Embed Size (px)
Citation preview

- 48 -
3. 실험데이터의 통계적 취급
모든 측정자료에 포함된 불확정성을 적절히 취급하고 의미 있는 결론을 이끌어 내기 위
해서는 자료의 통계학적인 취급이 필수적이다. 그리고 실험을 설계할 때부터 실험데이터에
서 요구되는 정확도를 알아내고 필요한 검출기의 분해능과 실험의 지속시간 등을 추정하는
과정에서도 통계학은 중요한 역할을 하고 있다. 이 장에서는 핵 및 입자물리실험에 접하
게 관련된 부분으로 제한하여 통계학을 설명하고자 한다.
3.1 확률분포
통계학에서는 주사위를 던진다든지 주어진 시간 안에 붕괴하는 방사성 붕괴사건의 개수
추정 등과 같이 실험결과가 사건마다 일정하지 않은 임의과정(random process)을 취급하
고 있다. 임의과정은 각각의 가능한 결과에 대해 기대되는 빈도를 나타내는 확률 도
(probability density)에 의해 설명될 수 있다. 즉 임의과정의 결과는 모든 가능한 영역에서
분포하는 임의변수 에 의해 결정된다. 예를 들면 하나의 주사위를 던지는 경우 는 1부터
6까지의 정수 중 하나가 될 것이다. 그리고 이때 결과가 값을 가질 확률은 이
된다. 취급하는 과정에 따라 는 연속일 수도 있고 불연속일 수도 있다. 가 불연속이라면
는 각 점 에서 어떤 값을 가질 것이며, 이때 임의의 구간 ≤ ≤ 에서 사건이
일어날 확률은 다음과 같다.
≤ ≤
(3.1)
그러나 가 연속이라면 어떤 유한한 구간에서의 사건 발생 확률만이 가능하게 된다. 즉
와 사이에서 사건이 일어날 확률은 가 되고, 어떤 구간 ≤ ≤ 에서 사
건이 일어날 확률은 다음과 같다.
≤ ≤
(3.2)
보통 확률함수는 다음과 같이 규격화 되어 있다.
(3.3)
임의변수 의 기댓값(expectation value) 또는 평균(mean or average)은
⟨⟩
(3.4)

- 49 -
와 같이 정의되며, 임의의 함수 의 기댓값 또는 평균은
⟨⟩ (3.5)
로 정의된다. 그리고 분산(variance)은
(3.6)
로 정의된다. 이때 표준편차(standard deviation) 는 확률분포의 퍼진 정도를 나타내며 임
의변수 가 평균 주위로 얼마나 요동(fluctuate)치는지를 나타낸다.
앞에서 하나의 변수 만 고려하는 간단한 경우만 살펴보았다. 그러나 일반적으로 여러
개의 변수가 관련되는 경우에는 다변 확률분포함수 ⋯가 이용된다. 이때 각 변수
에 대한 평균과 분산은 이전과 같이 정의된다. 이에 더하여 각 변수 간의 선형적인 상관관
계(correlation)를 나타내는 공분산(covariance)이 다음과 같이 정의된다.
cov⟨ ⟩ (3.7)
그리고 때때로 공분산보다 다음과 같이 정의되는 상관계수(correlation coefficient)가 더 많
이 사용된다.
cov (3.8)
상관계수는 -1부터 1사이에 존재한다. 만약 변수들이 완전히 선형적으로 관계되어 있다면
이 되고, 전혀 선형적인 관계가 없다면 0이 된다.
3.2 확률분포함수의 예
무수히 많은 확률분포함수 가운데 물리학에서는 주로 이항(binomial), 푸아송(Poisson),
가우스(Gaussian)분포를 사용한다. 예를 들어, 동전을 번 던졌을 때 순서에 관계없이 앞
면이 번 나올 확률은 다음과 같은 이항분포로 주어진다.
(3.9)
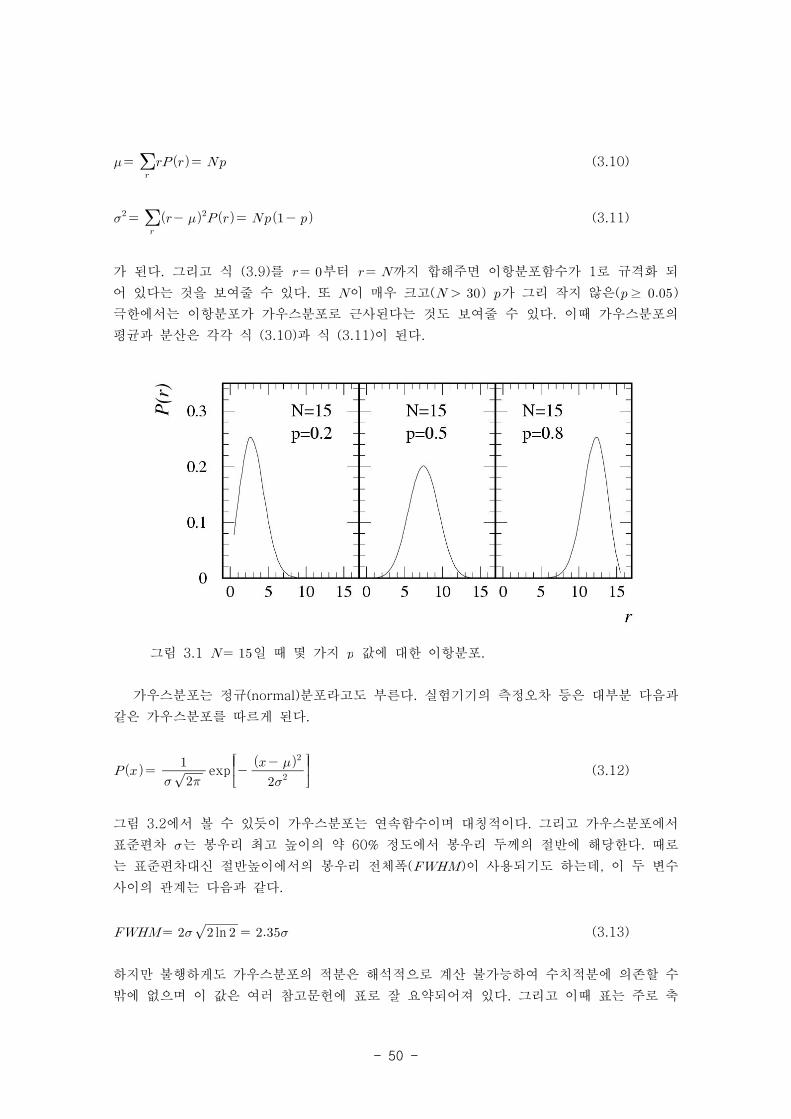
이때 는 한 번 던졌을 때 앞면이 나올 확률이다. 이항분포는 불연속 함수이며 몇 가지 예
를 그림 3.1에 보여주고 있다. 식 (3.4)와 (3.6)을 이용하여 평균과 분산을 구하면
- 50 -
(3.10)
(3.11)
가 된다. 그리고 식 (3.9)를 부터 까지 합해주면 이항분포함수가 1로 규격화 되
어 있다는 것을 보여줄 수 있다. 또 이 매우 크고( ) 가 그리 작지 않은(≥ )
극한에서는 이항분포가 가우스분포로 근사된다는 것도 보여줄 수 있다. 이때 가우스분포의
평균과 분산은 각각 식 (3.10)과 식 (3.11)이 된다.
그림 3.1 일 때 몇 가지 값에 대한 이항분포.
가우스분포는 정규(normal)분포라고도 부른다. 실험기기의 측정오차 등은 대부분 다음과
같은 가우스분포를 따르게 된다.
exp
(3.12)
그림 3.2에서 볼 수 있듯이 가우스분포는 연속함수이며 대칭적이다. 그리고 가우스분포에서
표준편차 는 봉우리 최고 높이의 약 60% 정도에서 봉우리 두께의 절반에 해당한다. 때로
는 표준편차대신 절반높이에서의 봉우리 전체폭( )이 사용되기도 하는데, 이 두 변수
사이의 관계는 다음과 같다.
ln (3.13)
하지만 불행하게도 가우스분포의 적분은 해석적으로 계산 불가능하여 수치적분에 의존할 수
밖에 없으며 이 값은 여러 참고문헌에 표로 잘 요약되어져 있다. 그리고 이때 표는 주로 축

- 51 -
약(reduced) 가우스분포( )를 이용하여 나타낸다. 모든 가우스분포는 다음과 같
은 변수변환을 이용하여 축약 가우스분포로 바꾸어 줄 수 있다.
(3.14)
실험데이터를 해석할 때 매우 유용하게 사용되는 것은 주어진 표준편차 범위 내에서 가우스
분포의 적분값이다. 즉 어떤 사건이 ± 내에 존재할 확률은 약 68.3%이고, ± 내에
존재할 확률은 약 85.5%이며, ± 내에 존재할 확률은 약 99.7%가 된다.
그림 3.2 가우스분포에서 표준편차 와 과의 관계.
사건의 수 이 무한대로 근사하고 확률 가 0으로 근사하여 평균 가 유한한 값
으로 남아야 한다는 조건을 만족한다면 이항분포는 다음의 푸아송분포로 표현될 수 있다.
exp
(3.15)
이항분포와 같이 푸아송분포도 불연속 함수이다. 그림 3.3에서 볼 수 있듯이 푸아송분포는
대칭이 아니며 따라서 봉우리의 최고 높이 지점이 평균도 아니다. 그러나 평균이 커지면 점
점 더 대칭성이 회복되어 결국 ≥ 에서 가우스분포로 근사하게 된다. 푸아송분포는 한
번 시도에서 사건이 일어날 확률은 거의 없지만 시도횟수가 매우 커서 결국 사건발생의 빈
도가 유한한 값인 경우에 잘 맞는다. 예를 들면, 핵 충돌이라든지 방사능 원소의 붕괴 등이
이에 해당한다고 할 수 있다. 푸아송분포의 중요한 점은 식 (3.15)에서 볼 수 있듯이 평균
만 나타나고 이나 는 나타나지 않는다는 사실과 라는 점이다. 이것이 왜 핵이
나 입자물리실험에서 평균의 제곱근이 중요한지를 설명해 주고 있다.

- 52 -
그림 3.3 여러 가지 값에 대한 푸아송분포.
이론적인 계산값과 실험데이터가 얼마나 잘 일치하는가를 판단하고 싶을 때는 주로 카이
제곱() 변수를 이용한다. 만약 개의 독립변수 ⋯ 가 있다고 가정하자. 그
리고 각각의 변수가 가우스분포를 따르고 평균과 표준편차가 각각 , 라고 가정한다면,
카이제곱은
(3.16)
로 정의되고 이는 평균값 주위로 데이터 의 요동정도를 나타내는 변수가 된다. 이때 주어
진 집합에 대한 의 확률분포함수는 다음과 같이 된다.
exp
(3.17)
여기서 정수 를 자유도(degrees of freedom)라고 부르며 식 (3.17)의 유일한 변수이고
은 감마함수이다. 자유도는 식 (3.16)의 독립변수의 개수와 관계된다. 그
림 3.4는 여러 가지 에 대한 카이제곱분포를 보여주고 있다. 이때 식 (3.4)와 (3.6)을 이용
하면 카이제곱분포의 평균과 분산이 각각 , 가 됨을 보여줄 수 있다.

- 53 -
만약 의 분포가 완벽한 가우스 확률분포를 따른다면 식 (3.16)으로부터 를
얻을 수 있다. 그리고 카이제곱은 이 평균값 근처로 식 (3.17)식에 따라 요동침을 알 수 있
다. 이와 같은 분석의 유용성은 측정한 실험데이터와 이론값 사이의 카이제곱이 이론값에
대한 실험데이터의 요동이 적당(reasonableness)한지를 판단할 수 있도록 해준다는데 있다.
즉 일 때 실험데이터는 어떤 맞춤함수 또는 이론값으로부터 완벽한 가우스분포를
이루고 맞춤이 잘 이루어졌음을 의미한다.
그림 3.4 여러 가지 자유도 에 대한 카이제곱분포.
3.3 측정과정과 오차
실험에서의 측정과정은 어떤 확률분포에 의해 표현될 수 있는 임의과정이라고 말할 수
있으며, 확률분포의 변수가 바로 우리가 원하는 정보를 내포하게 된다. 따라서 측정의 결과
는 이 확률분포의 표본이 되고 실험데이터의 오차는 표본오차라고 볼 수 있다. 오차에는 기
기오차(systematic error)와 통계오차(또는 임의오차)가 있다.
기기오차는 측정 당시 기기 자체의 문제로 인해 실험데이터가 정확한 값을 주지 못할 가
능성 때문에 발생하는 불확정성이다. 기기오차는 같은 조건에서 같은 기기로 얻은 측정값에
같은 방향으로 같은 양만큼 주어진다. 보통 기기오차는 실험데이터의 불확정성에 가장 중요
한 역할을 함에도 불구하고 잘 정의된 분석방법이 존재하지 않으므로 실험마다 개별적으로
취급해야만 한다.
이에 반해 통계오차는 무한히 많은 사건에서 유한한 임의표본을 추출함에 의해 발생하므
로 통계이론으로 다루어야만 한다. 예를 들어, 방사성 핵이 붕괴하는 경우를 생각해 보자.

- 54 -
이 핵의 붕괴 가능성은 양자역학적인 확률법칙에 의해 결정되므로, 주어진 시간 안에 발생
하는 붕괴사건의 수는 임의변수가 된다. 단위시간 안에 붕괴사건의 수를 측정하는 것은 핵
붕괴에 대한 확률분포의 표본을 취하는 것이다. 이때 처음 측정한 사건 수를 이라고 하
자. 그리고 계속해서 두 번째 및 세 번째 측정에서 및 사건 수를 측정했다고 하자.
그러면 이 데이터로부터 의 평균을 구할 수 있고, 데이터는 유한한 표본이므로 이 평균에
는 통계적인 불확정성이 있을 것이다. 이를 통계오차라고 부른다.
3.4 표본추출과 변수추정 (최대공산법)
표본추출은 우리가 알지 못하는 분포함수의 변수를 얻기 위한 실험적인 방법이다. 여론
조사에서 볼 수 있듯이 표본추출 시 편향(biased)되지 않은 표본을 얻는 것은 매우 중요하
다. 즉 실험데이터에서 실험자가 생각하기에 옳지 않은 것 같다고 판단하여 데이터 중의 일
부를 버리는 것은 매우 위험한 일이다. 실험데이터 중 일부를 버리기 위해서는 명백한 이유
가 있어야만 한다.
그렇다면 표본 데이터가 주어졌을 때 구하고자 하는 변수의 최적값(참값에 가장 가까운
값)을 정하는 방법을 무엇일까? 여기서 최적값이란 참값과 실험적인 추정값 사이의 분산이
최소가 되는 경우가 될 것이다. 통계학에서는 이를 추정(estimation)이라고 부른다. 추정문
제는 최적추정과 추정의 오차를 정하는 문제로 나뉜다. 최적추정에는 여러 가지 방법이 있
지만 가장 많이 사용되는 것이 최대공산법(maximum likelihood method)이다.
우선 평균이 이고 분산이 인 ⋯ 표본을 생각해 보자. 이때 표본평균은
표본의 산술적인 평균으로 정의된다.
(3.18)
이때 →∞ 극한에서는 표본평균이 평균으로 접근한다.
lim→∞
(3.19)
비슷하게 표본분산은
(3.20)
으로 정의되고 →∞ 극한에서는 분산 으로 접근한다. 그리고 변수가 두 개인 경우의 표
본공분산(sample covariance)은 다음과 같이 정의된다.

- 55 -
cov
(3.21)
물론 →∞ 극한에서는 식 (3.7)의 공분산으로 접근한다.
최대공산법은 표본이 추출된 분포의 형태를 알고 있을 때에만 적용 가능하다. 대부분 물
리실험의 경우에 이 분포는 가우스 또는 푸아송분포이다. 하지만 좀 더 일반적으로 이론적
인 분포인 로부터 추출된 개의 독립적인 측정값 ⋯ 을 생각해 보자. 여
기서 는 구하고자 하는 변수이다. 최대공산법은 다음과 같은 공산함수(likelihood
function)를 구하는 것으로부터 시작된다.
⋯ (3.22)
이 공산함수는 실험에서 ⋯ 의 순서로 측정할 확률이라고 생각하도록 하자. 최
대공산원리란 측정된 값에서 이 확률이 최대가 된다는 것이다. 따라서 변수 는 함수 이
최대가 되도록 정해져야 한다. 만약 이 정칙(regular)함수라면 을 풀어서 를
구할 수 있을 것이다. 만약 둘 이상의 변수가 존재한다면 각각의 변수에 대한 의 편미분
방정식을 이용하면 될 것이다. 어떤 경우에는 보다는 의 로그함수를 미분하는 것이 더
쉬울 수도 있다 (즉, ln ). 이 식의 해인 을 변수의 최대공산추정값
(estimator)이라고 부른다. 만약 두 번째 표본에서 을 구하면 이는 첫 번째 추정값과 다를
것이다. 따라서 추정값 역시 확률분포에 의해 묘사될 수 있다. 그렇다면 의 오차는 무엇일
까? 식 (3.6)을 이용하면 다음과 같이 의 분산을 구할 수 있다.
⋯ (3.23)
이 식은 일반적인 표현식이지만 불행하게도 해석적인 결과를 얻을 수 있는 경우는 매우 드
물다. 그러므로 더 쉬운 방법은 최대점에서 근사적으로 다음을 계산하는 것이다.
≃ ln
(3.24)
만약 두 개 이상의 변수가 있다면 위 이차미분식의 행렬을 만들어야 한다.
ln (3.25)
그러면 역행렬의 대각선 요소가 분산의 근사값이 된다.

- 56 -
≃ (3.26)
한 가지 주의할 점은 처음에 의 평균이 라고 가정하였다는 사실이다. 이는 →∞의 극
한에서 편향되지 않은 추정값에 대해 성립하는 근사로써 모든 추정값에 대해 성립하는 것은
아니다.
이제 최대공산법을 푸아송분포에 적용해 보자. 평균이 인 푸아송분포로부터
⋯ 을 측정했다고 가정하자. 이때 공산함수는
exp exp
(3.27)
이 되고, 이 식에서 곱셈을 없애기 위하여 로그를 취해 준다.
∗ ln
ln
ln (3.28)
이제 ∗를 로 미분한 식을 0으로 두면
∗
⇒
(3.29)
와 같이 표본평균을 얻을 수 있다. 그리고 의 분산은 식 (3.24)를 이용하여 구할 수 있을
것이다. 그러나 지금과 같이 특별한 경우에는 다른 방법을 써보도록 하자. 식 (3.6)의 분산
의 정의를 표본에 적용하고 항을 정리하면
⟨ ⟩⟨ ⟩ (3.30)
식 (3.30)의 유도에는 특별히 푸아송분포가 사용되지 않는다. 따라서 식 (3.30)은 일반적인
표현식이며 표본평균의 분산은 모분포의 분산을 표본의 크기 으로 나누어 준 것이다. 특별
히 푸아송분포에 대해서는 이므로 추정한 푸아송 평균에 대한 오차는 다음과 같다.
≃
(3.31)
이번에는 최대공산법을 가우스분포에 적용해 보자. 역시 평균이 인 가우스분포로부터
⋯ 을 측정했다고 가정하자. 그러면 공산함수 및 그것의 로그형은 각각

- 57 -
exp
(3.32)
∗ ln ln
(3.33)
이 된다. 이제 식 (3.33)을 에 대해 편미분하고 0으로 두면
∗
⇒
(3.34)
가 된다. 즉 가우스분포에 대한 최적추정평균 역시 푸아송분포의 경우와 마찬가지로 표본평
균이 됨을 알 수 있다. 이번에는 식 (3.33)을 에 대해 편미분하고 다시 0으로 두면
∗
(3.35)
이 되고 결국 다음과 같이 표본분산을 얻게 된다.
≃
(3.36)
그러나 유한한 표본의 수에 대해 표본분산은 편향된 추정값이 되며, 은 정확한 값이 되지
못하고 아래에서 볼 수 있듯이 일정한 상수만큼 작게 된다.
⟨⟩
(3.37)
그리고 →∞ 극한에서 은 진짜 분산으로 수렴하게 된다. 따라서 실제 실험데이터를 분
석할 때에는 표본분산의 평균에 요소를 곱해주는 것이 더욱 정확할 것이다.
(3.38)
결국 평균과는 다르게 한 개의 표본( )만으로는 표준편차를 추정하는 것이 불가능하다
는 것을 알 수 있다. 한편 일반적인 식 (3.30)을 이용하면
(3.39)

- 58 -
17.62 17.62 17.615 17.62 17.61
17.61 17.62 17.625 17.62 17.62
17.61 17.615 17.61 17.605 17.61
을 얻을 수 있고 이는 결국 식 (3.36)과 동일하며 보통 평균의 표준오차라고 부른다. 결국
표본의 개수 이 증가할수록 더욱 정확한 평균 를 얻게 되는 것이다.
지금까지 취급한 예는 모두 같은 기기로 측정된 같은 양의 표본만을 다루었다. 그러나
종종 두 개 이상의 서로 다른 양과 오차를 갖는 데이터를 합하여야 하는 경우가 발생한다.
이 경우 여러 데이터의 단순한 평균을 구하는 것은 어떤 데이터가 다른 것보다 더욱 정 하
게 측정되었다는 사실을 무시하는 것이다. 따라서 각각의 데이터에 오차에 따른 중요도를
고려한 평균 및 오차를 구하여야 한다. 예를 들어 평균은 로 같으나 표준편차가 로 서로
다른 가우스분포로부터 각각 ⋯ 표본을 추출했다고 가정하자. 이때 공산함수는
식 (3.32)에서 만 로 바꾸어 주면 된다. 이 공산함수를 최대화시킨다면 가중평균
(weighted mean)은 다음과 같다는 것을 보여줄 수 있다.
(3.40)
따라서 기대했던 대로 가 작은 는 더욱 큰 가중값을 갖게 된다. 그리고 식 (3.24)를 이
용하여 가중평균의 오차를 구하면
(3.41)
이 되고, 만약 모든 가 같은 값을 갖는다면 가중평균과 오차는 각각 식 (3.34)와 (3.39)로
돌아가게 된다.
3.5 몇 가지 예
(예 3.5.1) 접는 의자의 높이를 15번 측정하여 다음과 같은 실험데이터를 얻었다. 이 막대
의 길이에 대한 최적추정값은 얼마일까?
(풀이) 길이 측정의 오차가 기기(의자 또는 자)에 관련된 것이라고 가정하면 실험데이터는
가우스분포를 가질 것으로 예상할 수 있다. 식 (3.34)로부터 최적추정평균은 =
17.61533이 되고, 식 (3.38)로부터 표준편차는 = 5.855×10-3이 된다. 그러면 평균 의

- 59 -
2.198±0.001 μs 2.202±0.003 μs
2.1966±0.0020 μs 2.1948±0.0010 μs
2.203±0.004 μs 2.197±0.005 μs
2.198±0.002 μs
표준오차는 식 (3.39)에 의해 = 0.0015 임을 알 수 있다.
여기서 최종 결과를 나타낼 때의 끝수버림(rounding off)에 관해서 설명할 필요가 있다.
우리가 얻은 평균(여기서는 17.61533)에서 취하는 숫자의 개수는 그 결과의 오차(여기서는
0.0015)에 의해서 결정이 된다. 물론 오차에서는 0이 아닌 첫 번째 숫자만 의미가 있다 (여
기서는 소수 셋째자리까지). 그리고 평균도 오차와 동일한 자릿수를 갖는다 (역시 소수 셋
째자리까지). 끝수버림의 일반적인 방법은 버려지는 모든 숫자의 앞에 소수점을 부친 후
(여기서는 의 경우 0.33, 의 경우 0.5), 이 값이
(a) 0.5보다 작으면 마지막 유효숫자(여기서는 의 경우에는 5, 의 경우에는 1)
를 그대로 두고,
(b) 0.5보다 크면 마지막 숫자를 1만큼 올려주며,
(c) 정확히 0.5일 때는 마지막 유효숫자가 홀수인 경우에는 1만큼 올려주고, 짝수인
경우에는 그대로 둔다.
결국 의자길이에 대한 최적값은 = 17.615±0.002가 된다. 하지만 이 결과가 다른 데이터
분석에 사용되는 경우에는 일반적으로 오차에서 두 개의 숫자까지 유지할 것을 권한다. 이
때 두 번째 숫자는 축적된 끝수버림에 의한 오차를 피하는데 도움이 되기 때문이다. 따라서
이때는 의자길이에 대한 최적값은 = 17.6153±0.0015가 된다.
끝수버림에서 주의할 점 한 가지는 한 번에 숫자 하나씩 버리는 것은 옳지 않다는 것이
다. 예를 들면 임의로 2.346을 생각해 보자. 그리고 앞에서 설명한 방법으로 2.3을 얻었다
고 가정하자. 하지만 한 번에 숫자 하나씩 버려서 자릿수를 맞춘다면 2.346 → 2.35 →
2.4를 얻게 될 것이다.
(예 3.5.2) 7 개의 논문에서 뮤온의 평균수명을 찾아본 결과 다음과 같이 서로 다른 실험데
이터를 발견하였다. 최적값은 얼마인가?
(풀이) 각각의 데이터가 서로 다른 오차를 갖고 있으므로 가중평균 공식을 이용하여야만 한
다. 식 (3.40)을 이용하면 평균수명으로 2.19696 μs을 얻고, 식 (3.41)을 이용하면 평균수
명의 오차로 0.00061 μs을 얻는다. 이제 앞에서 설명한 끝수버림 방법을 이용하면 =
2.1970±0.0006 μs이 된다.
(예 3.5.3) 방사성 원소인 22Na 핵으로부터 1 분 간 일어나는 붕괴사건의 수를 5 번 측정하
여 다음과 같은 실험데이터를 얻었다. 이 핵의 붕괴율과 오차를 구하여라.

- 60 -
2201 2145 2222 2160 2300
(풀이) 방사능 붕괴는 푸아송분포에 의해 지배된다. 식 (3.29)를 이용하면 = 2205.6
을 얻고, 식 (3.31)을 이용하면 을 얻는다. 앞에서 설명한
끝수버림 방법을 이용하면 붕괴율은 (2206±21사건/분)이 된다.
그런데 만약 5분 동안 위의 모든 핵붕괴 사건(총 11028)을 한꺼번에 측정했다면 결과는
어떻게 될까? 이 경우의 오차는 이 될 것이다. 즉 붕괴율 =
(11028±106 사건/5 분) = (2206±21 사건/분)이 되어 이전과 같은 결과를 얻었다.
지금까지 살펴 본 몇 가지 예에서는 어떤 신호가 측정되었을 경우에 실험결과를 취급하
는 법을 다루었다. 하지만 핵물리 실험에서는 어떤 이론 또는 법칙에 의해 금지되어 있는
특정한 사건을 찾아야 하는 경우도 많이 있다. 만약 실험을 어떤 시간 동안 수행한 후,
특별한 신호를 찾지 못했다고 가정해 보자. 이 경우에는 비록 신호를 찾지 못했다고 하더라
도, 앞의 이론이나 법칙에 위배되는 사건이 100% 없다고 장담할 수는 없을 것이다. 따라서
대신 평균수명이나 붕괴율 등에 한계(limit)를 주게 된다. 이 과정을 설명하기 위하여 평균
반응율이 인 임의의 반응과정을 생각해 보자. 그러면 시간 동안 특정사건을 찾지 못할
확률은
exp (3.42)
가 된다. 한편 이 식은 시간 동안 특정사건을 발견하지 못하였을 때 의 확률분포로도
해석될 수 있다. 가 보다 작을 확률을 구해보면
≤
exp exp (3.43)
가 된다. 여기서 식 (3.42)를 로 규격화시켜 주었음에 유의하라. 이 확률을 구간 0과
사이의 신뢰수준(confidence level 또는 간단히 )이라고 부른다. 물론 신뢰수준이 높을
수록 더욱 믿을만한 데이터가 될 것이다. 그리고 신뢰수준에 따른 의 값은 식 (3.43)으로
부터
ln (3.44)
이 된다.
(예 3.5.4) 100일 동안 50g의 82Se에서 중성미자 방출이 없는 이중 베타붕괴 사건이 일어
나는지 관측하였다 (보통 이 사건은 경입자 보존법칙에 의해 금지되어 있으나, 최근의 입자
물리이론에서는 가능성이 제기되고 있음). 효율이 20%인 검출기로 이 사건을 발견하지 못

- 61 -
하였다고 가정하고 이 붕괴모드의 평균수명에 대한 높은 한계를 정하라.
(풀이) 만약 90%의 신뢰수준으로 평균수명을 구하고자 한다면, 식 (3.44)에 의해 는
ln × = 0.115/day
보다 작다는 것을 예상할 수 있다. 이제 이 한계를 82Se 핵의 평균수명으로 전환해야 한다.
50g 안에는 82Se 핵이
= [(6.022×1023/mol)/(82 g/mol)]×(50 g) = 3.67×1023 개
들어있다. 즉 핵 하나당 붕괴확률은
≤ = (0.115/day)/(3.67×1023) = 3.13×10-26/day
이 된다. 평균수명은 붕괴율의 역수이므로
≥ 8.75×1021 year (90% )
임을 알 수 있다. 결국 82Se 핵으로부터의 중성미자 방출이 없는 이중 베타붕괴 사건은 존
재 가능성을 완전히 배제할 수는 없으나, 매우 드문 사건임을 알 수 있다.
3.6 오차의 전파
오차를 포함하고 있는 어떤 데이터가 다른 물리변수를 계산하는데 사용된다면 그 오차가
어떻게 전파될까? 이를 이해하기 위하여 어떤 함수 를 고려해 보자. 이때 각 변
수 와 의 오차는 각각 , 라고 가정하자. 그러면 의 분산은
⟨ ⟩ (3.45)
와 같이 구할 수 있을 것이다. 여기서 의 평균은 가 된다. 첫 번째 미분항만
고려한다면
≃
(3.46)
이 성립하고, 양변을 제곱한 후 식 (3.45)를 대입하면

- 62 -
≃
cov
(3.47)
이 된다. 이때 공분산항은 그 부호에 따라 오차를 증가시킬 수도 있고 감소시킬 수도 있다.
만약 두 변수가 서로 독립적이라면 공분산항은 0이 된다. 다음에 몇 가지 예를 들어보자.
(a) 합의 오차 ( ):
cov (3.48)
(b) 차의 오차 ( ):
cov (3.49)
(c) 곱의 오차 ( ): ≃
cov
또는
≃
cov (3.50)
(d) 비의 오차 ( ): ≃
cov
또는
≃
cov (3.51)
(예 3.6.1) 양성자나 중성자와 같은 입자의 편극을 측정하는 고전적인 방법은 이들 입자를
적당한 분석표적(analyzing target)에 입사시킨 후, 산란된 입자의 비평형도(asymmetry)를
측정하는 것이다. 예를 들어, 빔의 오른쪽으로 산란된 입자수를 , 왼쪽으로 산란된 입자수
를 이라고 가정하면, 비평형도는 다음과 같이 계산할 수 있다.
이때 의 오차를 구하라.
(풀이) 에 대한 표현식을 미분하면 다음의 두 식을 얻는다.
여기서 이다. 만약 과 이 푸아송분포를 따르면 이들의 분산은 각각 ,
이 된다. 이때 측정이 독립적이어서 과 사이의 공분산항이 0이라고 가정하고 식
(3.47)을 이용하면

- 63 -
≃
을 얻는다. 비평형도가 매우 작아서 ≃≃라고 가정하면 위 식은 다음과 같이 쓸
수 있다.
≃
3.7 실험데이터 맞추기
임의의 함수 를 고려해 보자. 개의 좌표에서 값을 오차 로 측정했다
고 가정하자. 이 실험데이터를 함수 ⋯ 으로 맞추고자(fitting) 한다. 여기서
⋯ 은 미지의 변수이다. 물론 측정한 실험데이터의 개수 이 맞추고자 하는 변수
의 개수 보다 더 커야만 할 것이다 (≥ ). 최소제곱법(least square method)은 다음의
합이 최소가 될 때 가 최적이 된다는 것이다.
(3.52)
식 (3.16)과의 유사성 때문에 이 방법을 카이제곱최소법(chi-square minimization)이라고
부르기도 하나, 엄격히 이야기 하면 이는 함수가 평균이 이고 분산이 인 가우스
분포를 따를 때만 맞는 용어이다. 하지만 최소제곱법은 완전히 일반적인 것으로 모분포의
종류에 관계없이 성립한다. 만약 모분포를 이미 알고 있다면 최대공산법을 쓸 수도 있을 것
이다. 그리고 모분포가 가우스분포일 때는 두 결과가 같다는 것을 보여줄 수 있다. 참고로
와 가 모두 오차를 갖고 있을 경우에는 이들 오차를 각각 제곱하여 더한 후 제곱
근을 취한 값(quadrature 또는 quadratic sum)을 대신 사용하면 된다.
이제 를 구하기 위해 식 (3.52)를 미분해 주면
(3.53)
을 얻고 함수 의 종류에 따라 식 (3.53)은 해석적으로 풀 수도 있고, 그렇지 못할 경우
도 있다. 이제 의 최적값을 구하였다고 가정하고 이 변수의 오차를 구해보자. 이를 위해
소위 공분산행렬 또는 오차행렬이라고 부르는 를 만들어야 한다.
(3.54)

- 64 -
이때 이차미분은 최소영역에서 계산한다. 이때 의 대각선원소(diagonal element)가 바로
의 분산이 되며, 비대각선원소가 와 의 공분산이 된다.
cov cov⋯
cov cov⋯
cov cov ⋯
⋮ ⋮ ⋮ ⋱
(3.55)
만약 함수가 에 대해 선형적이라면 식 (3.53)은 해석적으로 풀 수 있다. 예를 들어, 다
음의 함수 를 생각해 보자.
(3.56)
여기서 변수 와 를 결정하기 위해 식 (3.52) 및 그 미분식을 구하면
(3.57)
(3.58)
(3.59)
을 얻는다. 이때 ∼를 다음과 같이 정의하면
(3.60)
(3.61)
을 얻게 된다. 이제 와 의 오차를 구하기 위해 의 역오차행렬을
(3.62)
라고 두자. 여기서

- 65 -
0 1 2 3 4 5
0.92 4.15 9.78 14.46 17.26 21.90
0.5 1.0 0.75 1.25 1.0 1.5
(3.63)
이다. 을 이용하여 식 (3.62)의 역을 구해보면
(3.64)
을 얻게 되므로,
(3.65)
cov
이 된다. 한편 맞춤의 질을 판단하기 위해서는 카이제곱의 평균(최소영역에서의 )을 이용
한다. 3.2절에서 이미 설명하였듯이 만약 데이터가 맞춤함수모양에 맞고 맞춤함수로부터 벗
어난 정도가 가우스분포를 하고 있다면 는 평균이 자유도 와 같은 카이제곱분포를 따를
것으로 예상되고 있다. 여기서 자유도 이고 선형맞춤의 경우에는 가 되므로
가 된다. 이때 일반적으로 매우 빠르고 쉬운 판단을 위하여 다음과 같이 정의되는
축약카이제곱을 자주 이용한다.
(3.66)
보통 잘된 맞춤에서는 축약 카이제곱이 1에 가까워야 하나 좀 더 자세한 분석에서는 카이
제곱이 보다 클 확률 ≥ 를 구하기도 한다. ≥ 가 5% 보다 큰 경우에 맞춤
은 받아들일 만 하다고 말할 수 있다. 또 다른 주의할 점은 가 매우 작을 때이다. 이 경우
에는 데이터가 충분히 요동치지 않음을 말해 주는 것으로서 주로 데이터의 오차를 너무 크
게 할당한 경우에 해당한다.
(예 3.7.1) 다음 데이터를 기술하는 최적의 맞춤직선을 구하라.
(풀이) 식 (3.57) - (3.65)를 이용하면 다음의 결과를 얻을 수 있다.

- 66 -
(sec) 0 15 30 45 60 75 90 105 120 135
106 80 98 75 74 73 49 38 37 22
= 4.227, = 0.878, = 0.044, = 0.203, cov = -0.0629
그리고 맞춤이 얼마나 잘 되었는가를 판단하기 위하여 식 (3.57)을 이용하여 카이제곱을 구
하면 = 2.0788 임을 알 수 있다. 이때 독립적인 데이터 점이 모두 6개이고 2개의 변수
를 추출하였으므로 자유도 는 4이고, ≃ 0.5가 되어 좋은 맞춤임을 알 수 있다. 그리
고 4개의 자유도에 대하여 ≥ ≃ 97.5%가 되어 역시 좋은 맞춤임을 확인할 수
있다.
(예 3.7.2) 방사성 핵의 붕괴는 다음과 같이 지수함수에 의해 기술된다.
exp (3.67)
여기서 는 시간이고 는 = 0일 때 핵의 개수이며 는 평균수명이다. 매 15초 마다 방
사능 핵의 붕괴 사건의 수를 측정하여 다음 데이터를 얻었다. 이 핵의 평균수명은 얼마인
가?
(풀이) 식 (3.67)은 선형이 아니지만 양변에 로그를 취하면 선형으로 전환할 수 있다.
ln ln
식 (3.56)과 비교해 보면 ln , , ln이므로 최소제곱법을 이용할 수 있
다. 한 가지 주의할 점은 오차의 취급이다. 물론 은 푸아송분포이므로 통계적 오차는
이다. 그러나 맞춤에서는 ln이 사용되므로 오차전파 공식을 사용해야만 한다.
ln ln
식 (3.57)부터 (3.65)를 이용하면 = -0.008999, = 4.721, = 0.001, =
0.054를 얻으므로 = 111.1±0.1 sec이 된다. 이 때 축약카이제곱은 =
15.6/8 = 1.96으로 1 보다 좀 높은 것을 알 수 있다. 좀 더 자세히 맞춤의 질을 살펴보기
위해 카이제곱확률 ≥ ≃ 15% 임을 보면 겨우 받아들일 수 있는 조건임을 알 수
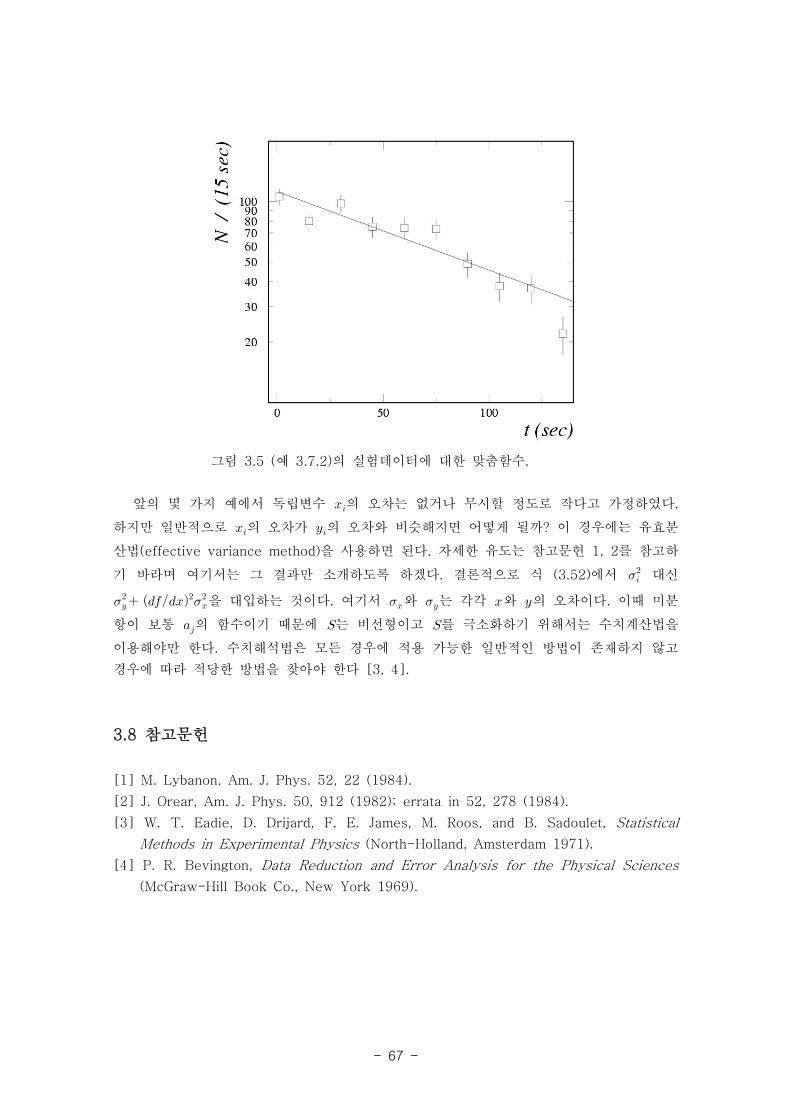
있다. 그림 3.5는 데이터 점들과 최적의 맞춤 선형함수를 보여주고 있다. 이와 같이 맞춤의
질이 만족할 만한 수준에 이르지 못할 때는 배경사건(background)의 포함여부 또는 방사능
핵에 다른 핵종이 섞여있을 가능성 등에 대하여 조사해 봐야 한다.
- 67 -
그림 3.5 (예 3.7.2)의 실험데이터에 대한 맞춤함수.
앞의 몇 가지 예에서 독립변수 의 오차는 없거나 무시할 정도로 작다고 가정하였다.
하지만 일반적으로 의 오차가 의 오차와 비슷해지면 어떻게 될까? 이 경우에는 유효분
산법(effective variance method)을 사용하면 된다. 자세한 유도는 참고문헌 1, 2를 참고하
기 바라며 여기서는 그 결과만 소개하도록 하겠다. 결론적으로 식 (3.52)에서 대신
을 대입하는 것이다. 여기서 와 는 각각 와 의 오차이다. 이때 미분
항이 보통 의 함수이기 때문에 는 비선형이고 를 극소화하기 위해서는 수치계산법을
이용해야만 한다. 수치해석법은 모든 경우에 적용 가능한 일반적인 방법이 존재하지 않고
경우에 따라 적당한 방법을 찾아야 한다 [3, 4].
3.8 참고문헌
[1] M. Lybanon, Am. J. Phys. 52, 22 (1984).
[2] J. Orear, Am. J. Phys. 50, 912 (1982); errata in 52, 278 (1984).
[3] W. T. Eadie, D. Drijard, F. E. James, M. Roos, and B. Sadoulet, Statistical
Methods in Experimental Physics (North-Holland, Amsterdam 1971).
[4] P. R. Bevington, Data Reduction and Error Analysis for the Physical Sciences
(McGraw-Hill Book Co., New York 1969).























![[분석]웹툰의 OSMU 가능성 예측을 위한 통계적 모델링](https://img.pdfslide.tips/doc/110x75/58cf18c91a28abc05f8b4ddf/-osmu-.jpg)





