値表 _ TRUE FALSE UNKNOWN
NOT FALSE TRUE UNKNOWN
AND真理値表 AND TRUE FALSE UNKNOWN
TRUE TRUE FALSE UNKNOWN
FALSE FALSE FALSE FALSE
UNKNOWN UNKNOWN FALSE UNKNOWN
OR真理値表 OR TRUE FALSE UNKNOWN
TRUE TRUE TRUE TRUE
FALSE TRUE FALSE UNKNOWN
UNKNOWN TRUE UNKNOWN UNKNOWN
BETWEEN演算子 BETWEEN 評 価
COL BETWEEN L1 AND L2 COL >= L1 AND COL <= L2
COL NOT BETWEEN L1 AND L2 NOT(COL>= L1 AND COL <= L2)→ COL < L1 OR COL > L2
15
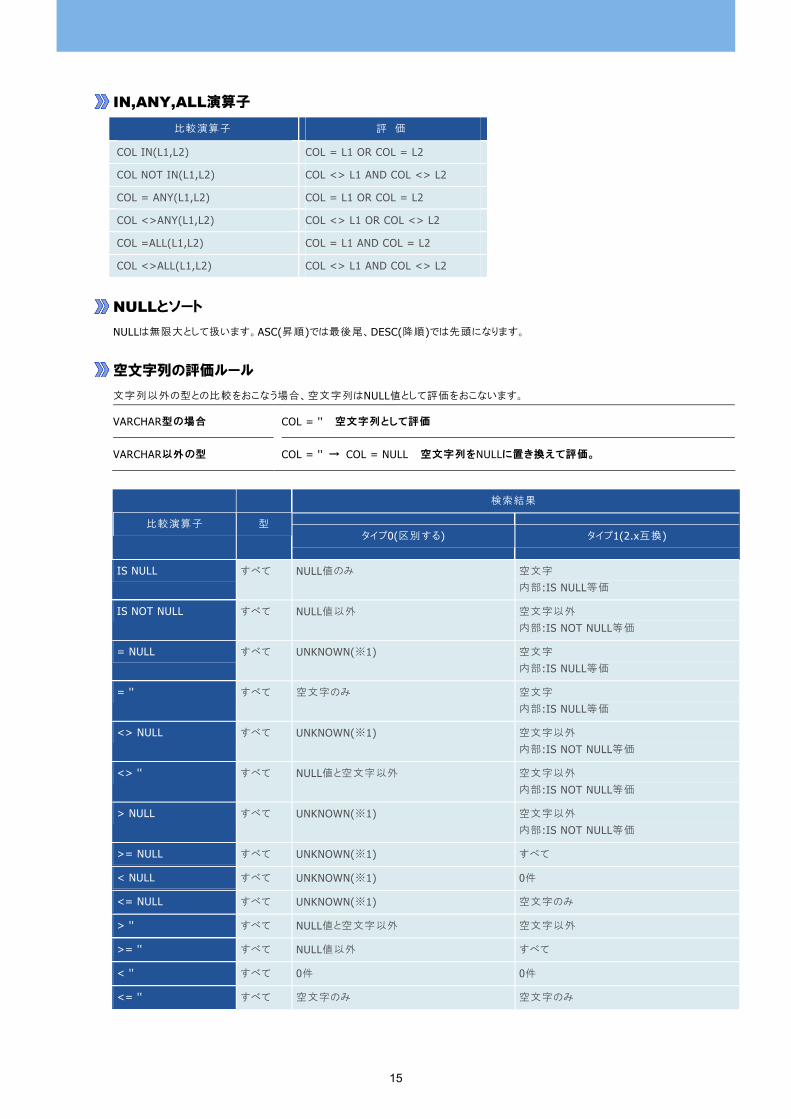
IN,ANY,ALL演算子 比較演算子 評 価
COL IN(L1,L2) COL = L1 OR COL = L2
COL NOT IN(L1,L2) COL <> L1 AND COL <> L2
COL = ANY(L1,L2) COL = L1 OR COL = L2
COL <>ANY(L1,L2) COL <> L1 OR COL <> L2
COL =ALL(L1,L2) COL = L1 AND COL = L2
COL <>ALL(L1,L2) COL <> L1 AND COL <> L2
NULLとソート NULLは無限大として扱います。ASC(昇順)では 後尾、DESC(降順)では先頭になります。
空文字列の評価ルール 文字列以外の型との比較をおこなう場合、空文字列はNULL値として評価をおこないます。
VARCHAR型の場合 COL = '' 空文字列として評価
VARCHAR以外の型 COL = '' → COL = NULL 空文字列をNULLに置き換えて評価。
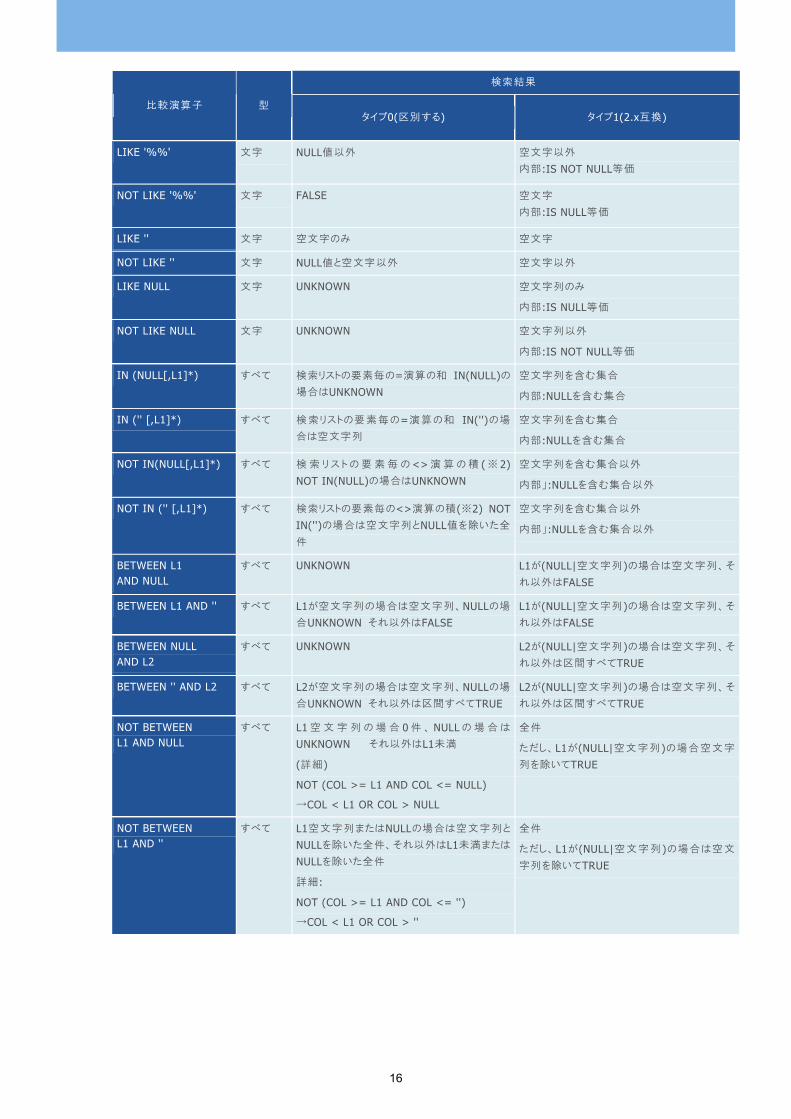
検索結果
比較演算子 型 タイプ0(区別する) タイプ1(2.x互換)
IS NULL すべて NULL値のみ 空文字 内部:IS NULL等価
IS NOT NULL すべて NULL値以外 空文字以外 内部:IS NOT NULL等価
= NULL すべて UNKNOWN(※1) 空文字 内部:IS NULL等価
= '' すべて 空文字のみ 空文字 内部:IS NULL等価
<> NULL すべて UNKNOWN(※1) 空文字以外 内部:IS NOT NULL等価
<> '' すべて NULL値と空文字以外 空文字以外 内部:IS NOT NULL等価
> NULL すべて UNKNOWN(※1) 空文字以外 内部:IS NOT NULL等価
>= NULL すべて UNKNOWN(※1) すべて
< NULL すべて UNKNOWN(※1) 0件
<= NULL すべて UNKNOWN(※1) 空文字のみ
> '' すべて NULL値と空文字以外 空文字以外
>= '' すべて NULL値以外 すべて
< '' すべて 0件 0件
<= '' すべて 空文字のみ 空文字のみ
16
検索結果
比較演算子 型 タイプ0(区別する) タイプ1(2.x互換)
LIKE '%%' 文字
NULL値以外 空文字以外 内部:IS NOT NULL等価
NOT LIKE '%%' 文字
FALSE 空文字 内部:IS NULL等価
LIKE '' 文字 空文字のみ 空文字
NOT LIKE '' 文字 NULL値と空文字以外 空文字以外
LIKE NULL 文字 UNKNOWN 空文字列のみ
内部:IS NULL等価
NOT LIKE NULL 文字 UNKNOWN 空文字列以外
内部:IS NOT NULL等価
IN (NULL[,L1]*) すべて 検索リストの要素毎の=演算の和 IN(NULL)の
場合はUNKNOWN
空文字列を含む集合
内部:NULLを含む集合
IN ('' [,L1]*) すべて 検索リストの要素毎の=演算の和 IN('')の場
合は空文字列
空文字列を含む集合
内部:NULLを含む集合
NOT IN(NULL[,L1]*) すべて 検 索 リ ス ト の 要 素 毎 の <> 演 算 の 積 ( ※ 2)
NOT IN(NULL)の場合はUNKNOWN
空文字列を含む集合以外
内部」:NULLを含む集合以外
NOT IN ('' [,L1]*) すべて 検索リストの要素毎の<>演算の積(※2) NOT
IN('')の場合は空文字列とNULL値を除いた全
件
空文字列を含む集合以外
内部」:NULLを含む集合以外
BETWEEN L1 AND NULL
すべて UNKNOWN L1が(NULL|空文字列)の場合は空文字列、そ
れ以外はFALSE
BETWEEN L1 AND '' すべて L1が空文字列の場合は空文字列、NULLの場
合UNKNOWN それ以外はFALSE
L1が(NULL|空文字列)の場合は空文字列、そ
れ以外はFALSE
BETWEEN NULL AND L2
すべて UNKNOWN L2が(NULL|空文字列)の場合は空文字列、そ
れ以外は区間すべてTRUE
BETWEEN '' AND L2 すべて L2が空文字列の場合は空文字列、NULLの場
合UNKNOWN それ以外は区間すべてTRUE
L2が(NULL|空文字列)の場合は空文字列、そ
れ以外は区間すべてTRUE
NOT BETWEEN L1 AND NULL
すべて L1 空 文 字 列 の 場 合 0 件 、 NULL の 場 合 は
UNKNOWN それ以外はL1未満
(詳細)
NOT (COL >= L1 AND COL <= NULL)
→COL < L1 OR COL > NULL
全件
ただし、L1が(NULL|空文字列 )の場合空文字
列を除いてTRUE
NOT BETWEEN L1 AND ''
すべて L1空文字列またはNULLの場合は空文字列と
NULLを除いた全件、それ以外はL1未満または
NULLを除いた全件
詳細:
NOT (COL >= L1 AND COL <= '')
→COL < L1 OR COL > ''
全件
ただし、L1が(NULL|空文字列 )の場合は空文
字列を除いてTRUE
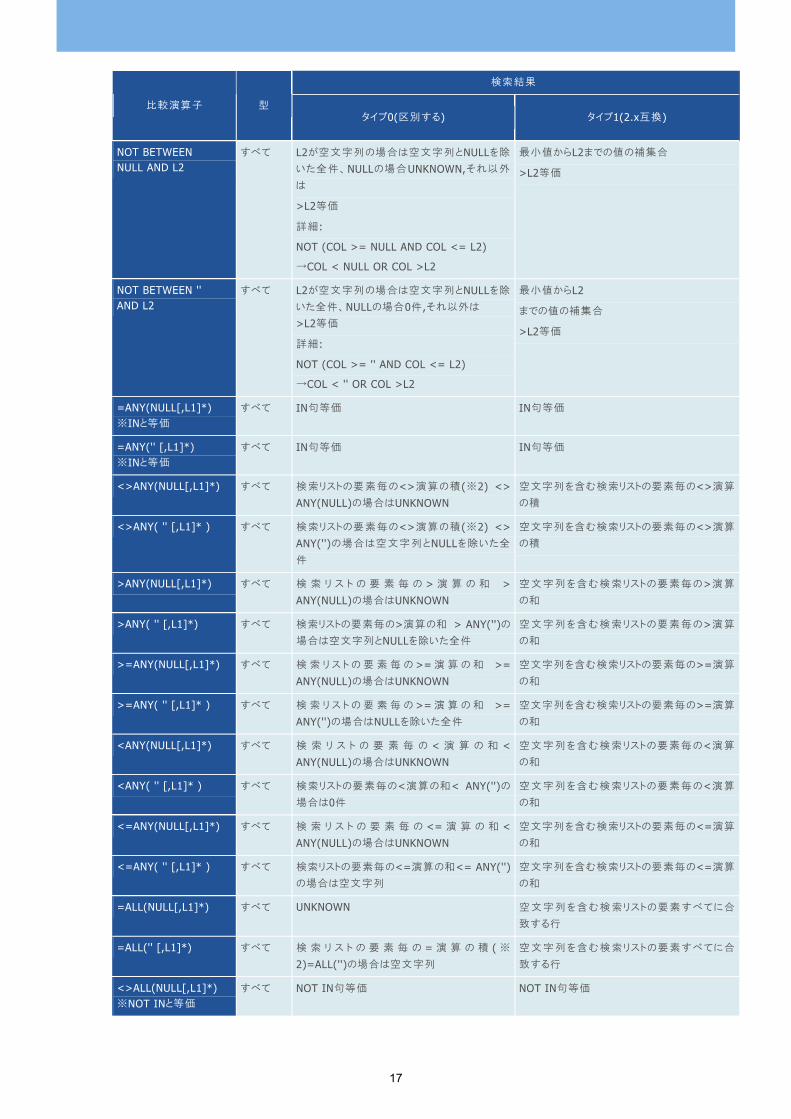
17
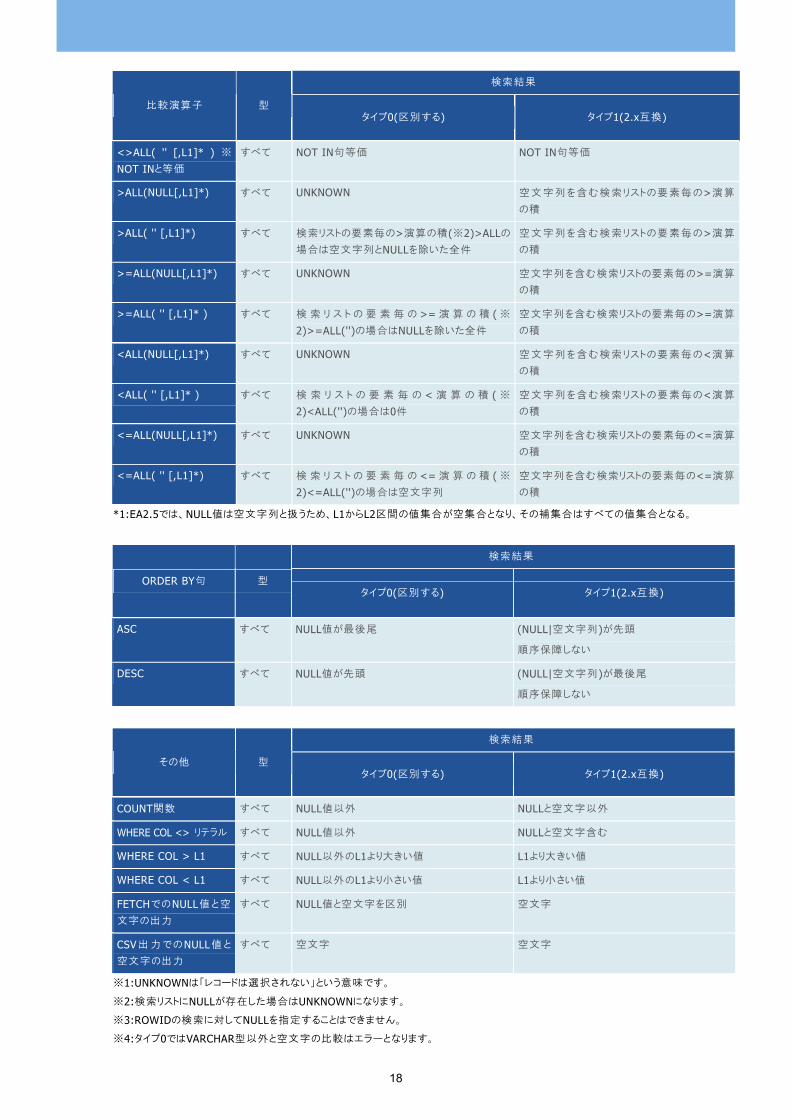
検索結果
比較演算子 型 タイプ0(区別する) タイプ1(2.x互換)
NOT BETWEEN NULL AND L2
すべて L2が空文字列の場合は空文字列とNULLを除
いた全件、NULLの場合UNKNOWN,それ以外
は
>L2等価
詳細:
NOT (COL >= NULL AND COL <= L2)
→COL < NULL OR COL >L2
小値からL2までの値の補集合
>L2等価
NOT BETWEEN '' AND L2
すべて L2が空文字列の場合は空文字列とNULLを除
いた全件、NULLの場合0件,それ以外は
>L2等価
詳細:
NOT (COL >= '' AND COL <= L2)
→COL < '' OR COL >L2
小値からL2
までの値の補集合
>L2等価
=ANY(NULL[,L1]*) ※INと等価
すべて IN句等価 IN句等価
=ANY('' [,L1]*) ※INと等価
すべて IN句等価 IN句等価
<>ANY(NULL[,L1]*) すべて 検索リストの要素毎の<>演算の積(※2) <>
ANY(NULL)の場合はUNKNOWN
空文字列を含む検索リストの要素毎の<>演算
の積
<>ANY( '' [,L1]* ) すべて 検索リストの要素毎の<>演算の積(※2) <>
ANY('')の場合は空文字列とNULLを除いた全
件
空文字列を含む検索リストの要素毎の<>演算
の積
>ANY(NULL[,L1]*) すべて 検 索 リ ス ト の 要 素 毎 の > 演 算 の 和 >
ANY(NULL)の場合はUNKNOWN
空文字列を含む検索リストの要素毎の>演算
の和
>ANY( '' [,L1]*) すべて 検索リストの要素毎の>演算の和 > ANY('')の
場合は空文字列とNULLを除いた全件
空文字列を含む検索リストの要素毎の>演算
の和
>=ANY(NULL[,L1]*) すべて 検 索 リ ス ト の 要 素 毎 の >= 演 算 の 和 >=
ANY(NULL)の場合はUNKNOWN
空文字列を含む検索リストの要素毎の>=演算
の和
>=ANY( '' [,L1]* ) すべて 検 索 リ ス ト の 要 素 毎 の >= 演 算 の 和 >=
ANY('')の場合はNULLを除いた全件
空文字列を含む検索リストの要素毎の>=演算
の和
<ANY(NULL[,L1]*) すべて 検 索 リ ス ト の 要 素 毎 の < 演 算 の 和 <
ANY(NULL)の場合はUNKNOWN
空文字列を含む検索リストの要素毎の<演算
の和
<ANY( '' [,L1]* ) すべて 検索リストの要素毎の<演算の和< ANY('')の
場合は0件
空文字列を含む検索リストの要素毎の<演算
の和
<=ANY(NULL[,L1]*) すべて 検 索 リ ス ト の 要 素 毎 の <= 演 算 の 和 <
ANY(NULL)の場合はUNKNOWN
空文字列を含む検索リストの要素毎の<=演算
の和
<=ANY( '' [,L1]* ) すべて 検索リストの要素毎の<=演算の和<= ANY('')の場合は空文字列
空文字列を含む検索リストの要素毎の<=演算
の和
=ALL(NULL[,L1]*) すべて UNKNOWN 空文字列を含む検索リストの要素すべてに合
致する行
=ALL('' [,L1]*) すべて 検 索 リ ス ト の 要 素 毎 の = 演 算 の 積 ( ※
2)=ALL('')の場合は空文字列
空文字列を含む検索リストの要素すべてに合
致する行
<>ALL(NULL[,L1]*) ※NOT INと等価
すべて NOT IN句等価 NOT IN句等価
18
検索結果
比較演算子 型 タイプ0(区別する) タイプ1(2.x互換)
<>ALL( '' [,L1]* ) ※
NOT INと等価
すべて NOT IN句等価 NOT IN句等価
>ALL(NULL[,L1]*) すべて UNKNOWN 空文字列を含む検索リストの要素毎の>演算
の積
>ALL( '' [,L1]*) すべて 検索リストの要素毎の>演算の積(※2)>ALLの
場合は空文字列とNULLを除いた全件
空文字列を含む検索リストの要素毎の>演算
の積
>=ALL(NULL[,L1]*) すべて UNKNOWN 空文字列を含む検索リストの要素毎の>=演算
の積
>=ALL( '' [,L1]* ) すべて 検 索 リ ス ト の 要 素 毎 の >= 演 算 の 積 ( ※
2)>=ALL('')の場合はNULLを除いた全件
空文字列を含む検索リストの要素毎の>=演算
の積
<ALL(NULL[,L1]*) すべて UNKNOWN 空文字列を含む検索リストの要素毎の<演算
の積
<ALL( '' [,L1]* ) すべて 検 索 リ ス ト の 要 素 毎 の < 演 算 の 積 ( ※
2)<ALL('')の場合は0件
空文字列を含む検索リストの要素毎の<演算
の積
<=ALL(NULL[,L1]*) すべて UNKNOWN 空文字列を含む検索リストの要素毎の<=演算
の積
<=ALL( '' [,L1]*) すべて 検 索 リ ス ト の 要 素 毎 の <= 演 算 の 積 ( ※
2)<=ALL('')の場合は空文字列
空文字列を含む検索リストの要素毎の<=演算
の積
*1:EA2.5では、NULL値は空文字列と扱うため、L1からL2区間の値集合が空集合となり、その補集合はすべての値集合となる。
検索結果
ORDER BY句 型 タイプ0(区別する) タイプ1(2.x互換)
ASC すべて NULL値が 後尾 (NULL|空文字列)が先頭
順序保障しない
DESC すべて NULL値が先頭 (NULL|空文字列)が 後尾
順序保障しない
検索結果
その他 型 タイプ0(区別する) タイプ1(2.x互換)
COUNT関数 すべて NULL値以外 NULLと空文字以外
WHERE COL <> リテラル すべて NULL値以外 NULLと空文字含む
WHERE COL > L1 すべて NULL以外のL1より大きい値 L1より大きい値
WHERE COL < L1 すべて NULL以外のL1より小さい値 L1より小さい値
FETCHでのNULL値と空
文字の出力
すべて NULL値と空文字を区別 空文字
CSV出力でのNULL値 と
空文字の出力
すべて 空文字 空文字
※1:UNKNOWNは「レコードは選択されない」という意味です。
※2:検索リストにNULLが存在した場合はUNKNOWNになります。
※3:ROWIDの検索に対してNULLを指定することはできません。
※4:タイプ0ではVARCHAR型以外と空文字の比較はエラーとなります。

19
文字列データ型
文字列データ型は、文字の並びです。文字列データ型には、文字列長があり、文字列長は0、または1以上の整数です。
VARCHAR型 ・VARCHAR [(<size>)] ・CHAR [(<size>)] ・VARYING CHARACTER [(<size>)]
説明 固定/可変長文字列。 大長65535文字、 小長0文字。
長さ0の文字列を許容します。NULLと長さ0の文字列は、異なるものとして扱います。 表における列定義としては、文字数1~255が指定可能です。文字数を指定しない場合は、65535が仮定されます。
VARCHAR型データは、VARCHAR型データと相互に比較可能です。また、他のデータ型、例えば
INTEGER型などとも明示的に型変換をおこなうことにより比較が可能です。 型変換については、「データ型変換表」(p.25)の項を参照してください。
文字列リテラル
文字列リテラルは、長さ指定がされていないVARCHAR型データとして扱われます。
シングルクォート「'」は、「' '」として表現します。
例 TBLに'''をインサートします。
INSERT INTO TBL VALUES ('''''''')
※Dr.Sum EA Ver2.×では上記のようなSQLは実行できません。
ダブルクォート「"」は、「" "」として表現します。
例 TBLに"""をインサートします。
INSERT INTO TBL VALUES ("""""""")

20
数値データ型
すべての数値データ型において、NULLと値0は異なるものとして扱われます。NUMERIC型以外の型は、すべて内部的にNUMERIC型に
自動変換されます。詳細については、「データ型変換表」(p.25)参照してください。
真数データ型
INTEGER型 ・INTEGER ・INT ・SMALLINT ・TINYINT
説明 Dr.Sum EA Ver3.0ではINTEGER型は存在せず、下位互換としてSQLレベルでテーブルの作成時に
上記の型を記述できます。また、内部データでは、NUMERIC(33,0)として持ちます。
NUMERIC型 ・NUMERIC ([precision, scale])
説明 固定小数点実数型。 大有効精度33桁。
表における列定義としては、桁数1~33桁(p)、小数点以下0~31桁(s)、(p>s)、が指定可能です。
有効桁数指定を省略した場合は、NUMERIC型の 大精度になります。
Dr.Sum EA Ver3.0は、NUMERIC型を常に10進数で表現し、33桁を超えた場合は、丸められた指
数表現になります。
NUMERIC型では、個々の演算の終了時点で有効精度33桁に丸めが実施されます。
NUMERICの保障 大値は-1e1000~ 1e1000となり、保障 大値の範囲を入れた場合には不正
な値が入ります。
NUMERICの保障 小絶対値は1e-1000となります。
Scaleの指定により小数点以下に"0"が埋められます。 例 NUMERIC(1,0)と指定した場合は、値の範囲は±0~9となります。 例 NUMERIC(4,3)と指定した場合は、値の範囲は±0~9.999となります。
DECIMAL型 ・DECIMAL ([precision, scale])
説明 NUMERICと同等です。
REAL型 ・REAL
説明 入力範囲は-1.79769313486231570e308 ~1.79769313486231570e308となります。REAL族
関数の戻り値の精度は、C doubleとします。 内部形式はNUMERIC型であるため、NUMERIC型の保障 大値が有効になります。
ODBC、JDBC経由ではdouble精度に落とされます。
概数データ型
FLOAT型 ・FLOAT
説明 REAL型と同等です。
DOUBLE型 ・DOUBLE
説明 REAL型と同等です。

21
数値リテラル
数値リテラルは、演算過程においては有効精度33桁の浮動小数点NUMERIC型として扱われます。
数値リテラルの表現は、10進数表現と指数表現に対応します。
日付データ型
Dr.Sum EA Ver3.0の日付型データには、DATE型、TIMESTAMP型があります。
変換関数を使用して日付型データを表したり、演算したりすることが可能です。
日付型データ-日付型データの結果はINTERVAL型で差分の秒数が返されます。
日付型データを指定する場合は、シングルクォート「'」、またはダブルクォート「"」で囲む必要があります。
TIMESTAMP型 ・YYYY/MM/DD HH:MI:SS
・YYYYMMDDHHMISS
説明 日時を表現するデータ型です。
Dr.Sum EA Ver3.0がTIMESTAMP型データを返す際の書式のデフォルトはEnterprise Managerで
の設定内容に従います。
INSERT時などにTO_TIMESTAMP関数を使わなくても以下の形式で入力可能です。 ・YYYY/MM/DD HH:MI:SS ・YYYY/MM/DD ・YY/MM/DD ・YYYYMMDDHHMISS ・YYYYMMDD ・YYMMDD
DATE型(YYYYMMDD)の格納時にはデフォルト値00:00:00が適用されます。
・YYYY=年(西暦)(-9999~9999) ・MM=月(01~12) ・DD=日(01~31) ・HH=時(24時間制、00~23) ・MI=分(00~59) ・SS=秒(00~59)
詳細については、「日付操作関数」(p.53)を参照してください。
使用できるデリミタは、次のものになります。 ・DATE部のデリミタ "/", "-", "." ・TIME部のデリミタ ":", "-", "." ・DATE部とTIME部を分けるデリミタ " "(半角スペース)
DATE型 ・YYYY/MM/DD
・YYYYMMDD
・YY/MM/DD、YYMMDD
説明 年月日を表現するデータ型です。
Dr.Sum EA Ver3.0がDATE型データを返す際の書式のデフォルトはEnterprise Managerでの設定
内容に従います。
INSERT時などにTO_DATE関数を使わなくても以下の形式で入力可能です。 ・YYYY/MM/DD ・YY/MM/DD ・YYYYMMDD ・YYMMDD

22
YYYY=年(西暦)(-9999~9999) ・MM=月(01~12) ・DD=日(01~31) 詳細については「日付操作関数」(p.53)を参照してください。
使用できるデリミタは次のものになります。
"/", "-", "."
日付リテラル SQL文中に日付リテラルを記述することが可能です。 日付リテラルは、内部的には文字列リテラルとして扱われます。左辺項が日付型との演算、比較時
には暗黙に日付型に型変換されて演算、比較がおこなわれます。 通常のSQL文中では、日付リテラル中の/、-、:といった区切り文字の有無は、SQL文の内容や結果
に影響しません。
期間型
INTERVAL型 ・DD HH:MI:SS
説明 期間を表現するデータ型です。
INTERVAL型の 大値は36500日=100年間(3153600000秒)、 小値は-36500日=-100年間
(-3153600000秒)です。
Dr.Sum EA Ver3.0がINTERVAL型データを返す形式のデフォルトはEnterprise Managerでの設定
内容に従います。
INSERT時などにTO_INTERVAL関数を使わなくても以下の形式で入力可能です。 ・DD HH:MI:SS
詳細については「日付操作関数」(p.53)してください。
使用できるデリミタは次のものになります。 ・TIME部のデリミタ ":", "-", "." ・DATE部とTIME部を分けるデリミタ " "(半角スペース)
※デリミタの変更はServer Settingsでおこないます。
TIME型 ・HH:MI:SS
説明 時分秒を表現するデータ型です。
Dr.Sum EA Ver3.0がTIME型データを返す形式のデフォルトはEnterprise Managerでの設定内容
に従います。
INSERT時などにTO_TIME関数を使わなくても以下の形式で入力可能です。
・HH:MI:SS
・HHMISS
・HH:MI
・HHMI
HH=時(24時間制、00~23)
MI=分(00~59)
SS=秒(00~59)。
詳細については、「日付操作関数」(p.53)を参照してください。
使用できるデリミタは次のものになります。 ":", "-", "."
期間リテラル 変換関数を使用することにより、SQL文中に時間量を表す期間リテラルを記述することが可能です。
内部的には期間リテラルはNUMERIC型が使用され、単位は秒として扱われます。期間リテラルの
大値は36500日=100年間(3153600000秒)です。

23
SQL文中に指定する場合は、デフォルト表示形式(DD HH:MI:SS)、TO_INTERVAL関数を使用しま
す。
INSERTの時もデフォルト表示形式で指定する必要があります。
例 INSERT INTO test VALUES('11 10:00:01')
インターバル型を使用することで、日付・時間・分・秒などの期間を指定して日付データ型の値に
INTERVAL値を加算、または減算したり、日付データ型間で減算をおこなってINTERVAL値を得たり
することができます。
INTERVALのフィールドの区切り記号は、日付データ型と同じものを使用します。ただし、年月は指定
できません。 ※フィールドの区切り記号を先頭に持ってくることはできません。
日時型データと期間型データでは、次の10種類の演算が可能です。
・日時+期間 結果タイプ:日時
・日時-期間 結果タイプ:日時
・期間+日時 結果タイプ:日時
・日時-日時 結果タイプ:期間
・期間+期間 結果タイプ:期間
・期間-期間 結果タイプ:期間
・期間 * 数値 結果タイプ:期間
・数値 * 期間 結果タイプ:期間
・期間 / 数値 結果タイプ:期間
・期間 / 期間 結果タイプ:数値
例 テーブル「foo」の日時型の値を持つentry_date列に30日と10時間を追加します。
SELECT entry_date + TO_INTERVAL('30:10','DD:HH') FROM
foo
※計算の結果、秒以下の小数以下は四捨五入されます。
※小数値のINSERTはエラーになります。
デリミタの変更はServer Settingsでおこないます。
Dr.Sum EA Ver2.×では任意にデリミタを設定できましたが、Dr.Sum EA Ver3.0は使用可能なデリミ
タは:「,」、「,」、「.」の三種類になります。

24
オブジェクトデータ型(非推奨)
オブジェクト型は、任意のバイナリデータを格納するためのデータ型です。オブジェクト型に格納できるデータは長さ1バイト以上、1GB以下
のバイナリデータです。
オブジェクト型に対する比較はおこなえません。
オブジェクト型に対する検索はおこなえます。ただしOIDのみとなります。同一OIDは、複数の行に格納することが可能です。
オブジェクト型の列に対して、INSERT/UPDATE可能な値はOIDかNULLです。
SaveObject、UpdateObjectでは、表名、列名を指定する必要があります。
表や行を削除すると、当該表、行に格納されていたOIDのデータも削除されます。Dr.Sum EAサーバは、OIDの参照カウンタを管理してお
り、参照カウンタが0のもののみを削除します。
トランザクションがロールバックされた場合、当該トランザクション中に確保されたOIDやオブジェクト格納域もロールバックされます。
オブジェクト型には2つの状態があります。
SaveObjectした後に、 INSERT文
によりOIDを入れなかった場合
SaveObjectを実行した際に返されるOIDをユーザが管理する必要があります。バイナリデータは格
納されていますが、登録した際のOIDを忘れてしまうと、二度とバイナリデータの取得はできなくなりま
す。OIDを登録していないため、SELECTしても登録されているOIDを調べられません。 テーブル再構築をおこなうとバイナリデータは削除されます。
SAVE OBJECTを実行後、COMMITを発行しなければ確定はしません。
ROWID C1
1
SaveObjectした後に、 INSERT文
によりOIDを入れた場合 SELECTにより現在登録されているバイナリデータを呼び出すためのOIDを確認する事ができます。
ただし、テーブル再構築をおこなうとOIDが変わります。
OIDが変わってしまった場合、LoadObjectをする前に該当レコードのOIDをSELECTにて取得して
LoadObjectに渡す必要があります。
ROWID C1
1 25
オブジェクト型に対するDML操作
ブジェクト型に対して、次のDML操作を実行できます。
INSERT SavaObjectで返されたOIDのみ有効です。
UPDATE SavaObjectで返されたOIDのみ有効です。
DELETE 参照数が0のバイナリデータは削除されます。
オブジェクト型に対するその他の制限
オブジェクト型に対するその他の制限は、次の通りです。
Joinには使用できません。
表制約は設定できません。
Dr.Sum EA Ver2.×のデータベースをコンバートした場合、OIDが変わります。
インポートすると0が設定されます。
テーブルにエクスポートすると0が設定されます。
CSVにエクスポートした場合は、設定されているOIDが出力されます。
25
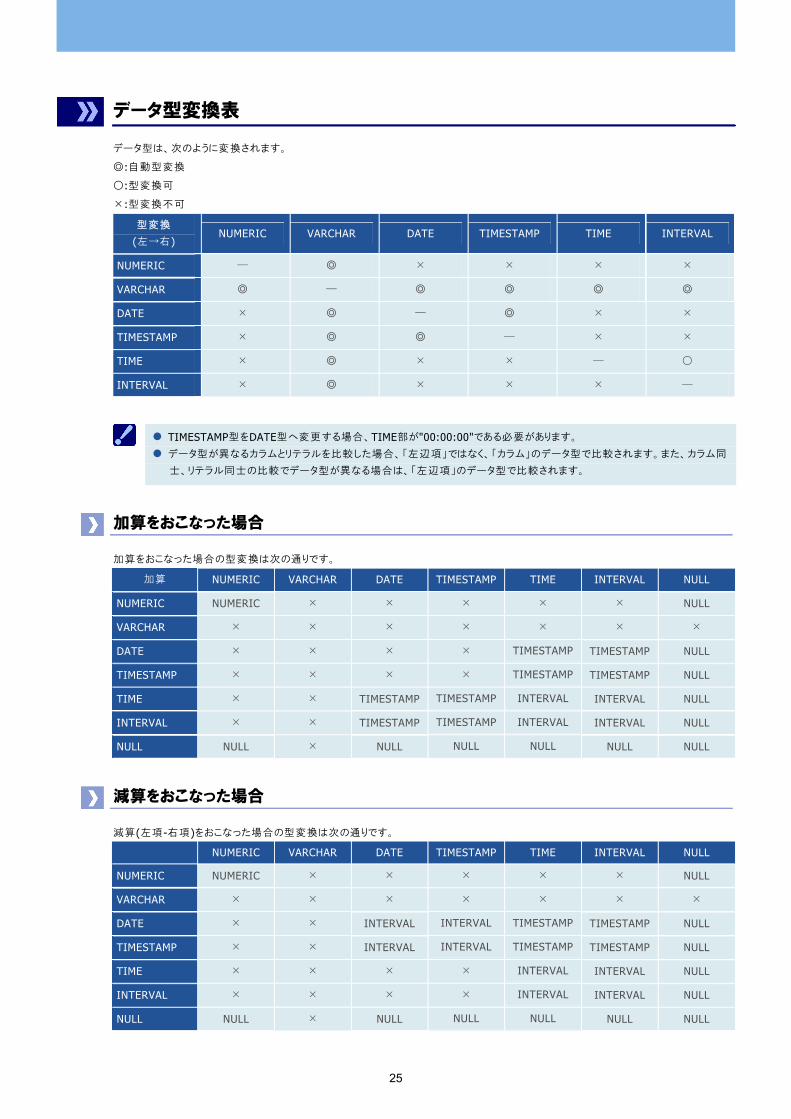
データ型変換表
データ型は、次のように変換されます。
◎:自動型変換
○:型変換可
×:型変換不可
型変換
(左→右) NUMERIC VARCHAR DATE TIMESTAMP TIME INTERVAL
NUMERIC ― ◎ × × × ×
VARCHAR ◎ ― ◎ ◎ ◎ ◎
DATE × ◎ ― ◎ × ×
TIMESTAMP × ◎ ◎ ― × ×
TIME × ◎ × × ― ○
INTERVAL × ◎ × × × ―
TIMESTAMP型をDATE型へ変更する場合、TIME部が"00:00:00"である必要があります。 データ型が異なるカラムとリテラルを比較した場合、「左辺項」ではなく、「カラム」のデータ型で比較されます。また、カラム同
士、リテラル同士の比較でデータ型が異なる場合は、「左辺項」のデータ型で比較されます。
加算をおこなった場合
加算をおこなった場合の型変換は次の通りです。
加算 NUMERIC VARCHAR DATE TIMESTAMP TIME INTERVAL NULL
NUMERIC NUMERIC × × × × × NULL
VARCHAR × × × × × × ×
DATE × × × × TIMESTAMP TIMESTAMP NULL
TIMESTAMP × × × × TIMESTAMP TIMESTAMP NULL
TIME × × TIMESTAMP TIMESTAMP INTERVAL INTERVAL NULL
INTERVAL × × TIMESTAMP TIMESTAMP INTERVAL INTERVAL NULL
NULL NULL × NULL NULL NULL NULL NULL
減算をおこなった場合
減算(左項-右項)をおこなった場合の型変換は次の通りです。
NUMERIC VARCHAR DATE TIMESTAMP TIME INTERVAL NULL
NUMERIC NUMERIC × × × × × NULL
VARCHAR × × × × × × ×
DATE × × INTERVAL INTERVAL TIMESTAMP TIMESTAMP NULL
TIMESTAMP × × INTERVAL INTERVAL TIMESTAMP TIMESTAMP NULL
TIME × × × × INTERVAL INTERVAL NULL
INTERVAL × × × × INTERVAL INTERVAL NULL
NULL NULL × NULL NULL NULL NULL NULL
26
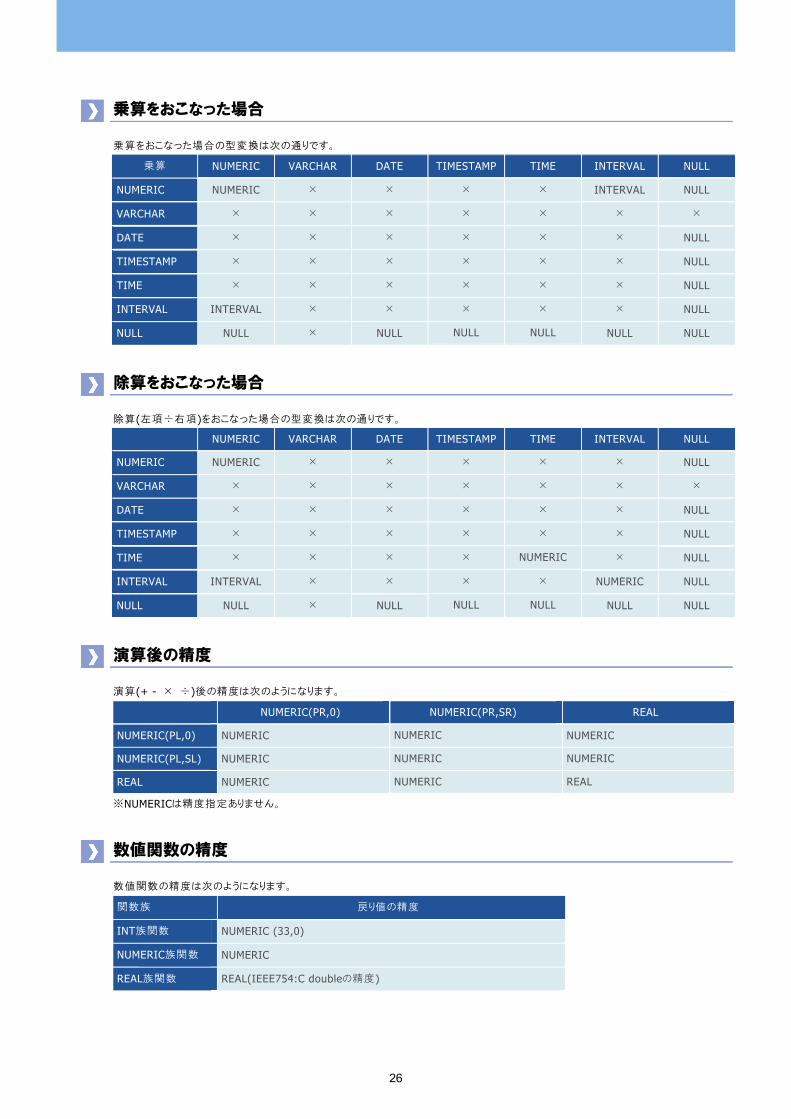
乗算をおこなった場合
乗算をおこなった場合の型変換は次の通りです。
乗算 NUMERIC VARCHAR DATE TIMESTAMP TIME INTERVAL NULL
NUMERIC NUMERIC × × × × INTERVAL NULL
VARCHAR × × × × × × ×
DATE × × × × × × NULL
TIMESTAMP × × × × × × NULL
TIME × × × × × × NULL
INTERVAL INTERVAL × × × × × NULL
NULL NULL × NULL NULL NULL NULL NULL
除算をおこなった場合
除算(左項÷右項)をおこなった場合の型変換は次の通りです。
NUMERIC VARCHAR DATE TIMESTAMP TIME INTERVAL NULL
NUMERIC NUMERIC × × × × × NULL
VARCHAR × × × × × × ×
DATE × × × × × × NULL
TIMESTAMP × × × × × × NULL
TIME × × × × NUMERIC × NULL
INTERVAL INTERVAL × × × × NUMERIC NULL
NULL NULL × NULL NULL NULL NULL NULL
演算後の精度
演算(+ - × ÷)後の精度は次のようになります。
NUMERIC(PR,0) NUMERIC(PR,SR) REAL
NUMERIC(PL,0) NUMERIC NUMERIC NUMERIC
NUMERIC(PL,SL) NUMERIC NUMERIC NUMERIC
REAL NUMERIC NUMERIC REAL
※NUMERICは精度指定ありません。
数値関数の精度
数値関数の精度は次のようになります。
関数族 戻り値の精度
INT族関数 NUMERIC (33,0)
NUMERIC族関数 NUMERIC
REAL族関数 REAL(IEEE754:C doubleの精度)

27
4 演算子 SQL文で使用できる演算子について記載します。演算子には、次の6種類が用意されています。
・算術演算子
・連結演算子
・比較演算子
・特殊演算子
・論理演算子
・集合演算子
演算子の優先順位
演算子には優先順位が設定されています。Dr.Sum EA Ver3.0では、SQL文中の式にある複数の演算子を次のような順序で評価します。
+ - (正負記号)
* / %
+ - ||
= != < > <= >= IS NULL LIKE BETWEEN IN
NOT
AND
OR
算術演算子
算術演算子には次のものがあります。
+ 式が正であることを表します。
- 式が負であることを表します。
* 掛け算をおこないます。
/ 割り算をおこないます。
+ 足し算をおこないます。
- 引き算をおこないます。
% 剰余を計算します。除数が0である場合、被序数がそのまま戻されます。
日付型データの演算については、「日付データ型」(p.21)を参照してください。
連結演算子
連結演算子には次のものがあります。
|| 文字列の連結をおこないます。NULLとの連結はNULLを返します。
Dr.Sum EA Ver2.×では、文字列の連結に「+」が使用できましたが、Dr.Sum EA Ver3.0では、「+」
は算術演算子としてのみ動作します。
高い
低い
28
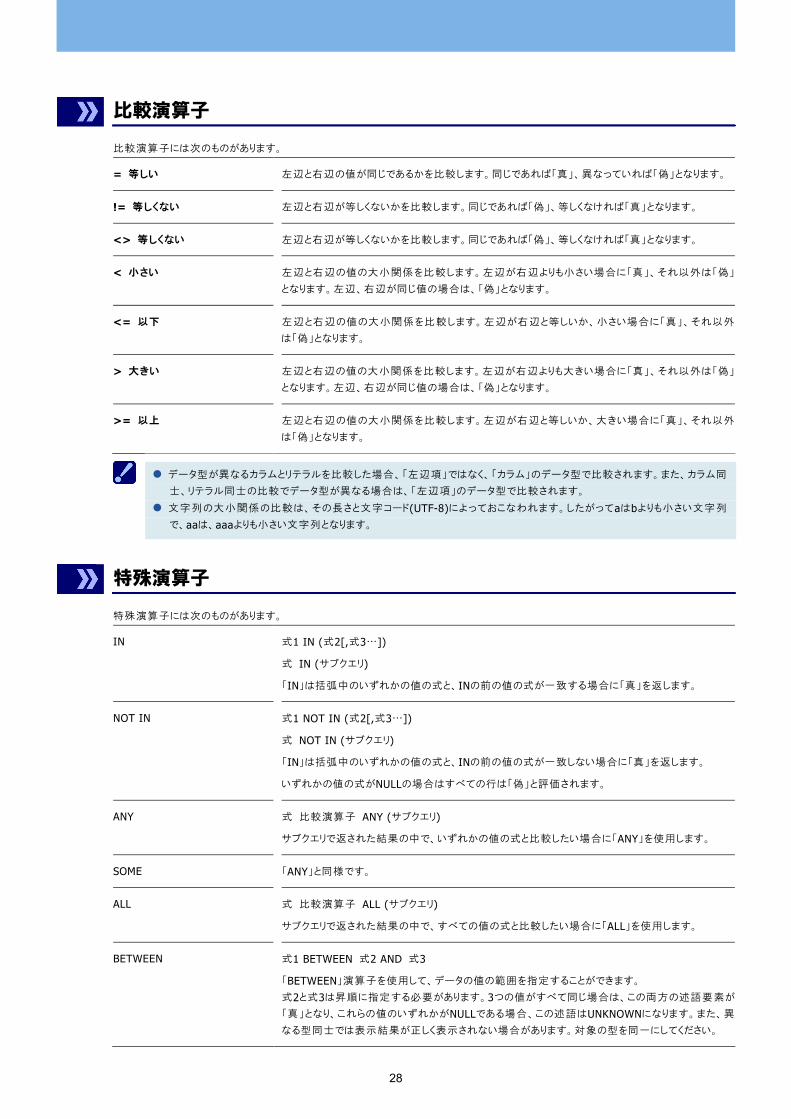
比較演算子
比較演算子には次のものがあります。
= 等しい 左辺と右辺の値が同じであるかを比較します。同じであれば「真」、異なっていれば「偽」となります。
!= 等しくない 左辺と右辺が等しくないかを比較します。同じであれば「偽」、等しくなければ「真」となります。
<> 等しくない 左辺と右辺が等しくないかを比較します。同じであれば「偽」、等しくなければ「真」となります。
< 小さい 左辺と右辺の値の大小関係を比較します。左辺が右辺よりも小さい場合に「真」、それ以外は「偽」
となります。左辺、右辺が同じ値の場合は、「偽」となります。
<= 以下 左辺と右辺の値の大小関係を比較します。左辺が右辺と等しいか、小さい場合に「真」、それ以外
は「偽」となります。
> 大きい 左辺と右辺の値の大小関係を比較します。左辺が右辺よりも大きい場合に「真」、それ以外は「偽」
となります。左辺、右辺が同じ値の場合は、「偽」となります。
>= 以上 左辺と右辺の値の大小関係を比較します。左辺が右辺と等しいか、大きい場合に「真」、それ以外
は「偽」となります。
データ型が異なるカラムとリテラルを比較した場合、「左辺項」ではなく、「カラム」のデータ型で比較されます。また、カラム同
士、リテラル同士の比較でデータ型が異なる場合は、「左辺項」のデータ型で比較されます。
文字列の大小関係の比較は、その長さと文字コード(UTF-8)によっておこなわれます。したがってaはbよりも小さい文字列
で、aaは、aaaよりも小さい文字列となります。
特殊演算子
特殊演算子には次のものがあります。
IN 式1 IN (式2[,式3…])
式 IN (サブクエリ)
「IN」は括弧中のいずれかの値の式と、INの前の値の式が一致する場合に「真」を返します。
NOT IN 式1 NOT IN (式2[,式3…])
式 NOT IN (サブクエリ)
「IN」は括弧中のいずれかの値の式と、INの前の値の式が一致しない場合に「真」を返します。
いずれかの値の式がNULLの場合はすべての行は「偽」と評価されます。
ANY 式 比較演算子 ANY (サブクエリ)
サブクエリで返された結果の中で、いずれかの値の式と比較したい場合に「ANY」を使用します。
SOME 「ANY」と同様です。
ALL 式 比較演算子 ALL (サブクエリ)
サブクエリで返された結果の中で、すべての値の式と比較したい場合に「ALL」を使用します。
BETWEEN 式1 BETWEEN 式2 AND 式3
「BETWEEN」演算子を使用して、データの値の範囲を指定することができます。 式2と式3は昇順に指定する必要があります。3つの値がすべて同じ場合は、この両方の述語要素が
「真」となり、これらの値のいずれかがNULLである場合、この述語はUNKNOWNになります。また、異
なる型同士では表示結果が正しく表示されない場合があります。対象の型を同一にしてください。
29
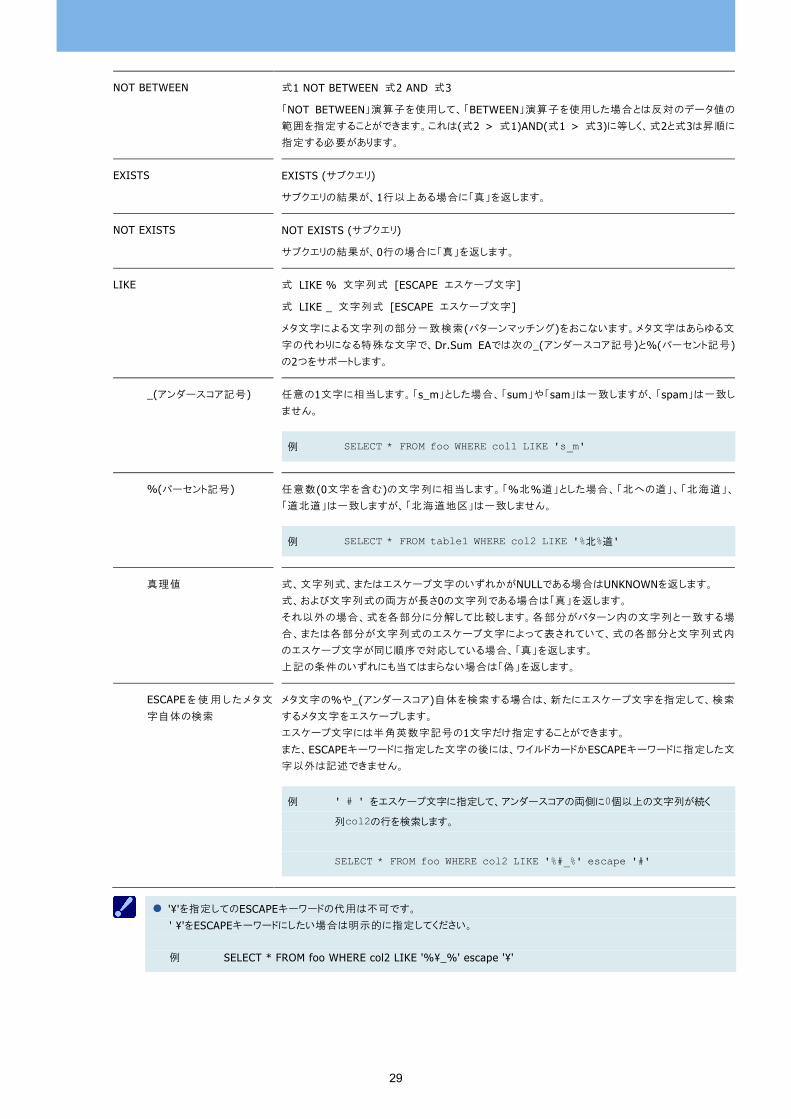
NOT BETWEEN 式1 NOT BETWEEN 式2 AND 式3
「NOT BETWEEN」演算子を使用して、「BETWEEN」演算子を使用した場合とは反対のデータ値の
範囲を指定することができます。これは(式2 > 式1)AND(式1 > 式3)に等しく、式2と式3は昇順に
指定する必要があります。
EXISTS EXISTS (サブクエリ)
サブクエリの結果が、1行以上ある場合に「真」を返します。
NOT EXISTS NOT EXISTS (サブクエリ)
サブクエリの結果が、0行の場合に「真」を返します。
LIKE 式 LIKE % 文字列式 [ESCAPE エスケープ文字]
式 LIKE _ 文字列式 [ESCAPE エスケープ文字]
メタ文字による文字列の部分一致検索(パターンマッチング)をおこないます。メタ文字はあらゆる文
字の代わりになる特殊な文字で、Dr.Sum EAでは次の_(アンダースコア記号)と%(パーセント記号)の2つをサポートします。
_(アンダースコア記号) 任意の1文字に相当します。「s_m」とした場合、「sum」や「sam」は一致しますが、「spam」は一致し
ません。
例 SELECT * FROM foo WHERE col1 LIKE 's_m'
%(パーセント記号) 任意数(0文字を含む)の文字列に相当します。「%北%道」とした場合、「北への道」、「北海道」、
「道北道」は一致しますが、「北海道地区」は一致しません。
例 SELECT * FROM table1 WHERE col2 LIKE '%北%道'
真理値 式、文字列式、またはエスケープ文字のいずれかがNULLである場合はUNKNOWNを返します。 式、および文字列式の両方が長さ0の文字列である場合は「真」を返します。 それ以外の場合、式を各部分に分解して比較します。各部分がパターン内の文字列と一致する場
合、または各部分が文字列式のエスケープ文字によって表されていて、式の各部分と文字列式内
のエスケープ文字が同じ順序で対応している場合、「真」を返します。 上記の条件のいずれにも当てはまらない場合は「偽」を返します。
ESCAPEを使 用 したメタ文
字自体の検索
メタ文字の%や_(アンダースコア)自体を検索する場合は、新たにエスケープ文字を指定して、検索
するメタ文字をエスケープします。 エスケープ文字には半角英数字記号の1文字だけ指定することができます。 また、ESCAPEキーワードに指定した文字の後には、ワイルドカードかESCAPEキーワードに指定した文
字以外は記述できません。
例 ' # ' をエスケープ文字に指定して、アンダースコアの両側に0個以上の文字列が続く
列col2の行を検索します。
SELECT * FROM foo WHERE col2 LIKE '%#_%' escape '#'
'¥'を指定してのESCAPEキーワードの代用は不可です。
' ¥'をESCAPEキーワードにしたい場合は明示的に指定してください。 例 SELECT * FROM foo WHERE col2 LIKE '%¥_%' escape '¥'
30
NOT LIKE 式 NOT LIKE % 文字列式[ESCAPE エスケープ文字] 式 NOT LIKE _ 文字列式[ESCAPE エスケープ文字]
メタ文字による文字列の部分一致検索(パターンマッチング)をおこない、抽出条件として指定した文
字列を含まない場合に「真」を返します。
IS NULL 値の存在しない状態、値が不定な状態を検索します。
NULLは、=では検索されません。
IS NOT NULL 値がNULLでない状態を検索します。
IS NOT NULLは、!=NULLでは検索されません。
論理演算子
論理演算子には次のものがあります。
NOT NOT a
「NOT」演算子はaが「真」であった場合は「偽」を返し、「偽」であった場合は「真」を返します。
AND a AND b
「AND」演算子はaとbの値がともに「真」であった場合に「真」を返し、それ以外の組み合わせの場合
は「偽」を返します。
OR a OR b
「OR」演算子はaとbの値のどちらかが「真」であった場合は「真」を返し、両方共に「偽」であった場合
は「偽」を返します。
集合演算子
集合演算子には次のものがあります。
集合演算子が使用できるのは、Enterprise Editionのみです。
UNION 複数のSELECT文を和結合し、そこから重複する行を削除したものを返します。 結合させるSELECT文の選択列リストは、数、型ともに同じである必要があります。
UNION ALL 複数のSELECT文を和結合し、そこから重複する行を削除せず、すべての行を取得します。 結合させるSELECT文の選択列リストは、数、型ともに同じでなくてはなりません。
INTERSECT 複数のSELECT文を積結合します。積集合では、それらの結果から同じものだけを抽出します。 結合させるSELECT文の選択列リストは、数、型ともに同じである必要があります。
EXCEPT 複数のSELECT文をその順番に差結合し、そこから重複する行を削除したものを返します。 結合させるSELECT文の選択列リストは、数、型ともに同じである必要があります。
MINUS 「EXCEPT」と同様です。

31
5 制約 データベースでは、データを正確に管理するために、データの整合性や一貫性を保持する必要があります。制約を使用することによって、
データの整合性を保つことができます。
制約
制約は、データベースに入力されるデータが満たされていなければならない条件を定義します。
制約には次の2種類があります。
列制約 列制約は列定義の一部として指定され、列のみに適用されます。複数の列にそれぞれ制約を設定
することができます。
表制約 表制約はテーブル定義として指定され、複数列に制約を設定します。制約には制約の名前をつける
必要があります。
CHECK制約(データを追加、更新する際の有効なデータを定義する規則)はサポートしていません。
CREATE TABLEを使用する際に制約を設定することもできますし、ALTER TABLEを使用して後から設定・変更・削除することが可能です。
CREATE TABLEについては、p.75を参照してください。ALTER TABLEについては、p.100を参照してください。
列制約
列制約には、次の種類があります。
NOT NULL制約 属性としてNULLを許可しないことを設定します。 許可する場合は「NULL」を列の型の次に記述します。省略した場合はNULLを許可することになりま
す。
UNIQUE制約 指定した列の値がテーブルの中で一意になるように、他の行に同じ値を持つことを拒否します。ただ
し、NULLはUNIQUE制約の対象ではないため、NULL値を持つ行は複数持つことができます。
デフォルト値の設定 列にデフォルト値を設定することができます。デフォルト値を指定した場合、INSERT時に値が指定さ
れない列にはデフォルトに設定されている値がINSERTされます。
Dr.Sum EA Ver3.0ではPRIMARY制約を列につけることはできません。単一列の場合はNOT NULL UNIQUE制約をつけてく
ださい。複数列に対して制約を付与する場合は、表制約を使用してください。
表制約
表制約には制約の名前をつける必要があります。その際、名前は既存の列名と重複しないように設定します。
表制約は、複数の列に対して一つの制約を付与したい場合に使用します。
単一の列に対して、表制約を指定することはできません。単一列の場合は列制約を使用してください。

32
NOT NULL UNIQUE制約 (COMPOUND KEY NOT NULLUNIQUE)
指定した複数列の値の組み合わせを一つの値とみなし、他の行に同じ値を持つことを拒否し、かつ、
NULL値を持つ行を許可しないことを設定します。 表制約として複数の列に一つのNOT NULL UNIQUEを設定することも可能です。
UNIQUE制約 (COMPOUND KEY UNIQUE)
列制約のUNIQUE制約が一つの列に対して一意となる値という制約であったのに対し、表制約の
UNIQUE制約は指定した複数列の値の組み合わせを一つの値とみなし、その値に対して一意という
制約になります。
例 表制約のUNIQUE(COL1,COL2) COL1 COL2
"00001" "00001"
"00001" "00002"
上記の例ではCOL1には同じ値が格納されていますが、COL2の値が異なっているので、COL1,COL2双方の列に対して一意になっています。
NOT NULL制約 (COMPOUND KEY NOT NULL)
列制約のNOT NULL制約が一つの列に対してNULL値を許可しないという制約であったのに対し、表
制約の場合は指定した複数列に対してNOT NULL制約をかけます。 この場合、指定したカラムのうち一つでもNULL値でなければ、NULL値とはみなされません。
COMPOUND KEYの設定 (COMPOUND KEY)
表制約を付与しない場合でも、COMPOUND KEYを設定することができます。 この場合、COMPOUND KEYは複数の列のJOINに対して使用されます。
表制約が指定されているテーブルの結合 表制約が指定されている列同士でJOINをすることができます。
その場合、JOINする制約に少なくとも一つCOMPOUND KEY NOT NULL UNIQUE制約があることが条件となります。
JOINを指定するには列名の代わりにその制約名を指定します。
制約を指定した時の列順に結合されます。
例 COMPOUND KEY NOT NULL UNIQUE と COMPOUND KEYで結合します。
CREATE TABLE foo1
( col1 varchar, col2 varchar, name varchar,
CONSTRAINT COMPOUND KEY pk(col1,col2) NOT NULL UNIQUE);
※CONSTRAINTは省略可です。
CREATE TABLE foo2
(col1 varchar,col2 varchar,data1 numeric(33,15), COMPOUND KEY fk(col1,col2));
表制約を使用した結合は次のようになります。
SELECT * from foo1,foo2 where pk = fk
33
制約とJOINについて
以下の2表が存在した場合、制約とJOINの関係は次のとおりです。
テーブルM テーブルF
C1 C1
C2 C2
区分 制約 結合条件 可否
単一列 列制約 テーブルM 以下の列制約をかける C1:NOT NULL UNIQUE テーブルF 列制約なし
M.C1 = F.C1 可
列制約 テーブルM 以下の列制約をかける C1:NOT NULL UNIQUE C2:NOT NULL UNIQUE テーブルF 列制約なし
M.C1 = F.C1 AND M.C2 = F.C2
否
(2表間で複数結合
条件は不可)
M.C1 = F.C1 AND M.C2 = F.C2
否
(2表間で複数結合
条件は不可)
表制約 テーブルM 以下の表制約をかける COMPOUND KEY PKEY(C1, C2): NOT NULL UNIQUE テーブルF 以下の表制約をかける COMPOUND KEY FKEY(C1, C2)
M.PKEY = F.FKEY
可
M.C1 = F.C1 AND M.C2 = F.C2
否
(2表間で複数結合
条件は不可)
複数列
列制約、表制約 テーブルM 以下の列制約、表制約をかける C1:NOT NULL UNIQUE C2:NOT NULL UNIQUE COMPOUND KEY PKEY(C1, C2): NOT NULL UNIQUE テーブルF 以下の表制約をかける COMPOUND KEY FKEY(C1, C2)
M.PKEY = F.FKEY
可

34
6 式 式とは、1つのデータ値を取得できる記号と演算子の組み合わせをいいます。単純式には、1つの定数、列、またはスカラー関数を指定で
きます。演算子を使用すると、2つ以上の単純式を結合して、複合式を作成することができます。
スカラー式(値式)
スカラー式は「1次子」(アトム、列参照、関数参照)に関する算術式です。この式には、前置演算子の+と-、中置演算子の+、-、*、/、を
使用できます。優先順位を指定するため、括弧を含むことも可能です。
構文は、次のようになります。
スカラー式 { 項
|スカラー式{"+"|"-"|"%"|"||"|"&"}項}
項 因子
|項{ * | / }因子}
因子 [+|-] 1次子
1次子 アトム
|関数参照
|列参照
|(スカラー式)
アトム パラメータ参照
|定数
列参照 [列修飾子. ] 列
関数参照 COUNT( * )
|DISTINCT関数参照
|ALL関数参照
DISTINCT関数参照 {AVG|MAX|MIN|SUM|COUNT|FIRST}
(DISTINCT 列参照)
ALL関数参照 {AVG|MAX|MIN|SUM|FIRST}
([ALL] スカラー式)
35
7 関数 この章では、Dr.Sum EAで使用できる関数について記載します。
集計関数
集計関数は、グループ内の行を対象として集計処理をおこなう関数です。グループはSELECT命令のGROUP BY句で指定されますが、こ
れを省略した場合は、テーブル全体が1つのグループとして扱われます。
グループ化する項目は、集計関数の後に指定することができます。 例 SELECT AVG(a), b FROM bar GROUP BY b
Dr.Sum EA Ver3.0では集計関数を集計関数2レベルまでネストさせることができます。この場合、GROUP BYしたキー項目はレベル1のみ
にかかります。
例 SELECT SUM(COUNT(col1)+col2)+SUM(COUNT(col2))
FROM test01 GROUP BY col2
集計関数には、次の関数が用意されています。各関数の集計可能なデータ型は次のようになります。
○:集計可 ×:集計不可
NUMERIC(OBJECT) INTERVAL CHAR / DATE /
TIMESTAMP / TIME
AVG ○ ○ ×
COUNT ○ ○ ○
MAX ○ ○ ○
MIN ○ ○ ○
SUM ○ ○ ×
FIRST ○ ○ ○
集計後の各関数の型と精度は次のようになります。
型 Precision Scale
AVG 精度なしのNUMERIC型 0 0
COUNT NUMERIC型 33 0
MAX 元カラムの型 元カラムのPrecision 元カラムのScale
MIN 元カラムの型 元カラムのPrecision 元カラムのScale
SUM 元カラムの型 33 元カラムのScale
FIRST 元カラムの型 元カラムのPrecision 元カラムのScale
※SUMの結果が33桁を超えた場合、上位から34桁目以降の値が丸められ、PrecisionとScaleは変動しません。
・ODBC、JDBCを経由する精度指定なしのNUMERIC型はDOUBLE型となります。
・ODBC、JDBCを経由するINTERVALのSUM、AVG、演算はVARCHAR(33, 0)となります。

36
AVG 平均値
書式 AVG ( [ DISTINCT |ALL ] n )
機能 グループ内の指定した列nの平均値を求めます。 戻り値の型は、常にNUMERIC型となります。
引数nを「DISTINCT」で修飾すると、nに対して重複を取り除いた状態で平均を計算します。「ALL」
を指定するとすべての値から平均を計算します。どちらも指定しない場合は「ALL」とみなします。
NULL値は無視されます。
Dr.Sum EA Ver2.×では「ALL」を明示的に指定することはできません。
例1 テーブル「bar」のa列の値に対する平均値を計算します。
SELECT AVG( a ) FROM bar
例2 テーブル「bar」のb列項目でグループ化したa列の値に対する平均値を計算します。
SELECT b, AVG( a ) FROM bar GROUP BY b
計算結果はNumeric型の 大桁数で表示されます。
COUNT 行数のカウント
書式 COUNT ( [ DISTINCT |ALL ] n )
機能 グループ内の行数を求めます。 対象となるテーブルのすべての行を得る場合は * を引数nに指定します。* を指定した場合は
NULLを含むすべての行が返ります。 引数nには列を指定することも可能です。この場合、指定された列の内容がNULL値であるものを除
いた行数が返ります。
引数nを「DISTINCT」で修飾すると、n列の内容で重複を取り除いた状態で行数を計算します。
「ALL」を指定するとすべての行数を計算します。どちらも指定しない場合は「ALL」とみなします。
Dr.Sum EA Ver2.×では「ALL」を明示的に指定することはできません。
例1 テーブル「bar」のNULLを含むすべての行数を計算します。
SELECT COUNT( * ) FROM bar
例2 テーブル「bar」のa列でNULLと重複を除いた行数を計算します。
SELECT COUNT( DISTINCT a ) FROM bar
例3 テーブル「bar」のb列項目でグループ化したa列のNULL以外の行数を計算します。
SELECT b, COUNT( a ) FROM bar GROUP BY b

37
MAX 大値
書式 MAX ( n )
機能 NULL値を除いたグループ内の 大値を求めます。GROUP BY句を指定しないSELECTではテーブ
ル全体が1グループとなります。 数値型、文字列型、日付型について 大値を求めることが可能です。 戻り値の型は、nと同じになります。
例1 テーブル「bar」のa列の 大値を計算します。
SELECT MAX( a ) FROM bar
例2 テーブル「bar」のb列項目でグループ化したa列の 大値を計算します。
SELECT b, MAX( a ) FROM bar GROUP BY b
MIN 小値
書式 MIN ( n )
機能 NULL値を除いたグループ内の 小値を求めます。GROUP BY句を指定しないSELECTではテーブ
ル全体が1グループとなります。
数値型、文字列型、日付型について 小値を求めることが可能です。 戻り値の型は、nと同じになります。
例1 テーブル「bar」のa列の 小値を計算します。
SELECT MIN( a ) FROM bar
例2 テーブル「bar」のb列項目でグループ化したa列の 小値を計算します。
SELECT b, MIN( a ) FROM bar GROUP BY b
SUM 合計値
書式 SUM ( [ DISTINCT |ALL ] n )
機能 グループ内の指定した列nの合計を求めます。 戻り値の型は、与えられた引数の型となります。
NULL値は無視されます。
引数nを「DISTINCT」で修飾すると、nに対して重複を取り除いた状態で合計を計算します。「ALL」
を指定するとすべての値の合計を計算します。どちらも指定しない場合は「ALL」とみなします。
Dr.Sum EA Ver2.×では「ALL」を明示的に指定することはできません。
例1 テーブル「bar」のa列の合計を計算します。
SELECT SUM( a ) FROM bar

38
例2 テーブル「bar」のb列項目でグループ化したa列の合計を計算します。
SELECT b, SUM( a ) FROM bar GROUP BY b
FIRST 初の値の検索
書式 FIRST ( n )
機能 GROUP BY句でグループ化した列nの 初の値(レコードの格納上においてGROUP BYされたレコード
格納後の 初の値)を返します。
NULL値は無視されません。 引数に他の関数をネストすることはできません。
例 テーブル「bar」のb列項目でグループ化したa列の 初の値を検索します。
SELECT b, FIRST( a ) FROM bar GROUP BY b
文字列操作関数
文字列操作関数は、文字や文字列を操作するための関数です。文字列操作関数には次のものがあります。
CHR 文字変換
書式 CHR ( n )
機能 ASCII文字コードnの文字を返します。
nは、9, 10, 32~127の範囲で指定します。
VARCHAR型を返します。
NULLの場合は、NULLを返します。
CONCAT 文字列の連結
書式 CONCAT ( a [, b] )
機能 文字列aに文字列bを連結したものを返します。この関数は連結演算子('||')と同等です。 文字列a、文字列b共に変更されることはありません。
VARCHAR型を返します。 いずれかの引数がNULLの場合は、NULLを返します。
INTERVAL型・数値型・日付型であっても文字列に変換されます。

39
INITCAP 頭文字を大文字にそれ以外を小文字に変換
書式 INITCAP ( string )
機能 文字列string内の各単語の 初の文字を大文字に、その他の文字を小文字にしたものを返しま
す。全角文字の場合も変換します。 この関数における単語は、下記で区切られた文字列をいいます。 空白 , . ; : /
VARCHAR型を返します。
NULLの場合は、NULLを返します。
例 INITCAP( 'GOOD morning') = 'Good Morning'
INITCAP( ' g o od morning') = 'G O Od Morning'
INITCAP( '123Days') = '123days'
INITCAP( 'A1B2C3D A1B2カタカナC3D') = 'A1b2c3d A1b2カタカナC3d'
INITCAP( 'G_O-O:D morning') = 'G_o-o:D Morning'
LCASE 小文字への変換
書式 LCASE ( string )
機能 文字列stringをすべて小文字に変換して返します。全角英文字も小文字に変換されます。
LOWER関数と同等です。
VARCHAR型を返します。NULLの場合は、NULLを返します。
LENGTH 文字数の取得
書式 LENGTH ( string )
機能 文字列stringの文字数を返します。 空白や記号、全角文字も1文字と数えます。
NUMERIC型を返します。
NULLの場合はNULLが返ります。
LENGTHB バイト数の取得
書式 LENGTHB ( string )
機能 文字列stringの長さをクライアントの文字符号(コーデック)に換算したバイト数で返します。
Dr.Sum EA Ver3.0ではすべてのデータをUTF-8で格納しますが、ここで返す数はクライアントのコー
デックに換算したバイト数です。
NUMERIC型を返します。
NULLの場合はNULLが返ります。
LOWER 小文字への変換
LCASEと同様です。

40
LPAD 左文字埋め
書式 LPAD ( string , length [ , padding_string ] )
機能 文字列stringの左に、padding_stringを埋め込んで、全体の桁数をlength桁にして返します。
padding_stringを省略した場合は、半角スペース1文字が指定されたものをみなします。
lengthは文字数ではなく桁数です。これはlengthがクライアントの文字符号(コーデック)に換算した
バイト数であることを意味します。
LPAD関数は、まずstringの長さがlength以下であるかどうかを調べます。
stringの長さがlength超の場合は、stringの右側を削除して、長さがlength以下となるように調整し
ます。この時、stringの length桁目が全角1バイト目であった場合は、当該全角文字も削除し、
stringの長さをlength-1桁に調整します。
次に、LPAD関数は、調整されたstringの左側にpadding_stringを埋め込みます。padding_stringは左側の文字から順に埋め込みに利用されます。1桁の埋め込みスペースに対して全角のpadding文字が該当した場合、当該padding文字は埋め込まれません。その結果、埋め込まれた文字列の
長さがlength-1桁となるため、LPAD関数は先頭に半角スペースを1文字追加して返すことになりま
す。
VARCHAR型を返します。
stringがNULLの場合は、NULLを返します。
LTRIM 左指定文字削除
書式 LTRIM ( string [ , set ] )
機能 文字列stringを左(先頭)からスキャンし、連続するsetに含まれる文字列を削除します。setに含ま
れない文字列が見つかった時点でスキャンを停止し、結果を返します。
setのデフォルトは1文字の半角スペースです。中間または右にある半角スペースを削除しません。
全角文字と半角文字、大文字と小文字をそれぞれ区別します。
VARCHAR型を返します。 すべての文字が除去された場合、結果は空になり、可変長ストリング(長さゼロ)が戻されます。
NULLの場合は、NULLを返します。
LTRIMのstringが空文字列で、かつsetがNULLでない場合は空文字列を返します。setがNULLの場
合はNULを返します。
LTRIMのsetが空文字列で、かつstringがNULLでない場合はstringを返します。stringがNULLの場
合はNULを返します。
例1 次のSQLの場合、結果として'a'を返します。
SELECT LTRIM ('aaa', 'aa') FROM __dw__
例2 次のSQLの場合、結果として'a'を返します。
SELECT LTRIM ('a', 'aaa') FROM __dw__

41
MID 文字列の抽出
書式 MID ( string , start [ , length ] )
機能 文字列stringのstart番目の文字からlength文字分の文字列を抽出して返します。
startが0の場合は1として扱います。
startが1以上の場合、stringの先頭から数えます。
startが-1以下の場合、stringの 後から数えます。
lengthを指定しない場合、start以降(以前)のすべての文字を返します。
lengthが0以下の場合、長さゼロのVARCHARを返します。
start、lengthに非整数値を指定した場合はエラーとなります。
VARCHAR型を返します。 引数のいずれかがNULLの場合は、NULLを返します。
例 SELECT MID('abcdefg', 3, 2) FROM __dw__;
→ 'cd'
SELECT MID('abcdefg', -3, 2) FROM __dw__;
→ 'ef'
REPLACE 文字列の置換
書式 REPLACE ( string , search_string [ , replacement_string ] )
機能 文字列stringから文字列search_stringを検索し、replacement_stringに変換して返します。
replacement_stringを指定しない場合、すべてのsearch_stringは削除されます。
VARCHAR型を返します。
stringがNULL場合、NULLを返します。
search_stringがNULLの場合、stringを返します。
replacement_stringがNULLの場合、すべてのsearch_stringは削除されます。

42
RPAD 右文字埋め
書式 RPAD ( string , length [ , padding_string ] )
機能 文字列stringの右に、padding_stringを埋め込んで全体の桁数をlength桁にして返します。
padding_stringを省略した場合は、半角スペース1文字が指定されたものをみなします。
lengthは文字数ではなく桁数です。これはlengthがクライアントの文字符号(コーデック)に換算した
バイト数であることを意味します。
RPAD関数は、まずstringの長さがlength以下であるかどうかを調べます。stringの長さがlength超
の場合は、stringの右左側を削除して、長さがlength以下となるように調整します。この時、stringの
length桁目が全角1バイト目であった場合は、当該全角文字も削除し、stringの長さをlength-1桁
に調整します。
次に、RPAD関数は、調整されたstringの右側にpadding_stringを埋め込みます。padding_stringは左側の文字から順に埋め込みに利用されます。1桁の埋め込みスペースに対して全角のpadding文字が該当した場合、当該padding文字は埋め込まれません。その結果、埋め込まれた文字列の
長さがlength-1桁となるため、RPAD関数は先頭に半角スペースを1文字追加して返すことになりま
す。
VARCHAR型を返します。 引数のいずれかがNULLの場合は、NULLを返します。
RTRIM 右指定文字削除
書式 RTRIM ( string [ , set ] )
機能 文字列stringを右(末尾)からスキャンし、連続するsetに含まれる文字列を削除します。setに含ま
れない文字列が見つかった時点でスキャンを停止し、結果を返します。
setのデフォルトは1文字の半角スペースです。中間または左にある半角スペースを削除しません。
全角文字と半角文字、大文字と小文字を区別します。
VARCHAR型を返します。すべての文字が除去された場合、結果は空になり、可変長ストリング (長
さゼロ) が戻されます。NULLの場合は、NULLを返します。
RTRIMのstringが空文字列で、かつsetがNULLでない場合は空文字列を返します。setがNULLの
場合は、NULを返します。
RTRIMのsetが空文字列で、かつstringがNULLでない場合はstringを返します。stringがNULLの場
合は、NULを返します。
例 次のSQLの場合、結果として'a'を返します。
SELECT RTRIM ('aaa', 'aa') FROM __dw__
次のSQLの場合、結果として'a'を返します。
SELECT RTRIM ('a', 'aaa') FROM __dw__

43
SUBSTR 文字列の抽出
MIDと同様です。
SUBSTRING 文字列の抽出
MIDと同様です。
TRIM 左右指定文字削除
書式 TRIM ( string [ , set ] )
機能 文字列stringを左右(前後)からスキャンし、setに含まれる文字列を削除します。setに含まれない
文字列が見つかった時点でスキャンを停止し、結果を返します。
setのデフォルトは1文字の半角スペースです。中間にある半角スペースを削除しません。
全角文字と半角文字、大文字と小文字をそれぞれ区別します。
VARCHAR型を返します。すべての文字が除去された場合、結果は空になり、可変長ストリング (長
さゼロ) が戻されます。NULLの場合は、NULLを返します。
TRIMのstringが空文字列で、かつsetがNULLでない場合は空文字列を返します。setがNULLの場
合は、NULを返します。
TRIMのsetが空文字列で、かつstringがNULLでない場合はstringを返します。stringがNULLの場
合は、NULを返します。
例 次のSQLの場合、結果として'a'を返します。
SELECT TRIM ('aaa', 'aa') FROM __dw__
次のSQLの場合、結果として'a'を返します。
SELECT TRIM ('a', 'aaa') FROM __dw__
UCASE 大文字への変換
書式 UCASE ( string )
機能 文字列stringをすべて大文字にして返します。全角英文字も大文字に変換されます。
UPPER関数と同等です。
VARCHAR型を返します。
NULLの場合はNULLを返します。
UPPER 大文字への変換
UCASEと同様です。

44
数値操作関数
数値操作関数は、数値を操作するための関数です。数値操作関数には次のものがあります。
ABS 絶対値
書式 ABS ( n )
機能 nの絶対値を返します。 戻り値の型は、NUMERIC型になります。
NULLの場合は、NULLを返します。
例 SELECT ABS(-3) FROM __dw__;
3
ACOS 逆コサイン
書式 ACOS ( n )
機能 nの逆コサインを返します。
戻り値の型は、常にNUMERIC型となります。
入力値nは、-1≦n≦1の範囲で、戻り値retは0≦ret≦πの範囲となります。
NULLの場合は、NULLを返します。
内部的に浮動小数点演算をおこなっているため、誤差が生じる可能性があります。
ASIN 逆サイン
書式 ASIN ( n )
機能 nの逆サインを返します。
戻り値の型は、常にNUMERIC型となります。
入力値nは、-1≦n≦1の範囲で、戻り値retは-π/2≦ret≦π/2の範囲となります。
NULLの場合は、NULLを返します。
内部的に浮動小数点演算をおこなっているため、誤差が生じる可能性があります。

45
ATAN 逆タンジェント
書式 ATAN ( n )
機能 nの逆タンジェントを返します。
戻り値の型は、常にNUMERIC型となります。
入力値nには範囲制限はありません。戻り値retは-π/2≦ret≦π/2の範囲となります。
NULLの場合は、NULLを返します。
内部的に浮動小数点演算をおこなっているため、誤差が生じる可能性があります。
ATAN2 逆タンジェント
書式 ATAN2 ( n, m )
機能 引数n、mに対する逆タンジェントを返します。
戻り値の型は、常にNUMERIC型となります。
入力値n、mには範囲制限はありません。
n,mどちらかがNULLの場合は、NULLを返します。
内部的に浮動小数点演算をおこなっているため、誤差が生じる可能性があります。
CEIL 小数点以下の切り上げ
書式 CEIL ( n )
機能 小数点以下の切り上げをおこないます(n以上の 小の整数を返します)。
戻り値の型は、常にNUMERIC型となります。
NULLの場合は、NULLを返します。
nが負の場合は、nの絶対値でみると切り捨てになります。
例 CEIL ( 1.5 ) = 2
CEIL ( -1.5 ) = -1
COS コサイン
書式 COS ( n )
機能 引数nに対するコサインを計算して返します。引数nにはラジアン単位で任意の数値を指定できま
す。
戻り値の型は、NUMERIC型です。
NULLの場合は、NULLを返します。
内部的に浮動小数点演算をおこなっているため、誤差が生じる可能性があります。

46
COSH 双曲線コサイン
書式 COSH ( n )
機能 引数nに対する双曲線コサインを計算して返します。
引数nにはラジアン単位で任意の数値を指定できます。
戻り値の型は、NUMERIC型です。
NULLの場合は、NULLを返します。
nの値により返す値がオーバーフローします。
内部的に浮動小数点演算をおこなっているため、誤差が生じる可能性があります。
EXP 指数関数値
書式 EXP ( n )
機能 引数nに対する指数関数値を返します。
eのn乗を計算します(e = 2.71828183…)。
戻り値の型は、NUMERIC型です。
NULLの場合は、NULLを返します。
内部的に浮動小数点演算をおこなっているため、誤差が生じる可能性があります。
FLOOR 大整数
書式 FLOOR ( n )
機能 小数点以下の切捨てをおこない、n以下の 大の整数を返します。
戻り値の型は、常にNUMERIC型となります。
NULLの場合は、NULLを返します。
nが負の場合は、nの絶対値でみると切り上げになります。
例 FLOOR ( 1.5 ) = 1
FLOOR ( -1.5 ) = -2
GREATEST 引数のうちの 大値
書式 GREATEST(引数1,引数2 [ , 引数3 , …. ])
機能 可変長の引数のうち、 も大きい値を返します。
引数には文字列や日付型を指定することができます。
引数にNULLが一つでも入ればNULLを返します。
自動型変換はおこなわれませんので、型は混在しないようにしてください。
引数すべてをNULLにすることは可能です(結果はNULLを返します)。

47
引数は10個まで動作を保証します。
LEAST 引数のうちの 小値
書式 LEAST(引数1,引数2 [ , 引数3 , …. ])
機能 可変長の引数のうち、 も小さい引数を返します。
引数には文字列や日付型を指定することができます。
引数にNULLが一つでも入ればNULLを返します。
自動型変換はおこなわれませんので、型は混在しないようにしてください。
引数すべてをNULLにすることは可能です(結果はNULLを返します)。
引数は10個まで動作を保証します。
LN 自然対数
書式 LN ( n )
機能 引数nの自然対数を返します。引数に0を与えることはできません。
返される値はNUMERIC型です。NULLの場合は、NULLを返します。
内部的に浮動小数点演算をおこなっているため、誤差が生じる可能性があります。
LOG 対数
書式 LOG ( n, m )
機能 mのnを底とする対数を返します。mに0を与えることはできません。
返される値はNUMERIC型です。n、mどちらかがNULLの場合は、NULLを返します。
nは1以外の正の実数になります。
mは正の実数になります。
内部的に浮動小数点演算をおこなっているため、誤差が生じる可能性があります。
POWER べき乗
書式 POWER ( n, m )
機能 nのm乗を計算して返します。
mが整数値の時も小数値のときも戻り値の型は、常にNUMERIC型となります。
第1引数が0の場合は第2引数に負の数を指定することはできません。
n、mどちらかがNULLの場合は、NULLを返します。
mが整数の場合 大精度で返します。
mが実数の場合、内部的に浮動小数点演算をおこなっているため誤差が生じる可能性があります。

48
ROUND 四捨五入
書式 ROUND ( n [ , m ] )
機能 小数点以下m桁を有効にして、値nを丸めた値を返します。mが省略された場合、m=0を仮定しま
す。
mに負の数を指定した場合、整数部での丸めがおこなわれます。
ROUND関数での丸めは、指定した桁位置m+1の桁位置で四捨五入します。
戻り値の型は、常にNUMERIC型となります。
n、mどちらかがNULLの場合は、NULLを返します。
第2引数のとりうる範囲は-1000≦m≦1000となります。
mに実数を入れた場合に小数部は切り捨てられます。
SIGN 引数の符号
書式 SIGN ( n )
機能 引数nの符号を返します。正の値の場合1、負の値の場合は‐1、0の場合は、0が返ります。
NULLの場合は、NULLを返します。
SIN サイン
書式 SIN ( n )
機能 引数nに対するサインを返します。引数nにはラジアン単位で任意の数値を指定できます。返される
値はNUMERIC型です。NULLの場合は、NULLを返します。
内部的に浮動小数点演算をおこなっているため、誤差が生じる可能性があります。
SINH 双曲線サイン
書式 SINH ( n )
機能 引数nに対する双曲線サインを返します。引数nにはラジアン単位で任意の数値を指定できます。返
される値はNUMERIC型です。NULLの場合は、NULLを返します。
nの値により返す値がオーバーフローします。
内部的に浮動小数点演算をおこなっているため、誤差が生じる可能性があります。
SQRT 平方根
書式 SQRT ( n )
機能 引数nに対する平方根を返します。引数nには負の値を指定することはできません。返される値は
NUMERIC型です。NULLの場合は、NULLを返します。
内部的に浮動小数点演算をおこなっているため、誤差が生じる可能性があります。

49
TAN タンジェント
書式 TAN ( n )
機能 引数nに対するタンジェントを返します。引数nにはラジアン単位で任意の数値を指定できます。返さ
れる値はNUMERIC型です。NULLの場合は、NULLを返します。
nの値により返す値がオーバーフローします。
内部的に浮動小数点演算をおこなっているため、誤差が生じる可能性があります。
TANH 双曲線タンジェント
書式 TANH ( n )
機能 引数nに対する双曲線タンジェントを返します。引数nにはラジアン単位で任意の数値を指定できま
す。返される値はNUMERIC型です。NULLの場合は、NULLを返します。
内部的に浮動小数点演算をおこなっているため、誤差が生じる可能性があります。
TRUNC 小数点以下の切り捨て
書式 TRUNC ( n [ , m ] )
機能 TRUNC関数は、小数点以下を切り捨てた値を返します。
小数点以下の何桁を有効にして切り捨てるかをmに指定できます。mには整数のみを指定します。
mを1とした場合は、小数点以下1桁を有効にするので、2桁目で切り捨てます。mが省略された場合
は小数点以下を切り捨てます。
mに負の数を指定した場合、整数部にさかのぼって切捨てをおこなうことができます。
戻り値の型は、常にNUMERIC型となります。
いずれかの引数がNULLの場合は、NULLを返します。

50
日付書式指定子
使用できる日付書式の指定子について記載します。
フォーマット(TO_CHAR)
'YYYY' 西暦年(4桁)
'YY' 西暦年下2桁
'MM' 月
'MONTH' 月(January, …, December)
'MON' 月(Jan, Feb, …,Nov, Decなど短縮形)
'DD' 日
'HH' 時(24時間制)
'HH24' 時(24時間制)
'HH12' 時(12時間制)
'MI' 分
'SS' 秒
'AM' AM
'PM' PM
'DAY' 曜日(Sunday、…,Saturday)
'DY' 曜日(Sun,Mon,Tue,Wed,Thu,Fri,Sat)
'WW' 第一週はその年の1月1で始まり1月7日で終了する
'DDD' 年初から通算の日
フォーマットを指定する際、大文字と小文字は区別しません。ただし、Amのように大文字と小文字を組み合わせて指定する
ことはできません。
第2引数にはフォーマットとデリミタ以外は記述できません。

51
フォーマット(TO_TIMESTAMP)
'YYYY' 西暦年(4桁)
'YY' 西暦年下2桁(1980~2079年)
'MM' 月
'DD' 日
'HH' 時(24時間制)
'HH24' 時(24時間制)
'HH12' 時(12時間制)
'AM' AM
'PM' PM
'MI' 分
'SS' 秒
'DDD' 年初から通算の日
AM/PMフォーマットは、HH12とセットで記述してください。
第2引数には、フォーマットとデリミタ以外は記述できません。
HHMISSのみを指定した場合は、その月初めが入ります。 例 2007/03/14に操作をおこなった場合
設定 SELECT TO_TIMESTAMP('12', 'HH') FROM __dw__;
結果 '2007/03/01 12:00:00'
フォーマット(TO_DATE)
'YYYY' 西暦年(4桁)
'YY' 西暦年下2桁(1980~2079年)
'MM' 月
'DD' 日
'DDD' 年初から通算の日
第2引数には、フォーマットとデリミタ以外は記述できません。 例 TO_DATE('001,','DDD'), TO_DATE('04',HH)
DDのみを指定した場合は、その月が入ります。 例 2007/03/14に操作をおこなった場合
設定 SELECT TO_DATE('05', 'DD') FROM __dw__;
結果 '2007/03/05
TIMESTAMP型にTO_DATEをおこなうと、時分秒の値を切り捨て、DATE型の値に変換します。

52
フォーマット(TO_INTERVAL)
'DD' 00
'HH' 00
'MI' 00
'SS' 00
第2引数には、フォーマットとデリミタ以外は記述できません。
フォーマット(TO_TIME)
'HH' 時(24時間制)
'HH24' 時(24時間制)
'HH12' 時(12時間制)
'AM' AM
'PM' PM
'MI' 分
'SS' 秒
AM/PMフォーマットは、HH12とセットで記述してください。
第2引数には、フォーマットとデリミタ以外は記述できません。

53
日付操作関数
日付操作関数は、日付・時刻を操作するための関数です。年、月、日、時、分、秒、曜日を取得する場合は、型変換関数(TO_CHAR関
数)を利用します。
例 WHERE DATECOL>='20010101'
ADD_MONTHS 月数の加算
書式 ADD_MONTHS(引数1, 引数2)
機能 基準とする日付に指定された月数を加算します。 第1引数には基準とする日付値を、第2引数には加算する月数を指定します。 第2引数に負の値を指定すると、減算ができます。 引数に小数は入力できません。 第1引数にはDATE型、TIMESTAMP型が指定できます。 第1引数の型を返します。 第1引数、第2引数どちらかがNULLの場合は、NULLを返します。
LAST_DAY 月の 終日
書式 LAST_DAY(引数)
機能 入力された日付を含む月の 終日を返します。日付値に時間がある場合は 終日+時間の値を戻
します。 引数には日付値を指定します。 引数にはDATE型、TIMESTAMP型が指定できます。 引数の型を返します。 引数がNULLの場合は、NULLを返します。
MONTHS_BETWEEN 月単位の差
書式 MONTHS_BETWEEN(引数1, 引数2)
機能 日付値を指定した第1引数と第2引数の月単位の差をNUMERIC型で返します。 引数が2つとも月の 終日の場合は、日にちは等しいものとして計算されます。 二つの引数の日にちの値が同じ場合は、HHMISSは無視されます。 第1引数, 第2引数ともにDATE型、TIMESTAMP型が指定できます。 上記以外の場合は、1ヶ月を31日として計算します。 第1引数、第2引数どちらかがNULLの場合は、NULLを返します。
例 設定1 例MONTHS_BETWEEN('2001/02/05', '2001/01/01')
結果 (2-1) + (5-1)/31 =1.12903225806451612903225806451613
設定2 MONTHS_BETWEEN('2001/02/05 12:34:56', '2001/01/05 0
0: 00:00')
結果 (2-1) =1
上記の場合は、日にちが同じなのでHH:MI:SSは無視されます。

54
NEXT_DAY 翌日
書式 NEXT_DAY(引数1, 引数2)
機能 基準となる日の次の指定した曜日の日付を返します。 第1引数には基準とする日付値を、第2引数には曜日を指定します。 曜日の形式は整数と文字列を取ります。 日曜日から土曜日までを1~7までの整数値を取ります。文字列の場合はアルファベットをとります。
アルファベットの場合は、はじめの3文字で返されます。 第1引数がNULLの場合は、第2引数にかかわらずNULLを返します。 第1引数にはDATE型、TIMESTAMP型が指定できます。 第1引数の型を返します。 第1引数、第2引数どちらかがNULLの場合は、NULLを返します。
ROUND 四捨五入
書式 ROUND ( date [ , format ] )
機能 日付型データをformatで指定した単位に丸めます。formatを指定しない場合は日単位で丸めま
す。
formatには書式指定キーワードのうちの一つを指定します。 丸める単位が月の場合は、月の15日以前は切り捨て、16日以降は切り上げ処理されます。対象月
が何月であっても、常に15/16日を丸め境界として処理します。 第1引数の型を返します。
date、formatどちらかがNULLの場合は、NULLを返します。
例 ROUND (TO_TIMESTAMP('2004/04/24'), 'MM' ) = 2004/05/01 00:00:00
INTERVAL型、TIME型には使用できません
SYSDATE 現在の日付時刻
書式 SYSDATE
機能 現在の日付、時刻を返します。YYYYMMDDHHMISSの形式で文字列を返します。
TIMESTAMP型への挿入にはそのままの形で使用できます。
DATE型やTIMESTAMP型への比較をおこなうときには、TO_CHAR関数を使用し型変換をおこなっ
てください。
TRUNC 切り捨て
書式 TRUNC ( date [ , format ] )
機能 日付型データをformatで指定された単位での切り捨てをおこないます。formatを指定しない場合
は、日単位で切り捨てをおこないます。 引数の型を返します。
INTERVAL型、TIME型には使用できません。
date、formatどちらかがNULLの場合は、NULLを返します。

55
変換関数
変換関数は、データを変換するための関数です。変換関数には次のものがあります。
COALESCE 初の引数
書式 COALESCE(引数1, [ , 引数2 , …. ])
機能 引数を複数持つことが可能で、NULL値でない 初の引数を返します。
引数がすべてNULLの場合は、NULLを返します。
DECODE 値の変換
書式 DECODE(式, 引数a, 引数b[, …][,デフォルト値])
機能 式を評価し、引数aの値を引数bの値に変換します。
どの値とも一致しなかった場合は、デフォルト値を返します。引数は可変長です。
デフォルト値のない場合は、NULLが返ります。
評価する値が同じ場合は、先に記述されている評価セットを優先します。
式と評価がNULLの場合は、条件の一致とみなします。
式と評価、結果において型の混在を許しません(自動型変換はおこないません)。
例1 COL1に[1],[2],[3]が入っている場合でデフォルト値がない場合
設定例 DECODE(COL1, 1, '男',2, '女')
結果 ['男'], ['女'] ,[NULL]
例2 COL1に[1],[2],[3]が入っている場合でデフォルト値がある場合
設定例 DECODE(COL1, 1, '男',2, '女','不明')
結果 ['男'], ['女'] ,['不明']
引数セットは10セットまで動作を保証します。
NULLIF 等しい場合にNULLを返す
書式 NULLIF(引数1, 引数2)
機能 2つの引数が等しい場合にNULLを返します。 等しくない場合は、第1引数を返します。
型の混在を許しません(自動型変換はおこないません)。

56
NVL NULL値の変換
書式 NVL(引数1, 引数2)
機能 NULL値を、指定した値に変換します。
第1引数にはNULL値である可能性がある値を、第2引数にはNULLの代わりに使用する値を指定し
ます。第1引数に指定した値がNULL値ではない場合は、そのまま第1引数の値が返されます。NULL値の場合は、第2引数で指定した値が返されます。
型の混在を許しません(自動型変換はおこないません)。
戻り値は第1引数の型を使用します。
型変換関数
型変換関数は、データ型を変換するための関数です。型変換関数には次のものがあります。
TO_CHAR 数値→文字列変換
書式 TO_CHAR('引数1' [, '引数2'])
機能 数値型の値を文字列に変換します。第1引数には文字列に変換したい式を、第2引数には変換
フォーマットを指定します。
第2引数を指定しない場合、変換した文字列をそのまま返します。
第1引数の整数部がフォーマットの整数部文字列を超えた場合は、#で埋められた文字列を返しま
す。#の数は、フォーマット+1文字[先頭のスペース]となります。
第2引数はリテラルのみになります。
第1引数、第2引数どちらかがNULLの場合は、NULLを返します。
フォーマット
, カンマを入れます。
カンマで始めたり、小数部をカンマにしたりすることはできません。
. ピリオドを入れます。
一つの数値に一つだけ指定可能です。
$ $を入れます。
数値の前にのみ表示することができます。
¥ ¥を入れます。
数値の前にのみ表示することができます。
0 数値を戻します。
整数部、小数部が0の場合は、0を返します。
9 数値を戻します。
整数部が0の場合は、空白を返し、小数部の場合は、0を返します。

57
例 設定例1 TO_CHAR(10123.45,'000,000.000')
結果 次の文字列が返ります。
010,123.450
設定例2 TO_CHAR(-3.85,'000')
結果 次の文字列が返ります。暗黙的なround等はおこないません。
-003
設定例3 TO_CHAR(-33.85,'0.00')
結果 次の文字列が返ります。暗黙的なround等はおこないません。
#####
TO_CHAR 日付→文字列変換
書式 TO_CHAR('引数1'[, '引数2'])
機能 日付型の値を文字列に変換します。
第1引数には文字列に変換したい式を、第2引数には変換フォーマットを指定します。
第2引数を指定しない場合、変換した文字列をそのまま返します。
第2引数はリテラルのみになります。
第1引数、第2引数どちらかがNULLの場合は、NULLを返します。
例 設定例1 TO_CHAR(TO_DATE('2004/05/31','YYYY/MM/DD'),'YY-MM-DD HH:MI:SS')
結果 次の文字列が返ります。
04-05-31 00:00:00
例 設定例2 TO_CHAR(TO_DATE('20050102','YYYYMMDD'),'DD MON YYYY WW HH:MI:SS
')
結果 次の文字列が返ります。
02 Jan 2005 01 00:00:00
TO_CHAR 期間→文字列変換
書式 TO_CHAR('引数1'[, '引数2'])
機能 期間型の値を文字列に変換します。
第1引数には文字列に変換したい式を、第2引数には変換フォーマットを指定します。
第2引数を指定しない場合、変換した文字列をそのまま返します。
第2引数はリテラルのみになります。
第1引数、第2引数ともにNULLの場合は、NULLを返します。
期間型を第1引数にとる場合は、第2引数のフォーマットにより小数値が返る場合があります。
NTERVALCOLの値が33日12時間23分41秒となっている場合

58
例 設定例1 TO_CHAR(INTERVALCOL,'DD HH:MI:SS')
結果 次の文字列が返ります。
33 12:23:41
設定例2 TO_CHAR(INTERVALCOL,'DD')
結果 次の文字列が返ります。
33.5164467592592592592592592592593
設定例3 TO_CHAR(INTERVALCOL,'DD SS')
結果 次の文字列が返ります。
33 44621
設定例4 TO_CHAR(INTERVALCOL,'DD SS:HH')
結果 次の文字列が返ります。
33 1421:12
TO_NUMERIC 文字列→数値変換
書式 TO_NUMERIC(引数1, [ 引数2 ])
機能 文字列型の値を数値に変換します。
第2引数には変換する際のフォーマットを指定することができます。
整数部、小数部ともに第1引数はフォーマットを超えないようにしてください。
整数部フォーマットが0の場合は、第1引数とフォーマットの桁数を揃える必要があります。
第2引数はリテラルのみになります。
第1引数、第2引数どちらかがNULLの場合は、NULLを返します。
例 設定例1 TO_NUMERIC ('10,123.45','00,000.00')
結果 次の数値を返します。
10123.45
設定例2 TO_NUMERIC('123','000')
結果 次の数値を返します。
123
設定例3 TO_NUMERIC('12','000')
結果 エラーになります。
TO_TIMESTAMP 文字列→日付変換
書式 TO_TIMESTAMP('引数1'[, '引数2'])
機能 文字列型の値を日付値に変換します。
第1引数には文字列に変換したい式を、第2引数には入力フォーマットを指定します。
戻される要素以外のフォーマットを指定することはできません。
戻り値はYYYY/MM/DD HH:MI:SSの形になります。
第2引数を省略する場合、第1引数はTIMESTAMP型カラムへのINSERTフォーマットで入力します。

59
デリミタ使用時は、第1引数と第2引数のデリミタを合わせてください。
第1引数、第2引数どちらかがNULLの場合は、NULLを返します。
戻り値のデリミタはServer Settingにより変わります。
例 設定例1 TO_TIMESTAMP('2004-12-24 13:44:00')
結果 2004/12/24 13:44:00
設定例2 TO_TIMESTAMP ('04/12/24')
結果 2004/12/24 00:00:00
設定例3 TO_TIMESTAMP ('2004-12-24 13:44:00')
結果 2004/12/24 13:44:00
設定例4 TO_TIMESTAMP('232004dec5906 58', 'hhyyyymonmidd ss')
結果 2004/12/06 23:59:58
設定例5 TO_TIMESTAMP ('30dec08', 'yymondd')
結果 2030/12/08 00:00:00
TO_DATE 文字列→日付変換
書式 TO_DATE('引数1'[, '引数2'])
機能 文字列型の値を日付値に変換します。
第1引数には文字列に変換したい式を、第2引数には入力フォーマットを指定します。
戻される要素以外のフォーマットを指定することはできません。
戻り値はYYYY/MM/DDの形になります。
第2引数を省略する場合、第1引数はDATE型カラムへのINSERTフォーマットで入力します。
デリミタ使用時は、第1引数と第2引数のデリミタを合わせてください。
第1引数、第2引数どちらかがNULLの場合は、NULLを返します。
戻り値のデリミタはServer Settingにより変わります。
例 設定例1 TO_DATE('2004-12-24')
結果 2004/12/24
設定例2 TO_DATE('04/12/24')
結果 2004/12/24
設定例3 TO_DATE('30dec08', 'yymondd')
結果 2030/12/08
TO_TIME 文字列→日付変換
書式 TO_TIME('引数1'[, '引数2'])
機能 文字列型の値を日付値に変換します。
第1引数には文字列に変換したい式を、第2引数には入力フォーマットを指定します。
戻される要素以外のフォーマットを指定することはできません。
戻り値はHH:MI:SSの形になります。

60
第2引数を省略する場合、第1引数はTIME型カラムへのINSERTフォーマットで入力されなければな
りません。
デリミタ使用時は、第1引数と第2引数のデリミタを合わせてください。
第2引数はリテラルのみになります。
第1引数、第2引数どちらかがNULLの場合は、NULLを返します。
戻り値のデリミタはServer Settingにより変わります。
例 設定例1 TO_TIME('13:44:00')
結果 13:44:00
設定例2 TO_TIME ('390658', 'mihhss')
結果 06:39:58
TO_INTERVAL 期間変換
書式 TO_INTERVAL(引数1, [ 引数2 ])
機能
型の値をINTERVAL式に変換します。第2引数には変換する際のフォーマットを指定することができ
ます。
第2引数はリテラルのみになります。
第1引数、第2引数どちらかがNULLの場合は、NULLを返します。
TO_COMPOUND COMPOUND KEYの検索
書式 TO_COMPOUND(引数1,引数2 [ , 引数3 , …. ])
機能 COMPOUND KEYの検索時に使用します。
第1引数にはCompoundKey名を入れます。
第2引数以下にCompoundKeyの生成時の列属性に対応するリテラル値を記述します。
第2引数以下にすべてNULLを指定した場合は内部ではNULLとして扱います。
Dr.Sum EAセッション関数
Dr.Sum EAセッション関数について記載します。
GET_USER_INFO ユーザ情報の取得
書式 GET_USER_INFO({ ID | NICKNAME | COMMENT | ENV1 | ENV2 | ENV3 | ENV4 })
機能 パラメータごとにログインユーザ情報を取得します。
パラメータ パラメータには次のものが用意されています。
ID ユーザIDを取得します。
NICKNAME ニックネームを取得します(Ver3.0SP1)。
COMMENT ユーザコメントを取得します。

61
ENV1 ユーザ環境変数1を取得します。
ENV2 ユーザ環境変数2を取得します。
ENV3 ユーザ環境変数3を取得します。
ENV4 ユーザ環境変数4を取得します。
GET_GROUP_INFOとは異なり、SELECTリストやGroup By内でも使用可能です。
GET_USER_INFOが定義されたビューを含むマルチビューの場合、マスタの情報を使用するか、スレーブの情報を使用する
かを選択することができます。設定はServer Settingsの[データベース]タブの[ユーザ情報をスレーブサーバに引き継ぐ]で
おこないます。詳細については、「Dr.Sum EA ユーザーズ・マニュアル サーバ編」を参照してください。
文字型以外のカラムに対してGET_USER_INFOを使用して環境変数を取得する場合、該当ユーザに環境変数が指定され
ていないとフォーマットエラーが発生します。
GET_GROUP_INFO グループの取得
書式 GET_GROUP_INFO({ ID | COMMENT | ENV1 | ENV2 | ENV3 | ENV4 })
機能 パラメータごとにログインユーザの所属グループ情報をリストで取得します。
パラメータ パラメータには次のものが用意されています。
COMMENT グループコメントを取得します。
ENV1 グループ環境変数1を取得します。
ENV2 グループ環境変数2を取得します。
ENV3 グループ環境変数3を取得します。
ENV4 グループ環境変数4を取得します。
返り値が複数になるため、SELECTリスト、Group By、Order By内でこの関数を使用することはできません。条件句内のin句
内などで使用します。
GET_GROUP_INFOが定義されたビューを含むマルチビューの場合、マスタの情報を使用するか、スレーブの情報を使用す
るかを選択することができます。設定はServer Settingsの[データベース]タブの[ユーザ情報をスレーブサーバに引き継ぐ]でおこないます。詳細については、「Dr.Sum EA ユーザーズ・マニュアル サーバ編」を参照してください。
文字型以外のカラムに対してGET_GROUP_INFOを使用して環境変数を取得する場合、該当グループに環境変数が指定
されていないとフォーマットエラーが発生します。
62
8 クエリとサブクエリ SQLではデータベースからデータを取り出すことをクエリと呼びます。クエリを実行する場合は、SELECT文を使います。
SELECT文の中に別のSELECT文を記述することによって、クエリの中で別のクエリを実行することができます。このように、クエリの中に埋め
込まれた(ネストした)クエリのことをサブクエリと呼びます。
基本構文
クエリの基本構文は、次のようになります。
SELECT [ALL|DISTINCT] 選択列リスト
FROM句
WHERE句
GROUP BY句
HAVING句
UNION or EXCEPT or INTERSECT
ORDER BY句
SELECT文については、p.66を参照してください。
サブクエリの使用例は次の通りです。
SELECT 列名 FROM テーブル名
WHERE 列名
比較演算子
(SELECT 列名 FROM テーブル名 [WHERE 検索条件] )
サブクエリの使用
サブクエリの使用について説明します。
選択列リストでのサブクエリ
選択列リストにサブクエリを記述することができます。ただし、記述する場合は、単一の値を返すSELECT文であることが条件となります。
例 SELECT (SELECT AVG(col1) from tab1) AS t_avg,c2,sum(c1) from tab group by c2;

63
FROM句でのサブクエリ
FROM句でサブクエリを使用することができますが、このサブクエリの中では、集計関数を使用する場合に集計項目に別列名称をかならず
指定する必要があります。
また、この句で指定するサブクエリは、括弧でくくり、別名をつけなければなりません。
例 SELECT * FROM (SELECT SUM(col1) as c1 FROM table1) a
WHERE句でのサブクエリ
条件設定において、関係演算子を使用する場合は、サブクエリの結果を1つだけ返すようにする必要があります。複数行の結果を返すと
エラーになります。
WHERE 列名 =(サブクエリ)
WHERE 列名 >(サブクエリ)
WHERE 列名 <(サブクエリ)
WHERE 列名 >=(サブクエリ)
WHERE 列名 <=(サブクエリ)
演算子とサブクエリ
複数の結果を返すサブクエリの場合は、IN / EXISTS / ANY / ALL演算子を使用します。
IN / EXISTS / ANY / ALL演算子は、サブクエリが返す複数の値に対して、「真」または「偽」の評価をおこないます。
サブクエリで返された値の集合を結果セットと呼びます。
IN演算子 結果セットのいずれかの値を評価対象とします。
関係演算子と共に用いられ、結果セットの値のいずれかが関係演算子の関係を満たす場合に
「真」、満たさない場合に「偽」を返します。サブクエリが生成する値(行)は複数でも構いません。
IN演算子は、値を評価する場合に関係演算子を用いません。
EXISTS演算子 結果セットの有無を評価します。
サブクエリが生成した値が1つ以上ある場合は「真」、存在しない場合は「偽」を返します。
NOT EXISTSとすると、サブクエリの中に値が1つも存在しない場合に「真」となります。
ANY演算子 結果セットのいずれかの値を評価対象とします。
関係演算子と共に用いられ、結果セットの値のいずれかが関係演算子の関係を満たす場合に
「真」、満たさなければ「偽」を返します。サブクエリが生成する値(行)は複数でも構いません。
SOME演算子もANY演算子と同様です。
ALL演算子 結果セットのすべての値を評価対象とします。
関係演算子と共に用いられ、結果セットの値のすべてが関係演算子の関係を満たす場合に「真」、
満たさなければ「偽」を返します。サブクエリが生成する値(行)は複数でも構いません。

64
HAVING句でのサブクエリ
GROUP BY句などを使用する集計クエリでは、サブクエリをHAVING句の検索条件に使うことができます。
例 SELECT col1, AVG(col3)
FROM table1 GROUP BY col1
HAVING AVG(col3) >
(SELECT AVG(col3)
FROM table1)
集計関数の使用
集計関数のSUM/COUNT/MIN/MAX/AVGも、サブクエリの中で使用することができます。
例 X.col2 * Y.col3の平均よりも大きい条件で検索します。
SELECT X.col5, X.col2 * Y.col3
FROM table1 X, table2 Y
WHERE X.col1 = Y.col2
AND X.col2 * Y.col3 >
(SELECT AVG (X.col2 * Y.col3)
FROM table1 X, table2 Y
WHERE X.col1 = Y.col2)
サブクエリのネスト
サブクエリの中にさらに別のサブクエリを埋め込む(ネストする)ことができます。

65
9 SQLコマンド Dr.Sum EA Ver3.0で使用できるSQLコマンドについて説明します。
SQLの機能分類
SQLはその機能により次の3つに分類されます。
データ操作言語(DML) データベースのデータの追加・更新・削除やデータの検索など、データを操作するための言語をデー
タ操作言語(DML)と呼びます。 これに属するSQL命令には次のようなものがあります。
SELECT データを検索します。
INSERT データを追加します。
UPDATE データを更新します。
DELETE データを削除します。
データ定義言語(DDL) テーブルの定義・作成など、データを定義するための言語をデータ定義言語(DDL)と呼びます。 これに属するSQL命令には次のようなものがあります。
CREATE オブジェクトを作成します。
ALTER オブジェクトの構造を変更します。
DROP オブジェクトを削除します。
TRUNCATE テーブル内データを削除します。
GRANT オブジェクトを操作する権限をユーザに付与します。
REVOKE ユーザに付与していたオブジェクト操作権限を取り消します。
データ制御言語(DCL) データベースのセキュリティやデータの整合性を維持するなど、データを制御するための言語をデー
タ制御言語(DCL)と呼びます。 これに属するSQL命令には次のようなものがあります。
COMMIT データの変更を確定します。
ROLLBACK データの変更を取り消します。
66
データ操作言語(DML)
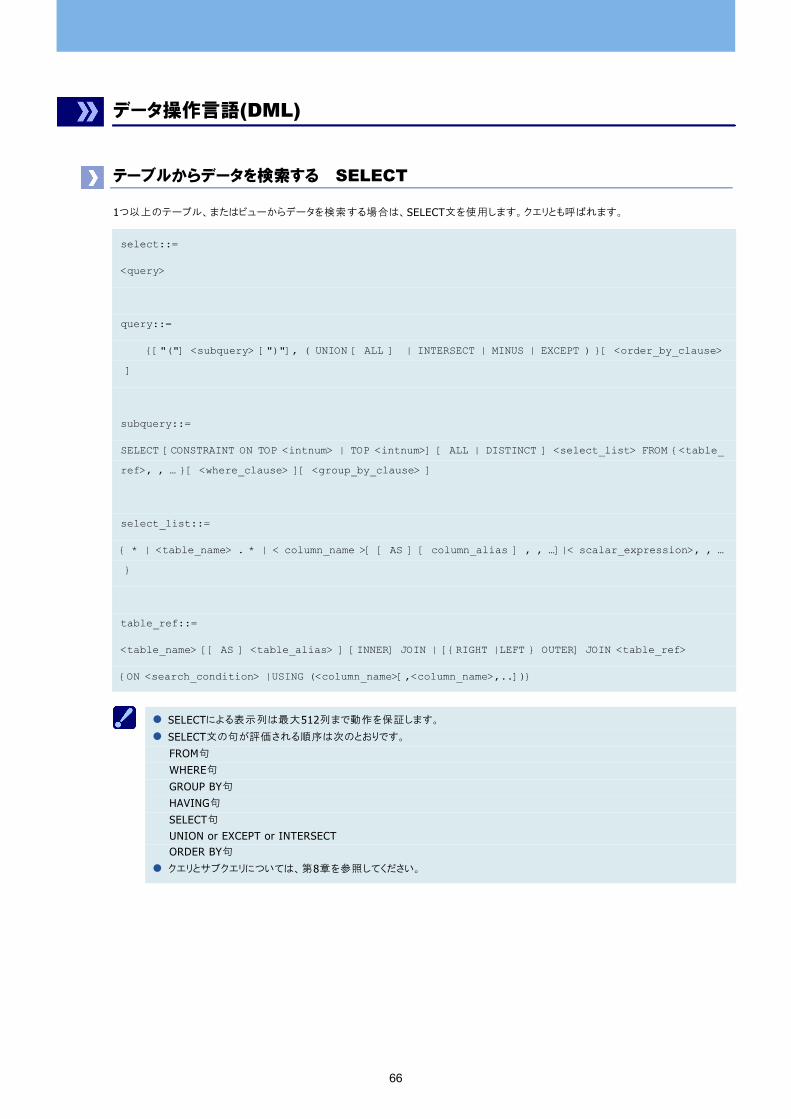
テーブルからデータを検索する SELECT
1つ以上のテーブル、またはビューからデータを検索する場合は、SELECT文を使用します。クエリとも呼ばれます。
select::=
<query>
query::=
{["("] <subquery> [")"], ( UNION [ ALL ] | INTERSECT | MINUS | EXCEPT ) }[ <order_by_clause>
]
subquery::=
SELECT [CONSTRAINT ON TOP <intnum> | TOP <intnum>] [ ALL | DISTINCT ] <select_list> FROM {<table_
ref>, , … }[ <where_clause> ][ <group_by_clause> ]
select_list::=
{ * | <table_name> . * | < column_name >[ [ AS ] [ column_alias ] , , …]|< scalar_expression>, , …
}
table_ref::=
<table_name> [[ AS ] <table_alias> ] [INNER] JOIN | [{RIGHT |LEFT } OUTER] JOIN <table_ref>
{ON <search_condition> |USING (<column_name>[,<column_name>,..])}
SELECTによる表示列は 大512列まで動作を保証します。
SELECT文の句が評価される順序は次のとおりです。
FROM句
WHERE句
GROUP BY句
HAVING句
SELECT句 UNION or EXCEPT or INTERSECT ORDER BY句
クエリとサブクエリについては、第8章を参照してください。

67
データに対して行制約をかける CONSTRAINT ON TOP指定 テーブルのデータに対して行制約をかける場合にCONSTRAINT ON TOPを指定します。<intnum>には制約をかけたい行数を指定しま
す。
例1 Table1に20行の行制約をかけます(先頭から20行)。
SELECT CONSTRAINT ON TOP 20 * FROM table1
指定した行数を戻す TOP指定 結果セットの先頭から、指定した行数だけ戻す場合にTOPを指定します。<intnum>には戻したい行数を指定します。
例1 SELECTの実行結果の先頭から20行を取得します。
SELECT TOP 20 * FROM table1
例2 下記SELECTの実行結果(ソートした後)の先頭から200行取得します。
SELECT TOP 200 a, b
FROM table1
ORDER BY a, b
すべての行を戻す ALL指定 重複行を含め、選択されたすべての行を戻す場合にALLを指定します。デフォルトはALLです。
重複行を1行だけ戻す DISTINCT指定 重複する行を1度だけ戻す場合にDISTINCTを指定します。
すべての列を選択する アスタリスク「*」 FROM句に指定されているすべてのテーブルとビューのすべての列を選択する場合に、アスタリスクを指定します。
結合時には、{<table_name> . *}のように特定のテーブルまたはビューの全列を指定することができます。
例1 Table1の全行を取得します。
SELECT * FROM table1
例2 table1とtable2を結合して、table1の全列とtable2のcol2列を取得します。
SELECT table1.*, table2.col2
FROM table1, table2
WHERE table1.col1=table2.col1

68
取り出す列/式を指定する select_list select_listには、データベースから取り出す列、または式を記述します。指定する列または式に別名をつけることができます。ここに指定さ
れた順番で結果を得ることができます。
テーブルに定義されていない列を指定した場合は、エラーとなります。
サブクエリを1列に一つだけ記述することができます。ただし単一の値を返すSELECT文であることが条件となります。
列の別名を指定する AS select_listの各値にはcolumn_alias(別名)を指定することができます。column_nameの後に、スペースで区切ってcolumn_aliasを記述
します。column_nameとcolumn_aliasを明示的にAS演算子でつなぐこともできます。
複数のテーブルに同じ名前の列名がある場合は、テーブルの名前でその列名を修飾する必要があります。それ以外の場合は、修飾した
列名はオプションになります。
別名に使用できる文字は、半角英数字、半角カナ文字、全角文字、半角下線(アンダースコア)、に限られます。ただし、半角数字とアン
ダースコアを、先頭の文字として利用することができません。
識別子については、「識別子」(p.9)を参照してください。
例1 SELECT col1 AS 番号, col2 AS 名前 FROM foo
例2 SELECT foo.col1, bar.col1
FROM table1 foo, table2 bar
WHERE foo.col2=bar.col3
テーブルの別名を指定する AS table_name(テーブル名)にtable_alias(別名)を指定することができます。
FROM句のtable_nameの後に、スペースで区切ってtable_aliasを記述します。table_nameとtable_aliasを明示的にAS演算子でつなぐ
こともできます。
別名に使用できる文字は、半角英数字、半角カナ文字、全角文字、半角下線(アンダースコア)、に限られます。ただし、半角数字とアン
ダースコアを、先頭の文字として利用することができません。
識別子については、「識別子」(p.9)を参照してください。
テーブルに別名をつけた場合、参照名に本来のテーブル名を使用することはできません。
例1 テーブル「foo」に別名x、テーブル「bar」に別名yをつけた場合
SELECT x.col1, y.col2 FROM foo x, bar y WHERE x.col1=y.col1
次の式は正しくありません。
× SELECT foo.col1, bar.col2 FROM foo x, bar y WHERE x.col1=y.col1
複数テーブルを指定する FROM句 「FROM句」には結果を取得したいテーブルを記述します。複数のテーブルを結合してSELECTしたい場合は、テーブル名を複数カンマで
区切って記述します。また、JOINを使用して結合条件をFROM句で指定することもできます。

69
テーブルを結合する テーブルを結合する場合、スキーマがスタースキーマ、またはスノーフレークスキーマであることを前提としています。そのため、結合の中
心となる「基準表」が決定可能であることが必須となります。
文法上正しいJOINであっても、外部結合のつけ方などにより基準表の決定ルールから外れる場合、JOINは失敗します。 基準表の決定ルールについては「第10章 Appendix 基準表の決定方法」(p.129)を参照してください。
テーブルの結合方法には、内部結合(INNER JOIN)と外部結合(OUTER JOIN)の2種類があります。
内部結合(INNER JOIN) 結合条件が成立する行だけを出力します。
外部結合(OUTER JOIN) 結合条件が成立するか否かにかかわらず、左側または右側のすべての行を出力します。 外部結合には ・LEFT [OUTER] JOIN ・RIGHT [OUTER] JOIN があります。 「table1 LEFT JOIN table2」とすると左側にあるtable1のすべての行を残し、「table1 RIGHT JOIN
table2」とすると右側にあるtable2のすべての行を残します。
Dr.Sum EAではFULL OUTER JOINをサポートしていません。
同一のテーブルを別々のテーブルとみなして結合することも可能です(自己結合)。ただし、かならずテーブルに別名をつける必要がありま
す。
FROM句で複数テーブルを結合し、結合条件を指定する FROM句にはテーブル同士の結合条件を記述することができます。条件式は、ON句、またはUSING句を続けて記載します。
内部結合のON句は抽出条件・結合条件の両方指定することができます。外部結合のON句に設定できるのは結合条件のみです。抽出
条件をつけることができません。抽出条件を指定する場合は、WHERE句に設定します。
例 FROM テーブル名1
{[INNER]|{LEFT|RIGHT}[OUTER]}
JOIN テーブル名2
ON テーブル名1.列名 = テーブル名2.列名
結合するテーブルに同名の列があり、その列を結合条件として指定する場合は、USING句に続けて括弧内に列名を指定することができ
ます。
例 FROM テーブル名1
{[INNER]|{LEFT|RIGHT}[OUTER]}
JOIN テーブル名2
USING(列名)
INNER JOINの場合は、INNERを省略してJOINと記述することができます。

70
3つ以上のテーブルを結合する 3つ以上のテーブルを結合する場合は、次のように記述します。
例 FROM テーブル1 JOIN テーブル2 JOIN テーブル3
ON テーブル2.COL1 = テーブル3.COL2
ON テーブル1.COL1 = テーブル2.COL1
WHERE句での複数テーブルの結合 テーブルを結合する場合は、FROM句に記述した結合するテーブル同士の関係をWHERE句に結合条件として記述します。
SELECT テーブル1.列名, テーブル2.列名
FROM テーブル名1, テーブル名2
WHERE テーブル名1.列名 {=|*=|=*} テーブル名2.列名
[AND 検索条件….]
WHERE句では結合条件に「=」「*=」「=*」の記号を使用します。
= INNER JOIN
*= LEFT [OUTER] JOIN
=* RIGHT [OUTER] JOIN
抽出条件を指定する WHERE句 WHERE句には行を選択する条件式を記述します。条件に合致する行だけを結果として返します。
where_clause::=
WHERE <search_condition>
条件式には、列のほか、演算子や関数やサブクエリを使った式を記述することができます。また、結合をおこなう場合は、テーブル同士の
関係を条件式として記述できます。ただし、WHERE句の中で集合関数を使うことはできません。
検索条件が複数ある場合は、ANDもしくはORに続けて条件式を記述します。
例1 SELECT col1, col2 FROM foo WHERE col1>100
データを並べ替える ORDER BY句 ORDER BYに続いて指定した列を基準に、データの並べ替えをすることができます。
order_by_clause::=
ORDER BY
{ <scalar_exp>[ ASC |DESC]
| <intnum>[ ASC |DESC]
|<table_name>[ . <column_name>][ ASC |DESC] }

71
並べ替えの種類に、昇順(ASC)または降順(DESC)を指定することができます。デフォルトは昇順です。
例 SELECT col1,col2,col3 FROM table1 ORDER BY col3 DESC
基準にする列を指定するには列名を記述するほか、<intnum>列番号を記述することもできます。列番号は1から始まる任意の整数値で、
この番号はselect_list (選択列リスト)に現れる順番に対応しています。
例 SELECT col1*col2,col3 FROM table1 ORDER BY 2 DESC
複数の列を並べ替えの基準に指定することができます。この場合は、ORDER BY句に続く列の並んでいる順に並べ替えられます。列名と
列番号を併記することも可能です。
例 SELECT col1,col2,col3 FROM table1 ORDER BY col3 DESC, 2
ORDER BY句を使用して並べ替えた結果を得る場合、基準となる列名(または式)がselect_list(選択列リスト)にない場合でも指定するこ
とができます。
例1 SELECT col1, COUNT(col2), SUM(col2)
FROM bar GROUP BY col1 ORDER BY AVG(col2)
例2 SELECT col1, COUNT(col2), SUM(col2)
FROM bar GROUP BY col1 ORDER BY AVG(col3)
例3 SELECT col1, col2 FROM bar ORDER BY col3
グループ別に集計する GROUP BY句 GROUP BY句を使用して、同じ列内で同じ値を持つデータごとに集合化することができます。scaler_expを指定する場合は、1つ以上の列
を含み、同じ値式が選択列リストに含まれていなければなりません。
group_by_clause::=
{ <having_clause> GROUP BY { <table_name>[ . <column_name>] ,
[scaler_exp] ….}
|GROUP BY { <table_name>[ . <column_name>] , ….} [ <having_clause>] }
例 SELECT col1,SUM(col2) FROM table1 GROUP BY col1
GROUP BYを使用する際に、グループ化の基準となる列名(または式)を、集計関数の後に記述することができます。
例 SELECT SUM(col2),col1 FROM table1 GROUP BY col1

72
集計結果を条件として絞込む HAVING句 GROUP BY句でグループ化された情報に対して条件を設定し、その条件を満たすデータだけを抽出することもできます。これにはGROUP
BY句でグループ化する列名を指定した後、HAVING句を続けて抽出条件を記述します。処理順序には変更がないため、GROUP BY句と
HAVING句を入れ替えて記述することができます。
having_clause::=
HAVING <search_condition>
WHERE句、GROUP BY句、HAVING句は、この順序で処理されます。そのためWHERE句とGROUP BY句を指定すると、検索条件が実行
されてからグループ化がおこなわれます。一方、GROUP BY句とHAVING句を指定すると、集計が行われてから検索条件が実行されま
す。
例 SELECT col1,SUM(col2)
FROM table1
GROUP BY col1
HAVING SUM(col2) >=50
HAVINGを使用する際、select_list(選択列リスト)にない集合関数を抽出条件に指定することができます。
例 SELECT col1,COUNT(col2)
FROM table1
GROUP BY col1
HAVING SUM(col3) >50
サブクエリ SELECT文の中に別のSELECT文を記述することによって、クエリの中で別のクエリを実行することができます。このように、クエリの中に埋め
込まれた(ネストした)クエリのことをサブクエリと呼びます。詳細については「第8章 クエリとサブクエリ」を参照してください。
SELECT <column_expressions> FROM [ <subqueries> ]
subquery::=
( SELECT [ALL|DISTINCT] <select_list> { <from_caluse>|[<where_clause>] | [<group_by_clause>])

73
データを追加する INSERT
既存のテーブルにレコードを追加する場合は、INSERT文を使用します。
INSERT INTO <table_name> VALUES ( … )
INSERT INTO <table_name> <subqueries>
<table_name> 操作対象となるテーブル名
VALUES ( … ) 追加するデータ
VALUESに続く括弧内に記述します。この場合、追加するテーブルの列の定義どおり列名が並んでい
る順に、対応する値を記述します。
NULL値を追加する場合は、NULLと指定します。ただし、NOT NULL指定の列に対しておこなうとエ
ラーになります。 あらかじめ列制約により入力できる値に制限があるような場合は、その制約に従う値を入力しなけれ
ばなりません。
列名を指定してデータを追加することもできます。 列名を指定した場合は、その列のみの値だけを追加することができます。指定しなかった列の値に
は、NULL値が入ります。ただし、NOT NULLが指定されている場合は、エラーになります。 列名を指定する場合の列名の記述順序は問われません。
<subqueries> サブクエリ
サブクエリを使用して、別テーブルに複数のデータを挿入することができます。 ただし、INSERT文を実行する前に、データコピー先のテーブルの列と、選択射影列が同じ定義・
データ型で作成済みである必要があります。
コピー元テーブルとコピー先テーブルに同じテーブルは指定できません。
INSERT INTO句に指定する列の数は、サブクエリから返される列の数と同じである必要があります。
例1 テーブル「table1」にデータを追加します。
INSERT INTO table1 VALUES ( value1, valule2, value3)
例2 テーブル「table1」に列「col1」と列「col3」に、それぞれデータ「value1」と「value2」を追加します。
INSERT INTO table1( col1, col3) VALUES ( value1, value2)
例3 テーブル「table2」にテーブル「table1」のすべてのデータをコピーします。
INSERT INTO table2 SELECT * FROM table1

74
データを変更する UPDATE
テーブルに登録されているデータを変更する場合は、UPDATE文を使用します。UPDATEは、WHERE句の検索条件を満たすすべての行
に対して、指定された列に指定された値を設定します。
UPDATE <table_name>
SET <column_name> =
{NULL|scalar_exp} [,<column_name> = {NULL|scalar_exp}]…] <where_clause>
UPDATE <table_name>
SET … WHERE <search_conditions>
例 col1列の値がxであるすべての行のcol2列の値をYに変更します。
UPDATE table1 SET col2 = 'Y' WHERE col1 = 'x'
複数の列を更新する場合は、<column_name>(列名) = {NULL|scalar_exp}(NULLまたは値)をカンマで区切って繰り返し記述するこ
とで、複数列を一度に更新することができます。
例 col1列の値がxであるすべての行において、col1列の値をZに変更し、col2列の値もYに変更します。
UPDATE table1 SET col2 = ' Y ', col1 = ' Z ' WHERE col1 = ' x '
次のように更新する値にサブクエリを記述することはできません。 例 UPDATE table1 SET col2 = ( SELECT MIN( col1 ) FROM table1 ) WHERE col1 = 2
データを削除する DELETE
テーブルに登録されているデータを削除する場合は、DELETE文を使用します。DELETEは行単位でデータを削除します。個別の列の値
を削除することはできません。
DELETEはWHERE句の検索条件を満たす行をテーブルから削除します。WHERE句を省略した場合は、すべての行を削除します。
すべての行を削除する場合は、TRUNCATE文を使用することもできます。
DELETE FROM <table_name> [where_clause]
WHERE句 特定行のデータを削除する場合は、WHERE句を記述します。WHERE句の検索条件を満たさない場合、行は削除されませんが、文法的
には正しいのでエラーにはなりません。
例1 テーブル「table1」内のすべての行を削除します。
DELETE FROM table1
例2 テーブル「table1」の列「col1」について、値が500より大きいすべての行を削除します
DELETE FROM table1 WHERE col1 > 500

75
データ定義言語(DDL)
テーブルを作成する CREATE TABLE
テーブルを作成する場合は、CREATE TABLE文を使用します。
SQLを発行するユーザは、データベースの書込み権限を持つグループに所属している必要があります。
CREATE TABLE <table_name>
{ (<column_def> [, <column_def> ….] [, <constraint>] )| AS < subquery > }
column_def::=
<column_name> <data_type> [ { <column_def_option> } ]
column_def_option::=
NOT NULL | UNIQUE |DEFAULT
Constraint::=
COMPOUND KEY <pk_name>
(<column_name >,<column_name > [, < column_name > ….])
[ UNIQUE | NOT NULL UNIQUE | NOT NULL | NULL ]
SELECT文を利用して作成することも可能です。
CREATE TABLE <table_name> [<column_name_list>] AS SELECT…
列数 合計512個まで定義できます。ビューも同様です。
権限 テーブルへのアクセスは、そのテーブルへのアクセス権限を付与されたグループだけがおこなうことが
できます。同様に列へのアクセスは列へのアクセス権限が付与されているグループだけがおこなうこと
ができます。 詳細については、「GRANT」(p.120)を参照してください。

76
列の定義 列定義(<column_def>)のデータ型(<data_type>)には次の型を定義することができます。
<data_type>::=
{ { VARCHAR | CHAR |VARYING CHARACTER} [ (length) ]
| { INTEGER | INT | SMALLINT | TINYINT }
| { REAL| FLOAT |DOUBLE }
| NUMERIC | DECIMAL [ (precision [, scale]) ]
| DATE
| INTERVAL
| OBJECT
}
例1 次の列からなるテーブル「foo」を作成します。 列a INT型 列b VARCHAR型、データサイズ20
CREATE TABLE foo(a INT, b VARCHAR(20))
例2 次の列からなるテーブル「bar」を作成します。 列a REAL型 列b NUMERIC型、データ精度4、スケール2
CREATE TABLE bar(a REAL, b NUMERIC(4, 2))
データ型については、「第3章 データ型」(p.13)を参照してください。
列制約の設定 テーブルには複数の列を作成することができ、それぞれに制約を設定することができます。
■ NOT NULL制約 列には、属性としてNULLを許可するか否かを設定することが可能です。NULLを許可しない場合は「NOT NULL」を、許可する場合は、
「NULL」を列の型の次に記述します。省略した場合は、NULLを許可することになります。
例 次の列からなるテーブル「foo」を作成します。 列a INT型 列b INT型、NOT NULL
CREATE TABLE foo (a int, b int NOT NULL)

77
■ UNIQUE制約 指定した列の値(または列の組み合わせ)がテーブルの中で一意になるように、他の行の同じ値の設定を拒否します。NULLはUNIQUE制
約の対象ではないため、NULL値を持つ行が複数あっても制約違反にはなりません。
例 次の列からなるテーブル「foo」を作成します。 列a INT型 列b INT型、UNIQUE
CREATE TABLE foo (a int, b int UNIQUE)
■ デフォルト値の設定 列にデフォルト値を設定することができます。デフォルト値を指定した場合、INSERT時に値が指定されない列にはデフォルトに設定されて
いる値がINSERTされます。
例 次の列からなるテーブル「foo」を作成します。 列a INT型 列b INT型、NOT NULL デフォルト値16
CREATE TABLE foo (a int, b int not null DEFAULT 16)
制約については、「第5章 制約」(p.31)を参照してください。
テーブルをコピーする サブクエリを使用してテーブルをコピーすることもできます。
CREATE TABLE <table_name>[ (<column_name>,…) ]
AS SELECT <statement>
<table_name> 作成するテーブル名
<column_name> 使用する列名を任意数記述します。
基になるテーブル内の列名を保持したくない場合は、<column_name>を指定します。ただし、次の
条件が該当する場合は、常に列に別名をつけなければなりません。 ・列のいずれか2つが同一の名前を持つ場合。
・クエリ内でAS句を使用して列に名前を割り当てた場合を除き、いずれかの列に計算値、または基に
なるテーブルから直接抽出した以外の値が含まれる場合。
列に別名をつける場合は、すべての列に別名をつけなければならず、<column_name>の数と、
SELECT句の列の数が同じでなければなりません。
AS句に続けてSELECT句を記述します。このクエリの結果がコピーされるテーブルのデータになりま
す。
クエリ内で列をすべて選択するためにはSELECT * を使用できます。この場合、内部ですべての列のリストに変換されます。
例 CREATE TABLE mytable (myname, mydef, myprice)
AS SELECT foo.name1, bar.def, foo.price*1.15
FROM table1 foo, table2 bar
WHERE foo.cord1 = bar.cord1

78
リンクテーブルを作成する
他のデータベース内に存在するテーブルを、別のデータベースから参照することができます。これを「リンクテーブル」と呼びます。
異なるデータベース上に同一のテーブルを作成したい場合、リンクテーブルを利用すれば、データベースごとに同じ内容のテーブルを作成
する必要がありません。リンクテーブルは、ビューを構成するテーブルとしても使用することが可能です。
参照できるのは、同一Dr.Sum EAサーバ内に保存されているデータベース間のみです。
リンクテーブルのリンク元となるオブジェクトはテーブルのみです。ビュー・マルチビュー・リンクテーブルにはリンクできません。
DROP TABLEをするとリンク情報のみ削除されリンク先のテーブルには影響しません。
リンクテーブルに対して、ALTER TABLEは実行できません。
INSERT、UPDATE、DELETEはできません。
テーブルを作成する場合は、CREATE LINK TABLE文を使用します。
CREATE LINK TABLE <table_name> FROM <link_table_name>@<linkdb>
<table_name> 作成するリンクテーブル名
<link_table_name> リンク先のテーブル名
<linkdb> リンク先テーブルが含まれるデータベース名
リンクテーブルを削除する場合は、通常のテーブルと同じようにDROP TABLE <table_name>を使用します。
検索インデックスを作成する CREATE INDEX
検索インデックスを作成する場合は、CREATE INDEX文を使用します。
Administratorsグループに所属するユーザのみが実行できます。
CREATE INDEX <index_name> ON <table_name>( <column_name> )
<index_name> 作成するインデックス名 検索インデックス名は、データベース内で一意である必要があります。
<table_name> 対象とするテーブル名 システムテーブル、ビュー、マルチビュー、ディストリビュータ、リンクテーブルは指定できません。
<column_name> 対象とするカラム名
例1 検索インデックス「tab_idx」を作成します。
CREATE INDEX tab_idx ON tab1 (col1)

79
結合インデックスを作成する CREATE JOIN INDEX
結合インデックスを作成する場合は、CREATE JOIN INDEX文を使用します。
Administratorsグループに所属するユーザのみが実行できます。
CREATE JOIN INDEX <index_name> ON <table_name>( <column_name> )REFERENCES <table_name> ( <column
_name> )
<index_name> 作成するインデックス名 結合インデックス名は、データベース内で一意である必要があります。
ON句の後
<table_name> 対象とするテーブル名 システムテーブル、ビュー、マルチビュー、ディストリビュータ、リンクテーブルは指定できません。
<column_name> 対象とするカラム名
REFERENCES句の後
<table_name> 結合先のテーブル名 システムテーブル、ビュー、マルチビュー、ディストリビュータ、リンクテーブルは指定できません。
<column_name> 結合先のカラム名
例1 結合インデックス「tab_join_idx」を作成します。
CREATE JOIN INDEX tab_join_idx ON tab1 (col1) REFERENCES tab2(col2)

80
ビューを作成する CREATE VIEW
ビューは、データベース上に実際存在するテーブル(実テーブル)の内容をSELECT命令によって仮想テーブルとして参照する機能です。
テーブルはデータを格納して保存するために、ディスク容量を必要としますが、ビューは定義のみ保持します。ビューの内容を取得する
SQL文が発行されると、定義されたSELECT文によるクエリが実行され、実テーブルから必要なデータが抽出されます。頻繁に要求される
SELECT文をビューとして作成しておくことによって、ユーザ側での処理を簡略することや、ユーザのデータ操作を制限するができます。
ビューを作成する場合、CREATE VIEW文を使用します。
CREATE VIEW <table_name>[ (<column_name>,…) ]
AS SELECT statement
SQLを発行するユーザはビュー定義を変更できる権限を持っている必要があります。
CREATE VIEW文は、65536文字以内で記述してください。
<view_name> 作成するビュー名
<column_name> ビューで使用する列名 使用する列名を任意数記述します。ビューの基になるテーブル内の列名を保持したくない場合は、
<column_name>を指定します。ただし、次の条件が該当する場合は、常に列に別名をつけなけれ
ばなりません。
・列のいずれか2つが同一の名前を持つ場合。 ・クエリ内でAS句を使用して列に名前を割り当てた場合を除き、いずれかの列に計算値、または基に
なるテーブルから直接抽出した以外の値が含まれる場合。
列に別名をつける場合は、すべての列に別名をつけなければならず、<column_name>の数と、
ビューに含まれるクエリのSELECT句の列の数が同じでなければなりません。
AS句に続けてSELECT句を記述します。このクエリの結果がビューのデータになります。このSELECT句の中ではUNION演算子、TOP句、CONSTRAINT ON TOP句、ORDER BY句は使用できません。
クエリ内で列をすべて選択するためにはSELECT * を使用できます。この場合、内部ですべての列のリストに変換されます。
例1 CREATE VIEW myview (myname, mydef, myprice)
AS SELECT foo.name1, bar.def, foo.price*1.15
FROM table1 foo, table2 bar
WHERE foo.cord1 = bar.cord1
例2 CREATE VIEW V1(name1,name2)
AS SELECT SUM(a), b
FROM foo GROUP BY b

81
ビューを参照作成する 既存のビューをもとに、別のビューを作成することができます。
例 CREATE VIEW testview
AS SELECT *
FROM myview
WHERE myprice > 10000
参照作成する場合は、3階層まで動作を保証します。
ビューに対するクエリ 作成したビューに対するクエリに対し、集合演算をおこなったり、実テーブルに対するクエリの場合と同じようにORDER BY句、GROUP BY
句、HAVING句などを使って出力結果を制御したりすることができます。
ビューの元テーブルが重複していてもJOINが可能です。
例 SELECT myname, MAX(myprice)
FROM myview
GROUP BY myname
HAVING MAX(myprice) >=20000
ビューの検索 ビューはテーブルと同じように検索できます。ただし、ビューの結合(テーブル、またはビュー同士)もテーブルの場合の制限と同じになります。
そのため、ビュー列がNOT NULL UNIQUEである必要があります。元テーブルの列をそのまま参照していれば、ビューの列はNOT NULL
UNIQUEになります。
計算式や集約が入っている列は結合条件として使用できません。
ビューがNOT NULL UNIQUEであるかどうかは、SQLでは確認できません。Enterprise Managerを使用して、ビューのプロパティを参照して
確認します。
ビュー列が計算式の場合の結合式はJOIN式とは見なされず、通常の検索条件式として判断されます。
例 次の場合、JOIN式と見なされるのは a.col2 = b.col2のみです。a.col1 = b.col1は通常の
検索条件式として扱われます。
CREATE VIEW vfoo as SELECT col1 + 1 as col1,col2 from tfoo;
--col2はNOT NULL UNIQUE
SELECT a.col1 From vfoo a,vfoo b where a.col1 = b.col1 and a.col2 = b.c
ol2;
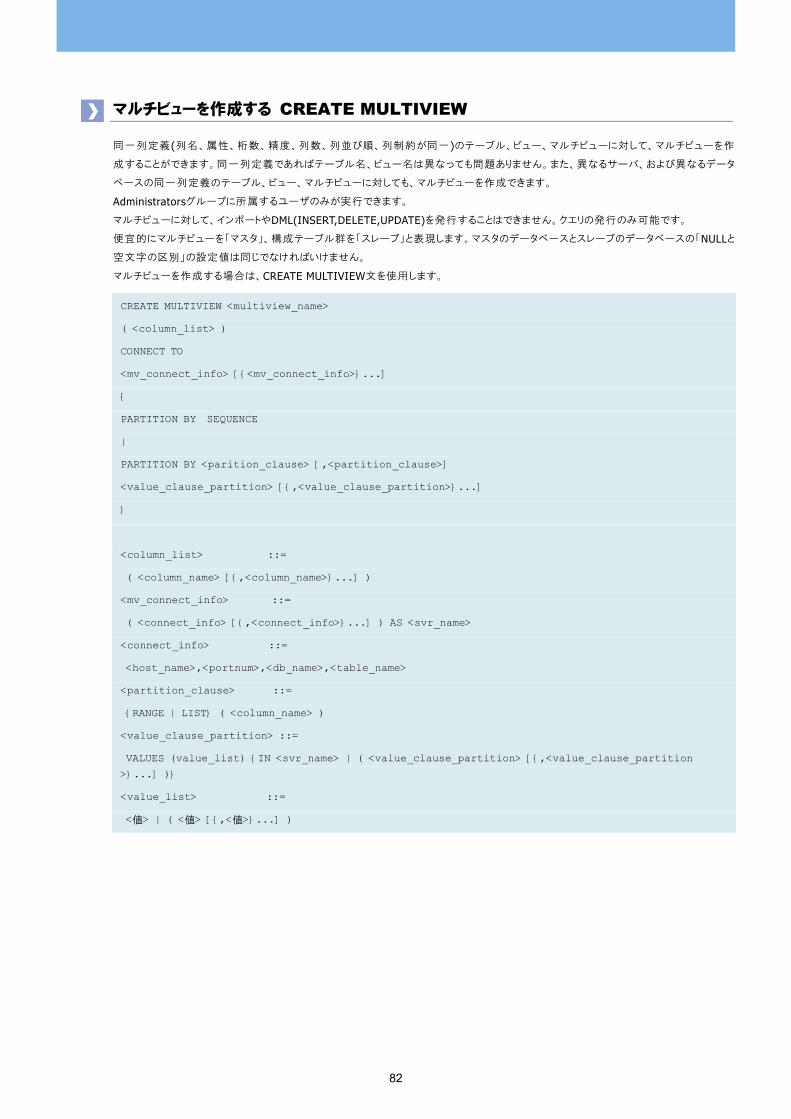
82
マルチビューを作成する CREATE MULTIVIEW
同一列定義(列名、属性、桁数、精度、列数、列並び順、列制約が同一)のテーブル、ビュー、マルチビューに対して、マルチビューを作
成することができます。同一列定義であればテーブル名、ビュー名は異なっても問題ありません。また、異なるサーバ、および異なるデータ
ベースの同一列定義のテーブル、ビュー、マルチビューに対しても、マルチビューを作成できます。
Administratorsグループに所属するユーザのみが実行できます。
マルチビューに対して、インポートやDML(INSERT,DELETE,UPDATE)を発行することはできません。クエリの発行のみ可能です。
便宜的にマルチビューを「マスタ」、構成テーブル群を「スレーブ」と表現します。マスタのデータベースとスレーブのデータベースの「NULLと
空文字の区別」の設定値は同じでなければいけません。
マルチビューを作成する場合は、CREATE MULTIVIEW文を使用します。
CREATE MULTIVIEW <multiview_name>
( <column_list> )
CONNECT TO
<mv_connect_info> [{<mv_connect_info>}...]
{
PARTITION BY SEQUENCE
|
PARTITION BY <parition_clause> [,<partition_clause>]
<value_clause_partition> [{,<value_clause_partition>}...]
}
<column_list> ::=
( <column_name> [{,<column_name>}...] )
<mv_connect_info> ::=
( <connect_info> [{,<connect_info>}...] ) AS <svr_name>
<connect_info> ::=
<host_name>,<portnum>,<db_name>,<table_name>
<partition_clause> ::=
{RANGE | LIST} ( <column_name> )
<value_clause_partition> ::=
VALUES (value_list) {IN <svr_name> | ( <value_clause_partition> [{,<value_clause_partition
>}...] )}
<value_list> ::=
<値> | ( <値> [{,<値>}...] )

83
CONNECT句 CONNECT句の<mv_connect_info>では、スレーブへの接続情報を記載します。
CONNECT TO
<mv_connect_info> [{<mv_connect_info>}...]
接続情報には、次の情報が含まれます。
コンピュータ名、ポート番号、データベース名、テーブル、またはビュー名、またはマルチビュー名
コンピュータ名はシングルクォート「'」でくくります。
接続情報には、明示的に別名を付与しなければなりません。この別名をサーバグループと言います。サーバグループは 大30文字です。
複数の接続情報をまとめて1つのサーバグループとして付与することが可能です(Enterprise Managerでは複数の接続情
報を同じサーバグループ名で設定し、連続表示させることで定義可能となります)。
CONNECT句でサーバグループは重複してはいけません。一意に付与してください。
PARTITION BY句 PARTITION BY句は順序型と条件型の2種類に分類されます。
条件型マルチビューを作成すると、マルチビューへのクエリ発行時WHERE句の内容から該当するサーバグループを絞り込んで結果を得る
ことが可能です。これをクエリ 適化といいます。順序型では、クエリ 適化は実施されません。
PARTITION BY句の列名には、どの列のデータをしきい値として分割するかを指定します。この列のことを分割列と言います。
分割列はNOT NULL制約が作成されている列のみ指定可能です。
順序型 PARTITION BY SEQUENCE
条件型 PARTITION BY RANGE(列名)
PARTITION BY LIST(列名)
順序型にVALUES句は指定できません。
条件型は2階層まで定義可能です。ただしレンジ-リスト、レンジ-レンジ、リスト-リスト、リスト-レンジの4種類であり、順序型との混在はでき
ません。
便宜的に第1階層を「親」、第2階層を「子」、同じ親を持つ子の集合を「兄弟」と表現します。
例 PARTITION BY RANGE(COL1),LIST(COL2)
PARTITION BY RANGE(COL1),RANGE(COL2)
PARTITION BY LIST(COL1),LIST (COL2)
PARTITION BY LIST(COL1),RANGE(COL2)
条件型のVALUES句には「どのテーブル、ビューにどのような値のデータが格納されているか」を表す値を記述します。これを分割条件値
といいます。分割条件値には関数や算術の実施はできません。
レンジのVALUES句には格納されているデータの非包括的上限値(指定値を含まない、つまり指定値未満のデータが格納されているこ
と)を記述し、サーバグループと対応付けます。
レンジのVALUES句の記載順番は、分割条件値の昇順でなければいけません。
レンジのVALUES句で非包括的上限値が未定の場合、直前に指定したレンジ値から無限大までを表す「その他」のレンジを定義できま
す。この場合VALUES句の括弧には値を指定しません。

84
例 SV1には売上日付が2007/01/01未満のデータ、SV2には売上日付が2008/01/01未満のデータ、
SV3には売上日付が2007/01/01以上のデータが格納されています。
PARTITION BY RANGE(売上日付)
VALUES('2007/01/01') IN SV1,
VALUES('2008/01/01') IN SV2,
VALUES() IN SV3
リストのVALUES句には格納されているデータの値を記述し、サーバグループと対応付けます。リストのVALUES句には値リストを記述する
ことが可能です。Enterprise Managerで定義する時には、値リストは記述できません。
リストのVALUES句で値が未定の場合、先に列挙したリスト値以外を表す「その他」のリストを定義できます。この場合VALUES句の括弧に
は値を指定しません。
例 SV1には地区が北海道または東北のデータ、SV2には地区が関東のデータ、SV3には地区が{北海
道,東北,関東}以外のデータが格納されています。
PARTITION BY LIST(地区)
VALUES('北海道','東北') IN SV1,
VALUES('関東') IN SV2,
VALUES() IN SV3
CONNECT句で指定したサーバグループは、すべてVALUES句で対応付けされている必要があります。
VALUES句におけるサーバグループの対応付けは、 下位層で記述します。
2階層の場合は、2階層目のVALUES句でサーバグループの対応付けを記述します。
CONNECT句で指定したサーバグループは、VALUES句で複数回指定できます。
例 SV1には地区が北海道のデータ、SV1には地区が北海道のデータ、SV2には地区が{北海道,東北}以外のデータが格納されています。
PARTITION BY LIST(地区)
VALUES('北海道') IN SV1,
VALUES('東北') IN SV1,
VALUES() IN SV2
VALUES句において、同じ親を持つ同一階層の集合の中で分割条件値は重複してはいけません。
例1 作成エラー:1階層のとき
PARTITION BY LIST(地区)
VALUES('北海道') IN SV1,
VALUES('東北') IN SV1,
VALUES('北海道') IN SV2 ← '北海道'が重複エラー

85
例2 作成エラー:2階層のとき
PARTITION BY RANGE(売上日付),LIST(地区)
VALUES('2007/01/01')
(
VALUES('北海道','東北') IN SV1,
VALUES('北海道') IN SV2 ← 同じ親を持つ同一階層中で'北海道'が重複エラー。
),
VALUES('2008/01/01')
(
VALUES('北海道','東北') IN SV3, ← 親が異なるのでここはエラーとなりません。
VALUES('関東') IN SV4
)
マルチビューに対してビューを作成することができます。
マルチビューは永続RSの対象外です。
マルチビュー定義の作成・変更時、分割定義に基づく既存格納データの再編成は実施しません。
既存格納データが分割定義と合致しているか否かは、Enterprise Managerの「データのチェック」機能で確認することができます。
マルチビューを構成する各テーブル、ビューへ分割定義に合致しないデータがインポートやDMLにて挿入・更新されても、リアルタイムに
チェックする機能はありません。
マルチビューを参照するビューをスレーブとして設定することを禁止します(動作保証はいたしません)。
Enterprise Managerのデータのチェック機能は全スレーブが生存しているときのみ実行可能です。一部のスレーブが停止している場合
はデータのチェック機能はエラーを返します。
スレーブを同一データベース内に持つマルチビューが存在するデータベースをバックアップし、別名のデータベースに復元した場合、
CONNECT句に記載されているデータベース名はバックアップ時のデータベース名のままとなります。CONNECT句で復元後のデータ
ベース名にするためにはマルチビューの再定義が必要です。
リストのときクエリ 適化できないパターンは次の通りです。クエリ 適化できない場合は、全スレーブへクエリを発行します。
①条件式の分割列に関数または算術が実施されているとき。
例 WHERE SUBSTR(商品分類コード,1,1) = 'A'
②条件式の比較演算子がLIKEまたはIS NULLのとき。
例 WHERE 住所 LIKE '%北区%'
③条件式の比較に否定(NOT、<>、!)が含まれているとき。
例 WHERE 地区 <> '北海道 '
④条件式の比較演算子が範囲検索のとき。
例 WHERE 地区 BETWEEN '北海道 ' AND '関東 '
レンジのときクエリ 適化できないパターンは次の通りです。クエリ 適化できない場合は、全スレーブへクエリを発行します。
①条件式の分割列に関数または算術が実施されているとき。
例 WHERE TO_CHAR(売上日付,'YYYY/MM/DD') = '2007/10/01'
②条件式の比較演算子がLIKEまたはIS NULLのとき。
例 WHERE 商品分類コード LIKE 'A%'
③条件式の比較に否定(NOT、<>、!)が含まれているとき。
例 WHERE 売上日付 <> '2007/10/01'
WHERE句の検索条件がいずれものレンジ、リストの分割条件に該当しない場合は、クエリ 適化はせず、全スレーブへクエリを発行しま
す。

86
マルチビューに対して指定したサーバ別名のみクエリを発行したいとき下記のSQLを実行できます。
SELECT <column_list>
FROM <mulitiview_name> [PARTITION ( <node_alias> )]
[<where_clause>]
例 SELECT * FROM 売上MV PARTITION(SV1) WHERE 売上日付 >= '2007/01/01'
条件型マルチビューに対してクエリ 適化をしたくない場合、次のSQLを実行できます。
SELECT <column_list>
FROM <mulitiview_name> [NOPARTITION]
[<where_clause>]
例 SELECT * FROM 売上MV NOPARTITION WHERE 売上日付 >= '2007/01/01'
次のマルチビューを想定し、検索条件付きクエリがどのようにサーバグループを絞り込むかについて説明します。
CREATE MULTIVIEW 売上MV
(売上日付,地区,得意先コード,商品コード,売上数量,売上金額 )
CONNECT TO
('localhost',6001,SALES1,売上明細) as SV1
('localhost',6001,SALES2,売上明細) as SV2
('localhost',6001,SALES3,売上明細) as SV3
('localhost',6001,SALES4,売上明細) as SV4
('localhost',6001,SALES5,売上明細) as SV5
('localhost',6001,SALES6,売上明細) as SV6
PARTITION BY RANGE(売上日付),LIST(地区)
VALUES('2006/04/01')
(VALUES('北海道','東北') IN SV1,
VALUES('関東') IN SV2,
VALUES('関西') IN SV3),
VALUES('2007/04/01')
(VALUES('北海道','東北') IN SV4,
VALUES('関東') IN SV5,
VALUES('関西') IN SV6)

87
②第1階層列を指定した検索条件のとき
SELECT * FROM 売上MV
WHERE 売上日付 = '2005/04/01';
絞込み対象サーバグループ SV1,SV2,SV3
② 第2階層列を指定した検索条件のとき
SELECT * FROM 売上MV
WHERE 地区 = '関西';
絞込み対象サーバグループ SV3,SV6
③ 第1階層、第2階層両者の列指定した検索条件のとき
SELECT * FROM 売上MV
WHERE 売上日付 = '2007/03/01' AND 地区 = '北海道';
絞込み対象サーバグループ SV4
④ 分割列を含まない検索条件のとき
SELECT * FROM 売上MV
WHERE 売上金額 >= 1000000;
絞込み対象サーバグループ SV1,SV2,SV3,SV4,SV5,SV6
例1 順序型マルチビューの作成例
CREATE MULTIVIEW 売上MV
(売上日付,
売上ブロック,
売上数量,
売上金額)
CONNECT TO
('DRSV1',6001,SALES,売上明細) AS SV1
('DRSV2',6001,SALES,売上明細) AS SV2
('DRSV3',6001,SALES,売上明細) AS SV3
PARTITION BY SEQUENCE

88
例2 1階層条件型マルチビューの作成例(レンジの場合)
CREATE MULTIVIEW 売上MV
(売上日付,
売上ブロック,
売上数量,
売上金額)
CONNECT TO
('DRSV1',6001,SALES,売上明細) AS SV1
('DRSV2',6001,SALES,売上明細) AS SV2
('DRSV3',6001,SALES,売上明細),
('DRSV4',6001,SALES,売上明細),
('DRSV5',6001,SALES,売上明細) AS SV3
PARTITION BY RANGE(売上日付)
VALUES ('2006/04/01') IN SV1,
VALUES ('2007/04/01') IN SV2,
VALUES () IN SV3
例3 1階層条件型マルチビューの作成例(リストの場合)
CREATE MULTIVIEW 売上MV
(売上日付,
売上ブロック,
売上数量,
売上金額)
CONNECT TO
('DRSV1',6001,SALES,売上明細) AS SV1
('DRSV2',6001,SALES,売上明細) AS SV2
('DRSV3',6001,SALES,売上明細),
('DRSV4',6001,SALES,売上明細),
('DRSV5',6001,SALES,売上明細) AS SV3
PARTITION BY LIST(売上ブロック)
VALUES ('北海道','東北') IN SV1,
VALUES ('関東','甲信越') IN SV2,
VALUES () IN SV3

89
例4 2階層条件型マルチビューの作成例(レンジ-リストの場合)
CREATE MULTIVIEW 売上MV
(売上日付,
売上ブロック,
売上数量,
売上金額)
CONNECT TO
('DRSV1',6001,SALES,売上明細) AS SV1
('DRSV2',6001,SALES,売上明細) AS SV2
('DRSV3',6001,SALES,売上明細),
('DRSV4',6001,SALES,売上明細),
('DRSV5',6001,SALES,売上明細) AS SV3
('DRSV6',6001,SALES,売上明細) AS SV4
('DRSV7',6001,SALES,売上明細) AS SV5
PARTITION BY RANGE(売上日付),LIST(売上ブロック)
VALUES ('2006/04/01')
(
VALUES ('北海道','東北') IN SV1,
VALUES ('関東','甲信越') IN SV2,
VALUES () IN SV3
)
,
VALUES ('2007/04/01')
(
VALUES ('北海道','東北','甲信越') IN SV4,
VALUES ('関東','関西') IN SV5,
VALUES () IN SV3
)
,
VALUES ()
(VALUES () IN SV3)

90
ディストリビュータを作成する CREATE DISTRIBUTOR
同一列定義(列名、属性、桁数、精度、列数、列並び順、列制約が同一)のテーブルに対して、ディストリビュータを作成することができま
す。同一列定義であればテーブル名は異なっても問題ありません。また、同一サーバの同一列定義のテーブルに対しても、ディストリ
ビュータを作成できます。同一サーバであればデータベースが異なっても問題ありません。
ディストリビュータに対してインポート、およびDML(INSERT、UPDATE、DELETE)の発行が可能です。ただし、クエリを発行し、結果セットを
得ることはできません。
Administratorsグループに所属するユーザのみが実行できます。
便宜的にディストリビュータを「マスタ」、構成テーブル群を「スレーブ」と表現します。マスタのデータベースとスレーブのデータベースの
「NULLと空文字の区別」の設定値が同じである必要があります。
ディストリビュータを作成する場合は、CREATE DISTRIBUTOR文を使用します。
CREATE DISTRIBUTOR <distributor_name>
CONNECT TO
<dst_connect_info> [{<dst_connect_info>}...]
{
PARTITION BY SEQUENCE RECYCLE {ON | OFF}
<value_clause_sequence> [{,<value_clause_sequence>}...]
|
PARTITION BY <parition_clause> [,<partition_clause>]
<value_clause_partition> [{,<value_clause_partition>}...]
}
<dst_connect_info> ::=
( <connect_info> ) AS <svr_name>
<connect_info> ::=
<host_name>,<portnum>,<db_name>,<table_name>
<partition_clause> ::=
{RANGE | LIST} ( <column_name> )
<value_clause_sequnce> ::=
VALUES ( <数値> ) IN <svr_name>
<value_clause_partition> ::=
VALUES (value_list) {IN <svr_name> | ( <value_clause_partition> [{,<value_clause_partition
>}...] )}
<value_list> ::=
<値> | ( <値> [{,<値>}...] )

91
CONNECT句 CONNECT句の<dst_connect_info>では、スレーブへの接続情報を記載します。
Enterprise Editionを利用している場合は、ローカルサーバに加え、リモートサーバも指定できます。ただし、条件型のみが対応しています。
順序型には対応していません。
CONNECT TO
<dst_connect_info> [{<dst_connect_info>}...]
接続情報には、次の情報が含まれます。
コンピュータ名、ポート番号、データベース名、テーブル名
コンピュータ名はシングルクォート「'」でくくります。
接続情報には、明示的に別名を付与しなければなりません。この別名をサーバグループと言います。サーバグループは 大30文字です。
1つの接続情報を1つのサーバグループとして付与します。
CONNECT句でサーバグループは重複してはいけません。一意に付与してください。
PARTITION BY句 PARTITION BY句は順序型と条件型の2種類に分類されます。
条件型ディストリビュータを作成すると、投入データの内容から該当するサーバグループを絞り込んで処理をおこないます。
PARTITION BY句の列名には、どの列のデータをしきい値として分割するかを指定します。この列のことを分割列と言います。
分割列はNOT NULL制約が作成されている列のみ指定可能です。
順序型 PARTITION BY SEQUENCE RECYCLE {ON|OFF}
条件型 PARTITION BY RANGE(列名)
PARTITION BY LIST(列名)
PARTITION BY句の列名には、どの列のデータをしきい値として分割するかを指定します。この列のことを分割列と言います。分割列は
NOT NULL制約が作成されている列のみ指定可能です。
順序型ディストリビュータを作成することで、CONNECT句で記載した順番にインポートすることができます。
順序型では、前回インポートが終了したサーバグループを保存しておきます。このサーバグループをインポートポジションと言います。
順序型ではRECYCLE句でインポート中に 後のテーブルの上限件数に達したとき、 初のテーブルにインポートポジションが戻り、既存
データを全件削除してインポートを続行するか否かを設定できます。この設定を循環設定と言います。
順序型のVALUES句には各構成テーブルの件数上限値を記述します。
順序型のVALUES句を指定しない場合は、製品Editionのテーブル件数上限値が採用されます。
条件型ディストリビュータを作成することで、インポートやDML文発行時、データ内容から(UPDATEとDELETEはWHERE句の内容から)
該当するサーバグループを絞り込んで処理します。
条件型は2階層まで定義可能です。ただしレンジ-リスト、レンジ-レンジ、リスト-リスト、リスト-レンジの4種類であり、順序型との混在はでき
ません。便宜的に第1階層を「親」、第2階層を「子」、同じ親を持つ子の集合を「兄弟」と表現します。
例 PARTITION BY RANGE(COL1),LIST(COL2)
PARTITION BY RANGE(COL1),RANGE(COL2)
PARTITION BY LIST(COL1),LIST (COL2)
PARTITION BY LIST(COL1),RANGE(COL2)
条件型のVALUES句には「どのテーブルにどのような値のデータが格納されているか」を表す値を記述します。これを分割条件値といい
ます。

92
条件型のVALUES句の分割条件値には、関数や算術の実施はできません。
レンジのVALUES句には格納されているデータの非包括的上限値(指定値を含まない、つまり指定値未満のデータが格納されているこ
と)を記述し、サーバグループと対応付けます。
レンジのVALUES句の記載順番は、分割条件値の昇順でなければいけません。
レンジのVALUES句で直前に指定したレンジ値から無限大までを表す「その他」のレンジをかならず定義する必要があります。この場合
VALUES句の括弧には値を指定しません。
例 SV1には売上日付が2007/01/01未満のデータ、SV2には売上日付が2008/01/01未満のデータ、
SV3には売上日付が2007/01/01以上のデータが格納されています。
PARTITION BY RANGE(売上日付)
VALUES('2007/01/01') IN SV1,
VALUES('2008/01/01') IN SV2,
VALUES() IN SV3
リストのVALUES句には格納されているデータの値を記述し、サーバグループと対応付けます。リストのVALUES句には値リストを記述する
ことが可能です。Enterprise Managerで定義する時には、値リストは記述できません。
リストのVALUES句で値が未定の場合、先に列挙したリスト値以外を表す「その他」のリストをかならず定義する必要があります。この場合
VALUES句の括弧には値を指定しません。
例 SV1には地区が北海道または東北のデータ、SV2には地区が関東のデータ、SV3には地区が{北海
道,東北,関東}以外のデータが格納されています。
PARTITION BY LIST(地区)
VALUES('北海道','東北') IN SV1,
VALUES('関東') IN SV2,
VALUES() IN SV3
CONNECT句で指定したサーバグループは、すべてVALUES句で使用されなければいけません。
VALUES句におけるサーバグループの対応付けは 下位層で記述します。2階層の場合は、2階層目のVALUES句でサーバグループの
対応付けを記述します。
CONNECT句で指定したサーバグループはVALUES句で複数回指定できます。
例 SV1には地区が北海道のデータ、SV2には地区が{北海道 ,東北}以外のデータが格納されていま
す。
PARTITION BY LIST(地区)
VALUES('北海道') IN SV1,
VALUES('東北') IN SV1,
VALUES() IN SV2

93
VALUES句において同じ親を持つ同一階層の集合の中で分割条件値は重複してはいけません。
例1 作成エラー:1階層のとき
PARTITION BY LIST(地区)
VALUES('北海道') IN SV1,
VALUES('東北') IN SV1,
VALUES('北海道') IN SV2, ← '北海道'が重複エラー。
VALUES() IN SV3
例2 作成エラー:2階層のとき
PARTITION BY RANGE(売上日付),LIST(地区)
VALUES('2007/01/01')
(
VALUES('北海道','東北') IN SV1,
VALUES('北海道') IN SV2, ← 兄弟で'北海道'が重複エラー。
VALUES() IN SV3
),
VALUES()
(
VALUES('北海道','東北') IN SV4, ← 親が異なるのでここはエラーとならない。
VALUES('関東') IN SV5
VALUES() IN SV6
)
ディストリビュータ定義の作成・変更時、分割定義に基づく既存格納データの再編成は実施しません。
ディストリビュータへのサブクエリを用いたINSERT INTO~ SELECT文は発行できません。
スレーブを同一データベース内に持つディストリビュータが存在するデータベースをバックアップし、別名のデータベースに復元した場合、
CONNECT句に記載されているデータベース名はバックアップ時のデータベース名のままとなります。CONNECT句で復元後のデータ
ベース名にするためにはディストリビュータの再定義が必要です。
既存格納データが分割定義と合致しているか否かは、Enterprise Managerの「データのチェック」機能で確認することができます。
「データのチェック」機能は全スレーブが生存しているときのみ実行可能です。一部のスレーブが停止している場合は「データのチェック」
機能はエラーを返します。
ディストリビュータを構成する各テーブルへ分割定義に合致しないデータがインポートやDMLにて挿入・更新されても、リアルタイムに
チェックする機能はありません。
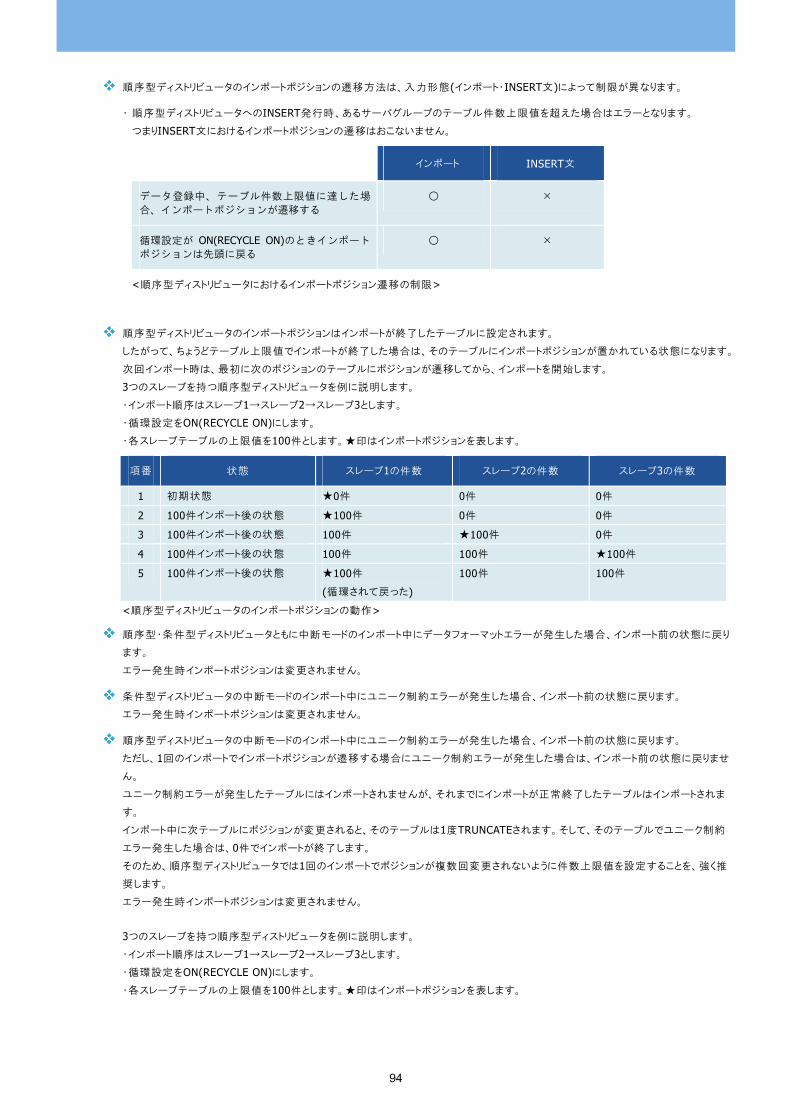
94
順序型ディストリビュータのインポートポジションの遷移方法は、入力形態(インポート・INSERT文)によって制限が異なります。
・ 順序型ディストリビュータへのINSERT発行時、あるサーバグループのテーブル件数上限値を超えた場合はエラーとなります。
つまりINSERT文におけるインポートポジションの遷移はおこないません。
インポート INSERT文
データ登録中、テーブル件数上限値に達した場
合、インポートポジションが遷移する ○ ×
循環設定が ON(RECYCLE ON)のときインポート
ポジションは先頭に戻る ○ ×
<順序型ディストリビュータにおけるインポートポジション遷移の制限>
順序型ディストリビュータのインポートポジションはインポートが終了したテーブルに設定されます。
したがって、ちょうどテーブル上限値でインポートが終了した場合は、そのテーブルにインポートポジションが置かれている状態になります。
次回インポート時は、 初に次のポジションのテーブルにポジションが遷移してから、インポートを開始します。
3つのスレーブを持つ順序型ディストリビュータを例に説明します。
・インポート順序はスレーブ1→スレーブ2→スレーブ3とします。
・循環設定をON(RECYCLE ON)にします。
・各スレーブテーブルの上限値を100件とします。★印はインポートポジションを表します。
項番 状態 スレーブ1の件数 スレーブ2の件数 スレーブ3の件数
1 初期状態 ★0件 0件 0件
2 100件インポート後の状態 ★100件 0件 0件
3 100件インポート後の状態 100件 ★100件 0件
4 100件インポート後の状態 100件 100件 ★100件
5 100件インポート後の状態 ★100件
(循環されて戻った)
100件 100件
<順序型ディストリビュータのインポートポジションの動作>
順序型・条件型ディストリビュータともに中断モードのインポート中にデータフォーマットエラーが発生した場合、インポート前の状態に戻り
ます。
エラー発生時インポートポジションは変更されません。
条件型ディストリビュータの中断モードのインポート中にユニーク制約エラーが発生した場合、インポート前の状態に戻ります。
エラー発生時インポートポジションは変更されません。
順序型ディストリビュータの中断モードのインポート中にユニーク制約エラーが発生した場合、インポート前の状態に戻ります。
ただし、1回のインポートでインポートポジションが遷移する場合にユニーク制約エラーが発生した場合は、インポート前の状態に戻りませ
ん。
ユニーク制約エラーが発生したテーブルにはインポートされませんが、それまでにインポートが正常終了したテーブルはインポートされま
す。
インポート中に次テーブルにポジションが変更されると、そのテーブルは1度TRUNCATEされます。そして、そのテーブルでユニーク制約
エラー発生した場合は、0件でインポートが終了します。
そのため、順序型ディストリビュータでは1回のインポートでポジションが複数回変更されないように件数上限値を設定することを、強く推
奨します。
エラー発生時インポートポジションは変更されません。
3つのスレーブを持つ順序型ディストリビュータを例に説明します。
・インポート順序はスレーブ1→スレーブ2→スレーブ3とします。
・循環設定をON(RECYCLE ON)にします。
・各スレーブテーブルの上限値を100件とします。★印はインポートポジションを表します。

95
項番 状態 スレーブ1の件数 スレーブ2の件数 スレーブ3の件数
1 初期状態 ★0件 0件 0件
2 205件インポート後の状態(202
件目、つまりスレーブ3でユニー
ク違反発生)
★100件 100件 0件
3 インポートポジションをスレーブ
3へ変更
100件 100件 ★0件
4 105件インポート後の状態(102
件目、つまりスレーブ1でユニー
ク違反発生)
0件
TRUNCATE → IMPORT 中
にユニーク違反発生のた
め0件
100件 ★100件
5 インポートポジションをスレーブ
1へ変更
★0件 100件 100件
6 205件インポート後の状態(202
件目、つまりスレーブ3でユニー
ク違反発生)
★100件 100件 0件
TRUNCATE → IMPORT 中
にユニーク違反発生のた
め0件
<順序型ディストリビュータのユニーク制約エラー発生時の動作>
順序型ディストリビュータにおいて循環設定がOFFのとき、スレーブ全体の件数上限値を超えるデータをインポートした場合、中断・続行
モードに関わらずエラーとなり、インポート前の状態に戻ります。
ディストリビュータ定義作成後、スレーブのテーブル定義を変更しインポートすると、エラーが発生します。
条件型ディストリビュータにおいて、各スレーブの件数上限値を超えるデータをインポートした場合、中断・続行モードに関わらずエラーと
なり、インポート前の状態に戻ります。
条件型ディストリビュータへINSERT文発行時、サーバグループを1つに限定できない場合は、エラーとなります。
マルチスレッドで実行することでインポート速度の向上が可能です。Server Settingsの[ 大ディストリビュータ同時スレッド数]で制御しま
す。
例1 順序型ディストリビュータの作成例:明示的に件数上限値を指定する場合
CREATE DISTRIBUTOR 売上DST
CONNECT TO
('localhost',6001,SALES1,売上明細) AS DB1
('localhost',6001,SALES2,売上明細) AS DB2
('localhost',6001,SALES3,売上明細) AS DB3
PARTITION BY SEQUENCE RECYCLE ON
VALUES (10000000) IN DB1,
VALUES (10000000) IN DB2,
VALUES (10000000) IN DB3;
例2 順序型ディストリビュータの作成例:製品Edition別の件数上限値とする場合
CREATE DISTRIBUTOR 売上DST
CONNECT TO
('DRSV1',6001,SALES1,売上明細) AS DB1

96
('DRSV1',6001,SALES2,売上明細) AS DB2
('DRSV1',6001,SALES3,売上明細) AS DB3
PARTITION BY SEQUENCE RECYCLE ON;
例3 1階層条件型ディストリビュータの作成例(レンジの場合)
CREATE DISTRIBUTOR 売上DST
CONNECT TO
('localhost',6001,SALES1,売上明細) AS DB1
('localhost',6001,SALES2,売上明細) AS DB2
('localhost',6001,SALES3,売上明細) AS DB3
PARTITION BY RANGE(売上日付)
VALUES ('2006/04/01') IN DB1,
VALUES ('2007/04/01') IN DB2,
VALUES () IN DB3;
例4 1階層条件型ディストリビュータの作成例(リストの場合)
CREATE DISTRIBUTOR 売上DST
CONNECT TO
('localhost',6001,SALES1,売上明細) AS DB1
('localhost',6001,SALES2,売上明細) AS DB2
('localhost',6001,SALES3,売上明細) AS DB3
PARTITION BY LIST(売上ブロック)
VALUES ('北海道','東北') IN DB1,
VALUES ('関東','甲信越') IN DB2,
VALUES () IN DB3;
例5 2階層条件型ディストリビュータの作成例(レンジ-リストの場合)
CREATE DISTRIBUTOR 売上DST
CONNECT TO
('localhost',6001,SALES1,売上明細) AS SV1
('localhost',6001,SALES2,売上明細) AS SV2
('localhost',6001,SALES3,売上明細) AS SV3
('localhost',6001,SALES4,売上明細) AS SV4
('localhost',6001,SALES5,売上明細) AS SV5
PARTITION BY RANGE(売上日付),LIST(売上ブロック)
VALUES ('2006/04/01')

97
(
VALUES('北海道','東北') IN SV1,
VALUES('関東','甲信越') IN SV2,
VALUES() IN SV3
),
VALUES ('2007/04/01')
(
VALUES('北海道','東北','甲信越') IN SV4,
VALUES('関東','関西') IN SV5,
VALUES() IN SV3
),
VALUES ()
(VALUES() IN SV3)
例6 1階層条件型ディストリビュータの作成例(リモート、レンジの場合)
CREATE DISTRIBUTOR 売上DST
CONNECT TO
('localhost',6001,SALES1,売上明細) AS DB1
('remotehost1',6001,SALES1,売上明細) AS DB2
('remotehost2',6001,SALES1,売上明細) AS DB3
PARTITION BY RANGE(売上日付)
VALUES ('2006/04/01') IN DB1,
VALUES ('2007/04/01') IN DB2,
VALUES () IN DB3;
例7 階層条件型ディストリビュータの作成例(リモート、レンジの場合)
Dr.Sum EAサーバに、Service Controllerがセットアップされている場合にのみ、localhost(同一コン
ピュータ)に別ポートを設定できます。
CREATE DISTRIBUTOR 売上DST
CONNECT TO
('localhost',6001,SALES1,売上明細) AS DB1
('localhost',6002,SALES2,売上明細) AS DB2
('localhost',6003,SALES3,売上明細) AS DB3
PARTITION BY RANGE(売上日付)
VALUES ('2006/04/01') IN DB1,
VALUES ('2007/04/01') IN DB2,
VALUES () IN DB3;

98
グループを作成する CREATE GROUP
ユーザグループを作成する場合は、CREATE GROUP文を使用します。Administratorsグループに所属するユーザのみが実行できます。
CREATE GROUP <group_name> [ COMMENT <comment> ]
<group_name> 作成するグループ名 通常、<group_name>に予約語や、識別子に使用できない文字は使用できませんが、シングル
クォート「'」、またはダブルクォート「"」でくくる事により、これらの文字を使用することが可能です。
<comment> グループに対するコメント グループ作成と同時にコメントを 大1023文字まで記述することができます。 コメントはシングルクォート「'」、またはダブルクォート「"」でくくります。使用可能な文字は、SQL文に利
用可能な文字集合の内、タブ、改行を除いたものとなります。
例1 グループ「team_sum」を作成します。
CREATE GROUP team_sum
例2 予約語である「DATE」という名前のグループを作成します。
CREATE GROUP 'DATE'
例3 グループ「team_sum」を作成し、コメント「テストチーム」を設定します。
CREATE GROUP team_test COMMENT 'テストチーム'
グループに対する権限の付与はGRANT文でおこないます。詳細については、「GRANT」(p.120)を参照してください。
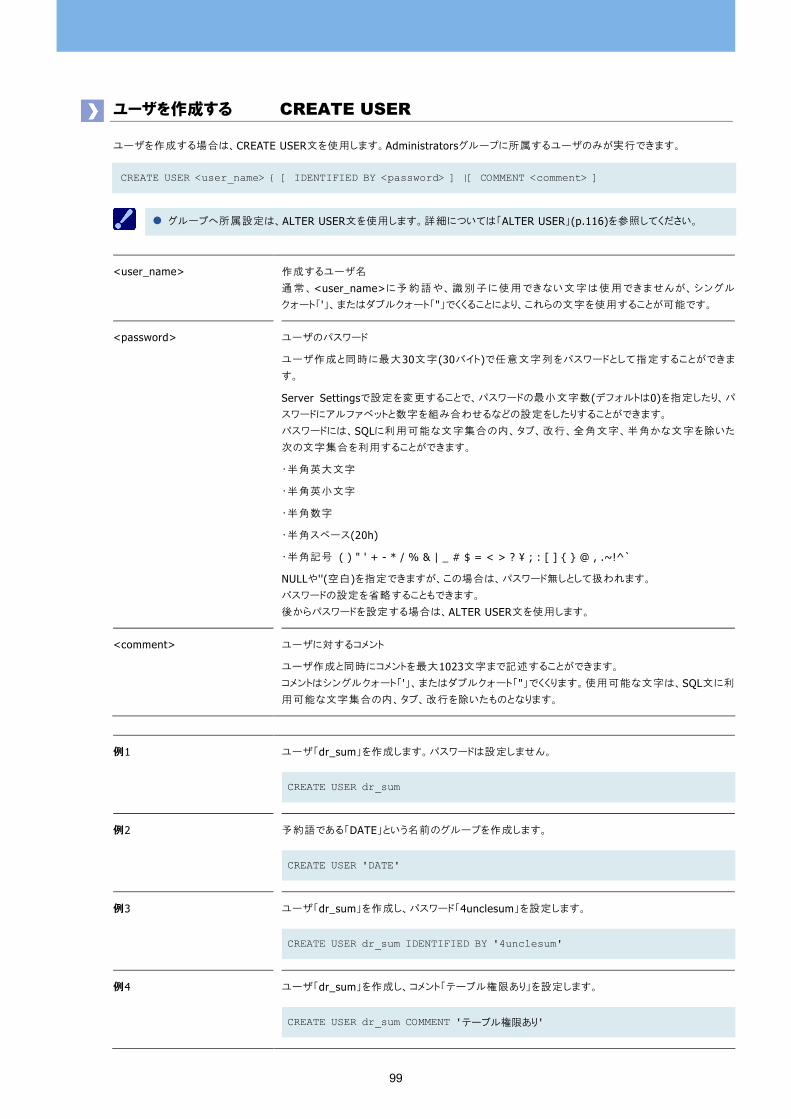
99
ユーザを作成する CREATE USER
ユーザを作成する場合は、CREATE USER文を使用します。Administratorsグループに所属するユーザのみが実行できます。
CREATE USER <user_name> { [ IDENTIFIED BY <password> ] |[ COMMENT <comment> ]
グループへ所属設定は、ALTER USER文を使用します。詳細については「ALTER USER」(p.116)を参照してください。
<user_name> 作成するユーザ名 通常、<user_name>に予約語や、識別子に使用できない文字は使用できませんが、シングル
クォート「'」、またはダブルクォート「"」でくくることにより、これらの文字を使用することが可能です。
<password> ユーザのパスワード
ユーザ作成と同時に 大30文字(30バイト)で任意文字列をパスワードとして指定することができま
す。
Server Settingsで設定を変更することで、パスワードの 小文字数(デフォルトは0)を指定したり、パ
スワードにアルファベットと数字を組み合わせるなどの設定をしたりすることができます。 パスワードには、SQLに利用可能な文字集合の内、タブ、改行、全角文字、半角かな文字を除いた
次の文字集合を利用することができます。
・半角英大文字
・半角英小文字
・半角数字
・半角スペース(20h)
・半角記号 ( ) " ' + - * / % & | _ # $ = < > ? ¥ ; : [ ] { } @ , .~!^`
NULLや''(空白)を指定できますが、この場合は、パスワード無しとして扱われます。 パスワードの設定を省略することもできます。 後からパスワードを設定する場合は、ALTER USER文を使用します。
<comment> ユーザに対するコメント
ユーザ作成と同時にコメントを 大1023文字まで記述することができます。 コメントはシングルクォート「'」、またはダブルクォート「"」でくくります。使用可能な文字は、SQL文に利
用可能な文字集合の内、タブ、改行を除いたものとなります。
例1 ユーザ「dr_sum」を作成します。パスワードは設定しません。
CREATE USER dr_sum
例2 予約語である「DATE」という名前のグループを作成します。
CREATE USER 'DATE'
例3 ユーザ「dr_sum」を作成し、パスワード「4unclesum」を設定します。
CREATE USER dr_sum IDENTIFIED BY '4unclesum'
例4 ユーザ「dr_sum」を作成し、コメント「テーブル権限あり」を設定します。
CREATE USER dr_sum COMMENT 'テーブル権限あり'

100
テーブルの定義を変更する ALTER TABLE
既存テーブルへの列の追加と削除、列属性・列名の変更、列コメントの変更、削除、表制約の追加と削除または、テーブル名、テーブル
コメントの変更がおこなう場合は、ALTER TABLE文を使用します。
SQLを発行するユーザはテーブル定義を変更できる権限を持っている必要があります。
ALTER TABLE <table_name>{
RENAME TO <new_table_name>
| MODIFY COMMENT <new comment>
| MODIFY <column_name> COMMENT <new comment>
| DROP COMMENT
| DROP COMMENT <column_name>
| ADD CONSTRAINT <table_constraint_def>
| DROP CONSTRAINT <constraint_name>
}
列の変更 列の変更をおこなう場合は、次の構文を使用します。
ALTER TABLE <table_name> {
ADD [ COLUMN ] <column_def>
|ALTER [ COLUMN ] <column_def>
| ALTER [ COLUMN ] <column_name> [{ SET DEFAULT<defalult_option> | DROP DEFAULT}]
|DROP [ COLUMN ] <column_name>
}
列の追加 列の追加をおこなう場合は、次の構文を使用します。
ALTER TABLE <table_name> ADD <column_def>
<table_name> 操作対象のテーブル名
<column_def> 追加する列の定義 列名 列の型
例 ALTER TABLE foo ADD col1 varchar(20)
列は追加時にすべてNULLが埋まります。同時に列制約はできません。 再度ALTER TABLEを実行する必要があります。
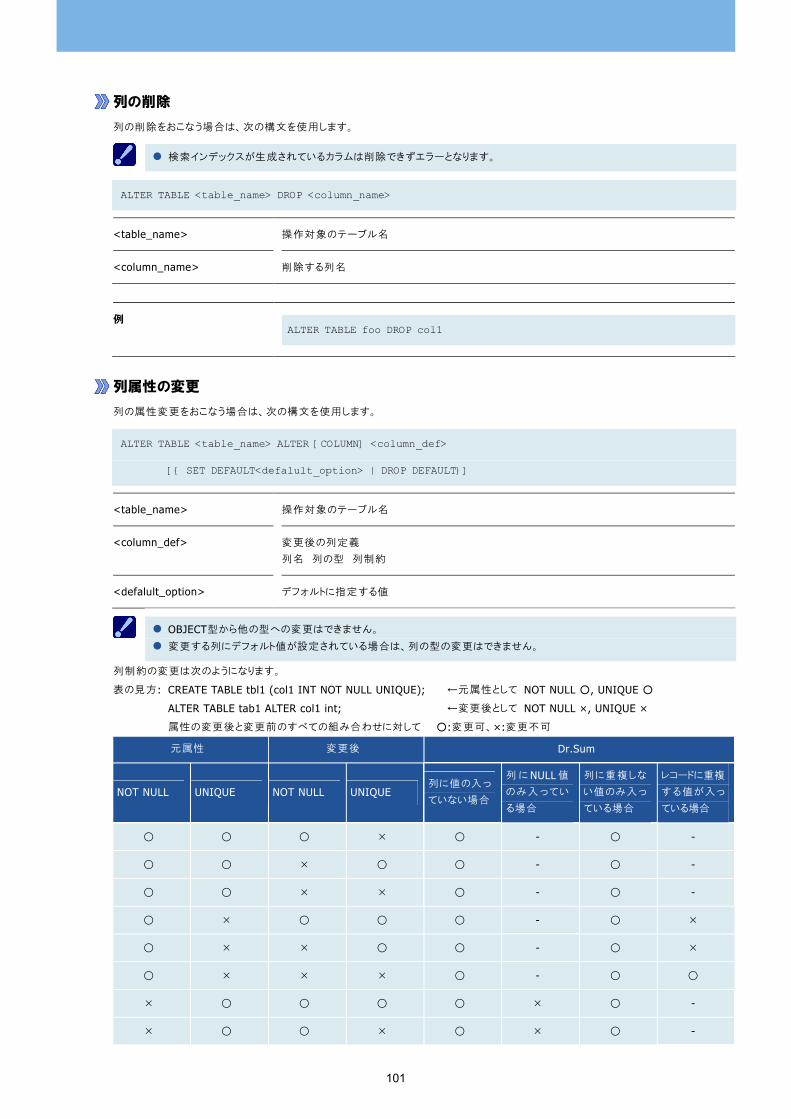
101
列の削除 列の削除をおこなう場合は、次の構文を使用します。
検索インデックスが生成されているカラムは削除できずエラーとなります。
ALTER TABLE <table_name> DROP <column_name>
<table_name> 操作対象のテーブル名
<column_name> 削除する列名
例 ALTER TABLE foo DROP col1
列属性の変更 列の属性変更をおこなう場合は、次の構文を使用します。
ALTER TABLE <table_name> ALTER [COLUMN] <column_def>
[{ SET DEFAULT<defalult_option> | DROP DEFAULT}]
<table_name> 操作対象のテーブル名
<column_def> 変更後の列定義 列名 列の型 列制約
<defalult_option> デフォルトに指定する値
OBJECT型から他の型への変更はできません。
変更する列にデフォルト値が設定されている場合は、列の型の変更はできません。
列制約の変更は次のようになります。
表の見方: CREATE TABLE tbl1 (col1 INT NOT NULL UNIQUE); ←元属性として NOT NULL ,○ UNIQUE ○
ALTER TABLE tab1 ALTER col1 int; ←変更後として NOT NULL ×, UNIQUE ×
属性の変更後と変更前のすべての組み合わせに対して ○:変更可、×:変更不可
元属性 変更後 Dr.Sum
NOT NULL UNIQUE NOT NULL UNIQUE 列に値の入っ
ていない場合
列 に NULL 値
のみ入ってい
る場合
列に重複しな
い値のみ入っ
ている場合
レコードに重複
する値が入っ
ている場合
○ ○ ○ × ○ - ○ -
○ ○ × ○ ○ - ○ -
○ ○ × × ○ - ○ -
○ × ○ ○ ○ - ○ ×
○ × × ○ ○ - ○ ×
○ × × × ○ - ○ ○
× ○ ○ ○ ○ × ○ -
× ○ ○ × ○ × ○ -

102
元属性 変更後 Dr.Sum
NOT NULL UNIQUE NOT NULL UNIQUE 列に値の入っ
ていない場合
列 に NULL 値
のみ入ってい
る場合
列に重複しな
い値のみ入っ
ている場合
レコードに重複
する値が入っ
ている場合
× ○ × × ○ ○ ○ -
× × ○ ○ ○ × ○ ×
× × ○ × ○ × ○ ○
× × × ○ ○ ○ ○ ×
※ビュー生成時の結合主キーである列のNOT NULL、UNIQUE制約をはずした場合、ビューの参照ができなくなります。
型変換をする前の列にNOT NULL制約、またはUNIQUE制約のどちらかが設定されている場合、変換時にどちらかを再度指定することで
制約を設定することができます。
例1 データ型がnumeric(2,1)でユニーク制約設定のある列col1を、データ型realでユニーク制約設定あ
りに変更します。 ただし、変更前のcol1の値は値が入っていないものとします。
ALTER TABLE foo ALTER col1 real unique
例2 データ型がnumeric(2,1)でNOT NULL制約とユニーク制約設定のある列col1を、データ型realで制
約設定なしに変更します。 ただし、変更前のcol1には値が入っていないものとします。
ALTER TABLE foo ALTER col1 real
デフォルト値の変更・削除 列にデフォルト値を設定したり、デフォルト値の変更・削除をおこなったりする場合は、次の構文を使用します。
ALTER TABLE <table_name> ALTER [COLUMN] <column_name>
{ SET DEFAULT<defalult_option> | DROP DEFAULT}
<table_name> 操作対象のテーブル名
<column_ name> デフォルトを変更する列名
<defalult_option> デフォルトに指定する値
例1 データ型がvarchar(20)の列col1に、デフォルト値「0001」を追加設定します。 ただし、変更前のcol1にはunique制約がなく、値が入っていないものとします。
ALTER TABLE foo ALTER col1 SET DEFAULT '0001'
例2 デフォルト値が設定されているcol1列から設定を削除します。 ただし、変更前のcol1には値が入っていないものとします。
ALTER TABLE foo ALTER col1 DROP DEFAULT

103
列名の変更 列名を変更する場合は、次の構文を使用します。
ALTER TABLE <table_name> RENAME <old_col_name> TO <new_col_name>
<table_name> 操作対象のテーブル名
<old_col_name> 変更する列名
<new_col_name> 名称変更後の列名
例 テーブル「foo」内の列「col1」の名称を「col2」に変更します。
ALTER TABLE foo RENAME col1 TO col2
列コメントの変更 列コメントを変更する場合は、次の構文を使用します。
ALTER TABLE<table_name>MODIFY<col_name>COMMENT<new_comment>
<table_name> 操作対象のテーブル名
<col_name> コメントを変更する列名
<new_comment> 変更後のコメント 大1023文字まで記述することができます。
コメントはシングルクォート「'」、またはダブルクォート「"」でくくります。使用可能な文字は、SQL文に利
用可能な文字集合の内、タブ、改行を除いたものとなります。
例 テーブル「foo」内の列「col1」のコメントを「新しいコメント!」に変更します。
ALTER TABLE foo MODIFY col1 COMMENT '新しいコメント!'
列コメントの削除 列コメントを削除する場合は、次の構文を使用します。
ALTER TABLE<table_name>DROP COMMENT <col_name>
<table_name> 操作対象のテーブル名
<col_name> コメントを削除する列名
例 テーブル「foo」内の列「col1」のコメントを削除します。
ALTER TABLE foo DROP COMMENT col1

104
テーブル名の変更 テーブル名を変更する場合は、次の構文を使用します。
ALTER TABLE <old_tab_name> RENAME TO <new_tab_name>
または
Rename <old_tab_name> TO <new_tab_name>
<old_tab_name> 操作対象のテーブル名
<new_tab_name> 名称変更後のテーブル名
例 テーブル名「foo」を「bar」に変更します。
ALTER TABLE foo RENAME TO bar
または
RENAME foo TO bar
テーブルコメントの変更 テーブルのコメントを変更する場合は、次の構文を使用します。
ALTER TABLE <table_name> MODIFY COMMENT <new_comment>
<table_name> 操作対象のテーブル名
<new_comment> 変更後のコメント
大1023文字まで記述することができます。 コメントはシングルクォート「'」、またはダブルクォート「"」でくくります。使用可能な文字は、SQL文に利
用可能な文字集合の内、タブ、改行を除いたものとなります。
例 テーブル「foo」のコメントを「新しいコメント!」に変更します。
ALTER TABLE foo MODIFY COMMENT '新しいコメント!'
テーブルコメントの削除 テーブルのコメントを削除する場合は、次の構文を使用します。
ALTER TABLE <table_name> DROP COMMENT
<table_name> 操作対象のテーブル名
例 テーブル「foo」のコメントのコメントを削除します。
ALTER TABLE foo DROP COMMENT

105
表制約の変更 テーブルの制約を変更する場合は、次の構文を使用します。
ALTER TABLE <table_name> ADD CONSTRAINT <table_constraint_def>
<table_name> 操作対象のテーブル名
<table_constraint_def> 制約の種類 制約名(列名,,,) ここで使用できる制約の種類はcompound keyのみです。
例 テーブル「foo」に制約を設定します。
ALTER TABLE foo ADD CONSTRAINT compound key pk_foo(col1,col2,col3) not
null unique;
表制約の削除 テーブルの制約を削除する場合は、次の構文を使用します。
ALTER TABLE <table_name> DROP CONSTRAINT <constraint_name>
<table_name> 操作対象のテーブル名
<constraint_name> 制約名
例 テーブル「foo」に設定されている制約を削除します。
ALTER TABLE foo DROP CONSTRAINT pk_foo;

106
検索インデックスの有効・無効を切り替える ALTER INDEX
既存の検索インデックスの情報の有効・無効を切り替える場合は、ALTER INDEX文を使用します。
Administratorsグループに所属するユーザのみが実行できます。
ALTER INDEX <index_name>{
ENABLE
|DISABLE
}
ENABLEを指定すると、対象の検索インデックスを再構築し、有効状態になります。
DISABLEを指定すると、対象の検索インデックスが無効状態になります。
無効になった検索インデックスは、元テーブルの変更に追従せず、検索でも使用されません。
<index_name> 操作対象の検索インデックス
例 tab_idxという検索インデックスを有効にします。
ALTER INDEX tab_idx ENABLE
結合インデックスの有効・無効を切り替える ALTER JOIN INDEX
既存の結合インデックスの有効・無効を切り替える場合は、ALTER JOIN INDEX文を使用します。
Administratorsグループに所属するユーザのみが実行できます。
ALTER JOIN INDEX <index_name>{
ENABLE
|DISABLE
}
ENABLEを指定すると、対象の結合インデックスを再構築し、有効状態になります。
DISABLEを指定すると、対象の結合インデックスが無効状態になります。
無効になった結合インデックスは、元テーブルの変更に追従せず、結合でも使用されません
<index_name> 操作対象の結合インデックス
例 tab_join_idxという結合インデックスを有効にします。
ALTER JOIN INDEX tab_join_idx ENABLE

107
ビューの定義を変更する ALTER VIEW
既存ビューの名前の変更、ビューコメントの変更・削除、ビュー定義の変更をおこなう場合は、ALTER VIEW文を使用します。
SQLを発行するユーザはビュー定義を変更できる権限を持っている必要があります。
ALTER VIEW <view_name>{
RENAME TO <new_view_name>
| MODIFY COMMENT <new_comment>
| DROP COMMENT }
| AS SELECT <statement>
}
|REFRESH
ビュー名の変更 ビュー名を変更する場合は、次の構文を使用します。
ALTER VIEW <view_name> RENAME TO <new_view_name>
<view_name> 操作対象のビュー名
<new_view_name> 名称変更後のビュー名
例 ビュー名「foo」を「bar」に変更します。
ALTER VIEW foo RENAME TO bar
ビューコメントの変更 ビューのコメントを変更する場合は、次の構文を使用します。
ALTER VIEW <view_name> MODIFY COMMENT <new_comment>
<view_name> 操作対象のビュー名
<new_comment> 変更後のコメント
大1023文字まで記述することができます。 コメントはシングルクォート「'」、またはダブルクォート「"」でくくります。使用可能な文字は、SQL文に利
用可能な文字集合の内、タブ、改行を除いたものとなります。
例 ビュー「myview」のコメントを「新規ビュー」に変更します。
ALTER VIEW myview MODIFY COMMENT '新規ビュー'

108
ビューコメントの削除 ビューのコメントを削除する場合は、次の構文を使用します。
ALTER VIEW <view_name> DROP COMMENT
<view_name> 操作対象のビュー名
例 ビュー「myview」のコメントのコメントを削除します。
ALTER VIEW myview DROP COMMENT
ビューのスキーマ情報の更新 ビューのスキーマ情報はビュー作成時に決定されますが、作成後、参照テーブルの変更などによりスキーマ情報が実態と乖離する場合
があります。この構文によりビューのスキーマ情報を 新の状態に更新できます。
Enterprise Managerを使用してビューを作成した場合、ビューのプロパティ画面に参照テーブルが表示されますが、この構
文を実行しても配置されているテーブル情報は更新されません。 テーブル情報を更新するには、テーブルを選択し、右クリックで表示されるメニューから[ 新の情報に更新]を選択する必
要があります。
ビューのスキーマ情報を更新する場合は、次の構文を使用します。
ALTER VIEW <view_name> REFRESH
<view_name> 操作対象のビュー名
例 ビュー「myview」のスキーマ情報を更新します。
ALTER VIEW myview REFRESH

109
マルチビューの定義を変更する ALTER MULTIVIEW
既存マルチビューの名前の変更、コメントの追加・変更・削除をおこなう場合は、ALTER MULTIVIEW文を使用します。エラー発生時の処
理の継続・停止の指定、カラム情報の再定義もできます。
Administratorsグループに所属するユーザのみが実行できます。
ALTER MULTIVIEW <multiview_name>
{
RENAME TO <new_view_name>
|
MODIFY COMMENT <comment>
|
DROP COMMENT
|
CONNECT ERROR {INTERRUPT | CONTINUE}
|REFRESH
}
上記以外の定義を変更したい場合は、次のように記述します。CREATE MULTIVIEWと同一構文となります。詳細については「CREATE
MULTIVIEW」(p.82)を参照ください。
ALTER MULTIVIEW <multiview_name>
( <column_list> )
CONNECT TO
<mv_connect_info> [{<mv_connect_info>}...]
{
PARTITION BY SEQUENCE
|
PARTITION BY <parition_clause> [,<partition_clause>]
<value_clause_partition> [{,<value_clause_partition>}...]
}
<column_list> ::=
( <column_name> [{,<column_name>}...] )
<mv_connect_info> ::=
( <connect_info> [{<connect_info>}...] ) AS <svr_name>
<connect_info> ::=
<host_name>,<portnum>,<db_name>,<table_name>

110
<partition_clause> ::=
{RANGE | LIST} ( <column_name> )
<value_clause_partition> ::=
VALUES (value_list) {IN <svr_name> | ( <value_clause_partition> [{,<value_clause_partition
>}...] )}
<value_list> ::=
<値> | ( <値> [{,<値>}...] )
マルチビュー名の変更 マルチビュー名を変更する場合は、次の構文を使用します。
ALTER MULTIVIEW <multiview_name> RENAME TO <new_view_name>
<multiview_name> 操作対象のマルチビュー名
<new_view_name> 名称変更後のマルチビュー名
例 マルチビュー名を「mv_uriage」から「mv_uriage2」に変更します。
ALTER MULTIVIEW mv_uriage RENAME TO mv_uriage2
マルチビューコメントの変更 マルチビューのコメントを変更する場合は、次の構文を使用します。
ALTER MULTIVIEW <multiview_name> MODIFY COMMENT <new_comment>
<multiview_name> 操作対象のマルチビュー名
<new_comment> 変更後のコメント
大1023文字まで記述することができます。 コメントはシングルクォート「'」、またはダブルクォート「"」でくくります。使用可能な文字は、SQL文に利
用可能な文字集合の内、タブ、改行を除いたものとなります。
例 マルチビューにコメントを追加(または書き換え)します。
ALTER MULTIVIEW mv_uriage MODIFY COMMENT 'コメント'

111
マルチビューコメントの削除 マルチビューのコメントを削除する場合は、次の構文を使用します。
ALTER MULTIVIEW <multiview_name> DROP COMMENT
<multiview_name> 操作対象のマルチビュー名
例 マルチビューのコメントを削除します。
ALTER MULTIVIEW mv_uriage DROP COMMENT
マルチビューのスキーマ情報の更新 マルチビューのスキーマ情報を更新する場合は、次の構文を使用します。
ALTER MULTIVIEW <multiview_name> REFRESH
<multiview_name> 操作対象のマルチビュー名
例 マルチビュー「mv_uriage」のスキーマ情報を更新します。
ALTER MULTIVIEW mv_uriage REFRESH
エラー発生時の処理の継続・停止 一部の結果取得にエラー発生した場合に、処理を継続するか停止するかを指定する場合は、次の構文を使用します。
ALTER MULTIVIEW <multiview_name> CONNECT ERROR {INTERRUPT | CONTINUE}
<multiview_name> 操作対象のマルチビュー名
CONNECT ERROR 処理の停止、または継続の指定
INTERRUPT(停止)、CONTINUE(継続)のいずれかを指定します。
例1 一部の結果取得に失敗しても処理を「継続する」に変更します。
ALTER MULTIVIEW mv_uriage CONNECT ERROR CONTINUE
例2 一部の結果取得に失敗しても処理を「継続しない」に変更します。
ALTER MULTIVIEW mv_uriage CONNECT ERROR INTERRUPT

112
ディストリビュータの定義を変更する ALTER DISTRIBUTOR
既存ディストリビュータの名前の変更、コメントの追加・変更・削除、インポートポジションの変更、循環設定の有無の変更をおこなう場合は、
ALTER DISTRIBUTOR文を使用します。エラー発生時の処理の継続・停止の指定、カラム情報の再定義もできます。
Administratorsグループに所属するユーザのみが実行できます。
Enterprise Editionを利用している場合は、ローカルサーバに加え、リモートサーバも指定できます。ただし、条件型のみが対応しています。
順序型には対応していません。
ALTER DISTRIBUTOR <distributor_name>
{
RENAME TO <new_distributor_name>
|MODIFY COMMENT <comment>
|DROP COMMENT
|CHANGE POSITION <svr_name>
|RECYCLE {ON | OFF}
|REFRESH
}
上記以外の定義を変更したいときは、次のように記述します。CREATE DISTRIBUTORと同一構文になります。詳細については「CREATE
DISTRIBUTOR」(p.90)を参照ください。
ALTER DISTRIBUTOR <distributor_name> ( <column_list> )
CONNECT TO
<dst_connect_info> [{<dst_connect_info>}...]
{
PARTITION BY SEQUENCE RECYCLE {ON | OFF}
<value_clause_sequence> [{,<value_clause_sequence>}...]
|
PARTITION BY <parition_clause> [,<partition_clause>]
<value_clause_partition> [{,<value_clause_partition>}...]
}
<dst_connect_info> ::=
( <connect_info> ) AS <svr_name>
<connect_info> ::=
<host_name>,<portnum>,<db_name>,<table_name>
<partition_clause> ::=
{RANGE | LIST} ( <column_name> )
<value_clause_sequnce> ::=
VALUES ( <数値> ) IN <svr_name>

113
<value_clause_partition> ::=
VALUES (value_list) {IN <svr_name> | ( <value_clause_partition> [{,<value_clause_partition
>}...] )}
<value_list> ::=
<値> | ( <値> [{,<値>}...] )
ディストリビュータ名の変更 ディストリビュータ名を変更する場合は、次の構文を使用します。
ALTER DISTRIBUTOR <distributor_name> RENAME TO <new_distributor_name>
<multiview_name> 操作対象のディストリビュータ名
<new_distributor_name> 名称変更後のディストリビュータ名
例 ディストリビュータ名を「dst_uriage」から「dst_uriage2」に変更します。
ALTER DISTRIBUTOR dst_uriage RENAME TO dst_uriage2
ディストリビュータコメントの変更 ディストリビュータのコメントを変更する場合は、次の構文を使用します。
ALTER DISTRIBUTOR <distributor_name> MODIFY COMMENT <new_comment>
<distributor_name> 操作対象のディストリビュータ名
<new_comment> 変更後のコメント
大1023文字まで記述することができます。 コメントはシングルクォート「'」、またはダブルクォート「"」でくくります。使用可能な文字は、SQL文に利
用可能な文字集合の内、タブ、改行を除いたものとなります。
例 ディストリビュータにコメントを追加(または書き換え)します。
ALTER DISTRIBUTOR dst_uriage MODIFY COMMENT 'コメント'

114
ディストリビュータコメントの削除 ディストリビュータのコメントを削除する場合は、次の構文を使用します。
ALTER DISTRIBUTOR <distributor_name> DROP COMMENT
<distributor_name> 操作対象のディストリビュータ名
例 ディストリビュータのコメントを削除します。
ALTER DISTRIBUTOR dst_uriage DROP COMMENT
インポートポジションの変更 インポートポジションを変更する場合は、次の構文を使用します。
ALTER DISTRIBUTOR <distributor_name> CHANGE POSITION <svr_name>
<distributor_name> 操作対象のディストリビュータ名
<svr_name> サーバ名
例1 順序型ディストリビュータのインポートポジションを変更します。
ALTER DISTRIBUTOR dst_uriage CHANGE POSITION sv1
ディストリビュータのスキーマ情報の更新 ディストリビュータのスキーマ情報を更新する場合は、次の構文を使用します。
ALTER DISTRIBUTOR <distributor_name> REFRESH
<distributor_name> 操作対象のディストリビュータ名
例 ディストリビュータ「dst_uriage」のスキーマ情報を更新します。
ALTER DISTRIBUTOR dst_uriage REFRESH

115
循環設定の有無の変更 循環設定の有無を変更する場合は、次の構文を使用します。
ALTER DISTRIBUTOR <distributor_name> RECYCLE {ON | OFF}
<distributor_name> 操作対象のディストリビュータ名
RECYCLE 循環設定の有無
ON(有り)、OFF(無し)を指定します。
例 順序型ディストリビュータの循環設定をONに変更します。
ALTER DISTRIBUTOR dst_uriage RECYCLE ON
グループの定義を変更する ALTER GROUP
既存グループのコメントの変更・削除、グループ名の変更をおこなう場合は、ALTER GROUP文を使用します。Administratorsグループに
所属するユーザのみが実行できます。
ALTER GROUP <group_name>{
MODIFY COMMENT <new_comment>
| DROP COMMENT }
| RENAME <new_name> }
}
グループ名の変更 グループ名を変更する場合は、次の構文を使用します。
ALTER GROUP <group_name> RENAME <new_name>
<group_name> 操作対象のグループ名
<new_name> 名称変更後のグループ名
例 グループ名を「team_sum」から「team_sum2」に変更します。
ALTER GROUP team_sum RENAME team_sum2

116
グループコメントの変更 グループコメントを変更する場合は、次の構文を使用します。
ALTER GROUP <group_name> MODIFY COMMENT <new_comment>
<group_name> 操作対象のグループ名
<new_comment> 変更後のコメント 大1023文字まで記述することができます。
コメントはシングルクォート「'」、またはダブルクォート「"」でくくります。使用可能な文字は、SQL文に利
用可能な文字集合の内、タブ、改行を除いたものとなります。
例 グループ「dr_sum」のコメントを「team_sum」に変更します。
ALTER GROUP dr_sum MODIFY COMMENT 'team_sum'
グループコメントの削除 グループコメントを削除する場合は、次の構文を使用します。
ALTER GROUP <group_name> DROP COMMENT
<group_name> 操作対象のグループ名
例 グループ「dr_sum」のコメントを削除します。
ALTER GROUP dr_sum DROP COMMENT
権限の変更はGRANT文、REVOKE文でおこないます。詳細については、それぞれ「GRANT」(p.120)、「REVOKE」(p.124)を参照してください。
ユーザの定義を変更する ALTER USER
ユーザパスワードの変更、ユーザグループへのユーザの追加、ユーザグループからユーザの削除、ユーザコメントの変更・削除をおこなう
場合は、ALTER USER文を使用します。
ALTER USER <user_name>{
IDENTIFIED BY <password>
| JOIN TO GROUP <group_name>
| QUIT FROM GROUP <group_name>
| MODIFY COMMENT <new comment>
| DROP COMMENT
}

117
パスワードの変更 すべてのユーザは、自分のパスワードを変更することができます。ユーザ作成時点でパスワードを設定しなかった場合も、ALTER USER文
で新たにパスワードを設定できます。
Administratorsグループに所属するユーザのみが、他のユーザのパスワードを変更することができます。
パスワードを変更する場合は、次の構文を使用します。
ALTER USER <user_name> IDENTIFIED BY <password>
<user_name> 操作対象のユーザ名
<password> 新しいパスワード 小6文字、 大14文字(14バイト)で指定します。Server Settingsで設定を変更することで、パス
ワードの 小文字数(デフォルトは6)を指定したり、パスワードにアルファベットと数字を組み合わせる
などの設定をしたりすることができます。 パスワードには、SQLに利用可能な文字集合の内、タブ、改行、全角文字、半角かな文字を除いた
次の文字集合を利用することができます。
・半角英大文字
・半角英小文字
・半角数字
・半角スペース(20h)
・半角記号 ( ) " ' + - * / % & | _ # $ = < > ? ¥ ; : [ ] { } @ , .~!^`
NULLや''(空白)を指定できますが、この場合は、パスワード無しとして扱われます。 パスワードの設定を省略することもできます。
例 ユーザ「dr_sum」のパスワードを「2unclesum」に設定します。
ALTER USER dr_sum IDENTIFIED BY '2unclesum'
グループへの所属 ユーザをグループに追加する場合は、次の構文を使用します。指定するグループが既存であることを前提とします。Administratorsグ
ループに所属するユーザのみが実行できます。
ALTER USER <user_name> JOIN TO GROUP <group_name>
<user_name> 操作対象のユーザ名
<group_name> 所属させるグループ名
例 ユーザ「dr_sum」をグループ「team_sum」に所属させます。
ALTER USER dr_sum JOIN TO GROUP team_sum

118
グループからの削除 ユーザをユーザグループから削除する場合は、次の構文を使用します。
ALTER USER <user_name> QUIT FROM GROUP <group_name>
<user_name> 操作対象のユーザ名
<group_name> 所属を解除するグループ名
例 ユーザ「dr_sum」をグループ「team_sum」からはずします。
ALTER USER dr_sum QUIT FROM GROUP team_sum
ユーザコメントの変更 ユーザコメントを変更する場合は、次の構文を使用します。
ALTER USER <user_name> MODIFY COMMENT <new_comment>
<user_name> 操作対象のユーザ名
<new_comment> 変更後のコメント 大1023文字まで記述することができます。
コメントはシングルクォート「'」、またはダブルクォート「"」でくくります。使用可能な文字は、SQL文に利
用可能な文字集合の内、タブ、改行を除いたものとなります。
例 ユーザ「dr_sum」のコメントを「team_sumリーダー」に変更します。
ALTER USER dr_sum MODIFY COMMENT 'team_sumリーダー'
ユーザコメントの削除 ユーザコメントを削除する場合は、次の構文を使用します。
ALTER USER <user_name> DROP COMMENT
<user_name> 操作対象のユーザ名
例 ユーザ「dr_sum」のコメントを削除します。
ALTER USER dr_sum DROP COMMENT
テーブル名を変更する RENAME
テーブル名を変更する場合は、RENAME文を使用します。
RENAME <table_name> TO <new_table_name>
<table_name> 操作対象のテーブル名
<new_table_name> 新しいテーブル名

119
テーブルを削除する DROP TABLE
テーブルを削除する場合は、DROP TABLE文を使用します。テーブルに含まれているデータも削除されます。
DROP TABLE <table_name>
<table_name> 削除するテーブル名
他のプロセスによってテーブルがロックされている場合、ロックが解除されるまで待ち続けます。
検索インデックスを削除する DROP INDEX
検索インデックスを削除する場合は、DROP INDEX文を使用します。
Administratorsグループに所属するユーザのみが実行できます。
DROP INDEX <index_name>
<index_name> 削除する検索インデックス名
結合インデックスを削除する DROP JOIN INDEX
結合インデックスを削除する場合は、DROP JOIN INDEX文を使用します。
Administratorsグループに所属するユーザのみが実行できます。
DROP JOIN INDEX <index_name>
<index_name> 削除する結合インデックス名
ビューを削除する DROP VIEW
ビューが削除されても、基になるテーブルのデータは削除されません。
別ビューを参照作成したビューの場合、元になるビューが削除されるとそのビューは無効になります。削除された元ビューと同名のビューが
再作成されると、その名前を参照しているビューも再び使用可能になります。
ビューの元テーブルが削除されてもそのテーブルを参照しているビューは削除されません。再び同名のテーブルが作成されれば、その
テーブルを参照してビューは動作します。しかしテーブル定義が変更されている場合は、参照列名が違うなど不整合が起こる可能性があ
ります。元テーブルが再作成された場合は、ビューも再作成することを推奨します。
ビューを削除する場合は、DROP VIEW文を使用します。
DROP VIEW <view_name>
<view_name> 削除するビュー名
Dr.Sum EAでは、CASCADE句やRESTRICT句はサポートしません。

120
マルチビューを削除する DROP MULTIVIEW
マルチビューを削除する場合は、DROP MULTIVIEW文を使用します。Administratorsグループに所属するユーザのみ削除可能です。
DROP MULTIVIEW <multiview _name>
<multiview _name> 削除するマルチビュー名
ディストリビュータを削除する DROP DISTRIBUTOR
ディストリビュータを削除する場合は、DROP DISTRIBUTOR文を使用します。Administratorsグループに所属するユーザのみ削除可能
です。
DROP DISTRIBUTOR <distributor_name>
<distributor_name> 削除するディストリビュータ名
グループを削除する DROP GROUP
グループを削除する場合は、DROP GROUP文を使用します。Administratorsグループに所属するユーザのみが実行できます。
DROP GROUP <group_name>
<distributor_name> 削除するグループ名
ユーザを削除する DROP USER
ユーザを削除する場合は、DROP USER文を使用します。Administratorsグループに所属するユーザのみが実行できます。
DROP USER <user_name>
<user_name> 削除するユーザ名
Dr.Sum EAでは、ユーザがオブジェクトを所有することはないため、CASCADE句はサポートしません。
グループにアクセス権限を付与する GRANT
グループに各オブジェクト(テーブル・ビュー・列・データベース)へのアクセス権限を付与する場合は、GRANT文を使用します。
権限が設定されていないグループは、データベースへの接続、テーブル、ビュー、または任意の列へのアクセスが許可されません。
Administratorsグループは常にすべての権限を有しているため、グループの設定先にAdministratorsを指定することはできません。
GRANT {<table_privilege> | <view_privilege>|
<column_privilege>|<database_privilege>}
ON<database_name>["."(table_name["."(column_name|"*")]|"*"]
TO {<group_name>,"," }
<column_privilege> ::=

121
COLUMN
ENABLED
<table_privilege>::=
ALL
|{ SELECT | UPDATE }
<view_privilege>::=
SELECT
<database_privilege>::=
WRITE
テーブル、ビューの名称が変更された場合、権限も更新されます。
対象のオブジェクトが削除されると、関連するすべてのオブジェクトへのアクセス権限も削除されます。
Administratorsグループは常にすべての権限を有しているため、<group_name>にAdministratorsを指定することはでき
ません。
<database_name> 対象のオブジェクトが含まれるデータベース名(必須)
<database_name>.<table_name>
対象のテーブル・ビュー名 テーブル名を*にした場合は、データベース内のすべてのテーブル・ビューが選択されます。
<database_name>.<table_name>.<column_name>
対象の列名 列名を指定する時はかならず<database_name>.<table_name>.<column_name>を指定する
必要があります。
<group_name> 対象のグループ名 複数グループを指定する場合は、カンマ区切りで記述します。
<database_privilege> グループに付与するデータベースへのアクセス権限
<table_privilege> グループに付与するテーブルへのアクセス権限
<view_privilege> グループに付与するビューへのアクセス権限
<column_privilege> グループに付与する列へのアクセス権限
権限を付与できるオブジェクトは、SQL発行時にCONNECTしているデータベースに含まれているものです。
122
データベースへのアクセス権限の付与 設定可能なデータベースへのアクセス権限は次のとおりです。
CONNECT権限 CONNECT権限が付与されても、ユーザはSQLでは操作できません。Enterprise Manager上でのみ
操作可能となります。
WRITE権限 WRITE権限が付与されると、次のSQL文を発行できるようになります。
CREATE GROUP, CREATE TABLE, CREATE USER, CREATE VIEW
DROP GROUP, DROP TABLE, DROP USER, DROP VIEW
ALTER GROUP, ALTER TABLE, ALTER USER, ALTER VIEW
例 グループ「team_sum」に対し、データベース「db1」への書き込み権限を付与します。
GRANT WRITE ON db1 TO team_sum
テーブル・ビューへのアクセス権限の付与 設定可能なテーブル・ビューへのアクセス権限は次のとおりです。
権限を明示的に指定する場合は、SELECT、UPDATEのいずれかから1つ以上指定します。UPDATE権限を付与すると自動的にSELECT
権限が付与されます。
グループにSELECT、UPDATEのすべての権限を付与する場合は、ALLを指定します。
SELECT権限 SELECT権限が付与されると、次のSQL文を実行できます。
SELECT
UPDATE権限 UPDATE権限が付与されると、次のSQL文を実行できます。
INSERT ,UPDATE ,DELETE
指定するオブジェクトを含むデータベースに対してCONNECT権限が付与されている必要があります。
ビューに対してのアクセス権限では、付与できる権限はSELECT権限のみになります。
例1 グループ「team_sum」に対し、テーブル「foo」へのSELECT, UPDATE権限を付与します。
GRANT SELECT, UPDATE ON db1.foo TO team_sum
例2 グループ「team_sum」に対し、テーブル「foo」へのすべてのアクセス権限を付与します。
GRANT ALL ON db1.foo TO team_sum2
例3 グループ「team_sum」に対し、データベース「db1」内のすべてのテーブルへのSELECT権限を付与
します。
GRANT SELECT ON db1.* TO team_sum2

123
列へのアクセス権限の付与 テーブル、またはビュー内の任意の列に対してアクセスを許可しない設定をすることができます。例えば、社員情報が格納されているテー
ブルの生年月日や給与の列にこの設定をすることで、別途ビューなどを作成することなく、社員全員がそのテーブルを個人情報が含まれ
ない社員名簿として閲覧することができます。
デフォルトではすべての列に対してENABLED権限が付与されています。
指定する列を含むテーブルに対してSELECT権限が付与されている必要があります。
例1 グループ「team_sum」に対し、列「col」へのENABLED権限を付与します。
GRANT COLUMN ENABLED ON db1.foo.col TO team_sum
例2 グループ「team_sum」に対し、テーブル「foo」内のすべての列へのENABLED権限を付与します。
GRANT COLUMN ENABLED ON db1.foo.* TO team_sum

124
グループのアクセス権限を取り消す REVOKE
グループの各オブジェクト(テーブル・ビュー・列・データベース)へのアクセス権限を取り消す場合は、REVOKE文を使用します。
REVOKE {<table_privilege> |<view_privilege>|
<column_privilege>|<database_privilege>}
ON<database_name>["."(table_name["."(column_name|"*")]|"*"]
FROM <group_name>
<column_privilege> ::=
COLUMN
ENABLED
<table_privilege>::=
ALL
|{ SELECT | UPDATE }
<view_privilege>::=
SELECT
<database_privilege>::=
WRITE
<database_name> 対象のオブジェクトが含まれるデータベース名(必須)
<database_name>.<table_name>
対象のテーブル・ビュー名 テーブル名を*にした場合は、データベース内のすべてのテーブル・ビューが選択されます。
<database_name>.<table_name>.<column_name>
対象の列名 列名を指定する時はかならず<database_name>.<table_name>.<column_name>を指定する
必要があります。
<group_name> 対象のグループ名 複数グループを指定する場合は、カンマ区切りで記述します。
<database_privilege> グループから取り消すデータベースへのアクセス権限
<table_privilege> グループから取り消すテーブルへのアクセス権限
<view_privilege> グループから取り消すビューへのアクセス権限
<column_privilege> グループから取り消す列へのアクセス権限
権限を付与できるオブジェクトは、SQL発行時にCONNECTしているデータベースに含まれているものです。
Administratorsグループは常にすべての権限を有しているため、<group_name>にAdministratorsを指定することはでき
ません。

125
データベースへのアクセス権限の取り消し グループからデータベースへの書き込み権限を取り消す場合は、WRITEを指定します。
例 グループ「team_sum」からデータベース「db1」に対するWRITE権限を取り消す。
REVOKE WRITE ON db1 FROM team_sum
テーブル・ビューへのアクセス権限の取り消し グループからテーブルに対するSELECT、UPDATEのすべての権限を取り消す場合は、ALLを指定します。
権限を明示的に指定する場合は、SELECT、UPDATEのいずれかから1つ以上指定します。SELECT権限を取り消すと、すべての権限と、
テーブルに付随していた列権限は初期状態に戻ります(列権限の初期状態はENABLEDです)。
ビュー権限で取り消せるのはSELECT権限のみになります。
例1 グループ「team_sum」からテーブル「foo」に対するSELECT, UPDATE権限を取り消します。
REVOKE SELECT, UPDATE ON db1.foo FROM team_sum
例2 グループ「team_sum」からテーブル「foo」に対するすべての権限を取り消します。
REVOKE ALL ON db1.foo FROM team_sum
例3 グループ「team_sum」からデータベース「db1」内のすべてのテーブルに対するSELECT権限を取り
消します。
REVOKE SELECT ON db1.* FROM team_sum
列へのアクセス権限の取り消し デフォルトではすべての列に対してENABLED権限が付与されています。
指定する列を含むテーブルに対してSELECT権限が付与されている必要があります。
テーブルに対して、すべての列のENABLED権限を取り消す事はできません。
例1 グループ「team_sum」から列「col」に対するENABLED権限を取り消します。
REVOKE COLUMN ENABLED ON db1.foo.col FROM team_sum

126
断片化したROWIDの再構成をおこなう COMPACTION TABLE
断片化したROWIDを再構成する場合に、COMPACTION TABLE文を使用します。テーブルのROWIDを付与しなおします。
COMPACTION TABLEには、他セッションとの競合があった場合の振る舞いを決定するためのオプションを指定できます。
COMPACTION TABLE <table_name>
[EXCLUSIVE | PROTECTION | NO PROTECTION]
<table_name> 操作対象のテーブル名
オプション 他セッションとの競合があった場合の振る舞いを指定します。
EXCLUSIVE 当該処理が優先されます。そのため他セッションの処理が失敗する場合があります。
PROTECTION 再付与時に他セッションによりSELECTされている場合、当該処理が優先されます。
NO PROTECTION 再付与時に他セッションによりSELECTされている場合、当該処理が失敗します。
EXCLUSIVE以外のオプションを指定した場合や他セッションで当該テーブルに変更があった場合、処理は失敗します。
テーブルを再構築する REBUILD TABLE
テーブルを再構築する場合は、REBUILD TABLE文を使用します。テーブルのROWIDを付与しなおす事により、断片化したROWIDを再
構成します。
REBUILD TABLEには、他セッションとの競合があった場合の振る舞いを決定するためのオプションを指定できます。
REBUILD TABLE <table_name> [EXCLUSIVE | PROTECTION | NO PROTECTION]
<table_name> 操作対象のテーブル名
オプション 他セッションとの競合があった場合の振る舞いを指定します。
EXCLUSIVE 当該処理が優先されます。そのため他セッションの処理が失敗する場合があります。
PROTECTION 再構築時に他セッションによりSELECTされている場合、当該処理が優先されます。
NO PROTECTION 再構築時に他セッションによりSELECTされている場合、当該処理が失敗します。
EXCLUSIVE以外のオプションを指定した場合や他セッションで当該テーブルに変更があった場合、処理は失敗します。
検索インデックスを再構築する REBUILD INDEX
検索インデックスの再構築をおこなう場合に、REBUILD INDEX文を使用します。元テーブルから乖離した状態の検索インデックスを再構
築し、 新の状態にします。
REBUILD INDEX <index_name>
<index_name> 再構築する検索インデックス名
127
結合インデックスを再構築する REBUILD JOIN INDEX
結合インデックスの再構築をおこなう場合に、REBUILD JOIN INDEX文を使用します。元テーブルから乖離した状態の結合インデックス
を再構築し、 新の状態にします。
REBUILD JOIN INDEX <index_name>
<index_name> 再構築する結合インデックス名
システムテーブルを再構築する REBUILD SYSTEMTABLES
システムテーブルを再構築する場合は、REBUILD SYSTEMTABLES文を使用します。断片化したデータを再構成します。
REBUILD SYSTEMTABLES
テーブル「__all_triggers__」は再構成されません。
表の全データを切り捨てる TRUNCATE
表の全データを切り捨てる場合は、TRUNCATE文を使用します。TRUNCATEを実行するためには、テーブルへの書込み権限が必要となり
ます。
TRUNCATE TABLE <table_name>
テーブル内のすべての行を削除する場合は、DELETEよりも高速に処理することができます。ただし、ROLLBACKすることはできません。

128
データ制御言語(DCL)
Dr.Sum EA Ver3.0では、自動的にトランザクションが開始されます。COMMIT文を発行して変更処理を確定するか、またはROLLBACK文
を発行して変更処理を取り消した時点で、トランザクションが終了します。
COMMIT文でトランザクションを終了した場合は、トランザクションの処理結果がデータベースに反映されます。
ROLLBACK文でトランザクションを終了した場合は、トランザクションが開始される前の状態にデータベースが戻されます。この場合、トラン
ザクションの対象になる処理はINSERT、UPDATE、DELETEのいずれかのDML文だけであり、DDL文やDCL文による処理はその都度トラン
ザクションが終了されます。
他ユーザは、コミットするまでに変更された値を見ることができません。
トランザクションを開始する BEGIN
トランザクションの開始を明示的に宣言します。BEGINは省略することが可能です。
BEGIN
・・・・
COMMIT
トランザクションを確定する COMMIT
トランザクションによる変更処理を確定し、その処理結果をデータベースに反映するには、COMMIT文を使用します。ただし、COMMIT文を
発行する前にDDL文を発行すると自動的にCOMMITされてトランザクションは終了します。
トランザクションを破棄する ROLLBACK
トランザクションによる変更処理を破棄し、トランザクションが開始される前の状態にデータベースを戻すには、ROLLBACK文を使用します。
トランザクションを終了すると、そのトランザクションで設定されていたすべてのロックが解除されます。
BEGIN
・・・・
ROLLBACK
テーブルへのトランザクションを制御する LOCK TABLE
テーブルのトランザクションを制御する場合は、LOCK TABLE文を使用します。
COMMIT、ROLLBACKの契機でUNLOCKされます。
LOCK TABLE <table_name>
<table_name> ロックするテーブル名
例 テーブル「tab1」をロックします。
LOCK TABLE tab1;
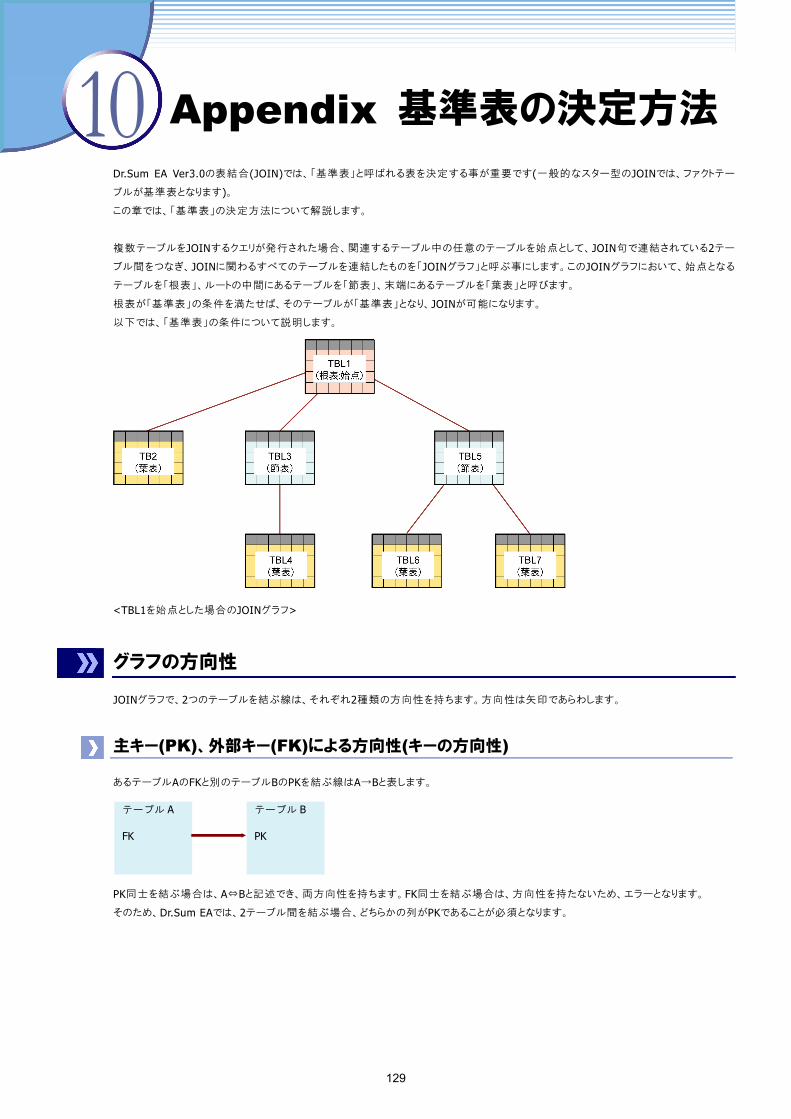
129
10 Appendix 基準表の決定方法 Dr.Sum EA Ver3.0の表結合(JOIN)では、「基準表」と呼ばれる表を決定する事が重要です(一般的なスター型のJOINでは、ファクトテー
ブルが基準表となります)。
この章では、「基準表」の決定方法について解説します。
複数テーブルをJOINするクエリが発行された場合、関連するテーブル中の任意のテーブルを始点として、JOIN句で連結されている2テー
ブル間をつなぎ、JOINに関わるすべてのテーブルを連結したものを「JOINグラフ」と呼ぶ事にします。このJOINグラフにおいて、始点となる
テーブルを「根表」、ルートの中間にあるテーブルを「節表」、末端にあるテーブルを「葉表」と呼びます。
根表が「基準表」の条件を満たせば、そのテーブルが「基準表」となり、JOINが可能になります。
以下では、「基準表」の条件について説明します。
<TBL1を始点とした場合のJOINグラフ>
グラフの方向性
JOINグラフで、2つのテーブルを結ぶ線は、それぞれ2種類の方向性を持ちます。方向性は矢印であらわします。
主キー(PK)、外部キー(FK)による方向性(キーの方向性)
あるテーブルAのFKと別のテーブルBのPKを結ぶ線はA→Bと表します。
PK同士を結ぶ場合は、A⇔Bと記述でき、両方向性を持ちます。FK同士を結ぶ場合は、方向性を持たないため、エラーとなります。
そのため、Dr.Sum EAでは、2テーブル間を結ぶ場合、どちらかの列がPKであることが必須となります。
テーブル A FK
テーブル B PK
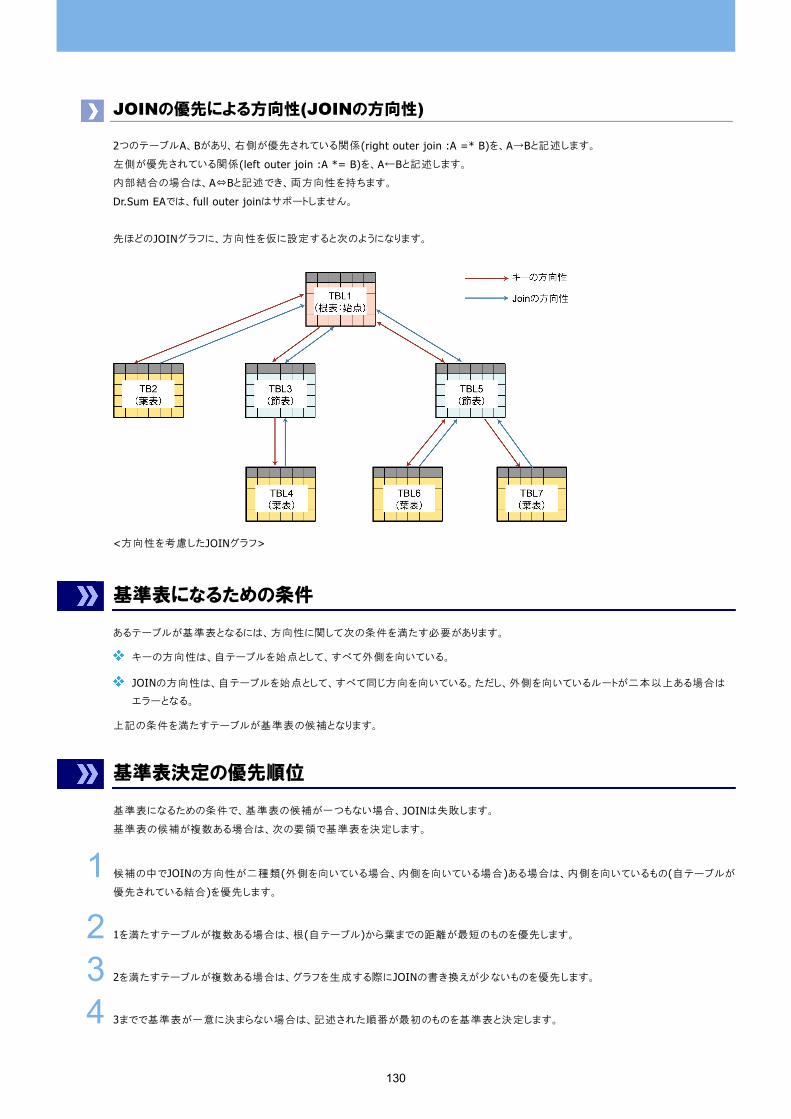
130
JOINの優先による方向性(JOINの方向性)
2つのテーブルA、Bがあり、右側が優先されている関係(right outer join :A =* B)を、A→Bと記述します。
左側が優先されている関係(left outer join :A *= B)を、A←Bと記述します。
内部結合の場合は、A⇔Bと記述でき、両方向性を持ちます。
Dr.Sum EAでは、full outer joinはサポートしません。
先ほどのJOINグラフに、方向性を仮に設定すると次のようになります。
<方向性を考慮したJOINグラフ>
基準表になるための条件
あるテーブルが基準表となるには、方向性に関して次の条件を満たす必要があります。
キーの方向性は、自テーブルを始点として、すべて外側を向いている。
JOINの方向性は、自テーブルを始点として、すべて同じ方向を向いている。ただし、外側を向いているルートが二本以上ある場合は
エラーとなる。
上記の条件を満たすテーブルが基準表の候補となります。
基準表決定の優先順位
基準表になるための条件で、基準表の候補が一つもない場合、JOINは失敗します。
基準表の候補が複数ある場合は、次の要領で基準表を決定します。
1 候補の中でJOINの方向性が二種類(外側を向いている場合、内側を向いている場合)ある場合は、内側を向いているもの(自テーブルが
優先されている結合)を優先します。
2 1を満たすテーブルが複数ある場合は、根(自テーブル)から葉までの距離が 短のものを優先します。
3 2を満たすテーブルが複数ある場合は、グラフを生成する際にJOINの書き換えが少ないものを優先します。
4 3までで基準表が一意に決まらない場合は、記述された順番が 初のものを基準表と決定します。

131
例 テーブルが次のような構成の場合
「基準表になるための条件」の1を満たすものは、TBL1、TBL2、TBL5、TBL6
そのうち、2を満たすものは、TBL1、TBL3、TBL5
したがって、基準表の候補はTBL1、TBL5となります。
「基準表決定の優先順位」により、TBL1、TBL5ともに、JOINの方向性が内側を向いている(自テーブルが優先されている)ためどちらも候
補として残ります。
しかし、TBL1を根とした場合、葉テーブルまでの 大距離は2ですが、TBL5を根とした場合、葉テーブルまでの 大距離は3となるため、
この場合、TBL1が基準表と決定されます。
VIEWを含むJOIN
VIEW定義を解析し、すべて実テーブルに展開してから、同様のルールで基準表を決定します。ただし、VIEW定義に集計を含む場合は、
一度集計をおこなう必要があるため、集計後の結果セットをJOINテーブルとして扱います。

132

索引-1
A
ABS ............................................................................ 44
ACOS .......................................................................... 44
ADD_MONTHS ............................................................. 53
ALL............................................................................. 67
ALTER DISTRIBUTOR ...................................................112
ALTER GROUP .............................................................115
ALTER INDEX ..............................................................106
ALTER JOIN INDEX ......................................................106
ALTER MULTIVIEW ......................................................109
ALTER TABLE ..............................................................100
ALTER USER ...............................................................116
ALTER VIEW ...............................................................107
AS .............................................................................. 68
ASIN ........................................................................... 44
ATAN .......................................................................... 45
ATAN2......................................................................... 45
AVG ............................................................................ 36
B
BEGIN........................................................................128
C
CEIL ........................................................................... 45
CHR ............................................................................ 38
COALESCE ................................................................... 55
COMMIT .....................................................................128
COMPACTION TABLE....................................................126
Compound Key表制約 ..................................................... 3
CONCAT ...................................................................... 38
CONNECT句 ............................................................ 83, 91
CONSTRAINT ON TOP ................................................... 67
COS ............................................................................ 45
COSH .......................................................................... 46
COUNT........................................................................ 36
CREATE DISTRIBUTOR .................................................. 90
CREATE GROUP............................................................ 98
CREATE INDEX............................................................. 78
CREATE JOIN INDEX ..................................................... 79
CREATE MULTIVIEW ..................................................... 82
CREATE TABLE ............................................................. 75
CREATE USER .............................................................. 99
CREATE VIEW .............................................................. 80
D
DCL ..................................................................... 65, 128
DDL ....................................................................... 65, 75
DECODE.......................................................................55
DELETE........................................................................74
DISTINCT.....................................................................67
DML....................................................................... 65, 66
DROP DISTRIBUTOR.................................................... 120
DROP GROUP ............................................................. 120
DROP INDEX............................................................... 119
DROP JOIN INDEX....................................................... 119
DROP MULTIVIEW ....................................................... 120
DROP TABLE ............................................................... 119
DROP USER ................................................................ 120
DROP VIEW ................................................................ 119
DWテーブル ................................................................... 4
E
EXP .............................................................................46
F
FIRST ..........................................................................38
FLOOR .........................................................................46
FROM句 .......................................................................68
G
GET_GROUP_INFO ........................................................61
GET_USER_INFO...........................................................60
GRANT....................................................................... 120
GREATEST ....................................................................46
GROUP BY句 .................................................................71
H
HAVING句 ....................................................................72
I
INITCAP.......................................................................39
INSERT ........................................................................73
J
JOIN.................................................................... 33, 130
L
LAST_DAY ....................................................................53
LCASE..........................................................................39
索引-2
LEAST ......................................................................... 47
LENGTH ...................................................................... 39
LENGTHB .................................................................... 39
LN .............................................................................. 47
LOG ............................................................................ 47
LOWER ....................................................................... 39
LPAD .......................................................................... 40
LTRIM ......................................................................... 40
M
MAX............................................................................ 37
MID ............................................................................ 41
MIN ............................................................................ 37
MONTHS_BETWEEN...................................................... 53
N
NEXT_DAY................................................................... 54
NOT NULL制約 ............................................................. 76
NULLIF........................................................................ 55
NULL値 ....................................................................... 13
NULL値の変換 .............................................................. 56
NVL ............................................................................ 56
O
OID ............................................................................ 12
ORDER BY句 ................................................................ 70
P
PARTITION BY句 ..................................................... 83, 91
POWER ....................................................................... 47
R
REBUILD INDEX ..........................................................126
REBUILD JOIN INDEX ..................................................127
REBUILD SYSTEMTABLES .............................................127
REBUILD TABLE ..........................................................126
RENAME ............................................................. 118, 128
REPLACE ..................................................................... 41
REVOKE .....................................................................124
ROLLBACK ..................................................................128
ROUND .................................................................. 48, 54
ROWID ....................................................................... 12
RPAD .......................................................................... 42
RTRIM ........................................................................ 42
S
SELECT ........................................................................66
select_list.....................................................................68
SIGN ...........................................................................48
SIN..............................................................................48
SINH ...........................................................................48
SQLコメント ....................................................................10
SQRT ...........................................................................48
SUBSTR .......................................................................43
SUBSTRING ..................................................................43
SUM ............................................................................37
SYSDATE ......................................................................54
T
TAN .............................................................................49
TANH ...........................................................................49
TO_CHAR ..........................................................50, 56, 57
TO_COMPOUND ............................................................60
TO_DATE ............................................................... 51, 59
TO_INTERVAL......................................................... 52, 60
TO_NUMERIC................................................................58
TO_TIME................................................................ 52, 59
TO_TIMESTAMP ...................................................... 51, 58
TOP .............................................................................67
TRIM ...........................................................................43
TRUNC................................................................... 49, 54
TRUNCATE ................................................................. 127
U
UCASE .........................................................................43
UNIQUE制約 .................................................................77
UPDATE .......................................................................74
UPPER .........................................................................43
W
WHERE句 .....................................................................70
あ
アスタリスク ....................................................................67
値の変換 ......................................................................55
え
演算子 .........................................................................27

索引-3
お
大文字への変換 ............................................................ 43
オブジェクトID ................................................................ 12
オブジェクトデータ型 ........................................................ 24
表制約 .....................................................................3, 31
か
概数データ型 ................................................................ 20
外部キー.....................................................................129
囲み文字 ....................................................................... 8
数定数 .......................................................................... 9
型変換 ........................................................................ 25
型変換関数 .................................................................. 56
関数 ........................................................................... 35
き
期間型 ........................................................................ 22
基準表 ................................................................. 69, 129
逆コサイン..................................................................... 44
逆サイン ....................................................................... 44
逆タンジェント................................................................. 45
行数のカウント................................................................ 36
切り捨て ....................................................................... 54
く
クエリ ........................................................................... 62
グループの取得 ............................................................. 61
グループの定義を変更 ...................................................115
グループを削除 .............................................................120
グループを作成 .............................................................. 98
け
結合 ........................................................................3, 69
結合インデックスの作成 ................................................... 79
結合インデックスの有効・無効を切り替え .............................106
結合インデックスを再構築 ...............................................127
結合インデックスを削除 ..................................................119
権限の取り消し .............................................................124
権限を付与 .................................................................120
言語 ............................................................................. 7
検索インデックスの作成 ................................................... 78
検索インデックスの有効・無効を切り替え .............................106
検索インデックスを再構築 ...............................................126
検索インデックスを削除 ..................................................119
こ
合計値 .........................................................................37
構文 ............................................................................. 7
コサイン.........................................................................45
コピー ...........................................................................77
コメント ..........................................................................10
小文字への変換 .............................................................39
さ
再構成 ....................................................................... 126
終日 .........................................................................53
小値 ................................................................... 37, 47
初の値の検索 .............................................................38
初の引数 ...................................................................55
大整数 ......................................................................46
大値 ................................................................... 37, 46
サイン ...........................................................................48
サブクエリ ............................................................ 2, 62, 72
左右指定文字削除 .........................................................43
算術演算子 ...................................................................27
し
識別子 .......................................................................... 9
字句規則 ....................................................................... 9
自己結合 ....................................................................... 3
四捨五入 ................................................................ 48, 54
指数関数値 ...................................................................46
システムテーブルを再構築 .............................................. 127
自然対数 ......................................................................47
集計関数 ......................................................................35
集合演算子 ...................................................................30
主キー ........................................................................ 129
順序型 ................................................................... 83, 91
条件型 ................................................................... 83, 91
小数点以下の切り上げ .....................................................45
小数点以下の切り捨て .....................................................49
す
数値操作関数 ...............................................................44
数値データ型 .................................................................20
数値リテラル ..................................................................21
スカラー式 .....................................................................34
せ
制約 ............................................................................31
セッション関数 ................................................................60

索引-4
絶対値 ........................................................................ 44
そ
双曲線コサイン .............................................................. 46
双曲線サイン ................................................................ 48
双曲線タンジェント .......................................................... 49
た
対数 ........................................................................... 47
タンジェント .................................................................... 49
ち
地域 ............................................................................. 7
置換 ........................................................................... 41
抽出 ........................................................................... 43
つ
月数の加算 .................................................................. 53
月単位の差 .................................................................. 53
月の 終日 .................................................................. 53
て
定数 ............................................................................. 8
ディストリビュータの定義を変更 .........................................112
ディストリビュータを削除 ...................................................120
ディストリビュータを作成 .................................................... 90
データ型....................................................................... 13
データ制御言語 ...................................................... 65, 128
データ操作言語 ........................................................ 65, 66
データ定義言語 ........................................................ 65, 75
データディクショナリ ........................................................... 4
テーブルの定義を変更 ...................................................100
テーブル名を変更 .........................................................118
テーブルを再構築 .........................................................126
テーブルを削除 ............................................................119
テーブルを作成 ............................................................. 75
デフォルト値 ...............................................................3, 77
と
トークン .......................................................................... 9
特殊演算子 .................................................................. 28
トランザクションを開始 .....................................................128
トランザクションを確定 .....................................................128
トランザクションを破棄 .....................................................128
な
並べ替え.......................................................................70
は
バイト数の取得................................................................39
ひ
比較演算子 ...................................................................28
引数 ............................................................................55
引数の符号 ...................................................................48
左指定文字削除 ............................................................40
左文字埋め ...................................................................40
日付時刻 ......................................................................54
日付書式指定子 ............................................................50
日付操作関数 ...............................................................53
日付データ型 .................................................................21
ビュー ............................................................................ 4
ビューの定義を変更 ....................................................... 107
ビューを削除 ................................................................ 119
ビューを作成 ..................................................................80
ビューを参照作成 ...........................................................81
表記 ............................................................................. 7
ふ
フォーマット .........................................................50, 51, 52
副問合せ ....................................................................... 2
へ
平均値 .........................................................................36
平方根 .........................................................................48
べき乗 ..........................................................................47
変換関数 ......................................................................55
ま
真数データ型 .................................................................20
マルチビューの定義を変更 .............................................. 109
マルチビューを削除 ....................................................... 120
マルチビューを作成 .........................................................82
み
右指定文字削除 ............................................................42
右文字埋め ...................................................................42
も
文字 ............................................................................. 7
索引-5
文字数の取得 ............................................................... 39
文字変換 ..................................................................... 38
文字列 ........................................................................ 19
文字列操作関数 ........................................................... 38
文字列定数 .................................................................... 8
文字列の抽出 ............................................................... 41
文字列の連結 ............................................................... 38
文字列リテラル .............................................................. 19
ゆ
ユーザ情報の取得 ......................................................... 60
ユーザの定義を変更 ......................................................116
ユーザを削除 ...............................................................120
ユーザを作成 ................................................................ 99
よ
翌日 ............................................................................54
予約語 .........................................................................11
り
リンクテーブルを作成 ........................................................78
れ
列制約 ................................................................... 31, 76
列選択 .......................................................................... 3
連結演算子 ...................................................................27
ろ
論理演算子 ...................................................................30

Dr.Sum EA SQL リファレンス Ver3.0SP3
販売元: ウイングアーク テクノロジーズ株式会社 [本社]〒150-0044 東京都渋谷区円山町 28-5 1st 渋谷ビル TEL:03-5962-7300(代表) FAX:03-5962-7301 ホームページ:http://www.wingarc.co.jp
2010年 6月 第1版
開発元: ディジタル・ワークス株式会社 〒060-0808 北海道札幌市北区北 8 条西 3-32 8・3 スクエア北ビル 8F
※本マニュアルは予告なく変更することがあります。 ※本マニュアルに記載されている社名および商品名は、一般に各社の商標および登録商標です。






![Dr.Sum EA Connect 4.0 アップグレードガイド...Dr.Sum EA Connectの厐卥に勖単されるメニュー匷・タブ匷・プロパティ儅目匷および値・ボタン匷は[]で囲んで太](https://img.pdfslide.tips/doc/110x75/5f4fdb3044a73e1a2c475735/drsum-ea-connect-40-fffffff-drsum-ea-connectoeffffoeffoefffffcoeffoefoe.jpg)






















