Embed Size (px)
Citation preview

progettodidattica in rete
prog
etto
dida
ttica
in re
teDipartimento di Georisorse e TerritorioPolitecnico di Torino, dicembre 2000
Lezioni di TopografiaParte II - Il trattamento statistico delle misure
A. Manzino
otto editore

DISPENSE DI TOPOGRAFIA
P
ARTE
II – I
L
TRATTAMENTO
STATISTICO
DELLE
MISURE
A
.
MANZINO
Otto Editore P.zza Vittorio Veneto 14 – 10123 Torinowww.otto.to.it

i
INDICE
PARTE SECONDA – IL TRATTAMENTO STATISTICO DELLE MISURE
6. STATISTICA DI BASE...................................................................1
6.1 P
RIMI
TEOREMI
DELLE
DISTRIBUZIONI
DI
PROBABILITÀ
......................3a. Teorema della probabilità totale ..........................................................3b. Definizione di probabilità condizionata..............................................4c. Definizione di indipendenza stocastica................................................4
6.2 V
ARIABILI
CASUALI
..................................................................................4Esempio di variabile casuale continua .....................................................5Funzione densità di probabilità ...............................................................6Dalla variabile casuale alla variabile statistica...........................................7La costruzione di istogrammi ..................................................................8La media...................................................................................................9La varianza ............................................................................................ 10
6.3 T
EOREMA
DI
T
CHEBYCHEFF
............................................................... 11
Teorema
................................................................................................ 11Il teorema nel caso di variabili statistiche.............................................. 12
6.4 L
A
VARIABILE
CASUALE
FUNZIONE
DI
UNA
VARIABILE
CASUALE
....... 13Esempio 1 ............................................................................................. 15Esempio 2 ............................................................................................ 16
6.5 T
EOREMA
DELLA
MEDIA
...................................................................... 16
Corollario 1
............................................................................................ 16

ii
Corollario 2
............................................................................................ 17Esempio................................................................................................. 18
6.6 L
EGGE
DI
PROPAGAZIONE
DELLA
VARIANZA
...................................... 18Osservazioni al teorema di propagazione della varianza....................... 18Esempio di applicazione del teorema di propagazione della varianza.. 19
6.7 A
LCUNE
IMPORTANTI
VARIABILI
CASUALI
.......................................... 19Distribuzione di Bernoulli o binomiale................................................ 19Distribuzione normale o di Gauss........................................................ 21La distribuzione
χ
2 (chi quadro).......................................................... 22Distribuzione
t
di Student .................................................................... 24La distribuzione
F
di Fisher .................................................................. 25
7. LA VARIABILE CASUALE A
n
DIMENSIONI .......................27
Esempio 1 ............................................................................................. 28Esempio 2 ............................................................................................. 29
7.1 D
ISTRIBUZIONI
MARGINALI
................................................................. 30
7.2 D
ISTRIBUZIONI
CONDIZIONATE
......................................................... 31
7.3
INDIPENDENZA
STOCASTICA
............................................................... 32Leggi relative alle distribuzioni.............................................................. 32
7.4 V
ARIABILI
CASUALI
FUNZIONI
DI
ALTRE
VARIABILI
CASUALI
............. 33Trasformazione di variabili ................................................................... 33Esempio di applicazione della trasformazione ad un caso lineare........ 34
7.5 M
OMENTI
DI
VARIABILI
n
-
DIMENSIONALI
......................................... 36Teorema della media per variabili casuali
n
-dimensionali .................. 37
Corollario 1
............................................................................................ 37
Corollario 2
............................................................................................ 37Momenti di ordine di una variabile casuale
n
- di-mensionale............................................................................... 37La propagazione della varianza nel caso lineare ad
n
-dimensioni ....... 39Esercizio 1 ............................................................................................ 40Esercizio 2 ............................................................................................ 41
7.6 L
A
LEGGE
DI
PROPAGAZIONE
DELLA
VARIANZA
NEL
CASO
DI
FUNZIONI
NON
LINEARI
....................................................................................... 42Esercizio 3 ............................................................................................ 43La propagazione della varianza da
n
dimensioni ad una dimensione . 45Esercizio 1 ............................................................................................ 45Esercizio 2 ............................................................................................ 45Esercizio 3 ............................................................................................ 46Esercizio 4 ............................................................................................ 46Esercizio 5 ............................................................................................ 46
7.7 I
NDICE
DI
CORRELAZIONE
LINEARE
.................................................. 47
n1 n2 … nk,,,( )

iii
7.8 P
ROPRIETÀ
DELLE
VARIABILI
NORMALI
AD
n
-
DIMENSIONI
.............. 48
7.9 S
UCCESSIONI
DI
VARIABILI
CASUALI
................................................... 52
7.10 C
ONVERGENZA
«
IN
L
EGGE
» ............................................................... 53
7.11 T
EOREMA
CENTRALE
DELLA
STATISTICA
........................................... 53Teorema ............................................................................................... 53Prima osservazione al teorema centrale della statistica ........................ 53Seconda osservazione al teorema centrale della statistica ..................... 54
7.12 L
E
STATISTICHE
CAMPIONARIE
E
I
CAMPIONI
B
ERNOULLIANI
........ 55Osservazione ........................................................................................ 55Definizione di
statistica campionaria
.................................................... 55
7.13 L
E
STATISTICHE
«
CAMPIONARIE
»
COME
«
STIME
»
DELLE
CORRISPONDENTI
QUANTITÀ
TEORICHE
DELLE
VARIABILI
CASUALI
56Stima corretta o non deviata ................................................................ 56Stima consistente ................................................................................. 56Stima efficiente ..................................................................................... 56Stima di massima verosimiglianza ....................................................... 56
7.14 F
UNZIONE
DI
VEROSIMIGLIANZA
E
PRINCIPIO
DI
MASSIMA
VEROSIMIGLIANZA
............................................................................... 58
7.15 L
A
MEDIA
PONDERATA
(
O
PESATA
)..................................................... 60
8. APPLICAZIONI DEL PRINCIPIO DEI MINIMI QUADRATI AL TRATTAMENTO DELLE OSSERVAZIONI ...................62
8.1 I
MINIMI
QUADRATI
APPLICATI
AD
EQUAZIONI
DI
CONDIZIONE
CON
MODELLO
LINEARE
.............................................................................. 64Esempio applicativo: anello di livellazione .......................................... 65
8.2 M
INIMI
QUADRATI, FORMULE RISOLUTIVE NEL CASO DELL'UTILIZZO DI PARAMETRI AGGIUNTIVI ................................................................. 67Esempio applicativo ............................................................................. 70
8.3 MINIMI QUADRATI : EQUAZIONI DI CONDIZIONE E PARAMETRI AGGIUNTIVI ......................................................................................... 72
8.4 PROPRIETÀ DELLE STIME ED , LORO DISPERSIONE ................... 74Pure equazioni di condizione .............................................................. 75Pure equazioni parametriche ............................................................... 75
8.5 IL PRINCIPIO DEI MINIMI QUADRATI IN CASI NON LINEARI.............. 76
8.6 ESERCIZIO............................................................................................. 78Modello geometrico............................................................................. 79Modello stocastico e soluzione ai minimi quadrati.............................. 80
y x

1
PARTE II – IL TRATTAMENTO STATISTICO
DELLE MISURE
6. STATISTICA DI BASE
1
In questo capitolo ci doteremo di alcuni strumenti statistici per il trattamento dellemisure.
Vediamo come si inserisce la statistica nella tecnica di misura e, per iniziare, comepossiamo definire una misura. Conosciamo tre tipi di operazioni di misura:
– Misure dirette: vengono eseguite contando il numero di unità campione conte-nute in una quantità precostituita. Concettualmente funziona così ad esempiouna bilancia a piatti, così è quando si misura col metro un oggetto ecc…
– Misure indirette: sono definite da un legame funzionale a misure dirette; adesempio la misura indiretta della superficie del triangolo noti due lati el'angolo compreso misurati direttamente. Il legame è nell'esempio
.
– Misure dirette condizionate: sono delle misure dirette, ma fra loro sonolegate da un legame funzionale interno. Ad esempio la misura diretta di treangoli di un triangolo piano deve verificare la legge:
Nel capitolo 6 tratteremo prevalentemente le misure dirette, nel capitolo 7 quelleindirette (teorema della propagazione della varianza); infine le misure dirette condi-zionate saranno maggiormente trattate al capitolo 8 (minimi quadrati).
1
Questa parte prende molti spunti, che liberamente interpreta, da «Fernando Sansò: Il trattamentostatistico delle misure. - Clup 1990.» Da questo testo sono tratte inoltre dimostrazioni ed esempi.
S 1 2⁄ ab γsin=
α β γ+ + π=

STATISTICA
DI
BASE
2
L'operazione di misura, diretta o meno, ha in comune il fatto, che sotto opportuneipotesi, può essere considerata un'estrazione da una variabile casuale: vediamoinfatti tre esempi che ci porteranno a giustificare questo paragone.
a. Dato un corpo rigido di lunghezza poco maggiore di 3 m ed un metrocampione suddiviso in mm, si desidera misurare il corpo con il metodo delriporto (o delle alzate).
b. Il lancio di dadi non truccati.
c. Si misurano le coordinate
x, y
del punto ove cade un proiettile su un bersa-glio rettangolare sparato da uno stesso tiratore.
Questi esperimenti hanno in comune il fatto che, a priori, è
impossibile predire
inmodo deterministico il risultato dell'esperimento: se si ripete infatti, si otterrannodiversi risultati.
Nell'esempio a. il fatto che ripetendo l'operazione di misura si ottengano diversirisultati, porta a dire che in questa operazione si commettono degli «errori», neglialtri casi il diverso risultato è dovuto alle variazioni non note dell'ambiente esternoe dell'oggetto di misura (e di come questi interagiscono), o ad una sua scarsa cono-scenza globale e puntuale del fenomeno.
Questi «errori» possono classificarsi in:
–
Errori grossolani
: sono i più banali anche se spesso i più difficili a indivi-duare. Possono essere ad esempio il mancato conteggio di una alzata, la tra-scrizione errata di una misura, la codifica errata di un punto, ecc.
I rimedi per evitarli sono l'acquisizione e il trattamento automatici, il con-trollo e la ripetizione delle misure possibilmente indipendenti ed ancoraautomatici. Non sono questi gli «errori» a cui intendiamo riferircinell’esempio a.
–
Errori sistematici
: sono dovuti ad esempio all'imperfetta taratura dello stru-mento di misura o legati ad errori di modello (ad es. la misura indiretta diun angolo di un triangolo piano quando questo sia in realtà meglio«modellabile» sulla superficie ellissoidica), hanno la caratteristica di conser-vare valore e segno: nell’esempio a. la misura con più alzate tra due punti Ae B, sarà sempre superiore alla reale, se i punti intermedi non sono esatta-mente sull'allineamento AB.
Sono eliminabili con tarature, con opportune procedure operative, o ren-dendoli di segno alterno (cioè pseudo accidentali): si può usare nel casodella bilancia non rettificata, ad esempio, il metodo della doppia pesata.Anche questi «errori» non sono quelli che giustificano i diversi risultatidegli esperimenti a. b. e c.
–
Fluttuazioni accidentali
: sono a priori imprevedibili, sono di segno alterno edipendono in senso lato dall'ambiente.
La fluttuazione accidentale della misura è un fenomeno
aleatorio
(casuale,probabilistico). Sono questi gli «errori» commessi negli esperimentidescritti. La scienza che studia questi fenomeni è la statistica matematica,perciò ne forniremo i concetti di base utili al trattamento delle misure geo-

STATISTICA
DI
BASE
detiche e topografiche. Ora cerchiamo di capire meglio in che ambito sicala la statistica nel trattamento delle misure. Potremmo definire la stati-stica la scienza che tenta di descrivere con certezza l'incertezza.
Nell'esempio del metro, notiamo che, se avessimo preteso di stimare la lun-ghezza del corpo al mm, avremmo ottenuto numeri apparentemente piùvariabili, mentre, chiedendo la misura al cm, il risultato sarebbe stato sem-pre uguale. Ne segue che, per la misura di una grandezza, l'indetermina-zione si presenta solo
con procedure di misura che spingono l'approssimazione aiconfini delle capacità di misura dell'apparato usato
.
Data per scontata questa indeterminazione, dobbiamo tuttavia dire che ci aspet-tiamo un risultato poco disperso, o meglio una gamma di possibili valori ed unordine di priorità tra di essi.
Questa priorità, espressa come numero reale compreso tra zero e uno si chiama
probabi-lità
. Ne diamo ora la più usata definizione detta
assiomatica
che consiste nel definire ladistribuzione di probabilità in base alle proprietà (assiomatiche) che deve soddisfare:
una distribuzione di probabilità
P
su un insieme
S
di valori argomentali, è unamisura su una famiglia di sottoinsiemi di
S
(che include
S
stesso e l'insieme vuoto
φ
) che, oltre agli assiomi della misura:
soddisfa alla:
Vediamomentali c
a «croce»
x
=1 sull'a
I sottoins
Si ha P({
φ
6.1 P
RIM
a. Teorem
Dati
o
B
,
Se
A
6.1
6.2
6.3
P A( ) 0≥P φ( ) 0=
P A B∪( ) P A( ) P B( )+=
P
P
6.4P S( ) 1=
3
un esempio pratico: il lancio della moneta. S è costituito da 2 valori argo-he possiamo rendere numerici associando ad esempio x = 0 a «testa» ed x = 1. S è l'insieme dei valori argomentali {0,1} dei punti di coordinate x=0,sse x.
iemi di S sono {φ}, {0}, {1}, {0,1}.
}) = 0; P({0}) = 1/2; P({1}) = 1/2; P({0,1}) = 1.
I TEOREMI DELLE DISTRIBUZIONI DI PROBABILITÀ
a della probabilità totale
due eventi A e B, sottoinsiemi disgiunti di S, la probabilità che si verifichi Acioè è:
6.5
e B non sono disgiunti:
6.6
P A B∪( )
A B∪( ) P A( ) P B( )+= se A B∩ φ=
A B∪( ) P A B–( ) P B( )+= P A( ) P B( ) P AB( )–+=

STATISTICA
DI
BASE
b. Definizione di probabilità condizionata
Si presenta quando si desidera esaminare la distribuzione solo su di una parte deivalori argomentali, restringendo
S
ad un sottoinsieme. Isolando una parte dei valoriargomentali si genera un'altra distribuzione di probabilità.Ad esempio in una popolazione di 100 persone caratterizzata dai possibili valoriargomentali: capelli chiari o scuri, occhi chiari o scuri (vedi tabella 6.1), si desideraconoscere qual è la probabilità di estrarre una persona con occhi chiari fra quellecon i capelli chiari. Questa probabilità condizionata si indica
P(A|B)
(probabilitàdi
A
condizionata a
B)
e vale:
Nell
c. Defini
Dici
Per
cioè
Dun
bili
affe
6.2 V
AR
Definizi
lità il cui
probabili
Tab
6.7P A|B( ) P AB( )P B( )
----------------=
'esempio P(B) = 50/100, P(AB) = 40/100, P(A|B) = 0.8
zione di indipendenza stocastica
amo A e B stocasticamente indipendenti se:
6.8
la 6.7 si ha:
:
6.9
que due eventi A e B sono stocasticamente indipendenti se e solo se la proba-tà composta P(AB) si scinde nel prodotto delle singole probabilità. Questarmazione è il teorema della probabilità composta.
IABILI CASUALI
one: una variabile casuale (vc) a una dimensione è una distribuzione di probabi- insieme di valori argomentali S sia rappresentabile in , tale che sia definita la
. 6.1
→ CAPELLI C S
Occhi C 40 10
S 10 40
P A|B( ) P A( )=
P A|B( ) P AB( )P A( )
---------------- P B( )= =
P AB( ) P A( )P B( )=
lR
4
tà per qualunque insieme (ordinabile con x0) del tipo:

STATISTICA
DI
BASE
5
6.10
In questo modo sarà perciò caratterizzata dalla funzione di
x
0
:
6.11
F prende il nome di funzione di distribuzione e gode delle proprietà:
6.12
6.13
6.14
Una vc si dice
discreta
se l'insieme S è formato da un numero discreto di punti suiquali è
concentrata
una probabilità; se viceversa la probabilità che
x
assuma un
sin-golo
valore è sempre uguale a zero allora la vc è
continua
.
Nel primo caso avremo una funzione di distribuzione discontinua, nel secondocontinua. Ad esempio il lancio di una moneta è rappresentato da una vc
discreta
:
i valori argomentali sono ; la variabile casuale
x
può rappresentarsiattraverso la tabella:
6.15
Per ; per e per e la suafunzione di distribuzione è disegnata in figura
6.1
.
Fig. 6.1
Esempio di variabile casuale continua
Consideriamo una distribuzione di probabilità definita in
6.16
Siamo nel caso di
distribuzione uniforme
, la sua funzione di distribuzione F, riportatain figura
6.2
, sarà:
I x0( ) x x0≤{ } S∩=
F x0( ) P x I x0( )∈[ ]=
F x 0( ) è definita su x0 lR∈∀
0 F x( ) 1≤ ≤
F x( )x0 ∞–→lim 0;= F x( )
x0 ∞→lim 1=
F x2( ) F x1( )≥ x2∀ x1≥
x1 0 x2 1=;=
x1 0= x2 1=
p 1 2⁄= p 1 2⁄=
x 0 F x( ) 0=≤ 0 x< 1 F x( ) 1 2⁄=≤ x 1 F x( ) 1>>
P
X0 1
0,5
1
S 0 1,[ ]= lR∈
P a x b≤ ≤( ) b a– cost= =

STATISTICA DI BASE
6
Fig. 6.2
Funzione densità di probabilità
Una qualunque variabile casuale può caratterizzarsi attraverso la sua funzione didistribuzione F. Se la vc è continua ci si chiede quale sarà la probabilità P che x siacompresa tra due valori . Si avrà:
6.17
Se ∆x è piccolo ed F differenziabile:
dove f (x ) vien detta densità di probabilità ed è funzione di x , si ha:
6.18
che, per le caratteristiche di F, (monotona e crescente) sarà:
La funzione di distribuzione si ottiene allora come funzione integrale della densitàdi probabilità:
6.19
con l'ipotesi di normalizzazione (o standardizzazione, vedi 6.4):
6.20
F x( ) 0= x 0≤F x( ) x= 0 x 1≤ ≤F x( ) 1= x 1>
F
X0 1
1
x0 x0 ∆x+,[ ]
P x0 x x0 ∆x+≤ ≤( ) F x0 ∆x+( )=
P x0 x x0 ∆x+≤ ≤( ) dF x0( ) F ' x0( )∆x f x0( )∆x= = =
f x0( ) F ' x0( )P x0 x x0 ∆x+≤ ≤( )
∆x----------------------------------------------
∆x 0→lim= =
f x0( ) 0≥ x∀
F x( ) f t( ) td∞–
x
∫=
f t( ) td∞–
∞
∫ 1=

STATISTICA DI BASE
Si noti che:
Si abbia ad esempio la variabile casuale x definita così:
(vedi figura 6.2), la funzione densità di probabilità relativa è uniforme e vale:
Fig. 6.3 – Funzione di densità di probabilità costante e uniforme.
Dalla variabile casuale alla variabile statistica
Se, per mezzo della variabile casuale si vuole rappresentare l'insieme dei possibilirisultati di un esperimento non deterministico, si possono organizzare i dati in unatabella a doppia entrata in base ai risultati delle ripetizioni dell'esperimento.
Ad esempio:
Definiamo variabile statistica (vs) ad una dimensione la tabella di due sequenze dinumeri che specifica come un dato si distribuisce fra la popolazione N:
f x( ) xda
b
∫ F b( ) F a( )– P a x b≤ ≤( )= =
F0 x 0≤x 0 x 1≤ ≤1 x 1>
=
f x( ) 1 0 x 1≤ ≤0 x 0 x 1>;<
=
0 1 X
f (x)
testa croce
con n1 n2 N=+
n1 volte n2 volte
6.21x1 x2…xn
F1 F2…Fn
ovverox1 x2…xn
f1 f2…fn
7

STATISTICA DI BASE
x i sono i valori argomentali, Fi le frequenze assolute ed fi = Fi/N le frequenze rela-tive. Si ha:
6.22
Confrontando la 6.21 e la 6.22 si vede che la prima definisce una variabile casualecon distribuzione di probabilità concentrata sui valori , è sufficiente porre:
Con ciò,valere anvariabili
La sostanai valori valore pimente il
La probaquenza, empirici.
Per mezzbili casuaquenza Fargomen
La costru
Il concetché la su
Questo ipuò defistica.
È tuttavibili casuattraverso
Il confrovariabile dei risult
Fi1
n
∑ N ;= fi1
n
∑ N=
x1…xn
6.23P x xi=( ) fi=
8
ogni definizione data e ogni proprietà mostrata per le variabili casuali deveche per le variabili statistiche, poiché formalmente identificabili con lecasuali attraverso la 6.23.
ziale differenza è di contenuto: sulla variabile casuale i numeri pi associatixi misurano un grado di possibilità che il risultato dell'esperimento abbia
j ; nel caso della variabile statistica il numero fi registra a posteriori sola-fatto che su N ripetizioni si sono ottenuti Fi risultati di valore xi.
bilità, legata alla variabile casuale, è un ente aprioristico assiomatico, la fre-legata alla variabile statistica è un indice che misura a posteriori risultati
o di questa identità formale, la funzione di distribuzione F(x) delle varia-li, prende il nome, per le variabili statistiche, di funzione cumulativa di fre-
(x) e rappresenta la percentuale di elementi della popolazione il cui valoretale xi risulta minore o uguale a x.
6.24
zione di istogrammi
to di densità di probabilità non è applicabile ad una variabile discreta per-a funzione di distribuzione è in ogni punto discontinua o costante.
mplica, per l'analogia tra variabili casuali e variabili statistiche che non sinire un concetto analogo alla densità di probabilità per la variabile stati-
a importante poter confrontare la variabile statistica con particolari varia-ali ben conosciute attraverso la funzione densità di probabilità, ciò si fa la costruzione di istogrammi.
nto vien fatto tra probabilità (nella variabile casuale) e frequenza (dellastatistica) in questo modo: si fissa un intervallo e si esamina la percentualeati che cadono nello stesso intervallo:
6.25
F x( ) fii
∑ Ni∑N
------------= = xi x≤∀
∆F x0( )N x0 ∆x,( )
N-----------------------=

STATISTICA DI BASE
dove il numeratore rappresenta il numero di elementi che cadono in detto inter-vallo. Il confronto è valido per N grande (ad esempio N>200).
Si abbiano ad esempio una serie di valori nell'intervallo I = (b–a ).
Si riporta sull'asse x l'intervallo (a,b) e si divide in n parti (con n< m valori dati),non necessariamente uguali .
Per ogni intervallo si contano il numero di risultati che cadono in Ii = N (Ii) e sisommano le frequenze relative a detto intervallo .
Si disegna sopra Ii un rettangolo di altezza .
Abbiamo costruito così una tabella:
6.26
dove xi sono le ascisse dei valori medi degli intervalli Ii.
Si può verificare infine che:
6.27
La media
La descrizione completa di una variabile casuale deriva dalla conoscenza della suafunzione di distribuzione o della densità di probabilità od altro di equivalente. Permolti usi pratici la vc è ben localizzata, cioè distribuita in una ristretta zona di valoriammissibili. Ad esempio, nella misura con distanziometri elettronici di distanze,una distanza di 1 km può avere ripetizioni che al più differiscono di 2-3 mm; pertutte queste variabili le informazioni più importanti da conoscere sono dove è loca-lizzata la distribuzione e quanto è dispersa. Allo scopo, sono utili due indici: mediae varianza.
Definizione: si chiama media della vc x, quando esista, il numero:
6.28
Si noti l'analogia col momento statico di f(x ).
Nel caso di una vc discreta:
6.29
e, per analogia per una variabile statistica, la media, che si indica con m vale:
I1 I2 …, I, n,( )
fK∑ fi=fK∑ Ii⁄
x1 x2…xn
f1 f2…fn
fi∑ fK
I i---- I i
K∑
i∑ 1= =
M x[ ] µ x f x( ) dx∞–
∞
∫= =
M x[ ] xi pi∑=
6.30m M x[ ] x xi∑= = = fi
xi Ni
N-----------∑=
9

STATISTICA DI BASE
10
Dove con si intende l'operazione matematica (l'operatore) che, da unadistribuzione, sia essa a priori vc o a posteriori vs, calcola un numero che è la mediadella distribuzione.
La 6.30 evidenzia in Ni il numero di volte che il valore argomentale xi è statoestratto, presupponendo la costruzione di una tabella ordinata allo scopo, se invececon xj indichiamo il singolo valore estratto si ha:
6.31
Si può dimostrare che la media è un operatore lineare cioè gode delle proprietà:
6.32
6.33
La varianza
È un indice che misura il grado di dispersione di una vc x attorno alla media.
Per definizione, se esiste vale
6.34
Si definisce la variabile scarto ν
6.35
La varianza si ottiene cioè applicando l'operatore media al quadrato della variabilescarto, in altri termini è il momento del secondo ordine della variabile scarto e siindica con , o solo .
Per la variabile statistica, per analogia, la varianza si indica con , o solo. La radice quadrata della varianza si chiama scarto quadratico medio e si indica
con sqm o con σ , tale valore è più usato della varianza, in quanto dimensional-mente omogeneo a x. Si ha dunque:
6.36
e, per una vc discreta:
6.37
Con la solita analogia tra variabile casuale e variabile statistica, per quest'ultima siha:
6.38
M ⋅[ ]
m x1N---- xi∑= = j 1 … N,,=
M x y+[ ] M x[ ] M y[ ]+=
M kx[ ] k M x[ ]=
σ 2 x[ ] M x µx–( )2[ ]=
ν x µx–( )=
σ 2 x[ ] σ x2 σ 2
S 2 x( ) S x2
S 2
σ x2 X µx–( )2 f X( ) dx
∞–
∞
∫=
σ x2 Xi µx–( )2 pi
i∑=
S 2 Xi Mx–( )2Ni
N-----
i∑ 1
N---- Xj Mx–( )2
j∑
ν j2
j∑
N--------------= = =

STATISTICA DI BASE
11
Le ultime due espressioni valgono per una vc non ordinata: per questo si è sostitu-ito l'indice j all'indice i.
Dalla definizione di varianza, tenendo conto della linearità dell'operatore media esviluppando si ha:
6.39
che permette di calcolare senza passare dalla variabile scarto. Per una vs nonordinata la 6.39 si trasforma:
6.40
Nella 6.39 rappresenta il momento del 2° ordine della vc che è dato dalla sommadella varianza e del quadrato del valor medio.
6.3 TEOREMA DI TCHEBYCHEFF
Nell'analogia meccanica in cui la probabilità viene considerata come una distribu-zione di massa concentrata o distribuita sull'asse x, la media esprime (a parte unacostante di standardizzazione), la posizione del baricentro (il momento statico) e lavarianza ha il senso di momento di inerzia rispetto al baricentro.
Più le masse sono disperse e più è alto il momento di inerzia, cioè la varianza. Que-sta nozione qualitativa è espressa in termini probabilistici quantitativi dal teoremadi Tchebycheff che vale per qualsiasi tipo di distribuzione.
Teorema
Preso , e variabile casuale x, vale la disuguaglianza:
6.41
Il teorema ci dice qual è la dimensione dell'intervallo λσ attorno alla media entrocui, per qualunque distribuzione di x , siamo sicuri di racchiudere una probabilitàminima di (1 – 1/λ2).
Dimostrazione
Partiamo dalla definizione di , cioè:
restringendo l'intervallo di integrazione sarà sempre vero che:
6.42
σ x2 M X 2 2µX– µ2+[ ] M X 2[ ] 2µM X[ ]– µ2+ M X 2[ ] µ2–= = =
σ 2
S 2 X( ) 1N---- X j
2
j∑ m2–=
λ∀ 1> ∀
P x µx– λσ x≤( ) 11λ2-----–≥
σ x2
σ x2 σ 2 X µx–( )2 f x( ) dx
∞–
∞
∫= =
σ 2 x µ–( )2 f x( ) dxx µ– λσ≥
∫≥

STATISTICA DI BASE
12
Il primo termine all'interno dell'integrale varrà, per lo meno nell'intervallo di inte-grazione:
dunque l'espressione 6.42 varrà a maggior ragione sostituendo a lacostante :
e, dividendo per :
cioè:
c.v.d.
Il teorema nel caso di variabili statistiche
Consideriamo la variabile:
e facciamo l’ipotesi che sia stata ordinata nel senso crescente
per definizione:
Anche gli scarti νi saranno allora crescenti. Possiamo dividere in tre parti la somma-toria di cui sopra:
s 2 sarà sempre maggiore od uguale alle prime due sommatorie, cioè:
A maggior ragione, essendo nella sommatoria:
x µ–( )2 λσ( )2≥
x µ–( )2
λσ( )2
σ 2 λ2σ 2≥
σ 2
1λ2----- f x( ) dx
x µ– λσ≥∫≥
1λ2----- P x µx– λσ≥( )≥
x1…xn
f1…fn
x1 x2< … xn<
s 2 xi m–( )2 fi
1
n
∑=
s 2 ν i2 fi ν j
2 fj ν k2 fk
k 1=
λ s– v λ s< <
∑+j 1=
v λ s≥
∑+i 1=
v λ s<
∑=
s 2 ν i j,2 fi j,
i j v⁄, λ s≥∑≥ s 2 ν i j,
2 fi j,i j v⁄, λ s≥
∑≥⇒

STATISTICA DI BASE
13
dividendo entrambi i membri per s 2:
dividendo ancora per λ 2 e considerando che :
cioè:
c.v.d.
6.4 LA VARIABILE CASUALE FUNZIONE DI UNA VARIABILE CASUALE
Seguiamo quest'esempio: sia x la vc che rappresenta il lancio di un dado non truc-cato, si ha, chiamando (p,d) i possibili eventi (pari o dispari):
L'insieme S è costituito dall'unione di:
con
prendiamo ora una vc y che rappresenta il lancio di una moneta non truccata eleghiamola alla vc x con questa corrispondenza:
essendo i possibili valori ed associamo per y i valori numerici 0 e 1 a testae croce.
Con ciò . Si ha:
Le due vc si esprimono allora:
ν λ s≥ cioè λ s ν<,
s 2 λ2s2 fi j,i j v⁄, λ s≥
∑≥
1 λ2 fi j,∑≥
fk∑ 1 fi j,∑–=
1λ2----- 1 fk∑–≥
fk∑ 1 1λ2-----–≥
P x p∈( ) 12--- ;= P x d∈( ) 1
2---=
xp{ } xd{ }∪ S=
xp{ } xd{ }∩ φ=
Y g X( )xp y testa↔
xd y croce↔
= =
1 xi 6≤ ≤
0 yi 1≤ ≤
g 2( ) g 4( ) g 6( ) testa 0= = = =
g 1( ) g 3( ) g 5( ) croce 1= = = =

STATISTICA DI BASE
14
Questo esempio è stato fatto su variabili casuali discrete ma può generalizzarsi alcaso di variabili continue in cui una funzione y = g(x) sia definita su tutto l'insiemeSX dei valori argomentali della x.
La g(x) trasforma lo spazio SX nello spazio dei valori argomentali SY.
Cerchiamo ora invece una corrispondenza più interna, più puntuale: poniamo chela funzione g(x) sia una funzione continua: quella tracciata ad esempio in figura 6.4.
Fig. 6.4 – Variabile casuale funzione di variabile casuale.
dove il dominio dei valori argomentali è: SX = (a, b ) SY = (c , d ).
Sia AY un sottoinsieme di SY; a questo sottoinsieme corrisponderà un insieme:
cioè, per definizione:
6.43
Ed ora cerchiamo l'annunciata corrispondenza puntuale: scegliamo per AY unintervallo dy (y0) attorno a y0 e, nell'ipotesi che g(x) sia continua e differenziabile, siavrà che AX sarà formata da uno o più intervalli attorno a xi anch'essi di ampiezzadxi, per cui si avrà la corrispondenza in termini probabilistici di:
6.44
(con il simbolo Σ si intende qui l'operatore unione insiemistica ).
Si ha allora che:
X 1 6⁄ 1 6⁄ 1 6⁄ 1 6⁄ 1 6⁄ 1 6⁄1 2 3 4 5 6
=
Y 0 11 2⁄ 1 2⁄
=
a
yd
bx
c
y=g(x)
dx1 dx2 dx3
x1 x2 x3
dy y0
AX SX g AX( )⁄∈ AY=
P y AY∈( ) P x AX∈( )=
AY dy y0( ) AX→← dxi xi( )∑= =
∪
P y dy y 0( )∈( ) P x dxi xi( )∈( )1
m
∑=

STATISTICA DI BASE
cioè
6.45
in quanto per un intervallo infinitesimo il secondo membro è uguale a ,dove è la densità di probabilità della vc x. Dividendo entrambi i membridella 6.45 per si ottiene:
e, per definizione del primo membro:
che è la formula di trasformazione di variabili casuali fra loro legate da una fun-zione g.
Esempio 1
Il legame fra due vc x ed y sia:
si ha:
quel che serve tuttavia è avere una funzione esplicita di fy in funzione di y cioè fy(y ):
Se nell'esempio scegliamo per fx la funzione definita normale standardizzata o Gaus-siana:
si avrà:
Si può dsformazvariabile
f y( ) dy f x( ) dx∑=
fX x( ) dxfX x( ) dx
dy
P y dy y 0( )∈( )dy
------------------------------------P x dxi xi( )∈( )
dy----------------------------------
fX xi( )dydx------
-------------∑=∑=
y ax b+=
g ' x( ) a ;= fy y( )fx x( )
a-----------=
fy y( )fx
y b–a
----------
a---------------------=
6.47a
6.47b
fx x( ) 1
2π---------- e
x 2
2-------–
=
fy y( ) 1
2π a----------------- e
12--- y b–
a------------
2–
=
6.46fy y 0( )fx xi( )g ' xi( )
----------------i
∑=
15
imostrare che la media della vc y è b ed il suo sqm è ± a. Attraverso la tra-ione lineare precedente si passa cioè dalla variabile non standardizzata alla standardizzata di Gauss.

STATISTICA DI BASE
Esempio 2
Il legame sia y = x 2 cioè . Ad un unico valore di y corrispondono duevalori di x:
Se, come sopra, è la 6.47a si avrà:
6.48
Il quadrato di una variabile gaussiana 6.47 ha dunque funzione di distribuzione diequazione 6.48 che vedremo essere la variabile ad una dimensione cioè .
6.5 TEOREMA DELLA MEDIA
Siano x ed y due variabili casuali legate dalla relazione y = g(x); allora la media diy, se esiste vale:
6.49
È cioè possibile fare il cambiamento di variabili nell'operatore media .
Dimostrazione
Poniamoci, solo per semplicità, nel caso che g(x) sia monotona e crescente(g'(x )>0). Ricordando la definizione di media e la 6.46:
Seguono due importantissimi corollari del teorema.
Corollario 1
La media è un operatore lineare, vale a dire se x ed y sono due vc ed
Infatti:
x y±=
x1 y ;–= x2 y=
g' x1( ) 2x1 2 y ;–= = g' x2( ) 2x2 2 y ;= =
fy y( )fx y–( )
2 y –---------------------
fx y–( )2 y
---------------------+∑ fx y–( ) fx y( )+
2 y ----------------------------------------------= =
fx y( )
fy y( ) 1
2 2πy -------------------- e
12--- y–( )2– 1
2 2πy -------------------- e
12--- y( )2–
+1
2 2πy -------------------- e
y2---–
= = per y 0≥( )
χ2 χ12
µy My= y[ ] Mx g x( )[ ]=
M ⋅[ ]
My y[ ] y fy y( ) dy∞–
∞
∫ yfx x( )g' x( )----------- dy
∞–
∞
∫ g x( )fx x( )g' x( )----------- g' x( )dx⋅
∞–
∞
∫= = =
My y[ ] g x( ) fx x( )dx∞–
∞
∫ Mx g x( )[ ]= = c.v.d.
6.50y ax b+= My y[ ]⇒ aMx x[ ] b+=
16
STATISTICA DI BASE
Corollario 2
Sia y = g(x); sotto opportune ipotesi della g rispetto alle distribuzioni di x ed y econ una certa approssimazione vale:
Fig. 6.5
Dimostr
Sia x unponiamun into
Svilupp
Il secondella va
L'equaz
M y y[ ] Mx ax b+[ ] ax b+( ) fx x( ) dx∞–
∞
∫ a x fx x( ) dx b x fx x( ) dx∞–
∞
∫+∞–
∞
∫= = =
M y y[ ] aMx x[ ] b+=
6.51µy M y= y[ ] g µx( )=
17
– Dimostrazione del 2° corollario del Teorema della media.
azione del 2° corollario
a vc abbastanza concentrata attorno a µx (che abbia cioè piccolo σx), sup-o poi che g(x) abbia andamento molto regolare attorno a µx, per lo meno inrno [a ,b ].
ando g(x) si ha, al primo ordine:
do termine del secondo membro è nullo in quanto rappresenta la mediariabile scarto, risulta dunque provata la 6.51.
ione 6.51 si trasforma nella 6.50 nel caso lineare, nel quale è rigorosa.
µx
µx
y
xa b
y=g(x)
g( )
g x( ) g µx( ) g' µx( ) x µx–( )+≅
µy My y[ ] g x( ) fx x( )dx g µx( ) g' µx( ) x µx–( )+[ ] fx x( )dx∞–
∞
∫≅∞–
∞
∫= =
g µx( ) f x x( ) dx g' µx( ) x µx–( ) fx x( )dx∞–
∞
∫+∞–
∞
∫

STATISTICA DI BASE
18
Esempio
Di un anello si è più volte misurato direttamente il diametro, ottenendo il valoremedio di ; si desidera conoscere la superficie interna media in modo indiretto.Applicando la 6.51 si ha:
6.6 LEGGE DI PROPAGAZIONE DELLA VARIANZA
Sotto le ipotesi del secondo corollario del teorema della media se la vc y è una fun-zione della vc x :
6.52
Dimostrazione
Poniamoci nel solito intervallo [a ,b ] che comprende quasi tutto l'insieme SX, nelqua l e v a l gono l a 6 . 5 0 e l a 6 . 5 1 . Pe r f unz i on i mono tone s i h a
, dunque:
e, sviluppando g(x):
cioè a dire la 6.52.
Osservazioni al teorema di propagazione della varianza
La 6.52 è una formula rigorosa nel caso che g(x ) sia una funzione lineare; in tal casoinfatti:
x
y πx2
4--------=
y g x( )=
σ 2 g' µx( )2 σ x2=
f x x( ) d x f y y( ) d y=
σ y2 g x( ) µx–( )2 fx x( )dx
a
b
∫=
σ y2 g µx/( ) g' µx( ) x µx–( ) µy/–+[ ] 2 fx x( )dx
a
b
∫≅
σ y2 g ' µx( )2 x µx–( )2 fx x( )dx
a
b
∫ g' µx( )2 x µx–( )2 fx x( )dxa
b
∫≅ ≅
y ax b+= µy⇒ a µx b+=
σ y2 My y µy–( )2[ ] M ax b aµx– b–+( )2[ ] a2M x µx–( )2[ ]= = =
σ y2 a2 σ x
2= c.v.d.

STATISTICA DI BASE
19
Data una variabile casuale x qualunque è sempre possibile con una trasformazionelineare costruire da questa una variabile casuale z tale che:
6.53
detta variabile casuale standardizzata.
Grazie al teorema della media e della propagazione della varianza basta infattiporre:
6.54
e si avrà;
Esempio di applicazione del teorema di propagazione della varianza
Nel calcolo della superficie interna di un anello si è misurato il diametro medio x = 5 cme stimato si desidera calcolare la superficie media e la relativavarianza:
Quante cifre hanno senso in questo calcolo?
Ha senso definire dunque al massimo a due cifre dopo la virgola:
.
6.7 ALCUNE IMPORTANTI VARIABILI CASUALI
Distribuzione di Bernoulli o binomiale
Consideriamo un esperimento stocastico ε e siano S i suoi possibili risultati. Suppo-niamo che S sia costituita da due insiemi disgiunti A e B di eventi incompatibili 0ed 1 aventi rispettivamente probabilità p e q=(1–p):
6.55
µz 0 ;= σ z2 1=
zx µx–
σ x-------------=
M z[ ] 1σ x-----M x µx–[ ] 0= =
σ 2 z[ ] 1σx----- σ x
2 1= =
σx 0.01cm±=
yπx 2
4---------19.63495 cm2=
σ y2 2 x π
4---
2
σ x2 ;= σ y
x π2
-------σ x =
σ y 0.0785 cm2±=
y
y 19.63 cm2 0.078 cm2±=
P A( ) p ;= P B( ) q ;= ε0 1q p
:=

STATISTICA DI BASE
con:
Da questa vc discreta ne costruiamo una seconda: consideriamo n ripetizioni indi-pendenti di ε ed indichiamo con β la vc discreta (intera) che descrive la probabilitàche, su n esperimenti ε , k abbiano un risultato in A e (n – k) un risultato in B. Percostruire la seconda riga della vc k:
abbiamo ora bisogno di conoscere il teorema delle probabilità totali che dice inquesto caso: la probabilità di k successi su n prove è uguale alla somma delle proba-bilità di (k–1) successi su (n–1) prove per la probabilità p di un nuovo successo, piùla probabilità di k successi in (n–1) prove per la probabilità q di un insuccesso.
È possibile cioè ricavare la formula ricorsiva:
6.56
Partiamo da una prova dell'esperimento: la probabilità di successo sarà p e di insuc-cesso q:
6.57
Si ha ad esempio, applicando la 6.56:
ed in genere P(n ,0) = qn. Viceversa:
in genere P(n,n) = p e, per valori qualunque di (n,k) si dimostra che vale:
6.58
Dunque la vc discreta β è così definita:
M ε xi pi∑ p ;= = σ 2 ε 1 p–( )2p 0 p–( )2q+ p q= =
ββ = 0 1 2 3 …n
– – – – –
:=
P nk( ) p P n 1 k 1–,–( ) q P n 1 k,–( )⋅+⋅=
P 1 1,( ) p ;= P 1 0,( ) q=
P 2 0,( ) p 0 q q⋅+⋅ q2= =
P 2 1,( ) p P 1 0,( ) q P 1 1,( )⋅+⋅ P 2 1,( ) pq pq+ 2pq= = = =
P 1 2,( ) p P 0 1,( ) q P 0 2,( )⋅+⋅ 0= =
P 2 2,( ) p P 1 1,( ) q P 1 2,( )⋅+⋅ p2= =
P n k,( )n
k pkqn k–=
6.59βk =
0 1 2 … n
qnn
2 p2qn 1– … … pn
:=
20

STATISTICA DI BASE
21
Per ricavare media e varianza della 6.59 possiamo con maggior facilità applicare ilteorema della media e quello della propagazione della varianza. Essendo β la vcsomma delle n variabili ε :
ed avendo ciascuna variabile ε media uguale a p e varianza uguale a pq:
6.60
6.61
La distribuzione binomiale ha la forma di figura 6.6 (è discreta e dunque costituitada un insieme distinto di punti).
Fig. 6.6 – Distribuzione binomiale o di Bernoulli.
Distribuzione normale o di Gauss
La funzione densità di probabilità è data dalla:
6.62
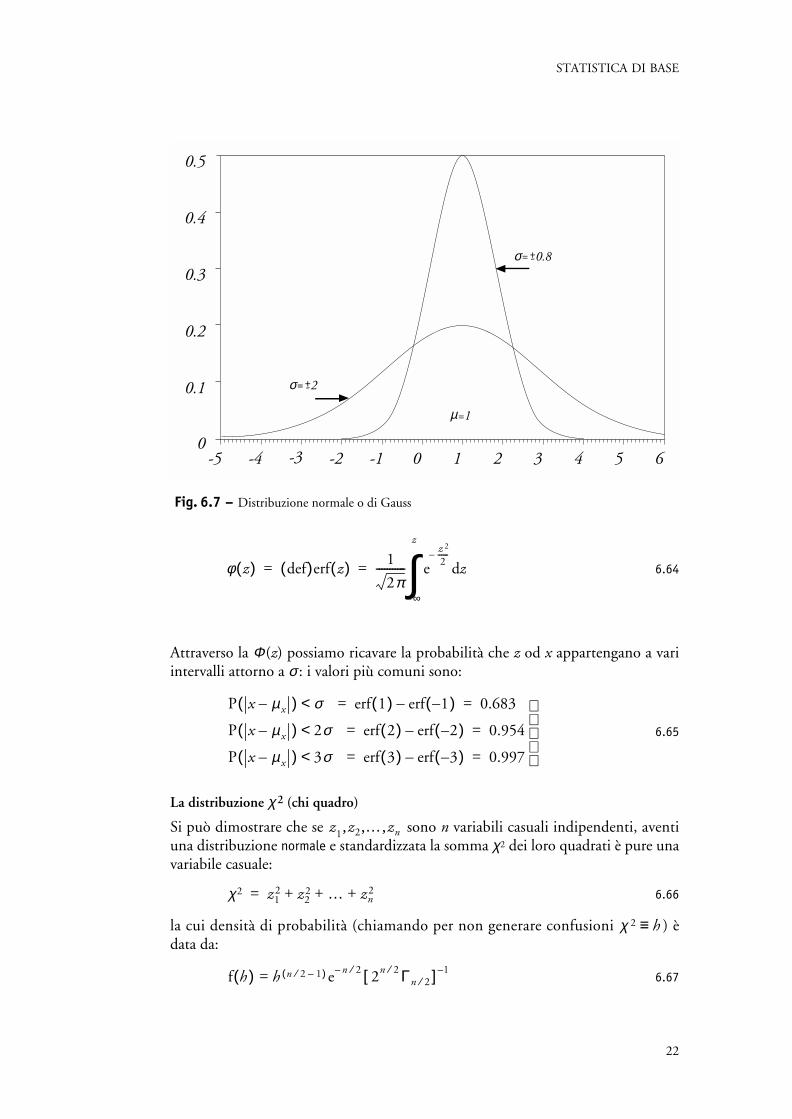
dove si può verificare che µ e σ 2 sono media e varianza della variabile casuale giàvista nella 6.47. La figura 6.7 mostra due distribuzioni normali con stessa media, µ = 1ma con σ =±0.8 e σ =±2 rispettivamente.
La standardizzazione della 6.62 conduce alla variabile z con distribuzione:
6.63
Se cerchiamo la funzione di distribuzione della 6.63 si ha:
β ε1 ε2 … εn+ + +=
M β[ ] np=
σ 2 β[ ] npq=
P1
i0.0
0.1
0.2
0.3
0.4
0.5
0.6
0 2 4 6 8 10 12 14 16 18 20
n = 10
n = 50
fx x( ) 1
σ 2π---------------- e
x µ–
σ 2-----------
2–
= ∞ x ∞≤ ≤–
fz z( ) 1
2π---------- e
z 2
2------–
=
STATISTICA DI BASE
Fig. 6.7 – Distribuzione normale o di Gauss
6.64
Attraverso la Φ(z) possiamo ricavare la probabilità che z od x appartengano a variintervalli attorno a σ : i valori più comuni sono:
6.65
La distribuzione χ 2 (chi quadro)
Si può dimostrare che se sono n variabili casuali indipendenti, aventiuna distribuzione normale e standardizzata la somma χ2 dei loro quadrati è pure unavariabile casuale:
6.66
la cui densità di probabilità (chiamando per non generare confusioni ) èdata da:
0
0.1
0.2
0.3
0.4
0.5
-5 -4 -3 -2 -1 0 1 2 3 4 5 6
0.8=+-σ
2=+-σ
µ=1
φ z( ) def( )erf z( ) 1
2π----------- e
z 2
2------–
zd
∞–
z
∫= =
P x µx–( ) σ < erf 1( ) erf 1–( )– 0.683= =
P x µx–( ) 2σ < erf 2( ) erf 2–( )– 0.954= =
P x µx–( ) 3σ < erf 3( ) erf 3–( )– 0.997= =
z1 z2 … zn,,,
χ2 z12 z2
2 … zn2+ + +=
χ 2 h≡
6.67f h( ) h n 2 1–⁄( ) e n 2⁄– 2n 2⁄ Γn 2⁄[ ] 1–=
22
STATISTICA DI BASE
23
Come si vede χ2 dipende anche dal parametro intero n, detto grado di libertà. Nella6.67 il termine entro la quadra è una costante che fa si che la relativa funzione didistribuzione valga .
Nelle 6.67, in parentesi, compare la funzione Γ di Eulero, generalizzazione dellafunzione fattoriale; per numeri reali si calcola attraverso:
6.68
Per valori di s semi-interi si usa la più comoda formula ricorsiva
6.69
6.70
Si dimostra che:
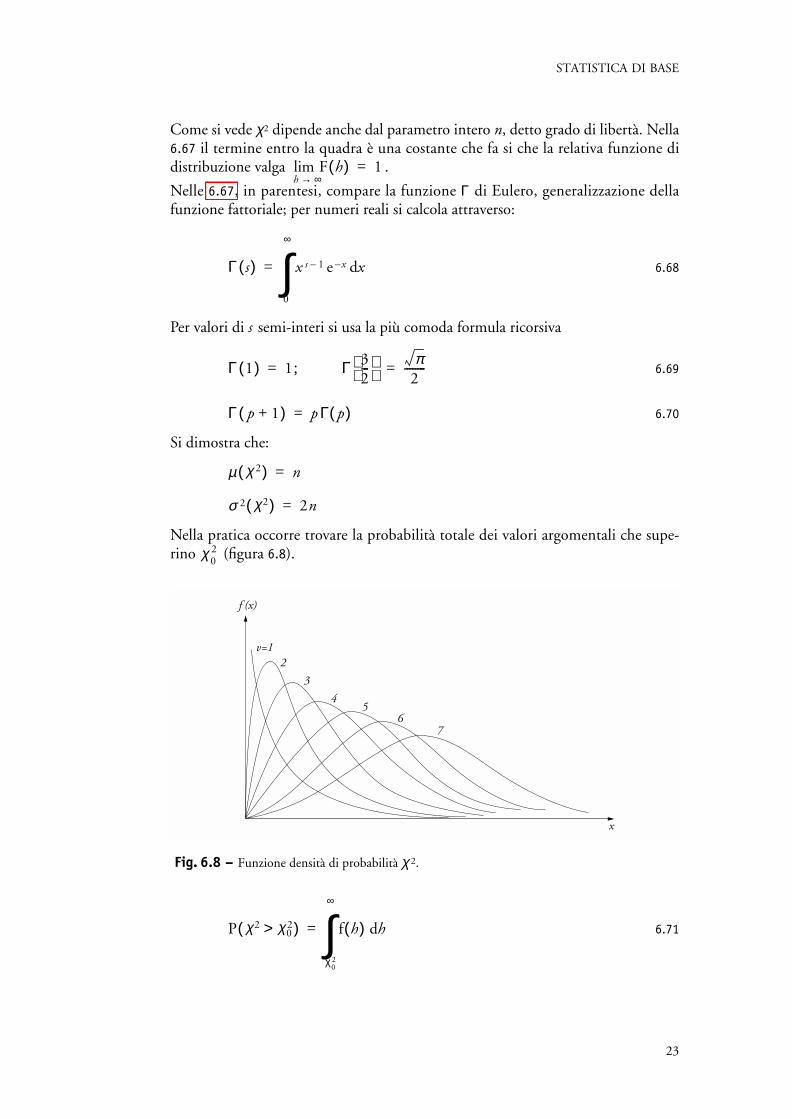
Nella pratica occorre trovare la probabilità totale dei valori argomentali che supe-rino (figura 6.8).
Fig. 6.8 – Funzione densità di probabilità χ 2.
6.71
F h( )h ∞→lim 1=
Γ s( ) x s 1– e x– xd
0
∞
∫=
Γ 1( ) 1 ;= Γ 32---
π2
-------- =
Γ p 1+( ) p Γ p( )=
µ χ 2( ) n=
σ 2 χ2( ) 2n=
χ 02
f (x)
x
v=12
3
45
67
P χ2 χ02>( ) f h( ) hd
χ02
∞
∫=

STATISTICA DI BASE
24
Questi valori sono in genere tabulati in funzione di e di n. Tale variabile siindica spesso anche con per evidenziare il numero di gradi di libertà.
Distribuzione t di Student
Sia z una normale standardizzata e zi altre variabili normali standardizzate i = 1…ne sia:
6.72
una seconda variabile casuale così costruita ed indipendente da z.
Si definisce la variabile t come:
6.73
Si dimostra che la funzione densità di probabilità f(t ) vale:
6.74
La 6.74 è simmetrica rispetto all'origine, dunque:
6.75
Si prova che:
6.76
Per grandi valori di n , t è molto simile alla variabile z.
Per un certo valore del grado di libertà n i valori della funzione di distribuzione diquesta variabile casuale si trovano tabulati in funzione delle probabilità ; adesempio per α = 5% si trova tabulato:
6.77
χ 02
χ n2
y z12 z2
2 … zn2+ + + χn
2= =
t tnz n
χn2
---------- z n
z12 z2
2 … zn2+ + +
--------------------------------------------= = =
f t( ) 1 t 2
n----+
n 1+
2------------– Γ n 1+
2------------
πn Γ n 2⁄( )------------------------------=
µ t( ) 0=
σ 2 t( ) nn 2–------------= per n 2>
α t1 α–n,
P t tα<( ) 1 α–=

STATISTICA DI BASE
25
Fig. 6.9 – Distribuzione t di Student.
La distribuzione F di Fisher
Siano date due vc χ 2 ad n ed m gradi di libertà ed indipendenti tra loro; allora ilrapporto
6.78
è una vc detta F di Fisher ad (n,m ) gradi di libertà.
Si può dimostrare che:
6.79
e che:
6.80
6.81
-4 -3 -2 -1 0 1 2 3 4
0.08
0.16
0.24
0.32
0.40
Distribuzione di "Student"
(N=4 G. di lib.=3)
Distribuzione normale standard (G. di lib.= ∞)
Fχn
2 1n---⋅
χm2 1
m----⋅
--------------- Fn m,= =
f F( ) F n 2–( ) 2⁄
nF m+( ) n m+( ) 2⁄---------------------------------------nn 2⁄ mm 2⁄ Γ n m+
2-------------
Γ n 2⁄( ) Γ m 2⁄( )------------------------------------------------⋅= per F 0≥
M F[ ] nn 2–------------= n 2>( )
σ 2 F( ) 2n2 m n 2–+( )m n 2–( )2 n 4–( )-----------------------------------------=
STATISTICA DI BASE
26
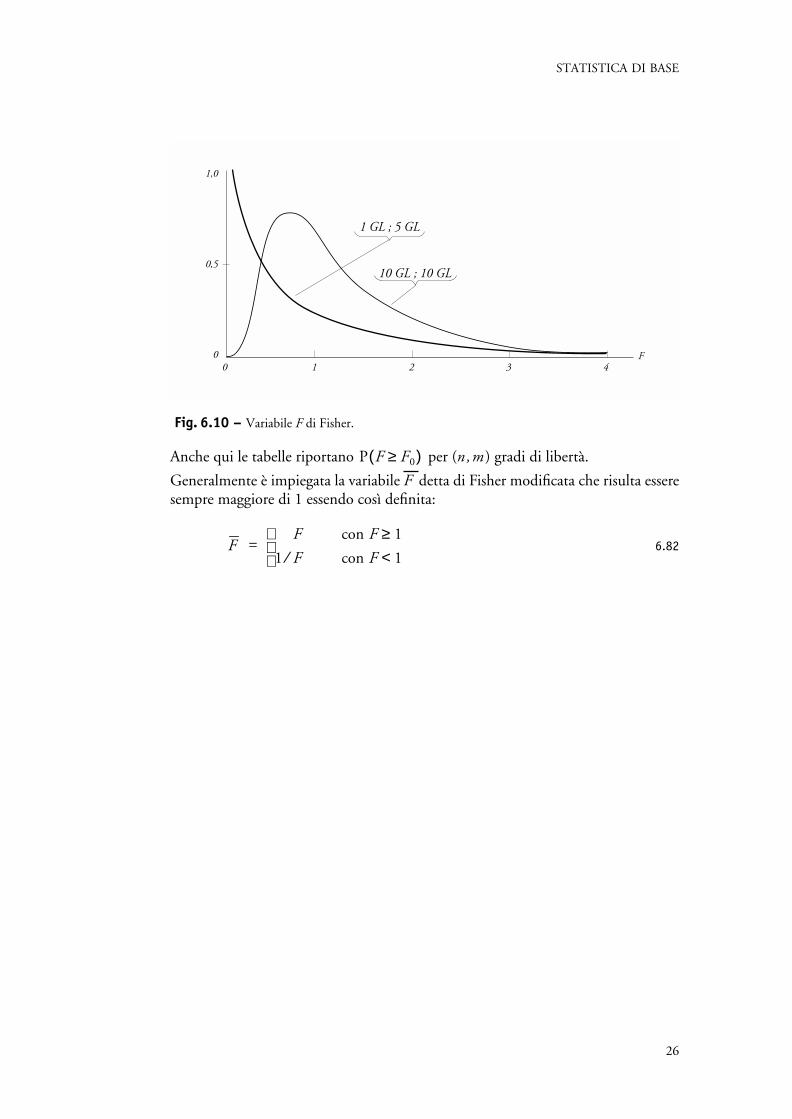
Fig. 6.10 – Variabile F di Fisher.
Anche qui le tabelle riportano per (n,m ) gradi di libertà.
Generalmente è impiegata la variabile F detta di Fisher modificata che risulta esseresempre maggiore di 1 essendo così definita:
6.82
0 1 2 3 4F0
0,5
1,0
1 GL ; 5 GL
10 GL ; 10 GL
P F F0≥( )
FF con F 1≥
1 F⁄ con F 1<
=

27
7. LA VARIABILE CASUALE A
n
DIMENSIONI
Partiamo col definire una variabile casuale discreta a
n
dimensioni cioè quella varia-bile per cui ogni valore argomentale può essere indicato come un vettore ,cioè un punto nello spazio :
7.1
L'insieme dei valori argomentali S sarà dunque un insieme in cui è definitala nostra distribuzione di probabilità.
La vc si dice
discreta
se la distribuzione di probabilità è concentrata solo su
k
punti
x
i
,
i =
1
,…,k
con la condizione:
7.2
In caso opposto la vc si dice
continua
. Analogamente alla vc discreta ad una dimen-sione si potrà rappresentare una vc discreta ad
n
dimensioni con una tabellan-dimensionale.
Nel caso di vc doppia ad esempio si può costruire la tabella:
x lRn∈lRn
x
x1
x2
.
.
.
xn
=
S lRn∈
P x xi=( )i 1=
k
∑ 1=
x x11 x1
2 … x1k
x21
x22
x2h
p11 p1
2 … p1k
p21 p2
2 … p2k
ph1 ph
2 … phk
Pij P x1 x1i= , x2 x2
i=( )=

LA
VARIABILE
CASUALE
A
n
DIMENSIONI
28
La vc discreta è sempre assimilabile alla variabile statistica, sostituendo alle
p
ij
le fre-quenze relative
f
ij
:
Una distribuzione di probabilità viene chiamata variabile casuale quando è definitala probabilità
per ogni
insieme del tipo:
Anche in questo caso possiamo definire la funzione densità di probabilità dellavariabile casuale
x
se esiste, attraverso il limite:
7.3
dove
ω
(A) è la misura dell'insieme A e
ρ
è il suo «diametro» che tende a zero in attorno al punto
x
.
La
7.3
può essere riscritta con:
7.4
dove d
V
(
x
) è un elemento di volume in
attorno a
x
. Dalla definizione prece-dente si ha:
7.5
e la funzione di distribuzione
7.6
derivando la
7.6
si ricava:
7.7
Esempio 1
In un urna sono contenute due palline bianche (
b, B
) e due nere (
n , N
). La varia-bile casuale discreta che descrive l'estrazione in blocco delle due palline e la relativaprobabilità sono
1
:
1
Si ricorda che gli esempi sono tratti dal già citato testo di F. Sansò.
fijNij
N-------=
x1 x01; …xn x0n<≤{ }
P x1 x01; …xn x0n<≤( ) F x01; x02; …x0n( ) F x 0( )==
f x( ) P A( )ω A( )-------------
ρ 0→lim=
lRn
f x( ) dP x( )dV x( )---------------=
lRn
P x A∈( ) f x( ) dV x( )
A∫=
F x01, x02,…, x0n( ) dx1… f x( )dxn
∞–
∞
∫∞–
∞
∫=
f x( ) ∂nF x( )∂x1…∂xn----------------------=

LA
VARIABILE
CASUALE
A
n
DIMENSIONI
29
Nell'ipotesi di due estrazioni successive con sostituzione (reintegrazione) invece lavc sarà:
Esempio 2
Osservando un gran numero di tiri al bersaglio possiamo dire quanto segue:
a. in ogni zona del bersaglio i colpi tendono a distribuirsi uniformemente aparità di distanza dal centro
b. contando i punteggi si è visto che, indicando con r la distanza dal centro
7.8
Fig. 7.1 –
Distribuzione bidimensionale.
La costante σ 2 è un parametro di bravura del tiratore.
Si vuole trovare la distribuzione bidimensionale dei tiri (figura 7.1).
Notiamo che la 7.8 fornisce la probabilità che P[ξ ,η ] ∈ dC con dC elemento dicorona circolare attorno ad r0.
b B n N 1A ESTRAZIONE
b / bB bn bN
→
0 1/12 1/12 1/12 2A estrazione Bn Bb / Bn BN 1/12 0 1/12 1/12
N nb nB / nN 1/12 1/12 0 1/12
/ Nb NB NB / 1/12 1/12 1/12 0
b B n N 1A ESTRAZIONE
b bb bB bn bN
→
1/16 1/16 1/16 1/16 2A estrazione Bn Bb BB Bn BN 1/16 1/16 1/16 1/16
N nb nB nn nN 1/16 1/16 1/16 1/16
/ Nb NB NB NN 1/16 1/16 1/16 1/16
P r dr r0( )∈[ ]r0
σ 2------ e
r0
2
2σ 2----------–
dr=
dC
d
η
ω
ξ
ϑ dr
ro0
d

LA VARIABILE CASUALE A n DIMENSIONI
Siccome in dC la probabilità è uniformemente distribuita, allora:
Per la definizione di densità di probabilità:
La 7.9 ra
7.1 DIS
Lo scopozionate èpendenti
Conside
È facile inel cercastia in dnale si getale che:
Questa v
ricordanzione F s
Una vc n
P ξ ,η( ) dω∈[ ] P x dC∈[ ] dωdC-------- P x dC∈[ ] dϑ
2π------- 1
σ 2------ e
r0
2
2σ 2---------–
r dr dϑ2π-------= = =
f ξ ,η( ) P ξ ,η( ) dω∈[ ]dω
------------------------------------ P ξ ,η( ) dω∈[ ]r dr dϑ
------------------------------------= =
P[
f x1
7.9f ξ ,η( ) 12πσ 2-------------- e
r2
2σ 2---------– 1
2πσ 2-------------- e
ξ 2 η2+
2σ 2-----------------–
= =
30
ppresenta l'equazione della distribuzione normale a due dimensioni.
TRIBUZIONI MARGINALI
dell'introduzione delle distribuzioni marginali e delle distribuzioni condi-, ai nostri fini, capire se e quando due variabili casuali sono fra loro indi-.
riamo l'evento A:
ntuire che la classe di questi eventi dipende solo dalla variabile casuale x 1 e,re la probabilità dell'evento Ai , domandiamo qual è la probabilità che x 1
x 1 qualunque valore assunto per x2…xn. Da una distribuzione n-dimensio-nera cioè una distribuzione mono-dimensionale ed una corrispondente vc x1
c è detta marginale della x ed ha densità di probabilità:
do la definizione di densità di probabilità 6.23 come derivata dalla fun-i ha:
7.10
-dimensionale avrà n marginali mono-dimensionali.
A x1 dx1 x01( ); ∞– x2 ∞; … ∞– xn ∞< << <∈{ }=
x1 dx1∈ ] P x A∈[ ] dx1 dx 2 dx3… dxn f x01,x2,…xn( )
∞–
∞
∫∞–
∞
∫∞–
∞
∫= =
x 01( ) P x A∈[ ]dx1
---------------------- dx 2 dx 3… dxn f x 01,x 2,…xn( )
∞–
∞
∫∞–
∞
∫∞–
∞
∫= =
f x1x 01( ) ∂
∂x1-------- F x 01, ∞ , ∞ ,…, ∞+ + +( )=

LA VARIABILE CASUALE A n DIMENSIONI
Oltre alle distribuzioni marginali ad una componente si possono anche introdurredistribuzioni marginali di insiemi di componenti: (x1, x2), (x1, x3) ecc. Ad esempio:
che, integrata, fornisce la probabilità che un certo gruppo di componenti (x 1,x 2)appartengano ad un certo elemento di volume dV2 per qualunque valore assunto dallealtre componenti.
7.2 DISTRIBUZIONI CONDIZIONATE
Ci si chiede qual è la probabilità che m variabili, ad esempio (x 1… xm) stiano in unelemento di volume dVm, mentre le altre (xm+1… xn) sono certamente vincolate adun elemento di volume dVm-n.
I due eventi A e B sono:
Si desidera calcolare che vale secondo la 6.7:
Tale distribuzione di probabilità genera una densità di probabilità per le variabili(x1…xm) per qualunque valore delle rimanenti variabili (xm+1…xn) che vale:
f x1 x2x1, x2( ) dx3… dxn f x 01,x 02,…xn( )
∞–
∞
∫∞–
∞
∫=
A x1 …xm( ) dVm∈{ } ; B xm 1+ …xn( ) dVn m–∈{ }P A B[ ]
P A B[ ] P AB[ ]P B[ ]
----------------f x x( )dVm dVn m–
dVn m– f x x1…xm, xm 1+ …xn( )dVm
R m
∫---------------------------------------------------------------------------------------- = =
P A B[ ]f x x1…xm, xm 1+ …xn( )dx1…dxm
dx1… dxm f x x1…xm, xm 1+ …xn( )
∞–
∞
∫∞–
∞
∫---------------------------------------------------------------------------------------------=
f x1…xm xm 1+ …xnx1…xm xm 1+ …xn( )
f x x1…xm, xm 1+ …xn( )
dx1… dxm f x x 1…xm, x m 1+ …xn( )
∞–
∞
∫∞–
∞
∫------------------------------------------------------------------------------------------- =
7.11f x1…xm xm 1+ …xnx1…xm xm 1+ …xn( )
f x x1…xm, xm 1+ …xn( )f xm 1+ …xn
xm 1+ …xn( )-------------------------------------------------------=
31

LA
VARIABILE
CASUALE
A
n
DIMENSIONI
7.3
INDIPENDENZA
STOCASTICA
Leggi relative alle distribuzioni
Ricordando le
6.8
due eventi si definiscono stocasticamente indipendenti se:
6.8
Se ci limitiamo ad esaminare un elemento di volume d
V
m
:
si ha allora che, nel caso di eventi indipendenti, la
7.11
deve essere uguale anche a, cioè a dire:
7.12
Se ciò è verificato le variabili casuali sono stocasticamente indipendentidalle rimanenti .
Se, al contrario, la densità di probabilità totale può essere fattorizzata nelprodotto:
7.13
le prime variabili sono indipendenti dalle seconde.
Si nota che i termini al secondo membro sono proporzionali alle marginali. Siarriva così al teorema:
Condizione necessaria e sufficiente affinché
siano stocasticamenteindipendenti da
e viceversa, è che la densità di probabilità con-giunta si spacchi nel prodotto delle due marginali:
7.14
Ne segue un facile corollario:
Condizione necessaria e sufficiente affinché le
n
componenti di una vc
n
-dimensio-nale siano tutte tra loro indipendenti è che la densità di probabilità congiunta sispacchi nel prodotto delle
n
-marginali:
Si noti,
sioni pu
P A B[ ] P A[ ]=
P A[ ] P x1…xm( ) dVm∈[ ] f x1…xmx1…xm( )dVm= =
fx1…xmx1…xm( )
f x1…xm xm 1+ …xn( ) f x x( ) f x1…xmx1…xm( ) f xm 1+ …x n
xm 1+ …xn( )= =
x1…xm( )xm 1+ …xn( )
f x x( )
f x x( ) φ x1…xm( )ψ xm 1+ …xn( )=
x1…xm( )xm 1+ …xn( )
f x x( ) f x1…xmx1…xm( ) fxm 1+ …xn
xm 1+ …xn( )=
7.15f x x( ) f x1x1( ) f x2
x2( )…f xnxn( )=
32
a proposito, che la 7.9 che rappresenta la variabile di Gauss a due dimen-ò rappresentarsi anch’essa dal prodotto:
f ξ η⋅( ) f ξ( ) f η( )⋅ 1
2π σ------------------ e
12--- ξ
σ-------
2
1
2π σ------------------ e
12---– η
σ-------
2
⋅= =

LA
VARIABILE
CASUALE
A
n
DIMENSIONI
33
7.4 V
ARIABILI
CASUALI
FUNZIONI
DI
ALTRE
VARIABILI
CASUALI
Trasformazione di variabili
Supponiamo che sia data una funzione g che trasformi variabili da
a
:
7.16
( g è un vettore di funzioni).
Si può dimostrare che, a partire da una distribuzione di probabilità in possiamocostruirne una in così fatta:
Sia d
V
m
(
Y
0
)
un'elemento di volume di in un intorno di
Y
0
,
e sia
A
(
Y
0
)
l'immagine inversa di
d
V
m
(
Y
0
),
vale a dire l'insieme di:
Si pone:
7.17
ammesso che il secondo termine sia misurabile.
Dunque da una variabile casuale (a destra dell'uguale) possiamo costruirne unaseconda (a sinistra dell'uguale).
Ci si chiede: conoscendo la distribuzione di come sarà distribuita la variabile ?
I casi da prendere in considerazione sono tre:
Escludiamo subito il caso
m
>
n
,
infatti, se
g(
x
)
è differenziabile l'insieme dei valoriargomental
i
è un insieme in , ma avrebbe misura nulla: nonci interessa per il trattamento delle misure analizzare distribuzioni singolari.
Nel caso in cui n=m, se lo jacobiano J della funzione non è nullo, si ha una cosid-detta trasformazione regolare:
ciò ci permette di dire che esiste anche la relazione inversa che porta da a .
Sia allora dVn( y) un elemento di volume attorno ad e dVn( x) l'elemento divolume corrispondente attorno ad .
Il primo intorno lo otteniamo applicando ad la trasformazione g, cioè è l'intorno:
lRn lRn
y g x( )=
lRn
lRn
lRn
x∀ lRn g x( )⁄ dVm Y0( )∈ ∈
P Y dVm Y0( )∈[ ] P x A Y0( )∈( )=
x
x y
m n;<m n;=
m n.>
Y g x( ) x⁄ lRn∈= lRn
J g( ) ∂g∂x------ det.
∂g1
∂x1--------…
∂g1
∂xn-------
∂gn
∂x1--------…
∂gn
∂xn---------
0≠= = x∀ lRn∈
y x
yx
x

LA VARIABILE CASUALE A n DIMENSIONI
7.18
Per la definizione della probabilità ad n-dimensioni si ha poi l'equazione:
7.19
e, per la definizione di densità di probabilità:
cioè:
7.20
Ma la derivata al denominatore è qualcosa di già noto, infatti è lo Jacobiano di ,:
7.21
e allora la 7.20 si trasforma in:
7.22a
dove:
7.22b
Esempio di applicazione della trasformazione ad un caso lineare
Sia data una trasformazione lineare e regolare da a 1
con:
1 Qui di svettori. tralasciadimostr
dVn y( ) g dVn x( )( )=
P Y dVn y( )∈[ ] P X dVn x( )∈[ ]=
fy y( ) dVn y( ) f x x( ) dVn x( )=
f y y( )f x x( )
dVn y( )
dVn x( )-------------------
------------------------=
gJ g( )
det. ∂g∂x------ ∂g
∂x-----
dVn y( )
dVn x( )------------------= =
f y y( )f x x( )
∂g∂x-------
-------------=
x g 1– y( )=
lRn lRm
7.23y A x b+=
34
eguito indicheremo di tanto in tanto con doppia sottolineatura le matrici e con singola iQuesta notazione è usata per rendere più chiaro il discorso all'inizio di un problema ed èta se il senso della formula è univoco, od in genere, per brevità, all'interno di unaazione già avviata.
A det.A ∂g∂x----- 0≠==

LA VARIABILE CASUALE A n DIMENSIONI
Si ha:
7.24
7.25
Sia la funzione di distribuzione , ad esempio, il prodotto di n normali stan-dardizzate, tali che:
7.26a
che può essere anche scritta come:
Dalla
Si ott
Esam
Definsibile
di mo
La 7.2babilisenta conce
Esam
Ad u
x A 1– y b–( )=
f y y( )f x A 1– y b–( )( )
A------------------------------------=
f x x( )
fx x( ) 1
2π-----------e x– 1
2 2⁄ … 1
2π-----------e x– n
2 2⁄ 12π( )n 2⁄------------------- e
x 12 2⁄∑–
= =
x =
7.26bfx x( ) 12π( )n 2⁄-------------------e
x Tx( )2
--------------–=
7.24 ricaviamo:
iene infine dalla 7.25:
7.27
iniamo l'esponente della 7.27.
ita A2 una matrice reale, simmetrica e positiva, si dimostra che è sempre pos-scomporla nel prodotto:
7.28
do che la 7.27 diviene:
9tàatt
in
n
x T A 1– y b–( )[ ] T y b–( )T A 1–( )T= =
fy y( ) 12π( )n 2⁄ A
--------------------------e12--- y b–( )T A 1–( )T A 1– y b–( )–
=
A2 AT A AAT= =
A
7.29fy y( ) 12π( )n 2⁄ A
-------------------------e12--- y b–( )T A2( ) 1– y b–( )–
=
35
rappresenta la forma nella quale è possibile scrivere la funzione densità di pro- di una qualsiasi variabile normale n-dimensionale non standardizzata e rappre-nche, con la 7.23 e la 7.28 la via da seguire per la standardizzazione. Questii saranno ripresi ed estesi in seguito.
iamo infine il caso di una trasformazione da a con m < n, cioè:
7.30
elemento di volume può corrispondere un insieme di che non ha misura finita:
lRn lRm
y 1 g1 x1…xn( )=
ym gm x1 …xn( )=
dVm y( )X dVm( )

LA VARIABILE CASUALE A n DIMENSIONI
36
Ponendo:
si ha:
7.31
Oltre alla 7.31, se non intervengono ulteriori ipotesi, non si può in questo caso dire altro.
7.5 MOMENTI DI VARIABILI n-DIMENSIONALI
Anche per le variabili casuali n-dimensionali possono generalizzarsi i concetti vistiad una dimensione.
Se esiste la media della variabile casuale n-dimensionale questa è per definizioneun vettore n-dimensionale µx dato da:
7.32
dove il simbolo • sta per prodotto scalare. La componente i-esima di µx vale:
7.33
dalla 7.32 si nota che per calcolare basta conoscere la distribuzione marginaledi xi, infatti:
7.34
cioè la componente i-esima della media di è uguale alla media della compo-nente i-esima.
Nel caso ad esempio di una variabile statistica doppia , rappresentata alsolito dalla tabella:
dVm y( ) g AX dVm( )[ ]=
P Y dVm Y0( )∈[ ] P x AX 0∈[ ]=
fY y( ) 1dVm y( )------------------ f x x( ) dVn x( )
AX dVm( )∫=
x
µ x M x[ ] dVn x( )f x x( )
Rn
∫ x•= =
µxiM xi[ ] dVn x( )xi fx x( )
R n
∞
∫= =
µ xi
µ xidxi dVn 1– xi f x x( )
βn
∫ dxi xi dx1…dx i 1– dx i 1+ …dxn f x x( )∞–
∞
∫∞–
∞
∫= =
µ xidxi xi f x i
xi( )∞–
∞
∫=
x
x y,[ ]

LA VARIABILE CASUALE A n DIMENSIONI
37
possiamo, sfruttando la solita analogia, ricavare:
Teorema della media per variabili casuali n-dimensionali
Sia una trasformazione da a , con variabile casuale e variabile per definizione di media, se esiste, si ha:
7.35
In questo caso il teorema della media afferma che:
7.36
Corollario 1
Nel caso in cui la funzione vettoriale g sia lineare, nel caso cioè in cui:
7.37
Corollario 2
se la variabile è ben concentrata in una zona di attorno alla media µx e,nella stessa zona la funzione che lega le due variabili casuali: è lenta-mente variabile allora:
7.38
in analogia a quanto visto per vc ad una dimensione.
Momenti di ordine di una variabile casuale n-dimensionale
Si definiscono momenti di ordine di una variabile casuale n-dimen-sionale gli scalari:
7.39
x x1, x2,… x r,=
y y1, y2,… y s,=
M x[ ] x 1r--- xi∑= =
M y[ ] y 1s--- yj∑= =
lRn lRm x x lRn∈ yy lRn∈
M y[ ] My g x( )[ ] g x( )fx x( ) xd
lR n
∫= =
MY y[ ] Mx g x( )[ ]=
y A x b+=
µ y A µ xb+=
x lRn
y g x( )=
µ y g µx( )=
n1 n2 … nk,,,( )n1 n2 … nk,,,( )
µ i1,i2,… ,ik
n1,n2,… ,nk M xi1
n1 , xi2
n2, …, x ik
nk[ ]=

LA VARIABILE CASUALE A n DIMENSIONI
Si definiscono momenti centrali i corrispondenti momenti della variabile scarto:
Molto spesso tuttavia i momenti più usati sono quelli del secondo ordine che, perdefinizione indichiamo con:
7.40
Notiamo che per i=k si ha:
7.41
cioè i momenti centrali del secondo ordine per i=k sono le varianze della compo-nente i-esima di .
I coefficienti per si indicano anche con e sono detti coefficienti dicovarianza delle componenti e .
Come evidente dalla 7.40 , la 7.40 e la 7.41 espresse in forma matricialedivengono:
7.42
La è detta per ovvi motivi matrice di varianza covarianza o matrice di dispersioneed è simmetrica.
Si può dimostrare, analogamente al caso mono-dimensionale, che:
Cerchiamnenti di
In quest
e, osserv
si trova,
ν x µx–=
cik M xi µxi–( ) xk µxk–( )[ ] M ν iνk[ ]= =
cii σ i2 M xi µxi–( )2[ ]= =
x
cik i k≠ σ ikxi xk
cik cki=
Cxx cik[ ] M xi µxi–( ) xk µxk–( )[ ] Cxx M x µx–( ) x µx–( )T[ ]= = = =
Cxx
M xi xk[
M xi xk[
7.43Cxx M xxT[ ] µx µxT–=
38
o ora un'altra espressione della 7.42 nel caso particolare in cui le compo- x siano fra loro indipendenti.
o caso può essere scritta come prodotto delle marginali 7.15:
ando che ogni marginale è normalizzata per suo conto, cioè che:
per , ricordando la 7.40,
7.44
f x( )
f x( ) f x1x1( )… f xn
xn( )=
f xjxj( ) xjd
∞–
∞
∫ 1=
i k≠
] xi xk f x x( ) x1…d xnd∫=
f x1x1( ) x1d
∞–
∞
∫
f x2x2( ) x2d
∞–
∞
∫
xi f xixi( ) xid
∞–
∞
∫
xk f xkxk( ) xkd
∞–
∞
∫
=
] µxi µxk
=

LA VARIABILE CASUALE A n DIMENSIONI
ma, ricordando la 7.43:
ne deriva che:
7.45
cioè, per componenti di indipendenti, la matrice è diagonale e assume laforma:
7.46
Si può verificare in molti casi che non è vero viceversa, cioè la forma diagonale di non significa necessariamente che le n-componenti siano fra loro indipendenti.
La propagazione della varianza nel caso lineare ad n-dimensioni
Come nel caso mono-dimensionale ci domandiamo cosa vale la matrice divarianza covarianza di una variabile casuale funzione di una secondavariabile .
L'ipotesi è che la relazione g sia lineare, cioè e che .
Per il teorema della media:
dunque:
ma per
sfruttan
È questa
cik M xi xk[ ] µxi µkk
–=
cik σik 0= = i∀ k≠
x Cxx
Cxx
σ 12…0
0…σ n2
=
Cxx
y lRm∈x lRn∈
y A x b+= m n≤
µy A µxb+=
7.47y µy–( ) A x µ x–( )=
definizione di :
do la linearità dell'operatore media, M[•] , si ha:
Cyy
C yy M y µy–( ) y µy–( )T[ ] M A x µx–( ) x µx–( )T AT[ ]= =
7.48Cyy A M x µx–( ) x µx–( )T[ ] AT A Cxx AT= =
39
la legge di propagazione della varianza nel caso lineare.

LA VARIABILE CASUALE A n DIMENSIONI
40
Esercizio 1
Con un teodolite si misurano le direzioni che ipotizziamo estratte dauna vc a tre dimensioni con media , indipendenti fra di loro e convarianze:
Si determini, valor medio, varianza e covarianza degli angoli azimutali α 1 e α 2così definiti:
Fig. 7.2
L'esercizio è lasciato allo svolgimento del lettore con questo suggerimento: data lamatrice
si applichi il teorema della media e la propagazione della varianza da a .
θ 1 θ 2 θ 3,,θ 1 θ 2 θ 3,,( )
σϑ 1σϑ 2
σϑ 310 10 4–⋅ gon± σ= = = =
α 1 ϑ 1 ϑ 2–=
α 2 ϑ 2 ϑ 3–=
α
α
OP C
B
A
P
2
1
θ3
θ2
θ1
Cϑϑ
σ 2
0
0
0
σ 2
0
0
0
σ 2
=
lR3 lR2

LA VARIABILE CASUALE A n DIMENSIONI
41
Esercizio 2
Si calcoli la covarianza fra x e y e le rispettive varianze per la seguente variabilestatistica doppia:
Si ricavano dapprima le frequenze pi e qj delle marginali; i valori medi sono ricavatiattraverso le frequenze marginali:
Per definizione:
Al secondo membro il secondo termine vale ed il terzo vale ,infine il quarto vale essendo:
Si ha infine:
7.49
y = →x = ↓
4 5 9 pi
↓
1 0.1 0.2 0.1 0.4
2 0.1 0.2 0 0.3
3 0 0.1 0.1 0.2
4 0 0 0.1 0.1
qj → 0.2 0.5 0.3 1
Mx xi pi
1
n 4=
∑ 1 0.4⋅ 2 0.3⋅ 3 0.2⋅+ + 4 0.1⋅+ 2= = =
My yj qj
1
m 3=
∑ 4 0.2⋅ 5 0.5⋅ 9 0.3⋅+ + 6= = =
σxy i 1=
n
∑ x i Mx–( )j 1=
m
∑ yj My–( )f ij=
σxy i 1=
n
∑ xi y j fij
j 1=
m
∑ i 1=
n
∑ xi M y fij
j 1=
m
∑ j 1=
m
∑ yj Mx fij
i 1=
n
∑ i 1=
n
∑ Mx My fij
j 1=
m
∑+––=
My Mx– Mx My–Mx My
fij
j 1=
m
∑i 1=
n
∑ 1=
σxy i 1=
n
∑ xi yj fij
j 1=
m
∑ Mx My–=

LA VARIABILE CASUALE A n DIMENSIONI
42
che rappresenta l'estensione della 7.43. Sostituendo infatti x ad y o viceversa sitrova:
Applicando tutto ciò ai dati dell'esercizio si ricava:
Si ha allora che:
7.6 LA LEGGE DI PROPAGAZIONE DELLA VARIANZA NEL CASO DI FUNZIONI NON LINEARI
Poniamoci ancora nel caso (n, m ) dimensionale in cui e sia:
7.50
una funzione non più lineare della variabile casuale .
Nell'ipotesi che sia ben concentrato attorno alla sua media µ x ed sia pocovariabile attorno a si può operare la linearizzazione:
7.51
È ora possibile utilizzare le 7.47 e 7.48 ricavate per il caso lineare con le seguentisostituzioni:
7.52
σ x2
i 1=
n
∑ x i2
i 1=
n
∑ Mx2–=
σ x2 xi
2 pi
i 1=
4
∑ Mx2– 1 0.4⋅ 4 0.3⋅ 9 0.2⋅ 16 0.1⋅+ + +( ) 4 1=–= =
σ y2 yj
2 qj
j 1=
3
∑ My2– 16 0.2⋅ 25 0.5⋅ 81 0.3⋅++( ) 36 4=–= =
σxy x i 1
4
∑ yj fij
1
3
∑ Mx My– = =
1 4 0.1⋅ 5 0.2⋅ 9 0.1⋅+ +( )⋅ 2 4 0.1⋅ 5 0.2⋅+( )+⋅+=
3 5 0.1⋅ 9 0.1⋅+( ) 4 9 0.1⋅( )⋅ 12–+⋅+
σxy 2.3 2.8 4.2 3.6 12–+ + + 0.9= =
C xy
1 0.9
0.9 4 =
m n≤
y g x( )=
x
x yg µ x( )
y g µ x( ) ∂g∂x-----
x µ x–( )+≅
b g µ x( )=

LA VARIABILE CASUALE A n DIMENSIONI
7.53
La matrice A è detta matrice disegno. La 7.48 diviene allora:
Le matri
Si fissi innale; si anell'ipot
Se scompos
Con Λ
tesi dimo
La radicgono
Esercizio
Di utate
Calcdell'
La trasfdirette
(x , y ) son
A ∂g∂x-----=
Cxx
UTU =
λ
(
ηx
y=
7.54C yy∂g∂x----- Cxx
∂g∂x-----
T
=
ci e sono sempre strettamente definite positive, cioè (definizione):
7.55
fatti e si consideri , con y variabile casuale mono-dimensio-vrà come logico e se x non ha distribuzioni singolari comeesi di trasformazioni regolari.
è regolare (invertibile) e simmetrica, è sempre poi possibile questaizione:
Cxx C yy
Cxx 0: a∀ lRn∈> a T Cxx a 0>⁄
a y aTx=σ y
2 0≥ σ y2 0>
7.56C xx K 2 UΛUT= =
43
matrice diagonale degli autovalori di ed U matrice ortogonale che contiene gli autovettori di . È facile dopo questa ipo-
strare che:
7.57
e quadrata di una matrice diagonale Λ è la matrice i cui elementi val-.
3
n punto P si sono misurate la distanza dall'origine r e l'anomalia ϑ , rappresen- dalle variabili casuali ρ e ϑ con media e sqm seguenti:
olare media e covarianza delle coordinate (x , y ) del punto P e media e varianzaarea A del rettangolo che ha OP per diagonale.
ormazione g permette di ricavare (x, y) in funzione delle misure.
o misurabili cioè indirettamente.
CxxUUT I= Cxx
K UΛ1 2⁄ UT=
i
ρ 1 km= σρ 1mm±= ρ 106 mm=( )
ϑ π 6⁄= σϑ 2 10⋅ 6– rad( )±=
ρ ϑ, )
; ξ
ρϑ
;= Cξξ
σ ρ2 0
0 σ ϑ2
1mm2 0
0 4 10⋅ 12– = =
LA VARIABILE CASUALE A n DIMENSIONI
44
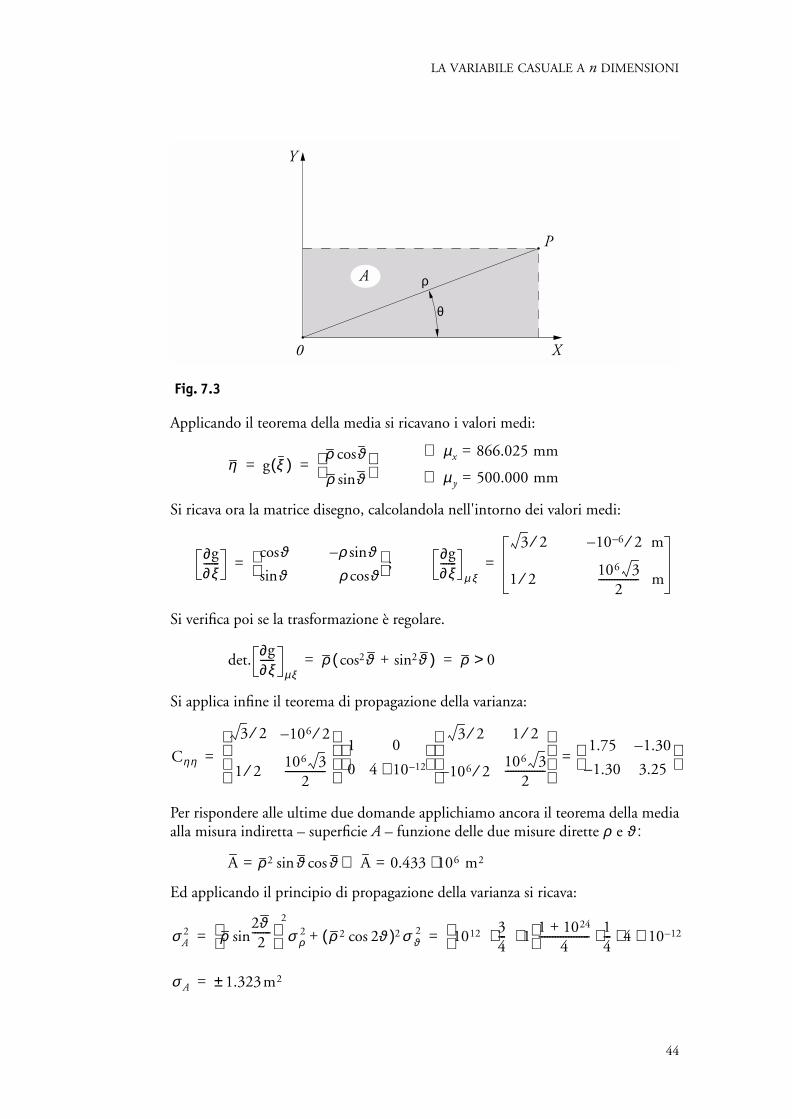
Fig. 7.3
Applicando il teorema della media si ricavano i valori medi:
Si ricava ora la matrice disegno, calcolandola nell'intorno dei valori medi:
Si verifica poi se la trasformazione è regolare.
Si applica infine il teorema di propagazione della varianza:
Per rispondere alle ultime due domande applichiamo ancora il teorema della mediaalla misura indiretta – superficie A – funzione delle due misure dirette ρ e ϑ :
Ed applicando il principio di propagazione della varianza si ricava:
ρA
Y
P
X0
θ
η g ξ( )ρ ϑcos
ρ ϑsin = =
µx 866.025 mm=⇒
µ y 500.000 mm=⇒
∂g∂ξ------
ϑcos ρ ϑsin–
ϑsin ρ ϑcos ;=
∂g∂ξ------
µ ξ
3 2⁄ 10– 6– 2 m⁄
1 2⁄ 106 32
--------------- m=
det.∂g∂ξ-----
µξρ ϑcos2 ϑsin2+( ) ρ 0>= =
Cηη
3 2⁄
1 2⁄
10– 6 2⁄
106 32
--------------- 1
0
0
4 10 12–⋅
3 2⁄
10– 6 2⁄
1 2⁄
106 32
--------------- 1.75
1.30–
1.30–
3.25 = =
A ρ2 ϑ ϑcossin= A 0.433 106 m2 ⋅=⇒
σA2 ρ
2ϑ2
-------sin
2
σ ρ2 ρ 2 2ϑcos( )2 σ ϑ
2+ 1012 34--- 1⋅⋅
1 1024+4
------------------- 14--- 4 10 12–⋅ ⋅ ⋅ = =
σ A 1.323m2±=

LA VARIABILE CASUALE A n DIMENSIONI
Si lascia come esercizio ricavare quest'ultimo risultato a partire dalla relazioneA = xy, con ricavata come sopra.
La propagazione della varianza da n dimensioni ad una dimensione
L'esercizio precedente è un caso particolare nel quale è possibile ricavare una for-mula semplificata rispetto alle 7.48 e 7.54.
Nel caso di trasformazione da n-dimensioni ad una dimensione, l'unica incognita è lavarianza .
Partendo dalla relazione:
7.58
con matrice di varianza covarianza di . La 7.54 diviene:
Cηη
σ y2
y f x1,x2,… xn,( )=
Cxx x
7.59σ y2 ∂f
∂x1--------
2σ x1
2 ∂f∂x2-------
2σ x2
2 … 2∂f∂x1------- ∂f
∂x2--------⋅
σ 12 …2∂f∂xi------ ∂f
∂xk--------⋅
σ ik+ + + +=
45
A conclusione di questa prima parte del trattamento statistico delle misure si pro-pongono questi esercizi.
Esercizio 1
Sia data una v.s. x
Calcolare: - l'istogramma- la funzione di distribuzione- la media, la mediana (è l'ascissa per cui P = 1/2)- la varianza- verificare il teorema di Tchebjcheff tra (µ–10) e ( µ+10).
Esercizio 2
Sia di una v. casuale f (x ) = k.Calcolare:
- k- - - verificare il Teorema di Tchebjcheff
Fig.7.4
x 10 12÷ 12 15÷ 15 20÷ 20 30÷ 30 50÷0.04 0.18 0.40 0.20 0.18
=
xσ x
2
Y
0a b x
f(x)=k

LA VARIABILE CASUALE A n DIMENSIONI
46
Esercizio 3
Sia di una v. casuale f (x ) = kx .Calcolare:
- k- - - verificare il Teorema di Tchebjcheff
Fig.7.5
Esercizio 4
Trasformazioni di variabili casuali. Sia:
trovare: - k
-
- e
- verificare il Teorema di Tchebjcheff
Fare lo stesso esercizio per: ; verificare se .
Esercizio 5
Di un triangolo si sono misurati direttamente a ,b e l’angolo compreso γ.Dati , calcolare la superficie media S ed il suo sigma.
Fig.7.6
xσ x
2
Y
0a b x
f(x)=k x
f x x( ) cost=
y x 2=
f y y( )
M y[ ] σ 2 y( )
y log x( )= M y[ ] g M x[ ]( )=
σa σb σγ,,
S
B
A
b
a
C
γ

LA VARIABILE CASUALE A n DIMENSIONI
47
7.7 INDICE DI CORRELAZIONE LINEARE
Supponiamo che e siano variabili casuali ad n-dimensioni e che siano fra loroindipendenti. Si avrà allora:
7.60
Ipotizziamo ora invece che y sia funzionalmente dipendente da x , e che lo sia inol-tre in modo lineare:
Ne deriva che, come già visto:
Cerchiamo ora le covarianze tra x ed y :
cioè:
7.61
Ora poniamoci nel caso di x ed y ad una componente; nell'ipotesi di indipendenzadella 7.59 si avrà che , mentre nell'ipotesi che ha portato alla 7.61
; inoltre, siccome , applicando la propagazione dellavarianza si ricava , cioè .
Definiamo indice di correlazione lineare di x ed y lo scalare :
7.62
Nella seconda ipotesi di dipendenza lineare si ha:
Nella prima ipotesi 7.60 di indipendenza si può facilmente verificare che:
Questo parametro varia dunque nell'intervallo ± 1 e vale zero per variabili casualifra loro indipendenti.
Si osservi che, viceversa, se le due variabili casuali si dicono incorrelate manon è detto che siano indipendenti.
La figura 7.7 mostra un caso di distribuzione di densità di probabilità di variabilidipendenti ma incorrelate.
è un parametro molto utilizzato grazie a queste sue proprietà:
x y
σ xy M xy[ ] µx µy– 0= =
y A x b+=
y µy–( ) A x µx–( )=
Cxy xy M x µx–( )T y µy–( )[ ] M x µx–( )TA x µx–( )[ ]= =
Cxy xy ACxx=
σxy 0=σxy a2 σ x
2= y ax b+=σ y
2 a2 σ x2= σ y a σ x=
ρxy
ρxy def.( )σxy
σxσy-----------= =
ρxy
aσx2
σx a σy---------------- 1±= =
ρxy0
σxσy---------- 0= =
ρxy 0=
ρxy

LA VARIABILE CASUALE A n DIMENSIONI
– è invariante in modulo per trasformazioni lineari, cioè non cambia se cam-biano linearmente le unità di misura di x e y.
– se x e y sono variabili indipendenti ; se al contrario sono linear-mente dipendenti, assume valore ; +1 per a > 0, e –1 per a < 0, siha cioè .
Fig. 7.7 – Variabili incorrelate ma non indipendenti.
Si può dimostrare che per una variabile doppia non ordinata vale:
7.63
7.8 PROPRIETÀ DELLE VARIABILI NORMALI AD n-DIMENSIONI
Ricordiamo l'espressione 7.26b della variabile normale n -dimensionale con:
7.64
cioè:
7.65
Supponiamo ancora di eseguire una trasformazione lineare del tipo 7.23: y = A x + bma ora ipotizziamo che la matrice A possa essere scritta in questo modo:
7.66
con U matrice ortogonale e Λ1/2 matrice diagonale. Ricordando la 7.29 si ha:
ρxy 0=ρxy 1±=
σxy σ x± σ y=
Y
0 X
ρxy=0
ρxy
N xi yi∑ x i∑ yi∑⋅–
N xi2∑ xi∑
2
– N yi2∑ yi∑
2
–
---------------------------------------------------------------------------------------------------------=
M x[ ] 0=
Cxi xidiag σxi
2( ) 1= =
Cxi xk0=
Cxx I=
A Λ1 2⁄ U=
7.67fy y( ) 12πn 2⁄ ΛU--------------------------- e
12----– y b–( )T UΛ U T( ) 1– y b–( )
=
48

LA VARIABILE CASUALE A n DIMENSIONI
Ora, ricordando la 7.56 che esprime la forma di una qualsiasi matrice regolare simme-trica possiamo sfruttare il risultato a ritroso per standardizzare la variabile casuale y.
La trasformazione inversa sarà dunque:
7.68
Questa operazione si chiama appunto standardizzazione della variabile casuale y, laquale ha media e matrice di varianza covarianza
Per dichiarare che y appartiene ad una distribuzione normale con tali medie evarianze si scrive:
Vediamo due proprietà delle variabili casuali normali:
1. Il concetto di correlazione ed indipendenza stocastica si equivalgono.
2. Tutte le trasformazioni lineari trasformano variabili normali in variabilinormali; cioè se:
e se:
allora, ammesso che e che il rango di A sia pieno, :
.
Si osserva che la variabile:
è una variabile casuale a n gradi di libertà; ciò consente di trovare attorno al vet-tore media una regione simmetrica nella quale sia contenuta una prefissataprobabilità cioè:
I valori più usati sono p = 50 %, p = 90 %.
La regione:
risulta e
e dunqu
x Λ 1 2⁄– UT y b–( ) Cyy1 2⁄– y b–( )= =
µy b= Cyy
y N b,Cyy[ ]=
x N µx ,Cxx[ ]=
y Ax b+=
m n≤ r A( ) m=
y N A µx b; ACxx AT+[ ]=
χn2
µx lRn∈P p=
P x µ–( )T C xx1– x µ–( ) χn
2≤[ ] p=
7.70x µ–( )T Cxx1– x µ–( ) χ n
2≤
7.69x µ–( )T Cx x1– x µ–( ) zTz z i
2
i 1=
n
∑ χn2= = =
49
ssere un iper-ellissoide. Per n = m = 2 ad esempio, si noti che:
e:
det Cxx( ) σ x2σy
2 σ xy– σ x2σ y
2 ρ 2σ x2σ y
2– σ x2σ y
2 1 ρ 2–( )= = =
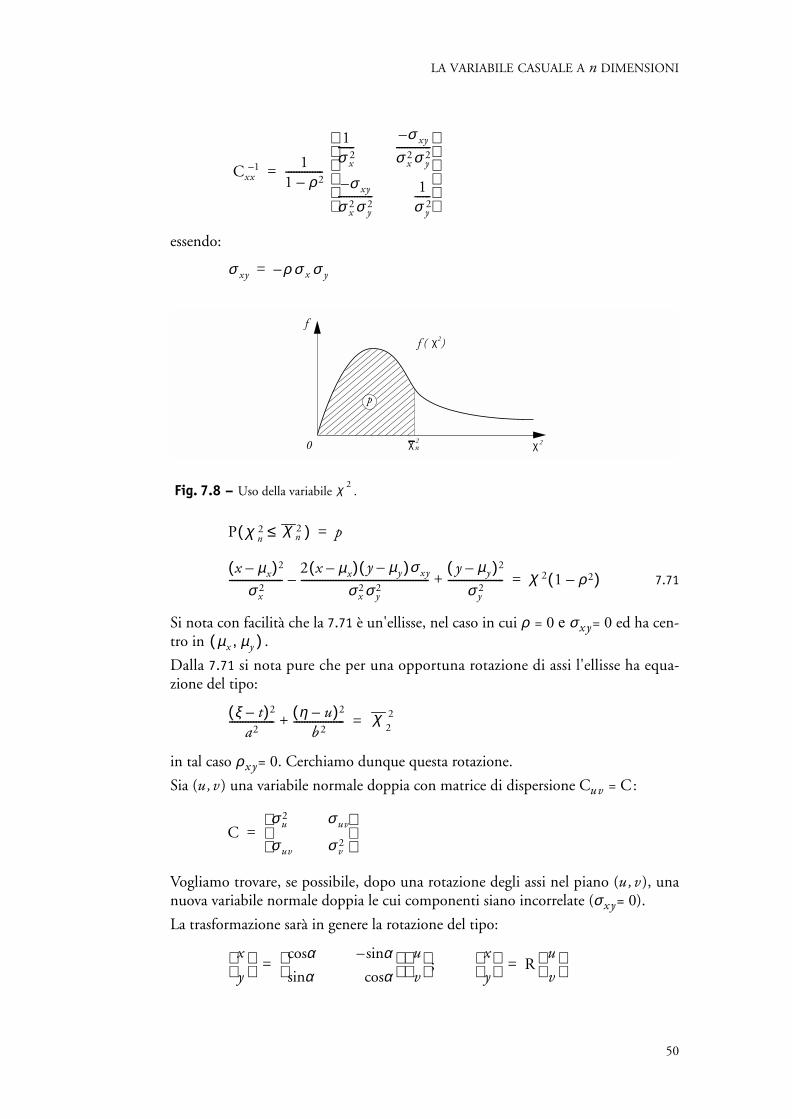
LA VARIABILE CASUALE A n DIMENSIONI
50
essendo:
Fig. 7.8 – Uso della variabile .
7.71
Si nota con facilità che la 7.71 è un'ellisse, nel caso in cui ρ = 0 e σxy= 0 ed ha cen-tro in .
Dalla 7.71 si nota pure che per una opportuna rotazione di assi l'ellisse ha equa-zione del tipo:
in tal caso ρxy= 0. Cerchiamo dunque questa rotazione.
Sia (u,v ) una variabile normale doppia con matrice di dispersione Cuv = C:
Vogliamo trovare, se possibile, dopo una rotazione degli assi nel piano (u,v ), unanuova variabile normale doppia le cui componenti siano incorrelate (σxy= 0).
La trasformazione sarà in genere la rotazione del tipo:
Cxx1– 1
1 ρ2–--------------
1σ x
2------
σ xy–
σ x2σ y
2-------------
σ xy–
σ x2σ y
2------------- 1
σ y2
------
=
σ xy ρ σ x σ y–=
χ
f
0
p
f ( )2
χ 2χ 2n
χ 2
P χ n2 χ n
2≤( ) p=
x µx–( )2
σ x2
--------------------2 x µx–( ) y µy–( )σ xy
σ x2σ y
2------------------------------------------------
y µy–( )2
σ y2
---------------------+– χ 2 1 ρ2–( )=
µx µy,( )
ξ t–( )2
a2----------------- η u–( )2
b 2-------------------+ χ
22=
Cσu
2 σuv
σuv σv2
=
x
y αcos αsin–
αsin αcos u
v ;=
x
y R
u
v =

LA VARIABILE CASUALE A n DIMENSIONI
Si avrà, applicando la legge della propagazione della varianza:
e, sviluppando i prodotti si ottiene:
7.72
7.73
imponendo σxy= 0, e utilizzando le formule:
ricaviamo:
Ricavat
Si dimminim
Tali valellissoid
Estendsibile tvariabil
Per ultenale, n
Anche dagli au
Cxy
σ x2 0
0 σ y2
RCuvRT= =
σ x2 σu
2 αcos2 2σuv α αsincos σv2 αsin2+–=
σ y2 σu
2 αsin2 2σuv α αcossin σv2 αcos2+ +=
σ xy σu2 σv
2–( ) α αsincos σuv αcos2 αsin2–( )+=
α αsincos 2αsin2
--------------=
2αcos αcos2 αsin2–( )=
7.74tg2α2σuv
σv2 σu
2–------------------
=
51
a la rotazione α si sostituisce nelle 7.72 e 7.73 e si ricavano i valori σx ,σy.
ostra che questi valori sono rispettivamente i valori di massimo e dio σ 2, e si indicano perciò rispettivamente con σI ,σII .
ori si chiamano semiassi principali dell'ellisse d'errore, o dell'ellissoide od iper-e nel caso in cui fossimo nello spazio a più di due dimensioni.
endo il risultato ad n-dimensioni si può infatti ancora dimostrare che è pos-rovare una matrice di rotazione U tale che attraverso il cambiamento die dovuto alla matrice U:
riori approfondimenti si veda l’appendice A. Per una variabile bidimensio-ell’ipotesi semplificativa µx=µ y=0 la 7.70 diviene:
questa curva rappresenta un’ellisse. I semiassi principali sono rappresentatitovalori della matrice Cxx (non di ) che ricaviamo da:
y U x=
Cyy diag cii( )=
x y( )σ x
2 σ xy
σ xy σ y2
x
y cost =
C xx1–
C λ I– 0=

LA VARIABILE CASUALE A n DIMENSIONI
52
cioè:
ricaviamo λ 1 e λ 2 (σ I e σ II):
7.75a
cioè:
7.75b
In alternativa, ricavando in funzione di ricavato con la 7.74 si ottiene:
7.75c
L’inclinazione è data dagli autovettori che rappresentano i coseni direttori degli assiprincipali. Basta sostituire i valori di λ e normalizzare:
7.9 SUCCESSIONI DI VARIABILI CASUALI
Sia una successione di variabili casuali. Si dice che tende stocastica-mente a zero per se:
Ciò significa che tende alla variabile casuale x concentrata nell'origine(P(x = 0) = 1).
Usando il teorema di Tchebjcheff si può così dimostrare che:Condizione sufficiente affinché converga stocasticamente a zero è che:
7.76
7.77
σ x2 λ– σ xy
σ xy σ y2 λ–
0=
σ x2 λ–( ) σ y
2 λ–( ) σ xy2– 0= σ x
2σ y2 λ2 λ σ x
2 σ y2+( ) σ xy
2––+ 0=⇒
σ I II, λ1 2,σ x
2 σ y2+
2------------------
12--- σ x
2 σ y2+( )2 4 σ x
2σ y2 σ xy
2–( )–±= =
σ I II, λ1 2,σ x
2 σ y2+
2------------------
12--- σ x
2 σ y2–( )2 4σ xy
2+±= =
2αsin tg2α
σ I II, λ1 2,12--- σ x
2 σ y2+( ) σ xy 2αsin⁄±= =
vσ x
2 λ1;– σ xy
σ xy ; σ y2 λ–
1= =
σ xy2 σ y
2 λ2–( )2+[ ] 1 2⁄ 1=
x n{ } xn{ }n ∞→
P xn
ε<( )n ∞→lim 1= ε∀ 0>
x n{ }
x n{ }
M xn
[ ]n ∞→lim 0=
σ 2 xn
[ ]n ∞→lim 0=

LA VARIABILE CASUALE A n DIMENSIONI
53
Diremo poi che converge stocasticamente a se converge stocasti-camente a zero.
7.10 CONVERGENZA «IN LEGGE»
Oltre alla convergenza stocastica della successione di vc ad si può definireuna convergenza in legge:
Si dice che tende ad «in legge» se, essendo la successionedelle funzioni di distribuzione di ed la funzione di distribuzione di
si ha:
7.78
Questo tipo di convergenza serve per studiare il comportamento asintotico disomme di variabili casuali del tipo:
7.79
Si può dimostrare infatti che sotto opportune ipotesi sulla successione delle lasuccessione tende asintoticamente in legge ad una distribuzione normale.
7.11 TEOREMA CENTRALE DELLA STATISTICA
Teorema
Sia una successione di variabili casuali indipendenti, tutte con la stessadistribuzione e con:
Allora la successione:
tende asintoticamente in legge (si indica con il simbolo ~) alla normale del tipo:
7.80
distribuzione delle .
Prima osservazione al teorema centrale della statistica
Il teorema interpreta un fatto riconosciuto sperimentalmente – gli errori di misuratendono a distribuirsi normalmente – quando il procedimento di misura è usato allimite della sua precisione massima.
Gli errori di misura cioè dipendono da una serie di fattori ambientali, strumentali e
x n{ } x x n–{ }
x n{ } x
x n{ } x Fn x( ){ }xn{ } F x( )
x
Fn x( )n ∞→lim F x( )=
Sn xi per n ∞→i 1=
n
∑=
xi{ }Sn{ }
xi{ }
M xi[ ] µ ;= σ 2 xi( ) σ 2=
Sn xi
i 1=
n
∑=
Sn N nµ , nσ 2[ ]∼
∀ xi{ }

LA VARIABILE CASUALE A n DIMENSIONI
soggettivi che hanno, ciascuno isolatamente, influenza impercettibile sul procedi-mento di misura ( ), ciascuno di questi fattori assume anche perciòl'aspetto di una vc indipendente dalle altre (umidità, pressione, temperatura,luminosità ecc.).
Tutti questi fattori assieme producono tuttavia un effetto sensibile: l'errore dimisura, che sarà descritto dalla vc somma di molte altre. Per il teorema centralel'errore di misura tende ad essere distribuito normalmente .
Seconda osservazione al teorema centrale della statistica
Il teorema è meno teorico di quanto possa apparire perché permette di usare la nor-male N come distribuzione approssimata di quantità importanti come il valoremedio m (media campionaria).
Sia x una vc comunque distribuita e sia la vc n-dimensionale gene-rata pensando di ripetere n estrazioni dalla vc x . La descrive i cam-pioni di numerosità n della x . La media campionaria vale:
Nell'ipotesi che, per ciascun x i :
sarà dunque:
Se supponiamo che il campione sia numeroso (n grande) possiamo applicare ad mil teorema centrale e dire che ∀ distribuzione iniziale di x , m tenderà asintotica-mente in legge a:
Si noti c
dovrebbpendent
nel casointegrali
µ 0≅ σ 2, 0≅
N nµ nσ 2,[ ]
x1 x2 … xn, , ,{ }x1 x2 … xn, , ,{ }
m1n--- x i
i 1=
n
∑x i
n---- con
xi
n--- v.c. indipendenti
i 1=
n
∑= =
M xi[ ] µ ;= σ 2 x i( ) σ 2=
Mxi
n--- µ
n--- ;= σ 2
xi
n---
σ 2
n2-----=
7.81m N n µn--- , nσ 2
n2------∼ N µ , σ
2
n 2-------=
54
he, se si volesse ricavare la distribuzione esatta di m cioè di , si
ero calcolare n integrali di convoluzione seguenti (infatti le x i sono indi-i):
particolare, siccome si dovrebbero calcolare n di convoluzione di f (x ) con se stessa.
1n--- xi
i 1=
n
∑
f m( ) fx1x1( ) f x2
x2( ) …fxnxn( ) x1…d xnd
∞–
∞
∫=
fxixi( ) fxj
xj( ) f x( )= =

LA VARIABILE CASUALE A n DIMENSIONI
È anche matematicamente possibile dimostrare il teorema, infatti, presa una qualsi-asi f (x ) di partenza, l'integrale di convoluzione di f (x ) con se stessa tende, per ngrande, alla funzione di Gauss.
Si noti che la 7.81 giustifica il fatto che come valore rappresentativo della popola-zione si scelga la media campionaria: rispetto ad una qualsiasi xi ha varianza nvolte minore.
7.12 LE STATISTICHE CAMPIONARIE E I CAMPIONI BERNOULLIANI
Definiamo campione Bernoulliano, tratto da una vc x (che descrive l'esperimentostocastico ξ), l'insieme dei risultati ottenuti dalla ripetizione per n volte in manieraindipendente dello stesso esperimento ξ (esempio: l'estrazione da un'urna con sos-tituzione).
Osservazione
Lo stesso campione Bernoulliano, per l'indipendenza, può essere visto alternativa-mente o come risultato di n estrazioni dalla vc x o come estrazione da una vc a n-dimensioni (x1…xn) tutte indipendenti e tutte distribuite come x. (Esempio: illancio di una moneta n volte e il lancio di n monete una sola volta).Se x ha densità di probabilità la ha densità:
per
Definizio
La cam
Ad esem
t può espionario,
Tutto cin-dimen
Ad esem
t 0 rappr
fx x( ) x n
7.82fxn fxn x1…xn( ) fx x1( ) fx x2( )…fx xn( )= =
55
l'ipotesi di indipendenza.
ne di statistica campionaria
statistica campionaria t è un (∀ ) operatore statistico applicato a una variabilepionaria.
pio:
7.83
sere la media campionaria, la varianza campionaria, il momento di ordine m cam- la correlazione campionaria, ecc.
ò significa che t sarà a sua volta una vc (a una dimensione) funzione della vcsionale .
pio se t è l'operatore media m:
esenta l'estrazione dalla statistica campionaria t .
t t x1 ,x2,… xn,( );=
x n
m1n--- xi
i 1=
n
∑ t0= =

LA VARIABILE CASUALE A n DIMENSIONI
7.13 LE STATISTICHE «CAMPIONARIE» COME «STIME» DELLE CORRISPONDENTI QUANTITÀ TEORICHE DELLE VARIABILI CASUALI
Qual è il rapporto tra la vc statistica campionaria t, di cui disponiamo di una estra-zione t 0 ed il valore teorico (ϑ ) del parametro corrispondente a t ? Ad esempio a mxcorrisponde µ x , ad corrisponde ; quale rapporto esiste fra questi valori? Ilrapporto viene detto stima.
Ad esempio si dice che m è stima di µ , od anche è stima di se è corretta econsistente. Vediamo che significano questi aggettivi.
Stima corretta o non deviata
Si dice che la stima è corretta quando la variabile casuale t ammette come mediateorica ϑ :
7.84
Stima consistente
Si ha quando per la corrispondente successione di variabili casuali tn tendestocasticamente a ϑ , cioè:
7.85
Per il teorema centrale della statistica ciò è verificato se:
Stima efficie
In molti castima t piùt di ϑ di m
Stima di ma
Vi è infine tore t che r
Come esemcome stima
La media cdella vc ,
– cor
s2 σ 2
s2 σ 2
M t[ ] M t x1…xn( )[ ] ϑ= =
n ∞→
tn ϑ=n ∞→lim
x
M
7.86M tn[ ] ϑ=n ∞→lim
7.87σ 2 tn[ ] 0=n ∞→lim
56
nte
si esiste più di una stima corretta e consistente di ϑ , allora si cerca quella concentrata attorno a ϑ cioè una stima efficiente, definita come la stimainima varianza.
ssima verosimiglianza
la stima di massima verosimiglianza che consiste nel trovare quell'opera-ende massima una funzione L detta di verosimiglianza.
pio ed esercizio vediamo se la media campionaria m può essere presa della quantità teorica µ .
ampionaria m è una stima corretta e consistente della media teorica µ infatti soddisfa a:
rettezza
m[ ] M1n--- xi∑ 1
n--- M∑ xi[ ] 1
n---nµ µ= = = = i∀ 1…n=( )

LA VARIABILE CASUALE A n DIMENSIONI
– consistenza: per quanto visto la 7.86 è facilmente provata,
7.88
Per provare la 7.87 si può scrivere:
Per la propagazione della varianza ricaviamo:
ed allora è facile vedere che:
Si può vstime co
Cerchiam
con la co
Questo èLagrang
Il differe
Dunquemedia cvarianza
Come u
dove m é
M m[ ] µ=n ∞→lim
mxi
n---∑=
σ 2 m( ) 1n2-----σ 2 xi( )∑ nσ 2
n2--------- σ 2
n------= = =
7.89σ 2 m( ) 0=n ∞→lim C.V.D.
57
erificare che tutte le stime lineari tali che sonorrette di µ ma m è quella di minima varianza (cioè efficiente).
o infatti il minimo della quantità:
ndizione:
un problema di minimo condizionato che si risolve con i moltiplicatori die minimizzando la funzione:
nziale totale di dovrà annullarsi:
si sceglie come valore rappresentativo di tutta la popolazione di misure laampionaria non solo perché ha varianza n volte minore rispetto alla di ciascun campione, ma anche perché ha la minima varianza.
lteriore esempio vediamo se la varianza campionaria è una stima di :
la media campionaria.
m ' λ i xi∑= λ i∑ 1=
σ 2 m '( ) λ i2σ 2∑=
λ i∑ 1=
φ λi2σ 2∑ λ i∑( ) 1–( ) k⋅+ min= =
φ
∂φ∂λ i--------∀ 0= 2σ 2λ i k+ 0= λ i
k2σ 2---------–=⇒ ⇒
λ i∑ nk2σ 2---------– 1 k⇒ 2σ 2
n---------–= = =
λ i1n---= m'⇒ m= C.V.D.
s2 σ2
s2 1n--- xi m–( )2∑
v i2∑
n------------= =

LA VARIABILE CASUALE A n DIMENSIONI
58
Verifichiamo la correttezza, se cioè:
scriviamo in questo modo:
7.90
Applichiamo alla 7.89 l'operatore media:
per definizione:
inoltre:
7.91
Cioè la stima non è corretta. Si dimostra che è invece corretta la stima dell’operatore ( ) definita da:
7.92
ed è consistente; infatti è facile verificare che:
7.14 FUNZIONE DI VEROSIMIGLIANZA E PRINCIPIO DI MASSIMA VEROSIMIGLIANZA
Partiamo al solito dalla vc n -dimensionale x descritta dalla funzione secondo la forma 7.82 ma ora anche in funzione di operatori statistici ϑ , ad esem-pio , cioè esprimiamo la funzione f attraverso:
M s2[ ] σ 2=
s 2
s 2 1n--- xi µ–( ) µ m–( )+[ ] 2∑ = =
1n--- xi µ–( )2∑ 2
n--- xi µ–( )∑ µ m–( ) µ m–( )2[ ] =+ +=
1n--- xi µ–( )2∑ 2 m µ–( ) µ m–( ) µ m–( )2 + +=
s 2 1n--- xi µ–( )2∑ m µ–( )2–=
M s 2[ ] 1n--- M xi µ–( )2[ ] M m µ–( )2[ ]–∑=
M xi µ–( )2[ ] σ 2=
M m µ–( )2[ ] σ 2 m( ) σ 2
n-----= =
M s2[ ] 1n---/
/n σ 2 σ 2
n-----–
n 1–n
------------σ 2 σ 2≠= =
s 2 M s 2[ ] σ 2=
s 2xi m–( )2∑n 1–( )
----------------------------=
σ 2 s 2( ) nn 1–------------
2
σ 2 s 2( )=n ∞→lim 0=
fx x1…xn( )
ϑ µ σ 2,[ ] T=
fx xi, ϑ( )

LA VARIABILE CASUALE A n DIMENSIONI
per le ipotesi di indipendenza delle n variabili x i , ricordando ancora la 7.82:
7.93
Il secondo uguale definisce la funzione L detta di verosimiglianza (likely hood).
È evidente che nulla abbiamo detto sul generico ϑ ; un criterio di scelta è prendereun valore generico t e cercare di rendere massima L(x i ,ϑ ) verificando che sia mas-sima per ϑ =t , cioè cercare:
7.94
cioè, per la 7.93:
7.95
Ad esempio per la variabile normale standardizzata zn :
7.96
si ha in questo caso:
Il valore massimo di L si ha cercando il minimo dell'esponente:
7.97
con ϑ , variabile scarto. In questo caso il principio di massima verosimiglianza portaalla stima di minima varianza e cioè alla ricerca di uno stimatore efficiente.
Per variabili normali non standardizzate, ricordando la 7.67 e la 7.69 occorre ren-dere minima la quantità:
7.98
La 7.98 spesso viene scritta utilizzando un'altra matrice definita matrice dei pesi P,( è una costante positiva):
È questonale, pu
fx xi, ϑ( ) fx xi, ϑ( )i 1=
n
∏ L xi, ϑ( )= =
t / max L xi, ϑ( )ϑ t=
∂L∂ϑ-------⇒ 0
∂ L( )log∂ϑ
------------------⇒ 0= =∃
∂f xi, ϑ( )∂ϑ
---------------------i 1=
n
∑ 0=
L f x f x xi( )∏ 12π σ2( ) n 2⁄------------------------- e
xi µi–( )2∑2σ 2
--------------------------------–= = =
ϑ µ ,σ 2[ ] T=
12σ 2---------+ xi µi–( )2
i 1=
n
∑ 12σ 2--------- vTv min= =
χ n2 x µ–( )TC xx
1– x µ–( ) vTC xx1– v min= = =
σ 02
7.99P C xx1– σ0
2=
59
il principio dei minimi quadrati che, nel caso in cui P sia una matrice diago-ò essere scritto nella forma:
7.100piv i2
i 1=
n
∑ min σ 02 χ n
2= =

LA VARIABILE CASUALE A n DIMENSIONI
Dobbiamo tuttavia affermare che la stima di minima varianza, che coincide conquella di massima verosimiglianza per variabili normali e che porta al principio deiminimi quadrati, prescinde da ipotesi sulla distribuzione delle misure.
7.15 LA MEDIA PONDERATA (O PESATA)
Poniamo di eseguire n misure di una v.c x , fatte con diversa precisione ma indipen-denti tra loro; ciascuna x i può considerarsi come estrazione da popolazioni condiverse varianze ma con la stessa media µ x . Ci si chiede quale è lastima più attendibile del valore medio di x . Avevamo verificato per la media cam-pionaria che tutte le stime del tipo:
sono cortato non x i con σAnche qminimo
e minimi
ricaviamo
Come pevalore:
cosicché
ma, impo
σ 2 xi( ) σ i2=
7.101x λ i xi∑=
60
rette, d'altra parte non possiamo usare i valori perché il risul-sarà stima di minima varianza; dovremmo, intuitivamente, pesare di più le
i minore.
ui cerchiamo uno stimatore che sia stima efficiente, e troviamo ilcondizionato attraverso i moltiplicatori di Lagrange:
7.102
zziamo la funzione:
:
7.103
r la 7.99, presa una seconda costante positiva, , viene definito peso il
7.104
la 7.103 può scriversi:
nendo la seconda delle 7.102, si ricava k:
λ i 1 n⁄=
x
σ 2 x( ) λ i2σ i
2∑ min= =
λ i 1=∑
φ λi2σ i
2∑ k λ i∑ 1–[ ]–=
∂φ∂λ i
-------- 0 2λ i σi2 k– 0=⇒=
λ ik2---
1σ i
2-------=
σ02
pi
σ02
σ i2-------=
λ ik2---
pi
σ02
-------=
k2σ0
2
pi∑-----------=

LA VARIABILE CASUALE A n DIMENSIONI
61
per cui la 7.103 può essere riscritta:
7.105
dunque la 7.101 diviene:
7.106
Si nota pure che il minimo cercato nella stima di vale:
7.107
Se non si conoscono i valori ma si conoscono solo i pesi pi e (dalla 7.106), la7.107 non è direttamente utilizzabile. Dopo il calcolo di , si dimostra che:
7.108
7.109
λ i
σ02
pi∑-----------
pi
σ02------
pi
pi∑-----------= =
xpixi∑pi∑
----------------=
σ 2 x( )
σ 2 x( ) min λ iσ i2∑
pi2σ i
2∑pi∑( )2
------------------= = =
σ i2 x
x
σ02 1
n 1–------------ pi xi x–( )2∑
piv i2∑
n 1–-----------------= =
σ 2 x( ) σ02
1pi∑
------------piv i
2∑n 1–( ) pi∑
-----------------------------= =

8. APPLICAZIONI DEL PRINCIPIO DEI MINIMI QUADRATI
AL TRATTAMENTO DELLE OSSERVAZIONI
Fig. 8.1
Prendiamo in esame la variabile casuale tridimensionale che rap-presenta le misure che possono essere fatte su un esperimento E
del quale si conoscagià un
modello fisico
, lineare del tipo:
che rapp
sibili
. Sia
la somm
Facciamindispen
Queste i
π
Y2
Y3
Y1
0
v
y y
<
<
y0
a1 y1 + a y2 + 2a y3 = d3
y y1 y2 y3, ,( )=
8.1a1 y1 a2 y2 a3 y3 d=+ +
resenta l'equazione di un piano nello spazio detto piano delle misure ammis- ad esempio E l'esperimento la misura dei tre angoli di un triangolo piano:a di questi deve essere uguale a π.
o poi l'ipotesi che le misure abbiano distribuzione normale (ipotesi nonsabile), media diversa da zero e varianza unitaria, vale a dire:
y
8.2y N y , I[ ]=
62
potesi vengono definite modello stocastico.

APPLICAZIONE
DEL
PRINCIPIO
DEI
MINIMI
QUADRATI
Della variabile casuale si conosce una estrazione, la misura che, a causa delladispersione di non è detto soddisfi la
8.1
. A causa di errori accidentali infatti è fuori da questo piano ad una distanza . In genere cioè si ha:
8.3
tuttavia, siccome è estratto dalla stessa variabile casuale , il suo valore mediosarà identico al valore medio di
y
:
8.4
Ora noi cerchiamo una stima di (il simbolo sta per stima di massimaverosimiglianza) che sia la più vicina possibile a ma che appartenga ancora aivalori ammissibili del piano
π
; in questo caso è intuitivo scegliere per la normalea
π
condotta da , cioè:
tale che renda minimo lo scalare distanza al quadrato:
8.6
Vedremo ora se questa equazione è sufficiente a risolvere il problema, si tratta cioèdi ricavare e le caratteristiche della dispersione di a partire dalle ipotesi stoca-stiche su
y
8.2
, dal modello geometrico
8.1
e dalle condizioni di stima
8.6
. Nel casoin cui la
8.6
si modifica nella già nota equazione di minimi quadrati:
Il princimiglianzciente d
quadratic
come è o
esprima
scegliend
si arriva
che è app
y y0
y y0
v
a1 y01 a2 y02 a3 y03 d u 0≠=–+ +
y0 y
M y0[ ] y=
y y yy0
yy
0
d 2 vT v y0 y–( )T y0 y–( ) min===
y y
Cyy I≠
Cxx I=
8.7d 2 y0 y–( )T Cyy1– y0 y–( ) min==
8.5y y0 v–=
63
pio dei minimi quadrati, che coincide con il principio di massima verosi-a nel caso di distribuzione normale, conduce a trovare uno stimatore effi-i minima norma: la distanza al quadrato 8.7 si chiama infatti normaa del vettore . Il minimo di detta norma rimane tale, come dimostrato evvio, anche per trasformazioni lineari del sistema di riferimento. Che la 8.7poi una distanza è evidente; partendo infatti da variabili casuali x con, il minimo della distanza quadratica vale appunto:
8.8
o una qualsiasi matrice di rotazione per cui:
alla:
8.9
unto un altro modo di vedere la formula 8.7.
v
x0 x–( )T x0 x–( ) min=–
y0 y–( ) R 1– x0 x–( )=
d 2 min y0 y–( )T RTR 1– y0 y–( )= =

APPLICAZIONE
DEL
PRINCIPIO
DEI
MINIMI
QUADRATI
64
8.1 I
MINIMI
QUADRATI
APPLICATI
AD
EQUAZIONI
DI
CONDIZIONE
CON
MODELLO
LINEARE
Vediamo se esiste una soluzione all'equazione
8.7
. Per le ipotesi di minimo lasoluzione cercata sarà la stessa a meno di una costante moltiplicativa .
È possibile allora cercare questo minimo anche partendo dalla conoscenza dellamatrice P che, a meno di una costante moltiplicativa è proporzionale a C
yy :
8.10
P è definita matrice dei pesi. Si cerca ora il minimo della quantità scalare:
8.11
col modello stocastico definito da:
8.12
e le equazioni di condizione, generalizzazione delle
8.1:
1
8.13
Si desidera ricavare la stima delle quantità:
(Il simbolo indica: stima di). Per la ricerca del minimo condizionato si utiliz-zano i moltiplicatori di Lagrange prendendo come funzione obiettivo la funzione
Φ
costruita con le
8.11
e 8.13:
8.14
con:
8.15
dove l è il numero di condizioni ed m il numero di misure.
Imponendo la stazionarietà della funzione Φ si ha:
1 Ad esempio, nel caso della misura di angoli interni di un triangolo, si provi a risolvere come segueil problema nell'ipotesi di avere le misure:
.
y1 σ0
2⁄
σ02
1σ0
2------Cyy Q P 1–= = P⇒ σ02Cyy
1–=
y0 y–( )P y0 y–( ) min=
P Q 1– σ02Cyy
1– σ02diag σ y i
2( ) 1–== =
l m≤
Dy d=
y01 60 gon y0
2; 70 gon y03 70.003 gon con σy
2;=; cost 10 3– gon±= = = =
y y≈
σ 02ˆ σ0
2≈
Cy y
Cyy≈
≈
Φ 12--- y0 y–( )T P y0 y–( ) Dy d–( )λ+=
λ λ 1, λ2, …, λl ( ) l m≤=
dΦ 0 dy TP y0 y–( )– dy TDTλ 0 dy T∀=+= =

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
cioè:
8.16
8.17
che posta nella 8.13 permette di ricavare:
Se definiamo le matrici:
ed il vetto
dove U so
Quest'ulti
Si dimostr
Esempio a
Si sono mlivellazion
dove α è ui dislivelli
P y0 y–( ) DTλ=
y y0 P 1– DTλ–=
D y0 P 1– Dλ–( ) d– 0=
Dy0 DP 1– DTλ d 0=––
K
σ
∆
8.18K DP 1–= DT
re:
8.19
no definiti errori di chiusura, si ha:
ma, posta nella 8.17 permette di ricavare :
U Dy0= d–
λ Dy0 d–( ); λ K 1– Dy0 d–( )==
y
8.20y y0 P 1– DTK 1– U–=
a poi che la stima di vale:σ 02
8.21σ 02 UT K 1– U
l ---------------------=
65
pplicativo: anello di livellazione
isurati i tre dislivelli di un anello di tre lati, attraverso unae geometrica. Si sa che in questo caso:
na costante e D è la distanza percorsa fra i punti espressa in km. Si sa chedebbono soddisfare all'equazione:
∆120 ; ∆23
0 ; ∆130 ,
∆ α D±=
12 ∆23 ∆13 0=–+

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
66
Fig. 8.2 – Anello di livellazione.
Applicando le formule risolutive ricavate nell'esempio proposto si ha:
Per semplicità, nel calcolo della matrice dei pesi, possiamo trascurare la costante e porre:
Applicando la 8.18 si ha:
e cioè in definitiva:
ed applicando la 8.20 si ha:
Si ricava infine la soluzione:
∆ ∆
∆
1 2
1 3
2 3
1
2
3
D 1 1 1 –( )=
Cyy1– σ0
2 diag1
D12-------- ;
1D23-------- ;
1D31--------
⋅=
σ02
Q P 1– diag D12; D23; D31( )= =
K 1, 1, 1–( )diag D12; D23; D31( ) 1, 1, 1–( )T=
K Dij∑=
U Dy0 d– ∆120 ∆23
0 ∆130–+( )==
y ∆12° , ∆23
° , ∆13°( )T diag D12 , D23 , D31( )
1
1
1–
K 1– ∆12° ∆23
° ∆13°–+( )–=
y1 ∆12ˆ ∆12
°D12U
Dij∑--------------–= =
y2 ∆23ˆ ∆23
°D23U
Dij∑--------------–= =

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
Si ottiene dunque quanto intuitivamente si poteva già capire: che cioè l'errore dichiusura U si ripartisce in tre parti, proporzionali secondo la formula della mediaponderata, con pesi , che sono le distanze fra i capisaldi altimetrici delle reti.
8.2 MINIMI QUADRATI, FORMULE RISOLUTIVE NEL CASO DELL'UTILIZZO DI PARAMETRI AGGIUNTIVI
Sia dato un modello stocastico definito dai valori osservati (campionem-dimensionale):
che ipotizziamo abbia media:
8.22a
e dispersione:
8.22b
con costante positiva incognita e Q (o P) matrice nota e definita positiva.
Per ipotesi il modello deterministico è ancora lineare.
Per motivi fisici o geometrici ipotizziamo che y sia ristretto a stare su un iperpianoπ (varietà lineare) a n -dimensioni con n<m , del tipo:
con r(A
Le dimeneature
Le com
In funzminima
y3 ∆ 13ˆ ∆13
°D13U
Dij∑--------------–= =
Dij
y0
y01
�
y0m
tratto da y
y1
�
ym
==
M y[ ] y=
Cyy σ02Q σ0
2P 1–= =
σ02
8.23y A x a+=
67
) = n , vale a dire risulta di rango n1 pieno e invertibile.
nsioni di ed , (che brevemente in seguito indicheremo senza sottoli-) sono:
8.24
ponenti di x sono dette parametri aggiuntivi, o più spesso solo parametri.
ione delle misure y 0 estratte da y si vogliono trovare le stime e di varianza:
ATA
x a
x
x1
�
xn
; a
a1
�
am
==
y σ02ˆ
y y≈
σ02ˆ σ0
2≈

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
e la relativa matrice di varianza covarianza . Occorre trovare, ricordando la 8.5:
con le (m
Come alzata seccasuali y8.26 dall
Anche qcondizio
con:
si ha:
Annullanequazion
Da quest
ma, ricor
allora:
che, sost
cioè:
e, dalla 8
C y y
8.25min y0 y–( )TP y0 y–( ) min v T P v min χm-n2==
-n ) condizioni aggiuntive: , cioè:y π∈
8.26y A x a+=
trove si è notato, la 8.25 rappresenta il minimo di una distanza generaliz-ondo la «metrica» P, mentre la 8.26 esprime il fatto che alle variabili sono legati n parametri aggiuntivi che dipendono nel modo linearee misure .
ui il problema si risolve con i moltiplicatori di Lagrange, si cerca il minimonato della funzione :
8.27
8.28
do i termini che moltiplicano i due differenziali si devono soddisfare lei:
8.29
8.30
'ultima si ottiene, essendo la matrice P definita positiva:
dando anche la 8.26:
ituita nella 8.29 permette di scrivere:
xy
Φ x y,( )
Φ x y,( ) 12--- y0 y–( )T P y0 y–( ) y A x– a–( )λ min=+=
λ λ 1…λm( )T; n m<=
dΦ dyT P y0 y–( )– d x T λ d x T AT λ 0=–+=
ATλ 0=
P y0 y–( )– λ 0=+
y y0 P 1– λ–=
P 1– λ y0 A x– a–=
λ P y0 a–( ) PA x–=
AT P y0 a–( ) AT PA x 0=–
8.31ax AT PA( ) 1– AT P y0 a–( )=
68
.26 si può ricavare .y

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
Definito poi vettore dei termini noti l :
8.32
e definita matrice normale N:
si può anche scrivere:
8.31b
Infine si può dimostrare che la stima di vale:
dove il numero intero:
8.35
viene detta ridondanza globale o ridondanza.
Lo scalare , (a parte la costante r ), rappresenta dunque la distanza quadratica delvettore nella metrica P o, in alternativa, il valore della 8.25.
Dalla 8.32 e dalla definizione di ricaviamo:
8.36
Si dimostra che la matrice di varianza covarianza dei parametri compensati vale:
8.37
È possibile ricavare inoltre la matrice di varianza covarianza degli scarti, dopo lacompensazione:
8.38
Infine si può dimostrare che la matrice:
8.39
8.40
è una matrice di dimensione m•m detta di ridondanza, contenente dei numeri puri edindipendente dal sistema di riferimento scelto. La proprietà di questa matrice è indi-care il contributo che ogni singola misura apporta alla ridondanza globale r = m-n. Sipuò dimostrare infatti che:
y0 a–( ) l=
x N 1– AT Pl=
σ02ˆ σ0
2
r m n–=
σ02ˆ
v χ2
v
v l A x–=
Cx x σ02ˆ N 1– ;=
Cv v σ02ˆ P 1– AN 1– AT–[ ]=
R1
σ02ˆ
------PCv v
=
R I PAN 1– AT–=
8.41tr R( ) rjj m n–( ) r= =l
m
∑=
8.34σ02ˆ
y0 y–( )T P y0 y–( )m n–
--------------------------------------------vTP vm n–-------------= =
8.33N AT PA=
69

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
70
con chiamato ridondanza locale dell'osservazione j . Osservando la 8.41 si notache è possibile ricavare R senza aver eseguito le misure y0.
Similmente possiamo notare che anche altre formule già ricavate non dipendonodalle misure eseguite.
Più in generale, nel caso in cui il problema sia il progetto di una rete topografica, sipossono ricavare a priori le precisioni dei parametri, la precisione delle misure dopola compensazione, il contributo delle stesse alla rigidità della rete. È cioè possibilegià in fase di progetto della rete prevedere le precisioni finali, togliere le misure pocosignificative, o che potrebbero nascondere errori che più facilmente sfuggono ai testdi controllo, migliorare infine l'affidabilità della rete.
Esempio applicativo
Compensiamo secondo il metodo dei parametri aggiuntivi la rete di livellazioneprecedentemente vista (fig. 8.2). Si sono misurati i dislivelli:
Si possono identificare i vettori:
Dei dislivelli, che possono ritenersi misurati in modo indipendente, si conoscono ivalori misurati con livellazione geometrica. Si conosce anche:
ove D è la distanza fra i punti espressa in km; per queste ipotesi si potrà porre:
che in questo caso diviene:
I parametri incogniti sono le quote dei tre vertici.
Se effettivamente decidessimo di mantenere come parametri incogniti tutte questetre quote troveremmo tuttavia ben presto una deficienza di rango nella matrice nor-male N. A cosa è dovuta? Nel passaggio dallo «spazio delle misure» allo «spazio deiparametri» dobbiamo considerare in questo caso che le prime, essendo invariantiper traslazione, sono definite a meno di una traslazione del sistema di riferimento.
Nel caso dell'utilizzo dei parametri aggiuntivi «coordinate» in un problema ai
rjj
∆12 Q2 Q1–=
∆23 Q3 Q2–=
∆13 Q3 Q1–=
y
∆12
∆23
∆13
; xQ2
Q3
; y
∆ 12ˆ
∆ 23ˆ
∆ 13ˆ
; y0
∆120
∆230
∆130
====
∆120 ∆23
0 ∆130, ,
σ∆i j1mm D±=
P Q 1– diag σ∆12
2 , σ∆23
2 , σ∆13
2( ) 1–= =
P 1mm( ) 2– diag1
D12--------- ,
1D23--------- ,
1D31---------
=

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
71
minimi quadrati, occorre allora definire (anche arbitrariamente) questo sistema diriferimento, detto datum, dal quale non dipendono le misure ma dipendono invecei parametri aggiuntivi. Nel caso in esame ciò si fa, senza perdere di generalità, fis-sando ad esempio la quota del punto 1 (ad esempio Q 1= 0 m). In tal modo riman-gono incognite solo le quote dei punti 2 e 3.
Nell'esempio proposto si ha n = 2 (numero dei parametri incogniti) ed m = 3(numero di misure) per cui r = 1. La relazione 8.26 si scrive:
Si ha poi:
La matrice normale vale:
Sviluppando i calcoli si ottiene:
ed il vettore b, formato da due valori, risulta:
Ora si può risolvere il sistema od invertire la matrice N e ricavare:
y
∆ 12ˆ
∆ 23ˆ
∆ 13ˆ
1 0
1 1–
0 1
Q 2
Q 3
Q 1–
0
Q 1–
A x a+=+= =
y0 a–( ) l
∆ 120
∆130
∆230
Q 1+
Q 1+
= =
ATPA N1
0
1–
1
0
1 diag Dij( ) 1–
1
1–
0
0
1
1
= =
n11 1
D12-------- 1
D23--------+=
n12 n211
D23---------–= =
n22 1
D23-------- 1
D13---------+=
AT Pl b=
b11 1
D12-------- ∆ 12 Q1+( ) 1
D23--------∆ 23–=
b21 1
D23---------∆ 23
1D13---------∆ 13+=
x N 1– b=

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
72
Si verifica inoltre, (numericamente è in questo caso più facile), che la stima dellemisure:
è la stessa ricavata con il metodo delle sole equazioni di condizione, visto per lo stessoesempio.
Si ricavano infine gli scarti:
che permettono di calcolare la 8.34:
che, ancora, deve risultare identico al valore calcolabile con la 8.21.
8.3 MINIMI QUADRATI: EQUAZIONI DI CONDIZIONE E PARAMETRI AGGIUNTIVI
È questo il caso misto che comprende i due precedentemente trattati.
Premettiamo subito che è difficile poter applicare i risultati che si otterranno inquesto caso al calcolo automatico, a causa della quasi impossibile generalizzazionedel problema per scopi topografici; in programmazione questi problemi si risol-vono secondo l'analisi ed i metodi risolutivi visti nel caso delle equazioni aiparametri in quanto è più facile invece ricondurre questo caso al precedente.Daremo tuttavia, per completezza, uno sguardo alla soluzione teorica del problema.
Sia:
il vettore dei parametri, funzione (lineare) delle m quantità osservate y, (ad esempiole quote sono funzioni lineari dei dislivelli).
Le osservabili y sono legate da relazioni lineari contenenti n parametri aggiun-tivi x ( ) secondo il modello:
8.42
dove le dimensioni coinvolte sono:
Al solito le ipotesi stocastiche su y sono:
y A N 1– b( ) a+=
v y0 y ∆ ij0 ∆ ij–=–=
σ 02 vTP v
3 2–------------ min= =
x
x1
�
xn
=
l n l < m≤
Dy Ax d+=
m
l 1
m n
l 1
n
1
l =
y N y , σ 02Q[ ] con M y0[ ] y,==

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
Il problema è ricavare le stime:
8.43
secondo il modello fisico2:
8.44
e infine secondo la condizione di stima:
Introduciamo i moltiplicatori e minimizziamo la funzione:
ricaviam
che perm
ma, rico
e ricorda
che inser
ed allora
2 Intenden
y y≈
x x≈σ 0
2 σ 02≈
Cyy
Cyy≈
Cxx
Dy Ax d; r D( ) l ; r A( ) n==+=
y0 y–( )P y0 y–( ) min=
λ λ1…λn( )=
8.45Φ x ; y( ) y0 y–( )T P y0 y–( ) Dy A x– d–( )Tλ+=
o il differenziale:
ette ancora di scrivere:
dΦ 2d yT P y0 y–( )– dy T DTλ dx T ATλ 0=–+=
P y0 y–( )– DTλ 2 0=⁄+
ATλ 0=
8.46y y0 P 1– DTλ 2⁄–=
rdando la si ha:
ndo la definizione 8.18 di K:
Dy0 DP 1– DTλ 2⁄ A x d+=–
8.47λ 2K 1– Dy0 d–( ) 2K 1– A x–=
73
ita nella ottiene:
:
8.48a
do per r(• ) il rango del contenuto (• ).
ATλ 0=
AT K 1– Dy0 d–( ) AT K 1– A x 0=–
x AT K 1– A( ) 1– AT K 1– Dy0 d–( )=

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
simile alla 8.31a. Chiamando infatti:
8.48b
Ricavato poi λ dalla 8.47:
per definizione di U:
8.49
si ha, usando la 8.46:
8.4 PRO
Le stime
Conside
ed allora
Per la co
Non si dla quale
Cerchiail vettor
la 8.48b
Propaga
N AT K 1– A=
x N 1– AT K 1– Dy0 d–( )=
λ 2 K 1– Dy0 d A x––( ) 2 K 1– U==
U Dy0 A x d––=
M x[ ]
8.50y y0 P 1– DT K 1– U–=
PRIETÀ DELLE STIME ED , LORO DISPERSIONE
ed sono stime corrette di x ed y. Vediamo dapprima la ; ricordiamo che:
riamo il valore medio di U e ricordiamo la 8.49 e la 8.45:
si ha:
CVD
rrettezza di partiamo considerando la 8.50:
8.51
imostra qui la consistenza, si ricorda invece che l'efficienza è l'ipotesi, con ricavammo dette stime e dunque è già verificata.
mo ora le matrici di varianza-covarianza delle stime. Chiamiamo con ue:
8.52
assume la forma:
y x
y x x
Dy A x d+=
M U[ ] Dy d Ax 0=––=
AT K 1– A( ) 1– AT K 1– DM y0[ ] d–( ) AT K 1– A( ) 1– AT K 1– Ax 0===
y
M y[ ] M y0[ ] P 1– D K 1– M U[ ] M y0[ ] y CVD==–=
u Dy0 d–=
8.53x AT K 1– A( ) 1– AT K 1– u Su==
74
ndo la varianza attraverso la 8.52 si ha:
Cuu DCy0 y0DT σ 0
2DQDT σ 02K===

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
75
ed ancora propagando, usando stavolta la 8.53:
che semplificata ottiene:
8.54
Per ottenere la matrice si propaga la varianza a partire dalla 8.50; non si svolge qui ilcalcolo abbastanza laborioso che permette di ricavare:
8.55
con:
8.56
dove l è il numero di condizioni o vincoli, n è il numero di parametri incogniti edm è il numero di misure.
Riassumiamo qui le formule utilizzate nel caso di pure equazioni di condizione e dipure equazioni parametriche utilizzando il risultato generale appena ricavato.
Pure equazioni di condizione
Pure equazioni parametriche
Cx x SCuu ST AT K 1– A( ) 1– AT K 1– σ 02K K 1– A AT K 1– A( ) 1–==
Cx x σ 02 AT K 1– A( ) 1– σ 0
2 N 1–==
Cy y
σ 02 Q QDT K 1– K A N 1– AT–[ ] K 1– DQ–{ }=
σ 02 U T K 1– U
l n–---------------------=
D B; A 0; K BQBT; U By0 b–====
y y0 QBT BQBT( ) 1– By0 b–( )–=
Cu u
σ 02K σ 0
2 BQBT==
σ 02 By0 b–( )T K 1– By0 b–( )
1 n–--------------------------------------------------------=
Cv v σ 02Q BT K 1– BQ=
Cy y
σ 02 Q Cv v–[ ]=
D I; K Q P 1– ; N AT PA== ==
U y0 y–( ) v;= =
x AT PA( ) 1– AT P y0 d–( ); = l y0 d–=
y A x d+=

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
76
Si noti che:
8.57
Infine la matrice di ridondanza vale:
8.58
chiamando:
i pesi degli scarti dopo la compensazione.
Se P è diagonale si ha:
8.59
Attraverso la 8.58 e l’espressione della si ha:
8.60
8.5 IL PRINCIPIO DEI MINIMI QUADRATI IN CASI NON LINEARI
Premettiamo che in casi non lineari il metodo perde le proprietà di ottimalitàdescritte in precedenza e può anche ammettere più soluzioni.
Siano date equazioni, funzioni delle osservabili y e dei parametri x:
8.61
v l A x–=
σ 02
vT P vm n–-------------=
Cx x σ 02 N 1– ;=
Cuu Cv v σ 02 P 1– A N 1– AT–[ ]= =
Cy y
σ 02A N 1– AT=
Cv v Cyy Cy y
–=
R1
σ 02
------PCv v=
piˆσ vi
2
σ 02-------=
r ii pi
pii
-----=
Cv v
R I PAN 1– AT–=
l
g x,y( )
g1 x,y( )
g2 x,y( )
:.g1 x,y( )
0= =
con y lRm ed x lRn ∈∈

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
Si cercano le stime , tali che , sotto la condizione.
Supponiamo di conoscere i valori approssimati , e che, nell'intorno di dettivalori, g sia ben linearizzabile, dimodoché:
8.62
Linearizzando attorno ai valori approssimati si ottiene:
Chiamia
la matri
ed infin
Si arriva
notiamo
si ha:
Si noti p
e, posto
si ha da
sotto la
x y y0 y–( )T P y0 y–( ) min=g x , y( ) 0=
x y
y y η+=
x x ξ+=
g x , y( ) 0= x , y( )
8.63g x , y( ) 0 g x , y( ) ∂g∂x-----
ξ ∂g∂y-----
η+ +≅=
77
mo con:
8.64
ce disegno calcolata nei valori ; con:
8.65
e con:
8.66
perciò al sistema linearizzato:
8.67
che essendo:
8.68
oi che:
:
soddisfare:
8.69
condizione 8.67.
∂g∂x-----
∂g i
∂xj------- A= =
x , y( )
∂g∂y-----
∂g i
∂yk------- D–= =
g x , y( ) d=
Dη Aξ d+=
y y η+=
Cηη Cy y
σ02Q= =
y0 y–( )T P y0 y–( ) y0 y– η–( )P y0 y– η–( )=
η0 y0 y–=
η0 η–( )T P η0 η–( ) min=

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
78
Da questo punto in poi la soluzione è quindi analoga al caso lineare già visto.
Dopo aver ricavato la soluzione in ed in si calcola il vettore degli scarti:
8.70
Gli errori di chiusura valgono:
Ricordando la 8.63 che si scrive anche:
si ha:
8.71
Se gli scarti sono elevati si itera il procedimento, a partire dalle stime ed , uti-lizzate ora come valori approssimati. Si prosegue nelle iterazioni sinché:
8.72
Una seconda alternativa nella scelta di fermare o proseguire le iterazioni consiste nelverificare che le correzioni alle misure ed ai parametri sono trascurabili; scelto cosìun valore ε piccolo a piacere:
8.73
Infine si osservi che se le funzioni g(x ,y ) sono date in forma esplicita rispetto alleosservabili, cioè se sono del tipo:
8.74
non occorre linearizzare rispetto ad y ; questo è in realtà il caso nel quale riusciamoquasi sempre a ricondurre le equazioni nelle osservabili (equazioni generatrici).
Anche complicando un poco la funzione g, è preferibile ricondurci a questoapproccio, perché più semplice da programmare: ci si riduce infatti al caso di osser-vazioni non lineari con soli parametri aggiuntivi.
Si noti ancora che, nel caso di equazioni lineari non occorre la conoscenza diparametri approssimati, cosa invece indispensabile in caso contrario.
Nella ricerca della trasformazione 8.74 in forma esplicita, se è possibile, occorre pri-vilegiare la linearità della funzione a motivo delle proprietà di ottimalità descritte.
8.6 ESERCIZIO
Si desidera esaminare e risolvere il problema della rototraslazione con doppia varia-zione di scala (relativa cioè ai due assi) di un sistema ortogonale su un sistema nonortogonale (fig. 8.3).
ξ η
v η0 η–( )=
U Dy0 A x d Dη0 A ξ– d–=––=
g x , y( ) d A ξ Dη 0=–+=
U g x , y( ) g x ξ , y η+ +( )==
x y
ση i 1+( )2 vi 1+
T P vi 1+ ση i( )2<=
ξ i 1+ ξ i– ε1 oppure η i 1+ η i– ε2<<
y g x( )=

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
Trascuriamo per semplicità espositive per ora l’effetto dovuto alla traslazione. Esa-miniamo prima il modello geometrico, poniamo poi alcune semplici ipotesi suquello stocastico e risolviamo infine il problema ai minimi quadrati secondo la tec-nica dei parametri aggiuntivi.
Fig. 8.3 – Trasformazione affine tra due sistemi di coordinate.
Modello geometrico
Consideriamo il punto P (fig. 8.3) di coordinate (E,N ) nel sistema cartesiano orto-gonale e di coordinate (x,y ) nel sistema di assi non ortogonali.
Sia α l'angolo orario da x verso Est e β l'angolo da y verso Nord; chiamiamo «affi-nità» l'angolo δ=β–α .
Si avrà:
chiamando:
si può scrivere il sistema lineare; si arriva alla stessa conclusione considerandol’espressione dei versori degli assi (x e y):
Ora avviene che, se si ipotizzano due fattori di scala per ciascun asse:
α
α
αδ
β
β
y
y
0 E F Est
x
x
H
PQ N
Nord
N PH HE y β x αsin+cos=+=
E OF EF– x α y– βsincos==
α a, α c=sin=cos
βsin– b, β d=cos=
E ax by+=
N cx dy+=con le condizioni
a2 c2 1=+
b2 d2 1=+
x λx X=
y λ yY=
8.75E aλx x bλ y y def( ) AX BY+= =+=
8.76N cλx x dλy y def( ) CX DY+= =+=
79

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
80
mentre le condizioni di normalizzazione riportate sopra per A,B,C,D , divengono:
È possibile verificare inoltre che:
Sfruttando queste relazioni e tenendo conto che:
si ricava:
Abbiamo sinora esaminato il modello fisico-geometrico senza traslazioni di assi, checi ha portati nelle condizioni di risolvere un sistema di equazioni lineari 8.75 ed8.76. Nel caso generale tuttavia rimane ancora da considerare una traslazione fradue sistemi; la 8.75 e la 8.76 divengono allora:
8.77
8.78
Se, di un numero n di punti dei quali sono note le coordinate (X ,Y ), si sono misu-rate anche le coordinate (E,N ), le due equazioni possono essere scritte sintetica-mente in forma matriciale:
8.79
Modello stocastico e soluzione ai minimi quadrati
È facile riconoscere qui sopra le misure y nelle coordinate che ipotizziamoincorrelate, tali che .
Riconosciamo poi i sei parametri incogniti nel vettore trasposto ed i coefficienti diquesti parametri come matrice A.
Perché il problema possa avere una soluzione occorrerà avere a disposizione almenotre coppie di coordinate in entrambi i sistemi. Applicando la 8.23 a questo esempiosi nota che a=0.
Ipotizzando di scrivere dapprima tutte le equazioni nelle e poi tutte quelle
A2 C 2 αλ x2cos2 αλ x
2sin2 λx2=+=+
B 2 D 2 β λy2sin2 β λy
2cos2 λ y2=+=+
CA--- c
a-- tgα= =
BD----- b
d--- tg β=–=–
tgδ tg β α–( ) β α β αsincos–cossinβ α β αsinsin+coscos
--------------------------------------------------==
tgδ AB CD+BC DA–----------------------=
E AX BY E∆+ +=
N CX DY N∆+ +=
Ei
Ni Xi Yi 0 0 1 0
0 0 Xi Yi 0 1
A ,B ,C ,D , E , N∆∆( )T=
Ei Ni,CEN σ2 I=
Ei Ni

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
81
possono costruirsi la matrice disegno ed il vettore dei termini noti che assumonola forma:
8.80
Facciamo poi l'ipotesi semplificativa che:
La normalizzazione della 8.80
La costruzione della matrice normale 8.33 , porta ad ottenere unamatrice di dimensioni ed un vettore b di dimensione .
È facile ottenere questo risultato per la matrice normale moltiplicando fra loro lecolonne di A e moltiplicando le colonne di A e di l per i termini noti normalizzati.
Occorre ora risolvere un sistema lineare di sei equazioni in sei incognite, ma è pos-sibile una ulteriore semplificazione. Si nota che, se con un artificio, rendessimonulli alcuni termini: si semplificherebbe dimolto il problema: scomparirebbero così le ultime righe e colonne di N. Ciò è pos-sibile, se le coordinate nei due sistemi di partenza, che ora chiamiamo ed
sono tali che, calcolate le coordinate dei baricentri:
Si definiscano le coordinate X, Y, E, N in questo modo:
l y0 Ei,Ni( )T= =
A
Xi
�
Xn
0
�
0
Yi
�
Yn
0
�
0
0
�
0Xi
�
Xn
0
�
0Yi
�
Yn
1
�
10
�
0
0
�
01
�
1
;= l
Ei
�
En
Ni
�
Nn
=
σ 02 σ i
2= 1; P I==
N AT PA=N6
6 AT A= 6 b⋅ AT Pl=
N
Xi2∑
simm
XiYi∑Y i
2∑
0
0
X i2∑
0
0
XiYi∑Y i
2∑
X i∑Yi∑
0
0
n
0
0
X i∑Yi∑
0
n
; b
XiEi∑Yi Ei∑Xi Ni∑Yi Ni∑
Ei∑Ni∑
==
Ei∑ Ni∑ X i∑ Yi∑ 0= = = =
X ' Y ',( )E ' N ',( )
X G
X '∑n
------------ ;=
EG
E '∑n
----------- ;=
YG
Y '∑n
------------=
NG
N '∑n
-------------=

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
82
Così si avrà sempre che:
e similmente:
In questo modo il problema si riduce al calcolo di soli 4 parametri a due a dueincorrelati: (A,B ) e (C,D ):
8.81
che può essere diviso nei due sistemi:
8.82
Si ottiene facilmente la stima di questi parametri: chiamando con ∆ il determinantedella matrice N:
Le formule:
risolvono il problema. Si ricava poi, ricordando le 8.5, 8.25 e 8.26:
X X ' X G;–=
N N ' NG;–=
Y Y ' YG–=
E E ' EG–=
X i X ' nX G 0=–∑=∑
Yi Ei Ni 0=∑=∑=∑
X i2∑
Simm
XiYi∑Yi
2∑
0
0
Xi2∑
0
0
XiYi∑Yi
2∑ A
B
C
D XiEi∑
YiEi∑XiNi∑YiNi∑
=
N
N
A, B( )T
C, D( )Tb1
b2 =
∆ X i2 Y i
2∑∑ X iYi∑( )2–=
A Y i2 X iEi∑∑ X iEi Yi Ei∑∑–( ) ∆⁄=
B X iYi X iEi∑∑– X i2 Yi Ei∑∑+( ) ∆⁄=
C Y i2 X iNi∑∑ X iYi YiNi∑∑–( ) ∆⁄=
D X iYi X iNi∑∑– X i2 Yi Ni∑∑+( ) ∆⁄=
v y0 Ax–=
vEi Ei xi– A– YiB–=
vNi Ni X iC– Yi D–=

APPLICAZIONE DEL PRINCIPIO DEI MINIMI QUADRATI
83
Utilizzando poi la 8.45 si ha:
cioè:
Ricavando poi:
si nota ancora che le varianze delle coordinate ricavabili da X e Y sono iden-tiche e valgono:
mentre sono nulle le covarianze sempre ammessa l'ipotesi di partire da unamatrice dei pesi proporzionale alla matrice identità.
σ 02 vTv
2n 4–---------------=
Cx x σ 02 N 1–=
σA2 σ 0
2 Yi2 ∆ σ
C2=⁄∑=
σA B2 σ 0
2 X iYi∑– ∆ σC D2=⁄=
σB2 σ 0
2 X i2∑ ∆⁄ σ
D2= =
Cy y
σ 02 A N 1– AT=
E N,
σE2 σ
N2 σ
A2 X 2 σ
B2 Y 2 2σ
ABXY+ += =
σE N






























