Embed Size (px)
Citation preview

1CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
TỔNG BIÊN TẬPTS. Vũ Chí Kiên
PHÓ TỔNG BIÊN TẬP
TS. Đinh Thị Thu Phong
BAN THƯ KÝ - BẠN ĐỌC
ThS. Nguyễn Thị Thu Thủy
ThS. Bùi Thị Huyền
Tel: (844) 37737136 (máy lẻ 27,22)
LIÊN HỆ QUẢNG CÁO PHÁT HÀNHQuảng cáo: Trịnh Hồng Hả[email protected]: 0912011031Phát hành: Đoàn Thị Yế[email protected]: 0904162626
MỸ THUẬTĐoàn Phong
ĐỊA CHỈ: 18 NGUYỄN DU, HÀ NỘI
Toà soạn: 110 Bà Triệu, Hà Nội
Tel:(84.4)37737136; (84.4) 37737137
Fax: (84.4) 37737130
Email: [email protected];
Website: http://www. tapchibcvt.gov.vn;
http://www.ictvietnam.vn
CHI NHÁNH TẠI TP.HCM
Địa chỉ: 27 Nguyễn Bỉnh Khiêm - Phường Đakao, Quận 1, TP. Hồ Chí Minh
Trưởng chi nhánh: Nguyễn Văn Nguyễn
Email: [email protected]
Tel/Fax: 08.39105379
Mobile: 0944909139
N ă m t h ứ 5 4 s ố 5 2 9 ( 7 1 9 )11.2016
B Ộ T H Ô N G T I N V À T R U Y Ề N T H Ô N G
TẠP CHÍ CÔNG NGHỆ THÔNG TIN TRUYỀN THÔNG
Giá bán: 25.000đ
Giấy phép xuất bản số: 365/GP-BTTTT ngày 19/12/2014 In tại Công ty TNHH MTV in Quân đội 1. In xong và nộp lưu chiểu tháng 11/2016
3-6
10-15
7-9
16-18
19-23
VẤN ĐỀ - SỰ KIỆN
Lan Phương: Ngày An toàn thông tin Việt Nam 2016: Kỷ nguyên mới về an ninh mạng
INterNet
thS. Phạm thị Ngọc Quyên: Giải pháp quản lý hệ thống đại lý Internet cung cấp dịch vụ trò chơi điện tử công cộng
AN toàN bảo mật
minh thiện: Bảo đảm An toàn thông tin với sản phẩm thương hiệu Việt
Đào Như Ngọc: Xác thực chuyển tiếp trong mạng IEEE 802.15.8 PAC
Nguyễn trọng tâm: Để an toàn trước mã độc tống tiền

2 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
24-27
33-37
28-32
38-46
47-49
50-56
57-64
AN toàN bảo mật
bH: No more ransom - Nền tảng chống phần mềm tống tiền
Đỗ Hữu tuyến: U2F và UAF - Giải pháp bảo mật an toàn cho các tài khoản Internet
Dương thị thanh tú, Đỗ minh Hiệp, Đỗ thị thu thủy: Bảo mật cho dữ liệu lớn trên điện toán đám mây
Võ Văn trường, trịnh minh Đức, Lê Khánh Dương, Nguyễn Văn Vinh: Đề xuất giải pháp trích chọn đặc trưng cho các thuật toán phân lớp dữ liệu trong kỹ thuật học máy giám sát và ứng dụng hiệu quả vào bài toán phát hiện mã độc
thu Hằng: Doanh nghiệp nhỏ và thách thức về bảo mật
Hồ Kim Giàu, Nguyễn Hiếu minh: Tăng tốc truy vấn cơ sở dữ liệu mã trên các dịch vụ thuê ngoài
tống Văn Vạn, Nguyễn Linh Giang, trần Quang Đức: Phân loại tên miền sử dụng các đặc trưng ngữ nghĩa trong hệ thống phát hiện DGA Botnet

3CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Vấn đề - Sự kiện
Ngày An toàn thông tin Việt Nam 2016: Kỷ nguyên mới về an ninh mạng
Ngày An toàn thông tin (ATTT) 2016 với trung tâm của sự kiện là Hội thảo quốc
tế với chủ đề “Kỷ nguyên mới của an ninh mạng” diễn ra vào ngày 17/11 tại TP. HCM và 2/12 tại Hà Nội. Đây là sự kiện thường niên được tổ chức dưới sự bảo trợ của Bộ TTTT và là một trong những hoạt động CNTT quan trọng trong năm được đông đảo cộng đồng ứng dụng và phát triển CNTT, giới truyền thông và toàn xã hội quan tâm, mong đợi. Sự kiện năm nay được bốn đơn vị: Hiệp hội ATTT Việt Nam, Cục ATTT, Trung tâm ứng cứu khẩn cấp máy tính Việt Nam (VNCERT), Bộ TTTT và Cục CNTT, Bộ Quốc phòng, đồng tổ chức.
Bàn thảo về nguy cơ mới trên không gian mạng
Tại buổi gặp mặt báo chí tại Hà Nội đầu tháng 11 thông báo về các hoạt động nhân ngày ATTT 2016, ông Vũ Quốc Thành, Phó Chủ tịch kiêm Tổng thư ký Hiệp hội ATTT Việt Nam (VNISA) nhấn mạnh: So với trước đây, các cuộc tấn công hiện nay có sự khác biệt, đó là các cuộc tấn công đang chuyển từ lượng sang chất. Thời gian trước, các cuộc tấn công thường là tấn công dành riêng và chúng ta tìm cách chống đỡ. Bây giờ, các cuộc tấn công được tiến hành có chủ đích nhằm vào các hệ thống CNTT quan trọng. 100 cuộc tấn công thì có tới 98 tấn công có chủ đích. Một hệ thống có thể bị tấn công bởi hàng chục
cuộc tấn công có chủ đích và làm tê liệt hệ thống. Điều này gây khó cho người làm ATTT, khó cho giới công nghệ, giải pháp ATTT.
Ông Thành cũng cho hay, năm 2016 là năm Chính phủ Mỹ chính thức tuyên bố chiến tranh mạng chống lại nhà nước tự xưng IS. Hàng loạt hạ tầng kinh tế kỹ thuật của xã hội như hệ thống cung cấp điện của Ucraina (1/2016) bị tấn công, hệ thống mạng của hãng hàng không Delta Airline bị đánh sập (tháng 8/2016), hệ thống thông tin của cảng sân bay Nội Bài và Tân Sơn Nhất bị gián đoạn (tháng 7/2016). “Những vụ việc đó khẳng định lời đánh giá của nhiều chuyên gia, đã bắt đầu một thập kỷ mới trên không gian mạng, thay vì thập kỷ
LAN PHươNG

4 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Vấn đề - Sự kiện
phá hoại trên không gian mạng trong những năm 90 hoặc thập kỷ tội phạm mạng trong những năm 2000”.
Vì thế, ngày ATTT Việt Nam 2016 với một chuỗi các sự kiện, đặc biệt là Hội thảo quốc tế được tổ chức tại TP. HCM (17/11) và Hà Nội (2/12) là nơi để các chuyên gia ATTT có thể bàn thảo kỹ và rõ hơn về “Kỷ nguyên mới của an ninh mạng”.
Theo ông Nguyễn Huy Dũng, Phó Cục trưởng Cục ATTT (Bộ TT&TT), Ban Tổ chức ngày ATTT năm nay mạnh dạn đề xuất chủ đề “Kỷ nguyên mới của an ninh mạng” để muốn nêu rõ sự thay đổi hay là xu hướng của ATTT - an ninh mạng. Hội thảo sẽ tập trung chủ yếu vào ATTT. ATTT và an ninh thông tin đã được định
nghĩa trong Luật ATTT, Nghị định 72 của Chính phủ về sử dụng Internet. Tuy là hai khái niệm khác nhau nhưng có quan hệ mật thiết. ATTT là tiền đề để đảm bảo an ninh thông tin.
Hội thảo lần này thu hút sự tham gia của hầu hết các tập đoàn, công ty lớn trên thế giới như: Google, Microsoft, Cisco, IBM, Splunk, Samsung, công ty Arbor Netwoks (Vương quốc Anh) lần đầu tham gia… với các báo cáo sẽ chia sẻ các kinh nghiệm, giải pháp, công cụ trong việc đảm bảo ATTT cho các hệ thống thông tin quan trọng.
Cũng tại phiên Hội thảo, VNISA đưa ra một báo cáo tổng hợp kết quả điều tra, đánh giá thực trạng ATTT tại Việt Nam trong năm vừa qua và công bố Chỉ số ATTT Việt
Nam (Vietnam Information Security Index) 2016. Cục ATTT – Bộ TTTT sẽ có báo cáo về những chính sách, qui định quản lý mới của nhà nước về lĩnh vực ATTT trong bối cảnh Luật ATTT mạng chính thức có hiệu lực.
Phiên hội thảo chuyên đề gồm 3 phiên: Phiên hội thảo bàn tròn với chủ đề “Đổi mới về chính sách trong đảm bảo ATTT” sẽ tập trung cho việc trình bày các nội dung chính về các nghị định, chính sách về ATTT được ban hành trong năm, trao đổi tháo gỡ các vướng mắc, tạo thống nhất trong việc thực thi Luật ATTT mạng cùng các Nghị định và chính sách mới được
ban hành; Phiên hội thảo với chủ đề “Đổi mới về công nghệ trong đảm bảo ATTT” sẽ tiếp nối với các báo cáo của các tổ chức, doanh nghiệp (DN) chia sẻ những kinh nghiệm, công cụ, giải pháp trong việc đảm bảo ATTT cho các hệ thông tin; Phiên hội thảo với chủ đề “Đổi mới trong hệ thống giám sát, phát hiện sớm và điều hành ứng cứu hệ thống thông tin”: các chuyên gia ATTT của các tổ chức, DN trong và ngoài nước sẽ tập trung phân tích, cung cấp giải pháp đồng thời chia sẻ kinh nghiệm nâng cao kỹ năng phát hiện nguy cơ và khắc phục, khôi phục lại hệ thống sau khi bị tấn công - một trong các vấn đề hiện đang được các tổ chức, DN đặc biệt quan tâm.
Toàn cảnh buổi gặp gỡ báo chí nhân ngày ATTT Việt Nam 2016

5CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Nhiều hoạt động nâng cao ý thức cộng đồng về ATTT
Trong khuôn khổ sự kiện Ngày ATTT 2016 còn có nhiều hoạt động nhằm nâng cao nhận thức của cộng đồng về ATTT, thúc đẩy đào tạo nguồn nhân lực có trình độ cao về ATTT và khuyến khích quảng bá việc ứng dụng, phát triển CNTT một cách bảo mật và an toàn.
Điểm nhấn trong các hoạt động này là cuộc thi quốc gia “Sinh viên với ATTT”. Việc tổ chức cuộc thi về ATTT cho học sinh, sinh viên đã trở thành nhiệm vụ chính thức được Thủ tướng Chính phủ giao cho Bộ Giáo dục và Đào tạo (GD&ĐT) trong Đề án 893/QĐ-TTg “Tuyên truyền, phổ biến nâng cao nhận thức và trách nhiệm về ATTT đến năm 2020”. Cuộc thi được Bộ GD&ĐT chỉ đạo, Hiệp hội ATTT Việt Nam và Cục CNTT – Bộ GD&ĐT phối hợp tổ chức. Đây là lần thứ 9 cuộc thi về ATTT cho sinh viên được tổ chức và là năm thứ 7 cuộc thi được tổ chức trên quy mô toàn quốc với sự tham dự đông nhất từ trước đến nay cả về số trường và số đội: 59 đội đến từ 30 trường Đại học (ĐH) có khoa CNTT trên cả nước.
Cuộc thi được diễn ra với 2 vòng thi. Vòng thi sơ khảo sẽ diễn ra vào ngày 5/11/2016 tại 3 địa điểm: Học viện Kỹ thuật quân sự (Hà Nội), Đại học Duy Tân (Đà Nẵng) và Đại học Tôn Đức Thắng (Tp Hồ Chí Minh). Vòng thi
chung khảo sẽ diễn ra vào ngày 2/12/2016 tại Hà Nội). Thời gian thi là 8 giờ liên tục.
Hình thức ra đề thi đã đạt trình độ tương đương với hình thức ra đề thi khu vực và quốc tế về ATTT. Hình thức ra đề thi tại vòng thi sơ khảo là hình thức thử thách theo chủ đề (jeopardy). Còn hình thức thi của vòng thi chung khảo là hình thức thi đối kháng Tấn công và Phòng thủ trên mạng (Attack & Defence). Hai đội có kết quả tốt nhất của 3 vòng thi sơ khảo tại ba địa điểm cùng 4 đội có kết quả tốt nhất còn lại sẽ vào vòng thi chung khảo. Mỗi trường không có quá 2 đội được quyền vào dự vòng thi chung khảo.
Ông Tô Thành Nam, Phó Cục trưởng Cục CNTT, Bộ GD&ĐT cho biết cuộc thi đã tạo sân chơi lành
mạnh, bổ ích cho sinh viên CNTT nói chung, và sinh viên ATTT nói riêng, nhằm tuyên truyền, nâng cao nhận thức, trách nhiệm, cũng như phát hiện tài năng, tôn vinh tài năng, tạo một phong trào học tập, nghiên cứu trao đổi kiến thức giữa sinh viên các trường đào tạo CNTT, ATTT trong cả nước.
Ban Tổ chức cuộc thi đã chọn được 10 đội vào Chung khảo, trong đó có 2 đội đến từ ĐH CNTT - ĐH Quốc gia TP. HCM, 2 đội từ Học viện Kỹ thuật mật mã, 2 đội của ĐH Duy Tân và 4 đội đạt điểm cao nhất đều đến từ các trường phía Bắc là Học viện Công nghệ BCVT, Học viện Kỹ thuật Quân sự, ĐH Bách khoa, ĐH CNTT – ĐH Quốc gia Hà Nội. Lễ Công bố kết quả cuộc thi và trao giải thưởng sẽ diễn ra tại phiên toàn thể Hội

6 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
thảo Quốc tế Hà Nội vào ngày 2/12/2016.
Theo ông Tô Thành Nam trong bối cảnh ATTT diễn biến tinh vi, cuộc thi được kỳ vọng sẽ tiếp tục thu hút được nhiều học sinh từ nhiều trường tham gia, nhằm chọn được nhân tài, thúc đẩy nhân lực ATTT của Việt trước nguy cơ mất ATTT đang diễn ra phức tạp hiện nay.
Một hoạt động đáng chú ý nữa trong chuỗi sự kiện ngày ATTT năm 2016 là Bình chọn danh hiệu “Sản phẩm ATTT có chất lượng cao và dịch vụ ATTT tiêu biểu của năm 2016”. Đây là năm thứ hai tổ chức bình chọn danh hiệu “Sản phẩm ATTT chất lượng cao” và là năm đầu tiên tổ chức bình chọn danh hiệu “Dịch
vụ ATTT tiêu biểu” của các DN trong nước. Việc bình chọn được tổ chức nghiêm túc, chặt chẽ và khoa học, nhằm đánh giá chính xác chất lượng sản phẩm và dịch vụ, qua đó phát hiện và quảng bá tôn vinh các sản phẩm về ATTT của DN trong nước. Nhiều phòng thí nghiệm về ATTT của các tổ chức sẽ được mời tham gia đánh giá, đo đạc các thông số chất lượng của sản phẩm. Kết quả bình chọn sẽ được công bố vào tháng 6/2017 tại Hà Nội.
Theo ông Nguyễn Chí Thành, Chánh Văn phòng VNISA, việc bình chọn danh hiệu sản phẩm và dịch vụ ATTT chất lượng, nhằm động viên các DN đăng ký để đưa những sản phẩm tốt, dịch vụ tốt đến người dùng. Đồng
thời đây là dịp động viên các DN trong nước, quảng bá được các sản phẩm trong nước và làm chủ được sản phẩm. Tiêu chí đánh giá sản phẩm và dịch vụ ATTT có khác so với các giải thưởng khác, đó là dùng thiết bị đánh giá chỉ tiêu của sản phẩm, chứ không thuần túy dựa trên hồ sơ, kiểm định tính năng của sản phẩm để công bố cho người dùng. Hiện nay đã có một số sản phẩm đáng chú ý như giải pháp đảm bảo ATTT cho máy tính cá nhân và nối mạng. Bằng nội lực các DN đã có giải pháp vừa tầm, không đòi hỏi kinh phí mà đáp ứng được yêu cầu đảm bảo ATTT.
Trong chuỗi các sự kiện nâng cao nhận thức ATTT, còn có khoá đào tạo ngắn hạn về ATTT với chủ đề “Lập trình an toàn trên điện thoại di động” cho cán bộ quản trị hệ thống thông tin, và Điều tra thực trạng về ATTT trên phạm vi toàn quốc. Đối tượng điều tra là các sở TTTT của các tỉnh, thành phố trực thuộc trung ương, các trung tâm thông tin của các Bộ, ngành và hàng trăm tổ chức, DN ứng dụng và phát triển CNTT.
Hy vọng rằng, các hoạt động trong khuôn khổ “Ngày ATTT Việt Nam” năm nay tiếp tục nhận được sự quan tâm của lãnh đạo nhà nước, các bộ, ban, ngành trung ương và địa phương, các cơ quan truyền thông, báo chí và giới CNTT trong cả nước để sự kiện thực sự mang lại ý nghĩa to lớn, thiết thực trong việc nâng cao nhận thức cộng đồng về ATTT số.

7CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
internet
GIẢI PHÁP QUẢN LÝ HỆ THỐNG ĐẠI LÝ INTERNET CUNG CẤP DỊCH VỤ TRÒ CHƠI ĐIỆN TỬ CÔNG CỘNG
thS. PHạm tHị NGọc QuyêN
Trong thời đại bùng nổ thông tin hiện nay, mạng Internet đã trở thành phương tiện thông tin liên lạc không thể thiếu trong việc trao đổi thông tin, giao lưu, hợp tác giữa mọi cá nhân, tổ
chức và quốc gia trên thế giới. Internet là công cụ tiện lợi nhất để truyền tải thông tin với tốc độ nhanh nhất đến tất cả mọi người, không còn cách biệt về biên giới địa lý; qua đó có thể tìm kiếm thông tin ở mọi lúc, mọi nơi.
Đại lý Internet là một trong những loại hình dịch vụ để người dân, cộng đồng, đặc biệt là ở vùng nông thôn, miền núi, vùng sâu, vùng xa có điều kiện thuận lợi tiếp cận với thông tin qua mạng, góp phần rút ngắn khoảng cách thông tin giữa các vùng miền. Hệ thống đại lý Internet công cộng cũng là một trong những quy định trong tiêu chí Nông
thôn mới của ngành Thông tin và Truyền thông. Tuy nhiên, bên cạnh những mặt tích cực thì loại hình dịch vụ này cũng còn nhiều bất cập. Nhiều điểm truy cập Internet công cộng đã không tuân thủ các quy định của pháp luật về quản lý Internet, hầu hết các đại lý Internet công cộng đều cung cấp dịch vụ trò chơi điện tử công cộng (game online). Một số chủ điểm cung cấp dịch vụ thường thiếu trách nhiệm, mở quá giờ quy định, không kiểm soát được nội dung truy cập Internet của khách hàng, có lúc, có nơi còn xảy ra hiện tượng gây mất tình trạng an ninh trật tự trong
khu vực và làm ảnh hưởng đến tâm lý, đạo đức của một bộ phận thanh thiếu niên trên địa bàn nhất là học sinh, sinh viên…
Trong thời gian qua, mặc dù Nhà nước đã ban hành nhiều văn bản liên quan đến quản lý điểm truy nhập Internet công cộng và cung cấp game online, song vẫn chưa có công cụ hữu hiệu để quản lý, giám sát chặt chẽ các cơ sở cung cấp dịch vụ này. Hiện nay trên thị trường, các phần mềm quản lý phòng máy chuyên nghiệp do các doanh nghiệp cung cấp chỉ có chức năng quản lý hoạt động truy nhập, thanh toán của các máy con, hỗ trợ khách hàng download và chơi game trực tuyến, chứ chưa có các nội dung phục vụ cho các cơ quan quản lý nhà nước trong việc quản lý, kiểm soát các đại lý Internet cung cấp dịch vụ game online. Xuất phát

8 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
internet
từ thực trạng trên, Sở Thông tin và Truyền thông Quảng Nam đã đề xuất thực hiện đề tài cấp tỉnh: “Ứng dụng công nghệ thông tin trong quản lý hệ thống đại lý cung cấp dịch vụ trò chơi trực tuyến công cộng”. Hệ thống được triển khai sử dụng tại địa chỉ web: http://quanlyphongmay.qti.vn/
Với phần mềm quản lý này, Sở TT&TT sẽ thuận lợi hơn trong việc quản lý, kiểm tra, giám sát hoạt động của các đại lý Internet cung cấp game online.
Phần mềm được triển khai với các ứng dụng:
Giám sát trực tuyến hoạt động của các đại lý cung cấp dịch vụ trò chơi điện tử công cộng
Hệ thống phần mềm quản lý sẽ kết nối với các phần mềm quản lý phòng máy tại các đại lý Internet, hỗ trợ cho các cơ quan quản lý như Sở Thông tin Truyền thông, phòng Văn hóa và Thông tin, Công an… thực hiện công tác quản lý các đại lý cung cấp dịch vụ game online trên địa bàn tỉnh. Thông qua phần mềm sẽ giám sát được các nội dung:
- Quản lý thông tin về đại lý Internet.
- Giám sát các vi phạm hoạt động về giờ giấc tại các đại lý.
- Giám sát các vi phạm nội dung truy cập.
- Thực hiện công tác thống kê, báo cáo.
Phần mềm có chức năng cảnh báo các hoạt động vi phạm quy định của pháp luật trong hoạt động kinh doanh của các đại lý Internet, đó là các vi phạm về giờ giấc hoạt động của các đại lý, các vi phạm về truy nhập các trang web cấm. Phần mềm còn có chức năng thống kê, báo cáo phục vụ cho công tác báo cáo, quản lý số liệu tại Sở Thông tin và Truyền thông. Từ đó, các cơ quan quản lý như Sở Thông tin và Truyền thông, phòng Văn hóa và Thông tin cấp huyện sẽ dễ dàng theo dõi, thanh kiểm tra, xử lý hành vi vi phạm của các chủ đại lý. Ngoài ra phần mềm còn giúp ngăn chặn các hiểm họa ảnh hưởng đến máy tính như: Hacker, Virus Trojan, chặn các trang web đen…
Hỗ trợ việc thực hiện thủ tục cấp Giấy chứng nhận đủ điều kiện hoạt động điểm cung cấp dịch vụ trò chơi điện tử công cộng thông qua mạng Internet
Theo quy định tại Nghị định 72/2013/NĐ-CP ngày 15/7/2013 và Thông tư số 23/2013/TT-BTTTT ngày 24/12/2013 của Bộ Thông tin và Truyền thông, điểm cung cấp dịch vụ trò chơi điện tử công cộng ngoài
Mục tiêu của đề tài nhằm xây dựng giải pháp nâng cao hiệu quả trong công tác quản lý nhà nước về loại hình dịch vụ đại lý Internet cung cấp dịch vụ game online trên địa bàn tỉnh:
- Đề xuất giải pháp, cơ chế phối hợp liên ngành trong lĩnh vực cấp phép, quản lý, thanh kiểm tra các đại lý Internet, điểm cung cấp dịch vụ trò chơi trực tuyến công cộng.
- Xây dựng phần mềm quản lý các đại lý Internet và điểm cung cấp dịch vụ trò chơi trực tuyến công cộng trên địa bàn tỉnh.
Hội nghị phổ biến quy định pháp luật trong lĩnh vực kinh doanh Internet và cung cấp trò chơi điện tử công cộng

9CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
việc thực hiện đăng ký thủ tục kinh doanh đại lý Internet còn phải thực hiện việc đăng ký cấp Giấy chứng nhận đủ điều kiện hoạt động điểm cung cấp dịch vụ trò chơi điện tử công cộng.
Thông qua phần mềm, mọi tổ chức, công dân có nhu cầu đăng ký cấp giấy chứng nhận sẽ thực hiện đăng ký trực tuyến qua mạng, hồ sơ đăng ký sẽ được bộ phận một cửa kiểm tra và chuyển cho các bộ phận liên quan xử lý. Đồng thời, các tổ chức, cá nhân có thể tra cứu thủ tục hành chính, quy trình xử lý, thời gian xử lý của hồ sơ, tra cứu tiến độ xử lý hồ sơ. Đây là một trong những bước ứng dụng công nghệ thông tin trong việc thực hiện cải cách hành chính, nhằm đơn giản hóa các thủ tục hành chính, giảm thiểu tối đa công sức của người dân và chính quyền trong việc giải quyết các thủ tục hành chính.
Đại lý Internet cung cấp dịch vụ game online là loại hình dịch vụ kinh doanh có điều kiện nên cần phải được giám sát, kiểm tra. Hiện nay, việc kiểm tra giám sát hoạt động của các đại lý cung cấp dịch
vụ game online thường do đội kiểm tra liên ngành 814 tại địa phương thực hiện. Việc theo dõi vi phạm hoạt động quá giờ của đại lý là việc làm khó khăn đối với cán bộ kiểm tra. Nhờ hệ thống quản lý này, cán bộ của phòng Văn hóa và Thông tin, Sở Thông tin và Truyền thông sẽ nhanh chóng phát hiện được những đơn vị thường vi phạm hoạt động quá giờ để có các biện pháp kiểm tra, nhắc nhở hoặc xử lý hành chính, ổn định hoạt động kinh doanh của các đại lý Internet cung cấp dịch vụ game online trên địa bàn.
Hệ thống tự động cập nhật số liệu, thông tin từ các phần mềm quản lý phòng máy của các doanh nghiệp, do đó các số liệu thống kê, báo cáo sẽ được thực hiện tổng hợp một cách nhanh chóng, chính xác. Thực hiện quản lý và cấp phép qua mạng sẽ tạo điều kiện thuận lợi cho tổ chức, cá nhân tham gia xin cấp phép hoạt động cung cấp dịch vụ trò chơi điện tử công cộng, góp phần đẩy mạnh thực hiện cải cách thủ tục hành chính trong giai đoạn mới.
Kết quả nghiên cứu của đề tài làm căn cứ khoa học để ban hành các quy định hướng dẫn về việc quản lý, cập nhật, khai thác sử dụng thông tin cho các đơn vị: doanh nghiệp viễn thông, doanh nghiệp cung cấp phần mềm quản lý phòng máy, đại lý Internet cung cấp dịch vụ game online, các phòng chức năng của Sở Thông tin và Truyền thông, các phòng Văn hóa Thông tin cấp huyện. Đề tài sẽ góp phần nâng cao hiệu quả công tác quản lý nhà nước đối với hoạt động Internet, giúp quản lý chặt chẽ, phục vụ hiệu quả cho công tác quản lý nhà nước hệ thống đại lý Internet cung cấp dịch vụ game online trong tình hình hiện nay.
Tiếp nhận hồ sơ tại bộ phận một cửa

10 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Bảo đảm an toàn thông tin với sản phẩm thương hiệu Việt
Chiến tranh mạng có thể diễn ra bất cứ lúc nào
Tình hình an toàn, an ninh thông tin trên thế giới, khu vực và trong nước tiếp tục có những diễn biến hết sức phức tạp, không chỉ đe dọa trực tiếp đến hoạt động và tài sản của các cá nhân, tổ chức và doanh nghiệp mà còn ảnh hưởng đến hạ tầng cơ sở của một xã hội hiện đại như điện, nước, giao thông… và ảnh hưởng tới an ninh quốc gia. Đến nay, tấn công mạng đã trở thành một phương thức tấn công thực sự, được sử dụng để giải quyết mâu thuẫn giữa một số quốc gia. Các quốc gia cũng thường tiến hành các cuộc tấn công mạng chống lại nhau. Truyền thông thường nhắc tới các vụ tấn công mạng xảy ra liên quan tới những nước như Mỹ, Nga, Trung Quốc.
Tuy nhiên trên thực tế, những vụ tấn công mạng không chỉ giới hạn ở những nước này.
Tần suất các cuộc tấn công này ngày càng tăng, và mức độ thù địch trong đó, tuy không phải là xung đột bạo lực, nhưng lại có nguy cơ diễn tiến thành một việc
tồi tệ hơn - một cuộc chiến lớn. Vụ tấn công DDoS ở Estonia trong khoảng thời gian từ 26/4/2007 đến 23/5/2007 được coi cuộc tấn công chiến tranh mạng đầu tiên trên thế giới. Hầu hết các nguồn nghiên cứu đều chỉ ra có mối liên hệ đến chính phủ Nga tấn công
mINH tHIỆN
An toàn bảo mật

11CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Estonia. Các hệ thống chính phục vụ chính phủ điện tử của Estonia đều bị tấn công gián đoạn dịch vụ, nhiều đợt gián đoạn lên đến hơn 10h. Sau này, khi xảy ra tranh chấp chính trị, quân sự giữa Nga và một số nước thành viên Liên Xô cũ đều có kèm theo các đợt tấn công DDoS vào các hệ thống chính phủ Georgia (2008), Kyrygistan (2009).
Mới đây, Cơ quan an ninh liên bang Nga (FSB) đã phát hiện chương trình phần mềm gián điệp độc hại trong mạng máy tính của khoảng 20 tổ chức Nga. Theo thông tin được đăng trên Hãng tin Sputnik vào ngày 30/7/2016, hệ thống máy tính của cơ quan công quyền, các tổ chức khoa học và quân sự, các doanh nghiệp thuộc khu phức hợp quân sự - công nghiệp và các cơ sở hạ tầng quan trọng khác của nước này đã bị nhiễm phần mềm độc hại. FSB ghi nhận mục tiêu là sự lây lan của phần mềm độc hại, cho thấy hoạt động phá hoại đã được dự tính một cách chuyên nghiệp. Như đánh giá của các chuyên gia, theo phong cách lập trình và phương pháp lây nhiễm, đây là chương trình phần mềm tương tự giống như phần mềm đã được sử dụng trong các hoạt động gián điệp tấn công không gian mạng gần đây tại Nga và trên thế giới.
Văn phòng quản lý nhân sự Mỹ (Office of Personnel Management) bị tấn công
vào tháng 7/2015 làm lộ thông tin 22 triệu người, thông tin bị mất là thông tin về số an sinh xã hội, địa chỉ, quá trình học tập, các mối quan hệ làm việc và gia đình bạn bè, tình hình tài chính gia đình, vợ chồng, con cái của nhân viên nhà nước đang làm việc hoặc đã nghỉ hưu. Đặc biệt trong đó có 1,1 triệu vân tay của các nhân viên chính phủ. Thủ phạm bị cáo buộc là các cơ quan tình báo Trung Quốc.
Đầu năm nay, cơ quan tình báo Hàn Quốc thông tin với các nghị sĩ rằng, số các vụ tấn công mạng của CHDCND Triều Tiên đã tăng gấp đôi chỉ trong một tháng. Theo trang tin công nghệ Venturebeat, nói cụ thể hơn thì số vụ tấn công mạng của CHDCND Triều Tiên trong tháng 2 đã tăng gấp đôi so với tháng 1/2015. Các hacker CHDCND Triều Tiên tìm cách tấn công vào hệ thống kiểm soát xe lửa và mạng máy tính của
các cơ quan tài chính Hàn Quốc nhưng đã không thành công. Cơ quan tình báo quốc gia Hàn Quốc cũng cáo buộc CHDCND Triều Tiên đã cố tình tấn công vào điện thoại thông minh của 300 cán bộ ngoại giao, an ninh, quân đội, và thâm nhập thành công vào 40 điện thoại trong đó.
Một loạt vụ tấn công mạng khác khá đình đám như: các vụ tấn công vào hệ thống máy tính của Nhà Trắng, Ngân hàng JP Morgan Chase, công ty Chứng khoán Dow Jones, các công ty bảo hiểm, cung cấp dịch vụ y tế, các hãng hàng không, một số báo, tạp chí lớn và nhiều trường đại học của Mỹ. Bên cạnh đó, nhiều website, hệ thống mạng của các tổ chức, quốc gia lớn khác như: Hệ thống phòng thủ tên lửa và phòng không Patriot (Đức), Quốc hội Đức, các cơ quan chính phủ và học viện của Ấn Độ, chính phủ Anh, Cơ quan Tình báo

12 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Canada, Ủy ban Bầu cử Trung ương Nga, Bộ Thương mại và Cảnh sát liên bang Úc, Tòa trọng tài thường trực (PCA) tại Hà Lan, Bộ Quốc phòng, Bộ Thông tin và Công nghệ Truyền thông Thái Lan... cũng bị xâm nhập, cài đặt mã độc, thay đổi giao diện.
Một số quốc gia mặc dù luôn lên án, phản đối các hoạt động tấn công mạng nhưng cũng đã bị phát hiện đang đầu tư, tăng cường các hoạt động gián điệp mạng với quy mô lớn trên thế giới, có tổ chức chặt chẽ, có hệ thống, mục tiêu tấn công rõ ràng. Cách thức thực hiện chủ yếu thông qua các công cụ tấn công mạng rất mạnh và phức tạp để kiểm soát, giám sát mục tiêu, sử dụng mã độc nguy hiểm, có khả năng lây nhiễm cao hoặc cài đặt phần mềm gián điệp vào các thiết bị công nghệ để tấn công xâm nhập, thu thập thông tin tình báo, phá hoại.
Nước Mỹ cũng đã tham gia vào cuộc đua với Trung Quốc và Nga trong việc phát triển các loại vũ khí tấn công mạng có khả năng phá hủy cơ sở hạ tầng của các nước khác. Theo ông Scott Borg, Giám đốc điều hành Tổ chức nghiên cứu không gian mạng của Mỹ, một nhà cố vấn về an ninh mạng cho chính phủ và doanh nghiệp Mỹ, cả ba quốc gia này đang xây dựng kho vũ khí gồm những loại virút, sâu, mã độc máy tính tinh vi nhất.
Hậu quả của các cuộc tấn công mạng không hề nhỏ. Theo đánh giá từ Trung tâm Nghiên cứu Quốc tế và Chiến lược cho thấy,
các vụ tấn công mạng làm thế giới thất thoát khoảng hơn 400 tỉ USD/năm, trong đó châu Á nói chung và Đông Nam Á nói riêng là khu vực bị thiệt hại nhiều nhất. Do đó, công tác bảo đảm an ninh, an toàn mạng hiện nay đang nhận được sự quan tâm đặc biệt ở nhiều quốc gia, trong đó vấn đề củng cố hệ thống pháp luật, điều chỉnh chính sách về an ninh mạng, đầu tư ngân sách, hiện đại hóa trang thiết bị an ninh mạng, nâng cao nhận thức cho người dùng luôn được ưu tiên hàng đầu.
Thúc đẩy doanh nghiệp Việt Nam làm chủ thị trường ATTT trong nước
Thực tế tại Việt Nam, nhiều hệ thống CNTT được thiết kế từ lâu, không có phương án bảo đảm an toàn, an ninh thông tin từ đầu nên dễ bị tấn công. Nhiều hệ thống quan trọng nhưng không có giải pháp bảo vệ như tường lửa (Firewall), thiết bị chống tấn công, xâm nhập (EPS); Các thiết bị bảo vệ hết bản quyền (license) nhưng không được gia hạn, làm mất khả năng phòng vệ.
Ý thức bảo vệ an ninh, an toàn thông tin khi sử dụng máy tính của người dùng còn hạn chế. Máy tính phần lớn sử dụng phần mềm bẻ khóa, không có bản quyền nên không nhận được sự hỗ trợ bảo mật, nâng cấp của nhà sản xuất. Đa số máy tính không cài đặt phần mềm phòng chống mã độc. Mật khẩu truy nhập máy tính, email, thậm chí cả mật khẩu
quản trị hệ thống còn đặt đơn giản và không thường xuyên thay đổi. Cá biệt có trường hợp đặt mật khẩu nhưng lại lưu trữ công khai tệp tin chứa mật khẩu trên các trang mạng
Một số cơ quan, đơn vị có nhận thức sai về an ninh, an toàn thông tin, cho rằng chỉ việc đầu tư thiết bị mà không chú trọng về nhân lực quản trị, vận hành hệ thống. Đa số nhân viên chuyên trách CNTT phải kiêm nhiệm công tác bảo đảm an toàn, an ninh mạng; chưa được quan tâm bồi dưỡng chuyên môn hoặc chế độ chính sách chưa thỏa đáng. Các trang thiết bị, giải pháp kỹ thuật bảo đảm an ninh, an toàn thông tin đa phần do đối tác nước ngoài cung cấp. Do không làm chủ được công nghệ dẫn đến không phát huy hết được hiệu quả.
Trước thực trạng này, Bộ Thông tin và Truyền thông đang xây dựng Kế hoạch triển khai Quyết định số 898/QĐ-TTg ngày 27/5/2016 của Thủ tướng Chính phủ Phê duyệt phương hướng, mục tiêu, nhiệm vụ bảo đảm an toàn thông tin mạng giai đoạn 2016 – 2020. Trong chương trình này đặt ra mục tiêu “Phát triển tối thiểu 5 sản phẩm an toàn thông tin thương hiệu Việt Nam được sử dụng phổ biến tại thị trường trong nước. Doanh nghiệp Việt Nam đóng vai trò chủ đạo tại thị trường dịch vụ an toàn thông tin trong nước”.
Hiện nay, tại Việt Nam nguồn ngân sách cho CNTT nói chung và ngân sách cho an toàn an ninh thông tin còn rất hạn chế,
An toàn bảo mật

13CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
nguồn nhân lực cho ATTT rất thiếu và yếu. Các giải pháp về an toàn thông tin “Made in Vietnam” còn rất thiếu, chủ yếu là các giải pháp chống mã độc trên máy tính cá nhân, mobile. Bất kỳ giải pháp an toàn an ninh thông tin nào khi triển khai đều cần quan tâm đến 3 khía cạnh Con người, Chính sách và Công nghệ. Thiếu một trong 3 yếu tố này, giải pháp nào cũng không mang lại hiệu quả mong muốn. Chính vì vậy, việc hoạch định chính sách phát triển ATTT quốc gia thúc đẩy các doanh nghiệp Việt Nam làm chủ công nghệ, tự thiết kế, phát triển sản phẩm, giải pháp ATTT của chính mình là yếu tố vô cùng quan trọng. Chỉ có làm chủ công nghệ thì mới kiểm soát
được an ninh thông tin, đảm bảo được chủ quyền trên không gian mạng. Nhiều doanh nghiệp Việt Nam đã đưa ra những giải pháp, dịch vụ về ATTT nhưng ở mức nhỏ lẻ, chủ yếu là phần mềm diệt virut cho các thiết bị đầu cuối. Rất ít giải pháp mang tính tổng thể, có hệ thống, có khả năng bảo vệ đa lớp và triển khai trên diện rộng. Nếu có giải pháp ATTT thương hiệu Việt thỏa mãn những yêu cầu kể trên thì sẽ dễ dàng chiếm lĩnh thị trường trong nước thông qua nhiều hình thức như bán, cho thuê dịch vụ ATTT, đặc biệt hiện nay hình thức thuê dịch vụ CNTT đang được Việt Nam khuyến khích.
Trên thế giới, hiện xu hướng thuê dịch vụ giám sát ATTT
(Managed Security Services) phát triển mạnh, do có nhiều ưu điểm hơn so với việc các đơn vị đầu tư hệ thống giám sát an toàn mạng (SIEM) và tự vận hành. Việc thuê một đơn vị có năng lực về ATTT triển khai và vận hành giải pháp ATTT là giải pháp tối ưu về chi phí và hiệu quả cho các cổng thông tin điện tử. Mới đây, Viettel vừa tuyên bố đã hoàn tất nghiên cứu, triển khai đa dạng hoá và nâng cao chất lượng các sản phẩm và giải pháp bảo mật, đặc biệt là các sản phẩm bảo mật kênh truyền, bảo mật hệ thống truyền hình hội nghị, bảo mật cơ sở dữ liệu, bảo mật mạng công nghệ thông tin, các thiết bị di động, đa dạng dịch vụ… sẵn sàng đáp ứng nhanh chóng nhu cầu bảo mật của Chính phủ, các Bộ, Ngành, địa phương và các doanh nghiệp.
Viettel đã tự xây dựng hệ sinh thái các giải pháp ATTT từ quản lý giám sát và xử lý tập trung các vấn đề ATTT, phòng chống tấn công APT, quản lý ATTT mạng văn phòng, Giải pháp ATTT đặc thù (tích hợp mạng lưới là thế mạnh riêng của nhà cung cấp mạng Viễn thông và Internet) dành cho khách hàng di động và khách hàng Internet; Giải pháp phát hiện bất thường và quản lý ATTT cho mạng viễn thông. Hệ sinh thái giải pháp ATTT của Viettel đầy đủ các thành phần: Giải pháp bảo vệ vòng ngoài cho serverFarm như: Web Application Firewall, AntiDDos; Giải pháp chống APT cho máy tính cá nhân (Endpoint Security),

14 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
giám sát APT lớp mạng (Network Anomaly Detection), chống APT cho Email (Email Gateway Security); Hệ thống quản lý sự kiện và an toàn mạng (SIEM – Security Information and Event Management); Các hệ thống phân tích tự động nhận diện mã độc thông minh (Cloud Analysis), Security Datamining.
Ông Tống Viết Trung, Phó Tổng Giám đốc Viettel, cho biết: Năm 2015, Viettel đã hoàn thành xây dựng và triển khai bộ giải pháp ATTT giám sát 24/07 tất cả các thành phần của mạng lưới thông qua trung tâm giám sát ATTT toàn cầu (GSOC) để bảo vệ cho mạng Viettel tại Việt Nam và 09 thị trường nước ngoài.
Từ đầu năm 2016, Viettel đã triển khai hệ thống phát hiện và ngăn chặn tự động tấn công DDoS băng thông lớn cho khách hàng, hiện nay mỗi ngày hệ thống trung bình ngăn chặn khoảng 80 đợt tấn công DDoS.
Do tất cả lưu lượng của khách hàng đều chạy qua hạ tầng do nhà mạng cung cấp thì vấn đề máy tính của khách hàng bị nhiễm mã độc chịu sự kiểm soát của máy chủ điều khiển (C&C) nếu nhìn đầy đủ từ nhà mạng sẽ có một bức tranh về bản đồ mã độc. Nhà mạng có thể ngăn chặn mức mạng lưới các kết nối của mã độc tới máy chủ điều khiển, qua đó vô hiệu hóa mã độc cho máy tính, điện thoại của khách hàng. Từ đầu năm 2015, nhà mạng này đã đưa hệ thống Bản đồ mã độc (Botnet Map) vào triển khai cho toàn mạng lưới. Đội ngũ chuyên
gia của Viettel đã thực hiện theo dõi các nhóm APT tấn công vào Việt Nam, các mạng Botnet trong nước và trên thế giới, giúp nhìn thấy tình trạng mã độc đến từng khách hàng và thực hiện ngăn chặn trên mạng lưới, đến nay đã ngăn chặn để bảo vệ cho hơn 450.000 khách hàng của Viettel.
Ngoài việc triển khai bảo vệ cho nội bộ Tập đoàn và các thị trường, Viettel còn triển khai bảo vệ cho cho các hệ thống website của các đơn vị trong Bộ Quốc phòng, website hochiminh.vn. Các website này cũng được đưa vào giám sát 24/07 thông qua GSOC. Bộ giải pháp chống APT cho mạng Office và bộ giải pháp giám sát, bảo vệ cho ServerFarm của Viettel được triển khai bảo vệ hiệu quả cho cổng thông tin điện tử chính phủ (từ 5/2014) và Vietnam Airlines (7/2016).
Cuối năm 2016 Viettel sẽ tiếp tục cung cấp cho khách hàng giải pháp Viettel Mobile Security tích hợp sâu vào mạng lưới để bảo vệ cho khách hàng mobile có nhiều tính năng ưu việt so sánh với các
giải pháp Mobile Security đang có trên thị trường hiện nay.
Viettel sẽ triển khai gói dịch vụ ATTT đầy đủ bảo vệ cho CPĐT
Dịch vụ Web Security hướng đến một hệ thống bảo vệ hiệu quả với ngân sách tối ưu cho cổng thông tin điện tử của các tỉnh, bộ ngành. Dịch vụ là lớp bảo vệ vòng ngoài cho các cổng thông tin điện tử tin để chống lại các đợt tấn công DDoS (cả tấn công ở layer 7, Volume-base) và tấn công xâm nhập thông qua việc khai thác lỗ hổng ứng dụng web.
Dịch vụ có ưu điểm là khách hàng không phải triển khai hạ tầng giải pháp ATTT (hệ thống bảo vệ được triển khai ở phía Viettel), việc vận hành và giám sát 24/07 do đội ngũ chuyên gia của Viettel thực hiện, do đó cả về chi phí và hiệu quả đều tối ưu hơn việc đơn vị tự đầu tư giải pháp và vận hành.
Đối với các đơn vị lớn, Viettel sẽ
Ông Tống Viết Trung, Phó Tổng Giám đốc Viettel

15CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
cung cấp dịch vụ giám sát ATTT (Managed Security Services) cho tất cả các khách hàng có nhu cầu, dịch vụ được cung cấp đi kèm bộ giải pháp ATTT do Viettel tự xây dựng.
Tổ chức nhân sự của GSOC được phân lớp chuyên nghiệp, chia thành các tier thực hiện các nhiệm vụ như: Tier 1 Giám sát 24/7 phát hiện, ứng cứu sự cố ATTT; Tier 2 phân tích, xử lý triệt để sự cố; Tier 3 phân tích, điều tra, truy vết tấn công. Bên cạnh đó là sự hỗ trợ của các nhóm về phân tích tối ưu, phát triển công cụ tự động hóa, phân tích rủi ro, các nguy cơ tấn công. Tất cả đều được vận hành, xử lý chuyên nghiệp theo bộ quy trình, hướng dẫn, KPI vận hành giám sát, xử lý ATTT GSOC của Viettel.
“Với hệ sinh thái đầy đủ “made in Vietnam, made by Viettel” này, với nguồn lực chuyên gia ATTT đầy nhiệt huyết có lý tưởng bảo vệ đất nước, Viettel hoàn toàn đủ năng lực đáp ứng bảo đảm ATTT hỗ trợ CPĐT của Việt Nam”, ông Tống Viết Trung khẳng định.
Cùng với các doanh nghiệp, các cơ quan chuyên trách về ATTT của nhà nước cũng đang chủ động nâng cao năng lực cung cấp, tích hợp, huấn luyện triển khai chứng thư số và dịch vụ chứng thực chữ ký số chuyên dùng đáp ứng nhu cầu ngày càng tăng của các cơ quan Đảng, Nhà nước và các tổ chức Chính trị xã hội; Tập trung nghiên cứu việc tích hợp giải pháp bảo mật, xác thực chữ ký số chuyên dùng đối với các thiết bị cầm tay, di động nhằm đáp ứng yêu cầu thực tế trong công tác lãnh đạo, chỉ đạo điều hành của Chính phủ và các
Bộ, Ngành, địa phương.
Bộ TT&TT đang xây dựng để chuẩn bị trình Thủ tướng Chính phủ phê duyệt 2 đề án gồm: “Đề án giám sát ATTT mạng cho các hệ thống chính phủ điện tử” và “Đề án nâng cao năng lực điều phối, ứng cứu sự cố, phòng chống tấn công, bảo đảm ATTT mạng quốc gia”. Những Đề án này góp phần nâng cao năng lực cho hệ thống giám sát ATTT, có khả năng cảnh báo sớm, chính xác các nguy cơ gây mất an toàn thông tin cho các mạng công nghệ thông tin; tăng cường khả năng hỗ trợ ứng cứu, sẵn sàng tham gia hỗ trợ giải quyết các sự cố an ninh mạng khi có yêu cầu. Bộ TT&TT cũng đang nghiên cứu xây dựng cơ chế tài chính đặc thù cho lực lượng cán bộ chuyên trách giám sát, điều phối, ứng cứu sự cố, bảo đảm ATTT mạng. Mặt khác, những chính sách mới được xây dựng và ban hành sẽ tạo cơ hội cho các doanh nghiệp Việt Nam có điều kiện tốt hơn để phát triển và triển khai sản phẩm ATTT thương hiệu Việt cho thị trường nội địa.

16 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Xác thực chuyển tiếp trong mạng IEEE 802.15.8 PAC
Đào NHư NGọc
Sự phát triển bùng nổ các ứng dụng dựa trên kết nối mạng xã hội và truyền thông ngang hàng cự ly gần giữa các thiết bị di động đòi hỏi một tiêu chuẩn thống nhất để đảm bảo về chất lượng và an toàn dịch vụ. căn cứ trên nhu cầu đó, iEEE 802.15.8 được xây dựng nhằm cung cấp một bộ quy chuẩn kỹ thuật chung cho kết nối không dây nhận thức ngang hàng (pac) với thời gian thiết lập thấp, tốc độ truyền tải cao, đa kết nối và bảo mật. với đặc trưng hoàn toàn không phụ thuộc vào hạ tầng mạng, việc đảm bảo an toàn thông tin trong pac hiện nay vẫn đang là một thách thức không nhỏ.
Các công nghệ cho phép thiết lập kết nối truyền thông ngang hàng đã được ứng dụng từ rất sớm kể từ khi điện thoại di động được sử dụng phổ biến. Theo đà phát triển chung của công
nghệ thông tin di động, các công nghệ kết nối ngang hàng như sóng hồng ngoại (IR), Bluetooth, WiFi Direct, NFC, ProSe,… lần lượt ra đời đáp ứng các nhu cầu trao đổi thông tin khác nhau. Cho đến thời điểm hiện tại, không thể phủ nhận sự thành công và tính ứng dụng rộng rãi của các công nghệ kể trên, tuy nhiên, chúng đều chưa đáp ứng đầy đủ các yêu cầu thiết yếu cho các dịch vụ dựa trên kết nối ngang hàng hiện tại. Các ứng dụng dựa trên kết nối mạng xã hội, ứng dụng chia sẻ đa phương tiên, ứng dụng thông báo khẩn cấp cho các dịch vụ an ninh công cộng,… đòi hỏi công nghệ kết nối ngang hàng phải
đảm bảo đồng thời: không phụ thuộc vào hạ tầng viễn thông cố định, thiết lập kết nối nhanh, tốc độ cao, hỗ trợ đa kết nối và đảm bảo an toàn thông tin.
Chuẩn IEEE 802.15.8 được Hiệp hội các kỹ sư điện, điện tử (IEEE) xây dựng nhằm cung cấp một bộ quy chuẩn kỹ thuật chung cho kết nối không dây nhận thức ngang hàng (PAC) đáp ứng đầy đủ các yêu cầu kể trên. Phiên bản đầu của bộ chuẩn này đã được thông qua nội bộ vào tháng 6/2016. IEEE 802.15.8 tập chung chủ yếu vào các cải tiến kỹ thuật trong lớp vật lý PHY và lớp điều khiển truy cập môi trường MAC.
Mô hình kết nối truyền thông nhận thức ngang hàng PAC được trình bày trong Hình 1. PAC cho phép một thiết bị có thể tham gia đồng thời một hoặc nhiều kết nối 1:1, 1:n và n:n. Do không phụ thuộc vào hạ tầng viễn thông cố định, việc đảm bảo
An toàn bảo mật

17CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
an toàn thông tin trong IEEE 802.15.8 được đề xuất sử dụng xác thực dựa trên số nhận dạng cá nhân (PIN) kết hợp với cơ chế an toàn thông tin lớp vật lý. Tuy nhiên, phương pháp này bộc lộ một số nhược điểm như gây bất tiện cho người sử dụng, dễ dàng bị đánh cắp số nhận dạng cá nhân,... Để khắc phục các vấn đề này, cơ chế xác thực chuyển tiếp có thể được sử dụng kết hợp mang lại giải pháp khả thi toàn diện hơn.
XÁC THỰC CHUYỂN TIẾPMô hình mạng PAC điển hình với đầy đủ 3 loại kết
nối (1:1, 1:n, n:n) và đa kết nối trên một thiết bị được mô tả trong Hình 2. Kiến trúc truyền thông ngang hàng hoàn toàn không dựa trên thành phần quản lý trung gian hay hạ tầng mạng, thay vào đó, các thiết bị tham gia trao đổi thông tin kết nối trực tiếp với nhau. Quá trình trao đổi thông tin giữa các thiết bị trong mạng PAC chia làm 4 giai đoạn: đồng bộ thời gian, dò tìm đối tác, thiết lập kênh (bao gồm cả quá trình xác thực), và truyền tải thông tin. Khi một thiết bị mới (X) muốn tham gia vào mạng PAC, đầu
tiên nó cần thực hiện lắng nghe bản tin điều khiển trên mỗi kênh hoa tiêu, tương ứng với các dải tần số được sử dụng trong khoảng thời gian một chu kì siêu khung. Bằng cách đối sánh giữa các thông tin nhận được trên kênh hoa tiêu, từ các thiết bị hoạt động trong mạng PAC, X tính toán và xác lập thời gian đồng bộ cho việc thu phát bản tin.
Sau khi đã đồng bộ thời gian, trong chu kì dò tìm đối tác, X thực hiện phát bản tin thông báo trên kênh chung và lắng nghe bản tin phản hồi để xây dựng danh sách các đối tác khả dụng cho việc kết nối. Các thông tin được trao đổi trong bản tin thông báo do người dùng tự định nghĩa, thông thường bao gồm: ID thiết bị, ID nhóm, ID ứng dụng, thông tin đặc thù của ứng dụng, ID người dùng,… Có 3 loại bản tin thông báo được sử dụng:
• Bảntinthôngbáomộtchiều:Xtựquảngbásựhiện diện của mình đến các thiết bị khác.
• Bảntinthôngbáohaichiềukhôngxácđịnhđốitác: X gửi bản tin dò tìm tất cả các thiết bị đang hoạt động trên kênh chung và yêu cầu bản tin hồi đáp.
• Bảntinthôngbáohaichiềucóchủđích:Xgửi
Hình 1: Mô hình kết nối truyền thông nhận thức ngang hàng IEEE 802.15.8 PAC
Hình 2: PAC điển hình với đầy đủ 3 loại kết nối (1:1, 1:n, n:n) và đa kết nối trên một thiết bị

18 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
bản tin dò tìm có chứa thông tin định danh đối tác mà mình muốn kết nối trên kênh chung và yêu cầu bản tin hồi đáp.
Quá trình thiết lập kênh kết nối giữa hai thiết bị được thực hiện bằng cách trao đổi bản tin yêu cầu kết nối trực tiếp. Hình 3 mô tả các thủ tục xác thực chuyển tiếp giữa A và X. Lưu ý do khoảng cách giữa A và X tương đối xa nên D được lựa chọn đóng vai trò như một điểm trung gian chuyển tiếp bản tin (PAC hỗ trợ kỹ thuật đa bước nhảy multi-hop). Thủ tục xác thực chuyển tiếp giữa A và X được thực hiện như sau:
• XgửibảntinyêucầukếtnốivớiđịachỉđíchlàA. D nhận bản tin và chuyển tiếp.
• AnhậnbảntinyêucầukếtnốidoXgửiđượcchuyển tiếp từ D. A gửi báo nhận ACK và yêu cầu xác thực chuyển tiếp X do giữa A và X chưa từng thỏa thuận xác thực qua số PIN.
• Agửi cácbản tinunicast tới các thiếtbị kháctrên kết nối 1:1 (B, C, F) trong mạng PAC, nhằm kiểm tra khả năng giúp xác thực chuyển tiếp X.
• CảB,C,FđềucóthôngtinvềXdođãtừngthựchiện xác thực với X trước đó. B, C, F gửi bản tin xác nhận khả năng xác thực chuyển tiếp X về A.
• Dựatrêndanhsáchcácthiếtbịkhảdụngchoviệc xác thực chuyển tiếp X, A lựa chọn ngẫu nhiên B và C để gửi bản tin yêu cầu xác thực chuyển tiếp X.
• B, C tiến hành xác thực ngang hàng với X vàthỏa thuận lựa chọn sinh khóa tạm (B – X: 2222; C – X: 3333), sau đó đồng thời gửi các cặp khóa tạm đã
thỏa thuận về A.
• Agửibản tin tớiXyêucầukếthợpkhóa tạmtừ B và C để tạo khóa riêng giữa A và X. Khóa riêng 2323 được thiết lập. Quá trình xác thực thành công.
Quá trình xác thực giữa A và X được thực hiện tự động, không thông qua số nhận dạng PIN. Bảng 1 so sánh các ưu nhược điểm giữa hai phương pháp này.
Công nghệ 802.15.8 PAC được IEEE chuẩn hóa nhằm đảm bảo các tiêu chí về tính tương thích, thời gian thiết lập thấp, tốc độ truyền tải cao, đa kết nối và bảo mật. Dựa trên thế mạnh về tính liên kết xã hội giữa các thiết bị trong PAC, xác thực chuyển tiếp được sử dung kết hợp với xác thực dựa theo số PIN giúp bù lấp nhược điểm của nhau, hoàn thiện khả năng bảo mật thông tin trong mạng. Với tính ứng dụng cao trong các dịch vụ quảng cáo nhận thức vị trí, thông báo khẩn cấp, chia sẻ ngang hàng,… PAC hứa hẹn sẽ trở thành công nghệ quan trọng trong tương lại không xa.
Tài liệu tham khảo:[1]. http://www.ieee802.org/15/pub/TG8.html
[2]. IEEE 802.15.8 v.0.8 draft, June, 2016.
[3]. NA, WOONGSOO, et al. Fully distributed multicast routing protocol for IEEE 802.15.8 peer-aware communication, International Journal of Distributed Sensor Networks, 2015.
[4]. LI, HUAN-BANG, AND RYU MIURA, Discovery Protocol for Peer Aware Communication Networks, in Proc. of IEEE VTC Fall, 2015.
[5]. JUNG, SOOJUNG, AND SUNGCHEOL CHANG, A discovery scheme for device-to-device communications in synchronous distributed networks, in Proc. of IEEE ICACT, 2014.
[6]. PARK, HYUNHO, HYEONG HO LEE, AND SEUNG-HWAN LEE, IEEE 802 standardization on heterogeneous network interworking, in Proc. of IEEE ICACT, 2014.
Hình 1: Mô hình kết nối truyền thông nhận thức ngang hàng IEEE 802.15.8 PAC
Bảng 1: So sánh giữa xác thực chuyển tiếp và xác thực dựa trên số PIN.
An toàn bảo mật

19CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
NGuyễN trọNG tâm
Trong một vài năm trở lại đây, mã độc tống tiền (ransomware) đã gia tăng chóng mặt và trở thành một trong những mối đe dọa phổ biến nhất trên Internet. Việc lây nhiễm ransomware
khiến người dùng mất quyền truy cập vào các tập tin quan trọng, và phải trả tiền chuộc nếu muốn lấy lại dữ liệu đó. Bài viết giới thiệu các kỹ thuật thường được sử dụng để phân phối ransomware, tại sao các cuộc tấn công này thành công và khuyến nghị những giải pháp cần thiết để bảo đảm an toàn cho hệ thống của bạn.
Ransomware là gì?Ransomware là loại mã độc chuyên tấn công
cướp quyền truy cập vào máy tính hoặc thiết bị di động của bạn chúng đặt khóa mã hóa toàn bộ tài liệu của bạn để đòi tiền chuộc. Một trong những
ví dụ điển hình nhất của loại malware này có tên là CryptoLocker, nó sẽ tiến hành “bắt cóc” dữ liệu của người dùng làm con tin và đòi họ chi trả hàng trăm USD để “chuộc” lại chúng. Kể từ khi xuất hiện lần đầu vào năm 2013, CryptoLocker đã đánh dấu một giai đoạn phát triển mới của các biến thể ransomware được phát tán thông qua thư rác và các bộ kit tấn công (Exploit kit), nhằm tống tiền người dùng cá nhân và doanh nghiệp.
Mã độc thường sử dụng các thuật toán mã hóa tốt nên việc khôi phục lấy lại dữ liệu sau khi bị mã hóa là rất khó khăn, thậm chí chúng còn có khả năng xóa toàn bộ thông tin của System Restore để không có cách nào khác khôi phục lại dữ liệu.
Nguy hiểm hơn khi các biến thể mới của mã độc xuất hiện vào cuối năm 2015 còn mang theo nhiều các tính năng cao cấp hơn như phát tán lây nhiễm qua website, các file đính kèm email hay tập tin trên mạng chia sẻ (network sharing) và thậm chí trên các
Để an toàn trước mã độc tống tiền

20 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
thiết bị di động. Mặc dù có nhiều điểm khác nhau nhưng các biến thể của ransomware cùng có một mục tiêu chung là tống tiền các nạn nhân thông qua kỹ thuật lừa đảo và đe dọa thẳng thừng. Yêu cầu trả tiền chuộc đã ngày càng tăng cao, dẫn tới những tổn thất lớn về tài chính cho các tổ chức, doanh nghiệp bị tấn công. Trung tâm y tế Hollywood Presbyterian (Mỹ) đã phải trả 17.000 USD tiền chuộc bằng đồng Bitcoin (40 Bitcoin) để lấy lại quyền truy cập vào các file do bị tin tặc tấn công và chiếm quyền kiểm soát hệ thống máy tính của bệnh viện. Trong khi đó, bệnh viện tim Kansas ngay sau khi đã trả một khoản tiền chuộc để truy cập vào các file của mình đã phải đối mặt với yêu cầu trả tiền chuộc lần hai.
Mới đây nhất, các chuyên gia Kaspersky Lab đã phát hiện biến thể mới của ransomware RAA - phần mềm độc hại được viết toàn bộ bằng JScript. Đặc điểm của mã độc mới này là gửi tập tin zip có chứa file .js độc hại đến nạn nhân và phiên bản mới có thể mã hóa offline mà không cần key từ máy chủ. Ransomware RAA xuất hiện vào tháng 6/2016 và là ransomware đầu tiên viết bằng JScript được biết đến. Các chuyên gia tin rằng những kẻ tấn công đang sử dụng phiên bản này để tấn công doanh nghiệp trên toàn cầu bằng cách mã hóa dữ liệu của họ và đòi tiền chuộc.
Cách thức ransomware hoạt độngTương tự như các loại malware khác, ransomware
xâm nhập vào máy tính người dùng thông qua hai cách chính: các email có đính kèm mã độc, một website giả mạo hoặc website đã bị chèn mã độc.
Email độc hại
Email được xem là phương thức tấn công truyền thống. Trojan và các dạng phần mềm độc hại thường được giấu trong các email chui vào hộp thư của người dùng rồi từ đó đột nhập vào máy tính của người dùng. Ngày nay, rất khó có thể nhận biết được các email giả mạo mà tin tặc tạo ra, chúng thường rất đúng ngữ pháp và không có lỗi chính tả, được viết theo một phương thức có liên quan đến bạn và doanh nghiệp của bạn.
Khi được mở ra, các tập tin dạng nén (zip) xuất hiện có chứa một file .txt thông thường.
Tuy nhiên, khi chạy các tập tin được này, ransomware sẽ được tải về và cài đặt vào máy tính của bạn. Trong ví dụ này, nó thực sự là một tập tin JavaScript giả mạo một file .txt, đó là Trojan horse. Ngoài ra còn có rất nhiều biến thể khác của các email độc hại, chẳng hạn như tài liệu Microsoft Word với macro độc hại và short cut file (.lnk).
Các trang web độc hại
Một cách phổ biến khác khiến người dùng bị lây nhiễm là truy cập một trang web hợp pháp mà đã bị nhiễm bộ kit tấn công (exploit kit). Thậm chí, các trang web chính thống này có thể bị thỏa hiệp tạm thời. Bộ kit tấn công là một dạng ứng dụng web độc hại chứa đựng khả năng khai thác các lỗ hổng trong trình duyệt cũng như các plug-in trình duyệt chẳng hạn như Java, Flash Player, Adobe Reader và Silverlight. Khi vào truy nhập vào các trang web bị hack và click vào một liên kết tìm kiếm vô hại, di chuột qua một quảng cáo hoặc trong nhiều trường hợp chỉ cần vào trang đó, tất cả đã đủ để tải các tập

21CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Một thông báo đòi tiền chuộc sẽ xuất hiện trên máy tính
tin ransomware về máy tính của bạn.
Và tiếp theo…
Sau khi xâm nhập vào máy tính, nó sẽ tiến hành các hoạt động tiếp theo:
- Liên lạc máy chủ chỉ huy và điều khiển của kẻ tấn công, gửi thông tin các máy tính bị nhiễm và tải về khóa công khai cá nhân.
- Các loại tập tin cụ thể (có thể thay đổi tùy theo loại ransomware) như tài liệu Office, các file cơ sở dữ liệu, các file PDF, tài liệu CAD, HTML, XML, v.v..., được mã hóa trên máy tính, các thiết bị di động và tất cả các ổ đĩa mạng có thể truy cập.
- Thường xuyên xóa các bản sao lưu tự động hệ điều hành Windows để ngăn ngừa khôi phục dữ liệu.
- Sau khi mã hóa dữ liệu của bạn, nó sẽ đưa ra cho bạn danh sách các phần mềm để bẻ khóa dữ liệu khi bạn tiến hành tìm kiếm trên mạng. Tất nhiên các phần mềm này đều có phí. Nhiều Ransomware được ngụy trang khá tốt. Đôi khi nó còn được gọi là “scareware” bởi chúng sẽ đưa ra những cảnh báo giả cho người dùng như “Máy tính của bạn đã bị nhiễm malware, hãy mua phần mềm [xxx] để tiến hành loại bỏ malware này” hoặc “Máy tính của bạn đã được sử dụng để tải về các dữ liệu vi phạm pháp luật, hãy nộp phạt để có thể tiếp tục sử dụng máy tính”. Một số trường hợp khác, Ransomware sẽ trực tiếp nêu lên vấn đề cho bạn. Chúng sẽ thâm nhập sâu vào bên trong hệ thống của máy rồi hiển thị một
thông báo rằng chúng sẽ chỉ biến mất khi bạn trả tiền chuộc.
- Cuối cùng, các ransomware tự xóa để lại các tập tin được mã hóa và thông báo đòi tiền chuộc
Tại sao các cuộc tấn công ransomware lại thành công?
Hầu hết các tổ chức hay cá nhân đều có sử dụng một số phương thức bảo mật tối thiểu. Vậy tại sao các ransomware lại vẫn xâm nhập được vào mạng? Đó là do:
1. Các kỹ thuật tấn công ngày càng tinh vi và liên tục đổi mới
- Việc truy cập vào các chương trình MaaS (Malware-as-a-Service: Mã độc dưới dạng dịch vụ) có sẵn khiến cho việc khởi động một cuộc tấn công trở nên đơn giản hơn, dễ dàng thành công, ngay cả đối với những tội phạm ít hiểu biết về công nghệ.
- Kỹ thuật lừa đảo (social engineering) khéo léo được sử dụng để thúc giục người dùng chạy đoạn chương trình cài đặt của ransomware. Ví dụ, bạn có

22 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
thể nhận được một email như thế này: “Các yêu cầu của doanh nghiệp của tôi như trong file đính kèm, xin vui lòng cung cấp cho tôi một báo giá”.
- Những kẻ phát tán ransomware hoạt động theo một phương thức chuyên nghiệp cao, chúng thường cung cấp một công cụ giải mã sau khi nạn nhân đã trả tiền chuộc.
2. Các lỗ hổng bảo mật tại các công ty
- Thiếu chiến lược sao lưu phù hợp (không có các bản sao lưu thời gian thực, sao lưu ngoại tuyến/off-site).
- Bản nâng cấp/bản vá lỗi cho hệ điều hành và các ứng dụng không được thực hiện đủ nhanh chóng
- Cấp quyền truy nhập không phù hợp: Nhiều người dùng được cấp quyền truy nhập hơn mức cần thiết cho công việc của họ, thậm chí như các quản trị viên.
- Thiếu đào tạo bảo mật cho người dùng, ví dụ cách nhận biết một email lừa đảo hay làm gì khi phát hiện tài liệu có đính mã độc)
- Các hệ thống bảo mật (Quét virus, tường lửa, IPS, cổng email /web) không được thực thi hoặc không được cấu hình đúng.
- Thiếu kiến thức bảo mật (Các file .exe có thể bị chặn trong email nhưng không bị chặn trong macro của office hoặc nội dung hoạt động khác).
3. Thiếu công nghệ phòng chống tiên tiến
- Nhiều tổ chức có một số hình thức bảo vệ chung. Ransomware liên tục được cập nhật để khai thác và tránh các bảo vệ này. Ví dụ: Tự xóa một cách nhanh chóng sau khi mã hóa tập tin mà nó không thể phân tích được.
- Các giải pháp cần phải được thiết kế đặc biệt để chống lại các kỹ thuật ransomware tiến tiến
Làm thế nào để ngăn chặn ransomware tấn công?
Đối với người dùng cá nhân
Sao lưu dữ liệu quan trọng hằng ngày, thường xuyên ra thiết bị lưu trữ bên ngoài là cách hiệu quả nhất chống lại ransomware mã hóa dữ liệu. Khi đó bạn không sợ phải trả tiền chuộc cho các mối đe dọa bị mã hóa mất dữ liệu trên máy tính. Có thể máy tính của bạn bị khóa, bị tấn công mã hóa toàn bộ, nhưng bạn đã có bản sao lưu dự phòng bên ngoài nên không lo ngại gì đến việc tập tin quan trọng trên máy tính bị hỏng mà ta sẽ thẳng tay xóa sạch rồi phục hồi lại tài liệu đã lưu trữ bên ngoài để tiếp tục làm việc. Lưu ý những tài liệu đã sao lưu không được chia sẻ và kết nối với hệ thống mạng máy tính, vì đây lại là nguy cơ ransomware sẽ tấn công như máy tính của bạn.
Không nên nhấp vào những liên kết đáng ngờ hoặc mở email Unknown Spam vì khi đó các máy tính sẽ có nguy cơ nhiễm mã độc ransomware qua thao tác nhấp vào một liên kết hoặc mở một email file đính kèm trong email Spam lừa đảo. Điều này có lẽ không xa lạ với đa số người làm việc sử dụng máy tính có kỹ năng, nhưng để đánh lừa người sử dụng thì mã độc ransomware đã nghĩ ra một cách thông minh lừa mọi người nhấp vào các URL đã bị nhiễm virus malware quảng cáo độc hại. Thường những link hình ảnh quảng cáo trên các trang web mà bạn biết và cho là tin tưởng thì sẽ lừa bạn nhấp chuột vào để xem khi đó chúng sẽ tấn công máy tính của bạn. Tốt nhất là hãy tập cho mình có thói quen cảnh giác với các tập tin được chia sẻ ở các nguồn cung cấp hay người dùng không an toàn và “chính chủ”.

23CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Việc kiểm tra bất kỳ lỗ hổng của phần mềm đang sử dụng cập nhật bản vá lỗi liên tục cũng có thể là một trong những cách tốt nhất để ngăn chặn chống lại tội phạm tống tiền trên mạng tấn công. Ngoài ra cần cài đặt các phần mềm bảo mật phòng chống virus có bản quyền như Bkav Pro , Kaspersky, Symantec, AVG... Nếu sử dụng các tiện ích ứng dụng của bên thứ ba như plug-in không được cập nhật ví như Java hoặc Flash nó sẽ sử dụng chúng để truy cập vào máy tính của bạn.
Đặc biệt luôn cập nhật với các tính năng bảo mật mới trong các ứng dụng doanh nghiệp của bạn, ví dụ Office 2016 hiện nay bao gồm cả tính năng được gọi là “Chặn macro chạy trong các tập tin Office từ Internet”, giúp bảo vệ chống lại các nội dung độc hại bên ngoài mà không ngăn cản bạn sử dụng các macro trong nội bộ.
Đối với các tổ chức, doanh nghiệp
Để bảo đảm an toàn trước sự tấn công của ransomware, các tổ chức, doanh nghiệp cần thực thi các giải pháp bảo mật để bảo vệ hiệu quả ở mọi nơi, mọi giai đoạn của một cuộc tấn công.
Ngăn chặn các mối đe dọa từ email
Đây là vai trò của mail-gateway. Các công nghệ chống thư rác chặn các mã độc tống tiền phát tán qua email, trong khi quét virus và ngăn chặn các mối đe dọa khác từ email.
Ngăn chặn mối đe dọa từ web
Mối đe dọa web thường bị vô hiệu hóa tại tường lửa và web gateway. Các bộ lọc URL chặn các trang web lưu trữ ransomware, cũng như các máy chủ chỉ huy và kiểm soát của chúng. Và bằng cách thực thi kiểm soát chặt chẽ, bạn có thể ngăn chặn các file nhiễm ransomware từ các tài liệu đang được tải về.
Bảo vệ máy chủ
Danh sách trắng máy chủ và lockdown giúp các máy chủ của bạn an toàn bằng cách tạo danh sách các ứng
dụng được xác thực và xác định những gì có thể thay đổi và cập nhật - tất cả các hoạt động khác nhằm thực hiện thay đổi sẽ bị chặn tự động, nhằn ngăn chặn ransomware ngay từ khi khởi phát. Việc phát hiện lưu lượng độc hại cũng cản trở ransomware liên lạc với máy chủ chỉ huy và điều khiển cũng như tải về tải của nó.
Đào tạo nhân viên
Các công ty cần có kế hoạch cho nhân viên của họ đi học lớp đào tạo an ninh mạng để giảm nguy cơ mã độc tấn công, nếu các nhân viên có thể được đào tạo căn bản thì việc nhận email spam hay sử dụng internet cũng có thể giảm đáng kể nguy cơ toàn bộ hệ thống máy tính công ty rơi vào một cuộc tấn công của ransomware.
Tài liệu tham khảo:1. Sophos, How to Stay Protected Against Ransomware,
August 2016.
2. Kaspersky Lab, New Version of RAA Ransomware Updated to Attack Business Targets.
3. The Growing Threat of Ransomware, http://www.pcmag.com.
Một chương trình MaaS

24 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
bH
Bùng nổ mã độc tống tiền Ngay từ giữa năm 2015, công ty an ninh mạng
FireEye đã đưa ra cảnh báo với các doanh nghiệp về sự gia tăng của ransomware. Thực tế cho thấy, nạn nhân là doanh nghiệp sẽ đem lại lợi nhuận cao hơn; thêm vào đó sự phát triển của ransomware dưới dạng dịch vụ (MaaS - Malware as a service) cũng đã tạo ra một phương thức mới, giúp tội phạm dễ dàng thực hiện các cuộc tấn công hơn.
Trong năm 2016, mối đe dọa ransomware cho các doanh nghiệp toàn cầu đã tăng mạnh, trong đó đáng chú ý là tháng 3/2016. Cục điều tra liên bang Mỹ (FBI) cho biết chỉ tính riêng ba tháng đầu năm 2016, số tiền chuộc phải trả cho các vụ tấn công ransomware đã lên tới 210 triệu USD. Từ kết quả khảo sát, các nhà nghiên cứu của FireEye Labs cho rằng sự gia tăng này xuất phát từ hai chiến dịch thư rác toàn cầu có liên quan tới mã độc tống tiền Locky, được phát hiện tại 50 quốc gia. Thêm vào đó, một biến thể mới của mã độc ngân hàng trực tuyến, Dridex, sẽ lây nhiễm cho các hệ thống ngay khi nạn nhân click vào email có đính kèm các tệp tin độc hại giả dạng “thông báo hóa đơn”, “ảnh” và “tiêu đề tài liệu”. Các nhà nghiên cứu bảo mật lưu ý rằng mã độc Locky bao gồm downloader JavaScript (.js) cùng với downloader macro của Microsoft Word và Excel đã chi phối các chiến dịch ban đầu.
Trong đó, Microsoft Windows vẫn là mục tiêu lớn nhất. Các biến thể của ransomware CryptoLocker, như TorrentLocker và CTB-Locker nhằm các doanh nghiệp trên toàn thế giới thông qua việc lợi dụng những người tìm kiếm các bản nâng cấp Windows 10. Đặc biệt, mã độc Keranger, được Palo Alto Systems phát hiện là loại đầu tiên tấn công các hệ thống Mac OS X.
Các chuyên gia nhận định việc trả tiền chuộc
No MorE rANsoM - Nền tảng chống phần mềm tống tiền
trong thời gian gần đây, một Số loại mã độc tống tiền với hình thức lây nhiễm mới, có nhiều tính năng mới và nguy hiểm đã bị phát hiện. thEo các chuyên gia, đây là những biến thể mới, bước phát triển mới của mã độc tống tiền (ranSomwarE). do đó, hơn lúc nào hết vấn đề an toàn và bảo mật hệ thống trở nên vô cùng quan trọng và cấp thiết đối với nhiều tổ chức, doanh nghiệp.

25CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
trong các vụ tấn công tin tặc đang tạo ra một xu hướng nguy hiểm. Không chỉ tấn công vào ngân hàng hoặc ăn cắp các thông tin cá nhân nhằm tư lợi riêng, các hacker còn từng thực hiện những vụ “khủng bố” vào hệ thống điện lực, y tế gây ảnh hưởng đến cuộc sống của hàng triệu người.
Trong tháng 2/2016, các hệ thống máy tính của Trung tâm Y tế Presbyterian ở Hollywood đã bị tấn công và bệnh viện này đã phải trả số tiền chuộc lên tới 17.000 USD để giải mã các thông tin này, nhằm giúp bệnh viện hoạt động bình thường. Trước đó, tổ chức chăm sóc sức khỏe Anthem bị mất cắp thông tin của 80 triệu khách hàng được cho là nạn nhân của hacker được chính phủ Trung Quốc tài trợ.
Vụ việc hệ thống điện lực tại Ukraine bị tấn công hồi tháng 3/2016 đã khiến hàng trăm ngôi nhà mất điện. Các tin tặc đã tấn công các trung tâm truyền tải điện quốc gia bằng cách cài mã độc vào các máy chủ.
Trong khi các cuộc tấn công vào bệnh viện là đáng báo động và có khả năng đe dọa tính mạng thì các doanh nghiệp khác cũng đã trả tiền chuộc để lấy lại dữ liệu có giá trị lớn. Nhóm đua xe chuyên nghiệp người Mỹ Circle Sport Levine Family Racing cũng đã gặp phải một cuộc tấn công ransomware TelsaCrypt vào tháng 4/2016 ngay sau khi có người nhận thấy thông tin bất thường giữa các hệ thống
máy tính của họ và một tài khoản Dropbox. Các tập tin được mã hóa, trong đó có dữ liệu quan trọng mà tương ứng với hàng triệu đô la, sẽ rất khó để khôi phục lại. Nhóm này đã trả số tiền ước tính khoảng 500 USD bằng bitcoin, và khôi phục dữ liệu bằng cách sử dụng khóa giải mã. Cũng trong tháng 6/2016, trường đại học Calgary, Canada xác nhận đã trả hơn 15.000 USD để chuộc dữ liệu sau khi bị tin tặc tấn công bằng mã độc tống tiền.
Những vụ việc trên đã làm gia tăng lo ngại về các phần mã độc tống tiền nhắm vào các cơ quan, tổ chức thời gian gần đây.
Không thanh toán, dữ liệu sẽ mấtThực tế, phần lớn các doanh nghiệp đều không
trả tiền chuộc. Theo một nghiên cứu của Osterman Research được thực hiện trong tháng 8/2016, 39% trong số 540 tổ chức, doanh nghiệp tại Mỹ, Canada, Đức và Anh tham gia khảo sát cho biết đã gặp phải tấn công ransomware trong 12 tháng qua. Hơn 1/3 (37%) doanh nghiệp có máy bị nhiễm đã phải trả tiền chuộc cho tin tặc.
Kết quả nghiên cứu cũng cho thấy lĩnh vực chăm sóc sức khỏe và dịch vụ tài chính bị tấn công nhiều nhất. Các chuyên gia bảo mật cho rằng hai lĩnh vực này đều phụ thuộc nhiều vào việc truy cập thông tin
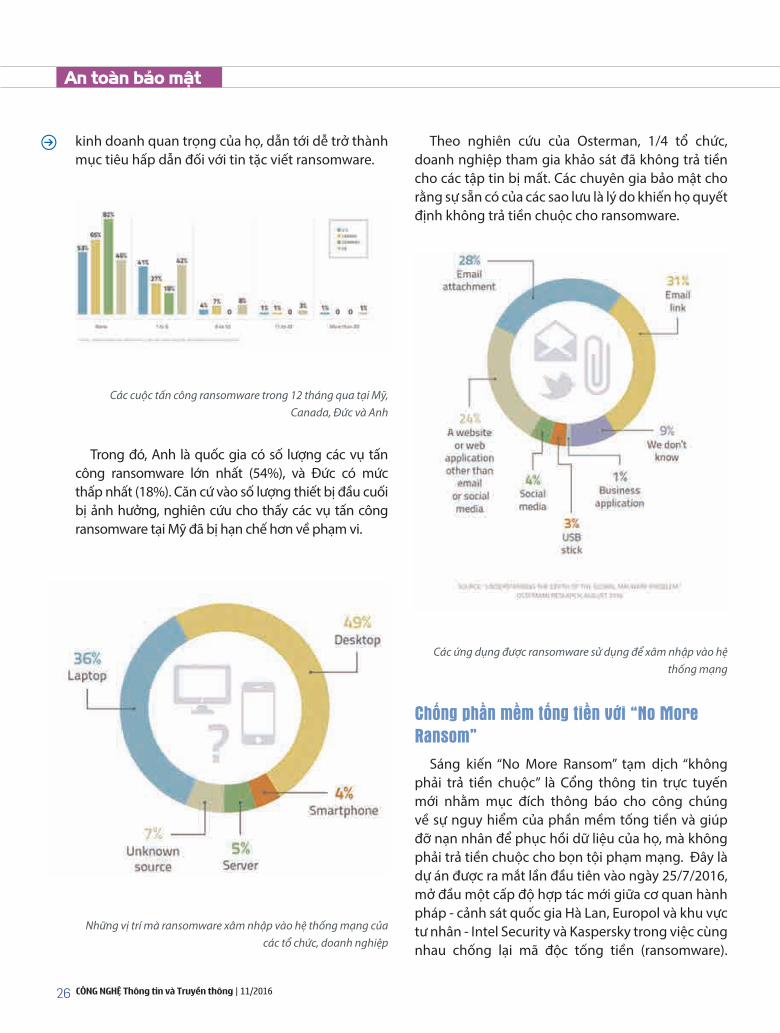
26 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
kinh doanh quan trọng của họ, dẫn tới dễ trở thành mục tiêu hấp dẫn đối với tin tặc viết ransomware.
Các cuộc tấn công ransomware trong 12 tháng qua tại Mỹ, Canada, Đức và Anh
Trong đó, Anh là quốc gia có số lượng các vụ tấn công ransomware lớn nhất (54%), và Đức có mức thấp nhất (18%). Căn cứ vào số lượng thiết bị đầu cuối bị ảnh hưởng, nghiên cứu cho thấy các vụ tấn công ransomware tại Mỹ đã bị hạn chế hơn về phạm vi.
Những vị trí mà ransomware xâm nhập vào hệ thống mạng của các tổ chức, doanh nghiệp
Theo nghiên cứu của Osterman, 1/4 tổ chức, doanh nghiệp tham gia khảo sát đã không trả tiền cho các tập tin bị mất. Các chuyên gia bảo mật cho rằng sự sẵn có của các sao lưu là lý do khiến họ quyết định không trả tiền chuộc cho ransomware.
Các ứng dụng được ransomware sử dụng để xâm nhập vào hệ thống mạng
Chống phần mềm tống tiền với “No More Ransom”
Sáng kiến “No More Ransom” tạm dịch “không phải trả tiền chuộc” là Cổng thông tin trực tuyến mới nhằm mục đích thông báo cho công chúng về sự nguy hiểm của phần mềm tống tiền và giúp đỡ nạn nhân để phục hồi dữ liệu của họ, mà không phải trả tiền chuộc cho bọn tội phạm mạng. Đây là dự án được ra mắt lần đầu tiên vào ngày 25/7/2016, mở đầu một cấp độ hợp tác mới giữa cơ quan hành pháp - cảnh sát quốc gia Hà Lan, Europol và khu vực tư nhân - Intel Security và Kaspersky trong việc cùng nhau chống lại mã độc tống tiền (ransomware).

27CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Không chỉ cung cấp thông tin và các công cụ giải mã miễn phí, cổng thông tin này còn cho phép các nạn nhân tải lên một tập tin ransomware mẫu để xác định biến thể.
Hiện có rất nhiều các họ phần mềm độc hại và các biến thể, trang web www. nomoreransom.org tập trung vào ba loại chính: dựa trên mã hóa (AES-256), màn hình khóa (chủ yếu là điện thoại di động) và master boot record - mã hóa mã MBR của máy tính và ngăn chặn tải của hệ điều hành.
Sau 2 tháng ra mắt, hơn 2.500 người dùng đã có thể giải mã được dữ liệu của mình mà không phải trả tiền cho tội phạm mạng bằng cách sử dụng công cụ giải mã trên nền tảng (CoinVault, WildFire and Shade). Và sau 3 tháng đã có thêm các cơ quan hành pháp tại 13 quốc gia đăng ký đồng hành cùng các công ty tư nhân chống lại ransomware. Các thành viên mới tham gia dự án No More Ransom là Bosnia và Herzegovina, Bulgaria, Colombia, Pháp, Hungary, Ireland, Ý, Latvia, Lithuania, Bồ Đào Nha, Tây Ban Nha, Thụy Sĩ và Vương quốc Anh.
Chương trình được kỳ vọng sẽ có sự tham gia của nhiều cơ quan hành pháp và các tổ chức tư nhân trong thời gian tới. Sự hợp tác sẽ cho ra đời nhiều công cụ giải mã miễn phí hơn, hỗ trợ nhiều nạn nhân giải mã thiết bị và mở khóa thông tin của họ và khiến tội phạm mạng phải chịu tổn thất về tài chính.
Theo khuyến cáo của Kaspersky Lab, nếu hệ thống của bạn đang bị tấn công hãy ngắt kết nối các máy tính bị nhiễm khỏi mạng Internet ngay lập tức, bởi có thể mất đến 30 phút để phần mềm độc hại mã hóa các tập tin, và các doanh nghiệp sẽ có cơ hội tốt để cứu một số tập tin. Tuy nhiên, không phải lúc nào chiến lược này cũng hiệu quả. Circle Sport Levine Family Racing đã ngay lập tức ngắt kết nối của các máy tính ngay sau khi phát hiện hoạt động đáng ngờ trên Dropbox nhưng vẫn bị ransomware xâm nhập. Do đó, để giảm thiểu nguy cơ bị lây nhiễm, doanh nghiệp nên cân nhắc những lời khuyên sau:
- Sử dụng công nghệ bảo mật endpoint và giải pháp chống virus mạnh mẽ, chắn chắn mọi chức năng phát hiện đều được kích hoạt.
- Cần thường xuyên sao lưu dữ liệu có giá trị cao - trước khi một sự cố có thể xảy ra - và lưu trữ các bản sao lưu offline. Khi đó, nếu các hệ thống máy tính bị nhiễm ransomware và tin tặc yêu cầu tiền chuộc để giải mã tập tin, doanh nghiệp có thể sử dụng các bản sao lưu để khôi phục lại hệ thống của mình.
- Tăng nhận thức về an toàn thông tin mạng cho nhân viên.
- Thường xuyên cập nhật phần mềm trên máy tính (các bản vá, ứng dụng).
- Thường xuyên kiểm soát an ninh.
- Chú ý đến phần mở rộng của tập tin trước khi mở chúng ra. Những tập tin ẩn chứa nguy hiểm bao gồm: .exe, .hta, .wsf, .js, v.v…
- Hãy cảnh giác với mọi email từ người gửi không rõ danh tính.
Tài liệu tham khảo:1. Osterman Research, Understanding the Depth of the Global
Ransomware Problem, August 2016.
2. Computerweekly, Cyber Security Trends ASEAN 2016.
3. http://searchsecurity.techtarget.com

28 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
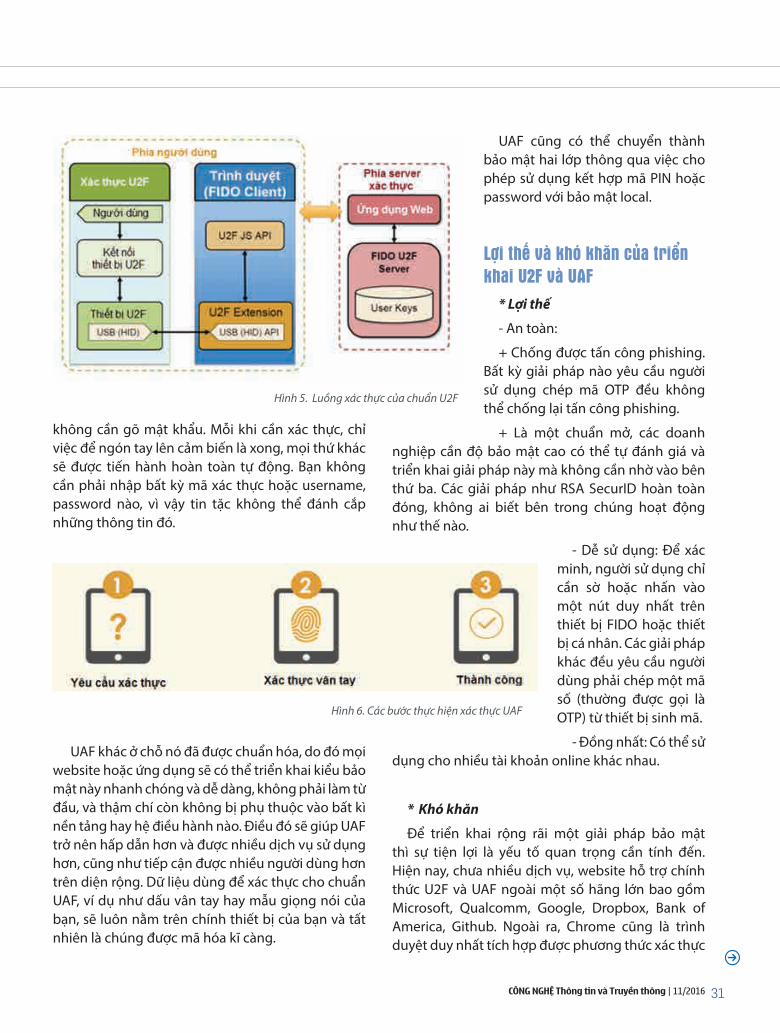
Đỗ Hữu tuyếN
Bảo mật 2 lớp là một cách cơ bản giúp bạn bảo vệ những tài khoản online
quan trọng. Đó có thể là tài khoản email, tài khoản lưu trữ đám mây, tài khoản ngân hàng online hay tài khoản để đăng nhập vào website... Thông thường, các ứng dụng hay dịch vụ có hỗ trợ bảo mật hai lớp thì sẽ yêu cầu bạn đăng nhập với các bước (Hình 1).
1. Mở trang web hoặc dịch vụ, gõ username và password để đăng nhập
2. Sau đó, một mã xác thực sẽ được gửi đến bạn
theo nhiều cách khác nhau: có thể là qua SMS, qua email, đọc mã bằng điện thoại, hoặc sử dụng một số ứng dụng chuyên biệt.
3. Khi đã có mã xác thực, bạn tiếp tục nhập mã đó vào website hoặc dịch vụ thì mới đăng nhập thành công.
ngày nay, tình trạng đánh cắp dữ liệu, Email, mật khẩu tài khoản cá nhân của người dùng ngày càng gia tăng. các hackEr luôn tìm cách Sử dụng những thủ đoạn tinh vi hơn để đánh lừa người dùng. thậm chí, cả phương thức bảo mật 2 lớp cũng không còn đảm bảo an toàn tuyệt đối. vậy làm thế nào để chúng ta có thể tự bảo vệ tài khoản của mình một cách chắc chắn hơn? chuẩn bảo mật u2F và uaF ra đời có thể Sẽ giúp chúng ta giải quyết vấn đề này. đây được coi là “chiếc chìa khóa vật lý” cho các tài khoản intErnEt trên thiết bị cá nhân. vậy hai chuẩn này là gì và làm cách nào chúng có thể bảo vệ được tài khoản của bạn?
U2F Và UAF - Giải pháp bảo mật an toàn cho các tài khoản Internet
Hình 1. Phương thức xác thực bảo mật hai lớp thông thường

29CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Về cơ bản, lớp bảo mật thứ hai có tác dụng ngăn chặn sự xâm nhập trái phép vào tài khoản ngay cả khi bạn đã bị lộ username và password thì hacker cũng khó có thể lấy được mã xác thực vì nó gửi tới điện thoại hoặc email đã đăng ký nhận mã. Tất nhiên, nếu chúng có được điện thoại hoặc biết cách đăng nhập email của bạn nữa thì đã ngoài tầm kiểm soát. Rất nhiều người dùng hiện nay dùng chung mật khẩu email cho nhiều trang web và dịch vụ online nên kẻ xấu vẫn có thể truy cập vào hộp thư rồi lấy mã bảo mật hai lớp. Với SMS gửi tới điện thoại di động, thậm chí không cần phải đánh cắp, kẻ xấu vẫn có thể thấy được mã xác thực gửi đến điện thoại của bạn khi thông báo hiện ra màn hình khóa. Các phương thức tưởng chừng như đơn giản nhưng nếu bạn sơ hở thì lợi ích của cơ chế bảo mật 2 lớp hoàn toàn biến mất và mang lại hậu quả nghiêm trọng.
Các vấn đề bảo mật liên quan tới password hiện nay được chỉ ra trong Hình 2.
Giải pháp xác thực mới
Hiện nay, các phương pháp xác thực (kể cả xác thực hai lớp) đều lộ nhiều điểm yếu, hơn nữa, mỗi dịch vụ lại sử dụng giao thức xác thực khác nhau, gây khó khăn cho người dùng trong việc sử dụng cũng như bảo mật. Chuẩn U2F và UAF ra đời để giải quyết những hạn chế này.
U2F và UAF được phát triển bởi liên minh FIDO (Fast IDentity Online), với sự tham gia của rất nhiều “ông lớn” như Google, Microsoft, PayPal, American Express, MasterCard, VISA, Intel, ARM, Samsung, Qualcomm, Bank of
America... Tính đến tháng 6/2016, FIDO đã có 200 thành viên từ nhiều quốc gia khác nhau và đang không ngừng tăng. FIDO hiện đang rất tích cực trong việc quảng bá U2F, UAF từ phần cứng đến phần mềm, và trong tương lai nó sẽ xuất hiện ở khắp mọi nơi.
U2F (Universal Second Factor) là một chuẩn xác thực hai lớp mới sử dụng phần cứng để làm mã xác thực nên người dùng không phải lo lắng việc kẻ xấu lấy được mã qua email hoặc tin nhắn. Việc đăng nhập bắt buộc phải thực hiện với sự có mặt của phần cứng đó, không thể hack hay đột nhập từ xa nên giảm được nhiều rủi ro. Hiện tại phần cứng U2F phổ biến nhất là đầu thẻ dạng USB, nó có kích thước rất nhỏ gọn nên dễ đem theo bên mình mọi lúc mọi
Hình 3. Giải pháp đảm bảo thống nhất, bảo mật cho các tài khoản Internet của người dùng
Hình 2. Các vấn đề liên quan tới xác thực tài khoản hiện nay

30 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
nơi. Trong tương lai, các thiết bị U2F cũng có thể tích hợp lên nhẫn, vòng tay, vòng cổ, chìa khóa, đồng hồ thông minh và rất nhiều vật dụng khác. Chúng sẽ giao tiếp với máy tính bằng nhiều cách khác nhau như cổng USB, NFC, Bluetooth.
UAF (Universal Authentication Framework) là một chuẩn đăng nhập không cần nhập password (nên được gọi là passwordless). UAF yêu cầu phải có một biện pháp xác thực nào đó nằm ở trên chính thiết bị của người dùng và không truyền ra bên ngoài. Một vài ví dụ của biện pháp xác thực này đó là cảm biến vân tay, cảm biến mống mắt, nhận diện gương mặt, nhận diện giọng nói. Sau khi đã đăng kí với dịch vụ online, mỗi khi cần đăng nhập thì người dùng chỉ cần quét ngón tay qua cảm biến hay đưa mặt lại gần camera là xong.
Cách hoạt động của U2F và UAF* U2F
Với U2F, khi bạn cần đăng nhập vào một dịch vụ online, ví dụ Gmail, bạn vẫn phải nhập username và password như bình thường. Ở bước kế tiếp, bạn sẽ được yêu cầu cắm đầu thẻ USB tương thích U2F
vào máy tính. Trình duyệt Chrome ngay lập tức phát hiện ra sự hiện diện của thiết bị và sử dụng các công nghệ mã hóa để lấy dữ liệu từ nó (bạn sẽ phải nhấn một cái nút trên đầu thẻ USB). Chrome tiếp tục xác nhận dữ liệu có đúng, có hợp chuẩn hay không và nếu mọi thứ đều ổn thì bạn sẽ được đăng nhập tiếp vào Gmail.
Trong quá trình trình duyệt xác thực thông tin, có rất nhiều tiến trình diễn ra để đảm bảo sự an toàn cho bạn. Đầu tiên, trình duyệt sẽ kiểm tra xem liệu nó có đang giao tiếp với website thật thông qua giao thức https hay không. Điều này giúp tránh tình trạng bạn dùng bảo mật hai lớp với một website giả mạo. Sau đó, trình duyệt sẽ gửi một mã lấy từ đầu thẻ USB của bạn lên thẳng website nên về lý thuyết, một kẻ tấn công sẽ không thể lấy được mã này trong lúc dữ liệu đang truyền đi. Tất cả các dữ liệu truyền đi đều được mã hóa đảm bảo an toàn.
Theo cấu hình của U2F, ngoài việc nhập password đầy đủ như bình thường, các website cũng có thể cho bạn tùy chọn nhập mã PIN ngắn, sau đó ấn một nút trên thiết bị USB để tiếp tục đăng nhập. Bằng cách này bạn có thể đơn giản hóa việc ghi nhớ password cũng như tiết kiệm thời gian hơn trong
quá trình sử dụng dịch vụ.
* UAF
Việc xác thực qua UAF cũng rất đơn giản, tương tự như cách Apple dùng Touch ID để đăng nhập App Store, hay cách Samsung dùng cảm biến vân tay để mua hàng PayPal mà Hình 4. Các bước thực hiện xác thực U2F
31CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
không cần gõ mật khẩu. Mỗi khi cần xác thực, chỉ việc để ngón tay lên cảm biến là xong, mọi thứ khác sẽ được tiến hành hoàn toàn tự động. Bạn không cần phải nhập bất kỳ mã xác thực hoặc username, password nào, vì vậy tin tặc không thể đánh cắp những thông tin đó.
UAF khác ở chỗ nó đã được chuẩn hóa, do đó mọi website hoặc ứng dụng sẽ có thể triển khai kiểu bảo mật này nhanh chóng và dễ dàng, không phải làm từ đầu, và thậm chí còn không bị phụ thuộc vào bất kì nền tảng hay hệ điều hành nào. Điều đó sẽ giúp UAF trở nên hấp dẫn hơn và được nhiều dịch vụ sử dụng hơn, cũng như tiếp cận được nhiều người dùng hơn trên diện rộng. Dữ liệu dùng để xác thực cho chuẩn UAF, ví dụ như dấu vân tay hay mẫu giọng nói của bạn, sẽ luôn nằm trên chính thiết bị của bạn và tất nhiên là chúng được mã hóa kĩ càng.
UAF cũng có thể chuyển thành bảo mật hai lớp thông qua việc cho phép sử dụng kết hợp mã PIN hoặc password với bảo mật local.
Lợi thế và khó khăn của triển khai U2F và UAF
* Lợi thế
- An toàn:
+ Chống được tấn công phishing. Bất kỳ giải pháp nào yêu cầu người sử dụng chép mã OTP đều không thể chống lại tấn công phishing.
+ Là một chuẩn mở, các doanh nghiệp cần độ bảo mật cao có thể tự đánh giá và triển khai giải pháp này mà không cần nhờ vào bên thứ ba. Các giải pháp như RSA SecurID hoàn toàn đóng, không ai biết bên trong chúng hoạt động như thế nào.
- Dễ sử dụng: Để xác minh, người sử dụng chỉ cần sờ hoặc nhấn vào một nút duy nhất trên thiết bị FIDO hoặc thiết bị cá nhân. Các giải pháp khác đều yêu cầu người dùng phải chép một mã số (thường được gọi là OTP) từ thiết bị sinh mã.
- Đồng nhất: Có thể sử dụng cho nhiều tài khoản online khác nhau.
* Khó khăn
Để triển khai rộng rãi một giải pháp bảo mật thì sự tiện lợi là yếu tố quan trọng cần tính đến. Hiện nay, chưa nhiều dịch vụ, website hỗ trợ chính thức U2F và UAF ngoài một số hãng lớn bao gồm Microsoft, Qualcomm, Google, Dropbox, Bank of America, Github. Ngoài ra, Chrome cũng là trình duyệt duy nhất tích hợp được phương thức xác thực
Hình 5. Luồng xác thực của chuẩn U2F
Hình 6. Các bước thực hiện xác thực UAF

32 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
này, Firefox và Edge đang được tích hợp nhưng chưa hoàn thiện.
Tuy có thể sử dụng một thiết bị xác thực cho nhiều tài khoản, phương thức bảo mật rất an toàn, nhưng việc chưa nhiều website, dịch vụ hỗ trợ, đồng thời việc khách hàng phải mua thiết bị phần cứng (cho đến nay phổ biến là đầu thẻ USB với giá từ vài
đô-la đến vài chục đô-la Mỹ) chuyên dụng cũng ngăn cản người dùng sử dụng phương thức xác thực này.
Trong tương lai, đây sẽ là một giải pháp hứa hẹn mang đến môi trường Internet an toàn hơn. Dĩ nhiên, bảo mật là cả một quy trình chứ không phải là một sản phẩm riêng lẻ. Tin tặc lại thường nhắm vào những đối tượng có nhiều sơ hở nhất, đó chính là người dùng. Việc đảm bảo an toàn cho người dùng cuối sẽ ra tăng đáng kể cho sự an toàn của cả quy trình bảo mật hệ thống.
Tài liệu tham khảo:[1]. Fido U2F&UAF Tutorial
[2]. Henry Chai, Fido UAF Overview
[3]. http://www.vnsecurity.net/tutorial/2016/08/31/FIDO- U2F-cong-nghe-xac-minh-hai-buoc-chong-phishing.html
Hình 7. Cách hoạt động của UAF

33CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
DươNG tHị tHANH tú, Đỗ mINH HIỆP,
Đỗ tHị tHu tHủy
1. Giới thiệu chung Việc số hóa thông tin ngày này qua ngày khác
trong điện thoại thông minh, máy tính, đồng hồ kết nối Internet, mạng xã hội, các đối tượng kết nối và công nghệ trực tuyến... tạo ra một khối lượng lớn nguồn thông tin kỹ thuật số, tăng lên theo cấp số nhân mỗi ngày. Nguồn thông tin này là gọi là dữ liệu lớn (Big Data), được nhiều tổ chức sử dụng trong các lĩnh vực khác nhau để tự động trích xuất thông tin trong thời gian thích hợp [1].
Dữ liệu lớn đang trở thành một phần không thể thiếu trong các công ty hàng đầu để đạt được mục tiêu của mình, bằng cách thích ứng với các danh mục đầu tư sao cho phù hợp với nhu cầu của khách hàng. Tuy vậy, việc xử lý và phân tích số lượng lớn và không đồng nhất dữ liệu như vậy, không thể thực hiện được bằng cách sử dụng cơ sở dữ liệu có cấu trúc và phương pháp thông thường.
Bảo mật cho dữ liệu lớn trên điện toán đám mây
Hình 1: Mối quan hệ giữa Big data và điện toán đám mây

34 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
Điện toán đám mây là một giải pháp toàn diện cung cấp công nghệ thông tin như một dịch vụ; một giải pháp điện toán dựa trên Internet trong đó các máy tính trong đám mây được cấu hình để làm việc cùng nhau. Điện toán đám mây cho phép người dùng lưu trữ và phân tích dữ liệu của họ bằng cách sử dụng tài nguyên máy tính được chia sẻ, đồng thời dễ dàng xử lý sự biến đổi lượng và tốc độ của dữ liệu.
Chính vì thế, điện toán đám mây nhanh chóng trở thành một công cụ cho việc xử lý và phân tích dữ liệu lớn với ưu điểm giảm giá thành, dễ dàng mở rộng việc kết nối cho hệ thống, xác định dịch vụ,... [2]. Tuy nhiên, điện toán đám mây cũng tạo thêm nhiều rủi ro bởi cơ sơ hạ tầng máy tính được chia sẻ - điều chưa từng tồn tại trong kiến trúc tính toán truyền thống. Thêm vào đó, những nhà cung cấp và người sử dụng đám mây có thể là thực thể không đáng tin cậy – những người cố tình làm xáo trộn việc lưu trữ hay tính toán dữ liệu. Vì vậy, bảo mật cho dữ liệu lớn trong môi trường điện toán đám mây gần đây đã thu hút được rất nhiều sự quan tâm nghiên cứu.
2. Những vấn đề bảo mật cho dữ liệu lớn sử dụng điện toán đám mây
2.1. Thách thức an ninh và đảm bảo tính riêng tư cho dữ liệu trong dữ liệu lớn
Dữ liệu lớn là một cơ hội to lớn cho nhiều các ngành công nghiệp và các nhà sản xuất, nhưng kèm theo đó là thách thức trong việc đảm bảo sự riêng tư và các vấn đề an ninh. Thách thức này phát sinh từ thực tế, việc sử dụng các công cụ phân tích bao gồm lưu trữ, quản lý và phân tích hiệu quả dữ liệu đa dạng được tập hợp từ tất cả các nguồn có thể hoặc có sẵn. Hậu quả là dữ liệu người sử dụng trở thành các mục tiêu dễ bị ngắm tới bởi vì tính kết hợp và khai thác dữ liệu hành vi cụ thể. Nghĩa là kẻ tấn công có thể thu thập nhiều dữ liệu hơn so với quyền hạn của mình dẫn
đến vi phạm một loạt vấn đề an ninh và riêng tư.
Có một tập hợp các mối quan tâm riêng tư và bảo mật cần phải xem xét trước khi xây dựng một môi trường dữ liệu lớn. Dưới đây là một số thách thức quan trọng nhất nên được xem xét cẩn thận khi xử lý dữ liệu lớn:
- Phân bố ngẫu nhiên: Khái niệm về Big Data Analytics chủ yếu dựa trên các phương pháp song song, điều này khiến các dữ liệu lớn phải được lưu trữ và xử lý tại cụm khác nhau, đó là một tập hợp các máy chủ phân phối vòng quanh thế giới và hoạt động như một trạm. Vấn đề chính với cấu trúc này là rất khó để biết chính xác vị trí lưu trữ và xử lý dẫn đến khó có thể đảm bảo an ninh trước các hành vi vi phạm quy định.
- Tính riêng tư: Thách thức chính với Big Data Analytics là khó có thể phân phối lưu trữ và xử lý theo quy định đối với các dữ liệu nhạy cảm. Các công nghệ phân tích dữ liệu lớn hiện hành đối xử với tất cả các dữ liệu với cùng độ ưu tiên giống như mã hóa hoặc xử lý giống nhau với tất cả các loại dữ

35CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
liệu [3]. Như vậy, một hacker hay một nút độc hại có thể cưỡng chế truy cập vào các cụm để dễ dàng ăn cắp, khai thác trái phép hoặc thay đổi các nguồn thông tin.
- Xử lý: Ý tưởng chính đằng sau dữ liệu lớn là để trích xuất những thông tin hữu ích cho các hoạt động xử lý cụ thể. Tuy nhiên, điều quan trọng là đảm bảo an toàn và bảo vệ những xử lý để tránh bất kỳ rủi ro hay các hành vi cố gắng thay đổi hoặc do thám các kết quả trích xuất.
- Tính toàn vẹn: Trong một bối cảnh mở dữ liệu lớn, một khối lượng lớn nội dung không phải luôn đưa ra một chỉ số tốt cho chất lượng kết quả trích xuất. Do đó, trước khi tìm kiếm thông tin và ra quyết định dựa trên dữ liệu lớn, điều quan trọng là phải đảm bảo tính hợp lệ và mức độ tin cậy của dữ liệu, để tránh tin tưởng nhầm vào một bản ghi dữ liệu đáng nghi hoặc đã bị cưỡng chiếm.
- Truyền thông: Dữ liệu lớn được lưu trữ trong một số các nút thuộc nhiều cụm được phân phối trên toàn thế giới. Tất cả các thông tin liên lạc giữa các cụm và các nút được đảm bảo thông qua các mạng công cộng và các mạng riêng. Tuy nhiên, nếu ai đó có thể thay đổi truyền thông liên nút sẽ dễ dàng trích xuất thông tin có giá trị. Vì vậy, một thách thức khác cho các công cụ dữ liệu lớn thông qua các giao thức mạng là đảm bảo an toàn để bảo vệ tương tác giữa các bên khác nhau.
- Quản lý truy cập: Trong một bối cảnh dữ liệu lớn, truy cập vào các dữ liệu cần được quản lý bởi một hệ thống kiểm soát truy cập mạnh mẽ để bất kỳ các thành phần không được phép truy cập đến các máy chủ lưu trữ sẽ bị từ chối. Từ đó chỉ các nút với quyền quản trị đầy đủ mới có khả năng quản lý và xử lý bất kỳ thông tin nào. Hơn nữa, bất kỳ thay đổi trong trạng thái cụm như bổ sung hoặc xóa các nút phải được giám sát bởi một cơ chế xác thực để bảo vệ hệ thống khỏi các nút độc hại.
2.2. Bảo mật dữ liệu trong điện toán đám mây
Điện toán đám mây có thể tạo ra rủi ro với các thông tin nhạy cảm, những rủi ro này xuất phát từ nhu cầu giao phó việc bảo vệ dữ liệu cho nhà cung cấp điện toán đám mây. Điểm khác biệt lớn so với
các môi trường truyền thống là trong môi trường điện toán đám mây, việc xử lý dữ liệu có thể bị điều khiển hoặc quản lý bởi các bên không tin cậy khác nhau và có thể bị tổn thương do sự tấn công từ người thuê điện toán đám mây khác. Hay nói cách khác, đối tượng độc hại có thể xuất hiện từ bên trong lẫn bên ngoài.
Khi người sở hữu dữ liệu buông lỏng sự kiểm soát dữ liệu của mình trong môi trường đám mây, họ yêu cầu rằng dữ liệu của họ vẫn được bảo vệ tốt. Ngày nay, sự đảm bảo này là những lời hứa pháp lý mà những nhà cung cấp điện toán đám mây đưa ra cho người sử dụng – thỏa thuận cấp độ dịch vụ (Service Level Agreement - SLA). Mật mã hóa là một giải pháp cho phép người chủ dữ liệu bảo vệ tài nguyên của họ một cách chủ động thay vì phản hồi đơn độc trên thỏa thuận pháp lý. Ba mục đích bảo mật truyền thống dưới đây luôn được xem xét với mỗi đề xuất bảo mật sử dụng mã hóa trong điện toán đám mây [4]:
- Độ tin tưởng: Tất cả các dữ liệu nhạy cảm (đầu vào máy tính, đầu ra hay trạng thái trung gian) được giữ bí mật khỏi bất kì mối nguy hại hay đối tượng không đáng tin cậy.
- Tính toàn vẹn: Có khả năng phát hiện bất kì sự sửa đổi trái phép hoặc sửa đổi dữ liệu nhạy cảm nào.

36 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
- Giá trị: Người sở hữu dữ liệu (hay người tiếp nhận kết quả) được đảm bảo tiếp cận với dữ liệu của họ và tài nguyên tính toán.
3. Kỹ thuật mã hóa dữ liệu đảm bảo an toàn cho dữ liệu lớn trong điện toán đám mây
Mã hóa luôn là một kỹ thuật tốt để bảo vệ dữ liệu nhạy cảm. Trong trường hợp dữ liệu lớn, mã hóa có thể được sử dụng trong tất cả các khâu: lưu trữ, tính toán và truyền thông.
Đối với môi trường điện toán đám mây, có nhiều kĩ thuật mã hóa khác đã từng được sử dụng trong bảo mật như mã hóa dựa trên nhận dạng và mã hóa dựa trên thuộc tính. Tuy nhiên trong nội dung giới hạn của bài báo chỉ giới thiệu 3 kỹ thuật mã hóa có khả năng ứng dụng để đạt được bảo mật dữ liệu lớn trong điện toán đám mây. Đó là: mã hóa đồng nhất (homomorphic encryption - HE), tính toán xác thực (Verifiable computation - VC) và tính toán bảo mật đa chiều (secure multi-party computation - MPC).
3.1 Mã hóa Homomorphic
Mã hóa Homomorphic là một kiểu mã hóa cho phép chức năng xử lý dữ liệu được mã hóa mà không cần giải mã nó. Một cách chính thức, Ek(m) là một thông điệp mã hóa m với chìa khóa là k. Một chương trình mã hóa gọi là homomorphic đối với một hàm f nếu tồn tại một hàm f‘ tương ứng sao cho Dk(f’ (Ek(m)) = f (m), trong đó Dk là thuật toán giải mã dưới khóa k.
Hình 2 minh họa phương pháp mã hóa này trong đó I đề cập tới nút đầu vào, C đề cập đến nút tính toán, S kí hiệu cho nút lưu trữ, R kí hiệu cho nút kết quả, và X+ là 1 hay nhiều nút giao tiếp cho phép X ∈ I,C,S,R. Những điểm nút trên điện toán đám mây không được tin cậy để bảo vệ tính bí mật, người gửi dữ liệu sẽ mã hóa dữ liệu trước khi đưa vào điện toán đám mây, người nhận dữ liệu sẽ thực hiện giải mã sau khi dữ liệu rời khỏi đám mây. Những chiếc khóa kí hiệu cho mã hóa và giải mã.
Chú ý rằng mã hóa Homomorphic chỉ đảm bảo độ tin tưởng của dữ liệu mà không đảm bảo tính toàn vẹn của dữ liệu. Tuy nhiên, nó có thể được kết
hợp với các tính toán xác thực (được giới thiệu trong phần 3.2). Sự kết hợp mã hóa và tính toán xác thực này cho phép tính toán an toàn, thậm chí trên điện toán đám mây hoàn toàn không được tin tưởng.
3.2 Xác thực
Tính toán xác thực (VC) cho phép người sở hữu dữ liệu kiểm tra tính toàn vẹn của việc tính toán. Trong một chương trình tính toán xác thực, VC cho phép chủ sở hữu gửi dữ liệu của mình cùng với một bản liệt kê những kỹ thuật tính toán mong muốn mà chúng ta gọi là Prover. Các Prover đảm bảo kết quả đầu ra là kết quả của việc tính toán quy định, cùng với một số “lập luận thuyết phục” hoặc “minh chứng” rằng dữ liệu này là chính xác với yêu cầu đã đưa ra trước đó.
Hình 3: Sơ đồ tính toán xác thực
Hình 2: Sơ đồ cấu trúc mã hóa Homomorphic

37CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Hình 3 minh họa phương pháp tính toán xác thực. Trong đó, các nút trên điện toán đám mây không được tin cậy để bảo vệ tính toàn vẹn của dữ liệu. Nút tính toán cung cấp các bằng chứng về tính chính xác và người tiếp nhận dữ liệu sẽ kiểm chứng các bằng chứng ấy. Các nét đứt biểu thị cách ly vật lý với hệ thống xung quanh.
3.3 Bảo mật tính toán đa chiều (MPC)
Việc bảo mật cho tính toán đa chiều (nhiều bên) thích hợp để tận dụng việc thiết lập các đám mây bán tin tưởng. MPC thúc đẩy sự hiện diện của các bên một cách trung thực mà không nhất thiết phải biết bên nào trung thực, để đạt được độ tin tưởng và tính toàn vẹn của dữ liệu và việc tính toán. Trong MPC, không tồn tại duy nhất một đối tượng nào học được bất cứ điều gì về dữ liệu. Tuy nhiên, nếu nhiều bên cùng bị tấn công bởi 1 đối thủ và góp chung thông tin, chúng có thể phá vỡ độ tin tưởng của hệ thống MPC. Hình 4 minh họa hoạt động của MPC trên đám mây. Trong đó, điện toán đám mây là bán tin cậy. Người giữ đầu vào chia sẻ bí mật dữ liệu giữa các nút tính toán, nơi thực hiện tính toán nhiều bên. Người nhận kết quả tái cấu trúc dữ liệu đầu ra.
Hình 4: Bảo mật việc tính toán đa chiều
4. Kết luận Sự phát triển mạnh mẽ về nhu cầu của các tổ
chức, cá nhân trong thời đại công nghệ thông tin đã tạo ra một khái niệm mới, đó là dữ liệu lớn. Dữ liệu lớn đem lại sức mạnh về lưu trữ, sự tối ưu và sự cải thiện trong thời đại công nghệ thông tin. Tuy nhiên với trách nhiệm đảm đương khối dữ liệu khổng lồ ấy thì dữ liệu lớn cũng tự biến mình trở thành mục tiêu tấn công nhằm đánh cắp, thay đổi thông tin của một hệ thống hay tổ chức cá nhân, đặc biệt khi triển khai trên mô hình điện toán đám mây nhằm mang lại sự tiện lợi cũng như giảm chi phí đầu tư. Để giải quyết vấn đề này, sự kết hợp các kỹ thuật mã hóa bao gồm mã hóa đồng nhất (homomorphic encryption - HE), tính toán xác thực (verifiable computation -VC) và tính toán bảo mật đa chiều (secure multi-party computation - MPC) được biết đến như là những công cụ tốt nhất để bảo vệ an toàn thông tin trong kỉ nguyên của dữ liệu lớn với môi trường điện toán đám mây.
Tài liệu tham khảo:1. YOUSSEF GAHI, “Big Data Analytics: Security and Privacy
Challenges “, IEEE Symposium on Computers and Communication (ISCC), 2016.
2. “Big Data in the Cloud: Converging Technologies” , Intel IT Center, April 2015.
3. NATALIA MILOSLAVSKAYA, “Survey of Big Data Information Security “, 4th International Conference on Future Internet of Things and Cloud Workshop, 2016.
4. SOPHIA YAKOUBOV, “A Survey of Cryptographic Approaches to Securing Big-Data Analytics in the Cloud”, IEEE 2014.

38 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
Võ VăN trườNG* trịNH mINH Đức*
Lê KHáNH DươNG*NGuyễN VăN VINH**
I. GIỚI THIỆUNgày nay song song với sự bùng nổ mạnh mẽ của
công nghệ thông tin và sự phát triển của Internet toàn cầu là các nguy cơ mất an toàn thông tin (ATTT)
đang trở nên trầm trọng và nguy hiểm hơn, trong đó mã độc hại đang là các hiểm họa hàng đầu bởi khả năng có thể lây lan phát tán trên các hệ thống máy tính và thực hiện các hành vi tấn công bất hợp pháp. Mã độc đang ngày càng tiến hóa với những biến thể đa dạng, với những cách thức che dấu ngày càng tinh vi hơn. Có thể nói phát hiện và ngăn chặn mã độc đang là một thách thức được đặt ra trong lĩnh vực ATTT. Các phương pháp phát hiện mã độc thông thường chủ yếu sử dụng kỹ thuật so sánh mẫu dựa trên cơ sở dữ liệu mã độc được xây dựng và định nghĩa từ trước, tuy nhiên phương pháp này bộc lộ nhiều nhược điểm đó là không có khả năng phát hiện ra các mẫu mã độc mới, số lượng dữ liệu mã độc ngày càng gia tăng làm cho cơ sở dữ liệu mẫu ngày càng lớn. Hiện nay hướng nghiên cứu dựa vào các mô hình học máy để phân loại và phát hiện mã độc đang tỏ ra là phương pháp tiềm năng và hiệu quả khi có thể cải thiện được các nhược điểm đã nêu ở trên so với phương pháp truyền thống.
Đề xuất giải pháp trích chọn đặc trưng cho các thuật toán phân lớp dữ liệu trong kỹ thuật học máy giám sát và ứng dụng hiệu quả vào bài toán phát hiện mã độc
* Trường Đại học Công nghệ thông tin và Truyền thông - Đại học Thái Nguyên**Trường Đại học Công nghệ - Đại học Quốc gia Hà Nội
hiện nay học máy đang là một hướng nghiên cứu được ứng dụng trong nhiều lĩnh vực, đặc biệt là trong các bài toán phân lớp dữ liệu. bài viết trình bày một hướng nghiên cứu trong đó ứng dụng kỹ thuật học máy vào việc phân lớp và phát hiện mã độc. bài báo đề xuất và xây dựng một giải pháp trích chọn đặc trưng nâng cao hiệu quả và phù hợp cho các bài toán phân lớp dữ liệu. quá trình được thực nghiệm và phân tích trên các bộ dữ liệu mã độc chỉ ra rằng phương pháp đề xuất cho kết quả phân lớp chính xác và hiệu Suất tương đối tốt.

39CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Tuy nhiên, một trong những vấn đề được quan tâm là làm sao để xây dựng được mô hình học máy tốt nhất đạt hiệu quả chính xác và hiệu suất cao. Trong đó một yếu tố quan trọng được xem là quyết định chính là giải pháp trích chọn đặc trưng. Bài viết trình bày về phương pháp ứng dụng học máy vào xây dựng các mô hình phát hiện mã độc, trong đó các thực nghiệm dựa trên phương pháp phân tích tĩnh mã độc, tiền xử lý dữ liệu bằng kỹ thuật dịch ngược đưa các file dữ liệu mẫu về dạng mã hex và thực hiện khai phá dữ liệu text sử dụng các mã n-gram byte là các đặc trưng ban đầu. Sau đó, các dữ liệu đặc trưng này sẽ được trích chọn ra một bộ dữ liệu đặc trưng tốt nhất để xây dựng mô hình trên cơ sở giải pháp trích chọn đặc trưng mà bài báo tập trung nghiên cứu và đề xuất. Các kết quả của bài báo được thực nghiệm trên khoảng 4698 file mẫu thực thi trên nền Windows trong đó 2373 file mã thông thường và 2325 file mẫu mã độc với nhiều thể loại đa dạng như Backdoor, Virus, Trojan, Worm...
II. CÁC NGHIÊN CỨU LIÊN QUANCác nghiên cứu về hướng tiếp cận học máy trong
phát hiện và nhận diện mã độc đã được nhiều tác giả tham gia và nghiên cứu [9], trong đó nổi bật lên là sử dụng các phương pháp phân tích mã độc và trích rút các đặc trưng là các mã byte hay các mã opcode [1] hay sử dụng các hàm gọi đến API [6] Mỗi phương pháp tiếp cận có những ưu điểm và nhược điểm khác nhau, phương pháp dựa vào mã opcode cho kết quả khá tốt, tuy nhiên, việc dịch ngược ra các mã opcode này đôi khi là khó chính xác cũng như việc tiền xử lý dữ liệu trở nên phức tạp, các phương pháp dựa trên các hàm API lại không bao phủ được đầy đủ các thông tin, phương pháp dựa vào mã byte là một phương pháp hiệu quả dễ dàng trong tiền xử lý tuy nhiên khó khăn trong việc trích chọn các đặc trưng thực sự có hiệu quả. Nhìn chung, các phương pháp ở trên đều dựa vào các nguyên lý trong kỹ thuật học máy và khai phá dữ liệu mà đối tượng là các mã độc [8]. Các nghiên cứu chủ yếu sử dụng phương pháp n-gram [4, 5] và quá trình trích rút đặc trưng dựa vào việc tính tần số xuất hiện của các đặc
trưng, tuy nhiên các tập đặc trưng này thường lớn và gây khó khăn cũng như giảm hiệu quả trong quá trình xây dựng mô hình, một số phương pháp chọn đặc trưng như nén các đặc trưng hay giảm số chiều các đặc trưng khá hiệu quả nhưng đôi khi không lọc được các đặc trưng gây nhiễu. Trong nghiên cứu này, chúng tôi đề xuất một giải pháp cho phép lựa chọn các đặc trưng tốt nhất và loại bỏ các đặc trưng có thể gây nhiễu cho mô hình, các đặc trưng này được đánh giá từ chính dữ liệu đầu vào phù hợp với mô hình. Để đơn giản các thực nghiệm và so sánh, chúng tôi sử dụng phương pháp n-gram byte trong việc trích xuất các đặc trưng đầu vào.
III. TỔNG QUAN VỀ PHƯƠNG PHÁP THỰC HIỆNBài viết này chúng tôi tập trung nghiên cứu các
loại mã độc thực thi trên nền Windows các file mã độc được thu thập từ trang chủ “Vxheaven” [12] và các file mã thông thường là các file hệ thống thuộc kiểu file “PE” chủ yếu là các file “.exe” chạy trên trên hệ điều hành Windows. Tổng quan về phương pháp được mô tả qua 6 bước sau:
Bước 1: Thu thập dữ liệu các file mã độc và các file PE thông thường.
Hình 1. Mô tả tổng quan phương pháp thực hiện.

40 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
Bước 2: Các file này sẽ được dịch ngược về mã hex thông qua một chương trình được tác giả viết bằng ngôn ngữ Python.
Bước 3: Sau khi dịch ngược thì các dữ liệu huấn luyện sẽ được trích rút ra các đặc trưng là các mã hex dựa vào phương pháp n-gram. Trong bài báo này, kích thước chúng tôi sử dụng là 2-gram.
Bước 4: Từ các đặc trưng là các mã n-gram thực hiện tính tần số xuất hiện (TF) của các mã n-gram này trên mỗi tập dữ liệu. Sau đó áp dụng thuật toán mà chúng tôi sẽ đề xuất để chọn ra được một bộ đặc trưng tốt nhất.
Bước 5: Từ bộ đặc trưng có được ta đưa chúng vào xây dựng các mô hình học máy ở đây chúng tôi sử dụng hai giải thuật để thực nghiệm và so sánh là cây quyết định và svm.
Bước 6: Sau khi xây dựng xong mô hình thì đưa các dữ liệu test vào để đánh giá kết quả.
A. Tiền xử lý dữ liệu
1) Kỹ thuật phân tích mã độc:
Hiện nay phân tích mã độc chủ yếu dựa vào 2 phương pháp chính là phân tích động và phân tích tĩnh. Mỗi phương pháp lại đều có những ưu và nhược điểm khác nhau. Phân tích động xác định chính xác mã độc bằng việc quan sát và phân tích các hành vi của nó thông qua việc tạo ra các môi trường thực thi phù hợp cho mã độc, phương pháp này có ưu thế là quá trình phân tích nhanh, dễ dàng ngay cả với những mã độc bị mã hóa phức tạp tuy nhiên lại không hiệu quả khi gặp phải những mã độc chạy theo thời gian hoặc các mã độc có khả năng nhận ra sự theo dõi và sẽ không thực thi các chức năng của nó. Phương pháp phân tích tĩnh dựa vào việc thực hiện dịch ngược mã độc về dạng assembly hay dạng mã hex và phân tích các dấu hiệu của mã độc, phương pháp này tuy gặp khó khăn với những mã độc bị mã hóa hay đóng gói phức tạp nhưng có ưu điểm là có thể phát hiện ra mã độc ngay cả khi không cần thực thi nó và các đặc trưng của mã độc cũng như cấu trúc của nó cho phép phát hiện mã độc một cách chính xác.
Hiện nay đa số quá trình phân tích mã độc còn thủ
công tốn nhiều thời gian, vì vậy việc ứng dụng học máy để xây dựng các hệ thống có khả năng tự động phát hiện mã độc là điều hết sức cần thiết. Trong nội dung nghiên cứu và thử nghiệm này, chúng tôi sử dụng phương pháp phân tích tĩnh, ở giai đoạn tiền xử lý này các file thông thường và các file mã độc là các file dạng PE sẽ được dịch ngược về các mã hex có rất nhiều công cụ cho phép thực hiện điều này có thể kể ra như: IDA, OLLYDBG… Tuy nhiên để đồng bộ và phát triển các hệ thống tự động sau này, chúng tôi đã xây dựng một chương trình dựa trên cấu trúc của một file PE cho phép dịch ngược các file này về mã hex. Chương trình được viết bằng ngôn ngữ Python và sử dụng thư viện Pefile. Các file dữ liệu mẫu sau khi được dịch ngược sẽ được xử lý để lấy các mã hex quan trọng, chủ yếu chúng nằm ở các phần PE header và Section nơi chứa các mã chương trình (Executable Code Section), các dữ liệu (Data Section), các tài nguyên (Resources Section), các thư viện (Import Data ,Export Data)...
Các file thông thường và mã độc sau khi được dịch ngược sẽ lấy nội dung các mã hex của từng file này và lưu lại thành các file text tương đương phục vụ cho quá trình trích chọn đặc trưng và xây dựng mô hình dự đoán.
2) Phương pháp n-gram:
Trong nghiên cứu này chúng tôi sử dụng chuỗi các byte là các đặc trưng đầu vào trong đó ở giai đoạn tiền xử lý các file dữ liệu mẫu được trích xuất dựa vào việc tính tần suất các n-gram byte. N-gram byte là một dãy các byte liên tiếp có độ dài N được mô tả như sau:
Với một dãy các mã hex sau khi dịch ngược giả sử là “AB C0 EF 12” thì dãy các n-gram byte thu được là:
Có thể nhận thấy rằng với độ dài n càng cao thì kích thước đặc trưng càng lớn. Đối với mã hex có

41CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
16 giá trị khác nhau như vậy không gian đặc trưng của 1-gram sẽ là 162=256 với 2-gram là 164=65536. Trong nội dung nghiên cứu này chúng tôi chủ yếu tập trung vào phương pháp chọn đặc trưng, vì vậy để tiết kiệm thời gian và tài nguyên tính toán các kết quả được chúng tôi thử nghiệm trên dãy 2-gram. Như vậy ở giai đoạn tiền xử lý các file dữ liệu mẫu được dịch ngược sang các mã hex và sau đó tiếp tục được trích rút ra các đặc trưng dựa vào phương pháp n-gram.
3) Tính tần số xuất hiện (Term Frequency):
Như chúng ta đã phân tích ở các phần trên, dữ liệu mẫu sau khi thực hiện tiền xử lý sẽ được lưu dưới dạng các file text và được trích rút các dãy n-gram. Một trong những phương pháp được biết đến trong các bài toán khai phá và phân lớp dữ liệu text đó là phương pháp tính tần số xuất hiện (TF). Dựa vào phương pháp như vậy, ở bước này chúng tôi thực hiện tính toán tần số xuất hiện của mỗi n-gram khác nhau trên từng file dữ liệu mẫu. Các kết quả này được lưu như mỗi véc tơ đặc trưng và trước khi được đưa vào mô hình học sẽ được xử lý để trích ra một bộ đặc trưng tốt nhất.
Công thức tính tần số xuất hiện được cho như sau:
Tần số xuất hiện của một mã n-gram byte trong một tập mẫu (file dữ liệu mẫu đã được đưa về dạng text) được tính bằng thương của số lần xuất hiện n-gram byte đó trong tập mẫu và số lần xuất hiện nhiều nhất của một n-gram byte bất kỳ trong tập mẫu đó (giá trị sẽ thuộc khoảng [0, 1])
• f(t,d)-số lầnxuấthiệncủamộtn-grambytettrong tập mẫu d.
• maxf(w,d):w∈d - số lần xuất hiện nhiều nhất của một n-gram byte bất kỳ trong tập mẫu.
B. Đề xuất giải pháp trích chọn đặc trưng
Trong phương pháp học máy, có thể thấy rằng khi số lượng đặc trưng lớn sẽ làm giảm hiệu suất và đôi khi là chất lượng của mô hình học. Lượng đặc
trưng quá nhiều sẽ khiến cho quá trình huấn luyện và phân lớp dữ liệu tốn kém về mặt tài nguyên cũng như thời gian xử lý, thậm chí nếu nhiều đặc trưng phổ biến sẽ dẫn đến dư thừa gây nhiễu và ảnh hướng đến chất lượng khi xây dựng mô hình.Chính vì vậy bài toán đặt ra và cần thiết là làm sao loại bỏ được các đặc trưng gây nhiễu và chọn được một tập đặc trưng đại diện tốt nhất mà vẫn đảm bảo độ chính xác hiệu quả của mô hình dự đoán. Trong phương pháp n-gram nêu trên ta thấy sẽ có các đặc trưng mà tần số xuất hiện của chúng tương tự nhau trên 2 lớp vì vậy khi đưa vào mô hình học máy sẽ không đạt kết quả cao.
Phương pháp trích chọn đặc trưng bài báo đề xuất mục đích là tìm ra tập các đặc trưng mà giá trị tần số xuất hiện trung bình của chúng trên 2 lớp cần phân chia có độ lệch lớn nhất. Cụ thể là các mã n-gram mà có tần số xuất hiện trên các tập của lớp này khác nhất với chính nó trên các tập của lớp còn lại.
1) Mô tả giải pháp:
Gọi D là tập các đặc trưng có độ dài “d” phần tử là các mã n-gram byte. 2 lớp cần phân chia lớp thứ 1 có độ dài là “n” tập mẫu. Lớp thứ 2 có độ dài là “m” tập mẫu.
Gọi TF1[i] là tập chứa các giá trị tần số xuất hiện của đặc trưng D[i] ∈ D; i ∈ [0,d] trên các mẫu dữ liệu thuộc lớp thứ 1. Mỗi TF1[i] với i ∈ [0,d] là một mảng chứa ‘n’ phần tử .
Gọi TF2[i] là tập chứa các giá trị tần số xuất hiện của đặc trưng D[i] ∈ D; i ∈ [0,d] trên các mẫu dữ liệu thuộc lớp thứ 2. Mỗi TF2[i] với i ∈ [0,d] là một mảng chứa ‘m’ phần tử.
Bước 1: Với mỗi giá trị i ∈ [0,d] sắp xếp các phần tử trong TF1[i] và TF2[i] theo chiều giảm hoặc tăng dần
Bước 2: Sau khi thực hiện sắp xếp ở bước 1:
Với mỗi i ∈ [0,d] ta thực hiện chia các phần tử trong TF1[i] tương ứng thành “k” đoạn liên tiếp bắt đầu từ phần tử đầu tiên, mỗi đoạn chứa C1 phần tử (số phần tử trong các đoạn có thể không bằng nhau).

42 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
Tương tự với mỗi i ∈ [0,d] ta cũng thực hiện chia các phần tử trong TF2[i] tương ứng thành “k” đoạn liên tiếp bắt đầu từ phần tử đầu tiên, mỗi đoạn chứa C2 phần tử (số phần tử trong các đoạn có thể không bằng nhau)
Bước 3: Tính trung bình cộng tần số xuất hiện trên từng khoảng đã chia trên mỗi TF1[i]; i ∈ [0,d] với mỗi TF1[i] ta thu được “k” giá trị TB1[i][j] với i ∈ [0,d]; j∈[0,k] là giá trị tần số xuất hiện trung bình của D[i] trên đoạn j của TF1[i]
Tương tự thực hiện tính trung bình cộng tần số xuất hiện trên từng khoảng đã chia trên mỗi TF2[i]; i ∈[0,d] với mỗi TF2[i] ta thu được “k” giá trị TB2[i][j] với i ∈ [0,d]; j∈[0,k] là giá trị tần số xuất hiện trung bình của D[i] trên đoạn j của TF2[i]
Bước 4: Tính độ lệch tần số xuất hiện trung bình trên “k” đoạn đã chia của mỗi TF1[i] và TF2[i].
Gọi TB[i][j] là độ lệch trung bình của đặc trưng D[i] trên đoạn j của 2 tập TF1[i] và TF2[i] thì TB[i][j] được tính bằng trị tuyệt đối của phép trừ giữa TB1[i][j] và TB2[i][j] ta có:
TB[i][j] =| TB1[i][j] - TB2[i][j] |
( i ∈ [0,d]; j ∈ [0,k] )
Với mỗi i trên đoạn [0,d] thực hiện tính các TB[i][j] của nó với mỗi j ∈ [0,k] trên 2 tập TF1[i] và TF2[i] tương ứng.
Bước 5: Với mỗi i ∈ [0,d] ta thực hiện tính độ lệch trung bình giá trị tần số của đặc trưng D[i] tương ứng trên toàn tập bằng cách tính sau:
Trong đó DL[i] với i ∈[0,d] là độ lệch trung bình của đặc trưng D[i] trên 2 lớp cần phân chia.
Bước 6: Kết thúc bước 5 ta sẽ thu được kết quả độ lệch trung bình tần số xuất hiện của “d” đặc trưng ban đầu từ “d” đặc trưng này thực hiện chọn ra một bộ đặc trưng có giá trị độ lệch cao nhất để đưa vào xây dựng mô hình.
2) Ví dụ:
Bài toán: Giả sử cho 2 lớp với các đặc trưng là các mã hex 2-gram byte có số tập mẫu khác nhau và tần
số xuất hiện như sau:
Bước 1: sau khi đã tính tần số xuất hiện của các đặc trưng trên mỗi tập mẫu thuộc 2 lớp thực hiện sắp xếp các giá trị theo chiều giảm dần ở mỗi đặc trưng trong cả 2 lớp như sau:
Bước 2: Tiến hành chia lớp 1 và lớp 2 mỗi lớp thành k đoạn. Giả sử ta chọn k=2, như vậy với lớp 1 mỗi đoạn sẽ có 2 giá trị tần số liên tiếp cạnh nhau, với lớp 2 mỗi đoạn có 3 giá trị tần số liên tiếp cạnh nhau.
0[ ][ ]
k
jTB i j
k=∑
DL[i]=
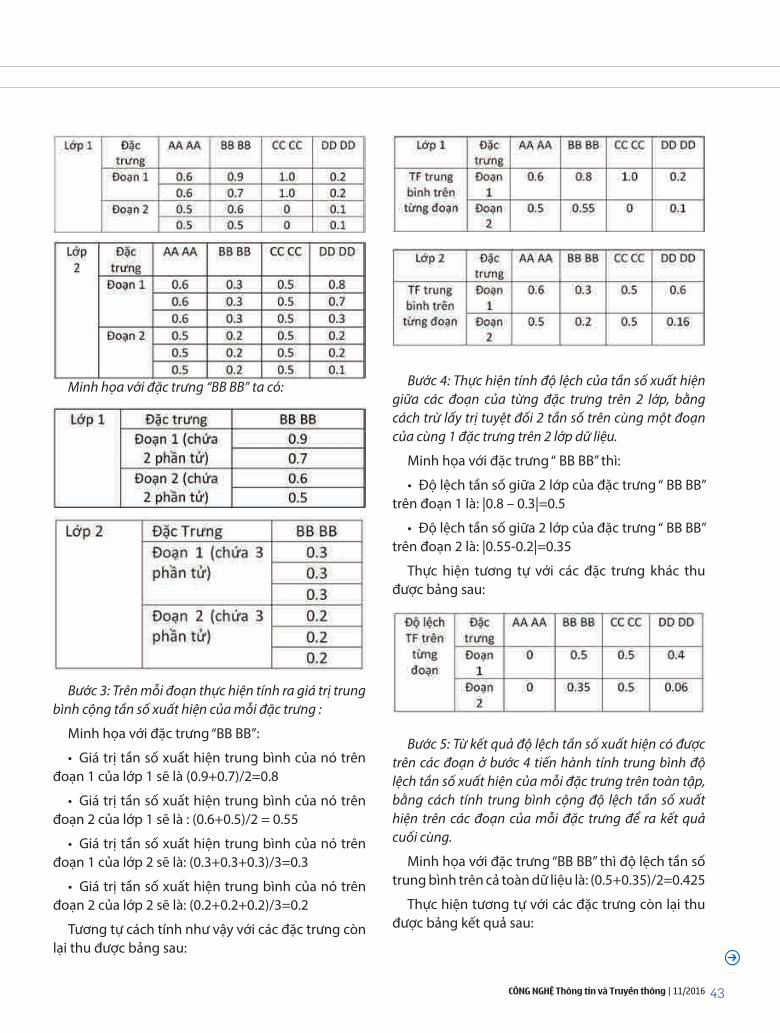
43CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Minh họa với đặc trưng “BB BB” ta có:
Bước 3: Trên mỗi đoạn thực hiện tính ra giá trị trung bình cộng tần số xuất hiện của mỗi đặc trưng :
Minh họa với đặc trưng “BB BB”:
• Giátrịtầnsốxuấthiệntrungbìnhcủanótrênđoạn 1 của lớp 1 sẽ là (0.9+0.7)/2=0.8
• Giátrịtầnsốxuấthiệntrungbìnhcủanótrênđoạn 2 của lớp 1 sẽ là : (0.6+0.5)/2 = 0.55
• Giátrịtầnsốxuấthiệntrungbìnhcủanótrênđoạn 1 của lớp 2 sẽ là: (0.3+0.3+0.3)/3=0.3
• Giátrịtầnsốxuấthiệntrungbìnhcủanótrênđoạn 2 của lớp 2 sẽ là: (0.2+0.2+0.2)/3=0.2
Tương tự cách tính như vậy với các đặc trưng còn lại thu được bảng sau:
Bước 4: Thực hiện tính độ lệch của tần số xuất hiện giữa các đoạn của từng đặc trưng trên 2 lớp, bằng cách trừ lấy trị tuyệt đối 2 tần số trên cùng một đoạn của cùng 1 đặc trưng trên 2 lớp dữ liệu.
Minh họa với đặc trưng “ BB BB” thì:
• Độlệchtầnsốgiữa2lớpcủađặctrưng“BBBB”trên đoạn 1 là: |0.8 – 0.3|=0.5
• Độlệchtầnsốgiữa2lớpcủađặctrưng“BBBB”trên đoạn 2 là: |0.55-0.2|=0.35
Thực hiện tương tự với các đặc trưng khác thu được bảng sau:
Bước 5: Từ kết quả độ lệch tần số xuất hiện có được trên các đoạn ở bước 4 tiến hành tính trung bình độ lệch tần số xuất hiện của mỗi đặc trưng trên toàn tập, bằng cách tính trung bình cộng độ lệch tần số xuất hiện trên các đoạn của mỗi đặc trưng để ra kết quả cuối cùng.
Minh họa với đặc trưng “BB BB” thì độ lệch tần số trung bình trên cả toàn dữ liệu là: (0.5+0.35)/2=0.425
Thực hiện tương tự với các đặc trưng còn lại thu được bảng kết quả sau:

44 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
Như vậy dễ thấy các tập có độ lệch cao nhất là “CC CC” và “BB BB” sau đó là “DD DD” ta có thể xác định được các tập này có sự sai khác lớn về tần số xuất hiện của 2 lớp đúng theo thứ tự.
Bước 6: Từ các kết quả có được thực hiện chọn ra T đặc trưng có độ lệch về giá trị tần số xuất hiện lớn nhất.
C. Xây dựng mô hình dự đoán
Sau khi chọn được tập đặc trưng dựa vào phương pháp đã trình bày phía trên, bước tiếp theo ở giai đoạn này là tiến hành đưa các giá trị tần số xuất hiện của các đặc trưng n-gram đã được chọn trên các tập mẫu ban đầu vào các thuật toán trong học máy để xây dựng mô hình dự đoán, các dữ liệu mẫu được gán nhãn thành 2 lớp mã độc và file bình thường. Giai đoạn này sử dụng các véc tơ đặc trưng như là dữ liệu huấn luyện đầu vào cho các thuật toán phân lớp dữ liệu [6] [11] có thể áp dụng như: k láng giềng (KNN), Naive Bayes (NB), cây quyết định (DT), Rừng ngẫu nhiên (RF), máy véc tơ hỗ trợ (SVM)… Trong phương pháp học máy giám sát khó có thể nói là thuật toán phân lớp nào tốt nhất, vì mỗi thuật toán có những ưu, nhược điểm riêng phù hợp cho mỗi loại dữ liệu khác nhau. Riêng đối với các bài toán phân lớp dữ liệu văn bản thì SVM và cây quyết định là 2 thuật toán được cho là có độ chính xác cao và được sử dụng khá phổ biến [10]. Trong đó thuật toán máy véc tơ hỗ trợ (SVM) được đánh giá là rất phù hợp và hiệu quả trong các bài toán phân lớp dữ liệu văn bản [10], trong khi đó cây quyết định (DT) là thuật toán dễ hiểu, dựa vào việc sinh luật khá gần gũi tư duy của con người .Trong nghiên cứu này chúng tôi lựa chọn 2 thuật toán tiêu biểu là cây quyết định và máy véc tơ hỗ trợ để xây dựng mô hình đự đoán phát hiện mã độc, đồng thời các kết quả của 2 phương pháp sẽ được so sánh và đánh giá thông qua quá trình thực nghiệm.
IV. THỰC NGHIỆM VÀ ĐÁNH GIÁCác kết quả của bài báo được chúng tôi thực
nghiệm với đầu vào là 4698 file dữ liệu mẫu trong đó 2373 file mã thông thường và 2325 file mã độc, file mã độc được thu thập từ trang chủ “Vxheaven” [12] và các file mã thông thường là các file hệ thống thuộc kiểu file “PE” chủ yếu là các file “.exe” chạy trên hệ điều hành Windows, số lượng các mẫu mã độc được mô tả như sau:
Trong đó tỷ lệ các mẫu mã độc được biểu diễn trực quan trong biểu đồ Hình 2.
Hình 2. Biểu đồ mô tả tỷ lệ mẫu mã độc tham gia thực nghiệm
Từ các dữ liệu mẫu tiến hành trích rút các đặc trưng 2-gram byte như vậy toàn bộ không gian đặc trưng sẽ là 164=65536 đặc trưng, sau đó áp dụng thuật toán đã đề xuất chúng tôi thực hiện thu gọn và trích chọn ra 800 đặc trưng tốt nhất. Trong tổng số 4698 file thực hiện chọn ra 400 file test (trong đó 200 file mã độc và 200 file thông thường) các file còn lại độc lập với dữ liệu test được dùng làm dữ liệu huấn luyện. Tiến hành kiểm tra chéo trên các tập dữ liệu bằng cách chọn ngẫu nhiên 400 file test khác nhau với các file huấn luyện độc lập còn lại và thực hiện kiểm tra nhiều lần, các kết quả được
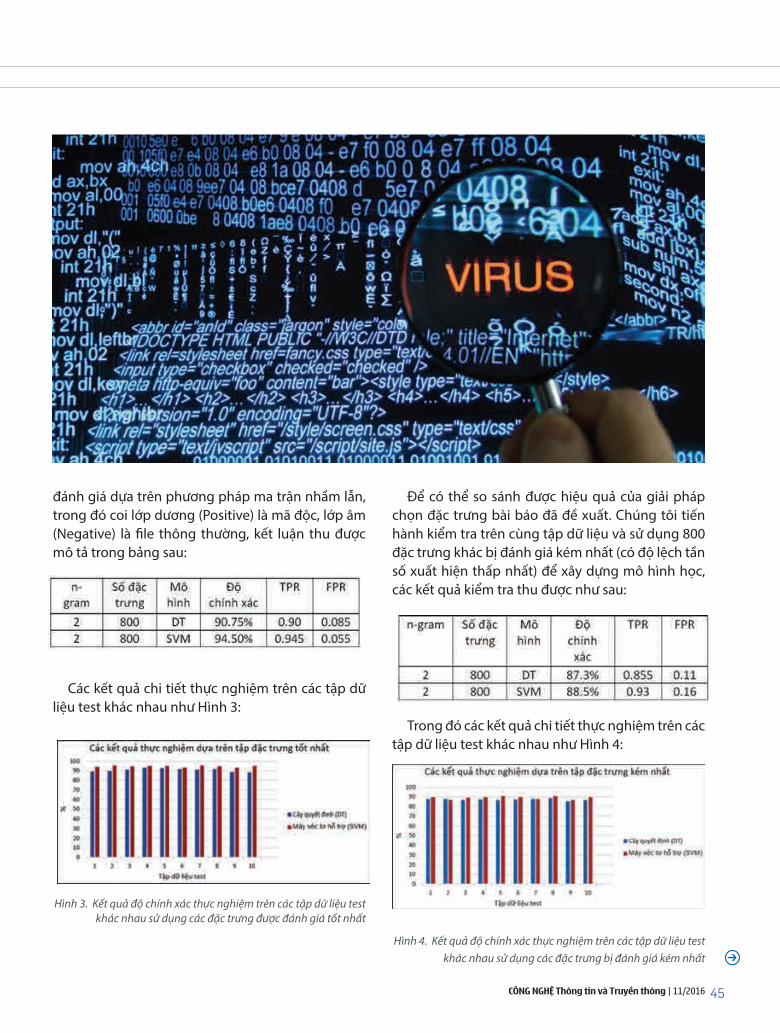
45CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
đánh giá dựa trên phương pháp ma trận nhầm lẫn, trong đó coi lớp dương (Positive) là mã độc, lớp âm (Negative) là file thông thường, kết luận thu được mô tả trong bảng sau:
Các kết quả chi tiết thực nghiệm trên các tập dữ liệu test khác nhau như Hình 3:
Hình 3. Kết quả độ chính xác thực nghiệm trên các tập dữ liệu test khác nhau sử dụng các đặc trưng được đánh giá tốt nhất
Để có thể so sánh được hiệu quả của giải pháp chọn đặc trưng bài báo đã đề xuất. Chúng tôi tiến hành kiểm tra trên cùng tập dữ liệu và sử dụng 800 đặc trưng khác bị đánh giá kém nhất (có độ lệch tần số xuất hiện thấp nhất) để xây dựng mô hình học, các kết quả kiểm tra thu được như sau:
Trong đó các kết quả chi tiết thực nghiệm trên các tập dữ liệu test khác nhau như Hình 4:
Hình 4. Kết quả độ chính xác thực nghiệm trên các tập dữ liệu test khác nhau sử dụng các đặc trưng bị đánh giá kém nhất

46 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
An toàn bảo mật
Như vậy dựa vào các kết quả thực nghiệm có thể thấy tập đặc trưng được đánh giá cao mà thuật toán đã tìm ra cho kết quả tốt hơn rất nhiều so với tập đặc trưng bị đánh giá thấp.
V. KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂNBài báo đã trình bày một hướng tiếp cận có hiệu
quả trong đó ứng dụng kỹ thuật học máy vào việc nhận, diện và phát hiện mã độc. Đồng thời đề xuất một giải pháp chọn đặc trưng để có thể gia tăng hiệu suất mà vẫn đảm bảo độ chính xác và hiệu quả của mô hình dự đoán, các kết quả được tiến hành thực nghiệm và đánh giá trên các tệp dữ liệu chạy trên nền Windows cho thấy với kỹ thuật chọn đặc trưng bài báo đã đề xuất thuật toán máy véc tơ hỗ trợ (SVM) tỏ ra hiệu quả hơn so với thuật toán học cây quyết định (DT). Hướng phát triển tiếp theo của nghiên cứu là mở rộng phương pháp với nhiều hướng tiếp cận phân tích mã độc hơn như phân tích động, phân tích dựa trên kinh nghiệm, từ đó phối
hợp với các thuật toán học máy vào quá trình xây dựng các hệ thống có khả năng tự động nhận diện với đa dạng mã độc một cách chính xác, đồng thời tiếp tục nghiên cứu, phát triển và áp dụng nhiều hơn các kỹ thuật trích chọn đặc trưng nhằm nâng cao hiệu quả hiệu suất của mô hình dự đoán.
Tài liệu tham khảo:[1] ASAF SHABTAI, ROBERT MOSKOVITCH, CLINT FEHER, SHLOMI
DOLEV AND YUVAL ELOVICI “Detecting unknown malicious code by applying classification techniques on OpCode patterns,” Security Informatics 2012 1:1. doi:10.1186/2190-8532-1-1
[2] A. SHABTAI, R. MOSKOVITCH, Y. ELOVICI, C.GLEzER: “Detection of malicious code by applying machine learning classifiers on static features: A state-of-the-art survey,” Information Security Technical Report 2009.
[3] CAI DM, GOKHALE M, THEILER J “Comparison of feature selection and classification algorithms in identifying malicious executables,”. Computational Statistics and Data Analysis 2007.
[4] D KRISHNA SANDEEP REDDY - ARUN K PUJARI “N-gram analysis for computer virus detection,” Springer-Verlag France 2006, doi 10.1007/s11416-006-0027-8
[5] IGOR SANTOS, YOSEBA K. PENYA, JAIME DEVESA AND PABLO G. BRINGAS “n-grams-based file signatures for malware detection,” Deusto Technological Foundation, Bilbao, Basque Country
[6] MADHU K. SHANKARAPANI - SUBBU RAMAMOORTHY - RAM S. MOVVA - SRINIVAS MUKKAMALA “Malware detection using assembly and API call sequences,” Springer-Verlag France 2010, doi 10.1007/s11416-010-0141-5
[7] PETER HARRINGTON, “Machine Learning in Action,” in Part 1 Classification, by Manning Publications, 2012 , pp. 1–129.
[8] SCHULTz M, ESKIN E, zADOK E, STOLFO S “Data mining methods for detection of new malicious executables,” Proc of the IEEE Symposium on Security and Privacy, IEEE Computer Society 2001.
[9] SMITA RANVEER, SWAPNAJA HIRAY, “Comparative Analysis of Feature Extraction Methods of Malware Detection,” International Journal of Computer Applications (0975 8887), Volume 120 - No. 5, June 2015
[10] THORSTEN JOACHIMS: “Text categorization with support vector machines: learning with many relevant features”, Proceedings of ECML-98, 10th European Conference on Machine Learning, Springer Verlag, Heidelberg, DE, 1998, pp. 137-142
[11] TRENT HAUCK, “scikit-learn Cookbook”, in Chapter 4 Classifying Data with scikit-learn, by Packt Publishing, 2014, pp. 119-157
[12] VXheavens, Website: url:http://vx.netlux.org.

47CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Cùng với sự phát triển bùng nổ của Internet và thương mại điện tử, các vụ tấn công trên Internet ngày càng gia tăng và gây ra những thiệt hại đáng kể. Nguyên nhân chủ yếu là do vấn đề
bảo mật trực tuyến thường không được chú trọng, nghiêm trọng hơn là tin tặc hiện đang nhắm đến doanh nghiệp nhỏ.
Gia tăng các cuộc tấn công vào doanh nghiệp nhỏ
Số lượng các cuộc tấn công mạng vào những doanh nghiệp vừa và nhỏ đang ngày càng gia tăng. Theo Báo cáo hiện trạng các mối đe dọa bảo mật Internet do Tập đoàn Symantec công bố tháng 4/2016, những cuộc tấn công có chủ đích ngày càng nhắm nhiều hơn đến các doanh nghiệp nhỏ có quy mô ít hơn 250 nhân viên. Bản thân các doanh nghiệp nhỏ đã là những mục tiêu béo bở, bên cạnh đó, họ còn là cửa ngõ để những kẻ tấn công nhằm vào những công ty liên đới có quy mô lớn hơn.
Sự gia tăng này được cho là do tấn công giả mạo có mục tiêu (spear phishing) và mã độc tống tiền
(ransomware). Theo số liệu được dẫn từ báo cáo của Symantec, trong năm 2015, khoảng 43% doanh nghiệp nhỏ bị tấn công phishing, tăng 2,4 lần so với
năm 2011.
Còn thống kê của tổ chức An ninh mạng liên minh quốc gia của Mỹ cũng cho thấy cứ 5 doanh nghiệp nhỏ ở Mỹ thì có 1 doanh nghiệp trở thành nạn nhân của tội phạm mạng mỗi năm. Hyatt, Sheraton, Marriott, Westin và nhiều khách sạn khác tại 10 bang của nước Mỹ là những cái tên đã bị tin tặc “ghé thăm” và chiếm lấy nguồn dữ liệu của hệ thống thanh toán. Cụ thể, ngày 15/8/2016, HEI Hotels & Resorts, hãng điều hành khoảng 60 khách sạn và khu nghỉ dưỡng với nhiều thương hiệu khác nhau, công bố phát hiện một phần mềm độc hại trong hệ thống xử lý thanh toán tại 20 cơ sở của hãng sau khi đơn vị phụ trách thẻ tín dụng thông báo về nguy cơ bị đột nhập. Theo đó, phần mềm độc hại trên được thiết kế để thu thập thông tin như tên, số tài khoản, ngày hết hạn, mã xác thực của các thẻ tín dụng và ghi nợ chạy qua hệ thống.
Trước đó không lâu, hãng thức ăn nhanh Wendy’s và Cici’s Pizza cũng bị tin tặc ghé thăm. Wendy là chuỗi cửa hàng hamburger lớn thứ ba thế giới, sau
tHu HằNG
Cio
DoANh NghIệP Nhỏ và thách thức về bảo mật

48 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
McDonald’s. Công ty có hơn 6.000 cửa hàng và vụ tấn công đã ảnh hưởng tới hơn một nghìn cửa hàng của Wendy, gây rò rỉ dữ liệu thẻ thanh toán của các khách hàng.
Theo một cuộc khảo sát do Bộ Kinh doanh, đổi mới và kỹ năng của Anh thực hiện, gần ¾ số doanh nghiệp nhỏ Anh tham gia cho biết đã từng bị xâm phạm dữ liệu. Chi phí từ xâm phạm dữ liệu gây ra cho một công ty là từ 75.000 £ đến 300.000 £, chủ yếu là do gián đoạn kinh doanh, mất doanh thu, thu hồi tài sản, tiền phạt và bồi thường.
Với lượng thẻ tín dụng giao dịch vô cùng lớn, các hãng bán lẻ và nhiều doanh nghiệp nhỏ đã trở thành miếng mồi béo bở cho những tin tặc tìm cách đánh cắp thông tin khách hàng và bán lại cho những kẻ khác trên mạng Internet. Theo nghiên cứu do Kaspersky Lab và B2B International thực hiện, tổn thất về tài chính của doanh nghiệp vừa và nhỏ do các cuộc tấn công mạng gây ra tiếp tục tăng lên, đạt mức trung bình 38.000 USD vào năm 2015. Con số này bao gồm chi phí thuê chuyên gia xử lí hậu quả, mất cơ hội kinh doanh và tổn thất do trì hoãn công việc.
Các doanh nghiệp nhỏ thường có khả năng bảo mật yếu nhất
Những cuộc tấn công có chủ đích ngày càng nhắm nhiều hơn tới các doanh nghiệp nhỏ do họ có ít nguồn lực để tự bảo vệ mình hơn. Mặc dù các
doanh nghiệp nhỏ cho rằng bản thân họ không có lý do gì để trở thành mục tiêu của những cuộc tấn công có chủ đích, nhưng tội phạm mạng lại cho thấy ngày càng hào hứng hơn với thông tin tài khoản ngân hàng, dữ liệu khách hàng và tài sản sở hữu trí tuệ của những tổ chức này. Bởi những doanh nghiệp nhỏ thường thường thiếu các biện pháp và hạ tầng bảo mật phù hợp, do đó dễ dàng tạo kẽ hở cho tin tặc tấn công. Mặt khác, khi xảy ra xâm phạm, do thiếu giám sát, đánh giá, hệ thống cảnh báo cũng như bảo vệ an ninh nên hậu quả thường lớn và trầm trọng.
Thực tế cho thấy, doanh nghiệp nhỏ không có nghĩa là lợi ích tấn công của hacker nhỏ. Các lỗ hổng trong đảm bảo an toàn thông tin hệ thống CNTT của những công ty nhỏ có thể cung cấp nhiều dữ liệu hữu ích cho các đối tượng lớn hơn. Vì thế một loạt các vụ tấn công các doanh nghiệp nhỏ tạo điều kiện cho một tấn công lớn hơn, bằng việc khai thác dữ liệu của nhân viên: đăng nhập dịch vụ đám mây, dữ liệu khách hàng, thông tin tài khoản ngân hàng... Ví dụ kẻ tấn công sẽ chiếm quyền điều khiển 1 trang web, chẳng hạn như 1 trang blog hay trang web của doanh nghiệp nhỏ (thường xuyên được các đối tượng mục tiêu ghé thăm). Khi đối tượng mục tiêu truy nhập chiếm quyền điều khiển website, tiến trình tấn công sẽ được ngấm ngầm cài đặt và thực thi trên máy tính của họ. Mối đe dọa Elderwood Gang là dạng đầu tiên khởi xướng kiểu tấn công này và trong năm 2012, chúng đã lây nhiễm lên tới 500 tổ chức chỉ trong 1 ngày.
Các ứng dụng sử dụng để tấn công thường bao gồm sẵn kịch bản thăm dò chứa hàng ngàn địa chỉ IP trên web, tìm kiếm các cổng mở ở các máy tính người dùng cuối, cái đặt spyware (loại phần mềm chuyên thu thập các thông tin từ các máy chủ) hay Trojan horse (một phần mềm cài đặt trái phép vào máy tính của bạn với mục đích đánh cắp thông tin) trên website sử dụng những lỗ hổng trong công nghệ như Java và Flash, hoặc gửi đi hàng ngàn phishing mail với mục đích chỉ cần một vài người truy cập sẽ nhận được những phần mềm độc hại ẩn mình trong máy tính, nhằm chuẩn bị cho những cuộc tấn công sắp tới.
Sự tinh vi của các cuộc tấn công cùng với tính phức
Gia tăng các cuộc tấn công phishing nhằm vào các doanh nghiệp
Cio

49CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
tạp của CNTT ngày nay, như công nghệ ảo hóa, đám mây và di động, đòi hỏi các doanh nghiệp, đặc biệt là các doanh nghiệp nhỏ phải luôn chủ động và áp dụng các biện pháp bảo mật theo chiều sâu để bảo vệ mình an toàn trước các mối đe dọa này
Để không trở thành mục tiêu “béo bở” của tin tặc
Thông thường, việc xâm nhập thị trường và ổn định tài chính là ưu tiên hàng đầu đối với những người chủ doanh nghiệp nhỏ, do đó họ rất ít hoặc không chú ý đến vấn đề bảo mật thông tin. Do nhu cầu phát triển, các doanh nghiệp cần đẩy mạnh ứng dụng các công nghệ mới, dẫn tới doanh nghiệp dần gắn chặt hoạt động với trực tuyến, tới mức dường như không thể thiếu kết nối Internet và thẻ tín dụng. Điều đó cũng có nghĩa là tin tặc từ không gian mạng có nhiều cơ hội gây khó dễ cho doanh nghiệp.
Một trong những thách thức khó khăn nhất là biết khi nào tổ chức của bạn nằm trong tầm ngắm của những kẻ tấn công mạng. Nhiều doanh nghiệp luôn cho rằng tin tặc chỉ nhắm mục tiêu vào các tổ chức, doanh nghiệp lớn, mà nắm giữ các bí mật quốc gia, các dữ liệu quan trọng,… nên các hoạt động kinh doanh nhỏ không thể là mục tiêu tiềm năng. Thực tế cho thấy không phải lúc nào cũng như vậy, vụ tấn công công ty General Linen Services là một ví dụ điển hình. Đây là một doanh nghiệp nhỏ, chỉ với 35 nhân viên, chuyên cung cấp dịch vụ đồ vải lanh cho các nhà hàng và khách sạn, bao gồm đồng phục và giặt thảm. Tin tặc đã xâm nhập vào hệ thống của công ty này trong 2 năm, đánh cắp thông tin khách hàng bằng cách truy cập vào hoá đơn viết cho công ty mục tiêu, tạo cơ sở để thực hiện cuộc tấn công vào các doanh nghiệp lớn (khách hàng của General Linen Services).
Hiện nay, tội phạm mạng đang không ngừng đẩy mạnh các cuộc tấn công, cả về mức độ và phạm vi. Chúng liên tục sáng tạo ra những cách thức mới để đánh cắp thông tin quan trọng của các tổ chức ở mọi quy mô. Vì vậy, lãnh đạo doanh nghiệp nhỏ cần phải nâng cao nhận thức về tình hình bảo mật cũng như
tăng cường triển khai các biện pháp cần thiết nhằm đảm bảo an toàn cho hệ thống.
Doanh nghiệp nhỏ thì nguồn ngân sách dành cho CNTT thường nhỏ nên việc đầu tư một hệ thống bảo mật đồ sộ tương đương như của các nhà cung cấp dịch vụ Internet hay các doanh nghiệp lớn là điều không thể. Nhưng để bảo vệ dữ liệu và an toàn hệ thống thông tin, các doanh nghiệp nhỏ cần có những biện pháp phòng ngừa tối thiểu sau đây: Tường lửa, Tuân thủ hệ thống bảo mật của nhà sản xuất thiết bị và hệ điều hành trên máy; Cập nhật bản vá lỗi ngay khi có thể, tuy nhiên cần cảnh giác những thông báo giả mạo; Tạo mật khẩu truy cập đủ phức tạp và khó đoán; Không sử dụng những file, download phi pháp phần mềm (thường đã bị thay đổi), đường link trong những web site lạ,…
Do các hình thức bảo mật thông thường như phần mềm chống virus, tường lửa,… đang ngày càng dễ bị qua mặt bởi những hình thức tấn công tinh vi mới, việc triển khai một hệ thống phòng chống xâm nhập (IPS) và phát hiện xâm nhập (IDS) là rất cần thiết, nhằm cung cấp thêm một lớp bảo vệ chống lại các nguy cơ và phần mềm độc hại. Thêm vào đó, các doanh nghiệp nhỏ có thể xem xét triển khai các giải pháp bảo mật mang tính tổng thể dành cho doanh nghiệp nhỏ, hiệu quả hơn với chi phí thấp hơn mà nhiều hãng bảo mật đưa ra hiện nay.
Tất cả những tài nguyên, thiết bị như website, máy tính để bàn, laptop, smartphone và tất cả các dịch vụ trực tuyến được sử dụng để quản lý các hoạt động của kinh doanh đều là những nơi tiềm năng cho một cuộc tấn công. Do đó, các doanh nghiệp nhỏ phải luôn chú ý áp dụng các biện pháp gia tăng phòng thủ tại những điểm yếu mà tin tặc có thể khai thác tấn công, nhằm đảm bảo an toàn cho hoạt động kinh doanh của mình.
Tài liệu tham khảo:1. Symantec, Internet Security Threat Report, Volume 21, April
2016
2. http://www.computerweekly.com
3. http://searchsecurity.techtarget.com

50 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
I. GIỚI THIỆU CHUNG Trên thế giới, để quản lý thông tin của mình, hầu
hết các tổ chức, doanh nghiệp đều lưu trữ dữ liệu dưới dạng cơ sở dữ liệu (CSDL). Điều này giúp người chủ sở hữu dữ liệu (Data Owner - DO) dễ dàng truy xuất thông tin và có thể chia sẻ cho nhiều người dùng. Có hai hình thức lưu trữ CSDL là lưu trữ trong nội bộ tổ chức (in house database) và lưu trữ trực tuyến.
Với hình thức lưu trữ nội bộ, DO quản lý cơ sở dữ liệu trên máy chủ của mình, không chia sẻ qua mạng Internet. Như vậy, DO phải có hệ thống máy chủ gồm: máy tính, hệ điều hành, hệ quản trị CSDL và nhân viên vận hành hệ thống.
Khi nhu cầu lưu trữ và xử lý dữ liệu tăng đòi hỏi DO phải tốn chi phí cho nâng cấp phần cứng, cập nhập bản quyền phần mềm, phát triển đội ngũ nhân viên,...
Với hình thức lưu trữ trực tuyến, DO đặt máy chủ
của mình ở môi trường mạng và quản lý nó. Như vậy, ngoài chi phí như lưu trữ nội bộ, DO tốn thêm chi phí thuê máy chủ, đồng thời bảo vệ máy chủ khỏi các nguy cơ tấn công trên Internet.
Ngày nay, khi điện toán đám mây phát triển mạnh mẽ thì các tổ chức, doanh nghiệp có thêm một phương án tiếp cận mới trong việc quản lý, khai thác CSDL, đó là dịch vụ thuê ngoài CSDL (Outsourced Database Service – ODBS) [1].
Hình 1. Mô hình thuê ngoài CSDL [1]
TĂNG TỐC TRUY VẤN CƠ SỞ DỮ LIỆU MÃ TRÊN CÁC DỊCH VỤ THUÊ NGOÀI
Hồ KIm GIàu*NGuyễN HIếu mINH**
Sự phát triển nhanh chóng của điện toán đám mây đã dẫn đến xuất hiện dịch vụ thuê ngoài cơ Sở dữ liệu và đó là giải pháp thiết yếu để giảm chi phí cho chủ Sở hữu dữ liệu. để đảm bảo dữ liệu được an toàn, chủ Sở hữu dữ liệu thường mã hóa dữ liệu trước khi lưu trữ lên đám mây. tuy nhiên, việc mã hóa trước khi lưu trữ Sẽ tăng thời gian xử lý mã/giải mã khi truy vấn cơ Sở dữ liệu. vì vậy, vấn đề tăng tốc độ truy vấn trên dữ liệu đã mã hóa là rất cần thiết. trong bài báo này, chúng tôi đề xuất một giải pháp để nâng cao tốc độ truy vấn trên dữ liệu mã Sử dụng tính toán Song Song. các kết quả thực nghiệm chứng minh hiệu quả của giải pháp đề xuất.
* Học viện Kỹ thuật Quân sự ** Học viện Kỹ thuật Mật mã
An toàn bảo mật

51CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Với dịch vụ này, các tổ chức và doanh nghiệp sẽ được một nhà cung cấp dịch vụ (Database Service Provider – DSP) quản lý và duy trì hoạt động CSDL của mình. DO khai thác cơ sở dữ liệu thông qua các phương thức do DSP cung cấp. Theo phương án này, DO sẽ giảm được chi phí trong việc đầu tư tài nguyên và nhân công để quản lý, duy trì CSDL.
Trong nhiều trường hợp, CSDL chứa nhiều dữ liệu nhạy cảm, DO không muốn những người không cấp phép được truy cập. Tuy nhiên, luôn luôn có những cuộc tấn công, cố gắng lấy hoặc phá hoại CSDL bất hợp pháp. Vì vậy, DO cần phải có chiến lược bảo vệ CSDL của mình. Theo số liệu của Sách Trắng về Công nghệ thông tin và Truyền thông (CNTT-TT) Việt Nam 2014, cả nước có trên 100.000 dịch vụ công trực tuyến [2]. Hầu hết các đơn vị này đều đang lưu trữ với khối lượng CSDL rất lớn và có rất nhiều dữ liệu quan trọng (thông tin ngân hàng, bí mật quân sự, an ninh quốc phòng,...). Theo các đánh giá, phần lớn CSDL tại các đơn vị này đều được quản lý theo mô hình CSDL truyền thống (in-house database) và mặc dù các đơn vị đều quan tâm đến vấn đề bảo đảm an toàn cho CSDL như dùng firewall, chống mã độc, phân quyền truy cập,... nhưng trong thực tế, khi dữ liệu bị rò rỉ thì nguy cơ lộ lọt thông tin là không thể tránh khỏi (do thông tin là bản rõ). Để đảm bảo được tính bí mật của dữ liệu, các nhà nghiên cứu đưa ra giải pháp mã hoá dữ liệu trước khi đưa lên
môi trường thuê ngoài. Tuy nhiên, chính việc mã hóa này làm tăng tính phức tạp trong truy vấn dữ liệu, ảnh hưởng rất nhiều đến hiệu năng của CSDL. Việc lựa chọn cơ chế mã hóa đảm bảo tính bí mật và hiệu năng tính toán là cần thiết.
Để tăng tốc truy vấn trên dữ liệu mã, chúng tôi đề xuất giải pháp tính toán song song. Q.Zhang và cộng sự đề xuất công cụ Qscheduler [3] để truy vấn song song trên hệ thống CSDL. Tuy nhiên, giải pháp này thực hiện trên CSDL rõ và thực hiện song song các câu truy vấn cùng lúc truy xuất đến CSDL. Ying-Fu Huang cũng đưa ra phương pháp truy vấn song song trên dữ liệu rõ [4] và thực hiện các phép giao, nối, sắp xếp, nhóm,… của các bảng dữ liệu. Samraddhi Shastri đưa ra giải pháp tăng tốc trên dữ liệu mã [5], tuy nhiên, phương pháp này thực hiện truy vấn song song tìm kiếm nhị phân trên dữ liệu mã.
Trong phạm vi bài báo này, nhóm tác giả trình bày phương pháp tính toán song song trên dữ liệu mã khi truy vấn. Do kết quả truy vấn là bản mã nên để dữ liệu trả về là bản rõ thì máy chủ DO phải giải mã từng bản ghi CSDL. Nếu số lượng bản ghi lớn thì thời gian trả về kết quả truy vấn khá lâu. Giải pháp được đề xuất đã giảm đáng kể thời gian thực thi để giải mã các bản ghi khi truy vấn cơ sở dữ liệu có số lượng bản ghi lớn.

52 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
II. MỘT SỐ CÔNG TRÌNH LIÊN QUAN Rất nhiều nhà nghiên cứu đã công bố các công
trình về phương pháp truy vấn dữ liệu mã, trong đó có thể chia ra làm ba hướng chính: 1). Dùng siêu dữ liệu (metadata) hoặc cấu trúc cây (XML) lưu trữ các thông tin phụ trợ để hỗ trợ truy vấn trên dữ liệu mã [6, 7]; 2). Dùng máy chủ trung gian để chuyển đổi câu truy vấn [8, 9]; 3). Truy vấn trực tiếp trên dữ liệu mã (phương pháp này chỉ hỗ trợ một số dạng truy vấn) [10-13].
Hacigumus và cộng sự của mình đã đề xuất một giải pháp thực hiện truy vấn trên CSDL đã được mã hoá [6]. Ý tưởng của giải pháp này là dùng chương trình biến đổi truy vấn (Query Translator) để chuyển đổi câu truy vấn dạng rõ của người dùng sang truy vấn dạng mã. Các dữ liệu được mã hóa trước khi lưu trữ ở máy chủ của SP. Ngoài ra, dữ liệu có thêm thông tin phụ trợ (metadata), là các chỉ mục cho phép thực hiện truy vấn CSDL tại máy chủ của SP mà không cần phải giải mã. DO dùng metadata để chuyển đổi các truy vấn của Client thành các truy vấn thích hợp để thực thi trên máy chủ, và Client sẽ nhận được kết quả sau khi thực hiện truy vấn được trả về từ máy chủ của SP. Dựa trên các thông tin phụ trợ đã được lưu trữ, truy vấn sẽ được chia thành hai phần: (1) Các truy vấn ở phía máy chủ (Server Site) về
các dữ liệu đã được mã hóa, truy vấn này được thực hiện tại máy chủ của SP, (2) Các truy vấn phía người dùng (Client Site), truy vấn này được thực hiện trên máy của Client, thông qua máy của DO và kết quả truy vấn sau khi được lọc sẽ trả về từ DO cho Client. Tuy nhiên, phương pháp này có những nhược điểm là tăng chi phí lưu trữ, và chi phí để tính toán lại sau hoạt động cập nhật cơ sở dữ liệu. Các truy vấn gộp (SUM, COUNT, AVERAGE…) không thực hiện được.
R. Brinkman đưa ra một phương pháp tìm kiếm trên dữ liệu mã bằng cách so các thẻ dữ liệu trong XML đã được mã hoá với dữ liệu trên dịch vụ thuê ngoài [7]. Với phương pháp này, dữ liệu được chia thành nhiều khối và mã hoá các khối này trước khi đưa lên server. DO lưu trữ các thông tin về mã hoá để thực hiện giải mã ở quá trình truy vấn kết quả. Khi tìm kiếm, chuỗi dữ liệu cần tìm sẽ được mã hóa và chuyển đến cho server để so sánh với các thẻ và xác định ra vị trí của đoạn dữ liệu mã hóa đó. Giai đoạn nhận dữ liệu, kết quả mã hóa sẽ được giải mã dựa theo các thông tin mã hóa được ghi nhận tại giai đoạn lưu trữ. Phương pháp này chỉ đáp ứng các câu truy vấn tìm kiếm so trùng các thẻ dữ liệu trong XML mà không xử lý đến nội dung dữ liệu bên trong thẻ đó.
A. Popa và cộng sự trình bày một mô hình mã hoá và cách thức thực thi truy vấn trên CSDL mã bằng cách sử dụng một máy chủ làm trung gian gọi là CryptDB proxy [8]. CryptDB proxy lưu trữ khoá bí mật, lược đồ CSDL, và các lớp mã hoá hiện tại của mỗi cột. Máy chủ CSDL lưu trữ một lược đồ ẩn danh (tên bảng và tên cột được thay thế bằng định danh), dữ liệu người dùng được mã hóa, và một số bảng phụ trợ được sử dụng bởi CryptDB. CryptDB cũng cung cấp cho các máy chủ với một số chức năng người dùng định nghĩa (UDF) cho phép các máy chủ tính toán trên dữ liệu mã với một số phép toán nhất định.
Điểm mạnh của CryptDB là cho phép các máy chủ tính toán trên dữ liệu mã hóa mà không cần giải mã và cho kết quả cũng là giá trị mã hóa. CryptDB là hệ thống trung gian có thể cung cấp bảo mật hiệu suất cao cho các ứng dụng trực tuyến trên DBMS.
An toàn bảo mật

53CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Nó có thể thực hiện một số lượng lớn các truy vấn SQL trên các dữ liệu được mã hóa mà không đòi hỏi bất kỳ thay đổi bên trong của máy chủ DBMS và kết quả được giải mã bởi các user đáng tin cậy. Nó có thể làm việc với hầu hết các hệ thống cơ sở dữ liệu SQL với chi phí rất ít. Để đạt được điều này, CryptDB tự động thay đổi kiểu mã hóa dựa trên khối lượng công việc truy vấn để lựa chọn nhanh chóng và đảm bảo đủ các thao tác trên dữ liệu.
CryptDB cơ bản giải quyết được vấn đề hỗ trợ tất cả các loại truy vấn SQL trên CSDL mã hoá và đảm bảo tính riêng tư của dữ liệu. Đồng thời, CryptDB có thời gian thực hiện với chi phí thấp. Tuy nhiên, CryptDB cần một proxy hoàn toàn tin cậy, nhưng đây là nơi mà kẻ tấn công lợi dụng. Nếu kẻ tấn công xâm nhập được CryptDB, chúng có thể giải mã các bản ghi CSDL, lấy được toàn bộ thông tin dữ liệu. Như vậy, vấn đề bảo mật proxy cần được xem xét. Mặt khác, CryptDB chưa hỗ trợ hết tất cả các câu truy vấn dữ liệu.
III. TÍNH TOÁN SONG SONG KHI TRUY VẤN CSDL MÃ
A. Mô hình lưu trữ cơ sở dữ liệu mã
Chủ CSDL sẽ mã hoá CSDL trước khi lưu trữ ở CSDL thuê ngoài (Outsourced Database). Để biết được cấu trúc của CSDL khi tính toán, tại máy chủ của DO sẽ lưu trữ các chỉ mục dữ liệu trong một tập tin XML để tham chiếu đến cấu trúc bảng dữ liệu được mã hóa.
Hình 2. Mô hình lưu trữ CSDL mã
Như vậy, thay vì tên bảng, tên trường là bản rõ thì DO dùng hàm băm để mã giá trị đó thành bản mã. Trong trường hợp này, người tấn công và ngay cả SP
cũng không nắm được cấu trúc CSDL của DO.
XML là tài liệu được tổ chức từ các thẻ, dựa vào các thẻ này, chúng ta có thể tạo ra một cấu trúc dữ liệu, có thể truy xuất trực tiếp hoặc xây dựng thành cây tìm kiếm. XML được hỗ trợ trên hầu hết các ngôn ngữ lập trình hiện nay với các bộ parser như SAX, DOM hoặc STAX. Cấu trúc của XML là dạng text nên tập tin XML có dung lượng nhỏ, thời gian truy cập nhanh. Mỗi lần truy vấn CSDL, thay vì dùng hàm băm để tính toán tên trường, tên bảng để truy vấn thì máy chủ DO chỉ cần tham chiếu tên trường trong tập tin XML, do đó rút ngắn thời gian rất nhiều nếu thực thi hàm băm mật mã.
Ví dụ: Cho CSDL có bảng Nhanvien(Manv, Hoten, Ngaysinh, Gioitinh, Diachi) thì tập tin XML biểu diễn như Hình 3:
Hình 3. Cấu trúc tập tin XML
Khi đó, bảng Nhanvien sẽ có cấu trúc theo ánh xạ 1-1:
Như vậy, khi lưu trữ CSDL trên server, thay vì lưu trữ tên bảng là Nhanvien thì DO lưu trữ tên bảng là:
941694f7e6cab8b4446ad3aa6c9cf205.
B. Truy vấn cơ sở dữ liệu mã
Khi muốn thao tác trên dữ liệu, người dùng gửi yêu cầu lên máy chủ và được trả về dữ liệu rõ. Một cách tiếp cận khi truy vấn CSDL mã hóa là tải toàn bộ CSDL về máy chủ DO, sau đó giải mã từng bản ghi rồi thực

54 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
hiện truy vấn. Tuy nhiên phương pháp này tốn nhiều tài nguyên và thời gian tính toán. Một cách tiếp cận khác là truy vấn các dữ liệu có liên quan, sau đó giải mã các bản ghi và thực hiện các tính toán trên bản ghi đó. Trong quá trình truy vấn trên dữ liệu mã phải được tham chiếu qua bảng XML để đảm bảo các bản ghi trả về là đúng đắn.
Các loại truy vấn như SELECT, INSERT, UPDATE, DELETE đều có thể thực hiện trực tiếp trên dữ liệu mã, trong khi các câu truy vấn gộp (truy vấn lồng nhau) thì cần thực hiện các phép biến đổi, viết lại câu truy vấn. Trong phạm vi bài báo này, nhóm tác giả thực hiện các truy vấn INSERT, UPDATE, DELETE; truy vấn SELECT với các phép toán như SUM, AVERAGE, MAX, MIN…
Ví dụ: người dùng muốn cập nhập lại địa chỉ mới của nhân viên có mã là ‘01’.
Câu truy vấn rõ sẽ là: UPDATE Nhanvien SET Diachi = <địa chỉ mới> WHERE Manv= ‘01’.
Câu truy vấn trên dữ liệu mã là: UPDATE t SET f5 = Enc(<địa chỉ mới>, key) WHERE f1= Enc(‘01’, key). Trong đó t là dữ liệu truy xuất trong file XML tương ứng với thẻ Nhanvien, f1 tương ứng thẻ Manv, f5 tương ứng thẻ địa chỉ, Enc(data, key) là một hàm mã hoá với khoá key được xác định trước.
Hình 4. Mô hình truy vấn dữ liệu
C. Tính toán song song
Tính toán song song là một quá trình tính toán trong đó nhiều phép tính được thực hiện đồng thời, hoạt động trên nguyên tắc là những vấn đề lớn đều có thể chia thành nhiều phần nhỏ hơn, sau đó được giải quyết tương tranh. Có nhiều hình thức khác nhau của tính toán song song: song song cấp bit, song song cấp lệnh, song song dữ liệu và song song tác vụ. Tính toán song song được sử dụng chủ yếu
trong lĩnh vực tính toán hiệu năng cao. Những năm gần đây, hình thức tính toán này được quan tâm nhiều hơn, do những hạn chế vật lý ngăn chặn việc tăng hiệu năng tính toán chỉ bằng cách tăng tần số. Vì việc tiêu hao điện năng (dẫn đến sinh nhiệt) từ máy tính đã trở thành một mối lo ngại, tính toán song song đã trở thành mô hình thống trị trong lĩnh vực kiến trúc máy tính, phần lớn là dưới dạng bộ xử lý đa nhân.
Hình 5. Tính toán tuần tự
Hình 6. Tính toán song song
Các máy tính song song có thể được phân loại tùy theo cấp độ hỗ trợ song song của phần cứng, với những chiếc máy tính đa nhân và đa xử lý có bộ phận đa xử lý trong một máy đơn lẻ, trong khi cụm máy tính, xử lý song song hàng loạt, và điện toán lưới sử dụng nhiều máy tính để xử lý cùng một công việc. Những kiến trúc máy tính song song chuyên dụng thỉnh thoảng cũng sử dụng các bộ xử lý truyền thống, nhằm tăng tốc độ cho những công việc đặc trưng.
D. Đề xuất thuật toán tính toán song song khi truy vấn cơ sở dữ liệu mã
Hình 7. Mô hình tính toán song song
An toàn bảo mật
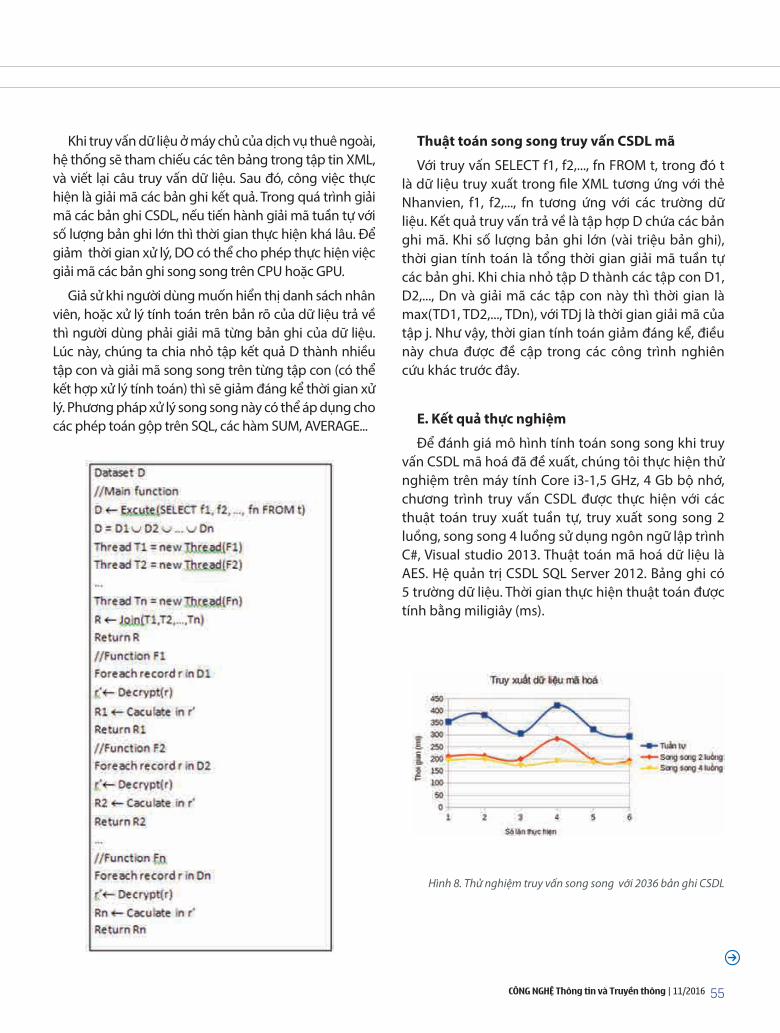
55CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Khi truy vấn dữ liệu ở máy chủ của dịch vụ thuê ngoài, hệ thống sẽ tham chiếu các tên bảng trong tập tin XML, và viết lại câu truy vấn dữ liệu. Sau đó, công việc thực hiện là giải mã các bản ghi kết quả. Trong quá trình giải mã các bản ghi CSDL, nếu tiến hành giải mã tuần tự với số lượng bản ghi lớn thì thời gian thực hiện khá lâu. Để giảm thời gian xử lý, DO có thể cho phép thực hiện việc giải mã các bản ghi song song trên CPU hoặc GPU.
Giả sử khi người dùng muốn hiển thị danh sách nhân viên, hoặc xử lý tính toán trên bản rõ của dữ liệu trả về thì người dùng phải giải mã từng bản ghi của dữ liệu. Lúc này, chúng ta chia nhỏ tập kết quả D thành nhiều tập con và giải mã song song trên từng tập con (có thể kết hợp xử lý tính toán) thì sẽ giảm đáng kể thời gian xử lý. Phương pháp xử lý song song này có thể áp dụng cho các phép toán gộp trên SQL, các hàm SUM, AVERAGE...
Thuật toán song song truy vấn CSDL mã
Với truy vấn SELECT f1, f2,..., fn FROM t, trong đó t là dữ liệu truy xuất trong file XML tương ứng với thẻ Nhanvien, f1, f2,..., fn tương ứng với các trường dữ liệu. Kết quả truy vấn trả về là tập hợp D chứa các bản ghi mã. Khi số lượng bản ghi lớn (vài triệu bản ghi), thời gian tính toán là tổng thời gian giải mã tuần tự các bản ghi. Khi chia nhỏ tập D thành các tập con D1, D2,..., Dn và giải mã các tập con này thì thời gian là max(TD1, TD2,..., TDn), với TDj là thời gian giải mã của tập j. Như vậy, thời gian tính toán giảm đáng kể, điều này chưa được đề cập trong các công trình nghiên cứu khác trước đây.
E. Kết quả thực nghiệm
Để đánh giá mô hình tính toán song song khi truy vấn CSDL mã hoá đã đề xuất, chúng tôi thực hiện thử nghiệm trên máy tính Core i3-1,5 GHz, 4 Gb bộ nhớ, chương trình truy vấn CSDL được thực hiện với các thuật toán truy xuất tuần tự, truy xuất song song 2 luồng, song song 4 luồng sử dụng ngôn ngữ lập trình C#, Visual studio 2013. Thuật toán mã hoá dữ liệu là AES. Hệ quản trị CSDL SQL Server 2012. Bảng ghi có 5 trường dữ liệu. Thời gian thực hiện thuật toán được tính bằng miligiây (ms).
Hình 8. Thử nghiệm truy vấn song song với 2036 bản ghi CSDL

56 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Hình 9. Thử nghiệm truy vấn song song với 5045 bản ghi CSDL
Hình 10. Thử nghiệm truy vấn song song với 11.000 bản ghi CSDL
Các kết quả thực nghiệm (Hình 8, 9, 10) cho thấy, khi số lượng bản ghi của CSDL ít, thì thời gian tính toán tuần tự và song song chênh lệch nhau không nhiều. Tính toán song song thực sự có ý nghĩa khi số lượng bản ghi lớn. Việc phân chia số lượng phép toán song song cũng cần tính toán, mặc dù chia nhiều luồng song song mang lại kết quả tốt hơn, nhưng trong một số trường hợp, khi các phép toán ở một số luồng thực hiện xong thì sẽ có độ trễ, lúc đó sẽ không có sự khác biệt về thời gian, thậm chí sẽ chậm hơn khi xử lý ít luồng.
IV. KẾT LUẬNViệc đảm bảo tính bảo mật của dữ liệu thường
được giải quyết bằng cách mã hoá dữ liệu trước khi lưu trữ trên máy chủ. Bài toán đặt ra là giải quyết tốc độ xử lý khi truy vấn dữ liệu đó. Trong bài báo này, chúng tôi đề xuất giải pháp tính toán song song trên dữ liệu mã. Tuy nhiên, để cải thiện được tốc độ khi truy vấn còn cần nhiều giải pháp hỗ trợ, trong
đó, thuật toán mã hoá cũng là một yếu tố làm chậm quá trình tính toán trên dữ liệu mã. Do đó, cần phải lựa chọn các phương pháp mã hoá làm sao để tối ưu nhất về tốc độ xử lý. Xu hướng dùng thuật toán mã hoá đối xứng thì xử lý mã hoá – giải mã nhanh nhưng không tính toán được trên dữ liệu mã. Như vậy tốn nhiều chi phí nếu người dùng muốn tính toán. Máy chủ bắt buộc phải giải mã để được bản rõ, tính toán trên bản rõ, rồi mã hoá lại kết quả gửi về cho người dùng. Nếu dùng thuật toán mã hoá đồng cấu (homomorphic) thì hỗ trợ tính toán trên dữ liệu mã nhưng bù lại tốn chi phí trong việc mã hoá và giải mã. Xu hướng dùng hỗn hợp các thuật toán mã hoá, phân chia trường hợp truy vấn tương ứng với dữ liệu mã phù hợp là một xu hướng hiện tại.
Tài liệu tham khảo:[1] http://sprout.ics.uci.edu/past_projects/odb/.
[2] Sách Trắng về Công nghệ thông tin và Truyền thông: Bộ Thông tin và Truyền thông, 2014.
[3] Q. zHANG, S. LI, and J. XU, “QScheduler: A Tool for Parallel Query Processing in Database Systems,” in Engineering of Complex Computer Systems (ICECCS), 2014 19th International Conference on, 2014, pp. 73-76.
[4] Y.-F. HUANG and W.-C. CHEN, “Parallel Query on the In-Memory Database in a CUDA Platform,” in 2015 10th International Conference on P2P, Parallel, Grid, Cloud and Internet Computing (3PGCIC), 2015, pp. 236-243.
[5] S. SHASTRI, R. KRESMAN, and J. K. LEE, “An Improved Algorithm for Querying Encrypted Data in the Cloud,” in Communication Systems and Network Technologies (CSNT), 2015 Fifth International Conference on, 2015, pp. 653-656.
[6] H. HACIGüMüş, B. IYER, C. LI, and S. MEHROTRA, “Executing SQL over encrypted data in the database-service-provider model,” in Proceedings of the 2002 ACM SIGMOD international conference on Management of data, 2002, pp. 216-227.
[7] R. Brinkman, L. Feng, J. Doumen, P. H. Hartel, and W. JONKER, “Efficient tree search in encrypted data,” Information System Security Journal, vol. vol.13, pp. 14-21, 2004.
[8] R. A. POPA, C. REDFIELD, N. zELDOVICH, and H. BALAKRISHNAN, “CryptDB: Processing queries on an encrypted database,” Communications of the ACM, vol. 55, pp. 103-111, 2012.
[9] B. H. CHEN, P. CHEUNG, P. Y. CHEUNG, and Y.-K. KWOK, “CypherDB: A Novel Architecture for Outsourcing Secure Database Processing,” p. 1, 2015.
[10] z.-F. WANG and A.-G. TANG, “Implementation of encrypted data for outsourced database,” in Computational Intelligence and Natural Computing Proceedings (CINC), 2010 Second International Conference on, 2010, pp. 150-153.
An toàn bảo mật

57CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Các mạng botnet giữ vai trò then chốt trong một số đe dọa vào mạng máy tính như tấn công từ chối dịch vụ DDoS, tấn công bằng thư rác,... Nhiều dạng botnet sử dụng cơ chế điều khiển tập trung và
che dấu các máy chủ C&C trong một danh sách ngẫu nhiên được sinh bằng thuật toán tạo tên miền (DGA). Việc phát hiện và theo dõi các DGA botnet trở nên cấp thiết do tính đơn giản của mô hình, khả năng che giấu của các máy chủ C&C.
Bài báo giới thiệu phương pháp phát hiện DGA botnet dựa vào phân tích lưu lượng DNS. Phương pháp sử dụng các đặc trưng ngữ nghĩa của tên miền, kết hợp với độ đo entropy để đánh giá khả năng xuất hiện của tên miền. Quá trình phân loại tên miền được thực hiện qua các bước: lọc các tên miền, phân tích các đặc trưng ngữ nghĩa và phân cụm dựa trên biến thể của khoảng cách Mahalanobis. Quá trình này là cải tiến của phương pháp Phoenix [6], trong đó sử dụng biến thể thuật toán K-means để cải thiện hiệu năng của bước huấn luyện hệ thống. Hệ thống phát hiện DGA botnet đã được triển khai và thử nghiệm trên bộ dữ liệu thu thập từ trang Alexa và các tên miền giả mạo.
1. GIỚI THIỆUBotnet là mạng các máy tính, thiết bị tính toán bị
lây nhiễm (bot) và bị điều khiển bằng các máy chủ C&C qua những kênh liên lạc đặc thù. Những kiến trúc mạng botnet chủ yếu bao gồm: kiến trúc tập trung, kiến trúc mạng ngang hàng và kiến trúc lai.
Hình 1. Kiến trúc tập trung và mạng ngang hàng P2P.
Kiến trúc tập trung
Kiến trúc tập trung bao gồm một trạm điều khiển trung tâm, hệ thống các máy chủ điều khiển C&C và nhóm các máy trạm chịu điều khiển của máy chủ C&C. Trạm này sẽ gửi các thông điệp điều khiển tới toàn mạng. Mô hình này dễ thực thi và tùy chỉnh. Tuy nhiên, mô hình này rất dễ bị phát hiện bởi các IDS. Một số botnet sử dụng mô hình này là AgoBot [15], SDBot [16], and Zotob.
Kiến trúc ngang hàng P2P
Để khắc phục những hạn chế của mô hình trung tâm, các botnet chuyển sang mô hình P2P. So với mô hình trung tâm, mô hình ngang hàng P2P khó bị phát hiện và phá hủy, và có thể gửi thông tin từ bất kì điểm nào trong mạng đến các điểm khác. Tuy nhiên việc thiết kế các mô hình này khá phức tạp. Một số botnet sử dụng mô hình này là: Phatbot [17] và Peacomm [18].
tốNG VăN VạN, NGuyễN LINH GIANG,
trầN QuANG Đức
Phân loại tên miền sử dụng các đặc trưng ngữ nghĩa trong hệ thống phát hiện DGA Botnet

58 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Mô hình lai
Trong mô hình lai, bot không trực tiếp liên hệ tới botmaster mà chỉ lắng nghe và chờ các kết nối và các lệnh từ botmaster. Botmaster sẽ quét ngẫu nhiên trên mạng Internet và sau đó gửi thông điệp khi đã phát hiện được bot.
DGA (Domain Generation Algorithm) Botnet
Hiện nay, phần lớn các botnet vẫn đang sử dụng kiến trúc tập trung do dễ xây dựng và phát triển. Các DGA botnet được thiết kế để khắc phục những nhược điểm của kiến trúc tập trung. Với các botnet trước đây, bot sẽ kết nối định kì đến máy chủ C&C và chờ lệnh. Do đó, nếu máy chủ C&C bị phát hiện thì mạng botnet sẽ bị phá hủy.
Trong các DGA botnet, tên miền của máy chủ C&C sẽ được sinh ngẫu nhiên. Khi bot muốn kết nối đến máy chủ C&C, chúng sẽ chạy thuật toán và sinh ra tập tên miền, sau đó bot sẽ kết nối lần lượt với từng tên miền trong tập này. Tại từng thời điểm botmaster biết tập tên miền do bot tạo ra để đăng kí địa chỉ cho máy chủ C&C. Những tên miền của các máy chủ C&C trong tập hợp tên miền do botmaster sinh ra phần lớn không được đăng ký và tương ứng với địa chỉ IP, và là những tên miền không tồn tại NXDomain (Non-eXistent Domain).
Ưu điểm của DGA Botnet là nếu địa chỉ của máy chủ C&C bị phát hiện và chặn tất cả kết nối đến những địa chỉ này, mạng botnet vẫn không bị loại bỏ hoàn toàn. Vấn đề là ở chỗ tại mỗi thời điểm, tập tên miền được sinh ra sẽ khác nhau. Do đó, tại những lần kết nối sau đó, tập tên miền sau sẽ khác so với lúc trước. Botmaster chỉ cần đăng kí một địa chỉ mới và bot vẫn sẽ hoạt động như bình thường.
Hiện nay có rất nhiều công trình nghiên cứu về botnet đã được công bố. Cơ chế phát hiện botnet do Etienne [1] đề xuất sử dụng hành vi của botnet thông qua những đặc trưng lưu lượng DNS. Cơ chế này cho phép không cần duy trì danh sách đen hay cập nhật các dấu hiệu của bot. Phương pháp sử dụng các đặc trưng của lưu lượng DNS như bản ghi Name Server, địa chỉ IP, thời gian tồn tại của tên miền và các chữ cái xuất hiện trong tên miền. Quá trình phân loại được thực hiện bằng thuật toán Naive Bayes. Hiệu quả của
cách tiếp cận này không cao do việc sử dụng các đặc trưng và thuật toán nêu trên không đủ để phát hiện chính xác.
Yadav và Reddy [2] đề xuất phương pháp phát hiện botnet dựa vào phân bố xác xuất của các kí tự trong lưu lượng DNS, và ánh xạ chúng với tập địa chỉ IP. Phương pháp này sử dụng khoảng cách K-L (Kullback-Leibler), khoảng cách biến đổi và chỉ số Jaccard để phát hiện NXDomain.
Nhauo Davuth and Sung-Ryul Kim [3] đưa ra phương pháp phân loại tên miền dựa vào SVM và phân phối bi-gram của tập dữ liệu. Các đặc trưng bi-gram của tên miền được sử dụng và trích rút và được lọc theo ngưỡng. Sau đó, bộ phân loại SVM Light [4] được sử dụng để phân lớp các tên miền bình thường và NXDomain. Phương pháp này có hiệu quả khá cao tuy vậy chỉ cho phép phân biệt các dạng botnet đã biết, khi có những dạng botnet chưa biết (chưa được huấn luyện) thì hiệu quả phân loại giảm xuống.
Zhou, Li, Miao, and Yim [5] đề xuất cơ chế phát hiện DGA Botnet dựa vào phân tích lưu lượng DNS do các NXDomain sinh ra. Phương pháp sử dụng những đặc trưng: khoảng thời gian hoạt động, thời gian tồn tại của mỗi tên miền. Những đặc trưng này được xác định dựa trên phân tích lưu lượng DNS. Hệ thống đề xuất kết hợp với địa chỉ IP với các đặc trưng nêu trên phân cụm những tên miền này. Danh sách các DGA Botnet được xác định dựa trên tính toán độ tương tự của mỗi nhóm tên miền.
Schiavoni, Schiavoni, Maggi, Zanero [6] đã đề xuất cơ chế Phoenix dựa vào thông tin ngữ nghĩa của tên miền và các đặc trưng dựa vào địa chỉ IP để phát hiện các tên miền được sinh bởi DGA. Ban đầu Phoenix lọc bớt những NXDomain dựa vào danh sách các tên miền đen (Blacklist). Sau đó hệ thống phân loại các tên miền thành hai tập: tên miền bình thường và tên miền không tồn tại NXDomain. Trong quá trình này, hệ thống sử dụng hàm khoảng cách Mahalanobis để đánh giá độ tương hợp và dùng địa chỉ IP để phân cụm các NXDomain. Những NXDomain trong một cụm có khả năng lớn sẽ do cùng một thuật toán DGA tạo sinh. Sau quá trình phân cụm, chúng ta có các cụm tên miền tương ứng với những thuật toán DGA
An toàn bảo mật

59CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
khác nhau sinh ra. Đặc trưng của mỗi cụm NXDomain sẽ được xác định để phục vụ quá trình phân loại và phát hiện những tên miền chưa biết.
Chúng tôi cải tiến một số giai đoạn của Phoenix để nâng cao hiệu năng của hệ thống, trong đó tập trung vào độ chính xác của quá trình phát hiện tên miền, giảm thời gian tính toán các đặc trưng, khoảng cách trong quá trình huấn luyện và phát hiện. Những cải tiến đó bao gồm:
- Sử dụng nhiều đặc trưng ngữ nghĩa hơn so với Phoenix, bao gồm trọng số bi-gram, tần suất của bi-gram, entropy và mức độ ý nghĩa của tên miền.
- Khảo sát dữ liệu tên miền và sử dụng hàm khoảng cách Mahalanobis giản lược để giảm thời gian tính toán trong thực tế.
- Sử dụng thuật toán K-means thay vì sử dụng DBSCAN như trong Phoenix và thực hiện một số cải tiến nhỏ để đạt hiệu quả phân cụm tốt hơn.
2. PHÂN LOẠI TÊN MIỀN TRONG PHÁT HIỆN DGA BOTNET
Hệ thống phát hiện DGA botnet tập trung vào phân tích lưu lượng DNS, để từ đó phát hiện những tên miền thuộc tập tên miền do một thuật toán DGA đặc trưng của một botnet tạo sinh ra. Kết quả của quá trình phân tích cho phép cảnh báo những tấn công sử dụng dạng botnet do hệ thống phát hiện được. Hệ thống phát hiện DGA botnet sẽ bao gồm hai thành phần chính: khối huấn luyện và khối phát hiện botnet.
- Khối huấn luyện thực hiện phân tích các dữ liệu liên quan tới tên miền của những dạng botnet đã biết, xác định các dạng tên miền liên quan tới từng botnet xác định, do những thuật toán DGA khác nhau tạo sinh.
- Khối phát hiện sẽ phân tích lưu lượng DNS, xác định những tên miền thu nhận được thuộc nhóm tên miền bình thường hay tên miền thuộc một dạng botnet nào đó.
Bài báo này tập trung vào quá trình huấn luyện với mục tiêu cơ bản là phát hiện các đặc trưng của
tên miền do một thuật toán DGA tạo sinh. Kết quả của quá trình huấn luyện là các phân lớp tên miền NXDomain đại diện cho các thuật toán DGA.
Hình 2. Các pha huấn luyện hệ thống.
Hệ thống huấn luyện phân loại tên miền (Hình 2) gồm có các thành phần sau:
- Cơ sở dữ liệu các tên miền: Tên miền sau khi được thu thập sẽ được lưu vào cơ sở dữ liệu.
- Khối lọc tên miền DF: Trong quá trình thu thập và khảo sát tên miền trong lưu lượng DNS, nhiều tên miền bình thường như: facebook.com, youtube.com, yahoo.com… bị lẫn trong tập dữ liệu thu được. Vấn đề là cần thu thập và phân tích các tên miền NXDomain nghi ngờ do DGA botnet sinh ra, do đó tập dữ liệu tên miền sau khi thu thập sẽ được lọc và tinh chỉnh bằng bước lọc trong khối DF. Sau khi được lọc, tập các tên miền còn lại có khả năng cao là NXDomain do thuật toán DGA của các botnet tạo ra.
- Khối lọc DGA: Tập dữ liệu còn lại sau bước lọc tên miền sẽ được phân tách bằng khối DGA Filtering. Tại đây, các tên miền sẽ được phân loại thành hai nhóm: nhóm tên miền bình thường và nhóm NXDomain do các thuật toán sinh tên miền của botnet tạo ra.
- Khối phân cụm DGA DGA Clustering: Sau khi lọc DGA, các tên miền trong phân lớp NXDomain sẽ được phân cụm bằng khối DGA Clustering dựa vào thuật toán phân cụm K-means. Trong đó, NXDomain sẽ được phân nhóm thành các cụm khác nhau. Mỗi cụm tương ứng với một dạng DGA botnet và do cùng một thuật toán DGA tạo sinh. Quá trình phân cụm sử dụng đặc trưng địa chỉ IP của tên miền để phân loại. Thông thường, mỗi tên miền sẽ có một tập người dùng kết nối đến và địa chỉ IP của những người dùng này sẽ được sử dụng để xác định khoảng cách của hai tên miền.

60 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Chi tiết từng pha trong phương pháp phát hiện NXDomain sẽ được trình bày dưới đây.
A) Lọc tên miền DF
Trong quá trình tên miền được thu thập, có rất nhiều tên miền bình thường bị lẫn vào trong tập dữ liệu như: amazon.com, wikipedia.org, instagram.com… Các tên miền này có thể làm nhiễu tập dữ liệu thu được và sẽ làm ảnh hưởng đến kết quả phân loại NXDomain. Do đó ở khối DF, chúng tôi xây dựng một bộ lọc để lọc bớt những tên miền bình thường. Trong đó chúng tôi sử dụng hai kĩ thuật là lọc dựa vào những tên miền bình thường đã biết và dựa vào các đặc điểm ngữ nghĩa của tên miền.
i. Lọc sử dụng danh sách White-list
Chúng tôi sử dụng 1.000.000 tên miền được truy nhập nhiều nhất của Alexa. Sau giai đoạn này, một số tên miền bình thường như: dantri.com.vn, vnexpress.net… sẽ bị lọc bỏ. Tập dữ liệu sau khi đi qua khối này sẽ giảm đi đáng kể.
ii. Trích xuất đặc trưng
Pha trích xuất đặc trưng sử dụng những đặc trưng ngữ pháp sau:
- Trọng số bi-gram:
Đặc trưng này cho biết mức độ xuất hiện của các bi-gram trong tên miền. Nếu một tên miền được sinh ra bởi DGA Botnet thì đặc trưng này sẽ nhỏ. Chúng tôi tách ra p bi-gram của một tên miền d, sau đó dựa vào tần suất xuất hiện và thứ hạng của tên miền trong từ điển tiếng Anh để đánh giá trọng số.
Trong đó: n(t) là tần suất xuất hiện bi-gram t trong tên miền d.
|p| là số phần tử bi-gram của tên miền d.
- Tần suất của bi-gram:
Đặc trưng này cho biết được tần suất xuất hiện của các bi-gram thường hay xuất hiện và bi-gram ít xuất hiện. Chúng tôi đã khảo sát 100.000 tên miền có thứ
hạng cao của Alexa thấy xuất hiện 1459 cụm bi-gram khác nhau. Quá trình phân tích tần suất được thực hiện dựa trên ngưỡng θ, phân biệt các bi-gram xuất hiện nhiều và các bi-gram xuất hiện ít. Sau khi khảo sát tập dữ liệu trên, chúng tôi chọn θ= 520. Độ đo tần suất F bằng tỉ lệ giữa số bi-gram xuất hiện nhiều và xuất hiện ít của một tên miền để đánh giá mức độ xuất hiện của một tên miền đó.
- Entropy:
Entropy đặc trưng cho độ bất định của một tên miền. Ví dụ tần số xuất hiện của chữ x sẽ khác chữ phổ biến hơn t. Những tên miền nào được sinh ra bởi thuật toán DGA sẽ có đặc trưng này cao hơn so với tên miền bình thường.
Trong đó:
t là một bi-gram trong p bi-gram của tên miền d.
count(t) là chỉ số của bi-gram t trong tập từ điển.
N là số phần tử trong tập từ điển.
- Mức độ ý nghĩa tên miền
Đặc trưng này cho thấy mức độ ý nghĩa của tên miền. Những tên miền do DGA botnet sinh ra sẽ có giá trị này thấp.
Tên miền được chia thành những từ w(i) ≥ 3. Khi đó với tên miền d ta có:
Trong đó: p là số kí tự của tên miền d.
n là số từ có ý nghĩa trong tên miền.
Nếu mức độ ý nghĩa của tên miền R(d) được tính như trong công thức (3) thì thời gian tính toán của thuật toán khá lớn. Do đó, chúng tôi sử dụng ba đặc trưng gồm tần suất của bi-gram, trọng số bi-gram, entropy để ước lượng mức độ ý nghĩa của tên miền.
Giá trị R(d) được ước lượng như sau:
Hình 1. Phạm vi hoạt động và tốc độ truyền tin của các công nghệ kết nối không dây trong IoT
||
)(*)()(
p
tntcountdS pt
∑∈=
∑∈
−=pt N
tcountN
tcountdE ))(log(*)()(
p
iwdR ni
∑∈=
)()(
(1)
(2)
(3)
An toàn bảo mật

61CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
If S(d) ≥ 325 and E(d) ≤ 0.28 and F(d) ≤ 0.32 then
R(d) = 0.5 Else R(d) = 0
Các giá trị ngưỡng 300, 0.25, 0.3 được đưa ra dựa vào quá trình khảo sát và đánh giá tập tên miền ở trên.
iii. Lọc tên miền dựa trên đặc trưng ngữ pháp
Sau khi tập dữ liệu tên miền được lọc bởi danh sách Whitelist của Alexa, các tên miền trong tập dữ liệu sẽ được rút ra các đặc trưng ngữ nghĩa để phục vụ cho các giai đoạn phía sau. Chúng tôi sử dụng 4 đặc trưng ngữ nghĩa ở trên và đưa ra một ngưỡng để lọc một số tên miền ra khỏi tập dữ liệu. Hơn 100.000 tên miền bình thường có thứ hạng cao nhất của Alexa và hơn 300.000 NXDomain của DGA Botnet được khảo sát để đưa ra giá trị ngưỡng trong quá trình lọc sao cho số lượng NXDomain bị lọc theo tên miền bình thường là không đáng kể.
Thuật toán của quá trình lọc được mô tả như sau:
If S(d) ≥ 300 and E(d) ≤ 0.25 and F(d) ≤ 0.3 and R(d) = 0.5
then domain d is discarded
B) Lọc DGA
Sau khi qua khối lọc tên miền DF, tập dữ liệu sẽ được lọc tiếp bằng khối lọc DGA. Các đặc trưng đề xuất trong mục trước sẽ tham gia vào vector đặc trưng
v(d) = [R(d),S[d],E[d]]T.
Tập dữ liệu để huấn luyện và trích xuất đặc trưng gồm 10.000 tên miền có thứ hạng cao của Alexa, rút ra các đặc trưng trên và tính ra giá trị trung bình của mỗi giá trị và ma trận tương quan C cho biết giá trị trung bình của các đặc trưng và tương quan giữa các đặc trưng đó.
Các tên miền sẽ được phân loại bằng sử dụng khoảng cách Mahalanobis. Với một tên miền d’ chúng tôi sẽ ước lượng khoảng cách giữa x = v(d’) và trọng tâm µ. Khoảng cách này được tính như sau:
Những tên miền bình thường sẽ gần trọng tâm hơn so với NXDomain. Ngưỡng khoảng cách được
xác định dựa trên quan sát trên tập hợp dữ liệu thử nghiệm. Nếu dmah(x) > θd thì x được phân loại là NXDomain và x sẽ được gán nhãn là tên miền bình thường nếu ngược lại. Ngưỡng θd = 1.9, được chúng tôi chọn dựa vào quá trình khảo sát tập dữ liệu tên miền ở trên.
C) Phân cụm DGA
Đây là bước phân cụm các NXDomain có khả năng cao cùng do một thuật toán DGA tạo ra. Thuật toán K-means được áp dụng và điều chỉnh phù hợp với việc xác định số cụm động.
Đối với K-means, ta phải xác định trước số cụm cần đưa ra. Ban đầu chúng tôi để mặc định là hai. Sau khi phân cụm xong, nếu khoảng cách giữa một phần tử trong cụm Ωi với tâm cụm µi lớn hơn một ngưỡng θi xác định thì phần tử đó sẽ được tách ra thành một cụm mới. Như vậy, trong cụm chỉ còn lại những phần tử đủ gần so với tâm cụm, tức là có khoảng cách tới µi nhỏ hơn ngưỡng xác định θi. Khoảng cách giữa hai tên miền trong một cụm được xác định bằng danh sách các người dùng kết nối tới tên miền.
Gọi U1 và U2 lần lượt là tập hợp các người dùng kết nối đến hai tên miền d1 và d2, khoảng cách giữa hai tên miền:
Distance(d1, d2) = Chi tiết giải thuật như sau:Khởi tạo ngẫu nhiên trọng tâm của các phân cụm
Ω1, Ω2, ..., Ωn là µ1 , µ2, , ...., µn ;Repeat until convergence:Gán mỗi điểm xi vào cụm Ωk với đại diện là µk theo
khoảng cách nhỏ nhấtTính lại giá trị trọng tâm µk cho mỗi cụm ΩkEnd UntilFor k from 1 to n Foreach tên miền d in cluster Ωk If distance(d, µk) > θk then numk = numk +1 End If End For If numk > θc then Tạo cụm mới từ các thành viên có tên
miền cách trọng tâm µk lớn hơn ngưỡng µk > θck n = n + 1 End IfEnd For
1 2| |U U∩
)()-(x 1T µµ −− xC (4)dmah(x) =
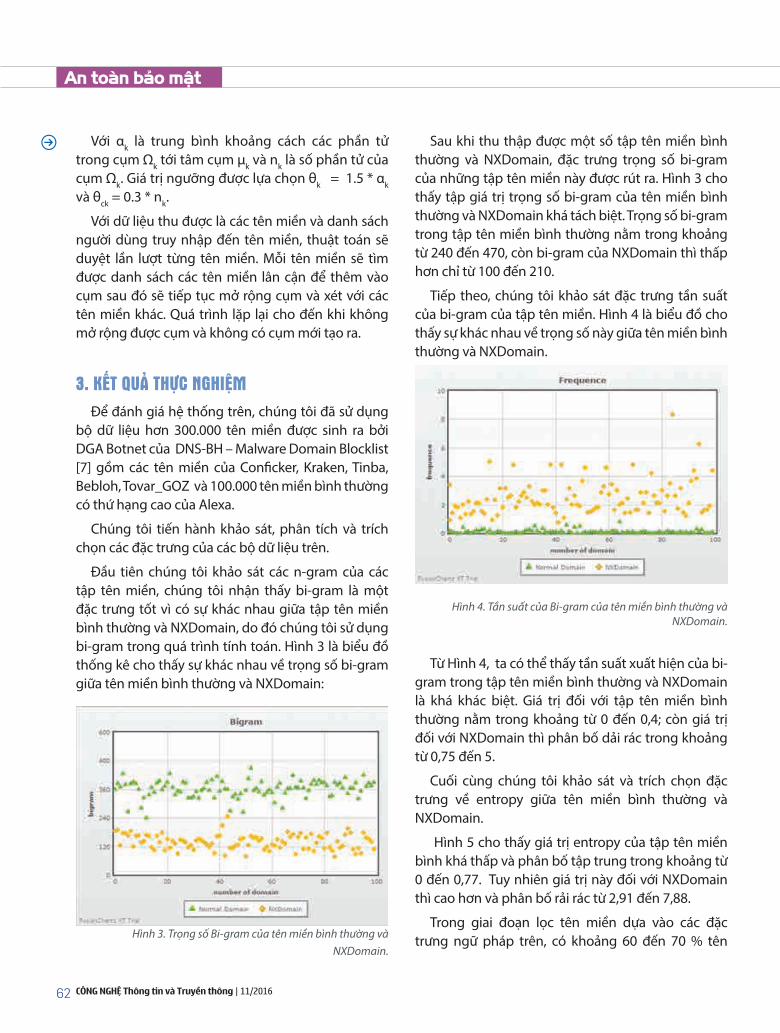
62 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Với αk là trung bình khoảng cách các phần tử trong cụm Ωk tới tâm cụm µk và nk là số phần tử của cụm Ωk. Giá trị ngưỡng được lựa chọn θk = 1.5 * αk và θck = 0.3 * nk.
Với dữ liệu thu được là các tên miền và danh sách người dùng truy nhập đến tên miền, thuật toán sẽ duyệt lần lượt từng tên miền. Mỗi tên miền sẽ tìm được danh sách các tên miền lân cận để thêm vào cụm sau đó sẽ tiếp tục mở rộng cụm và xét với các tên miền khác. Quá trình lặp lại cho đến khi không mở rộng được cụm và không có cụm mới tạo ra.
3. KẾT QUẢ THỰC NGHIỆMĐể đánh giá hệ thống trên, chúng tôi đã sử dụng
bộ dữ liệu hơn 300.000 tên miền được sinh ra bởi DGA Botnet của DNS-BH – Malware Domain Blocklist [7] gồm các tên miền của Conficker, Kraken, Tinba, Bebloh, Tovar_GOZ và 100.000 tên miền bình thường có thứ hạng cao của Alexa.
Chúng tôi tiến hành khảo sát, phân tích và trích chọn các đặc trưng của các bộ dữ liệu trên.
Đầu tiên chúng tôi khảo sát các n-gram của các tập tên miền, chúng tôi nhận thấy bi-gram là một đặc trưng tốt vì có sự khác nhau giữa tập tên miền bình thường và NXDomain, do đó chúng tôi sử dụng bi-gram trong quá trình tính toán. Hình 3 là biểu đồ thống kê cho thấy sự khác nhau về trọng số bi-gram giữa tên miền bình thường và NXDomain:
Hình 3. Trọng số Bi-gram của tên miền bình thường và
NXDomain.
Sau khi thu thập được một số tập tên miền bình thường và NXDomain, đặc trưng trọng số bi-gram của những tập tên miền này được rút ra. Hình 3 cho thấy tập giá trị trọng số bi-gram của tên miền bình thường và NXDomain khá tách biệt. Trọng số bi-gram trong tập tên miền bình thường nằm trong khoảng từ 240 đến 470, còn bi-gram của NXDomain thì thấp hơn chỉ từ 100 đến 210.
Tiếp theo, chúng tôi khảo sát đặc trưng tần suất của bi-gram của tập tên miền. Hình 4 là biểu đồ cho thấy sự khác nhau về trọng số này giữa tên miền bình thường và NXDomain.
Hình 4. Tần suất của Bi-gram của tên miền bình thường và NXDomain.
Từ Hình 4, ta có thể thấy tần suất xuất hiện của bi-gram trong tập tên miền bình thường và NXDomain là khá khác biệt. Giá trị đối với tập tên miền bình thường nằm trong khoảng từ 0 đến 0,4; còn giá trị đối với NXDomain thì phân bố dải rác trong khoảng từ 0,75 đến 5.
Cuối cùng chúng tôi khảo sát và trích chọn đặc trưng về entropy giữa tên miền bình thường và NXDomain.
Hình 5 cho thấy giá trị entropy của tập tên miền bình khá thấp và phân bố tập trung trong khoảng từ 0 đến 0,77. Tuy nhiên giá trị này đối với NXDomain thì cao hơn và phân bố rải rác từ 2,91 đến 7,88.
Trong giai đoạn lọc tên miền dựa vào các đặc trưng ngữ pháp trên, có khoảng 60 đến 70 % tên
An toàn bảo mật
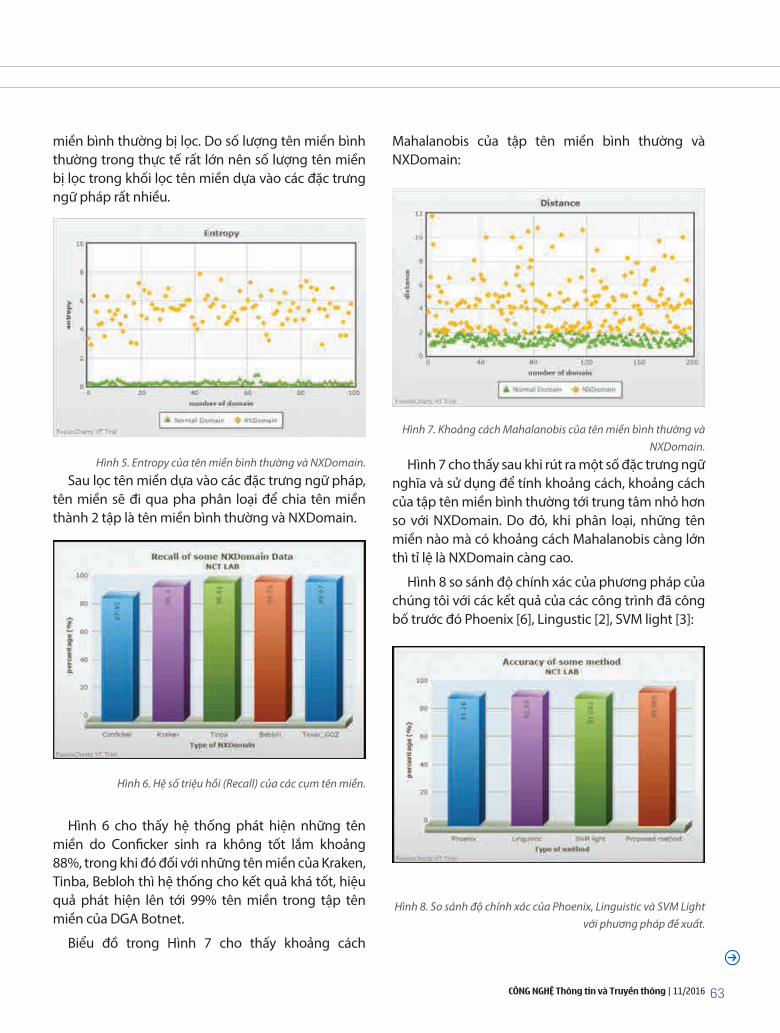
63CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
miền bình thường bị lọc. Do số lượng tên miền bình thường trong thực tế rất lớn nên số lượng tên miền bị lọc trong khối lọc tên miền dựa vào các đặc trưng ngữ pháp rất nhiều.
Hình 5. Entropy của tên miền bình thường và NXDomain.
Sau lọc tên miền dựa vào các đặc trưng ngữ pháp, tên miền sẽ đi qua pha phân loại để chia tên miền thành 2 tập là tên miền bình thường và NXDomain.
Hình 6. Hệ số triệu hồi (Recall) của các cụm tên miền.
Hình 6 cho thấy hệ thống phát hiện những tên miền do Conficker sinh ra không tốt lắm khoảng 88%, trong khi đó đối với những tên miền của Kraken, Tinba, Bebloh thì hệ thống cho kết quả khá tốt, hiệu quả phát hiện lên tới 99% tên miền trong tập tên miền của DGA Botnet.
Biểu đồ trong Hình 7 cho thấy khoảng cách
Mahalanobis của tập tên miền bình thường và NXDomain:
Hình 7. Khoảng cách Mahalanobis của tên miền bình thường và NXDomain.
Hình 7 cho thấy sau khi rút ra một số đặc trưng ngữ nghĩa và sử dụng để tính khoảng cách, khoảng cách của tập tên miền bình thường tới trung tâm nhỏ hơn so với NXDomain. Do đó, khi phân loại, những tên miền nào mà có khoảng cách Mahalanobis càng lớn thì tỉ lệ là NXDomain càng cao.
Hình 8 so sánh độ chính xác của phương pháp của chúng tôi với các kết quả của các công trình đã công bố trước đó Phoenix [6], Lingustic [2], SVM light [3]:
Hình 8. So sánh độ chính xác của Phoenix, Linguistic và SVM Light
với phương pháp đề xuất.

64 CÔNG NGHỆ Thông tin và Truyền thông | 11/2016
Trong đó độ chính xác được tính theo công thức:
Với: TP và FP lần lượt là tỉ lệ NXDomain được nhận diện đúng và sai.
TN và FN lần lượt là tỉ lệ tên miền bình thường được nhận diện đúng và sai.
Hệ thống đề xuất này đã cải tiến Phoenix [6] ở các bước lọc tên miền DF, lọc và phân cụm DGA. Những hiệu chỉnh này làm tăng thêm hiệu quả cho các thuật toán như trong khối lọc các tên miền bình thường để giảm nhiễu trong quá trình phân loại tên miền. Hình 8 cho thấy độ chính xác của phương pháp đề xuất dường như tốt hơn so với Phoenix, và một số phương pháp khác.
4. KẾT LUẬNBài báo đã đề cập tới một số cải tiến quá trình huấn
luyện và phát hiện tên miền không tồn tại [6], một bước quan trọng trong phát hiện botnet. Kết quả thử nghiệm thu được khá khả quan. Khoảng 88% đến 99,72% tên miền trong tập dữ liệu NXDomain bị phát hiện. Ngoài ra tỉ lệ tên miền bình thường bị phát hiện sai là khá nhỏ, chỉ khoảng 2 đến 3 % . Điều này đạt được do hệ thống đã lọc bớt những tên miền bình thường dựa vào các đặc trưng ngữ nghĩa và danh sách tên miền thực (whitelist). Những kết quả thu được còn nhiều hạn chế và cần có những cải tiến phù hợp để tăng khả năng phát hiện đúng tên miền. Hơn nữa, phương pháp đề xuất chỉ cho phép phát hiện được những tên miền do thuật toán DGA sinh ra, nhưng chưa thể phát hiện được những tên miền được đặt tên giống tên miền bình thường. Do đó, để có thể phát hiện những tên miền này, cần phải dựa vào những thông tin bổ sung, như địa chỉ IP, số luồng truy nhập trong một đơn vị thời gian, số gói tin trên một luồng, kích thước mỗi gói tin, tần suất gửi gói tin, khoảng thời gian gửi.
Tài liệu tham khảo:[1] E. STALMANS, “A Framework for DNS Based Detection and
Mitigation of Malware Infections on a Network”, Information Security South Africa Conference, 2011.
[2] S. YADAV, A. K. K. REDDY, A. N. REDDY, and S. RANJAN, “Detecting algorithmically generated malicious domain names”, Proceedings of the 10th annual Conference on Internet Measurement, IMC ’10, pages 48–61, New York, NY, USA, 2010, ACM.
[3] NHAUO DAVUTH, SUNG-RYUL KIM, “Classification of Malicious Domain Names using Support Vector Machine and Bi-gram Method”, International Journal of Security and Its Applications, Vol. 7, No. 1, January, 2013.
[4] T. JOACHIMS,” SVM light, Making large-Scale SVM Learning Practical”, Advances in Kernel Methods - Support Vector Learning, B. Schölkopf and C. Burges and A. Smola (eds.), MIT-Press, 1999.
[5] zHOU, LI, MIAO, and YIM, “DGA-Based Botnet Detection Using DNS Traffic”, Journal of Internet Services and Information Security (JISIS), volume: 3, number: 3/4, pages 116-123.
[6] STEFANO SCHIAVONI, FEDERICO MAGGI, LORENzO CAVALLARO, STEFANO zANERO, “Phoenix: DGA-Based Botnet Tracking and Intelligence”, Chapter Detection of Intrusions and Malware, and Vulnerability Assessment Volume 8550 of the series Lecture Notes in Computer Science pages 192-211, Springer, 2014.
[7] http://www.malwaredomains.com/?cat=111[8] http://www.alexa.com/[9] G. EASON, B. NOBLE, I. N. SNEDDON, “On certain integrals
of Eggdrop: Open source IRC bot, http://www.eggheads.org/,1993.[10] C. Associates. GTBot1, http://www3.ca.com/
securityadvisor/pest/pest.aspx?id=453073312, 1998.[11] CHAO LI, WEI JIANG, XIN zOU, “Botnet: Survey and Case
Study”, Fourth International Conference on Innovative Computing, Information and Control , 2009.
[12] RAJAB MA, zARFOSS J, MONROSE F, TERzIS A, “A multifaceted approach to understanding the botnet phenomenon”, Almeida JM, AlmeidaVAF, Barford P, eds. Proc. of the 6th ACM Internet MeasurementConf. (IMC 2006). Rio de Janeriro: ACM Press, pages 41-52, 2006.
[13] ABEBE TESFAHUN, D.LALITHA BHASKARI, “Botnet Detection and Countermeasures-A Survey”, International Journal of Emerging Trends & Technology in Computer Science, Volume 2, Issue 4, July – August, 2013.
[14] Sophos, Troj/Agobot-A, http://www.sophos.com/ virusinfo/analyses/ trojagobota.html, 2002.
[15] Sophos, Troj/SDBot, http://www.sophos.com/ virusinfo/analyses/trojsd bot.html, 2002.
[16] Phatbot Trojan Analysis, http://www.secureworks. com/ research/threats/phatbot.
[17] M. SUENAGA, M. CIUBOTARIU, “Symantec: Trojan. peacomm.”http://www.symantec.com/security response/writeup.jsp?docid=2007011917-1403-99, February 2007.
[18] YING zHANG, YONGzHENG zHANG, JUN XIAO, “Detecting the DGA-Based Malicious Domain Names”, ISCTCS 2013, CCIS 426, pages 130–137, 2014.
(5)100*N F+N T+P F+P T
N T+P T=Accuracy
An toàn bảo mật





























