Embed Size (px)
Citation preview

1/14
第19回先端技術大賞応募論文 「データマイニングに基づくセキュリティ・インテリジェンス技術の研究開発」
日本電気株式会社 中央研究所 山西健司・竹内純一・丸山祐子 1.はじめに 世の中で ITやネットワークが普及し、多くのサービスがインターネットを介して行われるようになってきた。その結果、電子メール、E-コマースなどといった安価で便利なサービスを気軽に利用できる世界が到来し、今やその勢いはとどめるところを知らない。しかし、その一方で、IT 固有に生じる深刻な脅威に日々さらされるようになった。例えば、「コンピュータ・セキュリティ」の問題
がある。コンピュータへの不正アクセス、コンピュータウイルス等が横行し、ユーザが知らないうち
に自分の情報が盗まれたり、インターネットを通じて外部に流出したりといった不安にさらされる ようになってきたのである。
情報処理振興事業協会報告 http://www.ipa.go.jp/security/ CERT/CC報告 http://www.cert.org/stats/#alerts
図1.ウイルス届出推移とインシデント数の推移 情報処理振興事業協会(IPA)によると,IPAに報告のあった 2004年ウイルス届出件数は,52,151
件と過去最大を記録した(図1)。また、ITを通じた情報漏洩や内部情報流出といった犯罪も深刻化している。2003年 12月に起きた Yahooの 451万人の顧客情報流出事件では、その損害賠償額は 40億円に上った。 セキュリティのような人間の悪意に基づく行動ばかりが脅威なのではない。私たちが情報を預ける
「コンピュータシステムの障害」といった脅威にもさらされている。2002年 4月に起きた、みずほ銀行の基幹システムの障害は預金者に大きな不安を与え、当銀行の被害額は 18億円に上った。 以上のような脅威において最も深刻なのは、これまで見たこともない「未知の」攻撃や障害が発生
したときに、これを検出するのが難しいという問題であった。この問題を解決していくことは、IT社会の健全な発展にとって最も重要な要件の1つである。従来の対策は人海戦術によるところが多く、
莫大な人手をかけて対処してきた。しかし今後も脅威が拡大する中で、未知の攻撃や障害をできるだ
け人手をかけずに早期に検出し、リスクを軽減できる技術が渇望されている。 我々は上記問題の解決に向けて、データマイニングとよばれる人工知能技術を活用した技術体系-
「セキュリティ・インテリジェンス」-を構築した。これはコンピュータのアクセス記録からリアル
タイムで異常を発見することによって、セキュリティインシデントやシステム障害を自動的に検出す
る、まぎれもないブレークスルー技術であった。我々はこの技術体系を学問的に立証して国内外の

2/14
学会で認知されたばかりでなく、現場での実証実験を通じて有効性実証に成功し、現在、製品化を 目前にしている。 2. 研究開発の背景 2.1 従来のサイバーテロ対策の限界
図2.不正侵入検出の種類
コンピュータ・セキュリティ、とくにウイルスや DoS(Denial of Access)攻撃の検出といった問題においては IDS(Intrusion Detection System)のようなフィルタ手段がよく用いられている。 この多くは署名ベースという方式を採用している。これはログと呼ばれるアクセス記録を観察し、 既知のウイルスや攻撃のパタンを署名(シグネチャ)として登録し、今後同じものが発生したら、 署名とマッチングをとって検出する方式である。しかし、この方式では未知のウイルスが新しく発生
しても検出できないという問題を抱えていた。一方、ポリシーベースと呼ばれる、人が定めたセキュ
リティポリシーに違反するデータを検出する方式がある。しかし、この方式でも、たまたまポリシー
を満たすような巧妙な手口を使ったウイルスや攻撃が入ってきたときに、これを検出できないという
問題があった(図2)。そもそも上記のいずれの方式も人手で書いたルールをベースにして対処する
以上、ウイルスや攻撃が多様化していく今日において、未知のウイルスや攻撃を検出するには限界が
ある。情報漏洩対策や、システム障害の検出の問題についても、事態は同様であった。 一方、人手に頼らず未知のウイルスを検出する方式として異常検出がある。これは過去ログから 正常時のパタンを記憶し、これから著しく外れたデータをコンピュータで検出する方式である。 しかしながら、その多くの方法はデータの正常な範囲の閾値を設定し、閾値以上のデータが現れたら
アラームを出すといった単純なものであった。これには、1)正常なパタンが複雑な時系列なパタン

3/14
を構成する場合には対処できない、2)正常なパタンが時間ともに変化する場合に適応できない、 といった問題があった。その結果として異常を検出するタイミングが遅くなり、実際上は使い物に ならなかった。 2.2 セキュリティ・インテリジェンス-データマイニングを利用した異常検出の体系
図3.セキュリティ・インテリジェンスの体系
我々は上記の1)、2)の問題を解決し、未知のウイルスや障害をより高い精度で効率よく発見 するために、データマイニングの技術を活用した新しい異常検出技術の研究開発に挑んだ。データ マイニングとは、大量データから複雑な統計的パタンを「学習」し、これを活用するインテリジェン
トな機能である。我々は、データマイニング技術で学習したパタンに基づいて、これから逸脱した 異常を検出することにより、ウイルスや障害を検出しようと考えた。このような発想でデータマイニ
ング技術をコンピュータ・セキュリティや障害解析に向けに開発適用し、実質的に効果を上げること
は世界的にも例が少なかった。 一概にウイルスや障害といっても様々な形態がある。そのような形態の多様性に応じて以下の3つ
の基本エンジンの開発を目指した。(図3) 1)外れ値検出エンジン SmartSifter 2)変化点検出エンジン ChangeFinder 3)異常行動検出エンジン AccessTracer
1)は独立に発生するデータのパタンを学習し、パタンから外れた統計的外れ値を検出することに
より不正アクセスなどを検出するエンジンである。一方、2)はデータの時系列的な性質を学習し、
時系列中の変化点を検出することによって、未知のウイルスの発生などを検知するエンジンである。
一方、3)はログに示される行動パタンを学習し、いつもとは異なる振舞いを検出することにより 「なりすまし」などを検出するエンジンである。我々はこれらのエンジンをラインアップとし、広範
囲な異常検出問題に対応できる「セキュリティ・インテリジェンス」の体系の構想を描いた。(図3)

4/14
これに成功すれば、大規模データを集めてインシデント情報をリアルタイムで解析するセキュリテ
ィ・オペレーション・センター事業やネットワーク監視事業といった、将来需要が見込まれる サービス事業に対して、高い付加価値を与えることが予想された (図4)。
図4.セキュリティ・オペレーションセンター 3. 外れ値検出エンジン SmartSifterへの取り組み 3.1. リアルタイム適応型外れ値検出へのチャレンジ-「オンライン忘却型学習」 先ず最初に取り組んだのが、外れ値検出エンジンの開発である。不正アクセスなどの行為は、 パケットの統計的なパタンから外れた異常値として高い確率で検出できることが経験上分かって いた。そこで、他のデータ群から著しく離れた異常値を高速かつ高精度に自動検出する技術を開発 することで、不正アクセス検出を実現しようと考えた。 外れ値検出の問題は統計学の分野で古くから研究されている。しかしその多くは1)計算量が膨大
になる、オンラインに処理できない、2)データの発生分布は時間とともに変化する場合には適応で
きない、等の問題があった。そこで、この問題を解決するために、前人未踏の「リアルタイム適応型
の外れ値検出」へのチャレンジが始まった。 リアルタイム適応型外れ値検出の基本的考え方は、先ずはデータの統計モデルをオンラインで学習
し、次に各データがそのモデルからどれだけ外れているかをスコアリングすることである。そのため
に、我々はそこに以下のアイデアを織り込んだ。
図5.SmartSifterの流れ

5/14
1)統計的モデル: データの統計的モデルを、離散値変数に関してはヒストグラム分布で表現し、
連続値変数に関してはガウス混合モデルとよばれる有限個のガウス分布の線形の重ねあわせで表現
し(図5中の山形曲線)、これらを階層的に組み合わせるモデルを考えた。これによってデータの 独立発生分布をほとんど全て表現できようになった。 2)学習: 上記の統計的モデルを学習するためのアルゴリズムとして「オンライン忘却型学習 アルゴリズム」を発明した。これはデータを逐次的に取り込む毎に、過去のデータを“ほど良く忘れ
る”ように学習する仕組みを世界で初めて実現したアルゴリズムである。これによって、正常な
パタンの統計モデルが変化しても、これに適応しながら正常・異常を判定することを可能にした。
しかも計算量はデータ数に対しては線形、データの次元については 2乗オーダを実現し、まさに
リアルタイム処理を可能にした。
図6.SmartSifterのインターフェース 3)スコアリング: 各データの異常スコアを、学習されたモデルに対するデータの Shannon情報量とよばれる情報理論の基本量を用いて計算した。 以上の数学的原理により、リアルタイム適応型外れ値検出のエンジンの仕様が固まった。我々は これをソフトウェアとして実装し、SmartSifterというコードネームを与えた(図6)。 3.2 不正侵入検出ベンチマークデータで有効性実証 果たして SmartSifterは実際にどれくらい精度と速度を達成できるのであろうか? KDDCup99[12]と呼ばれる一般に公開されているネットワークログのベンチマークデータを用いてSmartSifterによるネットワーク不正侵入検出の実証実験を行った。その結果、1700件の侵入が 含まれている 50万件のデータに対して、スコアの上位 5%の中から全体の侵入の 8割を検出する ことに成功した(図7)。その計算時間はわずか 140秒であった。結果的に、侵入検出に必要な調査工数はランダム調査に比べて 10分の 1以下に激減できることが実証された。しかも、この精度と速度は競合方式である Burge&Shawe-Taylor による自己組織化マップに基づく方法(B-S 法)[9] を遥かに上回っていた。この SmartSifter の有効性はデータマイニングに関する世界最大の国際学会KDDでも認められた [1]。

6/14
図7.SmartSifterの性能評価 4. 変化点検出エンジン ChangeFinderへの取り組み 4.1.リアルタイム変化点検出へのチャレンジ-「2段階オンライン学習」
SmartSifter が実現した外れ値検出では、データの発生モデルは独立分布であると仮定していた。しかしながら、実際には、データの時系列的な性質に着目しなければならない場合がある。例えば、
ウイルスが発生したときのトラフィック量は急増する。そのような時系列の急激な変化の開始時点―
「変化点」―を検出することができれば、これらを早期に検出できるはずである。そこで、我々は 変化点検出エンジンの開発に取り組んだ。 変化点検出問題に対する従来の代表的な手法は「統計的検定」に基づくものであった。これは、 データ列に多項式回帰モデルをあてはめ、変化点の候補となる点の前後で別々にモデルを当てはめた
場合が、そうしない場合に比べて当てはめ誤差を有意に少なくできるかどうかを検定し、YES ならば、その候補点を変化点とみなす方式であった(図8)。
図8.統計的検出に基づく従来の変化点検出手法

7/14
しかしながら、この方式では一般に計算時間がかかり、実用的ではない。未知のウイルスを一刻も
早く検出しなければならないセキュリティの現場では、より計算効率が高くオンライン処理に向いた
変化点検出が要求された。そこで、上記問題を解決するために、技術的にはこれまでにない「リアル
タイム変化点検出」へのチャレンジが始まった。 我々は「リアルタイム変化点検出」のコア技術として、「オンライン 2段階学習アルゴリズム」を発明した。これは大きく以下の 3ステップから成る。 【ステップ1:第一段階学習】時系列データのモデルとして自己回帰モデルと呼ばれるモデルを用
意し(図 13)、これを SmartSifter と同様のオンライン忘却型学習アルゴリズムで学習し、各時点のデータに対して基本的な変動の大きさを測る外れ値スコアを計算する。 【ステップ2:平滑化】次に一定サイズのウインドウを設けて、ウインドウ内のデータに関して ステップ1で求めた外れ値スコアの平均を計算し平滑化を行う。このウインドウをスライドすること
によって移動平均スコアの時系列を新たに構成する。 【ステップ3:第二段階学習】この時系列に対して新たな自己回帰モデルをあてはめ、これをオン
ライン忘却型学習アルゴリズムで 2 回目の学習を行い、各時点の外れ値スコアを「変化点スコア」として計算する。この値が大きいほど変化点である可能性が高い。 上記アルゴリズムの鍵は、第一段階学習では時系列中の外れ値しか検出できないところを、外れ
値スコアの平滑化を通じて、ノイズに反応した外れ値を除去し、2回目の学習によって、本質的な変動のみを検出できるようにしたところにある。これをオンラインで実装した。
図9.2段階オンライン学習方式
その計算量は、データ数に関しては線形オーダに抑えることができた。一方で、従来の統計的検定
に基づく方式はデータ数の 2乗のオーダを要するので、これに比べてはるかに高速に、しかも オンラインで変化点を検出することが可能になった。我々は上記アルゴリズムをソフトウェアとして
実装し、ChangeFinderというコードネームを与えた。

8/14
図10.ChangeFinderを用いた未知ウイルス検出実験 4.2 サイバーテロ対策の現場で未知ワームの早期検出に成功 果たして ChangeFinderは実際にどれくらい精度と速度を達成できるのであろうか?2004年 7-8月、我々は某組織のメールシステムのログの監視と運用を行っているサイバーテロ対策チームの協力を得て実証実験を行った。そのチームでは、未知ワーム対策がかねてからの課題であったが、
決定的に有効な手段を持ち合わせず、もっぱら人海戦術に頼ってきた。そんな中、もっと早く未知 ワームを検出する方法が渇望されていた。我々は、そのチームから特定のMessage IDを有する メールの通数(1分あたりのメールの流通量)の時系列データの提供を受け、これに ChangeFinderを適用して変化点を調べた。 7月 13日に変化点スコアが異常に高くなり、アラームが上がった。実際、この日には LOVGATEと呼ばれる新種ウイルスが発生し、メールサーバーの一時停止といった障害を引き起こしていた。 このウイルスは受信メール内のメッセージに自身のコピーを添付して返信するワーム型ウイルスで
あり、トラフィックの急増をもたらしていたのだ。この日に現場が LOVGATE を発見した時刻は10:00amであったのに対し、ChangeFniderは、1時間 6分早く 8:54amにこれを検出していた。 (図10参照)ChangeFinderは 7-8月の期間中、他にも幾つかアラームを上げた。その全てが ワームやメールの大量発信を知らせる意味のあるアラームであった。この実証実験の結果、
ChangeFinderの有効性が実証された。 5. 異常行動検出エンジン AccessTracerへの取り組み 5.2 ダイナミック異常行動検出へのチャレンジ-「動的モデル選択」
ChangeFinderは時系列データのローカルな異常変化を検出することができた。しかしながら、 一連の行動履歴の「中身」まで見て、いつもと振舞いが違うといった行動パタンの異常を検出する ことはできなかった。このような異常な振舞いを検出することを「異常行動検出」とよぶ。例えば、
あるオペレーターの UNIX のコマンド履歴系列を観測し、いつもと異なるコマンド履歴のパタンを

9/14
発見できれば、そのオペレーターに「なりすまし」て情報漏洩や内部情報流出を行う犯罪を高い確率
で検出することができる(図11)。異常行動検出は、近年ますます深刻になってきている情報漏洩
につながる「なりすまし検出問題」に対して、1つの有力な解決手段を与える。
図11.異常行動検出によるなりすまし検出 従来の代表的な異常行動検出の研究としては、ナイーブベイズモデルといった素朴な統計モデルを
用いる研究があった[11]。これらはどのコマンドが発生しやすいか?といった簡単な統計モデルを 学習し、珍しいコマンドがでてきた場合にアラームを出すにとどまっていた。その結果、その方法で
は「動き」を捉えることができなかった。しかも、現実には「動き」のパタンは複数混在しており、
パタンの数やその内容が時間と共に変化する。このような「動き」が「非定常」な状況の中で精度良
く異常行動を検出することは難しく、これを実現する技術は存在しなかった。そこで我々は、この 難問を解決する「ダイナミック異常行動検出」の研究開発に挑んだ。 ある一まとまりの行動履歴(例、一定時間のコマンド履歴)を示す時系列データをセッションと 呼ぶ。我々はセッション単位で異常行動を検出する方式を考えた。そのコア技術として「動的モデル
選択」によるダイナミックな行動パタンの学習方式を発明した。その基本的な流れを図 12 に示す。以下にそのエッセンスを3つのステップにまとめる。
図12.異常行動検出の原理

10/14
1)オンライン忘却型学習アルゴリズムによる行動モデルの学習:セッションの発生分布を「混合
隠れマルコフモデル」で表した。これは、一つの行動パタンを隠れマルコフモデルとよばれる コマンドの遷移関係などを表現する確率モデルで表し(図 13 中のコマンド遷移関係を表すグラフ)、複数の行動パタンが混在している状況を、それらの線形結合である混合分布で表したものである。 そのときの混合している数(「混合数」)は異なる行動パタンの数に相当する。異なる混合数をもつ 「混合隠れマルコフモデル」を用意し、各々を並列に SmartSifterと同様の「オンライン忘却型学習アルゴリズム」を用いて学習した。 2)動的モデル選択:上で学習された、異なる混合数をもつ「混合隠れマルコフモデル」の中で最適
な混合数をもつものを、情報理論的な基準に基づいて選択した。これによってデータに含まれる行動
パタンの数の最適値を決定できるようになった。 3)ユニバーサル仮説検定量に基づくスコアリング:学習されたモデルに基づいて各セッションの
異常スコアを、「ユニバーサル仮説検定量」とよばれる情報量を用いて計算した。 「動的モデル選択」は、機械学習理論や統計学においても全く新しい考え方であった。これを UNIXコマンドを用いた「なりしまし検出」の例を用いて直観的に示そう。先ず大抵の場合、正規ユーザは
決まった手順の操作をする。たとえば『ls(ディレクトリ表示)→cat(内容表示)→lpr(プリンタ
ーで印刷)』という具合である。このセッション(コマンドのまとまり)をパタン1として学習する。
そこへ侵入(なりすまし)者が入ってきて『vi(テキスト編集)→ps(プロセス表示)』という操作
を繰り返すと、「動的モデル選択」は、これを新しいパタン2が加わったと判断して検出する。
この場合、最適な行動パタン数が1つから2つへとダイナミックに変化したことを検出したことに
なる(図13)。
図13.動的モデル選択
我々は上記アルゴリズムをソフトウェアとして実装し、AccessTracer というコードネームを与えた(図14)。

11/14
5.2. なりすまし検出、未知ワーム検出、障害検出で有効性実証 我々は UNIXのコマンド履歴からの「なりすまし検出」問題に対して、AccessTracerの ベンチマークテストを行った。用いたデータは一般に公開されているデータであり[13]、これには 正規ユーザのコマンド履歴に「なりすまし行為」が実際にしのばせてあった。 このなりすまし行為
をいかに早く検出できるか?を評価した。実験の結果、ナイーブベイズ法と呼ばれる従来最も高い
成績を上げている手法よりも、同一の誤警報率(10~20%)を保ったまま、50%以上少ないコマンド
数からなりすましを検出できることが実証された[6]。
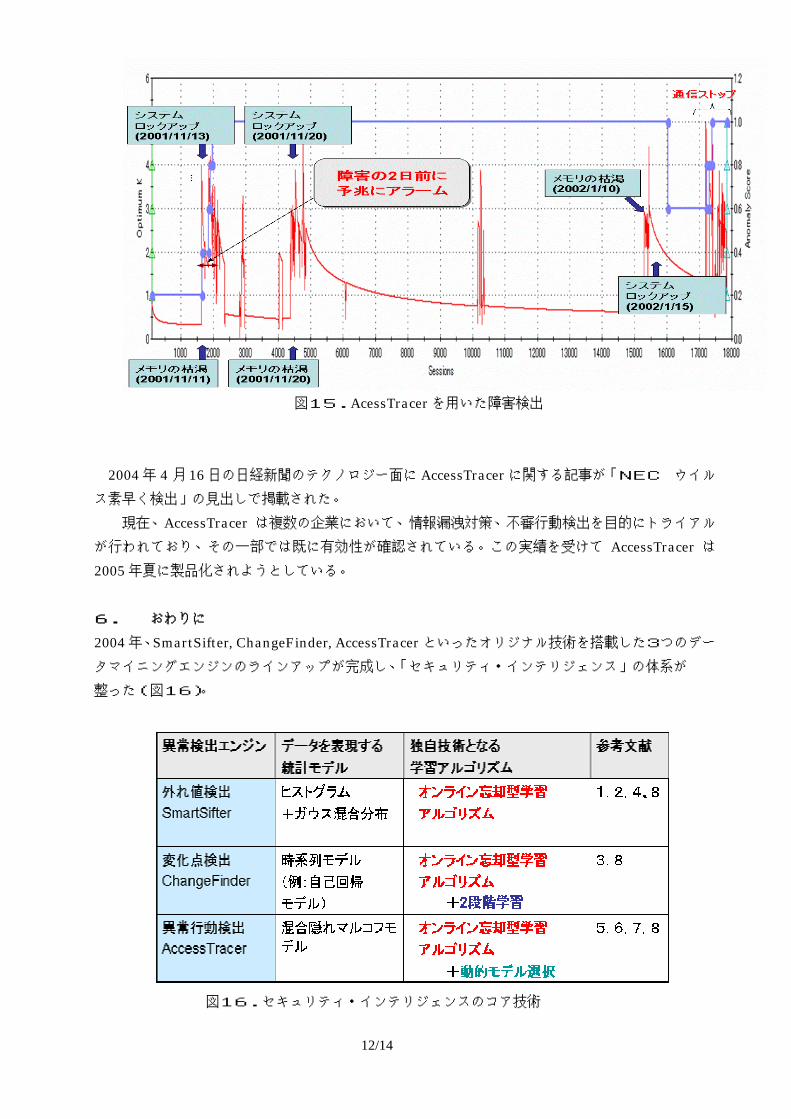
図14.AccessTracerのインターフェース 次に AccessTracerをコンピュータシステムの障害検出に応用した。実際にネットワークを構成 する ATMサーバの Syslogとよばれるメッセージデータに対して、AccessTracerを用いてコンピュータの障害を早期に検知できるかどうかを調べた。その結果、AccessTracer はシステムロックアップという重大な障害の 2日前にその予兆を発見して高い異常スコアを与えた(図14)。AccessTracerの障害早期検出における有効性が立証された。
12/14
図15.AcessTracerを用いた障害検出
2004年 4月 16日の日経新聞のテクノロジー面に AccessTracerに関する記事が「NEC ウイルス素早く検出」の見出しで掲載された。 現在、AccessTracer は複数の企業において、情報漏洩対策、不審行動検出を目的にトライアルが行われており、その一部では既に有効性が確認されている。この実績を受けて AccessTracer は2005年夏に製品化されようとしている。 6. おわりに 2004年、SmartSifter, ChangeFinder, AccessTracerといったオリジナル技術を搭載した3つのデータマイニングエンジンのラインアップが完成し、「セキュリティ・インテリジェンス」の体系が 整った(図16)。
図16.セキュリティ・インテリジェンスのコア技術

13/14
セキュリティ・インテリジェンスに関する技術をデータマイニングの分野の最高峰と云われる国際
会議である KDD(ACM Conference on Knowledge Discovery and Data Mining)に論文にまとめて投稿した結果、競争率 30%弱の中で 2000年から 2002年にかけて 3年連続で採録され、世界中に知れ渡るところとなった[1],[2],[3]。また、SmartSifterに関する成果はデータマイニング分野における最も権威ある国際ジャーナルである「Data Mining and Knowledge Discovery」誌に採録され、2004 年 3 月に掲載された[4]。動的モデル選択理論の成果は、情報理論の国際会議である IEEE Information Theory Workshop に受理され、2004年 10月に米国で発表した[5]。2001年 4月から2005年 3月までの招待講演の数は9件、招待解説記事は9件にのぼった。 さらに我々は 2004年 8月より、NICT(情報通信機構)のセキュリティ高度化グループに参加し、
民間 ISPで構成される TelecomISAC Japanにおけるセキュリティ分析センター立ち上げのための 研究にも参加してきた。そこにおいてもセキュリティ・インテリジェンスの手法を適用して、新種の ウイルスの分析などに成功し、NICTに顕著な貢献を果たしてきた。今や我々が創出したセキュリティ・インテリジェンスは一企業の戦略製品の域を超えて、学会と産業界の両面で広く貢献している。 今後は、本技術をデータ収集技術やポリシー技術と連携させながら、システムのリスク対策を根本
から強化する総合的なインテリジェント技術へと発展させていく所存である。 7.参考資料 ●主要論文
1. K.Yamanishi, J.Takeuchi, G.Williams, and P.Milne: “On-line Unsupervised Oultlier Detection Using
Finite Mixtures with Discounting Learning Algorithms,”in Proc. of the Sixth ACM SIGKDD Int’l. Conf. on
Knowledge Discovery and Data Mining(KDD2000), ACM Press, pp:320--324 2000.
2. K.Yamanishi and J.Takeuchi: “Discovering Outlier Filetering Rules From Unlabeled Data,” in Proceedings of
the Seventh ACM SIGKDD Int’l. Conf. on Knowledge Discovery and Data Mining (KDD2001), ACM
Press, pp:389-394, 2001.
3. K.Yamanishi and J.Takeuchi: “A Unifying Approach to Detecting Outliers and Change- Points from
Non-stationary Data,” in Proc. the Eighth ACM SIGKDD Int’l. Conf. on Knowledge Discovery and Data
Mining (KDD2002), ACM Press, pp:676-681, 2002.
4. K.Yamanishi, J.Takeuchi, G.Williamas, and P.Milne: “On-line Unsupervised Oultlier Detection Using Finite
Mixtures with Discounting Learning Algorithms," Data Mining and Knowledge Discovery Journal,
pp:275-300, May 2004, Volume 8, Issue 3.
5. Y.Maruyama and K.Yamanishi: “Dynamic Model Selection with Its Applications to Computer Security,” in
Proceedings of The IEEE Information Theory 2004(ITW2004).
6. 松永, 山西: “情報理論的手法に基づく異常行動検出,”第 2回情報科学技術フォーラム(FIT2003)予稿集(情報
技術レターズ), pp. 123-124, 2003.
7. 丸山、山西: “動的モデル選択とセキュリティ、障害検出への応用,”情報論的学習理論ワークショップ (IBIS2004)
予稿集(ISBN4-9902248-0-9), pp:15-22, 2004.
8. 山西、竹内、丸山: “統計的異常検出 3手法,” 情報処理、2005年 1月
9. P.Burge and J.Shawe-Taylor: “Detecting cellular fraud using adaptive prototypes,’’ in Proceedings of AI
Approaches to Fraud Detection and Risk Management, pp:9-13, 1997.

14/14
10. V.Guralnik and J.Srivastava: “Event detection from time series data,” in Proceedings of the Sixth ACM
SIGKDD Int‘l. Conf. on Data Mining and Knowledge Discovery, ACM Press, pp:32-42, 1999.
11. R.A.Maxion and T.N.Townsend: Masquerade detection using truncated command lines, in Proceedings of
International Conference on Dependable Systems and Networks, pp:219-228, 2002.
12. http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
13. http://www.research.att.com/~schonlau
●プレスリリース
2004年 4/16 日経新聞本誌掲載「NEC ウイルス素早く検出―電算機の記録、常に監視」
●特許
1.特願平 11-275437外れ値度計算装置 国内登録、 米、豪 : 出願済み
2.特願 2001-194077 外れ値判定ルール生成装置と外れ値検出装置(以下略) 国内出願、米公開済み
3.特願 2002-207718 時系列データに対する自己回帰モデル学習装置(以下略)国内出願、米公開済み
4.特願 2003-169986 変化点検出装置,変化点検出方法(以下略)手続補正(補正書提出)、米出願済み5.特願
2003-171481 確率分布推定装置および異常行動検出装置(以下略)国内出願
6.特願 2003-336648 外れ値度計算装置及びそれに用いる確率密度推定装置(以下略)国内出願
7.特願 2003-379273 モデル選択計算装置,動的モデル選択装置(以下略)日米英独仏出願済み
●HP
http://www.labs.nec.co.jp/DTmining/solution/security.htm
http://www.sw.nec.co.jp/innovation/tech_sch/dmsi/
以 上

















![設備工事編 (地中送電線路)1 検 査 記 録 一 覧 表(その1) [ 現 場 検 査 ] 検 査 項 目 検 査 記 録 社検対象 社検以外 書類 検査 現地](https://img.pdfslide.tips/doc/110x75/5f9635d8761a834e2a4cff25/ec-ioeeecei-1-oe-e-eoe-e-ei1i.jpg)











