Embed Size (px)
Citation preview

A Kinematic Model for Human Motion and Gait Analysis
Shiloh L. Dockstader†‡ and A. Murat Tekalp‡* ‡Dept. of Electrical and Computer Engineering, University of Rochester, Rochester, NY 14627
*College of Engineering, Koç University, Istanbul, Turkey URL: http://www.ece.rochester.edu/~dockstad/research/
† Corresponding Author: [email protected]
Abstract
This work introduces a new model-based approach towards the 3-D tracking of human motion. We suggest a parametric body model, with both coarse and fine res-olution levels, characterized by hard and soft kinematic constraints. The hard constraints place physical limi-tations on possible model configurations while the soft constraints take the form of a priori, stochastic distributions learned from previous examples of human body configurations. This prior knowledge is used to define a natural acceleration of body parameters towards their expected values. Coupled with the hierarchical structural model, these kinematic constraints yield tracking that is robust to complex motion and occlusions. We demonstrate the utility of the proposed model on video sequences of human motion captured in a home environment.
1. Introduction
The analysis of human motion and gait finds consid-erable utility in applications ranging from the develop-ment of more intelligent human-computer interfaces and visual surveillance systems to the video-based inter-pretation of mobility disorders. To measure and interpret human motion, one must first perceive it. This perception is most comfortably and efficiently performed using sequences of visual data. Successful processing of this data often commands a strong foundation in kinematic, dynamic, and structural modeling; feature tracking; and, ultimately, some form of pattern understanding. In classical gait analysis, most information is derived from the trajectories of points on the human body that correspond to significant anatomical landmarks. For example, Song et al. [1] describe an approach for detecting and labeling the human body in monocular image sequences using Johansson displays. The method takes advantage of the Johansson markers to simplify the
tracking problem and subsequently uses the extracted spatio-temporal patterns of motion to perform human detection and labeling in a maximum-likelihood fashion. Other approaches to human motion and gait analysis have proposed the use of image and vector field templates [2], feature trajectories in 2-D and 3-D, and even articulated and kinematic object parameter trajectories [3]. Cunado et al. [4] suggest a method of gait extraction and description using the velocity Hough transform. They use an articulated model with a set of thick lines joined at a single point to represent the legs and a periodic, pendulum motion model to describe the gait pattern. In general, the most straightforward and reliable method for performing human motion and, in particular, gait analysis is one in which a parametric model is used to describe a set of image observations, from which a set of variables can more easily be extracted. Traditional 3-D modeling of moving people has employed volumetric bodies based on elliptical cylinders, tapered super-quadrics, or other more highly parameterized primitives or configurations. Alternatives to using literal 3-D models include the use of 2-D models that represent the projection of 3-D data onto some plane, point distribution models (PDM), 2-D/3-D contour modeling, stick figure and medial axis modeling, or even generalized shape and region modeling [5]. Many modeling approaches provide a simple, structural approach to constraining the tracking of human motion, but others also consider the use of added kinematic and dynamic constraints. This is an especially important consideration, as the interdependence of kinematics and dynamics is often significant. Monheit and Badler [6], for example, suggest a variety of kinematic constraints in an attempt to build a more accurate model of the spine and torso. Similarly, Rasmussen [7] discusses the utility of applying kinematic constraints to the tracking of the human arm using a constrained joint likelihood filter. In addition to constrained structural modeling, others have considered the use of stochastic modeling [8], based on learned motions or activities. In an extension of

parametric motion modeling, Yacoob and Davis [9] demonstrate a method for decomposing a motion vector field into components caused by independent object motion and those due to camera motion. The decomposition uses models of learned human motion to recognize, and subsequently improve the accuracy of the motion estimates in, image regions corresponding to that motion. Sidenbladh and Black [10] introduce a technique that applies natural image statistics to video tracking. The process learns the likelihood of observing the spatial and temporal filter responses of edges and ridges corresponding to tracked foreground objects as well as arbitrary backgrounds. Wren et al. [11] describe a recursive, 3-D tracking algorithm that enables high-level contextual knowledge to improve the perception of human motion. For a more detailed discussion of human motion analysis, we refer the reader to the excellent reviews provided by Gavrila [12] and Aggarwal and Cai [13]. In contrast to earlier work in this area, the proposed contribution focuses on the integration of complex and simplistic models with hard and soft kinematic constraints and, in particular, the introduction of probabilistic kinematics and its application to motion tracking. Based on learned patterns of kinematic composition, the appli-cation of stochastic kinematics to dynamic modeling takes the form of a natural acceleration that encourages the model structure to exhibit typical configurations during periods of gait movement. This derivation of human dynamics from kinematic structure is shown to produce robust and stable model-based tracking results in the presence of complex occlusions and articulated motion.
2. Theory
2.1. Hierarchical Structural Model
For the proposed structural model, we suggest the fusion of a simple bounding volume with a moderately more sophisticated stick model component; each element of the model is measured in three-dimensional, body-centered coordinates, as indicated in Figure 1. The origin of the coordinate system, p0, corresponds to a fixed position on the 3-D stick model. The time-varying coordinate axes are uniquely determined at each frame, k, by interpreting the velocity of the origin. We assume that during a normal gait cycle, the body moves forward, tangential to the transverse (TP, x-y) and saggital (SP, x-z) planes and orthogonal to the coronal plane (CP, y-z). These 3-D points are indicated as ( , , )x y z=z . This method of pose estimation is suitable for typical gait patterns, but would require modification for more generalized human movement.
!!
Figure 1. Structural object model.
There are fifteen parameters (p1…p15) that define the structure of the stick component and ten (p16…p25) that define that of the bounding volume. The suggested stick model is similar to the configuration proposed by Chen and Lee [14] and is an attempt to represent the human body as a collection of connected, rigid components using as few parameters as possible. Each parameter in the stick model is a 3-D position relative to the body-centered origin, p0. The bounding volume component provides an alternative means of tracking that is more robust, but possibly less accurate, than the stick component. The algorithm estimates the bounding volume by combining tracked bounding boxes [15] from multiple views, as often performed in the creation of a visual hull [16]. Parameters p16 and p17 measure the location of the upper and lower transverse planes while parameters p18, p19, p22, and p23 measure the location of the right and left saggital and back and front coronal planes, respectively. Parameters p20, p21, p24, and p25 are analogous to parameters p18, p19, p22, and p23, but instead model the bounding rectangle in the transverse plane for the lower body. In Figure 1, the images on the left indicate the parameters in the saggital and coronal plane views of the bounding volume component while the image on the right illustrates the parameters of the 3-D stick component, relative to p0 and the bounding volume.
2.2. Kinematic Constraints
To further limit the variability and increase the tracking accuracy of the body model, we impose additional hard and soft kinematic constraints. Hard constraints represent upper and lower bounds on quantities like distance, velocity, and acceleration. Particular to this work, we consider upper bounds on the velocity and acceleration magnitudes (vMAX and aMAX, respectively), minimum and maximum spanning distances for each pair of model parameters, and also an individualized scaling parameter, α. Each of these parameters is based on actual measurements of the human body and is, in turn, customized to fit different body sizes

using the appropriate scaling factor, α. When implementing upper bounds on velocity and acceleration, we use in our notation the factors, cv and ca, respectively. These values are adaptively scaled for each parameter to ensure that the overall velocity and acceleration never exceed their corresponding limits. For convenience, let us refer to this set of hard kinematic constraints as KΩ . The left side of Figure 2 illustrates typical hard constraints placed on the connectedness and variability of the structural model.
!!
α
α
α
α
α
α
ααα
α α
α
α " # $#
Figure 2. Kinematic model constraints.
Not based on physical measurements, but rather on learned examples of human motion, are the soft kinematic constraints. Each model parameter is defined by a 3-D probability density function (PDF), where the PDF for the mth parameter ( 25m N≤ = ) is indicated by ( )m zP . It should be noted that ( )m zP is an unconstrained dist-ribution measured relative to the body-centered coord-inates. The actual distribution is built using previous examples of typical body configurations taken during gait-related activities. The right-most image in Figure 2 illustrates the concept of parameter-specific prior distrib-utions. Some parameters (e.g., p11 and p14) are expected to vary considerably, but predictably, during periods of typical gait patterns. Other parameters (e.g., p4 and p16), perhaps those closer to rigid components of the human body, will invariably exhibit less variation during periods of normal gait motion. One might suitably predict, for instance, that 11 4>C C or 24 17>C C , where
3 3
( ) ( )T
m m mE d d − − ∫ ∫C z z z z z z z zP P (1)
and E ⋅ indicates the expectation function. These prior distributions are represented as point sets and built using training sequences of persons performing specific gait-related activities. The domain of these sets is finite due to the hard constraints placed on the variability of the human body. To compensate for a potential lack of training data, we filter the estimated PDF for each para-meter using a symmetric Gaussian kernel with a covar-
iance comparable in magnitude to that of the point set being filtered. Each distribution is then characterized by certain critical values denoted by 1 mm m m≡ ωω ω ω , where ( ) , ( ) 0m m mH∇ = <ω z z 0 zP P (2)
and H indicates the Hessian of a real-valued function. The above set of 3-D positions records the location of all modal values for the mth feature’s prior distribution. It is hypothesized that this information correlates with typical configurations of the human model, as indicated by previously observed examples. Since the actual domain of z is finite, computing the critical points is easily per-formed using a hierarchical grid search.
2.3. System Dynamics
The utility of the proposed structural model and kinematic constraints is best demonstrated by using them to define a more accurate dynamic model for tracking human motion. In particular, we describe a standard second-order autoregressive process in which the sampled position of an arbitrary point or feature in 3-D can be described by 1 2
2[ ] [ 1] [ 1] [ 1] ( )k k k t k t′ ′′= − + − ⋅∆ + − ⋅ ∆z z z z , (3) where k is a discrete instant in time, t∆ is the change in time or distance between temporal samples, and [ 1]k′ −z and [ 1]k′′ −z are first and second derivatives of position. A considerable amount of research has attempted to better describe the dynamics of human motion by more carefully modeling the velocity, [ ]k′z , of moving features. Less attention, however, has been paid to the potential acceleration, [ ]k′′z , that drives the motion of the human body. It is our submission that the body assumes num-erous, but predictable and repetitive, configurations while performing certain tasks. Because of the connected nature of the body and the physics of motion, there will be a natural tendency for body parts to return to their comfort-able, or typical, positions after performing some activity. The pendular motion of the arms, for instance, demon-strates the effects of acceleration as the arm deviates only so far from its steady state position before naturally returning. This force can be thought of as an acceleration of particles towards their characteristic arrangements. The most significant novelty of this research is the application of a priori statistical models of kinematic configuration to traditional system and object dynamics. The actual tracking of the proposed kinematic model could be performed using any number of techniques. We choose Kalman filtering since it provides a simple means of incorporating a priori object motion via the state transition matrix, [ ]kΨ . With a sufficiently accurate motion model, the Gaussian noise assumption taken by the

Kalman filter places little restriction on the overall system dynamics. This is particularly true if the noise modeling is allowed to be non-stationary. An alternative, but more computationally complex, approach might employ Con-densation tracking [17] to more accurately model a non-Gaussian noise process. However, since the method of generating image observations is based on motion estimation, and not just on the visual tracking of specific features, the observation and state densities are consider-ably less likely to exhibit non-Gaussian behavior. Thus, we introduce a time-varying state vector, within the context of a Kalman filter, as
[ ]1 2 2 1[ ] [ ] [ ] [ ] [ ] Tm Nk k k k k+≡σ σ σ σ σ . (4)
Here, [ ], m k m N≤σ denotes the 3-D position of the mth parameter in our body-centered coordinate system, while
1[ ][ ] m
m Nm N
kkk+ +
≤
∂=∂σσ (5)
indicates an approximation of the true velocity of the mth parameter. Following the form of (3), we define an estimate of the mth parameter as
( )ˆ 12
1
ˆ [ 1] ˆ [ 1]2( )
ˆ ˆ ˆ[ ] [ 1] [ 1]
( ) (1 ) m v m Nmi
m m v m N
k c ka m tt
k k c k t
c t l + +
+ +
− − ⋅ −∆∆
= − + − ⋅ ∆
+ ∆ − −ω σ σ
σ σ σ, (6)
where, dropping the dependence of ˆ [ ]mi k on m and k for simplicity, ˆ ˆ ˆ[ ] arg min [ 1]m m mi
ii i k k≡ = − −σ ω , (7)
( )
( )ˆ
ˆ [ 1][0,1]m m
mm mi
kl
−∈
σω
PP
, (8)
and cv and ca are our familiar, adaptive constants for velocity and acceleration. Relating (6) to (3), we can clearly see that ˆ[ 1] [ 1]mk k− = −z σ , 1ˆ[ 1] [ 1] zz σ
MAXm N vk k+ + ′ <
′ − = − , (9)
and with the constraint that z MAXa′′ < , [ ]2
2(1 )ˆ( )
ˆ[ 1] [ 1] [ 1]mlmmitk k k t−
∆′′ ′− = − − − − ∆z ω σ z . (10)
An inspection of (10) indicates that the actual acceleration of a parameter is a function of both a variance-like contribution in ml as well as the location of the modal values, mω , in its prior distribution. Also notice that both the velocity (9) and acceleration terms (10) for a particular parameter’s motion model are forced to never exceed the hard limits of MAXv and MAXa , respectively. Since Kalman filtering is a well-known and familiar processing tool, we omit the processing details here, but refer the reader to [18] for more information. It is sufficient to remark that the above equations define only the motion model that guides the dynamics of the Kalman filter. The corresponding prediction using these equations would be given, for the mth feature, by
1 1
ˆ ˆ[ ] [ 1][ ]
ˆ ˆ[ ] [ 1]m m
mm N m N
k kk
k k+ + + +
− = −
σ σΨ
σ σ, (11)
where
( ) ( )ˆ ˆ(1 ) [ 1] 1ˆ [ 1]1 1
[ ]0 1
a m mmi
m a
c l kv a mk c
mc c t l
k− − −
− + ∆ − − =
ω σσΨ . (12)
The required observations for the Kalman filter are based on image measurements extracted from the video sequences. For this task, we refer to our previous work on the tracking and extraction of features from multiple views [19]. In essence, this method performs the simultaneous [constrained] tracking of image features from multiple views and then integrates the tracked observations using an occlusion-adaptive algorithm. Observations are defined using estimated motion vectors in the vicinity of tracked features. These observations are then incorporated into a Kalman filter that leverages the kinematic-based dynamic motion model described in this contribution. The algorithm enforces hard constraints during the Kalman filtering process when searching for image observations. We start with the most reliable parameter (based on its Kalman minimum mean square error matrix) and construct an observation that is subject to the hard constraints, KΩ . Then, in a highest confidence first (HCF) fashion, we estimate an observation for each parameter subject to the hard constraints and to the locations of previously positioned, presumably more reliable, parameters. This is implemented while tracking 2-D image measurements by simply restricting the search, in accordance with the hard constraints, for the best motion correspondence between neighboring frames. Additional details regarding the standard application of hard and structural constraints to tracking are readily available in the literature [7][20].
3. Experimental Results
To test the proposed contribution, we measure hard kinematic constraints for two test subjects and soft constraints on the same subjects while walking in a home environment. The training is performed in a semi-automatic fashion and uses a total of 2500 video frames, with a sampling rate of 1
30 sect∆ = , for building the a priori stochastic model distributions. For experimental testing, the same subjects carry out a number of characteristic activities involving gait-based locomotion in a home environment. The results are based on a total of 927 frames, captured from three distinct views, extracted at various times during the course of a day. Select results of the tracking are shown in Figures 3 and 4; in each case, we show the output, as seen from all views in the system, for both the bounding volume and
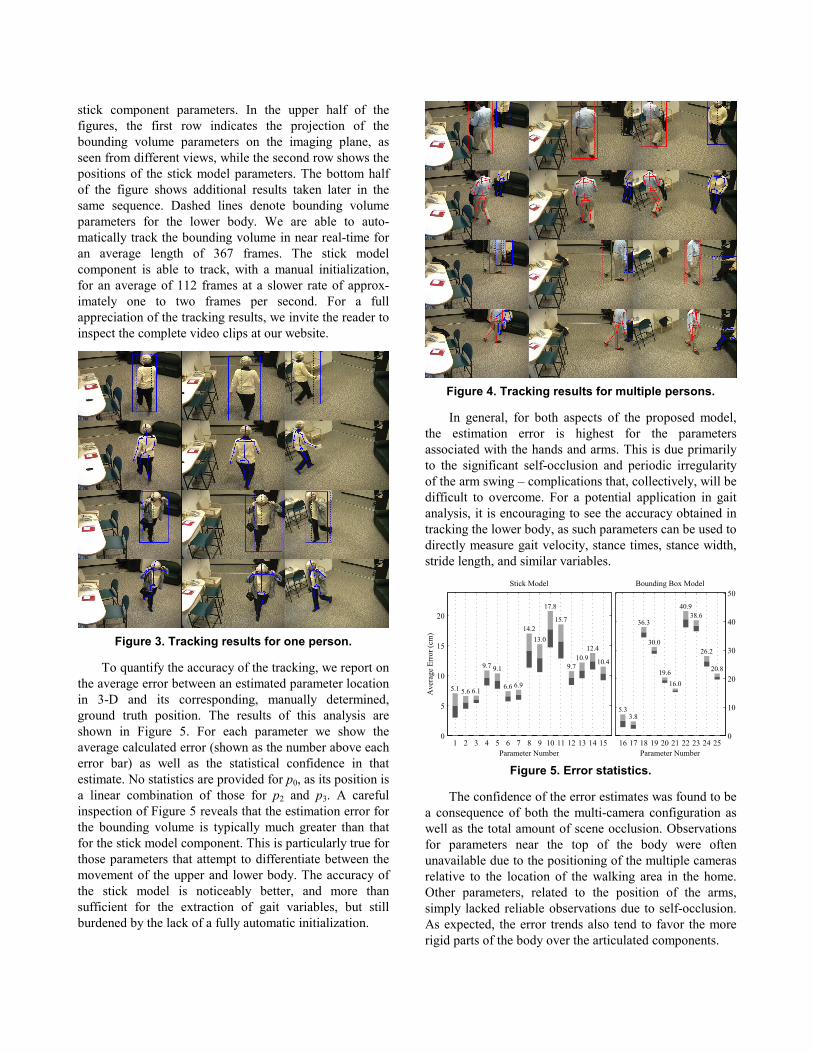
stick component parameters. In the upper half of the figures, the first row indicates the projection of the bounding volume parameters on the imaging plane, as seen from different views, while the second row shows the positions of the stick model parameters. The bottom half of the figure shows additional results taken later in the same sequence. Dashed lines denote bounding volume parameters for the lower body. We are able to auto-matically track the bounding volume in near real-time for an average length of 367 frames. The stick model component is able to track, with a manual initialization, for an average of 112 frames at a slower rate of approx-imately one to two frames per second. For a full appreciation of the tracking results, we invite the reader to inspect the complete video clips at our website.
Figure 3. Tracking results for one person.
To quantify the accuracy of the tracking, we report on the average error between an estimated parameter location in 3-D and its corresponding, manually determined, ground truth position. The results of this analysis are shown in Figure 5. For each parameter we show the average calculated error (shown as the number above each error bar) as well as the statistical confidence in that estimate. No statistics are provided for p0, as its position is a linear combination of those for p2 and p3. A careful inspection of Figure 5 reveals that the estimation error for the bounding volume is typically much greater than that for the stick model component. This is particularly true for those parameters that attempt to differentiate between the movement of the upper and lower body. The accuracy of the stick model is noticeably better, and more than sufficient for the extraction of gait variables, but still burdened by the lack of a fully automatic initialization.
Figure 4. Tracking results for multiple persons.
In general, for both aspects of the proposed model, the estimation error is highest for the parameters associated with the hands and arms. This is due primarily to the significant self-occlusion and periodic irregularity of the arm swing – complications that, collectively, will be difficult to overcome. For a potential application in gait analysis, it is encouraging to see the accuracy obtained in tracking the lower body, as such parameters can be used to directly measure gait velocity, stance times, stance width, stride length, and similar variables.
%&'(&)
*
+
#&
#,-
. . .
. .
. .
.
.
.
.
.
.
.
.
%&'(&)
(-
..
.
.
.
.
.
.
.
.
Figure 5. Error statistics.
The confidence of the error estimates was found to be a consequence of both the multi-camera configuration as well as the total amount of scene occlusion. Observations for parameters near the top of the body were often unavailable due to the positioning of the multiple cameras relative to the location of the walking area in the home. Other parameters, related to the position of the arms, simply lacked reliable observations due to self-occlusion. As expected, the error trends also tend to favor the more rigid parts of the body over the articulated components.

4. Conclusions and Future Work
This contribution introduces an improved model for tracking complex human motion using 3-D observations derived from a multiple camera configuration. We suggest a structural model of the human body that leverages the simplicity and robustness of a 3-D bounding volume and the elegance and accuracy of a more highly parameterized stick model. This hierarchical structural model is accompanied by hard and soft kinematic constraints. The hard constraints, derived from actual body measurements, include limits on velocity and acceleration, an individ-ualized scaling factor for the body model, and a set of minimum and maximum spanning distances for all pairs of model parameters. The soft constraints take the form of a priori, probabilistic distributions for each model parameter and are based on learned examples of human motion. We use these soft kinematic constraints to derive an acceleration term for each tracked feature. This factor is used to augment the potentially time-varying velocity of a classical dynamic motion model. The result is an increase in tracking accuracy in the presence of significant occlusion and articulated movement.
Acknowledgments
This research was supported in part by grants and financial support from Eastman Kodak Company and the Center for Future Health. We would also like to recognize Stephanie C. Dockstader and Kelly A. Bergkessel for their assistance in building training samples for the a priori kinematic model and defining 3-D ground truth for quant-ifying the accuracy of the proposed algorithm.
References [1] Y. Song, L. Gonclaves, E. Di Bernardo, and P. Perona,
“Monocluar Perception of Biological Motion in Johansson Displays,” Computer Vision and Image Understanding, vol. 81, no. 3, pp. 303-327, 2001.
[2] A. F. Bobick and J. W. Davis, “The Recognition of Human Movement Using Temporal Templates,” IEEE Trans. on Pattern Analysis and Machine Intelligence, vol. 23, no. 3, pp. 257-267, 2001.
[3] Y. Yacoob and M. J. Black, “Parameterized Modeling and Recognition of Activities,” Computer Vision and Image Understanding, vol. 73, no. 2, pp. 232-247, 1999.
[4] D. Cunado, J. M. Nash, M. S. Nixon, and J. N. Carter, “Gait extraction and description by evidence-gathering,” Proc. of the Int. Conf. on Audio and Video-Based Bio-metric Person Authentication, Washington, DC, 22-23 March 1999, pp. 43-48.
[5] A. Baumberg and D. Hogg, “Learning flexible models from image sequences,” Proc. of the Eur. Conf. on Computer
Vision, Stockholm, Sweden, 2-6 May 1994, vol. 1, pp. 299-308.
[6] G. Monheit and N. I. Badler, “A Kinematic Model of the Human Spine,” IEEE Computer Graphics and Appli-cations, vol. 11, no. 2, pp. 29-38, 1991.
[7] C. Rasmussen, “Joint likelihood methods for mitigating visual tracking differences,” Proc. of the Int. Workshop on Multi-Object Tracking, Vancouver, Canada, 8 July 2001, pp. 69-76.
[8] H. Sidenbladh, M. J. Black, and D. J. Fleet, “Stochastic tracking of 3D human figures using 2D image motion,” Proc. of the European Conf. on Computer Vision, Dublin, Ireland, 26 June - 1 July 2000, pp. 702-718.
[9] Y. Yacoob and L. S. Davis, “Learned Models for Estimation of Rigid and Articulated Human Motion from Stationary or Moving Camera,” Int. J. of Computer Vision, vol. 12, no. 1, pp. 5-30, 2000.
[10] H. Sidenbladh and M. Black, “Learning image statistics for Bayesian tracking,” Proc. of the Int. Conf. on Computer Vision, Vancouver, Canada, 9-12 July 2001, vol. 2, pp. 709-716.
[11] C. R. Wren, B. P. Clarkson, and A. P. Pentland, “Under-standing purposeful human motion,” Proc. of the Int. Conf. on Automatic Face and Gesture Recognition, Grenoble, France, 28-30 March 2000, pp. 378-383.
[12] D. M. Gavrila, “The Visual Analysis of Human Movement: A Survey,” Computer Vision and Image Understanding, vol. 73, no. 1, pp. 82-98, 1999.
[13] J. K. Aggarwal and Q. Cai, “Human Motion Analysis: A Review,” Computer Vision and Image Understanding, vol. 73, no. 3, pp. 428-440, 1999.
[14] Z. Chen and H. I. Lee, “Knowledge-Guided Visual Perception of 3D Human Gait from a Single Image Sequence,” IEEE Trans. on Systems, Man, and Cyber-netics, vol. 22, no. 2, pp. 336-342, 1992.
[15] S. L. Dockstader and A. M. Tekalp, “On the Tracking of Articulated and Occluded Video Object Motion,” Real-Time Imaging, vol. 7, no. 5, pp. 415-432, 2001.
[16] G. Shakhnarovich, L. Lee, and T. Darrell, “Integrated face and gait recognition from multiple views,” Proc. of the Conf. on Computer Vision and Pattern Recognition, Lihue, Kauai, HI, 11-13 December 2001, vol. 1, pp. 439-446.
[17] M. Isard and A. Blake, “Condensation - Conditional Density Propagation for Visual Tracking,” Int. J. of Computer Vision, vol. 29, no. 1, pp. 5-28, 1998.
[18] A. Azarbayejani and A. P. Pentland, “Recursive Estimation of Motion, Structure, and Focal Length,” IEEE Trans. on Pattern Analysis and Machine Intelligence, vol. 17, no. 6, pp. 562-575, 1995.
[19] S. L. Dockstader and A. M. Tekalp, “Multiple Camera Tracking of Interacting and Occluded Human Motion,” Proc. of the IEEE, vol. 89, no. 10, pp. 1441-1455, 2001.
[20] J. Deutscher, A. Davison, and I. Reid, “Automatic partitioning of high dimensional search spaces with articulated body motion capture,” Proc. of the Conf. on Computer Vision and Pattern Recognition, Lihue, Kauai, HI, 8-14 December 2001, vol. 2, pp. 669-676.



![[GAIT DISORDERS IN PARKINSON’S AND HUNTINGTON’S DISEASES]Sofia... · Gait disorders in Parkinson’s and Huntington’s diseases 3 Gait disorders in Parkinson’s and Huntington’s](https://img.pdfslide.tips/doc/110x75/5f0f95af7e708231d444e3b1/gait-disorders-in-parkinsonas-and-huntingtonas-diseases-sofia-gait-disorders.jpg)