Embed Size (px)
Citation preview

哈尔滨工程大学
2017 年深圳杯数学建模挑战赛论文
网络侧估计终端用户视频体验建模与研究
参赛队员:谢洪乐
吴天行
聂磊鑫
指导教师:王淑娟
参赛选题:A 题
2017.8.12-17

2 / 65
网络侧估计终端用户视频体验建模与研究
摘要
随着智能终端设备的逐渐普及,移动视频业务迅猛发展,终端用户的网络视频体验
越来越受到广大消费者及运营商的关注。该领域先后提出了 vMOS、U-vMOS 等一系列
有效的量化评价指标。但实时动态、复杂的网络传输状态对视频体验的影响,用户体验
评价变量(初始缓冲时延、卡顿时长占比)与网络侧变量(初始缓冲峰值速率、播放阶
段平均下载速率、E2E RTT)之间的函数关系,对改善用户体验、优化移动运营商的网络
布局具有重要的价值,还需要进一步研究。
针对上述一系列问题,建立数学模型如下:
模型一:为描述初始缓冲时延与网络侧变量(初始缓冲峰值速率,播放阶段平均下
载速率,E2E RTT) 之间的函数关系,构建了初始缓冲时延模型。根据控制单一变量的
思想,分别绘制初始缓冲时延与各个网络侧变量的关系散点图,估计其大致的函数关系;
然后,依据预测关系建立含参数方程,将实验数据导入 MATLAB 中求解最优参数,得
到初步拟合模型;最终,通过对基于 TCP 协议的视频初始缓冲过程的深入分析,在物
理层次进一步完善了该模型,全面分析了初始缓冲时延的影响因素,在优化模型中,准
确地计算出了综合影响关系公式。
模型二:卡顿时长占比原理的分析与建模。模型深入分析了卡顿时长占比与初始缓
冲峰值速率,播放阶段平均下载速率,E2E RTT 等因素之间的物理层关系。依据物理涵
义初步估计函数关系,构建含参方程,由数值拟合优化量化求解了卡顿时长占比和播放
阶段平均下载速率等因素之间的函数公式。在量化模型中,卡顿时长占比与初始缓冲峰
值速率构成较弱的反比例关系,卡顿时长占比与播放阶段平均下载速率构成较强的反比
例关系,实验数据表明可以忽略 E2E RTT 对卡顿时长占比的影响。为对模型进行进一
步优化,将关系函数改进为分段函数。首先,通过滤波取均值的方法大致确定分段函数
的分界点;然后,引入机器学习中的异常检测算法,多次迭代剔除过于分散的异常数据,
从而很好地提升了拟合精度;最终,在模型中加入随机因子,用以模拟在网络状况较差
时,由于下载速率及视频码率的波动造成的干扰因素,得到综合影响关系公式,并数值
模拟误差情况,进行了一系列的改进,优化后模型具备较高的准确性和稳健性。
整体模型分析了户体验评价变量与网络侧变量的量化函数关系,通过新增数据实现
了模型的检验,提出皮尔逊相关系数等一系列指标对我们的模型进行了可靠的评价,并
对网络视频业务提出了一些高效可行的建议,研究结果具有较好的可用性。
关键词:终端用户视频体验模型;初始缓冲时延;卡顿时长占比;多元线性回归;
非线性曲线方程拟合;机器学习.

3 / 65
目 录
摘要 ....................................................................................................................................................... 2
目录 ....................................................................................................................................................... 3
一、研究背景 ........................................................................................................................................ 5
二、问题重述 ........................................................................................................................................ 5
三、问题分析 ........................................................................................................................................ 6
四、模型的假设 .................................................................................................................................... 6
五、符号的约定 .................................................................................................................................... 7
六、初始缓冲时延模型的建立与求解 ................................................................................................ 7
6.1 视频初始缓冲原理模型 .............................................................................................................. 7
6.2 初始缓冲时延与初始缓冲峰值速率的关系 ............................................................................... 8
6.3 初始缓冲时延与播放阶段平均下载速率的关系 ..................................................................... 10
6.4 初始缓冲时延与端到端环回时间 E2E RTT 的关系 .................................................................. 10
6.5 初始缓冲时延的综合影响因素数值拟合模型 ......................................................................... 13
6.6 初始缓冲时延的综合影响因素实际物理模型 ......................................................................... 15
七、卡顿时长占比模型建立与求解 .................................................................................................. 18
7.1 视频卡顿原理模型 .................................................................................................................... 18
7.2 卡顿时长占比与初始缓冲峰值速率的关系 ............................................................................. 20
7.3 卡顿时长占比与播放阶段平均下载速率的关系 ..................................................................... 21
7.4 卡顿时长占比与端到端环回时间 E2E RTT 的关系 .................................................................. 22
7.5 卡顿时长占比的综合影响因素模型 ........................................................................................ 24
7.6 模型改进一:分段函数的引入及数值拟合的优化 ................................................................. 25
7.6.1 总体思路 ............................................................................................................................. 25
7.6.2 分段函数分界点的初步选择 ............................................................................................. 26
7.6.3 直线拟合预处理:分散数据点的筛除 .............................................................................. 27
7.6.4 直线拟合、分段函数分界点的最终确定及优化结果 ...................................................... 31
7.7 模型改进二:残差分析及概率模型 ........................................................................................ 32
7.6.1 残差分析 ............................................................................................................................. 32
7.6.2 概率误差模型的建立 ......................................................................................................... 34
7.6.3 误差模型物理意义分析 ..................................................................................................... 37
7.6.4 优化结果:卡顿时长占比综合影响因素概率模型 .......................................................... 37
八、补充数据的模型检验 .................................................................................................................. 39
8.1 模型检验总述 ............................................................................................................................ 39
8.2 初始缓冲时延模型对补充数据的拟合..................................................................................... 39
8.2.1 数值拟合模型 ..................................................................................................................... 39
8.2.1 实际物理模型 ..................................................................................................................... 40
8.3 卡顿时长占比模型对补充数据的拟合..................................................................................... 43
8.4.检验指标的建立与评价 ............................................................................................................ 45
8.4.1 皮尔逊相关系数指标 ........................................................................................................ 45
8.4.2 修正的欧氏距离指标 ........................................................................................................ 46
8.4.3 辅助距离指标 .................................................................................................................... 46
8.5 模型拟合效果评价指标的量化分析 ........................................................................................ 47

4 / 65
8.6 模型检验的结论 ........................................................................................................................ 49
8.6.1 模型的适用性相关的结论 ................................................................................................. 49
8.6.2 模型检验的总结与展望 ..................................................................................................... 51
九、模型的可用性分析 ...................................................................................................................... 51
十、模型的科学性分析 ...................................................................................................................... 53
10.1 假设和思维的合理性 .............................................................................................................. 53
10.2 方法的科学性 .......................................................................................................................... 53
10.3 方法的可靠性 .......................................................................................................................... 53
十一、模型的评价 .............................................................................................................................. 54
11.1 模型的优点 .............................................................................................................................. 54
11.2 模型的缺点 .............................................................................................................................. 54
11.3 模型的推广与应用 .................................................................................................................. 54
十二、参考文献 .................................................................................................................................. 55
十三、附 录........................................................................................................................................ 56
附录 1:𝒕𝒔𝒕𝒂𝒍𝒍-𝒗(𝒕)关系模型的计算过程(以 k=2 为例) ......................................................... 56
附录 2: 关键程序算法 .................................................................................................................. 57
附录 2.1:读取 EXCEL 表格数据并转存为 txt 文件的程序 ....................................................... 57
附录 2.2:正规方程组函数 ........................................................................................................ 57
附录 2.3:初始缓冲时延模型相关程序算法 ............................................................................. 57
附录 2.4:卡顿时长占比模型相关程序算法(1) ........................................................................ 59
附录 2.5:卡顿时长占比模型相关程序算法(2) ........................................................................ 60
附录 2.6:计算高斯分布的参数相关的程序算法 ..................................................................... 63
附录 2.7:高斯分布概率密度函数程序..................................................................................... 63
附录 2.8:绘制高斯分布的概率密度分布图程序 ..................................................................... 63
附录 2.9:E2E RTT 与初始缓冲时延及卡顿时长占比关系求解程序 ....................................... 64
附录 2.10:初始缓冲时延和卡顿时长占比数值拟合偏离程度计算程序 ............................... 64
附录 2.11:补充数据的模型检验相关程序 ............................................................................... 65

5 / 65
一、研究背景
随着智能手机、平板电脑等移动终端设备的普及,高品质网络逐渐成熟,视频已经
成为移动终端上主要的数据业务类别。据移动网络运营商的数据和视频优化解决方案的
领先供应商 ByteMobile 统计,移动视频目前已经占据了成熟市场移动数据网络中逾 50%
的流量,成为网络中最主要的数据类型。作为一种集娱乐、通讯、信息、安保等功能为
一体的媒体形式,视频在网络流量中占有重要地位,对于改善运营商网络投资战略和优
化终端用户体验都具有指导意义[1]。(详见《华为移动视频报告 2016》)
因此,用户观看网络视频的体验也成为了网络移动业务的核心影响因素。
消费者对移动视频的需求不但体现在内容的丰富度上,更体现在流畅的网络传输体
验。为了定量评估视频的质量,ITU-T 于 2012 年在参考语音 MOS 指标体系基础上,提
出了针对视频业务的质量指标 vMOS(video Mean Opinion Score)。此后,中国华为公司
对 vMOS 进行了一系列的改进,设计了以用户体验为中心的视频体验衡量体系 U-vMOS
评价标准[2],量化并综合了视频体验 TOP3 影响因子,即视频源质量(sQaultiy),播放启
动时的操作体验(sInteraction)和播放过程中的体验(sView)[3]。
针对使用小屏幕观看视频点播的业务场景,华为 mLAB 通过与牛津大学和北京大学
联合对消费者进行定性研究,发现视频内容清晰度、初始缓冲时延和卡顿时长占比是影
响移动视频 MOS 最重要的三个网络相关因素,并提出了 Mobile U-vMOS 标准[4]。作为
U-vMOS 在移动小屏场景下的子集,该标准[5]指出,播放启动时的操作体验取决于初始
缓冲时延(sLoading),播放过程中的体验取决于卡顿(sStalling)情况(《基于移动视频的移
动承载网络要求白皮书》)。
在视频内容清晰度确定的情况下,如何利用网络侧变量(初始缓冲峰值速率、E2E
RTT、播放阶段平均下载速率)和用户体验评价变量(初始缓冲时延、卡顿时长占比)
之间的函数关系,定量地建立网络能力和视频体验之间的关系模型,以便通过 Mobile
U-vMOS 目标值来定义网络需求,对于指引运营商规划、优化网络具有重要意义。
二、问题重述
随着无线宽带网络的升级,以及智能终端的普及,越来越多的用户选择在移动智能
终端上应用客户端 APP 观看网络视频,这是一种基于 TCP 的视频传输及播放。影响
网络视频用户体验的两个关键指标是初始缓冲等待时间和在视频播放过程中的卡顿缓
冲时间,因此,可以利用初始缓冲时延和卡顿时长占比(卡顿时长占比=卡顿时长/视频
播放时长)来定量评价用户体验。研究表明影响初始缓冲时延和卡顿时长占比的主要因
素有初始缓冲峰值速率、播放阶段平均下载速率、端到端环回时间(E2E RTT),以及
视频参数。然而,这些因素和初始缓冲时延和卡顿时长占比之间的关系并不明确。

6 / 65
基于附件中提供的实验数据,我们将通过数学模型的建立来研究:用户体验评价变
量(初始缓冲时延,卡顿时长占比)与网络侧变量(初始缓冲峰值速率,播放阶段平均
下载速率,E2E RTT)之间的函数关系。
三、问题分析
1、建立初始缓冲时延的数学模型,首先需要研究影响初始缓冲时延的因素。视频
的总初始缓冲阶段主要分为视频解析阶段(信令交互阶段)、数据下载阶段、播放器加
载阶段。主要研究的网络侧变量为 E2E RTT(端到端环回时间)和初始缓冲峰值速率。
根据理论分析,初始缓冲时延与 E2E RTT 成正比、与初始缓冲峰值速率成反比。将附
件给出的实验数据导入 Matlab 中,分别绘制变量间的散点图,即可初步验证这一结论[6]。
然后,建立含参数的函数关系方程,利用实验数据进行数值拟合,可进一步求出各个参
数的最优估计值,准确地拟合出各个变量间的函数关系式[7]。考虑到初始缓冲阶段中数
据下载阶段的复杂性,可以深入研究 TCP 启动过程,从而得出更加精确的物理过程模
型,并通过实验数据检验,进一步优化该数学模型。
2、视频传输产生卡顿现象的原因与视频播放原理密切相关。在视频播放过程中,
数据下载和播放这两个过程同时进行,涉及实时下载速率、视频码率等变量。当缓冲区
数据消耗至卡顿门限时即造成卡顿现象。我们首先根据该物理意义,以实时下载速率为
自变量,卡顿时长占比为研究对象,利用附件中的实验数据,数值拟合,计算出卡顿时
长占比的模型,从而估计卡顿时长占比与网络侧变量的比例关系,最后,利用我们建立
的模型,进行一些误差分析,并依据实际的数值拟合情况进行相应的修正,最终解算出
卡顿时长占比的综合影响因素模型。
四、模型的假设
(1)忽略网络传输中丢包、重传对数据下载的影响。
(2)假设用户观看视频过程中暂停、快进、快退等操作对传输速率的影响可忽略。
(3)在控制单一变量讨论时,可以仅考虑附件中实验数据提供,且模型要求中所需要
研究的参数的影响,其他无关参数的影响忽略不计。
(4)假设初始缓冲峰值速率、播放阶段平均下载速率、E2E RTT 之间不存在内部强耦
合的函数关系,利用数值拟合可量化得到有效的关系函数。
(5)假设视频解析阶段所需的 RTT 个数为常数。
(6)假设附件中的实验数据具备一般性和普适性,利用该数据拟合的结果能够充分说
明实际网络传输情况,因此所建立的数学模型具备一定的实际应用价值。
(7)假设实验数据中存在的少量与模型偏差较大“异常点”可以忽略,并且剔除这些
点后对模型的适用性影响可以忽略。
7 / 65
五、符号的约定
符号 解释与说明 符号 解释与说明
𝑡𝑤𝑎𝑖𝑡 初始缓冲时延 𝑅𝑇𝑇 端到端环回时间(E2E RTT)
𝑡𝑠𝑡𝑎𝑙𝑙 卡顿缓冲时长 𝑡𝑠𝑔𝑛𝑙 初始缓冲信令交互时长
𝑡𝑙𝑜𝑎𝑑 初始缓冲数据下载阶段时长 𝑡𝑟𝑒𝑠𝑝 初始缓冲终端、服务器响应时长
𝑡𝑝𝑙𝑎𝑦 视频播放时长 𝐷𝑎𝑡𝑎 初始缓冲数据量
𝑆𝑠𝑡𝑎𝑙𝑙 卡顿时长占比 𝐷𝑟𝑒𝑝𝑙𝑎𝑦 重播放门限阈值
𝑣𝑡ℎ𝑟𝑝 初始缓冲峰值速率 𝑣𝑙𝑜𝑎𝑑 播放阶段平均下载速率
𝑣(𝑡) 实时下载速率 t 播放时间
𝑁𝑖𝑡𝑒𝑟𝑎𝑡𝑖𝑜𝑛 迭代次数 𝑁𝑒𝑟𝑟𝑜𝑟 “异常点”数量
𝑁𝑠𝑎𝑚𝑝𝑙𝑒 样本容量 MSS 最大报文段长度
𝑁𝑠𝑡𝑎𝑙𝑙 卡顿次数 N 网络传输过程 RTT 循环的次数
𝑡𝑡𝑒𝑟𝑚𝑖𝑛𝑎𝑙 终端响应时间 𝑡𝑠𝑒𝑟𝑣𝑒𝑟 服务器响应时间
六、初始缓冲时延模型的建立与求解
6.1 视频初始缓冲原理模型
基于 TCP/IP 协议的网络视频文件传输过程如图 6-1 所示,主要分为信令交互阶段、
最小解码缓冲媒体报文下载阶段(数据下载阶段)和播放器加载阶段等 3 个阶段。
图 6-1 视频初始缓冲过程原理图
信令交互阶段 数据下载阶段 播放器加载阶段 播放阶段
TCP 层传输速率
时间

8 / 65
假设信令交互时间为𝑡𝑠𝑔𝑛𝑙,数据下载时间为𝑡𝑙𝑜𝑎𝑑,终端和服务器响应时间为𝑡𝑟𝑒𝑠𝑝。
因此,视频的初始缓冲时延𝑡𝑤𝑎𝑖𝑡的计算公式为:
𝑡𝑤𝑎𝑖𝑡 = 𝑡𝑠𝑔𝑛𝑙 + 𝑡𝑙𝑜𝑎𝑑 + 𝑡𝑟𝑒𝑠𝑝 (6-1)
其中,信令交互时间𝑡𝑠𝑔𝑛𝑙过程,依次包括建立视频下载请求、生成视频 URL、重定
向视频地址等时间,这些步骤均为单独的 TCP 数据流,其时长是 E2E RTT 的若干倍数。
在网络数据下载过程中,视频文件在开始播放前需要先缓存一定数量的视频内容,才能
够开始播放视频,依据 vMOS 标准,这一段时间称为数据下载时间。
视频缓冲过程由视频通信协议 TCP 过程的启动阶段和稳态阶段构成,由于初始缓
冲所需的数据量(初始缓冲量)是给定的固有量,所以前者与 E2E RTT 成正比,后者
与初始缓冲峰值速率成反比。而终端、服务器响应时间则分别与终端处理能力和内容提
供商的实际情况有关,可视为恒定常数。
根据以上分析,依据物理意义,可初步估测初始缓冲时延与 E2E RTT 成正比、与
初始缓冲峰值速率𝑣𝑡ℎ𝑟𝑝成反比,即:
𝑡𝑤𝑎𝑖𝑡 ∝ 𝑅𝑇𝑇 , 𝑡𝑤𝑎𝑖𝑡 ∝1
𝑣𝑡ℎ𝑟𝑝 (6-2)
为验证公式 6-2 中模型分析的正确性,将附件中实验数据导入 MATLAB 进行数据
处理。利用控制单一变量法,基于散点图的绘制,分析各个影响因素的对应关系。然后,
系统地考虑各影响因素的函数,即用户体验评价变量(初始缓冲时延、卡顿时长占比)
与网络侧变量(初始缓冲峰值速率、播放阶段平均下载速率、E2E RTT)之间的函数关系,
其中,所需研究的变量间主要对应关系如图 6-2 所示。
初始缓冲时延
用户体验评价变量
卡顿时长占比
初始缓冲峰值速率
网络侧变量
播放阶段平均下载速率
E2E RTT
图 6-2 用户体验评价变量与网络侧变量对应关系
6.2 初始缓冲时延与初始缓冲峰值速率的关系
为研究初始缓冲时延𝑡𝑤𝑎𝑖𝑡与初始缓冲峰值速率𝑣𝑡ℎ𝑟𝑝的关系,利用附件中实验数据,
绘制初始缓冲时延与初始缓冲峰值速率散点图,如图 6-3 所示。
9 / 65
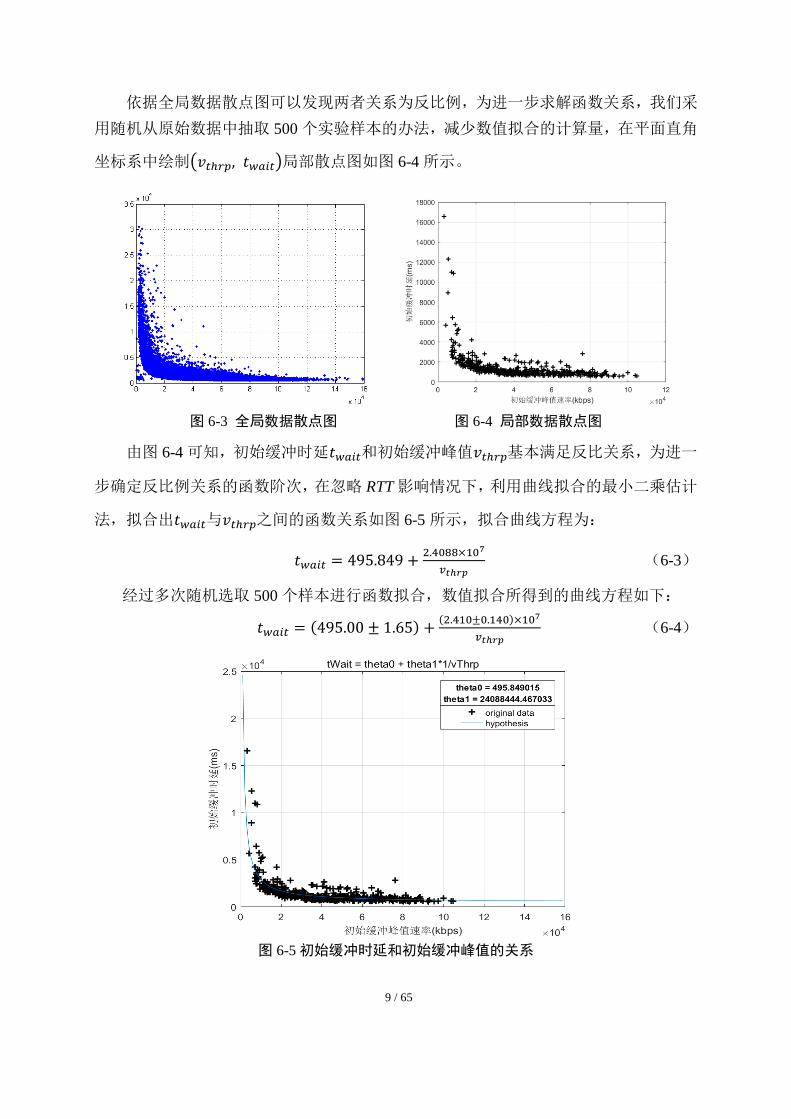
依据全局数据散点图可以发现两者关系为反比例,为进一步求解函数关系,我们采
用随机从原始数据中抽取 500 个实验样本的办法,减少数值拟合的计算量,在平面直角
坐标系中绘制(𝑣𝑡ℎ𝑟𝑝, 𝑡𝑤𝑎𝑖𝑡)局部散点图如图 6-4 所示。
图 6-3 全局数据散点图 图 6-4 局部数据散点图
由图 6-4 可知,初始缓冲时延𝑡𝑤𝑎𝑖𝑡和初始缓冲峰值𝑣𝑡ℎ𝑟𝑝基本满足反比关系,为进一
步确定反比例关系的函数阶次,在忽略 RTT 影响情况下,利用曲线拟合的最小二乘估计
法,拟合出𝑡𝑤𝑎𝑖𝑡与𝑣𝑡ℎ𝑟𝑝之间的函数关系如图 6-5 所示,拟合曲线方程为:
𝑡𝑤𝑎𝑖𝑡 = 495.849 +2.4088×107
𝑣𝑡ℎ𝑟𝑝 (6-3)
经过多次随机选取 500 个样本进行函数拟合,数值拟合所得到的曲线方程如下:
𝑡𝑤𝑎𝑖𝑡 = (495.00 ± 1.65) +(2.410±0.140)×107
𝑣𝑡ℎ𝑟𝑝 (6-4)
图 6-5 初始缓冲时延和初始缓冲峰值的关系
10 / 65
6.3 初始缓冲时延与播放阶段平均下载速率的关系
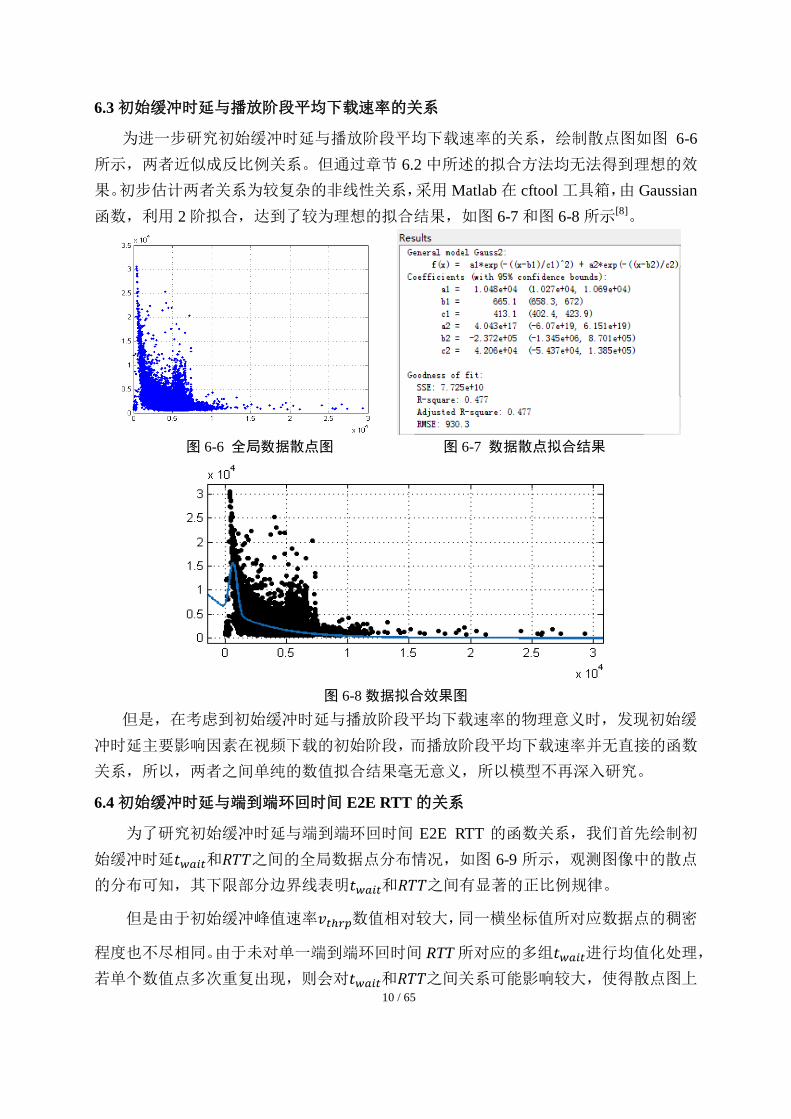
为进一步研究初始缓冲时延与播放阶段平均下载速率的关系,绘制散点图如图 6-6
所示,两者近似成反比例关系。但通过章节 6.2 中所述的拟合方法均无法得到理想的效
果。初步估计两者关系为较复杂的非线性关系,采用 Matlab 在 cftool 工具箱,由 Gaussian
函数,利用 2 阶拟合,达到了较为理想的拟合结果,如图 6-7 和图 6-8 所示[8]。
图 6-6 全局数据散点图 图 6-7 数据散点拟合结果
图 6-8 数据拟合效果图
但是,在考虑到初始缓冲时延与播放阶段平均下载速率的物理意义时,发现初始缓
冲时延主要影响因素在视频下载的初始阶段,而播放阶段平均下载速率并无直接的函数
关系,所以,两者之间单纯的数值拟合结果毫无意义,所以模型不再深入研究。
6.4 初始缓冲时延与端到端环回时间 E2E RTT 的关系
为了研究初始缓冲时延与端到端环回时间 E2E RTT 的函数关系,我们首先绘制初
始缓冲时延𝑡𝑤𝑎𝑖𝑡和𝑅𝑇𝑇之间的全局数据点分布情况,如图 6-9 所示,观测图像中的散点
的分布可知,其下限部分边界线表明𝑡𝑤𝑎𝑖𝑡和𝑅𝑇𝑇之间有显著的正比例规律。
但是由于初始缓冲峰值速率𝑣𝑡ℎ𝑟𝑝数值相对较大,同一横坐标值所对应数据点的稠密
程度也不尽相同。由于未对单一端到端环回时间 RTT 所对应的多组𝑡𝑤𝑎𝑖𝑡进行均值化处理,
若单个数值点多次重复出现,则会对𝑡𝑤𝑎𝑖𝑡和𝑅𝑇𝑇之间关系可能影响较大,使得散点图上
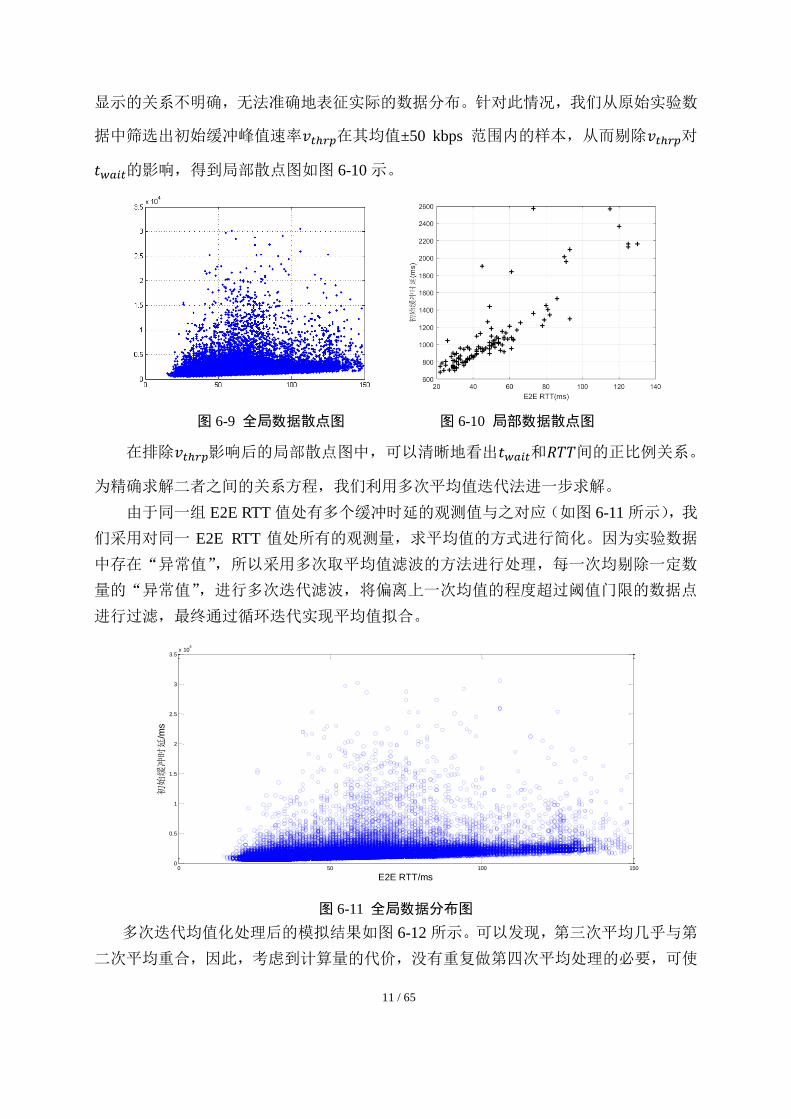
11 / 65
显示的关系不明确,无法准确地表征实际的数据分布。针对此情况,我们从原始实验数
据中筛选出初始缓冲峰值速率𝑣𝑡ℎ𝑟𝑝在其均值±50 kbps 范围内的样本,从而剔除𝑣𝑡ℎ𝑟𝑝对
𝑡𝑤𝑎𝑖𝑡的影响,得到局部散点图如图 6-10 示。
图 6-9 全局数据散点图 图 6-10 局部数据散点图
在排除𝑣𝑡ℎ𝑟𝑝影响后的局部散点图中,可以清晰地看出𝑡𝑤𝑎𝑖𝑡和𝑅𝑇𝑇间的正比例关系。
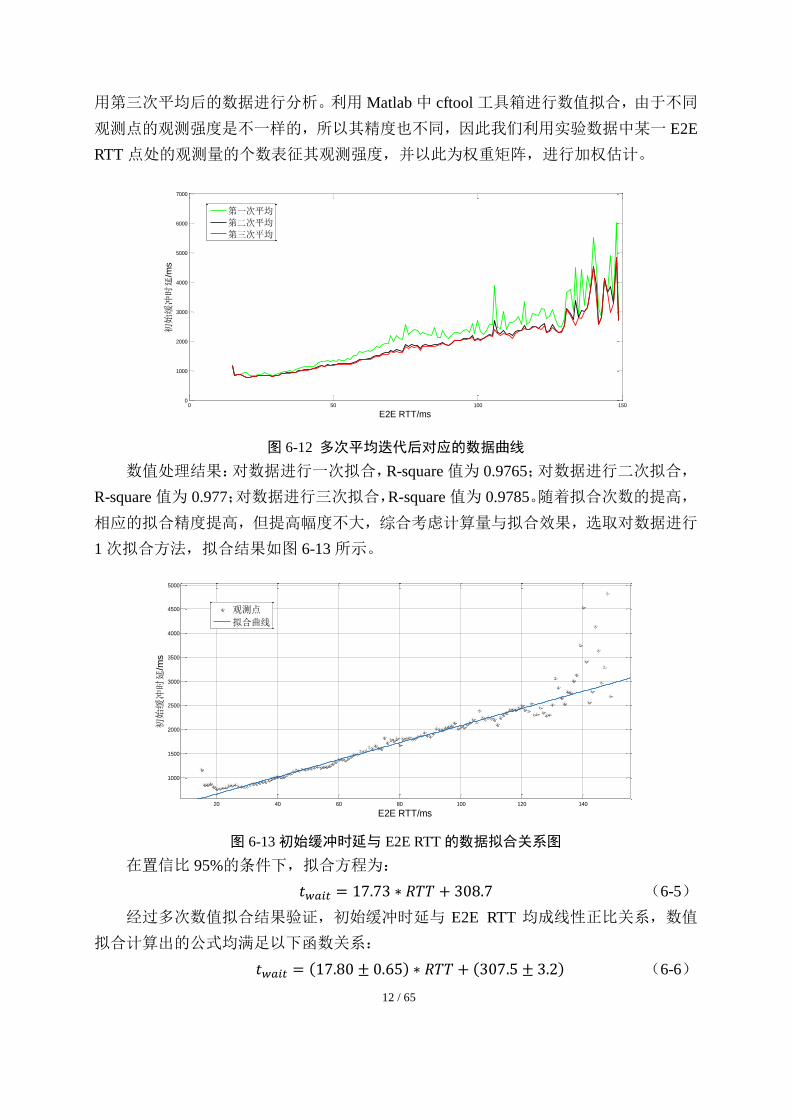
为精确求解二者之间的关系方程,我们利用多次平均值迭代法进一步求解。
由于同一组 E2E RTT 值处有多个缓冲时延的观测值与之对应(如图 6-11 所示),我
们采用对同一 E2E RTT 值处所有的观测量,求平均值的方式进行简化。因为实验数据
中存在“异常值”,所以采用多次取平均值滤波的方法进行处理,每一次均剔除一定数
量的“异常值”,进行多次迭代滤波,将偏离上一次均值的程度超过阈值门限的数据点
进行过滤,最终通过循环迭代实现平均值拟合。
图 6-11 全局数据分布图
多次迭代均值化处理后的模拟结果如图 6-12 所示。可以发现,第三次平均几乎与第
二次平均重合,因此,考虑到计算量的代价,没有重复做第四次平均处理的必要,可使
0 50 100 1500
0.5
1
1.5
2
2.5
3
3.5x 10
4
E2E RTT/ms
初始缓冲时延
/ms
12 / 65
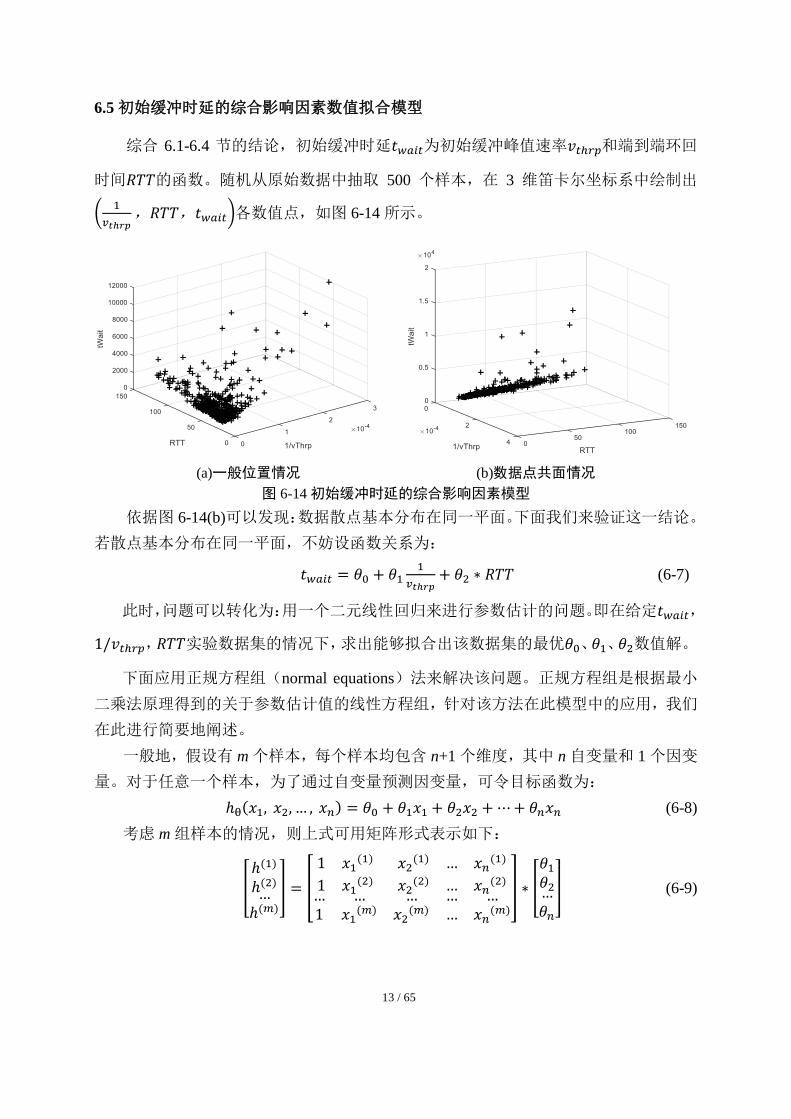
用第三次平均后的数据进行分析。利用 Matlab 中 cftool 工具箱进行数值拟合,由于不同
观测点的观测强度是不一样的,所以其精度也不同,因此我们利用实验数据中某一 E2E
RTT 点处的观测量的个数表征其观测强度,并以此为权重矩阵,进行加权估计。
图 6-12 多次平均迭代后对应的数据曲线
数值处理结果:对数据进行一次拟合,R-square 值为 0.9765;对数据进行二次拟合,
R-square 值为 0.977;对数据进行三次拟合,R-square 值为 0.9785。随着拟合次数的提高,
相应的拟合精度提高,但提高幅度不大,综合考虑计算量与拟合效果,选取对数据进行
1 次拟合方法,拟合结果如图 6-13 所示。
图 6-13 初始缓冲时延与 E2E RTT 的数据拟合关系图
在置信比 95%的条件下,拟合方程为:
𝑡𝑤𝑎𝑖𝑡 = 17.73 ∗ 𝑅𝑇𝑇 + 308.7 (6-5)
经过多次数值拟合结果验证,初始缓冲时延与 E2E RTT 均成线性正比关系,数值
拟合计算出的公式均满足以下函数关系:
𝑡𝑤𝑎𝑖𝑡 = (17.80 ± 0.65) ∗ 𝑅𝑇𝑇 + (307.5 ± 3.2) (6-6)
0 50 100 1500
1000
2000
3000
4000
5000
6000
7000
E2E RTT/ms
初始缓冲时延
/ms
第一次平均
第二次平均
第三次平均
20 40 60 80 100 120 140
1000
1500
2000
2500
3000
3500
4000
4500
5000
E2E RTT/ms
初始缓冲时延
/ms
观测点
拟合曲线
13 / 65
6.5 初始缓冲时延的综合影响因素数值拟合模型
综合 6.1-6.4 节的结论,初始缓冲时延𝑡𝑤𝑎𝑖𝑡为初始缓冲峰值速率𝑣𝑡ℎ𝑟𝑝和端到端环回
时间𝑅𝑇𝑇的函数。随机从原始数据中抽取 500 个样本,在 3 维笛卡尔坐标系中绘制出
(1
𝑣𝑡ℎ𝑟𝑝,𝑅𝑇𝑇,𝑡𝑤𝑎𝑖𝑡)各数值点,如图 6-14 所示。
(a)一般位置情况 (b)数据点共面情况
图 6-14 初始缓冲时延的综合影响因素模型
依据图 6-14(b)可以发现:数据散点基本分布在同一平面。下面我们来验证这一结论。
若散点基本分布在同一平面,不妨设函数关系为:
𝑡𝑤𝑎𝑖𝑡 = 𝜃0 + 𝜃11
𝑣𝑡ℎ𝑟𝑝+ 𝜃2 ∗ 𝑅𝑇𝑇 (6-7)
此时,问题可以转化为:用一个二元线性回归来进行参数估计的问题。即在给定𝑡𝑤𝑎𝑖𝑡,
1/𝑣𝑡ℎ𝑟𝑝,𝑅𝑇𝑇实验数据集的情况下,求出能够拟合出该数据集的最优𝜃0、𝜃1、𝜃2数值解。
下面应用正规方程组(normal equations)法来解决该问题。正规方程组是根据最小
二乘法原理得到的关于参数估计值的线性方程组,针对该方法在此模型中的应用,我们
在此进行简要地阐述。
一般地,假设有 m 个样本,每个样本均包含 n+1 个维度,其中 n 自变量和 1 个因变
量。对于任意一个样本,为了通过自变量预测因变量,可令目标函数为:
ℎθ(𝑥1, 𝑥2, … , 𝑥𝑛) = 𝜃0 + 𝜃1𝑥1 + 𝜃2𝑥2 + ⋯ + 𝜃𝑛𝑥𝑛 (6-8)
考虑 m 组样本的情况,则上式可用矩阵形式表示如下:
[ℎ(1)
ℎ(2)…
ℎ(𝑚)
] = [
1 𝑥1(1)
1 𝑥1(2)
𝑥2(1) …
𝑥2(2) …
𝑥𝑛(1)
𝑥𝑛(2)
… …1 𝑥1
(𝑚)… …
𝑥2(𝑚) …
…𝑥𝑛
(𝑚)
] ∗ [
𝜃1
𝜃2…𝜃𝑛
] (6-9)
14 / 65
我们进一步,假设:𝑋 = [
1 𝑥1(1)
1 𝑥1(2)
𝑥2(1) …
𝑥2(2) …
𝑥𝑛(1)
𝑥𝑛(2)
… …1 𝑥1
(𝑚)… …
𝑥2(𝑚) …
…𝑥𝑛
(𝑚)
],𝜃 = [
𝜃1
𝜃2…𝜃𝑛
]。
于是,公式 6-9 化简为:
ℎ𝜃(𝑥) = 𝑋 ∗ 𝜃 (6-10)
将所有样本数据中的因变量组成的一个向量定义如下:
y = [𝑦(1) 𝑦(2) … 𝑦(𝑚)]𝑇 (6-11)
为了预测因变量,我们希望ℎ𝜃(𝑥) = 𝑦,故有:𝑋 ∗ 𝜃 = 𝑦,经变换最终可得:
𝜃 = (𝑋𝑇𝑋)−1𝑋𝑇𝑦 (6-12)
针对(1
𝑣𝑡ℎ𝑟𝑝,𝑅𝑇𝑇,𝑡𝑤𝑎𝑖𝑡)数值拟合问题,将1/𝑣𝑡ℎ𝑟𝑝、𝑅𝑇𝑇视为自变量,将𝑡𝑤𝑎𝑖𝑡视为
目标函数变量。把附件中的实验数据带入上式 6-12 中,使用 MATLAB 软件进行数值计
算,即可求出相应的𝜃值。实际求得的结果如下:
𝜃 = [−2.248719 ∗ 102
2.246998 ∗ 107
1.529269 ∗ 101
] (6-13)
最终,由正规方程法求解,得到的初始缓冲时延的综合影响因素模型为:
𝑡𝑤𝑎𝑖𝑡 = −224.87 +2.25∗107
𝑣𝑡ℎ𝑟𝑝+ 15.29 ∗ 𝑅𝑇𝑇 (6-14)
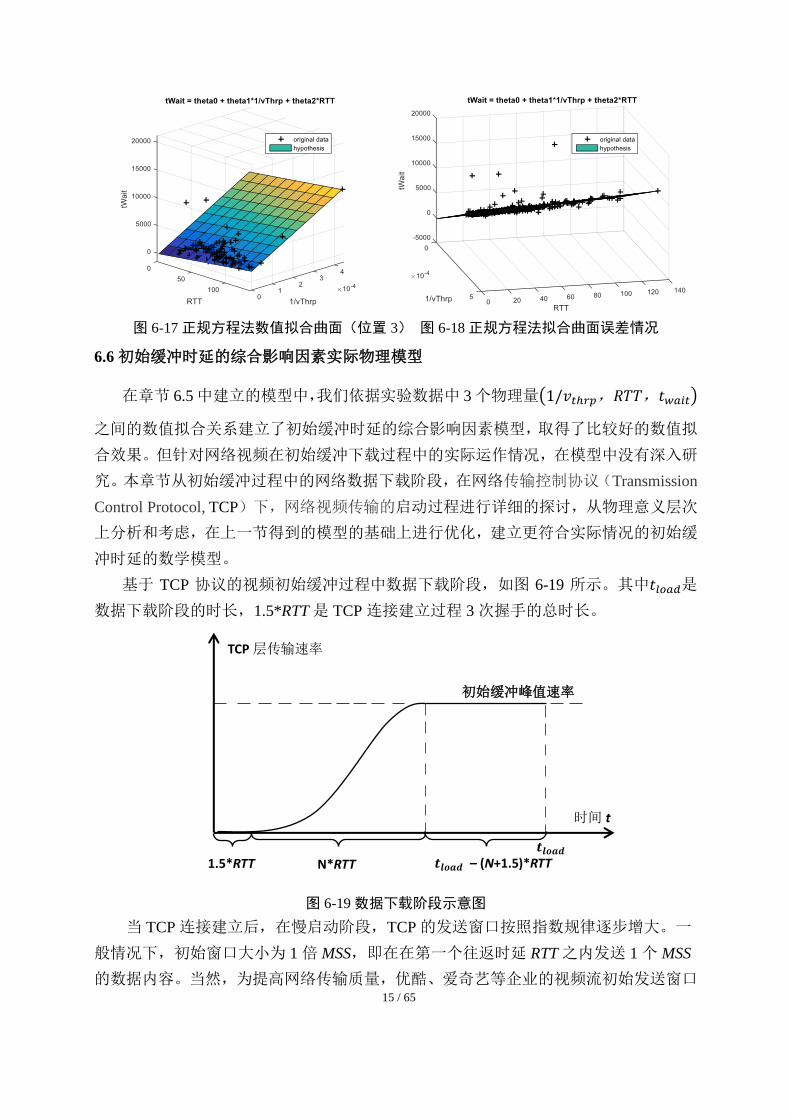
利用综合影响因素模型进行数值拟合,我们将正规方程法数值拟合的曲面绘制在 3
维空间内,选取不同位置和角度,数据点分布和拟合曲面的情况如图 6-15、图 6-16 和
图 6-17 所示。其拟合误差情况的表征 3 维图,如图 6-18 所示,经计算发现:97%以上
的数据点均很好地符合拟合的曲面。所以该模型可以非常好地反应出初始缓冲时延𝑡𝑤𝑎𝑖𝑡
与初始缓冲峰值速率𝑣𝑡ℎ𝑟𝑝以及端到端环回时间 RTT 之间的关系。
图 6-15 正规方程法数值拟合曲面(位置 1) 图 6-16 正规方程法数值拟合曲面(位置 2)
15 / 65
图 6-17 正规方程法数值拟合曲面(位置 3) 图 6-18 正规方程法拟合曲面误差情况
6.6 初始缓冲时延的综合影响因素实际物理模型
在章节 6.5 中建立的模型中,我们依据实验数据中 3 个物理量(1/𝑣𝑡ℎ𝑟𝑝,𝑅𝑇𝑇,𝑡𝑤𝑎𝑖𝑡)
之间的数值拟合关系建立了初始缓冲时延的综合影响因素模型,取得了比较好的数值拟
合效果。但针对网络视频在初始缓冲下载过程中的实际运作情况,在模型中没有深入研
究。本章节从初始缓冲过程中的网络数据下载阶段,在网络传输控制协议(Transmission
Control Protocol, TCP)下,网络视频传输的启动过程进行详细的探讨,从物理意义层次
上分析和考虑,在上一节得到的模型的基础上进行优化,建立更符合实际情况的初始缓
冲时延的数学模型。
基于 TCP 协议的视频初始缓冲过程中数据下载阶段,如图 6-19 所示。其中𝑡𝑙𝑜𝑎𝑑是
数据下载阶段的时长,1.5*RTT 是 TCP 连接建立过程 3 次握手的总时长。
图 6-19 数据下载阶段示意图
当 TCP 连接建立后,在慢启动阶段,TCP 的发送窗口按照指数规律逐步增大。一
般情况下,初始窗口大小为 1 倍 MSS,即在在第一个往返时延 RTT 之内发送 1 个 MSS
的数据内容。当然,为提高网络传输质量,优酷、爱奇艺等企业的视频流初始发送窗口
TCP 层传输速率
初始缓冲峰值速率
时间 t
1.5*RTT N*RTT 𝒕𝒍𝒐𝒂𝒅 – (N+1.5)*RTT 𝒕𝒍𝒐𝒂𝒅

16 / 65
大小实际为 10 倍 MSS,因此在上述客户端中浏览网络视频时,在第 N 组 RTT 接收的数
据量应当为10 ∗ 2𝑁−1 ∗ 𝑀𝑆𝑆,是原始模型中的 10 倍,所以需要视具体情况讨论。
在计算机网络中,往返时延 RTT 是一个非常重要的性能指标,表示从发送端发送数
据开始,到发送端接收到来自接收端的确认,所经历的总时间延迟的长度。当数据初始
发送窗口为 1 倍 MSS 时,在第一个往返时延 RTT 之内发送 1 个 MSS 的数据内容;在第
N 次 RTT 过程中,发送2𝑁−1 ∗ MSS大小的数据内容。其中,MSS 表示最大报文段长度,
一般为 1460 字节。此后进入稳态阶段,数据传输速率达到峰值,即初始缓冲峰值速率
𝑣𝑡ℎ𝑟𝑝。因此在数据下载阶段,TCP 层的瞬时传输速率可表示为:
𝑉𝑇𝐶𝑃 = {𝑇𝐶𝑃 𝑊𝑖𝑛𝑑𝑜𝑤 𝑆𝑖𝑧𝑒
𝑅𝑇𝑇=
2𝑁−1∗𝑀𝑆𝑆
𝑅𝑇𝑇, 𝑡 < (1.5 + 𝑁) ∙ 𝑅𝑇𝑇
𝑣𝑡ℎ𝑟𝑝 , 𝑜𝑡ℎ𝑒𝑟𝑠 (6-15)
其中,TCP 层传输速率为VTCP,TCP Window Size 表示 TCP 发送数据的窗口大小值,
由于 TCP 通过滑动窗口的概念来进行流量控制,滑动窗口本质上是描述接受方的 TCP
数据报缓冲区大小的数据,发送方根据这个数据来计算自己最多能发送多长的数据。初
始缓冲峰值速率为𝑣𝑡ℎ𝑟𝑝。
针对慢启动过程的端到端环回次数 N,在传统模型中,常常将 N 视为常数,往往取
决于历史经验数据。事实上,TCP 慢启动阶段的用时是一个变化的量,且应当为初始缓
冲峰值速率𝑣𝑡ℎ𝑟𝑝与端到端环回时间 RTT 的函数,为准确求解 N 值,我们将对 TCP 数据
传输过程进行深入地分析。
对于视频初始缓冲中的慢启动阶段,令视频流初始发送窗口大小为 10 倍 MSS,设
在数据传输进行到第 N 个 RTT 时指数增长阶段结束,则此时 TCP 层的瞬时传输速率为
𝑉𝑇𝐶𝑃 =𝑇𝐶𝑃 𝑊𝑖𝑛𝑑𝑜𝑤 𝑆𝑖𝑧𝑒
𝑅𝑇𝑇=
10∗2𝑁−1∗𝑀𝑆𝑆
𝑅𝑇𝑇 (6-16)
又因为当𝑉𝑇𝐶𝑃达到峰值𝑣𝑡ℎ𝑟𝑝时进入稳态阶段,因此有:
10∗2𝑁−1∗𝑀𝑆𝑆
𝑅𝑇𝑇≤ 𝑣𝑡ℎ𝑟𝑝 <
10∗2𝑁∗𝑀𝑆𝑆
𝑅𝑇𝑇 (6-17)
解得端到端环回次数 N 范围为:
log2𝑅𝑇𝑇∗𝑣𝑡ℎ𝑟𝑝
10∗𝑀𝑆𝑆< N ≤ log2
𝑅𝑇𝑇∗𝑣𝑡ℎ𝑟𝑝
10∗𝑀𝑆𝑆+ 1 (6-18)
数据下载阶段需要下载的数据量,即初始缓冲数据量 Data(单位:byte)是给定的,
Data 值通常取决于终端用户的请求指令,该模型中利用给出的条件中明确指出为:初始
缓冲阶段需要下载的数据量 Data 大小为初始缓冲量和视频码率的乘积。其中,规定初
始缓冲量为 4 秒。而且,初始缓冲数据量 Data 等于图 6-19 中 TCP 层传输速率曲线所包
围的面积,该面积分为两部分:

17 / 65
①第一部分是慢启动阶段的数据下载量,在每个 RTT 时间的下载量是2𝑁−1 ∗ 𝑀𝑆𝑆(暂
设初始窗口为 1 倍 MSS),总计为 N 次。
②第二部分是 TCP 下载速率达到𝑣𝑡ℎ𝑟𝑝后的数据下载量。因此在不考虑丢包和重传的
情况下,初始缓冲数据量的计算公式为:
𝐷𝑎𝑡𝑎 = ∑ 2𝑖−1𝑁𝑖=1 ∗ 𝑀𝑆𝑆 + (𝑡𝑙𝑜𝑎𝑑 − (1.5 + 𝑁) ∗ 𝑅𝑇𝑇) ∗ 𝑣𝑡ℎ𝑟𝑝 (6-19)
根据等比数列求和公式可得:∑ 2𝑖−1𝑁𝑖=1 = 2𝑁 − 1,公式可化简为:
𝐷𝑎𝑡𝑎 = (2𝑁 − 1) ∗ 𝑀𝑆𝑆 + (𝑡𝑙𝑜𝑎𝑑 − (1.5 + 𝑁) ∗ 𝑅𝑇𝑇) ∗ 𝑣𝑡ℎ𝑟𝑝 (6-20)
利用方程 6-20 进一步变形,求解𝑡𝑙𝑜𝑎𝑑得:
𝑡𝑙𝑜𝑎𝑑 = 𝐷𝑎𝑡𝑎−(2𝑁−1)∗𝑀𝑆𝑆
𝑣𝑡ℎ𝑟𝑝+ (1.5 + 𝑁) ∗ 𝑅𝑇𝑇 (6-21)
考虑到各项数据的单位有 kbps(千比特每秒)、byte(字节)、ms(毫秒)等,单位
不统一,则可根据换算公式 1byte = 8bit 进行换算。统一单位后的𝑡𝑙𝑜𝑎𝑑(ms)表达式为:
𝑡𝑙𝑜𝑎𝑑 = 8 ∗ 𝐷𝑎𝑡𝑎−(2𝑁−1)∗𝑀𝑆𝑆
𝑣𝑡ℎ𝑟𝑝+ (1.5 + 𝑁) ∗ 𝑅𝑇𝑇 (6-22)
针对信令交互阶段,可设
𝑡𝑠𝑔𝑛𝑙 = 𝑘 ∗ 𝑅𝑇𝑇 (6-23)
针对终端和服务器响应时间,有
𝑡𝑟𝑒𝑠𝑝 = 𝑡𝑡𝑒𝑟𝑚𝑖𝑛𝑎𝑙 + 𝑡𝑠𝑒𝑟𝑣𝑒𝑟 (6-24)
其中,𝑡𝑡𝑒𝑟𝑚𝑖𝑛𝑎𝑙 表示终端响应时间(Terminal response time),𝑡𝑠𝑒𝑟𝑣𝑒𝑟表示服务器响应
时间(Server response time)。综合以上分析,可以得出改进后的初始缓冲时延模型如下:
𝑡𝑤𝑎𝑖𝑡 = 8 ∗ 𝐷𝑎𝑡𝑎−(2𝑁−1)∗𝑀𝑆𝑆
𝑣𝑡ℎ𝑟𝑝+ (1.5 + 𝑘 + 𝑁) ∗ 𝑅𝑇𝑇 + 𝑡𝑟𝑒𝑠𝑝 (6-25)
考虑 10 倍 MSS 值时,初始缓冲时延的综合影响因素模型为:
𝑡𝑤𝑎𝑖𝑡 = 8 ∗ 𝐷𝑎𝑡𝑎−(2𝑁−1)∗10∗𝑀𝑆𝑆
𝑣𝑡ℎ𝑟𝑝+ (1.5 + 𝑘 + 𝑁) ∗ 𝑅𝑇𝑇 + 𝑡𝑟𝑒𝑠𝑝 (6-26)
其中 N = floor(log2𝑅𝑇𝑇∗𝑣𝑡ℎ𝑟𝑝
10∗𝑀𝑆𝑆+ 1),其中,“floor”即向下取整。根据华为公司发布
的《MBB 时代基于用户体验建网的目标研究——业务等待时间》一文中提供的数据有:
1、“请求视频内容所需要的信令交互时间约为 6 个 RTT 的时长,其他视频客户端也
基本一致”
2、“对于视频业务,N 一般在 6 到 8 之间”
3、“终端响应时间约为 200ms 服务器响应时间平均约为 80s
因此,可初步将上式中参数赋值如下:𝑘 = 6,𝑁 = 6,7,8,𝑡𝑟𝑒𝑠𝑝 ∈ [70, 280]
取 N = 6,𝑡𝑟𝑒𝑠𝑝 = 200,绘制该模型预测情况如下图 6-20 和图 6-21 所示:
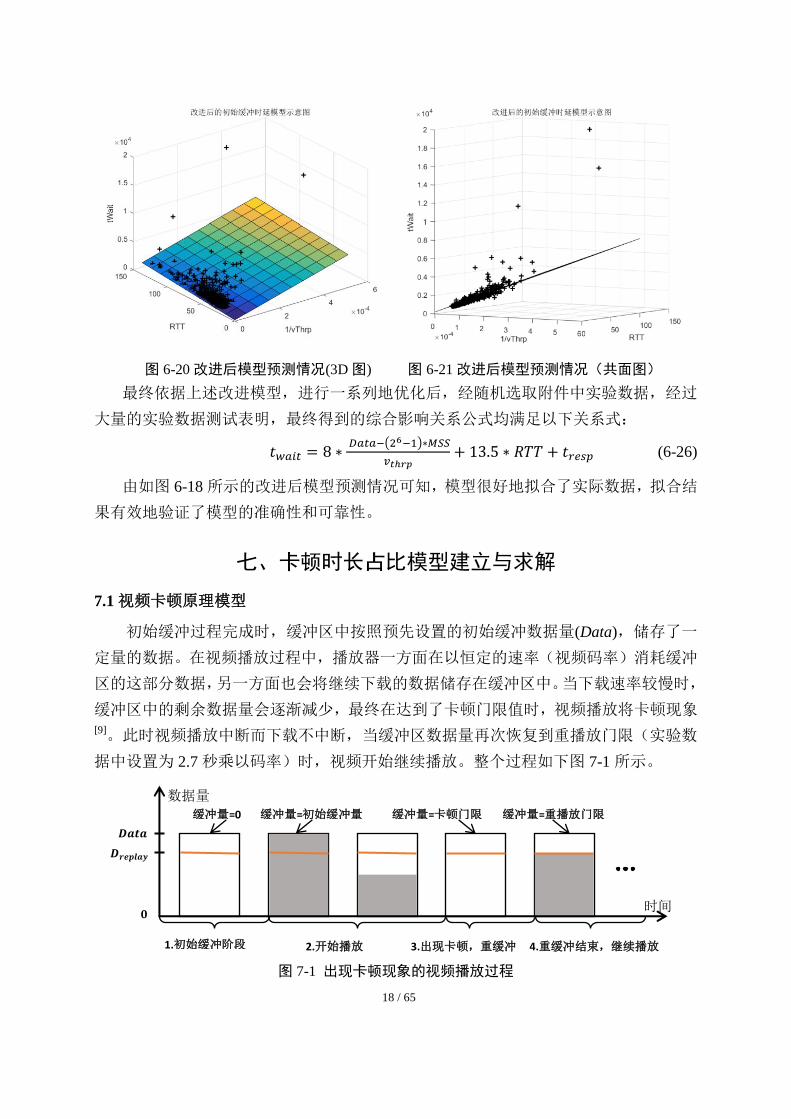
18 / 65
图 6-20 改进后模型预测情况(3D 图) 图 6-21 改进后模型预测情况(共面图)
最终依据上述改进模型,进行一系列地优化后,经随机选取附件中实验数据,经过
大量的实验数据测试表明,最终得到的综合影响关系公式均满足以下关系式:
𝑡𝑤𝑎𝑖𝑡 = 8 ∗ 𝐷𝑎𝑡𝑎−(26−1)∗𝑀𝑆𝑆
𝑣𝑡ℎ𝑟𝑝+ 13.5 ∗ 𝑅𝑇𝑇 + 𝑡𝑟𝑒𝑠𝑝 (6-26)
由如图 6-18 所示的改进后模型预测情况可知,模型很好地拟合了实际数据,拟合结
果有效地验证了模型的准确性和可靠性。
七、卡顿时长占比模型建立与求解
7.1 视频卡顿原理模型
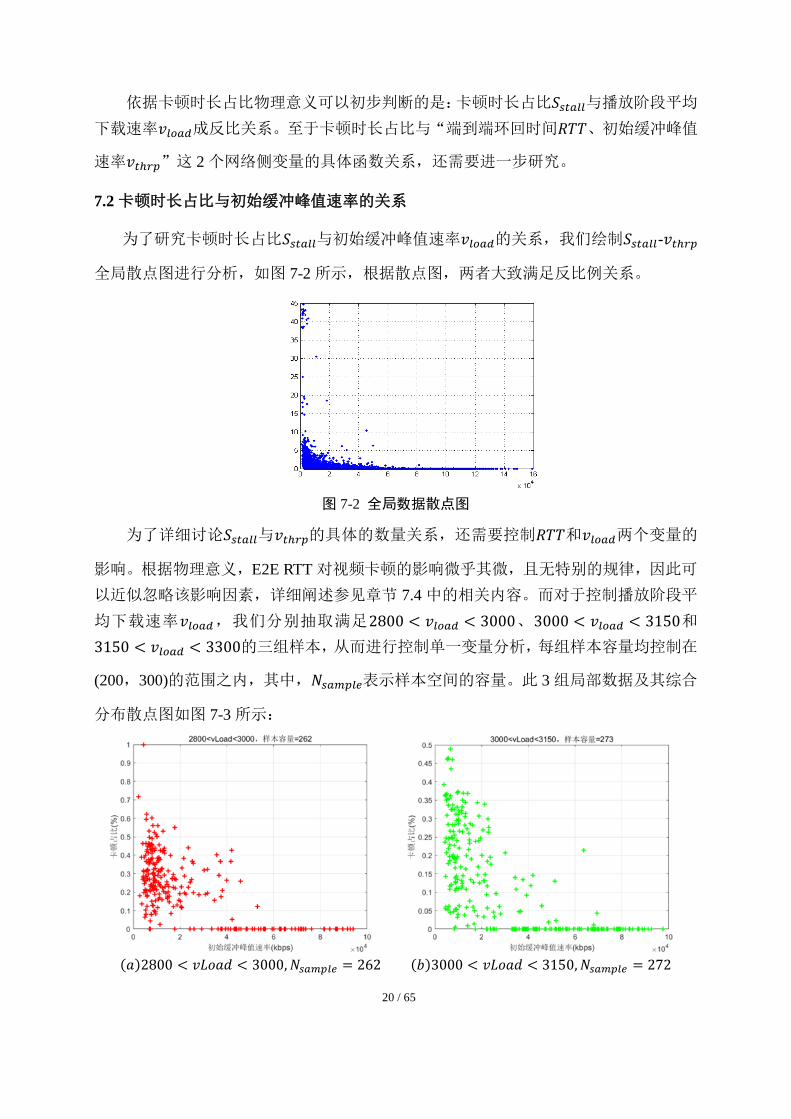
初始缓冲过程完成时,缓冲区中按照预先设置的初始缓冲数据量(Data),储存了一
定量的数据。在视频播放过程中,播放器一方面在以恒定的速率(视频码率)消耗缓冲
区的这部分数据,另一方面也会将继续下载的数据储存在缓冲区中。当下载速率较慢时,
缓冲区中的剩余数据量会逐渐减少,最终在达到了卡顿门限值时,视频播放将卡顿现象[9]。此时视频播放中断而下载不中断,当缓冲区数据量再次恢复到重播放门限(实验数
据中设置为 2.7 秒乘以码率)时,视频开始继续播放。整个过程如下图 7-1 所示。
图 7-1 出现卡顿现象的视频播放过程
数据量
𝑫𝒂𝒕𝒂
𝑫𝒓𝒆𝒑𝒍𝒂𝒚
𝟎
缓冲量=0 缓冲量=初始缓冲量 缓冲量=卡顿门限 缓冲量=重播放门限
时间
1.初始缓冲阶段 2.开始播放 3.出现卡顿,重缓冲 4.重缓冲结束,继续播放

19 / 65
根据上述情况,我们发现视频的播放过程和污水均流池的原理非常类似。如果给出
视频播放过程中的实时下载速率,则可以根据实时下载速率、实时播放速率(即视频码
率)和缓冲区剩余数据量三者的关系建立方程,并且结合卡顿门限、重播放门限等题目
预设的参数确定具体播放过程,从而得到一个类似于均流池模型的精确的卡顿时长模型。
设实时下载速率为𝑣(𝑡),视频码率为𝑣𝑝𝑙𝑎𝑦,播放时间为 t。根据文章开头的符号约
定, 𝑡𝑝𝑙𝑎𝑦为播放总时长,𝑡𝑠𝑡𝑎𝑙𝑙为卡顿时长,Data 为初始缓冲数据量,𝐷𝑟𝑒𝑝𝑙𝑎𝑦为重播放
门限。为进一步分析𝑡𝑠𝑡𝑎𝑙𝑙与𝑣(𝑡)之间的关系,我们将模型作如下讨论:
构造函数φ(t) = ∫ (𝑣𝑝𝑙𝑎𝑦 − 𝑣(𝑥))𝑑𝑥𝑡
0,其反函数为𝜑−1(𝑥);
构造函数ω(t) = ∫ 𝑣(𝑥)𝑑𝑥𝑡
0,其反函数为ω−1(t);
1° 当φ(𝑡𝑝𝑙𝑎𝑦) ≤ Data时:
卡顿次数𝑁𝑠𝑡𝑎𝑙𝑙 = 0,𝑡𝑠𝑡𝑎𝑙𝑙 = 0;
2° 当φ(𝑡𝑝𝑙𝑎𝑦) > Data,且φ(𝑡𝑝𝑙𝑎𝑦) − φ(𝑡1 + ∆𝑡1) ≤ 𝐷𝑟𝑒𝑝𝑙𝑎𝑦时:
卡顿次数𝑁𝑠𝑡𝑎𝑙𝑙 = 1,𝑡𝑠𝑡𝑎𝑙𝑙 = ∆𝑡1,
其中𝑡1 = 𝜑−1(𝐷𝑎𝑡𝑎),∆𝑡1 = ω−1 (𝐷𝑟𝑒𝑝𝑙𝑎𝑦 + ω(𝑡1)) − 𝑡1;
3° 当φ(𝑡𝑝𝑙𝑎𝑦) − φ(𝑡1 + ∆𝑡1) > 𝐷𝑟𝑒𝑝𝑙𝑎𝑦,且φ(𝑡𝑝𝑙𝑎𝑦) − φ(𝑡2 + ∆𝑡2) ≤ 𝐷𝑟𝑒𝑝𝑙𝑎𝑦时:
卡顿次数𝑁𝑠𝑡𝑎𝑙𝑙 = 2,𝑡𝑠𝑡𝑎𝑙𝑙 = ∆𝑡1 + ∆𝑡2,
其中𝑡2 = 𝜑−1(𝐷𝑟𝑒𝑝𝑙𝑎𝑦 + φ(𝑡1 + ∆𝑡1)),∆𝑡2 = ω−1 (𝐷𝑟𝑒𝑝𝑙𝑎𝑦 + ω(𝑡2)) − 𝑡2;
… …
(k+1)º 当 φ(𝑡𝑝𝑙𝑎𝑦) − φ(𝑡𝑘−1 + ∆𝑡𝑘−1) > 𝐷𝑟𝑒𝑝𝑙𝑎𝑦 , 并 且 φ(𝑡𝑝𝑙𝑎𝑦) − φ(𝑡𝑘 + ∆𝑡𝑘) ≤
𝐷𝑟𝑒𝑝𝑙𝑎𝑦时:
卡顿次数𝑁𝑠𝑡𝑎𝑙𝑙 = 𝑘,𝑡𝑠𝑡𝑎𝑙𝑙 = ∑ ∆𝑡𝑖𝑘𝑖=1 , (k ≥ 2),
其中𝑡𝑘 = 𝜑−1(𝐷𝑟𝑒𝑝𝑙𝑎𝑦 + φ(𝑡𝑘−1 + ∆𝑡𝑘−1)),∆𝑡𝑘 = ω−1 (𝐷𝑟𝑒𝑝𝑙𝑎𝑦 + ω(𝑡𝑘)) − 𝑡𝑘.
以上即为𝑡𝑠𝑡𝑎𝑙𝑙与𝑣(𝑡)之间的关系模型,具体计算过程参见《附录 1》。但由于视频下
载实际情况的复杂性,实时下载速率𝑣(𝑡)并非一成不变,且受到很多干扰因素的影响,
因此,不可以直接将实时下载速率𝑣(𝑡)等同于播放阶段平均下载速率𝑣𝑙𝑜𝑎𝑑。所以,纯粹
通过物理意义建模的方案可行性不强,我们决定根据比例关系,利用数值拟合的方法建
立卡顿时长占比的数学模型。
20 / 65
依据卡顿时长占比物理意义可以初步判断的是:卡顿时长占比𝑆𝑠𝑡𝑎𝑙𝑙与播放阶段平均
下载速率𝑣𝑙𝑜𝑎𝑑成反比关系。至于卡顿时长占比与“端到端环回时间𝑅𝑇𝑇、初始缓冲峰值
速率𝑣𝑡ℎ𝑟𝑝”这 2 个网络侧变量的具体函数关系,还需要进一步研究。
7.2 卡顿时长占比与初始缓冲峰值速率的关系
为了研究卡顿时长占比𝑆𝑠𝑡𝑎𝑙𝑙与初始缓冲峰值速率𝑣𝑙𝑜𝑎𝑑的关系,我们绘制𝑆𝑠𝑡𝑎𝑙𝑙-𝑣𝑡ℎ𝑟𝑝
全局散点图进行分析,如图 7-2 所示,根据散点图,两者大致满足反比例关系。
图 7-2 全局数据散点图
为了详细讨论𝑆𝑠𝑡𝑎𝑙𝑙与𝑣𝑡ℎ𝑟𝑝的具体的数量关系,还需要控制𝑅𝑇𝑇和𝑣𝑙𝑜𝑎𝑑两个变量的
影响。根据物理意义,E2E RTT 对视频卡顿的影响微乎其微,且无特别的规律,因此可
以近似忽略该影响因素,详细阐述参见章节 7.4 中的相关内容。而对于控制播放阶段平
均下载速率𝑣𝑙𝑜𝑎𝑑,我们分别抽取满足2800 < 𝑣𝑙𝑜𝑎𝑑 < 3000、3000 < 𝑣𝑙𝑜𝑎𝑑 < 3150和
3150 < 𝑣𝑙𝑜𝑎𝑑 < 3300的三组样本,从而进行控制单一变量分析,每组样本容量均控制在
(200,300)的范围之内,其中,𝑁𝑠𝑎𝑚𝑝𝑙𝑒表示样本空间的容量。此 3 组局部数据及其综合
分布散点图如图 7-3 所示:
(𝑎)2800 < 𝑣𝐿𝑜𝑎𝑑 < 3000, 𝑁𝑠𝑎𝑚𝑝𝑙𝑒 = 262 (𝑏)3000 < 𝑣𝐿𝑜𝑎𝑑 < 3150, 𝑁𝑠𝑎𝑚𝑝𝑙𝑒 = 272
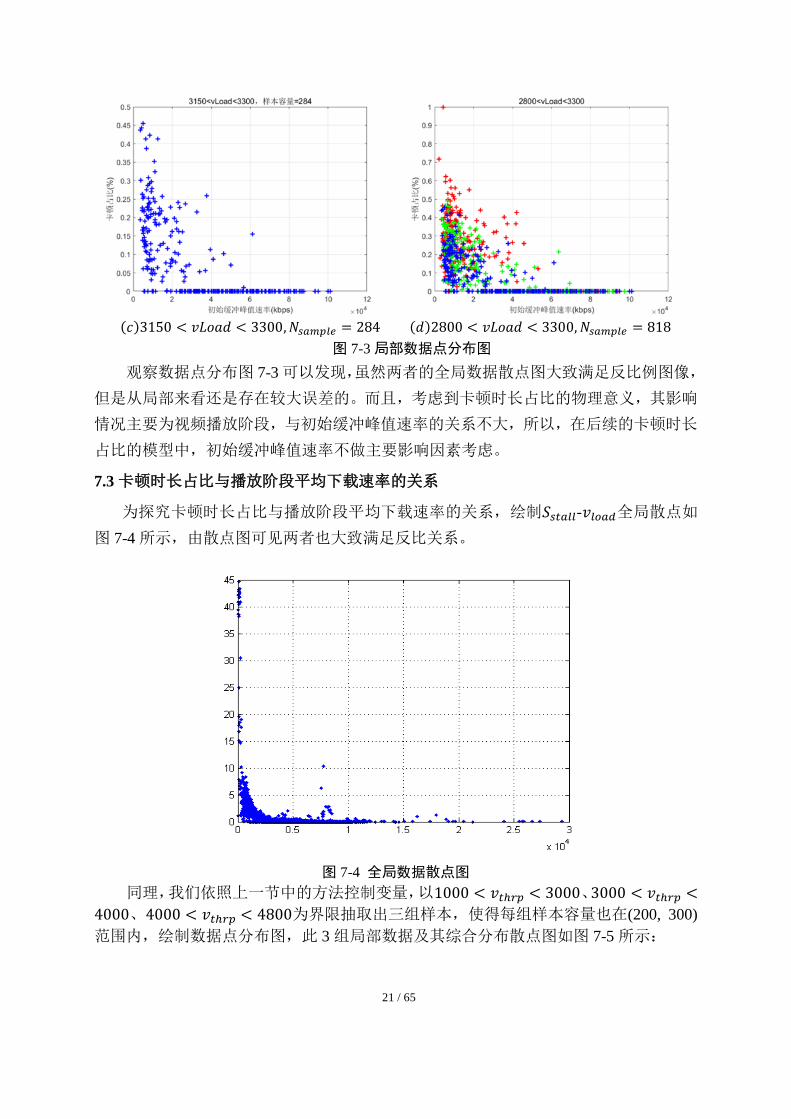
21 / 65
(𝑐)3150 < 𝑣𝐿𝑜𝑎𝑑 < 3300, 𝑁𝑠𝑎𝑚𝑝𝑙𝑒 = 284 (𝑑)2800 < 𝑣𝐿𝑜𝑎𝑑 < 3300, 𝑁𝑠𝑎𝑚𝑝𝑙𝑒 = 818
图 7-3 局部数据点分布图
观察数据点分布图 7-3 可以发现,虽然两者的全局数据散点图大致满足反比例图像,
但是从局部来看还是存在较大误差的。而且,考虑到卡顿时长占比的物理意义,其影响
情况主要为视频播放阶段,与初始缓冲峰值速率的关系不大,所以,在后续的卡顿时长
占比的模型中,初始缓冲峰值速率不做主要影响因素考虑。
7.3 卡顿时长占比与播放阶段平均下载速率的关系
为探究卡顿时长占比与播放阶段平均下载速率的关系,绘制𝑆𝑠𝑡𝑎𝑙𝑙-𝑣𝑙𝑜𝑎𝑑全局散点如
图 7-4 所示,由散点图可见两者也大致满足反比关系。
图 7-4 全局数据散点图
同理,我们依照上一节中的方法控制变量,以1000 < 𝑣𝑡ℎ𝑟𝑝 < 3000、3000 < 𝑣𝑡ℎ𝑟𝑝 <
4000、4000 < 𝑣𝑡ℎ𝑟𝑝 < 4800为界限抽取出三组样本,使得每组样本容量也在(200, 300)
范围内,绘制数据点分布图,此 3 组局部数据及其综合分布散点图如图 7-5 所示:
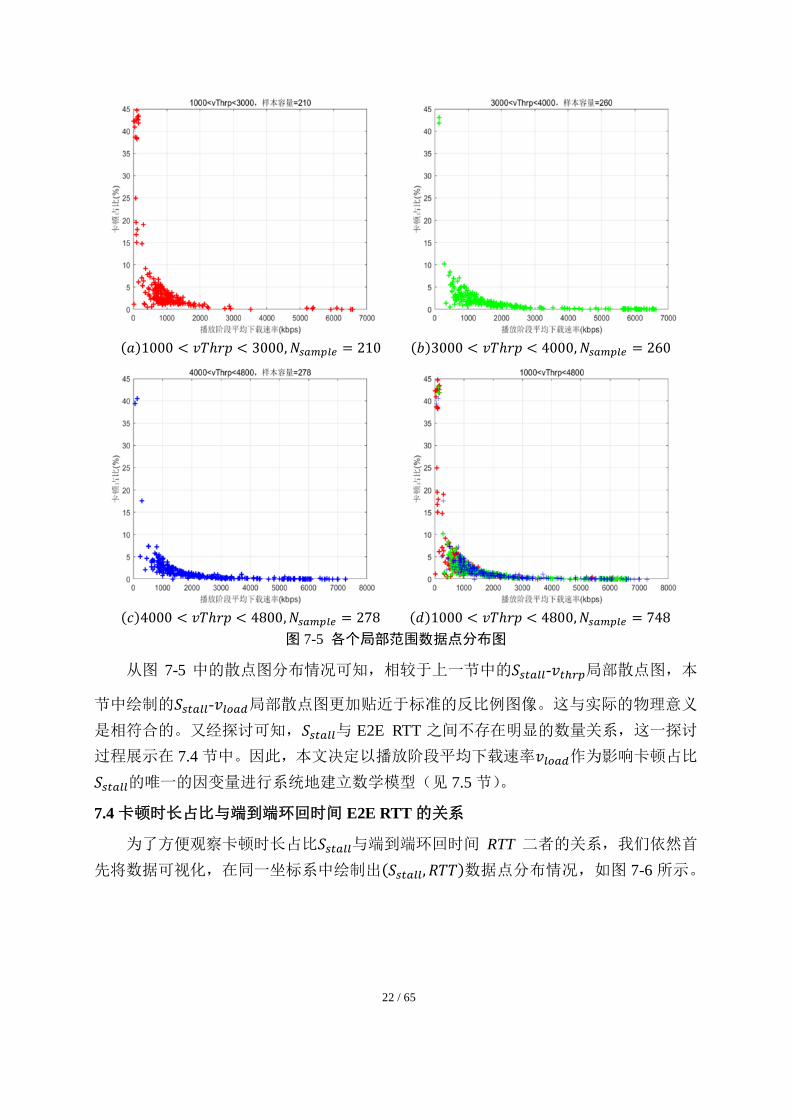
22 / 65
(𝑎)1000 < 𝑣𝑇ℎ𝑟𝑝 < 3000, 𝑁𝑠𝑎𝑚𝑝𝑙𝑒 = 210 (𝑏)3000 < 𝑣𝑇ℎ𝑟𝑝 < 4000, 𝑁𝑠𝑎𝑚𝑝𝑙𝑒 = 260
(𝑐)4000 < 𝑣𝑇ℎ𝑟𝑝 < 4800, 𝑁𝑠𝑎𝑚𝑝𝑙𝑒 = 278 (𝑑)1000 < 𝑣𝑇ℎ𝑟𝑝 < 4800, 𝑁𝑠𝑎𝑚𝑝𝑙𝑒 = 748
图 7-5 各个局部范围数据点分布图
从图 7-5 中的散点图分布情况可知,相较于上一节中的𝑆𝑠𝑡𝑎𝑙𝑙-𝑣𝑡ℎ𝑟𝑝局部散点图,本
节中绘制的𝑆𝑠𝑡𝑎𝑙𝑙-𝑣𝑙𝑜𝑎𝑑局部散点图更加贴近于标准的反比例图像。这与实际的物理意义
是相符合的。又经探讨可知,𝑆𝑠𝑡𝑎𝑙𝑙与 E2E RTT 之间不存在明显的数量关系,这一探讨
过程展示在 7.4 节中。因此,本文决定以播放阶段平均下载速率𝑣𝑙𝑜𝑎𝑑作为影响卡顿占比
𝑆𝑠𝑡𝑎𝑙𝑙的唯一的因变量进行系统地建立数学模型(见 7.5 节)。
7.4 卡顿时长占比与端到端环回时间 E2E RTT 的关系
为了方便观察卡顿时长占比𝑆𝑠𝑡𝑎𝑙𝑙与端到端环回时间 RTT 二者的关系,我们依然首
先将数据可视化,在同一坐标系中绘制出(𝑆𝑠𝑡𝑎𝑙𝑙, 𝑅𝑇𝑇)数据点分布情况,如图 7-6 所示。
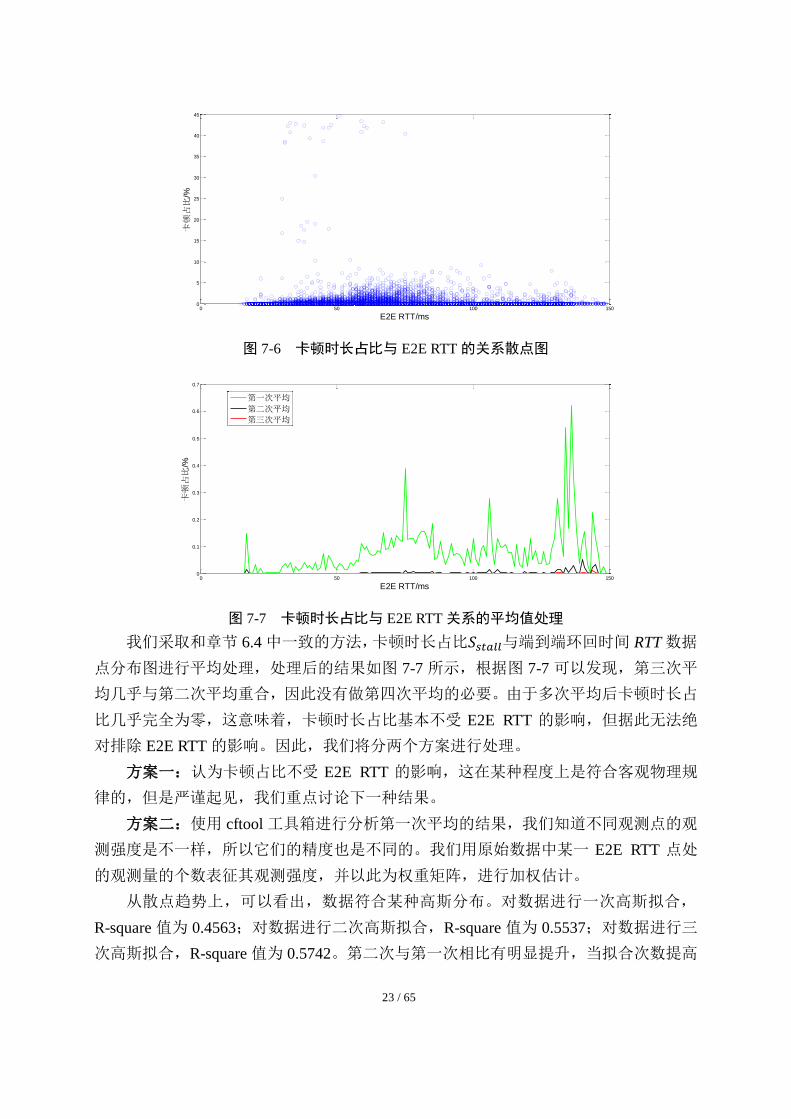
23 / 65
图 7-6 卡顿时长占比与 E2E RTT 的关系散点图
图 7-7 卡顿时长占比与 E2E RTT 关系的平均值处理
我们采取和章节 6.4 中一致的方法,卡顿时长占比𝑆𝑠𝑡𝑎𝑙𝑙与端到端环回时间 RTT 数据
点分布图进行平均处理,处理后的结果如图 7-7 所示,根据图 7-7 可以发现,第三次平
均几乎与第二次平均重合,因此没有做第四次平均的必要。由于多次平均后卡顿时长占
比几乎完全为零,这意味着,卡顿时长占比基本不受 E2E RTT 的影响,但据此无法绝
对排除 E2E RTT 的影响。因此,我们将分两个方案进行处理。
方案一:认为卡顿占比不受 E2E RTT 的影响,这在某种程度上是符合客观物理规
律的,但是严谨起见,我们重点讨论下一种结果。
方案二:使用 cftool 工具箱进行分析第一次平均的结果,我们知道不同观测点的观
测强度是不一样,所以它们的精度也是不同的。我们用原始数据中某一 E2E RTT 点处
的观测量的个数表征其观测强度,并以此为权重矩阵,进行加权估计。
从散点趋势上,可以看出,数据符合某种高斯分布。对数据进行一次高斯拟合,
R-square 值为 0.4563;对数据进行二次高斯拟合,R-square 值为 0.5537;对数据进行三
次高斯拟合,R-square 值为 0.5742。第二次与第一次相比有明显提升,当拟合次数提高
0 50 100 1500
5
10
15
20
25
30
35
40
45
E2E RTT/ms
卡顿占比
/%
0 50 100 1500
0.1
0.2
0.3
0.4
0.5
0.6
0.7
E2E RTT/ms
卡顿占比
/%
第一次平均
第二次平均
第三次平均
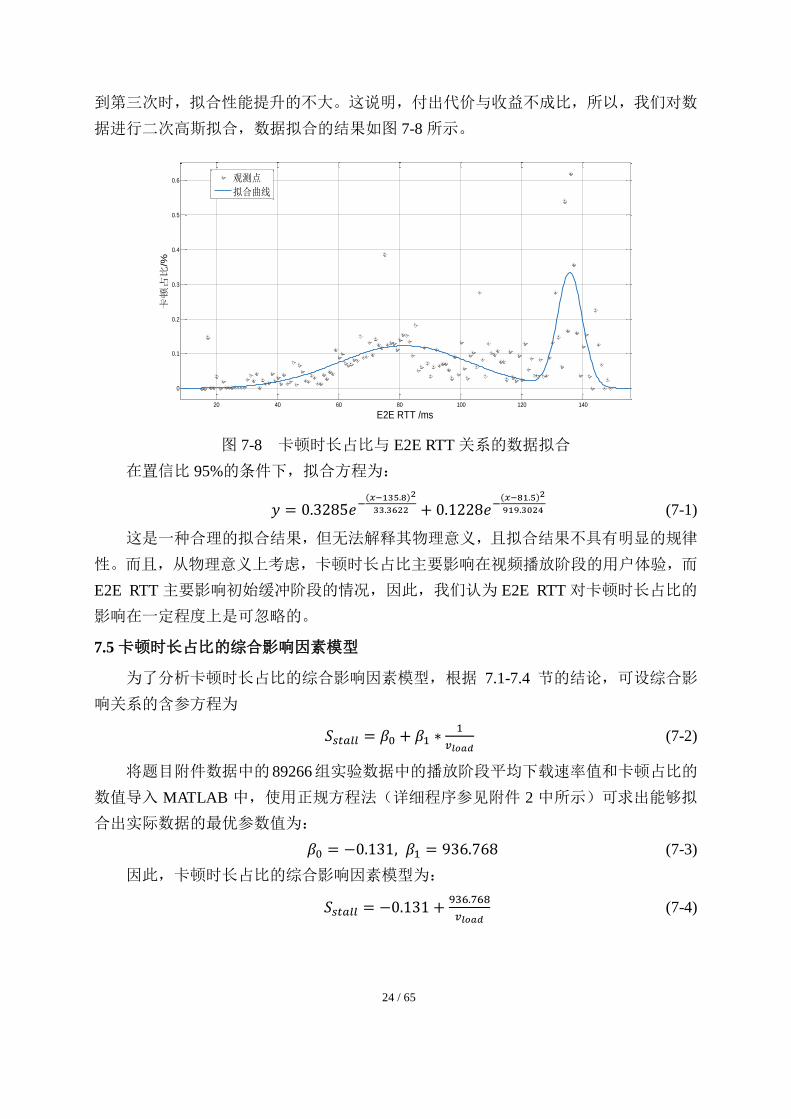
24 / 65
到第三次时,拟合性能提升的不大。这说明,付出代价与收益不成比,所以,我们对数
据进行二次高斯拟合,数据拟合的结果如图 7-8 所示。
图 7-8 卡顿时长占比与 E2E RTT 关系的数据拟合
在置信比 95%的条件下,拟合方程为:
𝑦 = 0.3285𝑒−(𝑥−135.8)2
33.3622 + 0.1228𝑒−(𝑥−81.5)2
919.3024 (7-1)
这是一种合理的拟合结果,但无法解释其物理意义,且拟合结果不具有明显的规律
性。而且,从物理意义上考虑,卡顿时长占比主要影响在视频播放阶段的用户体验,而
E2E RTT 主要影响初始缓冲阶段的情况,因此,我们认为 E2E RTT 对卡顿时长占比的
影响在一定程度上是可忽略的。
7.5 卡顿时长占比的综合影响因素模型
为了分析卡顿时长占比的综合影响因素模型,根据 7.1-7.4 节的结论,可设综合影
响关系的含参方程为
𝑆𝑠𝑡𝑎𝑙𝑙 = 𝛽0 + 𝛽1 ∗1
𝑣𝑙𝑜𝑎𝑑 (7-2)
将题目附件数据中的 89266组实验数据中的播放阶段平均下载速率值和卡顿占比的
数值导入 MATLAB 中,使用正规方程法(详细程序参见附件 2 中所示)可求出能够拟
合出实际数据的最优参数值为:
𝛽0 = −0.131, 𝛽1 = 936.768 (7-3)
因此,卡顿时长占比的综合影响因素模型为:
𝑆𝑠𝑡𝑎𝑙𝑙 = −0.131 +936.768
𝑣𝑙𝑜𝑎𝑑 (7-4)
20 40 60 80 100 120 140
0
0.1
0.2
0.3
0.4
0.5
0.6
E2E RTT /ms
卡顿占比
/%
观测点
拟合曲线
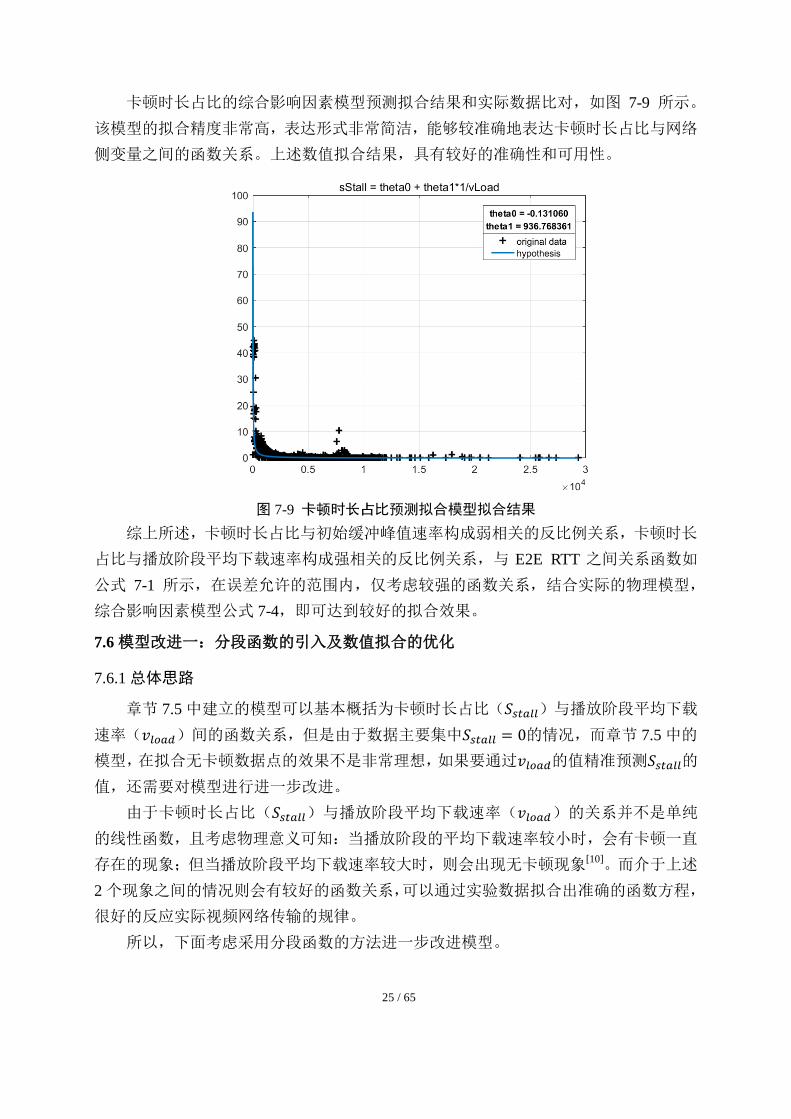
25 / 65
卡顿时长占比的综合影响因素模型预测拟合结果和实际数据比对,如图 7-9 所示。
该模型的拟合精度非常高,表达形式非常简洁,能够较准确地表达卡顿时长占比与网络
侧变量之间的函数关系。上述数值拟合结果,具有较好的准确性和可用性。
图 7-9 卡顿时长占比预测拟合模型拟合结果
综上所述,卡顿时长占比与初始缓冲峰值速率构成弱相关的反比例关系,卡顿时长
占比与播放阶段平均下载速率构成强相关的反比例关系,与 E2E RTT 之间关系函数如
公式 7-1 所示,在误差允许的范围内,仅考虑较强的函数关系,结合实际的物理模型,
综合影响因素模型公式 7-4,即可达到较好的拟合效果。
7.6 模型改进一:分段函数的引入及数值拟合的优化
7.6.1 总体思路
章节 7.5 中建立的模型可以基本概括为卡顿时长占比(𝑆𝑠𝑡𝑎𝑙𝑙)与播放阶段平均下载
速率(𝑣𝑙𝑜𝑎𝑑)间的函数关系,但是由于数据主要集中𝑆𝑠𝑡𝑎𝑙𝑙 = 0的情况,而章节 7.5 中的
模型,在拟合无卡顿数据点的效果不是非常理想,如果要通过𝑣𝑙𝑜𝑎𝑑的值精准预测𝑆𝑠𝑡𝑎𝑙𝑙的
值,还需要对模型进行进一步改进。
由于卡顿时长占比(𝑆𝑠𝑡𝑎𝑙𝑙)与播放阶段平均下载速率(𝑣𝑙𝑜𝑎𝑑)的关系并不是单纯
的线性函数,且考虑物理意义可知:当播放阶段的平均下载速率较小时,会有卡顿一直
存在的现象;但当播放阶段平均下载速率较大时,则会出现无卡顿现象[10]。而介于上述
2 个现象之间的情况则会有较好的函数关系,可以通过实验数据拟合出准确的函数方程,
很好的反应实际视频网络传输的规律。
所以,下面考虑采用分段函数的方法进一步改进模型。
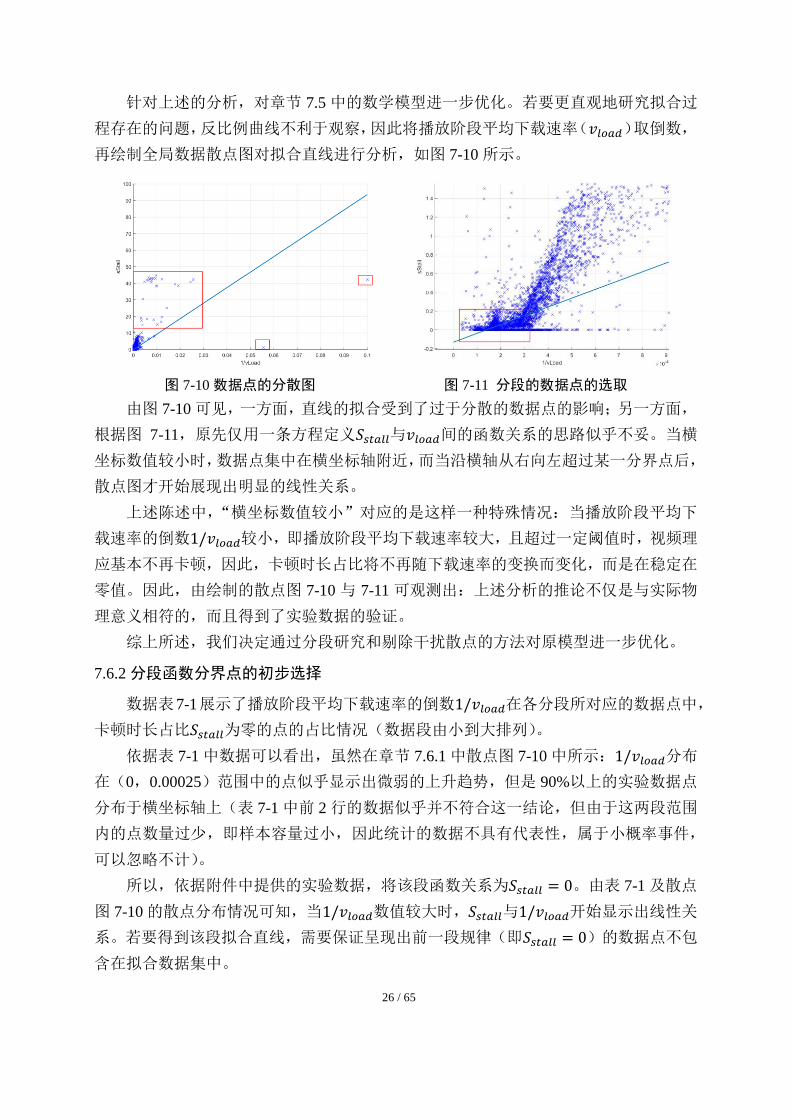
26 / 65
针对上述的分析,对章节 7.5 中的数学模型进一步优化。若要更直观地研究拟合过
程存在的问题,反比例曲线不利于观察,因此将播放阶段平均下载速率(𝑣𝑙𝑜𝑎𝑑)取倒数,
再绘制全局数据散点图对拟合直线进行分析,如图 7-10 所示。
图 7-10 数据点的分散图 图 7-11 分段的数据点的选取
由图 7-10 可见,一方面,直线的拟合受到了过于分散的数据点的影响;另一方面,
根据图 7-11,原先仅用一条方程定义𝑆𝑠𝑡𝑎𝑙𝑙与𝑣𝑙𝑜𝑎𝑑间的函数关系的思路似乎不妥。当横
坐标数值较小时,数据点集中在横坐标轴附近,而当沿横轴从右向左超过某一分界点后,
散点图才开始展现出明显的线性关系。
上述陈述中,“横坐标数值较小”对应的是这样一种特殊情况:当播放阶段平均下
载速率的倒数1/𝑣𝑙𝑜𝑎𝑑较小,即播放阶段平均下载速率较大,且超过一定阈值时,视频理
应基本不再卡顿,因此,卡顿时长占比将不再随下载速率的变换而变化,而是在稳定在
零值。因此,由绘制的散点图 7-10 与 7-11 可观测出:上述分析的推论不仅是与实际物
理意义相符的,而且得到了实验数据的验证。
综上所述,我们决定通过分段研究和剔除干扰散点的方法对原模型进一步优化。
7.6.2 分段函数分界点的初步选择
数据表7-1展示了播放阶段平均下载速率的倒数1/𝑣𝑙𝑜𝑎𝑑在各分段所对应的数据点中,
卡顿时长占比𝑆𝑠𝑡𝑎𝑙𝑙为零的点的占比情况(数据段由小到大排列)。
依据表 7-1 中数据可以看出,虽然在章节 7.6.1 中散点图 7-10 中所示:1/𝑣𝑙𝑜𝑎𝑑分布
在(0,0.00025)范围中的点似乎显示出微弱的上升趋势,但是 90%以上的实验数据点
分布于横坐标轴上(表 7-1 中前 2 行的数据似乎并不符合这一结论,但由于这两段范围
内的点数量过少,即样本容量过小,因此统计的数据不具有代表性,属于小概率事件,
可以忽略不计)。
所以,依据附件中提供的实验数据,将该段函数关系为𝑆𝑠𝑡𝑎𝑙𝑙 = 0。由表 7-1 及散点
图 7-10 的散点分布情况可知,当1/𝑣𝑙𝑜𝑎𝑑数值较大时,𝑆𝑠𝑡𝑎𝑙𝑙与1/𝑣𝑙𝑜𝑎𝑑开始显示出线性关
系。若要得到该段拟合直线,需要保证呈现出前一段规律(即𝑆𝑠𝑡𝑎𝑙𝑙 = 0)的数据点不包
含在拟合数据集中。
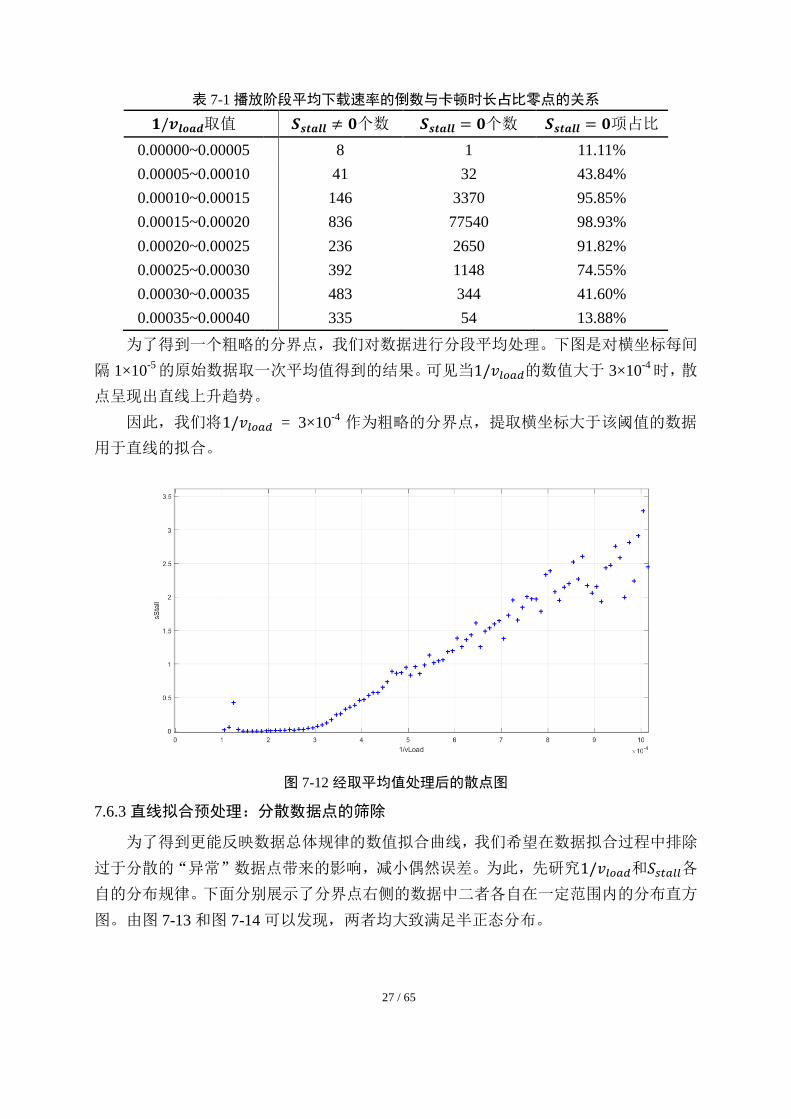
27 / 65
表 7-1 播放阶段平均下载速率的倒数与卡顿时长占比零点的关系
𝟏/𝒗𝒍𝒐𝒂𝒅取值 𝑺𝒔𝒕𝒂𝒍𝒍 ≠ 𝟎个数 𝑺𝒔𝒕𝒂𝒍𝒍 = 𝟎个数 𝑺𝒔𝒕𝒂𝒍𝒍 = 𝟎项占比
0.00000~0.00005 8 1 11.11%
0.00005~0.00010 41 32 43.84%
0.00010~0.00015 146 3370 95.85%
0.00015~0.00020 836 77540 98.93%
0.00020~0.00025 236 2650 91.82%
0.00025~0.00030 392 1148 74.55%
0.00030~0.00035 483 344 41.60%
0.00035~0.00040 335 54 13.88%
为了得到一个粗略的分界点,我们对数据进行分段平均处理。下图是对横坐标每间
隔 1×10-5的原始数据取一次平均值得到的结果。可见当1/𝑣𝑙𝑜𝑎𝑑的数值大于 3×10
-4时,散
点呈现出直线上升趋势。
因此,我们将1/𝑣𝑙𝑜𝑎𝑑 = 3×10-4 作为粗略的分界点,提取横坐标大于该阈值的数据
用于直线的拟合。
图 7-12 经取平均值处理后的散点图
7.6.3 直线拟合预处理:分散数据点的筛除
为了得到更能反映数据总体规律的数值拟合曲线,我们希望在数据拟合过程中排除
过于分散的“异常”数据点带来的影响,减小偶然误差。为此,先研究1/𝑣𝑙𝑜𝑎𝑑和𝑆𝑠𝑡𝑎𝑙𝑙各
自的分布规律。下面分别展示了分界点右侧的数据中二者各自在一定范围内的分布直方
图。由图 7-13 和图 7-14 可以发现,两者均大致满足半正态分布。
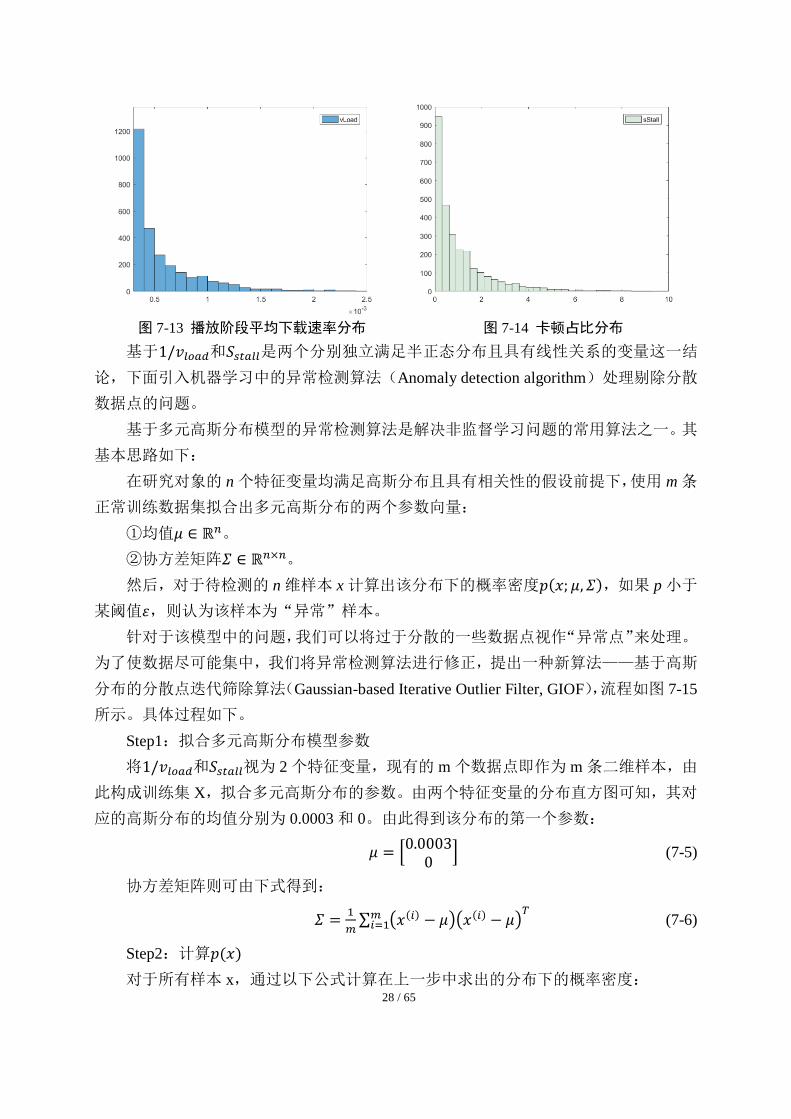
28 / 65
图 7-13 播放阶段平均下载速率分布 图 7-14 卡顿占比分布
基于1/𝑣𝑙𝑜𝑎𝑑和𝑆𝑠𝑡𝑎𝑙𝑙是两个分别独立满足半正态分布且具有线性关系的变量这一结
论,下面引入机器学习中的异常检测算法(Anomaly detection algorithm)处理剔除分散
数据点的问题。
基于多元高斯分布模型的异常检测算法是解决非监督学习问题的常用算法之一。其
基本思路如下:
在研究对象的 n 个特征变量均满足高斯分布且具有相关性的假设前提下,使用 m 条
正常训练数据集拟合出多元高斯分布的两个参数向量:
①均值𝜇 ∈ ℝ𝑛。
②协方差矩阵𝛴 ∈ ℝ𝑛×𝑛。
然后,对于待检测的 n 维样本 x 计算出该分布下的概率密度𝑝(𝑥; 𝜇, 𝛴),如果 p 小于
某阈值𝜀,则认为该样本为“异常”样本。
针对于该模型中的问题,我们可以将过于分散的一些数据点视作“异常点”来处理。
为了使数据尽可能集中,我们将异常检测算法进行修正,提出一种新算法——基于高斯
分布的分散点迭代筛除算法(Gaussian-based Iterative Outlier Filter, GIOF),流程如图 7-15
所示。具体过程如下。
Step1:拟合多元高斯分布模型参数
将1/𝑣𝑙𝑜𝑎𝑑和𝑆𝑠𝑡𝑎𝑙𝑙视为 2 个特征变量,现有的 m 个数据点即作为 m 条二维样本,由
此构成训练集 X,拟合多元高斯分布的参数。由两个特征变量的分布直方图可知,其对
应的高斯分布的均值分别为 0.0003 和 0。由此得到该分布的第一个参数:
𝜇 = [0.0003
0] (7-5)
协方差矩阵则可由下式得到:
𝛴 =1
𝑚∑ (𝑥(𝑖) − 𝜇)(𝑥(𝑖) − 𝜇)
𝑇𝑚𝑖=1 (7-6)
Step2:计算𝑝(𝑥)
对于所有样本 x,通过以下公式计算在上一步中求出的分布下的概率密度:
29 / 65
𝑝(𝑥) =1
(2𝜋)𝑛2∗|𝛴|
12
exp (−1
2(𝑥 − 𝜇)𝑇𝛴−1(𝑥 − 𝜇)) (7-7)
Step3:根据阈值查找并筛除异常点
设定阈值𝜀,将满足𝑝(𝑥) < 𝜀的数据点从训练集中剔除。
Step4:重复 Step1~Step3,直至异常点数量为零。
开始
输入原始数据
拟合μ和Σ值
计算概率密度p(x)
存在P(x)<ε的数据点?
输出拟合数据
结束
删除P(x)<ε的数据点
Yes
No
图 7-15“GIOF”算法流程图
在实际操作中,当参数选取ε = 0.05,取得了较好的效果,其中,分散点筛除程序
的运行结果在表格 7-2 中所示,我们可以发现,随着迭代次数的增加,“异常点”的数
量逐渐减少,在本次仿真实验中,经过 11 次迭代后,“异常点”不再出现,𝑁𝑒𝑟𝑟𝑜𝑟稳定
在 0,成功实现了对于“异常点”的有效的筛除。
表 7-2 逐循环迭代中“异常点”的数量表
迭代次数
𝑵𝒊𝒕𝒆𝒓𝒂𝒕𝒊𝒐𝒏
“异常点”数量
𝑵𝒆𝒓𝒓𝒐𝒓
迭代次数
𝑵𝒊𝒕𝒆𝒓𝒂𝒕𝒊𝒐𝒏
“异常点”数量
𝑵𝒆𝒓𝒓𝒐𝒓
1 30 7 5
2 35 8 4
3 33 9 4
4 24 10 2
5 7 11 0
6 9 12 0
为进一步直观地体现“异常点”筛除的过程,第 1、3、5、7、9、11 次迭代的运行
结果如图 7-16 所示。其中,粉色圆圈所标注位置是每一次检测出的分散点坐标。可以
看出,随着迭代次数的增加,“异常点”逐渐减少直至消失,在第 11 次迭代后数据的集
中分布基本达到了稳定状态,不再出现“异常点”。
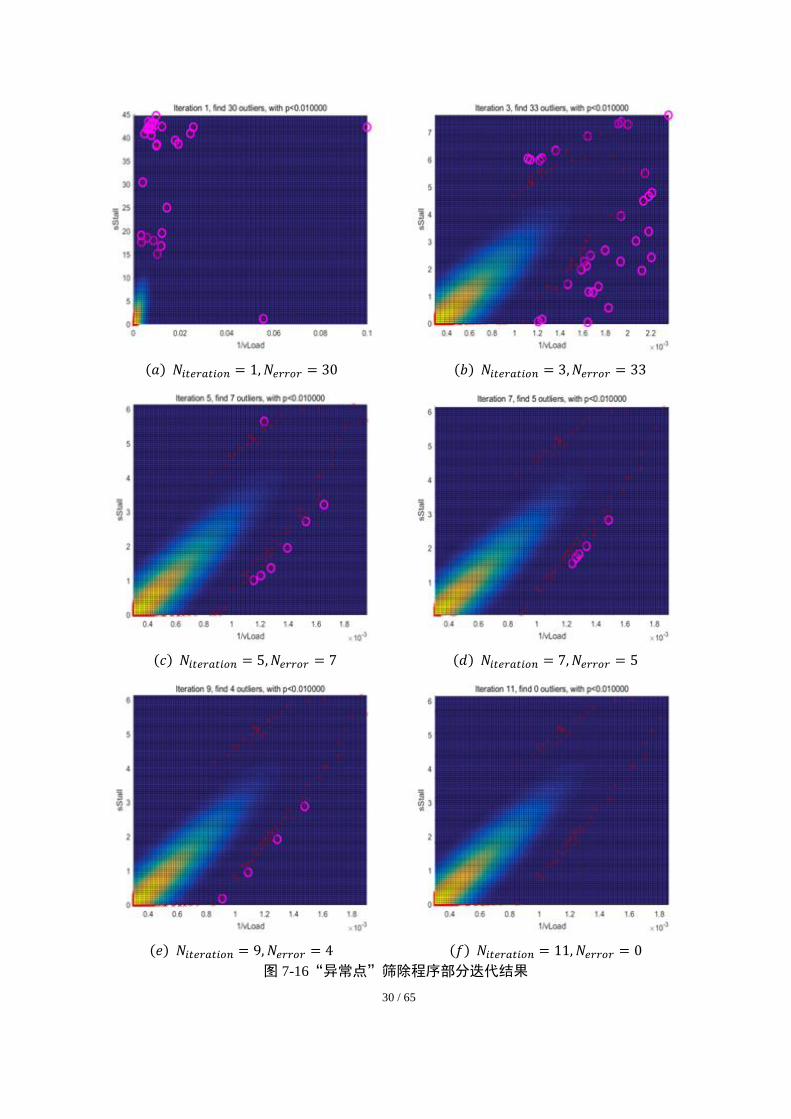
30 / 65
(𝑎) 𝑁𝑖𝑡𝑒𝑟𝑎𝑡𝑖𝑜𝑛 = 1, 𝑁𝑒𝑟𝑟𝑜𝑟 = 30 (𝑏) 𝑁𝑖𝑡𝑒𝑟𝑎𝑡𝑖𝑜𝑛 = 3, 𝑁𝑒𝑟𝑟𝑜𝑟 = 33
(𝑐) 𝑁𝑖𝑡𝑒𝑟𝑎𝑡𝑖𝑜𝑛 = 5, 𝑁𝑒𝑟𝑟𝑜𝑟 = 7 (𝑑) 𝑁𝑖𝑡𝑒𝑟𝑎𝑡𝑖𝑜𝑛 = 7, 𝑁𝑒𝑟𝑟𝑜𝑟 = 5
(𝑒) 𝑁𝑖𝑡𝑒𝑟𝑎𝑡𝑖𝑜𝑛 = 9, 𝑁𝑒𝑟𝑟𝑜𝑟 = 4 (𝑓) 𝑁𝑖𝑡𝑒𝑟𝑎𝑡𝑖𝑜𝑛 = 11, 𝑁𝑒𝑟𝑟𝑜𝑟 = 0
图 7-16“异常点”筛除程序部分迭代结果
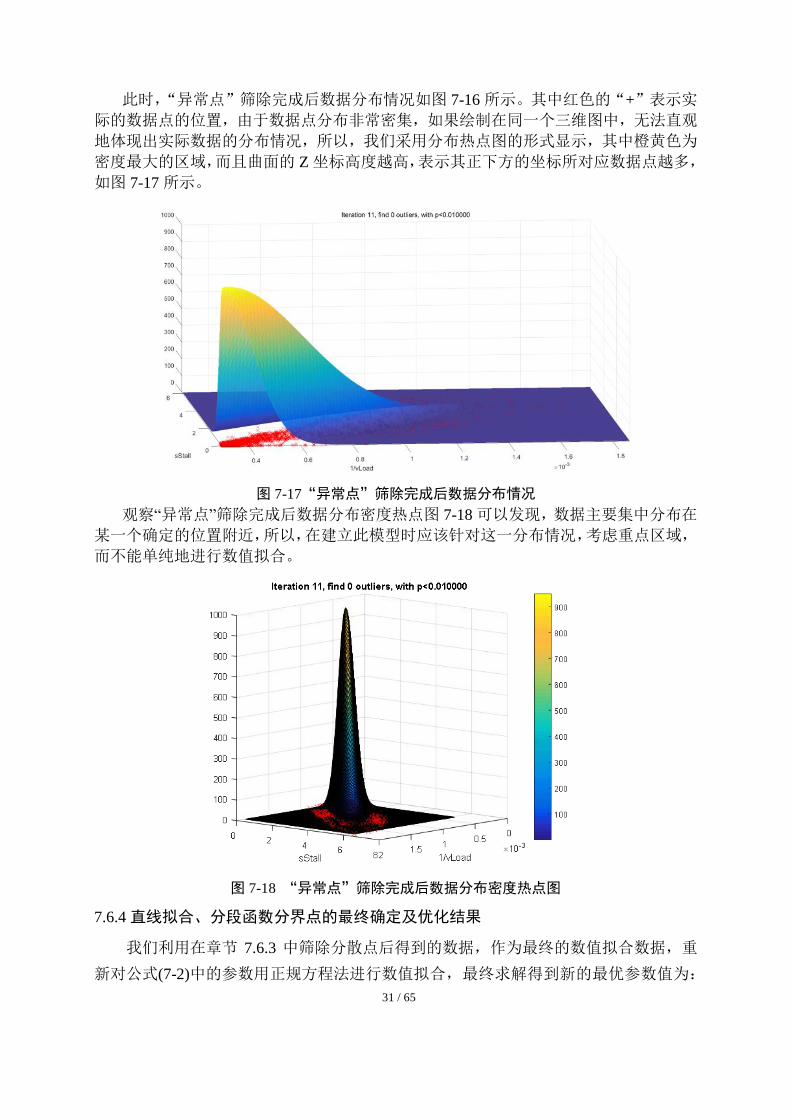
31 / 65
此时,“异常点”筛除完成后数据分布情况如图 7-16 所示。其中红色的“+”表示实
际的数据点的位置,由于数据点分布非常密集,如果绘制在同一个三维图中,无法直观
地体现出实际数据的分布情况,所以,我们采用分布热点图的形式显示,其中橙黄色为
密度最大的区域,而且曲面的 Z 坐标高度越高,表示其正下方的坐标所对应数据点越多,
如图 7-17 所示。
图 7-17“异常点”筛除完成后数据分布情况
观察“异常点”筛除完成后数据分布密度热点图 7-18 可以发现,数据主要集中分布在
某一个确定的位置附近,所以,在建立此模型时应该针对这一分布情况,考虑重点区域,
而不能单纯地进行数值拟合。
图 7-18 “异常点”筛除完成后数据分布密度热点图
7.6.4 直线拟合、分段函数分界点的最终确定及优化结果
我们利用在章节 7.6.3 中筛除分散点后得到的数据,作为最终的数值拟合数据,重
新对公式(7-2)中的参数用正规方程法进行数值拟合,最终求解得到新的最优参数值为:
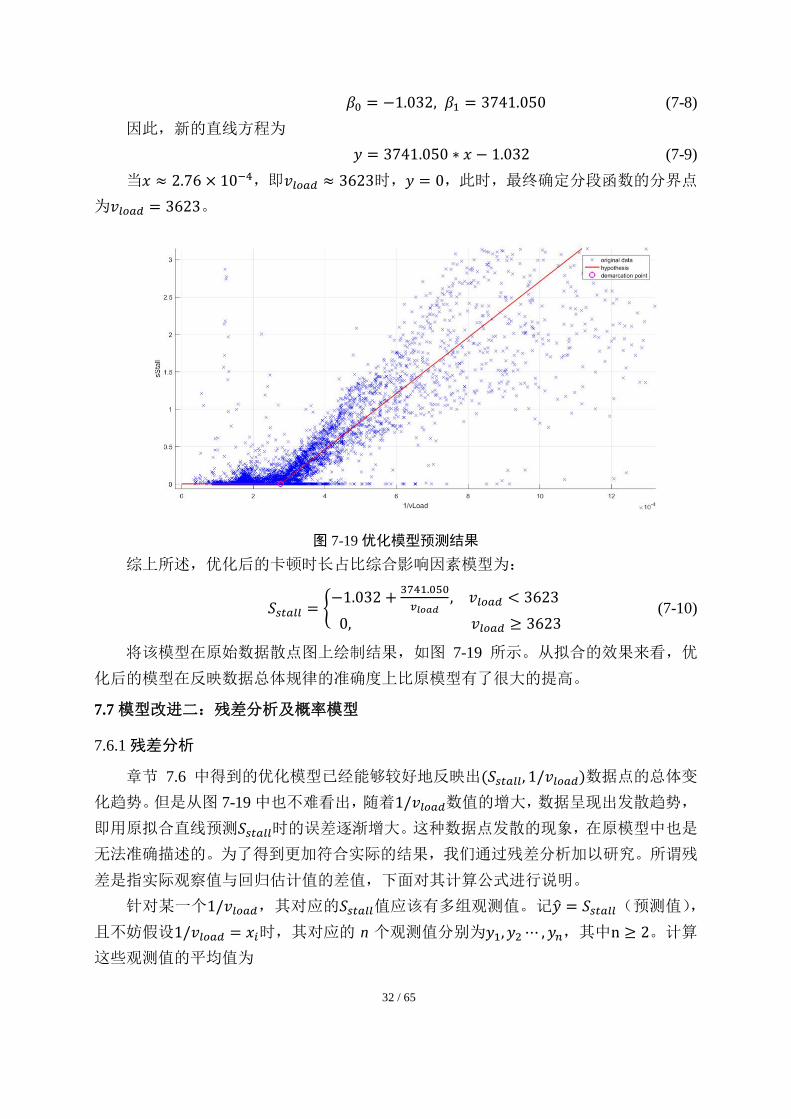
32 / 65
𝛽0 = −1.032, 𝛽1 = 3741.050 (7-8)
因此,新的直线方程为
𝑦 = 3741.050 ∗ 𝑥 − 1.032 (7-9)
当𝑥 ≈ 2.76 × 10−4,即𝑣𝑙𝑜𝑎𝑑 ≈ 3623时,𝑦 = 0,此时,最终确定分段函数的分界点
为𝑣𝑙𝑜𝑎𝑑 = 3623。
图 7-19 优化模型预测结果
综上所述,优化后的卡顿时长占比综合影响因素模型为:
𝑆𝑠𝑡𝑎𝑙𝑙 = {−1.032 +
3741.050
𝑣𝑙𝑜𝑎𝑑, 𝑣𝑙𝑜𝑎𝑑 < 3623
0, 𝑣𝑙𝑜𝑎𝑑 ≥ 3623 (7-10)
将该模型在原始数据散点图上绘制结果,如图 7-19 所示。从拟合的效果来看,优
化后的模型在反映数据总体规律的准确度上比原模型有了很大的提高。
7.7 模型改进二:残差分析及概率模型
7.6.1 残差分析
章节 7.6 中得到的优化模型已经能够较好地反映出(𝑆𝑠𝑡𝑎𝑙𝑙, 1/𝑣𝑙𝑜𝑎𝑑)数据点的总体变
化趋势。但是从图 7-19 中也不难看出,随着1/𝑣𝑙𝑜𝑎𝑑数值的增大,数据呈现出发散趋势,
即用原拟合直线预测𝑆𝑠𝑡𝑎𝑙𝑙时的误差逐渐增大。这种数据点发散的现象,在原模型中也是
无法准确描述的。为了得到更加符合实际的结果,我们通过残差分析加以研究。所谓残
差是指实际观察值与回归估计值的差值,下面对其计算公式进行说明。
针对某一个1/𝑣𝑙𝑜𝑎𝑑,其对应的𝑆𝑠𝑡𝑎𝑙𝑙值应该有多组观测值。记�̂� = 𝑆𝑠𝑡𝑎𝑙𝑙(预测值),
且不妨假设1/𝑣𝑙𝑜𝑎𝑑 = 𝑥𝑖时,其对应的 n 个观测值分别为𝑦1, 𝑦2 ⋯ , 𝑦𝑛,其中n ≥ 2。计算
这些观测值的平均值为
33 / 65
𝑦�̅� =1
𝑛∑ 𝑦𝜏
𝜏=𝑛𝜏=0 (7-11)
进一步计算残差,公式如下:
𝑒𝑖 = 𝑦�̅� − 𝑦�̂� (7-12)
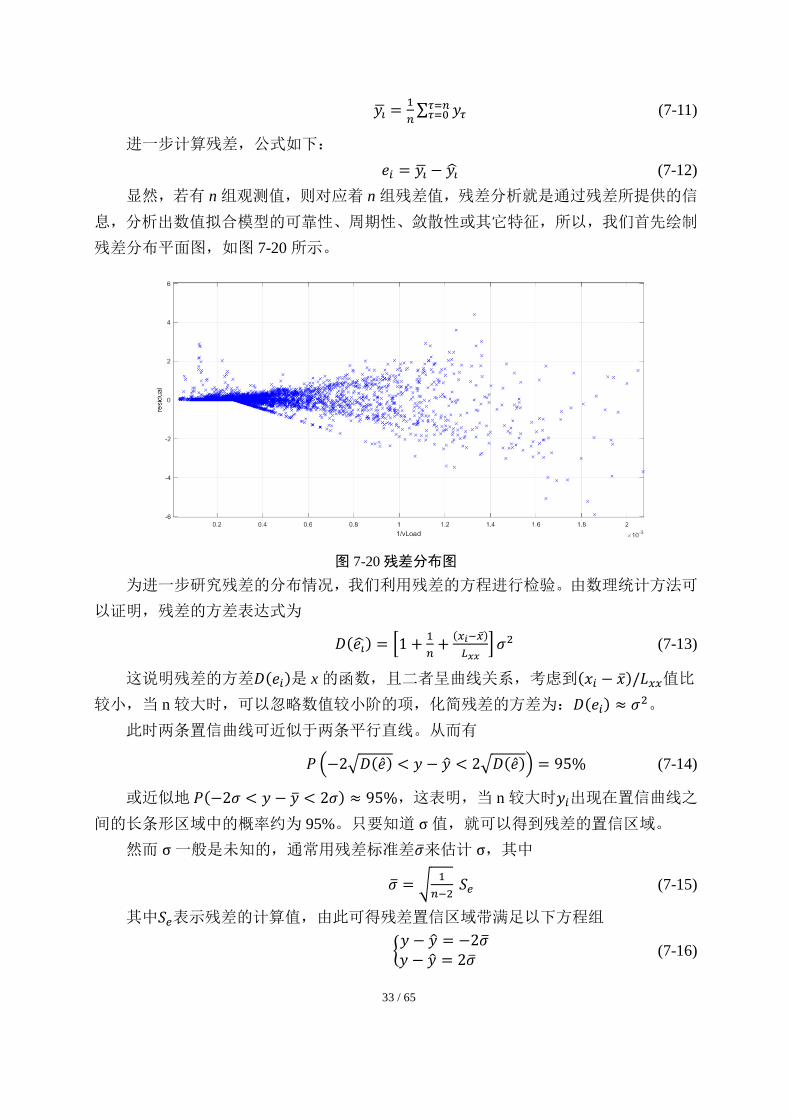
显然,若有 n 组观测值,则对应着 n 组残差值,残差分析就是通过残差所提供的信
息,分析出数值拟合模型的可靠性、周期性、敛散性或其它特征,所以,我们首先绘制
残差分布平面图,如图 7-20 所示。
图 7-20 残差分布图
为进一步研究残差的分布情况,我们利用残差的方程进行检验。由数理统计方法可
以证明,残差的方差表达式为
𝐷(𝑒�̂�) = [1 +1
𝑛+
(𝑥𝑖−�̅�)
𝐿𝑥𝑥] 𝜎2 (7-13)
这说明残差的方差𝐷(𝑒𝑖)是 x 的函数,且二者呈曲线关系,考虑到(𝑥𝑖 − �̅�)/𝐿𝑥𝑥值比
较小,当 n 较大时,可以忽略数值较小阶的项,化简残差的方差为:𝐷(𝑒𝑖) ≈ 𝜎2。
此时两条置信曲线可近似于两条平行直线。从而有
𝑃 (−2√𝐷(�̂�) < 𝑦 − �̂� < 2√𝐷(�̂�)) = 95% (7-14)
或近似地 𝑃(−2𝜎 < 𝑦 − �̅� < 2𝜎) ≈ 95%,这表明,当 n 较大时𝑦𝑖出现在置信曲线之
间的长条形区域中的概率约为 95%。只要知道 σ 值,就可以得到残差的置信区域。
然而 σ 一般是未知的,通常用残差标准差�̅�来估计 σ,其中
�̅� = √1
𝑛−2 𝑆𝑒 (7-15)
其中𝑆𝑒表示残差的计算值,由此可得残差置信区域带满足以下方程组
{𝑦 − �̂� = −2�̅�𝑦 − �̂� = 2�̅�
(7-16)

34 / 65
一般对残差在置信带以外的数据都要进行检查,以区别是否是异常数据,大部分数
据是分布在残差置信带内的。从残差分布直方图可以发现:当1/𝑣𝑙𝑜𝑎𝑑比较小时,即下载
速率非常大的情况下,我们的模型能够非常精确地描述实际的网络视频传输过程,并且
绝大部分数据的数值拟合结果的残差值小于 0.25,所以能够满足实际应用的需求。
但是当下载速率比较小的情况下,即1/𝑣𝑙𝑜𝑎𝑑比较大时,拟合的数据开始发散,为了
进一步评价我们模型的准确性,我们建立了模型进行误差分析。首先采用线性回归进行
分析,结合之前模型的特点,可知线性回归的基本形式如下:
𝑦 = 𝛽0 + 𝛽1𝑥 + 𝑒 (7-17)
其中 e 为随机误差项,且满足高斯分布。为了保证回归参数估计量具有良好的统计
性质,经典线性回归模型的一个重要假定是:总体回归函数中的随机误差项,满足同方
差性,即𝐷(𝑒) = 𝜎2,𝜎2为常数(前文已说明)。那么满足这一假设的预测模型其残差�̂�也
必然满足同方差性(图 7-21),而由图 7-20 可知,本模型的残差并不是一直趋于稳定,
其方差随1/𝑣𝑙𝑜𝑎𝑑的增大而增大,因此,可推断原模型存在异方差性(图 7-22)。
图 7-21 同方差 图 7-22 递增异方差
一般情况下,可以通过模型变换等方法消除异方差性,但是由于在本题的特定环境
下,这种递增异方差性是与物理意义相符的,这一点我们在下一章节会有详细的阐述。
因此,我们在这一节中对回归模型的误差项进行建模,最终,利用概率的形式表达𝑆𝑠𝑡𝑎𝑙𝑙与
1/𝑣𝑙𝑜𝑎𝑑的函数关系。
7.6.2 概率误差模型的建立
考虑一般情况下,误差均呈高斯分布(Gaussian distribution),又名正态分布(Normal
distribution)。为便于表述,在本章节中令1/𝑣𝑙𝑜𝑎𝑑 = 𝑥。假设误差为 x 的函数,且满足正
态分布,即:𝑒(𝑥)~𝑁(𝜇(𝑥), 𝜎(𝑥)2)。下面我们讨论如何计算𝜎(𝑥)的函数表达式。
由于误差项𝑒是理想模型中的参数,无法直接获得,故利用残差�̂�的分布来估计𝑒的
分布。对于残差图中所有的(x, �̂�), 𝑥𝜖(0.00030,0.00100),在 x 的研究区间中,以间隔
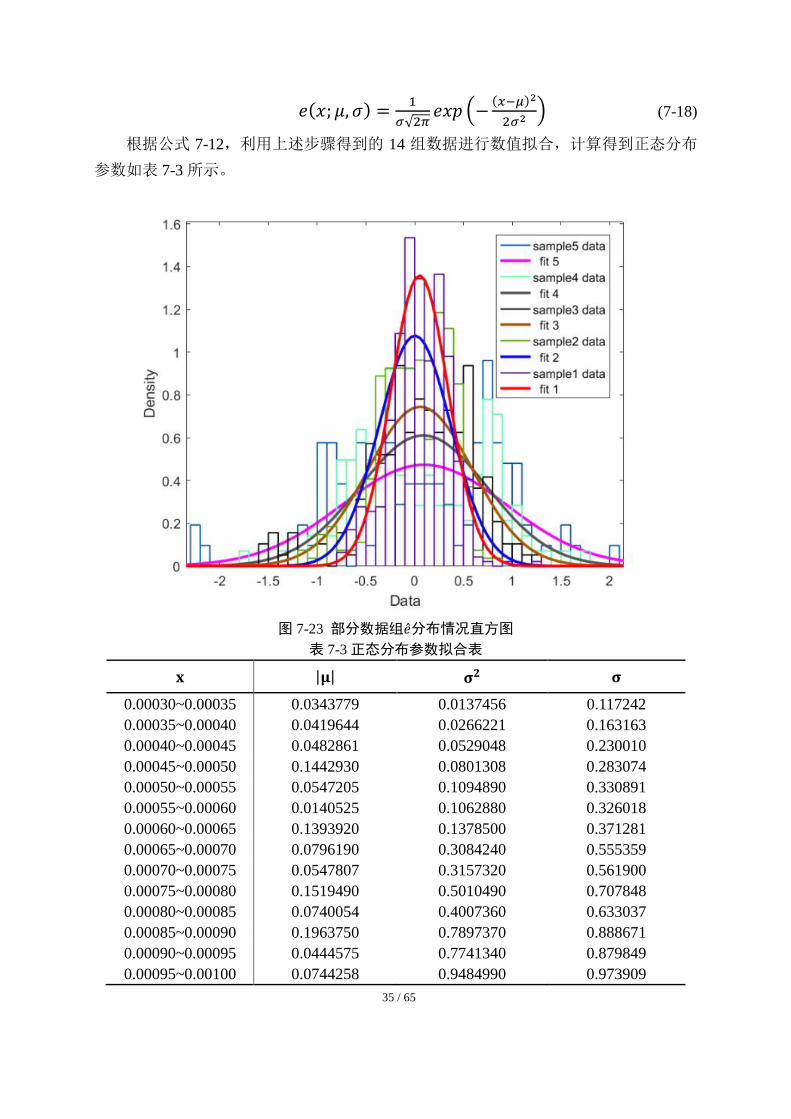
长度为 5×10-5取 14 组数据,分别绘制各组�̂�的分布直方图如图 7-23 所示,观察图像 7-23
可以发现,数据的分布规律确实很符合正态分布,其中𝜇(𝑥) = 0。我们进一步考虑利用
正态分布的情况进行拟合。
由于𝑒(𝑥)~𝑁(𝜇(𝑥), 𝜎(𝑥)2),其一般形式如下
y
x
y
x
35 / 65
𝑒(𝑥; 𝜇, 𝜎) =1
𝜎√2𝜋𝑒𝑥𝑝 (−
(𝑥−𝜇)2
2𝜎2) (7-18)
根据公式 7-12,利用上述步骤得到的 14 组数据进行数值拟合,计算得到正态分布
参数如表 7-3 所示。
图 7-23 部分数据组�̂�分布情况直方图
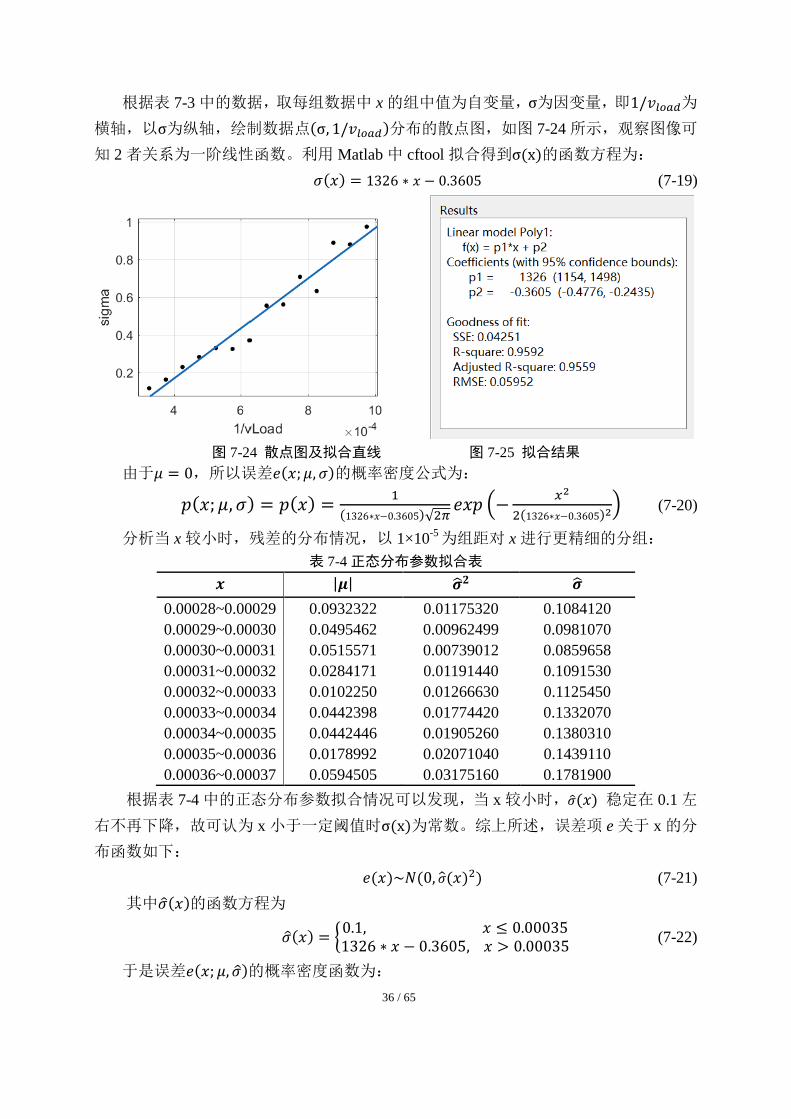
表 7-3 正态分布参数拟合表
𝐱 |𝛍| 𝛔𝟐 𝛔
0.00030~0.00035 0.0343779 0.0137456 0.117242
0.00035~0.00040 0.0419644 0.0266221 0.163163
0.00040~0.00045 0.0482861 0.0529048 0.230010
0.00045~0.00050 0.1442930 0.0801308 0.283074
0.00050~0.00055 0.0547205 0.1094890 0.330891
0.00055~0.00060 0.0140525 0.1062880 0.326018
0.00060~0.00065 0.1393920 0.1378500 0.371281
0.00065~0.00070 0.0796190 0.3084240 0.555359
0.00070~0.00075 0.0547807 0.3157320 0.561900
0.00075~0.00080 0.1519490 0.5010490 0.707848
0.00080~0.00085 0.0740054 0.4007360 0.633037
0.00085~0.00090 0.1963750 0.7897370 0.888671
0.00090~0.00095 0.0444575 0.7741340 0.879849
0.00095~0.00100 0.0744258 0.9484990 0.973909
36 / 65
根据表 7-3 中的数据,取每组数据中 x 的组中值为自变量,σ为因变量,即1/𝑣𝑙𝑜𝑎𝑑为
横轴,以σ为纵轴,绘制数据点(σ, 1/𝑣𝑙𝑜𝑎𝑑)分布的散点图,如图 7-24 所示,观察图像可
知 2 者关系为一阶线性函数。利用 Matlab 中 cftool 拟合得到σ(x)的函数方程为:
𝜎(𝑥) = 1326 ∗ 𝑥 − 0.3605 (7-19)
图 7-24 散点图及拟合直线 图 7-25 拟合结果
由于𝜇 = 0,所以误差𝑒(𝑥; 𝜇, 𝜎)的概率密度公式为:
𝑝(𝑥; 𝜇, 𝜎) = 𝑝(𝑥) =1
(1326∗𝑥−0.3605)√2𝜋𝑒𝑥𝑝 (−
𝑥2
2(1326∗𝑥−0.3605)2) (7-20)
分析当 x 较小时,残差的分布情况,以 1×10-5为组距对 x 进行更精细的分组:
表 7-4 正态分布参数拟合表
𝒙 |𝝁| �̂�𝟐 �̂�
0.00028~0.00029 0.0932322 0.01175320 0.1084120
0.00029~0.00030 0.0495462 0.00962499 0.0981070
0.00030~0.00031 0.0515571 0.00739012 0.0859658
0.00031~0.00032 0.0284171 0.01191440 0.1091530
0.00032~0.00033 0.0102250 0.01266630 0.1125450
0.00033~0.00034 0.0442398 0.01774420 0.1332070
0.00034~0.00035 0.0442446 0.01905260 0.1380310
0.00035~0.00036 0.0178992 0.02071040 0.1439110
0.00036~0.00037 0.0594505 0.03175160 0.1781900
根据表 7-4 中的正态分布参数拟合情况可以发现,当 x 较小时,�̂�(𝑥) 稳定在 0.1 左
右不再下降,故可认为 x 小于一定阈值时σ(x)为常数。综上所述,误差项 e 关于 x 的分
布函数如下:
𝑒(𝑥)~𝑁(0, �̂�(𝑥)2) (7-21)
其中�̂�(𝑥)的函数方程为
�̂�(𝑥) = {0.1, 𝑥 ≤ 0.000351326 ∗ 𝑥 − 0.3605, 𝑥 > 0.00035
(7-22)
于是误差𝑒(𝑥; 𝜇, �̂�)的概率密度函数为:
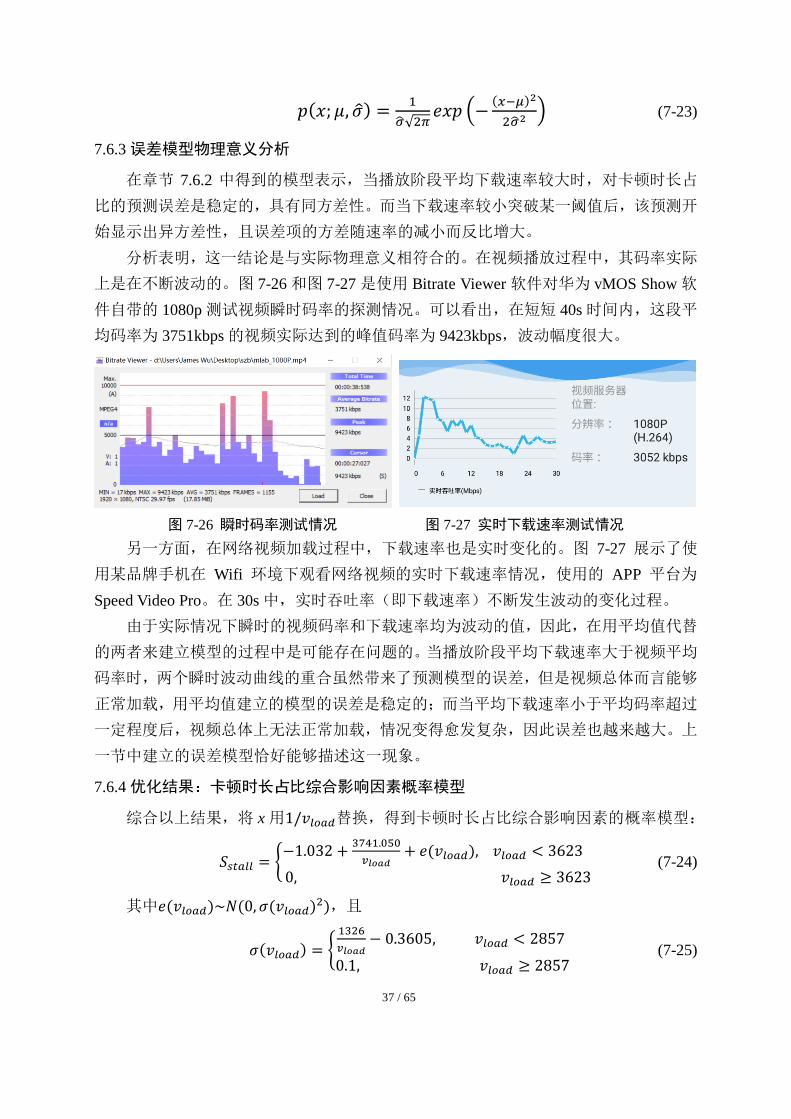
37 / 65
𝑝(𝑥; 𝜇, �̂�) =1
�̂�√2𝜋𝑒𝑥𝑝 (−
(𝑥−𝜇)2
2�̂�2) (7-23)
7.6.3 误差模型物理意义分析
在章节 7.6.2 中得到的模型表示,当播放阶段平均下载速率较大时,对卡顿时长占
比的预测误差是稳定的,具有同方差性。而当下载速率较小突破某一阈值后,该预测开
始显示出异方差性,且误差项的方差随速率的减小而反比增大。
分析表明,这一结论是与实际物理意义相符合的。在视频播放过程中,其码率实际
上是在不断波动的。图 7-26 和图 7-27 是使用 Bitrate Viewer 软件对华为 vMOS Show 软
件自带的 1080p 测试视频瞬时码率的探测情况。可以看出,在短短 40s 时间内,这段平
均码率为 3751kbps 的视频实际达到的峰值码率为 9423kbps,波动幅度很大。
图 7-26 瞬时码率测试情况 图 7-27 实时下载速率测试情况
另一方面,在网络视频加载过程中,下载速率也是实时变化的。图 7-27 展示了使
用某品牌手机在 Wifi 环境下观看网络视频的实时下载速率情况,使用的 APP 平台为
Speed Video Pro。在 30s 中,实时吞吐率(即下载速率)不断发生波动的变化过程。
由于实际情况下瞬时的视频码率和下载速率均为波动的值,因此,在用平均值代替
的两者来建立模型的过程中是可能存在问题的。当播放阶段平均下载速率大于视频平均
码率时,两个瞬时波动曲线的重合虽然带来了预测模型的误差,但是视频总体而言能够
正常加载,用平均值建立的模型的误差是稳定的;而当平均下载速率小于平均码率超过
一定程度后,视频总体上无法正常加载,情况变得愈发复杂,因此误差也越来越大。上
一节中建立的误差模型恰好能够描述这一现象。
7.6.4 优化结果:卡顿时长占比综合影响因素概率模型
综合以上结果,将 x 用1/𝑣𝑙𝑜𝑎𝑑替换,得到卡顿时长占比综合影响因素的概率模型:
𝑆𝑠𝑡𝑎𝑙𝑙 = {−1.032 +
3741.050
𝑣𝑙𝑜𝑎𝑑+ 𝑒(𝑣𝑙𝑜𝑎𝑑), 𝑣𝑙𝑜𝑎𝑑 < 3623
0, 𝑣𝑙𝑜𝑎𝑑 ≥ 3623 (7-24)
其中𝑒(𝑣𝑙𝑜𝑎𝑑)~𝑁(0, 𝜎(𝑣𝑙𝑜𝑎𝑑)2),且
𝜎(𝑣𝑙𝑜𝑎𝑑) = {
1326
𝑣𝑙𝑜𝑎𝑑− 0.3605, 𝑣𝑙𝑜𝑎𝑑 < 2857
0.1, 𝑣𝑙𝑜𝑎𝑑 ≥ 2857 (7-25)
38 / 65
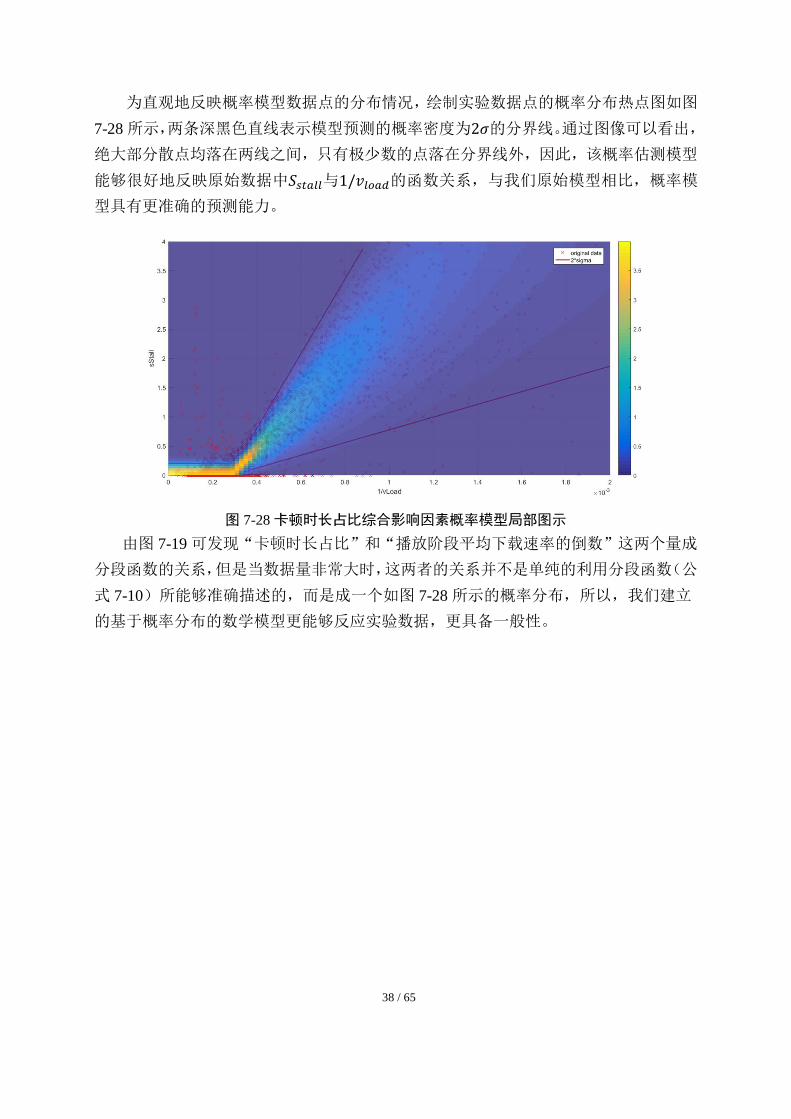
为直观地反映概率模型数据点的分布情况,绘制实验数据点的概率分布热点图如图
7-28 所示,两条深黑色直线表示模型预测的概率密度为2𝜎的分界线。通过图像可以看出,
绝大部分散点均落在两线之间,只有极少数的点落在分界线外,因此,该概率估测模型
能够很好地反映原始数据中𝑆𝑠𝑡𝑎𝑙𝑙与1/𝑣𝑙𝑜𝑎𝑑的函数关系,与我们原始模型相比,概率模
型具有更准确的预测能力。
图 7-28 卡顿时长占比综合影响因素概率模型局部图示
由图 7-19 可发现“卡顿时长占比”和“播放阶段平均下载速率的倒数”这两个量成
分段函数的关系,但是当数据量非常大时,这两者的关系并不是单纯的利用分段函数(公
式 7-10)所能够准确描述的,而是成一个如图 7-28 所示的概率分布,所以,我们建立
的基于概率分布的数学模型更能够反应实验数据,更具备一般性。
39 / 65
八、补充数据的模型检验
8.1 模型检验总述
我们根据原有的 89266 组数据建立了初始缓冲时延综合影响模型和卡顿时长占比的
综合影响模型。为进一步验证模型的准确性和普适性,针对新补充的数据,利用已经建
立的模型进行拟合,依据相关参数的拟合情况对模型拟合效果评价,作为模型适用性的
一个补充说明和实验数据的验证。我们会基于新补充的 5295 组数据对建立的模型的适
用性进行量化的评价,并且建立新的评价指标,借助评价指标与新补充的数据对原来的
模型进行定量分析,对模型做出适用范围的评价,并得到了一些适用的结论。
8.2 初始缓冲时延模型对补充数据的拟合
8.2.1 数值拟合模型
对于章节 6.5 中利用数据拟合得到的初始缓冲时延模型,我们也将基于新补充的数
据,借助量化指标对其进行相应的分析评价。模型的计算表达式如下:
𝑡𝑤𝑎𝑖𝑡 = −224.87 +2.25∗107
𝑣𝑡ℎ𝑟𝑝+ 15.29 ∗ 𝑅𝑇𝑇 (8-1)
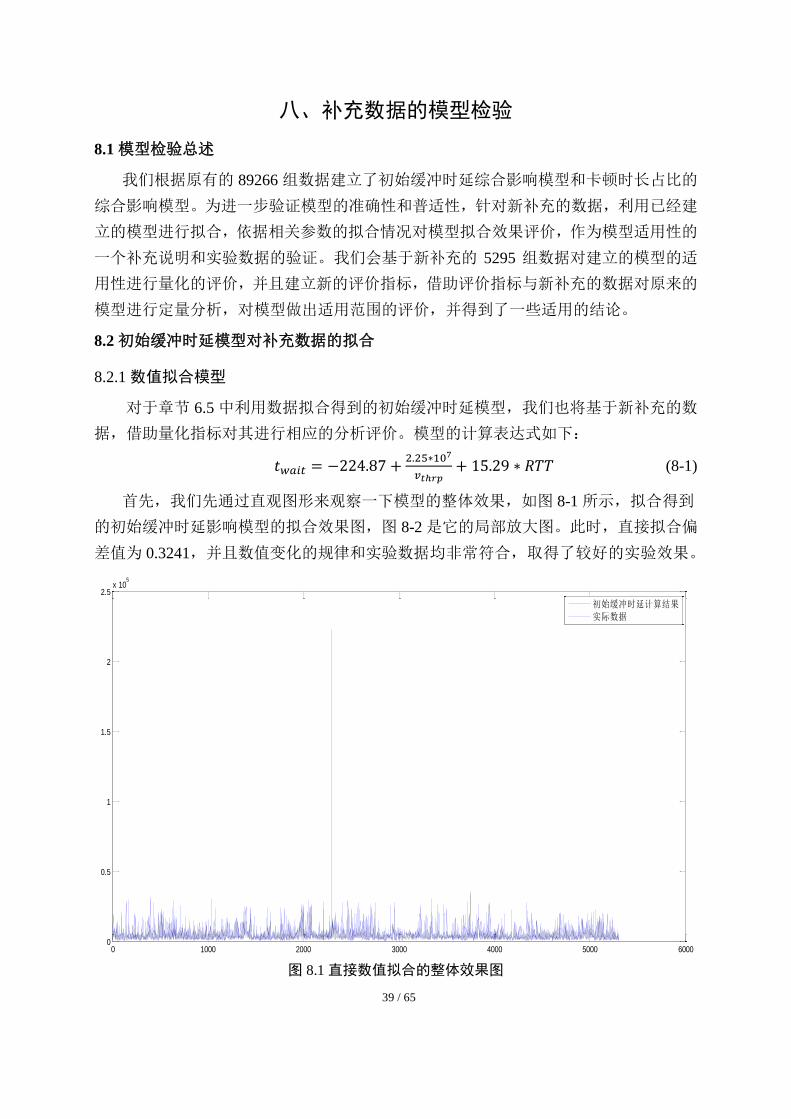
首先,我们先通过直观图形来观察一下模型的整体效果,如图 8-1 所示,拟合得到
的初始缓冲时延影响模型的拟合效果图,图 8-2 是它的局部放大图。此时,直接拟合偏
差值为 0.3241,并且数值变化的规律和实验数据均非常符合,取得了较好的实验效果。
图 8.1 直接数值拟合的整体效果图
0 1000 2000 3000 4000 5000 60000
0.5
1
1.5
2
2.5x 10
5
初始缓冲时延计算结果
实际数据
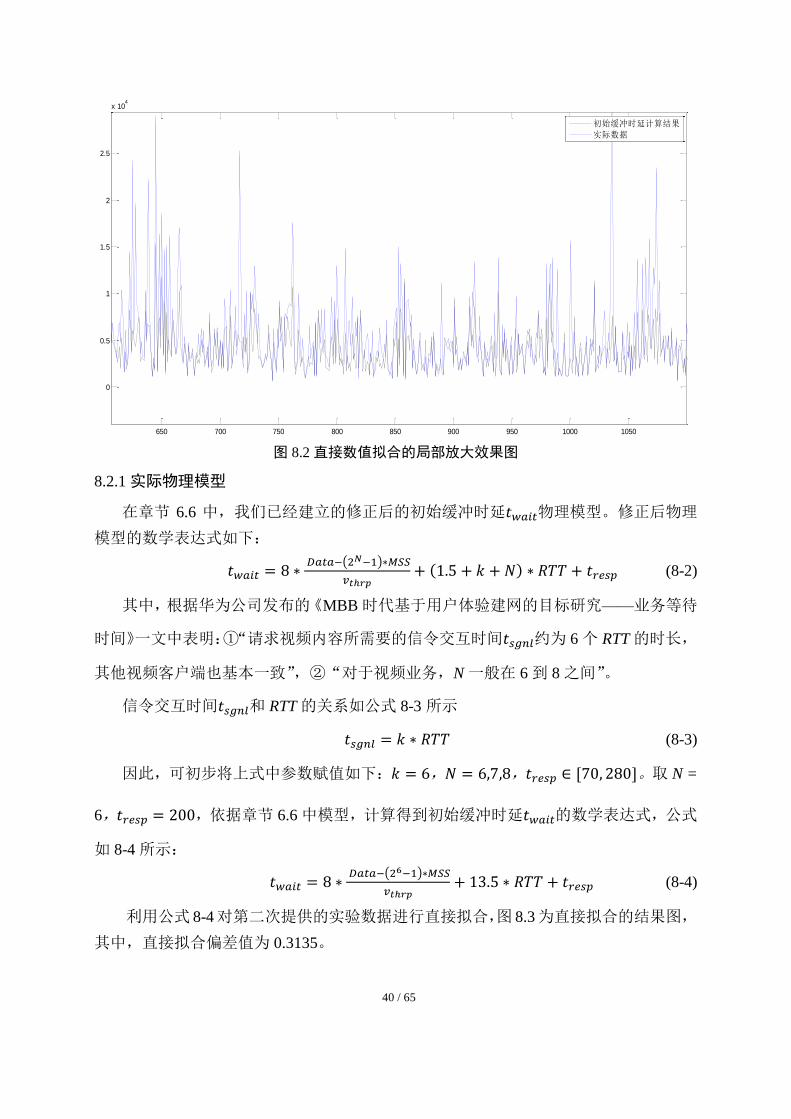
40 / 65
图 8.2 直接数值拟合的局部放大效果图
8.2.1 实际物理模型
在章节 6.6 中,我们已经建立的修正后的初始缓冲时延𝑡𝑤𝑎𝑖𝑡物理模型。修正后物理
模型的数学表达式如下:
𝑡𝑤𝑎𝑖𝑡 = 8 ∗ 𝐷𝑎𝑡𝑎−(2𝑁−1)∗𝑀𝑆𝑆
𝑣𝑡ℎ𝑟𝑝+ (1.5 + 𝑘 + 𝑁) ∗ 𝑅𝑇𝑇 + 𝑡𝑟𝑒𝑠𝑝 (8-2)
其中,根据华为公司发布的《MBB 时代基于用户体验建网的目标研究——业务等待
时间》一文中表明:①“请求视频内容所需要的信令交互时间𝑡𝑠𝑔𝑛𝑙约为 6 个 RTT 的时长,
其他视频客户端也基本一致”,②“对于视频业务,N 一般在 6 到 8 之间”。
信令交互时间𝑡𝑠𝑔𝑛𝑙和 RTT 的关系如公式 8-3 所示
𝑡𝑠𝑔𝑛𝑙 = 𝑘 ∗ 𝑅𝑇𝑇 (8-3)
因此,可初步将上式中参数赋值如下:𝑘 = 6,𝑁 = 6,7,8,𝑡𝑟𝑒𝑠𝑝 ∈ [70, 280]。取 N =
6,𝑡𝑟𝑒𝑠𝑝 = 200,依据章节 6.6 中模型,计算得到初始缓冲时延𝑡𝑤𝑎𝑖𝑡的数学表达式,公式
如 8-4 所示:
𝑡𝑤𝑎𝑖𝑡 = 8 ∗ 𝐷𝑎𝑡𝑎−(26−1)∗𝑀𝑆𝑆
𝑣𝑡ℎ𝑟𝑝+ 13.5 ∗ 𝑅𝑇𝑇 + 𝑡𝑟𝑒𝑠𝑝 (8-4)
利用公式 8-4对第二次提供的实验数据进行直接拟合,图 8.3为直接拟合的结果图,
其中,直接拟合偏差值为 0.3135。
650 700 750 800 850 900 950 1000 1050
0
0.5
1
1.5
2
2.5
x 104
初始缓冲时延计算结果
实际数据
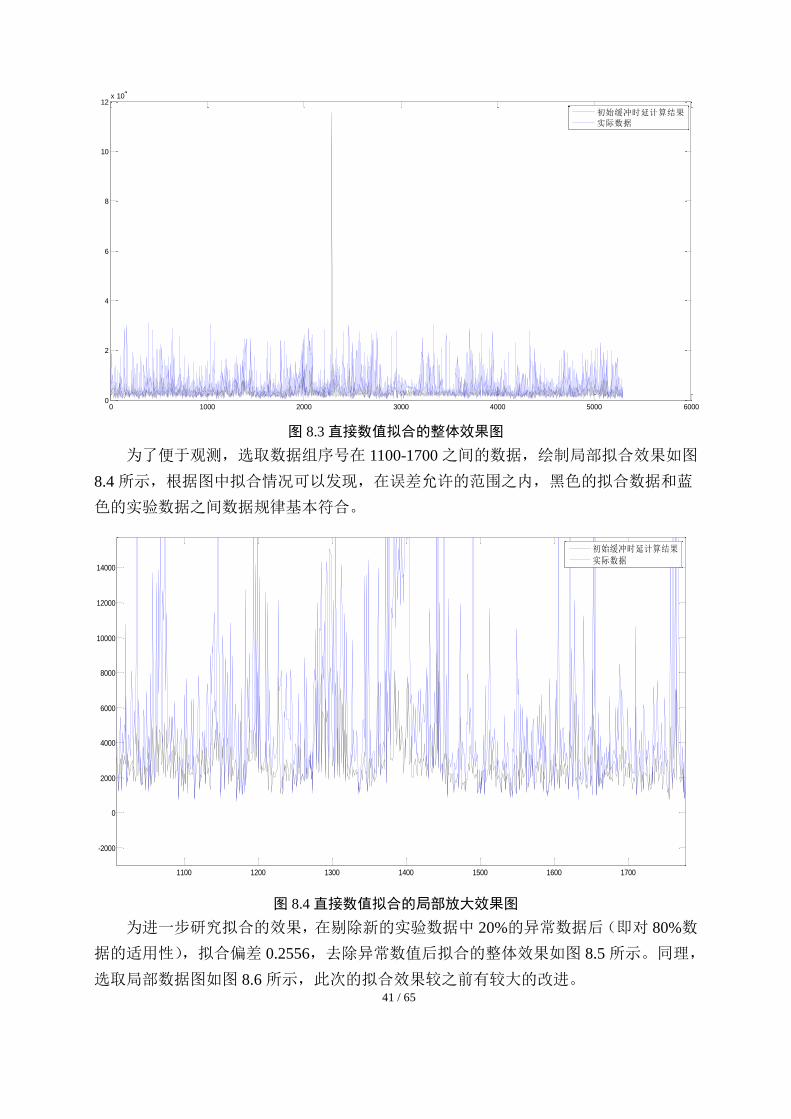
41 / 65
图 8.3 直接数值拟合的整体效果图
为了便于观测,选取数据组序号在 1100-1700 之间的数据,绘制局部拟合效果如图
8.4 所示,根据图中拟合情况可以发现,在误差允许的范围之内,黑色的拟合数据和蓝
色的实验数据之间数据规律基本符合。
图 8.4 直接数值拟合的局部放大效果图
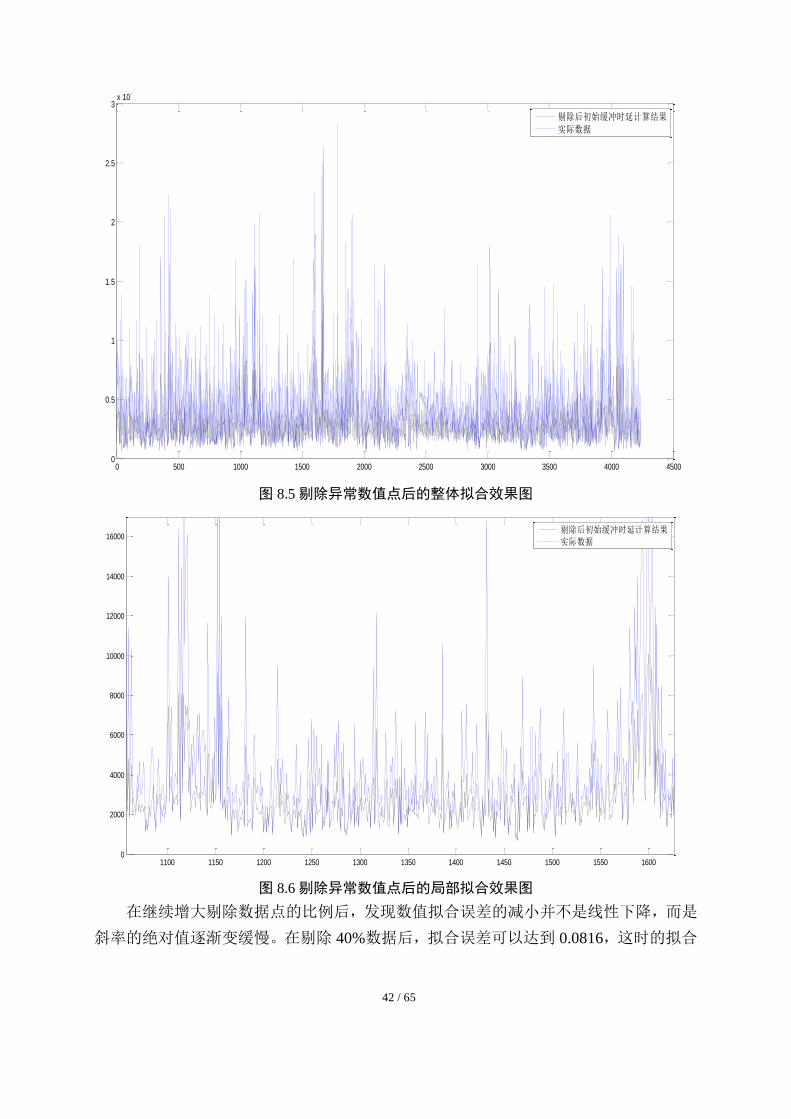
为进一步研究拟合的效果,在剔除新的实验数据中 20%的异常数据后(即对 80%数
据的适用性),拟合偏差 0.2556,去除异常数值后拟合的整体效果如图 8.5 所示。同理,
选取局部数据图如图 8.6 所示,此次的拟合效果较之前有较大的改进。
0 1000 2000 3000 4000 5000 60000
2
4
6
8
10
12x 10
4
初始缓冲时延计算结果
实际数据
1100 1200 1300 1400 1500 1600 1700
-2000
0
2000
4000
6000
8000
10000
12000
14000
初始缓冲时延计算结果
实际数据
42 / 65
图 8.5 剔除异常数值点后的整体拟合效果图
图 8.6 剔除异常数值点后的局部拟合效果图
在继续增大剔除数据点的比例后,发现数值拟合误差的减小并不是线性下降,而是
斜率的绝对值逐渐变缓慢。在剔除 40%数据后,拟合误差可以达到 0.0816,这时的拟合
0 500 1000 1500 2000 2500 3000 3500 4000 45000
0.5
1
1.5
2
2.5
3x 10
4
剔除后初始缓冲时延计算结果
实际数据
1100 1150 1200 1250 1300 1350 1400 1450 1500 1550 16000
2000
4000
6000
8000
10000
12000
14000
16000
剔除后初始缓冲时延计算结果
实际数据
43 / 65
精度非常高,但此时,高准确度的模型仅适用于补充数据中 60%的数据,所以,模型还
需进一步改进。
针对补充数据拟合效果不佳的问题,做出一些分析。从局部图可以看出,模型计算
结果总是小于实际数据,可以尝试进一步修改模型参数。可以修改的途径包括:
① 减小 MSS 的值(计算时取得 1460);
② 增大 k 的取值(也就是说增大 RTT 前乘的系数);
③ 增大𝑡𝑟𝑒𝑠𝑝的值。
8.3 卡顿时长占比模型对补充数据的拟合
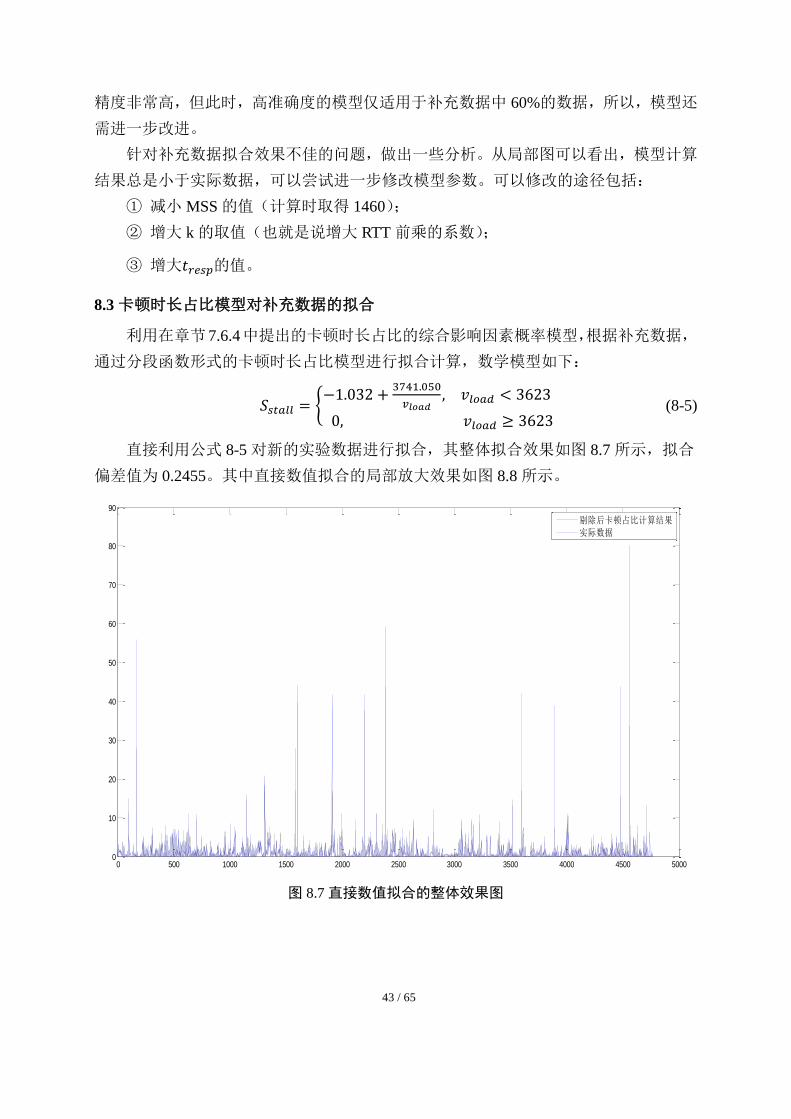
利用在章节 7.6.4中提出的卡顿时长占比的综合影响因素概率模型,根据补充数据,
通过分段函数形式的卡顿时长占比模型进行拟合计算,数学模型如下:
𝑆𝑠𝑡𝑎𝑙𝑙 = {−1.032 +
3741.050
𝑣𝑙𝑜𝑎𝑑, 𝑣𝑙𝑜𝑎𝑑 < 3623
0, 𝑣𝑙𝑜𝑎𝑑 ≥ 3623 (8-5)
直接利用公式 8-5 对新的实验数据进行拟合,其整体拟合效果如图 8.7 所示,拟合
偏差值为 0.2455。其中直接数值拟合的局部放大效果如图 8.8 所示。
图 8.7 直接数值拟合的整体效果图
0 500 1000 1500 2000 2500 3000 3500 4000 4500 50000
10
20
30
40
50
60
70
80
90
剔除后卡顿占比计算结果
实际数据
44 / 65
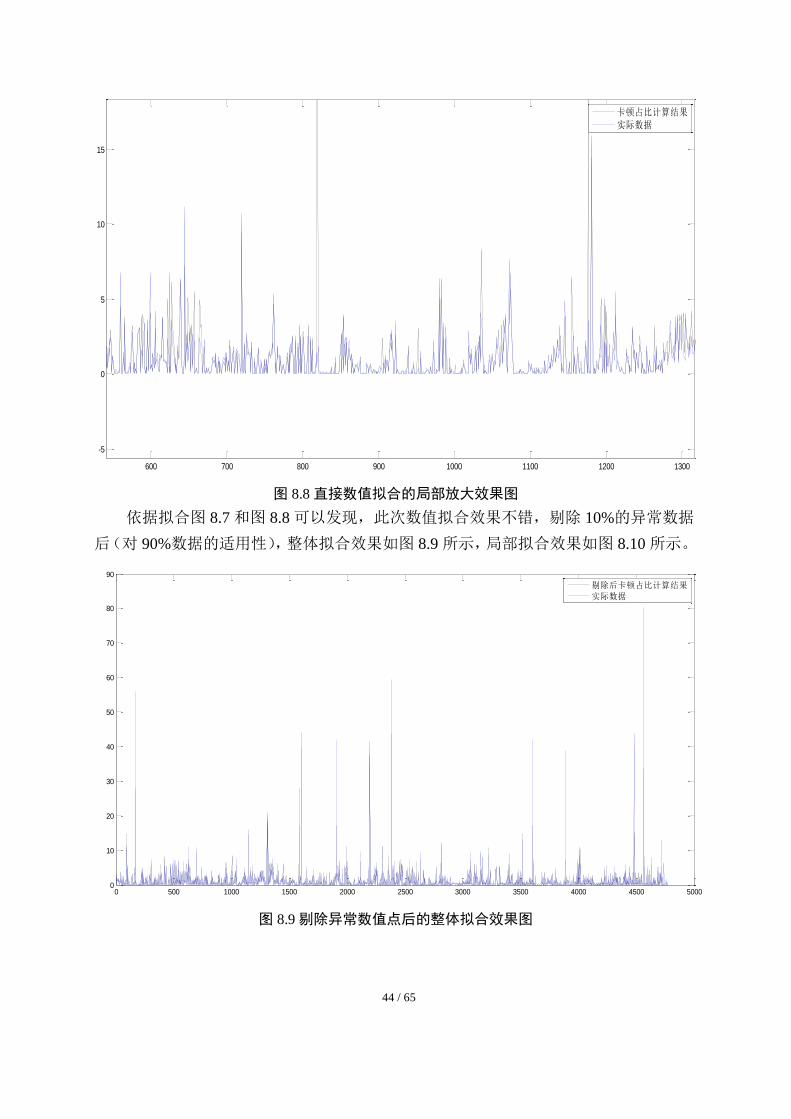
图 8.8 直接数值拟合的局部放大效果图
依据拟合图 8.7 和图 8.8 可以发现,此次数值拟合效果不错,剔除 10%的异常数据
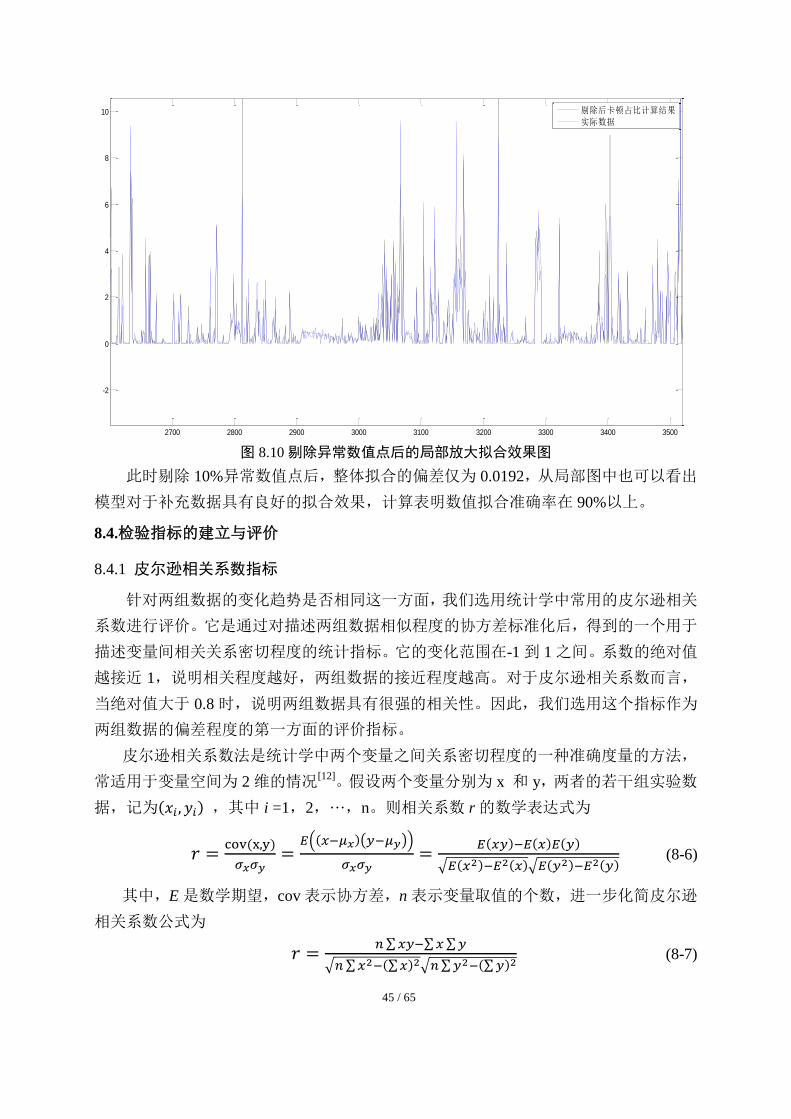
后(对 90%数据的适用性),整体拟合效果如图 8.9 所示,局部拟合效果如图 8.10 所示。
图 8.9 剔除异常数值点后的整体拟合效果图
600 700 800 900 1000 1100 1200 1300
-5
0
5
10
15
卡顿占比计算结果
实际数据
0 500 1000 1500 2000 2500 3000 3500 4000 4500 50000
10
20
30
40
50
60
70
80
90
剔除后卡顿占比计算结果
实际数据
45 / 65
图 8.10 剔除异常数值点后的局部放大拟合效果图
此时剔除 10%异常数值点后,整体拟合的偏差仅为 0.0192,从局部图中也可以看出
模型对于补充数据具有良好的拟合效果,计算表明数值拟合准确率在 90%以上。
8.4.检验指标的建立与评价
8.4.1 皮尔逊相关系数指标
针对两组数据的变化趋势是否相同这一方面,我们选用统计学中常用的皮尔逊相关
系数进行评价。它是通过对描述两组数据相似程度的协方差标准化后,得到的一个用于
描述变量间相关关系密切程度的统计指标。它的变化范围在-1 到 1 之间。系数的绝对值
越接近 1,说明相关程度越好,两组数据的接近程度越高。对于皮尔逊相关系数而言,
当绝对值大于 0.8 时,说明两组数据具有很强的相关性。因此,我们选用这个指标作为
两组数据的偏差程度的第一方面的评价指标。
皮尔逊相关系数法是统计学中两个变量之间关系密切程度的一种准确度量的方法,
常适用于变量空间为 2 维的情况[12]。假设两个变量分别为 x 和 y,两者的若干组实验数
据,记为(𝑥𝑖 , 𝑦𝑖) ,其中 i =1,2,···,n。则相关系数 r 的数学表达式为
𝑟 =cov(x,y)
𝜎𝑥𝜎𝑦=
𝐸((𝑥−𝜇𝑥)(𝑦−𝜇𝑦))
𝜎𝑥𝜎𝑦=
𝐸(𝑥𝑦)−𝐸(𝑥)𝐸(𝑦)
√𝐸(𝑥2)−𝐸2(𝑥)√𝐸(𝑦2)−𝐸2(𝑦) (8-6)
其中,E 是数学期望,cov 表示协方差,n 表示变量取值的个数,进一步化简皮尔逊
相关系数公式为
𝑟 =𝑛 ∑ 𝑥𝑦−∑ 𝑥 ∑ 𝑦
√𝑛 ∑ 𝑥2−(∑ 𝑥)2√𝑛 ∑ 𝑦2−(∑ 𝑦)2 (8-7)
2700 2800 2900 3000 3100 3200 3300 3400 3500
-2
0
2
4
6
8
10
剔除后卡顿占比计算结果
实际数据

46 / 65
记�̅�、�̅�分别为 n 次试验数据的平均值,则皮尔逊相关系数公式可化简为
𝑟 =∑ (𝑥𝑖−�̅�)𝑛
𝑖=1 (𝑦𝑖−�̅�)
√∑ (𝑥𝑖−�̅�)2 ∑ (𝑦𝑖−�̅�)2𝑛𝑖=1
𝑛𝑖=1
(8-8)
其中,相关系数 r 的取值范围为|r|≤1。皮尔逊相关系数满足以下特点:
①若|r|越接近 1,则表明 x 与 y 线性相关程度越高。
②若 r=-1,表明 x 与 y 之间为完全负线性相关关系。
③若 r=+1,表明 x 与 y 之间为完全正线性相关关系。
④若 r=0,表明两者不存在线性相关关系。
一般情况下,r 的取值在(-1,1)之间,相关程度可分为表 8-1 中所述的几种情况:
表 8-1 皮尔逊相关系数
相关系数 r 的大小 两个变量之间的相关程度
|r|≥0.8 高度相关
0.5≤|r|<0.8 中度相关
0.3≤|r|<0.5 低度相关
|r|<0.3 相关程度极弱,可视为非线性相关
8.4.2 修正的欧氏距离指标
针对实验数据和模型估测数据这 2 组数据之间的偏离距离大小情况的评价,我们采
用自主定义的两点间修正的欧氏距离 L 参数进行评价。定义修正的欧氏距离 L 如下:
𝐿 = 𝜎 ∙ 𝐿0 (8-9)
其中,𝐿0为通过模型计算出的用户侧变量与实际用户侧变量的偏差的绝对值,即两
点的欧氏距离;σ为修正系数,定义为𝐿0与计算得到的用户侧变量和实际用户侧变量中
较大值的比值,即计算出的用户侧变量与实际用户侧变量的相对偏差。其值在 0 到 1 之
间。这个值越接近 0,说明偏离越小,两组数据的接近程度越高。
它的实际意义为,在实际变量较小和实际变量较大时,即使偏差的绝对值𝐿0相同,
他们反映的偏离程度是不一样的。因此,不能简单的使用𝐿0进行评价。而直接使用相对
偏差σ做评价,对于计算出的变量或实际变量中有一方为 0 的情况下也不能有效区分。
所以,我们定义修正的欧氏距离 L 对两组数据的偏离距离大小进行评价。
8.4.3 辅助距离指标
为防止修正的欧氏距离 L 出现差错,我们引入一个简单直观的变量做辅助评价。这
个变量是,对于所有补充数据而言,通过模型计算得到的用户侧变量的均值与实际用户
侧变量的均值的相对偏差 LP。当 LP 较小时,自然说明偏离距离较小。它的物理意义是
十分明显的,再次不做赘述。由于它利用所有数据仅能得到一个结果,不能对适用范围

47 / 65
做出评价,不能直接用于模型评价指标。它的作用仅在于,防止使用自定义变量出现评
价偏差,起辅助校验检错作用。
接下来,我们将使用建立的这些评价指标,基于新补充的数据,对之前建立的两个
模型的适用性做出分析与评价。
8.5 模型拟合效果评价指标的量化分析
通过图 8-1 至图 8-8 的图像的直观分析,我们可以清楚地发现,模型在个别点时会
有极大的拟合偏差,模型拟合效果不佳。因此,需要进一步分析数值拟合的偏差,首先,
我们采取直接对所有补充数据利用量化指标计算评价值的方法,如表 8-2 所示。
表 8-2 量化指标对整体补充数据的直接评价值
数学模型 相关系数 修正的欧氏距离 辅助距离
初始缓冲时延综合影响数值模型 0.4088 0.1969 0.2528
初始缓冲时延综合影响物理模型 0.4092 0.3185 0.4935
卡顿占比综合影响模型 0.6028 0.2937 0.1971
在数据表 8-2 中,评价指标均为标准化后的变量,其值均在 0~1 之间。相关系数越
大越好,距离类的两个指标越接近 0 越好。
依据表 8-2 中数据,我们也能看出,我们通过图像直观得到的结论是没有问题的。
但由于个别点的影响,整体评价指标值并不是太高。接下来,我们会剔除部分不适用的
数据,来考虑模型的适用范围的大小。
因为皮尔逊相关系数与辅助距离指标均只能对所有 5295 组数据得到一个整体评价
的值,无法用于筛除不适用的异常值。所以筛选异常点的思路为,分别对每一组数据计
算它的修正的欧氏距离,剔除其中值较大的(越大说明该点拟合效果越差)。
将拟合效果较好的数据保留下来,计算符合指标要求的数据在总共 5295 组数据中
所占的比例,作为模型的适用范围大小的评价。
当保留下来的数据,通过我们之前建立的数学模型计算得到的用户侧变量与实际用
户侧变量的皮尔逊相关系数的值大于 0.8,则达到较好的数值拟合效果较好。
剔除部分不适用数据后,我们绘制三个评价指标的值随保留数据比例的变化趋势,
其中,图 8-11 和图 8-12 分别为初始缓冲时延综合影响数值模型和物理模型的指标变化
趋势图,图 8-13 为卡顿时长占比综合影响模型的指标变化趋势图。
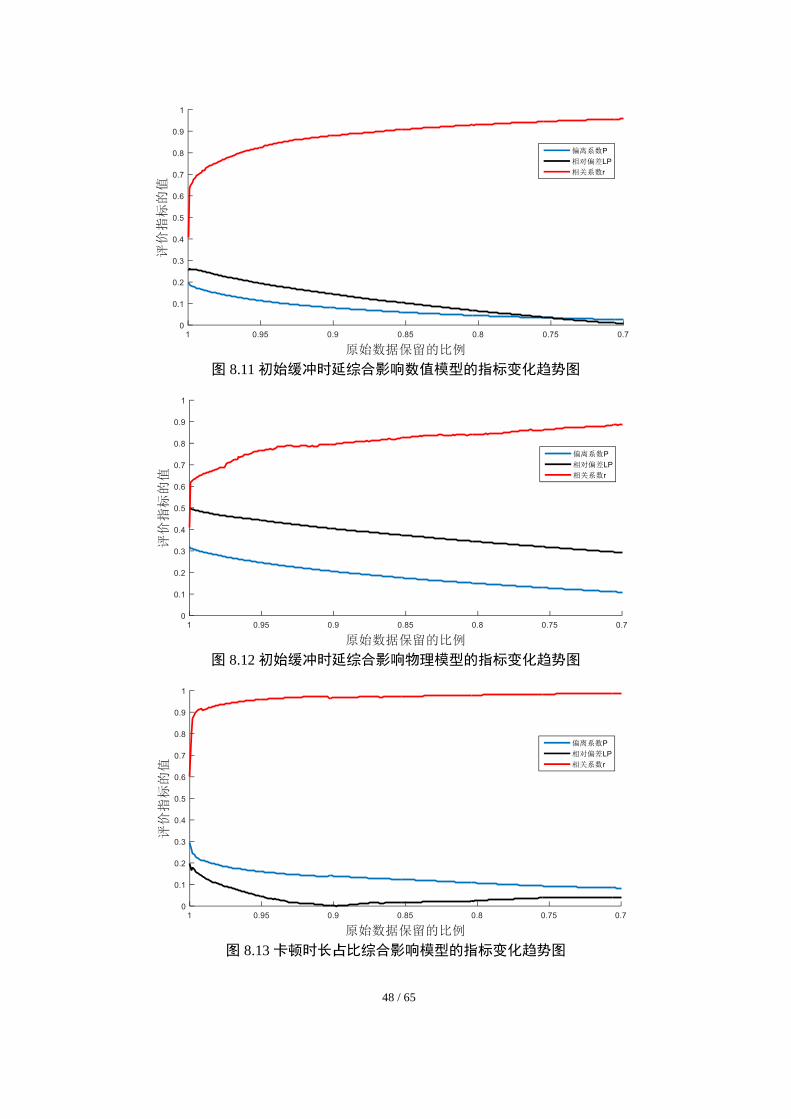
48 / 65
图 8.11 初始缓冲时延综合影响数值模型的指标变化趋势图
图 8.12 初始缓冲时延综合影响物理模型的指标变化趋势图
图 8.13 卡顿时长占比综合影响模型的指标变化趋势图
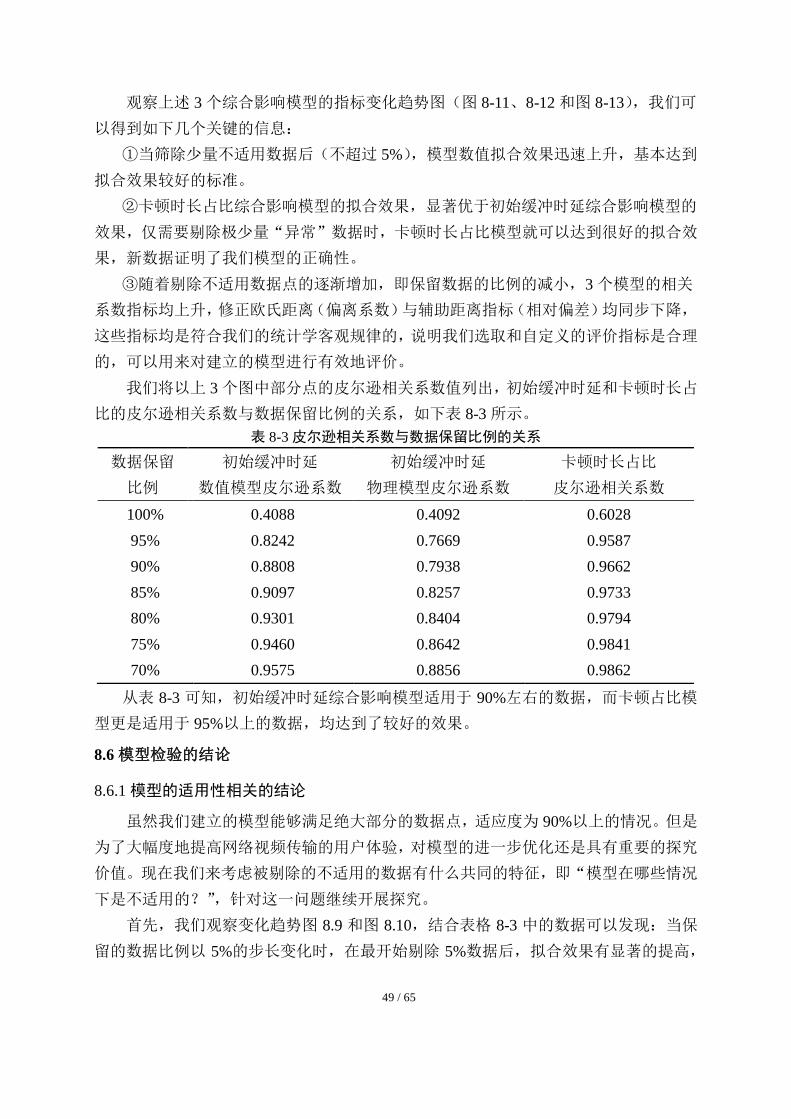
49 / 65
观察上述 3 个综合影响模型的指标变化趋势图(图 8-11、8-12 和图 8-13),我们可
以得到如下几个关键的信息:
①当筛除少量不适用数据后(不超过 5%),模型数值拟合效果迅速上升,基本达到
拟合效果较好的标准。
②卡顿时长占比综合影响模型的拟合效果,显著优于初始缓冲时延综合影响模型的
效果,仅需要剔除极少量“异常”数据时,卡顿时长占比模型就可以达到很好的拟合效
果,新数据证明了我们模型的正确性。
③随着剔除不适用数据点的逐渐增加,即保留数据的比例的减小,3 个模型的相关
系数指标均上升,修正欧氏距离(偏离系数)与辅助距离指标(相对偏差)均同步下降,
这些指标均是符合我们的统计学客观规律的,说明我们选取和自定义的评价指标是合理
的,可以用来对建立的模型进行有效地评价。
我们将以上 3 个图中部分点的皮尔逊相关系数值列出,初始缓冲时延和卡顿时长占
比的皮尔逊相关系数与数据保留比例的关系,如下表 8-3 所示。
表 8-3 皮尔逊相关系数与数据保留比例的关系
数据保留
比例
初始缓冲时延
数值模型皮尔逊系数
初始缓冲时延
物理模型皮尔逊系数
卡顿时长占比
皮尔逊相关系数
100% 0.4088 0.4092 0.6028
95% 0.8242 0.7669 0.9587
90% 0.8808 0.7938 0.9662
85% 0.9097 0.8257 0.9733
80% 0.9301 0.8404 0.9794
75% 0.9460 0.8642 0.9841
70% 0.9575 0.8856 0.9862
从表 8-3 可知,初始缓冲时延综合影响模型适用于 90%左右的数据,而卡顿占比模
型更是适用于 95%以上的数据,均达到了较好的效果。
8.6 模型检验的结论
8.6.1 模型的适用性相关的结论
虽然我们建立的模型能够满足绝大部分的数据点,适应度为 90%以上的情况。但是
为了大幅度地提高网络视频传输的用户体验,对模型的进一步优化还是具有重要的探究
价值。现在我们来考虑被剔除的不适用的数据有什么共同的特征,即“模型在哪些情况
下是不适用的?”,针对这一问题继续开展探究。
首先,我们观察变化趋势图 8.9 和图 8.10,结合表格 8-3 中的数据可以发现:当保
留的数据比例以 5%的步长变化时,在最开始剔除 5%数据后,拟合效果有显著的提高,

50 / 65
之后效果不是十分明显。这说明最开始剔除的数据是“真正”的模型不适用的数据,因此
我们来分别对两个模型分析最初剔除的 5%的数据有什么共同的特征。
对于初始缓冲时延综合影响数值模型而言,受初始缓冲峰值速率,视频码率,E2E
RTT 等因素的影响。对所有 5295 组数据计算平均值得,初始缓冲峰值速率的平均值为
12004kbps,视频码率的平均值为 3017kbps,E2E RTT 的平均值为 69.2ms。当剔除数据
分别为 1%,3%,5%时被剔除数据的相应的平均值如下表 8-4 所示,
表 8-4 数值模型被剔除数据的各指标的均值
剔除数据
比例
被剔除数据的初始缓
冲峰值速率/kbps
被剔除数据的视
频码率/kbps
被剔除数据的
E2E RTT/ms
1% 8176 3007 72.4
3% 8093 3001 77.2
5% 8463 3005 74.5
同理,相对于初始缓冲时延综合影响物理模型而言,当剔除数据分别为 1%,3%,
5%时,被剔除数据的相应的平均值如下表 8-5 所示。
表 8-5 物理模型被剔除数据的各指标的均值
剔除数据
比例
被剔除数据的初始缓
冲峰值速率/kbps
被剔除数据的视
频码率/kbps
被剔除数据的
E2E RTT/ms
1% 8700 2996 65.8
3% 7333 2997 75.3
5% 7082 3000 75.2
从中我们看出,被剔除数据的 E2E RTT 没有明显的规律,而初始缓冲峰值速率一
直小于全体数据的平均值。经过研究大量实验数据后证实,建立的初始缓冲时延综合影
响模型不适用于初始缓冲峰值速率极小的情况下。
对于卡顿时长占比的综合模型而言,卡顿时长占比的主要影响因素为播放阶段平均
速率。我们对新增实验数据表中所有 5295 组数据计算平均值得,播放阶段平均速率的
平均值为 3495kbps。当剔除数据分别为 1%,3%,5%时,被剔除数据的相应的播放阶
段平均速率平均值如下表 8-6 所示。
表 8-6 被剔除数据的速率均值变化情况表
剔除数据比例 被剔除数据的播放阶段平均速率/kbps
1% 599
3% 1098
5% 1274
从数据表 8-5 中可以发现,被剔除数据的播放阶段平均速率的平均值一直显著小于
全体数据的平均值。所以,我们认为建立的卡顿时长占比综合影响模型,不能够很好地

51 / 65
适用于播放阶段平均速率非常小的情况下。但针对于播放阶段平均速率非常小的情况,
我们在章节 7.6.4 中已经阐述,并且建立了含概率因子的分段函数模型。
8.6.2 模型检验的总结与展望
通过这一部分的分析,我们得到如下结论:
①本文建立的初始缓冲时延综合影响模型,适用于 90%以上的情况,其中,不适用
的场合为初始缓冲峰值速率极小的情况。
②本文建立的卡顿时长占比综合影响模型,适用于 95%以上的情况,其中不适用的
场合为播放阶段平均速率极小的情况。
③初始缓冲时延、卡顿时长占比模型对于补充数据的拟合效果很好,对 90%以上的
补充数据都可以很高精度的拟合和估计,因此可以应用实际的网络视频传输领域。
我们建立的初始缓冲时延、卡顿时长占比模型拟合实验数据的趋势还是非常准确的。
但是存在少量“异常”数据,模型检验评价中进行定量的剔除考虑,并且对于“异常”
数据产生的原因进行了分析。
更加精确、普适性高的模型还需要进一步深入研究。
九、模型的可用性分析
为研究文中所建立的数学模型的可用性,我们引入一项该领域常用的评价指标:用
户观看移动视频主观体验的客观评价分数 vMOS(Video Mean Opinion Score)。
针对 vMOS 指标,华为 mLAB、联通公司等相继进行了一系列改进,陈楚雄等人研
究的《视频业务体验评估和优化提升探讨》指出,vMOS 是视频片源清晰度、视频初始
缓冲、视频卡顿等业务关键绩效指标(Key Performance Indicator, KPI)的综合,建立了这
主观感受(MOS 1~5 分)和几个 KPI 指标之间的映射关系[3]。映射关系是基于人因工程
的实验分析得来。其中,vMOS 的计算公式为:
𝑣𝑀𝑂𝑆 = 𝑠𝑄𝑢𝑎𝑙𝑖𝑡𝑦 × (1
5(𝑃1+𝑃2)× (𝑃1 × 𝑠𝐿𝑜𝑎𝑑𝑖𝑛𝑔 + 𝑃2 × 𝑠𝑆𝑡𝑎𝑙𝑙𝑖𝑛𝑔)) (9-1)
其中,sQuality 表示视频质量,取决于视频本身的分辨率, 分辨率越高,其 sQuality
值越高,其中 360P~5K 的分辨率所对应的 sQuality 分值分别为 2.8~5 分。初始缓冲时延
分值𝑠𝐿𝑜𝑎𝑑𝑖𝑛𝑔和卡顿占比分值𝑠𝑆𝑡𝑎𝑙𝑙𝑖𝑛𝑔的权重分别为𝑃1和𝑃2,一般情况下取值分为 0.23
和 0.27。初始缓冲时延及卡顿占比分值取值情况如表 9-1 所示,从表中的 KPI 得分对应
关系可以发现,只要通过我们所建立的模型计算出视频初始缓冲时延、卡顿时长占比等
指标,就可以非常便捷地计算出用户体验评分 vMOS 值。
为了计算 vMOS 值,我们将模型中有关于初始缓冲时延和卡顿时长占比的一部分计
算公式,整理如下:

52 / 65
表 9-1 初始缓冲时延和卡顿占比分值与𝑡𝑤𝑎𝑖𝑡与𝑆𝑠𝑡𝑎𝑙𝑙的对应关系
分值 初始缓冲时延𝑡𝑤𝑎𝑖𝑡/ms 卡顿占比𝑆𝑠𝑡𝑎𝑙𝑙/%
5 100 0
4 1000 5
3 3000 10
2 5000 15
1 10000 30
(1) 初始缓冲时延的计算公式
①由章节6.5的正规方程法求解,得到的初始缓冲时延的综合影响因素数值模型为:
𝑡𝑤𝑎𝑖𝑡 = −224.87 +2.25∗107
𝑣𝑡ℎ𝑟𝑝+ 15.29 ∗ 𝑅𝑇𝑇 (9-2)
②由章节 6.6 的物理层改进模型得到的综合影响关系,初始缓冲时延计算公式为:
𝑡𝑤𝑎𝑖𝑡 = 8 ∗ 𝐷𝑎𝑡𝑎−(26−1)∗𝑀𝑆𝑆
𝑣𝑡ℎ𝑟𝑝+ 13.5 ∗ 𝑅𝑇𝑇 + 𝑡𝑟𝑒𝑠𝑝 (9-3)
(2) 卡顿时长占比的计算公式
①由章节 7.5 的卡顿时长占比综合影响因素模型,简化的卡顿时长占比计算公式为:
𝑆𝑠𝑡𝑎𝑙𝑙 = −0.131 +936.768
𝑣𝑙𝑜𝑎𝑑 (9-4)
②由章节 7.6 的分段函数优化后的卡顿时长占比综合影响因素模型,其计算公式为:
𝑆𝑠𝑡𝑎𝑙𝑙 = {−1.032 +
3741.050
𝑣𝑙𝑜𝑎𝑑, 𝑣𝑙𝑜𝑎𝑑 < 3623
0, 𝑣𝑙𝑜𝑎𝑑 ≥ 3623 (9-5)
③由章节 7.7 的残差分析与概率模型,得到卡顿时长占比综合影响因素的概率模型:
𝑆𝑠𝑡𝑎𝑙𝑙 = {−1.032 +
3741.050
𝑣𝑙𝑜𝑎𝑑+ 𝑒(𝑣𝑙𝑜𝑎𝑑), 𝑣𝑙𝑜𝑎𝑑 < 3623
0, 𝑣𝑙𝑜𝑎𝑑 ≥ 3623 (9-6)
其中𝑒(𝑣𝑙𝑜𝑎𝑑)~𝑁(0, 𝜎(𝑣𝑙𝑜𝑎𝑑)2),且
𝜎(𝑣𝑙𝑜𝑎𝑑) = {
1326
𝑣𝑙𝑜𝑎𝑑− 0.3605, 𝑣𝑙𝑜𝑎𝑑 < 2857
0.1, 𝑣𝑙𝑜𝑎𝑑 ≥ 2857 (9-7)
将公式 9-2 至公式 9-7 中的初始缓冲时延和卡顿时长占比计算公式,代入 vMOS 值
的计算公式 9-1,则实现了将网络侧变量(初始缓冲峰值速率、播放阶段平均下载速率、
E2E RTT)和用户体验评价变量(初始缓冲时延、卡顿时长占比)之间的计算“桥梁”
给成功建立了起来。通过网络侧变量能够直接地计算出用户体验评价变量,并且通过公
式 9-1 可便捷地求解 vMOS 值,即用户观看移动视频主观体验的客观评价分数。其中不
同视频分辨率的 vMOS 值对于关系如表 9-2 所示,依据表中的数据可以直接判断用户对
网络视频传输情况的满意程度。

53 / 65
表 9-2 不同视频分辨率的 vMOS 值
视频分辨率 vMOS(优秀) vMOS(良好)
1080P 4.0 3.6
720P 3.6 3.2
480P 3.2 2.8
320P 2.3 1.9
伴随着 4K/8K高清视频越来越受到观众的推崇,对网络侧相关参数指标的要求也越
来越高。视频分辨率越高,则 vMOS 值期望值越大。利用我们建立的模型可以定量地分
析网络视频传输的各项指标的影响,并且由于我们所建立的模型具有比较简洁的数学表
达形式,能够通过 vMOS 值期望值,利用我们的模型计算公式求对网络侧变量的相关参
数的值,即数值方法求逆解问题比较简便。
综上所述,我们所建立的数学模型能够非常好地满足实际需求,能够帮助网络运营
商进一步地提高用户观看移动视频主观体验的客观评价分数,提高我们对网络的良好体
验程度,推进互联网业务升级的进程,更好地改善我们的生活质量。
十、模型的科学性分析
10.1 假设和思维的合理性
在系统建模过程中,通过控制变量法,对影响用户体验评价变量(初始缓冲时延,
卡顿时长占比)的因素逐一进行分析,假设合理地忽略了其他因素的影响,并全面考虑
实验数据库中各影响因素之间的内部联系。在数学模型与实验数据的拟合之间,利用多
种数值拟合算法,进行对比,最终选取最佳的拟合方法,而且将拟合的结果反复利用实
际数据进行矫正,最终得到优化的综合影响因素模型,具有较好的合理性。
10.2 方法的科学性
本文利用 MATLAB 对模型进行数值拟合与求解,首先分析初始缓冲时延、卡顿时
长占比的原理,再综合考虑物理意义和数据拟合情况得到模型,通过实际工程意义和实
验数据拟合结果,双重拟合效果,满足模型要求,方法科学合理,并通过对初始缓冲峰
值速率,播放阶段平均下载速率,E2E RTT 的函数建模,实现了最优的拟合。
利用新增的实验数据检验了我们的模型,并且提出皮尔逊相关系数指标、修正的欧
式距离指标和辅助距离指标等参数,有效地评价了数学模型的特点,客观地阐述了我们
模型的优劣,方法科学合理。
10.3 方法的可靠性
根据物理意义构建了初始缓冲时延和卡顿时长占比与初始缓冲峰值速率、播放阶段
平均下载速率、E2E RTT 之间的数学模型。依据各种影响因素的实际物理意义,通过物

54 / 65
理意义做出初步估计,然后通过函数关系进行数据拟合,最终得到利用 Matlab 及其 cftool
工具箱实现了数值计算,并提出模型的评价指标,多次优化了模型。方法具有较高的合
理性和可靠性。
十一、模型的评价
11.1 模型的优点
(1)针对初始缓冲时延及卡顿时长占比模型,提出了由数据拟合得到的以及物理意义
分析得到的两种模型,可以更加精确地表达在本题前提条件下的用户评价变量和
网络侧变量间函数关系,同时全面考虑了多个因素影响,推广性更强。
(2)模型探讨了一般性情况,均利用 Matlab 程序实现了数据拟合,具有普适性。
(3)模型提出了皮尔逊相关系数等多个量化评价指标,并多次对模型进行修正,在新
实验数据中也验证了模型的准确性。
(4)模型的表达形式简洁,具有较好的可用性。
11.2 模型的缺点
(1)在数据拟合过程中,去除了一部分“异常”干扰点,存在一定的误差。
(2)在建立卡顿占比模型时,由于缺乏充分的理论依据的支撑,无法直接依据物理意
义计算含参方程,拟合函数的对实际网络传输情况的适用性有待提高。
(3)模型未深入研究提高用户体验指标的具体措施、成本等具体模型,在后期需要进
一步完善和改进。
11.3 模型的推广与应用
我们建立的模型对影响视频体验指标的各种因素,按初始缓冲峰值速率,播放阶段
平均下载速率,E2E RTT 等 3 个维度进行分析探讨,并量化分析了这 3 个因素对于用户
体验评价变量(初始缓冲时延,卡顿时长占比)的影响,并且在我们建立的模型中,能
够定量的表述了将各个因素间的影响关系,关系函数均经过实验数据的验证,能够准确、
恰当地反映实际网络视频传输的情况,模型具备较好的实用价值。
建议运营商在制定提高用户观看移动视频主观体验的客观评价分值的具体措施时,
应该综合地考虑网络侧变量和用户体验变量之间的关系,并且适应网络观众对于视频传
输的切实需求,人性化地改善用户体验,这样既能够提升用户的满意度,又能够实现对
于数据和宽带资源的有效利用。我们建立的模型能够定量计算网络侧变量和用户体验变
量之间的关系,但进一步地推广应用还需要深入研究。
总结文中对网络侧估计终端用户视频体验建模的相关工作,其研究方法和工作思路
均可以应用于改进网络视频传输领域的用户体验,对日益重要的视频优化工作开展有一
定的指导意义。

55 / 65
十二、参考文献
[1]华为技术有限公司,移动视频报告,2016 年.
[2]华为 mLab、iLab,基于移动视频的移动承载网络要求白皮书,2016 年
[3]陈楚雄, 柯江毅, 覃道满. 视频业务体验评估和优化提升探讨[J]. 邮电设计技术,
2017(2).
[4]华为 mLab,MBB 时代基于用户体验建网的目标研究——业务等待时间.
[5]华为 iLab,基于视频体验的固定承载网络要求白皮书,2016 年.
[6]姜启源,数学模型,北京:高等教育出版社,2004 年.
[7]龚纯、王正林著,精通 MATLAB 最优化计算,北京:电子工业出版社,2009 年.
[8]Duane H,Bruce L,著,精通 MATLAB 7,朱广峰译,北京,清华大学出版社,2006 年.
[9]成实,王浩东,王伟,詹丽平. 基于互联网DPI的视频业务体验质量分析方法研究[J]. 软
件导刊,2017,(02):141-143.
[10]Staelens N, Pinson M, Corriveau P, et al. Measuring video quality in the network: from
quality of service to user experience[C]// 9th International Workshop on Video Processing and
Consumer Electronics (VPQM 2015). 2015:5-6.
[11]康亚谦. 无线视频流业务的用户体验质量估计模型及其应用[D].浙江大学,2014年.
[12] HUAWEI TECHNOLOGIES CO. LTD. Huawei launches video experience measurement
system-U-vMOS[J]. Voice & Data, 2015.
[12]沈继红,高振滨,张晓威. 数学建模,北京:清华大学出版社,2011.10 P48-50.
[13]史志明. 网络视频质量评估方法与测试技术研究[D].北京邮电大学,2013年.
[14]Huifang Chen, Lei Xie, Yaqian Kang. Mobile video service user experience quality
evaluation method based on ordinal regression:, CN 103152599 A[P]. 2013.
[15]Yue T, Wei A M, Wang H B, et al. A comprehensive data-driven approach to evaluating
quality of experience on large-scale internet video service[C]// International Conference on
Natural Computation and, Fuzzy Systems and Knowledge Discovery. 2016:1479-1486.
[16]陈希宏. 移动终端视频质量主观评价体系的研究与实现[D].北京邮电大学,2015年.
[17] Wang X, Wei A, Yang Y, et al. Characterizing the correlation between video types and
user quality of experience in the large-scale internet video service[C]// International
Conference on Fuzzy Systems and Knowledge Discovery. IEEE, 2016:2086-2092.

56 / 65
十三、附 录
附录 1:𝒕𝒔𝒕𝒂𝒍𝒍-𝒗(𝒕)关系模型的计算过程(以 k=2 为例)
若卡顿次数𝑁𝑠𝑡𝑎𝑙𝑙 = 2,必然在第一次卡顿后将缓冲区数据消耗殆尽,故有:
∫ (𝑣𝑝𝑙𝑎𝑦 − 𝑣(𝑥))𝑑𝑥𝑡𝑝𝑙𝑎𝑦
𝑡1+∆𝑡1
> 𝐷𝑟𝑒𝑝𝑙𝑎𝑦
即 φ(𝑡𝑝𝑙𝑎𝑦) − φ(𝑡1 + ∆𝑡1) > 𝐷𝑟𝑒𝑝𝑙𝑎𝑦 (1)
从第一次卡顿重播放后到缓冲区数据恰好消耗完时,开始第二次卡顿:
∫ (𝑣𝑝𝑙𝑎𝑦 − 𝑣(𝑥))𝑑𝑥𝑡2
𝑡1+∆𝑡1
= 𝐷𝑟𝑒𝑝𝑙𝑎𝑦
即 ∫ (𝑣𝑝𝑙𝑎𝑦 − 𝑣(𝑥))𝑑𝑥𝑡2
0− ∫ (𝑣𝑝𝑙𝑎𝑦 − 𝑣(𝑥))𝑑𝑥
𝑡1+∆𝑡1
0= 𝐷𝑟𝑒𝑝𝑙𝑎𝑦
∴ φ(𝑡2) − φ(𝑡1 + ∆𝑡1) = 𝐷𝑟𝑒𝑝𝑙𝑎𝑦 ∴ φ(𝑡2) = 𝐷𝑟𝑒𝑝𝑙𝑎𝑦 − φ(𝑡1 + ∆𝑡1)
所以 𝑡2 = 𝜑−1(𝐷𝑟𝑒𝑝𝑙𝑎𝑦 + φ(𝑡1 + ∆𝑡1)). (2)
从卡顿到重播放的过程中,加载数据量等于重播放门限:
∫ 𝑣(𝑥)𝑑𝑥𝑡2+∆𝑡2
𝑡2
= 𝐷𝑟𝑒𝑝𝑙𝑎𝑦
即 ∫ 𝑣(𝑥)𝑑𝑥 − ∫ 𝑣(𝑥)𝑑𝑥𝑡2
0
𝑡2+∆𝑡2
0= 𝐷𝑟𝑒𝑝𝑙𝑎𝑦
即 ∫ 𝑣(𝑥)𝑑𝑥𝑡2+∆𝑡2
0= 𝐷𝑟𝑒𝑝𝑙𝑎𝑦 + ∫ 𝑣(𝑥)𝑑𝑥
𝑡2
0
故 ∆𝑡2 + 𝑡2 = ω−1 (𝐷𝑟𝑒𝑝𝑙𝑎𝑦 + ω(𝑡2))
所以 ∆𝑡2 = ω−1 (𝐷𝑟𝑒𝑝𝑙𝑎𝑦 + ω(𝑡2)) − 𝑡2 (3)
重播放后,如果缓冲区数据再次消耗殆尽则会造成第三次卡顿,因此需控制在视频
播放时长𝑡𝑝𝑙𝑎𝑦内缓冲区数据大于或等于零,故有:
∫ (𝑣𝑝𝑙𝑎𝑦 − 𝑣(𝑥))𝑑𝑥𝑡𝑝𝑙𝑎𝑦
𝑡2+∆𝑡2
≤ 𝐷𝑟𝑒𝑝𝑙𝑎𝑦
即 φ(𝑡𝑝𝑙𝑎𝑦) − φ(𝑡2 + ∆𝑡2) ≤ 𝐷𝑟𝑒𝑝𝑙𝑎𝑦 (4)
总卡顿时长为第一次卡顿时长和第二次卡顿时长之和,即:
𝑡𝑠𝑡𝑎𝑙𝑙 = ∆𝑡1 + ∆𝑡2 (5)
由此,即可计算得到:当k=2时,𝑡𝑠𝑡𝑎𝑙𝑙与v(t)之间的函数关系。其中,式(1)、(4)为
分类条件,(2)、(3)、(5)为推论。

57 / 65
附录 2: 关键程序算法
附录 2.1:读取 EXCEL 表格数据并转存为 txt 文件的程序
%Name: readExcel_saveTxt.m clear; close all; clc;
filename = 'SpeedVideoDataforModeling.xlsx';
origData = xlsread(filename); % read data
save origData.txt origData -ascii; % save data
附录 2.2:正规方程组函数
%Name: normalEqn.m function [theta] = normalEqn(X, y)
% input:X, y
% output:theta
theta = zeros(size(X, 2), 1);
theta = inv(X' * X) * X' *y; end
附录 2.3:初始缓冲时延模型相关程序算法
%Name: bufferModel.m
%% ======Part1:初始化=========
clear; close all; clc;
%% ======Part2:载入数据=======
fprintf('Loading data... \n');
load('origData.txt');
% data has previously been read and saved as .txt
y1 = origData(: , 5); % y1:初始缓冲时延
y2 = origData(: , 6); % y2:卡顿时长占比
X = origData(: , [2, 3, 4]); % X:三大影响因素
x1 = X(: , 1); % x1:初始缓冲峰值速率
x2 = X(: , 2); % x2:端到端环回时间(E2E RTT)
x3 = X(: , 3); % x3:播放阶段平均下载速率
m = size(X, 1);
%% ======Part3:绘制散点图======
%%缓冲时延和初始缓冲峰值速率的数据
fprintf('Ploting data(vThrp, tWait)... \n');
% Randomly select 200 points
randIndex = randperm(m); % 生成1~m的随机序列
index1 = randIndex(1:500); relation1 = [x1 , y1];
samp1 = relation1(index1, :);
plot(samp1(:,1), samp1(:,2), 'k+', 'LineWidth', 1.5);
xlabel('初始缓冲峰值速率(kbps)');
ylabel('初始缓冲时延(ms)');
grid on;
fprintf('Program paused. Press enter to continue.\n');
fprintf('\n');
pause;
%% ====Part4:拟合tWait&vThrp参数======
fprintf('Solving tWait&vThrp with normal equations... \n');
x1_inv = 1 ./ x1;
% x1_inv是x1各元素的倒数,非逆!
% Add intercept term to x1_inv
x1_invPlus = [ones(m,1) x1_inv];
% Initialize prameter : theta1
theta1 = zeros(2, 1);
% Compute theta1
theta1 = normalEqn(x1_invPlus, y1);
% Give answer fprintf('theta1 computed from normal equations: \n');
fprintf('%d \n', theta1);
fprintf('\n');
fprintf('Program paused. Press enter to continue. \n'); fprintf('\n');
pause;
%% ====Part5:显示tWait&vThrp拟合结果====
fprintf('Visualizing result... \n')
x1_max = max(x1);
x1_toDraw = [0:1000:x1_max]'; x1_inv_toDraw = [ones(length(x1_toDraw), 1) , 1 ./
x1_toDraw];
h = x1_inv_toDraw * theta1;
hold on; plot(x1_toDraw, h);
title('tWait = theta0 + theta1*1/vThrp');
l = legend('original data' , 'hypothesis'); title(l, sprintf('theta0 = %f\ntheta1
= %f',theta1(1),theta1(2)));
hold off;
grid on; fprintf('Program paused. Press enter to continue.\n');
fprintf('\n');
pause;
%% ======Part6:绘制散点图=======
%%控制峰值速率,作缓冲时延和E2E RTT的散点图
fprintf('Ploting data(RTT, tWait)... \n')
x1_ave = sum(x1) / m;
index2 = find(x1 > (x1_ave - 50) & x1 < (x1_ave + 50)); relation2 = [x2 y1];
samp2 = relation2(index2 , :);
figure;
plot(samp2(: , 1), samp2(: , 2), 'k+', 'LineWidth', 1.5); xlabel('E2E RTT(ms)');
ylabel('初始缓冲时延(ms)');
grid on;
fprintf('Program paused. Press enter to continue.\n');

58 / 65
fprintf('\n');
pause;
%% =======Part7:绘制散点图======
%%作缓冲时延、峰值速率和E2E RTT的散点图
fprintf('Ploting data(1/vThrp, RTT, tWait)... \n');
relation3 = [x1_inv , x2 , y1];
% samp3 = relation3(index1, :); samp3 = relation3;
figure;
plot3(samp3(:, 1), samp3(:, 2),samp3(:, 3), 'k+', 'LineWidth',
1.5); xlabel('1/vThrp');
ylabel('RTT');
zlabel('tWait');
grid on; fprintf('Program paused. Press enter to continue.\n');
fprintf('\n');
pause;
%% ====Part8:拟合tWait&vThrp&RTT参数====
fprintf('Solving tWait&vThrp&RTT with normal
equations... \n') % Create matrix x1_x2
x1_x2 = [x1_invPlus, x2];
% Initialize Prameter: theta2
theta2 = zeros(3, 1); % Compute theta2
theta2 = normalEqn(x1_x2, y1);
% Give answer
fprintf('theta2 computed from normal equations: \n'); fprintf('%d \n', theta2);
fprintf('\n');
fprintf('Program paused. Press enter to continue. \n');
fprintf('\n'); pause;
%% ====Part9:显示tWait&vThrp&RTT拟合结果====
fprintf('Visualizing result... \n')
hold on;
leng1 = max(samp3(:,1));
step1 = leng1/10; leng2 = max(samp3(:,2));
step2 = leng2/10;
[a, b] = meshgrid(0:step1:leng1, 0:step2:leng2);
c = theta2(1) + theta2(2)*a +theta2(3)*b; surf(a, b, c, 'EdgeColor','none', 'FaceAlpha',0.8);
grid on;
title('tWait = theta0 + theta1*1/vThrp + theta2*RTT'); l = legend('original data' , 'hypothesis');
title(l, sprintf('theta0 = %f\ntheta1 = %f\ntheta2 = %f'...
,theta2(1),theta2(2),theta2(3)));
hold off; fprintf('Program paused. Press enter to continue. \n');
fprintf('\n');
pause;
%% ======Part10:模型改进1======
%% 1.散点图
fprintf('Ploting data(1/vThrp, RTT, tWait)... \n');
relation3 = [x1_inv , x2 , y1];
% samp3 = relation3(index1, :); samp3 = relation3;
figure;
plot3(samp3(:, 1), samp3(:, 2),samp3(:, 3), 'k+',…
'LineWidth', 1.5);
xlabel('1/vThrp'); ylabel('RTT');
zlabel('tWait');
fprintf('Program paused. Press enter to continue.\n');
fprintf('\n'); pause;
%% 2.显示结果
fprintf('Visualizing result... \n') hold on;
leng1 = max(samp3(:,1));
step1 = leng1/10;
leng2 = max(samp3(:,2)); step2 = leng2/10;
Tload = 200;
N = 6;
k = 6; [a, b] = meshgrid(0:step1:leng1, 0:step2:leng2);
c = Tload + 8*(4000*2934/8 - 1460*(2^N - 1))*a +…
(1.5 + k + N)*b;
surf(a, b, c, 'EdgeColor','none', 'FaceAlpha',0.8); grid on;
title('改进后的初始缓冲时延模型示意图');
hold off;
fprintf('Program paused. Press enter to continue. \n');
fprintf('\n');
pause;
%% =====Part11:模型改进2====
%% 1.散点图
fprintf('Ploting data(1/vThrp, RTT, tWait)... \n');
relation3 = [x1_inv , x2 , y1]; % samp3 = relation3(index1, :);
samp3 = relation3;
figure;
plot3(samp3(:, 1), samp3(:, 2),samp3(:, 3), 'k+',… 'LineWidth', 1.5);
xlabel('1/vThrp');
ylabel('RTT');
zlabel('tWait'); fprintf('Program paused. Press enter to continue.\n');
fprintf('\n');
pause;
%% 2.显示结果
fprintf('Visualizing result... \n')
hold on; leng1 = max(samp3(:,1));
step1 = leng1/100;
leng2 = max(samp3(:,2));
step2 = leng2/100; [a, b] = meshgrid(0:step1:leng1, 0:step2:leng2);
N = floor(log(b.*(1./a)/(8*10*1460))/log(2) + 1);
N(N<0) = 0;
c = (8+N).*b + 8*(4000*2934/8 - (2.^N - 1)*… (10*1460)).*a + 200;
surf(a, b, c, 'EdgeColor','none', 'FaceAlpha',0.8);
grid on;
title('新模型示意图');
hold off;
%% ===Part12:计算一些与误差相关的量===
%%(误差在10%以下的数据所占比重)
%% 模型1,原始数据

59 / 65
h_1 = theta2(1) + theta2(2) * x1_inv + theta2(3) * x2;
residual_1 = y1 - h_1;
error_1 = residual_1./y1; length(find(abs(error_1)<0.1))/m
% 模型2,原始数据
h_2 = 200 + 8*(4000*3017/8 - 1460*(2^6 - 1)) * x1_inv + (1.5 + 6 + 6) * x2;
residual_2 = y1 - h_2;
error_2 = residual_2./y1;
length(find(abs(error_2)<0.1))/m
% 模型3,原始数据
N = floor(log(x2.*x1/(8*10*1460))/log(2) + 1); N(N<0) = 0;
h_3 = (8+N).*x2 + 8*(4000*2934/8 - (2.^N -
1)*(10*1460)).*x1_inv + 200;
residual_3 = y1 - h_3; error_3 = residual_3./y1;
length(find(abs(error_3)<0.1))/m
% 导入新数据
load('newData.txt')
x1_new = newData(:,2);
x2_new = newData(:,3); y1_new = newData(:,5);
x1_inv_new = 1./x1_new;
m_new = size(x1_new,1);
% 模型1,新数据(用的还是老数据算出来的模型)
h_1_new = theta2(1) + theta2(2) * x1_inv_new + theta2(3)
* x2_new;
residual_1_new = y1_new - h_1_new; error_1_new = residual_1_new./y1_new;
length(find(abs(error_1_new)<0.1))/m_new
% 模型2,新数据
h_2_new = 200 + 8*(4000*3017/8 - 1460*(2^6 - 1)) *…
x1_inv_new + (1.5 + 6 + 6) * x2_new;
residual_2_new = y1_new - h_2_new; error_2_new = residual_2_new./y1_new;
length(find(abs(error_2_new)<0.1))/m_new
% 模型3,新数据
N_new = floor(log(x2_new.*x1_new/(8*10*1460))/…
log(2) + 1);
N_new(N_new<0) = 0;
h_3_new = (8+N_new).*x2_new + 8*(4000*3017/8 … - (2.^N_new - 1)*(10*1460)).*x1_inv_new + 200;
residual_3_new = y1_new - h_3_new;
error_3_new = residual_3_new./y1_new; length(find(abs(error_3_new)<0.1))/m_new
附录 2.4:卡顿时长占比模型相关程序算法(1)
%%Name: stallModel_1.m
%% =======Part1:初始化=======
clear; close all; clc;
%% =======Part2:载入数据=====
fprintf('Loading data... \n\n');
load('origData.txt');
% data has previously been read and saved as .txt
y1 = origData(: , 5); % y1:初始缓冲时延
y2 = origData(: , 6); % y2:卡顿时长占比
X = origData(: , [2, 3, 4]); % X:三大影响因素
x1 = X(: , 1); % x1:初始缓冲峰值速率
x2 = X(: , 2); % x2:端到端环回时间(E2E RTT)
x3 = X(: , 3); % x3:播放阶段平均下载速率
m = size(X, 1);
%% ======Part3:绘制散点图=======
%%作卡顿占比和初始缓冲峰值速率的散点图
fprintf('Ploting vThrp & sStall... \n');
ind3_1 = find(x3>2800 & x3<3000); ind3_2 = find(x3>3000 & x3<3150);
ind3_3 = find(x3>3150 & x3<3300);
samp1_1a = x1(ind3_1);
samp1_2a = x1(ind3_2); samp1_3a = x1(ind3_3);
samp1_1b = y2(ind3_1);
samp1_2b = y2(ind3_2);
samp1_3b = y2(ind3_3); figure;
plot(samp1_1a, samp1_1b, 'r+','Linewidth', 1.5);
xlabel('初始缓冲峰值速率(kbps)');
ylabel('卡顿占比(%)');
title('2800<vLoad<3000,样本容量=262');
grid on;
fprintf('Program paused. Press enter to continue. \n');
pause; figure;
plot(samp1_2a, samp1_2b, 'g+','Linewidth', 1.5);
xlabel('初始缓冲峰值速率(kbps)');
ylabel('卡顿占比(%)');
title('3000<vLoad<3150,样本容量=273');
grid on;
fprintf('Program paused. Press enter to continue. \n');
pause; figure;
plot(samp1_3a, samp1_3b, 'b+','Linewidth', 1.5);
xlabel('初始缓冲峰值速率(kbps)');
ylabel('卡顿占比(%)');
title('3150<vLoad<3300,样本容量=284');
grid on;
fprintf('Program paused. Press enter to continue. \n');
pause;
figure;
plot(samp1_1a, samp1_1b, 'r+','Linewidth', 1.5);
hold on;
plot(samp1_2a, samp1_2b, 'g+','Linewidth', 1.5); hold on;
plot(samp1_3a, samp1_3b, 'b+','Linewidth', 1.5);
hold off;
xlabel('初始缓冲峰值速率(kbps)');
ylabel('卡顿占比(%)');
title('2800<vLoad<3300');
grid on;
fprintf('Program paused. Press enter to continue. \n\n'); pause;
%% =====Part4:绘制散点图=====
%%控制峰值速率
%%绘制卡顿占比和播放阶段平均下载速率散点图
fprintf('Ploting vLoad & sStall... \n');
ind1_1 = find(x1>1000 & x1<3000);
ind1_2 = find(x1>3000 & x1<4000); ind1_3 = find(x1>4000 & x1<4800);
samp3_1a = x3(ind1_1);
samp3_2a = x3(ind1_2);

60 / 65
samp3_3a = x3(ind1_3);
samp3_1b = y2(ind1_1);
samp3_2b = y2(ind1_2); samp3_3b = y2(ind1_3);
figure;
plot(samp3_1a, samp3_1b, 'r+','Linewidth', 1.5);
xlabel('播放阶段平均下载速率(kbps)');
ylabel('卡顿占比(%)');
title('1000<vThrp<3000,样本容量=210');
grid on;
fprintf('Program paused. Press enter to continue. \n'); pause;
figure;
plot(samp3_2a, samp3_2b, 'g+','Linewidth', 1.5);
xlabel('播放阶段平均下载速率(kbps)');
ylabel('卡顿占比(%)');
title('3000<vThrp<4000,样本容量=260');
grid on; fprintf('Program paused. Press enter to continue. \n');
pause;
figure;
plot(samp3_3a, samp3_3b, 'b+','Linewidth', 1.5);
xlabel('播放阶段平均下载速率(kbps)');
ylabel('卡顿占比(%)');
title('4000<vThrp<4800,样本容量=278');
grid on;
fprintf('Program paused. Press enter to continue. \n');
pause;
figure; plot(samp3_1a, samp3_1b, 'r+','Linewidth', 1.5);
hold on;
plot(samp3_2a, samp3_2b, 'g+','Linewidth', 1.4);
hold on; plot(samp3_3a, samp3_3b, 'b+','Linewidth', 1);
hold off;
xlabel('播放阶段平均下载速率(kbps)');
ylabel('卡顿占比(%)');
title('1000<vThrp<4800'); grid on;
fprintf('Program paused. Press enter to continue. \n\n');
pause;
%% ====Part5:正规方程法拟合参数=====
fprintf('Solving sStall & vLoad with normal equations... \n');
% Compute 1/x3
x3_inv = 1 ./ x3;
% x3_inv是x3各元素的倒数,不是逆!
% Add intercept term to x3_inv x3_invPlus = [ones(m,1) x3_inv];
% Initialize prameter : theta
% theta = zeros(2, 1);
% Compute theta theta = normalEqn(x3_invPlus, y2);
% Give answer
fprintf('theta1 computed from normal equations: \n');
fprintf('%d \n', theta); fprintf('Program paused. Press enter to continue. \n\n');
pause;
%% ====Part6:显示拟合结果====
fprintf('Visualizing result... \n')
% 1.曲线(全局)
x3_max = max(x3);
x3_toDraw = [0:10:x3_max]';
x3_inv_toDraw = [ones(length(x3_toDraw), 1) , 1 ./
x3_toDraw]; h = x3_inv_toDraw * theta;
figure;
plot(x3, y2, 'k+', 'LineWidth', 1.5); hold on;
plot(x3_toDraw, h, 'LineWidth', 1.5);
title('sStall = theta0 + theta1*1/vLoad');
l = legend('original data' , 'hypothesis'); title(l, sprintf('theta0 = %f\ntheta1 = %f',theta(1),theta(2)));
hold off;
grid on;
fprintf('Program paused. Press enter to continue.\n'); fprintf('\n');
pause;
% 2.直线(全局)
x3_inv_max = max(x3_inv);
x3_inv_toDraw = [0:0.00001:x3_inv_max]';
x3_inv_toDraw = [ones(length(x3_inv_toDraw),
1) ,x3_inv_toDraw]; h = x3_inv_toDraw * theta;
figure;
hold on;
plot(x3_inv, y2, 'bx') plot(x3_inv_toDraw(:,2), h, 'LineWidth', 1.5)
xlabel('1/vLoad');
ylabel('sStall');
grid on; hold off;
附录 2.5:卡顿时长占比模型相关程序算法(2)
%%Name: stallModel_2.m
%% ======Part1:初始化=======
clear; close all; clc;
%% ======Part2:载入数据======
fprintf('Loading data... \n\n');
load('origData.txt'); % load('newData.txt');
% data has previously been read and saved as .txt
y1 = origData(: , 5); % y1:初始缓冲时延
y2 = origData(: , 6); % y2:卡顿时长占比
X = origData(: , [2, 3, 4]); % X:三大影响因素
x1 = X(: , 1); % x1:初始缓冲峰值速率
x2 = X(: , 2); % x2:端到端环回时间(E2E RTT)
x3 = X(: , 3); % x3:播放阶段平均下载速率
m = size(X, 1);
% y1_new = newData(: , 5); % y1:初始缓冲时延
% y2_new = newData(: , 6); % y2:卡顿时长占比
% X_new = newData(: , [2, 3, 4]); % X:三大影响因素
% x1_new = X(: , 1); % x1:初始缓冲峰值速率
% x2_new = X(: , 2); % x2:端到端环回时间(E2E RTT)
% x3_new = X(: , 3); % x3:播放阶段平均下载速率
% m_new = size(X_new, 1);
%% ======Part3:绘制散点图======
%%作卡顿占比和播放阶段平均下载速率的散点图

61 / 65
figure;
plot(x3, y2, 'kx');
xlabel('播放阶段平均下载速率(kbps)');
ylabel('卡顿占比(%)');
grid on;
fprintf('Program paused. Press enter to continue. \n\n');
pause;
% 转为线性关系
x3_inv = 1./x3;
figure;
plot(x3_inv, y2, 'bx') xlabel('1/vLoad');
ylabel('sStall');
grid on;
fprintf('Program paused. Press enter to continue. \n\n'); pause;
%% ====Part4:计算分段函数的分界点=====
% Plan A:计算各段下载速率对应的卡顿占比值中
%非零项占总数的比值
% for i = 0.0001:0.00005:0.00035
% floor = i; % ceil = i+0.00005;
% notZero = length(find(x3_inv>floor &…
x3_inv<ceil & y2>0));
% isZero = length(find(x3_inv>floor & x3_inv<ceil & y2==0));
% ratio = isZero/(notZero+isZero);
%
% fprintf('1/vLoad = %.5f~%.5f:\nnotZero: %d\t\... tisZero: %d\t\tnotZeroRatio: %.4f\n\n',…
floor,ceil,notZero,isZero,ratio);
% end
% Plan B:
%通过分段取平均得到平滑的散点图,估计分界点取值
figure;
xl = 0.0001;
xh = 0.002; step = 0.00001;
y_mean = zeros(round((xh-xl)/step), 1);
x_mean = zeros(round((xh-xl)/step), 1);
num = 1; for i = xl:step:xh
floor = i;
ceil = i+step;
y_mean(num) = mean(y2(x3_inv>floor & x3_inv<ceil)); x_mean(num) = (floor+ceil)/2;
num = num +1;
end
plot(x_mean, y_mean, 'b+', 'LineWidth', 1.5); xlabel('1/vLoad');
ylabel('sStall');
grid on;
fprintf('Program paused. Press enter to continue. \n\n'); pause;
%% ====Part5:根据分界点估计值选取拟合数据=====
% 剔除分界点之前的数据
x3_inv_plus = x3_inv(x3_inv>0.0003); y2_plus = y2(x3_inv>0.0003);
X = [x3_inv_plus, y2_plus];
%% =====Part6:绘制散点图=====
%%代多次使用异常检测算法剔除较分散的点
for i = 1:100
%% 求解多元正态概率分布
fprintf('Visualizing Gaussian fit.\n\n');
% 计算均值、协方差
[mu sigma2] = estimateGaussian(X);
% 计算概率密度
p = multivariateGaussian(X, mu, sigma2);
% 显示分布图
figure;
visualizeFit(X, mu, sigma2);
xlabel('1/vLoad'); ylabel('sStall');
grid on;
%% 查找并显示异常点
epsilon = 0.01; % 阈值
%% 查找阈值外的点
outliers = find(p < epsilon);
num_outliers = length(outliers);
% 用红圈标注异常点
hold on plot(X(outliers, 1), X(outliers, 2), 'mo', …
'LineWidth', 2, 'MarkerSize', 10);
title(sprintf('Iteration %d, find %d outliers, with p<%f',i,
num_outliers, epsilon)); hold off
%% 剔除异常点,显示结果
X(outliers,:) = []; figure;
plot(X(:, 1), X(:, 2), 'rx');
xlabel('1/vLoad');
ylabel('sStall'); title(sprintf('After Iteration %d',i));
grid on;
%% 循环,直至不再检测到异常点
if num_outliers == 0
break
end end
%得到最终的“好”的拟合数据
good_x3_inv = X(:,1);
good_y2 = X(:,2);
m_good = length(good_y2);
fprintf('Program paused. Press enter to continue. \n\n'); pause;
%% ======Part7:正规方程法拟合直线======
fprintf('Solving sStall & vLoad with normal equations...
\n');
% 添加截距项
good_x3_invPlus = [ones(m_good,1) good_x3_inv];
% 计算参数theta、分界点demarcation
theta = normalEqn(good_x3_invPlus, good_y2);
demarcation = -theta(1)/theta(2);
fprintf('theta computed from normal equations: \n'); fprintf('%d \n', theta);
fprintf('demarcation point computed from normal…
equations: \n');
fprintf('%d \n', 1/demarcation); fprintf('Program paused. Press enter to continue. \n\n');
pause;
%% =======Part8:显示拟合结果=======
fprintf('Visualizing result... \n')

62 / 65
% 1.直线(局部)
good_x3_inv_max = max(good_x3_inv); good_x3_inv_toDraw = [0:0.00001:good_x3_inv_max]';
x3_inv_toDraw = [ones(length(good_x3_inv_toDraw),
1) ,good_x3_inv_toDraw];
h = x3_inv_toDraw * theta; h(h<0) = 0;
figure;
hold on;
plot(good_x3_inv, good_y2, 'bx') plot(x3_inv_toDraw(:,2), h, 'LineWidth', 1.5)
plot(demarcation, 0, 'mo', 'LineWidth', 1.5,…
'MarkerSize', 8);
xlabel('1/vLoad'); ylabel('sStall');
grid on;
hold off;
fprintf('Program paused. Press enter to continue. \n\n'); pause;
% 2.直线(全局)
x3_inv_max = max(x3_inv);
x3_inv_toDraw = [0:0.00001:x3_inv_max]';
x3_inv_toDraw = [ones(length(x3_inv_toDraw),
1) ,x3_inv_toDraw]; h = x3_inv_toDraw * theta;
h(h<0) = 0;
figure;
hold on; plot(x3_inv, y2, 'bx')
plot(x3_inv_toDraw(:,2), h, 'LineWidth', 1.5, 'Color', 'r')
plot(demarcation, 0, 'mo', 'LineWidth', 1.5, 'MarkerSize',
8); xlabel('1/vLoad');
ylabel('sStall');
l = legend('original data' , 'hypothesis', 'demarcation point');
grid on; hold off;
fprintf('Program paused. Press enter to continue. \n\n');
pause;
% 3.曲线(全局)
x3_max = max(x3);
x3_toDraw = [0:10:x3_max]'; x3_inv_toDraw = [ones(length(x3_toDraw), 1) , 1 ./
x3_toDraw];
h = x3_inv_toDraw * theta;
h(h<0) = 0; figure;
plot(x3, y2, 'k+', 'LineWidth', 1.5);
hold on;
plot(x3_toDraw, h, 'LineWidth', 1.5); plot(1/demarcation, 0, 'mo', 'LineWidth', 1.5, 'MarkerSize',
8);
title('sStall = theta0 + theta1*1/vLoad');
l = legend('original data' , 'hypothesis', 'demarcation point'); title(l, sprintf('theta0 = %f\ntheta1 = %f',theta(1),theta(2)));
hold off;
grid on;
%% =======Part9:残差分析========
x3_inv_withItcpt = [ones(m,1), x3_inv]; residual = y2 - x3_inv_withItcpt * theta;
residual(x3>3623) = y2(x3>3623);
figure;
plot(x3_inv, residual, 'bx');
xlabel('1/vLoad');
ylabel('residual');
grid on;
%% =======Part10:建立概率模型=======
x_toDraw = [0:0.00002:0.002]'; % x_toDraw = [0:0.00002:0.02]';
y_toDraw = [0:0.04:4]';
% y_toDraw = [0:0.1:100]';
x_toDraw_withItcpt = [ones(length(x_toDraw),1), x_toDraw];
h = x_toDraw_withItcpt * theta;
h(h<0) = 0;
sigma = x_toDraw_withItcpt * [-0.3605; 1326]; sigma(sigma<0.1) = 0.1;
p = bsxfun(@rdivide, (2*pi)^(-1/2) .*
exp(-bsxfun(@rdivide, bsxfun(@minus,...
y_toDraw, h').^2, 2.*(sigma'.^2))), sigma'); [a,b] = meshgrid(x_toDraw', y_toDraw');
figure;
if (sum(isinf(p)) == 0)
surf(x_toDraw, y_toDraw, p, 'EdgeColor','none', 'FaceAlpha',0.8);
end
hold on;
points = plot(x3_inv(x3_inv<0.002 & y2<4),y2(x3_inv<0.002 & y2<4), 'rx' );
% plot(x3_inv(x3_inv<0.02),y2(x3_inv<0.02), 'rx' );
h_ceil = h + 2*sigma; h_floor = h - 2*sigma;
h_floor(h_floor<0) = 0;
line1 = plot(x_toDraw(h_ceil<4), h_ceil(h_ceil<4),
'LineWidth', 1.5 ,'Color','r'); line2 = plot(x_toDraw(h_floor<4), h_floor(h_floor<4),
'LineWidth', 1.5,'Color','r');
view(2)
colorbar legend([points, line1], 'original data' , '2*sigma');
xlabel('1/vLoad');
ylabel('sStall');
% sample1 = residual(x3_inv>0.00030 & x3_inv<0.00035 & y2~=0);
% sample2 = residual(x3_inv>0.00035 & x3_inv<0.00040
& y2~=0);
% sample3 = residual(x3_inv>0.00040 & x3_inv<0.00045 & y2~=0);
% sample4 = residual(x3_inv>0.00045 & x3_inv<0.00050
& y2~=0);
% sample5 = residual(x3_inv>0.00050 & x3_inv<0.00055 & y2~=0);
% sample6 = residual(x3_inv>0.00055 & x3_inv<0.00060
& y2~=0);
% sample7 = residual(x3_inv>0.00060 & x3_inv<0.00065
& y2~=0);
% sample8 = residual(x3_inv>0.00065 & x3_inv<0.00070
& y2~=0);
% sample9 = residual(x3_inv>0.00070 & x3_inv<0.00075 & y2~=0);
% sample10 = residual(x3_inv>0.00075 & x3_inv<0.00080
& y2~=0);
% sample11 = residual(x3_inv>0.00080 & x3_inv<0.00085 & y2~=0);
% sample12 = residual(x3_inv>0.00085 & x3_inv<0.00090
& y2~=0);
% sample13 = residual(x3_inv>0.00090 & x3_inv<0.00095

63 / 65
& y2~=0);
% sample14 = residual(x3_inv>0.00095 & x3_inv<0.00100
& y2~=0); % a_1 =
[0.000325;0.000375;0.000425;0.000475;0.000525;0.00057
5;0.000625;0.000675;0.000725;0.000775;0.000825;0.0008
75;0.000925;0.000975]; % b_1 =
[0.117242;0.163163;0.23001;0.283074;0.330891;0.326018;
0.371281;0.555359;0.5619;0.707848;0.633037;0.888671;0.
879849;0.973909]; % sample1 = residual(x3_inv>0.00028 & x3_inv<0.00029
& y2~=0);
% sample2 = residual(x3_inv>0.00029 & x3_inv<0.00030
& y2~=0); % sample3 = residual(x3_inv>0.00030 & x3_inv<0.00031
& y2~=0);
% sample4 = residual(x3_inv>0.00031 & x3_inv<0.00032
& y2~=0);
% sample5 = residual(x3_inv>0.00032 & x3_inv<0.00033
& y2~=0); % sample6 = residual(x3_inv>0.00033 & x3_inv<0.00034
& y2~=0);
% sample7 = residual(x3_inv>0.00034 & x3_inv<0.00035
& y2~=0); % sample8 = residual(x3_inv>0.00035 & x3_inv<0.00036
& y2~=0);
% sample9 = residual(x3_inv>0.00036 & x3_inv<0.00037
& y2~=0); %
% a_2 =
[0.000285;0.000295;0.000305;0.000315;0.000325;0.00033
5;0.000345;0.000355;0.000365]; % b_2 =
[0.108412;0.098107;0.0859658;0.109153;0.112545;0.1332
07;0.138031;0.143911;0.17819];
附录 2.6:计算高斯分布的参数相关的程序算法
%Name: estimateGaussian.m function [mu sigma2] = estimateGaussian(X)
%计算高斯分布的参数
% input:数据集X
% output:均值mu,协方差矩阵sigma2
[m, n] = size(X);
% 指定半高斯分布的均值
mu = zeros(n,1);
mu(1) = 0.00030;
mu(2) = 0;
% 计算协方差矩阵
sigma2 = 1/m * (bsxfun(@minus, X, mu'))'*
bsxfun(@minus, X, mu'); end
& y2~=0);
% sample4 = residual(x3_inv>0.00031 & x3_inv<0.00032 & y2~=0);
% sample5 = residual(x3_inv>0.00032 & x3_inv<0.00033 & y2~=0);
% sample6 = residual(x3_inv>0.00033 & x3_inv<0.00034
& y2~=0);
% sample7 = residual(x3_inv>0.00034 & x3_inv<0.00035 & y2~=0);
% sample8 = residual(x3_inv>0.00035 & x3_inv<0.00036
& y2~=0);
% sample9 = residual(x3_inv>0.00036 & x3_inv<0.00037 & y2~=0);
%
% a_2 =
[0.000285;0.000295;0.000305;0.000315;0.000325;0.000335;0.000345;0.000355;0.000365];
% b_2 =
[0.108412;0.098107;0.0859658;0.109153;0.112545;0.1332
07;0.138031;0.143911;0.17819];
附录 2.7:高斯分布概率密度函数程序
%Name: visualizeFit.m
function p = multivariateGaussian(X, mu, Sigma2)
%高斯分布概率密度函数
% input:样本X,均值mu,协方差矩阵Sigma2
% output:概率密度p
k = length(mu);
X = bsxfun(@minus, X, mu(:)'); p = (2 * pi) ^ (- k / 2) * det(Sigma2) ^ (-0.5) * ...
exp(-0.5 * sum(bsxfun(@times, X * pinv(Sigma2), X), 2));
end
附录 2.8:绘制高斯分布的概率密度分布图程序
%Name: multivariateGaussian.m
function visualizeFit(X, mu, sigma2)
%显示高斯分布的概率密度分布图
X1_max = max(X(:,1)); X1_min = min(X(:,1));
X2_max = max(X(:,2));
X2_min = min(X(:,2));
[X1,X2] = meshgrid(X1_min:((X1_max-X1_min)/100):X1_max, X2_min:((X2_max-X2_min)/100):X2_max);
Z = multivariateGaussian([X1(:) X2(:)],mu,sigma2);

64 / 65
Z = reshape(Z,size(X1));
hold on;
plot(X(:, 1), X(:, 2),'rx'); % Do not plot if there are infinities
if (sum(isinf(Z)) == 0)
% contour(X1, X2, Z, 10,'LineWidth', 1);
surf(X1,X2,Z, 'FaceAlpha',0.9); end
hold off;
end
附录 2.9:E2E RTT 与初始缓冲时延及卡顿时长占比关系求解程序
%Name: data_processing.m
%E2E RTT与初始缓冲时延及卡顿占比关系
%采用多次求平均的方式
clc;
clear all;
close all;
load data; %数据在data.mat中
a = m(:,1); %E2E RTT
b = m(:,2); %初始缓冲时延
c = m(:,3); %卡顿占比
gate = 1; %判断门限
al = min(a); ah = max(a);
%第一次求平均
d1 = zeros(ah-al+1,3);
w = zeros(ah-al+1,1); %权重矩阵
for i = 1:ah-al+1
tmp = m(m(:,1) == i+al-1,:);
w(i) = length(tmp(:,1))/length(a);
d1(i,1) = i+al-1; d1(i,2) = mean(tmp(:,2));
d1(i,3) = mean(tmp(:,3));
end
%第二次求平均
d2 = zeros(ah-al+1,3);
for i = 1:ah-al+1
tmp = m(m(:,1) == i+al-1,:);
d2(i,1) = i+al-1;
temp = abs((tmp(:,2)-d1(i,2))./d1(i,2));
tag = [tmp,temp]; tag(tag(:,4) > gate,:) = [];
d2(i,2) = mean(tag(:,2));
temp = abs((tmp(:,3)-d1(i,3))./d1(i,3));
tag = [tmp,temp];
tag(tag(:,4) > gate,:) = []; d2(i,3) = mean(tag(:,3));
end
%第三次求平均
d3 = zeros(ah-al+1,3);
for i = 1:ah-al+1
tmp = m(m(:,1) == i+al-1,:); d3(i,1) = i+al-1;
temp = abs((tmp(:,2)-d2(i,2))./d2(i,2));
tag = [tmp,temp]; tag(tag(:,4) > gate,:) = [];
d3(i,2) = mean(tag(:,2));
temp = abs((tmp(:,3)-d2(i,3))./d2(i,3)); tag = [tmp,temp];
tag(tag(:,4) > gate,:) = [];
d3(i,3) = mean(tag(:,3));
end
%绘图设置
xx = d1(:,1); %采用cftool处理,以w加权拟合
yy = d3(:,2); %线性拟合
zz = d1(:,3); %二次高斯拟合
figure; plot(a,b,'o');
hold on; plot(d1(:,1),d1(:,2),'g');
hold on; plot(d2(:,1),d2(:,2),'k');
hold on; plot(d3(:,1),d3(:,2),'r'); figure;
plot(a,c,'o');
figure; plot(d1(:,1),d1(:,3),'g');
hold on; plot(d2(:,1),d2(:,3),'k'); hold on; plot(d3(:,1),d3(:,3),'r');
附录 2.10:初始缓冲时延和卡顿时长占比数值拟合偏离程度计算程序
%Name: newdata_figure.m
%模型计算的偏离程度图形直观描述
clc;clear all;close all;
%% 数据读入与参数设置
load newdata;Tresp = 200;
Data = 4000*Data/8; %单位转化为 Byte
MSS = 1500;N = 6;k = 6;
%% 根据模型计算与结果绘制
T = 8*(Data-(2^N-1)*MSS)./Vthrp + (N+k+1.5)*RTT +
Tresp; %初始缓冲时延计算模型
%卡顿占比计算模型
S = zeros(length(Sstall),1);
for i = 1:length(S)
if Vload(i) < 3623
S(i) = 3741.05/Vload(i)-1.032;
end end
%绘图
figure; plot(T,'k');hold on;plot(Twait);
hold off;legend('初始缓冲时延计算结果','实际数据');
figure;
plot(S,'k');hold on;plot(Sstall);
hold off;legend('卡顿占比计算结果','实际数据');

65 / 65
附录 2.11:补充数据的模型检验相关程序
%Name: newdata_calculating.m
clc;clear all;close all;
%%数据读入与参数设置
load newdata;
Tresp = 200;
Data = 4000*Data/8; %单位转化为Byte
MSS = 1500;
N = 6;
k = 6;
%% 根据模型计算
% T = 8*(Data-(2^N-1)*MSS)./Vthrp +…
(N+k+1.5)*RTT + Tresp; %初始缓冲时延计算模型
T = -224.87+2.25*(10^7)./Vthrp + 15.29*RTT ;
S = zeros(length(Sstall),1); %卡顿时长占比计算模型
for i = 1:length(S)
if Vload(i) < 3623 S(i) = 3741.05/Vload(i)-1.032;
end
end
%% 直接计算评价指标
%计算两个模型在每个点上的偏离系数
p1 = zeros(1,length(T));
p2 = zeros(1,length(S));
for i = 1:length(T)
p1(i) = (abs(T(i)-Twait(i))/max(T(i),Twait(i)))*abs(T(i)-Twait(i));
if max(S(i),Sstall(i)) == 0
p2(i) = 0;
else p2(i) =
(abs(S(i)-Sstall(i))/max(S(i),Sstall(i)))*abs(S(i)-Sstall(i));
end
end P10 = mean(p1)/max(mean(T),mean(Twait));
P20 = mean(p2)/max(mean(S),mean(Sstall));
LP10 = …
abs(mean(T)-mean(Twait))/max(mean(T),mean(Twait)); LP20 = …
abs(mean(S)-mean(Sstall))/max(mean(S),mean(Sstall));
Q10 = corrcoef(T,Twait); Q10 = Q10(1,2);
Q20 = corrcoef(S,Sstall); Q20 = Q20(1,2);
%% 剔除部分数据后的计算
rstep = 0.001; %变化的步长
rate0 = 0.99; %分析节点
rate_final = 0.7; %下降的终点,最小为rstep;
过小没有意义,建议不小于0.6
rate = 1:-rstep:rate_final;
I = round((1-rate0)/rstep+1);
P1 = zeros(1,length(rate));LP1 = zeros(1,length(rate));
Q1 = zeros(1,length(rate));
P2 = zeros(1,length(rate));LP2 = zeros(1,length(rate));
Q2 = zeros(1,length(rate)); tmp1 = sort(p1); tmp2 = sort(p2);
for i = 1:length(rate)
tp1 = p1; tT = T; tTwait = Twait;
tp2 = p2; tS = S; tSstall = Sstall; tag1 = tmp1(round(rate(i)*length(tmp1)));
tag2 = tmp2(round(rate(i)*length(tmp2)));
tp1(p1 > tag1) = [];tT(p1 > tag1) = [];
tTwait(p1 > tag1) = [];
tp2(p2 > tag2) = [];tS(p2 > tag2) = [];
tSstall(p2 > tag2) = [];
P1(i) = mean(tp1)/max(mean(tT),mean(tTwait));
P2(i) = mean(tp2)/max(mean(tS),mean(tSstall)); LP1(i) = …
abs(mean(tT)-mean(tTwait))/max(mean(tT),mean(tTwait));
LP2(i) = …
abs(mean(tS)-mean(tSstall))/max(mean(tS),mean(tSstall)); Q3 = corrcoef(tT,tTwait); Q1(i) = Q3(1,2);
Q4 = corrcoef(tS,tSstall); Q2(i) = Q4(1,2);
%相关分析
if i == I
a1 = mean(Data(p1 > tag1));
a2 = mean(Vthrp(p1 > tag1));
a3 = mean(RTT(p1 > tag1)); b = mean(Vload(p2 > tag2));
end
end
%% 输出与绘图设置
figure; hold on; plot(rate,P1,'Linewidth',2);plot(rate,LP1,'k','Linewidth',2);p
lot(rate,Q1,'r','Linewidth',2);
set(gca,'xdir','reverse'); hold off; xlim([rate_final,1]);
ylim([0 1]);
xlabel('原始数据保留的比例','fontsize',16);
ylabel('评价指标的值','fontsize',16);
%title('初始缓冲时延物理模型的指标变化图…
','fontsize',16);
legend('偏离系数P','相对偏差LP','相关系数r');
figure; hold on;
plot(rate,P2,'Linewidth',2);
plot(rate,LP2,'k','Linewidth',2);
plot(rate,Q2,'r','Linewidth',2); set(gca,'xdir','reverse');
hold off; xlim([rate_final,1]); ylim([0 1]);
xlabel('原始数据保留的比例','fontsize',16);
ylabel('评价指标的值','fontsize',16);
title('卡顿占比模型的指标变化图','fontsize',16);
legend('偏离系数P','相对偏差LP','相关系数');
disp('对于初始缓冲时延模型:');
fprintf('补充数据的平均码率为%.5fkbps,
',mean(Data)/500);fprintf('剔除%.2f数据时,剔除数据的
平均码率为%.5fkbps\n',1-rate0,a1/500);
fprintf('补充数据的平均初始峰值速率为%.5fkbps,
',mean(Vthrp));fprintf('剔除%.2f数据时,剔除数据的平均
初始峰值速率为%.5fkbps\n',1-rate0,a2);
fprintf('补充数据的平均RTT为%.5fms,
',mean(RTT));fprintf('剔除%.2f数据时,剔除数据的平均
RTT为%.5fms\n',1-rate0,a3);
disp('对于卡顿占比模型:');
fprintf('补充数据的平均加载速率为%.5fkbps,
',mean(Vload));fprintf('剔除%.2f数据时,剔除数据的平均
加载速率为%.5fkbps\n',1-rate0,b);