Embed Size (px)
Citation preview

1
Capítulo 11:
Predicciones Genéticas
En este momento ya debería estar claro que la tasa de cambio genético en una población
depende en gran medida de la precisión de la predicción o más exactamente, en la precisión
de los valores de cría predichos o estimados.
La precisión puede ser incrementada hasta un cierto punto al aumentar la heredabilidad de
los caracteres. Manejar los animales de manera uniforme, tomando minuciosas medidas,
ajustando por efectos ambientales conocidos, utilizando grupos contemporáneos – todo
ayuda. Sin embargo, para aumentar la precisión aún más se requiere el uso de tanta
información como sea posible y ponderar cada una apropiadamente. Para hacerla corta,
requiere el uso de la tecnología de predicción genética.
El propósito de este capítulo es proveer un panorama de dos metodologías estrechamente
relacionadas que se utilizan comúnmente para la predicción genética: el índice de selección
y la mejor predicción linear insesgada. No se examinarán estas tecnologías en detalle, pues
esto requeriría conocimientos de estadística y álgebra matricial que muy pocos estudiantes
tienen. El énfasis aquí no es como los índices de selección y la mejor predicción linear
insesgada trabajan, más vale en cuando deberían ser usadas y también de qué son capaces.
En el capítulo 12 se trata la presentación e interpretación de las predicciones genéticas
producidas con estas tecnologías.
COMPARACIÓN DE ANIMALES UTILIZANDO DATOS DE GRUPOS GENÉTICAMENTE
SIMILARES – EL INDICE DE SELECCIÓN.
La teoría del índice de selección fue desarrollada por primera vez en 1930 y 1940, como
método para la predicción genética y como un medio para combinar de caracteres en la
selección de animales de la manera más óptima económicamente. En este capítulo
consideraremos el índice de selección como una metodología de predicción. Su rol en la
selección multicarácter será discutido en el capítulo 14.
Un índice de selección es esencialmente una combinación linear o índice de varios tipos de
información fenotípica y factores de ponderación apropiados.
Toman la siguiente forma:
Donde
I = un valor índice o predicción genética
bi= un factor de ponderación.

2
xi= un simple ítem de información fenotípica – un registro de producción o el promedio de los registros de producción de un grupo.
n= número total de ítems de información fenotípica.
En un índice de selección (o en cualquier método de predicción genética) la información utilizada en el cálculo de las predicciones genéticas para un individuo proviene de tres clases de fuentes: (1) registros de performance del propio individuo, (2) registros de producción de antecesores y/o parientes colaterales de los individuos (datos de pedigrí o genealógicos), y (3) los registros de producción de los descendientes del individuo (datos de la progenie).
Las cantidades relativas de datos de estas tres fuentes varían. Animales no nacidos o muy
jóvenes tienen solamente datos de pedigrí. Como estos animales crecerán y envejecerán
ellos adquirirán datos de performance propios. (Asumiendo, por supuesto, que ellos pueden
adquirir datos propios, ya que algunos caracteres tienen limitación de sexo. Los machos
lecheros por ejemplo no tienen datos de performance propios para caracteres de lactación y
leche) Si los animales son seleccionados para convertirse en padres, ellos generarán datos de
progenie, y si se vuelven populares, tendrán una gran cantidad de datos de progenie.
Cualquiera de los tres tipos de registros se puede tomar de cualquier carácter para el cual se
calcularán las predicciones, o pueden ser datos de otros caracteres genéticamente
correlacionados. Por ejemplo, en las especies en las cuales la distocia es una preocupación,
las predicciones de la susceptibilidad genética hacia ellas pueden ser determinadas por la
medida directa de las distocias como grados de distocia, por el peso al nacimiento (un
carácter genéticamente correlacionado), o por ambos.
Los datos utilizados en el índice de selección – el x1s – provienen de muchas fuentes dentro
de las categorías: de la propia performance, del pedigrí, y los datos de progenie. Por
ejemplo, x1 podría ser un registro de performance individual propia para un carácter, x2
podría ser el promedio de performance de los medio hermano paternos del individuo para el
mismo carácter, x3 podría ser el promedio de la performance de la progenie del individuo, y
x4, x5 y x6 podrían representar la performance del individuo, medio hermanos, y progenie
respectivamente para un carácter correlacionado. En todos los casos cada x es un número.
En un índice de selección cada ítem de la información fenotípica es normalmente expresado
como el desvío de la media de un grupo contemporáneo. Como bien se vio en el capítulo 9,
expresando la performance de esa forma, se tiene en cuenta las diferencias ambientales
entre grupos contemporáneos. EL problema con este enfoque, es que se asume que todos
los grupos contemporáneos son genéticamente similares. Un desvío de +10 unidades en un
grupo contemporáneo se asume como el equivalente genético de una desviación de +10
unidades en cualquier otro grupo contemporáneo. Si la media del valor de cría en cada
grupo es la misma, (es decir si los grupos contemporáneos son realmente genéticamente
similares) esta asunción es correcta. Sin embargo, si el valor de cría medio de los grupos
contemporáneos difiere, el uso de las desviaciones de las medias del grupo contemporáneo
crea sesgos en los datos.

3
Los registros provenientes de los grupos contemporáneos genéticamente más pobres
parecen mejores de lo que deberían, y los registros de los grupos contemporáneos
genéticamente superiores parecen peores de lo que deberían.
Por esta razón, los índices de selección solo deberían ser usados para las predicciones
genéticas cuando los datos de performance provienen de un grupo contemporáneo que se
piensa son genéticamente similares. En la práctica, esto significa que probablemente
deberían ser utilizados dentro de rodeos o majadas individuales y no en toda una población.
Y si un determinado rebaño ha experimentado cambios genéticos significativos en el tiempo,
los datos provenientes de los grupos contemporáneos más antiguos – grupos con valores de
cría más “antiguos“y por lo tanto diferentes – deberían ser excluidos del índice.
Los índices de selección podrán ser de aplicación restringida, pero son muy útiles. Suponga,
por ejemplo, que usted está criando ovejas y quiere comparar sus carneros sobre la base de
la performance de sus progenies dentro de su majada. Usted podría usar un índice de
selección para producir progenie, basado en EBVs o EPDs para cada carnero. Los cálculos
involucrados son bastante simples, no requieren nada más que una calculadora de mano.
Usted necesitará una computadora para aplicaciones más complejas de los índices de
selección pero aún así una PC y una hoja de cálculo serán suficientes.
Índice de selección: Una combinación linear de información fenotípica y factores de
ponderación que es usada para la predicción genética cuando los datos de performance
provienen de grupos contemporáneos genéticamente similares.
Datos de performance del propio individuo: Información sobre el fenotipo del propio
individuo.
Datos de genealogía: Información sobre el genotipo o la performance de antecesores y/o
parientes colaterales de un individuo.
Datos de la progenie: Información sobre el genotipo o la performance de los descendientes
de un individuo.
Sesgo: Cualquier factor que causa la distorsión de las predicciones genéticas.
Predicciones usando regresión: una revisión
El índice de selección no es nada más que una ecuación de predicción, recuerde la forma
general de una ecuación de predicción:
Valor predicho = coeficiente de regresión * “evidencia”.
En el índice de selección, el valor índice (Y) es un valor predicho – normalmente un EVB, EPD,
o MPPA. El xys en el índice es la evidencia, información fenotípica consistente en registros de
performance individual o medias de grupo de registros de performance (expresados como
desvío de la media de un grupo contemporáneo). Los bys en el índice de selección son

4
coeficientes de regresión. Ellos son regresiones de valores reales (BV, PD, o PA) sobre la
evidencia. En otras palabras, miden el cambio esperado en los valores verdaderos por
unidad de cambio en la evidencia. Las fórmulas para bys de los índices de selección son
bastante complicadas como se verá, y el mayor desafío matemático en el uso de los índices
de selección es calcular los valores numéricos de bys. (Técnicas de derivación de las fórmulas
para las regresiones del índices de selección y algunos ejemplos se dan en el Apéndice).
( )
De la simple ecuación de predicción al índice de selección con una sola fuente.
La ecuación simple de predicción se expresa como
Donde
un valor de predicción para el animal i
la media de las medias esperadas para los animales de la población
la regresión de los valores que se estan estimando sobre la evidendencia
la evidencia del animal i , expresada como la desviacion de la media poblacional
En el índice de selección más simple utilizando solo una fuente de evidencia, el valor predicho es
el valor índice, o
Valor de cría, diferencia de progenie, etc., promedian cero en la población, asimismo sus
predicciones, entonces
0
El coeficiente de regresion es
b
La evidencia en un índice de selección se expresa como desviacion de la media de un grupo
contemporaneo, entonces
( ) x
Poniendo todo junto,

5
Predicción utilizando una sola fuente de información.
Los índices de selección más simple son aquellos que involucran una sola fuente de
información x. Estos índices son de la siguiente forma:
I = bx
Son fáciles de calcular porque se necesita solo una ecuación para resolver el coeficiente de
regresión b. Este es el tipo de índice de selección que usted puede determinar utilizando
solo una calculadora de mano.
Algunas fórmulas para coeficientes de regresión utilizados en algunos índices de selección de
una sola fuente común, se pueden ver en la Tabla 11.1.
Identificado en la columna más a la izquierda de la tabla está el tipo de valor predicho – EBV,
EPD, o MPPA.
La siguiente columna muestra el tipo de valor de cría predicho verdadero.
La tercera columna describe la única fuente de información (x) o la evidencia a ser utilizada,
seguida por la columna de fórmulas para los coeficientes de regresión apropiados (b).
La última columna tiene las fórmulas para la precisión de la predicción – la correlación entre
el verdadero valor (BV, PD o PA) y sus predicciones (el valor índice Y). Las predicciones
genéticas para un animal individual se acompañan frecuentemente de un valor de precisión-
una correlación entre valores reales y sus predicciones. Las correlaciones son medidas
poblacionales y como tal podría parecer raro que sean asignadas a un individuo. Sólo
valores, recuerde, se supone que son aplicados a los individuos.
Las precisiones son de hecho medidas poblacionales, pero la “población” es muy teórica. Es
una población de animales hipotéticos que tienen exactamente la misma clase y cantidad de
información predictiva como el animal en cuestión. Un valor de precisión entonces, mide la
fortaleza de la relación entre valores reales y predicciones en esta población abstracta y al
mismo tiempo tiene relevancia para un animal individual.

6
Tabla 11.1 Una muestra de fórmulas para (1) coeficientes de regresión usados para calcular
predicciones de una sola fuente de información, y (2) Precisiones asociadas.
Para practicar el uso de la Tabla 11.1 suponga que desea calcular el MPPA para rendimiento
lechero de una vaca lechera. Llamemos a esta vaca Iris. La fuente de información en este
caso es la historia propia de lactación de Iris. Una vaca vieja, que ha tenido cinco registros de
lactación con un promedio de 1072 libras por sobre la media de su grupo contemporáneo. La
fórmula para el coeficiente de regresión apropiado, ubicado en la tercera fila de la Tabla 11.1
es:
( )

7
La Repetibilidad (r) del rendimiento lechero es de alrededor de 0,5 y el número de registros
de Iris (n) es 5. Entonces
( )
( )
( )( )
Por cada libra de aumento en la media de los 5 registros de Iris, aumentamos nuestra
expectativa de su verdadera habilidad productiva en 0,833 libras.
Para calcular la MPPA de Iris debemos ahora substituir este coeficiente de regresión por el
índice de selección. Así
( )
La MPPA de Iris es + 893 libras. En otras palabras esperamos que ella produzca 893 libras
más de leche que la media de sus contemporáneas. Si los rendimientos promedio de
lactación en este rodeo fueran 14.000 libras, nuestra predicción del próximo registro de Iris
es de 14.893 libras de leche.
Podemos calcular la precisión de esta predicción ( ) usamos la fórmula en la última
columna de la Tabla 11.1. Así:
√
( )
√ ( )
( )( )
√
Ajuste para mucha cantidad de información
Note que aunque el promedio de Iris es de más de 1072 libras que la media de sus
contemporáneas, nuestra predicción de su habilidad productiva es menor que esa cifra. Esto
es porque la predicción ha sido sujeto de lo que a veces se denomina regresión por cantidad
de información. Este es un proceso matemático que provoca que las predicciones genéticas

8
sean más o menos “conservadoras” (más cercanas a la media) dependiendo de la cantidad
de información utilizada para calcularlas.
Para tener una mejor idea de cómo la regresión por cantidad de información considere otras
dos vacas en el mismo rodeo Violet y Rose. Violet tiene dos registros de lactancia con un
promedio de 1204 libras por sobre la media del grupo contemporáneo. En su caso,
( )
( )
( )( )
La MPPA de Violet es entonces
( )
√
( )
√
Rose tiene solamente un registro, ella produjo 918 libras menos de leche que la media de su
grupo contemporáneo. En el caso de Rose
( )
( )
( )( )
La MPPA de Rose es entonces
( )

9
Con una precisión de
√
( )
√
Las medias de lactación y MPPA para Iris, Violet y Rose se muestran gráficamente en la
Figura 11.1. La MPPA de iris (+893 libras) es apenas menor que su verdadera media de
lactancia (+1072 libras). Con seis registros, Iris nos proveyó de considerable información
(evidenciada por una precisión de 0,91) y nosotros podemos confiar que ella
verdaderamente tiene una alta habilidad de producción. Aún así cinco registros no son
suficientes para estar totalmente convencidos. Es posible que Iris se haya beneficiado de una
secesión favorable de efectos ambientales temporarios (Et). Para contabilizar esta
posibilidad su MPPA ha sido ajustada en pequeño grado (la cantidad de regresión en este
caso, 1072- 893 = 179 libras, es en realidad una estimación de la media de los efectos
ambientales temporarios de Iris).
Violet tiene el promedio de lactación más alto (+1024 libras), pero su MPPA no es tan alto
como el de Iris. Esto es porque este fue más ajustado. Con solo dos registros (precisión
=0,82) no podemos confiar en la habilidad de Violet, entonces le asignamos una predicción
más conservadora.
Rose tiene solo un registro entonces su MPPA ha sido ajustada severamente – de -918 a -459
lb. Porque su primer registro es negativo la MPPA de Rose ha sido ajustada en alza, esta vez
a favor de Rose. Hay una buena posibilidad de que Rose haya experimentado un efecto
ambiental temporario durante su primera lactancia, entonces le damos el beneficio de la
duda.
El ejemplo de la vaca lechera muestra como las MPPAs son ajustadas por la cantidad de
información, pero ejemplos similares pueden ser construidos para cualquiera de las

10
predicciones listadas en la Tabla 11.1. En el ejemplo del MPPA el grado en el cual la
predicción ha sido ajustada es una función del número de registros y de la repetiblidad del
carácter. En los ejemplos que involucran EBV o EPDs el ajuste por regresión es una función
del número de registros, de la heredabilidad, de la repetibilidad del carácter (en los casos
donde se tienen registros repetidos) y relaciones de parentesco entre los animales que están
siendo medidos y el animal cuya predicción está siendo calculada. Con la excepción de las
relaciones de pedigrí, las fórmulas de los coeficientes de regresión de la Tabla 11.1 indican
exactamente qué factores entran en juego en cada situación.
El ajuste de las predicciones genéticas por cantidad de información resulta en predicciones
insesgadas. Esto simplemente significa que cuanto mayor es la información utilizada en las
predicciones subsecuentes para el mismo animal, las predicciones pueden cambiar en una
dirección positiva o en una negativa. Debido a que las predicciones genéticas son ajustadas
de acuerdo a la cantidad de información, ellas son en esencia, ajustadas por la precisión. En
otras palabras la precisión de una predicción es tomada en cuenta para la predicción misma.
El beneficio de ajustar por precisión es que ello permite comparaciones directas de
predicciones para diferentes animales sin tener en cuenta la precisión de dichas
predicciones. Por ejemplo si dos animales tienen el mismo EBV, pero la precisión de un
animal es mucho más alta que el de otro, se justifica que usted considere a los dos animales
genéticamente iguales. Por supuesto existe un gran riesgo de que el verdadero valor de cría
del animal que tiene la precisión más baja sea significativamente más pobre que la esperada.
Este representa un gran riesgo de selección. Por otro lado hay una posibilidad mayor de que
el verdadero valor genético de este animal sea significativamente mejor que lo esperado. En
este caso él representa una gran oportunidad de selección.
El gran beneficio de los valores de precisión es que permiten la selección de animales en una
forma compatible con la particular actitud de cada uno hacia la toma de riesgos.
Ajuste por cantidad de información: El proceso matemático que provoca que las
predicciones genéticas sean más o menos “conservadoras” (más cerca de la media)
dependiendo de la cantidad de información utilizada para calcularlas.
Insesgada: Una predicción genética es considerada insesgada si cuanto mayor es la
información utilizada en las predicciones subsecuentes para el mismo animal, las
predicciones pueden cambiar en una dirección positiva o en una negativa.
Estimaciones para ambientes comunes
Las fórmulas de coeficiente de regresión y precisiones en la Tabla 11.1 explican el parecido
en la performance de parientes, este parecido que ocurre porque los parientes tienen genes
en común. Pero algunas veces los parientes se desempeñan en forma semejante por otras
razones. Por ejemplo, los hermanos enteros tienen la misma madre, ellos experimentan un
ambiente común – en este caso un ambiente materno común. Como ellos tienen ambos

11
padres en común también comparten una proporción más grande de combinaciones de
genes que los individuos no emparentados o aún los medio hermanos. Y ésta fuente de
parecido genético a menos que sea expresamente tenida en cuenta de alguna otra manera,
forma parte del ambiente común de los hermanos enteros también. A causa del ambiente
común, los registros de performance para hermanos enteros tienden a ser más parecidos de
lo esperado dada la proporción de genes que tienen en común (50%), por cual los registros
adicionales sobre hermanos enteros provee menos información que en otros casos.
En teoría los efectos ambientales comunes, pueden ocurrir dentro de familias de cualquier
clase. Es conocido que se dan por ejemplo, dentro de las familias de medio hermano
paternos de los animales lecheros. Los tamberos muchas veces tratan a las hijas de un
macho en forma diferenciada que a las hijas de otros machos, esto crea un efecto ambiental
común.
El caso más claro de efectos ambientales es dentro de las familias de hermanos enteros. Los
efectos ambientales comunes son por lo tanto especialmente importantes en la especies
politocas como los cerdos, conejos, gatos, perros y ratones. Cuando existen efectos
ambientales comunes, pero no son tomados en cuenta en las predicciones genéticas, los
coeficientes de regresión (factores de ponderación) y las precisiones asociadas son sesgadas
en alza, es decir no lo son suficientemente conservadoras.
Para tomar en cuenta los efectos ambientales comunes en forma apropiada, se incorpora
una medida de covariación entre parientes causada por el ambiente común, que se
representa con c2. Dos de los 10 escenarios que se listan en la Tabla 11.1 (línea 6 y 9) utilizan
información proveniente de hermanos enteros. Note el uso de c2 en los denominadores de
las fórmulas para los coeficientes de regresión y precisiones. Al aumentar sus
denominadores, disminuimos el tamaño del coeficiente de regresión y las precisiones
haciéndolos más conservadores.
efectos ambientales comunes: Un incremento en la similitud en la performance de los
miembros de una familia causada por su ambiente común compartido. Los efectos
ambientales comunes son particularmente importantes en las camadas (hermanos enteros)
Factores que afectan la precisión de la predicción
Muchos de los factores que afectan la precisión de las predicciones pueden verse en las
fórmulas de precisión listadas en la columna de la derecha de la tabla 11.1. Son los mismos
que los factores que afectan los coeficientes de regresión: número de registros,
heredabilidad, repetibilidad y relaciones genealógicas.
Para tener una idea de la importancia relativa de esos factores en la precisión de las
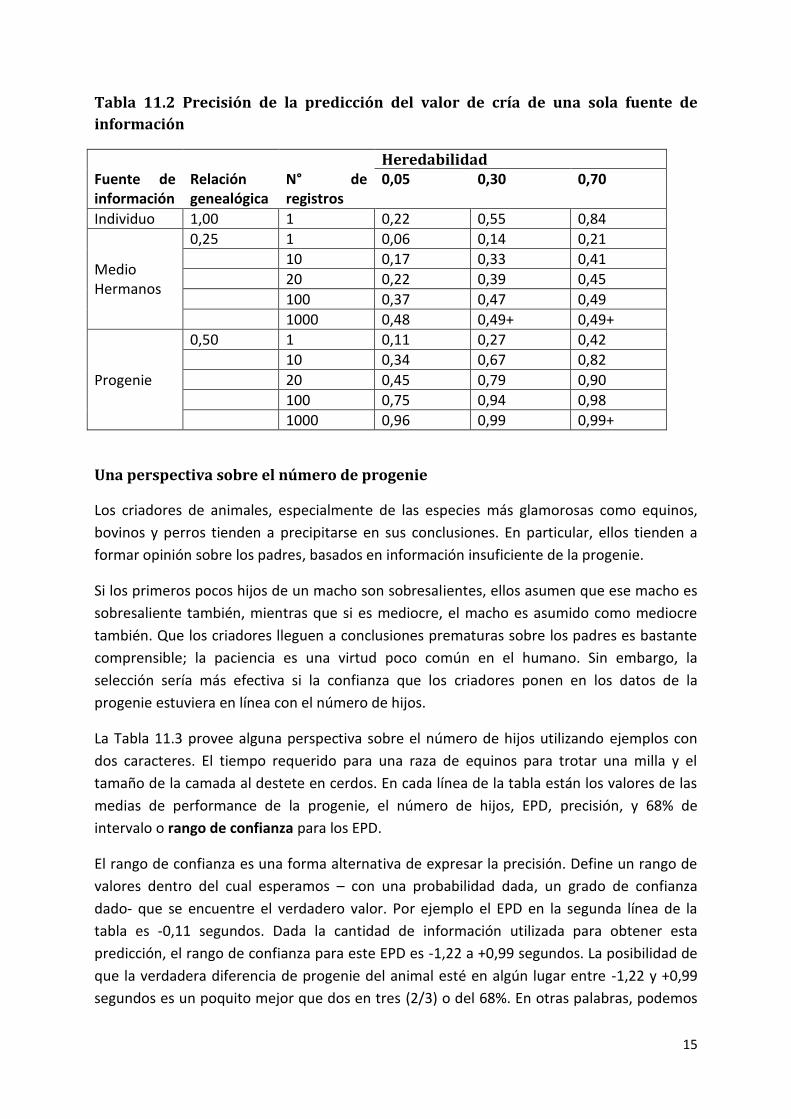
predicciones, es útil examinar diferentes situaciones de predicción. En la Tabla 11.2, hay
valores para la precisión o exactitud de la predicción de los valores de cría, provenientes de
diferentes fuentes de información.

12
Las fuentes varían en las relaciones genealógicas y el número de registros. “Individuo” se
refiere al animal del cual se están prediciendo los valores de cría. En todos los casos, se
asume un solo registro por animal y cada fuente es considerada independientemente (es
decir, como una sola fuente de información). Se muestran precisiones correspondientes a
tres niveles de heredabilidad.
Lo primero que se puede notar en la tabla es que cuando aumenta la heredabilidad, lo hace
la precisión de la predicción – sin importar la fuente de información. Elija cualquiera de las
filas de la tabla. Mientras usted va desde izquierda a derecha (en otras palabras a medida
que la heredabilidad aumenta) la precisión aumenta también. Esto tiene sentido porque la
heredabilidad mide la fortaleza de la relación entre los valores de cría y los valores
fenotípicos. Cuanto más fuerte es esta relación mejor será el registro de producción de cada
animal como indicador del valor de cría de este.
Cuando la fuente de información es el registro del propio individuo, la heredabilidad mide la
fortaleza de la relación entre el valor de cría que estamos tratando de predecir y la fuente de
información. La heredabilidad es precisión (o para ser técnicamente correcto, el cuadrado de
la precisión).
Cuando la fuente de información no es el individuo mismo sino algún grupo de parientes
(por ejemplo medio hermanos), la heredabilidad más alta provoca que los registros de
performance de cada hermano sea un mejor indicador de sus propios valores de cría y por lo
tanto, un mejor indicador de los valores de cría de su hermano – el individuo en cuestión.
La precisión también aumenta con las relaciones genealógicas. Los números en la columna
de las relaciones de pedigrí de la Tabla 11.2 miden la proporción de genes que tienen en
común diferentes tipos de parientes. EL individuo tiene el 100% de los genes en común
consigo mismo, el 25% en común con los medio hermanos y el 50% con su progenie.
Compare la fila de los registros del propio individuo con las filas de un medio hermano y de
una cría. La precisión es más alta para los registros del individuo, seguida por los registros de
la progenie y luego los registros de medio hermanos. Cuanto más cercana la relación del
individuo con los animales que proveen los registros de performance, mejor esos registros
como indicadores del valor de cría del individuo.
La precisión de la predicción aumenta con el número de registros. Mire cada una de las filas
para los medio hermanos o las filas para la progenie en la tabla. Cuanto mayor es el número
de registros, mejor la precisión. Claramente, más cantidad de registros proveen más
información en la cual basar la predicción.
La Tabla 11.2, ofrece una mirada dentro del valor del registro propio del individuo, en vez de
los registros de parientes. Cuando la heredabilidad es alta, los registros del propio individuo
son especialmente valorados. Con una heredabilidad = 0,7 (la última columna en la tabla), el
registro del propio individuo (precisión = 0,84) es más revelador que los registros de 10 hijos
(precisión de 0,82) y mejor que 1000 registros de medio hermanos (precisión= 0,49). Esto

13
sigue directamente la definición de heredabilidad: la fuerza de la relación existente entre la
performance y el valor de cría. Cuando la heredabilidad es alta, el registro de performance
propio de un individuo debería ser un buen indicador de su valor de cría.
Si la performance individual tiene un mayor valor con altos niveles de heredabilidad, ello
explica la razón de que los registros de performance de los parientes deberían valorar más a
bajos niveles de heredabilidad. Con una heredabilidad de 0,5 (la primera columna de
precisiones en la tabla), el registro del propio individuo provee la misma cantidad de
información (precisión =0,22) que los registros de 20 hermanos o entre cuatro o cinco hijos,
pero no está cerca de proveer la información equivalente de un número más alto de
parientes.
Los registros de la progenie son la última fuente de información para predecir valores de
cría. Note las altas precisiones de predicción en la Tabla 11.2 cuando hay un gran número de
hijos. Con suficiente progenie, la precisión es alta aún cuando la heredabilidad es baja por la
siguiente razón. Los registros de la progenie proveen una medida del valor de los genes que
un individuo transmite. Un registro de una sola cría puede no ser muy revelador por varias
razones: (1) los efectos ambientales pueden tener más influencia que los efectos genéticos
(la heredabilidad puede ser baja), (2) el valor de cría del otro progenitor (madre) no es
tenido en cuenta y (3) la cría puede haber recibido una muestra particularmente buena o
mala de genes del individuo – puede haber sido beneficiado o sufrido el muestreo
mendeliano.
Sin embargo, los efectos ambientales, el valor de cría del otro progenitor y los efectos del
muestro mendeliano pueden disminuirse con un gran número de hijos. La performance
promedio de muchos hijos es un buen indicador del valor de cría de un individuo.
Esto es un punto importante para recordar. A menudo se asume que es virtualmente
imposible el progreso genético en caracteres que son de baja heredabilidad, debido a la
dificultad de identificar los individuos genéticamente superiores. Esto es verdad si limitamos
nuestra fuente de información a los registros de performance del propio individuo. Sin
embargo con registros de la progenie – y un gran número de ellos – el problema de la
heredabilidad baja puede ser sobrepasado. Podemos determinar precisamente aquellos
animales con los mejores valores de cría.
Los registros de los hermanos pueden aumentar la precisión solo hasta un punto. Fíjese en la
línea de la Tabla 11.2 correspondiente a los 1000 medio hermanos. Aún con esta enorme
cantidad de datos, la precisión no excede 0,5. De hecho 0,5 es el límite de precisión para las
predicciones derivadas de registros de medio hermanos, sin importar el número de registros
o la heredabilidad del carácter. Esto es porque los datos del medio hermano, proveen
información de solo la mitad de la genealogía del individuo, y no tiene en cuenta el muestreo
mendeliano.

14
En la Figura 11.2 se ilustra como los registros de los medio hermanos paternos influencian la
predicción del valor de cría de un individuo. Si existe gran cantidad de registros de medio
hermanos, el valor de cría del padre del individuo, será bien establecido. Los registros de los
medio hermanos son después de todo, registros de progenie para su padre. Pero establecer
el valor de cría del padre no es lo mismo que determinar el valor de cría del individuo. No
podemos decir a partir de los registros de los medio hermanos, si el individuo heredó una
mejor o peor muestra de genes de sus padres que el promedio – si este sufrió o se benefició
del muestreo mendeliano. En otras palabras, no podemos decir si el individuo heredó más o
menos que la mitad del valor de cría de su padre. Es más no tenemos información sobre el
valor de cría de la madre o de la muestra de genes heredados de ella.
En el caso improbable de que un gran número de medio hermanos de ambos padres
(materno y paterno) esté disponible, es posible tener precisión en la predicción por sobre
0,5. En este caso, tenemos una buena estimación de los valores de cría de la madre y del
padre del individuo, pero aún así no tenemos información sobre el muestreo mendeliano y
el límite superior de precisión tiende a ser la raíz cuadrada de 0,5 o 0,71.
Lo que es cierto para los datos de los medio hermanos, también es cierto para lo datos de
genealogía en general. Registros de performance de los padres, antecesores y parientes
colaterales de un individuo pueden ser útiles, pero por sí mismos nunca pueden producir
predicciones genéticas con precisiones especialmente altas.
15
Tabla 11.2 Precisión de la predicción del valor de cría de una sola fuente de
información
Heredabilidad Fuente de información
Relación genealógica
N° de registros
0,05 0,30 0,70
Individuo 1,00 1 0,22 0,55 0,84
Medio Hermanos
0,25 1 0,06 0,14 0,21
10 0,17 0,33 0,41
20 0,22 0,39 0,45
100 0,37 0,47 0,49
1000 0,48 0,49+ 0,49+
Progenie
0,50 1 0,11 0,27 0,42
10 0,34 0,67 0,82
20 0,45 0,79 0,90
100 0,75 0,94 0,98
1000 0,96 0,99 0,99+
Una perspectiva sobre el número de progenie
Los criadores de animales, especialmente de las especies más glamorosas como equinos,
bovinos y perros tienden a precipitarse en sus conclusiones. En particular, ellos tienden a
formar opinión sobre los padres, basados en información insuficiente de la progenie.
Si los primeros pocos hijos de un macho son sobresalientes, ellos asumen que ese macho es
sobresaliente también, mientras que si es mediocre, el macho es asumido como mediocre
también. Que los criadores lleguen a conclusiones prematuras sobre los padres es bastante
comprensible; la paciencia es una virtud poco común en el humano. Sin embargo, la
selección sería más efectiva si la confianza que los criadores ponen en los datos de la
progenie estuviera en línea con el número de hijos.
La Tabla 11.3 provee alguna perspectiva sobre el número de hijos utilizando ejemplos con
dos caracteres. El tiempo requerido para una raza de equinos para trotar una milla y el
tamaño de la camada al destete en cerdos. En cada línea de la tabla están los valores de las
medias de performance de la progenie, el número de hijos, EPD, precisión, y 68% de
intervalo o rango de confianza para los EPD.
El rango de confianza es una forma alternativa de expresar la precisión. Define un rango de
valores dentro del cual esperamos – con una probabilidad dada, un grado de confianza
dado- que se encuentre el verdadero valor. Por ejemplo el EPD en la segunda línea de la
tabla es -0,11 segundos. Dada la cantidad de información utilizada para obtener esta
predicción, el rango de confianza para este EPD es -1,22 a +0,99 segundos. La posibilidad de
que la verdadera diferencia de progenie del animal esté en algún lugar entre -1,22 y +0,99
segundos es un poquito mejor que dos en tres (2/3) o del 68%. En otras palabras, podemos

16
tener un 68% de confianza de que el verdadero EPD esté dentro de este intervalo. Si el 68%
parece un nivel de confianza un poco arbitrario – bueno, lo es. Sin embargo, es el nivel
arbitrario estándar.
Miremos la parte superior de la Tabla 11.3, la parte que contiene el tiempo para trotar una
milla. Cada fila corresponde a registros para diferentes números de hijos de un solo caballo.
Para simplificar se asume que hay solo un registro por hijo (es decir, solo el registro de la
primera carrera de cada hijo es utilizado en los cálculos) y sin importar el número de hijos, la
media de la progenie es la misma: -1 segundo o 1 segundo más veloz que la media de los
contemporáneos.
Debería notar algún patrón enseguida. El primero es un buen ejemplo de ajuste por cantidad
de información. Aunque la media de la progenie no cambia, los EPD sí, y los cambios en los
EPD son un reflejo de cuanto han sido ajustados por cantidad de información. Cuanto mayor
el número de progenie menor el ajuste de los EPDs – más lejos de cero estarán. Con sólo un
registro de la progenie de -1 segundo, el EPD de nuestro caballo es -11 segundos, pero con
100 hijos promediando -1 segundo, su EPD es -0,93 segundos. En el primer caso, el EPD es
ajustado severamente por la escasa cantidad de información disponible, en el segundo caso,
es ajustado muy poco debido a la abundante cantidad de información.
También notará que al aumentar el número de hijos, también aumentan las precisiones. Y al
aumentar el número de hijos, el 68% del rango de confianza es menor. Con un solo registro
de progenie podemos esperar que la diferencia de progenie real del caballo esté entre -1,22
y +0,99 segundos, una duración total de 2,21 segundos. Con 100 hijos el rango es de -1,24 a
0,61 segundos, una duración de solo 0,63 segundos. Cuanta mayor cantidad de hijos,
estaremos más cerca de identificar el verdadero valor de diferencia en la progenie, por lo
tanto será más estrecho el rango de confianza.
El mensaje más importante que le debería quedar de la Tabla 11.3 es que harán falta
bastante más que unos pocos registros de progenie para conocer mucho acerca del padre.
Sin registros de progenie – ninguna información- la diferencia de progenie del caballo se
predice que es 0 o promedio y el 68% de rango de confianza para esta predicción es de -1,17
a +1,17 segundos un total de 2,43 segundos. Con cinco registros de progenie, el rango de
confianza es de -1,31 a 0,53 o 1,84 segundos en total. El rango es más pequeño con cinco
registros que con ninguno, pero no tanto. Note que el límite de confianza superior es aún
mayor que cero (+0,53). En otras palabras, con cinco hijos no tenemos seguridad de que
nuestro caballo es genéticamente superior que la media. Solo cuando el número de hijos es
cercano a 20, cuando el límite superior del rango de confianza va por debajo de cero,
podemos estar razonablemente confiados en que el animal dará hijos más rápido que el
promedio.
Las mismas conclusiones pueden ser tomadas de la mitad hacia debajo de la Tabla 11.3, para
el carácter números de lechones destetados. En este ejemplo los EPDs son calculados para
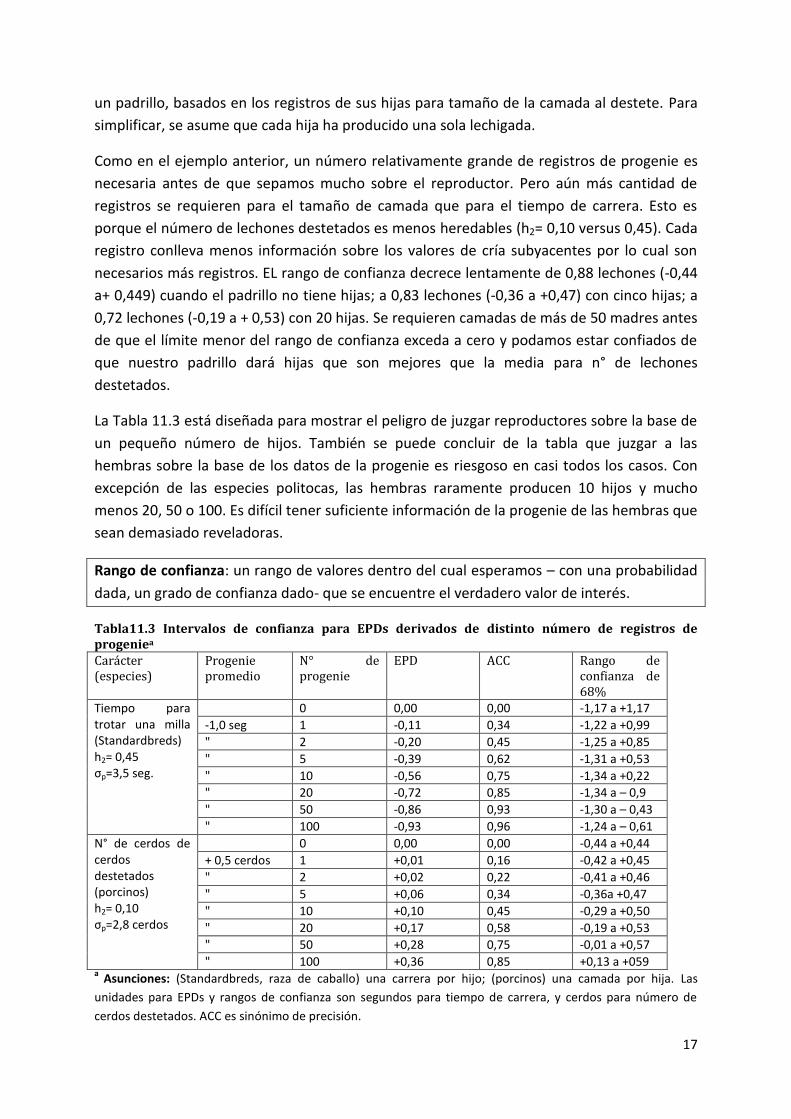
17
un padrillo, basados en los registros de sus hijas para tamaño de la camada al destete. Para
simplificar, se asume que cada hija ha producido una sola lechigada.
Como en el ejemplo anterior, un número relativamente grande de registros de progenie es
necesaria antes de que sepamos mucho sobre el reproductor. Pero aún más cantidad de
registros se requieren para el tamaño de camada que para el tiempo de carrera. Esto es
porque el número de lechones destetados es menos heredables (h2= 0,10 versus 0,45). Cada
registro conlleva menos información sobre los valores de cría subyacentes por lo cual son
necesarios más registros. EL rango de confianza decrece lentamente de 0,88 lechones (-0,44
a+ 0,449) cuando el padrillo no tiene hijas; a 0,83 lechones (-0,36 a +0,47) con cinco hijas; a
0,72 lechones (-0,19 a + 0,53) con 20 hijas. Se requieren camadas de más de 50 madres antes
de que el límite menor del rango de confianza exceda a cero y podamos estar confiados de
que nuestro padrillo dará hijas que son mejores que la media para n° de lechones
destetados.
La Tabla 11.3 está diseñada para mostrar el peligro de juzgar reproductores sobre la base de
un pequeño número de hijos. También se puede concluir de la tabla que juzgar a las
hembras sobre la base de los datos de la progenie es riesgoso en casi todos los casos. Con
excepción de las especies politocas, las hembras raramente producen 10 hijos y mucho
menos 20, 50 o 100. Es difícil tener suficiente información de la progenie de las hembras que
sean demasiado reveladoras.
Rango de confianza: un rango de valores dentro del cual esperamos – con una probabilidad
dada, un grado de confianza dado- que se encuentre el verdadero valor de interés.
Tabla11.3 Intervalos de confianza para EPDs derivados de distinto número de registros de progeniea Carácter (especies)
Progenie promedio
N° de progenie
EPD ACC Rango de confianza de 68%
Tiempo para trotar una milla (Standardbreds) h2= 0,45 σp=3,5 seg.
0 0,00 0,00 -1,17 a +1,17
-1,0 seg 1 -0,11 0,34 -1,22 a +0,99
" 2 -0,20 0,45 -1,25 a +0,85
" 5 -0,39 0,62 -1,31 a +0,53
" 10 -0,56 0,75 -1,34 a +0,22
" 20 -0,72 0,85 -1,34 a – 0,9
" 50 -0,86 0,93 -1,30 a – 0,43
" 100 -0,93 0,96 -1,24 a – 0,61
N° de cerdos de cerdos destetados (porcinos) h2= 0,10 σp=2,8 cerdos
0 0,00 0,00 -0,44 a +0,44
+ 0,5 cerdos 1 +0,01 0,16 -0,42 a +0,45
" 2 +0,02 0,22 -0,41 a +0,46
" 5 +0,06 0,34 -0,36a +0,47
" 10 +0,10 0,45 -0,29 a +0,50
" 20 +0,17 0,58 -0,19 a +0,53
" 50 +0,28 0,75 -0,01 a +0,57
" 100 +0,36 0,85 +0,13 a +059 a
Asunciones: (Standardbreds, raza de caballo) una carrera por hijo; (porcinos) una camada por hija. Las
unidades para EPDs y rangos de confianza son segundos para tiempo de carrera, y cerdos para número de
cerdos destetados. ACC es sinónimo de precisión.

18
Predicción usando múltiples fuentes de información
Podemos estar interesados en predecir un valor para un individuo basado en más de una
sola fuente de información. Por ejemplo, podríamos querer predecir el valor de cría de un
animal basado en su propia performance, la performance media de sus medio hermanos
paternos y el promedio de performance de su progenie. El índice de selección en este caso
aparecería como
O
Para calcular este EBV necesitamos valores para los tres factores de ponderación b1, b2 y b3 y
eso requiere de la construcción y solución simultánea de tres ecuaciones. Es posible lograrlo
√( )
√( )
(
)
( ( ) )
√( ( ))( )
La relación matemática entre el rango de confianza y la precisión
Sea T para algún valor real (es decir, BV, PD, PA, etc.). Entonces
Ejemplo
En los escenarios mostrados en la Tabla 11.3 para el tiempo para correr una milla,
Y
Entonces
68%de rango de confianza = √( )
De la Tabla 11.3,
Co 10 hijos
68%de rango de confianza = √( )

19
a mano pero no sin un considerable dolor de cabeza. Los cálculos para índices de selección
que involucran más de dos fuentes de información es mejor dejarlas para la computadora.
Ponderación de cada fuente de información
( )
√
Un ejemplo de cuatro ecuaciones
Suponga que queremos predecir el valor de cría de un animal para un caracter no repetido basado en 4 fuentes de información(1) performance del individuo (2) performance promedio de medio hermanos paternos (3) performance promedio de medio hermanos maternos (4) performance promedio de la progenie. El índice de selección es entonces
O
Las 4 ecuaciones que se deberán resolver simultaneamente para determinar los coeficientes de regresion (b1,b2,b3, y b4) son:
( )
=
( )
=
Donde las RS hacen referencia a las relaciones de pedigree, y n1, n2, y n3 hacen referencia al número de medio hermanos paternos, medio hermanos maternos, y progenie, respectivamente. Específicamente,
+
+
+
= 1
+
( )
+ 0 +
=
+ 0 +
( )
+
=
+
+
+
( )
=
Los coeficientes de regresión son funciones de la heredabilidad, de las relaciones de pedirgee y de los números de registros de cada grupo de parientes. Una vez que se han determinado los valores de los bs, simplemente se sustituyen en la ecuación para calcular el índice de EBV del animal. la exactitud del índice es:
Para muestras de la aplicación de estos índices, mire los datos de la Tabla 11.4. Ellos fueron derivados de las ecuaciones de índices listadas arriba.

20
Como podría adivinarse, los valores de bs, es decir los factores de ponderación necesarios
para los índices de selección que involucran fuentes de información múltiples, varían
dependiendo de la cantidad y relevancia de los datos de cada fuente. Por ejemplo, si un
animal tiene muchos datos de genealogía y registros de performance propios, pero pocos
datos de progenie, esperamos que en el cálculo del EBV de ese animal el mayor énfasis sea
colocado en los datos de genealogía y su propia información. Por otra parte, si el mismo
animal adquiere una vasta cantidad de datos de progenie, esperamos que el énfasis cambie
a esa fuente de información. Los datos de la progenie, después de todo, proveen la última
prueba del valor de cría de un individuo. Cuando se usan ecuaciones simultáneas para
resolver la ponderación en los índices de selección, cada factor de ponderación
automáticamente refleja la cantidad apropiada de énfasis que se debería colocar en su
correspondiente fuente de información. Se podría pensar en esto como en la solución
mágica de las ecuaciones simultáneas. La Tabla 11.4 ha sido construida para ilustrar algunos
aspectos de esta magia matemática.
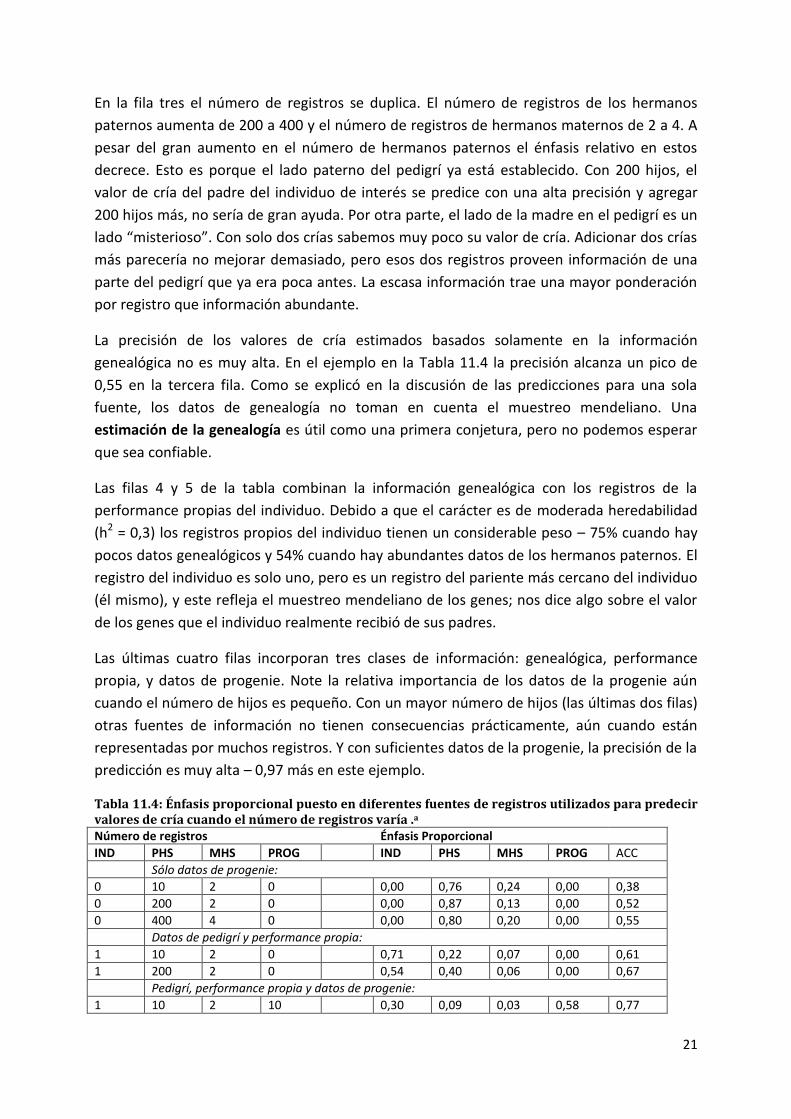
En la Tabla 11.4 se pueden ver proporciones decimales representando el énfasis relativo
dado a cada fuente de información en particular, para la predicción del valor de cría. Cada
línea representa un escenario diferente, cada uno involucrando diferente cantidad de datos
sobre la performance individual (IND), la performance media de medio hermanos paternos
(PHS), el promedio de la performance de medio hermano maternos (MHS), y la performance
media de la progenie (PROG). El carácter medido se asume que no es repetido (cada animal
puede tener un solo registro) con una heredabilidad de 0,3.
Las líneas (escenarios) en la Tabla 11.4 se agrupan en tres secciones. Las primeras tres
representan situaciones en las cuales solo está disponible la información genealógica de un
individuo. Quizás el individuo todavía no haya nacido o sea demasiado joven para tener
registros de performance propios. Las siguientes dos filas reflejan la combinación de los
datos de genealogía y de la performance del propio individuo. Las últimas cuatro filas
combinan genealogía, performance propia, e información de la progenie – datos que
podrían estar disponibles solamente para un animal más viejo. Note que la precisión de la
predicción del valor de cría (la columna de la derecha) aumenta con la cantidad de
información.
El escenario representado en la primera fila representa una modesta cantidad de
información del pedigrí. La madre del individuo de interés – el individuo cuyo valor de cría
estamos prediciendo- tiene dos crías previas, y el macho es probablemente joven, teniendo
solamente 10 hijos. Un mayor énfasis se da a los registros de los hermanos paternos que a
los registros de los hermanos maternos porque hay más registros para aquellos, pero todos
juntos proveen poca información y la precisión es baja (0,30).
En la segunda fila, el padre del individuo de interés con 200 registros de progenie, está bien
evaluado. EL énfasis sobre la información de los hermanos paternos aumenta en
consecuencia y la precisión es más alta.
21
En la fila tres el número de registros se duplica. El número de registros de los hermanos
paternos aumenta de 200 a 400 y el número de registros de hermanos maternos de 2 a 4. A
pesar del gran aumento en el número de hermanos paternos el énfasis relativo en estos
decrece. Esto es porque el lado paterno del pedigrí ya está establecido. Con 200 hijos, el
valor de cría del padre del individuo de interés se predice con una alta precisión y agregar
200 hijos más, no sería de gran ayuda. Por otra parte, el lado de la madre en el pedigrí es un
lado “misterioso”. Con solo dos crías sabemos muy poco su valor de cría. Adicionar dos crías
más parecería no mejorar demasiado, pero esos dos registros proveen información de una
parte del pedigrí que ya era poca antes. La escasa información trae una mayor ponderación
por registro que información abundante.
La precisión de los valores de cría estimados basados solamente en la información
genealógica no es muy alta. En el ejemplo en la Tabla 11.4 la precisión alcanza un pico de
0,55 en la tercera fila. Como se explicó en la discusión de las predicciones para una sola
fuente, los datos de genealogía no toman en cuenta el muestreo mendeliano. Una
estimación de la genealogía es útil como una primera conjetura, pero no podemos esperar
que sea confiable.
Las filas 4 y 5 de la tabla combinan la información genealógica con los registros de la
performance propias del individuo. Debido a que el carácter es de moderada heredabilidad
(h2 = 0,3) los registros propios del individuo tienen un considerable peso – 75% cuando hay
pocos datos genealógicos y 54% cuando hay abundantes datos de los hermanos paternos. El
registro del individuo es solo uno, pero es un registro del pariente más cercano del individuo
(él mismo), y este refleja el muestreo mendeliano de los genes; nos dice algo sobre el valor
de los genes que el individuo realmente recibió de sus padres.
Las últimas cuatro filas incorporan tres clases de información: genealógica, performance
propia, y datos de progenie. Note la relativa importancia de los datos de la progenie aún
cuando el número de hijos es pequeño. Con un mayor número de hijos (las últimas dos filas)
otras fuentes de información no tienen consecuencias prácticamente, aún cuando están
representadas por muchos registros. Y con suficientes datos de la progenie, la precisión de la
predicción es muy alta – 0,97 más en este ejemplo.
Tabla 11.4: Énfasis proporcional puesto en diferentes fuentes de registros utilizados para predecir valores de cría cuando el número de registros varía .a Número de registros Énfasis Proporcional
IND PHS MHS PROG IND PHS MHS PROG ACC
Sólo datos de progenie:
0 10 2 0 0,00 0,76 0,24 0,00 0,38
0 200 2 0 0,00 0,87 0,13 0,00 0,52
0 400 4 0 0,00 0,80 0,20 0,00 0,55
Datos de pedigrí y performance propia:
1 10 2 0 0,71 0,22 0,07 0,00 0,61
1 200 2 0 0,54 0,40 0,06 0,00 0,67
Pedigrí, performance propia y datos de progenie:
1 10 2 10 0,30 0,09 0,03 0,58 0,77

22
1 200 2 10 0,27 0,20 0,03 0,50 0,79
1 10 2 200 0,03 0,01 0,00 0,96 0,97
1 200 2 200 0,03 0,02 0,00 0,95 0,97 aIND = individuo: PHS= medio hermanas paternas; MHS= medio hermanas maternas; PROG= progenie; ACC=
precisión de la predicción; h2 = 0,3.
Estimación del pedigrí: Una predicción genética basada solamente en datos genealógicos.
COMPARACIÓN DE ANIMALES USANDO DATOS DE DIFERNTES GRUPOS GENÉTICOS
–MEJOR PREDICCIÓN LINEAR INSESGADA.
El índice de selección es un poderoso método para la predicción genética. Sin embargo una
asunción básica del índice de selección es que la información de performance utilizada
proviene de grupos contemporáneos genéticamente similares. ¿Y si queremos hacer
predicciones usando datos de grupos contemporáneos genéticamente diferentes? – grupos
de diferentes establecimientos o de diferentes décadas. Una extensión de la metodología de
los índices de selección conocida como mejor predicción linear insesgada o BLUP por su
sigla en inglés (Best Linear Unbiased Predicition) está diseñada para este tipo de
información. La distinción hecha aquí entre índice de selección y BLUP refleja diferencias en
como las dos tecnologías han sido aplicadas históricamente. Es teóricamente posible
construir índices de selección que podrían tomar en cuenta las diferencias genéticas entre
grupos contemporáneos y que podrían ser para propósitos prácticos tan buenos como la
más sofisticada tecnología BLUP. Sin embargo, estos índices de selección no han sido
utilizados por la simple razón de que no tienen ventajas particulares sobre procedimientos
BLUP análogos.
La teoría estadística detrás del BLUP es casi tan vieja como la teoría detrás del índice de
selección. Sin embargo no fue hasta principios de 1980 que las computadoras y los
algoritmos matemáticos han avanzado hasta el punto de que la difusión de la aplicación del
BLUP para las evaluaciones genéticas se convirtió en factible. BLUP requiere de computación
intensivamente. Tal como los índices de selección que utilizan múltiples fuentes de
información, BLUP involucra la solución simultánea de un gran número de ecuaciones. Sin
embargo, una aplicación típica del BLUP incorpora muchas veces el número de ecuaciones
que serían utilizadas por el correspondiente índice de selección, en parte porque un análisis
BLUP simple provee predicciones para una población entera de animales – no solo para un
animal a la vez (que es el caso de la mayoría de las aplicaciones del índice de selección).
Debido a su habilidad para tomar en cuenta las diferencias entre grupos contemporáneos y
debido a que provee predicciones genéticas para muchos animales a la vez, BLUP es el
método preferido para las evaluaciones genéticas a gran escala: la evaluación genética de
poblaciones grandes, típicamente razas enteras. Los registros de performance utilizados en
dichas evaluaciones usualmente provienen de datos de campo, datos que regularmente son
reportados por criadores individuales a las asociaciones de cría de las razas o a las agencias
gubernamentales.

23
Mejor predicción linear insesgada BLUP: Un método de predicción genética que es
particularmente apropiado cuando los datos de performance provienen de grupos
contemporáneos genéticamente diversos.
Evaluaciones genéticas a gran escala: la evaluación genética de poblaciones grandes,
típicamente razas enteras.
Datos de campo: datos que regularmente son reportados por criadores individuales a las
asociaciones de cría de las razas o a las agencias gubernamentales.
Tipos de modelos de BLUP
BLUP es una técnica que puede ser concebida como una familia de modelos estadísticos, es
decir, representaciones matemáticas de performance animal que incluye varios efectos
ambientales y genéticos y que son usados para las predicciones genéticas. Hay modelos
padre, modelos padre-abuelo materno, modelo animal, modelo de medidas repetidas,
modelos materno-directo, modelos multicarácter- la lista continua y continua. Las
diferencias entre modelos tienen que ver primariamente con que animales recibirán las
predicciones genéticas (solamente los padres, todos los progenitores, o todos los animales),
el número y clase de predicciones generadas y la dificultad computacional. En general
cuanto más sofisticado el modelo, involucra más ecuaciones y más cantidad de recursos
informáticos requiere.
Modelo estadístico: Representación matemática de la performance de un animal que
incluye varios efectos genéticos y ambientales y es utilizado para la predicción genética.
Potencial de los modelos BLUP avanzados
La predicción BLUP es un asunto complicado, y los criadores a menudo tienen preguntas
sobre las capacidades de los procedimientos BLUP. En particular, se preguntan si los análisis
BLUP pueden sobrepasar la clase de sesgo que usualmente traen los datos de campo. A
continuación hay una discusión sobre los atributos del BLUP que ha sido diseñada para
contestar muchas de estas preguntas. Es siempre peligroso generalizar acerca de los
modelos BLUP. Cada uno difiere del próximo de una forma u otra, y dos de ellos no tienen
exactamente las mismas capacidades. El modelo particular previsto en la construcción de
ésta sección es el más básico, todavía el más avanzado y actualmente el tipo más popular de
modelo BLUP – el modelo animal.
El modelo animal tiene una cantidad de cualidades deseables de las cuales la más obvia es su
habilidad para evaluar “todos los animales” (en contraposición a solo los machos) en una
población.
Modelo Animal: Modelo estadístico avanzado para la predicción genética que es utilizado
para evaluar todos los animales (al contrario de solo los padres) en una población.

24
Niveles genéticos de los grupos contemporáneos
Los modelos BLUP tienen en cuenta las diferencias en los valores de cría promedio de los
grupos contemporáneos. En otras palabras, tienen en cuenta el hecho de que la
performance superior en un grupo contemporáneo genéticamente inferior, no es
equivalente a la performance superior en un grupo contemporáneo superior. En un análisis
BLUP la performance de un caballo ganador en su tercera carrera en una feria común en el
país no es considerada tan impresionante como la performance del ganador del Derbi de
Kentucky.
El índice de selección como se recordará no puede hacer esta distinción. A causa de que usa
desvíos de la media de los grupos contemporáneos (en el ejemplo del caballo de carrera,
desviaciones del tiempo medio para correr una carrera dada) el índice de selección no puede
tener en cuenta el nivel de la competencia. Una desviación de - 0,5 es una desviación de -5
segundos si la carrera es en el Derbi de Kentucky o una de las tantas de las ferias del país.
Los modelos BLUP no utilizan desviaciones de las medias de los grupos contemporáneos. En
cambio incluyen ecuaciones que realmente resuelven los efectos del grupo contemporáneo
(Ecg), es decir efectos ambientales comunes a todos los miembros de un grupo
contemporáneo. Y lo hacen mediante la comparación de la performance de parientes en
grupos contemporáneos diferentes. Si los animales en un grupo contemporáneo en
particular no producen como deberían de acuerdo a lo determinado por la performance de
sus parientes en otros grupos contemporáneos, entonces, el efecto ambiental común a ese
grupo contemporáneo se estima que es más bajo que la media. Igualmente, si los animales
en el grupo producen mejor que lo que deberían, el Ecg se estima que es superior a la media.
A través de la solución simultánea de ecuaciones, las estimaciones de los efectos de los
grupos contemporáneos proveen la información que se utiliza para producir una predicción
genética más confiable para animales individuales y viceversa. Así los procedimientos BLUP
tienen en cuenta el hecho de que la información de performance utilizada en las
predicciones proviene de grupos contemporáneos que difieren por razones ambientales y
genéticas. Se puede comparar directamente las predicciones genéticas provenientes de los
modelos BLUP, aún cuando esas predicciones derivan grandemente de registros producidos
en ambientes muy diferentes y/o en grupos contemporáneos que difieren ampliamente en
el mérito genético promedio.
Tendencia genética
Un corolario de las capacidades de los modelos BLUP para contabilizar los niveles genéticos
de los grupos contemporáneos es su habilidad para tomar en cuenta la tendencia genética.
Si una población ha sido objeto de una selección efectiva por un período de tiempo
considerable (es decir si ha experimentado una tendencia genética significativa), el valor de
cría promedio de los grupos contemporáneos más nuevos deberían ser mejores que los

25
valores de cría promedio de los grupos contemporáneos más viejos. Pero a causa de que los
procedimientos BLUP toman en cuenta las diferencias genéticas entre grupos
contemporáneos, las tendencias genéticas usualmente no son un problema (las tendencias
genéticas causarían sesgos en un índice de selección utilizando desvíos de las medias de los
grupos contemporáneos). Con los modelos BLUP podemos utilizar registros de performance
legítimamente provenientes de animales de diferentes épocas – desde aquellos que desde
hace mucho tiempo que están muertos hasta los recién nacidos.
Uso de todos los datos
Las aplicaciones tradicionales de los índices de selección utilizan registros de relativamente
pocas fuentes. El índice de selección utilizado para generar los valores en la Tabla 11.4, por
ejemplo, utiliza cuatro fuentes: el registro de un individuo, los registros de hermanos
maternos y paternos, y los registros de la progenie. Los modelos BLUP pueden usar
información de muchas más fuentes. De hecho, a menudo utilizan información proveniente
de todos los animales en una población.
El beneficio de esto puede no ser grande; los registros de los parientes lejanos
potencialmente no contribuyen mucho a una predicción. Aún así la habilidad de los BLUP de
incorporar información de toda clase de parientes suma precisión a la predicción, aunque
solamente fuera poco. También clarifica las relaciones genealógicas. Lo que podría ser
considerado el registro de un medio hermano en un índice de selección típico podría ser
representado más correctamente en un análisis BLUP como el registro de un pariente que es
medio hermano y primo hermano (vea la Figura 11.3 y la leyenda que la acompaña). Este
registro por lo tanto podría recibir una ponderación más apropiada con BLUP que con los
índices de selección.
El uso de todos los datos también puede ser interpretado como medio para utilizar los datos
de caracteres correlacionados. Los modelos BLUP multicarácter, modelos estadísticos
utilizados para predecir valores para más de un carácter a la vez, permite que la información
sobre un carácter sea utilizada en la predicción de valores para otro carácter. Esto es
especialmente útil cuando la información en el segundo carácter es escasa. Por ejemplo,
generalmente hay mucha más información sobre pesos al destete que sobre pesos al
nacimiento tomados a campo en el ganado de carne. Cuando estos caracteres son
incorporados en un modelo multicarácter, la información del peso al destete ayuda a
predecir valores del peso al nacimiento y viceversa. El resultado es más preciso para ambos
caracteres.

26
Modelos BLUP multicarácter: modelos estadísticos utilizados para predecir valores para más
de un carácter a la vez.
Apareamientos no aleatorios
Los productores son reacios a aparear animales al azar (es decir asignar machos a las
hembras en una forma aleatoria). ¿Puede usted culparlos? Si estuviera pagando una tarifa
de stud de $50,000 por el servicio de un famoso semental, ¿Lo aparearía con cualquier
hembra? Por supuesto que no. Maximizaría la probabilidad de producir un potrillo
sobresaliente apareando al semental con su mejor hembra. El problema con esta estrategia
desde el punto de vista de la predicción genética es que le da ventaja a algunos animales
sobre los otros – incrementa el sesgo. Aquellos machos que se piensan que son mejores son
apareados con las mejores hembras, y por lo tanto es factible que obtengan una progenie
con las mejores performances. Los restantes machos son relegados a las peores hembras y
por lo tanto es probable que tengan una progenie con una performance más pobre. Los
procedimientos BLUP tienen en cuenta los apareamientos no aleatorios de ésta clase, en
esencia ajustando las predicciones por el mérito genético de los progenitores (padre y
madre).Las predicciones genéticas para los machos y hembras se producen
simultáneamente y la solución simultánea de ecuaciones provoca que cada predicción sea
tenida en cuenta para todas las otras. El feliz resultado (dependiendo de su perspectiva) es
que no es posible hacer lucir a un individuo mejor de lo que es asignándole un macho o una
hembra superior.
Apareamiento no aleatorio: Cualquier sistema de apareamiento en el cual los machos no
son asignados de manera aleatoria a las hembras

27
Refugo por baja performance
Otra clase de sesgo es causado por el refugo por baja performance en caracteres repetidos o
en un carácter que es registrado antes del registro de otro carácter genéticamente
relacionado. Un ejemplo de este tipo de sesgo, es el que afecta a los caballos de carrera
como se ilustra la Figura 11.4. Los equinos pura sangre de carrera usualmente comienzan a
correr a los dos años de edad. Si tienen éxito en su primera temporada, continúan corriendo.
De otra manera son refugados por baja performance. Refugar así causa sesgo si la progenie
de alguno de los macho es rechazada más severamente que la progenie de otros machos.
En la Figura 11.4 la performance de la progenie del macho B es mucho mejor que la progenie
del macho A, a los dos años de edad. Claramente el macho B debería tener el mejor valor de
cría para performance en la carrera. Entre las temporadas de carrera, algunos de ambos
machos son refugados por baja performance, pero a causa de que la progenie del macho A
tiene una performance más baja de lo normal, una proporción mucho más grande de su
progenie que de la progenie del macho B es refugada. La poca progenie remanente del
macho A corre bien en años posteriores, entonces la diferencia en la media de la
performance subsecuente de la progenie de los dos machos ( ) es relativamente
pequeña. Note que esta diferencia es mucho más pequeña que si no hubiera habido refugo.
Si muchos de los datos utilizados para predecir los valores de cría para estos machos
proviene de la progenie que mayor de tres años o más, el macho A tendrá una ventaja
relativa y el macho B una desventaja relativa.

28
Los modelos BLUP multicarácter tienen en cuenta este sesgo causado por el refugo por baja
performance. Si el carácter en el cual se basa el refugo es incluido en el análisis y si las
relaciones genéticas (correlaciones genéticas) entre ese carácter y caracteres subsecuentes
se incorporan también, las predicciones para el segundo carácter no son afectadas por el
refugo. Si el BLUP es utilizado para evaluar caballos de carrera, las predicciones de los
valores de cría para la performance de una carrera a edades más altas no sufrirán sesgo por
el refugo por la performance a los dos años de edad.
Predicción de los componentes genéticos directos y maternos de los caracteres
Todos los caracteres tienen lo que se denomina componente directo, el efecto de los genes
de un individuo sobre su propia performance. Algunos caracteres tienen un componente
materno, el efecto de los genes de la madre de un individuo que influencia en la
performance de este a través del ambiente provisto por la ella.
El ejemplo clásico de un carácter con ambos componentes directo y materno es el peso al
destete. El peso al destete de un animal es una función de su habilidad heredada para la tasa
de crecimiento y la producción de leche y habilidad materna de su madre. La tasa de
crecimiento heredada está determinada por los genes del animal. Este comprende el
componente directo del peso al destete. La producción de leche y la habilidad materna de la
madre están determinadas por los genes de ésta (así como por el ambiente). Los genes de la
madre para estos caracteres no afectan la tasa de crecimiento de la progenie directamente,
pero si afectan el ambiente experimentado por la cría. La producción de leche y la habilidad
materna comprende el componente materno del peso al destete.
Otros caracteres que tienen componente materno importante incluyen la distocia y la
sobrevivencia. El componente directo de la distocia está relacionado con el tamaño y la
forma del feto. El componente materno está asociado con el tamaño y la conformación de la
pelvis de la madre y otros factores fisiológicos y psicológicos más sutiles. El componente
directo de la sobrevivencia es una función de esos genes en los animales jóvenes que
afectan la fortaleza física, la respuesta inmune, y el instinto de supervivencia. El componente
materno se relaciona con la habilidad de la madre para amamantar y proteger a su cría.
Los procedimientos BLUP son capaces de separar los componentes directos y maternos de un
carácter, proveyendo predicciones para ambos. En el caso del peso al destete, las
predicciones están disponibles para el componente de crecimiento, así como para el
componente leche/ habilidad materna.
Los criadores a menudo se preguntan cómo es posible eso, dado que el componente
materno del peso al destete no se mide directamente. Nadie ordeña cerdas, ovejas o vacas
de carne y registra sus rendimientos lecheros. En su lugar la información para la predicción
del componente materno proviene de los mismos pesos al destete. La verdadera explicación
de esta aparente paradoja yace en la solución simultánea de ecuaciones, pero usted puede
pensar en ellos y no incorrectamente como una simple cuestión de substracción.

29
Suponga por ejemplo, que un macho produce un gran número de hijos y de los pesos al
destete de éstos obtenemos una predicción confiable de los valores de cría de ese macho
para el carácter tasa de crecimiento predestete - el componente directo del peso al destete.
Las hijas de este macho son entonces apareadas y producen su propia progenie. Nosotros ya
tenemos una expectativa de los pesos al destete de esa progenie – nietos del macho –
basada en lo que ya conocemos sobre el potencial crecimiento de sus madres. Si los pesos al
destete de estos nietos exceden dichas expectativas, entonces se puede asumir que la
diferencia es debida a la habilidad materna superior de sus madres (producción de leche
superior). Por el otro lado, si los pesos al destete de los nietos no alcanzan las expectativas,
la diferencia es atribuida a la habilidad materna inferior de sus madres. Así la predicción para
el componente materno del peso al destete, está determinado por la diferencia entre la
performance real y las expectativas de performance al destete. Toda la situación es
complicada por el hecho de que el macho mismo pudo haber sido apareado con las mejores
o peores hembras que la media, y sus hijas con machos peores o mejores que la media, pero
BLUP toma en cuenta eso, y otras consideraciones igualmente confusas.
Una discusión de los componentes directos y maternos de los caracteres no estaría completa
sin mencionar un tercer componente, el componente paterno. Una definición de
componente paterno sería análoga a la de componente materno. De acuerdo a eso, el
componente paterno de un carácter es el efecto de los genes en el padre de un individuo
que influyen en su performance a través del ambiente provisto por el padre. Sin embargo,
para los animales domésticos, una definición de este tipo es rara, los machos tienen muy
poco que ver con la crianza de sus hijos y por lo tanto no tienen efecto ambiental sobre la
performance de estos. Efectos paternos sí existen para especies de pájaros silvestres y para
algunos – jacanas y pingüino emperador, por ejemplo – los componentes paternos de
incubabilidad y sobrevivencia de los pichones pueden ser hasta más importantes que el
componente materno.
Una segunda definición de componente paterno se aplica a los caracteres de fertilidad. Las
medidas de fertilidad que son consideradas caracteres de la madre o de la cría, pero que
están afectadas por la fertilidad del macho y su habilidad física para el servicio, se dice que
tienen un componente paterno. Hablamos por ejemplo, del componente paterno para la
tasa de concepción. Esta segunda definición tiene una mayor aplicación práctica en el
mejoramiento de las especies domésticas.
Componente directo: el efecto de los genes de un individuo sobre su propia performance.
Componente materno: el efecto de los genes de la madre de un individuo que influencia en
la performance de este a través del ambiente provisto por su madre.
Componente paterno: es el efecto de los genes del padre de un individuo que influyen en la
performance de este a través del ambiente provisto por el padre. Los caracteres de la madre
o del hijo que son afectados por la fertilidad y habilidad para reproducirse del macho
también se dice que tienen un componente paterno.

30
Predicción de varios tipos de valores
Los procedimientos BLUP, típicamente producen EBVs o EPDs para los componentes
directos de los caracteres, como así también para caracteres con componentes maternales
importantes, (EBVs o EPDs para estos también). Sin embargo, las predicciones de los análisis
BLUP no se limitan solamente a eso. También es posible la predicción de los efectos
ambientales permanentes para caracteres repetidos, y eso significa que BLUP puede ser
usado para predecir la habilidad de producción. Así
PA = BV + Ep
Donde se asume que Ep contiene el efecto permanente y el valor combinatorio de los genes,
entonces
= +
Podemos calcular la MPPA de una hembra lechera para producción de leche asumiendo su
valor de cría estimado y la predicción de su efecto ambiental permanente. Note cuanto más
sofisticado es este MPPA comparado con el MPPA computado anteriormente en este
capítulo utilizando un índice de selección de una sola fuente. En ese cálculo, la información
utilizada se limitaba a la propia performance de lactación de la hembra. En contraste, la
información utilizada para calcular la MPPA de un análisis BLUP incluye registros de lactación
de todo tipo de parientes.
Otro valor comúnmente estimado por los procedimientos BLUP es el llamado valor materno
total (BVtm). EL valor materno total combina los valores de cría para los componentes
maternos y directos del carácter. Por ejemplo, el valor materno total de una vaca de carne
para peso al destete representa su habilidad genética para producir peso al destete. Como
tal, incluye los efectos de sus genes para la producción de leche y su habilidad materna (el
componente maternal para peso al destete) así como también los efectos de sus genes para
la tasa de crecimiento predestete que ella transmite a su ternero – el componente directo
del peso al destete. (Se usa una vaca de carne en este ejemplo. Predecimos valores
maternos totales para machos también. Pero debido a que los genes del padre para el
componente materno del peso al destete no son expresados en el peso al destete de su hijo,
un ejemplo utilizando un macho es más difícil de entender).
En forma de ecuación,
Donde los subíndices WW, m y d representan el peso al destete, materno y directo
respectivamente. El valor materno total de la vaca contiene todo su valor de cría para el
componente materno de peso al destete y solo la mitad de su valor de cría para el
componente directo de peso al destete. Esto es debido a que todos sus genes que

31
influencian el componente producción de leche/habilidad materna afectan a la performance
de su ternero, pero debido a que transmite solo la mitad de los genes al ternero, solo la
mitad de sus genes que influencian la tasa de crecimiento predestete afecta la performance
del ternero. En términos de predicciones genéticas
Y
Los EBVs maternos totales y los EPDs maternos totales son fáciles de confundir. EL EBV
materno total de una hembra es una predicción de su habilidad genética para producir algo
medido en su hijo. Es nuestra expectativa de su propia producción (excluyendo los efectos
ambientales). El EPD materno total de un individuo, por el otro lado, es nuestra expectativa
sobre la producción de las hijas de un individuo.
El EVB materno total de una vaca para peso al destete es una predicción de la parte
heredable de su habilidad para producir el peso al destete del ternero – su valor de cría para
la producción de peso al destete. Podemos ir un paso más allá y calcular el MPPA de una
vaca para peso al destete. Esto podría incluir cualquier efecto ambiental permanente en la
producción de peso al destete. Matemáticamente
Los análisis BLUP también producen estimativas de los efectos ambientales comunes a todos
los miembros del grupo contemporáneo (Ecg). A pesar de que no son rutinariamente
utilizados, podrían ser útiles desde el punto de vista del manejo. Podrían indicar situaciones
donde los calendarios sanitarios son inefectivos, las pasturas están siendo sobrepastoreadas,
etc. Cuando las estimaciones de los efectos de grupos contemporáneos en una población
son trazadas a través del tiempo, revelan la tendencia ambiental – cambio en la
performance media de una población a través del tiempo causada por los cambios en el
ambiente.
Valor materno total (BVtm): Una combinación de los valores de cría para los componentes
directo y materno de un carácter. El valor materno total de una hembra representa la parte
heredable de su habilidad para producir una cantidad que es medida en sus hijos.
Tendencia ambiental: cambio en la performance media de una población a través del
tiempo causada por los cambios en el ambiente.

32
Predicciones para todos los animales
Los procedimientos BLUP pueden ser utilizados para generar predicciones de cualquier
animal en una población. Las predicciones están disponibles para machos y hembras, padres
y no padres, animales que todavía no han sido concebidos y animales que han muerto hace
mucho tiempo, y animales con registros de performance o animales sin ellos.