Embed Size (px)
DESCRIPTION
뇌를 자극하는 SQL Server 2005. 9 장 . 인덱스. 인덱스 개념. 책의 뒷부분에 있는 색인 ( 또는 찾아보기 ) 와 비슷한 개념 작은 데이터에는 없어도 별 차이가 없지만 , 대량의 데이터에는 인덱스가 있어야만 데이터를 빠른 시간에 검색할 수 있음 인덱스의 장단점 장점 검색은 속도가 무척 빨라질 수 있다 . ( 물론 반드시 그런 것은 아니다 .) 그 결과 시스템의 부하가 줄어들어서 , 결국 시스템 전체의 성능이 향상된다 . 단점 - PowerPoint PPT Presentation
Citation preview

뇌를 자극하는
SQL Server 2005
9 장 . 인덱스
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
2 / 25
인덱스 개념 책의 뒷부분에 있는 색인 ( 또는 찾아보기 ) 와 비슷한 개념 작은 데이터에는 없어도 별 차이가 없지만 , 대량의 데이터에는
인덱스가 있어야만 데이터를 빠른 시간에 검색할 수 있음
• 인덱스의 장단점▫ 장점
검색은 속도가 무척 빨라질 수 있다 . ( 물론 반드시 그런 것은 아니다 .) 그 결과 시스템의 부하가 줄어들어서 , 결국 시스템 전체의 성능이 향상된다 .
▫ 단점 인덱스가 데이터베이스 공간을 차지해서 추가적인 공간이 필요해 진다 . ( 대략
데이터베이스의 10% 내외의 공간이 추가로 필요하다 ) 인덱스를 생성하는데 시간이 많이 소요될 수 있다 . 데이터의 변경 작업 (Insert, Update, Delete) 이 자주 일어날 경우에는 성능이
많이 나빠질 수도 있다 .

뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
3 / 25
인덱스 종류
▫종류 클러스터형 인덱스 영어사전과 비슷한 개념 비클러스터형 인덱스 일반 책의 ‘찾아보기’와 비슷한 개념
▫특징 클러스터형 인덱스는 테이블당 1 개만 생성 비클러스터형 인덱스는 테이블당 여러 개 생성 클러스터형 인덱스는 행 데이터를 인덱스로 지정한 열에
맞춰서 자동 정렬한다 . 제약조건 없이 테이블 생성시에 인덱스를 만들 수 없다 . 인덱스가 자동생성되기 위한 열의 제약조건은 Primary Key 와
Unique 뿐이다 .
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
4 / 25
• 실습 목표▫ 제약조건 생성시에 자동으로 생성되는 인덱스를 파악한다 .▫ 클러스터형 /비클러스터형 인덱스를 직접 지정해서 생성하는
방법을 익힌다 .
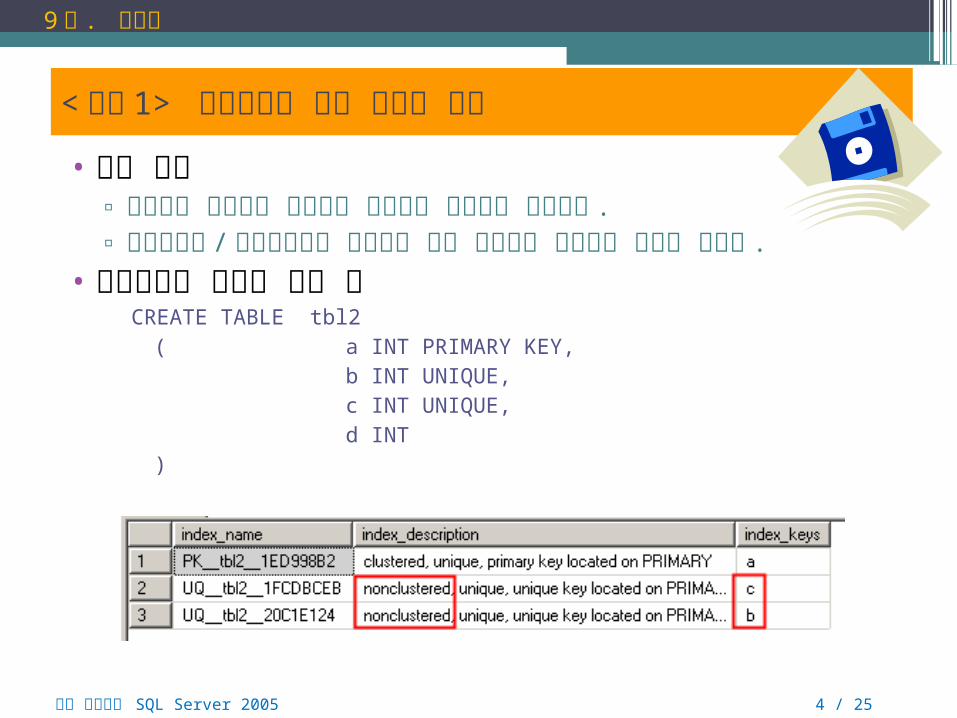
• 제약조건과 인덱스 생성 예CREATE TABLE tbl2
( a INT PRIMARY KEY,b INT UNIQUE,c INT UNIQUE,d INT
)
< 실습 1> 제약조건은 통한 인덱스 생성
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
5 / 25
인덱스의 내부 작동 (1)
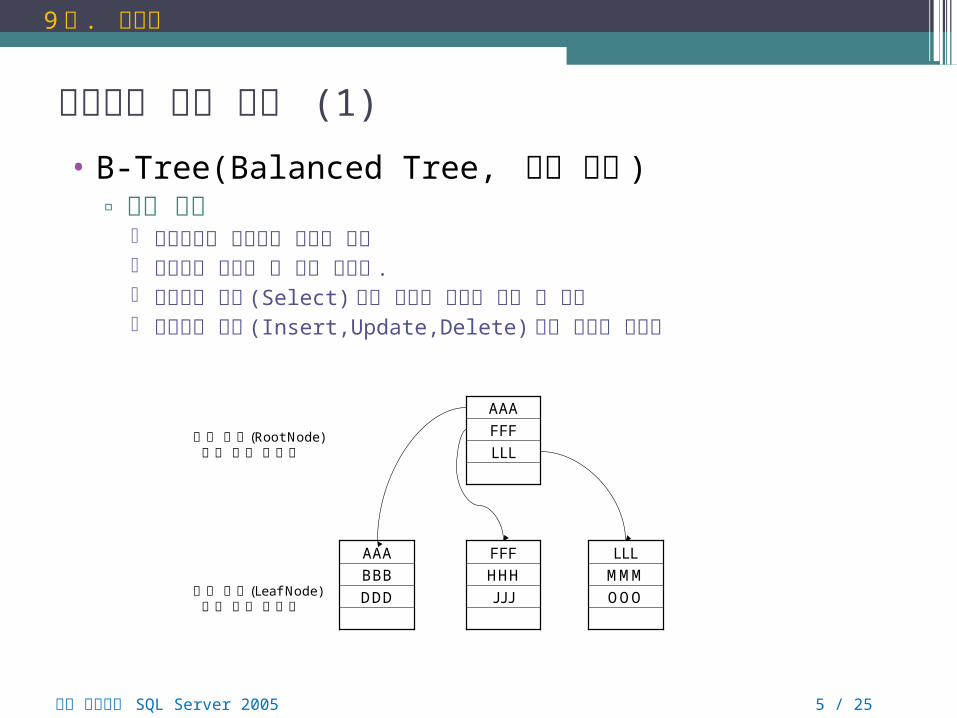
• B-Tree(Balanced Tree, 균형 트리 )▫ 기본 개념
범용적으로 사용되는 데이터 구조 인덱스를 표현할 때 많이 사용됨 . 데이터의 검색 (Select) 시에 뛰어난 성능을 보일 수 있음 데이터의 변경 (Insert,Update,Delete) 시에 성능이 나빠짐
FFFLLL
AAA
AAA
DDDBBB
FFF
J J JHHH
LLL
OOOMMM
루트 노드(Root Node)또는 루트 페이지
리프 노드(Leaf Node)또는 리프 페이지
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
6 / 25
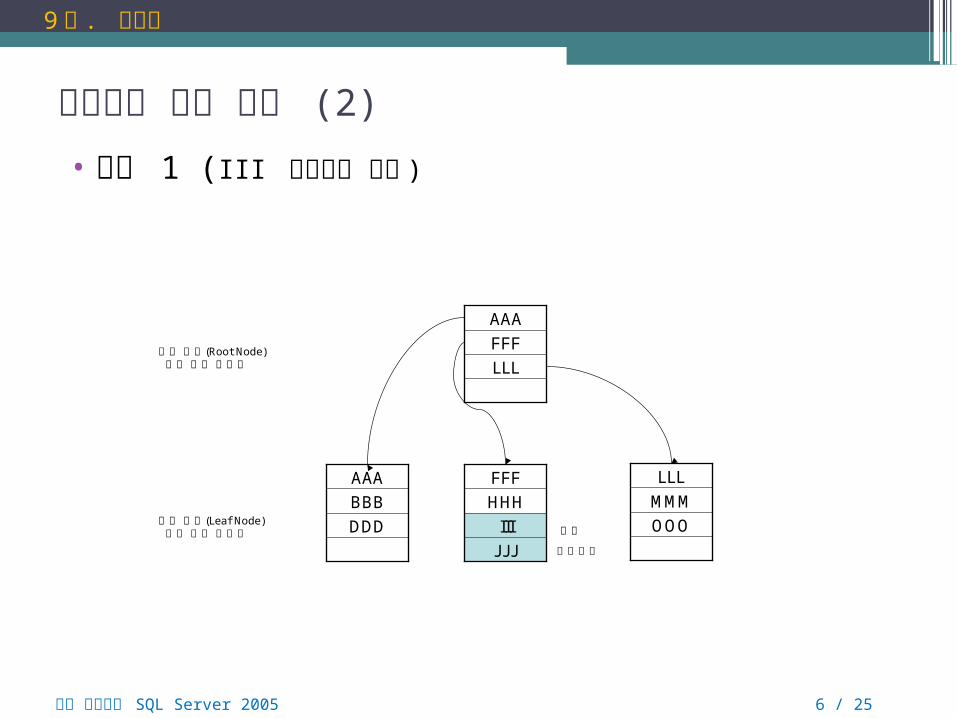
인덱스의 내부 작동 (2)
• 분할 1 (III 삽입후의 변화 )
FFFLLL
AAA
AAA
DDDBBB
FFF
J J JIII
HHH
LLL
OOOMMM
루트 노드(Root Node)또는 루트 페이지
리프 노드(Leaf Node)또는 리프 페이지
한칸이동
삽입
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
7 / 25
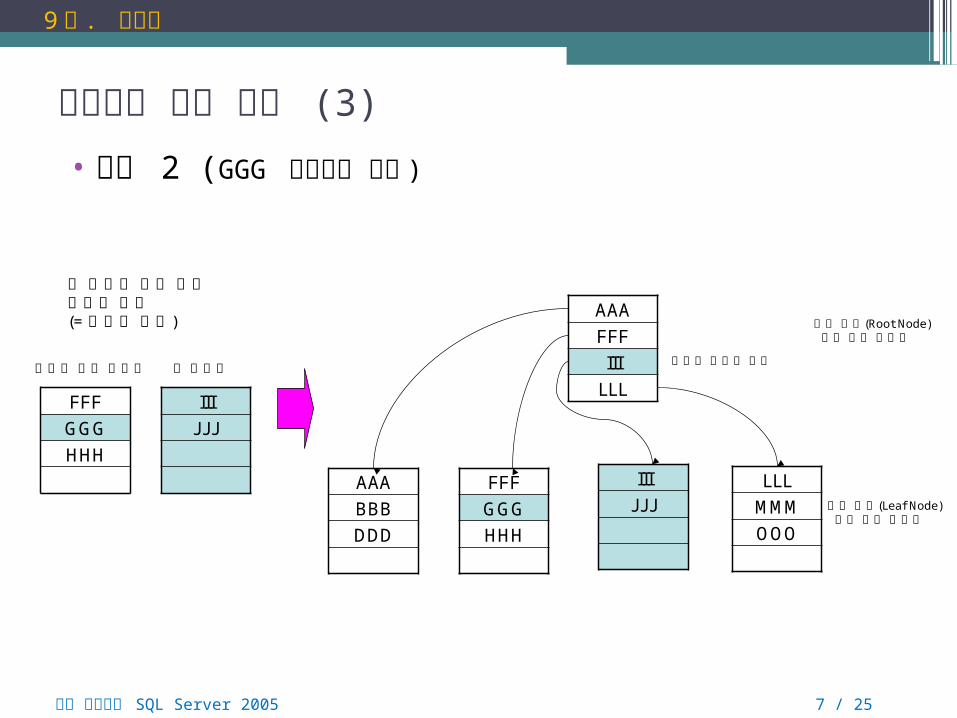
인덱스의 내부 작동 (3)
• 분할 2 (GGG 삽입후의 변화 )
AAAFFFIII
LLL
AAABBBDDD
FFFGGGHHH
LLLMMMOOO
루트 노드(Root Node)또는 루트 페이지
리프 노드(Leaf Node)또는 리프 페이지
IIIJ J J
새 페이지 확보 후에데이터 분할(= 페이지 분할)
새 페이지
FFFGGGHHH
IIIJ J J
새로운 페이지 등록세번째 리프 페이지
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
8 / 25
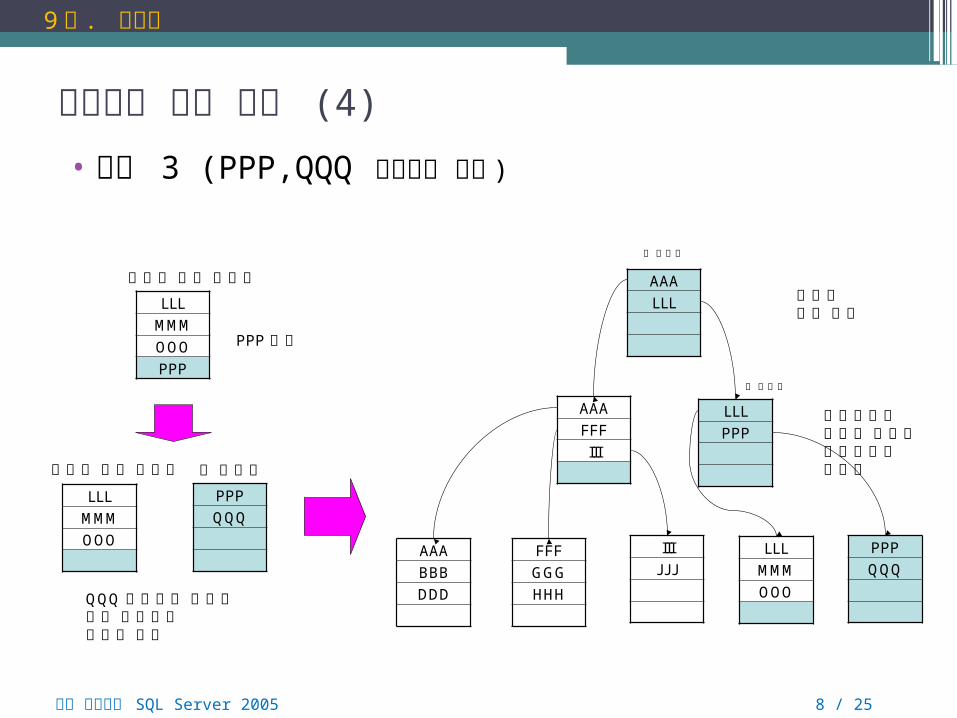
인덱스의 내부 작동 (4)
• 분할 3 (PPP,QQQ 삽입후의 변화 )
AAAFFFIII
AAABBBDDD
PPP 삽입
FFFGGGHHH
IIIJ J J
네번째 리프 페이지
LLLMMMOOOPPP
QQQ 삽입으로 인해서리프 페이지의페이지 분할
네번째 리프 페이지
LLLMMMOOO
새 페이지
PPPQQQ
LLLMMMOOO
PPPQQQ
LLLPPP
AAALLL
새 페이지
새 페이지
루트노드의페이지 분할로중간노드가형성됨
새로운루트 생성
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
9 / 25
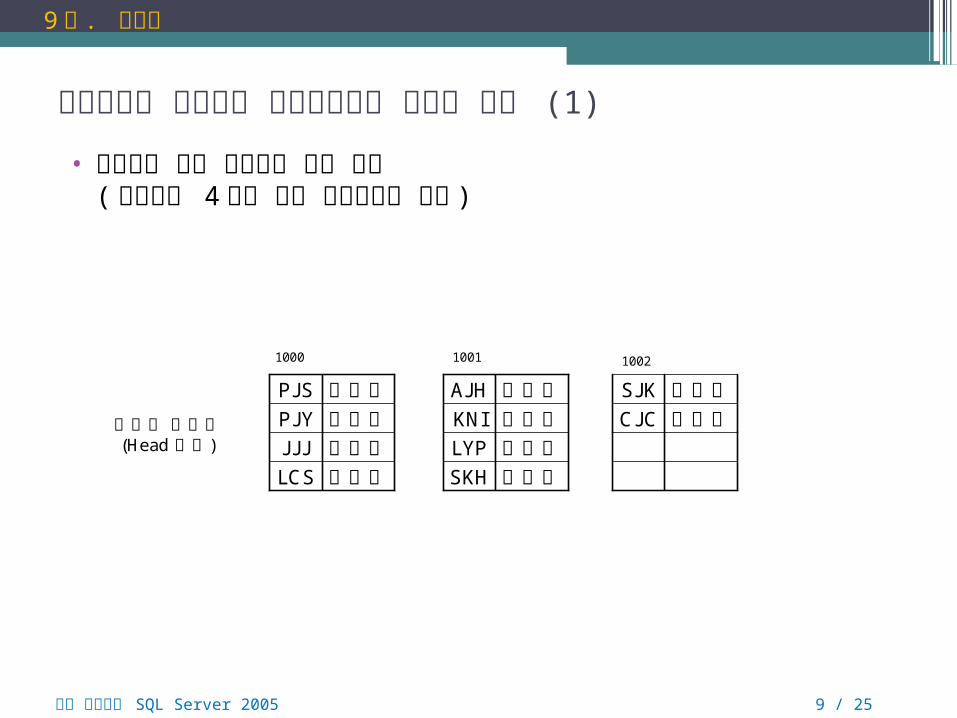
클러스터형 인덱스와 비클러스터형 인덱스 구조 (1)
• 인덱스가 없는 테이블의 내부 구성 ( 페이지당 4 개의 행이 입력된다고 가정 )
LCSJ J JPJ YPJ S 박지성
이천수조재진박주영데이터 페이지
(Head 영역)
SKHLYPKNIAJ H 안정환
설기현이영표김남일 CJ C
SJ K 송종국최진철
1000 1001 1002
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
10 / 25
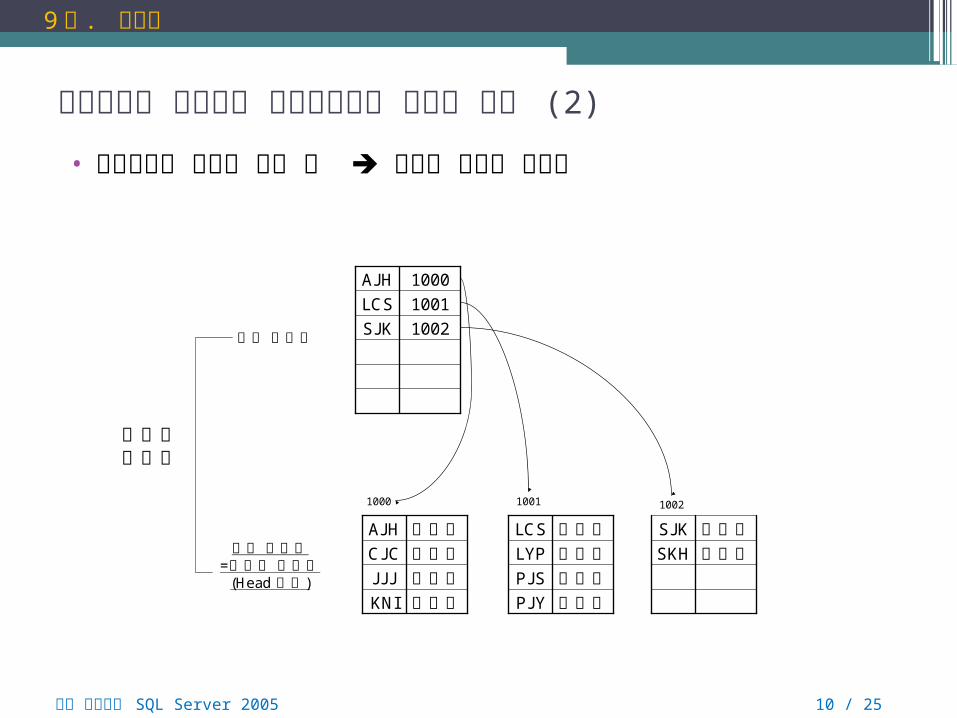
클러스터형 인덱스와 비클러스터형 인덱스 구조 (2)
• 클러스터형 인덱스 구성 후 내부적 정렬이 일어남
KNI
J J JCJ CAJ H 안정환
김남일조재진최진철리프 페이지
=데이터 페이지(Head 영역)
PJ Y
PJ SLYPLCS 이천수
박주영박지성이영표 SKH
SJ K 송종국설기현
1000 1001 1002
SJ KLCSAJ H 1000
10021001
루트 페이지
인덱스페이지
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
11 / 25
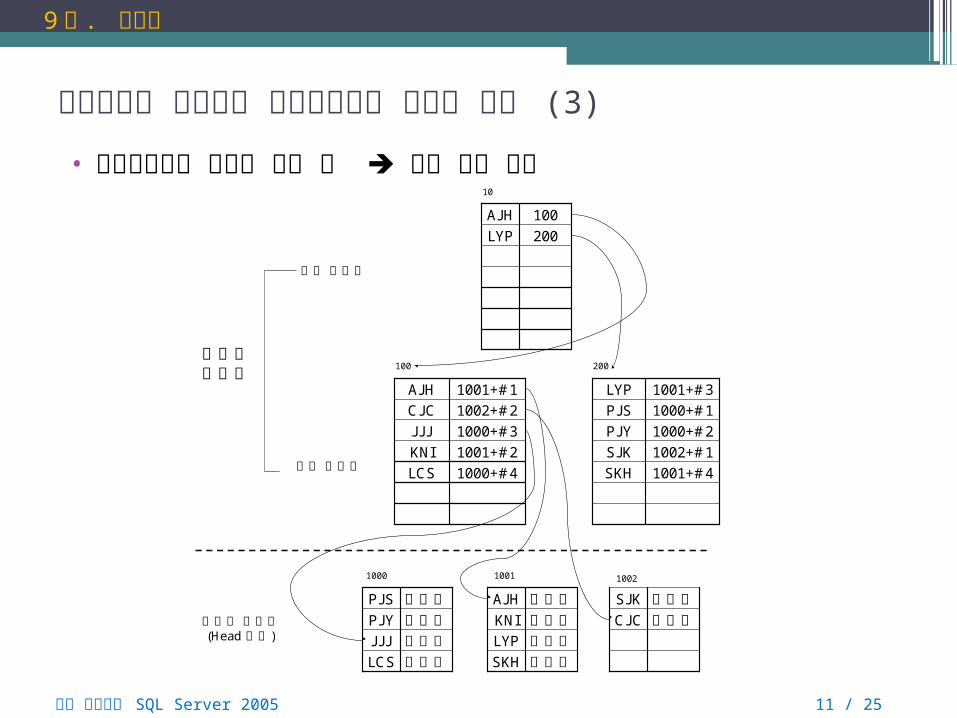
클러스터형 인덱스와 비클러스터형 인덱스 구조 (3)
• 비클러스터형 인덱스 구성 후 정렬 되지 않음
LCS
J J JPJ Y
PJ S 박지성
이천수조재진박주영데이터 페이지
(Head 영역)
SKH
LYPKNI
AJ H 안정환
설기현이영표김남일 CJ C
SJ K 송종국최진철
1000 1001 1002
1000+#4LCS
1001+#2KNIJ J J
CJ C
AJ H 1001+#1
1000+#3
1002+#2
1000+#2PJ Y1002+#1SJ K
1001+#4SKH
1001+#3LYP
1000+#1PJ S
리프 페이지
루트 페이지
인덱스페이지 100 200
LYP
AJ H 100
200
10
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
12 / 25
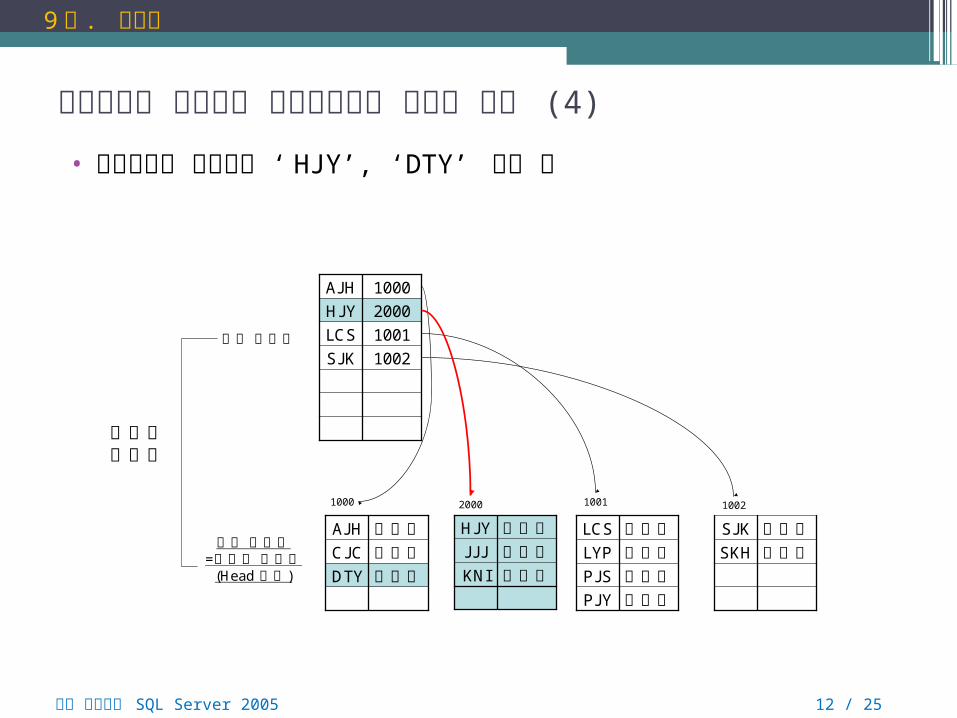
클러스터형 인덱스와 비클러스터형 인덱스 구조 (4)
• 클러스터형 인덱스에 ‘ HJY’, ‘DTY’ 추가 후
DTY
CJ C
AJ H 안정환
당탕이최진철
리프 페이지=데이터 페이지
(Head 영역)
PJ Y
PJ S
LYP
LCS 이천수
박주영박지성이영표 SKH
SJ K 송종국설기현
1000 1001 1002
1002SJ K
LCS
HJ Y
AJ H 1000
1001
2000
루트 페이지
인덱스페이지
KNI
J J J
HJ Y 한주연
김남일조재진
2000
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
13 / 25
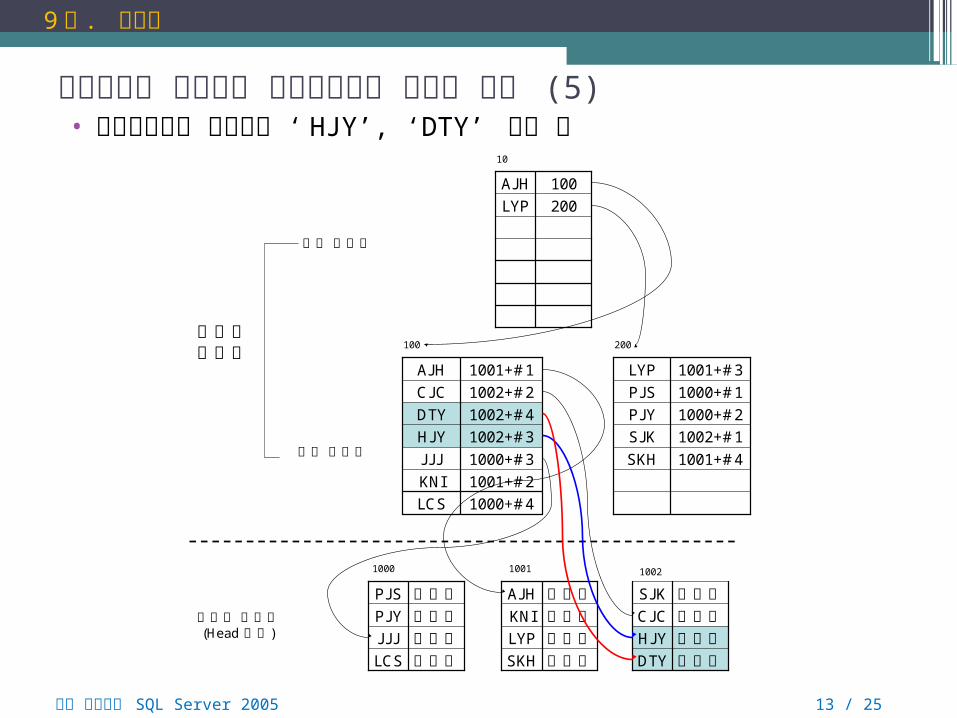
클러스터형 인덱스와 비클러스터형 인덱스 구조 (5)• 비클러스터형 인덱스에 ‘ HJY’, ‘DTY’ 추가 후
LCSJ J JPJ YPJ S 박지성
이천수조재진박주영데이터 페이지
(Head 영역)
SKHLYPKNIAJ H 안정환
설기현이영표김남일
DTYHJ YCJ CSJ K 송종국
당탕이한주연최진철
1000 1001 1002
1001+#2KNI1000+#3J J J1002+#3HJ Y
LCS
DTYCJ CAJ H 1001+#1
1000+#4
1002+#41002+#2
1000+#2PJ Y1002+#1SJ K1001+#4SKH
1001+#3LYP1000+#1PJ S
리프 페이지
루트 페이지
인덱스페이지 100 200
LYPAJ H 100
200
10

뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
14 / 25
클러스터형 인덱스와 비클러스터형 인덱스 구조 (6)
• 클러스터형 인덱스의 특징 클러스터형 인덱스의 생성시에는 데이터페이지 전체를 다시 정렬하게 된다 . 그러므로 , 클러스터형 인덱스를 생성은 심각한 시스템 부하를 줄 수 있다 . 클러스터형 인덱스는 인덱스 자체의 리프 페이지가 곧 데이터이다 . 비 클러스터형 보다 검색속도는 더 빠르다 . 하지만 , 데이터의 입력 /수정 /
삭제는 더 느리다 . 클러스터 인덱스는 성능이 좋지만 , 테이블에 한 개밖에 생성하지 못한다 .
그러므로 , 어느 열에 클러스터형 인덱스를 생성하느냐에 따라서 시스템의 성능이 달라질 수 있다 .
• 비클러스터형 인덱스의 특징 비클러스터형 인덱스의 생성시에는 데이터페이지는 그냥 둔 상태에서 별도의
페이지에 인덱스를 구성한다 . 비클러스터형 인덱스는 인덱스 자체의 리프 페이지는 데이터가 아니라
데이터가 위치하는 포인터 (RID) 이다 . 클러스터형 보다 검색속도는 더 느리지만 , 데이터의 변경은 더 빠르다 . 비클러스터형 인덱스는 여러 개 생성할 수가 있다 . 하지만 , 함부로 남용할
경우에는 오히려 시스템의성능을 떨어뜨리는 결과를 초래할 수 있다 .
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
15 / 25
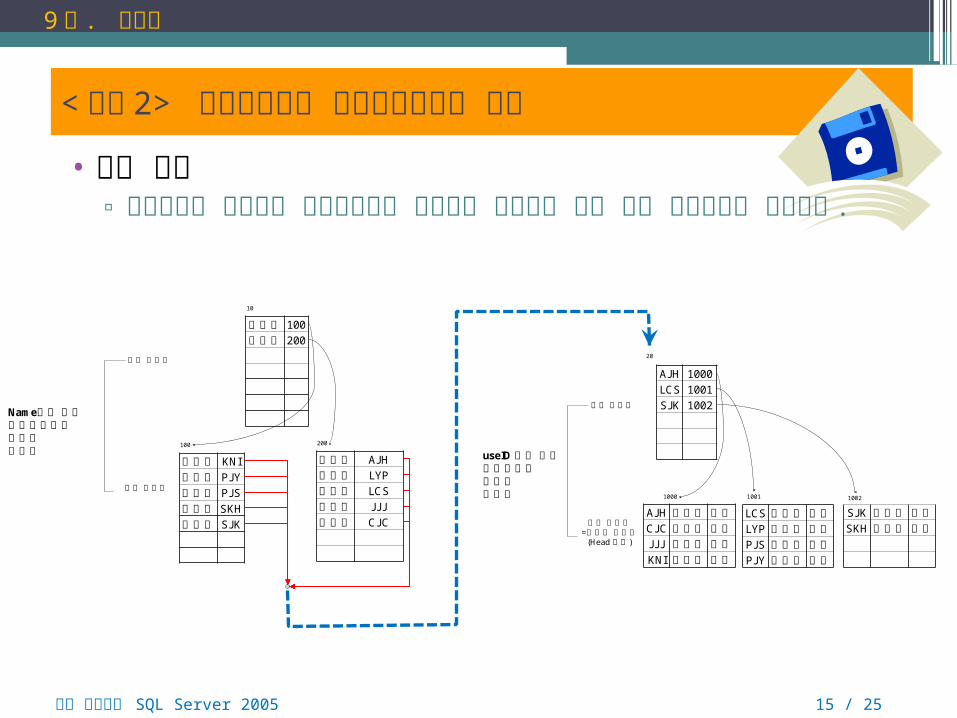
< 실습 2> 클러스터형과 비클러스터형의 혼합
• 실습 목표▫ 클러스터형 인덱스와 비클러스터형 인덱스가 혼합되어 있을 때의
내부구조를 이해한다 .
김남일 KNI박주영 PJ Y박지성 PJ S설기현 SKH송종국 SJ K
안정환 AJ H이영표 LYP이천수 LCS조재진 J J J최진철 CJ C
리프 페이지
루트 페이지
Name열에 대한비클러스터형인덱스페이지
100 200
김남일 100안정환 200
10
AJ H 안정환 강원CJ C 최진철 제주J J J 조재진 충북KNI 김남일 경북
리프 페이지=데이터 페이지
(Head 영역)
LCS 이천수 인천LYP 이영표 전북PJ S 박지성 서울PJ Y 박주영 경기
SJ K 송종국 경기SKH 설기현 서울
1000 1001 1002
AJ H 1000LCS 1001SJ K 1002루트 페이지
useID 열에 대한클러스터형인덱스페이지
20
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
16 / 25
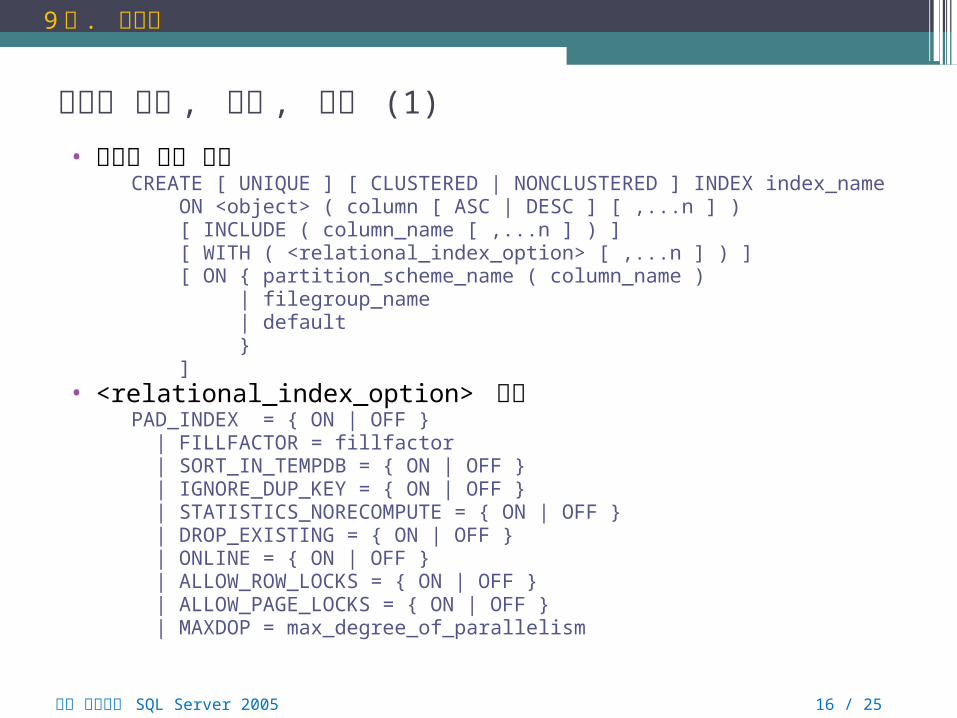
인덱스 생성 , 변경 , 삭제 (1)
• 인덱스 생성 구문CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ ,...n ] ) [ INCLUDE ( column_name [ ,...n ] ) ] [ WITH ( <relational_index_option> [ ,...n ] ) ] [ ON { partition_scheme_name ( column_name ) | filegroup_name | default } ]
• <relational_index_option> 부분 PAD_INDEX = { ON | OFF } | FILLFACTOR = fillfactor | SORT_IN_TEMPDB = { ON | OFF } | IGNORE_DUP_KEY = { ON | OFF } | STATISTICS_NORECOMPUTE = { ON | OFF } | DROP_EXISTING = { ON | OFF } | ONLINE = { ON | OFF } | ALLOW_ROW_LOCKS = { ON | OFF } | ALLOW_PAGE_LOCKS = { ON | OFF } | MAXDOP = max_degree_of_parallelism
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
17 / 25
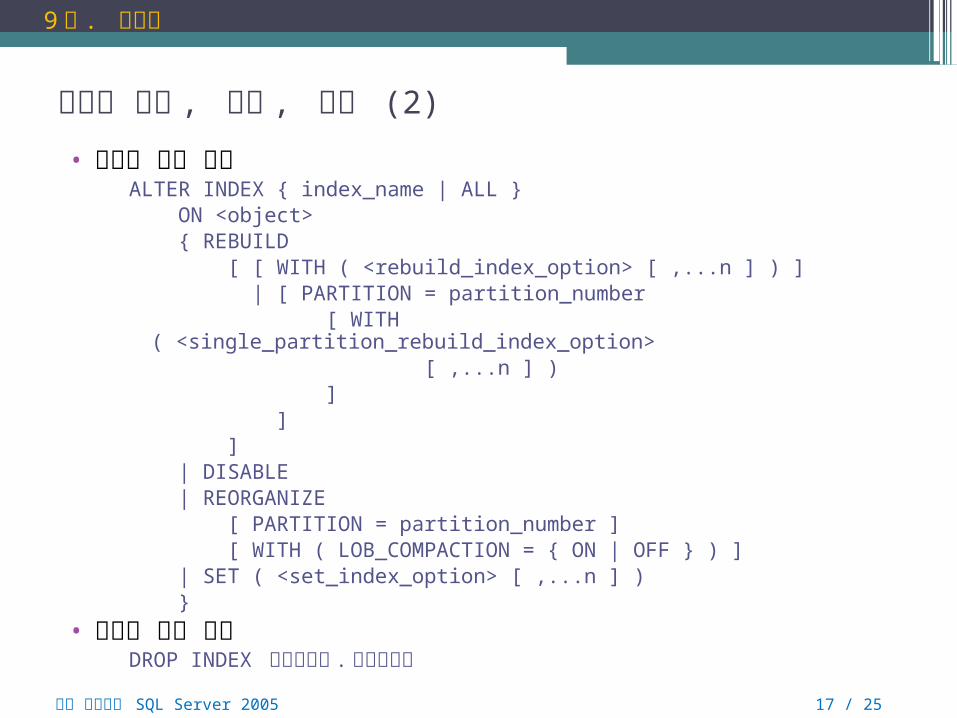
인덱스 생성 , 변경 , 삭제 (2)
• 인덱스 변경 구문ALTER INDEX { index_name | ALL } ON <object> { REBUILD [ [ WITH ( <rebuild_index_option> [ ,...n ] ) ] | [ PARTITION = partition_number [ WITH ( <single_partition_rebuild_index_option> [ ,...n ] ) ] ] ] | DISABLE | REORGANIZE [ PARTITION = partition_number ] [ WITH ( LOB_COMPACTION = { ON | OFF } ) ] | SET ( <set_index_option> [ ,...n ] ) }
• 인덱스 제거 구문DROP INDEX 테이블이름 . 인덱스이름
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
18 / 25
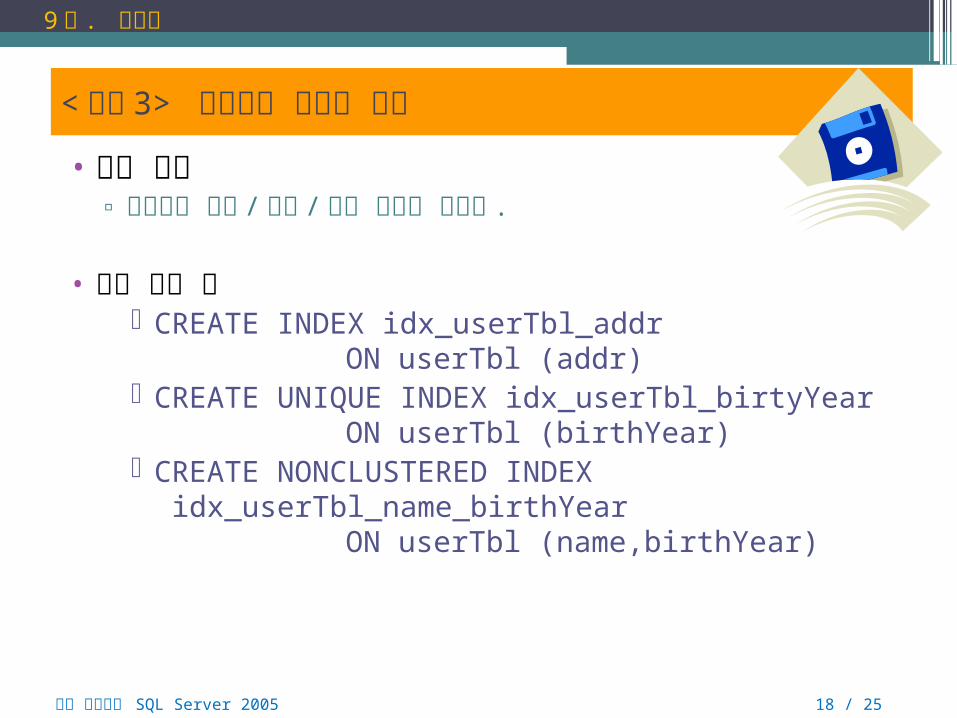
< 실습 3> 인덱스의 생성과 사용
• 실습 목표▫ 인덱스의 생성 /변경 /제거 방법을 익힌다 .
• 사용 구문 예 CREATE INDEX idx_userTbl_addr
ON userTbl (addr) CREATE UNIQUE INDEX idx_userTbl_birtyYear
ON userTbl (birthYear) CREATE NONCLUSTERED INDEX
idx_userTbl_name_birthYearON userTbl (name,birthYear)
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
19 / 25
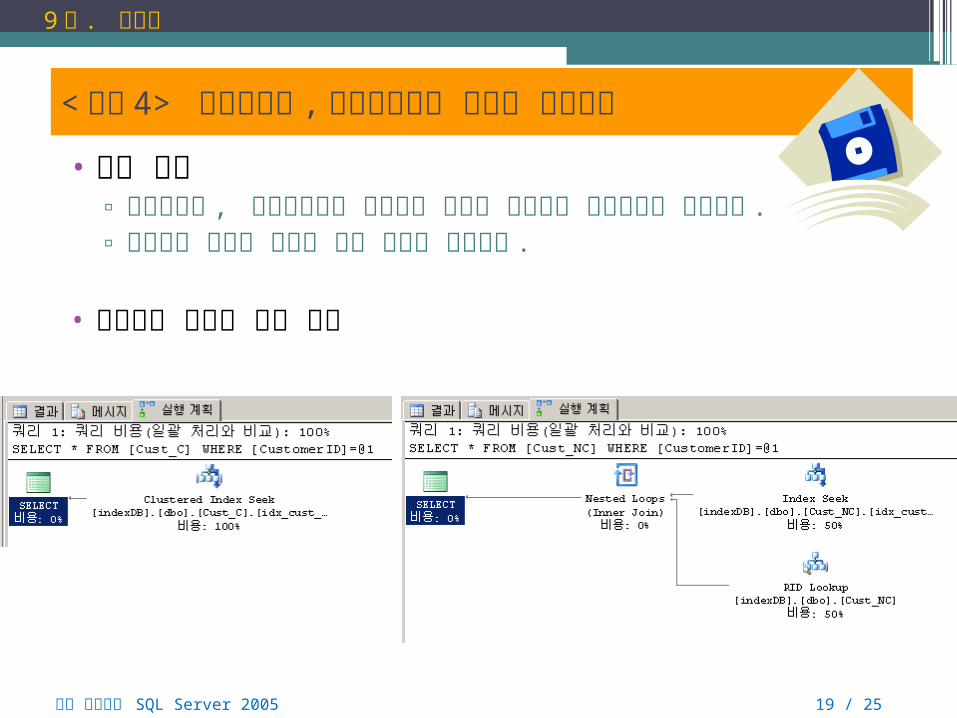
< 실습 4> 클러스터형 , 비클러스터형 인덱스 성능비교
• 실습 목표▫ 클러스터형 , 비클러스터형 인덱스의 성능이 어느것이
우수한지를 확인한다 .▫ 인덱스를 만들지 말아야 하는 경우를 알아본다 .
• 인덱스를 사용한 조회 결과
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
20 / 25
인덱스를 생성해야 하는 경우와 그렇지 않은 경우 (1)
• 인덱스는 열 단위에 생성된다 .• Where 절에서 사용되는 컬럼을 인덱스로 만든다 .• Where 절에 사용되더라도 자주 사용해야 가치가 있다 .• 데이터의 중복도가 높은 열은 인덱스를 만들어도 별 효용이 없다 .• 외래키가 사용되는 열에는 인덱스를 되도록 생성해 주는 것이 좋다 .• JOIN 에 자주 사용되는 열에는 인덱스를 생성해 주는 것이 좋다 .• INSERT/UPDATE/DELETE 가 얼마나 자주 일어나는 지를 고려한다 .• 클러스터형 인덱스는 하나만 생성할 수 있다 .• 클러스터형 인덱스가 테이블에 아예 없는 것이 좋은 경우도 있다 .• 사용하지 않는 인덱스는 제거하자 .• 계산열에도 인덱스를 활용할 수 있다 .
• 실습 목표 계산열에서 인덱스를 활용하는 방법을 익힌다 .
< 실습 5> 계산열에 인덱스 생성

뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
21 / 25
인덱스를 생성해야 하는 경우와 그렇지 않은 경우 (2)
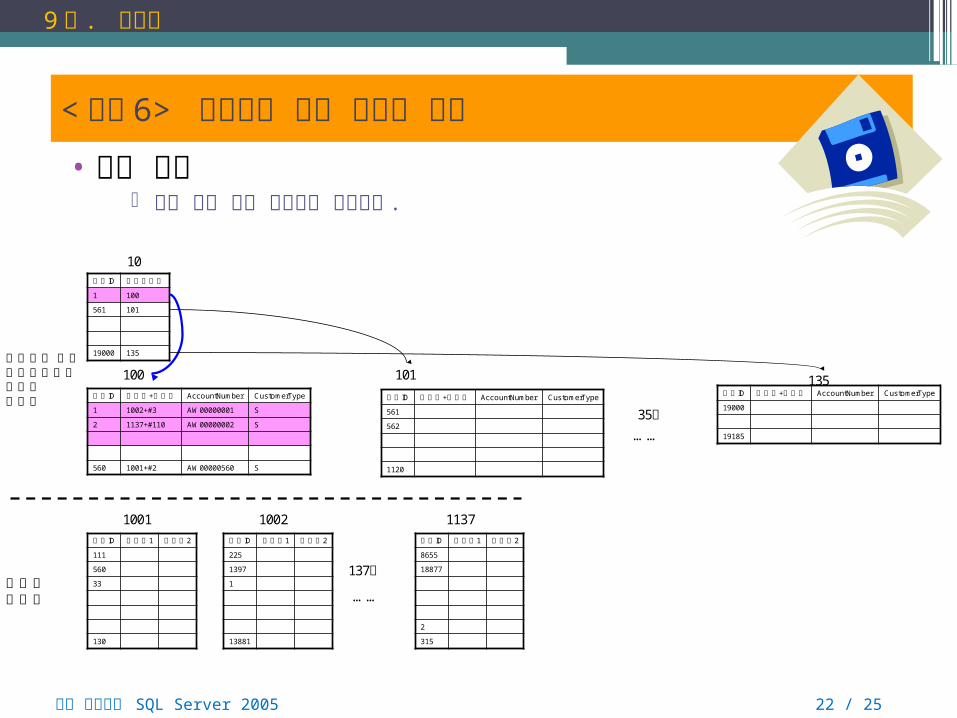
• 포괄 열이 있는 비클러스터형 인덱스를 활용하면 쿼리의 성능을 높일 수 있다 .
• 포괄 열이 있는 인덱스 특징▫ 포괄열이 있는 인덱스는 비클러스터형 인덱스에만 생성할 수 있다 . ▫ 포괄열이 있는 인덱스는 인덱스의 크기가 커지는 단점이 있다 .▫ 포괄열이 있는 인덱스 생성 후에 , 쿼리문의 성능이 급격히 향상될 수
있다 .▫ 포괄열이 있는 인덱스가 있더라도 SELECT 의 열이 그 포괄 열에
포함되지 않으면 , 어차피 인덱스는 사용되지 않는다 .▫ 인덱스를 만들 열은 총합이 900바이트를 넘지 않아야 한다 . 그럴
경우에는 포괄열이 있는 인덱스로 만들어서 해결할 수 있다 ..
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
22 / 25
• 실습 목표 포괄 열이 있는 인덱스를 이해한다 .
< 실습 6> 포괄열이 있는 인덱스 생성
고객ID 기타열1 기타열2
111
560
33
130
고객ID 기타열1 기타열2
225
1397
1
13881
고객ID 기타열1 기타열2
8655
18877
2
315
1001 1002 1137
고객ID 페이지+오프셋 AccountNumber CustomerType
1 1002+#3 AW00000001 S
2 1137+#110 AW00000002 S
560 1001+#2 AW00000560 S
100
137개
포괄열이 있는비클러스터형인덱스페이지
데이터페이지
101 135
35개
고객ID 페이지번호
1 100
561 101
19000 135
10
……
……
고객ID 페이지+오프셋 AccountNumber CustomerType
561
562
1120
고객ID 페이지+오프셋 AccountNumber CustomerType
19000
19185
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
23 / 25
데이터베이스 엔진 튜닝 관리자
• 쿼리의 성능을 높이기 위한 도구• 쿼리의 성능을 향상시키기 위한 인덱스 생성을 권장해 줌• SQL Server 2000 의 인덱스 튜닝 마법사의 업그레이드된 도구
• 실습 목표▫ 데이터베이스 엔진 튜닝 관리자의 기본적이 사용법을 익힌다 .
< 실습 7> 데이터베이스 엔진 튜닝 관리자의 사용
뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
24 / 25
분할 인덱스
• 대용량의 인덱스일 경우에 인덱스를 파일그룹별로 분할해서 성능을 높이고자 할 경우에 사용
• 특별한 경우가 아니라면 분할 테이블에 인덱스를 생성시에는 분할 테이블과 동일하게 각각의 파티션별로 인덱스가 생성됨
• 실습 목표▫ 분할인덱스를 생성하는 실습을 한다 .
< 실습 8> 분할 인덱스를 생성

뇌를 자극하는 SQL Server 2005
9 장 . 인덱스
25 / 25
인덱싱된 뷰
• 뷰의 실체는 SELECT 구문 뿐이지만 , 인덱싱된 뷰에는 실체가 존재한 존재하며 , 그 데이터는 고유 클러스터형 인덱스에 의해서 정렬되어 있는 뷰를 말한다 .
• 잘 활용할 경우 일부 쿼리의 성능을 향상시킬 수 있다 .• 실제 테이블이 변경될 경우에 인덱싱된 뷰에 존재하는 데이터도
변경되어야 하므로 시스템의 부하가 커질 수 있다 .
• 실습 목표▫ 인덱싱된 뷰의 생성 및 사용법을 확인한다 .
• 실습 구문 예제CREATE VIEW vProductSum WITH SCHEMABINDING AS
SELECT P.ProductID, COUNT_BIG(*) AS Count, P.Name, SUM(O.OrderQty) AS SumOrderQty,
SUM(O.LineTotal)……
< 실습 9> 인덱싱된 뷰의 활용