Embed Size (px)
Citation preview

KANDIDATUPPSATS Hösten 2013 Statistiska institutionen Uppsala
Antal hörnor i Premier League-matcher
En modell för att uppskatta antalet hörnor i fotbollsmatcher
Handledare: Rolf Larsson
Författare:
Erik Holmberg

Sammanfattning
Detta arbete handlar om framtagandet av regressionsmodeller för att kunna prediktera antalet
hörnor i fotbollsmatcher, i den engelska högsta ligan Premier League, samt att utföra detta i
praktiken, genom att jämföra modellens predikterade odds med de odds som spelbolagen
erbjuder. Spelen läggs sedan då spelbolagens odds är högre än oddset enligt modellen.
Grundtanken har varit att det totala antalet hörnor på en match följer en Poisson-fördelning
och inträffar mer eller mindre slumpmässigt oberoende av vilka lag som spelar. Utifrån detta
har olika variabler, som eventuellt påverkar antalet hörnor, tagits fram från data samlat under
tre säsonger och från det har modeller tagits fram genom Poisson-regression. Målet har varit
att skapa en relativt okomplicerad modell som går att använda på så kallade live-spel, alltså
spel hos spelbolagen som sker under matchens gång.
Det visade sig att det blir fler hörnor i matcher som förväntas bli ojämna. En variabel som
hade signifikant påverkan på antalet hörnor i en match var det lägsta av det genomsnittliga
oddset satta på hemma- respektive bortaseger. Matcher med låga odds på hemma- eller
bortaseger tenderar att resultera i fler hörnor generellt. Denna variabel är den enda
förklaringsvariabel som ingår i den slutgiltiga modell som sedan använts.

Innehållsförteckning
Inledning ..................................................................................................................................... 1
Syfte och frågeställning .............................................................................................................. 2
Teori ........................................................................................................................................... 3
Sportsbettingteori .................................................................................................................... 3
Poisson/Poissonregression ...................................................................................................... 4
Metod ......................................................................................................................................... 6
Material och data .................................................................................................................... 6
Tillvägagångssätt .................................................................................................................... 6
Program .................................................................................................................................. 7
Resultat & utförande .................................................................................................................. 8
Poisson som modell ................................................................................................................ 8
Förklaringsvariabler .............................................................................................................. 10
Oberoende ............................................................................................................................. 11
Poisson-regressionen ............................................................................................................ 15
Slutlig modell ....................................................................................................................... 18
Resultat ................................................................................................................................. 22
Diskussion ................................................................................................................................ 25
Referenslista ............................................................................................................................. 28
Appendix

1
Inledning
De senaste två decennierna har sportsbetting-branschen i Sverige och världen ökat dramatiskt.
Det svenska spelmonopolet har mer och mer naggats i kanten i takt med att fler och fler
svenska och internationella spelbolag startats och tillgängligheten förbättrats tack vare
internet. Idag betalar bolagen med den minsta marginalen ut upp emot 98 % per satsad krona
till spelarna. Att jämföra med svenska spel, som i år höjde sin utdelningsprocent till ca 85 %
beroende på spelform. (Svenska spel (2013)).
Detta och den ökade konkurrensen har förbättrat möjligheterna för spelarna att tjäna pengar på
sportsbetting. Det går idag lätt att på internet hitta hemsidor där de olika spelbolagens odds
jämförs. Detta har gjort att man som innehavare av spelkonton i flera bolag får en fördel
gentemot spelbolagen.
Utvecklingen har också gjort att det idag går att spela på en mängd olika typer av spel både
innan matchen har startat och under matchens gång genom så kallad live-betting.
I denna uppsats ligger fokus på spel på hörnor och då så kallade över/under-spel vilket är en
relativt liten del av det utbud av spel som spelbolagen erbjuder.

2
Syfte och frågeställning
Syftet med detta arbete är att ta fram en modell för att kunna prediktera antalet hörnor i
fotbollsmatcher. Den modellen ska sedan användas inom sportsbetting genom att jämföra, den
från modellen uppskattade sannolikheten för ett visst utfall, med det av spelbolaget satta
oddset för samma utfall. Målet är att ta fram en modell som är så pass tillförlitlig att man i det
långa loppet kommer att vinna pengar om man följer en enkel strategi och spelar då modellens
uppskattade sannolikhet för ett utfall är högre än spelbolagets dito.
Datainsamlandet och analysen begränsas till den engelska högsta ligan, Premier League.
Grundtesen jag haft är att antalet hörnor i en match följer en Poisson-fördelning och att det är
helt slumpmässigt. Det spelar alltså ingen roll vilken match i Premier League det är och vilka
lag det är som spelar.
Min frågeställning är: Finns det någonting annat än slumpen som avgör hur många hörnor
det blir i Premier League-matcher och går det att ta fram en så pass bra modell så att man
kan tjäna pengar på att använda den inom sportsbetting?

3
Teori
Sportsbettingteori
Spelbolagens filosofi för att tjäna pengar är enkel. De sätter oddsen som ger de själva en
marginal, vilket gör att de i de flesta fallen gör vinst oavsett utfall. Vid ett visst spel så sätter
de odds så att de ligger några procentenheter under 100 %.
Ett exempel kan vara ett spel på över/under 10,5 hörnor i en fotbollsmatch. Det är alltså ett
spel med två möjliga utfall. Oddsen för bolagen skulle då kunna ligga på 1,83 för över och
1,97 för under.
Oddsen räknas om till procent med följande formel: 1/odds = uppskattad sannolikhet.
I detta exempel innebär det 1/1,83= 0,5464 respektive 1/1,97= 0,5076
Summan av de båda sannolikheterna blir då 0,5076+0,5464 = 1,0540. Normalt så ska ju
summan av sannolikheterna för två möjliga utfall som är ömsesidigt uteslutande bli ett.
Spelbolagen måste dock ha en marginal, i detta exempel 5,4 %. Denna marginal är det som
gör att spelbolagen tjänar pengar och att de flesta spelare inte gör det.
Som spelare blir strategin då att leta odds som man tycker är felsatta. Om man i exemplet
ovan anser att det är större sannolikhet än 50,8 % att det blir under 10,5 hörnor i den aktuella
matchen så är det rimligt att lägga det spelet. Om spelaren nu har en bra modell eller goda
kunskaper i att uppskatta dessa sannolikheter så ger det att han i det långa loppet kommer att
gå plus på sitt spelande. Spelaren har även det stora utbudet av spelbolag på sin sida. Han kan
helt enkelt välja det bolag som erbjuder det högsta oddset.
När det gäller liveodds, alltså spel då matchen har börjat, så är principen densamma.
Skillnaden ligger i att oddsen ändras succesivt beroende på vad som sker i matchen. Ett odds
på ett spel för under ett visst antal hörnor i en match kommer således bli lägre och lägre ju
längre matchen fortskrider så länge det inte inträffar någon hörna. De ständigt förändrade
oddsen gör det svårare för spelaren att jämföra odds mellan olika spelbolag. Man hinner inte
med att kolla upp så många olika spelbolags odds innan de har ändrats. Samma problem har
dock spelbolagen som, när det gäller liveodds, inte i samma utsträckning kan jämföra sina
odds med konkurrenternas för att se till så att man gjort en korrekt uppskattning.

4
Poisson/Poissonregression
Det jag kommer att använda mig av i detta arbete är framför allt Poisson-regression. Poisson-
regression är en regression som används för att uppskatta sannolikheten för ett visst utfall i en
Poisson-fördelning. Poisson-fördelningen kännetecknas som en diskret fördelning där antalet
oberoende händelser som inträffar under en viss tid är det väsentliga. Regressionen för det är
då en modell där det finns ett visst antal förklarande variabler och där antalet inträffade
händelser är den beroende variabeln som påverkas av dessa.
Poisson-fördelningens sannolikhetsfunktion är:
( )
Där parametervärdet µ är både väntevärdet och variansen och där Y kan anta ett värde mellan
noll och oändligheten. Här är väntevärdet = E(Y) = µ, konstant medan det i Poisson-
regression kan anta olika värden beroende på de oberoende variablerna där:
( )
( )
(Kleinbaum, Kupper, Nizam & Muller, 2008, s.666)
Omnibus-test är det test som används för att testa om någon av de oberoende variablerna
förklarar något av variationen i Y. Det är samma test som det F-test som används i vanlig
linjär regression. Vidare används också t-test på samma sätt som i vanlig regression då man
testar varje enskild variabels eventuella signifikanta påverkan.
För regression med diskreta variabler, så som Poisson-regression, så används inte R2 som ett
mått på förklaringsgraden eftersom inte minstakvadratmetoden används. Istället använder
man deviance som ett mått på hur bra modellen är. Desto lägre deviance-värdet är ju bättre
förklarar modellen. (Gelman & Hill, 2007, s.100).

5
Deviance för aktuell modell:
( ) ( ( ) ( ̂ ))
där ( ̂ ) är log likelihood för aktuell modell och ( ) är log likelihood för den fulla
modell vilket är då det finns en parameter per obeservation så att varje observation passar
modellen perfekt, alltså då y=ŷ. (Olsson, 2002, s.45)

6
Metod
Material och data
Det datamaterial som används i denna uppsats är hämtat från Premier League’s officiella
hemsida www.premierleague.com samt från www.cornerstats.com. Insamlandet har skett för
matcher tre säsonger tillbaka i tiden. Det är totalt 1140 matcher som spelats under dessa
säsonger och det har blivit totalt 12751 hörnor. Antalet hörnor i varje match är dessutom
uppdelat på första respektive andra halvlek. Vidare har mer detaljerad fakta för den senaste av
dessa tre säsonger analyserats gällande antalet hörnor för lagen individuellt.
Från den senaste säsongen har även de ordinarie match-oddsen för alla matcher samlats in.
Det är det genomsnittliga oddset för hemmaseger och bortaseger från ungefär 45 olika
bettbolag per match. Dessa data är taget från www.betexplorer.com.
Tillvägagångssätt
Denna process kan sägas ha haft en arbetsordning uppdelad i tre faser. Först datainsamlande,
därefter utarbetande av en modell och slutligen att praktiskt anamma modellen genom att
spela på matcherna. Dessa tre steg har dock inte helt följt denna logiska ordning. Delar av
data har exempelvis samlats in under processens gång då nya idéer har väckts. Jag började
även i ett tidigt stadie att testa den första grundläggande modellen som endast bygger på ett
medelvärde för alla matcher. Anledningen till det var för att snabbt få en uppfattning om det
fanns någon anledning att fortsätta med analysarbetet. Varje spel jag har lagt har
dokumenterats i Excel med information om lag, odds, matchminut för spelet och vinst/förlust
samt differensen mellan spelat odds och oddsen enligt min modell. Dokumentationen har skett
för att kunna värdera och eventuellt kunna revidera strategin.
Det praktiska spelandet har gått till så att jag innan matchstart har gjort klart med det
medelvärde som gäller för den aktuella matchen. Utifrån det har sedan procentsatser för de
olika möjliga utfallen tagits fram. Detta har jag gjort för varje ny femminutersperiod. Så då
varje ny femminutersperiod startar så jämför jag de odds som erbjuds av spelbolagen med de
odds som utfallet ”borde ha” enligt modellen. Har bolaget satt ett högre odds än min modell
så lägger jag spelet. Att dessa situationer uppkommer då bolaget har satt ett högre odds än

7
modellen sker med ojämna mellanrum. Ibland kan så vara fallet redan innan matchen startar
andra gånger kan man tvingas vänta långt in i matchen. Man ska komma ihåg att varje bolag
har sina egna modeller och erbjuder utifrån dem odds med en marginal till sin egen fördel.
Det är därför inte ovanligt, utan snarare vanligt, att bolagens odds, i ett spel med två möjliga
utfall, är lägre för båda utfallen än de odds som modellen visar. I dessa situationer är det så
klart bara att vänta eller att kolla upp hur de andra bolagen har satt sina odds. Att ha flera
spelbolag ökar så klart möjligheterna att hitta ett spelbart odds. I detta arbete har jag använt
mig av Unibet och Bet365.
Program
De statistikprogram jag använt mig av i denna uppsats är Minitab 16 och SPSS 21. Det är
framför allt vid utförande av Poisson-regression som SPSS har använts då det inte finns
tillgängligt i Minitab. Jag har även använt Excel vid vissa enklare uträkningar samt för
nedskrivandet av resultaten från spelstrategin.
I och med att jag inte kommenterar var enskilt p-värde i de test jag gör i denna uppsats så kan
det vara viktigt att poängtera att jag alltid använt mig av en signifikansnivå på 5 % i detta
arbete.

8
Resultat & utförande
Poisson som modell
Till att börja med tas beskrivande statistik för hela datamaterialet fram, alltså för alla 1140
observationer under tre säsonger. Jag har utgått från den genomsnittliga matchtiden som är 95
minuter. 95 minuter är alltså de ordinarie 90 minuterna plus den genomsnittliga så kallade
stopptiden på fem minuter.
Tabell 1. Descriptive Statistics: Hörnor Variable N N* Mean Variance Minimum Maximum
totalt 1140 0 11,180 13,886 1,000 25,000
Här kan vi se medelvärdet som ligger på 11,18 hörnor per match. Vad som här visar sig
problematiskt är att variansen är något större än medelvärdet. I en Poisson-fördelning så ska
medelvärdet och variansen beskrivas av samma parameter: λ. Medelvärdet och variansen ska
således vara lika. I och med att jag har ett så pass stort urval som 1140 så är det rimligt att
anta att medelvärdet och variansen inte är lika för antalet hörnor per match utifrån den
beskrivande statistiken ovan.
Jag går då vidare med att testa hur väl datamaterialet följer en Poisson-fördelning genom att
göra ett Goodness of fit-test.
∑ ( ) ̂
( )̂

9
Hörnor
>=22212019181716151413121110987654
<=3
140
120
100
80
60
40
20
0
Va
lue
Expected
Observed
Chart of Observed and Expected Values
Diagram 1
15461810814111316972012<=
32117519
>=2
2
16
14
12
10
8
6
4
2
0
Hörnor
Co
ntr
ibu
ted
Va
lue
Chart of Contribution to the Chi-Square Value by Category
Diagram 2
Tabell 2 N N* DF Chi-Sq P-Value
1140 0 18 61,5565 0,000
Här ser vi att de förväntade och de observerade värdena inte matchar nog mycket. Chi2-värdet
är närmare 62 och p-värdet 0 vilket indikerar att vi måste förkasta nollhypotesen att
datamaterialet skulle komma från en Poisson-fördelning.
Utifrån detta diagram så kan man se det som nämndes ovan, att variansen är större än vad den
rimligtvis borde vara för att följa en Poisson-fördelning på ett bra sätt. Det är alltså främst
värdena i svansarna på diagrammet som gör att testet misslyckas med att acceptera

10
nollhypotesen. Detta visar på att vi har ”överspridning”. Det innebär att den Poisson-
fördelning jag testar har varians som är större än medelvärdet. Som en lösning på detta kan
man använda sig av en negativ binomial-fördelning istället för Poisson-fördelning. Man får då
två olika parametrar, för medelvärdet och en för variansen. Det skulle kunna ge ett bättre
utfall för goodness of fit-testet. (Olsson, 2002, s.133)
För att anpassa data till en negativ binomial-fördelningen så får man se varje minut som ett
försök och varje hörna som ett lyckat försök. Problemet med det är då att det i verkligheten
kan ske mer än en hörna per minut. Det är något jag har varit tvunget att ha överseende med i
och med att jag testat detta. Medelvärdet för antalet hörnor per match (11,18) har delats med
antal minuter (95) för att få fram sannolikheten för inträffad hörna under en minut. Den
sannolikheten blir då 0,1177.
Det visar sig dock att denna fördelning knappast är en bättre passande fördelning här.
Goodness of fit-testet för negativ binomial över datamaterialet visar ett chi2-värde på 112.
Eftersom 112 överstiger det kritiska värdet på 5 % signifikansnivå och 18 frihetsgrader,
28,869, så förkastas nollhypotesen att datamaterialet skulle komma från en negativ binomial-
fördelning. (Kleinbaum, Kupper, Nizam & Muller, 2008, s.824).
Förklaringsvariabler
Då även den negativa binomial-fördelningen har svårt att förklara variationen i datamaterialet
så återstår möjligheten att återgå till Poisson och ta hänsyn till möjliga förklaringsvariabler för
att kunna utföra en Poisson-regression. Jag håller mig här till en säsong (den för 2012/13) för
att kunna ta fram data rörande variabler som inte finns tillgängligt längre tillbaka i tiden.
I framtagandet av förklaringsvariablerna har jag tagit två saker i beaktande. Först så har jag
försökt gå ner på lag-nivå för att se hur antalet hörnor skiljer mellan lag. Svårigheterna här är
att lagen ständigt förändras. Ett lag kan byta tränare, spelare och/eller taktik när som helst
under säsongen. Lagen spelar dessutom ofta olika beroende på motstånd. På lag-nivå blir
dessutom datamängden mindre då varje enskilt lag endast spelar 38 matcher i Premier League
per säsong. Det hela kompliceras ytterligare i och med att tre av lagen byts ut efter varje
säsong. Vad jag gjort för att få fram en bra rimlig variabel för detta är att jag tagit fram
medelantalet hörnor för respektive lags senaste hemma- och bortamatcher hittills under

11
säsongen, alltså ett genomsnitt för hemmalagets antal hörnor per hemmamatch och bortalagets
antal hörnor per bortamatch. Varje lags första hemma- respektive bortamatch har således inte
tagits med i datamaterialet.
Det andra jag utgått ifrån då jag tagit fram förklaringsvariabler är med hänsyn till den
matchtyp som är aktuell. Min tanke här har varit att gruppera matcherna efter hur jämn eller
ojämn en match förväntas bli. Dels har jag tagit fram en variabel som utgår ifrån oddset på
matchen. Det odds jag valt är det odds för hemmaseger respektive bortaseger som varit lägst.
Ett lågt odds indikerar att ett av lagen är storfavorit att vinna vilket rimligtvis borde leda till
en ojämn match. Ett högt odds för, eller snarare en match där oddset för hemmaseger och
bortaseger är relativt lika ger i motsats indikation om en jämn match. Därför väljer jag det
lägsta oddset av de två att ha som variabel så att det möjliggör ett linjärt samband. Denna
variabel har jag tagit med för att se om man kan se någon förväntad skillnad i antalen hörnor
beroende på förväntad jämnhet i matchen. Oddsen för matcherna är tagna från websidan:
www.betexplorer.com och är ett genomsnittsodds från ett fyrtiotal olika bettbolags respektive
odds.
Den tredje variabeln jag har tagit fram är en variant av den andra. Här har jag dock gjort en
subjektiv bedömning och delat upp matcherna i fyra olika kategorier. Lagen har delats upp i
två grupper. En med sex lag och en med de resterande 14. Den första gruppen är de sex bästa
lagen i serien. Arsenal, Chelsea, Liverpool, Manchester City, Manchester United och
Tottenham. Dessa kodas i denna dummyvariabel som ”1” för bra lag och övriga lag kodas
som ”0”. Det blir då totalt sett fyra olika grupper beroende om lagen spelar borta eller hemma.
Gruppernas respektive kod blir där av: 1.1, 1.0, 0.1 samt 0.0. De två dummyvariablerna får
namnen Hemmalag respektive bortalag.
Oberoende
Innan jag går vidare med Poisson-regressionen så analyserar jag datamaterialet ytterligare. Ett
antagande jag gör i användandet av Poisson-regression är att händelserna är oberoende. I mitt
insamlade data har jag även tagit med antalet hörnor i första och andra halvlek. Tanken var att
det här skulle kunna finnas ett beroende på så vis att en match med många hörnor i första
halvlek med större sannolikhet leder till många hörnor i andra halvlek och tvärtom. För att
testa det så gör jag ett Wilcoxons parvisa test. Då den andra halvleken generellt är längre än

12
den första på grund av tilläggsminuter i slutet på halvlekarna så korrigerade jag det genom att
dela varje observation för antalet hörnor i en halvlek med det genomsnittliga antalet minuter
som en halvlek varar. Genomsnittslängden för första halvlek är strax över 46 minuter och
motsvarande siffra för andra halvlek är 49. Nollhypotesen är att medelvärdet för korrigerad
första halvlek och korrigerad andra halvlek är lika.
Tabell 3. Wilcoxon Signed Ranks Test
Ranks
N Mean Rank Sum of Ranks
KorrAndraHalv –
KorrFörstaHalv
Negative Ranks 554a 515,79 285749,00
Positive Ranks 586b 622,22 364621,00
Ties 0c
Total 1140
a. KorrAndraHalv < KorrFörstaHalv
b. KorrAndraHalv > KorrFörstaHalv
c. KorrAndraHalv = KorrFörstaHalv
Tabell 4
Test Statisticsa
KorrAndraHalv -
KorrFörstaHalv
Z -3,547b
Asymp. Sig. (2-tailed) ,000
a. Wilcoxon Signed Ranks Test
b. Based on negative ranks.
Vi har ett P-värde på 0,000 vilket indikerar att vi på 5 % signifikansnivå förkastar
nollhypotesen till förmån för alternativhypotesen. Resultatet av testet visar på att det finns en
skillnad även då man tagit hänsyn till halvlekarnas medellängd. För att belysa vad det innebär
så tar jag fram en Poisson-regression med antalet hörnor som beroende variabel och antal
hörnor i första halvlek som förklarande variabel.

13
Tabell 5
Parameter Estimates
Parameter B Std. Error
95% Wald Confidence Interval Hypothesis Test
Lower Upper
Wald Chi-
Square df Sig.
(Intercept) 5,367 ,1712 5,031 5,702 982,323 1 ,000
FörstaHalvlek ,105 ,0301 ,046 ,164 12,122 1 ,000
(Scale) 1a
Dependent Variable: AndraHalvlek
Model: (Intercept), FörstaHalvlek
a. Fixed at the displayed value.
Här kan vi tydligt se sambandet. Antalet hörnor i första halvlek har en signifikant påverkan på
antalet hörnor i andra halvlek. För varje hörna i första halvlek så blir det enligt modellen 0,1
hörna extra i andra halvlek utöver interceptet på 5,367. Detta kan dock ses som en relativt
liten påverkan. Om det exempelvis blir tio hörnor i första halvlek, vilket är ett extremt högt
antal, så kan man förvänta sig att det blir en hörna extra i andra halvlek. Det föreligger dock
signifikans för att antal hörnor i första halvlek påverkar antalet hörnor i andra halvlek, vilket
man bör ha i åtanke. Det bör således finnas något annat än slumpen som påverkar antalet
hörnor. Vad som skulle kunna förklara detta är det jag kommer att gå vidare med. Man kan
tänka sig att de olika matchtyperna eller lagen har betydelse här. I en match där det förväntade
antalet hörnor är högt så borde ju även det förväntade antalet hörnor för varje enskild halvlek
också vara det. Det kan möjligen förklara sambandet.
De grupper jag beskrivit ovan och som jag kommer att använda i Poisson-regressionen är
baserade på om hemmalaget och/eller bortalaget är ett ”bra” lag eller inte. De så kallade bra
lagen beskrivs inte sällan i brittisk media som ”the big six”. Det ger då en uppdelning av
datamaterialet i fyra grupper utifrån de kombinationer av de lagen som spelar hemma och
borta. För att få en överblick över de grupperna tar jag fram en Anova för att jämföra
gruppernas olika medelvärden.

14
Tabell 6. One-way ANOVA: totalt versus Matchtyp Source DF SS MS F P
Matchtyp 3 108,4 36,1 2,61 0,050
Error 1136 15707,7 13,8
Total 1139 15816,1
S = 3,718 R-Sq = 0,69% R-Sq(adj) = 0,42%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ------+---------+---------+---------+---
0,0 545 10,971 3,658 (-----*------)
0,1 253 11,134 3,782 (--------*--------)
1,0 252 11,746 3,922 (--------*--------)
1,1 90 10,989 3,289 (---------------*--------------)
------+---------+---------+---------+---
10,50 11,00 11,50 12,00
Vi har här ett p-värde på 0,05 så det är gränsfall ifall man på 5 % signifikansnivå kan hävda
att det råder skillnad mellan de olika gruppernas medelvärden.
Vad som visar sig när man fortsätter analysera dessa grupper är att tre av fyra kan antas följa
en Poisson-fördelning om man testar dem separat på 5 % signifikansnivå.
Tabell 7. Goodness-of-Fit Test for Poisson Distribution Data column: 1.1
Poisson mean for 1.1 = 10,9889
N N* DF Chi-Sq P-Value
90 0 12 11,6697 0,473
Data column: 1.0
Poisson mean for 1.0 = 11,7460
N N* DF Chi-Sq P-Value
252 0 16 24,6656 0,076
Data column: 0.1
Poisson mean for 0.1 = 11,1344
N N* DF Chi-Sq P-Value
253 0 15 20,8808 0,141
Data column: 0.0
Poisson mean for 0.0 = 10,9908
N N* DF Chi-Sq P-Value
545 0 17 29,6650 0,029

15
Det är alltså endast den grupp som kodats 0.0 som på 5 % signifikansnivå inte kan antas vara
Poisson-fördelad. Gruppen 0.0 har i goodness-of-fit-testet ett p-värde på 0,029 vilket gör att
nollhypotesen, att data kommer från en Poisson-fördelning, förkastas. För övriga grupper kan
nollhypotesen inte förkastas på 5 % signifikansnivå. Det är å andra sidan den grupp som
består av det största urvalet vilket kan påverka.
Poisson-regressionen
Jag vill nu försöka ta fram en bra modell för att prediktera antalet hörnor i en match. För att
göra det använder jag mig av Poisson-regression i SPSS. De förklaringsvariabler jag har tagit
fram är, som nämnts tidigare, följande:
1. Medelantal Hörnor
2. Favoritodds
3. Hemmalag
4. Bortalag
Jag tar här hänsyn till den integrerade effekten av mina två dummy-variabler; Hemmalag och
Bortalag vilket leder till att jag får fyra förklaringsvariabler utifrån dessa då de båda är kodade
”0” och ”1”. Det fyra variablerna representerar de fyra grupperna som jag delat in
datamaterialet i.
I utskrifterna, som jag bifogar i appendix, får man först ut ett test kallat omnibus test. Det är
ett F-test som jämför den aktuella modellen med en modell med endast interceptet.
Hypoteserna för testet är:
Ett p-värde under 0,05 visar således på att det finns signifikans för att minst en av
förklaringsvariablerna i modellen förklarar någonting av variationen i beroendevariabeln.
Vidare finner man under ”Tests of model effects” Chi2-värden för interceptet och
förklaringsvariablerna med p-värden som visar på eventuell signifikans för de olika
variablerna. Dessa testas precis som i vanlig regression med t-test med hypoteserna:

16
I den tredje delen av utskriften kan man även se parametrarnas konfidensintervall som inte
ska innesluta noll om den aktuella förklaringsvariabeln ska ha signifikant påverkan på den
beroende variabeln.
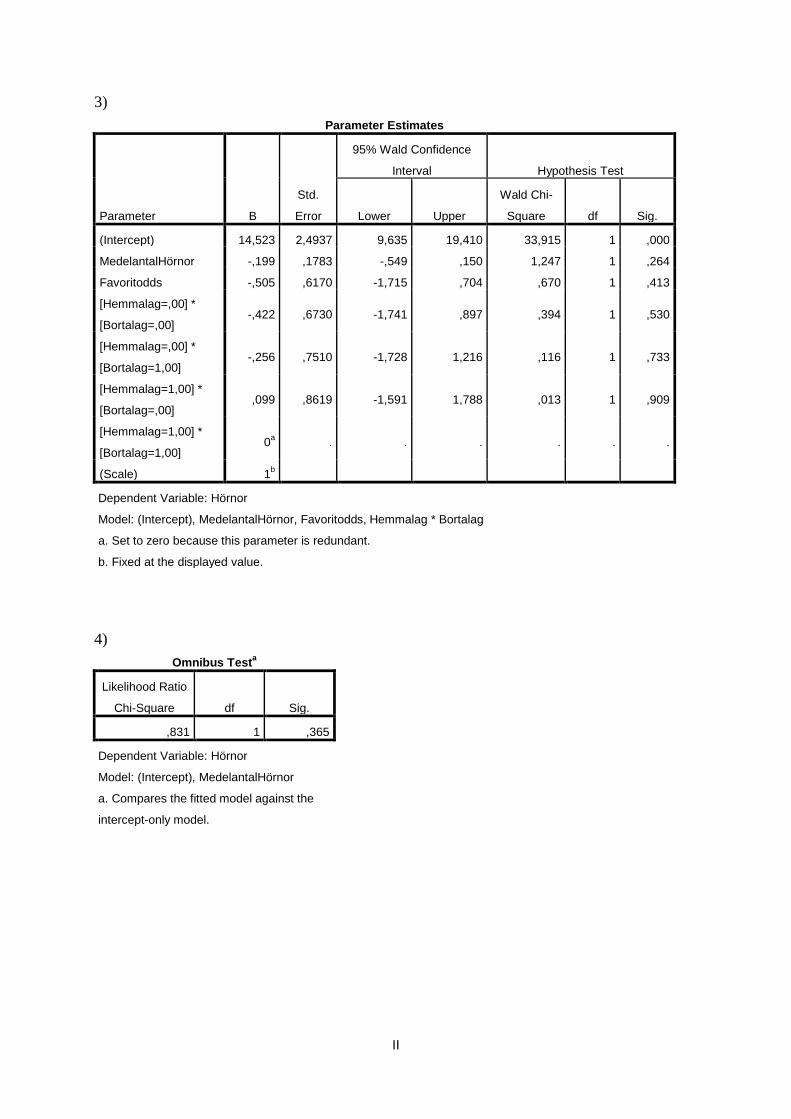
I den första modellen testar jag med alla mina fyra förklaringsvariabler. Här har vi endast 363
observationer eftersom data för variabeln ”medelantal hörnor” endast är insamlat från en
säsong. Utskrifterna för detta test finns i appendix, tabell 1-3.
Vi kan här se respektive förklaringsvariabels p-värde och att ingen av dem har en signifikant
påverkan på variationen för antalet hörnor. Hela modellen har ett p-värde på 0,385 vilket
indikerar att det inte finns signifikans för att någon av förklaringsvariablerna i modellen är
skild från noll. Jag går sedan vidare med analys av variabeln ”medelantal hörnor” genom att
utföra samma procedur med endast den som förklarande variabel. Dessa utskrifter finns i
appendix, tabell 4-6.
Inte heller nu så är förklaringsvariabeln signifikant. P-värdet är 0,365 så man kan alltså inte
påstå att variabeln ”medelantalet hörnor” påverkar antalet hörnor då det är den enda
förklaringsvariabeln i modellen. Sammanfattningsvis så finns det inget som tyder på att antal
hörnor i en match påverkas av de medverkande lagens hörnsnitt. Jag väljer därför att
fortsättningsvis inrikta mig på de övriga variablerna. Alltså de två dummy-variablerna
”hemmalag” och ”bortalag” samt variabeln ”Favoritodds”. När det gäller dessa två variabler
så är datamaterialet också större då insamlingen här skett för tre säsonger tillbaka i tiden,
vilket motsvarar 1140 observationer. Utskrifterna för Poisson-regressionen med dessa som
förklarande variabler finns i appendix, tabell 7-9.
I och med borttagandet av variabeln ”medelantal hörnor” så har nu modellen förbättrats. P-
värdet för modellen är nu 0,058 mot 0,385 tidigare. Det visar en bättre modell men har på 5 %
signifikansnivå ändå inte en signifikant förklaringsgrad. Tittar man på de enskilda variablerna
är de heller inte signifikant skilda från noll utan har istället alla väldigt höga p-värden. Detta
skulle rimligtvis kunna tyda på multikollinearitet. Alltså att förklaringsvariablerna förklarar
samma del av variationen i beroendevariabeln. Ett tydligt tecken på det brukar vara just lågt

17
p-värde för modellen samtidigt som förklaringsvariablerna är icke-signifikanta. (Asteriou &
Hall, 2011, s.102-104).
Dummy-variabeln är ju utformad på ett sådant sätt att de olika grupperna inte skiljer sig i så
stor grad från variabeln ”favoritodds”. I gruppen 1.0 exempelvis, som är den grupp där något
av de bra lagen spelar hemma mot något av de sämre lagen, så är det i stort sett uteslutande
låga odds på hemmaseger. Medelvärdena för variabeln ”Favoritodds” sammanfattas i följande
tabell:
Tabell 8. Descriptive Statistics: Favoritodds Variable grupp N Mean Minimum Maximum
Favoritodds 0.0 546 2,0859 1,3600 2,6800
0.1 252 1,8395 1,1900 2,6200
1.0 252 1,3618 1,0900 2,3500
1.1 90 2,1080 1,4900 2,7100
Det verkar alltså rimligt att testa Poisson-regressionen med dessa variabler enskilt som
förklaringsvariabler i modellen. Alltså dummy-variablerna för sig och variabeln
”Favoritodds” för sig i var sin Poisson-regression.
När det gäller dummy-variablerna testar jag både att ta hänsyn till integrationen, alltså så att
det blir fyra olika grupper, på samma sätt som jag gjort tidigare, samt att inte ta hänsyn till
integrationen mellan dummy-variablerna för att se om någon av dem har en separat påverkan.
Anledningen till att jag testar båda dessa sätt är att Poisson-regressionen då integreringen
mellan dummy-variablerna tas hänsyn till visar en signifikant modell men icke-signifikanta
variabler på 5 % signifikantnivå. Detta kan ses i appendix, tabell 10-12.
I de påföljande tabellerna; 13-15 i appendix så ges resultatet för Poisson-regressionen utan
integrerade dummy-variabler. Här ser vi till skillnad från i föregående tabeller att en av
variablerna (Hemmaodds) har en signifikant påverkan på modellen. Å andra sidan så är nu
modellen ånyo icke-signifikant. Om man då istället endast tar med dummy-variabeln
”Hemmalag” så blir modellen bättre. (Tabell 16-18 i appendix). Både modellen och
förklaringsvariabeln är då signifikanta på 5 % signifikantnivå. Detta är alltså en modell som
predikterar antalet hörnor i en match utifrån om hemmalaget tillhör ett av de sex bra lagen
eller inte. Det blir således en uppdelning i två grupper där den med ett bra hemmalag har ett
väntevärde på 11,535 hörnor per match medan den andra gruppen med ett av de dåliga lagen
som hemmalag har ett väntevärde på 11,04.

18
Slutlig modell
Den sista kvarvarande variabeln att testa är nu ”Favoritodds”. Resultatet av Poisson-
regressionen med den som förklaringsvariabel finns i appendix, tabell 19-22. Här har vi en
modell med en förklaringsvariabel som är signifikant på 5 % signifikansnivå och då det är
endast en förklarande variabel så är även modellens förklaringsgrad signifikant. Här är det
alltså inte frågan om en dummy-variabel som i tidigare fall så det predikterade antalet hörnor
varierar beroende på oddsen på hemma- och bortaseger i den aktuella matchen.
Den här modellen är, om man jämför utskrifterna, i det närmaste likvärdig som modellen med
”Hemmalag” som förklarande variabel. Det är dock denna senast framtagna modell jag valt
att använda mig av. Anledningen till att den valdes före den till synes likvärdiga modellen
med förklaringsvariabeln ”Hemmalag” hade med gruppernas medelvärden att göra. Här så
kommer grupperna 1.0 och 1.1 att betraktas som en grupp. Gruppernas urvalsmedelvärden är
10,99 respektive 11,75. De är förvisso inte signifikant skilda då man tittar på Anova-testet,
tidigare i arbetet. Urvalsstorleken är dock relativt liten för grupp 1.0 och jag vill hålla
möjligheten öppen för att det faktiskt är skillnad mellan medelvärdet i dessa grupper och
väljer därför modellen med variabeln ”Favoritodds” som förklaringsvariabel.
Det antagandet som görs i Poisson-regression är att E(Y) = Var(Y). Det görs genom ett
överspridningstest som är ett chi2-test.
∑
Här får vi fram 1423/1138= 1,251, vilket även kan ses i tabell 19 i appendix. Det kritiska
värdet för testet är 334 vilket är klart högre än 1,251. Vi kan således inte förkasta
nollhypotesen att E(Y) = Var(Y) på 5 % signifikansnivå. De standardiserade residualerna bör
ha en standardavvikelse nära ett. (Gelman & Hill, S.115). I normalitetstestet för residualerna
nedan kan vi se att i detta fall är det 1,117 vilket alltså är roten ur 1,251. Vi kan även i detta
diagram se att residualerna är normalfördelade på 5 % signifikansnivå. Detta är viktigt då man
bör ha approximativt normalfördelade residualer för ett så pass stort urval om modellen ska
vara korrekt specificerad. (Idre UCLA, 2014).

19
43210-1-2-3-4-5
99,99
99
95
80
50
20
5
1
0,01
Standardized Residuals
Pe
rce
nt
Mean -0,06294
StDev 1,117
N 1140
AD 0,603
P-Value 0,117
Probability Plot of Standardized ResidualsNormal
Diagram 3
När det gäller residualernas spridning så är den större för högre predikterade värden i och med
att varians är lika med väntevärde för Poisson-fördelningen. Ett diagram för detta kan ses här
nedan (diagram 4) där de standardiserade residualerna från regressionen plottas mot de
predikterade värdena. I detta diagram kan man även upptäcka eventuella uteliggare. Det bör
inte finnas observationer större än ungefär |3|, då det är definitionen för så kallade uteliggare.
(Kleinbaum, Kupper, Nizam & Muller, 2008, s.295-300). Denna tolkning av residualerna
gäller linjär regression så väl som Poisson-regression.
Diagram 4

20
Det kan i detta diagram vara svårt att se en ökad spridning för högre predikterade värden.
Detta beror på att skalan och de relativt små skillnaderna mellan värdena på x-axeln. När det
gäller uteliggare kan man se att det finns några enstaka. Att plocka bort uteliggarna ut
datamaterialet visar sig försämra p-värdet för modellen. Istället så ändrar jag alla så att alla
matcher med hörnor över 20 till 20. Anledningen till det är att få ett medelvärde för hela
datamaterialet som bättre stämmer in med antalet för de olika utfallet som är rimliga att spela
på då modellen ska omsättas i praktik. De vanligaste spelutbuden som finns inför en match är
över/under; 9,5, 10,5 och 11,5. Grundmodellen, där endast medelvärdet och inga
förklaringsvariabler tas hänsyn till, uppskattar dessa olika utfall på följande sätt innan
uteliggarna har tagits bort:
Tabell 9
Hörnor över under
9,5 66,05% 33,95%
10,5 54,56% 45,44%
11,5 43,77% 56,23%
Om man däremot utgår från datamaterialet och ser hur stora delar av de 1140 matcherna som
antagit de olika utfallen så ser fördelningen lite annorlunda ut.
Tabell 10
Hörnor över under
9,5 67,96% 32,04%
10,5 56,24% 43,76%
11,5 44,32% 55,68%
I och med det stora urval som gjorts så är detta en rimlig fördelning. Då Poisson-fördelningen
inte följs helt i grundmodellen och då det finns en hel del observerade extremvärden framför
allt i högersvansen på fördelningen, så är det bra om modellen kan redigeras något. Då jag
redigerat modellen genom att ha plockat bort uteliggarna så ligger medelvärdet istället på
11,1485 hörnor per match. Det ger en grundmodell vars fördelning för dessa utfall blir:

21
Tabell 11
Hörnor över under
9,5 67,63% 32,37%
10,5 55,87% 44,13%
11,5 43,95% 56,05%
Fördelningen ligger nu efter borttagande av uteliggarna närmare det faktiska utfallet från
insamlat datamaterial.
Utskriften från den redigerade slutgiltiga ser då ut på följande sätt:
Tabell 12
Omnibus Testa
Likelihood Ratio
Chi-Square Df Sig.
4,798 1 ,028
Dependent Variable: RedigeradeHörnor
Model: (Intercept), Favoritodds
a. Compares the fitted model against the
intercept-only model.
Tabell 12
Tests of Model Effects
Source
Type III
Wald Chi-
Square Df Sig.
(Intercept) 694,133 1 ,000
Favoritodds 4,803 1 ,028
Dependent Variable: RedigeradeHörnor
Model: (Intercept), Favoritodds

22
Tabell 13
Parameter Estimates
Parameter B Std. Error
95% Wald Confidence Interval Hypothesis Test
Lower Upper
Wald Chi-
Square df Sig.
(Intercept) 12,139 ,4607 11,236 13,042 694,133 1 ,000
Favoritodds -,524 ,2392 -,993 -,055 4,803 1 ,028
(Scale) 1a
Dependent Variable: RedigeradeHörnor
Model: (Intercept), Favoritodds
a. Fixed at the displayed value.
I och med borttagandet av uteliggarna så har nu modellen förändrats något. P-värdet har blivit
lite högre för förklaringsvariabeln men har fortfarande en signifikant påverkan på modellen på
5 % signifikansnivå. Detsamma gäller modellen som helhet i Omnibus-testet.
Interceptet är 12,139 vilket innebär att en match med ett väldigt lågt odds kommer att ha ett
predikterat antal hörnor nära 11,6. För varje ökning av oddset med ett kommer det förväntade
antalet hörnor i matchen att minska med 0,524. Det maximala värdet på variabeln
”Favoritodds” ligger runt 2,7. Detta beror på att variabeln består av det lägsta av oddset för
hemma-respektive bortaseger vilka är beroende av varandra. Så när exempelvis oddset för
hemmaseger ligger över 2,7 så kommer oddset för bortaseger vara under 2,7 vilket gör att det
då blir det lägre oddset som ingår i variabeln. Det högsta värdet (oddset) i det datamaterial jag
använt är 2,71 och det kan alltså inte i praktiken vara speciellt mycket högre än så. Det
predikterade antalet hörnor för en match kommer därför att vara som lägst ungefär 10,7 och
alltså som högst ungefär 11,6.
Resultat
Som beskrivits tidigare så har arbetande med framtagningen av denna modell skett samtidigt
som det praktiska anammandet av modellen. Jag har eftersom jag fått fram nytt data och nya
förklaringsvariabler lagt till dem och fått nya förutsättningar för spelandet. Den största delen
av spelandet har hittills skett med det som jag i denna uppsats kallar grundmodellen. Det är
den modell som endast utgår från ett medelvärde och där ingen skillnad görs beroende på
matcher eller lag. Förutsättningarna för spelandet har sedan förändrats i takt med att jag tagit
med andra variabler och samlat mer data.

23
Tillvägagångsättet under matcherna har dock inte förändrats. Jag har utgått från framtagna
excel-dokument som grundas på modellens medelvärde för den aktuella matchen. Nya
förutsättningar har tagits fram för varje ny femminutersperiod i dokumentet. Här nedan är ett
exempel på hur det ser ut för förutsättningarna fem minuter in i en match med favoritodds 2,1
gånger pengarna.
Tabell 14
Efter 5 min spel
Frekvens Kumulativ Odds under Odds över
f(0) 0,0000 F(0) 0,0000 under 0,5 34756,09 Över 0,5 1,00
f(1) 0,0003 F(1) 0,0003 under 1,5 3033,85 Över 1,5 1,00
f(2) 0,0016 F(2) 0,0019 under 2,5 525,64 Över 2,5 1,00
f(3) 0,0055 F(3) 0,0074 under 3,5 135,42 Över 3,5 1,01
f(4) 0,0143 F(4) 0,0217 under 4,5 46,05 Över 4,5 1,02
f(5) 0,0300 F(5) 0,0517 under 5,5 19,35 Över 5,5 1,05
f(6) 0,0522 F(6) 0,1039 under 6,5 9,62 Över 6,5 1,12
f(7) 0,0780 F(7) 0,1819 under 7,5 5,50 Över 7,5 1,22
f(8) 0,1020 F(8) 0,2839 under 8,5 3,52 Över 8,5 1,40
f(9) 0,1185 F(9) 0,4023 under 9,5 2,49 Över 9,5 1,67
f(10) 0,1239 F(10) 0,5262 under 10,5 1,90 Över 10,5 2,11
f(11) 0,1177 F(11) 0,6439 under 11,5 1,55 Över 11,5 2,81
f(12) 0,1026 F(12) 0,7465 under 12,5 1,34 Över 12,5 3,94
f(13) 0,0825 F(13) 0,8290 under 13,5 1,21 Över 13,5 5,85
f(14) 0,0616 F(14) 0,8906 under 14,5 1,12 Över 14,5 9,14
f(15) 0,0430 F(15) 0,9336 under 15,5 1,07 Över 15,5 15,05
f(16) 0,0281 F(16) 0,9616 under 16,5 1,04 Över 16,5 26,07
f(17) 0,0173 F(17) 0,9789 under 17,5 1,02 Över 17,5 47,41
f(18) 0,0100 F(18) 0,9889 under 18,5 1,01 Över 18,5 90,38
f(19) 0,0055 F(19) 0,9945 under 19,5 1,01 Över 19,5 180,37
I denna tabell kan man alltså läsa av modellens uppskattade sannolikhet och odds för de
rimliga utfallen. I kolumnen för kumulativa sannolikheter så innebär varje rad sannolikheten
för att det blir det aktuella antalet eller färre hörnor från nu. Så om det hittills har blivit två
hörnor i matchen innebär värdet till höger om F(10) sannolikheten att det blir under 12,5
hörnor i matchen totalt. Detta gäller i och med att jag antagit oberoende. I de färgade
kolumnerna är sedan varje sannolikhet omräknad till det motsvarande oddset i den form som
de framställs på spel-sajterna. Det man gör är sedan bara att jämföra de odds modellen
predikterar med de odds som spelbolaget erbjuder. Har spelbolaget ett högre odds än
modellen så lägger man ett spel.

24
För att kunna utvärdera modellen så registrerar jag alla spel i excel med information från varje
lagt spel enligt följande:
Tabell 15
Minut Match Över/Under
Odds enligt
modell Odds
spelbolag Insats Vinst Kr Differens
5 Ars- Ast u12,5 1,97 2,25 100 125 6,3%
40 Che- Ast ö5,5 2 2,2 100 130 4,5%
30 Ful- Ars ö12,5 2,1 2,35 100 135 5,1%
15 New- WeH ö10,5 1,67 1,83 100 -100 5,2%
20 Eve- Wba u8,5 2,1 2,3 100 -100 4,1%
35 Sou- Sun u10,5 1,7 1,8 100 80 3,3%
45 Sto- CrP ö8,5 1,86 2 100 -100 3,8%
70 Hul- Nor ö4,5 1,4 1,5 100 50 4,8%
15 Ast- Liv ö8,5 1,66 1,83 100 83 5,6%
Här jämförs modellens odds med spelbolagets odds vilket ger en differens i procentenheter
räknat. Denna differens bör inte vara allt för låg. Jag har använt mig av en gräns på tre
procentenheter som lägst differens för att spela på det aktuella spelet. Detta för att ha en viss
marginal för modellen. Då det finns ett spelbart spel med en nog hög differens, för ett av
alternativen över eller under, så tenderar det att fortsätta vara en differens för det spelet i
fortsättningen av matchen. Uppenbarligen är det då något som spelbolaget bedömer
annorlunda eller som skiljer deras modell från min. Därför spelar jag endast ett spel per match
oavsett om nya spelbara spel uppkommer. Det gör jag för att inte riskera att förlora för mycket
på en och samma match. Det spel jag lägger är alltid 100 kronor. Den eventuella vinsten
alternativt förlusten på 100 kronor skrivs sedan in i kolumnen ”vinst kr”. (Utskrift för alla
bokförda spel, se tabell 23 Appendix).
Totalt sett har jag hittills spelat 170 spel. Det är då räknat med både grundmodellen och, den
här, senast framtagna modellen som använts i de senaste 76 spelen. Totalt sett har det
inneburit en vinst på 1435 kronor. Inom sportsbetting används ofta uttrycket ROI (return on
investment) som ett mått på hur framgångsrik en spelstrategi är (Sportsbettingpal, 2013). Det
räknas ut med att ta den totala nettovinsten delat med den totala omsättningen. I detta fall
skulle det innebära ett ROI på 8,4 %. Vilket indikerar 8 kronor vinst på varje satsad hundring.
När det gäller endast den slutligen framtagna modellen som är testad på 76 spel så är
nettovinsten 630 kr med ett ROI på 8,3 %.

25
Diskussion
Mitt mål med detta arbete har varit att ta fram en bra och enkel modell för att använda inom
sportsbetting. Ibland har det inneburit att tillvägagångsättet inte alltid varit helt korrekt ur en
statistisk synvinkel. Tanken har varit att om det går att tjäna pengar på modellen så är det
sekundärt om ett goodness-of-fit-test förkastas eller uteliggare ändras i datamaterialet. Det går
så klart inte att få fram en perfekt modell men förhoppningsvis en som är jämnbra med de
som spelbolagen använder. Att spelbolagen har liknande modeller som de använder sig av blir
ganska uppenbart då man under matchens gång väntar på, från deras sida, för högt satta odds.
Allt som oftast följer deras odds de odds man själv, genom modellen, uppskattat.
Den frågeställning jag formulerade i början av denna uppsats handlade om huruvida det gick
att hitta någon variabel bortsett från slumpen som påverkar antalet hörnor i en fotbollsmatch.
Samt om det gick att ta fram en modell utifrån det som fungerade i praktiken. När det gäller
den första frågan visar det sig att vilken typ av match det handlar om påverkar det förväntade
antalet hörnor på så vis att på förhand ojämna matcher tenderar att resultera i fler hörnor än
andra matcher. Detta faktum visade sig gälla både då jag gjorde en subjektiv uppdelning av
lagen samt då jag använde mig av spelbolagens odds. Vid framtagning av odds har dessa två
förklaringsvariabler olika för- och nackdelar som. Dummyvariabeln ”Hemmalag” är väldigt
praktisk att använda sig av då den endast ger två möjliga väntevärden. Möjligen blir dock
modellen lite för simpel då olika typer av matcher med till synes olika väntevärden ändå
kommer att predikteras lika i modellen. Detta är inget problem då man istället använder sig av
modellen med ”Favoritodds” som förklaringsvariabel. Med den variabeln uppkommer istället
praktiska problem då det blir en mängd olika möjliga prediktioner. Det blir en ny prediktion
för varje odds mellan ungefär 1,10 och 2,70. Därefter ska sannolikheterna för alla rimliga
utfall för varje predikterat värde tas fram. I och med att jag lagt fokus på livebetting så ska allt
detta egentligen tas fram för varje ny minut i matchen. Jag brukar dock nöja mig med var
femte minut. Detta visar på lite av de praktiska problem som uppkommer i och med den
modellen och svårigheten som uppstår om man skulle ta fram en mer komplicerad modell
med fler förklaringsvariabler.
Vad som visade sig svårt att visa var de olika lagens påverkan på antalet hörnor. Det är
möjligt att det har betydelse men det var svårt att hitta en bra variabel för det. Problemet då
man går ner på lagnivå är att det blir färre antal möjliga observationer samt lagens ständiga
förändring. Det sätt jag gjorde på var att använda mig av lagets genomsnittliga antal hörnor,

26
hittills i säsongen, som variabel. Man kan tänka sig att denna variabel hade kunnat ha en
signifikant påverkan i slutet på säsongen då varje lags genomsnitt baseras på ett större antal
observationer och därför är mer korrekt. Å andra sidan om detta samband skulle varit stark, så
borde det ha gett utslag även över en hel säsong om än i mindre utsträckning.
En viktig del i framtagandet av denna modell och anammandet av strategin är att anta
oberoende. Principen har varit att det alltid är en viss sannolikhet för att det ska bli över eller
under ett visst antal hörnor vid en specifik tidpunkt i matchen. Det ska alltså vara oberoende
av hur många hörnor det har blivit hittills. Detta testade jag genom att jämföra antalet hörnor i
första och andra halvlek. Det visade sig att det fanns ett beroende på så vis att fler hörnor i
första halvlek ökade sannolikheten för att det skulle bli många hörnor även i den andra
halvleken. Även om detta visade sig signifikant så var påverkan relativt liten och min slutsats
av det är att den påverkan som finns förklaras i just den variabeln jag tagit med i modellen.
Sammanfattningsvis så har jag hittat en viktigt förklarande variabel till antalet hörnor samt
kunnat utesluta en stark påverkan på lagnivå. En slutsats är att det är kombinationen av lagen
som spelar som påverkar antalet hörnor och inte lagen för sig. En match mellan två lag, som
normalt spelar matcher där det blir många hörnor, innebär inte automatiskt att sannolikheten
för att det ska bli många hörnor i den matchen är större än annars. Jag har utifrån det fått fram
en bra modell som hittills har visat sig effektiv i den meningen att det genererat vinst och jag
har till viss mån kunnat utesluta ett allt för starkt beroende.
Då även den simpla grundmodellen visade sig vara rimlig så kan man tänka sig att liknande
modeller även skulle kunna fungera för andra fotbollsligor i andra länder.
Är då detta en modell som är så pass bra så att alla kan tjäna pengar på den och på så sätt
utgöra ett problem för spelbolagen? Att alla skulle kunna använda den är självklart. I alla fall
om man har lite erfarenhet av livebetting. Sedan ska man vara beredd att lägga ungefär 30
minuter av sin tid varje gång det spelas en match. Jag skulle uppskatta att det är ungefär tre
timmar i veckan i och med att vissa matcher spelas samtidigt. Skulle allt för många börja
spela på liknande sätt skulle dock spelbolagen förr snarare än senare märka att de förlorar
pengar och då göra något åt det. Om allt för mycket pengar kommer in på ett spelalternativ så
sänker spelbolaget oddset automatiskt vilket gör att bara de som är snabbast hinner spela.
Spelbolaget skulle även kunna höja sin egen marginal för att på så vis göra det svårare för
spelaren att hitta odds som är höga nog att ge värde, alltså vara högre än det odds som
modellen predikterar. Många spelbolag använder sig också av limits på spelare. Dom sätter då

27
en maxgräns för hur mycket en spelare får spela på varje spel. Detta sker, hos många
spelbolag, för spelare som mer eller mindre kontinuerlig plockar ut pengar från sina
spelkonton. Det är väl dock tveksamt om denna modell skulle vara så pass framgångsrik att
det skulle få spelbolagen att göra allt för stora förändringar.

28
Referenslista
Asteriu, D. och Hall, S.G. (2011, 2:a utgåvan). Applied econometrics. England: Palgrave
macmillan
Gelman, A. och Hill, J. (2007). Data analyses using regression and multilivevel/hierarchical
models. Cambridge, England: Cambridge university press.
Idre UCLA (2014). R Data Analysis Examples: Poisson Regression.
http://www.ats.ucla.edu/stat/r/dae/poissonreg.htm, (Hämtat 2014-01-20)
Kleinbaum, D.G., Kupper, L.L., Nizan, A. och Muller, K.E. (2008, 4:e utgåvan). Applied
regression analysis and other multivariable methods. Belmont, USA: Brooks/Cole Cengage
Learning.
Olsson, U. (2002). Generalized linear models an applied approach. Lund, Sverige:
Studentlitteratur.
Sportbettingpal (2013). Math & ROI. http://www.sportsbettingpal.com/math-roi, (Hämtat
2013-12-01)
Svenska spel (2013-10-18). Svenska spel stärker sportspelserbjudandet. Visby:
http://media.svenskaspel.se/sv/2013/10/18/svenska-spel-starker-sportspelserbjudandet/ ,
(Hämtat 2013-12-01)

I
Appendix
1)
Omnibus Testa
Likelihood Ratio
Chi-Square df Sig.
5,257 5 ,385
Dependent Variable: Hörnor
Model: (Intercept), MedelantalHörnor,
Favoritodds, Hemmalag * Bortalag
a. Compares the fitted model against the
intercept-only model.
2)
Tests of Model Effects
Source
Type III
Wald Chi-
Square df Sig.
(Intercept) 38,139 1 ,000
MedelantalHörnor 1,247 1 ,264
Favoritodds ,670 1 ,413
Hemmalag * Bortalag ,971 3 ,808
Dependent Variable: Hörnor
Model: (Intercept), MedelantalHörnor, Favoritodds, Hemmalag *
Bortalag
II
3)
Parameter Estimates
Parameter B
Std.
Error
95% Wald Confidence
Interval Hypothesis Test
Lower Upper
Wald Chi-
Square df Sig.
(Intercept) 14,523 2,4937 9,635 19,410 33,915 1 ,000
MedelantalHörnor -,199 ,1783 -,549 ,150 1,247 1 ,264
Favoritodds -,505 ,6170 -1,715 ,704 ,670 1 ,413
[Hemmalag=,00] *
[Bortalag=,00] -,422 ,6730 -1,741 ,897 ,394 1 ,530
[Hemmalag=,00] *
[Bortalag=1,00] -,256 ,7510 -1,728 1,216 ,116 1 ,733
[Hemmalag=1,00] *
[Bortalag=,00] ,099 ,8619 -1,591 1,788 ,013 1 ,909
[Hemmalag=1,00] *
[Bortalag=1,00] 0
a . . . . . .
(Scale) 1b
Dependent Variable: Hörnor
Model: (Intercept), MedelantalHörnor, Favoritodds, Hemmalag * Bortalag
a. Set to zero because this parameter is redundant.
b. Fixed at the displayed value.
4)
Omnibus Testa
Likelihood Ratio
Chi-Square df Sig.
,831 1 ,365
Dependent Variable: Hörnor
Model: (Intercept), MedelantalHörnor
a. Compares the fitted model against the
intercept-only model.

III
5)
Tests of Model Effects
Source
Type III
Wald Chi-
Square df Sig.
(Intercept) 45,530 1 ,000
MedelantalHörnor ,821 1 ,362
Dependent Variable: Hörnor
Model: (Intercept), MedelantalHörnor
6)
Parameter Estimates
Parameter B Std. Error
95% Wald Confidence
Interval Hypothesis Test
Lower Upper
Wald Chi-
Square df Sig.
(Intercept) 12,899 1,9116 9,152 16,645 45,530 1 ,000
MedelantalHörnor -,159 ,1751 -,502 ,185 ,821 1 ,365
(Scale) 1a
Dependent Variable: Hörnor
Model: (Intercept), MedelantalHörnor
a. Fixed at the displayed value.
7)
Omnibus Testa
Likelihood Ratio
Chi-Square df Sig.
9,134 4 ,058
Dependent Variable: Hörnor
Model: (Intercept), Favoritodds, Hemmalag
* Bortalag
a. Compares the fitted model against the
intercept-only model.

IV
8)
Tests of Model Effects
Source
Type III
Wald Chi-
Square df Sig.
(Intercept) 319,952 1 ,000
Favoritodds ,056 1 ,813
Hemmalag * Bortalag 3,961 3 ,266
Dependent Variable: Hörnor
Model: (Intercept), Favoritodds, Hemmalag * Bortalag
9)
Parameter Estimates
Parameter B Std. Error
95% Wald Confidence
Interval Hypothesis Test
Lower Upper
Wald Chi-
Square df Sig.
(Intercept) 11,134 ,7925 9,581 12,688 197,420 1 ,000
[Hemmalag=,00] *
[Bortalag=,00] ,021 ,3769 -,718 ,759 ,003 1 ,957
[Hemmalag=,00] *
[Bortalag=1,00] ,163 ,4177 -,656 ,981 ,151 1 ,697
[Hemmalag=1,00] *
[Bortalag=,00] ,712 ,4819 -,233 1,656 2,182 1 ,140
[Hemmalag=1,00] *
[Bortalag=1,00] 0
a . . . . . .
Favoritodds -,080 ,3372 -,740 ,581 ,056 1 ,813
(Scale) 1b
Dependent Variable: Hörnor
Model: (Intercept), Hemmalag * Bortalag, Favoritodds
a. Set to zero because this parameter is redundant.
b. Fixed at the displayed value.

V
10)
Omnibus Testa
Likelihood Ratio
Chi-Square df Sig.
9,079 3 ,028
Dependent Variable: Hörnor
Model: (Intercept), Hemmalag * Bortalag
a. Compares the fitted model against the
intercept-only model.
11)
Tests of Model Effects
Source
Type III
Wald Chi-
Square df Sig.
(Intercept) 8638,201 1 ,000
Hemmalag * Bortalag 8,892 3 ,031
Dependent Variable: Hörnor
Model: (Intercept), Hemmalag * Bortalag
12)
Parameter Estimates
Parameter B Std. Error
95% Wald Confidence
Interval Hypothesis Test
Lower Upper
Wald Chi-
Square df Sig.
(Intercept) 10,967 ,3491 10,282 11,651 987,000 1 ,000
[Hemmalag=,00] *
[Bortalag=,00] ,022 ,3768 -,716 ,761 ,004 1 ,953
[Hemmalag=,00] *
[Bortalag=1,00] ,184 ,4076 -,615 ,983 ,204 1 ,651
[Hemmalag=1,00] *
[Bortalag=,00] ,771 ,4104 -,033 1,576 3,533 1 ,060
[Hemmalag=1,00] *
[Bortalag=1,00] 0
a . . . . . .
(Scale) 1b
Dependent Variable: Hörnor
Model: (Intercept), Hemmalag * Bortalag
a. Set to zero because this parameter is redundant.
b. Fixed at the displayed value.

VI
13)
Omnibus Testa
Likelihood Ratio
Chi-Square df Sig.
5,383 2 ,068
Dependent Variable: Hörnor
Model: (Intercept), Hemmalag, Bortalag
a. Compares the fitted model against the
intercept-only model.
14)
Tests of Model Effects
Source
Type III
Wald Chi-
Square df Sig.
(Intercept) 9073,217 1 ,000
Hemmalag 5,000 1 ,025
Bortalag ,171 1 ,679
Dependent Variable: Hörnor
Model: (Intercept), Hemmalag, Bortalag
15)
Parameter Estimates
Parameter B Std. Error
95% Wald Confidence
Interval Hypothesis Test
Lower Upper
Wald Chi-
Square df Sig.
(Intercept) 11,468 ,2445 10,989 11,947 2199,409 1 ,000
[Hemmalag=,00] -,489 ,2186 -,917 -,060 5,000 1 ,025
[Hemmalag=1,00
] 0
a . . . . . .
[Bortalag=,00] ,089 ,2162 -,334 ,513 ,171 1 ,679
[Bortalag=1,00] 0a . . . . . .
(Scale) 1b
Dependent Variable: Hörnor
Model: (Intercept), Hemmalag, Bortalag
a. Set to zero because this parameter is redundant.
b. Fixed at the displayed value.

VII
16)
Omnibus Testa
Likelihood Ratio
Chi-Square df Sig.
5,212 1 ,022
Dependent Variable: Hörnor
Model: (Intercept), Hemmalag
a. Compares the fitted model against the
intercept-only model.
17)
Tests of Model Effects
Source
Type III
Wald Chi-
Square df Sig.
(Intercept) 10715,024 1 ,000
Hemmalag 5,151 1 ,023
Dependent Variable: Hörnor
Model: (Intercept), Hemmalag
18)
Parameter Estimates
Parameter B Std. Error
95% Wald Confidence
Interval Hypothesis Test
Lower Upper
Wald Chi-
Square df Sig.
(Intercept) 11,535 ,1837 11,175 11,895 3945,000 1 ,000
[Hemmalag=,00] -,495 ,2181 -,922 -,068 5,151 1 ,023
[Hemmalag=1,00] 0a . . . . . .
(Scale) 1b
Dependent Variable: Hörnor
Model: (Intercept), Hemmalag
a. Set to zero because this parameter is redundant.
b. Fixed at the displayed value.

VIII
19)
Goodness of Fita
Value df Value/df
Deviance 1423,306 1138 1,251
Scaled Deviance 1423,306 1138
Pearson Chi-Square 1409,025 1138 1,238
Scaled Pearson Chi-Square 1409,025 1138
Log Likelihoodb -3110,899
Akaike's Information
Criterion (AIC) 6225,799
Finite Sample Corrected AIC
(AICC) 6225,809
Bayesian Information
Criterion (BIC) 6235,876
Consistent AIC (CAIC) 6237,876
Dependent Variable: Hörnor
Model: (Intercept), Favoritodds
a. Information criteria are in smaller-is-better form.
b. The full log likelihood function is displayed and used in computing
information criteria.
20)
Omnibus Testa
Likelihood Ratio
Chi-Square df Sig.
5,164 1 ,023
Dependent Variable: Hörnor
Model: (Intercept), Favoritodds
a. Compares the fitted model against the
intercept-only model.
21)
Tests of Model Effects
Source
Type III
Wald Chi-
Square df Sig.
(Intercept) 702,990 1 ,000
Favoritodds 5,169 1 ,023
Dependent Variable: Hörnor
Model: (Intercept), Favoritodds

IX
22)
Parameter Estimates
Parameter B Std. Error
95% Wald Confidence
Interval Hypothesis Test
Lower Upper
Wald Chi-
Square df Sig.
(Intercept) 12,206 ,4604 11,304 13,108 702,990 1 ,000
Favoritodds -,543 ,2390 -1,012 -,075 5,169 1 ,023
(Scale) 1a
Dependent Variable: Hörnor
Model: (Intercept), Favoritodds
a. Fixed at the displayed value.
23)
Minut Match Över/Under
Odds enligt
modell Odds
spelbolag Insats Vinst Kr Differens
5 Ars- Ast u12,5 1,97 2,25 100 125 6,3%
40 Che- Ast ö5,5 2 2,2 100 130 4,5%
30 Ful- Ars ö12,5 2,1 2,35 100 135 5,1%
15 New- WeH ö10,5 1,67 1,83 100 -100 5,2%
20 Eve- Wba u8,5 2,1 2,3 100 -100 4,1%
35 Sou- Sun u10,5 1,7 1,8 100 80 3,3%
45 Sto- CrP ö8,5 1,86 2 100 -100 3,8%
70 Hul- Nor ö4,5 1,4 1,5 100 50 4,8%
15 Ast- Liv ö8,5 1,66 1,83 100 83 5,6%
49 MaC- Hul u13,5 1,7 1,8 100 80 3,3%
5 Nor- Sou ö9,5 1,62 1,72 100 -100 3,6%
20 Car- Eve ö12,5 1,91 2 100 -100 2,4%
25 New- Ful ö9,5 1,72 1,9 100 90 5,5%
30 WeH- Sto ö8,5 1,55 1,66 100 -100 4,3%
10 CrP- Sun ö10,5 1,84 2,1 100 110 6,7%
10 Wba- Swa ö10,5 1,72 1,83 100 -100 3,5%
30 Ars- Tot u12,5 1,8 1,85 100 85 1,5%
65 Ars- Tot u13,5 1,64 1,72 100 72 2,8%
25 MaU- CrP u12,5 2,28 2,37 100 137 1,7%
5 Sun- Ars ö10,5 1,62 1,7 100 70 2,9%
10 Tot- Nor u9,5 1,88 1,9 100 90 0,6%
40 Sto- MaC ö9,5 2,12 2,2 100 -100 1,7%
45 Ful -Wba ö8,5 1,86 2,2 100 120 8,3%
45 Eve- Che u11,5 1,78 2,1 100 -100 8,6%
10 Swa- Liv u11,5 1,88 2 100 100 3,2%
5 Nor- Ast ö10,5 2 2,2 100 120 4,5%

X
15 Liv- Sou u11,5 1,83 1,95 100 -100 3,4%
5 New- Hul ö9,5 1,6 1,72 100 -100 4,4%
15 WeH- Eve ö10,5 1,92 2,05 100 -100 3,3%
20 Wba- Sun ö10,5 1,52 1,66 100 66 5,5%
10 Ars- Sto ö9,5 1,87 2 100 100 3,5%
5 CrP- Swa ö10,5 1,52 1,9 100 90 13,2%
49 MaC- MaU ö10,5 1,62 1,72 100 72 3,6%
35 Car- Tot u12,5 1,7 1,75 100 -100 1,7%
15 Tot- Che ö10,5 2,2 2,4 100 -100 3,8%
35 Ast- MaC ö11,5 2 2,05 100 105 1,2%
20 MaU- Wba u12,5 1,38 1,4 100 -100 1,0%
25 Ful- Car u15,5 1,46 1,5 100 -100 1,8%
38 Hul- WeH u15,5 1,67 1,72 100 72 1,7%
40 Sou- CrP u12,5 1,89 2 100 100 2,9%
20 Swa- Ars ö10,5 1,77 1,87 100 -100 3,0%
45 Sto- Nor ö9,5 1,68 1,78 100 78 3,3%
80 Sun- Liv u15,5 1,7 1,8 100 -100 3,3%
65 Eve- New ö4,5 1,38 1,72 100 -100 14,3%
15 MaC- Eve u12,5 1,53 1,83 100 83 10,7%
1 Liv- CrP u11,5 1,8 1,9 100 -100 2,9%
3 Car- New ö9,5 1,6 1,72 100 -100 4,4%
5 Ful- Sto ö9,5 1,6 1,72 100 72 4,4%
35 Sun- MaU u9,5 1,7 1,83 100 83 4,2%
0 Sou- Swa ö10,5 1,77 2,15 100 115 10,0%
5 Nor- Che ö9,5 1,62 1,83 100 83 7,1%
15 Wba- Ars ö9,5 1,67 1,72 100 -100 1,7%
25 Tot- WeH u9,5 1,46 1,5 100 -100 1,8%
45 New- Liv u16,5 1,6 1,72 100 72 4,4%
10 Ars- Nor u13,5 1,75 1,9 100 90 4,5%
20 Eve- Hul ö11,5 2,07 2,2 100 120 2,9%
25 MaU- Sou ö8,5 1,72 1,83 100 -100 3,5%
30 Che- Car u13,5 1,7 2,1 100 -100 11,2%
5 Sto- Wba ö10,5 1,8 2,2 100 120 10,1%
50 Swa- Sun ö8,5 2,05 2,25 100 125 4,3%
35 WeH- MaC ö10,5 2 2,2 100 -100 4,5%
10 Ast- Tot u13,5 1,4 1,5 100 50 4,8%
10 CrP- Ars ö10,5 1,92 2,1 100 -100 4,5%
0 Liv- CrP u11,5 1,8 2 100 -100 5,6%
0 Nor- Car ö10,5 1,77 1,83 100 83 1,9%
5 MaU- Sto u11,5 1,6 1,72 100 -100 4,4%
50 Ast- Eve u12,5 1,78 1,83 100 -100 1,5%
25 Sou- Ful ö9,5 1,72 1,8 100 80 2,6%
45 Tot- Hul u12,5 2 2,2 100 120 4,5%
48 Swa- WeH ö12,5 1,64 1,83 100 83 6,3%
48 Che- MaC u12,5 1,75 1,83 100 83 2,5%
0 New- Che ö10,5 1,77 1,8 100 80 0,9%

XI
0 Ful- MaU ö10,5 1,77 1,83 100 -100 1,9%
0 Swa- Car ö10,5 1,77 1,85 100 -100 2,4%
40 Che- Wba ö10,5 1,93 2,2 100 120 6,4%
40 Liv- Ful ö11,5 1,49 1,66 100 66 6,9%
55 Sou- Hul ö9,5 1,78 2 100 100 6,2%
80 CrP-Eve u9,5 1,97 2 100 -100 0,8%
30 Nor- WeH ö9,6 1,6 1,66 100 -100 2,3%
10 Tot- New ö9,5 1,58 1,8 100 80 7,7%
0 Eve- Liv u11,5 1,72 1,83 100 -100 3,5%
5 New- Nor ö9,5 1,8 2 100 -100 5,6%
10 Ful- Swa ö10,5 1,53 1,72 100 72 7,2%
25 Sto- Sun ö12,5 1,87 2,1 100 -100 5,9%
20 Ars- Sou ö8,5 1,79 1,9 100 90 3,2%
48 Hul- CrP u14,5 1,72 1,83 100 -100 3,5%
10 WeH- Che ö10,5 1,9 2,1 100 110 5,0%
40 MaC- Tot ö9,5 1,73 1,9 100 90 5,2%
5 Car- MaU ö9,5 1,63 1,72 100 72 3,2%
20 Wba- Ast ö9,5 2,1 2,2 100 -100 2,2%
30 Hul- Liv u11,5 1,93 2,2 100 120 6,4%
10 Car- Ars ö10,5 2,5 2,62 100 -100 1,8%
0 MaC- Swa ö11,5 1,98 2,1 100 -100 2,9%
5 Che- Sou u12,5 1,72 1,83 100 83 3,5%
20 CrP- WeH ö9,5 1,88 2 100 -100 3,2%
30 Ful- Tot u13,5 1,93 2,1 100 -100 4,2%
0 Ars- Hul ö10,5 1,61 1,8 100 80 6,6%
0 MaU- Eve ö10,5 1,61 1,72 100 72 4,0%
25 Sou- Ast u12,5 1,52 1,72 100 72 7,6%
20 Wba- MaC ö8,5 1,72 1,9 100 -100 5,5%
40 Sun - Che ö10,5 1,63 1,72 100 -100 3,2%
10 CrP-Car ö9,5 1,57 1,72 100 72 5,6%
15 Sto- Che ö9,5 1,72 1,83 100 -100 3,5%
15 Wba- Nor u12,5 1,83 1,9 100 -100 2,0%
50 Liv- WeH ö11,5 1,83 1,9 100 90 2,0%
5 Ful- Ast ö10,5 1,73 1,83 100 83 3,2%
5 Ars- Eve ö10,5 1,79 1,9 100 -100 3,2%
0 Swa- Hul ö10,5 1,83 2 100 100 4,6%
59 Eve- Ful u15,5 2,39 2,5 100 150 1,8%
15 Che- CrP ö9,5 1,62 1,8 100 -100 6,2%
54 Car- Wba u12,5 1,94 2 100 -100 1,5%
5 New- Sou u13,5 1,73 1,8 100 -100 2,2%
0 MaC- Ars ö10,5 1,76 1,87 100 87 3,3%
5 Hul- Sto ö9,5 1,7 1,8 100 80 3,3%
0 Nor- Swa ö10,5 1,9 2,12 100 112 5,5%
15 Ast- MaU ö10,5 1,65 1,8 100 -100 5,1%
0 Tot- Liv u10,5 2,1 2,4 100 -100 6,0%
20 Nor- Swa ö9,5 1,6 1,83 100 83 7,9%

XII
54 Liv- Swa ö8,6 1,37 1,61 100 61 10,9%
0 Sto- Ast ö10,5 1,9 2,06 100 106 4,1%
0 CrP- New ö10,5 1,9 2,23 100 -100 7,8%
0 Wba- Hul ö10,5 1,76 1,83 100 83 2,2%
20 Sun- Nor u11,5 1,54 1,61 100 -100 2,8%
40 Ful- MaC ö10,5 1,95 2,1 100 -100 3,7%
40 MaU- WeH ö8,5 1,56 1,83 100 83 9,5%
0 Sou- Tot u10,5 2,11 2,39 100 139 5,6%
5 Swa- Eve ö9,5 1,72 1,8 100 80 2,6%
10 Ars- Che ö10,5 1,61 1,72 100 72 4,0%
0 Hul-MaU ö10,5 1,72 1,9 100 90 5,5%
0 Che- Swa ö10,5 1,58 1,8 100 80 7,7%
66 Car- Sou u10,5 1,5 1,61 100 61 4,6%
15 Eve- Sun u9,5 1,84 2 100 -100 4,3%
10 New- Sto ö9,5 1,82 2 100 100 4,9%
0 Nor- Ful ö10,5 1,76 1,95 100 -100 5,5%
30 Tot- Wba u13,5 1,86 2 100 -100 3,8%
35 WeH- Ars ö10,5 1,76 1,97 100 -100 6,1%
0 MaC- Liv u10,5 2,32 2,58 100 -100 4,3%
45 WeH- Wba u13,5 2,04 2,2 100 120 3,6%
0 Hul- Ful ö10,5 1,76 1,88 100 -100 3,6%
0 Nor- MaU ö10,5 1,76 1,87 100 87 3,3%
25 MaC- CrP u14,5 1,6 1,9 100 -100 9,9%
5 Ast- Swa u10,5 1,9 2 100 100 2,6%
70 Car- Sun u12,5 1,6 1,72 100 72 4,4%
0 New- Ars ö10,5 1,76 1,86 100 -100 3,1%
1 Eve- Sou u11,5 1,78 1,83 100 83 1,5%
0 Che- Liv u10,5 2,1 2,4 100 140 6,0%
15 Tot- Sto u11,5 1,59 1,66 100 66 2,7%
10 Swa- MaC ö9,5 1,73 1,83 100 83 3,2%
0 Ars- Car ö10,5 1,58 1,88 100 88 10,1%
0 Sto- Eve ö10,5 1,76 1,95 100 -100 5,5%
0 Wba New ö10,5 1,9 2,23 100 -100 7,8%
30 CrP- Nor ö7,5 1,58 1,72 100 72 5,2%
25 Ful- WeH u10,5 1,83 1,9 100 -100 2,0%
40 Liv- Hul ö8,5 1,83 2 100 -100 4,6%
25 Sou- Che ö9,5 1,7 1,8 100 80 3,3%
25 Sun- Ast u10,5 2 2 100 -100 0,0%
0 MaU- Tot ö10,5 1,76 1,88 100 88 3,6%
59 Hul- Che ö10,5 1,72 1,83 100 -100 3,5%
0 Eve- Nor ö10,5 1,72 1,8 100 80 2,6%
10 Tot- CrP u11,5 1,73 1,8 100 -100 2,2%
10 New- MaC ö10,5 1,78 1,9 100 90 3,5%
30 Sun- Sou ö10,5 1,65 1,72 100 72 2,5%
0 Ars- Ful ö10,5 1,58 1,74 100 -100 5,8%
0 Nor- Hul ö10,5 1,9 2,07 100 107 4,3%

XIII
0 WeH- New ö10,5 1,9 2,19 100 -100 7,0%
25 CrP- Sto u11,5 2,05 2,1 100 110 1,2%
20 MaC- car ö13,5 2,1 2,5 100 150 7,6%
45 Liv- Ast u10,5 1,75 2,2 100 120 11,7%
25 Swa- Tot ö9,5 1,66 1,86 100 86 6,5%
0 Che- MaU ö10,5 1,76 1,88 100 -100 3,6%























![[KUG PP 29th] Premier League Wears Prada (by Tony Adams6)](https://img.pdfslide.tips/doc/110x75/54b892264a795982368b45b4/kug-pp-29th-premier-league-wears-prada-by-tony-adams6.jpg)





