Embed Size (px)
Citation preview

POLITECHNIKA WARSZAWSKA
WYDZIA MATEMATYKII NAUK INFORMACYJNYCH
PRACA DYPLOMOWA MAGISTERSKA
Analiza gradacyjna teoria i zastosowania
Grade Correspondence Analysis - theory and applications
Autor:El»bieta Anna Kªopotek
Promotordr in». Przemysªaw Biecek
WARSZAWA, CZERWIEC 2012

1
................podpis promotora
................podpis autora

Streszczenie
Gradacyjna analiza danych (GAD), zaproponowana i rozwijana w Instytucie Podstaw Infor-matyki PAN, jest metod¡ wizualizacji pewnych podstawowych konceptów dotycz¡cych analizypar zmiennych w próbkach niezale»nych oraz zale»nych.
Niniejsza praca stanowi prób¦ syntetycznej ekspozycji GAD, wskazania podobie«stwi ró»nic w stosunku do poj¦¢ znanych z u»ycia m.in. klasycznej statystyki oraz wskazaniaobszarów zastosowania GAD, czemu sªu»y m.in. przeprowadzone w ramach pracy studiumdanych nt. ocen egzaminacyjnych studentów.
Wskazano na u»yteczno±¢ wizualizacji zale»no±ci ocen z poszczególnych przedmiotów zapomoc¡ krzywych koncentracji (uogólnionych krzywych Lorenza), stopniowanych krzywychkoncentracji, wykresów wspóªczynnika polowego (jako substytutu indeksu Giniego) oraz in-deksu Giniego-Simpsona (uogólnienie GAD klasycznego indeksu Giniego-Simpsona). Dlacelów wspomnianych bada« przygotowano zestaw programów w j¦zyku R, który staª si¦ pod-staw¡ ilustracji w niniejszym tek±cie.
Skupiono si¦ na tych jej skªadowych, które s¡ istotne z punktu widzenia danych z systemuUSOS, b¦d¡cych przedmiotem prac eksperymentalnych, tzn. analizie par zmiennych o takichsamych zbiorach warto±ci w niezale»nych próbkach oraz analizie par zmiennych dla jednejpróbki. Ograniczono si¦ do zmiennych porz¡dkowych dyskretnych.
W pracy przestawiono denicje poj¦¢ GAD, ich interpretacj¦ oraz wybrane wªasno±ci,opieraj¡c si¦ na literaturze przedmiotu, uzupeªniaj¡c je wªasnymi przemy±leniami.
W szczególno±ci w niniejszej pracy okre±lono zakres indeks Giniego-Simpsona GAD,zbadano wpªyw przekodowania dziedzin zmiennych na ksztaªt krzywej koncentracji, okre±lonowarto±¢ minimaln¡ i maksymaln¡ funkcji nadreprezentacji, a dla niezale»nych zmiennych jejwarto±¢ oczekiwan¡. Udowodnione twierdzenia maj¡ znaczenie dla implementacji programówwizualizacyjnych, a tak»e celowo±ci transformacji dziedzin zmiennych.
Ponadto drobnym wkªadem jest uporz¡dkowanie denicji krzywej koncentracji orazpowierzchni koncentracji.
Podstawowym walorem GAD jest nacisk na wizualn¡ interpretacj¦ poj¦¢. Na podstawiewizualizacji krzywych koncentracji oraz map nadreprezentacji do±¢ ªatwo mo»na dostrzec jakieprzedmioty ªatwiej zaliczy¢, czy te» który z prowadz¡cych ten sam przedmiot jest surowszyw ocenianiu studentów, jak ucz¡ si¦ poszczególnych przedmiotów studentki w porównaniuze studentami, jaka jest ªatwo±¢ zaliczania w kolejnych terminach egzaminów, na ile dobreoceny z jednych przedmiotów zale»¡ od innych, czy uprawianie sportu wpªywa na uzyskiwanewyniki nauczania.
Podsumowuj¡c wydaje si¦, »e w fazie eksploracji danych gradacyjna analiza danych mo»euªatwi¢ dostrze»enie pewnych tendencji poprzez dotarcie do obrazowej wyobra¹ni analitykai przez to stymulowa¢ jego prace badawcze.
1

Abstract
Grade Correspondence Analysis (GCA, in Polish Gradacyjna analiza danych GAD), proposedand developed at the Institute of Computer Science, is a method of visualizing certain basicconcepts for the analysis of pairs of variables in independent and dependent samples.
This thesis is an attempt to expose synthetically GCA, identify similarities and dierencesin relation to concepts known from usage in classic statistics and to identify areas of GCAapplication. In particular, the methodology is applied to examination grades of students ofone Polish university.
The usefulness of visualization of dependencies between grades of individual subjects us-ing concentration curves (generalized Lorenz curves), graded concentration curves, area factorgraphs (as a substitute for the Gini index) and the Gini-Simpson index (the GCA generaliza-tion of the classical Gini-Simpson index) was demonstrated. For the purposes of these studiesthere was a set of programs in R, which became the basis of the illustrations in the text.
We focus on the components, which are signicant from a point of view of the data fromthe USOS system that was used for experimental work, i.e. analysis of pairs of variables withthe same set of values from independent samples and analysis of pairs of variables of a singlesample under restriction to discrete ordinal variables.
In the thesis basic GCA denitions, their interpretations and selected properties are pre-sented, based on the bibliography while complementing them with own thoughts.
In particular, range of Gini-Simpson index is investigated, the inuence of recoding vari-ables domains on the shape of the curve of concentration is tested, minimum and maximumvalues for overrepresentation functions and expected values of overrepresentation function forindependent variables are identied. Selected theorems are proven. They are important forimplementation of visualization programs and provide basis for making decisions on transfor-mation of variable domains.
In addition, a small contribution is a clarication of the denition of the concentrationcurve and surface concentration.
The main advantage of GCA is emphasis on the visual interpretation of various concepts.On the basis of visualization of the concentration curves and overrepresentation maps it iseasy to see, what exams are easier to pass, or which teacher engaging in the same subject isstricter in assessing students, how are female and male students learning, how easy is it topass in the subsequent dates of examinations, how good is the evaluation of some subjectsdepending on others, whether sport aects the learning achievements etc..
In conclusion, it appears that GCA in the phase of data mining , can make it easier to seecertain trends through pictorial visualization for the analyst and help him to do his job.
2

Podzi¦kowania
Przede wszystkim pragn¦ gor¡co podzi¦kowa¢ memu Promotorowi, Panu Doktorowi Prze-mysªawowi Bieckowi, którego niezwykªa »yczliwo±¢, do±wiadczenie oraz pomoc pomogªy miprzygotowa¢ przedªo»on¡ prac¦.
3

Spis tre±ci
1 Wprowadzenie 6
1.1 Motywacja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.2 Cel pracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.3 Ukªad pracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Analiza gradacyjna jednej zmiennej 8
2.1 Bazowe poj¦cia analizy gradacyjnej - uj¦cie nieformalne . . . . . . . . . . . . . 82.2 Podstawowe denicje . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
3 Metody gradacyjne dla pary rozkªadów niezale»nych 19
3.1 Krzywe koncentracji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193.2 Krzywa Lorenza a krzywa nasycenia GAD . . . . . . . . . . . . . . . . . . . . 213.3 Wspóªczynnik polowy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233.4 Indeks Giniego a wspóªczynnik polowy . . . . . . . . . . . . . . . . . . . . . . 233.5 Indeks Giniego-Simpsona . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233.6 Klasyczny indeks Giniego-Simpsona a indeks GS w GAD . . . . . . . . . . . . 233.7 Funkcjonaª gradacyjny . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4 Analiza rozkªadów zale»nych 25
4.1 Rozkªady dwuwymiarowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.2 Powierzchnia koncentracji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.3 Mapy nadreprezentacji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.3.1 Dyskretne mapy nadreprezentacji . . . . . . . . . . . . . . . . . . . . . 28
5 Analiza danych rzeczywistych 33
5.1 Cel bada« . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335.2 Opis zbioru danych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335.3 Zastosowane metody analizy . . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.4 Wyniki i ich interpretacja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.4.1 Krzywa koncentracji raport_krzyweKonc . . . . . . . . . . . . . . . . 365.4.2 "Terminowa" krzywa koncentracji - raport_terminowa_krzkonc . . . 375.4.3 Warto±¢ oczekiwana raport_pow_oczek . . . . . . . . . . . . . . . . . 375.4.4 raport_pow_zmiennosvci - Zmienno±¢ . . . . . . . . . . . . . . . . . 375.4.5 Wspóªczynnik polowy raport_wsp_polowy . . . . . . . . . . . . . . . 375.4.6 Krzywa pierwszego momentu raport_krz1momentu . . . . . . . . . . . 385.4.7 Mapy nadreprezentacji raport_mapanadLeg . . . . . . . . . . . . . . . 38
6 Podsumowanie 40
4

SPIS TRECI 5
Indeks rzeczowy 43
Wykaz rysunków 43

Rozdziaª 1
Wprowadzenie
1.1 Motywacja
Eksploracyjna analiza danych to dziaª statystyki, do rozwoju którego przyczyniªy si¦ w du»ymstopniu prace Tukeya [Tuk77]. Podczas gdy klasyczna statystyka koncentrowaªa si¦ natestowaniu postawionych hipotez, eksploracyjna analiza danych zmierza do sformuªowaniahipotez nt. przyczyn obserwowanych zjawisk, bada poprawno±¢ (speªnianie) zaªo»e« dlawnioskowania statystycznego, wspiera dobór wªa±ciwych technik i narz¦dzi statystycznychdo bada« hipotez oraz formuªuje zadania zbierania dalszych danych poprzez obserwacje i/lubdo±wiadczenia. Tukey zach¦caª statystyków m.in. do korzystania z metod wizualizacji danych,nim zaczn¡ formuªowa¢ hipotezy, badane na nowych kolekcjach danych [FM00].
Do metod eksploracyjnej analizy danych zalicza si¦ mi¦dzy innymi zapocz¡tkowan¡ w In-stytucie Podstaw Informatyki Polskiej Akademii Nauk gradacyjn¡ analiz¦ danych (GAD)[KPR04]. Charakteryzuje si¦ ona tym, »e:
• Bazuje na tzw. przeksztaªceniach gradacyjnych i korzysta z pomiaru koncentracji1 doanalizy odpowiednio±ci2
Metoda ta jest stosowana szczególnie cz¦sto w naukach biologicznych oraz socjolog-icznych, gdzie cz¦sto wyst¦puj¡ macierze kontyngencji., analizy skupie«, analizy regresji,oceny regularno±ci danych i rozwi¡zywania innych zagadnie« analizy danych.
• Przeksztaªcenie gradacyjne zamienia par¦ zmiennych tak, aby ich rozkªady brzegowebyªy (prawie) równomierne.
• Podstawowymi narz¦dziami GAD s¡ tzw. miary nierówno±ci, krzywe koncentracji orazkoncept regularno±ci rozkªadów dwuwymiarowych.
• Mo»na j¡ okre±li¢ jako metod¦ analizy bezmodelowej (nieparametrycznej), gdy» pomijaona zaªo»enia o rozkªadzie analizowanych zmiennych.
• Dopuszcza zmienne mierzone w ró»nych skalach: ilorazowej, porz¡dkowej jak i nominal-nej.
1Do podstawowych narz¦dzi GAD nale»¡ tzw. krzywe koncentracji, opisane w denicji 3.1.1 na stronie 19.Reprezentuj¡ one zag¦szczenie (stosunek prawdopodobie«stw warto±ci) jednej zmiennej losowej w stosunkudo drugiej przy zaªo»eniu, »e obie maj¡ takie same dziedziny.
2Analiza odpowiednio±ci (korespondencji) w eksploracyjnej analizie macierzy kontengencji usiªuje zidenty-kowa¢ ci¡gªe zmienne ukryte, których wyrazem s¡ kategoryczne zmienne wiersza i kolumny. Przypisywanewarto±ci ci¡gªe winny maksymalizowa¢ wspóªczynnik korelacji Pearsona pomi¦dzy zmiennymi ukrytymi.
6

ROZDZIA 1. WPROWADZENIE 7
• Zakªada reprezentacj¦ danych z próbki w postaci dwuwymiarowej tablicy kontyngencjikolumn i wierszy, przy czym zakªada si¦, »e istniej¡ jakie± ukryte czynniki (zmienneukryte, nie obserwowane) porz¡dkuj¡ce wiersze / kolumny w taki sposób, »e wyra¹nastaje si¦ zale»no±¢ w danych, w szczególno±ci zale»no±¢ wierszowej i kolumnowej porz¡d-kuj¡cej zmiennej ukrytej.
• Podobnie jak klasyczna analiza korespondencji oblicza znormalizowane czynniki ukrytewierszowy i kolumnowy w taki sposób, by uzyska¢ maksymaln¡ pozytywn¡ zale»no±¢.
• Podczas gdy klasyczna analiza korespondencji optymalizowaªa warto±¢ wspóªczynnikakorelacji Pearsona jako miary zale»no±ci, GAD optymalizuje wspóªczynnik ρ Spearmana.Dlatego zadowala si¦ skalami porz¡dkowymi. Normalizacja w GAD jest tak»e odmiennaod klasycznej analizy korespondencji.
GAD znalazªa liczne zastosowania w praktycznej analizie danych, m.in. w np. danychmedycznych [KMPW05] czy sytuacji ekonomicznej rm [Cio05].
1.2 Cel pracy
Celem pracy byªo zbadanie wªasno±ci algorytmów stosowanych w analizie gradacyjnej podk¡tem mo»liwo±ci zastosowania w eksploracyjnej analizie danych. W cz¦±ci teoretycznejnale»aªo przedstawi¢ przegl¡d metod gradacyjnej analizy danych oraz postawi¢ i udowodni¢wybrane twierdzenia dotycz¡ce zgodno±ci tych metod. W cz¦±ci praktycznej nale»aªo zaimple-mentowa¢ algorytmy realizuj¡ce przedstawione metody gradacyjnej analizy danych w j¦zykuR, jak równie» przedstawi¢ wyniki zastosowania wymienionych algorytmów do analizy zbiorudanych z systemu USOS.
1.3 Ukªad pracy
W rozdziale 2 przedstawiono podstawowe koncepcje GAD w zakresie analizy jednej zmiennej.Rozdziaª 3 prezentuje metody wizualizacji dla par zmiennych pochodz¡cych z niezale»nych
próbek, w szczególno±ci omawiana jest krzywa koncentracji oraz jej odniesienie do klasycznejkrzywej Lorenza.
W rozdziale 4 omawiana jest tzw. mapa nadreprezentacji, b¦d¡ca proponowanym przezGAD sposobem wizualizacji zale»no±ci pary zmiennych.
W rozdziaªach 2-4 przedstawiono wybrane twierdzenia, dotycz¡ce wªasno±ci prezen-towanych koncepcji, oraz ich dowody.
Rozdziaª 5 po±wi¦cony jest zastosowaniu GAD do analizy danych nt. ocen egzamina-cyjnych wybranej grupy studentów z systemu USOS.
Prac¦ podsumowuje rozdziaª 6.

Rozdziaª 2
Analiza gradacyjna jednej zmiennej
2.1 Bazowe poj¦cia analizy gradacyjnej - uj¦cie niefor-
malne
Metody gradacyjne mierz¡ niepodobie«stwo mi¦dzy rozkªadami. Dzi¦ki nim mo»na wykrywa¢trendy w danych, podpopulacje zwi¡zane ze strukturami funkcyjnymi, obserwacje odstaj¡ce,tworzy¢ naturalne grupy obserwacji (klastry). Opieraj¡ si¦ na poj¦ciu koncentracji. Deniuj¡jeden rozkªad w odniesieniu do drugiego za pomoc¡ tzw. krzywej koncentracji.
Krzywa koncentracji to krzywa opisuj¡ca stopie« koncentracji rozkªadu zmiennej losowejwzgl¦dem rozkªadu innej zmiennej losowej (tzw. rozkªad bazowy).
Warto±¢ nadreprezentacji jest ilorazem wzgl¦dnej proporcji dla rozkªadu i wzgl¦dnej pro-porcji rozkªadu bazowego dla ka»dej kategorii rozkªadu.
2.2 Podstawowe denicje
Niech (R, τ) b¦dzie przestrzeni¡ topologiczn¡. Zbiór borelowski deniuje si¦ jako elementnale»¡cy do najmniejszego σ-ciaªa przestrzeni R, które zawiera wszystkie podzbiory otwarteR.
Denicja 2.2.1 Zmienn¡ losow¡ na przestrzeni probabilistycznej (Ω,F ,P) nazywamydowoln¡ rzeczywist¡ funkcj¦ mierzaln¡ ν : Ω → R, tzn. funkcj¦ ν speªniaj¡c¡ warunek
ν−1(B) ∈ F
dla ka»dego zbioru borelowskiego B ⊆ R.
W poni»szej ekspozycji gradacyjnej analizy danych bazujemy na ksi¡»ce [KPR04].Wprowadzane poj¦cia w du»ej mierze odpowiadaj¡ konceptom klasycznej statystyki, ale dlautrzymania spójno±ci z pracami twórców GAD b¦dziemy si¦ w dalszym ci¡gu posªugiwa¢ ichterminologi¡.
Denicja 2.2.2 Zmienn¡ losow¡ nazwiemy zmienn¡ lilipuci¡ (ozn. ξ), je±li przyjmujewarto±ci z przedziaªu [0,1], jest dyskretna, ci¡gªa b¡d¹ dyskretna-ci¡gªa. Dystrybuanta oz-naczana przez Fξ jest niemalej¡c¡ krzyw¡, le»¡c¡ w kwadracie jednostkowym, ª¡cz¡c¡ punkty(0,0) oraz (1,1).
8

ROZDZIA 2. ANALIZA GRADACYJNA JEDNEJ ZMIENNEJ 9
W klasycznej statystyce zmiennymi lilipucimi s¡ np. zmienne losowe o rozkªadzie beta.Zbiór wszystkich lilipucich zmiennych losowych nazywamy Jednowymiarowym Modelem
Lilipucim i oznaczamy przez ULM (z ang. the Univariate Lilliputian Model)
Denicja 2.2.3 Zmienna lilipucia jest ci¡gªa, je±li jej dystrybuanta jest ci¡gªa i jej pochodnawyra»ona wzorem:
fξ(u) =dFξ(u)
du
zwana g¦sto±ci¡ zmiennej ξ, istnieje prawie wsz¦dzie w sensie miary Lebesgue'a. Dziedzin¡ ujest przedziaª [0,1].
Funkcj¦ odwrotn¡ do dystrybuanty nazywa¢ b¦dziemy funkcj¦ kwantylow¡.
Denicja 2.2.4 Zmienna lilipucia jest dyskretna, je±li istnieje ci¡g punktów ui, ui ∈[0, 1], i = 1, 2, ... i ci¡g prawdopodobie«stw pξ(ui) takich, »e
∑i pξ(ui) = 1. Dystrybuanta
Fξ speªnia:pξ(ui) = dFξ(ui) = dFξ(ui+)− dFξ(ui−) > 0
Podstawowym wkªadem GAD jest wprowadzenie nowych metod wizualizacji podsta-wowych poj¦¢ statystycznych.
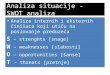
Zacznijmy od wizualizacji dystrybuanty zmiennej lilipuciej. Przykªad takiej dystrybuantywidzimy na rysunku 3.1 na stronie 20. Chwilowo zignorujmy fakt, i» osie s¡ opisane zmiennymi- w nast¦pnym rozdziale b¦dziemy mówi¢ o zamianie pary zmiennych w zmienn¡ lilipuci¡.Wtedy b¦dziemy sobie wyobra»a¢ rozkªad zmiennej z osi Y w przestrzeni "skrzywionej" przezzmienn¡ osi X, czyli w tym wypadku zmiennej Bazy Danych wzgl¦dem Algebry. Na tejilustracji jak i na wszystkich innych w niniejszej pracy prezentowane s¡ dane pochodz¡cez systemu USOS, opisanego szerzej w rozdziale 5. Obecnie spójrzmy na ten wykres jakowykres dystrybuanty zmiennej lilipuciej Bazy-danych-wzgl¦dem-Algebry. Zarówno dziedzinajak i zbiór warto±ci tej zmiennej to przedziaªy [0,1]. Sama krzywa dystrybuanty ª¡czy punkt[0,0] z punktem [1,1] na wykresie i jest niemalej¡ca (jak na dystrybuant¦ przystaªo).
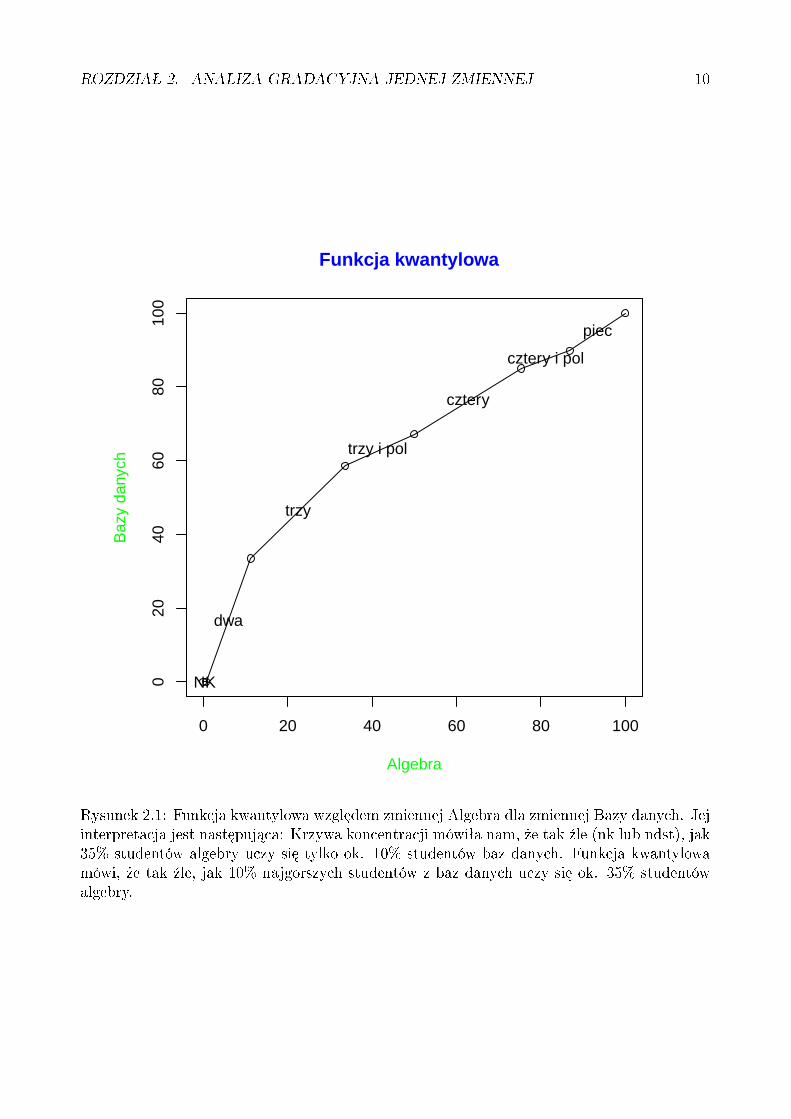
Odpowiadaj¡c¡ jej funkcj¦ kwantylow¡ widzimy na rysunku 2.1Warto±¢ oczekiwana zmiennej lilipuciej mo»e by¢ przedstawiona jako pewien obszar na
kwadracie jednostkowym. Jest ona równa polu nad krzyw¡ lilipuci¡, odpowiadaj¡c¡ zmi-ennej ξ, lub polu kwadratu pomniejszonemu o pole pod krzyw¡ lilipuci¡. Matematyczniezdeniowana jest jako:
E(ξ) =
∫ 1
0
udFξ(u) = 1−∫ 1
0
Fξ(u)du =
∫ 1
0
(1− Fξ(1− u))du
Rysunek 2.2 ilustruje powierzchni¦ odpowiadaj¡c¡ warto±ci oczekiwanej wspomnianej zmi-ennej lilipuciej Bazy-danych-wzgl¦dem-Algebry o dystrybuancie z rys. 3.1.
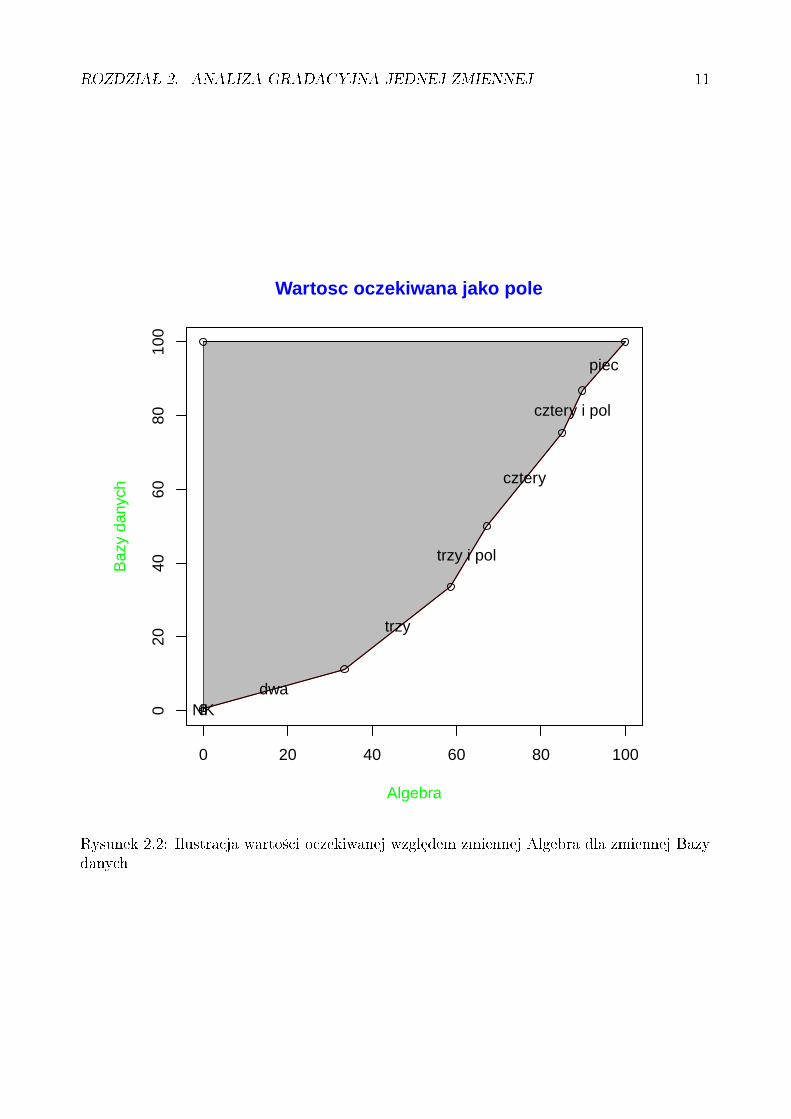
Denicja 2.2.5 Wspóªczynnik ar (wspóªczynnik polowy, z ang. "area") zmiennej lilipuciejdeniujemy jako:
ar(ξ) =E(ξ)− E(U)
1− E(U)= 2E(ξ)− 1 = 2
∫ 1
0
(u− Fξ(u))du
ROZDZIA 2. ANALIZA GRADACYJNA JEDNEJ ZMIENNEJ 10
0 20 40 60 80 100
020
4060
8010
0
Algebra
Baz
y da
nych
Funkcja kwantylowa
NK
dwa
trzy
trzy i pol
cztery
cztery i pol
piec
Rysunek 2.1: Funkcja kwantylowa wzgledem zmiennej Algebra dla zmiennej Bazy danych. Jejinterpretacja jest nast¦puj¡ca: Krzywa koncentracji mówiªa nam, »e tak ¹le (nk lub ndst), jak35% studentów algebry uczy si¦ tylko ok. 10% studentów baz danych. Funkcja kwantylowamówi, »e tak ¹le, jak 10% najgorszych studentów z baz danych uczy si¦ ok. 35% studentówalgebry.
ROZDZIA 2. ANALIZA GRADACYJNA JEDNEJ ZMIENNEJ 11
0 20 40 60 80 100
020
4060
8010
0
Algebra
Baz
y da
nych
Wartosc oczekiwana jako pole
NKdwa
trzy
trzy i pol
cztery
cztery i pol
piec
Rysunek 2.2: Ilustracja warto±ci oczekiwanej wzgledem zmiennej Algebra dla zmiennej Bazydanych
ROZDZIA 2. ANALIZA GRADACYJNA JEDNEJ ZMIENNEJ 12
0 20 40 60 80 100
020
4060
8010
0
Algebra
Baz
y da
nych
NKdwa
trzy
trzy i pol
cztery
cztery i pol
piec
Wspólczynnik polowy
Rysunek 2.3: Wspóªczynnik polowy wzgledem zmiennej Algebra dla zmiennej Bazy danych

ROZDZIA 2. ANALIZA GRADACYJNA JEDNEJ ZMIENNEJ 13
Mo»e by¢ on równie» wyra»ony jako podwojona ró»nica dwóch obszarów: pola pomi¦dzydiagonal¡ i krzyw¡ lilipuci¡ (pod diagonal¡) oraz pola pomi¦dzy diagonal¡ i krzyw¡ lilipuci¡(nad diagonal¡):
ar(ξ) = 2
∫u>Fξ(u)
(u− Fξ(u))du− 2
∫u<Fξ(u)
(Fξ(u)− u)du
Przykªad wizualizacji tego wspóªczynnika mamy na rysunku 2.3. Jest on zaznaczony dlawspomnianej zmiennej lilipuciej Bazy-danych-wzgl¦dem-Algebry o dystrybuancie z rys. 3.1.Poniewa» dystrybuanta ta le»aªa poni»ej przek¡tnej, wspóªczynnik polowy jest dodatni, ana rysunku odpowiadaj¡ce mu pole oznaczono kolorem zielonym. (Gdyby dystrybuantale»aªa powy»ej przek¡tnej, wspóªczynnik byªby ujemny, a oznaczaj¡ce go pole oznaczyliby±mykolorem niebieskim. Ogólnie warto±¢ wspóªczynnika to ró»nica mi¦dzy polem zielonym apolem niebieskim).
Taka interpretacja wspóªczynnika polowego zmiennej lilipuciej odpowiada geometrycznejinterpretacji indeksu Giniego znanego z klasycznej statystyki.
Indeks ar(Fξ(ξ)) to numeryczna miara nieci¡gªo±ci dla ξ.Jedn¡ z miar zmienno±ci jest indeks Giniego-Simpsona ozn. GS(ξ) U±rednia on
bezwzgl¦dne ró»nice dla wszystkich par warto±ci. Formalna denicja jest nast¦puj¡ca:
Denicja 2.2.6 Niech ξ′ b¦dzie zmienn¡ niezale»n¡ od ξ oraz niech ma tak¡ sam¡ dystry-buant¦ jak ξ. Wtedy:
GS(ξ) =E|ξ − ξ′|2E(ξ)
(2.1)
Geometryczn¡ interpretacj¡ indeksu Giniego-Simpsona jest pole pomi¦dzy dystrybuantamiFξ i F
2ξ podzielone przez pole nad dystrybuant¡ Fξ
Twierdzenie 2.2.1 GS(ξ) le»y w zakresie [0,1].
Dowód Poniewa» funkcja Fξ jest dystrybuant¡, wi¦c przyjmuje warto±ci z przedziaªu [0,1].Zatem 0 ≤ 1−Fξ(ξ) ≤ 1. Obustronnie mno»¡c przez Fξ dostajemy 0 ≤ Fξ(ξ)−F 2
ξ (ξ) ≤ Fξ(ξ),
co po obustronnym caªkowaniu od 0 do 1 daje 0 ≤∫ 1
0Fξ(ξ)dξ −
∫ 1
0F 2ξ (ξ)dξ ≤
∫ 1
0Fξ(ξ)dξ.
Wykluczaj¡c ekstremalny przypadek, gdy Fξ ma caª¡ mas¦ skupion¡ w punkcie ξ = 1, ostatniacaªka b¦dzie dodatnia. Dziel¡c przez ni¡ obustronnie otrzymujemy
0 ≤∫ 1
0Fξ(ξ)dξ −
∫ 1
0F 2ξ (ξ)dξ∫ 1
0Fξ(ξ)dξ
≤ 1
co zgodnie z przytoczon¡ interpretacj¡ oznacza zamkni¦cie GS(ξ) w przedziale [0,1], czegonale»aªo dowie±¢.
Rysunek 2.4 ilustruje wspomnian¡ geometryczn¡ interpretacj¦ GS dla wspomnianej zmi-ennej lilipuciej Bazy-danych-wzgl¦dem-Algebry o dystrybuancie z rys. 3.1. Obszar oznaczonyna czerwono to licznik, a obszar zielony to mianownik powy»szego uªamka.
Denicja 2.2.7 Dla ka»dej zmiennej ξ ∈ ULM mo»emy zdeniowa¢ tzw. zmienn¡ pierwszegomomentu ξ(1) o dystrybuancie danej wzorem:
Fξ(1)(u) =E(ξ; ξ ≤ u)
E(ξ),
gdzie E(ξ; ξ ≤ u) =∫ u
0tdFξ(t).

ROZDZIA 2. ANALIZA GRADACYJNA JEDNEJ ZMIENNEJ 14
0 20 40 60 80 100
020
4060
8010
0
Algebra
Baz
y da
nych
Indeks Giniego−Simpsona jako pole
NKdwa
trzy
trzy i pol
cztery
cztery i pol
piec
Rysunek 2.4: Powierzchnie indeksu Giniego-Simpsona dla zmiennej Bazy danych
ROZDZIA 2. ANALIZA GRADACYJNA JEDNEJ ZMIENNEJ 15
0 20 40 60 80 100
020
4060
8010
0
Algebra
Baz
y da
nych
Krzywa pierwszego momentu
NKdwa
trzy
trzy i pol
cztery
cztery i pol
piec
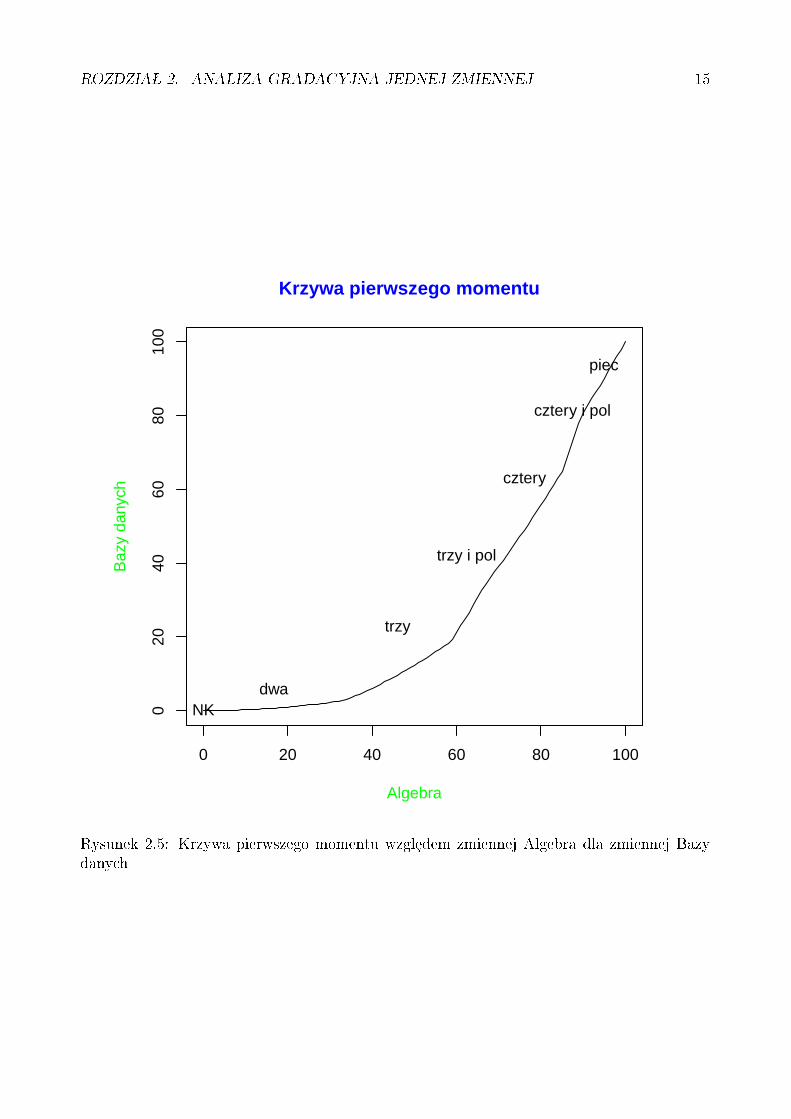
Rysunek 2.5: Krzywa pierwszego momentu wzgledem zmiennej Algebra dla zmiennej Bazydanych

ROZDZIA 2. ANALIZA GRADACYJNA JEDNEJ ZMIENNEJ 16
Rysunek 2.5 ilustruje krzyw¡ dystrybuanty zmiennej pierwszego momentu dla wspomni-anej zmiennej lilipuciej Bazy-danych-wzgl¦dem-Algebry o dystrybuancie z rys. 3.1.
Denicja 2.2.8 Wariancj¦ zmiennej lilipuciej ozn. var(ξ) deniujemy jako:
var(ξ) = E(ξ − E(ξ))2 = E(ξ2)− (E(ξ))2
Mamy poni»szy zwi¡zek:
var(ξ)
E(ξ)= E(ξ(1))− E(ξ) =
ar(ξ(1))− ar(ξ)
2.
Z powy»szego wynika, »e "zmienno±¢" (ang. index of dispersion, dispersion index, coecient
of dispersion, lub variance-to-mean ratio (VMR) lub Fano index) V (ξ) = var(ξ)E(ξ)
mo»e by¢przedstawiona w nast¦puj¡cy sposób:
V (ξ) = ar(ξ(1))−ar(ξ)2
=2∫ 10 (u−F
ξ(1)(u))du−2
∫ 10 (u−Fξ(u))du
2
=∫ 1
0(u− Fξ(1)(u)− u+ Fξ(u))du
=∫ 1
0(Fξ(u)− Fξ(1)(u))du
=(∫ 1
0Fξ(u)du
)−
(∫ 1
0Fξ(1)(u)du
).
(2.2)
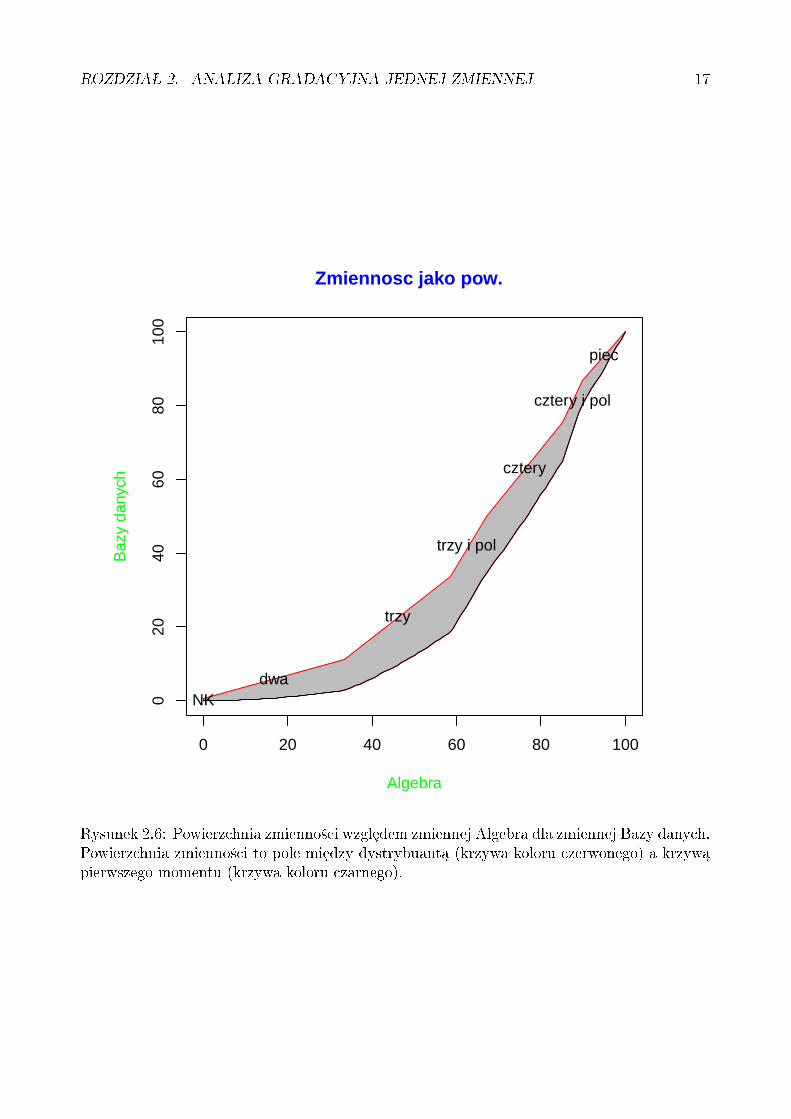
Wobec tego zmienno±¢ jest obszarem mi¦dzy krzywymi Fξ(u) i Fξ(1)(u).Rysunek 2.6 ilustruje powierzchni¦ reprezentuj¡c¡ zmienno±¢ wspomnianej zmiennej lilipu-
ciej Bazy-danych-wzgl¦dem-Algebry o dystrybuancie z rys. 3.1.Wariancja z kolei to zmienno±¢ razy warto±¢ oczekiwana, która jest mniejsza od jeden, wi¦c
mo»na j¡ przedstawi¢ jako stosownie proporcjonalny wycinek obszaru mi¦dzy tymi krzywymi.
Denicja 2.2.9 Wygªadzon¡ funkcj¦ ξ deniujemy jako:
Fξ(ξ) =Fξ(ξ+)− Fξ(ξ−)
2,
gdzie Fξ(ξ+) to zmienna losowa przyjmuj¡ca warto±ci prawostronnej granicy funkcji Fξ(u) wpunkcie ξ = u, a Fξ(ξ−) to zmienna losowa przyjmuj¡ca warto±ci lewostronnej granicy funkcjiFξ(u) w punkcie ξ = u.
Niech FZ b¦dzie dystrybuant¡ zmiennej losowej Z.
Lemat 2.2.2 Je±li Z jest zmienn¡ ci¡gª¡, to zmienna FZ(Z) ma rozkªad jednostajny naprzedziale [0, 1].
Dowód Zachodzi to, poniewa» taka transformacja przeksztaªca warto±ci zmiennej Z z przedzi-aªu [−∞, z] do [FZ(−∞), FZ(z)] = [0, u]. FZ(z) przyjmuje warto±ci z przedziaªu [0, 1] z praw-dopodobie«stwem FZ(z) = u, czyli ma rozkªad jednostajny.
ROZDZIA 2. ANALIZA GRADACYJNA JEDNEJ ZMIENNEJ 17
0 20 40 60 80 100
020
4060
8010
0
Algebra
Baz
y da
nych
Zmiennosc jako pow.
NKdwa
trzy
trzy i pol
cztery
cztery i pol
piec
Rysunek 2.6: Powierzchnia zmienno±ci wzgledem zmiennej Algebra dla zmiennej Bazy danych.Powierzchnia zmienno±ci to pole mi¦dzy dystrybuant¡ (krzywa koloru czerwonego) a krzyw¡pierwszego momentu (krzywa koloru czarnego).

ROZDZIA 2. ANALIZA GRADACYJNA JEDNEJ ZMIENNEJ 18
Tak¡ transformacj¦ opisuje tzw. funkcja prawdopodobie«stwa przej±cia GZ([0, u]; z) zden-iowana nast¦puj¡co:
GZ([0, u]; z) =
1 dla FZ(z) ≤ u0 dla FZ(z) > u
Zmienna losowa otrzymana po zastosowaniu funkcji GZ ma rozkªad jednostajny, gdy»:∫ 1
0
GZ([0, u]; z)dFZ(z) =
∫FZ(z)≤u
dFZ(z) = u
Je±li FZ jest zmienn¡ nieci¡gª¡, to dla ka»dego u ∈ (0, 1) istnieje punkt zu taki, »eFZ(zu−) ≤ FZ(zu). Dlatego musimy u»y¢ innej funkcji prawdopodobie«stwa przej±cia tzw.monotonicznej funkcji prawdopodobie«stwa przej±cia F ∗
Z zdeniowanej nast¦puj¡co:
F ∗Z([0, u]; z) =
1 dla FZ(z) ≤ u
u−FZ(z−)FZ(z)−FZ(z−)
dla FZ(z−) < u ≤ FZ(z)
0 dla FZ(z) > u
Przej±cie ze zmiennej losowej X o warto±ciach rzeczywistych do zmiennej lilipuciej Uo rozkªadzie jednostajnym nazwiemy jednostajnym przeksztaªceniem gradacyjnym zmiennejlosowej X.
Dzi¦ki przeksztaªceniom gradacyjnym otrzymujemy uci¡glon¡ dystrybuant¦ dla zmiennejlilipuciej, zwan¡ krzyw¡ koncentracji, b¡d¹ dla pary zmiennych lilipucich zwan¡ powierzchni¡koncentracji.

Rozdziaª 3
Metody gradacyjne dla pary rozkªadów
niezale»nych
3.1 Krzywe koncentracji
Niech zmienne losowe X i Y maj¡ dystrybuanty istniej¡ce wsz¦dzie na zbiorze liczb rzeczy-wistych.
Denicja 3.1.1 Rozpatrzmy krzyw¡ w [0, 1]× [0, 1] zadan¡ wzorem:
Z = (FX(x), FY (x));x ∈ R
Niech krzywa C skªada si¦ z krzywej Z oraz nast¦puj¡cych punktów:
• (0, 0) = (FX(−∞), FY (−∞))
• (1, 1) = (FX(+∞), FY (+∞))
• Dla punktu x0 niech (FX(x0), FY (x0))+ ::= (limx→x+
0FX(x), limx→x+
0FY (x)). Je±li
(FX(x0), FY (x0))+ = (FX(x0), FY (x0)), wtedy C zawiera tak»e λ(FX(x0), FY (x0))
+ +(1− λ)(FX(x0), FY (x0)) dla wszystkich λ ∈ [0, 1].
• Dla punktu x0 niech (FX(x0), FY (x0))− ::= (limx→x−
0FX(x), limx→x−
0FY (x)). Je±li
(FX(x0), FY (x0))− = (FX(x0), FY (x0)), wtedy C zawiera tak»e λ(FX(x0), FY (x0))
− +(1− λ)(FX(x0), FY (x0)) dla wszystkich λ ∈ [0, 1].
Ostatnie dwie kropki dotycz¡ te» warto±ci niewªa±ciwych x czyli −∞ oraz +∞. Krzywa taª¡czy punkty (0, 0) i (1, 1) i nazywamy j¡ krzyw¡ koncentracji Y do X (lub krzyw¡ nasycenia)i oznaczamy przez C(Y : X).
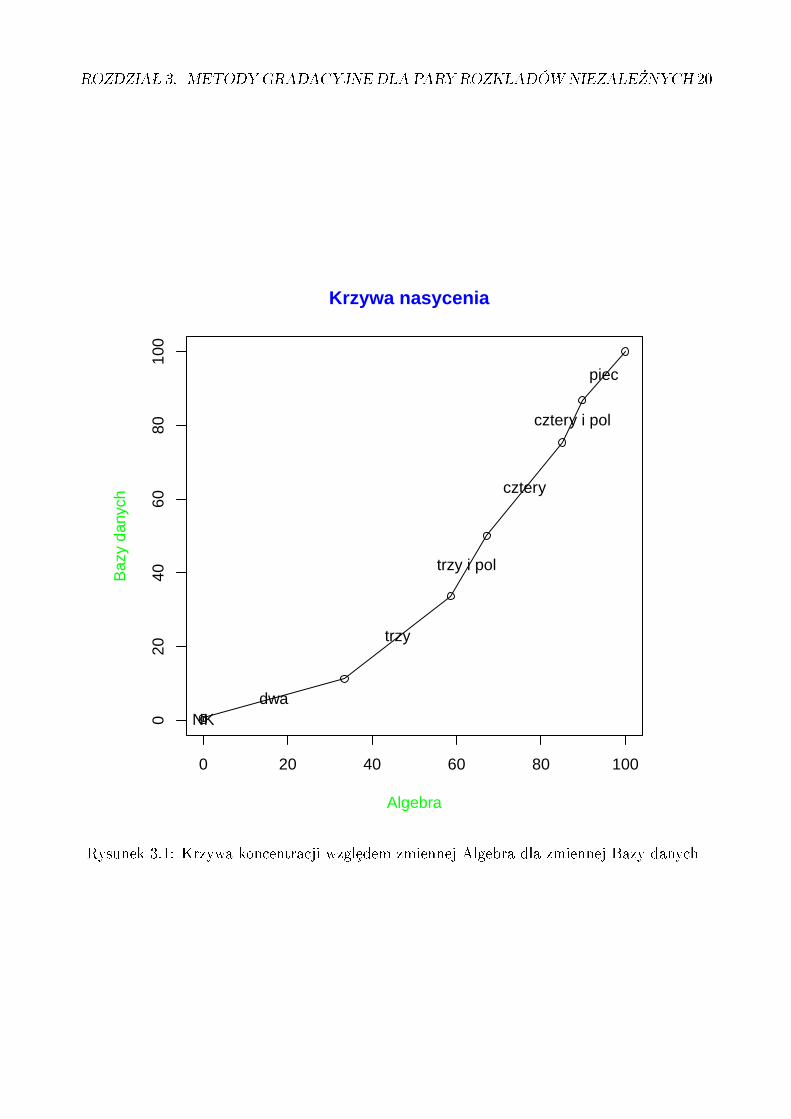
W sposób nieformalny mówimy, »e C(Y : X) zawiera Z i jest uzupeªniana przez interpo-lacj¦ liniow¡. Na rysunku 3.1 narysowano przykªadowy wykres krzywej koncentracji dla zmi-ennej Bazy danych wzgledem zmiennej Algebra, pochodz¡cych z bazy USOS (patrz rozdziaª5). Dziedzinami obu zmiennych s¡ oceny: NK (nie klasykowani), oraz oceny 2, 3, 3.5, 4,4.5 i 5. Nachylenie poszczególnych odcinków powstaªej ªamanej mówi nam o proporcjachmi¦dzy cz¦sto±ciami poszczególnych ocen dla obu przedmiotów. I tak udziaª dwójek z Bazdanych jest zdecydowanie wy»szy ni» z Algebry (ponad 30% kontra ok. 10%), podczas gdyk¡t nachylenia dla 4.5 jest powy»ej 45o, co ±wiadczy o wy»szym udziale tych ocen na Bazach
19
ROZDZIA 3. METODYGRADACYJNE DLA PARY ROZKADÓWNIEZALENYCH 20
0 20 40 60 80 100
020
4060
8010
0
Algebra
Baz
y da
nych
Krzywa nasycenia
NKdwa
trzy
trzy i pol
cztery
cztery i pol
piec
Rysunek 3.1: Krzywa koncentracji wzgledem zmiennej Algebra dla zmiennej Bazy danych

ROZDZIA 3. METODYGRADACYJNE DLA PARY ROZKADÓWNIEZALENYCH 21
danych w porównaniu z Algebr¡. Je±li krzywa koncentracji przebiega poni»ej przek¡tnej, jakma to miejsce na rysunku, to znaczy »e generalnie udziaª danej oceny i ocen ni»szych jestmniejszy dla Baz danych ni» dla Algebry (albo mówi¡c odwrotnie z baz danych uzyskuje si¦lepsze oceny ni» z Algebry).
O parze zmiennych Y : X mówimy, »e jest ona C-równowa»na parze zmiennych Q : S,je±li ich krzywe C(Y : X) i C(Q : S) s¡ identyczne.
Twierdzenie 3.1.1 Dla pary zmiennych porz¡dkowych (nad t¡ sam¡ dziedzin¡), krzywa kon-centracji nie zale»y od kodowania warto±ci liczbami rzeczywistymi przy zachowaniu porz¡dkudziedziny.
Dowód Aby przekona¢ si¦ o prawdziwo±ci tego twierdzenia zauwa»my, »e warto±ci zmiennychnie odgrywaj¡ przy konstrukcji krzywej »adnej roli, a jedynie fakt, »e dla tej samej warto±cizmiennych porównujemy ich dystrybuanty i warto±ci funkcji dystrybuant odgrywaj¡ rol¦ przykre±leniu krzywej.
W szczególno±ci np. krzywe koncentracji dla zmiennych X,Y b¦d¡ takie same jak dlaX3, Y 3.
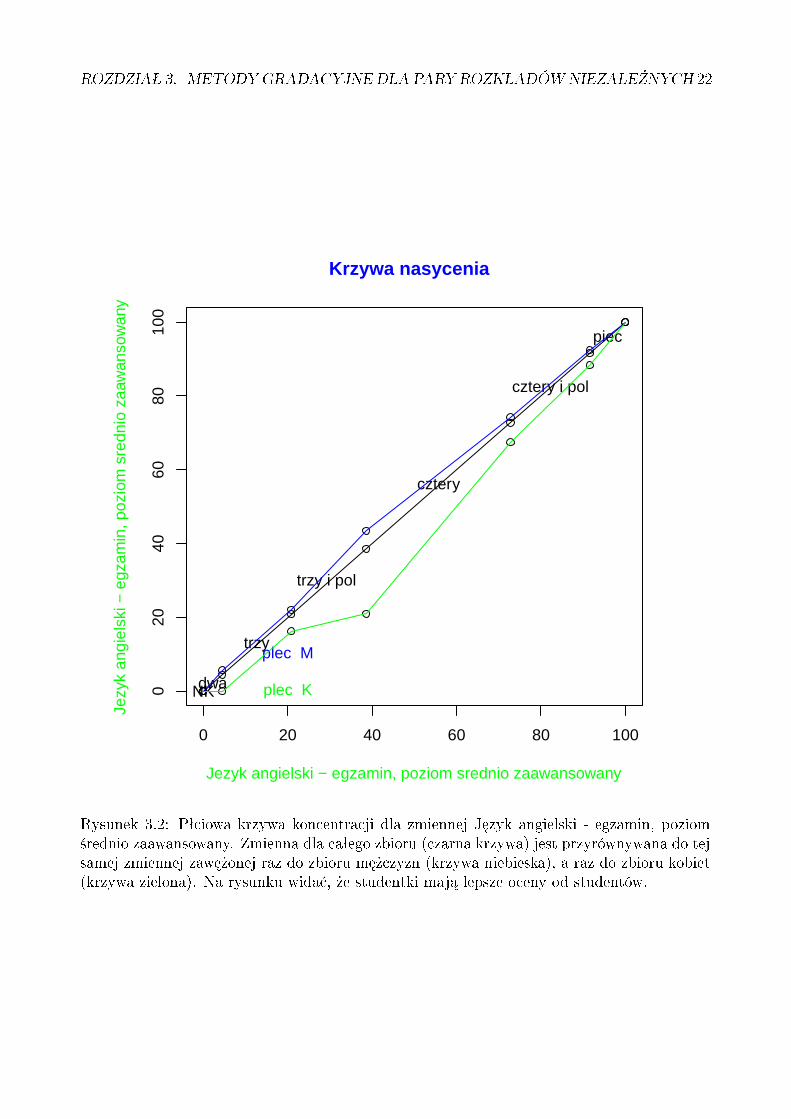
W GAD rozpatruje si¦ tak»e krzywe koncentracji, w których jedna ze zmiennych przeb-iega podzbiór obiektów, które przebiega druga z nich. Wtedy takich podzmiennych nanosisi¦ zwykle kilka. I tak na rysunku 3.2 zmienna J¦zyk angielski - egzamin, poziom ±redniozaawansowany naniesiona na o± X jest przyrównywana do tej samej zmiennej zaw¦»onej razdo zbioru m¦»czyzn, a raz do zbioru kobiet. Na rysunku wida¢, »e studentki maj¡ lepszeoceny od studentów.
Odpowiednikiem krzywej koncentracji w statystyce klasycznej jest krzywa Lorenza (patrz[Kle05] oraz rozdz.3.2), która podobnie jest ªaman¡ na kwadracie jednostkowym.
3.2 Krzywa Lorenza a krzywa nasycenia GAD
Krzywa Lorenza jest stosowana w ekonomii do wizualizacji dystrybucji dochodów b¡d¹ bo-gactwa w aspekcie "nierówno±ci" lub "koncentracji" [Kle05]. Zakªada si¦ pewn¡ populacj¦obiektów o, z których ka»dy jest opisany pewn¡ ci¡gª¡ addytywn¡ zmienn¡ (cech¡) c(o), np.o to gospodarstwa domowe, a c(o) to ich roczne dochody. Niech ci¡g oi b¦dzie ci¡giemwszystkich tych obiektów bez powtórze« taki, »e dla i > 0 zachodzi c(oi−1) ≤ c(oi). Niech
obiektów tych b¦dzie n+1; Krzywa Lorenza skªada si¦ z punktów(
in,∑i
j=0 c(oj)∑nj=0 c(oj)
)dla i = 0, ..., n
oraz odcinków ª¡cz¡cych kolejne punkty na pªaszczy¹nie.Krzywa nasycenia (lub koncentracji) zdeniowana w ramach GAD jest w pewnym sensie
uogólnieniem krzywej Lorenza i gracznie mo»e si¦ wydawa¢ ªudz¡co podobna, ale istnieje za-sadnicza ró»nica koncepcyjna. Mianowicie po pierwsze dominuj¡cym obszarem zastosowaniaKrzywej Lorenza s¡ zagadnienia ekonomiczne, podczas gdy twórcy GAD eksplorowali takiedziedziny jak medycyna, wyniki wyborów i zakªadaj¡, »e mo»liwe jest prezentowanie danychz dowolnych dziedzin, np. ocen studentów na uczelni. Po drugie cecha obiektu, który mo»eby¢ przedmiotem porównania, nie musi by¢ ci¡gªa, ale dopuszcza si¦ porz¡dkowe a nawetnominalne warto±ci. Po trzecie, to nie cecha c jest przedmiotem zainteresowania lecz jejkumulatywne sumy. Wreszcie po czwarte - i to chyba jest fundamentalna ró»nica - krzywenasycenia GAD nadaj¡ si¦ do (i s¡ chyba przeznaczone) analizy niezale»nych próbek. W tym
ROZDZIA 3. METODYGRADACYJNE DLA PARY ROZKADÓWNIEZALENYCH 22
0 20 40 60 80 100
020
4060
8010
0
Jezyk angielski − egzamin, poziom srednio zaawansowany
Jezy
k an
giel
ski −
egz
amin
, poz
iom
sre
dnio
zaa
wan
sow
any
Krzywa nasycenia
NKdwa
trzy
trzy i pol
cztery
cztery i pol
piec
plec M
plec K
Rysunek 3.2: Pªciowa krzywa koncentracji dla zmiennej J¦zyk angielski - egzamin, poziom±rednio zaawansowany. Zmienna dla caªego zbioru (czarna krzywa) jest przyrównywana do tejsamej zmiennej zaw¦»onej raz do zbioru m¦»czyzn (krzywa niebieska), a raz do zbioru kobiet(krzywa zielona). Na rysunku wida¢, »e studentki maj¡ lepsze oceny od studentów.

ROZDZIA 3. METODYGRADACYJNE DLA PARY ROZKADÓWNIEZALENYCH 23
kontek±cie jedna z realizacji krzywej mo»e odzwierciedla¢ statystyk¦ testu Manna-Witneya-Wilcoxona.
Warto ponadto podkre±li¢, »e krzywa Lorenza ze swej natury jest wypukªa [Kle05], akrzywa nasycenia GAD - niekoniecznie.
3.3 Wspóªczynnik polowy
Denicj¦ indeksu ar mo»na rozszerzy¢ dla par zmiennych losowych (X;Y ) o warto±ciachrzeczywistych: Niech para zmiennych Y : X b¦dzie C-równowa»na parze zmiennych ξ : U .Wtedy:
ar(Y : X) := ar(ξ)
Zachodzi wtedy:ar(ξ) = ar(ξ : U)
Jest uzupeªnieniem indeksu Giniego-Simpsona (który b¦dziemy oznacza¢ jako GS(ξ)),o którym piszemy dalej.
3.4 Indeks Giniego a wspóªczynnik polowy
W ekonomii indeks Giniego jest rozwa»any jako podwojone pole mi¦dzy krzyw¡ Lorenza a od-cinkiem ((0,0),(1,1)). Indeks Giniego przyjmuje warto±ci od 0 (dla spoªecze«stwa egalitarnego)po 1 (dla spoªecze«stwa totalitarnego, ze skupieniem bogactwa w jednym r¦ku).
W GAD poj¦cie to w oczywisty sposób zostaªo uogólnione do wspóªczynnika polowego.Jednak»e uogólnienie krzywej Lorenza do krzywej nasycenia niesie ze sob¡ podstawow¡ kon-sekwencj¦ polegaj¡c¡ na mo»liwo±ci górowania tej»e nad przek¡tn¡ - dla pola powy»ej przek¡t-nej zarezerwowano wi¦c warto±ci ujemne, a dla poni»ej - dodatnie. W GAD wspóªczynnikpolowy z ekonomii mo»e zatem przyjmowa¢ warto±ci od -1 do 1.
3.5 Indeks Giniego-Simpsona
Niech para zmiennych Y : X b¦dzie C-równowa»na parze zmiennych ξ : U . GS(ξ) b¦dziewtedy miar¡ odmienno±ci zmiennych X,Y .
3.6 Klasyczny indeks Giniego-Simpsona a indeks GS w
GAD
Indeks GS w GAD, wspomniany wy»ej, to adaptacja klasycznego indeksu Giniego-Simpsona,stosowanego pierwotnie w ekologii, sociologii, psychologii oraz w nauce o zarz¡dzaniu. Klasy-czny indeks Giniego-Simpsona wyra»a prawdopodobie«stwo, »e dwa obiekty wylosowane zezwracaniem b¦d¡ ró»nego rodzaju (np. gatunku). W ekologii nazywa si¦ go st¡d praw-dopodobie«stwem spotkania mi¦dzygatunkowego (PIE) [JJvEC02] i wyra»any jest formuª¡
1−N∑i=1
p2i

ROZDZIA 3. METODYGRADACYJNE DLA PARY ROZKADÓWNIEZALENYCH 24
gdzie N to np. liczba gatunków. Inne nazwy tego indeksu to indeks Gibbsa-Martina lubindeks Blaua.
Indeks GS w GAD ró»ni si¦ nieco koncepcyjnie po pierwsze dlatego, »e bierze pod uwag¦poniek¡d "odlegªo±¢" mi¦dzy losowanymi obiektami (st¡d ma mianownik, który jakby normal-izuje przez ±redni¡ warto±¢ prawdopodobie«stwa). Po drugie obiekty przynale»¡ce do jednejgrupy nie s¡ traktowane identycznie. Milcz¡co zakªada si¦ w analogii np. do ocen studentów,»e podziaª na kategorie (oceny studentów) jest nieco sztuczny, powstaªy przez progowanie,wobec czego w tle za stopniuj¡cymi kategoriami jest jakie± domy±lne kontinuum.
3.7 Funkcjonaª gradacyjny
Niech PX oraz QY b¦d¡ miarami indukowanymi przez zmienne losowe odpowiednio X i Y.Iloraz wiarogodno±ci hY :X jest zdeniowany na zbiorze dPX
d(PX+QY )(z) > 0 jako:
hY :X =dQY
d(PX +QY )/
dPX
d(PX +QY )(z).
Je±li funkcjonaª ten jest rosn¡cy, to wtedy rozkªad jest reprezentowany przez wypukª¡dystrybuant¦, a ci¡gªa zmienna lilipucia ma niemalej¡c¡ g¦sto±¢.

Rozdziaª 4
Analiza rozkªadów zale»nych
4.1 Rozkªady dwuwymiarowe
Na wzór Jednowymiarowego Modelu Lilipuciego wprowad¹my Dwuwymiarowy Model Lilipuci.
Denicja 4.1.1 Par¦ zmiennych losowych nazwiemy lilipuci¡ par¡ zmiennych (ozn. ξ, ν),je±li przyjmuje warto±ci z produktu przedziaªów [0, 1] × [0, 1], jest dyskretna, ci¡gªa b¡d¹dyskretna-ci¡gªa. Dystrybuanta oznaczana przez Fξ,ν jest niemalej¡c¡ powierzchni¡, le»¡c¡w kostce jednostkowej, ª¡cz¡cej punkty (0,0,0) oraz (1,1,1).
Zbiór wszystkich lilipucich par zmiennych losowych nazywamy Dwuwymiarowym ModelemLilipucim i oznaczamy przez BLM (z ang. the Bivariate Lilliputian Model)
4.2 Powierzchnia koncentracji
Niech zmienne losowe X i Y maj¡ dystrybuanty FX , FY oraz ª¡czn¡ dystrybuant¦ FXY ist-niej¡ce wsz¦dzie na zbiorze liczb rzeczywistych.
Denicja 4.2.1 Rozpatrzmy powierzchni¦ w [0, 1]× [0, 1]× [0, 1] zadan¡ wzorem:
Z = (FX(x), FY (y), FXY (x, y));x, y ∈ R
Niech powierzchnia S skªada si¦ z powierzchni Z oraz nast¦puj¡cych punktów:
• (0, 0, 0) = (FX(−∞), FY (−∞), FXY (−∞,−∞))
• (1, 1, 1) = (FX(+∞), FY (+∞), FXY (−∞,−∞))
• Dla punktu (x0, y0) niech
(FX(x0), FY (y0), FXY (x0, y0))++ ::= (limx→x+
0FX(x), limy→y+0
FY (y), limx→x+0 ,y→y+0
FXY (x, y)).
(FX(x0), FY (y0), FXY (x0, y0))+. ::= (limx→x+
0FX(x), FY (y0), limy→x+
0FXY (x, y0)).
(FX(x0), FY (y0), FXY (x0, y0)).+ ::= (FX(x0), limy→y+0
FY (y), limy→y+0FXY (x0, y)).
(FX(x0), FY (y0), FXY (x0, y0))−− ::= (limx→x+
0FX(x), limy→y−0
FY (y), limy→x+0 ,y→y−0
FXY (x, y)).
(FX(x0), FY (y0), FXY (x0, y0))−. ::= (limx→x−
0FX(x), FY (y0), limx→x−
0FXY (x, y0)).
25

ROZDZIA 4. ANALIZA ROZKADÓW ZALENYCH 26
(FX(x0), FY (y0), FXY (x0, y0)).− ::= (FX(x0), limy→y−0
FY (y), limy→y−0FXY (x0, y)).
(FX(x0), FY (y0), FXY (x0, y0))+− ::= (limx→x+
0FX(x), limy→y−0
FY (y), limx→x+0 ,y→y−0
FXY (x, y)).
(FX(x0), FY (y0), FXY (x0, y0))−+ ::= (limx→x−
0FX(x), limy→y+0
FY (y), limx→x−0 ,y→y+0
FXY (x, y)).
• Je±li (FX(x0), FY (y0), FXY (x0, y0))++ = (FX(x0), FY (y0), FXY (x0, y0)), wtedy S
zawiera tak»e górn¡ powierzchni¦ λXλY (FX(x0), FY (y0), FXY (x0, y0))++ + (1 −
λX)λY (FX(x0), FY (y0), FXY (x0, y0)).+ + λX(1 − λY )(FX(x0), FY (y0), FXY (x0, y0))
+. +(1− λX)(1− λY )(FX(x0), FY (x0)) dla wszystkich λX , λY ∈ [0, 1].
• Je±li (FX(x0), FY (y0), FXY (x0, y0))−− = (FX(x0), FY (y0), FXY (x0, y0)), wtedy S
zawiera tak»e powierzchni¦ λX(FX(x0), FY (y0), FXY (x0, y0))−− + (1 − λX)(1 −
λY )(FX(x0), FY (y0), FXY (x0, y0)).− + λY (FX(x0), FY (x0)) oraz powierzchni¦
λX(FX(x0), FY (y0), FXY (x0, y0))−−+(1−λX)(1−λY )(FX(x0), FY (y0), FXY (x0, y0))
−.+λY (FX(x0), FY (x0)) a pochodna na tych powierzchniach przyjmowana jest umownie
fxy−f−−xy
(fx−f−x )(fy−f−
y )dla wszystkich λX , λY ∈ [0, 1]. i tak dalej ....
Dotyczy to te» warto±ci niewªa±ciwych x oraz y czyli −∞ oraz +∞. Powierzchnia ta ª¡czypunkty (0, 0, 0) i (1, 1, 1) i nazywamy j¡ powierzchni¡ koncentracji Y do X i oznaczamy przezS(Y : X).
O parze zmiennych Y : X mówimy, »e jest ona S-równowa»na parze zmiennych Q : S, je±liich powierzchnie S(Y : X) i S(Q : S) s¡ identyczne.
4.3 Mapy nadreprezentacji
W przestrzeni BLM dla dystrybuanty reprezentowanej przez powierzchni¦ S(ν : ξ) map¡nadreprezentacji nazywamy funkcj¦ pochodn¡ δS
δξδν, zdeniowan¡ wsz¦dzie tam, gdzie istnieje.
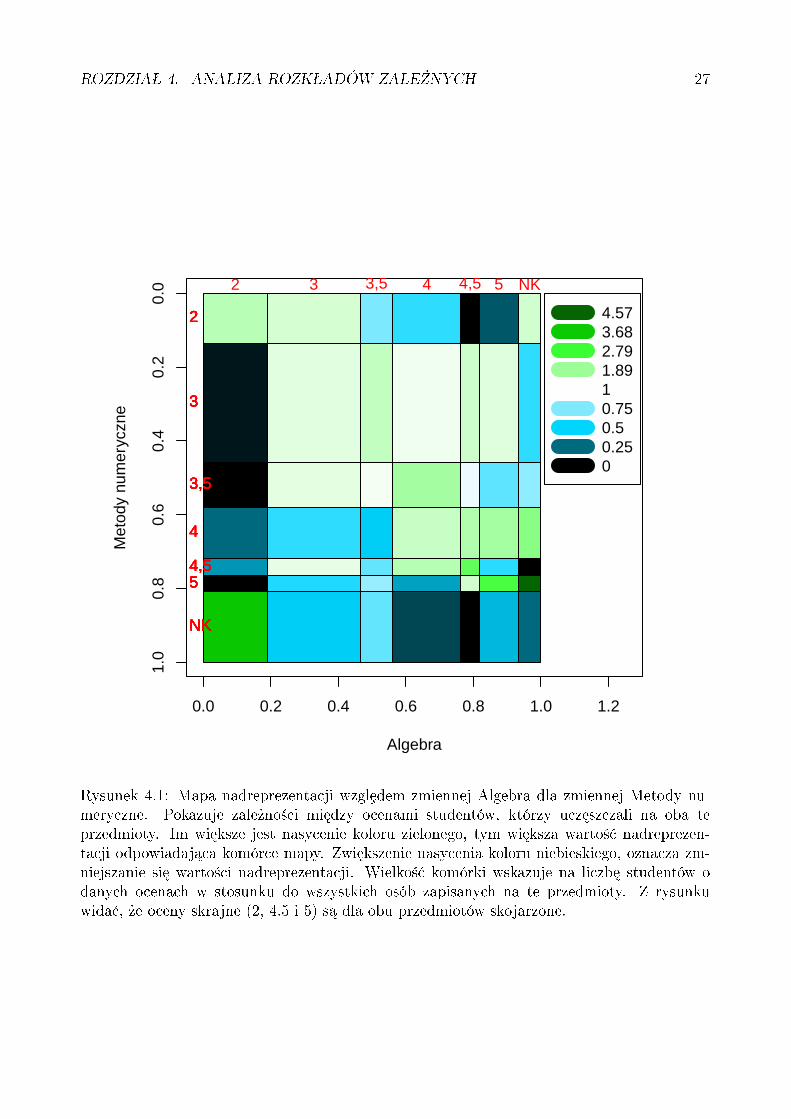
Mapy nadreprezentacji s¡ u»ytecznym narz¦dziem przy wizualizacji trendów zale»no±ci.Na rysunku 4.1 zaprezentowana zostaªa mapa nadreprezentacji dla dwóch przedmiotów
akademickich: Algebra i Metody numeryczne. Pokazuje zale»no±ci mi¦dzy ocenami studen-tów, którzy ucz¦szczali na oba te przedmioty. Im wi¦ksze jest nasycenie koloru zielonego,tym wi¦ksza warto±¢ nadreprezentacji odpowiadaj¡ca komórce mapy. Natomiast zwi¦kszenienasycenia koloru niebieskiego oznacza zmniejszanie si¦ warto±ci nadreprezentacji. Niekiedywarto±ci reprezentowane przez odcienie koloru niebieskiego nazywane s¡ niedoreprezentacj¡.
Gdy spojrzymy na komórk¦ z liczb¡ 4.5, zauwa»ymy, »e jest ona prawie symetryczna.Oznacza to, »e mniej wi¦cej tyle samo ludzi ma 4.5 z Algebry i Metod numerycznych. Wielko±¢komórki wskazuje na ich niewielk¡ liczb¦ w stosunku do wszystkich osób zapisanych na teprzedmioty. Komórka jest koloru jasno-zielonego, czyli zag¦szczenie studentów w tej komórcejest okoªo 2 razy wi¦ksze, ni» jakie byªoby, gdyby byli oni rozªo»eni losowo. Podobnie mamydla prostok¡ta z liczb¡ 5, z tym, »e zag¦szczenie studentów jest tu prawie 3 razy wi¦ksze.Patrz¡c na ten rysunek mo»na doj±¢ do wniosku, »e oceny skrajne (2, 4.5 i 5) s¡ dla obuprzedmiotów skojarzone.
Dwuwymiarowy indeks koncentracji nazwiemy wspóªczynnikiem ρ∗ Spearmana i zdeniu-jemy jako:
ρ∗(X,Y ) =
∫ 1
0
∫ 1
0Cop(X,Y )(u, v)dudv −
∫ 1
0
∫ 1
0uvdudv∫ 1
0
∫ 1
0Fr+(X∗,Y ∗)(u, v)dudv −
∫ 1
0
∫ 1
0uvdudv
ROZDZIA 4. ANALIZA ROZKADÓW ZALENYCH 27
0.0 0.2 0.4 0.6 0.8 1.0 1.2
1.0
0.8
0.6
0.4
0.2
0.0
Algebra
Met
ody
num
eryc
zne
2
3
3,5
4
4,55
NK
2
2
3
3,5
4
4,55
NK
3
2
3
3,5
4
4,55
NK
3,5
2
3
3,5
4
4,55
NK
4
2
3
3,5
4
4,55
NK
4,5
2
3
3,5
4
4,55
NK
5
2
3
3,5
4
4,55
NK
NK
4.573.682.791.8910.750.50.250
Rysunek 4.1: Mapa nadreprezentacji wzgledem zmiennej Algebra dla zmiennej Metody nu-meryczne. Pokazuje zale»no±ci mi¦dzy ocenami studentów, którzy ucz¦szczali na oba teprzedmioty. Im wi¦ksze jest nasycenie koloru zielonego, tym wi¦ksza warto±¢ nadreprezen-tacji odpowiadaj¡ca komórce mapy. Zwi¦kszenie nasycenia koloru niebieskiego, oznacza zm-niejszanie si¦ warto±ci nadreprezentacji. Wielko±¢ komórki wskazuje na liczb¦ studentów odanych ocenach w stosunku do wszystkich osób zapisanych na te przedmioty. Z rysunkuwida¢, »e oceny skrajne (2, 4.5 i 5) s¡ dla obu przedmiotów skojarzone.

ROZDZIA 4. ANALIZA ROZKADÓW ZALENYCH 28
= 12
∫ 1
0
∫ 1
0
(Cop(X,Y )(u, v)− uv)dudv
4.3.1 Dyskretne mapy nadreprezentacji
Je±li obie zmienne X,Y s¡ dyskretne, z t¡ sam¡ dziedzin¡ (dom(X)), map¦ nadreprezen-tacji otrzymujemy w nast¦puj¡cy sposób: Konstruujemy tabel¦ kontyngencji TX,Y tak¡, »eTX,Y [i, j] = k oznacza, »e dla k obiektów atrybuty przyjmuj¡ warto±ci: X = dom(X)[i], Y =dom(X)[j]. Nast¦pnie konstruujemy tablic¦ mapy
MX,Y [i, j] =TX,Y [i, j] · (
∑i∈dom(X)
∑j∈dom(X) TX,Y [i, j])
(∑
i∈dom(X) TX,Y [i, j]) · (∑
j∈dom(X) TX,Y [i, j])
dla tych par i, j, dla których mianownik jest niezerowy, a dla pozostaªych MX,Y [i, j] = 1.Wizualizacja mapy to prostok¡t podzielony na prostok¡ty za pomoc¡ kraty tak, aby pole
prostok¡ta nr (i,j) byªo proporcjonalne do (∑
i∈dom(X) TX,Y [i, j]) · (∑
j∈dom(X) TX,Y [i, j]).
Kolor tego prostok¡ta odzwierciedla warto±¢ MX,Y [i, j].
Twierdzenie 4.3.1 Je»eli zmienne X,Y s¡ niezale»ne, to warto±¢ oczekiwana MX,Y [i, j] = 1.
Dowód Niech c oznacza liczb¦ elementów w komórce (i,j) tablicy T, w′ liczb¦ elementóww wierszu i prócz komórki (i,j), k′ liczb¦ elementów w kolumnie j prócz komórki (i,j), a N ′
liczb¦ elementów poza itym wierszem i jt¡ kolumn¡. w′+k′+ c+N ′ = N czyli ª¡cznej liczbieelementów. w = w′ + c, k = k′ + c. Warto±¢ oczekiwana dla ustalonego N wyra»a si¦ wzorem
E(MX,Y [i, j]) =∑
c,w,k;0≤c≤w,c≤k,w≤N,k≤NcNwk
(Nc
)(pi · pj)c
(N−ck′
)((1− pi) · pj)k
′
(N−c−k′
w′
)(pi · (1− pj))
w′((1− pi) · (1− pj))
N−c−w′−k′
= N∑N
c=1
(Nc
)c · (pi · pj)c
∑N−ck′=0
(N−ck′
)1
k′+c((1− pi) · pj)k
′
∑N−c−k′
w′=0
(N−c−k′
w′
)1
w′+c(pi · (1− pj))
w′((1− pi) · (1− pj))
N−w′−k′−c
= N∑N
c=1
(Nc
)c · (pi · pj)c
∑N−ck′=0
(N−ck′
)1
k′+c((1− pi) · pj)k
′(1− pj)
N−k′−c
∑N−c−k′
w′=0
(N−c−k′
w′
)1
w′+c(pi)
w′((1− pi))
N−w′−k′−c
= N∑N
c=1
(Nc
)c · (pi · pj)c(1− pipj)
N−c∑N−c
k′=0
(N−ck′
)1
k′+c
((1−pi)·pj1−pipj
)k′ (1−pj1−pipj
)N−k′−c
∑N−c−k′
w′=0
(N−c−k′
w′
)1
w′+c(pi)
w′((1− pi))
N−w′−k′−c
(4.1)
W powy»szym przyj¦to sumowanie od c=1, poniewa» dla c=0 skªadnik znika.Zauwa»my, »e
E(1
1 +X) =
1− (1− p)n+1
p(n+ 1)
gdzie X ∼ Bin(n, p). Powód jest nast¦puj¡cy:

ROZDZIA 4. ANALIZA ROZKADÓW ZALENYCH 29
E( 11+X
) =∑n
x=01
1+x·(nx
)· px · (1− p)n−x
=∑n
x=01
1+x· n!x!·(n−x)!
· px · (1− p)n−x
=∑n
x=0n!
(x+1)!·(n−x)!· px · (1− p)n−x
=∑n
x=0n!
(x+1)!·(n−x)!n+1n+1
· px pp· (1− p)n−x
= 1p(n+1)
∑nx=0
(n+1)!(x+1)!·(n+1−(x−1))!
· px+1 · (1− p)(n+1)−(x+1)
(4.2)
Zast¡pmy x+ 1 przez x′ oraz n+ 1 przez n′
= 1p(n+1)
∑n′
x′=1n′!
x′!∗(n′−x′)!· px′ · (1− p)n
′−x′
= 1p(n+1)
(−(1− p)n
′ ∑n′
x′=0n′!
x′!·(n′−x′)!· px′ · (1− p)n
′−x′)
= 1p(n+1)
(−(1− p)n
′+ 1
)= 1−(1−p)n+1
p(n+1).
(4.3)
Je±li warto±ci n b¦d¡ "du»e", a p "niezbyt maªe", to jest to w przybli»eniu 1E(X)
.
E( 1c+X
) dla c wi¦kszych od 1 b¦d¡ niew¡tpliwie mniejsze, ale je±li dla maªych x praw-dopodobie«stwa b¦d¡ niskie, to dla du»ych x skªadniki sumy b¦d¡ dominuj¡ce, a poniewa»1/(1+x) nie b¦dzie si¦ "nadmiernie" ró»ni¢ od 1/(c+x), wi¦c E( 1
c+X) nie b¦dzie zbytnio ró»ne
od E( 11+X
) Mo»emy zatem przyj¡¢, »e dla staªej N i zmiennych losowych c, w′, c′ zachodzi
E(MX,Y [i, j]) ≈NE(c)
E(w∗)E(k)=
N ·N · pi · pjNN
((1−pi)·pj1−pipj
)Npi
≈ 1
(gdzie w∗ to rozkªad zmodykowany jak w powy»szych wzorach). Badania symulacyjne1
dla pi, pj z zakresu 0.1 − 0.9 oraz N rz¦du 100 pokazaªy, »e oszacowanie to jest do±¢ dobre(+/− 0.1%).
Twierdzenie 4.3.2 Minimalna mo»liwa warto±¢ MX,Y [i, j] wynosi 0.
Dowód jest prosty - zauwa»my, »e w tablicy kontyngencji minimalna zawarto±¢ komórki to 0.St¡d z denicji tablicy M , o ile mianownik jest niezerowy M [i, j] wyniesie 0. Ujemne warto±cinie mog¡ wyst¡pi¢ w T , a wi¦c i w mianowniku M .
Twierdzenie 4.3.3 Maksymalna mo»liwa warto±¢ MX,Y [i, j] wynosi∑i∈dom(X)
∑j∈dom(X) TX,Y [i, j].
Dowód Najpierw poka»emy, »e ta warto±¢ jest w ogóle mo»liwa, a potem, »e inne warto±cis¡ zawsze nie wi¦ksze.
1Konstruowano tabel¦ kontyngencji 2x2 dla dwóch niezale»nych zmiennych losowych przez losowanie Nobiektów ze stosownym prawdopodobie«stwem przynale»no±ci do poszczególnych komórek

ROZDZIA 4. ANALIZA ROZKADÓW ZALENYCH 30
Zatem rozpatrzmy tabel¦ kontyngencji TX,Y tak¡, »e wiersz i oraz kolumna j zawieraj¡same zera z wyj¡tkiem komórki (i,j), która zawiera 1. Wtedy
MX,Y [i, j] =TX,Y [i,j]·(
∑i∈dom(X)
∑j∈dom(X) TX,Y [i,j])
(∑
i∈dom(X) TX,Y [i,j])·(∑
j∈dom(X) TX,Y [i,j])
=1·(
∑i∈dom(X)
∑j∈dom(X) TX,Y [i,j])
1·1 =∑
i∈dom(X)
∑j∈dom(X) TX,Y [i, j]
(4.4)
Ta warto±¢ jest osi¡gana.Teraz rozpatrzmy tabel¦ kontyngencji TX,Y tak¡, »e wiersz i oraz kolumna j zawieraj¡ same
zera z wyj¡tkiem komórki (i,j), która zawiera k > 1. Wtedy
MX,Y [i, j] =TX,Y [i,j]·(
∑i∈dom(X)
∑j∈dom(X) TX,Y [i,j])
(∑
i∈dom(X) TX,Y [i,j])·(∑
j∈dom(X) TX,Y [i,j])
=k·(
∑i∈dom(X)
∑j∈dom(X) TX,Y [i,j])
k·k = 1k
∑i∈dom(X)
∑j∈dom(X) TX,Y [i, j]
(4.5)
Warto±¢ mniejsza od (4.4).Teraz rozpatrzmy ogóln¡ tabel¦ kontyngencji TX,Y oraz drug¡ T ′
X,Y takie, »e dla pewnejkolumny l zachodzi: T ′
X,Y [i, l] = TX,Y [i, l]−1 i T ′X,Y [i, j] = TX,Y [i, j]+1 a pozostaªe odpowied-
nie komórki s¡ identyczne.Wtedy
MX,Y [i, j] =TX,Y [i,j]·(
∑i∈dom(X)
∑j∈dom(X) TX,Y [i,j])
(∑
i∈dom(X) TX,Y [i,j])·(∑
j∈dom(X) TX,Y [i,j])
=(T ′
X,Y [i,j]−1)·(∑
i∈dom(X)
∑j∈dom(X) T
′X,Y [i,j])
(∑
i∈dom(X) T′X,Y [i,j])·(−1+
∑j∈dom(X) T
′X,Y [i,j])
≤ (T ′X,Y [i,j])·(
∑i∈dom(X)
∑j∈dom(X) T
′X,Y [i,j])
(∑
i∈dom(X) T′X,Y [i,j])·(
∑j∈dom(X) T
′X,Y [i,j])
= M ′X,Y [i, j]
(4.6)
co oznacza, »e "czyszcz¡c" wiersz i wstawiaj¡c wszystko do jednej komórki (i, j) otrzy-mujemy coraz wi¦ksze warto±ci M [i, j]. Analogicznie dzieje si¦ dla kolumny j. A na tematwyczyszczonego wiersza i kolumny ju» si¦ wypowiedzieli±my, kiedy M jest najwi¦ksze: gdyT [i, j] = 1. To ko«czy dowód.
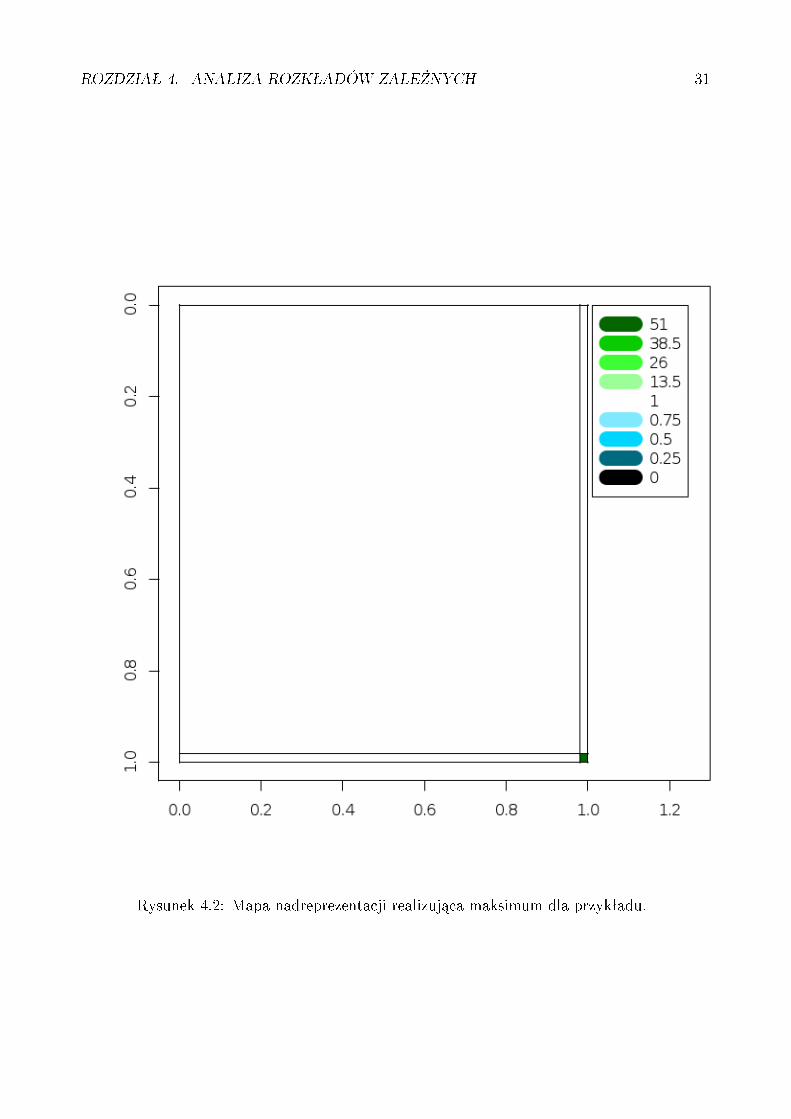
Przykªad:Zaªó»my, »e w±ród pi¦¢dziesi¦ciu jeden studentów, który chodz¡ na Algebr¦ i Analiz¦, 50
ma ocen¦ 3.5 z Algebry i ocen¦ 4 z Analizy oraz jeden ma z obu tych przedmiotów ocen¦5. Wówczas warto±¢ komórki tablicy mapy odpowiadaj¡ca temu studentowi b¦dzie miaªawarto±¢ 51. A caªa mapa b¦dzie wygl¡da¢ tak jak na rysunku (4.2).
Rozkªad prawdopodobie«stwa komórki mapy :Niech
• w - oznacza sum¦ elementów w wierszu tablicy kontyngencji
• k - oznacza sum¦ elementów w kolumnie tablicy kontyngencji
• c - oznacza sum¦ elementów w komórce tablicy kontyngencji
• N - oznacza sum¦ wszystkich elementów w tablicy kontyngencji
ROZDZIA 4. ANALIZA ROZKADÓW ZALENYCH 31
Rysunek 4.2: Mapa nadreprezentacji realizuj¡ca maksimum dla przykªadu.

ROZDZIA 4. ANALIZA ROZKADÓW ZALENYCH 32
• oraz 0 < c, k, w ≤ N , w ≥ c, k ≥ c, N ≥ c,
Wtedy rozkªad prawdopodobie«stwa komórki mapy wyra»a si¦ wzorem:
pm = P (c, k, w;N, pi, pj) =(Nc
)(N−cw−c
)(N−w−2c
k−c
)pccp
(w−c)w p
(k−c)k p
(N−w−k−2c)r
=(Nc
)(N−cw−c
)(N−w−2c
k−c
)(pipj)
cp(w−c)i p
(k−c)j (1− pi − pj + pipj)
(N−w−k−2c)
=(Nc
)(N−cw−c
)(N−w−2c
k−c
)pwi p
cj[(1− pi)(1− pj)]
(N−w−k−2c)
A dystrybuanta wyra»a si¦ wzorem:
F (z) = P ( cNwk
≤ z) =∑
cNwk
≤z pm
=∑
cNwk
≤z
(Nc
)(N−cw−c
)(N−w−2c
k−c
)pwi p
cj[(1− pi)(1− pj)]
(N−w−k−2c)

Rozdziaª 5
Analiza danych rzeczywistych
5.1 Cel bada«
Celem bada« jest wizualizacja procesu studiowania na podstawie systemu USOS UniwersytetuWarszawskiego.
5.2 Opis zbioru danych
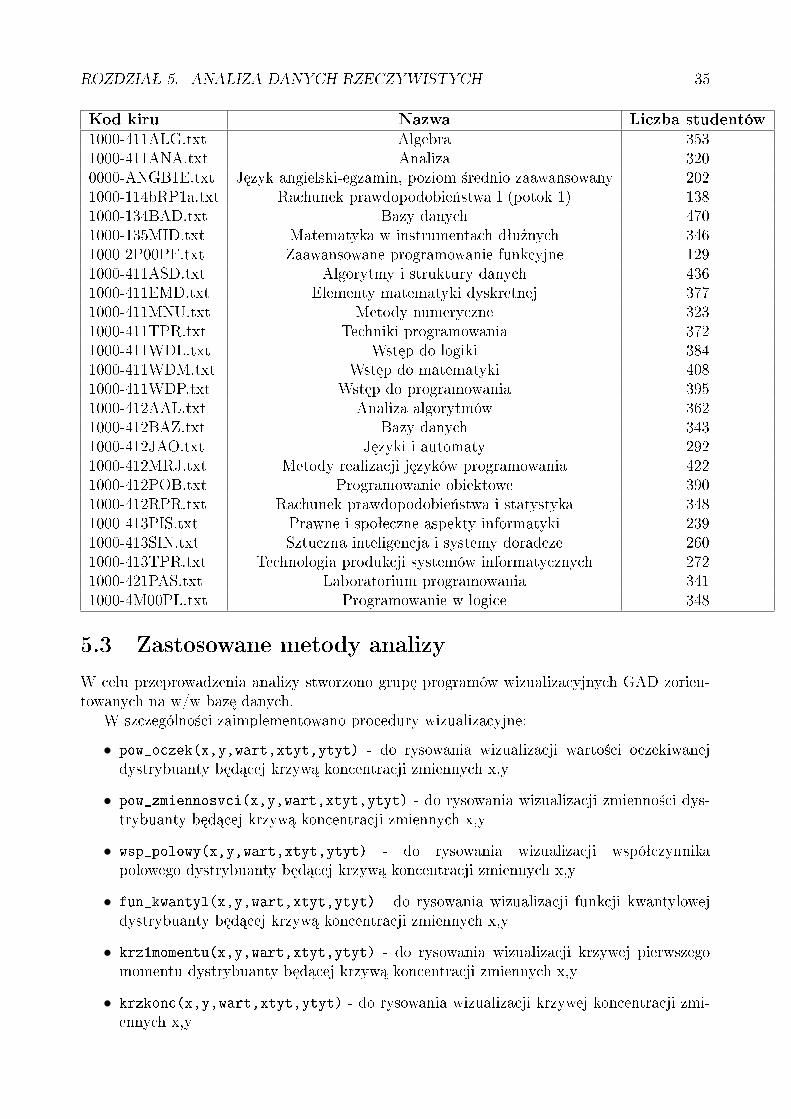
Dane zawieraj¡ 6262 pliki z informacjami o ocenach studentów, z poszczególnych przed-miotów, wyci¡gni¦tych z systemu USOS Uniwersytetu Warszawskiego. Dane reprezentuj¡wyniki nauczania z okresu od 1999 do 2009 z kilku wydziaªów.
Ka»dy plik dotyczy jednego przedmiotu (egzaminu/zaliczenia za jeden semestr) i zawiera12 zmiennych:
• os_id - identykator studenta (liczba naturalna jednoznacznie identykuj¡ca studenta)
• data_ur - miesi¡c i rok urodzenia (w formacie rrrr-mm)
• plec - pªe¢ studenta (M-m¦»czyzna, K-kobieta)
• cdyd_kod - rocznik, którym student ucz¦szczaª na przedmiot (jest 11 ró»nych roczników,lata 1999-2009 )
• prz_kod - kod przedmiotu
• nazwa - nazwa przedmiotu
• tpro_kod - sposób zaliczenia przedmiotu (egzamin lub zaliczenie)
• prot_id - identykator protokoªu
• term_prot_id - termin, w którym zostaª zdany/zaliczony przedmiot (przyjmuje warto±ci1,2 lub 3)
• toc_kod - zmienna zwi¡zana z tpro_kod (tpro-kod = EGZ => toc_kod = STD,tpro_kod = ZAL => toc_kod = ZAL, tpro_kod = ZAL-OCENA => toc_kod =STD, tpro_kod = ZAL-LUB-OCENA => toc_kod = ZAL-STD)
33

ROZDZIA 5. ANALIZA DANYCH RZECZYWISTYCH 34
• wartosc - ocena z separtorem .
• opis - ocena z separtorem ,
8 plików jest pustych, pozostaªe 6254 zawieraj¡ co najmniej jeden rekord (wiersz z infor-macjami o ocenach studenta).
Oceny studentów maj¡ 7 poziomów (NK,2,3,3.5,4,4.5,5). Nale»y oceni¢, jak du»e powinnyby¢ próbki, aby wyniki analiz, w tym przypadku porównywalne z tworzeniem histogramów,miaªy sens. Spo±ród wielu oszacowa« [But] zwró¢my uwag¦ na tzw. oszacowanie pier-wiastkowe. Tzn. liczba przedziaªów winna by¢ mniejsza od pierwiastka z wielko±ci próbki,czyli w naszym przypadku wielko±¢ próbki winna wynosi¢ 49. Z kolei na wykªadach zestatystyki [Grz10] uczono, »e absolutnym minimum do liczenia takich wielko±ci jak ±red-nia to 3 obserwacje. Poniewa» w pewnym sensie jeden sªupek histogramu jest porównywalnyz liczeniem ±redniej, mo»na przyj¡¢, »e minimalna wielko±¢ próbki winna wynie±¢ co najm-niej 21. Dlatego te» w pierwszej kolejno±ci odrzuciªam te pliki, w których byªo mniej ni» 21rekordów. W rezultacie pozostaªy 872 pliki z przedmiotami. Jako komproms mi¦dzy 49 a 21mo»na uzna¢ ich ±redni¡ (czyli 35). Po odrzuceniu plików, które miaªy mniej ni» 35 rekordów,pozostaªo 665 plików z przedmiotami i nimi b¦d¦ si¦ dalej zajmowa¢ w analizie. W tychplikach jest 3074 ró»nych studentów z 11 roczników (1999-2009).
Ostatecznie, odrzuciwszy przedmioty, ko«cz¡ce si¦ zaliczeniem bez oceny, poprzez in-spekcj¦ map nadreprezentacji wzgl¦dem przedmiotu ALGEBRA wybraªam 25 przedmiotów,dla których mapy te wygl¡daªy interesuj¡co.
ROZDZIA 5. ANALIZA DANYCH RZECZYWISTYCH 35
Kod kiru Nazwa Liczba studentów
1000-411ALG.txt Algebra 3531000-411ANA.txt Analiza 3200000-ANGB1E.txt J¦zyk angielski-egzamin, poziom ±rednio zaawansowany 2021000-114bRP1a.txt Rachunek prawdopodobie«stwa I (potok 1) 1381000-134BAD.txt Bazy danych 4701000-135MID.txt Matematyka w instrumentach dªu»nych 3461000-2P00PF.txt Zaawansowane programowanie funkcyjne 1291000-411ASD.txt Algorytmy i struktury danych 4361000-411EMD.txt Elementy matematyki dyskretnej 3771000-411MNU.txt Metody numeryczne 3231000-411TPR.txt Techniki programowania 3721000-411WDL.txt Wst¦p do logiki 3841000-411WDM.txt Wst¦p do matematyki 4081000-411WDP.txt Wst¦p do programowania 3951000-412AAL.txt Analiza algorytmów 3621000-412BAZ.txt Bazy danych 3431000-412JAO.txt J¦zyki i automaty 2921000-412MRJ.txt Metody realizacji j¦zyków programowania 4221000-412POB.txt Programowanie obiektowe 3901000-412RPR.txt Rachunek prawdopodobie«stwa i statystyka 3481000-413PIS.txt Prawne i spoªeczne aspekty informatyki 2391000-413SIN.txt Sztuczna inteligencja i systemy doradcze 2601000-413TPR.txt Technologia produkcji systemów informatycznych 2721000-421PAS.txt Laboratorium programowania 3411000-4M00PL.txt Programowanie w logice 348
5.3 Zastosowane metody analizy
W celu przeprowadzenia analizy stworzono grup¦ programów wizualizacyjnych GAD zorien-towanych na w/w baz¦ danych.
W szczególno±ci zaimplementowano procedury wizualizacyjne:
• pow_oczek(x,y,wart,xtyt,ytyt) - do rysowania wizualizacji warto±ci oczekiwanejdystrybuanty b¦d¡cej krzyw¡ koncentracji zmiennych x,y
• pow_zmiennosvci(x,y,wart,xtyt,ytyt) - do rysowania wizualizacji zmienno±ci dys-trybuanty b¦d¡cej krzyw¡ koncentracji zmiennych x,y
• wsp_polowy(x,y,wart,xtyt,ytyt) - do rysowania wizualizacji wspóªczynnikapolowego dystrybuanty b¦d¡cej krzyw¡ koncentracji zmiennych x,y
• fun_kwantyl(x,y,wart,xtyt,ytyt) - do rysowania wizualizacji funkcji kwantylowejdystrybuanty b¦d¡cej krzyw¡ koncentracji zmiennych x,y
• krz1momentu(x,y,wart,xtyt,ytyt) - do rysowania wizualizacji krzywej pierwszegomomentu dystrybuanty b¦d¡cej krzyw¡ koncentracji zmiennych x,y
• krzkonc(x,y,wart,xtyt,ytyt) - do rysowania wizualizacji krzywej koncentracji zmi-ennych x,y

ROZDZIA 5. ANALIZA DANYCH RZECZYWISTYCH 36
• przyrkrzkonc(x,y,kolor,podpkolor,pozkolor) - do rysowania wizualizacji wielukrzywych koncentracji na jednym rysunku
• plotkwLeg(m,colors,xtyt,ytyt) - do rysowania wizualizacji mapy nadreprezentacji
• raport_start(nazwa_raportu,nazwa_listy) - do generowania raportów, opisanychw nast¦pnym podrozdziale.
5.4 Wyniki i ich interpretacja
Wykresy przedstawiono w zaª¡cznikach do pracy na pªycie CD w postaci raportów:
1. raport_pow_oczek
2. raport_pow_zmiennosvci
3. raport_wsp_polowy
4. raport_krzyweKonc
5. raport_terminowa_krzkonc
6. raport_krz1momentu
7. raport_mapanadLeg
5.4.1 Krzywa koncentracji raport_krzyweKonc
Krzywa koncentracji jest wyrazem wzajemnych relacji mi¦dzy grupami studentów dla ró»nychprzedmiotów. W szczególno±ci po zmieniaj¡cych si¦ k¡tach nachylenia krzywej wida¢, któr¡ocen¦ ªatwiej byªo zdoby¢.
Przykªadem zastosowania analizy GAD mo»e by¢ analiza grup studentów realizuj¡cychten sam przedmiot w tzw. "potokach" (np. gad.krzkonc_przed("1000-114bRP1a","1000-114bRP1b"); ). Je±li zaªo»ymy, »e podziaª odbyª si¦ (z punktu widzenia zdolno±ci studentów)w sposób losowy, to nale»aªoby oczekiwa¢, »e krzywa koncentracji dla dwóch potoków winnaby¢ przek¡tn¡ kwadratu jednostkowego. Rzucenie okiem na stosowny wykres dla rachunkuprawdopodobie«stwa wskazuje, »e nie do ko«ca tak jest dla przedmiotu rachunek praw-dopodobie«stwa I. Jedna z grup ró»ni si¦ od drugiej nadmiarow¡ liczb¡ studentów nieklasy-kowanych. Poza tym rzeczywi±cie krzywa koncentracji jest prawie prosta z wyj¡tkiem ró»nicyw liczbie ocen ponad dobrych i bardzo dobrych.
Dla równa« ró»niczkowych krzywa koncentracji jest bardziej "falista", a generalnie dla ocenponi»ej 5 w potoku b byª wi¦kszy udziaª tych ocen ni» w potoku a, gdzie z kolei wy»sza byªaliczba osób nieklasykowanych. W potoku 1 analizy matematycznej widzimy lekk¡ tendencj¦do stawiania ni»szych ocen. Geometria z algebr¡ liniow¡ I nie wykazuje specjalnych ró»nicmi¦dzy potokami.
Dla przedmiotu J¦zyk angielski - egzamin, poziom ±rednio zaawansowany ocena ndst byªazdecydowanie rzadsza ni» dla algebry, podobne zachowanie wida¢ dla trójek. Za to pozostaªeoceny stawiano cz¦±ciej, w szczególno±ci ponad dobry.

ROZDZIA 5. ANALIZA DANYCH RZECZYWISTYCH 37
5.4.2 "Terminowa" krzywa koncentracji - raport_terminowa_krzkonc
Ten raport pokazuje korzy±ci z ogl¡du krzywych koncentracji dla danego przedmiotupodzbiorów danych wzgl¦dem caªego zbioru, w tym wypadku podzbiory to zdawanie w ter-minie 1,2 i 3.
Dla algebry widzimy, »e w drugim terminie rzadziej otrzymywano oceny niedostateczneni» w zbiorze ogólnym, natomiast w trzecim terminie studenci dostali same dwóje.
Podobne tendencje widzimy dla przedmiotu analiza, przy czym w drugim terminie wida¢wyra¹niejsz¡ tendencj¦ do lepszych ocen.
Zaawansowane programowanie funkcyjne charakteryzuje najlepsza zdawalno±¢ w pier-wszym terminie. W drugim podej±ciu obserwujemy troch¦ wi¦cej dwój, ale ponad poªowaosób otrzymaªa stopie« bardzo dobry. W trzecim terminie wszyscy, którzy zdali, zaliczyliprzedmiot na ocen¦ dostateczn¡.
Dla algorytmów i struktur danych mo»emy zauwa»y¢ podobne zachowanie w rozkªadzieocen pierwszego terminu w stosunku do ogólnego zbioru. Natomiast w trzecim terminieotrzymywano praktycznie same dwóje. Podobne zachowanie przedstawiaj¡ wykresy dla el-ementów matematyki dyskretnej, z t¡ ró»nic¡ w trzecim terminie, »e poza przytªaczaj¡c¡wi¦kszo±ci¡ dwój, pojawiªy si¦ nieliczne czwórki.
Jednak nie sposób nie zauwa»y¢, »e osoby, które nie zaliczyªy danego przedmiotu w pier-wszym ani w drugim terminie, nie zdaj¡ równie» przy trzecim podej±ciu.
5.4.3 Warto±¢ oczekiwana raport_pow_oczek
Rysunki w tym raporcie odzwierciedlaj¡ warto±¢ oczekiwan¡ dystrybuanty powstaªej jakokrzywa koncentracji Algebry do pewnego przedmiotu X z listy.
Warto±¢ oczekiwana reprezentowana jest przez pokolorowan¡ powierzchni¦ (powy»ej krzy-wej koncentracji). Wysoka warto±¢ oznacza, i» przedmiot X jest "ªatwiejszy" od Algebry(gorszych studentów z X jest mniej ni» z Algebry). Dotyczy to np. przedmiotu J¦zyk angiel-ski - egzamin, poziom ±rednio zaawansowany, Prawne i spoªeczne aspekty informatyki, j¦zykii automaty, czy rachunek prawdopodobie«stwa i statystyka.
Z kolei mniejsza powierzchnia (jak np. dla Algorytmy i struktury danych) sugeruje, »eprzedmiot X jest trudniejszy od Algebry.
5.4.4 raport_pow_zmiennosvci - Zmienno±¢
Zmienno±¢ jest wyrazem dynamiki odchyle« od ±redniej w stosunku do warto±ci oczekiwanej.W analizowanych danych szczególnie wyró»nia si¦ przedmiot Zaawansowane pro-
gramowanie funkcyjne wzgl¦dem Algebry, gdy» w ich krzywej koncentracji nast¦puje ostryprzeªom mi¦dzy grup¡ osób ocenianych na 2 i na 3.
Dla przedmiotu Bazy danych obserwujemy nisk¡ zmienno±¢. Krzywa koncentracji jest tusilnie wypukªa. Dosy¢ maªa zmienno±¢ widoczna jest równie» dla prawnych i spoªecznychaspektów informatyki, przy czym dla ocen mi¦dzy trzy a cztery "lekko" wzrasta.
5.4.5 Wspóªczynnik polowy raport_wsp_polowy
Wspóªczynnik polowy to odpowiednik indeksu Gini. Du»a jego warto±¢ ±wiadczy o odbieganiurozkªadu ocen jednego przedmiotu od drugiego - na niekorzy±¢ przedmiotu na osi X.

ROZDZIA 5. ANALIZA DANYCH RZECZYWISTYCH 38
Do ilustracji grup studentów realizuj¡cych ten sam przedmiot w tzw. "potokach" (np.gad.wsp_polowy("1000-1M05TRa","1000-1M05TRb"); ) mo»na wykorzysta¢ wspóªczynnikpolowy. Przy zaªo»eniu, »e podziaª odbyª si¦ (z punktu widzenia zdolno±ci studentów)w sposób losowy, oczekuje si¦, »e wspóªczynniki polowy dla dwóch potoków winien by¢ jak na-jcie«sz¡ przek¡tn¡ kwadratu jednostkowego. Po spojrzeniu na odpowiedni wykres dla Teoriiryzyka w ubezpieczeniach, mo»na zauwa»y¢, »e niezaliczenie przedmiotu (nieklasykowaniei dwóje) oraz ocena bardzo dobra nie zale»¡ od tego, na który potok ucz¦szczaª student (poleim odpowiadaj¡ce jest dosy¢ w¡skie), natomiast w potoku b, wi¦cej osób dostaªo zwªaszczaoceny 3. Z kolei dla przedmiotu Rachunek prawdopodobie«stwa II, rozkªad ocen jest mniejwi¦cej porównywalny, z tym »e w potoku I jest tendencja do stawiania ni»szych ocen, a w po-toku II mamy wi¦cej nieklasykowanych osób. Wykres dla matematyki obliczeniowej wskazujena to, »e ci¦»ej zdoby¢ zaliczenie w potoku II. Natomiast pozostaªe oceny s¡ rozªo»one prawierównomiernie z "lekk¡" tendencj¡ do stawiania oceny ponad dostatecznej w potoku I.
Ciekawostk¡ mo»e by¢ przedmiot topologia I, gdzie w jednym potoku widoczna jest ten-dencja do stawiania ni»szych ocen: dwój i trój, a w drugim przewa»aj¡ oceny od 3.5 w gór¦.Oznacza to, »e potok I ci¦»ej jest zaliczy¢. Podobne zachowanie wida¢ dla Algebry I, z tym,»e dla potoku I przewa»aj¡ dwóje i niezaliczenia, a w potoku II najwi¦cej jest ocen mi¦dzydostateczn¡ a dobr¡. Dla przedmiotu Wst¦p do informatyki II wi¦kszo±¢ osób otrzymaªaoceny mi¦dzy dobr¡ a ponad dobr¡ dla potoku I, czyli ªatwiej byªo zaliczy¢ ten potok.
5.4.6 Krzywa pierwszego momentu raport_krz1momentu
Krzywa pierwszego momentu odbiegaj¡ca silnie od dystrybuanty ±wiadczy o tym, jak du»ajest zmienno±¢.
Dla przedmiotu zaawansowane programowanie funkcyjne krzywa pierwszego momentu jestsilnie wypukªa. Sugeruje to, »e prawdopodobnie zmienno±¢ jest du»a, podobnie jak w przy-padku elementów matematyki dyskretnej.
Podobn¡ tendencj¦ wykazuje j¦zyk angielski-egzamin, poziom ±rednio zaawansowany. Jed-nak gdy naniesiemy na jeden wykres z dystrybuant¡, oka»e si¦, »e zmienno±¢ jest niewielka.Dlatego te» sama krzywa pierwszego momentu niesie jedynie przesªanki o tym, jak du»a jestzmienno±¢.
5.4.7 Mapy nadreprezentacji raport_mapanadLeg
Mapy nadreprezentacji dotycz¡ zmiennych mierzonych na tej samej grupie obiektów, zatempokazuj¡ "korelacj¦" mi¦dzy nimi.
Mapa nadreprezentacji Algebry wzgl¦dem Algebry nie jest oczywi±cie informatywna, nato-miast pokazuje wspomniany w pracy efekt, i» im wi¦ksza jest grupa, tym z denicji ma ni»szymaksymalny wska¹nik nadreprezentacji.
Mapa algebry i analizy wskazuje, »e na skrajnych ko«cach skali ocen - pi¡tki i dwójki- s¡ zdecydowanie nieprzypadkowe i brak umiej¦tno±ci w jednej dziedzinie odzwierciedla si¦w drugiej. Podobnie jest z du»¡ wiedz¡.
Ciekawostk¡ jest by¢ mo»e asymetria wykresu dla przedmiotów Algebra kontra Algorytmyi struktury danych. Tu dwójka z Algebry jest silnie nadreprezentowana w kontek±cie nieklasy-kowania z algorytmów. Ponadto otrzymywanie ocen najwy»szych (ponad dobry i bardzodobry) jest ze sob¡ silnie zwi¡zane - mamy du»¡ nadreprezntacj¦. W analogiczny sposóbwypada zestawienie algebry z elementami matematyki dyskretnej, technikami programowania,

ROZDZIA 5. ANALIZA DANYCH RZECZYWISTYCH 39
wst¦pem do programowania, analiz¡ algorytmów, czy te» prawnymi i spoªecznymi aspektamiinformatyki.
Na uwag¦ zasªuguje te» mapa dla Algebry i Matematyki w instrumentach dªu»nych. Wida¢nadreprezentacj¦ odpowiednio 4.5 z dwójkami. Analogiczn¡ sytuacj¦ da si¦ zauwa»y¢ dlaalgebry z bazami danych. Pozostaªe oceny dla odpowiednich par przedmiotów zdaj¡ si¦ niemie¢ ze sob¡ powi¡zania.
Nasuwa si¦ pytanie, czy istnieje jakie± powi¡zanie mi¦dzy t¦»yzn¡ zyczn¡ a umysªow¡.A mianowicie, czy i jak wpªywa zaliczenie wychowania zycznego na zaliczenie przedmiotu±cisªego, w naszym przypadku algebry. Wyniki okazuj¡ si¦ zaskakuj¡ce, bowiem w ogólno±ciosoby nieklasykowane z algebry zaliczaj¡ wychowanie zyczne. Tak jest dla np. aerobiku,tenisa ziemnego, karate, jogi, badmintona, czy pªywania. Z kolei osoby, które chodz¡ naalgebr¦, nie przejmuj¡ si¦ zaliczeniem zaj¦¢ sportowych.
Co ciekawe, w przypadku algebra kontra taniec towarzyski, osoby otrzymuj¡ce z algebryocen¦ dostateczn¡ i dobr¡, przejmuj¡ si¦ zaliczeniem sportu. Natomiast zaliczenie ta«cai zaliczenie algebry na 4.5 nie s¡ ze sob¡ zwi¡zane. Kolejny wyj¡tek stanowi krav-maga(samoobrona). Tutaj studenci, którzy otrzymali stopnie ponad dostateczne i bardzo dobre,przejmuj¡ si¦ zaliczeniem wf-u. A niezaliczenie krav-magi nie zale»y od zaliczenia algebry na3.5.
Warto byªoby zastanowi¢ si¦ nad wpªywem ucz¦szczania na przedmioty humanistyczne,wyniki osi¡gane w przedmiotach ±cisªych. Czy pomagaj¡ w zdawalno±ci, czy te» j¡ utrudniaj¡.Wida¢ podobn¡ zale»no±¢, co w przypadku zaliczenia sportu; osoby zaliczaj¡ce przedmiotyhumanistyczne s¡ nieklasykowane z algebry. Takie zachowanie wida¢ dla np. narz¦dzi i metodprzetwarzania tekstu, protokoªów komunikacyjnych, algorytmiki, matematyki przy klawiaturze,akademii lmowej, varsavianistyki czy praktyk pedagogicznych.
Interesuj¡cy mo»e by¢ silny zwi¡zek mi¦dzy niezaliczeniem systemów rozproszonycha wynikiem ponad dobrym z algebry. Co wi¦cej, ani studenci czwórkowi,ani pi¡tkowi, nieprzejmuj¡ si¦ zaliczeniem z systemów. Na uwag¦ zasªuguje równie» fakt, »e pi¡tka z algebryjest niezale»na z niezaliczeniem zagadnie« programowania obiektowego, a ju» 4.5 z algebryi niezaliczenie zagadnie« s¡ silnie powi¡zane.

Rozdziaª 6
Podsumowanie
W niniejszej pracy przedstawiono podstawowe koncepcje gradacyjnej analizy danych (GAD).Opisano ich relacje z wybranymi poj¦ciami klasycznej statystyki.
Skupiono si¦ na tych jej skªadowych, które s¡ istotne z punktu widzenia analizy danychz systemu USOS, b¦d¡cych przedmiotem prac eksperymentalnych, tzn. analizie par zmien-nych o takich samych zbiorach warto±ci w niezale»nych próbkach oraz analizie par zmiennychdla jednej próbki. Ograniczono si¦ do zmiennych porz¡dkowych dyskretnych. Dlatego po-mini¦to np. analiz¦ skupie« GAD [Cio02, Cio00, KNB02] która w swej istocie zmierza dowprowadzenia najkorzystniejszego porz¡dku dla zmiennych nominalnych.
W pracy przestawiono denicje poj¦¢ GAD, ich interpretacj¦ oraz wybrane wªasno±ci,opieraj¡c si¦ na literaturze przedmiotu, uzupeªniaj¡c je wªasnymi przemy±leniami.
W szczególno±ci w niniejszej pracy pokazano, »e indeks Giniego-Simpsona mie±ci si¦ w za-kresie [0,1] (tw. 2.2.1). Sformuªowano i naszkicowano dowód twierdzenia o przekodowa-niu dziedzin zmiennych dla krzywej koncentracji (tw. 3.1.1). Sformuªowano i przedstaw-iono dowód twierdzenia o warto±ci minimalnej (tw.4.3.2) oraz maksymalnej (tw.4.3.3) funkcjinadreprezentacji, a dla zmiennych niezale»nych o jej warto±ci oczekiwanej (tw. 4.3.1).
Te trzy ostatnie twierdzenia maj¡ znaczenie przy pisaniu programu wizualizuj¡cego map¦nadreprezentacji. Tw. 3.1.1 rozstrzyga o celowo±ci transformacji dziedzin zmiennych. Nato-miast tw. 2.2.1 uwypukla zwi¡zek GS z z GAD i tradycyjnego indeksu GS.
Ponadto drobnym wkªadem jest uporz¡dkowanie denicji krzywej koncentracji (def.3.1.1)oraz powierzchni koncentracji (def.4.2.1).
Analiza gradacyjna nie jest radykalnie nowym kierunkiem eksploracyjnej analizy danych,lecz raczej prób¡ uogólnie« znanych koncepcji. Jej podstawowym walorem jest jednak naciskna wizualn¡ interpretacj¦ poj¦¢, zwyczajowo reprezentowanych przez podsumowuj¡ce liczby,takich jak warto±¢ oczekiwana, zmienno±¢, wspóªczynnik polowy (analog indeksu Giniego)itp. Ponadto wgl¡d w dane umo»liwia krzywa koncentracji (analog krzywej Lorenza) orazmapa nadreprezentacji.
Aby przybli»y¢ t¦ warto±¢ dodan¡, wykre±lono te reprezentacje graczne dla wybranychwyników egzaminów dla próbki danych z systemu USOS. Ilustracje zawieraj¡ zaª¡czniki, opisza± zawarty jest w rozdziale 5. Z wykresów mo»na m.in. odczyta¢, jakie przedmioty ªatwiejzaliczy¢, czy te» który z prowadz¡cych ten sam przedmiot jest surowszy w ocenianiu studen-tów, jak ucz¡ si¦ poszczególnych przedmiotów studentki w porównaniu ze studentami, jakajest ªatwo±¢ zaliczania w kolejnych terminach egzaminów, na ile dobre oceny z jednych przed-miotów zale»¡ od innych, czy uprawianie sportu wpªywa na uzyskiwane wyniki nauczania.
W celu realizacji eksperymentów wykorzystuj¡cych analiz¦ gradacyjn¡ do eksploracjidanych nt. wyników egzaminów zaimplementowano wybrane metody gradacyjne w j¦zyku
40

ROZDZIA 6. PODSUMOWANIE 41
programowania R. M.in. mo»na za ich pomoc¡ uzyska¢ obszarow¡ reprezentacj¦ warto±cioczekiwanej, zmienno±ci, wspóªczynnika polowego, indeksu Giniego-Simpsona, a tak»e krzywekoncentracji i mapy nadreprezentacji.
Podsumowuj¡c, wydaje si¦, »e w fazie eksploracji danych gradacyjna analiza danych mo»euªatwi¢ dostrze»enie pewnych tendencji poprzez dotarcie do obrazowej wyobra¹ni analitykai przez to stymulowa¢ jego prace badawcze.

Bibliograa
[But] Tony Buttereld. Statistical data visualization, chemical engineering, universityof utah.
[Cio00] A. Ciok. Double versus optimal grade clusterings. In Groenen P.J.F. Schader M.Kiers H.A.L., Rasson J.-P., editor, Data Analysis, Classication, and RelatedMethods, pages 4146. Springer-Verlag, 2000.
[Cio02] A. Ciok. Grade correspondence-cluster analysis applied to separate componentsof reversely regular mixtures. In Jajuga K., Sokoªowski A., Bock H.-H., editors,Classication, Clustering and Data Analysis, Recent Advances and Applications,pages 211218. Springer-Verlag, 2002.
[Cio05] A. Ciok. Grade analysis of repeated multivariate measurements. In P. Grze-gorzewski, O. Hryniewicz, M.A. Gil, editors, Soft Methods in Probability, Statis-tics and Data Analysis, pages 266273. Physica-Verlag, May 2005.
[FM00] Luisa T. Fernholz, Stephan Morgenthaler. A conversation with John W. Tukeyand Elizabeth Tukey. Statist. Sci., 15(1):7994, 2000.
[Grz10] P. Grzegorzewski. Wykªady ze statystyki i, wydziaª matematyki i nauk informa-cyjnych, rok akademicki 2009/2010., 2010.
[JJvEC02] Brower JE, Zar JH, von Ende CN. Field and laboratory techniques for generalecology. William. C. Brown Publishers, 2002.
[Kle05] Christian Kleiber. The lorenz curve in economics and econometrics. In Gini-Lorenz Centennial Conference, Siena, May 2326, 2005. May 2005.
[KMPW05] J. Ksi¡»yk, O. Matyja, E. Pleszczy«ska, M. Wiech. Analiza danych medycznych idemogracznych przy u»yciu programu GradeStat. Intytut Podstaw InformatykiPAN, Instytut "Pomnik - Centrum Zdrowia Dziecka", Warszawa, 2005.
[KNB02] T. Kowalczyk, M. Niewiadomska-Bugaj. A new grade measure of monotonemultivariate separability. In C. Cuadras, Fortiana J., J. Rodriquez-Lallena, edi-tors, Distributions with Given Marginals and Statistical Modelling, pages 143151.Kluwer Academic Publishers, 2002.
[KPR04] T. Kowalczyk, E. Pleszczy«ska, F. (eds) Ruland. Grade Models and Methods forData Analysis: With Applications for the Analysis of Data Populations, volume151 of Studies in Fuzziness and Soft Computing. Springer-Verlag, 2004.
[Tuk77] J. W. Tukey. Exploratory Data Analysis. Addison-Wesley, 1977.
42

Indeks rzeczowy
dwuwymiarowy indeks koncentracji, 26Dwuwymiarowy Model Lilipuci, 25
funkcja kwantylowa, 9funkcja prawdopodobie«stwa przej±cia, 18Funkcjonaª gradacyjny, 24
indeks Giniego, 23indeks Giniego-Simpsona, 13, 23
jednostajne przeksztaªcenie gradacyjne, 18Jednowymiarowy Model Lilipuci, 9
krzywa koncentracji, 19krzywa Lorenza, 21
wariancja zmiennej lilipuciej, 16warto±¢ oczekiwana zmiennej lilipuciej, 9wspóªczynnik ρ∗ Spearmana, 26wspóªczynnik polowy, 9, 23wygªadzona funkcja ξ, 16
zmienna lilipucia, 8, 25zmienna pierwszego momentu, 13zmienno±¢ zmiennej lilipuciej, 16
43

Wykaz rysunków
2.1 Funkcja kwantylowa wzgledem zmiennej Algebra dla zmiennej Bazy danych.Jej interpretacja jest nast¦puj¡ca: Krzywa koncentracji mówiªa nam, »e tak ¹le(nk lub ndst), jak 35% studentów algebry uczy si¦ tylko ok. 10% studentów bazdanych. Funkcja kwantylowa mówi, »e tak ¹le, jak 10% najgorszych studentówz baz danych uczy si¦ ok. 35% studentów algebry. . . . . . . . . . . . . . . . 10
2.3 Wspóªczynnik polowy wzgledem zmiennej Algebra dla zmiennej Bazy danych 122.4 Powierzchnie indeksu Giniego-Simpsona dla zmiennej Bazy danych . . . . . . 14
3.1 Krzywa koncentracji wzgledem zmiennej Algebra dla zmiennej Bazy danych . 203.2 Pªciowa krzywa koncentracji dla zmiennej J¦zyk angielski - egzamin, poziom
±rednio zaawansowany. Zmienna dla caªego zbioru (czarna krzywa) jestprzyrównywana do tej samej zmiennej zaw¦»onej raz do zbioru m¦»czyzn(krzywa niebieska), a raz do zbioru kobiet (krzywa zielona). Na rysunku wida¢,»e studentki maj¡ lepsze oceny od studentów. . . . . . . . . . . . . . . . . . . 22
4.1 Mapa nadreprezentacji wzgledem zmiennej Algebra dla zmiennej Metody nu-meryczne. Pokazuje zale»no±ci mi¦dzy ocenami studentów, którzy ucz¦szczalina oba te przedmioty. Im wi¦ksze jest nasycenie koloru zielonego, tym wi¦kszawarto±¢ nadreprezentacji odpowiadaj¡ca komórce mapy. Zwi¦kszenie nasyce-nia koloru niebieskiego, oznacza zmniejszanie si¦ warto±ci nadreprezentacji.Wielko±¢ komórki wskazuje na liczb¦ studentów o danych ocenach w stosunkudo wszystkich osób zapisanych na te przedmioty. Z rysunku wida¢, »e ocenyskrajne (2, 4.5 i 5) s¡ dla obu przedmiotów skojarzone. . . . . . . . . . . . . . 27
4.2 Mapa nadreprezentacji realizuj¡ca maksimum dla przykªadu. . . . . . . . . . 31
44

Warszawa, dnia ...............
O±wiadczenie
O±wiadczam, »e prac¦ magistersk¡ pod tytuªem: "Analiza gradacyjna teoria i zas-tosowania" , której promotorem jest dr in». Przemysªaw Biecek wykonaªam samodzielnie, copo±wiadczam wªasnor¦cznym podpisem.
................................................El»bieta Anna Kªopotek