Embed Size (px)
DESCRIPTION
2002 年くらいから伸びてきた分野です。最近は機械学習、データ工学系の学会で相当数の論文が発表されています。 こういうご時勢ですから、ひょっとすると重要な技術要素になるかもしれません。. 個人情報保護が叫ばれ る 複数の企業、組織が協力しないと日本はどんどん遅れていく. プライバシ保護データマイニング (PPDM). 東京大学 中川裕志. PPDM の基礎概念. 2種類のPPDM. 摂動法 データベースに雑音を加え、利用者がデータベースに質問しても真のデータベースの内容が利用者には取得できないようにする - PowerPoint PPT Presentation
Citation preview

プライバシ保護データマイニング(PPDM)
東京大学中川裕志
2002 年くらいから伸びてきた分野です。最近は機械学習、データ工学系の学会で相
当数の論文が発表されています。
こういうご時勢ですから、ひょっとすると重要な技術要素になるかもしれませ
ん。
個人情報保護が叫ばれる複数の企業、組織が協力しないと日本はどんどん遅
れていく

PPDM の基礎概念

2種類のPPDM 摂動法
データベースに雑音を加え、利用者がデータベースに質問しても真のデータベースの内容が利用者には取得できないようにする
プライベートな情報は漏れないようにしたいが、一方でできるだけ正確なデータマイニング結果も得たい!
暗号法 データ保持者をパーティと呼ぶ。複数のパーティが自分
のデータは公開鍵暗号で暗号化する。当然、他のパーティには自分のデータは知られない。暗号化したまま何らかの計算をしてデータマイニングの結果だけは全パーティが共有する。
3

摂動法

摂動法に関して2002 年から 2006 年ころまでに導入された概念
摂動法による PPDM を始めた動機 k- 匿名性( k-anonymity ) l- 多様性( l-diversity ) t-closeness

動機 複数の組織がプライシーに係わるクリティカルなデータ
(sensitive data) を持ち、場合によっては公開している microdata (vs. aggregated macrodata) と呼ばれる詳細データが解析
やマイニングに利用される状況である。(USでは公開は法令で義務化 )
microdata の保護のため sanitized (不要部分の削除など) 例えば、 explicit identifiers (Social Security Number, name, phone #)
の削除
しかし、それで十分か? 否 ! link attacks の脅威
公開データからプライバシー情報を推測できる可能性あり

link attack の例 Sweeney [S01a] によれば、 Massachussetts 州知事の医療記
録が公開情報から特定可能 MA では、収集した医療データを sanitize して公開している
(下図) (microdata) 左円内 一方、選挙の投票者名簿は公開 右円内
• 両者をつきあわせると• 6 人が知事と同じ生年月日 うち 3 人が男 うち 1 人が同じ zipcode
• 1990 年の the US 1990 census data によれば– 87% の人が (zipcode, 性別 , 生年月日 ) によって一意特定可能
[S01a] より

microdata のプライバシー microdata の属性
explicit identifiers は削除 quasi identifiers ( QI =擬 ID) は個人特定に利用可能 sensitive attributes は sensitive 情報を持つ
identifier
quasi identifiers sensitive
名前 誕生日 性別 Zipcode 病名
太朗 21/1/79 男 53715 風邪
花子 10/1/81 女 55410 肺炎
光子 1/10/44 女 90210 気管支炎
次郎 21/2/84 男 02174 ねんざ
明菜 19/4/72 女 02237 エイズ
プライバシー保護の目標は、個人をsensitive 情報から特定できないようにす
ること
Sanitize!

k- 匿名性( k-anonymity ) k- 匿名性によるプライバシー保護 , Sweeney and Samarati [S01,
S02a, S02b] k- 匿名性 : 個人を他の k-1 人に紛れさせる
つまり、 公開された microdata においては、 Quasi Identifier:QI の値が同一の個人は少なくとも k 人存在することを保証
よって、 link attack でも個人特定の確率は 1/k
実現方法 一般化 and 抑圧 当面はデータの値の perturbation (摂動)は考えない。摂動は、後に差分プライバシーのところで活用されることになる
プライバシーとデータマイニングにおける有用性のトレードオフ 必要以上に匿名化しない

k- 匿名性 の例
匿名化手法 一般化
例えば、対象分野のデータは抽象度によって階層化されているなら、上の階層のデータを公開
抑圧 特異性のあるデータ項目は削除
誕生日 性別 Zipcode
21/1/79 男 53715
10/1/79 女 55410
1/10/44 女 90210
21/2/83 男 02274
19/4/82 男 02237
誕生日 性別Zipcode
group 1*/1/79 人 5****
*/1/79 人 5****
suppressed
1/10/44 女 90210
group 2*/*/8* 男 022**
*/*/8* 男 022**
original microdata 2-anonymous data

一般化を行う束: lattice K-anonymity
zipcode 誕生日 性別
全 Qi に対して一般化を行う束を構成
目的k-anonymity を満たしつつ、最小
限の一般化を行う
一般
化
less
more
Z0
Z1
Z2
={53715, 53710, 53706, 53703}
={5371*, 5370*}
={537**}
B0
B1
={26/ 3/ 1979, 11/ 3/ 1980, 16/ 5/ 1978}
={*}
<S0, Z0>
<S1, Z0> <S0, Z1>
<S1, Z1>
<S1, Z2>
<S0, Z2>
[0, 0]
[1, 0] [0, 1]
[1, 1]
[1, 2]
[0, 2]
S0
S1
={Male, Female}
={Person}

一般化のために束構造を使うincognito [LDR05]
単調性の利用
<S0, Z0>
<S1, Z0> <S0, Z1>
<S1, Z1>
<S1, Z2>
<S0, Z2>
(I) 一般化の性質 (~rollup)if k-anonymity があるノードで成立then そのノードの任意の上位ノードでも成立
(II) 部分集合の性質 (~apriori)if あるノードで QI の属性の集合が k-anonymity でないthen その集合を含む集合でも k-anonymity でない
e.g., <S1, Z0> k-anonymous <S1, Z1> も <S1, Z2> k-anonymous
e.g., <S0, Z0> k-anonymous でない <S0, Z0, B0> and <S0, Z0, B1> k-anonymous でない
<S,Z,B> を全部使って描くと複雑すぎるので <S,Z> のみ

分割によっては匿名化できない例incognito の例
2 QI 属性 , 7 このデータ点
zipcode
sex
group 1w. 2 tuples
group 2w. 3 tuples
group 3w. 2 tuples
性別
を一般
化
郵便番号を一般化
not 2-anonymous
2-anonymous

一般化の良い例、悪い例 [LDR05, LDR06]
各次元を順次一様に一般化
incognito [LDR05]
各次元を個別に一般化mondrian [LDR06]
多次元まとめて一般化
topdown [XWP+06]
一般化の強さ

mondrian[LDR06]
2-anonymous

グループの周囲長を利用してグループ化[XWP+06]:
まずい一般化長い箱
データマイニングの精度が低い
良い一般化正方形に近い
データマイニングの精度が高い

Topdown [XWP+06]
split algorithm最も遠い2点を種にして開始• これはヒューリスティックではある• 種から2グループへ成長させる
各データ点を調べ、近くの種(あるいは種から成長したグループ)に周囲長が最小になる点を追加して新しいグループとする
右図では、全ての点は、元々は赤と緑に分離されていなかったが、アニメーションに示すような流れで 2 グループに分離された。

外部 DB を逆に利用 外部データは通常攻撃側が使うが、これを逆利用して役立てたい join k-anonymity (JKA) [SMP]
x3
k- 匿名
x3 x3
合併
JKA
マイクロデータ
公開データ
3- 匿名
合併 3- 匿名anonymous
合併されたマイクロデータ

k- 匿名性の問題点 k- 匿名性 の例 Homogeneity による攻撃 : 最終グループは全員 cancer 背景知識による攻撃 : 第 1 グループで、日本人は心臓疾患にかかりにくい
ことが知られていると。。。
id Zipcode
年齢 国籍 病名
1 13053 28 ロシア 心臓病2 13068 29 US 心臓病3 13068 21 日本 感染症4 13053 23 US 感染症5 14853 50 インド がん6 14853 55 ロシア 心臓病7 14850 47 US 感染症8 14850 49 US 感染症9 13053 31 US がん
10 13053 37 インド がん11 13068 36 日本 がん12 13068 35 US がん
id Zipcode
年齢 国籍 病名
1 130** <30 ∗ 心臓病2 130** <30 ∗ 心臓病3 130** <30 ∗ 感染症4 130** <30 ∗ 感染症5 1485* ≥40 ∗ がん6 1485* ≥40 ∗ 心臓病7 1485* ≥40 ∗ 感染症8 1485* ≥40 ∗ 感染症9 130** 3∗ ∗ がん
10 130** 3∗ ∗ がん11 130** 3∗ ∗ がん12 130** 3∗ ∗ がん
microdata 4-anonymous data

l- 多様性[MGK+06]
各グループにおいて sensitiveなデータの値がうまく管理されていることを目指す homogeneity 攻撃を防ぐ背景知識攻撃を防ぐ
l- 多様性 (簡単な定義 )あるグループが l- 多様性を持つとは、そのグループ内では少なくとも l 種類の sensitive なデータ値が存在する
• group 内に l 種類の sensitive な値があり、できるだけ均等に出現することが望ましい。

21
名前 年齢 性別 病名
一郎 65 男 インフルエンザ
次郎 30 男 胃炎
三子 43 女 肺炎
四郎 50 男 インフルエンザ
五子 70 女 肺炎
六夫 32 男 インフルエンザ
七子 60 女 インフルエンザ
八郎 55 男 肺炎
九美 40 女 鼻炎
一郎 インフル
六夫 インフル
七子 インフル
四郎 インフル
三子 肺炎
五子 肺炎
八郎 肺炎
次郎 胃炎
九美 鼻炎一郎 インフル
七子 インフル
三子 肺炎
八郎 肺炎
九美 鼻炎
六夫 インフル
四郎 インフル
五子 肺炎
次郎 胃炎
3 つのグループはいずれも 3 種類の病名 (sebnsitive data) を含む: l-diversity
病名の頻度順に並んだ DB
algorithm• sensitive values を
bucket に割り当て• 大きい順に l 個の bucket
からデータを引き出してグループを形成

Anatomy グループ化したデータを QI の表と sensitive データ
の表に分割 3-diversity
22
グループID
病名 頻度
1 インフル 2
1 肺炎 2
1 鼻炎 1
2 インフル 2
2 肺炎 1
2 胃炎 1
名前:匿名化する
QI:年齢
QI:性別
グループ ID
一郎 65 男 1
七子 60 女 1
三子 43 女 1
八郎 55 男 1
九美 40 女 1
六夫 32 男 2
四郎 50 男 2
五子 70 女 2
次郎 30 男 2これらの 2 つの表からデータマイニングする

t-closeness l- 多様性があっても、ある属性が a の確率 99%,b の確率 1% というように偏りが激しいと、プライバシーは危険
2つのグループ(上記 a 属性のグループと b 属性のグループ)は、 sensitive データの分布における距離と、全属性の分布における距離が t 以下であるとき、 t-closeness である。
上記の分布間の距離としては、属性を各次元としてにおいて Earth Mover’s distance(EMD) を用いる
23
1
,1,10..
min,
andbewteen flow
:andbetween distance,,..,,,,..,,
111 1
11
1 1
1 1
2121
m
i i
m
i i
m
i
m
j ij
i
m
j ji
m
j ijiij
ij
m
i
m
j ijf
ij
m
i
m
j ijij
jiij
jiijmm
qpf
qffpmjmifts
fdQPEMD
EMDfdf
qpf
given qpdqqqQpppP
ij
最適化したのがを変化させて
:
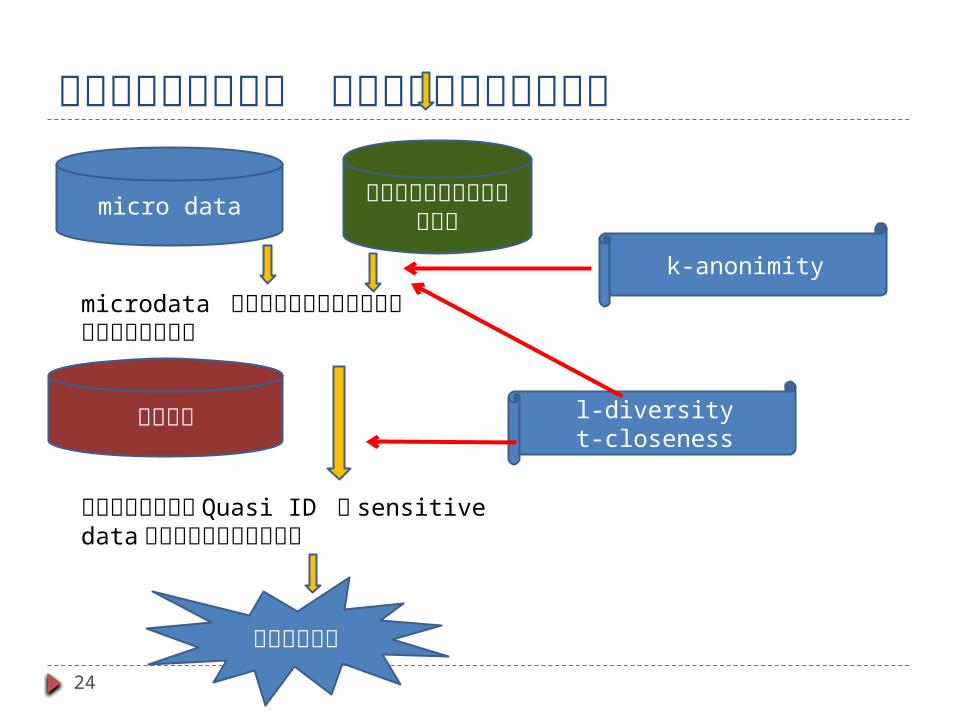
攻撃を断ち切るには をどこか断ち切れば良い
24
microdata と公開外部データとの突き合わせを狙う攻撃
背景知識を用いた Quasi ID と sensitive data の突き合わせを狙う攻撃
micro data 公開された外部データベース
背景知識
個人情報流出
k-anonimity
l-diversityt-closeness

k-anonymity, l-diversity, t-closeness の参考文献 [LDR 05]LeFevre, K., DeWitt, D.J., Ramakrishnan, R. Incognito: Efficient Full-domain k-
Anonymity. SIGMOD, 2005. [LDR06]LeFevre, K., DeWitt, D.J., Ramakrishnan, R. Mondrian Multidimensional k-Anonymity.
ICDE, 2006. [XWP+06] Xu, J., Wang, W., Pei, J., Wang, X., Shi, B., Fu, A., Utility-Based Anonymization Using
Local Recoding. SIGKDD, 2006. [MGK2007]MACHANAVAJJHALA,A. KIFER,D. GEHRKE,J. and VENKITASUBRAMANIAM,
U. l-Diversity: Privacy Beyond k-Anonymity. ACM Transactions on Knowledge Discovery from Data, Vol. 1, No. 1, Article 3,2007
[S01] Samarati, P. Protecting Respondents' Identities in Microdata Release. IEEE TKDE, 13(6):1010-1027, 2001.
[S02a] Sweeney, L. k-Anonymity: A Model for Protecting Privacy. International Journal on Uncertainty, Fuzziness and Knowledge-based Systems, 2002.
[S02b] Sweeney, L. k-Anonymity: Achieving k-Anonymity Privacy Protection using Generalization and Suppresion. International Journal on Uncertainty, Fuzziness and Knowledge-based Systems, 2002.
Ninghui Li,Tiancheng Li,Venkatasubramanian, S. “t-Closeness: Privacy Beyond k-Anonymity and –Diversity”. ICDE2007, pp.106-115, 2007.
[SMP] Sacharidis, D., Mouratidis, K., Papadias, D. k-Anonymity in the Presence of External Databases( to be appeared)
25

ここまで述べてきたように、公開された複数のデータベースを串刺しする攻撃への対策は、 t-closenessに至って、一段落した感あり。
攻撃者は、データベースへの質問者の場合を想定 攻撃者の事前知識に左右されることなく、データ
ベースのプライバシー保護の強度を数学的に制御できる概念として、 2006 年以降、マイクロソフトのCynthia Dwork が中心になって提案した差分プライバシーがトレンドとなった。
26

DIFFERENTIAL PRIVACY差分プライバシー 同じドメインのデータベース: D1,D2 要素が 1 個だけ異なる
任意の D1,D2 において、両者を質問 f に対して区別できない結果を返す データベースの内容が利用者に同定しにくいという相対的安全性: 差分プライバシー
X=D1 or D2 に対して Y をうまく決めて t=f(X)+Y p(t-f(D1)) ≦ eε p(t-f(D2)) あるいは としたい。 このような Y の分布はラプラス分布で実現
D2 D1 α 1要素だけ違う
2
1log
Dftp
Dftp
27

28
pDfDfDfDf
DftDft
Dft
Dft
Dftp
Dftp
tLapalacep
exp)2()1(exp)2()1(
exp
)2(||)1(exp
/)2(exp
/)1(exp
))2((
))1((
exp2
1:
がラプラス分布
p
LaplaceXftYp
LaplaceXftpYp
DfDfpDD
~)()(
11max2,1
パラメータ ε の調整
どんな関数 f がこの枠組みに入れるのかが研究課題
安全度高い
ここは等しい
大 小
安全度低い

Differential Privacy の文献 C. Dwork. Differential privacy. In ICALP, LNCS, pp.1–12,
2006. C. Dwork. Dierential privacy: A survey of results. In
TAMC, pp. 1-19, 2008. Cynthia Dwork, Frank McSherry, Kunal Talwar. “The
Price of Privacy and the Limits of LP Decoding”. STOC’07, pp.85-94, 2007
29

PPDM に関する最近の研究の動向KDD2010 より

分類 必ずしも信用できないクラウドサーバ計算を任せる場合
の元データのプライバシー維持 Privacy-Preserving Outsourcing Support Vector Machines with
Random Transformation k-Support Anonymity Based on Pseudo Taxonomy for Outsourcing of
Frequent Itemset Mining 差分プライバシー
Data Mining with Differential Privacy Discovering Frequent Patterns in Sensitive Data
Versatile Publishing for Privacy Preservation これらは摂動法
これは暗号法 暗号技術による分散データからのマイニング
Collusion-Resistant Privacy-Preserving Data Mining 31

必ずしも信用できないクラウドサーバ計算を任せる場合の元データのプライバシー維持

(1)Privacy-Preserving Outsourcing Support Vector Machines with Random Transformation 信用できない外部のサーバに SVM を outsourcing するときに、元データを推定されないように Kernel をランダム変換するアルゴリズム 従来は、教師データからランダムに選んだ小さな部分で
SVM の学習をする方法。そこそこの精度。ただし、テストにおいては外部サーバにデータを知られてしまう。
そこで新規提案
33
データの持ち主
ランダム変換
摂動教師データ
摂動 SVM分類器
外部サーバ
摂動教師データでSVM 学習
教師データテストデー
タ
データの持ち主
ランダム変換
摂動テストデータ
摂動データで学習した SVMで予測
予測ラベル
外部サーバ
学習予測

Privacy-Preserving Outsourcing Support Vector Machines with Random Transformation まず、準備として m 個の教師データのうち m’(<<m)
個の部分集合だけを用いる Reduced SVM を説明。本来は少ないメモリで SVM を行うアルゴリズム
Y.-J. Lee and O. L. Mangasarian. RSVM: Reduced support vector machines. In Proceedings of the 1st SIAM International Conference on Data Mining (SDM), 2001.
データは m 個。1つのデータは n次元のベクトル。 y= 分類の誤り許容度(ソフトマージン)の列ベクトル、 γ=原点からの距離 A=教師データ (n×m行列) Dii=1 if 分類 i が正解 e=- 1 if 不正解 . if i≠j then Dij=0 最適化の定式化 e は全要素が1の 列ベクトル
34

概念図
35
A -
A +
分離平面 x’w=γ
Margin =2/||w||2
w
xTwー γ=ー 1
xTwー γ= 1

図のように線形分離できないときは、 yi というソフトマージンのパラメータを使って制約を以下のように緩和
最適化問題は以下のようになる
制約なし最適化に書き直すと
36
22
2,
2
,,
2
1
2min
0
..2
1
2min
11
11
1
1
wweAwDe
y
eyeAwDts
wwyy
DandAxforywx
DandAxforywx
T
Rw
TT
Ryw
iiiT
iT
iiiT
iT
n
nm
m 個のxTwー γ= 1xTwー γ=ー 1に対応する制約式群
x+ = max{0, x} 次のページに具体例

37
0
..2
1
2min
11
11
2
,, 1
y
eyeAwDts
wwyy
DandAxforywx
DandAxforywx
TT
Ryw
iiiT
iT
iiiT
iT
nm
1
1
1
1
1
1
100
010
001
100
010
001
)(
1232131
2222121
1212111
3
2
1
2
1
32
22
12
31
21
11
3
2
1
2
1
32
22
12
31
21
11
ywawa
ywawa
ywawa
y
y
y
w
w
a
a
a
a
a
a
y
y
y
w
w
a
a
a
a
a
a
yeAwD
A-
A +
分離平面 x1w1+x2w2=γ
(w1,w2)
x1w1+x2w2=γ-1
x1w1+x2w2=γ+1(a31,a32)
(a21,a22)
(a11,a12)

y= 分類の誤りの列ベクトル、 γ=原点からの距離 A=教師データ Dii=1 if 分類 i が正解 else =- 1 w= 重みベクトル =ATD u
分離平面 xTw= γ xT AT D u = γ linear kernel K(xT AT)D u = γ さらに D をかけると DK(xT AT)D u = Dγ
38
学習するのはこの u
A-
A +
分離平面 x’w=γ
Margin =2/||w||2
w
xTw=γ-1
xTw=γ+1
次のページに具体例
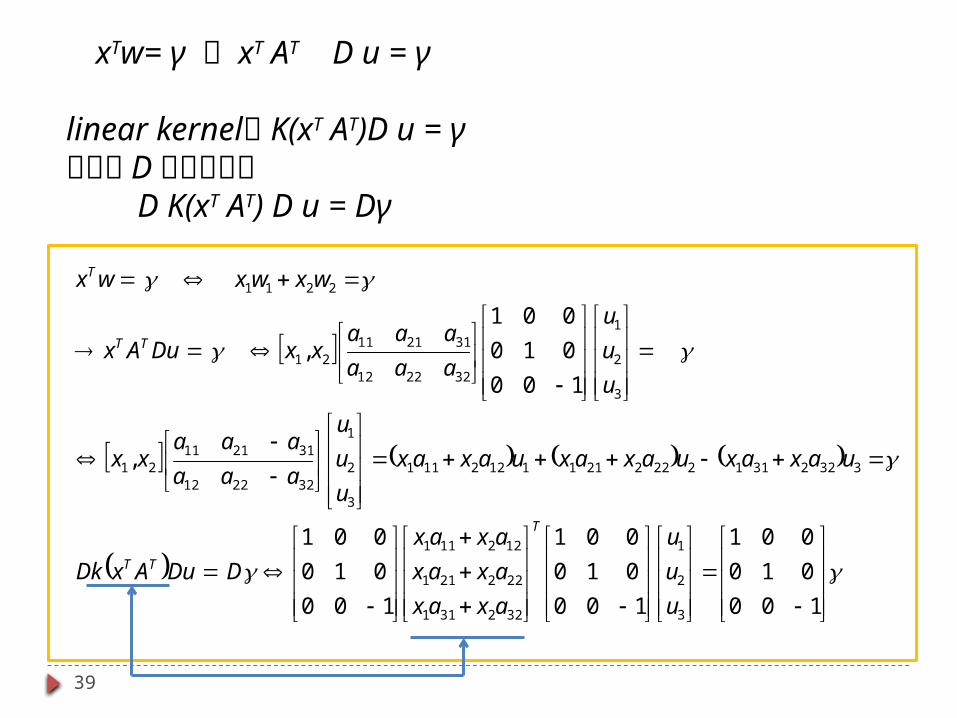
39
xTw= γ xT AT D u = γ linear kernel K(xT AT)D u = γさらに D をかけると D K(xT AT) D u = Dγ
100
010
001
100
010
001
100
010
001
,
100
010
001
,
3
2
1
322311
222211
122111
332231122222111122111
3
2
1
322212
31211121
3
2
1
322212
31211121
2211
u
u
u
axax
axax
axax
DDuAxDk
uaxaxuaxaxuaxax
u
u
u
aaa
aaaxx
u
u
u
aaa
aaaxx DuAx
wxwx wx
T
TT
TT
T

すると SVM の最適化は ( ただし A’=AT)
これは条件なし最小化問題 (10)
Newton 法などで解ける。 ここで、カーネル行列 K(A,AT) は大きすぎてメモリに乗らないので、 A の次元を m とすると、より小さな次元 m’<<m の ( これは A のランダムな部分集合)を用いたカーネル行列 を (10) に代入し最適化問題を解くのが RSVM
この を A とは関係ない乱数にしてしまうのが次ページのアイデア 40
A),(
TAAK
A
22
2,
2
,,
2
1,
2min
0
,..
2
1
2min
1
12
uueDuAAKDe
y
eyeDuAAKDts
uuyy
TT
Ru
T
TT
Ryu
m
m

Privacy-Preserving Outsourcing Support Vector Machines with Random Transformation
教師データ x に行列M で表されるランダム変換を施した Mx とm’ 個のランダムデータ r に逆変換した (MT)-1r を外部サーバに送り、この 2 種のデータ間でのペアからなる kernel k(xi,rj)で SVM を学習。 (m’<<m) K(A,A’) による Reduced SVM
ランダムベクトルで学習するので、 kernel matrix k(xi,xj) も外部サーバに知られない。ランダムベクトルは漏れなければ他の学習データも漏れない。
ランダムデータは人手などによって分類を与えれば、使える。 線形カーネルの場合は、置換した Mx を計算サーバに与えて計
算する識別関数は、以下の通り
(Mx)T(MT)-1r=xTMT(MT)-1r=xTr なので、多項式カーネルも計算できる
41
brxkvbrMMxkvxf j
m
j jjTTm
j j
,)(
'
1
1'
1

よって、実際のテストデータ z は Mz と変換して計算を outsource すれば、計算は O(m’) で少なく、データ内容を(かなり)保護できる。
精度の実験結果は以下 (m’=m/10)
42
brxkvbrMMxkvxf
m
j
m
j jjTTm
j j
,)(
''
1
1'
1
個数とするをランダム教師入力の
上の図は以下より抜粋: Keng-Pei Lin,Ming-Syan Chen. Privacy-Preserving Outsourcing Support Vector Machines with Random Transformation , KDD2010

(2)k-Support Anonymity Based on Pseudo Taxonomy for Outsourcing of Frequent Itemset Mining 頻出アイテムセットのマイニングをアウトソーシング
するときに k-support anonymity という概念を提案 k-support anonymity = 同一の support値のアイテムが
k 個以上存在
k-support anonymity を実現し、かつ匿名化した擬似分類木を導入して頻出アイテムセットマイニングをアウトソース
匿名化された結果を得たら復号化して欲する結果を得る
43
(x)supportT(y)supportTTy :itemk
item) eS(sensitivx
T:DB)(T:DB
INN
NI
個の匿名化少なくとも
においてされたとなものに置き換えるこ名前をの暗号化真の fake

44
○の中の数は、その部分木に含まれるtransaction の数の合計
3-support anonymity support 2 の item にはa,g,h の3 種類あり
データベースの example
原 DB: T1 匿名化 DB:TN
Transaction ID
実アイテム Transaction ID 匿名化アイテム
1 ワイン 1 c,d,g
2 たばこ、ワイン 2 b,d,g
3 たばこ、茶 3 b,h
4 ビール、たばこ、ワイン 4 a,b,c
5 ビール、茶、ワイン 5 a,c,d,h
5 4
4 4 2 2
2 3 3
5
3b: たばこ{ 2,3,4}
k
j
e g h {1,2} {3,5}
f
i
a b c d{4,5} {2,3,4} {1,4,5} {1,2,5}
5
5 2
4 4
2 3
全商品
h:茶{ 3,5}
f:ワイン{ 1,2,4,5}a:ビー
ル{ 4,5}
嗜好品
安い嗜好品
(a)(b)

45
1,2 は p3 には含まれているので
sup(茶 ) に影響なし
sup(p6)=3<sup(ワイン )sup(p7)=1<sup(ワイン )sup(ワイン ) に影響な
し
insert
split
increase
1,5 を追加しても
sup(ワイン ) は不変。
insert 、 split 、 increase という木構造の変更によって supTN(child node)<supTI(sensitive node)<supTN(parent node)という関係を崩さなければ、 support の計算は保存される
5
52
4 4
2 3
k
f:ワイン{ 1,2,4,5}b: たば
こ{ 2,3,4}
a:ビール{ 4,5}
i
e f:ワイン g h:茶{1,2,4,5} {1,2} {3,5}
b: たばこ{ 2,3,4}
a:ビール{ 4,5}
5
5 4
4 4
2 3
k
i
P12 2
茶{3,5}
5
5 4
44
2 3
k
i
e2 2
b: たばこ c d{ 2,3,4} {1,4,5} {2}
a:ビール{ 4,5}
3 1f:ワイン g h:茶 {1,2} {3,5}
5
5 4
4 4
2 3
k
i
e2 2
b: たばこ c d{ 2,3,4} {1,4,5} {1,2,5}
a:ビール{ 4,5}
33
f:ワイン g h:茶{1,2,4,5} {1,2} {3,5}
j
(a)
(b)
(c)
(d)
j j

差分プライバシー

(3)Discovering Frequent Patterns in Sensitive Data Sensitive なデータのデータセットからトップ k 個の再頻出パタン ( most frequent patterns: top k FPM) を抽出するにあたって、 ε 差分プライバシーを満たすような細工をする。
近似 top k FPM f k を k番目に多いパタンの真の頻度とする。 信頼度= ρ: 確率 (1- ρ)以上で以下の条件を満たす
Soundness: 真の頻度が (f k− γ) より少ない頻度のパタンは出力しない。
Completeness: 真の頻度が (f k+ γ) より大きいパタンは全て出力する。
Precision: 出力された全パタンの頻度は真の頻度から ±η の範囲に入る。
47

提案アルゴリズム
入力:パタン集合 =U, データセットサイズ =n 前処理: γ = (8k/εn)ln(|U|/ρ) とし、通常の
Frequent Pattern Mining アルゴリズムで、頻度> (f k− γ) のパタン集合 U を抽出。残りのパタンの頻度は (f k− γ) と見なす
雑音加算とサンプリング: U の各パタンの頻度に Laplace(4k/εn) で生成した値を加算。この加算の結果からトップ k パタンを通常の FPM で抽出 する。これを S と呼ぶ。
摂動 (Perturbation): S 中のパタンの頻度にLaplace(2k/εn) で生成した値を加算し、雑音加算された頻度を得、これを最終結果として出力する。48
ここで ε/2-差分
private
ここで ε/2-差分
private
併せて ε-差分private

提案されたアルゴリズムは ε差分プライバシー
少なくとも 1-ρ の確率で、真の頻度が (f k− γ) より大きなパタン全てを抽出でき、 U 中で (f k+γ) より大きなパタン全てが出力される。ただし、 γ = (8k/εn)ln(|U|/ρ)
少なくとも 1-ρ の確率で、雑音加算された頻度と真の頻度の差は η以下。ただし、 η = (2k/εn)ln(k/ρ)
Top k パタンの抽出の計算量は O(k’+klogk) ただし、 k’ は頻度 > (f k− γ) のパタンの個数
49

(4)Data Mining with Differential Privacy
データを属性の値によって分類する ID3 における 分類木 (decision tree) 構築時には、分類木のある node にぶら下がるデータを split し、 information gain が最大の split の仕方を選ぶ。 information gain
= ( データ全体のエントロピー )
ー ( ある属性でデータを分割した場合のエントロピー ) この論文では、 info. gain 以外にも GINI 係数、最大値など
を利用して実験比較している。 そこで、 split したデータの個数に Laplace 分布に応じ
たノイズを加え、これにより 差分プライバシーを実現
50

その他(6)Versatile Publishing for Privacy Preservation Micro data を公開しても quasi ID sensitive data
という推論ができないようにデータベースを変形する手法
禁止する推論 QIDS の集合を {QS} とする。 全データを以下のようにして分割し変形し {QS} が禁止されるようにする。 全データから部分 T を切り出す。この T は上記の推論が
できないように 匿名化する。 別の部分 T’ を追加して既存の {T} が {QS} のルールを満
たす場合は、 T から S を除去する。
51

暗号化準同型性公開鍵暗号を用いた PPDM プロトコル
52

プライバシ保護データマイニングの目的
Alice は彼女のデータベースを Bob に開示したくない. Bob も彼のデータベースを Alice に開示したくない. ただし,結合されたデータ XA∪XB についてデータマ
イニングや統計処理を実行し,その結果のみを知りたい.
PPDM では Alice や Bob を「パーティ」と呼ぶ。53
XA XB×AliceBob
XA ∪ XB

プライバシー保護データマイニング (PPDM)では 自分自身のデータを持つ多数のパーティが、各々の
データを他のパーティに知られることなく、全パーティのデータを統合的に利用したデータマイニング結果を入手すること .
暗号技術に基づく PPDM 実現が目標 . このような PPDM には多数の応用分野がある
多数の病院が協調して疫病の感染ルート追跡 多数の金融機関が協調して個人の信用情報を得る(与信)
競合数社が共同して市場調査

暗号学的アプローチ データマイニングを複数の分散計算に分割. セキュリティプロトコルや暗号学的ツールを組み合わせて,
それぞれの計算をプライバシを保護して実行. 準同型性公開鍵暗号により,暗号化されたデータ同士の加
算や乗算を組み合わせた計算が可能. Epk(m) をメッセージ m を公開鍵 pk で暗号化したものとすると
Epk(m1)* Epk(m2)= Epk(m1+m2)
55
XA XB
暗号プロトコルによる関数の評価
BobAlice
XA XB
暗号化暗号化

暗号法の参考文献 プライバシー保護データマイニング J.ヴァイダヤ、 C.W. クリフトン、 Y.M.ズー著 シュプリンガージャパン 2010
(原著は 2006 ) 計算機科学、機械学習の国際会議として
は、 KDD,ICML,ICDM, などに論文が発表されている。
56

A knows x and m, B knows y and n Both A and B knows public key : pk A only knows secret key: sk A B Epk(x) , Epk(m) B generates random z Epk(y)z =Epk(yz), Epk(n)z =Epk(nz), Epk(m)z =Epk(mz), Epk(x)z =Epk(xz), Epk(yz)xEpk(xz)=Epk(z(x+y)) Epk(mz)xEpk(nz)= Epk(z(m+n))Dsk( Epk(z(x+y))) /Dsk( Epk(z(m+n)) ) =z(x+y)/z(m+n) = (x+y)/(m+n) (x+y)/(m+n)
Both A and B knows (x+y)/(m+n)Note: A couldn’t know z nor y because couldn’t factor out z or y from z(x+y)
大きな数の因数分解の不可能性
準同型性公開鍵暗号による平均値の計算プロトコル

内積をプライバシー保護しつつ計算し、結果を乱数としてシェアを計算するプロトコル.
ここで rB は, Bob しか知らない乱数である. 準同型性公開鍵暗号を用いれば,実現できる. シェアしているのは乱数だが、足せば内積が得られる
58
Alice Bob
入力 xA yB
出力 (xA)T yB - rB rB
Alice BobAlice Bob
公開鍵 pk を生成.ci = Encpk(xi) (i = 1,…,d)
Alice Bob
公開鍵 pk を生成.ci = Encpk(xi) (i = 1,…,d)
wi = ciyi (i = 1,…,d)
w = Πi=1d wi
Alice Bob
公開鍵 pk を生成.ci = Encpk(xi) (i = 1,…,d)
wi = ciyi (i = 1,…,d)
w = Πi=1d wi
乱数 rB を生成.w’ = w * Encpk(-rB)
Alice Bob
公開鍵 pk を生成.ci = Encpk(xi) (i = 1,…,d)
Decsk(w’ ) = (xA)T yB – rB
wi = ciyi (i = 1,…,d)=Enc((xA)T yB
w = Πi=1d wi
乱数 rB を生成.w’ = w * Encpk(-rB)

付録: 1-out of-2 Oblivious Transfer protocol:OT
n- out of –N も同様 Alice will send Bob one of two messages. Bob will receive one, and Alice will not
know which.
Alice Bob
(m1, m2) m1 を受け取ると決める (pk1, sk1), (pk2, sk2) pk1, pk2 K:symmetric key,
Epk1(K)
Alice は pk1,pk2 のどちらで encrypt されたか分からない。 Dsk1( Epk1(K))=K, Dsk2(Epk1(K))=G
EK(m1), EG(m2) DK(EK(m1))= m1, DK(EG(m2))

データマイニング 上記のプライバシー保護計算のプロトコルを基礎に、
より高度なデータマイニングアルゴリズムを実現する。
全データはデータ保持者であるパーティ毎への分割は水平分割と垂直分割の 2 種類あり(次ページ)
水平、垂直分割データにおける EMアルゴリズム、K-means などを実現するプロトコルが知られている。
60

データ分割のモデル 垂直分割と水平分割
61
エンティティ 属性1 属性2 属性3
1 a A α
2 b B β
3 c C γ
4 d D δ
5 e E ε
6 f F ζ
7 g G η
エンティティ 属性1 属性2 属性3
1 a A α
2 b B β エンティティ
属性1
1 a
2 b
3 c
4 d
5 e
6 f
7 g
エンティティ
属性2
1 A
2 B
3 C
4 D
5 E
6 F
7 G
エンティティ
属性3
1 α
2 β
3 γ
4 δ
5 ε
6 ζ
7 η
エンティティ 属性1 属性2 属性3
3 c C γ
4 d D δ
エンティティ 属性1 属性2 属性3
5 e E ε
6 f F ζ
7 g G η
パーティ1
パーティ1 パーティ2
パーティ2
パーティ3
パーティ3
水平分割垂直分割

水平分割における K-means パーティ数はr パーティ i の m番目のデータの属性 j j=1,..,J(J次元)
のデータを di×m-j J次元のベクトル空間の距離はユークリッド距離など適
当なものを用いる k番目のクラスタの属性 j の値を γkj クラスタ数は K γkj の初期値は γkj0
目的: K 個のクラスタの γkj の K-means の計算結果を全パーティが知る。ただし、個別のパーティのデータは他へは漏れない。
62
γk はクラスタ k の重心

パーティ1とパーティrは特殊 Step 1
パーティ1は乱数 Rb を生成し、パーティ r だけに送信
Step 2
パーティ r は公開鍵 pk を作り全パーティに送る。秘密鍵 sk は自分だけで保持。
63

Step 3
for all m (in パーティ 1)
{ パーティ 1 は自分のデータに d1×m に対してクラスタ中心 γk が一番近いクラスタの J次元ベクトル ΓkJ に d1×m を加算し、カウント Ck にも 1 を加算}
以上によって生成された ΓkJ と Ck はパーティ 1 がクラス k にもっとも近いデータの属性の総和と、そのようなデータの個数
次は自分のデータを隠す乱数 Rb の加算と暗号化をし、その結果をパーティ2に送る
for j=1,J
Epk[Γkj+Rb] パーティ2に送るend for
Epk[Ck+ Rb」パーティ2に送る
64
パーティ1は 1番目であるが、それが保持している情
報は Rb によって保護される

Step 4 for i=2 から r-1 パーティ i-1 から受け取った J+1種のデータを
Epk[Γ’kj+Rb] ( j=1,..,J )、 Epk[Ck’+Rb] とする Γkj=0. Ck=0 パーティ i は自分のデータに di×m に対してクラ
スタ中心 γk が一番近いクラスタの J次元ベクトル ΓkJ に d1×m を加算し、カウント Ck にも 1 を加算
Epk[Γ’kj+Rb]E[Γkj ]
=Epk[Γ’kj+ Γkj +Rb] ( j=1,..,J )、 Epk[Ck’+Rb]E[Ck]=Epk[Ck’+Ck+Rb]
を計算してパーティ i+1 に送る65

Step 5 パーティ r においての操作
まず、 Step 4 と同様に自分のデータを用いてEpk[Γ’kj+ Γkj +Rb] ( j=1,..,J )、 Epk[Ck’+Rb]E[Ck]=Epk[Ck’+Ck+Rb]
を計算秘密鍵 sk でこれらを復号し、 Rb を差し引いた上で比をとる。すなわち
Dsk Epk[Γ’kj+ Γkj +Rb]- Rb=Σ パーティ1から r Γkj=Akj
Dsk Epk[Ck’+Ck+Rb] - Rb=Σ パーティ1から r Ck=Bk
Akj/Bk = γkj すなわち次元 j におけるクラスタ k の属性の平均値がわかった。これを全パーティに送信
66
パーティ r は平均値以外には、他の個々のパーティの情報は得ることができない。

Step 6
Step 5 でパーティ r から送られた γkj を新たなクラスタ k の中心の属性 j の値として、 Step 3, 4, 5 を γkj が収束するまで繰り返す。
67
γkj の収束判定はパーティ 1 か r が直前の γkj と比較して行えばよい

垂直分割における K-means J.Vaidya et.al. Privacy Preserving k-means clustering over
vartically partitioned data. KDD2003, 206-215, 2003
垂直分割の場合は、各パーティのデータを保護するために水平分割の場合とは異なる工夫が必要
パーティ数は r 各データは r 個の属性値からなる クラスタ数は K 総データ数は N
パーティ i は N 個のデータ y(i)n (n=1,..,N) を持つ (データの属性は 1 個)
68

パーティ毎のデータ保持状況 クラスタ k (k=1,..,K) は属性 i (i=1,..,r) に対してそのク
ラスタに属すると想定されるデータの平均値 μki を持つ パーティ i が保持している N 個のデータは yni という値を
持つ パーティ i はデータ毎に属性 i の値をクラスタ k の平均値
との差 X(i)nk= y(i)ni ー μki を成分とするベクトルを持つ(下図参照)
69
データ i パーティ1 … パーティ i … パーティ r
クラスタ1 X(i)11 X(i)r1
…..
クラスタ k X(i)nk= y(i)ni ーμki
…..
クラスタ K X(i)1k X(i)rk
N枚ある

分散データに対する K-means 各パーティ i において以下を繰り返す
ただし、パーティ i が保持しているのは yni (n=1,..,N) と μki
1. for n=1,N
2. for k=1,K
3. X(i)nk= yni ー μki ( 前頁の行列の成分の計算 )
4. end for
5. SecureNearestCluster: n番目のデータの一番近いクラ スタを求める6. end for
7. 6. までで各データに一番近いクラスタが求まったら、それを用いてクラスタ k に対応する属性 i の平均値 μki を再計算する
70
この作業を各パーティのデータを保護しつつ行うアルゴリズムを次のページ以降で述べる

SecureNearestCluster アルゴリズム Key Idea 順同型公開鍵暗号を使う。公開鍵は 乱数 V を利用して各パーティのデータの流出を防ぐ 距離の比較計算は比較結果だけを得て公開 クラスタの順番を秘匿された置換 π で隠す 特別な機能を果たす 3 パーティを P1,P2,Pr とする 全パーティ 1,..r のデータを総合的にみて、データ
n ( 値は yni (i=1,..,r)) にもっとも近いクラスタ kn を求める
次ページ以降では n は省略する。71
r
iKk
i1
nk,..,1
Xminargkn

SecureNearestCluster アルゴリズム -1 3 つの特別パーティを P1, P2 , Pr とする
P1 は K次元の乱数ベクトル を r 個 ( i=1,..,r)生成。
ただし
P1 は K次元の乱数ベクトルの各要素を置換する置換 π を生成
iV
Tr
i
Vi 001
0

SecureNearestCluster プロトコルのstage1 各パーティ i(i≠1,r) とパーティ1の間で以下の計算を行う
P1 Pi,V
iX
TNiXEiXEiXE ,,1 ①
TNN ViXEViXEViXE ,,)( 11 ②
準同型性暗号 : E[x]*E[y] = E[x+y]
)( ViX ②を復号し
TTNN iXiXiXiXVVV n ,,,,1,,1
P1 には暗号化により X(i) の内容はわからない
Pi には置換 πと乱数 V の加算により、元のデータとの対応はわから
ない

SecureNearestCluster プロトコルの stage2stage1 でパーティ i が得た結果をパーティ r に送り X(i) の総和を得る
P1
P2
,iV
22 XE
)2( 2VXE
Pr-1
VrrXE )(
1rXE
))1(( 1 rVrXE
Stage 1
Pr-1
Pr
)1( 1VX
11 rVrX
Stage 2
iViXi
2
P3 P3
この結果と P2 のデータを secure に比較して目的のクラスタを求める
rXE
これは Pr にて復号される
P1 から戻った結果を復
号
π と V で漏洩を防いでいる

SecureNearestCluster プロトコルの stage3stage2 の結果と P2 のデータを総合して、 Pr と P2 の間で最も近いクラスタを求めるプロトコル
k-1番目まで調べたところで、 X(i) のベクトルの m番目に対応するクラスタがデータ i に一番近いと想定されているとしよう。
この状況で、次の k番目のクラスタがそれより近いかどうかを判定できればよい
75
を知っているととはまた
が知っているのはただし、
を調べる。
VimmiXVkXP
VikkiX
VikiXVimiX
ViiXViiX
r
ik
i
r
i
r
i
r
i
r
i
r
i
122
2
11
111
2
Pr
0

データ n に一番近いクラスタの index を求めるプロトコル(私案)
Pr は乱数 Ra を生成
76
P2 は公開鍵 pk と秘密鍵 sk を作り
pk を Pr に送る と を Pr に送る sk で復号 sk で復号 これらを割り
RaVimmiXpk
VimmiXpk
RaVinkiXpk
VinkiXpk
VikkiXpk
VkXpkVinkiXpk
r
i
Rar
i
r
i
Rar
i
r
i
ki
1
1
1
1
1
22
E
E
E
E
E
2EE
r
i
k
VimmiXEpk
VkXpk
1
22E
km thenkm if1
1
1
1
1
kmVimmiX
VikkiX
RaVimmiX
RaVikkiX
r
i
r
i
r
i
r
i
一番近いものにm を更新

上記までで求まったクラスタ index はまだ置換されたまま。
そこでこれを P1 に送り π -1を作用させ、真の indexを求める
このような stage 1,2,3,4 の操作を N 個すべてのデータに対して行うと、各データがどのクラスタに属するかわかる。
この後、 Pi は i番目の属性のクラスタ毎の平均値をローカルに計算できる。
77

ややこしい! 以上が垂直分割データに対するプライバシー保護
K-meansアルゴリズムだが大変にややこしい。 しかも、暗号化、復号の回数も多く、速度は遅い。
K-means ではないが類似のタスクで我々が実験したところ、 3GHz,32GB のサーバでパーティ数 4 、データ数1000 で 40 分程度かかった。
このような PPDM プロトコルが実用になるには、もう一歩の break through が必要のようだ

ここまで述べた暗号技術を用いる PPDM プロトコルにおいてはさらに結託攻撃が強敵
結託攻撃とは t 個の パーティが結託して、別のパーティのデータを入手すること
定義 t-private :上記の結託攻撃を防げるなら、 PPDM は t-private という .
総パーティ数 = M のとき , M-1-private なら full-private と呼ぶ .
full-private は PPDM の安心な利用の試金石 .
79

これまで提案された PPDM は full-private ではない
full-private PPDM の実現が目標。具体的には full-private な secure dot-products calculation, secure ratio calculation, secure comparison を提案した . Bin Yang, Hiroshi Nakagawa, Issei Sato, Jun Sakuma. “Collusion-
Resistant Privacy-Preserving Data Mining”. 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,(KDD2010) pp.483-492 , Washington, DC , USA, July 25-28 , 2010
Works Methods Methods Party Anti-Collusion
S. Jha 2005 K-Means 2 NA
M. Ozarar 2007 -Means Multi ×
J. Vaidya 2004 JNaive Bayes Multi ×
J. Vaidya 2003 K-Means Multi ×
80





























