Embed Size (px)
Citation preview

ANÁLISE DE DADOSPARACIÊNCIAS SOCIAISA Complementaridade do SPSS
6ªEDIÇÃO
Revista,Atualizadae Aumentada
MARIA HELENA PESTANAJOÃO NUNES GAGEIRO
Este livro, fruto da experiência académicae profissional dos autores, foi agora, nesta6ª edição, enriquecido com esquemas,resumos e 157 aplicações práticas, queinovam nas associações que estabele-cem entre os diferentes capítulos, simpli-ficando e consolidando os temas nelestratados, tornando-o acessível a todosos leitores, mesmo aqueles com poucasbases de matemática, estatística e infor-mática.
A introdução da do IBM-SPSS per-mite, para qualquer distribuição e dimen-são da amostra, calcular todas as proba-bilidades associadas, identificar os acon-tecimentos mais prováveis, determinaros erros e a potência do teste, bem comorecorrer tanto às distribuições exatas comoàs aproximadas.
Importância particular é dada à partici-pação ativa do leitor, tornando o livroestimulante e útil para todos os que a elerecorram.
syntax
EDIÇÕES SÍLABO
Ficheiros SPSS para download
www.si labo.pt
MARIA HELENA PESTANA é professora do ISCTE desde 1982. Édoutorada em Métodos Quantitativos de Gestão, na área de Pes-quisa de Mercados. É investigadora em Estatística, Econometria, eAnálise de Dados aplicados nos domínios de Demografia, Econo-mia, Finanças, Gerontologia, Gestão, Psicologia, Saúde, Sociologia,e Turismo. É autora de livros e de vários artigos científicos em publi-cações nacionais e estrangeiras.
JOÃO NUNES GAGEIRO, licenciou-se em Organização e Gestãode Empresas no ISCTE e concluiu o curso «Hotel and HospitalityManagement», da Universidade de Cornell em Ithaca (NY), nosEUA. É investigador em Turismo e Análise de Dados aplicados nosdomínios de Economia, Finanças, Gerontologia, Gestão, Psicologia,Saúde e Sociologia. É autor de livros e de vários artigos científicosem publicações nacionais e estrangeiras.
6ªEDIÇÃO
A obrade referência
da Análisede Dados em
Portugal
ISBN 978-972-618-775-2
9 789726 187752
A publicação desta obra teve o apoio:
••
••••••••••
••
•••
••••• paramétricos/
/•
Gini, Bayes, CV, MADMédias: ponderada/aparada//geométrica/harmónica
/influência/resíduosÍndicesContrastes/tendênciaVariáveis artificiais
ANOVA/MANOVA/ANCOVAMedidas RepetidasFatorial
/padrões/substituiçãoOR, RR, sensibilidade,prevalênciaCurva ROCMRLS, MRLM, 2SLS, WLS,Logística
DiscriminanteAmostras independentes//emparelhadasT, F, Normal, Qui-QuadradoMDS/MCA/ANACORDecisão/sig/potência
/Estimação/EMVTestesnão paramétricos
Outliers
Cluster
Missings
Path analysis
Syntax
Graphs
26A
Com
plementaridade do SPSS
AN
ÁLISE D
E DA
DO
SPA
RA
CIÊN
CIA
S SOC
IAIS


Análise de Dados para
Ciências Sociais
A Complementariedade do SPSS
MARIA HELENA PESTANA JOÃO NUNES GAGEIRO
6ª EDIÇÃO
EDIÇÕES SÍLABO

É expressamente proibido reproduzir, no todo ou em parte, sob qualquer forma ou meio, NOMEADAMENTE FOTOCÓPIA, esta obra. As transgressões serão passíveis das penalizações previstas na legislação em vigor.
Visite a Sílabo na rede
www.si labo.pt
Editor: Manuel Robalo
FICHA TÉCNICA:
Título: Análise de Dados para Ciências Sociais – A Complementariedade do SPSS Autores: Maria Helena Pestana, João Nunes Gageiro © Edições Sílabo, Lda. Capa: Pedro Mota
1ª Edição – Lisboa, outubro de 1998 6ª Edição – Lisboa, outubro de 2014 Impressão e acabamentos: Cafilesa – Soluções Gráficas, Lda. Depósito Legal: 382311/14 ISBN: 978-972-618-775-2
EDIÇÕES SÍLABO, LDA.
R. Cidade de Manchester, 2 1170-100 Lisboa Tel.: 218130345 Fax: 218166719 e-mail: [email protected] www.silabo.pt

Índice
Prefácio 17
Introdução
1. Iniciação ao IBM-SPSS 22 1.1. Ficheiro de dados 22 1.2. Definição de variáveis e casos 22 1.3. Análise estatística 27 1.4. Gráficos 28 1.5. Ajudas 29 1.6. Junção de informação de dois ficheiros 30
1.6.1. Junção de variáveis 30
1.6.2. Junção de casos 33
1.7. Edição de Informação 34 1.8. Definição e organização de dados 36 1.9. Transformação de dados 38
1.9.1. Criação de novas variáveis 39 1.9.2. Agregação de categorias 40 1.9.3. Inversão da ordem das categorias 42 1.9.4. Transformação de uma variável métrica em qualitativa 42 1.9.5. Conversão de uma variável string em numérica 43 1.9.6. Contagem de casos 44 1.9.7. Substituição de respostas omissas 44
1.10. Utilidades 44
2. Exercícios – Enunciados 45 3. Exercícios – Resolução 46

Capítulo 1
Estatística descritiva e indutiva
1. Introdução 53 1.1. Escalas de medida e tratamento estatístico 53
2. Estatística descritiva versus indutiva 57 3. Análise das respostas omissas 58
3.1. Exclude cases listwise 59 3.2. Exclude cases pairwise 60 3.3. Replace with mean 61 3.4. Análise univariada das respostas omissas 62 3.5. Padrão das respostas omissas 65 3.6. Aleatoriedade das respostas omissas 67 3.7. Não aleatoriedade das respostas omissas 68
4. Variáveis nominais 69 4.1. Quadro de distribuição de frequências 69 4.2. Moda 70 4.3. Gráficos de barras e circular 70
5. Variáveis ordinais 75 5.1. Quantis 75 5.2. Quadro de distribuição de frequências 76 5.3. Introdução de dados 77 5.4. Moda e conclusão 79
6. Variáveis métricas 81 6.1. Quadro de distribuição de frequências, moda e quantis 81 6.2. Outliers, Amplitude total e inter-quartil 83 6.3. Histograma, diagrama de caule e folhas e caixa de bigodes 85 6.4. Média e suas propriedades 90 6.5. Variância, desvio padrão, desvio absoluto médio e desigualdade de Tchebycheff 95 6.6. Erro padrão e intervalo de confiança para a média 97 6.7. Média aparada 99 6.8. Simetria e achatamento 103 6.9. Média ponderada, geométrica e harmónica 108 6.10. Coeficiente de variação e MAD 111
6.11. Distribuição normal e testes à normal 116

6.12. Transformações e estandardização 120
6.13. Categorização pelo método dos grupos extremos revisto 131
6.14. Criação de índices pela uniformização de escalas 134
7. Medida concentração: índice de Gini 139 8. Exercícios – Enunciados 141 9. Exercícios – Resolução 152 10. Fundamentos para a inferência 239
10.1. Testes paramétricos e não paramétricos 239
10.2. Estimadores e distribuições amostrais 240 10.2.1. Distribuições do Qui-Quadrado, t de Student e F de Snedecor 242
10.3. Estimação: pontual, por intervalos e ensaio de hipóteses 244
10.4. Regra de decisão 248
10.5. Aplicações 249 10.5.1. Desigualdade de Chebychev 250 10.5.2. Distribuição uniforme 250
10.5.2. Distribuição normal 251
10.5.4. Distribuição do Qui-Quadrado 256
10.5.5. Distribuição t de Student 258
10.5.6. Distribuição F de Snedecor 260
Capítulo 2
Contingência, associação e correlação
1. Introdução 269 2. Tabelas de contingência e teorema de Bayes 270
1.1. Construção de tabelas 270 1.2. Probabilidade conjunta, marginal e condicionada 271 1.3. Teorema de Bayes 273
3. Análise das tabelas de contingência 276 3.1. Testes de independência do Qui-Quadrado 277
3.1.1. Teste do Qui-Quadrado de Pearson 278 3.1.2. Teste do rácio da verosimilhança 286 3.1.3. Teste do Qui-Quadrado da correção de continuidade de Yates 292 3.1.4. Teste do Qui-Quadrado de Fisher 292 3.1.5. Teste Linear-by-Linear Association 299 3.1.6. Teste de McNemar 300

3.2. Odds e odds racio 301 3.2.1. Odds 301 3.2.2. Odds rácio 301 3.2.3. Propriedades 302 3.2.4. Intervalo de confiança para o odds rácio 303
3.3. Risco relativo, rácio de prevalência, diferença de proporções e intervalos de confiança 303 3.3.1. Risco relativo e rácio de prevalência 303 3.3.2. Intervalo de confiança para RR ou RP 304 3.3.3. Teste de homogeneidade e intervalo de confiança 304 3.3.4. Discrepância entre o odds rácio e o RP 306
3.4. Relação entre o odds rácio e RR ou RP 306
3.5. Associações marginais e condicionadas 307 3.5.1. Totais das k subtabelas são semelhantes 309
3.5.2. Totais das k subtabelas são diferentes 315
3.6. Concordância: Kappa de Cohen 319 3.6.1. Vulnerabilidade do Kappa de Coehen 321
3.7. Outras medidas de associação para variáveis nominais 323 3.7.1. Phi, V de Cramer, coeficiente de contingência 323 3.7.2. Lambda, Goodman e Kruskal’s tau e coeficiente de incerteza 324 3.7.3. Síntese 324
3.8. Outras medidas de associação para variáveis ordinais 330 3.8.1. Gamma, Kendall’s tau b, Kendall’s tau c, Somer’s d 330 3.8.2. Síntese 332
3.9. Sensibilidade, especificidade, valor preditivo, prevalência, rácio da verosimilhança 335 3.9.1. Síntese 337
3.10. Curva ROC 340 3.10.1. Síntese 342
3.11. Correlações simples e parciais: variáveis estandardizadas Z, Ró de Spearman e R de Pearson 345 3.11.1. Síntese 348
3.12. Eta e correlações biserial e point biserial 361 3.12.1. Síntese 362
4. Exercícios – Enunciados 367 5. Exercícios – Resolução 381 6. Fundamentos das tabelas de contingência 461

Capítulo 3
Anacor, MCA e MDS
1. Introdução 467 2. Anacor 468 3. MCA 471 4. MDS 473 5. Exercícios – Enunciados 478 6. Exercícios – Resolução 482
Capítulo 4
Análise das componentes principais e análise fatorial
1. Introdução 516 2. Análise das Componentes Principais (ACP) 518 3. Análise Fatorial (AF) 519
3.1. Existência de correlação e a adequação aos dados 520 3.2. Número de fatores a reter 521 3.3. Percentagem de variância explicada pelos fatores retidos 522 3.4. Percentagem de variância explicada por cada fator retido 522 3.5. Variáveis pertencentes a cada fator 523 3.6. Variáveis a reter 524 3.7. Indicadores da qualidade do modelo: GFI, AGFI e RMSR 525
3.7.1. Goodness of Fit Index (GFI): 526 3.7.2. AGFI 527 3.7.3. A Root Mean Square Residual (RMSR) é dada por: 527
3.8. Representação gráfica e interpretação dos fatores retidos 528 3.9. Exploração dos dados, outliers e respostas omissas 529
4. Análise fatorial em escalas 530 5. Análise da Consistência Interna 531
5.1. Alpha de Cronbach 531 5.2. Coeficiente de Bipartição 532 5.3. Modelos Paralelo e Estritamente Paralelo 532 5.4. Guttman 533 5.5. Coeficiente de Correlação Intra Classes 533

6. Exercícios – Enunciados 534 7. Exercícios – Resolução 538
Capítulo 5
Análise de clusters
1. Análise de Clusters 575 2. Exercícios – Enunciados 578 3. Exercícios – Resolução 579
Capítulo 6
Análise discriminante
1. Análise discriminante 604 1.1. Pressupostos 604 1.2. Seleção das variáveis explicativas 606 1.3. Número de funções discriminantes 608 1.4. Variáveis explicadas por cada função discriminante retida 609 1.5. Classificar casos e validar os resultados 610 1.6. Analisar as respostas omissas 611
2. Exercícios – Enunciados 611 3. Exercícios – Resolução 612
Capítulo 7
Regressão
1. Modelos de regressão 643
2. Modelo de Regressão Linear Simples − MRLS 644 2.1. Pressupostos 645 2.2. Exploração dos dados 647 2.3. Estimação 650 2.4. Previsão pontual e por intervalos 651 2.5. Medidas absolutas e relativas da qualidade do ajustamento 656 2.6. Teste t de Student 659 2.7. Teste F de Snedecor 661

2.8. Verificação das Hipóteses do MRLS 662 2.8.1. Linearidade e transformações 663 2.8.2. Normalidade 668 2.8.3. Homocedasticidade 669 2.8.4. Autocorrelação 673
2.9. Observações outliers e influentes 676 2.9.1. Outliers 676 2.9.2. Observações influentes 679
3. Escolha entre funções polinomiais 682 4. Relações não lineares 688
4.1. Função potência: elasticidade constante 688 4.2. Função logarítmica 694 4.3. Função exponencial: crescimento constante 696 4.4. Função inversa ou hiperbólica 702 4.5. Função exponencial inversa 709
5. Permanência de estrutura-MRLS 714 6. Variáveis artificiais ou dummies 721
6.1. Determinação do número de variáveis artificiais 721 6.2. Codificação das variáveis artificiais 722
6.2.1. Categoria de referência com o código zero 722 6.2.2. Contrastes 722
6.3. Interações 723
7. Multicolinearidade 737 7.1. Origens da multicolinearidade 738 7.2. Efeitos da elevada multicolinearidade 738 7.3. Oscilações nas estimativas dos coeficientes 739 7.4. Medidas de multicolinearidade 740 7.5. Sugestões para suprir a elevada multicolinearidade 742 7.6. Interpretação dos coeficientes da reta estimada no MRLM 743
8. Coeficiente de determinação ajustado 2aR 743
9. Covariância, R de Pearson, Ró de Spearman, correlações parciais e semiparciais 745 9.1. Covariância 745 9.2. R de Pearson 747 9.3. Ró de Spearman 748 9.4. Correlações parciais e semiparciais 749

10. Interpretação do teste F da Anova 751 11. Interpretação dos testes t e Fchange 752
12. Métodos de entrada de variáveis na regressão 754 12.1. Regressão múltipla standard (Method Enter): 755 12.2. Regressão hierárquica ou sequencial 755 12.3. Stepwise 756
13. Validação cruzada 757 13.1. R ao quadrado ajustado de Stein 757 13.2. Partição dos dados 758
14. Modelo de Regressão Linear Múltipla – MRLM 772 14.1. MRLM sem violação dos pressupostos 773
14.1.1. Exploração dos dados 776 14.1.2. Estimação e previsão 778
14.1.3. Hipóteses do MRLM 786
14.1.4. Observações Outliers e Influentes 790
14.2. 2SLS 794 14.3. WLS 798
14.3.1. Exploração da heterocedasticidade 801
14.3.2. Encontrar a fonte principal da heterocedasticidade 803
14.3.3. Escolha da potência ótima 804
14.3.5. Verificação da correção da heterocedasticidade 807
15. Permanência de estrutura – MRLM 808 15.1. MRLM com uma observação adicional 809 15.2. MRLM com m < k observações adicionais: teste de Gregory Chow 812
16. Path analysis 816 17. Exercícios – Enunciados 826 18. Exercícios – Resolução 830
Capítulo 8
Testes t e intervalos de confiança para médias
1. Introdução 867 2. Teste t de Student, intervalos de confiança para uma média
e cálculo do nível de significância 869

3. Testes t de Student e intervalos de confiança para a diferença de médias em amostras independentes. Cálculo do nível de significância 877 3.1. Teste t de Student e intervalos de confiança para a mesma variável métrica 877 3.2. Testes t de Student simultâneos vs. regressão logística binária 889
4. Teste t e intervalos de confiança em amostras emparelhadas 898 4.1. Vantagem das amostras emparelhadas vs. amostras independentes 899
5. Exercícios – Enunciados 903 6. Exercícios – Resolução 905
Capítulo 9
Testes não paramétricos
1. Introdução 923 2. Testes não paramétricos para amostras independentes 924
2.1. Teste da Binomial 924 2.1.1. Região crítica unilateral 924 2.1.2. Região crítica bilateral 927
2.2. Teste de aderência do Qui-Quadrado 929 2.3. Teste de ajustamento de Kolmogorov-Smirnov 933 2.4. Teste de Wilcoxon para uma mediana 938 2.5. Teste de Mann-Whitney 941
2.5.1. Com empates 943 2.5.2. Sem empates 948
2.6. Teste de Kruskal-Wallis 952 2.7. Teste de independência de Kolmogorov-Smirnov 959
3. Testes não paramétricos para amostras emparelhadas 964 3.1. Teste de McNemar 964
3.1.1. Diagonal secundária (b + c) > 20 966 3.1.2. Diagonal secundária (b + c) ≤ 20 969
3.2. Teste Q de Cochran 971 3.3. Teste do sinal 977 3.4. Teste de Wilcoxon 981 3.5. Teste de Friedman 985
4. Exercícios – Enunciados 990 5. Exercícios – Resolução 991

Capítulo 10
Anova, Ancova e Manova
1. Introdução 1007 2. One-Way Anova 1008
2.1. Pressupostos 1009 2.2. Análise de variância 1010
2.2.1. Dedução dos testes F 1012
2.3. Identificação das diferenças entre os grupos 1015 2.3.1. Tendência 1015 2.3.2. Testes a posteriori ou Post-hoc 1025 2.3.3. Testes a priori ou contrastes planeados 1028 2.3.4. One-Way Anova em escalas de avaliação 1039
3. Anova fatorial 1046 3.1. Anova a dois ou mais fatores 1047
3.1.1. Decomposição do teste F 1048 3.1.2. Dimensões semelhantes versus diferentes 1050 3.1.3. Vantagem da Anova versus One-Way Anova 1051
3.2. Testes a posteriori ou Post-hoc 1052 3.3. Testes a priori ou contrastes planeados 1052
3.3.1. Efeitos principais 1053 3.3.2. Efeitos interativos 1054 3.3.3. Exploração dos dados 1057 3.3.4. Comparação de dispersões 1062 3.3.5. Comparação de médias 1063 3.3.6. Qualidade do modelo 1064 3.3.7. Testes a priori ou constrastes planeados 1065 3.3.8. Testes a posteriori ou Post-hoc 1072
4. Ancova 1074 4.1. Pressupostos da Ancova 1074 4.2. Modelo estimado 1075
4.2.1. Normalidade e homocedasticidade 1078 4.2.2. Associação linear 1081 4.2.3. Médias da concomitante por categoria do fator 1083 4.2.4. Homogeneidade dos declives 1084 4.2.5. Resultados do modelo estimado 1085 4.2.6. Heterogeneidade dos declives 1094

5. Manova 1098 5.1. Pressupostos da Manova 1099 5.2. Testes multivariados 1100
5.2.1. Exploração dos dados 1104 5.2.2. Testes multivariados 1106 5.2.3. Um fator e quatro endógenas: avaliação dos pressupostos 1109 5.2.4. Paralelismo dos perfis 1112 5.2.5. Níveis dos perfis 1114 5.2.6. Achatamento dos perfis 1114
6. Exercícios – Enunciados 1118 7. Exercícios – Resolução 1125
Capítulo 11
Medidas repetidas
1. Análise de variância de medidas repetidas: hipóteses 1184 2. Pressupostos 1186 3. Efeitos e consistência interna 1187
3.1. Exploração dos dados 1189 3.1.1. Normalidade 1192 3.1.2. Covariâncias 1192 3.1.3. Esfericidade 1193 3.1.4. Consistência interna 1193
3.2. Comparação de médias 1195 3.3. Testes Post-hoc: comparação dos efeitos interativos 1198 3.4. Testes Post-hoc: Comparação dos efeitos principais 1200 3.5. Testes a priori 1204
4. Exercícios – Enunciados 1206 5. Exercícios – Resolução 1209
Bibliografia 1233


Prefácio
Apesar do pioneirismo encetado em 1998 com a 1ª edição deste livro em língua portuguesa, esta sexta edição não se fica pela reedição das anteriores, apresentando uma versão inovadora e aumentada, cujas principais alterações são a seguir indicadas.
De forma a facilitar a consulta do livro, introduziu-se um esquema global que identi-fica os os capítulos.
Cada capítulo inicia-se com o respetivo esquema, complementado com os aspetos relevantes, terminando com novos exercícios propostos e resolvidos, para além dos que acompanham a explicação teórica.
Estes novos exercícios permitem não só uma consolidação da matéria exposta, como simplificam a complexidade da estatística, devido às associações que estabele-cem com outros capítulos.
Substituíram-se as tabelas das distribuições teóricas, pelas obtidas de forma efi-ciente e expedita pelo IBM-SPSS, aplicáveis a qualquer dimensão da amostra ou a qualquer probabilidade, permitindo o cálculo dos níveis de significância, do erro tipo II e da função potência associadas a cada decisão.
A introdução ao IBM-SPSS foi substancialmente actualizada de forma a torná-la mais amigável para um iniciado, apresentando várias situações a que a ele se pode recorrer, com explicação passo a passo, evidenciando-se o seu vasto manancial de recursos.
O Capítulo 1 inclui agora o índice de Gini e as médias harmónicas e geométricas, bem como a análise das respostas omissas. Adicionaram-se os fundamentos para a inferência, distinguindo os testes paramétricos dos não paramétricos, definindo-se a desigualdade de Chebychev, os estimadores, as distribuições amostrais e as estima-ções: pontual, por intervalos e ensaio de hipóteses.
O Capítulo 2 inclui agora o teorema de Bayes e a curva ROC. O Capítulo 3 engloba também o MDS. No capítulo da regressão foram adicionados a permanência de estru-tura, os modelos 2SLS e WLS.
Sem sacrificar o rigor que procurámos imprimir à abordagem das diversas técnicas, a metodologia usada, resultante de uma experiência académica e profissional de alguns anos nesta área, centrou-se na exposição tão fácil quanto possível das matérias e na sua ilustração com recurso a exemplos práticos de modo a tornar acessível o texto a uma vasta gama de leitores, incluindo aqueles com menos bases de matemática.

Todos os capítulos foram objeto de aprofundamento, transformando-o no manual mais completo e de fácil manuseamento em língua portuguesa, indispensável à análise estatística dos dados.
Ainda que este livro seja da inteira responsabilidade dos autores, o seu conteúdo resultou em larga medida da leitura de obras de autores nacionais e estrangeiros, bem como das inúmeras discussões tidas ao longo do tempo com muitas das pessoas com que habitualmente trabalhamos. O seu contributo em muito melhorou o nosso entendi-mento dos múltiplos aspetos relacionados com o tema.
Queremos a todos agradecer. Em primeiro lugar às Edições Sílabo, que acreditaram e tiveram o otimismo necessário para tornar possível este livro. Ao Dr. João Pequito e Dra. Sandra Barão da PSE, que contribuíram para a atualização e apoio ao suporte informático.
Também não hesitamos em agradecer aos nossos alunos, colegas e leitores que nos estimulam com as suas críticas e sugestões sempre oportunas, que contribuíram para o aperfeiçoamento dos temas aqui tratados.
Uma palavra de apreço ao incansável amigo e consultor Dr. António Alexandre Sequeira, cuja competência e disponibilidade em muito tem contribuído para o bom fun-cionamento dos nossos computadores.
Finalmente uma saudação à nossa família pelo apoio e compreensão manifestado nas ausências devido às muitas horas de trabalho dedicadas à feitura do livro e em especial à nossa fonte inspiradora, o Manuel Pestana Gageiro.
De novo se deixa o endereço e-mail: [email protected] com a finalidade da continuação do proveitoso diálogo entre os leitores e os autores.
Pode descarregar os ficheiros das bases de dados do IBM-SPSS referenciadas ao longo do texto, na página do livro em www.silabo.pt.
Os autores

Introdução ao IBM-SPSS
Estatísticadescritiva/inferencial
Relação entre duas ou mais variáveisquantitativas (sem efeitos interativos)
Redução do n.º de variáveis quantitativas
Criação de grupos homogéneos de casos em função de variáveis quantitativas
Diferença entre dois ou mais grupos em função de variáveis quantitativas
Variáveis quantitativas em função de outras variáveis quantitativas
Uma ou mais variáveis quantitativas em funçãode 1 ou mais variáveis quantitativas
Comparação de uma ou mais médias
Estudounivariado
Variáveis nominais
Variáveis ordinais
Variáveis quantitativas/métricas
Tabelas de contingência(T. Bayes)
Tipologias
Gráficas
Semelhança/diferença entre duasou mais variáveis quantitaitivas
Análise Fatorial
Comparação de
Distribuições
Proporções
Médias de dois ou mais grupos
Amostrasindependentes
Amostrasemparelhados
Cap. 9
Amostrasindependentes
Amostrasemparelhados
Cap. 8
Amostrasindependentes
Amostrasemparelhados
Cap. 10
Cap. 11
Cap. 7
Cap. 6
Cap. 5
Cap. 4
Cap. 3
Cap. 2Cap. 2
Cap. 1
Criar/transformar/introduzir
Juntar/validar/importar/salvar
Variáveisqualitativas
ANACORMCAMDS
Testes do qui-quadrado
Medidas de associação
Curva ROC
Criação de índices
Análise de clusters
Análise discriminante
Modelosde regressão linear
Análisede variância
Análise de variânciade medidas repetidas
Testes t
Testes nãoparamétricos


Introdução
Ficheiro de dados Visionamento
Número do questionário
Criar variáveis
Agregar categorias
Inverter a ordem
Contar casos
Substituir respostas omissas
Casos
Variáveis
Sort cases
Split file
Definição de variáveis e casos
Transformação
Junção
Validação
Organização
Ajudas
Utilidades
A estatística é um instrumento matemático necessário para recolher, organizar, apresentar, analisar e interpretar dados.
Neste capítulo de iniciação ao IBM-SPSS, explica-se nomeadamente o acesso a um ficheiro de dados, a introdução dos dados e das variáveis, a junção de ficheiros, a defi-nição e organização de dados, a edição de informação, a transformação das variáveis, a inversão das escalas, a reconversão de escalas numéricas em categóricas, a recodifi-cação de dados, a contagem de casos, a substituição de respostas omissas aleatórias e a utilização de gráficos na exploração de dados.

22 A N Á L I S E D E D A D O S P A R A C I Ê N C I A S S O C I A I S
1. Iniciação ao IBM-SPSS
O IBM-SPSS é um programa informático amigável e poderoso de apoio à estatística e vai servir de suporte às aplicações práticas apresentadas neste livro.
1.1. Ficheiro de dados
Para trabalhar com os ficheiros do IBM-SPSS que constam do livro, deve aceder previamente ao link da Editora Sílabo da seguinte maneira:
www.silabo.pt/ Edições Sílabo Catálogo Estatística
Após localizar este livro, sobrepõe-se-lhe o cursor e com dois cliques surge a infor-mação:
Descarregar aqui os ficheiros Abrir
Entra-se em aqui para descarregar os ficheiros, onde se abrem e copiam para uma diretoria do computador do leitor.
Os ficheiros com os dados identificam-se pelo nome que lhes é atribuído seguido da extensão (.sav) e são exibidos no Data Editor.
1.2. Definição de variáveis e casos
Para se aceder a qualquer ficheiro deve previamente entrar-se na pasta que o con-tém, cuja denominação corresponde ao respetivo capítulo neste livro.
Para obter o ficheiro Portugal.sav, escolhe-se no ambiente de trabalho do Windows as seguintes instruções que contêm a negrito as escolhas do leitor e que por sua vez originam a janela abaixo:
Start Programs IBM SPSS Statistics File Open Data
Capítulo-Introdução File Name Portugal.sav Open

I N T R O D U Ç Ã O 23
File é o ficheiro que permite criar bases de dados, aceder aos dados já criados, exportá-los, salvá-los, imprimir ficheiros, conhecer os ficheiros recentemente utilizados tanto de dados como de resultados (outputs), sair da base de dados.
Para guardar a base de dados faz-se: File Save as File Name Portugal Save
Para sair da base de dados faz-se: File Exit
Sempre que se pretende voltar a aceder a este ficheiro do IBM-SPSS deve fazer-se:
File Open Data File Name Portugal.sav Open
O Data Editor desdobra-se no Data View, onde se inserem os dados, e no Variable View onde se definem as variáveis.
O Variable View dispõe de linhas destinadas a definir ou a alterar as características das variáveis, e inclui as seguintes informações, aqui concretizadas para o ficheiro Por-tugal.sav:
O nome da variável (Name), deverá iniciar-se por uma letra. Por exemplo, número, mês, país.
O tratamento estatístico depende da natureza da variável indicada em Measure, que pode ser nominal, ordinal ou quantitativa (Scale).
O tipo de variável (Type), pode ser numeric, comma, dot, scientific notation, date, dollar, custom currency e string. Por facilidade de tratamento estatístico, as variáveis introduzem-se na base de dados através de números, assumindo o Type numeric. No caso das variáveis qualitativas nominais ou ordinais, esses números correspondem às suas categorias e no caso das quantitativas ou métricas correspondem aos seus valo-res.

24 A N Á L I S E D E D A D O S P A R A C I Ê N C I A S S O C I A I S
Se as variáveis fossem introduzidas por carateres alfabéticos, por exemplo, para a variável Hotéis introduzidos como uma, duas, três, quatro e cinco estrelas, cujo Type é string, teriam de ser transformadas em códigos numéricos, passando a variável trans-formada a designar-se por HotéisR, conforme no ficheiro Portugal_string.sav:
Transform Automatic Recode Variable Hotéis New Name
HotéisR Recode Starting from Lowest value OK
O tipo de variável inclui ainda a definição da sua largura (Width) e do número de casas decimais (Decimal Places). Por exemplo, a variável mês está codificada como numéricas, com valores 1 (janeiro), 2 (fevereiro),..., 12 (dezembro).
Escolhe-se o valor 1 para largura, quando exista apenas um dígito para representar a variável, e o valor 0 para representar zero casas decimais, por serem inexistentes.
A etiqueta ou rótulo da variável (Label), que serve simplesmente para melhor expli-car o nome da variável, pode ir até 256 carateres identificativos do nome das variáveis. Por exemplo, Label residência habitual dos turistas como explicativo do nome região.
Os códigos utilizados (Values), são de grande utilidade quando se opera com variá-veis qualitativas, onde os números apenas definem as categorias da variável.
O Value Labels divide-se em dois itens: Value, onde se insere o código das catego-rias e Value Label, onde se insere o seu significado. Por exemplo, dado que 1 significa janeiro, inscreve-se no Value o valor 1 e no Value Label a palavra janeiro, seguida de ADD.
As respostas omissas ou não respostas (Missing), servem para identificar a informa-ção em falta, mas também podem ser utilizadas para excluir valores ou categorias da análise estatística.
O utilizador pode definir como Missing Values as três modalidades seguintes: a primeira até três valores individuais; a segunda um intervalo de valores; a terceira um valor individual e um intervalo de valores. O intervalo de valores só se aplica a variáveis numéricas.
Admitindo que há omissões na identificação do mês e que se quer proceder à aná-lise de todo o ano com exceção de dezembro, cujo código é 12, então introduz-se no Discrete missing values os números 99, indicador de omissões na resposta para mês, e 12 para excluir da análise dezembro, premindo-se OK.
Para identificar as não respostas, nas variáveis de Type Numeric, usam-se números que não pertençam à base de dados. Já nas variáveis Type String os campos vazios não são automaticamente considerados missings, pelo que têm de ser preenchidos, habitualmente por NR (não resposta) no Data View e introduzido NR, na coluna Missing do Variable View.
Retomando o ficheiro Portugal_string.sav, verificam-se omissões na categoria dos hotéis correspondentes a Nº 35 e Nº 40, que foram substituídas por NR como se mostra:

I N T R O D U Ç Ã O 25
Aquando da recodificação automática da variável alfabética Hotéis em numérica HotéisR, o programa assume automaticamente o código 6 para NR, visto ser aquele que sucede à última categoria de 5 estrelas:
O formato da coluna (Columns) controla simultaneamente a largura da coluna (Width) que aparece no Data Editor bem como o alinhamento dos valores (Text align-ment). Se a largura definida for insuficiente, aparecem asteriscos em vez dos números.
A disposição dos dados pode alinhar-se (Align) à esquerda, à direita ou ao centro.
Após a definição das variáveis, no Data View introduzem-se os dados, onde aqui se apresentam apenas dois questionários de entre 286 respondidos. Cada linha do ficheiro corresponde um caso, pelo que os dados referentes ao mesmo caso se inscrevem nessa linha.
Cada coluna do Data View corresponde a uma variável, sendo os dados referentes à mesma variável inscritos nessa coluna.
Neste ficheiro as variáveis são: Número do questionário (Nº), país de residência (País), ano da estada (Anos), categoria do hotel (Hotéis), número de dormidas (Dormi-das), número de hóspedes (Hóspedes), região donde proveem (região).
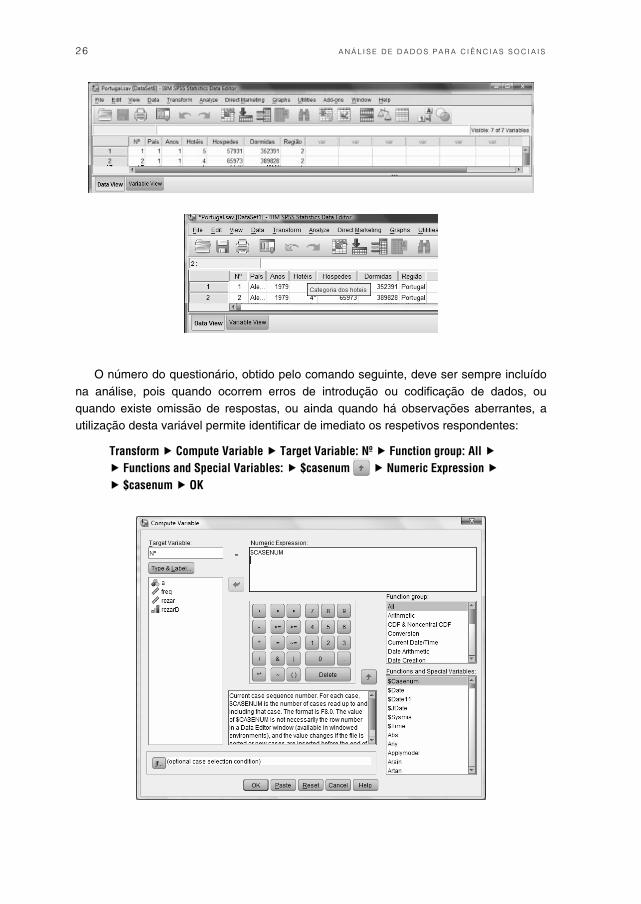
26 A N Á L I S E D E D A D O S P A R A C I Ê N C I A S S O C I A I S
O número do questionário, obtido pelo comando seguinte, deve ser sempre incluído na análise, pois quando ocorrem erros de introdução ou codificação de dados, ou quando existe omissão de respostas, ou ainda quando há observações aberrantes, a utilização desta variável permite identificar de imediato os respetivos respondentes:
Transform Compute Variable Target Variable: Nº Function group: All Functions and Special Variables: $casenum Numeric Expression $casenum OK

I N T R O D U Ç Ã O 27
Sobrepondo o cursor sobre cada uma das variáveis em coluna, visiona-se a descri-ção da sua identificação, aqui feita para a variável Hotéis.
O Menu principal permite passar do Data View para o Variable View ou vice-versa, sobrepondo o cursor no canto inferior esquerdo do ecrã, ou alterar permite ainda os carateres da fonte, ou modificar a apresentação da barra de ferramentas.
O visionamento no Data View dos dados em termos dos labels (códigos) ou dos value labels (etiquetas) obtém-se através de: View Value Labels
O comando Window permite aceder à base de dados, aos Outputs, à Syntax, ou minimizar/maximizar as janelas onde se opera.
1.3. Análise estatística
O comando Analyze tem por finalidade selecionar os procedimentos estatísticos a usar na análise de dados, como por exemplo, tabelas de frequências, exploração e descrição dos dados, testes paramétricos e não paramétricos, medidas de associação e de correlação, modelos de regressão linear, não linear, logística, curva ROC, previsão, sucessões cronológicas, análise de sobrevivência, análise fatorial, cluster, discriminante, pirâmides etárias.
Admitindo que se pretende uma tabela de frequências dos hotéis, procede-se da seguinte maneira:
Analyze Descriptive Statistics Frequencies Variable(s) Hotéis Display frequency tables OK
Sobrepondo o cursor para cada variável, pode-se alterar a disposição pretendida como se mostra na janela superior para a variável Hospedes.
A variável Hotéis que estava na janela esquerda, passa através da seta para o lado direito seguido de OK, que origina o painel de resultados (Output1) o qual se subdivide em duas janelas: a do lado esquerdo que resume o conteúdo dos resultados, enquanto que a do lado direito mostra a informação estatística pedida.

28 A N Á L I S E D E D A D O S P A R A C I Ê N C I A S S O C I A I S
Querendo obter a listagem dos casos recorre-se ao comando:
Analyze Reports Case Summaries
1.4. Gráficos
Os gráficos complementam a análise exploratória dos dados através de figuras e devem adequar-se à informação que pretendem representar, de forma a clarificar a sua compreensão, tendo em conta o publico a que é dirigido.
São exemplos de gráficos os: de barras e circulares, para representar percentagens e contagem de casos; os de linhas para representar médias; o diagrama de dispersão (scatter) para comparar duas variáveis métricas; o histograma para representar variá-veis métricas contínuas; a caixa de bigodes para comparar de forma robusta duas distri-buições em termos de quartis; o gráfico de erro, para representar simultaneamente uma medida de localização (média) com uma medida de dispersão (desvio padrão, erro padrão ou intervalo de confiança para a média), o gráfico de sequência para analisar o comportamento das variáveis ao longo do tempo.
Os gráficos são explicados com mais pormenor ao longo do livro e podem obter-se diretamente através do menu principal clicando em Graphs, o qual alerta para a correta especificação da natureza das variáveis contidas na coluna Measures do Variable View, seguido de Chart Builder.
Exemplificando, caso se pretenda visualizar a percentagem das categorias de hotéis por anos, após selecionar o gráfico de barras arrasta-se com o cursor para o Chart pre-view, onde no canto superior direito em Cluster se introduz Hotéis, na ordenada Per-centage e na abcissa Anos, finalizando com OK. O gráfico finalizado surge na janela dos Outputs.
Habitualmente para comparar contagens os gráficos de barras são de mais fácil per-ceção das diferenças do que os circulares.

I N T R O D U Ç Ã O 29
1.5. Ajudas
O menu Help tem como função esclarecer dúvidas do leitor e aparece em todas as caixas de diálogo do programa bem como no Menu principal que se mostram subdividi-das num painel de duas janelas, onde escolhendo um assunto do lado esquerdo apa-rece a sua explicação do lado direito.
O Topics exibe um painel sobre os tópicos e sua explicação; o Tutorial contém uma ajuda por assunto; a Command Syntax Reference mostra as instruções de construção dos resultados, a Programmability permite o acesso a outras linguagens informáticas ligadas ao IBM-SPSS; o Case Studies apresenta casos práticos de procedimentos estatísticos seguidos de algumas interpretações; o Algorithms apresenta as fórmulas subjacentes aos modelos; o Statistics Coach encaminha para o gráfico ou para o procedimento esta-tístico análogo ao que o leitor pretende fazer, marcado a sombreado na janela seguinte.

30 A N Á L I S E D E D A D O S P A R A C I Ê N C I A S S O C I A I S
1.6. Junção de informação de dois ficheiros
O IBM-SPSS permite juntar informação contida em ficheiros de texto ou em bases de dados, referentes a novas variáveis ou a novos casos quer sejam provenientes de ficheiros do IBM-SPSS ou de outros programas informáticos.
1.6.1. Junção de variáveis
Admitindo que se pretende adicionar ao ficheiro Portugal.sav informação sobre novas variáveis contidas na folha de cálculo Excel Portugal.xls, procede-se em três etapas:
1ª Etapa – Acede-se ao ficheiro para onde se pretende importar a informação, neste caso Portugal.sav, através da instrução:
File Open Data PortugalR.sav
2ª Etapa – Entra-se no ficheiro Excel que contém a informação a exportar, que se con-verte num ficheiro.sav.
Para tal, em Files of type escolhe-se Excel conforme assinalado a sombreado:

I N T R O D U Ç Ã O 31
Escolhe-se o ficheiro aqui com o mesmo nome com extensão.xls, que se introduz na janela em branco File Name, originando:
Premindo Open abre-se a janela onde está selecionada a leitura do nome das variá-veis que constam da primeira linha dos dados da folha do Excel pretendida, seguida de OK que conclui a importação para um novo ficheiro designado Untitled1.sav.
Este ficheiro foi renomeado através do comando com o nome inscrito a negrito:
File Save as File Name Portugal_estada.sav Save
3ª Etapa – Juntam-se os dois ficheiros com extensão .sav.
Para diferenciar o ficheiro Portugal.sav inicial aquele que resultará da adição da informação, faz-se uma cópia denominada PortugalR.sav.
Após se ter assegurado que ambos os ficheiros estão ordenados da mesma forma, aqui por ordem crescente do número de identificação (Nº) que vai servir de variável chave para a junção dos dois ficheiros com extensões .sav, entra-se no ficheiro copiado PortugalR.sav seguido dos comandos:
Data Merge Files Add Variables
Abre-se a seguinte caixa de diálogo onde se sobrepõe o cursor sobre o ficheiro que se pretende exportar, tornando-o sombreado.
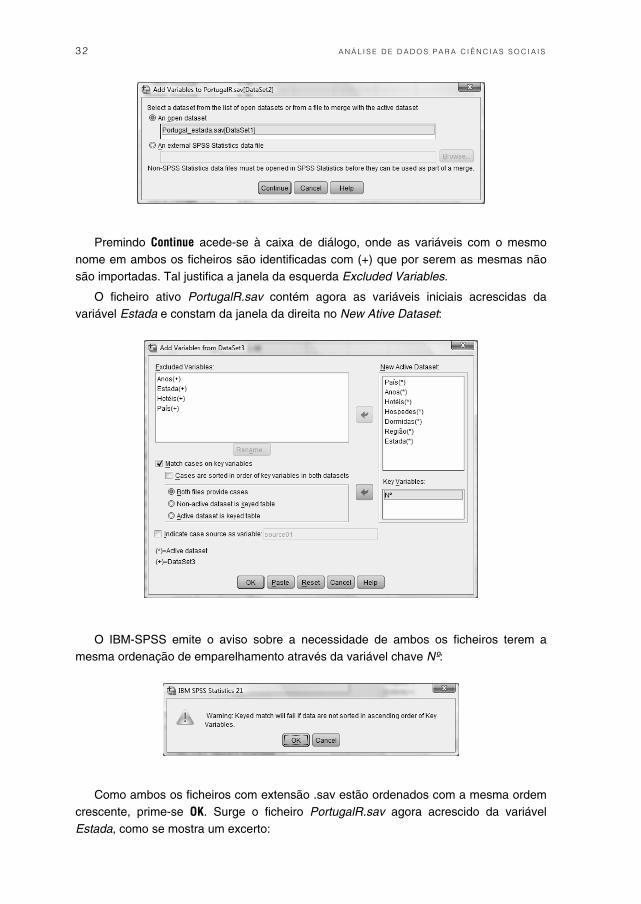
32 A N Á L I S E D E D A D O S P A R A C I Ê N C I A S S O C I A I S
Premindo Continue acede-se à caixa de diálogo, onde as variáveis com o mesmo nome em ambos os ficheiros são identificadas com (+) que por serem as mesmas não são importadas. Tal justifica a janela da esquerda Excluded Variables.
O ficheiro ativo PortugalR.sav contém agora as variáveis iniciais acrescidas da variável Estada e constam da janela da direita no New Ative Dataset:
O IBM-SPSS emite o aviso sobre a necessidade de ambos os ficheiros terem a mesma ordenação de emparelhamento através da variável chave Nº:
Como ambos os ficheiros com extensão .sav estão ordenados com a mesma ordem crescente, prime-se OK. Surge o ficheiro PortugalR.sav agora acrescido da variável Estada, como se mostra um excerto:

ANÁLISE DE DADOSPARACIÊNCIAS SOCIAISA Complementaridade do SPSS
6ªEDIÇÃO
Revista,Atualizadae Aumentada
MARIA HELENA PESTANAJOÃO NUNES GAGEIRO
Este livro, fruto da experiência académicae profissional dos autores, foi agora, nesta6ª edição, enriquecido com esquemas,resumos e 157 aplicações práticas, queinovam nas associações que estabele-cem entre os diferentes capítulos, simpli-ficando e consolidando os temas nelestratados, tornando-o acessível a todosos leitores, mesmo aqueles com poucasbases de matemática, estatística e infor-mática.
A introdução da do IBM-SPSS per-mite, para qualquer distribuição e dimen-são da amostra, calcular todas as proba-bilidades associadas, identificar os acon-tecimentos mais prováveis, determinaros erros e a potência do teste, bem comorecorrer tanto às distribuições exatas comoàs aproximadas.
Importância particular é dada à partici-pação ativa do leitor, tornando o livroestimulante e útil para todos os que a elerecorram.
syntax
EDIÇÕES SÍLABO
Ficheiros SPSS para download
www.si labo.pt
MARIA HELENA PESTANA é professora do ISCTE desde 1982. Édoutorada em Métodos Quantitativos de Gestão, na área de Pes-quisa de Mercados. É investigadora em Estatística, Econometria, eAnálise de Dados aplicados nos domínios de Demografia, Econo-mia, Finanças, Gerontologia, Gestão, Psicologia, Saúde, Sociologia,e Turismo. É autora de livros e de vários artigos científicos em publi-cações nacionais e estrangeiras.
JOÃO NUNES GAGEIRO, licenciou-se em Organização e Gestãode Empresas no ISCTE e concluiu o curso «Hotel and HospitalityManagement», da Universidade de Cornell em Ithaca (NY), nosEUA. É investigador em Turismo e Análise de Dados aplicados nosdomínios de Economia, Finanças, Gerontologia, Gestão, Psicologia,Saúde e Sociologia. É autor de livros e de vários artigos científicosem publicações nacionais e estrangeiras.
6ªEDIÇÃO
A obrade referência
da Análisede Dados em
Portugal
ISBN 978-972-618-775-2
9 789726 187752
A publicação desta obra teve o apoio:
••
••••••••••
••
•••
••••• paramétricos/
/•
Gini, Bayes, CV, MADMédias: ponderada/aparada//geométrica/harmónica
/influência/resíduosÍndicesContrastes/tendênciaVariáveis artificiais
ANOVA/MANOVA/ANCOVAMedidas RepetidasFatorial
/padrões/substituiçãoOR, RR, sensibilidade,prevalênciaCurva ROCMRLS, MRLM, 2SLS, WLS,Logística
DiscriminanteAmostras independentes//emparelhadasT, F, Normal, Qui-QuadradoMDS/MCA/ANACORDecisão/sig/potência
/Estimação/EMVTestesnão paramétricos
Outliers
Cluster
Missings
Path analysis
Syntax
Graphs
26
A C
omplem
entaridade do SPSS
AN
ÁLISE D
E DA
DO
SPA
RA
CIÊN
CIA
S SOC
IAIS





























