Embed Size (px)
Citation preview

Klasifikacija – dodatne metode
Nenad MitićMatematički fakultet

Klasifikatori zasnovani na pravilima
� Slogovi se klasifikuju pomoću skupa pravila oblika “if…then…”
� Pravilo: (Uslov) → y� gde je
� Uslov konjunkcija atributa� y je oznaka klase
� Leva strana pravila: (pred)uslov� Desna strana pravila: posledica� Primer pravila za klasifikaciju:
� (Tip krvi=Topla ∧ (Nosi jaja=Da) → Ptice� (Oporezivi prihod < 50K) ∧ (Vraća=Da) → izbegava=Ne
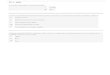
Klasifikatori zasnovani na pravilima (primer)
R1: (Give Birth = no) ∧ (Can Fly = yes) → BirdsR2: (Give Birth = no) ∧ (Live in Water = yes) → FishesR3: (Give Birth = yes) ∧ (Blood Type = warm) → MammalsR4: (Give Birth = no) ∧ (Can Fly = no) → ReptilesR5: (Live in Water = sometimes) → Amphibians
Name Blood Type Give Birth Can Fly Live in Water Classhuman warm yes no no mammalspython cold no no no reptilessalmon cold no no yes fisheswhale warm yes no yes mammalsfrog cold no no sometimes amphibianskomodo cold no no no reptilesbat warm yes yes no mammalspigeon warm no yes no birdscat warm yes no no mammalsleopard shark cold yes no yes fishesturtle cold no no sometimes reptilespenguin warm no no sometimes birdsporcupine warm yes no no mammalseel cold no no yes fishessalamander cold no no sometimes amphibiansgila monster cold no no no reptilesplatypus warm no no no mammalsowl warm no yes no birdsdolphin warm yes no yes mammalseagle warm no yes no birds
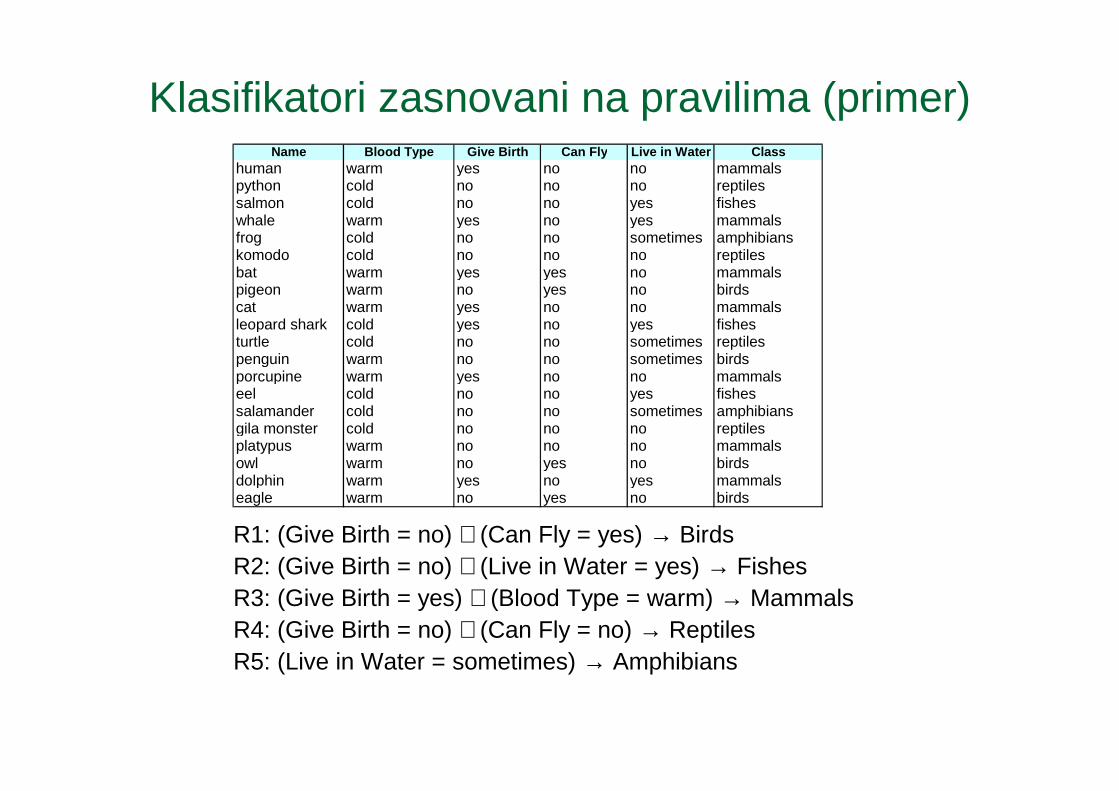
Primena klasifikatora zasnovanih na pravilima
� Pravilo r pokriva(obuhvata) instancu x ako atribut instance zadovoljava uslov pravila
R1: (Give Birth = no) ∧ (Can Fly = yes) → BirdsR2: (Give Birth = no) ∧ (Live in Water = yes) → Fishes
R3: (Give Birth = yes) ∧ (Blood Type = warm) → Mammals
R4: (Give Birth = no) ∧ (Can Fly = no) → ReptilesR5: (Live in Water = sometimes) → Amphibians
Pravilo R1 pokriva hawk => Bird
Pravilo R3 pokriva grizzly bear => Mammal
Name Blood Type Give Birth Can Fly Live in Water Classhawk warm no yes no ?grizzly bear warm yes no no ?
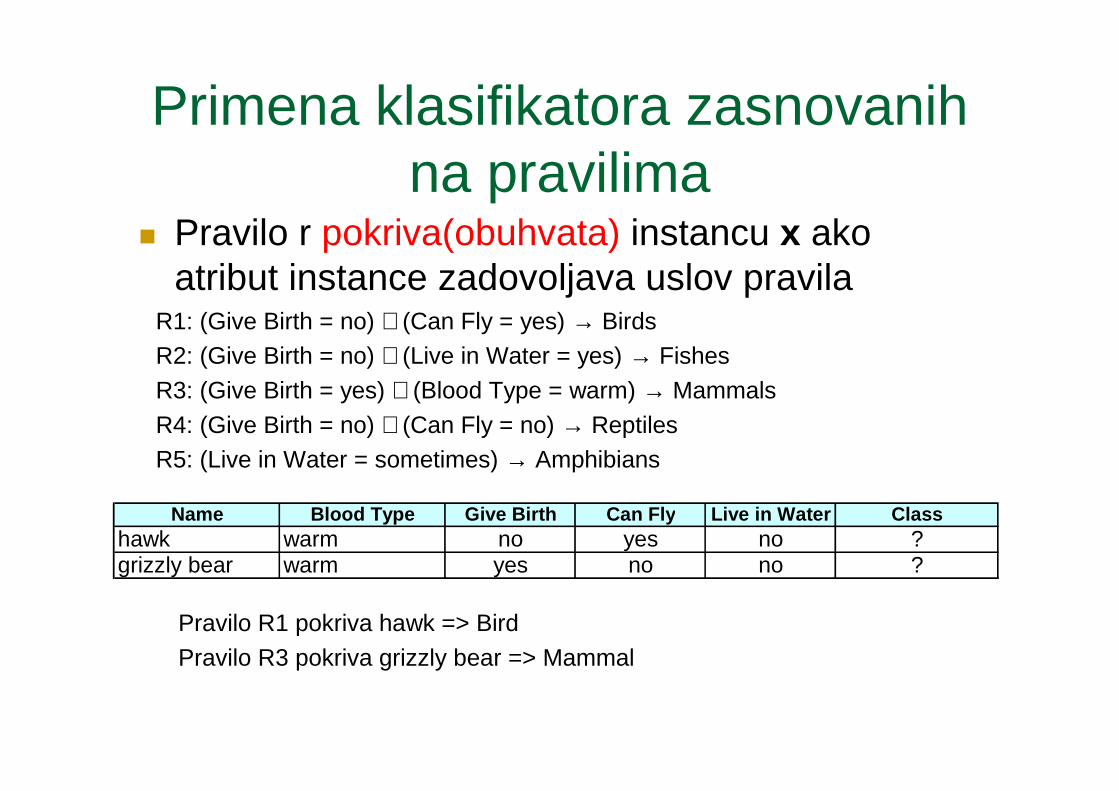
Preciznost (pouzdanost) i odziv pravila
� Odziv pravila:� Procenat broja slogova
koji zadovoljavaju levu stranu pravila
� Preciznost pravila:� Procenat broja slogova
koji zadovoljavaju desnu stranu pravila od slogova koji zadovoljavaju levu stranu pravila
Tid Refund Marital Status
Taxable Income Class
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes 10
(Status=Single) →→→→ NoCoverage = 40%, Accuracy = 50%

Način rada klasifikatora zasnovanog na pravilima
R1: (Give Birth = no) ∧ (Can Fly = yes) → Birds
R2: (Give Birth = no) ∧ (Live in Water = yes) → FishesR3: (Give Birth = yes) ∧ (Blood Type = warm) → Mammals
R4: (Give Birth = no) ∧ (Can Fly = no) → Reptiles
R5: (Live in Water = sometimes) → Amphibians
Lemur zadovoljava pravilo R3, pa je klasifikovan kao sisar
Kornjača zadovoljava pravila R4 i R5 (klasa?)
Male ajkule ne zadovoljavaju ni jedno od navedenih pravila (klasa ?)
N am e B lood Type G ive B irth Can F ly L ive in W ater C lasslem ur warm yes no no ?turtle cold no no som etim es ?dogfish shark cold yes no yes ?

Karakteristike klasifikatora zasnovnog na pravilima
� Uzajamno isključiva pravila� Klasifikator sadrži uzajamno isključiva pravila ako su
ona meñusobno nezavisna� Svaki slog je pokriven bar jednim pravilom
� Pravila pokrivaju sve mogućnosti� Klasifikator poseduje potpuno pokrivanje ako sadrži
kombinaciju pravila za sve moguće vrednosti atributa� Svaki slog je pokriven bar jednim pravilom
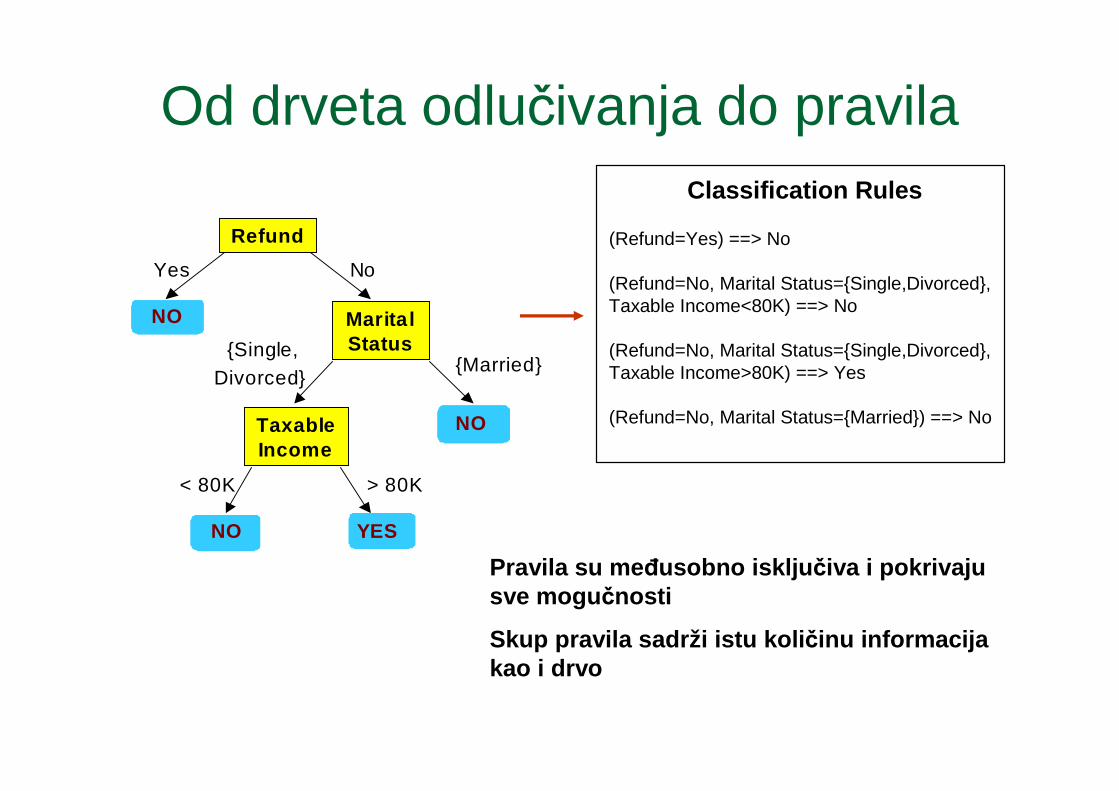
Od drveta odlučivanja do pravila
YESYESNONO
NONO
NONO
Yes No
{Married}{Single,
Divorced}
< 80K > 80K
Taxable Income
Marita l Status
Refund
Classification Rules
(Refund=Yes) ==> No
(Refund=No, Marital Status={Single,Divorced},Taxable Income<80K) ==> No
(Refund=No, Marital Status={Single,Divorced},Taxable Income>80K) ==> Yes
(Refund=No, Marital Status={Married}) ==> No
Pravila su me ñusobno isklju čiva i pokrivaju sve mogu čnosti
Skup pravila sadrži istu koli činu informacija kao i drvo
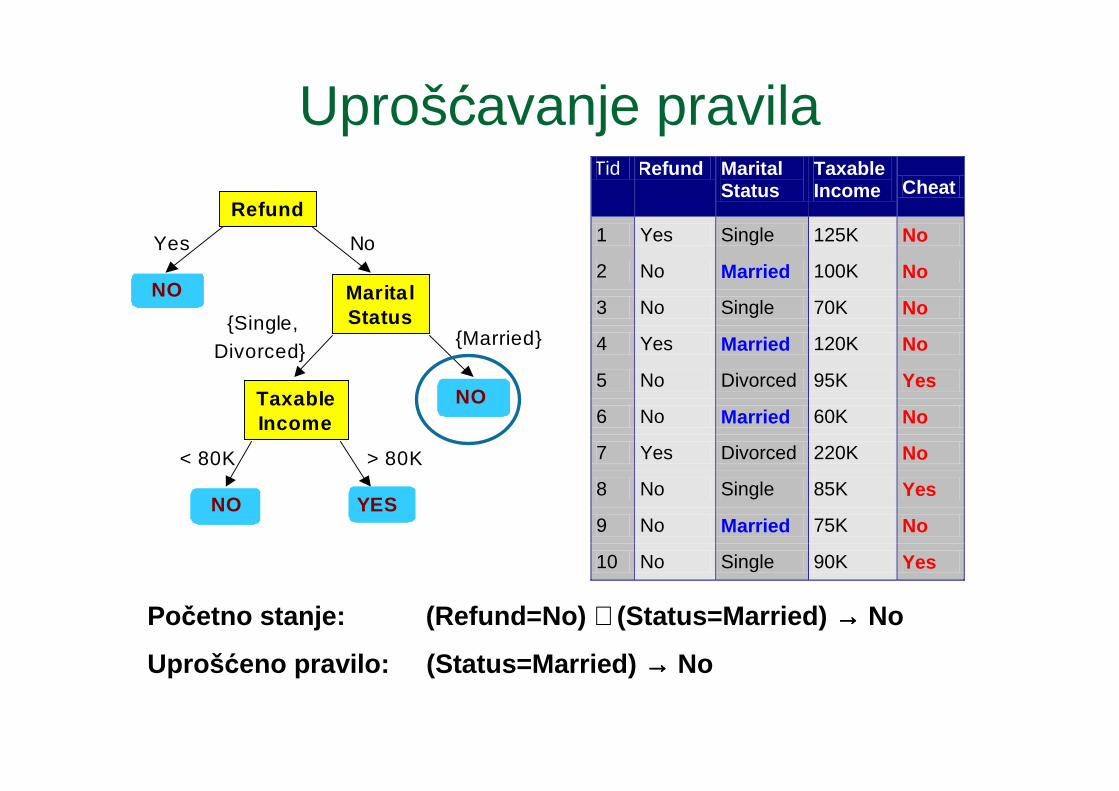
Uprošćavanje pravila
YESYESNONO
NONO
NONO
Yes No
{Married}{Single,
Divorced}
< 80K > 80K
Taxable Income
Marita l Status
Refund
Tid Refund Marital Status
Taxable Income Cheat
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes 10
Početno stanje: (Refund=No) ∧ (Status=Married) →→→→ No
Uproš ćeno pravilo: (Status=Married) →→→→ No

Efekat uprošćavanja pravila� Pravila nisu uzajamno isključiva
� Neke slogove može da pokriva više pravila� Rešenje?
� Skup pravila ureñen po redosledu� Neureñen skup pravila – koristi se izbor (glasački sistem)
� Pravila ne moraju da pokrivaju sve mogućnosti� Može da se desi da neki slog nije pokriven niti jednim
pravilom� Rešenje?
� Koristi se predefinisana (default) klasa

Skup pravila ureñen po redosledu
� Pravila se rangiraju prema njihovom prioritetu� Ureñen skup pravila je poznat i kao lista odlučivanja
� Kada se testni slog preda klasifikatoru� Dodeli mu se oznaka klase najvišeg ranga za koju postoji neko pravilo
koje pokriva taj slog
� Ako takvo pravilo ne postoji, dodeljuje mu se predefinisana klasa.
R1: (Give Birth = no) ∧ (Can Fly = yes) → BirdsR2: (Give Birth = no) ∧ (Live in Water = yes) → Fishes
R3: (Give Birth = yes) ∧ (Blood Type = warm) → Mammals
R4: (Give Birth = no) ∧ (Can Fly = no) → ReptilesR5: (Live in Water = sometimes) → Amphibians
Name Blood Type Give Birth Can Fly Live in Water Classturtle cold no no sometimes ?

Šeme odreñivanja ureñenja
� Ureñenje zasnovano na pravilima� Pojedinačna pravila se rangiraju prema njihovom kvalitetu
� Ureñenje zasnovano na klasama� Pravila koja pripadaju istoj klasi se grupišu jedno do drugog

Formiranje pravila klasifikacije
� Direktna metoda: � Pravila se izdvajaju direktno iz podataka� na primer: RIPPER, CN2, 1R
� Indirektna metoda:� Pravila se izdvajaju iz drugih klasifikacionih modela (npr.
drveta odlučivanja, neuronskih mreža, itd)� na primer: C4.5rules

Direktna metoda: sekvencijalno pokrivanje
1. Počinje se od praznog skupa pravila2. Pravila se izdvajaju za narednu klasu.
1. Pozitivi primeri – slogovi koji pripadaju toj klasi2. Negativni primeri – svi ostali slogovi
3. Skup pravila se proširuje korišćenjem funkcije Learn-One-Rule
4. Uklanjaju se slogovi za trening koji su pokriveni dodatim pravilom
5. Ponavljaju se koraci (2) i (3) do dostizanja kriterijuma zaustavljanja
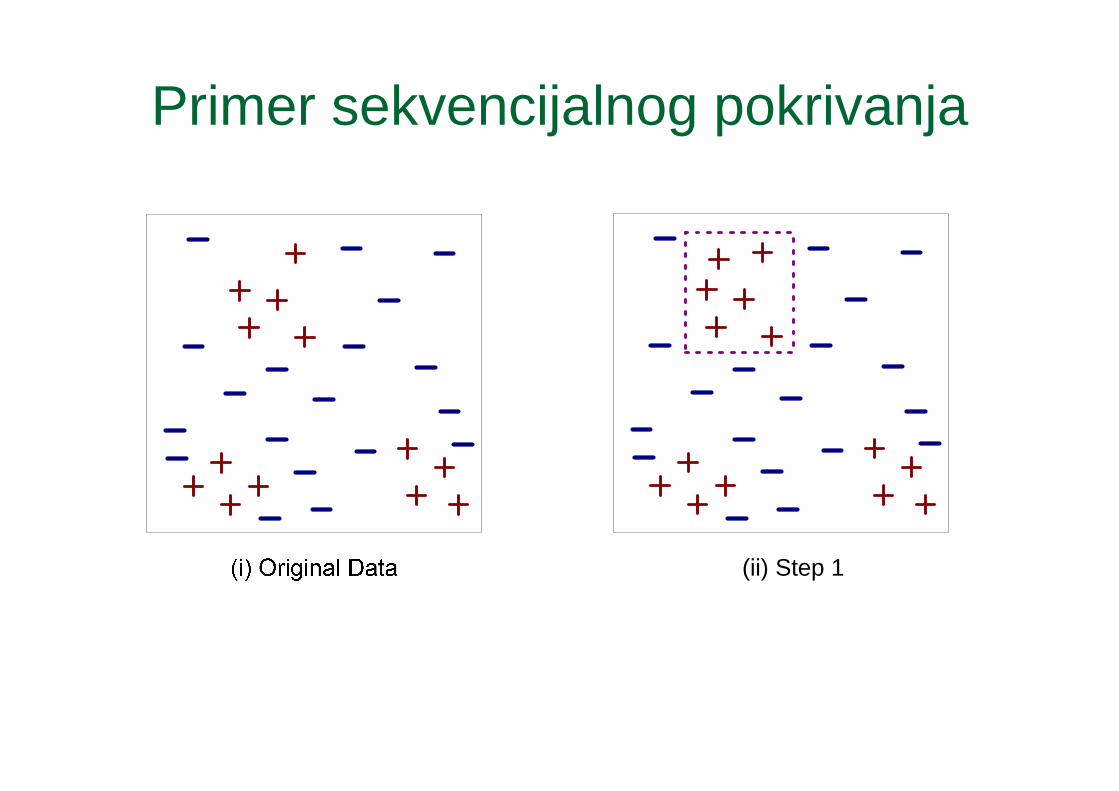
Primer sekvencijalnog pokrivanja
(ii) Step 1
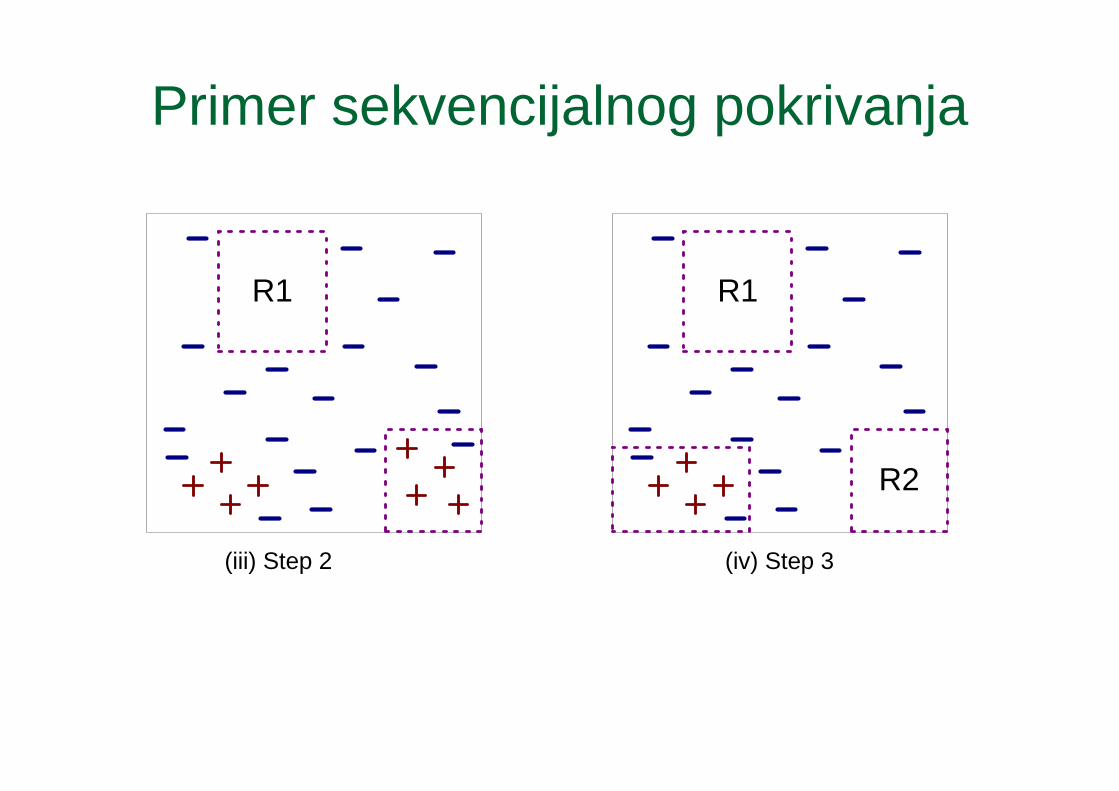
Primer sekvencijalnog pokrivanja
(iii) Step 2
R1
(iv) Step 3
R1
R2

Osobine sekvencijalnog pokrivanja
� Porast skupa pravila
� Eliminacija instanci
� Provera pravila
� Kriterijum zaustavljanja
� Potkresivanje (skupa) pravila
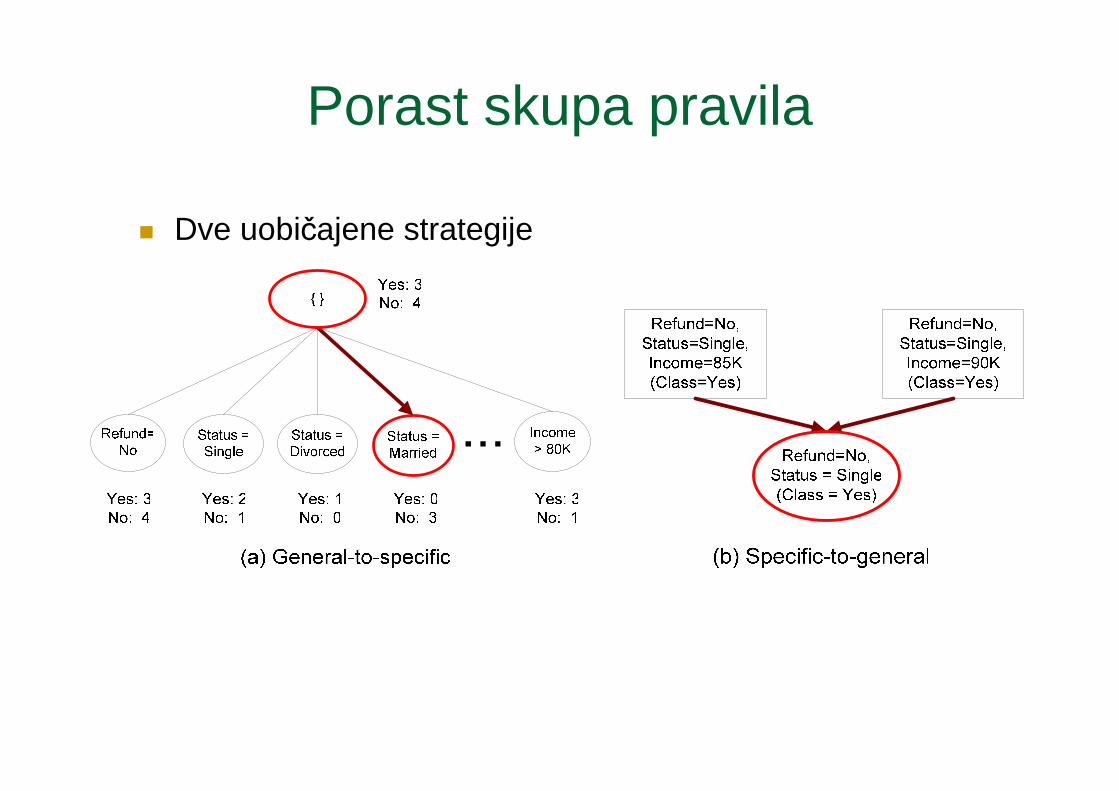
Porast skupa pravila
� Dve uobičajene strategije

Porast skupa pravila (primeri)
� CN2 algoritam:� Počni od praznog konjunkta: {}� Dodaj konjunkte koji minimizuju entropiju: {A}, {A,B}, …� Odredi redosled pravila uzimajući u najbrojnije klase instanci koje pokrivaju pravilo
� RIPPER algoritam:� Počni od praznog konjunkta : {} => class� Dodaj konjunkte koji maksimizuju FOIL-ovu meru dobiti kvaliteta informacije:
� R0: {} => class (početno pravilo)� R1: {A} => class (pravilo po dodavanju konjunkta)� Dobit(R0, R1) = t [ log (p1/(p1+n1)) – log (p0/(p0 + n0)) ]� gde je t broj instanci pokrivenih sa oba pravila R0 i R1 (tzv. pozitivne instance)
p0: broj pozitivnih instanci pokriven sa R0n0: broj negativnih instanci pokriven sa R0 (one koje nisu pokrivene sa R0)p1: broj pozitivnih instanci pokriven sa R1n1: broj negativnih instanci pokriven sa R1 (one koje nisu pokrivene sa R1)
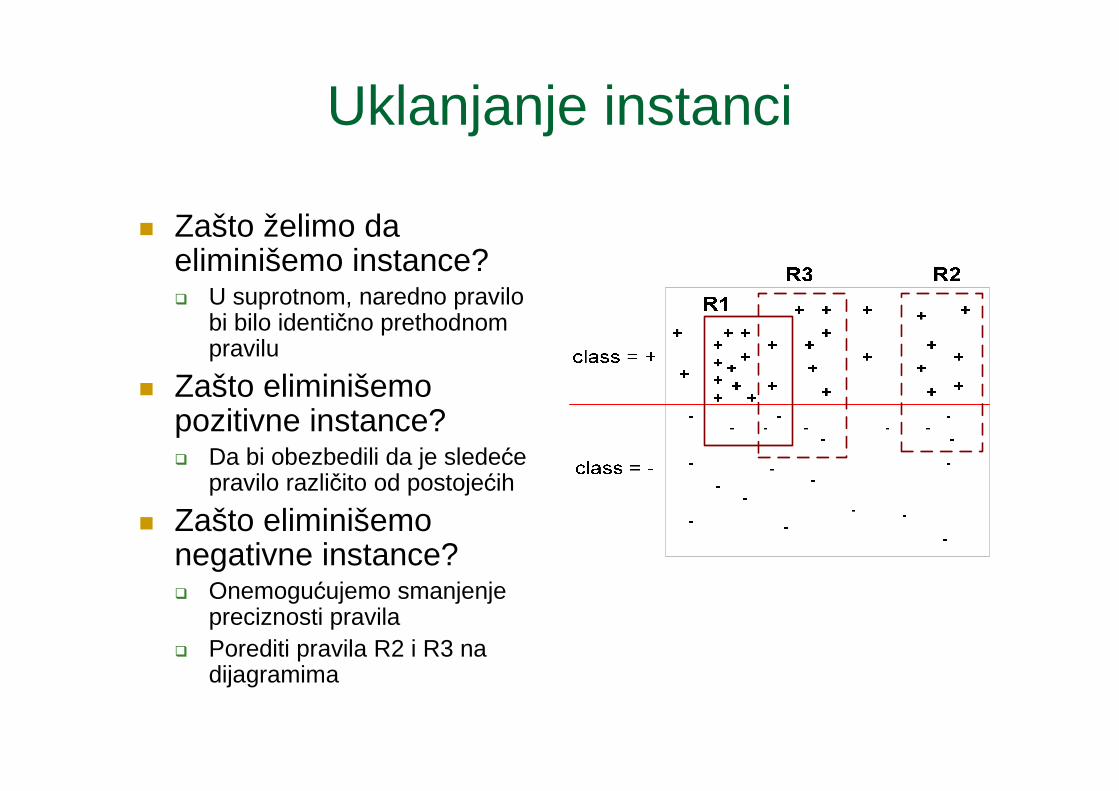
Uklanjanje instanci
� Zašto želimo da eliminišemo instance?� U suprotnom, naredno pravilo
bi bilo identično prethodnom pravilu
� Zašto eliminišemo pozitivne instance?� Da bi obezbedili da je sledeće
pravilo različito od postojećih
� Zašto eliminišemo negativne instance?� Onemogućujemo smanjenje
preciznosti pravila� Porediti pravila R2 i R3 na
dijagramima

Provera pravila
� Metrike:� Preciznost
� Laplas
� M-procenat
kn
nc
++= 1
kn
kpnc
++=
n : Broj instanci pokriven pravilom
nc : Broj pozitivnih instanci pokriven pravilom
k : Broj klasa
p : Ranija verovatnoća za pozitivne klase
n
nc=

Kriterijum zaustavljanja i potkresivanje pravila
� Kriterijum zaustavljanja� Izračunavanje dobiti� Ako dobit nije značajna, odbaci novo pravilo
� Potkresivanje pravila� Slično pokresivanju drveta odlučivanja� Smanjivanje greške potresivananjem:
� Ukloniti jedan od konjukata u pravilu� Porediti stari i novi nivo greške� Ako se greška povećava, isključiti konjunkt

Rezime direktnih metoda
� Rast (proširenje) pojedinačnog pravila
� Uklanjanje instanci iz pravila
� Pokresivanje pravila (po potrebi)
� Dodati pravilo u skup pravila
� Ponoviti postupak

Prednosti klasifikatora zasnovanih na pravilima
� Ista izražajna moć kao i drveta odlučivanja� Jednostavna interpretacija� Jednostavno formiranje
� Mogu brzo da klasifikuju nove instance� Performanse su uporedive sa drvetima
odlučivanja
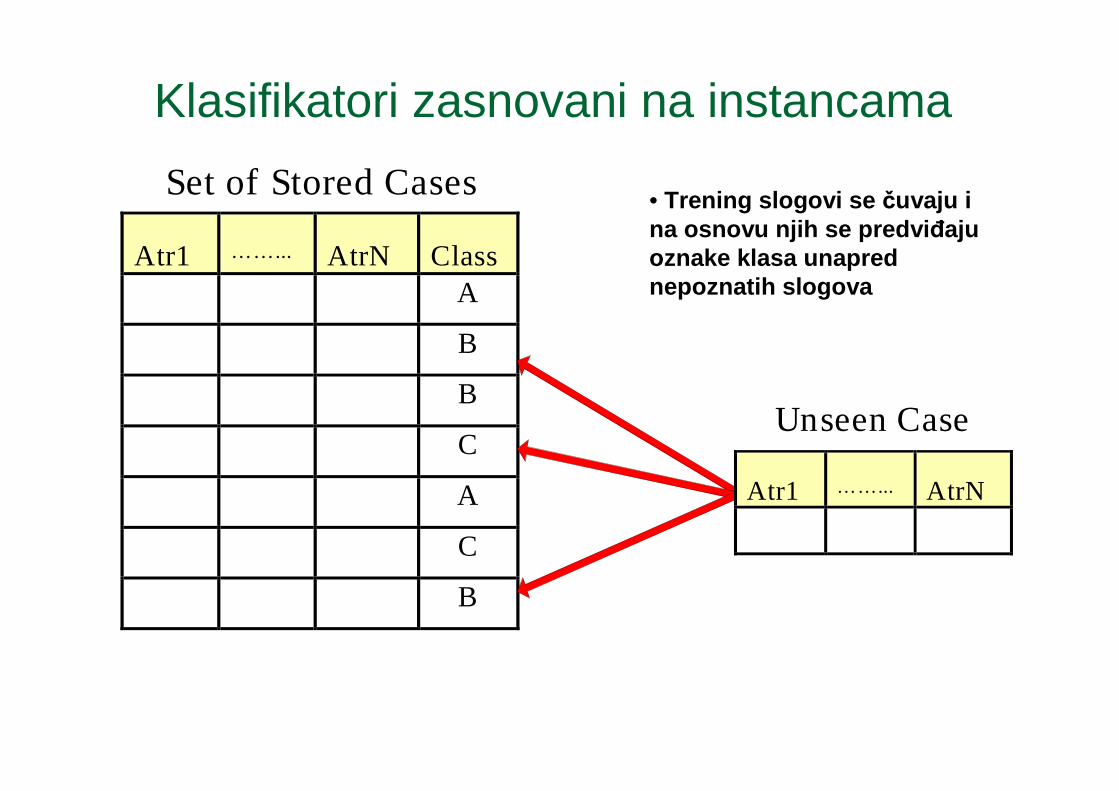
Klasifikatori zasnovani na instancama
Atr1 ……... AtrN ClassA
B
B
C
A
C
B
Set of Stored Cases
Atr1 ……... AtrN
Unseen Case
• Trening slogovi se čuvaju i na osnovu njih se predvi ñaju oznake klasa unapred nepoznatih slogova

Klasifikatori zasnovani na instancama
� Primeri:� Učenje napamet
� Čuva celokupan skup slogova za trening i sprovodi klasifikaciju samo ako se atributi novih slogova potpuno poklope sa atributima trening slogova
� Najbliži sused� Koristi k “najbližih” tačaka (najbližih suseda) za obavljanje klasifikacije
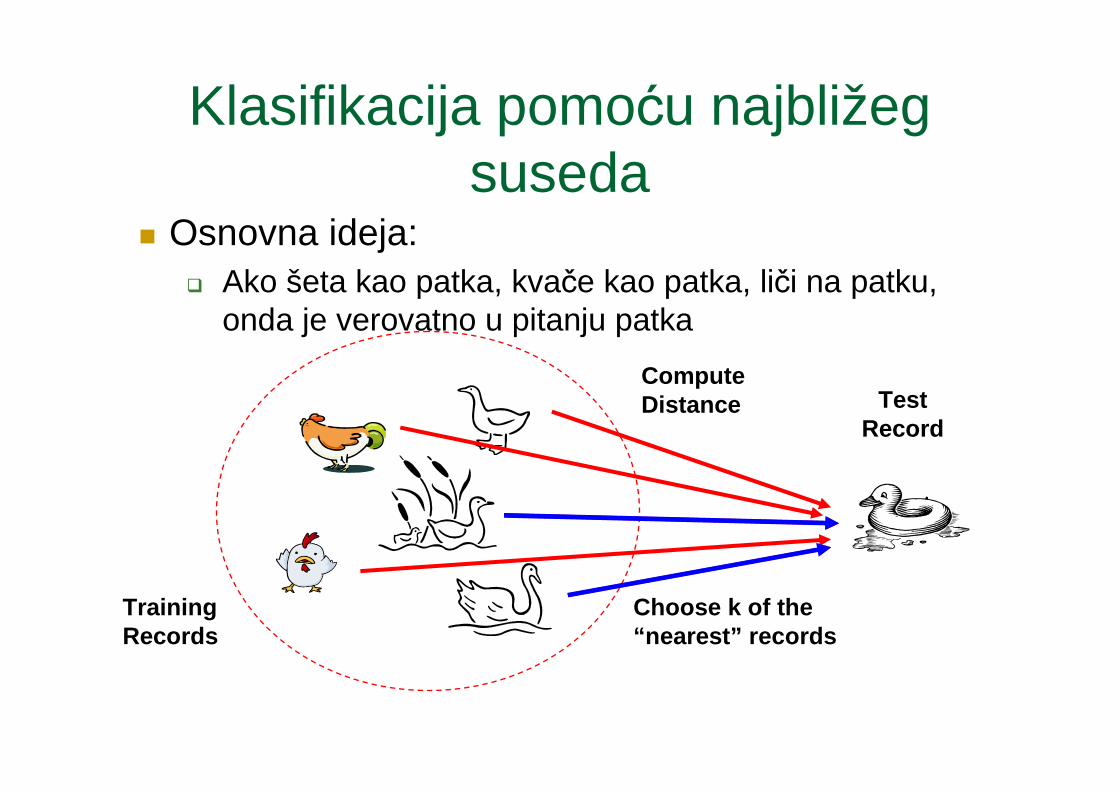
Klasifikacija pomoću najbližeg suseda
� Osnovna ideja:� Ako šeta kao patka, kvače kao patka, liči na patku,
onda je verovatno u pitanju patka
Training Records
Test Record
Compute Distance
Choose k of the “nearest” records
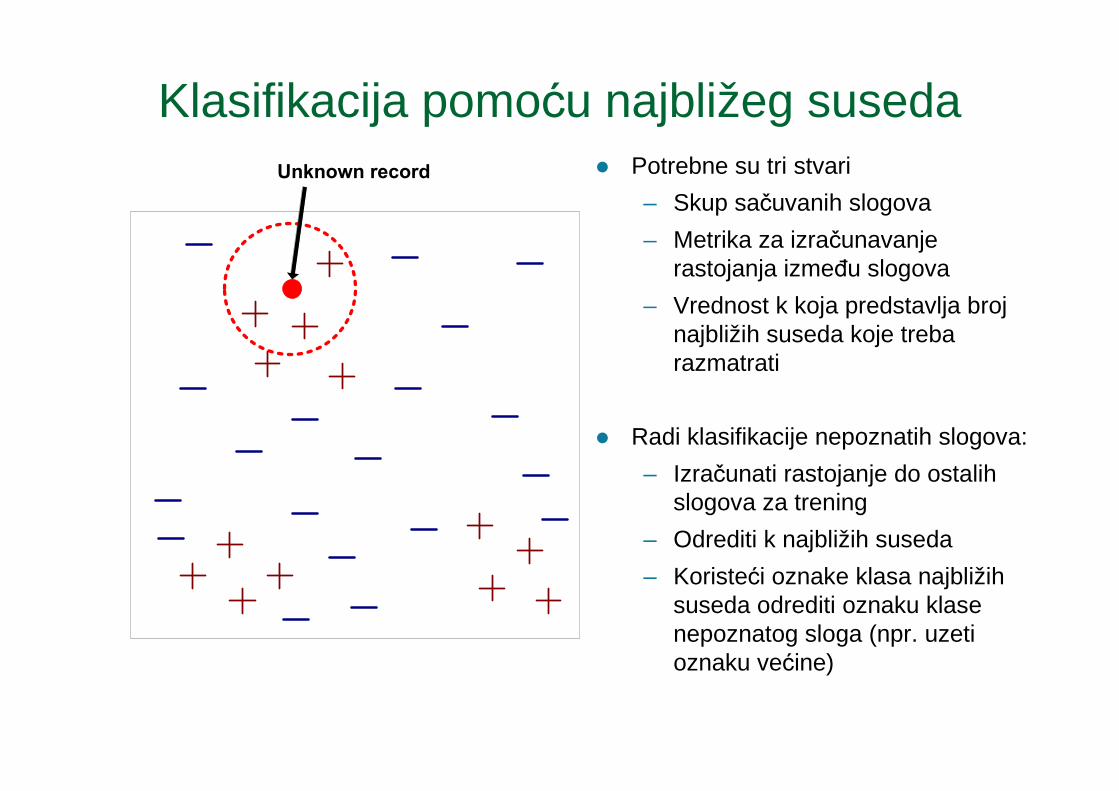
Klasifikacija pomoću najbližeg suseda� Potrebne su tri stvari
– Skup sačuvanih slogova
– Metrika za izračunavanje rastojanja izmeñu slogova
– Vrednost k koja predstavlja broj najbližih suseda koje treba razmatrati
� Radi klasifikacije nepoznatih slogova:
– Izračunati rastojanje do ostalih slogova za trening
– Odrediti k najbližih suseda
– Koristeći oznake klasa najbližih suseda odrediti oznaku klase nepoznatog sloga (npr. uzeti oznaku većine)
Unknown record

Definicija najbližeg suseda
X X X
(a) 1-nearest neighbor (b) 2-nearest neighbor (c) 3-nearest neighbor
K-najbližih suseda sloga x su podaci koji imaju k najmanjih rastojanja do x

1 najbliži sused
� Za dati skup tačaka dijagramVoronoi-a je podela prostora u regione unutar kojih su sve tačke bliže nekom pojedinačnom čvoru nego bilo kom drugom čvoru

Klasifikacija pomoću najbližeg suseda
� Izračunavanje rastojanja izmeñu dve tačke:� Euklidsko rastojanje
� Odrediti klasu iz liste najbližih suseda� uzeti oznaku klase većine od k-najbližih suseda� Rastojanja mogu da dobiju odreñene težine
� težinski faktor, w = 1/d2
∑ −=i ii
qpqpd 2)(),(
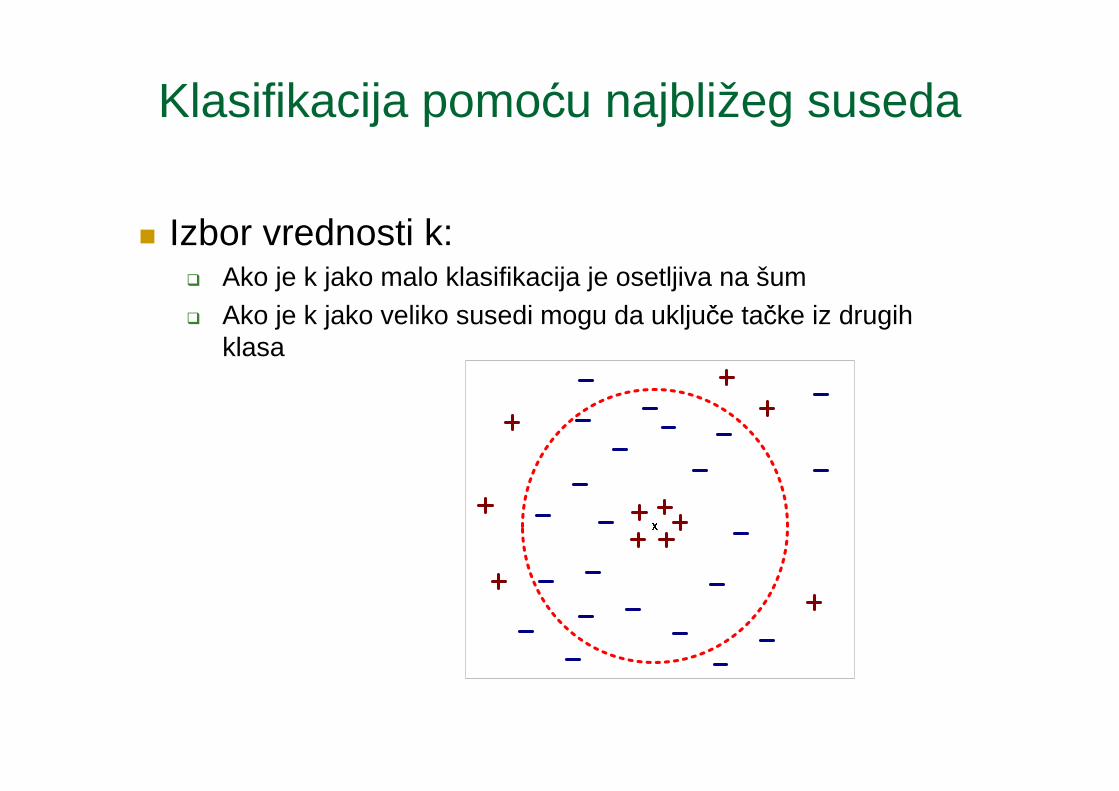
Klasifikacija pomoću najbližeg suseda
� Izbor vrednosti k:� Ako je k jako malo klasifikacija je osetljiva na šum� Ako je k jako veliko susedi mogu da uključe tačke iz drugih
klasa

Klasifikacija pomoću najbližeg suseda
� Skaliranje� Atributi mogu biti skalirani radi sprečavanja da u meri
rastojanja dominira jedan atribut
� Primer:� Visina osobe varira od 1.5m do 1.8m� Težina osobe varira od 50kg do 150kg� Prihod osobe varira od 20KD fo 20MD

Klasifikacija pomoću najbližeg suseda
� Problem euklidskog rastojanja:� Višedimenzionalni podaci� Mogu da se jave brojački-intuitivni rezultati
1 1 1 1 1 1 1 1 1 1 1 0
0 1 1 1 1 1 1 1 1 1 1 1
1 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 1vs
d = 1.4142 d = 1.4142
� Rešenje: normalizacija vektora na iste jedinice

Klasifikacija pomoću najbližeg suseda
� k-NN klasifikatori su lenji� Model se ne pravi eksplicitno� Klasifikacija nepoznatih slogova je relativno skupa
� Domaći zadatak: pronaći primere klasifikacije ovom metodom u bar dve različite oblasti

Bajesovski klasifikatori
� Verovatnosno okruženje za rešavanje problemaklasifikacije
� Uslovne verovatnoće:
� Bajesova teorema:
)()()|(
)|(AP
CPCAPACP =
)(),(
)|(
)(),(
)|(
CP
CAPCAP
AP
CAPACP
=
=

Primer Bajesove teoreme� Dato je:
� Doktor zna da meningitis u 50% slučajeva prouzrokuje kočenje vrata� Prethodna (poznata) verovatnoća da bilo koji pacijent ima
meningitis je 1/50,000� Prethodna verovatnoća da bilo koji pacijent ima ukočen vrat je 1/20
� Ako pacijent ima ukočen vrat, koja je verovatnoća da ima i meningitis?
0002.020/150000/15.0
)()()|(
)|( =×==SP
MPMSPSMP

Bajesovski klasifikatori� Posmatrajmo svaki atribut i svaku oznaku klase kao
nezavisne promenljive
� Za dati slog sa atributima (A1, A2,…,An) � Cilj je predvideti klasu C kojoj pripada� Posebno, želimo da nañemo vrednost C koja maksimizira
P(C| A1, A2,…,An )
� Da li se može proceniti P(C| A1, A2,…,An ) direktno na osnovu podataka?

Bajesovski klasifikatori� Pristup:
� izračunati posledičnu (eng. posterior) verovatnoću P(C | A1, A2, …, An) za sve vrednosti C koristeći Bajesovu teoremu
� Izabrati vrednost C koja maksimizujeP(C | A1, A2, …, An)
� Ekvivalentno, možemo da uzmemo i vrednost C koja maksimizuje P(A1, A2, …, An|C) P(C)
� Kako proceniti P(A1, A2, …, An | C )?
)()()|(
)|(21
21
21
n
n
n AAAP
CPCAAAPAAACP
ΚΚΚ =

Naivni Bajesovski klasifikatori
� Za datu klasu pretpostavimo nezavisnost izmeñu atributa Ai: � P(A1, A2, …, An |C) = P(A1| Cj) P(A2| Cj)… P(An| Cj)
� Može se izvršiti procena P(Ai| Cj) za svako Ai i Cj.
� Nove tačke su klasifikovane u Cj ako je P(Cj) Π P(Ai| Cj) maksimalan
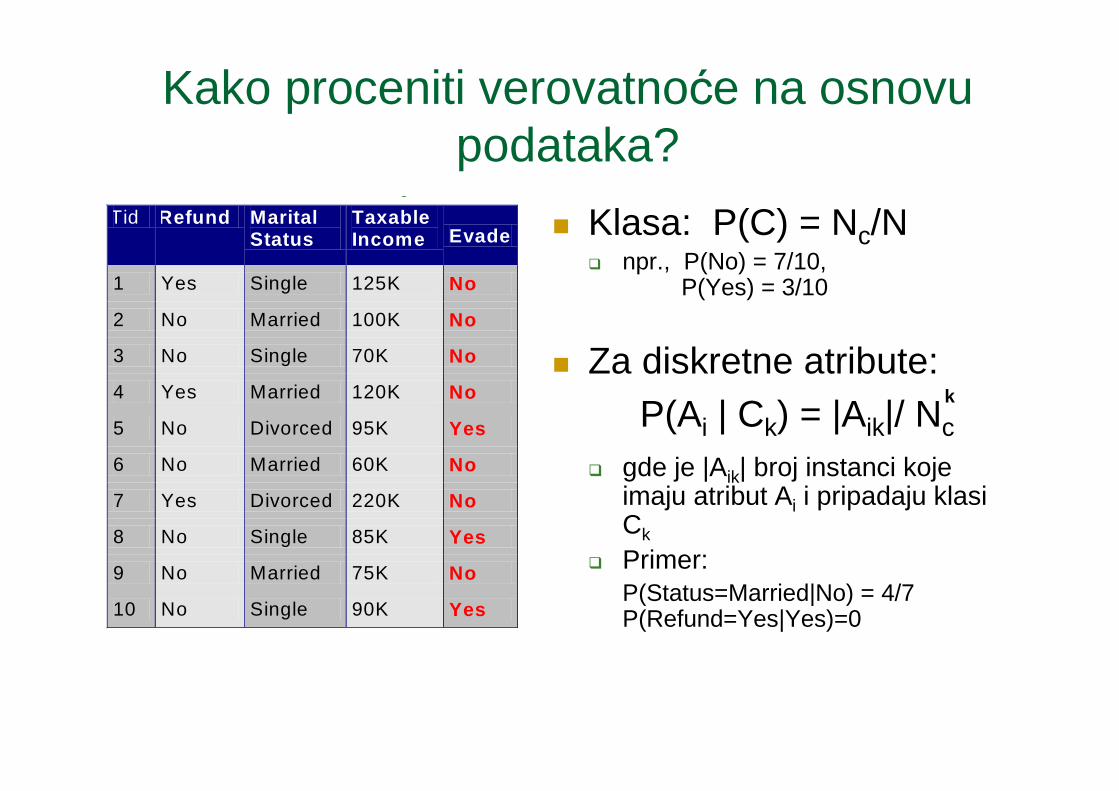
Kako proceniti verovatnoće na osnovu podataka?
� Klasa: P(C) = Nc/N� npr., P(No) = 7/10,
P(Yes) = 3/10
� Za diskretne atribute:P(Ai | Ck) = |Aik|/ Nc
� gde je |Aik| broj instanci koje imaju atribut Ai i pripadaju klasi Ck
� Primer:P(Status=Married|No) = 4/7P(Refund=Yes|Yes)=0
k
Tid Refund Marital Status
Taxable Income Evade
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes 10
categoric
al
categoric
al
continuous
class

Kako proceniti verovatnoće na osnovu podataka?
� Za neprekidne atribute: � Diskretizacija u grupe
� jedan redni atribut po grupi� kršenje pretpostavke o nezavisnosti
� Podela na dva dela: (A < v) or (A > v)� bira se samo jedan od dva segmenta kao novi atribut
� Procena gustine verovatnoće:� Pretpostavimo da atributi imaju normalnu raspodelu� Koristiti podatke za procenu parametara distribucije (npr.
sredine ili standardne devijacije)� Kada je raspodela verovatnoća poznata ona se može koristiti
za procenu uslovnih verovatnoća P(Ai|c)
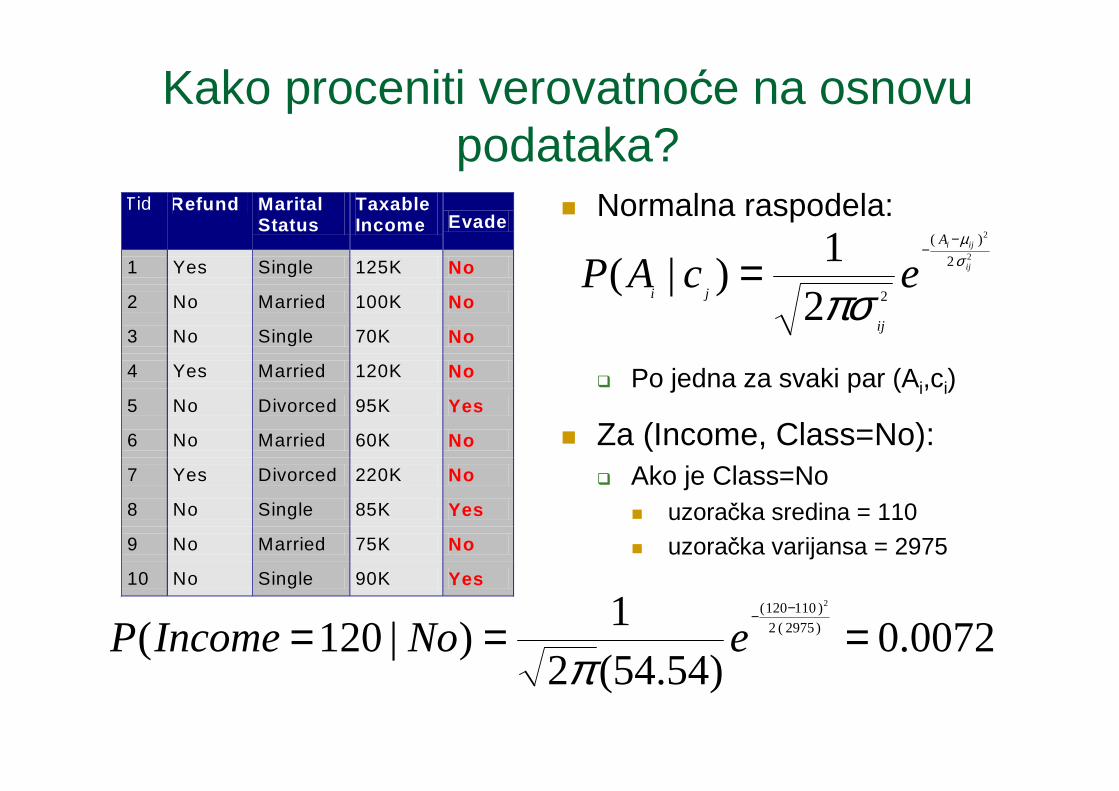
Kako proceniti verovatnoće na osnovu podataka?
� Normalna raspodela:
� Po jedna za svaki par (Ai,ci)
� Za (Income, Class=No):� Ako je Class=No
� uzoračka sredina = 110� uzoračka varijansa = 2975
Tid Refund Marital Status
Taxable Income Evade
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes 10
categoric
al
categoric
al
continuous
class
2
2
2
)(
221
)|( ij
ijiA
ij
jiecAP σ
µ
πσ
−−
=
0072.0)54.54(2
1)|120( )2975(2
)110120( 2
===−−
eNoIncomePπ

Primer naivnih Bajesovskih klasifikatora
P(Refund=Yes|No) = 3/7P(Refund=No|No) = 4/7P(Refund=Yes|Yes) = 0P(Refund=No|Yes) = 1P(Marital Status=Single|No) = 2/7P(Marital Status=Divorced|No)=1/7P(Marital Status=Married|No) = 4/7P(Marital Status=Single|Yes) = 2/7P(Marital Status=Divorced|Yes)=1/7P(Marital Status=Married|Yes) = 0
For taxable income:If class=No: sample mean=110
sample variance=2975If class=Yes: sample mean=90
sample variance=25
naive Bayes Classifier:
120K)IncomeMarried,No,Refund( ===X
� P(X|Class=No) = P(Refund=No|Class=No)× P(Married| Class=No)× P(Income=120K| Class=No)
= 4/7 × 4/7 × 0.0072 = 0.0024
� P(X|Class=Yes) = P(Refund=No| Class=Yes)× P(Married| Class=Yes)× P(Income=120K| Class=Yes)
= 1 × 0 × 1.2 × 10-9 = 0
Pošto P(X|No)P(No) > P(X|Yes)P(Yes)
Tada je P(No|X) > P(Yes|X) => Class = No
Za dati test slog:

Naivni Bajesovski klasifikatori
� Ako je jedna od uslovnih verovatnoća jednaka nuli, tada je i celokupna verovatnoća nula
� Procena verovatnoće:
mN
mpNCAP
cN
NCAP
N
NCAP
c
ici
c
ici
c
ici
++=
++=
=
)|(:procena-m
1)|(:Laplas
)|( :Original c: broj klasa
p: prethodna verovatnoća
m: parametar
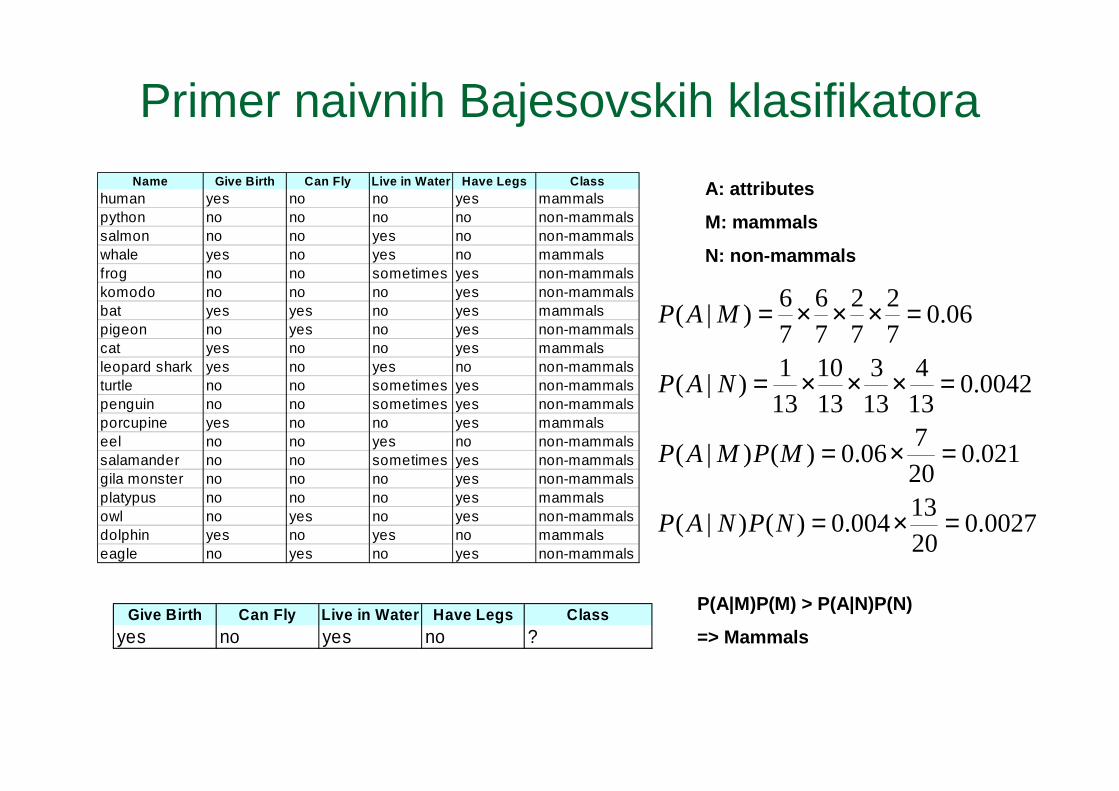
Primer naivnih Bajesovskih klasifikatoraName Give Birth Can Fly Live in Water Have Legs Class
human yes no no yes mammalspython no no no no non-mammalssalmon no no yes no non-mammalswhale yes no yes no mammalsfrog no no sometimes yes non-mammalskomodo no no no yes non-mammalsbat yes yes no yes mammalspigeon no yes no yes non-mammalscat yes no no yes mammalsleopard shark yes no yes no non-mammalsturtle no no sometimes yes non-mammalspenguin no no sometimes yes non-mammalsporcupine yes no no yes mammalseel no no yes no non-mammalssalamander no no sometimes yes non-mammalsgila monster no no no yes non-mammalsplatypus no no no yes mammalsowl no yes no yes non-mammalsdolphin yes no yes no mammalseagle no yes no yes non-mammals
Give Birth Can Fly Live in Water Have Legs Classyes no yes no ?
0027.02013
004.0)()|(
021.0207
06.0)()|(
0042.0134
133
1310
131
)|(
06.072
72
76
76
)|(
=×=
=×=
=×××=
=×××=
NPNAP
MPMAP
NAP
MAP
A: attributes
M: mammals
N: non-mammals
P(A|M)P(M) > P(A|N)P(N)
=> Mammals

Naivni Bajesovki klasifikatori -rezime
� Robusni su u odnosu na izolovani šum
� Barata nedostajućim vrednostima ignorišući instancu pri izračunavanju procene verovatnoće
� Robusni su u odnosu na irelevantne atribute
� Pretpostavka nezavisnost ne mora da važi za sve atribute� U tom slučaju se koriste druge tehnike kao
Bajesovske mreže poverenja (Bayesian Belief Networks, BBN)

Regresija� Regresija je proces pronalaženja ciljne funkcije f
koja preslikava skup x u izlaz y sa neprekidnim vrednostima.
� Cilj regresije je naći ciljnu funkciju koja može da ukalupi ulazne podatke sa minimalnom greškom.
� Greška može biti izražena preko apsolutne greške ili kvadrata greške.
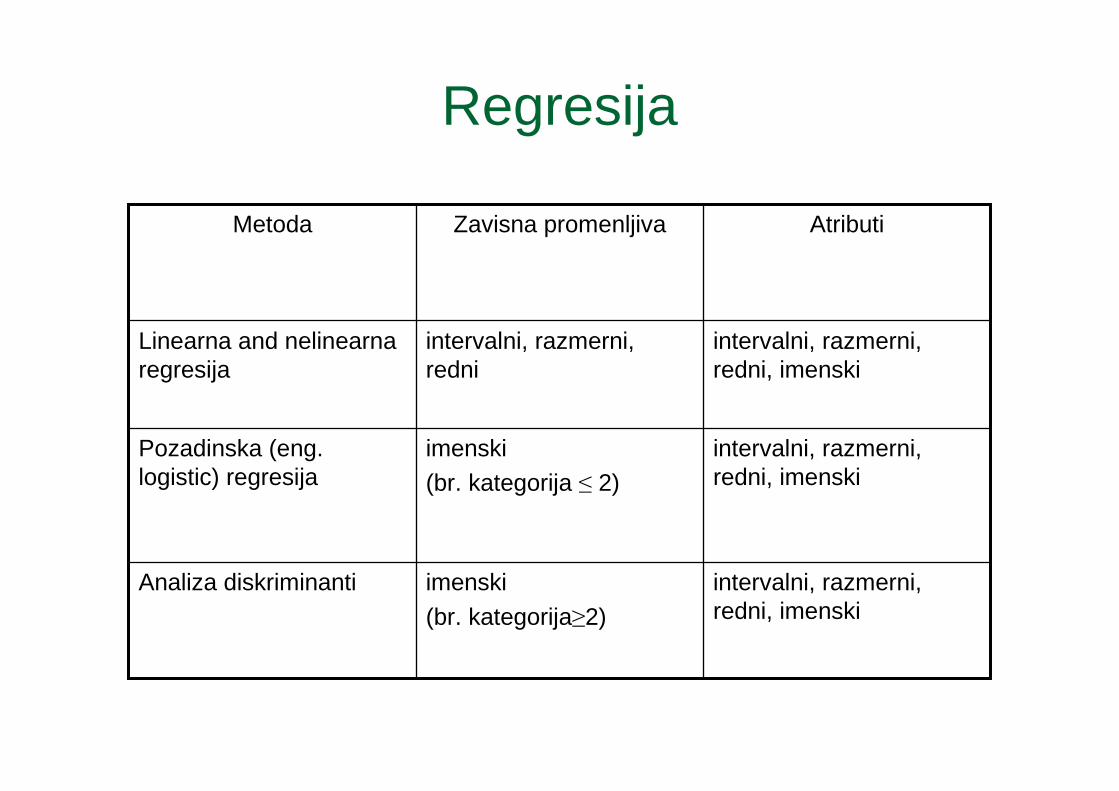
Regresija
intervalni, razmerni, redni, imenski
imenski
(br. kategorija≥2)
Analiza diskriminanti
intervalni, razmerni, redni, imenski
imenski(br. kategorija ≤ 2)
Pozadinska (eng. logistic) regresija
intervalni, razmerni, redni, imenski
intervalni, razmerni, redni
Linearna and nelinearnaregresija
AtributiZavisna promenljivaMetoda

Tipovi linearne i nelinearne regresije
� Obična regresija (sa metodom najmanjih kvadrata)
� Prosta linearna regresija
� Polinomijalna regresija� Linearna regresija po krivim (eng. curvilinear)� Nelinearna regresija
� Regresija sa težinskim najmanjim kvadratima� Robusna regresija (eng. robust regression)

Razlozi za ukalupljivanje podataka
� Interpolacija “unutar-izmeñu” y vrednosti
� Radi ekstrapolacije zbog predviñanja y vrednosti
� Radi odreñivanja vrednosti koeficijenata koji imaju fizičko značenje (npr. koeficijenta prenosa toplote, procene nekih konstanti, ...)

Jednačine koje se koriste u ukalupljivanju
� Empirijske jednačine� dobijene na osnovu matematičkih razmatranja� ne razmatraju šta je potrebno za formiranje podataka� koriste se jedino za interpolaciju� primena za ekstrapolaciju daje neizvesne rezultate
� Mehanističke jednačine� Dobijaju se iz analize situacije koju generišu podaci
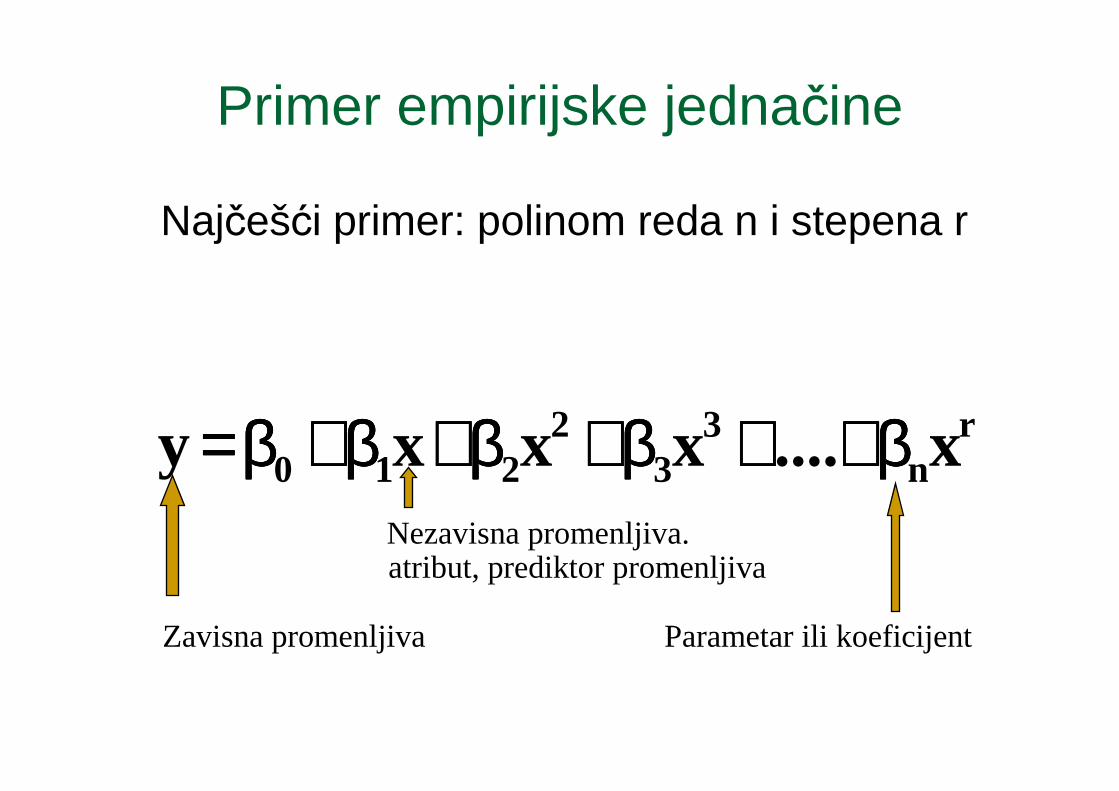
Primer empirijske jednačine
Najčešći primer: polinom reda n i stepena r
rn
33
2210 x....xxxy ββββ++++++++ββββ++++ββββ++++ββββ++++ββββ====
Zavisna promenljiva
Nezavisna promenljiva.
Parametar ili koeficijent
atribut, prediktor promenljiva

Klasifikacija metoda regresije: Linearnost jednačina
� Linearna regresija: jednačine su linearne sa nepoznatim parametrima. Moguće je da postoji nelinearnost u nezavisnim promenljivima.
� Nelinearna regresija: jednačine su nelinearne sa nepozantim parametrima.

Tipovi linearnih regresija
� Prosta linearna regresija (eng. Simple Linear Regression, SLR):
xy 10 ββββ++++ββββ====
• Višestruka linearna regresija:• Ostale linearne jednačine sa nepoznatim parametrima• Može da uključi više od jedne nezavisne promenljive• Uključuje polinomijalnu regresiju

Primeri jednačina koje se podvode pod u višestruku linearnu regresiju
2210 xxy ββββ++++ββββ++++ββββ====
21322110 xxxxy ββββ++++ββββ++++ββββ++++ββββ====
3213
222110 xxxxy ββββ++++ββββ++++ββββ++++ββββ====

Linearnost jednačina
Test linearnosti jednačina
Linearnost u parametrima
Nelinearnost u parametrima
Linearnaregresija
SLR MLR
Nelinearna regresija



![E nakagawaol [更新済み]...TEL:052-972-3523 FAX:052-962-4030 ・ … ・ … 1 2 3 4 5 避難ガイド ナゴヤ ・ ・ ・ NO NO NO YES YES YES NO YES 台風11 号 避難勧告](https://img.pdfslide.tips/doc/110x75/5e5e7d9a97b34e5b6d1a3497/e-nakagawaol-teli052-972-3523-faxi052-962-4030-f-f-1.jpg)