Embed Size (px)
Citation preview

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 142
6 Analisi della regressione lineare
L'obiettivo dell'analisi della regressione è quello di studiare la distribuzione di una variabile,diciamo Y, per valori fissi di una'altra variabile che indichiamo con X. I valori di X sono fissi opreselezionati attraverso un'esperimento e sono diciamo X1, X2,...,Xn. Valori aleatoriamentescelti sono osservati per ogni Xi, diciamo Y1, Y2,...,Yn.
Il più semplice modello lineare è quello riportato in [1]:
Yi = ß0 + ß1Xi + ξξi i=1,2,...,n [1]
dove:
ß0 = intercettaß1 = pendenza o coefficiente di regressioneXi = variabile indipendente o regressoreYi = variabile dipendente o di risposta
Ad ogni Xi corrisponde una popolazione di Yi distribuita normalmente, con media posta sullaretta di regressione. Le assunzioni per poter eseguire l'analisi della regressione riguardano gli ξξi
che devono:
- essere distribuiti normalmente; - essere indipendenti tra loro; - avere una media uguale a zero; - avere varianza omogenea.
Le n coppie di dati vengono utilizzate per la stima dei parametri secondo il metodo dei minimiquadrati, negli esempi di seguito illustrati.
Un aspetto dell'analisi della regressione è determinare se Y dipende da X come specificato nellafunzione di regressione. L'ipotesi nulla da verificare, nel caso della regressione semplice, èquindi:
H0 : ß1 = 0
Nel caso Y dipenda da più variabili il modello statistico sul quale effettueremo l'analisi dellaregressione, multipla in questo caso, è quello riportato in [2]:
Yi = ß0 + ß1Xi1 + ..... + ßkXik + ξξi i=1,2,...,n [2]
dove Xi1, Xi2,....,Xik sono i k regressori. La regressione semplice può quindi considerarsi uncaso della regressione multipla nel quale k = 1. L'ipotesi nulla è in questo caso:

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 143
H0 : ß1 = ß2 = .... = ßk = 0
Le variabili indipendenti X1, X2,..., Xk, accertato previamente che non risultino correlate traloro, potranno essere inserite nel modello se il corrispondente parametro ß risulterà esseresignificativamente <>0 (esempio 6.4). Se viceversa nel modello sarà identificata presenza dimulticollinearità, vale a dire un certo grado di correlazione tra i diversi regressori, l'uso deglistessi in un modello di regressione multipla avrà delle limitazioni, come vedremo nell'esempio6.3

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 144
6.1 Regressione lineare semplice
Le variabili utilizzate sono l'umidità (umid) di un prodotto industriale ottenuto per mescola didiversi componenti e la sua densità finale (dens). Si ritiene che l'umidità della mescola influenzila densità del prodotto finito. L'analisi della regressione viene quindi effettuata per verificare se,e in che misura, la densità finale possa essere stimata conoscendo il valore di umidità dellamescola durante la lavorazione.
PROGRAMMA SAS
Nella PROC REG viene effettuata la stima dei parametri ß0 e ß1 utilizzando l'istruzioneMODEL, nella quale viene richiesta l'opzione P, che produce anche la stampa dei valori stimatidi Y per ognuna delle Xi.Nella seconda PROC REG vengono stimati i parametri per la regressione dei valori stimati didens vs. i valori osservati; viene inoltre verificata l'ipotesi ß0=0, ß1=1 che, se accettata, ciinforma come il modello stimato sia adeguato.L'istruzione OUTPUT crea un data-set SAS che viene utilizzato nei successivi steps di grafica.In effetti, i grafici avrebbero potuto essere ottenuti anche dall'interno della PROC REG ma conrisultati inferiori, anche se sufficienti in fase esplorativa dei dati.
** 6.1 Regressione lineare semplice* Draper e Smith - esempio F pag.60*;DATA esempio; LABEL umid='umidità della mescola'; LABEL dens='densità'; INPUT umid dens @@; CARDS;4.7 3 5.0 35.2 4 5.2 55.9 10 4.7 25.9 9 5.2 35.3 7 5.9 65.6 6 5.0 4;PROC PRINT; TITLE '6.1 Regressione lineare semplice';PROC REG; MODEL dens = umid / P; OUTPUT OUT=esempio2 P=yatt R=residuo;PROC REG DATA=esempio2; MODEL yatt = dens; TEST INTERCEPT=0, dens=1;** SAS / GRAPH*;GOPTIONS DEVICE=HPLJ5P3 GACCESS='SASGASTD>LPT1:' ROTATE=PORTRAIT VSIZE=4 VORIGIN=1 HSIZE=3 HORIGIN=1

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 145
FTEXT=SWISSL HTEXT=2 ;SYMBOL1 H=2 V=SQUARE I=RLCLM95;SYMBOL2 H=2 V=SQUARE I=RLCLI95;SYMBOL3 H=2 V=SQUARE I=RL;SYMBOL4 H=2 V=SQUARE I=NONE;AXIS1 ORDER=1 TO 11 BY 1;AXIS2 LABEL=('residui') ORDER=-3 TO 3 BY 1;AXIS3 LABEL=('densità stimata') ORDER=1 TO 11 BY 1;AXIS4 ORDER=4.4 TO 6.2 BY 0.2;PROC GPLOT; PLOT dens*umid=1 / VAXIS=AXIS1 HAXIS=AXIS4 FRAME; PLOT dens*umid=2 / VAXIS=AXIS1 HAXIS=AXIS4 FRAME; PLOT yatt*dens=3 / VAXIS=AXIS3 HAXIS=AXIS1 FRAME; PLOT residuo*umid=4 / VAXIS=AXIS2 HAXIS=AXIS4 FRAME; TITLE2;RUN;
OUTPUT SAS
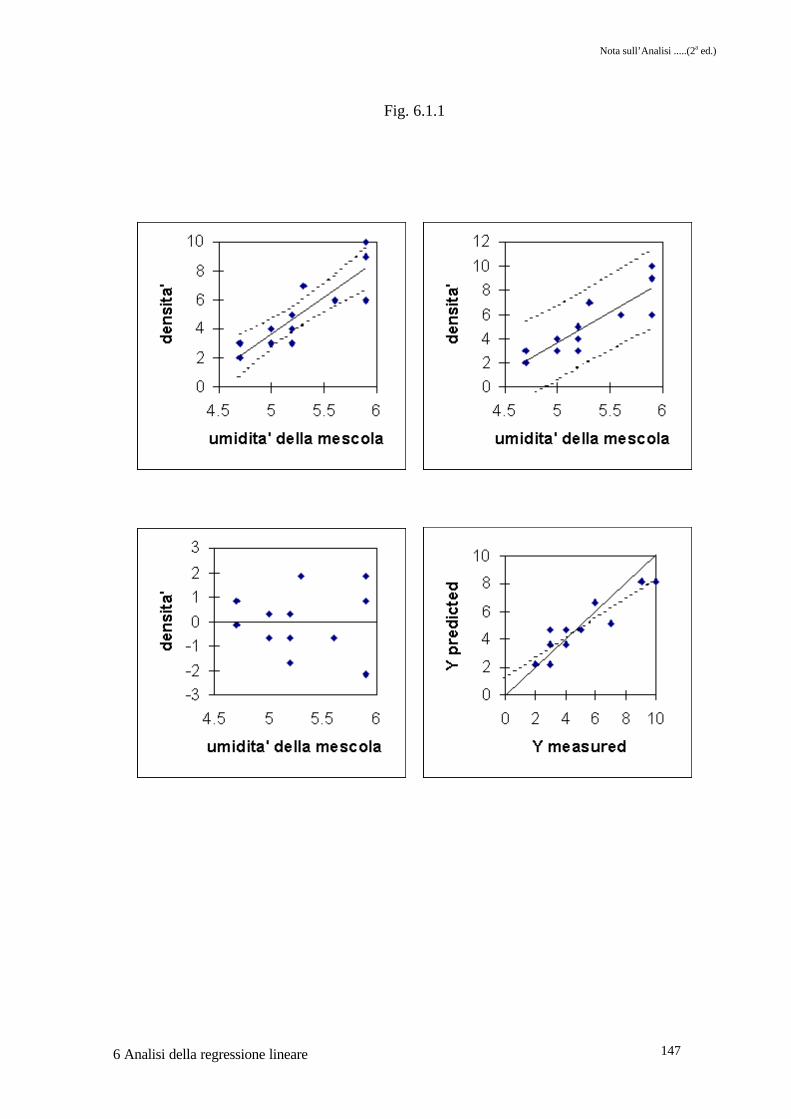
Il test F � ci permette di respingere l'ipotesi nulla. I parametri stimati ß0 � e ß1 � hannoaccanto l'errore standard relativo attraverso il quale è possibile calcolare i limiti fiduciari per iparametri stessi. Nell'ultima parte dell'OUTPUT troviamo, tra gli altri, i valori osservati dellavariabile dipendente �, quelli stimati � e i residui.Nel primo e secondo grafico della figura 6.1.1 (oltre ad essere riportati i punti osservazione ela retta di regressione relativa) sono riportati i limiti fiduciari per la media delle previsioni adogni Xi e per una singola previsione ad ogni Xi, rispettivamente.Nel terzo grafico sono riportati i residui vs. i valori di umidità. Questo grafico è molto utile inquanto consente di verificare se la varianza degli errori è costante e se la distribuzione deglierrori stessi mostra un qualche trend, che , se presente, ci indica come al modello debba essereaggiunto per esempio una componente quadratica, un punto di discontinuità ecc.Nella parte relativa all'ultima PROC REG il TEST e il valore di probabilità associato � ciinformano come ß0 e ß1 non siano significativamente differenti da 0 e 1 rispettivamente.Nel quarto grafico di fig. 6.1 sono infine riportati punti e la retta interpolante per valori stimatidi densità vs. i valori osservati.
6.1 Regressione lineare semplice
Model: MODEL1Dependent Variable: DENS densità
Analysis of Variance
Sum of MeanSource DF Squares Square F Value Prob>FModel 1 52.50000 52.50000 30.583 0.0003 �Error 10 17.16667 1.71667C Total 11 69.66667
Root MSE 1.31022 R-square 0.7536 Dep Mean 5.16667 Adj R-sq 0.7289 C.V. 25.35902
Parameter Estimates
Parameter Standard T for H0:

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 146
Variable DF Estimate Error Parameter=0 Prob> ]T[ INTERCEP 1 -21.333333 � 4.80681973 -4.438 0.0013 UMID 1 5.000000 � 0.90413512 5.530 0.0003
Variable Variable DF Label INTERCEP 1 Intercept UMID 1 umidità della mescola
Dep Var Predict Obs DENS Value Residual � � 1 3.0000 2.1667 0.8333 2 3.0000 3.6667 -0.6667 3 4.0000 4.6667 -0.6667 4 5.0000 4.6667 0.3333 5 10.0000 8.1667 1.8333 6 2.0000 2.1667 -0.1667 7 9.0000 8.1667 0.8333 8 3.0000 4.6667 -1.6667 9 7.0000 5.1667 1.8333 10 6.0000 8.1667 -2.1667 11 6.0000 6.6667 -0.6667 12 4.0000 3.6667 0.3333
Sum of Residuals -4.17444E-14Predicted Resid SS (Press) 26.3736
Model: MODEL1Dependent Variable: YATT Predicted Value of DENS
Analysis of Variance
Sum of Mean Source DF Squares Square F Value Prob>F
Model 1 39.56340 39.56340 30.583 0.0003 Error 10 12.93660 1.29366 C Total 11 52.50000
Root MSE 1.13739 R-square 0.7536 Dep Mean 5.16667 Adj R-sq 0.7289 C.V. 22.01404
Parameter Estimates Parameter Standard T for H0: Variable DF Estimate Error Parameter=0 Prob > |T| INTERCEP 1 1.273126 0.77685379 1.639 0.1323 DENS 1 0.753589 0.13626917 5.530 0.0003
Variable
Variable DF Label INTERCEP 1 Intercept DENS 1 densità
Test: Numerator: 2.1150 DF: 2 F value: 1.6349 Denominator: 1.29366 DF: 10 Prob>F: 0.2430 �
Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 147
Fig. 6.1.1

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 148
6.2 Deviazione dalla linearità
Se anche l'ipotesi nulla H0 : ß1 = 0 è respinta, questo non necessariamente significa chel'equazione di una retta sia la più adatta per rappresentare la relazione tra la Y e la X. Se perogni valore della Xi sono disponibili diverse osservazioni, si può costruire un test per valutarel'adeguatezza del modello. Il test si basa sul fatto che la varianza dovuta all'errore può esserescomposta in due componenti: errore puro (EP o deviazioni dei valori osservati ad ogni Xi
dalla loro media) e deviazione dalla linearità (DL o deviazione della media delle osservazionidal valore stimato, per ogni Xi), secondo l'equazione riportata in [3]:
(( )) (( )) (( ))i
m
ij ij
n
j== ==∑∑ ∑∑ ∑∑ ∑∑−− == −− ++ −−
1
2
1
2 2Y Y Y Y Y
SS SS SS
$ $Yij i i ii
RES EP DL
i [3]
dove:
$Yi = valore stimato di YYi = valore medio degli Yij a Xi
m = numero degli Xi differenti tra loron = numero totale delle osservazioni
Si può quindi eseguire il test:
FSS
SS== DL
EP
e si respinge l'adeguatezza del modello se:
(( ))F F>> −− ++ −−m p 1 ,n mαα
dove:
p = numero delle variabili indipendenti
Nell'esempio di seguito illustrato sarà utilizzato un data set nel quale sono disponibili piùosservazioni per la variabile Y ad ogni Xi.Sarà evidenziato come, pur avendo respinto l'ipotesi nulla, il modello non risulti adeguato sullabase del test F descritto precedentemente.
PROGRAMMA SAS
Nella prima PROC REG vengono stimati i parametri della regressione lineare; dati e residuiproducono i primi due grafici di fig. 6.2.1. Allo scopo di eseguire il test per la deviazione dellalinearità, viene creata una variabile ausiliaria, identica alla x e denominata xcod, che vieneutilizzata come variabile categorica nella PROC GLM. Questa procedura viene effettuata perottenere il calcolo del test dal SAS, non essendo possibile ottenerlo direttamente. In pratica il

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 149
MODEL utilizzato, con la variabile fittizia xcod, fa sì che l'errore rimasto sia la componentedell'errore già definita come errore puro, mentre la variabilità dovuta alla variabile xcod é lacomponente dovuta alla deviazione dalla linearità.La variabile xcod viene creata nel secondo step DATA assieme a x2, data questa dal quadratodi x.A seguito della significativa deviazione dalla linearità, nella successiva PROC REG vengonostimati i diversi parametri di una regressione curvilinea di secondo grado.
** 6.2 Deviazione dalla linearità* Draper e Smith - esempio E pag.138*;DATA esempio; INPUT y x; CARDS;4.2 13.8 13.0 22.3 31.8 42.0 42.2 42.0 52.5 62.7 6;PROC REG; MODEL y = x / P; OUTPUT OUT=esempio2 P=yatt R=residuo;DATA esempio; SET esempio; x2 = x**2; xcod = x;PROC PRINT; TITLE '6.2 Deviazione dalla linearità';PROC GLM; CLASS xcod; MODEL y = x xcod / SS3;PROC REG; MODEL y = x x2; OUTPUT OUT=esempio3 P=yatt R=residuo;RUN;** SAS / GRAPH*;GOPTIONS DEVICE=HPLJ5P3 GACCESS='SASGASTD>LPT1:' ROTATE=PORTRAIT VSIZE=4 VORIGIN=1 HSIZE=3 HORIGIN=1 FTEXT=SWISSL HTEXT=1.8 ;SYMBOL1 V=SQUARE I=RL;SYMBOL2 V=SQUARE I=NONE;SYMBOL3 V=SQUARE I=RQ;

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 150
SYMBOL4 V=SQUARE I=NONE;AXIS1 LABEL=('residui') ORDER=-1 TO 1 BY 0.2;AXIS2 LABEL=('residui') ORDER=-0.3 TO 0.3 BY 0.1;AXIS3 ORDER=0 TO 7 BY 1;PROC GPLOT DATA=esempio2; PLOT y*x=1 / HAXIS=AXIS3 FRAME; PLOT residuo*x=1 / HAXIS=AXIS3 VAXIS=AXIS1 FRAME; TITLE2 'regressione lineare';PROC GPLOT DATA=esempio3; PLOT y*x=3 / HAXIS=AXIS3 FRAME; PLOT residuo*x=4 / HAXIS=AXIS3 VAXIS=AXIS2 FRAME; TITLE2 'regressione quadratica';RUN;
OUTPUT SAS
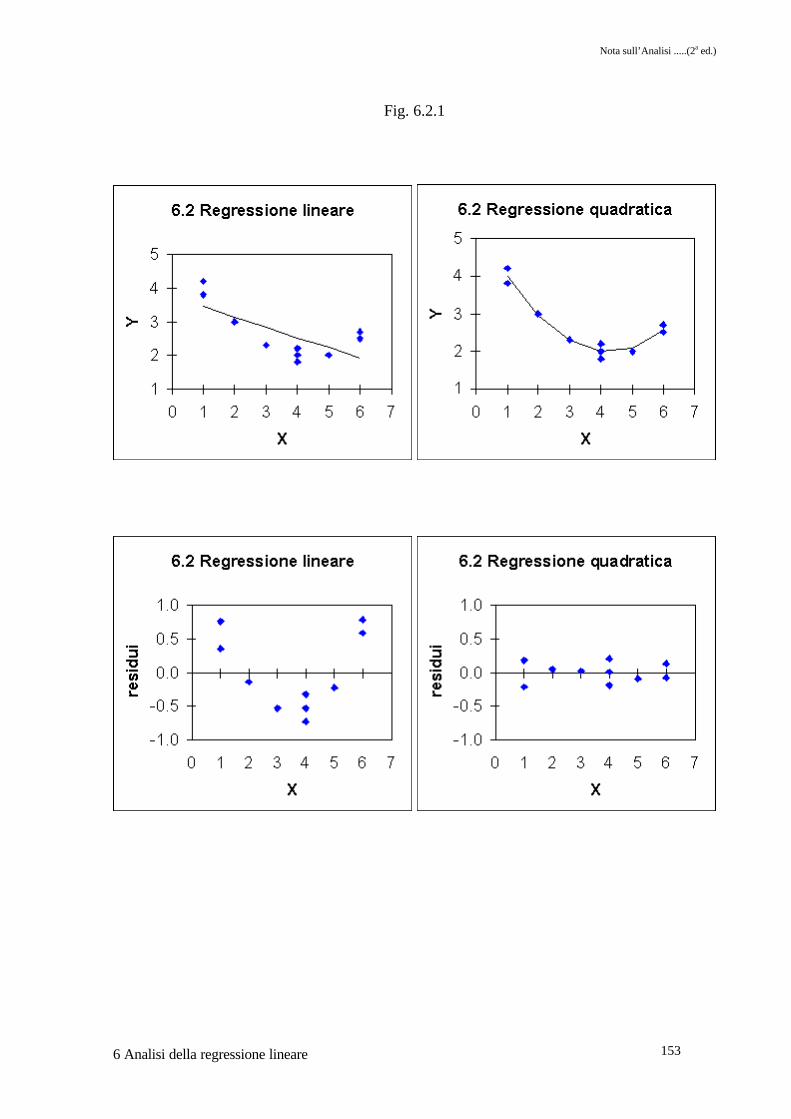
L'ipotesi nulla é respinta nella parte dell'output relativo alla prima PROC REG; l'R2 aggiustatorelativo all'interpolazione lineare é riportato in �. Dall'esame dei primi due grafici di fig. 6.2.1appare come i dati tendano a disporsi secondo una parabola, e come i residui mostrinoanch'essi un trend curvilineo.Dopo la stampa dei dati con le due variabili trasformate x2 e xcod, nella parte relativa allaPROC GLM troviamo in � la somma dei quadrati relativa all'errore puro e in � quella relativaalla deviazione dalla linearità. Il test F e il livello di probabilità associato � ci indicano come ladeviazione dalla linearità sia significativa, e quindi viene respinta l'adeguatezza del modello.Nella successiva PROC REG vengono calcolati i parametri ß0 �, ß1 � e ß2 �, essendo ß2 ilparametro per x2. Si ipotizza quindi che y sia una funzione quadratica di x. L'R2 aggiustato� ci informa su come una parabola interpoli i dati in esame in maniera molto più soddisfacentedi una retta. Il grafico dei residui, il quarto di fig. 6.2.1, mostra un'assenza di trendconfermandoci l'adeguatezza del modello.
6.2 Deviazione dalla linearità
Model: MODEL1Dependent Variable: Y
Analysis of Variance
Sum of MeanSource DF Squares Square F Value Prob>F
Model 1 2.84507 2.84507 7.795 0.0235Error 8 2.91993 0.36499C Total 9 5.76500
Root MSE 0.60415 R-square 0.4935 Dep Mean 2.65000 Adj R-sq 0.4302 � C.V. 22.79794
Parameter Estimates
Parameter Standard T for H0: Variable DF Estimate Error Parameter=0 Prob > |T|
INTERCEP 1 3.751316 0.43829321 8.559 0.0001 X 1 -0.305921 0.10957330 -2.792 0.0235
Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 151
Dep Var Predict Obs Y Value Residual
1 4.2000 3.4454 0.7546 2 3.8000 3.4454 0.3546 3 3.0000 3.1395 -0.1395 4 2.3000 2.8336 -0.5336 5 1.8000 2.5276 -0.7276 6 2.0000 2.5276 -0.5276 7 2.2000 2.5276 -0.3276 8 2.0000 2.2217 -0.2217 9 2.5000 1.9158 0.5842 10 2.7000 1.9158 0.7842
Sum of Residuals -1.9984E-15Sum of Squared Residuals 2.9199Predicted Resid SS (Press) 5.0119
6.2 Deviazione dalla linearità
OBS Y X X2 XCOD
1 4.2 1 1 1 2 3.8 1 1 1 3 3.0 2 4 2 4 2.3 3 9 3 5 1.8 4 16 4 6 2.0 4 16 4 7 2.2 4 16 4 8 2.0 5 25 5 9 2.5 6 36 6 10 2.7 6 36 6
General Linear Models Procedure Class Level Information
Class Levels Values
XCOD 6 1 2 3 4 5 6
Number of observations in data set = 10
Dependent Variable: Y Sum of MeanSource DF Squares Square F Value Pr > F
Model 5 5.5850000 1.1170000 24.82 0.0041
Error 4 0.1800000� 0.0450000
Corrected Total 9 5.7650000
R-Square C.V. Root MSE Y Mean
0.968777 8.004982 0.2121 2.650000
Source DF Type III SS Mean Square F Value Pr > F
X 0 0.0000000 . . .XCOD 4 2.7399342� 0.6849836 15.22 0.0109 �
Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 152
Model: MODEL1Dependent Variable: Y
Analysis of Variance
Sum of MeanSource DF Squares Square F Value Prob>FModel 2 5.57251 2.78625 101.323 0.0001Error 7 0.19249 0.02750C Total 9 5.76500
Root MSE 0.16583 R-square 0.9666 Dep Mean 2.65000 Adj R-sq 0.9571 � C.V. 6.25765
Parameter Estimates
Parameter Standard T for H0: Variable DF Estimate Error Parameter=0 Prob > |T|
INTERCEP 1 5.461518 � 0.20967033 26.048 0.0001 X 1 -1.638052 � 0.13709962 -11.948 0.0001 X2 1 0.192842 � 0.01936335 9.959 0.0001
Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 153
Fig. 6.2.1

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 154
6.3 Regressione multipla; multicollinearitàNel caso si abbiano a disposizione, per ogni valore osservato di Y, osservazioni relative a piùvariabili indipendenti X1, X2, ..., Xk, possiamo costruire un modello nel quale la Y sia funzionedi più regressori. In questo caso è opportuno verificare se uno o più regressori siano gli unicombinazioni lineari degli altri o, in altri termini, se i regressori risultano correlati tra loro.Ad esempio, in studi in pieno campo in una sola località, quando si consideri la rispostafenologica della pianta come funzione di temperatura e fotoperiodo, è frequente il caso in cui cisia una elevata correlazione tra le due variabili meteorologiche. Operando la stima deiparametri in queste condizioni si identifica una superfice di regressione molto instabile e quindidel tutto inutile ai fini previsionali.Nella PROC REG sono a disposizione una serie di indici che permettono di diagnosticareproblemi di multicollinearità (MC) tra regressori.Nell'esempio che segue ci si limiterà ad indicare qual'è il campo di variabilità o il valore sogliaper ciascun indice entro od oltre il quale si ha l'indicazione dell'esistenza di multicollinearità traregressori.
PROGRAMMA SAS
Nell'istruzione MODEL della PROC REG vengono richieste le opzioni che permettono ladiagnostica della multicollinearità.Nella successiva PROC CORR si valuta, a conferma di quanto emerso dallo step precedente,se esistono correlazioni tra i regressori in esame.
** 6.3 Regressione multipla - multicollinearità* Myers - esempio pag 232*;DATA esempio; INPUT x1 x2 x3 y; CARDS;89 25.5 4 304.37513 194.3 11 2616.32231 83.7 4 1139.1268 30.7 2 285.43319 129.8 6 1413.77276 180.8 6 1155.6882 43.4 4 383.78427 165.2 10 2174.27193 74.3 4 845.30224 60.8 5 1125.28729 319.2 12 3462.60951 376.2 12 3682.33;PROC PRINT; TITLE '6.3 Regressione multipla; multicollinearità';PROC REG; MODEL y = x1 x2 x3 / P CLI CLM SS1 SS2 I COVB COLLIN VIF;PROC CORR; VAR x1 x2 x3;RUN;

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 155
OUTPUT SAS
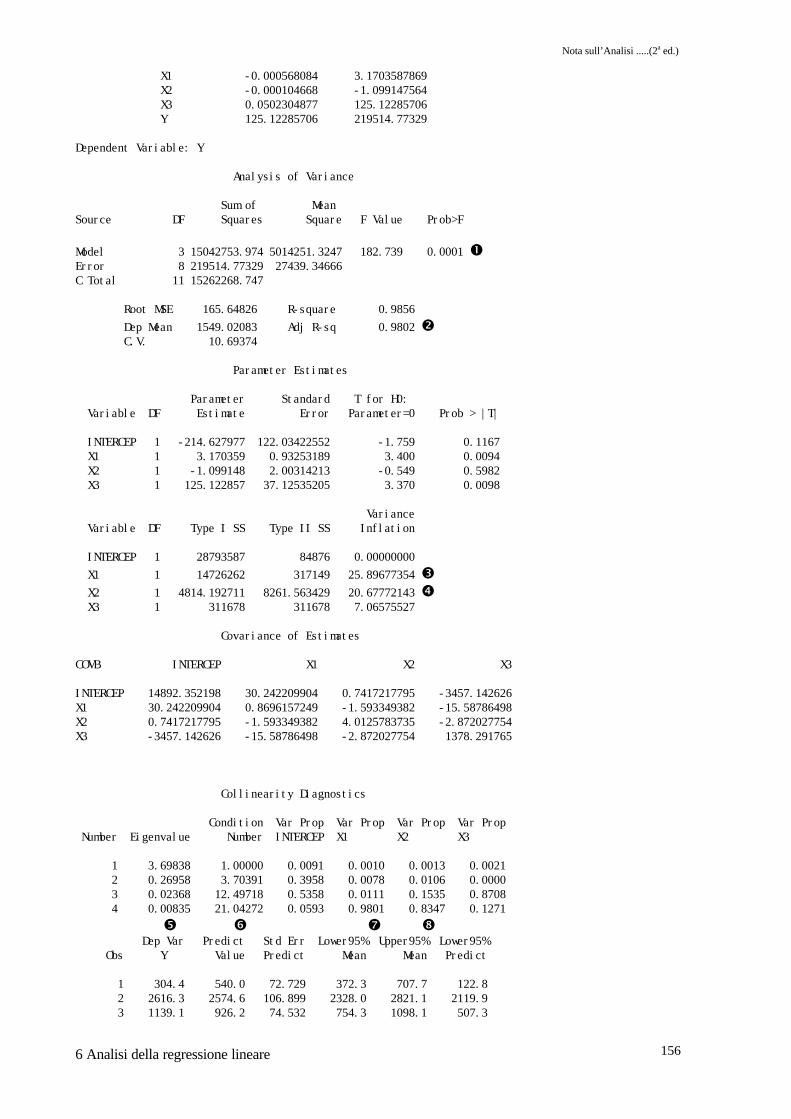
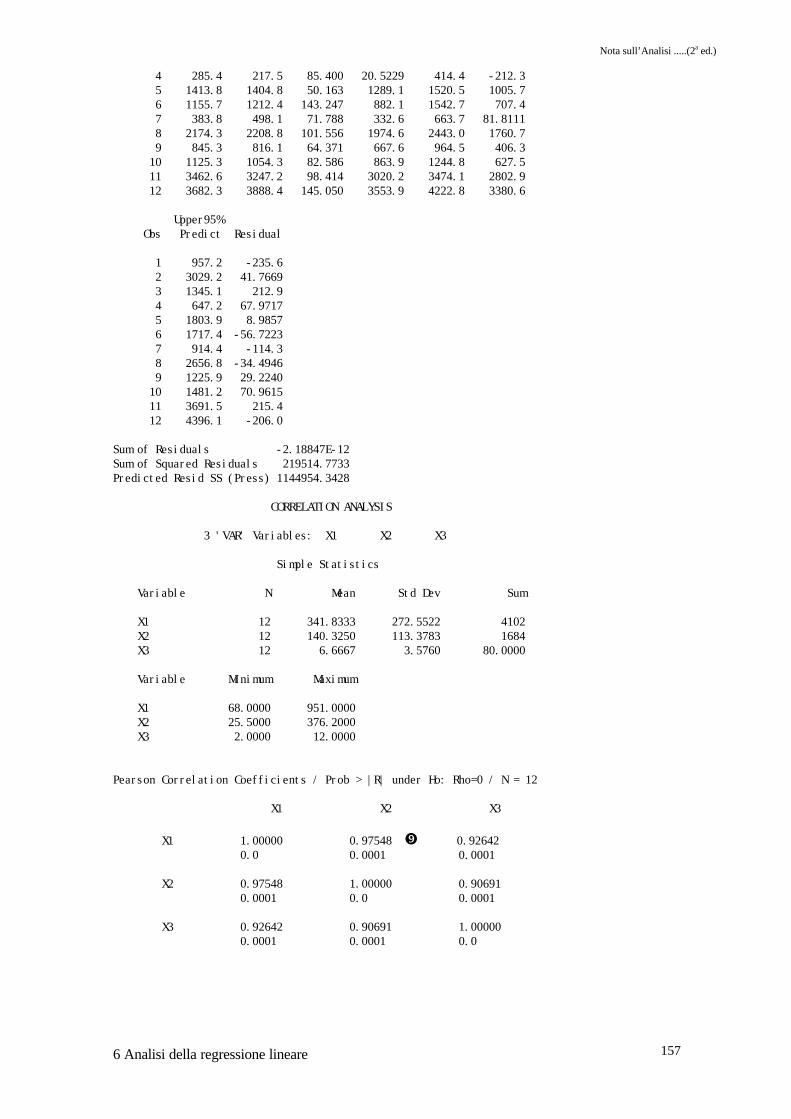
Il test F e il valore di probabilità associato � ci informano come l'ipotesi nulla debba essererespinta. Il valore dell'R2 � ci dice come una elevatissima parte della variabilità sia dovuta alletre variabili indipendenti scelte; tuttavia, il modello può essere di scarsissimo valore ai finiprevisionali se esiste una forte correlazione tra i regressori.Il primo indice diagnostico al fine di determinare se esistono problemi di MC è il VIF, ovariance inflation factor. Valori >10 indicano come molto probabili problemi a carico delregressore interessato. In � e � troviamo, per i regressori X1 e X2, valori >10.Un altro elemento per la diagnostica è Φ (condition number). Nell'output è dato dal � elevatoal quadrato, nel nostro caso Φ=442.81; quando questo numero è maggiore di 1000 si puòesser certi dell'esistenza di MC. In questo caso però sembrerebbe che ciò non accada.Ultimi elementi presenti nell'output per la diagnostica dell'MC sono gli eigenvalues (autovalori)e le variance proportion. Quando a valori molto piccoli dell'eigenvalue sono associati valoriprossimi ad 1 delle variance proportion, questo ci indica che i regressori interessati sono afflittida MC. Nel nostro caso al valore più piccolo dell'eigenvalue �, troviamo alti valori dellevariance proportion per X1 � e X2 �, già evindenziati dal VIF.Nella parte dell'output relativo alla PROC CORR, a conferma di quanto emersoprecedentemente, che la correlazione tra X1 e X2 è molto elevata �.In conclusione, la presenza di MC tra regressori ci impedisce di usarli contemporaneamente nelmodello. Si impone quindi una scelta tra le variabili indipendenti da usare, con metodologieche vedremo negli esempi successivi.
6.3 Regressione multipla; multicollinearità
OBS X1 X2 X3 Y
1 89 25.5 4 304.37 2 513 194.3 11 2616.32 3 231 83.7 4 1139.12 4 68 30.7 2 285.43 5 319 129.8 6 1413.77 6 276 180.8 6 1155.68 7 82 43.4 4 383.78 8 427 165.2 10 2174.27 9 193 74.3 4 845.30 10 224 60.8 5 1125.28 11 729 319.2 12 3462.60 12 951 376.2 12 3682.33
6.3 Regressione multipla; multicollinearità
Model: MODEL1
X'X Inverse, Parameter Estimates, and SSE
INTERCEP X1 X2
INTERCEP 0.5427371279 0.0011021476 0.0000270313 X1 0.0011021476 0.0000316923 -0.000058068 X2 0.0000270313 -0.000058068 0.0001462345 X3 -0.125992163 -0.000568084 -0.000104668 Y -214.6279772 3.1703587869 -1.099147564
X3 Y
INTERCEP -0.125992163 -214.6279772
Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 156
X1 -0.000568084 3.1703587869 X2 -0.000104668 -1.099147564 X3 0.0502304877 125.12285706 Y 125.12285706 219514.77329
Dependent Variable: Y
Analysis of Variance
Sum of MeanSource DF Squares Square F Value Prob>F
Model 3 15042753.974 5014251.3247 182.739 0.0001 �Error 8 219514.77329 27439.34666C Total 11 15262268.747
Root MSE 165.64826 R-square 0.9856 Dep Mean 1549.02083 Adj R-sq 0.9802 � C.V. 10.69374
Parameter Estimates
Parameter Standard T for H0: Variable DF Estimate Error Parameter=0 Prob > |T|
INTERCEP 1 -214.627977 122.03422552 -1.759 0.1167 X1 1 3.170359 0.93253189 3.400 0.0094 X2 1 -1.099148 2.00314213 -0.549 0.5982 X3 1 125.122857 37.12535205 3.370 0.0098
Variance Variable DF Type I SS Type II SS Inflation
INTERCEP 1 28793587 84876 0.00000000 X1 1 14726262 317149 25.89677354 � X2 1 4814.192711 8261.563429 20.67772143 � X3 1 311678 311678 7.06575527
Covariance of Estimates
COVB INTERCEP X1 X2 X3
INTERCEP 14892.352198 30.242209904 0.7417217795 -3457.142626X1 30.242209904 0.8696157249 -1.593349382 -15.58786498X2 0.7417217795 -1.593349382 4.0125783735 -2.872027754X3 -3457.142626 -15.58786498 -2.872027754 1378.291765
Collinearity Diagnostics
Condition Var Prop Var Prop Var Prop Var Prop Number Eigenvalue Number INTERCEP X1 X2 X3
1 3.69838 1.00000 0.0091 0.0010 0.0013 0.0021 2 0.26958 3.70391 0.3958 0.0078 0.0106 0.0000 3 0.02368 12.49718 0.5358 0.0111 0.1535 0.8708 4 0.00835 21.04272 0.0593 0.9801 0.8347 0.1271 � � � � Dep Var Predict Std Err Lower95% Upper95% Lower95% Obs Y Value Predict Mean Mean Predict
1 304.4 540.0 72.729 372.3 707.7 122.8 2 2616.3 2574.6 106.899 2328.0 2821.1 2119.9 3 1139.1 926.2 74.532 754.3 1098.1 507.3
Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 157
4 285.4 217.5 85.400 20.5229 414.4 -212.3 5 1413.8 1404.8 50.163 1289.1 1520.5 1005.7 6 1155.7 1212.4 143.247 882.1 1542.7 707.4 7 383.8 498.1 71.788 332.6 663.7 81.8111 8 2174.3 2208.8 101.556 1974.6 2443.0 1760.7 9 845.3 816.1 64.371 667.6 964.5 406.3 10 1125.3 1054.3 82.586 863.9 1244.8 627.5 11 3462.6 3247.2 98.414 3020.2 3474.1 2802.9 12 3682.3 3888.4 145.050 3553.9 4222.8 3380.6
Upper95% Obs Predict Residual
1 957.2 -235.6 2 3029.2 41.7669 3 1345.1 212.9 4 647.2 67.9717 5 1803.9 8.9857 6 1717.4 -56.7223 7 914.4 -114.3 8 2656.8 -34.4946 9 1225.9 29.2240 10 1481.2 70.9615 11 3691.5 215.4 12 4396.1 -206.0
Sum of Residuals -2.18847E-12Sum of Squared Residuals 219514.7733Predicted Resid SS (Press) 1144954.3428
CORRELATION ANALYSIS
3 'VAR' Variables: X1 X2 X3
Simple Statistics
Variable N Mean Std Dev Sum
X1 12 341.8333 272.5522 4102 X2 12 140.3250 113.3783 1684 X3 12 6.6667 3.5760 80.0000
Variable Minimum Maximum
X1 68.0000 951.0000 X2 25.5000 376.2000 X3 2.0000 12.0000
Pearson Correlation Coefficients / Prob > |R| under Ho: Rho=0 / N = 12
X1 X2 X3
X1 1.00000 0.97548 � 0.92642 0.0 0.0001 0.0001
X2 0.97548 1.00000 0.90691 0.0001 0.0 0.0001
X3 0.92642 0.90691 1.00000 0.0001 0.0001 0.0

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 158
6.4 Regressione multipla; scelta del miglior modello
La scelta del miglior modello, per quanto riguarda la scelta dei regressori, è uno dei problemiche si presentano nella regressione multipla. Una condizione estremamente importante nelloscegliere il modello, molto spesso volutamente trascurata, è data dal fatto che il modello stessodeve essere il più possibile semplice. Ciò può comportare l'opportunità di rinunciareall'introduzione di un regressore anche se questo migliora, in questo caso trascurabilmente,l'R2.Nella PROC REG sono disponibili alcuni indici che ci permettono di valutare quale sia ilmiglior compromesso tra precisione e semplicità, anche se, nei casi in cui la risposta delleprocedure statistiche non è univoco,la scelta finale deve essere fatta dal ricercatore sulla basedi considerazioni relative alla natura stessa del fenomeno studiato.Vedremo quindi come si possa selezionare il miglior modello attraverso alcuni metodi qualiSTEPWISE, ADJRSQ e CP, cercando successivamente conferma attraverso la PRESSstatistic.Il metodo STEPWISE parte introducendo nel modello i regressori uno per volta se questirisultano significativi ad un livello F predeterminato (0.15 di default, modificabile attraversol'opzione SLENTRY). Non essendo i regressori in pratica quasi mai perfettamente ortogonali,l'introduzione di un nuovo regressore nel modello può rendere non significativo l'F di quelloprecedentemente introdotto (per rimanere nel modello il livello F è 0.15 di default; può esseremodificato attraverso l'opzione SLSTAY). La selezione termina quando la procedura haprovato tutte le variabili disponibili, lasciando nel modello quelle che hanno mantenuto un Fsignificativo.Il metodo ADJRSQ prova modelli con tutte le combinazioni possibili di regressori, fornendoun elenco in cui i diversi modelli sono ordinati per valori decrescenti dell'R2 aggiustato. L'R2
aggiustato differisce dall'R2 in quanto tiene conto dei gradi di libertà associati al modello; i dueindici sono uguali nel caso di regressione semplice ma l'R2 aggiustato è minore nel caso dimodelli con due o più regressori.Il metodo CP si basa su un indice proposto da Mallow, il Cp, per la cui descrizione si rimandaal manuale SAS/STAT. Questo metodo ordina tutti i possibili modelli per valori crescenti diCp, essendo ritenuto migliore il modello che ha Cp simile a p, dove p è il numero dei regressoriimpiegati.Il numero di PRESS viene utilizzato come criterio di selezione in quanto la statistica relativastabilisce che il miglior modello fra quelli provati ha il valore di PRESS più basso.Nell'esempio che segue la lettura delle risultanze dell'analisi è lineare in quanto tutti i metodiconcordano tra loro; in altri casi la scelta non è invece semplice in quanto si possono ottenererisultati parzialmente contrastanti.
PROGRAMMA SAS
Nella prima PROC REG vengono richiesti, nelle tre istruzioni MODEL, i tre metodi diselezione decritti utilizzando per SLENTRY e SLSTAY il valore di default 0.15 .Sapendo a priori quali sarebbero stati i tre migliori modelli, nella seconda PROC REG,attraverso l'opzione P si ottiene il valore di PRESS relativo appunto ai modelli migliori.Ovviamente, analizzando i dati per la prima volta e non sapendo quindi quale può essere ilrisultato delle selezioni operate nella prima PROC REG, la seconda deve essere fatta giraresuccessivamente in un altro programma, cosa non fatta in questo esempio per brevità.
*

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 159
* 6.4 Regressione multipla - scelta del miglior modello*;DATA esempio; INPUT x1 x2 x3 x4 y; CARDS;5.5 31 10 8 79.32.5 55 8 6 200.18.0 67 12 9 163.23.0 50 7 16 200.13.0 38 8 15 146.02.9 71 12 17 177.78.0 30 12 8 30.99.0 56 5 10 291.94.0 42 8 4 160.06.5 73 5 16 339.45.5 60 11 7 159.65.0 44 12 12 86.36.0 50 6 6 237.55.0 39 10 4 107.23.5 55 10 4 155.0;PROC PRINT; TITLE '6.4 Regressione multipla; scelta del miglior modello';PROC REG; m1: MODEL y = x1 x2 x3 x4 / SELECTION=STEPWISE; m2: MODEL y = x1 x2 x3 x4 / SELECTION=ADJRSQ; m3: MODEL y = x1 x2 x3 x4 / SELECTION=CP CP;PROC REG; m4: MODEL y = x1 x2 x3 x4 / P; m5: MODEL y = x1 x2 x3 / P; m6: MODEL y = x2 x3 / P;RUN;
OUTPUT SAS
L'opzione STEPWISE fa entrare nel modello le variabili x3, x2 e x1 una alla volta in quantosignificative a P=0.15 (SLENTRY). Non entra invece x4 in quanto non risulta significativo l'Frelativo. L'introduzione di x2 e poi x1 non provoca l'uscita di nessuno dei regressoriprecedentemente introdotti (SLSTAY=0.15). STEPWISE si ferma quindi indicando comemiglior modello:
y = ß0 + ß1x1 + ß2x2 + ß3x3
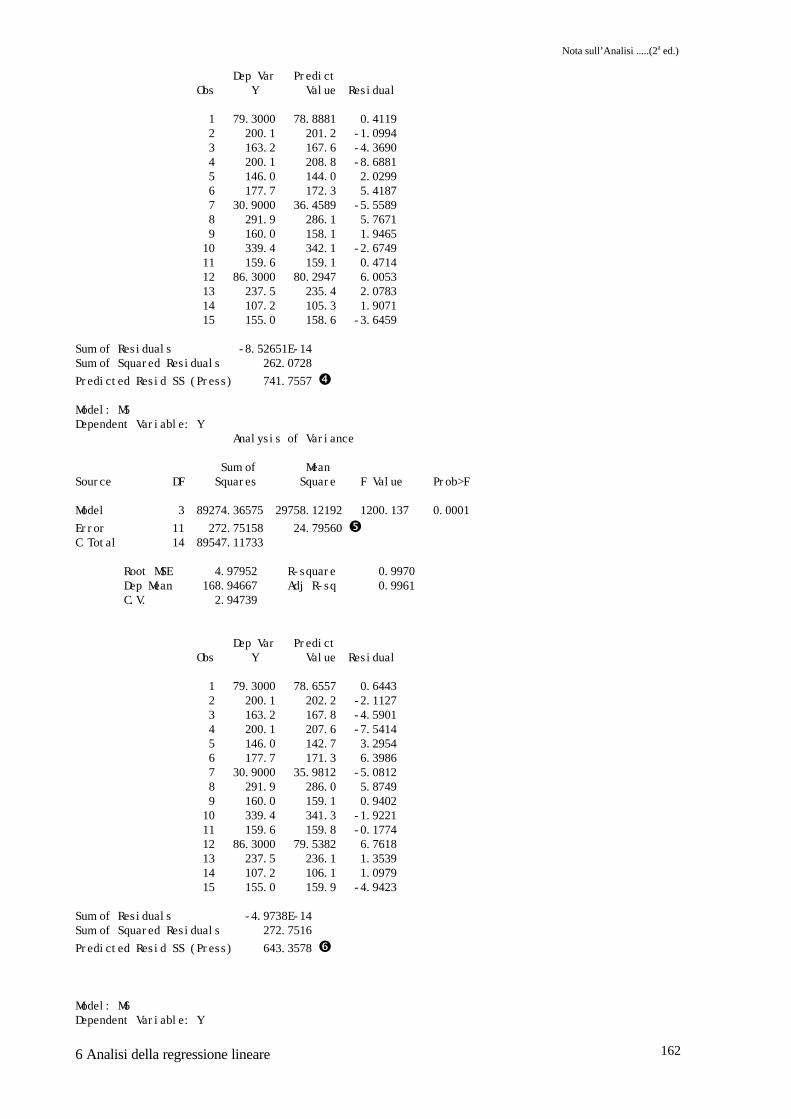
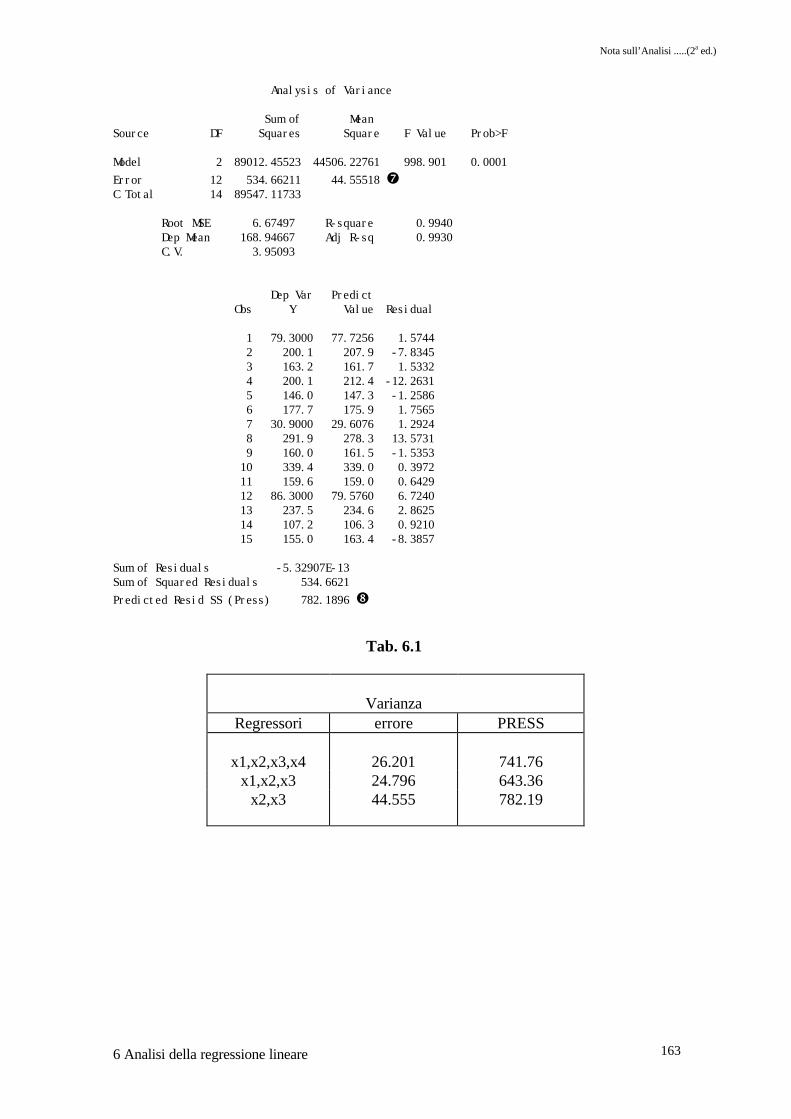
ADJRSQ � e CP � indicano anch'essi lo stesso modello.Il valore di PRESS in �, � e � e i valori della varianza dell'errore �, � e � ci permettonodi compilare la tabella 6.1 dalla quale risulta come il modello che ha il numero di PRESS e lavarianza dell'errore più piccoli è effettivamente quello individuato dai tre metodi di selezioneutilizzati.
Stepwise Procedure for Dependent Variable Y
Step 1 Variable X3 Entered R-square = 0.6372 C(p) =1228.4601516
DF Sum of Squares Mean Square F Prob>F
Regression 1 57064.23404888 57064.23404888 22.84 0.0004

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 160
Error 13 32482.88328446 2498.68332957Total 14 89547.11733333
Parameter Standard Type IIVariable Estimate Error Sum of Squares F Prob>F
INTERCEP 396.07331378 49.24843306 161613.46777294 64.68 0.0001X3 -25.05073314 5.24196424 57064.23404888 22.84 0.0004
Bounds on condition number: 1, 1------------------------------------------------------------------------Step 2 Variable X2 Entered R-square = 0.9940 C(p) = 11.40127931
DF Sum of Squares Mean Square F Prob>F
Regression 2 89012.45522761 44506.22761380 998.90 0.0001Error 12 534.66210573 44.55517548Total 14 89547.11733333
Parameter Standard Type IIVariable Estimate Error Sum of Squares F Prob>F
INTERCEP 189.82557816 10.12780796 15652.24747611 351.30 0.0001X2 3.56916914 0.13328856 31948.22117873 717.05 0.0001X3 -22.27442195 0.70761978 44148.00785187 990.86 0.0001
Bounds on condition number: 1.021939, 4.087755------------------------------------------------------------------------Step 3 Variable X1 Entered R-square = 0.9969 C(p) = 3.40747262
DF Sum of Squares Mean Square F Prob>F
Regression 3 89274.36575035 29758.12191678 1200.14 0.0001Error 11 272.75158298 24.79559845Total 14 89547.11733333
Parameter Standard Type IIVariable Estimate Error Sum of Squares F Prob>F
INTERCEP 178.52061971 8.31759314 11422.36466467 460.66 0.0001X1 2.10554670 0.64785185 261.91052275 10.56 0.0077X2 3.56240254 0.09945492 31813.25034778 1283.02 0.0001X3 -22.18799225 0.52855305 43695.17122702 1762.21 0.0001
Bounds on condition number: 1.024532, 9.15083------------------------------------------------------------------------
All variables in the model are significant at the 0.1500 level.No other variable met the 0.1500 significance level for entry into themodel.
Summary of Stepwise Procedure for Dependent Variable Y
Variable Number Partial ModelStep Entered Removed In R**2 R**2 C(p) F Prob>F
1 X3 1 0.6373 0.6373 1228.46 22.83 0.0004 2 X2 2 0.3568 0.9940 11.40 717.04 0.0001 3 X1 3 0.0029 0.9970 3.40 10.56 0.0077

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 161
6.4 Regressione multipla; scelta del miglior modello
N = 15 Regression Models for Dependent Variable: Y
Adjusted R-square Variables in Model R-square In
0.99612340 0.99695410 3 X1 X2 X3 � 0.99590269 0.99707335 4 X1 X2 X3 X4 0.99303414 0.99402927 2 X2 X3 0.99240992 0.99403636 3 X2 X3 X4 0.62725768 0.68050659 2 X3 X4 0.60935016 0.63725372 1 X3 0.60492910 0.68958715 3 X1 X3 X4 0.58196679 0.64168582 2 X1 X3 0.46263152 0.50101498 1 X2 0.42716291 0.50899678 2 X1 X2 0.42158860 0.50421880 2 X2 X4 0.38139228 0.51395107 3 X1 X2 X4 0.02306046 0.09284186 1 X4 -.03239856 0.11508695 2 X1 X4 -.06400231 0.01199786 1 X1 ----------------------------------
6.4 Regressione multipla; scelta del miglior modello
N = 15 Regression Models for Dependent Variable: Y
C(p) R-square Variables in Model In
3.40747 0.99695410 3 X1 X2 X3 � 5.00000 0.99707335 4 X1 X2 X3 X4 11.40128 0.99402927 2 X2 X3 13.37703 0.99403636 3 X2 X3 X4 1054 0.68958715 3 X1 X3 X4 1083 0.68050659 2 X3 X4 1215 0.64168582 2 X1 X3 1228 0.63725372 1 X3 1654 0.51395107 3 X1 X2 X4 1669 0.50899678 2 X1 X2 1685 0.50421880 2 X2 X4 1694 0.50101498 1 X2 3015 0.11508695 2 X1 X4 3089 0.09284186 1 X4 3365 0.01199786 1 X1 ----------------------------------
Model: M4Dependent Variable: Y Analysis of Variance
Sum of MeanSource DF Squares Square F Value Prob>F
Model 4 89285.04450 22321.26113 851.720 0.0001Error 10 262.07283 26.20728 �C Total 14 89547.11733
Root MSE 5.11930 R-square 0.9971 Dep Mean 168.94667 Adj R-sq 0.9959 C.V. 3.03013
Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 162
Dep Var Predict Obs Y Value Residual
1 79.3000 78.8881 0.4119 2 200.1 201.2 -1.0994 3 163.2 167.6 -4.3690 4 200.1 208.8 -8.6881 5 146.0 144.0 2.0299 6 177.7 172.3 5.4187 7 30.9000 36.4589 -5.5589 8 291.9 286.1 5.7671 9 160.0 158.1 1.9465 10 339.4 342.1 -2.6749 11 159.6 159.1 0.4714 12 86.3000 80.2947 6.0053 13 237.5 235.4 2.0783 14 107.2 105.3 1.9071 15 155.0 158.6 -3.6459
Sum of Residuals -8.52651E-14Sum of Squared Residuals 262.0728Predicted Resid SS (Press) 741.7557 �
Model: M5Dependent Variable: Y Analysis of Variance
Sum of MeanSource DF Squares Square F Value Prob>F
Model 3 89274.36575 29758.12192 1200.137 0.0001Error 11 272.75158 24.79560 �C Total 14 89547.11733
Root MSE 4.97952 R-square 0.9970 Dep Mean 168.94667 Adj R-sq 0.9961 C.V. 2.94739
Dep Var Predict Obs Y Value Residual
1 79.3000 78.6557 0.6443 2 200.1 202.2 -2.1127 3 163.2 167.8 -4.5901 4 200.1 207.6 -7.5414 5 146.0 142.7 3.2954 6 177.7 171.3 6.3986 7 30.9000 35.9812 -5.0812 8 291.9 286.0 5.8749 9 160.0 159.1 0.9402 10 339.4 341.3 -1.9221 11 159.6 159.8 -0.1774 12 86.3000 79.5382 6.7618 13 237.5 236.1 1.3539 14 107.2 106.1 1.0979 15 155.0 159.9 -4.9423
Sum of Residuals -4.9738E-14Sum of Squared Residuals 272.7516Predicted Resid SS (Press) 643.3578 �
Model: M6Dependent Variable: Y
Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 163
Analysis of Variance
Sum of MeanSource DF Squares Square F Value Prob>F
Model 2 89012.45523 44506.22761 998.901 0.0001Error 12 534.66211 44.55518 �C Total 14 89547.11733
Root MSE 6.67497 R-square 0.9940 Dep Mean 168.94667 Adj R-sq 0.9930 C.V. 3.95093
Dep Var Predict Obs Y Value Residual
1 79.3000 77.7256 1.5744 2 200.1 207.9 -7.8345 3 163.2 161.7 1.5332 4 200.1 212.4 -12.2631 5 146.0 147.3 -1.2586 6 177.7 175.9 1.7565 7 30.9000 29.6076 1.2924 8 291.9 278.3 13.5731 9 160.0 161.5 -1.5353 10 339.4 339.0 0.3972 11 159.6 159.0 0.6429 12 86.3000 79.5760 6.7240 13 237.5 234.6 2.8625 14 107.2 106.3 0.9210 15 155.0 163.4 -8.3857
Sum of Residuals -5.32907E-13Sum of Squared Residuals 534.6621Predicted Resid SS (Press) 782.1896 �
Tab. 6.1
VarianzaRegressori errore PRESS
x1,x2,x3,x4 26.201 741.76x1,x2,x3 24.796 643.36
x2,x3 44.555 782.19

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 164
6.5 Identificazione di dati anomali
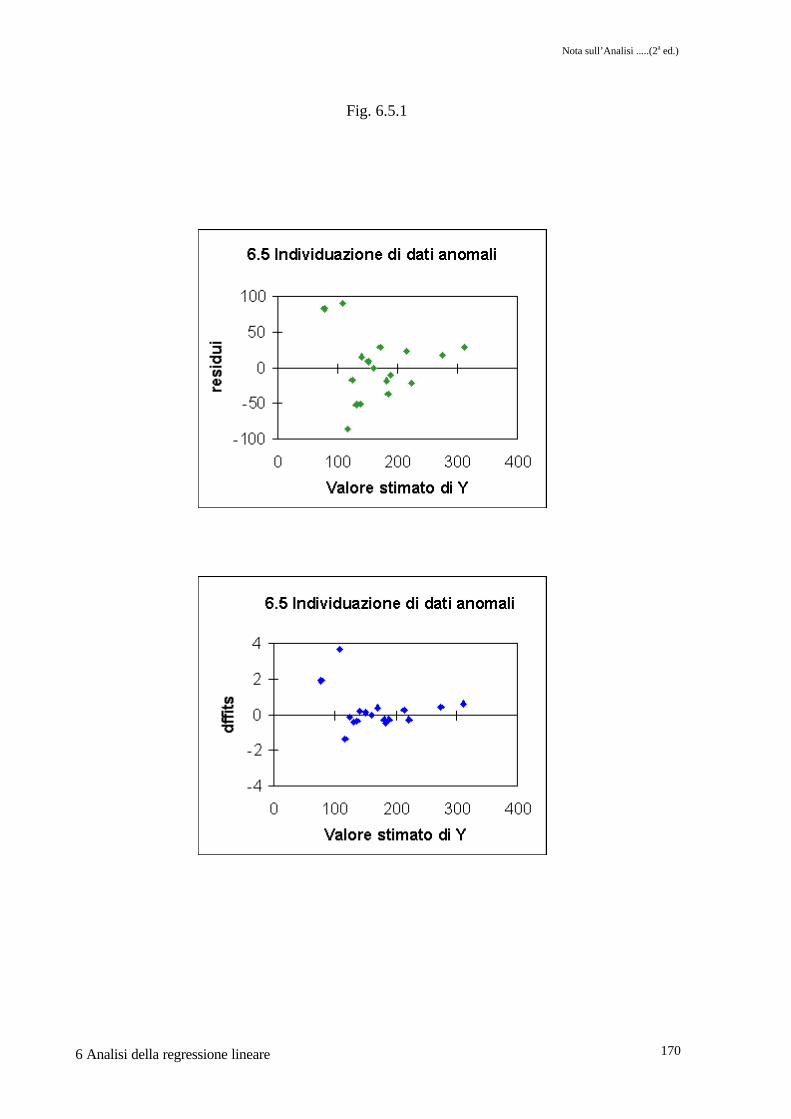
La presenza di dati anomali, o "outliers", influenza negativamente la stima dei parametri delmodello, che di conseguenza da una interpretazione meno precisa del fenomeno in studio. Ciòè a maggior ragione vero nel caso della regressione multipla, dove la mancata eliminazione didati anomali comporta non solo una stima erronea dei parametri, ma può anche far risultaresignificativi regressori che non lo sarebbero e viceversa.E' da sottilineare come, se pure esistono strumenti statistici per evidenziare dati che possonoessere esterni al campo di variabilità della variabile dipendente o indipendente, definire questidati anomali è un problema del ricercatore. Si deve infatti cercare di risalire alle cause chepossono aver determinato l'anomalia della misurazione giustificando quindi l'eliminazione deldato stesso.Il primo approccio nell'esame dei residui (differenze tra i valori stimati e misurati della variabiledi risposta) è dato da una valutazione visiva del grafico dei resisui vs. i valori misurati. Inquesto grafico tuttavia appaiono residui stimati con un diverso grado di precisione. Dividendo iresidui stessi per i loro errori standard si ottengono i residui standardizzati o "Studentizzati".L'uso dei residui, tal quali o standardizzati, nell'evidenziare dati anomali è però limitato dalfatto che, quando la stima dei parametri è effettuata secondo il metodo dei minimi quadraticome in PROC REG, i dati anomali "attraggono" la linea di regressione rendendo a volte menoevidente la misura dell'anomalia stessa. Per superare questa difficoltà sono disponibili alcuniindicatori nella PROC REG.Tra questi il COV RATIO, che misura i cambiamenti nel determinante della matrice X'X comeconseguenza dell'eliminazione dell'osservazione. Punti che comportano variazioni di rilievo nelnumero di COV RATIO possono essere considerati anomali.Altro indicatore è il DFFITS, che misura le differenze tra le stime effettuate con tutti i puntiosservazione e quelle effettuate senza il punto in esame; la differenza è standardizzata inquanto divisa per una stima della varianza d'errore ottenuta dalle equazioni relative agli altripunti. Con questo ultimo indicatore, differenze apprezzabili con difficoltà diventanoparticolarmente evidenti se relative a dati anomali.La statistica di un altro indice, il Cook's D, è essenzialmente la stessa dei DFFITS; essendo ledifferenze elevate al quadrato l'anomalia dei punti è ulteriormente evidenziata.Per illustrare le procedure di individuazione dei dati anomali viene di seguito utilizzato il data-set dell'esempio 6.4 integrato da due altri punti osservazione.
PROGRAMMA SAS
Ciò che caratterizza questo programma SAS in rapporto al problema affrontato è la richiestadelle opzioni R ed INFLUENCE nell'istruzione MODEL della PROC REG. Con l'istruzioneOUTPUT viene creato un nuovo data-set con il valore di y, residui, residui standardizzati edffits. Il data-set è utilizzato nello step successivo per ottenere alcuni grafici. Lo stessoMODEL viene richiesto (m2) con l'opzione per la selezione del modello secondo il metododell'R2 aggiustato. Nello step DATA successivo vengono eliminati le prime due osservazioni,giudicate anomale. Con il data-set ridotto, a questo punto uguale a quello utilizzatonell'esempio 6.4, la PROC REG permette di nuovo la stima dei parametri e la selezione delmodello secondo l'R2 aggiustato.Relativamente ai grafici, alcune istruzioni (AXIS2, AXIS3 e AXIS4) e alcune opzioni(VAXIS=... HAXIS=...) dimensionano la grafica per questo esempio specifico, come del restoin 6.1 e 6.2; lo stesso tipo d'analisi con un diverso data-set richiede o la modifica delle

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 165
istruzioni ad hoc o la loro eliminazione. In quest'ultimo caso vengono usati i valori di defaultper le scale degli assi.
** 6.5 Indiduazione dati anomali*;DATA esempio; INPUT x1 x2 x3 x4 y; CARDS;5.0 10 11 15 198.07.0 45 16 8 160.05.5 31 10 8 79.32.5 55 8 6 200.18.0 67 12 9 163.23.0 50 7 16 200.13.0 38 8 15 146.02.9 71 12 17 177.78.0 30 12 8 30.99.0 56 5 10 291.94.0 42 8 4 160.06.5 73 5 16 339.45.5 60 11 7 159.65.0 44 12 12 86.36.0 50 6 6 237.55.0 39 10 4 107.23.5 55 10 4 155.0;PROC PRINT; TITLE '6.5 Individuazione dati anomali';PROC REG; m1: MODEL y = x1 x2 x3 x4 / R INFLUENCE; OUTPUT OUT=esempio2 P=ystim R=yresid RSTUDENT=rstudent DFFITS=dffits; ID y; m2: MODEL y = x1 x2 x3 x4 / SELECTION=ADJRSQ;DATA esempio; SET esempio; IF _N_>2 THEN OUTPUT;PROC REG; m1: MODEL y = x1 x2 x3 x4 ; m2: MODEL y = x1 x2 x3 x4 / SELECTION=ADJRSQ;RUN;** SAS / GRAPH*;GOPTIONS DEVICE=HPLJ5P3 GACCESS='SASGASTD>LPT1:' ROTATE=PORTRAIT VSIZE=4 VORIGIN=1 HSIZE=3 HORIGIN=1 FTEXT=SWISSL HTEXT=2 ;SYMBOL1 H=2 V=CIRCLE;AXIS1 LABEL=('dffits') ORDER=-4 TO 4 BY 1;AXIS2 LABEL=('residui') ORDER=-100 TO 100 BY 20;PROC GPLOT DATA=ESEMPIO2;

Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 166
PLOT yresid*ystim=1 / FRAME VAXIS=AXIS2 VREF=0; PLOT dffits*ystim=1 / FRAME VAXIS=AXIS1 VREF=0;RUN;
OUTPUT SAS
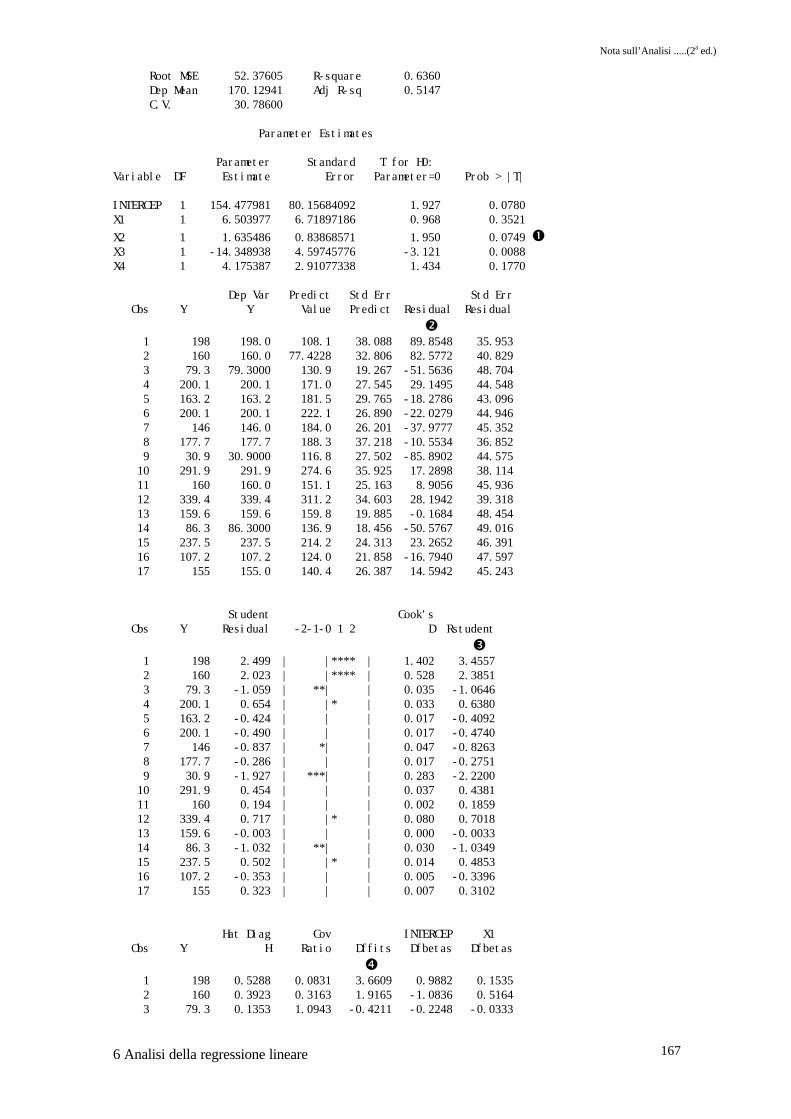
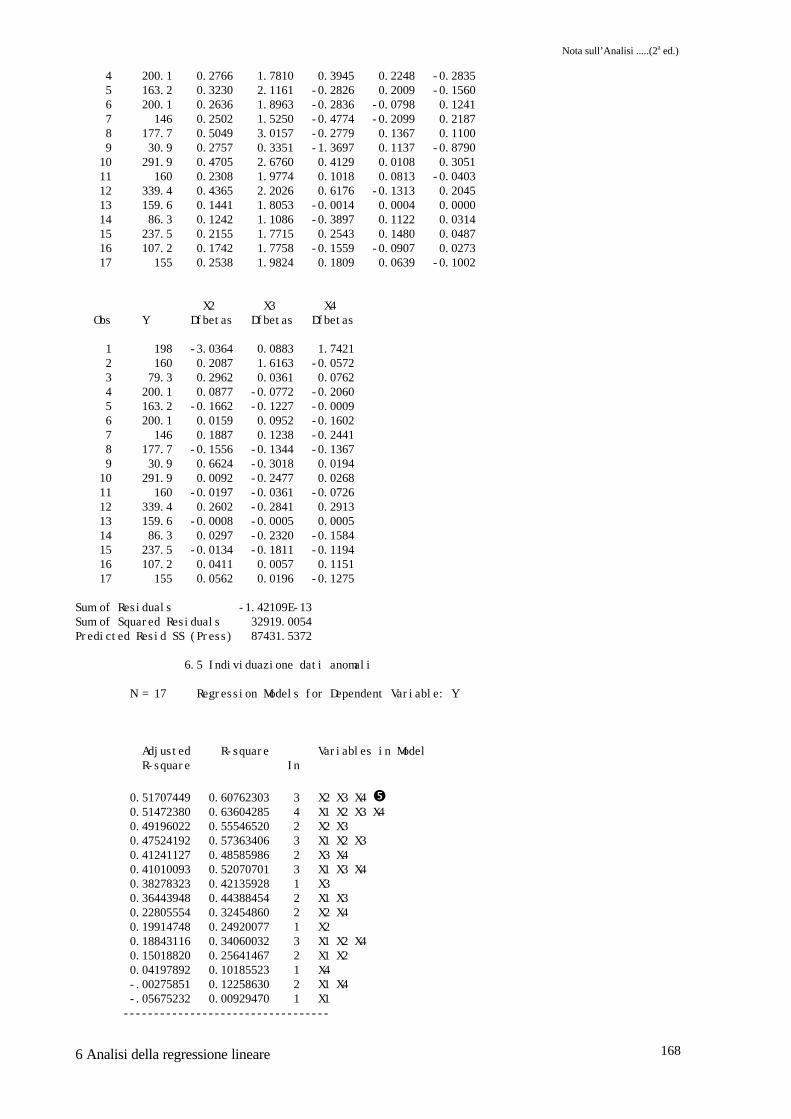
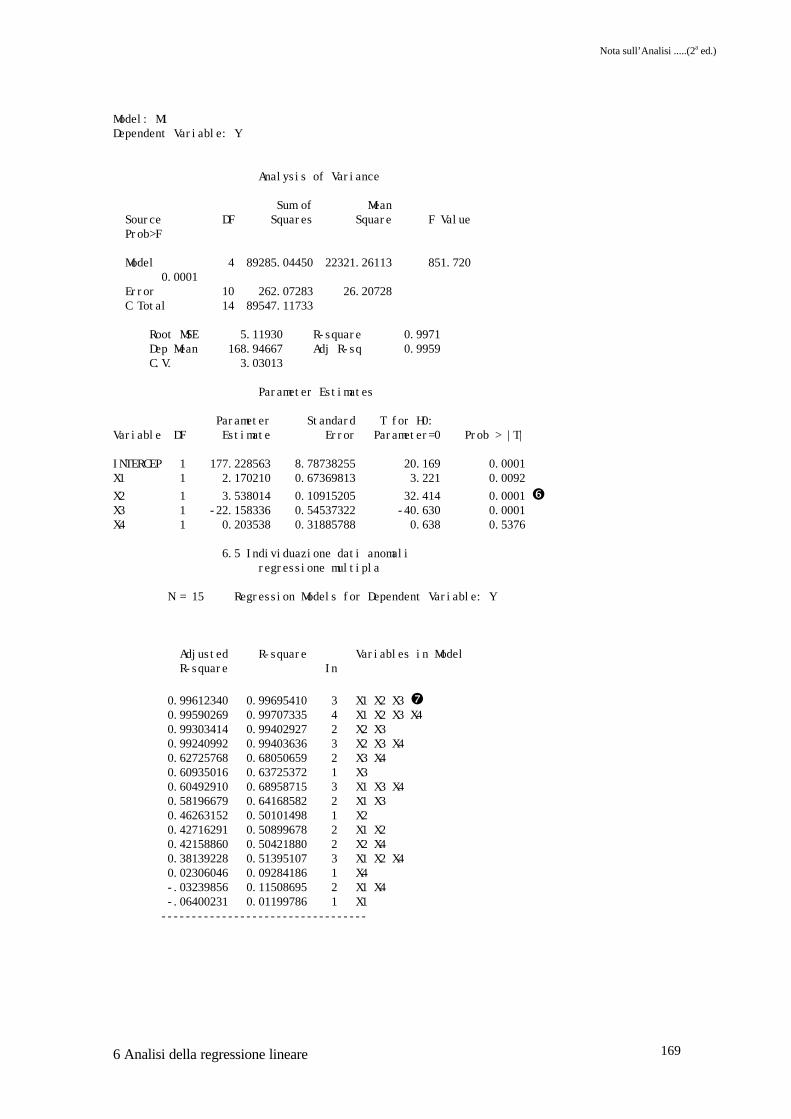
Sono da notare i parametri stimati per i quattro regressori e i livelli di probabilità associati �,che dovranno essere confrontati con gli stessi risultanti dalla stima operata con il data-setridotto. Esaminando la colonna dei residui �, si nota come le osservazioni 1, 2 e 9 hannoresidui molto alti, superiori a 80 in valore assoluto. I residui standardizzati �, hanno anch'essivalori elevati per le stesse osservazioni. La situazione si modifica, per quanto riguardal'osservazione 9, facendo riferimento alla colonna dei dffits � dove solo le osservazioni 1 e 2hanno valori molto elevati. I grafici di Fig. 6.5.1 rendono evidente quanto esposto,suggerendo quindi la possibilità che le prime due osservazioni siano anomale. Il migliorevalore dell'R2 aggiustato si ha per un modello che utilizza x2, x3 e x4 come regressori �.Eliminate le due osservazioni sospette, i nuovi parametri stimati sono riportati in �. E' dasottolineare come i parametri di x1, x2 e x3 siano adesso significativi, mentre peggiora lasituazione di x4. Il miglior modello, sempre sulla base dell'R2 aggiustato risulta essere quelloche utilizza appunto x1, x2 e x3 come regressori �.
6.5 Individuazione dati anomali
OBS X1 X2 X3 X4 Y
1 5.0 10 11 15 198.0 2 7.0 45 16 8 160.0 3 5.5 31 10 8 79.3 4 2.5 55 8 6 200.1 5 8.0 67 12 9 163.2 6 3.0 50 7 16 200.1 7 3.0 38 8 15 146.0 8 2.9 71 12 17 177.7 9 8.0 30 12 8 30.9 10 9.0 56 5 10 291.9 11 4.0 42 8 4 160.0 12 6.5 73 5 16 339.4 13 5.5 60 11 7 159.6 14 5.0 44 12 12 86.3 15 6.0 50 6 6 237.5 16 5.0 39 10 4 107.2 17 3.5 55 10 4 155.0
6.5 Individuazione dati anomali
Model: M1Dependent Variable: Y
Analysis of Variance
Sum of Mean Source DF Squares Square F Value Prob>F
Model 4 57528.46989 14382.11747 5.243 0.0112 Error 12 32919.00541 2743.25045 C Total 16 90447.47529
Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 167
Root MSE 52.37605 R-square 0.6360 Dep Mean 170.12941 Adj R-sq 0.5147 C.V. 30.78600
Parameter Estimates
Parameter Standard T for H0:Variable DF Estimate Error Parameter=0 Prob > |T|
INTERCEP 1 154.477981 80.15684092 1.927 0.0780X1 1 6.503977 6.71897186 0.968 0.3521X2 1 1.635486 0.83868571 1.950 0.0749 �X3 1 -14.348938 4.59745776 -3.121 0.0088X4 1 4.175387 2.91077338 1.434 0.1770
Dep Var Predict Std Err Std Err Obs Y Y Value Predict Residual Residual
� 1 198 198.0 108.1 38.088 89.8548 35.953 2 160 160.0 77.4228 32.806 82.5772 40.829 3 79.3 79.3000 130.9 19.267 -51.5636 48.704 4 200.1 200.1 171.0 27.545 29.1495 44.548 5 163.2 163.2 181.5 29.765 -18.2786 43.096 6 200.1 200.1 222.1 26.890 -22.0279 44.946 7 146 146.0 184.0 26.201 -37.9777 45.352 8 177.7 177.7 188.3 37.218 -10.5534 36.852 9 30.9 30.9000 116.8 27.502 -85.8902 44.575 10 291.9 291.9 274.6 35.925 17.2898 38.114 11 160 160.0 151.1 25.163 8.9056 45.936 12 339.4 339.4 311.2 34.603 28.1942 39.318 13 159.6 159.6 159.8 19.885 -0.1684 48.454 14 86.3 86.3000 136.9 18.456 -50.5767 49.016 15 237.5 237.5 214.2 24.313 23.2652 46.391 16 107.2 107.2 124.0 21.858 -16.7940 47.597 17 155 155.0 140.4 26.387 14.5942 45.243
Student Cook's Obs Y Residual -2-1-0 1 2 D Rstudent
� 1 198 2.499 | |**** | 1.402 3.4557 2 160 2.023 | |**** | 0.528 2.3851 3 79.3 -1.059 | **| | 0.035 -1.0646 4 200.1 0.654 | |* | 0.033 0.6380 5 163.2 -0.424 | | | 0.017 -0.4092 6 200.1 -0.490 | | | 0.017 -0.4740 7 146 -0.837 | *| | 0.047 -0.8263 8 177.7 -0.286 | | | 0.017 -0.2751 9 30.9 -1.927 | ***| | 0.283 -2.2200 10 291.9 0.454 | | | 0.037 0.4381 11 160 0.194 | | | 0.002 0.1859 12 339.4 0.717 | |* | 0.080 0.7018 13 159.6 -0.003 | | | 0.000 -0.0033 14 86.3 -1.032 | **| | 0.030 -1.0349 15 237.5 0.502 | |* | 0.014 0.4853 16 107.2 -0.353 | | | 0.005 -0.3396 17 155 0.323 | | | 0.007 0.3102
Hat Diag Cov INTERCEP X1 Obs Y H Ratio Dffits Dfbetas Dfbetas
� 1 198 0.5288 0.0831 3.6609 0.9882 0.1535 2 160 0.3923 0.3163 1.9165 -1.0836 0.5164 3 79.3 0.1353 1.0943 -0.4211 -0.2248 -0.0333
Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 168
4 200.1 0.2766 1.7810 0.3945 0.2248 -0.2835 5 163.2 0.3230 2.1161 -0.2826 0.2009 -0.1560 6 200.1 0.2636 1.8963 -0.2836 -0.0798 0.1241 7 146 0.2502 1.5250 -0.4774 -0.2099 0.2187 8 177.7 0.5049 3.0157 -0.2779 0.1367 0.1100 9 30.9 0.2757 0.3351 -1.3697 0.1137 -0.8790 10 291.9 0.4705 2.6760 0.4129 0.0108 0.3051 11 160 0.2308 1.9774 0.1018 0.0813 -0.0403 12 339.4 0.4365 2.2026 0.6176 -0.1313 0.2045 13 159.6 0.1441 1.8053 -0.0014 0.0004 0.0000 14 86.3 0.1242 1.1086 -0.3897 0.1122 0.0314 15 237.5 0.2155 1.7715 0.2543 0.1480 0.0487 16 107.2 0.1742 1.7758 -0.1559 -0.0907 0.0273 17 155 0.2538 1.9824 0.1809 0.0639 -0.1002
X2 X3 X4 Obs Y Dfbetas Dfbetas Dfbetas
1 198 -3.0364 0.0883 1.7421 2 160 0.2087 1.6163 -0.0572 3 79.3 0.2962 0.0361 0.0762 4 200.1 0.0877 -0.0772 -0.2060 5 163.2 -0.1662 -0.1227 -0.0009 6 200.1 0.0159 0.0952 -0.1602 7 146 0.1887 0.1238 -0.2441 8 177.7 -0.1556 -0.1344 -0.1367 9 30.9 0.6624 -0.3018 0.0194 10 291.9 0.0092 -0.2477 0.0268 11 160 -0.0197 -0.0361 -0.0726 12 339.4 0.2602 -0.2841 0.2913 13 159.6 -0.0008 -0.0005 0.0005 14 86.3 0.0297 -0.2320 -0.1584 15 237.5 -0.0134 -0.1811 -0.1194 16 107.2 0.0411 0.0057 0.1151 17 155 0.0562 0.0196 -0.1275
Sum of Residuals -1.42109E-13Sum of Squared Residuals 32919.0054Predicted Resid SS (Press) 87431.5372
6.5 Individuazione dati anomali
N = 17 Regression Models for Dependent Variable: Y
Adjusted R-square Variables in Model R-square In
0.51707449 0.60762303 3 X2 X3 X4 � 0.51472380 0.63604285 4 X1 X2 X3 X4 0.49196022 0.55546520 2 X2 X3 0.47524192 0.57363406 3 X1 X2 X3 0.41241127 0.48585986 2 X3 X4 0.41010093 0.52070701 3 X1 X3 X4 0.38278323 0.42135928 1 X3 0.36443948 0.44388454 2 X1 X3 0.22805554 0.32454860 2 X2 X4 0.19914748 0.24920077 1 X2 0.18843116 0.34060032 3 X1 X2 X4 0.15018820 0.25641467 2 X1 X2 0.04197892 0.10185523 1 X4 -.00275851 0.12258630 2 X1 X4 -.05675232 0.00929470 1 X1 ----------------------------------
Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 169
Model: M1Dependent Variable: Y
Analysis of Variance
Sum of Mean Source DF Squares Square F Value Prob>F
Model 4 89285.04450 22321.26113 851.720 0.0001 Error 10 262.07283 26.20728 C Total 14 89547.11733
Root MSE 5.11930 R-square 0.9971 Dep Mean 168.94667 Adj R-sq 0.9959 C.V. 3.03013
Parameter Estimates
Parameter Standard T for H0:Variable DF Estimate Error Parameter=0 Prob > |T|
INTERCEP 1 177.228563 8.78738255 20.169 0.0001X1 1 2.170210 0.67369813 3.221 0.0092X2 1 3.538014 0.10915205 32.414 0.0001 �X3 1 -22.158336 0.54537322 -40.630 0.0001X4 1 0.203538 0.31885788 0.638 0.5376
6.5 Individuazione dati anomali regressione multipla
N = 15 Regression Models for Dependent Variable: Y
Adjusted R-square Variables in Model R-square In
0.99612340 0.99695410 3 X1 X2 X3 � 0.99590269 0.99707335 4 X1 X2 X3 X4 0.99303414 0.99402927 2 X2 X3 0.99240992 0.99403636 3 X2 X3 X4 0.62725768 0.68050659 2 X3 X4 0.60935016 0.63725372 1 X3 0.60492910 0.68958715 3 X1 X3 X4 0.58196679 0.64168582 2 X1 X3 0.46263152 0.50101498 1 X2 0.42716291 0.50899678 2 X1 X2 0.42158860 0.50421880 2 X2 X4 0.38139228 0.51395107 3 X1 X2 X4 0.02306046 0.09284186 1 X4 -.03239856 0.11508695 2 X1 X4 -.06400231 0.01199786 1 X1 ----------------------------------
Nota sull’Analisi .....(2a ed.)
6 Analisi della regressione lineare 170
Fig. 6.5.1





























