Embed Size (px)
Citation preview

PONTIFÍCIA UNIVERSIDADE CATÓLICA DE SÃO PAULO
Programas de Pós Graduação em
Economia e
Administração da
PUC-SP
BOLETIM DE ANÁLISES ESTATÍSTICO
BASTA 2017 Vol. 2
IDHEs ÍNDICE DE DESENVOLVIMENTO HUMANO ESTADUAL
ATLAS BRASIL
DISCIPLINA: MÉTODOS QUALITATIVOS E QUANTITATIVOS DA PESQUISA EMPÍRICA PROF. ARNOLDO JOSÉ DE HOYOS GUEVARA
Diego Paulo Rhormens
1º SEMESTRE
São Paulo – SP
2017
A Importância e Impacto do Desemprego e Condições Básicas de Vida no País.

2
SUMÁRIO
INTRODUÇÃO 4
CAPÍTULO 1. AED ANÁLISE EXPLORATÓRIA DOS DADOS 2
1. As Variáveis de Análise 2
1.1. Análise das Variáveis 8
1.1.1. Dimensão Demográfica 8
1.1.2. Dimensão Educação 9
1.1.3. Dimensão Renda 11
1.1.4. Dimensão Trabalho 13
1.1.5. Dimensão Habitação 15
1.1.6. Dimensão Vulnerabilidade 18
1.1.7. Dimensão População 19
1.1.8. Dimensão IDHM 20
1.2. Considerações 23
CAPITULO 2. RELAÇÕES ENTRE VARIÁVEIS 23
2. Análise das Variáveis 23
2.1. Distribuição dos Municípios Brasileiros por Estado e Região 23
2.2. Análise do Dendograma 24
2.3. Considerações 45
CAPÍTULO 3. ANÁLISES DE TENDÊNCIAS 45
3. Entendendo os Dados 45
3.1. Entendendo as Variáveis 45
3.2. Tabelas dos dados analisados 46
3.3. Análise das Variáveis 48
3.4. Considerações 62
CAPÍTULO 4. REGRESSÃO LINEAR 63
4.1.Análise de Regressão 63
4.2. Considerações 73
CAPÍTULO 5. TESTES DE COMPARAÇÃO 73
5.1. Análise das Variáveis 73
5.2. Considerações 90
CAPÍTULO 6. AMOSTRAGEM 90

3
6.1. Análise dos Resultados 91
6.2. Considerações 111
CAPÍTULO 7. COMPONENTES PRINCIPAIS 112
7.1. Entendendo os Dados 112
7.2. Análise Descritiva dos Dados Normalizados e Positivados 115
7.3. Análise dos Dados 125
7.4. Considerações 149
CAPÍTULO 8. ANÁLISE DE CONFLOMERADOS 149
8.1. Entendendo as Variáveis 150
8.2. Análise dos Dados 151
8.3. Considerações Finais 157
CAPÍTULO 9. ANÁLISE DISCRIMINANTE 158
9.1. Análise Discriminante 158
9.2. Considerações 164
CAPÍTULO 10. REGRESSÃO LOGÍSTICA 164
10.1. Análise dos Dados 166
10.2. Considerações 176
CAPÍTULO 11. ANÁLISE DE CORRESPONDÊNCIA 177
11.1. Análise dos Dados 178
11.2. Considerações 185
CAPÍTULO 12. ÁRVORE DE CLASSIFICAÇÃO 186
12.1. Análise dos Dados 187
12.2. Considerações 192
CAPÍTULO 13. RANKING DOS ESTADOS 192
13.1. Análise dos Dados 193
13.2. Considerações 197
REFERÊNCIAS 198

4
INTRODUÇÃO
Este trabalho tem como objetivo realizar uma síntese dos 12 trabalhos
apresentados na disciplina Métodos Quantitativos e Qualitativos da Pesquisa Empírica do
Programa de Pós-Graduação em Administração da Pontifícia Universidade Católica de
São Paulo.
Cada um dos tópicos que serão apresentados neste trabalho final corresponde a
uma análise estatística diferente em torno das variáveis selecionadas que, em conjunto,
auxiliam a compreender melhor a realidade dos municípios e estados brasileiros.
Os dados para as análises que se seguem, são provenientes do Atlas do
Desenvolvimento Humano no Brasil, que apresentam indicadores de desenvolvimento
humano dos 5.565 municípios brasileiros. Os dados apresentam indicadores que se
relacionam com a demografia, educação, renda, trabalho, habitação, vulnerabilidade e
IDHM. Os dados para este trabalho foram extraídos do Censo Demográfico de 2010.
De acordo com a página do site Atlas do Desenvolvimento Humano no Brasil, a
disponibilidade dos dados de forma pública facilita a análise e pode mostrar um panorama
dos municípios e das desigualdades entre eles, para que se possa gerar informações úteis
para trabalhar com os desafios de fazer uma política pública voltada a satisfação das
necessidades dos indivíduos.
O desenvolvimento humano, de acordo com o site, pode ser entendido como o
processo de ampliação das liberdades individuais em relação a capacidades e
oportunidades, para que os indivíduos possam escolher a vida que desejam ter.
Para isso, é necessário o desenvolvimento no âmbito político, ambiental, social e
econômico, a fim de que cada um possa exercer suas potencialidades e ter qualidade de
vida. Existem três requisitos importantes para a expansão do IDH, o acesso a saúde de
qualidade para que o indivíduo possa ter uma vida longa e saudável, acesso à educação
para que todos possam obter o conhecimento e o ganho de renda para que todos possam
desfrutar de um padrão de vida digno.
Cada capítulo deste relatório apresenta uma análise estatística diferente. O
primeiro capítulo contém a análise exploratória dos dados, o segundo as relações entre as
variáveis, o terceiro análise de tendências, o quarto a regressão linear, o quinto os testes
de comparações, o sexto a amostragem, o sétimo o estudo dos componentes principais, o
oitavo a análise de conglomerados, o nono a análise discriminante, o décimo a regressão
logística, o décimo primeiro a análise de correspondência e o décimo segundo as árvores
de classificação.
As análises estatísticas realizadas nos capítulos I a XI foram feitas com o auxílio
do software estatístico MINITAB. Para realizar as análises do capítulo XII foi utilizado
o software SPSS.

5
CAPÍTULO 1. AED ANÁLISE EXPLORATÓRIA DOS DADOS
O presente capítulo tem como objetivo realizar uma análise exploratórias dos
dados provenientes do Atlas do Desenvolvimento Humano no Brasil, que apresentam
indicadores de desenvolvimento humano dos 5565 municípios brasileiros. Os dados
apresentam indicadores que se relacionam com a demografia, educação, renda, trabalho,
habitação, vulnerabilidade e IDHM. Os dados para este trabalho são provenientes do
Censo Demográfico de 2010.
Os testes realizados neste primeiro capítulo foram o cálculo da média, desvio
padrão, mediana (as três medidas com um grau de confiança de 95%), variância, primeiro
quartil, terceiro quartil, valor máximo e valor mínimo. O programa também construiu um
histograma para a melhor visualização dos dados.
O histograma é uma forma de representar os dados através de uma distribuição de
frequência, frequência relativa ou frequência percentual. O histograma é representado
com a variável de interesse no eixo horizontal, e a frequência no eixo vertical. A altura
das barras apresentadas no histograma é o valor da frequência (ANDERSON;
SWEENEY; WILLIAMS, 2011).
A média é uma medida da posição central dos dados, e pode ser calculada
somando-se todos os valores dos dados e dividindo este valor pelo número total da
quantidade de dados. A variância é uma medida de variabilidade que utiliza todos os
dados e se baseia na diferença entre o valor de todos os dados e a média. O desvio padrão
é a raiz quadrada positiva da variância, para que se possa facilitar a análise por utilizar a
mesma unidade da média (ANDERSON; SWEENEY; WILLIAMS, 2011).
A mediana também é uma medida da posição central de uma variável e representa
o valor intermediário quando os dados são organizados em ordem crescente. Quando
existe um número ímpar de quantidade de dados, a moda é o número intermediário, e
quando se trata de uma quantidade par de dados a moda é a média do valor dos dois dados
intermediários. O primeiro quartil é o valor que indica que 25% dos valores dos dados
estão abaixo dele, e o terceiro quartil indica o valor que 75% dos dados estão abaixo dele
(ANDERSON; SWEENEY; WILLIAMS, 2011).
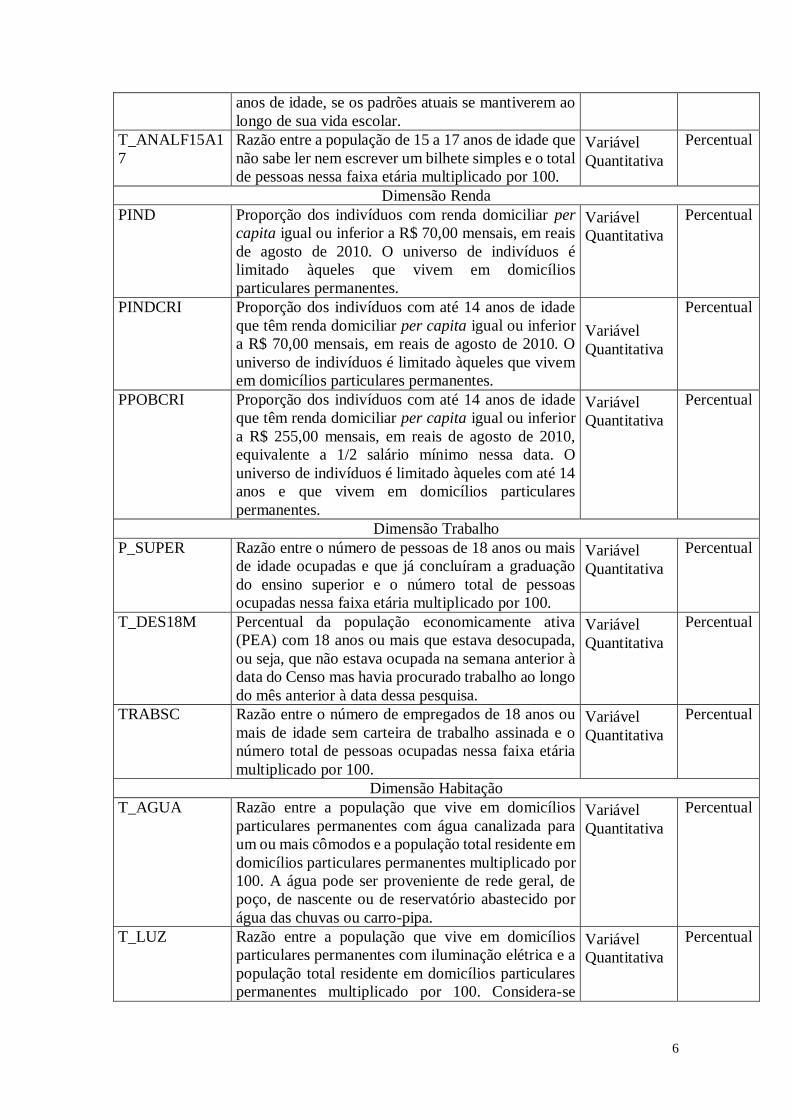
1. As Variáveis de Análise
Para a realização das análises estatísticas foram escolhidas algumas variáveis nas
dimensões de análise. A Tabela 1 apresenta as variáveis selecionadas para a análise.
Tabela 1: Variáveis Analisadas
Variável Significado Tipo Unidade
de Medida
NOMEMUN Nome do Município Variável
Qualitativa
Dimensão Demográfica
FECTOT Número médio de filhos que uma mulher deverá ter
ao terminar o período reprodutivo (15 a 49 anos de
idade).
Variável
Quantitativa
Unidade
MORT1 Número de crianças que não deverão sobreviver ao
primeiro ano de vida de cada 1000 crianças nascidas
vivas.
Variável
Quantitativa
Unidade
Dimensão Educação
E_ANOSESTU
DO
Número médio de anos de estudos que uma criança
que ingressa na escola deverá completar ao atingir 18 Variável
Quantitativa
Anos
6
anos de idade, se os padrões atuais se mantiverem ao
longo de sua vida escolar.
T_ANALF15A1
7
Razão entre a população de 15 a 17 anos de idade que
não sabe ler nem escrever um bilhete simples e o total
de pessoas nessa faixa etária multiplicado por 100.
Variável
Quantitativa
Percentual
Dimensão Renda
PIND Proporção dos indivíduos com renda domiciliar per
capita igual ou inferior a R$ 70,00 mensais, em reais
de agosto de 2010. O universo de indivíduos é
limitado àqueles que vivem em domicílios
particulares permanentes.
Variável
Quantitativa
Percentual
PINDCRI Proporção dos indivíduos com até 14 anos de idade
que têm renda domiciliar per capita igual ou inferior
a R$ 70,00 mensais, em reais de agosto de 2010. O
universo de indivíduos é limitado àqueles que vivem
em domicílios particulares permanentes.
Variável
Quantitativa
Percentual
PPOBCRI Proporção dos indivíduos com até 14 anos de idade
que têm renda domiciliar per capita igual ou inferior
a R$ 255,00 mensais, em reais de agosto de 2010,
equivalente a 1/2 salário mínimo nessa data. O
universo de indivíduos é limitado àqueles com até 14
anos e que vivem em domicílios particulares
permanentes.
Variável
Quantitativa
Percentual
Dimensão Trabalho
P_SUPER Razão entre o número de pessoas de 18 anos ou mais
de idade ocupadas e que já concluíram a graduação
do ensino superior e o número total de pessoas
ocupadas nessa faixa etária multiplicado por 100.
Variável
Quantitativa
Percentual
T_DES18M Percentual da população economicamente ativa
(PEA) com 18 anos ou mais que estava desocupada,
ou seja, que não estava ocupada na semana anterior à
data do Censo mas havia procurado trabalho ao longo
do mês anterior à data dessa pesquisa.
Variável
Quantitativa
Percentual
TRABSC Razão entre o número de empregados de 18 anos ou
mais de idade sem carteira de trabalho assinada e o
número total de pessoas ocupadas nessa faixa etária
multiplicado por 100.
Variável
Quantitativa
Percentual
Dimensão Habitação
T_AGUA Razão entre a população que vive em domicílios
particulares permanentes com água canalizada para
um ou mais cômodos e a população total residente em
domicílios particulares permanentes multiplicado por
100. A água pode ser proveniente de rede geral, de
poço, de nascente ou de reservatório abastecido por
água das chuvas ou carro-pipa.
Variável
Quantitativa
Percentual
T_LUZ Razão entre a população que vive em domicílios
particulares permanentes com iluminação elétrica e a
população total residente em domicílios particulares
permanentes multiplicado por 100. Considera-se
Variável
Quantitativa
Percentual
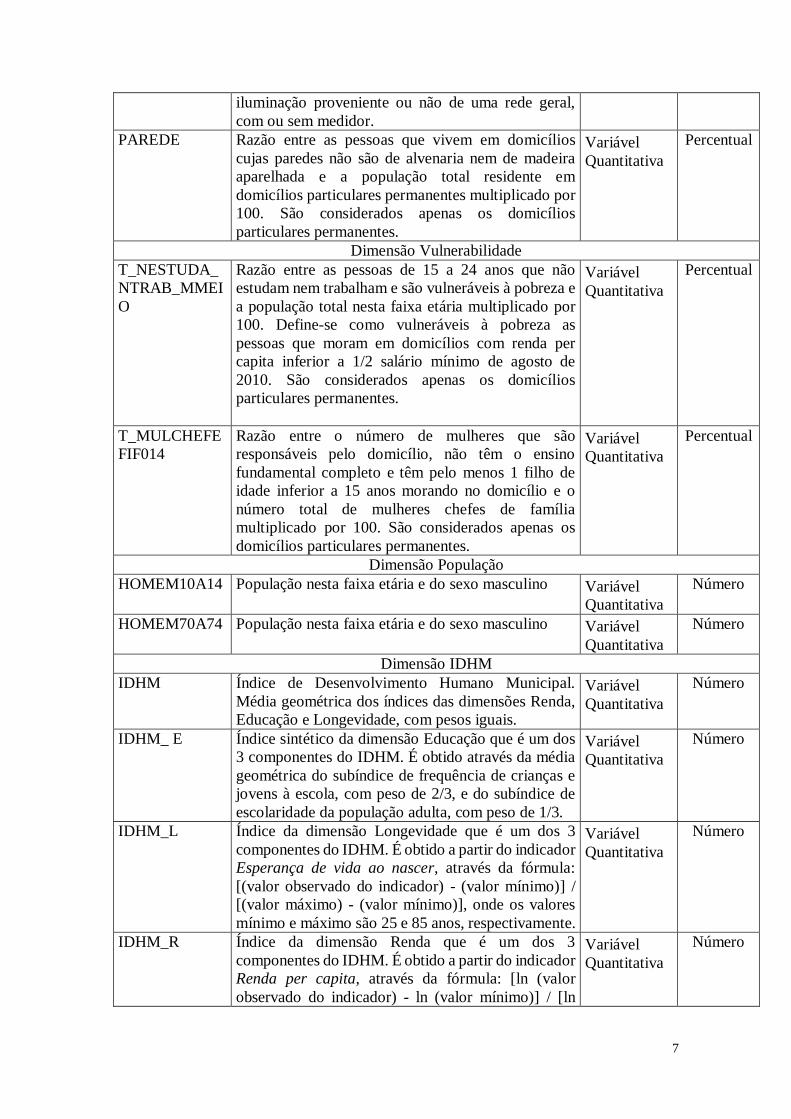
7
iluminação proveniente ou não de uma rede geral,
com ou sem medidor.
PAREDE Razão entre as pessoas que vivem em domicílios
cujas paredes não são de alvenaria nem de madeira
aparelhada e a população total residente em
domicílios particulares permanentes multiplicado por
100. São considerados apenas os domicílios
particulares permanentes.
Variável
Quantitativa
Percentual
Dimensão Vulnerabilidade
T_NESTUDA_
NTRAB_MMEI
O
Razão entre as pessoas de 15 a 24 anos que não
estudam nem trabalham e são vulneráveis à pobreza e
a população total nesta faixa etária multiplicado por
100. Define-se como vulneráveis à pobreza as
pessoas que moram em domicílios com renda per
capita inferior a 1/2 salário mínimo de agosto de
2010. São considerados apenas os domicílios
particulares permanentes.
Variável
Quantitativa
Percentual
T_MULCHEFE
FIF014
Razão entre o número de mulheres que são
responsáveis pelo domicílio, não têm o ensino
fundamental completo e têm pelo menos 1 filho de
idade inferior a 15 anos morando no domicílio e o
número total de mulheres chefes de família
multiplicado por 100. São considerados apenas os
domicílios particulares permanentes.
Variável
Quantitativa
Percentual
Dimensão População
HOMEM10A14 População nesta faixa etária e do sexo masculino Variável
Quantitativa
Número
HOMEM70A74 População nesta faixa etária e do sexo masculino Variável
Quantitativa
Número
Dimensão IDHM
IDHM Índice de Desenvolvimento Humano Municipal.
Média geométrica dos índices das dimensões Renda,
Educação e Longevidade, com pesos iguais.
Variável
Quantitativa
Número
IDHM_ E Índice sintético da dimensão Educação que é um dos
3 componentes do IDHM. É obtido através da média
geométrica do subíndice de frequência de crianças e
jovens à escola, com peso de 2/3, e do subíndice de
escolaridade da população adulta, com peso de 1/3.
Variável
Quantitativa
Número
IDHM_L Índice da dimensão Longevidade que é um dos 3
componentes do IDHM. É obtido a partir do indicador
Esperança de vida ao nascer, através da fórmula:
[(valor observado do indicador) - (valor mínimo)] /
[(valor máximo) - (valor mínimo)], onde os valores
mínimo e máximo são 25 e 85 anos, respectivamente.
Variável
Quantitativa
Número
IDHM_R Índice da dimensão Renda que é um dos 3
componentes do IDHM. É obtido a partir do indicador
Renda per capita, através da fórmula: [ln (valor
observado do indicador) - ln (valor mínimo)] / [ln
Variável
Quantitativa
Número
8
(valor máximo) - ln (valor mínimo)], onde os valores
mínimo e máximo são R$ 8,00 e R$ 4.033,00 (a
preços de agosto de 2010). Fonte: Atlas do Desenvolvimento Humano no Brasil
1.1 Análise das Variáveis
A partir dos dados disponíveis, foram realizados os testes de estatística descritiva
com o auxílio do software MINITAB. Inicialmente será discutido o resultado dos testes
para cada uma das variáveis nas oito dimensões.
1.1.1.Dimensão Demográfica
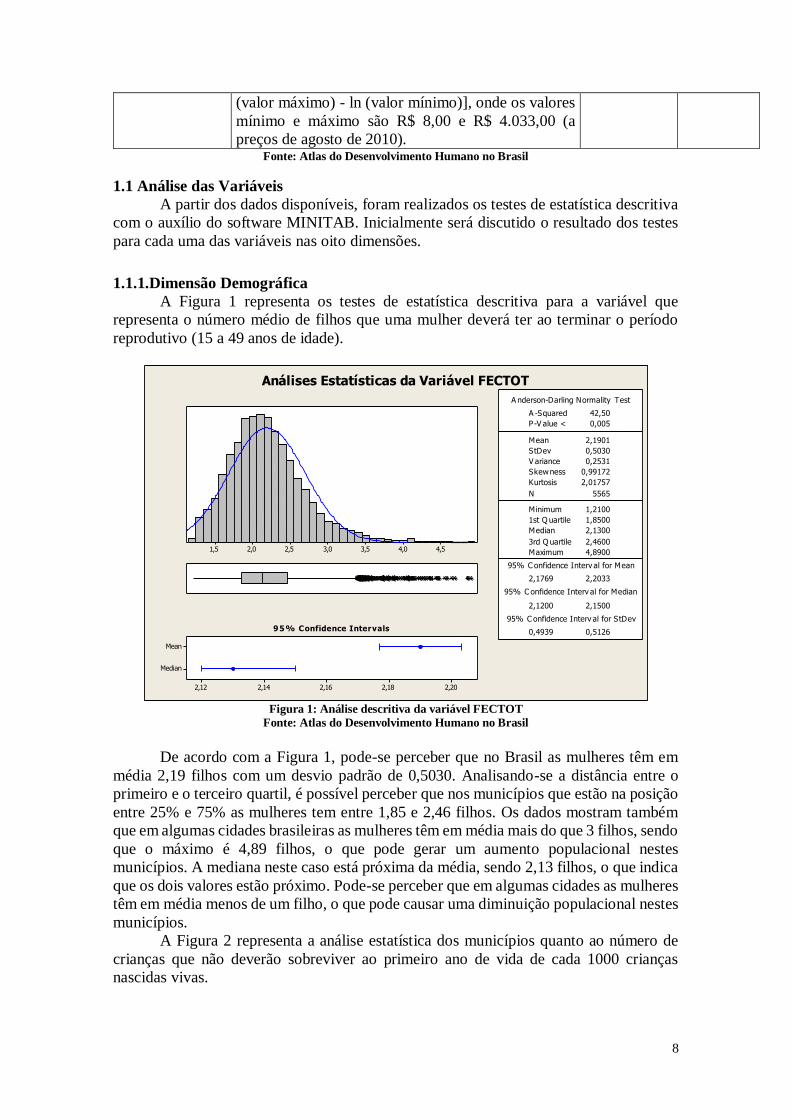
A Figura 1 representa os testes de estatística descritiva para a variável que
representa o número médio de filhos que uma mulher deverá ter ao terminar o período
reprodutivo (15 a 49 anos de idade).
4,54,03,53,02,52,01,5
Median
Mean
2,202,182,162,142,12
1st Q uartile 1,8500
Median 2,1300
3rd Q uartile 2,4600
Maximum 4,8900
2,1769 2,2033
2,1200 2,1500
0,4939 0,5126
A -Squared 42,50
P-V alue < 0,005
Mean 2,1901
StDev 0,5030
V ariance 0,2531
Skewness 0,99172
Kurtosis 2,01757
N 5565
Minimum 1,2100
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável FECTOT
Figura 1: Análise descritiva da variável FECTOT
Fonte: Atlas do Desenvolvimento Humano no Brasil
De acordo com a Figura 1, pode-se perceber que no Brasil as mulheres têm em
média 2,19 filhos com um desvio padrão de 0,5030. Analisando-se a distância entre o
primeiro e o terceiro quartil, é possível perceber que nos municípios que estão na posição
entre 25% e 75% as mulheres tem entre 1,85 e 2,46 filhos. Os dados mostram também
que em algumas cidades brasileiras as mulheres têm em média mais do que 3 filhos, sendo
que o máximo é 4,89 filhos, o que pode gerar um aumento populacional nestes
municípios. A mediana neste caso está próxima da média, sendo 2,13 filhos, o que indica
que os dois valores estão próximo. Pode-se perceber que em algumas cidades as mulheres
têm em média menos de um filho, o que pode causar uma diminuição populacional nestes
municípios.
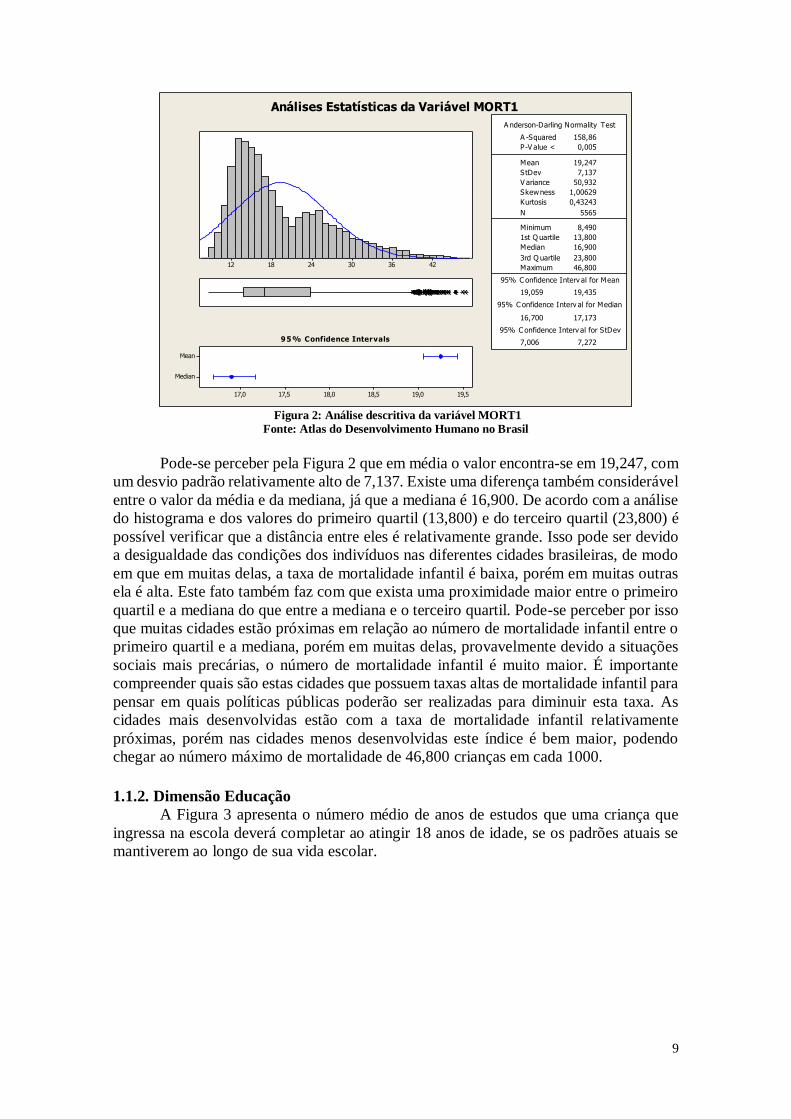
A Figura 2 representa a análise estatística dos municípios quanto ao número de
crianças que não deverão sobreviver ao primeiro ano de vida de cada 1000 crianças
nascidas vivas.
9
423630241812
Median
Mean
19,519,018,518,017,517,0
1st Q uartile 13,800
Median 16,900
3rd Q uartile 23,800
Maximum 46,800
19,059 19,435
16,700 17,173
7,006 7,272
A -Squared 158,86
P-V alue < 0,005
Mean 19,247
StDev 7,137
V ariance 50,932
Skewness 1,00629
Kurtosis 0,43243
N 5565
Minimum 8,490
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável MORT1
Figura 2: Análise descritiva da variável MORT1
Fonte: Atlas do Desenvolvimento Humano no Brasil
Pode-se perceber pela Figura 2 que em média o valor encontra-se em 19,247, com
um desvio padrão relativamente alto de 7,137. Existe uma diferença também considerável
entre o valor da média e da mediana, já que a mediana é 16,900. De acordo com a análise
do histograma e dos valores do primeiro quartil (13,800) e do terceiro quartil (23,800) é
possível verificar que a distância entre eles é relativamente grande. Isso pode ser devido
a desigualdade das condições dos indivíduos nas diferentes cidades brasileiras, de modo
em que em muitas delas, a taxa de mortalidade infantil é baixa, porém em muitas outras
ela é alta. Este fato também faz com que exista uma proximidade maior entre o primeiro
quartil e a mediana do que entre a mediana e o terceiro quartil. Pode-se perceber por isso
que muitas cidades estão próximas em relação ao número de mortalidade infantil entre o
primeiro quartil e a mediana, porém em muitas delas, provavelmente devido a situações
sociais mais precárias, o número de mortalidade infantil é muito maior. É importante
compreender quais são estas cidades que possuem taxas altas de mortalidade infantil para
pensar em quais políticas públicas poderão ser realizadas para diminuir esta taxa. As
cidades mais desenvolvidas estão com a taxa de mortalidade infantil relativamente
próximas, porém nas cidades menos desenvolvidas este índice é bem maior, podendo
chegar ao número máximo de mortalidade de 46,800 crianças em cada 1000.
1.1.2. Dimensão Educação
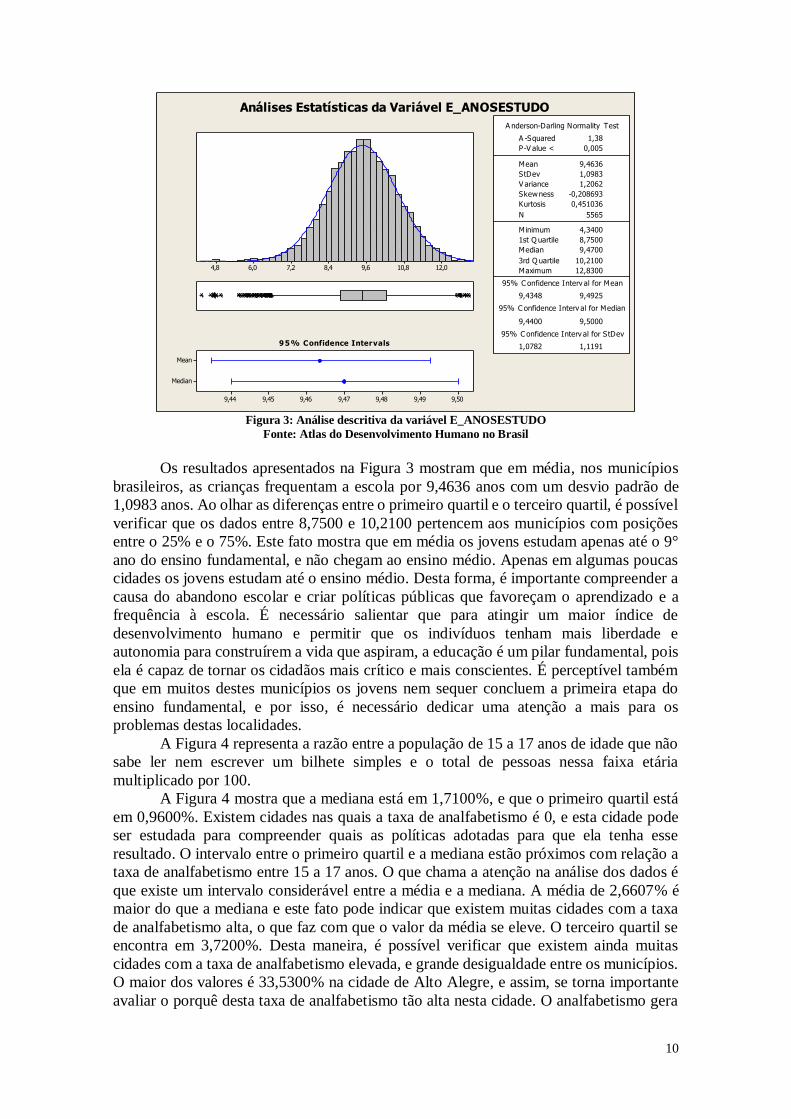
A Figura 3 apresenta o número médio de anos de estudos que uma criança que
ingressa na escola deverá completar ao atingir 18 anos de idade, se os padrões atuais se
mantiverem ao longo de sua vida escolar.
10
12,010,89,68,47,26,04,8
Median
Mean
9,509,499,489,479,469,459,44
1st Q uartile 8,7500
Median 9,4700
3rd Q uartile 10,2100
Maximum 12,8300
9,4348 9,4925
9,4400 9,5000
1,0782 1,1191
A -Squared 1,38
P-V alue < 0,005
Mean 9,4636
StDev 1,0983
V ariance 1,2062
Skewness -0,208693
Kurtosis 0,451036
N 5565
Minimum 4,3400
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável E_ANOSESTUDO
Figura 3: Análise descritiva da variável E_ANOSESTUDO
Fonte: Atlas do Desenvolvimento Humano no Brasil
Os resultados apresentados na Figura 3 mostram que em média, nos municípios
brasileiros, as crianças frequentam a escola por 9,4636 anos com um desvio padrão de
1,0983 anos. Ao olhar as diferenças entre o primeiro quartil e o terceiro quartil, é possível
verificar que os dados entre 8,7500 e 10,2100 pertencem aos municípios com posições
entre o 25% e o 75%. Este fato mostra que em média os jovens estudam apenas até o 9°
ano do ensino fundamental, e não chegam ao ensino médio. Apenas em algumas poucas
cidades os jovens estudam até o ensino médio. Desta forma, é importante compreender a
causa do abandono escolar e criar políticas públicas que favoreçam o aprendizado e a
frequência à escola. É necessário salientar que para atingir um maior índice de
desenvolvimento humano e permitir que os indivíduos tenham mais liberdade e
autonomia para construírem a vida que aspiram, a educação é um pilar fundamental, pois
ela é capaz de tornar os cidadãos mais crítico e mais conscientes. É perceptível também
que em muitos destes municípios os jovens nem sequer concluem a primeira etapa do
ensino fundamental, e por isso, é necessário dedicar uma atenção a mais para os
problemas destas localidades.
A Figura 4 representa a razão entre a população de 15 a 17 anos de idade que não
sabe ler nem escrever um bilhete simples e o total de pessoas nessa faixa etária
multiplicado por 100.
A Figura 4 mostra que a mediana está em 1,7100%, e que o primeiro quartil está
em 0,9600%. Existem cidades nas quais a taxa de analfabetismo é 0, e esta cidade pode
ser estudada para compreender quais as políticas adotadas para que ela tenha esse
resultado. O intervalo entre o primeiro quartil e a mediana estão próximos com relação a
taxa de analfabetismo entre 15 a 17 anos. O que chama a atenção na análise dos dados é
que existe um intervalo considerável entre a média e a mediana. A média de 2,6607% é
maior do que a mediana e este fato pode indicar que existem muitas cidades com a taxa
de analfabetismo alta, o que faz com que o valor da média se eleve. O terceiro quartil se
encontra em 3,7200%. Desta maneira, é possível verificar que existem ainda muitas
cidades com a taxa de analfabetismo elevada, e grande desigualdade entre os municípios.
O maior dos valores é 33,5300% na cidade de Alto Alegre, e assim, se torna importante
avaliar o porquê desta taxa de analfabetismo tão alta nesta cidade. O analfabetismo gera
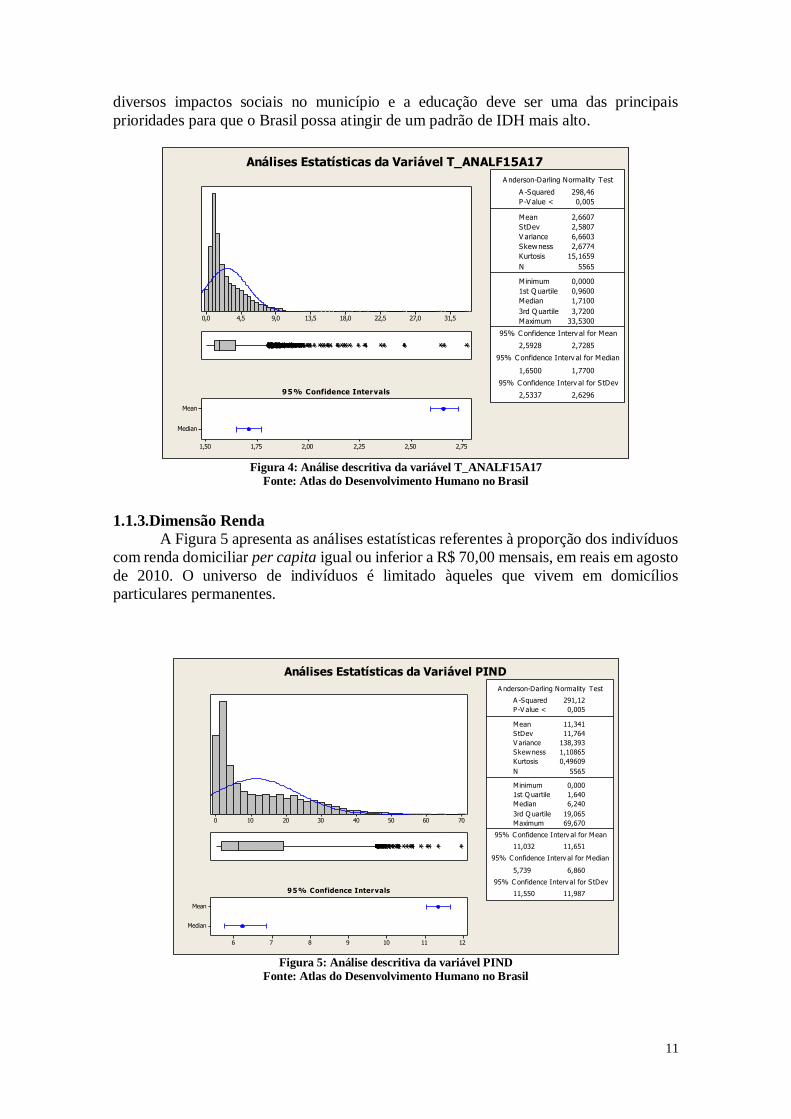
11
diversos impactos sociais no município e a educação deve ser uma das principais
prioridades para que o Brasil possa atingir de um padrão de IDH mais alto.
31,527,022,518,013,59,04,50,0
Median
Mean
2,752,502,252,001,751,50
1st Q uartile 0,9600
Median 1,7100
3rd Q uartile 3,7200
Maximum 33,5300
2,5928 2,7285
1,6500 1,7700
2,5337 2,6296
A -Squared 298,46
P-V alue < 0,005
Mean 2,6607
StDev 2,5807
V ariance 6,6603
Skewness 2,6774
Kurtosis 15,1659
N 5565
Minimum 0,0000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável T_ANALF15A17
Figura 4: Análise descritiva da variável T_ANALF15A17
Fonte: Atlas do Desenvolvimento Humano no Brasil
1.1.3.Dimensão Renda
A Figura 5 apresenta as análises estatísticas referentes à proporção dos indivíduos
com renda domiciliar per capita igual ou inferior a R$ 70,00 mensais, em reais em agosto
de 2010. O universo de indivíduos é limitado àqueles que vivem em domicílios
particulares permanentes.
706050403020100
Median
Mean
1211109876
1st Q uartile 1,640
Median 6,240
3rd Q uartile 19,065
Maximum 69,670
11,032 11,651
5,739 6,860
11,550 11,987
A -Squared 291,12
P-V alue < 0,005
Mean 11,341
StDev 11,764
V ariance 138,393
Skewness 1,10865
Kurtosis 0,49609
N 5565
Minimum 0,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável PIND
Figura 5: Análise descritiva da variável PIND
Fonte: Atlas do Desenvolvimento Humano no Brasil
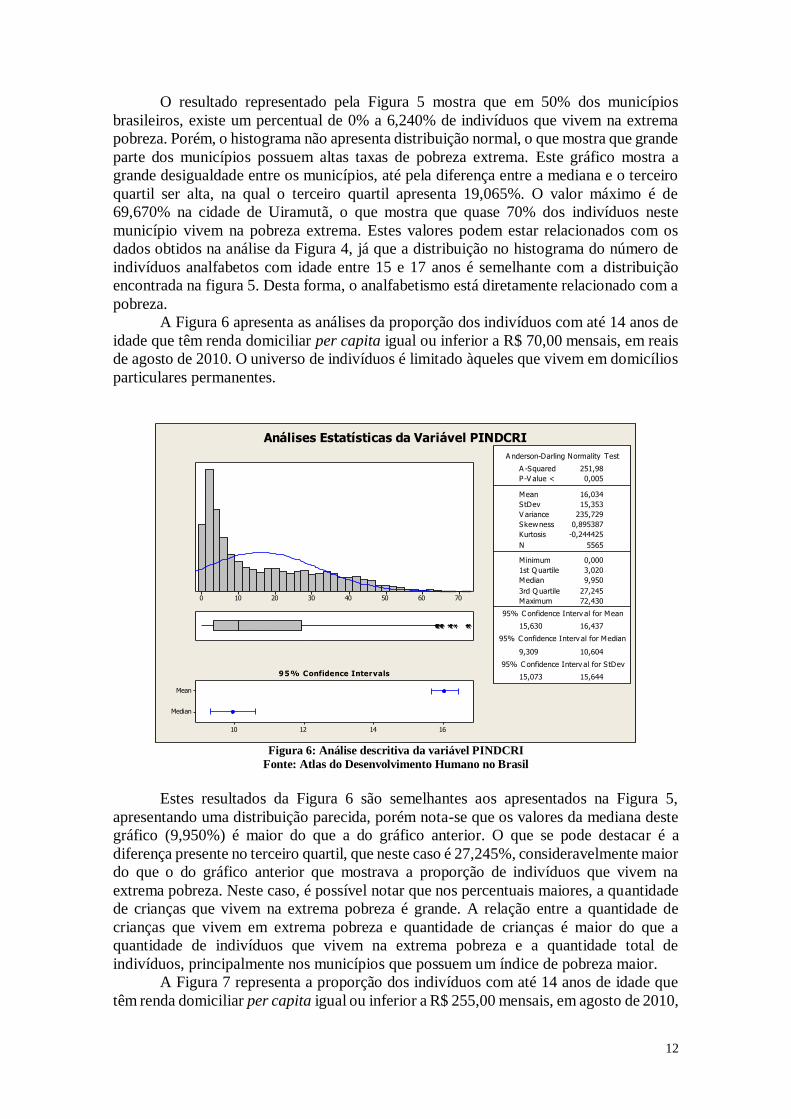
12
O resultado representado pela Figura 5 mostra que em 50% dos municípios
brasileiros, existe um percentual de 0% a 6,240% de indivíduos que vivem na extrema
pobreza. Porém, o histograma não apresenta distribuição normal, o que mostra que grande
parte dos municípios possuem altas taxas de pobreza extrema. Este gráfico mostra a
grande desigualdade entre os municípios, até pela diferença entre a mediana e o terceiro
quartil ser alta, na qual o terceiro quartil apresenta 19,065%. O valor máximo é de
69,670% na cidade de Uiramutã, o que mostra que quase 70% dos indivíduos neste
município vivem na pobreza extrema. Estes valores podem estar relacionados com os
dados obtidos na análise da Figura 4, já que a distribuição no histograma do número de
indivíduos analfabetos com idade entre 15 e 17 anos é semelhante com a distribuição
encontrada na figura 5. Desta forma, o analfabetismo está diretamente relacionado com a
pobreza.
A Figura 6 apresenta as análises da proporção dos indivíduos com até 14 anos de
idade que têm renda domiciliar per capita igual ou inferior a R$ 70,00 mensais, em reais
de agosto de 2010. O universo de indivíduos é limitado àqueles que vivem em domicílios
particulares permanentes.
706050403020100
Median
Mean
16141210
1st Q uartile 3,020
Median 9,950
3rd Q uartile 27,245
Maximum 72,430
15,630 16,437
9,309 10,604
15,073 15,644
A -Squared 251,98
P-V alue < 0,005
Mean 16,034
StDev 15,353
V ariance 235,729
Skewness 0,895387
Kurtosis -0,244425
N 5565
Minimum 0,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável PINDCRI
Figura 6: Análise descritiva da variável PINDCRI
Fonte: Atlas do Desenvolvimento Humano no Brasil
Estes resultados da Figura 6 são semelhantes aos apresentados na Figura 5,
apresentando uma distribuição parecida, porém nota-se que os valores da mediana deste
gráfico (9,950%) é maior do que a do gráfico anterior. O que se pode destacar é a
diferença presente no terceiro quartil, que neste caso é 27,245%, consideravelmente maior
do que o do gráfico anterior que mostrava a proporção de indivíduos que vivem na
extrema pobreza. Neste caso, é possível notar que nos percentuais maiores, a quantidade
de crianças que vivem na extrema pobreza é grande. A relação entre a quantidade de
crianças que vivem em extrema pobreza e quantidade de crianças é maior do que a
quantidade de indivíduos que vivem na extrema pobreza e a quantidade total de
indivíduos, principalmente nos municípios que possuem um índice de pobreza maior.
A Figura 7 representa a proporção dos indivíduos com até 14 anos de idade que
têm renda domiciliar per capita igual ou inferior a R$ 255,00 mensais, em agosto de 2010,

13
equivalente a 1/2 salário mínimo nessa data. O universo de indivíduos é limitado àqueles
com até 14 anos e que vivem em domicílios particulares permanentes.
Ao observar o histograma presente na Figura 7, é possível perceber que existem
dois picos de ponto máximo. Desta forma, no primeiro pico, pode-se observar os
municípios mais desenvolvidos, nos quais a porcentagem de crianças na situação de
pobreza é menor, e no segundo pico, os municípios nos quais a porcentagem de crianças
em situação de pobreza é maior. Estas diferenças podem ser causadas por questões
regionais, sendo que algumas regiões são mais ricas e outras mais pobres, o que acaba
por gerar essa distribuição. Também pode-se observar que a diferença entre o primeiro e
o terceiro quartil é grande, variando de 13,480% a 54,065% respectivamente. Este
histograma pode servir como base de apoio para a compreensão de quais são as áreas
mais carentes e necessitadas, e com isso possibilitar o estabelecimento de estratégias de
ação para elevar o índice de desenvolvimento humano nas áreas mais pobres. Chama a
atenção o fato de que em alguns municípios a porcentagem de crianças vivendo em
situação de pobreza chega a 84,660% nas cidades de Goiatins e Gilbués.
847260483624120
Median
Mean
34333231302928
1st Q uartile 13,480
Median 30,030
3rd Q uartile 54,065
Maximum 84,660
33,157 34,313
28,669 31,200
21,588 22,405
A -Squared 135,94
P-V alue < 0,005
Mean 33,735
StDev 21,989
V ariance 483,497
Skewness 0,27841
Kurtosis -1,27716
N 5565
Minimum 0,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável PMPOBCRI
Figura 7: Análise descritiva da variável PMPOBCRI
1.1.4.Dimensão Trabalho
A Figura 8 mostra as análises referentes a razão entre o número de pessoas de 18
anos ou mais de idade ocupadas e que já concluíram a graduação do ensino superior e o
número total de pessoas ocupadas nessa faixa etária multiplicado por 100.
A partir dos dados obtidos, é perceptível que a mediana dos municípios é 6,400%,
e que poucos são os estados que possuem mais do que 8,8150% de indivíduos com ensino
superior completo, já que este é o valor do terceiro quartil. O que pode ser analisado
também é que observando os pontos em outlier, alguns municípios isolados possuem uma
quantidade grande de indivíduos com ensino superior completo, sendo que a maior delas
é São Caetano do Sul, com 37,53%. Estes pontos representam municípios que são casos
isolados, e que poderiam servir como base para um estudo de quais as razões para terem
atingido este patamar mais elevado, e assim adotar as boas práticas em outros municípios.
A educação superior é um indicativo importante para o IDH, já que representa uma
escolha pessoal, e é uma forma do indivíduo construir sua história e alcançar suas
potencialidades.
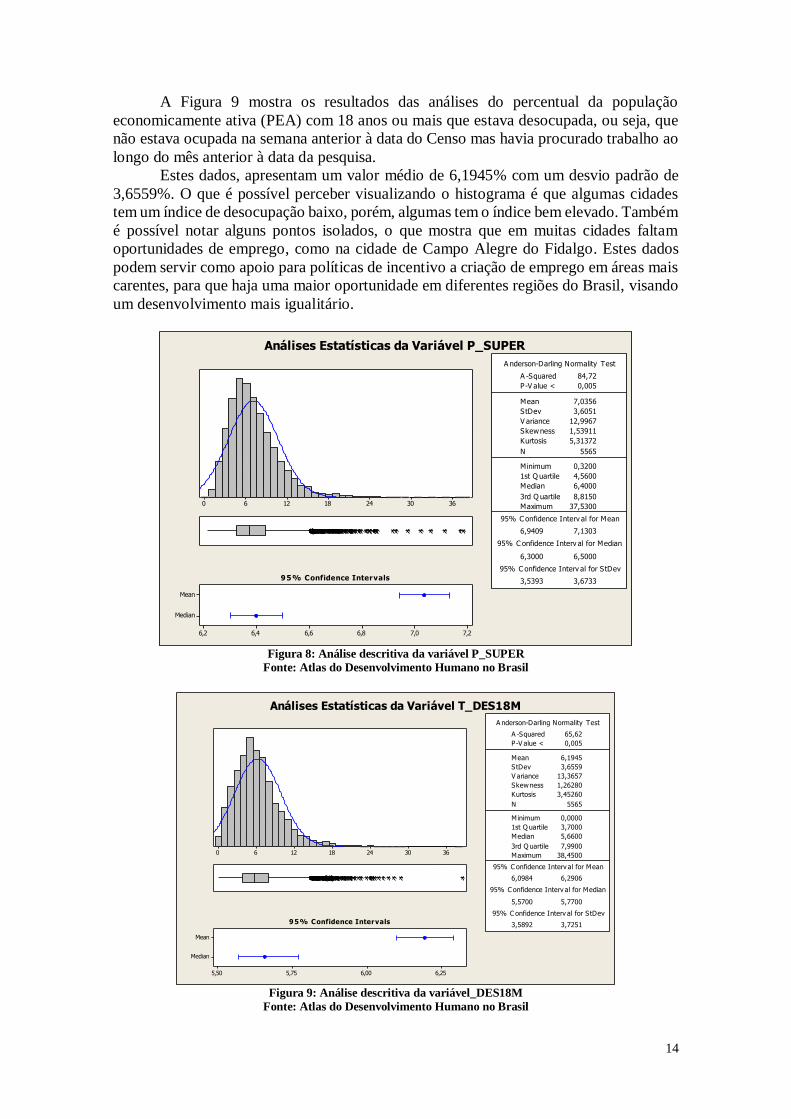
14
A Figura 9 mostra os resultados das análises do percentual da população
economicamente ativa (PEA) com 18 anos ou mais que estava desocupada, ou seja, que
não estava ocupada na semana anterior à data do Censo mas havia procurado trabalho ao
longo do mês anterior à data da pesquisa.
Estes dados, apresentam um valor médio de 6,1945% com um desvio padrão de
3,6559%. O que é possível perceber visualizando o histograma é que algumas cidades
tem um índice de desocupação baixo, porém, algumas tem o índice bem elevado. Também
é possível notar alguns pontos isolados, o que mostra que em muitas cidades faltam
oportunidades de emprego, como na cidade de Campo Alegre do Fidalgo. Estes dados
podem servir como apoio para políticas de incentivo a criação de emprego em áreas mais
carentes, para que haja uma maior oportunidade em diferentes regiões do Brasil, visando
um desenvolvimento mais igualitário.
363024181260
Median
Mean
7,27,06,86,66,46,2
1st Q uartile 4,5600
Median 6,4000
3rd Q uartile 8,8150
Maximum 37,5300
6,9409 7,1303
6,3000 6,5000
3,5393 3,6733
A -Squared 84,72
P-V alue < 0,005
Mean 7,0356
StDev 3,6051
V ariance 12,9967
Skewness 1,53911
Kurtosis 5,31372
N 5565
Minimum 0,3200
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável P_SUPER
Figura 8: Análise descritiva da variável P_SUPER
Fonte: Atlas do Desenvolvimento Humano no Brasil
363024181260
Median
Mean
6,256,005,755,50
1st Q uartile 3,7000
Median 5,6600
3rd Q uartile 7,9900
Maximum 38,4500
6,0984 6,2906
5,5700 5,7700
3,5892 3,7251
A -Squared 65,62
P-V alue < 0,005
Mean 6,1945
StDev 3,6559
V ariance 13,3657
Skewness 1,26280
Kurtosis 3,45260
N 5565
Minimum 0,0000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável T_DES18M
Figura 9: Análise descritiva da variável_DES18M
Fonte: Atlas do Desenvolvimento Humano no Brasil
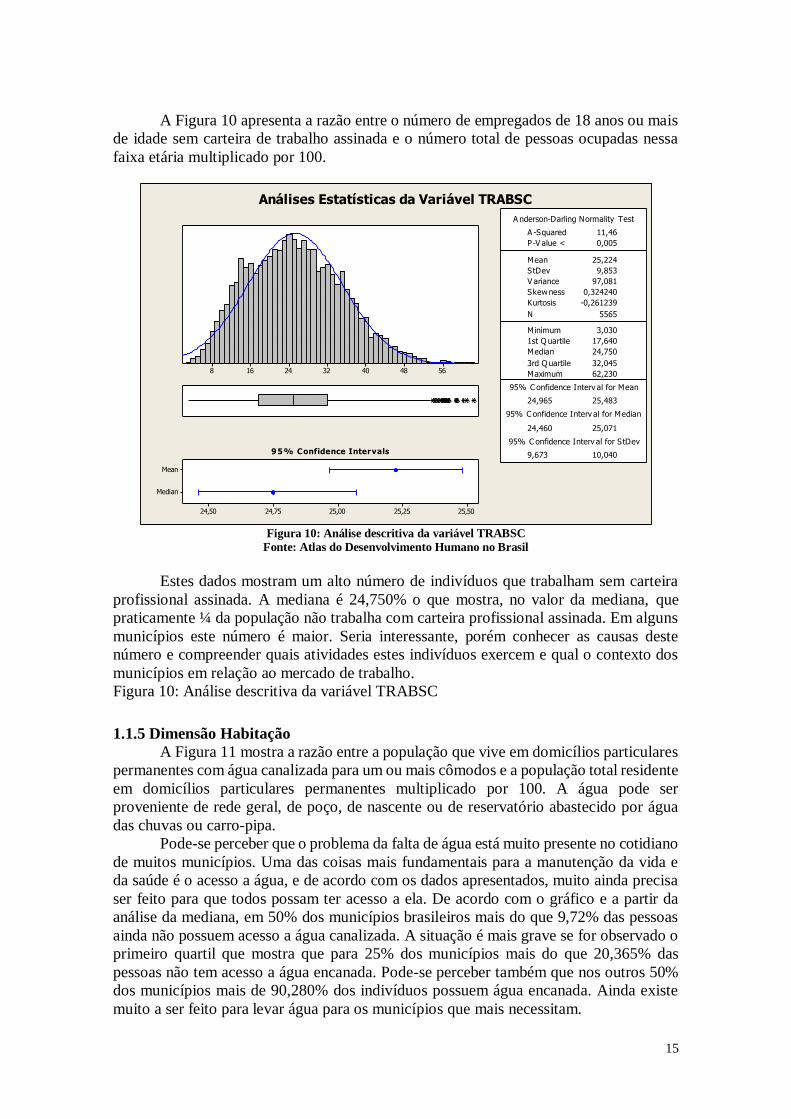
15
A Figura 10 apresenta a razão entre o número de empregados de 18 anos ou mais
de idade sem carteira de trabalho assinada e o número total de pessoas ocupadas nessa
faixa etária multiplicado por 100.
5648403224168
Median
Mean
25,5025,2525,0024,7524,50
1st Q uartile 17,640
Median 24,750
3rd Q uartile 32,045
Maximum 62,230
24,965 25,483
24,460 25,071
9,673 10,040
A -Squared 11,46
P-V alue < 0,005
Mean 25,224
StDev 9,853
V ariance 97,081
Skewness 0,324240
Kurtosis -0,261239
N 5565
Minimum 3,030
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável TRABSC
Figura 10: Análise descritiva da variável TRABSC
Fonte: Atlas do Desenvolvimento Humano no Brasil
Estes dados mostram um alto número de indivíduos que trabalham sem carteira
profissional assinada. A mediana é 24,750% o que mostra, no valor da mediana, que
praticamente ¼ da população não trabalha com carteira profissional assinada. Em alguns
municípios este número é maior. Seria interessante, porém conhecer as causas deste
número e compreender quais atividades estes indivíduos exercem e qual o contexto dos
municípios em relação ao mercado de trabalho.
Figura 10: Análise descritiva da variável TRABSC
1.1.5 Dimensão Habitação
A Figura 11 mostra a razão entre a população que vive em domicílios particulares
permanentes com água canalizada para um ou mais cômodos e a população total residente
em domicílios particulares permanentes multiplicado por 100. A água pode ser
proveniente de rede geral, de poço, de nascente ou de reservatório abastecido por água
das chuvas ou carro-pipa.
Pode-se perceber que o problema da falta de água está muito presente no cotidiano
de muitos municípios. Uma das coisas mais fundamentais para a manutenção da vida e
da saúde é o acesso a água, e de acordo com os dados apresentados, muito ainda precisa
ser feito para que todos possam ter acesso a ela. De acordo com o gráfico e a partir da
análise da mediana, em 50% dos municípios brasileiros mais do que 9,72% das pessoas
ainda não possuem acesso a água canalizada. A situação é mais grave se for observado o
primeiro quartil que mostra que para 25% dos municípios mais do que 20,365% das
pessoas não tem acesso a água encanada. Pode-se perceber também que nos outros 50%
dos municípios mais de 90,280% dos indivíduos possuem água encanada. Ainda existe
muito a ser feito para levar água para os municípios que mais necessitam.
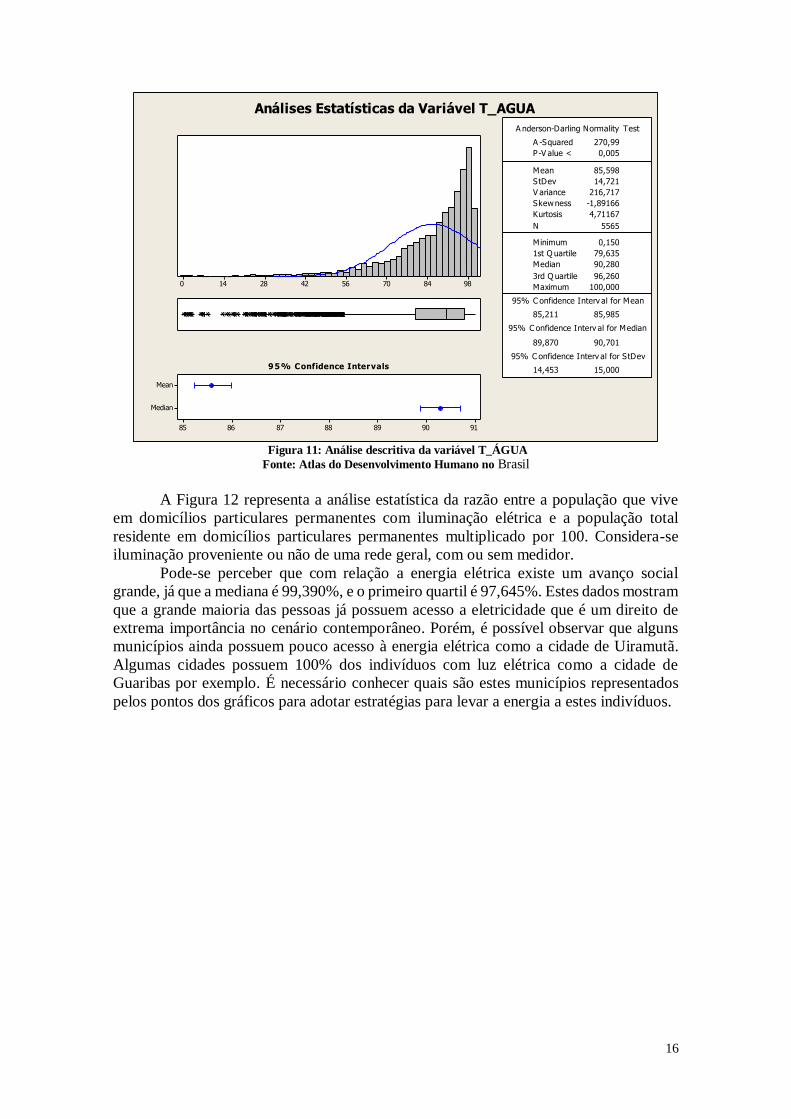
16
988470564228140
Median
Mean
91908988878685
1st Q uartile 79,635
Median 90,280
3rd Q uartile 96,260
Maximum 100,000
85,211 85,985
89,870 90,701
14,453 15,000
A -Squared 270,99
P-V alue < 0,005
Mean 85,598
StDev 14,721
V ariance 216,717
Skewness -1,89166
Kurtosis 4,71167
N 5565
Minimum 0,150
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável T_AGUA
Figura 11: Análise descritiva da variável T_ÁGUA
Fonte: Atlas do Desenvolvimento Humano no Brasil
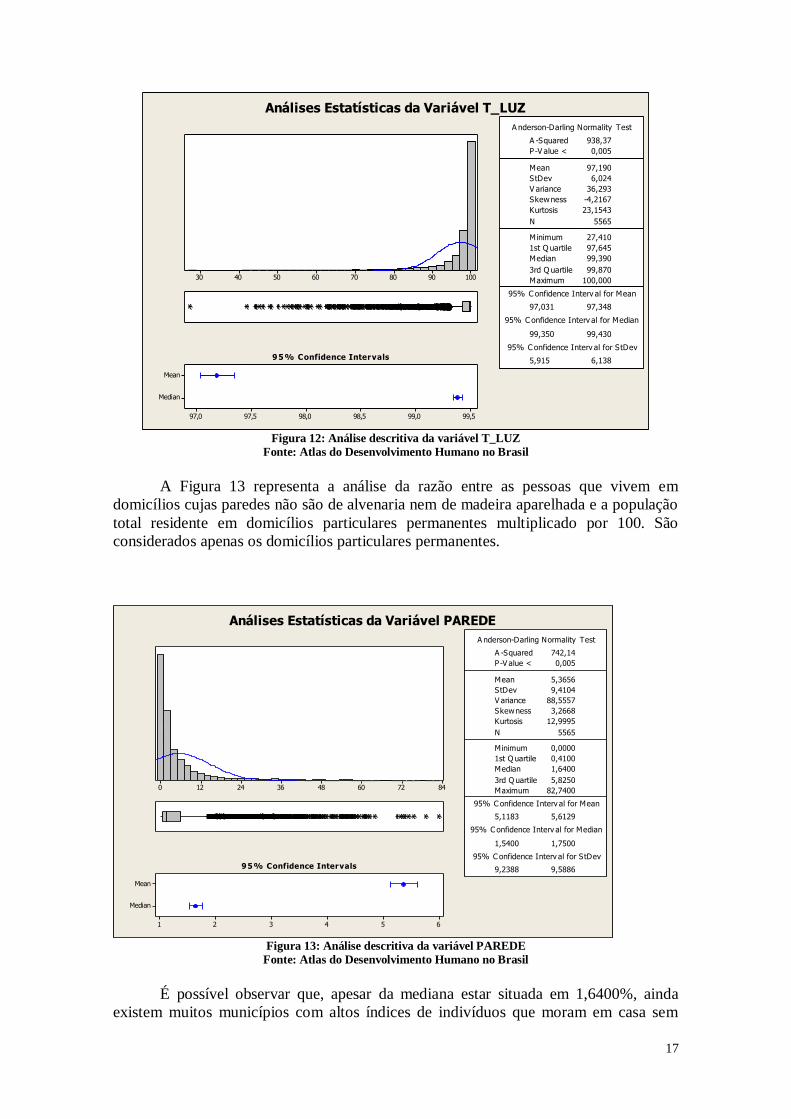
A Figura 12 representa a análise estatística da razão entre a população que vive
em domicílios particulares permanentes com iluminação elétrica e a população total
residente em domicílios particulares permanentes multiplicado por 100. Considera-se
iluminação proveniente ou não de uma rede geral, com ou sem medidor.
Pode-se perceber que com relação a energia elétrica existe um avanço social
grande, já que a mediana é 99,390%, e o primeiro quartil é 97,645%. Estes dados mostram
que a grande maioria das pessoas já possuem acesso a eletricidade que é um direito de
extrema importância no cenário contemporâneo. Porém, é possível observar que alguns
municípios ainda possuem pouco acesso à energia elétrica como a cidade de Uiramutã.
Algumas cidades possuem 100% dos indivíduos com luz elétrica como a cidade de
Guaribas por exemplo. É necessário conhecer quais são estes municípios representados
pelos pontos dos gráficos para adotar estratégias para levar a energia a estes indivíduos.
17
10090807060504030
Median
Mean
99,599,098,598,097,597,0
1st Q uartile 97,645
Median 99,390
3rd Q uartile 99,870
Maximum 100,000
97,031 97,348
99,350 99,430
5,915 6,138
A -Squared 938,37
P-V alue < 0,005
Mean 97,190
StDev 6,024
V ariance 36,293
Skewness -4,2167
Kurtosis 23,1543
N 5565
Minimum 27,410
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável T_LUZ
Figura 12: Análise descritiva da variável T_LUZ
Fonte: Atlas do Desenvolvimento Humano no Brasil
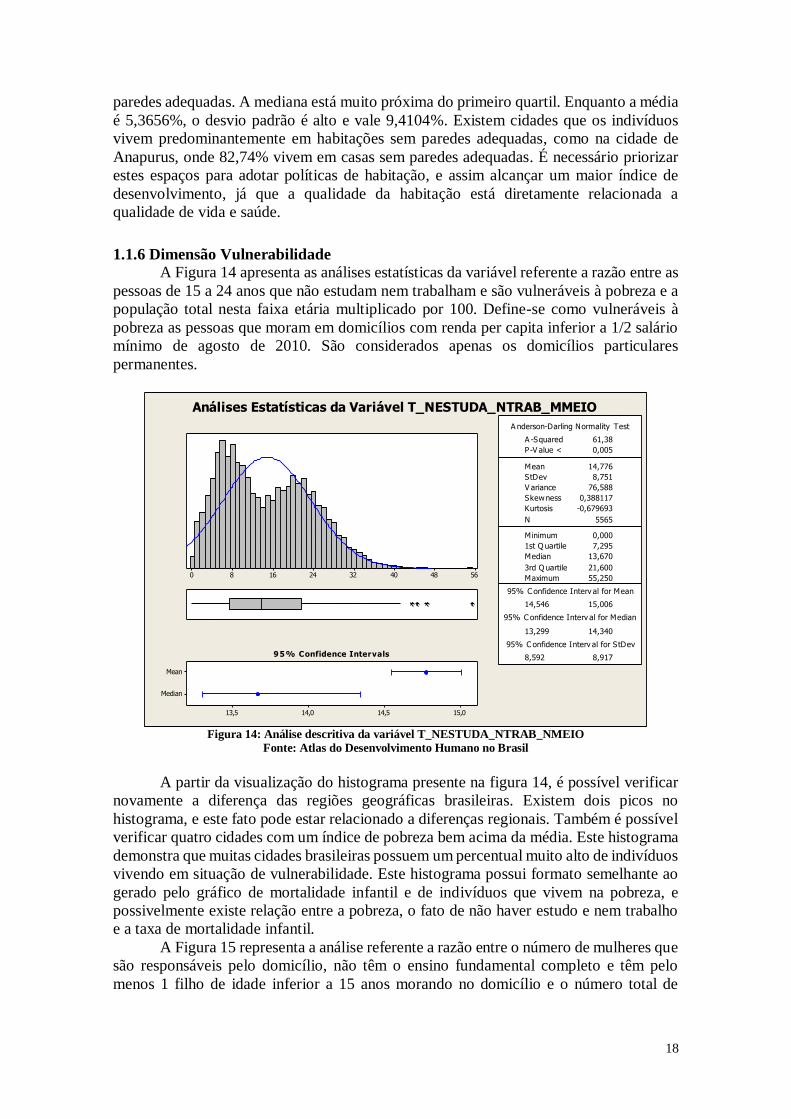
A Figura 13 representa a análise da razão entre as pessoas que vivem em
domicílios cujas paredes não são de alvenaria nem de madeira aparelhada e a população
total residente em domicílios particulares permanentes multiplicado por 100. São
considerados apenas os domicílios particulares permanentes.
847260483624120
Median
Mean
654321
1st Q uartile 0,4100
Median 1,6400
3rd Q uartile 5,8250
Maximum 82,7400
5,1183 5,6129
1,5400 1,7500
9,2388 9,5886
A -Squared 742,14
P-V alue < 0,005
Mean 5,3656
StDev 9,4104
V ariance 88,5557
Skewness 3,2668
Kurtosis 12,9995
N 5565
Minimum 0,0000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável PAREDE
Figura 13: Análise descritiva da variável PAREDE
Fonte: Atlas do Desenvolvimento Humano no Brasil
É possível observar que, apesar da mediana estar situada em 1,6400%, ainda
existem muitos municípios com altos índices de indivíduos que moram em casa sem
18
paredes adequadas. A mediana está muito próxima do primeiro quartil. Enquanto a média
é 5,3656%, o desvio padrão é alto e vale 9,4104%. Existem cidades que os indivíduos
vivem predominantemente em habitações sem paredes adequadas, como na cidade de
Anapurus, onde 82,74% vivem em casas sem paredes adequadas. É necessário priorizar
estes espaços para adotar políticas de habitação, e assim alcançar um maior índice de
desenvolvimento, já que a qualidade da habitação está diretamente relacionada a
qualidade de vida e saúde.
1.1.6 Dimensão Vulnerabilidade
A Figura 14 apresenta as análises estatísticas da variável referente a razão entre as
pessoas de 15 a 24 anos que não estudam nem trabalham e são vulneráveis à pobreza e a
população total nesta faixa etária multiplicado por 100. Define-se como vulneráveis à
pobreza as pessoas que moram em domicílios com renda per capita inferior a 1/2 salário
mínimo de agosto de 2010. São considerados apenas os domicílios particulares
permanentes.
56484032241680
Median
Mean
15,014,514,013,5
1st Q uartile 7,295
Median 13,670
3rd Q uartile 21,600
Maximum 55,250
14,546 15,006
13,299 14,340
8,592 8,917
A -Squared 61,38
P-V alue < 0,005
Mean 14,776
StDev 8,751
V ariance 76,588
Skewness 0,388117
Kurtosis -0,679693
N 5565
Minimum 0,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável T_NESTUDA_NTRAB_MMEIO
Figura 14: Análise descritiva da variável T_NESTUDA_NTRAB_NMEIO
Fonte: Atlas do Desenvolvimento Humano no Brasil
A partir da visualização do histograma presente na figura 14, é possível verificar
novamente a diferença das regiões geográficas brasileiras. Existem dois picos no
histograma, e este fato pode estar relacionado a diferenças regionais. Também é possível
verificar quatro cidades com um índice de pobreza bem acima da média. Este histograma
demonstra que muitas cidades brasileiras possuem um percentual muito alto de indivíduos
vivendo em situação de vulnerabilidade. Este histograma possui formato semelhante ao
gerado pelo gráfico de mortalidade infantil e de indivíduos que vivem na pobreza, e
possivelmente existe relação entre a pobreza, o fato de não haver estudo e nem trabalho
e a taxa de mortalidade infantil.
A Figura 15 representa a análise referente a razão entre o número de mulheres que
são responsáveis pelo domicílio, não têm o ensino fundamental completo e têm pelo
menos 1 filho de idade inferior a 15 anos morando no domicílio e o número total de
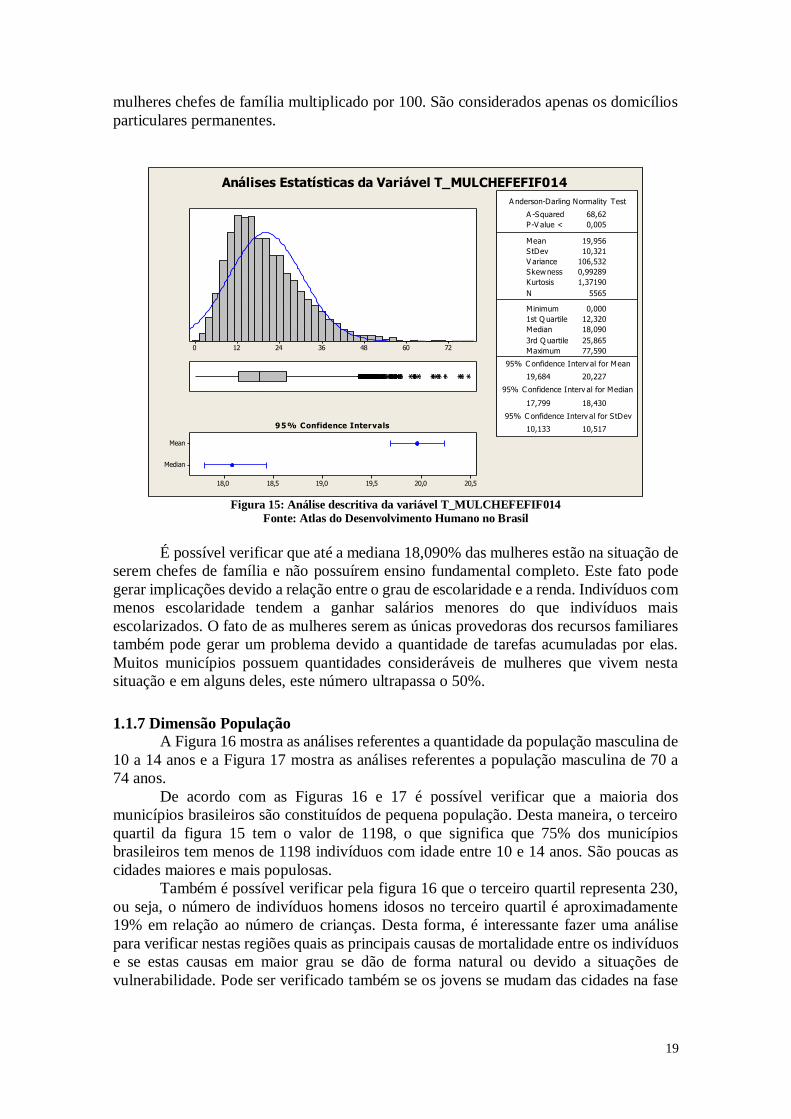
19
mulheres chefes de família multiplicado por 100. São considerados apenas os domicílios
particulares permanentes.
7260483624120
Median
Mean
20,520,019,519,018,518,0
1st Q uartile 12,320
Median 18,090
3rd Q uartile 25,865
Maximum 77,590
19,684 20,227
17,799 18,430
10,133 10,517
A -Squared 68,62
P-V alue < 0,005
Mean 19,956
StDev 10,321
V ariance 106,532
Skewness 0,99289
Kurtosis 1,37190
N 5565
Minimum 0,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável T_MULCHEFEFIF014
Figura 15: Análise descritiva da variável T_MULCHEFEFIF014
Fonte: Atlas do Desenvolvimento Humano no Brasil
É possível verificar que até a mediana 18,090% das mulheres estão na situação de
serem chefes de família e não possuírem ensino fundamental completo. Este fato pode
gerar implicações devido a relação entre o grau de escolaridade e a renda. Indivíduos com
menos escolaridade tendem a ganhar salários menores do que indivíduos mais
escolarizados. O fato de as mulheres serem as únicas provedoras dos recursos familiares
também pode gerar um problema devido a quantidade de tarefas acumuladas por elas.
Muitos municípios possuem quantidades consideráveis de mulheres que vivem nesta
situação e em alguns deles, este número ultrapassa o 50%.
1.1.7 Dimensão População
A Figura 16 mostra as análises referentes a quantidade da população masculina de
10 a 14 anos e a Figura 17 mostra as análises referentes a população masculina de 70 a
74 anos.
De acordo com as Figuras 16 e 17 é possível verificar que a maioria dos
municípios brasileiros são constituídos de pequena população. Desta maneira, o terceiro
quartil da figura 15 tem o valor de 1198, o que significa que 75% dos municípios
brasileiros tem menos de 1198 indivíduos com idade entre 10 e 14 anos. São poucas as
cidades maiores e mais populosas.
Também é possível verificar pela figura 16 que o terceiro quartil representa 230,
ou seja, o número de indivíduos homens idosos no terceiro quartil é aproximadamente
19% em relação ao número de crianças. Desta forma, é interessante fazer uma análise
para verificar nestas regiões quais as principais causas de mortalidade entre os indivíduos
e se estas causas em maior grau se dão de forma natural ou devido a situações de
vulnerabilidade. Pode ser verificado também se os jovens se mudam das cidades na fase
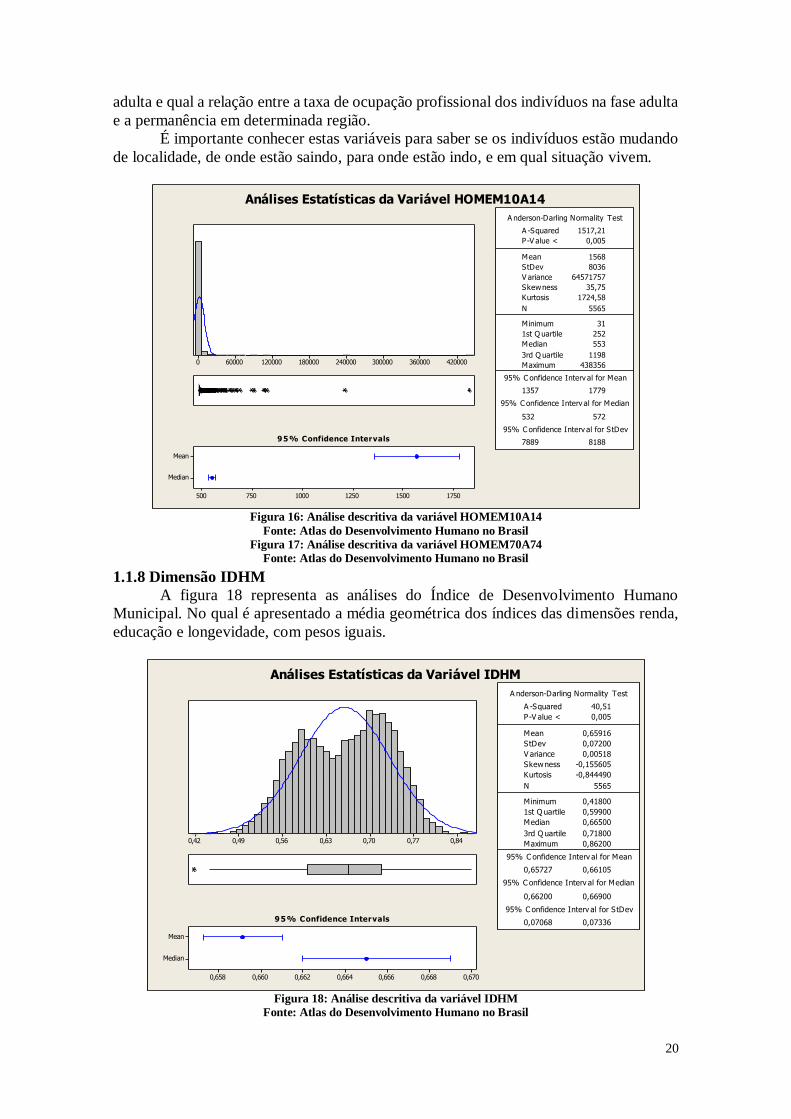
20
adulta e qual a relação entre a taxa de ocupação profissional dos indivíduos na fase adulta
e a permanência em determinada região.
É importante conhecer estas variáveis para saber se os indivíduos estão mudando
de localidade, de onde estão saindo, para onde estão indo, e em qual situação vivem.
420000360000300000240000180000120000600000
Median
Mean
1750150012501000750500
1st Q uartile 252
Median 553
3rd Q uartile 1198
Maximum 438356
1357 1779
532 572
7889 8188
A -Squared 1517,21
P-V alue < 0,005
Mean 1568
StDev 8036
V ariance 64571757
Skewness 35,75
Kurtosis 1724,58
N 5565
Minimum 31
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável HOMEM10A14
Figura 16: Análise descritiva da variável HOMEM10A14
Fonte: Atlas do Desenvolvimento Humano no Brasil
Figura 17: Análise descritiva da variável HOMEM70A74
Fonte: Atlas do Desenvolvimento Humano no Brasil
1.1.8 Dimensão IDHM
A figura 18 representa as análises do Índice de Desenvolvimento Humano
Municipal. No qual é apresentado a média geométrica dos índices das dimensões renda,
educação e longevidade, com pesos iguais.
0,840,770,700,630,560,490,42
Median
Mean
0,6700,6680,6660,6640,6620,6600,658
1st Q uartile 0,59900
Median 0,66500
3rd Q uartile 0,71800
Maximum 0,86200
0,65727 0,66105
0,66200 0,66900
0,07068 0,07336
A -Squared 40,51
P-V alue < 0,005
Mean 0,65916
StDev 0,07200
V ariance 0,00518
Skewness -0,155605
Kurtosis -0,844490
N 5565
Minimum 0,41800
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável IDHM
Figura 18: Análise descritiva da variável IDHM
Fonte: Atlas do Desenvolvimento Humano no Brasil
21
A distribuição do histograma mostra novamente as diferenças regionais do Brasil.
Pode-se perceber que de um lado se encontram as regiões com um maior IDHM
representadas pelo segundo pico, e de um outro as regiões com um menor IDHM,
representadas pelo primeiro pico. É necessário estabelecer políticas a fim de melhorar as
condições dos indivíduos que moram nas regiões menos desenvolvidas. O box-plot
também não apresenta simetria, e a distância entre o terceiro quartil e a mediana é menor
do que a distância entre o primeiro quartil e a mediana. É necessário realizar testes para
compreender exatamente quais as delimitações das duas regiões do Brasil com essa
disparidade e estabelecer políticas de desenvolvimento nestas localidades.
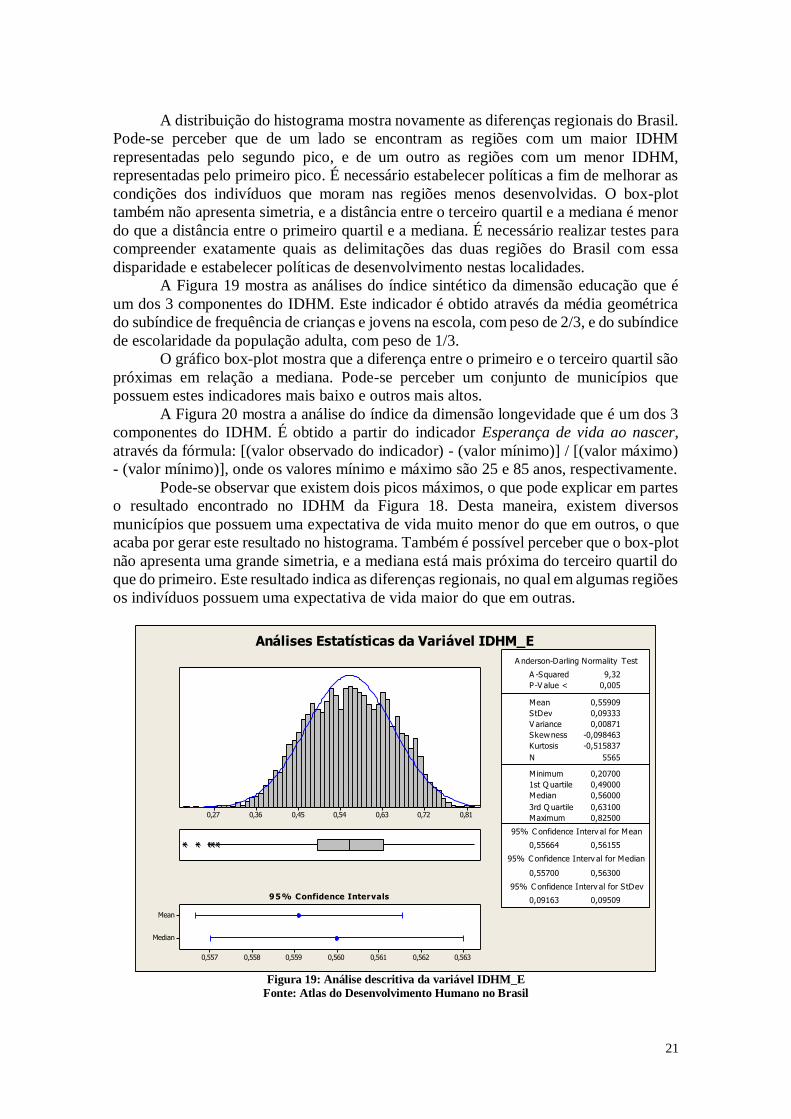
A Figura 19 mostra as análises do índice sintético da dimensão educação que é
um dos 3 componentes do IDHM. Este indicador é obtido através da média geométrica
do subíndice de frequência de crianças e jovens na escola, com peso de 2/3, e do subíndice
de escolaridade da população adulta, com peso de 1/3.
O gráfico box-plot mostra que a diferença entre o primeiro e o terceiro quartil são
próximas em relação a mediana. Pode-se perceber um conjunto de municípios que
possuem estes indicadores mais baixo e outros mais altos.
A Figura 20 mostra a análise do índice da dimensão longevidade que é um dos 3
componentes do IDHM. É obtido a partir do indicador Esperança de vida ao nascer,
através da fórmula: [(valor observado do indicador) - (valor mínimo)] / [(valor máximo)
- (valor mínimo)], onde os valores mínimo e máximo são 25 e 85 anos, respectivamente.
Pode-se observar que existem dois picos máximos, o que pode explicar em partes
o resultado encontrado no IDHM da Figura 18. Desta maneira, existem diversos
municípios que possuem uma expectativa de vida muito menor do que em outros, o que
acaba por gerar este resultado no histograma. Também é possível perceber que o box-plot
não apresenta uma grande simetria, e a mediana está mais próxima do terceiro quartil do
que do primeiro. Este resultado indica as diferenças regionais, no qual em algumas regiões
os indivíduos possuem uma expectativa de vida maior do que em outras.
0,810,720,630,540,450,360,27
Median
Mean
0,5630,5620,5610,5600,5590,5580,557
1st Q uartile 0,49000
Median 0,56000
3rd Q uartile 0,63100
Maximum 0,82500
0,55664 0,56155
0,55700 0,56300
0,09163 0,09509
A -Squared 9,32
P-V alue < 0,005
Mean 0,55909
StDev 0,09333
V ariance 0,00871
Skewness -0,098463
Kurtosis -0,515837
N 5565
Minimum 0,20700
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável IDHM_E
Figura 19: Análise descritiva da variável IDHM_E
Fonte: Atlas do Desenvolvimento Humano no Brasil
22
0,870,840,810,780,750,720,69
Median
Mean
0,8100,8080,8060,8040,8020,800
1st Q uartile 0,76900
Median 0,80800
3rd Q uartile 0,83600
Maximum 0,89400
0,80039 0,80274
0,80600 0,80900
0,04387 0,04553
A -Squared 35,06
P-V alue < 0,005
Mean 0,80156
StDev 0,04468
V ariance 0,00200
Skewness -0,409358
Kurtosis -0,486243
N 5565
Minimum 0,67200
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável IDHM_L
Figura 20: Análise descritiva da variável IDHM_L
Fonte: Atlas do Desenvolvimento Humano no Brasil
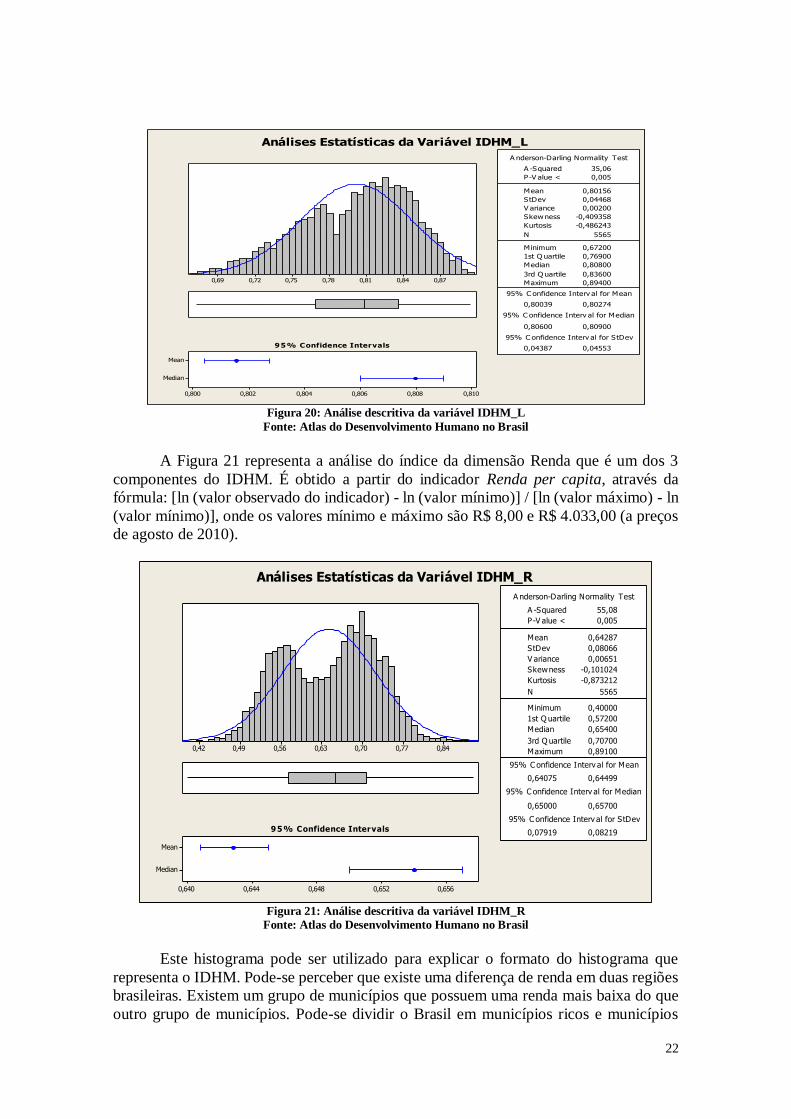
A Figura 21 representa a análise do índice da dimensão Renda que é um dos 3
componentes do IDHM. É obtido a partir do indicador Renda per capita, através da
fórmula: [ln (valor observado do indicador) - ln (valor mínimo)] / [ln (valor máximo) - ln
(valor mínimo)], onde os valores mínimo e máximo são R$ 8,00 e R$ 4.033,00 (a preços
de agosto de 2010).
0,840,770,700,630,560,490,42
Median
Mean
0,6560,6520,6480,6440,640
1st Q uartile 0,57200
Median 0,65400
3rd Q uartile 0,70700
Maximum 0,89100
0,64075 0,64499
0,65000 0,65700
0,07919 0,08219
A -Squared 55,08
P-V alue < 0,005
Mean 0,64287
StDev 0,08066
V ariance 0,00651
Skewness -0,101024
Kurtosis -0,873212
N 5565
Minimum 0,40000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável IDHM_R
Figura 21: Análise descritiva da variável IDHM_R
Fonte: Atlas do Desenvolvimento Humano no Brasil
Este histograma pode ser utilizado para explicar o formato do histograma que
representa o IDHM. Pode-se perceber que existe uma diferença de renda em duas regiões
brasileiras. Existem um grupo de municípios que possuem uma renda mais baixa do que
outro grupo de municípios. Pode-se dividir o Brasil em municípios ricos e municípios

23
pobres. Existe uma desigualdade de renda que faz com que o IDHM tenha estes dois
valores de pico.
O que é possível perceber é que se levarmos em conta o histograma da
longevidade e da renda, os dois agregados fazem com que o histograma do IDHM tenha
a curva que possui.
1.2 Considerações
A partir da observação dos dados, é possível verificar que o Brasil, em relação ao
IDHM, pode ser dividido em dois. De um lado existem municípios com o IDHM
relativamente alto e com um maior grau de desenvolvimento. Por outro lado, existem os
municípios com o IDHM baixo e com menor grau de desenvolvimento.
Analisando os histogramas é possível perceber que a má distribuição de renda e a
diferença nos graus de longevidade são os aspectos principais que levam a este resultado.
É necessário melhorar muito também no quesito educação, pois é perceptível que alguns
municípios possuem altas taxas de analfabetismo e indivíduos com baixa escolaridade.
É necessário realizar políticas que busquem desenvolver estes municípios pouco
desenvolvidos, para que eles possam se igualar aos municípios mais desenvolvidos
buscando uma maior equidade social.
Para que se alcance um maior IDHM, é necessário que os indivíduos tenham a
possibilidade de escolher a vida que pretendem levar, e atingir o seu potencial individual.
Para que esse caminho seja possível, é necessário o investimento em educação, pois ela é
capaz de fazer com que os indivíduos sejam mais críticos e tomem decisões mais
racionais.
Outro ponto a se destacar é que são necessárias políticas públicas que melhorem
a saúde, e levar os municípios menos desenvolvidos a se desenvolverem de forma a
melhorar a renda nas localidades mais carentes. Desta forma, pode-se diminuir o nível de
pobreza destes municípios.
CAPITULO 2. RELAÇÕES ENTRE VARIÁVEIS
Neste segundo capítulo será realizada inicialmente uma análise sobre o percentual
de municípios em cada estado e região brasileira, a fim de compreender melhor como se
dá a distribuição dos municípios. Após esta análise, será analisada a correlação entre as
variáveis escolhidas e descritas no capítulo 1 nas oito dimensões e, depois, será gerado o
dendograma dessas variáveis com o auxílio do software estatístico MINITAB.
2.Análise das Variáveis
A análise das variáveis está dividida em três tópicos. No primeiro, será analisado
a distribuição dos municípios nos diversos estados brasileiros e nas cinco regiões. O
segundo tópico consiste no estudo da correlação entre as variáveis, na construção de
diagramas de dispersão e suas respectivas análises. Na terceira parte será realizada a
construção do dendograma.
2.1.Distribuição dos Municípios Brasileiros por Estado e Região
A Figura 1 representa o gráfico de pizza que mostra a distribuição dos municípios
brasileiros de acordo com os estados. Pode-se perceber que o estado com mais municípios
é Minas Gerais, com 15,3% do total de municípios, seguida por São Paulo com 11,6%.
Os outros estados da região Sudeste são Espírito Santo com 1,4% e Rio de Janeiro
com 1,7% de municípios do total. Na região Sul, o percentual de municípios em relação
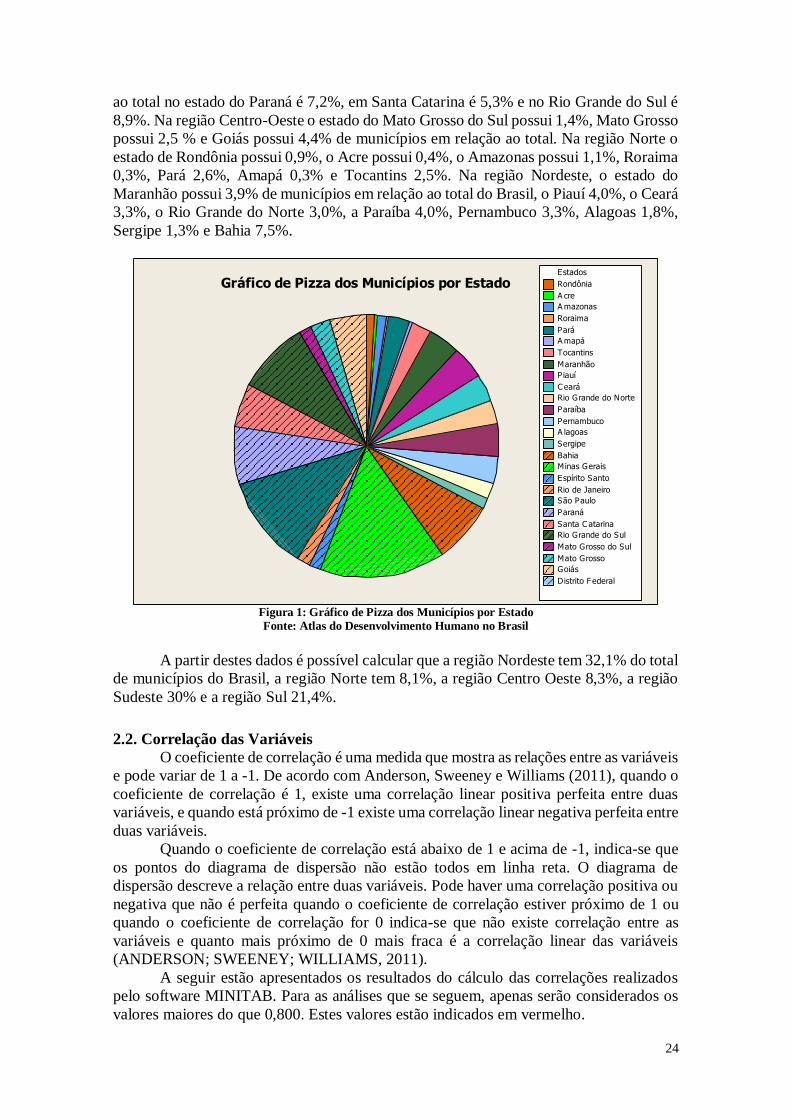
24
ao total no estado do Paraná é 7,2%, em Santa Catarina é 5,3% e no Rio Grande do Sul é
8,9%. Na região Centro-Oeste o estado do Mato Grosso do Sul possui 1,4%, Mato Grosso
possui 2,5 % e Goiás possui 4,4% de municípios em relação ao total. Na região Norte o
estado de Rondônia possui 0,9%, o Acre possui 0,4%, o Amazonas possui 1,1%, Roraima
0,3%, Pará 2,6%, Amapá 0,3% e Tocantins 2,5%. Na região Nordeste, o estado do
Maranhão possui 3,9% de municípios em relação ao total do Brasil, o Piauí 4,0%, o Ceará
3,3%, o Rio Grande do Norte 3,0%, a Paraíba 4,0%, Pernambuco 3,3%, Alagoas 1,8%,
Sergipe 1,3% e Bahia 7,5%.
C eará
Rio Grande do Norte
Paraíba
Pernambuco
A lagoas
Sergipe
Bahia
Minas Gerais
Espírito Santo
Rio de Janeiro
Rondônia
São Paulo
Paraná
Santa C atarina
Rio Grande do Sul
Mato Grosso do Sul
Mato Grosso
Goiás
Distrito Federal
A cre
A mazonas
Roraima
Pará
A mapá
Tocantins
Maranhão
P iauí
Estados
Gráfico de Pizza dos Municípios por Estado
Figura 1: Gráfico de Pizza dos Municípios por Estado
Fonte: Atlas do Desenvolvimento Humano no Brasil
A partir destes dados é possível calcular que a região Nordeste tem 32,1% do total
de municípios do Brasil, a região Norte tem 8,1%, a região Centro Oeste 8,3%, a região
Sudeste 30% e a região Sul 21,4%.
2.2. Correlação das Variáveis
O coeficiente de correlação é uma medida que mostra as relações entre as variáveis
e pode variar de 1 a -1. De acordo com Anderson, Sweeney e Williams (2011), quando o
coeficiente de correlação é 1, existe uma correlação linear positiva perfeita entre duas
variáveis, e quando está próximo de -1 existe uma correlação linear negativa perfeita entre
duas variáveis.
Quando o coeficiente de correlação está abaixo de 1 e acima de -1, indica-se que
os pontos do diagrama de dispersão não estão todos em linha reta. O diagrama de
dispersão descreve a relação entre duas variáveis. Pode haver uma correlação positiva ou
negativa que não é perfeita quando o coeficiente de correlação estiver próximo de 1 ou
quando o coeficiente de correlação for 0 indica-se que não existe correlação entre as
variáveis e quanto mais próximo de 0 mais fraca é a correlação linear das variáveis
(ANDERSON; SWEENEY; WILLIAMS, 2011).
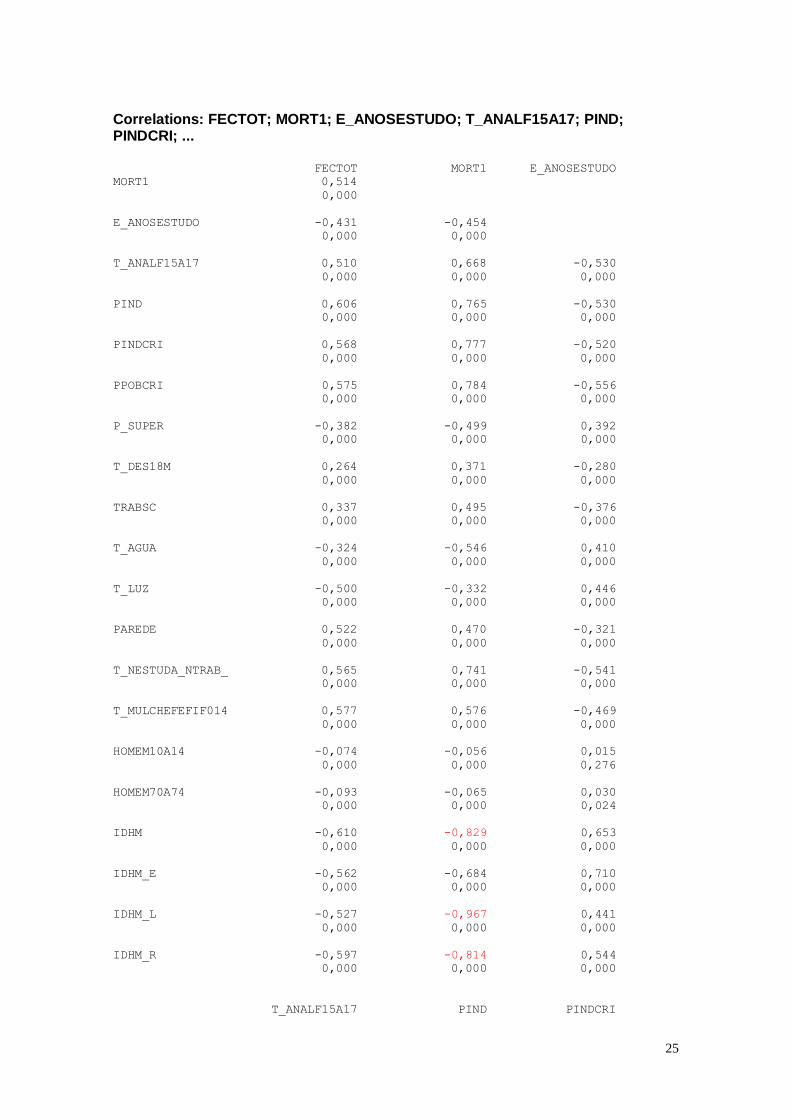
A seguir estão apresentados os resultados do cálculo das correlações realizados
pelo software MINITAB. Para as análises que se seguem, apenas serão considerados os
valores maiores do que 0,800. Estes valores estão indicados em vermelho.
25
Correlations: FECTOT; MORT1; E_ANOSESTUDO; T_ANALF15A17; PIND; PINDCRI; ... FECTOT MORT1 E_ANOSESTUDO
MORT1 0,514
0,000
E_ANOSESTUDO -0,431 -0,454
0,000 0,000
T_ANALF15A17 0,510 0,668 -0,530
0,000 0,000 0,000
PIND 0,606 0,765 -0,530
0,000 0,000 0,000
PINDCRI 0,568 0,777 -0,520
0,000 0,000 0,000
PPOBCRI 0,575 0,784 -0,556
0,000 0,000 0,000
P_SUPER -0,382 -0,499 0,392
0,000 0,000 0,000
T_DES18M 0,264 0,371 -0,280
0,000 0,000 0,000
TRABSC 0,337 0,495 -0,376
0,000 0,000 0,000
T_AGUA -0,324 -0,546 0,410
0,000 0,000 0,000
T_LUZ -0,500 -0,332 0,446
0,000 0,000 0,000
PAREDE 0,522 0,470 -0,321
0,000 0,000 0,000
T_NESTUDA_NTRAB_ 0,565 0,741 -0,541
0,000 0,000 0,000
T_MULCHEFEFIF014 0,577 0,576 -0,469
0,000 0,000 0,000
HOMEM10A14 -0,074 -0,056 0,015
0,000 0,000 0,276
HOMEM70A74 -0,093 -0,065 0,030
0,000 0,000 0,024
IDHM -0,610 -0,829 0,653
0,000 0,000 0,000
IDHM_E -0,562 -0,684 0,710
0,000 0,000 0,000
IDHM_L -0,527 -0,967 0,441
0,000 0,000 0,000
IDHM_R -0,597 -0,814 0,544
0,000 0,000 0,000
T_ANALF15A17 PIND PINDCRI
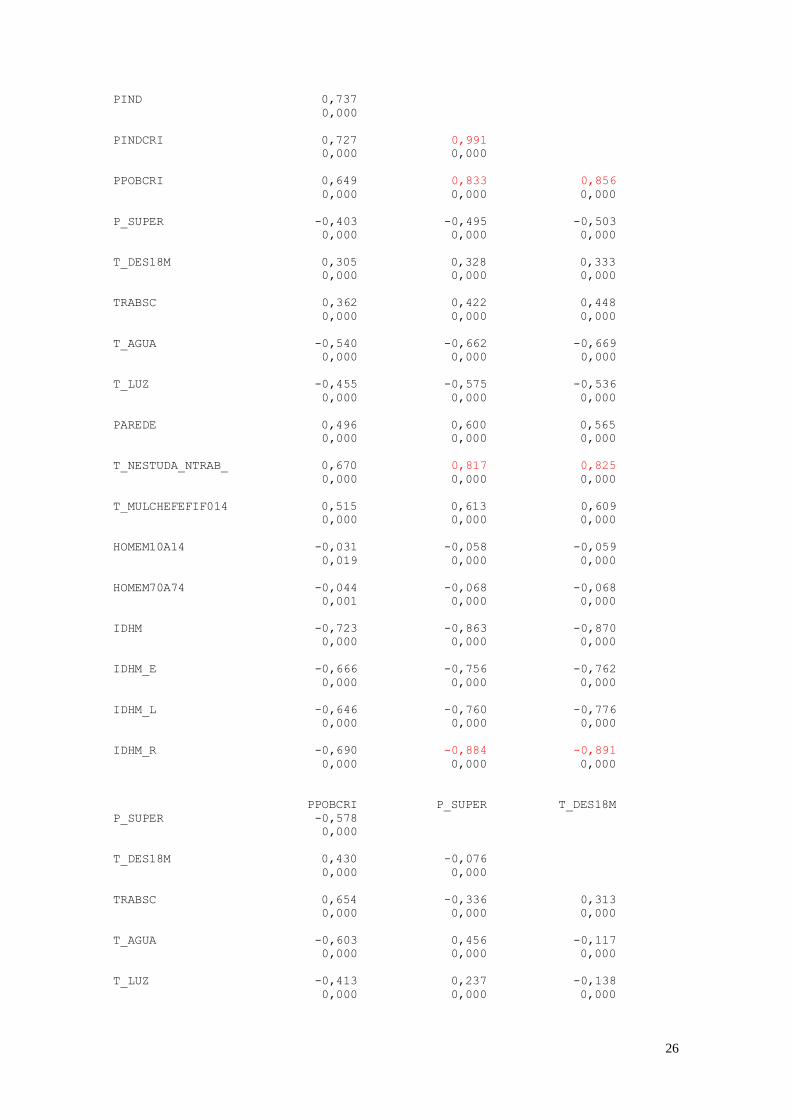
26
PIND 0,737
0,000
PINDCRI 0,727 0,991
0,000 0,000
PPOBCRI 0,649 0,833 0,856
0,000 0,000 0,000
P_SUPER -0,403 -0,495 -0,503
0,000 0,000 0,000
T_DES18M 0,305 0,328 0,333
0,000 0,000 0,000
TRABSC 0,362 0,422 0,448
0,000 0,000 0,000
T_AGUA -0,540 -0,662 -0,669
0,000 0,000 0,000
T_LUZ -0,455 -0,575 -0,536
0,000 0,000 0,000
PAREDE 0,496 0,600 0,565
0,000 0,000 0,000
T_NESTUDA_NTRAB_ 0,670 0,817 0,825
0,000 0,000 0,000
T_MULCHEFEFIF014 0,515 0,613 0,609
0,000 0,000 0,000
HOMEM10A14 -0,031 -0,058 -0,059
0,019 0,000 0,000
HOMEM70A74 -0,044 -0,068 -0,068
0,001 0,000 0,000
IDHM -0,723 -0,863 -0,870
0,000 0,000 0,000
IDHM_E -0,666 -0,756 -0,762
0,000 0,000 0,000
IDHM_L -0,646 -0,760 -0,776
0,000 0,000 0,000
IDHM_R -0,690 -0,884 -0,891
0,000 0,000 0,000
PPOBCRI P_SUPER T_DES18M
P_SUPER -0,578
0,000
T_DES18M 0,430 -0,076
0,000 0,000
TRABSC 0,654 -0,336 0,313
0,000 0,000 0,000
T_AGUA -0,603 0,456 -0,117
0,000 0,000 0,000
T_LUZ -0,413 0,237 -0,138
0,000 0,000 0,000
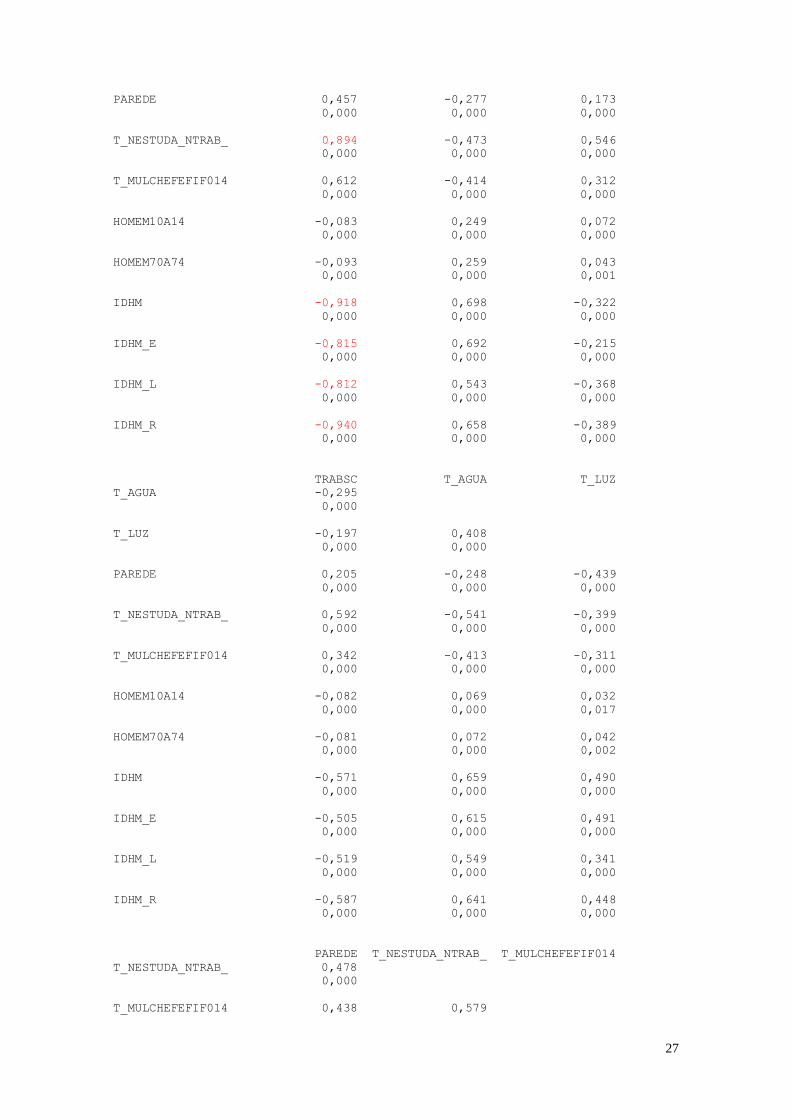
27
PAREDE 0,457 -0,277 0,173
0,000 0,000 0,000
T_NESTUDA_NTRAB_ 0,894 -0,473 0,546
0,000 0,000 0,000
T_MULCHEFEFIF014 0,612 -0,414 0,312
0,000 0,000 0,000
HOMEM10A14 -0,083 0,249 0,072
0,000 0,000 0,000
HOMEM70A74 -0,093 0,259 0,043
0,000 0,000 0,001
IDHM -0,918 0,698 -0,322
0,000 0,000 0,000
IDHM_E -0,815 0,692 -0,215
0,000 0,000 0,000
IDHM_L -0,812 0,543 -0,368
0,000 0,000 0,000
IDHM_R -0,940 0,658 -0,389
0,000 0,000 0,000
TRABSC T_AGUA T_LUZ
T_AGUA -0,295
0,000
T_LUZ -0,197 0,408
0,000 0,000
PAREDE 0,205 -0,248 -0,439
0,000 0,000 0,000
T_NESTUDA_NTRAB_ 0,592 -0,541 -0,399
0,000 0,000 0,000
T_MULCHEFEFIF014 0,342 -0,413 -0,311
0,000 0,000 0,000
HOMEM10A14 -0,082 0,069 0,032
0,000 0,000 0,017
HOMEM70A74 -0,081 0,072 0,042
0,000 0,000 0,002
IDHM -0,571 0,659 0,490
0,000 0,000 0,000
IDHM_E -0,505 0,615 0,491
0,000 0,000 0,000
IDHM_L -0,519 0,549 0,341
0,000 0,000 0,000
IDHM_R -0,587 0,641 0,448
0,000 0,000 0,000
PAREDE T_NESTUDA_NTRAB_ T_MULCHEFEFIF014
T_NESTUDA_NTRAB_ 0,478
0,000
T_MULCHEFEFIF014 0,438 0,579
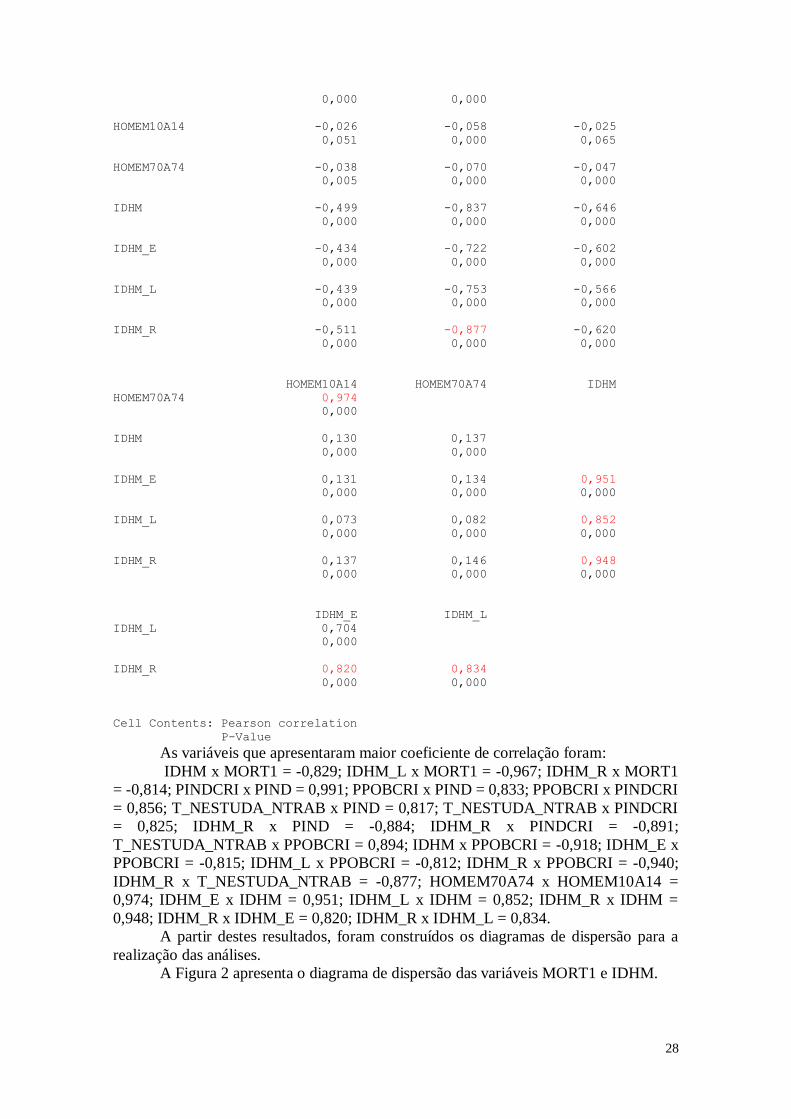
28
0,000 0,000
HOMEM10A14 -0,026 -0,058 -0,025
0,051 0,000 0,065
HOMEM70A74 -0,038 -0,070 -0,047
0,005 0,000 0,000
IDHM -0,499 -0,837 -0,646
0,000 0,000 0,000
IDHM_E -0,434 -0,722 -0,602
0,000 0,000 0,000
IDHM_L -0,439 -0,753 -0,566
0,000 0,000 0,000
IDHM_R -0,511 -0,877 -0,620
0,000 0,000 0,000
HOMEM10A14 HOMEM70A74 IDHM
HOMEM70A74 0,974
0,000
IDHM 0,130 0,137
0,000 0,000
IDHM_E 0,131 0,134 0,951
0,000 0,000 0,000
IDHM_L 0,073 0,082 0,852
0,000 0,000 0,000
IDHM_R 0,137 0,146 0,948
0,000 0,000 0,000
IDHM_E IDHM_L
IDHM_L 0,704
0,000
IDHM_R 0,820 0,834
0,000 0,000
Cell Contents: Pearson correlation
P-Value
As variáveis que apresentaram maior coeficiente de correlação foram:
IDHM x MORT1 = -0,829; IDHM_L x MORT1 = -0,967; IDHM_R x MORT1
= -0,814; PINDCRI x PIND = 0,991; PPOBCRI x PIND = 0,833; PPOBCRI x PINDCRI
= 0,856; T_NESTUDA_NTRAB x PIND = 0,817; T_NESTUDA_NTRAB x PINDCRI
= 0,825; IDHM_R x PIND = -0,884; IDHM_R x PINDCRI = -0,891;
T_NESTUDA_NTRAB x PPOBCRI = 0,894; IDHM x PPOBCRI = -0,918; IDHM_E x
PPOBCRI = -0,815; IDHM_L x PPOBCRI = -0,812; IDHM_R x PPOBCRI = -0,940;
IDHM_R x T_NESTUDA_NTRAB = -0,877; HOMEM70A74 x HOMEM10A14 =
0,974; IDHM_E x IDHM = 0,951; IDHM_L x IDHM = 0,852; IDHM_R x IDHM =
0,948; IDHM_R x IDHM_E = 0,820; IDHM_R x IDHM_L = 0,834.
A partir destes resultados, foram construídos os diagramas de dispersão para a
realização das análises.
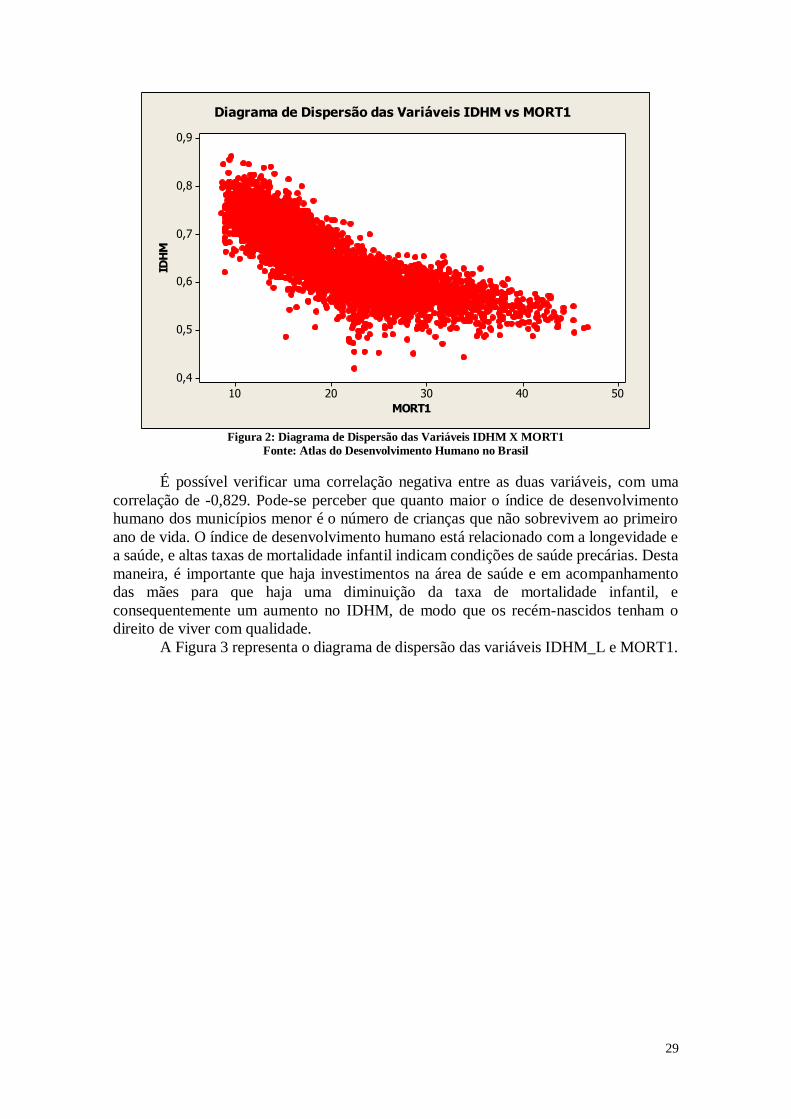
A Figura 2 apresenta o diagrama de dispersão das variáveis MORT1 e IDHM.
29
5040302010
0,9
0,8
0,7
0,6
0,5
0,4
MORT1
IDH
M
Diagrama de Dispersão das Variáveis IDHM vs MORT1
Figura 2: Diagrama de Dispersão das Variáveis IDHM X MORT1
Fonte: Atlas do Desenvolvimento Humano no Brasil
É possível verificar uma correlação negativa entre as duas variáveis, com uma
correlação de -0,829. Pode-se perceber que quanto maior o índice de desenvolvimento
humano dos municípios menor é o número de crianças que não sobrevivem ao primeiro
ano de vida. O índice de desenvolvimento humano está relacionado com a longevidade e
a saúde, e altas taxas de mortalidade infantil indicam condições de saúde precárias. Desta
maneira, é importante que haja investimentos na área de saúde e em acompanhamento
das mães para que haja uma diminuição da taxa de mortalidade infantil, e
consequentemente um aumento no IDHM, de modo que os recém-nascidos tenham o
direito de viver com qualidade.
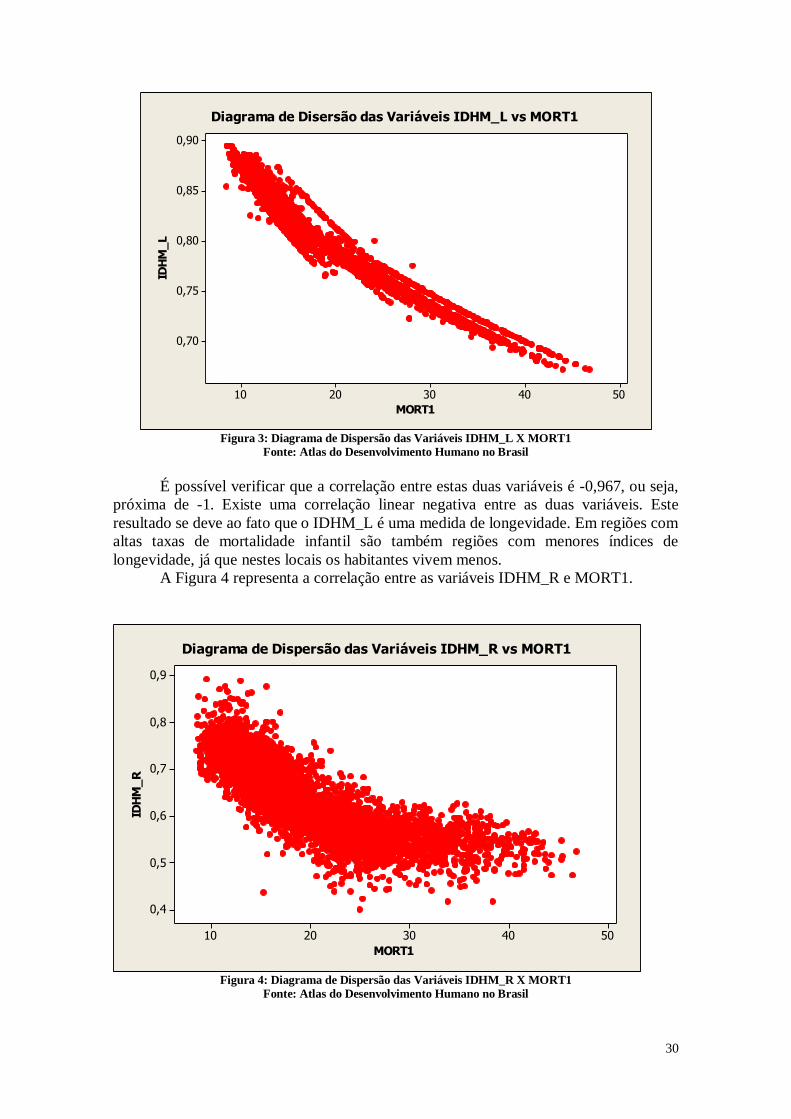
A Figura 3 representa o diagrama de dispersão das variáveis IDHM_L e MORT1.
30
5040302010
0,90
0,85
0,80
0,75
0,70
MORT1
IDH
M_
L
Diagrama de Disersão das Variáveis IDHM_L vs MORT1
Figura 3: Diagrama de Dispersão das Variáveis IDHM_L X MORT1
Fonte: Atlas do Desenvolvimento Humano no Brasil
É possível verificar que a correlação entre estas duas variáveis é -0,967, ou seja,
próxima de -1. Existe uma correlação linear negativa entre as duas variáveis. Este
resultado se deve ao fato que o IDHM_L é uma medida de longevidade. Em regiões com
altas taxas de mortalidade infantil são também regiões com menores índices de
longevidade, já que nestes locais os habitantes vivem menos.
A Figura 4 representa a correlação entre as variáveis IDHM_R e MORT1.
5040302010
0,9
0,8
0,7
0,6
0,5
0,4
MORT1
IDH
M_
R
Diagrama de Dispersão das Variáveis IDHM_R vs MORT1
Figura 4: Diagrama de Dispersão das Variáveis IDHM_R X MORT1
Fonte: Atlas do Desenvolvimento Humano no Brasil
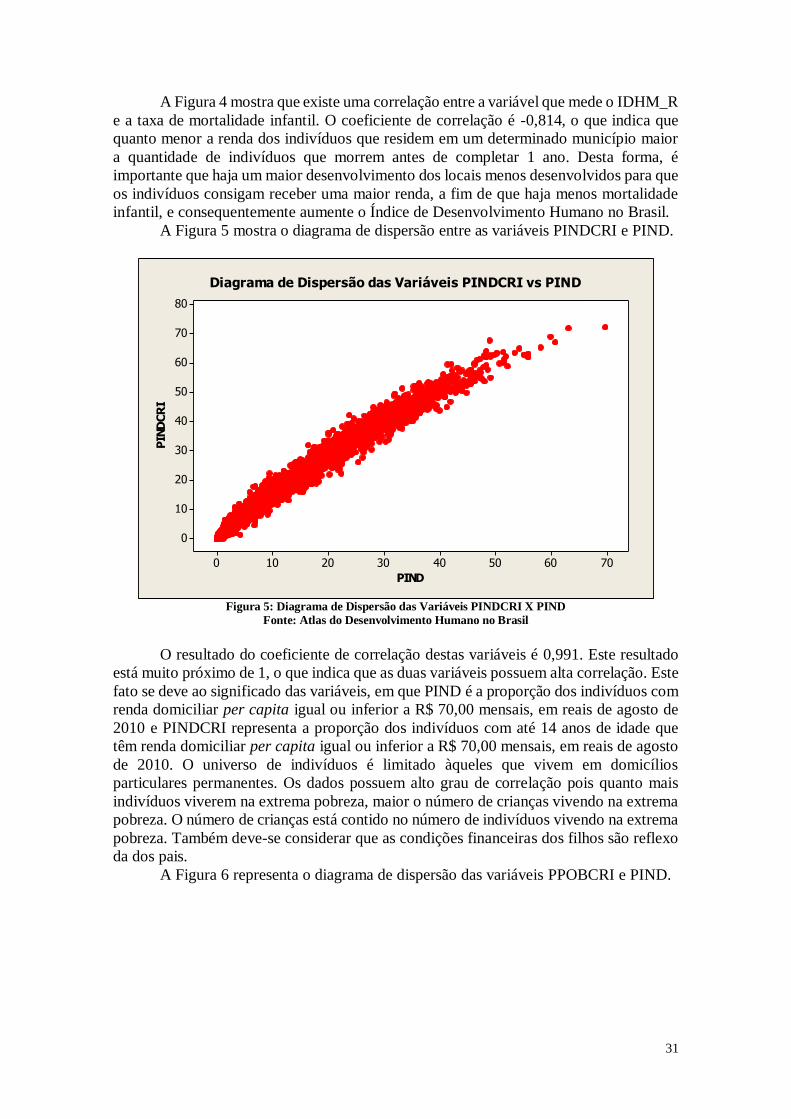
31
A Figura 4 mostra que existe uma correlação entre a variável que mede o IDHM_R
e a taxa de mortalidade infantil. O coeficiente de correlação é -0,814, o que indica que
quanto menor a renda dos indivíduos que residem em um determinado município maior
a quantidade de indivíduos que morrem antes de completar 1 ano. Desta forma, é
importante que haja um maior desenvolvimento dos locais menos desenvolvidos para que
os indivíduos consigam receber uma maior renda, a fim de que haja menos mortalidade
infantil, e consequentemente aumente o Índice de Desenvolvimento Humano no Brasil.
A Figura 5 mostra o diagrama de dispersão entre as variáveis PINDCRI e PIND.
706050403020100
80
70
60
50
40
30
20
10
0
PIND
PIN
DC
RI
Diagrama de Dispersão das Variáveis PINDCRI vs PIND
Figura 5: Diagrama de Dispersão das Variáveis PINDCRI X PIND
Fonte: Atlas do Desenvolvimento Humano no Brasil
O resultado do coeficiente de correlação destas variáveis é 0,991. Este resultado
está muito próximo de 1, o que indica que as duas variáveis possuem alta correlação. Este
fato se deve ao significado das variáveis, em que PIND é a proporção dos indivíduos com
renda domiciliar per capita igual ou inferior a R$ 70,00 mensais, em reais de agosto de
2010 e PINDCRI representa a proporção dos indivíduos com até 14 anos de idade que
têm renda domiciliar per capita igual ou inferior a R$ 70,00 mensais, em reais de agosto
de 2010. O universo de indivíduos é limitado àqueles que vivem em domicílios
particulares permanentes. Os dados possuem alto grau de correlação pois quanto mais
indivíduos viverem na extrema pobreza, maior o número de crianças vivendo na extrema
pobreza. O número de crianças está contido no número de indivíduos vivendo na extrema
pobreza. Também deve-se considerar que as condições financeiras dos filhos são reflexo
da dos pais.
A Figura 6 representa o diagrama de dispersão das variáveis PPOBCRI e PIND.
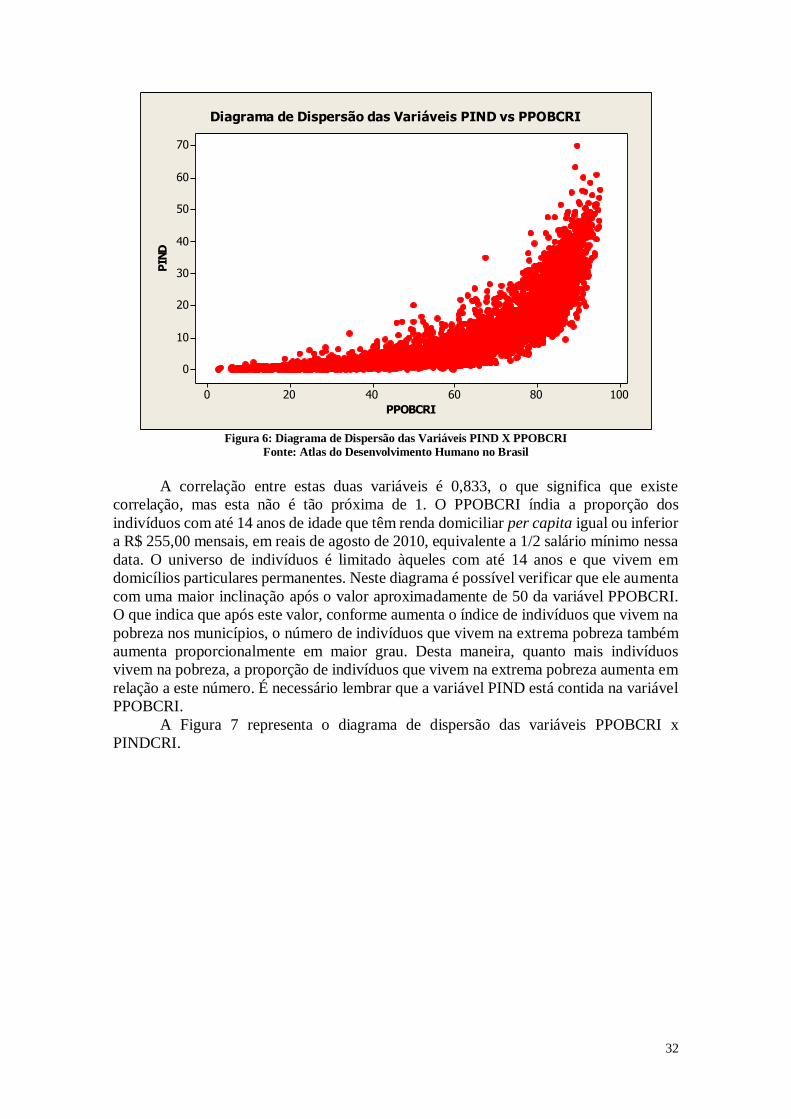
32
100806040200
70
60
50
40
30
20
10
0
PPOBCRI
PIN
D
Diagrama de Dispersão das Variáveis PIND vs PPOBCRI
Figura 6: Diagrama de Dispersão das Variáveis PIND X PPOBCRI
Fonte: Atlas do Desenvolvimento Humano no Brasil
A correlação entre estas duas variáveis é 0,833, o que significa que existe
correlação, mas esta não é tão próxima de 1. O PPOBCRI índia a proporção dos
indivíduos com até 14 anos de idade que têm renda domiciliar per capita igual ou inferior
a R$ 255,00 mensais, em reais de agosto de 2010, equivalente a 1/2 salário mínimo nessa
data. O universo de indivíduos é limitado àqueles com até 14 anos e que vivem em
domicílios particulares permanentes. Neste diagrama é possível verificar que ele aumenta
com uma maior inclinação após o valor aproximadamente de 50 da variável PPOBCRI.
O que indica que após este valor, conforme aumenta o índice de indivíduos que vivem na
pobreza nos municípios, o número de indivíduos que vivem na extrema pobreza também
aumenta proporcionalmente em maior grau. Desta maneira, quanto mais indivíduos
vivem na pobreza, a proporção de indivíduos que vivem na extrema pobreza aumenta em
relação a este número. É necessário lembrar que a variável PIND está contida na variável
PPOBCRI.
A Figura 7 representa o diagrama de dispersão das variáveis PPOBCRI x
PINDCRI.
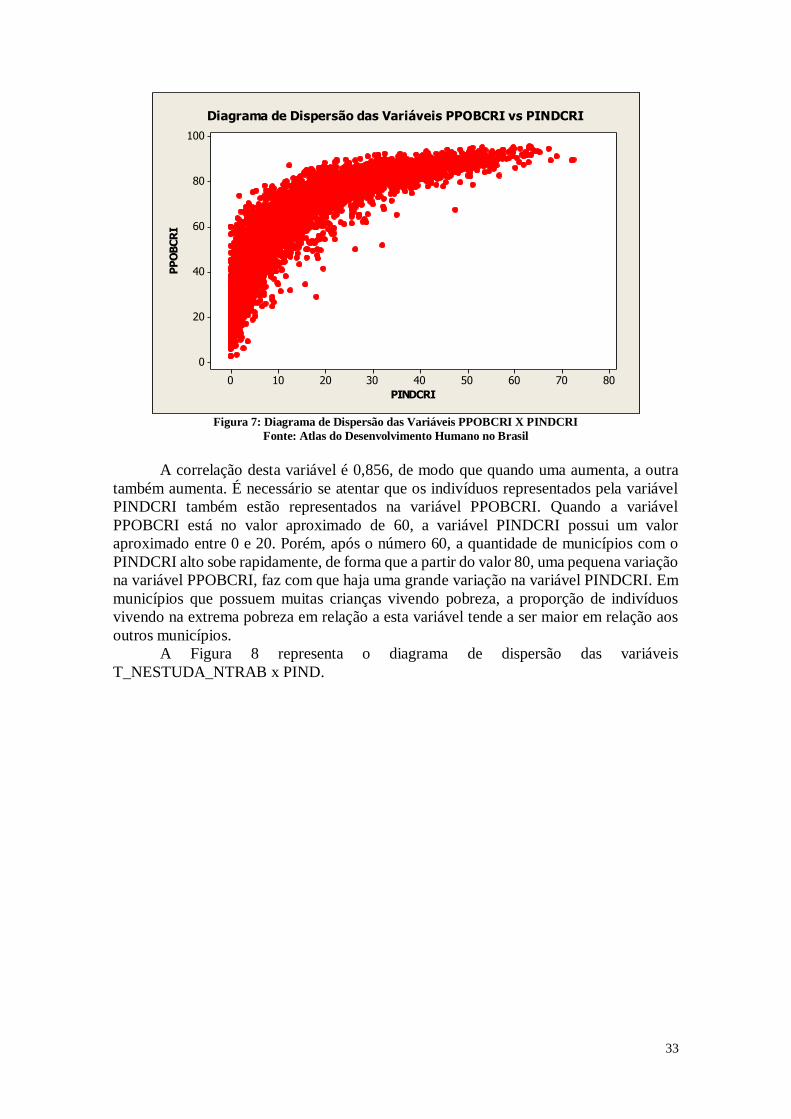
33
80706050403020100
100
80
60
40
20
0
PINDCRI
PP
OB
CR
I
Diagrama de Dispersão das Variáveis PPOBCRI vs PINDCRI
Figura 7: Diagrama de Dispersão das Variáveis PPOBCRI X PINDCRI
Fonte: Atlas do Desenvolvimento Humano no Brasil
A correlação desta variável é 0,856, de modo que quando uma aumenta, a outra
também aumenta. É necessário se atentar que os indivíduos representados pela variável
PINDCRI também estão representados na variável PPOBCRI. Quando a variável
PPOBCRI está no valor aproximado de 60, a variável PINDCRI possui um valor
aproximado entre 0 e 20. Porém, após o número 60, a quantidade de municípios com o
PINDCRI alto sobe rapidamente, de forma que a partir do valor 80, uma pequena variação
na variável PPOBCRI, faz com que haja uma grande variação na variável PINDCRI. Em
municípios que possuem muitas crianças vivendo pobreza, a proporção de indivíduos
vivendo na extrema pobreza em relação a esta variável tende a ser maior em relação aos
outros municípios.
A Figura 8 representa o diagrama de dispersão das variáveis
T_NESTUDA_NTRAB x PIND.
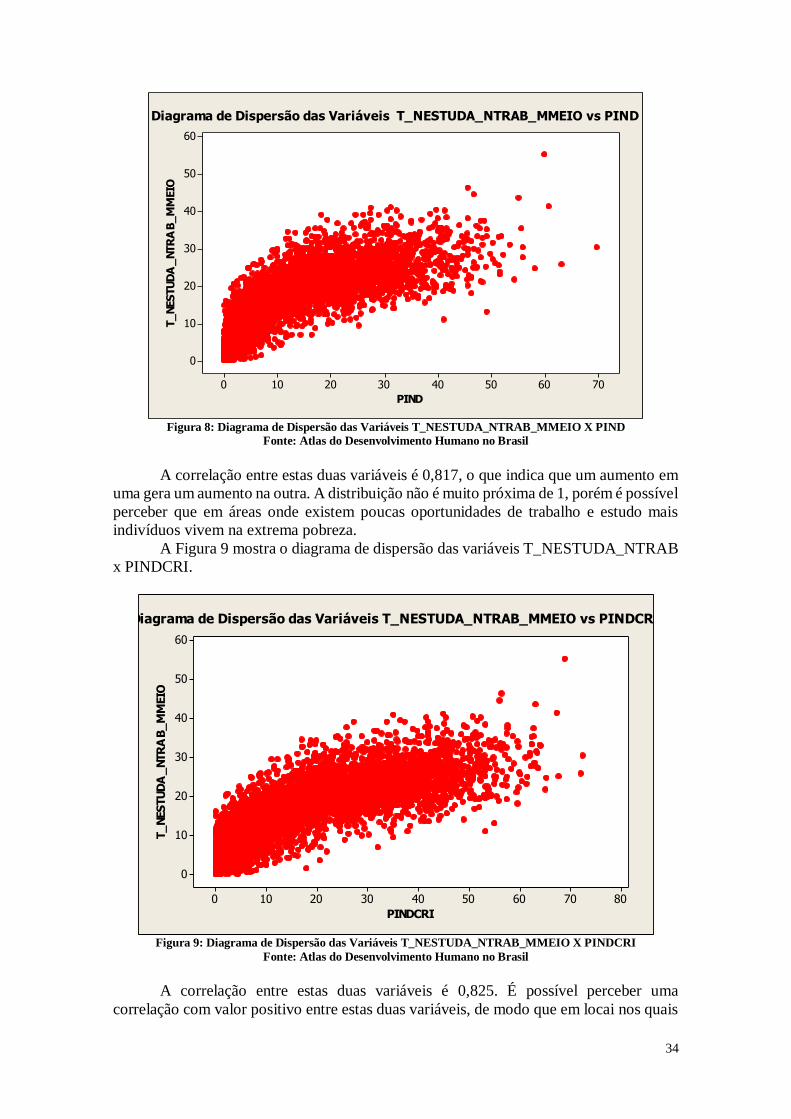
34
706050403020100
60
50
40
30
20
10
0
PIND
T_
NES
TU
DA
_N
TR
AB
_M
MEIO
Diagrama de Dispersão das Variáveis T_NESTUDA_NTRAB_MMEIO vs PIND
Figura 8: Diagrama de Dispersão das Variáveis T_NESTUDA_NTRAB_MMEIO X PIND
Fonte: Atlas do Desenvolvimento Humano no Brasil
A correlação entre estas duas variáveis é 0,817, o que indica que um aumento em
uma gera um aumento na outra. A distribuição não é muito próxima de 1, porém é possível
perceber que em áreas onde existem poucas oportunidades de trabalho e estudo mais
indivíduos vivem na extrema pobreza.
A Figura 9 mostra o diagrama de dispersão das variáveis T_NESTUDA_NTRAB
x PINDCRI.
80706050403020100
60
50
40
30
20
10
0
PINDCRI
T_
NES
TU
DA
_N
TR
AB
_M
MEIO
Diagrama de Dispersão das Variáveis T_NESTUDA_NTRAB_MMEIO vs PINDCRI
Figura 9: Diagrama de Dispersão das Variáveis T_NESTUDA_NTRAB_MMEIO X PINDCRI
Fonte: Atlas do Desenvolvimento Humano no Brasil
A correlação entre estas duas variáveis é 0,825. É possível perceber uma
correlação com valor positivo entre estas duas variáveis, de modo que em locai nos quais
35
a população não tem acesso à educação e nem ao trabalho, mais crianças vivem na
extrema pobreza. Se os pais não conseguem renda através do trabalho, consequentemente
as crianças também não vão ter renda. É necessário mudar esta realidade, buscando
desenvolver o país com mais igualdade para que todos tenham acesso à educação e
trabalho, e consequentemente aumente o IDHM. A educação é fator importante para que
os indivíduos consigam construir a história de vida que desejam.
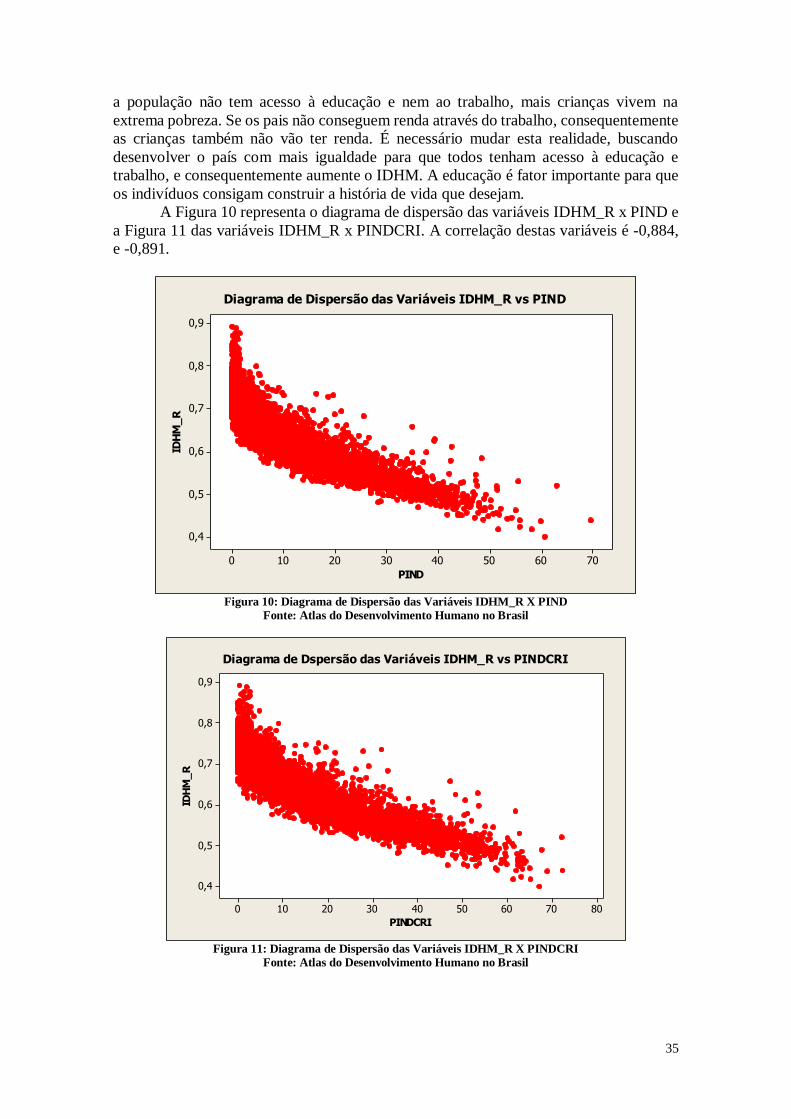
A Figura 10 representa o diagrama de dispersão das variáveis IDHM_R x PIND e
a Figura 11 das variáveis IDHM_R x PINDCRI. A correlação destas variáveis é -0,884,
e -0,891.
706050403020100
0,9
0,8
0,7
0,6
0,5
0,4
PIND
IDH
M_
R
Diagrama de Dispersão das Variáveis IDHM_R vs PIND
Figura 10: Diagrama de Dispersão das Variáveis IDHM_R X PIND
Fonte: Atlas do Desenvolvimento Humano no Brasil
80706050403020100
0,9
0,8
0,7
0,6
0,5
0,4
PINDCRI
IDH
M_
R
Diagrama de Dspersão das Variáveis IDHM_R vs PINDCRI
Figura 11: Diagrama de Dispersão das Variáveis IDHM_R X PINDCRI
Fonte: Atlas do Desenvolvimento Humano no Brasil
36
Existe uma correlação negativa entre estas variáveis. Este resultado se deve ao
fato de que o IDHM_R está diretamente relacionado com a renda do município, portanto,
municípios que possuem muitos indivíduos vivendo na extrema pobreza terão um valor
de IDHM_R menor, os diagramas das Figuras 10 e 11 são parecidos, já que o número de
crianças vivendo na extrema pobreza também está relacionado ao número de adultos
vivendo na extrema pobreza.
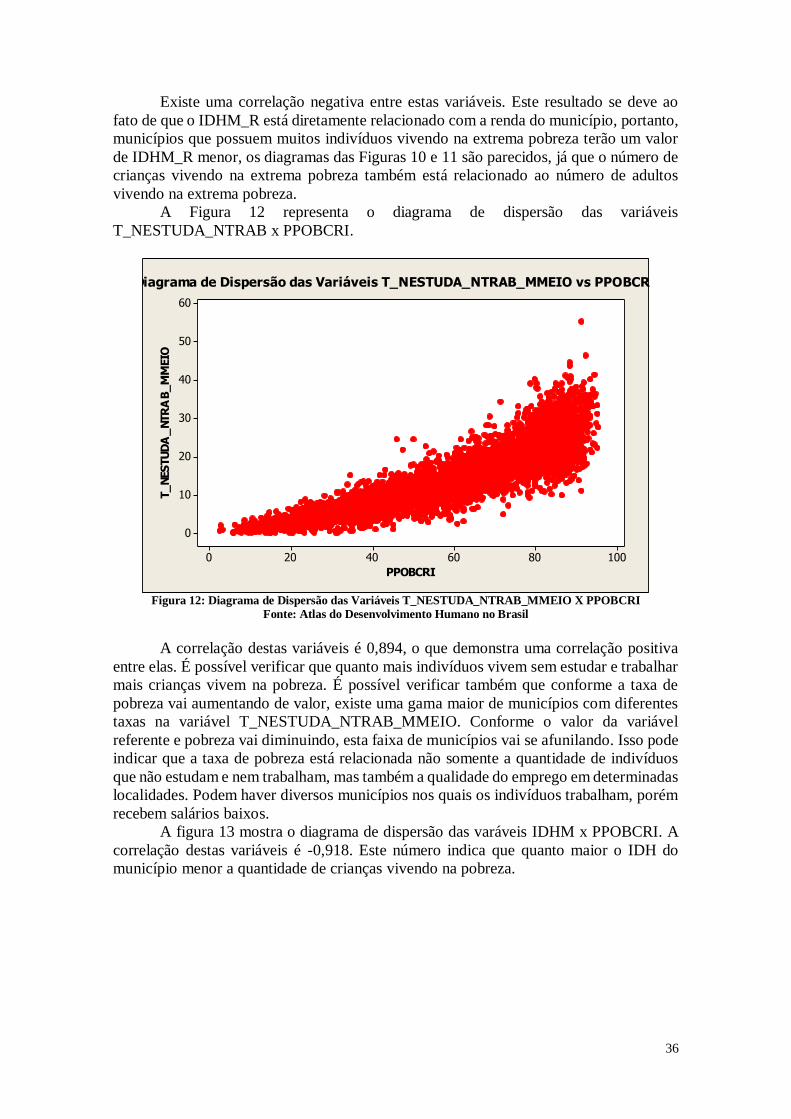
A Figura 12 representa o diagrama de dispersão das variáveis
T_NESTUDA_NTRAB x PPOBCRI.
100806040200
60
50
40
30
20
10
0
PPOBCRI
T_
NES
TU
DA
_N
TR
AB
_M
MEIO
Diagrama de Dispersão das Variáveis T_NESTUDA_NTRAB_MMEIO vs PPOBCRI
Figura 12: Diagrama de Dispersão das Variáveis T_NESTUDA_NTRAB_MMEIO X PPOBCRI
Fonte: Atlas do Desenvolvimento Humano no Brasil
A correlação destas variáveis é 0,894, o que demonstra uma correlação positiva
entre elas. É possível verificar que quanto mais indivíduos vivem sem estudar e trabalhar
mais crianças vivem na pobreza. É possível verificar também que conforme a taxa de
pobreza vai aumentando de valor, existe uma gama maior de municípios com diferentes
taxas na variável T_NESTUDA_NTRAB_MMEIO. Conforme o valor da variável
referente e pobreza vai diminuindo, esta faixa de municípios vai se afunilando. Isso pode
indicar que a taxa de pobreza está relacionada não somente a quantidade de indivíduos
que não estudam e nem trabalham, mas também a qualidade do emprego em determinadas
localidades. Podem haver diversos municípios nos quais os indivíduos trabalham, porém
recebem salários baixos.
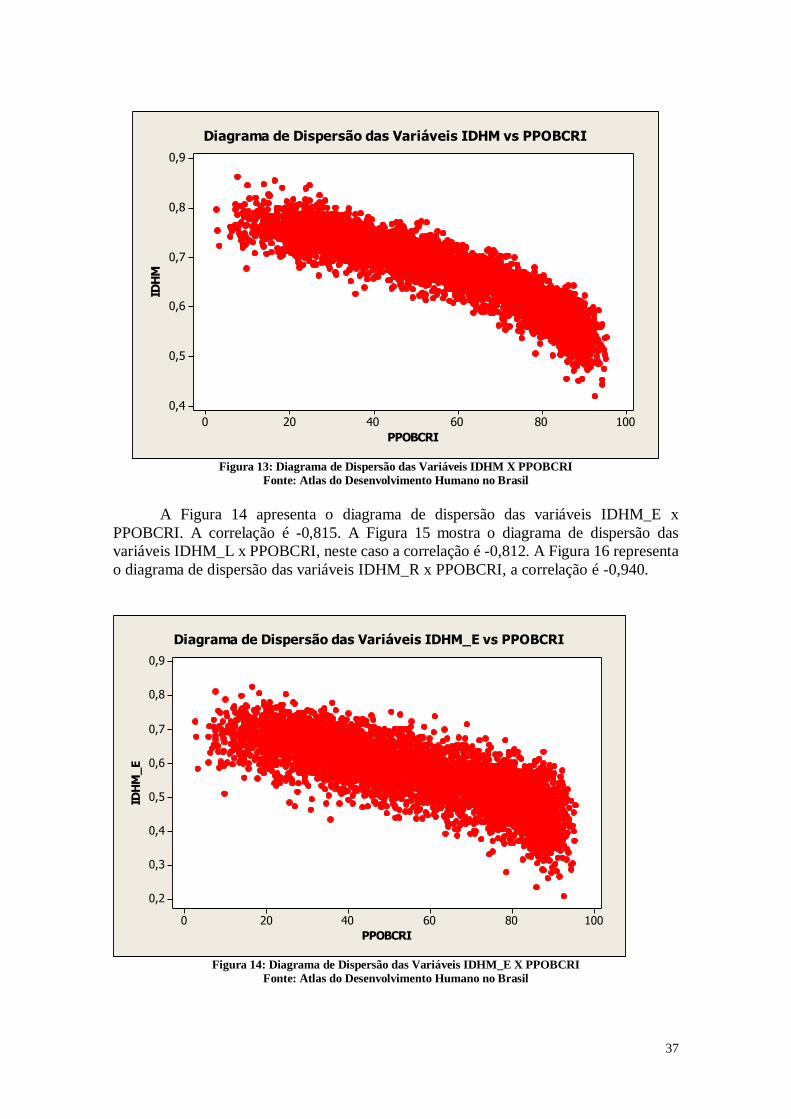
A figura 13 mostra o diagrama de dispersão das varáveis IDHM x PPOBCRI. A
correlação destas variáveis é -0,918. Este número indica que quanto maior o IDH do
município menor a quantidade de crianças vivendo na pobreza.
37
100806040200
0,9
0,8
0,7
0,6
0,5
0,4
PPOBCRI
IDH
M
Diagrama de Dispersão das Variáveis IDHM vs PPOBCRI
Figura 13: Diagrama de Dispersão das Variáveis IDHM X PPOBCRI
Fonte: Atlas do Desenvolvimento Humano no Brasil
A Figura 14 apresenta o diagrama de dispersão das variáveis IDHM_E x
PPOBCRI. A correlação é -0,815. A Figura 15 mostra o diagrama de dispersão das
variáveis IDHM_L x PPOBCRI, neste caso a correlação é -0,812. A Figura 16 representa
o diagrama de dispersão das variáveis IDHM_R x PPOBCRI, a correlação é -0,940.
100806040200
0,9
0,8
0,7
0,6
0,5
0,4
0,3
0,2
PPOBCRI
IDH
M_
E
Diagrama de Dispersão das Variáveis IDHM_E vs PPOBCRI
Figura 14: Diagrama de Dispersão das Variáveis IDHM_E X PPOBCRI
Fonte: Atlas do Desenvolvimento Humano no Brasil
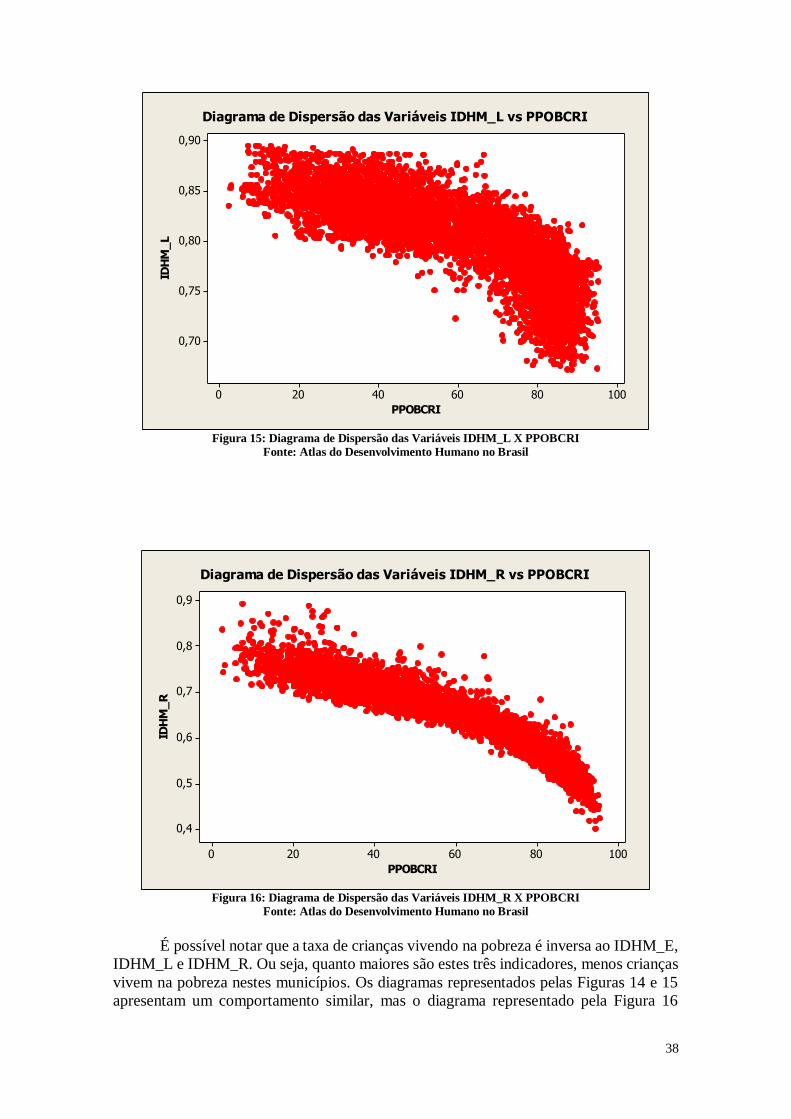
38
100806040200
0,90
0,85
0,80
0,75
0,70
PPOBCRI
IDH
M_
L
Diagrama de Dispersão das Variáveis IDHM_L vs PPOBCRI
Figura 15: Diagrama de Dispersão das Variáveis IDHM_L X PPOBCRI
Fonte: Atlas do Desenvolvimento Humano no Brasil
100806040200
0,9
0,8
0,7
0,6
0,5
0,4
PPOBCRI
IDH
M_
R
Diagrama de Dispersão das Variáveis IDHM_R vs PPOBCRI
Figura 16: Diagrama de Dispersão das Variáveis IDHM_R X PPOBCRI
Fonte: Atlas do Desenvolvimento Humano no Brasil
É possível notar que a taxa de crianças vivendo na pobreza é inversa ao IDHM_E,
IDHM_L e IDHM_R. Ou seja, quanto maiores são estes três indicadores, menos crianças
vivem na pobreza nestes municípios. Os diagramas representados pelas Figuras 14 e 15
apresentam um comportamento similar, mas o diagrama representado pela Figura 16
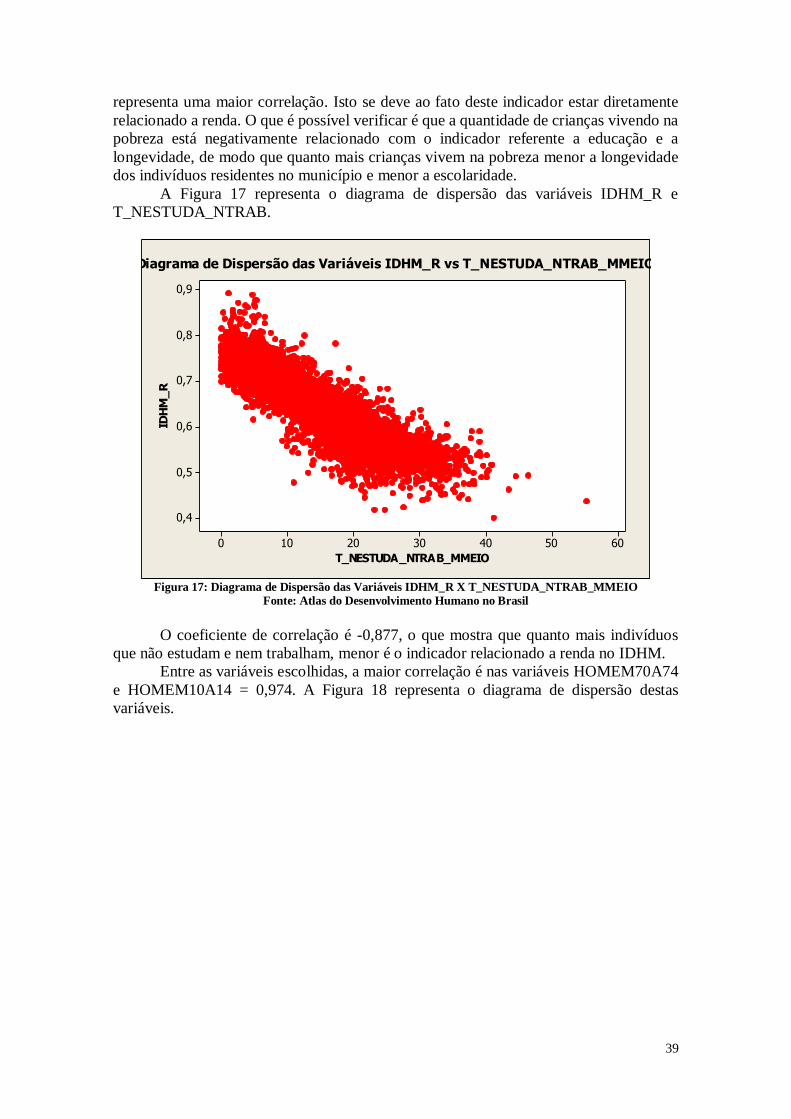
39
representa uma maior correlação. Isto se deve ao fato deste indicador estar diretamente
relacionado a renda. O que é possível verificar é que a quantidade de crianças vivendo na
pobreza está negativamente relacionado com o indicador referente a educação e a
longevidade, de modo que quanto mais crianças vivem na pobreza menor a longevidade
dos indivíduos residentes no município e menor a escolaridade.
A Figura 17 representa o diagrama de dispersão das variáveis IDHM_R e
T_NESTUDA_NTRAB.
6050403020100
0,9
0,8
0,7
0,6
0,5
0,4
T_NESTUDA_NTRAB_MMEIO
IDH
M_
R
Diagrama de Dispersão das Variáveis IDHM_R vs T_NESTUDA_NTRAB_MMEIO
Figura 17: Diagrama de Dispersão das Variáveis IDHM_R X T_NESTUDA_NTRAB_MMEIO
Fonte: Atlas do Desenvolvimento Humano no Brasil
O coeficiente de correlação é -0,877, o que mostra que quanto mais indivíduos
que não estudam e nem trabalham, menor é o indicador relacionado a renda no IDHM.
Entre as variáveis escolhidas, a maior correlação é nas variáveis HOMEM70A74
e HOMEM10A14 = 0,974. A Figura 18 representa o diagrama de dispersão destas
variáveis.
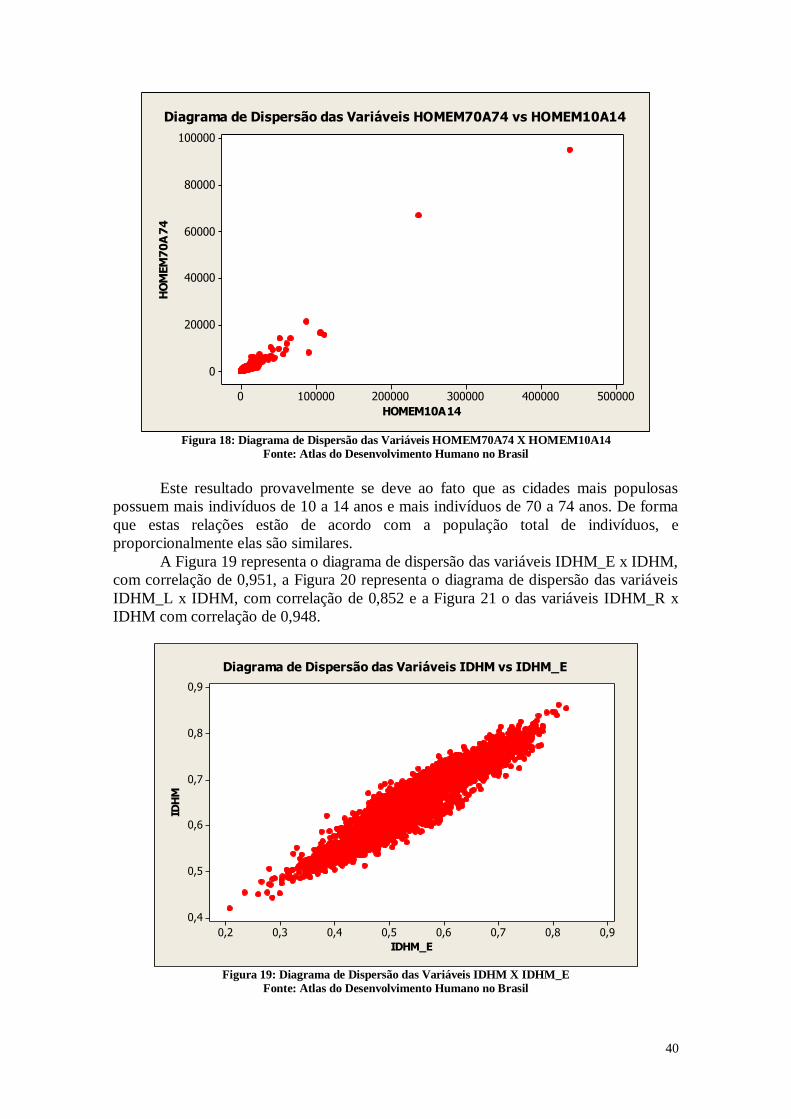
40
5000004000003000002000001000000
100000
80000
60000
40000
20000
0
HOMEM10A14
HO
MEM
70
A7
4
Diagrama de Dispersão das Variáveis HOMEM70A74 vs HOMEM10A14
Figura 18: Diagrama de Dispersão das Variáveis HOMEM70A74 X HOMEM10A14
Fonte: Atlas do Desenvolvimento Humano no Brasil
Este resultado provavelmente se deve ao fato que as cidades mais populosas
possuem mais indivíduos de 10 a 14 anos e mais indivíduos de 70 a 74 anos. De forma
que estas relações estão de acordo com a população total de indivíduos, e
proporcionalmente elas são similares.
A Figura 19 representa o diagrama de dispersão das variáveis IDHM_E x IDHM,
com correlação de 0,951, a Figura 20 representa o diagrama de dispersão das variáveis
IDHM_L x IDHM, com correlação de 0,852 e a Figura 21 o das variáveis IDHM_R x
IDHM com correlação de 0,948.
0,90,80,70,60,50,40,30,2
0,9
0,8
0,7
0,6
0,5
0,4
IDHM_E
IDH
M
Diagrama de Dispersão das Variáveis IDHM vs IDHM_E
Figura 19: Diagrama de Dispersão das Variáveis IDHM X IDHM_E
Fonte: Atlas do Desenvolvimento Humano no Brasil
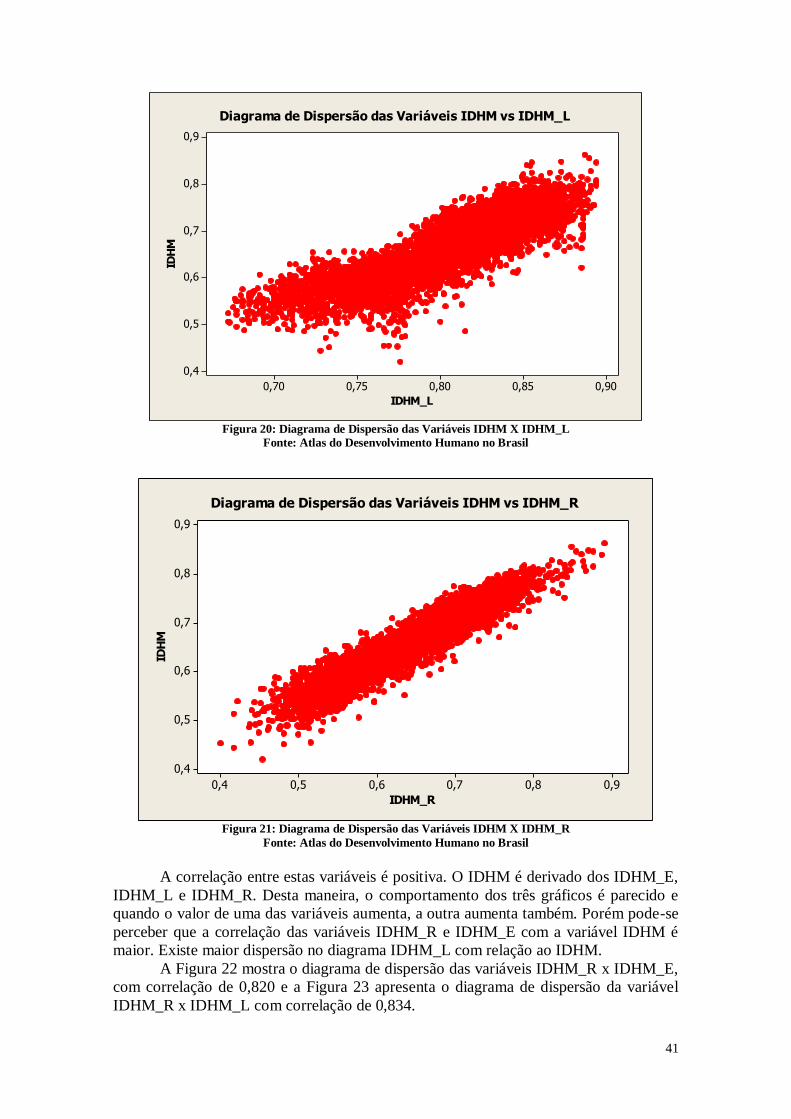
41
0,900,850,800,750,70
0,9
0,8
0,7
0,6
0,5
0,4
IDHM_L
IDH
M
Diagrama de Dispersão das Variáveis IDHM vs IDHM_L
Figura 20: Diagrama de Dispersão das Variáveis IDHM X IDHM_L
Fonte: Atlas do Desenvolvimento Humano no Brasil
0,90,80,70,60,50,4
0,9
0,8
0,7
0,6
0,5
0,4
IDHM_R
IDH
M
Diagrama de Dispersão das Variáveis IDHM vs IDHM_R
Figura 21: Diagrama de Dispersão das Variáveis IDHM X IDHM_R
Fonte: Atlas do Desenvolvimento Humano no Brasil
A correlação entre estas variáveis é positiva. O IDHM é derivado dos IDHM_E,
IDHM_L e IDHM_R. Desta maneira, o comportamento dos três gráficos é parecido e
quando o valor de uma das variáveis aumenta, a outra aumenta também. Porém pode-se
perceber que a correlação das variáveis IDHM_R e IDHM_E com a variável IDHM é
maior. Existe maior dispersão no diagrama IDHM_L com relação ao IDHM.
A Figura 22 mostra o diagrama de dispersão das variáveis IDHM_R x IDHM_E,
com correlação de 0,820 e a Figura 23 apresenta o diagrama de dispersão da variável
IDHM_R x IDHM_L com correlação de 0,834.
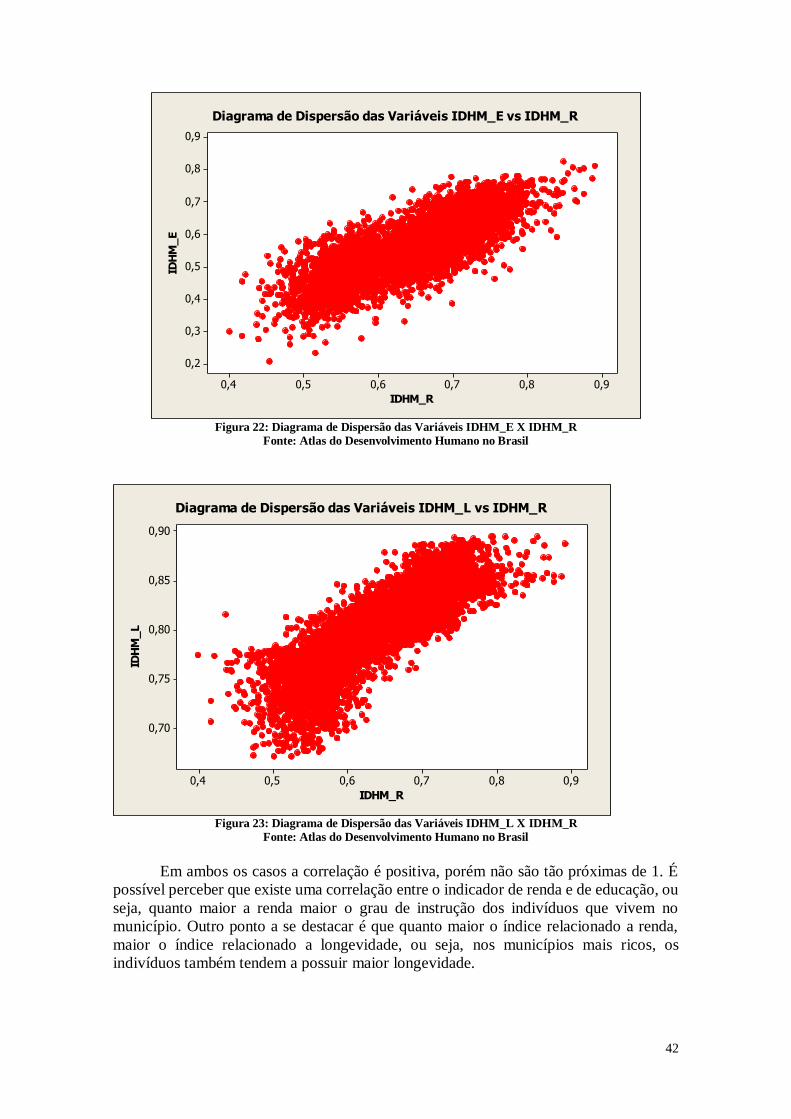
42
Figura 22: Diagrama de Dispersão das Variáveis IDHM_E X IDHM_R
Fonte: Atlas do Desenvolvimento Humano no Brasil
Figura 23: Diagrama de Dispersão das Variáveis IDHM_L X IDHM_R
Fonte: Atlas do Desenvolvimento Humano no Brasil
Em ambos os casos a correlação é positiva, porém não são tão próximas de 1. É
possível perceber que existe uma correlação entre o indicador de renda e de educação, ou
seja, quanto maior a renda maior o grau de instrução dos indivíduos que vivem no
município. Outro ponto a se destacar é que quanto maior o índice relacionado a renda,
maior o índice relacionado a longevidade, ou seja, nos municípios mais ricos, os
indivíduos também tendem a possuir maior longevidade.
0,90,80,70,60,50,4
0,9
0,8
0,7
0,6
0,5
0,4
0,3
0,2
IDHM_R
IDH
M_
E
Diagrama de Dispersão das Variáveis IDHM_E vs IDHM_R
0,90,80,70,60,50,4
0,90
0,85
0,80
0,75
0,70
IDHM_R
IDH
M_
L
Diagrama de Dispersão das Variáveis IDHM_L vs IDHM_R
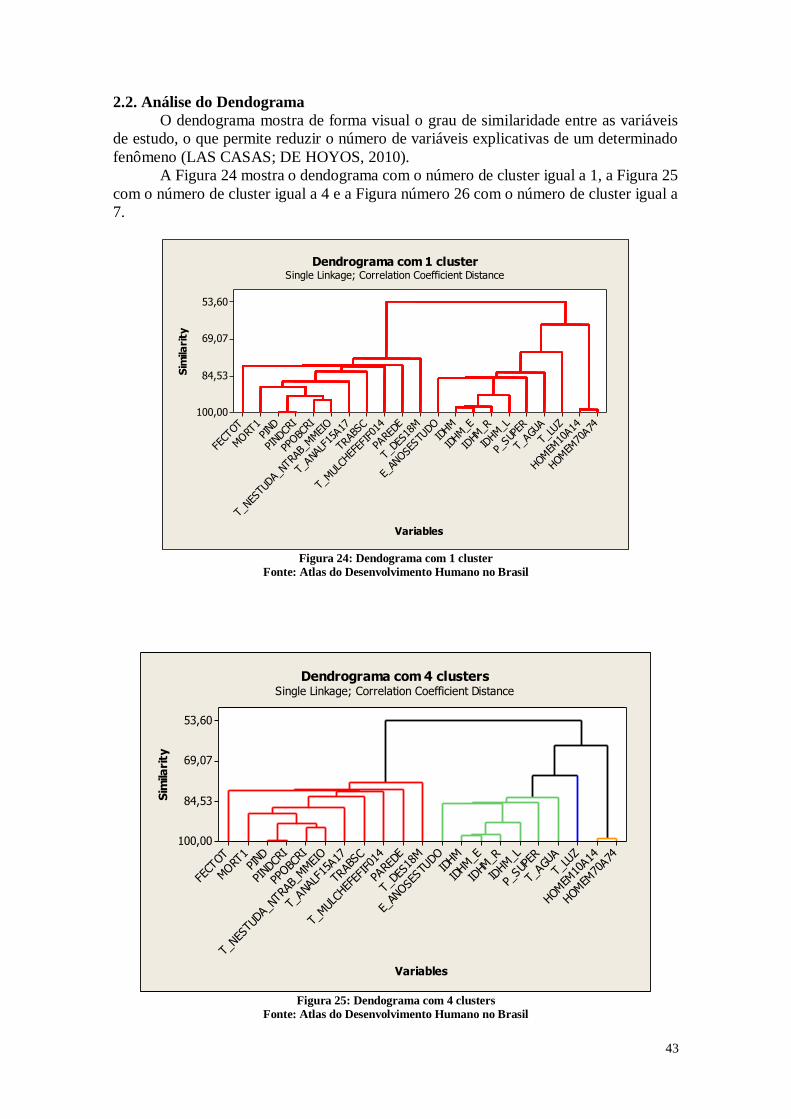
43
2.2. Análise do Dendograma
O dendograma mostra de forma visual o grau de similaridade entre as variáveis
de estudo, o que permite reduzir o número de variáveis explicativas de um determinado
fenômeno (LAS CASAS; DE HOYOS, 2010).
A Figura 24 mostra o dendograma com o número de cluster igual a 1, a Figura 25
com o número de cluster igual a 4 e a Figura número 26 com o número de cluster igual a
7.
HOMEM
70A7
4
HOMEM
10A1
4
T_LU
Z
T_AG
UA
P_SU
PER
IDHM
_L
IDHM
_R
IDHM
_E
IDHM
E_AN
OSEST
UDO
T_DE
S18M
PARE
DE
T_MUL
CHEF
EFIF01
4
TRAB
SC
T_AN
ALF1
5A17
T_NE
STUD
A_NT
RAB_
MMEIO
PPOBC
RI
PIND
CRI
PIND
MORT
1
FECT
OT
53,60
69,07
84,53
100,00
Variables
Sim
ilari
ty
Dendrograma com 1 clusterSingle Linkage; Correlation Coefficient Distance
Figura 24: Dendograma com 1 cluster
Fonte: Atlas do Desenvolvimento Humano no Brasil
Figura 25: Dendograma com 4 clusters
Fonte: Atlas do Desenvolvimento Humano no Brasil
HOMEM
70A7
4
HOMEM
10A1
4
T_LU
Z
T_AG
UA
P_SU
PER
IDHM
_L
IDHM
_R
IDHM
_E
IDHM
E_AN
OSEST
UDO
T_DE
S18M
PARE
DE
T_MUL
CHEF
EFIF01
4
TRAB
SC
T_AN
ALF1
5A17
T_NE
STUD
A_NT
RAB_
MMEIO
PPOBC
RI
PIND
CRI
PIND
MORT
1
FECT
OT
53,60
69,07
84,53
100,00
Variables
Sim
ilari
ty
Dendrograma com 4 clustersSingle Linkage; Correlation Coefficient Distance
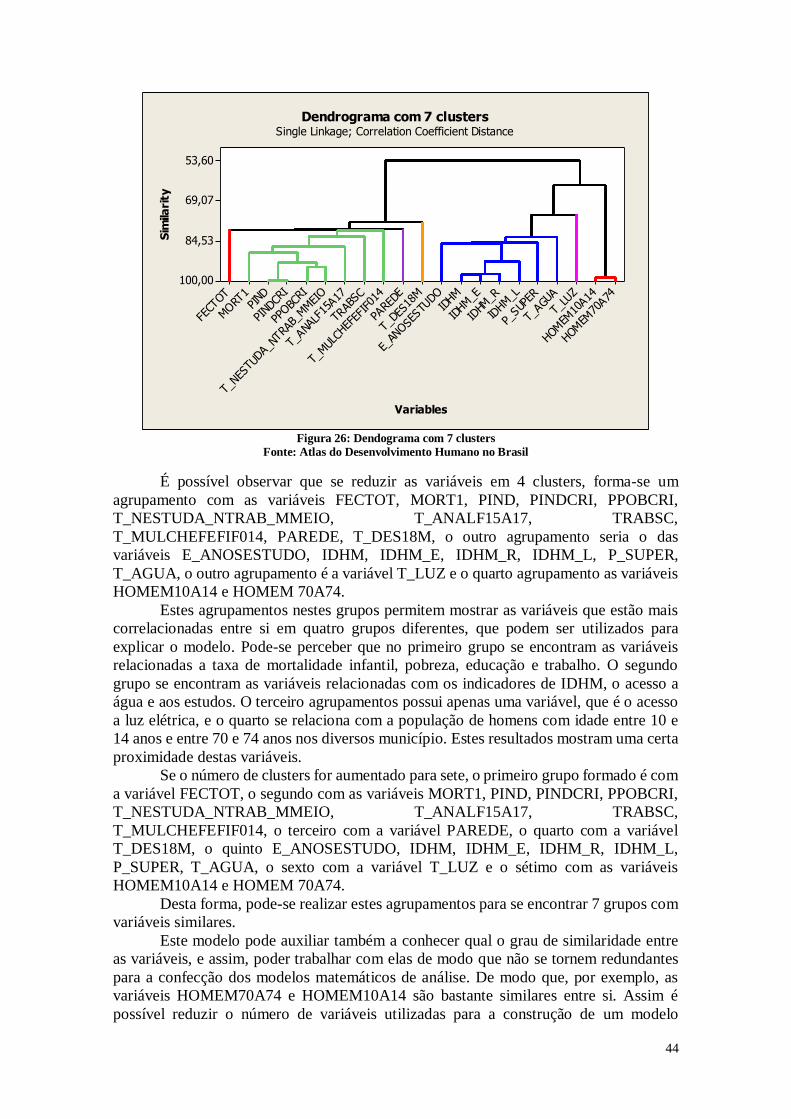
44
HOMEM
70A7
4
HOMEM
10A1
4
T_LU
Z
T_AG
UA
P_SU
PER
IDHM
_L
IDHM
_R
IDHM
_E
IDHM
E_AN
OSEST
UDO
T_DE
S18M
PARE
DE
T_MUL
CHEF
EFIF01
4
TRAB
SC
T_AN
ALF1
5A17
T_NE
STUD
A_NT
RAB_
MMEIO
PPOBC
RI
PIND
CRI
PIND
MORT
1
FECT
OT
53,60
69,07
84,53
100,00
Variables
Sim
ilari
ty
Dendrograma com 7 clustersSingle Linkage; Correlation Coefficient Distance
Figura 26: Dendograma com 7 clusters
Fonte: Atlas do Desenvolvimento Humano no Brasil
É possível observar que se reduzir as variáveis em 4 clusters, forma-se um
agrupamento com as variáveis FECTOT, MORT1, PIND, PINDCRI, PPOBCRI,
T_NESTUDA_NTRAB_MMEIO, T_ANALF15A17, TRABSC,
T_MULCHEFEFIF014, PAREDE, T_DES18M, o outro agrupamento seria o das
variáveis E_ANOSESTUDO, IDHM, IDHM_E, IDHM_R, IDHM_L, P_SUPER,
T_AGUA, o outro agrupamento é a variável T_LUZ e o quarto agrupamento as variáveis
HOMEM10A14 e HOMEM 70A74.
Estes agrupamentos nestes grupos permitem mostrar as variáveis que estão mais
correlacionadas entre si em quatro grupos diferentes, que podem ser utilizados para
explicar o modelo. Pode-se perceber que no primeiro grupo se encontram as variáveis
relacionadas a taxa de mortalidade infantil, pobreza, educação e trabalho. O segundo
grupo se encontram as variáveis relacionadas com os indicadores de IDHM, o acesso a
água e aos estudos. O terceiro agrupamentos possui apenas uma variável, que é o acesso
a luz elétrica, e o quarto se relaciona com a população de homens com idade entre 10 e
14 anos e entre 70 e 74 anos nos diversos município. Estes resultados mostram uma certa
proximidade destas variáveis.
Se o número de clusters for aumentado para sete, o primeiro grupo formado é com
a variável FECTOT, o segundo com as variáveis MORT1, PIND, PINDCRI, PPOBCRI,
T_NESTUDA_NTRAB_MMEIO, T_ANALF15A17, TRABSC,
T_MULCHEFEFIF014, o terceiro com a variável PAREDE, o quarto com a variável
T_DES18M, o quinto E_ANOSESTUDO, IDHM, IDHM_E, IDHM_R, IDHM_L,
P_SUPER, T_AGUA, o sexto com a variável T_LUZ e o sétimo com as variáveis
HOMEM10A14 e HOMEM 70A74.
Desta forma, pode-se realizar estes agrupamentos para se encontrar 7 grupos com
variáveis similares.
Este modelo pode auxiliar também a conhecer qual o grau de similaridade entre
as variáveis, e assim, poder trabalhar com elas de modo que não se tornem redundantes
para a confecção dos modelos matemáticos de análise. De modo que, por exemplo, as
variáveis HOMEM70A74 e HOMEM10A14 são bastante similares entre si. Assim é
possível reduzir o número de variáveis utilizadas para a construção de um modelo

45
matemático, utilizando aquelas que auxiliem a explicar o fenômeno estudado com uma
alta porcentagem de acerto sem haver redundância. O dendograma permite uma visão a
respeito de quais variáveis são similares entre si pelas suas correlações e em que medida
são similares.
2.3 Considerações
O presente trabalho apresentou uma visão sobre a distribuição dos municípios nos
estados brasileiros, pode-se perceber os estados com maior percentual de municípios são
Minas Gerais com 15,3%, seguida por São Paulo com 11,6%. Os estados com menos
municípios são Roraima e Amapá com 0,3%.
A região que concentra mais municípios é a Nordeste com 32,1%, seguida por
Sudeste com 30%, Sul com 21,4%, Centro-Oeste com 8,3% e Norte com 8,1%.
Foram calculados os índices de correlação das variáveis estudadas e traçados os
diagramas de dispersão, a fim de verificar quais das variáveis são mais correlacionadas e
se possuem correlações positivas ou negativas. As variáveis mais positivamente
correlacionadas foram PINDCRI e PIND com correlação de 0,991, seguida por
HOMEM10A14 E HOMEM70A74 com 0,974. As variáveis mais negativamente
correlacionadas são IDHM_L e MORT1 com correlação de -0,967, seguida por IDHM_R
e PPOBCRI, com correlação de -0,940.
Também foram apresentados os dendogramas, que permitiram visualizar as
similaridades entre as variáveis, e quais estavam mais correlacionadas entre si,
agrupando-as em quatro e em sete clusters.
CAPÍTULO 3. ANÁLISES DE TENDÊNCIAS
O presente capítulo tem como objetivo realizar uma análise de tendência e
projeções de três variáveis quantitativas. Os dados foram obtidos através do site do
Instituto Brasileiro de Geografia e Estatística (IBGE), que os disponibiliza para que se
possa realizar análises. Os dados são disponibilizados de forma ordenada, seguindo um
intervalo de tempo. O site possui dados das dimensões social, demográfica e econômica.
Os dados selecionados para a análise estão relacionados com a educação. De
acordo com o site do IBGE (2017), a educação escolar é um tema de grande importância
tanto no âmbito profissional dos indivíduos quanto no desenvolvimento da cidadania, já
que atualmente os indivíduos estão vivendo em um mundo globalizado, tecnológico e
com grande quantidade de informações disponíveis.
As variáveis selecionadas foram “Taxa de Analfabetismo Funcional”, “Média de
Anos de Estudo de Pessoas com 10 Anos ou Mais de Idade” e “Docentes com Nível
Superior no Ensino Fundamental na Rede Pública”
As análises estatísticas foram realizadas com o auxílio do software MINITAB.
3. Entendendo os Dados
Os dados são séries históricas, disponibilizados pelo IBGE e estão relacionados
com a educação e a qualidade da educação.
3.1 Entendendo as Variáveis
A Tabela 1 representa as variáveis selecionadas, o significado destas variáveis e
suas respectivas unidades de medida.
Tabela 1: Variáveis
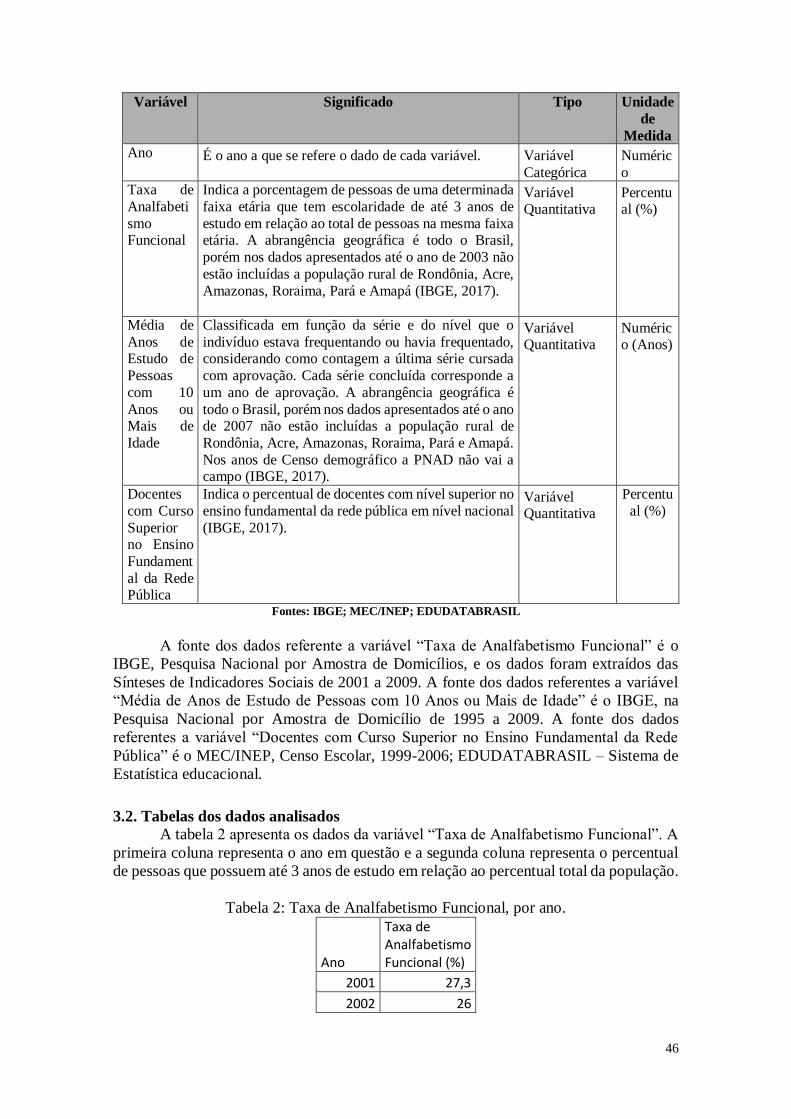
46
Variável Significado Tipo Unidade
de
Medida
Ano É o ano a que se refere o dado de cada variável. Variável
Categórica
Numéric
o
Taxa de
Analfabeti
smo Funcional
Indica a porcentagem de pessoas de uma determinada
faixa etária que tem escolaridade de até 3 anos de
estudo em relação ao total de pessoas na mesma faixa etária. A abrangência geográfica é todo o Brasil,
porém nos dados apresentados até o ano de 2003 não
estão incluídas a população rural de Rondônia, Acre,
Amazonas, Roraima, Pará e Amapá (IBGE, 2017).
Variável Quantitativa
Percentual (%)
Média de
Anos de Estudo de
Pessoas
com 10
Anos ou Mais de
Idade
Classificada em função da série e do nível que o
indivíduo estava frequentando ou havia frequentado, considerando como contagem a última série cursada
com aprovação. Cada série concluída corresponde a
um ano de aprovação. A abrangência geográfica é
todo o Brasil, porém nos dados apresentados até o ano de 2007 não estão incluídas a população rural de
Rondônia, Acre, Amazonas, Roraima, Pará e Amapá.
Nos anos de Censo demográfico a PNAD não vai a campo (IBGE, 2017).
Variável Quantitativa
Numérico (Anos)
Docentes
com Curso
Superior no Ensino
Fundament
al da Rede Pública
Indica o percentual de docentes com nível superior no
ensino fundamental da rede pública em nível nacional
(IBGE, 2017).
Variável Quantitativa
Percentu
al (%)
Fontes: IBGE; MEC/INEP; EDUDATABRASIL
A fonte dos dados referente a variável “Taxa de Analfabetismo Funcional” é o
IBGE, Pesquisa Nacional por Amostra de Domicílios, e os dados foram extraídos das
Sínteses de Indicadores Sociais de 2001 a 2009. A fonte dos dados referentes a variável
“Média de Anos de Estudo de Pessoas com 10 Anos ou Mais de Idade” é o IBGE, na
Pesquisa Nacional por Amostra de Domicílio de 1995 a 2009. A fonte dos dados
referentes a variável “Docentes com Curso Superior no Ensino Fundamental da Rede
Pública” é o MEC/INEP, Censo Escolar, 1999-2006; EDUDATABRASIL – Sistema de
Estatística educacional.
3.2. Tabelas dos dados analisados
A tabela 2 apresenta os dados da variável “Taxa de Analfabetismo Funcional”. A
primeira coluna representa o ano em questão e a segunda coluna representa o percentual
de pessoas que possuem até 3 anos de estudo em relação ao percentual total da população.
Tabela 2: Taxa de Analfabetismo Funcional, por ano.
Ano
Taxa de Analfabetismo Funcional (%)
2001 27,3
2002 26

47
2003 24,8
2004 24,4
2005 23,5
2006 22,2
2007 21,7
2008 21
2009 20,3 Fonte: IBGE, Pesquisa Nacional por Amostra de Domicílios; Sínteses de Indicadores Sociais de 2001 a 2009.
A tabela 3 apresenta os dados da variável “Média de Anos de Estudo de Pessoas
com 10 Anos ou Mais de Idade”. A primeira coluna representa o ano em questão e a
segunda coluna representa o número médio de anos de estudo de pessoas com 10 anos ou
mais.
Tabela 3: Média de Anos de Estudo de Pessoas com 10 Anos ou Mais de Idade, por ano.
Ano
Média de Anos
de Estudo de
Pessoas com 10
Anos ou Mais de
Idade (Anos)
1995 5,2
1996 5,3
1999 5,8
2001 6,1
2002 6,3
2003 6,5
2004 6,6
2005 6,7
2006 6,9
2007 7
2008 7,1
2009 7,2 Fonte: IBGE, Pesquisa Nacional por Amostra de Domicílio 1995 a 2009.
A tabela 4 representa os dados da variável “Docentes com Curso Superior no
Ensino Fundamental da Rede Pública”. A primeira coluna representa o ano em questão e
a segunda o percentual de professores do ensino fundamental que possuem ensino
superior.
Tabela 4: Docentes com Curso Superior no Ensino Fundamental da
Rede Pública,por ano.
Ano
Docentes com Curso Superior
no Ensino Fundamental da
Rede Pública (%)
1999 44,5
2000 45,9

48
2001 47,7
2002 50,2
2003 54,6
2004 56,9
2005 64
2006 70,7 Fonte: MEC/INEP, Censo Escolar, 1999-2006; EDUDATABRASIL – Sistema de Estatística educacional.
3.3 Análise das Variáveis
As variáveis foram analisadas com o auxílio do software estatístico MINITAB, e
buscou-se compreender as tendências e realizar projeções futuras para essas variáveis.
Para isso, as projeções e os gráficos de tendências foram traçados através dos modelos
linear, quadrático, exponencial e de curva S.
É possível observar que os gráficos de tendência com modelo linear apresentam
uma função de primeiro grau, do tipo Y(t) = b + a*t, os gráficos de tendência dos modelos
quadráticos apresentam uma função do tipo Y(t) = c + b*t + c*t² e os gráficos de tendência
dos modelos exponenciais apresentam uma função do tipo Y(t) = b*(a*t²).
Inicialmente, foi analisado a variável Taxa de Analfabetismo Funcional. A Figura
1 representa o gráfico de tendência com modelo linear dos dados desta variável. A Figura
2 representa o gráfico de tendência com modelo quadrático. A Figura 3 representa o
gráfico de tendência com modelo exponencial e a Figura 4 representa o gráfico de
tendência com modelo de curva S. Foram realizadas projeções para 10 anos a partir da
data limite do último ano disponível pelos dados obtidos através do site.
As Tabelas 5, 6, 7 e 8 apresentam os dados das previsões de 10 anos para os
modelos linear, quadrático, exponencial e S-Curve, respectivamente.
Nos gráficos que se seguem, os pontos e a linha preta representam os dados atuais
e reais, os pontos e a linha vermelha representam a linha de tendência ajustada e os pontos
e a linha verde representam as projeções futuras geradas a partir da tendência dos dados.
Os números apresentados nas tabelas a seguir serão retratados fielmente de acordo
com o que foi gerado pelo MINITAB, porém nas discussões e análises feitas no texto
serão utilizados os números aproximados com apenas uma casa decimal, a fim de estar
de acordo com a quantidade de algarismos significativos dos dados disponibilizados pelo
IBGE.
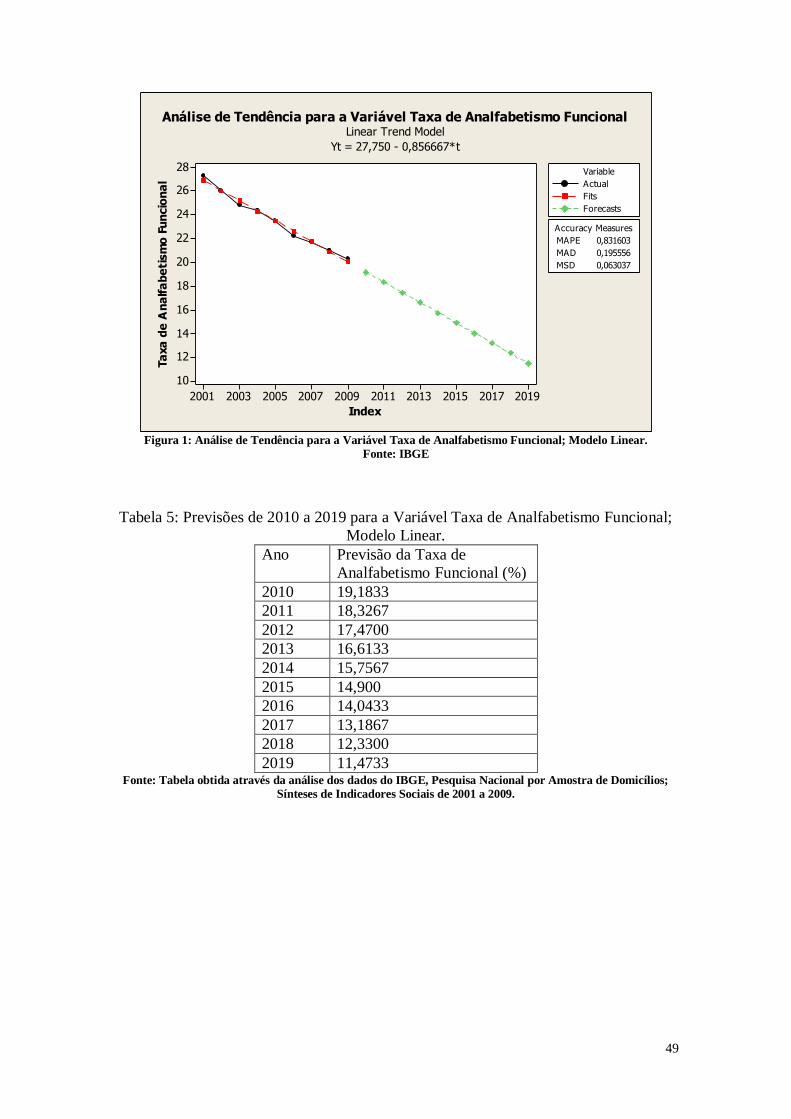
49
2019201720152013201120092007200520032001
28
26
24
22
20
18
16
14
12
10
Index
Ta
xa
de
An
alf
ab
eti
sm
o F
un
cio
na
l
MAPE 0,831603
MAD 0,195556
MSD 0,063037
Accuracy Measures
Actual
Fits
Forecasts
Variable
Análise de Tendência para a Variável Taxa de Analfabetismo FuncionalLinear Trend Model
Yt = 27,750 - 0,856667*t
Figura 1: Análise de Tendência para a Variável Taxa de Analfabetismo Funcional; Modelo Linear.
Fonte: IBGE
Tabela 5: Previsões de 2010 a 2019 para a Variável Taxa de Analfabetismo Funcional;
Modelo Linear.
Ano Previsão da Taxa de
Analfabetismo Funcional (%)
2010 19,1833
2011 18,3267
2012 17,4700
2013 16,6133
2014 15,7567
2015 14,900
2016 14,0433
2017 13,1867
2018 12,3300
2019 11,4733 Fonte: Tabela obtida através da análise dos dados do IBGE, Pesquisa Nacional por Amostra de Domicílios;
Sínteses de Indicadores Sociais de 2001 a 2009.
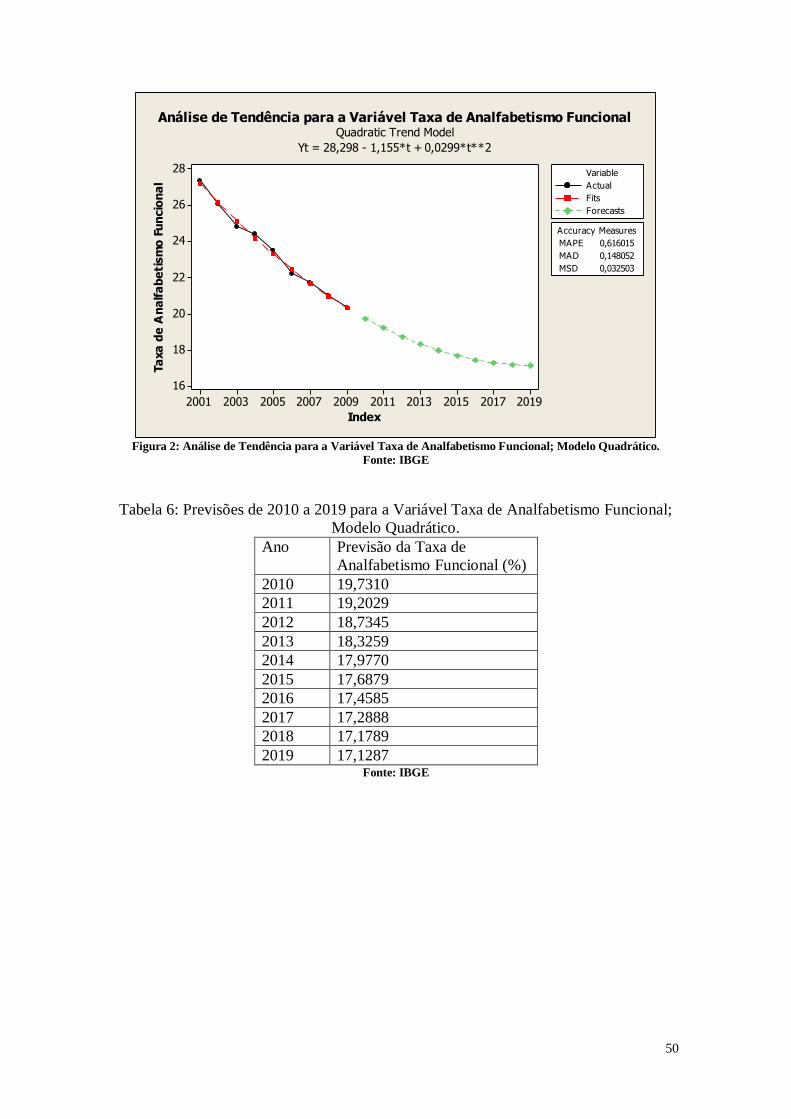
50
2019201720152013201120092007200520032001
28
26
24
22
20
18
16
Index
Ta
xa
de
An
alf
ab
eti
sm
o F
un
cio
na
l
MAPE 0,616015
MAD 0,148052
MSD 0,032503
Accuracy Measures
Actual
Fits
Forecasts
Variable
Análise de Tendência para a Variável Taxa de Analfabetismo FuncionalQuadratic Trend Model
Yt = 28,298 - 1,155*t + 0,0299*t**2
Figura 2: Análise de Tendência para a Variável Taxa de Analfabetismo Funcional; Modelo Quadrático.
Fonte: IBGE
Tabela 6: Previsões de 2010 a 2019 para a Variável Taxa de Analfabetismo Funcional;
Modelo Quadrático.
Ano Previsão da Taxa de
Analfabetismo Funcional (%)
2010 19,7310
2011 19,2029
2012 18,7345
2013 18,3259
2014 17,9770
2015 17,6879
2016 17,4585
2017 17,2888
2018 17,1789
2019 17,1287 Fonte: IBGE
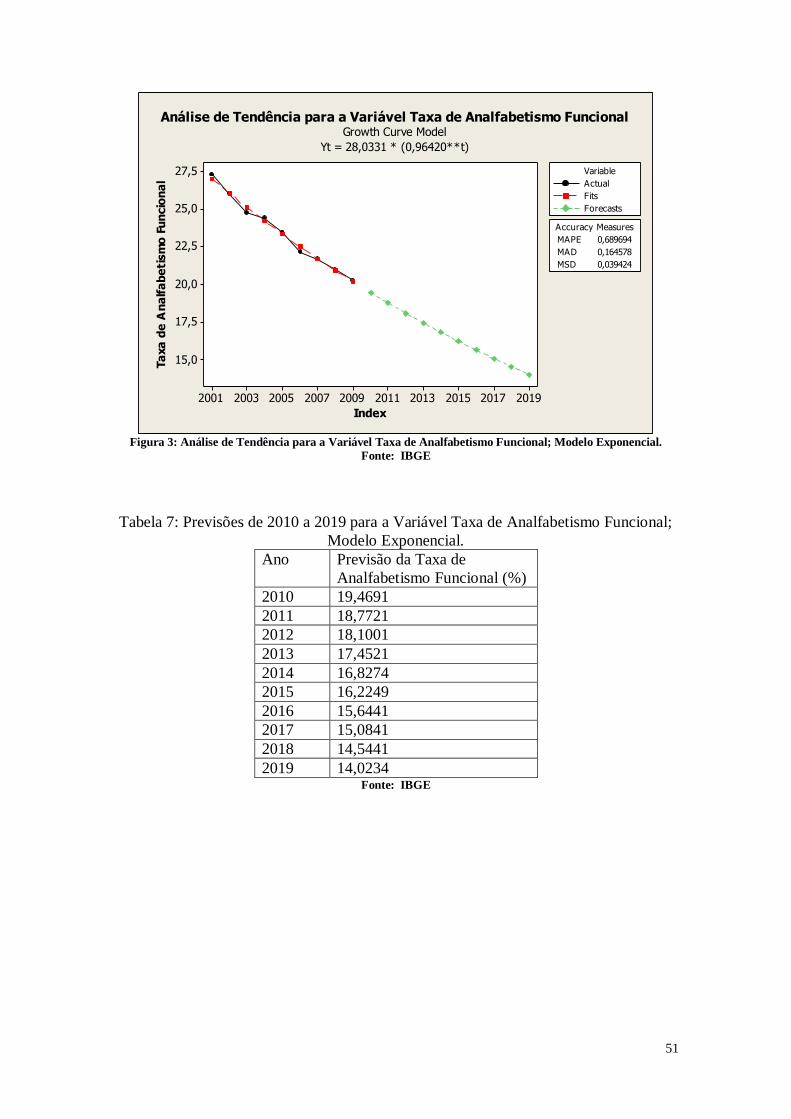
51
2019201720152013201120092007200520032001
27,5
25,0
22,5
20,0
17,5
15,0
Index
Ta
xa
de
An
alf
ab
eti
sm
o F
un
cio
na
l
MAPE 0,689694
MAD 0,164578
MSD 0,039424
Accuracy Measures
Actual
Fits
Forecasts
Variable
Análise de Tendência para a Variável Taxa de Analfabetismo FuncionalGrowth Curve Model
Yt = 28,0331 * (0,96420**t)
Figura 3: Análise de Tendência para a Variável Taxa de Analfabetismo Funcional; Modelo Exponencial.
Fonte: IBGE
Tabela 7: Previsões de 2010 a 2019 para a Variável Taxa de Analfabetismo Funcional;
Modelo Exponencial.
Ano Previsão da Taxa de
Analfabetismo Funcional (%)
2010 19,4691
2011 18,7721
2012 18,1001
2013 17,4521
2014 16,8274
2015 16,2249
2016 15,6441
2017 15,0841
2018 14,5441
2019 14,0234 Fonte: IBGE
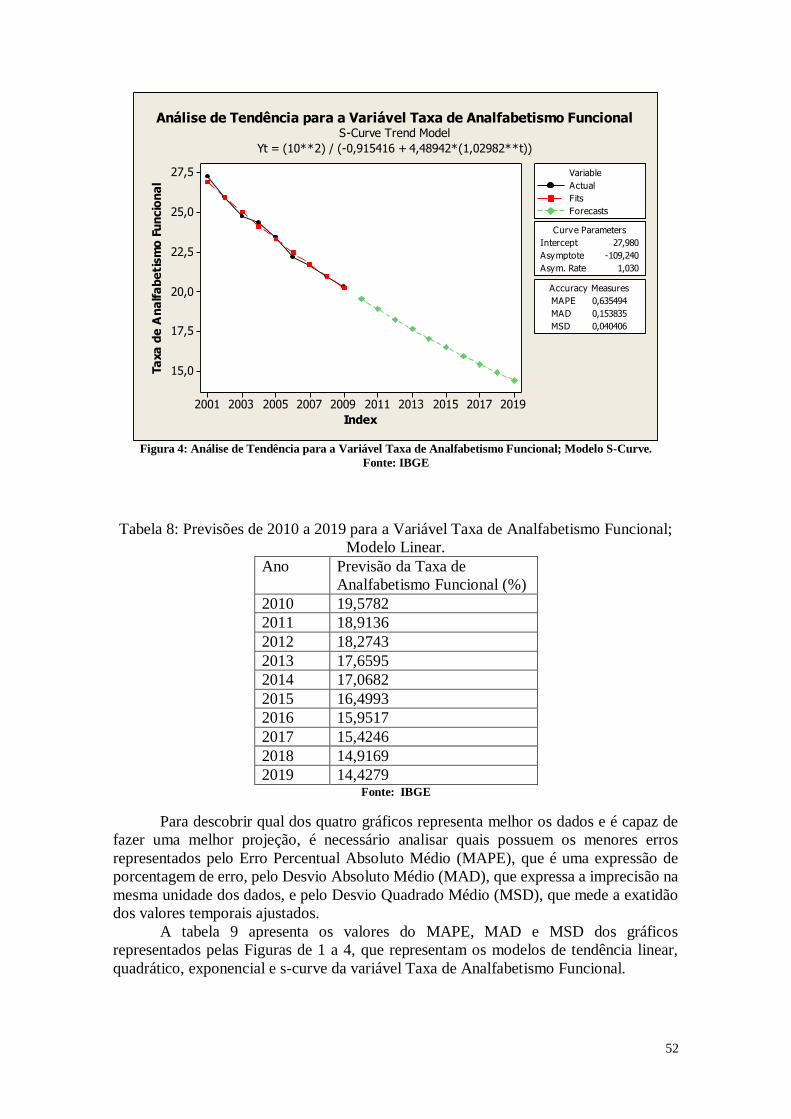
52
2019201720152013201120092007200520032001
27,5
25,0
22,5
20,0
17,5
15,0
Index
Ta
xa
de
An
alf
ab
eti
sm
o F
un
cio
na
l
Intercept 27,980
Asymptote -109,240
Asym. Rate 1,030
Curve Parameters
MAPE 0,635494
MAD 0,153835
MSD 0,040406
Accuracy Measures
Actual
Fits
Forecasts
Variable
Análise de Tendência para a Variável Taxa de Analfabetismo FuncionalS-Curve Trend Model
Yt = (10**2) / (-0,915416 + 4,48942*(1,02982**t))
Figura 4: Análise de Tendência para a Variável Taxa de Analfabetismo Funcional; Modelo S-Curve.
Fonte: IBGE
Tabela 8: Previsões de 2010 a 2019 para a Variável Taxa de Analfabetismo Funcional;
Modelo Linear.
Ano Previsão da Taxa de
Analfabetismo Funcional (%)
2010 19,5782
2011 18,9136
2012 18,2743
2013 17,6595
2014 17,0682
2015 16,4993
2016 15,9517
2017 15,4246
2018 14,9169
2019 14,4279 Fonte: IBGE
Para descobrir qual dos quatro gráficos representa melhor os dados e é capaz de
fazer uma melhor projeção, é necessário analisar quais possuem os menores erros
representados pelo Erro Percentual Absoluto Médio (MAPE), que é uma expressão de
porcentagem de erro, pelo Desvio Absoluto Médio (MAD), que expressa a imprecisão na
mesma unidade dos dados, e pelo Desvio Quadrado Médio (MSD), que mede a exatidão
dos valores temporais ajustados.
A tabela 9 apresenta os valores do MAPE, MAD e MSD dos gráficos
representados pelas Figuras de 1 a 4, que representam os modelos de tendência linear,
quadrático, exponencial e s-curve da variável Taxa de Analfabetismo Funcional.

53
Tabela 9: MAPE, MAD e MSD da variável Taxa de Analfabetismo Funcional.
Linear Quadrática Exponencial S-Curve
MAPE 0,831603 0,616015 0,689694 0,635494
MAD 0,153835 0,148052 0,164578 0,153835
MSD 0,040406 0,032503 0,039224 0,040406 Fonte: IBGE
Verifica-se através da observação da tabela que o modelo quadrático é o que
melhor se encaixa para realizar a análise de tendências e a projeção desta variável, já que
os valores do MAPE, MAD e MSD são menores do que todas as outras opções.
É possível perceber uma queda na taxa de analfabetismo funcional entre os anos
de 2001 e 2009, passando de aproximadamente 27,3% para 20,3%. Esta é uma queda
considerável. A projeção do gráfico para o ano de 2009 seria 19,7%, atingindo no ano de
2019 17,1%. Por se tratar de uma função quadrática, existe uma variação no intervalo de
queda de um ano para o outro, sendo que quanto mais o tempo passa, mais lentamente o
percentual da taxa de analfabetismo irá diminuir. Em outras palavras, a variação na
diminuição da taxa de analfabetismo funcional entre 2001 e 2003 foi de aproximadamente
-1%, e num mesmo intervalo de tempo de 2 anos, de acordo com o gráfico, a variação na
taxa de analfabetismo funcional de 2017 para 2019 será de aproximadamente -0,2%.
Esta variação indica, em termos matemáticos, que apesar de a taxa de
analfabetismo funcional ir diminuindo ao longo dos anos, ela irá diminuir cada vez mais
lentamente. Outro ponto a se destacar é que esta taxa está relacionada a outros fatores,
como por exemplo, o fator econômico, social, político, e durante os períodos de previsão
podem haver alguns eventos que causem mudanças neste cenário, fazendo com que os
dados se modifiquem e a função tenha um outro comportamento.
Também é perceptível a diferença dos resultados gerados pela previsão do modelo
linear e do modelo quadrático, enquanto no modelo linear o valor da taxa de
analfabetismo funcional em 2019 é de aproximadamente 11,5%, no modelo quadrático é
de 17,1%. Cabe ressaltar que o modelo linear é o que apresenta os maiores valores de
MAPE, MAD e MSD.
Também foram realizadas as análises para a variável “Média de Anos de Estudo
de Pessoas com 10 Anos ou Mais de Idade”. A Figura 5 representa o gráfico de tendência
com modelo linear dos dados desta variável, a Figura 6 representa o gráfico de tendência
com modelo quadrático, a Figura 7 representa o gráfico de tendência com modelo
exponencial e a Figura 8 representa o gráfico de tendência com modelo de curva S. Para
esta variável também foram realizadas projeções para 10 anos a partir da data limite do
último ano disponível pelos dados obtidos através do site do IBGE. As Tabelas 10, 11,
12 e 13 apresentam os dados das previsões de 10 anos para os modelos linear, quadrático,
exponencial e S-Curve, respectivamente, da variável.
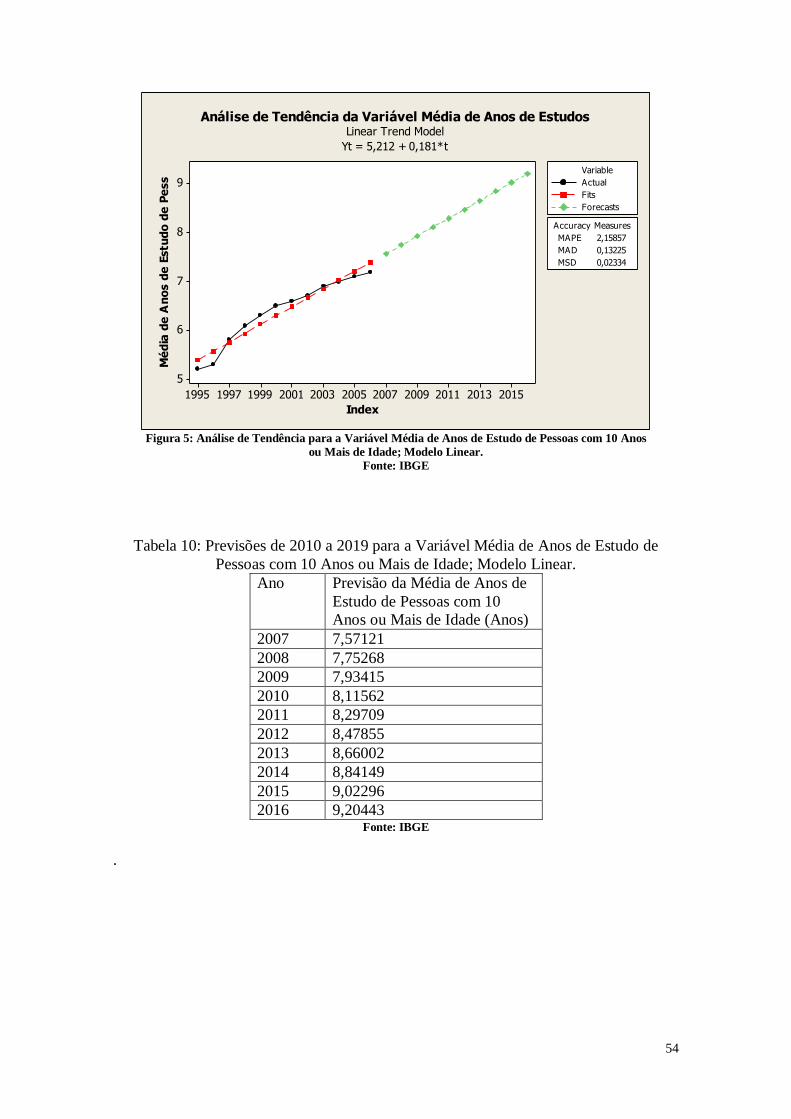
54
20152013201120092007200520032001199919971995
9
8
7
6
5
Index
Mé
dia
de
An
os d
e E
stu
do
de
Pe
ss
MAPE 2,15857
MAD 0,13225
MSD 0,02334
Accuracy Measures
Actual
Fits
Forecasts
Variable
Análise de Tendência da Variável Média de Anos de EstudosLinear Trend Model
Yt = 5,212 + 0,181*t
Figura 5: Análise de Tendência para a Variável Média de Anos de Estudo de Pessoas com 10 Anos
ou Mais de Idade; Modelo Linear.
Fonte: IBGE
Tabela 10: Previsões de 2010 a 2019 para a Variável Média de Anos de Estudo de
Pessoas com 10 Anos ou Mais de Idade; Modelo Linear.
Ano Previsão da Média de Anos de
Estudo de Pessoas com 10
Anos ou Mais de Idade (Anos)
2007 7,57121
2008 7,75268
2009 7,93415
2010 8,11562
2011 8,29709
2012 8,47855
2013 8,66002
2014 8,84149
2015 9,02296
2016 9,20443 Fonte: IBGE
.
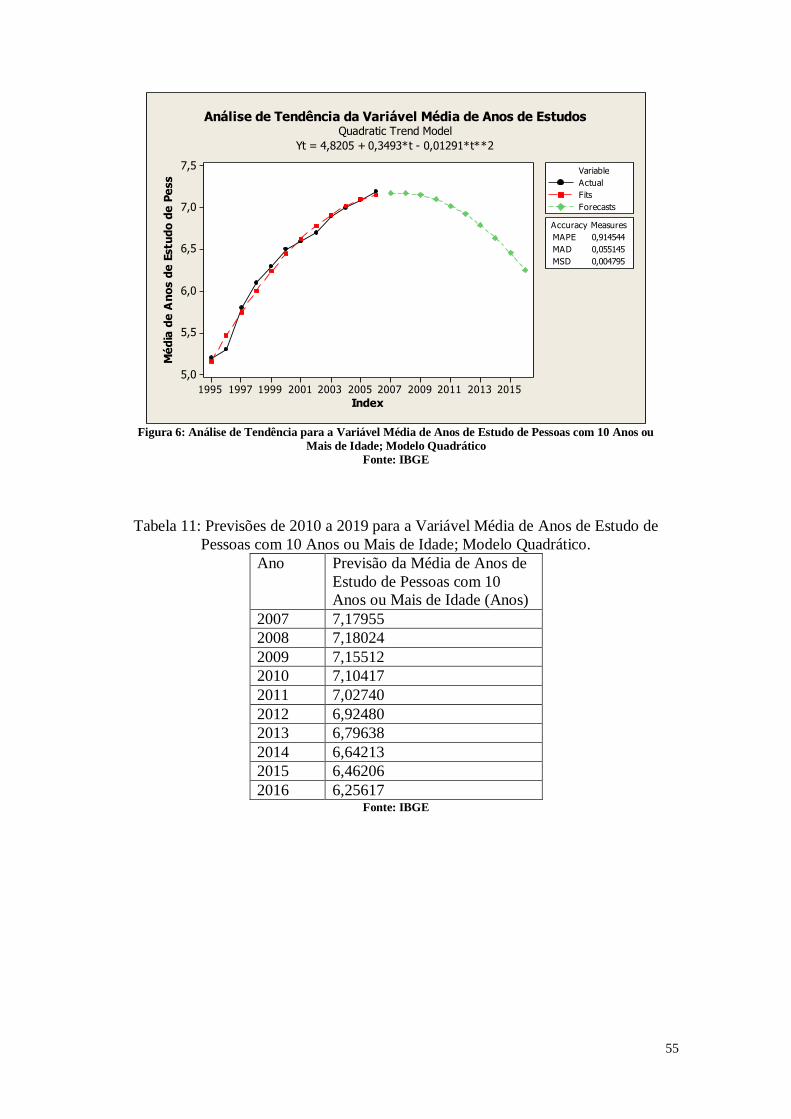
55
20152013201120092007200520032001199919971995
7,5
7,0
6,5
6,0
5,5
5,0
Index
Mé
dia
de
An
os d
e E
stu
do
de
Pe
ss
MAPE 0,914544
MAD 0,055145
MSD 0,004795
Accuracy Measures
Actual
Fits
Forecasts
Variable
Análise de Tendência da Variável Média de Anos de EstudosQuadratic Trend Model
Yt = 4,8205 + 0,3493*t - 0,01291*t**2
Figura 6: Análise de Tendência para a Variável Média de Anos de Estudo de Pessoas com 10 Anos ou
Mais de Idade; Modelo Quadrático
Fonte: IBGE
Tabela 11: Previsões de 2010 a 2019 para a Variável Média de Anos de Estudo de
Pessoas com 10 Anos ou Mais de Idade; Modelo Quadrático.
Ano Previsão da Média de Anos de
Estudo de Pessoas com 10
Anos ou Mais de Idade (Anos)
2007 7,17955
2008 7,18024
2009 7,15512
2010 7,10417
2011 7,02740
2012 6,92480
2013 6,79638
2014 6,64213
2015 6,46206
2016 6,25617 Fonte: IBGE
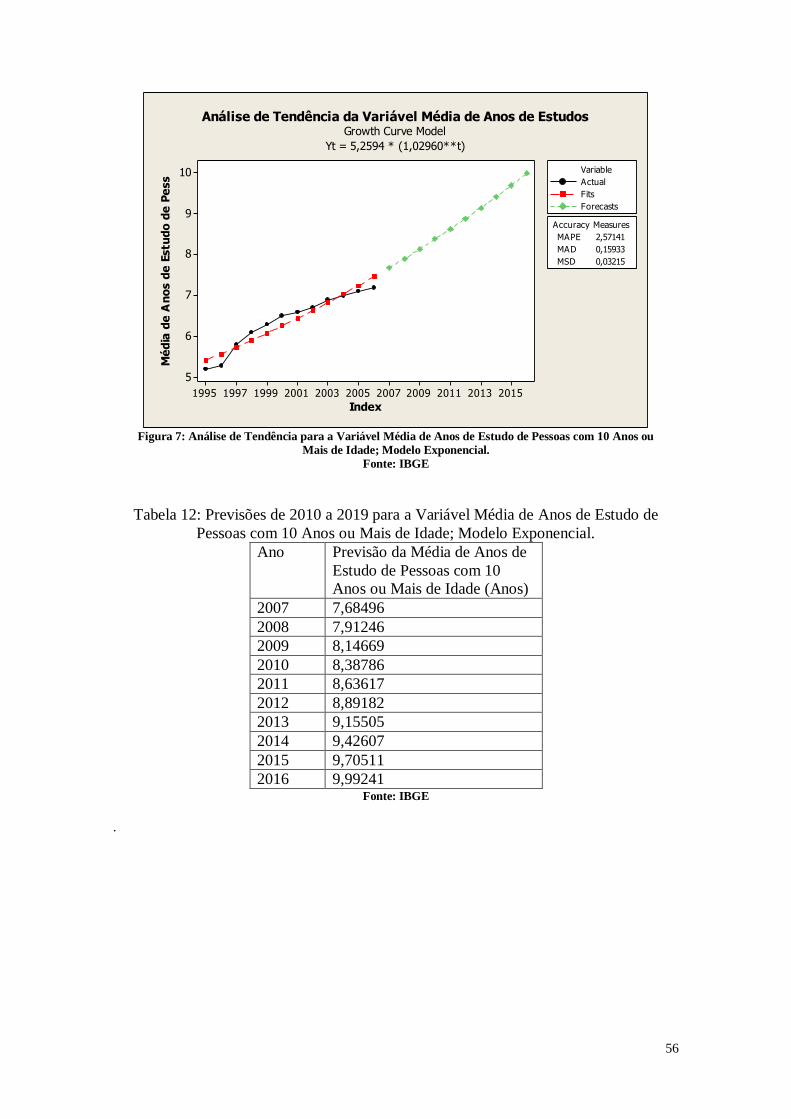
56
20152013201120092007200520032001199919971995
10
9
8
7
6
5
Index
Mé
dia
de
An
os d
e E
stu
do
de
Pe
ss
MAPE 2,57141
MAD 0,15933
MSD 0,03215
Accuracy Measures
Actual
Fits
Forecasts
Variable
Análise de Tendência da Variável Média de Anos de EstudosGrowth Curve Model
Yt = 5,2594 * (1,02960**t)
Figura 7: Análise de Tendência para a Variável Média de Anos de Estudo de Pessoas com 10 Anos ou
Mais de Idade; Modelo Exponencial.
Fonte: IBGE
Tabela 12: Previsões de 2010 a 2019 para a Variável Média de Anos de Estudo de
Pessoas com 10 Anos ou Mais de Idade; Modelo Exponencial.
Ano Previsão da Média de Anos de
Estudo de Pessoas com 10
Anos ou Mais de Idade (Anos)
2007 7,68496
2008 7,91246
2009 8,14669
2010 8,38786
2011 8,63617
2012 8,89182
2013 9,15505
2014 9,42607
2015 9,70511
2016 9,99241 Fonte: IBGE
.
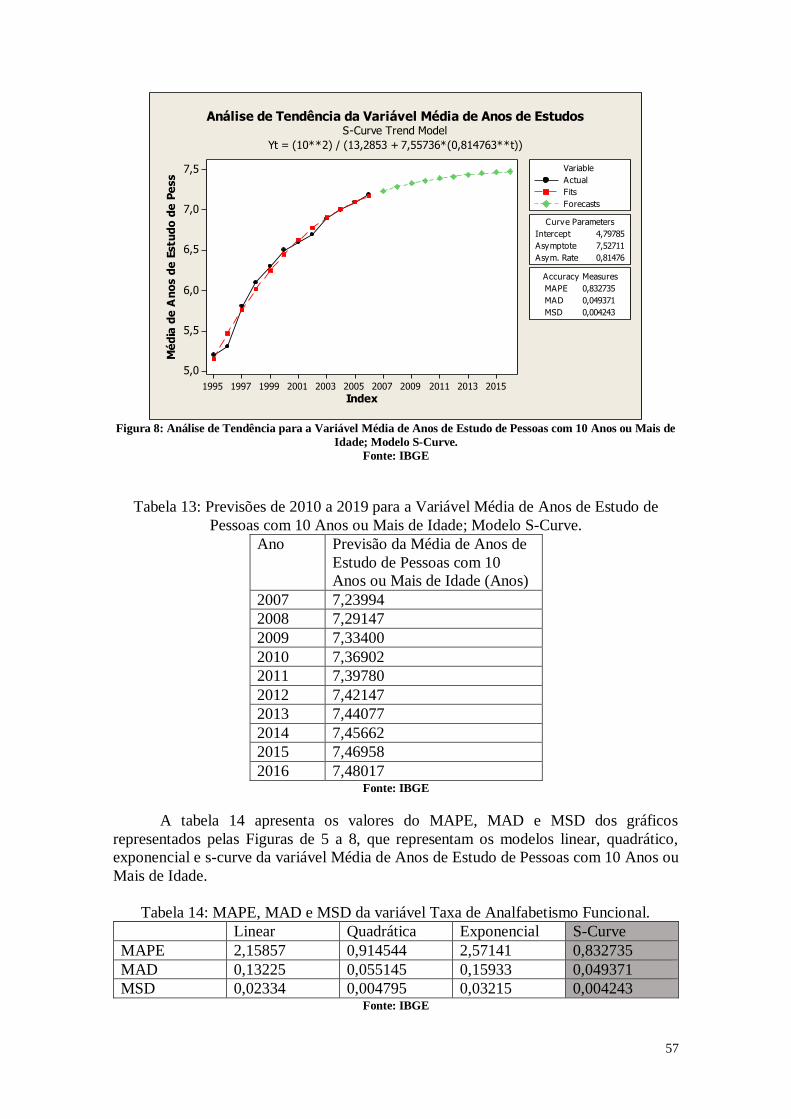
57
20152013201120092007200520032001199919971995
7,5
7,0
6,5
6,0
5,5
5,0
Index
Mé
dia
de
An
os d
e E
stu
do
de
Pe
ss
Intercept 4,79785
Asymptote 7,52711
Asym. Rate 0,81476
Curve Parameters
MAPE 0,832735
MAD 0,049371
MSD 0,004243
Accuracy Measures
Actual
Fits
Forecasts
Variable
Análise de Tendência da Variável Média de Anos de EstudosS-Curve Trend Model
Yt = (10**2) / (13,2853 + 7,55736*(0,814763**t))
Figura 8: Análise de Tendência para a Variável Média de Anos de Estudo de Pessoas com 10 Anos ou Mais de
Idade; Modelo S-Curve.
Fonte: IBGE
Tabela 13: Previsões de 2010 a 2019 para a Variável Média de Anos de Estudo de
Pessoas com 10 Anos ou Mais de Idade; Modelo S-Curve.
Ano Previsão da Média de Anos de
Estudo de Pessoas com 10
Anos ou Mais de Idade (Anos)
2007 7,23994
2008 7,29147
2009 7,33400
2010 7,36902
2011 7,39780
2012 7,42147
2013 7,44077
2014 7,45662
2015 7,46958
2016 7,48017 Fonte: IBGE
A tabela 14 apresenta os valores do MAPE, MAD e MSD dos gráficos
representados pelas Figuras de 5 a 8, que representam os modelos linear, quadrático,
exponencial e s-curve da variável Média de Anos de Estudo de Pessoas com 10 Anos ou
Mais de Idade.
Tabela 14: MAPE, MAD e MSD da variável Taxa de Analfabetismo Funcional.
Linear Quadrática Exponencial S-Curve
MAPE 2,15857 0,914544 2,57141 0,832735
MAD 0,13225 0,055145 0,15933 0,049371
MSD 0,02334 0,004795 0,03215 0,004243 Fonte: IBGE
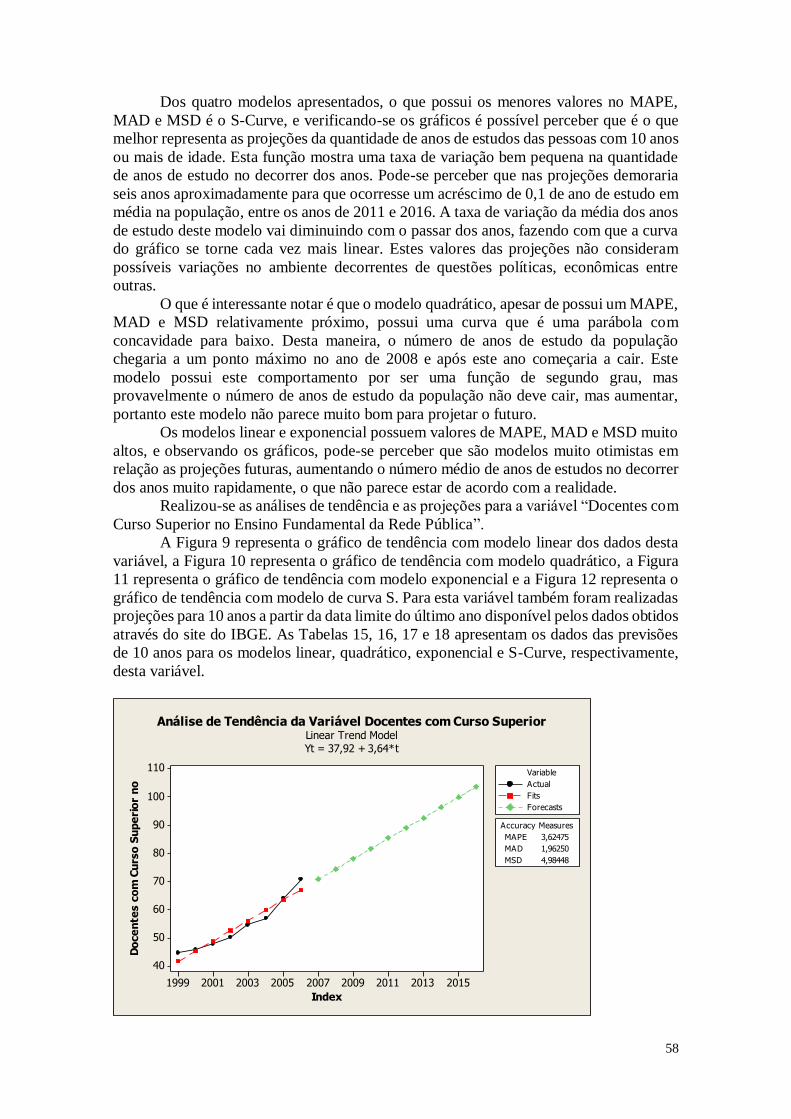
58
Dos quatro modelos apresentados, o que possui os menores valores no MAPE,
MAD e MSD é o S-Curve, e verificando-se os gráficos é possível perceber que é o que
melhor representa as projeções da quantidade de anos de estudos das pessoas com 10 anos
ou mais de idade. Esta função mostra uma taxa de variação bem pequena na quantidade
de anos de estudo no decorrer dos anos. Pode-se perceber que nas projeções demoraria
seis anos aproximadamente para que ocorresse um acréscimo de 0,1 de ano de estudo em
média na população, entre os anos de 2011 e 2016. A taxa de variação da média dos anos
de estudo deste modelo vai diminuindo com o passar dos anos, fazendo com que a curva
do gráfico se torne cada vez mais linear. Estes valores das projeções não consideram
possíveis variações no ambiente decorrentes de questões políticas, econômicas entre
outras.
O que é interessante notar é que o modelo quadrático, apesar de possui um MAPE,
MAD e MSD relativamente próximo, possui uma curva que é uma parábola com
concavidade para baixo. Desta maneira, o número de anos de estudo da população
chegaria a um ponto máximo no ano de 2008 e após este ano começaria a cair. Este
modelo possui este comportamento por ser uma função de segundo grau, mas
provavelmente o número de anos de estudo da população não deve cair, mas aumentar,
portanto este modelo não parece muito bom para projetar o futuro.
Os modelos linear e exponencial possuem valores de MAPE, MAD e MSD muito
altos, e observando os gráficos, pode-se perceber que são modelos muito otimistas em
relação as projeções futuras, aumentando o número médio de anos de estudos no decorrer
dos anos muito rapidamente, o que não parece estar de acordo com a realidade.
Realizou-se as análises de tendência e as projeções para a variável “Docentes com
Curso Superior no Ensino Fundamental da Rede Pública”.
A Figura 9 representa o gráfico de tendência com modelo linear dos dados desta
variável, a Figura 10 representa o gráfico de tendência com modelo quadrático, a Figura
11 representa o gráfico de tendência com modelo exponencial e a Figura 12 representa o
gráfico de tendência com modelo de curva S. Para esta variável também foram realizadas
projeções para 10 anos a partir da data limite do último ano disponível pelos dados obtidos
através do site do IBGE. As Tabelas 15, 16, 17 e 18 apresentam os dados das previsões
de 10 anos para os modelos linear, quadrático, exponencial e S-Curve, respectivamente,
desta variável.
201520132011200920072005200320011999
110
100
90
80
70
60
50
40
Index
Do
ce
nte
s c
om
Cu
rso
Su
pe
rio
r n
o
MAPE 3,62475
MAD 1,96250
MSD 4,98448
Accuracy Measures
Actual
Fits
Forecasts
Variable
Análise de Tendência da Variável Docentes com Curso SuperiorLinear Trend Model
Yt = 37,92 + 3,64*t
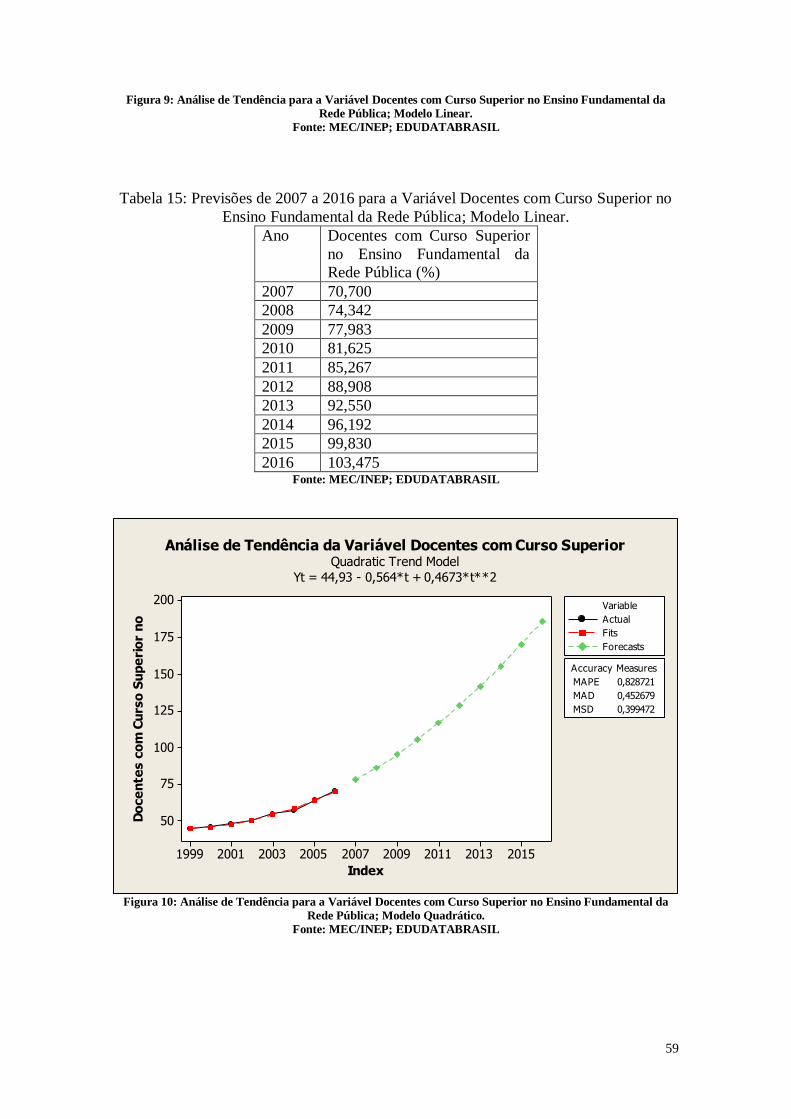
59
Figura 9: Análise de Tendência para a Variável Docentes com Curso Superior no Ensino Fundamental da
Rede Pública; Modelo Linear.
Fonte: MEC/INEP; EDUDATABRASIL
Tabela 15: Previsões de 2007 a 2016 para a Variável Docentes com Curso Superior no
Ensino Fundamental da Rede Pública; Modelo Linear.
Ano Docentes com Curso Superior
no Ensino Fundamental da
Rede Pública (%)
2007 70,700
2008 74,342
2009 77,983
2010 81,625
2011 85,267
2012 88,908
2013 92,550
2014 96,192
2015 99,830
2016 103,475 Fonte: MEC/INEP; EDUDATABRASIL
201520132011200920072005200320011999
200
175
150
125
100
75
50
Index
Do
ce
nte
s c
om
Cu
rso
Su
pe
rio
r n
o
MAPE 0,828721
MAD 0,452679
MSD 0,399472
Accuracy Measures
Actual
Fits
Forecasts
Variable
Análise de Tendência da Variável Docentes com Curso SuperiorQuadratic Trend Model
Yt = 44,93 - 0,564*t + 0,4673*t**2
Figura 10: Análise de Tendência para a Variável Docentes com Curso Superior no Ensino Fundamental da
Rede Pública; Modelo Quadrático.
Fonte: MEC/INEP; EDUDATABRASIL
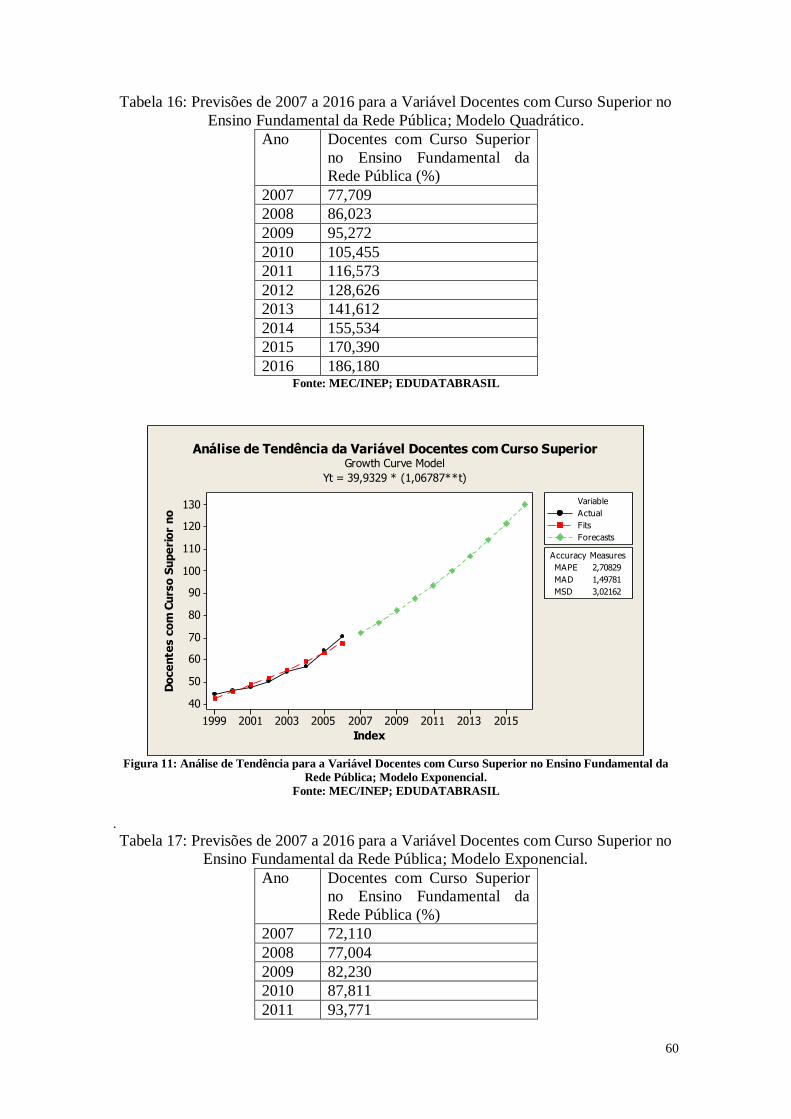
60
Tabela 16: Previsões de 2007 a 2016 para a Variável Docentes com Curso Superior no
Ensino Fundamental da Rede Pública; Modelo Quadrático.
Ano Docentes com Curso Superior
no Ensino Fundamental da
Rede Pública (%)
2007 77,709
2008 86,023
2009 95,272
2010 105,455
2011 116,573
2012 128,626
2013 141,612
2014 155,534
2015 170,390
2016 186,180 Fonte: MEC/INEP; EDUDATABRASIL
201520132011200920072005200320011999
130
120
110
100
90
80
70
60
50
40
Index
Do
ce
nte
s c
om
Cu
rso
Su
pe
rio
r n
o
MAPE 2,70829
MAD 1,49781
MSD 3,02162
Accuracy Measures
Actual
Fits
Forecasts
Variable
Análise de Tendência da Variável Docentes com Curso SuperiorGrowth Curve Model
Yt = 39,9329 * (1,06787**t)
Figura 11: Análise de Tendência para a Variável Docentes com Curso Superior no Ensino Fundamental da
Rede Pública; Modelo Exponencial.
Fonte: MEC/INEP; EDUDATABRASIL
.
Tabela 17: Previsões de 2007 a 2016 para a Variável Docentes com Curso Superior no
Ensino Fundamental da Rede Pública; Modelo Exponencial.
Ano Docentes com Curso Superior
no Ensino Fundamental da
Rede Pública (%)
2007 72,110
2008 77,004
2009 82,230
2010 87,811
2011 93,771

61
2012 100,135
2013 106,931
2014 114,118
2015 121,938
2016 130,214 Fonte: MEC/INEP; EDUDATABRASIL
201520132011200920072005200320011999
500
0
-500
-1000
-1500
Index
Do
ce
nte
s c
om
Cu
rso
Su
pe
rio
r n
o
Intercept 25,4559
Asymptote 31,7194
Asym. Rate 1,1069
Curve Parameters
MAPE 1,05906
MAD 0,56618
MSD 0,44014
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Docentes com Curso Superior noS-Curve Trend Model
Yt = (10**3) / (31,5265 - 7,75718*(1,10694**t))
Figura 12: Análise de Tendência para a Variável Docentes com Curso Superior no Ensino Fundamental da
Rede Pública; Modelo S-Curve.
Fonte: MEC/INEP; EDUDATABRASIL
Tabela 18: Previsões de 2007 a 2016 para a Variável Docentes com Curso Superior no
Ensino Fundamental da Rede Pública; Modelo S-Curve.
Ano Docentes com Curso Superior
no Ensino Fundamental da
Rede Pública (%)
2007 82,17
2008 99,01
2009 128,07
2010 189,68
2011 405,79
2012 -1533,60
2013 -244,86
2014 -126,71
2015 -82,59
2016 -59,62 Fonte: MEC/INEP; EDUDATABRASIL
A tabela 19 apresenta os valores do MAPE, MAD e MSD dos gráficos
representados pelas Figuras de 9 a 12, que representam os modelos linear, quadrático,
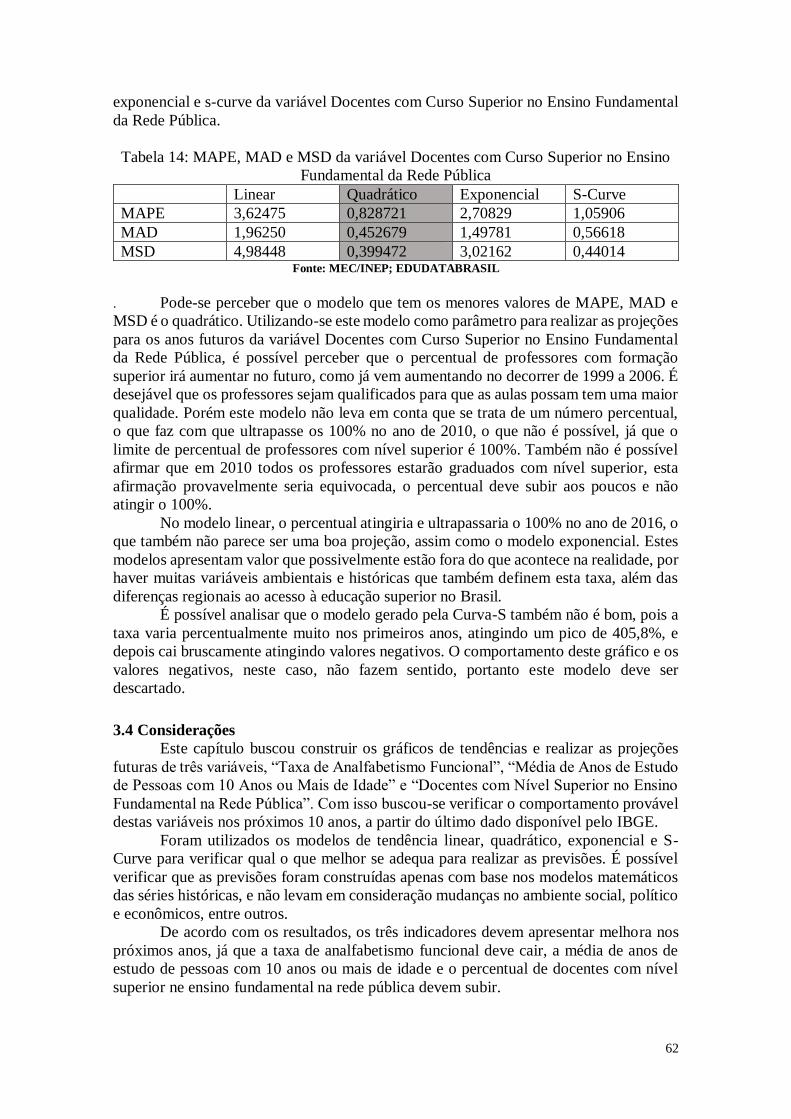
62
exponencial e s-curve da variável Docentes com Curso Superior no Ensino Fundamental
da Rede Pública.
Tabela 14: MAPE, MAD e MSD da variável Docentes com Curso Superior no Ensino
Fundamental da Rede Pública
Linear Quadrático Exponencial S-Curve
MAPE 3,62475 0,828721 2,70829 1,05906
MAD 1,96250 0,452679 1,49781 0,56618
MSD 4,98448 0,399472 3,02162 0,44014 Fonte: MEC/INEP; EDUDATABRASIL
. Pode-se perceber que o modelo que tem os menores valores de MAPE, MAD e
MSD é o quadrático. Utilizando-se este modelo como parâmetro para realizar as projeções
para os anos futuros da variável Docentes com Curso Superior no Ensino Fundamental
da Rede Pública, é possível perceber que o percentual de professores com formação
superior irá aumentar no futuro, como já vem aumentando no decorrer de 1999 a 2006. É
desejável que os professores sejam qualificados para que as aulas possam tem uma maior
qualidade. Porém este modelo não leva em conta que se trata de um número percentual,
o que faz com que ultrapasse os 100% no ano de 2010, o que não é possível, já que o
limite de percentual de professores com nível superior é 100%. Também não é possível
afirmar que em 2010 todos os professores estarão graduados com nível superior, esta
afirmação provavelmente seria equivocada, o percentual deve subir aos poucos e não
atingir o 100%.
No modelo linear, o percentual atingiria e ultrapassaria o 100% no ano de 2016, o
que também não parece ser uma boa projeção, assim como o modelo exponencial. Estes
modelos apresentam valor que possivelmente estão fora do que acontece na realidade, por
haver muitas variáveis ambientais e históricas que também definem esta taxa, além das
diferenças regionais ao acesso à educação superior no Brasil.
É possível analisar que o modelo gerado pela Curva-S também não é bom, pois a
taxa varia percentualmente muito nos primeiros anos, atingindo um pico de 405,8%, e
depois cai bruscamente atingindo valores negativos. O comportamento deste gráfico e os
valores negativos, neste caso, não fazem sentido, portanto este modelo deve ser
descartado.
3.4 Considerações
Este capítulo buscou construir os gráficos de tendências e realizar as projeções
futuras de três variáveis, “Taxa de Analfabetismo Funcional”, “Média de Anos de Estudo
de Pessoas com 10 Anos ou Mais de Idade” e “Docentes com Nível Superior no Ensino
Fundamental na Rede Pública”. Com isso buscou-se verificar o comportamento provável
destas variáveis nos próximos 10 anos, a partir do último dado disponível pelo IBGE.
Foram utilizados os modelos de tendência linear, quadrático, exponencial e S-
Curve para verificar qual o que melhor se adequa para realizar as previsões. É possível
verificar que as previsões foram construídas apenas com base nos modelos matemáticos
das séries históricas, e não levam em consideração mudanças no ambiente social, político
e econômicos, entre outros.
De acordo com os resultados, os três indicadores devem apresentar melhora nos
próximos anos, já que a taxa de analfabetismo funcional deve cair, a média de anos de
estudo de pessoas com 10 anos ou mais de idade e o percentual de docentes com nível
superior ne ensino fundamental na rede pública devem subir.

63
É necessário ficar atento aos resultados da variável “Docentes com Nível Superior
no Ensino Fundamental na Rede Pública”, pois aparentemente nenhum dos modelos foi
capaz de realizar projeções para o futuro de forma realista, o que indica que será
necessário considerar outras variáveis para explicar esta.
CAPÍTULO 4. REGRESSÃO LINEAR
O presente capítulo tem como objetivo realizar uma análise de regressão linear
múltipla a partir das variáveis selecionadas para estudo e descritas no capítulo 1.
A regressão linear múltipla é o estudo de como uma variável dependente y se
relaciona com outras variáveis independentes. Os modelos de regressão múltipla se
apresentam de modo similar a y = C + A*X1 + B*X2 + C*X3 + ... + e (ANDERSON;
SWEENEY; WILLIANS).
O trabalho buscará verificar como a variável PIND, que representa “A proporção
dos indivíduos com renda domiciliar per capita igual ou inferior a R$ 70,00 mensais, em
reais de agosto de 2010. O universo de indivíduos é limitado àqueles que vivem em
domicílios particulares permanentes”, se relaciona com as outras variáveis selecionadas
para o estudo.
Desta maneira, pode-se estimar as relações das variáveis independentes Xn, na
variável dependente y através do software estatístico MINITAB.
4.1.Análise de Regressão
Neste capítulo será apresentada a análise de regressão e Step-Wise entre a variável
PIND e as demais variáveis. Com as análises feitas pelo software estatístico MINITAB é
possível verificar como a variável PIND se relaciona com todas as outras variáveis
selecionadas para o estudo, exceto com as variáveis IDHM, IDHM_E, IDHM_L e
IDHM_R.
A seguir são apresentadas as análises realizadas pelo MINITAB.
Regression Analysis: PIND versus FECTOT; MORT1; ... The regression equation is
PIND = 7,63 + 1,12 FECTOT + 0,00062 MORT1 - 0,0934 E_ANOSESTUDO
+ 0,0419 T_ANALF15A17 + 0,726 PINDCRI - 0,0437 PPOBCRI - 0,00541
P_SUPER
- 0,00685 T_DES18M - 0,0168 TRABSC - 0,00955 T_AGUA - 0,0701 T_LUZ
+ 0,0431 PAREDE + 0,0599 T_NESTUDA_NTRAB_MMEIO - 0,00151
T_MULCHEFEFIF014
+ 0,000007 HOMEM10A14 - 0,000030 HOMEM70A74
Predictor Coef SE Coef T P
Constant 7,6342 0,4307 17,73 0,000
FECTOT 1,11584 0,04934 22,61 0,000
MORT1 0,000619 0,004340 0,14 0,887
E_ANOSESTUDO -0,09338 0,02060 -4,53 0,000
T_ANALF15A17 0,04192 0,01057 3,97 0,000
PINDCRI 0,726428 0,002960 245,39 0,000
PPOBCRI -0,043688 0,002297 -19,02 0,000
P_SUPER -0,005412 0,006346 -0,85 0,394
T_DES18M -0,006853 0,006061 -1,13 0,258
TRABSC -0,016827 0,002432 -6,92 0,000
T_AGUA -0,009554 0,001695 -5,64 0,000
T_LUZ -0,070086 0,003836 -18,27 0,000
PAREDE 0,043064 0,002432 17,71 0,000
T_NESTUDA_NTRAB_MMEIO 0,059923 0,005144 11,65 0,000
T_MULCHEFEFIF014 -0,001512 0,002347 -0,64 0,519
HOMEM10A14 0,00000672 0,00000957 0,70 0,483
HOMEM70A74 -0,00003017 0,00004407 -0,68 0,494
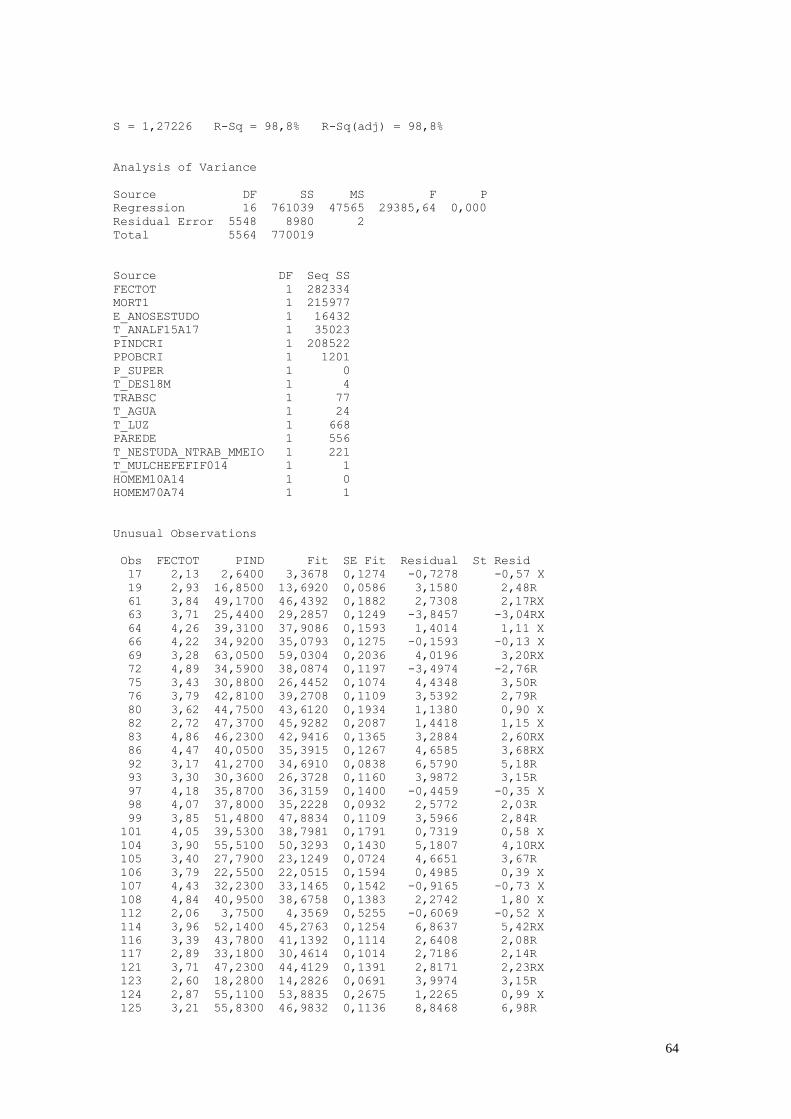
64
S = 1,27226 R-Sq = 98,8% R-Sq(adj) = 98,8%
Analysis of Variance
Source DF SS MS F P
Regression 16 761039 47565 29385,64 0,000
Residual Error 5548 8980 2
Total 5564 770019
Source DF Seq SS
FECTOT 1 282334
MORT1 1 215977
E_ANOSESTUDO 1 16432
T_ANALF15A17 1 35023
PINDCRI 1 208522
PPOBCRI 1 1201
P_SUPER 1 0
T_DES18M 1 4
TRABSC 1 77
T_AGUA 1 24
T_LUZ 1 668
PAREDE 1 556
T_NESTUDA_NTRAB_MMEIO 1 221
T_MULCHEFEFIF014 1 1
HOMEM10A14 1 0
HOMEM70A74 1 1
Unusual Observations
Obs FECTOT PIND Fit SE Fit Residual St Resid
17 2,13 2,6400 3,3678 0,1274 -0,7278 -0,57 X
19 2,93 16,8500 13,6920 0,0586 3,1580 2,48R
61 3,84 49,1700 46,4392 0,1882 2,7308 2,17RX
63 3,71 25,4400 29,2857 0,1249 -3,8457 -3,04RX
64 4,26 39,3100 37,9086 0,1593 1,4014 1,11 X
66 4,22 34,9200 35,0793 0,1275 -0,1593 -0,13 X
69 3,28 63,0500 59,0304 0,2036 4,0196 3,20RX
72 4,89 34,5900 38,0874 0,1197 -3,4974 -2,76R
75 3,43 30,8800 26,4452 0,1074 4,4348 3,50R
76 3,79 42,8100 39,2708 0,1109 3,5392 2,79R
80 3,62 44,7500 43,6120 0,1934 1,1380 0,90 X
82 2,72 47,3700 45,9282 0,2087 1,4418 1,15 X
83 4,86 46,2300 42,9416 0,1365 3,2884 2,60RX
86 4,47 40,0500 35,3915 0,1267 4,6585 3,68RX
92 3,17 41,2700 34,6910 0,0838 6,5790 5,18R
93 3,30 30,3600 26,3728 0,1160 3,9872 3,15R
97 4,18 35,8700 36,3159 0,1400 -0,4459 -0,35 X
98 4,07 37,8000 35,2228 0,0932 2,5772 2,03R
99 3,85 51,4800 47,8834 0,1109 3,5966 2,84R
101 4,05 39,5300 38,7981 0,1791 0,7319 0,58 X
104 3,90 55,5100 50,3293 0,1430 5,1807 4,10RX
105 3,40 27,7900 23,1249 0,0724 4,6651 3,67R
106 3,79 22,5500 22,0515 0,1594 0,4985 0,39 X
107 4,43 32,2300 33,1465 0,1542 -0,9165 -0,73 X
108 4,84 40,9500 38,6758 0,1383 2,2742 1,80 X
112 2,06 3,7500 4,3569 0,5255 -0,6069 -0,52 X
114 3,96 52,1400 45,2763 0,1254 6,8637 5,42RX
116 3,39 43,7800 41,1392 0,1114 2,6408 2,08R
117 2,89 33,1800 30,4614 0,1014 2,7186 2,14R
121 3,71 47,2300 44,4129 0,1391 2,8171 2,23RX
123 2,60 18,2800 14,2826 0,0691 3,9974 3,15R
124 2,87 55,1100 53,8835 0,2675 1,2265 0,99 X
125 3,21 55,8300 46,9832 0,1136 8,8468 6,98R

65
126 2,43 42,5600 40,5340 0,1231 2,0260 1,60 X
127 3,65 47,9900 43,2069 0,1215 4,7831 3,78R
129 4,44 25,9800 26,9791 0,1219 -0,9991 -0,79 X
133 4,33 30,9300 31,0524 0,1253 -0,1224 -0,10 X
137 4,06 59,8900 60,0276 0,2930 -0,1376 -0,11 X
138 3,57 51,4200 51,3373 0,3037 0,0827 0,07 X
144 2,64 36,2700 35,5449 0,1601 0,7251 0,57 X
146 3,12 47,5900 45,4409 0,2015 2,1491 1,71 X
151 3,45 69,6700 62,3950 0,2348 7,2750 5,82RX
155 3,22 45,6500 41,9619 0,1132 3,6881 2,91R
156 2,25 22,3600 16,1909 0,0782 6,1691 4,86R
160 4,09 38,5300 39,3345 0,1246 -0,8045 -0,64 X
161 1,70 4,1600 3,7778 0,1288 0,3822 0,30 X
164 2,86 33,5800 30,9627 0,0789 2,6173 2,06R
166 3,76 28,3400 30,8369 0,1242 -2,4969 -1,97 X
167 2,63 28,2100 25,5582 0,0531 2,6518 2,09R
170 1,69 3,5400 3,6676 0,1994 -0,1276 -0,10 X
176 2,36 26,6300 23,9529 0,0644 2,6771 2,11R
180 3,20 31,2500 27,6447 0,0812 3,6053 2,84R
188 2,53 43,4100 41,1456 0,1334 2,2644 1,79 X
192 3,17 24,5800 28,6945 0,1192 -4,1145 -3,25R
195 3,68 38,9900 34,7171 0,0816 4,2729 3,37R
210 3,01 31,6500 28,3950 0,0552 3,2550 2,56R
211 2,79 42,4100 39,6180 0,1278 2,7920 2,21RX
222 3,87 43,9200 42,1884 0,1659 1,7316 1,37 X
227 3,47 46,5500 43,7562 0,1357 2,7938 2,21RX
254 2,90 24,4300 25,2440 0,1351 -0,8140 -0,64 X
258 2,50 28,7900 26,0086 0,0802 2,7814 2,19R
269 3,34 36,2200 33,5643 0,1019 2,6557 2,09R
275 3,11 26,1800 22,5903 0,0770 3,5897 2,83R
292 3,26 44,6600 40,9250 0,0819 3,7350 2,94R
296 3,94 21,5300 22,7143 0,1244 -1,1843 -0,94 X
297 3,82 19,6500 22,8573 0,0846 -3,2073 -2,53R
303 2,25 5,8900 6,3856 0,1520 -0,4956 -0,39 X
307 4,68 37,7200 34,2311 0,1426 3,4889 2,76RX
309 4,64 36,8700 34,7090 0,1231 2,1610 1,71 X
319 2,78 17,6300 20,5103 0,0644 -2,8803 -2,27R
320 2,66 24,0600 21,3704 0,0722 2,6896 2,12R
331 2,89 22,0600 19,3578 0,0898 2,7022 2,13R
336 3,32 9,0700 11,8758 0,0846 -2,8058 -2,21R
345 3,31 30,5600 33,2322 0,1387 -2,6722 -2,11RX
370 3,47 25,4200 28,7507 0,1248 -3,3307 -2,63RX
372 3,27 13,8700 16,5723 0,0880 -2,7023 -2,13R
388 2,34 17,8300 14,0570 0,0690 3,7730 2,97R
402 3,33 31,8900 35,0792 0,1312 -3,1892 -2,52RX
409 3,23 15,3600 12,2504 0,0663 3,1096 2,45R
418 4,09 46,7800 48,0858 0,1628 -1,3058 -1,03 X
422 2,85 27,2000 29,1271 0,1283 -1,9271 -1,52 X
432 2,65 36,1500 36,8703 0,1500 -0,7203 -0,57 X
436 2,67 17,2000 14,2644 0,0706 2,9356 2,31R
439 2,35 7,4500 4,7976 0,0546 2,6524 2,09R
442 2,28 6,6800 3,0221 0,0555 3,6579 2,88R
447 2,51 22,2200 19,1305 0,0573 3,0895 2,43R
451 3,44 45,5400 44,2193 0,1321 1,3207 1,04 X
452 3,03 39,0200 36,2419 0,1019 2,7781 2,19R
453 2,78 37,9900 34,2596 0,1008 3,7304 2,94R
454 3,43 36,5500 38,4180 0,1417 -1,8680 -1,48 X
455 2,70 36,6600 33,7272 0,1021 2,9328 2,31R
462 2,94 32,9900 32,8970 0,1746 0,0930 0,07 X
464 3,06 34,7200 31,8436 0,0980 2,8764 2,27R
472 2,72 41,6200 40,1948 0,1246 1,4252 1,13 X
476 3,51 37,5600 34,9042 0,0718 2,6558 2,09R
477 4,11 58,1900 50,0654 0,1237 8,1246 6,42RX
484 2,89 34,8700 31,6312 0,0682 3,2388 2,55R
487 3,04 26,9800 27,4439 0,1495 -0,4639 -0,37 X
492 3,46 55,8600 50,3559 0,1215 5,5041 4,35R
494 3,49 51,3600 50,3691 0,1235 0,9909 0,78 X
498 2,81 36,1400 33,3273 0,0881 2,8127 2,22R

66
516 3,03 41,8300 38,7675 0,1112 3,0625 2,42R
520 3,32 51,6100 47,7506 0,1208 3,8594 3,05R
524 2,57 21,9900 23,6430 0,1247 -1,6530 -1,31 X
535 4,11 53,4400 49,9151 0,1256 3,5249 2,78RX
536 3,23 43,2100 42,4795 0,1364 0,7305 0,58 X
540 2,87 45,4900 41,4643 0,1349 4,0257 3,18RX
543 2,64 36,0100 31,0399 0,0945 4,9701 3,92R
544 3,06 54,2600 50,4586 0,1676 3,8014 3,01RX
555 2,85 23,1400 25,7977 0,0770 -2,6577 -2,09R
560 4,10 60,7200 57,5563 0,1722 3,1637 2,51RX
565 2,37 41,8600 37,1192 0,1278 4,7408 3,75RX
566 3,58 43,4500 39,6553 0,0833 3,7947 2,99R
567 2,84 50,2900 49,9824 0,1243 0,3076 0,24 X
575 2,42 24,8500 27,5671 0,0659 -2,7171 -2,14R
578 3,32 44,7700 39,7336 0,0896 5,0364 3,97R
580 2,83 40,3700 37,8098 0,0924 2,5602 2,02R
584 2,81 28,5600 25,6653 0,0588 2,8947 2,28R
588 3,73 42,7600 40,3456 0,1245 2,4144 1,91 X
600 3,10 51,8900 48,4550 0,1234 3,4350 2,71RX
601 2,53 27,0000 22,6016 0,0839 4,3984 3,46R
610 3,32 49,1200 46,3557 0,1157 2,7643 2,18R
617 2,92 47,1400 41,6782 0,1082 5,4618 4,31R
618 3,08 50,7800 46,0797 0,1293 4,7003 3,71RX
620 3,42 49,1400 49,3824 0,1484 -0,2424 -0,19 X
622 2,73 36,0300 33,0621 0,0688 2,9679 2,34R
628 2,59 45,5900 43,2199 0,1307 2,3701 1,87 X
629 3,52 34,9500 36,0590 0,1311 -1,1090 -0,88 X
631 3,35 37,0000 36,6475 0,1368 0,3525 0,28 X
634 2,81 37,5400 34,6069 0,0944 2,9331 2,31R
635 1,75 4,5300 4,5645 0,1886 -0,0345 -0,03 X
643 2,36 41,5700 38,3284 0,0898 3,2416 2,55R
644 2,98 44,5300 41,3658 0,1177 3,1642 2,50R
647 3,20 48,6800 46,6981 0,1466 1,9819 1,57 X
670 1,95 28,9100 31,8289 0,1285 -2,9189 -2,31RX
674 3,22 39,7200 35,5311 0,0848 4,1889 3,30R
678 2,65 20,7600 19,9375 0,1299 0,8225 0,65 X
679 2,31 22,6200 20,0130 0,0719 2,6070 2,05R
680 1,69 30,9400 32,2383 0,1242 -1,2983 -1,03 X
682 2,85 48,3200 46,8272 0,1641 1,4928 1,18 X
687 2,82 21,7500 26,3528 0,1062 -4,6028 -3,63R
690 2,19 36,9000 36,1421 0,1384 0,7579 0,60 X
694 2,62 42,1500 42,9850 0,1256 -0,8350 -0,66 X
699 2,12 22,6000 25,4191 0,1681 -2,8191 -2,24RX
702 2,56 26,3900 23,1246 0,1042 3,2654 2,58R
705 1,94 28,7300 26,0791 0,0586 2,6509 2,09R
708 2,32 23,6000 25,7427 0,1258 -2,1427 -1,69 X
710 2,06 44,8000 42,2705 0,2205 2,5295 2,02RX
717 2,58 40,1900 42,2754 0,1952 -2,0854 -1,66 X
719 2,78 45,5900 44,8467 0,1266 0,7433 0,59 X
730 2,40 39,4600 39,5866 0,1874 -0,1266 -0,10 X
734 2,75 21,2700 24,1644 0,0674 -2,8944 -2,28R
737 2,58 37,4900 35,7337 0,1779 1,7563 1,39 X
739 2,44 26,2400 31,1147 0,1774 -4,8747 -3,87RX
741 2,42 30,7000 34,3366 0,1351 -3,6366 -2,87RX
742 2,23 39,2300 40,9330 0,2037 -1,7030 -1,36 X
743 2,25 19,6000 22,1715 0,0577 -2,5715 -2,02R
746 3,08 36,2400 39,5626 0,1371 -3,3226 -2,63RX
751 2,18 26,4500 31,5094 0,0696 -5,0594 -3,98R
754 1,84 18,6200 21,3507 0,0556 -2,7307 -2,15R
758 2,80 43,4000 38,0910 0,1186 5,3090 4,19R
759 2,38 30,1100 27,2216 0,0651 2,8884 2,27R
765 2,45 21,3400 24,8919 0,0660 -3,5519 -2,80R
766 1,92 35,6400 33,7026 0,1438 1,9374 1,53 X
768 2,59 27,1400 24,1058 0,0766 3,0342 2,39R
772 2,53 45,4000 40,3855 0,0830 5,0145 3,95R
777 2,47 37,0100 34,1550 0,0740 2,8550 2,25R
780 2,28 48,0200 45,7970 0,1313 2,2230 1,76 X
781 2,48 36,3300 37,1933 0,1227 -0,8633 -0,68 X

67
782 2,46 22,0800 25,7980 0,0781 -3,7180 -2,93R
783 2,51 40,4700 35,6130 0,0960 4,8570 3,83R
789 2,61 12,4500 11,4826 0,1666 0,9674 0,77 X
795 1,99 43,9500 42,4743 0,1241 1,4757 1,17 X
799 3,04 45,6300 41,3701 0,1538 4,2599 3,37RX
803 2,66 19,1300 20,3005 0,1277 -1,1705 -0,92 X
805 2,93 28,3000 31,0742 0,0996 -2,7742 -2,19R
806 2,23 28,1500 30,7397 0,0771 -2,5897 -2,04R
807 2,01 34,6400 36,2968 0,1797 -1,6568 -1,32 X
809 2,64 33,1400 34,1011 0,1383 -0,9611 -0,76 X
812 2,87 35,2700 38,9459 0,1209 -3,6759 -2,90R
816 2,91 32,7700 28,8241 0,0889 3,9459 3,11R
818 2,19 23,2600 26,6281 0,1027 -3,3681 -2,66R
824 2,70 42,2700 39,4882 0,0961 2,7818 2,19R
825 2,72 42,6000 39,6031 0,0951 2,9969 2,36R
834 1,69 38,5500 34,5111 0,1052 4,0389 3,19R
835 2,83 28,5900 25,6237 0,0599 2,9663 2,33R
837 2,85 45,6700 42,8411 0,1165 2,8289 2,23R
838 2,76 41,3700 38,4155 0,0983 2,9545 2,33R
851 2,09 17,5700 21,0912 0,0662 -3,5212 -2,77R
852 2,09 48,3800 44,9479 0,1327 3,4321 2,71RX
854 2,64 35,0800 35,3439 0,1692 -0,2639 -0,21 X
855 2,43 32,2400 32,6329 0,1309 -0,3929 -0,31 X
858 2,26 33,9800 37,0576 0,1107 -3,0776 -2,43R
860 2,69 41,1200 41,6283 0,1622 -0,5083 -0,40 X
866 2,14 23,2900 26,5679 0,2046 -3,2779 -2,61RX
868 2,01 27,5600 30,5206 0,1130 -2,9606 -2,34R
873 2,96 36,5700 37,6221 0,1705 -1,0521 -0,83 X
874 2,62 40,5700 40,9694 0,1440 -0,3994 -0,32 X
881 2,50 23,5800 27,0153 0,1005 -3,4353 -2,71R
882 1,42 4,4400 3,9102 0,1452 0,5298 0,42 X
886 2,67 38,1900 39,6199 0,1515 -1,4299 -1,13 X
888 2,45 45,6800 40,5194 0,1167 5,1606 4,07R
889 1,89 31,4300 27,6747 0,1215 3,7553 2,97R
949 1,62 3,3600 3,0251 0,3340 0,3349 0,27 X
1022 2,31 24,5100 27,4160 0,0993 -2,9060 -2,29R
1040 2,42 27,4400 30,1196 0,0757 -2,6796 -2,11R
1090 2,03 20,0300 24,9727 0,0555 -4,9427 -3,89R
1116 2,14 25,8700 21,7893 0,0790 4,0807 3,21R
1126 2,69 15,1800 17,9864 0,0530 -2,8064 -2,21R
1135 2,42 24,4700 27,6596 0,0887 -3,1896 -2,51R
1139 1,93 41,3600 42,2224 0,1285 -0,8624 -0,68 X
1159 2,83 26,0000 29,2351 0,0744 -3,2351 -2,55R
1169 2,55 13,7900 16,6127 0,0859 -2,8227 -2,22R
1170 3,58 23,2000 26,4078 0,0890 -3,2078 -2,53R
1178 2,59 24,7200 27,5403 0,0638 -2,8203 -2,22R
1196 2,37 24,0900 26,8589 0,0683 -2,7689 -2,18R
1223 2,11 23,7500 20,9547 0,0700 2,7953 2,20R
1234 2,72 15,8900 18,9264 0,0623 -3,0364 -2,39R
1237 2,50 12,4700 15,0534 0,0648 -2,5834 -2,03R
1241 2,40 12,7200 9,8823 0,0872 2,8377 2,24R
1242 1,87 29,1400 25,1991 0,0762 3,9409 3,10R
1245 2,01 21,4300 24,3258 0,0504 -2,8958 -2,28R
1247 1,96 21,6400 23,0674 0,1358 -1,4274 -1,13 X
1248 2,34 21,5700 23,8206 0,1237 -2,2506 -1,78 X
1254 2,35 24,2000 28,0219 0,0655 -3,8219 -3,01R
1260 2,11 13,1500 13,9744 0,1417 -0,8244 -0,65 X
1263 2,49 32,0300 30,9883 0,1473 1,0417 0,82 X
1265 2,38 26,9300 29,8992 0,0589 -2,9692 -2,34R
1266 2,47 13,8300 17,4418 0,0756 -3,6118 -2,84R
1284 1,92 20,0800 24,3670 0,0510 -4,2870 -3,37R
1287 2,92 36,9700 33,5899 0,1434 3,3801 2,67RX
1290 1,92 27,0300 23,2128 0,0795 3,8172 3,01R
1298 2,00 24,5800 29,0067 0,0640 -4,4267 -3,48R
1327 1,59 12,5200 9,9561 0,0735 2,5639 2,02R
1332 1,85 13,9400 16,5397 0,0560 -2,5997 -2,05R
1334 2,59 22,0400 25,9041 0,0792 -3,8641 -3,04R
1346 1,62 22,5300 25,2571 0,1083 -2,7271 -2,15R

68
1367 2,26 33,3000 36,9822 0,0729 -3,6822 -2,90R
1368 2,31 31,9300 35,2885 0,0720 -3,3585 -2,64R
1373 1,96 28,0500 31,8275 0,0823 -3,7775 -2,98R
1375 2,19 22,4700 26,3743 0,0859 -3,9043 -3,08R
1376 1,95 20,7200 18,1396 0,1039 2,5804 2,03R
1387 2,17 22,8500 25,4932 0,0557 -2,6432 -2,08R
1391 1,69 16,7200 19,6596 0,0509 -2,9396 -2,31R
1394 1,68 13,2200 16,2354 0,0676 -3,0154 -2,37R
1400 1,97 31,1300 31,7751 0,1270 -0,6451 -0,51 X
1402 2,23 25,3300 28,0954 0,0755 -2,7654 -2,18R
1408 2,11 27,8500 28,1961 0,1621 -0,3461 -0,27 X
1409 1,85 21,3400 24,0131 0,0673 -2,6731 -2,10R
1418 2,08 15,9000 14,7573 0,1362 1,1427 0,90 X
1420 2,27 11,0000 13,6978 0,0606 -2,6978 -2,12R
1423 2,03 17,5400 21,3322 0,0740 -3,7922 -2,99R
1426 1,99 29,3100 32,9069 0,0807 -3,5969 -2,83R
1428 2,22 18,7400 21,2913 0,0827 -2,5513 -2,01R
1432 2,23 20,4500 23,4885 0,1048 -3,0385 -2,40R
1433 2,23 22,4600 24,5312 0,1399 -2,0712 -1,64 X
1447 2,09 21,6700 24,5212 0,0633 -2,8512 -2,24R
1451 2,85 28,3800 29,9359 0,1307 -1,5559 -1,23 X
1458 1,95 13,9100 12,8415 0,1497 1,0685 0,85 X
1459 1,65 19,8300 22,5359 0,0568 -2,7059 -2,13R
1471 2,28 18,9300 21,7503 0,0838 -2,8203 -2,22R
1498 1,92 42,7700 37,9002 0,0955 4,8698 3,84R
1534 2,33 28,7900 31,3450 0,0696 -2,5550 -2,01R
1541 2,64 41,1900 39,0218 0,1564 2,1682 1,72 X
1570 2,51 41,0500 38,0858 0,1335 2,9642 2,34RX
1582 2,21 34,3600 31,3354 0,0893 3,0246 2,38R
1587 2,91 23,2300 26,4413 0,0635 -3,2113 -2,53R
1596 1,35 4,7700 5,0586 0,1515 -0,2886 -0,23 X
1601 1,74 27,4700 26,1953 0,1447 1,2747 1,01 X
1610 1,90 16,2200 16,2818 0,1227 -0,0618 -0,05 X
1641 2,56 45,0800 41,6968 0,0870 3,3832 2,67R
1645 2,10 21,3400 23,0327 0,1296 -1,6927 -1,34 X
1658 2,66 43,5200 38,5266 0,0757 4,9934 3,93R
1660 2,03 13,7200 13,3713 0,1259 0,3487 0,28 X
1678 2,10 30,9000 26,8576 0,0816 4,0424 3,18R
1679 2,92 17,6400 16,7487 0,1219 0,8913 0,70 X
1681 2,27 39,2200 35,7819 0,0843 3,4381 2,71R
1685 2,59 44,9100 39,1530 0,0889 5,7570 4,54R
1696 1,77 5,2900 6,2131 0,1924 -0,9231 -0,73 X
1712 2,66 46,2500 43,6625 0,1148 2,5875 2,04R
1727 2,66 46,6600 41,3830 0,1059 5,2770 4,16R
1730 2,46 38,1200 35,3651 0,0775 2,7549 2,17R
1737 2,17 37,6700 33,6190 0,1008 4,0510 3,19R
1739 2,83 39,7000 37,1404 0,0931 2,5596 2,02R
1749 2,62 47,1500 45,7089 0,1371 1,4411 1,14 X
1774 2,21 17,5700 20,1494 0,0973 -2,5794 -2,03R
1780 2,31 16,8100 20,0996 0,0545 -3,2896 -2,59R
1804 2,79 36,4100 33,4809 0,0830 2,9291 2,31R
1816 2,30 20,1900 20,6360 0,1317 -0,4460 -0,35 X
1832 1,61 23,6900 28,8833 0,0852 -5,1933 -4,09R
1849 2,63 13,0500 16,4589 0,0657 -3,4089 -2,68R
1858 2,23 24,4300 27,6172 0,0615 -3,1872 -2,51R
1859 2,36 23,3000 25,9289 0,0725 -2,6289 -2,07R
1882 2,57 31,8200 35,1140 0,1050 -3,2940 -2,60R
1891 1,92 27,5800 27,8955 0,1444 -0,3155 -0,25 X
1899 3,18 40,5100 41,3968 0,1432 -0,8868 -0,70 X
1920 1,73 24,6900 27,4260 0,0804 -2,7360 -2,15R
1922 2,73 28,9300 31,6157 0,0719 -2,6857 -2,11R
1933 2,31 17,1800 19,8579 0,0894 -2,6779 -2,11R
1935 1,61 17,2900 20,1493 0,0621 -2,8593 -2,25R
1961 2,01 30,2100 27,3501 0,0610 2,8599 2,25R
1962 2,73 11,3600 14,1036 0,0468 -2,7436 -2,16R
1968 1,83 23,6700 26,7719 0,0737 -3,1019 -2,44R
2005 2,22 29,6500 26,5688 0,0667 3,0812 2,43R
2038 2,62 31,2300 28,3807 0,0747 2,8493 2,24R

69
2053 3,20 31,4700 35,9140 0,0987 -4,4440 -3,50R
2055 1,98 29,1000 26,2918 0,0748 2,8082 2,21R
2067 1,81 19,2900 22,8476 0,0853 -3,5576 -2,80R
2073 2,65 37,4500 34,7143 0,0730 2,7357 2,15R
2083 2,33 18,2500 21,1966 0,0583 -2,9466 -2,32R
2095 2,70 36,6600 32,6392 0,0717 4,0208 3,17R
2101 2,39 17,4000 20,1275 0,0563 -2,7275 -2,15R
2108 1,89 28,8900 25,8369 0,0726 3,0531 2,40R
2119 3,03 22,5200 25,2909 0,0588 -2,7709 -2,18R
2129 2,73 20,1600 23,3263 0,0830 -3,1663 -2,49R
2145 2,77 23,0900 26,1038 0,0485 -3,0138 -2,37R
2149 2,51 30,9200 26,1887 0,0554 4,7313 3,72R
2162 1,53 3,9700 4,3099 0,3483 -0,3399 -0,28 X
2167 2,35 15,0800 12,4608 0,0824 2,6192 2,06R
2181 2,44 11,3300 8,7588 0,0504 2,5712 2,02R
2204 3,24 47,7700 43,7281 0,1023 4,0419 3,19R
2207 2,58 30,5600 27,0113 0,0715 3,5487 2,79R
2234 2,24 19,4400 22,2850 0,0697 -2,8450 -2,24R
2236 1,91 23,3600 26,7853 0,0721 -3,4253 -2,70R
2242 2,94 15,2500 18,0708 0,0555 -2,8208 -2,22R
2309 1,33 0,7900 0,3457 0,2316 0,4443 0,36 X
2313 3,13 17,7000 20,7382 0,1298 -3,0382 -2,40RX
2334 3,22 20,0200 23,3290 0,0665 -3,3090 -2,60R
2376 1,60 10,5200 13,1654 0,0665 -2,6454 -2,08R
2443 1,85 19,0700 22,3800 0,0695 -3,3100 -2,61R
2457 2,16 14,1600 17,8000 0,0533 -3,6400 -2,86R
2480 1,70 6,8500 3,0538 0,0488 3,7962 2,99R
2484 1,89 20,9200 25,3846 0,0833 -4,4646 -3,52R
2531 2,01 10,4500 13,3174 0,0552 -2,8674 -2,26R
2539 2,61 9,8700 12,4743 0,0628 -2,6043 -2,05R
2549 2,33 9,4400 6,2481 0,0599 3,1919 2,51R
2553 1,81 7,4600 10,3552 0,0776 -2,8952 -2,28R
2556 1,69 20,8600 17,5179 0,0699 3,3421 2,63R
2635 2,57 11,5100 14,4301 0,0510 -2,9201 -2,30R
2644 2,11 18,3100 15,6355 0,0549 2,6745 2,10R
2650 2,13 11,3300 14,0865 0,0494 -2,7565 -2,17R
2741 3,01 32,2500 29,1664 0,0661 3,0836 2,43R
2761 2,47 19,3600 16,2863 0,0702 3,0737 2,42R
2770 2,28 25,3200 28,5694 0,0701 -3,2494 -2,56R
2779 2,19 27,4300 23,9671 0,0703 3,4629 2,73R
2789 1,33 1,2100 -2,3047 0,0616 3,5147 2,77R
2810 2,46 7,3300 9,8868 0,0513 -2,5568 -2,01R
2827 2,32 9,2100 6,5293 0,0552 2,6807 2,11R
2836 1,43 3,3100 0,5496 0,0588 2,7604 2,17R
2884 1,49 4,0800 6,7041 0,0571 -2,6241 -2,06R
2901 2,18 13,6700 16,6899 0,0546 -3,0199 -2,38R
2916 3,13 21,7000 24,6309 0,0700 -2,9309 -2,31R
2947 2,38 39,6900 37,0967 0,1082 2,5933 2,05R
3014 1,50 10,1800 12,8445 0,0504 -2,6645 -2,10R
3020 1,65 8,4000 5,3073 0,0718 3,0927 2,43R
3021 2,24 9,3300 12,8083 0,0663 -3,4783 -2,74R
3031 2,03 5,0500 2,4949 0,0718 2,5551 2,01R
3032 2,60 12,6000 15,6889 0,0576 -3,0889 -2,43R
3174 1,38 0,6400 0,1545 0,1532 0,4855 0,38 X
3199 1,73 2,8300 3,1628 0,1279 -0,3328 -0,26 X
3222 1,41 0,8000 0,4455 0,1967 0,3545 0,28 X
3242 1,56 1,2500 0,8576 0,8919 0,3924 0,43 X
3273 1,32 0,2400 -0,7367 0,1226 0,9767 0,77 X
3375 1,63 1,0600 1,2190 0,1373 -0,1590 -0,13 X
3451 2,09 5,4400 8,2223 0,0623 -2,7823 -2,19R
3479 1,68 1,9500 1,8893 0,2290 0,0607 0,05 X
3520 1,83 14,9800 17,9347 0,0666 -2,9547 -2,33R
3801 1,41 0,7800 0,4350 0,1284 0,3450 0,27 X
3809 1,25 0,6000 0,2529 0,1901 0,3471 0,28 X
3812 1,30 0,0900 -0,4476 0,1712 0,5376 0,43 X
3829 1,52 0,9200 0,6633 0,9540 0,2567 0,30 X
3947 1,53 3,3600 0,8062 0,0478 2,5538 2,01R
4005 1,58 0,4800 0,3764 0,1573 0,1036 0,08 X

70
4012 1,49 3,2800 6,5628 0,0521 -3,2828 -2,58R
4279 2,60 9,7600 12,5619 0,0643 -2,8019 -2,21R
4311 1,66 5,9600 10,6970 0,0670 -4,7370 -3,73R
4343 2,03 11,6700 8,7037 0,0610 2,9663 2,33R
4398 1,23 0,2700 -0,2763 0,1313 0,5463 0,43 X
4428 3,08 14,8700 17,6643 0,1108 -2,7943 -2,20R
4448 2,36 7,2400 10,0479 0,0560 -2,8079 -2,21R
4599 2,16 2,4200 5,1602 0,0820 -2,7402 -2,16R
4608 1,58 9,4800 14,2887 0,0791 -4,8087 -3,79R
4610 1,65 6,0000 8,9504 0,0564 -2,9504 -2,32R
4645 2,49 16,3300 19,4313 0,0895 -3,1013 -2,44R
4659 2,21 10,2100 12,9143 0,0563 -2,7043 -2,13R
4666 2,00 12,0400 16,7143 0,0681 -4,6743 -3,68R
4684 1,73 6,9000 12,5881 0,0899 -5,6881 -4,48R
4708 2,68 4,8700 8,3542 0,1003 -3,4842 -2,75R
4718 1,33 4,2200 -0,1307 0,0725 4,3507 3,43R
4727 1,82 7,0600 4,0911 0,0699 2,9689 2,34R
4729 1,98 6,2300 8,9681 0,0603 -2,7381 -2,15R
4747 2,35 16,4500 22,6936 0,0965 -6,2436 -4,92R
4750 2,68 5,2900 9,3596 0,0622 -4,0696 -3,20R
4755 2,53 10,0000 12,9280 0,0576 -2,9280 -2,30R
4757 2,00 9,2500 13,6258 0,0775 -4,3758 -3,45R
4768 2,19 9,8500 13,4440 0,0474 -3,5940 -2,83R
4819 1,91 5,3600 8,0295 0,0576 -2,6695 -2,10R
4820 2,10 2,4000 5,1679 0,0604 -2,7679 -2,18R
4828 1,85 16,1600 13,1197 0,0800 3,0403 2,39R
4870 1,43 8,6700 13,3966 0,0700 -4,7266 -3,72R
4928 1,54 0,9200 1,0895 0,1944 -0,1695 -0,13 X
4942 2,90 29,5100 33,0590 0,0863 -3,5490 -2,80R
4953 1,80 6,5800 11,6116 0,0556 -5,0316 -3,96R
4994 2,68 13,2500 16,3916 0,0659 -3,1416 -2,47R
5037 1,77 8,2500 12,3219 0,0663 -4,0719 -3,20R
5062 1,95 7,0500 10,2175 0,0562 -3,1675 -2,49R
5102 2,43 10,5800 13,8155 0,0705 -3,2355 -2,55R
5117 2,59 10,4600 14,9538 0,0439 -4,4938 -3,53R
5124 2,80 16,8700 21,1245 0,0777 -4,2545 -3,35R
5130 2,30 11,2400 15,7692 0,0477 -4,5292 -3,56R
5139 2,48 9,2900 11,8575 0,0482 -2,5675 -2,02R
5148 2,34 9,4500 12,7854 0,0401 -3,3354 -2,62R
5158 3,00 33,5400 37,6534 0,1147 -4,1134 -3,25R
5173 3,32 23,0700 26,2316 0,1084 -3,1616 -2,49R
5178 2,09 14,9100 12,2935 0,0826 2,6165 2,06R
5195 3,26 3,9100 6,8216 0,0840 -2,9116 -2,29R
5198 2,75 37,8200 43,7672 0,1712 -5,9472 -4,72RX
5211 2,48 8,4400 11,4077 0,0375 -2,9677 -2,33R
5222 2,68 34,9500 39,2375 0,2396 -4,2875 -3,43RX
5233 2,67 25,4000 19,3596 0,0821 6,0404 4,76R
5250 2,75 16,2400 22,4210 0,2050 -6,1810 -4,92RX
5251 2,62 12,9000 10,0753 0,0457 2,8247 2,22R
5253 2,30 18,1300 14,0713 0,0581 4,0587 3,19R
5260 1,68 14,7400 10,8178 0,0482 3,9222 3,09R
5278 2,46 9,2200 11,8394 0,0634 -2,6194 -2,06R
5297 2,61 14,5300 16,2082 0,1275 -1,6782 -1,33 X
5359 3,07 18,7200 15,8551 0,0876 2,8649 2,26R
5379 3,10 28,1100 32,2233 0,1353 -4,1133 -3,25RX
5394 1,83 14,2000 11,2901 0,0467 2,9099 2,29R
5405 2,35 29,2300 24,3968 0,0765 4,8332 3,81R
5413 1,42 0,5400 -0,0791 0,1276 0,6191 0,49 X
5424 2,12 3,4100 0,0237 0,0538 3,3863 2,66R
5454 2,26 9,0800 5,1029 0,0610 3,9771 3,13R
5548 2,86 9,5900 12,4161 0,0614 -2,8261 -2,22R
5552 2,21 14,5800 11,9435 0,0518 2,6365 2,07R
5565 1,75 1,1900 1,3903 0,4124 -0,2003 -0,17 X
R denotes an observation with a large standardized residual.
X denotes an observation whose X value gives it large leverage.

71
A equação gerada pelo MINITAB para a regressão foi PIND = 7,63 + 1,12
FECTOT + 0,00062 MORT1 - 0,0934 E_ANOSESTUDO + 0,0419 T_ANALF15A17 +
0,726 PINDCRI - 0,0437 PPOBCRI - 0,00541 P_SUPER - 0,00685 T_DES18M - 0,0168
TRABSC - 0,00955 T_AGUA - 0,0701 T_LUZ + 0,0431 PAREDE + 0,0599
T_NESTUDA_NTRAB_MMEIO - 0,00151 T_MULCHEFEFIF014 + 0,000007
HOMEM10A14 - 0,000030 HOMEM70A74
O valor de R-Sq foi de 98,8%. O valor encontrado foi alto, o que indica um bom
ajuste do modelo com os dados obtidos, e que 98,8% da variabilidade do PIND pode ser
explicada pela equação.
Os valores de P encontrados indicam a significância das variáveis independentes
para explicar a variável dependente. Desta maneira, quanto menor o valor de P maior o
nível de confiança desta variável no modelo. A maioria das variáveis obtiveram um valor
de P igual a 0,000, com exceção das variáveis MORT1 (0,887), P_SUPER (0,394),
T_DES18M (0,258), T_MULCHEFEFIF014 (0,519), HOMEM10A14 (0,483) e
HOMEM70A74 (0,494). Estes valores apresentam um valor muito alto de P, por isso não
se pode afirmar que a relação entre o PIND e estas variáveis é significativa.
Já as variáveis com o P indicado por 0,000 possuem relação significativa com a
variável PIND com alto grau de confiabilidade, e são elas FECTOT, E_ANOSESTUDO,
T_ANALF15A17, PINDCRI, PPOBCRI, TRABSC, T_AGUA, T_LUZ, PAREDE
T_NESTUDA_NTRAB_MMEIO.
Também é possível verificar que os coeficientes da maioria das variáveis
independentes indicados na equação estão muito próximos de 0 o que denota baixo poder
explicativo delas para a variável PIND, exceto para a variável FECTOT, que o coeficiente
é 1,12 e da variável PINDCRI que é 0,726.
Foi realizado a regressão Step-Wise para verificar quais as variáveis que são mais
capazes de explicar a variável PIND. Os resultados são apresentados abaixo.
Stepwise Regression: PIND versus FECTOT; MORT1; ... Alpha-to-Enter: 0,15 Alpha-to-Remove: 0,15
Response is PIND on 16 predictors, with N = 5565
Step 1 2 3 4 5 6
Constant -0,8292 11,5321 9,7007 6,2371 5,7542 6,3306
PINDCRI 0,7591 0,7332 0,7158 0,7067 0,7475 0,7405
T-Value 542,20 480,32 445,21 434,34 298,87 292,52
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
T_LUZ -0,1229 -0,1046 -0,0873 -0,0751 -0,0783
T-Value -31,60 -27,80 -23,26 -20,51 -21,61
P-Value 0,000 0,000 0,000 0,000 0,000
PAREDE 0,0614 0,0492 0,0436 0,0418
T-Value 24,91 19,93 18,21 17,65
P-Value 0,000 0,000 0,000 0,000
FECTOT 0,911 1,177 1,124
T-Value 19,23 24,86 23,96
P-Value 0,000 0,000 0,000
PPOBCRI -0,0324 -0,0471
T-Value -20,89 -24,26
P-Value 0,000 0,000
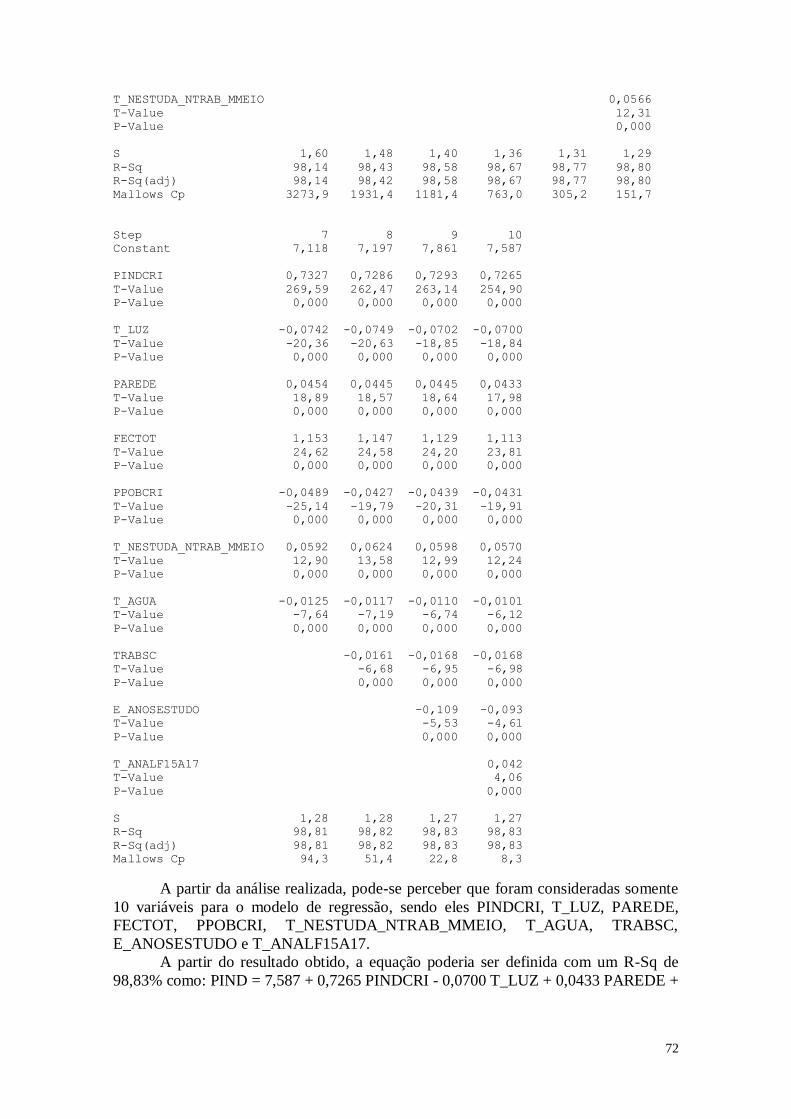
72
T_NESTUDA_NTRAB_MMEIO 0,0566
T-Value 12,31
P-Value 0,000
S 1,60 1,48 1,40 1,36 1,31 1,29
R-Sq 98,14 98,43 98,58 98,67 98,77 98,80
R-Sq(adj) 98,14 98,42 98,58 98,67 98,77 98,80
Mallows Cp 3273,9 1931,4 1181,4 763,0 305,2 151,7
Step 7 8 9 10
Constant 7,118 7,197 7,861 7,587
PINDCRI 0,7327 0,7286 0,7293 0,7265
T-Value 269,59 262,47 263,14 254,90
P-Value 0,000 0,000 0,000 0,000
T_LUZ -0,0742 -0,0749 -0,0702 -0,0700
T-Value -20,36 -20,63 -18,85 -18,84
P-Value 0,000 0,000 0,000 0,000
PAREDE 0,0454 0,0445 0,0445 0,0433
T-Value 18,89 18,57 18,64 17,98
P-Value 0,000 0,000 0,000 0,000
FECTOT 1,153 1,147 1,129 1,113
T-Value 24,62 24,58 24,20 23,81
P-Value 0,000 0,000 0,000 0,000
PPOBCRI -0,0489 -0,0427 -0,0439 -0,0431
T-Value -25,14 -19,79 -20,31 -19,91
P-Value 0,000 0,000 0,000 0,000
T_NESTUDA_NTRAB_MMEIO 0,0592 0,0624 0,0598 0,0570
T-Value 12,90 13,58 12,99 12,24
P-Value 0,000 0,000 0,000 0,000
T_AGUA -0,0125 -0,0117 -0,0110 -0,0101
T-Value -7,64 -7,19 -6,74 -6,12
P-Value 0,000 0,000 0,000 0,000
TRABSC -0,0161 -0,0168 -0,0168
T-Value -6,68 -6,95 -6,98
P-Value 0,000 0,000 0,000
E_ANOSESTUDO -0,109 -0,093
T-Value -5,53 -4,61
P-Value 0,000 0,000
T_ANALF15A17 0,042
T-Value 4,06
P-Value 0,000
S 1,28 1,28 1,27 1,27
R-Sq 98,81 98,82 98,83 98,83
R-Sq(adj) 98,81 98,82 98,83 98,83
Mallows Cp 94,3 51,4 22,8 8,3
A partir da análise realizada, pode-se perceber que foram consideradas somente
10 variáveis para o modelo de regressão, sendo eles PINDCRI, T_LUZ, PAREDE,
FECTOT, PPOBCRI, T_NESTUDA_NTRAB_MMEIO, T_AGUA, TRABSC,
E_ANOSESTUDO e T_ANALF15A17.
A partir do resultado obtido, a equação poderia ser definida com um R-Sq de
98,83% como: PIND = 7,587 + 0,7265 PINDCRI - 0,0700 T_LUZ + 0,0433 PAREDE +

73
1,113FECTOT - 0,0431 PPOBCRI + 0,0570 T_NESTUDA_NTRAB_MMEIO - 0,0101
T_AGUA - 0,0168 TRABSC - 0,093 E_ANOSESTUDO + 0,042 T_ANALF.
Porém, pode-se perceber que utilizando-se apenas cinco variáveis, o R-Sq é de
98,77%, desta maneira, elimina-se cinco variáveis e se perde pouco poder de explicação.
Desta forma, a equação passaria a ser: PIND = 5,7542 + 0,7475 PINDCRI – 0,0751
T_LUZ + 0,0436 PAREDE + 1,177 FECTOT – 0,0324 PPOBCRI.
É possível verificar também que a variável que mais influencia no modelo é a
PINDCRI, e o R-Sq é de 98,14% se apenas for utilizada esta variável. A equação ficaria
PIND = -0,8292 + 0,7591 PINDCRI.
Se for acrescentado ao modelo mais uma variável, a T_LUZ, o valor de R-Sq seria
de 98,43%, ou seja, aumentaria apenas 0,29% o poder de explicação.
Este modelo de regressão não diz muita coisa, apesar de seu alto poder explicativo,
porque as variáveis PIND e PINDCRI estão diretamente correlacionadas. É possível
perceber pela observação do dendograma e pelos valores apresentados de correlação entre
estas duas variáveis que a correlação é 0,991. Isto se deve ao significado destas duas
variáveis, no qual a variável PIND está relacionado aos indivíduos que vivem na extrema
pobreza e a variável PINDCRI está relacionada a crianças que vivem na extrema pobreza.
É de se esperar que em locais nos quais os indivíduos vivam na extrema pobreza, muitas
crianças também vivam na extrema pobreza, pois as condições das crianças é um reflexo
das condições dos pais.
Desta maneira, a equação contribui pouco como explicação da variável
dependente PIND pelas variáveis independentes selecionada, pois a relação entre as
variáveis PIND e PINDCRI acabaram se apresentando como óbvias e pouco
esclarecedoras. Mesmo aumentando a quantidade de variáveis e acrescentando outras
como T_LUZ e PAREDE, o poder de explicação da equação aumenta pouco.
4.2.Considerações
Este trabalho teve como objetivo apresentar um modelo de regressão múltipla da
variável PIND com as demais variáveis selecionadas provenientes do estudo realizado
pelo Atlas do Desenvolvimento Humano no Brasil.
De acordo com as análises realizadas, é possível perceber que a variável que mais
tem poder de explicação é a variável PINDCRI, e que mesmo que as outras forem
acrescentadas, o poder de explicação da equação não aumenta de forma considerável.
Devido ao significado destas variáveis, não se pode concluir muitas coisas a partir
dos resultados encontrados, já que uma se relaciona à quantidade de indivíduos que vive
na extrema pobreza e a outra a crianças que vivem em uma situação de extrema pobreza,
o que gera um alto grau de correlação entre si.
CAPÍTULO V – TESTES DE COMPARAÇÃO
Este trabalho apresenta uma comparação entre os valores apresentados pelas cinco
regiões brasileiras para cada variável escolhida. Inicialmente será feito o teste de One-
Way ANOVA de todas as variáveis do estudo e posteriormente serão selecionadas 6
variáveis para a análise de seus box-plots. O Distrito Federal não será considerado na
análise.
5.1.Análise das Variáveis
A seguir serão apresentados o valor do teste One-Way ANOVA para todas as
variáveis.
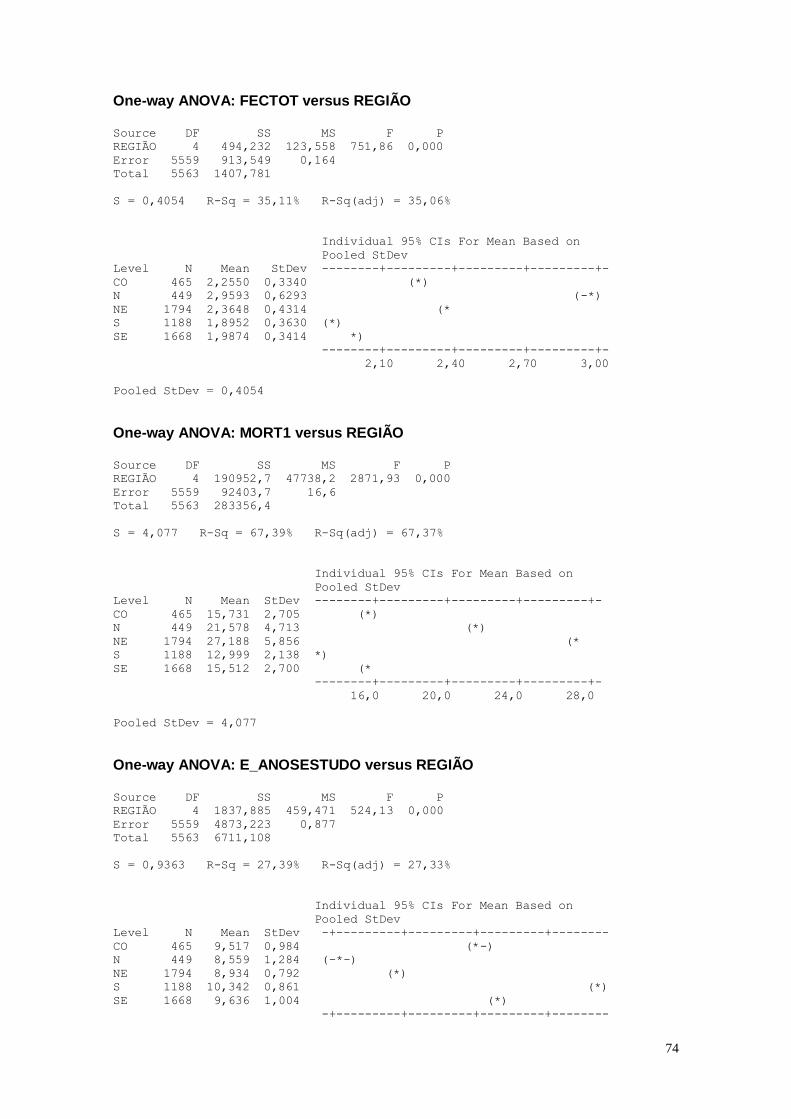
74
One-way ANOVA: FECTOT versus REGIÃO Source DF SS MS F P
REGIÃO 4 494,232 123,558 751,86 0,000
Error 5559 913,549 0,164
Total 5563 1407,781
S = 0,4054 R-Sq = 35,11% R-Sq(adj) = 35,06%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev --------+---------+---------+---------+-
CO 465 2,2550 0,3340 (*)
N 449 2,9593 0,6293 (-*)
NE 1794 2,3648 0,4314 (*
S 1188 1,8952 0,3630 (*)
SE 1668 1,9874 0,3414 *)
--------+---------+---------+---------+-
2,10 2,40 2,70 3,00
Pooled StDev = 0,4054
One-way ANOVA: MORT1 versus REGIÃO Source DF SS MS F P
REGIÃO 4 190952,7 47738,2 2871,93 0,000
Error 5559 92403,7 16,6
Total 5563 283356,4
S = 4,077 R-Sq = 67,39% R-Sq(adj) = 67,37%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev --------+---------+---------+---------+-
CO 465 15,731 2,705 (*)
N 449 21,578 4,713 (*)
NE 1794 27,188 5,856 (*
S 1188 12,999 2,138 *)
SE 1668 15,512 2,700 (*
--------+---------+---------+---------+-
16,0 20,0 24,0 28,0
Pooled StDev = 4,077
One-way ANOVA: E_ANOSESTUDO versus REGIÃO Source DF SS MS F P
REGIÃO 4 1837,885 459,471 524,13 0,000
Error 5559 4873,223 0,877
Total 5563 6711,108
S = 0,9363 R-Sq = 27,39% R-Sq(adj) = 27,33%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -+---------+---------+---------+--------
CO 465 9,517 0,984 (*-)
N 449 8,559 1,284 (-*-)
NE 1794 8,934 0,792 (*)
S 1188 10,342 0,861 (*)
SE 1668 9,636 1,004 (*)
-+---------+---------+---------+--------

75
8,50 9,00 9,50 10,00
Pooled StDev = 0,936
One-way ANOVA: T_ANALF15A17 versus REGIÃO Source DF SS MS F P
REGIÃO 4 16555,33 4138,83 1122,39 0,000
Error 5559 20498,90 3,69
Total 5563 37054,23
S = 1,920 R-Sq = 44,68% R-Sq(adj) = 44,64%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev --+---------+---------+---------+-------
CO 465 1,474 1,799 (*-)
N 449 4,155 4,208 (-*)
NE 1794 4,889 2,264 (*
S 1188 1,050 0,695 (*)
SE 1668 1,341 0,881 (*)
--+---------+---------+---------+-------
1,2 2,4 3,6 4,8
Pooled StDev = 1,920
One-way ANOVA: PIND versus REGIÃO Source DF SS MS F P
REGIÃO 4 449958,8 112489,7 1954,42 0,000
Error 5559 319957,4 57,6
Total 5563 769916,2
S = 7,587 R-Sq = 58,44% R-Sq(adj) = 58,41%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ------+---------+---------+---------+---
CO 465 5,476 6,015 (*)
N 449 21,104 12,468 (*)
NE 1794 22,538 9,765 (*
S 1188 3,079 3,476 (*)
SE 1668 4,196 5,378 (*)
------+---------+---------+---------+---
6,0 12,0 18,0 24,0
Pooled StDev = 7,587
One-way ANOVA: PINDCRI versus REGIÃO Source DF SS MS F P
REGIÃO 4 793912 198478 2132,08 0,000
Error 5559 517493 93
Total 5563 1311405
S = 9,648 R-Sq = 60,54% R-Sq(adj) = 60,51%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ---+---------+---------+---------+------
CO 465 7,807 7,989 (*)

76
N 449 26,538 14,377 (*)
NE 1794 31,449 12,077 (*)
S 1188 5,174 5,425 *)
SE 1668 6,662 7,699 (*
---+---------+---------+---------+------
7,0 14,0 21,0 28,0
Pooled StDev = 9,648
One-way ANOVA: PPOBCRI versus REGIÃO Source DF SS MS F P
REGIÃO 4 1765291 441323 2169,84 0,000
Error 5559 1130644 203
Total 5563 2895934
S = 14,26 R-Sq = 60,96% R-Sq(adj) = 60,93%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ---------+---------+---------+---------+
CO 465 48,90 12,92 (*)
N 449 73,80 12,03 (*-)
NE 1794 81,50 7,97 (*
S 1188 37,78 16,15 *)
SE 1668 48,73 18,41 (*
---------+---------+---------+---------+
48 60 72 84
Pooled StDev = 14,26
One-way ANOVA: P_SUPER versus REGIÃO Source DF SS MS F P
REGIÃO 4 15017,6 3754,4 366,22 0,000
Error 5559 56989,1 10,3
Total 5563 72006,6
S = 3,202 R-Sq = 20,86% R-Sq(adj) = 20,80%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -+---------+---------+---------+--------
CO 465 8,096 2,739 (-*--)
N 449 6,104 3,188 (--*-)
NE 1794 4,862 2,340 (-*)
S 1188 7,845 3,422 (*-)
SE 1668 8,742 3,891 (*)
-+---------+---------+---------+--------
4,8 6,0 7,2 8,4
Pooled StDev = 3,202
One-way ANOVA: T_DES18M versus REGIÃO Source DF SS MS F P
REGIÃO 4 20323,19 5080,80 522,64 0,000
Error 5559 54041,72 9,72
Total 5563 74364,91
S = 3,118 R-Sq = 27,33% R-Sq(adj) = 27,28%

77
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -+---------+---------+---------+--------
CO 465 5,522 2,304 (-*-)
N 449 7,362 3,545 (-*-)
NE 1794 8,307 4,008 (*)
S 1188 3,092 2,025 (-*)
SE 1668 6,004 2,714 (*)
-+---------+---------+---------+--------
3,0 4,5 6,0 7,5
Pooled StDev = 3,118
One-way ANOVA: TRABSC versus REGIÃO Source DF SS MS F P
REGIÃO 4 189777,9 47444,5 752,97 0,000
Error 5559 350271,3 63,0
Total 5563 540049,2
S = 7,938 R-Sq = 35,14% R-Sq(adj) = 35,09%
Individual 95% CIs For Mean Based on Pooled StDev
Level N Mean StDev +---------+---------+---------+---------
CO 465 27,460 7,547 (-*)
N 449 27,600 7,177 (*-)
NE 1794 31,622 8,051 *)
S 1188 15,666 6,332 (*)
SE 1668 23,893 9,064 (*)
+---------+---------+---------+---------
15,0 20,0 25,0 30,0
Pooled StDev = 7,938
One-way ANOVA: T_AGUA versus REGIÃO Source DF SS MS F P
REGIÃO 4 350371 87593 569,31 0,000
Error 5559 855288 154
Total 5563 1205659
S = 12,40 R-Sq = 29,06% R-Sq(adj) = 29,01%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ------+---------+---------+---------+---
CO 465 93,20 6,82 (-*-)
N 449 81,82 16,75 (-*-)
NE 1794 74,80 16,83 (*)
S 1188 91,44 7,58 (*-)
SE 1668 91,94 8,89 (*)
------+---------+---------+---------+---
78,0 84,0 90,0 96,0
Pooled StDev = 12,40
One-way ANOVA: T_LUZ versus REGIÃO Source DF SS MS F P
REGIÃO 4 49907,4 12476,9 456,25 0,000
Error 5559 152020,1 27,3

78
Total 5563 201927,5
S = 5,229 R-Sq = 24,72% R-Sq(adj) = 24,66%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ------+---------+---------+---------+---
CO 465 97,672 4,984 (-*)
N 449 88,614 10,850 (*-)
NE 1794 95,786 6,737 (*)
S 1188 99,485 1,052 (*)
SE 1668 99,237 1,744 (*)
------+---------+---------+---------+---
90,0 93,0 96,0 99,0
Pooled StDev = 5,229
One-way ANOVA: PAREDE versus REGIÃO Source DF SS MS F P
REGIÃO 4 103287,8 25821,9 368,61 0,000
Error 5559 389419,8 70,1
Total 5563 492707,6
S = 8,370 R-Sq = 20,96% R-Sq(adj) = 20,91%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -------+---------+---------+---------+--
CO 465 3,819 5,362 (-*-)
N 449 13,001 11,478 (-*-)
NE 1794 9,818 12,841 (*)
S 1188 2,067 2,557 (*)
SE 1668 1,305 2,861 (*)
-------+---------+---------+---------+--
3,5 7,0 10,5 14,0
Pooled StDev = 8,370
One-way ANOVA: T_MULCHEFEFIF014 versus REGIÃO Source DF SS MS F P
REGIÃO 4 177709,1 44427,3 595,10 0,000
Error 5559 415007,3 74,7
Total 5563 592716,4
S = 8,640 R-Sq = 29,98% R-Sq(adj) = 29,93%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -----+---------+---------+---------+----
CO 465 16,306 8,635 (-*-)
N 449 27,170 11,767 (-*-)
NE 1794 26,703 9,683 (*)
S 1188 14,376 7,116 (*)
SE 1668 15,751 7,354 (*)
-----+---------+---------+---------+----
16,0 20,0 24,0 28,0
Pooled StDev = 8,640

79
One-way ANOVA: T_NESTUDA_NTRAB_MMEIO versus REGIÃO Source DF SS MS F P
REGIÃO 4 250910,9 62727,7 1991,10 0,000
Error 5559 175131,3 31,5
Total 5563 426042,2
S = 5,613 R-Sq = 58,89% R-Sq(adj) = 58,86%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -------+---------+---------+---------+--
CO 465 11,283 5,202 (*)
N 449 20,874 6,596 (*)
NE 1794 23,134 5,615 *)
S 1188 6,665 4,532 *)
SE 1668 10,900 6,107 (*
-------+---------+---------+---------+--
10,0 15,0 20,0 25,0
Pooled StDev = 5,613
One-way ANOVA: HOMEM10A14 versus REGIÃO Source DF SS MS F P
REGIÃO 4 918840793 229710198 3,69 0,005
Error 5559 3,46469E+11 62325767
Total 5563 3,47388E+11
S = 7895 R-Sq = 0,26% R-Sq(adj) = 0,19%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ---+---------+---------+---------+------
CO 465 1134 3389 (-----------*-----------)
N 449 1989 5672 (-----------*-----------)
NE 1794 1486 4616 (-----*-----)
S 1188 982 3072 (------*-------)
SE 1668 2016 12898 (------*-----)
---+---------+---------+---------+------
600 1200 1800 2400
Pooled StDev = 7895
One-way ANOVA: HOMEM70A74 versus REGIÃO Source DF SS MS F P
REGIÃO 4 56500690 14125172 4,72 0,001
Error 5559 16646629124 2994537
Total 5563 16703129814
S = 1730 R-Sq = 0,34% R-Sq(adj) = 0,27%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -------+---------+---------+---------+--
CO 465 202 591 (---------*----------)
N 449 213 616 (---------*----------)
NE 1794 250 724 (-----*----)
S 1188 223 686 (------*-----)
SE 1668 449 2981 (-----*----)
-------+---------+---------+---------+--

80
150 300 450 600
Pooled StDev = 1730
One-way ANOVA: IDHM versus REGIÃO Source DF SS MS F P
REGIÃO 4 16,24279 4,06070 1795,58 0,000
Error 5559 12,57163 0,00226
Total 5563 28,81442
S = 0,04756 R-Sq = 56,37% R-Sq(adj) = 56,34%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev --+---------+---------+---------+-------
CO 465 0,68918 0,03680 (*)
N 449 0,60795 0,06016 (-*)
NE 1794 0,59068 0,04327 (*
S 1188 0,71411 0,04159 (*)
SE 1668 0,69898 0,05428 (*
--+---------+---------+---------+-------
0,595 0,630 0,665 0,700
Pooled StDev = 0,04756
One-way ANOVA: IDHM_E versus REGIÃO Source DF SS MS F P
REGIÃO 4 18,83643 4,70911 884,60 0,000
Error 5559 29,59293 0,00532
Total 5563 48,42936
S = 0,07296 R-Sq = 38,89% R-Sq(adj) = 38,85%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev --+---------+---------+---------+-------
CO 465 0,58380 0,05977 (-*-)
N 449 0,49043 0,09066 (-*-)
NE 1794 0,48842 0,06579 (*)
S 1188 0,61302 0,06520 (*)
SE 1668 0,60819 0,08287 (*)
--+---------+---------+---------+-------
0,490 0,525 0,560 0,595
Pooled StDev = 0,07296
One-way ANOVA: IDHM_L versus REGIÃO Source DF SS MS F P
REGIÃO 4 6,94138 1,73535 2318,18 0,000
Error 5559 4,16137 0,00075
Total 5563 11,10275
S = 0,02736 R-Sq = 62,52% R-Sq(adj) = 62,49%
Level N Mean StDev
CO 465 0,82234 0,01833
N 449 0,78038 0,02871

81
NE 1794 0,75433 0,03016
S 1188 0,83533 0,02616
SE 1668 0,82819 0,02674
Individual 95% CIs For Mean Based on Pooled StDev
Level ---------+---------+---------+---------+
CO (*)
N (*)
NE (*
S *)
SE *)
---------+---------+---------+---------+
0,775 0,800 0,825 0,850
Pooled StDev = 0,02736
One-way ANOVA: IDHM_R versus REGIÃO Source DF SS MS F P
REGIÃO 4 21,93443 5,48361 2143,97 0,000
Error 5559 14,21819 0,00256
Total 5563 36,15262
S = 0,05057 R-Sq = 60,67% R-Sq(adj) = 60,64%
Level N Mean StDev
CO 465 0,68411 0,04209
N 449 0,59282 0,06194
NE 1794 0,56226 0,04611
S 1188 0,71344 0,04419
SE 1668 0,68116 0,05769
Individual 95% CIs For Mean Based on Pooled StDev
Level +---------+---------+---------+---------
CO (*)
N (*)
NE (*
S *)
SE *)
+---------+---------+---------+---------
0,560 0,600 0,640 0,680
Pooled StDev = 0,05057
É possível verificar que com exceção das variáveis HOMEM10A14 e
HOMEM70A74, todas as outras análises tiveram um valor de P igual a 0,000. Estas duas
variáveis tiveram um valor de P igual a 0,005 e 0,001 respectivamente.
A partir da análise destes números e dos gráficos gerados pelos box-plots, é
possível verificar que existem diferenças significativas na média das variáveis escolhidas,
de modo que os municípios das regiões Norte e Nordeste tem uma situação social mais
precária enquanto as regiões Centro-Oeste, Sul e Sudeste possuem, no geral, municípios
com maior desenvolvimento. Desta maneira, entende-se que existem duas realidades
diferentes no Brasil.
Para realizar a escolha das seis variáveis a serem analisadas através dos box-plots,
foi adotado o critério de selecionar as que possuem os maiores valores de F gerados pela
análise. Estas são, com seus valores de F respectivos, MORT1 (2871,93), IDHM_L
(2318,18), IDHM_R (2143,97), PPOBCRI(2169,84), PINDCRI (2132,08) e
T_NESTUDA_NTRAB_MMEIO (1991,10).
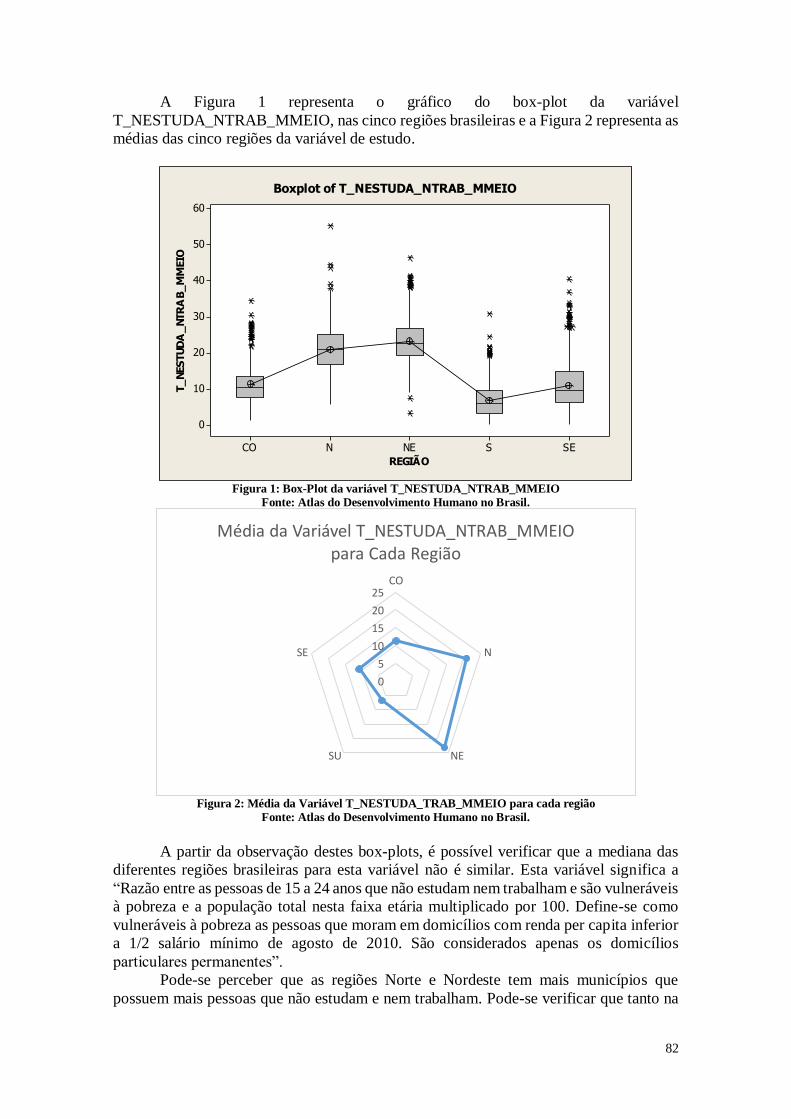
82
A Figura 1 representa o gráfico do box-plot da variável
T_NESTUDA_NTRAB_MMEIO, nas cinco regiões brasileiras e a Figura 2 representa as
médias das cinco regiões da variável de estudo.
SESNENCO
60
50
40
30
20
10
0
REGIÃO
T_
NES
TU
DA
_N
TR
AB
_M
MEIO
Boxplot of T_NESTUDA_NTRAB_MMEIO
Figura 1: Box-Plot da variável T_NESTUDA_NTRAB_MMEIO
Fonte: Atlas do Desenvolvimento Humano no Brasil.
Figura 2: Média da Variável T_NESTUDA_TRAB_MMEIO para cada região
Fonte: Atlas do Desenvolvimento Humano no Brasil.
A partir da observação destes box-plots, é possível verificar que a mediana das
diferentes regiões brasileiras para esta variável não é similar. Esta variável significa a
“Razão entre as pessoas de 15 a 24 anos que não estudam nem trabalham e são vulneráveis
à pobreza e a população total nesta faixa etária multiplicado por 100. Define-se como
vulneráveis à pobreza as pessoas que moram em domicílios com renda per capita inferior
a 1/2 salário mínimo de agosto de 2010. São considerados apenas os domicílios
particulares permanentes”.
Pode-se perceber que as regiões Norte e Nordeste tem mais municípios que
possuem mais pessoas que não estudam e nem trabalham. Pode-se verificar que tanto na
0
5
10
15
20
25CO
N
NESU
SE
Média da Variável T_NESTUDA_NTRAB_MMEIO para Cada Região
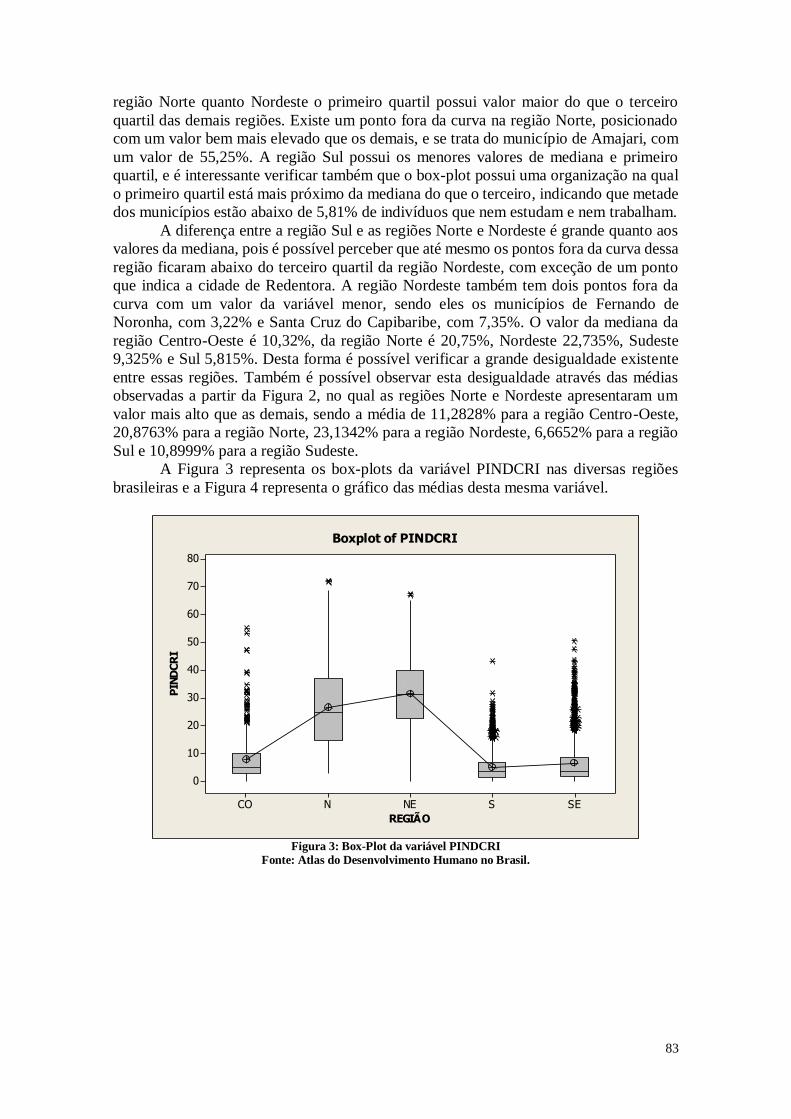
83
região Norte quanto Nordeste o primeiro quartil possui valor maior do que o terceiro
quartil das demais regiões. Existe um ponto fora da curva na região Norte, posicionado
com um valor bem mais elevado que os demais, e se trata do município de Amajari, com
um valor de 55,25%. A região Sul possui os menores valores de mediana e primeiro
quartil, e é interessante verificar também que o box-plot possui uma organização na qual
o primeiro quartil está mais próximo da mediana do que o terceiro, indicando que metade
dos municípios estão abaixo de 5,81% de indivíduos que nem estudam e nem trabalham.
A diferença entre a região Sul e as regiões Norte e Nordeste é grande quanto aos
valores da mediana, pois é possível perceber que até mesmo os pontos fora da curva dessa
região ficaram abaixo do terceiro quartil da região Nordeste, com exceção de um ponto
que indica a cidade de Redentora. A região Nordeste também tem dois pontos fora da
curva com um valor da variável menor, sendo eles os municípios de Fernando de
Noronha, com 3,22% e Santa Cruz do Capibaribe, com 7,35%. O valor da mediana da
região Centro-Oeste é 10,32%, da região Norte é 20,75%, Nordeste 22,735%, Sudeste
9,325% e Sul 5,815%. Desta forma é possível verificar a grande desigualdade existente
entre essas regiões. Também é possível observar esta desigualdade através das médias
observadas a partir da Figura 2, no qual as regiões Norte e Nordeste apresentaram um
valor mais alto que as demais, sendo a média de 11,2828% para a região Centro-Oeste,
20,8763% para a região Norte, 23,1342% para a região Nordeste, 6,6652% para a região
Sul e 10,8999% para a região Sudeste.
A Figura 3 representa os box-plots da variável PINDCRI nas diversas regiões
brasileiras e a Figura 4 representa o gráfico das médias desta mesma variável.
SESNENCO
80
70
60
50
40
30
20
10
0
REGIÃO
PIN
DC
RI
Boxplot of PINDCRI
Figura 3: Box-Plot da variável PINDCRI
Fonte: Atlas do Desenvolvimento Humano no Brasil.

84
Figura 4: Média da Variável PINDCRI para cada região
Fonte: Atlas do Desenvolvimento Humano no Brasil.
A variável PINDCRI representa a “Proporção dos indivíduos com até 14 anos de
idade que têm renda domiciliar per capita igual ou inferior a R$ 70,00 mensais, em reais
de agosto de 2010. O universo de indivíduos é limitado àqueles que vivem em domicílios
particulares permanentes”.
Pode-se perceber a partir da análise desta variável que existe uma distribuição
desigual entre os municípios. As regiões Norte e Nordeste possuem uma incidência maior
de crianças que vivem na situação de extrema pobreza, enquanto as regiões Sul, Sudeste
e Centro-Oeste possuem uma proporção menor. O maior outlier do gráfico está situado
na região Norte, e se trata da cidade de Senador Guiomard com 72,5%. Estes resultados
indicam a necessidade de maior atenção das políticas públicas às regiões Norte e
Nordeste, para que se possa diminuir estes índices extremamente altos de crianças que
vivem na extrema pobreza. As regiões Centro-Oeste, Sul e Sudeste apresentam uma
distribuição que não é simétrica, nas três regiões a distância entre o primeiro quartil e a
mediana é consideravelmente menor do que entre a mediana e o terceiro quartil. Estas
três regiões possuem uma quantidade considerável de pontos fora da curva, desta maneira
é interessante entender o contexto destes pontos, para verificar o motivo desses
municípios serem tão diferentes dos demais na mesma região. A mediana da região
Centro-Oeste é 5,1%, da região Norte é 24,88%, da região Nordeste é 31,22%, da região
Sul é 3,415% e da região Sudeste é 3,63%. A região Nordeste é a que possui os valores
mais altos para esta variável indicando a urgência de realizar políticas que diminuam esta
grande desigualdade. As regiões Sul e Sudeste possuem as medianas com um valor
próximo.
É possível perceber pelo gráfico que representa a média a disparidade entre estas
regiões, nos quais as regiões Norte e Nordeste possuem os valores mais elevados desta
variável. A média da região Centro-Oeste foi de 7,8074%, da região Norte foi de
26,5383%, da região Nordeste foi de 31,4489%, da região Sul de 5,1740% e da região
Sudeste 6,6623%.
A Figura 5 representa os box-plots da varável PPOBCRI das diferentes regiões e
a Figura 6 representa o gráfico das médias da mesma variável para as diferentes regiões.
05
101520253035
CO
N
NESU
SE
Média da Variável PINDCRI para Cada Região
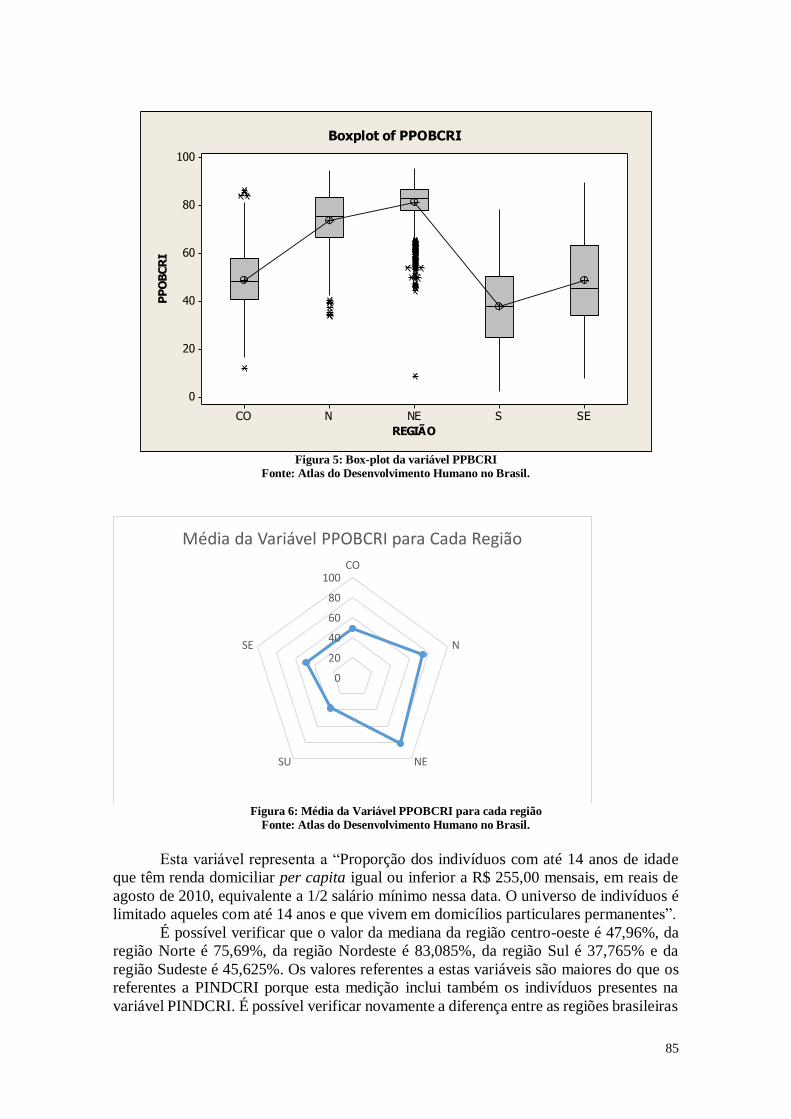
85
SESNENCO
100
80
60
40
20
0
REGIÃO
PP
OB
CR
I
Boxplot of PPOBCRI
Figura 5: Box-plot da variável PPBCRI
Fonte: Atlas do Desenvolvimento Humano no Brasil.
Figura 6: Média da Variável PPOBCRI para cada região
Fonte: Atlas do Desenvolvimento Humano no Brasil.
Esta variável representa a “Proporção dos indivíduos com até 14 anos de idade
que têm renda domiciliar per capita igual ou inferior a R$ 255,00 mensais, em reais de
agosto de 2010, equivalente a 1/2 salário mínimo nessa data. O universo de indivíduos é
limitado aqueles com até 14 anos e que vivem em domicílios particulares permanentes”.
É possível verificar que o valor da mediana da região centro-oeste é 47,96%, da
região Norte é 75,69%, da região Nordeste é 83,085%, da região Sul é 37,765% e da
região Sudeste é 45,625%. Os valores referentes a estas variáveis são maiores do que os
referentes a PINDCRI porque esta medição inclui também os indivíduos presentes na
variável PINDCRI. É possível verificar novamente a diferença entre as regiões brasileiras
0
20
40
60
80
100CO
N
NESU
SE
Média da Variável PPOBCRI para Cada Região
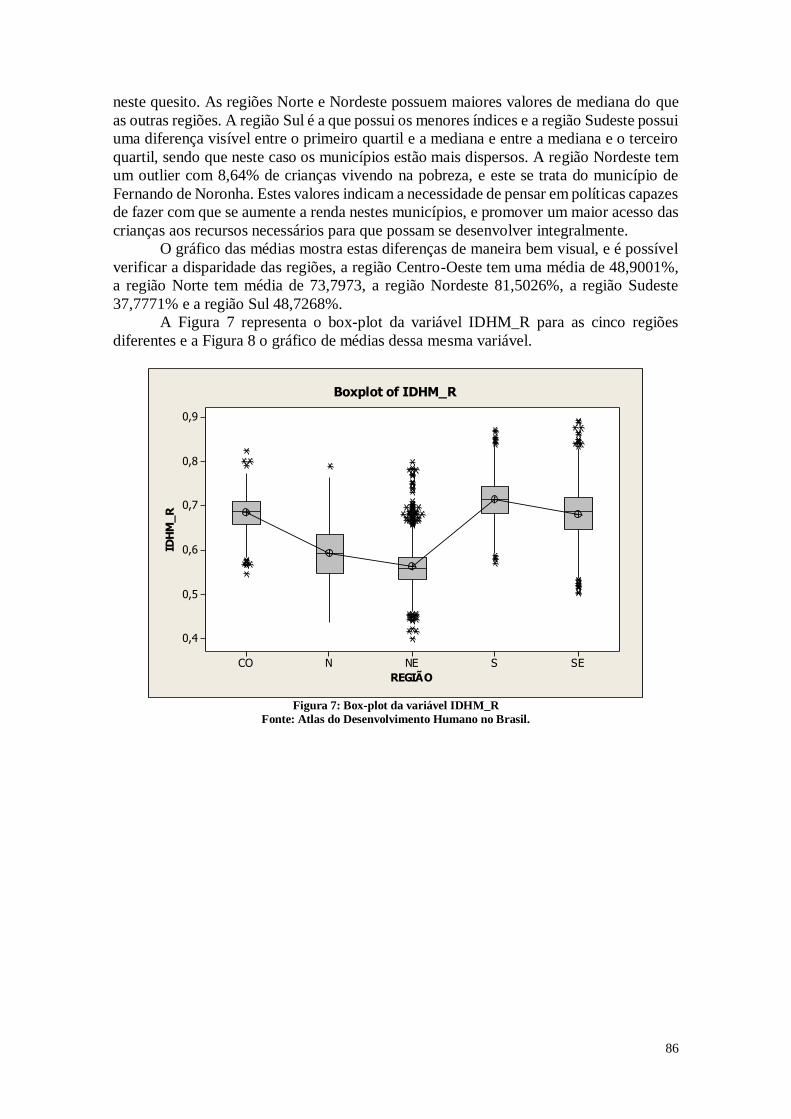
86
neste quesito. As regiões Norte e Nordeste possuem maiores valores de mediana do que
as outras regiões. A região Sul é a que possui os menores índices e a região Sudeste possui
uma diferença visível entre o primeiro quartil e a mediana e entre a mediana e o terceiro
quartil, sendo que neste caso os municípios estão mais dispersos. A região Nordeste tem
um outlier com 8,64% de crianças vivendo na pobreza, e este se trata do município de
Fernando de Noronha. Estes valores indicam a necessidade de pensar em políticas capazes
de fazer com que se aumente a renda nestes municípios, e promover um maior acesso das
crianças aos recursos necessários para que possam se desenvolver integralmente.
O gráfico das médias mostra estas diferenças de maneira bem visual, e é possível
verificar a disparidade das regiões, a região Centro-Oeste tem uma média de 48,9001%,
a região Norte tem média de 73,7973, a região Nordeste 81,5026%, a região Sudeste
37,7771% e a região Sul 48,7268%.
A Figura 7 representa o box-plot da variável IDHM_R para as cinco regiões
diferentes e a Figura 8 o gráfico de médias dessa mesma variável.
SESNENCO
0,9
0,8
0,7
0,6
0,5
0,4
REGIÃO
IDH
M_
R
Boxplot of IDHM_R
Figura 7: Box-plot da variável IDHM_R
Fonte: Atlas do Desenvolvimento Humano no Brasil.

87
Figura 8: Média da Variável IDHM_R para Cada Região
Fonte: Atlas do Desenvolvimento Humano no Brasil.
Esta variável representa o “Índice da dimensão Renda que é um dos 3
componentes do IDHM. É obtido a partir do indicador Renda per capita, através da
fórmula: [ln (valor observado do indicador) - ln (valor mínimo)] / [ln (valor máximo) - ln
(valor mínimo)], onde os valores mínimo e máximo são R$ 8,00 e R$ 4.033,00 (a preços
de agosto de 2010)”.
Esta variável representa o índice da dimensão renda do IDHM, e é possível
perceber que mais uma vez, no quesito rendimento, existe uma diferença perceptível entre
as regiões Norte e Nordeste e as regiões Centro-Oeste, Sul e Sudeste. O valor da mediana
destas regiões é 0,593, 0,559, 0,686, 0,713 e 0,687 respectivamente. É possível verificar
as diferenças regionais, e que é necessário buscar melhorar os indicadores das regiões
Norte e Nordeste em relação as outras regiões. A região Nordeste possui uma
considerável quantidade de outliers, tanto positivamente quanto negativamente. As
médias de cada região foram 0,6841 para a região Centro-Oeste, 0,5923 para a região
Norte, 0,5622 para a região Nordeste, 0,7134 para a região Sul e 0,6811 para a região
Sudeste.
A Figura 9 representa o box-plot da variável IDHM_L e a Figura 10 o gráfico de
médias desta mesma variável para cada região.
0
0,2
0,4
0,6
0,8CO
N
NESU
SE
Média da Variável IDHM_R para Cada Região
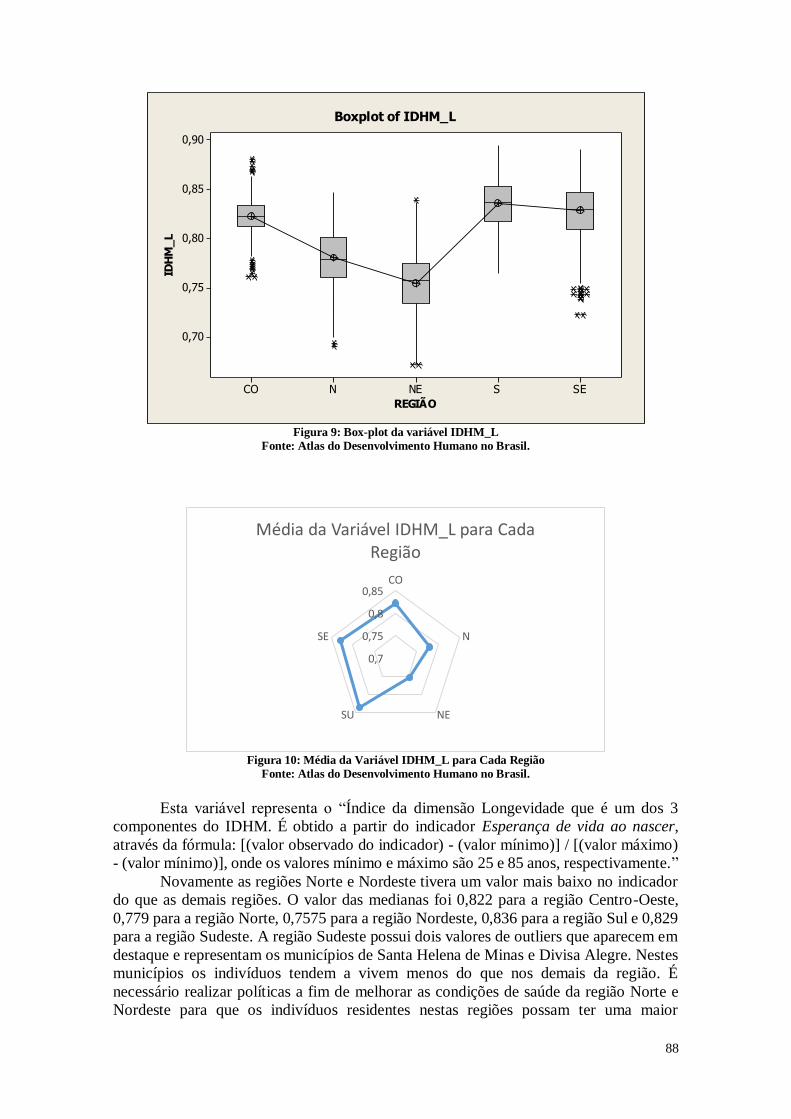
88
SESNENCO
0,90
0,85
0,80
0,75
0,70
REGIÃO
IDH
M_
L
Boxplot of IDHM_L
Figura 9: Box-plot da variável IDHM_L
Fonte: Atlas do Desenvolvimento Humano no Brasil.
Figura 10: Média da Variável IDHM_L para Cada Região
Fonte: Atlas do Desenvolvimento Humano no Brasil.
Esta variável representa o “Índice da dimensão Longevidade que é um dos 3
componentes do IDHM. É obtido a partir do indicador Esperança de vida ao nascer,
através da fórmula: [(valor observado do indicador) - (valor mínimo)] / [(valor máximo)
- (valor mínimo)], onde os valores mínimo e máximo são 25 e 85 anos, respectivamente.”
Novamente as regiões Norte e Nordeste tivera um valor mais baixo no indicador
do que as demais regiões. O valor das medianas foi 0,822 para a região Centro-Oeste,
0,779 para a região Norte, 0,7575 para a região Nordeste, 0,836 para a região Sul e 0,829
para a região Sudeste. A região Sudeste possui dois valores de outliers que aparecem em
destaque e representam os municípios de Santa Helena de Minas e Divisa Alegre. Nestes
municípios os indivíduos tendem a vivem menos do que nos demais da região. É
necessário realizar políticas a fim de melhorar as condições de saúde da região Norte e
Nordeste para que os indivíduos residentes nestas regiões possam ter uma maior
0,7
0,75
0,8
0,85CO
N
NESU
SE
Média da Variável IDHM_L para Cada Região
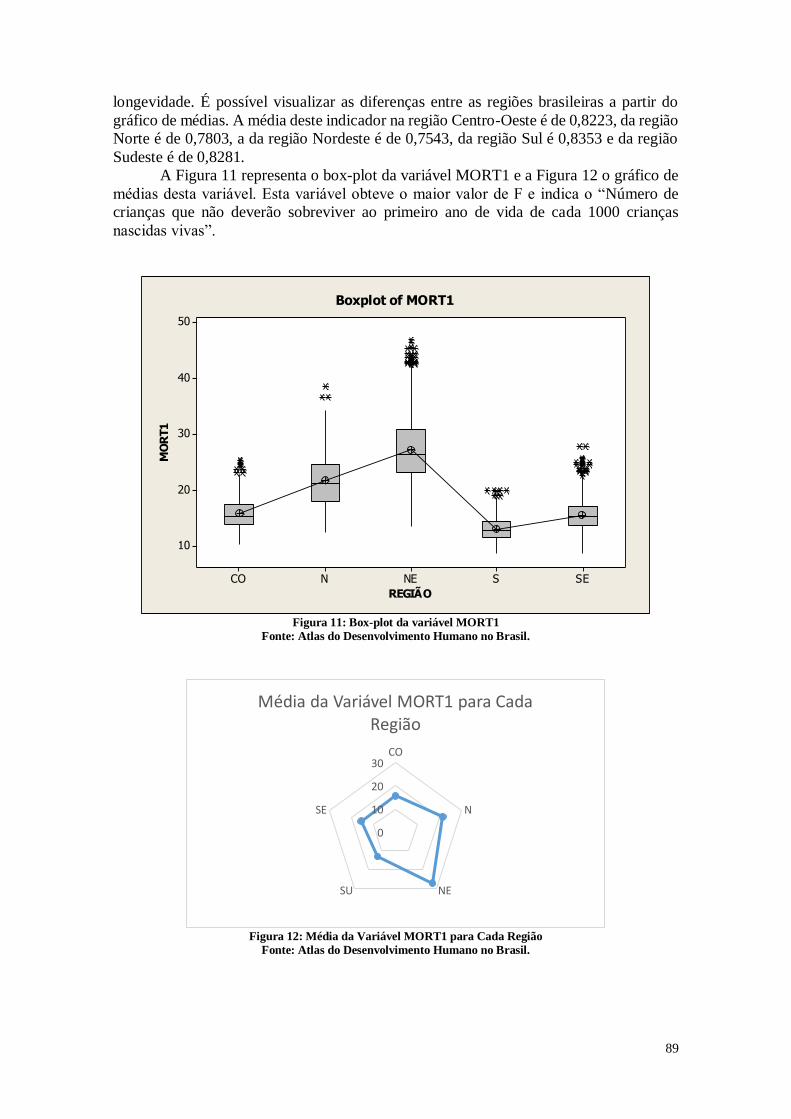
89
longevidade. É possível visualizar as diferenças entre as regiões brasileiras a partir do
gráfico de médias. A média deste indicador na região Centro-Oeste é de 0,8223, da região
Norte é de 0,7803, a da região Nordeste é de 0,7543, da região Sul é 0,8353 e da região
Sudeste é de 0,8281.
A Figura 11 representa o box-plot da variável MORT1 e a Figura 12 o gráfico de
médias desta variável. Esta variável obteve o maior valor de F e indica o “Número de
crianças que não deverão sobreviver ao primeiro ano de vida de cada 1000 crianças
nascidas vivas”.
SESNENCO
50
40
30
20
10
REGIÃO
MO
RT1
Boxplot of MORT1
Figura 11: Box-plot da variável MORT1
Fonte: Atlas do Desenvolvimento Humano no Brasil.
Figura 12: Média da Variável MORT1 para Cada Região
Fonte: Atlas do Desenvolvimento Humano no Brasil.
0
10
20
30CO
N
NESU
SE
Média da Variável MORT1 para Cada Região

90
Estes resultados mostram que a região na qual existe o maior número de
mortalidade de crianças com até um ano de idade é a Nordeste, seguida pela Norte. Estes
resultados indicam a necessidade de melhorar a qualidade da saúde nestas regiões. O valor
da mediana nas diferentes regiões é 15,2 no Centro-Oeste, 21,2 no Norte, 26,3 no
Nordeste, 12,8 no Sul e 15,4 no Sudeste. Desta maneira, pode-se perceber a diferença dos
valores das regiões Norte e Nordeste para as demais regiões. O Nordeste também possui
alguns municípios que são representados pelos outliers e que possuem um maior número
de taxa de mortalidade infantil. Um ponto que pode ser destacado é que o outlier com
valor mais elevado na região Sul tem o valor de 19,90, e compreende quatro municípios,
Cantagalo, Cruzmaltina, Bocaina do Sul e Capão Alto. Estes são os maiores valores da
variável nesta região e, mesmo assim, são menores que o valor do primeiro quartil da
região Nordeste que é 30,725 e da mediana da região Norte, que é 21,2.
Também é possível verificar as diferenças das regiões observando o gráfico das
médias. A média da região Centro-Oeste foi de 15,7313, da região Norte foi de 21,5776,
da região Nordeste 27,1878, da região Sul 12,9988 e da região Sudeste 15,5123.
5.2.Considerações
A partir das análises realizadas neste relatório foi possível verificar a existência
de duas realidades diferentes nos municípios brasileiros. A primeira é referente aos
municípios que se encontram na região Norte e Nordeste, e neste caso, os municípios
possuem condições mais precárias do que o das outras regiões. As regiões Sul, Sudeste e
Centro-Oeste possuem municípios que, no geral, são mais desenvolvidos.
As variáveis analisadas com maior profundidade por possuírem um valor de F
maior foram a T-NESTUDA-NTRAB-MMEIO, PINDCRI, PPOBCRI, IDHM_R,
IDHM_L e MORT1. Em todos os casos foi possível verificar as disparidades encontradas
nas regiões brasileiras.
CAPÍTULO 6. AMOSTRAGEM
O presente capítulo tem como objetivo realizar um estudo de amostragem das
variáveis selecionadas provenientes do Atlas do Desenvolvimento Humano no Brasil, que
apresentam indicadores de desenvolvimento humano dos 5565 municípios brasileiros.
Estes dados são provenientes do Censo Demográfico de 2010.
De acordo com Anderson, Sweeney e Williams (2011), “Uma população é um
conjunto de todos os elementos de interesse em um estudo” (ANDERSON; SWEENEY;
WILLIAMS, 2011, p. 238) e “Uma amostra é um subconjunto da população”
(ANDERSON; SWEENEY; WILLIAMS, 2011, p.238).
A estatística, muitas vezes busca estimar hipóteses de uma população a partir de
uma amostra, já que não é viável avaliar os valores das variáveis de toda uma população,
e por esse motivo, a amostra é capaz de gerar uma estimativa dos valores de uma
população (ANDERSON; SWEENEY; WILLIAMS, 2011).
As amostras podem ser aleatórias, de modo que quando se escolhe os elementos
da amostra todos os elementos da população tenham a mesma probabilidade de serem
escolhidos (ANDERSON; SWEENEY; WILLIAMS, 2011).
Para isso, serão realizadas comparações entre os valores das médias e dos box-
plots de diferentes amostragens aleatórias da população total de municípios para cada
variável selecionadas para o estudo de ANOVA no Capítulo 5.
Estas variáveis foram selecionadas entre as apresentadas no capítulo 1, e são elas
T_NESTUDA_NTRAB_MMEIO, MORT1, IDHM_L, IDHM_R, PPOBCRI e
PINDCRI. O motivo da seleção destas variáveis entre as outras é que o valor de F no teste
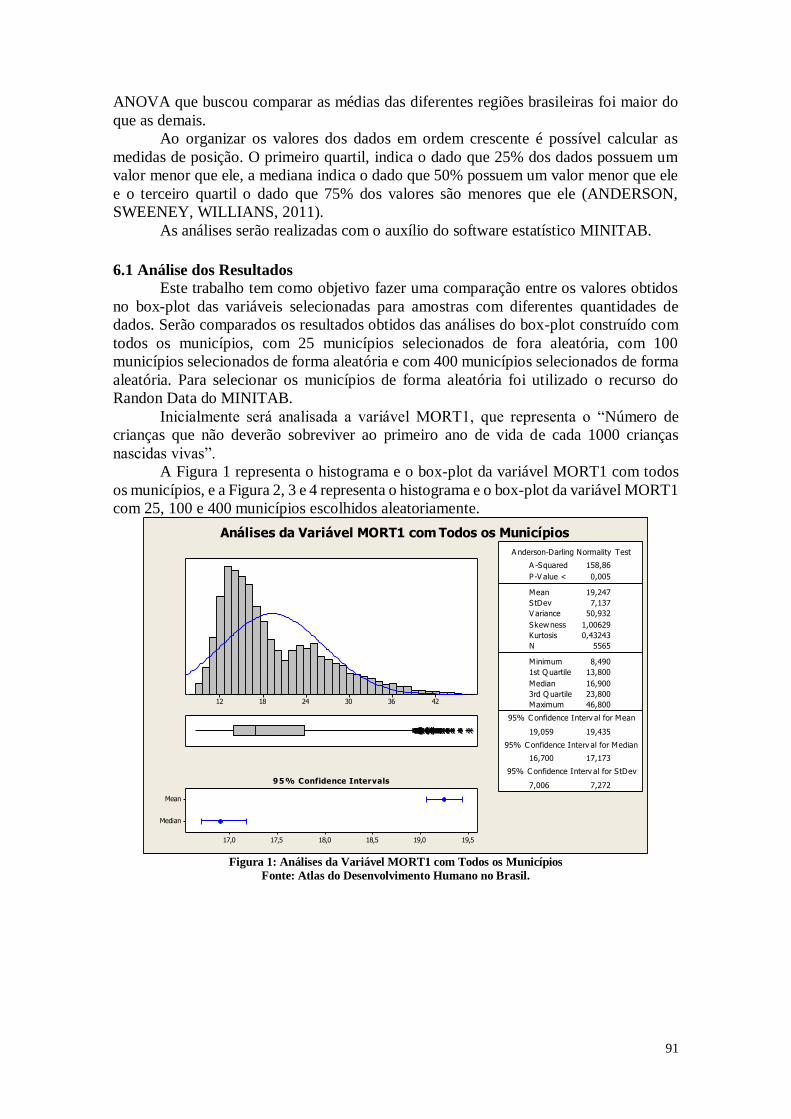
91
ANOVA que buscou comparar as médias das diferentes regiões brasileiras foi maior do
que as demais.
Ao organizar os valores dos dados em ordem crescente é possível calcular as
medidas de posição. O primeiro quartil, indica o dado que 25% dos dados possuem um
valor menor que ele, a mediana indica o dado que 50% possuem um valor menor que ele
e o terceiro quartil o dado que 75% dos valores são menores que ele (ANDERSON,
SWEENEY, WILLIANS, 2011).
As análises serão realizadas com o auxílio do software estatístico MINITAB.
6.1 Análise dos Resultados
Este trabalho tem como objetivo fazer uma comparação entre os valores obtidos
no box-plot das variáveis selecionadas para amostras com diferentes quantidades de
dados. Serão comparados os resultados obtidos das análises do box-plot construído com
todos os municípios, com 25 municípios selecionados de fora aleatória, com 100
municípios selecionados de forma aleatória e com 400 municípios selecionados de forma
aleatória. Para selecionar os municípios de forma aleatória foi utilizado o recurso do
Randon Data do MINITAB.
Inicialmente será analisada a variável MORT1, que representa o “Número de
crianças que não deverão sobreviver ao primeiro ano de vida de cada 1000 crianças
nascidas vivas”.
A Figura 1 representa o histograma e o box-plot da variável MORT1 com todos
os municípios, e a Figura 2, 3 e 4 representa o histograma e o box-plot da variável MORT1
com 25, 100 e 400 municípios escolhidos aleatoriamente.
423630241812
Median
Mean
19,519,018,518,017,517,0
1st Q uartile 13,800
Median 16,900
3rd Q uartile 23,800
Maximum 46,800
19,059 19,435
16,700 17,173
7,006 7,272
A -Squared 158,86
P-V alue < 0,005
Mean 19,247
StDev 7,137
V ariance 50,932
Skewness 1,00629
Kurtosis 0,43243
N 5565
Minimum 8,490
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises da Variável MORT1 com Todos os Municípios
Figura 1: Análises da Variável MORT1 com Todos os Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
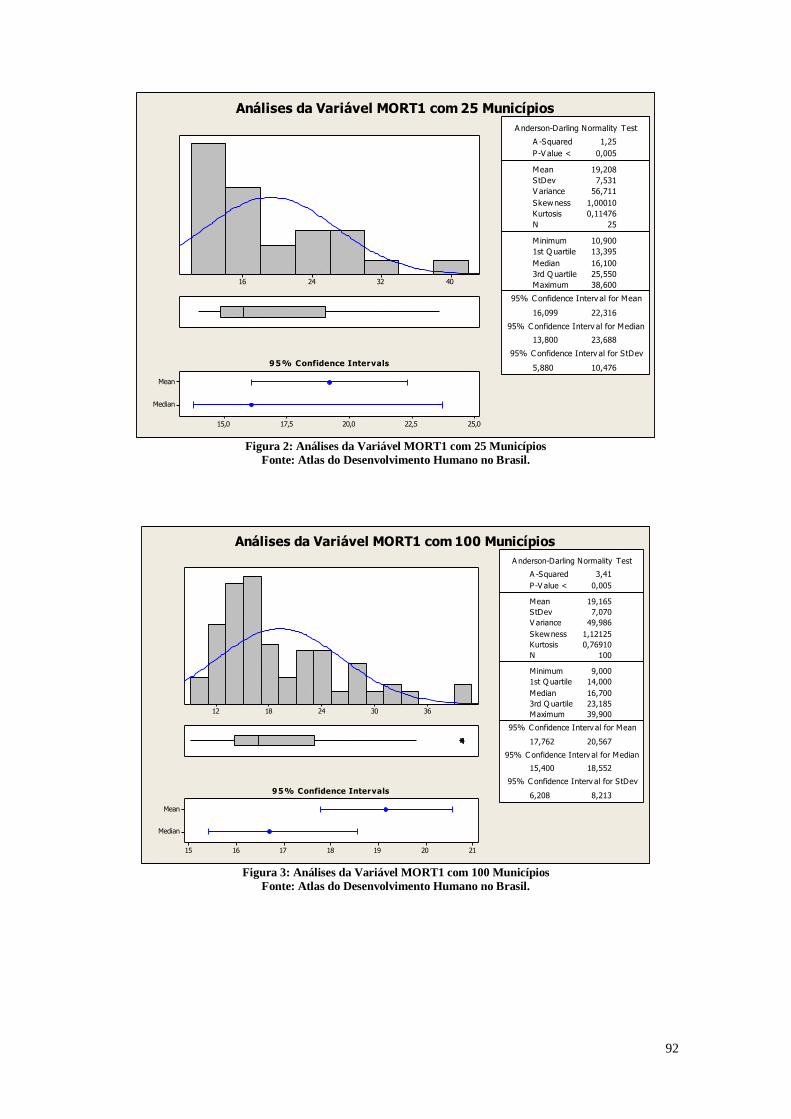
92
40322416
Median
Mean
25,022,520,017,515,0
1st Q uartile 13,395
Median 16,100
3rd Q uartile 25,550
Maximum 38,600
16,099 22,316
13,800 23,688
5,880 10,476
A -Squared 1,25
P-V alue < 0,005
Mean 19,208
StDev 7,531
V ariance 56,711
Skewness 1,00010
Kurtosis 0,11476
N 25
Minimum 10,900
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises da Variável MORT1 com 25 Municípios
Figura 2: Análises da Variável MORT1 com 25 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
3630241812
Median
Mean
21201918171615
1st Q uartile 14,000
Median 16,700
3rd Q uartile 23,185
Maximum 39,900
17,762 20,567
15,400 18,552
6,208 8,213
A -Squared 3,41
P-V alue < 0,005
Mean 19,165
StDev 7,070
V ariance 49,986
Skewness 1,12125
Kurtosis 0,76910
N 100
Minimum 9,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises da Variável MORT1 com 100 Municípios
Figura 3: Análises da Variável MORT1 com 100 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
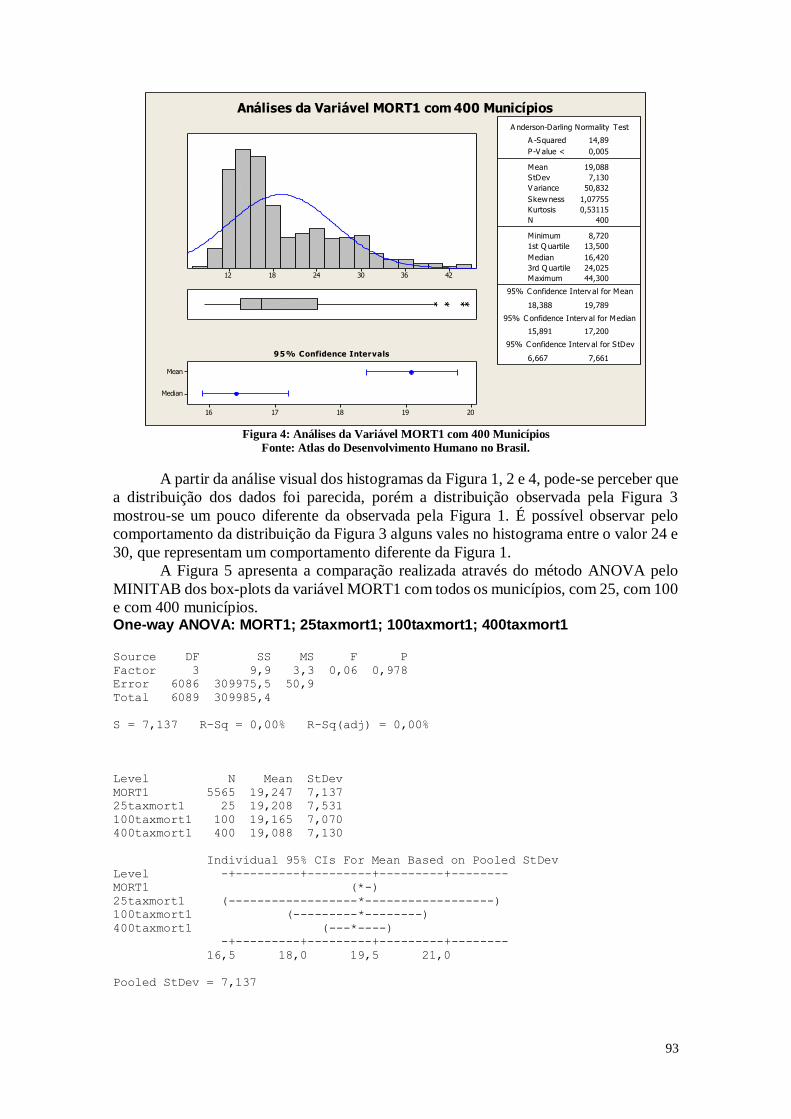
93
423630241812
Median
Mean
2019181716
1st Q uartile 13,500
Median 16,420
3rd Q uartile 24,025
Maximum 44,300
18,388 19,789
15,891 17,200
6,667 7,661
A -Squared 14,89
P-V alue < 0,005
Mean 19,088
StDev 7,130
V ariance 50,832
Skewness 1,07755
Kurtosis 0,53115
N 400
Minimum 8,720
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises da Variável MORT1 com 400 Municípios
Figura 4: Análises da Variável MORT1 com 400 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
A partir da análise visual dos histogramas da Figura 1, 2 e 4, pode-se perceber que
a distribuição dos dados foi parecida, porém a distribuição observada pela Figura 3
mostrou-se um pouco diferente da observada pela Figura 1. É possível observar pelo
comportamento da distribuição da Figura 3 alguns vales no histograma entre o valor 24 e
30, que representam um comportamento diferente da Figura 1.
A Figura 5 apresenta a comparação realizada através do método ANOVA pelo
MINITAB dos box-plots da variável MORT1 com todos os municípios, com 25, com 100
e com 400 municípios. One-way ANOVA: MORT1; 25taxmort1; 100taxmort1; 400taxmort1 Source DF SS MS F P
Factor 3 9,9 3,3 0,06 0,978
Error 6086 309975,5 50,9
Total 6089 309985,4
S = 7,137 R-Sq = 0,00% R-Sq(adj) = 0,00%
Level N Mean StDev
MORT1 5565 19,247 7,137
25taxmort1 25 19,208 7,531
100taxmort1 100 19,165 7,070
400taxmort1 400 19,088 7,130
Individual 95% CIs For Mean Based on Pooled StDev
Level -+---------+---------+---------+--------
MORT1 (*-)
25taxmort1 (------------------*------------------)
100taxmort1 (---------*--------)
400taxmort1 (---*----)
-+---------+---------+---------+--------
16,5 18,0 19,5 21,0
Pooled StDev = 7,137
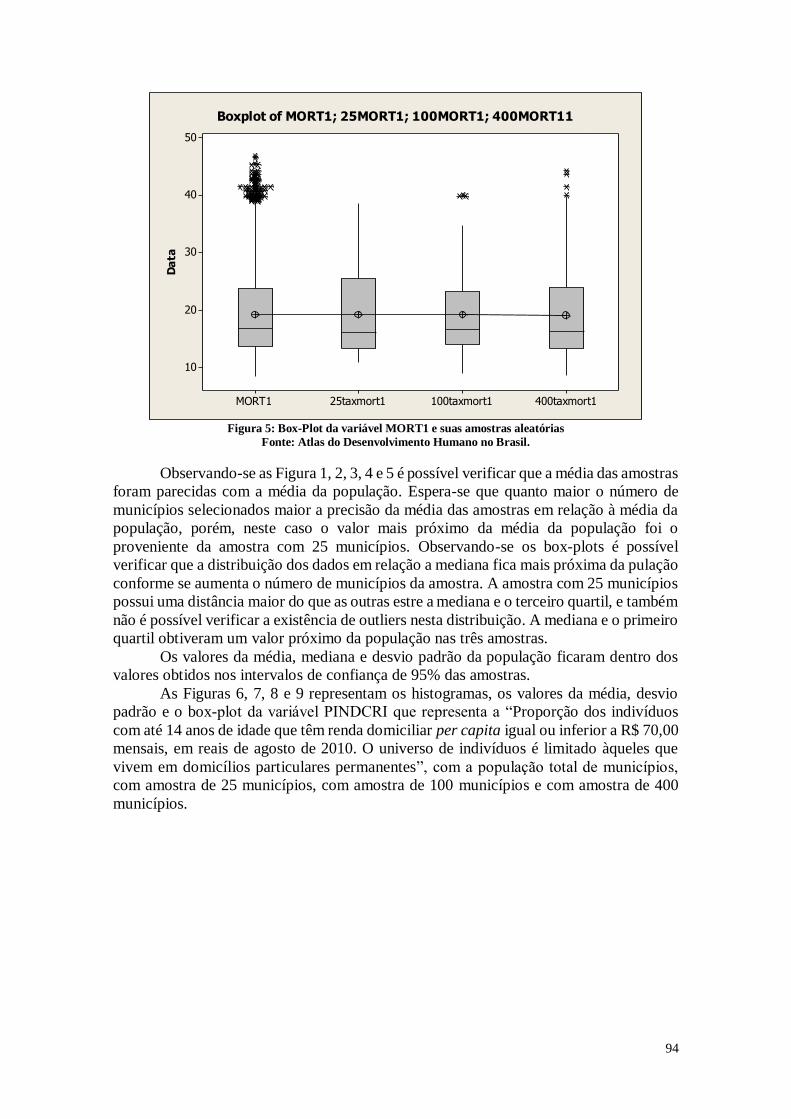
94
400taxmort1100taxmort125taxmort1MORT1
50
40
30
20
10
Da
ta
Boxplot of MORT1; 25MORT1; 100MORT1; 400MORT11
Figura 5: Box-Plot da variável MORT1 e suas amostras aleatórias
Fonte: Atlas do Desenvolvimento Humano no Brasil.
Observando-se as Figura 1, 2, 3, 4 e 5 é possível verificar que a média das amostras
foram parecidas com a média da população. Espera-se que quanto maior o número de
municípios selecionados maior a precisão da média das amostras em relação à média da
população, porém, neste caso o valor mais próximo da média da população foi o
proveniente da amostra com 25 municípios. Observando-se os box-plots é possível
verificar que a distribuição dos dados em relação a mediana fica mais próxima da pulação
conforme se aumenta o número de municípios da amostra. A amostra com 25 municípios
possui uma distância maior do que as outras estre a mediana e o terceiro quartil, e também
não é possível verificar a existência de outliers nesta distribuição. A mediana e o primeiro
quartil obtiveram um valor próximo da população nas três amostras.
Os valores da média, mediana e desvio padrão da população ficaram dentro dos
valores obtidos nos intervalos de confiança de 95% das amostras.
As Figuras 6, 7, 8 e 9 representam os histogramas, os valores da média, desvio
padrão e o box-plot da variável PINDCRI que representa a “Proporção dos indivíduos
com até 14 anos de idade que têm renda domiciliar per capita igual ou inferior a R$ 70,00
mensais, em reais de agosto de 2010. O universo de indivíduos é limitado àqueles que
vivem em domicílios particulares permanentes”, com a população total de municípios,
com amostra de 25 municípios, com amostra de 100 municípios e com amostra de 400
municípios.
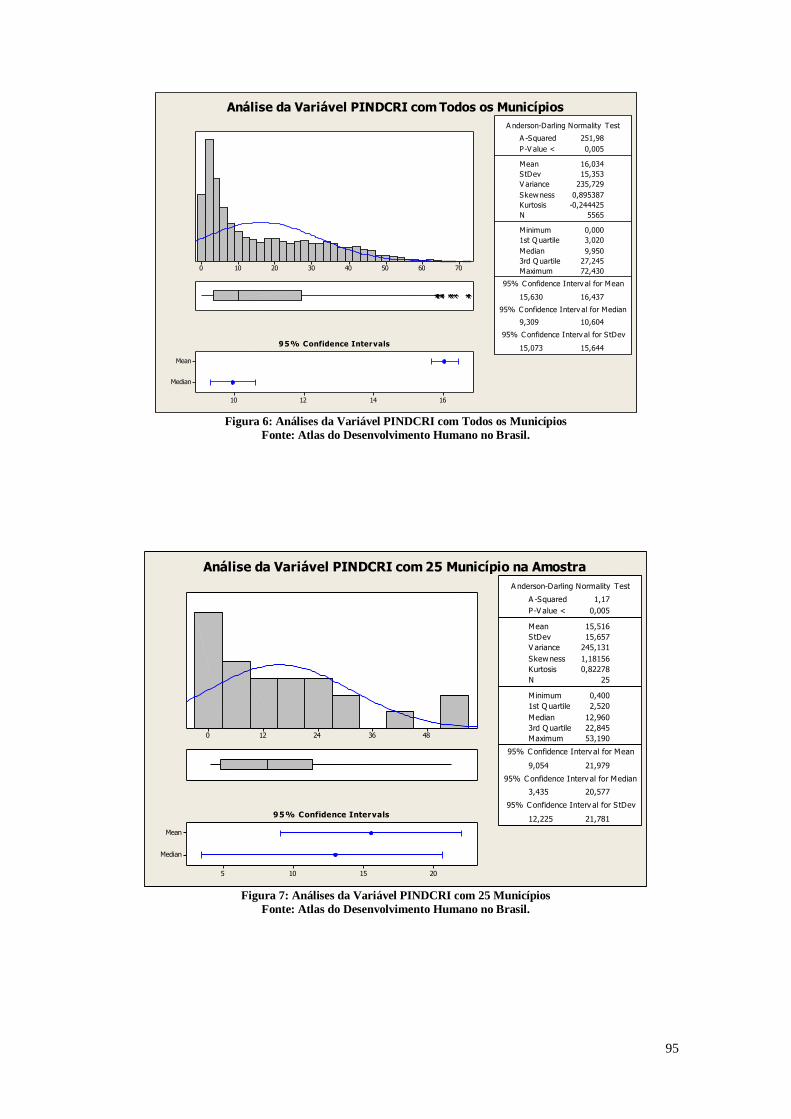
95
706050403020100
Median
Mean
16141210
1st Q uartile 3,020
Median 9,950
3rd Q uartile 27,245
Maximum 72,430
15,630 16,437
9,309 10,604
15,073 15,644
A -Squared 251,98
P-V alue < 0,005
Mean 16,034
StDev 15,353
V ariance 235,729
Skewness 0,895387
Kurtosis -0,244425
N 5565
Minimum 0,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável PINDCRI com Todos os Municípios
Figura 6: Análises da Variável PINDCRI com Todos os Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
483624120
Median
Mean
2015105
1st Q uartile 2,520
Median 12,960
3rd Q uartile 22,845
Maximum 53,190
9,054 21,979
3,435 20,577
12,225 21,781
A -Squared 1,17
P-V alue < 0,005
Mean 15,516
StDev 15,657
V ariance 245,131
Skewness 1,18156
Kurtosis 0,82278
N 25
Minimum 0,400
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável PINDCRI com 25 Município na Amostra
Figura 7: Análises da Variável PINDCRI com 25 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
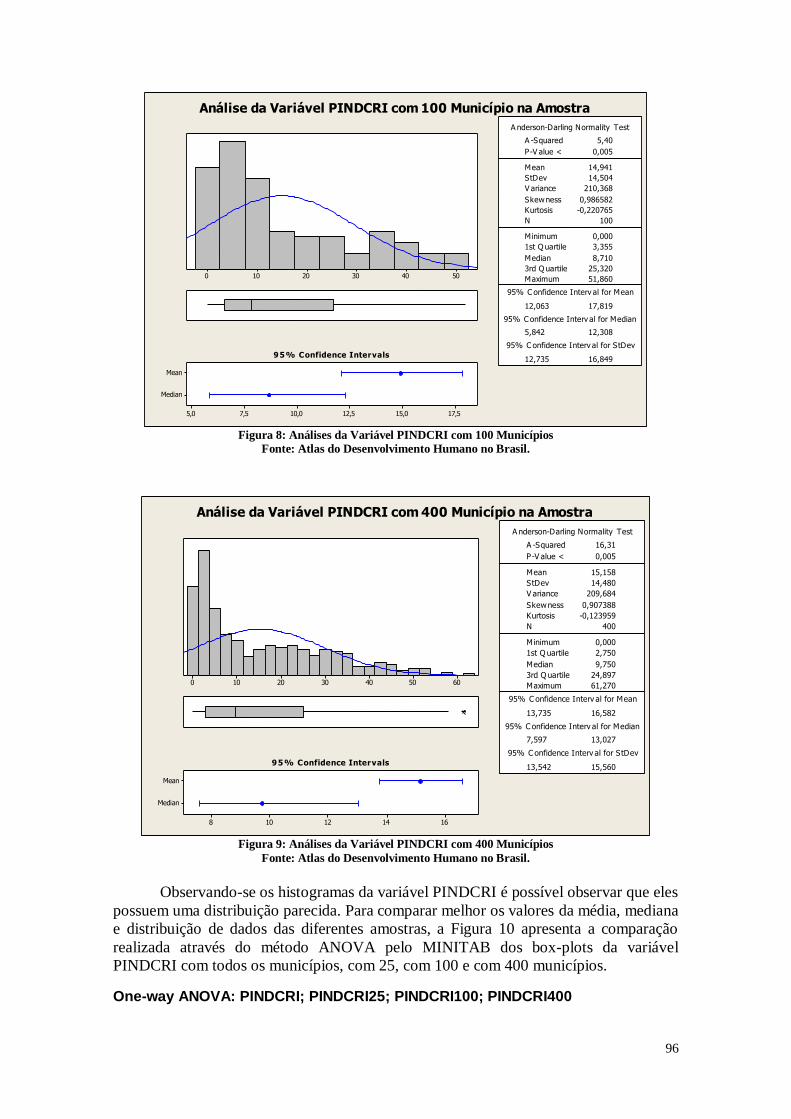
96
50403020100
Median
Mean
17,515,012,510,07,55,0
1st Q uartile 3,355
Median 8,710
3rd Q uartile 25,320
Maximum 51,860
12,063 17,819
5,842 12,308
12,735 16,849
A -Squared 5,40
P-V alue < 0,005
Mean 14,941
StDev 14,504
V ariance 210,368
Skewness 0,986582
Kurtosis -0,220765
N 100
Minimum 0,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável PINDCRI com 100 Município na Amostra
Figura 8: Análises da Variável PINDCRI com 100 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
6050403020100
Median
Mean
161412108
1st Q uartile 2,750
Median 9,750
3rd Q uartile 24,897
Maximum 61,270
13,735 16,582
7,597 13,027
13,542 15,560
A -Squared 16,31
P-V alue < 0,005
Mean 15,158
StDev 14,480
V ariance 209,684
Skewness 0,907388
Kurtosis -0,123959
N 400
Minimum 0,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável PINDCRI com 400 Município na Amostra
Figura 9: Análises da Variável PINDCRI com 400 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
Observando-se os histogramas da variável PINDCRI é possível observar que eles
possuem uma distribuição parecida. Para comparar melhor os valores da média, mediana
e distribuição de dados das diferentes amostras, a Figura 10 apresenta a comparação
realizada através do método ANOVA pelo MINITAB dos box-plots da variável
PINDCRI com todos os municípios, com 25, com 100 e com 400 municípios.
One-way ANOVA: PINDCRI; PINDCRI25; PINDCRI100; PINDCRI400
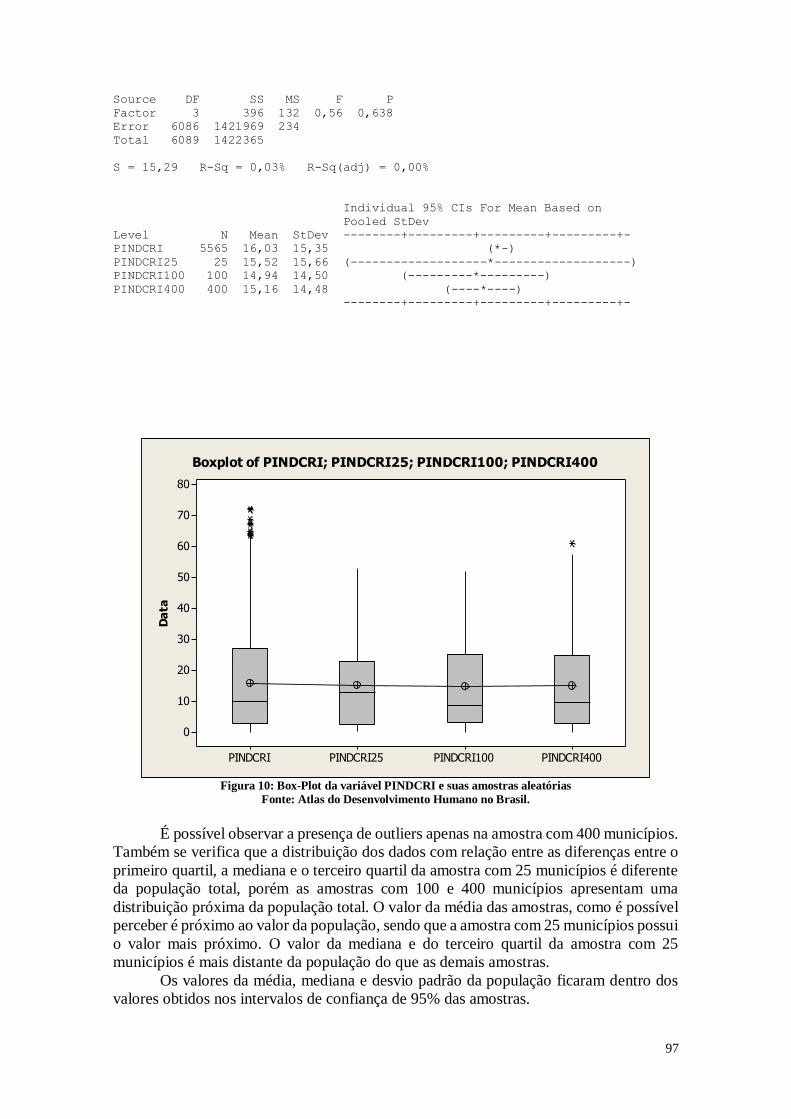
97
Source DF SS MS F P
Factor 3 396 132 0,56 0,638
Error 6086 1421969 234
Total 6089 1422365
S = 15,29 R-Sq = 0,03% R-Sq(adj) = 0,00%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev --------+---------+---------+---------+-
PINDCRI 5565 16,03 15,35 (*-)
PINDCRI25 25 15,52 15,66 (-------------------*-------------------)
PINDCRI100 100 14,94 14,50 (---------*---------)
PINDCRI400 400 15,16 14,48 (----*----)
--------+---------+---------+---------+-
PINDCRI400PINDCRI100PINDCRI25PINDCRI
80
70
60
50
40
30
20
10
0
Da
ta
Boxplot of PINDCRI; PINDCRI25; PINDCRI100; PINDCRI400
Figura 10: Box-Plot da variável PINDCRI e suas amostras aleatórias
Fonte: Atlas do Desenvolvimento Humano no Brasil.
É possível observar a presença de outliers apenas na amostra com 400 municípios.
Também se verifica que a distribuição dos dados com relação entre as diferenças entre o
primeiro quartil, a mediana e o terceiro quartil da amostra com 25 municípios é diferente
da população total, porém as amostras com 100 e 400 municípios apresentam uma
distribuição próxima da população total. O valor da média das amostras, como é possível
perceber é próximo ao valor da população, sendo que a amostra com 25 municípios possui
o valor mais próximo. O valor da mediana e do terceiro quartil da amostra com 25
municípios é mais distante da população do que as demais amostras.
Os valores da média, mediana e desvio padrão da população ficaram dentro dos
valores obtidos nos intervalos de confiança de 95% das amostras.

98
As Figuras 11, 12, 13 e 14 representam os histogramas, os valores da média,
desvio padrão e o box-plot da variável PPOBCRI que representa a “Proporção dos
indivíduos com até 14 anos de idade que têm renda domiciliar per capita igual ou inferior
a R$ 255,00 mensais, em reais de agosto de 2010, equivalente a 1/2 salário mínimo nessa
data. O universo de indivíduos é limitado àqueles com até 14 anos e que vivem em
domicílios particulares permanentes”, com a população total de municípios, com amostra
de 25 municípios, com amostra de 100 municípios e com amostra de 400 municípios.
847056422814
Median
Mean
6261605958
1st Q uartile 39,705
Median 61,040
3rd Q uartile 80,585
Maximum 95,440
58,389 59,588
60,029 62,162
22,402 23,250
A -Squared 113,40
P-V alue < 0,005
Mean 58,989
StDev 22,818
V ariance 520,660
Skewness -0,29009
Kurtosis -1,16334
N 5565
Minimum 2,450
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável PPOBCRI com Todos os Municípios
Figura 11: Análise da Variável PPOBCRI com Todos os Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
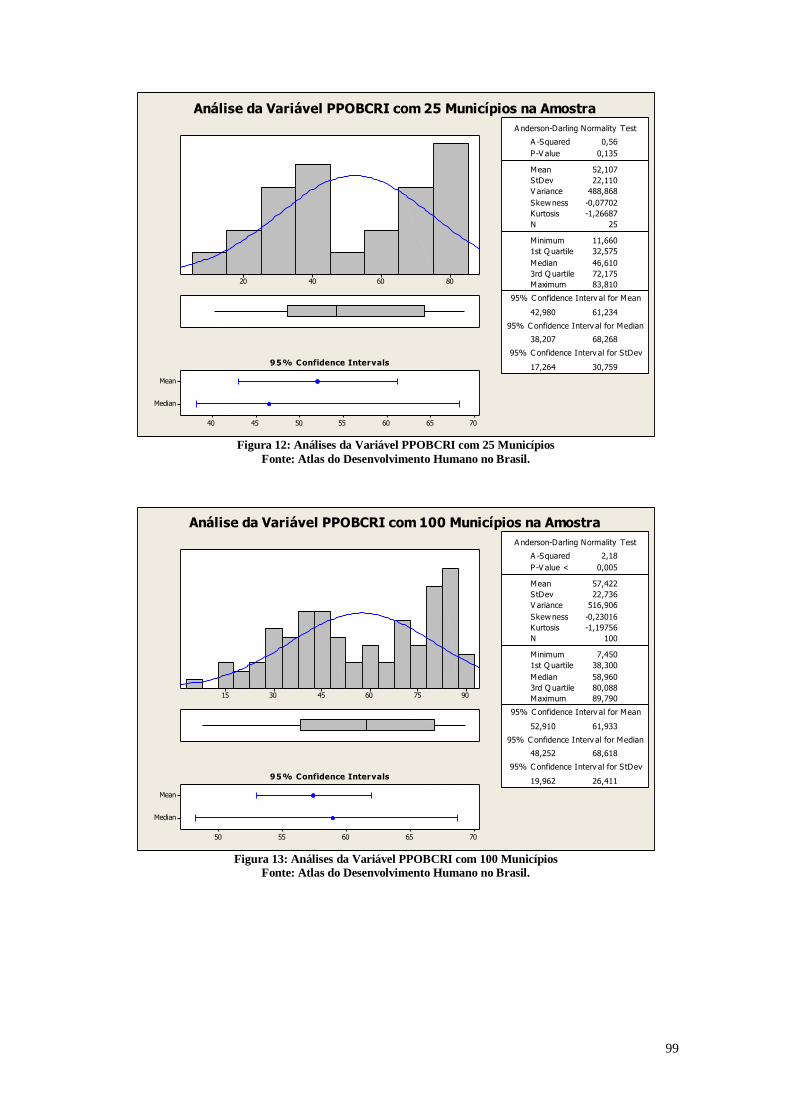
99
80604020
Median
Mean
70656055504540
1st Q uartile 32,575
Median 46,610
3rd Q uartile 72,175
Maximum 83,810
42,980 61,234
38,207 68,268
17,264 30,759
A -Squared 0,56
P-V alue 0,135
Mean 52,107
StDev 22,110
V ariance 488,868
Skewness -0,07702
Kurtosis -1,26687
N 25
Minimum 11,660
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável PPOBCRI com 25 Municípios na Amostra
Figura 12: Análises da Variável PPOBCRI com 25 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
907560453015
Median
Mean
7065605550
1st Q uartile 38,300
Median 58,960
3rd Q uartile 80,088
Maximum 89,790
52,910 61,933
48,252 68,618
19,962 26,411
A -Squared 2,18
P-V alue < 0,005
Mean 57,422
StDev 22,736
V ariance 516,906
Skewness -0,23016
Kurtosis -1,19756
N 100
Minimum 7,450
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável PPOBCRI com 100 Municípios na Amostra
Figura 13: Análises da Variável PPOBCRI com 100 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
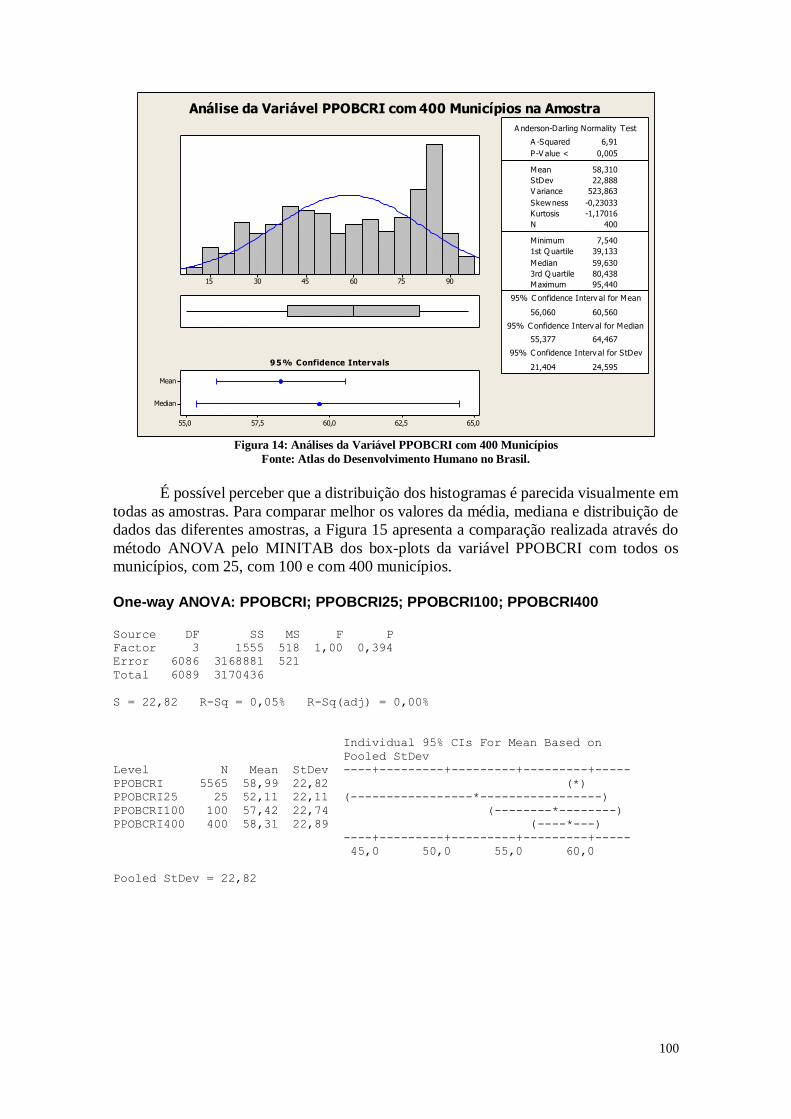
100
907560453015
Median
Mean
65,062,560,057,555,0
1st Q uartile 39,133
Median 59,630
3rd Q uartile 80,438
Maximum 95,440
56,060 60,560
55,377 64,467
21,404 24,595
A -Squared 6,91
P-V alue < 0,005
Mean 58,310
StDev 22,888
V ariance 523,863
Skewness -0,23033
Kurtosis -1,17016
N 400
Minimum 7,540
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável PPOBCRI com 400 Municípios na Amostra
Figura 14: Análises da Variável PPOBCRI com 400 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
É possível perceber que a distribuição dos histogramas é parecida visualmente em
todas as amostras. Para comparar melhor os valores da média, mediana e distribuição de
dados das diferentes amostras, a Figura 15 apresenta a comparação realizada através do
método ANOVA pelo MINITAB dos box-plots da variável PPOBCRI com todos os
municípios, com 25, com 100 e com 400 municípios.
One-way ANOVA: PPOBCRI; PPOBCRI25; PPOBCRI100; PPOBCRI400 Source DF SS MS F P
Factor 3 1555 518 1,00 0,394
Error 6086 3168881 521
Total 6089 3170436
S = 22,82 R-Sq = 0,05% R-Sq(adj) = 0,00%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ----+---------+---------+---------+-----
PPOBCRI 5565 58,99 22,82 (*)
PPOBCRI25 25 52,11 22,11 (-----------------*-----------------)
PPOBCRI100 100 57,42 22,74 (--------*--------)
PPOBCRI400 400 58,31 22,89 (----*---)
----+---------+---------+---------+-----
45,0 50,0 55,0 60,0
Pooled StDev = 22,82
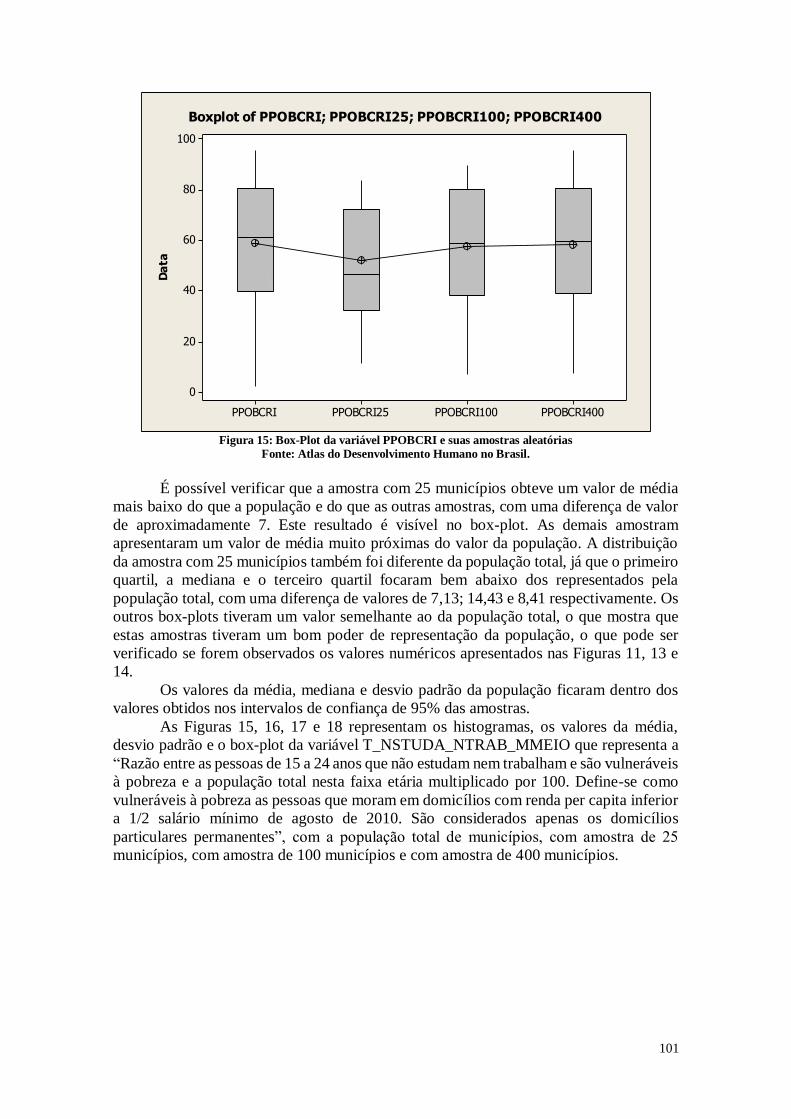
101
PPOBCRI400PPOBCRI100PPOBCRI25PPOBCRI
100
80
60
40
20
0
Da
ta
Boxplot of PPOBCRI; PPOBCRI25; PPOBCRI100; PPOBCRI400
Figura 15: Box-Plot da variável PPOBCRI e suas amostras aleatórias
Fonte: Atlas do Desenvolvimento Humano no Brasil.
É possível verificar que a amostra com 25 municípios obteve um valor de média
mais baixo do que a população e do que as outras amostras, com uma diferença de valor
de aproximadamente 7. Este resultado é visível no box-plot. As demais amostram
apresentaram um valor de média muito próximas do valor da população. A distribuição
da amostra com 25 municípios também foi diferente da população total, já que o primeiro
quartil, a mediana e o terceiro quartil focaram bem abaixo dos representados pela
população total, com uma diferença de valores de 7,13; 14,43 e 8,41 respectivamente. Os
outros box-plots tiveram um valor semelhante ao da população total, o que mostra que
estas amostras tiveram um bom poder de representação da população, o que pode ser
verificado se forem observados os valores numéricos apresentados nas Figuras 11, 13 e
14.
Os valores da média, mediana e desvio padrão da população ficaram dentro dos
valores obtidos nos intervalos de confiança de 95% das amostras.
As Figuras 15, 16, 17 e 18 representam os histogramas, os valores da média,
desvio padrão e o box-plot da variável T_NSTUDA_NTRAB_MMEIO que representa a
“Razão entre as pessoas de 15 a 24 anos que não estudam nem trabalham e são vulneráveis
à pobreza e a população total nesta faixa etária multiplicado por 100. Define-se como
vulneráveis à pobreza as pessoas que moram em domicílios com renda per capita inferior
a 1/2 salário mínimo de agosto de 2010. São considerados apenas os domicílios
particulares permanentes”, com a população total de municípios, com amostra de 25
municípios, com amostra de 100 municípios e com amostra de 400 municípios.
102
56484032241680
Median
Mean
15,014,514,013,5
1st Q uartile 7,295
Median 13,670
3rd Q uartile 21,600
Maximum 55,250
14,546 15,006
13,299 14,340
8,592 8,917
A -Squared 61,38
P-V alue < 0,005
Mean 14,776
StDev 8,751
V ariance 76,588
Skewness 0,388117
Kurtosis -0,679693
N 5565
Minimum 0,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável T_NESTUDA_NTRAB_MMEIO para Todos os Municípios
Figura 16: Análises da Variável T_NESTUDA_NTRAB_MMEIO com Todos os Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
241680
Median
Mean
201816141210
1st Q uartile 9,410
Median 14,860
3rd Q uartile 20,955
Maximum 28,140
11,630 18,061
10,089 19,249
6,083 10,837
A -Squared 0,28
P-V alue 0,618
Mean 14,846
StDev 7,790
V ariance 60,686
Skewness 0,044807
Kurtosis -0,963053
N 25
Minimum 0,780
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável T_NESTUDA_NTRAB_MMEIO na Amostra com 25 Municípios
Figura 17: Análises da Variável T_NESTUDA_NTRAB_MMEIO com 25 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
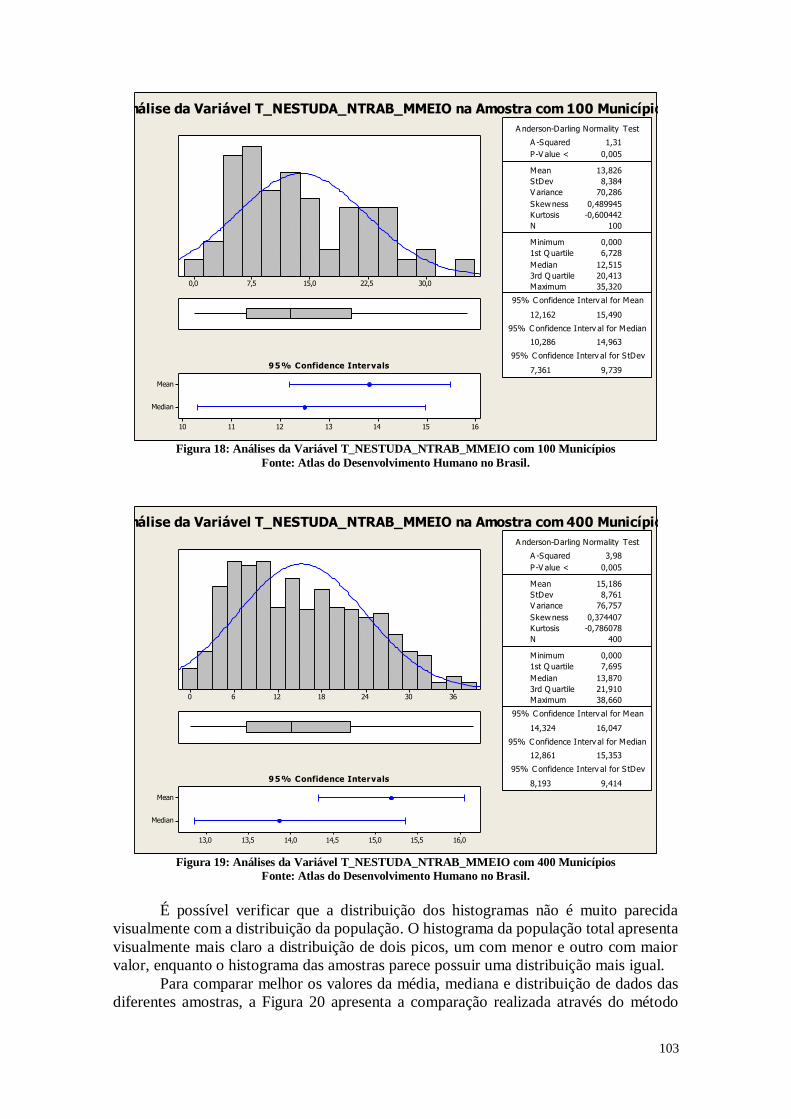
103
30,022,515,07,50,0
Median
Mean
16151413121110
1st Q uartile 6,728
Median 12,515
3rd Q uartile 20,413
Maximum 35,320
12,162 15,490
10,286 14,963
7,361 9,739
A -Squared 1,31
P-V alue < 0,005
Mean 13,826
StDev 8,384
V ariance 70,286
Skewness 0,489945
Kurtosis -0,600442
N 100
Minimum 0,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável T_NESTUDA_NTRAB_MMEIO na Amostra com 100 Municípios
Figura 18: Análises da Variável T_NESTUDA_NTRAB_MMEIO com 100 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
363024181260
Median
Mean
16,015,515,014,514,013,513,0
1st Q uartile 7,695
Median 13,870
3rd Q uartile 21,910
Maximum 38,660
14,324 16,047
12,861 15,353
8,193 9,414
A -Squared 3,98
P-V alue < 0,005
Mean 15,186
StDev 8,761
V ariance 76,757
Skewness 0,374407
Kurtosis -0,786078
N 400
Minimum 0,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável T_NESTUDA_NTRAB_MMEIO na Amostra com 400 Municípios
Figura 19: Análises da Variável T_NESTUDA_NTRAB_MMEIO com 400 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
É possível verificar que a distribuição dos histogramas não é muito parecida
visualmente com a distribuição da população. O histograma da população total apresenta
visualmente mais claro a distribuição de dois picos, um com menor e outro com maior
valor, enquanto o histograma das amostras parece possuir uma distribuição mais igual.
Para comparar melhor os valores da média, mediana e distribuição de dados das
diferentes amostras, a Figura 20 apresenta a comparação realizada através do método
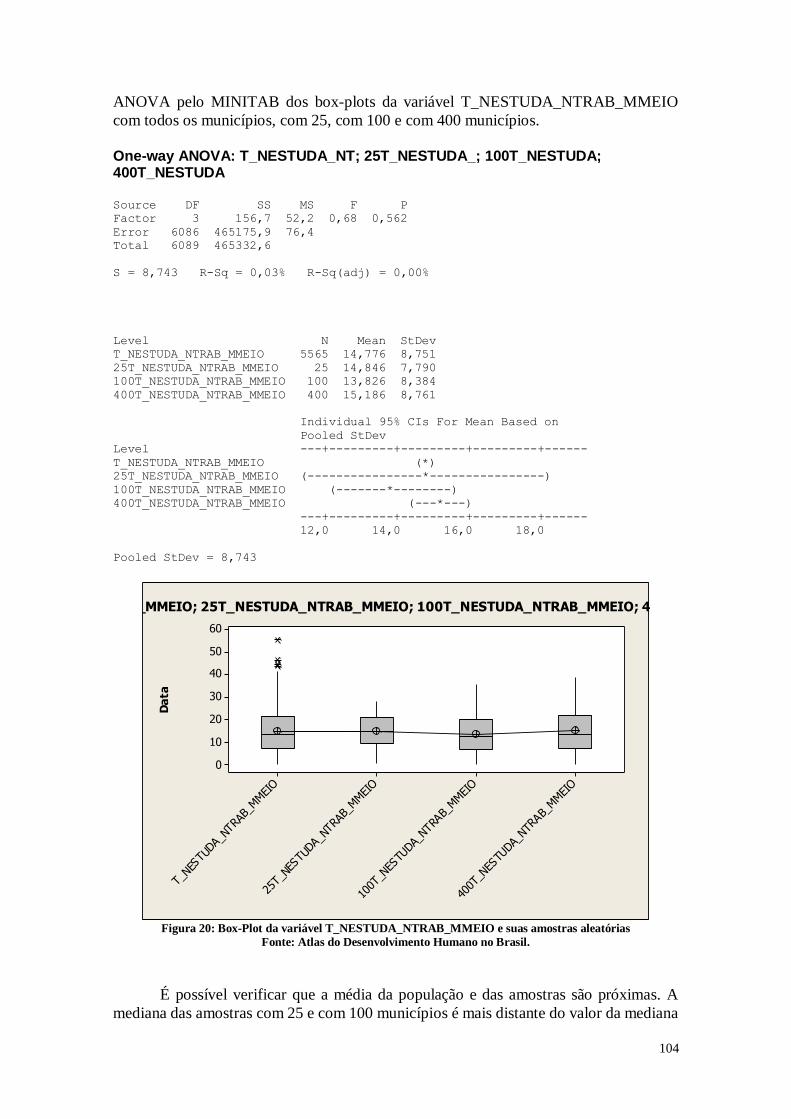
104
ANOVA pelo MINITAB dos box-plots da variável T_NESTUDA_NTRAB_MMEIO
com todos os municípios, com 25, com 100 e com 400 municípios.
One-way ANOVA: T_NESTUDA_NT; 25T_NESTUDA_; 100T_NESTUDA; 400T_NESTUDA Source DF SS MS F P
Factor 3 156,7 52,2 0,68 0,562
Error 6086 465175,9 76,4
Total 6089 465332,6
S = 8,743 R-Sq = 0,03% R-Sq(adj) = 0,00%
Level N Mean StDev
T_NESTUDA_NTRAB_MMEIO 5565 14,776 8,751
25T_NESTUDA_NTRAB_MMEIO 25 14,846 7,790
100T_NESTUDA_NTRAB_MMEIO 100 13,826 8,384
400T_NESTUDA_NTRAB_MMEIO 400 15,186 8,761
Individual 95% CIs For Mean Based on
Pooled StDev
Level ---+---------+---------+---------+------
T_NESTUDA_NTRAB_MMEIO (*)
25T_NESTUDA_NTRAB_MMEIO (----------------*----------------)
100T_NESTUDA_NTRAB_MMEIO (-------*--------)
400T_NESTUDA_NTRAB_MMEIO (---*---)
---+---------+---------+---------+------
12,0 14,0 16,0 18,0
Pooled StDev = 8,743
400T
_NES
TUDA
_NTR
AB_M
MEIO
100T
_NES
TUDA
_NTR
AB_M
MEIO
25T_
NEST
UDA_
NTRA
B_MMEIO
T_NE
STUD
A_NT
RAB_
MMEIO
60
50
40
30
20
10
0
Da
ta
RAB_MMEIO; 25T_NESTUDA_NTRAB_MMEIO; 100T_NESTUDA_NTRAB_MMEIO; 400T
Figura 20: Box-Plot da variável T_NESTUDA_NTRAB_MMEIO e suas amostras aleatórias
Fonte: Atlas do Desenvolvimento Humano no Brasil.
É possível verificar que a média da população e das amostras são próximas. A
mediana das amostras com 25 e com 100 municípios é mais distante do valor da mediana
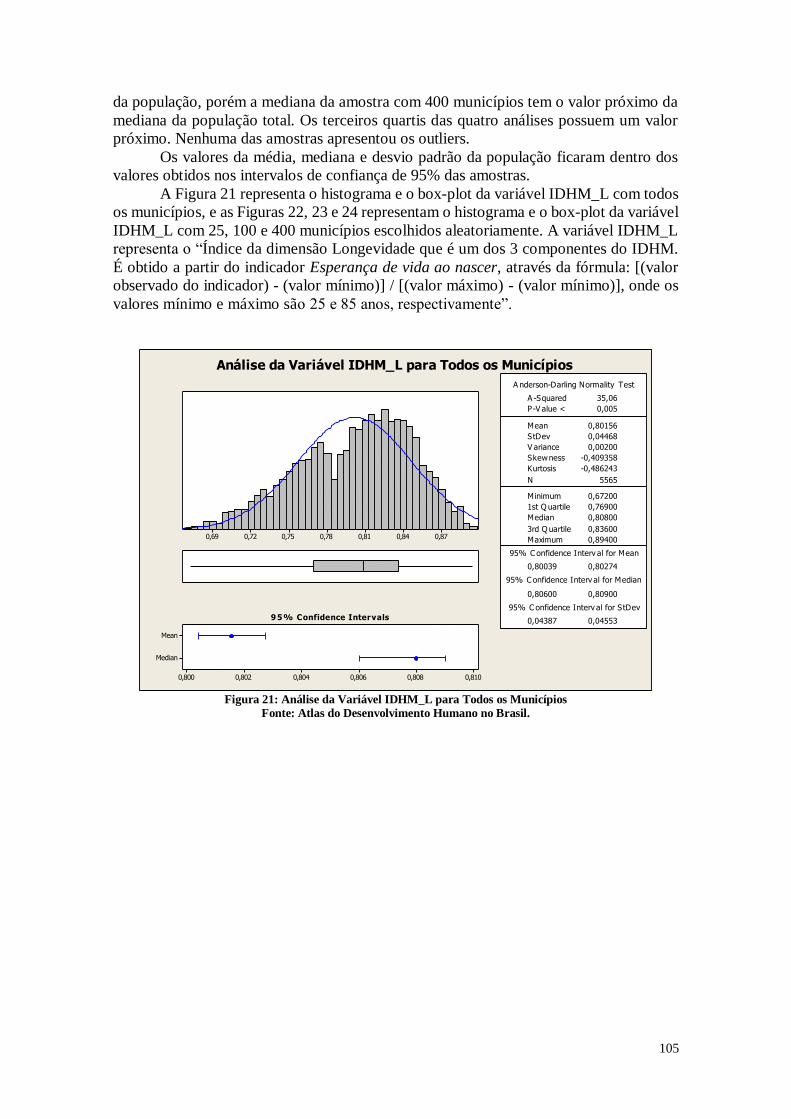
105
da população, porém a mediana da amostra com 400 municípios tem o valor próximo da
mediana da população total. Os terceiros quartis das quatro análises possuem um valor
próximo. Nenhuma das amostras apresentou os outliers.
Os valores da média, mediana e desvio padrão da população ficaram dentro dos
valores obtidos nos intervalos de confiança de 95% das amostras.
A Figura 21 representa o histograma e o box-plot da variável IDHM_L com todos
os municípios, e as Figuras 22, 23 e 24 representam o histograma e o box-plot da variável
IDHM_L com 25, 100 e 400 municípios escolhidos aleatoriamente. A variável IDHM_L
representa o “Índice da dimensão Longevidade que é um dos 3 componentes do IDHM.
É obtido a partir do indicador Esperança de vida ao nascer, através da fórmula: [(valor
observado do indicador) - (valor mínimo)] / [(valor máximo) - (valor mínimo)], onde os
valores mínimo e máximo são 25 e 85 anos, respectivamente”.
0,870,840,810,780,750,720,69
Median
Mean
0,8100,8080,8060,8040,8020,800
1st Q uartile 0,76900
Median 0,80800
3rd Q uartile 0,83600
Maximum 0,89400
0,80039 0,80274
0,80600 0,80900
0,04387 0,04553
A -Squared 35,06
P-V alue < 0,005
Mean 0,80156
StDev 0,04468
V ariance 0,00200
Skewness -0,409358
Kurtosis -0,486243
N 5565
Minimum 0,67200
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável IDHM_L para Todos os Municípios
Figura 21: Análise da Variável IDHM_L para Todos os Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
106
0,880,840,800,760,72
Median
Mean
0,820,810,800,790,780,77
1st Q uartile 0,76600
Median 0,79800
3rd Q uartile 0,83050
Maximum 0,88400
0,78234 0,81998
0,77258 0,81641
0,03559 0,06342
A -Squared 0,24
P-V alue 0,752
Mean 0,80116
StDev 0,04558
V ariance 0,00208
Skewness 0,217462
Kurtosis -0,583071
N 25
Minimum 0,71900
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável IDHM_L para Uma Amostra com 25 Municípios
Figura 22: Análise da Variável IDHM_L para Uma Amostra com 25 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
0,840,800,760,720,68
Median
Mean
0,8150,8100,8050,8000,7950,790
1st Q uartile 0,76425
Median 0,80400
3rd Q uartile 0,83475
Maximum 0,87000
0,79005 0,80753
0,79474 0,81477
0,03868 0,05118
A -Squared 0,72
P-V alue 0,057
Mean 0,79879
StDev 0,04406
V ariance 0,00194
Skewness -0,404751
Kurtosis -0,550106
N 100
Minimum 0,68700
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável IDHM_L para Uma Amostra com 100 Municípios
Figura 23: Análise da Variável IDHM_L para Uma Amostra com 100 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
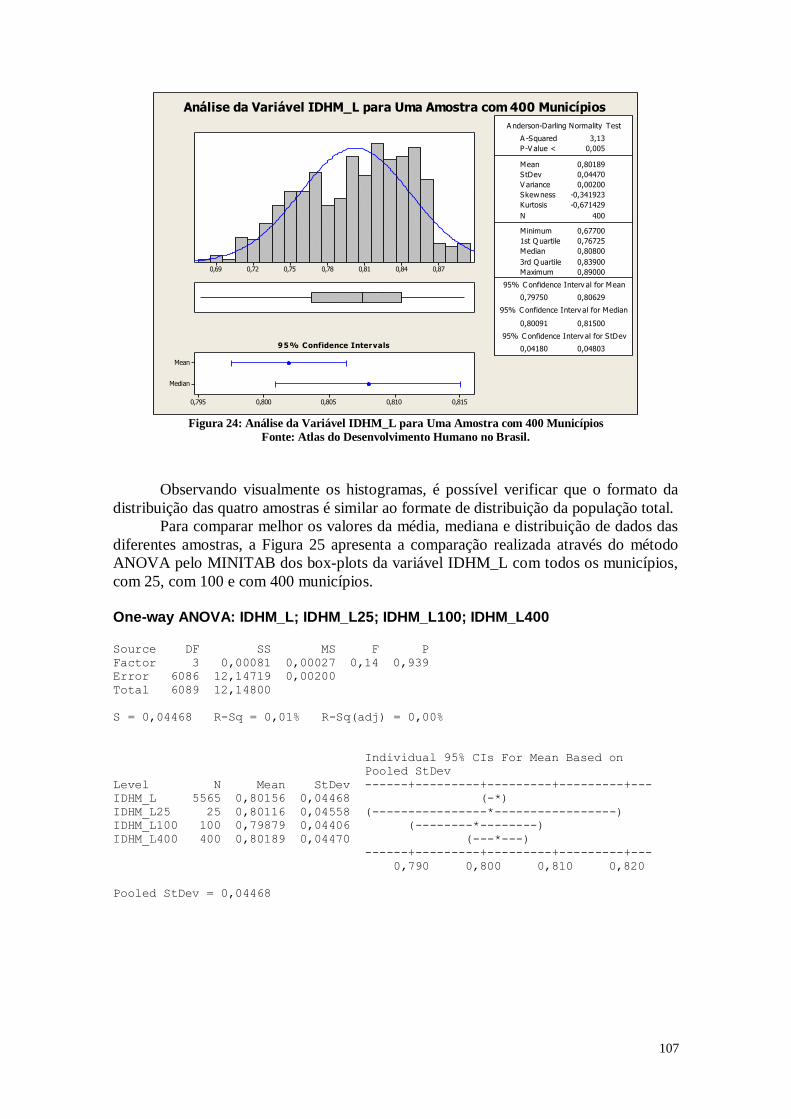
107
0,870,840,810,780,750,720,69
Median
Mean
0,8150,8100,8050,8000,795
1st Q uartile 0,76725
Median 0,80800
3rd Q uartile 0,83900
Maximum 0,89000
0,79750 0,80629
0,80091 0,81500
0,04180 0,04803
A -Squared 3,13
P-V alue < 0,005
Mean 0,80189
StDev 0,04470
V ariance 0,00200
Skewness -0,341923
Kurtosis -0,671429
N 400
Minimum 0,67700
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise da Variável IDHM_L para Uma Amostra com 400 Municípios
Figura 24: Análise da Variável IDHM_L para Uma Amostra com 400 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
Observando visualmente os histogramas, é possível verificar que o formato da
distribuição das quatro amostras é similar ao formate de distribuição da população total.
Para comparar melhor os valores da média, mediana e distribuição de dados das
diferentes amostras, a Figura 25 apresenta a comparação realizada através do método
ANOVA pelo MINITAB dos box-plots da variável IDHM_L com todos os municípios,
com 25, com 100 e com 400 municípios.
One-way ANOVA: IDHM_L; IDHM_L25; IDHM_L100; IDHM_L400 Source DF SS MS F P
Factor 3 0,00081 0,00027 0,14 0,939
Error 6086 12,14719 0,00200
Total 6089 12,14800
S = 0,04468 R-Sq = 0,01% R-Sq(adj) = 0,00%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ------+---------+---------+---------+---
IDHM_L 5565 0,80156 0,04468 (-*)
IDHM_L25 25 0,80116 0,04558 (----------------*-----------------)
IDHM_L100 100 0,79879 0,04406 (--------*--------)
IDHM_L400 400 0,80189 0,04470 (---*---)
------+---------+---------+---------+---
0,790 0,800 0,810 0,820
Pooled StDev = 0,04468
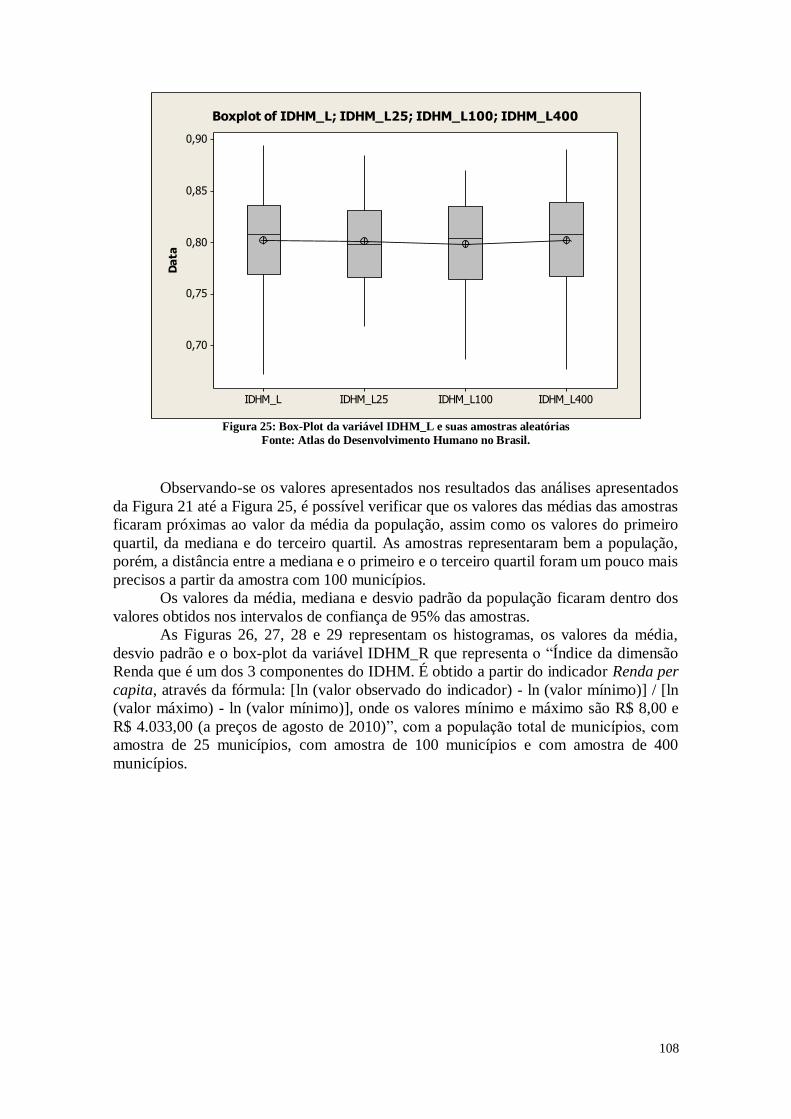
108
IDHM_L400IDHM_L100IDHM_L25IDHM_L
0,90
0,85
0,80
0,75
0,70
Da
ta
Boxplot of IDHM_L; IDHM_L25; IDHM_L100; IDHM_L400
Figura 25: Box-Plot da variável IDHM_L e suas amostras aleatórias
Fonte: Atlas do Desenvolvimento Humano no Brasil.
Observando-se os valores apresentados nos resultados das análises apresentados
da Figura 21 até a Figura 25, é possível verificar que os valores das médias das amostras
ficaram próximas ao valor da média da população, assim como os valores do primeiro
quartil, da mediana e do terceiro quartil. As amostras representaram bem a população,
porém, a distância entre a mediana e o primeiro e o terceiro quartil foram um pouco mais
precisos a partir da amostra com 100 municípios.
Os valores da média, mediana e desvio padrão da população ficaram dentro dos
valores obtidos nos intervalos de confiança de 95% das amostras.
As Figuras 26, 27, 28 e 29 representam os histogramas, os valores da média,
desvio padrão e o box-plot da variável IDHM_R que representa o “Índice da dimensão
Renda que é um dos 3 componentes do IDHM. É obtido a partir do indicador Renda per
capita, através da fórmula: [ln (valor observado do indicador) - ln (valor mínimo)] / [ln
(valor máximo) - ln (valor mínimo)], onde os valores mínimo e máximo são R$ 8,00 e
R$ 4.033,00 (a preços de agosto de 2010)”, com a população total de municípios, com
amostra de 25 municípios, com amostra de 100 municípios e com amostra de 400
municípios.
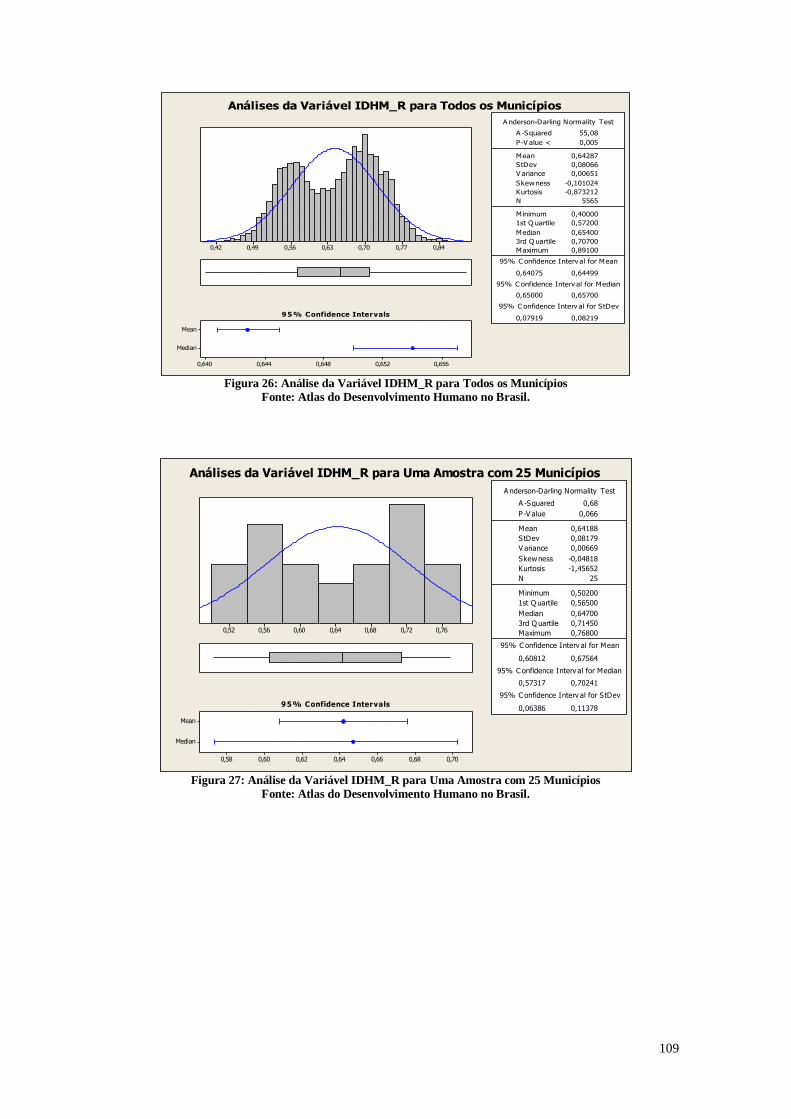
109
0,840,770,700,630,560,490,42
Median
Mean
0,6560,6520,6480,6440,640
1st Q uartile 0,57200
Median 0,65400
3rd Q uartile 0,70700
Maximum 0,89100
0,64075 0,64499
0,65000 0,65700
0,07919 0,08219
A -Squared 55,08
P-V alue < 0,005
Mean 0,64287
StDev 0,08066
V ariance 0,00651
Skewness -0,101024
Kurtosis -0,873212
N 5565
Minimum 0,40000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises da Variável IDHM_R para Todos os Municípios
Figura 26: Análise da Variável IDHM_R para Todos os Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
0,760,720,680,640,600,560,52
Median
Mean
0,700,680,660,640,620,600,58
1st Q uartile 0,56500
Median 0,64700
3rd Q uartile 0,71450
Maximum 0,76800
0,60812 0,67564
0,57317 0,70241
0,06386 0,11378
A -Squared 0,68
P-V alue 0,066
Mean 0,64188
StDev 0,08179
V ariance 0,00669
Skewness -0,04818
Kurtosis -1,45652
N 25
Minimum 0,50200
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises da Variável IDHM_R para Uma Amostra com 25 Municípios
Figura 27: Análise da Variável IDHM_R para Uma Amostra com 25 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
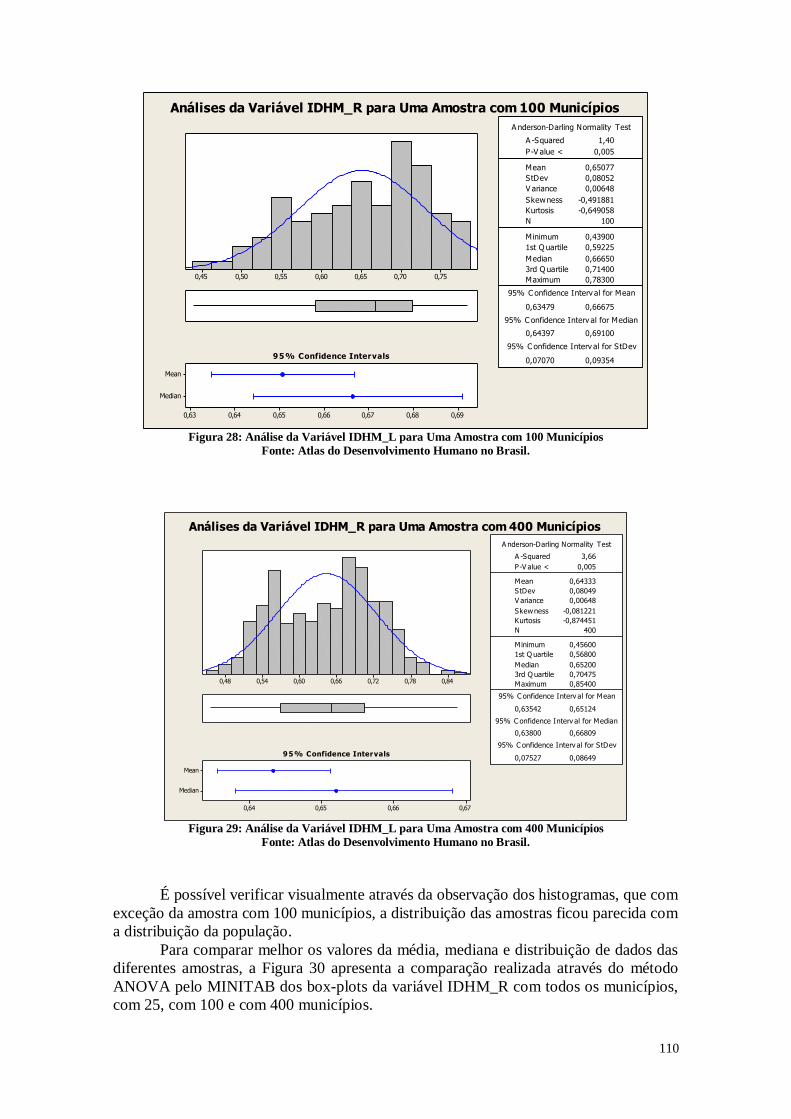
110
0,750,700,650,600,550,500,45
Median
Mean
0,690,680,670,660,650,640,63
1st Q uartile 0,59225
Median 0,66650
3rd Q uartile 0,71400
Maximum 0,78300
0,63479 0,66675
0,64397 0,69100
0,07070 0,09354
A -Squared 1,40
P-V alue < 0,005
Mean 0,65077
StDev 0,08052
V ariance 0,00648
Skewness -0,491881
Kurtosis -0,649058
N 100
Minimum 0,43900
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises da Variável IDHM_R para Uma Amostra com 100 Municípios
Figura 28: Análise da Variável IDHM_L para Uma Amostra com 100 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
0,840,780,720,660,600,540,48
Median
Mean
0,670,660,650,64
1st Q uartile 0,56800
Median 0,65200
3rd Q uartile 0,70475
Maximum 0,85400
0,63542 0,65124
0,63800 0,66809
0,07527 0,08649
A -Squared 3,66
P-V alue < 0,005
Mean 0,64333
StDev 0,08049
V ariance 0,00648
Skewness -0,081221
Kurtosis -0,874451
N 400
Minimum 0,45600
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises da Variável IDHM_R para Uma Amostra com 400 Municípios
Figura 29: Análise da Variável IDHM_L para Uma Amostra com 400 Municípios
Fonte: Atlas do Desenvolvimento Humano no Brasil.
É possível verificar visualmente através da observação dos histogramas, que com
exceção da amostra com 100 municípios, a distribuição das amostras ficou parecida com
a distribuição da população.
Para comparar melhor os valores da média, mediana e distribuição de dados das
diferentes amostras, a Figura 30 apresenta a comparação realizada através do método
ANOVA pelo MINITAB dos box-plots da variável IDHM_R com todos os municípios,
com 25, com 100 e com 400 municípios.
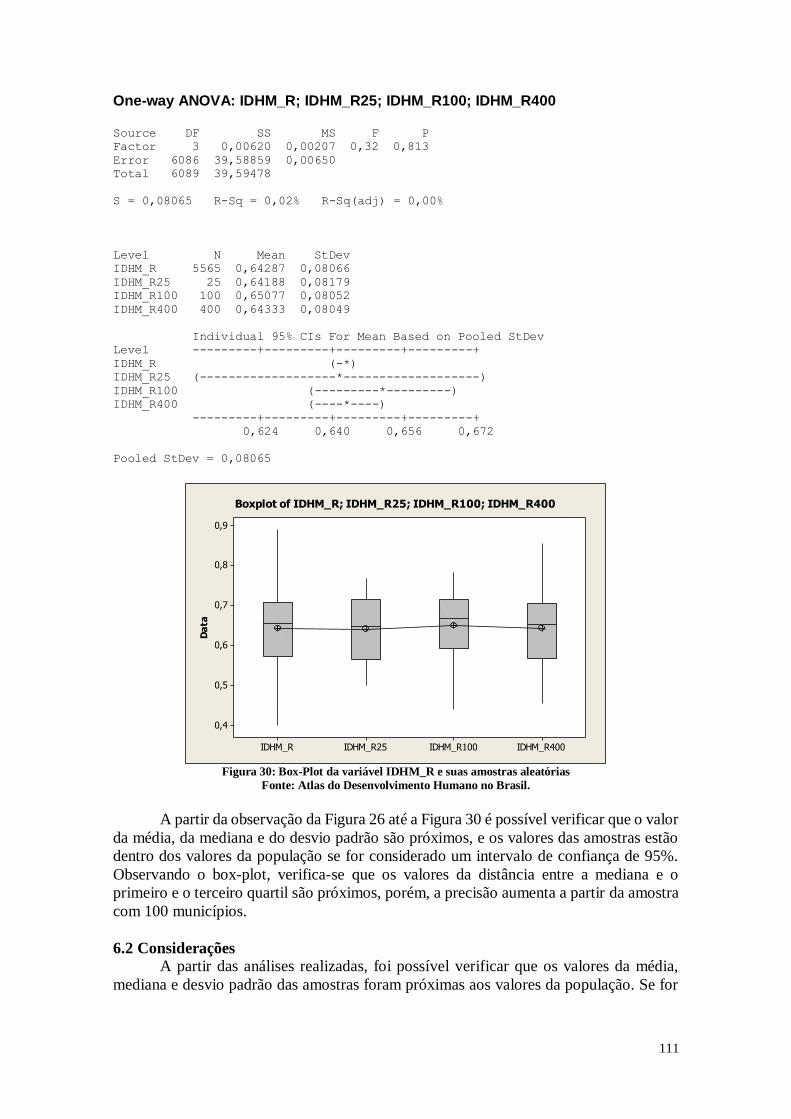
111
One-way ANOVA: IDHM_R; IDHM_R25; IDHM_R100; IDHM_R400 Source DF SS MS F P
Factor 3 0,00620 0,00207 0,32 0,813
Error 6086 39,58859 0,00650
Total 6089 39,59478
S = 0,08065 R-Sq = 0,02% R-Sq(adj) = 0,00%
Level N Mean StDev
IDHM_R 5565 0,64287 0,08066
IDHM_R25 25 0,64188 0,08179
IDHM_R100 100 0,65077 0,08052
IDHM_R400 400 0,64333 0,08049
Individual 95% CIs For Mean Based on Pooled StDev
Level ---------+---------+---------+---------+
IDHM_R (-*)
IDHM_R25 (-------------------*-------------------)
IDHM_R100 (---------*---------)
IDHM_R400 (----*----)
---------+---------+---------+---------+
0,624 0,640 0,656 0,672
Pooled StDev = 0,08065
IDHM_R400IDHM_R100IDHM_R25IDHM_R
0,9
0,8
0,7
0,6
0,5
0,4
Da
ta
Boxplot of IDHM_R; IDHM_R25; IDHM_R100; IDHM_R400
Figura 30: Box-Plot da variável IDHM_R e suas amostras aleatórias
Fonte: Atlas do Desenvolvimento Humano no Brasil.
A partir da observação da Figura 26 até a Figura 30 é possível verificar que o valor
da média, da mediana e do desvio padrão são próximos, e os valores das amostras estão
dentro dos valores da população se for considerado um intervalo de confiança de 95%.
Observando o box-plot, verifica-se que os valores da distância entre a mediana e o
primeiro e o terceiro quartil são próximos, porém, a precisão aumenta a partir da amostra
com 100 municípios.
6.2 Considerações
A partir das análises realizadas, foi possível verificar que os valores da média,
mediana e desvio padrão das amostras foram próximas aos valores da população. Se for

112
considerada a margem de erro com 95% de confiança, todas tiveram o valor dentro do
valor populacional.
Espera-se que quanto maior o tamanho da amostra, maior a capacidade de
representação da população, porém uma amostra com 25 municípios já conseguiu
mensurar de forma satisfatória os valores referentes a população.
Com este trabalho foi possível verificar que o tamanho da amostra está
relacionado a confiança desejada para avaliar uma população, os resultados das amostras
com maior número de município, no geral, representaram melhor a população, porém a
amostra de 25 municípios também a representaram bem.
CAPÍTULO 7. COMPONENTES PRINCIPAIS
O presente capítulo tem como objetivo realizar um estudo dos componentes
principais e das correlações dos dados provenientes das variáveis selecionadas do Atlas
do Desenvolvimento Humano no Brasil, que apresentam indicadores de desenvolvimento
humano dos 5565 municípios brasileiros. Estes dados são provenientes do Censo
Demográfico de 2010.
Para isso, inicialmente será realizada a normalização e positivação dos dados. A
normalização é realizada através da equação:
CY= (cX-MIN(cX))/(MAX(cX)-MIN(cX))
Onde CY é a célula de destino do resultado e cX a célula de origem dos dados a
serem normalizados. Este procedimento é realizado quando a variável aumenta com
resultados positivos, ou seja, quando quanto maior o valor da variável melhor o indicador.
No caso em que quanto maior o valor dos dados pior é o indicador, além da
normalização, também será realizada a positivação. Para isso deve ser utilizada a equação:
CY = 1-((cX-MIN(cX))/(MAX(cX)-MIN(cX)))
Após realizada esta etapa, serão realizadas as análises dos componentes principais
gerando variáveis sintéticas. A análise dos componentes principais tem como função
diminuir o número de variáveis do modelo.
Também serão realizadas as análises de correlação das variáveis normalizadas e
positivadas e traçado o dendorama.
As análises serão realizadas com o auxílio do software estatístico MINITAB.
7.1.Entendendo os Dados
As variáveis selecionadas para a realização das análises das regressões múltiplas
são os mesmos utilizados para a realização da análise do Capítulo I, porém, as variáveis
que se iniciarem com N foram normalizadas, e as que se iniciarem com NP foram
normalizadas e positivadas. A Tabela 1 apresenta as variáveis selecionadas para a análise.
Tabela 1: Variáveis Analisadas
Variável Significado Tipo Unidade
de Medida
NOMEMUN Nome do Município Variável
Qualitativa
Dimensão Demográfica
NP_FECTOT Número médio de filhos que uma mulher deverá ter
ao terminar o período reprodutivo (15 a 49 anos de
idade).
Variável
Quantitativa
Unidade
NP_MORT1 Número de crianças que não deverão sobreviver ao
primeiro ano de vida de cada 1000 crianças nascidas
vivas.
Variável
Quantitativa
Unidade
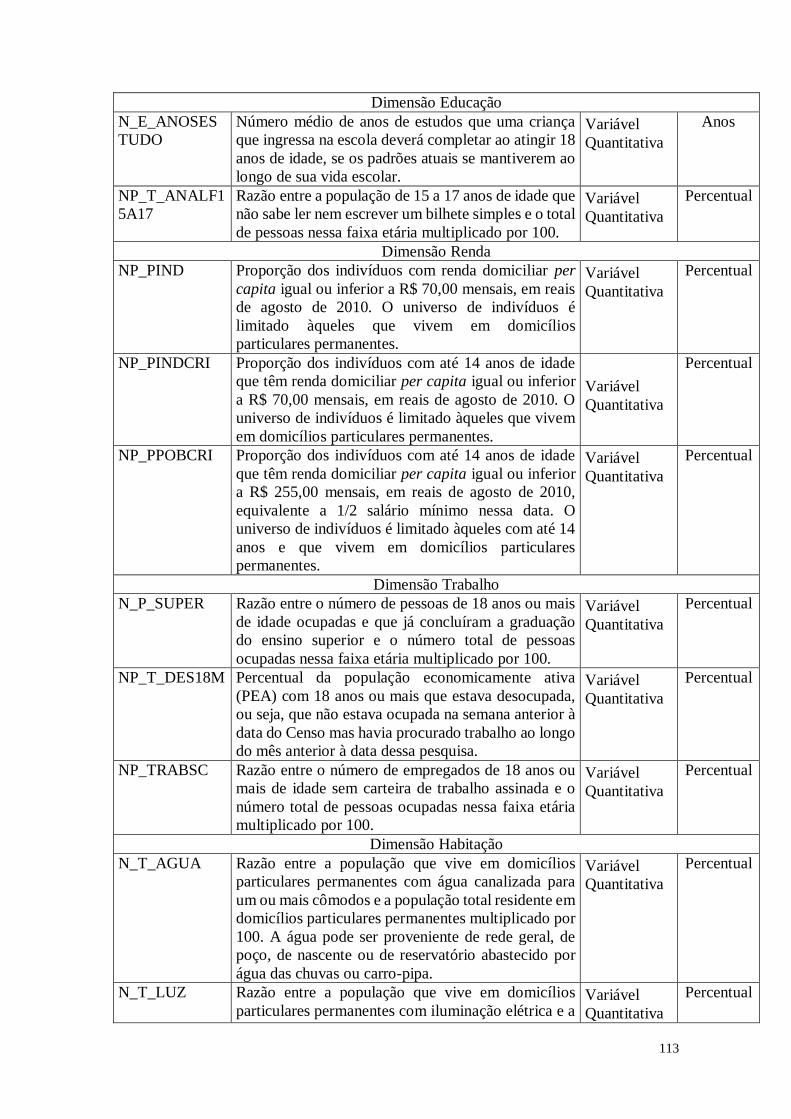
113
Dimensão Educação
N_E_ANOSES
TUDO
Número médio de anos de estudos que uma criança
que ingressa na escola deverá completar ao atingir 18
anos de idade, se os padrões atuais se mantiverem ao
longo de sua vida escolar.
Variável
Quantitativa
Anos
NP_T_ANALF1
5A17
Razão entre a população de 15 a 17 anos de idade que
não sabe ler nem escrever um bilhete simples e o total
de pessoas nessa faixa etária multiplicado por 100.
Variável
Quantitativa
Percentual
Dimensão Renda
NP_PIND Proporção dos indivíduos com renda domiciliar per
capita igual ou inferior a R$ 70,00 mensais, em reais
de agosto de 2010. O universo de indivíduos é
limitado àqueles que vivem em domicílios
particulares permanentes.
Variável
Quantitativa
Percentual
NP_PINDCRI Proporção dos indivíduos com até 14 anos de idade
que têm renda domiciliar per capita igual ou inferior
a R$ 70,00 mensais, em reais de agosto de 2010. O
universo de indivíduos é limitado àqueles que vivem
em domicílios particulares permanentes.
Variável
Quantitativa
Percentual
NP_PPOBCRI Proporção dos indivíduos com até 14 anos de idade
que têm renda domiciliar per capita igual ou inferior
a R$ 255,00 mensais, em reais de agosto de 2010,
equivalente a 1/2 salário mínimo nessa data. O
universo de indivíduos é limitado àqueles com até 14
anos e que vivem em domicílios particulares
permanentes.
Variável
Quantitativa
Percentual
Dimensão Trabalho
N_P_SUPER Razão entre o número de pessoas de 18 anos ou mais
de idade ocupadas e que já concluíram a graduação
do ensino superior e o número total de pessoas
ocupadas nessa faixa etária multiplicado por 100.
Variável
Quantitativa
Percentual
NP_T_DES18M Percentual da população economicamente ativa
(PEA) com 18 anos ou mais que estava desocupada,
ou seja, que não estava ocupada na semana anterior à
data do Censo mas havia procurado trabalho ao longo
do mês anterior à data dessa pesquisa.
Variável
Quantitativa
Percentual
NP_TRABSC Razão entre o número de empregados de 18 anos ou
mais de idade sem carteira de trabalho assinada e o
número total de pessoas ocupadas nessa faixa etária
multiplicado por 100.
Variável
Quantitativa
Percentual
Dimensão Habitação
N_T_AGUA Razão entre a população que vive em domicílios
particulares permanentes com água canalizada para
um ou mais cômodos e a população total residente em
domicílios particulares permanentes multiplicado por
100. A água pode ser proveniente de rede geral, de
poço, de nascente ou de reservatório abastecido por
água das chuvas ou carro-pipa.
Variável
Quantitativa
Percentual
N_T_LUZ Razão entre a população que vive em domicílios
particulares permanentes com iluminação elétrica e a Variável
Quantitativa
Percentual
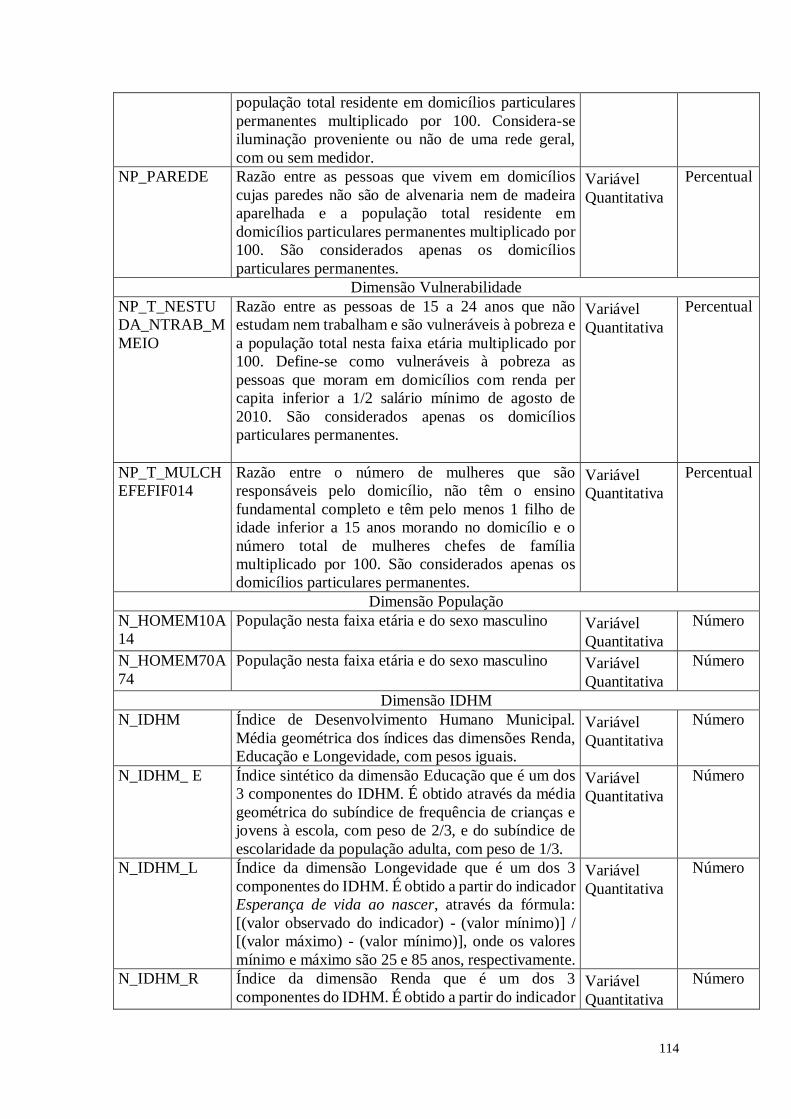
114
população total residente em domicílios particulares
permanentes multiplicado por 100. Considera-se
iluminação proveniente ou não de uma rede geral,
com ou sem medidor.
NP_PAREDE Razão entre as pessoas que vivem em domicílios
cujas paredes não são de alvenaria nem de madeira
aparelhada e a população total residente em
domicílios particulares permanentes multiplicado por
100. São considerados apenas os domicílios
particulares permanentes.
Variável
Quantitativa
Percentual
Dimensão Vulnerabilidade
NP_T_NESTU
DA_NTRAB_M
MEIO
Razão entre as pessoas de 15 a 24 anos que não
estudam nem trabalham e são vulneráveis à pobreza e
a população total nesta faixa etária multiplicado por
100. Define-se como vulneráveis à pobreza as
pessoas que moram em domicílios com renda per
capita inferior a 1/2 salário mínimo de agosto de
2010. São considerados apenas os domicílios
particulares permanentes.
Variável
Quantitativa
Percentual
NP_T_MULCH
EFEFIF014
Razão entre o número de mulheres que são
responsáveis pelo domicílio, não têm o ensino
fundamental completo e têm pelo menos 1 filho de
idade inferior a 15 anos morando no domicílio e o
número total de mulheres chefes de família
multiplicado por 100. São considerados apenas os
domicílios particulares permanentes.
Variável
Quantitativa
Percentual
Dimensão População
N_HOMEM10A
14
População nesta faixa etária e do sexo masculino Variável
Quantitativa
Número
N_HOMEM70A
74
População nesta faixa etária e do sexo masculino Variável
Quantitativa
Número
Dimensão IDHM
N_IDHM Índice de Desenvolvimento Humano Municipal.
Média geométrica dos índices das dimensões Renda,
Educação e Longevidade, com pesos iguais.
Variável
Quantitativa
Número
N_IDHM_ E Índice sintético da dimensão Educação que é um dos
3 componentes do IDHM. É obtido através da média
geométrica do subíndice de frequência de crianças e
jovens à escola, com peso de 2/3, e do subíndice de
escolaridade da população adulta, com peso de 1/3.
Variável
Quantitativa
Número
N_IDHM_L Índice da dimensão Longevidade que é um dos 3
componentes do IDHM. É obtido a partir do indicador
Esperança de vida ao nascer, através da fórmula:
[(valor observado do indicador) - (valor mínimo)] /
[(valor máximo) - (valor mínimo)], onde os valores
mínimo e máximo são 25 e 85 anos, respectivamente.
Variável
Quantitativa
Número
N_IDHM_R Índice da dimensão Renda que é um dos 3
componentes do IDHM. É obtido a partir do indicador Variável
Quantitativa
Número
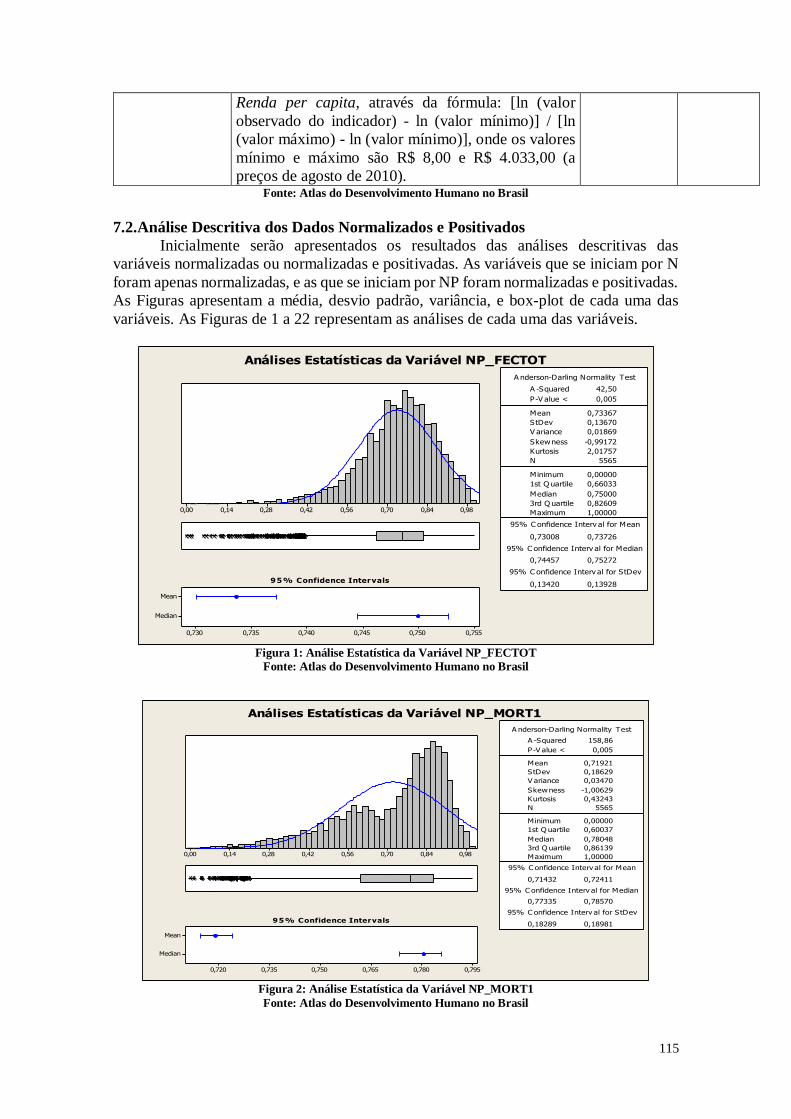
115
Renda per capita, através da fórmula: [ln (valor
observado do indicador) - ln (valor mínimo)] / [ln
(valor máximo) - ln (valor mínimo)], onde os valores
mínimo e máximo são R$ 8,00 e R$ 4.033,00 (a
preços de agosto de 2010). Fonte: Atlas do Desenvolvimento Humano no Brasil
7.2.Análise Descritiva dos Dados Normalizados e Positivados
Inicialmente serão apresentados os resultados das análises descritivas das
variáveis normalizadas ou normalizadas e positivadas. As variáveis que se iniciam por N
foram apenas normalizadas, e as que se iniciam por NP foram normalizadas e positivadas.
As Figuras apresentam a média, desvio padrão, variância, e box-plot de cada uma das
variáveis. As Figuras de 1 a 22 representam as análises de cada uma das variáveis.
0,980,840,700,560,420,280,140,00
Median
Mean
0,7550,7500,7450,7400,7350,730
1st Q uartile 0,66033
Median 0,75000
3rd Q uartile 0,82609
Maximum 1,00000
0,73008 0,73726
0,74457 0,75272
0,13420 0,13928
A -Squared 42,50
P-V alue < 0,005
Mean 0,73367
StDev 0,13670
V ariance 0,01869
Skewness -0,99172
Kurtosis 2,01757
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável NP_FECTOT
Figura 1: Análise Estatística da Variável NP_FECTOT
Fonte: Atlas do Desenvolvimento Humano no Brasil
0,980,840,700,560,420,280,140,00
Median
Mean
0,7950,7800,7650,7500,7350,720
1st Q uartile 0,60037
Median 0,78048
3rd Q uartile 0,86139
Maximum 1,00000
0,71432 0,72411
0,77335 0,78570
0,18289 0,18981
A -Squared 158,86
P-V alue < 0,005
Mean 0,71921
StDev 0,18629
V ariance 0,03470
Skewness -1,00629
Kurtosis 0,43243
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável NP_MORT1
Figura 2: Análise Estatística da Variável NP_MORT1
Fonte: Atlas do Desenvolvimento Humano no Brasil
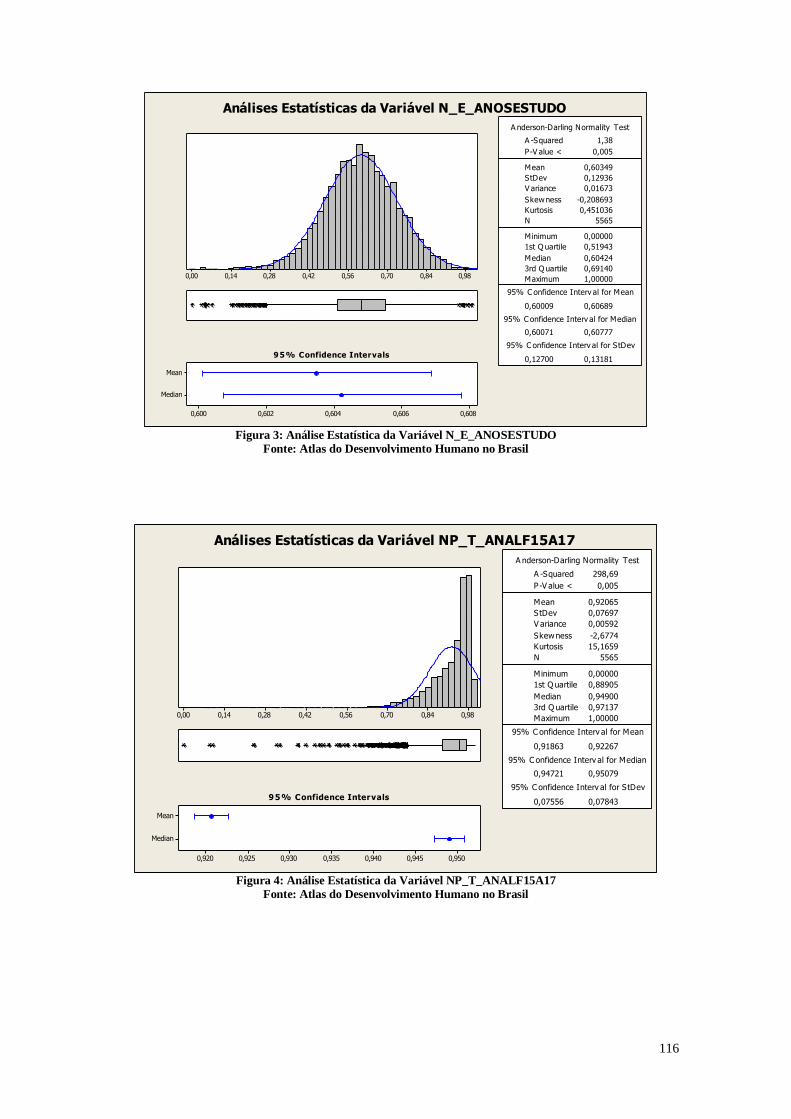
116
0,980,840,700,560,420,280,140,00
Median
Mean
0,6080,6060,6040,6020,600
1st Q uartile 0,51943
Median 0,60424
3rd Q uartile 0,69140
Maximum 1,00000
0,60009 0,60689
0,60071 0,60777
0,12700 0,13181
A -Squared 1,38
P-V alue < 0,005
Mean 0,60349
StDev 0,12936
V ariance 0,01673
Skewness -0,208693
Kurtosis 0,451036
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável N_E_ANOSESTUDO
Figura 3: Análise Estatística da Variável N_E_ANOSESTUDO
Fonte: Atlas do Desenvolvimento Humano no Brasil
0,980,840,700,560,420,280,140,00
Median
Mean
0,9500,9450,9400,9350,9300,9250,920
1st Q uartile 0,88905
Median 0,94900
3rd Q uartile 0,97137
Maximum 1,00000
0,91863 0,92267
0,94721 0,95079
0,07556 0,07843
A -Squared 298,69
P-V alue < 0,005
Mean 0,92065
StDev 0,07697
V ariance 0,00592
Skewness -2,6774
Kurtosis 15,1659
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável NP_T_ANALF15A17
Figura 4: Análise Estatística da Variável NP_T_ANALF15A17
Fonte: Atlas do Desenvolvimento Humano no Brasil
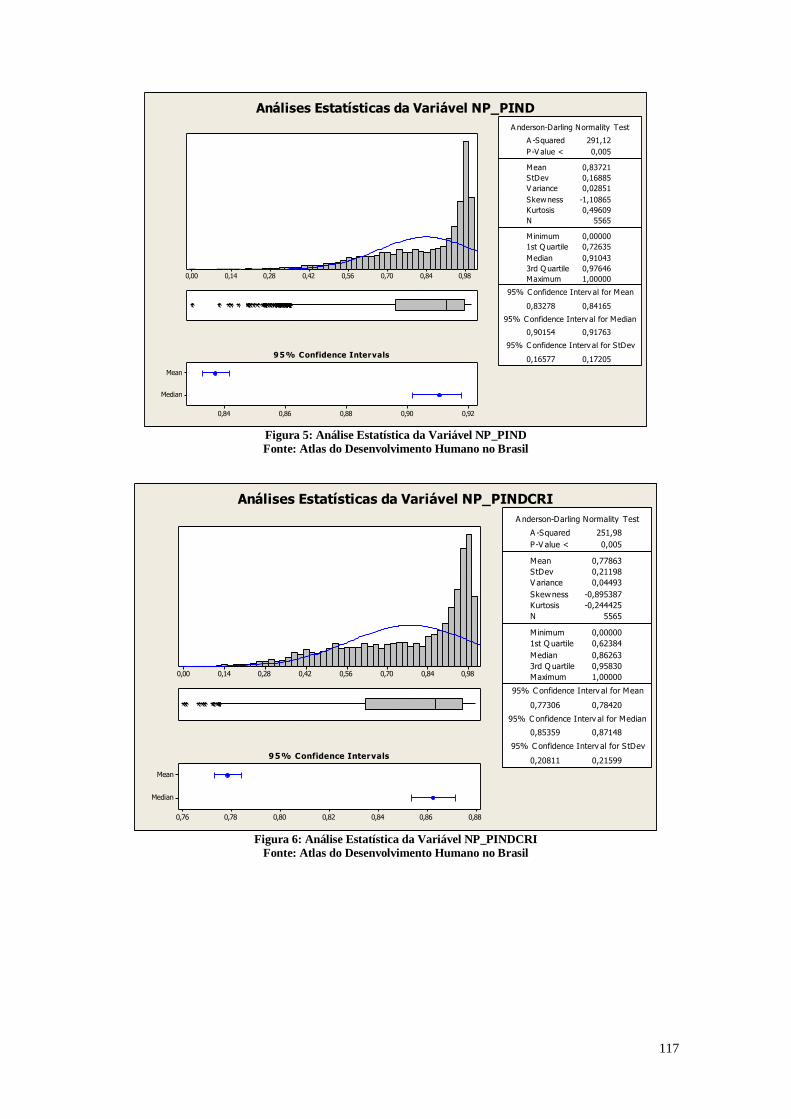
117
0,980,840,700,560,420,280,140,00
Median
Mean
0,920,900,880,860,84
1st Q uartile 0,72635
Median 0,91043
3rd Q uartile 0,97646
Maximum 1,00000
0,83278 0,84165
0,90154 0,91763
0,16577 0,17205
A -Squared 291,12
P-V alue < 0,005
Mean 0,83721
StDev 0,16885
V ariance 0,02851
Skewness -1,10865
Kurtosis 0,49609
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável NP_PIND
Figura 5: Análise Estatística da Variável NP_PIND
Fonte: Atlas do Desenvolvimento Humano no Brasil
0,980,840,700,560,420,280,140,00
Median
Mean
0,880,860,840,820,800,780,76
1st Q uartile 0,62384
Median 0,86263
3rd Q uartile 0,95830
Maximum 1,00000
0,77306 0,78420
0,85359 0,87148
0,20811 0,21599
A -Squared 251,98
P-V alue < 0,005
Mean 0,77863
StDev 0,21198
V ariance 0,04493
Skewness -0,895387
Kurtosis -0,244425
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável NP_PINDCRI
Figura 6: Análise Estatística da Variável NP_PINDCRI
Fonte: Atlas do Desenvolvimento Humano no Brasil
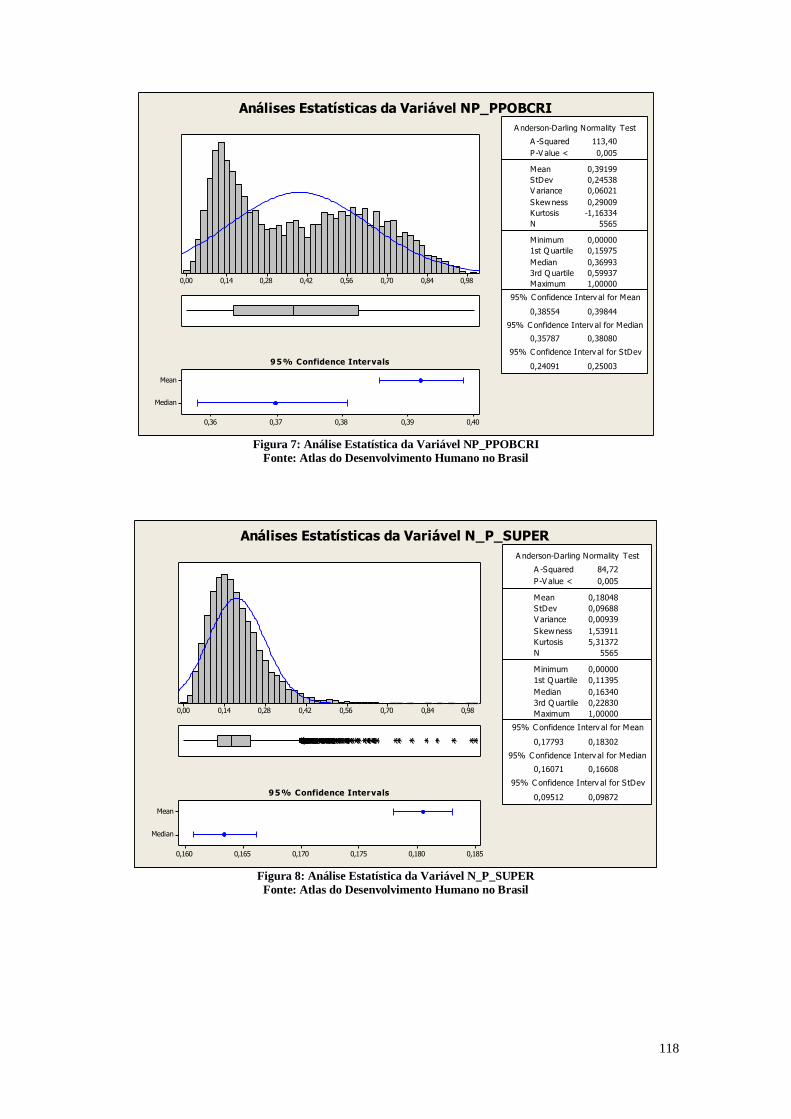
118
0,980,840,700,560,420,280,140,00
Median
Mean
0,400,390,380,370,36
1st Q uartile 0,15975
Median 0,36993
3rd Q uartile 0,59937
Maximum 1,00000
0,38554 0,39844
0,35787 0,38080
0,24091 0,25003
A -Squared 113,40
P-V alue < 0,005
Mean 0,39199
StDev 0,24538
V ariance 0,06021
Skewness 0,29009
Kurtosis -1,16334
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável NP_PPOBCRI
Figura 7: Análise Estatística da Variável NP_PPOBCRI
Fonte: Atlas do Desenvolvimento Humano no Brasil
0,980,840,700,560,420,280,140,00
Median
Mean
0,1850,1800,1750,1700,1650,160
1st Q uartile 0,11395
Median 0,16340
3rd Q uartile 0,22830
Maximum 1,00000
0,17793 0,18302
0,16071 0,16608
0,09512 0,09872
A -Squared 84,72
P-V alue < 0,005
Mean 0,18048
StDev 0,09688
V ariance 0,00939
Skewness 1,53911
Kurtosis 5,31372
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável N_P_SUPER
Figura 8: Análise Estatística da Variável N_P_SUPER
Fonte: Atlas do Desenvolvimento Humano no Brasil
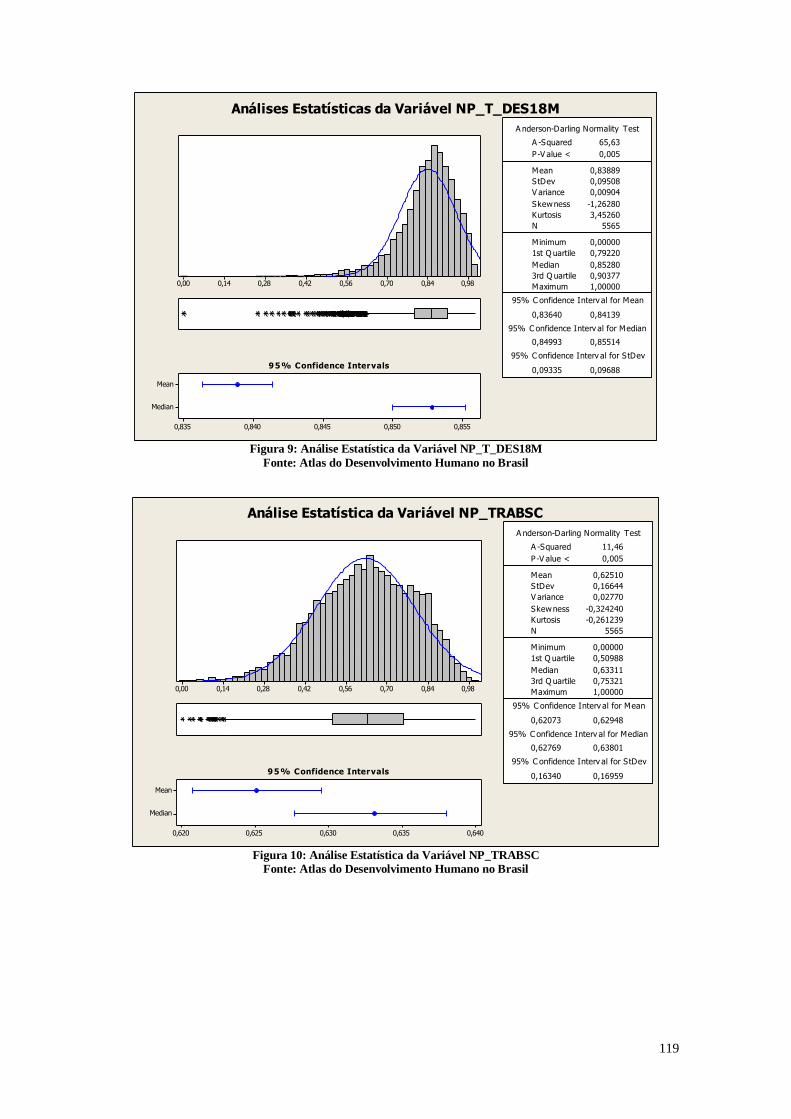
119
0,980,840,700,560,420,280,140,00
Median
Mean
0,8550,8500,8450,8400,835
1st Q uartile 0,79220
Median 0,85280
3rd Q uartile 0,90377
Maximum 1,00000
0,83640 0,84139
0,84993 0,85514
0,09335 0,09688
A -Squared 65,63
P-V alue < 0,005
Mean 0,83889
StDev 0,09508
V ariance 0,00904
Skewness -1,26280
Kurtosis 3,45260
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análises Estatísticas da Variável NP_T_DES18M
Figura 9: Análise Estatística da Variável NP_T_DES18M
Fonte: Atlas do Desenvolvimento Humano no Brasil
0,980,840,700,560,420,280,140,00
Median
Mean
0,6400,6350,6300,6250,620
1st Q uartile 0,50988
Median 0,63311
3rd Q uartile 0,75321
Maximum 1,00000
0,62073 0,62948
0,62769 0,63801
0,16340 0,16959
A -Squared 11,46
P-V alue < 0,005
Mean 0,62510
StDev 0,16644
V ariance 0,02770
Skewness -0,324240
Kurtosis -0,261239
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise Estatística da Variável NP_TRABSC
Figura 10: Análise Estatística da Variável NP_TRABSC
Fonte: Atlas do Desenvolvimento Humano no Brasil
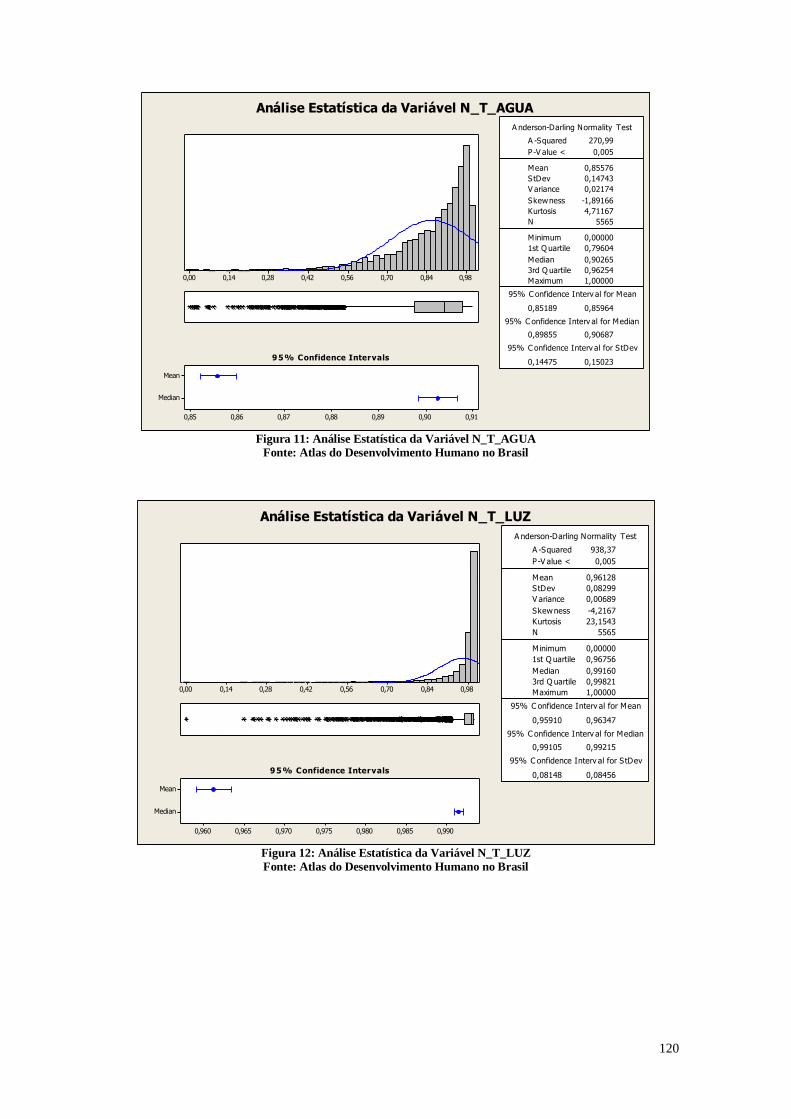
120
0,980,840,700,560,420,280,140,00
Median
Mean
0,910,900,890,880,870,860,85
1st Q uartile 0,79604
Median 0,90265
3rd Q uartile 0,96254
Maximum 1,00000
0,85189 0,85964
0,89855 0,90687
0,14475 0,15023
A -Squared 270,99
P-V alue < 0,005
Mean 0,85576
StDev 0,14743
V ariance 0,02174
Skewness -1,89166
Kurtosis 4,71167
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise Estatística da Variável N_T_AGUA
Figura 11: Análise Estatística da Variável N_T_AGUA
Fonte: Atlas do Desenvolvimento Humano no Brasil
0,980,840,700,560,420,280,140,00
Median
Mean
0,9900,9850,9800,9750,9700,9650,960
1st Q uartile 0,96756
Median 0,99160
3rd Q uartile 0,99821
Maximum 1,00000
0,95910 0,96347
0,99105 0,99215
0,08148 0,08456
A -Squared 938,37
P-V alue < 0,005
Mean 0,96128
StDev 0,08299
V ariance 0,00689
Skewness -4,2167
Kurtosis 23,1543
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise Estatística da Variável N_T_LUZ
Figura 12: Análise Estatística da Variável N_T_LUZ
Fonte: Atlas do Desenvolvimento Humano no Brasil
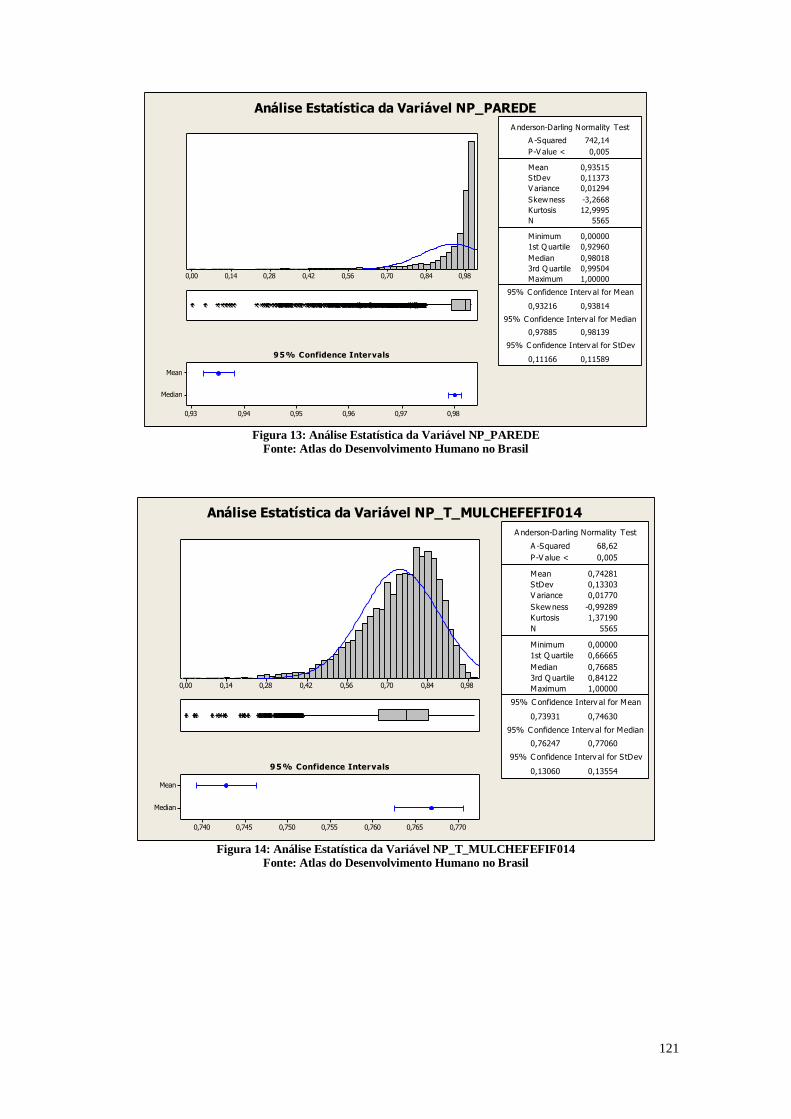
121
0,980,840,700,560,420,280,140,00
Median
Mean
0,980,970,960,950,940,93
1st Q uartile 0,92960
Median 0,98018
3rd Q uartile 0,99504
Maximum 1,00000
0,93216 0,93814
0,97885 0,98139
0,11166 0,11589
A -Squared 742,14
P-V alue < 0,005
Mean 0,93515
StDev 0,11373
V ariance 0,01294
Skewness -3,2668
Kurtosis 12,9995
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise Estatística da Variável NP_PAREDE
Figura 13: Análise Estatística da Variável NP_PAREDE
Fonte: Atlas do Desenvolvimento Humano no Brasil
0,980,840,700,560,420,280,140,00
Median
Mean
0,7700,7650,7600,7550,7500,7450,740
1st Q uartile 0,66665
Median 0,76685
3rd Q uartile 0,84122
Maximum 1,00000
0,73931 0,74630
0,76247 0,77060
0,13060 0,13554
A -Squared 68,62
P-V alue < 0,005
Mean 0,74281
StDev 0,13303
V ariance 0,01770
Skewness -0,99289
Kurtosis 1,37190
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise Estatística da Variável NP_T_MULCHEFEFIF014
Figura 14: Análise Estatística da Variável NP_T_MULCHEFEFIF014
Fonte: Atlas do Desenvolvimento Humano no Brasil
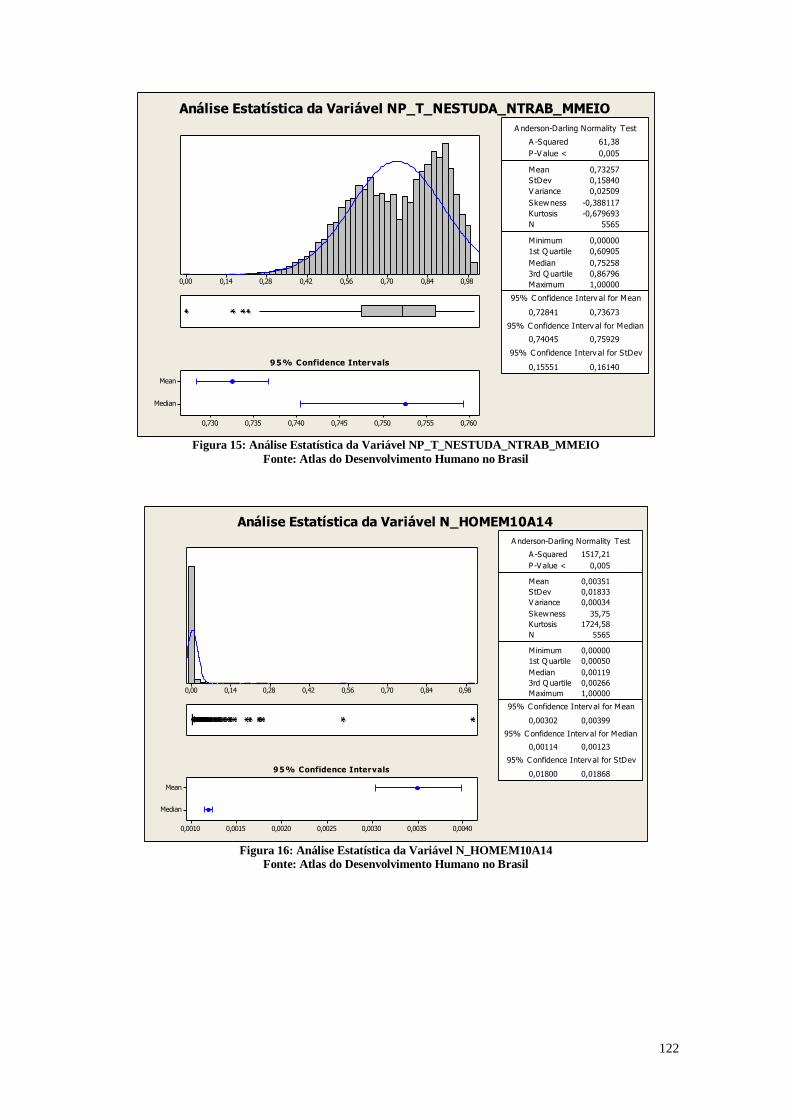
122
0,980,840,700,560,420,280,140,00
Median
Mean
0,7600,7550,7500,7450,7400,7350,730
1st Q uartile 0,60905
Median 0,75258
3rd Q uartile 0,86796
Maximum 1,00000
0,72841 0,73673
0,74045 0,75929
0,15551 0,16140
A -Squared 61,38
P-V alue < 0,005
Mean 0,73257
StDev 0,15840
V ariance 0,02509
Skewness -0,388117
Kurtosis -0,679693
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise Estatística da Variável NP_T_NESTUDA_NTRAB_MMEIO
Figura 15: Análise Estatística da Variável NP_T_NESTUDA_NTRAB_MMEIO
Fonte: Atlas do Desenvolvimento Humano no Brasil
0,980,840,700,560,420,280,140,00
Median
Mean
0,00400,00350,00300,00250,00200,00150,0010
1st Q uartile 0,00050
Median 0,00119
3rd Q uartile 0,00266
Maximum 1,00000
0,00302 0,00399
0,00114 0,00123
0,01800 0,01868
A -Squared 1517,21
P-V alue < 0,005
Mean 0,00351
StDev 0,01833
V ariance 0,00034
Skewness 35,75
Kurtosis 1724,58
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise Estatística da Variável N_HOMEM10A14
Figura 16: Análise Estatística da Variável N_HOMEM10A14
Fonte: Atlas do Desenvolvimento Humano no Brasil
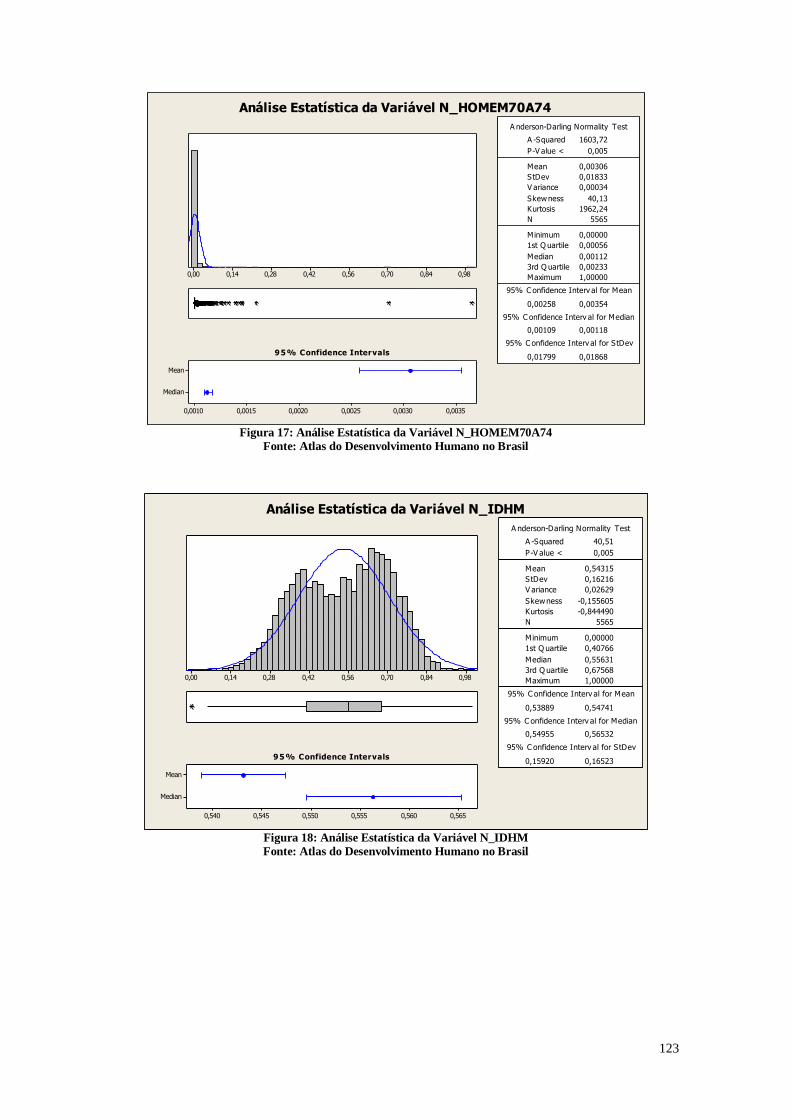
123
0,980,840,700,560,420,280,140,00
Median
Mean
0,00350,00300,00250,00200,00150,0010
1st Q uartile 0,00056
Median 0,00112
3rd Q uartile 0,00233
Maximum 1,00000
0,00258 0,00354
0,00109 0,00118
0,01799 0,01868
A -Squared 1603,72
P-V alue < 0,005
Mean 0,00306
StDev 0,01833
V ariance 0,00034
Skewness 40,13
Kurtosis 1962,24
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise Estatística da Variável N_HOMEM70A74
Figura 17: Análise Estatística da Variável N_HOMEM70A74
Fonte: Atlas do Desenvolvimento Humano no Brasil
0,980,840,700,560,420,280,140,00
Median
Mean
0,5650,5600,5550,5500,5450,540
1st Q uartile 0,40766
Median 0,55631
3rd Q uartile 0,67568
Maximum 1,00000
0,53889 0,54741
0,54955 0,56532
0,15920 0,16523
A -Squared 40,51
P-V alue < 0,005
Mean 0,54315
StDev 0,16216
V ariance 0,02629
Skewness -0,155605
Kurtosis -0,844490
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise Estatística da Variável N_IDHM
Figura 18: Análise Estatística da Variável N_IDHM
Fonte: Atlas do Desenvolvimento Humano no Brasil
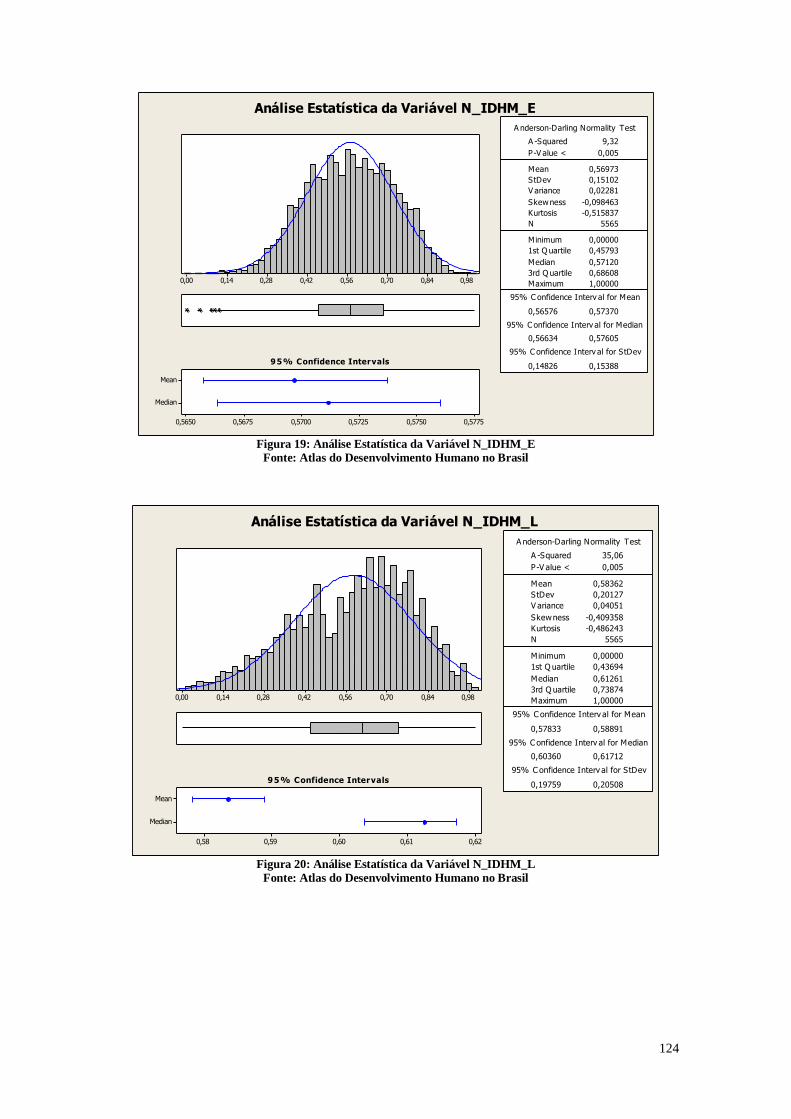
124
0,980,840,700,560,420,280,140,00
Median
Mean
0,57750,57500,57250,57000,56750,5650
1st Q uartile 0,45793
Median 0,57120
3rd Q uartile 0,68608
Maximum 1,00000
0,56576 0,57370
0,56634 0,57605
0,14826 0,15388
A -Squared 9,32
P-V alue < 0,005
Mean 0,56973
StDev 0,15102
V ariance 0,02281
Skewness -0,098463
Kurtosis -0,515837
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise Estatística da Variável N_IDHM_E
Figura 19: Análise Estatística da Variável N_IDHM_E
Fonte: Atlas do Desenvolvimento Humano no Brasil
0,980,840,700,560,420,280,140,00
Median
Mean
0,620,610,600,590,58
1st Q uartile 0,43694
Median 0,61261
3rd Q uartile 0,73874
Maximum 1,00000
0,57833 0,58891
0,60360 0,61712
0,19759 0,20508
A -Squared 35,06
P-V alue < 0,005
Mean 0,58362
StDev 0,20127
V ariance 0,04051
Skewness -0,409358
Kurtosis -0,486243
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise Estatística da Variável N_IDHM_L
Figura 20: Análise Estatística da Variável N_IDHM_L
Fonte: Atlas do Desenvolvimento Humano no Brasil
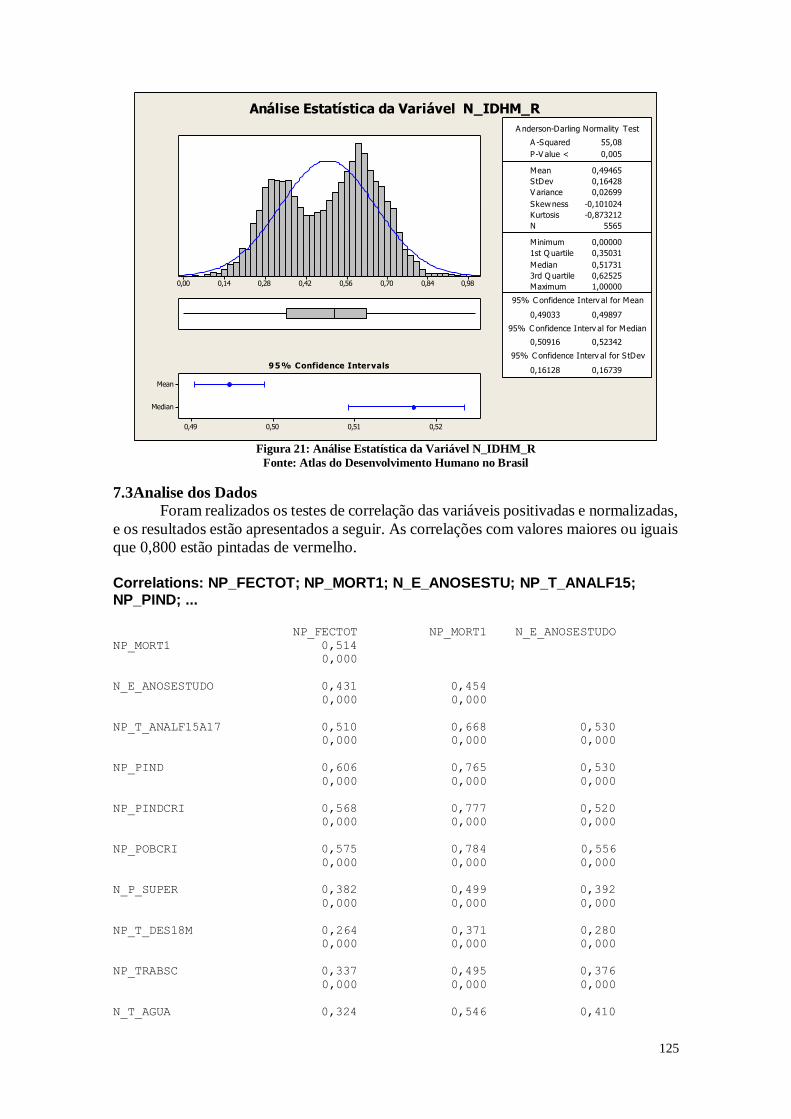
125
0,980,840,700,560,420,280,140,00
Median
Mean
0,520,510,500,49
1st Q uartile 0,35031
Median 0,51731
3rd Q uartile 0,62525
Maximum 1,00000
0,49033 0,49897
0,50916 0,52342
0,16128 0,16739
A -Squared 55,08
P-V alue < 0,005
Mean 0,49465
StDev 0,16428
V ariance 0,02699
Skewness -0,101024
Kurtosis -0,873212
N 5565
Minimum 0,00000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Análise Estatística da Variável N_IDHM_R
Figura 21: Análise Estatística da Variável N_IDHM_R
Fonte: Atlas do Desenvolvimento Humano no Brasil
7.3Analise dos Dados
Foram realizados os testes de correlação das variáveis positivadas e normalizadas,
e os resultados estão apresentados a seguir. As correlações com valores maiores ou iguais
que 0,800 estão pintadas de vermelho.
Correlations: NP_FECTOT; NP_MORT1; N_E_ANOSESTU; NP_T_ANALF15; NP_PIND; ... NP_FECTOT NP_MORT1 N_E_ANOSESTUDO
NP_MORT1 0,514
0,000
N_E_ANOSESTUDO 0,431 0,454
0,000 0,000
NP_T_ANALF15A17 0,510 0,668 0,530
0,000 0,000 0,000
NP_PIND 0,606 0,765 0,530
0,000 0,000 0,000
NP_PINDCRI 0,568 0,777 0,520
0,000 0,000 0,000
NP_POBCRI 0,575 0,784 0,556
0,000 0,000 0,000
N_P_SUPER 0,382 0,499 0,392
0,000 0,000 0,000
NP_T_DES18M 0,264 0,371 0,280
0,000 0,000 0,000
NP_TRABSC 0,337 0,495 0,376
0,000 0,000 0,000
N_T_AGUA 0,324 0,546 0,410
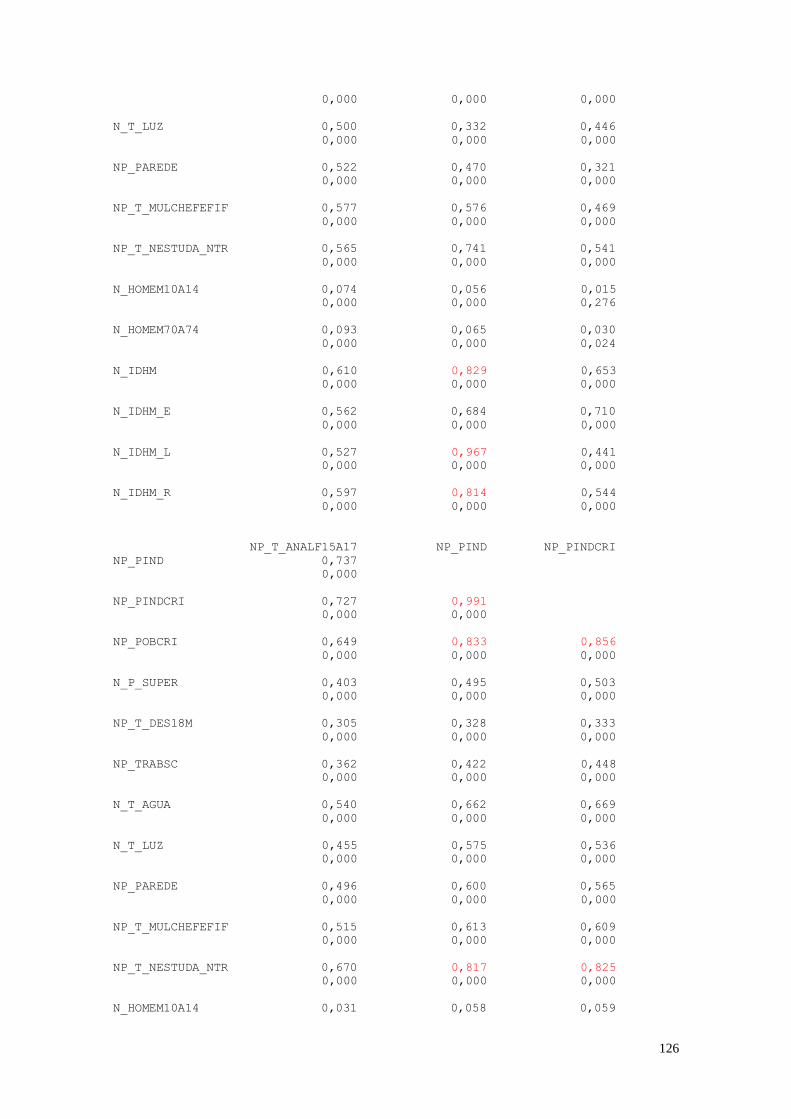
126
0,000 0,000 0,000
N_T_LUZ 0,500 0,332 0,446
0,000 0,000 0,000
NP_PAREDE 0,522 0,470 0,321
0,000 0,000 0,000
NP_T_MULCHEFEFIF 0,577 0,576 0,469
0,000 0,000 0,000
NP_T_NESTUDA_NTR 0,565 0,741 0,541
0,000 0,000 0,000
N_HOMEM10A14 0,074 0,056 0,015
0,000 0,000 0,276
N_HOMEM70A74 0,093 0,065 0,030
0,000 0,000 0,024
N_IDHM 0,610 0,829 0,653
0,000 0,000 0,000
N_IDHM_E 0,562 0,684 0,710
0,000 0,000 0,000
N_IDHM_L 0,527 0,967 0,441
0,000 0,000 0,000
N_IDHM_R 0,597 0,814 0,544
0,000 0,000 0,000
NP_T_ANALF15A17 NP_PIND NP_PINDCRI
NP_PIND 0,737
0,000
NP_PINDCRI 0,727 0,991
0,000 0,000
NP_POBCRI 0,649 0,833 0,856
0,000 0,000 0,000
N_P_SUPER 0,403 0,495 0,503
0,000 0,000 0,000
NP_T_DES18M 0,305 0,328 0,333
0,000 0,000 0,000
NP_TRABSC 0,362 0,422 0,448
0,000 0,000 0,000
N_T_AGUA 0,540 0,662 0,669
0,000 0,000 0,000
N_T_LUZ 0,455 0,575 0,536
0,000 0,000 0,000
NP_PAREDE 0,496 0,600 0,565
0,000 0,000 0,000
NP_T_MULCHEFEFIF 0,515 0,613 0,609
0,000 0,000 0,000
NP_T_NESTUDA_NTR 0,670 0,817 0,825
0,000 0,000 0,000
N_HOMEM10A14 0,031 0,058 0,059
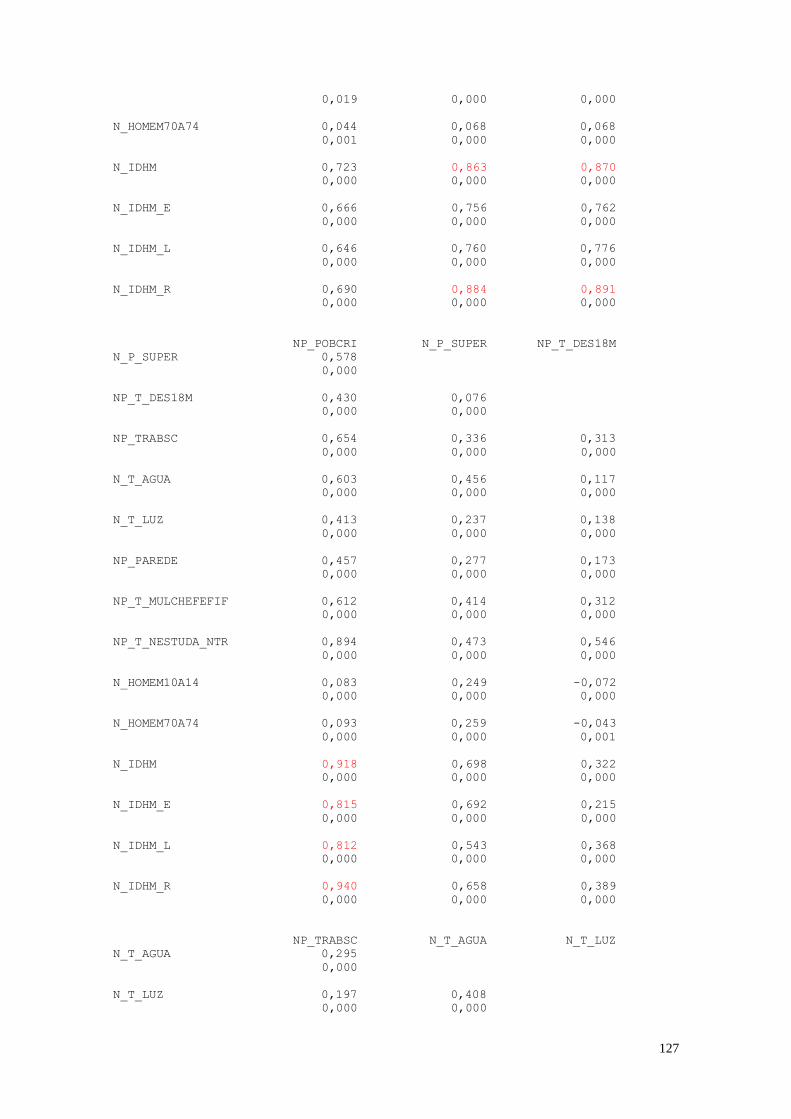
127
0,019 0,000 0,000
N_HOMEM70A74 0,044 0,068 0,068
0,001 0,000 0,000
N_IDHM 0,723 0,863 0,870
0,000 0,000 0,000
N_IDHM_E 0,666 0,756 0,762
0,000 0,000 0,000
N_IDHM_L 0,646 0,760 0,776
0,000 0,000 0,000
N_IDHM_R 0,690 0,884 0,891
0,000 0,000 0,000
NP_POBCRI N_P_SUPER NP_T_DES18M
N_P_SUPER 0,578
0,000
NP_T_DES18M 0,430 0,076
0,000 0,000
NP_TRABSC 0,654 0,336 0,313
0,000 0,000 0,000
N_T_AGUA 0,603 0,456 0,117
0,000 0,000 0,000
N_T_LUZ 0,413 0,237 0,138
0,000 0,000 0,000
NP_PAREDE 0,457 0,277 0,173
0,000 0,000 0,000
NP_T_MULCHEFEFIF 0,612 0,414 0,312
0,000 0,000 0,000
NP_T_NESTUDA_NTR 0,894 0,473 0,546
0,000 0,000 0,000
N_HOMEM10A14 0,083 0,249 -0,072
0,000 0,000 0,000
N_HOMEM70A74 0,093 0,259 -0,043
0,000 0,000 0,001
N_IDHM 0,918 0,698 0,322
0,000 0,000 0,000
N_IDHM_E 0,815 0,692 0,215
0,000 0,000 0,000
N_IDHM_L 0,812 0,543 0,368
0,000 0,000 0,000
N_IDHM_R 0,940 0,658 0,389
0,000 0,000 0,000
NP_TRABSC N_T_AGUA N_T_LUZ
N_T_AGUA 0,295
0,000
N_T_LUZ 0,197 0,408
0,000 0,000
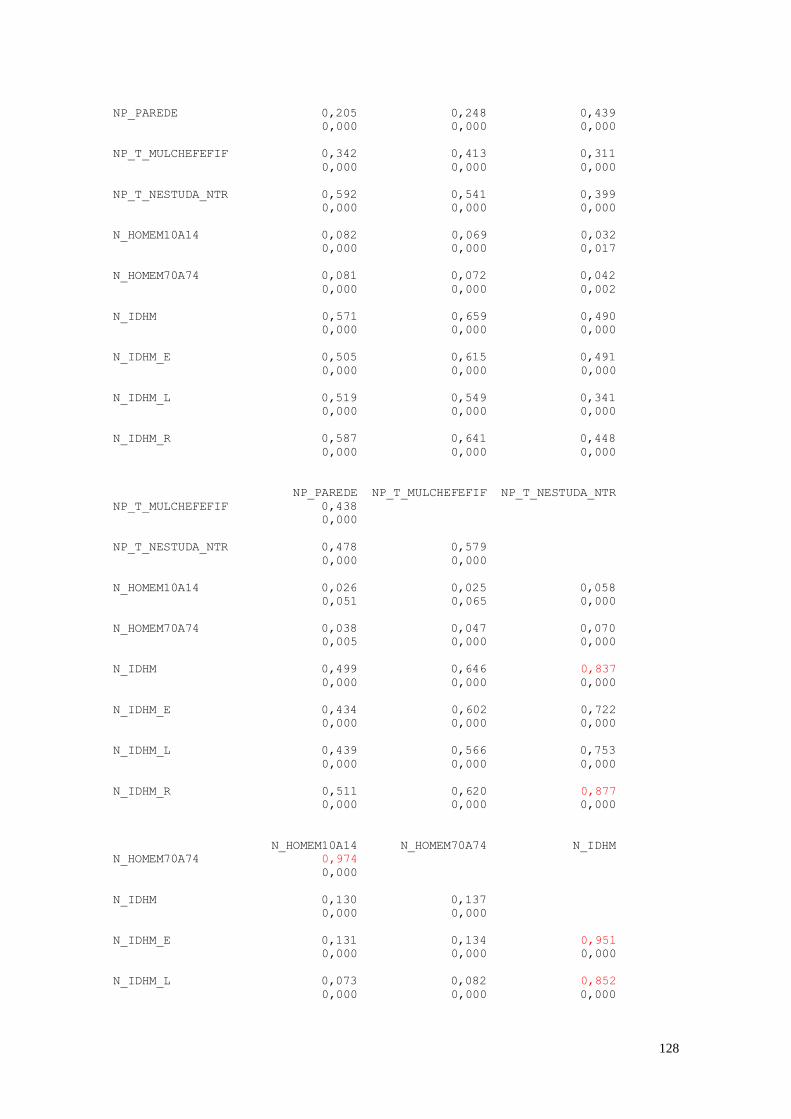
128
NP_PAREDE 0,205 0,248 0,439
0,000 0,000 0,000
NP_T_MULCHEFEFIF 0,342 0,413 0,311
0,000 0,000 0,000
NP_T_NESTUDA_NTR 0,592 0,541 0,399
0,000 0,000 0,000
N_HOMEM10A14 0,082 0,069 0,032
0,000 0,000 0,017
N_HOMEM70A74 0,081 0,072 0,042
0,000 0,000 0,002
N_IDHM 0,571 0,659 0,490
0,000 0,000 0,000
N_IDHM_E 0,505 0,615 0,491
0,000 0,000 0,000
N_IDHM_L 0,519 0,549 0,341
0,000 0,000 0,000
N_IDHM_R 0,587 0,641 0,448
0,000 0,000 0,000
NP_PAREDE NP_T_MULCHEFEFIF NP_T_NESTUDA_NTR
NP_T_MULCHEFEFIF 0,438
0,000
NP_T_NESTUDA_NTR 0,478 0,579
0,000 0,000
N_HOMEM10A14 0,026 0,025 0,058
0,051 0,065 0,000
N_HOMEM70A74 0,038 0,047 0,070
0,005 0,000 0,000
N_IDHM 0,499 0,646 0,837
0,000 0,000 0,000
N_IDHM_E 0,434 0,602 0,722
0,000 0,000 0,000
N_IDHM_L 0,439 0,566 0,753
0,000 0,000 0,000
N_IDHM_R 0,511 0,620 0,877
0,000 0,000 0,000
N_HOMEM10A14 N_HOMEM70A74 N_IDHM
N_HOMEM70A74 0,974
0,000
N_IDHM 0,130 0,137
0,000 0,000
N_IDHM_E 0,131 0,134 0,951
0,000 0,000 0,000
N_IDHM_L 0,073 0,082 0,852
0,000 0,000 0,000
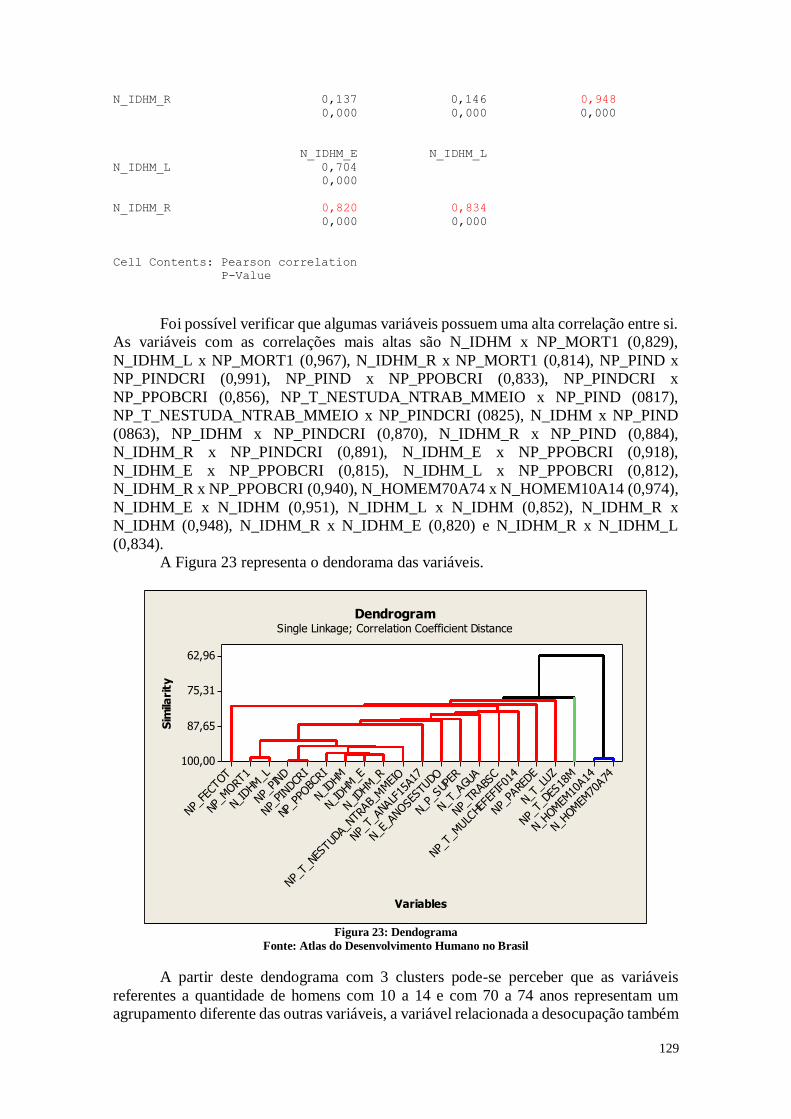
129
N_IDHM_R 0,137 0,146 0,948
0,000 0,000 0,000
N_IDHM_E N_IDHM_L
N_IDHM_L 0,704
0,000
N_IDHM_R 0,820 0,834
0,000 0,000
Cell Contents: Pearson correlation
P-Value
Foi possível verificar que algumas variáveis possuem uma alta correlação entre si.
As variáveis com as correlações mais altas são N_IDHM x NP_MORT1 (0,829),
N_IDHM_L x NP_MORT1 (0,967), N_IDHM_R x NP_MORT1 (0,814), NP_PIND x
NP_PINDCRI (0,991), NP_PIND x NP_PPOBCRI (0,833), NP_PINDCRI x
NP_PPOBCRI (0,856), NP_T_NESTUDA_NTRAB_MMEIO x NP_PIND (0817),
NP_T_NESTUDA_NTRAB_MMEIO x NP_PINDCRI (0825), N_IDHM x NP_PIND
(0863), NP_IDHM x NP_PINDCRI (0,870), N_IDHM_R x NP_PIND (0,884),
N_IDHM_R x NP_PINDCRI (0,891), N_IDHM_E x NP_PPOBCRI (0,918),
N_IDHM_E x NP_PPOBCRI (0,815), N_IDHM_L x NP_PPOBCRI (0,812),
N_IDHM_R x NP_PPOBCRI (0,940), N_HOMEM70A74 x N_HOMEM10A14 (0,974),
N_IDHM_E x N_IDHM (0,951), N_IDHM_L x N_IDHM (0,852), N_IDHM_R x
N_IDHM (0,948), N_IDHM_R x N_IDHM_E (0,820) e N_IDHM_R x N_IDHM_L
(0,834).
A Figura 23 representa o dendorama das variáveis.
N_HO
MEM
70A7
4
N_HO
MEM
10A1
4
NP_T
_DES
18M
N_T_
LUZ
NP_P
ARED
E
NP_T
_MUL
CHEF
EFIF01
4
NP_T
RABS
C
N_T_
AGUA
N_P_
SUPE
R
N_E_
ANOSE
STUD
O
NP_T
_ANA
LF15
A17
NP_T
_NES
TUDA
_NTR
AB_M
MEIO
N_IDHM
_R
N_ID
HM_E
N_ID
HM
NP_P
POBC
RI
NP_P
INDC
RI
NP_P
IND
N_ID
HM_L
NP_M
ORT1
NP_F
ECTO
T
62,96
75,31
87,65
100,00
Variables
Sim
ilari
ty
DendrogramSingle Linkage; Correlation Coefficient Distance
Figura 23: Dendograma
Fonte: Atlas do Desenvolvimento Humano no Brasil
A partir deste dendograma com 3 clusters pode-se perceber que as variáveis
referentes a quantidade de homens com 10 a 14 e com 70 a 74 anos representam um
agrupamento diferente das outras variáveis, a variável relacionada a desocupação também
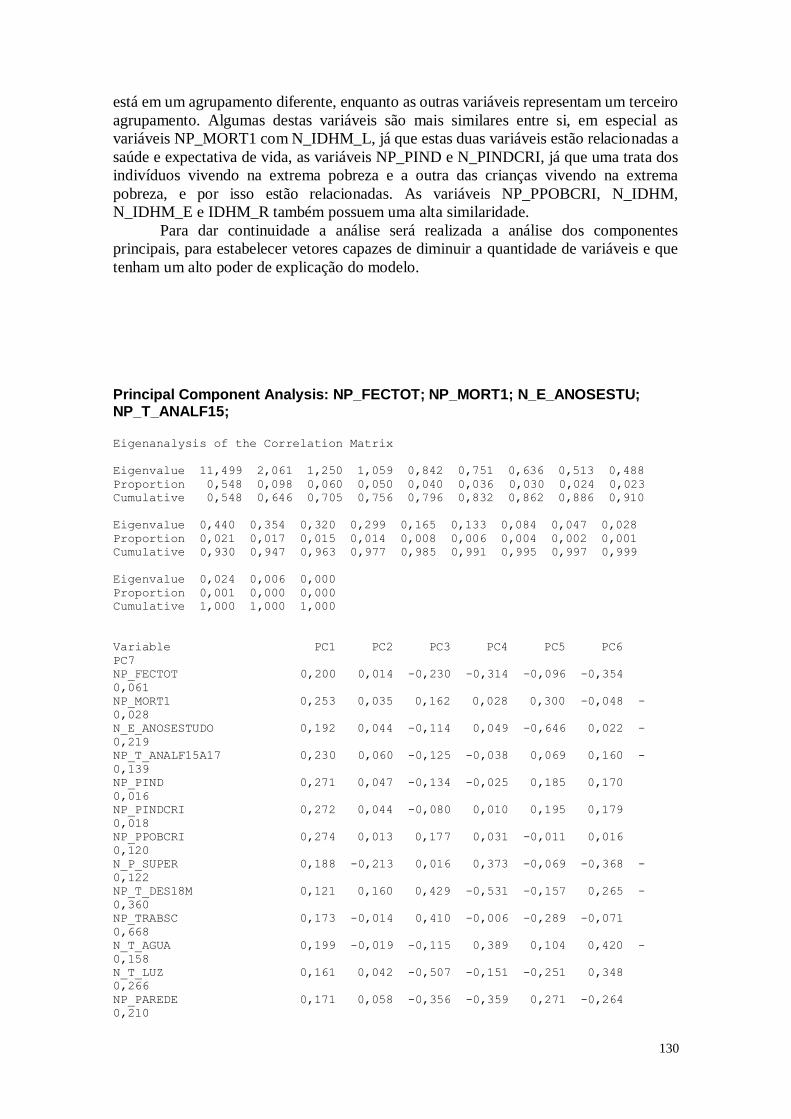
130
está em um agrupamento diferente, enquanto as outras variáveis representam um terceiro
agrupamento. Algumas destas variáveis são mais similares entre si, em especial as
variáveis NP_MORT1 com N_IDHM_L, já que estas duas variáveis estão relacionadas a
saúde e expectativa de vida, as variáveis NP_PIND e N_PINDCRI, já que uma trata dos
indivíduos vivendo na extrema pobreza e a outra das crianças vivendo na extrema
pobreza, e por isso estão relacionadas. As variáveis NP_PPOBCRI, N_IDHM,
N_IDHM_E e IDHM_R também possuem uma alta similaridade.
Para dar continuidade a análise será realizada a análise dos componentes
principais, para estabelecer vetores capazes de diminuir a quantidade de variáveis e que
tenham um alto poder de explicação do modelo.
Principal Component Analysis: NP_FECTOT; NP_MORT1; N_E_ANOSESTU; NP_T_ANALF15; Eigenanalysis of the Correlation Matrix
Eigenvalue 11,499 2,061 1,250 1,059 0,842 0,751 0,636 0,513 0,488
Proportion 0,548 0,098 0,060 0,050 0,040 0,036 0,030 0,024 0,023
Cumulative 0,548 0,646 0,705 0,756 0,796 0,832 0,862 0,886 0,910
Eigenvalue 0,440 0,354 0,320 0,299 0,165 0,133 0,084 0,047 0,028
Proportion 0,021 0,017 0,015 0,014 0,008 0,006 0,004 0,002 0,001
Cumulative 0,930 0,947 0,963 0,977 0,985 0,991 0,995 0,997 0,999
Eigenvalue 0,024 0,006 0,000
Proportion 0,001 0,000 0,000
Cumulative 1,000 1,000 1,000
Variable PC1 PC2 PC3 PC4 PC5 PC6
PC7
NP_FECTOT 0,200 0,014 -0,230 -0,314 -0,096 -0,354
0,061
NP_MORT1 0,253 0,035 0,162 0,028 0,300 -0,048 -
0,028
N_E_ANOSESTUDO 0,192 0,044 -0,114 0,049 -0,646 0,022 -
0,219
NP_T_ANALF15A17 0,230 0,060 -0,125 -0,038 0,069 0,160 -
0,139
NP_PIND 0,271 0,047 -0,134 -0,025 0,185 0,170
0,016
NP_PINDCRI 0,272 0,044 -0,080 0,010 0,195 0,179
0,018
NP_PPOBCRI 0,274 0,013 0,177 0,031 -0,011 0,016
0,120
N_P_SUPER 0,188 -0,213 0,016 0,373 -0,069 -0,368 -
0,122
NP_T_DES18M 0,121 0,160 0,429 -0,531 -0,157 0,265 -
0,360
NP_TRABSC 0,173 -0,014 0,410 -0,006 -0,289 -0,071
0,668
N_T_AGUA 0,199 -0,019 -0,115 0,389 0,104 0,420 -
0,158
N_T_LUZ 0,161 0,042 -0,507 -0,151 -0,251 0,348
0,266
NP_PAREDE 0,171 0,058 -0,356 -0,359 0,271 -0,264
0,210
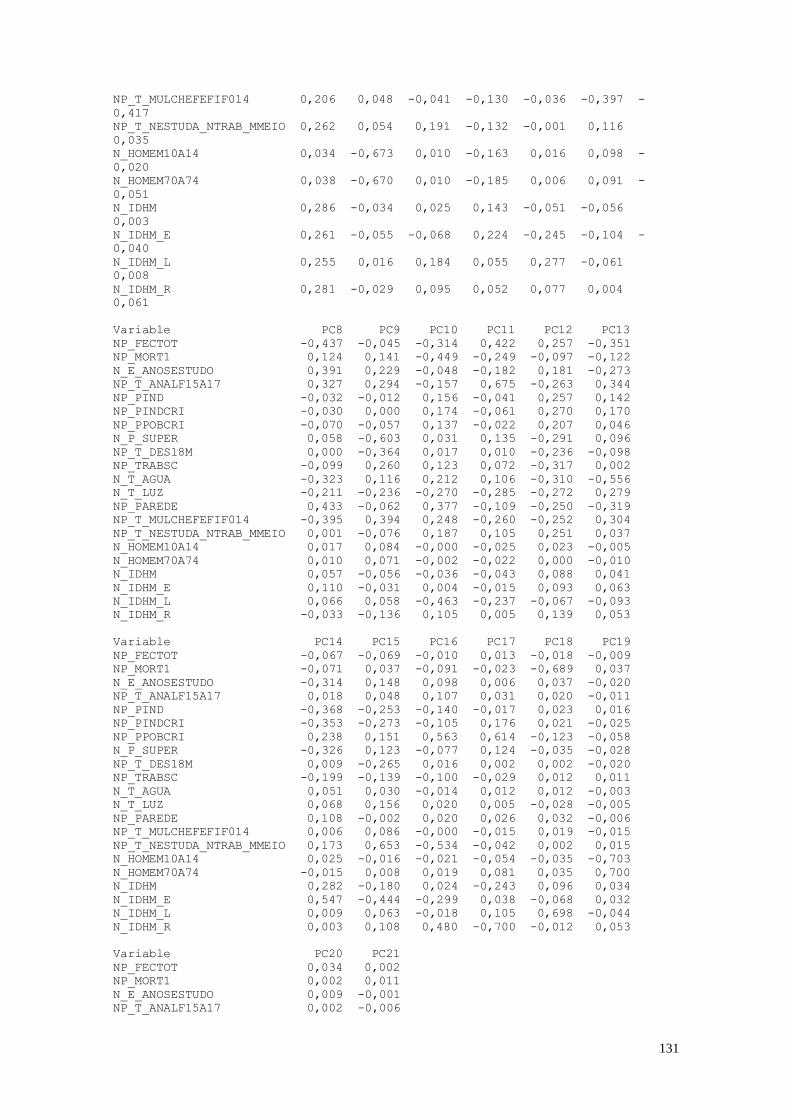
131
NP_T_MULCHEFEFIF014 0,206 0,048 -0,041 -0,130 -0,036 -0,397 -
0,417
NP_T_NESTUDA_NTRAB_MMEIO 0,262 0,054 0,191 -0,132 -0,001 0,116
0,035
N_HOMEM10A14 0,034 -0,673 0,010 -0,163 0,016 0,098 -
0,020
N_HOMEM70A74 0,038 -0,670 0,010 -0,185 0,006 0,091 -
0,051
N_IDHM 0,286 -0,034 0,025 0,143 -0,051 -0,056
0,003
N_IDHM_E 0,261 -0,055 -0,068 0,224 -0,245 -0,104 -
0,040
N_IDHM_L 0,255 0,016 0,184 0,055 0,277 -0,061
0,008
N_IDHM_R 0,281 -0,029 0,095 0,052 0,077 0,004
0,061
Variable PC8 PC9 PC10 PC11 PC12 PC13
NP_FECTOT -0,437 -0,045 -0,314 0,422 0,257 -0,351
NP_MORT1 0,124 0,141 -0,449 -0,249 -0,097 -0,122
N_E_ANOSESTUDO 0,391 0,229 -0,048 -0,182 0,181 -0,273
NP_T_ANALF15A17 0,327 0,294 -0,157 0,675 -0,263 0,344
NP_PIND -0,032 -0,012 0,156 -0,041 0,257 0,142
NP_PINDCRI -0,030 0,000 0,174 -0,061 0,270 0,170
NP_PPOBCRI -0,070 -0,057 0,137 -0,022 0,207 0,046
N_P_SUPER 0,058 -0,603 0,031 0,135 -0,291 0,096
NP_T_DES18M 0,000 -0,364 0,017 0,010 -0,236 -0,098
NP_TRABSC -0,099 0,260 0,123 0,072 -0,317 0,002
N_T_AGUA -0,323 0,116 0,212 0,106 -0,310 -0,556
N_T_LUZ -0,211 -0,236 -0,270 -0,285 -0,272 0,279
NP_PAREDE 0,433 -0,062 0,377 -0,109 -0,250 -0,319
NP_T_MULCHEFEFIF014 -0,395 0,394 0,248 -0,260 -0,252 0,304
NP_T_NESTUDA_NTRAB_MMEIO 0,001 -0,076 0,187 0,105 0,251 0,037
N_HOMEM10A14 0,017 0,084 -0,000 -0,025 0,023 -0,005
N_HOMEM70A74 0,010 0,071 -0,002 -0,022 0,000 -0,010
N_IDHM 0,057 -0,056 -0,036 -0,043 0,088 0,041
N_IDHM_E 0,110 -0,031 0,004 -0,015 0,093 0,063
N_IDHM_L 0,066 0,058 -0,463 -0,237 -0,067 -0,093
N_IDHM_R -0,033 -0,136 0,105 0,005 0,139 0,053
Variable PC14 PC15 PC16 PC17 PC18 PC19
NP_FECTOT -0,067 -0,069 -0,010 0,013 -0,018 -0,009
NP_MORT1 -0,071 0,037 -0,091 -0,023 -0,689 0,037
N_E_ANOSESTUDO -0,314 0,148 0,098 0,006 0,037 -0,020
NP_T_ANALF15A17 0,018 0,048 0,107 0,031 0,020 -0,011
NP_PIND -0,368 -0,253 -0,140 -0,017 0,023 0,016
NP_PINDCRI -0,353 -0,273 -0,105 0,176 0,021 -0,025
NP_PPOBCRI 0,238 0,151 0,563 0,614 -0,123 -0,058
N_P_SUPER -0,326 0,123 -0,077 0,124 -0,035 -0,028
NP_T_DES18M 0,009 -0,265 0,016 0,002 0,002 -0,020
NP_TRABSC -0,199 -0,139 -0,100 -0,029 0,012 0,011
N_T_AGUA 0,051 0,030 -0,014 0,012 0,012 -0,003
N_T_LUZ 0,068 0,156 0,020 0,005 -0,028 -0,005
NP_PAREDE 0,108 -0,002 0,020 0,026 0,032 -0,006
NP_T_MULCHEFEFIF014 0,006 0,086 -0,000 -0,015 0,019 -0,015
NP_T_NESTUDA_NTRAB_MMEIO 0,173 0,653 -0,534 -0,042 0,002 0,015
N_HOMEM10A14 0,025 -0,016 -0,021 -0,054 -0,035 -0,703
N_HOMEM70A74 -0,015 0,008 0,019 0,081 0,035 0,700
N_IDHM 0,282 -0,180 0,024 -0,243 0,096 0,034
N_IDHM_E 0,547 -0,444 -0,299 0,038 -0,068 0,032
N_IDHM_L 0,009 0,063 -0,018 0,105 0,698 -0,044
N_IDHM_R 0,003 0,108 0,480 -0,700 -0,012 0,053
Variable PC20 PC21
NP_FECTOT 0,034 0,002
NP_MORT1 0,002 0,011
N_E_ANOSESTUDO 0,009 -0,001
NP_T_ANALF15A17 0,002 -0,006
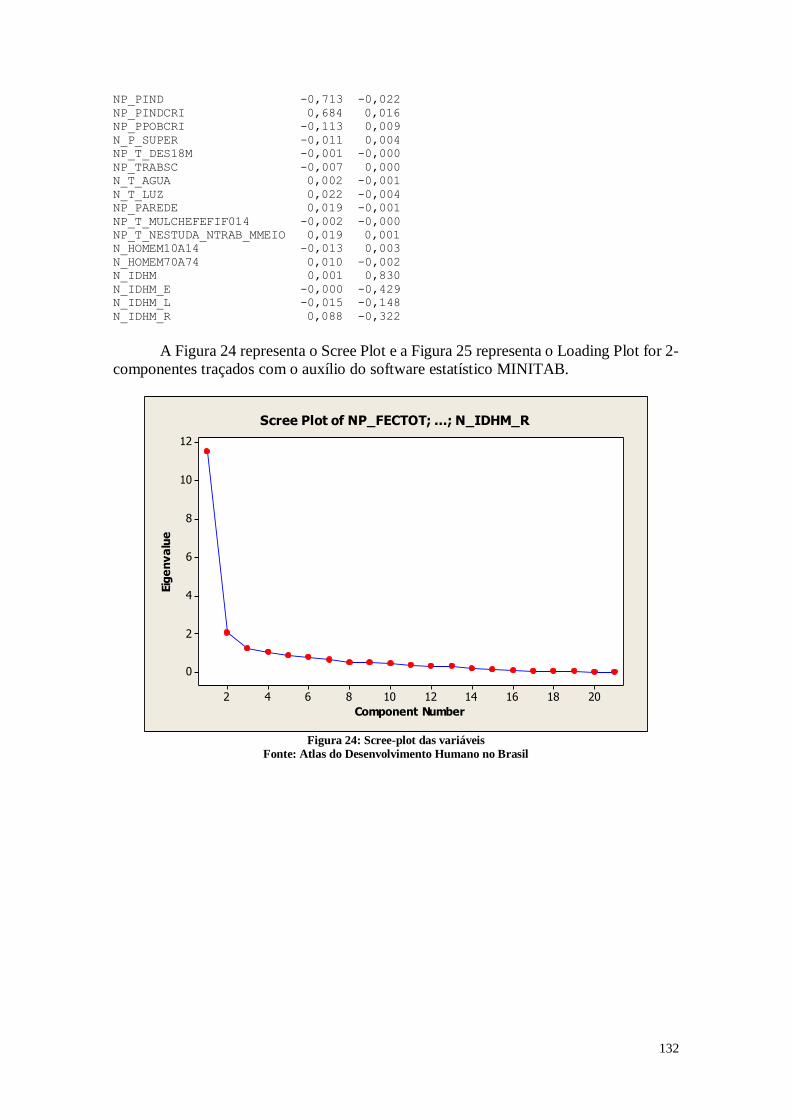
132
NP_PIND -0,713 -0,022
NP_PINDCRI 0,684 0,016
NP_PPOBCRI -0,113 0,009
N_P_SUPER -0,011 0,004
NP_T_DES18M -0,001 -0,000
NP_TRABSC -0,007 0,000
N_T_AGUA 0,002 -0,001
N_T_LUZ 0,022 -0,004
NP_PAREDE 0,019 -0,001
NP_T_MULCHEFEFIF014 -0,002 -0,000
NP_T_NESTUDA_NTRAB_MMEIO 0,019 0,001
N_HOMEM10A14 -0,013 0,003
N_HOMEM70A74 0,010 -0,002
N_IDHM 0,001 0,830
N_IDHM_E -0,000 -0,429
N_IDHM_L -0,015 -0,148
N_IDHM_R 0,088 -0,322
A Figura 24 representa o Scree Plot e a Figura 25 representa o Loading Plot for 2-
componentes traçados com o auxílio do software estatístico MINITAB.
2018161412108642
12
10
8
6
4
2
0
Component Number
Eig
en
va
lue
Scree Plot of NP_FECTOT; ...; N_IDHM_R
Figura 24: Scree-plot das variáveis
Fonte: Atlas do Desenvolvimento Humano no Brasil
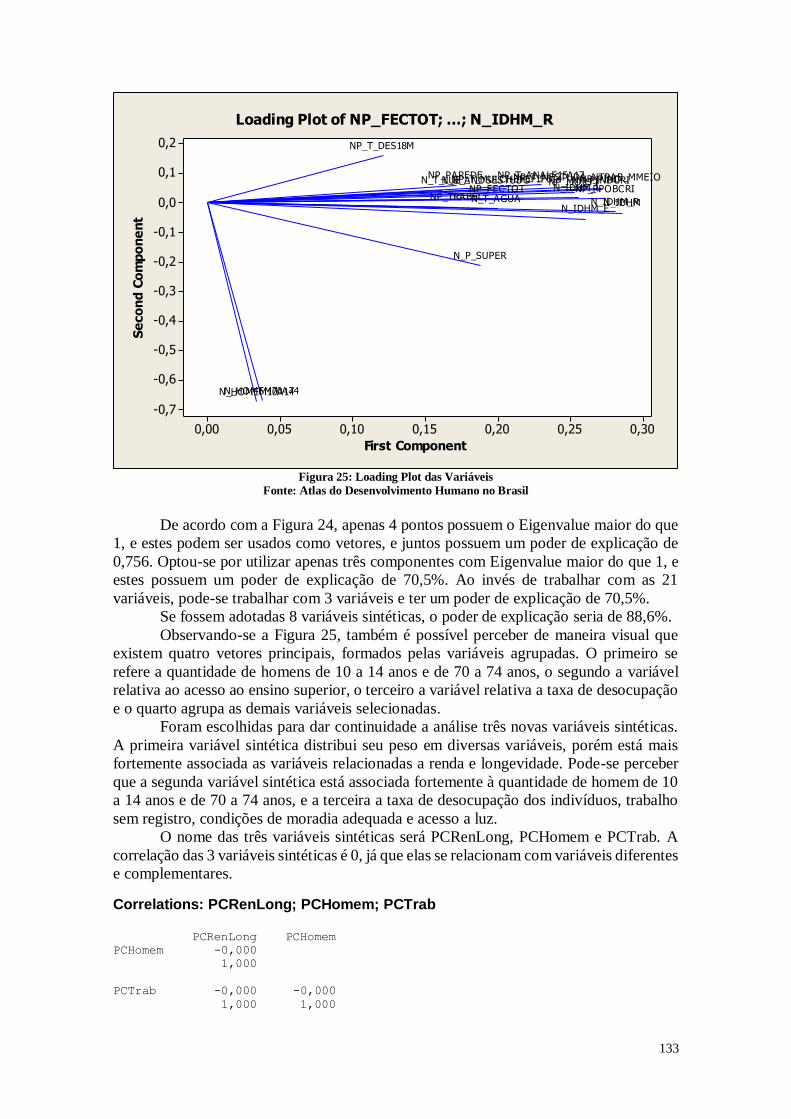
133
0,300,250,200,150,100,050,00
0,2
0,1
0,0
-0,1
-0,2
-0,3
-0,4
-0,5
-0,6
-0,7
First Component
Se
co
nd
Co
mp
on
en
t
N_IDHM_R
N_IDHM_L
N_IDHM_EN_IDHM
N_HOMEM70A74N_HOMEM10A14
NP_T_NESTUDA_NTRAB_MMEIONP_T_MULCHEFEFIF014NP_PAREDEN_T_LUZ
N_T_AGUANP_TRABSC
NP_T_DES18M
N_P_SUPER
NP_PPOBCRINP_PINDCRINP_PINDNP_T_ANALF15A17
N_E_ANOSESTUDO NP_MORT1NP_FECTOT
Loading Plot of NP_FECTOT; ...; N_IDHM_R
Figura 25: Loading Plot das Variáveis
Fonte: Atlas do Desenvolvimento Humano no Brasil
De acordo com a Figura 24, apenas 4 pontos possuem o Eigenvalue maior do que
1, e estes podem ser usados como vetores, e juntos possuem um poder de explicação de
0,756. Optou-se por utilizar apenas três componentes com Eigenvalue maior do que 1, e
estes possuem um poder de explicação de 70,5%. Ao invés de trabalhar com as 21
variáveis, pode-se trabalhar com 3 variáveis e ter um poder de explicação de 70,5%.
Se fossem adotadas 8 variáveis sintéticas, o poder de explicação seria de 88,6%.
Observando-se a Figura 25, também é possível perceber de maneira visual que
existem quatro vetores principais, formados pelas variáveis agrupadas. O primeiro se
refere a quantidade de homens de 10 a 14 anos e de 70 a 74 anos, o segundo a variável
relativa ao acesso ao ensino superior, o terceiro a variável relativa a taxa de desocupação
e o quarto agrupa as demais variáveis selecionadas.
Foram escolhidas para dar continuidade a análise três novas variáveis sintéticas.
A primeira variável sintética distribui seu peso em diversas variáveis, porém está mais
fortemente associada as variáveis relacionadas a renda e longevidade. Pode-se perceber
que a segunda variável sintética está associada fortemente à quantidade de homem de 10
a 14 anos e de 70 a 74 anos, e a terceira a taxa de desocupação dos indivíduos, trabalho
sem registro, condições de moradia adequada e acesso a luz.
O nome das três variáveis sintéticas será PCRenLong, PCHomem e PCTrab. A
correlação das 3 variáveis sintéticas é 0, já que elas se relacionam com variáveis diferentes
e complementares.
Correlations: PCRenLong; PCHomem; PCTrab PCRenLong PCHomem
PCHomem -0,000
1,000
PCTrab -0,000 -0,000
1,000 1,000
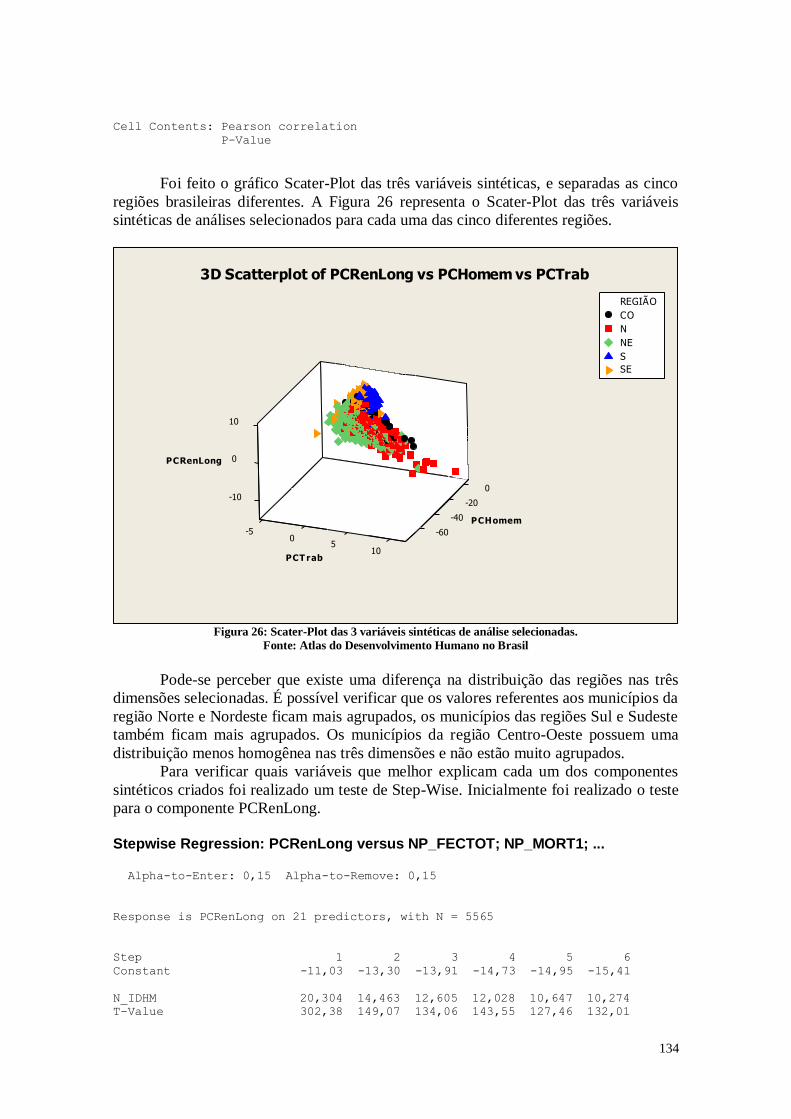
134
Cell Contents: Pearson correlation
P-Value
Foi feito o gráfico Scater-Plot das três variáveis sintéticas, e separadas as cinco
regiões brasileiras diferentes. A Figura 26 representa o Scater-Plot das três variáveis
sintéticas de análises selecionados para cada uma das cinco diferentes regiões.
0
-20-10
-40
0
-5
10
-600
510
PCRenLong
PCHomem
PCT rab
CO
N
NE
S
SE
REGIÃO
3D Scatterplot of PCRenLong vs PCHomem vs PCTrab
Figura 26: Scater-Plot das 3 variáveis sintéticas de análise selecionadas.
Fonte: Atlas do Desenvolvimento Humano no Brasil
Pode-se perceber que existe uma diferença na distribuição das regiões nas três
dimensões selecionadas. É possível verificar que os valores referentes aos municípios da
região Norte e Nordeste ficam mais agrupados, os municípios das regiões Sul e Sudeste
também ficam mais agrupados. Os municípios da região Centro-Oeste possuem uma
distribuição menos homogênea nas três dimensões e não estão muito agrupados.
Para verificar quais variáveis que melhor explicam cada um dos componentes
sintéticos criados foi realizado um teste de Step-Wise. Inicialmente foi realizado o teste
para o componente PCRenLong.
Stepwise Regression: PCRenLong versus NP_FECTOT; NP_MORT1; ... Alpha-to-Enter: 0,15 Alpha-to-Remove: 0,15
Response is PCRenLong on 21 predictors, with N = 5565
Step 1 2 3 4 5 6
Constant -11,03 -13,30 -13,91 -14,73 -14,95 -15,41
N_IDHM 20,304 14,463 12,605 12,028 10,647 10,274
T-Value 302,38 149,07 134,06 143,55 127,46 132,01
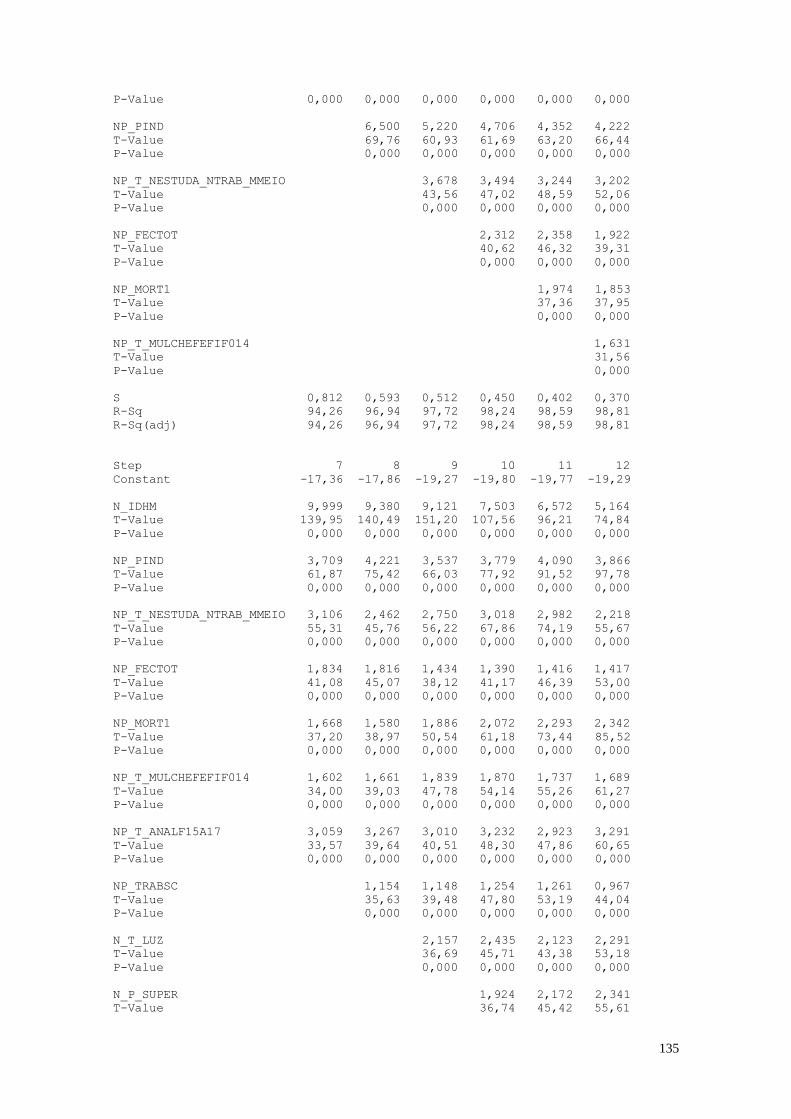
135
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_PIND 6,500 5,220 4,706 4,352 4,222
T-Value 69,76 60,93 61,69 63,20 66,44
P-Value 0,000 0,000 0,000 0,000 0,000
NP_T_NESTUDA_NTRAB_MMEIO 3,678 3,494 3,244 3,202
T-Value 43,56 47,02 48,59 52,06
P-Value 0,000 0,000 0,000 0,000
NP_FECTOT 2,312 2,358 1,922
T-Value 40,62 46,32 39,31
P-Value 0,000 0,000 0,000
NP_MORT1 1,974 1,853
T-Value 37,36 37,95
P-Value 0,000 0,000
NP_T_MULCHEFEFIF014 1,631
T-Value 31,56
P-Value 0,000
S 0,812 0,593 0,512 0,450 0,402 0,370
R-Sq 94,26 96,94 97,72 98,24 98,59 98,81
R-Sq(adj) 94,26 96,94 97,72 98,24 98,59 98,81
Step 7 8 9 10 11 12
Constant -17,36 -17,86 -19,27 -19,80 -19,77 -19,29
N_IDHM 9,999 9,380 9,121 7,503 6,572 5,164
T-Value 139,95 140,49 151,20 107,56 96,21 74,84
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_PIND 3,709 4,221 3,537 3,779 4,090 3,866
T-Value 61,87 75,42 66,03 77,92 91,52 97,78
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_T_NESTUDA_NTRAB_MMEIO 3,106 2,462 2,750 3,018 2,982 2,218
T-Value 55,31 45,76 56,22 67,86 74,19 55,67
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_FECTOT 1,834 1,816 1,434 1,390 1,416 1,417
T-Value 41,08 45,07 38,12 41,17 46,39 53,00
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_MORT1 1,668 1,580 1,886 2,072 2,293 2,342
T-Value 37,20 38,97 50,54 61,18 73,44 85,52
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_T_MULCHEFEFIF014 1,602 1,661 1,839 1,870 1,737 1,689
T-Value 34,00 39,03 47,78 54,14 55,26 61,27
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_T_ANALF15A17 3,059 3,267 3,010 3,232 2,923 3,291
T-Value 33,57 39,64 40,51 48,30 47,86 60,65
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_TRABSC 1,154 1,148 1,254 1,261 0,967
T-Value 35,63 39,48 47,80 53,19 44,04
P-Value 0,000 0,000 0,000 0,000 0,000
N_T_LUZ 2,157 2,435 2,123 2,291
T-Value 36,69 45,71 43,38 53,18
P-Value 0,000 0,000 0,000 0,000
N_P_SUPER 1,924 2,172 2,341
T-Value 36,74 45,42 55,61
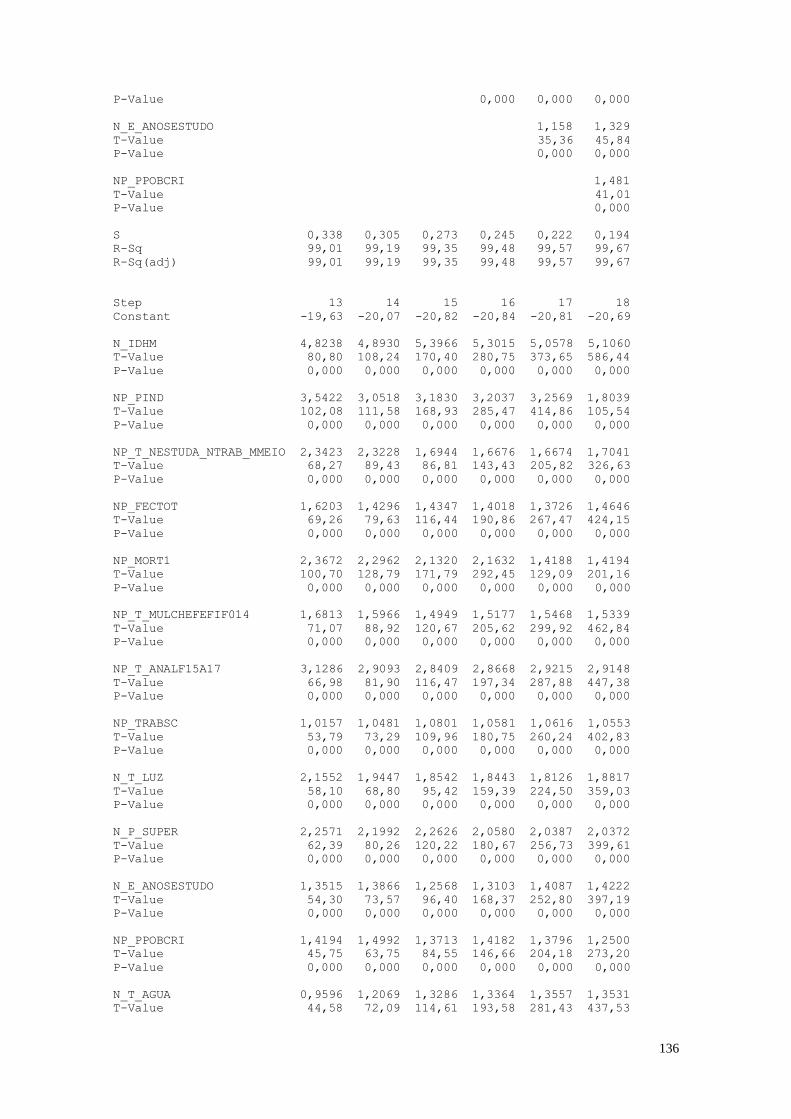
136
P-Value 0,000 0,000 0,000
N_E_ANOSESTUDO 1,158 1,329
T-Value 35,36 45,84
P-Value 0,000 0,000
NP_PPOBCRI 1,481
T-Value 41,01
P-Value 0,000
S 0,338 0,305 0,273 0,245 0,222 0,194
R-Sq 99,01 99,19 99,35 99,48 99,57 99,67
R-Sq(adj) 99,01 99,19 99,35 99,48 99,57 99,67
Step 13 14 15 16 17 18
Constant -19,63 -20,07 -20,82 -20,84 -20,81 -20,69
N_IDHM 4,8238 4,8930 5,3966 5,3015 5,0578 5,1060
T-Value 80,80 108,24 170,40 280,75 373,65 586,44
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_PIND 3,5422 3,0518 3,1830 3,2037 3,2569 1,8039
T-Value 102,08 111,58 168,93 285,47 414,86 105,54
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_T_NESTUDA_NTRAB_MMEIO 2,3423 2,3228 1,6944 1,6676 1,6674 1,7041
T-Value 68,27 89,43 86,81 143,43 205,82 326,63
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_FECTOT 1,6203 1,4296 1,4347 1,4018 1,3726 1,4646
T-Value 69,26 79,63 116,44 190,86 267,47 424,15
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_MORT1 2,3672 2,2962 2,1320 2,1632 1,4188 1,4194
T-Value 100,70 128,79 171,79 292,45 129,09 201,16
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_T_MULCHEFEFIF014 1,6813 1,5966 1,4949 1,5177 1,5468 1,5339
T-Value 71,07 88,92 120,67 205,62 299,92 462,84
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_T_ANALF15A17 3,1286 2,9093 2,8409 2,8668 2,9215 2,9148
T-Value 66,98 81,90 116,47 197,34 287,88 447,38
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_TRABSC 1,0157 1,0481 1,0801 1,0581 1,0616 1,0553
T-Value 53,79 73,29 109,96 180,75 260,24 402,83
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
N_T_LUZ 2,1552 1,9447 1,8542 1,8443 1,8126 1,8817
T-Value 58,10 68,80 95,42 159,39 224,50 359,03
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
N_P_SUPER 2,2571 2,1992 2,2626 2,0580 2,0387 2,0372
T-Value 62,39 80,26 120,22 180,67 256,73 399,61
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
N_E_ANOSESTUDO 1,3515 1,3866 1,2568 1,3103 1,4087 1,4222
T-Value 54,30 73,57 96,40 168,37 252,80 397,19
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_PPOBCRI 1,4194 1,4992 1,3713 1,4182 1,3796 1,2500
T-Value 45,75 63,75 84,55 146,66 204,18 273,20
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
N_T_AGUA 0,9596 1,2069 1,3286 1,3364 1,3557 1,3531
T-Value 44,58 72,09 114,61 193,58 281,43 437,53
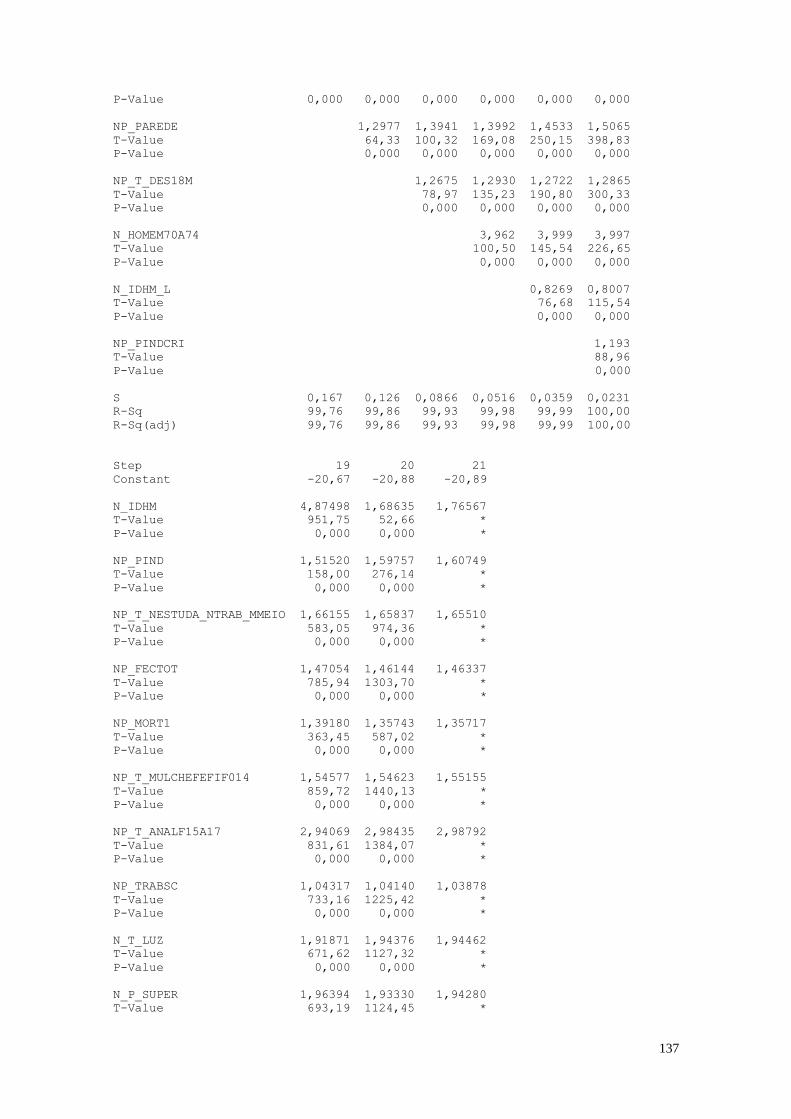
137
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_PAREDE 1,2977 1,3941 1,3992 1,4533 1,5065
T-Value 64,33 100,32 169,08 250,15 398,83
P-Value 0,000 0,000 0,000 0,000 0,000
NP_T_DES18M 1,2675 1,2930 1,2722 1,2865
T-Value 78,97 135,23 190,80 300,33
P-Value 0,000 0,000 0,000 0,000
N_HOMEM70A74 3,962 3,999 3,997
T-Value 100,50 145,54 226,65
P-Value 0,000 0,000 0,000
N_IDHM_L 0,8269 0,8007
T-Value 76,68 115,54
P-Value 0,000 0,000
NP_PINDCRI 1,193
T-Value 88,96
P-Value 0,000
S 0,167 0,126 0,0866 0,0516 0,0359 0,0231
R-Sq 99,76 99,86 99,93 99,98 99,99 100,00
R-Sq(adj) 99,76 99,86 99,93 99,98 99,99 100,00
Step 19 20 21
Constant -20,67 -20,88 -20,89
N_IDHM 4,87498 1,68635 1,76567
T-Value 951,75 52,66 *
P-Value 0,000 0,000 *
NP_PIND 1,51520 1,59757 1,60749
T-Value 158,00 276,14 *
P-Value 0,000 0,000 *
NP_T_NESTUDA_NTRAB_MMEIO 1,66155 1,65837 1,65510
T-Value 583,05 974,36 *
P-Value 0,000 0,000 *
NP_FECTOT 1,47054 1,46144 1,46337
T-Value 785,94 1303,70 *
P-Value 0,000 0,000 *
NP_MORT1 1,39180 1,35743 1,35717
T-Value 363,45 587,02 *
P-Value 0,000 0,000 *
NP_T_MULCHEFEFIF014 1,54577 1,54623 1,55155
T-Value 859,72 1440,13 *
P-Value 0,000 0,000 *
NP_T_ANALF15A17 2,94069 2,98435 2,98792
T-Value 831,61 1384,07 *
P-Value 0,000 0,000 *
NP_TRABSC 1,04317 1,04140 1,03878
T-Value 733,16 1225,42 *
P-Value 0,000 0,000 *
N_T_LUZ 1,91871 1,94376 1,94462
T-Value 671,62 1127,32 *
P-Value 0,000 0,000 *
N_P_SUPER 1,96394 1,93330 1,94280
T-Value 693,19 1124,45 *

138
P-Value 0,000 0,000 *
N_E_ANOSESTUDO 1,48072 1,48173 1,48744
T-Value 738,71 1237,88 *
P-Value 0,000 0,000 *
NP_PPOBCRI 1,13273 1,10930 1,11825
T-Value 422,95 686,32 *
P-Value 0,000 0,000 *
N_T_AGUA 1,34647 1,35232 1,35273
T-Value 803,32 1348,82 *
P-Value 0,000 0,000 *
NP_PAREDE 1,50130 1,50612 1,50695
T-Value 733,61 1231,52 *
P-Value 0,000 0,000 *
NP_T_DES18M 1,25469 1,25885 1,26933
T-Value 536,98 901,83 *
P-Value 0,000 0,000 *
N_HOMEM70A74 3,88102 3,84662 2,05641
T-Value 404,02 669,40 *
P-Value 0,000 0,000 *
N_IDHM_L 0,82380 1,27874 1,26883
T-Value 219,16 252,13 *
P-Value 0,000 0,000 *
NP_PINDCRI 1,33557 1,28917 1,28197
T-Value 181,26 291,39 *
P-Value 0,000 0,000 *
N_IDHM_R 0,54255 1,75723 1,71331
T-Value 115,58 141,00 *
P-Value 0,000 0,000 *
N_IDHM_E 1,78205 1,72609
T-Value 100,03 *
P-Value 0,000 *
N_HOMEM10A14 1,84543
T-Value *
P-Value *
S 0,0125 0,00746 0,000000
R-Sq 100,00 100,00 100,00
R-Sq(adj) 100,00 100,00 100,00
Pode-se perceber que a variável N_IDHM é a que mais explica o componente
PCRenLong, com o valor de 94,26%. A próxima variável que explica o componente é a
NP_PIND, com o valor de explicação agregado de 96,94%. A terceira variável é a
NP_T_NSTUDA_NTRAB_MMEIO, que no agregado fica 97,72%. Acrescentando-se
mais variáveis é possível perceber que os ganhos marginais no poder de explicação são
cada vez menores.
Foi realizado o teste para o componente PCHomem.
Stepwise Regression: PCHomem versus NP_FECTOT; NP_MORT1; ... Alpha-to-Enter: 0,15 Alpha-to-Remove: 0,15
Response is PCHomem on 21 predictors, with N = 5565
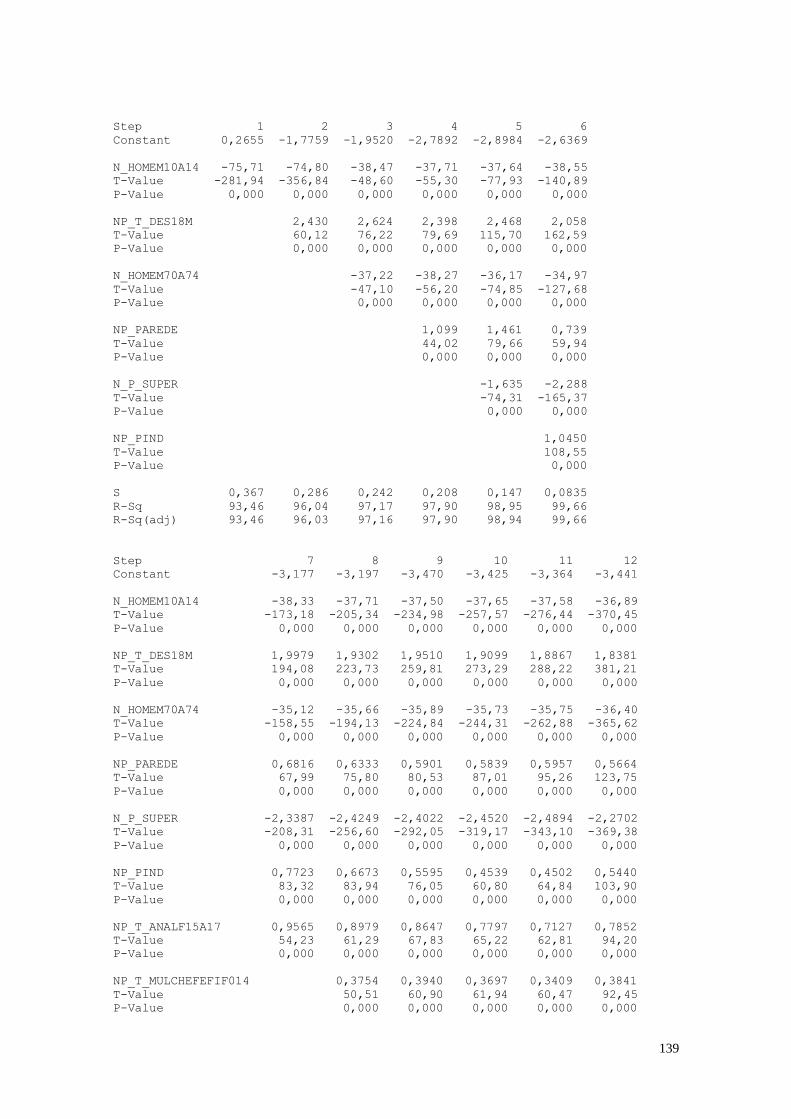
139
Step 1 2 3 4 5 6
Constant 0,2655 -1,7759 -1,9520 -2,7892 -2,8984 -2,6369
N_HOMEM10A14 -75,71 -74,80 -38,47 -37,71 -37,64 -38,55
T-Value -281,94 -356,84 -48,60 -55,30 -77,93 -140,89
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_T_DES18M 2,430 2,624 2,398 2,468 2,058
T-Value 60,12 76,22 79,69 115,70 162,59
P-Value 0,000 0,000 0,000 0,000 0,000
N_HOMEM70A74 -37,22 -38,27 -36,17 -34,97
T-Value -47,10 -56,20 -74,85 -127,68
P-Value 0,000 0,000 0,000 0,000
NP_PAREDE 1,099 1,461 0,739
T-Value 44,02 79,66 59,94
P-Value 0,000 0,000 0,000
N_P_SUPER -1,635 -2,288
T-Value -74,31 -165,37
P-Value 0,000 0,000
NP_PIND 1,0450
T-Value 108,55
P-Value 0,000
S 0,367 0,286 0,242 0,208 0,147 0,0835
R-Sq 93,46 96,04 97,17 97,90 98,95 99,66
R-Sq(adj) 93,46 96,03 97,16 97,90 98,94 99,66
Step 7 8 9 10 11 12
Constant -3,177 -3,197 -3,470 -3,425 -3,364 -3,441
N_HOMEM10A14 -38,33 -37,71 -37,50 -37,65 -37,58 -36,89
T-Value -173,18 -205,34 -234,98 -257,57 -276,44 -370,45
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_T_DES18M 1,9979 1,9302 1,9510 1,9099 1,8867 1,8381
T-Value 194,08 223,73 259,81 273,29 288,22 381,21
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
N_HOMEM70A74 -35,12 -35,66 -35,89 -35,73 -35,75 -36,40
T-Value -158,55 -194,13 -224,84 -244,31 -262,88 -365,62
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_PAREDE 0,6816 0,6333 0,5901 0,5839 0,5957 0,5664
T-Value 67,99 75,80 80,53 87,01 95,26 123,75
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
N_P_SUPER -2,3387 -2,4249 -2,4022 -2,4520 -2,4894 -2,2702
T-Value -208,31 -256,60 -292,05 -319,17 -343,10 -369,38
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_PIND 0,7723 0,6673 0,5595 0,4539 0,4502 0,5440
T-Value 83,32 83,94 76,05 60,80 64,84 103,90
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_T_ANALF15A17 0,9565 0,8979 0,8647 0,7797 0,7127 0,7852
T-Value 54,23 61,29 67,83 65,22 62,81 94,20
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_T_MULCHEFEFIF014 0,3754 0,3940 0,3697 0,3409 0,3841
T-Value 50,51 60,90 61,94 60,47 92,45
P-Value 0,000 0,000 0,000 0,000 0,000
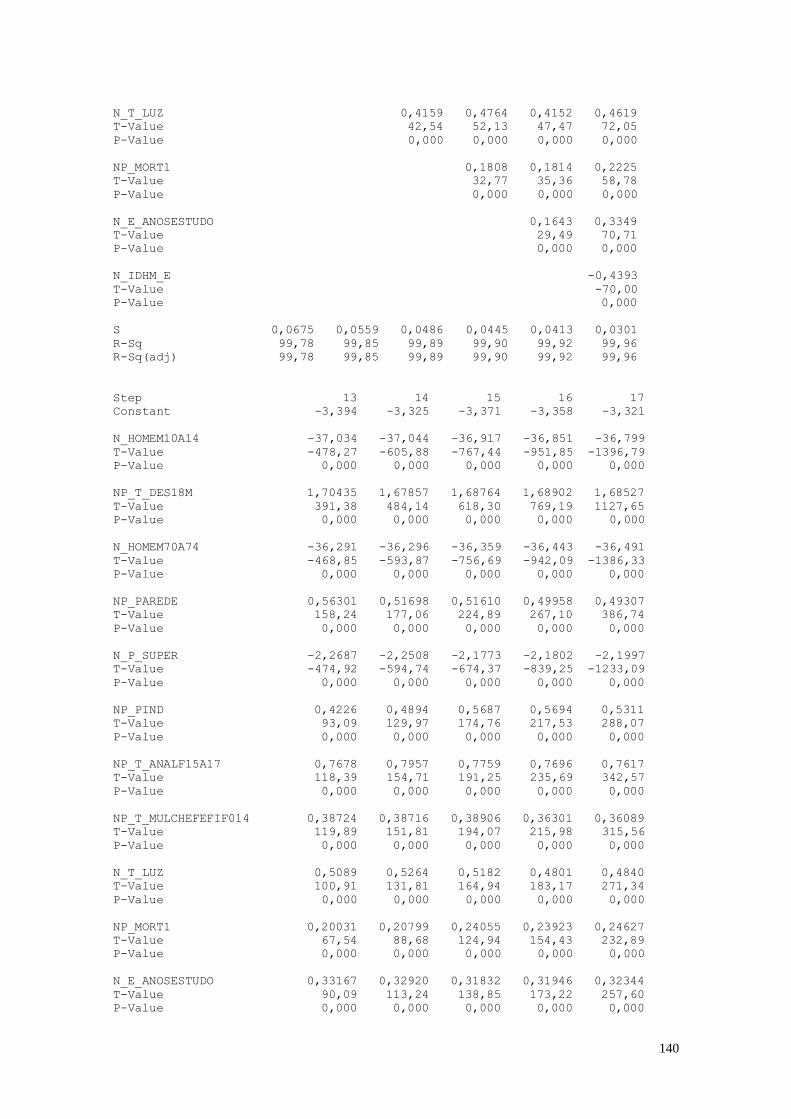
140
N_T_LUZ 0,4159 0,4764 0,4152 0,4619
T-Value 42,54 52,13 47,47 72,05
P-Value 0,000 0,000 0,000 0,000
NP_MORT1 0,1808 0,1814 0,2225
T-Value 32,77 35,36 58,78
P-Value 0,000 0,000 0,000
N_E_ANOSESTUDO 0,1643 0,3349
T-Value 29,49 70,71
P-Value 0,000 0,000
N_IDHM_E -0,4393
T-Value -70,00
P-Value 0,000
S 0,0675 0,0559 0,0486 0,0445 0,0413 0,0301
R-Sq 99,78 99,85 99,89 99,90 99,92 99,96
R-Sq(adj) 99,78 99,85 99,89 99,90 99,92 99,96
Step 13 14 15 16 17
Constant -3,394 -3,325 -3,371 -3,358 -3,321
N_HOMEM10A14 -37,034 -37,044 -36,917 -36,851 -36,799
T-Value -478,27 -605,88 -767,44 -951,85 -1396,79
P-Value 0,000 0,000 0,000 0,000 0,000
NP_T_DES18M 1,70435 1,67857 1,68764 1,68902 1,68527
T-Value 391,38 484,14 618,30 769,19 1127,65
P-Value 0,000 0,000 0,000 0,000 0,000
N_HOMEM70A74 -36,291 -36,296 -36,359 -36,443 -36,491
T-Value -468,85 -593,87 -756,69 -942,09 -1386,33
P-Value 0,000 0,000 0,000 0,000 0,000
NP_PAREDE 0,56301 0,51698 0,51610 0,49958 0,49307
T-Value 158,24 177,06 224,89 267,10 386,74
P-Value 0,000 0,000 0,000 0,000 0,000
N_P_SUPER -2,2687 -2,2508 -2,1773 -2,1802 -2,1997
T-Value -474,92 -594,74 -674,37 -839,25 -1233,09
P-Value 0,000 0,000 0,000 0,000 0,000
NP_PIND 0,4226 0,4894 0,5687 0,5694 0,5311
T-Value 93,09 129,97 174,76 217,53 288,07
P-Value 0,000 0,000 0,000 0,000 0,000
NP_T_ANALF15A17 0,7678 0,7957 0,7759 0,7696 0,7617
T-Value 118,39 154,71 191,25 235,69 342,57
P-Value 0,000 0,000 0,000 0,000 0,000
NP_T_MULCHEFEFIF014 0,38724 0,38716 0,38906 0,36301 0,36089
T-Value 119,89 151,81 194,07 215,98 315,56
P-Value 0,000 0,000 0,000 0,000 0,000
N_T_LUZ 0,5089 0,5264 0,5182 0,4801 0,4840
T-Value 100,91 131,81 164,94 183,17 271,34
P-Value 0,000 0,000 0,000 0,000 0,000
NP_MORT1 0,20031 0,20799 0,24055 0,23923 0,24627
T-Value 67,54 88,68 124,94 154,43 232,89
P-Value 0,000 0,000 0,000 0,000 0,000
N_E_ANOSESTUDO 0,33167 0,32920 0,31832 0,31946 0,32344
T-Value 90,09 113,24 138,85 173,22 257,60
P-Value 0,000 0,000 0,000 0,000 0,000
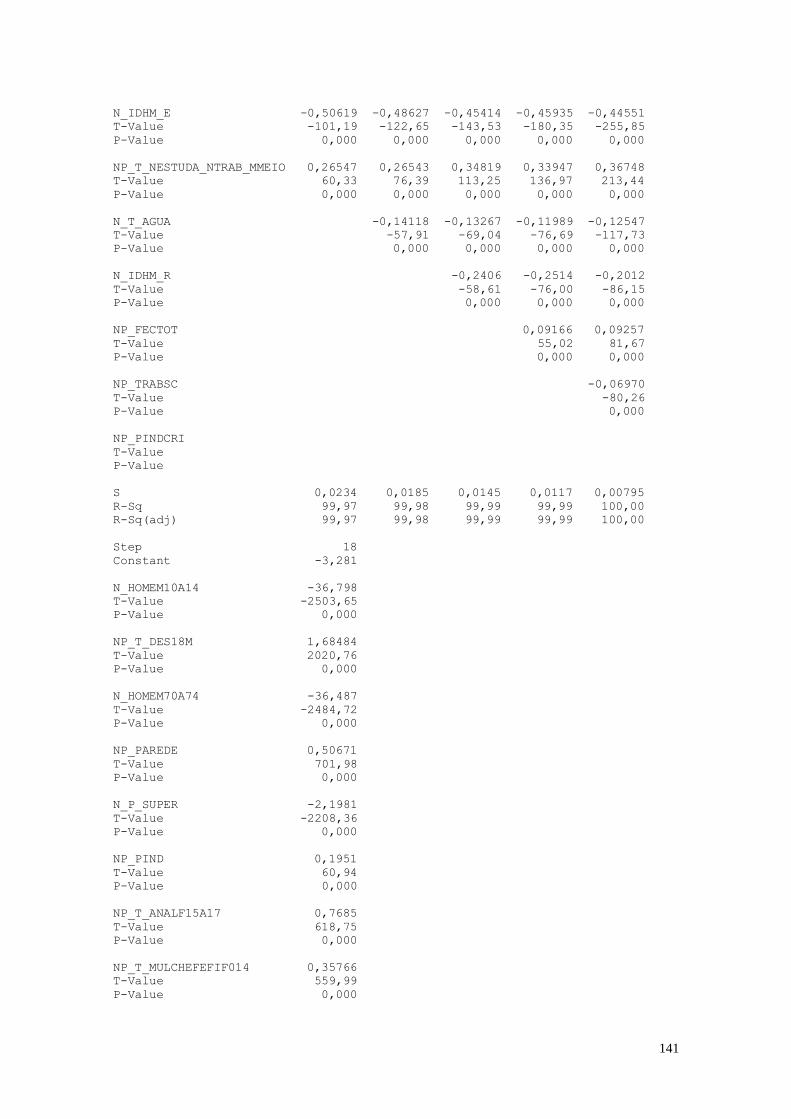
141
N_IDHM_E -0,50619 -0,48627 -0,45414 -0,45935 -0,44551
T-Value -101,19 -122,65 -143,53 -180,35 -255,85
P-Value 0,000 0,000 0,000 0,000 0,000
NP_T_NESTUDA_NTRAB_MMEIO 0,26547 0,26543 0,34819 0,33947 0,36748
T-Value 60,33 76,39 113,25 136,97 213,44
P-Value 0,000 0,000 0,000 0,000 0,000
N_T_AGUA -0,14118 -0,13267 -0,11989 -0,12547
T-Value -57,91 -69,04 -76,69 -117,73
P-Value 0,000 0,000 0,000 0,000
N_IDHM_R -0,2406 -0,2514 -0,2012
T-Value -58,61 -76,00 -86,15
P-Value 0,000 0,000 0,000
NP_FECTOT 0,09166 0,09257
T-Value 55,02 81,67
P-Value 0,000 0,000
NP_TRABSC -0,06970
T-Value -80,26
P-Value 0,000
NP_PINDCRI
T-Value
P-Value
S 0,0234 0,0185 0,0145 0,0117 0,00795
R-Sq 99,97 99,98 99,99 99,99 100,00
R-Sq(adj) 99,97 99,98 99,99 99,99 100,00
Step 18
Constant -3,281
N_HOMEM10A14 -36,798
T-Value -2503,65
P-Value 0,000
NP_T_DES18M 1,68484
T-Value 2020,76
P-Value 0,000
N_HOMEM70A74 -36,487
T-Value -2484,72
P-Value 0,000
NP_PAREDE 0,50671
T-Value 701,98
P-Value 0,000
N_P_SUPER -2,1981
T-Value -2208,36
P-Value 0,000
NP_PIND 0,1951
T-Value 60,94
P-Value 0,000
NP_T_ANALF15A17 0,7685
T-Value 618,75
P-Value 0,000
NP_T_MULCHEFEFIF014 0,35766
T-Value 559,99
P-Value 0,000

142
N_T_LUZ 0,5030
T-Value 498,13
P-Value 0,000
NP_MORT1 0,23942
T-Value 403,63
P-Value 0,000
N_E_ANOSESTUDO 0,33218
T-Value 471,24
P-Value 0,000
N_IDHM_E -0,45916
T-Value -468,91
P-Value 0,000
NP_T_NESTUDA_NTRAB_MMEIO 0,36081
T-Value 374,91
P-Value 0,000
N_T_AGUA -0,12694
T-Value -213,47
P-Value 0,000
N_IDHM_R -0,2035
T-Value -156,21
P-Value 0,000
NP_FECTOT 0,11267
T-Value 171,27
P-Value 0,000
NP_TRABSC -0,07739
T-Value -158,12
P-Value 0,000
NP_PINDCRI 0,2708
T-Value 110,80
P-Value 0,000
S 0,00444
R-Sq 100,00
R-Sq(adj) 100,00
Step 19 20 21
Constant -3,269 -3,266 -3,280
N_HOMEM10A14 -36,7311 -36,7260 -36,7314
T-Value -4589,19 -16801,53 *
P-Value 0,000 0,000 *
NP_T_DES18M 1,68247 1,68241 1,68245
T-Value 3711,43 13589,83 *
P-Value 0,000 0,000 *
N_HOMEM70A74 -36,5339 -36,5374 -36,5343
T-Value -4574,64 -16752,47 *
P-Value 0,000 0,000 *
NP_PAREDE 0,50696 0,51036 0,51065
T-Value 1293,05 4732,02 *
P-Value 0,000 0,000 *
N_P_SUPER -2,18809 -2,19272 -2,19435
T-Value -3996,55 -14564,16 *
P-Value 0,000 0,000 *
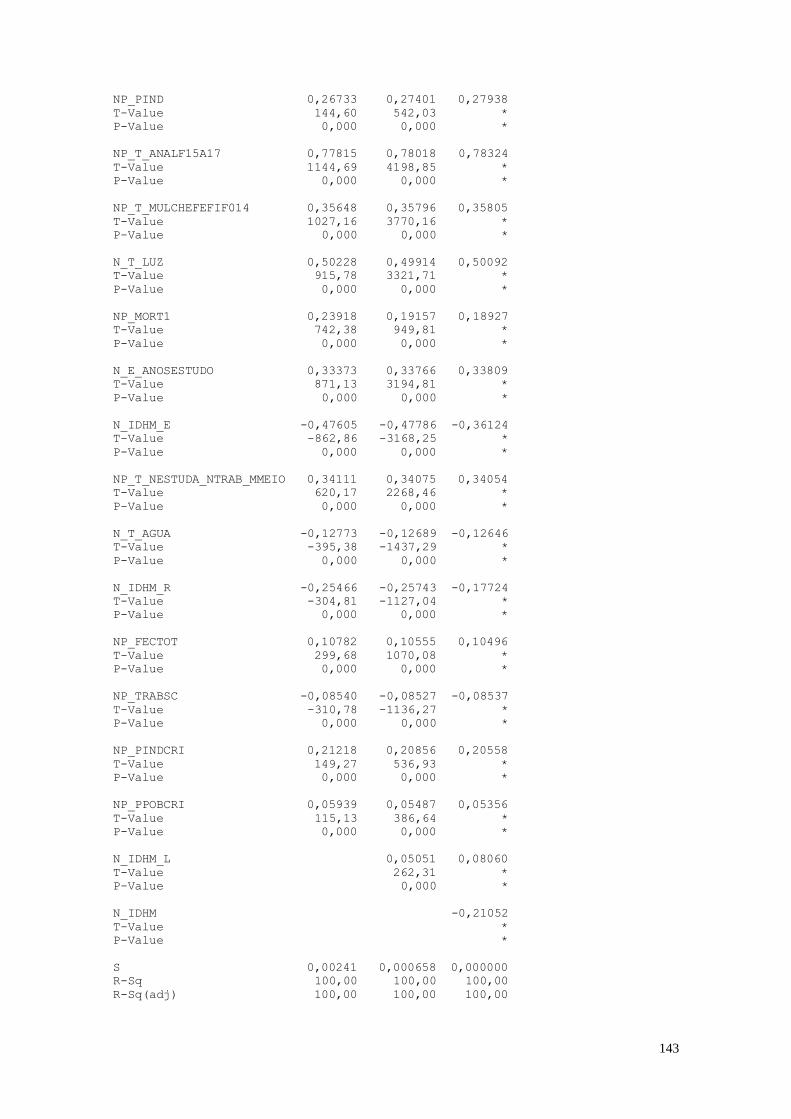
143
NP_PIND 0,26733 0,27401 0,27938
T-Value 144,60 542,03 *
P-Value 0,000 0,000 *
NP_T_ANALF15A17 0,77815 0,78018 0,78324
T-Value 1144,69 4198,85 *
P-Value 0,000 0,000 *
NP_T_MULCHEFEFIF014 0,35648 0,35796 0,35805
T-Value 1027,16 3770,16 *
P-Value 0,000 0,000 *
N_T_LUZ 0,50228 0,49914 0,50092
T-Value 915,78 3321,71 *
P-Value 0,000 0,000 *
NP_MORT1 0,23918 0,19157 0,18927
T-Value 742,38 949,81 *
P-Value 0,000 0,000 *
N_E_ANOSESTUDO 0,33373 0,33766 0,33809
T-Value 871,13 3194,81 *
P-Value 0,000 0,000 *
N_IDHM_E -0,47605 -0,47786 -0,36124
T-Value -862,86 -3168,25 *
P-Value 0,000 0,000 *
NP_T_NESTUDA_NTRAB_MMEIO 0,34111 0,34075 0,34054
T-Value 620,17 2268,46 *
P-Value 0,000 0,000 *
N_T_AGUA -0,12773 -0,12689 -0,12646
T-Value -395,38 -1437,29 *
P-Value 0,000 0,000 *
N_IDHM_R -0,25466 -0,25743 -0,17724
T-Value -304,81 -1127,04 *
P-Value 0,000 0,000 *
NP_FECTOT 0,10782 0,10555 0,10496
T-Value 299,68 1070,08 *
P-Value 0,000 0,000 *
NP_TRABSC -0,08540 -0,08527 -0,08537
T-Value -310,78 -1136,27 *
P-Value 0,000 0,000 *
NP_PINDCRI 0,21218 0,20856 0,20558
T-Value 149,27 536,93 *
P-Value 0,000 0,000 *
NP_PPOBCRI 0,05939 0,05487 0,05356
T-Value 115,13 386,64 *
P-Value 0,000 0,000 *
N_IDHM_L 0,05051 0,08060
T-Value 262,31 *
P-Value 0,000 *
N_IDHM -0,21052
T-Value *
P-Value *
S 0,00241 0,000658 0,000000
R-Sq 100,00 100,00 100,00
R-Sq(adj) 100,00 100,00 100,00
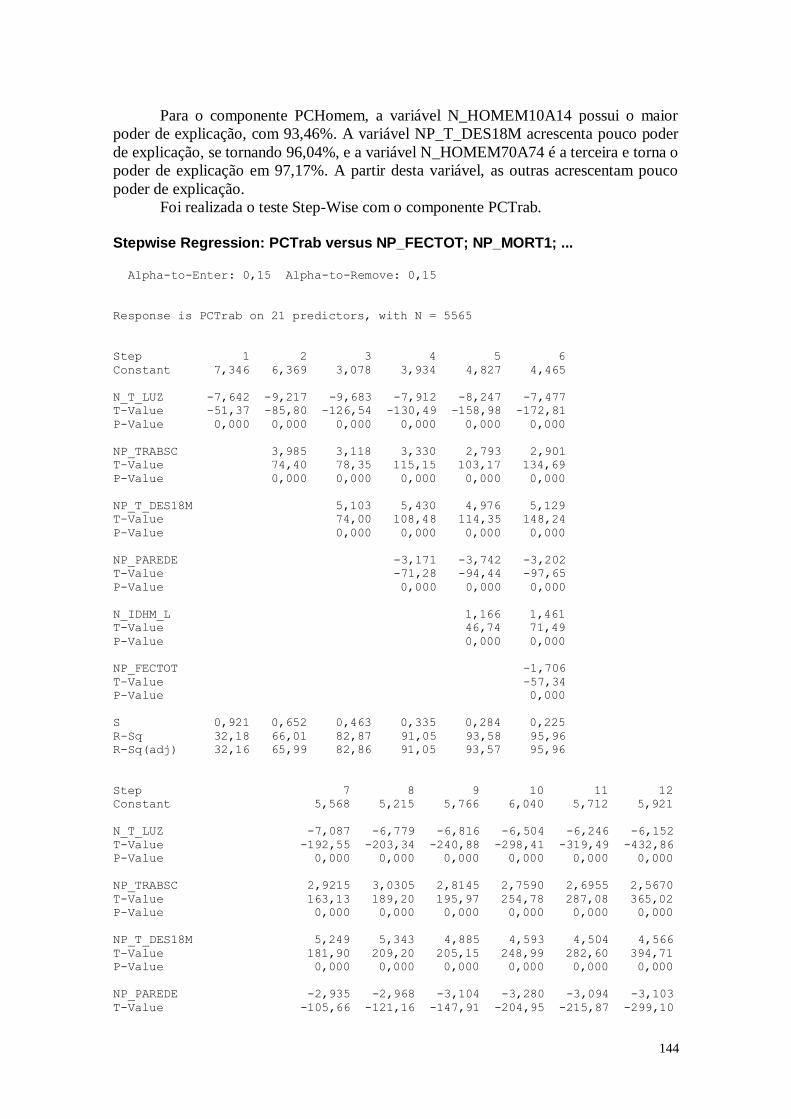
144
Para o componente PCHomem, a variável N_HOMEM10A14 possui o maior
poder de explicação, com 93,46%. A variável NP_T_DES18M acrescenta pouco poder
de explicação, se tornando 96,04%, e a variável N_HOMEM70A74 é a terceira e torna o
poder de explicação em 97,17%. A partir desta variável, as outras acrescentam pouco
poder de explicação.
Foi realizada o teste Step-Wise com o componente PCTrab.
Stepwise Regression: PCTrab versus NP_FECTOT; NP_MORT1; ... Alpha-to-Enter: 0,15 Alpha-to-Remove: 0,15
Response is PCTrab on 21 predictors, with N = 5565
Step 1 2 3 4 5 6
Constant 7,346 6,369 3,078 3,934 4,827 4,465
N_T_LUZ -7,642 -9,217 -9,683 -7,912 -8,247 -7,477
T-Value -51,37 -85,80 -126,54 -130,49 -158,98 -172,81
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_TRABSC 3,985 3,118 3,330 2,793 2,901
T-Value 74,40 78,35 115,15 103,17 134,69
P-Value 0,000 0,000 0,000 0,000 0,000
NP_T_DES18M 5,103 5,430 4,976 5,129
T-Value 74,00 108,48 114,35 148,24
P-Value 0,000 0,000 0,000 0,000
NP_PAREDE -3,171 -3,742 -3,202
T-Value -71,28 -94,44 -97,65
P-Value 0,000 0,000 0,000
N_IDHM_L 1,166 1,461
T-Value 46,74 71,49
P-Value 0,000 0,000
NP_FECTOT -1,706
T-Value -57,34
P-Value 0,000
S 0,921 0,652 0,463 0,335 0,284 0,225
R-Sq 32,18 66,01 82,87 91,05 93,58 95,96
R-Sq(adj) 32,16 65,99 82,86 91,05 93,57 95,96
Step 7 8 9 10 11 12
Constant 5,568 5,215 5,766 6,040 5,712 5,921
N_T_LUZ -7,087 -6,779 -6,816 -6,504 -6,246 -6,152
T-Value -192,55 -203,34 -240,88 -298,41 -319,49 -432,86
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_TRABSC 2,9215 3,0305 2,8145 2,7590 2,6955 2,5670
T-Value 163,13 189,20 195,97 254,78 287,08 365,02
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_T_DES18M 5,249 5,343 4,885 4,593 4,504 4,566
T-Value 181,90 209,20 205,15 248,99 282,60 394,71
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_PAREDE -2,935 -2,968 -3,104 -3,280 -3,094 -3,103
T-Value -105,66 -121,16 -147,91 -204,95 -215,87 -299,10
145
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
N_IDHM_L 1,8489 1,8612 1,5852 1,7583 1,8908 1,6758
T-Value 98,96 113,02 104,42 150,09 180,64 205,43
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_FECTOT -1,6034 -1,5251 -1,6291 -1,7253 -1,6916 -1,7575
T-Value -64,61 -69,45 -86,82 -121,65 -138,89 -198,28
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
NP_T_ANALF15A17 -2,328 -1,894 -2,295 -1,960 -1,756 -1,673
T-Value -49,88 -44,51 -61,83 -69,07 -71,01 -93,22
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
N_E_ANOSESTUDO -0,8681 -0,9929 -0,9242 -0,9323 -0,9773
T-Value -39,98 -53,33 -65,85 -77,50 -111,95
P-Value 0,000 0,000 0,000 0,000 0,000
NP_T_NESTUDA_NTRAB_MMEIO 1,112 1,405 1,773 1,412
T-Value 46,51 75,87 99,21 101,59
P-Value 0,000 0,000 0,000 0,000
N_T_AGUA -0,8480 -0,6738 -0,7806
T-Value -65,40 -57,22 -90,20
P-Value 0,000 0,000 0,000
NP_PIND -0,816 -1,247
T-Value -44,80 -85,96
P-Value 0,000 0,000
N_IDHM_R 1,170
T-Value 71,05
P-Value 0,000
S 0,187 0,165 0,140 0,105 0,0900 0,0651
R-Sq 97,21 97,83 98,44 99,12 99,35 99,66
R-Sq(adj) 97,21 97,83 98,44 99,12 99,35 99,66
Step 13 14 15 16 17
Constant 6,101 6,077 6,178 6,162 6,182
N_T_LUZ -6,1395 -6,0511 -6,1292 -6,1325 -6,1038
T-Value -496,92 -623,48 -915,61 -1179,60 -2097,03
P-Value 0,000 0,000 0,000 0,000 0,000
NP_TRABSC 2,4858 2,4728 2,4610 2,4586 2,4545
T-Value 388,16 496,78 723,91 931,15 1666,48
P-Value 0,000 0,000 0,000 0,000 0,000
NP_T_DES18M 4,5658 4,5282 4,5631 4,5811 4,5052
T-Value 454,18 578,23 851,13 1097,51 1856,77
P-Value 0,000 0,000 0,000 0,000 0,000
NP_PAREDE -3,0763 -3,1392 -3,1109 -3,1082 -3,1145
T-Value -340,39 -442,46 -640,89 -824,50 -1480,94
P-Value 0,000 0,000 0,000 0,000 0,000
N_IDHM_L 1,6369 0,9476 0,9172 0,9108 0,9533
T-Value 228,97 74,73 105,90 135,41 252,83
P-Value 0,000 0,000 0,000 0,000 0,000
NP_FECTOT -1,7693 -1,7498 -1,6495 -1,6592 -1,6524
T-Value -229,54 -291,90 -385,49 -498,74 -890,17
P-Value 0,000 0,000 0,000 0,000 0,000
NP_T_ANALF15A17 -1,6060 -1,6977 -1,6903 -1,6859 -1,6301
T-Value -102,48 -138,44 -201,98 -259,41 -445,48

146
P-Value 0,000 0,000 0,000 0,000 0,000
N_E_ANOSESTUDO -1,0121 -1,0494 -0,9981 -0,9942 -0,8779
T-Value -132,63 -176,13 -242,50 -311,00 -424,47
P-Value 0,000 0,000 0,000 0,000 0,000
NP_T_NESTUDA_NTRAB_MMEIO 1,2334 1,2450 1,2150 1,2182 1,2016
T-Value 96,38 125,26 178,88 230,95 407,94
P-Value 0,000 0,000 0,000 0,000 0,000
N_T_AGUA -0,7971 -0,8113 -0,7955 -0,7953 -0,7762
T-Value -105,84 -138,62 -198,95 -256,11 -446,07
P-Value 0,000 0,000 0,000 0,000 0,000
NP_PIND -1,2697 -1,3538 -1,3092 -1,2801 -1,2972
T-Value -100,62 -136,78 -193,20 -242,23 -439,56
P-Value 0,000 0,000 0,000 0,000 0,000
N_IDHM_R 0,7840 0,7991 0,8017 0,7103 0,7800
T-Value 46,23 60,67 89,20 99,46 193,46
P-Value 0,000 0,000 0,000 0,000 0,000
NP_PPOBCRI 0,4576 0,5120 0,5524 0,5774 0,6447
T-Value 42,42 60,78 95,73 128,31 249,69
P-Value 0,000 0,000 0,000 0,000 0,000
NP_MORT1 0,8034 0,8594 0,8742 0,8399
T-Value 60,46 94,50 123,71 212,47
P-Value 0,000 0,000 0,000 0,000
NP_T_MULCHEFEFIF014 -0,3417 -0,3390 -0,3132
T-Value -79,82 -101,97 -167,65
P-Value 0,000 0,000 0,000
N_HOMEM70A74 1,0674 1,1535
T-Value 60,44 116,76
P-Value 0,000 0,000
N_IDHM_E -0,3021
T-Value -110,87
P-Value 0,000
N_P_SUPER
T-Value
P-Value
S 0,0566 0,0440 0,0300 0,0233 0,0130
R-Sq 99,74 99,85 99,93 99,96 99,99
R-Sq(adj) 99,74 99,85 99,93 99,96 99,99
Step 18
Constant 6,153
N_T_LUZ -6,0883
T-Value -3047,35
P-Value 0,000
NP_TRABSC 2,4616
T-Value 2436,96
P-Value 0,000
NP_T_DES18M 4,5130
T-Value 2717,88
P-Value 0,000
NP_PAREDE -3,1173
T-Value -2169,09
P-Value 0,000

147
N_IDHM_L 0,9286
T-Value 357,91
P-Value 0,000
NP_FECTOT -1,6540
T-Value -1304,10
P-Value 0,000
NP_T_ANALF15A17 -1,6185
T-Value -646,36
P-Value 0,000
N_E_ANOSESTUDO -0,8701
T-Value -614,30
P-Value 0,000
NP_T_NESTUDA_NTRAB_MMEIO 1,2169
T-Value 602,02
P-Value 0,000
N_T_AGUA -0,7807
T-Value -655,98
P-Value 0,000
NP_PIND -1,2635
T-Value -613,34
P-Value 0,000
N_IDHM_R 0,6808
T-Value 225,20
P-Value 0,000
NP_PPOBCRI 0,6680
T-Value 373,60
P-Value 0,000
NP_MORT1 0,8652
T-Value 318,19
P-Value 0,000
NP_T_MULCHEFEFIF014 -0,3152
T-Value -246,93
P-Value 0,000
N_HOMEM70A74 1,0733
T-Value 157,28
P-Value 0,000
N_IDHM_E -0,3654
T-Value -180,53
P-Value 0,000
N_P_SUPER 0,1611
T-Value 79,62
P-Value 0,000
S 0,00887
R-Sq 99,99
R-Sq(adj) 99,99
Step 19 20 21
Constant 6,115 6,110 6,120
N_T_LUZ -6,11245 -6,11200 -6,11329
T-Value -11752,62 -56117,76 *
P-Value 0,000 0,000 *
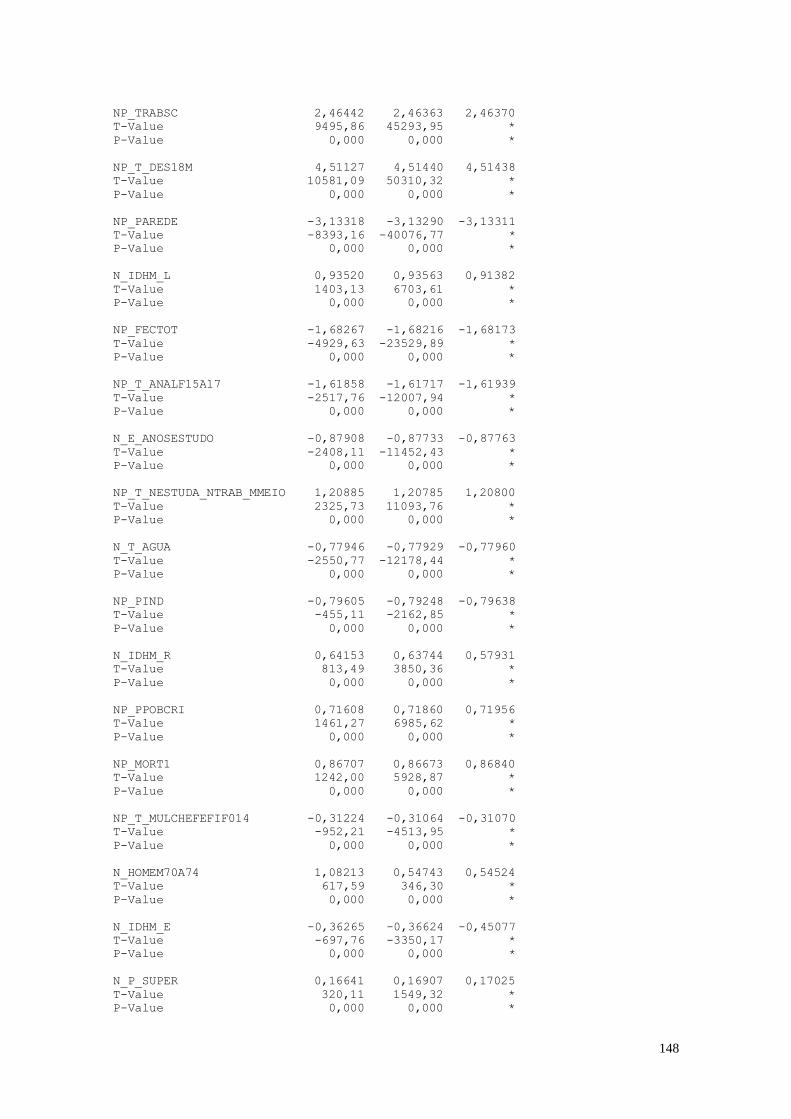
148
NP_TRABSC 2,46442 2,46363 2,46370
T-Value 9495,86 45293,95 *
P-Value 0,000 0,000 *
NP_T_DES18M 4,51127 4,51440 4,51438
T-Value 10581,09 50310,32 *
P-Value 0,000 0,000 *
NP_PAREDE -3,13318 -3,13290 -3,13311
T-Value -8393,16 -40076,77 *
P-Value 0,000 0,000 *
N_IDHM_L 0,93520 0,93563 0,91382
T-Value 1403,13 6703,61 *
P-Value 0,000 0,000 *
NP_FECTOT -1,68267 -1,68216 -1,68173
T-Value -4929,63 -23529,89 *
P-Value 0,000 0,000 *
NP_T_ANALF15A17 -1,61858 -1,61717 -1,61939
T-Value -2517,76 -12007,94 *
P-Value 0,000 0,000 *
N_E_ANOSESTUDO -0,87908 -0,87733 -0,87763
T-Value -2408,11 -11452,43 *
P-Value 0,000 0,000 *
NP_T_NESTUDA_NTRAB_MMEIO 1,20885 1,20785 1,20800
T-Value 2325,73 11093,76 *
P-Value 0,000 0,000 *
N_T_AGUA -0,77946 -0,77929 -0,77960
T-Value -2550,77 -12178,44 *
P-Value 0,000 0,000 *
NP_PIND -0,79605 -0,79248 -0,79638
T-Value -455,11 -2162,85 *
P-Value 0,000 0,000 *
N_IDHM_R 0,64153 0,63744 0,57931
T-Value 813,49 3850,36 *
P-Value 0,000 0,000 *
NP_PPOBCRI 0,71608 0,71860 0,71956
T-Value 1461,27 6985,62 *
P-Value 0,000 0,000 *
NP_MORT1 0,86707 0,86673 0,86840
T-Value 1242,00 5928,87 *
P-Value 0,000 0,000 *
NP_T_MULCHEFEFIF014 -0,31224 -0,31064 -0,31070
T-Value -952,21 -4513,95 *
P-Value 0,000 0,000 *
N_HOMEM70A74 1,08213 0,54743 0,54524
T-Value 617,59 346,30 *
P-Value 0,000 0,000 *
N_IDHM_E -0,36265 -0,36624 -0,45077
T-Value -697,76 -3350,17 *
P-Value 0,000 0,000 *
N_P_SUPER 0,16641 0,16907 0,17025
T-Value 320,11 1549,32 *
P-Value 0,000 0,000 *

149
NP_PINDCRI -0,37682 -0,37931 -0,37714
T-Value -280,35 -1347,25 *
P-Value 0,000 0,000 *
N_HOMEM10A14 0,55093 0,55485
T-Value 347,73 *
P-Value 0,000 *
N_IDHM 0,15258
T-Value *
P-Value *
S 0,00228 0,000477 0,000000
R-Sq 100,00 100,00 100,00
R-Sq(adj) 100,00 100,00 100,00
Para o componente PCTrab, pode-se perceber que a variável que mais o explica é
a N_T_LUZ, com um poder de explicação de 32,18%, seguida por NP_TRABSC com
um poder de explicação agregado de 66,01%. A terceira variável é a NP_T_DES18M
com um poder de explicação agregado de 82,87%. A quarta variável é a NP_PAREDE, e
o poder de explicação agregado é de 91,05%. Neste componente é possível perceber que
as quatro primeiras variáveis acrescentam um poder de explicação significativo para o
componente. A partir da quarta variável, o poder de explicação agregado se torna menor.
7.4.Considerações
De acordo com os resultados obtidos nas análises, foi possível verificar que é
possível diminuir o número de variáveis explicativas do modelo, utilizando menos
variáveis e tendo uma boa explicação dos resultados encontrados. Com isso é possível
simplificar as análises utilizando menos componentes e ter um resultado de análise
preciso.
A quantidade de componentes a ser utilizada depende da precisão desejada no
resultado, neste relatório optou-se por utilizar apenas 3 componentes com um poder de
explicação de 70,5%.
Utilizando-se oito componentes é possível chegar a um valor de explicação de
aproximadamente 90%. Ou seja, pode-se substituir as 21 variáveis selecionadas no estudo
por 8 e ter um poder de explicação de aproximadamente 90%.
CAPÍTULO 8. ANÁLISE DE CONFLOMERADOS
O presente capítulo tem como objetivo realizar um estudo de dendograma e cluster
dos dados provenientes das variáveis selecionadas do Atlas do Desenvolvimento Humano
no Brasil, que apresentam indicadores de desenvolvimento humano dos 5565 municípios
brasileiros. Estes dados são provenientes do Censo Demográfico de 2010.
Com este estudo é possível perceber, a partir dos agrupamentos realizados, quais
estados brasileiros possuem maior similaridade entre si e dividi-los em grupos.
Para realizar as análises serão utilizadas as variáveis normalizadas e positivadas
conforme apresentadas no Capítulo 7.
No Capítulo 7, foram construídas três variáveis sintéticas, a PCRenLong,
explicada 94,26% pela variável N_IDHM, a variável sintética PCHomem, explicada
96,46% pela variável N_HOMEM10A14, e no agregado 96,04% se adicionada a variável
NP_T_DES18M, e a variável sintética PCTrab, explicada por N_T_LUZ em 32,18 %, no
agregado a variável NP_TRABSC gera um poder de explicação de 66,01%, a variável
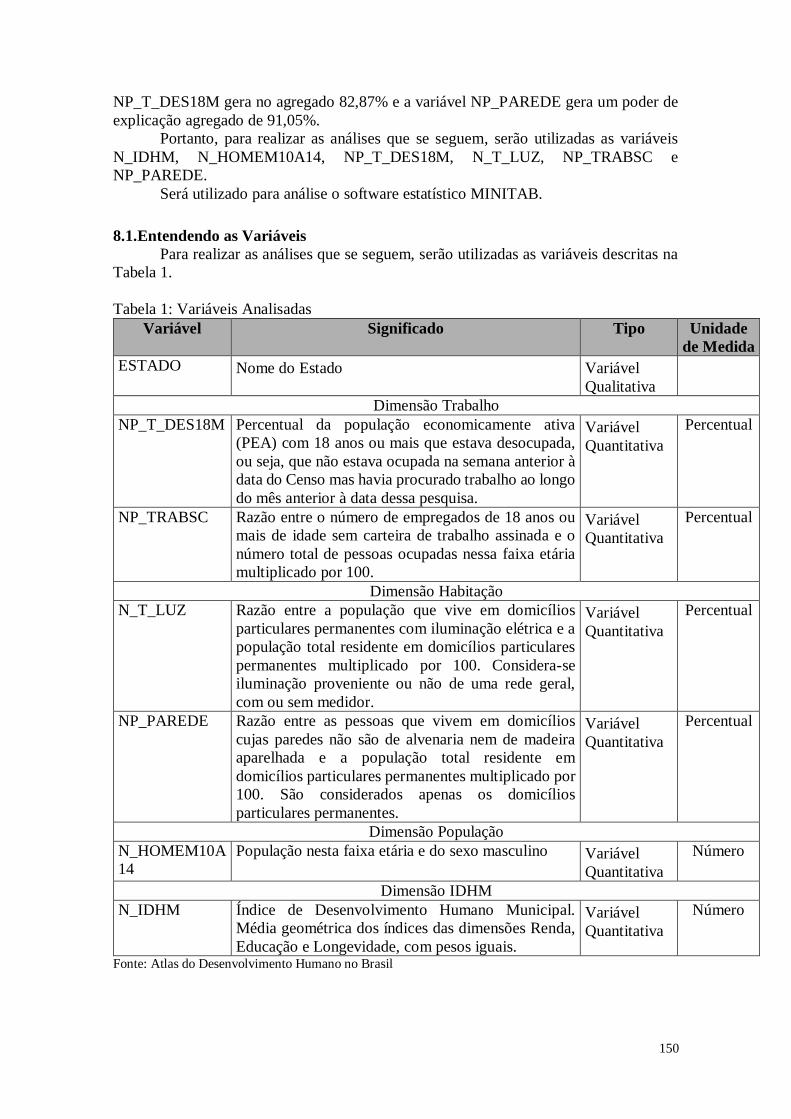
150
NP_T_DES18M gera no agregado 82,87% e a variável NP_PAREDE gera um poder de
explicação agregado de 91,05%.
Portanto, para realizar as análises que se seguem, serão utilizadas as variáveis
N_IDHM, N_HOMEM10A14, NP_T_DES18M, N_T_LUZ, NP_TRABSC e
NP_PAREDE.
Será utilizado para análise o software estatístico MINITAB.
8.1.Entendendo as Variáveis Para realizar as análises que se seguem, serão utilizadas as variáveis descritas na
Tabela 1.
Tabela 1: Variáveis Analisadas
Variável Significado Tipo Unidade
de Medida
ESTADO Nome do Estado Variável
Qualitativa
Dimensão Trabalho
NP_T_DES18M Percentual da população economicamente ativa
(PEA) com 18 anos ou mais que estava desocupada,
ou seja, que não estava ocupada na semana anterior à
data do Censo mas havia procurado trabalho ao longo
do mês anterior à data dessa pesquisa.
Variável
Quantitativa
Percentual
NP_TRABSC Razão entre o número de empregados de 18 anos ou
mais de idade sem carteira de trabalho assinada e o
número total de pessoas ocupadas nessa faixa etária
multiplicado por 100.
Variável
Quantitativa
Percentual
Dimensão Habitação
N_T_LUZ Razão entre a população que vive em domicílios
particulares permanentes com iluminação elétrica e a
população total residente em domicílios particulares
permanentes multiplicado por 100. Considera-se
iluminação proveniente ou não de uma rede geral,
com ou sem medidor.
Variável
Quantitativa
Percentual
NP_PAREDE Razão entre as pessoas que vivem em domicílios
cujas paredes não são de alvenaria nem de madeira
aparelhada e a população total residente em
domicílios particulares permanentes multiplicado por
100. São considerados apenas os domicílios
particulares permanentes.
Variável
Quantitativa
Percentual
Dimensão População
N_HOMEM10A
14
População nesta faixa etária e do sexo masculino Variável
Quantitativa
Número
Dimensão IDHM
N_IDHM Índice de Desenvolvimento Humano Municipal.
Média geométrica dos índices das dimensões Renda,
Educação e Longevidade, com pesos iguais.
Variável
Quantitativa
Número
Fonte: Atlas do Desenvolvimento Humano no Brasil
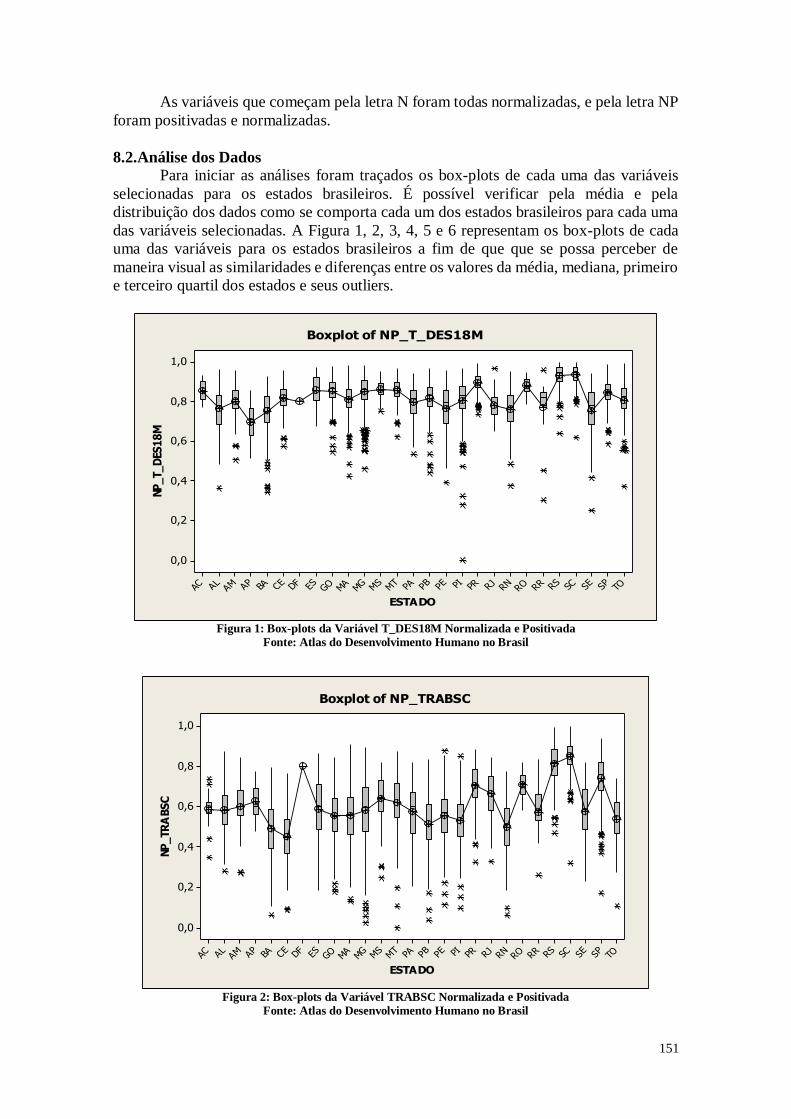
151
As variáveis que começam pela letra N foram todas normalizadas, e pela letra NP
foram positivadas e normalizadas.
8.2.Análise dos Dados
Para iniciar as análises foram traçados os box-plots de cada uma das variáveis
selecionadas para os estados brasileiros. É possível verificar pela média e pela
distribuição dos dados como se comporta cada um dos estados brasileiros para cada uma
das variáveis selecionadas. A Figura 1, 2, 3, 4, 5 e 6 representam os box-plots de cada
uma das variáveis para os estados brasileiros a fim de que que se possa perceber de
maneira visual as similaridades e diferenças entre os valores da média, mediana, primeiro
e terceiro quartil dos estados e seus outliers.
TOSPSESCRSRR
RORNRJPRPIPEPBPAMT
MS
MG
MA
GOESDFCEBAAPAMAL
AC
1,0
0,8
0,6
0,4
0,2
0,0
ESTADO
NP
_T_
DES
18
M
Boxplot of NP_T_DES18M
Figura 1: Box-plots da Variável T_DES18M Normalizada e Positivada
Fonte: Atlas do Desenvolvimento Humano no Brasil
TOSPSESCRSRR
RORNRJPRPIPEPBPAMT
MS
MG
MA
GOESDFCEBAAPAMAL
AC
1,0
0,8
0,6
0,4
0,2
0,0
ESTADO
NP
_TR
AB
SC
Boxplot of NP_TRABSC
Figura 2: Box-plots da Variável TRABSC Normalizada e Positivada
Fonte: Atlas do Desenvolvimento Humano no Brasil
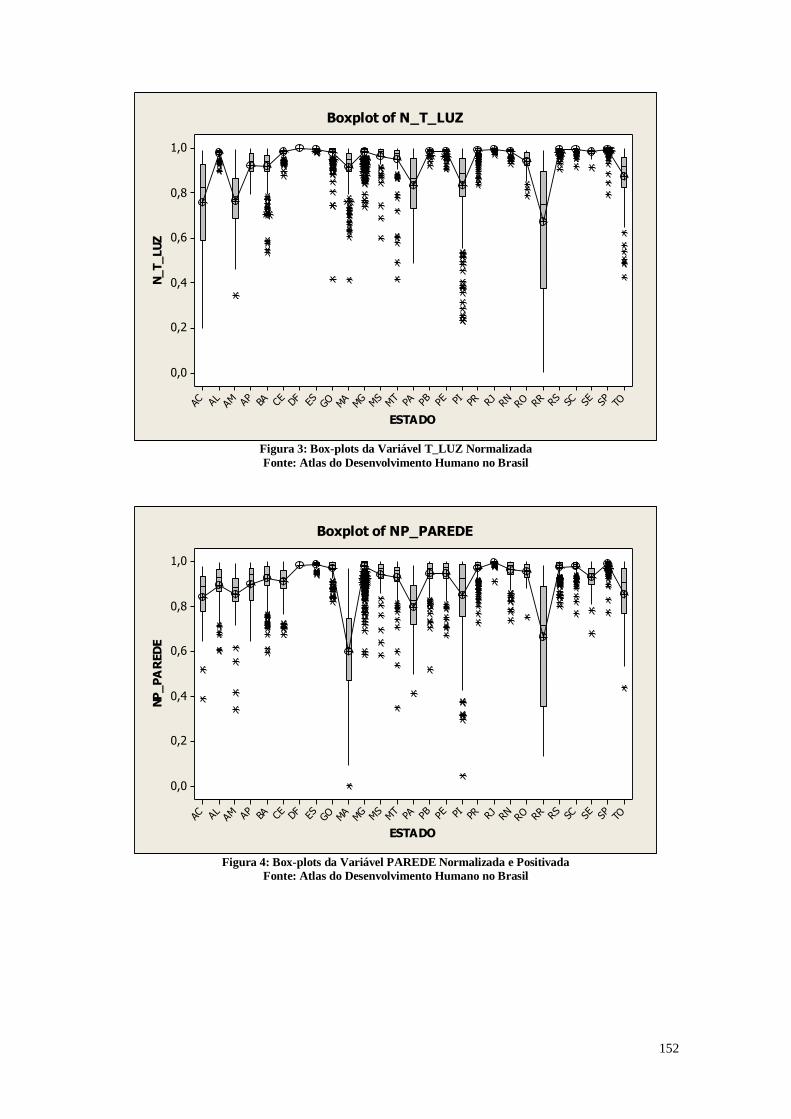
152
TOSPSESCRSRRRORNRJPRPIPEPBPAMT
MS
MG
MA
GOESDFCEBAAPAMALAC
1,0
0,8
0,6
0,4
0,2
0,0
ESTADO
N_
T_
LU
Z
Boxplot of N_T_LUZ
Figura 3: Box-plots da Variável T_LUZ Normalizada
Fonte: Atlas do Desenvolvimento Humano no Brasil
TOSPSESCRSRRRORNRJPRPIPEPBPAMT
MS
MG
MA
GOESDFCEBAAPAMALAC
1,0
0,8
0,6
0,4
0,2
0,0
ESTADO
NP
_P
AR
ED
E
Boxplot of NP_PAREDE
Figura 4: Box-plots da Variável PAREDE Normalizada e Positivada
Fonte: Atlas do Desenvolvimento Humano no Brasil
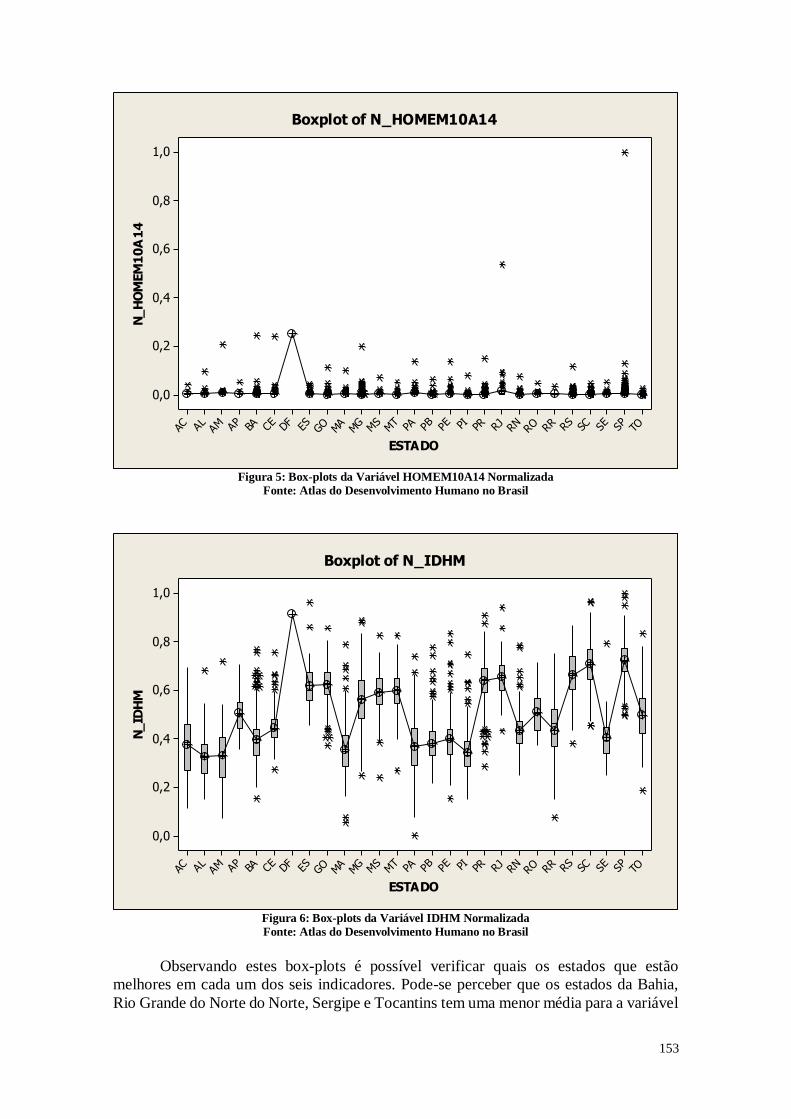
153
TOSPSESCRSRRRORNRJPRPIPEPBPAMT
MS
MG
MA
GOESDFCEBAAPAMALAC
1,0
0,8
0,6
0,4
0,2
0,0
ESTADO
N_
HO
MEM
10
A1
4
Boxplot of N_HOMEM10A14
Figura 5: Box-plots da Variável HOMEM10A14 Normalizada
Fonte: Atlas do Desenvolvimento Humano no Brasil
TOSPSESCRSRRRORNRJPRPIPEPBPAMT
MS
MG
MA
GOESDFCEBAAPAMALAC
1,0
0,8
0,6
0,4
0,2
0,0
ESTADO
N_
IDH
M
Boxplot of N_IDHM
Figura 6: Box-plots da Variável IDHM Normalizada
Fonte: Atlas do Desenvolvimento Humano no Brasil
Observando estes box-plots é possível verificar quais os estados que estão
melhores em cada um dos seis indicadores. Pode-se perceber que os estados da Bahia,
Rio Grande do Norte do Norte, Sergipe e Tocantins tem uma menor média para a variável

154
referente a quantidade de indivíduos que trabalham sem carteira assinada. O acesso a luz
é menor nas regiões do Norte, em especial nos estados do Acre, Amazonas e Pará. Neste
indicador Roraima é o estado que possui a menor média.
Na variável NP_PAREDE, que se refere a quantidade de pessoas que moram em
casas inadequadas, os estados do Maranhão e de Roraima apresentam menores índices,
portanto condições mais precárias de moradia.
A variável referente a quantidade de homens de 10 a 14 anos possuiu uma
distribuição parecida nas diferentes regiões.
Ao observar o box-plot da Figura 6, a variável referente ao IDHM apresenta
distribuições diferentes. É possível verificar que os estados do Sul, Sudeste e Centro-
Oeste possuem uma média melhor do que os demais estados.
As variáveis referentes a taxa de desocupação e ao número de trabalhadores sem
carteira também possui valores de média diferentes para cada estado brasileiro. É possível
verificar que alguns estados são mais similares e outros menos nestas variáveis.
Para dar continuidade as análises, foi realizado um teste de ANOVA para verificar
qual a média de cada uma das seis variáveis normatizadas e positivadas selecionadas para
cada estado brasileiro.
Com os valores das médias, obtidos para cada uma das variáveis em relação a cada
estado brasileiro, foi realizado o teste de cluster com o Linkage Mediun Single e a
Distance Measure Euclidean para as seis variáveis selecionadas com oito clusters.
Cluster Analysis of Observations: MediaNP_T_DE; MediaNP_TRAB; MediaN_T_LUZ; ... Euclidean Distance, Single Linkage
Amalgamation Steps
Number
of obs.
Number of Similarity Distance Clusters New in new
Step clusters level level joined cluster cluster
1 26 96,2811 0,028588 12 13 12 2
2 25 96,2669 0,028697 16 25 16 2
3 24 94,6705 0,040970 8 9 8 2
4 23 93,0269 0,053604 23 24 23 2
5 22 92,4024 0,058405 8 11 8 3
6 21 91,1329 0,068164 16 20 16 3
7 20 90,9694 0,069421 15 16 15 4
8 19 90,5190 0,072883 1 3 1 2
9 18 90,5094 0,072958 14 17 14 2
10 17 90,0572 0,076434 8 12 8 5
11 16 88,9116 0,085240 2 15 2 5
12 15 88,6338 0,087376 2 5 2 6
13 14 88,4854 0,088517 2 6 2 7
14 13 87,3302 0,097397 1 14 1 4
15 12 87,1875 0,098494 8 18 8 6
16 11 86,2062 0,106037 8 26 8 7
17 10 85,7001 0,109928 8 21 8 8
18 9 85,0060 0,115264 8 19 8 9
19 8 84,6716 0,117834 8 23 8 11
20 7 81,6305 0,141212 1 2 1 11
21 6 81,1068 0,145238 1 4 1 12
22 5 80,3511 0,151047 1 27 1 13
23 4 77,4155 0,173615 1 8 1 24
24 3 71,4674 0,219339 1 10 1 25
25 2 71,1862 0,221501 1 22 1 26
26 1 58,3788 0,319956 1 7 1 27
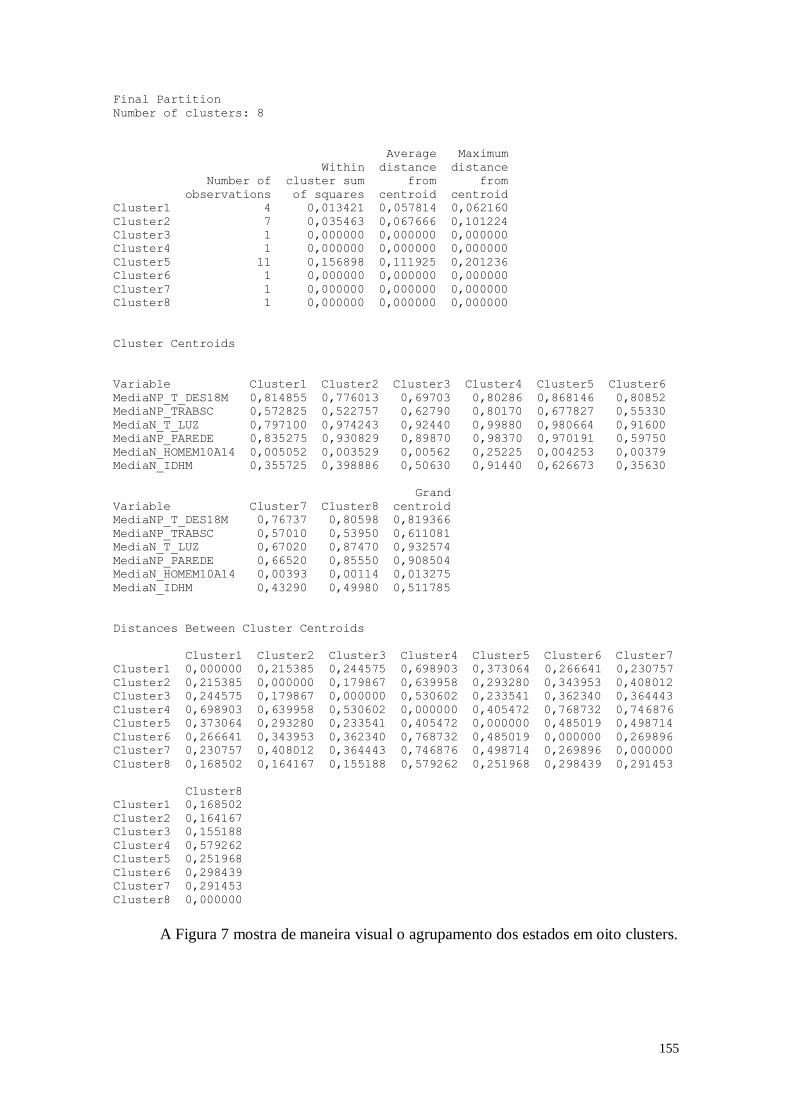
155
Final Partition
Number of clusters: 8
Average Maximum
Within distance distance
Number of cluster sum from from
observations of squares centroid centroid
Cluster1 4 0,013421 0,057814 0,062160
Cluster2 7 0,035463 0,067666 0,101224
Cluster3 1 0,000000 0,000000 0,000000
Cluster4 1 0,000000 0,000000 0,000000
Cluster5 11 0,156898 0,111925 0,201236
Cluster6 1 0,000000 0,000000 0,000000
Cluster7 1 0,000000 0,000000 0,000000
Cluster8 1 0,000000 0,000000 0,000000
Cluster Centroids
Variable Cluster1 Cluster2 Cluster3 Cluster4 Cluster5 Cluster6
MediaNP_T_DES18M 0,814855 0,776013 0,69703 0,80286 0,868146 0,80852
MediaNP_TRABSC 0,572825 0,522757 0,62790 0,80170 0,677827 0,55330
MediaN_T_LUZ 0,797100 0,974243 0,92440 0,99880 0,980664 0,91600
MediaNP_PAREDE 0,835275 0,930829 0,89870 0,98370 0,970191 0,59750
MediaN_HOMEM10A14 0,005052 0,003529 0,00562 0,25225 0,004253 0,00379
MediaN_IDHM 0,355725 0,398886 0,50630 0,91440 0,626673 0,35630
Grand
Variable Cluster7 Cluster8 centroid
MediaNP_T_DES18M 0,76737 0,80598 0,819366
MediaNP_TRABSC 0,57010 0,53950 0,611081
MediaN_T_LUZ 0,67020 0,87470 0,932574
MediaNP_PAREDE 0,66520 0,85550 0,908504
MediaN_HOMEM10A14 0,00393 0,00114 0,013275
MediaN_IDHM 0,43290 0,49980 0,511785
Distances Between Cluster Centroids
Cluster1 Cluster2 Cluster3 Cluster4 Cluster5 Cluster6 Cluster7
Cluster1 0,000000 0,215385 0,244575 0,698903 0,373064 0,266641 0,230757
Cluster2 0,215385 0,000000 0,179867 0,639958 0,293280 0,343953 0,408012
Cluster3 0,244575 0,179867 0,000000 0,530602 0,233541 0,362340 0,364443
Cluster4 0,698903 0,639958 0,530602 0,000000 0,405472 0,768732 0,746876
Cluster5 0,373064 0,293280 0,233541 0,405472 0,000000 0,485019 0,498714
Cluster6 0,266641 0,343953 0,362340 0,768732 0,485019 0,000000 0,269896
Cluster7 0,230757 0,408012 0,364443 0,746876 0,498714 0,269896 0,000000
Cluster8 0,168502 0,164167 0,155188 0,579262 0,251968 0,298439 0,291453
Cluster8
Cluster1 0,168502
Cluster2 0,164167
Cluster3 0,155188
Cluster4 0,579262
Cluster5 0,251968
Cluster6 0,298439
Cluster7 0,291453
Cluster8 0,000000
A Figura 7 mostra de maneira visual o agrupamento dos estados em oito clusters.
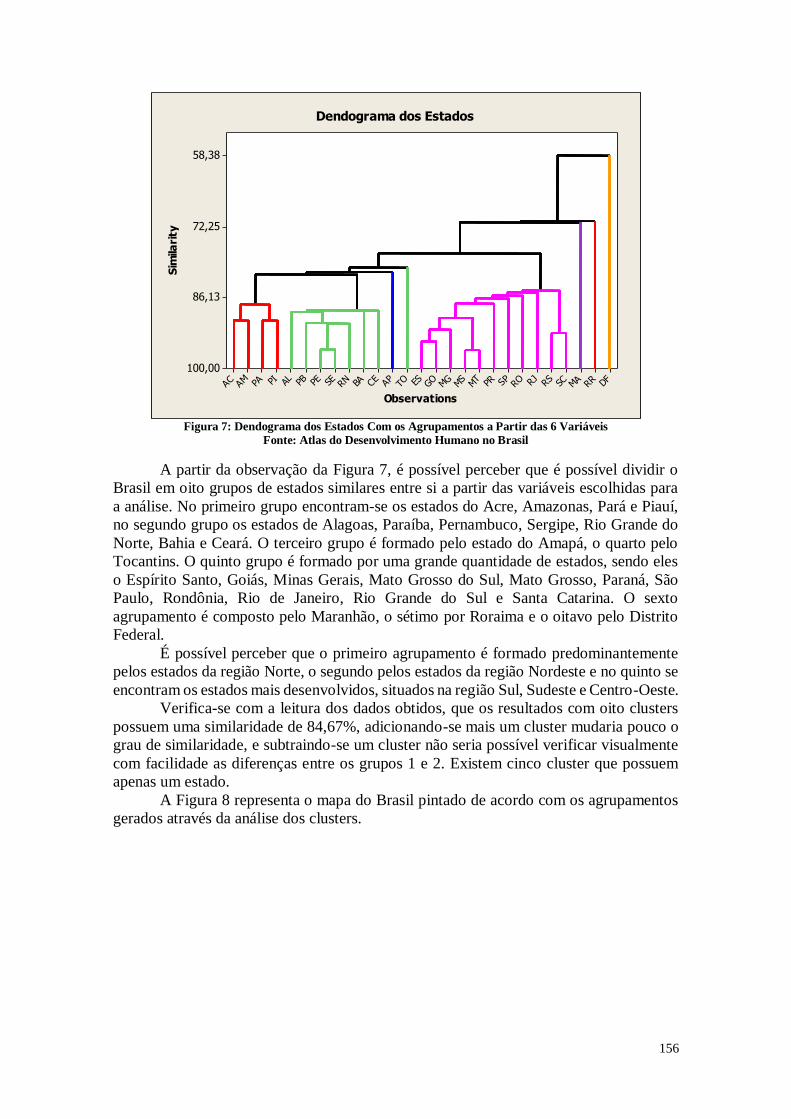
156
DFRRMASCRSRJROSPPRMT
MS
MGGOESTOAPCEBARNSEPEPBALPIPAAMAC
58,38
72,25
86,13
100,00
Observations
Sim
ilari
ty
Dendograma dos Estados
Figura 7: Dendograma dos Estados Com os Agrupamentos a Partir das 6 Variáveis
Fonte: Atlas do Desenvolvimento Humano no Brasil
A partir da observação da Figura 7, é possível perceber que é possível dividir o
Brasil em oito grupos de estados similares entre si a partir das variáveis escolhidas para
a análise. No primeiro grupo encontram-se os estados do Acre, Amazonas, Pará e Piauí,
no segundo grupo os estados de Alagoas, Paraíba, Pernambuco, Sergipe, Rio Grande do
Norte, Bahia e Ceará. O terceiro grupo é formado pelo estado do Amapá, o quarto pelo
Tocantins. O quinto grupo é formado por uma grande quantidade de estados, sendo eles
o Espírito Santo, Goiás, Minas Gerais, Mato Grosso do Sul, Mato Grosso, Paraná, São
Paulo, Rondônia, Rio de Janeiro, Rio Grande do Sul e Santa Catarina. O sexto
agrupamento é composto pelo Maranhão, o sétimo por Roraima e o oitavo pelo Distrito
Federal.
É possível perceber que o primeiro agrupamento é formado predominantemente
pelos estados da região Norte, o segundo pelos estados da região Nordeste e no quinto se
encontram os estados mais desenvolvidos, situados na região Sul, Sudeste e Centro-Oeste.
Verifica-se com a leitura dos dados obtidos, que os resultados com oito clusters
possuem uma similaridade de 84,67%, adicionando-se mais um cluster mudaria pouco o
grau de similaridade, e subtraindo-se um cluster não seria possível verificar visualmente
com facilidade as diferenças entre os grupos 1 e 2. Existem cinco cluster que possuem
apenas um estado.
A Figura 8 representa o mapa do Brasil pintado de acordo com os agrupamentos
gerados através da análise dos clusters.

157
Figura 8: Mapa do Brasil com os Estados Agrupados em 8 Clusters
Fonte: Atlas do Desenvolvimento Humano no Brasil
É possível perceber visualmente que as regiões Centro-Oeste, Sul e Sudeste
formam um agrupamento, sendo estes os municípios mais desenvolvidos. Rondônia,
apesar de pertencer a região Norte também faz parte deste agrupamento. Outro
agrupamento está relacionado com os municípios da região Nordeste, exceto o Piauí e o
Maranhão. Estes municípios, em geral, têm situação mais precárias do que o do
agrupamento cor de rosa. A região Norte também gera um agrupamento, com os estados
pintados de vermelho e o Piauí também está neste agrupamento. Percebe-se que o
Maranhão é um estado a parte, e que este estado também possui situação precária. O
Amapá e o Tocantins também fazem parte de um grupo com apenas um estado. O Distrito
Federal também é único em seu grupo.
8.3.Considerações
Este trabalho teve como objetivo realizar uma análise de cluster e construir um
dendograma para obter uma visão mais geral dos estados brasileiros agrupados por
similaridade.
De acordo com as análises realizadas, foi possível perceber que os estados das
regiões Sudeste, Sul e Centro-Oeste, incluindo o estado de Rondônia formam um
agrupamento. Os municípios que fazem parte destes estados são, em geral, mais
desenvolvidos do que os demais.
Os municípios pertencentes aos demais estados são, em geral, menos
desenvolvidos do que os do primeiro grupo, o que revela a importância de políticas
públicas capazes de levar um maior desenvolvimento a estes municípios.
Alguns municípios apresentaram pouca similaridade com os outros, como é o caso
do Maranhão, Roraima, Tocantins e o Distrito Federal. Desta maneira, eles ficam
sozinhos no agrupamento.
Os estados do Acre, Amazônia, Pará e Piauí formaram um outro agrupamento por
similaridade, e os estados do Rio Grande do Norte, Ceará, Pernambuco, Paraíba, Sergipe,
Alagoas e Bahia também formaram um outro agrupamento.

158
Desta maneira é possível perceber a partir desta divisão as diferentes realidades
do Brasil, e buscar políticas para auxiliar no desenvolvimento dos estados menos
desenvolvidos.
CAPÍTULO 9. ANÁLISE DISCRIMINANTE
O presente capítulo tem como objetivo dar continuidade ao estudo de dendograma
e cluster dos dados provenientes das variáveis selecionadas do Atlas do Desenvolvimento
Humano no Brasil, que apresentam indicadores de desenvolvimento humano dos 5565
municípios brasileiros. Este estudo teve início no Relatório VIII. Os dados são
provenientes do Censo Demográfico de 2010.
No capítulo 8 foi possível verificar na análise de agrupamentos, que alguns dos
estados brasileiros ficaram sozinhos no agrupamento, e poderiam ser melhor realocados
em grupos que tivessem mais similaridade. Desta maneira, este relatório irá realizar um
estudo de análise discriminante, a fim de reduzir a quantidade de grupos de estados
agrupados por similaridade, a fim de facilitar as análises e sintetizar melhor as
informações.
Com este estudo é possível perceber, a partir dos agrupamentos realizados, quais
estados brasileiros possuem maior similaridade entre si e dividi-los em grupos.
Para realizar as análises serão utilizadas as variáveis normalizadas e positivadas
geradas no estudo realizado e apresentado no Relatório 7.
No capítulo 7 foram construídas três variáveis sintéticas, a PCRenLong, explicada
94,26% pela variável N_IDHM, a variável sintética PCHomem, explicada 96,46% pela
variável N_HOMEM10A14, e no agregado 96,04% se adicionada a variável
NP_T_DES18M, e a variável sintética PCTrab, explicada por N_T_LUZ em 32,18 %, no
agregado a variável NP_TRABSC gera um poder de explicação de 66,01%, a variável
NP_T_DES18M gera no agregado 82,87% e a variável NP_PAREDE gera um poder de
explicação agregado de 91,05%.
Portanto, para realizar as análises de agrupamentos que se seguem, serão
utilizadas as variáveis N_IDHM, N_HOMEM10A14, NP_T_DES18M, N_T_LUZ,
NP_TRABSC e NP_PAREDE, conforme explicadas no capítulo 7.
Será utilizado para análise o software estatístico MINITAB.
9.1.Análise Discriminante
Com esta maneira de se agrupar os dados apresentada no capítulo 8, é possível
perceber que muitos estados ficam sozinhos no agrupamento, e que o Distrito Federal
também representa um agrupamento diferente. Para que seja possível melhorar e
simplificar as análises, diminuindo o número de agrupamentos e fazendo com que estes
consigam incluir os estados que ficaram sozinhos nos grupos mais similares, foram
realizadas análises discriminantes para verificar se estes agrupamentos foram adequados.
O Distrito Federal foi excluído das análises que se seguem.
Inicialmente foi realizada uma análise de cluster com o Linkage Method Complete
e o Distance Measure Manhattan com 8 agrupamentos para verificar em qual dos
agrupamentos poderiam ser inseridos os estados que estavam sozinhos ou que possuem
poucos estados no seu agrupamento, a fim de diminuir a quantidade de agrupamentos
para se ter uma melhor visualização das diferenças regionais brasileiras e maior síntese.
Cluster Analysis of Observations: MediaNP_T_DE; MediaNP_TRAB; MediaN_T_LUZ; ... Manhattan Distance, Complete Linkage
Amalgamation Steps
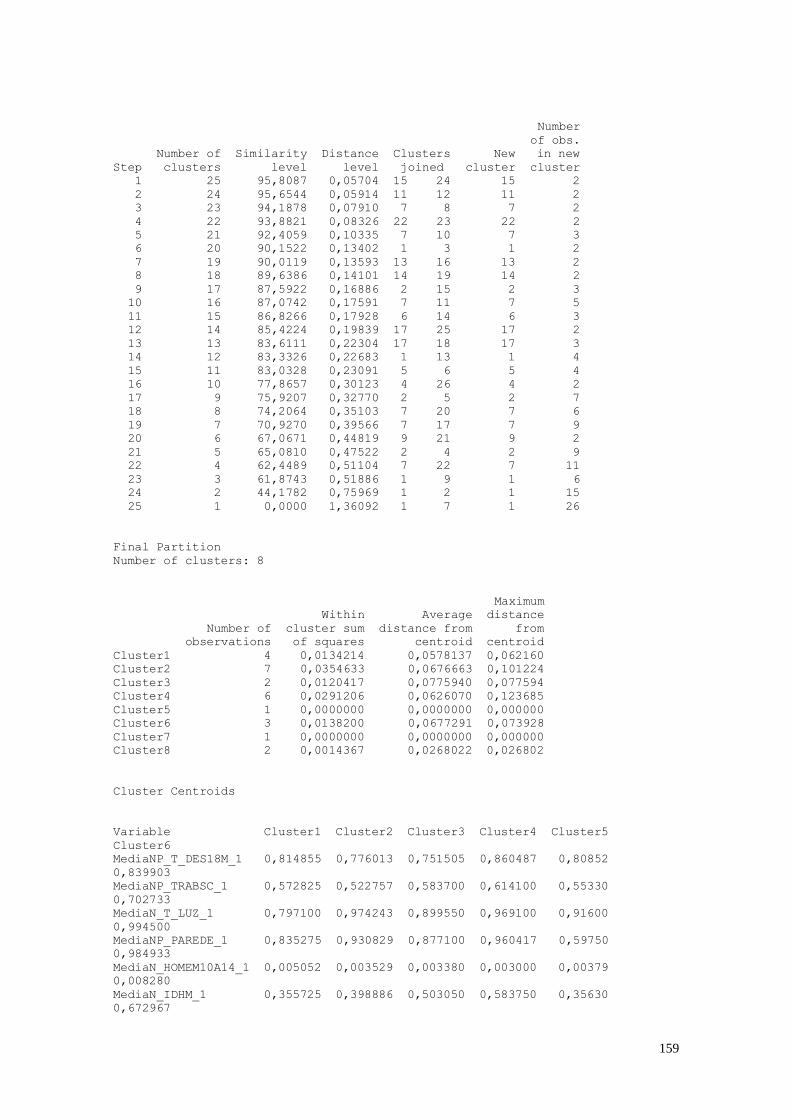
159
Number
of obs.
Number of Similarity Distance Clusters New in new
Step clusters level level joined cluster cluster
1 25 95,8087 0,05704 15 24 15 2
2 24 95,6544 0,05914 11 12 11 2
3 23 94,1878 0,07910 7 8 7 2
4 22 93,8821 0,08326 22 23 22 2
5 21 92,4059 0,10335 7 10 7 3
6 20 90,1522 0,13402 1 3 1 2
7 19 90,0119 0,13593 13 16 13 2
8 18 89,6386 0,14101 14 19 14 2
9 17 87,5922 0,16886 2 15 2 3
10 16 87,0742 0,17591 7 11 7 5
11 15 86,8266 0,17928 6 14 6 3
12 14 85,4224 0,19839 17 25 17 2
13 13 83,6111 0,22304 17 18 17 3
14 12 83,3326 0,22683 1 13 1 4
15 11 83,0328 0,23091 5 6 5 4
16 10 77,8657 0,30123 4 26 4 2
17 9 75,9207 0,32770 2 5 2 7
18 8 74,2064 0,35103 7 20 7 6
19 7 70,9270 0,39566 7 17 7 9
20 6 67,0671 0,44819 9 21 9 2
21 5 65,0810 0,47522 2 4 2 9
22 4 62,4489 0,51104 7 22 7 11
23 3 61,8743 0,51886 1 9 1 6
24 2 44,1782 0,75969 1 2 1 15
25 1 0,0000 1,36092 1 7 1 26
Final Partition
Number of clusters: 8
Maximum
Within Average distance
Number of cluster sum distance from from
observations of squares centroid centroid
Cluster1 4 0,0134214 0,0578137 0,062160
Cluster2 7 0,0354633 0,0676663 0,101224
Cluster3 2 0,0120417 0,0775940 0,077594
Cluster4 6 0,0291206 0,0626070 0,123685
Cluster5 1 0,0000000 0,0000000 0,000000
Cluster6 3 0,0138200 0,0677291 0,073928
Cluster7 1 0,0000000 0,0000000 0,000000
Cluster8 2 0,0014367 0,0268022 0,026802
Cluster Centroids
Variable Cluster1 Cluster2 Cluster3 Cluster4 Cluster5
Cluster6
MediaNP_T_DES18M_1 0,814855 0,776013 0,751505 0,860487 0,80852
0,839903
MediaNP_TRABSC_1 0,572825 0,522757 0,583700 0,614100 0,55330
0,702733
MediaN_T_LUZ_1 0,797100 0,974243 0,899550 0,969100 0,91600
0,994500
MediaNP_PAREDE_1 0,835275 0,930829 0,877100 0,960417 0,59750
0,984933
MediaN_HOMEM10A14_1 0,005052 0,003529 0,003380 0,003000 0,00379
0,008280
MediaN_IDHM_1 0,355725 0,398886 0,503050 0,583750 0,35630
0,672967

160
Grand
Variable Cluster7 Cluster8 centroid
MediaNP_T_DES18M_1 0,76737 0,93349 0,820001
MediaNP_TRABSC_1 0,57010 0,83165 0,603750
MediaN_T_LUZ_1 0,67020 0,99460 0,930027
MediaNP_PAREDE_1 0,66520 0,97740 0,905612
MediaN_HOMEM10A14_1 0,00393 0,00197 0,004083
MediaN_IDHM_1 0,43290 0,68600 0,496300
Distances Between Cluster Centroids
Cluster1 Cluster2 Cluster3 Cluster4 Cluster5 Cluster6 Cluster7
Cluster1 0,000000 0,215385 0,195152 0,317852 0,266641 0,423699 0,230757
Cluster2 0,215385 0,000000 0,153723 0,224847 0,343953 0,339049 0,408012
Cluster3 0,195152 0,153723 0,000000 0,176331 0,322734 0,267437 0,320720
Cluster4 0,317852 0,224847 0,176331 0,000000 0,438930 0,132338 0,458102
Cluster5 0,266641 0,343953 0,322734 0,438930 0,000000 0,529037 0,269896
Cluster6 0,423699 0,339049 0,267437 0,132338 0,529037 0,000000 0,536566
Cluster7 0,230757 0,408012 0,320720 0,458102 0,269896 0,536566 0,000000
Cluster8 0,499361 0,453028 0,383621 0,253086 0,593552 0,160139 0,602305
Cluster8
Cluster1 0,499361
Cluster2 0,453028
Cluster3 0,383621
Cluster4 0,253086
Cluster5 0,593552
Cluster6 0,160139
Cluster7 0,602305
Cluster8 0,000000
A figura 1 representa o dendograma desta análise.
SCRSRJSPPRROMT
MS
MG
GOESTOAPRNPBCEBASEPEALRRMAPIPAAMAC
0,00
33,33
66,67
100,00
Observations
Sim
ilari
ty
Dendograma dos Estados
Figura 1: Dendograma dos Estados com 8 Clusters
Fonte: Atlas do Desenvolvimento Humano no Brasil

161
Para facilitar a visualização das análises que se seguem, os resultados das análises
foram pintados de vermelho nos dados gerados pelo MINITAB.
Pode-se perceber que o cluster 3 possui apenas 2 estados, AP e TO, e que ele está
mais próximo do cluster 2, com 7 estados, AL, PE, SE, BA, CE, PB e RN. O Cluster 5
possui um estado, do MA, e está mais próximo do cluster 1, composto pelos estados AC,
AM, PA e PI. O cluster 6 possui 3 estados, PR, SP e RJ, e está próximo do cluster 4, que
conta com os estados do ES, GO, MG, MS, MT e RO. O cluster 7 possui 1 estado, RR, e
este está mais próximo do cluster 1. O cluster 8 possui dois estados, RS e SC, e está mais
perto do cluster 4.
Após realizado estas análises, foi possível reagrupar os estados em apenas 3
clusters, desta forma, foi possível sintetizar os dados em 3 grupos.
Após realizar este procedimento for realizada uma análise discriminante, para
verificar se o agrupamento nestes três grupos era adequado.
Discriminant Analysis: grupo4 versus MediaNP_T_DE; MediaNP_TRAB; ... Linear Method for Response: grupo4
Predictors: MediaNP_T_DES18M_1; MediaNP_TRABSC_1; MediaN_T_LUZ_1;
MediaNP_PAREDE_1; MediaN_HOMEM10A14_1; MediaN_IDHM_1
Group 1 2 3
Count 6 9 11
Summary of classification
True Group
Put into Group 1 2 3
1 6 0 0
2 0 9 0
3 0 0 11
Total N 6 9 11
N correct 6 9 11
Proportion 1,000 1,000 1,000
N = 26 N Correct = 26 Proportion Correct = 1,000
Squared Distance Between Groups
1 2 3
1 0,0000 33,3531 65,7687
2 33,3531 0,0000 24,0268
3 65,7687 24,0268 0,0000
Linear Discriminant Function for Groups
1 2 3
Constant -500,9 -569,8 -706,6
MediaNP_T_DES18M_1 716,8 613,9 706,2
MediaNP_TRABSC_1 -36,3 -42,6 -47,8
MediaN_T_LUZ_1 287,1 379,3 392,7
MediaNP_PAREDE_1 167,6 236,1 249,1
MediaN_HOMEM10A14_1 4459,3 3180,1 3713,4
MediaN_IDHM_1 181,6 232,7 302,9
Verifica-se que o primeiro grupo ficou com 6 estados, o segundo com 9 estados e
o terceiro com 11 estados. O valor de Proportion dos três grupos foi 1,000, o que indica
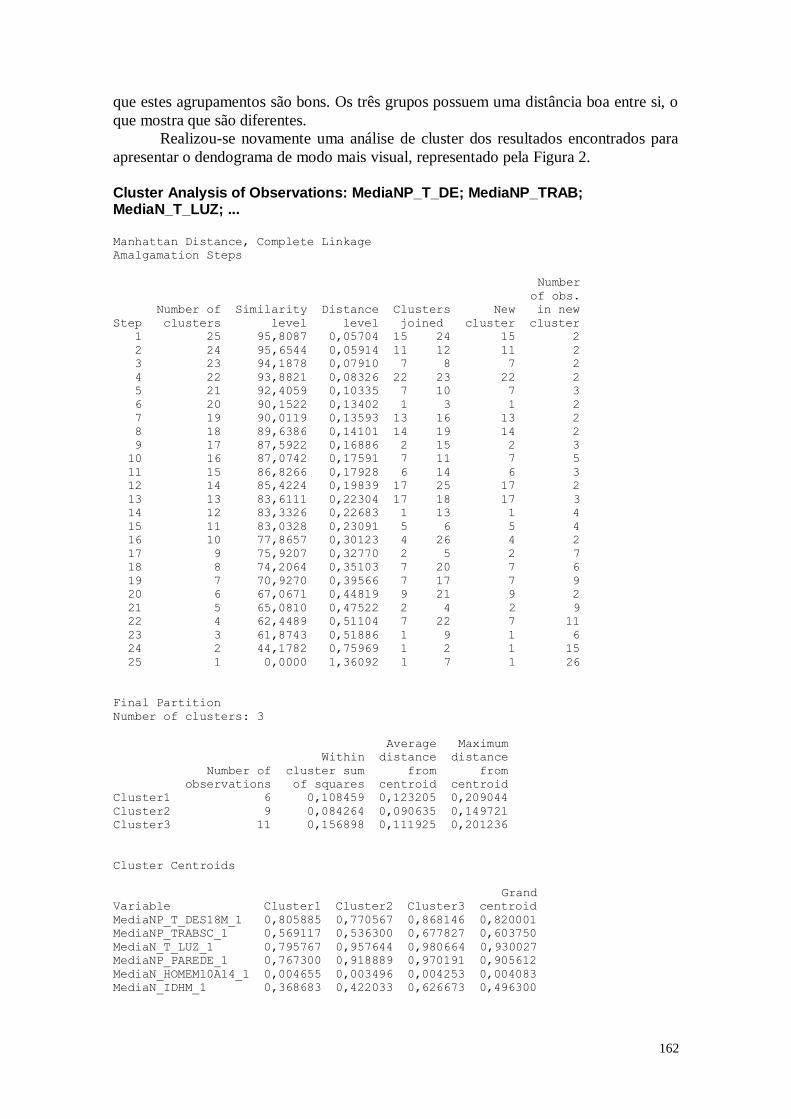
162
que estes agrupamentos são bons. Os três grupos possuem uma distância boa entre si, o
que mostra que são diferentes.
Realizou-se novamente uma análise de cluster dos resultados encontrados para
apresentar o dendograma de modo mais visual, representado pela Figura 2.
Cluster Analysis of Observations: MediaNP_T_DE; MediaNP_TRAB; MediaN_T_LUZ; ... Manhattan Distance, Complete Linkage
Amalgamation Steps
Number
of obs.
Number of Similarity Distance Clusters New in new
Step clusters level level joined cluster cluster
1 25 95,8087 0,05704 15 24 15 2
2 24 95,6544 0,05914 11 12 11 2
3 23 94,1878 0,07910 7 8 7 2
4 22 93,8821 0,08326 22 23 22 2
5 21 92,4059 0,10335 7 10 7 3
6 20 90,1522 0,13402 1 3 1 2
7 19 90,0119 0,13593 13 16 13 2
8 18 89,6386 0,14101 14 19 14 2
9 17 87,5922 0,16886 2 15 2 3
10 16 87,0742 0,17591 7 11 7 5
11 15 86,8266 0,17928 6 14 6 3
12 14 85,4224 0,19839 17 25 17 2
13 13 83,6111 0,22304 17 18 17 3
14 12 83,3326 0,22683 1 13 1 4
15 11 83,0328 0,23091 5 6 5 4
16 10 77,8657 0,30123 4 26 4 2
17 9 75,9207 0,32770 2 5 2 7
18 8 74,2064 0,35103 7 20 7 6
19 7 70,9270 0,39566 7 17 7 9
20 6 67,0671 0,44819 9 21 9 2
21 5 65,0810 0,47522 2 4 2 9
22 4 62,4489 0,51104 7 22 7 11
23 3 61,8743 0,51886 1 9 1 6
24 2 44,1782 0,75969 1 2 1 15
25 1 0,0000 1,36092 1 7 1 26
Final Partition
Number of clusters: 3
Average Maximum
Within distance distance
Number of cluster sum from from
observations of squares centroid centroid
Cluster1 6 0,108459 0,123205 0,209044
Cluster2 9 0,084264 0,090635 0,149721
Cluster3 11 0,156898 0,111925 0,201236
Cluster Centroids
Grand
Variable Cluster1 Cluster2 Cluster3 centroid
MediaNP_T_DES18M_1 0,805885 0,770567 0,868146 0,820001
MediaNP_TRABSC_1 0,569117 0,536300 0,677827 0,603750
MediaN_T_LUZ_1 0,795767 0,957644 0,980664 0,930027
MediaNP_PAREDE_1 0,767300 0,918889 0,970191 0,905612
MediaN_HOMEM10A14_1 0,004655 0,003496 0,004253 0,004083
MediaN_IDHM_1 0,368683 0,422033 0,626673 0,496300
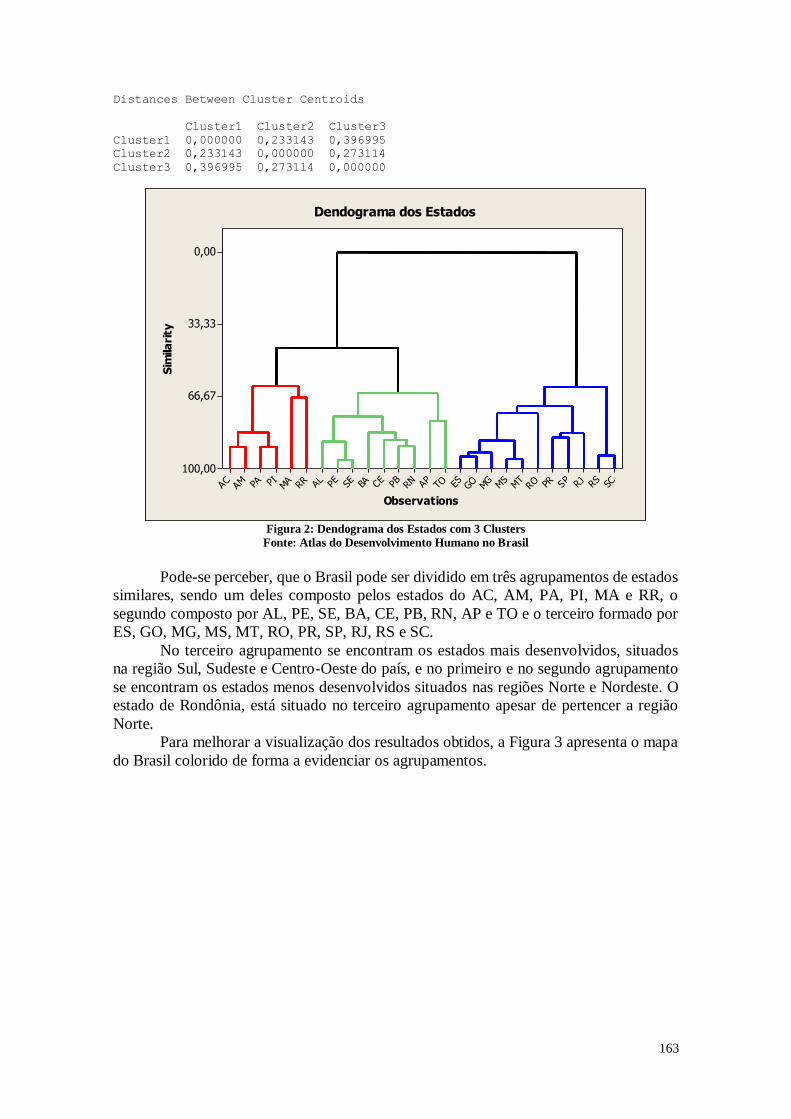
163
Distances Between Cluster Centroids
Cluster1 Cluster2 Cluster3
Cluster1 0,000000 0,233143 0,396995
Cluster2 0,233143 0,000000 0,273114
Cluster3 0,396995 0,273114 0,000000
SCRSRJSPPRROMT
MS
MG
GOESTOAPRNPBCEBASEPEALRRMAPIPAAMAC
0,00
33,33
66,67
100,00
Observations
Sim
ilari
ty
Dendograma dos Estados
Figura 2: Dendograma dos Estados com 3 Clusters
Fonte: Atlas do Desenvolvimento Humano no Brasil
Pode-se perceber, que o Brasil pode ser dividido em três agrupamentos de estados
similares, sendo um deles composto pelos estados do AC, AM, PA, PI, MA e RR, o
segundo composto por AL, PE, SE, BA, CE, PB, RN, AP e TO e o terceiro formado por
ES, GO, MG, MS, MT, RO, PR, SP, RJ, RS e SC.
No terceiro agrupamento se encontram os estados mais desenvolvidos, situados
na região Sul, Sudeste e Centro-Oeste do país, e no primeiro e no segundo agrupamento
se encontram os estados menos desenvolvidos situados nas regiões Norte e Nordeste. O
estado de Rondônia, está situado no terceiro agrupamento apesar de pertencer a região
Norte.
Para melhorar a visualização dos resultados obtidos, a Figura 3 apresenta o mapa
do Brasil colorido de forma a evidenciar os agrupamentos.

164
Figura 3: Mapa do Brasil Agrupado de Acordo com as 3 Regiões Encontradas.
Fonte: Atlas do Desenvolvimento Humano no Brasil
É possível verificar visualmente quais as regiões que necessitam de maiores
investimentos em políticas públicas para melhorar de condição. A região Sul é a mais
desenvolvida.
9.2.Considerações
Com as análises realizadas foi possível dividir o Brasil em três regiões diferentes
de acordo com sua similaridade. Cruzando-se os resultados obtidos com esta divisão e os
obtidos a partir da comparação das médias dos estados para cada uma das seis variáveis
utilizadas para a análise no capítulo 8, é possível chegar a algumas pistas de quais locais
devem receber atendimento prioritário para reduzir os problemas de desigualdade e
aumentar a qualidade de vida dos indivíduos.
A partir das análises obtidas pela comparação da ANOVA das seis variáveis
utilizadas nas análises do capítulo 8, foi possível observar quais estados estão melhores e
piores em cada uma das variáveis. Foi possível verificar que o acesso a luz é menor na
região Norte, nos estados do Acre, Rio Grande do Norte, Sergipe e Tocantins, o que
sugere a necessidade de maior investimento nesta região para que todos tenham acesso a
luz, assim como os estados do Maranhão e Roraima possuem em maior quantidade
indivíduos que não moram em casas com paredes adequadas, nesta região as variáveis
referentes a estrutura são mais precárias.
Já os estados do Nordeste como a Bahia, Rio Grande do Norte e Sergipe, além de
Tocantins possuem menos indivíduos trabalhando com carteira assinada do que os
demais, o que indica a necessidade de desenvolvimento da região.
O IDHM também é melhor nos Estados das regiões Sul, Sudeste e Centro-Oeste
do que nas regiões Norte e Nordeste, o que indica a necessidade de buscar melhorar o
IDHM nestas regiões.
CAPÍTULO 10. REGRESSÃO LOGÍSTICA O presente capítulo tem como objetivo dar continuidade ao estudo dos
agrupamentos dos estados brasileiros através das análises de regressão logística a partir
dos dados provenientes das variáveis selecionadas do Atlas do Desenvolvimento Humano

165
no Brasil, que apresentam indicadores de desenvolvimento humano dos 5565 municípios
brasileiros. Os dados são provenientes do Censo Demográfico de 2010.
No capítulo 8 foi possível verificar na análise de agrupamento, que alguns dos
estados brasileiros ficaram sozinhos no agrupamento realizados pelos dendogramas, e
poderiam ser melhor realocados em grupos que tivessem mais similaridade. No capítulo
9, foram realizadas novas análises a fim de reagrupar os estados brasileiros com maior
similaridade e diminuir o número de agrupamentos para 3. A Figura 1 representa
visualmente o Brasil dividido nos 3 agrupamentos diferentes, conforme as análises
realizadas pelo capítulo 9, os três agrupamentos são o vermelho, o verde e o azul.
Figura 1: Mapa do Brasil Agrupado de Acordo com o Relatório IX.
Fonte: Atlas do Desenvolvimento Humano no Brasil
Este capítulo buscará verificar as diferenças das regiões verde, vermelha e azul
com relação as 6 variáveis selecionadas para estudo, sendo elas N_IDHM,
N_HOMEM10A14, NP_T_DES18M, N_T_LUZ, NP_TRABSC e NP_PAREDE,
conforme definidas no capítulo 7.
Estas variáveis foram selecionadas devido ao fato que no capítulo 7 foram
construídas três variáveis sintéticas, a PCRenLong, explicada 94,26% pela variável
N_IDHM, a variável sintética PCHomem, explicada 96,46% pela variável
N_HOMEM10A14, e no agregado 96,04% se adicionada a variável NP_T_DES18M, e a
variável sintética PCTrab, explicada por N_T_LUZ em 32,18 %, no agregado a variável
NP_TRABSC gera um poder de explicação de 66,01%, a variável NP_T_DES18M gera
no agregado 82,87% e a variável NP_PAREDE gera um poder de explicação agregado
de 91,05%.
Este capítulo tem como proposta analisar as três regiões nas quais o Brasil foi
dividido em relação a cada uma das seis variáveis. Inicialmente serão realizados testes de
ANOVA para verificar as diferenças nas médias de cada variável para cada uma das três
regiões, e em seguida será feito um teste de regressão logística para verificar quais
variáveis devem receber maior atenção para melhorar as regiões menos desenvolvidas e
que explicam esta divisão.

166
Será utilizado para análise o software estatístico MINITAB.
10.1.Análise dos Dados
Inicialmente, foi realizado testes de ANOVA para verificar as diferenças das três
regiões encontradas para cada uma das seis variáveis selecionadas. Os resultados serão
apresentados a seguir.
One-way ANOVA: MediaNP_T_DES18M_1 versus grupo4 Source DF SS MS F P
grupo4 2 0,04869 0,02434 16,61 0,000
Error 23 0,03372 0,00147
Total 25 0,08240
S = 0,03829 R-Sq = 59,08% R-Sq(adj) = 55,53%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ----+---------+---------+---------+-----
1 6 0,80588 0,02773 (-------*--------)
2 9 0,77057 0,03834 (------*-----)
3 11 0,86815 0,04256 (-----*-----)
----+---------+---------+---------+-----
0,760 0,800 0,840 0,880
Pooled StDev = 0,03829
One-way ANOVA: MediaNP_TRABSC_1 versus grupo4 Source DF SS MS F P
grupo4 2 0,10850 0,05425 10,45 0,001
Error 23 0,11938 0,00519
Total 25 0,22789
S = 0,07205 R-Sq = 47,61% R-Sq(adj) = 43,06%
Individual 95% CIs For Mean Based on Pooled StDev
Level N Mean StDev ---------+---------+---------+---------+
1 6 0,56912 0,02501 (---------*---------)
2 9 0,53630 0,05501 (-------*--------)
3 11 0,67783 0,09594 (-------*------)
---------+---------+---------+---------+
0,540 0,600 0,660 0,720
Pooled StDev = 0,07205
One-way ANOVA: MediaN_T_LUZ_1 versus grupo4 Source DF SS MS F P
grupo4 2 0,14322 0,07161 31,00 0,000
Error 23 0,05313 0,00231
Total 25 0,19636
S = 0,04806 R-Sq = 72,94% R-Sq(adj) = 70,59%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev --+---------+---------+---------+-------
1 6 0,7958 0,0843 (-----*----)
2 9 0,9576 0,0414 (----*----)

167
3 11 0,9807 0,0198 (---*---)
--+---------+---------+---------+-------
0,770 0,840 0,910 0,980
Pooled StDev = 0,0481
One-way ANOVA: MediaNP_PAREDE_1 versus grupo4 Source DF SS MS F P
grupo4 2 0,16224 0,08112 25,75 0,000
Error 23 0,07247 0,00315
Total 25 0,23471
S = 0,05613 R-Sq = 69,12% R-Sq(adj) = 66,44%
Individual 95% CIs For Mean Based on Pooled StDev
Level N Mean StDev +---------+---------+---------+---------
1 6 0,7673 0,1092 (-----*-----)
2 9 0,9189 0,0329 (----*----)
3 11 0,9702 0,0205 (---*----)
+---------+---------+---------+---------
0,720 0,800 0,880 0,960
Pooled StDev = 0,0561
One-way ANOVA: MediaN_HOMEM10A14_1 versus grupo4 Source DF SS MS F P
grupo4 2 0,0000054 0,0000027 0,28 0,757
Error 23 0,0002201 0,0000096
Total 25 0,0002255
S = 0,003094 R-Sq = 2,39% R-Sq(adj) = 0,00%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -+---------+---------+---------+--------
1 6 0,004655 0,002138 (----------------*----------------)
2 9 0,003496 0,001643 (-------------*--------------)
3 11 0,004253 0,004191 (------------*------------)
-+---------+---------+---------+--------
0,0015 0,0030 0,0045 0,0060
Pooled StDev = 0,003094
One-way ANOVA: MediaN_IDHM_1 versus grupo4 Source DF SS MS F P
grupo4 2 0,33432 0,16716 54,38 0,000
Error 23 0,07070 0,00307
Total 25 0,40503
S = 0,05544 R-Sq = 82,54% R-Sq(adj) = 81,03%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev --------+---------+---------+---------+-
1 6 0,36868 0,03563 (----*----)
2 9 0,42203 0,05688 (---*---)
3 11 0,62667 0,06202 (---*--)
--------+---------+---------+---------+-
168
0,40 0,50 0,60 0,70
Pooled StDev = 0,05544
A Tabela 1 apresenta as médias e o valor de F das ANOVAS de cada uma das três
regiões para as seis variáveis, a fim de que se possa verificar mais facilmente a diferença
entre elas.
Tabela 1: Resultados das ANOVAS Para os Três Grupos de Estados.
NP_T_DES18M NP_TRABSC N_T_LUZ
Grupo
Vermelho
0,80588 0,56912 0,7958
Grupo
Verde
0,77057 0,53630 0,9576
Grupo
Azul
0,86815 0,67783 0,9807
F 16,61 10,45 31,00
NP_PAREDE N_HOMEM10A14 N_IDHM
Grupo
Vermelho
0,7673 0,004655 0,36868
Grupo
Verde
0,9189 0,003496 0,42203
Grupo
Azul
0,9702 0,004253 0,62667
F 25,75 0,28 54,38 Fonte: Atlas do Desenvolvimento Humano no Brasil
Com estes resultados, é possível afirmar que em média os estados da região verde
possuem piores taxas nas variáveis referentes a taxa de desocupação da população com
mais de 18 anos e na variável referente aos indivíduos que trabalham sem carteira de
trabalho assinada. Esta região também possui valor menor na variável referente a
quantidade de homens com idade entre 10 e 14 anos. O grupo dos estados da região
vermelha possuem indicadores piores referentes a infraestrutura, como na variável que
indica os indivíduos que vivem em residências sem acesso a luz e em casas sem paredes
com estrutura adequada. Esta região também possui valor menor na variável IDHM. O
grupo azul apresentou números melhores em todos os indicadores.
Observando as médias e os desvios padrão das análises feitas pelo MINITAB,
pode-se perceber que em muitas variáveis as médias de duas ou mais regiões estão
próximas umas das outras, estando inclusive dentro do desvio padrão.
Também foram feitos os testes de ANOVA para as cinco regiões geográficas
brasileiras (Norte, Nordeste, Centro-Oeste, Sudeste e Sul), para que se possa comparar os
valores entre elas.
One-way ANOVA: MediaNP_T_DES18M_1 versus regioes Source DF SS MS F P
regioes 4 0,05005 0,01251 8,12 0,000
Error 21 0,03235 0,00154
Total 25 0,08240
S = 0,03925 R-Sq = 60,74% R-Sq(adj) = 53,26%

169
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ----+---------+---------+---------+-----
1 7 0,80055 0,05934 (----*-----)
2 9 0,78306 0,02841 (----*---)
3 4 0,83368 0,03488 (------*------)
4 3 0,85783 0,00399 (-------*-------)
5 3 0,92013 0,02329 (------*-------)
----+---------+---------+---------+-----
0,780 0,840 0,900 0,960
Pooled StDev = 0,03925
One-way ANOVA: MediaNP_TRABSC_1 versus regioes Source DF SS MS F P
regioes 4 0,16305 0,04076 13,20 0,000
Error 21 0,06484 0,00309
Total 25 0,22789
S = 0,05557 R-Sq = 71,55% R-Sq(adj) = 66,13%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -+---------+---------+---------+--------
1 7 0,60089 0,05404 (---*---)
2 9 0,52689 0,04380 (---*---)
3 4 0,64240 0,07498 (-----*-----)
4 3 0,60343 0,04475 (-----*------)
5 3 0,78980 0,07449 (------*------)
-+---------+---------+---------+--------
0,50 0,60 0,70 0,80
Pooled StDev = 0,05557
One-way ANOVA: MediaN_T_LUZ_1 versus regioes Source DF SS MS F P
regioes 4 0,11473 0,02868 7,38 0,001
Error 21 0,08163 0,00389
Total 25 0,19636
S = 0,06235 R-Sq = 58,43% R-Sq(adj) = 50,51%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ---+---------+---------+---------+------
1 7 0,8238 0,0988 (-----*-----)
2 9 0,9522 0,0530 (----*----)
3 4 0,9931 0,0069 (-------*-------)
4 3 0,9642 0,0150 (---------*--------)
5 3 0,9930 0,0028 (--------*--------)
---+---------+---------+---------+------
0,800 0,880 0,960 1,040
Pooled StDev = 0,0623
One-way ANOVA: MediaNP_PAREDE_1 versus regioes Source DF SS MS F P
regioes 4 0,08251 0,02063 2,85 0,050
Error 21 0,15221 0,00725

170
Total 25 0,23471
S = 0,08513 R-Sq = 35,15% R-Sq(adj) = 22,80%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ----+---------+---------+---------+-----
1 7 0,8380 0,0906 (--------*-------)
2 9 0,8847 0,1128 (-------*------)
3 4 0,9874 0,0067 (----------*----------)
4 3 0,9475 0,0220 (-----------*------------)
5 3 0,9752 0,0039 (------------*------------)
----+---------+---------+---------+-----
0,800 0,880 0,960 1,040
Pooled StDev = 0,0851
One-way ANOVA: MediaN_HOMEM10A14_1 versus regioes Source DF SS MS F P
regioes 4 0,0000642 0,0000161 2,09 0,118
Error 21 0,0001613 0,0000077
Total 25 0,0002255
S = 0,002771 R-Sq = 28,48% R-Sq(adj) = 14,86%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ----+---------+---------+---------+-----
1 7 0,004686 0,002127 (-------*------)
2 9 0,003337 0,001380 (-----*------)
3 4 0,007225 0,006275 (---------*---------)
4 3 0,002640 0,000518 (----------*----------)
5 3 0,002173 0,000353 (----------*----------)
----+---------+---------+---------+-----
0,0000 0,0030 0,0060 0,0090
Pooled StDev = 0,002771
One-way ANOVA: MediaN_IDHM_1 versus regioes Source DF SS MS F P
regioes 4 0,34254 0,08563 28,78 0,000
Error 21 0,06249 0,00298
Total 25 0,40503
S = 0,05455 R-Sq = 84,57% R-Sq(adj) = 81,63%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -----+---------+---------+---------+----
1 7 0,43233 0,07429 (---*----)
2 9 0,38813 0,03984 (---*---)
3 4 0,63995 0,06778 (-----*-----)
4 3 0,60433 0,01764 (-----*------)
5 3 0,67050 0,03372 (-----*------)
-----+---------+---------+---------+----
0,40 0,50 0,60 0,70
Pooled StDev = 0,05455
171
Os resultados estão apresentados na tabela 2.
Tabela 2: Resultados das ANOVAS Para as Cinco Regiões Geográficas Brasileiras.
NP_T_DES18M NP_TRABSC N_T_LUZ
Norte 0,80055 0,60089 0,8238
Nordeste 0,78306 0,52689 0,9522
Centro-Oeste 0,83368 0,64240 0,9931
Sudeste 0,85783 0,60343 0,9642
Sul 0,92013 0,78980 0,9930
F 8,12 13,20 7,38
NP_PAREDE N_HOMEM10A14 N_IDHM
Norte 0,8380 0,004686 0,43233
Nordeste 0,8847 0,003337 0,38813
Centro-Oeste 0,9874 0,007225 0,63995
Sudeste 0,9475 0,002640 0,60433
Sul 0,9752 0,002173 0,67050
F 2,85 2,09 28,78 Fonte: Atlas do Desenvolvimento Humano no Brasil
A partir destes resultados, é possível verificar que que a região Nordeste, seguida
pela região Norte, tem os piores índices na variável referente a taxa de desocupação de
indivíduos com mais de 18 anos, indivíduos que trabalham sem carteira assinada e IDHM.
Também se verifica que as variáveis referentes aos indivíduos que não possuem acesso a
luz e a casas com paredes adequadas possuem valores mais baixos na região Norte
seguida pela região Nordeste. As demais regiões estão melhores nos 6 indicadores.
Estes valores estão de acordo com a divisão do Brasil em três grupos distintos.
Pode-se verificar que o grupo vermelho possui predominantemente estados da região
Norte, e o grupo verde predominantemente da região Nordeste, e o azul
predominantemente das regiões Centro-Oeste, Sudeste e Sul.
Os valores de F, que indicam se a variabilidade dos grupos é maior do que a
variabilidade dentro dos grupos, é maior para as variáveis NP_T_DES18M, N_T_LUZ,
NP_PAREDE e N_IDHM na divisão com três regiões (verde, vermelha e azul), e o valor
de F das variáveis NP_TRABSC e N_HOMEM10A14 é maior para a divisão do Brasil
em cinco regiões (Norte, Nordeste, Centro-Oeste, Sudeste e Sul).
Após realizadas estas comparações foram feitos testes de regressão logística
ordinal com cada uma das variáveis selecionadas para o estudo para a divisão do Brasil
em três regiões.
Não é possível utilizar mais do que uma variável por vez nos testes de regressão
logística devido à baixa quantidade de dados, o que acaba por gerar valores de P altos nas
análises.
Para dar continuidade, foi rodado o teste apenas com a variável IDHM.
Ordinal Logistic Regression: grupo4 versus MediaN_IDHM_1 Link Function: Logit
Response Information
Variable Value Count
grupo4 1 6

172
2 9
3 11
Total 26
Logistic Regression Table
Odds 95% CI
Predictor Coef SE Coef Z P Ratio Lower Upper
Const(1) 15,2141 5,40237 2,82 0,005
Const(2) 20,8241 7,21528 2,89 0,004
MediaN_IDHM_1 -40,2092 13,9935 -2,87 0,004 0,00 0,00 0,00
Log-Likelihood = -10,436
Test that all slopes are zero: G = 34,745, DF = 1, P-Value = 0,000
Goodness-of-Fit Tests
Method Chi-Square DF P
Pearson 24,4941 49 0,999
Deviance 20,8713 49 1,000
Measures of Association:
(Between the Response Variable and Predicted Probabilities)
Pairs Number Percent Summary Measures
Concordant 209 95,4 Somers' D 0,91
Discordant 10 4,6 Goodman-Kruskal Gamma 0,91
Ties 0 0,0 Kendall's Tau-a 0,61
Total 219 100,0
Com apenas esta variável o valor do P foi menor do que 5%, e o percentual de
concordância foi 95,4%. Desta forma, esta é uma variável que pode ser considerada como
importante fator na divisão do país nas três regiões do mapa.
Os estados que fazem parte da região vermelha possuem um menor índice de
IDHM, por isso é necessário realizar políticas públicas a fim de melhorar este indicador
nestes estados. Estes estados estão predominantemente na região Norte, o que indica que
é necessário realizar políticas de melhoria de renda, saúde e educação nesta região, já que
o IDHM é composto por estas dimensões. A região verde também possui um IDHM
baixo, apesar de ser um pouco melhor do que o da região vermelha. A região azul possui
o maior de todos os índices de IDHM.
Para dar continuidade a análise, foi realizado o teste de regressão logística para a
variável NP_PAREDE.
Ordinal Logistic Regression: grupo4 versus MediaNP_PAREDE_1 Link Function: Logit
Response Information
Variable Value Count
grupo4 1 6
2 9
3 11
Total 26
Logistic Regression Table

173
Odds 95% CI
Predictor Coef SE Coef Z P Ratio Lower Upper
Const(1) 80,9229 29,9663 2,70 0,007
Const(2) 89,0046 33,2252 2,68 0,007
MediaNP_PAREDE_1 -94,0177 35,0000 -2,69 0,007 0,00 0,00 0,00
Log-Likelihood = -8,849
Test that all slopes are zero: G = 37,918, DF = 1, P-Value = 0,000
Goodness-of-Fit Tests
Method Chi-Square DF P
Pearson 16,7110 47 1,000
Deviance 17,6986 47 1,000
Measures of Association:
(Between the Response Variable and Predicted Probabilities)
Pairs Number Percent Summary Measures
Concordant 211 96,3 Somers' D 0,93
Discordant 8 3,7 Goodman-Kruskal Gamma 0,93
Ties 0 0,0 Kendall's Tau-a 0,62
Total 219 100,0
Esta variável tem um percentual de concordância de 96,3%, com um valor de P
de 7%. Pode-se considerar também que esta é uma variável que explica a divisão do Brasil
nestas três regiões.
A região vermelha possui um índice de indivíduos que moram em casas sem
paredes adequadas em média significativamente pior do que as duas outras regiões. A
região verde se encontra em uma posição intermediária e a azul possui um bom indicador.
Desta maneira, é importante realizar políticas públicas que visem dar acesso a
moradia digna nas regiões mais precárias, em especial nos estados que fazem parte da
região vermelha. Esta deve ser uma preocupação prioritária, devido a importância da
qualidade de moradia na qualidade de vida dos indivíduos.
Foi realizada as análises de regressão para a variável N_T_LUZ
Ordinal Logistic Regression: grupo4 versus MediaN_T_LUZ_1 Link Function: Logit
Response Information
Variable Value Count
grupo4 1 6
2 9
3 11
Total 26
Logistic Regression Table
Odds 95% CI
Predictor Coef SE Coef Z P Ratio Lower Upper
Const(1) 34,5711 11,9788 2,89 0,004
Const(2) 38,2145 12,8232 2,98 0,003
MediaN_T_LUZ_1 -39,4276 13,1748 -2,99 0,003 0,00 0,00 0,00

174
Log-Likelihood = -16,047
Test that all slopes are zero: G = 23,522, DF = 1, P-Value = 0,000
Goodness-of-Fit Tests
Method Chi-Square DF P
Pearson 28,1272 49 0,993
Deviance 32,0942 49 0,970
Measures of Association:
(Between the Response Variable and Predicted Probabilities)
Pairs Number Percent Summary Measures
Concordant 192 87,7 Somers' D 0,75
Discordant 27 12,3 Goodman-Kruskal Gamma 0,75
Ties 0 0,0 Kendall's Tau-a 0,51
Total 219 100,0
Esta variável obteve um percentual de concordância menor do que 90%, apesar de
ter um valor de P menor que 5%. Optou-se por apenas utilizar para as análises as variáveis
com percentual de concordância maior que 90%.
As variáveis NP_T_DES18M, NP_TRABSC e N_HOMEM10A14, possuem
baixo valor de F no teste de ANOVA, valor de P maior do que 5% e percentual de
concordância menor do que 90% no teste da regressão logística conforme indicado nas
análises abaixo, portanto não são muito boas para explicar esta divisão do Brasil em três
regiões adotada.
Para realizar estas análises que se seguem, foi necessário transformar o número
do grupo vermelho de 1 para 2 , e o do grupo verde de 2 para 1, a fim de que fosse possível
realizar as análises de regressão logística ordinal do maior para o menor, pois nessas
variáveis a região verde possui indicadores menores do que a região vermelha.
Ordinal Logistic Regression: grupo5 versus MediaNP_T_DES18M_1 Link Function: Logit
Response Information
Variable Value Count
grupo5 1 9
2 6
3 11
Total 26
Logistic Regression Table
Odds 95% CI
Predictor Coef SE Coef Z P Ratio Lower Upper
Const(1) 42,6730 12,8427 3,32 0,001
Const(2) 44,7794 13,2511 3,38 0,001
MediaNP_T_DES18M_1 -53,8921 16,0445 -3,36 0,001 0,00 0,00 0,00
Log-Likelihood = -15,973
Test that all slopes are zero: G = 23,671, DF = 1, P-Value = 0,000
Goodness-of-Fit Tests

175
Method Chi-Square DF P
Pearson 39,9782 49 0,817
Deviance 31,9456 49 0,972
Measures of Association:
(Between the Response Variable and Predicted Probabilities)
Pairs Number Percent Summary Measures
Concordant 195 89,0 Somers' D 0,79
Discordant 23 10,5 Goodman-Kruskal Gamma 0,79
Ties 1 0,5 Kendall's Tau-a 0,53
Total 219 100,0
Ordinal Logistic Regression: grupo5 versus MediaNP_TRABSC_1 Link Function: Logit
Response Information
Variable Value Count
grupo5 1 9
2 6
3 11
Total 26
Logistic Regression Table
Odds 95% CI
Predictor Coef SE Coef Z P Ratio Lower Upper
Const(1) 19,0846 6,98810 2,73 0,006
Const(2) 20,7773 7,20822 2,88 0,004
MediaNP_TRABSC_1 -34,4614 12,2900 -2,80 0,005 0,00 0,00 0,00
Log-Likelihood = -18,013
Test that all slopes are zero: G = 19,590, DF = 1, P-Value = 0,000
Goodness-of-Fit Tests
Method Chi-Square DF P
Pearson 41,9706 49 0,751
Deviance 36,0266 49 0,916
Measures of Association:
(Between the Response Variable and Predicted Probabilities)
Pairs Number Percent Summary Measures
Concordant 186 84,9 Somers' D 0,70
Discordant 32 14,6 Goodman-Kruskal Gamma 0,71
Ties 1 0,5 Kendall's Tau-a 0,47
Total 219 100,0
Ordinal Logistic Regression: grupo5 versus MediaN_HOMEM10A14_1 Link Function: Logit
Response Information

176
Variable Value Count
grupo5 1 9
2 6
3 11
Total 26
Logistic Regression Table
95%
Odds CI
Predictor Coef SE Coef Z P Ratio Lower
Const(1) -0,342829 0,658967 -0,52 0,603
Const(2) 0,611433 0,665521 0,92 0,358
MediaN_HOMEM10A14_1 -70,9595 131,013 -0,54 0,588 0,00 0,00
Predictor Upper
Const(1)
Const(2)
MediaN_HOMEM10A14_1 5,02074E+80
Log-Likelihood = -27,657
Test that all slopes are zero: G = 0,301, DF = 1, P-Value = 0,583
Goodness-of-Fit Tests
Method Chi-Square DF P
Pearson 51,8076 49 0,365
Deviance 55,3148 49 0,249
Measures of Association:
(Between the Response Variable and Predicted Probabilities)
Pairs Number Percent Summary Measures
Concordant 105 47,9 Somers' D -0,03
Discordant 111 50,7 Goodman-Kruskal Gamma -0,03
Ties 3 1,4 Kendall's Tau-a -0,02
Total 219 100,0
10.2 Considerações
Este trabalho teve como objetivo verificar quais variáveis podem explicar melhor
a divisão do Brasil nas três regiões construídas a partir das análises estatísticas. Para isso
foram realizados testes de regressão logística, e pode-se verificar que as duas variáveis
dentre as selecionadas que mais contribuem para a divisão do Brasil nas regiões
Vermelha, Verde e Azul são o IDHM e o P_PAREDE.
Desta forma, evidencia-se a importância de investimentos em políticas públicas
capazes de fazer com que os indivíduos que vivem nas regiões mais precárias possam ter
melhor qualidade de moradia, e assim, uma melhor qualidade de vida.
Outro ponto a se destacar é a importância da melhoria dos índices da variável
IDHM nessas regiões, salientando que este indicador leva em consideração a educação,
longevidade e renda. Desta forma, para que se possa buscar a melhoria das regiões mais
precárias é necessário melhorar estas três dimensões, através de políticas públicas que
visem aumentar a renda, melhorar as condições de saúde e de educação.

177
CAPÍTULO 11. ANÁLISE DE CORRESPONDÊNCIA
O presente capítulo tem como objetivo dar continuidade aos estudos anteriores
através da análise de correspondência a partir dos dados provenientes das variáveis
selecionadas no Atlas do Desenvolvimento Humano no Brasil, que apresentam
indicadores de desenvolvimento humano dos 5565 municípios brasileiros. Os dados são
provenientes do Censo Demográfico de 2010.
No capítulo 8 foi possível verificar na análise de agrupamentos, que alguns dos
estados brasileiros ficaram sozinhos no agrupamento realizados pelas análises dos
dendogramas, e poderiam ser melhor realocados em grupos que tivessem mais
similaridade. No capítulo 9, foram realizadas novas análises a fim de reagrupar os estados
brasileiros com maior similaridade e diminuir o número de agrupamentos para 3. A Figura
representa visualmente o Brasil dividido nos 3 agrupamentos diferentes, conforme as
análises realizadas pelo capítulo 9.
Figura 1: Mapa do Brasil Agrupado de Acordo com o Relatório IX.
Fonte: Atlas do Desenvolvimento Humano no Brasil
Estes agrupamentos foram realizados utilizando as 6 variáveis selecionadas para
estudo, sendo elas N_IDHM, N_HOMEM10A14, NP_T_DES18M, N_T_LUZ,
NP_TRABSC e NP_PAREDE, conforme descritas no capítulo 7.
Estas variáveis foram selecionadas devido ao fato que no capítulo 7 foram
construídas três variáveis sintéticas, a PCRenLong, explicada 94,26% pela variável
N_IDHM, a variável sintética PCHomem, explicada 96,46% pela variável
N_HOMEM10A14, e no agregado 96,04% se adicionada a variável NP_T_DES18M, e a
variável sintética PCTrab, explicada por N_T_LUZ em 32,18 %, no agregado a variável
NP_TRABSC gera um poder de explicação de 66,01%, a variável NP_T_DES18M gera
no agregado 82,87% e a variável NP_PAREDE gera um poder de explicação agregado
de 91,05%.
Através do capítulo 10, no qual foram realizadas análises de regressão logística,
foi possível verificar que as duas variáveis que mais contribuem para a divisão do Brasil
em três grupos, o verde, o vermelho e o azul distintos foram IDHM e a P_PAREDE.
Este capítulo tem como proposta fazer uma análise de correspondência para
verificar quais estados, regiões geográficas (Norte, Nordeste, Centro-Oeste, Sudeste e
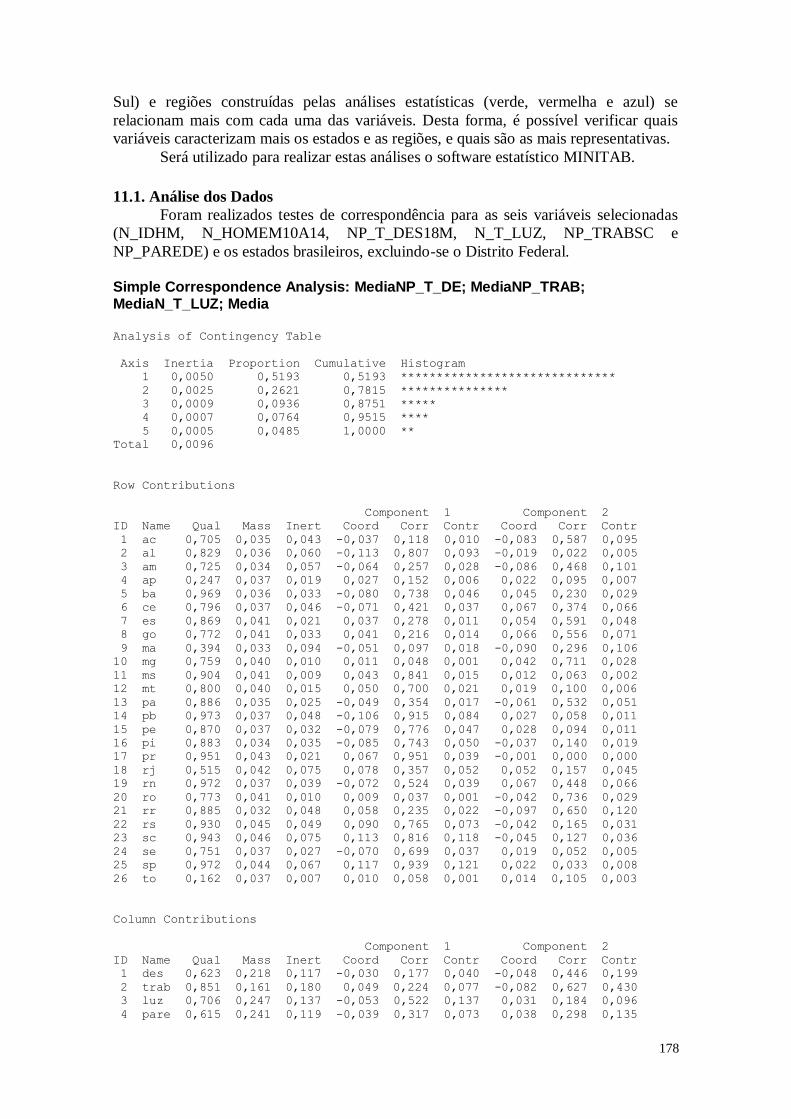
178
Sul) e regiões construídas pelas análises estatísticas (verde, vermelha e azul) se
relacionam mais com cada uma das variáveis. Desta forma, é possível verificar quais
variáveis caracterizam mais os estados e as regiões, e quais são as mais representativas.
Será utilizado para realizar estas análises o software estatístico MINITAB.
11.1. Análise dos Dados
Foram realizados testes de correspondência para as seis variáveis selecionadas
(N_IDHM, N_HOMEM10A14, NP_T_DES18M, N_T_LUZ, NP_TRABSC e
NP_PAREDE) e os estados brasileiros, excluindo-se o Distrito Federal.
Simple Correspondence Analysis: MediaNP_T_DE; MediaNP_TRAB; MediaN_T_LUZ; Media Analysis of Contingency Table
Axis Inertia Proportion Cumulative Histogram
1 0,0050 0,5193 0,5193 ******************************
2 0,0025 0,2621 0,7815 ***************
3 0,0009 0,0936 0,8751 *****
4 0,0007 0,0764 0,9515 ****
5 0,0005 0,0485 1,0000 **
Total 0,0096
Row Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 ac 0,705 0,035 0,043 -0,037 0,118 0,010 -0,083 0,587 0,095
2 al 0,829 0,036 0,060 -0,113 0,807 0,093 -0,019 0,022 0,005
3 am 0,725 0,034 0,057 -0,064 0,257 0,028 -0,086 0,468 0,101
4 ap 0,247 0,037 0,019 0,027 0,152 0,006 0,022 0,095 0,007
5 ba 0,969 0,036 0,033 -0,080 0,738 0,046 0,045 0,230 0,029
6 ce 0,796 0,037 0,046 -0,071 0,421 0,037 0,067 0,374 0,066
7 es 0,869 0,041 0,021 0,037 0,278 0,011 0,054 0,591 0,048
8 go 0,772 0,041 0,033 0,041 0,216 0,014 0,066 0,556 0,071
9 ma 0,394 0,033 0,094 -0,051 0,097 0,018 -0,090 0,296 0,106
10 mg 0,759 0,040 0,010 0,011 0,048 0,001 0,042 0,711 0,028
11 ms 0,904 0,041 0,009 0,043 0,841 0,015 0,012 0,063 0,002
12 mt 0,800 0,040 0,015 0,050 0,700 0,021 0,019 0,100 0,006
13 pa 0,886 0,035 0,025 -0,049 0,354 0,017 -0,061 0,532 0,051
14 pb 0,973 0,037 0,048 -0,106 0,915 0,084 0,027 0,058 0,011
15 pe 0,870 0,037 0,032 -0,079 0,776 0,047 0,028 0,094 0,011
16 pi 0,883 0,034 0,035 -0,085 0,743 0,050 -0,037 0,140 0,019
17 pr 0,951 0,043 0,021 0,067 0,951 0,039 -0,001 0,000 0,000
18 rj 0,515 0,042 0,075 0,078 0,357 0,052 0,052 0,157 0,045
19 rn 0,972 0,037 0,039 -0,072 0,524 0,039 0,067 0,448 0,066
20 ro 0,773 0,041 0,010 0,009 0,037 0,001 -0,042 0,736 0,029
21 rr 0,885 0,032 0,048 0,058 0,235 0,022 -0,097 0,650 0,120
22 rs 0,930 0,045 0,049 0,090 0,765 0,073 -0,042 0,165 0,031
23 sc 0,943 0,046 0,075 0,113 0,816 0,118 -0,045 0,127 0,036
24 se 0,751 0,037 0,027 -0,070 0,699 0,037 0,019 0,052 0,005
25 sp 0,972 0,044 0,067 0,117 0,939 0,121 0,022 0,033 0,008
26 to 0,162 0,037 0,007 0,010 0,058 0,001 0,014 0,105 0,003
Column Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 des 0,623 0,218 0,117 -0,030 0,177 0,040 -0,048 0,446 0,199
2 trab 0,851 0,161 0,180 0,049 0,224 0,077 -0,082 0,627 0,430
3 luz 0,706 0,247 0,137 -0,053 0,522 0,137 0,031 0,184 0,096
4 pare 0,615 0,241 0,119 -0,039 0,317 0,073 0,038 0,298 0,135
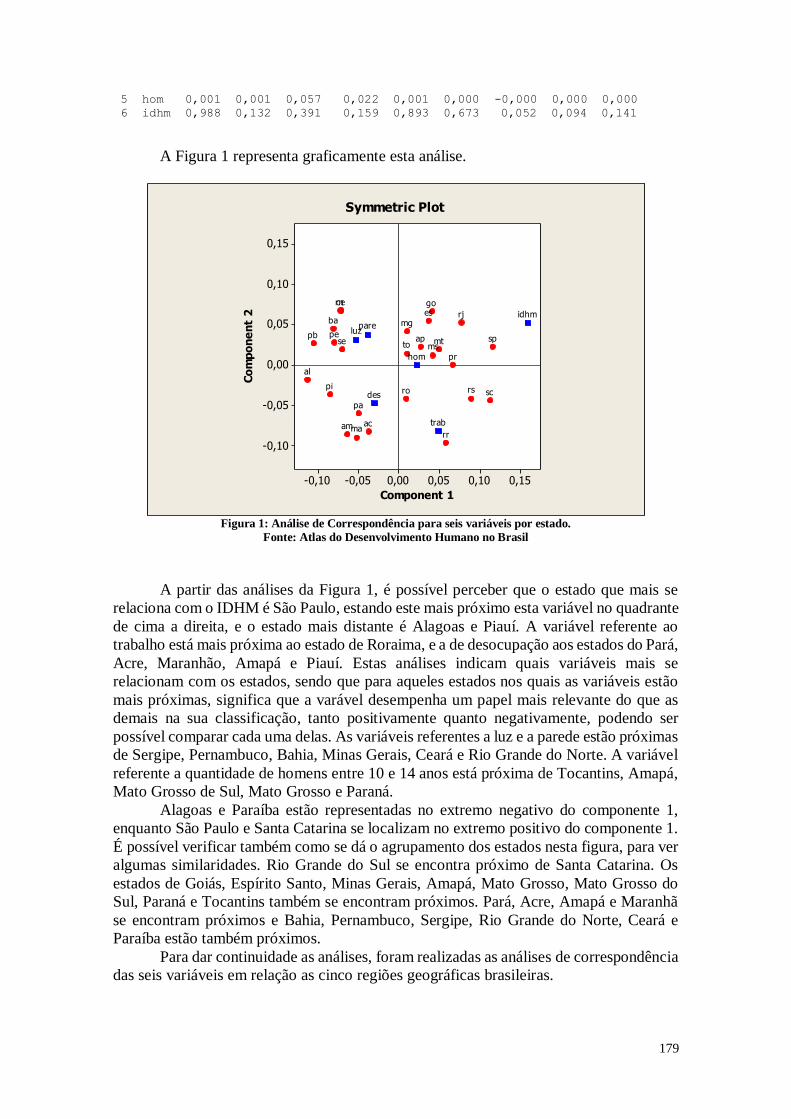
179
5 hom 0,001 0,001 0,057 0,022 0,001 0,000 -0,000 0,000 0,000
6 idhm 0,988 0,132 0,391 0,159 0,893 0,673 0,052 0,094 0,141
A Figura 1 representa graficamente esta análise.
0,150,100,050,00-0,05-0,10
0,15
0,10
0,05
0,00
-0,05
-0,10
Component 1
Co
mp
on
en
t 2 idhm
hom
pareluz
trab
des
tospse
scrs
rr
ro
rn
rj
pr
pi
pepb
pa
mtms
mg
ma
goes
ce
ba
ap
am
al
ac
Symmetric Plot
Figura 1: Análise de Correspondência para seis variáveis por estado.
Fonte: Atlas do Desenvolvimento Humano no Brasil
A partir das análises da Figura 1, é possível perceber que o estado que mais se
relaciona com o IDHM é São Paulo, estando este mais próximo esta variável no quadrante
de cima a direita, e o estado mais distante é Alagoas e Piauí. A variável referente ao
trabalho está mais próxima ao estado de Roraima, e a de desocupação aos estados do Pará,
Acre, Maranhão, Amapá e Piauí. Estas análises indicam quais variáveis mais se
relacionam com os estados, sendo que para aqueles estados nos quais as variáveis estão
mais próximas, significa que a varável desempenha um papel mais relevante do que as
demais na sua classificação, tanto positivamente quanto negativamente, podendo ser
possível comparar cada uma delas. As variáveis referentes a luz e a parede estão próximas
de Sergipe, Pernambuco, Bahia, Minas Gerais, Ceará e Rio Grande do Norte. A variável
referente a quantidade de homens entre 10 e 14 anos está próxima de Tocantins, Amapá,
Mato Grosso de Sul, Mato Grosso e Paraná.
Alagoas e Paraíba estão representadas no extremo negativo do componente 1,
enquanto São Paulo e Santa Catarina se localizam no extremo positivo do componente 1.
É possível verificar também como se dá o agrupamento dos estados nesta figura, para ver
algumas similaridades. Rio Grande do Sul se encontra próximo de Santa Catarina. Os
estados de Goiás, Espírito Santo, Minas Gerais, Amapá, Mato Grosso, Mato Grosso do
Sul, Paraná e Tocantins também se encontram próximos. Pará, Acre, Amapá e Maranhã
se encontram próximos e Bahia, Pernambuco, Sergipe, Rio Grande do Norte, Ceará e
Paraíba estão também próximos.
Para dar continuidade as análises, foram realizadas as análises de correspondência
das seis variáveis em relação as cinco regiões geográficas brasileiras.
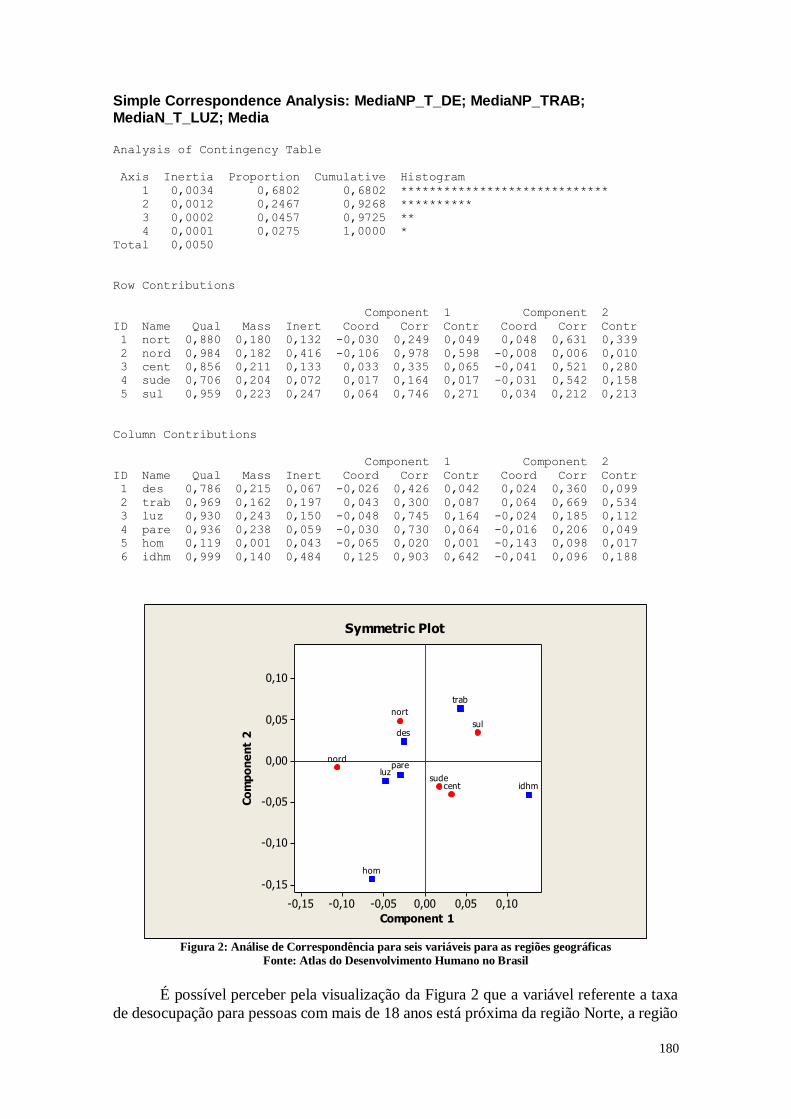
180
Simple Correspondence Analysis: MediaNP_T_DE; MediaNP_TRAB; MediaN_T_LUZ; Media Analysis of Contingency Table
Axis Inertia Proportion Cumulative Histogram
1 0,0034 0,6802 0,6802 *****************************
2 0,0012 0,2467 0,9268 **********
3 0,0002 0,0457 0,9725 **
4 0,0001 0,0275 1,0000 *
Total 0,0050
Row Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 nort 0,880 0,180 0,132 -0,030 0,249 0,049 0,048 0,631 0,339
2 nord 0,984 0,182 0,416 -0,106 0,978 0,598 -0,008 0,006 0,010
3 cent 0,856 0,211 0,133 0,033 0,335 0,065 -0,041 0,521 0,280
4 sude 0,706 0,204 0,072 0,017 0,164 0,017 -0,031 0,542 0,158
5 sul 0,959 0,223 0,247 0,064 0,746 0,271 0,034 0,212 0,213
Column Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 des 0,786 0,215 0,067 -0,026 0,426 0,042 0,024 0,360 0,099
2 trab 0,969 0,162 0,197 0,043 0,300 0,087 0,064 0,669 0,534
3 luz 0,930 0,243 0,150 -0,048 0,745 0,164 -0,024 0,185 0,112
4 pare 0,936 0,238 0,059 -0,030 0,730 0,064 -0,016 0,206 0,049
5 hom 0,119 0,001 0,043 -0,065 0,020 0,001 -0,143 0,098 0,017
6 idhm 0,999 0,140 0,484 0,125 0,903 0,642 -0,041 0,096 0,188
0,100,050,00-0,05-0,10-0,15
0,10
0,05
0,00
-0,05
-0,10
-0,15
Component 1
Co
mp
on
en
t 2
idhm
hom
pareluz
trab
dessul
sudecent
nord
nort
Symmetric Plot
Figura 2: Análise de Correspondência para seis variáveis para as regiões geográficas
Fonte: Atlas do Desenvolvimento Humano no Brasil
É possível perceber pela visualização da Figura 2 que a variável referente a taxa
de desocupação para pessoas com mais de 18 anos está próxima da região Norte, a região

181
Sudeste e Centro-Oeste estão próximas entre si e próximas das variáveis relacionadas a
estrutura das paredes e da luz. A variável trabalho está próxima da região Sul, sendo que
esta é a que mais a caracteriza. A região Nordeste está mais próxima das variáveis
referentes a luz, parede e desocupação. O IDHM e a quantidade de homens com 10 a 14
anos está distante das regiões, sendo que se encontram nos extremos da componente 2 e
1 respectivamente.
Observando-se os testes de ANOVA apresentados no capítulo 10, é possível notar
que a região Sul teve uma média consideravelmente maior do que as outras regiões na
varável referente a trabalho sem carteira assinada, sendo o destaque positivo nesta
variável. O Norte teve uma média melhor do que o Nordeste, na variável referente a taxa
de desocupação de indivíduos com 18 anos ou mais e o Nordeste foi melhor que o Norte
nas variáveis relativas aos indivíduos que moram em casas com paredes adequadas e que
possuem acesso a luz elétrica.
Foi realizado o teste com as seis variáveis para os três agrupamentos encontrados
pelos testes estatísticos, verde, vermelho e azul.
Simple Correspondence Analysis: MediaNP_T_DE; MediaNP_TRAB; MediaN_T_LUZ; Media Analysis of Contingency Table
Axis Inertia Proportion Cumulative Histogram
1 0,0033 0,6289 0,6289 ******************************
2 0,0019 0,3711 1,0000 *****************
Total 0,0052
Row Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 vermelho 1,000 0,300 0,330 -0,054 0,519 0,273 0,052 0,481 0,428
2 verde 1,000 0,327 0,279 -0,034 0,257 0,114 -0,057 0,743 0,559
3 azul 1,000 0,374 0,391 0,073 0,988 0,613 0,008 0,012 0,013
Column Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 des 1,000 0,221 0,183 -0,045 0,481 0,140 0,047 0,519 0,257
2 trab 1,000 0,161 0,106 0,005 0,008 0,001 0,058 0,992 0,285
3 luz 1,000 0,247 0,122 -0,025 0,241 0,047 -0,044 0,759 0,249
4 pare 1,000 0,240 0,080 -0,012 0,080 0,010 -0,040 0,920 0,197
5 hom 1,000 0,001 0,006 -0,085 0,261 0,002 0,143 0,739 0,012
6 idhm 1,000 0,128 0,503 0,143 0,999 0,799 0,003 0,001 0,001
182
0,150,100,050,00-0,05-0,10
0,15
0,10
0,05
0,00
-0,05
-0,10
Component 1
Co
mp
on
en
t 2
idhm
hom
pareluz
trabdes
azul
verde
vermelho
Symmetric Plot
Figura 3: Análise de Correspondência para seis variáveis para os três agrupamentos
Fonte: Atlas do Desenvolvimento Humano no Brasil
De acordo com os resultados obtidos, é possível verificar que o grupo azul está
mais próximo da variável IDHM, enquanto o grupo verde está mais próximo das variáveis
luz e parede e o grupo vermelho da variável taxa de desocupação e trabalho sem carteira
assinada.
Este resultado está relacionado com as análises feitas através da ANOVA no
capítulo 10, que revela que o grupo vermelho possui piores resultados nas médias das
variáveis referentes ao acesso a luz e a casa com parede adequada, enquanto o grupo verde
possui indicadores piores nas variáveis referentes a desocupação e quantidade de pessoas
que trabalham sem carteira assinada.
Após estas análises iniciais, foram realizadas novas análises de correspondência
utilizando-se apenas as três variáveis mais representativas, encontradas no relatório X,
sendo elas N_IDHM, N_T_LUZ e NP_PAREDE.
Inicialmente, será realizado o teste de correspondência para estas três variáveis e
os estados brasileiros.
Simple Correspondence Analysis: MediaN_T_LUZ_1; MediaNP_PAREDE_1; MediaN_IDHM_1 Analysis of Contingency Table
Axis Inertia Proportion Cumulative Histogram
1 0,0073 0,8448 0,8448 ******************************
2 0,0013 0,1552 1,0000 *****
Total 0,0086
Row Contributions
Component 1 Component 2
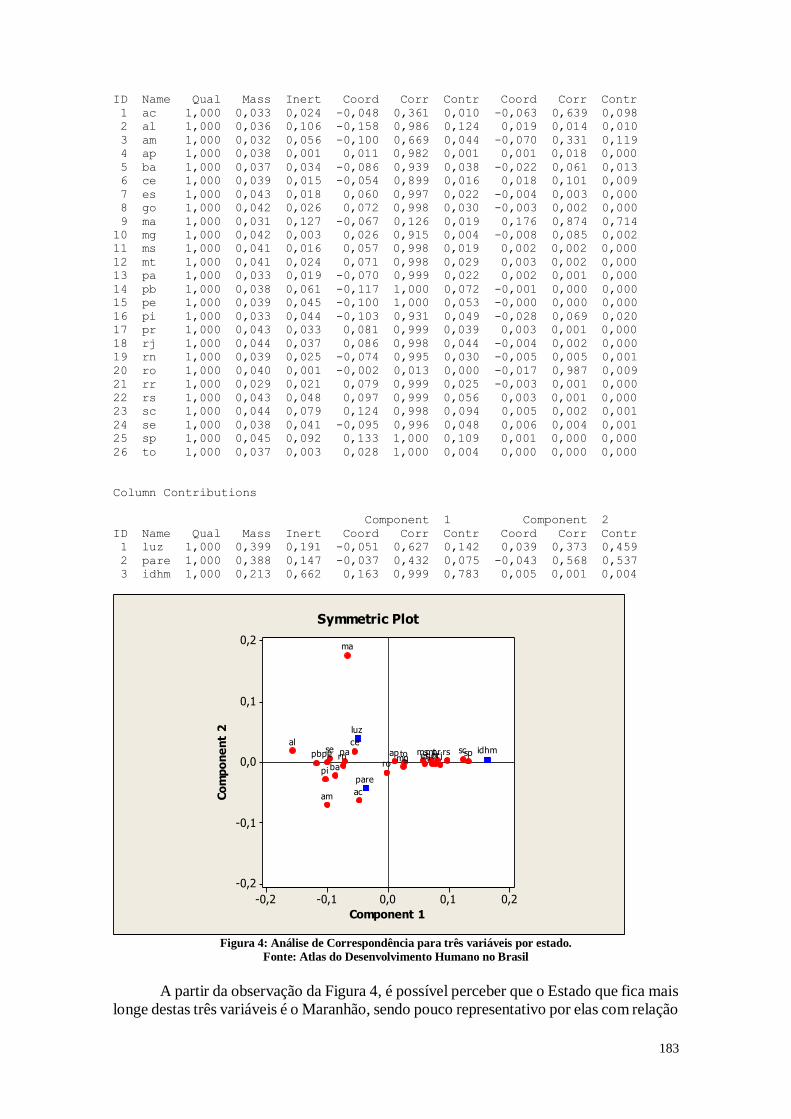
183
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 ac 1,000 0,033 0,024 -0,048 0,361 0,010 -0,063 0,639 0,098
2 al 1,000 0,036 0,106 -0,158 0,986 0,124 0,019 0,014 0,010
3 am 1,000 0,032 0,056 -0,100 0,669 0,044 -0,070 0,331 0,119
4 ap 1,000 0,038 0,001 0,011 0,982 0,001 0,001 0,018 0,000
5 ba 1,000 0,037 0,034 -0,086 0,939 0,038 -0,022 0,061 0,013
6 ce 1,000 0,039 0,015 -0,054 0,899 0,016 0,018 0,101 0,009
7 es 1,000 0,043 0,018 0,060 0,997 0,022 -0,004 0,003 0,000
8 go 1,000 0,042 0,026 0,072 0,998 0,030 -0,003 0,002 0,000
9 ma 1,000 0,031 0,127 -0,067 0,126 0,019 0,176 0,874 0,714
10 mg 1,000 0,042 0,003 0,026 0,915 0,004 -0,008 0,085 0,002
11 ms 1,000 0,041 0,016 0,057 0,998 0,019 0,002 0,002 0,000
12 mt 1,000 0,041 0,024 0,071 0,998 0,029 0,003 0,002 0,000
13 pa 1,000 0,033 0,019 -0,070 0,999 0,022 0,002 0,001 0,000
14 pb 1,000 0,038 0,061 -0,117 1,000 0,072 -0,001 0,000 0,000
15 pe 1,000 0,039 0,045 -0,100 1,000 0,053 -0,000 0,000 0,000
16 pi 1,000 0,033 0,044 -0,103 0,931 0,049 -0,028 0,069 0,020
17 pr 1,000 0,043 0,033 0,081 0,999 0,039 0,003 0,001 0,000
18 rj 1,000 0,044 0,037 0,086 0,998 0,044 -0,004 0,002 0,000
19 rn 1,000 0,039 0,025 -0,074 0,995 0,030 -0,005 0,005 0,001
20 ro 1,000 0,040 0,001 -0,002 0,013 0,000 -0,017 0,987 0,009
21 rr 1,000 0,029 0,021 0,079 0,999 0,025 -0,003 0,001 0,000
22 rs 1,000 0,043 0,048 0,097 0,999 0,056 0,003 0,001 0,000
23 sc 1,000 0,044 0,079 0,124 0,998 0,094 0,005 0,002 0,001
24 se 1,000 0,038 0,041 -0,095 0,996 0,048 0,006 0,004 0,001
25 sp 1,000 0,045 0,092 0,133 1,000 0,109 0,001 0,000 0,000
26 to 1,000 0,037 0,003 0,028 1,000 0,004 0,000 0,000 0,000
Column Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 luz 1,000 0,399 0,191 -0,051 0,627 0,142 0,039 0,373 0,459
2 pare 1,000 0,388 0,147 -0,037 0,432 0,075 -0,043 0,568 0,537
3 idhm 1,000 0,213 0,662 0,163 0,999 0,783 0,005 0,001 0,004
0,20,10,0-0,1-0,2
0,2
0,1
0,0
-0,1
-0,2
Component 1
Co
mp
on
en
t 2
idhm
pare
luz
to spse scrsrrro
rn rjpr
pi
pepb pa mtmsmg
ma
goes
ce
ba
ap
am
al
ac
Symmetric Plot
Figura 4: Análise de Correspondência para três variáveis por estado.
Fonte: Atlas do Desenvolvimento Humano no Brasil
A partir da observação da Figura 4, é possível perceber que o Estado que fica mais
longe destas três variáveis é o Maranhão, sendo pouco representativo por elas com relação
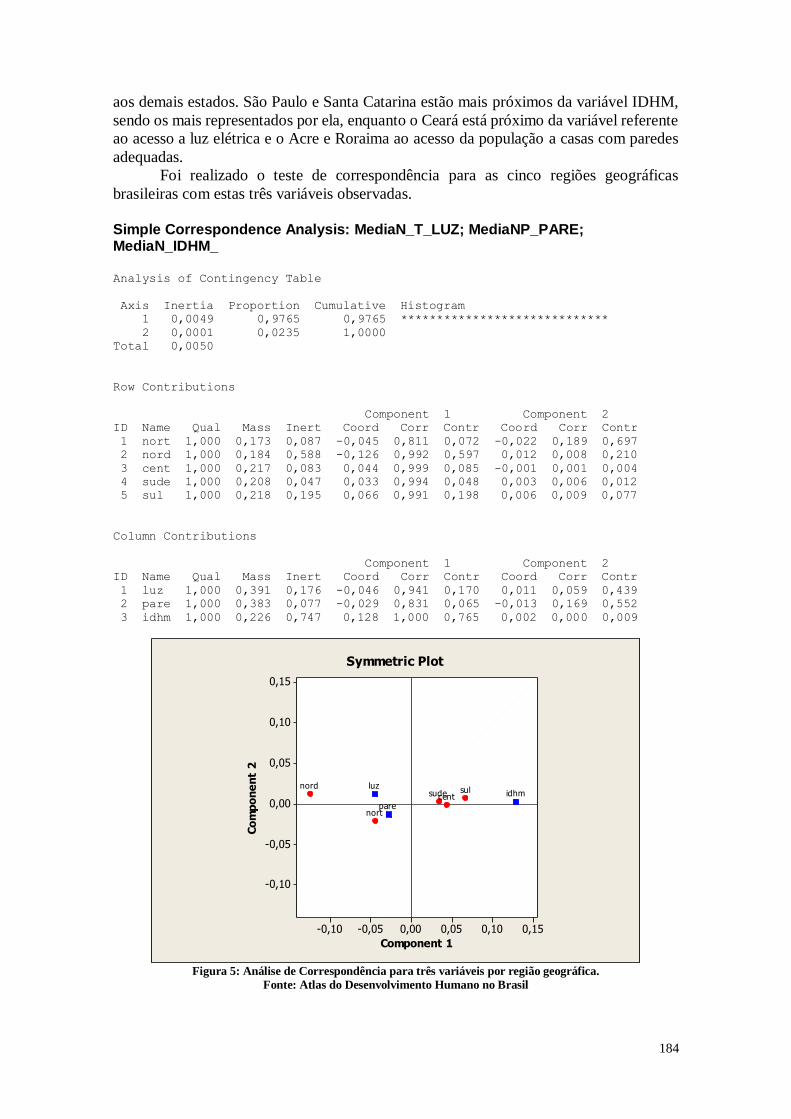
184
aos demais estados. São Paulo e Santa Catarina estão mais próximos da variável IDHM,
sendo os mais representados por ela, enquanto o Ceará está próximo da variável referente
ao acesso a luz elétrica e o Acre e Roraima ao acesso da população a casas com paredes
adequadas.
Foi realizado o teste de correspondência para as cinco regiões geográficas
brasileiras com estas três variáveis observadas.
Simple Correspondence Analysis: MediaN_T_LUZ; MediaNP_PARE; MediaN_IDHM_ Analysis of Contingency Table
Axis Inertia Proportion Cumulative Histogram
1 0,0049 0,9765 0,9765 *****************************
2 0,0001 0,0235 1,0000
Total 0,0050
Row Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 nort 1,000 0,173 0,087 -0,045 0,811 0,072 -0,022 0,189 0,697
2 nord 1,000 0,184 0,588 -0,126 0,992 0,597 0,012 0,008 0,210
3 cent 1,000 0,217 0,083 0,044 0,999 0,085 -0,001 0,001 0,004
4 sude 1,000 0,208 0,047 0,033 0,994 0,048 0,003 0,006 0,012
5 sul 1,000 0,218 0,195 0,066 0,991 0,198 0,006 0,009 0,077
Column Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 luz 1,000 0,391 0,176 -0,046 0,941 0,170 0,011 0,059 0,439
2 pare 1,000 0,383 0,077 -0,029 0,831 0,065 -0,013 0,169 0,552
3 idhm 1,000 0,226 0,747 0,128 1,000 0,765 0,002 0,000 0,009
0,150,100,050,00-0,05-0,10
0,15
0,10
0,05
0,00
-0,05
-0,10
Component 1
Co
mp
on
en
t 2
idhm
pare
luzsulsudecent
nord
nort
Symmetric Plot
Figura 5: Análise de Correspondência para três variáveis por região geográfica.
Fonte: Atlas do Desenvolvimento Humano no Brasil

185
A partir destas análises, é possível perceber que a região Norte está próxima das
variáveis relacionadas ao acesso a casas com paredes adequadas e a luz elétrica, enquanto
as regiões Sul, Centro-Oeste e Sudeste estão próximas da variável referente ao IDHM.
É possível observar que a região Norte possui indicadores piores nas variáveis
relacionadas ao acesso a luz elétrica e a casas com paredes adequadas, enquanto as regiões
Sul, Sudeste e Centro-Oeste possuem valores melhores para a variável IDHM.
Também foi realizado o teste de correspondência para os três agrupamentos
(verde, vermelho e azul) e os resultados são apresentados abaixo.
Simple Correspondence Analysis: MediaN_T_LUZ; MediaNP_PARE; MediaN_IDHM_ * NOTE * Fewer components than requested
Analysis of Contingency Table
Axis Inertia Proportion Cumulative Histogram
1 0,0046 1,0000 1,0000 ******************************
Total 0,0046
Row Contributions
Component 1
ID Name Qual Mass Inert Coord Corr Contr
1 vermelho 1,000 0,284 0,113 -0,043 1,000 0,113
2 verde 1,000 0,338 0,272 -0,061 1,000 0,272
3 azul 1,000 0,379 0,615 0,086 1,000 0,615
Column Contributions
Component 1
ID Name Qual Mass Inert Coord Corr Contr
1 luz 1,000 0,402 0,149 -0,041 1,000 0,149
2 pare 1,000 0,390 0,065 -0,028 1,000 0,065
3 idhm 1,000 0,208 0,785 0,132 1,000 0,785
* ERROR * Wrong axes pair specified
Não foi possível realizar esta análise devido à baixa quantidade de componentes.
11.2. Considerações
Após realizadas as análises de componentes, foi possível verificar quais variáveis
que mais representam os estados, as regiões e os agrupamentos estatísticos dos estados
brasileiros.
Realizando-se as análises a partir das seis variáveis, o estado mais relacionado
com a variável N_IDHM é São Paulo, os estados mais relacionados com a variável
N_HOMEM10A14 são Tocantins, Amapá, Mato Grosso do Sul, Mato Grosso e Paraná,
com a variável NP_T_DES18M são os estados do Pará, Acre, Maranhão, Amapá e Piauí,
com a variável N_T_LUZ e NP_PAREDE são Sergipe, Pernambuco, Bahia, Minas
Gerais, Ceará e Rio Grande do Norte e com a variável NP_TRABSC é Roraima.
Nas análises feitas com as cinco regiões geográficas, a variável NP_T_DES18M
está próxima da região Norte. As regiões Sudeste, Sul e Centro-Oeste estão próximas
entre si, e mais próximas das variáveis NP_PAREDE e N_T_LUZ. A região Nordeste
também está mais próxima da variável N_T_LUZ, NP_PAREDE e NP_T_DES18M.

186
A variável NP_TRABSC está próxima da região Sul, e esta região teve uma média
maior do que as demais nesta variável. O Norte teve uma média melhor do que o Nordeste,
na variável referente a taxa de desocupação de indivíduos com 18 anos ou mais e o
Nordeste foi melhor que o Norte nas variáveis relativas aos indivíduos que moram em
casas com parede adequadas e que possuem acesso a luz elétrica.
Foi realizado o teste com as seis variáveis para os três grupos no qual o Brasil foi
dividido. O grupo Azul esteve mais próximo da variável N_IDHM, enquanto o grupo
Vermelho esteve mais próximo das variáveis NP_T_DES18M e NP_TRASC e o grupo
Verde da variável NP_PAREDE e N_T_LUZ. Este resultado está relacionado com as
análises feitas através da ANOVA no capítulo 10, que revelam que o grupo vermelho
possui piores resultados nas médias das variáveis referentes ao acesso a luz e a casa com
parede adequada, enquanto o grupo verde possui indicadores piores nas variáveis
referentes a desocupação e quantidade de pessoas que trabalham sem carteira assinada.
Foram realizados testes com apenas as três variáveis que mais contribuem para a
divisão do Brasil nos três grupos, sendo elas a N_IDHM, NP_PAREDE e N_LUZ.
As análises das três variáveis e suas relações com os estados mostram que o
Maranhão ficou distante destas, São Paulo e Santa Catarina estão mais próximos da
variável N_IDHM, sendo os mais representados por ela, enquanto o Ceará está próximo
da variável N_LUZ e o Acre e Roraima à variável NP_PAREDE.
Foi realizado os testes com estas três variáveis para as cinco regiões geográficas,
e os resultados mostram que a região Norte está próxima das NP_PAREDE e N_LUZ,
enquanto as regiões Sul, Centro-Oeste e Sudeste estão próximas da variável N_IDHM. É
possível observar que a região Norte possui indicadores piores nas variáveis relacionadas
ao acesso a luz elétrica e a casas com paredes adequadas, enquanto as regiões Sul, Sudeste
e Centro-Oeste possuem valores melhores para a variável IDHM.
CAPÍTULO 12. ÁRVORE DE CLASSIFICAÇÃO O presente trabalho tem como objetivo dar continuidade aos estudos anteriores.
Para isso serão realizados testes estatísticos de árvore de classificação a partir dos dados
provenientes das variáveis selecionadas no Atlas do Desenvolvimento Humano no Brasil,
que apresentam indicadores de desenvolvimento humano dos 5565 municípios
brasileiros. Os dados são provenientes do Censo Demográfico de 2010.
Desta maneira, a partir das análises estatísticas feitas, será possível verificar quais
variáveis são mais capazes de classificar os estados brasileiros em diferentes regiões e
separá-los.
As análises foram realizadas utilizando as 6 variáveis selecionadas para estudo,
sendo elas N_IDHM, N_HOMEM10A14, NP_T_DES18M, N_T_LUZ, NP_TRABSC e
NP_PAREDE.
Estas variáveis foram selecionadas devido ao fato que no capítulo 7 foram
construídas três variáveis sintéticas, a PCRenLong, explicada 94,26% pela variável
N_IDHM, a variável sintética PCHomem, explicada 96,46% pela variável
N_HOMEM10A14, e no agregado 96,04% se adicionada a variável NP_T_DES18M, e a
variável sintética PCTrab, explicada por N_T_LUZ em 32,18 %, no agregado a variável
NP_TRABSC gera um poder de explicação de 66,01%, a variável NP_T_DES18M gera
no agregado 82,87% e a variável NP_PAREDE gera um poder de explicação agregado
de 91,05%.
Desta maneira, poderão ser comparados os resultados encontrados pela análise
discriminante no capítulo 9, regressão logística no capítulo 10 e árvore de classificação
neste capítulo.
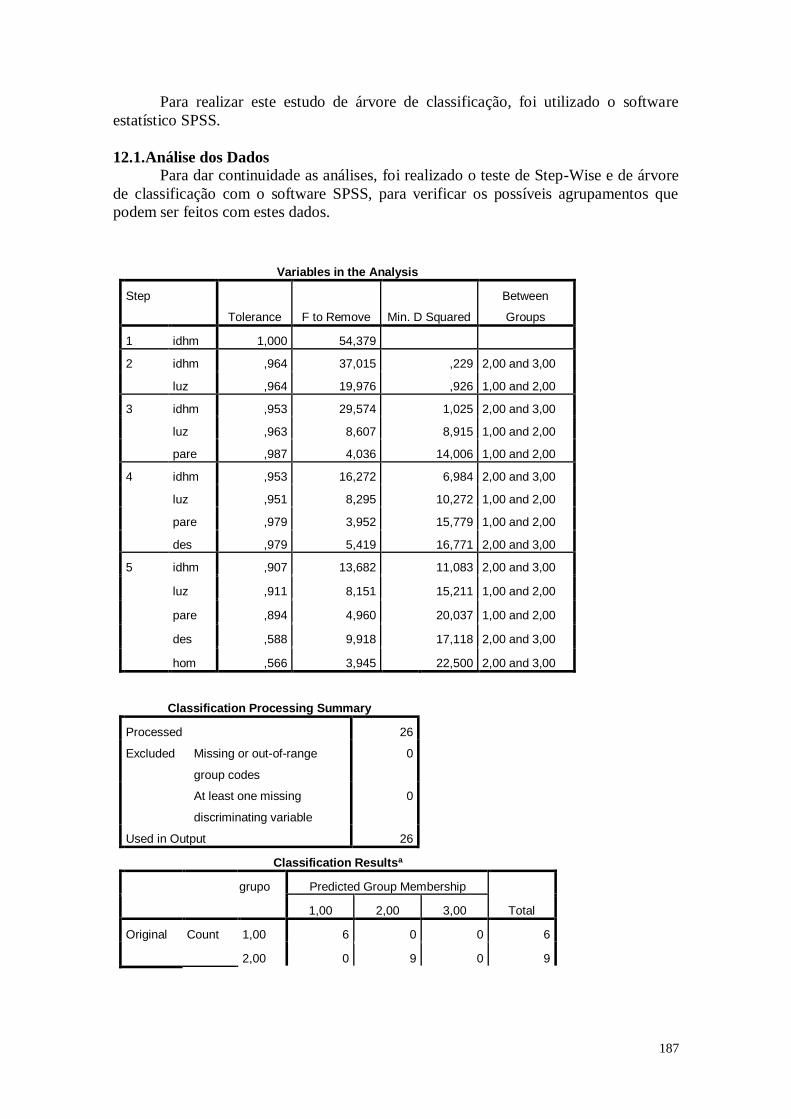
187
Para realizar este estudo de árvore de classificação, foi utilizado o software
estatístico SPSS.
12.1.Análise dos Dados
Para dar continuidade as análises, foi realizado o teste de Step-Wise e de árvore
de classificação com o software SPSS, para verificar os possíveis agrupamentos que
podem ser feitos com estes dados.
Variables in the Analysis
Step
Tolerance F to Remove Min. D Squared
Between
Groups
1 idhm 1,000 54,379
2 idhm ,964 37,015 ,229 2,00 and 3,00
luz ,964 19,976 ,926 1,00 and 2,00
3 idhm ,953 29,574 1,025 2,00 and 3,00
luz ,963 8,607 8,915 1,00 and 2,00
pare ,987 4,036 14,006 1,00 and 2,00
4 idhm ,953 16,272 6,984 2,00 and 3,00
luz ,951 8,295 10,272 1,00 and 2,00
pare ,979 3,952 15,779 1,00 and 2,00
des ,979 5,419 16,771 2,00 and 3,00
5 idhm ,907 13,682 11,083 2,00 and 3,00
luz ,911 8,151 15,211 1,00 and 2,00
pare ,894 4,960 20,037 1,00 and 2,00
des ,588 9,918 17,118 2,00 and 3,00
hom ,566 3,945 22,500 2,00 and 3,00
Classification Processing Summary
Processed 26
Excluded Missing or out-of-range
group codes
0
At least one missing
discriminating variable
0
Used in Output 26
Classification Resultsa
grupo Predicted Group Membership
Total 1,00 2,00 3,00
Original Count d
i
1,00 6 0 0 6
2,00 0 9 0 9
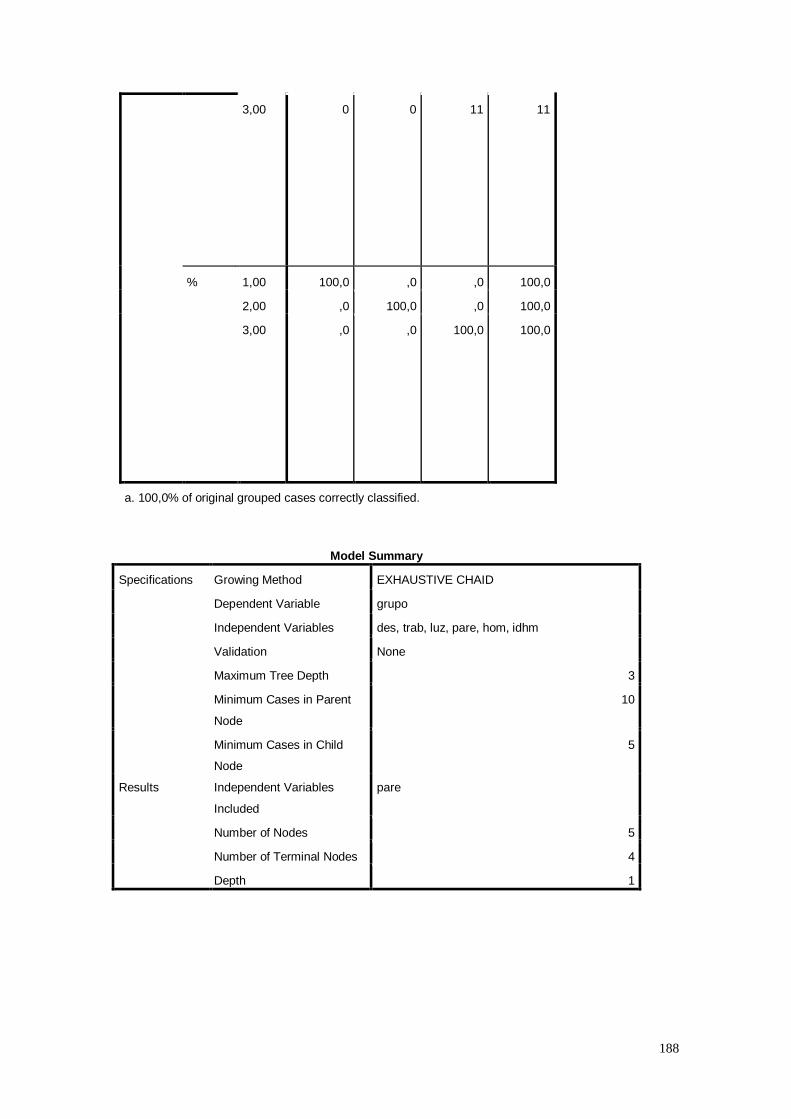
188
m
e
n
s
i
o
n
2
3,00 0 0 11 11
% d
i
m
e
n
s
i
o
n
2
1,00 100,0 ,0 ,0 100,0
2,00 ,0 100,0 ,0 100,0
3,00 ,0 ,0 100,0 100,0
a. 100,0% of original grouped cases correctly classified.
Model Summary
Specifications Growing Method EXHAUSTIVE CHAID
Dependent Variable grupo
Independent Variables des, trab, luz, pare, hom, idhm
Validation None
Maximum Tree Depth 3
Minimum Cases in Parent
Node
10
Minimum Cases in Child
Node
5
Results Independent Variables
Included
pare
Number of Nodes 5
Number of Terminal Nodes 4
Depth 1
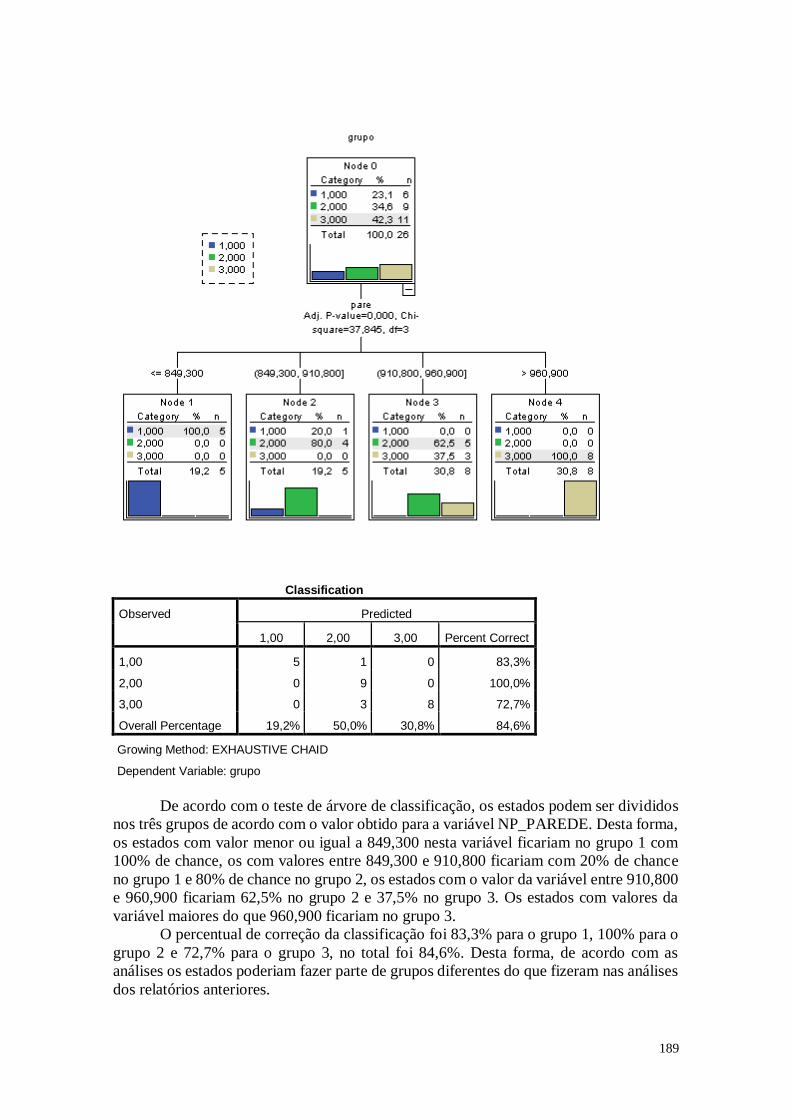
189
Classification
Observed Predicted
1,00 2,00 3,00 Percent Correct
1,00 5 1 0 83,3%
2,00 0 9 0 100,0%
3,00 0 3 8 72,7%
Overall Percentage 19,2% 50,0% 30,8% 84,6%
Growing Method: EXHAUSTIVE CHAID
Dependent Variable: grupo
De acordo com o teste de árvore de classificação, os estados podem ser divididos
nos três grupos de acordo com o valor obtido para a variável NP_PAREDE. Desta forma,
os estados com valor menor ou igual a 849,300 nesta variável ficariam no grupo 1 com
100% de chance, os com valores entre 849,300 e 910,800 ficariam com 20% de chance
no grupo 1 e 80% de chance no grupo 2, os estados com o valor da variável entre 910,800
e 960,900 ficariam 62,5% no grupo 2 e 37,5% no grupo 3. Os estados com valores da
variável maiores do que 960,900 ficariam no grupo 3.
O percentual de correção da classificação foi 83,3% para o grupo 1, 100% para o
grupo 2 e 72,7% para o grupo 3, no total foi 84,6%. Desta forma, de acordo com as
análises os estados poderiam fazer parte de grupos diferentes do que fizeram nas análises
dos relatórios anteriores.

190
No Node 1, se encontram os estados do AC, MA, PA, PI e RR, no Node 2 os
estados AL, AM, AP, TO e CE, no Node 3, se encontram os estados BA, MS, MT, PB,
PE, RN, RO e SE. Os estados pertencentes ao Node 4 são ES, GO, MG, PR, RJ, RS, SC
e SP.
Desta forma, é possível verificar como ficam os três grupos, de acordo com a
árvore de classificação gerada pelo SPSS.
Devido ao fato de que com esta árvore de classificação o Node 3 fica dividido
com percentuais próximos entre os grupos 2 e 3, foi feito um novo teste para subdividir
melhor estes dois agrupamentos. Os resultados seguem abaixo.
Model Summary
Specifications Growing Method EXHAUSTIVE CHAID
Dependent Variable grupo
Independent Variables des, trab, luz, pare, hom, idhm
Validation None
Maximum Tree Depth 3
Minimum Cases in Parent
Node
5
Minimum Cases in Child
Node
3
Results Independent Variables
Included
pare, des
Number of Nodes 7
Number of Terminal Nodes 5
Depth 2
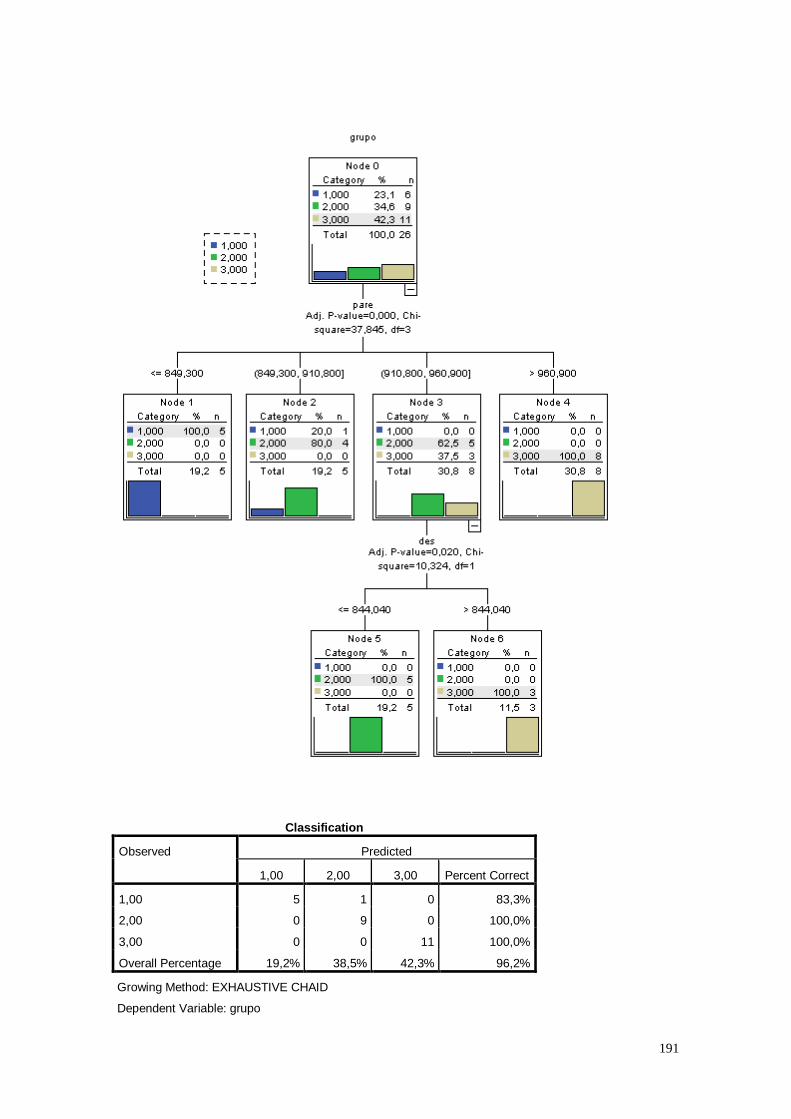
191
Classification
Observed Predicted
1,00 2,00 3,00 Percent Correct
1,00 5 1 0 83,3%
2,00 0 9 0 100,0%
3,00 0 0 11 100,0%
Overall Percentage 19,2% 38,5% 42,3% 96,2%
Growing Method: EXHAUSTIVE CHAID
Dependent Variable: grupo

192
Com esta nova análise, foi criado mais dois Nodes, utilizando-se a variável
T_DES18M. Desta maneira, o Node 3 foi dividido em Node 5 e 6, sendo que os 8 estados
do Node 3 foram divididos em 5 no grupo 2 e 3 no grupo 3. Assim, verifica-se que o
percentual de correção dos estados do grupo 2 e 3 foram 100%, e do grupo 1, foi 83,3%.
Com esta análise o percentual total foi 96,2%.
Os estados que passaram do Node 3 para o Node 5 foram BA, PB, PE, RN e SE,
e para o Node 6 foram MS, MT e RO.
12.2.Considerações
De acordo com a árvore de classificação encontrada, a variável NP_PAREDE é a
que mais é capaz de explicar a divisão do país nos três agrupamentos realizados, seguida
pela variável NP_T_DES18M. Estas duas variáveis juntas possuem um bom poder de
explicação para esta divisão.
Também é possível notar pelos testes de ANOVA apresentados no capítulo 9, que
as médias dos estados da região vermelha são mais precários na variável PAREDE,
enquanto os estados da região verde são mais precários em relação a variável T_DES18M,
o que pode ter causado esta divisão.
Na regressão logística apresentada no capítulo 10, as variáveis explicativas foram
IDHM, PAREDE e LUZ, e na análise discriminante também se verifica que a divisão do
Brasil nestes três grupos é satisfatória.
A variável PAREDE está presente tanto na regressão logística quanto na árvore
de classificação, e este fato indica a importância da realização de políticas públicas
capazes de fazer com que os indivíduos tenham mais acesso a moradia dignas e de
qualidade, em especial na região vermelha, que possui valores mais baixos para esta
variável. Também é importante fazer com que a região verde se desenvolva
economicamente e que os indivíduos tenham mais acesso a oportunidades melhores de
trabalho.
CAPÍTULO 13. RANKING DOS ESTADOS Este capítulo final tem como objetivo fazer um ranking dos estados brasileiros,
para que se possa compreender quais são os mais desenvolvidos e os menos
desenvolvidos.
Para isso, inicialmente serão realizados os testes de componentes principais com
as variáveis selecionadas para realizar os agrupamentos do Brasil nos três grupos distintos
construídos no capítulo 9. Estes agrupamentos foram realizados utilizando as variáveis
N_IDHM, N_HOMEM10A14, NP_T_DES18M, N_T_LUZ, NP_TRABSC e
NP_PAREDE, descritas no capítulo 7.
A Figura 1 representa visualmente o Brasil dividido nos 3 agrupamentos
diferentes, conforme as análises realizadas e apresentadas no capítulo 9.

193
Figura 1: Mapa do Brasil Agrupado de Acordo com o Capítulo 9.
Fonte: Através do Atlas do Desenvolvimento Humano no Brasil
13.1. Análise dos Dados
Para fazer a classificação dos 26 estados brasileiros em um ranking, variando do
mais desenvolvido para o menos desenvolvido, inicialmente foi realizado um teste de
componentes principais com as seis variáveis selecionadas.
Principal Component Analysis: MediaNP_T_DE; MediaNP_TRAB; MediaN_T_LUZ; MediaNP Eigenanalysis of the Correlation Matrix
Eigenvalue 2,9836 1,2077 1,0438 0,2850 0,2562 0,2236
Proportion 0,497 0,201 0,174 0,048 0,043 0,037
Cumulative 0,497 0,699 0,873 0,920 0,963 1,000
Variable PC1 PC2 PC3
MediaNP_T_DES18M_1 0,427 0,501 -0,080
MediaNP_TRABSC_1 0,440 0,225 -0,460
MediaN_T_LUZ_1 0,399 -0,388 0,452
MediaNP_PAREDE_1 0,440 -0,377 0,302
MediaN_HOMEM10A14_1 -0,032 -0,637 -0,671
MediaN_IDHM_1 0,520 -0,025 -0,189
Verifica-se que existem três componentes principais com Eigenvalue maior do
que 1, desta maneira, estas três componentes serão utilizadas para os cálculos do ranking
dos estados.
Rodou-se o teste de Step-wise para verificar quais variáveis são as principais do
componente PC1.
Stepwise Regression: PC1 versus MediaNP_T_DES18M; MediaNP_TRABSC_1; ... Alpha-to-Enter: 0,15 Alpha-to-Remove: 0,15
Response is PC1 on 6 predictors, with N = 26
194
Step 1 2 3 4 5 6
Constant -6,047 -10,357 -17,275 -17,414 -19,448 -19,165
MediaN_IDHM_1 12,18386 9,35499 6,49327 4,84735 4,00043 4,08363
T-Value 9,99 7,98 7,01 5,98 46,66 *
P-Value 0,000 0,000 0,000 0,000 0,000 *
MediaNP_PAREDE_1 6,30919 6,66730 7,07048 4,51086 4,54064
T-Value 4,10 6,56 9,08 45,55 *
P-Value 0,000 0,000 0,000 0,000 *
MediaNP_T_DES18M_1 9,77381 7,57962 7,80809 7,44093
T-Value 5,57 5,28 52,68 *
P-Value 0,000 0,000 0,000 *
MediaNP_TRABSC_1 3,95887 4,51879 4,60863
T-Value 4,12 45,27 *
P-Value 0,000 0,000 *
MediaN_T_LUZ_1 4,56660 4,50112
T-Value 44,21 *
P-Value 0,000 *
MediaN_HOMEM10A14_1 -10,6962
T-Value *
P-Value *
S 0,776 0,603 0,397 0,302 0,0311 0,000000
R-Sq 80,61 88,79 95,35 97,43 99,97 100,00
R-Sq(adj) 79,80 87,81 94,72 96,94 99,97 100,00
Desta forma, as duas variáveis que mais influenciam no PC1 é N_IDHM_1, com
um poder de explicação de 80,61%, seguida por NP_PAREDE, com poder de explicação
agregado de 88,79%.
Em seguida, rodou-se o teste de Step-Wise para a variável sintética PC2.
Stepwise Regression: PC2 versus MediaNP_T_DES18M; MediaNP_TRABSC_1; ... Alpha-to-Enter: 0,15 Alpha-to-Remove: 0,15
Response is PC2 on 6 predictors, with N = 26
Step 1 2 3 4 5
6
Constant 1,04632 6,34702 -0,65969 -0,89071 0,15366 -
0,01936
MediaN_HOMEM10A14_1 -256,233 -263,416 -208,506 -194,159 -213,291 -
212,171
T-Value -4,81 -6,29 -9,71 -16,29 -184,81
*
P-Value 0,000 0,000 0,000 0,000 0,000
*
MediaN_T_LUZ_1 -5,66797 -7,15332 -4,39479 -4,43249 -
4,37583
T-Value -3,99 -9,99 -8,04 -88,77
*
P-Value 0,001 0,000 0,000 0,000
*
MediaNP_T_DES18M_1 9,95596 11,17091 8,59665
8,72019

195
T-Value 8,61 17,06 108,87
*
P-Value 0,000 0,000 0,000
*
MediaNP_PAREDE_1 -3,74259 -3,94246 -
3,88652
T-Value -7,24 -83,19
*
P-Value 0,000 0,000
*
MediaNP_TRABSC_1 2,25377
2,35306
T-Value 49,96
*
P-Value 0,000
*
MediaN_IDHM_1 -
0,19374
T-Value
*
P-Value
*
S 0,801 0,629 0,308 0,168 0,0154
0,000000
R-Sq 49,04 69,90 93,11 98,03 99,98
100,00
R-Sq(adj) 46,92 67,28 92,17 97,65 99,98
100,00
Para a PC2, a variável que mais contribui para a explicação é N_HOMEM10A14,
com poder de explicação de 49,04%, seguida por N_T_LUZ com poder de explicação
agregado de 69,90%, seguida de NP_T_DES18M com poder de explicação de 93,11%.
Em seguida, rodou-se o teste de Step-Wise da variável PC3.
Stepwise Regression: PC3 versus MediaNP_T_DES18M; MediaNP_TRABSC_1; ... Alpha-to-Enter: 0,15 Alpha-to-Remove: 0,15
Response is PC3 on 6 predictors, with N = 26
Step 1 2 3 4 5
6
Constant 0,9524 -3,7217 -1,5801 -1,8455 -2,7722 -
1,8715
MediaN_HOMEM10A14_1 -233,244 -226,910 -212,619 -216,709 -213,965 -
223,453
T-Value -4,61 -5,46 -13,90 -21,26 -55,87
*
P-Value 0,000 0,000 0,000 0,000 0,000
*
MediaN_T_LUZ_1 4,99805 6,54620 4,69729 5,18852
5,10464
T-Value 3,55 12,30 9,52 27,30
*
P-Value 0,002 0,000 0,000 0,000
*

196
MediaNP_TRABSC_1 -6,02873 -6,45121 -5,15798 -
4,81888
T-Value -12,19 -19,09 -30,29
*
P-Value 0,000 0,000 0,000
*
MediaNP_PAREDE_1 2,49194 3,08101
3,11512
T-Value 5,37 16,97
*
P-Value 0,000 0,000
*
MediaN_IDHM_1 -1,72392 -
1,48675
T-Value -11,37
*
P-Value 0,000
*
MediaNP_T_DES18M_1 -
1,38695
T-Value
*
P-Value
*
S 0,759 0,623 0,229 0,152 0,0570
0,000000
R-Sq 47,01 65,78 95,58 98,14 99,75
100,00
R-Sq(adj) 44,81 62,80 94,98 97,79 99,69
100,00
Verifica-se que as variáveis que mais explicam essa é N_HOMEM10A14 com
47,01%, seguida por N_T_LUZ com um poder agregado de 65,78%, seguida por
NP_TRABSC com poder agregado de 95,58%.
A partir destes resultados obtidos, é possível construir uma equação utilizando a
Proportion de cada um dos três vetores e o R-Sq de cada variável para os vetores. Assim,
a equação de pontuação para os estados pode ser descrita como sendo:
Y = 0,497 * (0,8061 * N_IDHM + 0,0818 * NP_PAREDE) + 0,201 * (0,4904 *
N_HOMEM10A14 + 0,2086 * N_T_LUZ + 0,2321 * NP_T_DES18M) + 0,174 * (0,4701
* N_HOMEM10A14 + 0,1877 * N_T_LUZ + 0,298 * NP_TRABSC)
A partir desta equação é possível calcular o valor de cada estado num ranking, do
maior até o menor.
Os resultados obtidos foram normalizados e atribuídos um valor de 0 a 100 através
da expressão:
CY= 100 * (cX-MIN(cX))/(MAX(cX)-MIN(cX))
Os resultados do ranking de estados se encontram apresentados na Tabela 1
abaixo.
Tabela 1: Ranking dos Estados Brasileiros
Ranking Estados Posição

197
100 sc 1
99,22668 sp 2
90,27953 rs 3
82,15216 rj 4
80,71608 pr 5
72,80133 es 6
71,90206 go 7
66,6757 mt 8
65,96219 ms 9
59,97892 mg 10
50,95945 ro 11
42,01578 ap 12
37,62588 to 13
30,15315 ce 14
28,33828 rn 15
23,15136 pe 16
22,87445 se 17
18,96352 pb 18
16,59364 ba 19
11,6823 rr 20
10,04803 ac 21
8,438665 pa 22
6,729597 al 23
4,301474 ma 24
3,128545 pi 25
0 am 26 Fonte: Atlas do Desenvolvimento Humano no Brasil
A partir dos resultados encontrados é possível verificar quais são os melhores
estados brasileiros e quais se encontram em situação mais precária.
13.2. Considerações
Neste relatório final, foi construído um ranking dos estados brasileiros.
O melhor estado do Ranking é Santa Catarina, seguida por São Paulo, Rio Grande
do Sul, Rio de Janeiro e Paraná. Os cinco estados mais bem posicionados se encontram
nas regiões Sul e Sudeste.
O sexto estado mais bem posicionado é Espírito Santo, seguido por Goiás, Mato
Grosso, Mato Grosso do Sul e Minas Gerais. Desta forma observa-se que os dez melhores
estados brasileiros se encontram nas regiões Sul, Sudeste e Centro Oeste, e fazem parte
do agrupamento azul do mapa da Figura 1.
O décimo primeiro estado é Rondônia, seguido de Amapá, Tocantins, Ceará, Rio
Grande do Norte, Pernambuco, Sergipe, Paraíba, Bahia e Roraima. Estes estados possuem
condições mais precárias e notas mais baixas no ranking. Desta forma, é necessário
realizar políticas capazes de desenvolver estes estados nos indicadores selecionados para
que os moradores destas localidades possam ter melhor qualidade de vida.
Os seis estados mais mal posicionados no ranking, são Acre, Pará, Alagoas,
Maranhão, Piauí e Amazonas. Estes estados precisam de uma maior atenção, pois é

198
necessário que consigam se desenvolver para aumentar a qualidade de vida dos
indivíduos, melhorando indicadores como a saúde, educação, habitação e renda.
REFERÊNCIAS
ANDERSON, David R.; SWEENEY, Dennis J.; WILLIAMS, Thomas A. Estatística
aplicada à administração e economia. 2. ed. São Paulo: Thomson Learning,
2007.
ATLAS DO DESENVOLVIMENTO HUMANO NO BRASIL. Disponível em:
<http://www.atlasbrasil.org.br/2013/>. Acessado em: 17 mar. 2017.
IBGE, Instituto Brasileiro de Geografia e Estatística. Séries Históricas e Estatísticas.
Disponível em: <http://seriesestatisticas.ibge.gov.br/apresentacao.aspx>.
Acessado em: 30 mar. 2017.
LAS CASAS A., DE HOYOS A. Pesquisa de Marketing. São Paulo, Ed. Atlas, 2010.